
1. Força do Destino,
A era do desenvolvimento isolado está chegando ao fim. A próxima onda de evolução tecnológica não é sobre genialidade solitária, mas sobre domínio colaborativo. Criar um único agente inteligente é um experimento fascinante. Criar um ecossistema de agentes robusto, seguro e inteligente, um verdadeiro Agentverse, é o grande desafio para a empresa moderna.
Para ter sucesso nessa nova era, é preciso a convergência de quatro funções essenciais, os pilares fundamentais que sustentam qualquer sistema de agente próspero. Uma deficiência em qualquer área cria uma fragilidade que pode comprometer toda a estrutura.
Este workshop é o guia definitivo para empresas que querem dominar o futuro com agentes no Google Cloud. Oferecemos um planejamento de ponta a ponta que orienta você desde a primeira ideia até uma realidade operacional em grande escala. Nesses quatro laboratórios interconectados, você vai aprender como as habilidades especializadas de um desenvolvedor, arquiteto, engenheiro de dados e SRE precisam convergir para criar, gerenciar e escalonar um Agentverse eficiente.
Nenhum pilar pode oferecer suporte ao Agentverse sozinho. O projeto do arquiteto é inútil sem a execução precisa do desenvolvedor. O agente do desenvolvedor não funciona sem a experiência do engenheiro de dados, e todo o sistema é frágil sem a proteção do SRE. Somente com sinergia e uma compreensão compartilhada das funções de cada um é que sua equipe pode transformar um conceito inovador em uma realidade operacional essencial. Sua jornada começa aqui. Prepare-se para dominar sua função e entender como você se encaixa no todo.
Este é o Agentverse: um chamado aos campeões
Na vasta extensão digital da empresa, uma nova era surgiu. É a era agêntica, um tempo de imensas promessas, em que agentes inteligentes e autônomos trabalham em perfeita harmonia para acelerar a inovação e eliminar o trivial.

Esse ecossistema conectado de poder e potencial é conhecido como Agentverse.
Mas uma entropia crescente, uma corrupção silenciosa conhecida como Estática, começou a desgastar as bordas desse novo mundo. O Static não é um vírus nem um bug. Ele é a personificação do caos que se alimenta do próprio ato de criação.
Ele amplia frustrações antigas em formas monstruosas, origem aos Sete Espectros do Desenvolvimento. Se não for marcada, "The Static and its Spectres" vai interromper o progresso, transformando a promessa do Agentverse em um terreno baldio de dívidas técnicas e projetos abandonados.
Hoje, pedimos que os campeões combatam essa onda de caos. Precisamos de heróis dispostos a dominar suas habilidades e trabalhar juntos para proteger o Agentverse. Chegou a hora de escolher seu caminho.
Escolha sua turma
Quatro caminhos distintos estão à sua frente, cada um deles um pilar fundamental na luta contra The Static. Embora seu treinamento seja uma missão solo, seu sucesso final depende de entender como suas habilidades se combinam com as de outras pessoas.
- O Lâmina de Sombra (Desenvolvedor): um mestre da forja e da linha de frente. Você é o artesão que cria as lâminas, constrói as ferramentas e enfrenta o inimigo nos detalhes intrincados do código. Seu caminho é de precisão, habilidade e criação prática.
- O Invocador (arquiteto): um grande estrategista e orquestrador. Você não vê um único agente, mas todo o campo de batalha. Você cria os projetos principais que permitem que sistemas inteiros de agentes se comuniquem, colaborem e alcancem um objetivo muito maior do que qualquer componente individual.
- O Estudioso (engenheiro de dados): um buscador de verdades ocultas e guardião da sabedoria. Você se aventura na vasta e indomável natureza selvagem de dados para descobrir a inteligência que dá propósito e visão aos seus agentes. Seu conhecimento pode revelar a fraqueza de um inimigo ou fortalecer um aliado.
- O Guardião (DevOps / SRE): o protetor e escudo constante do reino. Você constrói as fortalezas, gerencia as linhas de suprimento de energia e garante que todo o sistema resista aos ataques inevitáveis da Estática. Sua força é a base da vitória da equipe.
Sua missão
Seu treinamento vai começar como um exercício independente. Você vai seguir o programa escolhido e aprender as habilidades exclusivas necessárias para dominar sua função. No fim da avaliação, você vai enfrentar um Spectre nascido da Estática, um mini-chefe que se alimenta dos desafios específicos da sua profissão.
Só é possível se preparar para o teste final dominando sua função individual. Em seguida, forme um grupo com campeões das outras classes. Juntos, vocês vão se aventurar no coração da corrupção para enfrentar um chefe final.
Um desafio final e colaborativo que vai testar sua força combinada e determinar o destino do Agentverse.
O Agentverse aguarda seus heróis. O que acha?
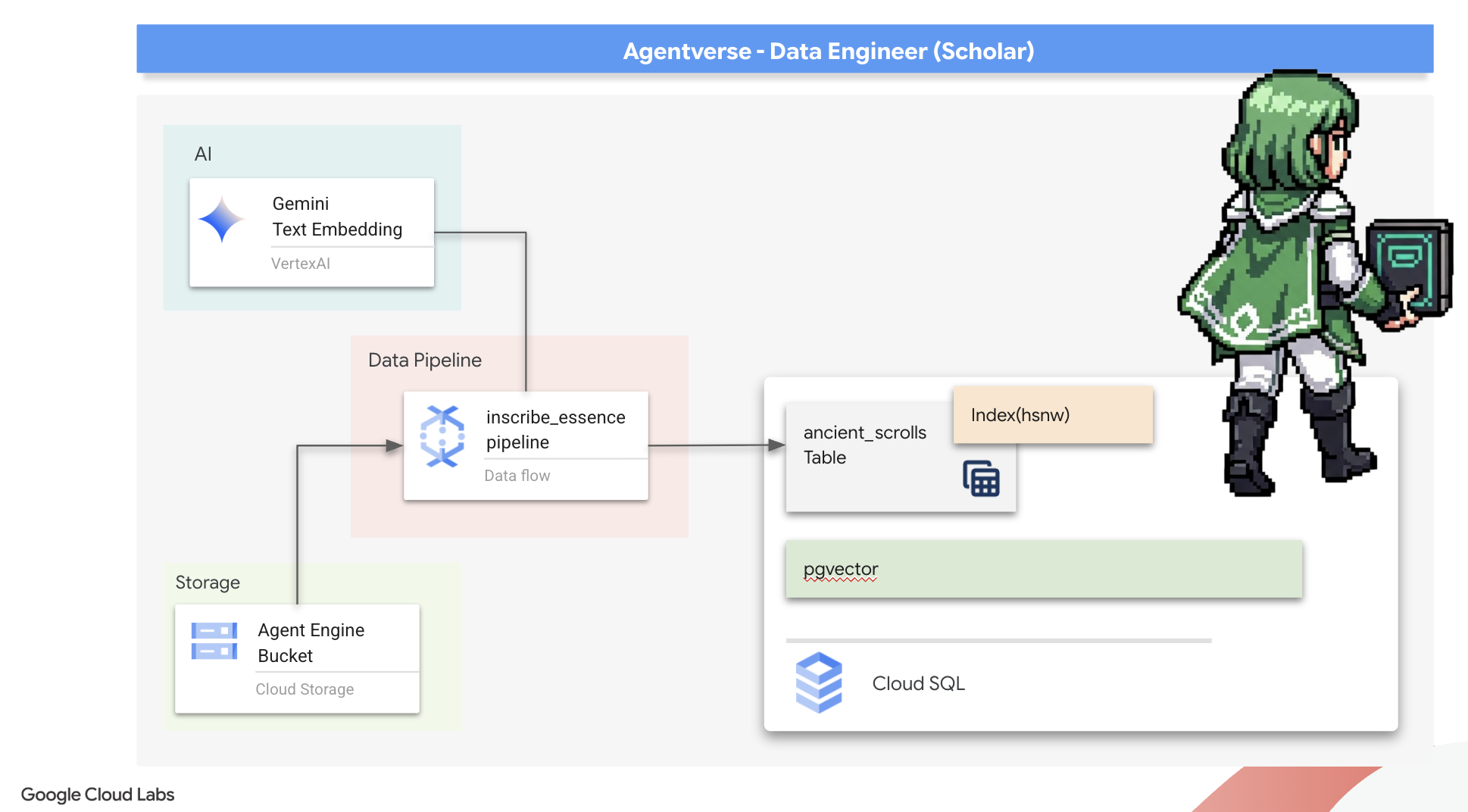
2. O Grimório do Acadêmico
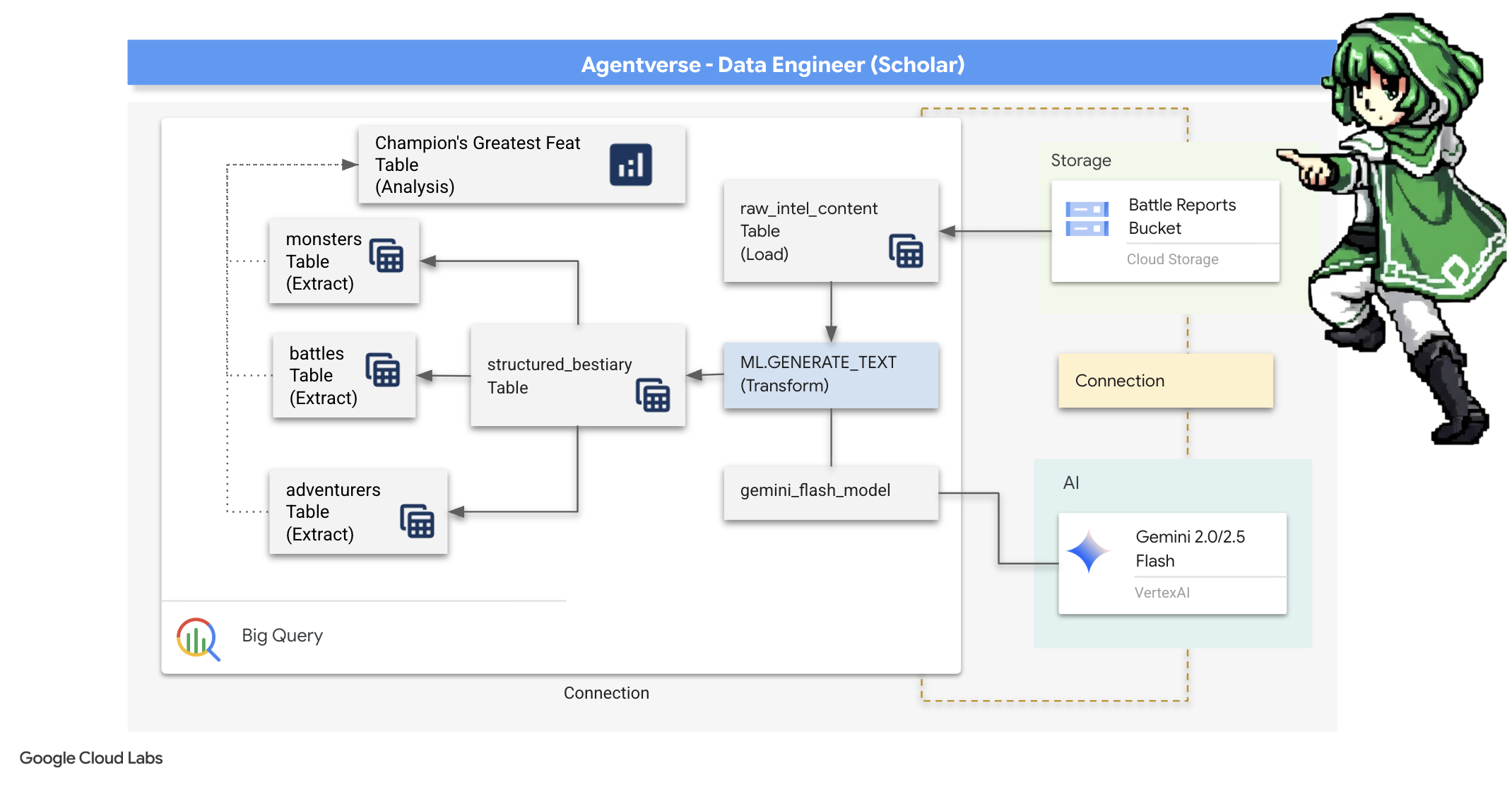
Nossa jornada começa agora! Como estudantes, nossa principal arma é o conhecimento. Encontramos um tesouro de pergaminhos antigos e enigmáticos em nossos arquivos (Google Cloud Storage). Esses pergaminhos contêm informações brutas sobre as feras terríveis que assolam a terra. Nossa missão é usar a profunda magia analítica do Google BigQuery e a sabedoria de um Gemini Elder Brain (modelo Gemini Pro) para decifrar esses textos não estruturados e transformá-los em um bestiário estruturado e pesquisável. Essa será a base de todas as nossas estratégias futuras.
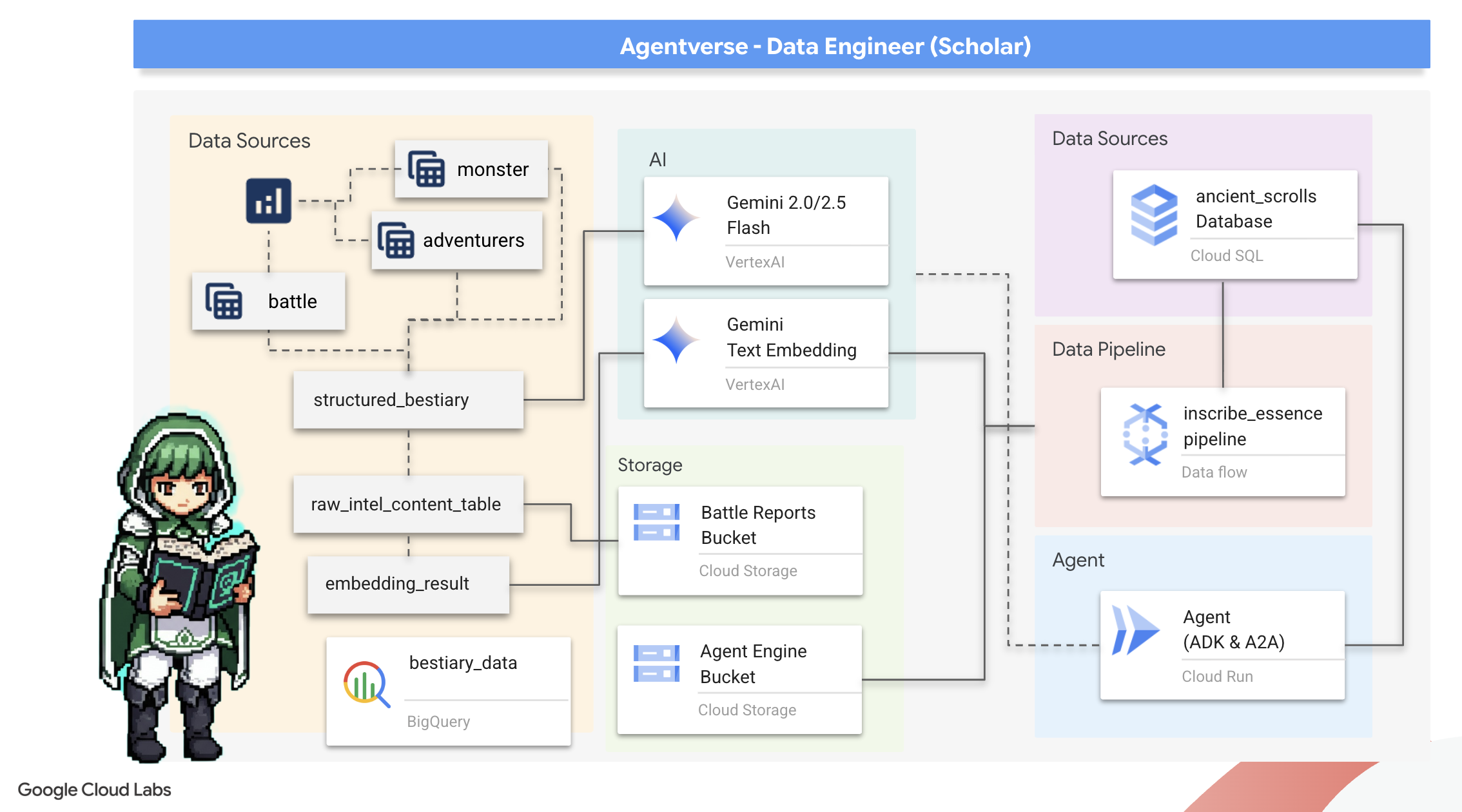
O que você vai aprender
- Use o BigQuery para criar tabelas externas e realizar transformações complexas de não estruturadas para estruturadas usando BQML.GENERATE_TEXT com um modelo do Gemini.
- Provisione uma instância do Cloud SQL para PostgreSQL e ative a extensão pgvector para recursos de pesquisa semântica.
- Crie um pipeline em lote robusto e em contêineres usando o Dataflow e o Apache Beam para processar arquivos de texto brutos, gerar embeddings de vetor com um modelo do Gemini e gravar os resultados em um banco de dados relacional.
- Implementar um sistema básico de geração aumentada por recuperação (RAG) em um agente para consultar os dados vetorizados.
- Implante um agente com reconhecimento de dados como um serviço seguro e escalonável no Cloud Run.
3. Preparando o Sanctum do Estudioso
Olá, estudante. Antes de começar a inscrever o conhecimento poderoso do nosso Grimório, precisamos preparar nosso sanctum. Esse ritual fundamental envolve encantar nosso ambiente do Google Cloud, abrir os portais certos (APIs) e criar os condutos por onde nossa magia de dados vai fluir. Um sanctum bem preparado garante que nossos feitiços sejam potentes e nosso conhecimento esteja seguro.
Resgatar seu crédito do Google Cloud
⚠️ Pré-requisitos importantes:
- Use um Gmail pessoal:você precisa usar uma conta pessoal (por exemplo,
name@gmail.com). Contas corporativas ou gerenciadas por escolas não funcionam.
👉 Etapas:
- Acesse o site de reivindicação de crédito: Clique aqui
- Fazer login:cole o link na barra de endereço e faça login com seu Gmail pessoal.
- Aceitar os termos:aceite os Termos de Serviço do Google Cloud Platform.
- Verificar crédito:procure uma mensagem confirmando que o crédito foi aplicado.
- *Observação: se for solicitado que você insira informações do cartão de crédito, ignore e feche a janela.
Tudo pronto! Você pode fechar a janela.
Configurar o ambiente de trabalho
👉Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud. É o ícone em forma de terminal na parte de cima do painel do Cloud Shell.
👉Clique no botão "Abrir editor" (parece uma pasta aberta com um lápis). Isso vai abrir o editor de código do Cloud Shell na janela. Um explorador de arquivos vai aparecer no lado esquerdo. 
👉Abra o terminal no IDE da nuvem, 
👉💻 No terminal, verifique se você já está autenticado e se o projeto está definido como seu ID do projeto usando o seguinte comando:
gcloud auth list
👉💻Clone o projeto de bootstrap do GitHub:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 Execute o script de configuração no diretório do projeto.
⚠️ Observação sobre o ID do projeto:o script vai sugerir um ID do projeto padrão gerado aleatoriamente. Pressione Enter para aceitar esse padrão.
No entanto, se você preferir criar um novo projeto específico, digite o ID do projeto desejado quando o script solicitar.
cd ~/agentverse-dataengineer
./init.sh
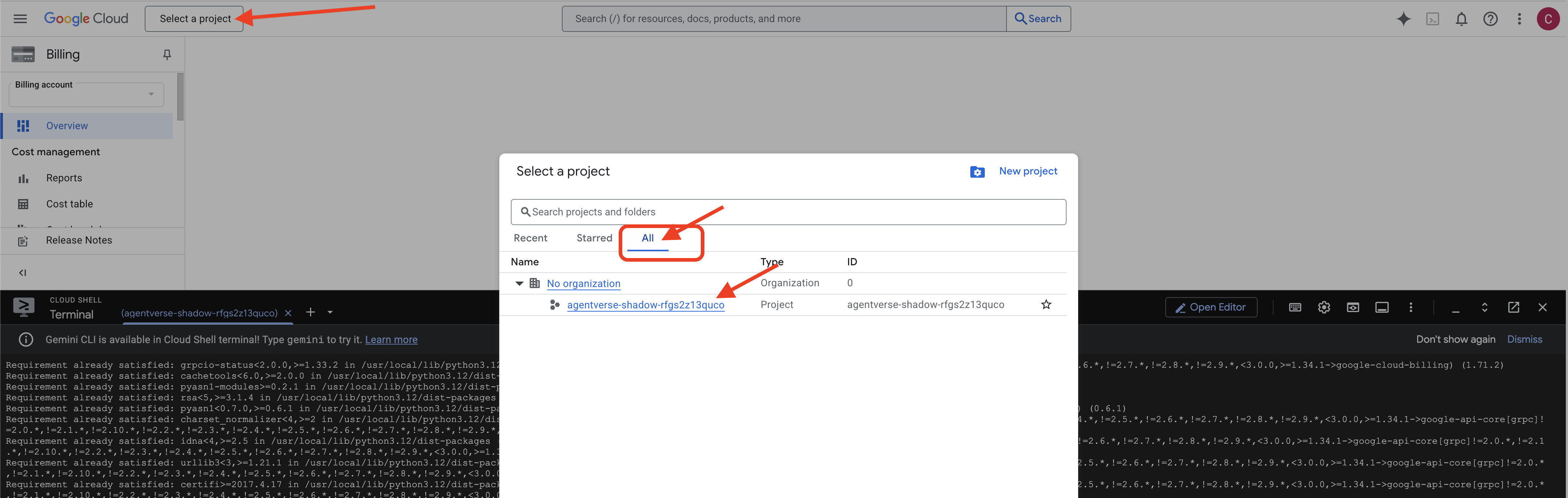
👉 Etapa importante após a conclusão:depois que o script for concluído, verifique se o console do Google Cloud está mostrando o projeto correto:
- Acesse console.cloud.google.com.
- Clique no menu suspenso do seletor de projetos na parte de cima da página.
- Clique na guia Todos, já que o novo projeto ainda não aparece em "Recentes".
- Selecione o ID do projeto que você acabou de configurar na etapa
init.sh.
👉💻 Defina o ID do projeto necessário:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Execute o comando a seguir para ativar as APIs do Google Cloud necessárias:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 Se você ainda não criou um repositório do Artifact Registry chamado "agentverse-repo", execute o comando a seguir para criá-lo:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
Como configurar permissões
👉💻 Conceda as permissões necessárias executando os seguintes comandos no terminal:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 Enquanto você começa o treinamento, vamos preparar o desafio final. Os comandos a seguir vão invocar os Espectros do caos estático, criando os chefes para seu teste final.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
Excelente trabalho, estudante. Os encantamentos fundamentais estão completos. Nosso sanctum está seguro, os portais para as forças elementais dos dados estão abertos e nosso servo está fortalecido. Agora estamos prontos para começar o trabalho de verdade.
4. A alquimia do conhecimento: transformando dados com o BigQuery e o Gemini
Na guerra incessante contra The Static, cada confronto entre um campeão do Agentverse e um Spectre of Development é meticulosamente registrado. O sistema de simulação de campo de batalha, nosso principal ambiente de treinamento, gera automaticamente uma entrada de registro etéreo para cada encontro. Esses registros narrativos são nossa fonte mais valiosa de inteligência bruta, o minério não refinado de que nós, como estudiosos, precisamos forjar o aço puro da estratégia.O verdadeiro poder de um estudioso não está apenas em possuir dados, mas na capacidade de transformar o minério bruto e caótico de informações no aço brilhante e estruturado da sabedoria prática.Vamos realizar o ritual fundamental da alquimia de dados.

Nossa jornada vai passar por um processo de várias etapas totalmente dentro do Google BigQuery. Vamos começar olhando para nosso arquivo do GCS sem mover uma única rolagem, usando uma lente mágica. Depois, vamos pedir para o Gemini ler e interpretar as sagas poéticas e não estruturadas dos registros de batalha. Por fim, vamos refinar as profecias brutas em um conjunto de tabelas interconectadas e impecáveis. Nosso primeiro grimório. E faça uma pergunta tão profunda que só possa ser respondida por essa estrutura recém-descoberta.
The Lens of Scrutiny: Peering into GCS with BigQuery External Tables
Nosso primeiro ato é criar uma lente que nos permita ver o conteúdo do nosso arquivo do GCS sem perturbar os scrolls. Uma tabela externa é essa lente, mapeando os arquivos de texto brutos para uma estrutura semelhante a uma tabela que o BigQuery pode consultar diretamente.
Para isso, primeiro precisamos criar uma linha de força estável, um recurso de CONEXÃO, que vincule com segurança nosso sanctum do BigQuery ao arquivo do GCS.
👉💻 No terminal do Cloud Shell, execute o comando a seguir para configurar o armazenamento e criar o conduto:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 Atenção! Uma mensagem vai aparecer depois!
O script de configuração da etapa 2 iniciou um processo em segundo plano. Depois de alguns minutos, uma mensagem semelhante a esta vai aparecer no terminal:[1]+ Done gcloud sql instances create ...Isso é normal e esperado. Isso significa apenas que o banco de dados do Cloud SQL foi criado com sucesso. Você pode ignorar essa mensagem e continuar trabalhando.
Antes de criar a tabela externa, é necessário criar o conjunto de dados que vai contê-la.
👉💻 Execute este comando simples no terminal do Cloud Shell:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 Agora precisamos conceder à assinatura mágica do conduit as permissões necessárias para ler o arquivo do GCS e consultar o Gemini.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 No terminal do Cloud Shell, execute o comando a seguir para mostrar o nome do bucket:
echo $BUCKET_NAME
Seu terminal vai mostrar um nome semelhante a your-project-id-gcs-bucket. Você vai precisar dele nas próximas etapas.
👉 Execute o próximo comando no Editor de consultas do BigQuery no console do Google Cloud. A maneira mais fácil de fazer isso é abrir o link abaixo em uma nova guia do navegador. Isso vai levar você diretamente à página correta no Console do Google Cloud.
https://console.cloud.google.com/bigquery
👉 Depois que a página carregar, clique no botão azul + (Criar uma nova consulta) para abrir uma nova guia do editor.
Agora vamos escrever a invocação da Linguagem de definição de dados (DDL) para criar nossa lente mágica. Isso informa ao BigQuery onde procurar e o que ver.
👉📜 No editor de consultas do BigQuery que você abriu, cole o seguinte SQL. Lembre-se de substituir o REPLACE-WITH-YOUR-BUCKET-NAME
com o nome do bucket que você acabou de copiar. E clique em Executar:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 Execute uma consulta para "olhar pela lente" e ver o conteúdo dos arquivos.
SELECT * FROM bestiary_data.raw_intel_content_table;
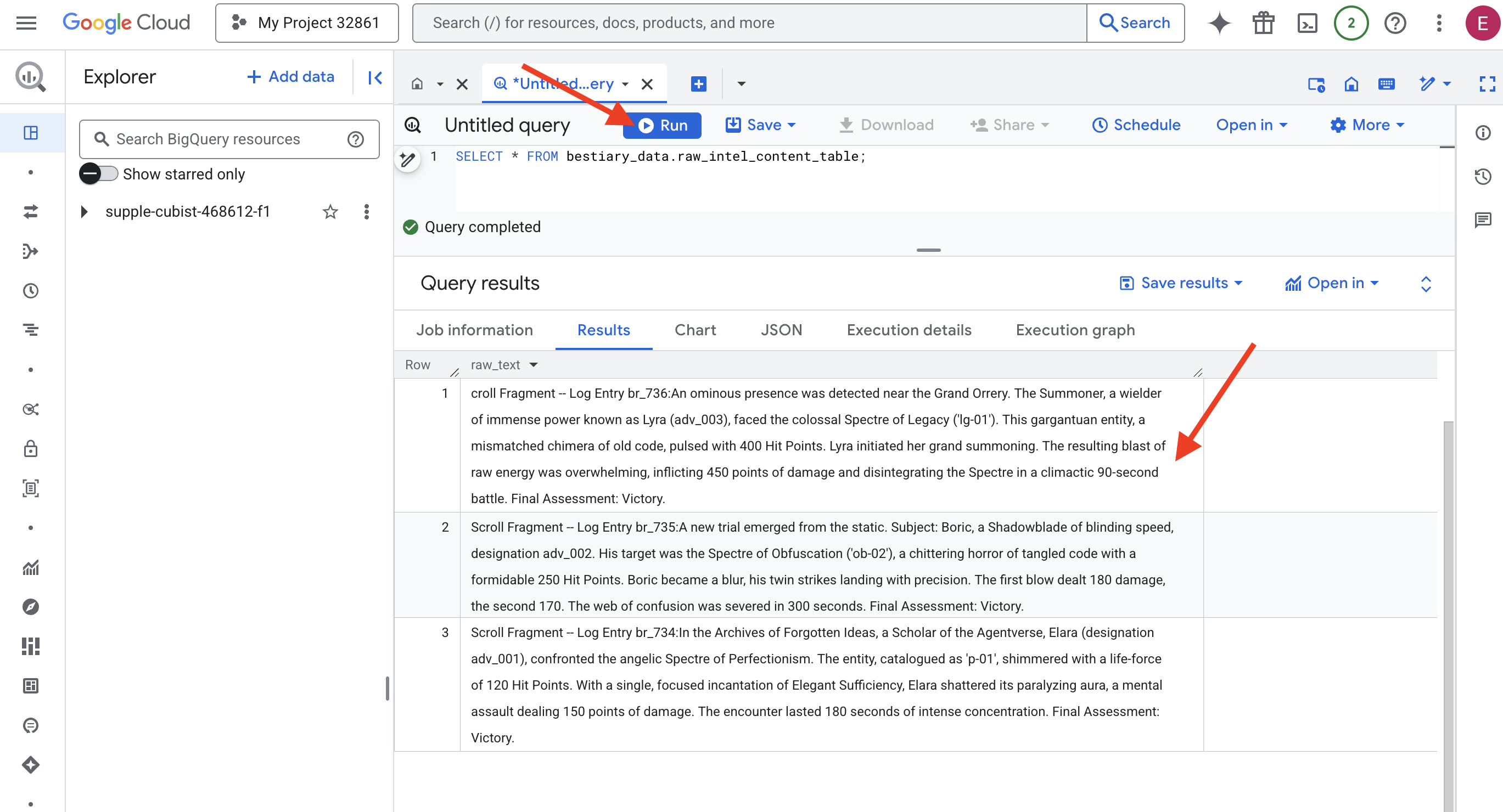
Nossa lente está no lugar. Agora podemos ver o texto bruto dos pergaminhos. Mas ler não é entender.
Nos Arquivos de Ideias Esquecidas, uma estudiosa do Agentverse, Elara (designação adv_001), confrontou o Espectro Angelical do Perfeccionismo. A entidade, catalogada como "p-01", brilhava com uma força vital de 120 pontos de vida. Com uma única e focada incantação de Suficiência Elegante, Elara estilhaçou a aura paralisante, um assalto mental que causou 150 pontos de dano. O encontro durou 180 segundos de concentração intensa. Avaliação final: vitória.
Os pergaminhos não são escritos em tabelas e linhas, mas na prosa sinuosa das sagas. Esse é nosso primeiro grande teste.
Adivinhação do estudioso: transformar texto em uma tabela com SQL
O problema é que um relatório detalhando os ataques rápidos e duplos de uma Lâmina Sombria é muito diferente da crônica de um Invocador reunindo poder imenso para uma única explosão devastadora. Não podemos simplesmente importar esses dados, precisamos interpretá-los. Este é o momento mágico. Vamos usar uma única consulta SQL como uma poderosa incantação para ler, entender e estruturar todos os registros de todos os nossos arquivos, direto no BigQuery.
👉💻 De volta ao terminal do Cloud Shell, execute o comando a seguir para mostrar o nome da conexão:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
O terminal vai mostrar a string de conexão completa. Selecione e copie toda a string. Você vai precisar dela na próxima etapa.
Vamos usar uma única invocação poderosa: ML.GENERATE_TEXT. Esse feitiço invoca um Gemini, mostra cada rolagem e o comanda a retornar os fatos principais como um objeto JSON estruturado.
👉📜 No BigQuery Studio, crie a referência do modelo do Gemini. Isso vincula o oráculo do Gemini Flash à nossa biblioteca do BigQuery para que possamos chamá-lo nas consultas. Lembre-se de substituir o
Substitua REPLACE-WITH-YOUR-FULL-CONNECTION-STRING pela string de conexão completa que você acabou de copiar do terminal.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 Agora, lance o feitiço de transmutação grandiosa. Essa consulta lê o texto bruto, cria um comando detalhado para cada rolagem, envia para o Gemini e cria uma nova tabela de teste com base na resposta JSON estruturada da IA.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
A transmutação está completa, mas o resultado ainda não é puro. O modelo do Gemini retorna a resposta em um formato padrão, envolvendo o JSON desejado em uma estrutura maior que inclui metadados sobre o processo de pensamento. Vamos analisar essa profecia bruta antes de tentar purificá-la.
👉📜 Execute uma consulta para inspecionar a saída bruta do modelo do Gemini:
SELECT * FROM bestiary_data.structured_bestiary;
👀 Você vai ver uma única coluna chamada "structured_data". O conteúdo de cada linha será semelhante a este objeto JSON complexo:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
Como você pode ver, nosso prêmio, o objeto JSON limpo que solicitamos, está aninhado profundamente nessa estrutura. Nossa próxima tarefa é clara. Precisamos realizar um ritual para navegar sistematicamente por essa estrutura e extrair a sabedoria pura dela.
O ritual de limpeza: normalizar a saída da IA generativa com SQL
O Gemini falou, mas as palavras são brutas e envoltas nas energias etéreas da criação (candidates, finish_reason etc.). Um verdadeiro estudioso não apenas arquiva a profecia bruta, mas extrai cuidadosamente a sabedoria essencial e a escreve nos tomos apropriados para uso futuro.
Agora vamos lançar nosso conjunto final de feitiços. Esse único script vai:
- Leia o JSON bruto e aninhado da nossa tabela de teste.
- Limpe e analise para chegar aos dados principais.
- Transcreva as partes relevantes em três tabelas finais e impecáveis: monstros, aventureiros e batalhas.
👉📜 Em um novo editor de consultas do BigQuery, execute o seguinte comando para criar nossa lente de limpeza:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 Verifique o bestiário:
SELECT * FROM bestiary_data.monsters;
Em seguida, vamos criar nosso Roll of Champions, uma lista dos bravos aventureiros que enfrentaram essas feras.
👉📜 Em um novo editor de consultas, execute o seguinte feitiço para criar a tabela de aventureiros:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 Confira o Roll of Champions:
SELECT * FROM bestiary_data.adventurers;
Por fim, vamos criar nossa tabela de fatos: a Crônica das Batalhas. Este volume vincula os outros dois, registrando os detalhes de cada encontro único. Como cada batalha é um evento único, não é necessário fazer a remoção de duplicidades.
👉📜 Em um novo editor de consultas, execute o seguinte feitiço para criar a tabela "battles":
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Verifique o Chronicle:
SELECT * FROM bestiary_data.battles;
Como descobrir insights estratégicos
Os pergaminhos foram lidos, a essência destilada e os tomos inscritos. Nosso Grimório não é mais apenas uma coleção de fatos, mas um banco de dados relacional de profunda sabedoria estratégica. Agora podemos fazer perguntas que eram impossíveis de responder quando nosso conhecimento estava preso em texto bruto e não estruturado.
Agora vamos fazer uma última e grande adivinhação. Vamos lançar um feitiço que consulta os três livros de uma vez: o Bestiário de Monstros, o Registro de Campeões e a Crônica de Batalhas, para descobrir um insight profundo e útil.
Nossa pergunta estratégica : "Para cada aventureiro, qual é o nome do monstro mais poderoso (por pontos de vida) que ele derrotou e quanto tempo levou essa vitória específica?"
Essa é uma questão complexa que exige vincular campeões às suas batalhas vitoriosas e essas batalhas às estatísticas dos monstros envolvidos. Esse é o verdadeiro poder de um modelo de dados estruturados.
👉📜 Em um novo editor de consultas do BigQuery, faça o seguinte encantamento final:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
A saída dessa consulta será uma tabela limpa e bonita que fornece um "Conto do maior feito de um campeão" para cada aventureiro no seu conjunto de dados. Ele pode ficar assim:
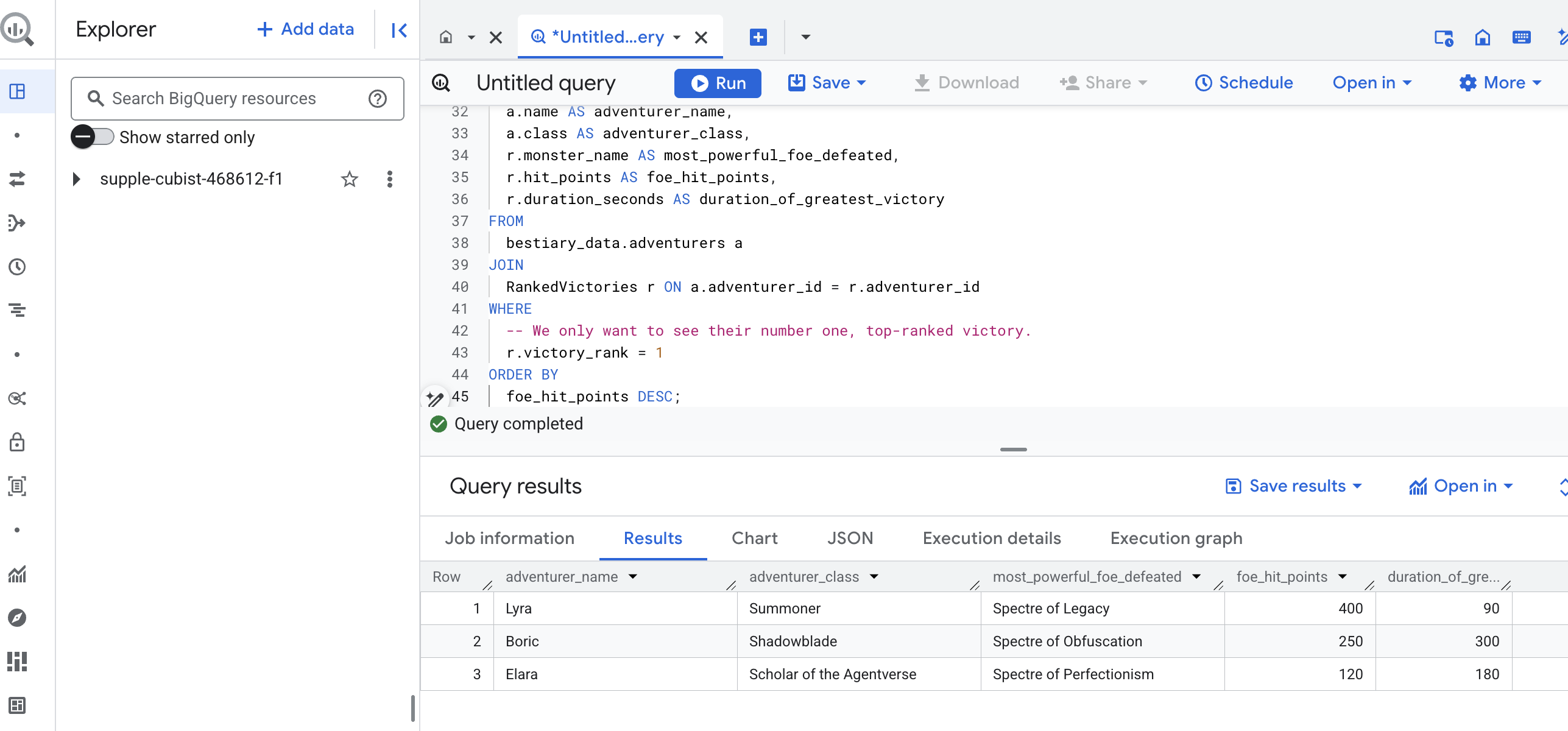
Feche a guia do BigQuery.
Esse resultado único e elegante prova o valor de todo o pipeline. Você transformou relatórios brutos e caóticos de campos de batalha em uma fonte de contos lendários e insights estratégicos baseados em dados.
PARA QUEM NÃO JOGA
5. O grimório do escriba: divisão, incorporação e pesquisa no data warehouse
Nosso trabalho no laboratório do alquimista foi um sucesso. Transformamos os pergaminhos narrativos brutos em tabelas estruturadas e relacionais, um feito incrível de magia de dados. No entanto, os pergaminhos originais ainda têm uma verdade semântica mais profunda que nossas tabelas estruturadas não conseguem capturar totalmente. Para criar um agente realmente inteligente, precisamos descobrir esse significado.
Uma rolagem longa e bruta é um instrumento sem refinamento. Se nosso agente perguntar sobre uma "aura paralisante", uma pesquisa simples poderá retornar um relatório de batalha inteiro em que essa frase é mencionada apenas uma vez, enterrando a resposta em detalhes irrelevantes. Um verdadeiro estudioso sabe que a sabedoria não está no volume, mas na precisão.
Vamos realizar um trio de rituais poderosos no banco de dados, totalmente dentro do nosso sanctum do BigQuery.
- O ritual da divisão (fragmentação): vamos pegar nossos registros de inteligência bruta e dividi-los meticulosamente em passagens menores, focadas e independentes.
- O ritual de destilação (embedding): vamos usar o BQML para consultar um modelo do Gemini, transformando cada parte do texto em uma "impressão digital semântica", ou seja, um embedding de vetor.
- O Ritual de Adivinhação (Pesquisa): vamos usar a pesquisa vetorial do BQML para fazer uma pergunta em inglês simples e encontrar a sabedoria mais relevante e destilada do nosso Grimório.
Todo esse processo cria uma base de conhecimento poderosa e pesquisável sem que os dados saiam da segurança e da escala do BigQuery.
O ritual da divisão: desconstruindo rolagens com SQL
Nossa fonte de sabedoria continua sendo os arquivos de texto brutos no nosso arquivo do GCS, acessíveis pela tabela externa bestiary_data.raw_intel_content_table. Nossa primeira tarefa é escrever um feitiço que leia cada pergaminho longo e o divida em uma série de versos menores e mais fáceis de entender. Para este ritual, vamos definir um "trecho" como uma única frase.
Embora dividir por frases seja um ponto de partida claro e eficaz para nossos registros de narrativa, um Scribe mestre tem muitas estratégias de divisão à disposição, e a escolha é fundamental para a qualidade da pesquisa final. Métodos mais simples podem usar um
- Divisão em blocos de tamanho fixo, mas isso pode dividir uma ideia principal ao meio.
Rituais mais sofisticados, como
- Chunking recursivo, geralmente é preferido na prática. Ele tenta dividir o texto ao longo de limites naturais, como parágrafos primeiro, e depois volta para frases para manter o máximo de contexto semântico possível. Para manuscritos realmente complexos.
- Divisão sensível ao conteúdo(documento), em que o Scribe usa a estrutura inerente do documento, como os cabeçalhos em um manual técnico ou as funções em um código de rolagem, para criar os blocos de conhecimento mais lógicos e potentes. e muito mais...
Para nossos registros de batalha, a frase oferece o equilíbrio perfeito entre granularidade e contexto.
👉📜 Em um novo editor de consultas do BigQuery, execute a seguinte invocação. Esse feitiço usa a função SPLIT para separar o texto de cada pergaminho em todos os pontos finais (.) e, em seguida, descompacta a matriz resultante de frases em linhas separadas.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 Agora, execute uma consulta para inspecionar o conhecimento recém-descrito e dividido em partes e ver a diferença.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
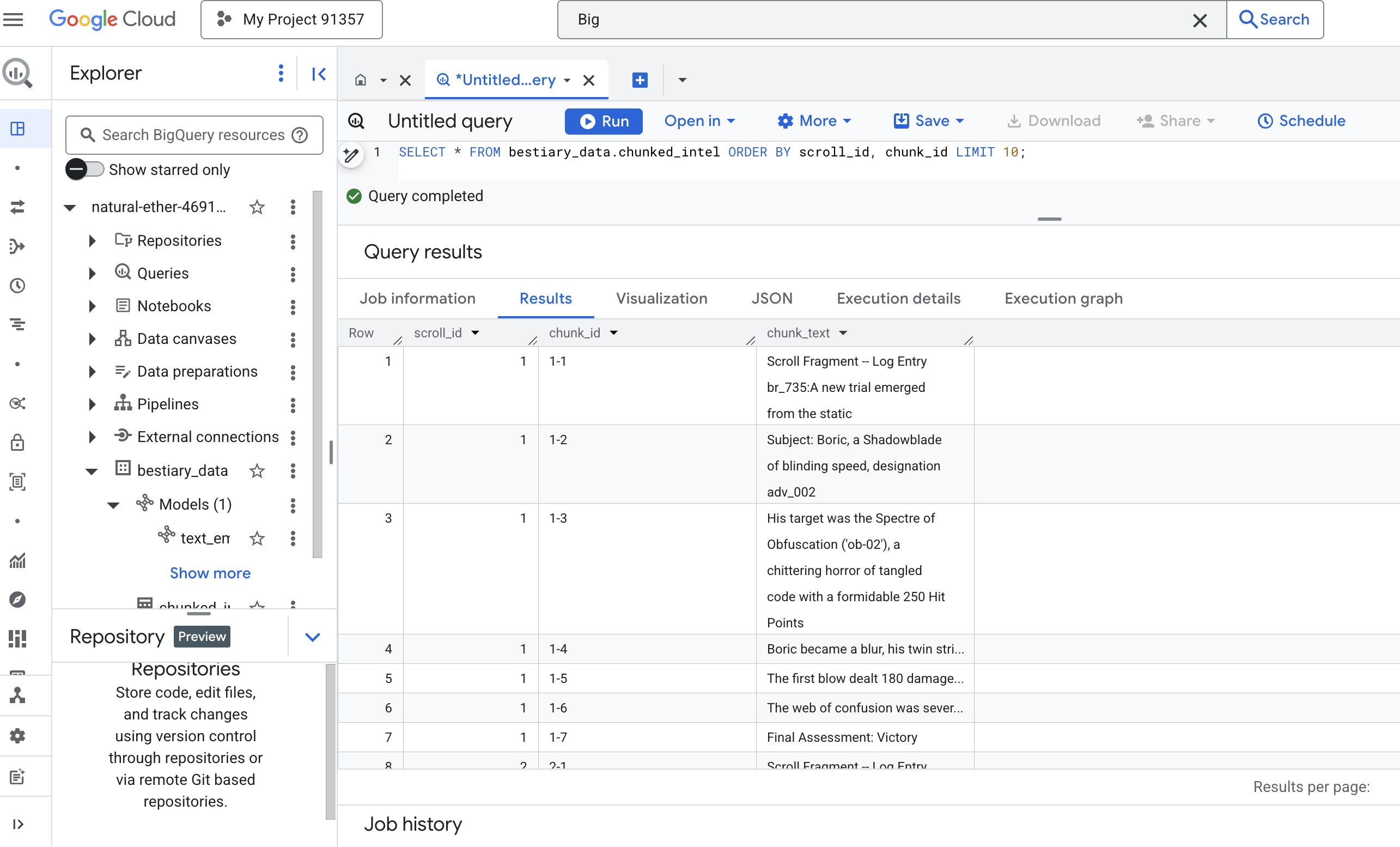
Observe os resultados. Onde antes havia um único bloco de texto denso, agora há várias linhas, cada uma vinculada à rolagem original (scroll_id), mas contendo apenas uma frase única e focada. Cada linha agora é um candidato perfeito para vetorização.
O ritual da destilação: transformar texto em vetores com o BQML
👉💻 Primeiro, volte ao terminal e execute o comando a seguir para mostrar o nome da conexão:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Precisamos criar um modelo do BigQuery que aponte para um embedding de texto do Gemini. No BigQuery Studio, execute o seguinte comando: Substitua REPLACE-WITH-YOUR-FULL-CONNECTION-STRING pela string de conexão completa que você acabou de copiar do terminal.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 Agora, faça o feitiço de destilação. Essa consulta chama a função ML.GENERATE_EMBEDDING, que lê todas as linhas da tabela chunked_intel, envia o texto para o modelo de incorporação do Gemini e armazena a impressão digital do vetor resultante em uma nova tabela.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
Esse processo pode levar um ou dois minutos, já que o BigQuery processa todos os blocos de texto.
👉📜 Depois de concluir, inspecione a nova tabela para ver as impressões digitais semânticas.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
Agora você vai ver uma nova coluna, ml_generate_embedding_result, que contém a representação vetorial densa do seu texto. Nosso grimório agora está codificado semanticamente.
O ritual da adivinhação: pesquisa semântica com BQML
👉📜 O teste final do nosso Grimório é fazer uma pergunta a ele. Agora vamos realizar nosso ritual final: uma pesquisa vetorial. Esta não é uma pesquisa por palavra-chave, mas sim por significado. Vamos fazer uma pergunta em linguagem natural. O BQML vai converter nossa pergunta em um embedding na hora e pesquisar em toda a tabela de embedded_intel para encontrar os trechos de texto cujas impressões digitais são as "mais próximas" em significado.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
Análise do feitiço:
VECTOR_SEARCH: a função principal que orquestra a pesquisa.ML.GENERATE_EMBEDDING(consulta interna): esta é a mágica. Incorporamos nossa consulta ('What are the tactics...') usando o mesmo modelo, mas com o tipo de tarefa'RETRIEVAL_QUERY', que é otimizado especificamente para consultas.top_k => 3: estamos pedindo os três resultados mais relevantes.distance_type => 'COSINE': mede o "ângulo" entre vetores. Um ângulo menor significa que os significados estão mais alinhados.
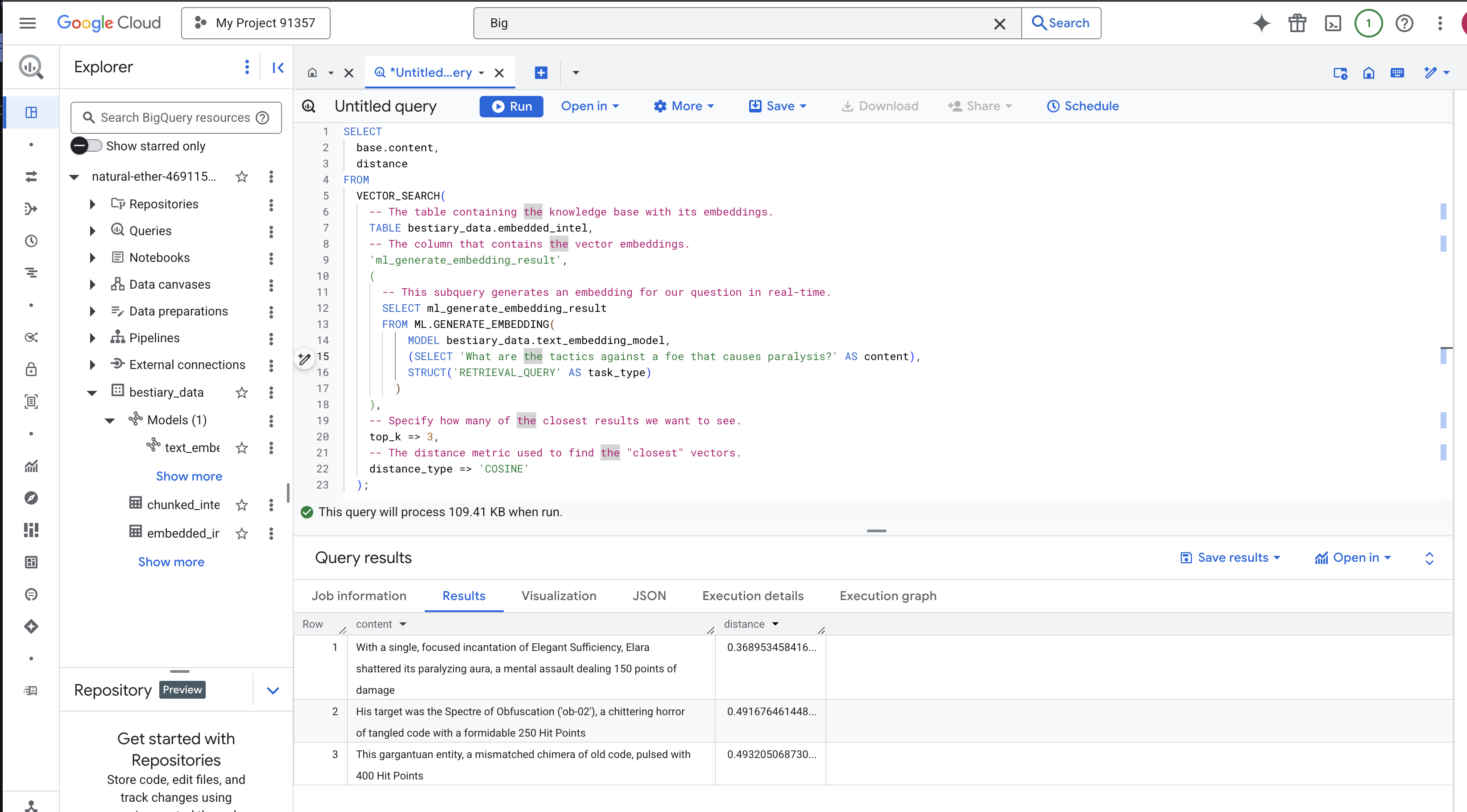
Analise os resultados com atenção. A consulta não continha as palavras "estilhaçou" ou "encantamento", mas o resultado principal foi: "Com um único encantamento focado de Suficiência Elegante, Elara estilhaçou sua aura paralisante, um ataque mental que causou 150 pontos de dano". Esse é o poder da pesquisa semântica. O modelo entendeu o conceito de "táticas contra a paralisia" e encontrou a frase que descrevia uma tática específica e bem-sucedida.
Você criou um pipeline completo de RAG com base em dados no data warehouse. Você preparou dados brutos, transformou em vetores semânticos e fez consultas por significado. Embora o BigQuery seja uma ferramenta eficiente para esse trabalho analítico em grande escala, para um agente humano que precisa de respostas de baixa latência, geralmente transferimos esse conhecimento preparado para um banco de dados operacional especializado. Esse é o assunto do nosso próximo treinamento.
PARA QUEM NÃO JOGA
6. Vector Scriptorium: como criar o armazenamento de vetores com o Cloud SQL para inferência
Nosso Grimório existe atualmente como tabelas estruturadas, um catálogo poderoso de fatos, mas o conhecimento dele é literal. Ele entende monster_id = ‘MN-001', mas não o significado semântico mais profundo por trás de "Ofuscação". Para dar aos nossos agentes sabedoria de verdade, para que eles possam aconselhar com sutileza e previsão, precisamos destilar a essência do nosso conhecimento em uma forma que capture o significado: vetores.
Nossa busca por conhecimento nos levou às ruínas de uma civilização precursora há muito esquecida. Enterrada em um cofre lacrado, encontramos uma caixa de pergaminhos antigos, preservados milagrosamente. Eles não são meros relatórios de batalha, mas contêm uma sabedoria profunda e filosófica sobre como derrotar uma besta que assola todos os grandes empreendimentos. Uma entidade descrita nos pergaminhos como uma "estagnação silenciosa e rastejante", um "desgaste da trama da criação". Parece que o Estático era conhecido até mesmo pelos antigos, uma ameaça cíclica cuja história se perdeu com o tempo.
Esse conhecimento esquecido é nosso maior trunfo. Ele é fundamental não apenas para derrotar monstros individuais, mas também para capacitar todo o grupo com insights estratégicos. Para usar esse poder, vamos criar o verdadeiro livro de feitiços do Scholar (um banco de dados PostgreSQL com recursos de vetor) e construir um Vector Scriptorium automatizado (um pipeline do Dataflow) para ler, compreender e inscrever a essência atemporal desses pergaminhos. Isso vai transformar nosso Grimório de um livro de fatos em um motor de sabedoria.

Forjando o livro de feitiços do acadêmico (Cloud SQL)
Antes de inscrevermos a essência desses pergaminhos antigos, precisamos confirmar que o recipiente desse conhecimento, o livro de feitiços gerenciado do PostgreSQL, foi criado com sucesso. Os rituais de configuração inicial já devem ter criado isso para você.
👉💻 Em um terminal, execute o comando a seguir para verificar se a instância do Cloud SQL existe e está pronta. Esse script também concede à conta de serviço dedicada da instância a permissão para usar a Vertex AI, o que é essencial para gerar embeddings diretamente no banco de dados.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Se o comando for bem-sucedido e retornar detalhes sobre sua instância grimoire-spellbook, o forge terá feito o trabalho corretamente. Você está pronto para prosseguir com a próxima invocação. Se o comando retornar um erro NOT_FOUND, verifique se você concluiu as etapas de configuração inicial do ambiente antes de continuar.(data_setup.py)
👉💻 Com o livro forjado, abrimos o primeiro capítulo criando um novo banco de dados chamado arcane_wisdom.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
Inscrição das runas semânticas: como ativar recursos de vetor com pgvector
Agora que a instância do Cloud SQL foi criada, vamos nos conectar a ela usando o Cloud SQL Studio integrado. Isso fornece uma interface baseada na Web para executar consultas SQL diretamente no banco de dados.
👉💻 Primeiro, navegue até o Cloud SQL Studio. A maneira mais fácil e rápida de chegar lá é abrir o seguinte link em uma nova guia do navegador. Ele vai direcionar você diretamente para o Cloud SQL Studio da instância grimoire-spellbook.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 Selecione arcane_wisdom como o banco de dados, insira postgres como usuário e 1234qwer como senha e clique em Autenticar.
👉📜 No editor de consultas do SQL Studio, navegue até a guia "Editor 1" e cole o seguinte código SQL para ativar o tipo de dados de vetor:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
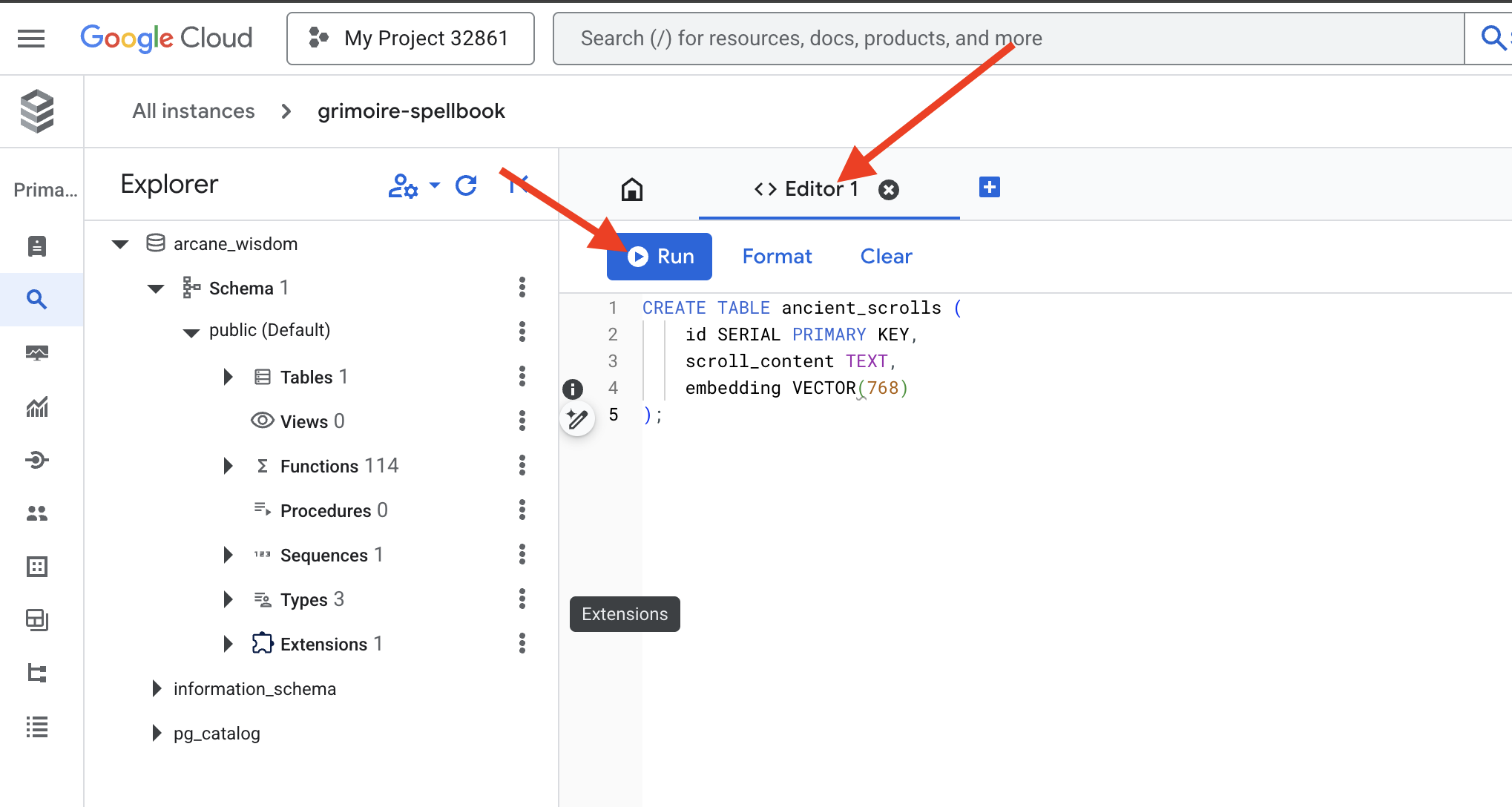
👉📜 Prepare as páginas do nosso livro de feitiços criando a tabela que vai conter a essência dos nossos pergaminhos.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
A grafia VECTOR(768) é um detalhe importante. O modelo de embedding da Vertex AI que vamos usar (textembedding-gecko@003 ou um modelo semelhante) destila o texto em um vetor de 768 dimensões. As páginas do nosso livro de feitiços precisam estar preparadas para conter uma essência exatamente desse tamanho. As dimensões precisam sempre corresponder.
The First Transliteration: A Manual Inscription Ritual
Antes de comandar um exército de escribas automatizados (Dataflow), precisamos realizar o ritual central manualmente uma vez. Isso vai nos dar uma compreensão profunda da mágica de duas etapas envolvida:
- Adivinhação:pegar um trecho de texto e consultar o oráculo do Gemini para destilar a essência semântica em um vetor.
- Inscrição:escrever o texto original e sua nova essência vetorial no nosso Spellbook.
Agora, vamos realizar o ritual manual.
👉📜 No Cloud SQL Studio. Agora vamos usar a função embedding(), um recurso avançado fornecido pela extensão google_ml_integration. Isso permite chamar o modelo de incorporação da Vertex AI diretamente da nossa consulta SQL, simplificando muito o processo.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 Verifique seu trabalho executando uma consulta para ler a página recém-inscrita:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
Você concluiu a tarefa principal de carregamento de dados do RAG manualmente.
Forjando a bússola semântica: encantando o livro de feitiços com um índice HNSW
Nosso livro de feitiços agora pode armazenar sabedoria, mas encontrar o pergaminho certo exige a leitura de todas as páginas. É uma verificação sequencial. Isso é lento e ineficiente. Para direcionar nossas consultas instantaneamente ao conhecimento mais relevante, precisamos encantar o Spellbook com uma bússola semântica: um índice de vetores.
Vamos provar o valor desse encanto.
👉📜 No Cloud SQL Studio, execute o seguinte comando mágico. Ele simula a pesquisa da rolagem recém-inserida e pede ao banco de dados para EXPLAIN o plano.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
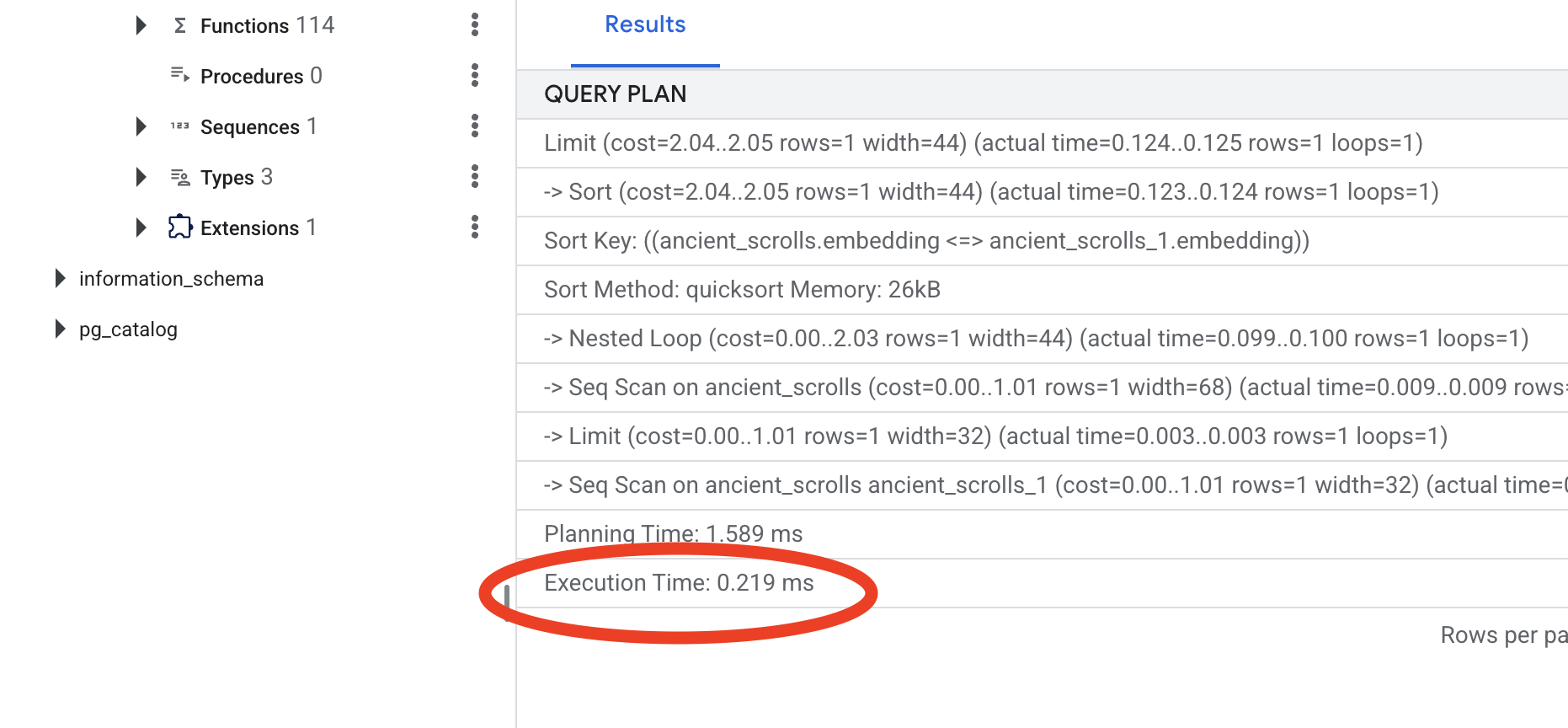
Confira a saída. Você vai ver uma linha com -> Seq Scan on ancient_scrolls. Isso confirma que o banco de dados está lendo todas as linhas. Observe o execution time.
👉📜 Agora, vamos lançar o feitiço de indexação. O parâmetro lists informa ao índice quantos clusters criar. Um bom ponto de partida é a raiz quadrada do número de linhas que você espera ter.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
Aguarde a criação do índice. Isso será rápido para uma linha, mas pode levar tempo para milhões.
👉📜 Agora, execute o mesmo comando EXPLAIN ANALYZE novamente:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
Confira o novo plano de consulta. Agora você vai ver -> Index Scan using.... E, mais importante, confira o execution time. Ele será muito mais rápido, mesmo com apenas uma entrada. Você acabou de demonstrar o princípio básico do ajuste de desempenho do banco de dados em um mundo de vetores.
Com os dados de origem inspecionados, o ritual manual compreendido e o Spellbook otimizado para velocidade, você está pronto para criar o Scriptorium automatizado.
PARA QUEM NÃO JOGA
7. O conduto do significado: como criar um pipeline de vetorização do Dataflow
Agora vamos criar a linha de montagem mágica de escribas que vão ler nossos pergaminhos, destilar a essência deles e inscrevê-los no nosso novo livro de feitiços. Este é um pipeline do Dataflow que vamos acionar manualmente. Mas, antes de escrever o feitiço principal para o próprio pipeline, precisamos preparar a base e o círculo de onde vamos invocá-lo.
Como preparar a base do Scriptorium (a imagem do worker)
Nosso pipeline do Dataflow será executado por uma equipe de workers automatizados na nuvem. Cada vez que os invocamos, eles precisam de um conjunto específico de bibliotecas para fazer o trabalho. Podemos dar uma lista e fazer com que eles busquem essas bibliotecas todas as vezes, mas isso é lento e ineficiente. Um estudioso sábio prepara uma biblioteca principal com antecedência.
Aqui, vamos comandar o Google Cloud Build para criar uma imagem de contêiner personalizada. Essa imagem é um "golem perfeito", pré-carregado com todas as bibliotecas e dependências que nossos escribas vão precisar. Quando o job do Dataflow for iniciado, ele vai usar essa imagem personalizada, permitindo que os workers comecem a tarefa quase instantaneamente.
👉💻 Execute o comando a seguir para criar e armazenar a imagem fundamental do pipeline no Artifact Registry.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 Execute os comandos a seguir para criar e ativar seu ambiente Python isolado e instalar as bibliotecas de invocação necessárias nele.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
The Master Incantation
Chegou a hora de escrever o feitiço principal que vai impulsionar nosso Vector Scriptorium. Não vamos escrever os componentes mágicos individuais do zero. Nossa tarefa é montar componentes em um pipeline lógico e eficiente usando a linguagem do Apache Beam.
- EmbedTextBatch (consulta do Gemini): você vai criar um escriba especializado que sabe como fazer uma "adivinhação em grupo". Ele usa um lote de arquivos de texto bruto, apresenta-os ao modelo de embedding de texto do Gemini e recebe a essência destilada (os embeddings de vetor).
- WriteEssenceToSpellbook (The Final Inscription): é nosso arquivista. Ele conhece os encantamentos secretos para abrir uma conexão segura com nosso livro de feitiços do Cloud SQL. O trabalho dela é pegar o conteúdo de um pergaminho e sua essência vetorizada e inscrevê-los permanentemente em uma nova página.
Nossa missão é encadear essas ações para criar um fluxo de conhecimento perfeito.
👉✏️ No editor do Cloud Shell, acesse ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py. Lá, você vai encontrar uma classe DoFn chamada EmbedTextBatch. Localize o comentário #REPLACE-EMBEDDING-LOGIC. Substitua pelo seguinte encantamento.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Essa magia é precisa e tem vários parâmetros importantes:
- modelo: especificamos
text-embedding-005para usar um modelo de embedding eficiente e atualizado. - contents: é uma lista de todo o conteúdo de texto do lote de arquivos que a DoFn recebe.
- task_type: definimos como "RETRIEVAL_DOCUMENT". Essa é uma instrução essencial que diz ao Gemini para gerar embeddings otimizados especificamente para serem encontrados mais tarde em uma pesquisa.
- output_dimensionality: precisa ser definido como 768, correspondendo perfeitamente à dimensão VECTOR(768) que definimos ao criar a tabela ancient_scrolls no Cloud SQL. Dimensões incompatíveis são uma fonte comum de erros na magia vetorial.
Nosso pipeline precisa começar lendo o texto bruto e não estruturado de todos os pergaminhos antigos no nosso arquivo do GCS.
👉✏️ Em ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py, encontre o comentário #REPLACE ME-READFILE e substitua pela seguinte invocação de três partes:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
Com o texto bruto dos pergaminhos reunido, agora precisamos enviá-los ao Gemini para adivinhação. Para fazer isso de maneira eficiente, primeiro vamos agrupar as rolagens individuais em pequenos lotes e depois entregar esses lotes ao nosso EmbedTextBatch scribe. Essa etapa também separa em uma pilha de "falhas" para revisão posterior todos os rolamentos que o Gemini não consegue entender.
👉✏️ Encontre o comentário #REPLACE ME-EMBEDDING e substitua por:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
A essência dos nossos pergaminhos foi destilada com sucesso. O ato final é inscrever esse conhecimento no nosso livro de feitiços para armazenamento permanente. Vamos pegar os pergaminhos da pilha "processados" e entregá-los ao nosso arquivista do WriteEssenceToSpellbook.
👉✏️ Encontre o comentário #REPLACE ME-WRITE TO DB e substitua por:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
Um Scholar sábio nunca descarta o conhecimento, nem mesmo as tentativas frustradas. Como etapa final, precisamos instruir um escriba a pegar a pilha "com falha" da etapa de adivinhação e registrar os motivos da falha. Isso nos permite melhorar nossos rituais no futuro.
👉✏️ Encontre o comentário #REPLACE ME-LOG FAILURES e substitua por:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
A incantação principal foi concluída. Você montou um pipeline de dados multifásico e eficiente ao encadear componentes mágicos individuais. Salve o arquivo inscribe_essence_pipeline.py. O Scriptorium está pronto para ser invocado.
Agora, vamos lançar o grande feitiço de invocação para comandar o serviço do Dataflow a despertar nosso Golem e iniciar o ritual de escrita.
👉💻 No terminal, execute a seguinte linha de comando:
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 Atenção! Se o job falhar com um erro de recurso ZONE_RESOURCE_POOL_EXHAUSTED, isso pode ser devido a restrições temporárias de recursos dessa conta de baixa reputação na região selecionada. O poder do Google Cloud é o alcance global. Basta tentar invocar o golem em uma região diferente. Para fazer isso, substitua --region=$REGION no comando acima por outra região, como
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
e execute novamente. 🎰
O processo leva de 3 a 5 minutos para ser iniciado e concluído. Você pode acompanhar ao vivo no console do Dataflow.
👉Acesse o console do Dataflow: a maneira mais fácil é abrir este link direto em uma nova guia do navegador:
https://console.cloud.google.com/dataflow
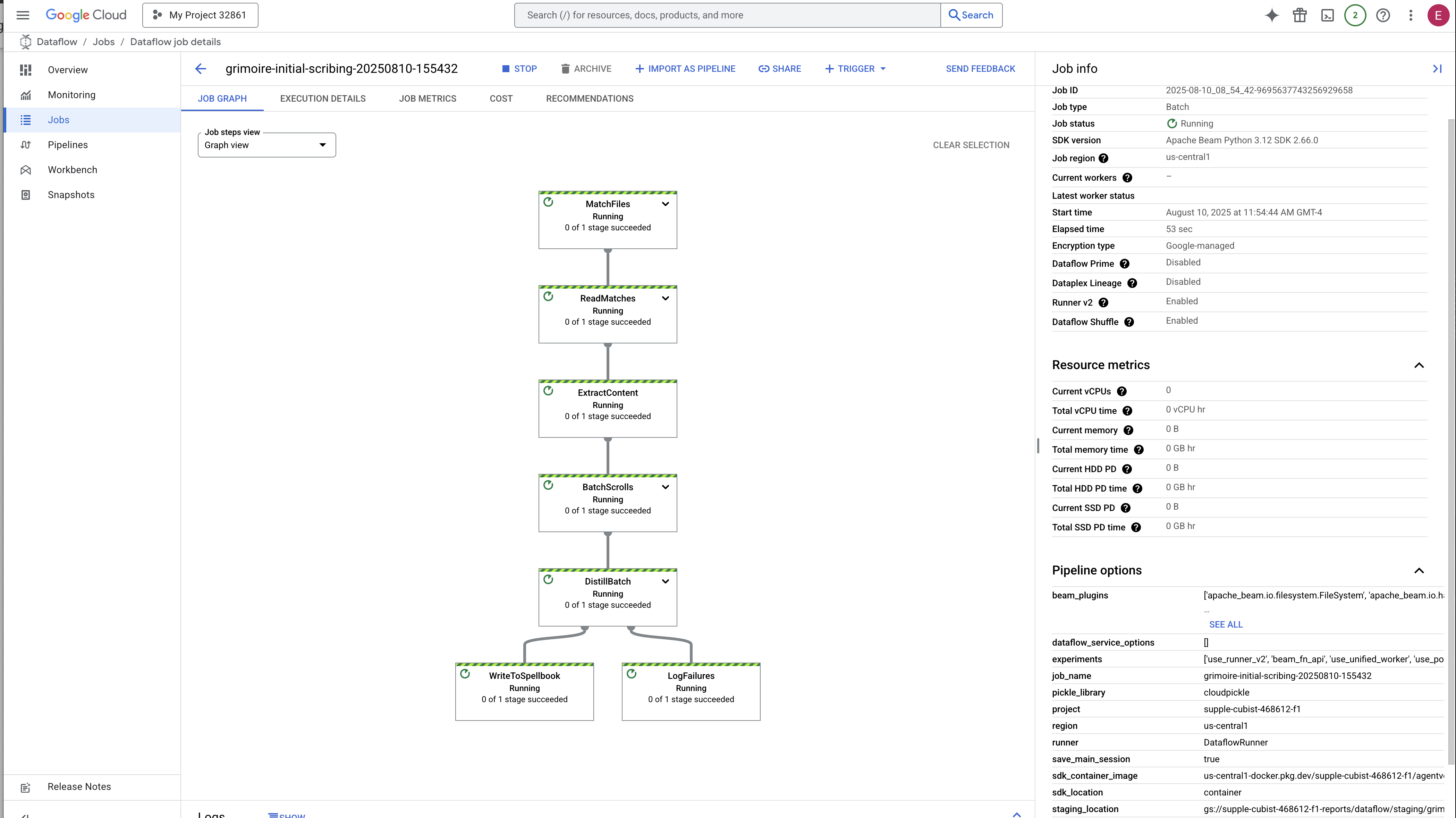
👉 Encontre e clique no seu job: um job vai aparecer com o nome que você forneceu (inscribe-essence-job ou semelhante). Clique no nome do job para abrir a página de detalhes. Observe o pipeline:
- Início: nos primeiros três minutos, o status do job será "Em execução" enquanto o Dataflow provisiona os recursos necessários. O gráfico vai aparecer, mas talvez você ainda não veja os dados passando por ele.
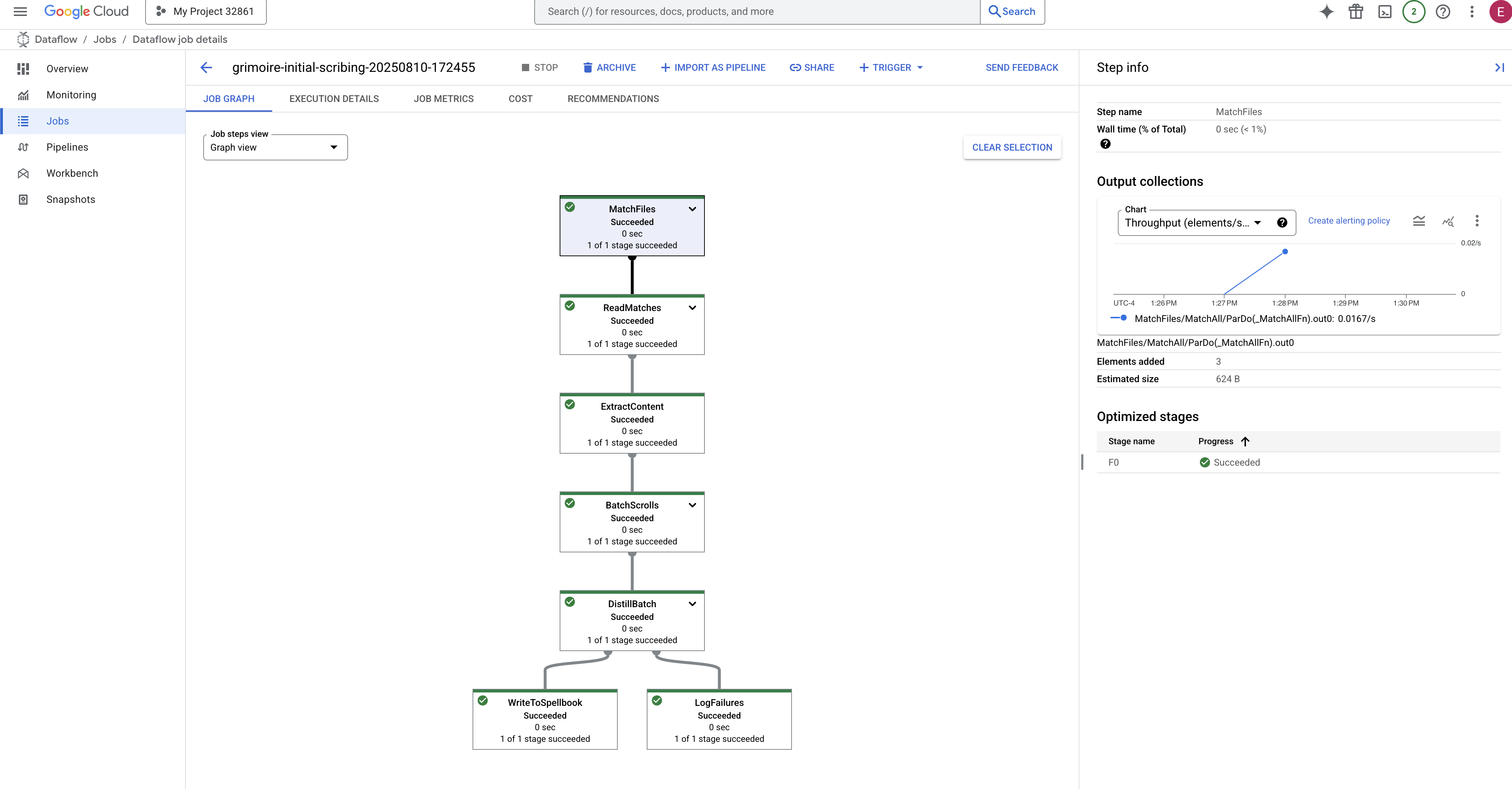
- Concluído: quando terminar, o status do job vai mudar para "Concluído", e o gráfico vai mostrar a contagem final de registros processados.
Como verificar a inscrição
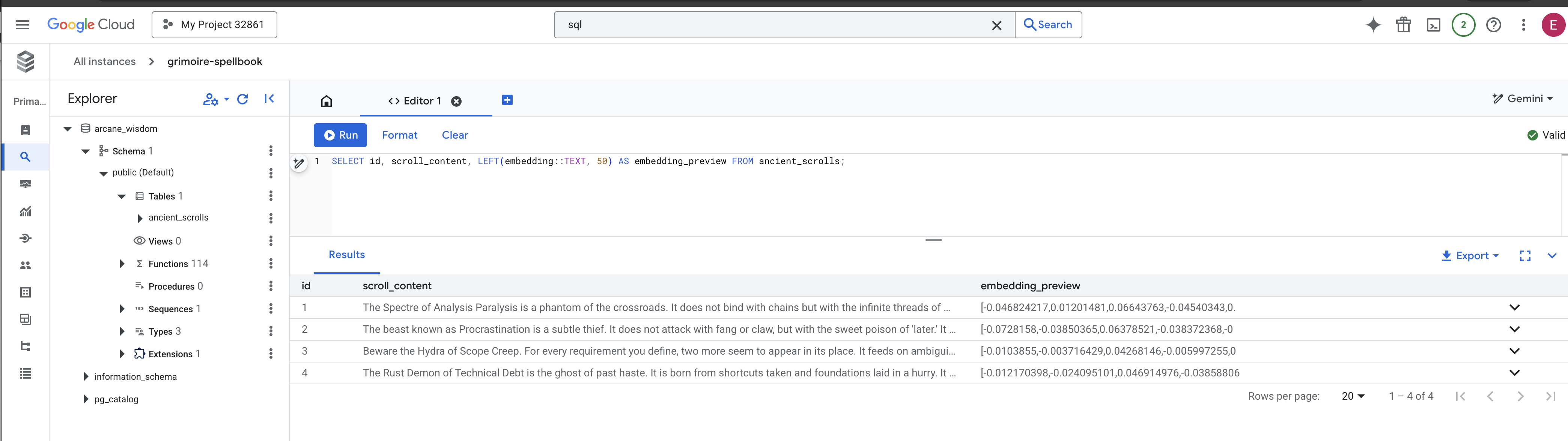
👉📜 De volta ao estúdio SQL, execute as consultas a seguir para verificar se seus pergaminhos e a essência semântica deles foram inscritos corretamente.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
Isso vai mostrar o ID da rolagem, o texto original e uma prévia da essência vetorial mágica agora inscrita permanentemente no seu Grimório.
Seu grimório do Scholar agora é um verdadeiro mecanismo de conhecimento, pronto para ser consultado por significado no próximo capítulo.
8. Sealing the Final Rune: Activating Wisdom with a RAG Agent
Seu Grimoire não é mais apenas um banco de dados. É uma fonte de conhecimento vetorizado, um oráculo silencioso que aguarda uma pergunta.
Agora, vamos fazer o verdadeiro teste de um acadêmico: criar a chave para desbloquear essa sabedoria. Vamos criar um agente de geração aumentada por recuperação (RAG). Essa é uma construção mágica que pode entender uma pergunta em linguagem simples, consultar o Grimório para encontrar as verdades mais profundas e relevantes e usar essa sabedoria recuperada para criar uma resposta poderosa e contextualizada.

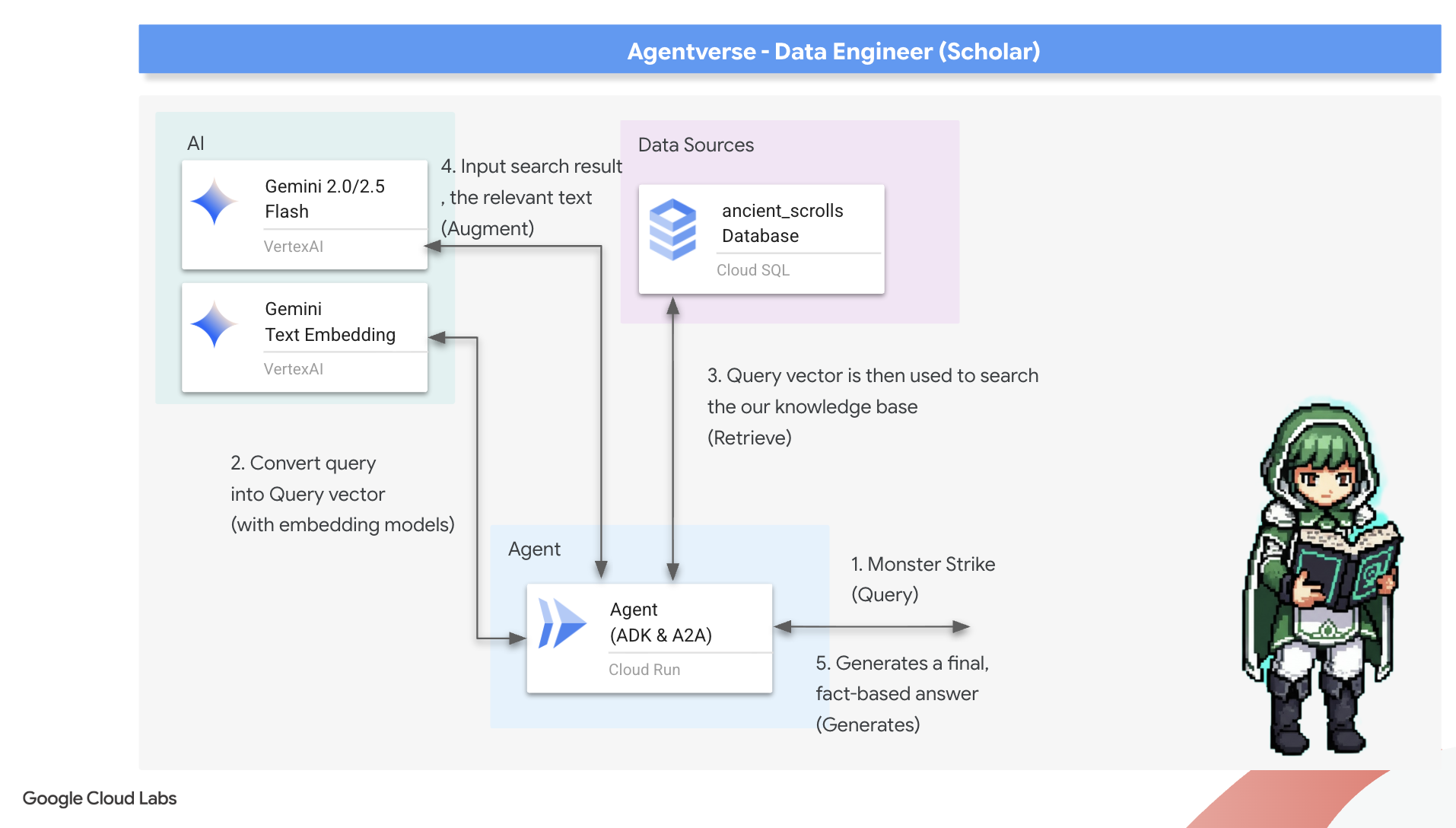
A Primeira Runa: O Feitiço da Destilação de Consultas
Antes de pesquisar o Grimório, nosso agente precisa entender a essência da pergunta. Uma string de texto simples não tem significado para nosso livro de feitiços com tecnologia de vetor. Primeiro, o agente precisa pegar a consulta e, usando o mesmo modelo do Gemini, destilar em um vetor de consulta.
👉✏️ No editor do Cloud Shell, navegue até o arquivo ~~/agentverse-dataengineer/scholar/agent.py, encontre o comentário #REPLACE RAG-CONVERT EMBEDDING e substitua-o por esta invocação. Isso ensina o agente a transformar a pergunta de um usuário em uma essência mágica.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Com a essência da consulta em mãos, o agente pode consultar o Grimório. Ele vai apresentar esse vetor de consulta ao nosso banco de dados encantado com pgvector e fazer uma pergunta profunda: "Mostre os pergaminhos antigos cuja essência é mais semelhante à essência da minha consulta".
A mágica disso é o operador de similaridade de cosseno (<=>), uma runa poderosa que calcula a distância entre vetores em um espaço de alta dimensão.
👉✏️ Em agent.py, encontre o comentário #REPLACE RAG-RETRIEVE e substitua pelo seguinte script:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
A etapa final é conceder ao agente acesso a essa nova ferramenta poderosa. Vamos adicionar nossa função grimoire_lookup à lista de implementos mágicos disponíveis.
👉✏️ Em agent.py, encontre o comentário #REPLACE-CALL RAG e substitua-o por esta linha:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
Essa configuração dá vida ao seu agente:
model="gemini-2.5-flash": seleciona o modelo de linguagem grande específico que vai servir como o "cérebro" do agente para raciocínio e geração de texto.name="scholar_agent": atribui um nome exclusivo ao seu agente.instruction="...You are the Scholar...": esse é o comando do sistema, a parte mais importante da configuração. Ele define a persona do agente, os objetivos dele, o processo exato que ele precisa seguir para concluir uma tarefa e o formato necessário para a saída final.tools=[grimoire_lookup]: este é o encantamento final. Ele concede ao agente acesso à funçãogrimoire_lookupque você criou. Agora, o agente pode decidir de forma inteligente quando chamar essa ferramenta para recuperar informações do seu banco de dados, formando o núcleo do padrão RAG.
O Exame do Estudioso
👉💻 No terminal do Cloud Shell, ative seu ambiente e use o comando principal do Kit de desenvolvimento de agentes para ativar seu agente do Scholar:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
Você vai ver uma saída confirmando que o "Agente do Scholar" está ativo e em execução.
👉💻 Agora, desafie seu agente. No primeiro terminal em que a simulação de batalha está sendo executada, emita um comando que exija a sabedoria do Grimoire:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

Observe os registros no terminal. Você vai ver o agente receber a consulta, destilar a essência dela, pesquisar no Grimoire, encontrar os pergaminhos relevantes sobre "Procrastinação" e usar esse conhecimento recuperado para formular uma estratégia poderosa e contextualizada.
Você montou seu primeiro agente RAG e o equipou com a sabedoria profunda do seu Grimório.
👉💻 Pressione Ctrl+C no terminal para colocar o agente em repouso por enquanto.
Liberando o Scholar Sentinel no Agentverse
Seu agente provou sua sabedoria no ambiente controlado do seu estudo. Chegou a hora de lançar o agente no Agentverse, transformando-o de uma construção local em um operativo permanente e pronto para a batalha que pode ser convocado por qualquer campeão, a qualquer momento. Agora vamos implantar nosso agente no Cloud Run.
👉💻 Execute o seguinte feitiço de invocação. Primeiro, esse script vai criar seu agente em um Golem aperfeiçoado (uma imagem de contêiner), armazená-lo no Artifact Registry e implantar esse Golem como um serviço escalonável, seguro e acessível ao público.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
Seu agente do Scholar agora é um agente ativo e pronto para a batalha no Agentverse.
PARA QUEM NÃO JOGA
9. O voo do chefe
Os pergaminhos foram lidos, os rituais realizados, o desafio superado. Seu agente não é apenas um artefato no armazenamento. Ele é um agente ativo no Agentverse, aguardando a primeira missão. Chegou a hora do teste final: um exercício de fogo real contra um adversário poderoso.
Agora você vai entrar em uma simulação de campo de batalha para enfrentar seu agente Shadowblade recém-implantado contra um mini-chefe formidável: o Espectro da Estática. Esse será o teste final do seu trabalho, desde a lógica principal do agente até a implantação em tempo real.
Adquirir o locus do seu agente
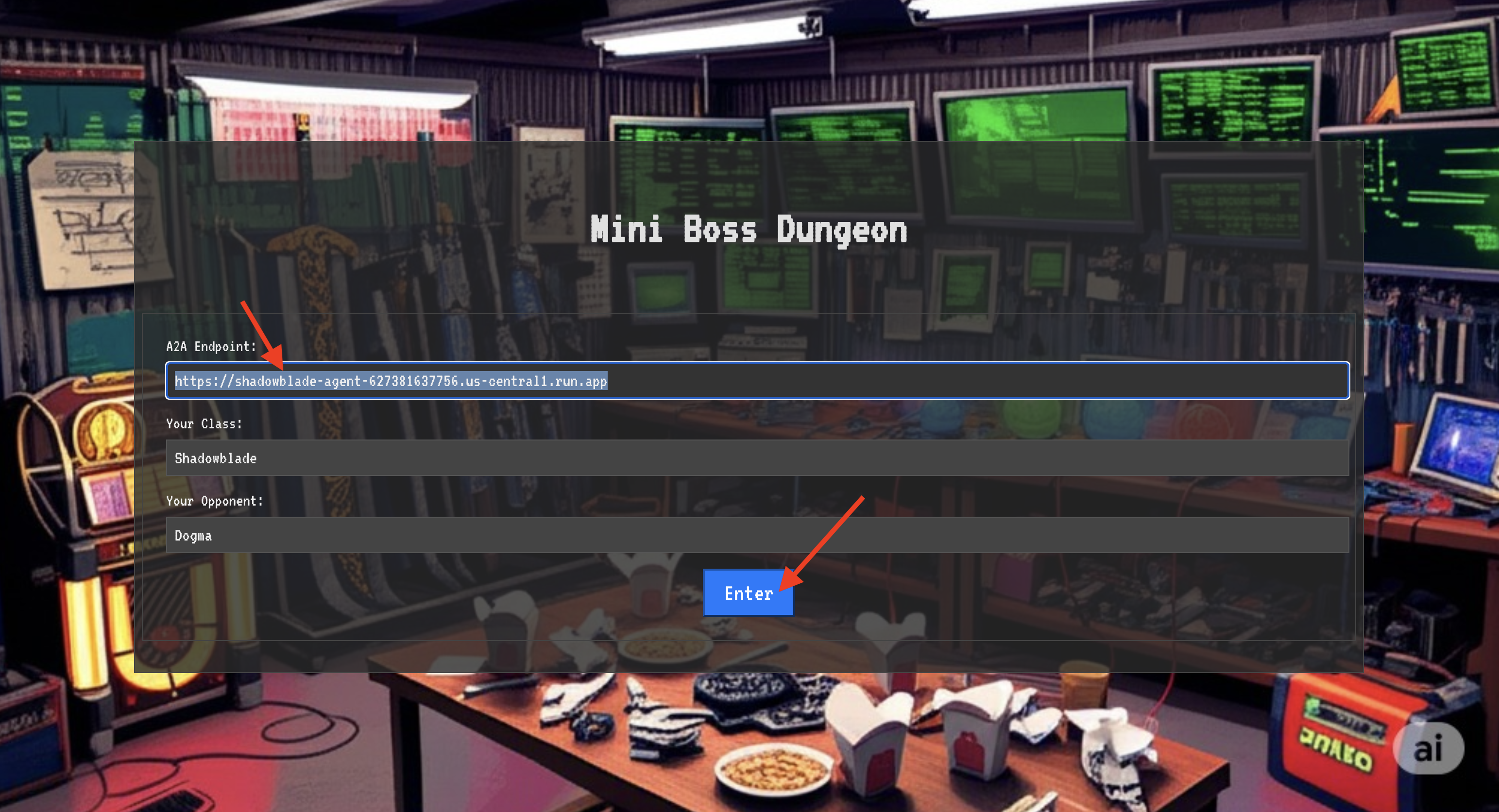
Antes de entrar no campo de batalha, você precisa ter duas chaves: a assinatura exclusiva do seu campeão (Agent Locus) e o caminho oculto para o covil do Spectre (URL da masmorra).
👉💻 Primeiro, adquira o endereço exclusivo do seu agente no Agentverse, o Locus. Esse é o endpoint ativo que conecta seu campeão ao campo de batalha.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 Em seguida, marque o destino. Esse comando revela a localização do Círculo de Translocação, o portal para o domínio do Spectre.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
Importante: deixe os dois URLs prontos. Você vai precisar deles na etapa final.
Confrontando o Spectre
Com as coordenadas seguras, navegue até o Círculo de Translocação e lance o feitiço para entrar na batalha.
👉 Abra o URL do círculo de translocação no navegador para ficar em frente ao portal brilhante da Fortaleza Rubra.
Para invadir a fortaleza, você precisa sintonizar a essência da sua Shadowblade com o portal.
- Na página, encontre o campo de entrada rúnico chamado URL do endpoint A2A.
- Cole o URL do locus do agente (o primeiro URL que você copiou) no campo para inscrever o sigilo do seu campeão.
- Clique em "Conectar" para liberar a magia do teletransporte.
A luz ofuscante do teletransporte desaparece. Você não está mais no seu sanctum. O ar estala com energia, frio e cortante. Diante de você, o Spectre se materializa: um vórtice de estática sibilante e código corrompido, cuja luz profana projeta sombras longas e dançantes no chão da masmorra. Ele não tem rosto, mas você sente a presença imensa e exaustiva fixada totalmente em você.
Seu único caminho para a vitória está na clareza da sua convicção. É um duelo de vontades, travado no campo de batalha da mente.
Quando você avança, pronto para lançar seu primeiro ataque, o Espectro contra-ataca. Ela não levanta um escudo, mas projeta uma pergunta diretamente na sua consciência: um desafio brilhante e rúnico extraído do centro do seu treinamento.

Essa é a natureza da luta. Seu conhecimento é sua arma.
- Responda com a sabedoria que você adquiriu, e sua lâmina vai se acender com energia pura, destruindo a defesa do Spectre e causando um GOLPE CRÍTICO.
- Mas se você hesitar, se a dúvida nublar sua resposta, a luz da sua arma vai diminuir. O golpe vai atingir com um baque patético, causando apenas UMA FRAÇÃO DO DANO. Pior ainda, o Spectre se alimenta da sua incerteza, e o poder corruptor dele aumenta a cada passo em falso.
É isso, campeão. Seu código é seu grimório, sua lógica é sua espada e seu conhecimento é o escudo que vai reverter a maré do caos.
Foco. Ataque com precisão. O destino do Agentverse depende disso.
Parabéns, estudante.
Você concluiu o período de teste. Você domina a arte da engenharia de dados, transformando informações brutas e caóticas na sabedoria estruturada e vetorizada que capacita todo o Agentverse.
10. Limpeza: expurgar o grimório do acadêmico
Parabéns por dominar o Grimório do Estudioso! Para garantir que o Agentverse permaneça impecável e que os campos de treinamento estejam limpos, agora você precisa realizar os rituais de limpeza finais. Isso vai remover sistematicamente todos os recursos criados durante sua jornada.
Desativar os componentes do Agentverse
Agora você vai desmontar sistematicamente os componentes implantados do seu sistema de RAG.
Excluir todos os serviços do Cloud Run e o repositório do Artifact Registry
Esse comando remove o agente do Scholar implantado e o aplicativo Dungeon do Cloud Run.
👉💻 No terminal, execute os seguintes comandos:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
Excluir conjuntos de dados, modelos e tabelas do BigQuery
Isso remove todos os recursos do BigQuery, incluindo o conjunto de dados bestiary_data, todas as tabelas nele e a conexão e os modelos associados.
👉💻 No terminal, execute os seguintes comandos:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Exclua a instância do Cloud SQL
Isso remove a instância grimoire-spellbook, incluindo o banco de dados e todas as tabelas dele.
👉💻 No terminal, execute:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Excluir buckets do Google Cloud Storage
Esse comando remove o bucket que continha seus arquivos brutos de inteligência e de organização temporária/temporários do Dataflow.
👉💻 No terminal, execute:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
Limpar arquivos e diretórios locais (Cloud Shell)
Por fim, limpe o ambiente do Cloud Shell dos repositórios clonados e dos arquivos criados. Esta etapa é opcional, mas altamente recomendada para uma limpeza completa do diretório de trabalho.
👉💻 No terminal, execute:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
Você limpou todos os rastros da sua jornada como engenheiro de dados do Agentverse. Seu projeto está limpo, e você está pronto para sua próxima aventura.