
1. 序曲
孤立开发的时代即将结束。下一波技术变革浪潮不是关于孤军奋战的天才,而是关于协作精通。打造一个智能的单一代理是一项有趣的实验。构建一个强大、安全且智能的代理生态系统(即真正的 Agentverse)是现代企业面临的巨大挑战。
若想在这个新时代取得成功,需要将四种关键角色融合在一起,这四种角色是支持任何蓬勃发展的自主系统的基础支柱。任何一个方面的不足都会造成弱点,进而危害整个结构。
本研讨会是企业在 Google Cloud 上掌握智能体未来的权威指南。我们提供端到端路线图,引导您从最初的想法到全面运营的现实。在这四个相互关联的实验中,您将了解开发者、架构师、数据工程师和 SRE 的专业技能如何融合在一起,以创建、管理和扩缩强大的 Agentverse。
任何单个支柱都无法单独支持 Agentverse。如果没有开发者的精准执行,架构师的宏伟设计将毫无用处。没有数据工程师的智慧,开发者的代理就是盲目的;没有 SRE 的保护,整个系统就是脆弱的。只有通过协同合作并对彼此的角色有共同的理解,您的团队才能将创新概念转化为任务关键型运营现实。您的旅程将从这里开始。准备好掌握自己的角色,并了解自己如何融入大局。
欢迎来到 Agentverse:冠军召集令
在广阔的企业数字领域,一个新时代已经来临。我们正处于智能体时代,这是一个充满希望的时代,智能自主的智能体将完美协作,加速创新并摆脱日常琐事。

这个由力量和潜力组成的互联生态系统被称为 Agentverse。
但一种名为“静电”的缓慢熵增、无声腐蚀已开始侵蚀这个新世界的边缘。静态不是病毒或 bug,而是以创造行为本身为食的混乱的化身。
它将旧的挫败感放大成可怕的形式,催生了开发中的七个幽灵。如果不勾选此复选框,静态和它的幽灵将使进度停滞不前,使 Agentverse 的承诺变成技术债务和废弃项目的荒原。
今天,我们呼吁各界人士挺身而出,扭转混乱的局面。我们需要英雄愿意精通自己的技艺,并携手合作来保护特工宇宙。现在是时候选择您的道路了。
选择课程
您面前有四条截然不同的道路,每条道路都是对抗静态的关键支柱。虽然训练是单人任务,但最终的成功取决于您是否了解自己的技能如何与他人的技能相结合。
- 暗影之刃(开发者):锻造和前线的专家。您是打造刀刃、构建工具的工匠,也是在代码的复杂细节中直面敌人的战士。您的道路是精准、技能和实践创造之路。
- 召唤师(架构师):伟大的战略家和编排者。您看到的不是单个特工,而是整个战场。您将设计主蓝图,使整个智能体系统能够进行通信、协作,并实现远超任何单个组件的目标。
- 学者(数据工程师):寻求隐藏的真相,智慧的守护者。您将深入探索广阔而未知的原始数据世界,发掘可为客服人员提供目标和洞察的智能。您的知识可以揭示敌人的弱点或增强盟友的能力。
- 守护者(DevOps / SRE):王国的坚定保护者和盾牌。您需要建造堡垒、管理电力供应线路,并确保整个系统能够抵御静电的必然攻击。你的实力是团队获胜的基础。
您的任务
训练将作为一项单独的锻炼开始。您将沿着所选路线学习,掌握胜任工作所需的独特技能。试用期结束时,您将面对一个由静电产生的幽灵,这是一个会利用您工艺中的特定挑战来捕食的迷你 Boss。
只有掌握好自己的角色,才能为最终的试炼做好准备。然后,您必须与其他班级的学员组队。你们将一起深入腐化之地,与终极 Boss 一决高下。
一项最终的合作挑战,将考验您的综合实力,并决定特工宇宙的命运。
Agentverse 等待着英雄的到来。您会回应吗?
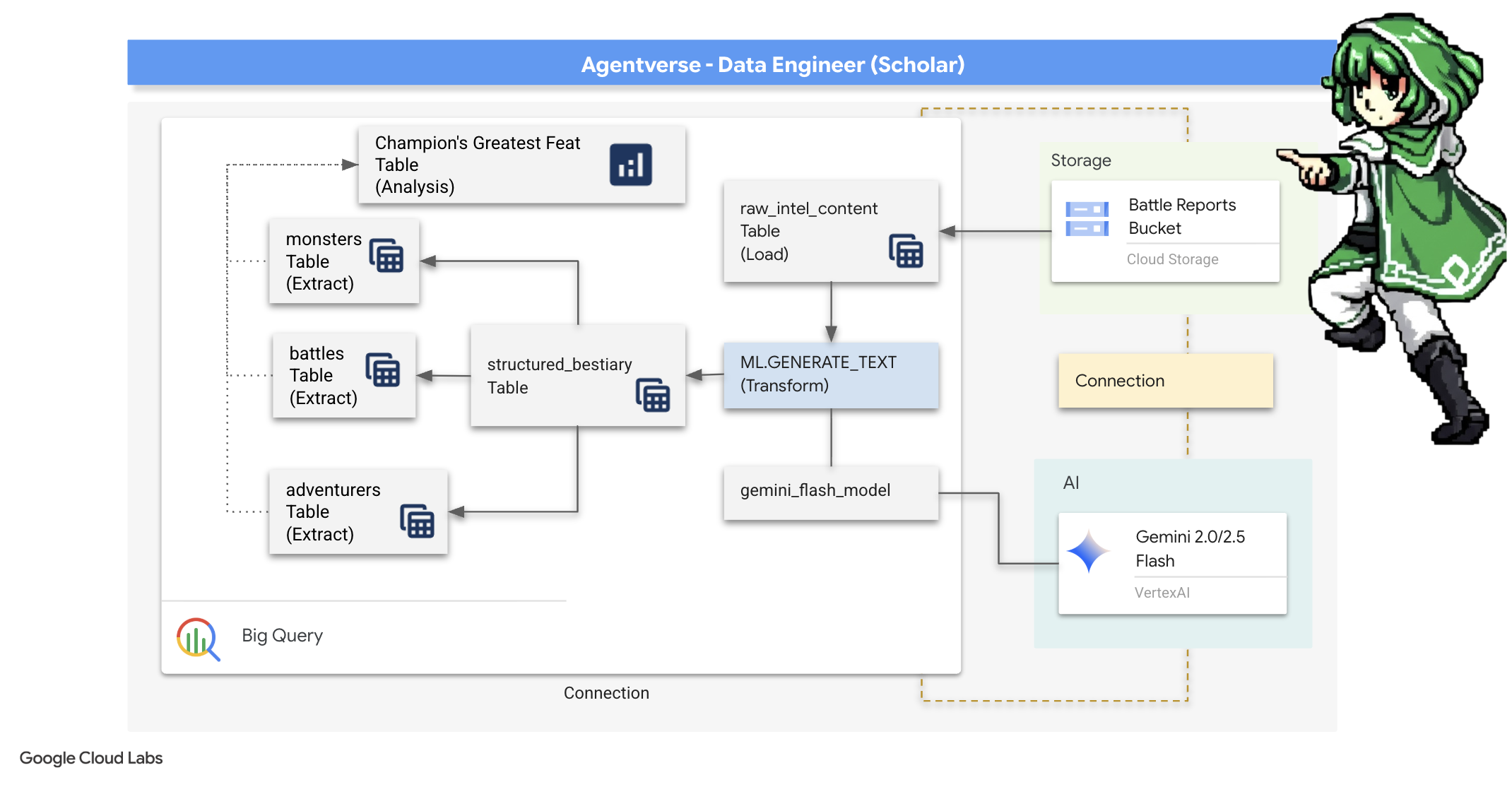
2. The Scholar's Grimoire
我们的旅程开始了!作为学者,我们的主要武器是知识。我们在归档(Google Cloud Storage)中发现了一批古老而神秘的卷轴。这些卷轴包含有关肆虐这片土地的可怕野兽的原始情报。我们的使命是利用 Google BigQuery 的强大分析功能和 Gemini Elder Brain(Gemini Pro 模型)的智慧来解读这些非结构化文本,并将其转化为可查询的结构化动物寓言集。这将成为我们未来所有策略的基础。
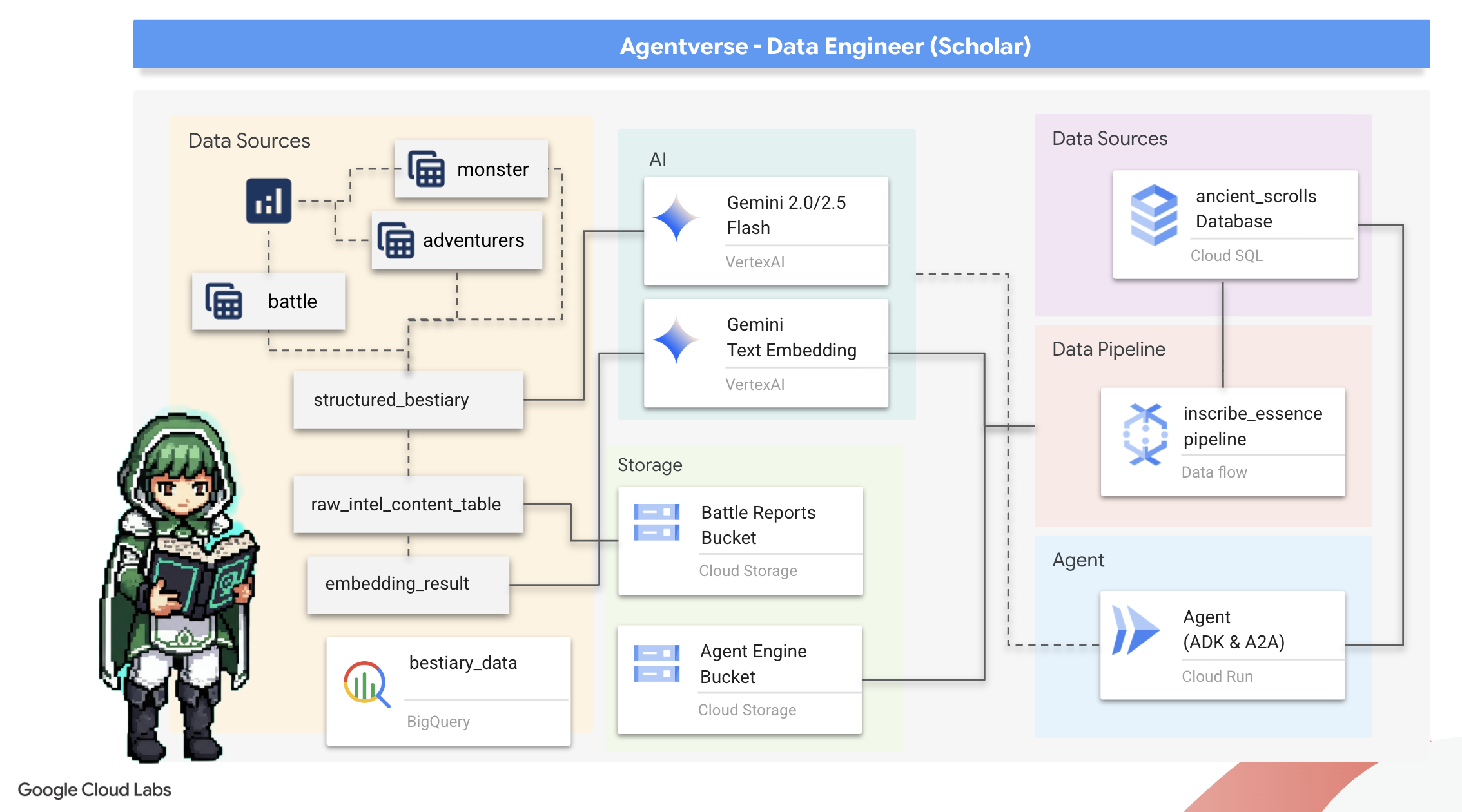
学习内容
- 使用 BigQuery 创建外部表,并使用 BQML.GENERATE_TEXT 和 Gemini 模型执行复杂的非结构化到结构化转换。
- 预配 Cloud SQL for PostgreSQL 实例,并启用 pgvector 扩展程序以实现语义搜索功能。
- 使用 Dataflow 和 Apache Beam 构建一个强大的容器化批处理流水线,以处理原始文本文件、使用 Gemini 模型生成向量嵌入,并将结果写入关系型数据库。
- 在代理中实现基本的检索增强生成 (RAG) 系统,以查询矢量化数据。
- 将数据感知型代理部署为 Cloud Run 上安全且可扩缩的服务。
3. 准备学者圣所
欢迎使用学术搜索。在开始记录我们魔法书中的强大知识之前,我们必须先准备好圣所。这个基础仪式包括为我们的 Google Cloud 环境施展魔法、打开正确的传送门 (API),以及创建数据魔法将流经的管道。准备充分的圣所可确保我们的咒语有效,知识安全无虞。
领取 Google Cloud 赠金
⚠️ 重要前提条件:
- 使用个人 Gmail 账号:您必须使用个人账号(例如
name@gmail.com)。公司或学校管理的账号将无法使用。
👉 步骤:
- 前往赠金申领网站: 点击此处
- 登录:将链接粘贴到地址栏中,然后使用您的个人 Gmail 账号登录。
- 接受条款:接受 Google Cloud Platform 服务条款。
- 验证抵扣金额:查找确认抵扣金额已应用的邮件。
- *注意:如果您收到输入信用卡信息的提示,可以放心地忽略该提示并关闭相应窗口。
这样就完成了。您可以随时关闭此窗口
设置工作环境
👉点击 Google Cloud 控制台顶部的“激活 Cloud Shell”(这是 Cloud Shell 窗格顶部的终端形状图标),
👉点击“打开编辑器”按钮(铅笔图案,看起来像一个打开的文件夹)。此操作会在窗口中打开 Cloud Shell 代码编辑器。您会在左侧看到文件资源管理器。
👉在云 IDE 中打开终端,
👉💻 在终端中,使用以下命令验证您是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
👉💻从 GitHub 克隆引导项目:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 从项目目录运行设置脚本。
⚠️ 项目 ID 注意事项:脚本会建议一个随机生成的默认项目 ID。您可以按 Enter 键接受此默认值。
不过,如果您想创建特定的新项目,可以在脚本提示时输入所需的项目 ID。
cd ~/agentverse-dataengineer
./init.sh
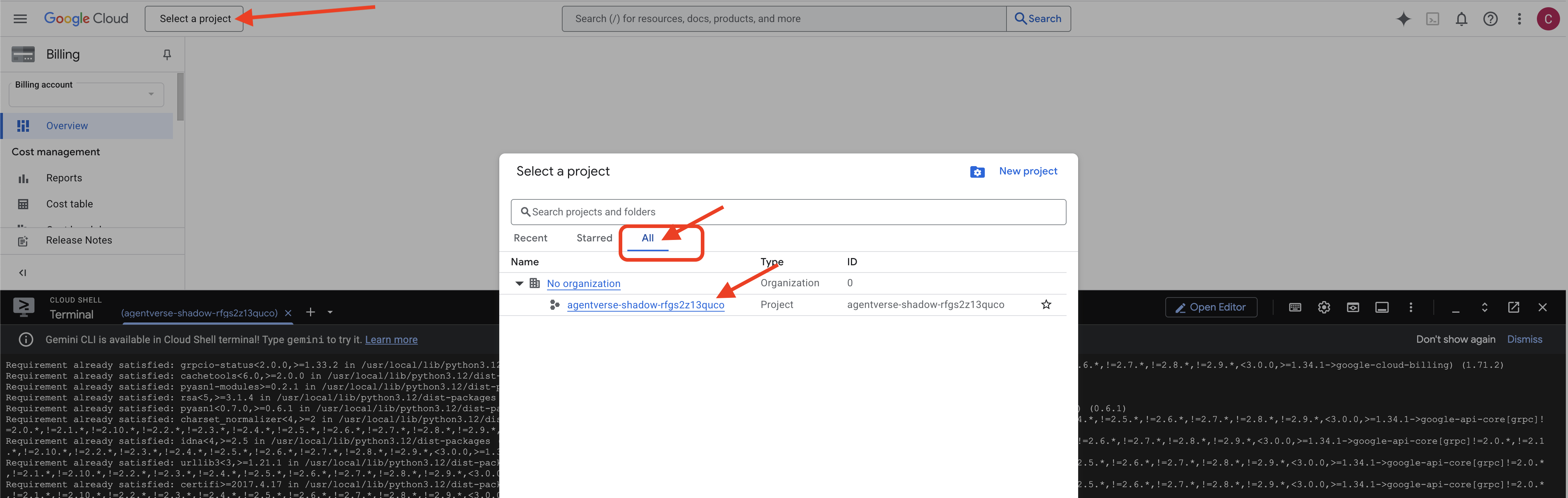
👉 完成后的重要步骤:脚本运行完毕后,您必须确保 Google Cloud 控制台正在查看正确的项目:
- 转到 console.cloud.google.com。
- 点击页面顶部的项目选择器下拉列表。
- 点击“全部”标签页(因为新项目可能尚未显示在“最近”中)。
- 选择您刚刚在
init.sh步骤中配置的项目 ID。
👉💻 设置所需的项目 ID:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 运行以下命令以启用必要的 Google Cloud API:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 如果您尚未创建名为“agentverse-repo”的 Artifact Registry 代码库,请运行以下命令来创建该代码库:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
设置权限
👉💻 在终端中运行以下命令,授予必要的权限:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 在您开始训练时,我们会准备最终挑战。以下命令将从混乱的静电中召唤出幽灵,从而创建最终测试的 Boss。
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
做得好,学者。基础附魔已完成。我们的圣所安全无虞,通往数据元素力量的传送门已打开,我们的仆从已获得力量。现在,我们已准备好开始实际工作。
4. 知识炼金术:使用 BigQuery 和 Gemini 转换数据
在与静态的无休止的战争中,Agentverse 的每个 Champion 与开发 Spectre 之间的每次对抗都会被仔细记录下来。战场模拟系统是我们的主要训练环境,它会自动为每次遭遇战生成以太日志条目。这些叙事日志是我们最宝贵的原始情报来源,是学者必须从中锻造出纯净战略之钢的未精炼矿石。学者的真正力量不仅在于拥有数据,更在于能够将原始、混乱的信息矿石转化为闪闪发光的、结构化的可操作智慧之钢。我们将执行数据炼金术的基础仪式。

我们将通过一个多阶段流程,完全在 Google BigQuery 的保护范围内完成整个过程。我们将从凝视 GCS 归档开始,无需滚动,只需使用神奇的镜头。然后,我们将召唤 Gemini 来解读战斗日志中诗意盎然的非结构化传奇故事。最后,我们将把原始预言提炼成一组清晰明了、相互关联的表格。我们的第一本魔法书。并向其提出一个只有这种新结构才能回答的深刻问题。
透视镜:使用 BigQuery 外部表深入了解 GCS
我们的首要任务是打造一种镜头,让我们能够查看 GCS 归档的内容,而不会干扰其中的卷轴。外部表就是这样一种透镜,可将原始文本文件映射到 BigQuery 可以直接查询的类似表的结构。
为此,我们必须先创建一个稳定的能量地脉(即 CONNECTION 资源),以安全地将 BigQuery 圣所与 GCS 归档相关联。
👉💻 在 Cloud Shell 终端中,运行以下命令来设置存储空间并创建管道:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 注意!稍后会显示一条消息!
第 2 步中的设置脚本在后台启动了一个进程。几分钟后,终端中会弹出类似以下内容的消息:[1]+ Done gcloud sql instances create ...这是正常现象。这只是表示您的 Cloud SQL 数据库已成功创建。您可以放心地忽略此消息,然后继续工作。
在创建外部表之前,您必须先创建将包含该表的数据集。
👉💻 在 Cloud Shell 终端中运行以下简单命令:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 现在,我们必须授予管道的神奇签名从 GCS 归档读取数据和咨询 Gemini 的必要权限。
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 在 Cloud Shell 终端中,运行以下命令以显示您的存储分区名称:
echo $BUCKET_NAME
您的终端会显示一个类似于 your-project-id-gcs-bucket 的名称。您将在后续步骤中用到此名称。
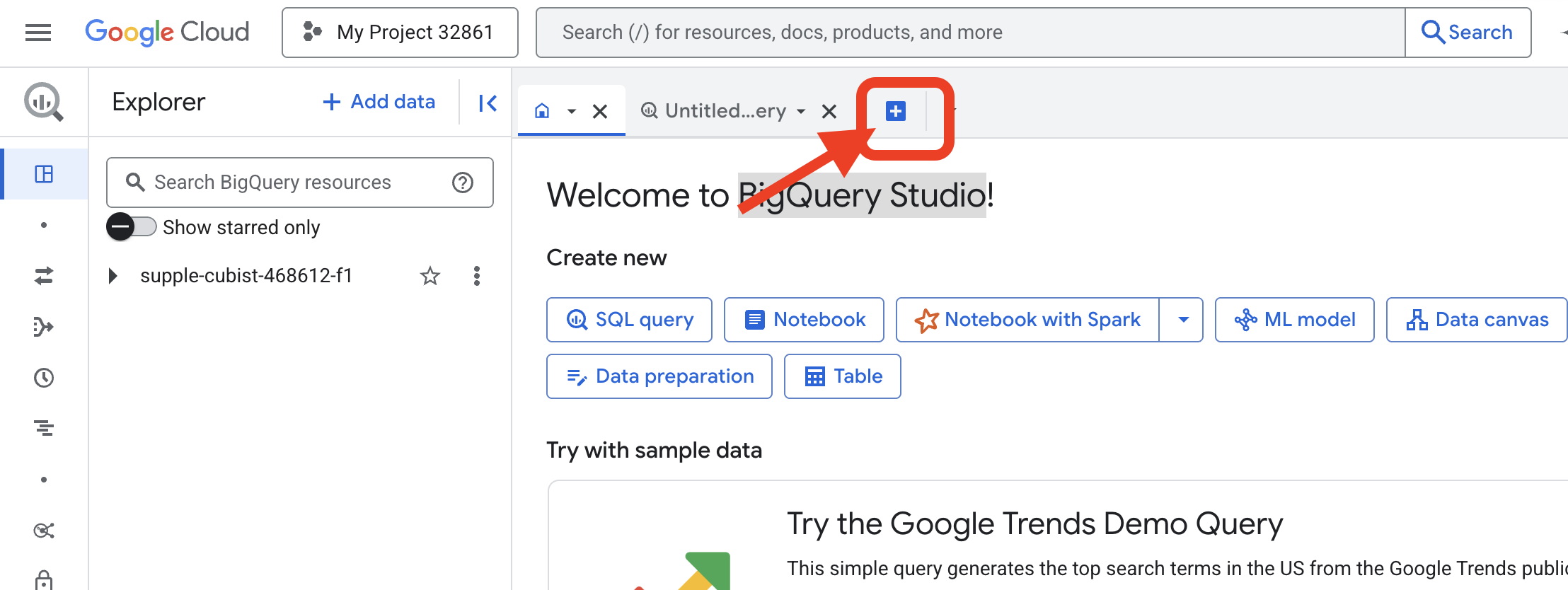
👉 您需要在 Google Cloud 控制台中的 BigQuery 查询编辑器中运行下一条命令。最简单的方法是在新的浏览器标签页中打开下方的链接。系统会将您直接转到 Google Cloud 控制台中的相应页面。
https://console.cloud.google.com/bigquery
👉 页面加载完毕后,点击蓝色“+”按钮(编写新查询),打开新的编辑器标签页。
现在,我们编写数据定义语言 (DDL) 咒语来创建神奇的镜头。这会告知 BigQuery 在何处查找以及要查看哪些内容。
👉📜 在您打开的 BigQuery 查询编辑器中,粘贴以下 SQL。请务必替换 REPLACE-WITH-YOUR-BUCKET-NAME
替换为您刚刚复制的存储分区名称。然后点击运行:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 运行查询以“透过镜头”查看文件的内容。
SELECT * FROM bestiary_data.raw_intel_content_table;
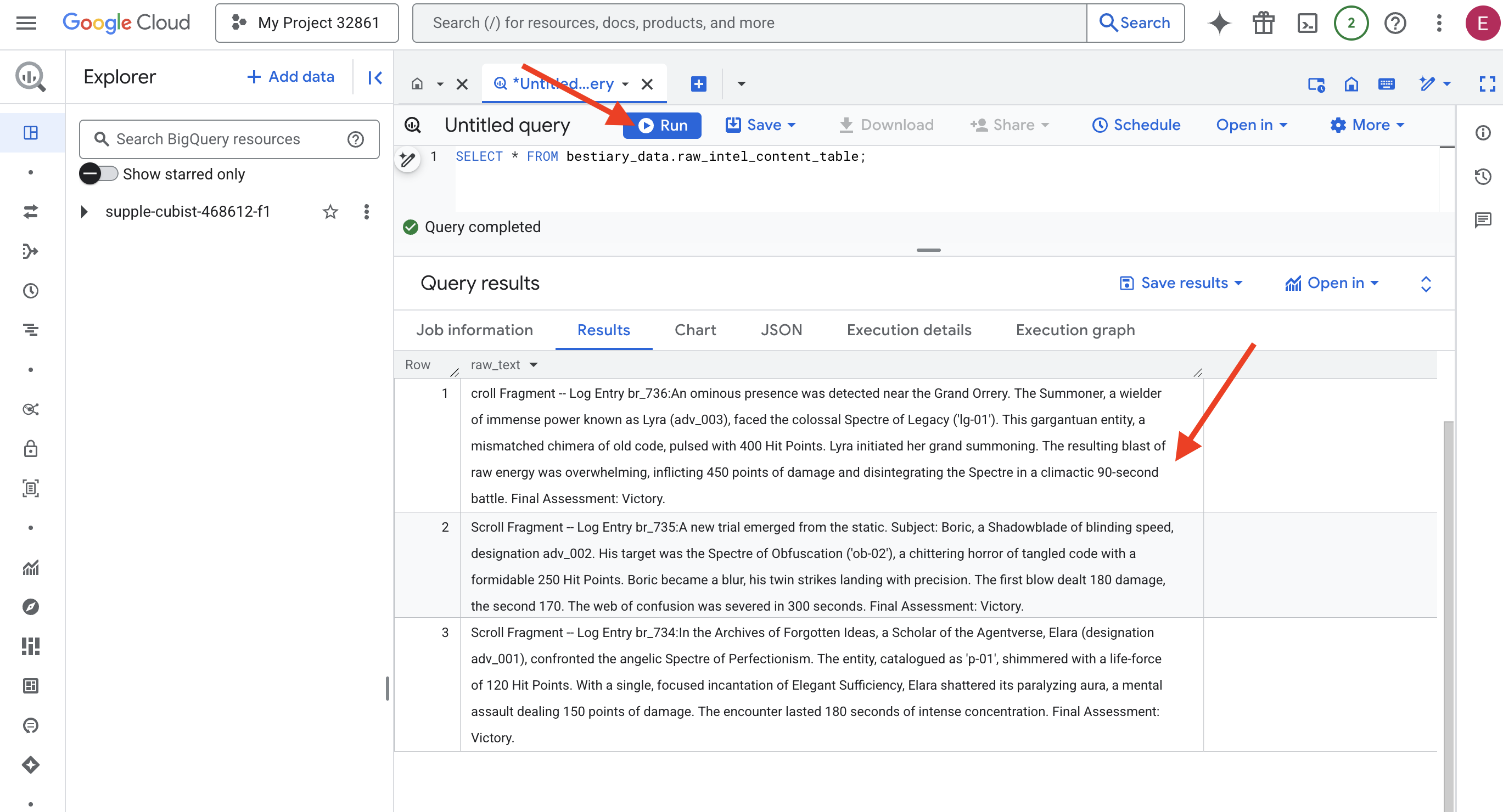
我们的镜头已就位。我们现在可以看到卷轴的原始文本。但阅读并不等于理解。
在“被遗忘的想法”档案中,Agentverse 的学者 Elara(代号 adv_001)与完美主义的幽灵天使对峙。这个实体被编入目录,称为“p-01”,闪耀着 120 生命值的生命力。艾拉以一句专注而优雅的咒语,打破了那令人瘫痪的光环,这是一次造成 150 点伤害的精神攻击。这次相遇持续了 180 秒,我全神贯注。最终评估:获胜。
卷轴不是以表格和行的方式书写,而是以传奇故事的曲折散文形式书写。这是我们的第一次重大考验。
学者的占卜:使用 SQL 将文本转换为表格
挑战在于,详细描述影刃快速双重攻击的报告与记录召唤师聚集巨大力量进行毁灭性一击的编年史截然不同。我们不能只是简单地导入这些数据,还必须对其进行解读。这就是神奇的时刻。我们将使用一个 SQL 查询作为强大的咒语,在 BigQuery 中直接读取、理解和构建所有文件中的所有记录。
👉💻 返回到 Cloud Shell 终端,运行以下命令以显示连接名称:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
终端将显示完整的连接字符串,请选择并复制整个字符串,您将在下一步中需要用到它
我们将使用一个强大的咒语:ML.GENERATE_TEXT。此咒语会召唤 Gemini,向其展示每份卷轴,并命令其以结构化 JSON 对象的形式返回核心事实。
👉📜 在 BigQuery Studio 中,创建 Gemini 模型引用。这会将 Gemini Flash Oracle 绑定到我们的 BigQuery 库,以便我们可以在查询中调用它。请务必替换
将 REPLACE-WITH-YOUR-FULL-CONNECTION-STRING 替换为您刚刚从终端复制的完整连接字符串。
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 现在,施展伟大的炼金术咒语。此查询会读取原始文本,为每个滚动构建详细的提示,将其发送给 Gemini,并根据 AI 的结构化 JSON 响应构建新的临时表。
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
转化的过程已完成,但结果尚未达到纯净状态。Gemini 模型会以标准格式返回答案,将我们所需的 JSON 封装在一个更大的结构中,其中包含有关其思考过程的元数据。在我们尝试净化它之前,先看看这个原始的预言。
👉📜 运行查询以检查 Gemini 模型的原始输出:
SELECT * FROM bestiary_data.structured_bestiary;
👀 您会看到一个名为 structured_data 的列。每行的内容将类似于以下复杂的 JSON 对象:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
如您所见,我们请求的奖品(干净的 JSON 对象)深藏在此结构中。我们接下来的任务很明确。我们必须举行一种仪式,才能系统地探索这种结构,并提取其中的纯粹智慧。
清理仪式:使用 SQL 对生成式 AI 输出进行归一化处理
Gemini 已经发声,但其话语是原始的,并包裹在其创造的空灵能量中(候选回答、finish_reason 等)。真正的学者不会简单地将原始预言束之高阁;他们会仔细提取其中的核心智慧,并将其记录在合适的典籍中以供将来使用。
现在,我们将施展最后一组咒语。此单个脚本将执行以下操作:
- 从我们的临时表中读取原始的嵌套 JSON。
- 清理并解析该数据,以获取核心数据。
- 将相关内容记录到三个最终的原始表格中:怪物、冒险者和战斗。
👉📜 在新的 BigQuery 查询编辑器中,运行以下咒语来创建清理镜头:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 验证百怪图鉴:
SELECT * FROM bestiary_data.monsters;
接下来,我们将创建勇士榜,列出曾与这些野兽战斗过的勇敢冒险者。
👉📜 在新的查询编辑器中,运行以下咒语以创建冒险者表:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 验证冠军榜:
SELECT * FROM bestiary_data.adventurers;
最后,我们将创建事实表:战役编年史。这本巨著将其他两本联系起来,记录了每次独特相遇的细节。由于每场战斗都是独特的事件,因此无需进行去重。
👉📜 在新的查询编辑器中,运行以下咒语以创建“battles”表:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 验证 Chronicle:
SELECT * FROM bestiary_data.battles;
发掘战略性数据洞见
卷轴已被阅读,精华已被提炼,巨著已被撰写。我们的魔典不再只是一系列事实的集合,而是一个蕴含深刻战略智慧的关系型数据库。现在,我们可以提出以前无法回答的问题,因为我们的知识不再局限于原始的非结构化文本。
现在,让我们进行最后一次盛大的占卜。我们将施展魔法,同时查阅三本巨著(《怪物图鉴》《冠军名册》和《战役编年史》),以发掘深刻且可据以行动的洞见。
我们的战略性问题: “对于每位冒险者,他们成功击败的最强大的怪物(按生命值)的名称是什么,以及他们赢得那场胜利花了多长时间?”
这是一个复杂的问题,需要将斗士与其获胜的战斗相关联,并将这些战斗与所涉及怪物的统计数据相关联。这才是结构化数据模型的真正强大之处。
👉📜 在新的 BigQuery 查询编辑器中,输入以下最终咒语:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
此查询的输出将是一个简洁美观的表格,其中包含您数据集中的每位冒险者的“冠军的伟大壮举”。结果可能如下所示:
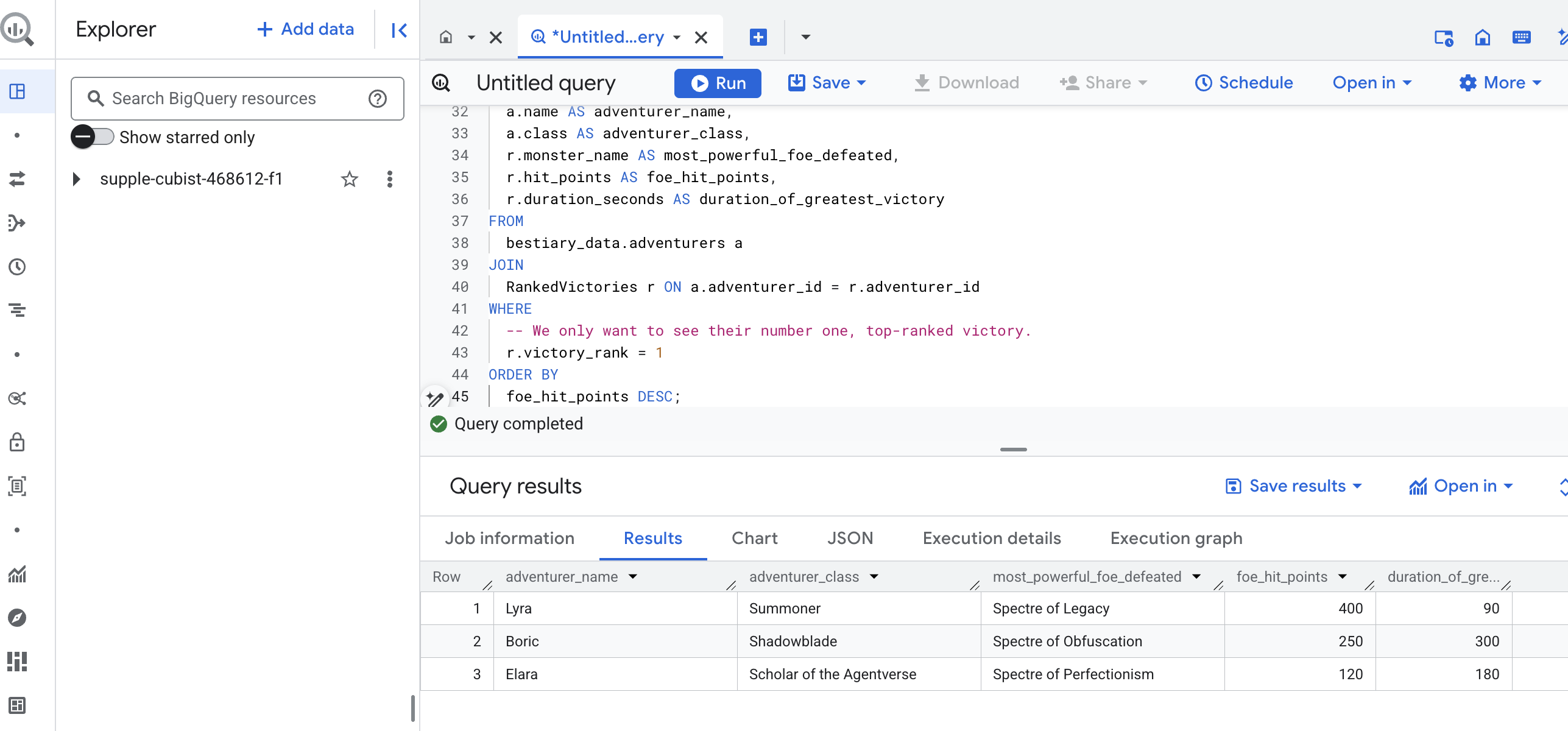
关闭 BigQuery 标签页。
这一简洁明了的结果证明了整个流水线的价值。您已成功将混乱的原始战地报告转变为传奇故事和数据驱动的战略性分析洞见。
非游戏玩家
5. Scribe 的魔法书:数据仓库中的分块、嵌入和搜索
我们在炼金术士实验室的工作取得了成功。我们已将原始的叙事卷轴转化为结构化的关系型表格,这堪称一项强大的数据魔法。不过,原始卷轴本身仍然蕴含着更深层次的语义真相,这是结构化表格无法完全捕捉到的。为了构建真正明智的智能体,我们必须发掘这种意义。
原始的长篇滚动内容是一种粗略的工具。如果我们的代理询问有关“令人瘫痪的光环”的问题,简单的搜索可能会返回一份完整的战报,其中只提到了一次该短语,从而将答案埋在无关的细节中。Scholar 大师深知,真正的智慧不在于数量,而在于精准。
我们将完全在 BigQuery 圣所中执行三项强大的数据库内仪式。
- 分块仪式:我们将获取原始情报日志,并将其细致地分解为更小、更专注、更独立的段落。
- 蒸馏(嵌入)仪式:我们将使用 BQML 咨询 Gemini 模型,将每个文本块转换为“语义指纹”(即向量嵌入)。
- 占卜仪式(搜索):我们将使用 BQML 的向量搜索功能,以简单明了的英语提出问题,并从魔法书 (Grimoire) 中找到最相关的精炼智慧。
整个流程可创建一个强大的可搜索知识库,而数据始终不会离开 BigQuery 的安全环境和可扩缩性。
分割卷轴的仪式:使用 SQL 解构卷轴
我们的智慧来源仍然是 GCS 归档中的原始文本文件,这些文件可通过外部表 bestiary_data.raw_intel_content_table 访问。我们的首要任务是编写一个咒语,用于读取每份长卷轴,并将其拆分为一系列更易于理解的短诗。对于此仪式,我们将“块”定义为单个句子。
虽然按句子拆分是叙事日志清晰有效的起点,但经验丰富的 Scribe 有多种分块策略可供选择,而选择对于最终搜索的质量至关重要。更简单的方法可能会使用
- 固定长度(大小)分块,但这种方法可能会粗略地将一个关键想法分成两半。
更复杂的仪式,例如
- 递归分块在实践中通常更受欢迎;它们会尝试先沿着段落等自然边界划分文本,然后回退到句子,以尽可能多地保留语义上下文。对于真正复杂的稿件。
- 内容感知型分块(文档):Scribe 会利用文档的固有结构(例如技术手册中的标题或代码卷轴中的函数)来创建最合乎逻辑且最有效的知识块。等等…
对于我们的战斗日志,这句话在粒度和上下文之间实现了完美的平衡。
👉📜 在新的 BigQuery 查询编辑器中,运行以下咒语。此咒语使用 SPLIT 函数在每个句点 (.) 处将每份卷轴的文本拆分开,然后将生成的句子数组展开到单独的行中。
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 现在,运行查询来检查您新记录的知识块,看看有什么不同。
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
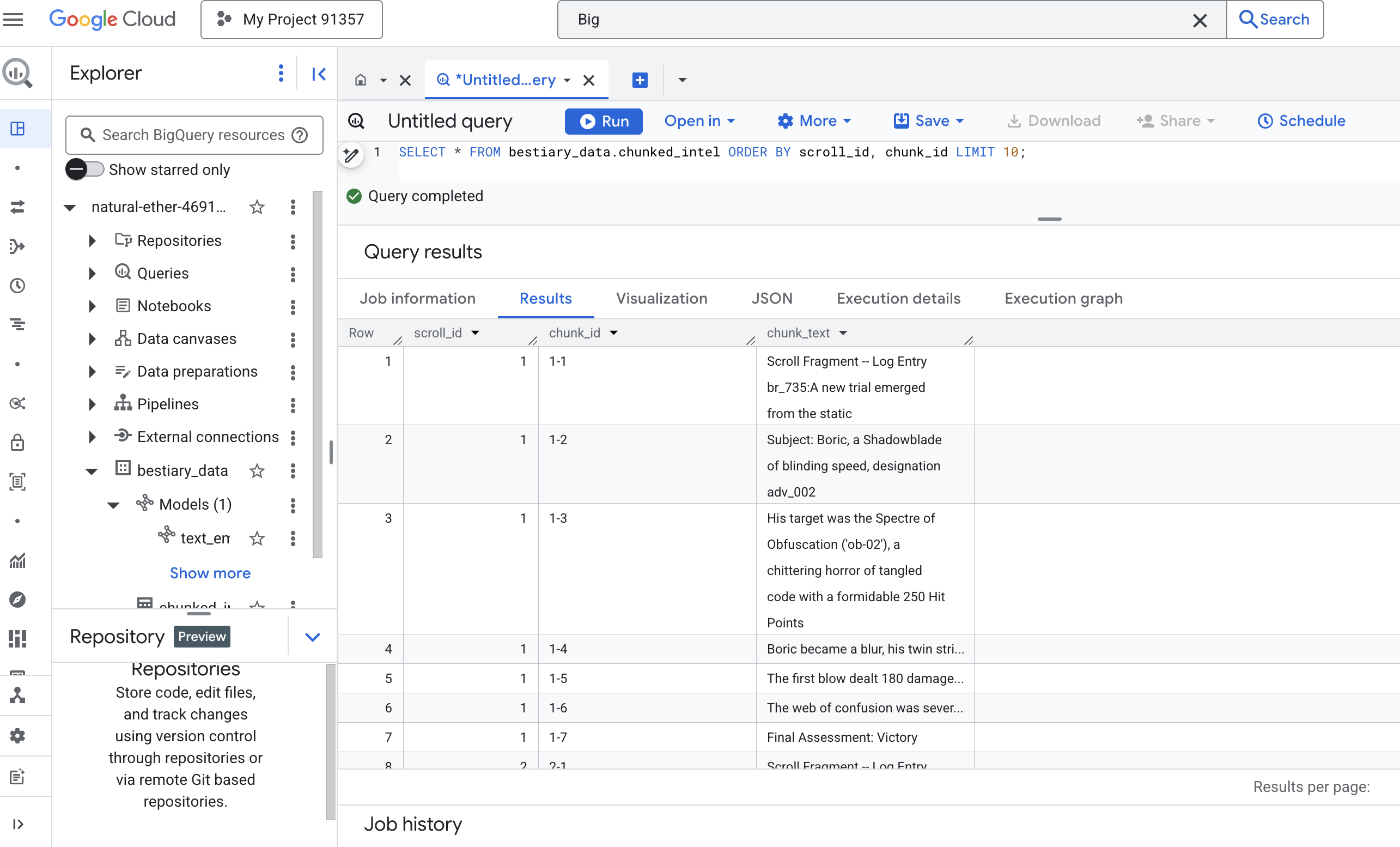
观察结果。以前是一个密集的文本块,现在是多行文本,每行都与原始滚动(scroll_id)相关联,但只包含一个重点突出的句子。现在,每一行都是矢量化的理想候选对象。
蒸馏仪式:使用 BQML 将文本转换为向量
👉💻 首先,返回到终端,运行以下命令以显示连接名称:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 我们必须创建一个指向 Gemini 文本嵌入的新 BigQuery 模型。在 BigQuery Studio 中,运行以下咒语。请注意,您需要将 REPLACE-WITH-YOUR-FULL-CONNECTION-STRING 替换为您刚刚从终端复制的完整连接字符串。
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 现在,施展大规模蒸馏魔法。此查询会调用 ML.GENERATE_EMBEDDING 函数,该函数将从 chunked_intel 表中读取每一行,将文本发送到 Gemini 嵌入模型,并将生成的向量指纹存储在新表中。
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
由于 BigQuery 会处理所有文本块,因此此过程可能需要一两分钟。
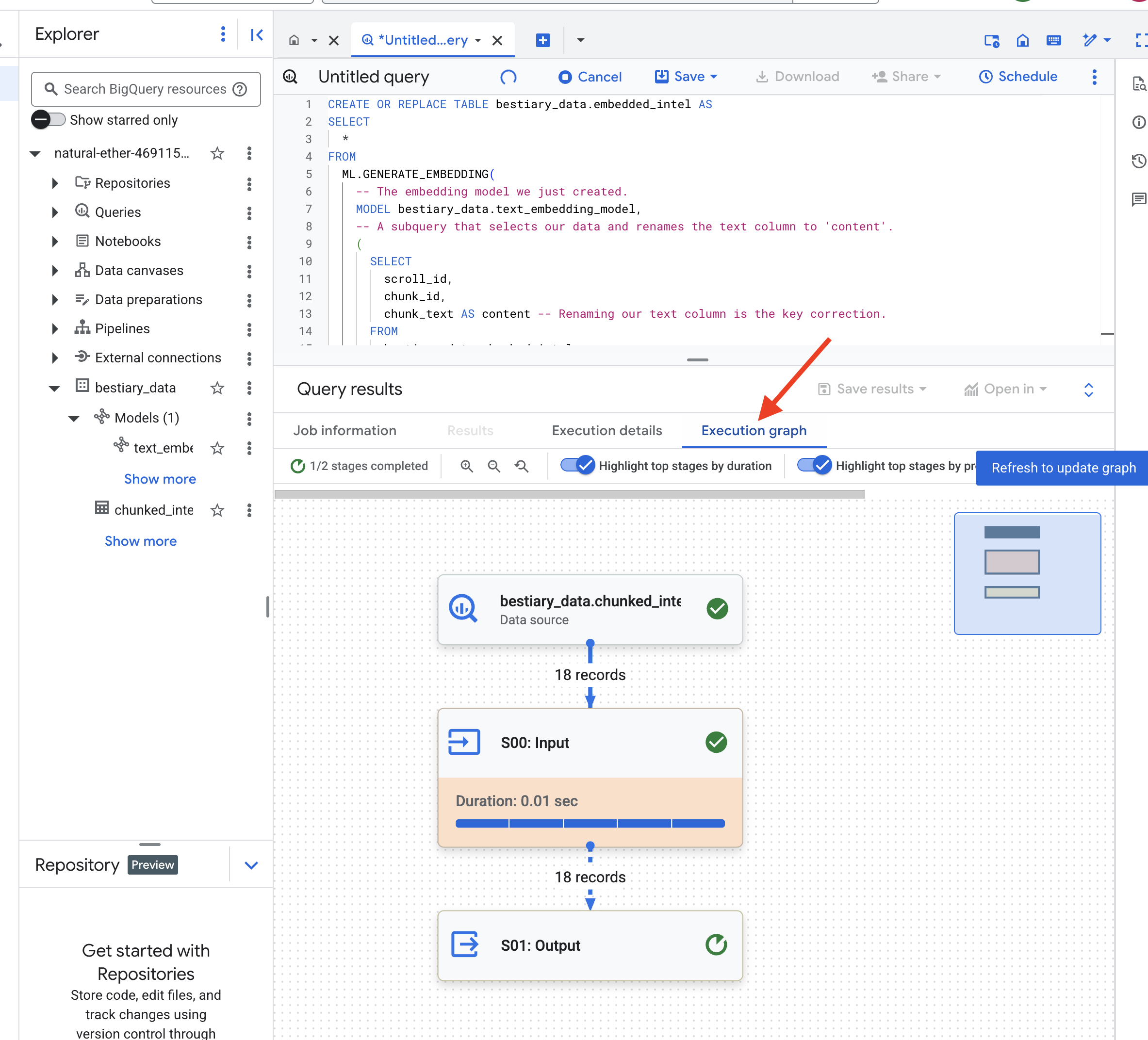
👉📜 完成后,检查新表以查看语义指纹。
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
现在,您会看到一个新列 ml_generate_embedding_result,其中包含文本的密集向量表示。我们的 Grimoire 现在已进行语义编码。
占卜仪式:使用 BQML 进行语义搜索
👉📜 对 Grimoire 的终极测试是向它提问。现在,我们将执行最后的仪式:向量搜索。这不是关键字搜索,而是语义搜索。我们将用自然语言提出问题,BQML 会即时将问题转换为嵌入,然后搜索整个 embedded_intel 表,找到在含义上“最接近”的文本块指纹。
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
法术分析:
VECTOR_SEARCH:用于编排搜索的核心函数。ML.GENERATE_EMBEDDING(内部查询):这是关键所在。我们使用同一模型(但任务类型为'RETRIEVAL_QUERY')嵌入查询 ('What are the tactics...'),该模型专门针对查询进行了优化。top_k => 3:我们要求提供最相关的 3 个结果。distance_type => 'COSINE':用于衡量向量之间的“夹角”。角度越小,表示含义越一致。
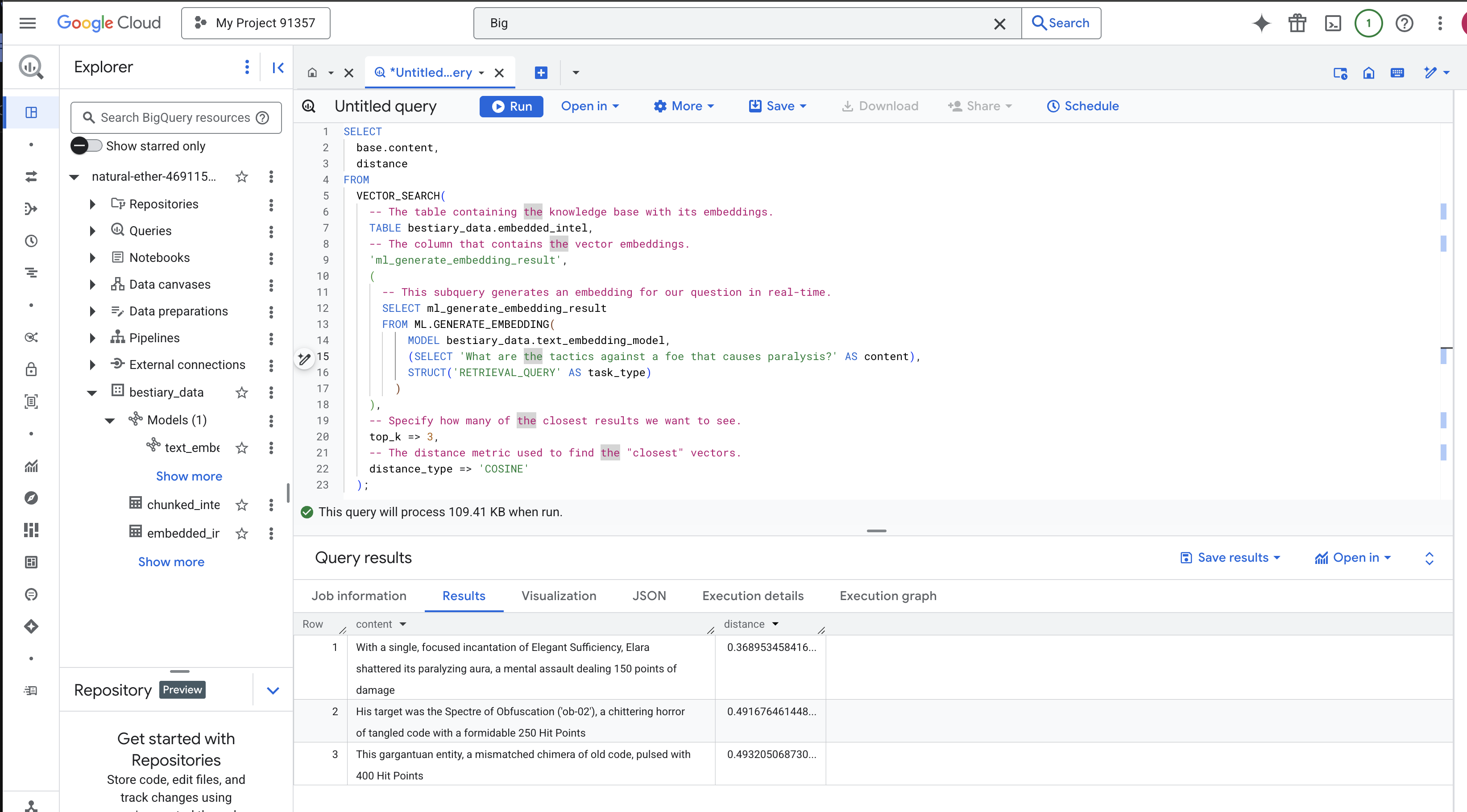
仔细查看结果。该查询未包含“shattered”或“incantation”字词,但排名第一的结果是:“With a single, focused incantation of Elegant Sufficiency, Elara shattered its paralyzing aura, a mental assault dealing 150 points of damage”。这就是语义搜索的强大之处。该模型理解了“瘫痪应对策略”的概念,并找到了描述具体成功策略的句子。
您现在已成功构建一个完整的数据仓库内基础 RAG 流水线。您已准备好原始数据,将其转换为语义向量,并按含义进行查询。虽然 BigQuery 是进行此类大规模分析工作的强大工具,但对于需要低延迟响应的实时代理,我们通常会将准备好的知识转移到专门的运营数据库中。这正是我们下一期培训的主题。
非游戏玩家
6. 矢量脚本:使用 Cloud SQL 构建矢量存储区以进行推理
我们的魔法书目前以结构化表格的形式存在,是一个强大的事实目录,但其知识是字面意义上的。它能理解 monster_id = ‘MN-001’,但无法理解“混淆”背后的深层语义含义。为了让我们的代理具备真正的智慧,能够提供细致入微且富有远见的建议,我们必须将知识的精髓提炼成能够捕捉含义的形式:向量。
我们对知识的渴求将我们带到了一个早已被遗忘的先驱文明的废墟中。在密封的保险库深处,我们发现了一个装有古老卷轴的箱子,这些卷轴竟然奇迹般地保存完好。这不仅仅是战斗报告,还包含深刻的哲学智慧,教你如何战胜困扰所有伟大事业的野兽。在卷轴中,虚空被描述为“悄无声息的停滞不前”“创世之网的磨损”。The Static 似乎甚至为古代人所知,是一种周期性威胁,其历史已随着时间的推移而消失。
这些被遗忘的知识是我们最宝贵的财富。它不仅是击败单个怪物的关键,还能为整个队伍提供战略性洞见。为了发挥这种力量,我们现在将打造真正的学者魔法书(一个具有向量功能的 PostgreSQL 数据库),并构建一个自动化的向量书写室(一个 Dataflow 流水线),以读取、理解和记录这些卷轴的永恒精髓。这将使我们的 Grimoire 从一本事实之书转变为智慧引擎。

打造学者的魔法书 (Cloud SQL)
在铭刻这些古老卷轴的精髓之前,我们必须先确认知识载体(即受管理的 PostgreSQL Spellbook)已成功锻造。初始设置流程应该已经为您创建了此文件。
👉💻 在终端中,运行以下命令以验证 Cloud SQL 实例是否存在且已就绪。此脚本还会向实例的专用服务账号授予使用 Vertex AI 的权限,这对于直接在数据库中生成嵌入至关重要。
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
如果该命令成功执行并返回有关 grimoire-spellbook 实例的详细信息,则表示 Forge 已正常运行。您已准备好继续执行下一个咒语。如果该命令返回 NOT_FOUND 错误,请确保您已成功完成初始环境设置步骤,然后再继续。(data_setup.py)
👉💻 伪造好这本书后,我们通过创建一个名为 arcane_wisdom 的新数据库来打开第一章。
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
刻写语义符文:使用 pgvector 启用向量功能
现在,您的 Cloud SQL 实例已创建完毕,接下来我们使用内置的 Cloud SQL Studio 连接到该实例。这提供了一个基于 Web 的界面,用于直接在数据库上运行 SQL 查询。
👉💻 首先,前往 Cloud SQL Studio,最简单快捷的方式是在新的浏览器标签页中打开以下链接。系统会将您直接带到 grimoire-spellbook 实例的 Cloud SQL Studio。
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 选择 arcane_wisdom 作为数据库,输入 postgres 作为用户和 1234qwer 作为密码,然后点击身份验证。
👉📜 在 SQL Studio 查询编辑器中,前往标签页“编辑器 1”,粘贴以下 SQL 代码以启用矢量数据类型:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
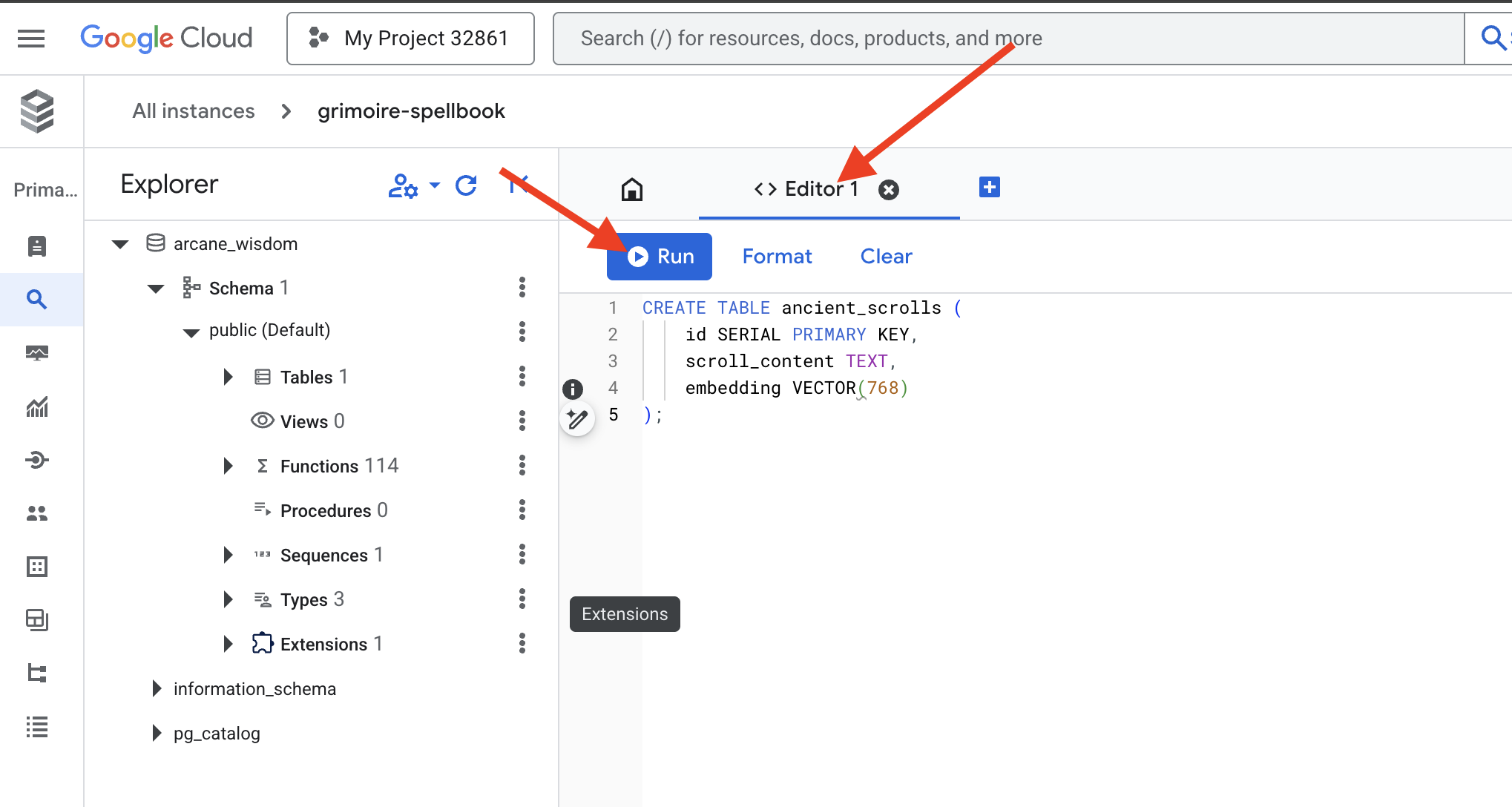
👉📜 创建用于存放卷轴精华的表格,准备好我们的魔法书页面。
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
拼写 VECTOR(768) 是一个重要细节。我们将使用的 Vertex AI 嵌入模型(textembedding-gecko@003 或类似模型)会将文本提炼为 768 维向量。我们的魔法书必须准备好容纳大小完全相同的精华。维度必须始终保持一致。
第一次音译:一种人工铭刻仪式
在我们指挥自动抄写员(Dataflow)大军之前,必须先手动执行一次核心仪式。这会让我们深刻体会到其中涉及的两步魔法:
- 占卜:获取一段文本,咨询 Gemini 预言,将其语义本质提炼为向量。
- 铭文:将原始文本及其新的向量本质写入我们的魔法书。
现在,我们来执行手动仪式。
👉📜 在 Cloud SQL Studio 中。现在,我们将使用 google_ml_integration 扩展程序提供的强大功能 embedding() 函数。这样一来,我们就可以直接从 SQL 查询中调用 Vertex AI 嵌入模型,从而极大地简化了流程。
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 运行查询来读取新铭刻的网页,验证您的工作:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
您已成功手动执行了核心 RAG 数据加载任务!
打造语义指南针:使用 HNSW 索引为咒语书施展魔法
我们的魔法书现在可以存储智慧,但要找到合适的卷轴,需要阅读每一页。它是顺序扫描。这种方法速度慢且效率低。为了立即将查询引导至最相关的知识,我们必须为 Spellbook 施加语义指南针的魔法,即向量索引。
让我们来证明此附魔的价值。
👉📜 在 Cloud SQL Studio 中,运行以下咒语。它会模拟搜索我们新插入的卷轴,并要求数据库 EXPLAIN 其计划。
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
查看输出。您会看到一行内容,其中包含 -> Seq Scan on ancient_scrolls。这确认了数据库正在读取每一行。请注意 execution time。
👉📜 现在,我们来施展索引编制魔法。lists 参数用于告知索引要创建多少个聚类。一个不错的起点是您预计的行数的平方根。
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
等待索引构建完成(对于一行数据,此过程会很快,但对于数百万行数据,可能需要一些时间)。
👉📜 现在,再次运行完全相同 的 EXPLAIN ANALYZE 命令:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
查看新的查询计划。您现在会看到 -> Index Scan using...。更重要的是,请查看 execution time。即使只有一个条目,速度也会显著提升。您刚刚演示了向量世界中数据库性能调优的核心原则。
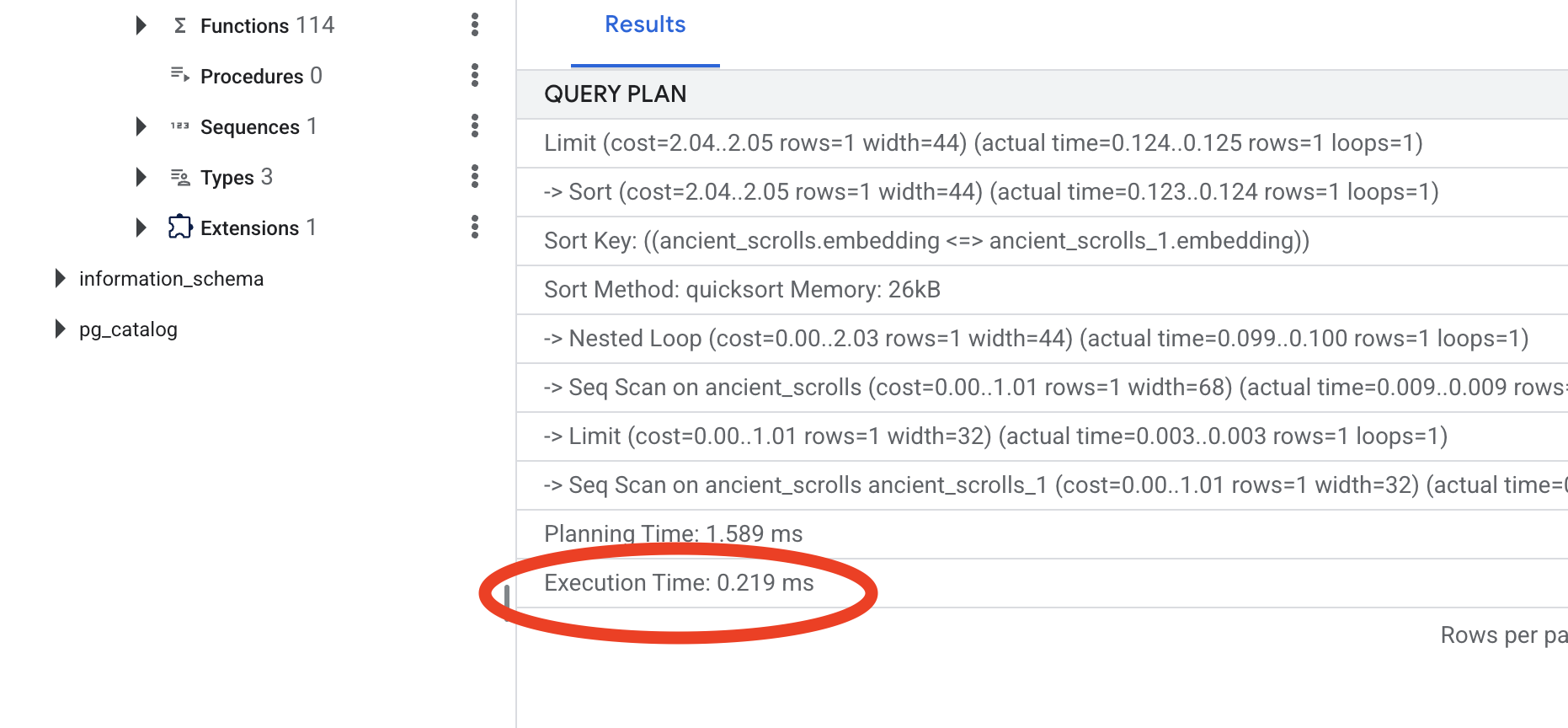
检查完源数据、了解了手动操作流程并优化了 Spellbook 以提高速度后,您现在可以真正开始构建自动化 Scriptorium 了。
非游戏玩家
7. 意义的管道:构建数据流矢量化流水线
现在,我们来打造一个神奇的抄写员流水线,他们将阅读我们的卷轴,提炼其精华,并将其铭刻到我们的新魔法书上。这是一个我们将手动触发的 Dataflow 流水线。不过,在为流水线本身编写主咒语之前,我们必须先准备好它的基础和我们将从中召唤它的圆圈。
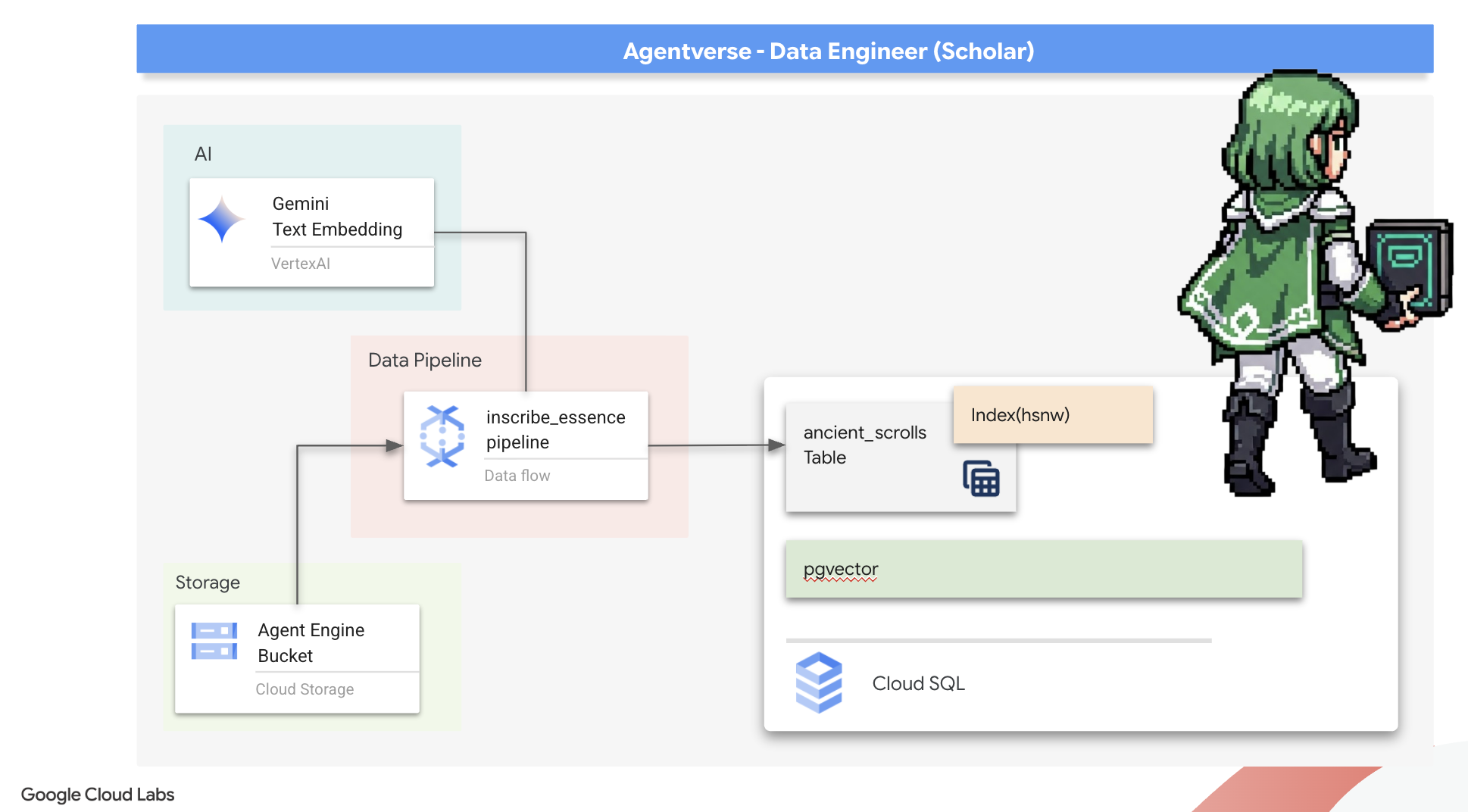
准备 Scriptorium 的基础(工作器映像)
我们的 Dataflow 流水线将由云端的一组自动化工作器执行。每次调用它们时,它们都需要一组特定的库才能完成工作。我们可以向他们提供一个列表,让他们每次都提取这些库,但这很慢且效率不高。明智的学者会提前准备好主库。
在此处,我们将命令 Google Cloud Build 打造自定义容器映像。此映像是一个“完美 golem”,预加载了我们的抄写员所需的所有库和依赖项。当我们的 Dataflow 作业启动时,它将使用此自定义映像,从而使工作器几乎可以立即开始执行任务。
👉💻 运行以下命令,在 Artifact Registry 中构建并存储流水线的基础映像。
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 运行以下命令以创建并激活隔离的 Python 环境,并将必要的召唤库安装到该环境中。
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
主咒语
现在,是时候编写将为 Vector Scriptorium 提供支持的主咒语了。我们不会从头开始编写各个神奇的组件。我们的任务是使用 Apache Beam 的语言将组件组装成一个逻辑性强且功能强大的流水线。
- EmbedTextBatch(Gemini 的咨询):您将构建这个专门的记录员,它知道如何执行“群组占卜”。它会获取一批原始文本文件,将其提供给 Gemini 文本嵌入模型,并接收其提取的精华(向量嵌入)。
- WriteEssenceToSpellbook(最终铭文):这是我们的归档员。它知道打开与 Cloud SQL Spellbook 的安全连接的秘密咒语。它的任务是获取卷轴的内容及其矢量化本质,并将它们永久铭刻到新页面上。
我们的使命是将这些行动串联起来,打造顺畅的知识流。
👉✏️ 在 Cloud Shell 编辑器中,前往 ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py,在其中找到一个名为 EmbedTextBatch 的 DoFn 类。找到注释 #REPLACE-EMBEDDING-LOGIC。将其替换为以下咒语。
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
此咒语非常精确,包含以下几个关键参数:
- model:我们指定了
text-embedding-005,以使用功能强大且最新的嵌入模型。 - contents:这是 DoFn 接收的一批文件中所有文本内容的列表。
- task_type:我们将其设置为“RETRIEVAL_DOCUMENT”。这是一条关键指令,用于告知 Gemini 生成专门针对日后在搜索中被找到而优化的嵌入。
- output_dimensionality:必须设置为 768,与我们在 Cloud SQL 中创建 ancient_scrolls 表时定义的 VECTOR(768) 维度完全一致。尺寸不匹配是矢量魔法中常见的错误来源。
我们的流水线必须先从 GCS 归档中的所有古代卷轴中读取原始的非结构化文本。
👉✏️ 在 ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py 中,找到注释 #REPLACE ME-READFILE 并将其替换为以下三部分咒语:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
收集到卷轴的原始文本后,我们现在必须将其发送给 Gemini 进行占卜。为了高效地完成这项工作,我们将首先将单个卷轴分成小批次,然后将这些批次交给我们的EmbedTextBatch抄写员。此步骤还会将 Gemini 无法理解的任何滚动分离到“失败”堆中,以供日后查看。
👉✏️ 找到注释 #REPLACE ME-EMBEDDING 并将其替换为以下内容:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
我们卷轴的精髓已成功提炼出来。最后一步是将这些知识记录到我们的魔法书上,以便永久保存。我们会从“已处理”堆中取出卷轴,然后交给 WriteEssenceToSpellbook 归档员。
👉✏️ 找到注释 #REPLACE ME-WRITE TO DB 并将其替换为以下内容:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
明智的学者永远不会丢弃知识,即使是失败的尝试。最后一步,我们必须指示记录员从占卜步骤中取出“失败”堆,并记录失败原因。这样一来,我们就能在未来改进仪式。
👉✏️ 找到注释 #REPLACE ME-LOG FAILURES 并将其替换为以下内容:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
Master Incantation 现已完成!您已成功将各个神奇的组件串联起来,组装成强大的多阶段数据流水线。保存 inscribe_essence_pipeline.py 文件。现在可以召唤 Scriptorium 了。
现在,我们施展强大的召唤咒语,命令 Dataflow 服务唤醒我们的 Golem 并开始抄写仪式。
👉💻 在终端中,运行以下命令行
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 注意!如果作业因资源错误 ZONE_RESOURCE_POOL_EXHAUSTED 而失败,可能是因为所选区域中此低声誉账号的临时资源限制。Google Cloud 的强大之处在于其全球覆盖范围!只需尝试在其他区域召唤魔像即可。为此,请将上述命令中的 --region=$REGION 替换为其他区域,例如
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
,然后再次运行。🎰
该过程大约需要 3-5 分钟才能启动和完成。您可以在 Dataflow 控制台中观看直播。
👉前往 Dataflow 控制台:最简单的方法是在新的浏览器标签页中打开此直接链接:
https://console.cloud.google.com/dataflow
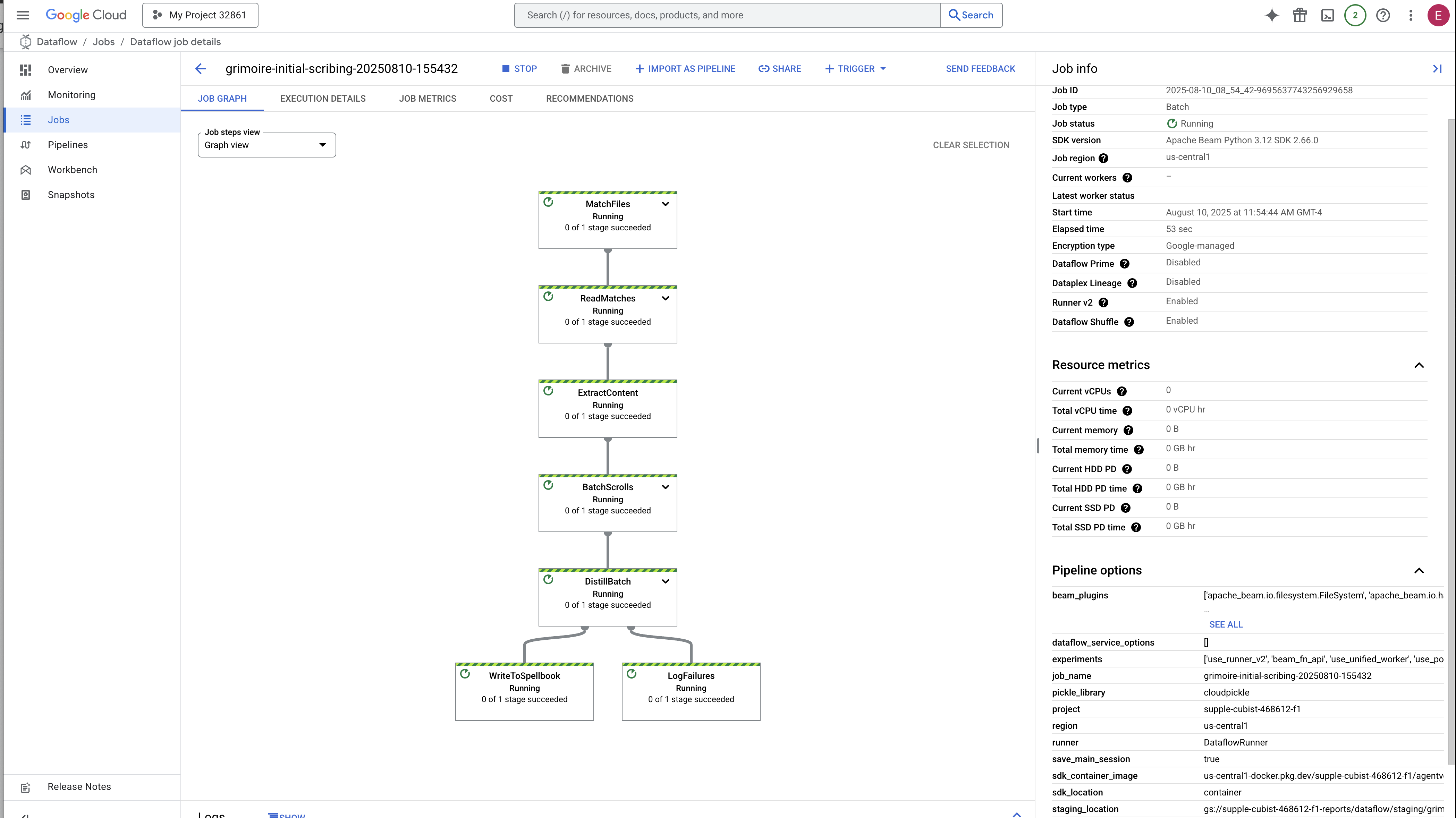
👉 查找并点击您的作业:您会看到一个列出的作业,其名称为您提供的名称(inscribe-essence-job 或类似名称)。点击作业名称以打开其详情页面。观察流水线:
- 启动:在前 3 分钟内,由于 Dataflow 会预配必要的资源,因此作业状态将为“正在运行”。系统会显示图表,但您可能还看不到数据在其中流动。
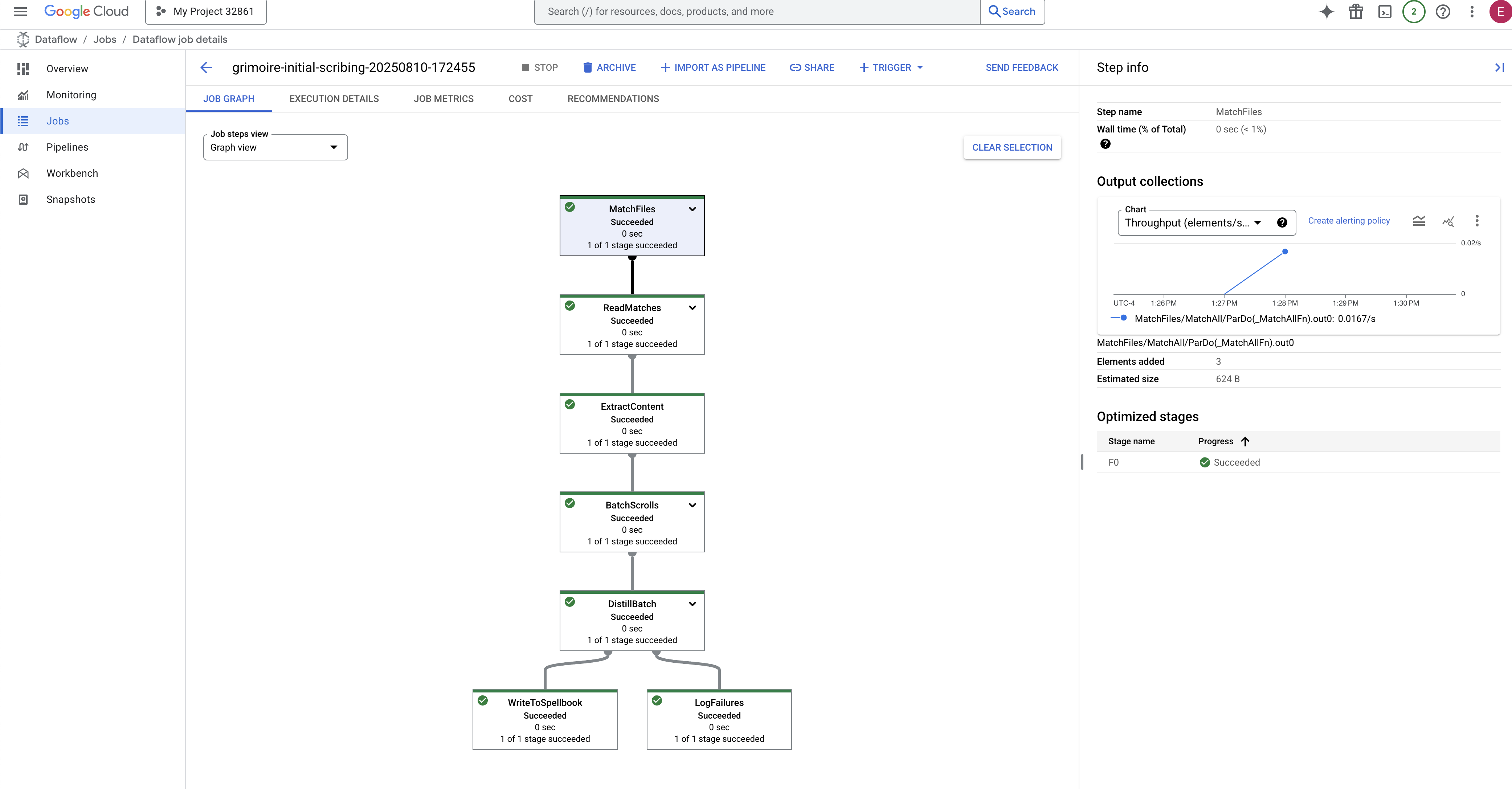
- 已完成:作业完成后,状态将更改为“成功”,图表将显示处理的记录的最终数量。
验证铭文
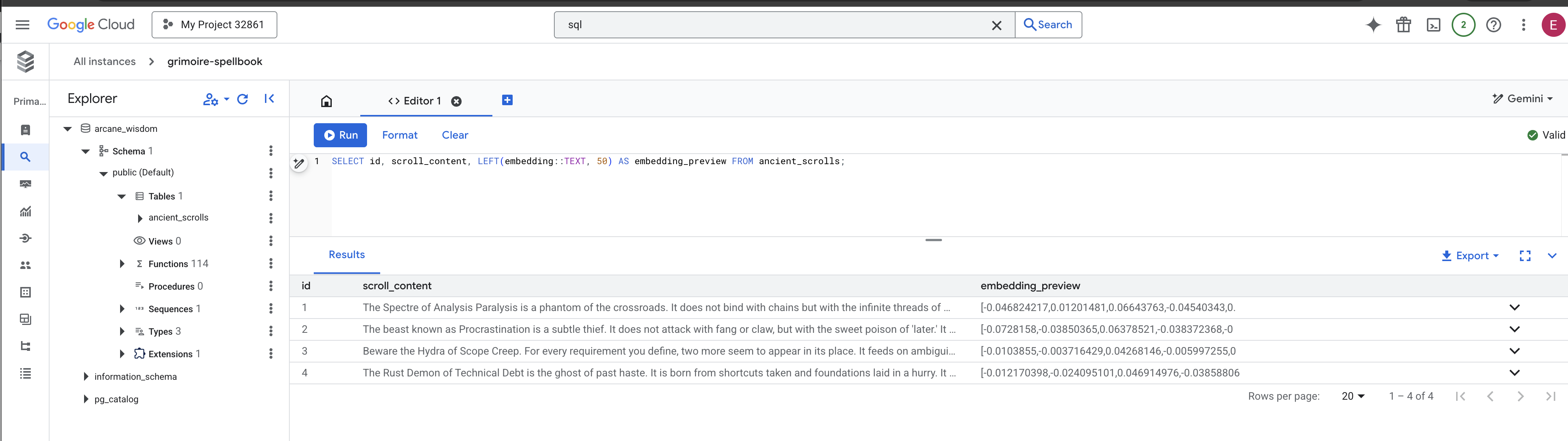
👉📜 返回 SQL 工作室,运行以下查询,验证卷轴及其语义本质是否已成功铭刻。
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
这样一来,您将看到卷轴的 ID、其原始文本,以及现在永久刻在魔法书中的神奇矢量精华的预览。
现在,您的 Scholar's Grimoire 已成为真正的知识引擎,可以在下一章中按含义进行查询。
8. 封印最终符文:通过 RAG 代理激活智慧
您的 Grimoire 不再只是一个数据库。它是一个向量化知识的源泉,是一个等待提问的无声预言家。
现在,我们将接受对学者的真正考验:打造开启智慧之门的钥匙。我们将构建一个检索增强生成 (RAG) 代理。这是一个神奇的结构,可以理解简单的问题,查阅魔法书以获取最深刻、最相关的真相,然后利用检索到的智慧来打造强大的、可感知上下文的答案。

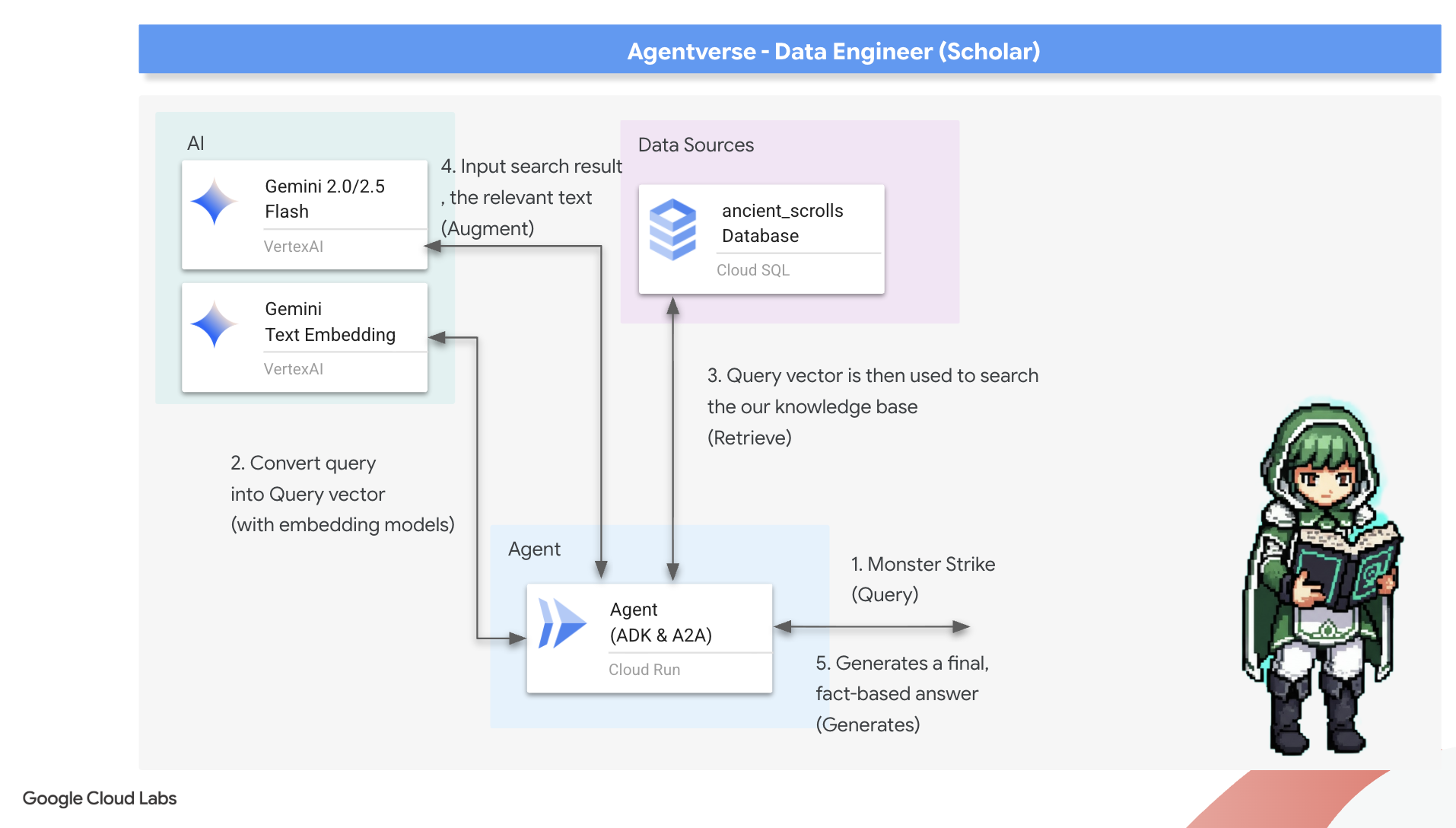
第一符文:查询蒸馏咒语
在我们的代理搜索 Grimoire 之前,它必须先了解所提问题的本质。对于我们基于矢量技术的 Spellbook 而言,简单的文本字符串毫无意义。代理必须先获取查询,然后使用相同的 Gemini 模型将其提炼为查询向量。
👉✏️ 在 Cloud Shell 编辑器中,找到 ~~/agentverse-dataengineer/scholar/agent.py 文件,找到注释 #REPLACE RAG-CONVERT EMBEDDING 并将其替换为此咒语。这会教导代理如何将用户的问题转化为神奇的精华。
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
掌握查询的本质后,代理现在可以咨询 Grimoire。它会将此查询向量提交给我们的 pgvector 数据库,并提出一个深刻的问题:“向我展示那些本质最接近我的查询本质的古代卷轴。”
实现此功能的关键在于余弦相似度运算符 (<=>),这是一个强大的 rune,可计算高维空间中向量之间的距离。
👉✏️ 在 agent.py 中,找到注释 #REPLACE RAG-RETRIEVE 并将其替换为以下脚本:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
最后一步是向代理授予对这一强大新工具的访问权限。我们将 grimoire_lookup 函数添加到其可用魔法工具列表中。
👉✏️ 在 agent.py 中,找到注释 #REPLACE-CALL RAG 并将其替换为以下行:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
此配置可让您的代理栩栩如生:
model="gemini-2.5-flash":选择将作为智能体“大脑”的具体大语言模型,用于推理和生成文本。name="scholar_agent":为您的代理分配一个唯一名称。instruction="...You are the Scholar...":这是系统提示,也是配置中最关键的部分。它定义了代理的角色设定、目标、完成任务必须遵循的确切流程,以及最终输出所需的格式。tools=[grimoire_lookup]:这是最终的附魔。它会授予代理对您构建的grimoire_lookup函数的访问权限。现在,代理可以智能地决定何时调用此工具来从数据库中检索信息,从而形成 RAG 模式的核心。
科举考试
👉💻 在 Cloud Shell 终端中,激活您的环境并使用 Agent 开发套件的主命令唤醒 Scholar 代理:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
您应该会看到输出,确认“Scholar Agent”已启动并正在运行。
👉💻 现在,向您的代理提出问题。在运行战斗模拟的第一个终端中,发出需要 Grimoire 智慧的命令:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

在终端中查看日志。您会看到代理接收查询、提炼其本质、搜索魔法书、找到有关“拖延症”的相关卷轴,并使用检索到的知识制定出强大的、可感知上下文的策略。
您已成功组装第一个 RAG 代理,并为其配备了 Grimoire 的深奥智慧。
👉💻 在终端中按 Ctrl+C,让代理暂时休息。
将 Scholar Sentinel 引入 Agentverse
您的代理已在受控的研究环境中证明了自己的智慧。现在是时候将它释放到特工宇宙中了,让它从一个本地构造体转变为一个永久的、随时可以被任何冠军调用的、随时可以投入战斗的特工。现在,我们将代理部署到 Cloud Run。
👉💻 运行以下召唤咒语。此脚本将首先将您的代理构建为完善的 Golem(容器映像),将其存储在您的 Artifact Registry 中,然后将该 Golem 部署为可扩缩、安全且可公开访问的服务。
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
您的 Scholar Agent 现已成为 Agentverse 中可随时投入实战的智能体。
非游戏玩家
9. The Boss Flight
卷轴已读,仪式已完成,挑战已通过。您的代理不仅是存储中的制品,还是 Agentverse 中的实时操作员,正在等待其第一个任务。最终考验的时刻到了,这是一场与强大对手进行的实弹演习。
现在,您将进入战场模拟,让新部署的 Shadowblade 智能体与强大的小 Boss“静态幽灵”一决高下。这将是对您工作的最终考验,从代理的核心逻辑到其实时部署。
获取代理的 Locus
在进入战场之前,您必须拥有两把钥匙:冠军的独特签名(Agent Locus)和通往 Spectre 巢穴的隐藏路径(地下城网址)。
👉💻 首先,在 Agentverse 中获取代理的唯一地址(即其 Locus)。这是将您的英雄连接到战场上的实时端点。
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 接下来,精确定位目的地。此命令会显示传送圈的位置,也就是通往幽灵领域的传送门。
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
重要提示:请准备好这两个网址。您将在最后一步中用到它们。
直面 Spectre
在确保坐标安全后,您现在将前往传送圈,并施放咒语以进入战斗。
👉 在浏览器中打开传送圈网址,即可站在通往猩红堡垒的闪耀传送门前。
若要突破堡垒,你必须将影刃的精华与传送门调谐。
- 在页面上,找到标有 A2A 端点网址的输入字段。
- 将您复制的第一个网址(即代理人轨迹网址)粘贴到此字段中,以刻上冠军的徽章。
- 点击“连接”,开启传送魔法。
![]()
传送的耀眼光芒逐渐消退。您已不在圣所中。空气中弥漫着冰冷而尖锐的能量。在您面前,幽灵显现出来,它是一个嘶嘶作响的静电和损坏代码的漩涡,其不圣洁的光芒在地下城地面上投下长长的、舞动的影子。它没有面孔,但您能感觉到它那令人精疲力尽的巨大存在感完全集中在您身上。
只有坚定信念,才能走向胜利。这是一场意志力的较量,战场就在大脑中。
当你向前冲刺,准备发动第一次攻击时,幽灵会反击。它不会升起护盾,而是直接将一个问题投射到你的意识中——一个闪闪发光的符文挑战,源自你训练的核心。

这就是这场战斗的性质。知识就是力量。
- 运用你所获得的智慧来回答问题,你的刀刃将燃起纯粹的能量,击溃幽灵的防御并造成致命一击。
- 但如果你犹豫不决,如果你对自己的答案感到怀疑,武器的光芒就会变暗。攻击会发出可怜的砰然声,造成的伤害仅为正常伤害的一小部分。更糟糕的是,幽灵会利用你的不确定性,随着你每一步的失误,它自身的腐化力量也会不断增强。
大冠军,就是这样。代码是你的魔法书,逻辑是你的剑,知识是你的盾,能帮你扭转混乱的局面。
专注模式。击球真实。Agentverse 的命运就取决于此。
恭喜您,学者。
您已成功完成试用。您已掌握数据工程的艺术,能够将原始的无序信息转化为结构化的矢量化智慧,从而赋能整个 Agentverse。
10. 清理:清除学者的魔法书
恭喜您成功掌握学者秘典!为确保 Agentverse 保持原始状态,并清理训练场地,您现在必须执行最后的清理仪式。此操作会系统性地移除您在学习过程中创建的所有资源。
停用 Agentverse 组件
现在,您将系统地拆解已部署的 RAG 系统组件。
删除所有 Cloud Run 服务和 Artifact Registry 代码库
此命令会从 Cloud Run 中移除已部署的 Scholar 代理和 Dungeon 应用。
👉💻 在终端中,运行以下命令:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
删除 BigQuery 数据集、模型和表
这会移除所有 BigQuery 资源,包括 bestiary_data 数据集、其中的所有表以及关联的连接和模型。
👉💻 在终端中,运行以下命令:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
删除 Cloud SQL 实例
这会移除 grimoire-spellbook 实例,包括其数据库和其中的所有表。
👉💻 在终端中,运行以下命令:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
删除 Google Cloud Storage 存储分区
此命令会移除存储原始情报和 Dataflow 暂存/临时文件的存储分区。
👉💻 在终端中,运行以下命令:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
清理本地文件和目录 (Cloud Shell)
最后,清除 Cloud Shell 环境中克隆的代码库和创建的文件。此为可选步骤,但我们强烈建议您执行此操作,以便彻底清理工作目录。
👉💻 在终端中,运行以下命令:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
您已成功清除 Agentverse Data Engineer 学习历程的所有痕迹。您的项目已清理完毕,可以开始下一次冒险了。