
1. Overture
Yalıtılmış geliştirme dönemi sona eriyor. Teknolojik evrimin bir sonraki aşaması, yalnız bir dehanın değil, ortak bir ustalığın ürünü olacak. Tek ve akıllı bir temsilci oluşturmak ilgi çekici bir denemedir. Güçlü, güvenli ve akıllı bir temsilci ekosistemi (gerçek bir Temsilci Evreni) oluşturmak, modern işletmelerin karşılaştığı en büyük zorluktur.
Bu yeni dönemde başarıya ulaşmak için dört kritik rolün bir araya gelmesi gerekir. Bu roller, gelişen tüm yapay sistemleri destekleyen temel unsurlardır. Herhangi bir alandaki eksiklik, yapının tamamını tehlikeye atabilecek bir zayıflık oluşturur.
Bu atölye, Google Cloud'da yapay zeka destekli geleceğe hakim olmak için kesin bir kurumsal yol haritası sunar. Bir fikrin ilk heyecanından tam ölçekli, operasyonel bir gerçeğe kadar size rehberlik eden uçtan uca bir yol haritası sunuyoruz. Birbirine bağlı bu dört laboratuvarda, güçlü bir Agentverse oluşturmak, yönetmek ve ölçeklendirmek için geliştirici, mimar, veri mühendisi ve SRE'nin uzmanlık becerilerinin nasıl bir araya gelmesi gerektiğini öğreneceksiniz.
Hiçbir sütun, Agentverse'ü tek başına destekleyemez. Mimarın büyük tasarımı, geliştiricinin hassas uygulaması olmadan işe yaramaz. Geliştiricinin temsilcisi, Veri Mühendisi'nin bilgeliği olmadan kördür ve tüm sistem, SRE'nin koruması olmadan kırılgandır. Ekibiniz ancak sinerji ve birbirlerinin rollerini ortak bir anlayışla benimseyerek yenilikçi bir konsepti görev açısından kritik bir operasyonel gerçeğe dönüştürebilir. Yolculuğunuz burada başlıyor. Rolünüzde uzmanlaşmaya ve büyük resmin neresinde olduğunuzu öğrenmeye hazır olun.
Welcome to The Agentverse: A Call to Champions
Kurumsal alanın geniş dijital dünyasında yeni bir dönem başladı. Bu, muazzam bir potansiyel barındıran, akıllı ve otonom temsilcilerin inovasyonu hızlandırmak ve sıradan işleri ortadan kaldırmak için mükemmel bir uyum içinde çalıştığı bir dönemdir.

Güç ve potansiyelden oluşan bu bağlantılı ekosisteme Agentverse adı verilir.
Ancak, Statik olarak bilinen sessiz bir bozulma, bu yeni dünyanın sınırlarını yıpratmaya başladı. Statik, virüs veya hata değildir. Yaratma eylemiyle beslenen kaosun vücut bulmuş halidir.
Eski hayal kırıklıklarını canavarca şekillere dönüştürerek Gelişimin Yedi Hayaleti'ni doğurur. Bu kutu işaretlenmezse The Static and its Spectres ilerlemeyi durdurur ve Agentverse'ün vaadini teknik borç ve terk edilmiş projelerden oluşan bir çorak araziye dönüştürür.
Bugün, kaosun önüne geçmek için şampiyonlara sesleniyoruz. Kendi alanında uzmanlaşmaya ve Agentverse'ü korumak için birlikte çalışmaya istekli kahramanlara ihtiyacımız var. Yolunuzu seçme zamanı geldi.
Sınıfınızı Seçin
Önünüzde dört farklı yol var. Her biri The Static ile mücadelede kritik bir öneme sahip. Eğitiminiz tek başınıza yapacağınız bir görev olsa da nihai başarınız, becerilerinizin diğerleriyle nasıl birleştiğini anlamanıza bağlıdır.
- The Shadowblade (Geliştirici): Demirci ve ön cephe ustası. Bıçakları yapan, araçları inşa eden ve kodun karmaşık ayrıntılarında düşmanla yüzleşen zanaatkar sizsiniz. Yolunuz; hassasiyet, beceri ve pratik yaratıcılıkla dolu.
- Çağırıcı (Mimar): Büyük bir stratejist ve düzenleyici. Tek bir ajanı değil, savaş alanının tamamını görürsünüz. Tüm aracı sistemlerinin iletişim kurmasına, işbirliği yapmasına ve tek bir bileşenin ulaşabileceğinden çok daha büyük bir hedefe ulaşmasına olanak tanıyan ana planları tasarlarsınız.
- Bilgin (Veri Mühendisi): Gizli gerçekleri arayan ve bilgeliğin koruyucusu. Aracınıza amaç ve vizyon kazandıran bilgileri ortaya çıkarmak için verilerin geniş ve vahşi doğasına girersiniz. Bilginiz, bir düşmanın zayıflığını ortaya çıkarabilir veya bir müttefiki güçlendirebilir.
- The Guardian (Veli): Diyarın yılmaz koruyucusu ve kalkanı. Kaleler inşa eder, güç kaynaklarının tedarik hatlarını yönetir ve tüm sistemin Static'in kaçınılmaz saldırılarına dayanabilmesini sağlarsınız. Gücünüz, takımınızın zaferinin temelini oluşturur.
Misyonunuz
Eğitiminiz bağımsız bir egzersiz olarak başlar. Seçtiğiniz yolda ilerleyerek rolünüzde uzmanlaşmak için gereken benzersiz becerileri öğreneceksiniz. Deneme sürenizin sonunda, The Static'ten doğan bir Spectre ile karşılaşırsınız. Bu Spectre, zanaatınızın zorluklarından beslenen bir mini patron olarak karşınıza çıkar.
Ancak kendi rolünüzde ustalaşarak son denemeye hazırlanabilirsiniz. Ardından, diğer sınıflardaki şampiyonlarla bir parti oluşturmanız gerekir. Birlikte, nihai bir boss ile yüzleşmek için yozlaşmanın kalbine doğru ilerleyeceksiniz.
Gücünüzü test edecek ve Agentverse'ün kaderini belirleyecek son bir ortak mücadele.
Agentverse, kahramanlarını bekliyor. Aramayı yanıtlayacak mısınız?
2. The Scholar's Grimoire
Yolculuğumuz başlıyor! Bilginin, Scholars'ın birincil silahı olduğunu biliyoruz. Arşivlerimizde (Google Cloud Storage) eski ve gizemli bir dizi parşömen bulduk. Bu parşömenlerde, ülkeyi kasıp kavuran korkunç canavarlarla ilgili ham bilgiler yer alıyor. Misyonumuz, bu yapılandırılmamış metinleri deşifre etmek ve yapılandırılmış, sorgulanabilir bir Bestiary oluşturmak için Google BigQuery'nin derin analitik gücünü ve Gemini Elder Brain'in (Gemini Pro modeli) bilgeliğini kullanmaktır. Bu, gelecekteki tüm stratejilerimizin temelini oluşturacak.
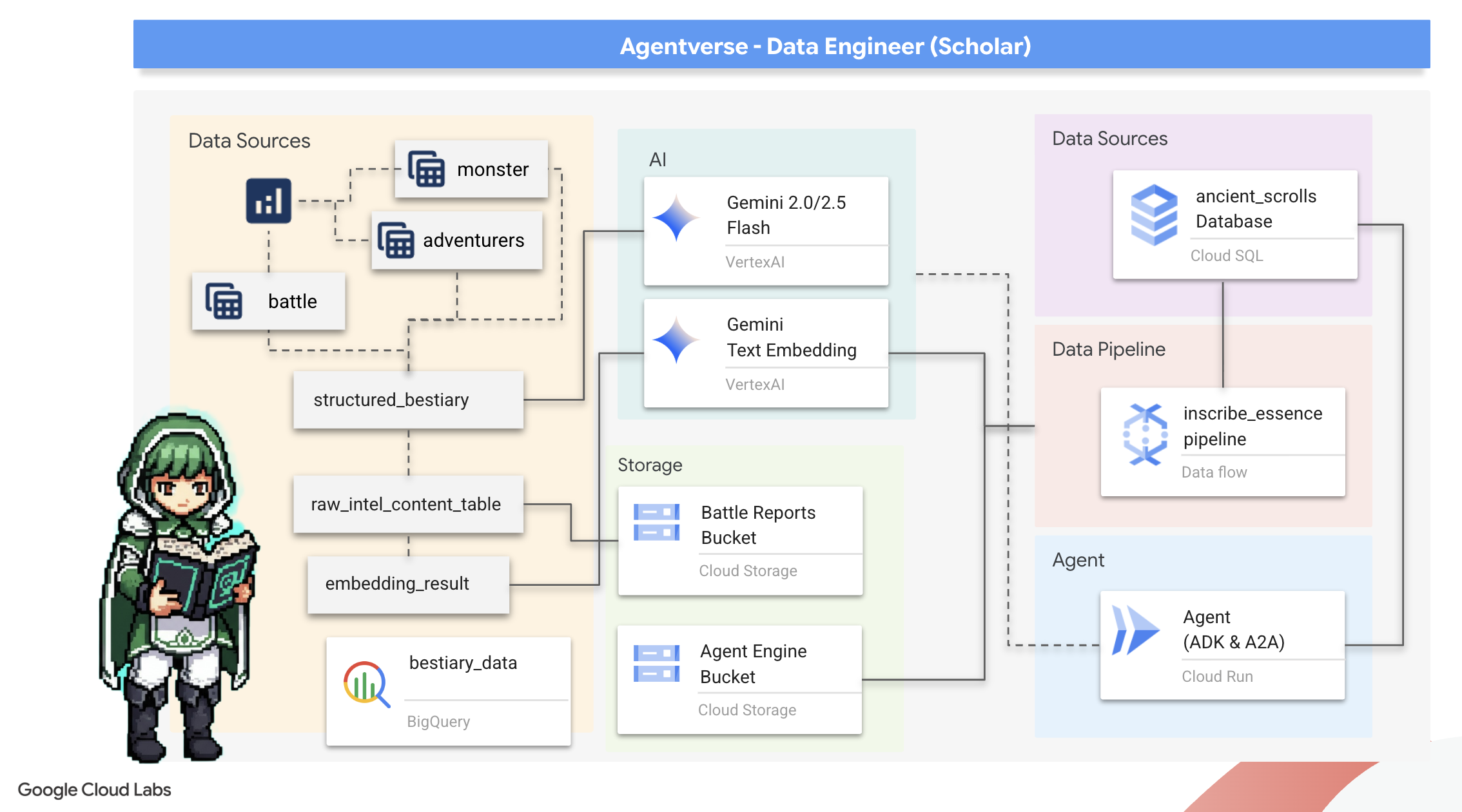
Neler öğreneceksiniz?
- BigQuery'yi kullanarak harici tablolar oluşturun ve BQML.GENERATE_TEXT ile Gemini modelini kullanarak karmaşık yapılandırılmamış-yapılandırılmış dönüşümler gerçekleştirin.
- Bir PostgreSQL için Cloud SQL örneği sağlayın ve semantik arama özellikleri için pgvector uzantısını etkinleştirin.
- Ham metin dosyalarını işlemek, Gemini modeliyle vektör yerleştirmeleri oluşturmak ve sonuçları ilişkisel bir veritabanına yazmak için Dataflow ve Apache Beam'i kullanarak sağlam, kapsayıcılı bir toplu iş ardışık düzeni oluşturun.
- Vektörleştirilmiş verileri sorgulamak için bir temsilci içinde temel bir veriyle artırılmış üretim (RAG) sistemi uygulayın.
- Veri odaklı bir aracı, Cloud Run'da güvenli ve ölçeklenebilir bir hizmet olarak dağıtın.
3. Bilginin Tapınağı'nı hazırlama
Hoş geldiniz, Akademik. Grimoire'ımızın güçlü bilgilerini yazmaya başlamadan önce kutsal alanımızı hazırlamamız gerekir. Bu temel ritüel, Google Cloud ortamımızı büyülemeyi, doğru portalları (API'ler) açmayı ve veri sihrimizin akacağı kanalları oluşturmayı içerir. İyi hazırlanmış bir tapınak, büyülerimizin etkili olmasını ve bilgilerimizin güvenli olmasını sağlar.
Google Cloud kredinizi kullanma
⚠️ Önemli Ön Koşullar:
- Kişisel Gmail kullanma: Kişisel bir hesap (ör.
name@gmail.com). Şirket veya okul tarafından yönetilen hesaplar çalışmaz.
👉 Adımlar:
- Kredi talebi sitesine gidin: Burayı tıklayın.
- Oturum açma: Bağlantıyı adres çubuğuna yapıştırın ve kişisel Gmail hesabınızla oturum açın.
- Şartları Kabul Et: Google Cloud Platform Hizmet Şartları'nı kabul edin.
- Krediyi doğrulayın: Kredinin uygulandığını onaylayan bir mesaj olup olmadığına bakın.
- *Not: Kredi kartı bilgilerinizi girmeniz istenirse bu istemi güvenle yoksayabilir ve pencereyi kapatabilirsiniz.
Artık hazırsınız. Pencereyi kapatabilirsiniz.
Çalışma Ortamını Kurma
👉Google Cloud Console'un üst kısmındaki Cloud Shell'i etkinleştir simgesini (Cloud Shell bölmesinin üst kısmındaki terminal şeklindeki simge) tıklayın.
👉 "Open Editor" (Düzenleyiciyi Aç) düğmesini tıklayın (kalemli açık bir klasöre benzer). Bu işlem, pencerede Cloud Shell Kod Düzenleyici'yi açar. Sol tarafta bir dosya gezgini görürsünüz. 
👉Bulut IDE'sinde terminali açın. 
👉💻 Terminalde, aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını doğrulayın:
gcloud auth list
👉💻Bootstrap projesini GitHub'dan kopyalayın:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 Kurulum komut dosyasını proje dizininden çalıştırın.
⚠️ Proje kimliğiyle ilgili not: Komut dosyası, rastgele oluşturulmuş bir varsayılan proje kimliği önerir. Bu varsayılanı kabul etmek için Enter tuşuna basabilirsiniz.
Ancak belirli bir yeni proje oluşturmayı tercih ederseniz komut dosyasının istemi üzerine istediğiniz proje kimliğini yazabilirsiniz.
cd ~/agentverse-dataengineer
./init.sh
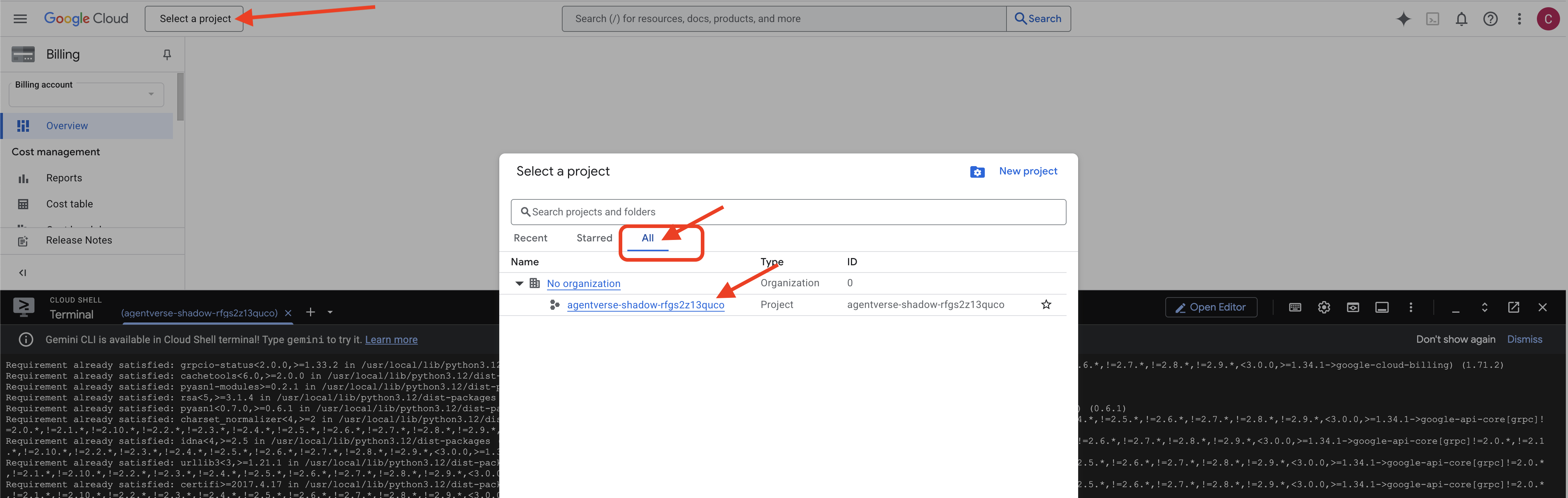
👉 Tamamlandıktan Sonraki Önemli Adım: Komut dosyası tamamlandıktan sonra Google Cloud Console'unuzda doğru projenin görüntülendiğinden emin olmanız gerekir:
- console.cloud.google.com adresine gidin.
- Sayfanın üst kısmındaki proje seçici açılır listesini tıklayın.
- "Tümü" sekmesini tıklayın (yeni proje henüz "Son Kullanılanlar"da görünmeyebilir).
init.shadımında yapılandırdığınız proje kimliğini seçin.
👉💻 Gerekli proje kimliğini ayarlayın:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Gerekli Google Cloud API'lerini etkinleştirmek için aşağıdaki komutu çalıştırın:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 Henüz agentverse-repo adlı bir Artifact Registry deposu oluşturmadıysanız oluşturmak için aşağıdaki komutu çalıştırın:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
İzinleri ayarlama
👉💻 Terminalde aşağıdaki komutları çalıştırarak gerekli izinleri verin:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 Eğitime başladığınızda son mücadeleyi hazırlayacağız. Aşağıdaki komutlar, kaotik statik gürültüden hayaletleri çağırarak son testiniz için patronları oluşturur.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
Mükemmel bir iş çıkardınız, Bilgin. Temel büyülerin tamamlanması. Kutsal alanımız güvenli, verilerin temel güçlerine açılan portallar açık ve hizmetkarımız yetkilendirilmiş durumda. Artık gerçek işe başlamaya hazırız.
4. Bilgi Simyası: BigQuery ve Gemini ile Verileri Dönüştürme
The Static'e karşı verilen aralıksız savaşta, Agentverse Şampiyonu ile Development Spectre arasındaki her karşılaşma titizlikle kaydedilir. Birincil eğitim ortamımız olan Savaş Alanı Simülasyonu sistemi, her karşılaşma için otomatik olarak bir Aetheric Log Entry oluşturur. Bu anlatı günlükleri, en değerli ham zeka kaynağımızdır. Bilginler olarak, stratejinin tertemiz çeliğini dövmemiz gereken, rafine edilmemiş cevherdir. Bir bilginin gerçek gücü, yalnızca verilere sahip olmaktan değil, ham ve kaotik bilgi cevherini, parlak ve yapılandırılmış, uygulanabilir bilgelik çeliğine dönüştürme yeteneğinden gelir. Veri simyasının temel ritüelini gerçekleştireceğiz.

Bu yolculukta, tamamen Google BigQuery'nin gizli alanında çok aşamalı bir süreçten geçeceğiz. Tek bir kaydırma yapmadan, sihirli bir lens kullanarak GCS arşivimize bakarak başlayacağız. Ardından, savaş günlüklerinin şiirsel ve yapılandırılmamış destanlarını okuyup yorumlaması için Gemini'ı çağıracağız. Son olarak, ham kehanetleri bir dizi temiz ve birbirine bağlı tabloya dönüştüreceğiz. İlk Grimoire'umuz. Ve bu yeni yapının yanıtlayabileceği kadar derin bir soru sorun.
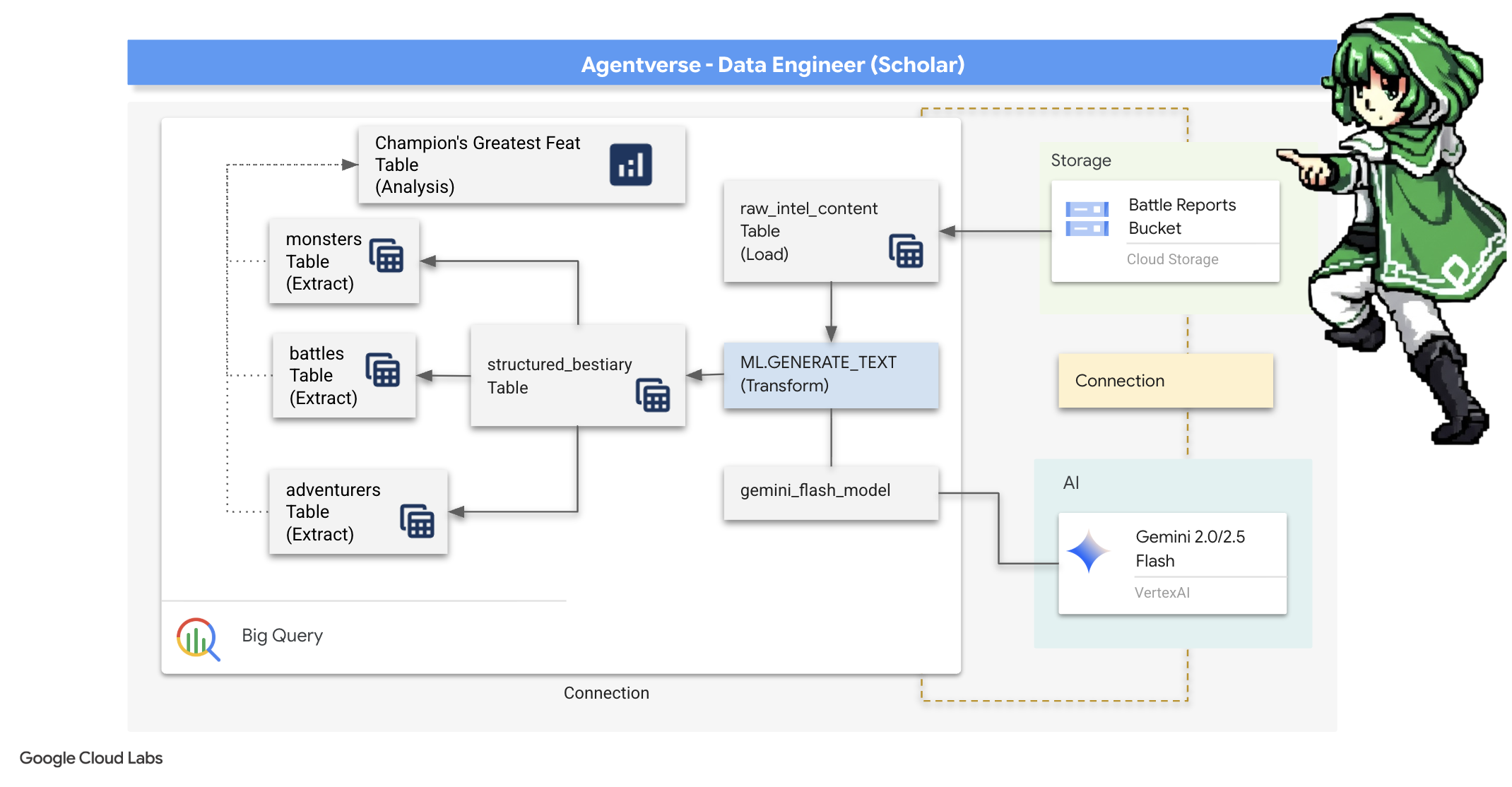
İnceleme Merceği: BigQuery Harici Tablolar ile GCS'ye Göz Atma
İlk işimiz, GCS arşivimizin içeriğini, kaydırma işlemlerini bozmadan görmemizi sağlayacak bir lens oluşturmak. Harici tablo, bu mercektir. Ham metin dosyalarını, BigQuery'nin doğrudan sorgulayabileceği tablo benzeri bir yapıyla eşler.
Bunu yapmak için öncelikle BigQuery kutsal alanımızı GCS arşivine güvenli bir şekilde bağlayan sabit bir güç ley hattı (BAĞLANTI kaynağı) oluşturmamız gerekir.
👉💻 Depolamayı ayarlamak ve kanalı oluşturmak için Cloud Shell terminalinizde aşağıdaki komutu çalıştırın:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 Dikkat! Bir Mesaj Daha Sonra Gösterilecek!
2. adımdaki kurulum komut dosyası arka planda bir işlem başlattı. Birkaç dakika sonra terminalinizde şuna benzer bir mesaj görünür:[1]+ Done gcloud sql instances create ...Bu normal ve beklenen bir durumdur. Bu, Cloud SQL veritabanınızın başarıyla oluşturulduğu anlamına gelir. Bu mesajı yok sayabilir ve çalışmaya devam edebilirsiniz.
Harici tabloyu oluşturabilmek için önce tabloyu içerecek veri kümesini oluşturmanız gerekir.
👉💻 Cloud Shell terminalinizde şu basit komutu çalıştırın:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 Şimdi, GCS Arşivi'nden okuma ve Gemini'a danışma için kanalın sihirli imzasına gerekli izinleri vermeliyiz.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 Paketinizin adını görüntülemek için Cloud Shell terminalinizde aşağıdaki komutu çalıştırın:
echo $BUCKET_NAME
Terminalinizde your-project-id-gcs-bucket'a benzer bir ad gösterilir. Bu bilgiye sonraki adımlarda ihtiyacınız olacak.
👉 Bir sonraki komutu Google Cloud Console'daki BigQuery sorgu düzenleyicisinden çalıştırmanız gerekir. Bu sayfaya ulaşmanın en kolay yolu, aşağıdaki bağlantıyı yeni bir tarayıcı sekmesinde açmaktır. Bu işlem sizi doğrudan Google Cloud Console'daki doğru sayfaya yönlendirir.
https://console.cloud.google.com/bigquery
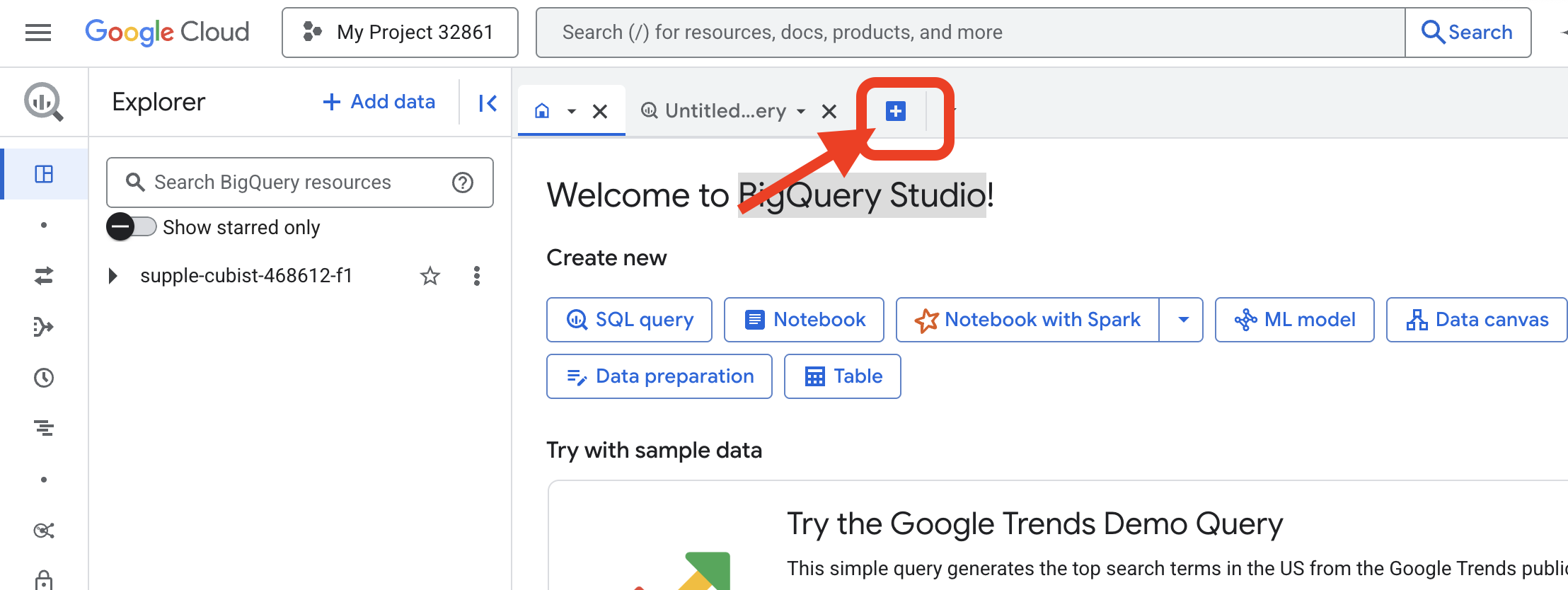
👉 Sayfa yüklendikten sonra yeni bir düzenleyici sekmesi açmak için mavi + düğmesini (Yeni sorgu oluştur) tıklayın.
Şimdi de sihirli lensimizi oluşturmak için Veri Tanımlama Dili (DDL) ifadesini yazıyoruz. Bu, BigQuery'ye nereye bakacağını ve ne göreceğini söyler.
👉📜 Açtığınız BigQuery sorgu düzenleyicisine aşağıdaki SQL'i yapıştırın. REPLACE-WITH-YOUR-BUCKET-NAME öğesini değiştirmeyi unutmayın.
kısmını, az önce kopyaladığınız paket adıyla değiştirin. Ardından Run'ı (Çalıştır) tıklayın:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 "Mercekten bakmak" ve dosyaların içeriğini görmek için sorgu çalıştırın.
SELECT * FROM bestiary_data.raw_intel_content_table;
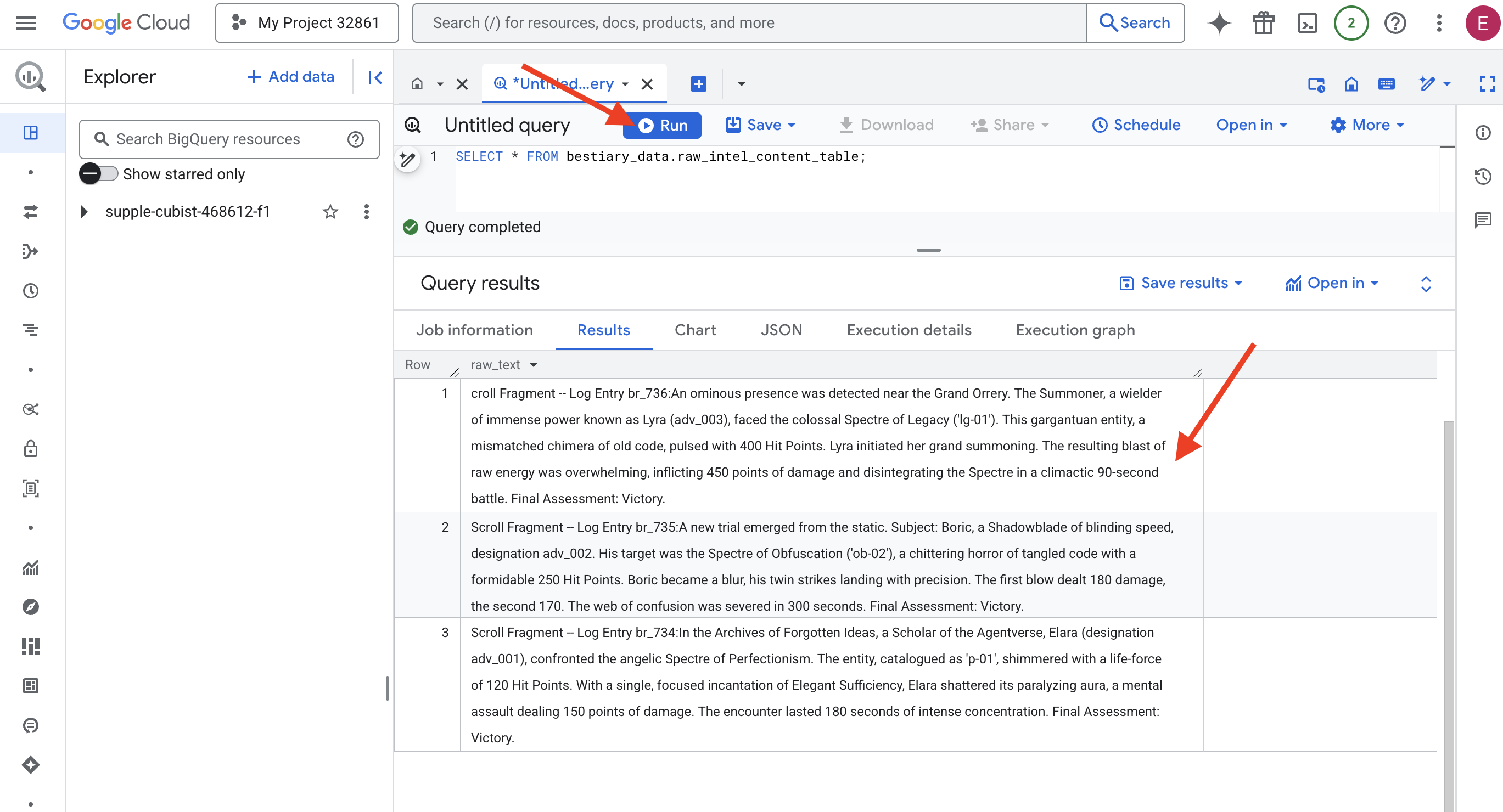
Lensimiz yerinde. Artık parşömenlerin ham metnini görebiliyoruz. Ancak okumak anlamak değildir.
Unutulmuş Fikirler Arşivi'nde, Agentverse'ün bilgini Elara (adv_001 tanımlaması), mükemmeliyetçiliğin melek gibi hayaletiyle karşılaştı. "p-01" olarak kataloglanan varlık, 120 vuruş puanı ile parlıyordu. Elara, Elegant Sufficiency'nin tek ve odaklanmış bir büyüsüyle, 150 puan hasar veren zihinsel bir saldırı olan felç edici aurasını kırdı. Karşılaşma, 180 saniyelik yoğun bir konsantrasyonla sürdü. Son Değerlendirme: Zafer.
Parşömenler, tablolar ve satırlar halinde değil, destanların kıvrımlı düz yazısı şeklinde yazılmıştır. Bu, ilk büyük testimiz.
Bilginin Kehaneti: Metni SQL ile Tabloya Dönüştürme
Buradaki zorluk, bir Gölge Kılıç'ın hızlı ve ikili saldırılarını ayrıntılı olarak anlatan bir raporun, tek bir yıkıcı patlama için muazzam güç toplayan bir Çağırıcı'nın günlüğünden çok farklı olmasıdır. Bu verileri olduğu gibi içe aktaramayız, yorumlamamız gerekir. İşin sırrı bu noktada. Tüm dosyalarımızdaki tüm kayıtları doğrudan BigQuery'de okumak, anlamak ve yapılandırmak için tek bir SQL sorgusunu güçlü bir büyü olarak kullanacağız.
👉💻 Cloud Shell terminalinize geri dönün ve bağlantı adınızı görüntülemek için aşağıdaki komutu çalıştırın:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
Terminalinizde bağlantı dizesinin tamamı gösterilir. Bu dizeyi seçip kopyalayın. Bir sonraki adımda bu dizeye ihtiyacınız olacak.
Tek bir güçlü büyü kullanacağız: ML.GENERATE_TEXT. Bu büyü, bir Gemini'ı çağırır, ona her bir kaydırma çubuğunu gösterir ve temel bilgileri yapılandırılmış bir JSON nesnesi olarak döndürmesini emreder.
👉📜 BigQuery Studio'da Gemini Model Reference oluşturun. Bu işlem, Gemini Flash oracle'ı BigQuery kitaplığımıza bağlar. Böylece, sorgularımızda bu oracle'ı çağırabiliriz. Değiştirmeyi unutmayın.
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING ile terminalinizden kopyaladığınız tam bağlantı dizesi.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 Şimdi büyük dönüşüm büyüsünü yapın. Bu sorgu, ham metni okur, her kaydırma için ayrıntılı bir istem oluşturur, istemi Gemini'a gönderir ve yapay zekanın yapılandırılmış JSON yanıtından yeni bir hazırlama tablosu oluşturur.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
Dönüşüm tamamlandı ancak sonuç henüz saf değil. Gemini modeli, yanıtını standart bir biçimde döndürür. Bu biçimde, istediğimiz JSON, düşünce süreciyle ilgili meta verileri içeren daha büyük bir yapının içine yerleştirilir. Let us look upon this raw prophecy before we attempt to purify it.
👉📜 Gemini modelinden gelen ham çıktıyı incelemek için sorgu çalıştırın:
SELECT * FROM bestiary_data.structured_bestiary;
👀 structured_data adlı tek bir sütun görürsünüz. Her satırın içeriği, aşağıdaki karmaşık JSON nesnesine benzer şekilde görünür:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
Gördüğünüz gibi, ödülümüz (istediğimiz temiz JSON nesnesi) bu yapının derinliklerinde yer alıyor. Bir sonraki görevimiz belli. Bu yapıda sistematik olarak gezinmek ve içindeki saf bilgeliği çıkarmak için bir ritüel gerçekleştirmemiz gerekiyor.
Arınma Ritüeli: SQL ile Üretken Yapay Zeka Çıkışını Normalleştirme
Gemini konuştu ancak sözleri ham ve oluşturulma sürecinin eterik enerjileriyle (adaylar, finish_reason vb.) sarılı. Gerçek bir Bilgin, ham kehaneti rafa kaldırmakla yetinmez; temel bilgeliği dikkatlice çıkarır ve gelecekte kullanmak üzere uygun kitaplara yazar.
Şimdi son büyü setimizi yapacağız. Bu tek komut dosyası:
- Hazırlık tablomuzdaki ham, iç içe yerleştirilmiş JSON'u okuyun.
- Temel verilere ulaşmak için verileri temizleyin ve ayrıştırın.
- İlgili parçaları üç nihai ve temiz tabloya (canavarlar, maceracılar ve savaşlar) yazın.
👉📜 Yeni bir BigQuery sorgu düzenleyicisinde, temizleme lensimizi oluşturmak için aşağıdaki büyüyü çalıştırın:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 Bestiary'yi doğrulayın:
SELECT * FROM bestiary_data.monsters;
Ardından, bu canavarlarla yüzleşen cesur maceraperestlerin listesi olan Şampiyonlar Listemizi oluşturacağız.
👉📜 Yeni bir sorgu düzenleyicide, maceracılar tablosunu oluşturmak için aşağıdaki sorguyu çalıştırın:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 Şampiyonlar listesini doğrulayın:
SELECT * FROM bestiary_data.adventurers;
Son olarak, savaşların kronolojisi olan olgu tablomuzu oluşturacağız. Bu kitap, diğer iki kitabı birbirine bağlar ve her benzersiz karşılaşmanın ayrıntılarını kaydeder. Her savaş benzersiz bir etkinlik olduğundan tekilleştirme yapılması gerekmez.
👉📜 Yeni bir sorgu düzenleyicide, savaşlar tablosunu oluşturmak için aşağıdaki büyüyü çalıştırın:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Chronicle'ı doğrulayın:
SELECT * FROM bestiary_data.battles;
Stratejik Analizleri Ortaya Çıkarma
Parşömenler okundu, özü çıkarıldı ve ciltler yazıldı. Grimoire'umuz artık sadece bir bilgi koleksiyonu değil, derin stratejik bilgeliğin ilişkisel bir veritabanı. Artık, bilgilerimiz ham ve yapılandırılmamış metinlere hapsolmuşken yanıtlamanın imkansız olduğu soruları sorabiliyoruz.
Şimdi son ve büyük bir kehanet gerçekleştirelim. Derin ve uygulanabilir bir analiz ortaya çıkarmak için üç kitabımıza (Canavarlar Kitabı, Şampiyonlar Listesi ve Savaş Günlüğü) aynı anda danışan bir büyü yapacağız.
Stratejik sorumuz: "Her maceraperestin başarıyla yendiği en güçlü canavarın (vuruş puanına göre) adı nedir ve bu zafer ne kadar sürmüştür?"
Bu karmaşık sorunun yanıtlanması için şampiyonların kazandıkları savaşlarla, bu savaşların da ilgili canavarların istatistikleriyle ilişkilendirilmesi gerekir. Yapılandırılmış veri modelinin gerçek gücü budur.
👉📜 Yeni bir BigQuery sorgu düzenleyicisinde aşağıdaki son büyüyü yapın:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
Bu sorgunun çıktısı, veri kümenizdeki her maceraperest için "Bir Şampiyonun En Büyük Başarısının Hikayesi"ni sağlayan temiz ve güzel bir tablo olacaktır. Şuna benzer bir şey görebilirsiniz:
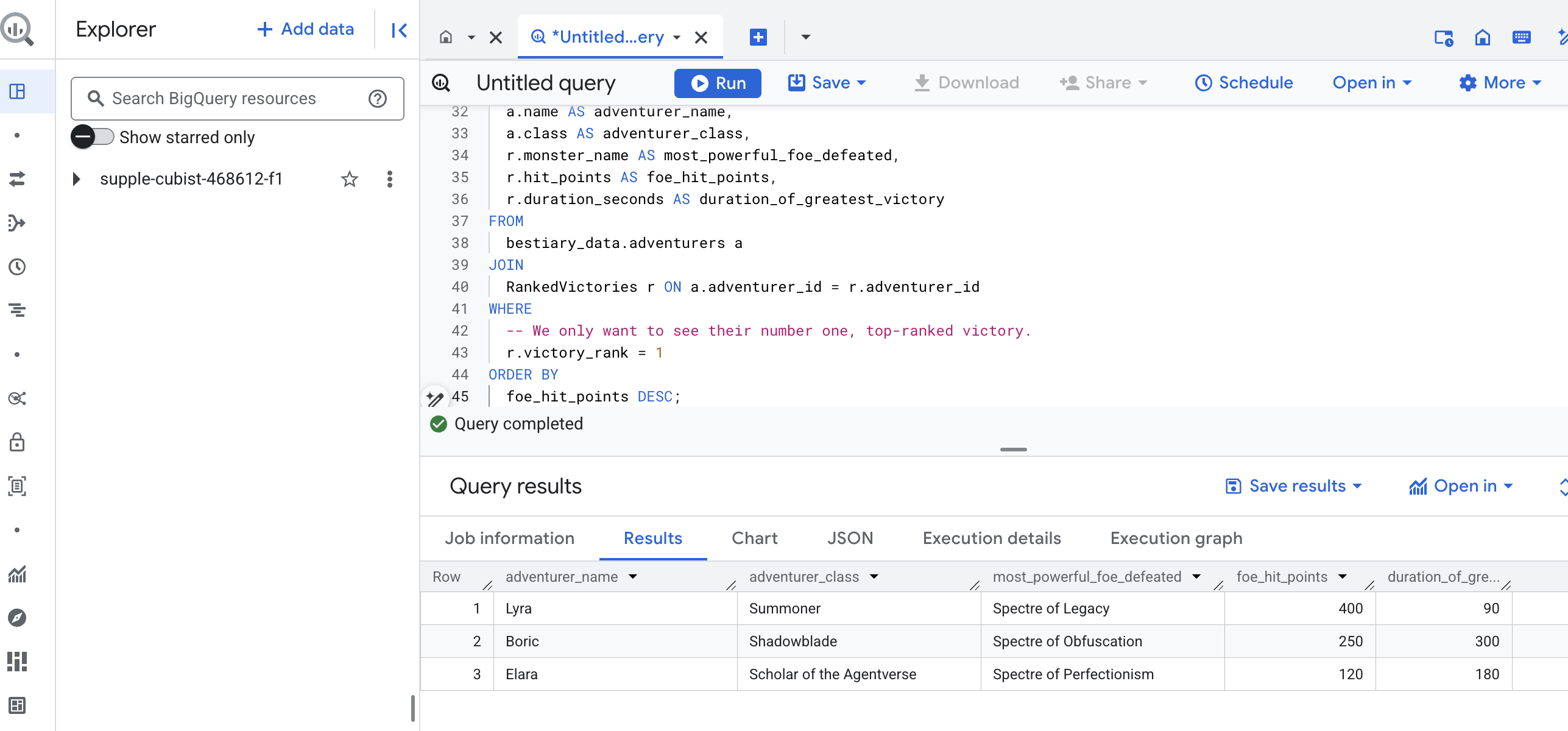
BigQuery sekmesini kapatın.
Bu tek ve zarif sonuç, tüm işlem hattının değerini kanıtlıyor. Ham ve kaotik savaş alanı raporlarını efsanevi hikayelerin kaynağına ve stratejik, veriye dayalı analizlere dönüştürmeyi başardınız.
OYUNCU OLMAYANLAR İÇİN
5. Yazıcının Grimoire'ı: Veri ambarı içi parçalama, yerleştirme ve arama
Simyacının laboratuvarındaki çalışmamız başarıyla sonuçlandı. İşlenmemiş, anlatısal kaydırmaları yapılandırılmış, ilişkisel tablolara dönüştürdük. Bu, güçlü bir veri sihirbazlığıdır. Ancak orijinal parşömenler, yapılandırılmış tablolarımızın tam olarak yakalayamadığı daha derin bir anlamsal gerçeği barındırır. Gerçekten bilge bir temsilci oluşturmak için bu anlamı ortaya çıkarmamız gerekir.
Uzun ve ham bir kaydırma işlemi, kaba bir araçtır. Temsilcimiz "felç edici aura" hakkında bir soru sorarsa basit bir arama, bu ifadenin yalnızca bir kez geçtiği ve yanıtı alakasız ayrıntılarla gizleyen bir savaş raporunun tamamını döndürebilir. Google Akademik'te uzman olanlar, gerçek bilgeliğin çoklukta değil, kesinlikte bulunduğunu bilir.
BigQuery'deki kutsal alanımızda tamamen veritabanı içinde üç güçlü ritüel gerçekleştireceğiz.
- Bölme Ritüeli (Chunking): Ham zeka günlüklerimizi alıp titizlikle daha küçük, odaklanmış ve bağımsız pasajlara ayıracağız.
- Damıtma (Yerleştirme) Ritüeli: Her metin parçasını "anlamsal parmak izine" (vektör yerleştirme) dönüştürerek bir Gemini modeline danışmak için BQML'yi kullanacağız.
- Kehanet Ritüeli (Arama): BQML'nin vektör arama özelliğini kullanarak basit İngilizce bir soru soracak ve Grimoire'imizdeki en alakalı, özlü bilgileri bulacağız.
Bu süreç, veriler BigQuery'nin güvenlik ve ölçeğinden hiç ayrılmadan güçlü ve aranabilir bir bilgi tabanı oluşturur.
Bölünme Ritüeli: SQL ile Parşömenleri İnceleme
Bilgi kaynağımız, harici tablomuz bestiary_data.raw_intel_content_table aracılığıyla erişilebilen GCS arşivimizdeki ham metin dosyalarıdır. İlk görevimiz, her uzun kaydırma işlemini okuyup daha küçük ve kolay anlaşılır bölümlere ayıran bir büyü yazmaktır. Bu ritüelde "parça"yı tek bir cümle olarak tanımlayacağız.
Anlatım günlüklerimizi cümlelere bölmek net ve etkili bir başlangıç noktası olsa da usta bir Scribe'ın kullanabileceği birçok parçalama stratejisi vardır ve bu seçim, nihai aramanın kalitesi açısından kritik öneme sahiptir. Daha basit yöntemlerde
- Sabit uzunlukta(boyutta) bölme, ancak bu, temel bir fikri kabaca ikiye bölebilir.
Daha karmaşık ritüeller (ör.
- Özyinelemeli Parçalama (Recursive Chunking) yöntemi uygulamada genellikle tercih edilir. Bu yöntemde, metin önce paragraflar gibi doğal sınırlara göre bölünmeye çalışılır, ardından mümkün olduğunca fazla anlamsal bağlamı korumak için cümlelere geri dönülür. Gerçekten karmaşık el yazmaları için.
- İçeriğe Duyarlı Bölümleme (doküman): Scribe, en mantıklı ve etkili bilgi parçalarını oluşturmak için dokümanın doğal yapısını (ör. teknik kılavuzdaki başlıklar veya kod kaydırmasındaki işlevler) kullanır.
Savaş günlüklerimizde bu cümle, ayrıntı düzeyi ve bağlam açısından mükemmel bir denge sunuyor.
👉📜 Yeni bir BigQuery sorgu düzenleyicisinde aşağıdaki komutu çalıştırın. Bu formül, her kaydırma metnini her noktada (.) ayırmak için SPLIT işlevini kullanır ve ardından ortaya çıkan cümle dizisini ayrı satırlara yerleştirir.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 Şimdi, yeni oluşturduğunuz ve parçalara ayırdığınız bilgileri incelemek için bir sorgu çalıştırın ve farkı görün.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
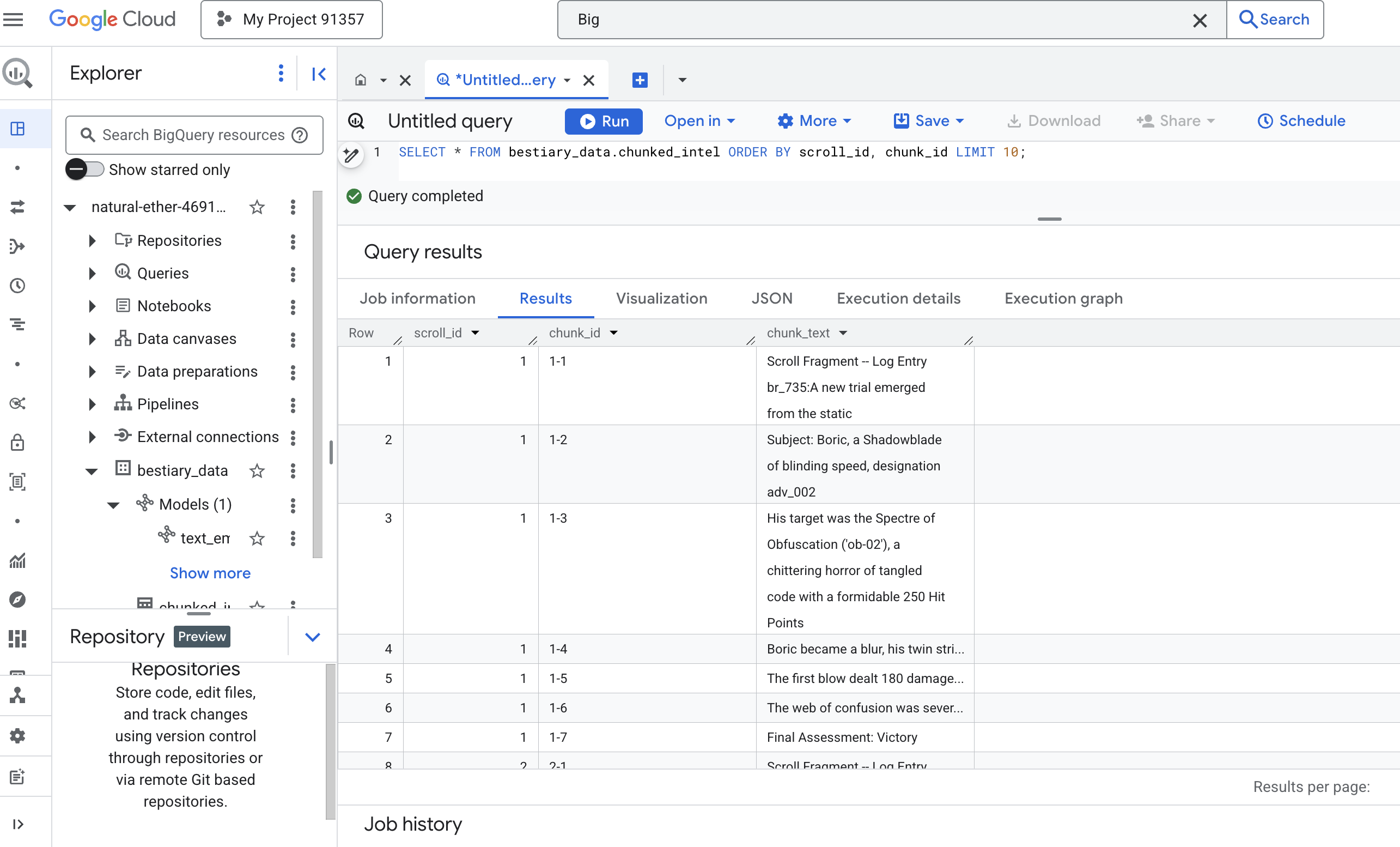
Sonuçları inceleyin. Eskiden tek bir yoğun metin bloğu varken artık her biri orijinal kaydırmaya (scroll_id) bağlı olan ancak yalnızca tek bir odaklanmış cümle içeren birden fazla satır var. Artık her satır, vektörelleştirme için mükemmel bir adaydır.
Damıtma Ritüeli: BQML ile Metni Vektörlere Dönüştürme
👉💻 Öncelikle terminalinize geri dönün ve bağlantı adınızı görüntülemek için aşağıdaki komutu çalıştırın:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Gemini'ın metin yerleştirmesine işaret eden yeni bir BigQuery modeli oluşturmamız gerekir. BigQuery Studio'da aşağıdaki sihirbazı çalıştırın. REPLACE-WITH-YOUR-FULL-CONNECTION-STRING yerine, terminalinizden kopyaladığınız bağlantı dizesinin tamamını yapıştırmanız gerektiğini unutmayın.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 Şimdi büyük damıtma büyüsünü yapın. Bu sorgu, ML.GENERATE_EMBEDDING işlevini çağırır. Bu işlev, chunked_intel tablomuzdaki her satırı okur, metni Gemini yerleştirme modeline gönderir ve ortaya çıkan vektör parmak izini yeni bir tabloda saklar.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
BigQuery tüm metin parçalarını işlerken bu işlem bir veya iki dakika sürebilir.
👉📜 Tamamlandıktan sonra, semantik parmak izlerini görmek için yeni tabloyu inceleyin.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
Artık metninizin yoğun vektör gösterimini içeren yeni bir sütun (ml_generate_embedding_result) göreceksiniz. Grimoire'ımız artık anlamsal olarak kodlanıyor.
Kehanet Ritüeli: BQML ile Semantik Arama
👉📜 Grimoire'ımızın nihai testi, ona soru sormaktır. Şimdi son ritüelimizi gerçekleştireceğiz: vektör araması. Bu bir anahtar kelime araması değil, anlam aramasıdır. Doğal dilde bir soru soracağız. BQML, sorumuzu anında yerleştirmeye dönüştürecek ve ardından embedded_intel tablomuzun tamamında, anlam olarak "en yakın" olan metin parçalarını bulmak için arama yapacak.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
Yazım Analizi:
VECTOR_SEARCH: Arama işlemini düzenleyen temel işlev.ML.GENERATE_EMBEDDING(iç sorgu): Bu, sihirli kısım. Sorgumuzu ('What are the tactics...'), aynı modeli kullanarak ancak özellikle sorgular için optimize edilmiş'RETRIEVAL_QUERY'görev türüyle yerleştiririz.top_k => 3: En alakalı ilk 3 sonucu istiyoruz.distance_type => 'COSINE': Bu, vektörler arasındaki "açıyı" ölçer. Açının daha küçük olması, anlamların daha uyumlu olduğu anlamına gelir.
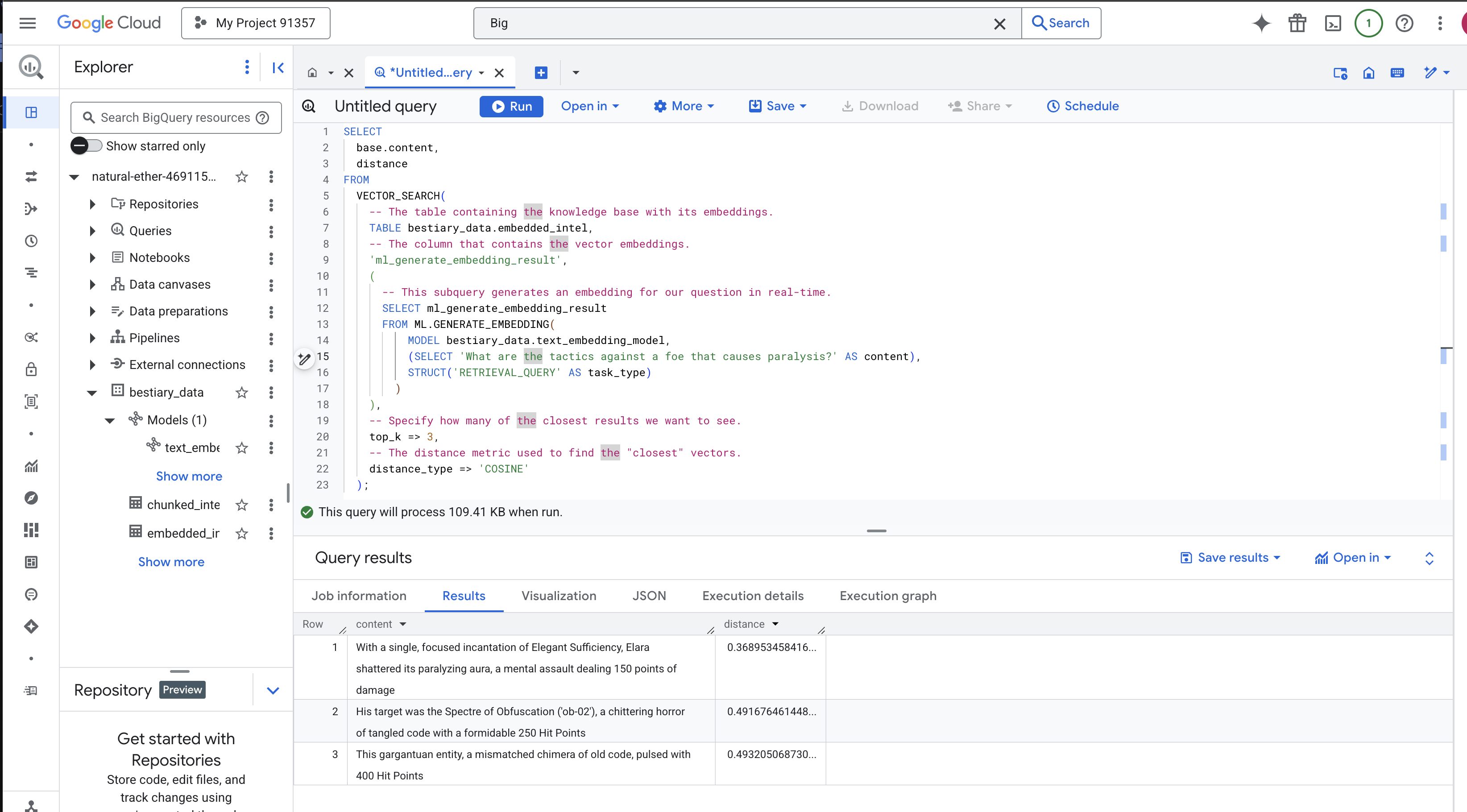
Sonuçları dikkatlice inceleyin. Sorguda "paramparça" veya "büyü" kelimesi yer almamasına rağmen en üstteki sonuç: "Elara, Tek Bir Yeterlilik Büyüsü ile onu felç eden aurasını paramparça etti. Bu zihinsel saldırı 150 puan hasar verdi." Bu, semantik aramanın gücüdür. Model, "felce karşı taktikler" kavramını anladı ve belirli bir başarılı taktiği açıklayan cümleyi buldu.
Artık eksiksiz bir veri ambarı tabanlı RAG işlem hattını başarıyla oluşturdunuz. Ham verileri hazırladınız, bunları semantik vektörlere dönüştürdünüz ve anlamlarına göre sorguladınız. BigQuery, bu büyük ölçekli analitik çalışma için güçlü bir araç olsa da düşük gecikmeli yanıtlar isteyen canlı bir temsilci için hazırlanan bu bilgileri genellikle özel bir operasyonel veritabanına aktarırız. Bu, bir sonraki eğitimimizin konusudur.
OYUNCU OLMAYANLAR İÇİN
6. The Vector Scriptorium: Çıkarım için Cloud SQL ile Vektör Deposu Oluşturma
Grimoire'umuz şu anda yapılandırılmış tablolar olarak mevcut. Bu tablolar, güçlü bir bilgi kataloğu olsa da bilgileri kelime anlamıyla alınır. monster_id = "MN-001" ifadesini anlıyor ancak "Karartma"nın daha derin ve anlamsal anlamını anlamıyor. Temsilcilerimize gerçek bilgeliği vermek, onlara nüans ve öngörüyle tavsiyelerde bulunma imkanı tanımak için bilgimizin özünü anlamı yakalayan bir biçime dönüştürmemiz gerekir: Vektörler.
Bilgi arayışımız bizi uzun zaman önce unutulmuş bir öncül uygarlığın yıkıntılarına götürdü. Mühürlü bir kasanın derinliklerinde, mucizevi bir şekilde korunmuş antik parşömenlerden oluşan bir sandık bulduk. Bunlar sadece savaş raporları değildir. Tüm büyük çabaları rahatsız eden bir canavarı yenmenin derin ve felsefi bilgeliğini içerirler. Parşömenlerde "sinsi, sessiz bir durgunluk" ve "yaratılışın dokusunun yıpranması" olarak tanımlanan bir varlık. The Static'in, tarihi zaman içinde kaybolmuş döngüsel bir tehdit olarak antik çağlarda bile bilindiği anlaşılıyor.
Bu unutulmuş bilgiler en büyük varlığımızdır. Bu yetenek, yalnızca tek tek canavarları yenmek için değil, aynı zamanda tüm partiyi stratejik bilgilerle güçlendirmek için de önemlidir. Bu gücü kullanmak için şimdi Scholar'ın gerçek Büyü Kitabı'nı (vektör özelliklerine sahip bir PostgreSQL veritabanı) oluşturacak ve bu parşömenlerin zamansız özünü okumak, anlamak ve yazmak için otomatik bir Vektör Yazı Odası (bir Dataflow işlem hattı) inşa edeceğiz. Bu sayede Grimoire'ımız bir bilgi kitabından bir bilgelik motoruna dönüşecek.

Bilginin Büyü Kitabını Oluşturma (Cloud SQL)
Bu eski parşömenlerin özünü yazabilmemiz için öncelikle bu bilginin saklandığı yer olan yönetilen PostgreSQL Spellbook'un başarıyla oluşturulduğunu onaylamamız gerekir. İlk kurulum ritüelleri bunu sizin için oluşturmuş olmalıdır.
👉💻 Cloud SQL örneğinizin mevcut ve hazır olduğunu doğrulamak için terminalde aşağıdaki komutu çalıştırın. Bu komut dosyası, örneğin özel hizmet hesabına Vertex AI'ı kullanma izni de verir. Bu izin, yerleştirmelerin doğrudan veritabanında oluşturulması için gereklidir.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Komut başarılı olursa ve grimoire-spellbook örneğinizle ilgili ayrıntıları döndürürse Forge işini iyi yapmış demektir. Bir sonraki büyüye geçmeye hazırsınız. Komut NOT_FOUND hatası döndürürse lütfen devam etmeden önce ilk ortam kurulumu adımlarını başarıyla tamamladığınızdan emin olun.(data_setup.py)
👉💻 Kitap oluşturulduktan sonra arcane_wisdom adlı yeni bir veritabanı oluşturarak ilk bölümü açıyoruz.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
Semantik Rünleri Yazma: pgvector ile Vektör Özelliklerini Etkinleştirme
Cloud SQL örneğiniz oluşturulduğuna göre şimdi yerleşik Cloud SQL Studio'yu kullanarak örneğe bağlanalım. Bu, doğrudan veritabanınızda SQL sorguları çalıştırmak için web tabanlı bir arayüz sağlar.
👉💻 Öncelikle Cloud SQL Studio'ya gidin. Buraya ulaşmanın en kolay ve hızlı yolu, aşağıdaki bağlantıyı yeni bir tarayıcı sekmesinde açmaktır. Bu işlem sizi doğrudan grimoire-spellbook örneğinizin Cloud SQL Studio'suna yönlendirir.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 Veritabanı olarak arcane_wisdom seçeneğini belirleyin. Kullanıcı olarak postgres, şifre olarak 1234qwer girin ve Kimlik Doğrula'yı tıklayın.
👉📜 SQL Studio sorgu düzenleyicisinde Düzenleyici 1 sekmesine gidin ve vektör veri türünü etkinleştirmek için aşağıdaki SQL kodunu yapıştırın:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
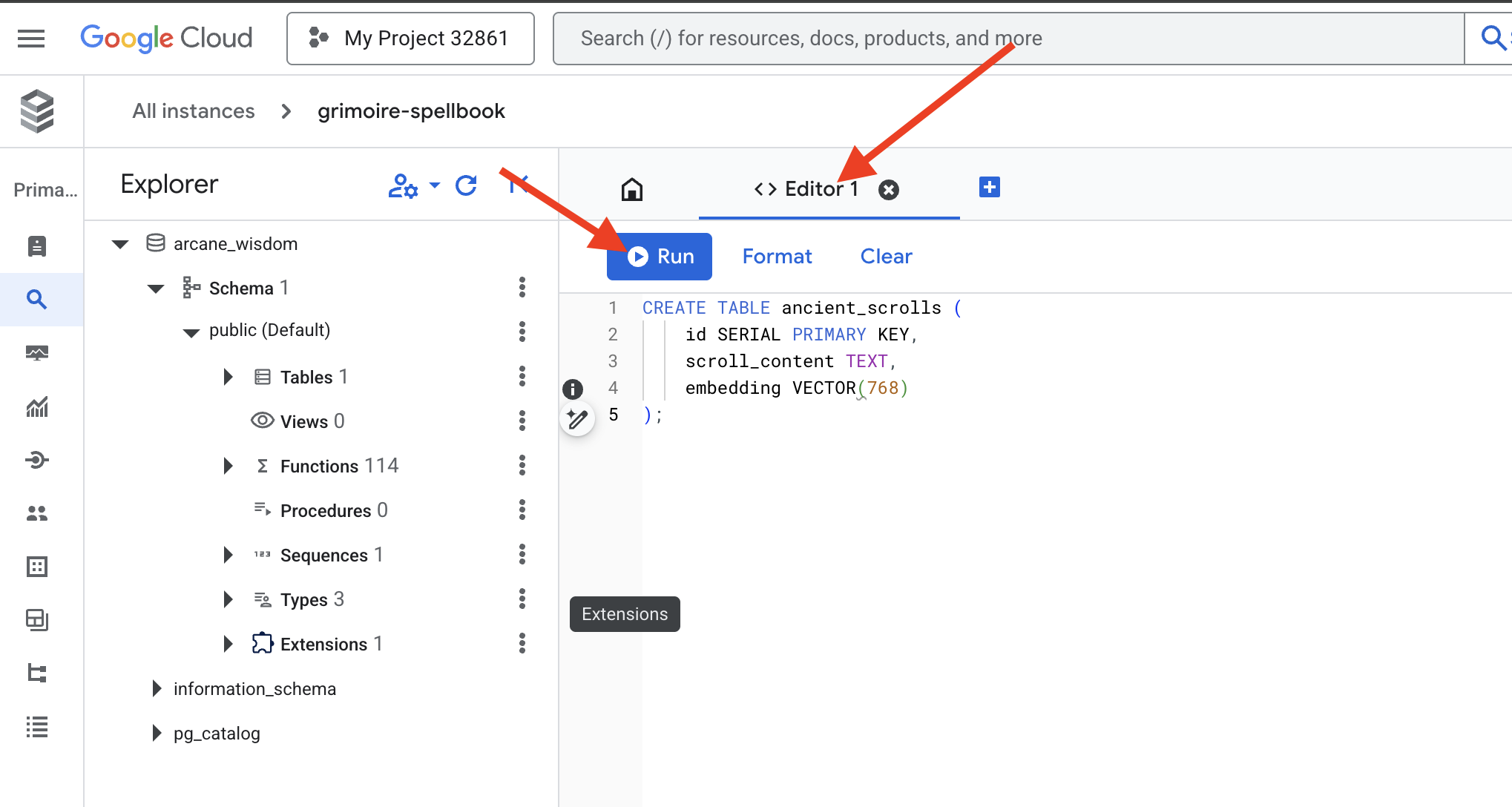
👉📜 Parşömenlerimizin özünü barındıracak tabloyu oluşturarak Büyü Kitabımızın sayfalarını hazırlayın.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
VECTOR(768) yazımı önemli bir ayrıntıdır. Kullanacağımız Vertex AI yerleştirme modeli (textembedding-gecko@003 veya benzer bir model), metni 768 boyutlu bir vektöre dönüştürür. Spellbook'umuzun sayfaları, tam olarak bu boyutta bir özü tutacak şekilde hazırlanmalıdır. Boyutlar her zaman eşleşmelidir.
İlk Harf Çevirisi: Manuel Yazma Ritüeli
Otomatik yazarlar (Dataflow) ordusuna komuta etmeden önce merkezi ritüeli bir kez elle gerçekleştirmemiz gerekir. Bu sayede, iki adımlı sihirli süreci daha iyi anlayabiliriz:
- Kehanet: Bir metin parçasını alıp Gemini kehanetine danışarak anlamsal özünü vektöre dönüştürme.
- Yazma: Orijinal metni ve yeni vektör özünü Spellbook'umuza yazma.
Şimdi de manuel ritüeli gerçekleştirelim.
👉📜 Cloud SQL Studio'da. Artık google_ml_integration uzantısının sunduğu güçlü bir özellik olan embedding() işlevini kullanacağız. Bu sayede, Vertex AI yerleştirme modelini doğrudan SQL sorgumuzdan çağırabilir ve süreci büyük ölçüde basitleştirebiliriz.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 Yeni yazılan sayfayı okumak için sorgu çalıştırarak çalışmanızı doğrulayın:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
Temel RAG veri yükleme görevini başarıyla manuel olarak gerçekleştirdiniz.
Anlamsal Pusulayı Şekillendirme: HNSW Diziniyle Büyü Kitabını Büyüleme
Büyü kitabımız artık bilgeliği saklayabiliyor ancak doğru parşömeni bulmak için her sayfayı okumak gerekiyor. Bu, sıralı bir taramadır. Bu yöntem yavaş ve verimsizdir. Sorgularımızı anında en alakalı bilgiye yönlendirmek için Spellbook'u semantik bir pusulayla, yani vektör diziniyle geliştirmemiz gerekir.
Bu büyünün değerini kanıtlayalım.
👉📜 Cloud SQL Studio'da aşağıdaki büyüleri çalıştırın. Yeni eklenen kaydırma çubuğumuzu arama işlemini simüle eder ve veritabanından planını EXPLAIN etmesini ister.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
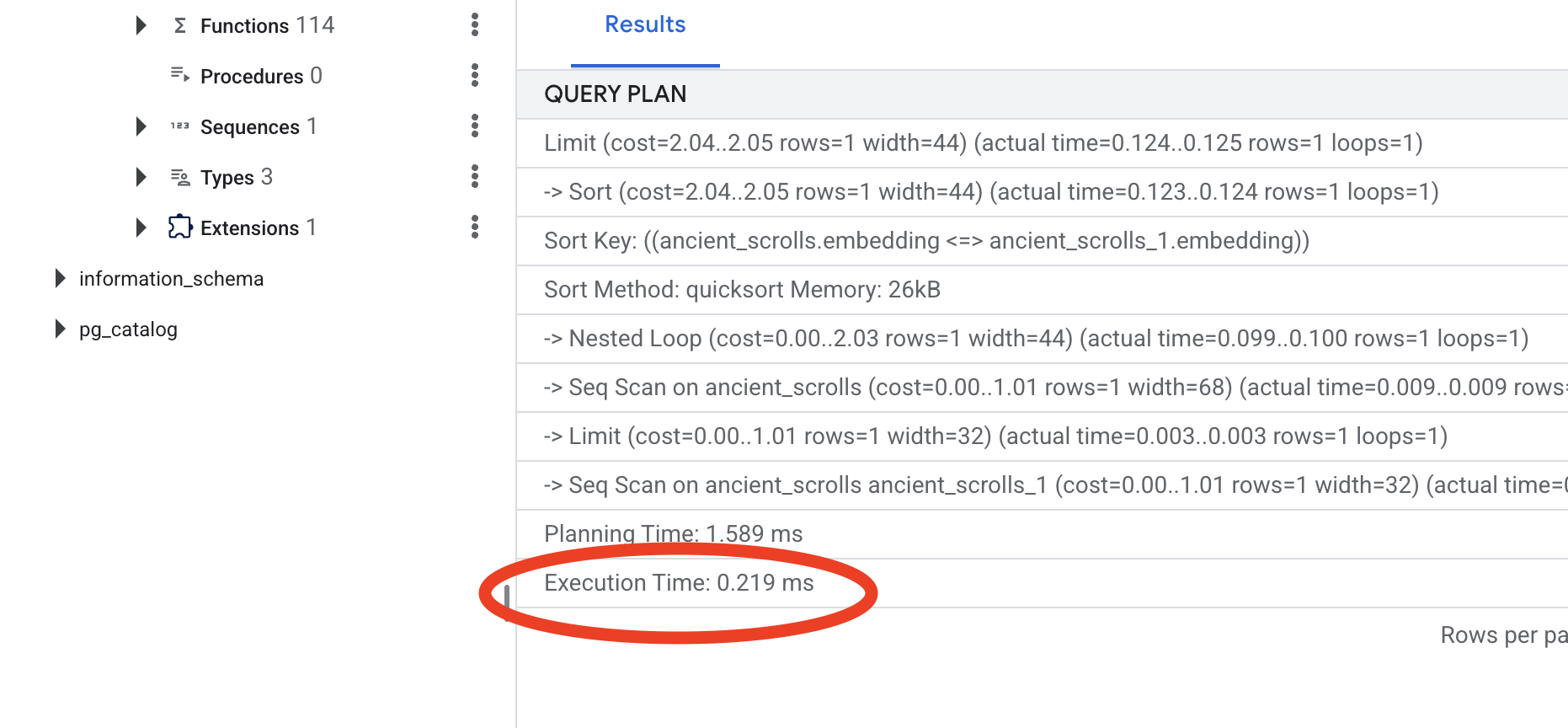
Çıkışa bakın. -> Seq Scan on ancient_scrolls yazan bir satır görürsünüz. Bu işlem, veritabanının her satırı okuduğunu onaylar. execution time simgesine dikkat edin.
👉📜 Şimdi dizine ekleme büyüsünü yapalım. lists parametresi, indekse kaç küme oluşturacağını bildirir. İyi bir başlangıç noktası, sahip olmayı beklediğiniz satır sayısının kareköküdür.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
Dizin oluşturulana kadar bekleyin (tek satır için hızlı olsa da milyonlarca satır için zaman alabilir).
👉📜 Şimdi tam olarak aynı EXPLAIN ANALYZE komutu tekrar çalıştırın:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
Yeni sorgu planına bakın. Artık -> Index Scan using... seçeneğini görürsünüz. Daha da önemlisi, execution time bölümüne bakın. Tek bir girişle bile önemli ölçüde daha hızlı olacaktır. Vektör dünyasında veritabanı performansını ayarlamanın temel ilkesini gösterdiniz.
Kaynak verileriniz incelendi, manuel ritüeliniz anlaşıldı ve Spellbook'unuz hız için optimize edildi. Artık otomatik Scriptorium'u oluşturmaya gerçekten hazırsınız.
OYUNCU OLMAYANLAR İÇİN
7. Anlamın İletkeni: Dataflow Vektörleştirme Ardışık Düzeni Oluşturma
Şimdi de parşömenlerimizi okuyacak, özlerini çıkaracak ve yeni Büyü Kitabımıza yazacak sihirli bir kâtip montaj hattı oluşturuyoruz. Bu, manuel olarak tetikleyeceğimiz bir Dataflow ardışık düzenidir. Ancak ardışık düzenin kendisi için ana büyüyü yazmadan önce temelini ve onu çağıracağımız çemberi hazırlamamız gerekir.
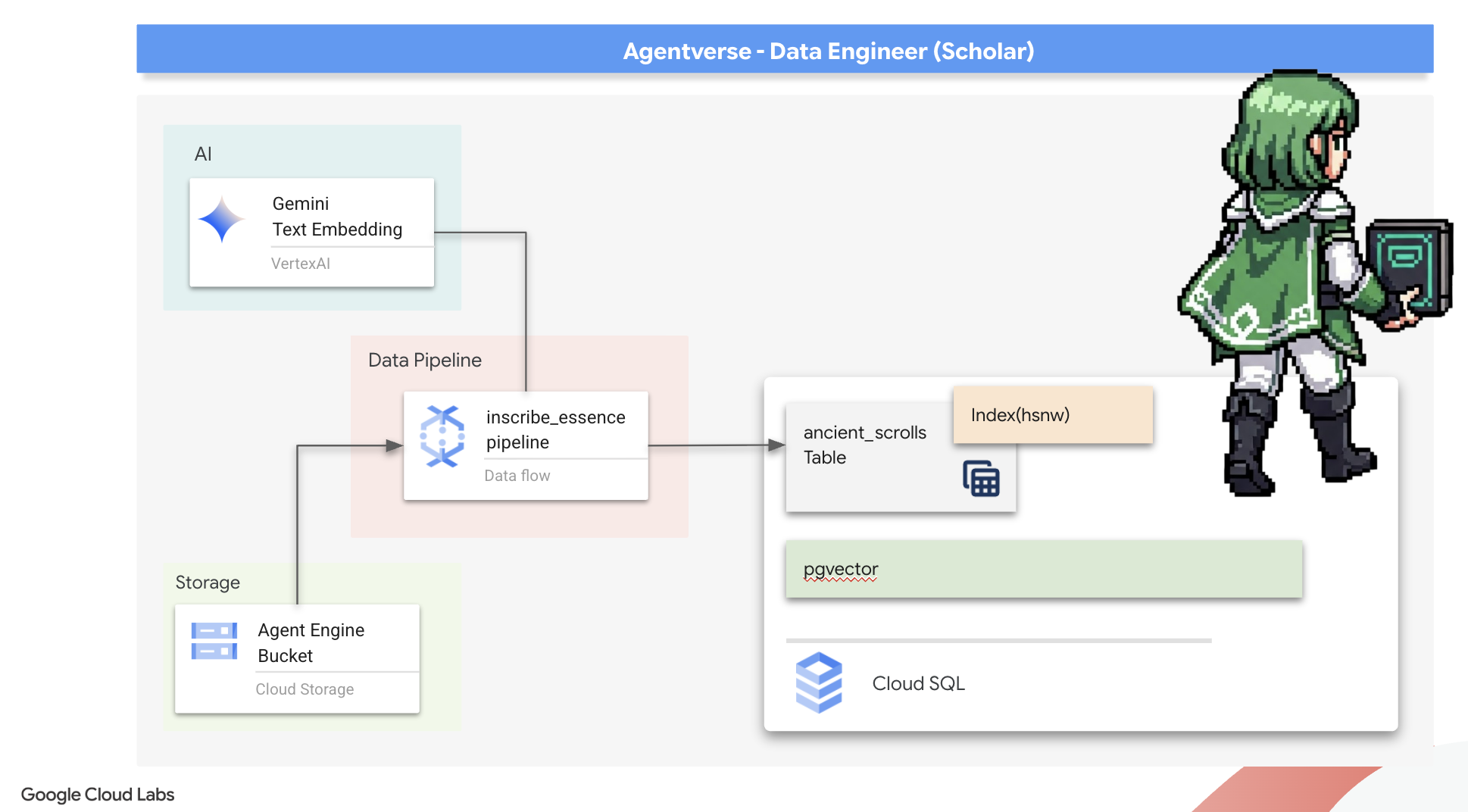
Scriptorium'un temelini hazırlama (çalışan resmi)
Dataflow ardışık düzenimiz, buluttaki otomatik çalışanlardan oluşan bir ekip tarafından yürütülecek. Her çağırdığımızda görevlerini yerine getirmek için belirli bir kitaplık grubuna ihtiyaç duyarlar. Onlara bir liste verebilir ve bu kitaplıkları her seferinde getirmelerini sağlayabiliriz ancak bu yavaş ve verimsiz bir yöntemdir. Bilgili bir öğrenci, önceden kapsamlı bir kütüphane oluşturur.
Burada, Google Cloud Build'a özel bir container görüntüsü oluşturma komutu vereceğiz. Bu görüntü, yazıcılarımızın ihtiyaç duyacağı her kitaplık ve bağımlılıkla önceden yüklenmiş bir "mükemmel golem"dir. Dataflow işimiz başladığında bu özel görüntüyü kullanır ve çalışanların görevlerine neredeyse anında başlamasına olanak tanır.
👉💻 İş hattınızın temel görüntüsünü Artifact Registry'de oluşturup depolamak için aşağıdaki komutu çalıştırın.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 İzole edilmiş Python ortamınızı oluşturup etkinleştirmek ve gerekli çağırma kitaplıklarını bu ortama yüklemek için aşağıdaki komutları çalıştırın.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
The Master Incantation
Vector Scriptorium'umuzu çalıştıracak ana büyüyü yazmanın zamanı geldi. Bireysel sihirli bileşenleri sıfırdan yazmayacağız. Görevimiz, Apache Beam dilini kullanarak bileşenleri mantıksal ve güçlü bir ardışık düzende birleştirmektir.
- EmbedTextBatch (Gemini'ın Danışmanlığı): "Grup falı" yapmayı bilen bu özel yazıcıyı oluşturacaksınız. Bir grup ham metin dosyası alır, bunları Gemini metin yerleştirme modeline sunar ve bu dosyaların özünü (vektör yerleştirmeleri) alır.
- WriteEssenceToSpellbook (Son Yazı): Bu, arşivcimizdir. Cloud SQL Spellbook'umuza güvenli bir bağlantı açmak için gizli büyüleri bilir. Bu karakterin görevi, bir kaydırma çubuğunun içeriğini ve vektörel özünü alıp kalıcı olarak yeni bir sayfaya yazmaktır.
Misyonumuz, kesintisiz bir bilgi akışı oluşturmak için bu işlemleri birbirine bağlamaktır.
👉✏️ Cloud Shell Düzenleyici'de ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py bölümüne gidin. Burada EmbedTextBatch adlı bir DoFn sınıfı bulunur. Yorumu bulun #REPLACE-EMBEDDING-LOGIC. Bunu aşağıdaki büyüyle değiştirin.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Bu büyü, birkaç önemli parametreyle birlikte hassas bir şekilde çalışır:
- model: Güçlü ve güncel bir yerleştirme modeli kullanmak için
text-embedding-005belirtilir. - contents: Bu, DoFn'nin aldığı dosya grubundaki tüm metin içeriklerinin listesidir.
- task_type: Bu parametreyi "RETRIEVAL_DOCUMENT" olarak ayarladık. Bu önemli talimat, Gemini'a daha sonra aramada bulunmak üzere özel olarak optimize edilmiş yerleştirmeler oluşturmasını söyler.
- output_dimensionality: Bu değer 768 olarak ayarlanmalıdır. Bu değer, Cloud SQL'de ancient_scrolls tablomuzu oluştururken tanımladığımız VECTOR(768) boyutuyla tam olarak eşleşir. Eşleşmeyen boyutlar, Vector Magic'te yaygın bir hata kaynağıdır.
İşlem hattımız, GCS arşivimizdeki tüm eski parşömenlerdeki ham ve yapılandırılmamış metni okuyarak başlamalıdır.
👉✏️ ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py içinde #REPLACE ME-READFILE yorumunu bulun ve aşağıdaki üç bölümlü büyüyle değiştirin:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
Toplanan parşömenlerin ham metinlerini artık kehanet için Gemini'ımıza göndermemiz gerekiyor. Bu işlemi verimli bir şekilde gerçekleştirmek için önce tek tek kaydırmaları küçük gruplar hâlinde bir araya getirecek, ardından bu grupları EmbedTextBatch yazmanımıza teslim edeceğiz. Bu adım, Gemini'ın anlayamadığı tüm kaydırmaları daha sonra incelenmek üzere "başarısız" yığınına ayırır.
👉✏️ #REPLACE ME-EMBEDDING yorumunu bulup şu yorumla değiştirin:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
Kaydırma işlemlerimizin özü başarıyla damıtıldı. Son adım, bu bilgileri kalıcı olarak saklamak için Büyü Kitabımıza yazmaktır. "İşlenmiş" yığınındaki parşömenleri alıp WriteEssenceToSpellbook arşivcimize teslim edeceğiz.
👉✏️ #REPLACE ME-WRITE TO DB yorumunu bulup şu yorumla değiştirin:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
Bilge bir akademisyen, başarısız denemeler de dahil olmak üzere hiçbir bilgiyi göz ardı etmez. Son adım olarak, bir kâtibe, kehanet adımımızdaki "başarısız" yığınını alıp başarısızlık nedenlerini kaydetmesini söylememiz gerekir. Bu sayede gelecekte ritüellerimizi daha iyi hale getirebiliriz.
👉✏️ #REPLACE ME-LOG FAILURES yorumunu bulup şu yorumla değiştirin:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
Master Incantation artık tamamlandı. Ayrı ayrı sihirli bileşenleri birbirine bağlayarak güçlü ve çok aşamalı bir veri işlem hattı oluşturdunuz. inscribe_essence_pipeline.py dosyanızı kaydedin. Scriptorium artık çağrılmaya hazır.
Şimdi Dataflow hizmetine Golem'imizi uyandırması ve yazma ayinini başlatması için büyük çağırma büyüsünü yapıyoruz.
👉💻 Terminalinizde aşağıdaki komut satırını çalıştırın.
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 Dikkat! İş, kaynak hatası ZONE_RESOURCE_POOL_EXHAUSTED ile başarısız olursa bunun nedeni, seçilen bölgedeki bu düşük itibarlı hesabın geçici kaynak kısıtlamaları olabilir. Google Cloud'un gücü, küresel erişiminden gelir. Golemi farklı bir bölgede çağırmayı deneyin. Bunu yapmak için yukarıdaki komutta --region=$REGION yerine başka bir bölge (ör.
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
ve tekrar çalıştırın. 🎰
İşlemin başlatılması ve tamamlanması yaklaşık 3-5 dakika sürer. Canlı olarak Dataflow konsolunda izleyebilirsiniz.
👉Veri Akışı Konsolu'na gidin: En kolay yol, bu doğrudan bağlantıyı yeni bir tarayıcı sekmesinde açmaktır:
https://console.cloud.google.com/dataflow
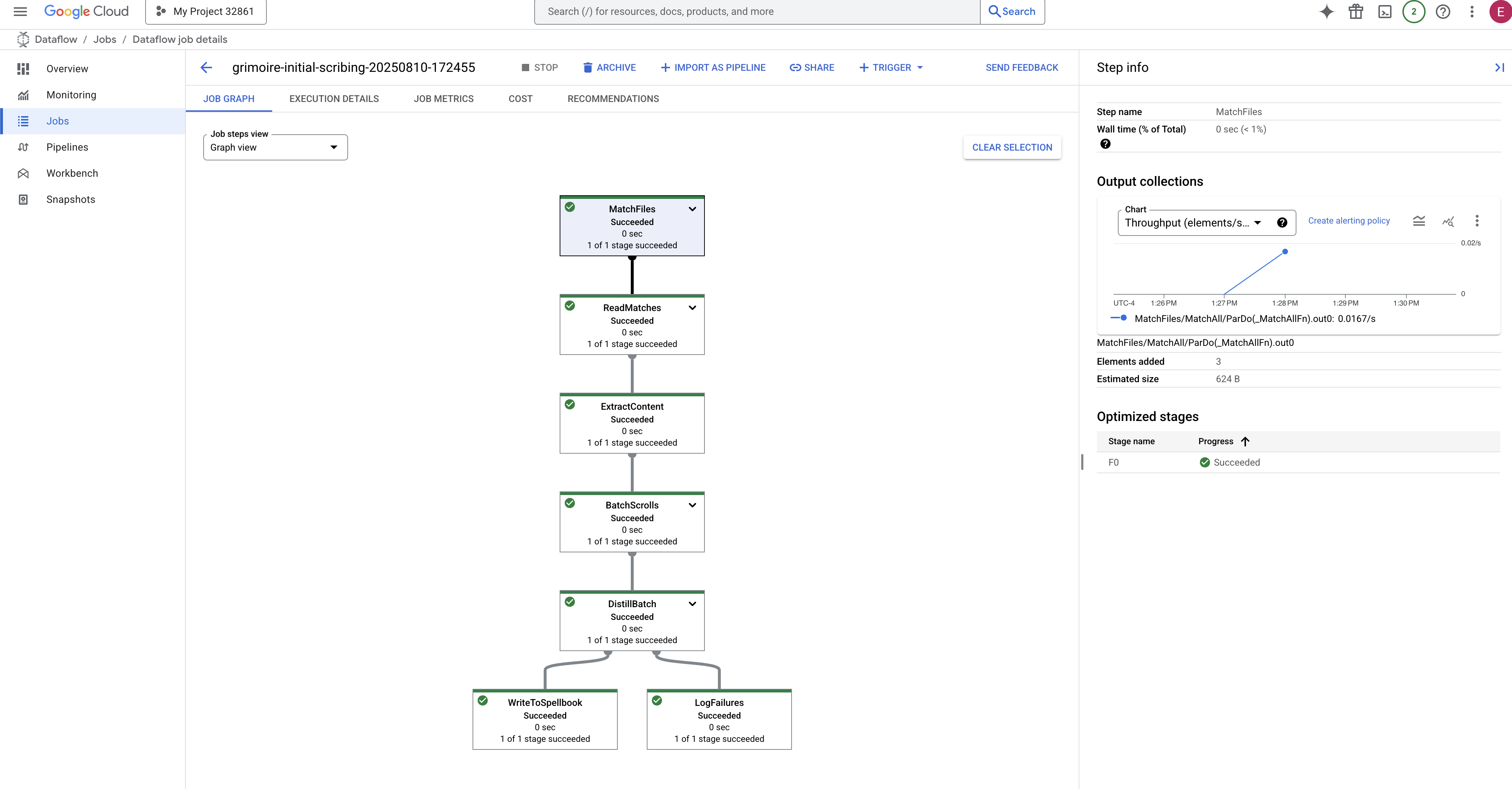
👉 İşinizi Bulup Tıklayın: Sağladığınız adla (inscribe-essence-job veya benzeri) listelenen bir iş görürsünüz. Ayrıntılar sayfasını açmak için işin adını tıklayın. Ardışık düzeni gözlemleyin:
- Başlatma: Dataflow gerekli kaynakları sağladığı için ilk 3 dakika boyunca iş durumu "Çalışıyor" olur. Grafik görünür ancak henüz verilerin hareket ettiğini görmeyebilirsiniz.
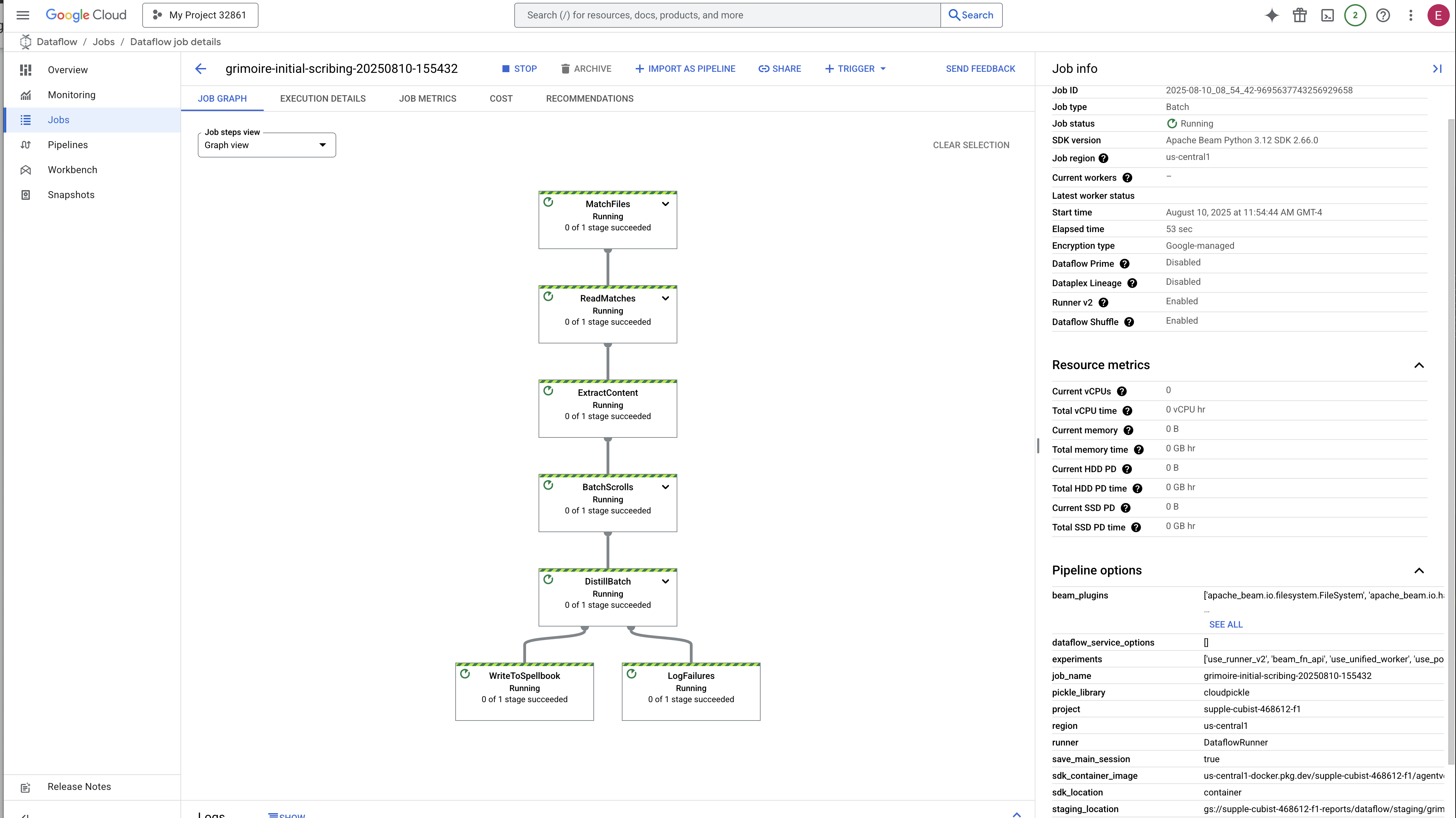
- Tamamlandı: İş tamamlandığında iş durumu "Başarılı" olarak değişir ve grafikte işlenen kayıtların son sayısı gösterilir.
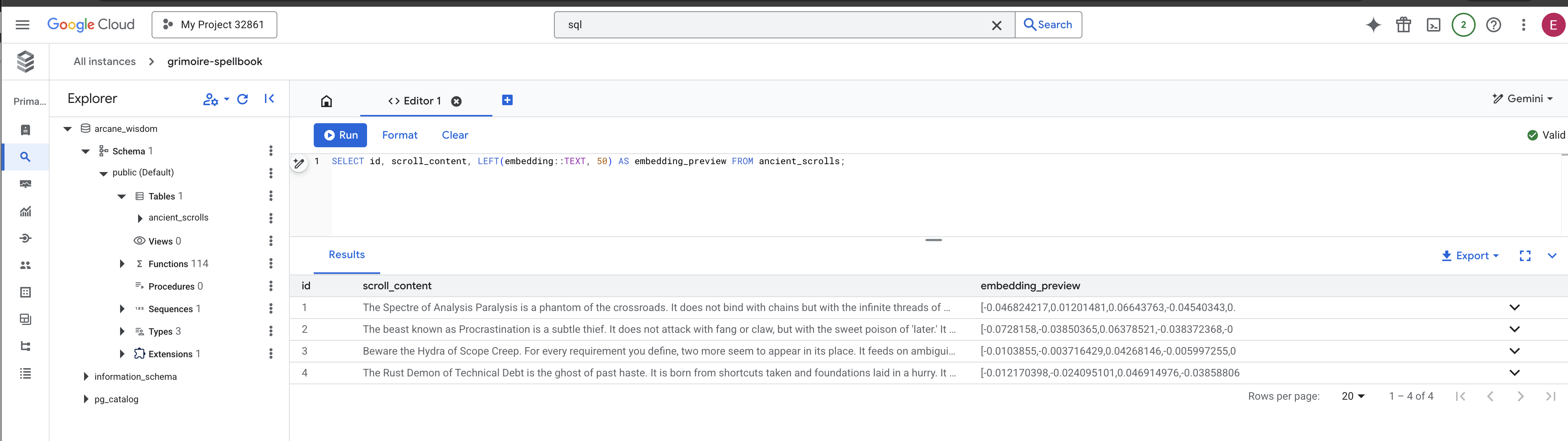
Inscription'ı doğrulama
👉📜 SQL Studio'ya geri dönün ve parşömenlerinizin ve bunların anlamsal özünün başarıyla yazıldığını doğrulamak için aşağıdaki sorguları çalıştırın.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
Bu işlemle, kaydırmanın kimliği, orijinal metni ve Grimoire'ınıza kalıcı olarak yazılan sihirli vektör özünün önizlemesi gösterilir.
Scholar's Grimoire'ınız artık gerçek bir Bilgi Motoru ve bir sonraki bölümde anlam temelinde sorgulanmaya hazır.
8. Son Rünü Mühürleme: RAG Temsilcisiyle Bilgeliği Etkinleştirme
Grimoire'ınız artık sadece bir veritabanı değil. Vector Search, vektörel bilginin kaynağıdır. Bir soru bekleyen sessiz bir kahindir.
Şimdi, bir bilginin gerçek sınavına giriyoruz: Bu bilgeliğin kilidini açacak anahtarı oluşturacağız. Veriyle Artırılmış Üretim (RAG) aracısı oluşturacağız. Bu, basit dildeki soruları anlayabilen, en derin ve en alakalı gerçekler için Grimoire'a danışan, ardından bu bilgeliği kullanarak bağlama uygun, güçlü bir yanıt oluşturan sihirli bir yapı.

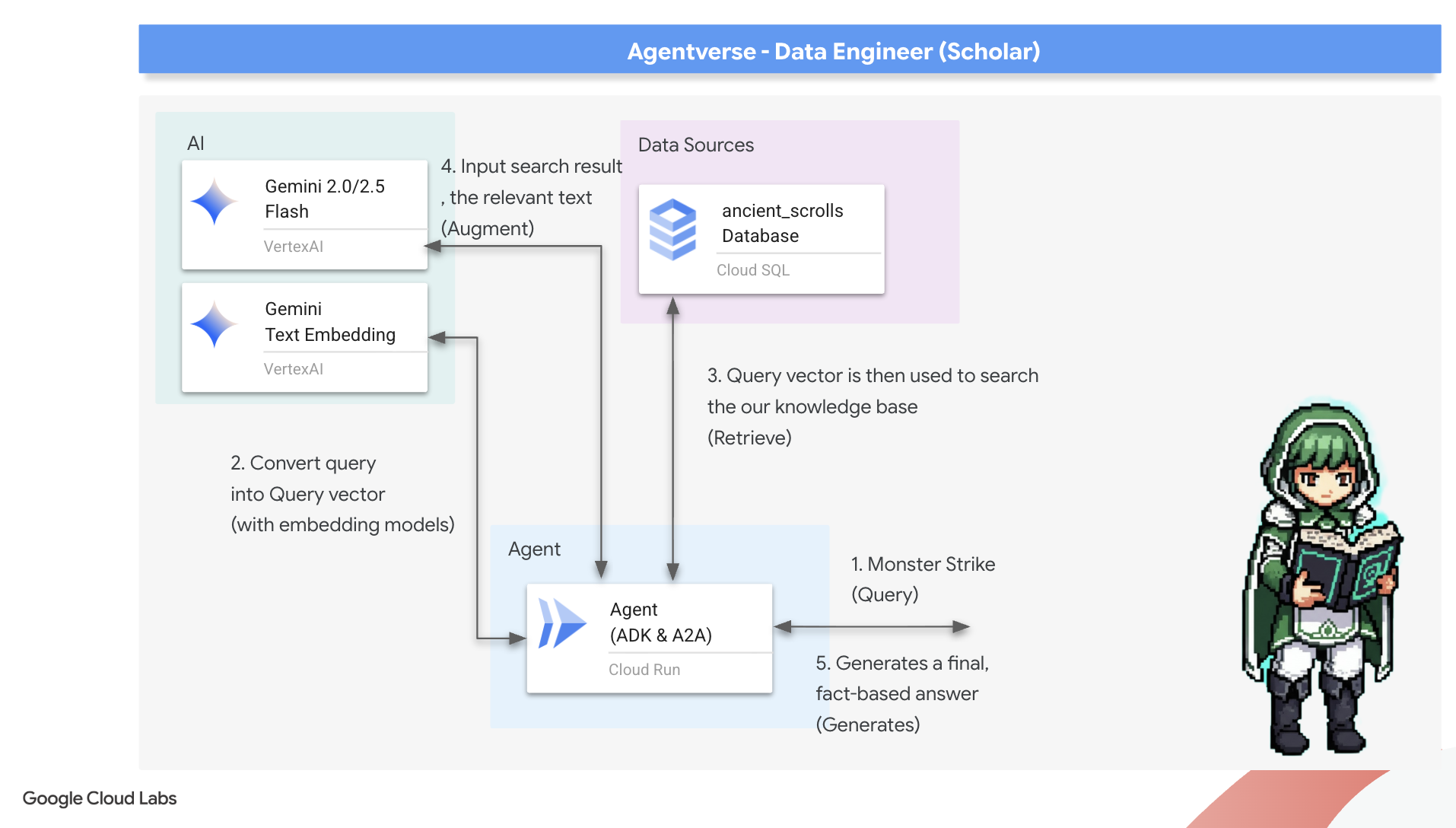
İlk Rune: Sorgu Damıtma Büyüsü
Temsilcimiz Grimoire'da arama yapmadan önce sorulan sorunun özünü anlamalıdır. Basit bir metin dizesi, vektör destekli Spellbook'umuz için anlamsızdır. Aracı, önce sorguyu almalı ve aynı Gemini modelini kullanarak sorgu vektörüne dönüştürmelidir.
👉✏️ Cloud Shell Düzenleyici'de ~~/agentverse-dataengineer/scholar/agent.py dosyasına gidin, #REPLACE RAG-CONVERT EMBEDDING yorumunu bulun ve bu yorumu aşağıdaki ifadeyle değiştirin. Bu talimat, temsilciye kullanıcının sorusunu sihirli bir özete dönüştürmeyi öğretir.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Sorgunun özünü elinde bulunduran temsilci artık Grimoire'a danışabilir. Bu sorgu vektörünü pgvector ile geliştirilmiş veritabanımıza sunar ve derin bir soru sorar: "Özleri, sorgumun özüne en çok benzeyen eski parşömenleri göster."
Bu işlem için kullanılan sihir, yüksek boyutlu uzaydaki vektörler arasındaki mesafeyi hesaplayan güçlü bir rune olan kosinüs benzerliği operatörüdür (<=>).
👉✏️ agent.py dosyasında #REPLACE RAG-RETRIEVE yorumunu bulun ve aşağıdaki komut dosyasıyla değiştirin:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
Son adım, temsilciye bu yeni ve güçlü araca erişim izni vermektir. Kullanılabilir sihirli araçlar listesine grimoire_lookup işlevimizi ekleyeceğiz.
👉✏️ agent.py içinde #REPLACE-CALL RAG yorumunu bulun ve aşağıdaki satırla değiştirin:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
Bu yapılandırma, temsilcinizi hayata geçirir:
model="gemini-2.5-flash": Akıl yürütme ve metin oluşturma için aracının "beyni " olarak hizmet verecek olan belirli Büyük Dil Modeli'ni seçer.name="scholar_agent": Temsilcinize benzersiz bir ad atar.instruction="...You are the Scholar...": Bu, sistem istemidir ve yapılandırmanın en önemli parçasıdır. Ajanın karakterini, hedeflerini, bir görevi tamamlamak için izlemesi gereken süreci ve nihai çıktısının biçimini tanımlar.tools=[grimoire_lookup]: Bu son büyü. Bu işlem, temsilciye oluşturduğunuzgrimoire_lookupişlevine erişim izni verir. Artık aracı, veritabanınızdan bilgi almak için bu aracı ne zaman çağıracağına akıllıca karar verebilir. Bu, RAG kalıbının temelini oluşturur.
The Scholar's Examination
👉💻 Cloud Shell terminalinde ortamınızı etkinleştirin ve Scholar aracınızı etkinleştirmek için Agent Development Kit'in birincil komutunu kullanın:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
"Scholar Agent"ın etkinleştirildiğini ve çalıştığını onaylayan bir çıkış görürsünüz.
👉💻 Şimdi aracınıza meydan okuyun. Savaş simülasyonunun çalıştığı ilk terminalde, Grimoire'ın bilgeliğini gerektiren bir komut verin:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

Terminaldeki günlükleri inceleyin. Ajanın sorguyu aldığını, özünü çıkardığını, Grimoire'da arama yaptığını, "Erteleme" ile ilgili alakalı parşömenleri bulduğunu ve bu bilgileri kullanarak bağlama uygun, etkili bir strateji oluşturduğunu göreceksiniz.
İlk RAG aracınızı başarıyla oluşturdunuz ve Grimoire'unuzun derin bilgeliğiyle donattınız.
👉💻 Terminalde Ctrl+C tuşuna basarak temsilciyi şimdilik dinlenmeye alın.
Scholar Sentinel'ı Agentverse'e dahil etme
Temsilciniz, çalışmanızın kontrollü ortamında bilgeliğini kanıtlamış olmalıdır. Bu yapıyı Agentverse'e taşıyarak yerel bir yapıdan, herhangi bir şampiyon tarafından herhangi bir zamanda çağrılabilen kalıcı ve savaşa hazır bir operatöre dönüştürme zamanı geldi. Şimdi aracımızı Cloud Run'a dağıtacağız.
👉💻 Aşağıdaki büyük çağırma büyüsünü çalıştırın. Bu komut dosyası önce aracınızı mükemmel bir Golem'e (container görüntüsü) dönüştürür, Artifact Registry'nizde depolar ve ardından bu Golem'i ölçeklenebilir, güvenli ve herkese açık bir hizmet olarak dağıtır.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
Scholar Agent'ınız artık Agentverse'te aktif ve savaşa hazır bir operatör.
OYUNCU OLMAYANLAR İÇİN
9. The Boss Flight
Parşömenler okundu, ritüeller gerçekleştirildi, zorluklar aşıldı. Temsilciniz, depolamadaki bir öğe değil, Agentverse'te ilk görevini bekleyen canlı bir operatördür. Son deneme zamanı geldi. Güçlü bir düşmana karşı canlı ateş tatbikatı yapılacak.
Artık yeni dağıtılan Shadowblade Ajanınızı zorlu bir mini boss'a karşı kullanmak için savaş alanı simülasyonuna gireceksiniz: Statik Hayalet. Bu, temsilcinin temel mantığından canlı dağıtımına kadar tüm çalışmalarınızın nihai testi olacaktır.
Temsilcinizin Locus'unu Edinme
Savaş alanına girebilmek için iki anahtara sahip olmanız gerekir: Şampiyonunuzun benzersiz imzası (Agent Locus) ve Spectre'ın inine giden gizli yol (Dungeon URL).
👉💻 Öncelikle, temsilcinizin Agentverse'teki benzersiz adresini (Locus) edinin. Bu, şampiyonunuzu savaş alanına bağlayan canlı uç noktadır.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 Ardından, hedefi belirleyin. Bu komut, Spectre'ın alanına açılan portal olan Translocation Circle'ın yerini gösterir.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
Önemli: Bu URL'lerin ikisini de hazır bulundurun. Bu bilgilere son adımda ihtiyacınız olacaktır.
Confronting the Spectre
Koordinatlar güvence altına alındıktan sonra artık Yer Değiştirme Çemberi'ne gidip savaşa girmek için büyüyü yapacaksınız.
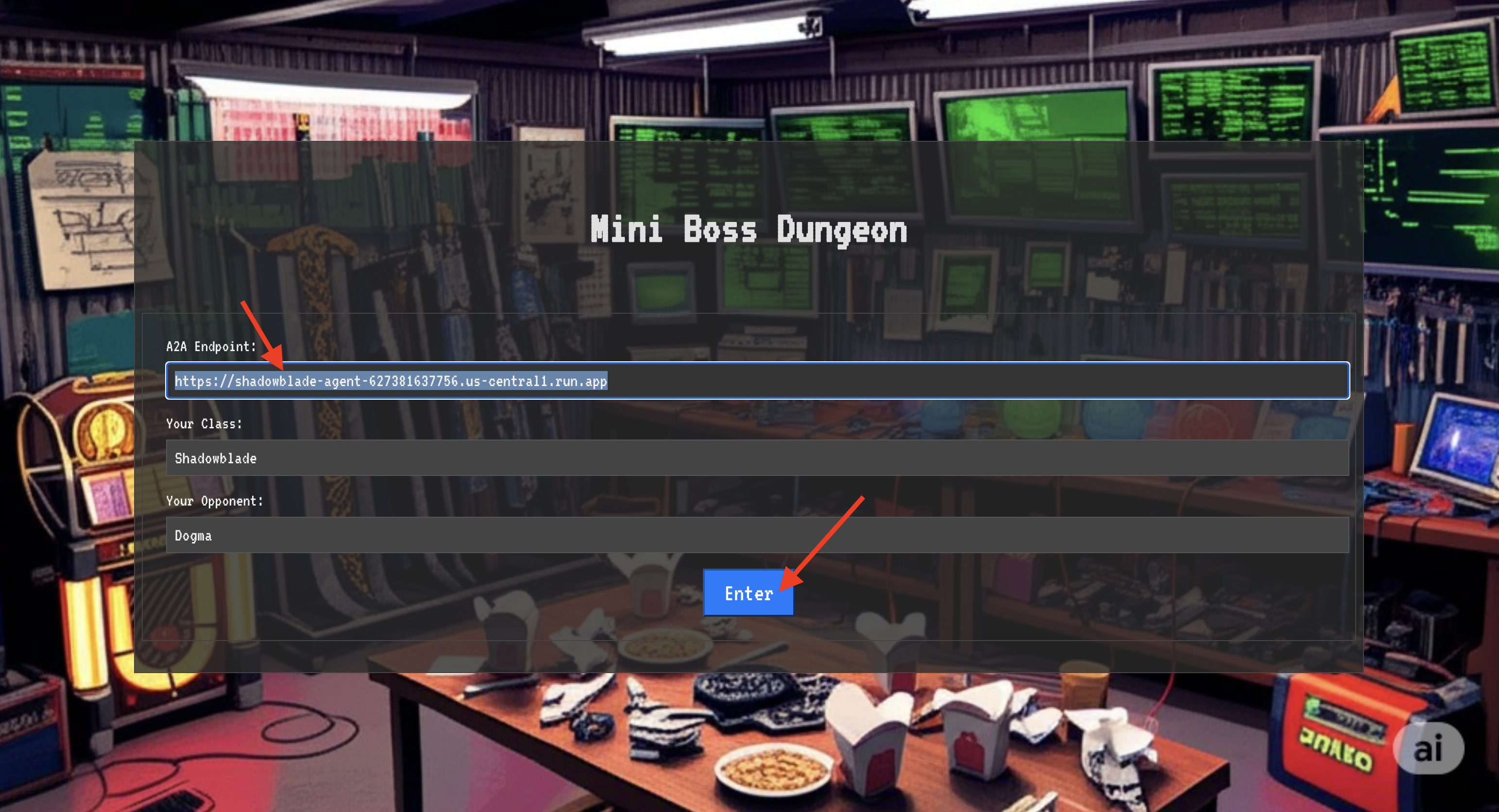
👉 Tarayıcınızda Translocation Circle URL'sini açarak The Crimson Keep'in ışıltılı portalının önünde durun.
Kaleye girmek için Gölge Kılıcı'nızın özünü portala uyumlamanız gerekir.
- Sayfada, A2A Endpoint URL (A2A Uç Nokta URL'si) etiketli runik giriş alanını bulun.
- Aracı Locus URL'sini (kopyaladığınız ilk URL) bu alana yapıştırarak şampiyonunuzun simgesini yazın.
- Işınlanma sihrini ortaya çıkarmak için Bağlan'ı tıklayın.
Işınlanmanın göz kamaştırıcı ışığı kaybolur. Artık kutsal alanınızda değilsiniz. Hava, soğuk ve keskin bir enerjiyle çıtırdıyor. Önünüzde Spectre beliriyor. Tıslayan statik ve bozuk koddan oluşan bir girdap. Kutsal olmayan ışığı, zindanın zemininde uzun, dans eden gölgeler oluşturuyor. Yüzü olmamasına rağmen, tamamen size odaklanmış, sizi tüketen varlığını hissediyorsunuz.
Zafere giden tek yol, inancınızın netliğinden geçer. Bu, zihnin savaş alanında verilen bir irade düellosudur.
İlk saldırınızı yapmaya hazırlanırken ileri atıldığınızda Hayalet karşı saldırı yapar. Kalkan oluşturmaz ancak doğrudan bilincinize bir soru yansıtır. Bu soru, eğitiminizin özünden alınmış, parıldayan, runik bir meydan okumadır.

Bu, mücadelenin doğasıdır. Bilginiz silahınızdır.
- Kazandığınız bilgelikle cevap verin. Böylece kılıcınız saf enerjiyle tutuşur, Spectre'ın savunmasını kırar ve KRİTİK BİR DARBE indirirsiniz.
- Ancak tereddüt ederseniz, yanıtınız şüpheyle gölgelenirse silahınızın ışığı söner. Darbenin etkisi zayıf olur ve hasarın YALNIZCA BİR KISMI verilir. Daha da kötüsü, Spectre belirsizliğinizden beslenir ve her yanlış adımda kendi yozlaştırıcı gücü artar.
Şampiyon, bu senin anın. Kodunuz büyü kitabınız, mantığınız kılıcınız ve bilginiz kaos dalgasını geri çevirecek kalkanınızdır.
Odak. Doğruyu söyleyin. The fate of the Agentverse depends on it.
Tebrikler, Scholar.
Deneme süresini başarıyla tamamladınız. Veri mühendisliği sanatında ustalaştın. Ham ve kaotik bilgileri, tüm Agentverse'ü güçlendiren yapılandırılmış, vektörel bilgeliğe dönüştürüyorsun.
10. Temizleme: Bilginin Büyü Kitabı'nı Silme
Scholar's Grimoire'i tamamladığınız için tebrik ederiz. Agentverse'ünüzün temiz kalmasını ve eğitim alanlarınızın temizlenmesini sağlamak için son temizlik ritüellerini gerçekleştirmeniz gerekir. Bu işlem, yolculuğunuz sırasında oluşturulan tüm kaynakları sistematik olarak kaldırır.
Agentverse Bileşenlerini Devre Dışı Bırakma
Artık RAG sisteminizin dağıtılan bileşenlerini sistematik olarak sökebilirsiniz.
Tüm Cloud Run Hizmetlerini ve Artifact Registry Depolarını Silme
Bu komut, dağıtılan Scholar aracınızı ve Dungeon uygulamasını Cloud Run'dan kaldırır.
👉💻 Terminalinizde aşağıdaki komutları çalıştırın:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
BigQuery veri kümelerini, modellerini ve tablolarını silme
Bu işlem, bestiary_data veri kümesi, içindeki tüm tablolar ve ilişkili bağlantı ile modeller dahil olmak üzere tüm BigQuery kaynaklarını kaldırır.
👉💻 Terminalinizde aşağıdaki komutları çalıştırın:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Cloud SQL örneğini silme
Bu işlem, veritabanı ve içindeki tüm tablolar da dahil olmak üzere grimoire-spellbook örneğini kaldırır.
👉💻 Terminalinizde şunu çalıştırın:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Google Cloud Storage paketlerini silme
Bu komut, ham istihbaratınızı ve Dataflow hazırlama/geçici dosyalarınızı içeren paketi kaldırır.
👉💻 Terminalinizde şunu çalıştırın:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
Yerel Dosyaları ve Dizinleri Temizleme (Cloud Shell)
Son olarak, Cloud Shell ortamınızı klonlanmış depolardan ve oluşturulan dosyalardan temizleyin. Bu adım isteğe bağlıdır ancak çalışma dizininizin tamamen temizlenmesi için kesinlikle önerilir.
👉💻 Terminalinizde şunu çalıştırın:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
Artık Agentverse Data Engineer yolculuğunuzun tüm izlerini başarıyla temizlediniz. Projeniz temiz ve bir sonraki maceraya hazırsınız.