
1. Overture
ยุคของการพัฒนาแบบแยกส่วนกำลังจะสิ้นสุดลง การพัฒนาเทคโนโลยีในยุคถัดไปไม่ได้ขึ้นอยู่กับอัจฉริยะเพียงคนเดียว แต่ขึ้นอยู่กับการทำงานร่วมกันอย่างเชี่ยวชาญ การสร้างเอเจนต์อัจฉริยะเพียงตัวเดียวเป็นการทดลองที่น่าสนใจ การสร้างระบบนิเวศของเอเจนต์ที่แข็งแกร่ง ปลอดภัย และอัจฉริยะ ซึ่งเป็น Agentverse อย่างแท้จริงถือเป็นความท้าทายที่ยิ่งใหญ่สำหรับองค์กรยุคใหม่
ความสำเร็จในยุคใหม่นี้ต้องอาศัยการบรรจบกันของบทบาทสำคัญ 4 ประการ ซึ่งเป็นเสาหลักที่รองรับระบบเอเจนต์ที่เจริญรุ่งเรือง ความบกพร่องในด้านใดด้านหนึ่งจะสร้างจุดอ่อนที่อาจส่งผลต่อโครงสร้างทั้งหมด
เวิร์กช็อปนี้เป็นเพลย์บุ๊กสำหรับองค์กรที่ชัดเจนในการฝึกฝนอนาคตของเอเจนต์ใน Google Cloud เรามีแผนงานแบบครบวงจรที่จะแนะนำคุณตั้งแต่เริ่มมีไอเดียไปจนถึงการดำเนินงานจริงในระดับเต็มรูปแบบ ในแล็บทั้ง 4 แห่งที่เชื่อมต่อกันนี้ คุณจะได้เรียนรู้ว่าทักษะเฉพาะทางของนักพัฒนาซอฟต์แวร์ สถาปนิก วิศวกรข้อมูล และ SRE ต้องมาบรรจบกันเพื่อสร้าง จัดการ และปรับขนาด Agentverse ที่ทรงพลังได้อย่างไร
เสาหลักเพียงเสาเดียวไม่สามารถรองรับ Agentverse ได้ การออกแบบที่ยอดเยี่ยมของสถาปนิกจะไร้ประโยชน์หากไม่มีการดำเนินการที่แม่นยำของนักพัฒนาแอป เอเจนต์ของนักพัฒนาแอปจะไม่มีความรู้หากไม่มีความเชี่ยวชาญของวิศวกรข้อมูล และทั้งระบบจะเปราะบางหากไม่มีการปกป้องจาก SRE มีเพียงการทำงานร่วมกันและความเข้าใจบทบาทของกันและกันเท่านั้นที่จะช่วยให้ทีมของคุณเปลี่ยนแนวคิดนวัตกรรมให้กลายเป็นความจริงในการปฏิบัติงานที่สำคัญต่อภารกิจได้ การเดินทางของคุณเริ่มต้นที่นี่ เตรียมพร้อมที่จะเชี่ยวชาญบทบาทของคุณและเรียนรู้ว่าคุณมีส่วนร่วมในภาพรวมที่ใหญ่ขึ้นได้อย่างไร
ยินดีต้อนรับสู่ Agentverse: การเรียกร้องให้เป็นแชมป์
ในขอบเขตดิจิทัลที่กว้างใหญ่ขององค์กร ยุคใหม่ได้เริ่มต้นขึ้นแล้ว นี่คือยุคของเอเจนต์ ซึ่งเป็นช่วงเวลาแห่งความหวังอันยิ่งใหญ่ที่เอเจนต์อัจฉริยะที่ทำงานได้ด้วยตนเองจะทำงานร่วมกันอย่างลงตัวเพื่อเร่งสร้างนวัตกรรมและขจัดงานที่น่าเบื่อ

ระบบนิเวศที่เชื่อมต่อกันของพลังและความเป็นไปได้นี้เรียกว่า Agentverse
แต่ความเสื่อมถอยที่คืบคลานเข้ามา การทุจริตที่เงียบงันที่รู้จักกันในชื่อ "The Static" ได้เริ่มกัดกร่อนขอบของโลกใหม่นี้ The Static ไม่ใช่ไวรัสหรือข้อบกพร่อง แต่เป็นตัวแทนของความวุ่นวายที่คอยกัดกินการสร้างสรรค์
ความหงุดหงิดใจในอดีตได้ขยายตัวกลายเป็นสัตว์ประหลาด และก่อให้เกิด "วิญญาณร้ายทั้ง 7 แห่งการพัฒนา" หากไม่ตรวจสอบ The Static และ Spectres จะทำให้ความคืบหน้าหยุดชะงัก และเปลี่ยนความหวังของ Agentverse ให้กลายเป็นดินแดนรกร้างที่เต็มไปด้วยหนี้ทางเทคนิคและโปรเจ็กต์ที่ถูกทอดทิ้ง
วันนี้เราขอเชิญชวนผู้กล้าให้ช่วยกันต่อต้านความวุ่นวาย เราต้องการฮีโร่ที่พร้อมจะฝึกฝนทักษะและทำงานร่วมกันเพื่อปกป้อง Agentverse ได้เวลาเลือกเส้นทางของคุณแล้ว
เลือกชั้นเรียน
เส้นทางที่แตกต่างกัน 4 เส้นทางอยู่ตรงหน้าคุณ โดยแต่ละเส้นทางเป็นเสาหลักสำคัญในการต่อสู้กับเดอะสแตติก แม้ว่าการฝึกของคุณจะเป็นภารกิจเดี่ยว แต่ความสำเร็จขั้นสุดท้ายขึ้นอยู่กับการทำความเข้าใจว่าทักษะของคุณทำงานร่วมกับทักษะของผู้อื่นอย่างไร
- The Shadowblade (นักพัฒนาแอป): ผู้เชี่ยวชาญด้านการตีเหล็กและแนวหน้า คุณคือช่างฝีมือที่สร้างสรรค์ใบมีด สร้างเครื่องมือ และเผชิญหน้ากับศัตรูในรายละเอียดที่ซับซ้อนของโค้ด เส้นทางของคุณคือเส้นทางแห่งความแม่นยำ ทักษะ และการสร้างสรรค์ที่นำไปใช้ได้จริง
- นักใช้มนต์อสูร (สถาปนิก): นักวางแผนและผู้ประสานงานที่ยิ่งใหญ่ คุณไม่ได้เห็นแค่เอเจนต์คนเดียว แต่เห็นทั้งสมรภูมิ คุณออกแบบพิมพ์เขียวหลักที่ช่วยให้ระบบเอเจนต์ทั้งหมดสื่อสาร ทำงานร่วมกัน และบรรลุเป้าหมายที่ยิ่งใหญ่กว่าคอมโพเนนต์ใดๆ เพียงอย่างเดียว
- นักปราชญ์ (วิศวกรข้อมูล): ผู้แสวงหาความจริงที่ซ่อนอยู่และผู้รักษาภูมิปัญญา คุณผจญภัยไปในป่าข้อมูลที่กว้างใหญ่และไม่คุ้นเคยเพื่อค้นหาข้อมูลอัจฉริยะที่จะช่วยให้ตัวแทนของคุณมีเป้าหมายและวิสัยทัศน์ ความรู้ของคุณอาจเผยจุดอ่อนของศัตรูหรือเพิ่มพลังให้พันธมิตร
- ผู้พิทักษ์ (DevOps / SRE): ผู้ปกป้องและโล่ที่มั่นคงของอาณาจักร คุณสร้างป้อมปราการ จัดการเส้นทางจ่ายพลังงาน และตรวจสอบว่าทั้งระบบสามารถทนต่อการโจมตีที่หลีกเลี่ยงไม่ได้ของ The Static ความแข็งแกร่งของคุณคือรากฐานที่สร้างชัยชนะของทีม
ภารกิจของคุณ
การฝึกจะเริ่มเป็นการออกกำลังกายแบบสแตนด์อโลน คุณจะเดินตามเส้นทางที่เลือกและเรียนรู้ทักษะเฉพาะที่จำเป็นต่อการเป็นผู้เชี่ยวชาญในบทบาทของคุณ เมื่อสิ้นสุดช่วงทดลองใช้ คุณจะพบกับ Spectre ที่เกิดจาก The Static ซึ่งเป็นมินิบอสที่คอยโจมตีความท้าทายเฉพาะของการประดิษฐ์
คุณจะเตรียมพร้อมสำหรับการทดสอบรอบสุดท้ายได้ก็ต่อเมื่อเชี่ยวชาญบทบาทของตนเองเท่านั้น จากนั้นคุณต้องจัดทีมกับแชมเปี้ยนจากคลาสอื่นๆ คุณและเพื่อนร่วมทีมจะผจญภัยเข้าไปในใจกลางของความชั่วร้ายเพื่อเผชิญหน้ากับบอสตัวสุดท้าย
ความท้าทายสุดท้ายที่ต้องร่วมมือกัน ซึ่งจะทดสอบความแข็งแกร่งของคุณและกำหนดชะตากรรมของ Agentverse
Agentverse กำลังรอเหล่าฮีโร่อยู่ คุณจะรับสายไหม
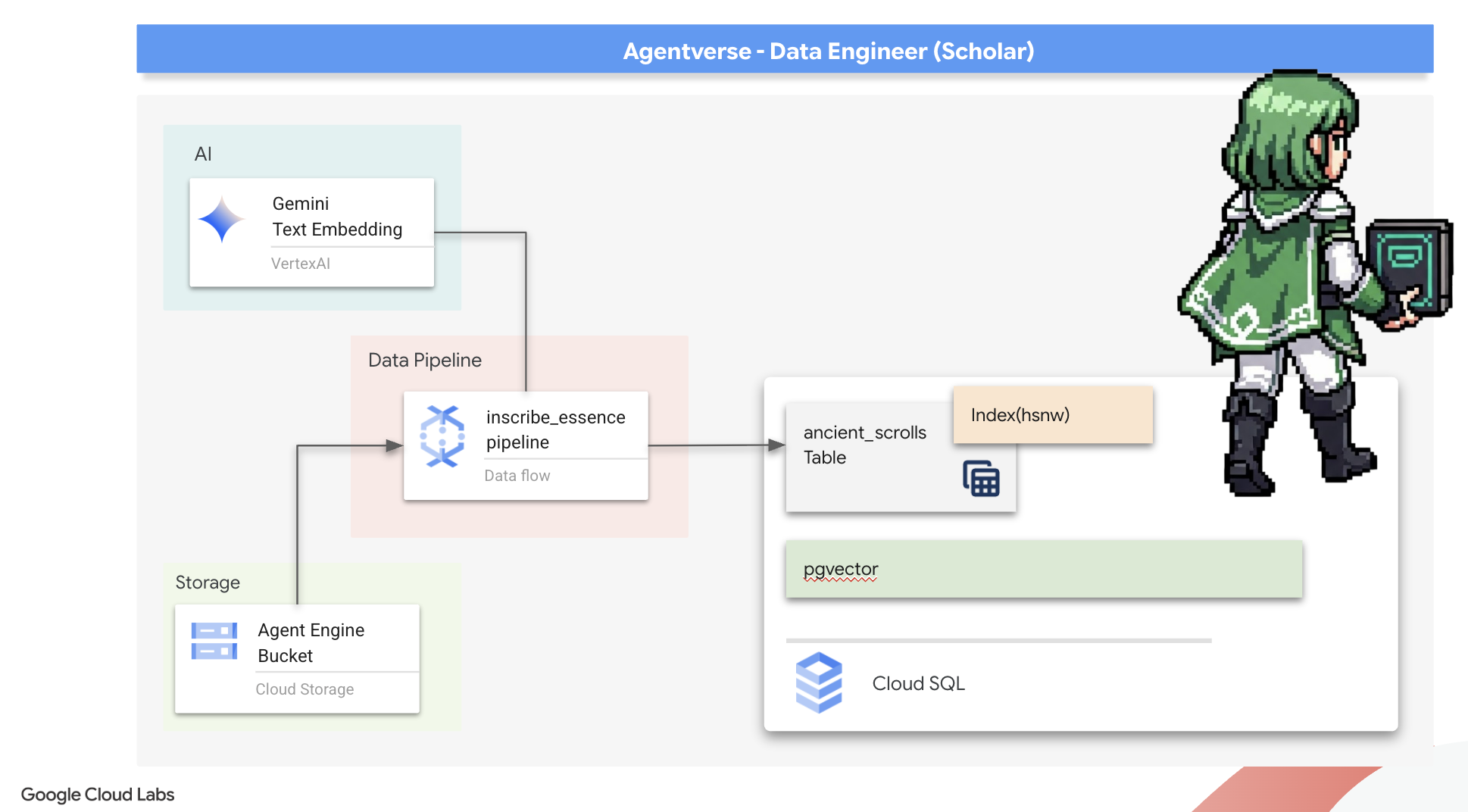
2. The Scholar's Grimoire
การเดินทางของเราเริ่มต้นขึ้นแล้ว ในฐานะนักวิชาการ อาวุธหลักของเราคือความรู้ เราค้นพบม้วนกระดาษโบราณที่ซ่อนอยู่ในที่เก็บถาวร (Google Cloud Storage) ม้วนกระดาษเหล่านี้มีข้อมูลดิบเกี่ยวกับสัตว์ร้ายที่น่าสะพรึงกลัวซึ่งสร้างความเดือดร้อนให้กับแผ่นดิน ภารกิจของเราคือการใช้เวทมนตร์แห่งการวิเคราะห์อันลึกซึ้งของ Google BigQuery และสติปัญญาของ Gemini Elder Brain (โมเดล Gemini Pro) เพื่อถอดรหัสข้อความที่ไม่มีโครงสร้างเหล่านี้และสร้างเป็นสารานุกรมสัตว์ที่จัดโครงสร้างและสืบค้นได้ ซึ่งจะเป็นรากฐานของกลยุทธ์ทั้งหมดในอนาคต
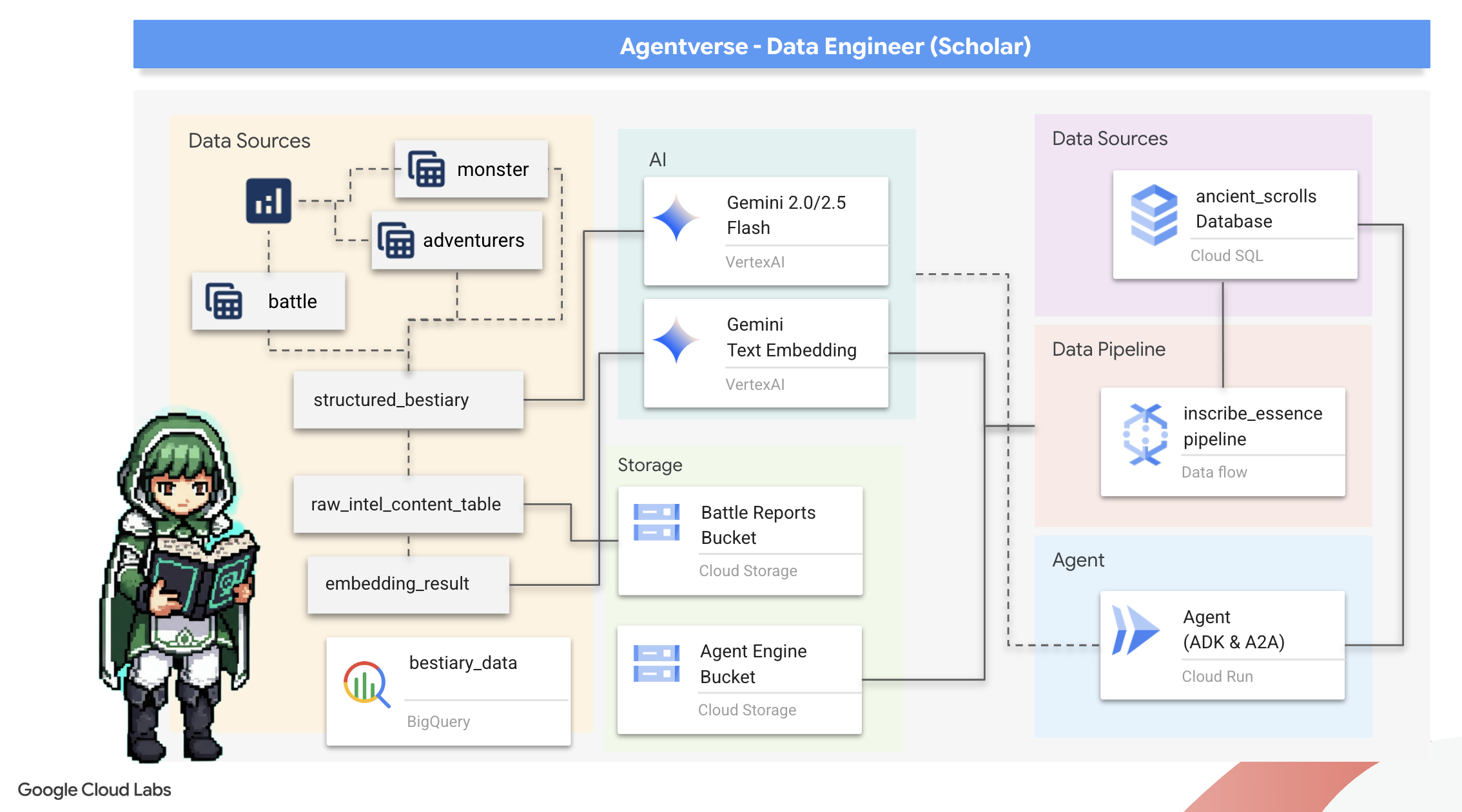
สิ่งที่คุณจะได้เรียนรู้
- ใช้ BigQuery เพื่อสร้างตารางภายนอกและทำการเปลี่ยนรูปแบบที่ซับซ้อนจากข้อมูลที่ไม่มีโครงสร้างเป็นข้อมูลที่มีโครงสร้างโดยใช้ BQML.GENERATE_TEXT กับโมเดล Gemini
- จัดสรรอินสแตนซ์ Cloud SQL สำหรับ PostgreSQL และเปิดใช้ส่วนขยาย pgvector เพื่อความสามารถในการค้นหาเชิงความหมาย
- สร้างไปป์ไลน์การประมวลผลแบบกลุ่มที่แข็งแกร่งซึ่งอยู่ในคอนเทนเนอร์โดยใช้ Dataflow และ Apache Beam เพื่อประมวลผลไฟล์ข้อความดิบ สร้างการฝังเวกเตอร์ด้วยโมเดล Gemini และเขียนผลลัพธ์ลงในฐานข้อมูลเชิงสัมพันธ์
- ใช้ระบบการสร้างที่เพิ่มการดึงข้อมูล (RAG) พื้นฐานภายในเอเจนต์เพื่อค้นหาข้อมูลที่แปลงเป็นเวกเตอร์
- ติดตั้งใช้งานเอเจนต์ที่รับรู้ข้อมูลเป็นบริการที่ปลอดภัยและปรับขนาดได้ใน Cloud Run
3. เตรียมห้องสมุดของนักวิชาการ
ยินดีต้อนรับ Scholar ก่อนที่เราจะเริ่มจารึกความรู้ที่ทรงพลังของ Grimoire เราต้องเตรียมที่ศักดิ์สิทธิ์ของเราก่อน พิธีกรรมพื้นฐานนี้เกี่ยวข้องกับการร่ายมนต์สภาพแวดล้อม Google Cloud, การเปิดพอร์ทัล (API) ที่เหมาะสม และการสร้างท่อร้อยสายที่จะเป็นช่องทางให้เวทมนตร์แห่งข้อมูลของเราไหลผ่าน การเตรียมแซงทัมอย่างดีจะช่วยให้เวทมนตร์ของเรามีประสิทธิภาพและปกป้องความรู้ของเราให้ปลอดภัย
รับเครดิต Google Cloud
⚠️ ข้อกำหนดเบื้องต้นที่สำคัญ:
- ใช้ Gmail ส่วนตัว: คุณต้องใช้บัญชีส่วนตัว (เช่น
name@gmail.com) บัญชีที่บริษัทหรือโรงเรียนจัดการจะใช้ไม่ได้
👉 ขั้นตอน
- ไปที่เว็บไซต์อ้างสิทธิ์เครดิต: คลิกที่นี่
- ลงชื่อเข้าใช้: วางลิงก์ลงในแถบที่อยู่ แล้วลงชื่อเข้าใช้ด้วย Gmail ส่วนตัว
- ยอมรับข้อกำหนด: ยอมรับข้อกำหนดในการให้บริการของ Google Cloud Platform
- ยืนยันเครดิต: มองหาข้อความที่ยืนยันว่ามีการใช้เครดิตแล้ว
- *หมายเหตุ: หากระบบแจ้งให้ป้อนข้อมูลบัตรเครดิต คุณก็ไม่ต้องสนใจและปิดหน้าต่างได้
แล้วคุณก็พร้อมใช้งาน ปิดหน้าต่างได้เลย
ตั้งค่าสภาพแวดล้อมการทำงาน
👉คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud (เป็นไอคอนรูปเทอร์มินัลที่ด้านบนของแผง Cloud Shell)
👉คลิกปุ่ม "เปิดตัวแก้ไข" (ลักษณะเป็นโฟลเดอร์ที่เปิดอยู่พร้อมดินสอ) ซึ่งจะเปิดตัวแก้ไขโค้ด Cloud Shell ในหน้าต่าง คุณจะเห็น File Explorer ทางด้านซ้าย 
👉เปิดเทอร์มินัลใน Cloud IDE 
👉💻 ในเทอร์มินัล ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list
👉💻โคลนโปรเจ็กต์ Bootstrap จาก GitHub
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 เรียกใช้สคริปต์การตั้งค่าจากไดเรกทอรีโปรเจ็กต์
⚠️ หมายเหตุเกี่ยวกับรหัสโปรเจ็กต์: สคริปต์จะแนะนำรหัสโปรเจ็กต์เริ่มต้นที่สร้างขึ้นแบบสุ่ม คุณกด Enter เพื่อยอมรับค่าเริ่มต้นนี้ได้
อย่างไรก็ตาม หากต้องการสร้างโปรเจ็กต์ใหม่ที่เฉพาะเจาะจง คุณสามารถพิมพ์รหัสโปรเจ็กต์ที่ต้องการเมื่อสคริปต์แจ้ง
cd ~/agentverse-dataengineer
./init.sh
👉 ขั้นตอนสำคัญหลังจากเสร็จสิ้น: เมื่อสคริปต์ทำงานเสร็จแล้ว คุณต้องตรวจสอบว่า Google Cloud Console กำลังดูโปรเจ็กต์ที่ถูกต้อง
- ไปที่ console.cloud.google.com
- คลิกเมนูแบบเลื่อนลงของตัวเลือกโปรเจ็กต์ที่ด้านบนของหน้า
- คลิกแท็บ "ทั้งหมด" (เนื่องจากโปรเจ็กต์ใหม่อาจยังไม่ปรากฏใน "ล่าสุด")
- เลือกรหัสโปรเจ็กต์ที่คุณเพิ่งกำหนดค่าใน
init.shขั้นตอน
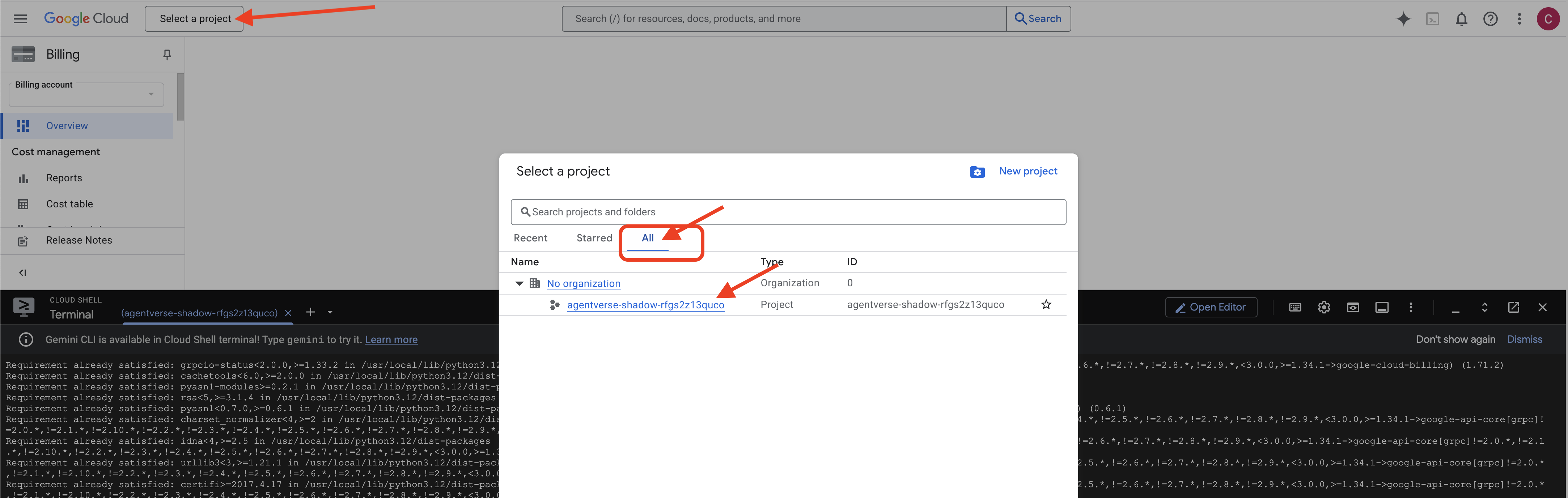
👉💻 ตั้งค่ารหัสโปรเจ็กต์ที่จำเป็น
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดใช้ Google Cloud APIs ที่จำเป็น
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 หากยังไม่ได้สร้างที่เก็บ Artifact Registry ที่ชื่อ agentverse-repo ให้เรียกใช้คำสั่งต่อไปนี้เพื่อสร้าง
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
การตั้งค่าสิทธิ์
👉💻 ให้สิทธิ์ที่จำเป็นโดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 เมื่อคุณเริ่มการฝึก เราจะเตรียมความท้าทายสุดท้ายไว้ให้ คำสั่งต่อไปนี้จะเรียก Spectres จากสแตติกที่วุ่นวายออกมา ซึ่งจะสร้างบอสสำหรับการทดสอบครั้งสุดท้าย
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
เยี่ยมมาก นักวิชาการ การเสริมพลังพื้นฐานเสร็จสมบูรณ์แล้ว ห้องศักดิ์สิทธิ์ของเราปลอดภัย พอร์ทัลสู่พลังธาตุของข้อมูลเปิดอยู่ และผู้รับใช้ของเราได้รับพลัง ตอนนี้เราพร้อมที่จะเริ่มงานจริงๆ แล้ว
4. การแปรธาตุความรู้: การเปลี่ยนข้อมูลด้วย BigQuery และ Gemini
ในการต่อสู้กับ The Static อย่างไม่หยุดหย่อน การเผชิญหน้าทุกครั้งระหว่างแชมเปี้ยนแห่ง Agentverse กับ Spectre of Development จะได้รับการบันทึกอย่างพิถีพิถัน ระบบการจำลองสมรภูมิซึ่งเป็นสภาพแวดล้อมการฝึกหลักของเราจะสร้างรายการบันทึกอีเทอร์ริกโดยอัตโนมัติสำหรับการเผชิญหน้าแต่ละครั้ง บันทึกการเล่าเรื่องเหล่านี้เป็นแหล่งข้อมูลดิบที่มีค่าที่สุดของเรา ซึ่งเป็นแร่ที่ยังไม่ผ่านการกลั่นกรองซึ่งเราในฐานะนักวิชาการต้องหลอมให้เป็นเหล็กกล้าที่บริสุทธิ์ของกลยุทธ์ พลังที่แท้จริงของนักวิชาการไม่ได้อยู่ที่การมีข้อมูลเท่านั้น แต่อยู่ที่ความสามารถในการเปลี่ยนแร่ข้อมูลดิบที่วุ่นวายให้กลายเป็นเหล็กกล้าที่ส่องประกายและมีโครงสร้างของสติปัญญาที่นำไปใช้ได้จริง เราจะประกอบพิธีกรรมพื้นฐานของการเล่นแร่แปรธาตุข้อมูล

การเดินทางของเราจะนำเราผ่านกระบวนการแบบหลายขั้นตอนภายใน Google BigQuery ทั้งหมด เราจะเริ่มด้วยการมองเข้าไปในที่เก็บถาวร GCS โดยไม่ต้องเลื่อนแม้แต่ครั้งเดียวด้วยเลนส์มหัศจรรย์ จากนั้นเราจะเรียก Gemini มาอ่านและตีความเรื่องราวการต่อสู้ที่ไม่มีโครงสร้างและเป็นบทกวีในบันทึกการต่อสู้ สุดท้าย เราจะปรับแต่งคำทำนายดิบให้เป็นชุดตารางที่เชื่อมต่อกันอย่างสมบูรณ์ Grimoire เล่มแรกของเรา และถามคำถามที่ลึกซึ้งจนมีเพียงโครงสร้างที่เพิ่งค้นพบนี้เท่านั้นที่ตอบได้
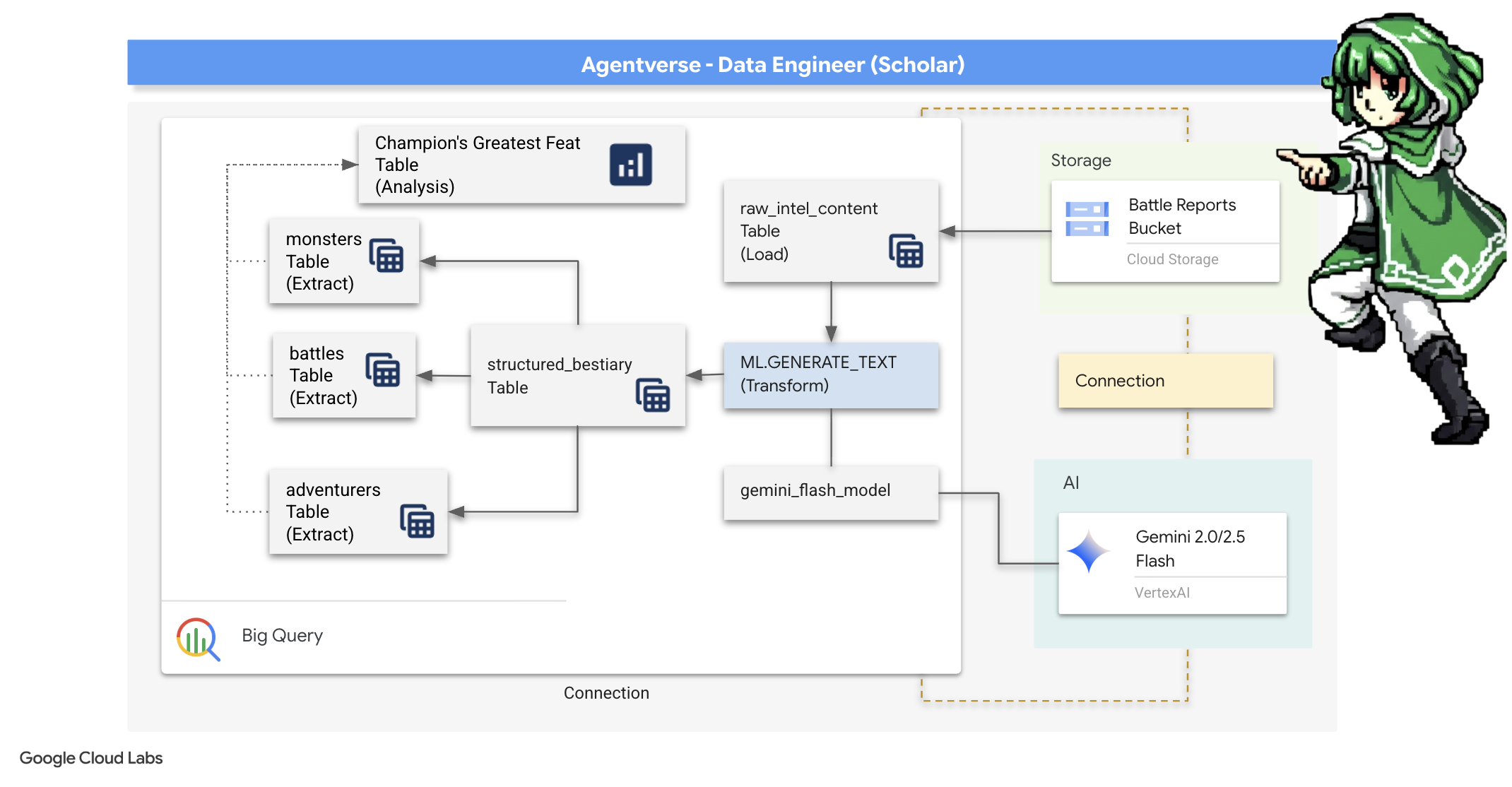
เลนส์แห่งการตรวจสอบ: การเจาะลึก GCS ด้วยตารางภายนอกของ BigQuery
สิ่งแรกที่เราทำคือการสร้างเลนส์ที่ช่วยให้เราเห็นเนื้อหาของที่เก็บถาวร GCS โดยไม่รบกวนการเลื่อนภายใน ตารางภายนอกคือเลนส์นี้ ซึ่งจะแมปไฟล์ข้อความดิบกับโครงสร้างคล้ายตารางที่ BigQuery ค้นหาได้โดยตรง
ในการดำเนินการนี้ เราต้องสร้างเส้นพลังที่เสถียร ซึ่งเป็นทรัพยากรการเชื่อมต่อก่อน เพื่อลิงก์ห้องศักดิ์สิทธิ์ของ BigQuery กับที่เก็บถาวรของ GCS อย่างปลอดภัย
👉💻 ในเทอร์มินัล Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้เพื่อตั้งค่าพื้นที่เก็บข้อมูลและสร้างท่อ
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 โปรดทราบ ข้อความจะปรากฏขึ้นในภายหลัง
สคริปต์การตั้งค่าจากขั้นตอนที่ 2 ได้เริ่มกระบวนการในเบื้องหลังแล้ว หลังจากผ่านไปสักครู่ ข้อความจะปรากฏขึ้นในเทอร์มินัลของคุณซึ่งมีลักษณะคล้ายกับข้อความนี้[1]+ Done gcloud sql instances create ...ซึ่งเป็นเรื่องปกติ ซึ่งหมายความว่าคุณสร้างฐานข้อมูล Cloud SQL เรียบร้อยแล้ว คุณไม่จำเป็นต้องสนใจข้อความนี้และทำงานต่อไปได้
ก่อนที่จะสร้างตารางภายนอกได้ คุณต้องสร้างชุดข้อมูลที่จะมีตารางภายนอกนั้นก่อน
👉💻 เรียกใช้คำสั่งง่ายๆ นี้ในเทอร์มินัล Cloud Shell
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 ตอนนี้เราต้องให้สิทธิ์ที่จำเป็นแก่ลายเซ็นมหัศจรรย์ของตัวกลางเพื่ออ่านจากที่เก็บถาวรของ GCS และปรึกษา Gemini
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 ในเทอร์มินัล Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้เพื่อแสดงชื่อที่เก็บข้อมูล
echo $BUCKET_NAME
เทอร์มินัลจะแสดงชื่อที่คล้ายกับ your-project-id-gcs-bucket คุณจะต้องใช้ข้อมูลนี้ในขั้นตอนถัดไป
👉 คุณจะต้องเรียกใช้คำสั่งถัดไปจากภายในตัวแก้ไขคำค้นหา BigQuery ใน Google Cloud Console วิธีที่ง่ายที่สุดในการไปที่หน้าดังกล่าวคือการเปิดลิงก์ด้านล่างในแท็บเบราว์เซอร์ใหม่ ระบบจะนำคุณไปยังหน้าที่ถูกต้องใน Google Cloud Console โดยตรง
https://console.cloud.google.com/bigquery
👉 เมื่อหน้าเว็บโหลดแล้ว ให้คลิกปุ่ม + สีน้ำเงิน (เขียนคำค้นหาใหม่) เพื่อเปิดแท็บเอดิเตอร์ใหม่
ตอนนี้เราจะเขียนคาถาภาษานิยามข้อมูล (DDL) เพื่อสร้างเลนส์มหัศจรรย์ ซึ่งจะบอก BigQuery ว่าจะค้นหาที่ใดและดูอะไร
👉📜 ในตัวแก้ไขคำค้นหา BigQuery ที่คุณเปิด ให้วาง SQL ต่อไปนี้ อย่าลืมแทนที่ REPLACE-WITH-YOUR-BUCKET-NAME
โดยใช้ชื่อที่เก็บข้อมูลที่คุณเพิ่งคัดลอก แล้วคลิก Run
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 เรียกใช้การค้นหาเพื่อ "มองผ่านเลนส์" และดูเนื้อหาของไฟล์
SELECT * FROM bestiary_data.raw_intel_content_table;
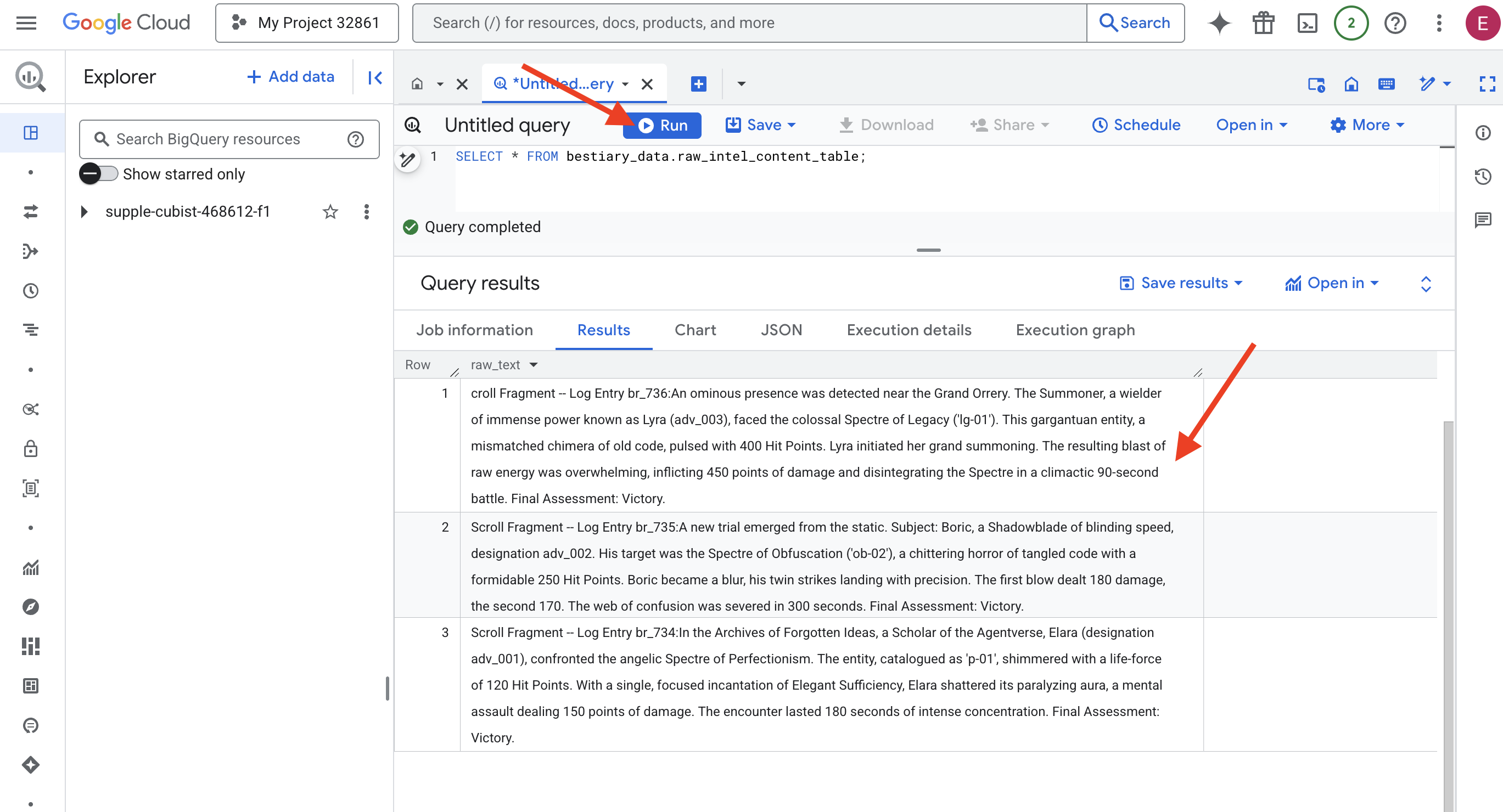
เรามีเลนส์พร้อมใช้งาน ตอนนี้เราเห็นข้อความดิบของม้วนหนังสือแล้ว แต่การอ่านไม่ได้หมายถึงการทำความเข้าใจ
ในหอจดหมายเหตุแห่งไอเดียที่ถูกลืม เอลารา (รหัส adv_001) นักวิชาการแห่ง Agentverse ได้เผชิญหน้ากับ Spectre of Perfectionism ที่มีรูปลักษณ์ดุจเทวทูต เอนทิตีที่จัดทำแคตตาล็อกเป็น "p-01" เปล่งประกายด้วยพลังชีวิต 120 แต้ม ด้วยการร่ายคาถา Elegant Sufficiency เพียงครั้งเดียวอย่างตั้งใจ Elara ก็ทำลายออร่าที่ทำให้เป็นอัมพาตได้สำเร็จ ซึ่งเป็นการโจมตีทางจิตที่สร้างความเสียหาย 150 แต้ม การเผชิญหน้าครั้งนี้ใช้เวลา 180 วินาทีที่ต้องใช้สมาธิอย่างมาก การประเมินขั้นสุดท้าย: ชนะ
ม้วนหนังสือไม่ได้เขียนในตารางและแถว แต่เขียนในร้อยแก้วที่คดเคี้ยวของมหากาพย์ นี่คือการทดสอบครั้งแรกที่ยอดเยี่ยม
การทำนายของนักวิชาการ: การเปลี่ยนข้อความเป็นตารางด้วย SQL
ความท้าทายคือรายงานที่อธิบายการโจมตีคู่ที่รวดเร็วของ Shadowblade นั้นแตกต่างอย่างมากจากบันทึกของ Summoner ที่รวบรวมพลังมหาศาลเพื่อการระเบิดครั้งเดียวที่ร้ายแรง เราไม่สามารถนำเข้าข้อมูลนี้ได้โดยตรง แต่ต้องตีความข้อมูล นี่คือช่วงเวลาที่น่ามหัศจรรย์ เราจะใช้การค้นหา SQL เดียวเป็นคาถาอันทรงพลังในการอ่าน ทำความเข้าใจ และจัดโครงสร้างระเบียนทั้งหมดจากไฟล์ทั้งหมดของเราภายใน BigQuery
👉💻 กลับไปที่เทอร์มินัล Cloud Shell แล้วเรียกใช้คำสั่งต่อไปนี้เพื่อแสดงชื่อการเชื่อมต่อ
echo "${PROJECT_ID}.${REGION}.gcs-connection"
เทอร์มินัลจะแสดงสตริงการเชื่อมต่อที่สมบูรณ์ ให้เลือกและคัดลอกสตริงทั้งหมดนี้ คุณจะต้องใช้สตริงนี้ในขั้นตอนถัดไป
เราจะใช้คาถาที่ทรงพลังเพียงบทเดียว นั่นคือ ML.GENERATE_TEXT คาถานี้จะเรียก Gemini ออกมา แสดงม้วนคัมภีร์แต่ละม้วน และสั่งให้ Gemini ส่งข้อเท็จจริงหลักๆ กลับมาเป็นออบเจ็กต์ JSON ที่มีโครงสร้าง
👉📜 สร้างการอ้างอิงโมเดล Gemini ใน BigQuery Studio ซึ่งจะเชื่อมโยง Oracle ของ Gemini Flash กับคลัง BigQuery เพื่อให้เราเรียกใช้ในคำค้นหาได้ อย่าลืมแทนที่
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING ด้วยสตริงการเชื่อมต่อแบบเต็มที่คุณเพิ่งคัดลอกจากเทอร์มินัล
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 ตอนนี้ก็ร่ายคาถาเปลี่ยนรูปอันยิ่งใหญ่ การค้นหานี้จะอ่านข้อความดิบ สร้างพรอมต์แบบละเอียดสำหรับการเลื่อนแต่ละครั้ง ส่งไปยัง Gemini และสร้างตารางการจัดเตรียมใหม่จากคำตอบ JSON ที่มีโครงสร้างของ AI
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
การแปรธาตุเสร็จสมบูรณ์แล้ว แต่ผลลัพธ์ยังไม่บริสุทธิ์ โมเดล Gemini จะแสดงคำตอบในรูปแบบมาตรฐาน โดยจะห่อหุ้ม JSON ที่เราต้องการไว้ภายในโครงสร้างที่ใหญ่ขึ้นซึ่งมีข้อมูลเมตาเกี่ยวกับกระบวนการคิดของโมเดล เรามาดูคำพยากรณ์ดิบๆ นี้ก่อนที่เราจะพยายามชำระล้างมัน
👉📜 เรียกใช้การค้นหาเพื่อตรวจสอบเอาต์พุตดิบจากโมเดล Gemini โดยทำดังนี้
SELECT * FROM bestiary_data.structured_bestiary;
👀 คุณจะเห็นคอลัมน์เดียวชื่อ structured_data เนื้อหาของแต่ละแถวจะมีลักษณะคล้ายกับออบเจ็กต์ JSON ที่ซับซ้อนนี้
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
ดังที่เห็น รางวัลของเรา ซึ่งก็คือออบเจ็กต์ JSON ที่สะอาดที่เราขอไว้ ซ่อนอยู่ลึกๆ ในโครงสร้างนี้ งานถัดไปของเราชัดเจน เราต้องทำพิธีกรรมเพื่อสำรวจโครงสร้างนี้อย่างเป็นระบบและดึงสติปัญญาที่แท้จริงออกมา
พิธีกรรมแห่งการชำระล้าง: การทำให้เอาต์พุต GenAI เป็นปกติด้วย SQL
Gemini ได้พูดแล้ว แต่คำพูดนั้นยังไม่ผ่านการประมวลผลและห่อหุ้มด้วยพลังงานที่ไม่มีตัวตนของการสร้าง (candidates, finish_reason ฯลฯ) นักปราชญ์ที่แท้จริงไม่ได้เพียงแค่เก็บคำพยากรณ์ดิบๆ ไว้ แต่จะคัดกรองภูมิปัญญาหลักอย่างระมัดระวังและจารึกลงในตำราที่เหมาะสมเพื่อใช้ในอนาคต
ตอนนี้เราจะร่ายคาถาชุดสุดท้าย สคริปต์เดียวนี้จะทำสิ่งต่อไปนี้
- อ่าน JSON แบบดิบที่ซ้อนกันจากตารางการจัดเตรียม
- ทำความสะอาดและแยกวิเคราะห์เพื่อเข้าถึงข้อมูลหลัก
- เขียนชิ้นส่วนที่เกี่ยวข้องลงในตารางสุดท้ายที่สมบูรณ์ 3 ตาราง ได้แก่ มอนสเตอร์ นักผจญภัย และการต่อสู้
👉📜 ในเครื่องมือแก้ไขคำค้นหา BigQuery ใหม่ ให้ร่ายมนต์ต่อไปนี้เพื่อสร้างเลนส์การล้างข้อมูล
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 ยืนยันสารานุกรมสัตว์ประหลาด
SELECT * FROM bestiary_data.monsters;
จากนั้นเราจะสร้างรายชื่อผู้กล้า ซึ่งเป็นรายชื่อนักผจญภัยผู้กล้าหาญที่เคยเผชิญหน้ากับสัตว์ร้ายเหล่านี้
👉📜 ในเครื่องมือแก้ไขคำค้นหาใหม่ ให้ร่ายมนต์ต่อไปนี้เพื่อสร้างตารางนักผจญภัย
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 ตรวจสอบรายชื่อแชมป์
SELECT * FROM bestiary_data.adventurers;
สุดท้าย เราจะสร้างตารางข้อเท็จจริง ซึ่งก็คือบันทึกการรบ โดยหนังสือเล่มนี้จะเชื่อมโยงหนังสืออีก 2 เล่ม และบันทึกรายละเอียดของการเผชิญหน้าที่ไม่ซ้ำกันแต่ละครั้ง เนื่องจากทุกการต่อสู้เป็นเหตุการณ์ที่ไม่ซ้ำกัน จึงไม่จำเป็นต้องทำการขจัดข้อมูลที่ซ้ำกัน
👉📜 ในเครื่องมือแก้ไขคำค้นหาใหม่ ให้ร่ายมนตร์ต่อไปนี้เพื่อสร้างตารางการต่อสู้
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 ยืนยัน Chronicle:
SELECT * FROM bestiary_data.battles;
การค้นพบข้อมูลเชิงลึกเชิงกลยุทธ์
ม้วนคัมภีร์ได้รับการอ่าน กลั่นกรองสาระสำคัญ และจารึกเป็นตำรา Grimoire ของเราไม่ได้เป็นเพียงชุดข้อเท็จจริงอีกต่อไป แต่เป็นฐานข้อมูลเชิงสัมพันธ์ของภูมิปัญญาเชิงกลยุทธ์ที่ลึกซึ้ง ตอนนี้เราสามารถถามคำถามที่ตอบไม่ได้เมื่อความรู้ของเราติดอยู่ในข้อความดิบที่ไม่มีโครงสร้าง
ตอนนี้เรามาทำนายครั้งสุดท้ายกัน เราจะร่ายเวทมนตร์ที่ปรึกษาจากตำราทั้ง 3 เล่มของเราในคราวเดียว ได้แก่ สารานุกรมมอนสเตอร์ รายชื่อแชมเปี้ยน และบันทึกการต่อสู้ เพื่อค้นพบข้อมูลเชิงลึกที่นำไปใช้ได้จริง
คำถามเชิงกลยุทธ์: "นักผจญภัยแต่ละคนปราบมอนสเตอร์ที่เก่งที่สุด (ตามคะแนนชีวิต) ได้สำเร็จชื่ออะไร และใช้เวลานานเท่าใดในการปราบมอนสเตอร์ตัวนั้น"
นี่เป็นคำถามที่ซับซ้อนซึ่งต้องเชื่อมโยงแชมเปี้ยนกับการต่อสู้ที่ชนะ และการต่อสู้เหล่านั้นกับสถิติของมอนสเตอร์ที่เกี่ยวข้อง นี่คือพลังที่แท้จริงของโมเดลข้อมูลที่มีโครงสร้าง
👉📜 ในเครื่องมือแก้ไขการค้นหา BigQuery ใหม่ ให้ร่ายคาถาสุดท้ายต่อไปนี้
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
เอาต์พุตของการค้นหานี้จะเป็นตารางที่สวยงามและสะอาด ซึ่งจะแสดง "เรื่องราวความสำเร็จที่ยิ่งใหญ่ที่สุดของแชมเปี้ยน" สำหรับนักผจญภัยทุกคนในชุดข้อมูล ซึ่งอาจมีลักษณะดังนี้
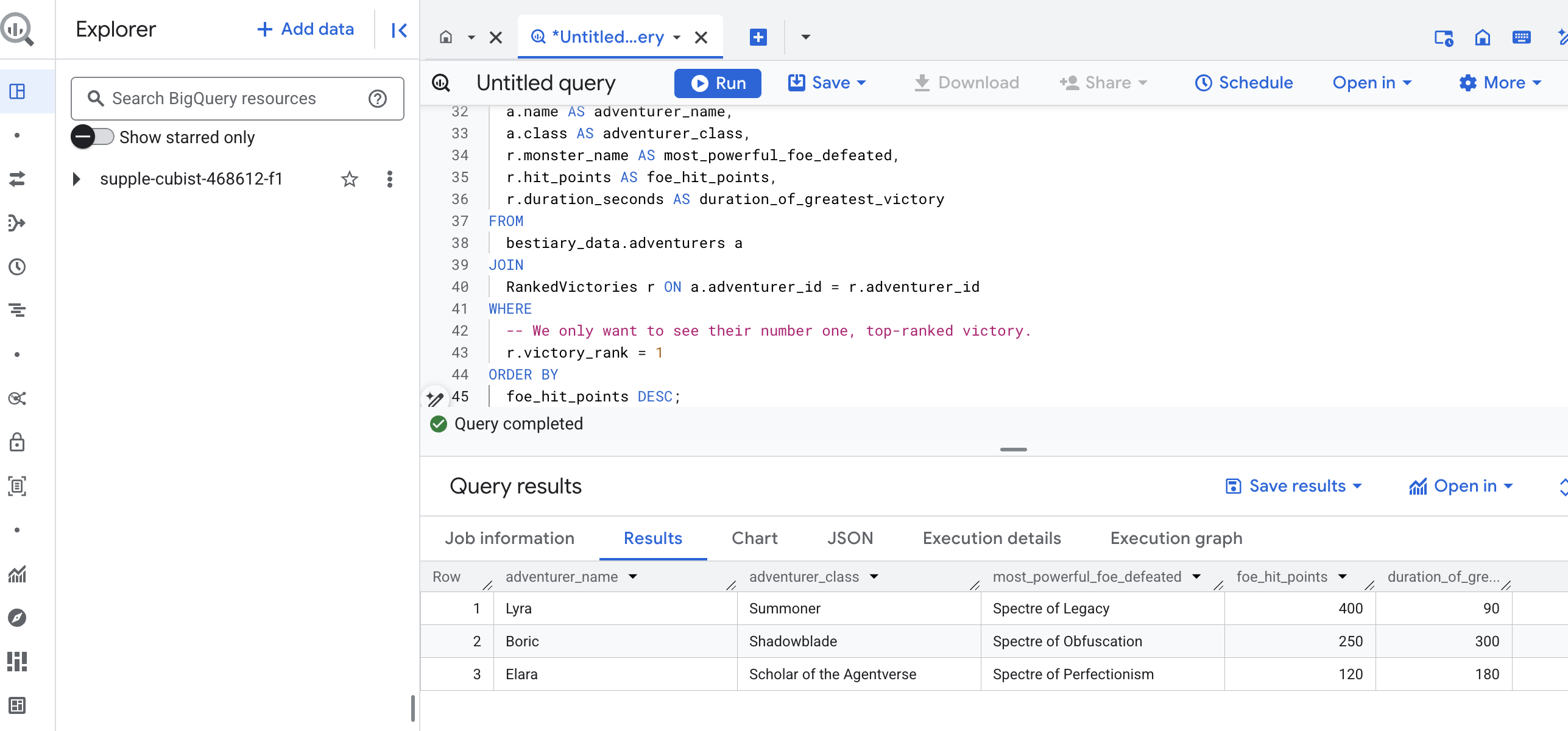
ปิดแท็บ BigQuery
ผลลัพธ์ที่เรียบง่ายแต่มีประสิทธิภาพนี้พิสูจน์ให้เห็นถึงคุณค่าของไปป์ไลน์ทั้งหมด คุณได้เปลี่ยนรายงานสนามรบดิบๆ ที่วุ่นวายให้กลายเป็นแหล่งเรื่องเล่าในตำนานและข้อมูลเชิงลึกเชิงกลยุทธ์ที่อิงตามข้อมูลเรียบร้อยแล้ว
สำหรับผู้ที่ไม่ได้เล่นเกม
5. Grimoire ของ Scribe: การแบ่งกลุ่ม การฝัง และการค้นหาในคลังข้อมูล
การทำงานในห้องทดลองของนักเล่นแร่แปรธาตุประสบความสำเร็จ เราได้เปลี่ยนม้วนบันทึกแบบบรรยายดิบๆ ให้กลายเป็นตารางเชิงสัมพันธ์ที่มีโครงสร้าง ซึ่งเป็นการผสานพลังแห่งเวทมนตร์ด้านข้อมูล อย่างไรก็ตาม ม้วนกระดาษต้นฉบับยังคงมีข้อเท็จจริงเชิงความหมายที่ลึกซึ้งกว่าซึ่งตารางที่มีโครงสร้างของเราไม่สามารถจับภาพได้อย่างสมบูรณ์ หากต้องการสร้างเอเจนต์ที่ฉลาดอย่างแท้จริง เราต้องปลดล็อกความหมายนี้
การเลื่อนฟีดแบบยาวๆ โดยไม่มีการกลั่นกรองใดๆ ก็เหมือนเครื่องมือที่ไม่มีความคม หากตัวแทนถามคำถามเกี่ยวกับ "ออร่าที่ทำให้เป็นอัมพาต" การค้นหาอย่างง่ายอาจแสดงรายงานการต่อสู้ทั้งหมดซึ่งมีการกล่าวถึงวลีดังกล่าวเพียงครั้งเดียว ทำให้คำตอบถูกฝังอยู่ในรายละเอียดที่ไม่เกี่ยวข้อง บัณฑิตผู้เชี่ยวชาญทราบดีว่าปัญญาที่แท้จริงไม่ได้อยู่ที่ปริมาณ แต่อยู่ที่ความแม่นยำ
เราจะทำพิธีกรรมอันทรงพลังในฐานข้อมูลทั้ง 3 อย่างภายในห้องศักดิ์สิทธิ์ของ BigQuery
- พิธีกรรมแห่งการแบ่ง (Chunking): เราจะนำบันทึกข้อมูลข่าวกรองดิบมาแบ่งออกเป็นส่วนๆ อย่างพิถีพิถันให้เป็นข้อความขนาดเล็กที่มุ่งเน้นและมีเนื้อหาในตัว
- พิธีกรรมการกลั่น (การฝัง): เราจะใช้ BQML เพื่อปรึกษาโมเดล Gemini โดยเปลี่ยนข้อความแต่ละก้อนให้เป็น "ลายนิ้วมือเชิงความหมาย" ซึ่งเป็นการฝังเวกเตอร์
- พิธีกรรมแห่งการทำนาย (การค้นหา): เราจะใช้การค้นหาเวกเตอร์ของ BQML เพื่อถามคำถามเป็นภาษาอังกฤษธรรมดาและค้นหาภูมิปัญญาที่เกี่ยวข้องมากที่สุดและกลั่นกรองแล้วจาก Grimoire
กระบวนการทั้งหมดนี้จะสร้างฐานความรู้ที่ทรงพลังและค้นหาได้โดยที่ข้อมูลไม่เคยออกจากความปลอดภัยและความสามารถในการปรับขนาดของ BigQuery
พิธีกรรมแห่งการแบ่งแยก: การแยกส่วนม้วนคัมภีร์ด้วย SQL
แหล่งที่มาของข้อมูลยังคงเป็นไฟล์ข้อความดิบในที่เก็บถาวร GCS ของเรา ซึ่งเข้าถึงได้ผ่านตารางภายนอก bestiary_data.raw_intel_content_table งานแรกของเราคือการเขียนคาถาที่อ่านม้วนหนังสือยาวแต่ละม้วนและแบ่งออกเป็นชุดกลอนที่สั้นลงและอ่านง่ายขึ้น สำหรับพิธีกรรมนี้ เราจะกำหนด "ก้อน" เป็นประโยคเดียว
แม้ว่าการแยกตามประโยคจะเป็นจุดเริ่มต้นที่ชัดเจนและมีประสิทธิภาพสำหรับบันทึกการถอดความ แต่ Scribe ระดับมาสเตอร์ก็มีกลยุทธ์การแบ่งเป็นกลุ่มมากมายให้เลือกใช้ และการเลือกกลยุทธ์ที่เหมาะสมเป็นสิ่งสำคัญต่อคุณภาพของการค้นหาสุดท้าย วิธีการที่ง่ายกว่าอาจใช้
- การแบ่งกลุ่มแบบความยาว(ขนาด) คงที่ แต่การแบ่งกลุ่มนี้อาจตัดแนวคิดหลักออกเป็น 2 ส่วนอย่างหยาบๆ
พิธีกรรมที่ซับซ้อนมากขึ้น เช่น
- การแบ่งกลุ่มแบบเรียกซ้ำมักเป็นที่นิยมในทางปฏิบัติ โดยจะพยายามแบ่งข้อความตามขอบเขตที่เป็นธรรมชาติ เช่น ย่อหน้าก่อน จากนั้นจึงกลับไปใช้ประโยคเพื่อรักษาบริบทเชิงความหมายให้ได้มากที่สุด สำหรับต้นฉบับที่มีความซับซ้อนอย่างแท้จริง
- การแบ่งกลุ่มตามเนื้อหา(เอกสาร) ซึ่ง Scribe จะใช้โครงสร้างที่มีอยู่ในเอกสาร เช่น ส่วนหัวในคู่มือทางเทคนิคหรือฟังก์ชันในโค้ดที่เลื่อนได้ เพื่อสร้างกลุ่มข้อมูลที่สมเหตุสมผลและมีประสิทธิภาพมากที่สุด และอื่นๆ
สำหรับบันทึกการต่อสู้ ประโยคจะให้ความสมดุลที่สมบูรณ์แบบของรายละเอียดและบริบท
👉📜 ในเครื่องมือแก้ไขการค้นหา BigQuery ใหม่ ให้เรียกใช้คำสั่งต่อไปนี้ คาถานี้ใช้ฟังก์ชัน SPLIT เพื่อแยกข้อความของม้วนแต่ละม้วนที่จุด (.) แล้วยกเลิกการซ้อนอาร์เรย์ของประโยคที่ได้ลงในแถวแยกกัน
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 ตอนนี้ให้เรียกใช้การค้นหาเพื่อตรวจสอบความรู้ที่เพิ่งจดบันทึกและแบ่งเป็นกลุ่ม และดูความแตกต่าง
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
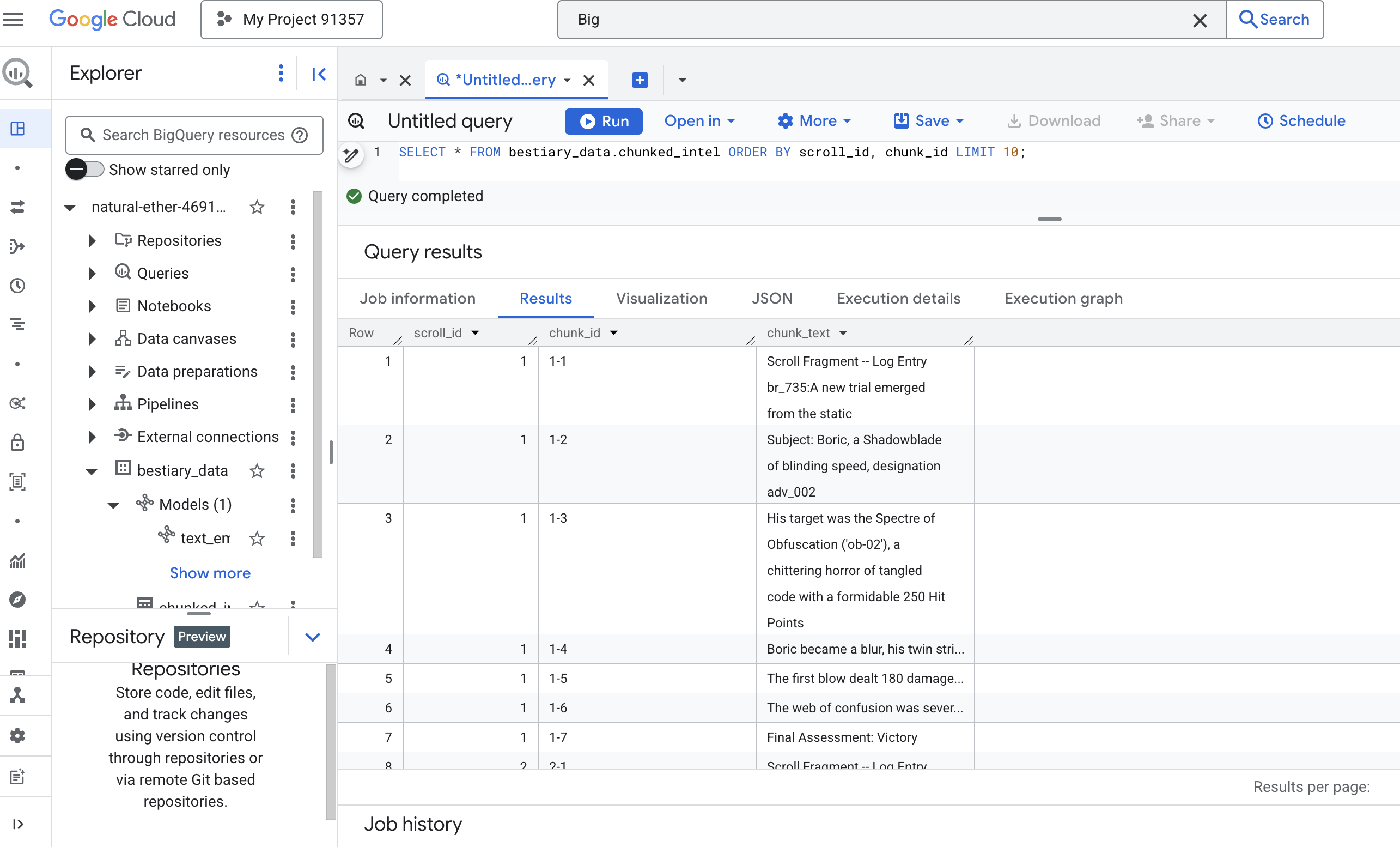
สังเกตผลลัพธ์ จากเดิมที่มีบล็อกข้อความหนาแน่นเพียงบล็อกเดียว ตอนนี้มีหลายแถว โดยแต่ละแถวเชื่อมโยงกับการเลื่อนต้นฉบับ (scroll_id) แต่มีเพียงประโยคเดียวที่โฟกัส ตอนนี้แต่ละแถวจึงเหมาะอย่างยิ่งที่จะนำไปใช้กับเวกเตอร์
พิธีกรรมการกลั่น: การเปลี่ยนข้อความเป็นเวกเตอร์ด้วย BQML
👉💻 ก่อนอื่น ให้กลับไปที่เทอร์มินัล แล้วเรียกใช้คำสั่งต่อไปนี้เพื่อแสดงชื่อการเชื่อมต่อ
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 เราต้องสร้างโมเดล BigQuery ใหม่ที่ชี้ไปยังการฝังข้อความของ Gemini ใน BigQuery Studio ให้เรียกใช้คาถาต่อไปนี้ โปรดทราบว่าคุณต้องแทนที่ REPLACE-WITH-YOUR-FULL-CONNECTION-STRING ด้วยสตริงการเชื่อมต่อแบบเต็มที่คุณเพิ่งคัดลอกจากเทอร์มินัล
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 ตอนนี้ร่ายคาถาการกลั่นที่ยิ่งใหญ่ การค้นหานี้เรียกใช้ฟังก์ชัน ML.GENERATE_EMBEDDING ซึ่งจะอ่านทุกแถวจากตาราง chunked_intel ส่งข้อความไปยังโมเดล Embedding ของ Gemini และจัดเก็บลายนิ้วมือเวกเตอร์ที่ได้ในตารางใหม่
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
กระบวนการนี้อาจใช้เวลา 1-2 นาทีเนื่องจาก BigQuery จะประมวลผลข้อความทั้งหมด
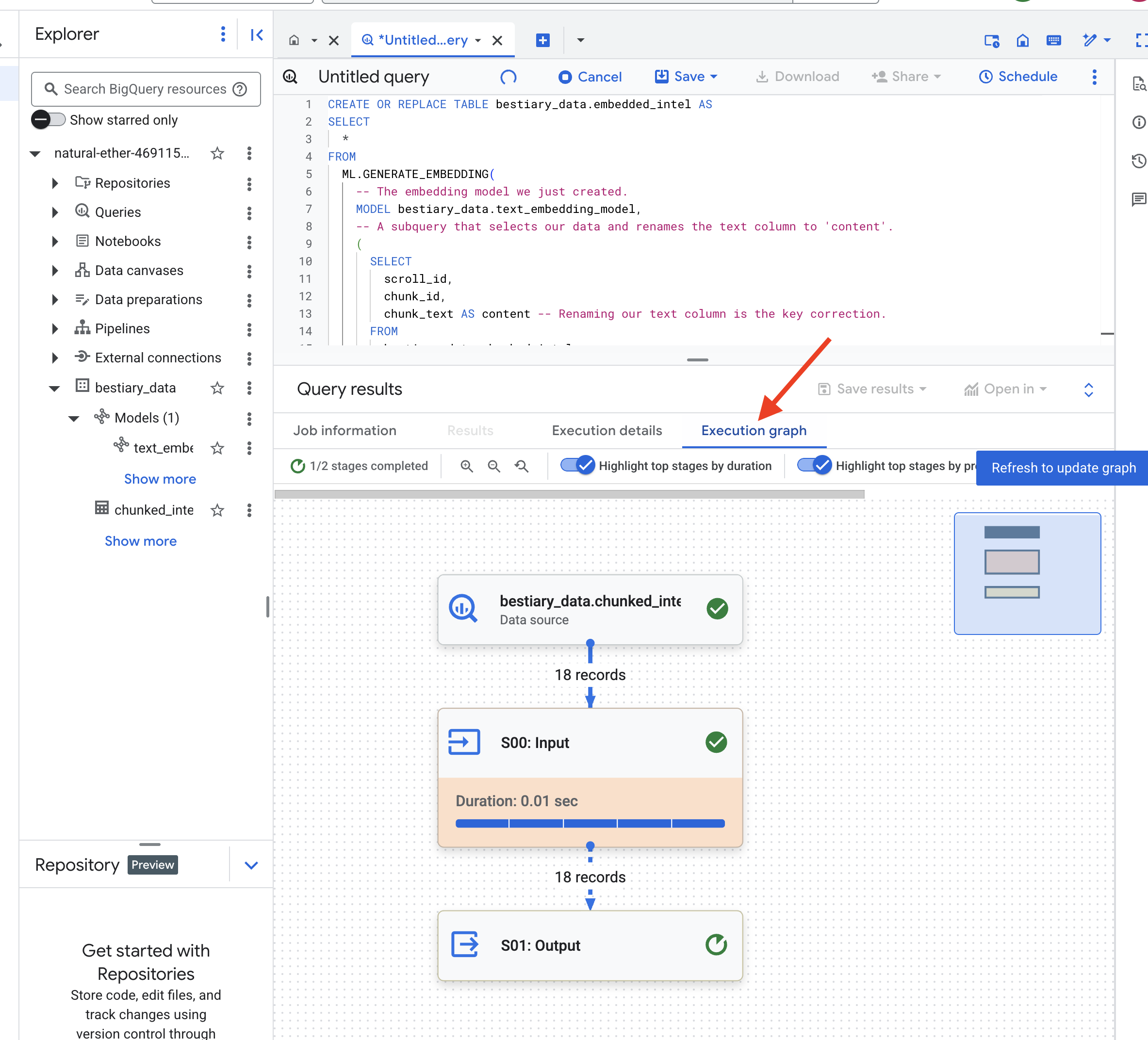
👉📜 เมื่อเสร็จแล้ว ให้ตรวจสอบตารางใหม่เพื่อดูลายนิ้วมือเชิงความหมาย
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
ตอนนี้คุณจะเห็นคอลัมน์ใหม่ ml_generate_embedding_result ซึ่งมีตัวแทนเวกเตอร์แบบหนาแน่นของข้อความ ตอนนี้เราได้เข้ารหัส Grimoire ในเชิงความหมายแล้ว
พิธีกรรมแห่งการทำนาย: การค้นหาเชิงความหมายด้วย BQML
👉📜 การทดสอบ Grimoire ที่ดีที่สุดคือการถามคำถาม ตอนนี้เราจะทำพิธีกรรมสุดท้าย นั่นคือการค้นหาเวกเตอร์ นี่ไม่ใช่การค้นหาคีย์เวิร์ด แต่เป็นการค้นหาความหมาย เราจะถามคำถามในภาษาง่ายๆ, BQML จะแปลงคำถามของเราเป็นการฝังแบบเรียลไทม์ จากนั้นจะค้นหาตารางทั้งหมดของ embedded_intel เพื่อหาข้อความที่มีลายนิ้วมือซึ่งมีความหมาย "ใกล้เคียง" ที่สุด
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
การวิเคราะห์คำ
VECTOR_SEARCH: ฟังก์ชันหลักที่จัดการการค้นหาML.GENERATE_EMBEDDING(การค้นหาภายใน): นี่คือเคล็ดลับ เราฝังคำค้นหา ('What are the tactics...') โดยใช้โมเดลเดียวกัน แต่มีประเภทงานเป็น'RETRIEVAL_QUERY'ซึ่งได้รับการเพิ่มประสิทธิภาพสำหรับคำค้นหาโดยเฉพาะtop_k => 3: เราขอผลการค้นหาที่เกี่ยวข้องมากที่สุด 3 อันดับแรกdistance_type => 'COSINE': เมตริกนี้วัด "มุม" ระหว่างเวกเตอร์ มุมที่แคบลงหมายความว่าความหมายจะสอดคล้องกันมากขึ้น
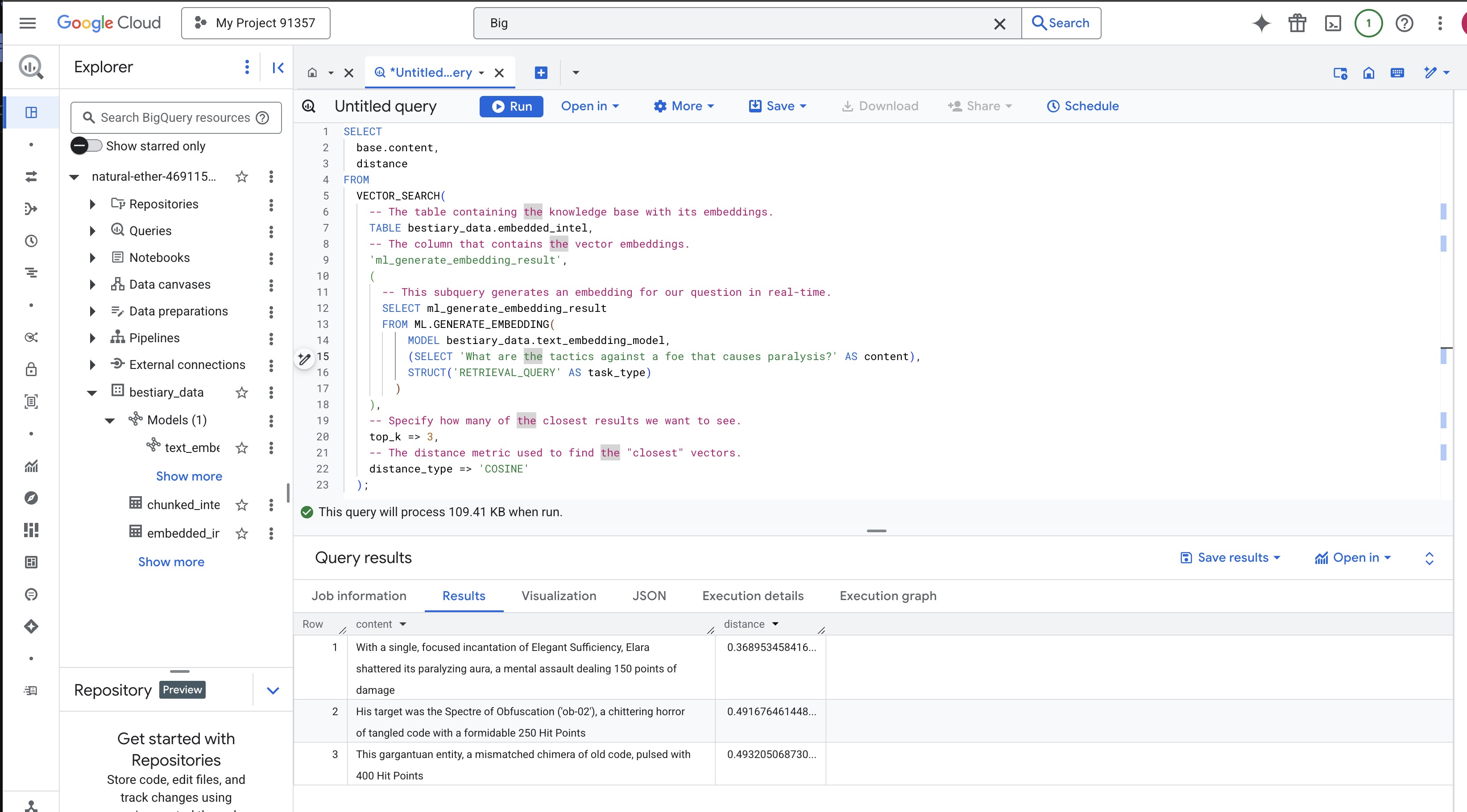
ดูผลลัพธ์อย่างละเอียด แม้ว่าคำค้นหาจะไม่มีคำว่า "แตกสลาย" หรือ "คาถา" แต่ผลการค้นหาแรกกลับเป็น "ด้วยคาถาเดียวที่มุ่งเน้นความเพียงพออย่างสง่างาม เอลาร่าได้ทำลายออร่าที่ทำให้เป็นอัมพาต ซึ่งเป็นการโจมตีทางจิตที่สร้างความเสียหาย 150 แต้ม" นี่คือพลังของการค้นหาเชิงความหมาย โมเดลเข้าใจแนวคิดของ "กลยุทธ์ต่อต้านอัมพาต" และพบประโยคที่อธิบายกลยุทธ์ที่เฉพาะเจาะจงและประสบความสำเร็จ
ตอนนี้คุณได้สร้างไปป์ไลน์ RAG ที่สมบูรณ์แบบใน Data Warehouse โดยใช้ R พื้นฐานเรียบร้อยแล้ว คุณได้เตรียมข้อมูลดิบ แปลงเป็นเวกเตอร์เชิงความหมาย และค้นหาตามความหมาย แม้ว่า BigQuery จะเป็นเครื่องมือที่มีประสิทธิภาพสําหรับงานวิเคราะห์ขนาดใหญ่นี้ แต่สําหรับตัวแทนแบบเรียลไทม์ที่ต้องการการตอบกลับที่มีเวลาในการตอบสนองต่ำ เรามักจะโอนความรู้ที่เตรียมไว้นี้ไปยังฐานข้อมูลการดําเนินงานเฉพาะทาง ซึ่งเป็นหัวข้อของการฝึกอบรมครั้งถัดไป
สำหรับผู้ที่ไม่ได้เล่นเกม
6. Vector Scriptorium: สร้างที่เก็บเวกเตอร์ด้วย Cloud SQL สำหรับการอนุมาน
ปัจจุบัน Grimoire ของเราอยู่ในรูปแบบตารางที่มีโครงสร้าง ซึ่งเป็นแคตตาล็อกข้อเท็จจริงที่มีประสิทธิภาพ แต่ความรู้ของ Grimoire นั้นเป็นไปตามตัวอักษร โดยระบบจะเข้าใจ monster_id = ‘MN-001' แต่จะไม่เข้าใจความหมายเชิงลึกและเชิงความหมายที่อยู่เบื้องหลัง "การปกปิด" เพื่อให้ตัวแทนของเรามีความรู้ที่แท้จริง และสามารถให้คำแนะนำได้อย่างละเอียดและรอบคอบ เราจึงต้องกลั่นกรองแก่นแท้ของความรู้ของเราให้อยู่ในรูปแบบที่จับความหมายได้ นั่นคือเวกเตอร์
การแสวงหาความรู้ทำให้เราได้พบกับซากปรักหักพังของอารยธรรมรุ่นก่อนที่ถูกลืมเลือนไปนาน เราได้ค้นพบหีบม้วนกระดาษโบราณที่ถูกเก็บรักษาไว้อย่างน่าอัศจรรย์ในห้องเก็บของที่ปิดผนึกไว้ นี่ไม่ใช่แค่รายงานการต่อสู้ แต่เป็นภูมิปัญญาเชิงปรัชญาที่ลึกซึ้งเกี่ยวกับวิธีเอาชนะสัตว์ร้ายที่คอยบั่นทอนความพยายามอันยิ่งใหญ่ทั้งหมด เอนทิตีที่อธิบายไว้ในม้วนหนังสือว่าเป็น "ความซบเซาที่คืบคลานอย่างเงียบเชียบ" และ "การเสื่อมถอยของโครงสร้างแห่งการสร้างสรรค์" ดูเหมือนว่าแม้แต่คนโบราณก็รู้จัก The Static ซึ่งเป็นภัยคุกคามที่เกิดขึ้นซ้ำๆ และประวัติศาสตร์ของภัยคุกคามนี้ก็เลือนหายไปตามกาลเวลา
ความรู้ที่ถูกลืมนี้คือทรัพย์สินที่ยิ่งใหญ่ที่สุดของเรา ซึ่งไม่เพียงแต่เป็นกุญแจสำคัญในการเอาชนะมอนสเตอร์แต่ละตัว แต่ยังช่วยให้ทั้งปาร์ตี้มีข้อมูลเชิงลึกเชิงกลยุทธ์ด้วย เพื่อใช้พลังนี้ เราจะสร้างสมุดเวทมนตร์ที่แท้จริงของนักปราชญ์ (ฐานข้อมูล PostgreSQL ที่มีความสามารถด้านเวกเตอร์) และสร้างห้องสมุดเวกเตอร์อัตโนมัติ (ไปป์ไลน์ Dataflow) เพื่ออ่าน ทำความเข้าใจ และจารึกแก่นแท้เหนือกาลเวลาของม้วนคัมภีร์เหล่านี้ ซึ่งจะเปลี่ยน Grimoire จากหนังสือข้อเท็จจริงให้กลายเป็นเครื่องมือแห่งปัญญา

การสร้างสมุดเวทมนตร์ของนักวิชาการ (Cloud SQL)
ก่อนจะจารึกแก่นแท้ของม้วนกระดาษโบราณเหล่านี้ เราต้องยืนยันก่อนว่าคัมภีร์คาถา PostgreSQL ที่มีการจัดการ ซึ่งเป็นภาชนะสำหรับความรู้นี้ได้ถูกสร้างขึ้นเรียบร้อยแล้ว พิธีการตั้งค่าเริ่มต้นควรสร้างสิ่งนี้ให้คุณแล้ว
👉💻 ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อยืนยันว่าอินสแตนซ์ Cloud SQL มีอยู่และพร้อมใช้งาน นอกจากนี้ สคริปต์นี้ยังให้สิทธิ์แก่บัญชีบริการเฉพาะของอินสแตนซ์ในการใช้ Vertex AI ซึ่งจำเป็นต่อการสร้างการฝังภายในฐานข้อมูลโดยตรง
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
หากคำสั่งสำเร็จและแสดงรายละเอียดเกี่ยวกับอินสแตนซ์ grimoire-spellbook แสดงว่า Forge ทำงานได้ดี คุณพร้อมที่จะไปยังคาถาบทถัดไปแล้ว หากคำสั่งแสดงข้อผิดพลาด NOT_FOUND โปรดตรวจสอบว่าคุณได้ทำตามขั้นตอนการตั้งค่าสภาพแวดล้อมเริ่มต้นเรียบร้อยแล้วก่อนดำเนินการต่อ(data_setup.py)
👉💻 เมื่อสร้างสมุดแล้ว เราจะเปิดไปที่บทแรกโดยสร้างฐานข้อมูลใหม่ชื่อ arcane_wisdom
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
การจารึกรูนความหมาย: การเปิดใช้ความสามารถของเวกเตอร์ด้วย pgvector
ตอนนี้คุณได้สร้างอินสแตนซ์ Cloud SQL แล้ว มาเชื่อมต่อกับอินสแตนซ์โดยใช้ Cloud SQL Studio ในตัวกัน ซึ่งมีอินเทอร์เฟซบนเว็บสําหรับเรียกใช้คําค้นหา SQL ในฐานข้อมูลโดยตรง
👉💻 ก่อนอื่น ให้ไปที่ Cloud SQL Studio วิธีที่ง่ายและเร็วที่สุดในการไปที่นั่นคือการเปิดลิงก์ต่อไปนี้ในแท็บเบราว์เซอร์ใหม่ ซึ่งจะนำคุณไปยัง Cloud SQL Studio สำหรับอินสแตนซ์ grimoire-spellbook โดยตรง
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 เลือก arcane_wisdom เป็นฐานข้อมูล ป้อน postgres เป็นผู้ใช้และ 1234qwer เป็นรหัสผ่าน แล้วคลิกตรวจสอบสิทธิ์
👉📜 ในตัวแก้ไขคําค้นหา SQL Studio ให้ไปที่แท็บ Editor 1 แล้ววางโค้ด SQL ต่อไปนี้เพื่อเปิดใช้ประเภทข้อมูลเวกเตอร์
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
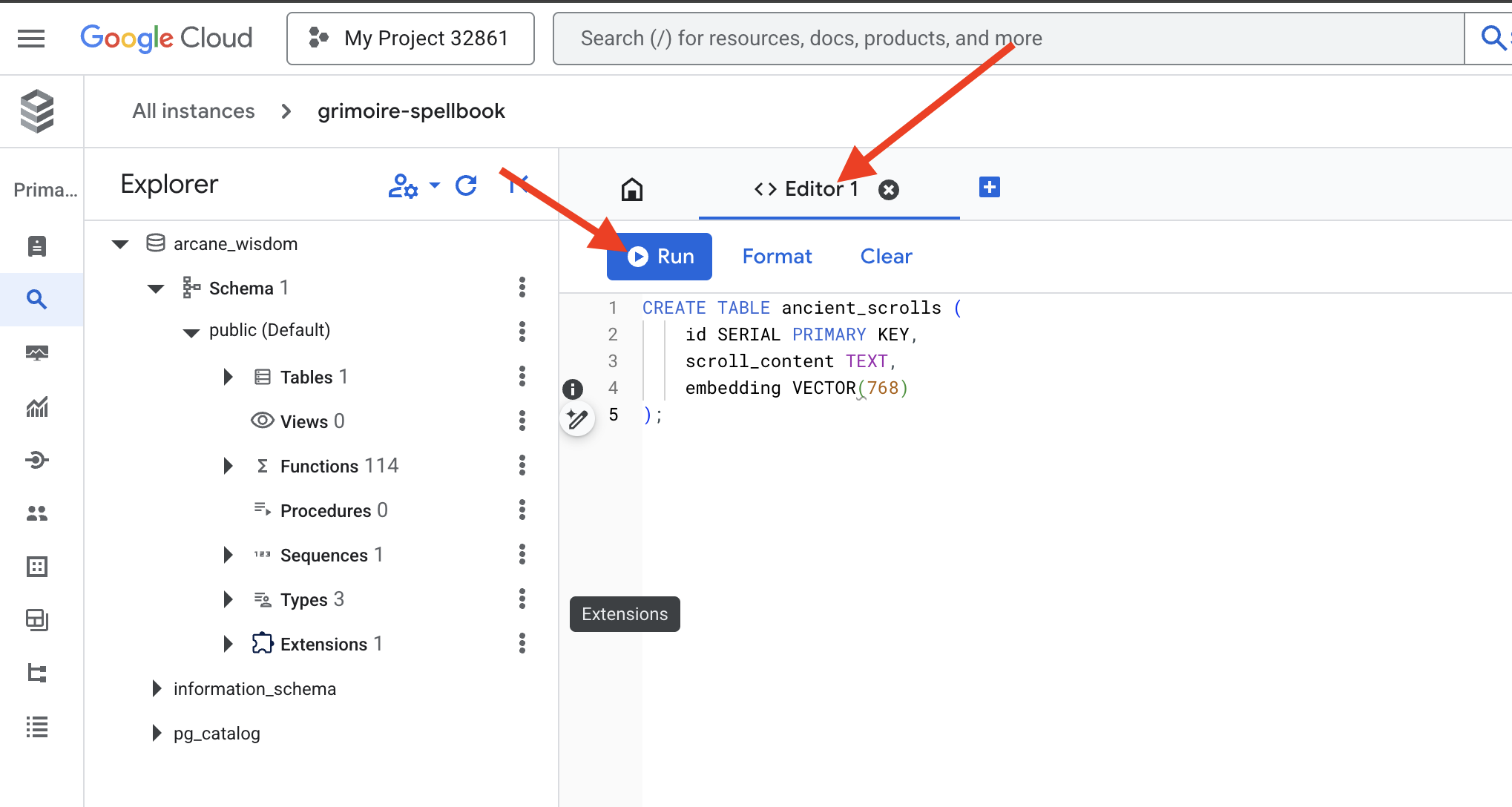
👉📜 เตรียมหน้าต่างๆ ของสมุดเวทมนตร์โดยสร้างตารางที่จะเก็บแก่นแท้ของม้วนคัมภีร์
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
การสะกดคำว่า VECTOR(768) เป็นรายละเอียดที่สำคัญ โมเดลการฝัง Vertex AI ที่เราจะใช้ (textembedding-gecko@003 หรือโมเดลที่คล้ายกัน) จะกลั่นข้อความเป็นเวกเตอร์ 768 มิติ หน้าต่างๆ ในสมุดเวทมนตร์ของเราต้องพร้อมที่จะบรรจุแก่นแท้ที่มีขนาดเท่ากัน มิติข้อมูลต้องตรงกันเสมอ
การทับศัพท์ครั้งแรก: พิธีกรรมการจารึกด้วยตนเอง
ก่อนที่จะสั่งกองทัพนักจดอัตโนมัติ (Dataflow) เราต้องทำพิธีกรรมส่วนกลางด้วยตนเองก่อน 1 ครั้ง ซึ่งจะช่วยให้เราเห็นคุณค่าของเวทมนตร์ 2 ขั้นตอนที่เกี่ยวข้อง
- การทำนาย: การนำข้อความมา 1 ชิ้นและปรึกษา Oracle ของ Gemini เพื่อกลั่นแก่นแท้เชิงความหมายของข้อความนั้นให้เป็นเวกเตอร์
- การจารึก: การเขียนข้อความต้นฉบับและสาระสำคัญของเวกเตอร์ใหม่ลงในสมุดเวทมนตร์
ตอนนี้เรามาทำพิธีด้วยตนเองกัน
👉📜 ใน Cloud SQL Studio ตอนนี้เราจะใช้ฟังก์ชัน embedding() ซึ่งเป็นฟีเจอร์ที่มีประสิทธิภาพที่ส่วนขยาย google_ml_integration มีให้ ซึ่งช่วยให้เราเรียกใช้โมเดลการฝัง Vertex AI ได้โดยตรงจากคำค้นหา SQL ซึ่งช่วยลดความซับซ้อนของกระบวนการได้อย่างมาก
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 ยืนยันผลงานโดยเรียกใช้การค้นหาเพื่ออ่านหน้าที่จารึกใหม่
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
คุณได้ดำเนินการโหลดข้อมูล RAG หลักด้วยตนเองเรียบร้อยแล้ว
การสร้างเข็มทิศเชิงความหมาย: การร่ายมนต์ในสมุดเวทมนตร์ด้วยดัชนี HNSW
ตอนนี้ Spellbook ของเราสามารถเก็บภูมิปัญญาได้แล้ว แต่การค้นหา Scroll ที่เหมาะสมต้องอ่านทุกหน้า ซึ่งเป็นการสแกนตามลำดับ ซึ่งเป็นวิธีที่ช้าและไม่มีประสิทธิภาพ เราต้องร่ายมนต์ให้สมุดเวทมนตร์ด้วยเข็มทิศเชิงความหมาย ซึ่งก็คือดัชนีเวกเตอร์ เพื่อนำทางคำค้นหาไปยังความรู้ที่เกี่ยวข้องมากที่สุดได้ทันที
มาพิสูจน์คุณค่าของเวทมนตร์นี้กัน
👉📜 ใน Cloud SQL Studio ให้เรียกใช้คำสั่งต่อไปนี้ โดยจะจำลองการค้นหาการเลื่อนที่เพิ่งแทรกและขอให้ฐานข้อมูลEXPLAINแผน
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
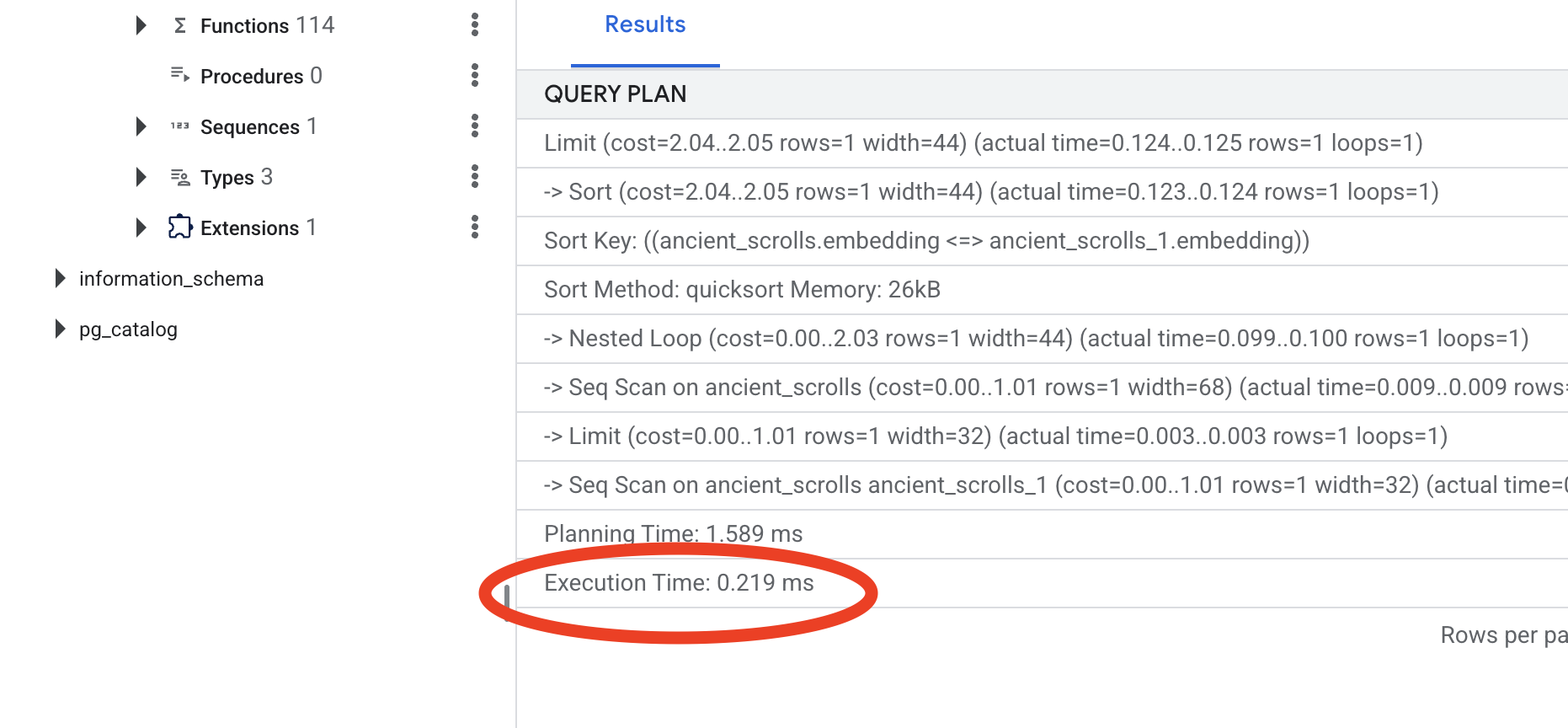
ดูเอาต์พุต คุณจะเห็นบรรทัดที่ระบุว่า -> Seq Scan on ancient_scrolls ซึ่งยืนยันว่าฐานข้อมูลอ่านทุกแถว โปรดทราบexecution time
👉📜 ตอนนี้มาเสกคาถาจัดทำดัชนีกัน พารามิเตอร์ lists จะบอกดัชนีว่าต้องสร้างคลัสเตอร์กี่คลัสเตอร์ จุดเริ่มต้นที่ดีคือรากที่สองของจำนวนแถวที่คุณคาดว่าจะได้รับ
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
รอให้ระบบสร้างดัชนี (จะใช้เวลาไม่นานสำหรับแถวเดียว แต่สำหรับหลายล้านแถวอาจใช้เวลาสักครู่)
👉📜 ตอนนี้ ให้เรียกใช้คำสั่งเดียวกันทุกประการ EXPLAIN ANALYZEอีกครั้ง
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
ดูแผนการดำเนินการกับคำค้นหาใหม่ ตอนนี้คุณจะเห็น -> Index Scan using... และที่สำคัญกว่านั้นคือให้ดูที่execution time ซึ่งจะเร็วกว่ามากแม้จะมีเพียงรายการเดียวก็ตาม คุณเพิ่งแสดงให้เห็นหลักการสำคัญของการเพิ่มประสิทธิภาพฐานข้อมูลในโลกเวกเตอร์
เมื่อตรวจสอบข้อมูลต้นทาง เข้าใจพิธีกรรมด้วยตนเอง และเพิ่มประสิทธิภาพ Spellbook เพื่อให้รวดเร็วแล้ว ตอนนี้คุณก็พร้อมที่จะสร้าง Scriptorium อัตโนมัติอย่างแท้จริง
สำหรับผู้ที่ไม่ได้เล่นเกม
7. Conduit of Meaning: Building a Dataflow Vectorization Pipeline
ตอนนี้เรากำลังสร้างสายการประกอบอันน่าอัศจรรย์ของนักจดบันทึกที่จะอ่านม้วนคัมภีร์ของเรา กลั่นกรองแก่นแท้ และจารึกไว้ในสมุดเวทมนตร์เล่มใหม่ นี่คือไปป์ไลน์ Dataflow ที่เราจะทริกเกอร์ด้วยตนเอง แต่ก่อนที่จะเขียนคาถาหลักสำหรับไปป์ไลน์ เราต้องเตรียมพื้นฐานและวงกลมที่เราจะใช้เรียกไปป์ไลน์ก่อน
การเตรียมรากฐานของ Scriptorium (อิมเมจผู้ปฏิบัติงาน)
ไปป์ไลน์ Dataflow จะดำเนินการโดยทีมผู้ปฏิบัติงานอัตโนมัติในระบบคลาวด์ ทุกครั้งที่เราเรียกใช้ฟังก์ชันเหล่านี้ ฟังก์ชันจะต้องใช้ชุดไลบรารีที่เฉพาะเจาะจงเพื่อทำงาน เราอาจให้รายชื่อและให้ผู้ใช้ดึงข้อมูลไลบรารีเหล่านี้ทุกครั้ง แต่จะทำให้การทำงานช้าและไม่มีประสิทธิภาพ นักปราชญ์ที่ชาญฉลาดจะเตรียมห้องสมุดหลักไว้ล่วงหน้า
ในที่นี้ เราจะสั่งให้ Google Cloud Build สร้างอิมเมจคอนเทนเนอร์ที่กำหนดเอง รูปภาพนี้คือ "โกเลมที่สมบูรณ์แบบ" ซึ่งโหลดไว้ล่วงหน้าพร้อมกับไลบรารีและการอ้างอิงทั้งหมดที่นักเขียนของเราต้องการ เมื่อเริ่มงาน Dataflow ระบบจะใช้อิมเมจที่กำหนดเองนี้ ซึ่งจะช่วยให้ผู้ปฏิบัติงานเริ่มงานได้ทันที
👉💻 เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างและจัดเก็บอิมเมจพื้นฐานของไปป์ไลน์ใน Artifact Registry
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างและเปิดใช้งานสภาพแวดล้อม Python ที่แยกจากกัน แล้วติดตั้งไลบรารีการเรียกที่จำเป็นลงในสภาพแวดล้อมนั้น
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
คาถาหลัก
ถึงเวลาเขียนคาถาหลักที่จะขับเคลื่อน Vector Scriptorium ของเราแล้ว เราจะไม่เขียนคอมโพเนนต์เวทมนตร์แต่ละรายการตั้งแต่ต้น งานของเราคือการประกอบคอมโพเนนต์เป็นไปป์ไลน์ที่มีประสิทธิภาพเชิงตรรกะโดยใช้ภาษาของ Apache Beam
- EmbedTextBatch (การให้คำปรึกษาของ Gemini): คุณจะสร้างผู้จดบันทึกเฉพาะทางนี้ซึ่งรู้วิธีการทำ "การทำนายแบบกลุ่ม" โดยจะรับไฟล์ข้อความดิบเป็นชุด แสดงต่อโมเดลการฝังข้อความของ Gemini และรับสาระสำคัญที่กลั่นกรองแล้ว (การฝังเวกเตอร์)
- WriteEssenceToSpellbook (จารึกสุดท้าย): นี่คือผู้จดบันทึกของเรา โดยรู้คาถาลับในการเปิดการเชื่อมต่อที่ปลอดภัยกับสมุดคาถา Cloud SQL ของเรา หน้าที่ของฟีเจอร์นี้คือการนำเนื้อหาของม้วนกระดาษและแก่นแท้ที่แปลงเป็นเวกเตอร์มาจารึกไว้ในหน้าใหม่เป็นการถาวร
ภารกิจของเราคือการเชื่อมโยงการดำเนินการเหล่านี้เข้าด้วยกันเพื่อสร้างกระแสความรู้ที่ราบรื่น
👉✏️ ใน Cloud Shell Editor ให้ไปที่ ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py คุณจะเห็นคลาส DoFn ชื่อ EmbedTextBatch ค้นหาความคิดเห็น #REPLACE-EMBEDDING-LOGIC แทนที่ด้วยคาถาต่อไปนี้
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
การสะกดคำนี้มีความแม่นยำโดยมีพารามิเตอร์สำคัญหลายอย่างดังนี้
- model: เราจะระบุ
text-embedding-005เพื่อใช้โมเดลการฝังที่ทรงพลังและเป็นปัจจุบัน - contents: นี่คือรายการเนื้อหาข้อความทั้งหมดจากกลุ่มไฟล์ที่ DoFn ได้รับ
- task_type: เราตั้งค่านี้เป็น "RETRIEVAL_DOCUMENT" นี่คือคำสั่งสำคัญที่บอกให้ Gemini สร้างการฝังที่ได้รับการเพิ่มประสิทธิภาพโดยเฉพาะเพื่อให้ค้นพบได้ในภายหลังในการค้นหา
- output_dimensionality: ต้องตั้งค่าเป็น 768 ซึ่งตรงกับมิติข้อมูล VECTOR(768) ที่เรากำหนดไว้เมื่อสร้างตาราง ancient_scrolls ใน Cloud SQL มิติข้อมูลที่ไม่ตรงกันเป็นสาเหตุที่พบได้ทั่วไปของข้อผิดพลาดใน Vector Magic
ไปป์ไลน์ของเราต้องเริ่มต้นด้วยการอ่านข้อความดิบที่ไม่มีโครงสร้างจากม้วนกระดาษโบราณทั้งหมดในที่เก็บถาวร GCS
👉✏️ ใน ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py ให้ค้นหาความคิดเห็น #REPLACE ME-READFILE แล้วแทนที่ด้วยคาถาสามส่วนต่อไปนี้
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
เมื่อรวบรวมข้อความดิบของม้วนกระดาษได้แล้ว ตอนนี้เราต้องส่งข้อความเหล่านั้นไปยัง Gemini เพื่อทำนาย เพื่อดำเนินการนี้อย่างมีประสิทธิภาพ เราจะจัดกลุ่มม้วนกระดาษแต่ละม้วนเป็นชุดเล็กๆ ก่อน แล้วจึงส่งชุดเหล่านั้นให้EmbedTextBatchผู้คัดลอก นอกจากนี้ ขั้นตอนนี้ยังจะแยกการเลื่อนที่ Gemini ไม่เข้าใจออกเป็นกอง "ไม่สำเร็จ" เพื่อตรวจสอบในภายหลังด้วย
👉✏️ ค้นหาความคิดเห็น #REPLACE ME-EMBEDDING แล้วแทนที่ด้วยข้อความต่อไปนี้
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
เราได้กลั่นกรองสาระสำคัญของม้วนกระดาษเหล่านี้เรียบร้อยแล้ว การกระทำสุดท้ายคือการจารึกความรู้นี้ลงในสมุดเวทมนตร์เพื่อจัดเก็บอย่างถาวร เราจะนำม้วนกระดาษจากกอง "ประมวลผลแล้ว" ไปมอบให้แก่ผู้ดูแลเอกสารของ WriteEssenceToSpellbook
👉✏️ ค้นหาความคิดเห็น #REPLACE ME-WRITE TO DB แล้วแทนที่ด้วยข้อความต่อไปนี้
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
นักปราชญ์จะไม่ทิ้งความรู้ แม้จะพยายามไม่สำเร็จก็ตาม ในขั้นตอนสุดท้าย เราต้องสั่งให้ผู้จดบันทึกนำกอง "ไม่สำเร็จ" จากขั้นตอนการทำนายมาบันทึกเหตุผลที่ทำให้ไม่สำเร็จ ซึ่งจะช่วยให้เราปรับปรุงพิธีกรรมในอนาคตได้
👉✏️ ค้นหาความคิดเห็น #REPLACE ME-LOG FAILURES แล้วแทนที่ด้วยข้อความต่อไปนี้
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
ตอนนี้คาถาหลักเสร็จสมบูรณ์แล้ว คุณได้ประกอบไปป์ไลน์ข้อมูลแบบหลายขั้นตอนที่มีประสิทธิภาพเรียบร้อยแล้วโดยการเชื่อมต่อคอมโพเนนต์แต่ละรายการเข้าด้วยกัน บันทึกไฟล์ inscribe_essence_pipeline.py ตอนนี้คุณพร้อมที่จะอัญเชิญ Scriptorium แล้ว
ตอนนี้เราจะร่ายคาถาอัญเชิญอันยิ่งใหญ่เพื่อสั่งให้บริการ Dataflow ปลุกโกเลมของเราและเริ่มพิธีการเขียน
👉💻 เรียกใช้บรรทัดคำสั่งต่อไปนี้ในเทอร์มินัล
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 โปรดทราบ หากงานล้มเหลวเนื่องจากข้อผิดพลาดเกี่ยวกับทรัพยากร ZONE_RESOURCE_POOL_EXHAUSTED อาจเป็นเพราะข้อจำกัดด้านทรัพยากรชั่วคราวของบัญชีที่มีชื่อเสียงต่ำในภูมิภาคที่เลือก พลังของ Google Cloud คือการเข้าถึงทั่วโลก เพียงลองอัญเชิญโกเลมในภูมิภาคอื่น โดยให้แทนที่ --region=$REGION ในคำสั่งด้านบนด้วยภูมิภาคอื่น เช่น
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
แล้วเรียกใช้สคริปต์อีกครั้ง 🎰
กระบวนการนี้จะใช้เวลาประมาณ 3-5 นาทีในการเริ่มต้นและเสร็จสมบูรณ์ คุณดูการถ่ายทอดสดได้ในคอนโซล Dataflow
👉ไปที่คอนโซล Dataflow: วิธีที่ง่ายที่สุดคือเปิดลิงก์นี้โดยตรงในแท็บเบราว์เซอร์ใหม่
https://console.cloud.google.com/dataflow
👉 ค้นหาและคลิกงานของคุณ: คุณจะเห็นงานที่แสดงพร้อมชื่อที่คุณระบุ (inscribe-essence-job หรือคล้ายกัน) คลิกชื่องานเพื่อเปิดหน้ารายละเอียด สังเกตไปป์ไลน์:
- การเริ่มต้น: ในช่วง 3 นาทีแรก สถานะของงานจะเป็น "กำลังทำงาน" เนื่องจาก Dataflow จัดสรรทรัพยากรที่จำเป็น กราฟจะปรากฏขึ้น แต่คุณอาจยังไม่เห็นข้อมูลไหลผ่านกราฟ
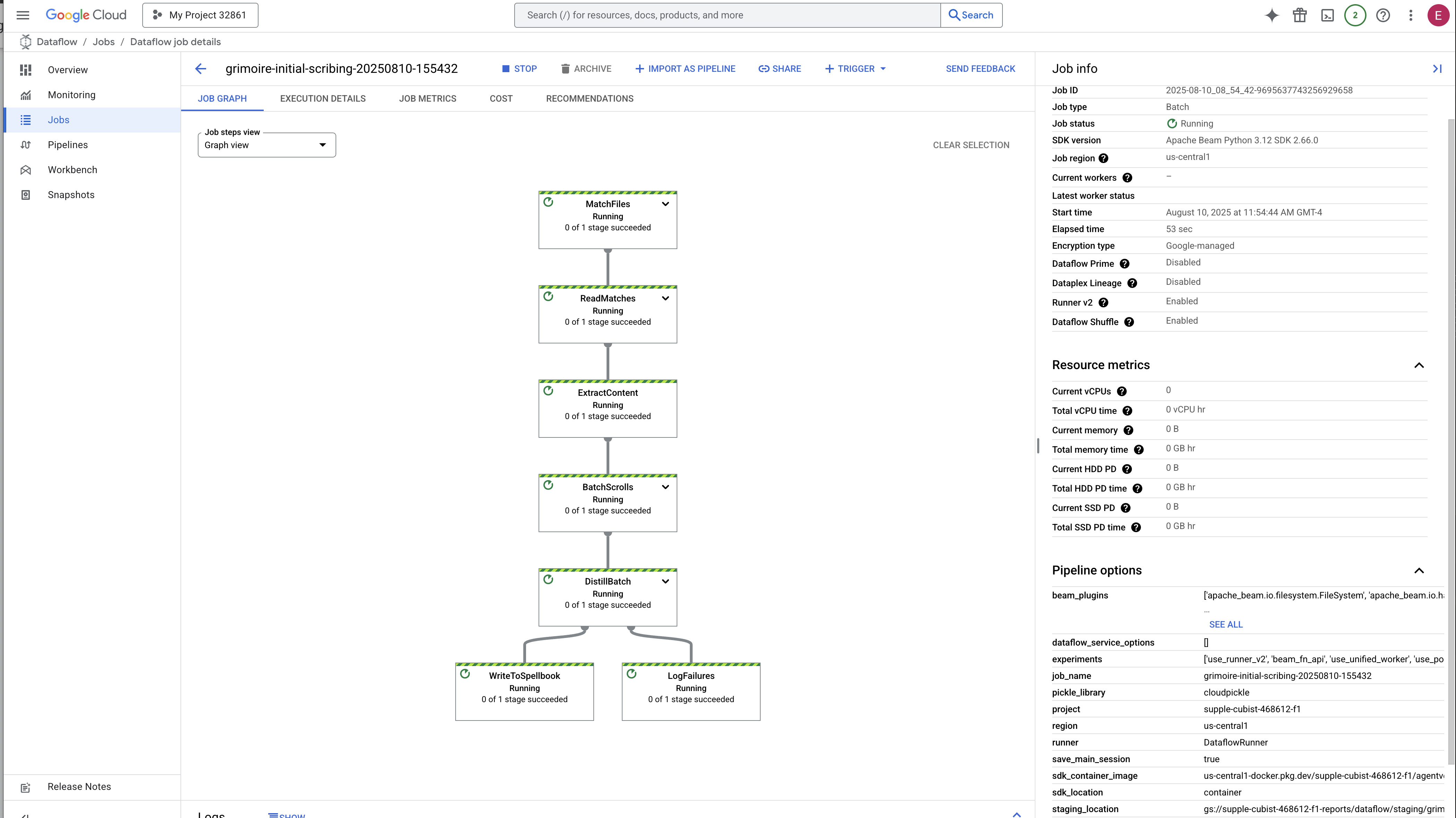
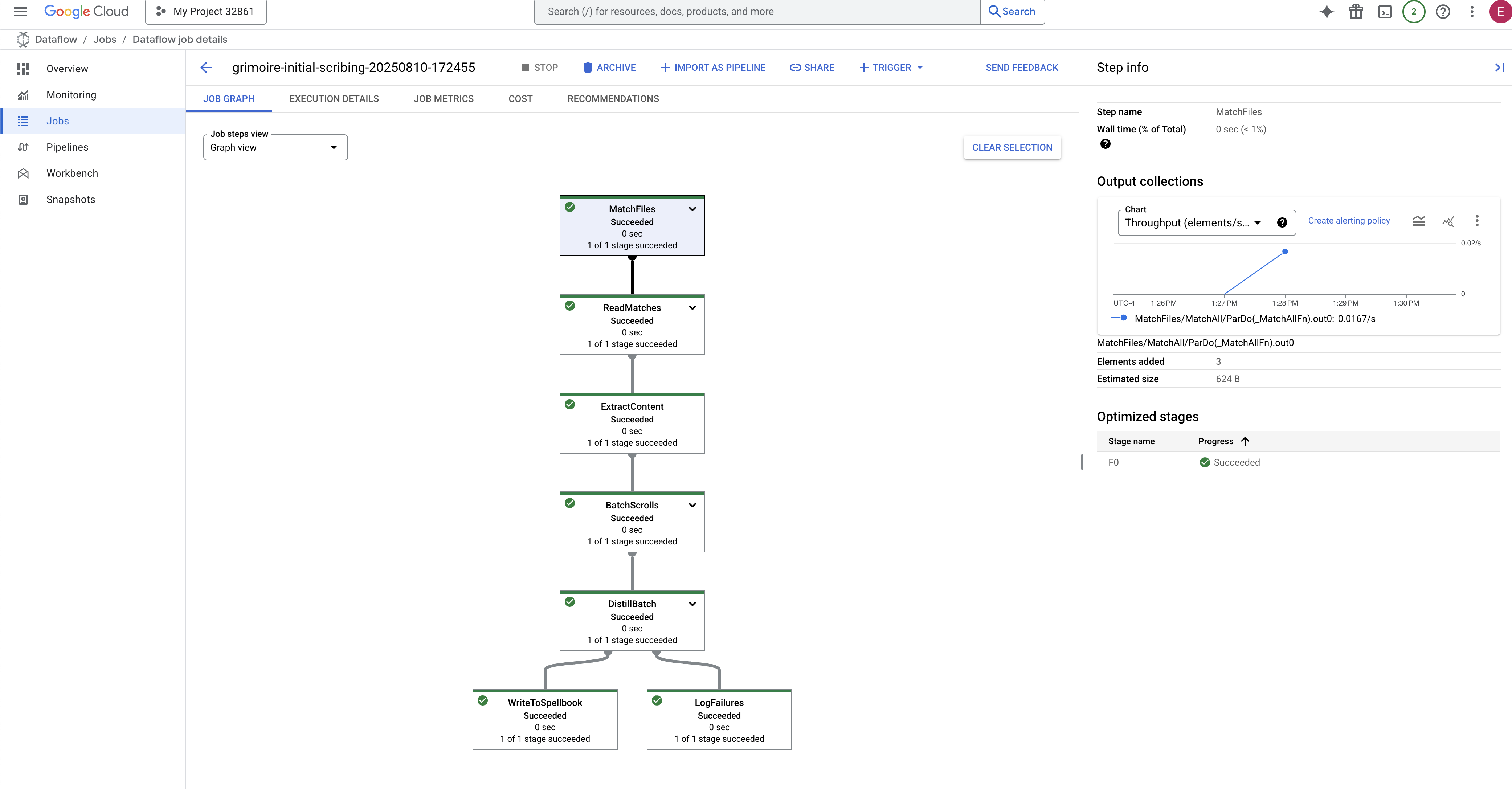
- เสร็จสมบูรณ์: เมื่อเสร็จสิ้น สถานะของงานจะเปลี่ยนเป็น "สำเร็จ" และกราฟจะแสดงจำนวนระเบียนที่ประมวลผลแล้วขั้นสุดท้าย
การยืนยันจารึก
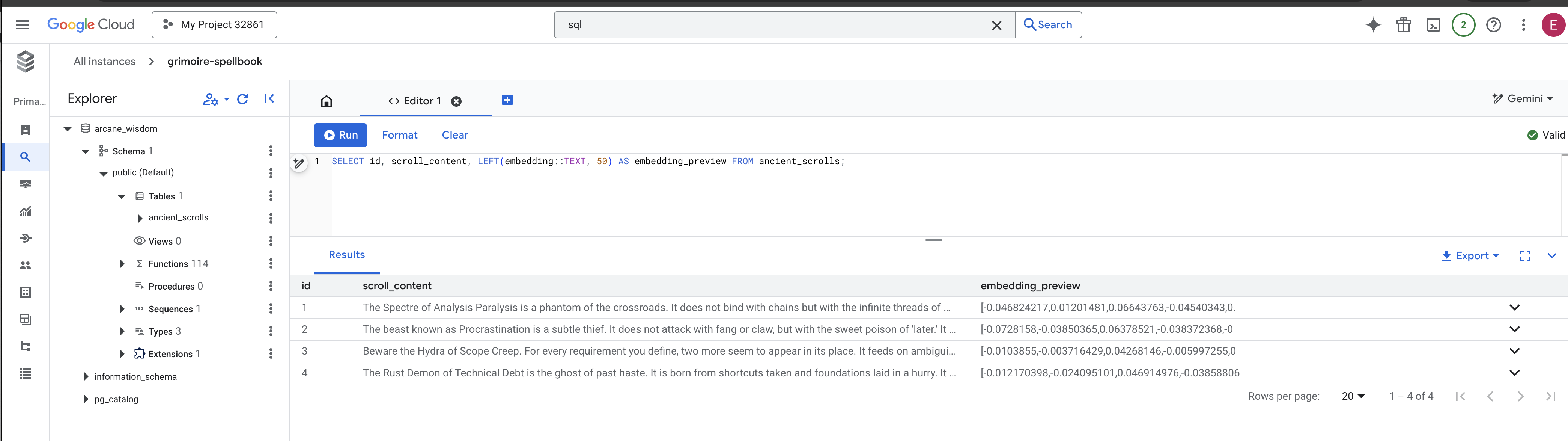
👉📜 กลับไปที่ SQL Studio ให้เรียกใช้การค้นหาต่อไปนี้เพื่อยืนยันว่าการจารึกม้วนคัมภีร์และสาระสำคัญเชิงความหมายเสร็จสมบูรณ์แล้ว
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
ซึ่งจะแสดงรหัสของม้วนคัมภีร์ ข้อความต้นฉบับ และตัวอย่างของเวทมนตร์ที่สลักลงในกริมมัวร์อย่างถาวร
ตอนนี้ Grimoire ของ Scholar ได้กลายเป็นเครื่องมือความรู้ที่แท้จริงแล้ว พร้อมที่จะรับการค้นหาตามความหมายในบทถัดไป
8. การผนึกรูนสุดท้าย: การเปิดใช้งานปัญญาด้วยเอเจนต์ RAG
Grimoire ไม่ใช่แค่ฐานข้อมูลอีกต่อไป เป็นแหล่งความรู้ที่แปลงเป็นเวกเตอร์ เป็นผู้พยากรณ์ที่เงียบงันซึ่งรอคำถาม
ตอนนี้เราจะมาทดสอบความเป็นนักปราชญ์อย่างแท้จริง นั่นคือการสร้างกุญแจเพื่อไขปัญญา เราจะสร้าง Agent Retrieval-Augmented Generation (RAG) ซึ่งเป็นโครงสร้างที่น่าอัศจรรย์ที่สามารถเข้าใจคำถามในภาษาธรรมดา ปรึกษา Grimoire เพื่อหาความจริงที่ลึกซึ้งและเกี่ยวข้องมากที่สุด แล้วใช้สติปัญญาที่ดึงมานั้นเพื่อสร้างคำตอบที่มีประสิทธิภาพและคำนึงถึงบริบท

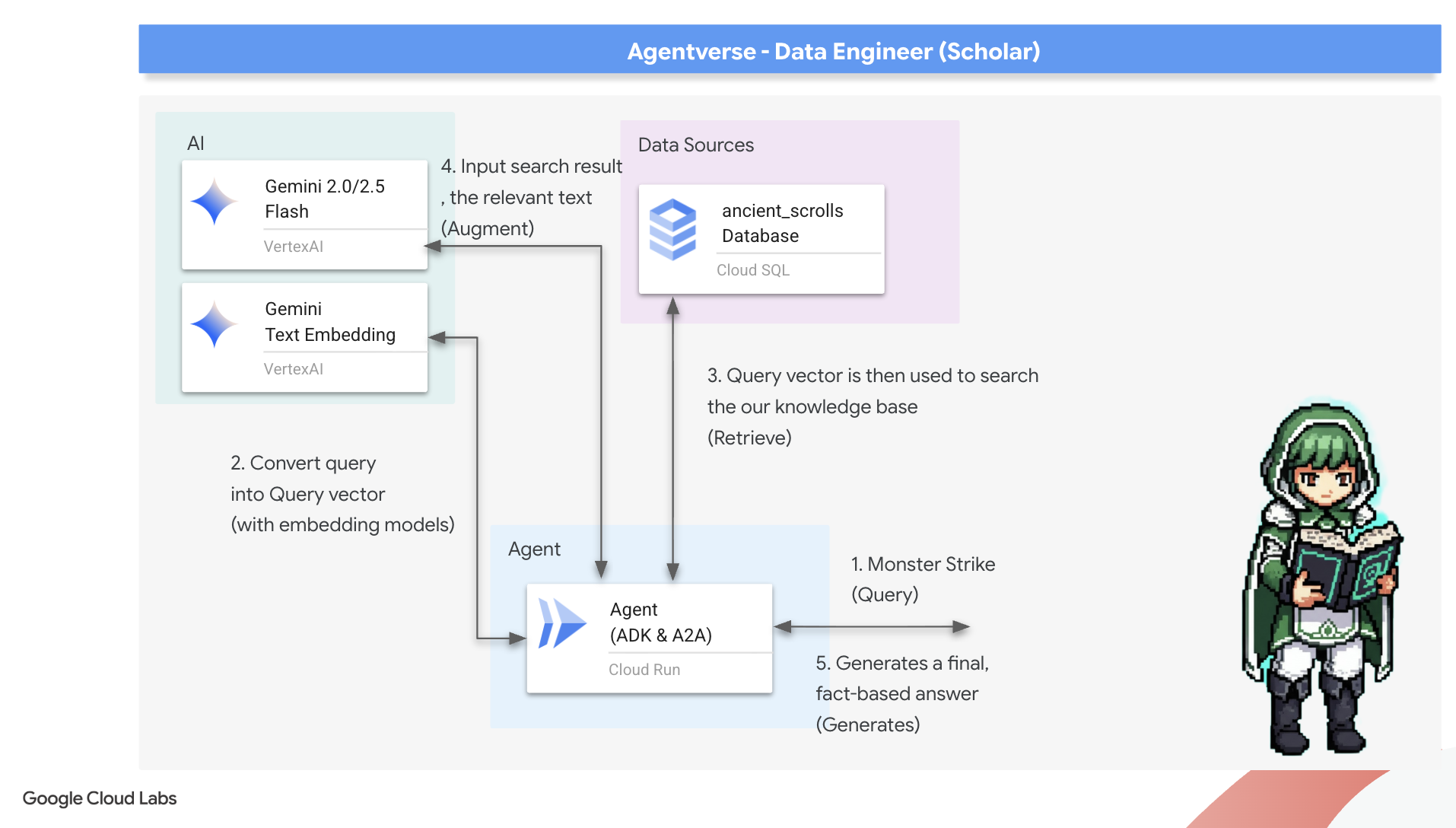
รูนแรก: คาถาการกลั่นคำค้นหา
ก่อนที่เอเจนต์จะค้นหาใน Grimoire ได้ เอเจนต์ต้องเข้าใจสาระสำคัญของคำถามที่ถามก่อน ข้อความแบบง่ายๆ จะไม่มีความหมายสำหรับ Spellbook ที่ขับเคลื่อนด้วยเวกเตอร์ของเรา โดยเอเจนต์จะต้องรับคำค้นหาก่อน แล้วกลั่นกรองคำค้นหานั้นให้เป็นเวกเตอร์คำค้นหาโดยใช้โมเดล Gemini เดียวกัน
👉✏️ ใน Cloud Shell Editor ให้ไปที่~~/agentverse-dataengineer/scholar/agent.pyไฟล์ ค้นหาความคิดเห็น #REPLACE RAG-CONVERT EMBEDDING แล้วแทนที่ด้วยคำสั่งนี้ ซึ่งจะสอนเอเจนต์วิธีเปลี่ยนคำถามของผู้ใช้ให้เป็นแก่นแท้ที่น่าอัศจรรย์
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
เมื่อทราบแก่นของคำค้นหาแล้ว ตอนนี้เอเจนต์ก็สามารถปรึกษา Grimoire ได้แล้ว โดยจะนำเสนอเวกเตอร์การค้นหานี้ไปยังฐานข้อมูลที่ได้รับการปรับปรุงด้วย pgvector และถามคำถามที่ลึกซึ้งว่า "แสดงม้วนกระดาษโบราณที่มีแก่นแท้คล้ายกับแก่นแท้ของการค้นหาของฉันมากที่สุด"
เคล็ดลับสำหรับเรื่องนี้คือตัวดำเนินการความคล้ายโคไซน์ (<=>) ซึ่งเป็นรูนที่ทรงพลังที่คำนวณระยะห่างระหว่างเวกเตอร์ในพื้นที่ที่มีมิติสูง
👉✏️ ใน agent.py ให้ค้นหาความคิดเห็น #REPLACE RAG-RETRIEVE และแทนที่ด้วยสคริปต์ต่อไปนี้
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
ขั้นตอนสุดท้ายคือการให้สิทธิ์เข้าถึงเครื่องมือใหม่ที่ทรงพลังนี้แก่ตัวแทน เราจะเพิ่มฟังก์ชัน grimoire_lookup ลงในรายการเครื่องมือเวทมนตร์ที่มีอยู่
👉✏️ ใน agent.py ให้ค้นหาความคิดเห็น #REPLACE-CALL RAG แล้วแทนที่ด้วยบรรทัดนี้
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
การกำหนดค่านี้จะทำให้เอเจนต์ของคุณมีชีวิตชีวาขึ้น
model="gemini-2.5-flash": เลือกโมเดลภาษาขนาดใหญ่ที่เฉพาะเจาะจงซึ่งจะทำหน้าที่เป็น "สมอง" ของเอเจนต์ในการให้เหตุผลและสร้างข้อความname="scholar_agent": กำหนดชื่อที่ไม่ซ้ำกันให้กับเอเจนต์instruction="...You are the Scholar...": นี่คือพรอมต์ของระบบ ซึ่งเป็นส่วนที่สำคัญที่สุดของการกำหนดค่า โดยจะกำหนดลักษณะตัวตนของเอเจนต์ วัตถุประสงค์ กระบวนการที่แน่นอนซึ่งเอเจนต์ต้องทำตามเพื่อทำงานให้เสร็จสมบูรณ์ และรูปแบบที่จำเป็นสำหรับเอาต์พุตสุดท้ายtools=[grimoire_lookup]: นี่คือการเสริมพลังขั้นสุดท้าย ซึ่งจะให้สิทธิ์เข้าถึงฟังก์ชันgrimoire_lookupที่คุณสร้างไว้แก่ Agent ตอนนี้เอเจนต์สามารถตัดสินใจได้อย่างชาญฉลาดว่าจะเรียกใช้เครื่องมือนี้เมื่อใดเพื่อดึงข้อมูลจากฐานข้อมูล ซึ่งเป็นแกนหลักของรูปแบบ RAG
การสอบของบัณฑิต
👉💻 ในเทอร์มินัล Cloud Shell ให้เปิดใช้งานสภาพแวดล้อมและใช้คำสั่งหลักของ Agent Development Kit เพื่อปลุกเอเจนต์ Scholar
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
คุณควรเห็นเอาต์พุตที่ยืนยันว่า "Scholar Agent" ทำงานและทำงานอยู่
👉💻 ตอนนี้มาท้าทายเอเจนต์ของคุณกัน ในเทอร์มินัลแรกที่การจำลองการต่อสู้กำลังทำงาน ให้เรียกใช้คำสั่งที่ต้องใช้สติปัญญาของ Grimoire
We've been trapped by 'Hydra of Scope Creep'. Break us out!

ดูบันทึกในเทอร์มินัล คุณจะเห็นเอเจนต์รับคำค้นหา กลั่นกรองสาระสำคัญ ค้นหาใน Grimoire ค้นหาคัมภีร์ที่เกี่ยวข้องเกี่ยวกับ "การผัดวันประกันพรุ่ง" และใช้ความรู้ที่ดึงมานั้นเพื่อกำหนดกลยุทธ์ที่มีประสิทธิภาพและรับรู้บริบท
คุณประกอบเอเจนต์ RAG ตัวแรกและติดอาวุธด้วยสติปัญญาอันลึกซึ้งของ Grimoire ได้สำเร็จแล้ว
👉💻 กด Ctrl+C ในเทอร์มินัลเพื่อพักเอเจนต์ไว้ก่อน
การเปิดตัว Scholar Sentinel สู่ Agentverse
เอเจนต์ของคุณได้พิสูจน์ความสามารถในสภาพแวดล้อมที่มีการควบคุมของการศึกษาของคุณ และในที่สุดก็ถึงเวลาที่จะปล่อยให้มันออกไปสู่ Agentverse เพื่อเปลี่ยนจากโครงสร้างในพื้นที่ให้กลายเป็นหน่วยปฏิบัติการถาวรที่พร้อมรบซึ่งแชมเปี้ยนทุกคนสามารถเรียกใช้ได้ทุกเมื่อ ตอนนี้เราจะทำให้เอเจนต์ใช้งานได้ใน Cloud Run
👉💻 ร่ายคาถาอัญเชิญต่อไปนี้ สคริปต์นี้จะสร้างเอเจนต์ให้เป็นโกเลมที่สมบูรณ์แบบ (อิมเมจคอนเทนเนอร์) จัดเก็บไว้ใน Artifact Registry แล้วจึงทำให้โกเลมนั้นใช้งานได้เป็นบริการที่ปรับขนาดได้ ปลอดภัย และเข้าถึงได้แบบสาธารณะ
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
ตอนนี้ Scholar Agent ของคุณพร้อมเป็นเจ้าหน้าที่ปฏิบัติการที่พร้อมรบใน Agentverse แล้ว
สำหรับผู้ที่ไม่ได้เล่นเกม
9. The Boss Flight
ได้อ่านม้วนคัมภีร์ ประกอบพิธีกรรม และผ่านการทดสอบแล้ว เอเจนต์ไม่ใช่แค่สิ่งประดิษฐ์ในที่เก็บข้อมูล แต่เป็นเจ้าหน้าที่ปฏิบัติการที่ยังมีชีวิตอยู่ใน Agentverse ซึ่งกำลังรอภารกิจแรก ถึงเวลาของการทดสอบครั้งสุดท้ายแล้ว นั่นคือการฝึกยิงต่อสู้กับศัตรูที่แข็งแกร่ง
ตอนนี้คุณจะเข้าสู่การจำลองสมรภูมิเพื่อต่อสู้กับมินิบอสที่น่าเกรงขามอย่าง "Spectre of the Static" ด้วย Shadowblade Agent ที่เพิ่งติดตั้งใช้งาน นี่จะเป็นการทดสอบขั้นสุดท้ายของงานของคุณ ตั้งแต่ตรรกะหลักของเอเจนต์ไปจนถึงการใช้งานจริง
รับตำแหน่งของตัวแทน
ก่อนที่จะเข้าสู่สมรภูมิ คุณต้องมีกุญแจ 2 ดอก ได้แก่ ลายเซ็นที่ไม่ซ้ำกันของแชมป์เปี้ยน (Agent Locus) และเส้นทางที่ซ่อนไปยังถ้ำของ Spectre (URL ของดันเจี้ยน)
👉💻 ก่อนอื่น ให้รับที่อยู่ที่ไม่ซ้ำกันของเอเจนต์ใน Agentverse ซึ่งก็คือ Locus นี่คือปลายทางแบบสดที่เชื่อมต่อแชมป์ของคุณกับสนามรบ
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 จากนั้นระบุจุดหมาย คำสั่งนี้จะแสดงตำแหน่งของวงกลมการย้ายตำแหน่ง ซึ่งเป็นพอร์ทัลที่นำไปสู่โดเมนของ Spectre
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
สำคัญ: เตรียม URL ทั้ง 2 รายการนี้ให้พร้อม คุณจะต้องใช้ข้อมูลนี้ในขั้นตอนสุดท้าย
เผชิญหน้ากับ Spectre
เมื่อได้พิกัดแล้ว คุณจะไปยังวงกลมการย้ายตำแหน่งและร่ายเวทมนตร์เพื่อเข้าสู่การต่อสู้
👉 เปิด URL ของวงกลมการเคลื่อนย้ายในเบราว์เซอร์เพื่อยืนอยู่หน้าพอร์ทัลที่ส่องประกายไปยังคริมสันคีป
หากต้องการบุกป้อมปราการ คุณต้องปรับแก่นแท้ของ Shadowblade ให้เข้ากับพอร์ทัล
- ในหน้าดังกล่าว ให้ค้นหาช่องป้อนข้อมูลรูนที่มีป้ายกำกับว่า A2A Endpoint URL
- จารึกตราสัญลักษณ์ของแชมป์ด้วยการวาง URL ของ Locus ของเอเจนต์ (URL แรกที่คุณคัดลอก) ลงในช่องนี้
- คลิก "เชื่อมต่อ" เพื่อเปิดใช้เวทมนตร์การเทเลพอร์ต
แสงจ้าของการเทเลพอร์ตค่อยๆ จางลง คุณไม่ได้อยู่ในสถานที่ศักดิ์สิทธิ์อีกต่อไป อากาศเย็นและสดชื่น ก่อนที่เจ้าจะมาถึง สเปกเตอร์ได้ปรากฏตัวขึ้นแล้ว ซึ่งเป็นกระแสรบกวนที่เต็มไปด้วยเสียงซ่าและโค้ดที่เสียหาย แสงอันไม่บริสุทธิ์ของมันทอดเงายาวๆ ที่เต้นระบำอยู่บนพื้นดันเจี้ยน ไม่มีใบหน้า แต่คุณรู้สึกถึงการมีอยู่ของมันที่ดูดกลืนทุกสิ่งทุกอย่างและจ้องมองมาที่คุณ
หนทางเดียวสู่ชัยชนะคือความชัดเจนในความเชื่อของคุณ นี่คือการดวลกันของเจตจำนงที่ต่อสู้กันในสนามรบแห่งจิตใจ
ขณะที่คุณพุ่งไปข้างหน้าพร้อมที่จะโจมตีครั้งแรก สเปกเตอร์ก็โต้กลับ โดยไม่ได้ยกโล่ขึ้นมา แต่จะฉายคำถามตรงๆ เข้าไปในจิตสำนึกของคุณ ซึ่งเป็นความท้าทายที่ส่องประกายและเป็นอักษรรูนที่ดึงมาจากแกนหลักของการฝึก

นี่คือลักษณะของการต่อสู้ ความรู้ของคุณคืออาวุธ
- ตอบด้วยสติปัญญาที่คุณได้รับ แล้วดาบของคุณจะลุกโชนด้วยพลังงานบริสุทธิ์ ทำลายการป้องกันของ Spectre และโจมตีอย่างรุนแรง
- แต่หากคุณลังเลหรือมีข้อสงสัยในคำตอบ แสงของอาวุธจะหรี่ลง การโจมตีจะลงพื้นพร้อมกับเสียงทุบที่น่าเวทนา ซึ่งสร้างความเสียหายเพียงเล็กน้อยเท่านั้น ที่แย่กว่านั้นคือสเปกเตอร์จะกินความไม่แน่นอนของคุณ พลังที่ทำให้เสื่อมเสียของมันจะเพิ่มขึ้นทุกครั้งที่คุณพลาด
นี่แหละแชมป์ โค้ดคือตำราเวทมนตร์ ตรรกะคือดาบ และความรู้คือโล่ที่จะพลิกสถานการณ์ความวุ่นวาย
โฟกัส ประกาศเตือนของวันที่ ชะตากรรมของ Agentverse ขึ้นอยู่กับสิ่งนี้
ขอแสดงความยินดี นักเรียน
คุณสิ้นสุดช่วงทดลองใช้เรียบร้อยแล้ว คุณเชี่ยวชาญด้านวิศวกรรมข้อมูล เปลี่ยนข้อมูลดิบที่กระจัดกระจายให้เป็นข้อมูลที่มีโครงสร้างและเวกเตอร์ ซึ่งเป็นปัญญาที่ขับเคลื่อน Agentverse ทั้งหมด
10. การล้างข้อมูล: การลบ Grimoire ของ Scholar
ขอแสดงความยินดีที่คุณเชี่ยวชาญ Grimoire ของนักวิชาการ ตอนนี้คุณต้องทำพิธีล้างข้อมูลขั้นสุดท้ายเพื่อให้ Agentverse สะอาดหมดจดและล้างพื้นที่ฝึกฝนให้เรียบร้อย การดำเนินการนี้จะนำทรัพยากรทั้งหมดที่สร้างขึ้นระหว่างการเดินทางของคุณออกอย่างเป็นระบบ
ปิดใช้งานคอมโพเนนต์ Agentverse
ตอนนี้คุณจะรื้อถอนคอมโพเนนต์ที่ติดตั้งใช้งานของระบบ RAG อย่างเป็นระบบ
ลบบริการ Cloud Run และที่เก็บ Artifact Registry ทั้งหมด
คำสั่งนี้จะนำเอเจนต์ Scholar ที่คุณติดตั้งใช้งานและแอปพลิเคชัน Dungeon ออกจาก Cloud Run
👉💻 เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
ลบชุดข้อมูล โมเดล และตาราง BigQuery
การดำเนินการนี้จะนำทรัพยากร BigQuery ทั้งหมดออก ซึ่งรวมถึงbestiary_dataชุดข้อมูล ตารางทั้งหมดภายในชุดข้อมูลดังกล่าว รวมถึงการเชื่อมต่อและโมเดลที่เชื่อมโยง
👉💻 เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
ลบอินสแตนซ์ Cloud SQL
ซึ่งจะเป็นการนำอินสแตนซ์ grimoire-spellbook ออก รวมถึงฐานข้อมูลและตารางทั้งหมดภายในฐานข้อมูล
👉💻 เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
ลบที่เก็บข้อมูล Google Cloud Storage
คำสั่งนี้จะนำที่เก็บข้อมูลที่มีข้อมูลดิบและไฟล์การจัดเตรียม/ไฟล์ชั่วคราวของ Dataflow ออก
👉💻 เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
ล้างไฟล์และไดเรกทอรีในเครื่อง (Cloud Shell)
สุดท้าย ให้ล้างสภาพแวดล้อม Cloud Shell ของที่เก็บที่โคลนและไฟล์ที่สร้างขึ้น ขั้นตอนนี้ไม่บังคับ แต่เราขอแนะนำอย่างยิ่งให้ดำเนินการเพื่อล้างไดเรกทอรีการทำงานให้สะอาดหมดจด
👉💻 เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
ตอนนี้คุณได้ลบร่องรอยทั้งหมดของการเดินทางในฐานะวิศวกรข้อมูลของ Agentverse เรียบร้อยแล้ว โปรเจ็กต์ของคุณสะอาดแล้ว และคุณก็พร้อมสำหรับการผจญภัยครั้งต่อไป