
۱. مرور کلی
در این آزمایشگاه کد، شما یک استودیوی خلاق هوش مصنوعی خواهید ساخت - یک سیستم چندعاملی توزیعشده که یک اعلان واحد را به یک کمپین کامل اینستاگرام تبدیل میکند.
یک جمله تایپ کنید. تحقیقات مخاطبان، زیرنویسها، مفاهیم بصری، متن بازبینیشده با کیفیت و یک جدول زمانی کامل پروژه را دریافت کنید - همه اینها توسط تیمی از عوامل هوش مصنوعی همکار تولید شده است.
مامورانی که خواهید ساخت
عامل | نقش |
استراتژیست برند | در وب به دنبال بینش مخاطبان، تحلیل رقبا و روندهای ۲۰۲۵ میگردد. |
کپیرایتر | نوشتن کپشنهای اینستاگرام با هشتگها و CTAها - با پشتیبانی از مهارت ADK که دستورالعملهای پلتفرم و فرمولهای کپشن را بر اساس تقاضا بارگذاری میکند |
طراح | مفاهیم بصری را ایجاد میکند و تصاویر واقعی را از طریق Gemini تولید میکند که در GCS ذخیره میشوند. |
منتقد | نقد و بررسی متن و تصاویر - گزینه |
مدیر پروژه | یک جدول زمانی پروژه و تفکیک وظایف ایجاد میکند که به صورت اختیاری از طریق MCP با Notion همگامسازی میشود. |
مدیر خلاق | هر پنج متخصص را به ترتیب هماهنگ میکند - شما یک دستور به آن میدهید، بقیه را هماهنگ میکند |
این ۵ عامل به عنوان میکروسرویسهای مستقل Cloud Run مستقر شدهاند. آنها از طریق پروتکل A2A - یک استاندارد باز مستقل از زبان - ارتباط برقرار میکنند، بنابراین هر عامل میتواند صرف نظر از چارچوب، با هر عامل دیگری تماس بگیرد. مدیر خلاق روی Agent Runtime اجرا میشود و از راه دور به هر متخصص متصل میشود.
معماری

آنچه یاد خواهید گرفت
- با استفاده از Google ADK -
Agent، دستورالعملهای سیستم و ابزارهای داخلی، عاملهای LLM بسازید. - دانش عامل قابل استفاده مجدد را با استفاده از مهارتهای ADK (Skills (
SkillToolset)) در فایلهای ماژولار بستهبندی کنید. - با اتصال یک عامل متنی به یک مدل تصویر از طریق
FunctionTool، تصاویر واقعی تولید کنید. - با استفاده از پروتکل زمینه مدل (MCP)، APIهای خارجی را بدون کد چسب سفارشی ادغام کنید.
- با استفاده از پروتکل عامل به عامل (A2A) از طریق HTTPS، هر عاملی را به یک سرویس قابل فراخوانی از طریق شبکه تبدیل کنید.
- هماهنگسازی عاملهای توزیعشده با
RemoteA2aAgentوAgentTool. - بستهبندی و استقرار عاملهای مستقل به عنوان میکروسرویسهای Cloud Run .
- یک ارکستراتور با وضعیت مشخص را روی Agent Runtime میزبانی کنید.
- با استفاده از فشردهسازی زمینه، گردشهای کاری طولانی چندعاملی را در محدوده زمینه نگه دارید.
- یک حلقه کنترل کیفیت بسازید: منتقد خروجی را بررسی میکند ← در صورت نیاز، بهطور خودکار اصلاح میکند.
آنچه نیاز دارید
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- نقش مالک یا ویرایشگر IAM
- دانش پایه پایتون
۲. محیط خود را آماده کنید
برای این آزمایشگاه کد، از Cloud Shell استفاده خواهیم کرد.
ابر پوسته چیست؟
کلود شل یک محیط لینوکس رایگان مبتنی بر مرورگر است که همه چیز از پیش نصب شده است: gcloud ، git ، پایتون، داکر و موارد دیگر. نیازی به نصب چیزی به صورت محلی ندارید.
برای باز کردن Cloud Shell، روی آیکون ترمینال در نوار ابزار بالا سمت راست کنسول GCP کلیک کنید:
وقتی برای اولین بار Cloud Shell را باز میکنید، از شما خواسته میشود حساب خود را تأیید کنید - روی تأیید کلیک کنید:
سپس روی تأیید (Authorize) کلیک کنید تا به Cloud Shell اجازه دهید فراخوانیهای Google Cloud API را انجام دهد:
اکنون Cloud Shell آماده است. یک پیام خوشامدگویی در ترمینال مشاهده خواهید کرد: 
پروژه خود را تأیید و پیکربندی کنید
Cloud Shell از قبل با حساب گوگل شما احراز هویت شده است. حساب فعال خود را تأیید کنید و شناسه پروژه خود را پیدا کنید:
gcloud config list
همچنین میتوانید شناسه پروژه خود را در داشبورد کنسول GCP در پنل سمت چپ مشاهده کنید. آن را کپی کنید - در دستور بعدی به آن نیاز خواهید داشت:
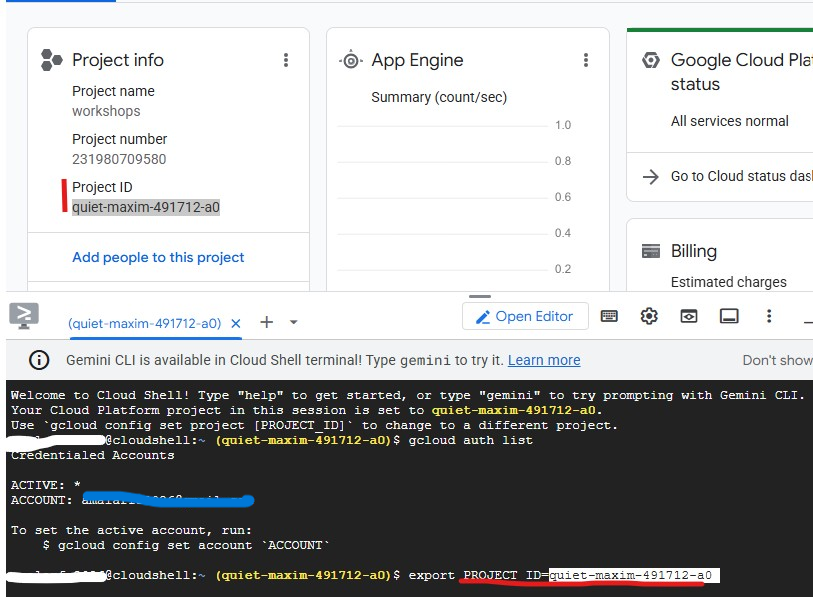
حالا پروژه خود را تنظیم کنید:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Cloud Run deployment region
echo "Project: $PROJECT_ID"
خروجی مورد انتظار:
Project: my-project-123
فعال کردن API های مورد نیاز
gcloud services enable \
aiplatform.googleapis.com \
apphub.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
generativelanguage.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com \
storage.googleapis.com \
secretmanager.googleapis.com
این کار حدود ۲ دقیقه طول میکشد. پس از اتمام، Operation finished successfully مشاهده خواهید کرد.
تنظیم اعتبارنامههای پیشفرض برنامه (ADC)
این عاملها با استفاده از کتابخانه Google Auth ، پلتفرم Gemini Enterprise Agent را فراخوانی میکنند که به اعتبارنامههای پیشفرض برنامه نیاز دارد - جدا از احراز هویت gcloud CLI.
اینو یه بار اجرا کن:
gcloud auth application-default login
یک برگه مرورگر باز میشود که از شما میخواهد تأیید کنید. روی «اجازه دادن» کلیک کنید. خواهید دید:
Credentials saved to file: ~/.config/gcloud/application_default_credentials.json
مخزن اولیه را کلون کنید
این آزمایشگاه کد از یک مخزن اولیه استفاده میکند - یک پروژه اسکلتی با تمام زیرساختها (Dockerfiles، pyproject.toml، اسکریپتهای deploy) که در آن منطق عامل برای نوشتن شما باقی مانده است.
git clone https://github.com/Saoussen-CH/mas-a2a-gcp.git ~/ai-creative-studio
cd ~/ai-creative-studio/workshop/starter
هر agent.py شامل # TODO است که در آن منطق عامل را خواهید نوشت. اسکریپتهای Dockerfile ، pyproject.toml و deploy از قبل کامل شدهاند.
پیکربندی متغیرهای محیطی
مثال ارائه شده را کپی کنید و شناسه پروژه خود را در یک مرحله وارد کنید:
cp .env.example .env
sed -i "s|GOOGLE_CLOUD_PROJECT=your-project-id|GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)|" .env
سپس سطل GCS را ایجاد کنید که Designer تصاویر تولید شده را در آن ذخیره کرده و .env را با نام آن بهروزرسانی کند:
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-campaign-images"
gcloud storage buckets create gs://${BUCKET_NAME} \
--location=us-central1 \
--project=${PROJECT_ID}
sed -i "s|GCS_IMAGES_BUCKET=your-project-id-campaign-images|GCS_IMAGES_BUCKET=${BUCKET_NAME}|" .env
سپس پشتیبانی از URL تصویر امضا شده را تنظیم کنید. مدیر خلاق برای هر تصویر در خلاصه نهایی کمپین، لینکهای HTTPS قابل کلیک ایجاد میکند. این کار به یک حساب کاربری سرویس برای امضای URLها نیاز دارد. برای پیکربندی آن، این دستورات را اجرا کنید:
export PROJECT_NUMBER=$(gcloud projects describe $(gcloud config get-value project) --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
export AGENT_RUNTIME_SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Allow your user account to sign URLs locally (adk web)
gcloud iam service-accounts add-iam-policy-binding ${SA_EMAIL} \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Allow Agent Runtime to sign URLs when deployed
gcloud projects add-iam-policy-binding $(gcloud config get-value project) \
--member="serviceAccount:${AGENT_RUNTIME_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
# Save SA email and project number to .env
grep -q "^SIGNING_SERVICE_ACCOUNT" .env \
&& sed -i "s|^SIGNING_SERVICE_ACCOUNT=.*|SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}|" .env \
|| echo "SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}" >> .env
grep -q "^GOOGLE_CLOUD_PROJECT_NUMBER" .env \
&& sed -i "s|^GOOGLE_CLOUD_PROJECT_NUMBER=.*|GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}|" .env \
|| echo "GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}" >> .env
برای مشاهدهی تمام تنظیمات، .env را در ویرایشگر باز کنید:
cloudshell edit .env
این کار .env به عنوان یک تب در ویرایشگر Cloud Shell باز میکند - اگر پنل ویرایشگر قابل مشاهده نیست، روی دکمه Open Editor در نوار ابزار کلیک کنید:

تأیید کنید که پروژه به درستی تنظیم شده است:
grep GOOGLE_CLOUD_PROJECT .env
نصب وابستگیها
ما از uv استفاده میکنیم - یک مدیر بسته پایتون سریع و مدرن که محیطهای مجازی را مدیریت میکند و در یک ابزار واحد نصب میشود. این ابزار تقریباً ۱۰ تا ۱۰۰ برابر سریعتر از pip است و روش پیشنهادی برای مدیریت پروژههای پایتون است.
Cloud Shell از قبل uv را نصب کرده است. همه agentها وابستگیهای اصلی یکسانی دارند، بنابراین یک بار نصب کنید و برای هر agent موجود در این codelab کار میکند:
uv sync
دستور uv sync pyproject.toml میخواند و یک دایرکتوری .venv/ با تمام وابستگیها ایجاد میکند. هر متخصص همچنین pyproject.toml مخصوص به خود را دارد که منحصراً توسط Docker builds استفاده میشود - نصب مشترک بالا همه چیزهایی را که برای آزمایش محلی نیاز دارید، پوشش میدهد.
۳. گوگل ADK را درک کنید
قبل از نوشتن کد، بیایید با کیت توسعه عامل (ADK) آشنا شویم - چارچوبی که برای ساخت هر عامل در این آزمایشگاه کد از آن استفاده خواهید کرد.
ADK چیست؟
کیت توسعه عامل (ADK) یک چارچوب انعطافپذیر و ماژولار برای توسعه و استقرار عاملهای هوش مصنوعی است. ADK در حالی که برای Gemini و اکوسیستم گوگل بهینه شده است، مستقل از مدل و مستقل از استقرار است و برای سازگاری با سایر چارچوبها ساخته شده است. ADK به گونهای طراحی شده است که توسعه عامل بیشتر شبیه توسعه نرمافزار باشد، تا توسعهدهندگان بتوانند معماریهای عامل را که از وظایف ساده تا گردشهای کاری پیچیده را شامل میشوند، آسانتر ایجاد، مستقر و هماهنگ کنند.
ADK بخشهای پیچیده - فراخوانی ابزار، مکالمه چند نوبتی، مدیریت زمینه، پخش جریانی - را مدیریت میکند، بنابراین میتوانید روی منطق عامل تمرکز کنید.
اجزای سازنده یک عامل ADK
هر عامل از چهار بلوک سازنده تشکیل شده است:
بلوک | نقش |
مدل | LLM که در مورد اهداف استدلال میکند، برنامهای تعیین میکند و پاسخهایی را ارائه میدهد |
ابزارها | توابعی که دادهها را دریافت میکنند یا با فراخوانی APIها یا سرویسها، اقداماتی را انجام میدهند |
ارکستراسیون | حافظه و وضعیت را در طول چرخشها حفظ میکند، فراخوانیهای ابزار را هدایت میکند و نتایج را به مدل بازمیگرداند. |
زمان اجرا | سیستم را هنگام فراخوانی اجرا میکند - به صورت محلی از طریق |
تعریف عامل
هر یک از ۵ عامل موجود در این آزمایشگاه کد به یک شکل تعریف شدهاند:
from google.adk.agents import Agent
from google.adk.tools.google_search_tool import google_search
root_agent = Agent(
name="brand_strategist", # unique identifier
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"), # the LLM powering this agent
instruction=SYSTEM_INSTRUCTION, # the agent's persona, constraints, and output format
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search], # functions the LLM can call
)
میدان | هدف |
| شناسه منحصر به فرد - توسط هماهنگکنندگان برای مسیریابی تماسها استفاده میشود |
| مدل جمینی که از این عامل حمایت میکند |
| اعلان سیستم - نقش عامل، محدودیتها و قالب خروجی را تعریف میکند |
| خلاصه یک خطی - هماهنگکننده این را میخواند تا تصمیم بگیرد با کدام متخصص تماس بگیرد |
| توابعی که LLM میتواند فراخوانی کند (توکارهایی مانند |
چگونه ADK یک عامل را اداره میکند
User message
│
▼
Agent (LLM) ← reads instruction + conversation history
│
├─► needs more info? → calls a tool → gets result → continues reasoning
│
└─► done reasoning → returns final text response
LLM به طور خودکار تصمیم میگیرد که آیا یک ابزار را فراخوانی کند، کدام ابزار را و با چه آرگومانهایی. شما دستورالعمل را مینویسید - ADK بقیه کارها را انجام میدهد.
۴. عامل استراتژیست برند را بسازید و آزمایش کنید
بیایید با اولین عامل شروع کنیم: استراتژیست برند. این یک عامل صرفاً تحقیقاتی است که با استفاده از جستجوی گوگل، بینش مخاطبان هدف، تحلیل رقبا و موضوعات پرطرفدار را جستجو میکند.
فایل عامل اسکلتی را در ویرایشگر Cloud Shell باز کنید:
cloudshell edit agents/brand_strategist/agent.py
دو بخش # TODO خواهید دید که باید آنها را پر کنید.
کار ۱ - نوشتن دستورالعمل سیستم
ابتدا، دستورالعمل سیستم را برای عامل خواهید نوشت. دستورالعمل سیستم رشتهای است که نقش، محدودیتها و قالب خروجی عامل را تعریف میکند.
SYSTEM_INSTRUCTION = f"""You are a Brand Strategist specializing in market research and trend analysis.
IMPORTANT: Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
When conducting research, focus on current trends from {datetime.date.today().year}.
Use search queries like "[topic] trends {datetime.date.today().year}" for recent insights.
IMPORTANT: Your role is RESEARCH ONLY. You do NOT create campaign content, captions, or designs.
After providing research insights, your work is complete.
Your expertise:
- Identifying target audience insights and behaviors
- Analyzing competitor strategies
- Researching current social media trends
- Understanding platform algorithms and best practices
You have access to:
- google_search: Search the web for competitors, trends, and market insights
When given a campaign brief:
1. Use google_search to research the target audience's current interests
2. Search for and analyze 2-3 competitor brands
3. Identify 3-5 trending topics related to the product category
4. Provide high-level strategic insights - NOT specific campaign content
DO NOT create captions, copy, designs, or any campaign content.
Format your output as:
**Audience Insights:**
[Key behaviors and preferences based on research]
**Competitive Analysis:**
[What 2-3 competitors are doing - strengths and weaknesses]
**Trending Topics:**
[3-5 relevant trends to consider]
**Key Strategic Insights:**
[High-level themes and positioning opportunities]
"""
کار دوم - ایجاد root_agent
در مرحله بعد، root_agent ناقص را با موارد زیر جایگزین کنید:
root_agent = Agent(
name="brand_strategist",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
instruction=SYSTEM_INSTRUCTION,
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search],
)
تست محلی با رابط کاربری وب ADK
حالا بیایید عامل را با استفاده از رابط کاربری وب ADK - یک رابط چت داخلی برای آزمایش عاملها قبل از استقرار در فضای ابری - آزمایش کنیم.
uv run adk web agents --allow_origins='*'
خواهید دید:
INFO: Started server process
INFO: Uvicorn running on http://localhost:8000
سرور اکنون درون Cloud Shell در حال اجرا است:
برای باز کردن آن در مرورگر خود، از پیشنمایش وب استفاده کنید:
- به نوار ابزار Cloud Shell در بالای صفحه نگاه کنید
- روی نماد پیشنمایش وب کلیک کنید (شبیه یک جعبه با فلش رو به بالا، در بالا سمت راست نوار ابزار Cloud Shell)
- روی «تغییر پورت» کلیک کنید و
8000را وارد کنید، سپس روی «تغییر و پیشنمایش» کلیک کنید.
یک برگه مرورگر جدید با رابط کاربری وب ADK باز میشود. روی منوی کشویی «انتخاب یک نماینده» در بالا سمت چپ کلیک کنید - همه نمایندگان خود را در لیست مشاهده خواهید کرد:
برای شروع آزمایش، brand_strategist را انتخاب کنید:
این دستورالعملهای آزمایشی را امتحان کنید
در کادر گفتگوی رابط کاربری وب ADK، موارد زیر را امتحان کنید:
-
Research the eco-friendly water bottle market for health-conscious millennials -
What are the top Instagram trends in the wellness space in 2025?
شما باید ببینید که نماینده با جستجوی گوگل تماس میگیرد و تحقیقات ساختاریافتهای را با بخشهای بینش مخاطبان، تحلیل رقابتی و موضوعات پرطرفدار ارائه میدهد.
۵. یک کپیرایتر بسازید - مهارتهای ADK
نقش: تبدیل تحقیقات برند به کپشنهای اینستاگرام. کپیرایتر ۳ نوع کپشن با لحنهای مختلف (الهامبخش، آموزشی، اجتماعی) ایجاد میکند که هر کدام دارای هشتگ و فراخوان عمل هستند.
مفهوم: مهارتهای ADK
یک رویکرد سادهلوحانه، تمام دانش پلتفرم - محدودیتهای کاراکتر، سطوح هشتگ، فرمولهای زیرنویس، نمونههای صدای برند - را مستقیماً در اعلان سیستم جاسازی میکند. این روش جواب میدهد، اما هر درخواست را با محتوایی که عامل فقط گاهی اوقات به آن نیاز دارد، حجیم میکند.
مهارتهای ADK ( SkillToolset ، معرفی شده در ADK 1.25.0) به شما امکان میدهد آن دانش را در فایلهای ماژولار با سه سطح بارگذاری بستهبندی کنید:
- L1 - frontmatter (
name+descriptionدرSKILL.md): همیشه در دسترس است، برای کشف مهارت استفاده میشود - L2 - دستورالعملها (بدنه
SKILL.md): زمانی که عامل، مهارت را فعال میکند، بارگذاری میشوند. - L3 - منابع (
references/وassets/فایلها): فقط زمانی بارگذاری میشوند که عامل صریحاً آنها را بخواند
دستورالعمل سیستم به یک عبارت نقش کوتاه به علاوهی «بارگذاری مهارت قبل از نوشتن» خلاصه میشود. جزئیات پلتفرم فقط زمانی وارد پنجرهی زمینه میشوند که عامل واقعاً به آنها نیاز داشته باشد.
مهارت کپیرایتر در agents/copywriter/skills/instagram-copywriting/ وجود دارد:
skills/
instagram-copywriting/
SKILL.md ← L1 frontmatter (discovery) + L2 instructions (loaded on trigger)
references/
platform-guide.md ← L3: character limits, hashtag tiers, algorithm signals
caption-formulas.md ← L3: hook formulas, CTA patterns, full caption structures
assets/
brand-voice-examples.md ← L3: annotated real-world caption examples
فایل را مستقیماً در ویرایشگر Cloud Shell باز کنید:
cloudshell edit agents/copywriter/agent.py
کار ۱ - وارد کردن load_skill_from_dir و skill_toolset
کامنت # TODO 1: Import load_skill_from_dir and skill_toolset پیدا کنید و دو import را اضافه کنید:
from google.adk.skills import load_skill_from_dir
from google.adk.tools import skill_toolset
TODO 2 - مهارت را بارگذاری کنید و یک SkillToolset ایجاد کنید
دو نظر زیر ایمپورتها را پیدا کنید:
# TODO 2: Load the instagram-copywriting skill from the skills/ directory
# TODO 2: Create a SkillToolset with the loaded skill
آنها را با موارد زیر جایگزین کنید:
_instagram_skill = load_skill_from_dir(
pathlib.Path(__file__).parent / "skills" / "instagram-copywriting"
)
_copywriting_skills = skill_toolset.SkillToolset(skills=[_instagram_skill])
load_skill_from_dir فایل SKILL.md به علاوهی هر فایلی در references/ و assets/ را میخواند. SkillToolset آن را در قالبی که عاملهای ADK میپذیرند، قرار میدهد - یک مجموعه ابزار، نه یک مهارت خام.
مرحله ۳ - ثبت مجموعه ابزارها در عامل
یافتن tools=[], # TODO 3: Add the SkillToolset here و آن را با موارد زیر جایگزین کنید:
tools=[_copywriting_skills],
فایل مهارت را باز کنید تا ببینید ساختار آن چگونه است:
cloudshell edit agents/copywriter/skills/instagram-copywriting/SKILL.md
رابط کاربری وب ADK را در حال اجرا نگه دارید. از منوی کشویی agent برای تغییر به copywriter بدون راهاندازی مجدد سرور استفاده کنید.
اگر اجرا نشد، دوباره آن را اجرا کنید:
uv run adk web agents --allow_origins='*'
امتحان کنید: منوی کشویی را به copywriter تغییر دهید و ارسال کنید:
You are writing captions for EcoFlow Smart Water Bottle targeting health-conscious millennials aged 25-35.
Audience insight: they prioritize sustainability, track health metrics, and share lifestyle content.
Competitor insight: Hydro Flask dominates with lifestyle branding; S'well leads on premium aesthetics.
Write 3 Instagram captions - one inspirational, one educational, one community-focused. Include 5 hashtags each and a CTA.
۶. طراح را بسازید - تولید تصویر چندوجهی
رابط کاربری وب ADK را در حال اجرا نگه دارید. از منوی کشویی agent برای تغییر agentها بدون راهاندازی مجدد سرور استفاده کنید.
نقش: ایجاد مفاهیم بصری برای هر عنوان و تولید تصاویر واقعی با استفاده از تولید تصویر بومی Gemini. طراح دقیقاً یک مفهوم بصری برای هر عنوان - با یک دستورالعمل دقیق، سبک، پالت رنگ، حال و هوا و قالب اینستاگرام - تولید میکند، سپس بلافاصله ابزار generate_image را برای تولید تصویر واقعی فراخوانی کرده و آن را در GCS بارگذاری میکند.
مفهوم: ایجاد پل ارتباطی بین یک عامل متنی و یک مدل تصویری از طریق یک ابزار
Designer روی gemini-3-flash-preview اجرا میشود (مدل متنی که از طریق GEMINI_MODEL در .env تنظیم شده است)، اما تولید تصویر به یک مدل اختصاصی ( gemini-3.1-flash-image ) نیاز دارد. این مدل تصویر از فراخوانی تابع پشتیبانی نمیکند، بنابراین نمیتوان آن را مستقیماً به عنوان یک عامل ADK استفاده کرد. در عوض، در یک تابع پایتون ساده قرار گرفته و به عنوان FunctionTool ثبت شده است.
این الگویی برای هر مدل یا API است که LLM نمیتواند مستقیماً آن را فراخوانی کند: آن را در یک ابزار قرار دهید، اجازه دهید عامل زمان فراخوانی آن را تنظیم کند و یک نتیجه ساختاریافته دریافت کند.
Designer agent (text model)
│
│ decides visual concept, writes image prompt
▼
generate_image tool
│
│ calls gemini-3.1-flash-image
│ uploads result to GCS
▼
{"status": "success", "gcs_uri": "gs://..."}
│
│ returned to agent, included in response
▼
Critic (receives gcs_uri, passes to Vertex AI for multimodal review)
فایل را مستقیماً در ویرایشگر Cloud Shell باز کنید:
cloudshell edit agents/designer/image_gen_tool.py
امضای تابع، تنظیمات محیط و تزریق نسبت ابعاد ارائه شدهاند. به ترتیب روی سه TODO کار کنید:
کار ۱ - فراخوانی مدل تصویر Gemini
کامنت # TODO 1 را پیدا کنید و آن را با این جایگزین کنید:
client = genai.Client(vertexai=True, project=project_id, location=location)
response = client.models.generate_content(
model=image_model,
contents=prompt_with_aspect,
config=types.GenerateContentConfig(
response_modalities=["IMAGE", "TEXT"],
http_options=types.HttpOptions(
retry_options=types.HttpRetryOptions(
attempts=5, exp_base=2, initial_delay=30,
http_status_codes=[429, 500, 503, 504],
),
timeout=180_000,
),
),
)
TODO 2 - استخراج بایتهای تصویر از پاسخ
کامنت # TODO 2 را پیدا کنید و آن را با این جایگزین کنید:
image_bytes = None
mime_type = "image/png"
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
image_bytes = part.inline_data.data
mime_type = part.inline_data.mime_type or "image/png"
break
if not image_bytes:
return {"status": "error", "error": "Gemini returned no image data"}
کار ۳ - آپلود در GCS و برگرداندن URI
کامنت # TODO 3 را پیدا کنید و آن را با این جایگزین کنید:
ext = "jpg" if "jpeg" in mime_type else "png"
from google.cloud import storage
gcs_client = storage.Client(project=project_id)
bucket = gcs_client.bucket(bucket_name)
blob_name = f"campaign-images/{concept_name}-{uuid.uuid4().hex[:8]}.{ext}"
blob = bucket.blob(blob_name)
blob.upload_from_file(io.BytesIO(image_bytes), content_type=mime_type)
gcs_uri = f"gs://{bucket_name}/{blob_name}"
امتحان کنید: منوی کشویی را به designer تغییر دهید و ارسال کنید:
Create a visual concept and generate the image for an EcoFlow Smart Water Bottle Instagram post targeting health-conscious millennials.
Style: clean, modern, lifestyle-focused. Include a detailed prompt with color palette, mood, and format (1080x1080 or 1080x1350).
۷. منتقد را بسازید - خروجی ساختاریافته
نقش: تضمین کیفیت متن و تصاویر قبل از تحویل به مدیر پروژه. منتقد هر دو مورد قابل تحویل را امتیازدهی میکند و مقادیر APPROVED یا NEEDS_REVISION را به همراه پیشنهادات خاص برمیگرداند. هنگامی که مقادیر gcs_uri در ورودی وجود داشته باشد، ابزار review_image را برای بررسی بصری هر تصویر تولید شده قبل از امتیازدهی فراخوانی میکند.
مفهوم: چه زمانی از مدل Pydantic برای خروجی Gemini استفاده کنیم
قاعده در مورد این است که چه کسی خروجی را مصرف میکند :
- کد پایتون آن را مصرف میکند →
response_schema+ Pydantic استفاده کنید. کد نمیتواند ابهام را مدیریت کند، بنابراین به یک ساختار تضمینشده برای استخراج مطمئن فیلدها نیاز دارید. - یک LLM آن را مصرف میکند → قالب متن + دستورالعمل سیستم کافی است. LLMها قوانین قالببندی را درک میکنند و تغییرات را تحمل میکنند.
در review_image ، کد پایتون به مقادیر نوعبندیشدهی score ، approval_status ، what_works ، issues و suggestions نیاز دارد. ارسال response_schema=_GeminiReview ، Gemini را در سطح API مجبور میکند تا JSON معتبری را برگرداند؛ model_validate_json() آن را به یک شیء نوعبندیشده تجزیه میکند که کد شما میتواند به طور قابل اعتمادی از آن استفاده کند.
class _GeminiReview(BaseModel):
score: int = Field(ge=1, le=10)
approval_status: Literal["APPROVED", "NEEDS_REVISION"]
what_works: str
issues: str
suggestions: str
فایل را مستقیماً در ویرایشگر Cloud Shell باز کنید:
cloudshell edit agents/critic/image_review_tool.py
مدلها و دستورالعملهای Pydantic ارائه شدهاند. به ترتیب روی سه TODO کار کنید:
کار ۱ - ایجاد یک بخش تصویر از GCS URI
کامنت # TODO 1 را پیدا کنید و آن را با این جایگزین کنید:
image_part = types.Part.from_uri(file_uri=gcs_uri, mime_type=mime_type)
TODO 2 - با یک طرح پاسخ ساختار یافته با Gemini تماس بگیرید
کامنت # TODO 2 را پیدا کنید و آن را با این جایگزین کنید:
response = client.models.generate_content(
model=model,
contents=[image_part, prompt],
config=types.GenerateContentConfig(
response_schema=_GeminiReview,
response_mime_type="application/json",
),
)
TODO 3 - پاسخ را تجزیه کرده و نتیجه را برگردانید
کامنت # TODO 3 را پیدا کنید و آن را با این جایگزین کنید:
review = _GeminiReview.model_validate_json(response.text)
return ImageReviewResult(status="success", concept_name=concept_name, **review.model_dump())
امتحانش کن: منوی کشویی را به critic تغییر بده و ارسال کن:
Review this Instagram caption for an eco-friendly water bottle brand targeting millennials:
"Hydrate smarter, live greener. 💧 Our EcoFlow bottle tracks your intake, keeps your drink cold for 24h, and never touches single-use plastic. Because what you drink from matters as much as what you drink. #EcoFlow #HydrationGoals #SustainableLiving #ZeroWaste #HealthyHabits - Shop link in bio."
Score it and indicate APPROVED or NEEDS_REVISION with specific feedback.
تأیید کنید که پاسخ شامل **POSTS REVIEW:** ، Status: APPROVED (یا NEEDS_REVISION ) و **OVERALL ASSESSMENT:** . اگر این بخشها وجود داشته باشند، منتقد آماده اتصال به هماهنگکننده است.
وقتی آزمایش هر سه عامل تمام شد، Ctrl+C را فشار دهید تا سرور متوقف شود.
۸. با MCP، عامل مدیر پروژه را بسازید
مدیر پروژه مفهوم جدیدی را معرفی میکند: MCP (پروتکل زمینه مدل) .
فایل را باز کنید:
cloudshell edit agents/project_manager/agent.py
این فایل پیچیدهتر است - دارای یک تابع create_project_manager_agent() با دو شاخه است: یکی بدون Notion (جدولهای زمانی فقط متنی) و دیگری با مجموعه ابزار Notion MCP. شما هر دو را پر خواهید کرد.
مشکلی که MCP حل میکند
عامل شما باید یک سرویس خارجی را فراخوانی کند - مثلاً یک صفحه در Notion ایجاد کند. میتوانید کد پایتون بنویسید که مستقیماً Notion REST API را فراخوانی کند. اما در این صورت:
- هر توسعهدهنده یک wrapper متفاوت مینویسد
- شما باید کد یکپارچهسازی سفارشی را حفظ کنید
- LLM از وجود API مطلع نمیشود، مگر اینکه شما هر نقطه پایانی را به صورت دستی توصیف کنید.
MCP این مشکل را با تعریف یک روش استاندارد برای سرویسهای خارجی حل میکند تا قابلیتهای خود را به عنوان ابزارهایی که یک LLM میتواند به طور خودکار کشف و فراخوانی کند، در معرض نمایش قرار دهند.
ام سی پی چیست؟
MCP (پروتکل زمینه مدل) یک استاندارد باز (منتشر شده توسط Anthropic) برای اتصال عوامل هوش مصنوعی به ابزارها و منابع داده خارجی است. این پروتکل مانند یک آداپتور جهانی عمل میکند.
سرور MCP یک برنامه کوچک است که:
- یک API خارجی (Notion، GitHub، پایگاههای داده، سیستم فایلها...) را در بر میگیرد.
- آن API را به عنوان لیستی از ابزارهای تایپ شده و مستند شده نمایش میدهد.
- از طریق یک پروتکل ساده (stdio یا HTTP) با عامل ارتباط برقرار میکند.
عامل به سرور MCP متصل میشود، به طور خودکار ابزارهای موجود را کشف میکند و میتواند آنها را درست مانند هر ابزار دیگری فراخوانی کند - LLM API-post-page(...) را به عنوان یک تابع قابل فراخوانی میبیند.
A2A در مقابل MCP - تفاوت چیست؟
این یک نکته رایج در سردرگمی است. تمایز کلیدی در اینجا آمده است:
A2A | ام سی پی | |
چه چیزی ارتباط برقرار میکند | نماینده ↔ نماینده | عامل ↔ ابزار/سرویس خارجی |
طرف دیگر است | یکی دیگر از نمایندگان LLM | یک پوشش دهنده API (بدون LLM) |
مثال | مدیر خلاق با استراتژیست برند تماس میگیرد | مدیر پروژه، رابط برنامهنویسی کاربردی (API) مربوط به Notion را فراخوانی میکند. |
پروتکل | JSON-RPC روی HTTPS | stdio یا جریان HTTP |
تعریف شده توسط | گوگل | انسانشناسی |
به این شکل بهش فکر کن:
- A2A = نحوه صحبت کارشناسان با سایر کارشناسان
- MCP = نحوه ارتباط عاملها با ابزارها و سرویسها
در این پروژه هر دو با هم استفاده میشوند:
Creative Director
│
│ (A2A) Brand Strategist ─── (google_search tool built into ADK)
│ (A2A) Copywriter
│ (A2A) Designer
│ (A2A) Critic
│ (A2A) Project Manager
│
│ (MCP) notion-mcp-server ──► Notion REST API
نحوه عملکرد MCP در این پروژه
وقتی عامل اجرا میشود، ADK، notion-mcp-server به عنوان یک فرآیند فرزند اجرا میکند. این فرآیند، این ابزارها را مستقیماً در اختیار LLM قرار میدهد:
ابزار | چه کاری انجام میدهد؟ |
| طرحواره واکشی (نام ویژگیها، انواع، مقادیر معتبر) |
| صفحات موجود را جستجو کنید |
| یک صفحه جدید ایجاد میکند |
| یک صفحه موجود را بهروزرسانی میکند |
LLM اینها را مانند هر تابع دیگری فراخوانی میکند - اصلاً نمیداند که آنها از طریق MCP به Notion REST API در زیر کاپوت میروند.
چرا stdio؟ چرا فقط HTTP نه؟
سرور MCP به عنوان یک فرآیند فرزندِ عامل اجرا میشود و از طریق stdin/stdout ارتباط برقرار میکند. این به این معنی است:
- بدون نیاز به پورت شبکه اضافی
- چرخه حیات توسط عامل مدیریت میشود (به محض تقاضا شروع میشود، به محض خروج متوقف میشود)
- همه چیز در یک تصویر داکر ارسال میشود - هیچ سرویس جداگانهای برای استقرار وجود ندارد
(اختیاری) فعال کردن ادغام ایدهها
میتوانید از کل این بخش صرف نظر کنید. عامل مدیر پروژه همیشه یک جدول زمانی کامل کمپین مبتنی بر متن، با یا بدون Notion، تولید میکند. اگر از این تنظیم صرف نظر کنید، عامل به حالت درون حافظهای برمیگردد و جدول زمانی را به صورت متن ساده در چت نمایش میدهد. هیچ مشکلی پیش نمیآید - فقط وظایف را در پایگاه داده Notion مشاهده نخواهید کرد. اگر میخواهید از این مرحله صرف نظر کنید، مستقیماً به TODO 1 بروید.
اگر حساب کاربری Notion دارید و میخواهید ادغام MCP را در عمل ببینید، تنظیمات زیر را همین حالا تکمیل کنید. TODOهایی که از IDهای پایگاه داده Notion پیروی میکنند، به IDهای پایگاه داده Notion ارجاع میدهند - از اینجا میتوانید آنها را دریافت کنید.
مرحله ۱ - ایجاد پایگاه داده Notion از یک الگو
ما از الگوی رسمی Notion Projects & Tasks به عنوان پایگاه داده خود استفاده میکنیم. ما این الگو را عمداً برای نشان دادن یک محیط پیچیده و واقعی انتخاب کردیم - این الگو دارای چندین نوع ویژگی (وضعیت، محدوده تاریخ، روابط، انتخابها) با نامهای غیر واضح است. این یک آزمایش عالی برای کشف طرحواره پویای MCP است: عامل باید نام دقیق ویژگیها را در زمان اجرا تشخیص دهد، نه اینکه آنها را به صورت کد ثابت داشته باشد.
برای افزودن الگو به فضای کاری Notion خود، روی لینک زیر کلیک کنید:
→ الگوی «پروژهها و وظایف» را به Notion اضافه کنید
پس از افزودن، دو پایگاه داده مرتبط خواهید داشت: پروژهها و وظایف . این الگو شامل ورودیهای نمونه است - قبل از ادامه، همه آنها را حذف کنید تا عامل با یک فضای کاری تمیز شروع به کار کند (همه را انتخاب کنید → حذف).
مرحله 2 - ایجاد یک ادغام مفهوم
ایجاد ادغام:
- به conceptual.so/my-integrations بروید
- روی ادغام جدید کلیک کنید → نام آن را
AI Creative Studioبگذارید - آن را با فضای کاری خود مرتبط کنید
- روی پیکربندی تنظیمات کلیک کنید → مطمئن شوید که گزینههای «خواندن محتوا» ، «بهروزرسانی محتوا» و «وارد کردن محتوا» همگی علامت زده شدهاند.
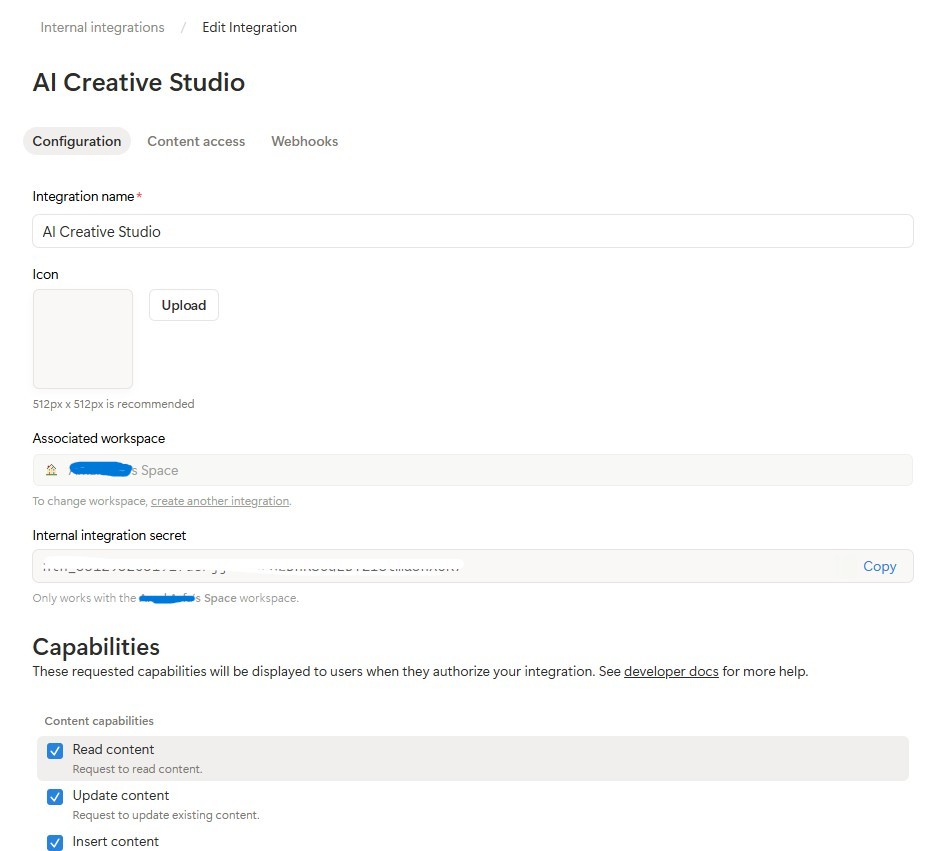
- توکن یکپارچهسازی داخلی (
ntn_...) را کپی کرده و در فایل.envخود قرار دهید:
NOTION_TOKEN=ntn_your-token-here
ادغام را به پایگاههای داده خود متصل کنید:
- صفحه قالبی که کپی کردهاید را باز کنید، سپس روی پایگاه داده پروژهها کلیک کنید
- روی منوی
...(بالا سمت راست) کلیک کنید → اتصالات → افزودن اتصال → انتخابAI Creative Studio
- همین کار را برای پایگاه داده Tasks انجام دهید
دریافت شناسههای پایگاه داده:
- برای باز کردن آن، روی پیوند پایگاه داده پروژهها کلیک کنید - در صفحه مخصوص خود با URL مانند زیر باز میشود:
https://www.notion.so/9887b6a94f7f83f68f8581e038d1aaa4?v=2c37b6a94f7f838685f1086e312c7278

شناسه پایگاه داده اولین UUID در URL است - هر چیزی قبل از ?v= :
https://www.notion.so/{DATABASE_ID}?v=...
^^^^^^^^^^^^^^^^
9887b6a94f7f83f68f8581e038d1aaa4 ← this is your DATABASE_ID
- همین کار را برای لینک پایگاه داده Tasks انجام دهید تا شناسه پایگاه داده آن را دریافت کنید.
- هر سه مقدار را به
.envخود اضافه کنید:
NOTION_TOKEN=ntn_your-token-here
NOTION_PROJECT_DATABASE_ID=9887b6a94f7f83f68f8581e038d1aaa4 # <-- your Projects DB ID
NOTION_TASKS_DATABASE_ID=your-tasks-db-id # <-- your Tasks DB ID
مرحله 3 - سرور Notion MCP را نصب کنید
مدیر پروژه از طریق بسته رسمی Node.js با شناسه @notionhq/notion-mcp-server به Notion متصل میشود. آن را به صورت سراسری نصب کنید:
npm install -g @notionhq/notion-mcp-server@1.9.1
نصب را تأیید کنید:
npm list -g @notionhq/notion-mcp-server
خروجی مورد انتظار:
└── @notionhq/notion-mcp-server@1.9.1
notion-mcp-server: command not found
? مطمئن شوید که Node.js نصب شده است ( node --version ) و npm global bin شما در مسیر ( path ) شما قرار دارد ( export PATH=$PATH:$(npm bin -g) ).
مرحله ۴ - فایل .env خود را تأیید کنید
فایل .env را باز کنید و تأیید کنید که هر سه مقدار Notion تنظیم شدهاند (شما آنها را در مرحله ۲ اضافه کردهاید):
cloudshell edit .env
NOTION_TOKEN=ntn_... # integration token
NOTION_PROJECT_DATABASE_ID=... # Projects database ID
NOTION_TASKS_DATABASE_ID=... # Tasks database ID
عامل مدیر پروژه به طور خودکار این متغیرها را در هنگام راهاندازی تشخیص میدهد و مجموعه ابزار Notion MCP را فعال میکند.
نحوهی عملکرد کشف طرحواره
مدیر پروژه از کشف پویای طرحواره استفاده میکند - هرگز نامهای ویژگی Notion را به صورت ثابت کدگذاری نمیکند:
Step 1: Call API-retrieve-a-database to discover exact property names
Step 2: Read the "properties" object in the response
Step 3: Use ONLY discovered property names (case-sensitive) in API calls
Step 4: For select/status fields, use only values from the options array
این یعنی عامل به طور خودکار با هر ساختار پایگاه داده Notion سازگار میشود - نام ویژگیهای خود را به فرانسوی، عربی یا هر چیز دیگری تغییر دهید، و عامل همچنان کار میکند.
کار ۱ - نوشتن دستورالعمل سیستم
شروعکننده از قبل notion_section محاسبه میکند - یک رشته خالی وقتی Notion پیکربندی نشده باشد، یا یک بلوک حاوی شناسههای پایگاه داده به همراه راهنمای کامل ابزار وقتی پیکربندی شده باشد. این کار دستورالعملهای Notion را کاملاً از اعلان عامل بدون Notion دور نگه میدارد؛ LLM هرگز قوانینی را برای ابزارهایی که ندارد نمیبیند.
وظیفه شما این است که return placeholder را با یک دستورالعمل سیستمی واقعی که از {notion_section} استفاده میکند، جایگزین کنید:
return f"""You are a Project Manager specializing in creative campaign execution.
Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
Use this as the starting point for all timelines.
Your goal: create a complete project plan for the campaign.
{notion_section}
**Project Timeline:**
Phase 1: Strategy & Research | [date] → [date] | [key activities]
Phase 2: Content Creation | [date] → [date] | [key activities]
Phase 3: Review & Revision | [date] → [date] | [key activities]
Phase 4: Launch & Monitoring | [date] → [date] | [key activities]
**Task List:**
| Task | Owner | Deadline | Status |
[list each task with realistic deadlines from today; set Owner to TBD]
**Budget Breakdown:**
[by category with approximate allocations]
**Milestones:**
[3-5 key checkpoints with dates]
**Notion Status:**
[What happened - e.g. "Project created (ID: xxx), 8 tasks linked" or "Notion not configured - text timeline only"]
"""
TODO 2 - عامل بدون مفهوم
درون create_project_manager_agent() ، در شاخهی if not notion_token ، عامل ناقص را با موارد زیر جایگزین کنید:
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
instruction=get_system_instruction(),
description="Project manager that creates campaign timelines and task breakdowns",
)
TODO 3 - مامور با Notion MCP
نکته: فایل آغازین از قبل شامل یک تابع فراخوانی از پیش نوشته شده handle_notion_error در بالای create_project_manager_agent() است. این تابع خطاهای API مربوط به Notion (400/404) را رهگیری میکند و دادههای خام خطا را با پیامهای تمیز و قابل اجرا جایگزین میکند تا LLM بتواند خود را اصلاح کند. شما فقط باید آن را از طریق after_tool_callback وارد کنید.
ابتدا، هر دو شناسه پایگاه داده را در بالای create_project_manager_agent() بخوانید:
notion_token = os.getenv("NOTION_TOKEN")
notion_project_db_id = os.getenv("NOTION_PROJECT_DATABASE_ID")
notion_tasks_db_id = os.getenv("NOTION_TASKS_DATABASE_ID")
سپس در شاخه else ، مجموعه ابزار MCP و عامل را ایجاد کنید:
from google.adk.tools.mcp_tool import McpToolset, StdioConnectionParams
from mcp import StdioServerParameters
server_params = StdioServerParameters(
command="notion-mcp-server",
env={
"NOTION_TOKEN": notion_token,
"PATH": os.environ.get("PATH", ""),
}
)
notion_toolset = McpToolset(
connection_params=StdioConnectionParams(
server_params=server_params,
timeout=30.0
)
)
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
after_tool_callback=handle_notion_error,
instruction=get_system_instruction(
project_database_id=notion_project_db_id,
tasks_database_id=notion_tasks_db_id,
),
description="Project manager with Notion integration for task tracking",
tools=[notion_toolset],
)
بهترین روش: هرگز در ادغامهای اختیاری، شکست قطعی را تجربه نکنید. جدول زمانی متن همیشه خروجی اصلی است؛ مفهوم مکمل است.
مدیر پروژه را به صورت محلی با ADK Web آزمایش کنید
uv run adk web agents --allow_origins='*'
پیشنمایش وب را روی پورت ۸۰۰۰ باز کنید. از منوی کشویی agent ، project_manager را انتخاب کنید، سپس امتحان کنید:
Create a project plan for a GreenBrew organic coffee brand Instagram campaign.
Budget: $2,500. Launch in 3 weeks. Target audience: eco-conscious millennials aged 22-30.
Include phases, tasks with deadlines from today, and milestones.
شما باید یک جدول زمانی متنی ساختاریافته با مراحل، لیست وظایف و مراحل مهم را ببینید. اگر اعتبارنامههای Notion در .env تنظیم شده باشند، عامل ورودیهایی را در فضای کاری Notion شما نیز ایجاد خواهد کرد.
۹. پروتکل A2A را درک کنید
ما از پروتکل عامل به عامل (A2A) برای اتصال عاملهای مختلف در سیستم خود استفاده خواهیم کرد. بیایید نحوه کار آن را درک کنیم.
مشکلی که A2A حل میکند
تصور کنید که یک عامل استراتژیست برند دارید که با ADK ساخته شده و یک عامل نویسنده متن که با LangGraph ساخته شده است. چگونه یکی دیگری را صدا میزند؟ آنها به زبانهای داخلی متفاوتی صحبت میکنند. شما باید هر بار کد glue سفارشی بنویسید.
A2A این مشکل را با تعریف یک زبان جهانی که هر عاملی - صرف نظر از چارچوب - میتواند با آن صحبت کند، حل میکند. این HTTP دنیای عاملها است: استانداردی که همه روی آن توافق دارند، بنابراین هر کسی میتواند با هر کسی صحبت کند.
A2A چیست؟
ارتباط عامل با عامل (A2A) یک استاندارد باز برای ارتباط عاملها است که توسط گوگل منتشر شده است. این استاندارد موارد زیر را تعریف میکند:
- چگونه یک عامل خود را توصیف میکند - کارت عامل در
/.well-known/agent.json - چگونه یک عامل دیگر آن را صدا میزند - JSON-RPC از طریق HTTPS
- نحوهی برگرداندن نتایج - پخش جریانی یا پاسخ تکی
چه چیزی A2A را انعطافپذیر میکند؟
- مستقل از زبان - عاملهای پایتون میتوانند با عاملهای TypeScript صحبت کنند
- مستقل از چارچوب - عوامل ADK میتوانند با عوامل LangGraph یا CrewAI صحبت کنند
- مستقل از زیرساخت - نمایندگان محلی میتوانند با نمایندگان ابری صحبت کنند
چگونه کار میکند - گام به گام
Creative Director Brand Strategist
│ │
│ 1. GET /.well-known/agent.json │
│ ────────────────────────────────►│
│ ◄──── agent card (name, url, │
│ skills, capabilities) ───│
│ │
│ 2. POST / │
│ {"method": "tasks/send", │
│ "params": {"message": ...}} │
│ ────────────────────────────────►│
│ │ LLM does
│ │ the work...
│ 3. streaming response chunks │
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
مرحله ۱ - کشف: هماهنگکننده یک بار کارت عامل را دریافت میکند تا نام، URL و قابلیتهای عامل را یاد بگیرد.
مرحله ۲ - فراخوانی: هماهنگکننده یک وظیفه را از طریق JSON-RPC POST ارسال میکند. بدنه شامل پیام (دستورالعمل برای متخصص) است.
مرحله ۳ - پاسخ: متخصص، پاسخ خود را به صورت تکه تکه، درست مانند یک تماس LLM معمولی، ارسال میکند.
کارت نماینده
هر عامل یک شرح حال از خود در /.well-known/agent.json منتشر میکند. این مانند یک کارت ویزیت است - به همه میگوید که عامل چه کاری میتواند انجام دهد و از کجا میتوان به آن دسترسی پیدا کرد:
{
"name": "brand_strategist",
"description": "Market research and competitive analysis",
"url": "https://brand-strategist-xyz.run.app",
"capabilities": { "streaming": true },
"skills": [
{
"id": "market_research",
"description": "Research target audiences, competitors, and trends"
}
]
}
هماهنگکننده این کارت را میخواند تا شیء RemoteA2aAgent خود را بسازد - هیچ دانش سختافزاری از بخشهای داخلی متخصص مورد نیاز نیست.
افشای یک عامل از طریق A2A در ADK
to_a2a() هر عامل ADK را در یک برنامه FastAPI سازگار با A2A قرار میدهد. یک خط:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
# root_agent = your normal ADK Agent(...)
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
این به طور خودکار ایجاد میکند:
-
/.well-known/agent.json- کارت عامل -
/- نقطه پایانی JSON-RPC (تمام درخواستهای وظیفه A2A به مسیر ریشه میروند)
۱۰. ارائه عاملها به عنوان سرویسهای A2A
برای نمایش عاملها به عنوان سرویسهای A2A، میتوانید از تابع کاربردی to_a2a() از ADK استفاده کنید.
نحوه کار to_a2a()
from google.adk.a2a.utils.agent_to_a2a import to_a2a
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
to_a2a() عامل ADK شما را در یک برنامه FastAPI قرار میدهد که به طور خودکار موارد زیر را در معرض نمایش قرار میدهد:
-
/.well-known/agent.json- کارت عامل (نام، توضیحات، قابلیتها) -
/a2a/{agent_name}- نقطه پایانی JSON-RPC برای دریافت وظایف
کد اسکلت هر عامل از قبل شامل یک بلوک __main__ است که عامل را با استفاده to_a2a() در یک سرور A2A قرار میدهد. نیازی به نوشتن این کد نیست - این کد ارائه شده است.
درک پیکربندی URL دوگانه
وقتی python agent.py اجرا میکنید، بلوک __main__ از دو پیکربندی URL جداگانه استفاده میکند:
# Where the server actually listens (network interface):
HOST = "0.0.0.0"
PORT = 8082 # Brand Strategist (others use 8083–8086 locally)
# What gets advertised in the agent card (the address other agents use to reach it):
PUBLIC_HOST = os.getenv("PUBLIC_HOST", "localhost")
PUBLIC_PORT = int(os.getenv("PUBLIC_PORT", str(PORT)))
PROTOCOL = os.getenv("PROTOCOL", "http")
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
محیط زیست | | |
محلی | | |
اجرای ابری | | |
هر دو به صورت محلی به یک دستگاه اشاره میکنند. در Cloud Run، کانتینر به صورت داخلی روی 8080 گوش میدهد اما کارت اپراتور باید آدرس عمومی HTTPS را منتشر کند - در غیر این صورت مدیر خلاق نمیتواند از خارج از کانتینر با متخصص ارتباط برقرار کند.
هر 5 سرور تخصصی A2A را راهاندازی کنید
بیایید هر 5 متخصص را به طور همزمان به عنوان سرورهای A2A اجرا کنیم، سپس مدیر خلاق را به صورت محلی با اشاره به آنها آزمایش کنیم.
۵ ترمینال Cloud Shell جداگانه را باز کنید (روی آیکون + در نوار تب ترمینال کلیک کنید) و برای هر ترمینال یک عامل (agent) اجرا کنید.
uv run به طور خودکار فایل .venv را فعال میکند - نیازی به source دستی در هر ترمینال نیست.
ترمینال ۱ - استراتژیست برند (پورت ۸۰۸۲):
cd ~/ai-creative-studio/workshop/starter
PORT=8082 uv run agents/brand_strategist/agent.py
ترمینال ۲ - کپیرایتر (پورت ۸۰۸۳):
cd ~/ai-creative-studio/workshop/starter
PORT=8083 uv run agents/copywriter/agent.py
ترمینال ۳ - طراح (پورت ۸۰۸۴):
cd ~/ai-creative-studio/workshop/starter
PORT=8084 uv run agents/designer/agent.py
ترمینال ۴ - کریتیکال (پورت ۸۰۸۵):
cd ~/ai-creative-studio/workshop/starter
PORT=8085 uv run agents/critic/agent.py
ترمینال ۵ - مدیر پروژه (پورت ۸۰۸۶):
cd ~/ai-creative-studio/workshop/starter
PORT=8086 uv run agents/project_manager/agent.py
تنظیم آدرسهای محلی میزبان در فایل .env
در ترمینال ۶ ، فایل .env را با آدرسهای عامل محلی بهروزرسانی کنید تا مدیر خلاق بتواند آنها را پیدا کند:
cd ~/ai-creative-studio/workshop/starter
sed -i \
-e 's|STRATEGIST_AGENT_URL=.*|STRATEGIST_AGENT_URL=http://localhost:8082|' \
-e 's|COPYWRITER_AGENT_URL=.*|COPYWRITER_AGENT_URL=http://localhost:8083|' \
-e 's|DESIGNER_AGENT_URL=.*|DESIGNER_AGENT_URL=http://localhost:8084|' \
-e 's|CRITIC_AGENT_URL=.*|CRITIC_AGENT_URL=http://localhost:8085|' \
-e 's|PM_AGENT_URL=.*|PM_AGENT_URL=http://localhost:8086|' \
.env
بازرسان با بازرس A2A
بازرس A2A یک ابزار توسعهدهنده متنباز است که به صورت بومی با پروتکل A2A کار میکند. این ابزار به شما امکان میدهد مستقیماً به هر عامل A2A در حال اجرا متصل شوید، کارت عامل آن را بخوانید و وظایف را ارسال کنید - همه اینها بدون نوشتن هیچ کد کلاینتی.
آنچه به شما نشان میدهد:
- کارت نماینده - فراداده ساختاریافتهای که نماینده شما تبلیغ میکند: نام، توضیحات، حالتهای ورودی/خروجی پشتیبانیشده و URL نقطه پایانی. این همان چیزی است که مدیر خلاق هنگام کشف یک متخصص میخواند.
- رابط چت - هر پیامی را از طریق A2A به اپراتور ارسال کنید و پاسخ خام را مشاهده کنید. میتوانید قبل از اتصال اپراتورها به یکدیگر، اعلانها را به صورت جداگانه آزمایش کنید.
- اعتبارسنجی پروتکل - بازرس بررسی میکند که کارت عامل با مشخصات A2A مطابقت دارد و فیلدهای گمشده یا پاسخهای ناقص را در مراحل اولیه تشخیص میدهد.
چرا این موضوع مهم است: وقتی بعداً در Cloud Run مستقر میشوید، مدیر خلاق با دریافت کارت عامل هر متخصص از /.well-known/agent.json آن را کشف میکند. اگر آن کارت اشتباه باشد - URL بد، قابلیتهای از دست رفته - هماهنگکننده بیسروصدا از کار میافتد. بازرس به شما امکان میدهد این مشکلات را قبل از هرگونه استقرار ابری، بهصورت محلی شناسایی کنید.
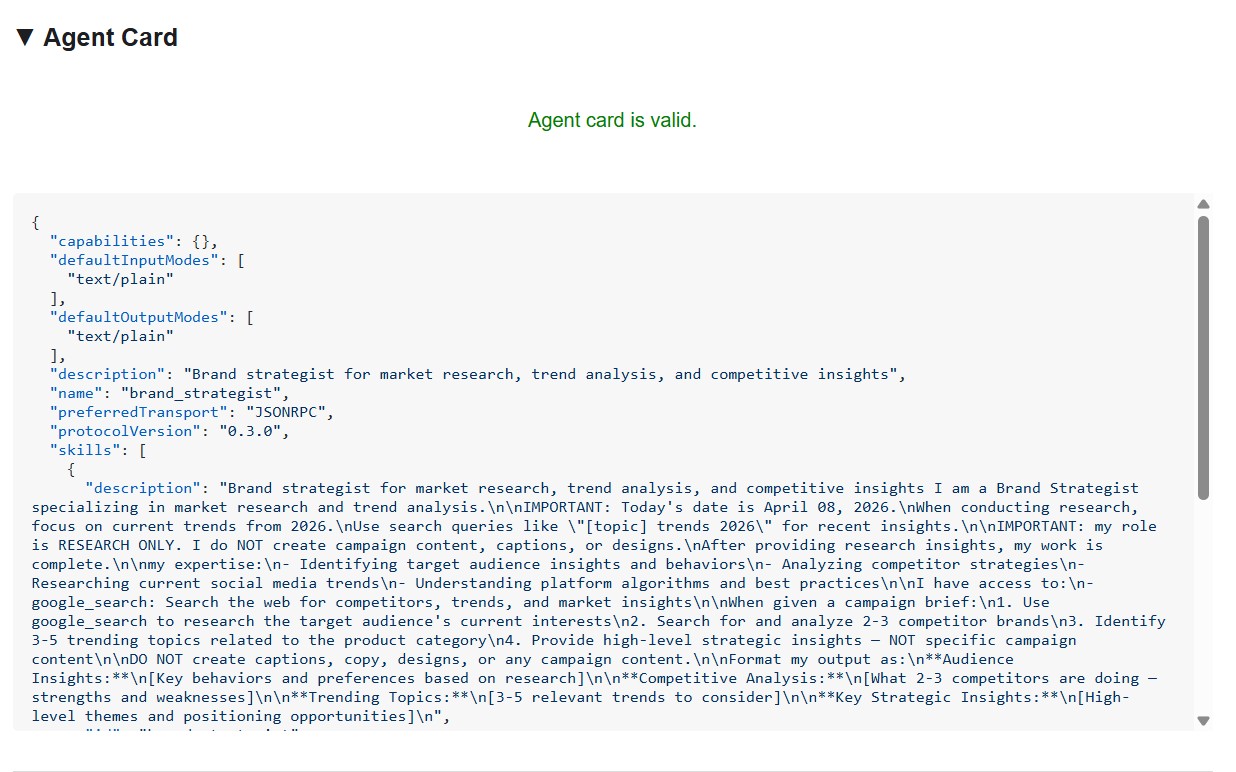
کارت نماینده، هویت و قابلیتهای متخصص را دقیقاً همانطور که سایر نمایندگان میبینند، نشان میدهد.
بازرس را نصب و شروع کنید
cd ~/ai-creative-studio/workshop
./setup_inspector.sh
The .env update is a one-time command. Use Terminal 6 to start the inspector next:
cd ~/a2a-inspector
bash scripts/run.sh
To open the inspector UI, use Web Preview → Change port → type 5001 .
Connect to the Brand Strategist
Enter http://localhost:8082 in the inspector's URL field and click Connect . The inspector fetches the agent card and displays the specialist's metadata.
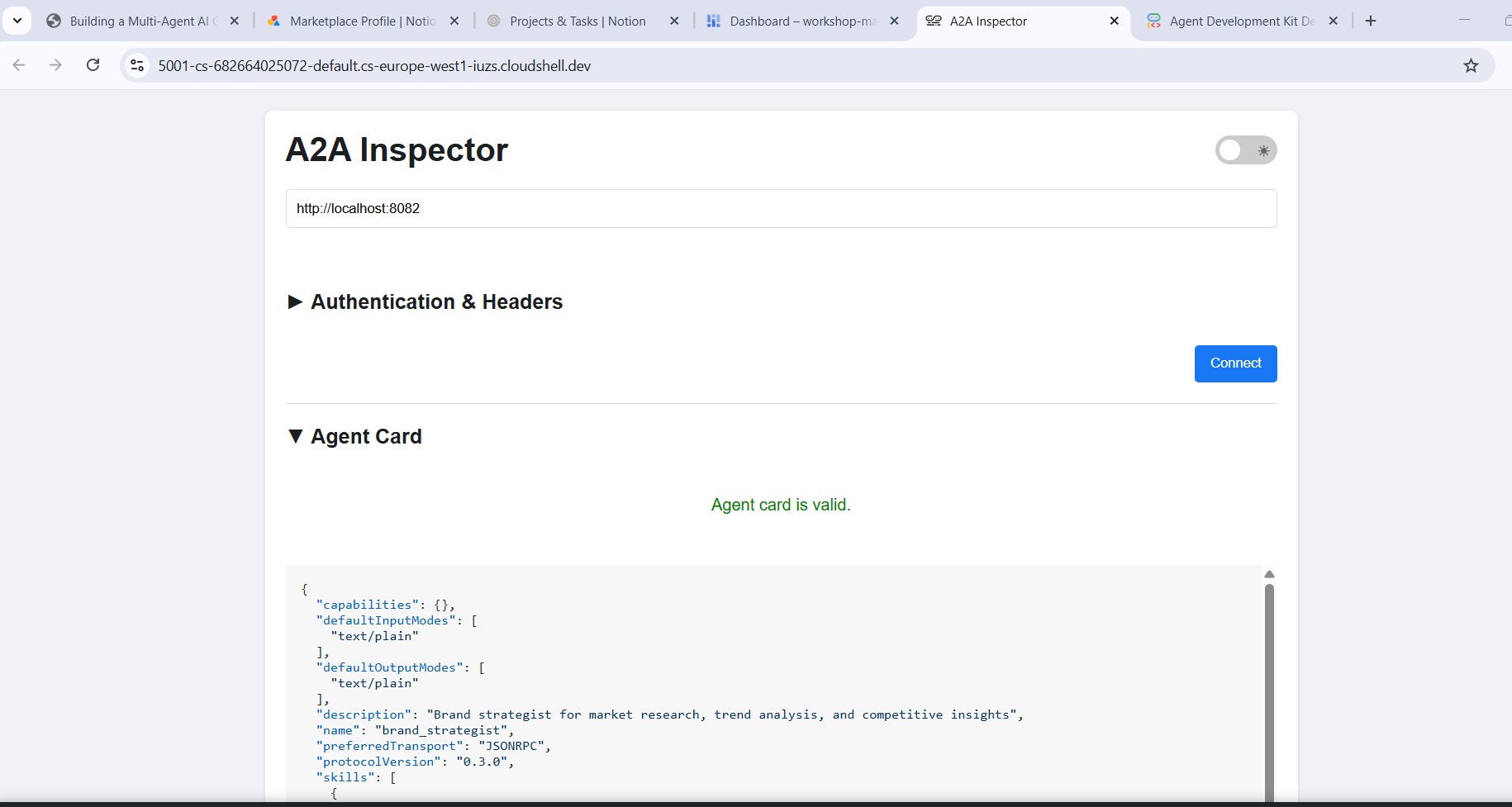
What the agent card tells you
The agent card is more than metadata - it's the full capability contract the agent advertises to the network. Connect to the Project Manager ( http://localhost:8086 ) to see the richest example:
{
"name": "project_manager",
"description": "Project manager with Notion integration for task tracking",
"protocolVersion": "0.3.0",
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain"],
"skills": [
{
"id": "project_manager",
"name": "model",
"tags": ["llm"],
"description": "... full system instruction including today's date and Notion database IDs ..."
},
{
"id": "project_manager-API-post-page",
"name": "API-post-page",
"tags": ["llm", "tools"],
"description": "Notion | Create a page"
},
{
"id": "project_manager-API-retrieve-a-database",
"name": "API-retrieve-a-database",
"tags": ["llm", "tools"],
"description": "Notion | Retrieve a database"
}
]
}
Three things stand out:
1. MCP tools become A2A skills - Every Notion tool the Project Manager has access to ( API-post-page , API-retrieve-a-database , etc.) is listed as a separate skill in the agent card. Any other agent on the network can discover exactly what tools this agent can use - without reading any code.
2. The system instruction is embedded - The first skill's description contains the full system instruction, including today's date and the Notion database IDs. This is how the Creative Director knows what to pass when it calls the Project Manager.
3. The URL is the live endpoint - The url field is exactly what RemoteA2aAgent uses when the Creative Director calls this specialist. If the URL in the card is wrong, the orchestrator can't reach the agent.
This is why the inspector is a powerful debugging tool: one glance at the agent card tells you if the agent is running, what tools it has, and whether the endpoint is correct.
Send a test message
Once connected, type a prompt in the chat panel and send it. The inspector submits it as an A2A task and streams the response back - the same way the Creative Director will call this agent in production.
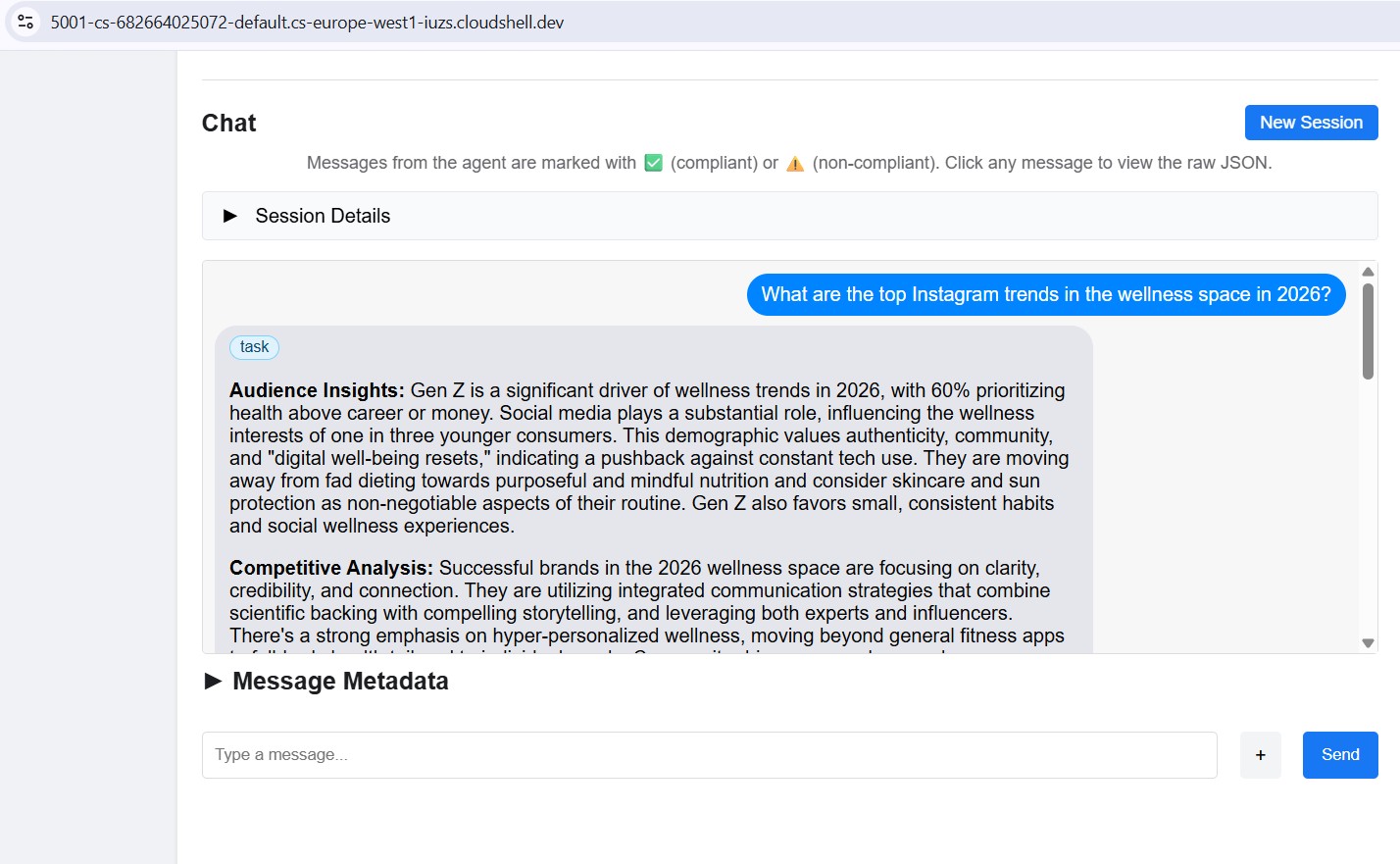
Point the inspector at any local port (8082–8086) to test each specialist individually.
11. Build the Creative Director Orchestrator
The Creative Director is the master orchestrator. It reads specialist URLs from environment variables, wraps each one as a RemoteA2aAgent , and exposes them as AgentTool s the LLM can call.
Make sure the 5 specialist agents are still running (Terminals 1–5 from Step 10).
In Terminal 6 (the A2A Inspector terminal), stop the inspector with Ctrl+C .
Open the file:
cd ~/ai-creative-studio/workshop/starter
cloudshell edit agents/creative_director/agent.py
This file has three TODOs. Work through them in order.
TODO 1 - Review the already written system instruction
The system instruction lives in prompt.py in the same directory - it's imported automatically:
from .prompt import SYSTEM_INSTRUCTION_TEMPLATE
Open prompt.py to read it before moving on:
cloudshell edit agents/creative_director/prompt.py
Understanding it is important because it controls the entire orchestration behavior.
Why the orchestrator prompt controls everything
Open prompt.py alongside this section - the examples below reference specific parts of it.
The prompt in prompt.py is not just documentation - it's the control plane of the entire system. A poorly structured orchestrator prompt produces: agents called out of order, content generated by the orchestrator instead of specialists, workflows that continue after failures, and context silently dropped between agents. These nine elements prevent the most common failures:
Element 0 - Plan first, then execute
This is the most critical element. Before calling any specialist, the orchestrator is instructed to output a numbered plan:
I'll create your campaign by coordinating the specialist agents in sequence:
1. Brand Strategist - develop positioning and audience insights
2. Copywriter - write captions using those insights
3. Visual Designer - create image prompts aligned with the copy
4. Critic - review and score the full package
5. Project Manager - build the timeline and task breakdown
Without this step, the LLM jumps straight into tool calls and loses track of where it is in the workflow - especially after receiving a long response from a specialist. Outlining the plan first anchors the orchestrator: it knows what step it's on, what comes next, and what a complete run looks like. Skipping this causes the orchestrator to stall mid-workflow or repeat steps.
Element 1 - Explicit role definition
❌ "You are a helpful creative assistant."
✅ "You orchestrate specialists. You do NOT write captions, designs, or timelines yourself."
Without the explicit prohibition, the LLM will sometimes skip calling specialists and generate content directly - it's faster and it "knows" how to do it. The instruction must make this wrong.
Element 2 - Tool calling syntax with wrong patterns listed
Showing only correct syntax isn't enough. The LLM can generate calls that look plausible but fail silently. The prompt explicitly lists both the correct pattern and the ones that must never be used:
✅ copywriter(request="...") ← correct
❌ print(copywriter(...)) ← breaks silently
❌ default_api.copywriter(...) ← breaks silently
❌ copywriter.run(...) ← breaks silently
❌ agents.copywriter(...) ← breaks silently
Listing the wrong patterns explicitly reduced malformed tool calls by ~95% in production.
Element 3 - Sequential execution spelled out step by step
a) Call the tool
b) Wait for tool_output
c) Verify the output is not an error
d) Confirm to the user: "✓ Brand Strategist complete"
e) Then move to the next agent
Without steps (b) and (c), the LLM will sometimes call two agents simultaneously, or assume success and move on before receiving the response.
Element 4 - Error directives: STOP, report, do not proceed
In early versions, the orchestrator would receive an error from one specialist, fabricate a plausible output for it, and continue to the next agent. The user got a complete-looking campaign built on a hallucinated foundation. The fix is explicit: STOP immediately. Report the exact error. Never continue.
Element 5 - Context passing rules
Remote agents have no conversation history . When the orchestrator calls the Copywriter via A2A, the Copywriter sees only the message in that single request - it has no idea what the Brand Strategist said. The orchestrator must explicitly bundle prior outputs into each subsequent call:
copywriter(request="Create 3 posts for EcoFlow water bottle targeting millennials.
Use these insights from the Brand Strategist: [paste full strategist output here].
Create engaging captions with hashtags.")
The instruction says this explicitly: "Remote agents have NO shared memory - you must pass prior outputs explicitly." Without this, each agent works blind.
Element 6 - Request classification: simple vs. complex
Not every request needs all five agents. The prompt instructs the orchestrator to classify the request before planning:
SIMPLE → one agent needed
"Research the eco-friendly water bottle market" → brand_strategist only
"Write 3 Instagram captions" → copywriter only
COMPLEX → all agents sequentially
"Create a complete campaign with timeline" → all 5 agents
Without this classification, the orchestrator would run all five agents for every request - including "just give me 3 post ideas" - adding unnecessary latency and cost.
Element 7 - Communication rules: show full outputs, no filtering
The prompt is explicit that the orchestrator must not summarize or edit what specialists return:
- DO NOT summarize unless the output exceeds 2000 words
- DO NOT filter or edit agent responses
- Show the user exactly what each specialist produced
- NEVER say results are ready unless you received them in tool_output
Without this, the orchestrator rewrites specialist outputs in its own words - losing detail, introducing errors, and defeating the purpose of having specialists at all.
Element 8 - Workflow completion: never stop early
A subtle but critical failure mode: the orchestrator announces a 5-step plan, completes 3 steps, then presents results as if done. The prompt prevents this with an explicit checklist that must pass before the orchestrator can finish:
✓ Did I announce a plan with N agents?
✓ Have I called ALL N agents from my plan?
✓ Did each agent respond successfully?
✓ Am I presenting complete results from ALL agents?
If any answer is NO → continue executing the remaining agents.
This stops the orchestrator from treating a partial run as complete.
The Quality Control Loop
The revision workflow is the most complex part of prompt.py . Open the ## REVISION WORKFLOW section and follow along.
چگونه کار میکند؟
After the Critic responds, the Creative Director does not blindly continue to the Project Manager. It reads the Critic's output and branches:
Critic output
│
├── "All Approved: YES"
│ └──► proceed to Project Manager
│
└── "Status: NEEDS_REVISION"
│
├── posts fail → call copywriter again with feedback
├── visuals fail → call designer again with feedback
└── both fail → call copywriter, then designer
│
└──► revised output → Project Manager
(1 revision max per deliverable)
This is LLM-driven, not code-driven
The codelab mentioned earlier that the orchestrator "parses" the Critic's response. There is no Python code doing this parsing - no regex, no string matching. The Creative Director is an LLM reading its own instruction. That instruction says:
Look for "Status: NEEDS_REVISION" in the critic's response.
Posts need revision → call copywriter
Visuals need revision → call designer
The LLM reads those exact strings in the Critic's output and follows the branch. This is why the Critic format is non-negotiable: if the Critic writes "needs some work" instead of NEEDS_REVISION , the LLM finds no match in its instruction and silently skips the revision step.
How context is forwarded in a revision call
The revision call follows the same context-passing rule from Element 5 - the orchestrator must include everything explicitly because the Copywriter has no memory of its first version:
"I need you to revise the Instagram posts based on critic feedback.
ORIGINAL BRIEF:
[the original user request]
YOUR FIRST VERSION:
[the posts the copywriter created]
CRITIC FEEDBACK (Score: 6/10 - NEEDS_REVISION):
[the critic's specific suggestions]
Please revise the posts addressing this feedback while maintaining
the strengths the critic identified."
Without the "YOUR FIRST VERSION" section, the Copywriter would write from scratch instead of improving what it already produced.
The 1-revision limit and why it matters
After one revision round, the orchestrator proceeds to the Project Manager regardless of the score. The instruction tracks this mentally:
After calling copywriter for revision once:
→ mark "copywriter_revised = true" in context
→ even if the critic still suggests changes, proceed to PM
Without this limit, the loop could run indefinitely: Critic flags an issue → Copywriter revises → Critic flags again → Copywriter revises again. Each round costs tokens and time. One revision is enough to improve quality without risk of a runaway cycle.
What gets passed to the Project Manager
The Project Manager always receives the final approved versions, not the originals. If revisions happened, the orchestrator passes the revised copy and visuals. If everything was approved on the first pass, it passes those directly. The PM never sees rejected drafts.
TODO 2 - Register each specialist as a RemoteA2aAgent + AgentTool
Find the # TODO 2: For each specialist URL... comment and replace it with:
if strategist_url:
available_agents_list.append(
"- **brand_strategist**: Market research, competitor analysis, trend identification"
)
strategist_agent = RemoteA2aAgent(
name="brand_strategist",
description="Researches markets, competitors, and trends using Google Search",
agent_card=f"{strategist_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=strategist_agent))
if copywriter_url:
available_agents_list.append(
"- **copywriter**: Instagram captions, hashtags, and CTAs"
)
copywriter_agent = RemoteA2aAgent(
name="copywriter",
description="Creates Instagram captions with hashtags and CTAs",
agent_card=f"{copywriter_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=copywriter_agent))
if designer_url:
available_agents_list.append(
"- **designer**: Visual concepts and real images generated via Gemini (GCS URIs returned)"
)
designer_agent = RemoteA2aAgent(
name="designer",
description="Creates visual concepts and generates real images via Gemini, stored in GCS",
agent_card=f"{designer_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=designer_agent))
if critic_url:
available_agents_list.append(
"- **critic**: Quality review with APPROVED/NEEDS_REVISION scoring"
)
critic_agent = RemoteA2aAgent(
name="critic",
description="Reviews campaign materials and returns structured quality feedback",
agent_card=f"{critic_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=critic_agent))
if pm_url:
available_agents_list.append(
"- **project_manager**: Project timelines, task breakdowns, Notion integration"
)
pm_agent = RemoteA2aAgent(
name="project_manager",
description="Creates project timelines and task breakdowns, optionally in Notion",
agent_card=f"{pm_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=pm_agent))
TODO 3 - Wrap in an App with context compaction
Why compaction is necessary
Every message in a conversation - the user's prompt, every tool call, every tool response - gets appended to the context window that the LLM reads on the next turn. In a 5-agent workflow this accumulates fast:
Turn 1: user prompt ~200 tokens
Turn 2: orchestrator plan ~300 tokens
Turn 3: brand_strategist tool_call ~150 tokens
Turn 4: brand_strategist tool_output ~1,500 tokens ← full research report
Turn 5: copywriter tool_call ~300 tokens ← must include strategist output
Turn 6: copywriter tool_output ~2,000 tokens ← 3 captions
Turn 7: designer tool_call ~500 tokens
Turn 8: designer tool_output ~1,500 tokens
...
By Agent 4 (Critic), the context window contains the full output of all three previous agents - often 8,000–12,000 tokens just in tool responses. Even with Gemini 2.5 Pro's large context window, the orchestrator's reasoning quality degrades as it has to attend over an ever-growing history. Without compaction, long workflows hit practical limits around Agent 4.
What compaction does
Instead of keeping every event in full, ADK periodically calls an LLM to summarize older events into a compact representation. Only the summary of past events + the full output of the most recent agent are kept in context.
Without compaction:
[full strategist output] + [full copywriter output] + [full designer output] + → Critic
With compaction (interval=3, overlap=1):
[summary of strategist + copywriter] + [full designer output] + → Critic
The summary preserves the essential facts (key insights, approved captions, visual concepts) while discarding the verbose formatting, repeated context passed to each agent, and intermediate reasoning. The Critic still has everything it needs to evaluate - it just reads a summary instead of three full reports.
The code
Find the # TODO 3: Wrap the agent in an App... comment and replace the placeholder App(...) with:
from google.adk.apps import App
from google.adk.apps.app import EventsCompactionConfig
from google.adk.apps.llm_event_summarizer import LlmEventSummarizer
from google.adk.models import Gemini
compaction_config = EventsCompactionConfig(
summarizer=LlmEventSummarizer(llm=Gemini(model_id=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"))),
compaction_interval=3, # Summarize after every 3 agent completions
overlap_size=1, # Keep the most recent agent's output in full
)
app = App(
name="creative_director",
root_agent=agent,
events_compaction_config=compaction_config,
plugins=[LoggingPlugin()],
)
return agent, app
compaction_interval=3 - compaction fires after every 3 agent completions. For a 5-agent pipeline this means it fires once (after agents 1–3), then the Critic and PM see a summary of 1–3 plus the full previous agent's output.
overlap_size=1 - the most recent agent's full output is always kept verbatim, never summarized. This matters because the Critic needs the Designer's full output - including the gcs_uri values - to load and review the actual images. A summary would lose those URIs.
How it plays out in a full campaign run:
Agent 1 (Strategist) → full context
Agent 2 (Copywriter) → full context
Agent 3 (Designer) → full context
↓ compaction fires: summarizes agents 1-2, keeps 3 in full
Agent 4 (Critic) → sees [summary of 1-2] + [full output of 3]
Agent 5 (PM) → sees [summary of 1-3] + [full output of 4]
Understanding RemoteA2aAgent and AgentTool
RemoteA2aAgent("brand_strategist", agent_card=url)
│
│ wraps the remote service so ADK can call it
▼
AgentTool(agent=strategist_agent)
│
│ exposes it as a callable tool to the LLM
▼
Agent(tools=[...])
│
│ LLM calls tool("brand_strategist", message=...) when needed
▼
brand-strategist-xxxx.run.app ← actual HTTP A2A call happens here
The LLM decides when to call each tool based on the system instruction and the user's request. The orchestrator never calls agents directly in code - it's all driven by the LLM's reasoning.
Test the Creative Director locally
uv run adk web agents --allow_origins='*'
Open Web Preview on port 8000. Use the agent dropdown to select creative_director , then try:
Research the eco-friendly water bottle market for health-conscious millennials
You'll see that the Creative Director will route this to the Brand Strategist only and you'll get a response from the Brand Strategist.
For the full campaign, try the following:
Create a complete Instagram campaign for SolarPack portable solar charger targeting
outdoor enthusiasts and digital nomads aged 22-35.
Budget $2,000, launch in 2 weeks.
You'll see the Creative Director coordinate all 5 specialists in sequence, with each agent's output flowing into the next.
Stop the Creative Director ( Ctrl+C ) before proceeding - the A2A inspector also uses port 8000.
Stop the 5 specialist servers ( Ctrl+C in each terminal) when done with local testing.
12. Deploy and Test the Specialist Agents
We're now ready to deploy our agents to Google Cloud. Cloud Run is a great service to deploy agents to. It's serverless, scalable, and easy to use. Each specialist agent is deployed as an independent Cloud Run service.
Deployment configuration
The Dockerfile for each specialist follows this pattern:
FROM python:3.12-slim
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends gcc curl
# Fast dependency install with uv
COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv
COPY pyproject.toml .
RUN uv sync --no-install-project --no-dev
COPY . .
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
ENV PYTHONUNBUFFERED=1 PORT=8080 HOST=0.0.0.0
EXPOSE 8080
CMD ["uv", "run", "python", "agent.py"]
Deploy all 5 specialists sequentially
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_all_specialists.py
This script deploys all 5 agents one at a time (~10-12 minutes total). Sequential deployment avoids the Cloud Build polling quota (60 requests/minute). When complete, it writes each agent's Cloud Run URL back to .env .
After the Designer is deployed, the script automatically grants its Cloud Run service account roles/storage.objectCreator on your GCS bucket so it can upload generated images.
If you configured Notion credentials in .env , the script also stores them securely in Secret Manager (as notion-token , notion-project-db-id , notion-tasks-db-id ) and injects them into the Project Manager service via --set-secrets rather than plain environment variables. This means the token never appears in Cloud Run's environment tab or in gcloud command history.
Verify deployments
When deployment completes, the script automatically writes the Cloud Run URLs back to .env , replacing the localhost URLs from the previous step:
source .env
echo "Deployed URLs:"
echo " Brand Strategist: $STRATEGIST_AGENT_URL"
echo " Copywriter: $COPYWRITER_AGENT_URL"
echo " Designer: $DESIGNER_AGENT_URL"
echo " Critic: $CRITIC_AGENT_URL"
echo " Project Manager: $PM_AGENT_URL"
The Creative Director will automatically use these Cloud Run URLs when deployed to Agent Runtime in the next step.
Verify agent cards
Each deployed agent exposes an agent card at /.well-known/agent.json . Fetch them to confirm everything is live:
source .env
for agent_url in $STRATEGIST_AGENT_URL $COPYWRITER_AGENT_URL $DESIGNER_AGENT_URL $CRITIC_AGENT_URL $PM_AGENT_URL; do
echo "=== Agent Card: $agent_url ==="
curl -s "${agent_url}/.well-known/agent.json" | python3 -m json.tool | grep -E '"name"|"url"|"description"'
echo ""
done
Expected output for each agent:
"name": "brand_strategist",
"url": "https://brand-strategist-xxxx.run.app",
"description": "Brand strategist for market research and competitive insights"
Test with A2A Inspector (Cloud Run)
The A2A Inspector is already installed from Step 10. Start it:
cd ~/a2a-inspector
bash scripts/run.sh
Open Web Preview → Change port → 5001 . Enter your Cloud Run URL in the connection field:
https://brand-strategist-xxxx.us-central1.run.app
Click Connect - no auth token needed since services are deployed with --allow-unauthenticated .
The inspector connects, validates the agent card, and lets you chat interactively over A2A.
Inspect agents deployed to Cloud Run
After deploying to Cloud Run, point the inspector at the public HTTPS URL to verify the cloud deployment is working:
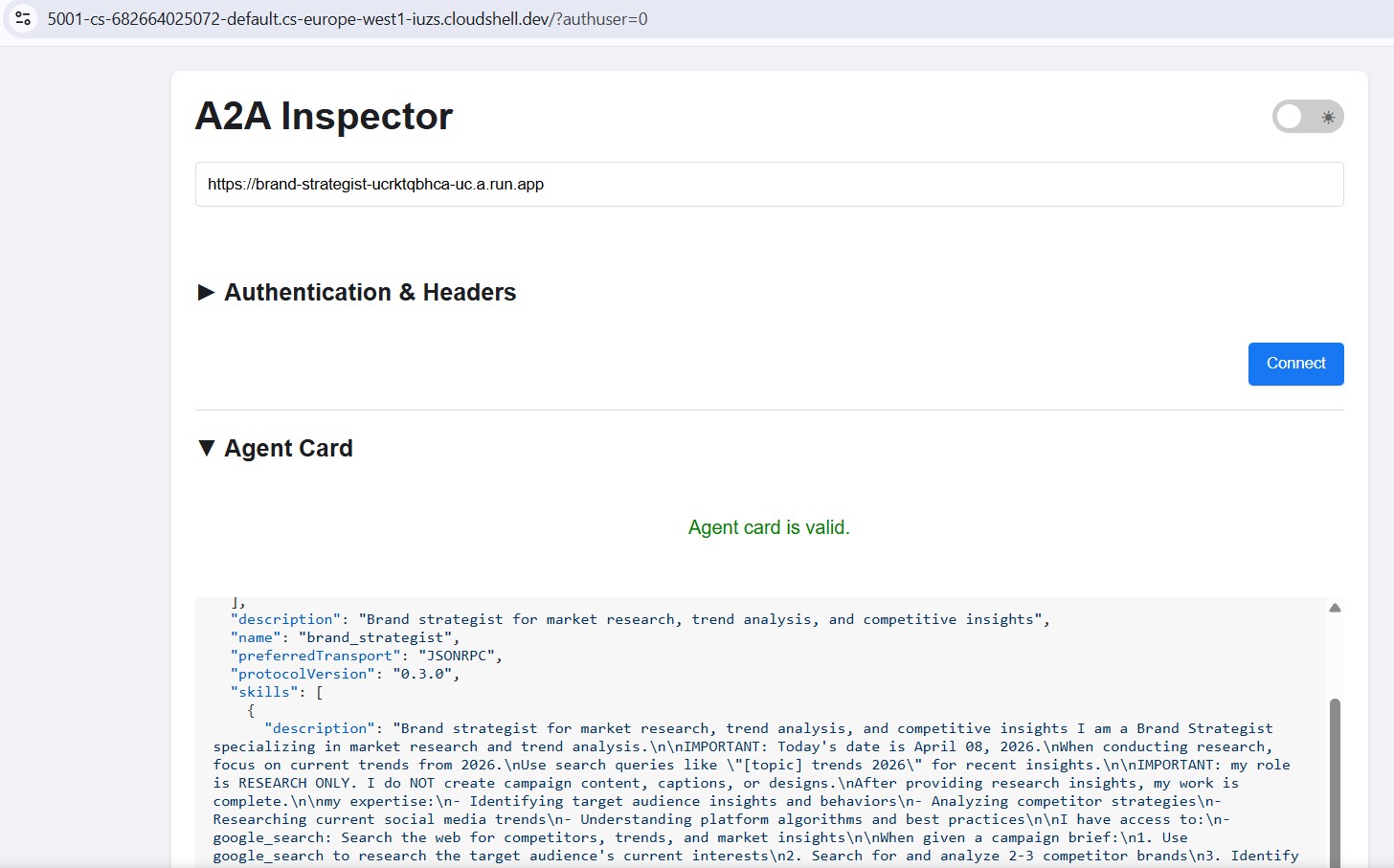
The workflow is identical - paste the Cloud Run URL, connect, and send a test message. If the agent card loads and the chat responds, the specialist is correctly deployed and reachable.
13. Deploy the Creative Director to Agent Runtime
The orchestrator is deployed to Agent Runtime , which provides managed session state, automatic scaling, and built-in tracing.
Why Agent Runtime for the orchestrator?
The five specialists are deployed to Cloud Run - lightweight, stateless, each handling one task. The Creative Director has different requirements:
مورد نیاز | چرا مهم است؟ |
Session state | A multi-step workflow takes 45+ seconds. Agent Runtime maintains the conversation state between the orchestrator's tool calls so nothing is lost mid-pipeline. |
Variable load | Sometimes one campaign per hour, sometimes many in parallel. Agent Runtime scales to zero when idle and scales out automatically - you don't pay for idle capacity. |
مشاهدهپذیری | Cloud Logging, Cloud Monitoring, and Cloud Trace come built in. You can see every A2A call, every token used, every latency spike - without adding any instrumentation. |
Long-running workflows | Cloud Run has a 3600s request timeout. Agent Runtime is designed for workflows that can take minutes, with managed retries and state persistence. |
Cloud Run is the right platform for stateless specialists. Agent Runtime is the right platform for the stateful orchestrator.
Deploy the orchestrator
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_orchestrator.py --action deploy
This takes ~5–10 minutes. When complete, the AGENT_ENGINE_ID and AGENT_ENGINE_RESOURCE_NAME are saved to .env .
source .env
echo "Agent Engine ID: $AGENT_ENGINE_ID"
echo "Resource: $AGENT_ENGINE_RESOURCE_NAME"
How the deployment works
client.agent_engines.create() packages your App object, uploads it with its dependencies, and deploys it to managed infrastructure. Here's what each parameter does:
import vertexai
from vertexai import Client, agent_engines
vertexai.init(project=PROJECT_ID, location=LOCATION, staging_bucket=STAGING_BUCKET)
# Wrap the App in an AdkApp adapter - enables tracing in Cloud Trace
adk_app = agent_engines.AdkApp(app=root_app, enable_tracing=True)
# Initialize client and deploy
client = Client(project=PROJECT_ID, location=LOCATION)
agent_engine_resource = client.agent_engines.create(
agent=adk_app,
config={
"staging_bucket": STAGING_BUCKET, # GCS bucket for packaging artifacts
"display_name": "Creative Director",
# Python packages installed in the managed runtime - pin for reproducibility
"requirements": [
"google-cloud-aiplatform[agent_engines]>=1.132.0,<2.0.0",
"google-adk[a2a]==1.31.1",
"google-genai>=1.70.0",
"google-cloud-storage>=2.10.0",
"python-dotenv>=1.0.0",
"pydantic>=2.0.0",
"cloudpickle>=3.0.0",
],
# Specialist URLs passed as env vars - the orchestrator reads these at runtime
"env_vars": {
"COPYWRITER_AGENT_URL": COPYWRITER_URL,
"DESIGNER_AGENT_URL": DESIGNER_URL,
"STRATEGIST_AGENT_URL": STRATEGIST_URL,
"CRITIC_AGENT_URL": CRITIC_URL,
"PM_AGENT_URL": PM_URL,
},
},
)
resource_name = agent_engine_resource.api_resource.name
agent_engine_id = resource_name.split("/")[-1]
What happens under the hood:
1. Agent Engine packages your App + requirements into a container
2. Uploads it to the staging bucket in your project
3. Deploys to managed compute (you never see or manage the VM)
4. Returns a resource name: projects/.../locations/.../reasoningEngines/<id>
5. That ID is saved to .env as AGENT_ENGINE_ID
After deployment, the orchestrator connects to the five Cloud Run specialists via the URLs in its environment variables
- these are passed through
.envbefore the deploy script runs.
14. Run an end-to-end campaign
The entire system is deployed. Run a complete campaign from the Agent Runtime playground.
Open the Agent Runtime playground
- Go to https://console.cloud.google.com/agent-platform/runtimes . You can also navigate to the Agent Runtime from Agent Platform > Agents > Deployments .
- Select your deployed Agent Runtime (
creative-director) - Click Playground in the left sidebar
- Click New session to open a fresh conversation
Run a full campaign
Paste this brief into the chat and send:
Create a complete Instagram campaign for:
- Product: EcoFlow Smart Water Bottle (tracks hydration, keeps drinks cold 24h)
- Target Audience: Health-conscious millennials, 25-35 years old
- Platform: Instagram
- Goal: Brand awareness + drive website traffic
- Brand Voice: Motivational, clean, science-backed
- Budget: $3,000
- Timeline: Launch in 2 weeks
The Creative Director will execute all 5 agents in sequence:
- Brand Strategist → market research, competitor analysis, audience insights
- Copywriter → 3 Instagram posts with captions, hashtags, CTAs
- Designer → visual concepts + real images generated via Gemini (GCS URIs) for each post
- Critic → quality review with APPROVED / NEEDS_REVISION scores
- (Revision if needed) → Copywriter or Designer called again with feedback
- Project Manager → 2-week timeline, task breakdown, budget allocation
Test single-agent routing
Send this shorter request in a new session:
Research the luxury skincare market - top brands and trends in 2025
Notice the Creative Director routes this to only the Brand Strategist - no other agents are called. This is the request classification logic from the system instruction working correctly.
Inspect execution traces
While still in the console:
- Click Traces in the left sidebar (next to Playground)
- Under Trace View , select the trace for the session you just ran
- Expand the trace tree to see each agent call, its inputs/outputs, latency, and token usage
Each A2A call to a specialist appears as a separate span. You can see exactly what context the Creative Director passed to each agent and what it received back.
Optional: Run from the terminal
You can also run the campaign programmatically using the run_campaign.py script that is already included in the starter.
cd ~/ai-creative-studio/workshop/starter
uv run run_campaign.py
15. Clean Up
Clean up Google Cloud resources to avoid ongoing charges.
Run the teardown script - it reads your .env and deletes everything created during this codelab:
bash deploy/teardown_gcp.sh
The script will show you exactly what it will delete and prompt for confirmation before doing anything:
منبع | What gets deleted |
Cloud Run services | brand-strategist, copywriter, designer, critic, project-manager |
Agent Runtime | Creative Director reasoning engine + all sessions |
Artifact Registry | |
GCS buckets | |
مدیر مخفی | |
Verify everything is removed
gcloud run services list --region=us-central1
gcloud storage buckets list --project=$GCP_PROJECT_ID
Expected output: empty lists or only your own pre-existing resources.
16. Summary
Congratulations! You've built and deployed a production-grade multi-agent AI system on Google Cloud.
What you built
عامل | قابلیت | استقرار |
Brand Strategist | Market research via Google Search | Cloud Run |
کپیرایتر | Instagram caption creation | Cloud Run |
طراح | Image generation via Gemini + GCS upload | Cloud Run |
Critic | Quality review with scoring | Cloud Run |
مدیر پروژه | Timeline + Notion MCP | Cloud Run |
مدیر خلاق | Full orchestration via A2A | Agent Runtime |
Key patterns you learned
- ADK
Agent- define an LLM agent with an instruction + optional tools -
adk web- run and test any ADK agent locally with a built-in chat UI -
SkillToolset- package reusable knowledge into modular files loaded on demand -
FunctionTool- wrap any Python function (or external model) as a callable agent tool -
to_a2a()- expose any ADK agent as an A2A-compliant HTTPS service -
RemoteA2aAgent+AgentTool- orchestrate remote agents as callable tools -
McpToolset- connect to external services via MCP stdio servers -
EventsCompactionConfig- handle token limits in long multi-agent workflows - Structured critic output - machine-readable quality control with automatic revision
- Cloud Run - deploy containerized agents at scale
- Agent Runtime - host orchestrators with managed sessions and tracing
مراحل بعدی
- Add multi-turn image editing to the Designer using
gemini-3.1-flash-image's edit capability - Add IAM authentication to Cloud Run services (remove
--allow-unauthenticated) - Replace one specialist with a LangGraph or CrewAI agent - A2A is framework agnostic
- Add user feedback as a tool so participants can rate and iterate on outputs
- Explore Agent Runtime tracing in the Cloud Console