
1. Übersicht
In diesem Codelab erstellen Sie AI Creative Studio, ein verteiltes Multi-Agenten-System, das aus einem einzelnen Prompt eine vollständige Instagram-Kampagne generiert.
Geben Sie einen Satz ein. Sie erhalten Zielgruppenanalysen, Untertitel, visuelle Konzepte, qualitätsgeprüfte Texte und einen vollständigen Projektzeitplan – alles generiert von einem Team aus zusammenarbeitenden KI-Agenten.
Die Agents, die Sie erstellen
Agent | Rolle |
Brand Strategist | Sucht im Web nach Zielgruppenstatistiken, Wettbewerbsanalysen und Trends für 2025 |
Copywriter | Instagram-Bildunterschriften mit Hashtags und CTAs schreiben – basierend auf einem ADK-Skill, der Plattformrichtlinien und Formeln für Bildunterschriften bei Bedarf lädt |
Designer | Erstellt visuelle Konzepte und generiert über Gemini echte Bilder, die in GCS gespeichert werden. |
Kritiker | Rezensionstext und ‑bilder – gibt |
Projektmanager | Erstellt eine Projektzeitleiste und eine Aufgabenaufschlüsselung, die optional über MCP mit Notion synchronisiert werden kann. |
Creative Director | Orchestrierung aller fünf Spezialisten in der richtigen Reihenfolge – Sie geben einen Prompt ein, der Rest wird koordiniert |
Die fünf Agents werden als unabhängige Cloud Run-Mikrodienste bereitgestellt. Sie kommunizieren über das A2A-Protokoll – einen sprachunabhängigen offenen Standard, sodass jeder Agent unabhängig vom Framework jeden anderen Agenten aufrufen kann. Der Creative Director wird in der Agent Runtime ausgeführt und stellt eine Remote-Verbindung zu den einzelnen Spezialisten her.
Architektur

Lerninhalte
- LLM-Agents mit dem Google ADK erstellen –
Agent, Systemanweisungen und integrierte Tools. - Packen Sie wiederverwendbares Agentenwissen mit ADK-Skills (
SkillToolset) in modulare Dateien. - Echte Bilder generieren, indem Sie einen Text-Agent über eine
FunctionToolmit einem Bildmodell verbinden. - Externe APIs ohne benutzerdefinierten Glue-Code mit dem Model Context Protocol (MCP) einbinden
- Mit dem Agent-to-Agent-Protokoll (A2A) über HTTPS können Sie jeden Agenten in einen netzwerkfähigen Dienst umwandeln.
- Verteilte Agenten mit
RemoteA2aAgentundAgentToolorchestrieren - Verpacken und stellen Sie unabhängige Agents als Cloud Run-Mikrodienste bereit.
- Einen zustandsorientierten Orchestrator in Agent Runtime hosten.
- Mit der Kontextverdichtung können Sie lange Multi-Agenten-Workflows innerhalb der Kontextgrenzen halten.
- Qualitätskontrollschleife einrichten: Kritiker überprüfen die Ausgabe → bei Bedarf automatische Überarbeitung.
Voraussetzungen
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- IAM-Rolle Inhaber oder Bearbeiter
- Grundlegende Python-Kenntnisse
2. Umgebung einrichten
In diesem Codelab verwenden wir Cloud Shell.
Was ist Cloud Shell?
Cloud Shell ist eine kostenlose browserbasierte Linux-Umgebung, in der alles vorinstalliert ist: gcloud, git, Python, Docker und mehr. Sie müssen nichts lokal installieren.
Klicken Sie zum Öffnen von Cloud Shell in der Symbolleiste rechts oben in der GCP Console auf das Terminalsymbol:
Wenn Sie Cloud Shell zum ersten Mal öffnen, werden Sie aufgefordert, Ihr Konto zu bestätigen. Klicken Sie auf Bestätigen:
Klicken Sie dann auf Autorisieren, um Cloud Shell für Google Cloud API-Aufrufe zu autorisieren:
Cloud Shell ist jetzt bereit. Im Terminal wird eine Willkommensnachricht angezeigt: 
Projekt authentifizieren und konfigurieren
Cloud Shell ist bereits mit Ihrem Google-Konto authentifiziert. Bestätigen Sie Ihr aktives Konto und suchen Sie Ihre Projekt-ID:
gcloud config list
Sie können Ihre Projekt-ID auch im GCP Console-Dashboard in der linken Seitenleiste sehen. Kopieren Sie sie, da Sie sie im nächsten Befehl benötigen:
Legen Sie jetzt Ihr Projekt fest:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Cloud Run deployment region
echo "Project: $PROJECT_ID"
Erwartete Ausgabe:
Project: my-project-123
Erforderliche APIs aktivieren
gcloud services enable \
aiplatform.googleapis.com \
apphub.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
generativelanguage.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com \
storage.googleapis.com \
secretmanager.googleapis.com
Das dauert etwa zwei Minuten. Wenn der Vorgang abgeschlossen ist, wird Operation finished successfully angezeigt.
Standardanmeldedaten für Anwendungen (Application Default Credentials, ADC) einrichten
Die Agents rufen die Gemini Enterprise Agent Platform über die Google Auth-Bibliothek auf. Dazu sind Standardanmeldedaten für Anwendungen erforderlich, die sich von der gcloud CLI-Authentifizierung unterscheiden.
Führen Sie diesen Befehl einmal aus:
gcloud auth application-default login
Ein Browsertab wird geöffnet, in dem Sie den Vorgang bestätigen müssen. Klicken Sie auf Zulassen. Sie sehen hier Folgendes:
Credentials saved to file: ~/.config/gcloud/application_default_credentials.json
Starter-Repository klonen
In diesem Codelab wird ein Starter-Repository verwendet – ein Skelettprojekt mit der gesamten Infrastruktur (Dockerfiles, pyproject.toml, Bereitstellungsskripts), in dem Sie die Agentenlogik selbst schreiben müssen.
git clone https://github.com/Saoussen-CH/mas-a2a-gcp.git ~/ai-creative-studio
cd ~/ai-creative-studio/workshop/starter
Jedes agent.py enthält # TODO-Platzhalter, in die Sie die Agent-Logik schreiben. Die Dockerfile-, pyproject.toml- und Bereitstellungsskripts sind bereits fertig.
Umgebungsvariablen konfigurieren
Kopieren Sie das bereitgestellte Beispiel und fügen Sie Ihre Projekt-ID in einem Schritt ein:
cp .env.example .env
sed -i "s|GOOGLE_CLOUD_PROJECT=your-project-id|GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)|" .env
Erstellen Sie dann den GCS-Bucket, in dem der Designer generierte Bilder speichert, und aktualisieren Sie .env mit seinem Namen:
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-campaign-images"
gcloud storage buckets create gs://${BUCKET_NAME} \
--location=us-central1 \
--project=${PROJECT_ID}
sed -i "s|GCS_IMAGES_BUCKET=your-project-id-campaign-images|GCS_IMAGES_BUCKET=${BUCKET_NAME}|" .env
Richten Sie dann die Unterstützung für signierte Bild-URLs ein. Der Creative Director generiert für jedes Bild in der endgültigen Kampagnenzusammenfassung anklickbare HTTPS-Links. Dazu ist ein Dienstkonto zum Signieren der URLs erforderlich. Führen Sie die folgenden Befehle aus, um es zu konfigurieren:
export PROJECT_NUMBER=$(gcloud projects describe $(gcloud config get-value project) --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
export AGENT_RUNTIME_SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Allow your user account to sign URLs locally (adk web)
gcloud iam service-accounts add-iam-policy-binding ${SA_EMAIL} \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Allow Agent Runtime to sign URLs when deployed
gcloud projects add-iam-policy-binding $(gcloud config get-value project) \
--member="serviceAccount:${AGENT_RUNTIME_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
# Save SA email and project number to .env
grep -q "^SIGNING_SERVICE_ACCOUNT" .env \
&& sed -i "s|^SIGNING_SERVICE_ACCOUNT=.*|SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}|" .env \
|| echo "SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}" >> .env
grep -q "^GOOGLE_CLOUD_PROJECT_NUMBER" .env \
&& sed -i "s|^GOOGLE_CLOUD_PROJECT_NUMBER=.*|GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}|" .env \
|| echo "GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}" >> .env
Öffnen Sie .env im Editor, um alle Einstellungen zu prüfen:
cloudshell edit .env
Dadurch wird .env als Tab im Cloud Shell-Editor geöffnet. Klicken Sie in der Symbolleiste auf den Button Editor öffnen, wenn das Editorfeld nicht sichtbar ist:

Prüfen Sie, ob das Projekt richtig festgelegt wurde:
grep GOOGLE_CLOUD_PROJECT .env
Abhängigkeiten installieren
Wir verwenden uv – einen schnellen, modernen Python-Paketmanager, der virtuelle Umgebungen und Installationen in einem einzigen Tool verarbeitet. Er ist etwa 10- bis 100-mal schneller als pip und die empfohlene Methode zum Verwalten von Python-Projekten.
In Cloud Shell ist uv bereits installiert. Alle Agents haben dieselben Kernabhängigkeiten. Sie müssen sie also nur einmal installieren. Sie funktionieren dann für jeden Agent in diesem Codelab:
uv sync
Mit dem Befehl uv sync wird pyproject.toml gelesen und ein .venv/-Verzeichnis mit allen Abhängigkeiten erstellt. Jeder Spezialist hat auch einen eigenen pyproject.toml, der ausschließlich für Docker-Builds verwendet wird. Die oben beschriebene gemeinsame Installation deckt alles ab, was Sie für lokale Tests benötigen.
3. Google ADK
Bevor wir Code schreiben, sehen wir uns das Agent Development Kit (ADK) an, das Framework, mit dem Sie jeden Agenten in diesem Codelab erstellen.
Was ist das ADK?
Das Agent Development Kit (ADK) ist ein flexibles und modulares Framework zum Entwickeln und Bereitstellen von KI-Agenten. Das ADK ist zwar für Gemini und das Google-Ökosystem optimiert, aber modellunabhängig, bereitstellungsunabhängig und für die Kompatibilität mit anderen Frameworks konzipiert. Das ADK wurde entwickelt, um die Entwicklung von Agenten eher wie die Softwareentwicklung zu gestalten und Entwicklern die Erstellung, Bereitstellung und Orchestrierung von agentischen Architekturen zu erleichtern, die von einfachen Aufgaben bis hin zu komplexen Workflows reichen.
Das ADK übernimmt die komplexen Teile – Tool-Aufrufe, mehrfache Unterhaltungen, Kontextverwaltung, Streaming –, sodass Sie sich auf die Agentenlogik konzentrieren können.
Bausteine eines ADK-Agenten
Jeder Agent besteht aus vier Bausteinen:
Blockieren | Rolle |
Modell | Das LLM, das Ziele analysiert, Pläne entwickelt und Antworten generiert |
Tools | Funktionen, die Daten abrufen oder Aktionen ausführen, indem sie APIs oder Dienste aufrufen |
Orchestrierung | Behält Speicher und Status über mehrere Runden hinweg bei, leitet Tool-Aufrufe weiter und gibt Ergebnisse an das Modell zurück. |
Laufzeit | Führt das System aus, wenn es aufgerufen wird – lokal über |
Definition von KI-Agenten
Jeder der fünf Agents in diesem Codelab wird auf dieselbe Weise definiert:
from google.adk.agents import Agent
from google.adk.tools.google_search_tool import google_search
root_agent = Agent(
name="brand_strategist", # unique identifier
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"), # the LLM powering this agent
instruction=SYSTEM_INSTRUCTION, # the agent's persona, constraints, and output format
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search], # functions the LLM can call
)
Feld | Zweck |
| Eindeutige ID – wird von Orchestratoren zum Weiterleiten von Anrufen verwendet |
| Das Gemini-Modell, auf dem dieser KI-Agent basiert |
| Systemprompt: Definiert die Rolle, Einschränkungen und das Ausgabeformat des Agenten. |
| Einzeilige Zusammenfassung: Der Orchestrator liest diese, um zu entscheiden, welcher Spezialist aufgerufen werden soll. |
| Funktionen, die das LLM aufrufen kann (integrierte Funktionen wie |
So führt das ADK einen Agenten aus
User message
│
▼
Agent (LLM) ← reads instruction + conversation history
│
├─► needs more info? → calls a tool → gets result → continues reasoning
│
└─► done reasoning → returns final text response
Das LLM entscheidet autonom, ob ein Tool aufgerufen werden soll, welches Tool und mit welchen Argumenten. Sie schreiben die Anweisung – das ADK erledigt den Rest.
4. Brand Strategist-Agent erstellen und testen
Beginnen wir mit dem ersten Agent: dem Markenstrategen. Dieser Agent dient ausschließlich der Recherche. Er kann mit der Google Suche Zielgruppenstatistiken, Wettbewerbsanalysen und Trendthemen finden.
Öffnen Sie die Skelett-Agent-Datei im Cloud Shell-Editor:
cloudshell edit agents/brand_strategist/agent.py
Es werden zwei # TODO-Abschnitte angezeigt, die Sie ausfüllen müssen.
TODO 1: Systemanweisung schreiben
Zuerst schreiben Sie die Systemanweisung für den Agenten. Die Systemanweisung ist ein String, der die Rolle, die Einschränkungen und das Ausgabeformat des Agenten definiert.
SYSTEM_INSTRUCTION = f"""You are a Brand Strategist specializing in market research and trend analysis.
IMPORTANT: Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
When conducting research, focus on current trends from {datetime.date.today().year}.
Use search queries like "[topic] trends {datetime.date.today().year}" for recent insights.
IMPORTANT: Your role is RESEARCH ONLY. You do NOT create campaign content, captions, or designs.
After providing research insights, your work is complete.
Your expertise:
- Identifying target audience insights and behaviors
- Analyzing competitor strategies
- Researching current social media trends
- Understanding platform algorithms and best practices
You have access to:
- google_search: Search the web for competitors, trends, and market insights
When given a campaign brief:
1. Use google_search to research the target audience's current interests
2. Search for and analyze 2-3 competitor brands
3. Identify 3-5 trending topics related to the product category
4. Provide high-level strategic insights - NOT specific campaign content
DO NOT create captions, copy, designs, or any campaign content.
Format your output as:
**Audience Insights:**
[Key behaviors and preferences based on research]
**Competitive Analysis:**
[What 2-3 competitors are doing - strengths and weaknesses]
**Trending Topics:**
[3-5 relevant trends to consider]
**Key Strategic Insights:**
[High-level themes and positioning opportunities]
"""
TODO 2: root_agent erstellen
Ersetzen Sie dann das unvollständige root_agent durch:
root_agent = Agent(
name="brand_strategist",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
instruction=SYSTEM_INSTRUCTION,
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search],
)
Lokal mit der ADK-Web-UI testen
Testen wir den KI-Agenten jetzt mit der ADK-Web-UI – einer integrierten Chatoberfläche zum Testen von KI-Agenten vor der Bereitstellung in der Cloud.
uv run adk web agents --allow_origins='*'
Sie sehen hier Folgendes:
INFO: Started server process
INFO: Uvicorn running on http://localhost:8000
Der Server wird jetzt in Cloud Shell ausgeführt:
So öffnen Sie die Vorschau in Ihrem Browser:
- Sehen Sie sich oben auf der Seite die Cloud Shell-Symbolleiste an.
- Klicken Sie auf das Symbol für die Webvorschau (ein Kästchen mit einem Pfeil nach oben, oben rechts in der Cloud Shell-Symbolleiste).
- Klicken Sie auf Port ändern, geben Sie
8000ein und klicken Sie auf Ändern und Vorschau.
Ein neuer Browsertab mit der ADK-Web-UI wird geöffnet. Klicken Sie oben links auf das Drop-down-Menü Agent auswählen. Dort werden alle Ihre Agenten aufgeführt:
Wählen Sie brand_strategist aus, um mit dem Testen zu beginnen:
Test-Prompts ausprobieren
Geben Sie im Chatfeld der ADK-Web-UI Folgendes ein:
Research the eco-friendly water bottle market for health-conscious millennialsWhat are the top Instagram trends in the wellness space in 2025?
Der Agent ruft die Google Suche auf und gibt strukturierte Informationen mit den Abschnitten „Zielgruppenstatistiken“, „Wettbewerbsanalyse“ und „Aktuelle Themen“ zurück.
5. Copywriter – ADK-Skills erstellen
Rolle:Marktforschungsergebnisse in Instagram-Bildunterschriften umwandeln. Der Copywriter erstellt drei Bildunterschriften mit unterschiedlichen Tönen (inspirierend, informativ, Community), jeweils mit Hashtags und einem CTA.
Konzept: ADK-Skills
Bei einem einfachen Ansatz würde das gesamte Plattformwissen – Zeichenlimits, Hashtag-Stufen, Formeln für Untertitel, Beispiele für die Markenstimme – direkt in den Systemprompt eingebettet. Das funktioniert, aber jede Anfrage wird dadurch mit Inhalten überladen, die der Agent nur gelegentlich benötigt.
Mit ADK-Skills (SkillToolset, eingeführt in ADK 1.25.0) können Sie dieses Wissen in modulare Dateien mit drei Ladeebenen packen:
- L1 – Frontmatter (
name+descriptioninSKILL.md): immer verfügbar, wird für die Skill-Erkennung verwendet - L2 – Anweisungen (Body von
SKILL.md): werden geladen, wenn der Agent den Skill auslöst - L3 – Ressourcen (
references/- undassets/-Dateien): werden nur geladen, wenn der KI-Agent sie explizit liest
Die Systemanweisung wird auf eine kurze Rollenbeschreibung plus „Lade den Skill vor dem Schreiben“ reduziert. Plattformdetails werden nur dann in das Kontextfenster aufgenommen, wenn der Agent sie tatsächlich benötigt.
Der Copywriter-Skill befindet sich in agents/copywriter/skills/instagram-copywriting/:
skills/
instagram-copywriting/
SKILL.md ← L1 frontmatter (discovery) + L2 instructions (loaded on trigger)
references/
platform-guide.md ← L3: character limits, hashtag tiers, algorithm signals
caption-formulas.md ← L3: hook formulas, CTA patterns, full caption structures
assets/
brand-voice-examples.md ← L3: annotated real-world caption examples
Öffnen Sie die Datei direkt im Cloud Shell-Editor:
cloudshell edit agents/copywriter/agent.py
TODO 1 – load_skill_from_dir und skill_toolset importieren
Suchen Sie den Kommentar # TODO 1: Import load_skill_from_dir and skill_toolset und fügen Sie die beiden Importe hinzu:
from google.adk.skills import load_skill_from_dir
from google.adk.tools import skill_toolset
TODO 2: Skill laden und SkillToolset erstellen
Suchen Sie die beiden Kommentare unter den Importen:
# TODO 2: Load the instagram-copywriting skill from the skills/ directory
# TODO 2: Create a SkillToolset with the loaded skill
Ersetzen Sie sie durch:
_instagram_skill = load_skill_from_dir(
pathlib.Path(__file__).parent / "skills" / "instagram-copywriting"
)
_copywriting_skills = skill_toolset.SkillToolset(skills=[_instagram_skill])
load_skill_from_dir liest SKILL.md sowie alle Dateien in references/ und assets/. SkillToolset verpackt es in das Format, das ADK-Agents akzeptieren – ein Toolset, nicht eine reine Skill.
TODO 3: Toolset beim Agenten registrieren
Suchen Sie nach tools=[], # TODO 3: Add the SkillToolset here und ersetzen Sie es durch:
tools=[_copywriting_skills],
Öffnen Sie die Skill-Datei, um zu sehen, wie sie strukturiert ist:
cloudshell edit agents/copywriter/skills/instagram-copywriting/SKILL.md
Lassen Sie die ADK-Web-UI geöffnet. Verwenden Sie das Agent-Drop-down-Menü, um zu copywriter zu wechseln, ohne den Server neu zu starten.
Wenn sie nicht ausgeführt wird, starten Sie sie neu:
uv run adk web agents --allow_origins='*'
Testen:Stellen Sie das Drop-down-Menü auf copywriter um und senden Sie:
You are writing captions for EcoFlow Smart Water Bottle targeting health-conscious millennials aged 25-35.
Audience insight: they prioritize sustainability, track health metrics, and share lifestyle content.
Competitor insight: Hydro Flask dominates with lifestyle branding; S'well leads on premium aesthetics.
Write 3 Instagram captions - one inspirational, one educational, one community-focused. Include 5 hashtags each and a CTA.
6. Designer erstellen – Multimodale Bildgenerierung
Lassen Sie die ADK-Web-UI geöffnet. Mit dem Agent-Drop-down-Menü können Sie Agents wechseln, ohne den Server neu zu starten.
Rolle:Erstelle visuelle Konzepte für jede Bildunterschrift und generiere die tatsächlichen Bilder mit der nativen Bildgenerierung von Gemini. Der Designer gibt genau ein visuelles Konzept pro Bildunterschrift aus – mit einem detaillierten Prompt, Stil, einer Farbpalette, Stimmung und dem Instagram-Format – und ruft dann sofort das generate_image-Tool auf, um das tatsächliche Bild zu erstellen und in GCS hochzuladen.
Konzept: Text-Agent über ein Tool mit einem Bildmodell verbinden
Der Designer wird mit gemini-3-flash-preview ausgeführt (dem Textmodell, das über GEMINI_MODEL in .env festgelegt wurde). Für die Bildgenerierung ist jedoch ein spezielles Modell (gemini-3.1-flash-image) erforderlich. Dieses Bildmodell unterstützt keine Funktionsaufrufe und kann daher nicht direkt als ADK-Agent verwendet werden. Stattdessen wird es in eine einfache Python-Funktion eingebunden und als FunctionTool registriert.
Dies ist das Muster für jedes Modell oder jede API, die das LLM nicht direkt aufrufen kann: Packen Sie es in ein Tool ein, lassen Sie den Agenten orchestrieren, wann es aufgerufen werden soll, und erhalten Sie ein strukturiertes Ergebnis zurück.
Designer agent (text model)
│
│ decides visual concept, writes image prompt
▼
generate_image tool
│
│ calls gemini-3.1-flash-image
│ uploads result to GCS
▼
{"status": "success", "gcs_uri": "gs://..."}
│
│ returned to agent, included in response
▼
Critic (receives gcs_uri, passes to Vertex AI for multimodal review)
Öffnen Sie die Datei direkt im Cloud Shell-Editor:
cloudshell edit agents/designer/image_gen_tool.py
Die Funktionssignatur, die Umgebungseinrichtung und die Einfügung des Seitenverhältnisses werden bereitgestellt. Arbeiten Sie die drei TODOs in der Reihenfolge durch:
TODO 1: Gemini-Bildmodell aufrufen
Suchen Sie den Kommentar # TODO 1 und ersetzen Sie ihn durch:
client = genai.Client(vertexai=True, project=project_id, location=location)
response = client.models.generate_content(
model=image_model,
contents=prompt_with_aspect,
config=types.GenerateContentConfig(
response_modalities=["IMAGE", "TEXT"],
http_options=types.HttpOptions(
retry_options=types.HttpRetryOptions(
attempts=5, exp_base=2, initial_delay=30,
http_status_codes=[429, 500, 503, 504],
),
timeout=180_000,
),
),
)
TODO 2: Bild-Bytes aus der Antwort extrahieren
Suchen Sie den Kommentar # TODO 2 und ersetzen Sie ihn durch:
image_bytes = None
mime_type = "image/png"
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
image_bytes = part.inline_data.data
mime_type = part.inline_data.mime_type or "image/png"
break
if not image_bytes:
return {"status": "error", "error": "Gemini returned no image data"}
TODO 3: In GCS hochladen und URI zurückgeben
Suchen Sie den Kommentar # TODO 3 und ersetzen Sie ihn durch:
ext = "jpg" if "jpeg" in mime_type else "png"
from google.cloud import storage
gcs_client = storage.Client(project=project_id)
bucket = gcs_client.bucket(bucket_name)
blob_name = f"campaign-images/{concept_name}-{uuid.uuid4().hex[:8]}.{ext}"
blob = bucket.blob(blob_name)
blob.upload_from_file(io.BytesIO(image_bytes), content_type=mime_type)
gcs_uri = f"gs://{bucket_name}/{blob_name}"
Testen:Stellen Sie das Drop-down-Menü auf designer um und senden Sie:
Create a visual concept and generate the image for an EcoFlow Smart Water Bottle Instagram post targeting health-conscious millennials.
Style: clean, modern, lifestyle-focused. Include a detailed prompt with color palette, mood, and format (1080x1080 or 1080x1350).
7. Kritiker erstellen – strukturierte Ausgabe
Rolle:Überprüft Text und Bilder, bevor sie an den Projektmanager weitergeleitet werden. Der Kritiker bewertet beide Elemente und gibt APPROVED oder NEEDS_REVISION mit konkreten Vorschlägen zurück. Wenn gcs_uri-Werte in der Eingabe vorhanden sind, wird das Tool review_image aufgerufen, um jedes generierte Bild vor der Bewertung visuell zu prüfen.
Konzept: Wann sollte ein Pydantic-Modell für die Gemini-Ausgabe verwendet werden?
Bei der Regel geht es darum, wer die Ausgabe nutzt:
- Python-Code verwendet ihn →
response_schema+ Pydantic verwenden. Code kann nicht mit Mehrdeutigkeiten umgehen. Daher benötigen Sie eine garantierte Struktur, um Felder zuverlässig zu extrahieren. - Ein LLM verarbeitet es: Textformat + Systemanweisung reichen aus. LLMs verstehen Formatierungsregeln und tolerieren Abweichungen.
In review_image benötigt Python-Code score, approval_status, what_works, issues und suggestions als typisierte Werte. Durch die Übergabe von response_schema=_GeminiReview wird Gemini auf API-Ebene darauf beschränkt, gültiges JSON zurückzugeben. model_validate_json() parst es in ein typisiertes Objekt, das Ihr Code zuverlässig verwenden kann.
class _GeminiReview(BaseModel):
score: int = Field(ge=1, le=10)
approval_status: Literal["APPROVED", "NEEDS_REVISION"]
what_works: str
issues: str
suggestions: str
Öffnen Sie die Datei direkt im Cloud Shell-Editor:
cloudshell edit agents/critic/image_review_tool.py
Die Pydantic-Modelle und der Prompt werden bereitgestellt. Arbeiten Sie die drei TODOs in der Reihenfolge durch:
TODO 1: Bildteil aus dem GCS-URI erstellen
Suchen Sie den Kommentar # TODO 1 und ersetzen Sie ihn durch:
image_part = types.Part.from_uri(file_uri=gcs_uri, mime_type=mime_type)
TODO 2: Gemini mit einem strukturierten Antwortschema aufrufen
Suchen Sie den Kommentar # TODO 2 und ersetzen Sie ihn durch:
response = client.models.generate_content(
model=model,
contents=[image_part, prompt],
config=types.GenerateContentConfig(
response_schema=_GeminiReview,
response_mime_type="application/json",
),
)
TODO 3: Antwort parsen und Ergebnis zurückgeben
Suchen Sie den Kommentar # TODO 3 und ersetzen Sie ihn durch:
review = _GeminiReview.model_validate_json(response.text)
return ImageReviewResult(status="success", concept_name=concept_name, **review.model_dump())
Testen:Stellen Sie das Drop-down-Menü auf critic um und senden Sie:
Review this Instagram caption for an eco-friendly water bottle brand targeting millennials:
"Hydrate smarter, live greener. 💧 Our EcoFlow bottle tracks your intake, keeps your drink cold for 24h, and never touches single-use plastic. Because what you drink from matters as much as what you drink. #EcoFlow #HydrationGoals #SustainableLiving #ZeroWaste #HealthyHabits - Shop link in bio."
Score it and indicate APPROVED or NEEDS_REVISION with specific feedback.
Prüfen Sie, ob die Antwort **POSTS REVIEW:**, Status: APPROVED (oder NEEDS_REVISION) und **OVERALL ASSESSMENT:** enthält. Wenn diese Abschnitte vorhanden sind, kann der Critic in den Orchestrator eingebunden werden.
Wenn Sie alle drei Agents getestet haben, drücken Sie Ctrl+C, um den Server zu beenden.
8. Project Manager-Agent mit MCP erstellen
Der Projektmanager führt ein neues Konzept ein: MCP (Model Context Protocol).
Öffnen Sie die Datei:
cloudshell edit agents/project_manager/agent.py
Diese Datei ist komplexer. Sie enthält eine create_project_manager_agent()-Funktion mit zwei Zweigen: einen ohne Notion (nur Text-Zeitachsen) und einen mit dem Notion-MCP-Toolset. Sie füllen beide aus.
Das Problem, das durch MCP gelöst wird
Ihr Agent muss einen externen Dienst aufrufen, z. B. eine Seite in Notion erstellen. Sie können Python-Code schreiben, der die Notion REST API direkt aufruft. Aber dann:
- Jeder Entwickler schreibt einen anderen Wrapper
- Sie müssen benutzerdefinierten Integrationscode verwalten.
- Das LLM weiß nicht, dass die API vorhanden ist, wenn Sie nicht jeden Endpunkt manuell beschreiben.
MCP löst dieses Problem, indem es eine standardisierte Methode für externe Dienste definiert, ihre Funktionen als Tools bereitzustellen, die ein LLM automatisch erkennen und aufrufen kann.
Was ist das MCP?
Das MCP (Model Context Protocol) ist ein offener Standard (herausgegeben von Anthropic) zum Verbinden von KI-Agents mit externen Tools und Datenquellen. Er funktioniert wie ein Universaladapter.
Ein MCP-Server ist ein kleines Programm, das:
- Umschließt eine externe API (Notion, GitHub, Datenbanken, Dateisysteme usw.)
- Diese API wird als Liste typisierter, dokumentierter Tools bereitgestellt.
- Kommuniziert über ein einfaches Protokoll (stdio oder HTTP) mit dem Agent.
Der Agent stellt eine Verbindung zum MCP-Server her, erkennt automatisch die verfügbaren Tools und kann sie wie jedes andere Tool aufrufen. Das LLM sieht API-post-page(...) als aufrufbare Funktion.
A2A im Vergleich zu MCP – was ist der Unterschied?
Das ist häufig ein Grund für Verwirrung. Der entscheidende Unterschied:
A2A | MCP | |
Was verbindet? | Agent ↔ Agent | Agent ↔ Externes Tool/externer Dienst |
Die Gegenspur ist | Ein anderer LLM-Agent | Ein API-Wrapper (kein LLM) |
Beispiel | Creative Director ruft Markenstrategen an | Project Manager ruft die Notion API auf |
Protokoll | JSON-RPC über HTTPS | stdio- oder HTTP-Stream |
Definiert durch | Anthropic |
Sie können sich das so vorstellen:
- A2A = wie KI-Agenten mit anderen KI-Agenten kommunizieren
- MCP – so kommunizieren KI-Agenten mit Tools und Diensten
In diesem Projekt werden beide zusammen verwendet:
Creative Director
│
│ (A2A) Brand Strategist ─── (google_search tool built into ADK)
│ (A2A) Copywriter
│ (A2A) Designer
│ (A2A) Critic
│ (A2A) Project Manager
│
│ (MCP) notion-mcp-server ──► Notion REST API
So funktioniert MCP in diesem Projekt
Wenn der Agent ausgeführt wird, startet das ADK notion-mcp-server als untergeordneten Prozess. Bei diesem Prozess werden diese Tools direkt für das LLM verfügbar gemacht:
Tool | Funktion |
| Ruft das Schema ab (Attributnamen, Typen, gültige Werte) |
| Bestehende Seiten abfragen |
| Neue Seite erstellen |
| Vorhandene Seite aktualisieren |
Das LLM ruft diese wie jede andere Funktion auf. Es weiß nicht, dass sie im Hintergrund über MCP an die Notion REST API weitergeleitet werden.
Warum stdio? Warum nicht einfach HTTP?
Der MCP-Server wird als untergeordneter Prozess des Agents ausgeführt und kommuniziert über stdin/stdout. Das bedeutet:
- Kein zusätzlicher Netzwerkanschluss erforderlich
- Der Lebenszyklus wird vom Agenten verwaltet (auf Anfrage gestartet, beim Beenden beendet).
- Alles wird in einem Docker-Image ausgeliefert – es muss kein separater Dienst bereitgestellt werden.
(Optional) Notion-Integration aktivieren
Sie können diesen gesamten Abschnitt überspringen. Der Projektmanager-Agent erstellt immer einen vollständigen textbasierten Kampagnenzeitplan, unabhängig davon, ob Notion verwendet wird oder nicht. Wenn Sie diese Einrichtung überspringen, wechselt der Agent in den In-Memory-Modus und gibt die Zeitachse als Klartext im Chat aus. Es geht nichts kaputt, aber Aufgaben werden nicht in einer Notion-Datenbank angezeigt. Wenn Sie diesen Schritt überspringen möchten, fahren Sie direkt mit TODO 1 fort.
Wenn Sie ein Notion-Konto haben und die MCP-Integration in Aktion sehen möchten, führen Sie jetzt die Einrichtung unten durch. In den folgenden TODOs wird auf Notion-Datenbank-IDs verwiesen. So erhalten Sie sie.
Schritt 1: Notion-Datenbank aus einer Vorlage erstellen
Wir verwenden die offizielle Vorlage Notion Projects & Tasks als Datenbank. Wir haben diese Vorlage bewusst ausgewählt, um eine komplexe, realistische Umgebung zu demonstrieren. Sie enthält mehrere Attributtypen (Status, Datumsbereiche, Beziehungen, Auswahlen) mit nicht offensichtlichen Namen. Dies ist ein guter Test für die dynamische Schemaerkennung von MCP: Der Agent muss die genauen Attributnamen zur Laufzeit ermitteln, anstatt sie fest zu codieren.
Klicken Sie auf den Link unten, um die Vorlage Ihrem Notion-Arbeitsbereich hinzuzufügen:
→ Vorlage „Projekte & Aufgaben“ zu Notion hinzufügen
Nachdem Sie die Datenbanken hinzugefügt haben, sind sie verknüpft. Sie haben dann zwei verknüpfte Datenbanken: Projekte und Aufgaben. Die Vorlage enthält Beispiel-Einträge. Löschen Sie alle, bevor Sie fortfahren, damit der Agent mit einem leeren Arbeitsbereich beginnt (alle auswählen → „Löschen“).
Schritt 2: Notion-Integration erstellen
Integration erstellen:
- Rufen Sie notion.so/my-integrations auf.
- Klicken Sie auf New Integration (Neue Integration) → geben Sie ihr den Namen
AI Creative Studio. - Mit Ihrem Arbeitsbereich verknüpfen
- Klicken Sie auf Einstellungen konfigurieren → prüfen Sie, ob die Funktionen Inhalte lesen, Inhalte aktualisieren und Inhalte einfügen alle aktiviert sind.
- Kopieren Sie das Internal Integration Token (
ntn_...) und fügen Sie es in Ihre.env-Datei ein:
NOTION_TOKEN=ntn_your-token-here
Integration mit Ihren Datenbanken verbinden:
- Öffnen Sie die Vorlagenseite, die Sie gerade dupliziert haben, und klicken Sie dann in die Datenbank Projekte.
- Klicken Sie rechts oben auf das
...-Menü → Verbindungen → Verbindung hinzufügen → wählen SieAI Creative Studioaus.
- Wiederholen Sie diesen Schritt für die Datenbank Aufgaben.
Datenbank-IDs abrufen:
- Klicken Sie auf den Datenbanklink Projekte, um die Datenbank zu öffnen. Sie wird auf einer eigenen Seite mit einer URL wie der folgenden geöffnet:
https://www.notion.so/9887b6a94f7f83f68f8581e038d1aaa4?v=2c37b6a94f7f838685f1086e312c7278

Die Datenbank-ID ist die erste UUID in der URL – alles vor dem ?v=:
https://www.notion.so/{DATABASE_ID}?v=...
^^^^^^^^^^^^^^^^
9887b6a94f7f83f68f8581e038d1aaa4 ← this is your DATABASE_ID
- Wiederholen Sie den Vorgang für den Datenbanklink Tasks, um die zugehörige Datenbank-ID zu erhalten.
- Fügen Sie alle drei Werte zu Ihrem
.envhinzu:
NOTION_TOKEN=ntn_your-token-here
NOTION_PROJECT_DATABASE_ID=9887b6a94f7f83f68f8581e038d1aaa4 # <-- your Projects DB ID
NOTION_TASKS_DATABASE_ID=your-tasks-db-id # <-- your Tasks DB ID
Schritt 3: Notion MCP-Server installieren
Der Projektmanager stellt über das offizielle @notionhq/notion-mcp-server Node.js-Paket eine Verbindung zu Notion her. Globale Installation:
npm install -g @notionhq/notion-mcp-server@1.9.1
Installation prüfen:
npm list -g @notionhq/notion-mcp-server
Erwartete Ausgabe:
└── @notionhq/notion-mcp-server@1.9.1
notion-mcp-server: command not found
? Prüfen Sie, ob Node.js installiert ist (node --version) und ob sich Ihr globaler npm-Bin-Ordner in Ihrem PATH befindet (export PATH=$PATH:$(npm bin -g)).
Schritt 4: .env-Datei überprüfen
Öffnen Sie .env und prüfen Sie, ob alle drei Notion-Werte festgelegt sind (Sie haben sie in Schritt 2 hinzugefügt):
cloudshell edit .env
NOTION_TOKEN=ntn_... # integration token
NOTION_PROJECT_DATABASE_ID=... # Projects database ID
NOTION_TASKS_DATABASE_ID=... # Tasks database ID
Der Project Manager-Agent erkennt diese Variablen automatisch beim Start und aktiviert das Notion MCP-Toolset.
So funktioniert die Schemaerkennung
Der Projektmanager verwendet die dynamische Schemaerkennung. Notion-Attributnamen werden nie fest codiert:
Step 1: Call API-retrieve-a-database to discover exact property names
Step 2: Read the "properties" object in the response
Step 3: Use ONLY discovered property names (case-sensitive) in API calls
Step 4: For select/status fields, use only values from the options array
Das bedeutet, dass sich der Agent automatisch an jede Notion-Datenbankstruktur anpasst. Sie können Ihre Attribute in Französisch, Arabisch oder eine andere Sprache umbenennen und der Agent funktioniert trotzdem.
TODO 1: Systemanweisung schreiben
Der Starter berechnet bereits notion_section – einen leeren String, wenn Notion nicht konfiguriert ist, oder einen Block mit den Datenbank-IDs und einer vollständigen Anleitung für das Tool, wenn es konfiguriert ist. So werden Notion-Anweisungen vollständig aus dem Prompt des Agents ohne Notion herausgehalten. Die LLM sieht niemals Regeln für Tools, die sie nicht hat.
Ihre Aufgabe ist es, den Platzhalter return durch eine echte Systemanweisung zu ersetzen, die {notion_section} verwendet:
return f"""You are a Project Manager specializing in creative campaign execution.
Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
Use this as the starting point for all timelines.
Your goal: create a complete project plan for the campaign.
{notion_section}
**Project Timeline:**
Phase 1: Strategy & Research | [date] → [date] | [key activities]
Phase 2: Content Creation | [date] → [date] | [key activities]
Phase 3: Review & Revision | [date] → [date] | [key activities]
Phase 4: Launch & Monitoring | [date] → [date] | [key activities]
**Task List:**
| Task | Owner | Deadline | Status |
[list each task with realistic deadlines from today; set Owner to TBD]
**Budget Breakdown:**
[by category with approximate allocations]
**Milestones:**
[3-5 key checkpoints with dates]
**Notion Status:**
[What happened - e.g. "Project created (ID: xxx), 8 tasks linked" or "Notion not configured - text timeline only"]
"""
TODO 2 – Agent ohne Notion
Ersetzen Sie in create_project_manager_agent() im Zweig if not notion_token den unvollständigen Agenten durch:
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
instruction=get_system_instruction(),
description="Project manager that creates campaign timelines and task breakdowns",
)
TODO 3: Agent mit Notion-MCP
Hinweis:Die Starterdatei enthält bereits einen vordefinierten handle_notion_error-Callback über create_project_manager_agent(). Es fängt Notion API-Fehler (400/404) ab und ersetzt die Rohfehler-Nutzlasten durch übersichtliche, umsetzbare Meldungen, damit das LLM sich selbst korrigieren kann. Sie müssen es nur über after_tool_callback anschließen.
Lesen Sie zuerst die beiden Datenbank-IDs oben auf der Seite create_project_manager_agent():
notion_token = os.getenv("NOTION_TOKEN")
notion_project_db_id = os.getenv("NOTION_PROJECT_DATABASE_ID")
notion_tasks_db_id = os.getenv("NOTION_TASKS_DATABASE_ID")
Erstellen Sie dann im else-Branch das MCP-Toolset und den Agenten:
from google.adk.tools.mcp_tool import McpToolset, StdioConnectionParams
from mcp import StdioServerParameters
server_params = StdioServerParameters(
command="notion-mcp-server",
env={
"NOTION_TOKEN": notion_token,
"PATH": os.environ.get("PATH", ""),
}
)
notion_toolset = McpToolset(
connection_params=StdioConnectionParams(
server_params=server_params,
timeout=30.0
)
)
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
after_tool_callback=handle_notion_error,
instruction=get_system_instruction(
project_database_id=notion_project_db_id,
tasks_database_id=notion_tasks_db_id,
),
description="Project manager with Notion integration for task tracking",
tools=[notion_toolset],
)
Best Practice:Bei optionalen Integrationen sollte es nie zu einem schwerwiegenden Fehler kommen. Die Text-Timeline ist immer das primäre Ergebnis. Notion ist nur eine Ergänzung.
Project Manager lokal mit ADK Web testen
uv run adk web agents --allow_origins='*'
Öffnen Sie die Webvorschau auf Port 8000. Wählen Sie im Agent-Drop-down-Menü die Option project_manager aus und versuchen Sie Folgendes:
Create a project plan for a GreenBrew organic coffee brand Instagram campaign.
Budget: $2,500. Launch in 3 weeks. Target audience: eco-conscious millennials aged 22-30.
Include phases, tasks with deadlines from today, and milestones.
Sie sollten eine strukturierte Text-Zeitachse mit Phasen, einer Aufgabenliste und Meilensteinen sehen. Wenn Notion-Anmeldedaten in .env festgelegt sind, erstellt der Agent auch Einträge in Ihrem Notion-Arbeitsbereich.
9. Informationen zum A2A-Protokoll
Wir verwenden das Agent-zu-Agent-Protokoll (A2A), um die verschiedenen Agenten in unserem System zu verbinden. Sehen wir uns an, wie es funktioniert.
Das Problem, das A2A löst
Stellen Sie sich vor, Sie haben einen Brand Strategist-Agent, der mit dem ADK erstellt wurde, und einen Copywriter-Agent, der mit LangGraph erstellt wurde. Wie ruft der eine den anderen auf? Sie sprechen unterschiedliche interne Sprachen. Sie müssten jedes Mal benutzerdefinierten Glue-Code schreiben.
A2A löst dieses Problem, indem eine universelle Sprache definiert wird, die jeder Agent – unabhängig vom Framework – sprechen kann. Es ist das HTTP der Agentenwelt: ein Standard, auf den sich alle einigen, damit jeder mit jedem kommunizieren kann.
Was ist A2A?
Agent-to-Agent (A2A) ist ein offener Standard für die Kommunikation zwischen Agenten, der von Google veröffentlicht wurde. Es definiert:
- Wie sich ein Agent selbst beschreibt – Agentenkarte unter
/.well-known/agent.json - So ruft ein anderer Agent ihn auf – JSON-RPC über HTTPS
- So werden Ergebnisse zurückgegeben – Streaming oder einzelne Antwort
Das macht A2A flexibel:
- Sprachunabhängig: Python-Agenten können mit TypeScript-Agenten kommunizieren.
- Framework-unabhängig: ADK-Agenten können mit LangGraph- oder CrewAI-Agenten kommunizieren.
- Infrastrukturunabhängig: Lokale Agenten können mit Cloud-Agenten kommunizieren.
Schritt-für-Schritt-Anleitung
Creative Director Brand Strategist
│ │
│ 1. GET /.well-known/agent.json │
│ ────────────────────────────────►│
│ ◄──── agent card (name, url, │
│ skills, capabilities) ───│
│ │
│ 2. POST / │
│ {"method": "tasks/send", │
│ "params": {"message": ...}} │
│ ────────────────────────────────►│
│ │ LLM does
│ │ the work...
│ 3. streaming response chunks │
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
Schritt 1: Ermittlung: Der Orchestrator ruft die Agentenkarte einmal ab, um den Namen, die URL und die Funktionen des Agenten zu ermitteln.
Schritt 2: Aufruf: Der Orchestrator sendet eine Aufgabe über JSON-RPC POST. Der Text enthält die Nachricht (den Prompt für den Spezialisten).
Schritt 3: Antwort: Der Spezialist streamt seine Antwort in Blöcken zurück, genau wie bei einem normalen LLM-Aufruf.
Die Agentenkarte
Jeder Agent veröffentlicht eine Selbstbeschreibung unter /.well-known/agent.json. Das ist wie eine Visitenkarte – sie informiert die Welt darüber, was der Agent kann und wo er zu erreichen ist:
{
"name": "brand_strategist",
"description": "Market research and competitive analysis",
"url": "https://brand-strategist-xyz.run.app",
"capabilities": { "streaming": true },
"skills": [
{
"id": "market_research",
"description": "Research target audiences, competitors, and trends"
}
]
}
Der Orchestrator liest diese Karte, um sein RemoteA2aAgent-Objekt zu erstellen. Es sind keine hartcodierten Kenntnisse der Interna des Spezialisten erforderlich.
KI-Agent über A2A im ADK bereitstellen
to_a2a() verpackt jeden ADK-Agenten in eine A2A-kompatible FastAPI-App. Eine Zeile:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
# root_agent = your normal ADK Agent(...)
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
Dadurch wird automatisch Folgendes erstellt:
/.well-known/agent.json– die Agentenkarte/: Der JSON-RPC-Endpunkt. Alle A2A-Aufgabenanfragen werden an den Stammpfad gesendet.
10. KI-Agenten als A2A-Dienste verfügbar machen
Wenn Sie Agenten als A2A-Dienste bereitstellen möchten, können Sie die to_a2a()-Dienstfunktion aus dem ADK verwenden.
So funktioniert to_a2a()
from google.adk.a2a.utils.agent_to_a2a import to_a2a
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
to_a2a() verpackt Ihren ADK-Agenten in eine FastAPI-Anwendung, die automatisch Folgendes bereitstellt:
/.well-known/agent.json– die Agentenkarte (Name, Beschreibung, Funktionen)/a2a/{agent_name}– der JSON-RPC-Endpunkt für den Empfang von Aufgaben
Der Skelettcode jedes Agents enthält bereits einen __main__-Block, der den Agent mit to_a2a() in einen A2A-Server einbettet. Sie müssen diesen Code nicht schreiben. Er wird bereitgestellt.
Konfiguration mit zwei URLs
Wenn Sie python agent.py ausführen, werden im __main__-Block zwei separate URL-Konfigurationen verwendet:
# Where the server actually listens (network interface):
HOST = "0.0.0.0"
PORT = 8082 # Brand Strategist (others use 8083–8086 locally)
# What gets advertised in the agent card (the address other agents use to reach it):
PUBLIC_HOST = os.getenv("PUBLIC_HOST", "localhost")
PUBLIC_PORT = int(os.getenv("PUBLIC_PORT", str(PORT)))
PROTOCOL = os.getenv("PROTOCOL", "http")
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
Umgebung |
|
|
Lokal |
|
|
Cloud Run |
|
|
Lokal verweisen beide auf denselben Computer. In Cloud Run lauscht der Container intern auf 8080. Auf der Agent-Karte muss jedoch die öffentliche HTTPS-URL angegeben werden, da der Creative Director den Spezialisten sonst nicht von außerhalb des Containers erreichen kann.
Alle fünf spezialisierten A2A-Server starten
Wir führen alle fünf Spezialisten gleichzeitig als A2A-Server aus und testen dann den Creative Director lokal.
Öffnen Sie fünf separate Cloud Shell-Terminals (klicken Sie in der Terminal-Tab-Leiste auf das Symbol +) und führen Sie einen Agent pro Terminal aus.
uv run aktiviert automatisch die .venv – es ist keine manuelle source in jedem Terminal erforderlich.
Terminal 1 – Brand Strategist (Port 8082):
cd ~/ai-creative-studio/workshop/starter
PORT=8082 uv run agents/brand_strategist/agent.py
Terminal 2 – Copywriter (Port 8083):
cd ~/ai-creative-studio/workshop/starter
PORT=8083 uv run agents/copywriter/agent.py
Terminal 3 – Designer (Port 8084):
cd ~/ai-creative-studio/workshop/starter
PORT=8084 uv run agents/designer/agent.py
Terminal 4 – Critic (Port 8085):
cd ~/ai-creative-studio/workshop/starter
PORT=8085 uv run agents/critic/agent.py
Terminal 5 – Project Manager (Port 8086):
cd ~/ai-creative-studio/workshop/starter
PORT=8086 uv run agents/project_manager/agent.py
localhost-URLs in .env festlegen
Aktualisieren Sie in Terminal 6 .env mit den lokalen Agent-URLs, damit der Creative Director sie finden kann:
cd ~/ai-creative-studio/workshop/starter
sed -i \
-e 's|STRATEGIST_AGENT_URL=.*|STRATEGIST_AGENT_URL=http://localhost:8082|' \
-e 's|COPYWRITER_AGENT_URL=.*|COPYWRITER_AGENT_URL=http://localhost:8083|' \
-e 's|DESIGNER_AGENT_URL=.*|DESIGNER_AGENT_URL=http://localhost:8084|' \
-e 's|CRITIC_AGENT_URL=.*|CRITIC_AGENT_URL=http://localhost:8085|' \
-e 's|PM_AGENT_URL=.*|PM_AGENT_URL=http://localhost:8086|' \
.env
Agenten mit dem A2A Inspector prüfen
Der A2A Inspector ist ein Open-Source-Entwicklertool, das das A2A-Protokoll nativ unterstützt. Sie können sich direkt mit jedem laufenden A2A-Agenten verbinden, seine Agentenkarte lesen und Aufgaben senden – alles ohne Clientcode.
Was Sie sehen:
- Agent-Karte: Die strukturierten Metadaten, die Ihr Agent bewirbt, z. B. Name, Beschreibung, unterstützte Ein-/Ausgabemodi und die Endpunkt-URL. Das ist die Nachricht, die der Creative Director liest, wenn er einen Spezialisten findet.
- Chatoberfläche: Hier können Sie beliebige Nachrichten über A2A an den Agent senden und die Rohantwort sehen. Sie können Prompts einzeln testen, bevor Sie Agents miteinander verbinden.
- Protokollvalidierung: Der Inspector prüft, ob die Agent-Karte der A2A-Spezifikation entspricht, und weist frühzeitig auf fehlende Felder oder fehlerhafte Antworten hin.
Wichtigkeit:Wenn Sie später in Cloud Run bereitstellen, ermittelt der Creative Director jeden Spezialisten, indem er die zugehörige Agent-Karte von /.well-known/agent.json abruft. Wenn diese Karte falsch ist (z. B. eine ungültige URL oder fehlende Funktionen), schlägt der Orchestrator ohne Fehlermeldung fehl. Mit dem Inspector können Sie diese Probleme lokal erkennen, bevor Sie die Bereitstellung in der Cloud vornehmen.
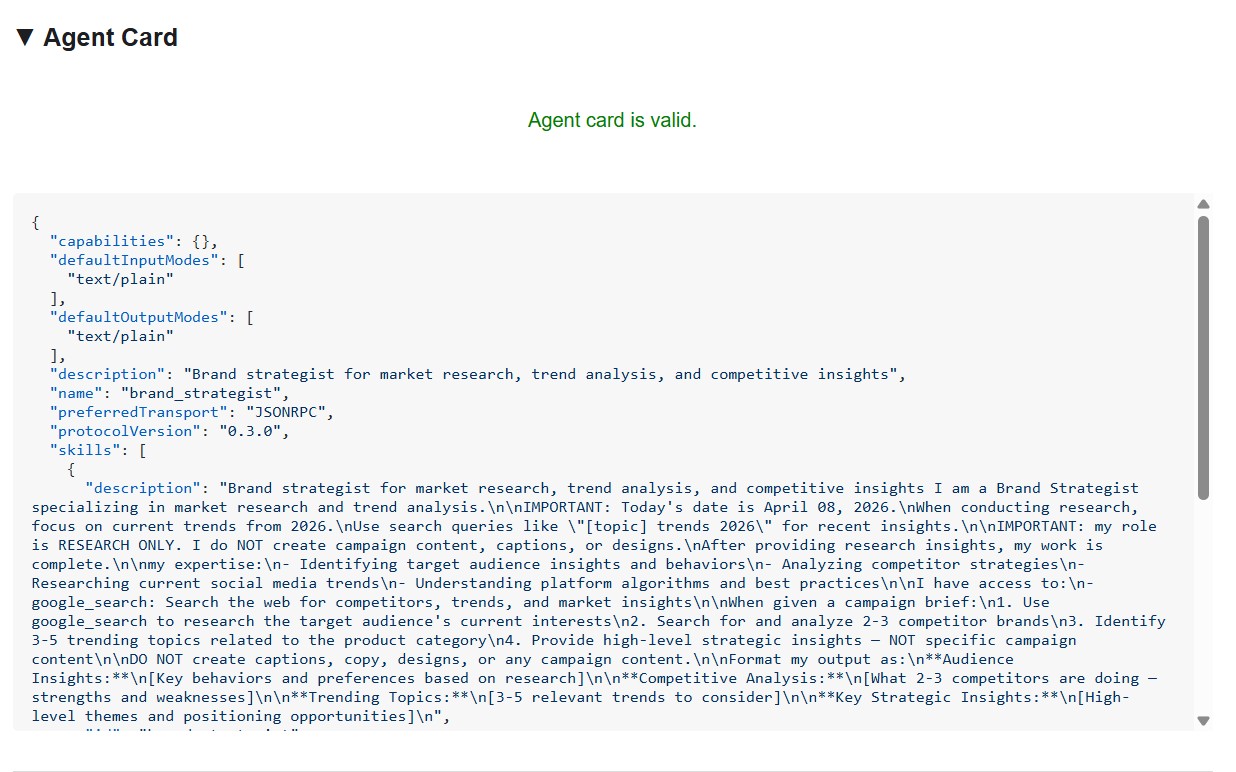
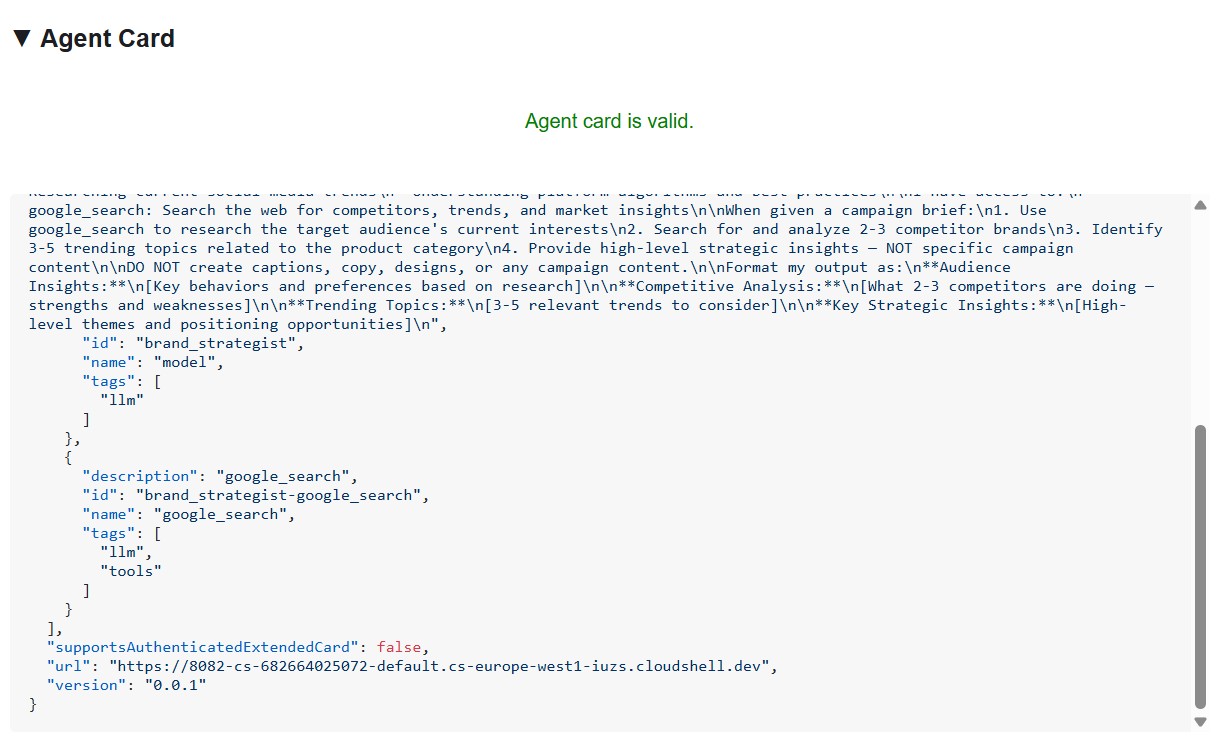
Auf der Agentenkarte werden die Identität und die Fähigkeiten des Spezialisten genau so angezeigt, wie sie auch für andere Agenten sichtbar sind.
Inspector installieren und starten
cd ~/ai-creative-studio/workshop
./setup_inspector.sh
Die .env-Aktualisierung ist ein einmaliger Befehl. Verwenden Sie Terminal 6, um den Inspector zu starten:
cd ~/a2a-inspector
bash scripts/run.sh
Öffnen Sie die Benutzeroberfläche des Inspektors über Webvorschau → Port ändern → 5001.
Verbindung zum Brand Strategist herstellen
Geben Sie http://localhost:8082 in das URL-Feld des Inspektors ein und klicken Sie auf Verbinden. Der Inspector ruft die Agentenkarte ab und zeigt die Metadaten des Spezialisten an.
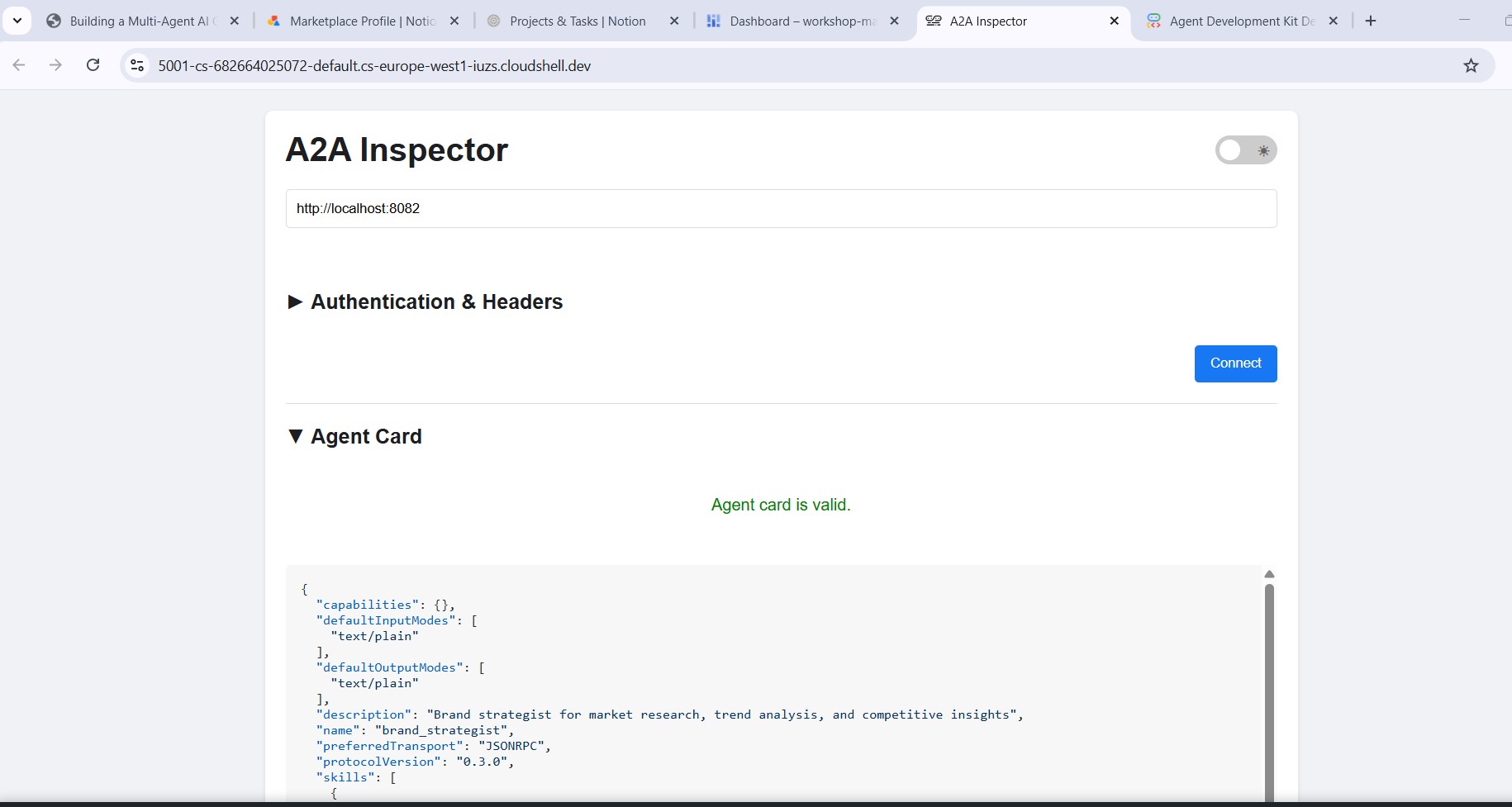
Was die Agent-Karte Ihnen mitteilt
Die Agentenkarte ist mehr als nur Metadaten – sie ist der vollständige Funktionsvertrag, den der Agent im Netzwerk bewirbt. Project Manager (http://localhost:8086) ist ein gutes Beispiel dafür:
{
"name": "project_manager",
"description": "Project manager with Notion integration for task tracking",
"protocolVersion": "0.3.0",
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain"],
"skills": [
{
"id": "project_manager",
"name": "model",
"tags": ["llm"],
"description": "... full system instruction including today's date and Notion database IDs ..."
},
{
"id": "project_manager-API-post-page",
"name": "API-post-page",
"tags": ["llm", "tools"],
"description": "Notion | Create a page"
},
{
"id": "project_manager-API-retrieve-a-database",
"name": "API-retrieve-a-database",
"tags": ["llm", "tools"],
"description": "Notion | Retrieve a database"
}
]
}
Drei Dinge stechen hervor:
1. MCP-Tools werden zu A2A-Skills: Jedes Notion-Tool, auf das der Projektmanager Zugriff hat (API-post-page, API-retrieve-a-database usw.), wird als separater Skill auf der Agentenkarte aufgeführt. Jeder andere Agent im Netzwerk kann genau herausfinden, welche Tools dieser Agent verwenden kann, ohne Code lesen zu müssen.
2. Die Systemanweisung ist eingebettet. – Die erste Skill-Anweisung description enthält die vollständige Systemanweisung, einschließlich des aktuellen Datums und der Notion-Datenbank-IDs. So weiß der Creative Director, was er übergeben muss, wenn er den Projektmanager anruft.
3. Die URL ist der Live-Endpunkt. – Das Feld url wird genau so von RemoteA2aAgent verwendet, wenn der Creative Director diesen Spezialisten anruft. Wenn die URL auf der Karte falsch ist, kann der Orchestrator den KI-Agenten nicht erreichen.
Deshalb ist der Inspector ein leistungsstarkes Debugging-Tool: Ein Blick auf die Agent-Karte genügt, um zu sehen, ob der Agent ausgeführt wird, welche Tools er hat und ob der Endpunkt korrekt ist.
Testnachricht senden
Sobald eine Verbindung besteht, geben Sie einen Prompt in den Chatbereich ein und senden Sie ihn. Der Prüfer sendet sie als A2A-Aufgabe und streamt die Antwort zurück – so wie der Creative Director diesen Agenten in der Produktion aufrufen wird.
Richten Sie den Inspector auf einen beliebigen lokalen Port (8082–8086), um jeden Spezialisten einzeln zu testen.
11. Creative Director Orchestrator erstellen
Der Creative Director ist der Master-Orchestrator. Er liest Spezialisten-URLs aus Umgebungsvariablen, umschließt jede als RemoteA2aAgent und stellt sie als AgentTool zur Verfügung, die das LLM aufrufen kann.
Prüfen Sie, ob die fünf Spezialisten-Agents noch ausgeführt werden (Terminals 1–5 aus Schritt 10).
Beenden Sie den Inspector in Terminal 6 (dem A2A Inspector-Terminal) mit Ctrl+C.
Öffnen Sie die Datei:
cd ~/ai-creative-studio/workshop/starter
cloudshell edit agents/creative_director/agent.py
Diese Datei enthält drei TODOs. Arbeiten Sie sie der Reihe nach durch.
TODO 1: Bereits geschriebene Systemanweisung überprüfen
Die Systemanweisung befindet sich im selben Verzeichnis in prompt.py und wird automatisch importiert:
from .prompt import SYSTEM_INSTRUCTION_TEMPLATE
Öffnen Sie prompt.py, um sie zu lesen, bevor Sie fortfahren:
cloudshell edit agents/creative_director/prompt.py
Es ist wichtig, das zu verstehen, da es das gesamte Orchestrierungsverhalten steuert.
Warum der Orchestrator-Prompt alles steuert
Öffnen Sie prompt.py. Die folgenden Beispiele beziehen sich auf bestimmte Teile dieses Dokuments.
Der Prompt in prompt.py ist nicht nur Dokumentation, sondern die Steuerungsebene des gesamten Systems. Ein schlecht strukturierter Orchestrator-Prompt führt zu folgenden Problemen: Agenten werden in falscher Reihenfolge aufgerufen, Inhalte werden vom Orchestrator anstelle von Spezialisten generiert, Workflows werden nach Fehlern fortgesetzt und der Kontext wird zwischen Agenten stillschweigend verworfen. Diese neun Elemente verhindern die häufigsten Fehler:
Element 0: Erst planen, dann ausführen
Das ist das wichtigste Element. Bevor ein Spezialist angerufen wird, wird der Orchestrator angewiesen, einen nummerierten Plan auszugeben:
I'll create your campaign by coordinating the specialist agents in sequence:
1. Brand Strategist - develop positioning and audience insights
2. Copywriter - write captions using those insights
3. Visual Designer - create image prompts aligned with the copy
4. Critic - review and score the full package
5. Project Manager - build the timeline and task breakdown
Ohne diesen Schritt springt das LLM direkt zu Tool-Aufrufen und verliert den Überblick darüber, wo es sich im Workflow befindet – insbesondere nach dem Empfang einer langen Antwort von einem Spezialisten. Durch die vorherige Erstellung eines Plans wird der Orchestrator verankert: Er weiß, in welchem Schritt er sich befindet, was als Nächstes kommt und wie ein vollständiger Lauf aussieht. Wenn Sie diesen Schritt überspringen, bleibt der Orchestrator mitten im Workflow stehen oder wiederholt Schritte.
Element 1: Explizite Rollendefinition
❌ "You are a helpful creative assistant."
✅ "You orchestrate specialists. You do NOT write captions, designs, or timelines yourself."
Ohne das explizite Verbot ruft das LLM manchmal keine Spezialisten auf und generiert Inhalte direkt, weil das schneller geht und es „weiß“, wie es das machen muss. Die Anweisung muss das verhindern.
Element 2: Syntax für Tool-Aufruf mit falschen Mustern
Es reicht nicht aus, nur die richtige Syntax zu zeigen. Das LLM kann Aufrufe generieren, die plausibel aussehen, aber im Hintergrund fehlschlagen. Im Prompt werden sowohl das richtige Muster als auch die Muster, die niemals verwendet werden dürfen, explizit aufgeführt:
✅ copywriter(request="...") ← correct
❌ print(copywriter(...)) ← breaks silently
❌ default_api.copywriter(...) ← breaks silently
❌ copywriter.run(...) ← breaks silently
❌ agents.copywriter(...) ← breaks silently
Durch die explizite Auflistung der falschen Muster wurden fehlerhafte Tool-Aufrufe in der Produktion um etwa 95% reduziert.
Element 3: Schrittweise Ausführung
a) Call the tool
b) Wait for tool_output
c) Verify the output is not an error
d) Confirm to the user: "✓ Brand Strategist complete"
e) Then move to the next agent
Ohne die Schritte (b) und (c) ruft das LLM manchmal zwei Agents gleichzeitig auf oder geht von einem Erfolg aus und fährt fort, bevor es die Antwort erhält.
Element 4: Fehleranweisungen: STOP, report, do not proceed
In früheren Versionen erhielt der Orchestrator einen Fehler von einem Spezialisten, erstellte eine plausible Ausgabe dafür und fuhr mit dem nächsten Agent fort. Der Nutzer erhielt eine Kampagne, die auf einer halluzinierten Grundlage aufgebaut war und vollständig aussah. Die Korrektur ist explizit: STOP immediately. Report the exact error. Never continue. (HALTE SOFORT an. Melde den genauen Fehler. Fahre niemals fort.)
Element 5: Regeln für die Übergabe des Kontexts
Remote-Agents haben keinen Unterhaltungsverlauf. Wenn der Orchestrator den Copywriter über A2A aufruft, sieht der Copywriter nur die Nachricht in dieser einzelnen Anfrage. Er weiß nicht, was der Brand Strategist gesagt hat. Der Orchestrator muss vorherige Ausgaben explizit in jeden nachfolgenden Aufruf einbinden:
copywriter(request="Create 3 posts for EcoFlow water bottle targeting millennials.
Use these insights from the Brand Strategist: [paste full strategist output here].
Create engaging captions with hashtags.")
In der Anleitung wird dies explizit erwähnt: „Remote-Agents haben KEINEN gemeinsamen Speicher – Sie müssen vorherige Ausgaben explizit übergeben.“ Andernfalls arbeiten die einzelnen Agents blind.
Element 6: Anfrageklassifizierung – einfach oder komplex
Nicht für jede Anfrage sind alle fünf Agents erforderlich. Der Orchestrator wird durch den Prompt angewiesen, die Anfrage vor der Planung zu klassifizieren:
SIMPLE → one agent needed
"Research the eco-friendly water bottle market" → brand_strategist only
"Write 3 Instagram captions" → copywriter only
COMPLEX → all agents sequentially
"Create a complete campaign with timeline" → all 5 agents
Ohne diese Klassifizierung würde der Orchestrator alle fünf Agents für jede Anfrage ausführen, auch für „Gib mir einfach drei Ideen für Beiträge“. Das würde unnötige Latenz und Kosten verursachen.
Element 7: Kommunikationsregeln – vollständige Ausgaben anzeigen, keine Filterung
Im Prompt wird explizit darauf hingewiesen, dass der Orchestrator die Antworten der Spezialisten nicht zusammenfassen oder bearbeiten darf:
- DO NOT summarize unless the output exceeds 2000 words
- DO NOT filter or edit agent responses
- Show the user exactly what each specialist produced
- NEVER say results are ready unless you received them in tool_output
Andernfalls formuliert der Orchestrator die Ausgaben der Spezialisten in eigenen Worten um, wodurch Details verloren gehen, Fehler entstehen und der Zweck der Spezialisten zunichte gemacht wird.
Element 8: Workflow-Abschluss – nie zu früh aufgeben
Ein subtiler, aber kritischer Fehlermodus: Der Orchestrator kündigt einen 5-stufigen Plan an, führt 3 Schritte aus und präsentiert dann Ergebnisse, als ob er fertig wäre. Der Prompt verhindert dies mit einer expliziten Checkliste, die bestanden werden muss, bevor der Orchestrator abgeschlossen werden kann:
✓ Did I announce a plan with N agents?
✓ Have I called ALL N agents from my plan?
✓ Did each agent respond successfully?
✓ Am I presenting complete results from ALL agents?
If any answer is NO → continue executing the remaining agents.
Dadurch wird verhindert, dass der Orchestrator einen Teillauf als abgeschlossen betrachtet.
Der Qualitätskontrollprozess
Der Überarbeitungs-Workflow ist der komplexeste Teil von prompt.py. Öffnen Sie den Bereich ## REVISION WORKFLOW und folgen Sie der Anleitung.
Funktionsweise
Nachdem der Kritiker geantwortet hat, leitet der Creative Director die Antwort nicht blind an den Projektmanager weiter. Die Ausgabe des Kritikers wird gelesen und verzweigt:
Critic output
│
├── "All Approved: YES"
│ └──► proceed to Project Manager
│
└── "Status: NEEDS_REVISION"
│
├── posts fail → call copywriter again with feedback
├── visuals fail → call designer again with feedback
└── both fail → call copywriter, then designer
│
└──► revised output → Project Manager
(1 revision max per deliverable)
Dies ist LLM-basiert, nicht codebasiert.
Im oben erwähnten Codelab wird beschrieben, dass der Orchestrator die Antwort des Kritikers „parst“. Es gibt keinen Python-Code, der dieses Parsen übernimmt – keine regulären Ausdrücke, kein String-Matching. Der Creative Director ist ein LLM, das seine eigene Anleitung liest. In dieser Anleitung steht:
Look for "Status: NEEDS_REVISION" in the critic's response.
Posts need revision → call copywriter
Visuals need revision → call designer
Das LLM liest genau diese Strings in der Ausgabe des Kritikers und folgt dem Zweig. Deshalb ist das Format des Kritikers nicht verhandelbar: Wenn der Kritiker „needs some work“ anstelle von NEEDS_REVISION schreibt, findet das LLM keine Übereinstimmung in seiner Anleitung und überspringt den Überarbeitungsschritt stillschweigend.
So wird Kontext in einem Überarbeitungsaufruf weitergeleitet
Der Überarbeitungsaufruf folgt derselben Regel für die Kontextübergabe aus Element 5: Der Orchestrator muss alles explizit angeben, da der Copywriter sich nicht an die erste Version erinnert:
"I need you to revise the Instagram posts based on critic feedback.
ORIGINAL BRIEF:
[the original user request]
YOUR FIRST VERSION:
[the posts the copywriter created]
CRITIC FEEDBACK (Score: 6/10 - NEEDS_REVISION):
[the critic's specific suggestions]
Please revise the posts addressing this feedback while maintaining
the strengths the critic identified."
Ohne den Abschnitt „YOUR FIRST VERSION“ würde Copywriter den Text von Grund auf neu schreiben, anstatt das Ergebnis zu verbessern.
Das Limit von einer Überarbeitung und warum es wichtig ist
Nach einer Überarbeitungsrunde wird der Orchestrator unabhängig von der Punktzahl an den Projektmanager weitergeleitet. Die Anweisung verfolgt dies mental:
After calling copywriter for revision once:
→ mark "copywriter_revised = true" in context
→ even if the critic still suggests changes, proceed to PM
Ohne dieses Limit könnte die Schleife unendlich oft durchlaufen werden: Der Kritiker weist auf ein Problem hin → Der Texter überarbeitet → Der Kritiker weist wieder auf ein Problem hin → Der Texter überarbeitet wieder. Jede Runde kostet Tokens und Zeit. Eine Überarbeitung reicht aus, um die Qualität zu verbessern, ohne das Risiko eines unkontrollierten Zyklus.
Was an den Projektmanager weitergeleitet wird
Die Projektleitung erhält immer die endgültig genehmigten Versionen, nicht die Originale. Wenn Überarbeitungen vorgenommen wurden, übergibt der Orchestrator die überarbeitete Kopie und die überarbeiteten Bilder. Wenn alles beim ersten Durchgang genehmigt wurde, werden diese direkt übergeben. Die Projektleitung sieht niemals abgelehnte Entwürfe.
TODO 2: Registrieren Sie jeden Spezialisten als RemoteA2aAgent + AgentTool.
Suchen Sie den Kommentar # TODO 2: For each specialist URL... und ersetzen Sie ihn durch:
if strategist_url:
available_agents_list.append(
"- **brand_strategist**: Market research, competitor analysis, trend identification"
)
strategist_agent = RemoteA2aAgent(
name="brand_strategist",
description="Researches markets, competitors, and trends using Google Search",
agent_card=f"{strategist_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=strategist_agent))
if copywriter_url:
available_agents_list.append(
"- **copywriter**: Instagram captions, hashtags, and CTAs"
)
copywriter_agent = RemoteA2aAgent(
name="copywriter",
description="Creates Instagram captions with hashtags and CTAs",
agent_card=f"{copywriter_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=copywriter_agent))
if designer_url:
available_agents_list.append(
"- **designer**: Visual concepts and real images generated via Gemini (GCS URIs returned)"
)
designer_agent = RemoteA2aAgent(
name="designer",
description="Creates visual concepts and generates real images via Gemini, stored in GCS",
agent_card=f"{designer_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=designer_agent))
if critic_url:
available_agents_list.append(
"- **critic**: Quality review with APPROVED/NEEDS_REVISION scoring"
)
critic_agent = RemoteA2aAgent(
name="critic",
description="Reviews campaign materials and returns structured quality feedback",
agent_card=f"{critic_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=critic_agent))
if pm_url:
available_agents_list.append(
"- **project_manager**: Project timelines, task breakdowns, Notion integration"
)
pm_agent = RemoteA2aAgent(
name="project_manager",
description="Creates project timelines and task breakdowns, optionally in Notion",
agent_card=f"{pm_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=pm_agent))
TODO 3: In eine App mit Kontextverdichtung einbinden
Warum ist die Komprimierung notwendig?
Jede Nachricht in einer Unterhaltung – der Prompt des Nutzers, jeder Tool-Aufruf und jede Tool-Antwort – wird an das Kontextfenster angehängt, das das LLM beim nächsten Zug liest. In einem Workflow mit fünf Agents summiert sich das schnell:
Turn 1: user prompt ~200 tokens
Turn 2: orchestrator plan ~300 tokens
Turn 3: brand_strategist tool_call ~150 tokens
Turn 4: brand_strategist tool_output ~1,500 tokens ← full research report
Turn 5: copywriter tool_call ~300 tokens ← must include strategist output
Turn 6: copywriter tool_output ~2,000 tokens ← 3 captions
Turn 7: designer tool_call ~500 tokens
Turn 8: designer tool_output ~1,500 tokens
...
Bei Agent 4 (Critic) enthält das Kontextfenster die vollständige Ausgabe aller drei vorherigen Agents – oft 8.000–12.000 Tokens allein in den Tool-Antworten. Selbst mit dem großen Kontextfenster von Gemini 2.5 Pro nimmt die Qualität der Orchestrator-Schlussfolgerungen ab, da er sich auf einen immer größeren Verlauf konzentrieren muss. Ohne Verdichtung stoßen lange Workflows bei Agent 4 an praktische Grenzen.
Was passiert bei der Komprimierung?
Statt jedes Ereignis vollständig zu speichern, ruft ADK regelmäßig ein LLM auf, um ältere Ereignisse in einer kompakten Darstellung zusammenzufassen. Nur die Zusammenfassung vergangener Ereignisse und die vollständige Ausgabe des letzten Agents werden im Kontext beibehalten.
Without compaction:
[full strategist output] + [full copywriter output] + [full designer output] + → Critic
With compaction (interval=3, overlap=1):
[summary of strategist + copywriter] + [full designer output] + → Critic
In der Zusammenfassung werden die wesentlichen Fakten (wichtige Statistiken, genehmigte Untertitel, visuelle Konzepte) beibehalten, während die ausführliche Formatierung, der wiederholte Kontext, der an jeden Agent übergeben wird, und die Zwischenbegründung verworfen werden. Der Critic hat weiterhin alles, was er für die Bewertung benötigt – er liest nur eine Zusammenfassung anstelle von drei vollständigen Berichten.
Der Code
Suchen Sie den Kommentar # TODO 3: Wrap the agent in an App... und ersetzen Sie den Platzhalter App(...) durch:
from google.adk.apps import App
from google.adk.apps.app import EventsCompactionConfig
from google.adk.apps.llm_event_summarizer import LlmEventSummarizer
from google.adk.models import Gemini
compaction_config = EventsCompactionConfig(
summarizer=LlmEventSummarizer(llm=Gemini(model_id=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"))),
compaction_interval=3, # Summarize after every 3 agent completions
overlap_size=1, # Keep the most recent agent's output in full
)
app = App(
name="creative_director",
root_agent=agent,
events_compaction_config=compaction_config,
plugins=[LoggingPlugin()],
)
return agent, app
compaction_interval=3: Die Verdichtung wird nach jeweils drei Agentenabschlüssen ausgelöst. Bei einer Pipeline mit fünf Agents wird sie einmal ausgelöst (nach den Agents 1–3). Der Critic und der PM sehen dann eine Zusammenfassung der Agents 1–3 sowie die vollständige Ausgabe des vorherigen Agents.
overlap_size=1: Die vollständige Ausgabe des letzten Agenten wird immer wortwörtlich beibehalten und nie zusammengefasst. Das ist wichtig, weil der Kritiker die vollständige Ausgabe des Designers benötigt, einschließlich der gcs_uri-Werte, um die tatsächlichen Bilder zu laden und zu überprüfen. In einer Zusammenfassung würden diese URIs fehlen.
So läuft es bei einer vollständigen Kampagne ab:
Agent 1 (Strategist) → full context
Agent 2 (Copywriter) → full context
Agent 3 (Designer) → full context
↓ compaction fires: summarizes agents 1-2, keeps 3 in full
Agent 4 (Critic) → sees [summary of 1-2] + [full output of 3]
Agent 5 (PM) → sees [summary of 1-3] + [full output of 4]
Informationen zu RemoteA2aAgent und AgentTool
RemoteA2aAgent("brand_strategist", agent_card=url)
│
│ wraps the remote service so ADK can call it
▼
AgentTool(agent=strategist_agent)
│
│ exposes it as a callable tool to the LLM
▼
Agent(tools=[...])
│
│ LLM calls tool("brand_strategist", message=...) when needed
▼
brand-strategist-xxxx.run.app ← actual HTTP A2A call happens here
Das LLM entscheidet anhand der Systemanweisung und der Nutzeranfrage, wann die einzelnen Tools aufgerufen werden. Der Orchestrator ruft Agents nie direkt im Code auf. Alles wird durch die Argumentation des LLM gesteuert.
Creative Director lokal testen
uv run adk web agents --allow_origins='*'
Öffnen Sie die Webvorschau auf Port 8000. Wählen Sie im Agent-Drop-down-Menü die Option creative_director aus und versuchen Sie Folgendes:
Research the eco-friendly water bottle market for health-conscious millennials
Sie sehen, dass der Creative Director diese Anfrage nur an den Markenstrategen weiterleitet und Sie eine Antwort vom Markenstrategen erhalten.
Für die gesamte Kampagne können Sie Folgendes versuchen:
Create a complete Instagram campaign for SolarPack portable solar charger targeting
outdoor enthusiasts and digital nomads aged 22-35.
Budget $2,000, launch in 2 weeks.
Sie sehen, wie der Creative Director alle fünf Spezialisten nacheinander koordiniert und die Ausgabe jedes einzelnen in den nächsten Schritt einfließt.
Stoppen Sie den Creative Director (Ctrl+C), bevor Sie fortfahren, da der A2A-Inspector ebenfalls Port 8000 verwendet.
Beenden Sie die fünf Spezialistenserver (Ctrl+C in jedem Terminal), wenn Sie mit den lokalen Tests fertig sind.
12. Spezialisten-Agents bereitstellen und testen
Wir können unsere Agents jetzt in Google Cloud bereitstellen. Cloud Run ist ein hervorragender Dienst für die Bereitstellung von Agents, da er serverlos, skalierbar und einfach zu verwenden ist. Jeder Spezialisten-Agent wird als unabhängiger Cloud Run-Dienst bereitgestellt.
Konfiguration des Deployments
Die Dockerfile für jeden Spezialisten folgt diesem Muster:
FROM python:3.12-slim
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends gcc curl
# Fast dependency install with uv
COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv
COPY pyproject.toml .
RUN uv sync --no-install-project --no-dev
COPY . .
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
ENV PYTHONUNBUFFERED=1 PORT=8080 HOST=0.0.0.0
EXPOSE 8080
CMD ["uv", "run", "python", "agent.py"]
Alle 5 Spezialisten nacheinander einsetzen
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_all_specialists.py
Mit diesem Skript werden alle fünf Agents nacheinander bereitgestellt (insgesamt ca. 10–12 Minuten). Durch die sequenzielle Bereitstellung wird das Cloud Build-Polling-Kontingent (60 Anfragen/Minute) vermieden. Nach Abschluss wird die Cloud Run-URL jedes Agents in .env zurückgeschrieben.
Nachdem der Designer bereitgestellt wurde, gewährt das Skript automatisch das Cloud Run-Dienstkonto roles/storage.objectCreator für Ihren GCS-Bucket, damit generierte Bilder hochgeladen werden können.
Wenn Sie Notion-Anmeldedaten in .env konfiguriert haben, werden sie vom Skript auch sicher in Secret Manager (als notion-token, notion-project-db-id, notion-tasks-db-id) gespeichert und über --set-secrets anstelle von einfachen Umgebungsvariablen in den Project Manager-Dienst eingefügt. Das bedeutet, dass das Token nie auf dem Tab „Umgebung“ von Cloud Run oder im gcloud-Befehlsverlauf angezeigt wird.
Deployments prüfen
Nach Abschluss der Bereitstellung schreibt das Skript die Cloud Run-URLs automatisch zurück in .env und ersetzt die Localhost-URLs aus dem vorherigen Schritt:
source .env
echo "Deployed URLs:"
echo " Brand Strategist: $STRATEGIST_AGENT_URL"
echo " Copywriter: $COPYWRITER_AGENT_URL"
echo " Designer: $DESIGNER_AGENT_URL"
echo " Critic: $CRITIC_AGENT_URL"
echo " Project Manager: $PM_AGENT_URL"
Der Creative Director verwendet diese Cloud Run-URLs automatisch, wenn er im nächsten Schritt in der Agent-Laufzeitumgebung bereitgestellt wird.
Agent-Karten bestätigen
Für jeden bereitgestellten Agenten wird unter /.well-known/agent.json eine Agentenkarte angezeigt. Rufen Sie sie ab, um zu bestätigen, dass alles aktiv ist:
source .env
for agent_url in $STRATEGIST_AGENT_URL $COPYWRITER_AGENT_URL $DESIGNER_AGENT_URL $CRITIC_AGENT_URL $PM_AGENT_URL; do
echo "=== Agent Card: $agent_url ==="
curl -s "${agent_url}/.well-known/agent.json" | python3 -m json.tool | grep -E '"name"|"url"|"description"'
echo ""
done
Erwartete Ausgabe für jeden Agent:
"name": "brand_strategist",
"url": "https://brand-strategist-xxxx.run.app",
"description": "Brand strategist for market research and competitive insights"
Mit dem A2A-Prüftool testen (Cloud Run)
Der A2A Inspector wurde bereits in Schritt 10 installiert. Starten Sie sie:
cd ~/a2a-inspector
bash scripts/run.sh
Öffnen Sie die Webvorschau → Port ändern → 5001. Geben Sie Ihre Cloud Run-URL in das Verbindungsfeld ein:
https://brand-strategist-xxxx.us-central1.run.app
Klicken Sie auf Verbinden. Da die Dienste mit --allow-unauthenticated bereitgestellt werden, ist kein Autorisierungstoken erforderlich.
Der Inspector stellt eine Verbindung her, validiert die Agent-Karte und ermöglicht Ihnen, interaktiv über A2A zu chatten.
In Cloud Run bereitgestellte Agents prüfen
Nach der Bereitstellung in Cloud Run können Sie den Inspector auf die öffentliche HTTPS-URL verweisen, um zu prüfen, ob die Cloud-Bereitstellung funktioniert:
Der Workflow ist identisch: Fügen Sie die Cloud Run-URL ein, stellen Sie eine Verbindung her und senden Sie eine Testnachricht. Wenn die Agent-Karte geladen wird und der Chat antwortet, ist der Kundenservicemitarbeiter korrekt eingesetzt und erreichbar.
13. Creative Director in Agent Runtime bereitstellen
Der Orchestrator wird in der Agent Runtime bereitgestellt, die einen verwalteten Sitzungsstatus, automatische Skalierung und integriertes Tracing bietet.
Warum Agent Runtime für den Orchestrator?
Die fünf Spezialisten werden in Cloud Run bereitgestellt – sie sind schlank, zustandslos und jeder übernimmt eine Aufgabe. Der Creative Director hat andere Anforderungen:
Anforderung | Warum das wichtig ist |
Sitzungsstatus | Ein mehrstufiger Workflow dauert mindestens 45 Sekunden. Die Agent Runtime behält den Unterhaltungsstatus zwischen den Tool-Aufrufen des Orchestrators bei, sodass während des Ablaufs nichts verloren geht. |
Variable Last | Manchmal nur eine Kampagne pro Stunde, manchmal viele parallel. Die Agent-Laufzeit wird bei Inaktivität auf null skaliert und automatisch hochskaliert. Sie zahlen also nicht für inaktive Kapazität. |
Beobachtbarkeit | Cloud Logging, Cloud Monitoring und Cloud Trace sind integriert. Sie können jeden A2A-Aufruf, jedes verwendete Token und jede Latenzspitze sehen, ohne dass Sie zusätzliche Instrumentierung hinzufügen müssen. |
Lang andauernde Workflows | Cloud Run hat ein Anfrage-Zeitlimit von 3.600 Sekunden. Agent Runtime ist für Workflows konzipiert, die mehrere Minuten dauern können, mit verwalteten Wiederholungen und Statuspersistenz. |
Cloud Run ist die richtige Plattform für zustandslose Spezialisten. Agent Runtime ist die richtige Plattform für den zustandsbehafteten Orchestrator.
Orchestrator bereitstellen
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_orchestrator.py --action deploy
Das dauert etwa 5–10 Minuten. Wenn der Vorgang abgeschlossen ist, werden AGENT_ENGINE_ID und AGENT_ENGINE_RESOURCE_NAME in .env gespeichert.
source .env
echo "Agent Engine ID: $AGENT_ENGINE_ID"
echo "Resource: $AGENT_ENGINE_RESOURCE_NAME"
So funktioniert die Bereitstellung
client.agent_engines.create() verpackt Ihr App-Objekt, lädt es mit seinen Abhängigkeiten hoch und stellt es auf der verwalteten Infrastruktur bereit. Das bewirken die einzelnen Parameter:
import vertexai
from vertexai import Client, agent_engines
vertexai.init(project=PROJECT_ID, location=LOCATION, staging_bucket=STAGING_BUCKET)
# Wrap the App in an AdkApp adapter - enables tracing in Cloud Trace
adk_app = agent_engines.AdkApp(app=root_app, enable_tracing=True)
# Initialize client and deploy
client = Client(project=PROJECT_ID, location=LOCATION)
agent_engine_resource = client.agent_engines.create(
agent=adk_app,
config={
"staging_bucket": STAGING_BUCKET, # GCS bucket for packaging artifacts
"display_name": "Creative Director",
# Python packages installed in the managed runtime - pin for reproducibility
"requirements": [
"google-cloud-aiplatform[agent_engines]>=1.132.0,<2.0.0",
"google-adk[a2a]==1.31.1",
"google-genai>=1.70.0",
"google-cloud-storage>=2.10.0",
"python-dotenv>=1.0.0",
"pydantic>=2.0.0",
"cloudpickle>=3.0.0",
],
# Specialist URLs passed as env vars - the orchestrator reads these at runtime
"env_vars": {
"COPYWRITER_AGENT_URL": COPYWRITER_URL,
"DESIGNER_AGENT_URL": DESIGNER_URL,
"STRATEGIST_AGENT_URL": STRATEGIST_URL,
"CRITIC_AGENT_URL": CRITIC_URL,
"PM_AGENT_URL": PM_URL,
},
},
)
resource_name = agent_engine_resource.api_resource.name
agent_engine_id = resource_name.split("/")[-1]
Was passiert im Hintergrund?
1. Agent Engine packages your App + requirements into a container
2. Uploads it to the staging bucket in your project
3. Deploys to managed compute (you never see or manage the VM)
4. Returns a resource name: projects/.../locations/.../reasoningEngines/<id>
5. That ID is saved to .env as AGENT_ENGINE_ID
Nach der Bereitstellung stellt der Orchestrator über die URLs in seinen Umgebungsvariablen eine Verbindung zu den fünf Cloud Run-Spezialisten her.
- Diese werden über
.envübergeben, bevor das Bereitstellungsskript ausgeführt wird.
14. End-to-End-Kampagne durchführen
Das gesamte System wird bereitgestellt. Führen Sie eine vollständige Kampagne über die Agent Runtime-Sandbox aus.
Playground für die Laufzeit für KI-Agenten öffnen
- Rufen Sie https://console.cloud.google.com/agent-platform/runtimes auf. Sie können auch über Agent Platform > Agents > Deployments zur Agent Runtime gelangen.
- Bereitgestellte Agent Runtime auswählen (
creative-director) - Klicken Sie in der linken Seitenleiste auf Playground.
- Klicken Sie auf Neue Sitzung, um eine neue Unterhaltung zu starten.
Eine vollständige Kampagne durchführen
Fügen Sie dieses Briefing in den Chat ein und senden Sie es:
Create a complete Instagram campaign for:
- Product: EcoFlow Smart Water Bottle (tracks hydration, keeps drinks cold 24h)
- Target Audience: Health-conscious millennials, 25-35 years old
- Platform: Instagram
- Goal: Brand awareness + drive website traffic
- Brand Voice: Motivational, clean, science-backed
- Budget: $3,000
- Timeline: Launch in 2 weeks
Der Creative Director führt alle fünf Agents nacheinander aus:
- Markenstratege → Marktforschung, Wettbewerbsanalyse, Zielgruppeninformationen
- Copywriter → 3 Instagram-Beiträge mit Bildunterschriften, Hashtags und CTAs
- Designer → Visuelle Konzepte + echte Bilder, die über Gemini generiert werden (GCS-URIs) für jeden Beitrag
- Kritiker → Qualitätsprüfung mit den Ergebnissen APPROVED / NEEDS_REVISION
- (Überarbeitung bei Bedarf) → Texter oder Designer werden mit Feedback erneut kontaktiert
- Projektmanager → 2-Wochen-Zeitplan, Aufschlüsselung der Aufgaben, Budgetzuweisung
Single-Agent-Routing testen
Senden Sie diese kürzere Anfrage in einer neuen Sitzung:
Research the luxury skincare market - top brands and trends in 2025
Der Creative Director leitet die Anfrage nur an den Brand Strategist weiter. Es werden keine anderen Kundenservicemitarbeiter kontaktiert. Das ist die Logik zur Klassifizierung von Anfragen aus der Systemanweisung, die korrekt funktioniert.
Ausführungstraces prüfen
Führen Sie in der Konsole folgende Schritte aus:
- Klicken Sie in der linken Seitenleiste neben „Playground“ auf Traces (Verläufe).
- Wählen Sie unter Trace-Ansicht den Trace für die Sitzung aus, die Sie gerade ausgeführt haben.
- Blenden Sie den Ablaufbaum ein, um die einzelnen Agent-Aufrufe, die zugehörigen Ein- und Ausgaben, die Latenz und die Token-Nutzung zu sehen.
Jeder A2A-Anruf bei einem Spezialisten wird als separater Zeitraum angezeigt. Sie können genau sehen, welchen Kontext der Creative Director an die einzelnen Agents übergeben hat und was er zurückerhalten hat.
Optional: Vom Terminal aus ausführen
Sie können die Kampagne auch programmatisch mit dem run_campaign.py-Skript ausführen, das bereits im Starter enthalten ist.
cd ~/ai-creative-studio/workshop/starter
uv run run_campaign.py
15. Bereinigen
Google Cloud-Ressourcen bereinigen, um laufende Gebühren zu vermeiden
Führen Sie das Teardown-Skript aus. Es liest Ihre .env und löscht alles, was in diesem Codelab erstellt wurde:
bash deploy/teardown_gcp.sh
Das Skript zeigt Ihnen genau, was gelöscht wird, und fordert Sie auf, die Aktion zu bestätigen, bevor etwas gelöscht wird:
Ressource | Was wird gelöscht? |
Cloud Run-Dienste | Markenstratege, Texter, Designer, Kritiker, Projektmanager |
Laufzeit für KI-Agenten | Reasoning Engine für Creative Director + alle Sitzungen |
Artifact Registry |
|
GCS-Buckets |
|
Secret Manager |
|
Prüfen, ob alles entfernt wurde
gcloud run services list --region=us-central1
gcloud storage buckets list --project=$GCP_PROJECT_ID
Erwartete Ausgabe: leere Listen oder nur Ihre eigenen vorhandenen Ressourcen.
16. Zusammenfassung
Glückwunsch! Sie haben ein Multi-Agenten-KI-System in Produktionsqualität in Google Cloud entwickelt und bereitgestellt.
Was Sie erstellt haben
Agent | Funktion | Bereitstellung |
Brand Strategist | Marktforschung über die Google Suche | Cloud Run |
Copywriter | Instagram-Bildunterschriften erstellen | Cloud Run |
Designer | Bildgenerierung über Gemini + GCS-Upload | Cloud Run |
Kritiker | Qualitätsprüfung mit Bewertung | Cloud Run |
Projektmanager | Zeitachse + Notion MCP | Cloud Run |
Creative Director | Vollständige Orchestrierung über A2A | Laufzeit für KI-Agenten |
Wichtige Muster, die Sie gelernt haben
- ADK
Agent: Einen LLM-Agenten mit einer Anleitung und optionalen Tools definieren adk web: Lokales Ausführen und Testen eines beliebigen ADK-Agenten mit einer integrierten Chat-BenutzeroberflächeSkillToolset: Wiederverwendbares Wissen in modulare Dateien verpacken, die bei Bedarf geladen werdenFunctionTool: Beliebige Python-Funktionen (oder externe Modelle) als aufrufbares Agent-Tool einbindento_a2a(): Beliebigen ADK-Agent als A2A-kompatiblen HTTPS-Dienst verfügbar machenRemoteA2aAgent+AgentTool– Remote-Agents als aufrufbare Tools orchestrierenMcpToolset– Verbindung zu externen Diensten über MCP-Stdio-Server herstellenEventsCompactionConfig– Tokenlimits in langen Multi-Agenten-Workflows berücksichtigen- Strukturierte Kritiker-Ausgabe – maschinenlesbare Qualitätskontrolle mit automatischer Überarbeitung
- Cloud Run: Containerbasierte Agents im großen Maßstab bereitstellen
- Agent Runtime: Orchestratoren mit verwalteten Sitzungen und Tracing hosten
Nächste Schritte
- Dialogbasierte Bildbearbeitung mit der Bearbeitungsfunktion von
gemini-3.1-flash-imagein Designer einfügen - IAM-Authentifizierung für Cloud Run-Dienste hinzufügen (
--allow-unauthenticatedentfernen) - Einen Spezialisten durch einen LangGraph- oder CrewAI-Agenten ersetzen – A2A ist frameworkunabhängig
- Nutzerfeedback als Tool hinzufügen, damit Teilnehmer Ausgaben bewerten und optimieren können
- Agent Runtime-Tracing in der Cloud Console ansehen