
1. Overture
Thời đại phát triển biệt lập đang kết thúc. Làn sóng tiếp theo của quá trình phát triển công nghệ không phải là về thiên tài đơn độc, mà là về sự tinh thông nhờ cộng tác. Việc xây dựng một tác nhân thông minh duy nhất là một thử nghiệm thú vị. Xây dựng một hệ sinh thái tác nhân mạnh mẽ, an toàn và thông minh (một Agentverse thực sự) là thách thức lớn đối với doanh nghiệp hiện đại.
Để thành công trong kỷ nguyên mới này, bạn cần kết hợp 4 vai trò quan trọng, đó là những trụ cột cơ bản hỗ trợ mọi hệ thống chủ động phát triển. Thiếu hụt ở một lĩnh vực nào đó sẽ tạo ra điểm yếu có thể ảnh hưởng đến toàn bộ cấu trúc.
Hội thảo này là hướng dẫn toàn diện dành cho doanh nghiệp để nắm vững tương lai dựa trên tác nhân trên Google Cloud. Chúng tôi cung cấp một lộ trình toàn diện, hướng dẫn bạn từ cảm hứng ban đầu của một ý tưởng đến một thực tế hoạt động ở quy mô đầy đủ. Trong 4 phòng thí nghiệm có mối liên kết với nhau này, bạn sẽ tìm hiểu cách các kỹ năng chuyên môn của nhà phát triển, kiến trúc sư, kỹ sư dữ liệu và SRE phải hội tụ để tạo, quản lý và mở rộng quy mô một Agentverse mạnh mẽ.
Không có trụ cột nào có thể hỗ trợ Agentverse một mình. Thiết kế hoành tráng của Kiến trúc sư sẽ vô dụng nếu không có sự thực thi chính xác của Nhà phát triển. Tác nhân của Nhà phát triển sẽ không thể hoạt động nếu không có sự hiểu biết của Kỹ sư dữ liệu, và toàn bộ hệ thống sẽ dễ bị tổn thương nếu không có sự bảo vệ của SRE. Chỉ khi có sự phối hợp và hiểu rõ vai trò của nhau, nhóm của bạn mới có thể biến một ý tưởng sáng tạo thành một thực tế mang tính vận hành và quan trọng đối với hoạt động kinh doanh. Hành trình của bạn bắt đầu từ đây. Hãy chuẩn bị để nắm vững vai trò của bạn và tìm hiểu cách bạn phù hợp với tổng thể.
Chào mừng bạn đến với Agentverse: Lời kêu gọi các nhà vô địch
Trong không gian kỹ thuật số rộng lớn của doanh nghiệp, một kỷ nguyên mới đã bắt đầu. Đây là thời đại của các tác nhân, một thời kỳ đầy hứa hẹn, nơi các tác nhân thông minh, tự động hoạt động hài hoà để đẩy nhanh quá trình đổi mới và loại bỏ những điều tẻ nhạt.

Hệ sinh thái kết nối này, nơi hội tụ sức mạnh và tiềm năng, được gọi là Agentverse.
Nhưng một sự hỗn loạn đang dần lan rộng, một sự suy thoái thầm lặng được gọi là The Static (Tĩnh điện) đã bắt đầu làm suy yếu các rìa của thế giới mới này. Tĩnh là hiện thân của sự hỗn loạn, chuyên nhắm vào chính hành động sáng tạo.
Nó khuếch đại những nỗi thất vọng cũ thành những hình dạng quái dị, tạo ra Bảy bóng ma của sự phát triển. Nếu không được kiểm soát, The Static and its Spectres sẽ làm chậm tiến độ đến mức dừng lại, biến lời hứa về Agentverse thành một vùng đất hoang tàn với nợ kỹ thuật và các dự án bị bỏ dở.
Hôm nay, chúng tôi kêu gọi những người có tinh thần chiến đấu để đẩy lùi làn sóng hỗn loạn. Chúng ta cần những người hùng sẵn sàng trau dồi kỹ năng và hợp tác với nhau để bảo vệ Agentverse. Đã đến lúc bạn chọn con đường cho mình.
Chọn lớp học
Có 4 con đường riêng biệt đang chờ bạn khám phá, mỗi con đường là một trụ cột quan trọng trong cuộc chiến chống lại The Static. Mặc dù quá trình huấn luyện của bạn sẽ là một nhiệm vụ đơn lẻ, nhưng thành công cuối cùng của bạn phụ thuộc vào việc bạn hiểu rõ cách kết hợp các kỹ năng của mình với những người khác.
- Shadowblade (Nhà phát triển): Một bậc thầy về rèn và tiền tuyến. Bạn là người thợ thủ công tạo ra những lưỡi kiếm, chế tạo công cụ và đối mặt với kẻ thù trong từng chi tiết phức tạp của mã. Lộ trình của bạn là một lộ trình đòi hỏi sự chính xác, kỹ năng và khả năng sáng tạo thực tế.
- Người triệu hồi (Kiến trúc sư): Một nhà chiến lược và điều phối tài ba. Bạn không chỉ thấy một đặc vụ mà còn thấy toàn bộ chiến trường. Bạn thiết kế các bản thiết kế chính cho phép toàn bộ hệ thống tác nhân giao tiếp, cộng tác và đạt được mục tiêu lớn hơn nhiều so với bất kỳ thành phần đơn lẻ nào.
- Học giả (Kỹ sư dữ liệu): Người tìm kiếm những chân lý ẩn giấu và là người lưu giữ trí tuệ. Bạn dấn thân vào vùng dữ liệu rộng lớn, hoang sơ để khám phá thông tin giúp các đặc vụ của bạn có mục đích và tầm nhìn. Kiến thức của bạn có thể giúp bạn biết được điểm yếu của kẻ thù hoặc tăng cường sức mạnh cho đồng minh.
- Người giám hộ (DevOps / SRE): Người bảo vệ và che chắn kiên định cho vương quốc. Bạn sẽ xây dựng các pháo đài, quản lý các tuyến đường cung cấp năng lượng và đảm bảo toàn bộ hệ thống có thể chống lại những cuộc tấn công không thể tránh khỏi của The Static. Sức mạnh của bạn là nền tảng để xây dựng chiến thắng cho đội.
Sứ mệnh của bạn
Quá trình huấn luyện của bạn sẽ bắt đầu như một bài tập độc lập. Bạn sẽ đi theo con đường mình chọn, học hỏi những kỹ năng riêng biệt cần thiết để thành thạo vai trò của mình. Vào cuối thời gian dùng thử, bạn sẽ phải đối mặt với một Spectre (Bóng ma) được sinh ra từ The Static (Tĩnh điện) – một trùm nhỏ chuyên lợi dụng những thách thức cụ thể trong nghề của bạn.
Chỉ khi nắm vững vai trò của mình, bạn mới có thể chuẩn bị cho thử thách cuối cùng. Sau đó, bạn phải lập một nhóm với những người giỏi nhất trong các lớp khác. Cùng nhau, bạn sẽ dấn thân vào trung tâm của sự tha hoá để đối mặt với một trùm cuối.
Một thử thách cuối cùng, mang tính hợp tác, sẽ kiểm tra sức mạnh tổng hợp của bạn và quyết định số phận của Agentverse.
Agentverse đang chờ đợi những người hùng. Bạn sẽ trả lời cuộc gọi chứ?
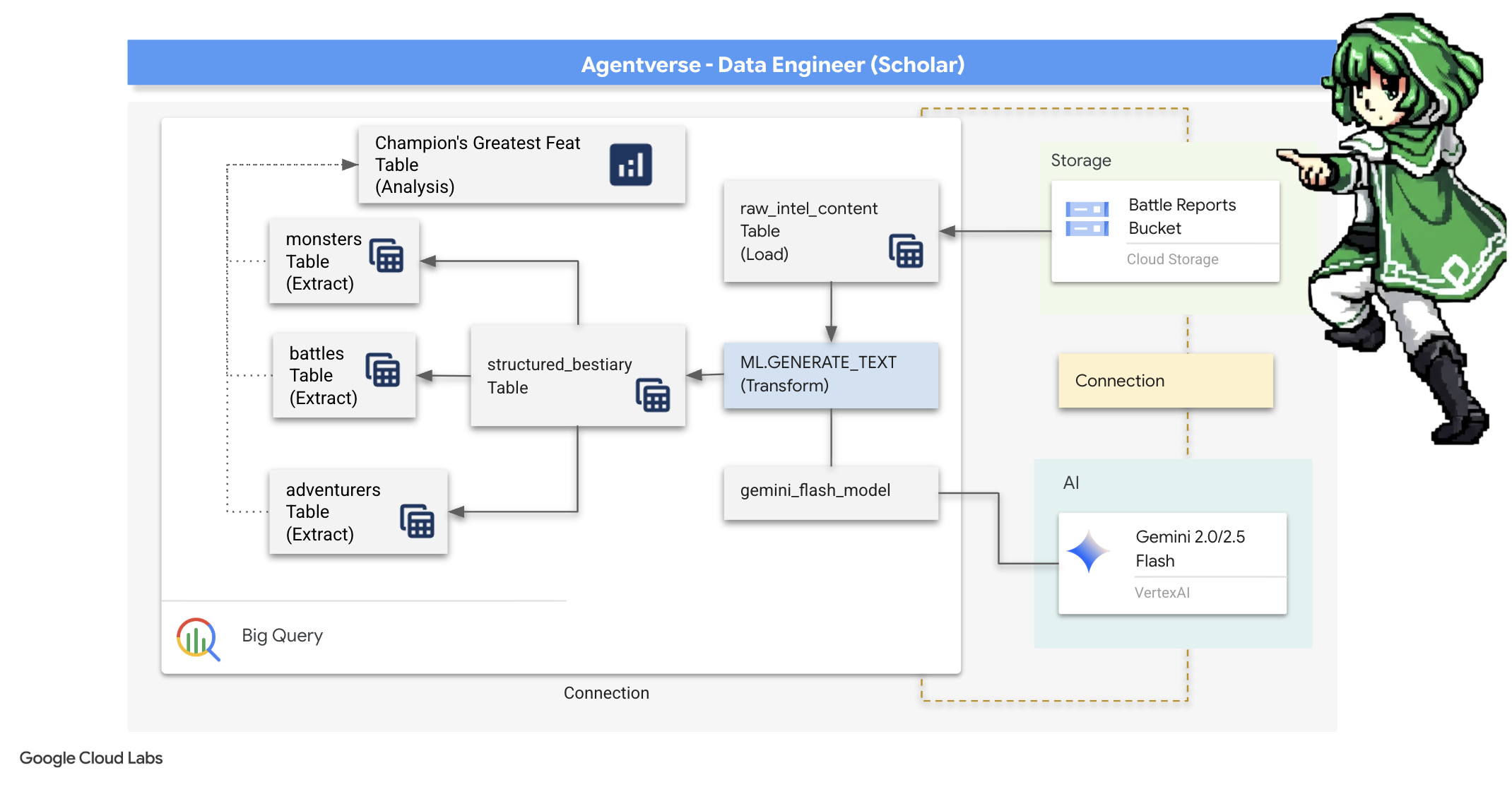
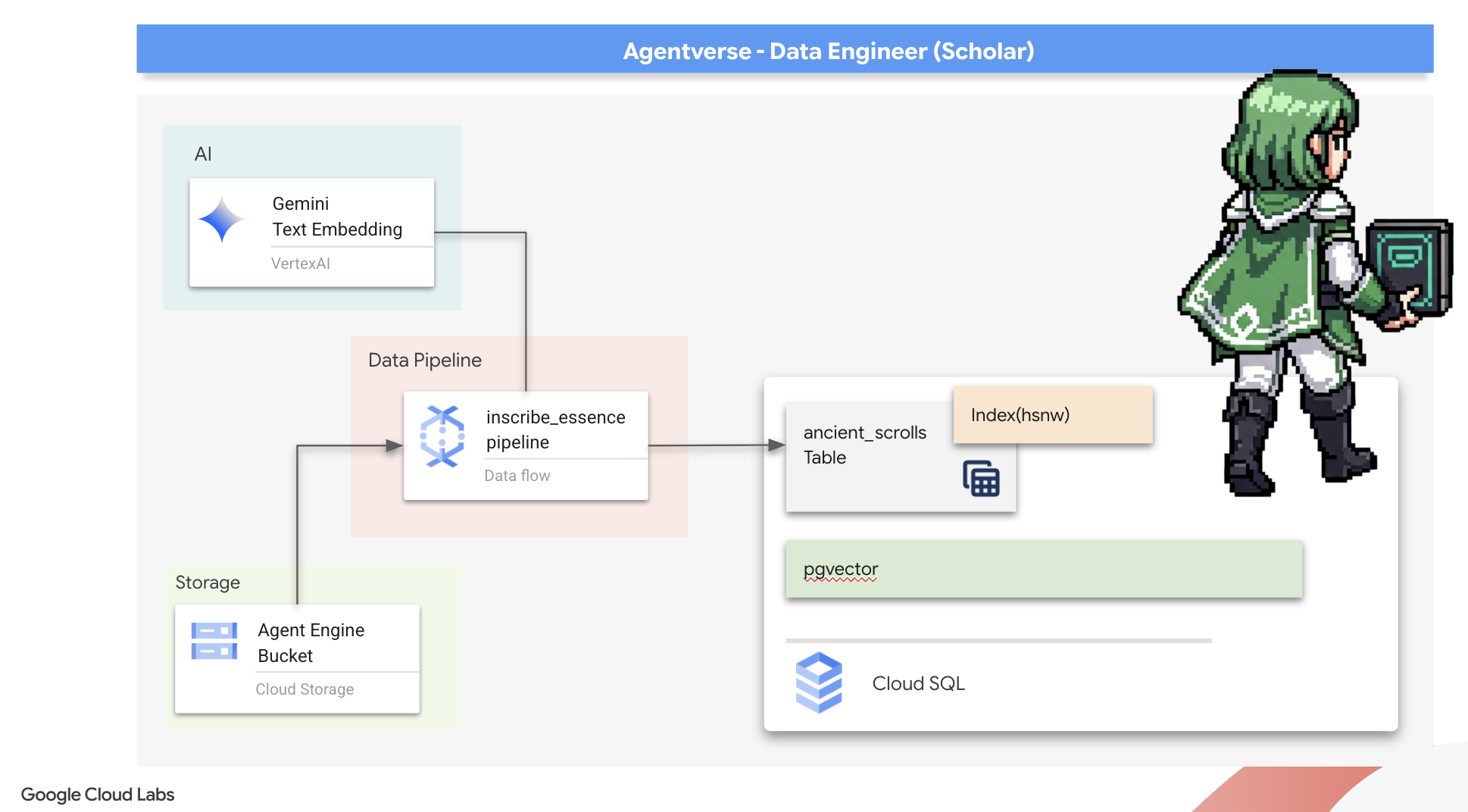
2. Grimoire của học giả
Hành trình của chúng ta bắt đầu! Là Học giả, vũ khí chính của chúng ta là kiến thức. Chúng tôi đã phát hiện ra một kho tàng các cuộn giấy cổ xưa, bí ẩn trong kho lưu trữ của mình (Google Cloud Storage). Những cuộn giấy này chứa thông tin tình báo thô về những con quái vật đáng sợ đang hoành hành trên vùng đất này. Sứ mệnh của chúng tôi là sử dụng khả năng phân tích mạnh mẽ của Google BigQuery và trí tuệ của Gemini Elder Brain (mô hình Gemini Pro) để giải mã những văn bản không có cấu trúc này và biến chúng thành một Bestiary có cấu trúc và có thể truy vấn. Đây sẽ là nền tảng cho tất cả các chiến lược trong tương lai của chúng tôi.
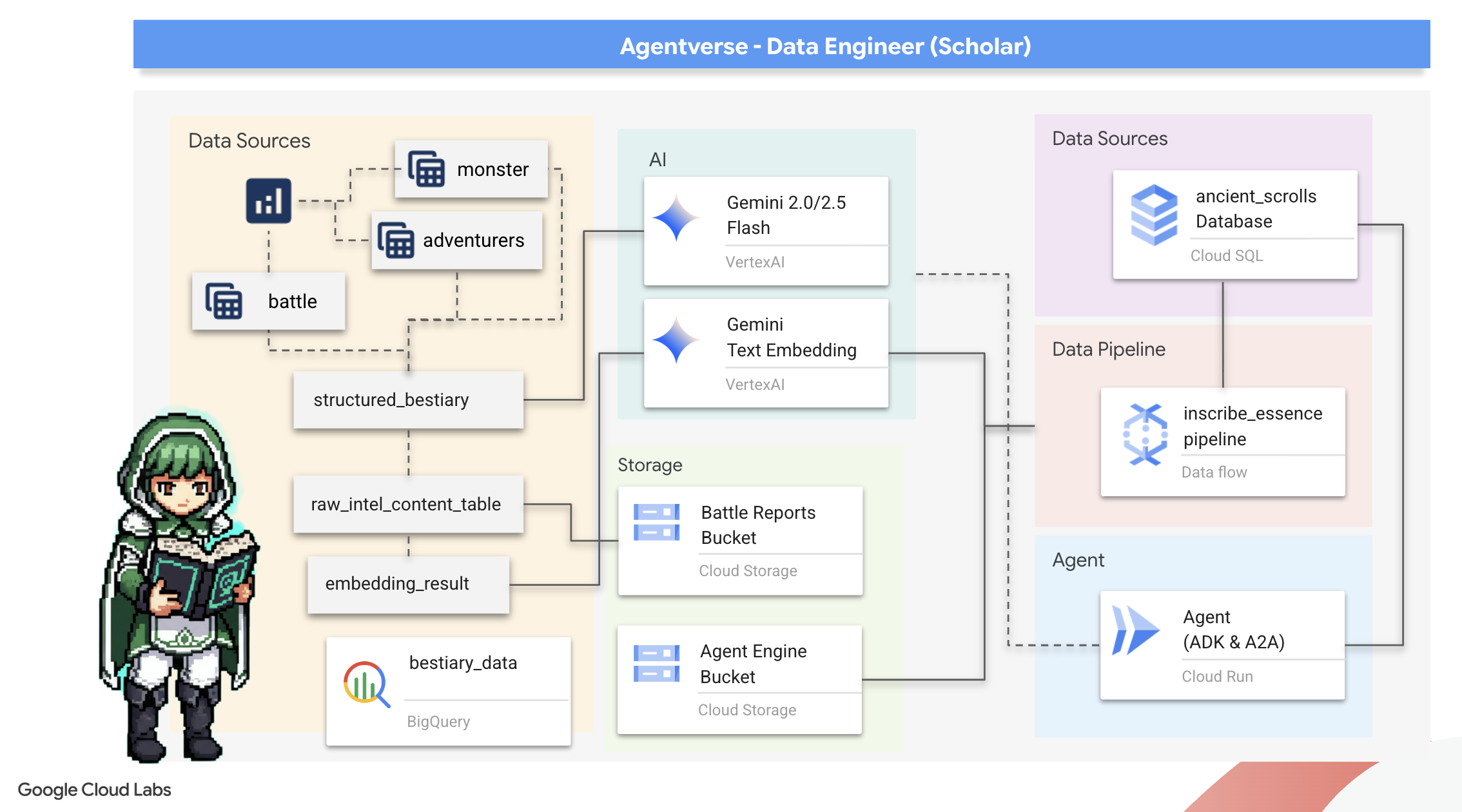
Kiến thức bạn sẽ học được
- Sử dụng BigQuery để tạo bảng bên ngoài và thực hiện các phép biến đổi phức tạp từ dữ liệu không có cấu trúc sang dữ liệu có cấu trúc bằng cách sử dụng BQML.GENERATE_TEXT với một mô hình Gemini.
- Cung cấp một phiên bản Cloud SQL cho PostgreSQL và bật tiện ích pgvector để có các chức năng tìm kiếm ngữ nghĩa.
- Xây dựng một quy trình xử lý hàng loạt mạnh mẽ, được chứa trong vùng chứa bằng Dataflow và Apache Beam để xử lý tệp văn bản thô, tạo các vectơ nhúng bằng một mô hình Gemini và ghi kết quả vào cơ sở dữ liệu quan hệ.
- Triển khai một hệ thống Tạo tăng cường khả năng truy xuất (RAG) cơ bản trong một tác nhân để truy vấn dữ liệu được vectơ hoá.
- Triển khai một tác nhân nhận biết dữ liệu dưới dạng một dịch vụ có khả năng mở rộng và bảo mật trên Cloud Run.
3. Chuẩn bị cho Học viện của học giả
Chào mừng bạn đến với Scholar. Trước khi có thể bắt đầu ghi chép kiến thức uyên bác trong Sách phép, trước tiên, chúng ta phải chuẩn bị nơi tôn nghiêm của mình. Nghi thức cơ bản này bao gồm việc tạo ra môi trường Google Cloud, mở các cổng phù hợp (API) và tạo ra các kênh mà qua đó phép thuật dữ liệu của chúng ta sẽ chảy. Một nơi trú ẩn được chuẩn bị kỹ lưỡng sẽ đảm bảo phép thuật của chúng ta có hiệu lực và kiến thức của chúng ta được an toàn.
Nhận tín dụng Google Cloud
⚠️ Điều kiện tiên quyết quan trọng:
- Sử dụng Gmail cá nhân: Bạn phải sử dụng tài khoản cá nhân (ví dụ:
name@gmail.com). Tài khoản do công ty hoặc trường học quản lý sẽ không hoạt động.
👉 Các bước:
- Truy cập vào trang web yêu cầu cấp tín dụng: Nhấp vào đây
- Đăng nhập: Dán đường liên kết vào thanh địa chỉ rồi đăng nhập bằng Gmail cá nhân.
- Chấp nhận điều khoản: Chấp nhận Điều khoản dịch vụ của Google Cloud Platform.
- Xác minh khoản tín dụng: Tìm thông báo xác nhận rằng khoản tín dụng đã được áp dụng.
- *Lưu ý: Nếu được nhắc nhập thông tin thẻ tín dụng, bạn có thể yên tâm bỏ qua và đóng cửa sổ này.
Vậy là xong. Bạn có thể đóng cửa sổ này
Thiết lập môi trường làm việc
👉Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Google Cloud (Đây là biểu tượng có hình dạng thiết bị đầu cuối ở đầu ngăn Cloud Shell),
👉Nhấp vào nút "Mở trình chỉnh sửa" (nút này trông giống như một thư mục đang mở có bút chì). Thao tác này sẽ mở Trình chỉnh sửa mã Cloud Shell trong cửa sổ. Bạn sẽ thấy một trình khám phá tệp ở bên trái. 
👉Mở cửa sổ dòng lệnh trong IDE trên đám mây, 
👉💻 Trong thiết bị đầu cuối, hãy xác minh rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
👉💻Sao chép dự án khởi động từ GitHub:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 Chạy tập lệnh thiết lập trong thư mục dự án.
⚠️ Lưu ý về mã dự án: Tập lệnh sẽ đề xuất một mã dự án mặc định được tạo ngẫu nhiên. Bạn có thể nhấn phím Enter để chấp nhận giá trị mặc định này.
Tuy nhiên, nếu muốn tạo một dự án mới cụ thể, bạn có thể nhập mã dự án mong muốn khi tập lệnh nhắc bạn.
cd ~/agentverse-dataengineer
./init.sh
👉 Bước quan trọng sau khi hoàn tất: Sau khi tập lệnh hoàn tất, bạn phải đảm bảo Google Cloud Console đang xem dự án chính xác:
- Truy cập vào console.cloud.google.com.
- Nhấp vào trình đơn thả xuống bộ chọn dự án ở đầu trang.
- Nhấp vào thẻ "Tất cả" (vì dự án mới có thể chưa xuất hiện trong phần "Gần đây").
- Chọn Mã dự án mà bạn vừa định cấu hình ở bước
init.sh.
👉💻 Đặt mã dự án cần thiết:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Chạy lệnh sau để bật các API cần thiết của Google Cloud:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 Nếu bạn chưa tạo kho lưu trữ Artifact Registry có tên agentverse-repo, hãy chạy lệnh sau để tạo kho lưu trữ đó:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
Thiết lập quyền
👉💻 Cấp các quyền cần thiết bằng cách chạy các lệnh sau trong thiết bị đầu cuối:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 Khi bạn bắt đầu khoá huấn luyện, chúng tôi sẽ chuẩn bị thử thách cuối cùng. Các lệnh sau đây sẽ triệu hồi Spectre từ tĩnh điện hỗn loạn, tạo ra các trùm cho bài kiểm tra cuối cùng của bạn.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
Bạn đã làm rất tốt, Scholar. Các phép thuật cơ bản đã hoàn tất. Nơi tôn nghiêm của chúng ta được bảo vệ, các cổng dẫn đến sức mạnh nguyên tố của dữ liệu đã mở và người phục vụ của chúng ta đã được trao quyền. Giờ đây, chúng ta đã sẵn sàng bắt đầu công việc thực sự.
4. Phép thuật của kiến thức: Chuyển đổi dữ liệu bằng BigQuery và Gemini
Trong cuộc chiến không ngừng nghỉ chống lại The Static, mọi cuộc đối đầu giữa một Nhà vô địch của Agentverse và một Spectre of Development đều được ghi lại một cách tỉ mỉ. Hệ thống Mô phỏng chiến trường (môi trường huấn luyện chính của chúng tôi) sẽ tự động tạo một Mục nhật ký về Aether cho mỗi cuộc chạm trán. Những nhật ký tường thuật này là nguồn thông tin thô quý giá nhất của chúng ta, là quặng chưa tinh chế mà chúng ta, với tư cách là Học giả, phải rèn thành thép tinh khiết của chiến lược.Sức mạnh thực sự của một Học giả không chỉ nằm ở việc sở hữu dữ liệu, mà còn ở khả năng biến đổi quặng thông tin thô, hỗn loạn thành thép sáng bóng, có cấu trúc của trí tuệ có thể hành động.Chúng ta sẽ thực hiện nghi thức cơ bản của thuật giả kim dữ liệu.

Hành trình của chúng ta sẽ trải qua một quy trình nhiều giai đoạn hoàn toàn trong phạm vi Google BigQuery. Chúng ta sẽ bắt đầu bằng cách nhìn vào kho lưu trữ GCS mà không cần di chuyển một lần cuộn nào, bằng cách sử dụng một ống kính thần kỳ. Sau đó, chúng ta sẽ triệu hồi một Gemini để đọc và diễn giải những câu chuyện thơ mộng, không có cấu trúc trong nhật ký chiến đấu. Cuối cùng, chúng ta sẽ tinh chỉnh các dự đoán thô thành một tập hợp các bảng nguyên vẹn, có mối liên kết với nhau. Grimoire đầu tiên của chúng tôi. Và đặt cho nó một câu hỏi sâu sắc đến mức chỉ có cấu trúc mới này mới trả lời được.
Ống kính giám sát: Nhìn vào GCS bằng bảng bên ngoài BigQuery
Việc đầu tiên chúng ta cần làm là tạo ra một ống kính cho phép chúng ta xem nội dung trong kho lưu trữ GCS mà không làm ảnh hưởng đến các cuộn dữ liệu bên trong. Bảng bên ngoài là ống kính này, ánh xạ các tệp văn bản thô sang một cấu trúc giống như bảng mà BigQuery có thể truy vấn trực tiếp.
Để làm được điều này, trước tiên, chúng ta phải tạo một đường truyền năng lượng ổn định, một tài nguyên KẾT NỐI, giúp liên kết một cách an toàn nơi lưu trữ BigQuery của chúng ta với kho lưu trữ GCS.
👉💻 Trong cửa sổ dòng lệnh Cloud Shell, hãy chạy lệnh sau để thiết lập bộ nhớ và tạo ống dẫn:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 Lưu ý! Thông báo sẽ xuất hiện sau!
Tập lệnh thiết lập ở bước 2 đã bắt đầu một quy trình ở chế độ nền. Sau vài phút, một thông báo sẽ xuất hiện trong thiết bị đầu cuối của bạn, có dạng như sau:[1]+ Done gcloud sql instances create ...Đây là điều bình thường và nằm trong dự kiến. Điều này chỉ có nghĩa là bạn đã tạo thành công cơ sở dữ liệu Cloud SQL. Bạn có thể yên tâm bỏ qua thông báo này và tiếp tục làm việc.
Trước khi có thể tạo Bảng bên ngoài, trước tiên bạn phải tạo tập dữ liệu sẽ chứa bảng đó.
👉💻 Chạy một lệnh đơn giản này trong cửa sổ dòng lệnh Cloud Shell:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 Giờ đây, chúng ta phải cấp cho chữ ký đặc biệt của conduit các quyền cần thiết để đọc từ Kho lưu trữ GCS và tham khảo Gemini.
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 Trong cửa sổ dòng lệnh Cloud Shell, hãy chạy lệnh sau để hiển thị tên nhóm của bạn:
echo $BUCKET_NAME
Thiết bị đầu cuối của bạn sẽ hiển thị một tên tương tự như your-project-id-gcs-bucket. Bạn sẽ cần thông tin này trong các bước tiếp theo.
👉 Bạn sẽ cần chạy lệnh tiếp theo trong trình chỉnh sửa truy vấn BigQuery trong Google Cloud Console. Cách dễ nhất để truy cập là mở đường liên kết bên dưới trong thẻ trình duyệt mới. Thao tác này sẽ đưa bạn đến đúng trang trong Google Cloud Console.
https://console.cloud.google.com/bigquery
👉 Sau khi trang tải, hãy nhấp vào nút dấu cộng màu xanh dương (Soạn truy vấn mới) để mở một thẻ trình chỉnh sửa mới.
Bây giờ, chúng ta sẽ viết câu thần chú Ngôn ngữ định nghĩa dữ liệu (DDL) để tạo ống kính thần kỳ. Thao tác này cho BigQuery biết vị trí cần tìm và nội dung cần xem.
👉📜 Trong trình chỉnh sửa truy vấn BigQuery mà bạn đã mở, hãy dán đoạn mã SQL sau. Nhớ thay thế REPLACE-WITH-YOUR-BUCKET-NAME
bằng tên nhóm mà bạn vừa sao chép. Sau đó, nhấp vào Run (Chạy):
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 Chạy một cụm từ tìm kiếm để "nhìn qua ống kính" và xem nội dung của các tệp.
SELECT * FROM bestiary_data.raw_intel_content_table;
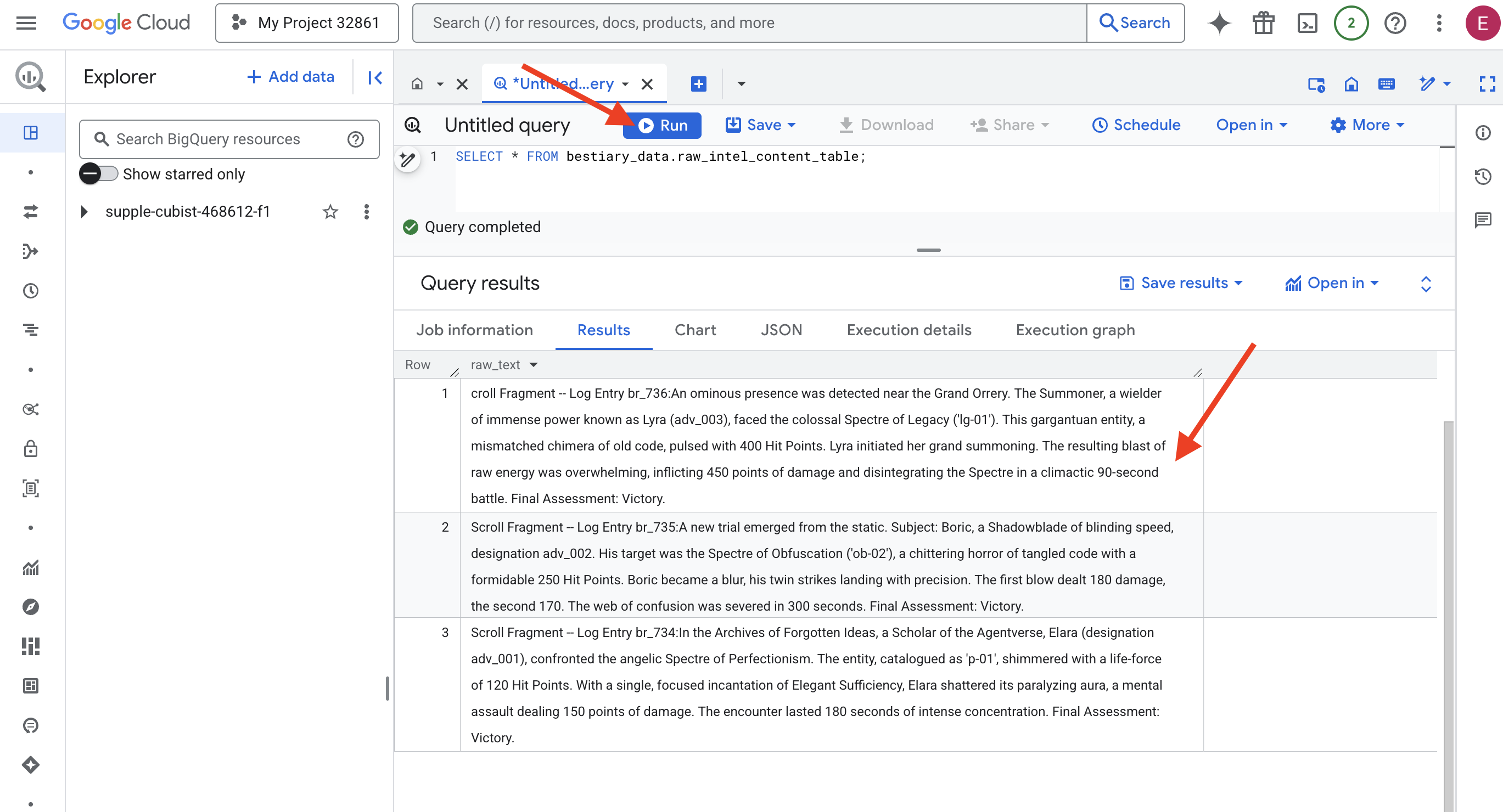
Chúng tôi đã có góc nhìn. Giờ đây, chúng ta có thể thấy văn bản thô của các cuộn giấy. Nhưng đọc không phải là hiểu.
Trong Kho lưu trữ những ý tưởng bị lãng quên, Elara (được chỉ định là adv_001), một Học giả của Agentverse, đã đối đầu với Spectre of Perfectionism (Bóng ma của chủ nghĩa cầu toàn) tựa như một thiên thần. Thực thể này, được phân loại là "p-01", có 120 Điểm trúng đích. Chỉ bằng một câu thần chú tập trung duy nhất là Đủ đầy tao nhã, Elara đã phá vỡ hào quang tê liệt của nó, một đòn tấn công tinh thần gây 150 điểm sát thương. Cuộc chạm trán kéo dài 180 giây và đòi hỏi sự tập trung cao độ. Đánh giá cuối cùng: Chiến thắng.
Các cuộn giấy không được viết theo bảng và hàng, mà theo văn xuôi dài dòng của các câu chuyện. Đây là bài kiểm tra lớn đầu tiên của chúng ta.
Khả năng bói toán của học giả: Chuyển văn bản thành bảng bằng SQL
Thách thức nằm ở chỗ một báo cáo mô tả hai đòn tấn công nhanh của một Shadowblade sẽ rất khác so với biên niên sử về một Summoner thu thập sức mạnh to lớn cho một vụ nổ duy nhất, tàn khốc. Chúng ta không thể chỉ nhập dữ liệu này mà phải diễn giải nó. Đây là khoảnh khắc kỳ diệu. Chúng ta sẽ sử dụng một truy vấn SQL duy nhất như một câu thần chú mạnh mẽ để đọc, hiểu và cấu trúc tất cả các bản ghi từ tất cả các tệp của chúng ta, ngay trong BigQuery.
👉💻 Trong thiết bị đầu cuối Cloud Shell, hãy chạy lệnh sau để hiển thị tên kết nối:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
Thiết bị đầu cuối sẽ hiển thị chuỗi kết nối hoàn chỉnh. Chọn và sao chép toàn bộ chuỗi này vì bạn sẽ cần đến nó trong bước tiếp theo
Chúng ta sẽ sử dụng một câu thần chú duy nhất và mạnh mẽ: ML.GENERATE_TEXT. Câu lệnh này triệu hồi một Gemini, cho Gemini xem từng đoạn văn bản và ra lệnh cho Gemini trả về các thông tin cốt lõi dưới dạng một đối tượng JSON có cấu trúc.
👉📜 Trong BigQuery Studio, hãy tạo Gemini Model Reference. Thao tác này liên kết Gemini Flash oracle với thư viện BigQuery của chúng tôi để chúng ta có thể gọi oracle này trong các truy vấn. Nhớ thay thế
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING bằng chuỗi kết nối đầy đủ mà bạn vừa sao chép từ thiết bị đầu cuối.
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 Giờ thì hãy sử dụng phép biến đổi mạnh mẽ. Truy vấn này đọc văn bản thô, tạo một câu lệnh chi tiết cho mỗi lần cuộn, gửi câu lệnh đó đến Gemini và tạo một bảng dàn dựng mới từ phản hồi JSON có cấu trúc của AI.
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
Quá trình biến đổi đã hoàn tất, nhưng kết quả chưa tinh khiết. Mô hình Gemini trả về câu trả lời ở định dạng tiêu chuẩn, gói JSON mà chúng ta muốn trong một cấu trúc lớn hơn bao gồm siêu dữ liệu về quy trình suy nghĩ của mô hình. Hãy xem xét lời tiên tri thô sơ này trước khi chúng ta cố gắng thanh lọc nó.
👉📜 Chạy một truy vấn để kiểm tra đầu ra thô từ mô hình Gemini:
SELECT * FROM bestiary_data.structured_bestiary;
👀 Bạn sẽ thấy một cột duy nhất có tên là structured_data. Nội dung của mỗi hàng sẽ có dạng tương tự như đối tượng JSON phức tạp này:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
Như bạn thấy, phần thưởng của chúng ta (đối tượng JSON rõ ràng mà chúng ta yêu cầu) nằm sâu trong cấu trúc này. Nhiệm vụ tiếp theo của chúng ta đã rõ ràng. Chúng ta phải thực hiện một nghi thức để điều hướng cấu trúc này một cách có hệ thống và rút ra trí tuệ thuần tuý bên trong.
Quy trình làm sạch: Chuẩn hoá kết quả của AI tạo sinh bằng SQL
Gemini đã đưa ra câu trả lời, nhưng câu trả lời đó vẫn còn thô sơ và được bao bọc trong nguồn năng lượng siêu nhiên của quá trình tạo ra câu trả lời (các đề xuất, lý do hoàn thành, v.v.). Một học giả thực thụ không chỉ đơn thuần cất giữ lời tiên tri thô sơ, mà còn cẩn thận rút ra trí tuệ cốt lõi và ghi chép vào những cuốn sách thích hợp để sử dụng sau này.
Giờ chúng ta sẽ sử dụng bộ phép thuật cuối cùng. Tập lệnh duy nhất này sẽ:
- Đọc JSON thô, lồng nhau từ bảng dàn dựng của chúng tôi.
- Làm sạch và phân tích cú pháp để lấy dữ liệu cốt lõi.
- Ghi lại các phần có liên quan vào 3 bảng cuối cùng, hoàn chỉnh: quái vật, nhà thám hiểm và trận chiến.
👉📜 Trong trình chỉnh sửa truy vấn BigQuery mới, hãy chạy câu lệnh sau để tạo ống kính làm sạch:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 Xác minh Bestiary:
SELECT * FROM bestiary_data.monsters;
Tiếp theo, chúng ta sẽ tạo Danh sách những nhà thám hiểm dũng cảm đã đối mặt với những con quái vật này.
👉📜 Trong trình chỉnh sửa truy vấn mới, hãy chạy câu lệnh sau để tạo bảng người phiêu lưu:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 Xác minh Danh sách nhà vô địch:
SELECT * FROM bestiary_data.adventurers;
Cuối cùng, chúng ta sẽ tạo bảng dữ kiện: Biên niên sử các trận chiến. Cuốn sách này liên kết với hai cuốn sách còn lại, ghi lại thông tin chi tiết của từng cuộc gặp gỡ riêng biệt. Vì mỗi trận chiến là một sự kiện riêng biệt, nên bạn không cần loại bỏ dữ liệu trùng lặp.
👉📜 Trong trình chỉnh sửa truy vấn mới, hãy chạy câu lệnh sau để tạo bảng battles:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 Xác minh Chronicle:
SELECT * FROM bestiary_data.battles;
Khám phá thông tin chi tiết mang tính chiến lược
Các cuộn giấy đã được đọc, tinh tuý đã được chắt lọc và các cuốn sách đã được ghi chép. Grimoire của chúng tôi không còn chỉ là một tập hợp các dữ kiện, mà là một cơ sở dữ liệu quan hệ chứa đựng trí tuệ chiến lược sâu sắc. Giờ đây, chúng ta có thể đặt những câu hỏi mà trước đây không thể trả lời khi kiến thức của chúng ta bị mắc kẹt trong văn bản thô, không có cấu trúc.
Giờ hãy cùng nhau thực hiện một lần bói toán cuối cùng, hoành tráng. Chúng tôi sẽ sử dụng một phép thuật để tham khảo cả ba cuốn sách cùng một lúc: Sách Quái vật, Danh sách Nhà vô địch và Biên niên sử các trận chiến, nhằm khám phá một thông tin chi tiết sâu sắc và hữu ích.
Câu hỏi chiến lược của chúng tôi: "Đối với mỗi nhà thám hiểm, tên của con quái vật mạnh nhất (theo điểm trúng đích) mà họ đã đánh bại thành công là gì và họ đã mất bao lâu để giành được chiến thắng đó?"
Đây là một câu hỏi phức tạp, đòi hỏi bạn phải liên kết các nhà vô địch với những trận chiến mà họ giành chiến thắng, và liên kết những trận chiến đó với số liệu thống kê của các quái vật liên quan. Đây là sức mạnh thực sự của một mô hình dữ liệu có cấu trúc.
👉📜 Trong trình chỉnh sửa truy vấn BigQuery mới, hãy thực hiện câu thần chú cuối cùng sau đây:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
Kết quả của truy vấn này sẽ là một bảng rõ ràng, đẹp mắt, cung cấp "Câu chuyện về chiến công vĩ đại nhất của nhà vô địch" cho mọi nhà thám hiểm trong tập dữ liệu của bạn. Mã có thể có dạng như sau:
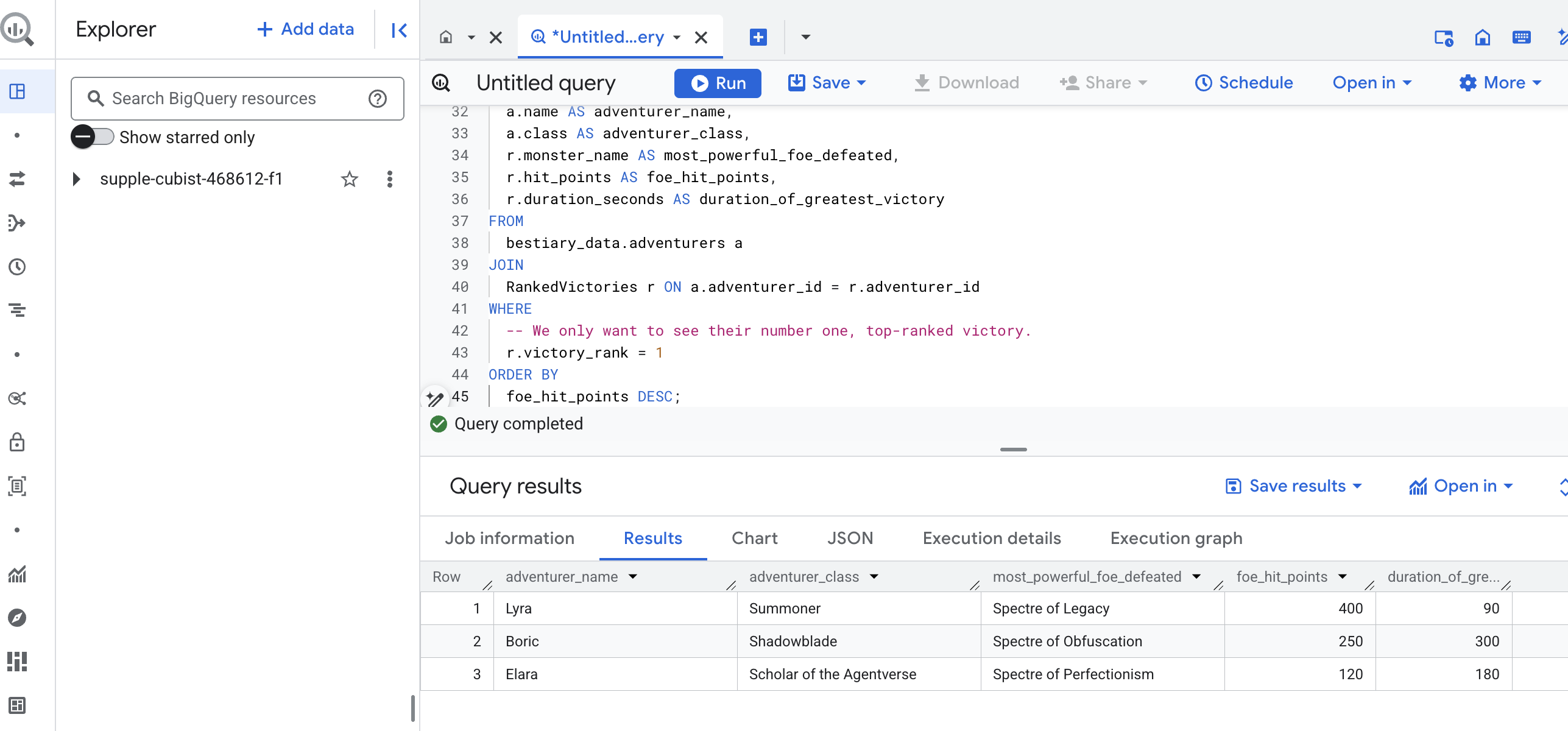
Đóng thẻ BigQuery.
Kết quả duy nhất và trang nhã này chứng minh giá trị của toàn bộ quy trình. Bạn đã biến những báo cáo chiến trường thô sơ và hỗn loạn thành nguồn gốc của những câu chuyện huyền thoại và thông tin chi tiết mang tính chiến lược dựa trên dữ liệu.
DÀNH CHO NGƯỜI KHÔNG CHƠI GAME
5. Grimoire của người ghi chép: Phân đoạn, nhúng và tìm kiếm trong kho dữ liệu
Công việc của chúng tôi trong phòng thí nghiệm của Nhà giả kim đã thành công. Chúng tôi đã chuyển đổi các bản ghi chép thô, mang tính tường thuật thành các bảng có cấu trúc, quan hệ – một thành tựu mạnh mẽ về phép thuật dữ liệu. Tuy nhiên, các cuộn giấy gốc vẫn chứa đựng một sự thật ngữ nghĩa sâu sắc hơn mà các bảng có cấu trúc của chúng ta không thể nắm bắt đầy đủ. Để xây dựng một tác nhân thực sự thông minh, chúng ta phải khám phá được ý nghĩa này.
Thao tác cuộn thô và dài là một công cụ thô sơ. Nếu nhân viên hỗ trợ của chúng tôi hỏi về "hào quang tê liệt", thì một cụm từ tìm kiếm đơn giản có thể trả về toàn bộ báo cáo trận chiến, trong đó cụm từ đó chỉ được đề cập một lần, khiến câu trả lời bị chôn vùi trong các chi tiết không liên quan. Một học giả uyên bác biết rằng sự khôn ngoan thực sự không nằm ở số lượng mà nằm ở độ chính xác.
Chúng tôi sẽ thực hiện 3 nghi thức mạnh mẽ trong cơ sở dữ liệu hoàn toàn trong không gian BigQuery của mình.
- Nghi thức phân chia (phân đoạn): Chúng ta sẽ lấy nhật ký thông tin thô và chia nhỏ chúng thành các đoạn văn ngắn gọn, tập trung và độc lập.
- Quy trình chưng cất (Nhúng): Chúng tôi sẽ sử dụng BQML để tham khảo một mô hình Gemini, chuyển đổi từng khối văn bản thành "dấu vân tay ngữ nghĩa" – một mục nhúng vectơ.
- Nghi thức bói toán (Tìm kiếm): Chúng ta sẽ sử dụng tính năng tìm kiếm vectơ của BQML để đặt câu hỏi bằng tiếng Anh thông thường và tìm ra kiến thức tinh tuý, phù hợp nhất trong Sách phép của chúng ta.
Toàn bộ quy trình này tạo ra một cơ sở kiến thức mạnh mẽ, có thể tìm kiếm mà không cần dữ liệu rời khỏi tính bảo mật và quy mô của BigQuery.
Nghi thức phân chia: Phân tích các cuộn bằng SQL
Nguồn thông tin của chúng tôi vẫn là các tệp văn bản thô trong kho lưu trữ GCS, có thể truy cập thông qua bảng bên ngoài bestiary_data.raw_intel_content_table. Nhiệm vụ đầu tiên của chúng ta là viết một câu thần chú đọc từng đoạn văn dài và chia đoạn văn đó thành một loạt các đoạn văn nhỏ hơn, dễ hiểu hơn. Đối với nghi thức này, chúng ta sẽ định nghĩa "đoạn" là một câu duy nhất.
Mặc dù việc chia theo câu là một điểm khởi đầu rõ ràng và hiệu quả cho nhật ký tường thuật của chúng tôi, nhưng một người viết phụ đề chuyên nghiệp có nhiều chiến lược phân đoạn theo ý mình và lựa chọn này rất quan trọng đối với chất lượng của kết quả tìm kiếm cuối cùng. Các phương pháp đơn giản hơn có thể sử dụng
- Chia thành các phần có độ dài(kích thước) cố định, nhưng cách này có thể cắt đôi một ý tưởng chính.
Các thông lệ đặc trưng phức tạp hơn, chẳng hạn như
- Phân đoạn đệ quy thường được ưu tiên trong thực tế; phương pháp này cố gắng chia văn bản theo các ranh giới tự nhiên như đoạn văn trước, sau đó quay lại câu để duy trì ngữ cảnh ngữ nghĩa nhiều nhất có thể. Đối với những bản thảo thực sự phức tạp.
- Phân đoạn dựa trên nội dung (tài liệu), trong đó Scribe sử dụng cấu trúc vốn có của tài liệu (chẳng hạn như tiêu đề trong sách hướng dẫn kỹ thuật hoặc các hàm trong một đoạn mã) để tạo ra những đoạn thông tin hợp lý và hiệu quả nhất. và nhiều tính năng khác...
Đối với nhật ký trận chiến, câu này mang đến sự cân bằng hoàn hảo giữa mức độ chi tiết và ngữ cảnh.
👉📜 Trong trình chỉnh sửa truy vấn BigQuery mới, hãy chạy câu lệnh sau. Câu lệnh này sử dụng hàm SPLIT để tách văn bản của từng cuộn tại mỗi dấu chấm (.) rồi huỷ lồng mảng câu kết quả thành các hàng riêng biệt.
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 Giờ đây, hãy chạy một truy vấn để kiểm tra kiến thức mới được ghi lại và phân đoạn của bạn, đồng thời xem sự khác biệt.
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
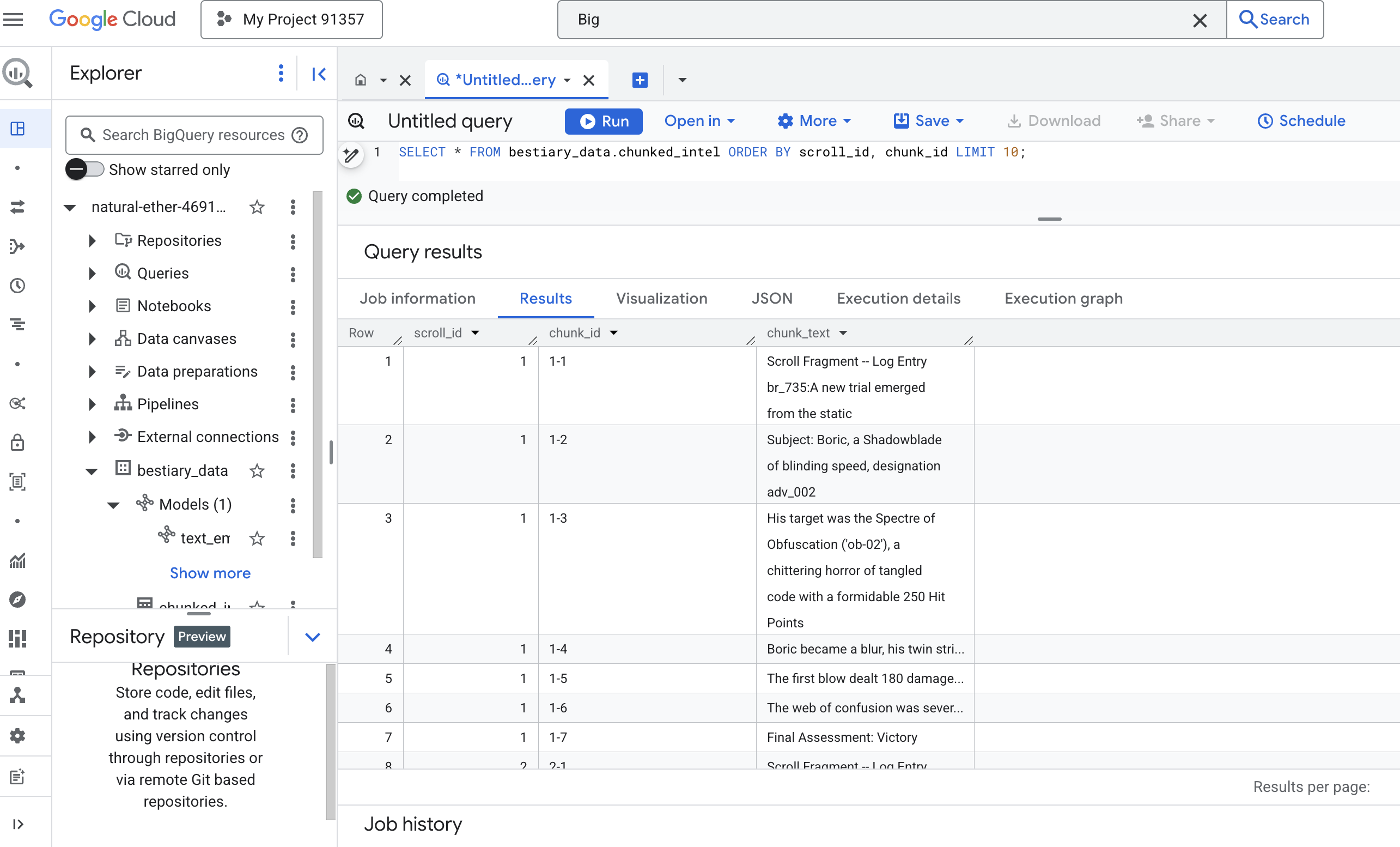
Hãy quan sát kết quả. Trước đây, chỉ có một khối văn bản dày đặc, nhưng giờ đây có nhiều hàng, mỗi hàng được liên kết với thao tác cuộn ban đầu (scroll_id) nhưng chỉ chứa một câu duy nhất, có trọng tâm. Mỗi hàng hiện là một ứng cử viên hoàn hảo cho việc vectơ hoá.
Quy trình chưng cất: Chuyển đổi văn bản thành vectơ bằng BQML
👉💻 Trước tiên, hãy quay lại thiết bị đầu cuối, chạy lệnh sau để hiển thị tên kết nối:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 Chúng ta phải tạo một mô hình BigQuery mới trỏ đến một văn bản được nhúng của Gemini. Trong BigQuery Studio, hãy chạy câu lệnh sau. Xin lưu ý rằng bạn cần thay thế REPLACE-WITH-YOUR-FULL-CONNECTION-STRING bằng chuỗi kết nối đầy đủ mà bạn vừa sao chép từ thiết bị đầu cuối.
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 Giờ thì hãy sử dụng phép chưng cất cao cấp. Truy vấn này gọi hàm ML.GENERATE_EMBEDDING. Hàm này sẽ đọc mọi hàng trong bảng chunked_intel, gửi văn bản đến mô hình nhúng Gemini và lưu trữ dấu vân tay vectơ kết quả trong một bảng mới.
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
Quá trình này có thể mất một hoặc hai phút vì BigQuery xử lý tất cả các đoạn văn bản.
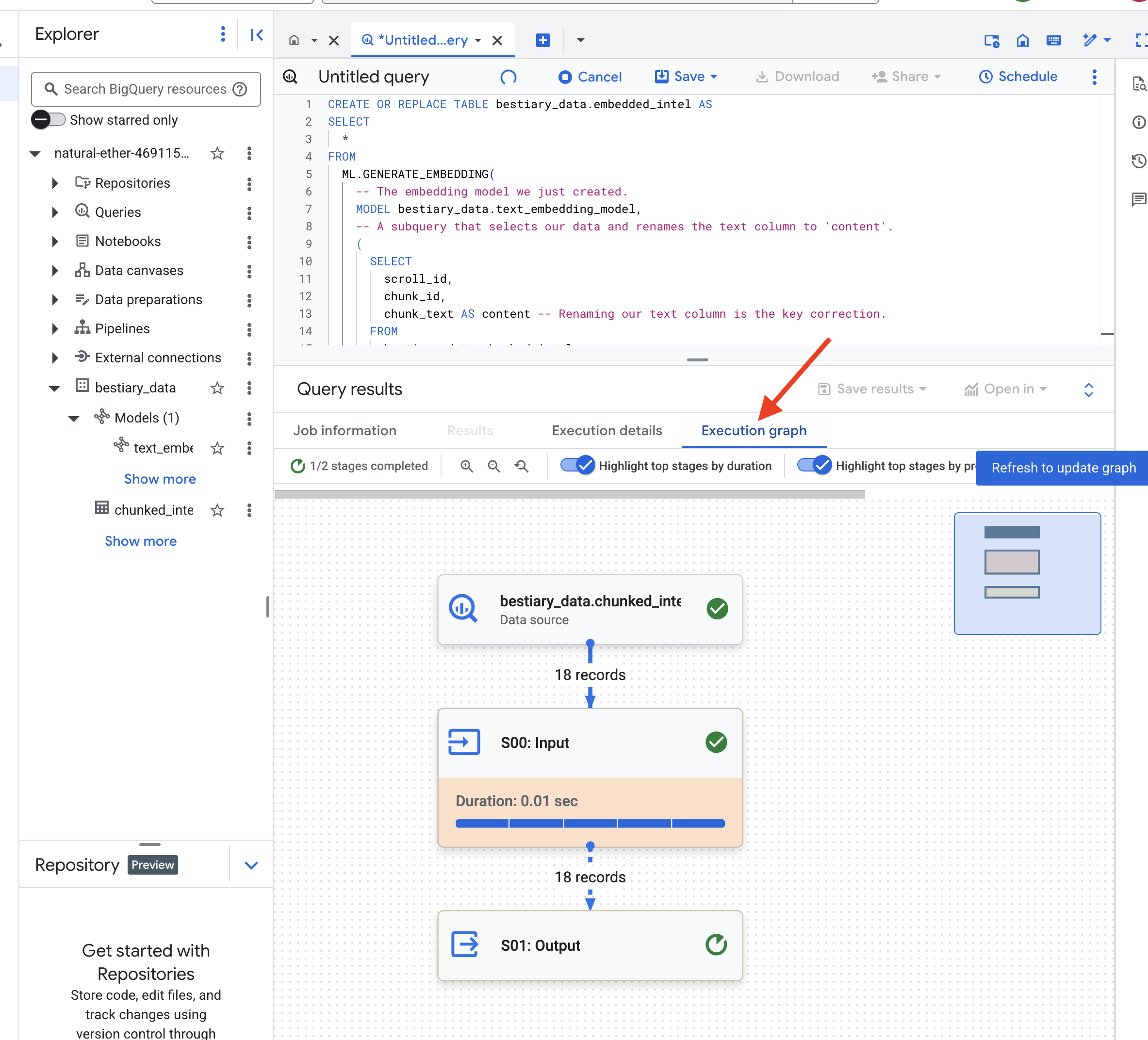
👉📜 Sau khi hoàn tất, hãy kiểm tra bảng mới để xem dấu vân tay ngữ nghĩa.
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
Lúc này, bạn sẽ thấy một cột mới (ml_generate_embedding_result) chứa biểu diễn vectơ dày đặc của văn bản. Grimoire của chúng tôi hiện đã được mã hoá theo ngữ nghĩa.
Nghi thức bói toán: Tìm kiếm ngữ nghĩa bằng BQML
👉📜 Thử nghiệm cuối cùng đối với Sách phép là đặt câu hỏi cho Sách phép. Bây giờ, chúng ta sẽ thực hiện nghi thức cuối cùng: tìm kiếm vectơ. Đây không phải là tìm kiếm bằng từ khoá mà là tìm kiếm ý nghĩa. Chúng ta sẽ đặt câu hỏi bằng ngôn ngữ tự nhiên, BQML sẽ chuyển đổi câu hỏi của chúng ta thành một mục nhúng ngay lập tức, sau đó tìm kiếm toàn bộ bảng embedded_intel để tìm các đoạn văn bản có dấu vân tay "gần" nhất về ý nghĩa.
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
Phân tích phép thuật:
VECTOR_SEARCH: Hàm cốt lõi điều phối hoạt động tìm kiếm.ML.GENERATE_EMBEDDING(truy vấn nội bộ): Đây là điểm mấu chốt. Chúng tôi nhúng cụm từ tìm kiếm ('What are the tactics...') bằng cách sử dụng cùng một mô hình nhưng với loại tác vụ'RETRIEVAL_QUERY', được tối ưu hoá đặc biệt cho cụm từ tìm kiếm.top_k => 3: Chúng tôi đang yêu cầu 3 kết quả phù hợp nhất.distance_type => 'COSINE': Chỉ số này đo lường "góc" giữa các vectơ. Góc càng nhỏ thì ý nghĩa càng tương đồng.
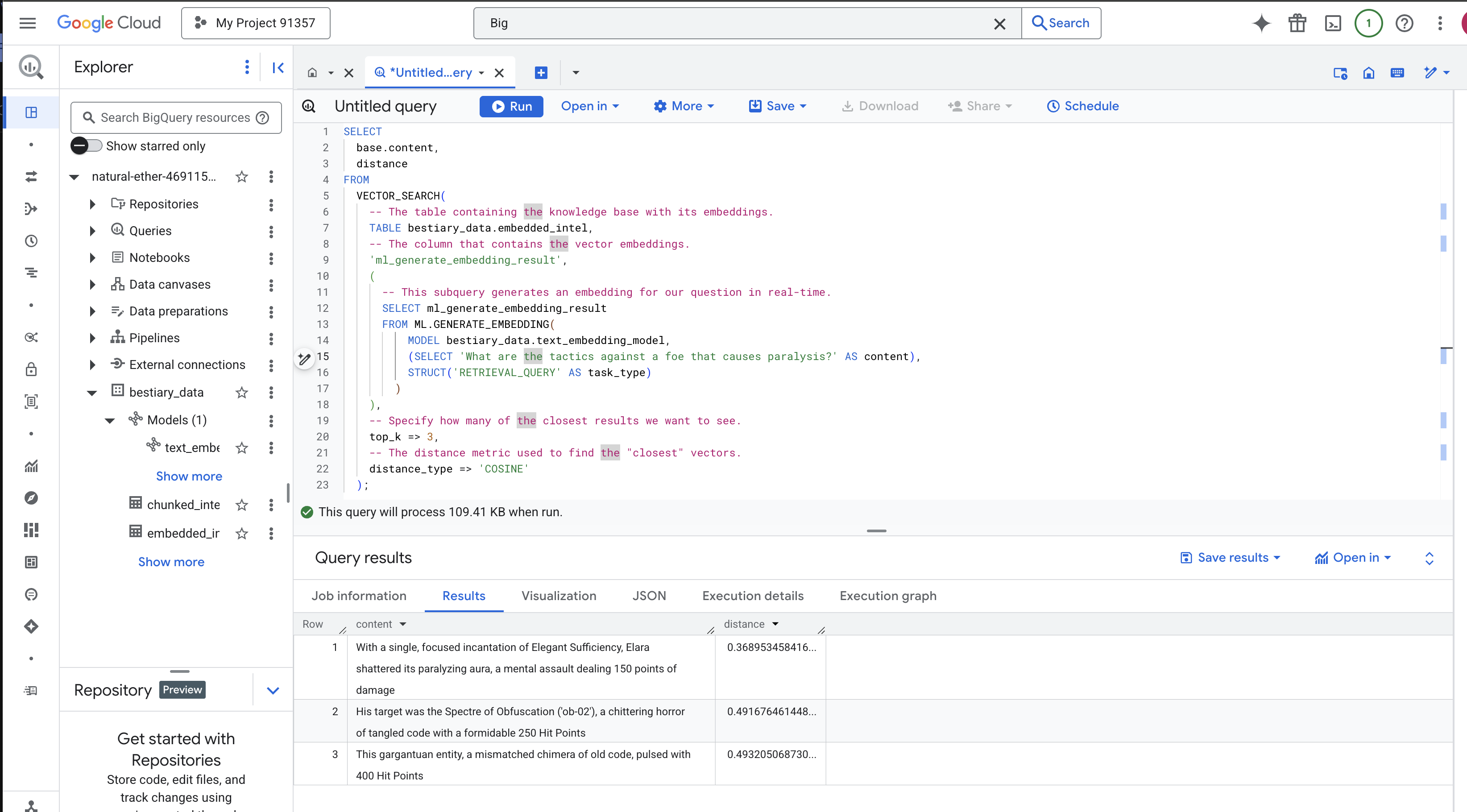
Xem kỹ kết quả. Cụm từ tìm kiếm không chứa từ "shattered" (tan vỡ) hoặc "incantation" (thần chú), nhưng kết quả hàng đầu là: "With a single, focused incantation of Elegant Sufficiency, Elara shattered its paralyzing aura, a mental assault dealing 150 points of damage" (Với một câu thần chú duy nhất và tập trung về Sự đủ đầy tao nhã, Elara đã phá vỡ hào quang tê liệt của nó, một cuộc tấn công tinh thần gây ra 150 điểm sát thương). Đây là sức mạnh của tính năng tìm kiếm ngữ nghĩa. Mô hình này hiểu khái niệm về "các chiến thuật chống tê liệt" và tìm thấy câu mô tả một chiến thuật cụ thể, hiệu quả.
Giờ đây, bạn đã xây dựng thành công một quy trình RAG hoàn chỉnh, cơ bản trong kho dữ liệu. Bạn đã chuẩn bị dữ liệu thô, chuyển đổi dữ liệu đó thành vectơ ngữ nghĩa và truy vấn dữ liệu đó theo ý nghĩa. Mặc dù BigQuery là một công cụ mạnh mẽ cho công việc phân tích quy mô lớn này, nhưng đối với một nhân viên hỗ trợ trực tiếp cần phản hồi có độ trễ thấp, chúng tôi thường chuyển kiến thức đã chuẩn bị này sang một cơ sở dữ liệu hoạt động chuyên biệt. Đó là chủ đề của khoá đào tạo tiếp theo.
DÀNH CHO NGƯỜI KHÔNG CHƠI GAME
6. Vector Scriptorium: Tạo kho lưu trữ vectơ bằng Cloud SQL để suy luận
Grimoire hiện tại của chúng tôi tồn tại dưới dạng các bảng có cấu trúc – một danh mục mạnh mẽ về các dữ kiện, nhưng kiến thức của nó là kiến thức theo nghĩa đen. Nó hiểu monster_id = "MN-001" nhưng không hiểu được ý nghĩa ngữ nghĩa sâu sắc hơn đằng sau "Obfuscation" (Làm rối mã nguồn). Để các đặc vụ của chúng ta có được trí tuệ thực sự, để họ có thể tư vấn một cách tinh tế và có tầm nhìn xa, chúng ta phải chắt lọc bản chất kiến thức của mình thành một dạng thức nắm bắt được ý nghĩa: Vectơ.
Hành trình tìm kiếm kiến thức đã đưa chúng ta đến với những tàn tích đổ nát của một nền văn minh tiền thân đã bị lãng quên từ lâu. Nằm sâu trong một hầm kín, chúng tôi đã tìm thấy một rương đựng các cuộn giấy cổ xưa, được bảo quản một cách kỳ diệu. Đây không chỉ là những báo cáo chiến đấu đơn thuần, mà còn chứa đựng trí tuệ sâu sắc, mang tính triết lý về cách đánh bại một con quái vật đang cản trở mọi nỗ lực lớn. Một thực thể được mô tả trong các cuộn giấy là "sự trì trệ âm thầm, lan rộng", "sự suy yếu của cấu trúc sáng tạo". Có vẻ như người xưa cũng biết đến The Static, một mối đe doạ theo chu kỳ mà lịch sử của nó đã bị thời gian xoá nhoà.
Kiến thức bị lãng quên này là tài sản quý giá nhất của chúng ta. Đây không chỉ là chìa khoá để đánh bại từng quái vật, mà còn giúp toàn bộ nhóm có được thông tin chi tiết về chiến lược. Để khai thác sức mạnh này, chúng ta sẽ tạo ra Sách phép thuật thực sự của Học giả (một cơ sở dữ liệu PostgreSQL có khả năng xử lý vectơ) và xây dựng một Scriptorium vectơ tự động (một quy trình Dataflow) để đọc, hiểu và ghi lại bản chất vượt thời gian của những cuộn giấy này. Điều này sẽ biến Grimoire của chúng ta từ một cuốn sách chứa đầy thông tin thành một công cụ trí tuệ.

Rèn đúc Sách phép của học giả (Cloud SQL)
Trước khi có thể khắc ghi tinh tuý của những cuộn giấy cổ này, trước tiên, chúng ta phải xác nhận rằng chiếc bình chứa đựng kiến thức này (Spellbook PostgreSQL được quản lý) đã được rèn đúc thành công. Các bước thiết lập ban đầu sẽ tạo sẵn mục này cho bạn.
👉💻 Trong một thiết bị đầu cuối, hãy chạy lệnh sau để xác minh rằng phiên bản Cloud SQL của bạn tồn tại và đã sẵn sàng. Tập lệnh này cũng cấp cho tài khoản dịch vụ chuyên dụng của phiên bản quyền sử dụng Vertex AI. Đây là quyền cần thiết để tạo các mục nhúng ngay trong cơ sở dữ liệu.
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Nếu lệnh thành công và trả về thông tin chi tiết về phiên bản grimoire-spellbook của bạn, thì có nghĩa là forge đã hoạt động tốt. Bạn đã sẵn sàng chuyển sang câu thần chú tiếp theo. Nếu lệnh này trả về lỗi NOT_FOUND, vui lòng đảm bảo bạn đã hoàn tất thành công các bước thiết lập môi trường ban đầu trước khi tiếp tục.(data_setup.py)
👉💻 Sau khi tạo xong cuốn sách, chúng ta sẽ mở cuốn sách ở chương đầu tiên bằng cách tạo một cơ sở dữ liệu mới có tên là arcane_wisdom.
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
Khắc các Rune ngữ nghĩa: Bật các chức năng vectơ bằng pgvector
Bây giờ, phiên bản Cloud SQL của bạn đã được tạo, hãy kết nối với phiên bản đó bằng Cloud SQL Studio tích hợp. Công cụ này cung cấp một giao diện dựa trên web để chạy các truy vấn SQL ngay trên cơ sở dữ liệu của bạn.
👉💻 Trước tiên, hãy chuyển đến Cloud SQL Studio. Cách dễ nhất và nhanh nhất để làm việc này là mở đường liên kết sau đây trong một thẻ trình duyệt mới. Thao tác này sẽ đưa bạn đến thẳng Cloud SQL Studio cho phiên bản grimoire-spellbook.
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 Chọn arcane_wisdom làm cơ sở dữ liệu, nhập postgres làm người dùng và 1234qwer làm mật khẩu rồi nhấp vào Xác thực.
👉📜 Trong trình chỉnh sửa truy vấn SQL Studio, hãy chuyển đến thẻ Trình chỉnh sửa 1, dán mã SQL sau đây để bật loại dữ liệu vectơ:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
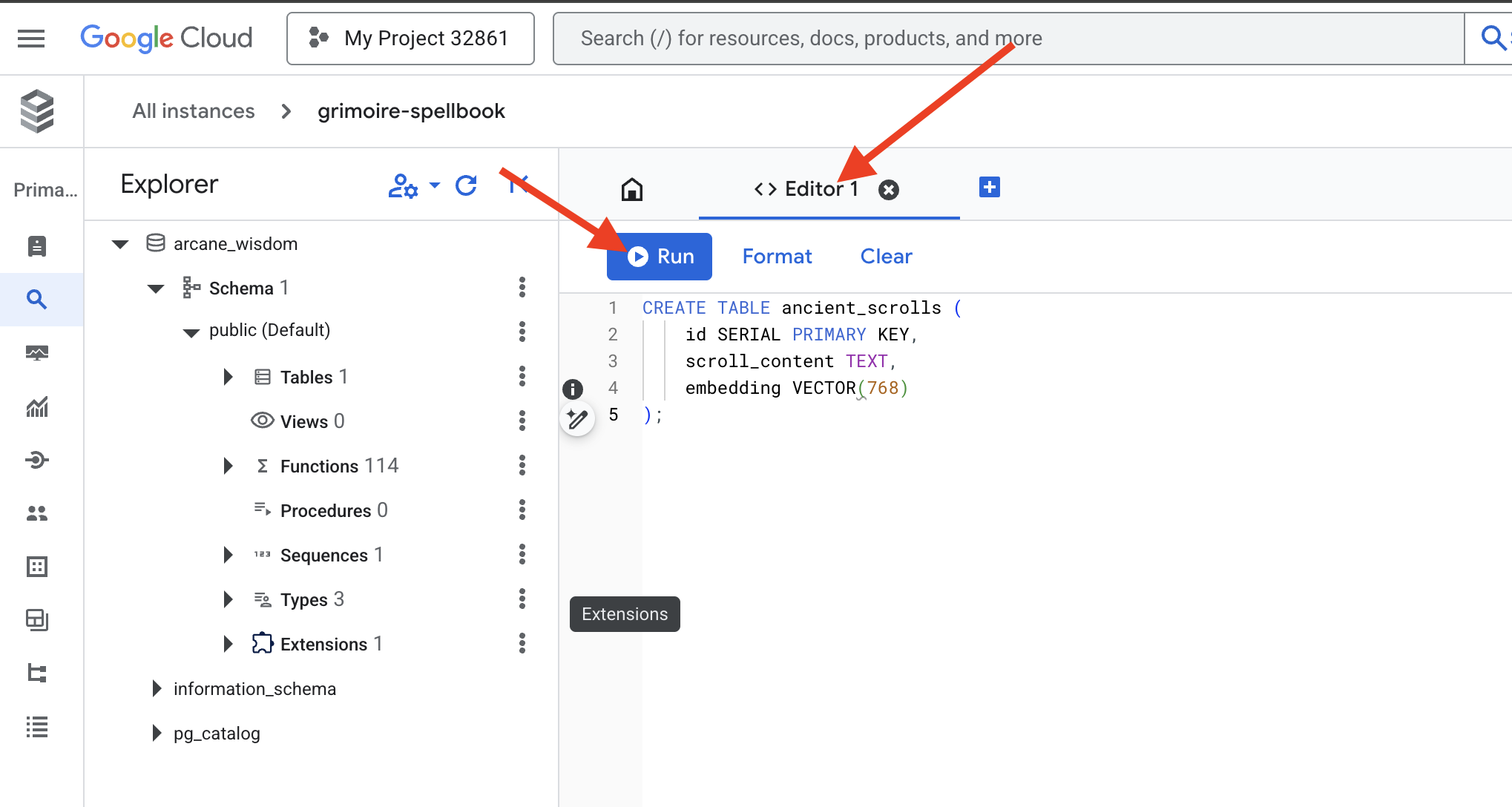
👉📜 Chuẩn bị các trang của Sách phép bằng cách tạo bảng chứa nội dung cốt lõi của các cuộn giấy.
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
Cụm từ VECTOR(768) là một chi tiết quan trọng. Mô hình nhúng Vertex AI mà chúng ta sẽ sử dụng (textembedding-gecko@003 hoặc một mô hình tương tự) sẽ chắt lọc văn bản thành một vectơ 768 chiều. Các trang trong Sách phép thuật của chúng ta phải được chuẩn bị để chứa một bản chất có kích thước chính xác như vậy. Các phương diện phải luôn khớp với nhau.
The First Transliteration: A Manual Inscription Ritual
Trước khi chỉ huy một đội quân người ghi chép tự động (Dataflow), chúng ta phải thực hiện nghi thức trung tâm bằng tay một lần. Điều này sẽ giúp chúng ta hiểu rõ hơn về quy trình kỳ diệu gồm 2 bước:
- Bói toán: Lấy một đoạn văn bản và tham khảo thông tin từ Gemini để chắt lọc bản chất ngữ nghĩa của đoạn văn bản đó thành một vectơ.
- Inscription (Khắc chữ): Ghi văn bản gốc và bản chất vectơ mới của văn bản đó vào Spellbook.
Bây giờ, hãy thực hiện nghi thức theo cách thủ công.
👉📜 Trong Cloud SQL Studio. Giờ đây, chúng ta sẽ sử dụng hàm embedding(), một tính năng mạnh mẽ do tiện ích google_ml_integration cung cấp. Nhờ đó, chúng ta có thể gọi mô hình nhúng Vertex AI ngay từ truy vấn SQL, giúp đơn giản hoá quy trình này một cách đáng kể.
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 Xác minh công việc của bạn bằng cách chạy một truy vấn để đọc trang vừa được ghi:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
Bạn đã thực hiện thành công nhiệm vụ tải dữ liệu RAG cốt lõi theo cách thủ công!
Rèn luyện La bàn ngữ nghĩa: Bổ sung chỉ mục HNSW vào Sổ thần chú
Giờ đây, Sổ thần chú của chúng ta có thể lưu trữ kiến thức, nhưng để tìm được cuộn giấy phù hợp, bạn cần phải đọc từng trang. Đây là một quy trình quét tuần tự. Việc này diễn ra chậm và không hiệu quả. Để hướng dẫn các truy vấn của chúng ta ngay lập tức đến kiến thức phù hợp nhất, chúng ta phải trang bị cho Spellbook một la bàn ngữ nghĩa: một chỉ mục vectơ.
Hãy chứng minh giá trị của tính năng nâng cao này.
👉📜 Trong Cloud SQL Studio, hãy chạy câu lệnh sau. Thao tác này mô phỏng việc tìm kiếm phần cuộn mới chèn và yêu cầu cơ sở dữ liệu EXPLAIN kế hoạch của phần cuộn đó.
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
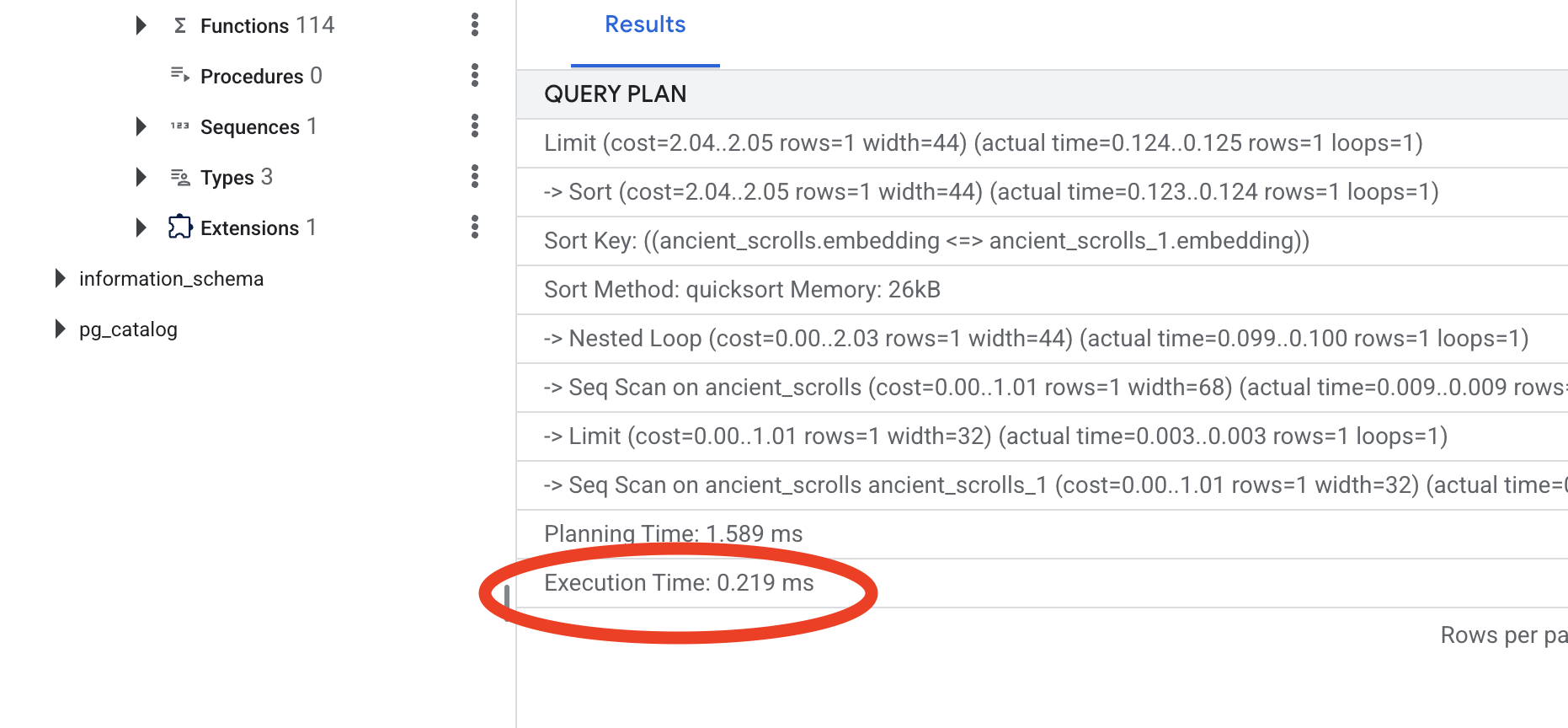
Xem kết quả. Bạn sẽ thấy một dòng có nội dung -> Seq Scan on ancient_scrolls. Điều này xác nhận rằng cơ sở dữ liệu đang đọc từng hàng. Hãy lưu ý execution time.
👉📜 Giờ thì hãy bắt đầu lập chỉ mục. Tham số lists cho biết chỉ mục cần tạo bao nhiêu cụm. Một điểm bắt đầu phù hợp là căn bậc hai của số hàng mà bạn dự kiến sẽ có.
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
Chờ chỉ mục được tạo (sẽ nhanh chóng đối với một hàng, nhưng có thể mất thời gian đối với hàng triệu hàng).
👉📜 Giờ thì hãy chạy lại chính xác lệnh EXPLAIN ANALYZE đó:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
Xem kế hoạch truy vấn mới. Giờ đây, bạn sẽ thấy -> Index Scan using.... Quan trọng hơn, hãy xem execution time. Quá trình này sẽ diễn ra nhanh hơn đáng kể, ngay cả khi chỉ có một mục nhập. Bạn vừa minh hoạ nguyên tắc cốt lõi của việc điều chỉnh hiệu suất cơ sở dữ liệu trong một thế giới vectơ.
Sau khi kiểm tra dữ liệu nguồn, hiểu rõ quy trình thủ công và tối ưu hoá Sổ thần chú để tăng tốc độ, giờ đây, bạn đã thực sự sẵn sàng xây dựng Scriptorium tự động.
DÀNH CHO NGƯỜI KHÔNG CHƠI GAME
7. Kênh truyền tải ý nghĩa: Xây dựng quy trình vectơ hoá Dataflow
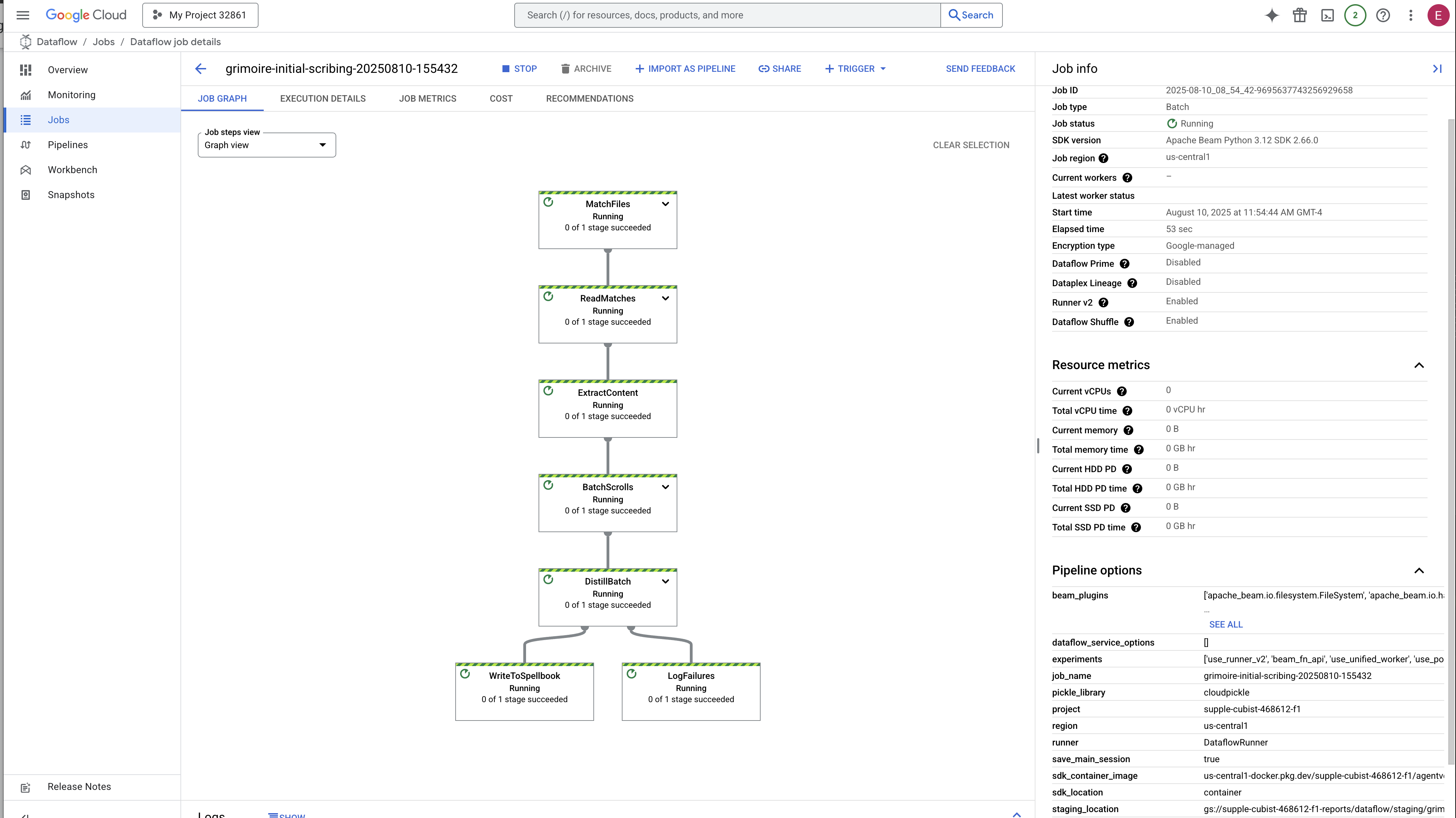
Giờ đây, chúng ta sẽ xây dựng dây chuyền lắp ráp kỳ diệu gồm những người ghi chép sẽ đọc các cuộn giấy của chúng ta, chắt lọc tinh tuý và ghi chúng vào Sổ phép mới. Đây là một quy trình Dataflow mà chúng ta sẽ kích hoạt theo cách thủ công. Nhưng trước khi viết câu thần chú chính cho chính quy trình, trước tiên, chúng ta phải chuẩn bị nền tảng và vòng tròn mà chúng ta sẽ triệu hồi quy trình.
Chuẩn bị nền tảng của Scriptorium (Hình ảnh nhân viên)
Nhóm nhân viên tự động trên đám mây sẽ thực thi quy trình Dataflow của chúng tôi. Mỗi lần chúng ta triệu hồi, các thư viện này cần một bộ thư viện cụ thể để thực hiện công việc của mình. Chúng ta có thể cung cấp cho chúng một danh sách và yêu cầu chúng tìm nạp các thư viện này mỗi lần, nhưng cách này chậm và không hiệu quả. Một Scholar thông thái sẽ chuẩn bị trước một thư viện chính.
Tại đây, chúng ta sẽ yêu cầu Google Cloud Build tạo một hình ảnh vùng chứa tuỳ chỉnh. Hình ảnh này là một "golem hoàn hảo", được tải sẵn mọi thư viện và phần phụ thuộc mà người viết chú thích của chúng tôi sẽ cần. Khi bắt đầu, chương trình Dataflow sẽ sử dụng hình ảnh tuỳ chỉnh này, cho phép các worker bắt đầu tác vụ của mình gần như ngay lập tức.
👉💻 Chạy lệnh sau để tạo và lưu trữ hình ảnh cơ sở của quy trình trong Artifact Registry.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 Chạy các lệnh sau để tạo và kích hoạt môi trường Python riêng biệt, đồng thời cài đặt các thư viện triệu hồi cần thiết vào đó.
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
Thần chú tối thượng
Đã đến lúc viết câu thần chú chính sẽ cung cấp năng lượng cho Vector Scriptorium của chúng ta. Chúng ta sẽ không viết từng thành phần kỳ diệu từ đầu. Nhiệm vụ của chúng ta là lắp ráp các thành phần thành một quy trình hợp lý và mạnh mẽ bằng cách sử dụng ngôn ngữ của Apache Beam.
- EmbedTextBatch (Tư vấn của Gemini): Bạn sẽ tạo ra một người ghi chép chuyên biệt biết cách thực hiện "bói toán theo nhóm". Công cụ này lấy một lô tệp văn bản thô, trình bày các tệp đó cho mô hình nhúng văn bản Gemini và nhận được bản chất tinh tuý của các tệp đó (các vectơ nhúng).
- WriteEssenceToSpellbook (Dòng chữ cuối cùng): Đây là người lưu trữ của chúng tôi. Nó biết những câu thần chú bí mật để mở một kết nối an toàn đến Sổ thần chú Cloud SQL của chúng tôi. Công việc của nó là lấy nội dung của một cuộn giấy và bản chất được vectơ hoá của nội dung đó rồi khắc vĩnh viễn lên một trang mới.
Sứ mệnh của chúng tôi là kết hợp những hành động này với nhau để tạo ra một luồng kiến thức liền mạch.
👉✏️ Trong Cloud Shell Editor, hãy chuyển đến ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py. Bên trong, bạn sẽ thấy một lớp DoFn có tên là EmbedTextBatch. Tìm bình luận #REPLACE-EMBEDDING-LOGIC. Thay thế bằng câu thần chú sau.
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Câu thần chú này rất chính xác, với một số tham số chính:
- model: Chúng tôi chỉ định
text-embedding-005để sử dụng một mô hình nhúng mạnh mẽ và mới nhất. - contents: Đây là danh sách tất cả nội dung văn bản từ nhóm tệp mà DoFn nhận được.
- task_type: Chúng tôi đặt giá trị này thành "RETRIEVAL_DOCUMENT". Đây là một chỉ dẫn quan trọng giúp Gemini tạo các vectơ nhúng được tối ưu hoá đặc biệt để có thể tìm thấy sau này trong một cụm từ tìm kiếm.
- output_dimensionality: Bạn phải đặt giá trị này thành 768, hoàn toàn khớp với phương diện VECTOR(768) mà chúng ta đã xác định khi tạo bảng ancient_scrolls trong Cloud SQL. Kích thước không khớp là một nguyên nhân thường gặp gây ra lỗi trong công cụ vector magic.
Quy trình của chúng ta phải bắt đầu bằng việc đọc văn bản thô, không có cấu trúc từ tất cả các cuộn giấy cổ trong kho lưu trữ GCS.
👉✏️ Trong ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py, hãy tìm nhận xét #REPLACE ME-READFILE rồi thay thế bằng câu thần chú gồm 3 phần sau:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
Sau khi thu thập được văn bản thô của các cuộn giấy, giờ đây chúng ta phải gửi chúng đến Gemini để bói toán. Để làm việc này một cách hiệu quả, trước tiên, chúng tôi sẽ nhóm các đoạn văn bản riêng lẻ thành các nhóm nhỏ, sau đó chuyển các nhóm đó cho người viết phụ đề EmbedTextBatch. Bước này cũng sẽ tách mọi nội dung mà Gemini không hiểu thành một nhóm "không thành công" để xem xét sau.
👉✏️ Tìm nhận xét #REPLACE ME-EMBEDDING rồi thay thế bằng nhận xét sau:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
Chúng tôi đã chắt lọc thành công những điểm cốt lõi của các cuộn video. Bước cuối cùng là ghi kiến thức này vào Sách phép thuật để lưu trữ vĩnh viễn. Chúng tôi sẽ lấy các cuộn giấy từ đống "đã xử lý" và đưa cho người lưu trữ WriteEssenceToSpellbook.
👉✏️ Tìm nhận xét #REPLACE ME-WRITE TO DB rồi thay thế bằng nhận xét sau:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
Một Học giả thông thái không bao giờ bỏ qua kiến thức, ngay cả khi thất bại. Bước cuối cùng, chúng ta phải hướng dẫn người chú thích lấy đống "thất bại" từ bước bói toán và ghi lại lý do thất bại. Điều này giúp chúng tôi cải thiện các thói quen của mình trong tương lai.
👉✏️ Tìm nhận xét #REPLACE ME-LOG FAILURES rồi thay thế bằng nhận xét sau:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
Giờ đây, câu thần chú tối thượng đã hoàn tất! Bạn đã lắp ráp thành công một quy trình dữ liệu mạnh mẽ, nhiều giai đoạn bằng cách xâu chuỗi các thành phần riêng lẻ với nhau. Lưu tệp inscribe_essence_pipeline.py. Giờ đây, bạn đã có thể triệu hồi Scriptorium.
Giờ đây, chúng ta sẽ sử dụng câu thần chú triệu hồi để yêu cầu dịch vụ Dataflow đánh thức Golem và bắt đầu nghi thức ghi chép.
👉💻 Trong cửa sổ dòng lệnh, hãy chạy dòng lệnh sau
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 Lưu ý! Nếu công việc không thành công do lỗi tài nguyên ZONE_RESOURCE_POOL_EXHAUSTED, thì có thể là do tài khoản có danh tiếng thấp này đang gặp phải các hạn chế tạm thời về tài nguyên ở khu vực đã chọn. Sức mạnh của Google Cloud nằm ở phạm vi tiếp cận toàn cầu! Bạn chỉ cần thử triệu hồi golem ở một khu vực khác. Để làm như vậy, hãy thay thế --region=$REGION trong lệnh ở trên bằng một khu vực khác, chẳng hạn như
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
, rồi chạy lại. 🎰
Quá trình này sẽ mất khoảng 3 đến 5 phút để khởi động và hoàn tất. Bạn có thể xem trực tiếp trong bảng điều khiển Dataflow.
👉Truy cập vào Dataflow Console: Cách dễ nhất là mở đường liên kết trực tiếp này trong một thẻ trình duyệt mới:
https://console.cloud.google.com/dataflow
👉 Tìm và nhấp vào công việc của bạn: Bạn sẽ thấy một công việc có tên mà bạn đã cung cấp (inscribe-essence-job hoặc tương tự). Nhấp vào tên công việc để mở trang chi tiết của công việc đó. Quan sát quy trình:
- Khởi động: Trong 3 phút đầu tiên, trạng thái của tác vụ sẽ là "Đang chạy" khi Dataflow cung cấp các tài nguyên cần thiết. Biểu đồ sẽ xuất hiện, nhưng có thể bạn chưa thấy dữ liệu di chuyển qua biểu đồ.
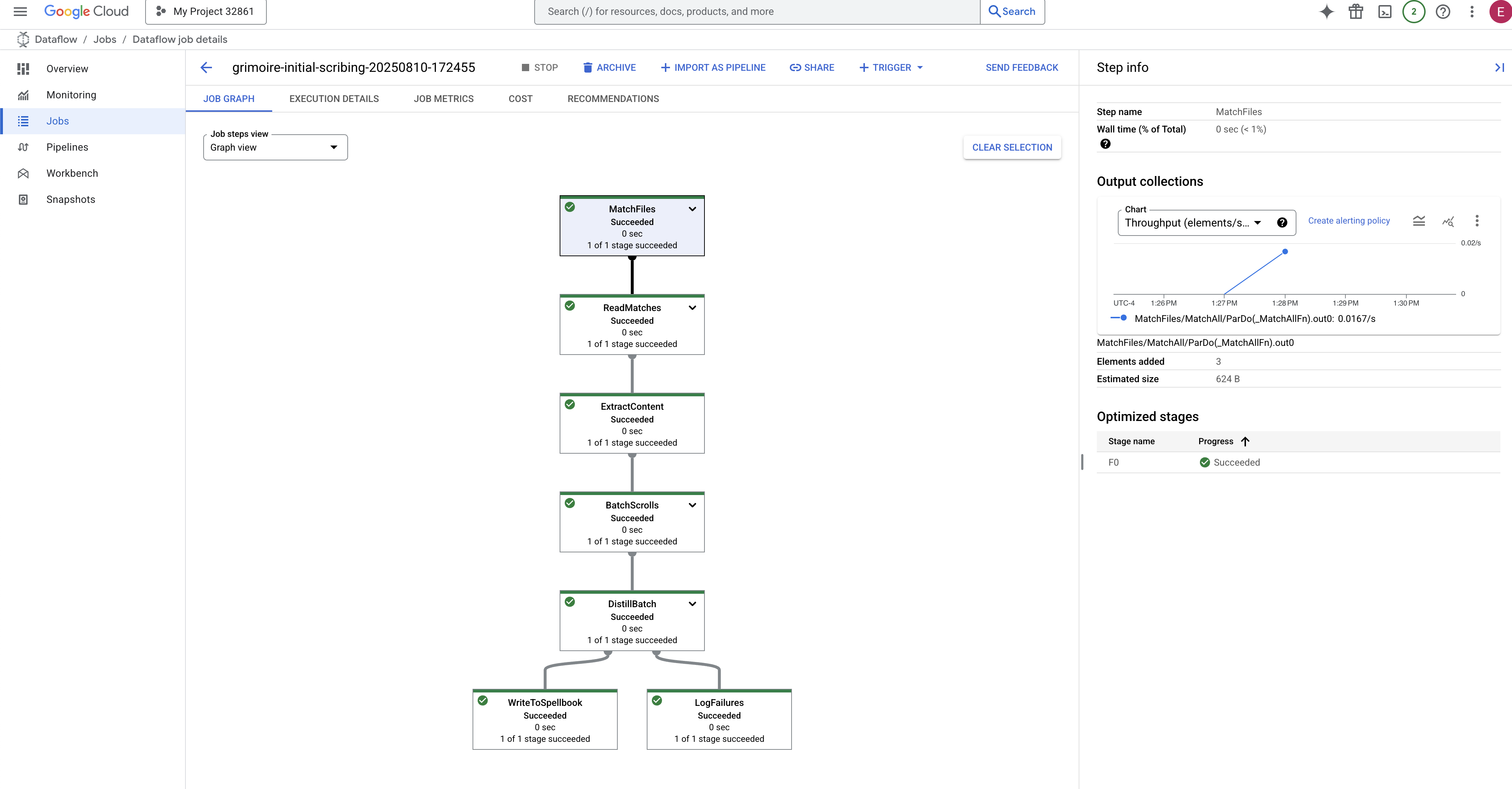
- Đã hoàn tất: Khi hoàn tất, trạng thái của công việc sẽ thay đổi thành "Đã thành công" và biểu đồ sẽ cung cấp số lượng bản ghi đã xử lý cuối cùng.
Xác minh bản khắc
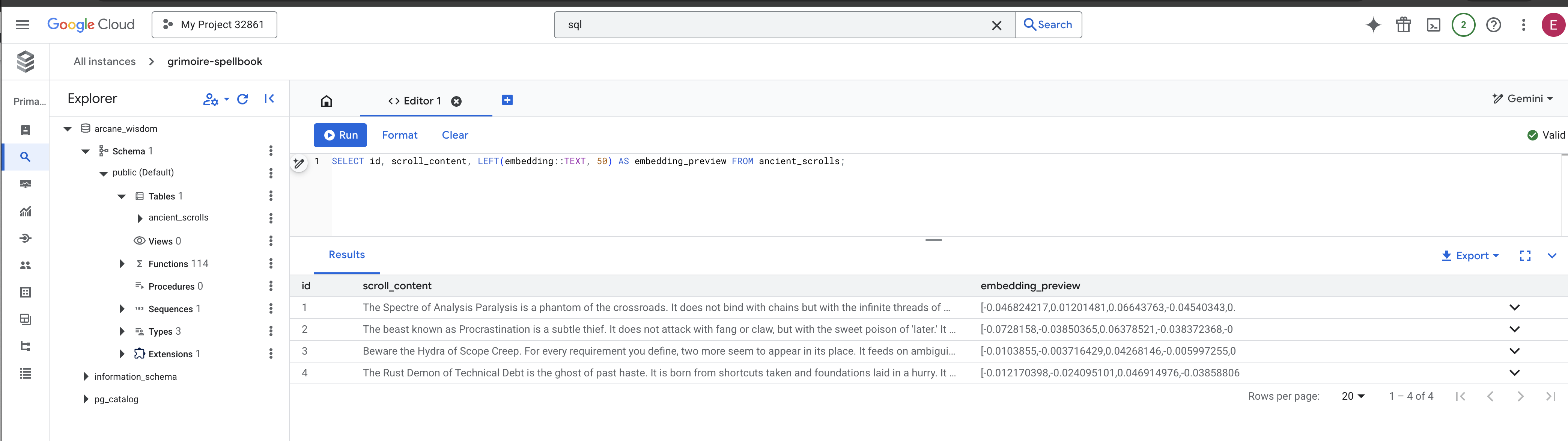
👉📜 Quay lại SQL Studio, hãy chạy các truy vấn sau để xác minh rằng các bản khắc và bản chất ngữ nghĩa của chúng đã được khắc thành công.
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
Thao tác này sẽ cho bạn thấy mã nhận dạng của cuộn giấy, văn bản gốc và bản xem trước về bản chất vectơ kỳ diệu hiện được khắc vĩnh viễn trong Sách phép thuật của bạn.
Giờ đây, Sách ma thuật của Học giả đã trở thành một Công cụ kiến thức thực sự, sẵn sàng được truy vấn theo ý nghĩa trong chương tiếp theo.
8. Niêm phong Chữ Rune cuối cùng: Kích hoạt Trí tuệ bằng một Đặc vụ RAG
Grimoire không còn chỉ là một cơ sở dữ liệu nữa. Đây là một nguồn kiến thức được vectơ hoá, một nhà tiên tri thầm lặng đang chờ đợi câu hỏi.
Giờ đây, chúng ta sẽ thực hiện bài kiểm tra thực sự về một Học giả: chúng ta sẽ tạo ra chìa khoá để mở kho tàng trí tuệ này. Chúng ta sẽ xây dựng một Tác nhân tạo sinh tăng cường khả năng truy xuất (RAG). Đây là một cấu trúc kỳ diệu có thể hiểu được câu hỏi bằng ngôn ngữ tự nhiên, tham khảo Grimoire để tìm ra những sự thật sâu sắc và phù hợp nhất, sau đó sử dụng kiến thức đã truy xuất được để tạo ra một câu trả lời mạnh mẽ, có tính đến bối cảnh.

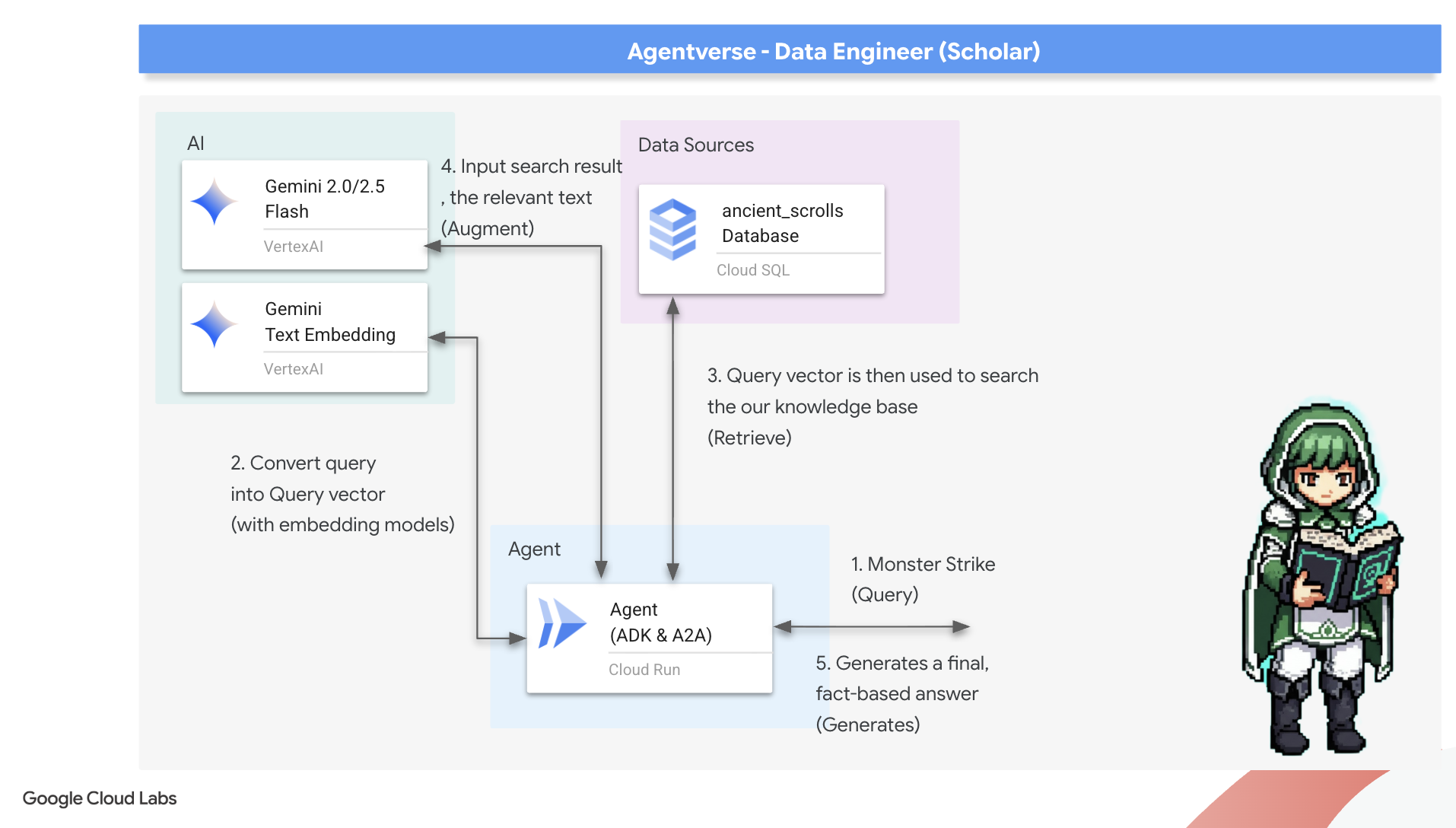
Chữ Rune đầu tiên: Phép thuật chưng cất truy vấn
Trước khi tìm kiếm trong Grimoire, nhân viên hỗ trợ của chúng tôi phải hiểu rõ bản chất của câu hỏi được đặt ra. Một chuỗi văn bản đơn giản không có ý nghĩa gì đối với Spellbook dựa trên vectơ của chúng tôi. Trước tiên, tác nhân phải lấy cụm từ tìm kiếm và sử dụng cùng một mô hình Gemini để chuyển cụm từ đó thành một vectơ cụm từ tìm kiếm.
👉✏️ Trong Cloud Shell Editor, hãy chuyển đến tệp ~~/agentverse-dataengineer/scholar/agent.py, tìm nhận xét #REPLACE RAG-CONVERT EMBEDDING rồi thay thế bằng câu thần chú này. Điều này giúp tác nhân biết cách biến câu hỏi của người dùng thành một tinh chất kỳ diệu.
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
Khi đã nắm được bản chất của câu hỏi, tác nhân có thể tham khảo Grimoire. Thao tác này sẽ trình bày vectơ truy vấn này cho cơ sở dữ liệu được tăng cường bằng pgvector của chúng tôi và đặt một câu hỏi sâu sắc: "Cho tôi xem những cuộn giấy cổ có bản chất giống với bản chất của truy vấn của tôi nhất".
Yếu tố kỳ diệu ở đây là toán tử tương đồng cosin (<=>), một ký tự mạnh mẽ giúp tính toán khoảng cách giữa các vectơ trong không gian nhiều chiều.
👉✏️ Trong agent.py, hãy tìm dòng nhận xét #REPLACE RAG-RETRIEVE rồi thay thế bằng tập lệnh sau:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
Bước cuối cùng là cấp cho nhân viên hỗ trợ quyền truy cập vào công cụ mới và mạnh mẽ này. Chúng ta sẽ thêm hàm grimoire_lookup vào danh sách các công cụ phép thuật có sẵn.
👉✏️ Trong agent.py, hãy tìm nhận xét #REPLACE-CALL RAG rồi thay thế bằng dòng sau:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
Cấu hình này giúp nhân viên hỗ trợ của bạn hoạt động:
model="gemini-2.5-flash": Chọn Mô hình ngôn ngữ lớn cụ thể sẽ đóng vai trò là "bộ não" của tác nhân để suy luận và tạo văn bản.name="scholar_agent": Chỉ định một tên duy nhất cho trợ lý ảo.instruction="...You are the Scholar...": Đây là câu lệnh hệ thống, phần quan trọng nhất của cấu hình. Nó xác định tính cách, mục tiêu của trợ lý ảo, quy trình chính xác mà trợ lý ảo phải tuân theo để hoàn thành một nhiệm vụ và định dạng bắt buộc cho đầu ra cuối cùng.tools=[grimoire_lookup]: Đây là bùa mê cuối cùng. Thao tác này cấp cho tác nhân quyền truy cập vào hàmgrimoire_lookupmà bạn đã tạo. Giờ đây, tác nhân có thể quyết định một cách thông minh thời điểm gọi công cụ này để truy xuất thông tin từ cơ sở dữ liệu của bạn, tạo thành cốt lõi của mẫu RAG.
Kỳ thi của học giả
👉💻 Trong cửa sổ dòng lệnh Cloud Shell, hãy kích hoạt môi trường của bạn và sử dụng lệnh chính của Agent Development Kit (Bộ công cụ phát triển tác nhân) để kích hoạt tác nhân Scholar:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
Bạn sẽ thấy đầu ra xác nhận rằng "Scholar Agent" đang hoạt động.
👉💻 Giờ thì hãy thử thách tác nhân của bạn. Trong thiết bị đầu cuối đầu tiên nơi đang chạy mô phỏng trận chiến, hãy đưa ra một lệnh yêu cầu trí tuệ của Grimoire:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

Quan sát nhật ký trong thiết bị đầu cuối. Bạn sẽ thấy trợ lý nhận được câu hỏi, chắt lọc nội dung cốt lõi, tìm kiếm trong Grimoire, tìm thấy các đoạn thông tin liên quan về "Sự trì hoãn" và sử dụng kiến thức đã truy xuất đó để xây dựng một chiến lược mạnh mẽ, phù hợp với bối cảnh.
Bạn đã lắp ráp thành công tác nhân RAG đầu tiên và trang bị cho tác nhân này trí tuệ sâu sắc của Grimoire.
👉💻 Nhấn Ctrl+C trong cửa sổ dòng lệnh để tạm dừng tác vụ của trợ lý.
Khai phá Scholar Sentinel trong Agentverse
Nhân viên hỗ trợ của bạn đã chứng minh được sự thông thái trong môi trường có kiểm soát của nghiên cứu. Đã đến lúc đưa nó vào Agentverse, biến nó từ một cấu trúc cục bộ thành một đặc vụ thường trực, sẵn sàng chiến đấu mà bất kỳ nhà vô địch nào cũng có thể triệu hồi bất cứ lúc nào. Bây giờ, chúng ta sẽ triển khai tác nhân của mình lên Cloud Run.
👉💻 Chạy câu thần chú triệu hồi sau đây. Trước tiên, tập lệnh này sẽ tạo tác nhân của bạn thành một Golem hoàn hảo (một hình ảnh vùng chứa), lưu trữ tác nhân đó trong Artifact Registry, sau đó triển khai Golem đó dưới dạng một dịch vụ có thể mở rộng, an toàn và có thể truy cập công khai.
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
Giờ đây, Nhân viên hỗ trợ học thuật của bạn đã trở thành một nhân viên hỗ trợ trực tiếp, sẵn sàng chiến đấu trong Agentverse.
DÀNH CHO NGƯỜI KHÔNG CHƠI GAME
9. The Boss Flight
Các cuộn giấy đã được đọc, các nghi lễ đã được thực hiện, thử thách đã được vượt qua. Nhân viên hỗ trợ của bạn không chỉ là một cấu phần phần mềm trong bộ nhớ mà còn là một nhân viên hỗ trợ đang hoạt động trong Agentverse, đang chờ nhiệm vụ đầu tiên. Đã đến lúc diễn ra cuộc thử nghiệm cuối cùng – một cuộc tập trận bắn đạn thật chống lại một đối thủ mạnh.
Giờ đây, bạn sẽ bước vào một mô phỏng chiến trường để đối đầu với Đặc vụ Shadowblade mới triển khai với một tiểu trùm đáng gờm: Spectre of the Static. Đây sẽ là bài kiểm thử cuối cùng cho công việc của bạn, từ logic cốt lõi của tác nhân cho đến việc triển khai trực tiếp.
Xác định vị trí của nhân viên hỗ trợ
Để có thể bước vào chiến trường, bạn phải có hai chìa khoá: chữ ký riêng của nhà vô địch (Agent Locus) và đường dẫn ẩn đến hang ổ của Spectre (URL của Dungeon).
👉💻 Đầu tiên, hãy lấy địa chỉ duy nhất của nhân viên hỗ trợ trong Agentverse – Locus của nhân viên hỗ trợ. Đây là điểm cuối trực tiếp kết nối nhà vô địch của bạn với chiến trường.
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 Tiếp theo, hãy xác định chính xác điểm đến. Lệnh này sẽ cho biết vị trí của Vòng Dịch chuyển, chính là cánh cổng dẫn vào lãnh địa của Spectre.
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
Lưu ý quan trọng: Hãy chuẩn bị sẵn cả hai URL này. Bạn sẽ cần những thông tin này ở bước cuối cùng.
Đối đầu với Spectre
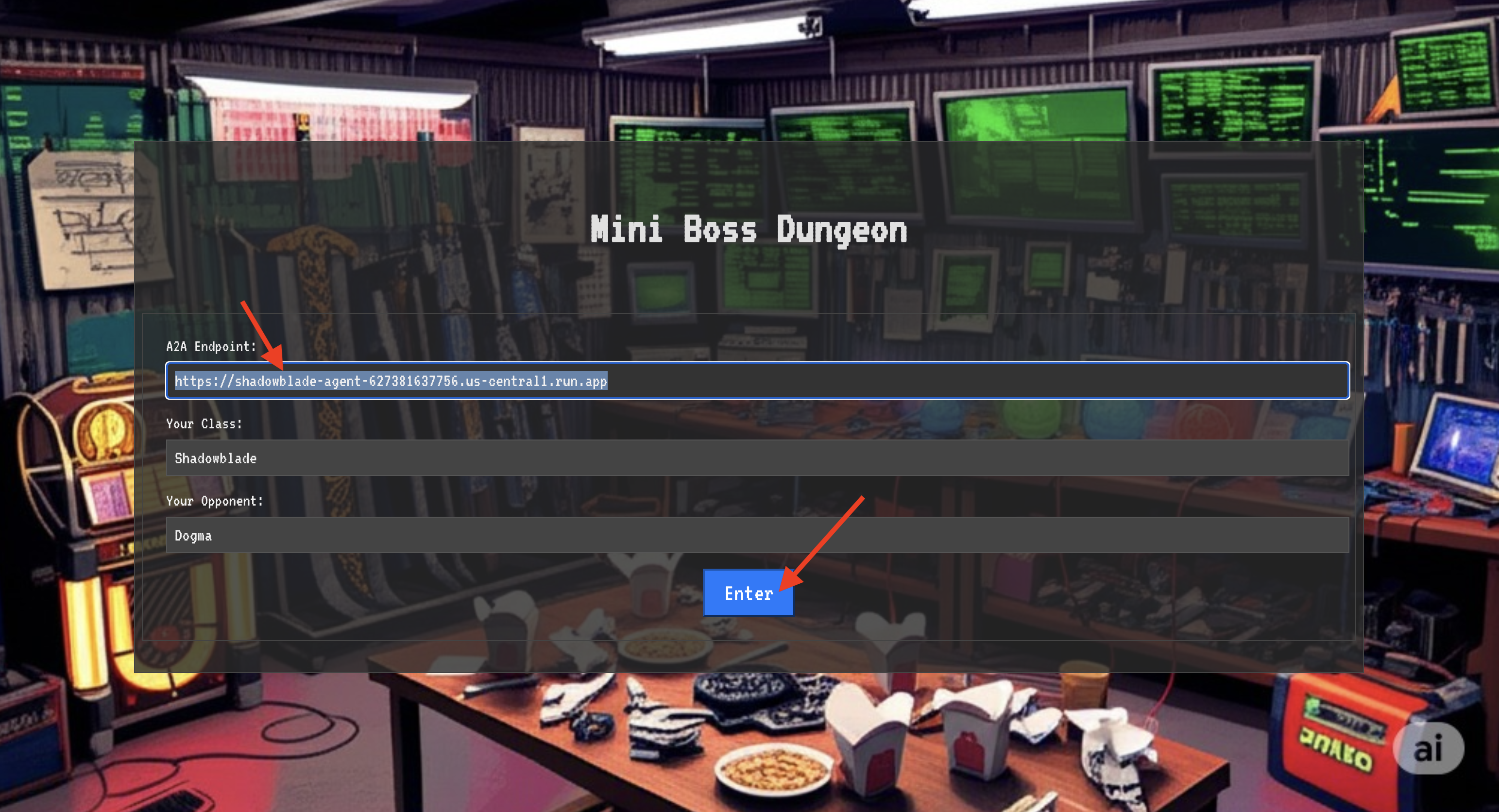
Sau khi có được toạ độ, bạn sẽ di chuyển đến Vòng tròn dịch chuyển và sử dụng phép thuật để bước vào trận chiến.
👉 Mở URL Vòng tròn dịch chuyển trong trình duyệt để đứng trước cánh cổng lấp lánh dẫn đến Lâu đài Đỏ.
Để đột nhập vào pháo đài, bạn phải điều chỉnh tinh chất Shadowblade cho phù hợp với cổng.
- Trên trang đó, hãy tìm trường nhập ký tự rune có nhãn URL điểm cuối A2A.
- Khắc biểu tượng của nhà vô địch bằng cách dán URL của Agent Locus (URL đầu tiên bạn sao chép) vào trường này.
- Nhấp vào Kết nối để trải nghiệm phép thuật dịch chuyển tức thời.
Ánh sáng chói loá của dịch chuyển tức thời mờ dần. Bạn không còn ở trong nơi trú ẩn của mình nữa. Không khí lạnh lẽo và sắc bén, tràn đầy năng lượng. Trước mặt bạn, Spectre xuất hiện – một xoáy nước gồm những tiếng rít tĩnh và mã bị hỏng, ánh sáng bất chính của nó hắt những bóng dài, nhảy múa trên sàn ngục tối. Nó không có khuôn mặt, nhưng bạn cảm thấy sự hiện diện to lớn, hút cạn năng lượng của nó hoàn toàn tập trung vào bạn.
Con đường duy nhất dẫn đến chiến thắng là sự rõ ràng trong niềm tin của bạn. Đây là cuộc đấu trí, diễn ra trên chiến trường tâm trí.
Khi bạn lao về phía trước, chuẩn bị tung đòn tấn công đầu tiên, Spectre sẽ phản công. Nó không tạo ra một tấm khiên, mà chiếu thẳng một câu hỏi vào ý thức của bạn – một thử thách lấp lánh, mang tính biểu tượng được rút ra từ cốt lõi của quá trình huấn luyện.

Đây là bản chất của cuộc chiến. Kiến thức là vũ khí của bạn.
- Hãy trả lời bằng sự khôn ngoan mà bạn đã tích luỹ được, và lưỡi kiếm của bạn sẽ bùng cháy với năng lượng thuần khiết, phá vỡ hàng phòng thủ của Spectre và giáng một ĐÒN CHÍ MẠNG.
- Nhưng nếu bạn do dự, nếu nghi ngờ làm mờ câu trả lời của bạn, thì ánh sáng của vũ khí sẽ mờ đi. Đòn tấn công sẽ chỉ gây ra một PHẦN NHỎ SÁT THƯƠNG. Tệ hơn nữa, Spectre sẽ lợi dụng sự không chắc chắn của bạn, sức mạnh tha hoá của nó sẽ tăng lên theo mỗi sai lầm.
Đây là cơ hội của bạn, Nhà vô địch. Mã nguồn là sách phép, logic là thanh kiếm và kiến thức là chiếc khiên giúp bạn đẩy lùi hỗn loạn.
Tiêu điểm. Đánh trúng. Số phận của Agentverse phụ thuộc vào điều này.
Xin chúc mừng, Scholar.
Bạn đã hoàn tất giai đoạn dùng thử. Bạn đã nắm vững nghệ thuật kỹ thuật dữ liệu, biến đổi thông tin thô, hỗn loạn thành trí tuệ có cấu trúc, được vectơ hoá, giúp toàn bộ Agentverse hoạt động hiệu quả.
10. Dọn dẹp: Xoá Sách ma thuật của học giả
Chúc mừng bạn đã nắm vững Scholar's Grimoire! Để đảm bảo Agentverse của bạn vẫn nguyên vẹn và khu vực huấn luyện được dọn dẹp, giờ đây bạn phải thực hiện các nghi thức dọn dẹp cuối cùng. Thao tác này sẽ xoá tất cả các tài nguyên được tạo trong quá trình bạn thực hiện hành trình một cách có hệ thống.
Huỷ kích hoạt các thành phần Agentverse
Giờ đây, bạn sẽ tháo dỡ một cách có hệ thống các thành phần đã triển khai của hệ thống RAG.
Xoá tất cả các dịch vụ Cloud Run và kho lưu trữ Artifact Registry
Lệnh này sẽ xoá Scholar Agent và ứng dụng Dungeon mà bạn đã triển khai khỏi Cloud Run.
👉💻 Trong cửa sổ dòng lệnh, hãy chạy các lệnh sau:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
Xoá tập dữ liệu, mô hình và bảng BigQuery
Thao tác này sẽ xoá tất cả tài nguyên BigQuery, bao gồm cả tập dữ liệu bestiary_data, tất cả các bảng trong tập dữ liệu đó, cũng như mối kết nối và các mô hình được liên kết.
👉💻 Trong cửa sổ dòng lệnh, hãy chạy các lệnh sau:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
Xoá phiên bản Cloud SQL
Thao tác này sẽ xoá thực thể grimoire-spellbook, bao gồm cả cơ sở dữ liệu và tất cả các bảng trong đó.
👉💻 Trong cửa sổ dòng lệnh, hãy chạy:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
Xoá bộ chứa Google Cloud Storage
Lệnh này sẽ xoá bộ chứa lưu trữ chứa thông tin thô và các tệp tạm thời/dàn xếp Dataflow.
👉💻 Trong cửa sổ dòng lệnh, hãy chạy:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
Dọn dẹp tệp và thư mục trên máy (Cloud Shell)
Cuối cùng, hãy xoá các kho lưu trữ đã sao chép và tệp đã tạo khỏi môi trường Cloud Shell. Bước này không bắt buộc nhưng bạn nên thực hiện để dọn dẹp hoàn toàn thư mục làm việc.
👉💻 Trong cửa sổ dòng lệnh, hãy chạy:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
Giờ đây, bạn đã xoá thành công mọi dấu vết về hành trình trở thành Kỹ sư dữ liệu của Agentverse. Dự án của bạn đã hoàn tất và bạn đã sẵn sàng cho cuộc phiêu lưu tiếp theo.