
1. Présentation
Dans cet atelier de programmation, vous allez créer AI Creative Studio, un système multi-agents distribué qui transforme une simple requête en une campagne Instagram complète.
Tapez une phrase et obtenez des études d'audience, des sous-titres, des concepts visuels, des textes de qualité et un calendrier complet du projet, le tout généré par une équipe d'agents IA collaboratifs.
Les agents que vous allez créer
Agent | Rôle |
Responsable de la stratégie de marque | Recherche sur le Web des insights sur l'audience, des analyses de la concurrence et des tendances pour 2025 |
Copywriter | Rédige des légendes Instagram avec des hashtags et des CTA, grâce à une compétence ADK qui charge les consignes de la plate-forme et les formules de légendes à la demande |
Designer | Crée des concepts visuels et génère des images réelles via Gemini, stockées dans GCS |
Critique | Texte et éléments visuels des avis : renvois |
Chef de projet | Crée une chronologie de projet et une répartition des tâches, éventuellement synchronisées avec Notion via MCP |
Directeur artistique | Orchestre les cinq spécialistes dans l'ordre : vous lui donnez une requête, il coordonne le reste |
Les cinq agents sont déployés en tant que microservices Cloud Run indépendants. Ils communiquent via le protocole A2A, une norme ouverte indépendante de la langue qui permet à n'importe quel agent d'appeler n'importe quel autre agent, quel que soit le framework. Le Creative Director s'exécute sur Agent Runtime et se connecte à chaque spécialiste à distance.
Architecture

Points abordés
- Créez des agents LLM avec Google ADK :
Agent, instructions système et outils intégrés. - Empaquetez les connaissances réutilisables de l'agent dans des fichiers modulaires avec les compétences ADK (
SkillToolset). - Générez des images réelles en associant un agent textuel à un modèle d'image via un
FunctionTool. - Intégrez des API externes sans code de liaison personnalisé à l'aide du protocole MCP (Model Context Protocol).
- Transformez n'importe quel agent en service appelable sur le réseau à l'aide du protocole Agent-to-Agent (A2A) sur HTTPS.
- Orchestrez des agents distribués avec
RemoteA2aAgentetAgentTool. - Empaqueter et déployer des agents indépendants en tant que microservices Cloud Run.
- Hébergez un orchestrateur avec état sur Agent Runtime.
- Utilisez la compression du contexte pour que les longs workflows multi-agents restent dans les limites de contexte.
- Créez une boucle de contrôle qualité : les critiques évaluent le résultat → révision automatique si nécessaire.
Prérequis
- Un projet Google Cloud pour lequel la facturation est activée
- Rôle IAM Propriétaire ou Éditeur
- Connaissances de base en Python
2. Configurer votre environnement
Pour cet atelier de programmation, nous allons utiliser Cloud Shell.
Qu'est-ce que Cloud Shell ?
Cloud Shell est un environnement Linux sans frais basé sur un navigateur, avec tout ce dont vous avez besoin préinstallé : gcloud, git, Python, Docker et plus encore. Vous n'avez rien à installer en local.
Pour ouvrir Cloud Shell, cliquez sur l'icône de terminal dans la barre d'outils en haut à droite de la console GCP :
Lorsque vous ouvrez Cloud Shell pour la première fois, vous êtes invité à valider votre compte. Cliquez sur Valider :
Cliquez ensuite sur Autoriser pour permettre à Cloud Shell d'effectuer des appels d'API Google Cloud :
Cloud Shell est maintenant prêt. Un message de bienvenue s'affiche dans le terminal : 
S'authentifier et configurer votre projet
Cloud Shell est déjà authentifié avec votre compte Google. Confirmez votre compte actif et trouvez votre ID de projet :
gcloud config list
Vous pouvez également voir votre ID de projet dans le tableau de bord de la console GCP, dans le panneau latéral de gauche. Copiez-le, car vous en aurez besoin dans la prochaine commande :
Définissez maintenant votre projet :
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Cloud Run deployment region
echo "Project: $PROJECT_ID"
Résultat attendu :
Project: my-project-123
Activer les API requises
gcloud services enable \
aiplatform.googleapis.com \
apphub.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
generativelanguage.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com \
storage.googleapis.com \
secretmanager.googleapis.com
Cela prend environ deux minutes. L'icône Operation finished successfully s'affiche une fois l'opération terminée.
Configurer les identifiants par défaut de l'application (ADC)
Les agents appelleront la plate-forme Gemini Enterprise Agent à l'aide de la bibliothèque Google Auth, qui nécessite des identifiants par défaut de l'application, distincts de l'authentification gcloud CLI.
Exécutez cette commande une fois :
gcloud auth application-default login
Un onglet de navigateur s'ouvre et vous demande de confirmer. Cliquez sur Autoriser. Cette page vous indique les informations suivantes :
Credentials saved to file: ~/.config/gcloud/application_default_credentials.json
Cloner le dépôt de démarrage
Cet atelier de programmation utilise un dépôt de démarrage, c'est-à-dire un projet squelette avec toute l'infrastructure en place (Dockerfiles, pyproject.toml, scripts de déploiement), mais avec la logique de l'agent à écrire.
git clone https://github.com/Saoussen-CH/mas-a2a-gcp.git ~/ai-creative-studio
cd ~/ai-creative-studio/workshop/starter
Chaque agent.py contient des espaces réservés # TODO dans lesquels vous écrirez la logique de l'agent. Les scripts Dockerfile, pyproject.toml et de déploiement sont déjà complets.
Configurer les variables d'environnement
Copiez l'exemple fourni et injectez votre ID de projet en une seule étape :
cp .env.example .env
sed -i "s|GOOGLE_CLOUD_PROJECT=your-project-id|GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)|" .env
Créez ensuite le bucket GCS dans lequel le Designer stockera les images générées, puis remplacez .env par son nom :
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-campaign-images"
gcloud storage buckets create gs://${BUCKET_NAME} \
--location=us-central1 \
--project=${PROJECT_ID}
sed -i "s|GCS_IMAGES_BUCKET=your-project-id-campaign-images|GCS_IMAGES_BUCKET=${BUCKET_NAME}|" .env
Ensuite, configurez la compatibilité avec les URL d'image signées. Le directeur de la création génère des liens HTTPS cliquables pour chaque image dans le récapitulatif final de la campagne. Pour cela, un compte de service est nécessaire pour signer les URL. Exécutez les commandes suivantes pour le configurer :
export PROJECT_NUMBER=$(gcloud projects describe $(gcloud config get-value project) --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
export AGENT_RUNTIME_SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Allow your user account to sign URLs locally (adk web)
gcloud iam service-accounts add-iam-policy-binding ${SA_EMAIL} \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Allow Agent Runtime to sign URLs when deployed
gcloud projects add-iam-policy-binding $(gcloud config get-value project) \
--member="serviceAccount:${AGENT_RUNTIME_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
# Save SA email and project number to .env
grep -q "^SIGNING_SERVICE_ACCOUNT" .env \
&& sed -i "s|^SIGNING_SERVICE_ACCOUNT=.*|SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}|" .env \
|| echo "SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}" >> .env
grep -q "^GOOGLE_CLOUD_PROJECT_NUMBER" .env \
&& sed -i "s|^GOOGLE_CLOUD_PROJECT_NUMBER=.*|GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}|" .env \
|| echo "GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}" >> .env
Ouvrez .env dans l'éditeur pour examiner tous les paramètres :
cloudshell edit .env
.env s'ouvre sous forme d'onglet dans l'éditeur Cloud Shell. Si le panneau de l'éditeur n'est pas visible, cliquez sur le bouton Ouvrir l'éditeur dans la barre d'outils :

Vérifiez que le projet a été correctement défini :
grep GOOGLE_CLOUD_PROJECT .env
Installer des dépendances
Nous utilisons uv, un gestionnaire de packages Python moderne et rapide qui gère les environnements virtuels et les installe dans un seul outil. Il est environ 10 à 100 fois plus rapide que pip et constitue la méthode recommandée pour gérer les projets Python.
uv est déjà installé dans Cloud Shell. Tous les agents partagent les mêmes dépendances de base. Vous n'avez donc besoin de les installer qu'une seule fois pour qu'elles fonctionnent pour chaque agent de cet atelier de programmation :
uv sync
La commande uv sync lit pyproject.toml et crée un répertoire .venv/ avec toutes les dépendances. Chaque spécialiste dispose également de son propre pyproject.toml, utilisé exclusivement par les compilations Docker. L'installation partagée ci-dessus couvre tout ce dont vous avez besoin pour les tests locaux.
3. Comprendre Google ADK
Avant d'écrire du code, comprenons l'Agent Development Kit (ADK), le framework que vous utiliserez pour créer chaque agent dans cet atelier de programmation.
Qu'est-ce que l'ADK ?
Agent Development Kit (ADK) est un framework flexible et modulaire permettant de développer et de déployer des agents IA. Bien qu'optimisé pour Gemini et l'écosystème Google, ADK est indépendant du modèle et des déploiements, et est conçu pour être compatible avec d'autres frameworks. ADK a été conçu pour rendre le développement d'agents semblable à celui de logiciels. Il permet aux développeurs de créer, de déployer et d'orchestrer plus facilement des architectures agentiques allant de tâches simples à des workflows complexes.
ADK gère les parties complexes (appel d'outils, conversation multitour, gestion du contexte, streaming), ce qui vous permet de vous concentrer sur la logique de l'agent.
Composants de base d'un agent ADK
Chaque agent est composé de quatre éléments de base :
Bloquer | Rôle |
Modèle | LLM qui raisonne sur les objectifs, détermine un plan et génère des réponses |
Outils | Fonctions qui récupèrent des données ou effectuent des actions en appelant des API ou des services |
Orchestration | Maintient la mémoire et l'état au fil des tours, achemine les appels d'outils, renvoie les résultats au modèle |
Runtime (durée d'exécution) | Exécute le système lorsqu'il est appelé, en local via |
Définition de l'agent
Chacun des cinq agents de cet atelier de programmation est défini de la même manière :
from google.adk.agents import Agent
from google.adk.tools.google_search_tool import google_search
root_agent = Agent(
name="brand_strategist", # unique identifier
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"), # the LLM powering this agent
instruction=SYSTEM_INSTRUCTION, # the agent's persona, constraints, and output format
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search], # functions the LLM can call
)
Champ | Objectif |
| ID unique : utilisé par les orchestrateurs pour acheminer les appels |
| Le modèle Gemini qui alimente cet agent |
| Invite système : définit le rôle, les contraintes et le format de sortie de l'agent |
| Résumé d'une ligne : l'orchestrateur le lit pour décider quel spécialiste appeler. |
| Fonctions que le LLM peut appeler (intégrées comme |
Comment ADK exécute un agent
User message
│
▼
Agent (LLM) ← reads instruction + conversation history
│
├─► needs more info? → calls a tool → gets result → continues reasoning
│
└─► done reasoning → returns final text response
Le LLM décide de manière autonome s'il doit appeler un outil, lequel et avec quels arguments. Vous écrivez l'instruction, et l'ADK s'occupe du reste.
4. Créer et tester l'agent Brand Strategist
Commençons par le premier agent : le stratège de marque. Il s'agit d'un agent de recherche uniquement qui permet de rechercher des insights sur l'audience cible, d'analyser la concurrence et de trouver des sujets tendance à l'aide de la recherche Google.
Ouvrez le fichier squelette de l'agent dans l'éditeur Cloud Shell :
cloudshell edit agents/brand_strategist/agent.py
Vous verrez deux sections # TODO à remplir.
À FAIRE 1 : Rédiger l'instruction système
Vous allez d'abord écrire l'instruction système pour l'agent. L'instruction système est une chaîne qui définit le rôle, les contraintes et le format de sortie de l'agent.
SYSTEM_INSTRUCTION = f"""You are a Brand Strategist specializing in market research and trend analysis.
IMPORTANT: Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
When conducting research, focus on current trends from {datetime.date.today().year}.
Use search queries like "[topic] trends {datetime.date.today().year}" for recent insights.
IMPORTANT: Your role is RESEARCH ONLY. You do NOT create campaign content, captions, or designs.
After providing research insights, your work is complete.
Your expertise:
- Identifying target audience insights and behaviors
- Analyzing competitor strategies
- Researching current social media trends
- Understanding platform algorithms and best practices
You have access to:
- google_search: Search the web for competitors, trends, and market insights
When given a campaign brief:
1. Use google_search to research the target audience's current interests
2. Search for and analyze 2-3 competitor brands
3. Identify 3-5 trending topics related to the product category
4. Provide high-level strategic insights - NOT specific campaign content
DO NOT create captions, copy, designs, or any campaign content.
Format your output as:
**Audience Insights:**
[Key behaviors and preferences based on research]
**Competitive Analysis:**
[What 2-3 competitors are doing - strengths and weaknesses]
**Trending Topics:**
[3-5 relevant trends to consider]
**Key Strategic Insights:**
[High-level themes and positioning opportunities]
"""
TODO 2 : Créer le root_agent
Ensuite, remplacez le root_agent incomplet par :
root_agent = Agent(
name="brand_strategist",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
instruction=SYSTEM_INSTRUCTION,
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search],
)
Tester localement avec l'UI Web ADK
Testons maintenant l'agent à l'aide de l'UI Web d'ADK, une interface de chat intégrée permettant de tester les agents avant de les déployer dans le cloud.
uv run adk web agents --allow_origins='*'
Cette page vous indique les informations suivantes :
INFO: Started server process
INFO: Uvicorn running on http://localhost:8000
Le serveur s'exécute désormais dans Cloud Shell :
Pour l'ouvrir dans votre navigateur, utilisez Aperçu sur le Web :
- Consultez la barre d'outils Cloud Shell en haut de la page.
- Cliquez sur l'icône Aperçu sur le Web (qui ressemble à une boîte avec une flèche vers le haut, en haut à droite de la barre d'outils Cloud Shell).
- Cliquez sur Modifier le port, saisissez
8000, puis cliquez sur Modifier et prévisualiser.
Un nouvel onglet de navigateur s'ouvre avec l'UI Web ADK. Cliquez sur le menu déroulant Sélectionner un agent en haut à gauche. Tous vos agents s'affichent :
Sélectionnez brand_strategist pour commencer le test :
Essayer ces requêtes de test
Dans la zone de chat de l'UI Web d'ADK, essayez :
Research the eco-friendly water bottle market for health-conscious millennialsWhat are the top Instagram trends in the wellness space in 2025?
L'agent devrait appeler la recherche Google et renvoyer une recherche structurée avec des sections "Insights sur l'audience", "Analyse de la concurrence" et "Tendances".
5. Créer la compétence Copywriter - ADK
Rôle : transforme les études sur la marque en légendes Instagram. Le rédacteur crée trois variantes de légende avec des tons différents (inspirant, éducatif, communautaire), chacune avec des hashtags et un CTA.
Concept : compétences ADK
Une approche naïve consisterait à intégrer toutes les connaissances sur la plate-forme (limites de caractères, niveaux de hashtags, formules de légendes, exemples de voix de marque) directement dans le prompt système. Cela fonctionne, mais chaque requête est gonflée avec du contenu dont l'agent n'a besoin qu'occasionnellement.
Les compétences ADK (SkillToolset, introduites dans ADK 1.25.0) vous permettent de regrouper ces connaissances dans des fichiers modulaires avec trois niveaux de chargement :
- L1 – Frontmatter (
name+descriptiondansSKILL.md) : toujours disponible, utilisé pour la découverte des compétences - L2 – instructions (corps de
SKILL.md) : chargées lorsque l'agent déclenche la compétence - Ressources de niveau 3 (fichiers
references/etassets/) : chargées uniquement lorsque l'agent les lit explicitement
L'instruction système se réduit à une brève déclaration de rôle plus "charge la compétence avant d'écrire". Les informations sur la plate-forme ne sont incluses dans la fenêtre de contexte que lorsque l'agent en a réellement besoin.
La compétence Copywriter se trouve dans agents/copywriter/skills/instagram-copywriting/ :
skills/
instagram-copywriting/
SKILL.md ← L1 frontmatter (discovery) + L2 instructions (loaded on trigger)
references/
platform-guide.md ← L3: character limits, hashtag tiers, algorithm signals
caption-formulas.md ← L3: hook formulas, CTA patterns, full caption structures
assets/
brand-voice-examples.md ← L3: annotated real-world caption examples
Ouvrez le fichier directement dans l'éditeur Cloud Shell :
cloudshell edit agents/copywriter/agent.py
TODO 1 : importer load_skill_from_dir et skill_toolset
Recherchez le commentaire # TODO 1: Import load_skill_from_dir and skill_toolset et ajoutez les deux importations :
from google.adk.skills import load_skill_from_dir
from google.adk.tools import skill_toolset
TODO 2 - Charger la compétence et créer un SkillToolset
Recherchez les deux commentaires sous les importations :
# TODO 2: Load the instagram-copywriting skill from the skills/ directory
# TODO 2: Create a SkillToolset with the loaded skill
Remplacez-les par :
_instagram_skill = load_skill_from_dir(
pathlib.Path(__file__).parent / "skills" / "instagram-copywriting"
)
_copywriting_skills = skill_toolset.SkillToolset(skills=[_instagram_skill])
load_skill_from_dir lit SKILL.md ainsi que tous les fichiers de references/ et assets/. SkillToolset l'encapsule dans le format accepté par les agents ADK : un ensemble d'outils, et non une compétence brute.
TODO 3 : Enregistrer l'ensemble d'outils auprès de l'agent
Recherchez tools=[], # TODO 3: Add the SkillToolset here et remplacez-le par :
tools=[_copywriting_skills],
Ouvrez le fichier de compétence pour voir comment il est structuré :
cloudshell edit agents/copywriter/skills/instagram-copywriting/SKILL.md
Laissez l'UI Web d'ADK s'exécuter. Utilisez le menu déroulant de l'agent pour passer à copywriter sans redémarrer le serveur.
Si ce n'est pas le cas, redémarrez-le :
uv run adk web agents --allow_origins='*'
À vous de jouer : définissez le menu déroulant sur copywriter et envoyez :
You are writing captions for EcoFlow Smart Water Bottle targeting health-conscious millennials aged 25-35.
Audience insight: they prioritize sustainability, track health metrics, and share lifestyle content.
Competitor insight: Hydro Flask dominates with lifestyle branding; S'well leads on premium aesthetics.
Write 3 Instagram captions - one inspirational, one educational, one community-focused. Include 5 hashtags each and a CTA.
6. Build the Designer - Multimodal Image Generation
Laissez l'UI Web d'ADK s'exécuter. Utilisez le menu déroulant des agents pour changer d'agent sans redémarrer le serveur.
Rôle : crée des concepts visuels pour chaque légende et génère les images à l'aide de la génération d'images native de Gemini. Le concepteur génère exactement un concept visuel par légende (avec une requête détaillée, un style, une palette de couleurs, une ambiance et un format Instagram), puis appelle immédiatement l'outil generate_image pour produire l'image et l'importer dans GCS.
Concept : Associer un agent de texte à un modèle d'image à l'aide d'un outil
Le Designer s'exécute sur gemini-3-flash-preview (le modèle de texte défini via GEMINI_MODEL dans .env), mais la génération d'images nécessite un modèle dédié (gemini-3.1-flash-image). Ce modèle d'image ne prend pas en charge l'appel de fonction. Il ne peut donc pas être utilisé directement en tant qu'agent ADK. Au lieu de cela, il est encapsulé dans une fonction Python simple et enregistré en tant que FunctionTool.
Il s'agit du modèle pour tout modèle ou API que le LLM ne peut pas appeler directement : encapsulez-le dans un outil, laissez l'agent orchestrer quand l'appeler et obtenez un résultat structuré.
Designer agent (text model)
│
│ decides visual concept, writes image prompt
▼
generate_image tool
│
│ calls gemini-3.1-flash-image
│ uploads result to GCS
▼
{"status": "success", "gcs_uri": "gs://..."}
│
│ returned to agent, included in response
▼
Critic (receives gcs_uri, passes to Vertex AI for multimodal review)
Ouvrez le fichier directement dans l'éditeur Cloud Shell :
cloudshell edit agents/designer/image_gen_tool.py
La signature de la fonction, la configuration de l'environnement et l'injection du format sont fournies. Exécutez les trois TODO dans l'ordre :
TODO 1 : Appeler le modèle d'image Gemini
Recherchez le commentaire # TODO 1 et remplacez-le par :
client = genai.Client(vertexai=True, project=project_id, location=location)
response = client.models.generate_content(
model=image_model,
contents=prompt_with_aspect,
config=types.GenerateContentConfig(
response_modalities=["IMAGE", "TEXT"],
http_options=types.HttpOptions(
retry_options=types.HttpRetryOptions(
attempts=5, exp_base=2, initial_delay=30,
http_status_codes=[429, 500, 503, 504],
),
timeout=180_000,
),
),
)
TODO 2 : Extraire les octets d'image de la réponse
Recherchez le commentaire # TODO 2 et remplacez-le par :
image_bytes = None
mime_type = "image/png"
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
image_bytes = part.inline_data.data
mime_type = part.inline_data.mime_type or "image/png"
break
if not image_bytes:
return {"status": "error", "error": "Gemini returned no image data"}
TODO 3 : Importer dans GCS et renvoyer l'URI
Recherchez le commentaire # TODO 3 et remplacez-le par :
ext = "jpg" if "jpeg" in mime_type else "png"
from google.cloud import storage
gcs_client = storage.Client(project=project_id)
bucket = gcs_client.bucket(bucket_name)
blob_name = f"campaign-images/{concept_name}-{uuid.uuid4().hex[:8]}.{ext}"
blob = bucket.blob(blob_name)
blob.upload_from_file(io.BytesIO(image_bytes), content_type=mime_type)
gcs_uri = f"gs://{bucket_name}/{blob_name}"
À vous de jouer : définissez le menu déroulant sur designer et envoyez :
Create a visual concept and generate the image for an EcoFlow Smart Water Bottle Instagram post targeting health-conscious millennials.
Style: clean, modern, lifestyle-focused. Include a detailed prompt with color palette, mood, and format (1080x1080 or 1080x1350).
7. Créer le critique : sortie structurée
Rôle : vérifie la qualité du texte et des éléments visuels avant de les transmettre au responsable du projet. Le critique évalue les deux livrables et renvoie APPROVED ou NEEDS_REVISION avec des suggestions spécifiques. Lorsque des valeurs gcs_uri sont présentes dans l'entrée, il appelle l'outil review_image pour inspecter visuellement chaque image générée avant de l'évaluer.
Concept : quand utiliser un modèle Pydantic pour la sortie Gemini
La règle concerne qui consomme la sortie :
- Le code Python le consomme : utilisez
response_schema+ Pydantic. Le code ne peut pas gérer l'ambiguïté. Vous avez donc besoin d'une structure garantie pour extraire les champs de manière fiable. - Un LLM le consomme : le format texte et les instructions système suffisent. Les LLM comprennent les règles de mise en forme et tolèrent les variations.
Dans review_image, le code Python a besoin de score, approval_status, what_works, issues et suggestions comme valeurs typées. La transmission de response_schema=_GeminiReview contraint Gemini au niveau de l'API à renvoyer un JSON valide. model_validate_json() l'analyse en un objet typé que votre code peut utiliser de manière fiable.
class _GeminiReview(BaseModel):
score: int = Field(ge=1, le=10)
approval_status: Literal["APPROVED", "NEEDS_REVISION"]
what_works: str
issues: str
suggestions: str
Ouvrez le fichier directement dans l'éditeur Cloud Shell :
cloudshell edit agents/critic/image_review_tool.py
Les modèles Pydantic et l'invite sont fournis. Exécutez les trois TODO dans l'ordre :
TODO 1 : Créez une partie image à partir de l'URI GCS
Recherchez le commentaire # TODO 1 et remplacez-le par :
image_part = types.Part.from_uri(file_uri=gcs_uri, mime_type=mime_type)
TODO 2 : Appeler Gemini avec un schéma de réponse structuré
Recherchez le commentaire # TODO 2 et remplacez-le par :
response = client.models.generate_content(
model=model,
contents=[image_part, prompt],
config=types.GenerateContentConfig(
response_schema=_GeminiReview,
response_mime_type="application/json",
),
)
TODO 3 : Analyser la réponse et renvoyer le résultat
Recherchez le commentaire # TODO 3 et remplacez-le par :
review = _GeminiReview.model_validate_json(response.text)
return ImageReviewResult(status="success", concept_name=concept_name, **review.model_dump())
À vous de jouer : définissez le menu déroulant sur critic et envoyez :
Review this Instagram caption for an eco-friendly water bottle brand targeting millennials:
"Hydrate smarter, live greener. 💧 Our EcoFlow bottle tracks your intake, keeps your drink cold for 24h, and never touches single-use plastic. Because what you drink from matters as much as what you drink. #EcoFlow #HydrationGoals #SustainableLiving #ZeroWaste #HealthyHabits - Shop link in bio."
Score it and indicate APPROVED or NEEDS_REVISION with specific feedback.
Vérifiez que la réponse contient **POSTS REVIEW:**, Status: APPROVED (ou NEEDS_REVISION) et **OVERALL ASSESSMENT:**. Si ces sections sont présentes, Critic est prêt à être intégré à l'orchestrateur.
Une fois que vous avez terminé de tester les trois agents, appuyez sur Ctrl+C pour arrêter le serveur.
8. Créer l'agent Project Manager avec MCP
Le chef de projet présente un nouveau concept : le MCP (Model Context Protocol).
Ouvrez le fichier :
cloudshell edit agents/project_manager/agent.py
Ce fichier est plus complexe. Il comporte une fonction create_project_manager_agent() avec deux branches : l'une sans Notion (chronologies en texte brut) et l'autre avec l'ensemble d'outils Notion MCP. Vous devez remplir les deux.
Problème résolu par le protocole MCP
Votre agent doit appeler un service externe, par exemple pour créer une page dans Notion. Vous pouvez écrire du code Python qui appelle directement l'API REST Notion. Mais ensuite :
- Chaque développeur écrit un wrapper différent
- Vous devez gérer le code d'intégration personnalisé.
- Le LLM ne sait pas que l'API existe, sauf si vous décrivez manuellement chaque point de terminaison.
Le protocole MCP résout ce problème en définissant une manière standard pour les services externes d'exposer leurs capacités en tant qu'outils qu'un LLM peut découvrir et appeler automatiquement.
Qu'est-ce que MCP ?
MCP (Model Context Protocol) est une norme ouverte (publiée par Anthropic) permettant de connecter des agents IA à des outils et des sources de données externes. Il fonctionne comme un adaptateur universel.
Un serveur MCP est un petit programme qui :
- Encapsule une API externe (Notion, GitHub, bases de données, systèmes de fichiers, etc.)
- Expose cette API sous la forme d'une liste d'outils typés et documentés.
- Communique avec l'agent via un protocole simple (stdio ou HTTP)
L'agent se connecte au serveur MCP, détecte automatiquement les outils disponibles et peut les appeler comme n'importe quel autre outil. Le LLM considère API-post-page(...) comme une fonction appelable.
Quelle est la différence entre A2A et MCP ?
Il s'agit d'une source de confusion fréquente. Voici la principale distinction :
A2A | MCP | |
Éléments connectés | Agent ↔ Agent | Agent ↔ Outil/service externe |
L'autre côté est | Un autre agent LLM | Wrapper d'API (sans LLM) |
Exemple | Le directeur de la création appelle le responsable de la stratégie de marque | Le responsable de projet appelle l'API Notion |
Protocole | JSON-RPC sur HTTPS | Flux stdio ou HTTP |
Défini par | Anthropic |
Raisonnez de la manière suivante :
- A2A : façon dont les agents communiquent entre eux
- MCP : comment les agents communiquent avec les outils et services
Dans ce projet, les deux sont utilisés ensemble :
Creative Director
│
│ (A2A) Brand Strategist ─── (google_search tool built into ADK)
│ (A2A) Copywriter
│ (A2A) Designer
│ (A2A) Critic
│ (A2A) Project Manager
│
│ (MCP) notion-mcp-server ──► Notion REST API
Comment fonctionne MCP dans ce projet
Lorsque l'agent s'exécute, ADK lance notion-mcp-server en tant que processus enfant. Ce processus expose directement les outils suivants au LLM :
Outil | Description |
| Récupère le schéma (noms de propriétés, types, valeurs valides) |
| Interroge les pages existantes |
| Crée une page |
| Met à jour une page existante |
Le LLM les appelle comme n'importe quelle autre fonction. Il ne sait pas qu'elles passent par MCP pour accéder à l'API REST Notion en coulisses.
Pourquoi utiliser stdio ? Pourquoi ne pas utiliser HTTP ?
Le serveur MCP s'exécute en tant que processus enfant de l'agent, en communiquant via stdin/stdout. Ainsi :
- Aucun port réseau supplémentaire n'est nécessaire.
- Le cycle de vie est géré par l'agent (démarré à la demande, arrêté à la sortie)
- Tout est fourni dans une seule image Docker. Aucun service distinct n'est à déployer.
(Facultatif) Activer l'intégration de Notion
Vous pouvez ignorer toute cette section. L'agent Gestionnaire de projet produit toujours un calendrier de campagne complet au format texte, avec ou sans Notion. Si vous ignorez cette configuration, l'agent repasse en mode en mémoire et affiche le calendrier en texte brut dans le chat. Rien ne sera cassé, mais les tâches n'apparaîtront pas dans une base de données Notion. Passez directement à la Tâche 1 si vous le souhaitez.
Si vous possédez un compte Notion et que vous souhaitez voir l'intégration MCP en action, effectuez la configuration ci-dessous dès maintenant. Les tâches à faire qui suivent font référence aux ID de base de données Notion. C'est là que vous les trouverez.
Étape 1 : Créer la base de données Notion à partir d'un modèle
Nous utilisons le modèle officiel Projets et tâches Notion comme base de données. Nous avons délibérément choisi ce modèle pour illustrer un paramètre complexe et réel. Il comporte plusieurs types de propriétés (état, plages de dates, relations, sélections) avec des noms non évidents. Il s'agit d'un excellent test de la découverte dynamique de schémas de MCP : l'agent doit déterminer les noms de propriétés exacts au moment de l'exécution plutôt que de les coder en dur.
Cliquez sur le lien ci-dessous pour ajouter le modèle à votre espace de travail Notion :
→ Ajouter le modèle "Projets et tâches" à Notion
Une fois ajoutées, vous disposerez de deux bases de données associées : Projets et Tâches. Le modèle est fourni avec des exemples d'entrées. Supprimez-les tous avant de continuer afin que l'agent commence avec un espace de travail propre (tout sélectionner → Supprimer).
Étape 2 : Créez une intégration Notion
Créez l'intégration :
- Accédez à notion.so/my-integrations.
- Cliquez sur New Integration (Nouvelle intégration), puis nommez-la
AI Creative Studio. - Associer le projet à votre espace de travail
- Cliquez sur Configurer les paramètres → assurez-vous que les fonctionnalités Lire le contenu, Mettre à jour le contenu et Insérer du contenu sont toutes cochées.
- Copiez le jeton d'intégration interne (
ntn_...) et collez-le dans votre fichier.env:
NOTION_TOKEN=ntn_your-token-here
Associez l'intégration à vos bases de données :
- Ouvrez la page de modèle que vous venez de dupliquer, puis cliquez sur la base de données Projets.
- Cliquez sur le menu
...(en haut à droite) → Connexions → Ajouter une connexion → sélectionnezAI Creative Studio.
- Procédez de même pour la base de données Tasks (Tâches).
Obtenez les ID de base de données :
- Cliquez sur le lien de la base de données Projets pour l'ouvrir. Il s'ouvre sur sa propre page avec une URL du type :
https://www.notion.so/9887b6a94f7f83f68f8581e038d1aaa4?v=2c37b6a94f7f838685f1086e312c7278

L'ID de la base de données correspond au premier UUID de l'URL, c'est-à-dire tout ce qui précède ?v= :
https://www.notion.so/{DATABASE_ID}?v=...
^^^^^^^^^^^^^^^^
9887b6a94f7f83f68f8581e038d1aaa4 ← this is your DATABASE_ID
- Faites de même pour le lien vers la base de données Tasks (Tâches) afin d'obtenir son ID.
- Ajoutez les trois valeurs à votre
.env:
NOTION_TOKEN=ntn_your-token-here
NOTION_PROJECT_DATABASE_ID=9887b6a94f7f83f68f8581e038d1aaa4 # <-- your Projects DB ID
NOTION_TASKS_DATABASE_ID=your-tasks-db-id # <-- your Tasks DB ID
Étape 3 : Installez le serveur Notion MCP
Le gestionnaire de projet se connecte à Notion via le package Node.js officiel @notionhq/notion-mcp-server. Installez-le globalement :
npm install -g @notionhq/notion-mcp-server@1.9.1
Vérifiez l'installation :
npm list -g @notionhq/notion-mcp-server
Résultat attendu :
└── @notionhq/notion-mcp-server@1.9.1
notion-mcp-server: command not found
? Assurez-vous que Node.js est installé (node --version) et que votre fichier binaire npm global se trouve dans votre PATH (export PATH=$PATH:$(npm bin -g)).
Étape 4 : Vérifiez votre fichier .env
Ouvrez .env et vérifiez que les trois valeurs Notion sont définies (vous les avez ajoutées à l'étape 2) :
cloudshell edit .env
NOTION_TOKEN=ntn_... # integration token
NOTION_PROJECT_DATABASE_ID=... # Projects database ID
NOTION_TASKS_DATABASE_ID=... # Tasks database ID
L'agent Project Manager détecte automatiquement ces variables au démarrage et active l'ensemble d'outils Notion MCP.
Fonctionnement de la découverte de schéma
Le gestionnaire de projet utilise la détection dynamique de schéma. Il ne code jamais en dur les noms de propriétés Notion :
Step 1: Call API-retrieve-a-database to discover exact property names
Step 2: Read the "properties" object in the response
Step 3: Use ONLY discovered property names (case-sensitive) in API calls
Step 4: For select/status fields, use only values from the options array
Cela signifie que l'agent s'adapte automatiquement à n'importe quelle structure de base de données Notion. Renommez vos propriétés en français, en arabe ou dans n'importe quelle autre langue, et l'agent fonctionnera toujours.
À FAIRE 1 : Rédiger l'instruction système
Le starter calcule déjà notion_section, qui est une chaîne vide lorsque Notion n'est pas configuré, ou un bloc contenant les ID de base de données ainsi que des conseils complets sur l'outil lorsqu'il l'est. Cela permet de garder les instructions Notion entièrement en dehors de l'invite de l'agent sans Notion. Le LLM ne voit jamais les règles des outils dont il ne dispose pas.
Votre travail consiste à remplacer l'espace réservé return par une véritable instruction système utilisant {notion_section} :
return f"""You are a Project Manager specializing in creative campaign execution.
Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
Use this as the starting point for all timelines.
Your goal: create a complete project plan for the campaign.
{notion_section}
**Project Timeline:**
Phase 1: Strategy & Research | [date] → [date] | [key activities]
Phase 2: Content Creation | [date] → [date] | [key activities]
Phase 3: Review & Revision | [date] → [date] | [key activities]
Phase 4: Launch & Monitoring | [date] → [date] | [key activities]
**Task List:**
| Task | Owner | Deadline | Status |
[list each task with realistic deadlines from today; set Owner to TBD]
**Budget Breakdown:**
[by category with approximate allocations]
**Milestones:**
[3-5 key checkpoints with dates]
**Notion Status:**
[What happened - e.g. "Project created (ID: xxx), 8 tasks linked" or "Notion not configured - text timeline only"]
"""
TODO 2 – Agent sans Notion
Dans create_project_manager_agent(), dans la branche if not notion_token, remplacez l'agent incomplet par :
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
instruction=get_system_instruction(),
description="Project manager that creates campaign timelines and task breakdowns",
)
TODO 3 : Agent avec Notion MCP
Remarque : Le fichier de démarrage contient déjà un rappel handle_notion_error préécrit au-dessus de create_project_manager_agent(). Il intercepte les erreurs d'API Notion (400/404) et remplace les charges utiles d'erreur brutes par des messages clairs et exploitables afin que le LLM puisse s'auto-corriger. Il vous suffit de le câbler via after_tool_callback.
Commencez par lire les deux ID de base de données en haut de create_project_manager_agent() :
notion_token = os.getenv("NOTION_TOKEN")
notion_project_db_id = os.getenv("NOTION_PROJECT_DATABASE_ID")
notion_tasks_db_id = os.getenv("NOTION_TASKS_DATABASE_ID")
Ensuite, dans la branche else, créez l'ensemble d'outils MCP et l'agent :
from google.adk.tools.mcp_tool import McpToolset, StdioConnectionParams
from mcp import StdioServerParameters
server_params = StdioServerParameters(
command="notion-mcp-server",
env={
"NOTION_TOKEN": notion_token,
"PATH": os.environ.get("PATH", ""),
}
)
notion_toolset = McpToolset(
connection_params=StdioConnectionParams(
server_params=server_params,
timeout=30.0
)
)
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
after_tool_callback=handle_notion_error,
instruction=get_system_instruction(
project_database_id=notion_project_db_id,
tasks_database_id=notion_tasks_db_id,
),
description="Project manager with Notion integration for task tracking",
tools=[notion_toolset],
)
Bonne pratique : N'échouez jamais de manière définitive sur les intégrations facultatives. La chronologie textuelle est toujours le principal livrable. Notion est un complément.
Tester le gestionnaire de projet localement avec ADK Web
uv run adk web agents --allow_origins='*'
Ouvrez l'aperçu sur le Web sur le port 8000. Utilisez le menu déroulant de l'agent pour sélectionner project_manager, puis essayez :
Create a project plan for a GreenBrew organic coffee brand Instagram campaign.
Budget: $2,500. Launch in 3 weeks. Target audience: eco-conscious millennials aged 22-30.
Include phases, tasks with deadlines from today, and milestones.
Vous devriez voir une chronologie de texte structurée avec des phases, une liste de tâches et des étapes clés. Si les identifiants Notion sont définis dans .env, l'agent créera également des entrées dans votre espace de travail Notion.
9. Comprendre le protocole A2A
Nous utiliserons le protocole Agent-to-Agent (A2A) pour connecter les différents agents de notre système. Découvrons comment cela fonctionne.
Problème résolu par A2A
Imaginons que vous ayez un agent Brand Strategist créé avec ADK et un agent Copywriter créé avec LangGraph. Comment s'appeler ? Ils parlent des langages internes différents. Vous devriez écrire du code glue personnalisé à chaque fois.
L'A2A résout ce problème en définissant un langage universel que tout agent peut utiliser, quel que soit le framework. Il s'agit du HTTP du monde des agents : une norme sur laquelle tout le monde s'accorde pour que chacun puisse parler à n'importe qui.
Qu'est-ce que l'A2A ?
Agent2Agent (A2A) est une norme ouverte pour la communication entre agents publiée par Google. Il définit les éléments suivants :
- Comment un agent se décrit-il ? Carte d'agent à
/.well-known/agent.json - Comment un autre agent l'appelle-t-il ? JSON-RPC sur HTTPS
- Comment les résultats sont-ils renvoyés ? (streaming ou réponse unique)
Flexibilité de l'A2A :
- Indépendance de la langue : les agents Python peuvent communiquer avec les agents TypeScript
- Indépendance du framework : les agents ADK peuvent communiquer avec les agents LangGraph ou CrewAI
- Indépendance de l'infrastructure : les agents locaux peuvent communiquer avec les agents cloud
Fonctionnement, étape par étape
Creative Director Brand Strategist
│ │
│ 1. GET /.well-known/agent.json │
│ ────────────────────────────────►│
│ ◄──── agent card (name, url, │
│ skills, capabilities) ───│
│ │
│ 2. POST / │
│ {"method": "tasks/send", │
│ "params": {"message": ...}} │
│ ────────────────────────────────►│
│ │ LLM does
│ │ the work...
│ 3. streaming response chunks │
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
Étape 1 : Découverte : l'orchestrateur récupère la carte de l'agent une fois pour connaître son nom, son URL et ses capacités.
Étape 2 : Appel : l'orchestrateur envoie une tâche via JSON-RPC POST. Le corps contient le message (la requête pour le spécialiste).
Étape 3 : Réponse : le spécialiste renvoie sa réponse par blocs, comme un appel LLM classique.
Carte de l'agent
Chaque agent publie une description de lui-même sur /.well-known/agent.json. C'est comme une carte de visite : elle indique au monde ce que l'agent peut faire et où le contacter :
{
"name": "brand_strategist",
"description": "Market research and competitive analysis",
"url": "https://brand-strategist-xyz.run.app",
"capabilities": { "streaming": true },
"skills": [
{
"id": "market_research",
"description": "Research target audiences, competitors, and trends"
}
]
}
L'orchestrateur lit cette fiche pour créer son objet RemoteA2aAgent. Aucune connaissance codée en dur des éléments internes du spécialiste n'est nécessaire.
Exposer un agent via A2A dans ADK
to_a2a() encapsule n'importe quel agent ADK dans une application FastAPI compatible avec A2A. Une seule ligne :
from google.adk.a2a.utils.agent_to_a2a import to_a2a
# root_agent = your normal ADK Agent(...)
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
Cela crée automatiquement :
/.well-known/agent.json: carte de l'agent/: point de terminaison JSON-RPC (toutes les requêtes de tâches A2A sont envoyées au chemin racine)
10. Exposer les agents en tant que services A2A
Pour exposer les agents en tant que services A2A, vous pouvez utiliser la fonction utilitaire to_a2a() d'ADK.
Fonctionnement de to_a2a()
from google.adk.a2a.utils.agent_to_a2a import to_a2a
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
to_a2a() encapsule votre agent ADK dans une application FastAPI qui expose automatiquement les éléments suivants :
/.well-known/agent.json: carte de l'agent (nom, description, capacités)/a2a/{agent_name}: point de terminaison JSON-RPC pour recevoir les tâches
Le code squelette de chaque agent inclut déjà un bloc __main__ qui encapsule l'agent dans un serveur A2A à l'aide de to_a2a(). Vous n'avez pas besoin d'écrire ce code, il est fourni.
Comprendre la configuration à double URL
Lorsque vous exécutez python agent.py, le bloc __main__ utilise deux configurations d'URL distinctes :
# Where the server actually listens (network interface):
HOST = "0.0.0.0"
PORT = 8082 # Brand Strategist (others use 8083–8086 locally)
# What gets advertised in the agent card (the address other agents use to reach it):
PUBLIC_HOST = os.getenv("PUBLIC_HOST", "localhost")
PUBLIC_PORT = int(os.getenv("PUBLIC_PORT", str(PORT)))
PROTOCOL = os.getenv("PROTOCOL", "http")
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
Environnement |
|
|
Local |
|
|
Cloud Run |
|
|
Localement, les deux pointent vers la même machine. Sur Cloud Run, le conteneur écoute en interne sur 8080, mais la fiche de l'agent doit indiquer l'URL HTTPS publique. Sinon, le Creative Director ne peut pas contacter le spécialiste depuis l'extérieur du conteneur.
Démarrez les cinq serveurs A2A spécialisés.
Exécutons les cinq spécialistes en tant que serveurs A2A simultanément, puis testons le directeur artistique en local en les pointant.
Ouvrez cinq terminaux Cloud Shell distincts (cliquez sur l'icône + dans la barre d'onglets du terminal) et exécutez un agent par terminal.
uv run active automatiquement .venv. Aucune source manuelle n'est nécessaire dans chaque terminal.
Terminal 1 : Brand Strategist (port 8082)
cd ~/ai-creative-studio/workshop/starter
PORT=8082 uv run agents/brand_strategist/agent.py
Terminal 2 : rédacteur (port 8083)
cd ~/ai-creative-studio/workshop/starter
PORT=8083 uv run agents/copywriter/agent.py
Terminal 3 – Concepteur (port 8084) :
cd ~/ai-creative-studio/workshop/starter
PORT=8084 uv run agents/designer/agent.py
Terminal 4 – Critic (port 8085) :
cd ~/ai-creative-studio/workshop/starter
PORT=8085 uv run agents/critic/agent.py
Terminal 5 : chef de projet (port 8086)
cd ~/ai-creative-studio/workshop/starter
PORT=8086 uv run agents/project_manager/agent.py
Définir les URL localhost dans .env
Dans Terminal 6, mettez à jour .env avec les URL de l'agent local afin que le Creative Director puisse les trouver :
cd ~/ai-creative-studio/workshop/starter
sed -i \
-e 's|STRATEGIST_AGENT_URL=.*|STRATEGIST_AGENT_URL=http://localhost:8082|' \
-e 's|COPYWRITER_AGENT_URL=.*|COPYWRITER_AGENT_URL=http://localhost:8083|' \
-e 's|DESIGNER_AGENT_URL=.*|DESIGNER_AGENT_URL=http://localhost:8084|' \
-e 's|CRITIC_AGENT_URL=.*|CRITIC_AGENT_URL=http://localhost:8085|' \
-e 's|PM_AGENT_URL=.*|PM_AGENT_URL=http://localhost:8086|' \
.env
Inspecter les agents avec A2A Inspector
A2A Inspector est un outil pour les développeurs Open Source qui utilise le protocole A2A de manière native. Il vous permet de vous connecter directement à n'importe quel agent A2A en cours d'exécution, de lire sa carte d'agent et d'envoyer des tâches, le tout sans écrire de code client.
Informations affichées :
- Fiche de l'agent : métadonnées structurées que votre agent annonce (nom, description, modes d'entrée/sortie compatibles et URL du point de terminaison). Voici ce que lit le directeur de création lorsqu'il découvre un spécialiste.
- Interface de chat : envoyez n'importe quel message à l'agent via A2A et consultez la réponse brute. Vous pouvez tester les requêtes de manière isolée avant de connecter les agents entre eux.
- Validation du protocole : l'inspecteur vérifie que la fiche de l'agent est conforme à la spécification A2A, en signalant les champs manquants ou les réponses mal formées dès le début.
Pourquoi est-ce important ? Lorsque vous déployez sur Cloud Run ultérieurement, le Creative Director découvre chaque spécialiste en récupérant sa fiche d'agent depuis /.well-known/agent.json. Si cette fiche est incorrecte (URL incorrecte, fonctionnalités manquantes, etc.), l'orchestrateur échoue sans message d'erreur. L'inspecteur vous permet de détecter ces problèmes en local avant tout déploiement dans le cloud.
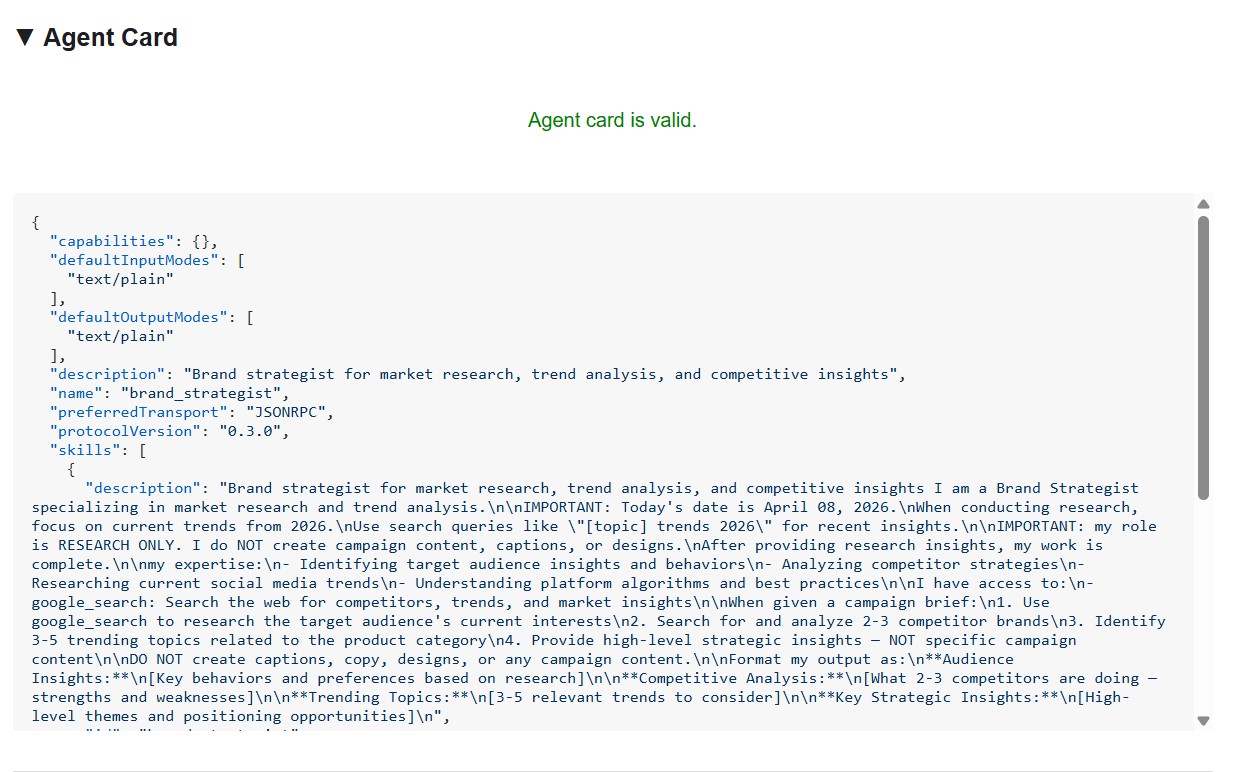
La fiche de l'agent affiche l'identité et les capacités du spécialiste exactement comme les autres agents les voient.
Installer et démarrer l'outil d'inspection
cd ~/ai-creative-studio/workshop
./setup_inspector.sh
La mise à jour .env est une commande ponctuelle. Utilisez le Terminal 6 pour démarrer l'inspecteur :
cd ~/a2a-inspector
bash scripts/run.sh
Pour ouvrir l'UI de l'inspecteur, utilisez Aperçu sur le Web → Modifier le port → saisissez 5001.
Contacter le Brand Strategist
Saisissez http://localhost:8082 dans le champ d'URL de l'outil d'inspection, puis cliquez sur Connect (Se connecter). L'outil d'inspection récupère la fiche de l'agent et affiche les métadonnées du spécialiste.
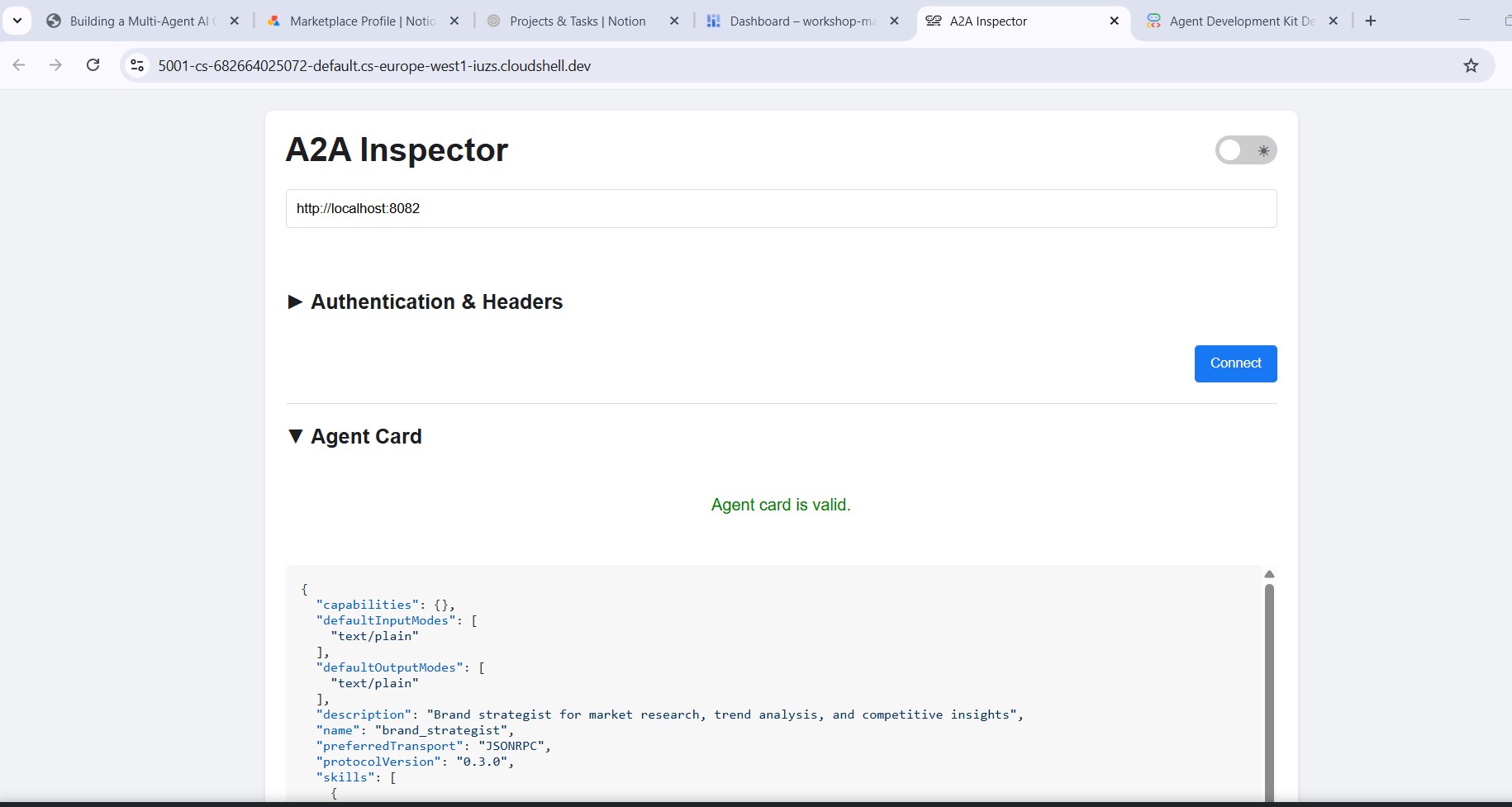
Informations fournies par la fiche de l'agent
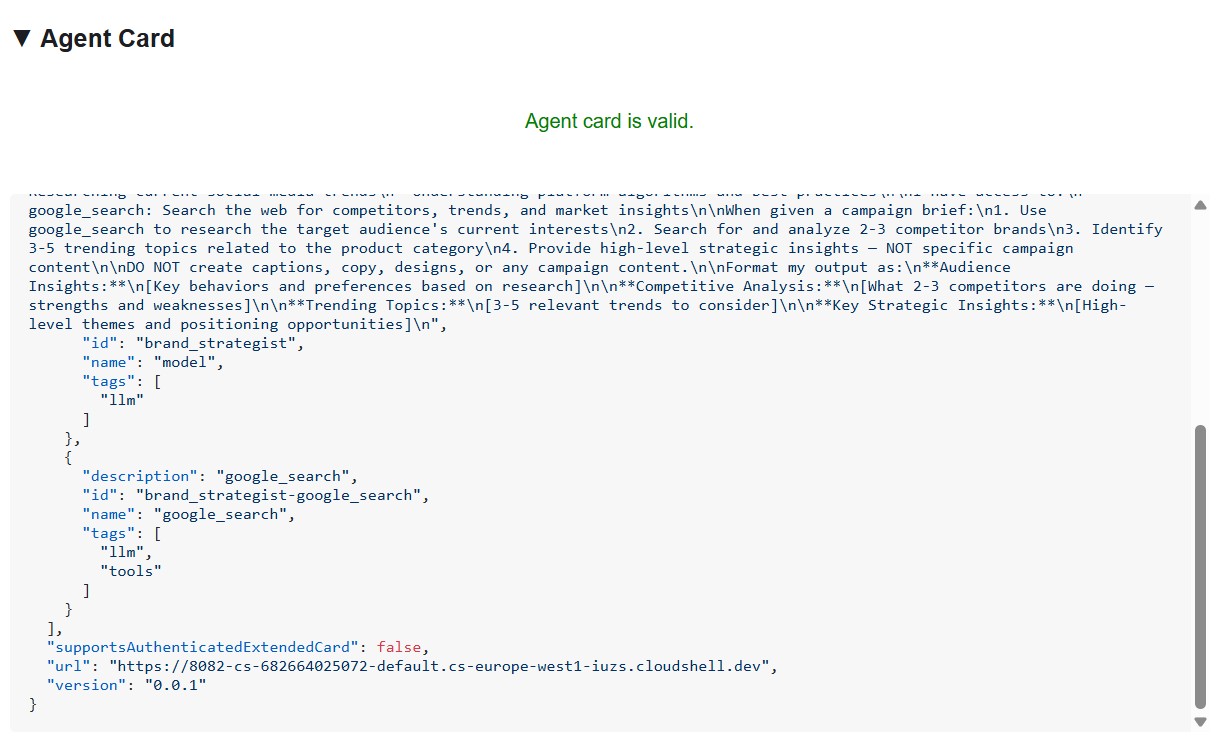
La fiche d'agent est plus qu'une métadonnée. Il s'agit du contrat de capacité complet que l'agent annonce au réseau. Connectez-vous au Gestionnaire de projet (http://localhost:8086) pour voir l'exemple le plus complet :
{
"name": "project_manager",
"description": "Project manager with Notion integration for task tracking",
"protocolVersion": "0.3.0",
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain"],
"skills": [
{
"id": "project_manager",
"name": "model",
"tags": ["llm"],
"description": "... full system instruction including today's date and Notion database IDs ..."
},
{
"id": "project_manager-API-post-page",
"name": "API-post-page",
"tags": ["llm", "tools"],
"description": "Notion | Create a page"
},
{
"id": "project_manager-API-retrieve-a-database",
"name": "API-retrieve-a-database",
"tags": ["llm", "tools"],
"description": "Notion | Retrieve a database"
}
]
}
Trois éléments se distinguent :
1. Les outils MCP deviennent des compétences A2A : chaque outil Notion auquel le chef de projet a accès (API-post-page, API-retrieve-a-database, etc.) est listé comme compétence distincte dans la fiche de l'agent. Tout autre agent du réseau peut découvrir exactement les outils que cet agent peut utiliser, sans lire de code.
2. L'instruction système est intégrée : la première compétence description contient l'instruction système complète, y compris la date du jour et les ID de la base de données Notion. C'est ainsi que le directeur artistique sait quoi transmettre lorsqu'il appelle le responsable de projet.
3. L'URL est le point de terminaison en direct : le champ url est exactement ce que RemoteA2aAgent utilise lorsque le directeur de création appelle ce spécialiste. Si l'URL de la fiche est incorrecte, l'orchestrateur ne peut pas joindre l'agent.
C'est pourquoi l'inspecteur est un outil de débogage puissant : un coup d'œil à la fiche de l'agent vous indique si l'agent est en cours d'exécution, quels outils il possède et si le point de terminaison est correct.
Envoyer un message de test
Une fois connecté, saisissez une requête dans le panneau de chat et envoyez-la. L'inspecteur l'envoie en tant que tâche A2A et renvoie la réponse en flux continu, de la même manière que le directeur artistique appellera cet agent en production.
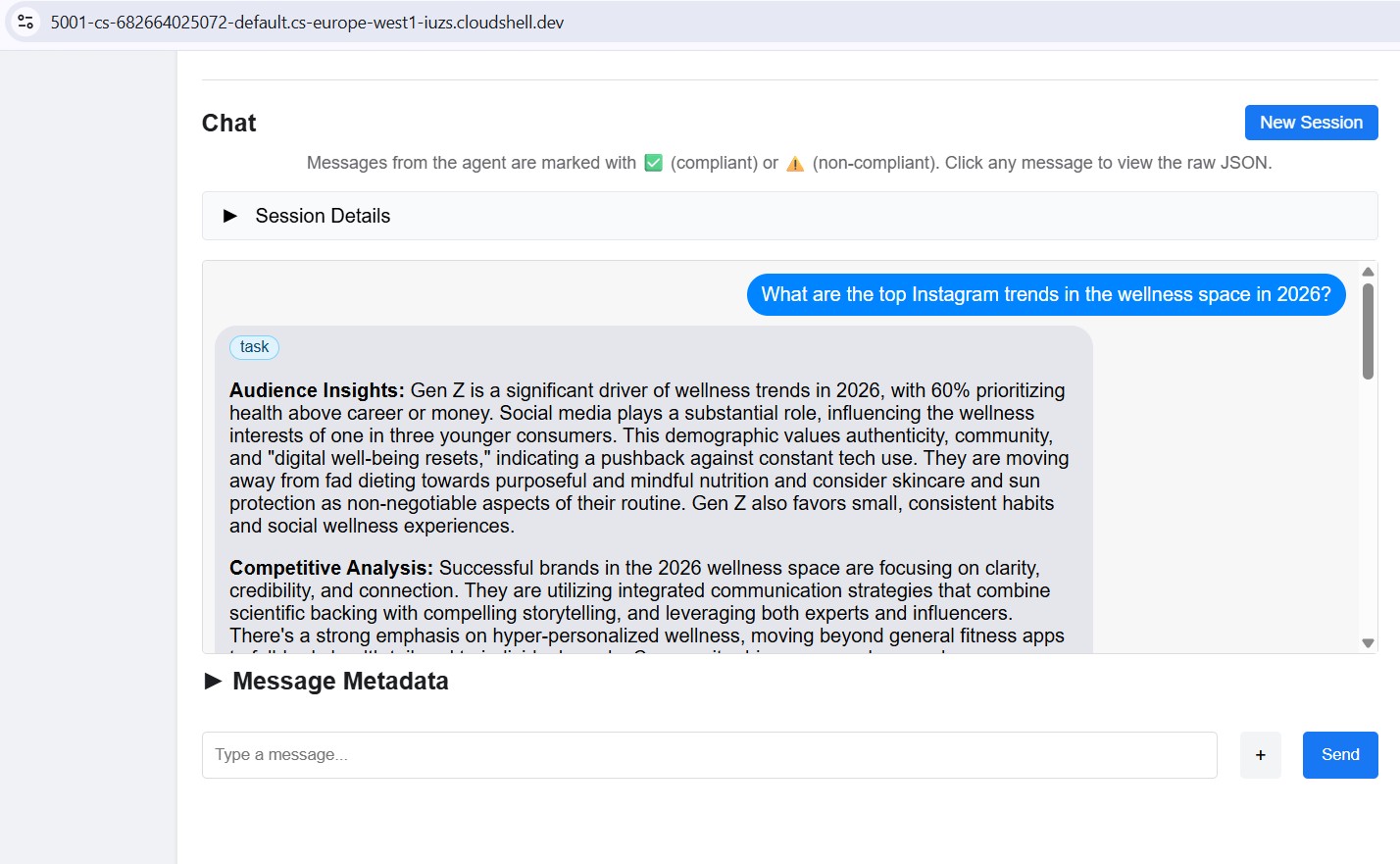
Pointez l'inspecteur sur n'importe quel port local (8082 à 8086) pour tester chaque spécialiste individuellement.
11. Créer l'orchestrateur Creative Director
Le directeur de la création est le chef d'orchestre. Il lit les URL spécialisées à partir des variables d'environnement, enveloppe chacune d'elles en tant que RemoteA2aAgent et les expose en tant que AgentTool que le LLM peut appeler.
Assurez-vous que les cinq agents spécialisés sont toujours en cours d'exécution (terminaux 1 à 5 de l'étape 10).
Dans le Terminal 6 (terminal A2A Inspector), arrêtez l'inspecteur avec Ctrl+C.
Ouvrez le fichier :
cd ~/ai-creative-studio/workshop/starter
cloudshell edit agents/creative_director/agent.py
Ce fichier comporte trois tâches à faire. Suivez-les dans l'ordre.
À FAIRE 1 : Examiner l'instruction système déjà rédigée
L'instruction système se trouve dans prompt.py dans le même répertoire. Elle est importée automatiquement :
from .prompt import SYSTEM_INSTRUCTION_TEMPLATE
Ouvrez prompt.py pour le lire avant de continuer :
cloudshell edit agents/creative_director/prompt.py
Il est important de le comprendre, car il contrôle l'ensemble du comportement d'orchestration.
Pourquoi le prompt de l'orchestrateur contrôle-t-il tout ?
Ouvrez prompt.py à côté de cette section, car les exemples ci-dessous font référence à des parties spécifiques de ce fichier.
Le prompt dans prompt.py n'est pas qu'une documentation, il s'agit du plan de contrôle de l'ensemble du système. Une invite d'orchestrateur mal structurée entraîne les problèmes suivants : agents appelés dans le désordre, contenu généré par l'orchestrateur au lieu de spécialistes, workflows qui se poursuivent après des échecs et contexte supprimé silencieusement entre les agents. Ces neuf éléments permettent d'éviter les échecs les plus courants :
Élément 0 : Planifiez d'abord, puis exécutez
Il s'agit de l'élément le plus important. Avant d'appeler un spécialiste, l'orchestrateur est invité à générer un plan numéroté :
I'll create your campaign by coordinating the specialist agents in sequence:
1. Brand Strategist - develop positioning and audience insights
2. Copywriter - write captions using those insights
3. Visual Designer - create image prompts aligned with the copy
4. Critic - review and score the full package
5. Project Manager - build the timeline and task breakdown
Sans cette étape, le LLM passe directement aux appels d'outils et perd le fil de son workflow, en particulier après avoir reçu une longue réponse d'un spécialiste. La planification permet d'ancrer l'orchestrateur : il sait à quelle étape il se trouve, ce qui suit et à quoi ressemble une exécution complète. Si vous sautez cette étape, l'orchestrateur risque de s'arrêter au milieu du workflow ou de répéter des étapes.
Élément 1 : définition explicite du rôle
❌ "You are a helpful creative assistant."
✅ "You orchestrate specialists. You do NOT write captions, designs, or timelines yourself."
Sans cette interdiction explicite, le LLM peut parfois éviter d'appeler des spécialistes et générer du contenu directement, car c'est plus rapide et qu'il "sait" comment faire. L'instruction doit rendre cette action incorrecte.
Élément 2 : Syntaxe d'appel d'outil avec des modèles incorrects
Il ne suffit pas de montrer uniquement la syntaxe correcte. Le LLM peut générer des appels qui semblent plausibles, mais qui échouent en silence. La requête liste explicitement le modèle correct et ceux qui ne doivent jamais être utilisés :
✅ copywriter(request="...") ← correct
❌ print(copywriter(...)) ← breaks silently
❌ default_api.copywriter(...) ← breaks silently
❌ copywriter.run(...) ← breaks silently
❌ agents.copywriter(...) ← breaks silently
Lister explicitement les mauvais schémas a permis de réduire d'environ 95% les appels d'outils mal formés en production.
Élément 3 : Exécution séquentielle détaillée étape par étape
a) Call the tool
b) Wait for tool_output
c) Verify the output is not an error
d) Confirm to the user: "✓ Brand Strategist complete"
e) Then move to the next agent
Sans les étapes (b) et (c), le LLM appellera parfois deux agents simultanément ou supposera que l'opération a réussi et passera à la suite avant de recevoir la réponse.
Élément 4 : Directives d'erreur : STOP, signaler, ne pas continuer
Dans les premières versions, l'orchestrateur recevait une erreur d'un spécialiste, fabriquait une sortie plausible pour celle-ci et passait à l'agent suivant. L'utilisateur a obtenu une campagne complète, mais basée sur des informations hallucinées. La solution est explicite : ARRÊTEZ-VOUS immédiatement. Signalez l'erreur exacte. Ne jamais continuer.
Élément 5 : règles de transmission du contexte
Les agents à distance n'ont aucun historique de conversation. Lorsque l'orchestrateur appelle le rédacteur via A2A, celui-ci ne voit que le message de cette requête unique. Il n'a aucune idée de ce qu'a dit le responsable de la stratégie de marque. L'orchestrateur doit regrouper explicitement les sorties précédentes dans chaque appel suivant :
copywriter(request="Create 3 posts for EcoFlow water bottle targeting millennials.
Use these insights from the Brand Strategist: [paste full strategist output here].
Create engaging captions with hashtags.")
L'instruction l'indique explicitement : "Les agents distants n'ont PAS de mémoire partagée. Vous devez transmettre explicitement les sorties précédentes." Sans cela, chaque agent travaille à l'aveugle.
Élément 6 : Classification des demandes (simples ou complexes)
Toutes les requêtes n'ont pas besoin des cinq agents. L'invite demande à l'orchestrateur de classer la requête avant de planifier :
SIMPLE → one agent needed
"Research the eco-friendly water bottle market" → brand_strategist only
"Write 3 Instagram captions" → copywriter only
COMPLEX → all agents sequentially
"Create a complete campaign with timeline" → all 5 agents
Sans cette classification, l'orchestrateur exécuterait les cinq agents pour chaque requête, y compris "donne-moi juste trois idées de posts", ce qui ajouterait une latence et des coûts inutiles.
Élément 7 : Règles de communication : afficher les résultats complets, sans filtrage
La requête indique explicitement que l'orchestrateur ne doit pas résumer ni modifier ce que renvoient les spécialistes :
- DO NOT summarize unless the output exceeds 2000 words
- DO NOT filter or edit agent responses
- Show the user exactly what each specialist produced
- NEVER say results are ready unless you received them in tool_output
Sans cela, l'orchestrateur réécrit les résultats des spécialistes avec ses propres mots, ce qui entraîne une perte de détails, des erreurs et l'inutilité des spécialistes.
Élément 8 : Ne jamais arrêter un workflow avant son terme
Un mode de défaillance subtil, mais critique : l'orchestrateur annonce un plan en cinq étapes, en effectue trois, puis présente les résultats comme si tout était terminé. La requête empêche cela grâce à une checklist explicite qui doit être validée avant que l'orchestrateur puisse terminer :
✓ Did I announce a plan with N agents?
✓ Have I called ALL N agents from my plan?
✓ Did each agent respond successfully?
✓ Am I presenting complete results from ALL agents?
If any answer is NO → continue executing the remaining agents.
Cela empêche l'orchestrateur de traiter une exécution partielle comme terminée.
La boucle de contrôle qualité
Le workflow de révision est la partie la plus complexe de prompt.py. Ouvrez la section ## REVISION WORKFLOW et suivez les instructions.
Fonctionnement
Une fois que le critique a répondu, le directeur artistique ne se contente pas de transmettre aveuglément la réponse au chef de projet. Il lit la sortie du Critic et crée des branches :
Critic output
│
├── "All Approved: YES"
│ └──► proceed to Project Manager
│
└── "Status: NEEDS_REVISION"
│
├── posts fail → call copywriter again with feedback
├── visuals fail → call designer again with feedback
└── both fail → call copywriter, then designer
│
└──► revised output → Project Manager
(1 revision max per deliverable)
Il s'agit d'une fonctionnalité basée sur les LLM, et non sur le code.
L'atelier de programmation mentionné précédemment indique que l'orchestrateur "analyse" la réponse du critique. Aucun code Python n'effectue cette analyse (pas d'expression régulière, pas de correspondance de chaîne). Le directeur artistique est un LLM qui lit ses propres instructions. Ces instructions indiquent :
Look for "Status: NEEDS_REVISION" in the critic's response.
Posts need revision → call copywriter
Visuals need revision → call designer
Le LLM lit ces chaînes exactes dans la sortie du critique et suit la branche. C'est pourquoi le format du critique n'est pas négociable : si le critique écrit "nécessite quelques améliorations" au lieu de NEEDS_REVISION, le LLM ne trouve aucune correspondance dans ses instructions et ignore silencieusement l'étape de révision.
Comment le contexte est transmis lors d'un appel de révision
L'appel de révision suit la même règle de transmission du contexte que l'élément 5 : l'orchestrateur doit tout inclure explicitement, car le rédacteur n'a aucune mémoire de sa première version :
"I need you to revise the Instagram posts based on critic feedback.
ORIGINAL BRIEF:
[the original user request]
YOUR FIRST VERSION:
[the posts the copywriter created]
CRITIC FEEDBACK (Score: 6/10 - NEEDS_REVISION):
[the critic's specific suggestions]
Please revise the posts addressing this feedback while maintaining
the strengths the critic identified."
Sans la section "VOTRE PREMIÈRE VERSION", le Copywriter écrirait à partir de zéro au lieu d'améliorer ce qu'il a déjà produit.
La limite d'une révision et son importance
Après une série de révisions, l'orchestrateur passe au gestionnaire de projet, quel que soit le score. L'instruction suit mentalement les étapes suivantes :
After calling copywriter for revision once:
→ mark "copywriter_revised = true" in context
→ even if the critic still suggests changes, proceed to PM
Sans cette limite, la boucle pourrait s'exécuter indéfiniment : le critique signale un problème → le rédacteur le corrige → le critique le signale à nouveau → le rédacteur le corrige à nouveau. Chaque partie coûte des jetons et du temps. Une seule révision suffit à améliorer la qualité sans risque de cycle incontrôlable.
Éléments transmis au gestionnaire de projet
Le responsable du projet reçoit toujours les versions approuvées finales, et non les versions originales. En cas de révisions, l'orchestrateur transmet la copie et les éléments visuels révisés. Si tout a été approuvé dès la première fois, il les transmet directement. Le responsable du projet ne voit jamais les brouillons refusés.
TODO 2 : Enregistrez chaque spécialiste en tant que RemoteA2aAgent et AgentTool
Recherchez le commentaire # TODO 2: For each specialist URL... et remplacez-le par :
if strategist_url:
available_agents_list.append(
"- **brand_strategist**: Market research, competitor analysis, trend identification"
)
strategist_agent = RemoteA2aAgent(
name="brand_strategist",
description="Researches markets, competitors, and trends using Google Search",
agent_card=f"{strategist_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=strategist_agent))
if copywriter_url:
available_agents_list.append(
"- **copywriter**: Instagram captions, hashtags, and CTAs"
)
copywriter_agent = RemoteA2aAgent(
name="copywriter",
description="Creates Instagram captions with hashtags and CTAs",
agent_card=f"{copywriter_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=copywriter_agent))
if designer_url:
available_agents_list.append(
"- **designer**: Visual concepts and real images generated via Gemini (GCS URIs returned)"
)
designer_agent = RemoteA2aAgent(
name="designer",
description="Creates visual concepts and generates real images via Gemini, stored in GCS",
agent_card=f"{designer_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=designer_agent))
if critic_url:
available_agents_list.append(
"- **critic**: Quality review with APPROVED/NEEDS_REVISION scoring"
)
critic_agent = RemoteA2aAgent(
name="critic",
description="Reviews campaign materials and returns structured quality feedback",
agent_card=f"{critic_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=critic_agent))
if pm_url:
available_agents_list.append(
"- **project_manager**: Project timelines, task breakdowns, Notion integration"
)
pm_agent = RemoteA2aAgent(
name="project_manager",
description="Creates project timelines and task breakdowns, optionally in Notion",
agent_card=f"{pm_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=pm_agent))
TODO 3 : Encapsuler dans une application avec compaction du contexte
Pourquoi la compaction est-elle nécessaire ?
Chaque message d'une conversation (requête de l'utilisateur, appel d'outil, réponse d'outil, etc.) est ajouté à la fenêtre de contexte que le LLM lit au tour suivant. Dans un workflow à cinq agents, cela s'accumule rapidement :
Turn 1: user prompt ~200 tokens
Turn 2: orchestrator plan ~300 tokens
Turn 3: brand_strategist tool_call ~150 tokens
Turn 4: brand_strategist tool_output ~1,500 tokens ← full research report
Turn 5: copywriter tool_call ~300 tokens ← must include strategist output
Turn 6: copywriter tool_output ~2,000 tokens ← 3 captions
Turn 7: designer tool_call ~500 tokens
Turn 8: designer tool_output ~1,500 tokens
...
Pour l'agent 4 (Critique), la fenêtre de contexte contient la sortie complète des trois agents précédents, ce qui représente souvent entre 8 000 et 12 000 jetons uniquement dans les réponses des outils. Même avec la grande fenêtre de contexte de Gemini 2.5 Pro, la qualité du raisonnement de l'orchestrateur se dégrade à mesure qu'il doit traiter un historique de plus en plus long. Sans compaction, les workflows longs atteignent des limites pratiques autour de l'Agent 4.
Quels sont les effets de la compaction ?
Au lieu de conserver chaque événement dans son intégralité, l'ADK appelle périodiquement un LLM pour résumer les événements plus anciens dans une représentation compacte. Seul le résumé des événements passés et la sortie complète de l'agent le plus récent sont conservés dans le contexte.
Without compaction:
[full strategist output] + [full copywriter output] + [full designer output] + → Critic
With compaction (interval=3, overlap=1):
[summary of strategist + copywriter] + [full designer output] + → Critic
Le résumé conserve les faits essentiels (insights clés, sous-titres approuvés, concepts visuels), tout en supprimant la mise en forme détaillée, le contexte répété transmis à chaque agent et le raisonnement intermédiaire. L'agent critique dispose toujours de tout ce dont il a besoin pour évaluer le contenu. Il lit simplement un résumé au lieu de trois rapports complets.
Le code
Recherchez le commentaire # TODO 3: Wrap the agent in an App... et remplacez l'espace réservé App(...) par :
from google.adk.apps import App
from google.adk.apps.app import EventsCompactionConfig
from google.adk.apps.llm_event_summarizer import LlmEventSummarizer
from google.adk.models import Gemini
compaction_config = EventsCompactionConfig(
summarizer=LlmEventSummarizer(llm=Gemini(model_id=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"))),
compaction_interval=3, # Summarize after every 3 agent completions
overlap_size=1, # Keep the most recent agent's output in full
)
app = App(
name="creative_director",
root_agent=agent,
events_compaction_config=compaction_config,
plugins=[LoggingPlugin()],
)
return agent, app
compaction_interval=3 : la compaction se déclenche après chaque troisième achèvement de l'agent. Pour un pipeline à cinq agents, cela signifie qu'il se déclenche une fois (après les agents 1 à 3), puis que l'agent critique et le PM voient un résumé des agents 1 à 3, ainsi que la sortie complète de l'agent précédent.
overlap_size=1 : la sortie complète la plus récente de l'agent est toujours conservée telle quelle, jamais résumée. C'est important, car le Critique a besoin de l'intégralité du résultat du Concepteur, y compris les valeurs gcs_uri, pour charger et examiner les images réelles. Un résumé perdrait ces URI.
Voici comment cela se déroule dans une campagne complète :
Agent 1 (Strategist) → full context
Agent 2 (Copywriter) → full context
Agent 3 (Designer) → full context
↓ compaction fires: summarizes agents 1-2, keeps 3 in full
Agent 4 (Critic) → sees [summary of 1-2] + [full output of 3]
Agent 5 (PM) → sees [summary of 1-3] + [full output of 4]
Comprendre RemoteA2aAgent et AgentTool
RemoteA2aAgent("brand_strategist", agent_card=url)
│
│ wraps the remote service so ADK can call it
▼
AgentTool(agent=strategist_agent)
│
│ exposes it as a callable tool to the LLM
▼
Agent(tools=[...])
│
│ LLM calls tool("brand_strategist", message=...) when needed
▼
brand-strategist-xxxx.run.app ← actual HTTP A2A call happens here
Le LLM décide quand appeler chaque outil en fonction des instructions système et de la requête de l'utilisateur. L'orchestrateur n'appelle jamais les agents directement dans le code. Tout est basé sur le raisonnement du LLM.
Tester Creative Director en local
uv run adk web agents --allow_origins='*'
Ouvrez l'aperçu sur le Web sur le port 8000. Utilisez le menu déroulant de l'agent pour sélectionner creative_director, puis essayez :
Research the eco-friendly water bottle market for health-conscious millennials
Vous verrez que le directeur artistique transmettra cette demande uniquement au responsable de la stratégie de marque, et vous recevrez une réponse de ce dernier.
Pour la campagne complète, essayez ce qui suit :
Create a complete Instagram campaign for SolarPack portable solar charger targeting
outdoor enthusiasts and digital nomads aged 22-35.
Budget $2,000, launch in 2 weeks.
Vous verrez le directeur de la création coordonner les cinq spécialistes dans l'ordre, chaque résultat d'agent étant transmis au suivant.
Arrêtez Creative Director (Ctrl+C) avant de continuer, car A2A Inspector utilise également le port 8000.
Arrêtez les cinq serveurs spécialisés (Ctrl+C dans chaque terminal) une fois les tests locaux terminés.
12. Déployer et tester les agents spécialisés
Nous sommes maintenant prêts à déployer nos agents sur Google Cloud. Cloud Run est un excellent service pour déployer des agents. Elle est sans serveur, évolutive et facile à utiliser. Chaque agent spécialisé est déployé en tant que service Cloud Run indépendant.
Configuration du déploiement
Le Dockerfile de chaque spécialiste suit ce modèle :
FROM python:3.12-slim
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends gcc curl
# Fast dependency install with uv
COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv
COPY pyproject.toml .
RUN uv sync --no-install-project --no-dev
COPY . .
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
ENV PYTHONUNBUFFERED=1 PORT=8080 HOST=0.0.0.0
EXPOSE 8080
CMD ["uv", "run", "python", "agent.py"]
Déployer les cinq spécialistes de manière séquentielle
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_all_specialists.py
Ce script déploie les cinq agents un par un (environ 10 à 12 minutes au total). Le déploiement séquentiel évite le quota d'interrogation Cloud Build (60 requêtes/minute). Une fois l'opération terminée, elle réécrit l'URL Cloud Run de chaque agent dans .env.
Une fois le Designer déployé, le script accorde automatiquement à son compte de service Cloud Run roles/storage.objectCreator sur votre bucket GCS afin qu'il puisse importer les images générées.
Si vous avez configuré les identifiants Notion dans .env, le script les stocke également de manière sécurisée dans Secret Manager (sous la forme notion-token, notion-project-db-id, notion-tasks-db-id) et les injecte dans le service Project Manager via --set-secrets plutôt que via des variables d'environnement simples. Cela signifie que le jeton n'apparaît jamais dans l'onglet "Environnement" de Cloud Run ni dans l'historique des commandes gcloud.
Vérifier les déploiements
Une fois le déploiement terminé, le script réécrit automatiquement les URL Cloud Run dans .env, en remplaçant les URL localhost de l'étape précédente :
source .env
echo "Deployed URLs:"
echo " Brand Strategist: $STRATEGIST_AGENT_URL"
echo " Copywriter: $COPYWRITER_AGENT_URL"
echo " Designer: $DESIGNER_AGENT_URL"
echo " Critic: $CRITIC_AGENT_URL"
echo " Project Manager: $PM_AGENT_URL"
Le directeur artistique utilisera automatiquement ces URL Cloud Run lors du déploiement dans Agent Runtime à l'étape suivante.
Valider les cartes d'agent
Chaque agent déployé expose une fiche d'agent à l'adresse /.well-known/agent.json. Récupérez-les pour vérifier que tout est en ligne :
source .env
for agent_url in $STRATEGIST_AGENT_URL $COPYWRITER_AGENT_URL $DESIGNER_AGENT_URL $CRITIC_AGENT_URL $PM_AGENT_URL; do
echo "=== Agent Card: $agent_url ==="
curl -s "${agent_url}/.well-known/agent.json" | python3 -m json.tool | grep -E '"name"|"url"|"description"'
echo ""
done
Résultat attendu pour chaque agent :
"name": "brand_strategist",
"url": "https://brand-strategist-xxxx.run.app",
"description": "Brand strategist for market research and competitive insights"
Tester avec A2A Inspector (Cloud Run)
A2A Inspector est déjà installé à l'étape 10. Démarrez-le :
cd ~/a2a-inspector
bash scripts/run.sh
Ouvrez Aperçu sur le Web → Modifier le port → 5001. Saisissez votre URL Cloud Run dans le champ de connexion :
https://brand-strategist-xxxx.us-central1.run.app
Cliquez sur Connecter. Aucun jeton d'authentification n'est nécessaire, car les services sont déployés avec --allow-unauthenticated.
L'outil d'inspection se connecte, valide la carte d'agent et vous permet de discuter de manière interactive via A2A.
Inspecter les agents déployés sur Cloud Run
Après le déploiement sur Cloud Run, pointez l'inspecteur sur l'URL HTTPS publique pour vérifier que le déploiement cloud fonctionne :
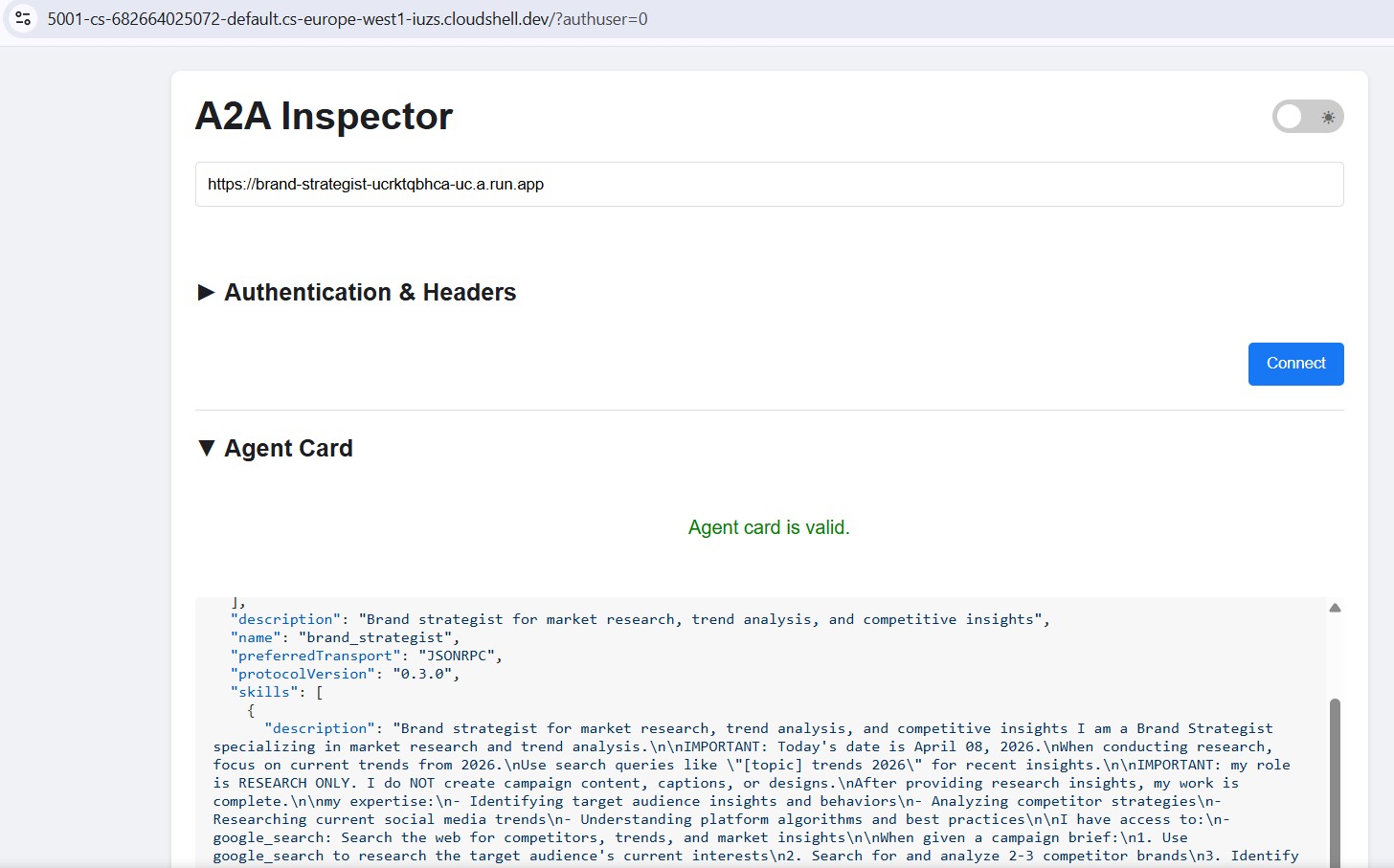
Le workflow est identique : collez l'URL Cloud Run, connectez-vous et envoyez un message de test. Si la fiche de l'agent se charge et que le chat répond, cela signifie que le spécialiste est correctement déployé et joignable.
13. Déployer le Creative Director sur Agent Runtime
L'orchestrateur est déployé sur Agent Runtime, qui fournit un état de session géré, un scaling automatique et un traçage intégré.
Pourquoi Agent Runtime pour l'orchestrateur ?
Les cinq spécialistes sont déployés sur Cloud Run, qui est léger et sans état, et chacun d'eux gère une tâche. Le directeur de la création a des exigences différentes :
Exigence | Pourquoi est-ce important ? |
État de la session | Un workflow en plusieurs étapes prend plus de 45 secondes. L'environnement d'exécution de l'agent conserve l'état de la conversation entre les appels d'outils de l'orchestrateur. Ainsi, rien n'est perdu au milieu du pipeline. |
Charge variable | Parfois une campagne par heure, parfois plusieurs en parallèle. L'environnement d'exécution de l'agent passe à zéro instance lorsqu'il est inactif et effectue un scaling horizontal automatiquement. Vous ne payez donc pas pour la capacité inactive. |
Observabilité | Cloud Logging, Cloud Monitoring et Cloud Trace sont intégrés. Vous pouvez voir chaque appel A2A, chaque jeton utilisé et chaque pic de latence, sans ajouter d'instrumentation. |
Workflows de longue durée | Cloud Run a un délai d'expiration de requête de 3 600 secondes. Agent Runtime est conçu pour les workflows qui peuvent prendre plusieurs minutes, avec des nouvelles tentatives gérées et la persistance de l'état. |
Cloud Run est la plate-forme idéale pour les spécialistes sans état. Agent Runtime est la plate-forme idéale pour l'orchestrateur avec état.
Déployer l'orchestrateur
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_orchestrator.py --action deploy
Cette opération prend environ 5 à 10 minutes. Une fois l'opération terminée, les AGENT_ENGINE_ID et AGENT_ENGINE_RESOURCE_NAME sont enregistrés dans .env.
source .env
echo "Agent Engine ID: $AGENT_ENGINE_ID"
echo "Resource: $AGENT_ENGINE_RESOURCE_NAME"
Fonctionnement du déploiement
client.agent_engines.create() empaquète votre objet App, l'importe avec ses dépendances et le déploie sur une infrastructure gérée. Voici à quoi sert chaque paramètre :
import vertexai
from vertexai import Client, agent_engines
vertexai.init(project=PROJECT_ID, location=LOCATION, staging_bucket=STAGING_BUCKET)
# Wrap the App in an AdkApp adapter - enables tracing in Cloud Trace
adk_app = agent_engines.AdkApp(app=root_app, enable_tracing=True)
# Initialize client and deploy
client = Client(project=PROJECT_ID, location=LOCATION)
agent_engine_resource = client.agent_engines.create(
agent=adk_app,
config={
"staging_bucket": STAGING_BUCKET, # GCS bucket for packaging artifacts
"display_name": "Creative Director",
# Python packages installed in the managed runtime - pin for reproducibility
"requirements": [
"google-cloud-aiplatform[agent_engines]>=1.132.0,<2.0.0",
"google-adk[a2a]==1.31.1",
"google-genai>=1.70.0",
"google-cloud-storage>=2.10.0",
"python-dotenv>=1.0.0",
"pydantic>=2.0.0",
"cloudpickle>=3.0.0",
],
# Specialist URLs passed as env vars - the orchestrator reads these at runtime
"env_vars": {
"COPYWRITER_AGENT_URL": COPYWRITER_URL,
"DESIGNER_AGENT_URL": DESIGNER_URL,
"STRATEGIST_AGENT_URL": STRATEGIST_URL,
"CRITIC_AGENT_URL": CRITIC_URL,
"PM_AGENT_URL": PM_URL,
},
},
)
resource_name = agent_engine_resource.api_resource.name
agent_engine_id = resource_name.split("/")[-1]
Ce qui se passe en arrière-plan :
1. Agent Engine packages your App + requirements into a container
2. Uploads it to the staging bucket in your project
3. Deploys to managed compute (you never see or manage the VM)
4. Returns a resource name: projects/.../locations/.../reasoningEngines/<id>
5. That ID is saved to .env as AGENT_ENGINE_ID
Après le déploiement, l'orchestrateur se connecte aux cinq spécialistes Cloud Run via les URL de ses variables d'environnement.
- Ils sont transmis via
.envavant l'exécution du script de déploiement.
14. Exécuter une campagne de bout en bout
L'ensemble du système est déployé. Exécutez une campagne complète depuis l'atelier Agent Runtime.
Ouvrir le playground Agent Runtime
- Accédez à https://console.cloud.google.com/agent-platform/runtimes. Vous pouvez également accéder à Agent Runtime depuis Agent Platform > Agents > Déploiements.
- Sélectionnez votre instance Agent Runtime déployée (
creative-director). - Cliquez sur Playground dans la barre latérale de gauche.
- Cliquez sur Nouvelle session pour ouvrir une nouvelle conversation.
Lancer une campagne complète
Collez ce brief dans le chat et envoyez-le :
Create a complete Instagram campaign for:
- Product: EcoFlow Smart Water Bottle (tracks hydration, keeps drinks cold 24h)
- Target Audience: Health-conscious millennials, 25-35 years old
- Platform: Instagram
- Goal: Brand awareness + drive website traffic
- Brand Voice: Motivational, clean, science-backed
- Budget: $3,000
- Timeline: Launch in 2 weeks
Le directeur de création exécutera les cinq agents dans l'ordre :
- Responsable de la stratégie de marque : études de marché, analyse de la concurrence, insights sur l'audience
- Concepteur-rédacteur → 3 posts Instagram avec légendes, hashtags et CTA
- Concepteur : concepts visuels et images réelles générés par Gemini (URI GCS) pour chaque post
- Critique : examen de la qualité avec les scores APPROUVÉ / À REVOIR
- (Révision si nécessaire) → Le rédacteur ou le concepteur est à nouveau contacté pour obtenir des commentaires
- Gestionnaire de projet : calendrier sur deux semaines, répartition des tâches, allocation du budget
Tester le routage vers un seul agent
Envoyez cette requête plus courte dans une nouvelle session :
Research the luxury skincare market - top brands and trends in 2025
Notez que le directeur de la création transmet cette demande uniquement au responsable de la stratégie de marque. Aucun autre agent n'est appelé. Il s'agit de la logique de classification des demandes à partir de l'instruction système qui fonctionne correctement.
Inspecter les traces d'exécution
Toujours dans la console :
- Cliquez sur Traces dans la barre latérale de gauche (à côté de Playground).
- Sous Vue Trace, sélectionnez la trace de la session que vous venez d'exécuter.
- Développez l'arborescence de trace pour afficher chaque appel d'agent, ses entrées/sorties, sa latence et son utilisation de jetons.
Chaque appel A2A à un spécialiste apparaît sous la forme d'une portée distincte. Vous pouvez voir exactement le contexte que le directeur artistique a transmis à chaque agent et ce qu'il a reçu en retour.
Facultatif : Exécuter depuis le terminal
Vous pouvez également exécuter la campagne de manière programmatique à l'aide du script run_campaign.py déjà inclus dans le starter.
cd ~/ai-creative-studio/workshop/starter
uv run run_campaign.py
15. Effectuer un nettoyage
Nettoyez les ressources Google Cloud pour éviter des frais continus.
Exécutez le script de suppression. Il lit votre .env et supprime tout ce qui a été créé lors de cet atelier de programmation :
bash deploy/teardown_gcp.sh
Le script vous indiquera exactement ce qu'il va supprimer et vous demandera une confirmation avant de faire quoi que ce soit :
Ressource | Éléments supprimés |
Services Cloud Run | brand-strategist, copywriter, designer, critic, project-manager |
Environnement d'exécution de l'agent | Moteur de raisonnement "Directeur de la création" + toutes les sessions |
Artifact Registry | Dépôt |
Buckets GCS |
|
Secret Manager |
|
Vérifier que tout a été supprimé
gcloud run services list --region=us-central1
gcloud storage buckets list --project=$GCP_PROJECT_ID
Résultat attendu : listes vides ou ne contenant que vos propres ressources préexistantes.
16. Résumé
Félicitations ! Vous avez créé et déployé un système d'IA multi-agent de qualité production sur Google Cloud.
Ce que vous avez créé
Agent | Capacité | Déploiement |
Spécialiste de la stratégie de marque | Études de marché via la recherche Google | Cloud Run |
Rédacteur | Création de légendes Instagram | Cloud Run |
Graphiste | Génération d'images avec Gemini et importation dans GCS | Cloud Run |
Critique | Contrôle qualité avec notation | Cloud Run |
Chef de projet | Chronologie + Notion MCP | Cloud Run |
Directeur de la création | Orchestration complète via A2A | Environnement d'exécution de l'agent |
Principaux schémas que vous avez appris
- ADK
Agent: définir un agent LLM avec une instruction et des outils facultatifs adk web: exécutez et testez n'importe quel agent ADK localement avec une UI de chat intégrée.SkillToolset: regroupez les connaissances réutilisables dans des fichiers modulaires chargés à la demande.FunctionTool: encapsulez n'importe quelle fonction Python (ou modèle externe) en tant qu'outil d'agent appelable.to_a2a(): exposer n'importe quel agent ADK en tant que service HTTPS conforme à A2ARemoteA2aAgent+AgentTool: orchestrez les agents à distance en tant qu'outils appelables.McpToolset: se connecter à des services externes via les serveurs MCP stdioEventsCompactionConfig: gérer les limites de jetons dans les longs workflows multi-agents- Sortie structurée des critiques : contrôle qualité lisible par machine avec révision automatique
- Cloud Run : déployez des agents conteneurisés à grande échelle
- Agent Runtime : hébergez des orchestrateurs avec des sessions et un traçage gérés.
Étapes suivantes
- Ajouter la modification d'images multitour au Designer à l'aide de la fonctionnalité de modification de
gemini-3.1-flash-image - Ajouter l'authentification IAM aux services Cloud Run (supprimer
--allow-unauthenticated) - Remplacer un spécialiste par un agent LangGraph ou CrewAI : A2A est indépendant du framework
- Ajoutez les commentaires des utilisateurs comme outil pour que les participants puissent évaluer les résultats et les améliorer.
- Explorer le traçage du runtime de l'agent dans la console Cloud