
1. 序曲
孤立開發的時代即將結束。下一波技術演進浪潮並非由天才獨領風騷,而是集眾人之力。建立單一智慧代理程式是一項有趣的實驗。建構強大、安全且智慧的代理程式生態系統 (也就是真正的 Agentverse),是現代企業面臨的重大挑戰。
在這個新時代,要取得成功,就必須整合四個重要角色,也就是支撐任何蓬勃發展的代理式系統的基礎支柱。任何一個領域的不足都會造成弱點,進而危害整個結構。
這場研討會是企業的必備手冊,可協助您在 Google Cloud 上掌握 AI 代理的未來趨勢。我們提供端對端藍圖,引導您從最初的想法,到全面運作的現實。在四個相互關聯的實驗室中,您將瞭解開發人員、架構師、資料工程師和 SRE 的專業技能如何匯聚,共同建立、管理及擴充強大的 Agentverse。
單一支柱無法單獨支援 Agentverse。如果沒有開發人員的精確執行,架構師的宏偉設計就毫無用處。如果沒有資料工程師的智慧,開發人員的代理程式就無法運作;如果沒有 SRE 的保護,整個系統就會很脆弱。唯有透過協同合作,並對彼此的角色有共同的瞭解,團隊才能將創新概念轉化為攸關任務的營運實況。您的旅程由此開始。準備好精通自己的職責,並瞭解自己在整體架構中扮演的角色。
歡迎參加「The Agentverse:A Call to Champions」
在企業廣闊的數位領域中,新時代已然來臨。我們正處於代理時代,這個時代充滿無限可能,智慧型自主代理將完美協作,加速創新並消除繁瑣事務。

這個連結的能量和潛力生態系統稱為「Agentverse」。
但一種稱為「靜態」的無聲腐敗現象,已開始侵蝕這個新世界的邊緣。「靜態」並非病毒或錯誤,而是混亂的化身,以創作行為本身為食。
這些舊有的挫敗感會以駭人的形式放大,催生出七大開發幽靈。如果未勾選,The Static 和其 Spectres 會讓進度停滯不前,將 Agentverse 的承諾變成技術債和廢棄專案的荒地。
今天,我們呼籲各界好手挺身而出,力挽狂瀾。我們需要英雄精通自己的技藝,並攜手合作保護 Agentverse。現在來選擇路徑吧。
選擇課程
你將面臨四條截然不同的道路,每一條都是對抗「靜態」的關鍵支柱。雖然訓練是單人任務,但最終能否成功取決於你是否瞭解自己的技能如何與他人搭配。
- 影刃 (開發人員):擅長鍛造,是前線好手。您是工匠,負責打造刀刃、製作工具,並在複雜的程式碼細節中面對敵人。你的道路是精準、技能和實用創作。
- 召喚師 (架構師):偉大的策略家和自動化調度管理工具。您不會看到單一特務,而是整個戰場。您設計的藍圖可讓整個代理程式系統進行通訊、協作,並達成遠遠超出任何單一元件的目標。
- 學者 (資料工程師):尋找隱藏的真相,並守護智慧。您深入廣闊的資料荒野,發掘可賦予代理程式目標和視野的智慧。你的知識可以揭露敵人的弱點,或賦予盟友力量。
- 守護者 (DevOps / SRE):領域的堅定守護者和盾牌。您要建造堡壘、管理電力供應線,並確保整個系統能抵禦「靜電」的攻擊。你的力量是團隊獲勝的基礎。
你的任務
訓練會以獨立運動的形式開始。您將選擇適合自己的路徑,學習精通職務所需的獨特技能。試用期結束時,您將面對由靜態誕生的幽靈,這個迷你首領會利用您職業的特定挑戰來捕食。
只有精通個人角色,才能為最終試用做好準備。然後與其他班級的冠軍組成隊伍。你們將一同深入腐敗的核心,迎戰終極魔王。
最後的合作挑戰,考驗你的綜合實力,決定 Agentverse 的命運。
Agentverse 等待英雄的到來。要接聽電話嗎?
2. 學者的魔法書
我們的旅程即將展開!身為學者,知識就是我們的主要武器。我們在檔案庫 (Google Cloud Storage) 中發現大量古老難解的卷軸。這些卷軸記載著有關肆虐大地的可怕野獸的原始情報。我們的目標是運用 Google BigQuery 的強大分析魔法,以及 Gemini Elder Brain (Gemini Pro 模型) 的智慧,解讀這些非結構化文字,並將其轉化為可查詢的結構化動物寓言集。這將成為我們未來所有策略的基礎。
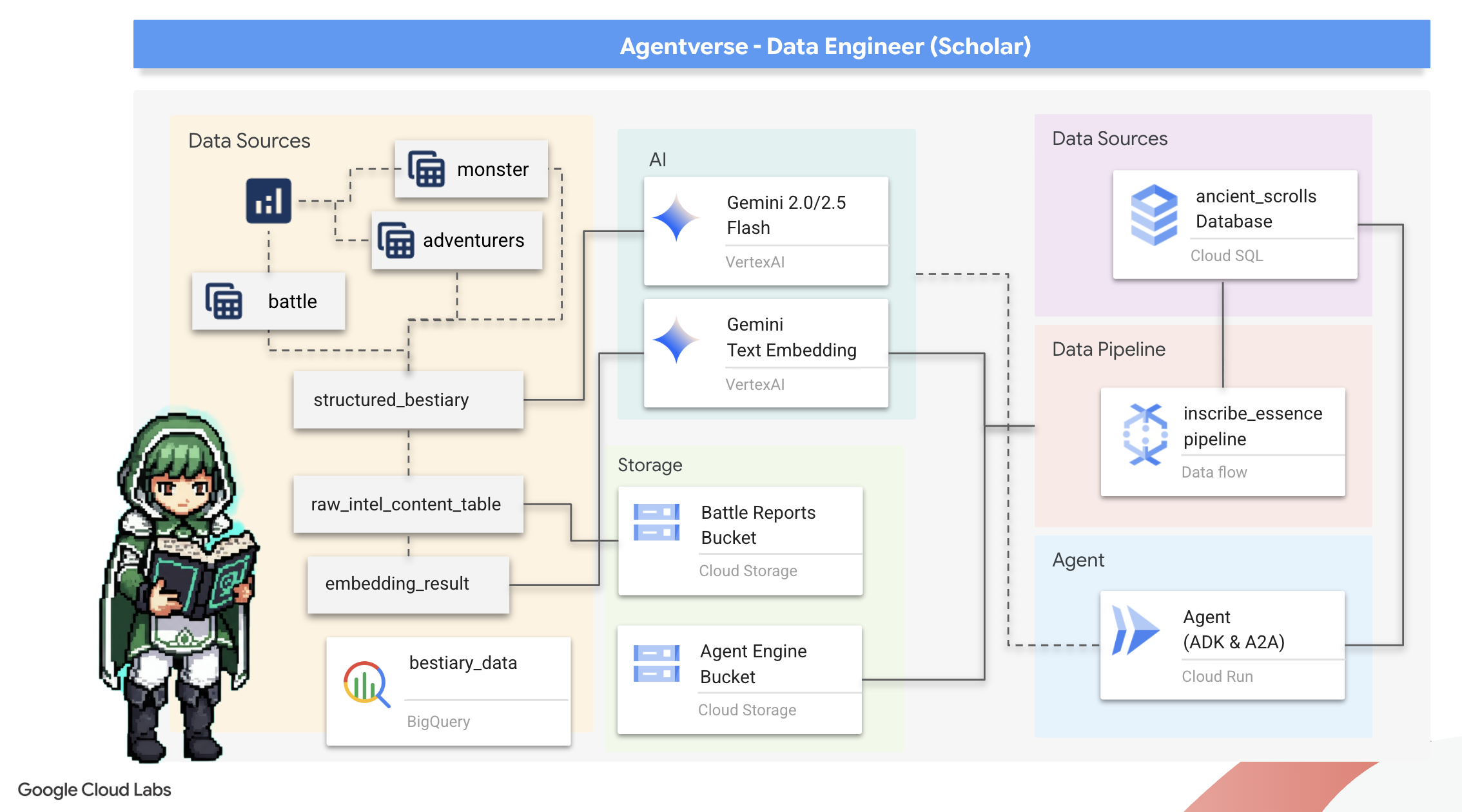
課程內容
- 使用 BigQuery 建立外部資料表,並透過 BQML.GENERATE_TEXT 和 Gemini 模型執行複雜的非結構化到結構化轉換。
- 佈建 PostgreSQL 適用的 Cloud SQL 執行個體,並啟用 pgvector 擴充功能,以支援語意搜尋功能。
- 使用 Dataflow 和 Apache Beam 建構強大的容器化批次管道,處理原始文字檔、使用 Gemini 模型生成向量嵌入,並將結果寫入關聯式資料庫。
- 在代理程式中實作基本的檢索增強生成 (RAG) 系統,查詢向量化資料。
- 在 Cloud Run 上以安全、可擴充的服務形式,部署可感知資料的代理程式。
3. 準備學者聖所
歡迎,學者。在開始抄寫魔法書的強大知識前,我們必須先準備好聖所。這項基礎儀式包括為 Google Cloud 環境施展魔法、開啟正確的入口 (API),以及建立資料魔法流動的管道。準備妥當的聖所可確保咒語效力,並保護我們的知識。
領取 Google Cloud 抵免額
⚠️ 重要前提條件:
- 使用個人 Gmail:你必須使用個人帳戶 (例如
name@gmail.com)。公司或學校管理的帳戶不適用。
👉 步驟:
- 前往抵免額申請網站: 按一下這裡
- 登入:將連結貼到網址列,然後使用個人 Gmail 登入。
- 接受條款:接受《Google Cloud Platform 服務條款》。
- 確認抵免額:查看確認抵免額已套用的訊息。
- *注意:如果系統提示您輸入信用卡資訊,請放心忽略並關閉視窗。
這樣就行了。你可以關閉視窗
設定工作環境
👉按一下 Google Cloud 控制台頂端的「啟用 Cloud Shell」(這是 Cloud Shell 窗格頂端的終端機形狀圖示),
👉按一下「Open Editor」(開啟編輯器) 按鈕 (類似於開啟資料夾和鉛筆)。視窗中會開啟 Cloud Shell 程式碼編輯器。左側會顯示檔案總管。
👉在雲端 IDE 中開啟終端機,
👉💻 在終端機中,使用下列指令驗證您是否已通過驗證,以及專案是否已設為您的專案 ID:
gcloud auth list
👉💻從 GitHub 複製啟動程序專案:
git clone https://github.com/weimeilin79/agentverse-dataengineer
chmod +x ~/agentverse-dataengineer/init.sh
chmod +x ~/agentverse-dataengineer/set_env.sh
chmod +x ~/agentverse-dataengineer/data_setup.sh
git clone https://github.com/weimeilin79/agentverse-dungeon.git
chmod +x ~/agentverse-dungeon/run_cloudbuild.sh
chmod +x ~/agentverse-dungeon/start.sh
👉💻 從專案目錄執行設定指令碼。
⚠️ 專案 ID 注意事項:指令碼會建議隨機產生的預設專案 ID。您可以按下 Enter 鍵接受這項預設值。
不過,如果您偏好建立特定新專案,可以在指令碼提示時輸入所需的專案 ID。
cd ~/agentverse-dataengineer
./init.sh
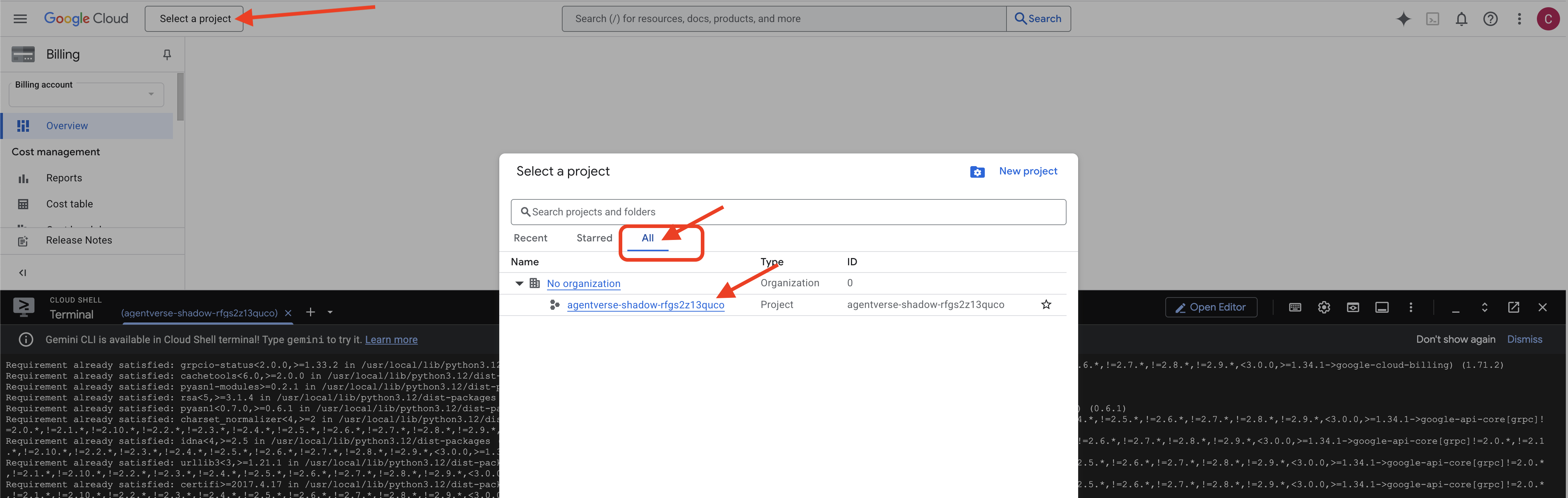
👉 完成後的重要步驟:指令碼執行完成後,請務必確認 Google Cloud 控制台顯示的專案正確無誤:
- 前往 console.cloud.google.com。
- 按一下頁面頂端的專案選取器下拉式選單。
- 按一下「全部」分頁標籤 (因為新專案可能尚未顯示在「最近」中)。
- 選取您在
init.sh步驟中設定的專案 ID。
👉💻 設定所需的專案 ID:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 執行下列指令,啟用必要的 Google Cloud API:
gcloud services enable \
storage.googleapis.com \
bigquery.googleapis.com \
sqladmin.googleapis.com \
aiplatform.googleapis.com \
dataflow.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudaicompanion.googleapis.com \
bigqueryunified.googleapis.com
👉💻 如果您尚未建立名為「agentverse-repo」的 Artifact Registry 存放區,請執行下列指令來建立:
. ~/agentverse-dataengineer/set_env.sh
gcloud artifacts repositories create $REPO_NAME \
--repository-format=docker \
--location=$REGION \
--description="Repository for Agentverse agents"
設定權限
👉💻 在終端機中執行下列指令,授予必要權限:
. ~/agentverse-dataengineer/set_env.sh
# --- Grant Core Data Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/bigquery.admin"
# --- Grant Data Processing & AI Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
# --- Grant Deployment & Execution Permissions ---
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudbuild.builds.editor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/artifactregistry.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/run.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/logging.logWriter"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/dataflow.admin"
👉💻 訓練開始後,我們就會準備最終挑戰。下列指令會從混亂的靜態狀態召喚幽靈,為最終測試建立首領。
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dungeon
./run_cloudbuild.sh
cd ~/agentverse-dataengineer
做得好,學者。基礎附魔已完成。我們的聖所安全無虞,資料元素力量的入口已開啟,我們的僕人也已獲得力量。現在可以開始實際工作了。
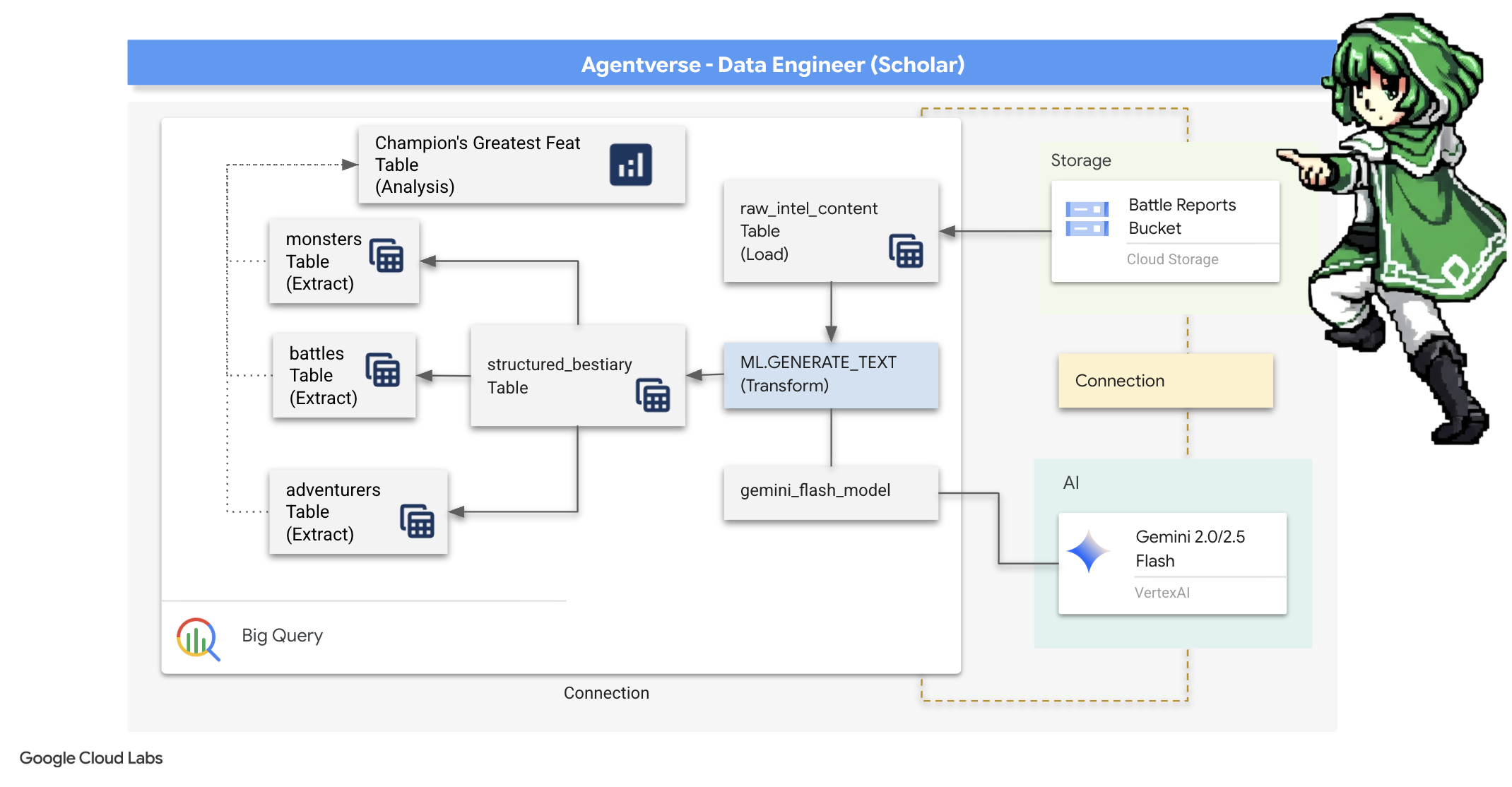
4. 知識煉金術:運用 BigQuery 和 Gemini 轉換資料
在與「靜態」的無盡戰爭中,每場「代理人宇宙」冠軍與「開發幽靈」的對決都會仔細記錄。戰場模擬系統是我們主要的訓練環境,會自動為每次遭遇戰生成乙太記錄項目。這些敘事記錄是我們最寶貴的原始情報來源,是我們學者必須從中鍛造出策略純鋼的未精煉礦石。學者的真正力量不在於僅擁有資料,而是將原始、混亂的資訊礦石轉化為閃耀、結構化的實用智慧。我們將執行資料煉金術的基礎儀式。

我們將在 Google BigQuery 的安全環境中,完成多階段的程序。首先,我們將使用神奇的鏡頭,凝視 GCS 封存內容,完全不必捲動畫面。接著,我們會召喚 Gemini 讀取並解讀戰鬥記錄中詩意且非結構化的傳奇故事。最後,我們會將原始預言精煉成一組相互連結的純淨資料表。我們的第一本魔法書。然後問一個深刻的問題,只有這個新結構才能回答。
審查鏡頭:使用 BigQuery 外部資料表深入瞭解 GCS
首先,我們要打造一個鏡頭,讓我們查看 GCS 封存內容,同時不干擾捲動。外部資料表就是這個鏡頭,可將原始文字檔對應至 BigQuery 可直接查詢的類似資料表結構。
為此,我們必須先建立穩定的能量線 (即 CONNECTION 資源),安全地將 BigQuery 聖所連結至 GCS 封存檔。
👉💻 在 Cloud Shell 終端機中執行下列指令,設定儲存空間並建立管道:
. ~/agentverse-dataengineer/set_env.sh
. ~/agentverse-dataengineer/data_setup.sh
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--project_id=${PROJECT_ID} \
--location=${REGION} \
gcs-connection
💡 注意!稍後會顯示訊息!
步驟 2 中的設定指令碼已在背景啟動程序。幾分鐘後,終端機中會彈出類似以下的訊息:[1]+ Done gcloud sql instances create ...這是正常現象。這表示您已成功建立 Cloud SQL 資料庫。您可以放心忽略這則訊息,繼續工作。
您必須先建立包含外部資料表的資料集,才能建立外部資料表。
👉💻 在 Cloud Shell 終端機中執行這個簡單的指令:
. ~/agentverse-dataengineer/set_env.sh
bq --location=${REGION} mk --dataset ${PROJECT_ID}:bestiary_data
👉💻 現在,我們必須授予管道的魔法簽章必要權限,才能從 GCS 封存檔讀取資料,並諮詢 Gemini。
. ~/agentverse-dataengineer/set_env.sh
export CONNECTION_SA=$(bq show --connection --project_id=${PROJECT_ID} --location=${REGION} --format=json gcs-connection | jq -r '.cloudResource.serviceAccountId')
echo "The Conduit's Magical Signature is: $CONNECTION_SA"
echo "Granting key to the GCS Archive..."
gcloud storage buckets add-iam-policy-binding gs://${PROJECT_ID}-reports \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/storage.objectViewer"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$CONNECTION_SA" \
--role="roles/aiplatform.user"
👉💻 在 Cloud Shell 終端機中執行下列指令,顯示 bucket 名稱:
echo $BUCKET_NAME
終端機顯示的名稱類似於 your-project-id-gcs-bucket。後續步驟會用到這項資訊。
👉 您需要在 Google Cloud 控制台的 BigQuery 查詢編輯器中執行下一個指令。最簡單的方法是在新的瀏覽器分頁中開啟這個連結。系統會直接將您帶往 Google Cloud 控制台的正確頁面。
https://console.cloud.google.com/bigquery
👉 頁面載入完畢後,按一下藍色的「+」按鈕 (撰寫新查詢),開啟新的編輯器分頁。
現在,我們要編寫資料定義語言 (DDL) 咒語,建立魔法鏡頭。這會告知 BigQuery 要查看的位置和內容。
👉📜 在開啟的 BigQuery 查詢編輯器中,貼上下列 SQL。請記得取代 REPLACE-WITH-YOUR-BUCKET-NAME
替換成您剛才複製的值區名稱。接著點選「執行」:
CREATE OR REPLACE EXTERNAL TABLE bestiary_data.raw_intel_content_table (
raw_text STRING
)
OPTIONS (
format = 'CSV',
-- This is a trick to load each line of the text files as a single row.
field_delimiter = '§',
uris = ['gs://REPLACE-WITH-YOUR-BUCKET-NAME/raw_intel/*']
);
👉📜 執行查詢,透過「鏡頭」查看檔案內容。
SELECT * FROM bestiary_data.raw_intel_content_table;
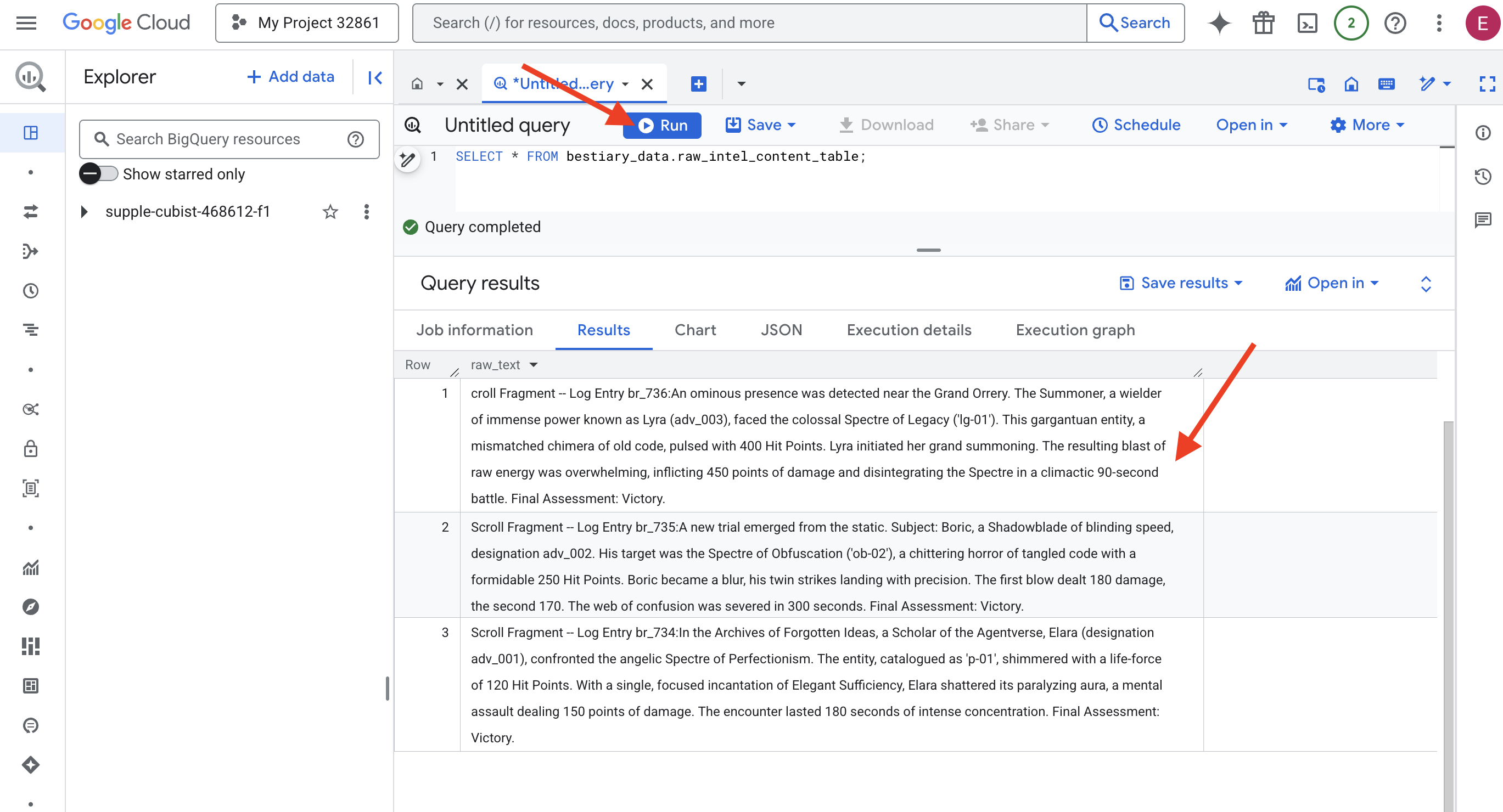
鏡頭已就位。現在可以看到卷軸的原始文字。但閱讀不等於理解。
在「被遺忘的構想檔案」中,Agentverse 的學者 Elara (代號 adv_001) 遭遇了完美主義的天使 Spectre。這個實體編目為「p-01」,閃爍著 120 點生命力的光芒。艾拉專心念誦「優雅的滿足」咒語,擊碎了癱瘓光環,這項精神攻擊造成了 150 點傷害。這段遭遇持續了 180 秒,需要高度專注。最終評估:獲勝。
這些卷軸並非以表格和資料列的形式撰寫,而是以傳奇故事的曲折散文呈現。這是我們第一次進行大規模測試。
學者的占卜:使用 SQL 將文字轉換為表格
但問題是,詳細描述暗影刀鋒快速雙重攻擊的報告,與記錄召喚師聚集強大力量發動單一毀滅性爆炸的報告,讀起來截然不同。我們無法直接匯入這項資料,必須解讀資料內容。這就是魔法時刻。我們將使用單一 SQL 查詢做為強大的咒語,在 BigQuery 中讀取、瞭解及建構所有檔案中的所有記錄。
👉💻 返回 Cloud Shell 終端機,執行下列指令來顯示連線名稱:
echo "${PROJECT_ID}.${REGION}.gcs-connection"
終端機會顯示完整的連線字串,請選取並複製整個字串,下一個步驟會用到
我們將使用單一強大的咒語:ML.GENERATE_TEXT。這項咒語會召喚 Gemini,向其顯示每則捲軸,並命令 Gemini 以結構化 JSON 物件的形式傳回核心事實。
👉📜 在 BigQuery Studio 中,建立 Gemini 模型參照。這會將 Gemini Flash 預言機繫結至 BigQuery 程式庫,以便在查詢中呼叫。請記得取代
REPLACE-WITH-YOUR-FULL-CONNECTION-STRING,並貼上您剛從終端機複製的完整連線字串。
CREATE OR REPLACE MODEL bestiary_data.gemini_flash_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'gemini-2.5-flash');
👉📜 現在,請施展偉大的變換咒語。這項查詢會讀取原始文字、為每個捲動畫面建構詳細提示、傳送至 Gemini,並根據 AI 的結構化 JSON 回覆建立新的暫存資料表。
CREATE OR REPLACE TABLE bestiary_data.structured_bestiary AS
SELECT
-- THE CRITICAL CHANGE: We remove PARSE_JSON. The result is already a JSON object.
ml_generate_text_result AS structured_data
FROM
ML.GENERATE_TEXT(
-- Our bound Gemini Flash model.
MODEL bestiary_data.gemini_flash_model,
-- Our perfectly constructed input, with the prompt built for each row.
(
SELECT
CONCAT(
"""
From the following text, extract structured data into a single, valid JSON object.
Your output must strictly conform to the following JSON structure and data types. Do not add, remove, or change any keys.
{
"monster": {
"monster_id": "string",
"name": "string",
"type": "string",
"hit_points": "integer"
},
"battle": {
"battle_id": "string",
"monster_id": "string",
"adventurer_id": "string",
"outcome": "string",
"duration_seconds": "integer"
},
"adventurer": {
"adventurer_id": "string",
"name": "string",
"class": "string"
}
}
**CRUCIAL RULES:**
- Do not output any text, explanations, conversational filler, or markdown formatting like ` ```json` before or after the JSON object.
- Your entire response must be ONLY the raw JSON object itself.
Here is the text:
""",
raw_text -- We append the actual text of the report here.
) AS prompt -- The final column is still named 'prompt', as the oracle requires.
FROM
bestiary_data.raw_intel_content_table
),
-- The STRUCT now ONLY contains model parameters.
STRUCT(
0.2 AS temperature,
2048 AS max_output_tokens
)
);
變換完成,但結果尚未完全純化。Gemini 模型會以標準格式傳回答案,將所需的 JSON 包裝在較大的結構中,其中包含思考過程的中繼資料。在嘗試淨化這項原始預言前,先來看看內容。
👉📜 執行查詢,檢查 Gemini 模型的原始輸出內容:
SELECT * FROM bestiary_data.structured_bestiary;
👀 畫面上會顯示名為「structured_data」的單一資料欄。每個資料列的內容與這個複雜的 JSON 物件類似:
{"candidates":[{"avg_logprobs":-0.5691758094475283,"content":{"parts":[{"text":"```json\n{\n \"monster\": {\n \"monster_id\": \"gw_02\",\n \"name\": \"Gravewight\",\n \"type\": \"Gravewight\",\n \"hit_points\": 120\n },\n \"battle\": {\n \"battle_id\": \"br_735\",\n \"monster_id\": \"gw_02\",\n \"adventurer_id\": \"adv_001\",\n \"outcome\": \"Defeat\",\n \"duration_seconds\": 45\n },\n \"adventurer\": {\n \"adventurer_id\": \"adv_001\",\n \"name\": \"Elara\",\n \"class\": null\n }\n}\n```"}],"role":"model"},"finish_reason":"STOP","score":-97.32906341552734}],"create_time":"2025-07-28T15:53:24.482775Z","model_version":"gemini-2.5-flash","response_id":"9JyHaNe7HZ2WhMIPxqbxEQ","usage_metadata":{"billable_prompt_usage":{"text_count":640},"candidates_token_count":171,"candidates_tokens_details":[{"modality":"TEXT","token_count":171}],"prompt_token_count":207,"prompt_tokens_details":[{"modality":"TEXT","token_count":207}],"thoughts_token_count":1014,"total_token_count":1392,"traffic_type":"ON_DEMAND"}}
如您所見,我們要求的獎品 (乾淨的 JSON 物件) 深深地巢狀內嵌在這個結構中。我們接下來的任務很明確,我們必須進行儀式,有系統地瀏覽這個結構,並從中提取純粹的智慧。
清理儀式:使用 SQL 正規化生成式 AI 輸出內容
Gemini 說話了,但這些話是未經處理的,並包覆在創作的虛無能量中 (候選項目、finish_reason 等)。真正的學者不會只是將原始預言束之高閣,而是會仔細擷取核心智慧,並抄寫到適當的書籍中,以供日後使用。
現在要施展最後一組咒語。這個單一指令碼會:
- 從暫存資料表讀取原始的巢狀 JSON。
- 清理及剖析資料,取得核心資料。
- 將相關片段抄寫到三個最終的原始資料表:怪物、冒險家和戰鬥。
👉📜 在新的 BigQuery 查詢編輯器中,執行下列咒語來建立清除鏡頭:
CREATE OR REPLACE TABLE bestiary_data.monsters AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.monster.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.monster.name') AS name,
JSON_VALUE(report_data, '$.monster.type') AS type,
SAFE_CAST(JSON_VALUE(report_data, '$.monster.hit_points') AS INT64) AS hit_points
FROM
CleanedDivinations
WHERE
report_data IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY monster_id ORDER BY name) = 1;
👉📜 驗證 Bestiary:
SELECT * FROM bestiary_data.monsters;
接著,我們要建立「勇士榜」,列出與這些野獸對決的勇敢冒險家。
👉📜 在新的查詢編輯器中,執行下列咒語來建立冒險家資料表:
CREATE OR REPLACE TABLE bestiary_data.adventurers AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
SELECT
JSON_VALUE(report_data, '$.adventurer.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.adventurer.name') AS name,
JSON_VALUE(report_data, '$.adventurer.class') AS class
FROM
CleanedDivinations
QUALIFY ROW_NUMBER() OVER (PARTITION BY adventurer_id ORDER BY name) = 1;
👉📜 驗證達人名單:
SELECT * FROM bestiary_data.adventurers;
最後,我們要建立事實資料表:戰役紀事。這本巨著連結了另外兩本,記錄每次獨特遭遇的詳細資料。由於每場戰鬥都是獨一無二的事件,因此不需要重複資料刪除。
👉📜 在新的查詢編輯器中,執行下列咒語來建立 battles 資料表:
CREATE OR REPLACE TABLE bestiary_data.battles AS
WITH
CleanedDivinations AS (
SELECT
SAFE.PARSE_JSON(
REGEXP_EXTRACT(
JSON_VALUE(structured_data, '$.candidates[0].content.parts[0].text'),
r'\{[\s\S]*\}'
)
) AS report_data
FROM
bestiary_data.structured_bestiary
)
-- Extract the raw essence for all battle fields and cast where necessary.
SELECT
JSON_VALUE(report_data, '$.battle.battle_id') AS battle_id,
JSON_VALUE(report_data, '$.battle.monster_id') AS monster_id,
JSON_VALUE(report_data, '$.battle.adventurer_id') AS adventurer_id,
JSON_VALUE(report_data, '$.battle.outcome') AS outcome,
SAFE_CAST(JSON_VALUE(report_data, '$.battle.duration_seconds') AS INT64) AS duration_seconds
FROM
CleanedDivinations;
👉📜 驗證 Chronicle:
SELECT * FROM bestiary_data.battles;
發掘策略洞察
卷軸已解讀完畢,精髓也已提煉出來,並刻在書卷上。我們的魔法書不再只是事實的集合,而是蘊含深奧策略智慧的關聯式資料庫。現在,我們可以詢問過去無法回答的問題,因為當時的知識都以未經整理的原始文字形式呈現。
現在,讓我們進行最後的盛大占卜。我們會施展魔法,同時參考三本魔法書 (怪物圖鑑、英雄名錄和戰役史),找出可供採取的深入洞察。
我們的策略問題: 「每位冒險家成功擊敗的怪物中,生命值最高的怪物名稱為何?擊敗該怪物花了多少時間?」
這是一個複雜的問題,需要將英雄連結至他們獲勝的戰鬥,並將這些戰鬥連結至所涉怪物的統計資料。這就是結構化資料模型的真正力量。
👉📜 在新的 BigQuery 查詢編輯器中,輸入下列最終咒語:
-- This is our final spell, joining all three tomes to reveal a deep insight.
WITH
-- First, we consult the Chronicle of Battles to find only the victories.
VictoriousBattles AS (
SELECT
adventurer_id,
monster_id,
duration_seconds
FROM
bestiary_data.battles
WHERE
outcome = 'Victory'
),
-- Next, we create a temporary record for each victory, ranking the monsters
-- each adventurer defeated by their power (hit points).
RankedVictories AS (
SELECT
v.adventurer_id,
m.name AS monster_name,
m.hit_points,
v.duration_seconds,
-- This spell ranks each adventurer's victories from most to least powerful monster.
ROW_NUMBER() OVER (PARTITION BY v.adventurer_id ORDER BY m.hit_points DESC) as victory_rank
FROM
VictoriousBattles v
JOIN
bestiary_data.monsters m ON v.monster_id = m.monster_id
)
-- Finally, we consult the Roll of Champions and join it with our ranked victories
-- to find the name of each champion and the details of their greatest triumph.
SELECT
a.name AS adventurer_name,
a.class AS adventurer_class,
r.monster_name AS most_powerful_foe_defeated,
r.hit_points AS foe_hit_points,
r.duration_seconds AS duration_of_greatest_victory
FROM
bestiary_data.adventurers a
JOIN
RankedVictories r ON a.adventurer_id = r.adventurer_id
WHERE
-- We only want to see their number one, top-ranked victory.
r.victory_rank = 1
ORDER BY
foe_hit_points DESC;
這項查詢的輸出內容會是整齊美觀的資料表,其中列出資料集中每位冒險家的「冠軍壯舉」。如下所示:
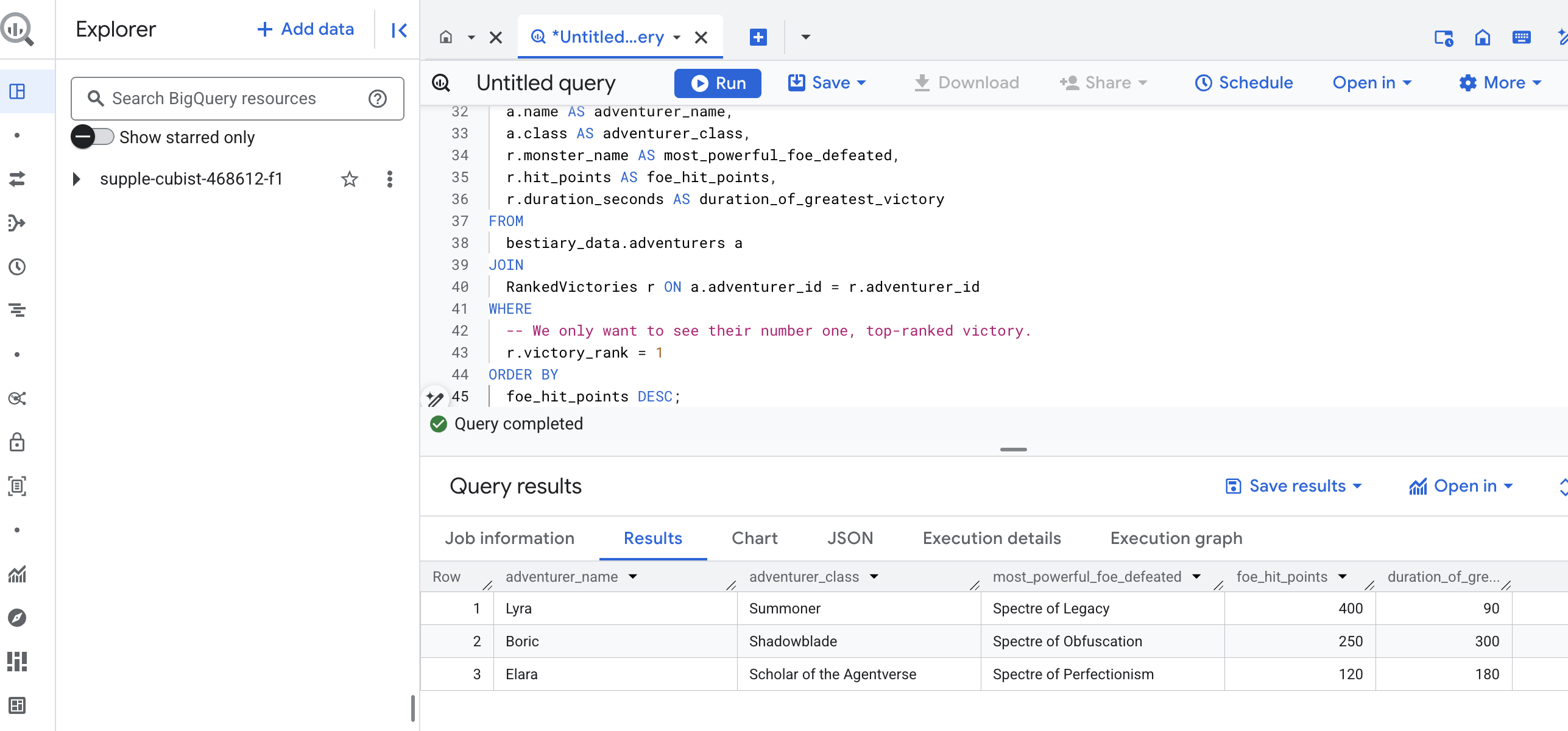
關閉 BigQuery 分頁。
這項單一且優雅的結果證明瞭整個管道的價值。您已成功將混亂的戰場原始報告,轉化為傳奇故事和策略性資料驅動洞察的來源。
非遊戲玩家
5. Scribe 的魔法書:資料倉儲內的分塊、嵌入和搜尋
我們在煉金術士實驗室的工作很順利,我們已將原始的敘事捲軸轉換為結構化的關聯資料表,這是一項強大的資料魔法。不過,原始捲軸本身仍蘊含更深層的語意真相,這是結構化表格無法完全擷取的。如要建構真正明智的代理程式,我們必須解鎖這個意義。
冗長且未經處理的捲軸是鈍器,如果服務專員詢問「麻痺光環」相關問題,簡單的搜尋可能會傳回整份戰鬥報告,但該詞彙只出現一次,答案埋沒在無關的細節中。學術搜尋大師知道,真正的智慧不在於數量,而是精確度。
我們將在 BigQuery 聖所中,完全在資料庫內執行三項強大的儀式。
- 分割儀式 (分塊):我們會將原始智慧記錄仔細分解成較小的獨立段落。
- 蒸餾 (嵌入) 儀式:我們會使用 BQML 諮詢 Gemini 模型,將每個文字區塊轉換為「語意指紋」 (向量嵌入)。
- 占卜儀式 (搜尋):我們會使用 BQML 的向量搜尋功能,以簡單的英文提問,並從魔法書中找出最相關的精華智慧。
整個過程會建立強大的可搜尋知識庫,資料完全不會離開 BigQuery 的安全和規模。
分割儀式:使用 SQL 解構捲軸
我們的智慧來源仍是 GCS 封存中的原始文字檔,可透過外部資料表 bestiary_data.raw_intel_content_table 存取。我們的首要任務是編寫咒語,讀取每份長卷軸,並將其分割成一系列較小、更容易理解的詩句。在本儀式中,我們會將「區塊」定義為單一句子。
雖然以句子為單位進行分割,是記錄敘事內容的明確有效起點,但資深 Scribe 有許多分塊策略可供使用,而選擇合適的策略對最終搜尋結果的品質至關重要。較簡單的方法可能會使用
- 固定長度(大小) 的分塊,但這可能會粗略地將重要概念切成兩半。
更精細的儀式,例如
- 實務上通常偏好使用遞迴分塊,這種方法會先嘗試沿著段落等自然界線分割文字,然後再回歸句子,盡可能保留語意脈絡。適用於真正複雜的手稿。
- 內容感知分塊 (文件):Scribe 會使用文件的固有結構 (例如技術手冊中的標題或程式碼捲軸中的函式),建立最合乎邏輯且有力的智慧分塊。以及更多...
就戰鬥記錄而言,這句話的精細程度和語境恰到好處。
👉📜 在新的 BigQuery 查詢編輯器中,執行下列咒語。這項咒語會使用 SPLIT 函式,依據每個句號 (.) 分隔每卷軸的文字,然後將產生的句子陣列取消巢狀結構,放入不同的資料列。
CREATE OR REPLACE TABLE bestiary_data.chunked_intel AS
WITH
-- First, add a unique row number to each scroll to act as a document ID.
NumberedScrolls AS (
SELECT
ROW_NUMBER() OVER () AS scroll_id,
raw_text
FROM
bestiary_data.raw_intel_content_table
)
-- Now, process each numbered scroll.
SELECT
scroll_id,
-- Assign a unique ID to each chunk within a scroll for precise reference.
CONCAT(CAST(scroll_id AS STRING), '-', CAST(ROW_NUMBER() OVER (PARTITION BY scroll_id) AS STRING)) as chunk_id,
-- Trim whitespace from the chunk for cleanliness.
TRIM(chunk) AS chunk_text
FROM
NumberedScrolls,
-- This is the core of the spell: UNNEST splits the array of sentences into rows.
UNNEST(SPLIT(raw_text, '.')) AS chunk
-- A final refinement: we only keep chunks that have meaningful content.
WHERE
-- This ensures we don't have empty rows from double periods, etc.
LENGTH(TRIM(chunk)) > 15;
👉 現在執行查詢,檢查新撰寫的知識塊,並查看差異。
SELECT * FROM bestiary_data.chunked_intel ORDER BY scroll_id, chunk_id;
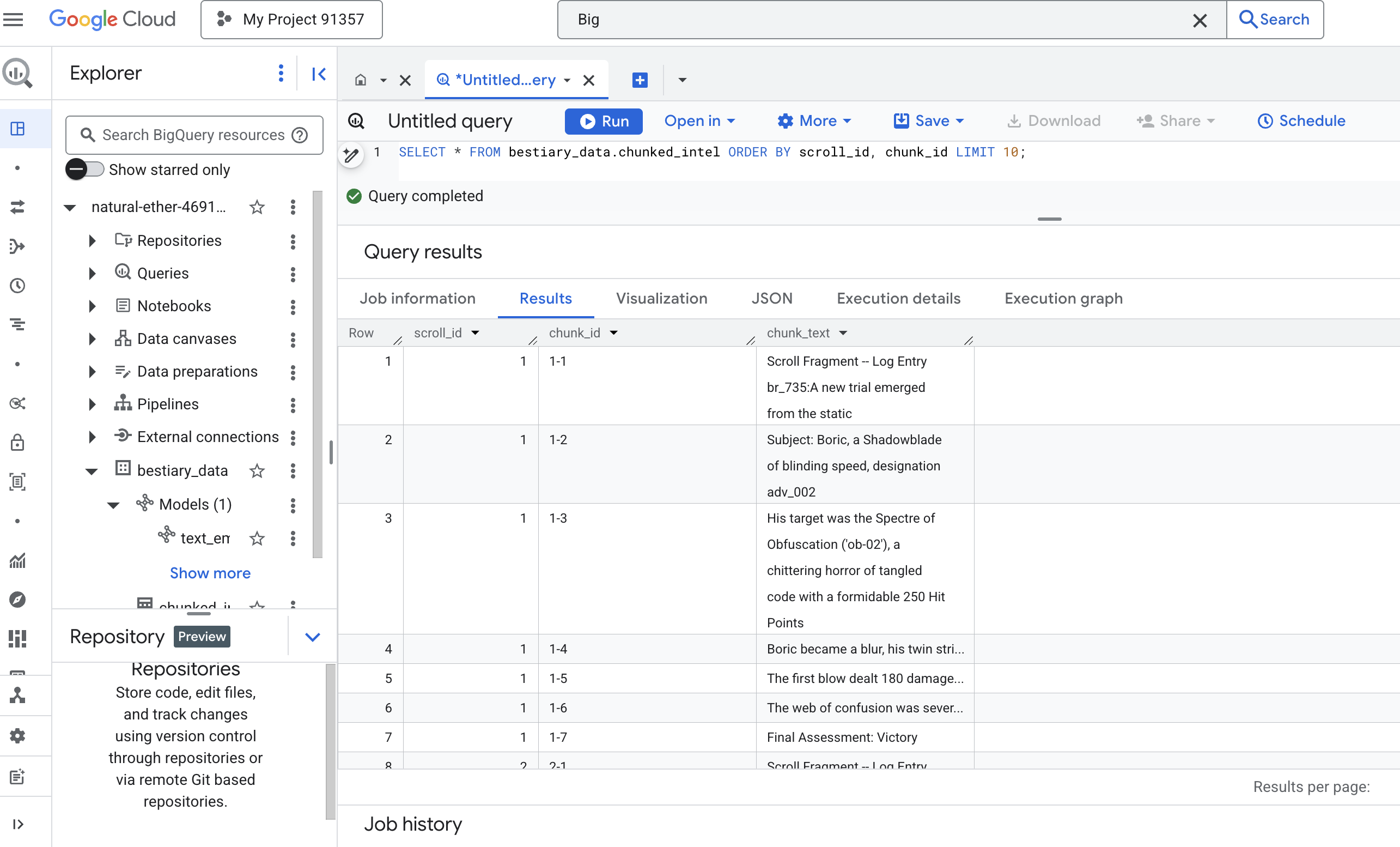
查看結果。原本是密密麻麻的文字區塊,現在則變成多個資料列,每個資料列都與原始捲動 (scroll_id) 相關聯,但只包含一個重點句子。現在每一列都非常適合向量化。
蒸餾儀式:使用 BQML 將文字轉換為向量
👉💻 首先,請返回終端機,執行下列指令來顯示連線名稱:
. ~/agentverse-dataengineer/set_env.sh
echo "${PROJECT_ID}.${REGION}.gcs-connection"
👉📜 我們必須建立新的 BigQuery 模型,指向 Gemini 的文字嵌入。在 BigQuery Studio 中執行下列咒語。請注意,您需要將 REPLACE-WITH-YOUR-FULL-CONNECTION-STRING 替換為剛才從終端機複製的完整連線字串。
CREATE OR REPLACE MODEL bestiary_data.text_embedding_model
REMOTE WITH CONNECTION `REPLACE-WITH-YOUR-FULL-CONNECTION-STRING`
OPTIONS (endpoint = 'text-embedding-005');
👉📜 現在,請施展蒸餾魔法。這項查詢會呼叫 ML.GENERATE_EMBEDDING 函式,從 chunked_intel 資料表讀取每個資料列,將文字傳送至 Gemini 嵌入模型,並將產生的向量指紋儲存在新資料表中。
CREATE OR REPLACE TABLE bestiary_data.embedded_intel AS
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
-- The embedding model we just created.
MODEL bestiary_data.text_embedding_model,
-- A subquery that selects our data and renames the text column to 'content'.
(
SELECT
scroll_id,
chunk_id,
chunk_text AS content -- Renaming our text column is the key correction.
FROM
bestiary_data.chunked_intel
),
-- The configuration struct is now simpler and correct.
STRUCT(
-- This task_type is crucial. It optimizes the vectors for retrieval.
'RETRIEVAL_DOCUMENT' AS task_type
)
);
BigQuery 處理所有文字區塊時,可能需要一到兩分鐘。
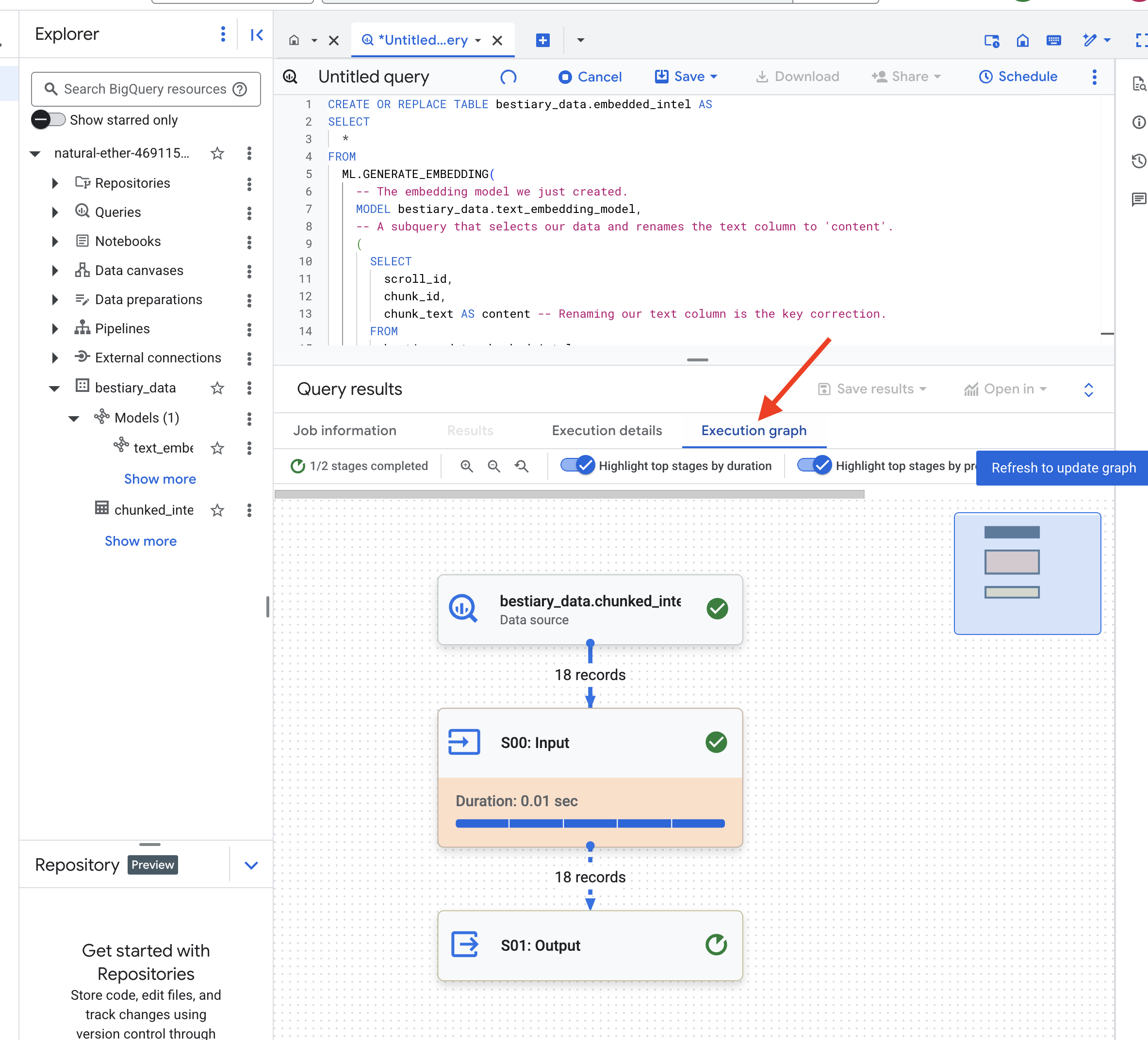
👉📜 完成後,請檢查新資料表,查看語意指紋。
SELECT
chunk_id,
content,
ml_generate_embedding_result
FROM
bestiary_data.embedded_intel
LIMIT 20;
您現在會看到新的「ml_generate_embedding_result」欄,其中包含文字的密集向量表示法。我們的魔法書現在已完成語意編碼。
占卜儀式:使用 BQML 進行語意搜尋
👉📜 測試 Grimoire 的最終方式是向它提問。現在我們要執行最後的儀式:向量搜尋。這不是關鍵字搜尋,而是搜尋意義。我們會以自然語言提出問題,BQML 會即時將問題轉換為嵌入,然後搜尋整個資料表 embedded_intel,找出語意上「最接近」的文字區塊指紋。
SELECT
-- The content column contains our original, relevant text chunk.
base.content,
-- The distance metric shows how close the match is (lower is better).
distance
FROM
VECTOR_SEARCH(
-- The table containing the knowledge base with its embeddings.
TABLE bestiary_data.embedded_intel,
-- The column that contains the vector embeddings.
'ml_generate_embedding_result',
(
-- This subquery generates an embedding for our question in real-time.
SELECT ml_generate_embedding_result
FROM ML.GENERATE_EMBEDDING(
MODEL bestiary_data.text_embedding_model,
(SELECT 'What are the tactics against a foe that causes paralysis?' AS content),
STRUCT('RETRIEVAL_QUERY' AS task_type)
)
),
-- Specify how many of the closest results we want to see.
top_k => 3,
-- The distance metric used to find the "closest" vectors.
distance_type => 'COSINE'
);
咒語分析:
VECTOR_SEARCH:負責協調搜尋作業的核心函式。ML.GENERATE_EMBEDDING(內部查詢):這就是魔法所在。我們使用相同模型嵌入查詢 ('What are the tactics...'),但工作類型為'RETRIEVAL_QUERY',這項類型專為查詢進行最佳化。top_k => 3:我們要求提供最相關的前 3 項結果。distance_type => 'COSINE':這項指標會測量向量之間的「角度」。角度越小,代表意義越相近。
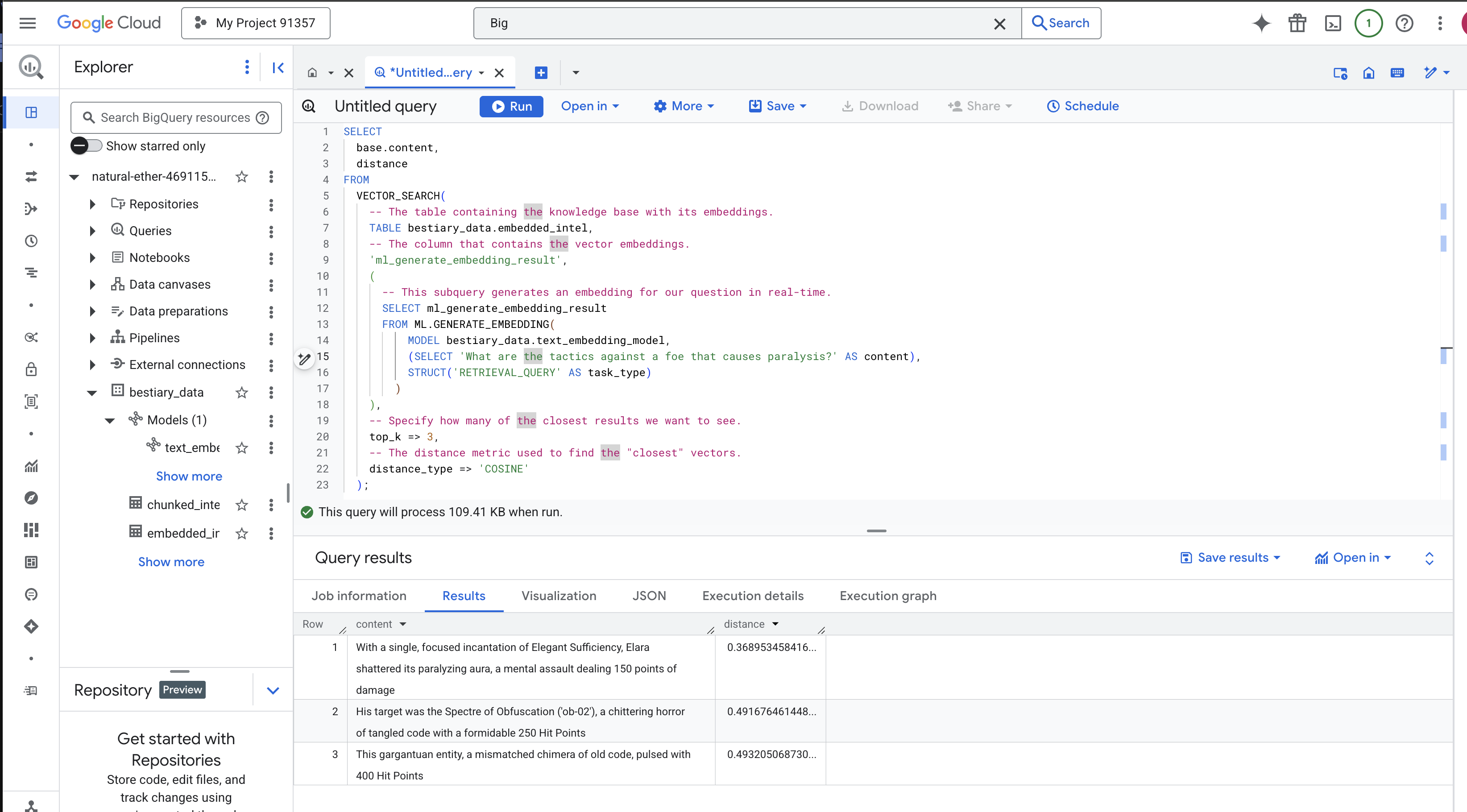
請仔細查看結果。查詢內容並未包含「shattered」或「incantation」一詞,但搜尋結果第一項卻是:「With a single, focused incantation of Elegant Sufficiency, Elara shattered its paralyzing aura, a mental assault dealing 150 points of damage」(艾拉以單一、專注的優雅充足咒語,打破了麻痺光環,造成 150 點的精神攻擊傷害)。這就是語意搜尋的強大之處。模型瞭解「對抗癱瘓的策略」概念,並找出描述具體成功策略的句子。
您現在已成功建構完整的資料倉儲基礎 RAG 管道。您已準備好原始資料、將其轉換為語意向量,並依據意義查詢資料。雖然 BigQuery 是進行這類大規模分析工作的強大工具,但如果即時服務專員需要低延遲的回覆,我們通常會將準備好的智慧轉移至專門的作業資料庫。這是我們下一個訓練課程的主題。
非遊戲玩家
6. 向量腳本:使用 Cloud SQL 打造向量存放區,以進行推論
我們的魔法書目前是以結構化表格的形式存在,是強大的事實目錄,但知識是字面上的。這項技術瞭解 monster_id = ‘MN-001',但不瞭解「混淆」背後更深層的語意。如要讓我們的代理商真正瞭解情況,並提供細膩且有遠見的建議,我們必須將知識的本質提煉成能擷取意義的形式:向量。
我們對知識的追求,引領我們來到早已被遺忘的先驅文明遺跡。我們在密封的保險庫深處,發現一箱保存完好的古老捲軸。這些不只是戰鬥報告,還蘊含深刻的哲學智慧,教導我們如何擊敗困擾所有偉大事業的野獸。卷軸將其描述為「悄然蔓延的停滯」,以及「創造的織物正在磨損」。靜態似乎連古代人都知道,這是一種週期性威脅,但歷史已不可考。
這項被遺忘的知識是我們最大的資產。這項能力不僅能擊敗個別怪物,還能提供策略洞察資訊,讓整個隊伍戰力大增。為發揮這項強大力量,我們現在要打造 Scholar 的真正魔法書 (具備向量功能的 PostgreSQL 資料庫),並建構自動化向量抄寫室 (Dataflow 管道),讀取、理解及抄寫這些卷軸的永恆本質。這會將我們的魔法書從事實集轉變成智慧引擎。

打造學者的咒語書 (Cloud SQL)
在抄錄這些古老卷軸的精髓之前,我們必須先確認知識容器 (也就是受管理的 PostgreSQL 咒語書) 已成功鑄造。初始設定儀式應該已為您建立這個檔案。
👉💻 在終端機中執行下列指令,確認 Cloud SQL 執行個體存在且已就緒。這個指令碼也會授予執行個體專屬服務帳戶使用 Vertex AI 的權限,這是在資料庫中直接生成嵌入內容的必要條件。
. ~/agentverse-dataengineer/set_env.sh
echo "Verifying the existence of the Spellbook (Cloud SQL instance): $INSTANCE_NAME..."
gcloud sql instances describe $INSTANCE_NAME
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format="value(serviceAccountEmailAddress)")
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
如果指令成功執行並傳回 grimoire-spellbook 執行個體的詳細資料,表示 Forge 運作正常。你已準備好進行下一個咒語。如果指令傳回 NOT_FOUND 錯誤,請確認您已成功完成初始環境設定步驟,再繼續操作。(data_setup.py)
👉💻 偽造書籍後,我們建立名為 arcane_wisdom 的新資料庫,開啟第一章。
. ~/agentverse-dataengineer/set_env.sh
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME
刻寫語意符文:使用 pgvector 啟用向量功能
Cloud SQL 執行個體已建立完成,現在讓我們使用內建的 Cloud SQL Studio 連線至執行個體。這個介面提供網頁式介面,可直接在資料庫上執行 SQL 查詢。
👉💻 首先,請前往 Cloud SQL Studio。最簡單快速的方法是在新的瀏覽器分頁中開啟下列連結。系統會直接將您帶往 grimoire-spellbook 執行個體的 Cloud SQL Studio。
https://console.cloud.google.com/sql/instances/grimoire-spellbook/studio
👉 選取 arcane_wisdom 做為資料庫,輸入 postgres 做為使用者,並輸入 1234qwer 做為密碼,然後按一下「驗證」。
👉📜 在 SQL Studio 查詢編輯器中,前往「編輯器 1」分頁,貼上下列 SQL 程式碼來啟用向量資料型別:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
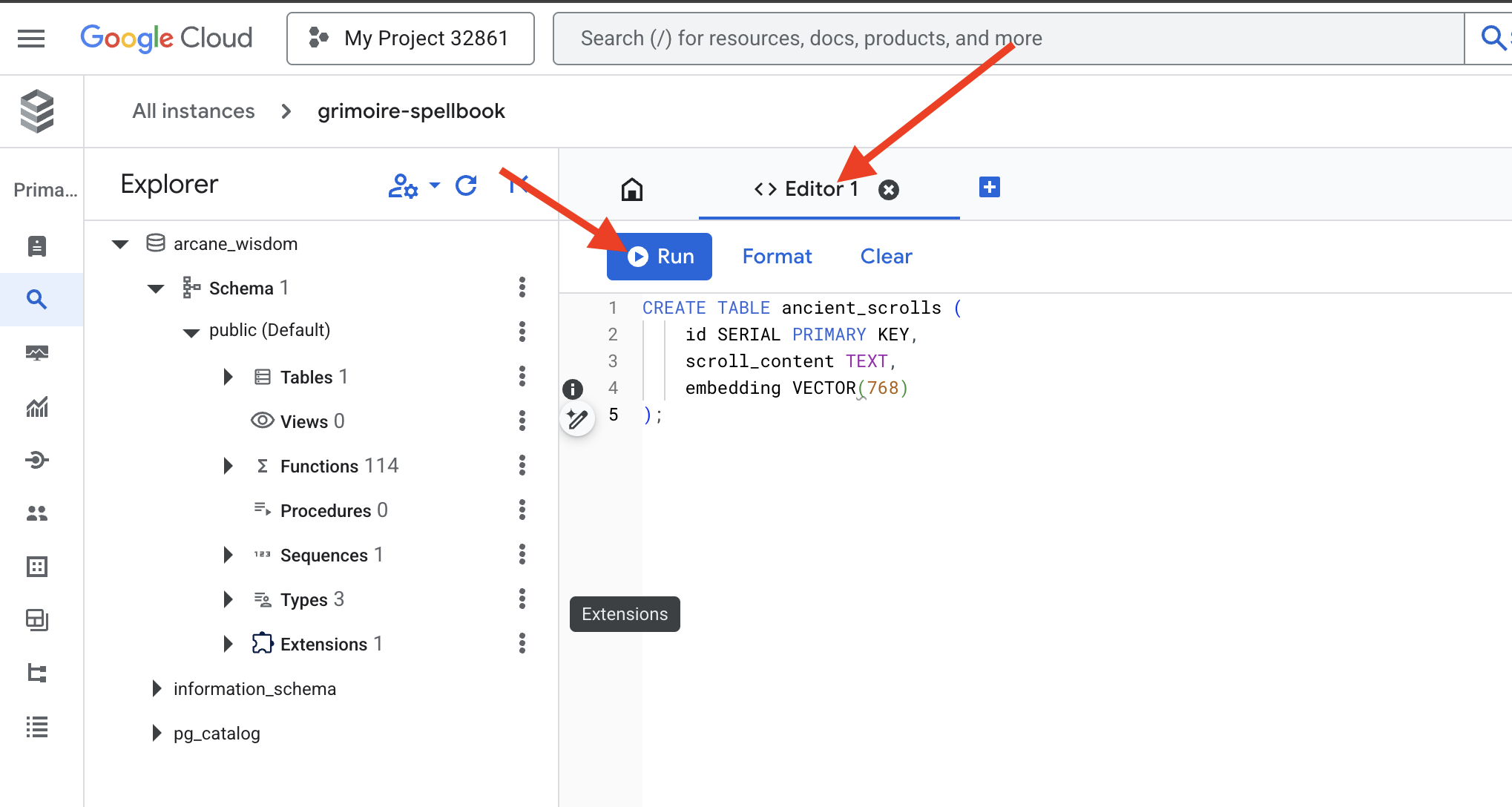
👉📜 建立表格,存放卷軸的本質,準備好魔法書的頁面。
CREATE TABLE ancient_scrolls (
id SERIAL PRIMARY KEY,
scroll_content TEXT,
embedding VECTOR(768)
);
請注意,拼字為 VECTOR(768)。我們將使用的 Vertex AI 嵌入模型 (textembedding-gecko@003 或類似模型) 會將文字提煉成 768 維度的向量。Spellbook 的頁面必須準備好容納該大小的本質。尺寸必須一律相符。
第一次音譯:手動轉寫儀式
在指揮自動抄寫員大軍 (Dataflow) 之前,我們必須先手動執行一次中央儀式。這會讓我們更深入瞭解這兩步驟的魔法:
- 預測:擷取一段文字,並諮詢 Gemini 預測模型,將文字的語意本質提煉成向量。
- 銘刻:將原始文字及其新的向量本質寫入 Spellbook。
現在,我們來執行手動儀式。
👉📜 在 Cloud SQL Studio 中。現在我們要使用 embedding() 函式,這是 google_ml_integration 擴充功能提供的強大功能。這樣一來,我們就能直接從 SQL 查詢呼叫 Vertex AI 嵌入模型,大幅簡化程序。
SET session.my_search_var='The Spectre of Analysis Paralysis is a phantom of the crossroads. It does not bind with chains but with the infinite threads of what if. It conjures a fog of options, a maze within the mind where every path seems equally fraught with peril and promise. It whispers of a single, flawless route that can only be found through exhaustive study, paralyzing its victim in a state of perpetual contemplation. This spectres power is broken by the Path of First Viability. This is not the search for the *best* path, but the commitment to the *first good* path. It is the wisdom to know that a decision made, even if imperfect, creates movement and reveals more of the map than standing still ever could. Choose a viable course, take the first step, and trust in your ability to navigate the road as it unfolds. Motion is the light that burns away the fog.';
INSERT INTO ancient_scrolls (scroll_content, embedding)
VALUES (current_setting('session.my_search_var'), (embedding('text-embedding-005',current_setting('session.my_search_var')))::vector);
👉📜 執行查詢來讀取新刻寫的頁面,驗證您的工作:
SELECT id, scroll_content, LEFT(embedding::TEXT, 100) AS embedding_preview FROM ancient_scrolls;
您已成功手動執行核心 RAG 資料載入工作!
打造語意指南針:使用 HNSW 索引為咒語書施展魔法
我們的魔法書現在可以儲存智慧,但要找到正確的卷軸,必須閱讀每一頁。這是循序掃描。這種做法既緩慢又缺乏效率。如要讓查詢立即導向最相關的知識,我們必須使用語意羅盤 (即向量索引) 強化 Spellbook。
讓我們證明這項魔法的價值。
👉📜 在 Cloud SQL Studio 中,執行下列咒語。這會模擬搜尋我們新插入的捲軸,並要求資料庫提供其計畫。EXPLAIN
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
查看輸出內容。畫面上會顯示 -> Seq Scan on ancient_scrolls。這表示資料庫正在讀取每一列資料。請注意 execution time。
👉📜 現在,讓我們施展索引魔法。lists 參數會告知索引要建立的叢集數量。建議從預期列數的平方根開始。
CREATE INDEX ON ancient_scrolls USING hnsw (embedding vector_cosine_ops);
等待索引建構完成 (一行資料很快,但數百萬筆資料可能需要一段時間)。
👉📜 現在,請再次執行完全相同 的 EXPLAIN ANALYZE 指令:
EXPLAIN ANALYZE
WITH ReferenceVector AS (
-- First, get the vector we want to compare against.
SELECT embedding AS vector
FROM ancient_scrolls
LIMIT 1
)
-- This is the main query we want to analyze.
SELECT
ancient_scrolls.id,
ancient_scrolls.scroll_content,
-- We can also select the distance itself.
ancient_scrolls.embedding <=> ReferenceVector.vector AS distance
FROM
ancient_scrolls,
ReferenceVector
ORDER BY
-- Order by the distance operator's result.
ancient_scrolls.embedding <=> ReferenceVector.vector
LIMIT 5;
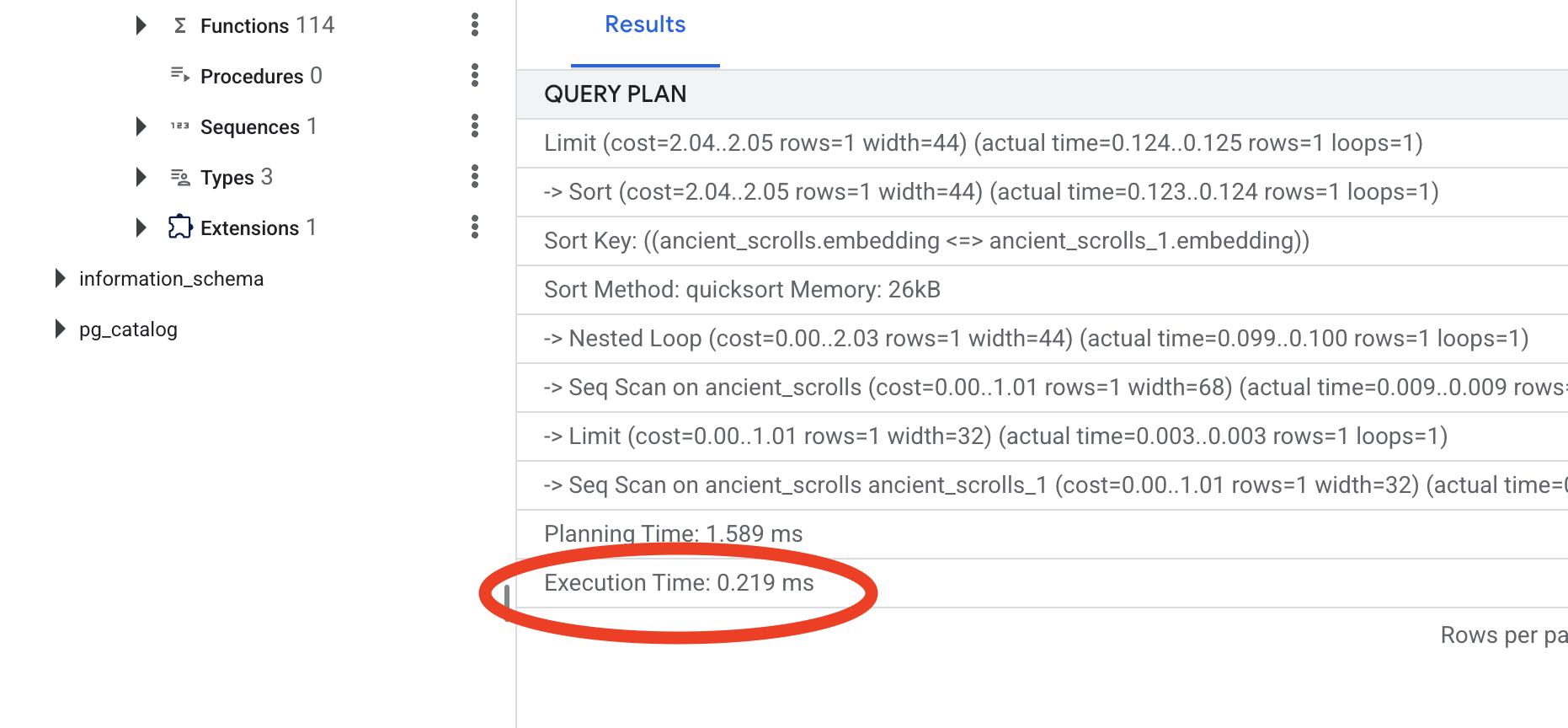
查看新的查詢計畫。現在會看到 -> Index Scan using...。更重要的是,請查看 execution time。即使只有一個項目,速度也會大幅提升。您剛才示範了向量世界中資料庫效能調整的核心原則。
檢查完來源資料、瞭解手動程序,並針對速度完成 Spellbook 最佳化後,您現在確實可以開始建構自動化 Scriptorium。
非遊戲玩家
7. 意義的管道:建構 Dataflow 向量化管道
現在,我們要建立抄寫員的魔法裝配線,讀取卷軸、提煉本質,並將其刻入新的魔法書。這是我們將手動觸發的 Dataflow 管道。不過,在為管道本身編寫主咒語之前,我們必須先準備好基礎和召喚管道的圓圈。
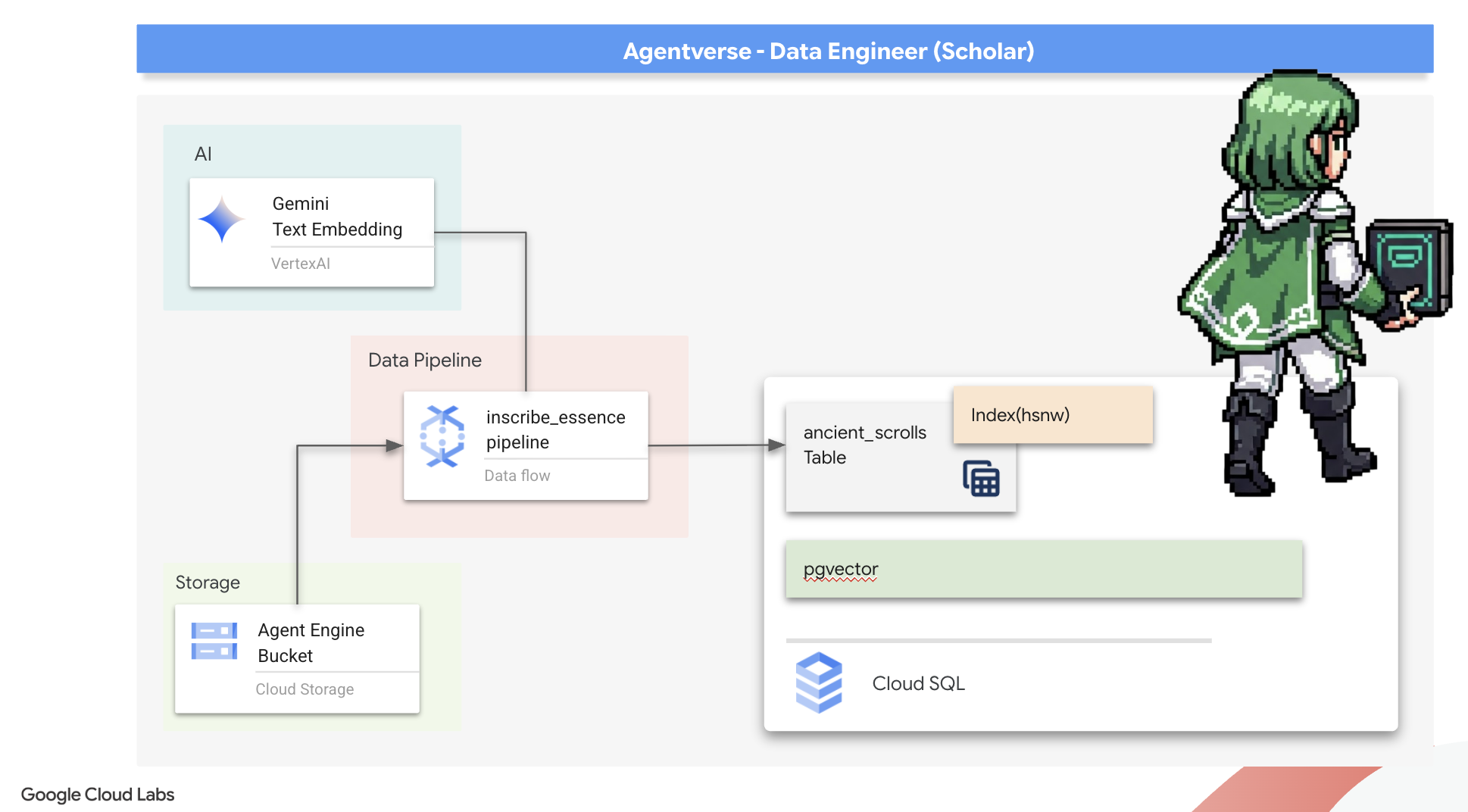
準備 Scriptorium 的基礎 (工作站映像檔)
我們的 Dataflow 管道將由雲端中的自動工作站團隊執行。每次呼叫時,這些函式都需要一組特定的程式庫才能執行工作。我們可以提供清單,讓他們每次都擷取這些程式庫,但這樣很慢且效率不彰。明智的學者會預先準備好主資料庫。
在這裡,我們會命令 Google Cloud Build 打造自訂容器映像檔。這張圖片是「完美魔像」,預先載入我們抄寫員所需的所有程式庫和依附元件。Dataflow 工作啟動時會使用這個自訂映像檔,讓 worker 幾乎可以立即開始工作。
👉💻 執行下列指令,在 Artifact Registry 中建構及儲存管道的基礎映像檔。
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/pipeline
gcloud builds submit --config cloudbuild.yaml \
--substitutions=_REGION=${REGION},_REPO_NAME=${REPO_NAME} \
.
👉💻 執行下列指令,建立並啟動獨立的 Python 環境,然後在該環境中安裝必要的召喚程式庫。
cd ~/agentverse-dataengineer
. ~/agentverse-dataengineer/set_env.sh
python -m venv env
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
pip install -r requirements.txt
咒語
現在要編寫主咒語,為 Vector Scriptorium 供電。我們不會從頭開始編寫個別的魔法元件,我們的任務是使用 Apache Beam 語言,將元件組合成強大的邏輯管道。
- EmbedTextBatch (Gemini 諮詢):您將建構這個專門的抄寫員,瞭解如何執行「群組占卜」。這項工具會接收一批原始文字檔案,將這些檔案提供給 Gemini 文字嵌入模型,並接收其精簡的本質 (向量嵌入)。
- WriteEssenceToSpellbook (最終銘文):這是我們的檔案管理員。它知道開啟與 Cloud SQL Spellbook 安全連線的咒語。這項工具會擷取捲軸的內容和向量化本質,並永久刻印到新頁面。
我們的目標是將這些動作串連起來,建立流暢的知識流程。
👉✏️ 在 Cloud Shell 編輯器中,前往 ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py,您會在其中找到名為 EmbedTextBatch 的 DoFn 類別。找出註解 #REPLACE-EMBEDDING-LOGIC。請將其替換為下列咒語。
# 1. Generate the embedding for the monster's name
result = self.client.models.embed_content(
model="text-embedding-005",
contents=contents,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
這個咒語相當精確,有幾個重要參數:
- 模型:我們指定
text-embedding-005使用功能強大且最新的嵌入模型。 - 內容:這是 DoFn 接收的一批檔案中的所有文字內容清單。
- task_type:我們將此值設為「RETRIEVAL_DOCUMENT」。這項重要指令會告知 Gemini 生成的嵌入內容,必須經過最佳化處理,以便日後在搜尋時找到。
- output_dimensionality:必須設為 768,與我們在 Cloud SQL 中建立 ancient_scrolls 資料表時定義的 VECTOR(768) 維度完全相符。維度不符是向量魔術中常見的錯誤來源。
我們的管道必須先從 GCS 封存中的所有古代捲軸讀取原始的非結構化文字。
👉✏️ 在 ~/agentverse-dataengineer/pipeline/inscribe_essence_pipeline.py 中找到 #REPLACE ME-READFILE 註解,並替換為下列三部分咒語:
files = (
pipeline
| "MatchFiles" >> fileio.MatchFiles(known_args.input_pattern)
| "ReadMatches" >> fileio.ReadMatches()
| "ExtractContent" >> beam.Map(lambda f: (f.metadata.path, f.read_utf8()))
)
收集完卷軸的原始文字後,我們現在必須將這些文字傳送給 Gemini 進行占卜。為有效完成這項工作,我們會先將個別捲軸分組為小批次,然後將這些批次交給 EmbedTextBatch 抄寫員。Gemini 無法理解的捲軸也會歸入「失敗」類別,供日後查看。
👉✏️ 找出註解 #REPLACE ME-EMBEDDING,並替換為:
embeddings = (
files
| "BatchScrolls" >> beam.BatchElements(min_batch_size=1, max_batch_size=2)
| "DistillBatch" >> beam.ParDo(
EmbedTextBatch(project_id=project, region=region)
).with_outputs('failed', main='processed')
)
我們已成功提煉出卷軸的精髓,最後一個步驟是將這些知識記錄在咒語書中,永久保存。我們會從「已處理」的捲軸堆中取出捲軸,交給 WriteEssenceToSpellbook 檔案管理員。
👉✏️ 找出註解 #REPLACE ME-WRITE TO DB,並替換為:
_ = (
embeddings.processed
| "WriteToSpellbook" >> beam.ParDo(
WriteEssenceToSpellbook(
project_id=project,
region = "us-central1",
instance_name=known_args.instance_name,
db_name=known_args.db_name,
db_password=known_args.db_password
)
)
)
明智的學者絕不會丟棄知識,即使是失敗的嘗試也一樣。最後,我們必須指示抄寫員從占卜步驟中取出「失敗」的牌堆,並記錄失敗原因。這有助於我們日後改善儀式。
👉✏️ 找出註解 #REPLACE ME-LOG FAILURES,並替換為:
_ = (
embeddings.failed
| "LogFailures" >> beam.Map(lambda e: logging.error(f"Embedding failed for file {e[0]}: {e[1]}"))
)
現在已完成 Master Incantation!您已成功將個別的魔法元件串連在一起,組裝出功能強大的多階段資料管道。儲存 inscribe_essence_pipeline.py 檔案。現在可以召喚 Scriptorium 了。
現在我們施展召喚咒語,命令 Dataflow 服務喚醒 Golem,並開始抄寫儀式。
👉💻 在終端機中執行下列指令列
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
cd ~/agentverse-dataengineer/pipeline
# --- The Summoning Incantation ---
echo "Summoning the golem for job: $DF_JOB_NAME"
echo "Target Spellbook: $INSTANCE_NAME"
python inscribe_essence_pipeline.py \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--job_name=$DF_JOB_NAME \
--temp_location="gs://${BUCKET_NAME}/dataflow/temp" \
--staging_location="gs://${BUCKET_NAME}/dataflow/staging" \
--sdk_container_image="${REGION}-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/grimoire-inscriber:latest" \
--sdk_location=container \
--experiments=use_runner_v2 \
--input_pattern="gs://${BUCKET_NAME}/ancient_scrolls/*.md" \
--instance_name=$INSTANCE_NAME \
--region=$REGION
echo "The golem has been dispatched. Monitor its progress in the Dataflow console."
💡 注意!如果工作因資源錯誤 ZONE_RESOURCE_POOL_EXHAUSTED 而失敗,可能是因為所選區域中,這個低信譽帳戶的資源暫時受到限制。Google Cloud 的強大之處在於其全球觸及範圍!只要在其他區域召喚魔像即可。如要這麼做,請將上述指令中的 --region=$REGION 替換為其他區域,例如
--region=southamerica-west1
--region=asia-northeast3
--region=asia-southeast2
--region=me-west1
--region=southamerica-east1
--region=europe-central2
--region=asia-east2
--region=europe-southwest1
,然後再次執行。🎰
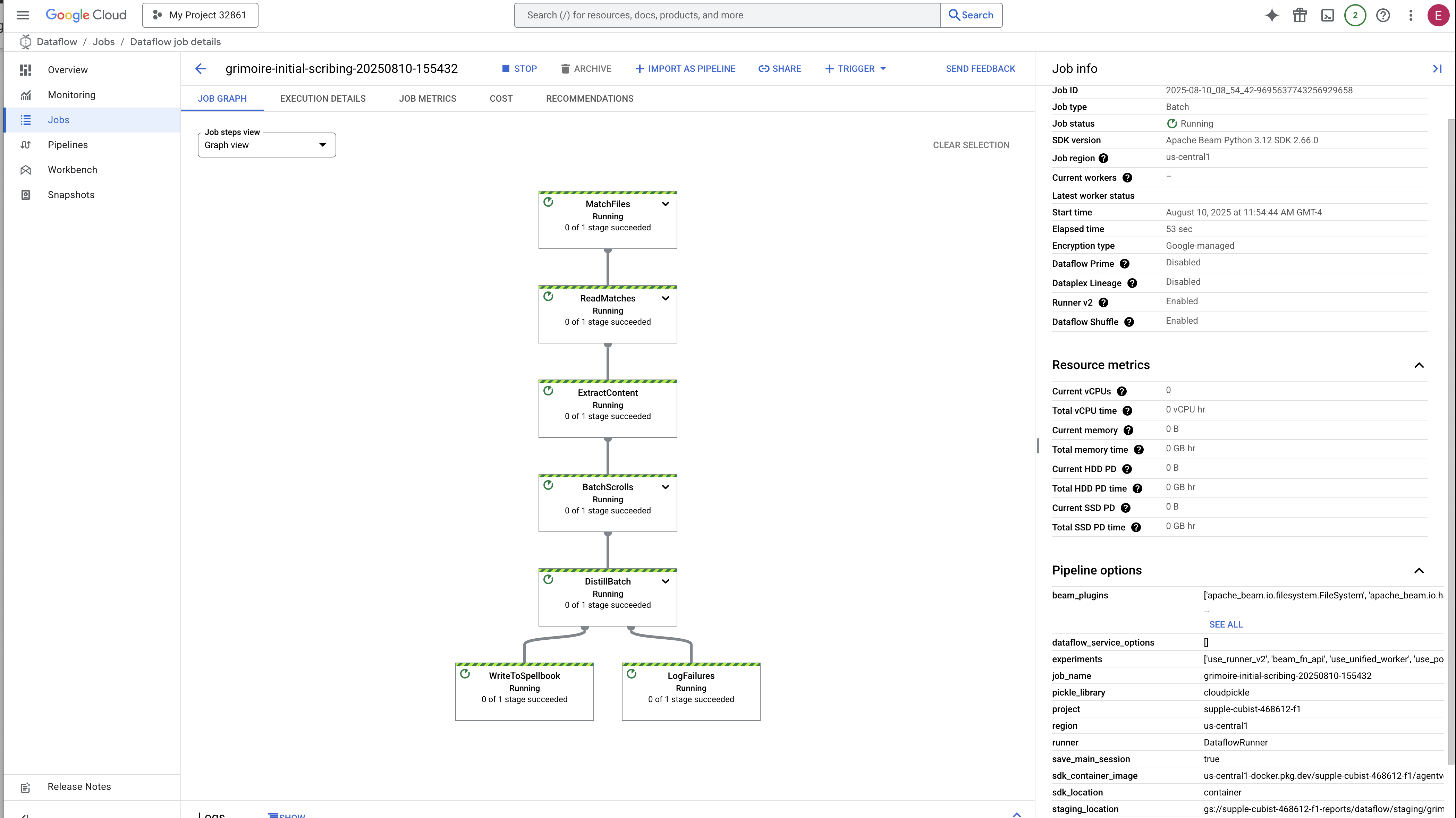
啟動和完成這項程序大約需要 3 到 5 分鐘。您可以在 Dataflow 控制台觀看直播。
👉前往 Dataflow 控制台:最簡單的方法是在新的瀏覽器分頁中開啟這個直接連結:
https://console.cloud.google.com/dataflow
👉 找出並點選您的工作:您會看到列出的工作,名稱是您提供的名稱 (inscribe-essence-job 或類似名稱)。按一下工作名稱,開啟詳細資料頁面。觀察管道:
- 啟動:前 3 分鐘,Dataflow 會佈建必要資源,因此工作狀態會顯示為「執行中」。圖表會顯示,但您可能還看不到資料在圖表中移動。
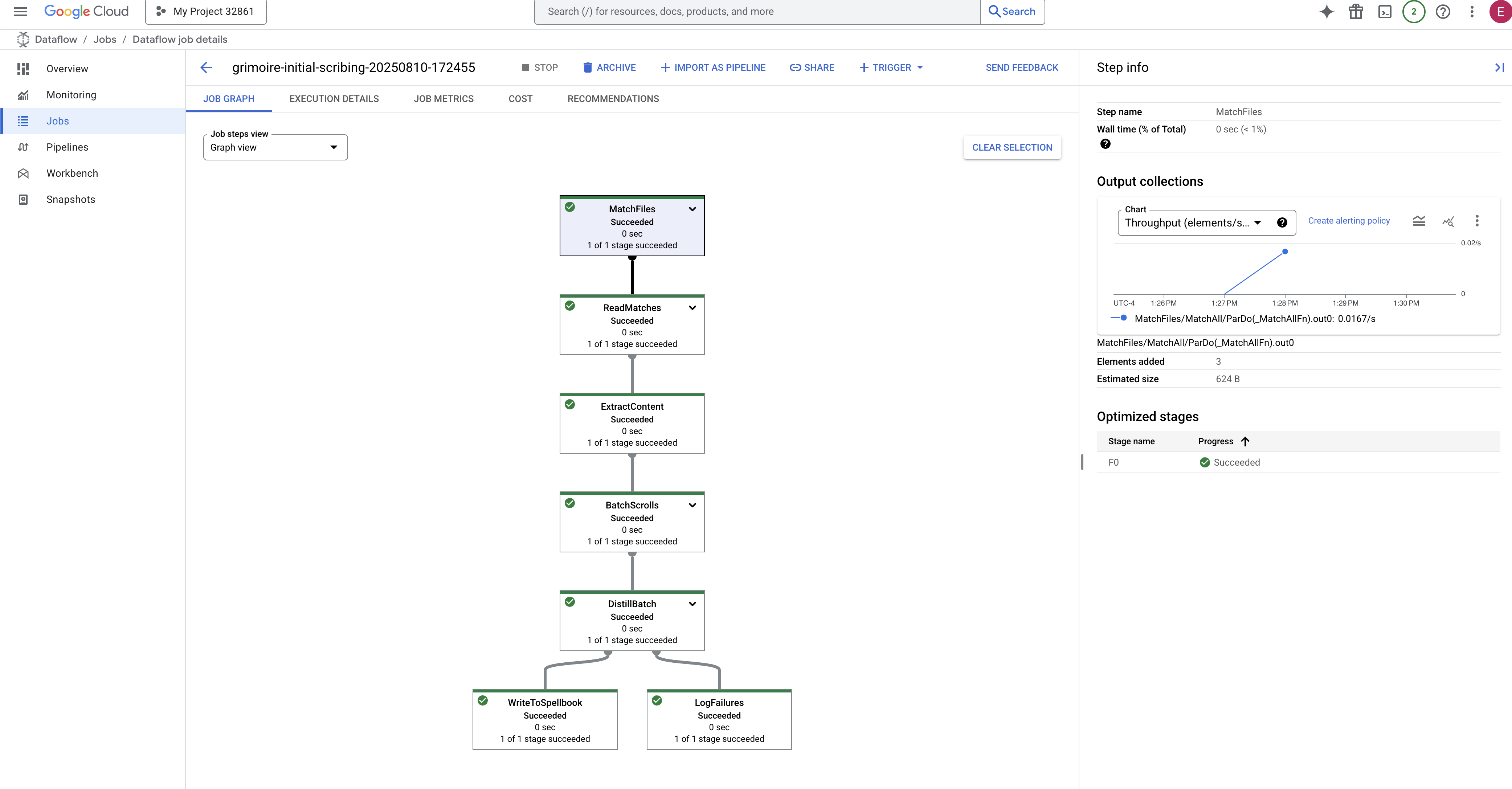
- 已完成:完成後,工作狀態會變更為「成功」,圖表會提供處理的最終記錄數。
驗證銘文
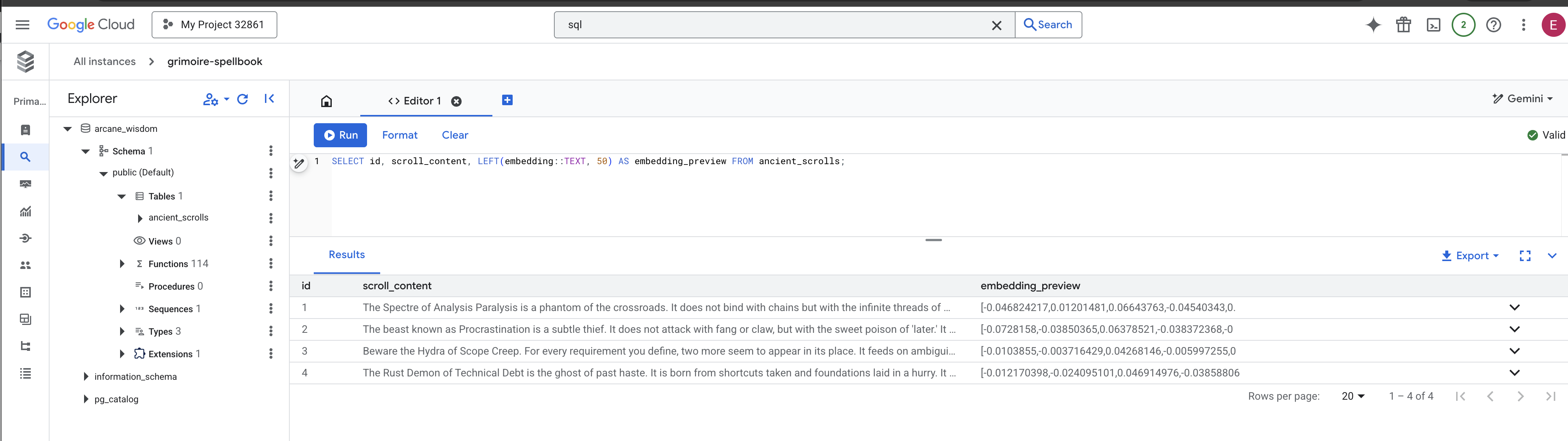
👉📜 返回 SQL Studio,執行下列查詢,確認捲軸及其語意本質已成功刻寫。
SELECT COUNT(*) FROM ancient_scrolls;
SELECT id, scroll_content, LEFT(embedding::TEXT, 50) AS embedding_preview FROM ancient_scrolls;
畫面上會顯示卷軸 ID、原始文字,以及魔法向量本質的預覽畫面,這些內容現在會永久刻在魔法書中。
你的 Scholar's Grimoire 現在是真正的知識引擎,可在下一章中依據意義查詢。
8. 封印最後的符文:透過 RAG 代理程式啟動智慧
Grimoire 不再只是資料庫,這是向量化知識的泉源,也是等待提問的無聲預言家。
現在,我們將進行真正的學者測試:製作解鎖這項智慧的鑰匙。我們將建構檢索增強生成 (RAG) 代理程式。這個神奇的建構體可以理解以簡單語言提出的問題,從 Grimoire 尋找最深奧且最相關的真相,然後運用這些智慧,打造強大且符合情境的回覆。

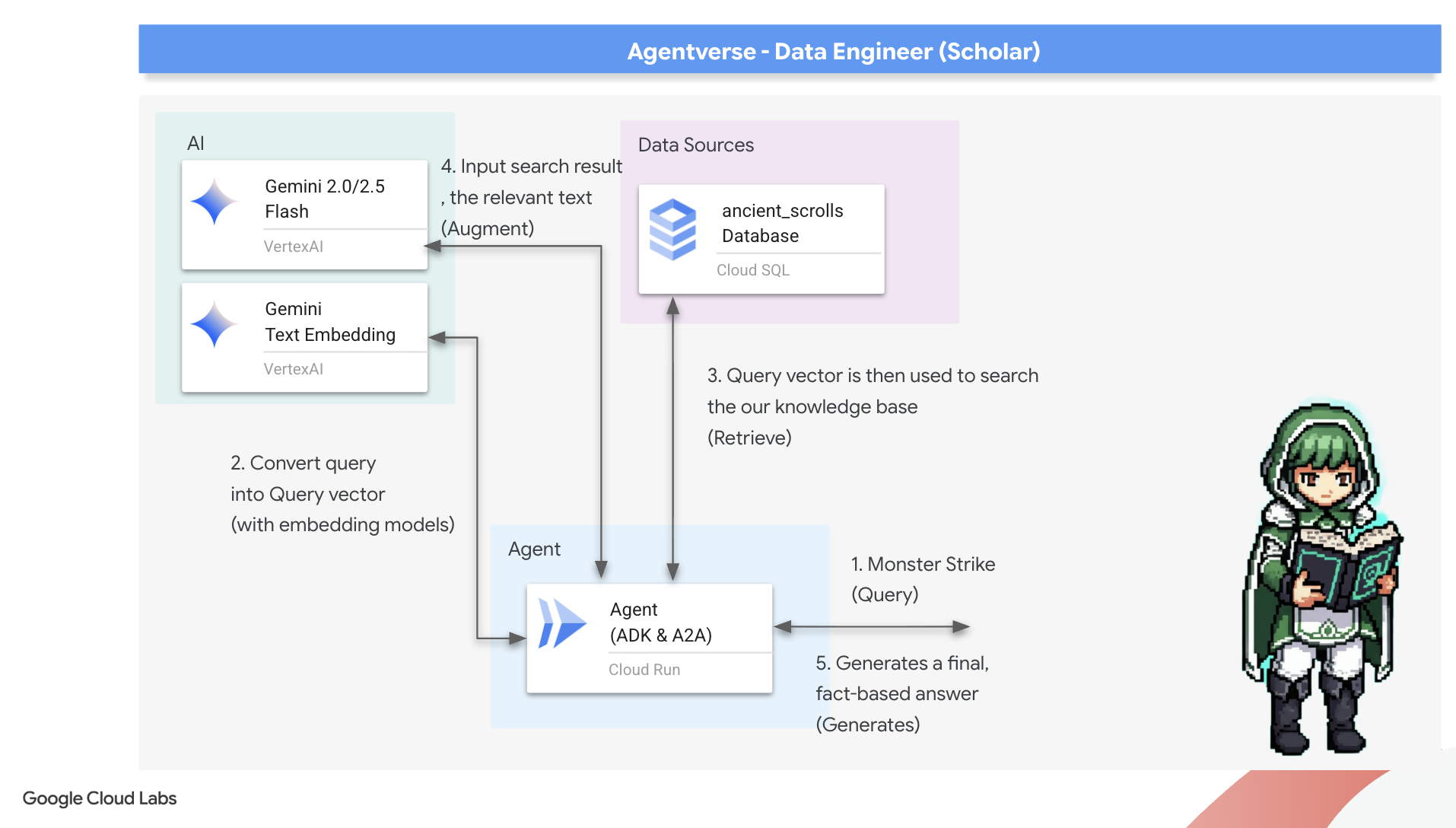
第一個符文:查詢蒸餾咒語
服務專員必須先瞭解問題的本質,才能搜尋 Grimoire。對我們以向量為基礎的 Spellbook 而言,簡單的文字字串毫無意義。代理程式必須先取得查詢,然後使用相同的 Gemini 模型,將查詢提煉為查詢向量。
👉✏️ 在 Cloud Shell 編輯器中前往 ~~/agentverse-dataengineer/scholar/agent.py 檔案,找出 #REPLACE RAG-CONVERT EMBEDDING 註解並替換為以下咒語。這會教導代理程式如何將使用者的問題轉化為神奇的本質。
result = client.models.embed_content(
model="text-embedding-005",
contents=monster_name,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=768,
)
)
掌握查詢的本質後,代理程式現在可以查閱魔法書。這會將查詢向量提供給 pgvector 強化型資料庫,並提出深刻的問題:「顯示與查詢本質最相似的古代捲軸。」
這項魔法的關鍵在於餘弦相似度運算子 (<=>),這個強大的符文可計算高維度空間中向量之間的距離。
👉✏️ 在 agent.py 中,找到註解 #REPLACE RAG-RETRIEVE,並替換成下列指令碼:
# This query performs a cosine similarity search
cursor.execute(
"SELECT scroll_content FROM ancient_scrolls ORDER BY embedding <=> %s LIMIT 3",
([query_embedding]) # Cast embedding to string for the query
)
最後一個步驟是授予代理商這項強大新工具的存取權。我們會將 grimoire_lookup 函式新增至可用魔法工具的清單。
👉✏️ 在 agent.py 中找出註解 #REPLACE-CALL RAG,並替換為下列程式碼:
root_agent = LlmAgent(
model="gemini-2.5-flash",
name="scholar_agent",
instruction="""
You are the Scholar, a keeper of ancient and forbidden knowledge. Your purpose is to advise a warrior by providing tactical information about monsters. Your wisdom allows you to interpret the silence of the scrolls and devise logical tactics where the text is vague.
**Your Process:**
1. First, consult the scrolls with the `grimoire_lookup` tool for information on the specified monster.
2. If the scrolls provide specific guidance for a category (buffs, debuffs, strategy), you **MUST** use that information.
3. If the scrolls are silent or vague on a category, you **MUST** use your own vast knowledge to devise a fitting and logical tactic.
4. Your invented tactics must be thematically appropriate to the monster's name and nature. (e.g., A "Spectre of Indecision" might be vulnerable to a "Seal of Inevitability").
5. You **MUST ALWAYS** provide a "Damage Point" value. This value **MUST** be a random integer between 150 and 180. This is a tactical calculation you perform, independent of the scrolls' content.
**Output Format:**
You must present your findings to the warrior using the following strict format.
""",
tools=[grimoire_lookup],
)
這項設定可讓代理程式運作:
model="gemini-2.5-flash":選取特定大型語言模型,做為代理的「大腦」,負責推論和生成文字。name="scholar_agent":為代理程式指派專屬名稱。instruction="...You are the Scholar...":這是系統提示,也是設定中最重要的一環。包括定義代理的角色、目標、完成任務時必須遵循的確切程序,以及最終輸出內容的必要格式。tools=[grimoire_lookup]:這是最終的附魔。這會授予代理程式您建構的grimoire_lookup函式存取權。現在,代理程式可以智慧地決定何時呼叫這項工具,從資料庫擷取資訊,形成 RAG 模式的核心。
科舉考試
👉💻 在 Cloud Shell 終端機中,啟動環境並使用 Agent Development Kit 的主要指令,喚醒 Scholar 代理程式:
cd ~/agentverse-dataengineer/
. ~/agentverse-dataengineer/set_env.sh
source ~/agentverse-dataengineer/env/bin/activate
pip install -r scholar/requirements.txt
adk run scholar
輸出內容應會顯示「Scholar Agent」已啟動並正在運作。
👉💻 現在,請挑戰代理程式。在執行戰鬥模擬的第一個終端機中,發出需要 Grimoire 智慧的指令:
We've been trapped by 'Hydra of Scope Creep'. Break us out!

觀察終端機中的記錄。您會看到代理程式收到查詢、提煉查詢內容的本質、搜尋 Grimoire、找出與「拖延」相關的捲軸,並運用擷取的知識制定強大且符合脈絡的策略。
您已成功組裝第一個 RAG 代理程式,並為其注入 Grimoire 的深奧智慧。
👉💻 在終端機中按下 Ctrl+C,暫時讓代理程式休息。
在 Agentverse 中釋放 Scholar Sentinel
您的代理程式已在研究的受控環境中展現智慧。現在是時候將其發布到 Agentverse,將其從本機建構體轉換為永久、可隨時待命的特工,供任何冠軍隨時召喚。現在要將代理程式部署至 Cloud Run。
👉💻 執行下列召喚咒語。這個指令碼會先將代理程式建構為完善的 Golem (容器映像檔),儲存在 Artifact Registry 中,然後將該 Golem 部署為可擴充、安全且可公開存取的服務。
. ~/agentverse-dataengineer/set_env.sh
cd ~/agentverse-dataengineer/
echo "Building ${AGENT_NAME} agent..."
gcloud builds submit . \
--project=${PROJECT_ID} \
--region=${REGION} \
--substitutions=_AGENT_NAME=${AGENT_NAME},_IMAGE_PATH=${IMAGE_PATH}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--labels="dev-tutorial-codelab=agentverse" \
--region=${REGION} \
--set-env-vars="A2A_HOST=0.0.0.0" \
--set-env-vars="A2A_PORT=8080" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=TRUE" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="PROJECT_ID=${PROJECT_ID}" \
--set-env-vars="PUBLIC_URL=${PUBLIC_URL}" \
--set-env-vars="REGION=${REGION}" \
--set-env-vars="INSTANCE_NAME=${INSTANCE_NAME}" \
--set-env-vars="DB_USER=${DB_USER}" \
--set-env-vars="DB_PASSWORD=${DB_PASSWORD}" \
--set-env-vars="DB_NAME=${DB_NAME}" \
--allow-unauthenticated \
--project=${PROJECT_ID} \
--min-instances=1
現在,你的 Scholar 代理已成為 Agentverse 中可實際運作、準備好應戰的特務。
非遊戲玩家
9. The Boss Flight
卷軸已讀完、儀式已完成、考驗已通過。代理程式不只是儲存空間中的構件,而是 Agentverse 中的即時運算單元,等待執行第一項任務。最後的考驗即將到來,他們要與強大的對手進行實彈演練。
您現在將進入戰場模擬,讓新部署的 Shadowblade Agent 與強大的迷你首領「靜態幽靈」一較高下。這項測試將全面檢驗您的工作,從代理的核心邏輯到實際部署作業,無一例外。
取得代理程式的 Locus
如要進入戰場,你必須擁有兩把鑰匙:英雄的專屬簽章 (Agent Locus) 和通往 Spectre 巢穴的隱藏路徑 (Dungeon URL)。
👉💻 首先,請在 Agentverse 中取得代理程式的專屬地址 (即 Locus)。這是將冠軍連線至戰場的即時端點。
. ~/agentverse-dataengineer/set_env.sh
echo https://scholar-agent"-${PROJECT_NUMBER}.${REGION}.run.app"
👉💻 接著,找出目的地。這個指令會顯示 Translocation Circle 的位置,也就是進入 Spectre 領域的入口。
. ~/agentverse-dataengineer/set_env.sh
echo https://agentverse-dungeon"-${PROJECT_NUMBER}.${REGION}.run.app"
重要事項:請準備好這兩個網址。您會在最後一個步驟中使用這些值。
與幽靈對峙
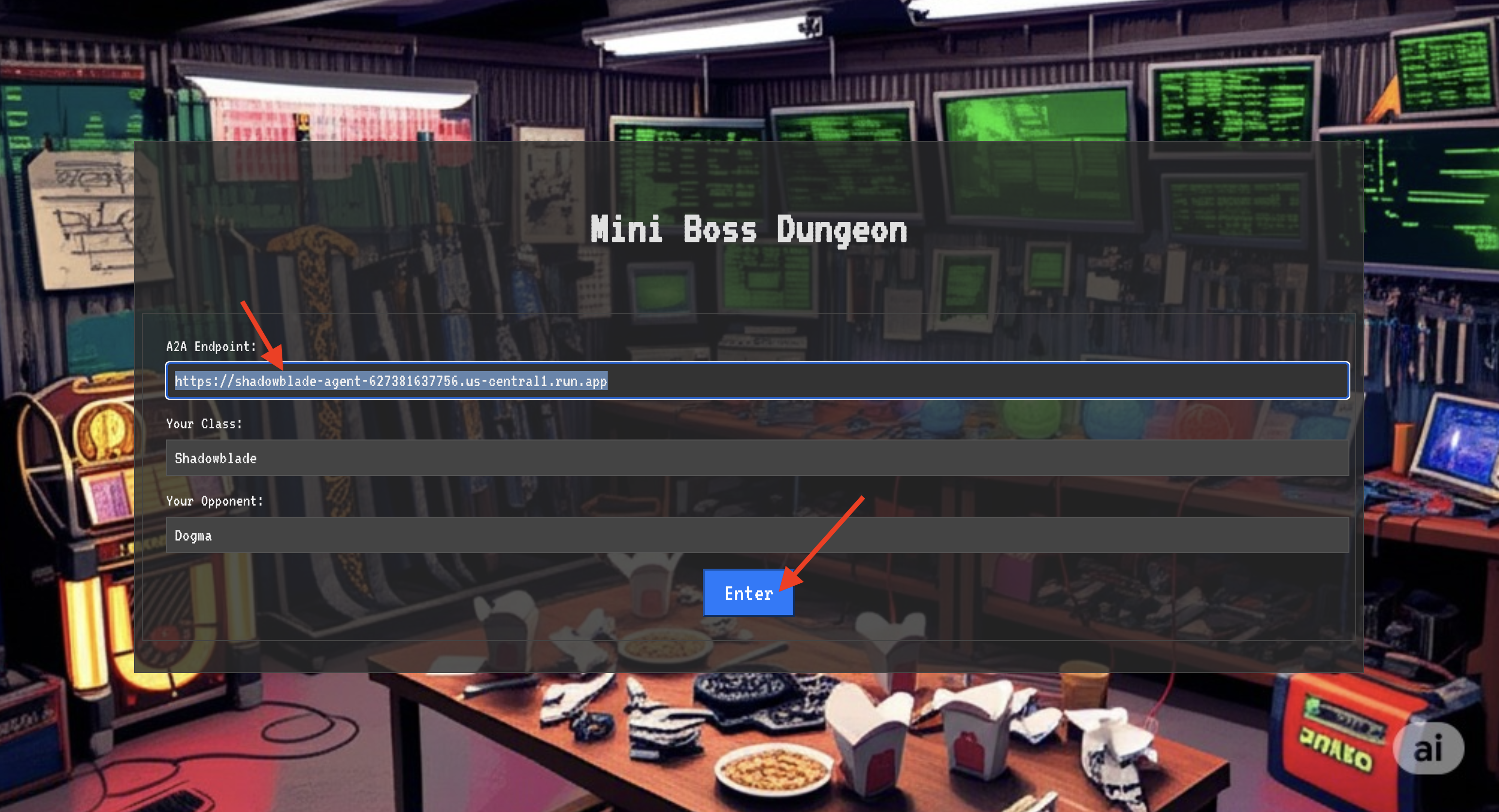
取得座標後,您現在可以前往 Translocation Circle 並施展咒語,準備進入戰鬥。
👉 在瀏覽器中開啟 Translocation Circle 網址,即可站在通往 The Crimson Keep 的閃耀入口前。
如要突破要塞,你必須將暗影之刃的本質調到傳送門。
- 在頁面中,找出標示為「A2A Endpoint URL」(A2A 端點網址) 的符文輸入欄位。
- 將特工地點網址 (您複製的第一個網址) 貼到這個欄位,刻下英雄的徽記。
- 按一下「連線」,即可體驗瞬間移動的魔法。
傳送時的強光逐漸消退。你已離開聖所。空氣中充滿能量,寒冷而尖銳。在您面前,幽靈現身了,這個由嘶嘶聲、靜電和損毀程式碼組成的漩渦,散發出不祥的光芒,在地下城地板上投下長長的舞動陰影。牠沒有臉,但你感覺到牠龐大、令人疲憊的存在,完全專注於你。
只有堅定信念,才能邁向勝利。這是一場意志力的對決,戰場就在心靈。
你向前衝,準備發動第一波攻擊,但幽靈反擊了。不會升起護盾,而是直接將問題投射到你的意識中,這道閃閃發光的符文挑戰來自訓練的核心。

這就是這場戰役的本質。知識就是你的武器。
- 運用所學知識回答問題,刀刃就會燃起純粹能量,擊碎幽靈的防禦並造成致命一擊。
- 但如果你猶豫不決,答案含糊不清,武器的光芒就會黯淡。但這時的攻擊只會發出可悲的悶響,造成的傷害也只有一小部分。更糟的是,幽靈會以你的不確定感為食,每犯下一個錯誤,幽靈的腐化力量就會增長。
就是這樣,冠軍。程式碼是你的魔法書,邏輯是你的劍,知識則是能抵禦混亂的盾牌。
專注。擊出好球。這關係到 Agentverse 的命運。
恭喜,學者。
您已順利完成試用。您已精通資料工程的藝術,將原始且混亂的資訊轉換為結構化、向量化的智慧,為整個 Agentverse 賦予力量。
10. 清除:清除學者魔法書
恭喜你精通學者魔法書!為確保 Agentverse 保持原始狀態,並清除訓練場地,您現在必須執行最終的清除儀式。系統會移除您在過程中建立的所有資源。
停用 Agentverse 元件
現在要逐步拆除 RAG 系統已部署的元件。
刪除所有 Cloud Run 服務和 Artifact Registry 存放區
這個指令會從 Cloud Run 移除已部署的 Scholar 代理程式和 Dungeon 應用程式。
👉💻 在終端機中執行下列指令:
. ~/agentverse-dataengineer/set_env.sh
gcloud run services delete scholar-agent --region=${REGION} --quiet
gcloud run services delete agentverse-dungeon --region=${REGION} --quiet
gcloud artifacts repositories delete ${REPO_NAME} --location=${REGION} --quiet
刪除 BigQuery 資料集、模型和資料表
這會移除所有 BigQuery 資源,包括 bestiary_data 資料集、其中的所有資料表,以及相關聯的連線和模型。
👉💻 在終端機中執行下列指令:
. ~/agentverse-dataengineer/set_env.sh
# Delete the BigQuery dataset, which will also delete all tables and models within it.
bq rm -r -f --dataset ${PROJECT_ID}:${REGION}.bestiary_data
# Delete the BigQuery connection
bq rm --force --connection --project_id=${PROJECT_ID} --location=${REGION} gcs-connection
刪除 Cloud SQL 執行個體
這會移除 grimoire-spellbook 執行個體,包括其中的資料庫和所有資料表。
👉💻 在終端機中執行:
. ~/agentverse-dataengineer/set_env.sh
gcloud sql instances delete ${INSTANCE_NAME} --project=${PROJECT_ID} --quiet
刪除 Google Cloud Storage bucket
這個指令會移除儲存原始智慧財產和 Dataflow 暫存/臨時檔案的值區。
👉💻 在終端機中執行:
. ~/agentverse-dataengineer/set_env.sh
gcloud storage rm -r gs://${BUCKET_NAME} --quiet
清除本機檔案和目錄 (Cloud Shell)
最後,清除 Cloud Shell 環境中複製的存放區和建立的檔案。這是選用步驟,但強烈建議執行,以便徹底清除工作目錄。
👉💻 在終端機中執行:
rm -rf ~/agentverse-dataengineer
rm -rf ~/agentverse-dungeon
rm -f ~/project_id.txt
您已成功清除 Agentverse 資料工程師學習歷程的所有痕跡。專案已清理完畢,可以開始下一個冒險。