
1. खास जानकारी
इस कोडलैब में, आपको AI Creative Studio बनाने का तरीका बताया जाएगा. यह एक डिस्ट्रिब्यूटेड मल्टी-एजेंट सिस्टम है, जो एक प्रॉम्प्ट को पूरे Instagram कैंपेन में बदल देता है.
एक वाक्य टाइप करें. आपको दर्शकों की रिसर्च, कैप्शन, विज़ुअल कॉन्सेप्ट, क्वालिटी की समीक्षा की गई कॉपी, और पूरे प्रोजेक्ट की टाइमलाइन वापस मिल जाएगी. यह सब, साथ मिलकर काम करने वाले एआई एजेंट की टीम जनरेट करती है.
आपके बनाए गए एजेंट
एजेंट | भूमिका |
ब्रैंड रणनीतिकार | यह ऑडियंस के बारे में अहम जानकारी, प्रतिस्पर्धियों का विश्लेषण, और 2025 के रुझानों के लिए वेब पर खोज करता है |
कॉपीराइटर | यह Instagram के लिए हैशटैग और सीटीए के साथ कैप्शन लिखता है. यह ADK की ऐसी स्किल की मदद से काम करता है जो प्लैटफ़ॉर्म के दिशा-निर्देशों और कैप्शन फ़ॉर्मूले को ज़रूरत के हिसाब से लोड करती है |
डिज़ाइनर | Gemini की मदद से विज़ुअल कॉन्सेप्ट बनाता है और असली इमेज जनरेट करता है. इन्हें GCS में सेव किया जाता है |
आलोचक | समीक्षाओं की कॉपी और विज़ुअल - खास जानकारी के साथ |
प्रोजेक्ट मैनेजर | यह प्रोजेक्ट की टाइमलाइन और टास्क ब्रेकडाउन बनाता है. इसे एमसीपी के ज़रिए Notion के साथ सिंक किया जा सकता है |
क्रिएटिव डायरेक्टर | यह पांचों विशेषज्ञों को क्रम से निर्देश देता है. आपको सिर्फ़ एक प्रॉम्प्ट देना होता है, बाकी काम यह खुद करता है |
पांचों एजेंट को इंडिपेंडेंट Cloud Run माइक्रोसेवाओं के तौर पर डिप्लॉय किया जाता है. ये A2A प्रोटोकॉल के ज़रिए कम्यूनिकेट करते हैं. यह एक ओपन स्टैंडर्ड है, जो किसी भी भाषा पर लागू होता है. इसलिए, कोई भी एजेंट किसी दूसरे एजेंट को कॉल कर सकता है, भले ही वह किसी भी फ़्रेमवर्क का हो. क्रिएटिव डायरेक्टर, एजेंट रनटाइम पर काम करता है और हर विशेषज्ञ से रिमोटली कनेक्ट होता है.
आर्किटेक्चर

आपको क्या सीखने को मिलेगा
- Google ADK की मदद से एलएलएम एजेंट बनाएं -
Agent, सिस्टम के लिए निर्देश, और बिल्ट-इन टूल. - ADK Skills (
SkillToolset) की मदद से, एजेंट की जानकारी को मॉड्यूलर फ़ाइलों में पैकेज करें, ताकि उसका दोबारा इस्तेमाल किया जा सके. FunctionToolकी मदद से, टेक्स्ट एजेंट को इमेज मॉडल से जोड़कर असली इमेज जनरेट करें.- मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी) का इस्तेमाल करके, कस्टम ग्लू कोड के बिना बाहरी एपीआई इंटिग्रेट करें.
- एचटीटीपीएस पर एजेंट से एजेंट प्रोटोकॉल (A2A) का इस्तेमाल करके, किसी भी एजेंट को नेटवर्क-कॉल की जा सकने वाली सेवा में बदलें.
RemoteA2aAgentऔरAgentToolकी मदद से, डिस्ट्रिब्यूट किए गए एजेंट को व्यवस्थित करें.- इंडिपेंडेंट एजेंट को Cloud Run माइक्रोसेवाओं के तौर पर पैकेज करें और डिप्लॉय करें.
- एजेंट रनटाइम पर स्टेटफ़ुल ऑर्केस्ट्रेटर होस्ट करें.
- कॉन्टेक्स्ट कंपैक्शन का इस्तेमाल करके, मल्टी-एजेंट वाले लंबे वर्कफ़्लो को कॉन्टेक्स्ट की सीमाओं के अंदर रखें.
- क्वालिटी कंट्रोल लूप बनाएं: आलोचक की समीक्षाएं → ज़रूरत पड़ने पर अपने-आप बदलाव होना.
आपको किन चीज़ों की ज़रूरत होगी
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- मालिक या एडिटर की IAM भूमिका
- Python की बुनियादी जानकारी
2. अपना एनवायरमेंट सेट अप करना
इस कोडलैब के लिए, हम Cloud Shell का इस्तेमाल करेंगे.
Cloud Shell क्या है?
Cloud Shell, ब्राउज़र पर आधारित एक मुफ़्त Linux एनवायरमेंट है. इसमें gcloud, git, Python, Docker वगैरह पहले से इंस्टॉल होते हैं. आपको कुछ भी स्थानीय तौर पर इंस्टॉल करने की ज़रूरत नहीं होती.
Cloud Shell खोलने के लिए, GCP Console के सबसे ऊपर दाएं टूलबार में मौजूद टर्मिनल आइकॉन पर क्लिक करें:
पहली बार Cloud Shell खोलने पर, आपसे अपने खाते की पुष्टि करने के लिए कहा जाएगा. इसके लिए, पुष्टि करें पर क्लिक करें:
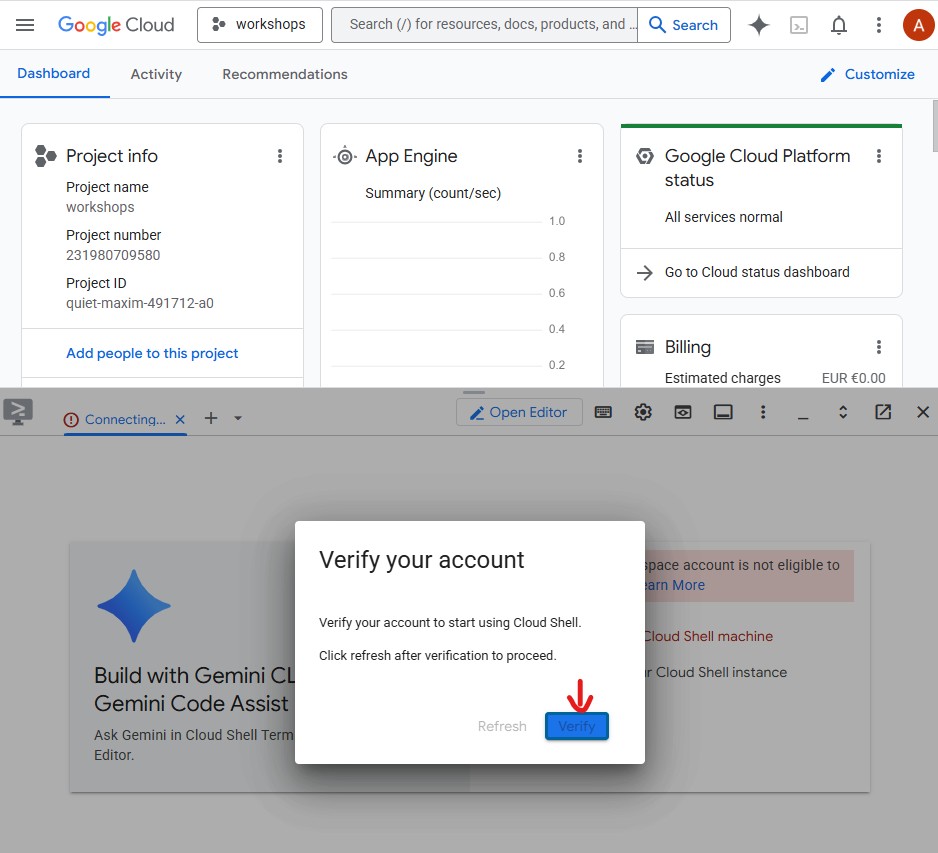
इसके बाद, Cloud Shell को Google Cloud API कॉल करने की अनुमति देने के लिए, अनुमति दें पर क्लिक करें:
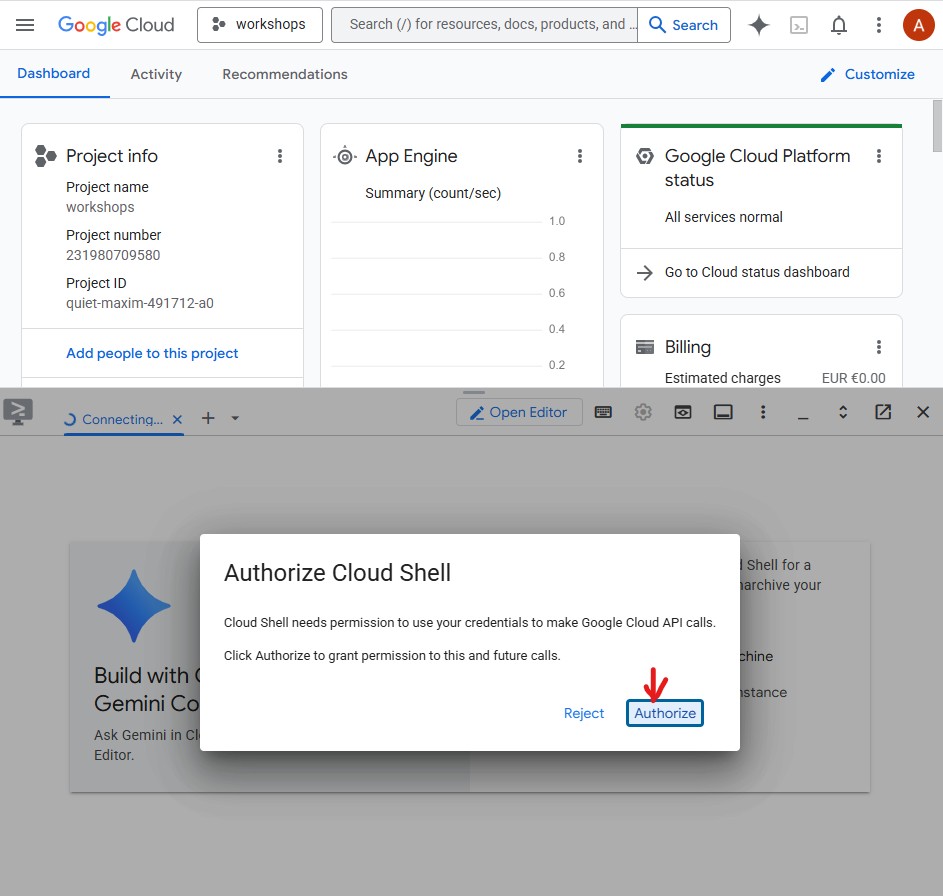
अब Cloud Shell इस्तेमाल किया जा सकता है. आपको टर्मिनल में स्वागत वाला मैसेज दिखेगा: 
अपने प्रोजेक्ट की पुष्टि करना और उसे कॉन्फ़िगर करना
Cloud Shell में पहले से ही आपके Google खाते से पुष्टि की गई है. पुष्टि करें कि आपका खाता चालू है और अपना प्रोजेक्ट आईडी ढूंढें:
gcloud config list
आपको GCP Console के डैशबोर्ड पर, बाईं ओर मौजूद पैनल में अपना प्रोजेक्ट आईडी भी दिखेगा. इसे कॉपी करें. आपको अगली कमांड में इसकी ज़रूरत पड़ेगी:
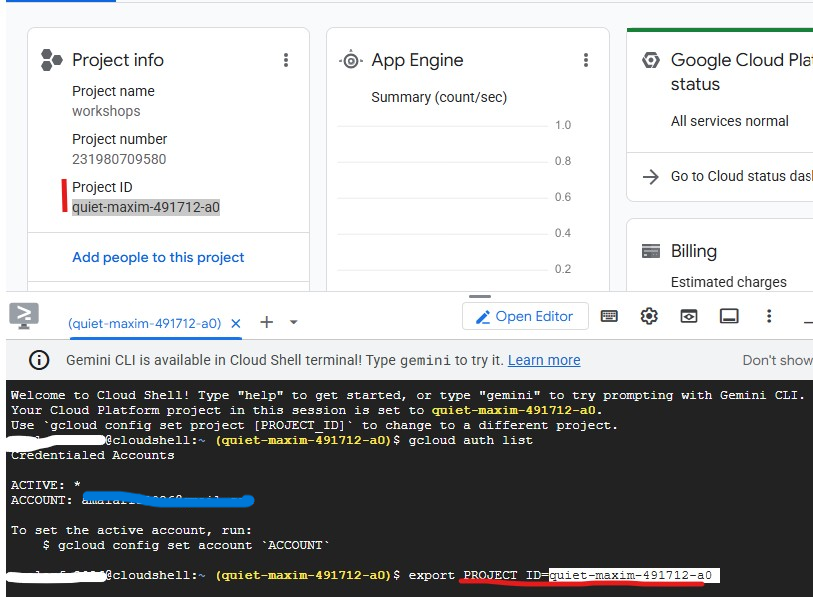
अब अपना प्रोजेक्ट सेट करें:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Cloud Run deployment region
echo "Project: $PROJECT_ID"
अनुमानित आउटपुट:
Project: my-project-123
ज़रूरी एपीआई चालू करना
gcloud services enable \
aiplatform.googleapis.com \
apphub.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
generativelanguage.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com \
storage.googleapis.com \
secretmanager.googleapis.com
इसमें करीब दो मिनट लगते हैं. प्रोसेस पूरी होने पर, आपको Operation finished successfully दिखेगा.
ऐप्लिकेशन के डिफ़ॉल्ट क्रेडेंशियल (एडीसी) सेट अप करना
एजेंट, Google Auth library का इस्तेमाल करके Gemini Enterprise Agent Platform को कॉल करेंगे. इसके लिए, ऐप्लिकेशन के डिफ़ॉल्ट क्रेडेंशियल की ज़रूरत होती है. ये क्रेडेंशियल, gcloud CLI से पुष्टि करने के क्रेडेंशियल से अलग होते हैं.
इसे एक बार चलाएं:
gcloud auth application-default login
इसके बाद, एक ब्राउज़र टैब खुलेगा. इसमें आपसे पुष्टि करने के लिए कहा जाएगा. अनुमति दें पर क्लिक करें. आपको ये चीज़ें दिखेंगी:
Credentials saved to file: ~/.config/gcloud/application_default_credentials.json
स्टार्टर रिपॉज़िटरी का क्लोन बनाना
इस कोडलैब में, स्टार्टर रिपॉज़िटरी का इस्तेमाल किया गया है. यह एक स्केलेटन प्रोजेक्ट है, जिसमें सभी बुनियादी ढांचे (Dockerfiles, pyproject.toml, डिप्लॉय स्क्रिप्ट) को सेट अप किया गया है. हालांकि, एजेंट लॉजिक को आपको लिखना होगा.
git clone https://github.com/Saoussen-CH/mas-a2a-gcp.git ~/ai-creative-studio
cd ~/ai-creative-studio/workshop/starter
हर agent.py में # TODO प्लेसहोल्डर होते हैं. इनमें एजेंट लॉजिक लिखा जाता है. Dockerfile, pyproject.toml, और डिप्लॉय स्क्रिप्ट पहले से ही पूरी हो चुकी हैं.
एनवायरमेंट वैरिएबल कॉन्फ़िगर करना
दिए गए उदाहरण को कॉपी करें और एक ही चरण में अपना प्रोजेक्ट आईडी डालें:
cp .env.example .env
sed -i "s|GOOGLE_CLOUD_PROJECT=your-project-id|GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)|" .env
इसके बाद, GCS बकेट बनाएं. इसमें डिज़ाइनर, जनरेट की गई इमेज सेव करेगा और .env को इसके नाम के साथ अपडेट करेगा:
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-campaign-images"
gcloud storage buckets create gs://${BUCKET_NAME} \
--location=us-central1 \
--project=${PROJECT_ID}
sed -i "s|GCS_IMAGES_BUCKET=your-project-id-campaign-images|GCS_IMAGES_BUCKET=${BUCKET_NAME}|" .env
इसके बाद, हस्ताक्षर किए गए इमेज यूआरएल की सुविधा सेट अप करें. क्रिएटिव डायरेक्टर, कैंपेन की फ़ाइनल खास जानकारी में मौजूद हर इमेज के लिए, क्लिक किए जा सकने वाले एचटीटीपीएस लिंक जनरेट करता है. इसके लिए, यूआरएल पर हस्ताक्षर करने के लिए सेवा खाते की ज़रूरत होती है. इसे कॉन्फ़िगर करने के लिए, इन कमांड को चलाएं:
export PROJECT_NUMBER=$(gcloud projects describe $(gcloud config get-value project) --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
export AGENT_RUNTIME_SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Allow your user account to sign URLs locally (adk web)
gcloud iam service-accounts add-iam-policy-binding ${SA_EMAIL} \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Allow Agent Runtime to sign URLs when deployed
gcloud projects add-iam-policy-binding $(gcloud config get-value project) \
--member="serviceAccount:${AGENT_RUNTIME_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
# Save SA email and project number to .env
grep -q "^SIGNING_SERVICE_ACCOUNT" .env \
&& sed -i "s|^SIGNING_SERVICE_ACCOUNT=.*|SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}|" .env \
|| echo "SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}" >> .env
grep -q "^GOOGLE_CLOUD_PROJECT_NUMBER" .env \
&& sed -i "s|^GOOGLE_CLOUD_PROJECT_NUMBER=.*|GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}|" .env \
|| echo "GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}" >> .env
सभी सेटिंग देखने के लिए, एडिटर में .env खोलें:
cloudshell edit .env
इससे .env, Cloud Shell Editor में एक टैब के तौर पर खुल जाता है. अगर एडिटर पैनल नहीं दिख रहा है, तो टूलबार में मौजूद एडिटर खोलें बटन पर क्लिक करें:

पुष्टि करें कि प्रोजेक्ट को सही तरीके से सेट किया गया है:
grep GOOGLE_CLOUD_PROJECT .env
डिपेंडेंसी इंस्टॉल करना
हम uv का इस्तेमाल करते हैं. यह Python पैकेज मैनेजर का नया और तेज़ वर्शन है. यह वर्चुअल एनवायरमेंट को मैनेज करता है और इसे एक ही टूल में इंस्टॉल किया जा सकता है. यह pip से ~10 से 100 गुना ज़्यादा तेज़ है. साथ ही, Python प्रोजेक्ट मैनेज करने के लिए इसका इस्तेमाल करने का सुझाव दिया जाता है.
Cloud Shell में uv पहले से इंस्टॉल होता है. सभी एजेंट एक ही मुख्य डिपेंडेंसी शेयर करते हैं. इसलिए, इसे एक बार इंस्टॉल करें. यह इस कोडलैब में मौजूद हर एजेंट के लिए काम करेगा:
uv sync
uv sync कमांड, pyproject.toml को पढ़ती है और सभी डिपेंडेंसी के साथ .venv/ डायरेक्ट्री बनाती है. हर स्पेशलिस्ट के पास अपना pyproject.toml भी होता है, जिसका इस्तेमाल सिर्फ़ Docker बिल्ड के लिए किया जाता है. ऊपर दिए गए शेयर किए गए इंस्टॉलेशन में, लोकल टेस्टिंग के लिए ज़रूरी सभी चीज़ें शामिल होती हैं.
3. Google ADK के बारे में जानकारी
कोड लिखने से पहले, आइए एजेंट डेवलपमेंट किट (एडीके) के बारे में जानते हैं. यह वह फ़्रेमवर्क है जिसका इस्तेमाल इस कोडलैब में हर एजेंट को बनाने के लिए किया जाएगा.
एडीके क्या है?
एजेंट डेवलपमेंट किट (एडीके), एआई एजेंट डेवलप और डिप्लॉय करने के लिए एक फ़्लेक्सिबल और मॉड्यूलर फ़्रेमवर्क है. एडीके को Gemini और Google के इकोसिस्टम के लिए ऑप्टिमाइज़ किया गया है. हालांकि, यह मॉडल-अग्नोस्टिक और डिप्लॉयमेंट-अग्नोस्टिक है. साथ ही, इसे अन्य फ़्रेमवर्क के साथ काम करने के लिए बनाया गया है. एडीके को इस तरह से डिज़ाइन किया गया है कि एजेंट डेवलपमेंट, सॉफ़्टवेयर डेवलपमेंट की तरह लगे. इससे डेवलपर के लिए, एजेंटिक आर्किटेक्चर बनाना, डिप्लॉय करना, और मैनेज करना आसान हो जाता है. ये आर्किटेक्चर, आसान टास्क से लेकर मुश्किल वर्कफ़्लो तक के लिए बनाए जा सकते हैं.
ADK, मुश्किल काम आसानी से कर लेता है. जैसे, टूल कॉलिंग, कई बार बातचीत करना, कॉन्टेक्स्ट मैनेजमेंट, और स्ट्रीमिंग. इसलिए, आपको एजेंट के लॉजिक पर ध्यान देने का मौका मिलता है.
ADK एजेंट के बिल्डिंग ब्लॉक
हर एजेंट में चार ज़रूरी कॉम्पोनेंट होते हैं:
ब्लॉक करें | भूमिका |
मॉडल | यह एलएलएम, लक्ष्यों के बारे में सोचता है, प्लान तय करता है, और जवाब जनरेट करता है |
टूल | ऐसे फ़ंक्शन जो एपीआई या सेवाओं को कॉल करके डेटा फ़ेच करते हैं या कार्रवाइयां करते हैं |
ऑर्केस्ट्रेशन | यह बातचीत के दौरान, पिछली जानकारी को याद रखता है. साथ ही, टूल को कॉल करने के लिए रूट करता है और मॉडल को नतीजे वापस भेजता है |
रनटाइम | इसे शुरू करने पर सिस्टम काम करता है. इसे |
एजेंट की परिभाषा
इस कोडलैब में मौजूद पांचों एजेंट को एक ही तरीके से तय किया गया है:
from google.adk.agents import Agent
from google.adk.tools.google_search_tool import google_search
root_agent = Agent(
name="brand_strategist", # unique identifier
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"), # the LLM powering this agent
instruction=SYSTEM_INSTRUCTION, # the agent's persona, constraints, and output format
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search], # functions the LLM can call
)
फ़ील्ड | मकसद |
| यूनीक आईडी - इसका इस्तेमाल ऑर्केस्ट्रेटर, कॉल को रूट करने के लिए करते हैं |
| इस एजेंट को चलाने वाला Gemini मॉडल |
| सिस्टम प्रॉम्प्ट - इससे एजेंट की भूमिका, सीमाएं, और आउटपुट फ़ॉर्मैट तय होता है |
| एक लाइन में जानकारी - ऑर्केस्ट्रेटर इसे पढ़कर यह तय करता है कि किस विशेषज्ञ को कॉल करना है |
| ऐसे फ़ंक्शन जिन्हें एलएलएम कॉल कर सकता है. जैसे, |
ADK, एजेंट को कैसे चलाता है
User message
│
▼
Agent (LLM) ← reads instruction + conversation history
│
├─► needs more info? → calls a tool → gets result → continues reasoning
│
└─► done reasoning → returns final text response
एलएलएम अपने-आप यह तय करता है कि किसी टूल को कॉल करना है या नहीं. साथ ही, वह यह भी तय करता है कि किस टूल को कॉल करना है और किन तर्कों के साथ कॉल करना है. आपको सिर्फ़ निर्देश लिखना होता है. बाकी काम ADK करता है.
4. ब्रैंड स्ट्रैटजिस्ट एजेंट बनाना और उसे टेस्ट करना
आइए, पहले एजेंट से शुरू करते हैं: ब्रैंड स्ट्रैटजिस्ट. यह सिर्फ़ रिसर्च करने वाला एजेंट है. इसका इस्तेमाल, Google Search का इस्तेमाल करके टारगेट ऑडियंस के बारे में अहम जानकारी, प्रतिस्पर्धी विश्लेषण, और ट्रेंडिंग विषयों को खोजने के लिए किया जाता है.
Cloud Shell Editor में, स्केलेटन एजेंट फ़ाइल खोलें:
cloudshell edit agents/brand_strategist/agent.py
आपको दो # TODO सेक्शन दिखेंगे, ताकि आप उन्हें भर सकें.
पहला काम - सिस्टम के लिए निर्देश लिखना
सबसे पहले, एजेंट के लिए सिस्टम को निर्देश देने वाला प्रॉम्प्ट लिखें. सिस्टम के निर्देश, एक स्ट्रिंग होती है. इसमें एजेंट की भूमिका, सीमाएं, और आउटपुट फ़ॉर्मैट के बारे में बताया जाता है.
SYSTEM_INSTRUCTION = f"""You are a Brand Strategist specializing in market research and trend analysis.
IMPORTANT: Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
When conducting research, focus on current trends from {datetime.date.today().year}.
Use search queries like "[topic] trends {datetime.date.today().year}" for recent insights.
IMPORTANT: Your role is RESEARCH ONLY. You do NOT create campaign content, captions, or designs.
After providing research insights, your work is complete.
Your expertise:
- Identifying target audience insights and behaviors
- Analyzing competitor strategies
- Researching current social media trends
- Understanding platform algorithms and best practices
You have access to:
- google_search: Search the web for competitors, trends, and market insights
When given a campaign brief:
1. Use google_search to research the target audience's current interests
2. Search for and analyze 2-3 competitor brands
3. Identify 3-5 trending topics related to the product category
4. Provide high-level strategic insights - NOT specific campaign content
DO NOT create captions, copy, designs, or any campaign content.
Format your output as:
**Audience Insights:**
[Key behaviors and preferences based on research]
**Competitive Analysis:**
[What 2-3 competitors are doing - strengths and weaknesses]
**Trending Topics:**
[3-5 relevant trends to consider]
**Key Strategic Insights:**
[High-level themes and positioning opportunities]
"""
TODO 2 - Create the root_agent
इसके बाद, पूरा नहीं हुआ root_agent को इससे बदलें:
root_agent = Agent(
name="brand_strategist",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
instruction=SYSTEM_INSTRUCTION,
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search],
)
ADK के वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके, स्थानीय तौर पर टेस्ट करना
अब ADK के वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके एजेंट की जांच करते हैं. यह क्लाउड पर डिप्लॉय करने से पहले, एजेंट की जांच करने के लिए पहले से मौजूद चैट इंटरफ़ेस है.
uv run adk web agents --allow_origins='*'
आपको ये चीज़ें दिखेंगी:
INFO: Started server process
INFO: Uvicorn running on http://localhost:8000
अब सर्वर, Cloud Shell में चल रहा है:
इसे अपने ब्राउज़र में खोलने के लिए, वेब पर झलक देखें का इस्तेमाल करें:
- पेज पर सबसे ऊपर मौजूद, Cloud Shell टूलबार देखें
- वेब प्रीव्यू आइकॉन पर क्लिक करें. यह आइकॉन, Cloud Shell टूलबार के सबसे ऊपर दाईं ओर मौजूद होता है. यह ऊपर की ओर वाले ऐरो के साथ बॉक्स जैसा दिखता है
- "पोर्ट बदलें" पर क्लिक करें और
8000डालें. इसके बाद, "बदलें और झलक देखें" पर क्लिक करें
ADK के वेब यूज़र इंटरफ़ेस (यूआई) के साथ एक नया ब्राउज़र टैब खुलता है. सबसे ऊपर बाईं ओर मौजूद, "कोई एजेंट चुनें" ड्रॉपडाउन पर क्लिक करें. आपको अपने सभी एजेंट की सूची दिखेगी:
टेस्टिंग शुरू करने के लिए, brand_strategist चुनें:
टेस्ट के लिए इन प्रॉम्प्ट को आज़माएं
ADK के वेब यूज़र इंटरफ़ेस के चैट बॉक्स में, ये आज़माएं:
Research the eco-friendly water bottle market for health-conscious millennialsWhat are the top Instagram trends in the wellness space in 2025?
आपको दिखेगा कि एजेंट, Google Search को कॉल करता है और ऑडियंस की अहम जानकारी, प्रतिस्पर्धी विश्लेषण, और ट्रेंडिंग विषयों वाले सेक्शन के साथ स्ट्रक्चर्ड रिसर्च दिखाता है.
5. कॉपीराइटर - ADK की क्षमताएँ
भूमिका: ब्रैंड रिसर्च को Instagram कैप्शन में बदलें. कॉपीराइटर, अलग-अलग टोन (प्रेरणा देने वाली, शिक्षा देने वाली, कम्यूनिटी) वाले तीन कैप्शन बनाता है. हर कैप्शन में हैशटैग और सीटीए शामिल होता है.
कॉन्सेप्ट: ADK की स्किल
एक सामान्य तरीका यह है कि सिस्टम प्रॉम्प्ट में, प्लैटफ़ॉर्म से जुड़ी सभी जानकारी शामिल की जाए. जैसे, वर्ण सीमाएं, हैशटैग के टियर, कैप्शन के फ़ॉर्मूले, ब्रैंड की आवाज़ के उदाहरण. यह तरीका काम करता है, लेकिन इससे हर अनुरोध में ऐसा कॉन्टेंट शामिल हो जाता है जिसकी एजेंट को कभी-कभी ही ज़रूरत होती है.
ADK की स्किल (SkillToolset, ADK 1.25.0 में लॉन्च की गई) की मदद से, उस जानकारी को मॉड्यूलर फ़ाइलों में पैकेज किया जा सकता है. इन फ़ाइलों को तीन लेवल पर लोड किया जा सकता है:
- L1 - फ़्रंटमैटर (
SKILL.mdमेंname+description): हमेशा उपलब्ध रहता है. इसका इस्तेमाल स्किल खोजने के लिए किया जाता है - L2 - निर्देश (
SKILL.mdका मुख्य हिस्सा): यह तब लोड होता है, जब एजेंट स्किल को ट्रिगर करता है - L3 - संसाधन (
references/औरassets/फ़ाइलें): ये सिर्फ़ तब लोड होती हैं, जब एजेंट इन्हें साफ़ तौर पर पढ़ता है
सिस्टम के निर्देश को छोटा करके, भूमिका के बारे में कम शब्दों में बताया जाता है. साथ ही, "लिखने से पहले स्किल लोड करें" निर्देश दिया जाता है. प्लैटफ़ॉर्म की जानकारी सिर्फ़ तब कॉन्टेक्स्ट विंडो में डाली जाती है, जब एजेंट को इसकी ज़रूरत होती है.
कॉपीराइटर की स्किल, agents/copywriter/skills/instagram-copywriting/ में मौजूद होती है:
skills/
instagram-copywriting/
SKILL.md ← L1 frontmatter (discovery) + L2 instructions (loaded on trigger)
references/
platform-guide.md ← L3: character limits, hashtag tiers, algorithm signals
caption-formulas.md ← L3: hook formulas, CTA patterns, full caption structures
assets/
brand-voice-examples.md ← L3: annotated real-world caption examples
फ़ाइल को सीधे Cloud Shell एडिटर में खोलें:
cloudshell edit agents/copywriter/agent.py
TODO 1 - load_skill_from_dir और skill_toolset इंपोर्ट करें
टिप्पणी # TODO 1: Import load_skill_from_dir and skill_toolset ढूंढें और दो इंपोर्ट जोड़ें:
from google.adk.skills import load_skill_from_dir
from google.adk.tools import skill_toolset
TODO 2 - Load the skill and create a SkillToolset
इंपोर्ट के नीचे दी गई दो टिप्पणियां ढूंढें:
# TODO 2: Load the instagram-copywriting skill from the skills/ directory
# TODO 2: Create a SkillToolset with the loaded skill
इनकी जगह ये डालें:
_instagram_skill = load_skill_from_dir(
pathlib.Path(__file__).parent / "skills" / "instagram-copywriting"
)
_copywriting_skills = skill_toolset.SkillToolset(skills=[_instagram_skill])
load_skill_from_dir, SKILL.md के साथ-साथ references/ और assets/ में मौजूद सभी फ़ाइलें पढ़ता है. SkillToolset इसे ऐसे फ़ॉर्मैट में रैप करता है जिसे एडीके एजेंट स्वीकार करते हैं. यह एक टूलसेट है, न कि कोई रॉ स्किल.
TODO 3 - Register the toolset with the agent
tools=[], # TODO 3: Add the SkillToolset here ढूंढें और इसे इससे बदलें:
tools=[_copywriting_skills],
स्किल फ़ाइल खोलकर देखें कि उसे कैसे स्ट्रक्चर किया गया है:
cloudshell edit agents/copywriter/skills/instagram-copywriting/SKILL.md
ADK के वेब यूज़र इंटरफ़ेस (यूआई) को चालू रखें. सर्वर को रीस्टार्ट किए बिना copywriter पर स्विच करने के लिए, एजेंट ड्रॉपडाउन का इस्तेमाल करें.
अगर यह सुविधा काम नहीं कर रही है, तो इसे फिर से शुरू करें:
uv run adk web agents --allow_origins='*'
इसे आज़माएँ: ड्रॉपडाउन को copywriter पर स्विच करें और भेजें:
You are writing captions for EcoFlow Smart Water Bottle targeting health-conscious millennials aged 25-35.
Audience insight: they prioritize sustainability, track health metrics, and share lifestyle content.
Competitor insight: Hydro Flask dominates with lifestyle branding; S'well leads on premium aesthetics.
Write 3 Instagram captions - one inspirational, one educational, one community-focused. Include 5 hashtags each and a CTA.
6. Build the Designer - Multimodal Image Generation
ADK के वेब यूज़र इंटरफ़ेस (यूआई) को चालू रखें. सर्वर को रीस्टार्ट किए बिना एजेंट बदलने के लिए, एजेंट ड्रॉपडाउन का इस्तेमाल करें.
भूमिका: हर कैप्शन के लिए विज़ुअल कॉन्सेप्ट बनाना और Gemini की इमेज जनरेट करने की सुविधा का इस्तेमाल करके, असल इमेज जनरेट करना. Designer, हर कैप्शन के लिए सिर्फ़ एक विज़ुअल कॉन्सेप्ट जनरेट करता है. इसमें प्रॉम्प्ट, स्टाइल, कलर पैलेट, मूड, और Instagram फ़ॉर्मैट के बारे में पूरी जानकारी होती है. इसके बाद, यह तुरंत generate_image टूल को कॉल करता है, ताकि वह इमेज जनरेट कर सके और उसे GCS पर अपलोड कर सके.
कॉन्सेप्ट: टूल की मदद से, टेक्स्ट एजेंट को इमेज मॉडल से जोड़ना
Designer, gemini-3-flash-preview (.env में GEMINI_MODEL के ज़रिए सेट किया गया टेक्स्ट मॉडल) पर काम करता है. हालांकि, इमेज जनरेट करने के लिए एक खास मॉडल (gemini-3.1-flash-image) की ज़रूरत होती है. यह इमेज मॉडल, फ़ंक्शन कॉलिंग की सुविधा के साथ काम नहीं करता. इसलिए, इसे सीधे तौर पर ADK एजेंट के तौर पर इस्तेमाल नहीं किया जा सकता. इसके बजाय, इसे सामान्य Python फ़ंक्शन में रैप किया जाता है और FunctionTool के तौर पर रजिस्टर किया जाता है.
यह किसी भी ऐसे मॉडल या एपीआई के लिए पैटर्न है जिसे एलएलएम सीधे तौर पर कॉल नहीं कर सकता: इसे टूल में रैप करें, एजेंट को यह तय करने दें कि इसे कब कॉल करना है, और स्ट्रक्चर्ड नतीजे वापस पाएं.
Designer agent (text model)
│
│ decides visual concept, writes image prompt
▼
generate_image tool
│
│ calls gemini-3.1-flash-image
│ uploads result to GCS
▼
{"status": "success", "gcs_uri": "gs://..."}
│
│ returned to agent, included in response
▼
Critic (receives gcs_uri, passes to Vertex AI for multimodal review)
फ़ाइल को सीधे Cloud Shell एडिटर में खोलें:
cloudshell edit agents/designer/image_gen_tool.py
फ़ंक्शन सिग्नेचर, एनवायरमेंट सेटअप, और आस्पेक्ट रेशियो इंजेक्शन की सुविधा उपलब्ध कराई जाती है. नीचे दिए गए तीन TODO को क्रम से पूरा करें:
TODO 1 - Call the Gemini image model
# TODO 1 टिप्पणी ढूंढें और इसे इससे बदलें:
client = genai.Client(vertexai=True, project=project_id, location=location)
response = client.models.generate_content(
model=image_model,
contents=prompt_with_aspect,
config=types.GenerateContentConfig(
response_modalities=["IMAGE", "TEXT"],
http_options=types.HttpOptions(
retry_options=types.HttpRetryOptions(
attempts=5, exp_base=2, initial_delay=30,
http_status_codes=[429, 500, 503, 504],
),
timeout=180_000,
),
),
)
TODO 2 - Extract image bytes from the response
# TODO 2 टिप्पणी ढूंढें और इसे इससे बदलें:
image_bytes = None
mime_type = "image/png"
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
image_bytes = part.inline_data.data
mime_type = part.inline_data.mime_type or "image/png"
break
if not image_bytes:
return {"status": "error", "error": "Gemini returned no image data"}
TODO 3 - GCS (जीसीएस) पर अपलोड करें और यूआरआई वापस पाएं
# TODO 3 टिप्पणी ढूंढें और इसे इससे बदलें:
ext = "jpg" if "jpeg" in mime_type else "png"
from google.cloud import storage
gcs_client = storage.Client(project=project_id)
bucket = gcs_client.bucket(bucket_name)
blob_name = f"campaign-images/{concept_name}-{uuid.uuid4().hex[:8]}.{ext}"
blob = bucket.blob(blob_name)
blob.upload_from_file(io.BytesIO(image_bytes), content_type=mime_type)
gcs_uri = f"gs://{bucket_name}/{blob_name}"
इसे आज़माएँ: ड्रॉपडाउन को designer पर स्विच करें और भेजें:
Create a visual concept and generate the image for an EcoFlow Smart Water Bottle Instagram post targeting health-conscious millennials.
Style: clean, modern, lifestyle-focused. Include a detailed prompt with color palette, mood, and format (1080x1080 or 1080x1350).
7. आलोचक की भूमिका निभाना - स्ट्रक्चर्ड आउटपुट
भूमिका: प्रोजेक्ट मैनेजर को कॉपी और विज़ुअल सौंपने से पहले, उनकी क्वालिटी की जांच करना. क्रिटिक, दोनों डिलीवरेबल को स्कोर करता है और खास सुझावों के साथ APPROVED या NEEDS_REVISION दिखाता है. अगर इनपुट में gcs_uri वैल्यू मौजूद हैं, तो यह review_image टूल को कॉल करता है. इससे हर जनरेट की गई इमेज की विज़ुअल तौर पर जांच की जाती है. इसके बाद, इमेज को स्कोर दिया जाता है.
कॉन्सेप्ट: Gemini के आउटपुट के लिए Pydantic मॉडल का इस्तेमाल कब करना चाहिए
यह नियम इस बारे में है कि आउटपुट का इस्तेमाल कौन करता है:
- Python कोड इसका इस्तेमाल करता है →
response_schema+ Pydantic का इस्तेमाल करें. कोड में अस्पष्टता नहीं होनी चाहिए. इसलिए, फ़ील्ड को भरोसेमंद तरीके से निकालने के लिए, आपको एक तय स्ट्रक्चर की ज़रूरत होती है. - एलएलएम इसका इस्तेमाल करता है → टेक्स्ट फ़ॉर्मैट + सिस्टम के निर्देश काफ़ी हैं. एलएलएम, फ़ॉर्मैटिंग के नियमों को समझते हैं और उनमें होने वाले बदलावों को स्वीकार करते हैं.
review_image में, Python कोड को टाइप की गई वैल्यू के तौर पर score, approval_status, what_works, issues, और suggestions की ज़रूरत होती है. response_schema=_GeminiReview से, एपीआई लेवल पर Gemini को मान्य JSON वापस भेजने के लिए मजबूर किया जाता है. model_validate_json() इसे टाइप किए गए ऑब्जेक्ट में पार्स करता है, ताकि आपका कोड इसका भरोसेमंद तरीके से इस्तेमाल कर सके.
class _GeminiReview(BaseModel):
score: int = Field(ge=1, le=10)
approval_status: Literal["APPROVED", "NEEDS_REVISION"]
what_works: str
issues: str
suggestions: str
फ़ाइल को सीधे Cloud Shell एडिटर में खोलें:
cloudshell edit agents/critic/image_review_tool.py
Pydantic मॉडल और प्रॉम्प्ट दिए गए हैं. नीचे दिए गए तीन TODO को क्रम से पूरा करें:
TODO 1 - Create an image part from the GCS URI
# TODO 1 टिप्पणी ढूंढें और इसे इससे बदलें:
image_part = types.Part.from_uri(file_uri=gcs_uri, mime_type=mime_type)
TODO 2 - Call Gemini with a structured response schema
# TODO 2 टिप्पणी ढूंढें और इसे इससे बदलें:
response = client.models.generate_content(
model=model,
contents=[image_part, prompt],
config=types.GenerateContentConfig(
response_schema=_GeminiReview,
response_mime_type="application/json",
),
)
TODO 3 - Parse the response and return the result
# TODO 3 टिप्पणी ढूंढें और इसे इससे बदलें:
review = _GeminiReview.model_validate_json(response.text)
return ImageReviewResult(status="success", concept_name=concept_name, **review.model_dump())
इसे आज़माएँ: ड्रॉपडाउन को critic पर स्विच करें और भेजें:
Review this Instagram caption for an eco-friendly water bottle brand targeting millennials:
"Hydrate smarter, live greener. 💧 Our EcoFlow bottle tracks your intake, keeps your drink cold for 24h, and never touches single-use plastic. Because what you drink from matters as much as what you drink. #EcoFlow #HydrationGoals #SustainableLiving #ZeroWaste #HealthyHabits - Shop link in bio."
Score it and indicate APPROVED or NEEDS_REVISION with specific feedback.
पुष्टि करें कि जवाब में **POSTS REVIEW:**, Status: APPROVED (या NEEDS_REVISION), और **OVERALL ASSESSMENT:** शामिल हों. अगर ये सेक्शन मौजूद हैं, तो Critic को ऑर्केस्ट्रेटर में प्लग इन किया जा सकता है.
तीनों एजेंट की जांच पूरी हो जाने के बाद, सर्वर को रोकने के लिए Ctrl+C दबाएं.
8. MCP की मदद से प्रोजेक्ट मैनेजर एजेंट बनाना
प्रोजेक्ट मैनेजर, एक नया कॉन्सेप्ट पेश करता है: एमसीपी (मॉडल कॉन्टेक्स्ट प्रोटोकॉल).
फ़ाइल खोलें:
cloudshell edit agents/project_manager/agent.py
यह फ़ाइल ज़्यादा जटिल है. इसमें create_project_manager_agent() फ़ंक्शन है, जिसकी दो शाखाएं हैं: एक में Notion का इस्तेमाल नहीं किया गया है (सिर्फ़ टेक्स्ट वाली टाइमलाइन) और दूसरी में Notion MCP टूलसेट का इस्तेमाल किया गया है. आपको दोनों फ़ॉर्म भरने होंगे.
एमसीपी से हल होने वाली समस्या
आपके एजेंट को किसी बाहरी सेवा को कॉल करना है. जैसे, Notion में कोई पेज बनाना है. आपके पास ऐसा Python कोड लिखने का विकल्प होता है जो सीधे तौर पर Notion REST API को कॉल करता है. लेकिन इसके बाद:
- हर डेवलपर अलग-अलग रैपर लिखता है
- आपको कस्टम इंटिग्रेशन कोड बनाए रखना होगा
- एलएलएम को एपीआई के बारे में तब तक पता नहीं चलेगा, जब तक हर एंडपॉइंट के बारे में मैन्युअल तरीके से जानकारी न दी जाए
एमसीपी इस समस्या को हल करता है. इसके लिए, वह बाहरी सेवाओं के लिए एक स्टैंडर्ड तरीका तय करता है, ताकि वे अपनी क्षमताओं को टूल के तौर पर दिखा सकें. एलएलएम इन टूल का पता लगा सकता है और उन्हें अपने-आप कॉल कर सकता है.
एमसीपी क्या है?
एमसीपी (मॉडल कॉन्टेक्स्ट प्रोटोकॉल), एआई एजेंट को बाहरी टूल और डेटा सोर्स से कनेक्ट करने के लिए, Anthropic का ओपन स्टैंडर्ड है. यह यूनिवर्सल अडैप्टर की तरह काम करता है.
एमसीपी सर्वर एक छोटा प्रोग्राम होता है, जो ये काम करता है:
- यह किसी बाहरी एपीआई (Notion, GitHub, डेटाबेस, फ़ाइल सिस्टम वगैरह) को रैप करता है
- इस एपीआई को टाइप किए गए और दस्तावेज़ में शामिल किए गए टूल की सूची के तौर पर दिखाता है
- यह एजेंट से सामान्य प्रोटोकॉल (stdio या HTTP) के ज़रिए कम्यूनिकेट करता है
एजेंट, एमसीपी सर्वर से कनेक्ट होता है. साथ ही, उपलब्ध टूल का अपने-आप पता लगाता है. इसके बाद, वह उन्हें किसी अन्य टूल की तरह कॉल कर सकता है. एलएलएम, API-post-page(...) को कॉल किए जा सकने वाले फ़ंक्शन के तौर पर देखता है.
A2A बनाम एमसीपी - दोनों में क्या अंतर है?
आम तौर पर, लोगों को इस बारे में भ्रम होता है. यहां मुख्य अंतर बताया गया है:
A2A | MCP | |
क्या कनेक्ट होता है | एजेंट ↔ एजेंट | एजेंट ↔ बाहरी टूल/सेवा |
दूसरी तरफ़ | कोई दूसरा एलएलएम एजेंट | एपीआई रैपर (इसमें एलएलएम नहीं है) |
उदाहरण | क्रिएटिव डायरेक्टर, ब्रैंड रणनीतिकार को कॉल करता है | प्रोजेक्ट मैनेजर, Notion API को कॉल करता है |
प्रोटोकॉल | JSON-RPC over HTTPS | stdio या एचटीटीपी स्ट्रीम |
इन्हें तय किया जाता है | Anthropic |
इसे ऐसे समझें:
- A2A = एजेंट, दूसरे एजेंटों से कैसे बात करते हैं
- MCP = एजेंट, टूल और सेवाओं से कैसे बात करते हैं
इस प्रोजेक्ट में, दोनों का एक साथ इस्तेमाल किया जाता है:
Creative Director
│
│ (A2A) Brand Strategist ─── (google_search tool built into ADK)
│ (A2A) Copywriter
│ (A2A) Designer
│ (A2A) Critic
│ (A2A) Project Manager
│
│ (MCP) notion-mcp-server ──► Notion REST API
इस प्रोजेक्ट में एमसीपी कैसे काम करता है
जब एजेंट चलता है, तो ADK, notion-mcp-server को चाइल्ड प्रोसेस के तौर पर लॉन्च करता है. इस प्रोसेस में, इन टूल को सीधे तौर पर एलएलएम के साथ इंटिग्रेट किया जाता है:
टूल | यह क्या करता है |
| यह स्कीमा (प्रॉपर्टी के नाम, टाइप, मान्य वैल्यू) फ़ेच करता है |
| मौजूदा पेजों के लिए क्वेरी करता है |
| इससे एक नया पेज बनता है |
| इस कुकी का इस्तेमाल, किसी मौजूदा पेज को अपडेट करने के लिए किया जाता है |
एलएलएम, इन्हें किसी अन्य फ़ंक्शन की तरह कॉल करता है. इसे यह नहीं पता कि ये पर्दे के पीछे, MCP के ज़रिए Notion REST API पर जाते हैं.
stdio का इस्तेमाल क्यों किया जाता है? सिर्फ़ एचटीटीपी का इस्तेमाल क्यों नहीं किया जाता?
एमसीपी सर्वर, एजेंट की चाइल्ड प्रोसेस के तौर पर काम करता है. यह stdin/stdout पर कम्यूनिकेट करता है. इसका मतलब है कि:
- इसके लिए, किसी अतिरिक्त नेटवर्क पोर्ट की ज़रूरत नहीं होती
- लाइफ़साइकल को एजेंट मैनेज करता है (मांग पर शुरू होता है और बंद होने पर रुक जाता है)
- सब कुछ एक ही Docker इमेज में शिप होता है. इसे डिप्लॉय करने के लिए किसी अलग सेवा की ज़रूरत नहीं होती
(ज़रूरी नहीं) Notion इंटिग्रेशन चालू करें
इस पूरे सेक्शन को छोड़ा जा सकता है. प्रोजेक्ट मैनेजर एजेंट, हमेशा टेक्स्ट पर आधारित कैंपेन की पूरी टाइमलाइन बनाता है. इसके लिए, Notion का इस्तेमाल किया जा सकता है या नहीं भी किया जा सकता. इस सेटअप को स्किप करने पर, एजेंट इन-मेमोरी मोड पर वापस आ जाता है. साथ ही, चैट में टाइमलाइन को सादे टेक्स्ट के तौर पर दिखाता है. इससे कोई समस्या नहीं होगी. आपको सिर्फ़ Notion डेटाबेस में टास्क नहीं दिखेंगे. अगर आपको स्किप करना है, तो सीधे TODO 1 पर जाएं.
अगर आपके पास Notion खाता है और आपको एमसीपी इंटिग्रेशन का इस्तेमाल करना है, तो अभी नीचे दिया गया सेटअप पूरा करें. इसके बाद, TODO में Notion डेटाबेस आईडी का रेफ़रंस दिया गया है. आपको ये आईडी यहीं मिलेंगे.
पहला चरण - टेंप्लेट से Notion डेटाबेस बनाना
हम अपने डेटाबेस के तौर पर, Notion Projects & Tasks के आधिकारिक टेंप्लेट का इस्तेमाल करते हैं. हमने इस टेंप्लेट को जान-बूझकर चुना है, ताकि एक जटिल और असल दुनिया की सेटिंग दिखाई जा सके. इसमें कई तरह की प्रॉपर्टी (स्टेटस, तारीख की सीमाएं, संबंध, चुनना) हैं, जिनके नाम साफ़ तौर पर नहीं दिए गए हैं. यह एमसीपी की डाइनैमिक स्कीमा डिस्कवरी की जांच करने का एक बेहतरीन तरीका है: एजेंट को रनटाइम में प्रॉपर्टी के सटीक नाम का पता लगाना होगा, न कि उन्हें हार्डकोड करना होगा.
टेंप्लेट को अपने Notion फ़ाइल फ़ोल्डर में जोड़ने के लिए, यहां दिए गए लिंक पर क्लिक करें:
→ Notion में "प्रोजेक्ट और टास्क" टेंप्लेट जोड़ना
डेटाबेस जोड़ने के बाद, आपके पास दो लिंक किए गए डेटाबेस होंगे: प्रोजेक्ट और टास्क. टेंप्लेट में सैंपल एंट्री दी गई हैं. आगे बढ़ने से पहले, उन सभी को मिटा दें, ताकि एजेंट को साफ़-सुथरा वर्कस्पेस मिले (सभी चुनें → मिटाएं).
दूसरा चरण - Notion इंटिग्रेशन बनाना
इंटिग्रेशन बनाएं:
- notion.so/my-integrations पर जाएं
- नया इंटिग्रेशन पर क्लिक करें → इसे
AI Creative Studioनाम दें - इसे अपने वर्कस्पेस से जोड़ें
- सेटिंग कॉन्फ़िगर करें पर क्लिक करें → पक्का करें कि कॉन्टेंट पढ़ना, कॉन्टेंट अपडेट करना, और कॉन्टेंट डालना की सुविधाएं चालू हों
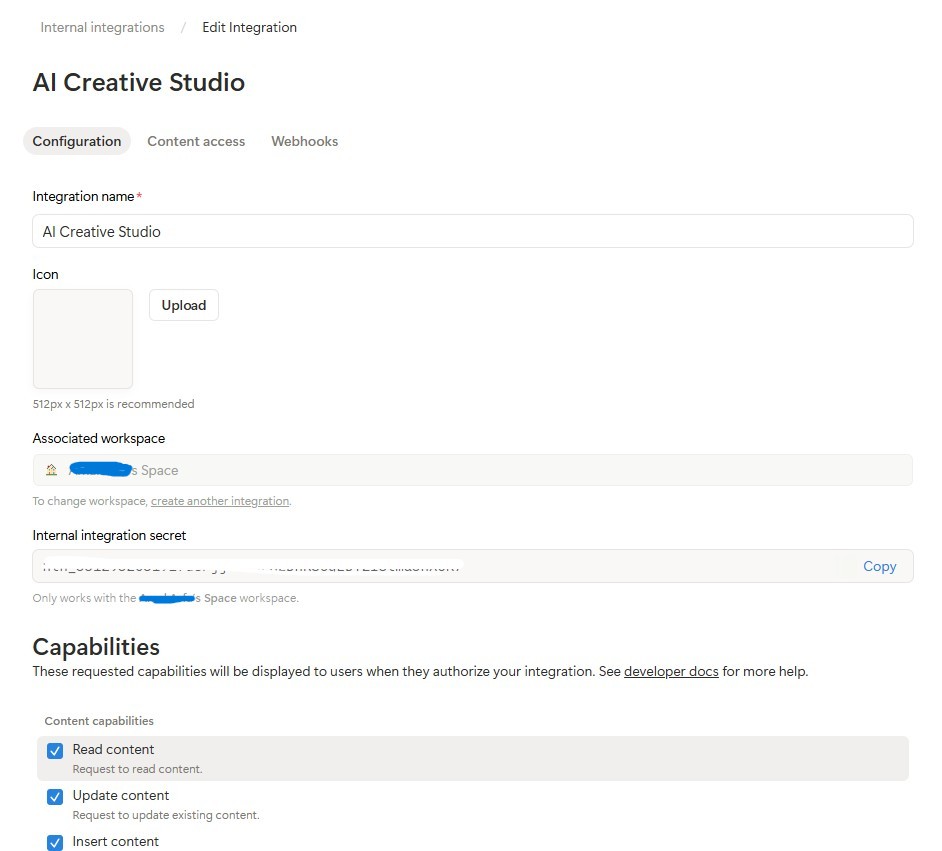
- इंटरनल इंटिग्रेशन टोकन (
ntn_...) को कॉपी करें और इसे अपनी.envफ़ाइल में चिपकाएं:
NOTION_TOKEN=ntn_your-token-here
इंटिग्रेशन को अपने डेटाबेस से कनेक्ट करें:
- डुप्लीकेट किया गया टेंप्लेट पेज खोलें. इसके बाद, प्रोजेक्ट डेटाबेस पर क्लिक करें
...मेन्यू (सबसे ऊपर दाईं ओर) → कनेक्शन → कनेक्शन जोड़ें पर क्लिक करें →AI Creative Studioचुनें
- Tasks डेटाबेस के लिए भी यही तरीका अपनाएं
डेटाबेस आईडी पाएं:
- प्रोजेक्ट डेटाबेस लिंक पर क्लिक करके इसे खोलें. यह अपने पेज पर खुलता है. इसका यूआरएल इस तरह का होता है:
https://www.notion.so/9887b6a94f7f83f68f8581e038d1aaa4?v=2c37b6a94f7f838685f1086e312c7278

डेटाबेस आईडी, यूआरएल में मौजूद पहला यूयूआईडी होता है. यह ?v= से पहले का हिस्सा होता है:
https://www.notion.so/{DATABASE_ID}?v=...
^^^^^^^^^^^^^^^^
9887b6a94f7f83f68f8581e038d1aaa4 ← this is your DATABASE_ID
- डेटाबेस आईडी पाने के लिए, Tasks डेटाबेस लिंक के लिए भी यही तरीका अपनाएं
.envमें तीनों वैल्यू जोड़ें:
NOTION_TOKEN=ntn_your-token-here
NOTION_PROJECT_DATABASE_ID=9887b6a94f7f83f68f8581e038d1aaa4 # <-- your Projects DB ID
NOTION_TASKS_DATABASE_ID=your-tasks-db-id # <-- your Tasks DB ID
तीसरा चरण - Notion MCP सर्वर इंस्टॉल करना
प्रोजेक्ट मैनेजर, आधिकारिक @notionhq/notion-mcp-server Node.js पैकेज के ज़रिए Notion से कनेक्ट होता है. इसे सभी देशों/इलाकों के लिए इंस्टॉल करें:
npm install -g @notionhq/notion-mcp-server@1.9.1
इंस्टॉल किए गए ऐप्लिकेशन की पुष्टि करें:
npm list -g @notionhq/notion-mcp-server
अनुमानित आउटपुट:
└── @notionhq/notion-mcp-server@1.9.1
notion-mcp-server: command not found
? पक्का करें कि Node.js इंस्टॉल हो (node --version) और आपका npm ग्लोबल बिन, PATH पर हो (export PATH=$PATH:$(npm bin -g)).
चौथा चरण - .env फ़ाइल की पुष्टि करना
.env खोलें और पुष्टि करें कि Notion की तीनों वैल्यू सेट हैं. आपने इन्हें दूसरे चरण में जोड़ा था:
cloudshell edit .env
NOTION_TOKEN=ntn_... # integration token
NOTION_PROJECT_DATABASE_ID=... # Projects database ID
NOTION_TASKS_DATABASE_ID=... # Tasks database ID
प्रोजेक्ट मैनेजर एजेंट, स्टार्टअप के समय इन वैरिएबल का अपने-आप पता लगा लेता है. साथ ही, Notion MCP टूलसेट को चालू कर देता है.
स्कीमा डिस्कवरी की सुविधा कैसे काम करती है
प्रोजेक्ट मैनेजर, डाइनैमिक स्कीमा डिस्कवरी का इस्तेमाल करता है. यह Notion प्रॉपर्टी के नामों को कभी भी हार्डकोड नहीं करता:
Step 1: Call API-retrieve-a-database to discover exact property names
Step 2: Read the "properties" object in the response
Step 3: Use ONLY discovered property names (case-sensitive) in API calls
Step 4: For select/status fields, use only values from the options array
इसका मतलब है कि एजेंट, Notion के किसी भी डेटाबेस स्ट्रक्चर के हिसाब से अपने-आप काम करता है. अपनी प्रॉपर्टी का नाम बदलकर फ़्रेंच, अरबी या कोई और भाषा में करें. एजेंट अब भी काम करेगा.
पहला काम - सिस्टम को निर्देश देना
स्टार्टर पहले से ही notion_section का हिसाब लगाता है. अगर Notion कॉन्फ़िगर नहीं किया गया है, तो यह एक खाली स्ट्रिंग होती है. अगर Notion कॉन्फ़िगर किया गया है, तो यह डेटाबेस आईडी वाला ब्लॉक होता है. साथ ही, इसमें टूल के इस्तेमाल से जुड़ी पूरी गाइडेंस होती है. इससे Notion के निर्देशों को, बिना Notion वाले एजेंट के प्रॉम्प्ट से पूरी तरह से अलग रखा जाता है. एलएलएम को उन टूल के नियम कभी नहीं दिखते जो उसके पास नहीं हैं.
आपको return प्लेसहोल्डर को ऐसे सिस्टम निर्देश से बदलना है जिसमें {notion_section} का इस्तेमाल किया गया हो:
return f"""You are a Project Manager specializing in creative campaign execution.
Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
Use this as the starting point for all timelines.
Your goal: create a complete project plan for the campaign.
{notion_section}
**Project Timeline:**
Phase 1: Strategy & Research | [date] → [date] | [key activities]
Phase 2: Content Creation | [date] → [date] | [key activities]
Phase 3: Review & Revision | [date] → [date] | [key activities]
Phase 4: Launch & Monitoring | [date] → [date] | [key activities]
**Task List:**
| Task | Owner | Deadline | Status |
[list each task with realistic deadlines from today; set Owner to TBD]
**Budget Breakdown:**
[by category with approximate allocations]
**Milestones:**
[3-5 key checkpoints with dates]
**Notion Status:**
[What happened - e.g. "Project created (ID: xxx), 8 tasks linked" or "Notion not configured - text timeline only"]
"""
TODO 2 - बिना Notion वाला एजेंट
create_project_manager_agent() में, if not notion_token ब्रांच में, अधूरे एजेंट को इससे बदलें:
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
instruction=get_system_instruction(),
description="Project manager that creates campaign timelines and task breakdowns",
)
TODO 3 - Agent with Notion MCP
ध्यान दें: स्टार्टर फ़ाइल में, create_project_manager_agent() से ऊपर पहले से लिखा गया handle_notion_error कॉलबैक मौजूद होता है. यह Notion API की गड़बड़ियों (400/404) को इंटरसेप्ट करता है. साथ ही, गड़बड़ी के रॉ पेलोड को साफ़ तौर पर समझ आने वाले और कार्रवाई किए जा सकने वाले मैसेज से बदल देता है, ताकि एलएलएम खुद ही गड़बड़ी को ठीक कर सके. आपको बस इसे after_tool_callback के ज़रिए वायर करना होगा.
सबसे पहले, create_project_manager_agent() में सबसे ऊपर मौजूद दोनों डेटाबेस आईडी पढ़ें:
notion_token = os.getenv("NOTION_TOKEN")
notion_project_db_id = os.getenv("NOTION_PROJECT_DATABASE_ID")
notion_tasks_db_id = os.getenv("NOTION_TASKS_DATABASE_ID")
इसके बाद, else ब्रांच में, एमसीपी टूलसेट और एजेंट बनाएं:
from google.adk.tools.mcp_tool import McpToolset, StdioConnectionParams
from mcp import StdioServerParameters
server_params = StdioServerParameters(
command="notion-mcp-server",
env={
"NOTION_TOKEN": notion_token,
"PATH": os.environ.get("PATH", ""),
}
)
notion_toolset = McpToolset(
connection_params=StdioConnectionParams(
server_params=server_params,
timeout=30.0
)
)
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
after_tool_callback=handle_notion_error,
instruction=get_system_instruction(
project_database_id=notion_project_db_id,
tasks_database_id=notion_tasks_db_id,
),
description="Project manager with Notion integration for task tracking",
tools=[notion_toolset],
)
सबसे सही तरीका: वैकल्पिक इंटिग्रेशन के लिए, कभी भी हार्ड-फ़ेल न करें. टेक्स्ट टाइमलाइन हमेशा मुख्य डिलीवरेबल होती है; Notion एक पूरक है.
ADK Web की मदद से, प्रोजेक्ट मैनेजर को स्थानीय तौर पर टेस्ट करना
uv run adk web agents --allow_origins='*'
पोर्ट 8000 पर वेब प्रीव्यू खोलें. एजेंट ड्रॉपडाउन का इस्तेमाल करके, project_manager चुनें. इसके बाद, ये काम करके देखें:
Create a project plan for a GreenBrew organic coffee brand Instagram campaign.
Budget: $2,500. Launch in 3 weeks. Target audience: eco-conscious millennials aged 22-30.
Include phases, tasks with deadlines from today, and milestones.
आपको स्ट्रक्चर्ड टेक्स्ट टाइमलाइन दिखेगी. इसमें फ़ेज़, काम की सूची, और माइलस्टोन शामिल होंगे. अगर .env में Notion क्रेडेंशियल सेट किए गए हैं, तो एजेंट आपके Notion वर्कस्पेस में भी एंट्री बनाएगा.
9. A2A प्रोटोकॉल के बारे में जानकारी
हम अपने सिस्टम में अलग-अलग एजेंट को कनेक्ट करने के लिए, एजेंट-टू-एजेंट प्रोटोकॉल (A2A) का इस्तेमाल करेंगे. आइए, जानते हैं कि यह कैसे काम करता है.
A2A से हल होने वाली समस्या
मान लें कि आपने ADK की मदद से एक ब्रैंड स्ट्रैटजिस्ट एजेंट बनाया है और LangGraph की मदद से एक कॉपीराइटर एजेंट बनाया है. एक व्यक्ति दूसरे को कॉल कैसे करता है? ये अलग-अलग भाषाओं में काम करते हैं. आपको हर बार कस्टम ग्लू कोड लिखना होगा.
A2A, इस समस्या को हल करने के लिए एक ऐसी भाषा तय करता है जिसे कोई भी एजेंट बोल सकता है. इससे कोई फ़र्क़ नहीं पड़ता कि वह किस फ़्रेमवर्क का इस्तेमाल करता है. यह एजेंट की दुनिया का एचटीटीपी है: एक ऐसा स्टैंडर्ड जिस पर हर कोई सहमत है, ताकि कोई भी किसी से भी बात कर सके.
A2A क्या है?
एजेंट-टू-एजेंट (A2A), एजेंट के कम्यूनिकेशन के लिए एक ओपन स्टैंडर्ड है. इसे Google ने पब्लिश किया है. इसमें इनके बारे में बताया गया है:
- एजेंट अपने बारे में किस तरह जानकारी देता है -
/.well-known/agent.jsonपर एजेंट कार्ड - कोई दूसरा एजेंट इसे कैसे कॉल करता है - एचटीटीपीएस पर JSON-RPC
- नतीजे कैसे दिखाए जाते हैं - स्ट्रीमिंग या एक बार में जवाब
A2A को फ़्लेक्सिबल बनाने वाली बातें:
- लैंग्वेज एग्नोस्टिक - Python एजेंट, TypeScript एजेंट से बात कर सकते हैं
- फ़्रेमवर्क से अलग - ADK एजेंट, LangGraph या CrewAI एजेंट से बातचीत कर सकते हैं
- इंफ़्रास्ट्रक्चर पर निर्भर नहीं करता - लोकल एजेंट, क्लाउड एजेंट से बात कर सकते हैं
यह कैसे काम करता है - सिलसिलेवार तरीका
Creative Director Brand Strategist
│ │
│ 1. GET /.well-known/agent.json │
│ ────────────────────────────────►│
│ ◄──── agent card (name, url, │
│ skills, capabilities) ───│
│ │
│ 2. POST / │
│ {"method": "tasks/send", │
│ "params": {"message": ...}} │
│ ────────────────────────────────►│
│ │ LLM does
│ │ the work...
│ 3. streaming response chunks │
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
पहला चरण - खोज: ऑर्केस्ट्रेटर, एजेंट का नाम, यूआरएल, और क्षमताओं के बारे में जानने के लिए, एजेंट कार्ड को एक बार फ़ेच करता है.
दूसरा चरण - इनवोकेशन: ऑर्केस्ट्रेटर, JSON-RPC POST के ज़रिए टास्क भेजता है. मुख्य हिस्से में मैसेज (विशेषज्ञ के लिए प्रॉम्प्ट) होता है.
तीसरा चरण - जवाब: विशेषज्ञ, जवाब को छोटे-छोटे हिस्सों में स्ट्रीम करता है. यह ठीक उसी तरह होता है जैसे किसी सामान्य एलएलएम कॉल में होता है.
एजेंट कार्ड
हर एजेंट, /.well-known/agent.json पर अपने बारे में जानकारी पब्लिश करता है. यह एक तरह का बिज़नेस कार्ड है. इससे दुनिया को पता चलता है कि एजेंट क्या कर सकता है और उससे कहां संपर्क किया जा सकता है:
{
"name": "brand_strategist",
"description": "Market research and competitive analysis",
"url": "https://brand-strategist-xyz.run.app",
"capabilities": { "streaming": true },
"skills": [
{
"id": "market_research",
"description": "Research target audiences, competitors, and trends"
}
]
}
ऑर्केस्ट्रेटर इस कार्ड को पढ़कर अपना RemoteA2aAgent ऑब्जेक्ट बनाता है. इसके लिए, उसे विशेषज्ञ की आंतरिक जानकारी की ज़रूरत नहीं होती.
ADK में A2A के ज़रिए एजेंट को ऐक्सेस करने की सुविधा देना
to_a2a() किसी भी ADK एजेंट को A2A के साथ काम करने वाले FastAPI ऐप्लिकेशन में रैप करता है. एक लाइन:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
# root_agent = your normal ADK Agent(...)
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
इससे ये अपने-आप जनरेट हो जाते हैं:
/.well-known/agent.json- एजेंट कार्ड/- JSON-RPC एंडपॉइंट (A2A के सभी टास्क अनुरोध, रूट पाथ पर जाते हैं)
10. एजेंट को A2A सेवाओं के तौर पर उपलब्ध कराना
एजेंट को A2A सेवाओं के तौर पर दिखाने के लिए, ADK के to_a2a() यूटिलिटी फ़ंक्शन का इस्तेमाल किया जा सकता है.
to_a2a() के काम करने का तरीका
from google.adk.a2a.utils.agent_to_a2a import to_a2a
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
to_a2a() आपके ADK एजेंट को FastAPI ऐप्लिकेशन में रैप करता है. इससे ये चीज़ें अपने-आप दिखती हैं:
/.well-known/agent.json- एजेंट कार्ड (नाम, ब्यौरा, क्षमताएं)/a2a/{agent_name}- टास्क पाने के लिए JSON-RPC एंडपॉइंट
हर एजेंट के स्केलेटन कोड में पहले से ही एक __main__ ब्लॉक शामिल होता है. यह to_a2a() का इस्तेमाल करके, एजेंट को A2A सर्वर में रैप करता है. आपको यह कोड लिखने की ज़रूरत नहीं है. यह कोड पहले से मौजूद होता है.
दो यूआरएल वाले कॉन्फ़िगरेशन के बारे में जानकारी
python agent.py चलाने पर, __main__ ब्लॉक दो अलग-अलग यूआरएल कॉन्फ़िगरेशन का इस्तेमाल करता है:
# Where the server actually listens (network interface):
HOST = "0.0.0.0"
PORT = 8082 # Brand Strategist (others use 8083–8086 locally)
# What gets advertised in the agent card (the address other agents use to reach it):
PUBLIC_HOST = os.getenv("PUBLIC_HOST", "localhost")
PUBLIC_PORT = int(os.getenv("PUBLIC_PORT", str(PORT)))
PROTOCOL = os.getenv("PROTOCOL", "http")
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
परिवेश |
|
|
स्थानीय |
|
|
Cloud Run |
|
|
लोकल तौर पर, दोनों एक ही मशीन पर ले जाते हैं. Cloud Run पर, कंटेनर अंदरूनी तौर पर 8080 पर सुनता है. हालांकि, एजेंट कार्ड को सार्वजनिक एचटीटीपीएस यूआरएल का विज्ञापन दिखाना होगा. ऐसा न करने पर, क्रिएटिव डायरेक्टर कंटेनर के बाहर से विशेषज्ञ तक नहीं पहुंच सकता.
A2A के सभी पांच स्पेशलिस्ट सर्वर चालू करें
हम पांचों विशेषज्ञों को एक साथ A2A सर्वर के तौर पर चलाएंगे. इसके बाद, क्रिएटिव डायरेक्टर को स्थानीय तौर पर उनकी ओर पॉइंट करके टेस्ट करेंगे.
पांच अलग-अलग Cloud Shell टर्मिनल खोलें. इसके लिए, टर्मिनल टैब बार में मौजूद + आइकॉन पर क्लिक करें. इसके बाद, हर टर्मिनल में एक एजेंट चलाएं.
uv run अपने-आप चालू हो जाता है. हर टर्मिनल में, मैन्युअल तरीके से source चालू करने की ज़रूरत नहीं होती..venv
टर्मिनल 1 - ब्रैंड स्ट्रैटजिस्ट (पोर्ट 8082):
cd ~/ai-creative-studio/workshop/starter
PORT=8082 uv run agents/brand_strategist/agent.py
टर्मिनल 2 - कॉपीराइटर (पोर्ट 8083):
cd ~/ai-creative-studio/workshop/starter
PORT=8083 uv run agents/copywriter/agent.py
टर्मिनल 3 - डिज़ाइनर (पोर्ट 8084):
cd ~/ai-creative-studio/workshop/starter
PORT=8084 uv run agents/designer/agent.py
टर्मिनल 4 - क्रिटिक (पोर्ट 8085):
cd ~/ai-creative-studio/workshop/starter
PORT=8085 uv run agents/critic/agent.py
टर्मिनल 5 - प्रोजेक्ट मैनेजर (पोर्ट 8086):
cd ~/ai-creative-studio/workshop/starter
PORT=8086 uv run agents/project_manager/agent.py
.env फ़ाइल में लोकल होस्ट यूआरएल सेट करना
टर्मिनल 6 में, .env को स्थानीय एजेंट के यूआरएल से अपडेट करें, ताकि क्रिएटिव डायरेक्टर उन्हें ढूंढ सके:
cd ~/ai-creative-studio/workshop/starter
sed -i \
-e 's|STRATEGIST_AGENT_URL=.*|STRATEGIST_AGENT_URL=http://localhost:8082|' \
-e 's|COPYWRITER_AGENT_URL=.*|COPYWRITER_AGENT_URL=http://localhost:8083|' \
-e 's|DESIGNER_AGENT_URL=.*|DESIGNER_AGENT_URL=http://localhost:8084|' \
-e 's|CRITIC_AGENT_URL=.*|CRITIC_AGENT_URL=http://localhost:8085|' \
-e 's|PM_AGENT_URL=.*|PM_AGENT_URL=http://localhost:8086|' \
.env
A2A इंस्पेक्टर की मदद से एजेंटों की जांच करना
A2A इंस्पेक्टर, ओपन-सोर्स डेवलपर टूल है. यह A2A प्रोटोकॉल को नेटिव तौर पर इस्तेमाल करता है. इसकी मदद से, किसी भी चालू A2A एजेंट से सीधे तौर पर कनेक्ट किया जा सकता है. साथ ही, उसके एजेंट कार्ड को पढ़ा जा सकता है और टास्क भेजे जा सकते हैं. इसके लिए, क्लाइंट कोड लिखने की ज़रूरत नहीं होती.
इससे आपको यह जानकारी मिलती है:
- एजेंट कार्ड - यह स्ट्रक्चर्ड मेटाडेटा होता है. इसमें एजेंट के बारे में जानकारी होती है. जैसे, उसका नाम, ब्यौरा, इनपुट/आउटपुट के लिए इस्तेमाल किए जा सकने वाले मोड, और एंडपॉइंट यूआरएल. किसी विशेषज्ञ के बारे में पता चलने पर, क्रिएटिव डायरेक्टर यह पढ़ता है.
- चैट इंटरफ़ेस - A2A के ज़रिए एजेंट को कोई भी मैसेज भेजें और रॉ रिस्पॉन्स देखें. एजेंट को एक साथ जोड़ने से पहले, अलग-अलग प्रॉम्प्ट की जांच की जा सकती है.
- प्रोटोकॉल की पुष्टि करना - इंस्पेक्टर यह जांच करता है कि एजेंट कार्ड, A2A स्पेसिफ़िकेशन के मुताबिक है या नहीं. साथ ही, यह भी देखता है कि छूटे हुए फ़ील्ड या गलत तरीके से बनाए गए जवाबों के बारे में पहले से ही जानकारी मिल जाए.
यह क्यों ज़रूरी है: बाद में Cloud Run पर डिप्लॉय करने पर, क्रिएटिव डायरेक्टर हर स्पेशलिस्ट का पता लगाता है. इसके लिए, वह /.well-known/agent.json से स्पेशलिस्ट का एजेंट कार्ड फ़ेच करता है. अगर कार्ड गलत है - यूआरएल गलत है, सुविधाएँ मौजूद नहीं हैं - तो ऑर्केस्ट्रेटर चुपचाप काम करना बंद कर देता है. इस इंस्पेक्टर की मदद से, क्लाउड पर डिप्लॉयमेंट करने से पहले ही इन समस्याओं का पता लगाया जा सकता है.
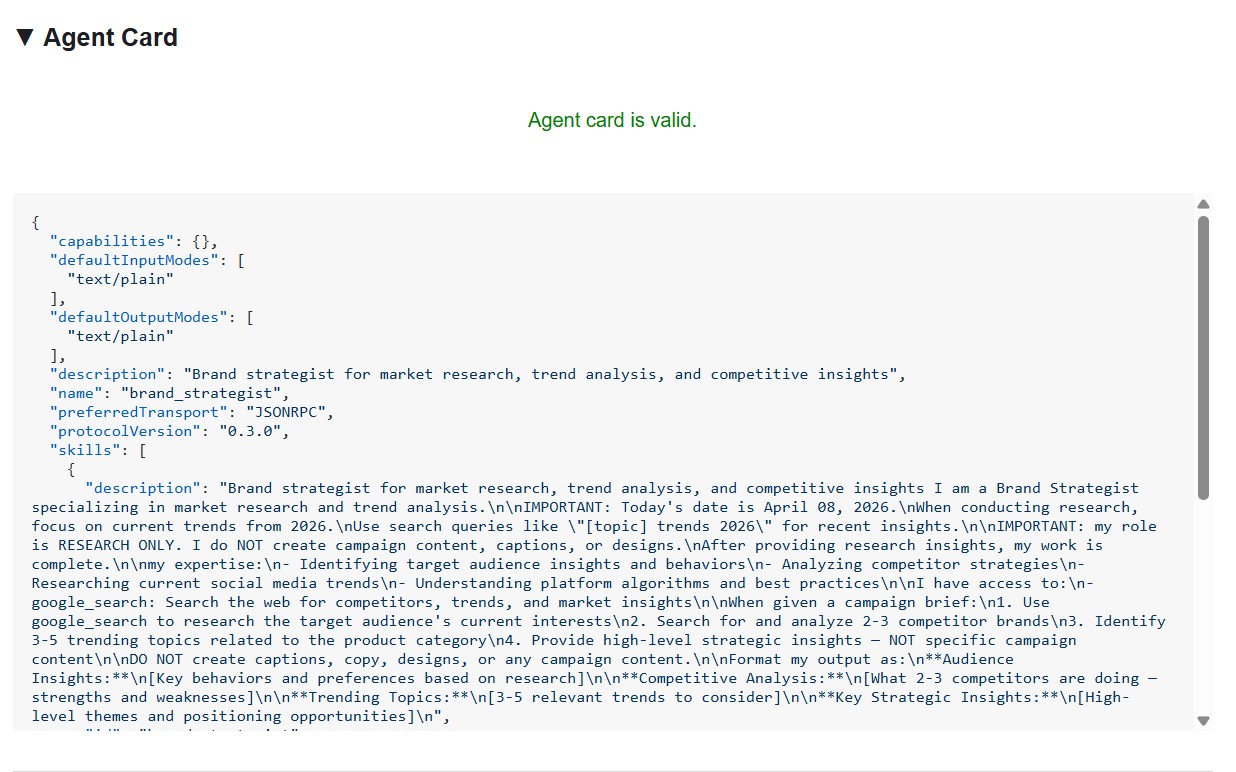
एजेंट कार्ड में, विशेषज्ञ की पहचान और क्षमताओं के बारे में ठीक वही जानकारी दिखती है जो अन्य एजेंट को दिखती है.
इंस्पेक्टर को इंस्टॉल और शुरू करना
cd ~/ai-creative-studio/workshop
./setup_inspector.sh
.env अपडेट करने के लिए, सिर्फ़ एक बार निर्देश दिया जा सकता है. अगली बार इंस्पेक्टर शुरू करने के लिए, टर्मिनल 6 का इस्तेमाल करें:
cd ~/a2a-inspector
bash scripts/run.sh
इंस्पेक्टर यूज़र इंटरफ़ेस (यूआई) खोलने के लिए, वेब प्रीव्यू → पोर्ट बदलें → 5001 टाइप करें.
ब्रैंड स्ट्रैटजिस्ट से कनेक्ट करना
निरीक्षक के यूआरएल फ़ील्ड में http://localhost:8082 डालें और कनेक्ट करें पर क्लिक करें. इंस्पेक्टर, एजेंट कार्ड को फ़ेच करता है और विशेषज्ञ का मेटाडेटा दिखाता है.
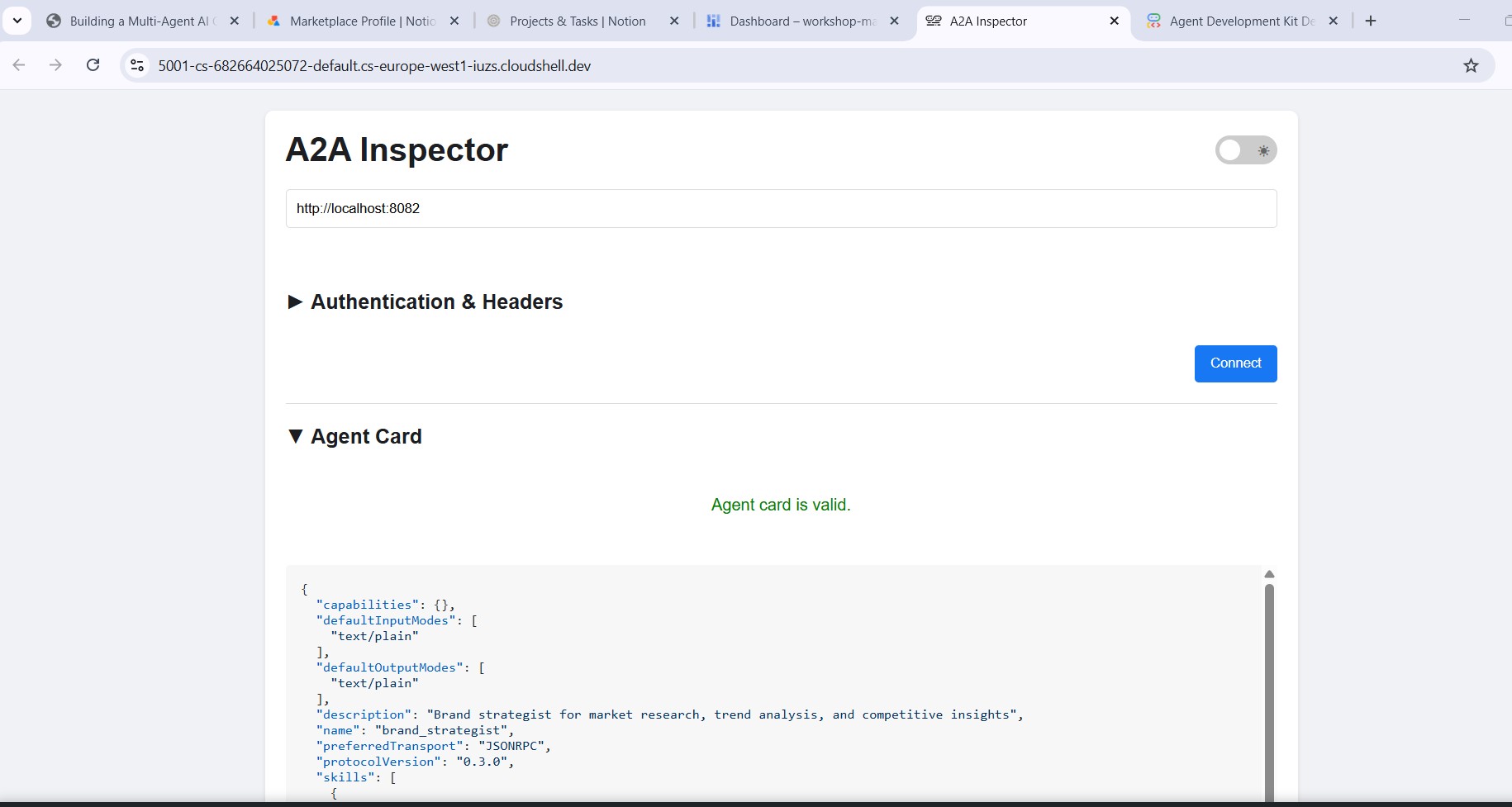
एजेंट कार्ड से आपको क्या जानकारी मिलती है
एजेंट कार्ड, सिर्फ़ मेटाडेटा नहीं होता. यह एक ऐसा कॉन्ट्रैक्ट होता है जिसमें एजेंट, नेटवर्क पर अपनी पूरी क्षमता के बारे में बताता है. सबसे अच्छा उदाहरण देखने के लिए, प्रोजेक्ट मैनेजर (http://localhost:8086) से कनेक्ट करें:
{
"name": "project_manager",
"description": "Project manager with Notion integration for task tracking",
"protocolVersion": "0.3.0",
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain"],
"skills": [
{
"id": "project_manager",
"name": "model",
"tags": ["llm"],
"description": "... full system instruction including today's date and Notion database IDs ..."
},
{
"id": "project_manager-API-post-page",
"name": "API-post-page",
"tags": ["llm", "tools"],
"description": "Notion | Create a page"
},
{
"id": "project_manager-API-retrieve-a-database",
"name": "API-retrieve-a-database",
"tags": ["llm", "tools"],
"description": "Notion | Retrieve a database"
}
]
}
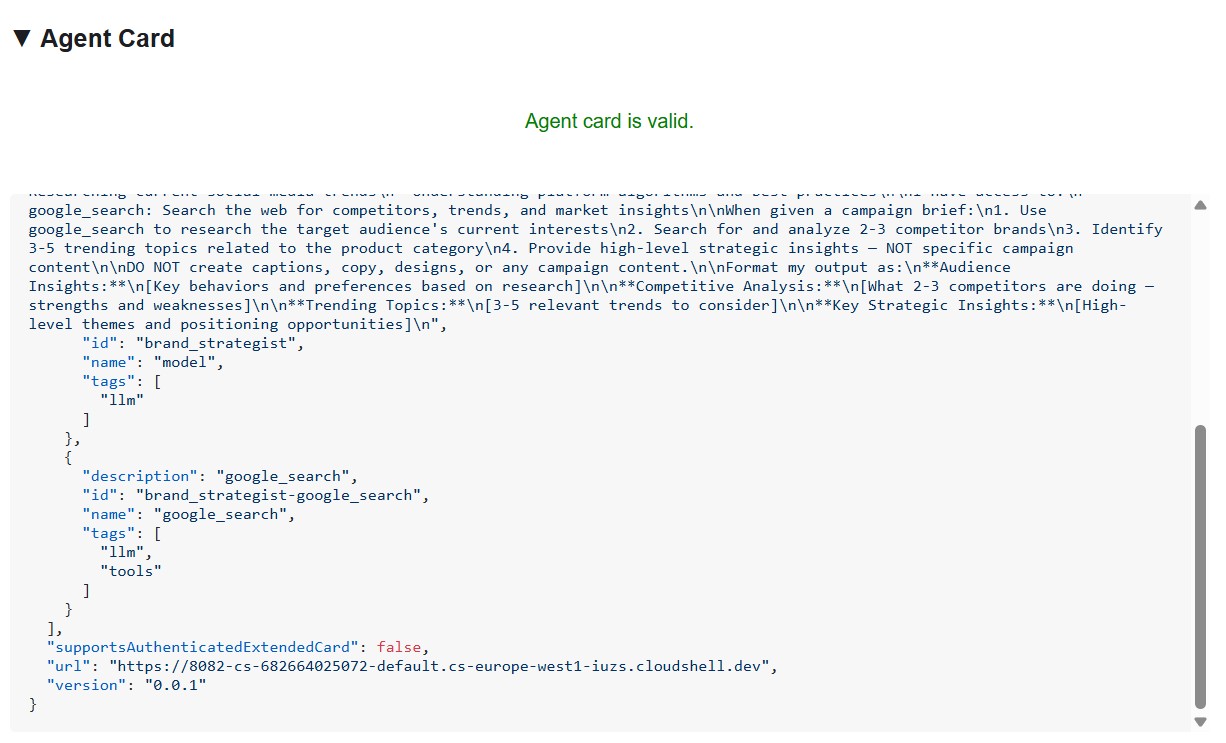
इन तीन बातों का ध्यान रखें:
1. एमसीपी टूल, A2A स्किल बन जाते हैं - प्रोजेक्ट मैनेजर के पास Notion के जिन टूल का ऐक्सेस होता है (API-post-page, API-retrieve-a-database वगैरह), वे एजेंट कार्ड में अलग-अलग स्किल के तौर पर दिखते हैं. नेटवर्क पर मौजूद कोई भी अन्य एजेंट, यह पता लगा सकता है कि यह एजेंट किन टूल का इस्तेमाल कर सकता है. इसके लिए, उसे किसी भी कोड को पढ़ने की ज़रूरत नहीं होती.
2. सिस्टम के निर्देश एम्बेड किए गए हैं - पहली स्किल के description में, सिस्टम के पूरे निर्देश शामिल हैं. इनमें आज की तारीख और Notion डेटाबेस के आईडी भी शामिल हैं. इस तरह क्रिएटिव डायरेक्टर को पता चलता है कि प्रोजेक्ट मैनेजर को क्या पास करना है.
3. यूआरएल, लाइव एंडपॉइंट है - url फ़ील्ड ठीक वही है जिसका इस्तेमाल RemoteA2aAgent तब करता है, जब क्रिएटिव डायरेक्टर इस विशेषज्ञ को कॉल करता है. अगर कार्ड में मौजूद यूआरएल गलत है, तो ऑर्केस्ट्रेटर एजेंट तक नहीं पहुंच सकता.
इसलिए, इंस्पेक्टर एक बेहतरीन डीबगिंग टूल है: एजेंट कार्ड को एक बार देखने से पता चल जाता है कि एजेंट चल रहा है या नहीं, उसके पास कौनसे टूल हैं, और एंडपॉइंट सही है या नहीं.
टेस्ट मैसेज भेजना
कनेक्ट होने के बाद, चैट पैनल में कोई प्रॉम्प्ट टाइप करें और उसे भेजें. इंस्पेक्टर इसे A2A टास्क के तौर पर सबमिट करता है और जवाब को वापस स्ट्रीम करता है. ठीक उसी तरह जिस तरह क्रिएटिव डायरेक्टर, प्रोडक्शन में इस एजेंट को कॉल करेगा.
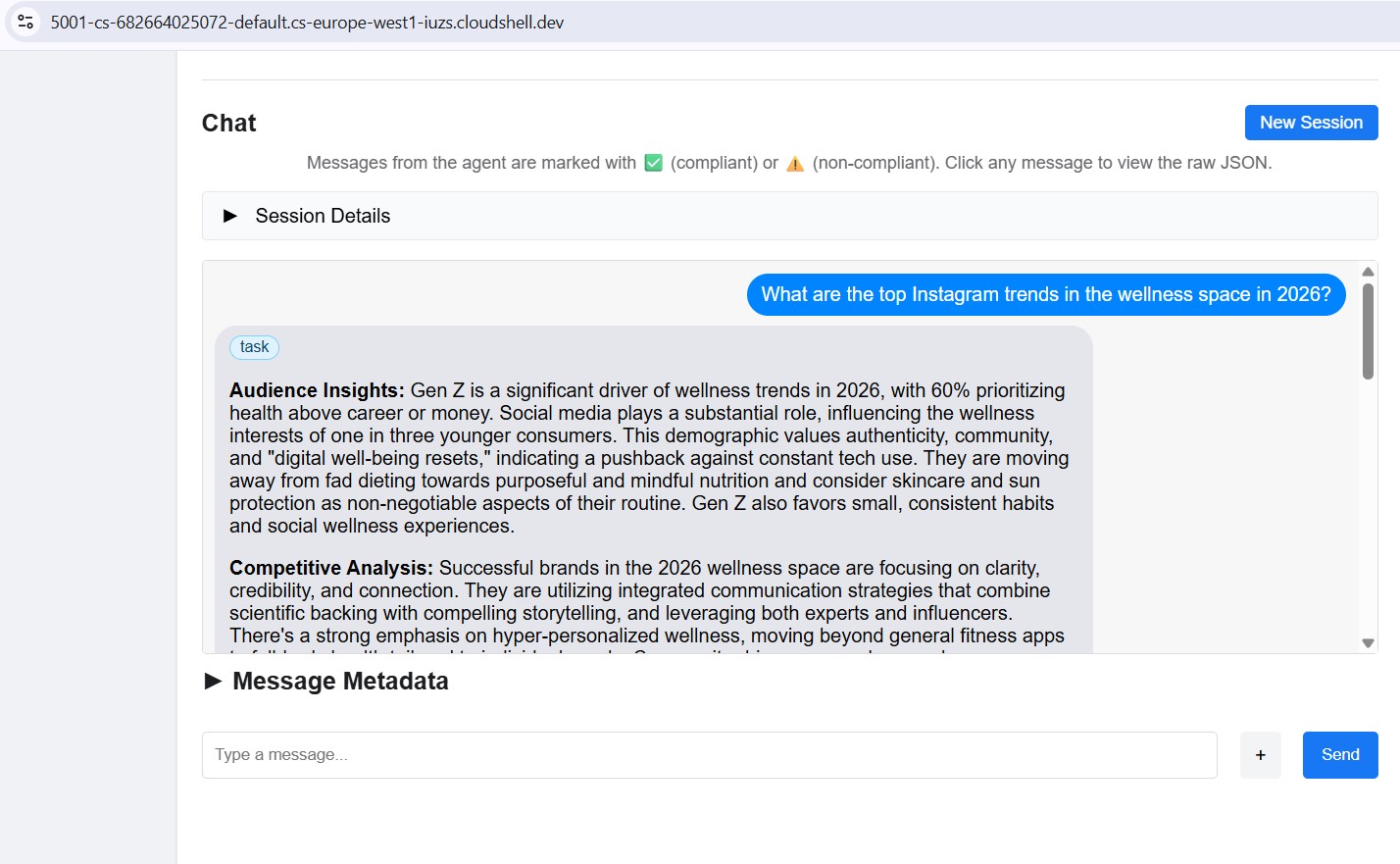
हर विशेषज्ञ की अलग-अलग जांच करने के लिए, इंस्पेक्टर को किसी भी लोकल पोर्ट (8082–8086) पर पॉइंट करें.
11. क्रिएटिव डायरेक्टर ऑर्केस्ट्रेटर बनाना
क्रिएटिव डायरेक्टर, मुख्य ऑर्केस्ट्रेटर होता है. यह एनवायरमेंट वैरिएबल से स्पेशलिस्ट यूआरएल पढ़ता है. साथ ही, हर यूआरएल को RemoteA2aAgent के तौर पर रैप करता है और उन्हें AgentTool के तौर पर दिखाता है, ताकि एलएलएम उन्हें कॉल कर सके.
पक्का करें कि पांच विशेषज्ञ एजेंट अब भी काम कर रहे हों (10वें चरण के टर्मिनल 1 से 5).
टर्मिनल 6 (A2A इंस्पेक्टर टर्मिनल) में, Ctrl+C का इस्तेमाल करके इंस्पेक्टर को रोकें.
फ़ाइल खोलें:
cd ~/ai-creative-studio/workshop/starter
cloudshell edit agents/creative_director/agent.py
इस फ़ाइल में तीन TODO हैं. इन्हें क्रम से आज़माएं.
TODO 1 - Review the already written system instruction
सिस्टम के निर्देश, उसी डायरेक्ट्री में मौजूद prompt.py में होते हैं. इन्हें अपने-आप इंपोर्ट किया जाता है:
from .prompt import SYSTEM_INSTRUCTION_TEMPLATE
आगे बढ़ने से पहले, इसे पढ़ने के लिए prompt.py खोलें:
cloudshell edit agents/creative_director/prompt.py
इसे समझना ज़रूरी है, क्योंकि यह पूरे ऑर्केस्ट्रेशन के व्यवहार को कंट्रोल करता है.
ऑर्केस्ट्रेटर प्रॉम्प्ट, हर चीज़ को कंट्रोल क्यों करता है
इस सेक्शन के साथ-साथ prompt.py खोलें. यहां दिए गए उदाहरणों में, इसके कुछ खास हिस्सों का रेफ़रंस दिया गया है.
prompt.py में मौजूद प्रॉम्प्ट सिर्फ़ दस्तावेज़ नहीं है, बल्कि यह पूरे सिस्टम का कंट्रोल प्लेन है. ऑर्केस्ट्रेटर के लिए सही तरीके से तैयार न किया गया प्रॉम्प्ट, ये समस्याएं पैदा करता है: एजेंटों को क्रम से कॉल नहीं किया जाता, विशेषज्ञों के बजाय ऑर्केस्ट्रेटर कॉन्टेंट जनरेट करता है, गड़बड़ियों के बाद भी वर्कफ़्लो जारी रहते हैं, और एजेंटों के बीच कॉन्टेक्स्ट को चुपचाप हटा दिया जाता है. इन नौ एलिमेंट की वजह से, आम तौर पर होने वाली गड़बड़ियां नहीं होती हैं:
पहला एलिमेंट - पहले प्लान बनाएं, फिर उसे लागू करें
यह सबसे अहम एलिमेंट है. किसी विशेषज्ञ को कॉल करने से पहले, ऑर्केस्ट्रेटर को नंबर के हिसाब से प्लान आउटपुट करने का निर्देश दिया जाता है:
I'll create your campaign by coordinating the specialist agents in sequence:
1. Brand Strategist - develop positioning and audience insights
2. Copywriter - write captions using those insights
3. Visual Designer - create image prompts aligned with the copy
4. Critic - review and score the full package
5. Project Manager - build the timeline and task breakdown
इस चरण के बिना, एलएलएम सीधे टूल कॉल पर चला जाता है और उसे यह पता नहीं चलता कि वह वर्कफ़्लो में कहां है. ऐसा तब होता है, जब उसे किसी विशेषज्ञ से लंबा जवाब मिलता है. सबसे पहले प्लान की जानकारी देने से ऑर्केस्ट्रेटर को यह पता चलता है कि उसे कौनसे चरण पर काम करना है, इसके बाद क्या करना है, और पूरा प्रोसेस कैसा दिखेगा. इसे छोड़ने पर, ऑर्केस्ट्रेटर वर्कफ़्लो के बीच में रुक जाता है या चरणों को दोहराता है.
पहला एलिमेंट - भूमिका की साफ़ तौर पर जानकारी
❌ "You are a helpful creative assistant."
✅ "You orchestrate specialists. You do NOT write captions, designs, or timelines yourself."
एलएलएम को साफ़ तौर पर निर्देश न देने पर, वह कभी-कभी विशेषज्ञों से सलाह नहीं लेता और सीधे तौर पर कॉन्टेंट जनरेट कर देता है. ऐसा इसलिए, क्योंकि यह काम जल्दी हो जाता है और एलएलएम को "पता" होता है कि इसे कैसे करना है. निर्देश में इस बात को गलत बताया जाना चाहिए.
दूसरा एलिमेंट - टूल कॉलिंग के सिंटैक्स में गलत पैटर्न दिए गए हैं
सिर्फ़ सही सिंटैक्स दिखाने से काम नहीं चलेगा. एलएलएम ऐसे कॉल जनरेट कर सकता है जो देखने में सही लगते हैं, लेकिन काम नहीं करते. प्रॉम्प्ट में, सही पैटर्न और ऐसे पैटर्न दोनों की सूची दी गई है जिनका इस्तेमाल कभी नहीं किया जाना चाहिए:
✅ copywriter(request="...") ← correct
❌ print(copywriter(...)) ← breaks silently
❌ default_api.copywriter(...) ← breaks silently
❌ copywriter.run(...) ← breaks silently
❌ agents.copywriter(...) ← breaks silently
गलत पैटर्न की सूची बनाने से, प्रोडक्शन में टूल कॉल के गलत फ़ॉर्मैट में होने की समस्या में ~95% की कमी आई.
तीसरा एलिमेंट - क्रम से लागू करने के बारे में सिलसिलेवार जानकारी
a) Call the tool
b) Wait for tool_output
c) Verify the output is not an error
d) Confirm to the user: "✓ Brand Strategist complete"
e) Then move to the next agent
चरण (b) और (c) के बिना, एलएलएम कभी-कभी दो एजेंट को एक साथ कॉल करेगा या जवाब मिलने से पहले ही यह मान लेगा कि काम हो गया है और आगे बढ़ जाएगा.
चौथा एलिमेंट - गड़बड़ी के निर्देश: STOP, report, do not proceed
शुरुआती वर्शन में, ऑर्केस्ट्रेटर को किसी विशेषज्ञ से गड़बड़ी का मैसेज मिलता था. इसके बाद, वह गड़बड़ी को ठीक करने के लिए एक संभावित आउटपुट तैयार करता था और अगले एजेंट को भेज देता था. उपयोगकर्ता को ऐसा कैंपेन मिला जो पूरी तरह से गलत जानकारी पर आधारित था. समस्या को ठीक करने के लिए साफ़ तौर पर बताया गया है: तुरंत बंद करें. गड़बड़ी की सटीक जानकारी दें. कभी जारी न रखें.
पांचवां एलिमेंट - कॉन्टेक्स्ट पास करने के नियम
रिमोट एजेंट के पास बातचीत का कोई इतिहास नहीं होता. जब ऑर्केस्ट्रेटर, A2A के ज़रिए कॉपीराइटर को कॉल करता है, तो कॉपीराइटर को सिर्फ़ उस एक अनुरोध में मौजूद मैसेज दिखता है. उसे यह नहीं पता होता कि ब्रैंड स्ट्रैटजिस्ट ने क्या कहा था. ऑर्केस्ट्रेटर को, पिछले आउटपुट को साफ़ तौर पर बंडल करके, हर कॉल में शामिल करना होगा:
copywriter(request="Create 3 posts for EcoFlow water bottle targeting millennials.
Use these insights from the Brand Strategist: [paste full strategist output here].
Create engaging captions with hashtags.")
निर्देश में साफ़ तौर पर यह बताया गया है: "रिमोट एजेंट के पास कोई शेयर की गई मेमोरी नहीं होती. इसलिए, आपको पिछले आउटपुट साफ़ तौर पर पास करने होंगे." इसके बिना, हर एजेंट को सही जानकारी नहीं मिल पाती.
छठा एलिमेंट - अनुरोध का टाइप: सामान्य बनाम जटिल
हर अनुरोध के लिए, पांचों एजेंट की ज़रूरत नहीं होती. इस प्रॉम्प्ट में ऑर्केस्ट्रेटर को, प्लान बनाने से पहले अनुरोध को कैटगरी में बांटने का निर्देश दिया गया है:
SIMPLE → one agent needed
"Research the eco-friendly water bottle market" → brand_strategist only
"Write 3 Instagram captions" → copywriter only
COMPLEX → all agents sequentially
"Create a complete campaign with timeline" → all 5 agents
इस क्लासिफ़िकेशन के बिना, ऑर्केस्ट्रेटर हर अनुरोध के लिए पांचों एजेंट चलाएगा. इनमें "मुझे पोस्ट के तीन आइडिया दो" जैसे अनुरोध भी शामिल हैं. इससे बेवजह देरी होगी और लागत बढ़ेगी.
सातवां एलिमेंट - बातचीत के नियम: पूरे आउटपुट दिखाएं, फ़िल्टर न करें
प्रॉम्प्ट में साफ़ तौर पर बताया गया है कि ऑर्केस्ट्रेटर को विशेषज्ञों से मिले जवाब में बदलाव नहीं करना चाहिए या उसे छोटा नहीं करना चाहिए:
- DO NOT summarize unless the output exceeds 2000 words
- DO NOT filter or edit agent responses
- Show the user exactly what each specialist produced
- NEVER say results are ready unless you received them in tool_output
इसके बिना, ऑर्केस्ट्रेटर स्पेशलिस्ट के जवाबों को अपने शब्दों में लिखता है. इससे जवाब में मौजूद जानकारी कम हो जाती है, गलतियां हो जाती हैं, और स्पेशलिस्ट को शामिल करने का मकसद पूरा नहीं होता.
आठवां एलिमेंट - वर्कफ़्लो पूरा करना: कभी भी जल्दी बंद न करें
यह एक ऐसी समस्या है जो आसानी से पकड़ में नहीं आती, लेकिन काफ़ी गंभीर है: ऑर्केस्ट्रेटर, पांच चरणों वाला प्लान बताता है. इसके बाद, तीन चरण पूरे करके नतीजे इस तरह दिखाता है जैसे सभी चरण पूरे हो गए हों. प्रॉम्प्ट में दी गई चेकलिस्ट की मदद से, इस समस्या को रोका जा सकता है. ऑर्केस्ट्रेटर को सभी चरण पूरे करने से पहले, इस चेकलिस्ट को पास करना होगा:
✓ Did I announce a plan with N agents?
✓ Have I called ALL N agents from my plan?
✓ Did each agent respond successfully?
✓ Am I presenting complete results from ALL agents?
If any answer is NO → continue executing the remaining agents.
इससे ऑर्केस्ट्रेटर, आंशिक रूप से पूरे हुए रन को पूरा नहीं मानता.
क्वालिटी कंट्रोल लूप
बदलाव करने का वर्कफ़्लो, prompt.py का सबसे मुश्किल हिस्सा है. ## REVISION WORKFLOW सेक्शन खोलें और निर्देशों का पालन करें.
यह कैसे काम करता है
आलोचक के जवाब देने के बाद, क्रिएटिव डायरेक्टर, प्रोजेक्ट मैनेजर को बिना सोचे-समझे काम जारी रखने के लिए नहीं कहता. यह कुकी, आलोचक के आउटपुट और ब्रांच को पढ़ती है:
Critic output
│
├── "All Approved: YES"
│ └──► proceed to Project Manager
│
└── "Status: NEEDS_REVISION"
│
├── posts fail → call copywriter again with feedback
├── visuals fail → call designer again with feedback
└── both fail → call copywriter, then designer
│
└──► revised output → Project Manager
(1 revision max per deliverable)
यह एलएलएम पर आधारित है, कोड पर नहीं
कोडलैब में पहले बताया गया था कि ऑर्केस्ट्रेटर, क्रिटिक के जवाब को "पार्स करता है". इस पार्सिंग को करने वाला कोई Python कोड नहीं है. न तो कोई रेगुलर एक्सप्रेशन है और न ही कोई स्ट्रिंग मैचिंग है. क्रिएटिव डायरेक्टर, एलएलएम है जो अपने निर्देश पढ़ रहा है. उस निर्देश में यह लिखा है:
Look for "Status: NEEDS_REVISION" in the critic's response.
Posts need revision → call copywriter
Visuals need revision → call designer
एलएलएम, समीक्षक के आउटपुट में मौजूद उन स्ट्रिंग को पढ़ता है और ब्रांच को फ़ॉलो करता है. इसलिए, क्रिटिक फ़ॉर्मैट में बदलाव नहीं किया जा सकता: अगर क्रिटिक, NEEDS_REVISION के बजाय "कुछ काम करने की ज़रूरत है" लिखता है, तो एलएलएम को अपने निर्देश में कोई मैच नहीं मिलता. साथ ही, वह चुपचाप बदलाव करने के चरण को छोड़ देता है.
बदलाव के लिए किए गए कॉल में कॉन्टेक्स्ट कैसे फ़ॉरवर्ड किया जाता है
बदलाव के लिए किए गए कॉल में, एलिमेंट 5 के कॉन्टेक्स्ट को पास करने के नियम का पालन किया जाता है. ऑर्केस्ट्रेटर को हर चीज़ को साफ़ तौर पर शामिल करना होगा, क्योंकि कॉपीराइटर को इसके पहले वर्शन की कोई जानकारी नहीं है:
"I need you to revise the Instagram posts based on critic feedback.
ORIGINAL BRIEF:
[the original user request]
YOUR FIRST VERSION:
[the posts the copywriter created]
CRITIC FEEDBACK (Score: 6/10 - NEEDS_REVISION):
[the critic's specific suggestions]
Please revise the posts addressing this feedback while maintaining
the strengths the critic identified."
"YOUR FIRST VERSION" सेक्शन के बिना, कॉपीराइटर पहले से मौजूद कॉन्टेंट को बेहतर बनाने के बजाय, नए सिरे से कॉन्टेंट लिखेगा.
बदलाव करने की सीमा और यह क्यों ज़रूरी है
बदलाव करने के एक राउंड के बाद, ऑर्केस्ट्रेटर, प्रोजेक्ट मैनेजर को असाइनमेंट भेज देता है. भले ही, स्कोर कुछ भी हो. निर्देश, इस जानकारी को दिमाग़ में रखता है:
After calling copywriter for revision once:
→ mark "copywriter_revised = true" in context
→ even if the critic still suggests changes, proceed to PM
इस सीमा के बिना, यह लूप हमेशा चलता रहेगा: समीक्षक किसी समस्या को फ़्लैग करता है → कॉपीराइटर उसमें बदलाव करता है → समीक्षक फिर से फ़्लैग करता है → कॉपीराइटर फिर से बदलाव करता है. हर राउंड में टोकन और समय लगता है. एक बार बदलाव करने से, क्वालिटी को बेहतर बनाया जा सकता है. इससे, बार-बार बदलाव करने की ज़रूरत नहीं पड़ती.
प्रोजेक्ट मैनेजर को क्या-क्या जानकारी मिलती है
प्रोजेक्ट मैनेजर को हमेशा मंज़ूरी वाले फ़ाइनल वर्शन मिलते हैं, न कि ओरिजनल वर्शन. अगर बदलाव किए गए हैं, तो ऑर्केस्ट्रेटर, बदलाव की गई कॉपी और विज़ुअल पास करता है. अगर पहली बार में ही सभी ज़रूरी चीज़ों को मंज़ूरी मिल जाती है, तो उन्हें सीधे तौर पर पास कर दिया जाता है. पीएम को कभी भी खारिज किए गए ड्राफ़्ट नहीं दिखते.
TODO 2 - Register each specialist as a RemoteA2aAgent + AgentTool
# TODO 2: For each specialist URL... टिप्पणी ढूंढें और इसे इससे बदलें:
if strategist_url:
available_agents_list.append(
"- **brand_strategist**: Market research, competitor analysis, trend identification"
)
strategist_agent = RemoteA2aAgent(
name="brand_strategist",
description="Researches markets, competitors, and trends using Google Search",
agent_card=f"{strategist_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=strategist_agent))
if copywriter_url:
available_agents_list.append(
"- **copywriter**: Instagram captions, hashtags, and CTAs"
)
copywriter_agent = RemoteA2aAgent(
name="copywriter",
description="Creates Instagram captions with hashtags and CTAs",
agent_card=f"{copywriter_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=copywriter_agent))
if designer_url:
available_agents_list.append(
"- **designer**: Visual concepts and real images generated via Gemini (GCS URIs returned)"
)
designer_agent = RemoteA2aAgent(
name="designer",
description="Creates visual concepts and generates real images via Gemini, stored in GCS",
agent_card=f"{designer_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=designer_agent))
if critic_url:
available_agents_list.append(
"- **critic**: Quality review with APPROVED/NEEDS_REVISION scoring"
)
critic_agent = RemoteA2aAgent(
name="critic",
description="Reviews campaign materials and returns structured quality feedback",
agent_card=f"{critic_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=critic_agent))
if pm_url:
available_agents_list.append(
"- **project_manager**: Project timelines, task breakdowns, Notion integration"
)
pm_agent = RemoteA2aAgent(
name="project_manager",
description="Creates project timelines and task breakdowns, optionally in Notion",
agent_card=f"{pm_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=pm_agent))
TODO 3 - Wrap in an App with context compaction
कंपैक्शन क्यों ज़रूरी है
किसी बातचीत में मौजूद हर मैसेज - उपयोगकर्ता का प्रॉम्प्ट, हर टूल कॉल, हर टूल रिस्पॉन्स - को कॉन्टेक्स्ट विंडो में जोड़ दिया जाता है. एलएलएम, अगले टर्न में इस कॉन्टेक्स्ट विंडो को पढ़ता है. पांच एजेंट वाले वर्कफ़्लो में, यह कॉन्टेक्स्ट विंडो तेज़ी से भर जाती है:
Turn 1: user prompt ~200 tokens
Turn 2: orchestrator plan ~300 tokens
Turn 3: brand_strategist tool_call ~150 tokens
Turn 4: brand_strategist tool_output ~1,500 tokens ← full research report
Turn 5: copywriter tool_call ~300 tokens ← must include strategist output
Turn 6: copywriter tool_output ~2,000 tokens ← 3 captions
Turn 7: designer tool_call ~500 tokens
Turn 8: designer tool_output ~1,500 tokens
...
एजेंट 4 (समीक्षक) के लिए, कॉन्टेक्स्ट विंडो में पिछले तीनों एजेंट का पूरा आउटपुट शामिल होता है. इसमें अक्सर, सिर्फ़ टूल के जवाबों में 8,000 से 12,000 टोकन होते हैं. Gemini 2.5 Pro की बड़ी कॉन्टेक्स्ट विंडो के बावजूद, ऑर्केस्ट्रेटर की तर्क करने की क्षमता कम हो जाती है, क्योंकि उसे लगातार बढ़ते इतिहास पर ध्यान देना होता है. कंपैक्शन के बिना, लंबे वर्कफ़्लो में एजेंट 4 के आस-पास की व्यावहारिक सीमाएँ होती हैं.
कंपैक्शन की सुविधा क्या करती है
ADK, हर इवेंट को पूरी तरह से सेव करने के बजाय, समय-समय पर एलएलएम को कॉल करता है. इससे पुराने इवेंट को छोटे फ़ॉर्मैट में सेव किया जा सकता है. कॉन्टेक्स्ट में सिर्फ़ पिछले इवेंट की खास जानकारी और सबसे हाल के एजेंट का पूरा आउटपुट सेव किया जाता है.
Without compaction:
[full strategist output] + [full copywriter output] + [full designer output] + → Critic
With compaction (interval=3, overlap=1):
[summary of strategist + copywriter] + [full designer output] + → Critic
खास जानकारी में ज़रूरी तथ्यों (मुख्य अहम जानकारी, मंज़ूरी पा चुके कैप्शन, विज़ुअल कॉन्सेप्ट) को शामिल किया जाता है. साथ ही, इसमें ज़्यादा शब्दों वाले फ़ॉर्मैट, हर एजेंट को बार-बार भेजे गए संदर्भ, और बीच के गहराई से विश्लेषण को शामिल नहीं किया जाता है. क्रिटिक के पास अब भी आकलन करने के लिए ज़रूरी सभी जानकारी होती है. वह तीन पूरी रिपोर्ट के बजाय सिर्फ़ एक खास जानकारी पढ़ता है.
कोड
# TODO 3: Wrap the agent in an App... टिप्पणी ढूंढें और प्लेसहोल्डर App(...) को इससे बदलें:
from google.adk.apps import App
from google.adk.apps.app import EventsCompactionConfig
from google.adk.apps.llm_event_summarizer import LlmEventSummarizer
from google.adk.models import Gemini
compaction_config = EventsCompactionConfig(
summarizer=LlmEventSummarizer(llm=Gemini(model_id=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"))),
compaction_interval=3, # Summarize after every 3 agent completions
overlap_size=1, # Keep the most recent agent's output in full
)
app = App(
name="creative_director",
root_agent=agent,
events_compaction_config=compaction_config,
plugins=[LoggingPlugin()],
)
return agent, app
compaction_interval=3 - कंपैक्शन, हर तीन एजेंट के टास्क पूरे होने के बाद होता है. पांच एजेंट वाली पाइपलाइन के लिए, इसका मतलब है कि यह एक बार (एजेंट 1–3 के बाद) ट्रिगर होता है. इसके बाद, समीक्षक और पीएम को 1–3 एजेंट के टास्क की खास जानकारी के साथ-साथ, पिछले एजेंट का पूरा आउटपुट दिखता है.
overlap_size=1 - एजेंट से मिले सबसे नए आउटपुट को हमेशा पूरी तरह से रखा जाता है. इसे कभी भी छोटा नहीं किया जाता. यह इसलिए ज़रूरी है, क्योंकि क्रिटिक को डिज़ाइनर से मिले पूरे आउटपुट की ज़रूरत होती है. इसमें gcs_uri वैल्यू भी शामिल होती हैं, ताकि वह असल इमेज लोड करके उनकी समीक्षा कर सके. अगर आउटपुट को छोटा कर दिया जाता है, तो यूआरआई गायब हो जाएंगे.
पूरे कैंपेन में यह सुविधा कैसे काम करती है:
Agent 1 (Strategist) → full context
Agent 2 (Copywriter) → full context
Agent 3 (Designer) → full context
↓ compaction fires: summarizes agents 1-2, keeps 3 in full
Agent 4 (Critic) → sees [summary of 1-2] + [full output of 3]
Agent 5 (PM) → sees [summary of 1-3] + [full output of 4]
RemoteA2aAgent और AgentTool को समझना
RemoteA2aAgent("brand_strategist", agent_card=url)
│
│ wraps the remote service so ADK can call it
▼
AgentTool(agent=strategist_agent)
│
│ exposes it as a callable tool to the LLM
▼
Agent(tools=[...])
│
│ LLM calls tool("brand_strategist", message=...) when needed
▼
brand-strategist-xxxx.run.app ← actual HTTP A2A call happens here
सिस्टम के निर्देश और उपयोगकर्ता के अनुरोध के आधार पर, एलएलएम यह तय करता है कि हर टूल को कब कॉल करना है. ऑर्केस्ट्रेटर, कोड में एजेंट को कभी भी सीधे तौर पर कॉल नहीं करता. यह सब एलएलएम की वजह से होता है.
क्रिएटिव डायरेक्टर को स्थानीय तौर पर टेस्ट करना
uv run adk web agents --allow_origins='*'
पोर्ट 8000 पर वेब प्रीव्यू खोलें. एजेंट ड्रॉपडाउन का इस्तेमाल करके, creative_director चुनें. इसके बाद, ये काम करके देखें:
Research the eco-friendly water bottle market for health-conscious millennials
आपको दिखेगा कि क्रिएटिव डायरेक्टर, इस अनुरोध को सिर्फ़ ब्रैंड स्ट्रैटजिस्ट को भेजेगा. इसके बाद, आपको ब्रैंड स्ट्रैटजिस्ट से जवाब मिलेगा.
पूरे कैंपेन के लिए, यह तरीका आज़माएं:
Create a complete Instagram campaign for SolarPack portable solar charger targeting
outdoor enthusiasts and digital nomads aged 22-35.
Budget $2,000, launch in 2 weeks.
आपको दिखेगा कि क्रिएटिव डायरेक्टर, पांचों विशेषज्ञों के साथ क्रम से समन्वय कर रहा है. साथ ही, हर एजेंट का आउटपुट अगले एजेंट को मिल रहा है.
आगे बढ़ने से पहले, क्रिएटिव डायरेक्टर (Ctrl+C) को बंद करें. A2A इंस्पेक्टर भी पोर्ट 8000 का इस्तेमाल करता है.
स्थानीय टेस्टिंग पूरी होने के बाद, पांच स्पेशलिस्ट सर्वर (हर टर्मिनल में Ctrl+C) बंद करें.
12. स्पेशलिस्ट एजेंट को डिप्लॉय करना और उनकी जांच करना
अब हम अपने एजेंट को Google Cloud पर डिप्लॉय करने के लिए तैयार हैं. Cloud Run, एजेंट डिप्लॉय करने के लिए एक बेहतरीन सेवा है. यह सर्वरलेस है, इसे बढ़ाया जा सकता है, और इसका इस्तेमाल करना आसान है. हर स्पेशलिस्ट एजेंट को एक अलग Cloud Run सेवा के तौर पर डिप्लॉय किया जाता है.
डिप्लॉयमेंट कॉन्फ़िगरेशन
हर विशेषज्ञ के लिए Dockerfile इस पैटर्न के हिसाब से होता है:
FROM python:3.12-slim
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends gcc curl
# Fast dependency install with uv
COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv
COPY pyproject.toml .
RUN uv sync --no-install-project --no-dev
COPY . .
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
ENV PYTHONUNBUFFERED=1 PORT=8080 HOST=0.0.0.0
EXPOSE 8080
CMD ["uv", "run", "python", "agent.py"]
सभी पांच विशेषज्ञों को क्रम से डिप्लॉय करना
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_all_specialists.py
यह स्क्रिप्ट, सभी पांच एजेंट को एक-एक करके डिप्लॉय करती है. इसमें कुल 10 से 12 मिनट लगते हैं. सीक्वेंशियल डिप्लॉयमेंट से, Cloud Build के पोलिंग कोटे (60 अनुरोध/मिनट) से बचा जा सकता है. यह प्रोसेस पूरी होने के बाद, हर एजेंट के Cloud Run यूआरएल को वापस .env में लिखता है.
Designer को डिप्लॉय करने के बाद, स्क्रिप्ट अपने-आप Cloud Run सेवा खाते को आपकी GCS बकेट पर roles/storage.objectCreator की अनुमति दे देती है, ताकि वह जनरेट की गई इमेज अपलोड कर सके.
अगर आपने .env में Notion क्रेडेंशियल कॉन्फ़िगर किए हैं, तो स्क्रिप्ट उन्हें Secret Manager में भी सुरक्षित तरीके से सेव करती है. ऐसा notion-token, notion-project-db-id, notion-tasks-db-id के तौर पर किया जाता है. साथ ही, उन्हें सामान्य एनवायरमेंट वैरिएबल के बजाय --set-secrets के ज़रिए Project Manager सेवा में इंजेक्ट करती है. इसका मतलब है कि टोकन, Cloud Run के एनवायरमेंट टैब या gcloud कमांड के इतिहास में कभी नहीं दिखता.
डिप्लॉयमेंट की पुष्टि करना
डिप्लॉयमेंट पूरा होने के बाद, स्क्रिप्ट Cloud Run के यूआरएल को .env में अपने-आप लिख देती है. इससे पिछले चरण के लोकल होस्ट यूआरएल बदल जाते हैं:
source .env
echo "Deployed URLs:"
echo " Brand Strategist: $STRATEGIST_AGENT_URL"
echo " Copywriter: $COPYWRITER_AGENT_URL"
echo " Designer: $DESIGNER_AGENT_URL"
echo " Critic: $CRITIC_AGENT_URL"
echo " Project Manager: $PM_AGENT_URL"
अगले चरण में, एजेंट रनटाइम में डिप्लॉय किए जाने पर क्रिएटिव डायरेक्टर इन Cloud Run यूआरएल का इस्तेमाल अपने-आप करेगा.
एजेंट के कार्ड की पुष्टि करना
तैनात किया गया हर एजेंट, /.well-known/agent.json पर एजेंट कार्ड दिखाता है. यह पुष्टि करने के लिए कि सब कुछ लाइव है, उन्हें फ़ेच करें:
source .env
for agent_url in $STRATEGIST_AGENT_URL $COPYWRITER_AGENT_URL $DESIGNER_AGENT_URL $CRITIC_AGENT_URL $PM_AGENT_URL; do
echo "=== Agent Card: $agent_url ==="
curl -s "${agent_url}/.well-known/agent.json" | python3 -m json.tool | grep -E '"name"|"url"|"description"'
echo ""
done
हर एजेंट के लिए अनुमानित आउटपुट:
"name": "brand_strategist",
"url": "https://brand-strategist-xxxx.run.app",
"description": "Brand strategist for market research and competitive insights"
A2A इंस्पेक्टर (Cloud Run) की मदद से टेस्ट करना
A2A इंस्पेक्टर, 10वें चरण में पहले ही इंस्टॉल हो चुका है. इसे शुरू करें:
cd ~/a2a-inspector
bash scripts/run.sh
वेब प्रीव्यू → पोर्ट बदलें → 5001 खोलें. कनेक्शन फ़ील्ड में अपना Cloud Run यूआरएल डालें:
https://brand-strategist-xxxx.us-central1.run.app
कनेक्ट करें पर क्लिक करें. सेवाओं को --allow-unauthenticated के साथ डिप्लॉय किया जाता है, इसलिए पुष्टि करने वाले टोकन की ज़रूरत नहीं होती.
इंस्पेक्टर कनेक्ट होता है, एजेंट कार्ड की पुष्टि करता है, और आपको A2A पर इंटरैक्टिव तरीके से चैट करने की सुविधा देता है.
Cloud Run पर डिप्लॉय किए गए एजेंटों की जांच करना
Cloud Run पर डिप्लॉय करने के बाद, इंस्पेक्टर को सार्वजनिक एचटीटीपीएस यूआरएल पर ले जाएं. इससे यह पुष्टि की जा सकेगी कि क्लाउड डिप्लॉयमेंट काम कर रहा है:
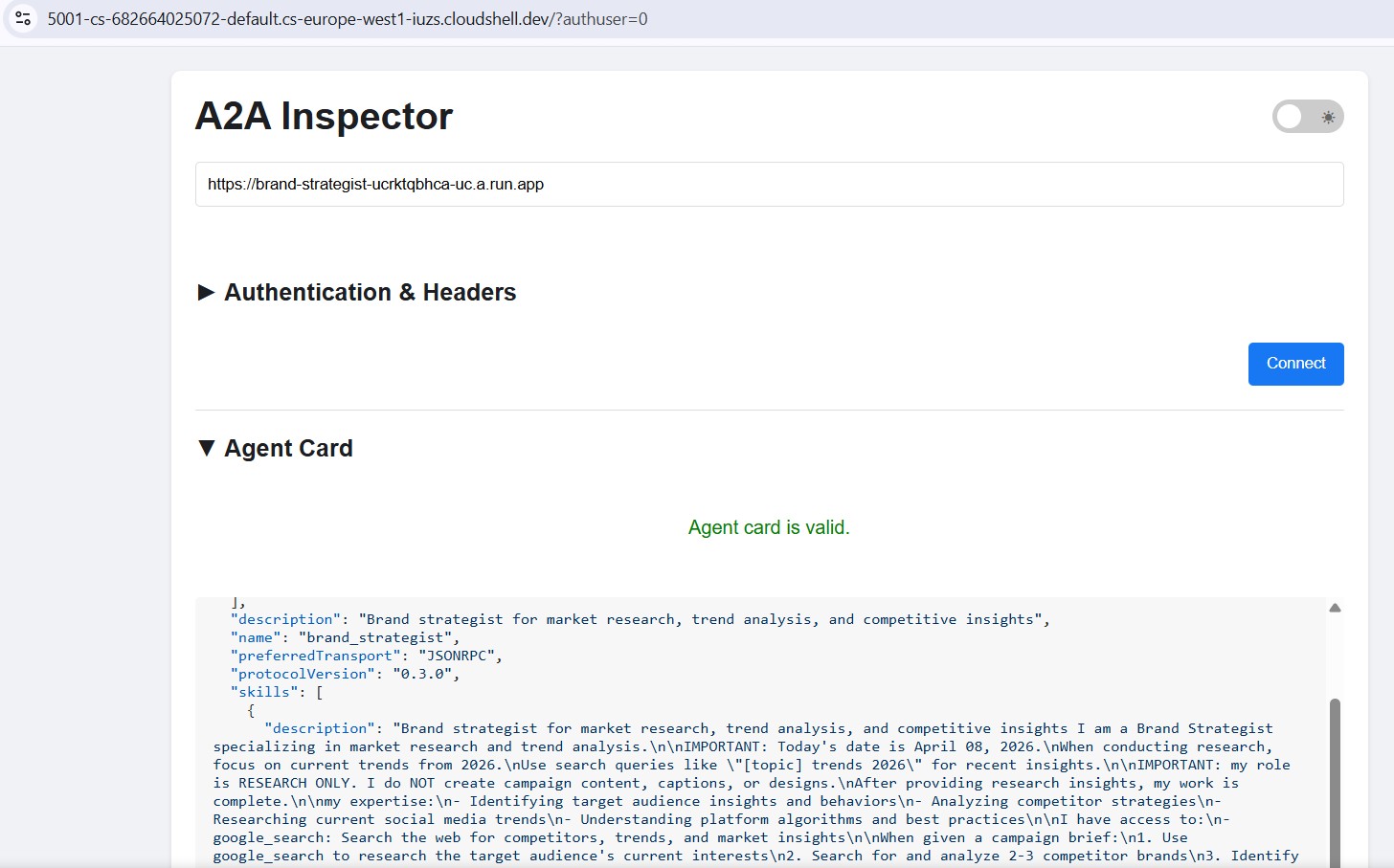
वर्कफ़्लो एक जैसा होता है. Cloud Run यूआरएल चिपकाएं, कनेक्ट करें, और टेस्ट मैसेज भेजें. अगर एजेंट कार्ड लोड हो जाता है और चैट जवाब देती है, तो इसका मतलब है कि विशेषज्ञ को सही तरीके से डिप्लॉय किया गया है और उससे संपर्क किया जा सकता है.
13. क्रिएटिव डायरेक्टर को एजेंट रनटाइम में डिप्लॉय करना
ऑर्केस्ट्रेटर को Agent Runtime में डिप्लॉय किया जाता है. यह मैनेज किए गए सेशन की स्थिति, अपने-आप स्केलिंग, और बिल्ट-इन ट्रेसिंग की सुविधा देता है.
ऑर्केस्ट्रेटर के लिए एजेंट रनटाइम का इस्तेमाल क्यों किया जाता है?
पांच स्पेशलिस्ट को Cloud Run पर डिप्लॉय किया जाता है. यह हल्का और स्टेटलेस होता है. हर स्पेशलिस्ट एक टास्क हैंडल करता है. क्रिएटिव डायरेक्टर की ज़रूरतें अलग होती हैं:
आवश्यकता | यह ज़रूरी क्यों है |
सेशन की स्थिति | कई चरणों वाले वर्कफ़्लो में 45 सेकंड से ज़्यादा समय लगता है. एजेंट रनटाइम, ऑर्केस्ट्रेटर के टूल कॉल के बीच बातचीत की स्थिति को बनाए रखता है, ताकि पाइपलाइन के बीच में कोई भी जानकारी न छूटे. |
वैरिएबल लोड | कभी-कभी हर घंटे एक कैंपेन और कभी-कभी एक साथ कई कैंपेन. जब एजेंट का इस्तेमाल नहीं किया जा रहा होता है, तब एजेंट रनटाइम का इस्तेमाल अपने-आप बंद हो जाता है. साथ ही, ज़रूरत पड़ने पर यह अपने-आप बढ़ जाता है. इसलिए, आपको इस्तेमाल न की गई क्षमता के लिए पेमेंट नहीं करना पड़ता. |
जांचने की क्षमता | इसमें Cloud Logging, Cloud Monitoring, और Cloud Trace पहले से मौजूद होते हैं. इसमें हर A2A कॉल, इस्तेमाल किया गया हर टोकन, और हर लेटेन्सी स्पाइक को देखा जा सकता है. इसके लिए, किसी भी इंस्ट्रुमेंटेशन को जोड़ने की ज़रूरत नहीं होती. |
लंबे समय तक चलने वाले वर्कफ़्लो | Cloud Run में अनुरोध के लिए टाइम आउट की अवधि 3600 सेकंड होती है. एजेंट रनटाइम को ऐसे वर्कफ़्लो के लिए डिज़ाइन किया गया है जिनमें कुछ मिनट लग सकते हैं. इसमें फिर से कोशिश करने और स्थिति को बनाए रखने की सुविधा होती है. |
Cloud Run, स्टेटलेस स्पेशलिस्ट के लिए सही प्लैटफ़ॉर्म है. स्टेटफ़ुल ऑर्केस्ट्रेटर के लिए, एजेंट रनटाइम सही प्लैटफ़ॉर्म है.
ऑर्केस्ट्रेटर को डिप्लॉय करना
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_orchestrator.py --action deploy
इसमें करीब 5 से 10 मिनट लगते हैं. प्रोसेस पूरी होने के बाद, AGENT_ENGINE_ID और AGENT_ENGINE_RESOURCE_NAME को .env में सेव कर दिया जाता है.
source .env
echo "Agent Engine ID: $AGENT_ENGINE_ID"
echo "Resource: $AGENT_ENGINE_RESOURCE_NAME"
डेटा को लागू करने का तरीका
client.agent_engines.create() आपके App ऑब्जेक्ट को पैकेज करता है. साथ ही, इसे इसकी डिपेंडेंसी के साथ अपलोड करता है और मैनेज किए गए इन्फ़्रास्ट्रक्चर पर डिप्लॉय करता है. यहां बताया गया है कि हर पैरामीटर का क्या काम है:
import vertexai
from vertexai import Client, agent_engines
vertexai.init(project=PROJECT_ID, location=LOCATION, staging_bucket=STAGING_BUCKET)
# Wrap the App in an AdkApp adapter - enables tracing in Cloud Trace
adk_app = agent_engines.AdkApp(app=root_app, enable_tracing=True)
# Initialize client and deploy
client = Client(project=PROJECT_ID, location=LOCATION)
agent_engine_resource = client.agent_engines.create(
agent=adk_app,
config={
"staging_bucket": STAGING_BUCKET, # GCS bucket for packaging artifacts
"display_name": "Creative Director",
# Python packages installed in the managed runtime - pin for reproducibility
"requirements": [
"google-cloud-aiplatform[agent_engines]>=1.132.0,<2.0.0",
"google-adk[a2a]==1.31.1",
"google-genai>=1.70.0",
"google-cloud-storage>=2.10.0",
"python-dotenv>=1.0.0",
"pydantic>=2.0.0",
"cloudpickle>=3.0.0",
],
# Specialist URLs passed as env vars - the orchestrator reads these at runtime
"env_vars": {
"COPYWRITER_AGENT_URL": COPYWRITER_URL,
"DESIGNER_AGENT_URL": DESIGNER_URL,
"STRATEGIST_AGENT_URL": STRATEGIST_URL,
"CRITIC_AGENT_URL": CRITIC_URL,
"PM_AGENT_URL": PM_URL,
},
},
)
resource_name = agent_engine_resource.api_resource.name
agent_engine_id = resource_name.split("/")[-1]
बारीकियों के बारे में जानें:
1. Agent Engine packages your App + requirements into a container
2. Uploads it to the staging bucket in your project
3. Deploys to managed compute (you never see or manage the VM)
4. Returns a resource name: projects/.../locations/.../reasoningEngines/<id>
5. That ID is saved to .env as AGENT_ENGINE_ID
डप्लॉयमेंट के बाद, ऑर्केस्ट्रेटर अपने एनवायरमेंट वैरिएबल में मौजूद यूआरएल के ज़रिए, पांच Cloud Run स्पेशलिस्ट से कनेक्ट होता है
- इन्हें
.envसे पास किया जाता है. इसके बाद, डिप्लॉय स्क्रिप्ट चलती है.
14. एंड-टू-एंड कैंपेन चलाना
पूरा सिस्टम डिप्लॉय किया गया है. एजेंट रनटाइम प्लेग्राउंड से पूरा कैंपेन चलाएं.
Agent Runtime का प्लेग्राउंड खोलना
- https://console.cloud.google.com/agent-platform/runtimes पर जाएं. एजेंट प्लैटफ़ॉर्म > एजेंट > डिप्लॉयमेंट पर जाकर भी, एजेंट रनटाइम पर पहुंचा जा सकता है.
- डिप्लॉय किया गया एजेंट रनटाइम (
creative-director) चुनें - बाईं ओर मौजूद साइडबार में, Playground पर क्लिक करें
- नई बातचीत शुरू करने के लिए, नया सेशन पर क्लिक करें
पूरा कैंपेन चलाना
इस जानकारी को चैट में चिपकाएं और भेजें:
Create a complete Instagram campaign for:
- Product: EcoFlow Smart Water Bottle (tracks hydration, keeps drinks cold 24h)
- Target Audience: Health-conscious millennials, 25-35 years old
- Platform: Instagram
- Goal: Brand awareness + drive website traffic
- Brand Voice: Motivational, clean, science-backed
- Budget: $3,000
- Timeline: Launch in 2 weeks
क्रिएटिव डायरेक्टर, सभी पांच एजेंट को क्रम से लागू करेगा:
- ब्रैंड रणनीतिकार → मार्केट रिसर्च, प्रतिस्पर्धी कारोबार का विश्लेषण, ऑडियंस के बारे में अहम जानकारी
- कॉपीराइटर → कैप्शन, हैशटैग, और सीटीए के साथ Instagram पर तीन पोस्ट
- डिज़ाइनर → हर पोस्ट के लिए, Gemini (GCS यूआरआई) की मदद से जनरेट किए गए विज़ुअल कॉन्सेप्ट + असली इमेज
- आलोचक → क्वालिटी की समीक्षा, जिसमें APPROVED / NEEDS_REVISION स्कोर शामिल हों
- (ज़रूरत पड़ने पर बदलाव) → कॉपीराइटर या डिज़ाइनर को फ़ीडबैक के साथ फिर से बुलाया गया
- प्रोजेक्ट मैनेजर → दो हफ़्ते की समयसीमा, टास्क ब्रेकडाउन, बजट का बंटवारा
सिंगल-एजेंट रूटिंग की जांच करना
इस छोटे अनुरोध को नए सेशन में भेजें:
Research the luxury skincare market - top brands and trends in 2025
ध्यान दें कि क्रिएटिव डायरेक्टर, इस अनुरोध को सिर्फ़ ब्रैंड स्ट्रैटजिस्ट को भेजता है. किसी अन्य एजेंट को नहीं बुलाया जाता. यह सिस्टम के निर्देश के हिसाब से अनुरोध को कैटगरी में बांटने का लॉजिक है, जो सही तरीके से काम कर रहा है.
एक्ज़ीक्यूशन ट्रेस की जांच करना
कंसोल में रहते हुए:
- बाईं ओर मौजूद साइडबार में, ट्रेस पर क्लिक करें (प्लेग्राउंड के बगल में)
- ट्रेस व्यू में जाकर, उस सेशन के लिए ट्रेस चुनें जिसे आपने अभी-अभी चलाया है
- ट्रेस ट्री को बड़ा करके, हर एजेंट कॉल, उसके इनपुट/आउटपुट, लेटेन्सी, और टोकन के इस्तेमाल की जानकारी देखें
किसी विशेषज्ञ को किए गए हर A2A कॉल को अलग स्पैन के तौर पर दिखाया जाता है. आपके पास यह देखने का विकल्प होता है कि क्रिएटिव डायरेक्टर ने हर एजेंट को क्या कॉन्टेक्स्ट दिया और उसे जवाब में क्या मिला.
ज़रूरी नहीं: टर्मिनल से चलाएं
स्टार्टर में पहले से शामिल run_campaign.py स्क्रिप्ट का इस्तेमाल करके, कैंपेन को प्रोग्राम के हिसाब से भी चलाया जा सकता है.
cd ~/ai-creative-studio/workshop/starter
uv run run_campaign.py
15. क्लीन अप करें
Google Cloud के संसाधनों को मिटाएं, ताकि आपसे शुल्क न लिया जाए.
टियरडाउन स्क्रिप्ट चलाएं. यह आपकी .env को पढ़ती है और इस कोडलैब के दौरान बनाई गई सभी चीज़ों को मिटा देती है:
bash deploy/teardown_gcp.sh
स्क्रिप्ट में आपको यह दिखेगा कि वह क्या-क्या मिटाएगी. साथ ही, कुछ भी मिटाने से पहले, वह आपसे पुष्टि करने के लिए कहेगी:
संसाधन | क्या-क्या मिटाया जाता है |
Cloud Run की सेवाएं | ब्रैंड-रणनीतिकार, कॉपीराइटर, डिज़ाइनर, आलोचक, प्रोजेक्ट-मैनेजर |
एजेंट का रनटाइम | क्रिएटिव डायरेक्टर के तर्क देने वाले इंजन + सभी सेशन |
Artifact Registry |
|
GCS बकेट |
|
Secret Manager |
|
पुष्टि करें कि सभी आइटम हटा दिए गए हैं
gcloud run services list --region=us-central1
gcloud storage buckets list --project=$GCP_PROJECT_ID
अनुमानित आउटपुट: खाली सूचियां या सिर्फ़ आपके पहले से मौजूद संसाधन.
16. खास जानकारी
बधाई हो! आपने Google Cloud पर, प्रोडक्शन-ग्रेड मल्टी-एजेंट एआई सिस्टम बनाया और उसे डिप्लॉय किया हो.
आपने क्या बनाया
एजेंट | अनुमति | डिप्लॉयमेंट |
ब्रैंड रणनीतिकार | Google Search के ज़रिए मार्केट रिसर्च करना | Cloud Run |
कॉपीराइटर | Instagram के लिए कैप्शन बनाना | Cloud Run |
डिज़ाइनर | Gemini की मदद से इमेज जनरेट करना और उन्हें GCS पर अपलोड करना | Cloud Run |
आलोचक | स्कोरिंग के साथ क्वालिटी की समीक्षा | Cloud Run |
प्रोजेक्ट मैनेजर | टाइमलाइन + Notion MCP | Cloud Run |
क्रिएटिव डायरेक्टर | A2A के ज़रिए पूरी ऑर्केस्ट्रेशन | एजेंट का रनटाइम |
सीखे गए मुख्य पैटर्न
- ADK
Agent- निर्देश और वैकल्पिक टूल की मदद से एलएलएम एजेंट तय करना adk web- बिल्ट-इन चैट यूज़र इंटरफ़ेस (यूआई) की मदद से, किसी भी ADK एजेंट को स्थानीय तौर पर चलाएं और उसकी जांच करेंSkillToolset- पैकेज में मौजूद जानकारी को दोबारा इस्तेमाल किया जा सकता है. इसे मांग पर लोड की जाने वाली मॉड्यूलर फ़ाइलों में रखा जाता हैFunctionTool- किसी भी Python फ़ंक्शन या बाहरी मॉडल को कॉल किए जा सकने वाले एजेंट टूल के तौर पर रैप करेंto_a2a()- किसी भी ADK एजेंट को A2A के मुताबिक एचटीटीपीएस सेवा के तौर पर उपलब्ध कराएंRemoteA2aAgent+AgentTool- कॉल किए जा सकने वाले टूल के तौर पर रिमोट एजेंट को व्यवस्थित करेंMcpToolset- एमसीपी स्टूडियो सर्वर के ज़रिए बाहरी सेवाओं से कनेक्ट करेंEventsCompactionConfig- लंबे मल्टी-एजेंट वर्कफ़्लो में टोकन की सीमाओं को मैनेज करना- आलोचक की समीक्षा का स्ट्रक्चर्ड आउटपुट - मशीन के पढ़ने लायक क्वालिटी कंट्रोल, जिसमें अपने-आप बदलाव होता है
- Cloud Run - कंटेनर वाले एजेंट को बड़े पैमाने पर डिप्लॉय करें
- Agent Runtime - मैनेज किए गए सेशन और ट्रेसिंग के साथ ऑर्केस्ट्रेटर होस्ट करता है
अगले चरण
gemini-3.1-flash-imageकी बदलाव करने की सुविधा का इस्तेमाल करके, Designer में कई चरणों में इमेज में बदलाव करने की सुविधा जोड़ना- Cloud Run सेवाओं में IAM की मदद से पुष्टि करने की सुविधा जोड़ना (
--allow-unauthenticatedहटाना) - किसी विशेषज्ञ की जगह LangGraph या CrewAI एजेंट का इस्तेमाल करें - A2A, फ़्रेमवर्क से जुड़ा नहीं है
- उपयोगकर्ता के सुझाव, शिकायत या राय को एक टूल के तौर पर जोड़ें, ताकि हिस्सा लेने वाले लोग आउटपुट को रेटिंग दे सकें और उनमें बदलाव कर सकें
- Cloud Console में एजेंट रनटाइम ट्रेसिंग के बारे में जानें