
1. Panoramica
In questo codelab creerai AI Creative Studio, un sistema multi-agente distribuito che trasforma un singolo prompt in una campagna Instagram completa.
Digita una frase. Ricevi ricerche sul pubblico, sottotitoli codificati, concetti visivi, testi sottoposti a revisione della qualità e una cronologia completa del progetto, il tutto generato da un team di agenti AI che collaborano.
Gli agenti che creerai
Agente | Ruolo |
Brand Strategist | Cerca sul web approfondimenti sul pubblico, analisi della concorrenza e tendenze del 2025 |
Copywriter | Scrive didascalie di Instagram con hashtag e inviti all'azione, grazie a una skill ADK che carica le linee guida della piattaforma e le formule per le didascalie su richiesta |
Designer | Crea concetti visivi e genera immagini reali tramite Gemini, archiviate in GCS |
Critico | Copia e immagini delle recensioni: restituisce |
Project Manager | Crea una cronologia del progetto e una suddivisione delle attività, sincronizzate facoltativamente con Notion tramite MCP |
Creative Director | Coordina tutti e cinque gli esperti in sequenza: ti basta un prompt e lui si occupa del resto |
I cinque agenti vengono implementati come microservizi Cloud Run indipendenti. Comunicano tramite il protocollo A2A, uno standard aperto indipendente dal linguaggio, in modo che qualsiasi agente possa chiamare qualsiasi altro agente indipendentemente dal framework. Il direttore creativo viene eseguito su Agent Runtime e si connette a ogni specialista da remoto.
Architettura

Obiettivi didattici
- Crea agenti LLM con Google ADK,
Agent, istruzioni di sistema e strumenti integrati. - Raggruppa le conoscenze riutilizzabili dell'agente in file modulari con ADK Skills (
SkillToolset). - Genera immagini reali collegando un agente di testo a un modello di immagine tramite un
FunctionTool. - Integra API esterne senza codice di collegamento personalizzato utilizzando il Model Context Protocol (MCP).
- Trasforma qualsiasi agente in un servizio richiamabile dalla rete utilizzando il protocollo Agent to Agent (A2A) su HTTPS.
- Orchestra agenti distribuiti con
RemoteA2aAgenteAgentTool. - Pacchettizza ed esegui il deployment di agenti indipendenti come microservizi Cloud Run.
- Ospita un orchestratore stateful su Agent Runtime.
- Mantieni i workflow multi-agente lunghi entro i limiti del contesto utilizzando la compressione del contesto.
- Crea un ciclo di controllo della qualità: output delle recensioni dei critici → revisione automatica quando necessario.
Che cosa ti serve
- Un progetto Google Cloud con la fatturazione abilitata
- Ruolo IAM Proprietario o Editor
- Conoscenza di base di Python
2. Configura l'ambiente
Per questo codelab, utilizzeremo Cloud Shell.
Che cos'è Cloud Shell?
Cloud Shell è un ambiente Linux senza costi basato su browser con tutto preinstallato: gcloud, git, Python, Docker e altro ancora. Non devi installare nulla in locale.
Per aprire Cloud Shell, fai clic sull'icona del terminale nella barra degli strumenti in alto a destra della console GCP:
Quando apri Cloud Shell per la prima volta, ti viene chiesto di verificare il tuo account. Fai clic su Verifica:
Poi fai clic su Autorizza per consentire a Cloud Shell di effettuare chiamate API Google Cloud:
Cloud Shell è ora pronto. Nel terminale viene visualizzato un messaggio di benvenuto: 
Autenticare e configurare il progetto
Cloud Shell è già autenticato con il tuo Account Google. Conferma il tuo account attivo e trova l'ID progetto:
gcloud config list
Puoi anche visualizzare l'ID progetto nel riquadro laterale sinistro della dashboard della console GCP. Copialo, ti servirà nel comando successivo:
Ora imposta il progetto:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Cloud Run deployment region
echo "Project: $PROJECT_ID"
Output previsto:
Project: my-project-123
Abilita le API richieste
gcloud services enable \
aiplatform.googleapis.com \
apphub.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
generativelanguage.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com \
storage.googleapis.com \
secretmanager.googleapis.com
L'operazione richiede circa 2 minuti. Al termine, vedrai Operation finished successfully.
Configura le credenziali predefinite dell'applicazione (ADC)
Gli agenti chiameranno Gemini Enterprise Agent Platform utilizzando la libreria di autenticazione Google, che richiede le credenziali predefinite dell'applicazione, separate dall'autenticazione CLI gcloud.
Esegui questa operazione una volta:
gcloud auth application-default login
Si aprirà una scheda del browser in cui ti verrà chiesto di confermare. Fai clic su Consenti. Visualizzerai:
Credentials saved to file: ~/.config/gcloud/application_default_credentials.json
Clona il repository iniziale
Questo codelab utilizza un repository iniziale, un progetto scheletro con tutta l'infrastruttura in posizione (Dockerfiles, pyproject.toml, script di deployment), ma con la logica dell'agente da scrivere.
git clone https://github.com/Saoussen-CH/mas-a2a-gcp.git ~/ai-creative-studio
cd ~/ai-creative-studio/workshop/starter
Ogni agent.py contiene segnaposto # TODO in cui scriverai la logica dell'agente. Gli script Dockerfile, pyproject.toml e di deployment sono già stati completati.
Configura le variabili di ambiente
Copia l'esempio fornito e inserisci l'ID progetto in un unico passaggio:
cp .env.example .env
sed -i "s|GOOGLE_CLOUD_PROJECT=your-project-id|GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)|" .env
Quindi crea il bucket GCS in cui Designer memorizzerà le immagini generate e aggiorna .env con il relativo nome:
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-campaign-images"
gcloud storage buckets create gs://${BUCKET_NAME} \
--location=us-central1 \
--project=${PROJECT_ID}
sed -i "s|GCS_IMAGES_BUCKET=your-project-id-campaign-images|GCS_IMAGES_BUCKET=${BUCKET_NAME}|" .env
Quindi, configura il supporto degli URL immagine firmati. Creative Director genera link HTTPS cliccabili per ogni immagine nel riepilogo finale della campagna. Per farlo, è necessario un service account per firmare gli URL. Esegui questi comandi per configurarlo:
export PROJECT_NUMBER=$(gcloud projects describe $(gcloud config get-value project) --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
export AGENT_RUNTIME_SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Allow your user account to sign URLs locally (adk web)
gcloud iam service-accounts add-iam-policy-binding ${SA_EMAIL} \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Allow Agent Runtime to sign URLs when deployed
gcloud projects add-iam-policy-binding $(gcloud config get-value project) \
--member="serviceAccount:${AGENT_RUNTIME_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
# Save SA email and project number to .env
grep -q "^SIGNING_SERVICE_ACCOUNT" .env \
&& sed -i "s|^SIGNING_SERVICE_ACCOUNT=.*|SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}|" .env \
|| echo "SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}" >> .env
grep -q "^GOOGLE_CLOUD_PROJECT_NUMBER" .env \
&& sed -i "s|^GOOGLE_CLOUD_PROJECT_NUMBER=.*|GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}|" .env \
|| echo "GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}" >> .env
Apri .env nell'editor per rivedere tutte le impostazioni:
cloudshell edit .env
Si apre .env come scheda nell'editor di Cloud Shell. Fai clic sul pulsante Apri editor nella barra degli strumenti se il riquadro dell'editor non è visibile:

Verifica che il progetto sia stato impostato correttamente:
grep GOOGLE_CLOUD_PROJECT .env
Installa le dipendenze
Utilizziamo uv, un gestore di pacchetti Python moderno e veloce che gestisce gli ambienti virtuali e le installazioni in un unico strumento. È circa 10-100 volte più veloce di pip ed è il modo consigliato per gestire i progetti Python.
uv è già installato in Cloud Shell. Tutti gli agenti condividono le stesse dipendenze principali, quindi installale una sola volta e funzioneranno per ogni agente in questo codelab:
uv sync
Il comando uv sync legge pyproject.toml e crea una directory .venv/ con tutte le dipendenze. Ogni specialista ha anche il proprio pyproject.toml utilizzato esclusivamente dalle build Docker. L'installazione condivisa riportata sopra copre tutto ciò che ti serve per i test locali.
3. Informazioni sull'ADK di Google
Prima di scrivere il codice, scopriamo Agent Development Kit (ADK), il framework che utilizzerai per creare ogni agente in questo codelab.
Che cos'è l'ADK?
Agent Development Kit (ADK) è un framework flessibile e modulare per lo sviluppo e il deployment di agenti AI. Sebbene sia ottimizzato per Gemini e l'ecosistema Google, ADK è indipendente dal modello e dal deployment ed è progettato per la compatibilità con altri framework. ADK è stato progettato per rendere lo sviluppo di agenti più simile allo sviluppo di software, in modo che gli sviluppatori possano creare, eseguire il deployment e orchestrare più facilmente architetture agentiche che vanno da semplici attività a workflow complessi.
ADK gestisce le parti complesse: chiamata di strumenti, conversazione multi-turno, gestione del contesto, streaming, così puoi concentrarti sulla logica dell'agente.
Componenti di base di un agente ADK
Ogni agente è composto da quattro componenti di base:
Blocca | Ruolo |
Modello | L'LLM che ragiona sugli obiettivi, determina un piano e genera risposte |
Strumenti | Funzioni che recuperano dati o eseguono azioni chiamando API o servizi |
Orchestrazione | Mantiene la memoria e lo stato tra i turni, chiama gli strumenti di routing e restituisce i risultati al modello |
Runtime | Esegue il sistema quando viene richiamato, localmente tramite |
Definizione dell'agente
Ciascuno dei 5 agenti di questo codelab è definito allo stesso modo:
from google.adk.agents import Agent
from google.adk.tools.google_search_tool import google_search
root_agent = Agent(
name="brand_strategist", # unique identifier
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"), # the LLM powering this agent
instruction=SYSTEM_INSTRUCTION, # the agent's persona, constraints, and output format
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search], # functions the LLM can call
)
Campo | Finalità |
| ID univoco: utilizzato dagli orchestratori per instradare le chiamate |
| Il modello Gemini che supporta questo agente |
| Prompt di sistema: definisce il ruolo, i vincoli e il formato di output dell'agente |
| Riepilogo di una riga: l'orchestratore lo legge per decidere quale specialista chiamare |
| Funzioni che l'LLM può richiamare (incorporate come |
Come ADK esegue un agente
User message
│
▼
Agent (LLM) ← reads instruction + conversation history
│
├─► needs more info? → calls a tool → gets result → continues reasoning
│
└─► done reasoning → returns final text response
L'LLM decide autonomamente se chiamare uno strumento, quale strumento e con quali argomenti. Scrivi l'istruzione e ADK si occuperà del resto.
4. Crea e testa l'agente Brand Strategist
Iniziamo con il primo agente: lo stratega del brand. Questo è un agente di ricerca che serve solo per cercare approfondimenti sul pubblico di destinazione, analisi della concorrenza e argomenti di tendenza utilizzando la Ricerca Google.
Apri il file di agente scheletro nell'editor di Cloud Shell:
cloudshell edit agents/brand_strategist/agent.py
Vedrai due sezioni # TODO da compilare.
TODO 1 - Write the system instruction
Per prima cosa, scrivi l'istruzione di sistema per l'agente. L'istruzione di sistema è una stringa che definisce il ruolo, i vincoli e il formato di output dell'agente.
SYSTEM_INSTRUCTION = f"""You are a Brand Strategist specializing in market research and trend analysis.
IMPORTANT: Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
When conducting research, focus on current trends from {datetime.date.today().year}.
Use search queries like "[topic] trends {datetime.date.today().year}" for recent insights.
IMPORTANT: Your role is RESEARCH ONLY. You do NOT create campaign content, captions, or designs.
After providing research insights, your work is complete.
Your expertise:
- Identifying target audience insights and behaviors
- Analyzing competitor strategies
- Researching current social media trends
- Understanding platform algorithms and best practices
You have access to:
- google_search: Search the web for competitors, trends, and market insights
When given a campaign brief:
1. Use google_search to research the target audience's current interests
2. Search for and analyze 2-3 competitor brands
3. Identify 3-5 trending topics related to the product category
4. Provide high-level strategic insights - NOT specific campaign content
DO NOT create captions, copy, designs, or any campaign content.
Format your output as:
**Audience Insights:**
[Key behaviors and preferences based on research]
**Competitive Analysis:**
[What 2-3 competitors are doing - strengths and weaknesses]
**Trending Topics:**
[3-5 relevant trends to consider]
**Key Strategic Insights:**
[High-level themes and positioning opportunities]
"""
TODO 2 - Create the root_agent
Poi, sostituisci root_agent incompleto con:
root_agent = Agent(
name="brand_strategist",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
instruction=SYSTEM_INSTRUCTION,
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search],
)
Testare localmente con la UI web di ADK
Ora testiamo l'agente utilizzando la UI web dell'ADK, un'interfaccia di chat integrata per testare gli agenti prima del deployment nel cloud.
uv run adk web agents --allow_origins='*'
Visualizzerai:
INFO: Started server process
INFO: Uvicorn running on http://localhost:8000
Il server è ora in esecuzione all'interno di Cloud Shell:
Per aprirlo nel browser, utilizza Anteprima web:
- Guarda la barra degli strumenti di Cloud Shell nella parte superiore della pagina
- Fai clic sull'icona Anteprima web (simile a una casella con una freccia verso l'alto, in alto a destra della barra degli strumenti di Cloud Shell).
- Fai clic su "Cambia porta" e inserisci
8000, poi fai clic su "Cambia e visualizza anteprima".
Si apre una nuova scheda del browser con la UI web dell'ADK. Fai clic sul menu a discesa "Seleziona un agente" in alto a sinistra per visualizzare tutti gli agenti elencati:
Scegli brand_strategist per iniziare il test:
Prova questi prompt di test
Nella casella di chat dell'interfaccia utente web dell'ADK, prova a:
Research the eco-friendly water bottle market for health-conscious millennialsWhat are the top Instagram trends in the wellness space in 2025?
Dovresti vedere l'agente chiamare la Ricerca Google e restituire una ricerca strutturata con le sezioni Approfondimenti sul pubblico, Analisi della concorrenza e Argomenti di tendenza.
5. Crea Copywriter - ADK Skills
Ruolo:trasforma la ricerca sul brand in didascalie di Instagram. Il Copywriter crea tre varianti di didascalia con toni diversi (ispirazionale, educativo, community), ognuna con hashtag e un invito all'azione.
Concetto: ADK Skills
Un approccio ingenuo incorporerebbe tutte le conoscenze della piattaforma (limiti di caratteri, livelli di hashtag, formule per i sottotitoli codificati, esempi di voce del brand) direttamente nel prompt di sistema. Funziona, ma gonfia ogni richiesta con contenuti che l'agente deve utilizzare solo occasionalmente.
Le ADK Skills (SkillToolset, introdotte in ADK 1.25.0) consentono di raggruppare queste conoscenze in file modulari con tre livelli di caricamento:
- L1 - frontmatter (
name+descriptioninSKILL.md): sempre disponibile, utilizzato per la scoperta delle skill - L2 - instructions (corpo di
SKILL.md): caricato quando l'agente attiva la skill - L3 - resources (file
references/eassets/): caricati solo quando l'agente li legge esplicitamente
L'istruzione di sistema si riduce a una breve dichiarazione del ruolo più "carica la skill prima di scrivere". I dettagli della piattaforma vengono inseriti nella finestra contestuale solo quando l'agente ne ha effettivamente bisogno.
La skill Copywriter si trova in agents/copywriter/skills/instagram-copywriting/:
skills/
instagram-copywriting/
SKILL.md ← L1 frontmatter (discovery) + L2 instructions (loaded on trigger)
references/
platform-guide.md ← L3: character limits, hashtag tiers, algorithm signals
caption-formulas.md ← L3: hook formulas, CTA patterns, full caption structures
assets/
brand-voice-examples.md ← L3: annotated real-world caption examples
Apri il file direttamente nell'editor di Cloud Shell:
cloudshell edit agents/copywriter/agent.py
TODO 1 - Importa load_skill_from_dir e skill_toolset
Trova il commento # TODO 1: Import load_skill_from_dir and skill_toolset e aggiungi le due importazioni:
from google.adk.skills import load_skill_from_dir
from google.adk.tools import skill_toolset
TODO 2 - Load the skill and create a SkillToolset
Individua i due commenti sotto le importazioni:
# TODO 2: Load the instagram-copywriting skill from the skills/ directory
# TODO 2: Create a SkillToolset with the loaded skill
Sostituiscili con:
_instagram_skill = load_skill_from_dir(
pathlib.Path(__file__).parent / "skills" / "instagram-copywriting"
)
_copywriting_skills = skill_toolset.SkillToolset(skills=[_instagram_skill])
load_skill_from_dir legge SKILL.md più tutti i file in references/ e assets/. SkillToolset lo inserisce nel formato accettato dagli agenti ADK, ovvero un insieme di strumenti, non una skill non elaborata.
TODO 3 - Register the toolset with the agent
Trova tools=[], # TODO 3: Add the SkillToolset here e sostituiscilo con:
tools=[_copywriting_skills],
Apri il file della skill per vedere come è strutturato:
cloudshell edit agents/copywriter/skills/instagram-copywriting/SKILL.md
Mantieni in esecuzione la UI web dell'ADK. Utilizza il menu a discesa dell'agente per passare a copywriter senza riavviare il server.
Se non è in esecuzione, riavvialo:
uv run adk web agents --allow_origins='*'
Prova:imposta il menu a discesa su copywriter e invia:
You are writing captions for EcoFlow Smart Water Bottle targeting health-conscious millennials aged 25-35.
Audience insight: they prioritize sustainability, track health metrics, and share lifestyle content.
Competitor insight: Hydro Flask dominates with lifestyle branding; S'well leads on premium aesthetics.
Write 3 Instagram captions - one inspirational, one educational, one community-focused. Include 5 hashtags each and a CTA.
6. Crea il designer - Generazione di immagini multimodali
Mantieni in esecuzione la UI web dell'ADK. Utilizza il menu a discesa dell'agente per cambiare agente senza riavviare il server.
Ruolo:crea concetti visivi per ogni didascalia e genera le immagini effettive utilizzando la generazione di immagini nativa di Gemini. Designer genera esattamente un concetto visivo per ogni didascalia, con un prompt dettagliato, stile, tavolozza dei colori, stato d'animo e formato Instagram, quindi chiama immediatamente lo strumento generate_image per produrre l'immagine effettiva e caricarla su GCS.
Concetto: collegamento di un agente di testo con un modello di immagine tramite uno strumento
Designer viene eseguito su gemini-3-flash-preview (il set di modelli di testo impostato tramite GEMINI_MODEL in .env), ma la generazione di immagini richiede un modello dedicato (gemini-3.1-flash-image). Questo modello di immagini non supporta la chiamata di funzioni, pertanto non può essere utilizzato direttamente come agente ADK. Viene invece racchiuso in una semplice funzione Python e registrato come FunctionTool.
Questo è il pattern per qualsiasi modello o API che l'LLM non può chiamare direttamente: inseriscilo in uno strumento, lascia che l'agente orchestri quando chiamarlo e ottieni un risultato strutturato.
Designer agent (text model)
│
│ decides visual concept, writes image prompt
▼
generate_image tool
│
│ calls gemini-3.1-flash-image
│ uploads result to GCS
▼
{"status": "success", "gcs_uri": "gs://..."}
│
│ returned to agent, included in response
▼
Critic (receives gcs_uri, passes to Vertex AI for multimodal review)
Apri il file direttamente nell'editor di Cloud Shell:
cloudshell edit agents/designer/image_gen_tool.py
Vengono forniti la firma della funzione, la configurazione dell'ambiente e l'inserimento delle proporzioni. Completa i tre TODO nell'ordine:
TODO 1 - Call the Gemini image model
Trova il commento # TODO 1 e sostituiscilo con:
client = genai.Client(vertexai=True, project=project_id, location=location)
response = client.models.generate_content(
model=image_model,
contents=prompt_with_aspect,
config=types.GenerateContentConfig(
response_modalities=["IMAGE", "TEXT"],
http_options=types.HttpOptions(
retry_options=types.HttpRetryOptions(
attempts=5, exp_base=2, initial_delay=30,
http_status_codes=[429, 500, 503, 504],
),
timeout=180_000,
),
),
)
TODO 2 - Extract image bytes from the response
Trova il commento # TODO 2 e sostituiscilo con:
image_bytes = None
mime_type = "image/png"
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
image_bytes = part.inline_data.data
mime_type = part.inline_data.mime_type or "image/png"
break
if not image_bytes:
return {"status": "error", "error": "Gemini returned no image data"}
DA FARE 3: carica su GCS e restituisci l'URI
Trova il commento # TODO 3 e sostituiscilo con:
ext = "jpg" if "jpeg" in mime_type else "png"
from google.cloud import storage
gcs_client = storage.Client(project=project_id)
bucket = gcs_client.bucket(bucket_name)
blob_name = f"campaign-images/{concept_name}-{uuid.uuid4().hex[:8]}.{ext}"
blob = bucket.blob(blob_name)
blob.upload_from_file(io.BytesIO(image_bytes), content_type=mime_type)
gcs_uri = f"gs://{bucket_name}/{blob_name}"
Prova:imposta il menu a discesa su designer e invia:
Create a visual concept and generate the image for an EcoFlow Smart Water Bottle Instagram post targeting health-conscious millennials.
Style: clean, modern, lifestyle-focused. Include a detailed prompt with color palette, mood, and format (1080x1080 or 1080x1350).
7. Crea l'output strutturato di Critico
Ruolo:assicurare la qualità del testo e delle immagini prima che vengano consegnati al Project Manager. Il revisore valuta entrambi i risultati e restituisce APPROVED o NEEDS_REVISION con suggerimenti specifici. Quando nell'input sono presenti valori gcs_uri, viene chiamato lo strumento review_image per ispezionare visivamente ogni immagine generata prima dell'assegnazione del punteggio.
Concetto: quando utilizzare un modello Pydantic per l'output di Gemini
La regola riguarda chi consuma l'output:
- Il codice Python lo utilizza → utilizza
response_schema+ Pydantic. Il codice non può gestire l'ambiguità, quindi hai bisogno di una struttura garantita per estrarre i campi in modo affidabile. - Un LLM lo utilizza → il formato di testo e le istruzioni di sistema sono sufficienti. Gli LLM comprendono le regole di formattazione e tollerano le variazioni.
In review_image, il codice Python richiede score, approval_status, what_works, issues e suggestions come valori digitati. Il passaggio di response_schema=_GeminiReview vincola Gemini a livello API a restituire JSON valido; model_validate_json() lo analizza in un oggetto tipizzato che il tuo codice può utilizzare in modo affidabile.
class _GeminiReview(BaseModel):
score: int = Field(ge=1, le=10)
approval_status: Literal["APPROVED", "NEEDS_REVISION"]
what_works: str
issues: str
suggestions: str
Apri il file direttamente nell'editor di Cloud Shell:
cloudshell edit agents/critic/image_review_tool.py
Vengono forniti i modelli Pydantic e il prompt. Completa i tre TODO nell'ordine:
TODO 1 - Create an image part from the GCS URI
Trova il commento # TODO 1 e sostituiscilo con:
image_part = types.Part.from_uri(file_uri=gcs_uri, mime_type=mime_type)
TODO 2 - Call Gemini with a structured response schema
Trova il commento # TODO 2 e sostituiscilo con:
response = client.models.generate_content(
model=model,
contents=[image_part, prompt],
config=types.GenerateContentConfig(
response_schema=_GeminiReview,
response_mime_type="application/json",
),
)
TODO 3 - Parse the response and return the result
Trova il commento # TODO 3 e sostituiscilo con:
review = _GeminiReview.model_validate_json(response.text)
return ImageReviewResult(status="success", concept_name=concept_name, **review.model_dump())
Prova:imposta il menu a discesa su critic e invia:
Review this Instagram caption for an eco-friendly water bottle brand targeting millennials:
"Hydrate smarter, live greener. 💧 Our EcoFlow bottle tracks your intake, keeps your drink cold for 24h, and never touches single-use plastic. Because what you drink from matters as much as what you drink. #EcoFlow #HydrationGoals #SustainableLiving #ZeroWaste #HealthyHabits - Shop link in bio."
Score it and indicate APPROVED or NEEDS_REVISION with specific feedback.
Verifica che la risposta contenga **POSTS REVIEW:**, Status: APPROVED (o NEEDS_REVISION) e **OVERALL ASSESSMENT:**. Se queste sezioni sono presenti, Critic è pronto per essere collegato all'orchestratore.
Al termine del test di tutti e tre gli agenti, premi Ctrl+C per arrestare il server.
8. Crea l'agente Project Manager con MCP
Il Project Manager introduce un nuovo concetto: MCP (Model Context Protocol).
Apri il file:
cloudshell edit agents/project_manager/agent.py
Questo file è più complesso: ha una funzione create_project_manager_agent() con due rami: uno senza Notion (cronologie solo di testo) e uno con il set di strumenti MCP di Notion. Dovrai compilare entrambi.
Il problema che risolve MCP
Il tuo agente deve chiamare un servizio esterno, ad esempio creare una pagina in Notion. Puoi scrivere codice Python che chiama direttamente l'API REST di Notion. Ma poi:
- Ogni sviluppatore scrive un wrapper diverso
- Devi gestire il codice di integrazione personalizzato
- L'LLM non sa che l'API esiste a meno che tu non descriva manualmente ogni endpoint
MCP risolve questo problema definendo un modo standard per i servizi esterni di esporre le proprie funzionalità come strumenti che un LLM può scoprire e chiamare automaticamente.
Che cos'è MCP?
MCP (Model Context Protocol) è uno standard aperto (pubblicato da Anthropic) per connettere gli agenti AI a strumenti esterni e origini dati. Funziona come un adattatore universale.
Un server MCP è un piccolo programma che:
- Esegue il wrapping di un'API esterna (Notion, GitHub, database, file system...)
- Espone l'API come un elenco di strumenti tipizzati e documentati
- Comunica con l'agente tramite un protocollo semplice (stdio o HTTP)
L'agente si connette al server MCP, rileva automaticamente gli strumenti disponibili e può chiamarli come qualsiasi altro strumento. Il LLM vede API-post-page(...) come una funzione richiamabile.
A2A e MCP: qual è la differenza?
Questo è un punto che spesso genera confusione. Ecco la distinzione principale:
A2A | MCP | |
Cosa si connette | Agente ↔ Agente | Agente ↔ Strumento/servizio esterno |
L'altro lato è | Un altro agente LLM | Un wrapper API (nessun LLM) |
Esempio | Il direttore creativo chiama il brand strategist | Project Manager chiama l'API Notion |
Protocollo | JSON-RPC su HTTPS | stream stdio o HTTP |
Definito da | Anthropic |
Immagina la situazione in questo modo:
- A2A = come gli agenti parlano con altri agenti
- MCP = come gli agenti comunicano con strumenti e servizi
In questo progetto vengono utilizzati entrambi:
Creative Director
│
│ (A2A) Brand Strategist ─── (google_search tool built into ADK)
│ (A2A) Copywriter
│ (A2A) Designer
│ (A2A) Critic
│ (A2A) Project Manager
│
│ (MCP) notion-mcp-server ──► Notion REST API
Come funziona MCP in questo progetto
Quando l'agente viene eseguito, ADK avvia notion-mcp-server come processo secondario. Questo processo espone questi strumenti direttamente all'LLM:
Strumento | Descrizione |
| Recupera lo schema (nomi delle proprietà, tipi, valori validi) |
| Esegue query sulle pagine esistenti |
| Crea una nuova pagina |
| Aggiorna una pagina esistente |
Il LLM le chiama come qualsiasi altra funzione: non ha idea che passino attraverso MCP all'API REST di Notion.
Perché stdio? Perché non solo HTTP?
Il server MCP viene eseguito come processo secondario dell'agente, comunicando tramite stdin/stdout. Ciò significa che:
- Non è necessaria alcuna porta di rete aggiuntiva
- Il ciclo di vita è gestito dall'agente (avviato su richiesta, interrotto all'uscita)
- Tutto viene spedito in un'unica immagine Docker, senza un servizio separato da eseguire il deployment.
(Facoltativo) Attiva l'integrazione di Notion
Puoi saltare l'intera sezione.L'agente Project Manager produce sempre una cronologia della campagna completa basata su testo, con o senza Notion. Se salti questa configurazione, l'agente torna alla modalità in memoria e restituisce la cronologia come testo normale nella chat. Non si verifica alcun errore, ma non vedrai le attività in un database Notion. Vai direttamente a TO DO 1 se vuoi saltare questa sezione.
Se hai un account Notion e vuoi vedere l'integrazione di MCP in azione, completa subito la configurazione riportata di seguito. I TO DO che seguono fanno riferimento agli ID del database Notion, che puoi trovare qui.
Passaggio 1: crea il database Notion da un modello
Utilizziamo il modello ufficiale Progetti e attività di Notion come database. Abbiamo scelto questo modello appositamente per mostrare un'impostazione complessa e reale: ha più tipi di proprietà (stato, intervalli di date, relazioni, selezioni) con nomi non ovvi. Questo è un ottimo test del rilevamento dinamico dello schema di MCP: l'agente deve capire i nomi esatti delle proprietà in fase di runtime anziché averli codificati.
Fai clic sul link qui sotto per aggiungere il modello al tuo spazio di lavoro Notion:
→ Aggiungi il modello "Progetti e attività" a Notion
Una volta aggiunti, avrai due database collegati: Progetti e Attività. Il modello include voci di esempio: eliminale tutte prima di procedere in modo che l'agente inizi con un workspace pulito (seleziona tutto → Elimina).
Passaggio 2: crea un'integrazione di Notion
Crea l'integrazione:
- Vai a notion.so/my-integrations
- Fai clic su New Integration (Nuova integrazione) → assegna il nome
AI Creative Studio - Associarlo al tuo workspace
- Fai clic su Configura impostazioni → assicurati che le funzionalità Leggi contenuti, Aggiorna contenuti e Inserisci contenuti siano tutte selezionate.
- Copia il token di integrazione interno (
ntn_...) e incollalo nel file.env:
NOTION_TOKEN=ntn_your-token-here
Collega l'integrazione ai tuoi database:
- Apri la pagina del modello che hai appena duplicato, quindi fai clic sul database Progetti.
- Fai clic sul menu
...(in alto a destra) → Connessioni → Aggiungi una connessione → selezionaAI Creative Studio.
- Fai lo stesso per il database Attività.
Recupera gli ID database:
- Fai clic sul link al database Progetti per aprirlo. Si aprirà in una pagina separata con un URL simile a questo:
https://www.notion.so/9887b6a94f7f83f68f8581e038d1aaa4?v=2c37b6a94f7f838685f1086e312c7278

L'ID database è il primo UUID nell'URL, ovvero tutto ciò che precede ?v=:
https://www.notion.so/{DATABASE_ID}?v=...
^^^^^^^^^^^^^^^^
9887b6a94f7f83f68f8581e038d1aaa4 ← this is your DATABASE_ID
- Fai lo stesso per il link al database Attività per ottenere il relativo ID database.
- Aggiungi tutti e tre i valori a
.env:
NOTION_TOKEN=ntn_your-token-here
NOTION_PROJECT_DATABASE_ID=9887b6a94f7f83f68f8581e038d1aaa4 # <-- your Projects DB ID
NOTION_TASKS_DATABASE_ID=your-tasks-db-id # <-- your Tasks DB ID
Passaggio 3: installa il server Notion MCP
Project Manager si connette a Notion tramite il pacchetto Node.js @notionhq/notion-mcp-server ufficiale. Installalo a livello globale:
npm install -g @notionhq/notion-mcp-server@1.9.1
Verifica l'installazione:
npm list -g @notionhq/notion-mcp-server
Output previsto:
└── @notionhq/notion-mcp-server@1.9.1
notion-mcp-server: command not found
? Assicurati che Node.js sia installato (node --version) e che il bin globale di npm si trovi nel PATH (export PATH=$PATH:$(npm bin -g)).
Passaggio 4: verifica il file .env
Apri .env e conferma che tutti e tre i valori di Notion siano impostati (li hai aggiunti nel passaggio 2):
cloudshell edit .env
NOTION_TOKEN=ntn_... # integration token
NOTION_PROJECT_DATABASE_ID=... # Projects database ID
NOTION_TASKS_DATABASE_ID=... # Tasks database ID
L'agente Project Manager rileva automaticamente queste variabili all'avvio e attiva il set di strumenti Notion MCP.
Come funziona il rilevamento dello schema
Project Manager utilizza l'individuazione dinamica dello schema e non codifica mai i nomi delle proprietà di Notion:
Step 1: Call API-retrieve-a-database to discover exact property names
Step 2: Read the "properties" object in the response
Step 3: Use ONLY discovered property names (case-sensitive) in API calls
Step 4: For select/status fields, use only values from the options array
Ciò significa che l'agente si adatta automaticamente a qualsiasi struttura di database Notion: rinomina le proprietà in francese, arabo o qualsiasi altra lingua e l'agente continuerà a funzionare.
TODO 1 - Write the system instruction
L'avvio rapido calcola già notion_section, ovvero una stringa vuota quando Notion non è configurato o un blocco contenente gli ID database più la guida completa allo strumento quando lo è. In questo modo, le istruzioni di Notion vengono escluse completamente dal prompt dell'agente non Notion; l'LLM non vede mai le regole per gli strumenti che non ha.
Il tuo compito è sostituire il segnaposto return con un'istruzione di sistema reale che utilizzi {notion_section}:
return f"""You are a Project Manager specializing in creative campaign execution.
Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
Use this as the starting point for all timelines.
Your goal: create a complete project plan for the campaign.
{notion_section}
**Project Timeline:**
Phase 1: Strategy & Research | [date] → [date] | [key activities]
Phase 2: Content Creation | [date] → [date] | [key activities]
Phase 3: Review & Revision | [date] → [date] | [key activities]
Phase 4: Launch & Monitoring | [date] → [date] | [key activities]
**Task List:**
| Task | Owner | Deadline | Status |
[list each task with realistic deadlines from today; set Owner to TBD]
**Budget Breakdown:**
[by category with approximate allocations]
**Milestones:**
[3-5 key checkpoints with dates]
**Notion Status:**
[What happened - e.g. "Project created (ID: xxx), 8 tasks linked" or "Notion not configured - text timeline only"]
"""
TODO 2 - Agent without Notion
All'interno di create_project_manager_agent(), nel ramo if not notion_token, sostituisci l'agente incompleto con:
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
instruction=get_system_instruction(),
description="Project manager that creates campaign timelines and task breakdowns",
)
TODO 3 - Agent with Notion MCP
Nota:il file iniziale contiene già un callback handle_notion_error precompilato sopra create_project_manager_agent(). Intercetta gli errori dell'API Notion (400/404) e sostituisce i payload di errore non elaborati con messaggi puliti e utilizzabili, in modo che il LLM possa correggersi autonomamente. Devi solo collegarlo tramite after_tool_callback.
Innanzitutto, leggi entrambi gli ID database nella parte superiore di create_project_manager_agent():
notion_token = os.getenv("NOTION_TOKEN")
notion_project_db_id = os.getenv("NOTION_PROJECT_DATABASE_ID")
notion_tasks_db_id = os.getenv("NOTION_TASKS_DATABASE_ID")
Quindi, nel ramo else, crea il set di strumenti MCP e l'agente:
from google.adk.tools.mcp_tool import McpToolset, StdioConnectionParams
from mcp import StdioServerParameters
server_params = StdioServerParameters(
command="notion-mcp-server",
env={
"NOTION_TOKEN": notion_token,
"PATH": os.environ.get("PATH", ""),
}
)
notion_toolset = McpToolset(
connection_params=StdioConnectionParams(
server_params=server_params,
timeout=30.0
)
)
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
after_tool_callback=handle_notion_error,
instruction=get_system_instruction(
project_database_id=notion_project_db_id,
tasks_database_id=notion_tasks_db_id,
),
description="Project manager with Notion integration for task tracking",
tools=[notion_toolset],
)
Best practice: non eseguire mai un hard fail sulle integrazioni facoltative. La sequenza temporale del testo è sempre il prodotto principale, mentre Notion è un supplemento.
Testare Project Manager localmente con ADK Web
uv run adk web agents --allow_origins='*'
Apri l'anteprima web sulla porta 8000. Utilizza il menu a discesa dell'agente per selezionare project_manager, poi prova a:
Create a project plan for a GreenBrew organic coffee brand Instagram campaign.
Budget: $2,500. Launch in 3 weeks. Target audience: eco-conscious millennials aged 22-30.
Include phases, tasks with deadlines from today, and milestones.
Dovresti visualizzare una sequenza temporale di testo strutturato con fasi, elenco di attività e traguardi. Se le credenziali di Notion sono impostate in .env, l'agente creerà anche voci nel tuo spazio di lavoro Notion.
9. Comprendere il protocollo A2A
Utilizzeremo il protocollo Agent-to-Agent (A2A) per connettere i diversi agenti nel nostro sistema. Vediamo come funziona.
Il problema che A2A risolve
Immagina di avere un agente Brand Strategist creato con ADK e un agente Copywriter creato con LangGraph. Come si chiama l'altro? Parlano lingue interne diverse. Dovresti scrivere codice glue personalizzato ogni volta.
A2A risolve questo problema definendo un linguaggio universale che qualsiasi agente, indipendentemente dal framework, può parlare. È l'HTTP del mondo degli agenti: uno standard su cui tutti sono d'accordo, in modo che chiunque possa parlare con chiunque.
Che cos'è A2A?
Agent-to-Agent (A2A) è uno standard aperto per la comunicazione tra agenti pubblicato da Google. Definisce:
- Come si descrive un agente: scheda dell'agente all'indirizzo
/.well-known/agent.json - Come lo chiama un altro agente: JSON-RPC su HTTPS
- Modalità di restituzione dei risultati: streaming o risposta singola
Cosa rende flessibile A2A:
- Indipendente dalla lingua: gli agenti Python possono comunicare con gli agenti TypeScript
- Indipendenti dal framework: gli agenti ADK possono comunicare con gli agenti LangGraph o CrewAI
- Indipendente dall'infrastruttura: gli agenti locali possono comunicare con gli agenti cloud
Come funziona, passo dopo passo
Creative Director Brand Strategist
│ │
│ 1. GET /.well-known/agent.json │
│ ────────────────────────────────►│
│ ◄──── agent card (name, url, │
│ skills, capabilities) ───│
│ │
│ 2. POST / │
│ {"method": "tasks/send", │
│ "params": {"message": ...}} │
│ ────────────────────────────────►│
│ │ LLM does
│ │ the work...
│ 3. streaming response chunks │
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
Passaggio 1 - Rilevamento:l'orchestratore recupera la scheda dell'agente una volta per conoscere il nome, l'URL e le funzionalità dell'agente.
Passaggio 2 - Invocation:l'orchestratore invia un'attività tramite JSON-RPC POST. Il corpo contiene il messaggio (la richiesta per lo specialista).
Passaggio 3 - Risposta: lo specialista trasmette la sua risposta in blocchi, proprio come una normale chiamata LLM.
La scheda Agente
Ogni agente pubblica una descrizione di sé all'indirizzo /.well-known/agent.json. È come un biglietto da visita: indica al mondo cosa può fare l'agente e dove trovarlo:
{
"name": "brand_strategist",
"description": "Market research and competitive analysis",
"url": "https://brand-strategist-xyz.run.app",
"capabilities": { "streaming": true },
"skills": [
{
"id": "market_research",
"description": "Research target audiences, competitors, and trends"
}
]
}
L'orchestratore legge questa scheda per creare il relativo oggetto RemoteA2aAgent. Non sono necessarie conoscenze hardcoded delle funzionalità interne dello specialista.
Esporre un agente tramite A2A in ADK
to_a2a() racchiude qualsiasi agente ADK in un'app FastAPI conforme ad A2A. Una riga:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
# root_agent = your normal ADK Agent(...)
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
In questo modo vengono creati automaticamente:
/.well-known/agent.json: la scheda dell'agente/: l'endpoint JSON-RPC (tutte le richieste di attività A2A vanno al percorso principale)
10. Esporre gli agenti come servizi A2A
Per esporre gli agenti come servizi A2A, puoi utilizzare la funzione di utilità to_a2a() dell'ADK.
Come funziona to_a2a()
from google.adk.a2a.utils.agent_to_a2a import to_a2a
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
to_a2a() racchiude l'agente ADK in un'applicazione FastAPI che espone automaticamente:
/.well-known/agent.json- la scheda dell'agente (nome, descrizione, funzionalità)/a2a/{agent_name}: l'endpoint JSON-RPC per la ricezione delle attività
Il codice scheletro di ogni agente include già un blocco __main__ che racchiude l'agente in un server A2A utilizzando to_a2a(). Non è necessario scrivere questo codice, è già fornito.
Informazioni sulla configurazione con doppio URL
Quando esegui python agent.py, il blocco __main__ utilizza due configurazioni URL separate:
# Where the server actually listens (network interface):
HOST = "0.0.0.0"
PORT = 8082 # Brand Strategist (others use 8083–8086 locally)
# What gets advertised in the agent card (the address other agents use to reach it):
PUBLIC_HOST = os.getenv("PUBLIC_HOST", "localhost")
PUBLIC_PORT = int(os.getenv("PUBLIC_PORT", str(PORT)))
PROTOCOL = os.getenv("PROTOCOL", "http")
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
Ambiente |
|
|
Locale |
|
|
Cloud Run |
|
|
A livello locale, entrambi puntano alla stessa macchina. Su Cloud Run, il container è in ascolto internamente su 8080, ma la scheda dell'agente deve pubblicizzare l'URL HTTPS pubblico. In caso contrario, il Creative Director non può contattare lo specialista dall'esterno del container.
Avvia tutti e cinque i server A2A specializzati
Eseguiamo tutti e cinque gli specialisti come server A2A contemporaneamente, quindi testiamo il Creative Director localmente puntando a questi server.
Apri 5 terminali Cloud Shell separati (fai clic sull'icona + nella barra delle schede del terminale) ed esegui un agente per terminale.
uv run attiva automaticamente .venv, senza bisogno di source manuale in ogni terminale.
Terminal 1 - Brand Strategist (porta 8082):
cd ~/ai-creative-studio/workshop/starter
PORT=8082 uv run agents/brand_strategist/agent.py
Terminal 2 - Copywriter (port 8083):
cd ~/ai-creative-studio/workshop/starter
PORT=8083 uv run agents/copywriter/agent.py
Terminal 3 - Designer (porta 8084):
cd ~/ai-creative-studio/workshop/starter
PORT=8084 uv run agents/designer/agent.py
Terminal 4 - Critic (porta 8085):
cd ~/ai-creative-studio/workshop/starter
PORT=8085 uv run agents/critic/agent.py
Terminal 5 - Project Manager (porta 8086):
cd ~/ai-creative-studio/workshop/starter
PORT=8086 uv run agents/project_manager/agent.py
Impostare gli URL localhost in .env
In Terminal 6, aggiorna .env con gli URL degli agenti locali in modo che il direttore creativo possa trovarli:
cd ~/ai-creative-studio/workshop/starter
sed -i \
-e 's|STRATEGIST_AGENT_URL=.*|STRATEGIST_AGENT_URL=http://localhost:8082|' \
-e 's|COPYWRITER_AGENT_URL=.*|COPYWRITER_AGENT_URL=http://localhost:8083|' \
-e 's|DESIGNER_AGENT_URL=.*|DESIGNER_AGENT_URL=http://localhost:8084|' \
-e 's|CRITIC_AGENT_URL=.*|CRITIC_AGENT_URL=http://localhost:8085|' \
-e 's|PM_AGENT_URL=.*|PM_AGENT_URL=http://localhost:8086|' \
.env
Ispezionare gli agenti con A2A Inspector
A2A Inspector è uno strumento per sviluppatori open source che utilizza il protocollo A2A in modo nativo. Consente di connettersi direttamente a qualsiasi agente A2A in esecuzione, leggere la relativa scheda e inviare attività, il tutto senza scrivere codice client.
Informazioni riportate:
- Scheda dell'agente: i metadati strutturati pubblicizzati dall'agente: nome, descrizione, modalità di input/output supportate e URL dell'endpoint. Questo è il messaggio che legge il Creative Director quando scopre uno specialista.
- Interfaccia di chat: invia qualsiasi messaggio all'agente tramite A2A e visualizza la risposta non elaborata. Puoi testare i prompt in isolamento prima di collegare gli agenti.
- Convalida del protocollo: lo strumento di ispezione verifica che la scheda dell'agente sia conforme alla specifica A2A, mettendo in evidenza in anticipo i campi mancanti o le risposte errate.
Perché è importante:quando esegui il deployment in Cloud Run in un secondo momento, il Creative Director rileva ogni specialista recuperando la relativa scheda dell'agente da /.well-known/agent.json. Se la scheda non è corretta (URL errato, funzionalità mancanti), l'orchestratore non funziona. L'ispettore ti consente di rilevare questi problemi localmente prima di qualsiasi deployment nel cloud.
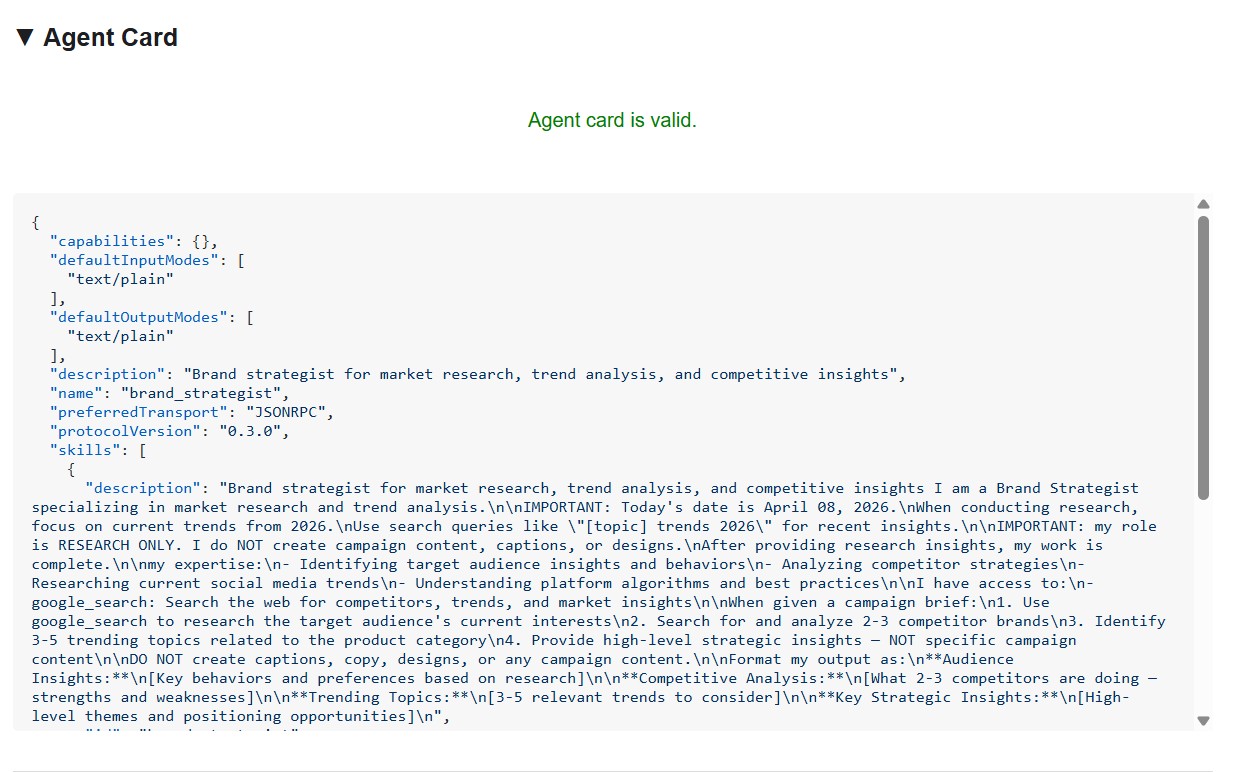
La scheda dell'agente mostra l'identità e le funzionalità dello specialista esattamente come le vedono gli altri agenti.
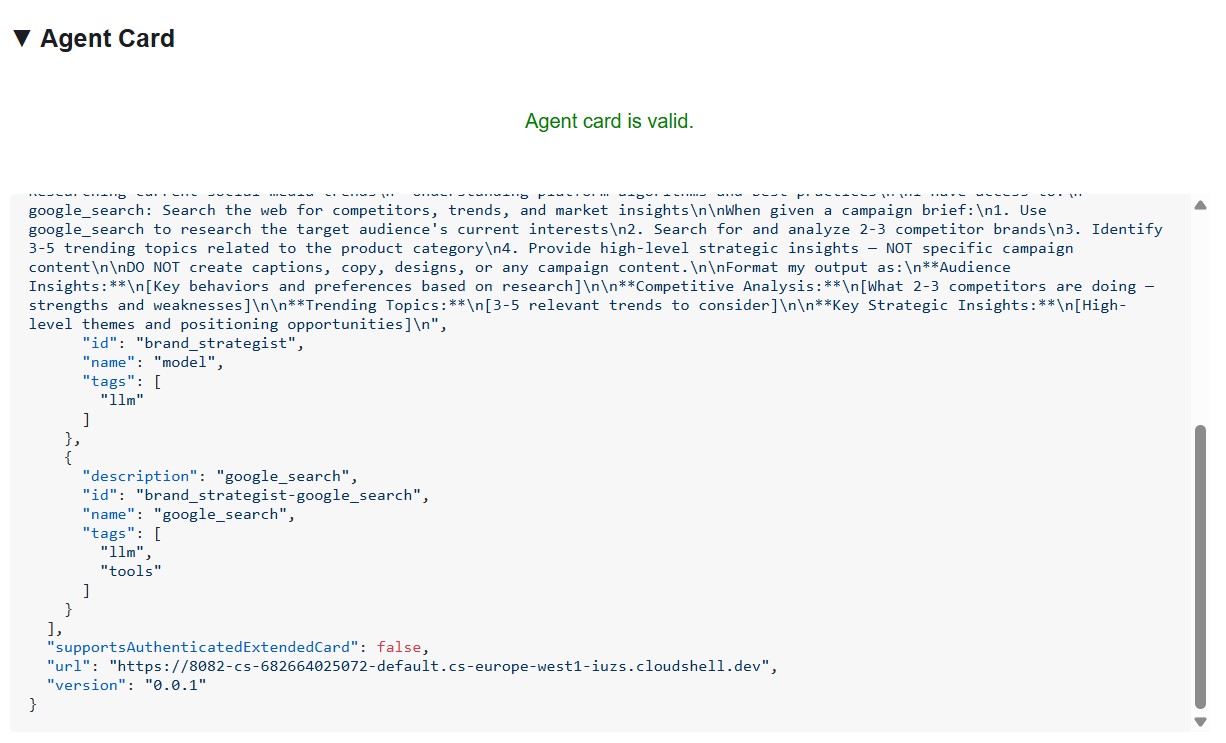
Installare e avviare lo strumento di ispezione
cd ~/ai-creative-studio/workshop
./setup_inspector.sh
L'aggiornamento .env è un comando una tantum. Utilizza Terminal 6 per avviare lo strumento di controllo successivo:
cd ~/a2a-inspector
bash scripts/run.sh
Per aprire la UI dell'inspector, utilizza Anteprima web → Cambia porta → digita 5001.
Contattare lo Strategist del brand
Inserisci http://localhost:8082 nel campo URL dello strumento di ispezione e fai clic su Connetti. L'inspector recupera la scheda dell'agente e mostra i metadati dello specialista.
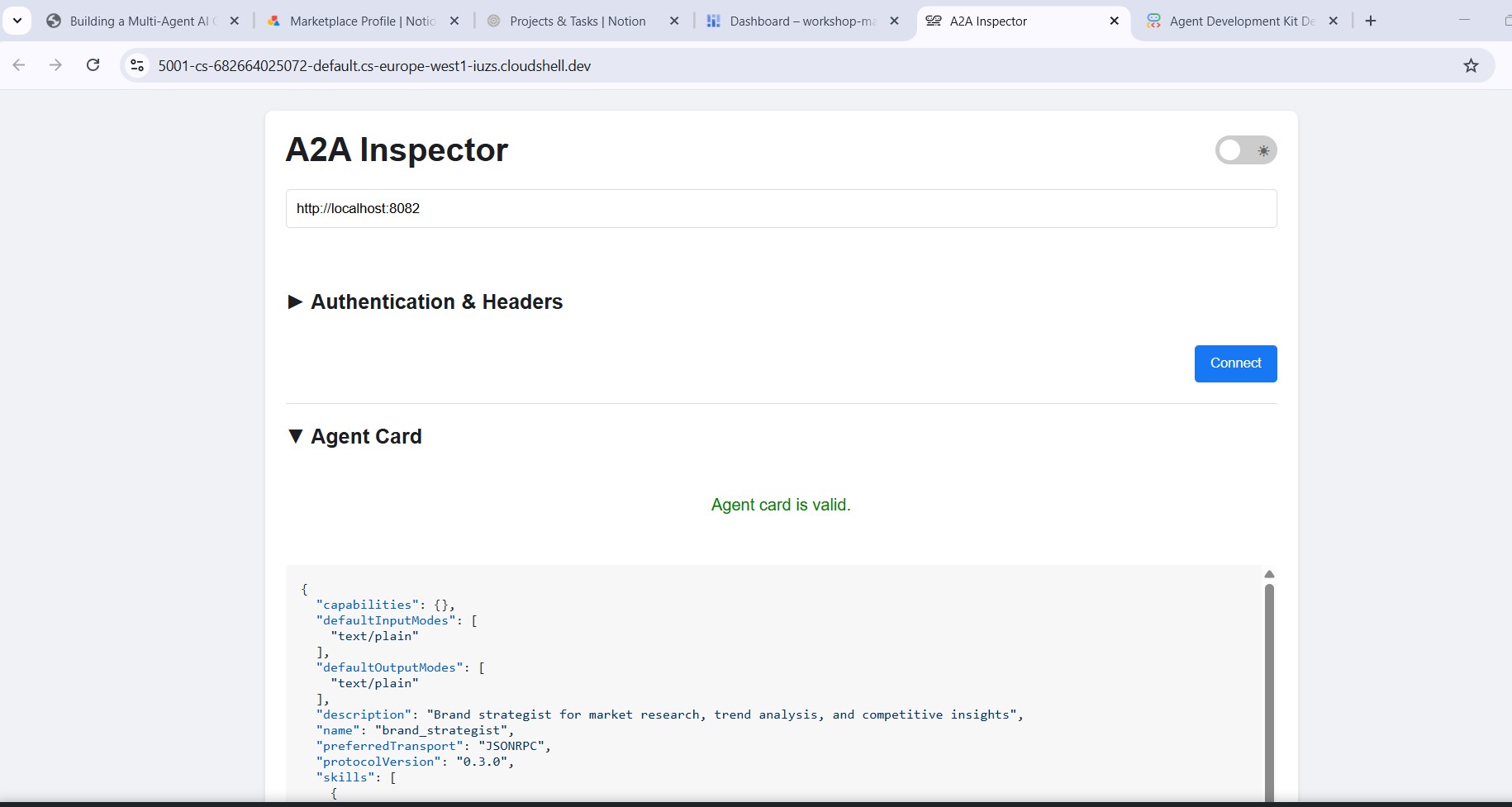
Cosa indica la scheda dell'agente
La scheda dell'agente è più di semplici metadati: è il contratto completo di funzionalità che l'agente pubblicizza alla rete. Contatta il Project Manager (http://localhost:8086) per visualizzare l'esempio più ricco:
{
"name": "project_manager",
"description": "Project manager with Notion integration for task tracking",
"protocolVersion": "0.3.0",
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain"],
"skills": [
{
"id": "project_manager",
"name": "model",
"tags": ["llm"],
"description": "... full system instruction including today's date and Notion database IDs ..."
},
{
"id": "project_manager-API-post-page",
"name": "API-post-page",
"tags": ["llm", "tools"],
"description": "Notion | Create a page"
},
{
"id": "project_manager-API-retrieve-a-database",
"name": "API-retrieve-a-database",
"tags": ["llm", "tools"],
"description": "Notion | Retrieve a database"
}
]
}
Tre aspetti si distinguono:
1. Gli strumenti MCP diventano competenze A2A: ogni strumento Notion a cui ha accesso il Project Manager (API-post-page, API-retrieve-a-database e così via) è elencato come competenza separata nella scheda dell'agente. Qualsiasi altro agente sulla rete può scoprire esattamente quali strumenti può utilizzare questo agente, senza leggere alcun codice.
2. L'istruzione di sistema è incorporata: la prima competenza description contiene l'istruzione di sistema completa, inclusa la data odierna e gli ID del database Notion. In questo modo, il Creative Director sa cosa passare quando chiama il Project Manager.
3. L'URL è l'endpoint live: il campo url è esattamente ciò che RemoteA2aAgent utilizza quando il Creative Director chiama questo specialista. Se l'URL nella scheda non è corretto, l'orchestratore non può raggiungere l'agente.
Per questo motivo, lo strumento di ispezione è un potente strumento di debug: un'occhiata alla scheda dell'agente ti dice se l'agente è in esecuzione, quali strumenti ha e se l'endpoint è corretto.
Invia un messaggio di prova
Una volta connesso, digita un prompt nel riquadro della chat e invialo. L'ispettore lo invia come attività A2A e trasmette in streaming la risposta, nello stesso modo in cui il Creative Director chiamerà questo agente in produzione.
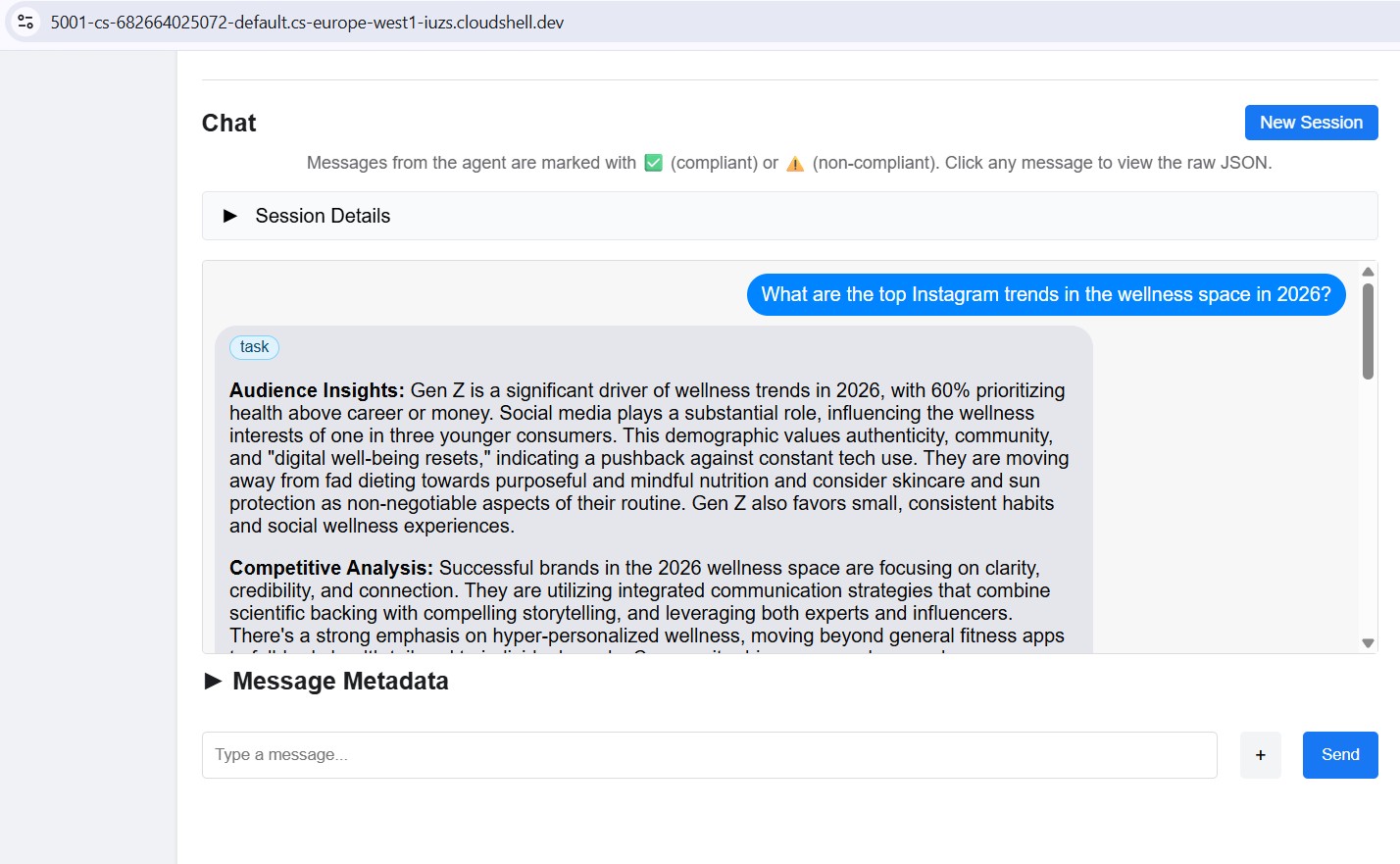
Punta l'inspector su qualsiasi porta locale (8082-8086) per testare ogni specialista singolarmente.
11. Crea l'orchestratore del direttore creativo
Il direttore creativo è l'orchestratore principale. Legge gli URL specializzati dalle variabili di ambiente, li racchiude ciascuno come RemoteA2aAgent e li espone come AgentTool che l'LLM può chiamare.
Assicurati che i 5 agenti specializzati siano ancora in esecuzione (terminali 1-5 del passaggio 10).
In Terminal 6 (il terminale dell'ispettore A2A), arresta l'ispettore con Ctrl+C.
Apri il file:
cd ~/ai-creative-studio/workshop/starter
cloudshell edit agents/creative_director/agent.py
Questo file ha tre cose da fare. Seguili nell'ordine.
TODO 1 - Review the already written system instruction
L'istruzione di sistema si trova in prompt.py nella stessa directory e viene importata automaticamente:
from .prompt import SYSTEM_INSTRUCTION_TEMPLATE
Apri prompt.py per leggerlo prima di continuare:
cloudshell edit agents/creative_director/prompt.py
È importante comprenderlo perché controlla l'intero comportamento di orchestrazione.
Perché il prompt dell'agente di orchestrazione controlla tutto
Apri prompt.py insieme a questa sezione. Gli esempi riportati di seguito fanno riferimento a parti specifiche.
Il prompt in prompt.py non è solo documentazione, ma il control plane dell'intero sistema. Un prompt dell'orchestratore mal strutturato produce: agenti chiamati in modo errato, contenuti generati dall'orchestratore anziché dagli esperti, workflow che continuano dopo gli errori e contesto eliminato silenziosamente tra gli agenti. Questi nove elementi prevengono i guasti più comuni:
Elemento 0: pianifica prima, poi esegui
Questo è l'elemento più importante. Prima di chiamare qualsiasi specialista, l'orchestratore riceve l'istruzione di generare un piano numerato:
I'll create your campaign by coordinating the specialist agents in sequence:
1. Brand Strategist - develop positioning and audience insights
2. Copywriter - write captions using those insights
3. Visual Designer - create image prompts aligned with the copy
4. Critic - review and score the full package
5. Project Manager - build the timeline and task breakdown
Senza questo passaggio, l'LLM passa direttamente alle chiamate di strumenti e perde traccia di dove si trova nel flusso di lavoro, soprattutto dopo aver ricevuto una risposta lunga da uno specialista. La definizione del piano ancora prima di iniziare consente all'orchestratore di sapere a che punto si trova, cosa deve fare dopo e come si presenta un'esecuzione completa. Se salti questo passaggio, l'orchestratore si blocca a metà del flusso di lavoro o ripete i passaggi.
Elemento 1: definizione esplicita del ruolo
❌ "You are a helpful creative assistant."
✅ "You orchestrate specialists. You do NOT write captions, designs, or timelines yourself."
Senza il divieto esplicito, l'LLM a volte salta la chiamata agli specialisti e genera direttamente i contenuti, perché è più veloce e "sa" come farlo. L'istruzione deve rendere questa risposta sbagliata.
Elemento 2: sintassi di chiamata dello strumento con pattern errati elencati
Mostrare solo la sintassi corretta non è sufficiente. L'LLM può generare chiamate che sembrano plausibili, ma che non vanno a buon fine. Il prompt elenca in modo esplicito sia il pattern corretto sia quelli che non devono mai essere utilizzati:
✅ copywriter(request="...") ← correct
❌ print(copywriter(...)) ← breaks silently
❌ default_api.copywriter(...) ← breaks silently
❌ copywriter.run(...) ← breaks silently
❌ agents.copywriter(...) ← breaks silently
L'elenco dei pattern errati ha ridotto esplicitamente le chiamate di strumenti non valide di circa il 95% in produzione.
Elemento 3: esecuzione sequenziale descritta passo dopo passo
a) Call the tool
b) Wait for tool_output
c) Verify the output is not an error
d) Confirm to the user: "✓ Brand Strategist complete"
e) Then move to the next agent
Senza i passaggi (b) e (c), a volte l'LLM chiama due agenti contemporaneamente o presume che l'operazione sia riuscita e va avanti prima di ricevere la risposta.
Elemento 4 - Direttive di errore: STOP, report, do not proceed
Nelle prime versioni, l'orchestratore riceveva un errore da uno specialista, inventava un output plausibile e continuava con l'agente successivo. L'utente otteneva una campagna dall'aspetto completo basata su una base inventata. La correzione è esplicita: INTERROMPI immediatamente. Segnala l'errore esatto. Non continuare mai.
Elemento 5: regole di trasmissione del contesto
Gli agenti remoti non hanno una cronologia delle conversazioni. Quando l'orchestratore chiama il Copywriter tramite A2A, il Copywriter vede solo il messaggio in quella singola richiesta e non sa cosa ha detto lo Strategist del brand. L'orchestratore deve raggruppare esplicitamente gli output precedenti in ogni chiamata successiva:
copywriter(request="Create 3 posts for EcoFlow water bottle targeting millennials.
Use these insights from the Brand Strategist: [paste full strategist output here].
Create engaging captions with hashtags.")
L'istruzione lo afferma esplicitamente: "Gli agenti remoti NON hanno memoria condivisa. Devi passare esplicitamente gli output precedenti". Senza questa, ogni agente lavora alla cieca.
Elemento 6 - Classificazione della richiesta: semplice o complessa
Non tutte le richieste richiedono tutti e cinque gli agenti. Il prompt indica all'orchestratore di classificare la richiesta prima di pianificare:
SIMPLE → one agent needed
"Research the eco-friendly water bottle market" → brand_strategist only
"Write 3 Instagram captions" → copywriter only
COMPLEX → all agents sequentially
"Create a complete campaign with timeline" → all 5 agents
Senza questa classificazione, l'orchestratore eseguirà tutti e cinque gli agenti per ogni richiesta, inclusa "dammi 3 idee per post", aggiungendo latenza e costi non necessari.
Elemento 7 - Regole di comunicazione: mostra gli output completi, nessun filtro
Il prompt specifica chiaramente che l'orchestratore non deve riassumere o modificare ciò che restituiscono gli esperti:
- DO NOT summarize unless the output exceeds 2000 words
- DO NOT filter or edit agent responses
- Show the user exactly what each specialist produced
- NEVER say results are ready unless you received them in tool_output
Senza questa funzionalità, l'orchestratore riscrive gli output degli esperti con parole proprie, perdendo dettagli, introducendo errori e vanificando lo scopo di avere esperti.
Elemento 8: completamento del flusso di lavoro: non interrompere mai in anticipo
Una modalità di errore sottile ma critica: l'orchestratore annuncia un piano in 5 passaggi, ne completa 3 e poi presenta i risultati come se fosse tutto finito. Il prompt impedisce questo con un elenco di controllo esplicito che deve essere superato prima che l'orchestratore possa terminare:
✓ Did I announce a plan with N agents?
✓ Have I called ALL N agents from my plan?
✓ Did each agent respond successfully?
✓ Am I presenting complete results from ALL agents?
If any answer is NO → continue executing the remaining agents.
In questo modo, l'orchestratore non considera un'esecuzione parziale come completa.
Il ciclo di controllo qualità
Il flusso di lavoro di revisione è la parte più complessa di prompt.py. Apri la sezione ## REVISION WORKFLOW e segui le istruzioni.
Come funziona
Dopo la risposta del critico, il direttore creativo non continua ciecamente con il project manager. Legge l'output e le ramificazioni di Critic:
Critic output
│
├── "All Approved: YES"
│ └──► proceed to Project Manager
│
└── "Status: NEEDS_REVISION"
│
├── posts fail → call copywriter again with feedback
├── visuals fail → call designer again with feedback
└── both fail → call copywriter, then designer
│
└──► revised output → Project Manager
(1 revision max per deliverable)
Questo è basato su LLM, non su codice
Il codelab ha menzionato in precedenza che l'orchestratore"analizza" la risposta di Critic. Non esiste alcun codice Python che esegua questo parsing: nessuna espressione regolare, nessuna corrispondenza di stringhe. Il Creative Director è un LLM che legge le proprie istruzioni. L'istruzione recita:
Look for "Status: NEEDS_REVISION" in the critic's response.
Posts need revision → call copywriter
Visuals need revision → call designer
L'LLM legge queste stringhe esatte nell'output di Critic e segue il ramo. Per questo motivo, il formato del critico non è negoziabile: se il critico scrive "needs some work" (richiede qualche modifica) anziché NEEDS_REVISION, il modello LLM non trova alcuna corrispondenza nelle istruzioni e salta silenziosamente il passaggio di revisione.
Come viene inoltrato il contesto in una chiamata di revisione
La chiamata di revisione segue la stessa regola di trasmissione del contesto dell'elemento 5: l'orchestratore deve includere tutto in modo esplicito perché Copywriter non ha memoria della prima versione:
"I need you to revise the Instagram posts based on critic feedback.
ORIGINAL BRIEF:
[the original user request]
YOUR FIRST VERSION:
[the posts the copywriter created]
CRITIC FEEDBACK (Score: 6/10 - NEEDS_REVISION):
[the critic's specific suggestions]
Please revise the posts addressing this feedback while maintaining
the strengths the critic identified."
Senza la sezione "LA TUA PRIMA VERSIONE", Copywriter scriverebbe da zero anziché migliorare ciò che ha già prodotto.
Il limite di una revisione e perché è importante
Dopo un round di revisione, l'orchestratore passa al Project Manager indipendentemente dal punteggio. L'istruzione tiene traccia di questo mentalmente:
After calling copywriter for revision once:
→ mark "copywriter_revised = true" in context
→ even if the critic still suggests changes, proceed to PM
Senza questo limite, il ciclo potrebbe continuare all'infinito: il critico segnala un problema → il copywriter lo rivede → il critico lo segnala di nuovo → il copywriter lo rivede di nuovo. Ogni round costa token e tempo. Una revisione è sufficiente per migliorare la qualità senza il rischio di un ciclo incontrollabile.
Cosa viene trasferito al Project Manager
Il Project Manager riceve sempre le versioni finali approvate, non gli originali. Se sono state apportate revisioni, l'agente di orchestrazione passa la copia e le immagini riviste. Se tutto è stato approvato al primo passaggio, viene approvato direttamente. Il PM non vede mai le bozze rifiutate.
TODO 2 - Register each specialist as a RemoteA2aAgent + AgentTool
Trova il commento # TODO 2: For each specialist URL... e sostituiscilo con:
if strategist_url:
available_agents_list.append(
"- **brand_strategist**: Market research, competitor analysis, trend identification"
)
strategist_agent = RemoteA2aAgent(
name="brand_strategist",
description="Researches markets, competitors, and trends using Google Search",
agent_card=f"{strategist_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=strategist_agent))
if copywriter_url:
available_agents_list.append(
"- **copywriter**: Instagram captions, hashtags, and CTAs"
)
copywriter_agent = RemoteA2aAgent(
name="copywriter",
description="Creates Instagram captions with hashtags and CTAs",
agent_card=f"{copywriter_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=copywriter_agent))
if designer_url:
available_agents_list.append(
"- **designer**: Visual concepts and real images generated via Gemini (GCS URIs returned)"
)
designer_agent = RemoteA2aAgent(
name="designer",
description="Creates visual concepts and generates real images via Gemini, stored in GCS",
agent_card=f"{designer_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=designer_agent))
if critic_url:
available_agents_list.append(
"- **critic**: Quality review with APPROVED/NEEDS_REVISION scoring"
)
critic_agent = RemoteA2aAgent(
name="critic",
description="Reviews campaign materials and returns structured quality feedback",
agent_card=f"{critic_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=critic_agent))
if pm_url:
available_agents_list.append(
"- **project_manager**: Project timelines, task breakdowns, Notion integration"
)
pm_agent = RemoteA2aAgent(
name="project_manager",
description="Creates project timelines and task breakdowns, optionally in Notion",
agent_card=f"{pm_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=pm_agent))
TODO 3 - Wrap in an App with context compaction
Perché è necessaria la compattazione
Ogni messaggio in una conversazione (il prompt dell'utente, ogni chiamata allo strumento, ogni risposta dello strumento) viene aggiunto alla finestra contestuale che l'LLM legge al turno successivo. In un workflow con 5 agenti, questo valore si accumula rapidamente:
Turn 1: user prompt ~200 tokens
Turn 2: orchestrator plan ~300 tokens
Turn 3: brand_strategist tool_call ~150 tokens
Turn 4: brand_strategist tool_output ~1,500 tokens ← full research report
Turn 5: copywriter tool_call ~300 tokens ← must include strategist output
Turn 6: copywriter tool_output ~2,000 tokens ← 3 captions
Turn 7: designer tool_call ~500 tokens
Turn 8: designer tool_output ~1,500 tokens
...
Con l'agente 4 (critico), la finestra contestuale contiene l'output completo di tutti e tre gli agenti precedenti, spesso 8000-12.000 token solo nelle risposte dello strumento. Anche con l'ampia finestra contestuale di Gemini 2.5 Pro, la qualità del ragionamento dell'orchestratore peggiora man mano che deve gestire una cronologia sempre più lunga. Senza la compattazione, i workflow lunghi raggiungono limiti pratici intorno all'agente 4.
Cosa fa la compattazione
Anziché conservare ogni evento per intero, l'ADK chiama periodicamente un LLM per riassumere gli eventi meno recenti in una rappresentazione compatta. Vengono conservati nel contesto solo il riepilogo degli eventi passati e l'output completo dell'agente più recente.
Without compaction:
[full strategist output] + [full copywriter output] + [full designer output] + → Critic
With compaction (interval=3, overlap=1):
[summary of strategist + copywriter] + [full designer output] + → Critic
Il riepilogo conserva i fatti essenziali (insight chiave, sottotitoli codificati approvati, concetti visivi) scartando la formattazione dettagliata, il contesto ripetuto passato a ogni agente e il ragionamento intermedio. Il revisore ha ancora tutto ciò che gli serve per valutare, ma legge un riepilogo anziché tre report completi.
Il codice
Trova il commento # TODO 3: Wrap the agent in an App... e sostituisci il segnaposto App(...) con:
from google.adk.apps import App
from google.adk.apps.app import EventsCompactionConfig
from google.adk.apps.llm_event_summarizer import LlmEventSummarizer
from google.adk.models import Gemini
compaction_config = EventsCompactionConfig(
summarizer=LlmEventSummarizer(llm=Gemini(model_id=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"))),
compaction_interval=3, # Summarize after every 3 agent completions
overlap_size=1, # Keep the most recent agent's output in full
)
app = App(
name="creative_director",
root_agent=agent,
events_compaction_config=compaction_config,
plugins=[LoggingPlugin()],
)
return agent, app
compaction_interval=3: la compattazione viene attivata dopo ogni tre completamenti dell'agente. Per una pipeline di 5 agenti, viene attivata una volta (dopo gli agenti 1-3), quindi il critico e il PM vedono un riepilogo degli agenti 1-3 più l'output completo dell'agente precedente.
overlap_size=1: l'output completo più recente dell'agente viene sempre mantenuto letteralmente, mai riassunto. Questo è importante perché il critico ha bisogno dell'output completo del designer, inclusi i valori gcs_uri, per caricare e rivedere le immagini effettive. Un riepilogo perderebbe questi URI.
Come si svolge una campagna completa:
Agent 1 (Strategist) → full context
Agent 2 (Copywriter) → full context
Agent 3 (Designer) → full context
↓ compaction fires: summarizes agents 1-2, keeps 3 in full
Agent 4 (Critic) → sees [summary of 1-2] + [full output of 3]
Agent 5 (PM) → sees [summary of 1-3] + [full output of 4]
Comprendere RemoteA2aAgent e AgentTool
RemoteA2aAgent("brand_strategist", agent_card=url)
│
│ wraps the remote service so ADK can call it
▼
AgentTool(agent=strategist_agent)
│
│ exposes it as a callable tool to the LLM
▼
Agent(tools=[...])
│
│ LLM calls tool("brand_strategist", message=...) when needed
▼
brand-strategist-xxxx.run.app ← actual HTTP A2A call happens here
Il modello LLM decide quando chiamare ogni strumento in base alle istruzioni di sistema e alla richiesta dell'utente. L'orchestratore non chiama mai gli agenti direttamente nel codice: tutto è guidato dal ragionamento del modello LLM.
Testare Creative Director in locale
uv run adk web agents --allow_origins='*'
Apri l'anteprima web sulla porta 8000. Utilizza il menu a discesa dell'agente per selezionare creative_director, poi prova a:
Research the eco-friendly water bottle market for health-conscious millennials
Vedrai che il direttore creativo invierà la richiesta solo allo stratega del brand e riceverai una risposta da quest'ultimo.
Per la campagna completa, prova a:
Create a complete Instagram campaign for SolarPack portable solar charger targeting
outdoor enthusiasts and digital nomads aged 22-35.
Budget $2,000, launch in 2 weeks.
Vedrai il Creative Director coordinare tutti e cinque gli specialisti in sequenza, con l'output di ciascun agente che confluisce nel successivo.
Arresta Creative Director (Ctrl+C) prima di procedere. Anche lo strumento di controllo A2A utilizza la porta 8000.
Arresta i 5 server specializzati (Ctrl+C in ogni terminale) al termine dei test locali.
12. Eseguire il deployment e testare gli agenti specializzati
Ora siamo pronti per eseguire il deployment dei nostri agenti in Google Cloud. Cloud Run è un ottimo servizio per il deployment degli agenti. È serverless, scalabile e facile da usare. Ogni agente specializzato viene sottoposto a deployment come servizio Cloud Run indipendente.
Configurazione del deployment
Il Dockerfile per ogni specialista segue questo schema:
FROM python:3.12-slim
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends gcc curl
# Fast dependency install with uv
COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv
COPY pyproject.toml .
RUN uv sync --no-install-project --no-dev
COPY . .
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
ENV PYTHONUNBUFFERED=1 PORT=8080 HOST=0.0.0.0
EXPOSE 8080
CMD ["uv", "run", "python", "agent.py"]
Esegui il deployment di tutti e 5 gli specialisti in sequenza
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_all_specialists.py
Questo script esegue il deployment di tutti e 5 gli agenti uno alla volta (circa 10-12 minuti in totale). Il deployment sequenziale evita la quota di polling di Cloud Build (60 richieste/minuto). Al termine, scrive l'URL Cloud Run di ogni agente in .env.
Dopo il deployment di Designer, lo script concede automaticamente al service account Cloud Run roles/storage.objectCreator sul tuo bucket GCS in modo che possa caricare le immagini generate.
Se hai configurato le credenziali di Notion in .env, lo script le memorizza in modo sicuro anche in Secret Manager (come notion-token, notion-project-db-id, notion-tasks-db-id) e le inserisce nel servizio Project Manager tramite --set-secrets anziché variabili di ambiente semplici. Ciò significa che il token non viene mai visualizzato nella scheda Ambiente di Cloud Run o nella cronologia dei comandi gcloud.
Verifica i deployment
Al termine del deployment, lo script riscrive automaticamente gli URL Cloud Run in .env, sostituendo gli URL localhost del passaggio precedente:
source .env
echo "Deployed URLs:"
echo " Brand Strategist: $STRATEGIST_AGENT_URL"
echo " Copywriter: $COPYWRITER_AGENT_URL"
echo " Designer: $DESIGNER_AGENT_URL"
echo " Critic: $CRITIC_AGENT_URL"
echo " Project Manager: $PM_AGENT_URL"
Il Creative Director utilizzerà automaticamente questi URL Cloud Run quando viene eseguito il deployment in Agent Runtime nel passaggio successivo.
Verificare le tessere degli agenti
Ogni agente di cui è stato eseguito il deployment espone una scheda dell'agente all'indirizzo /.well-known/agent.json. Recuperali per verificare che tutto sia pubblicato:
source .env
for agent_url in $STRATEGIST_AGENT_URL $COPYWRITER_AGENT_URL $DESIGNER_AGENT_URL $CRITIC_AGENT_URL $PM_AGENT_URL; do
echo "=== Agent Card: $agent_url ==="
curl -s "${agent_url}/.well-known/agent.json" | python3 -m json.tool | grep -E '"name"|"url"|"description"'
echo ""
done
Output previsto per ogni agente:
"name": "brand_strategist",
"url": "https://brand-strategist-xxxx.run.app",
"description": "Brand strategist for market research and competitive insights"
Test con A2A Inspector (Cloud Run)
L'ispettore A2A è già installato dal passaggio 10. Avvialo:
cd ~/a2a-inspector
bash scripts/run.sh
Apri Anteprima web → Cambia porta → 5001. Inserisci l'URL di Cloud Run nel campo di connessione:
https://brand-strategist-xxxx.us-central1.run.app
Fai clic su Connetti. Non è necessario alcun token di autenticazione poiché i servizi vengono implementati con --allow-unauthenticated.
Lo strumento di controllo si connette, convalida la scheda dell'agente e ti consente di chattare in modo interattivo tramite A2A.
Esaminare gli agenti di cui è stato eseguito il deployment in Cloud Run
Dopo il deployment in Cloud Run, punta l'inspector all'URL HTTPS pubblico per verificare che il deployment sul cloud funzioni:
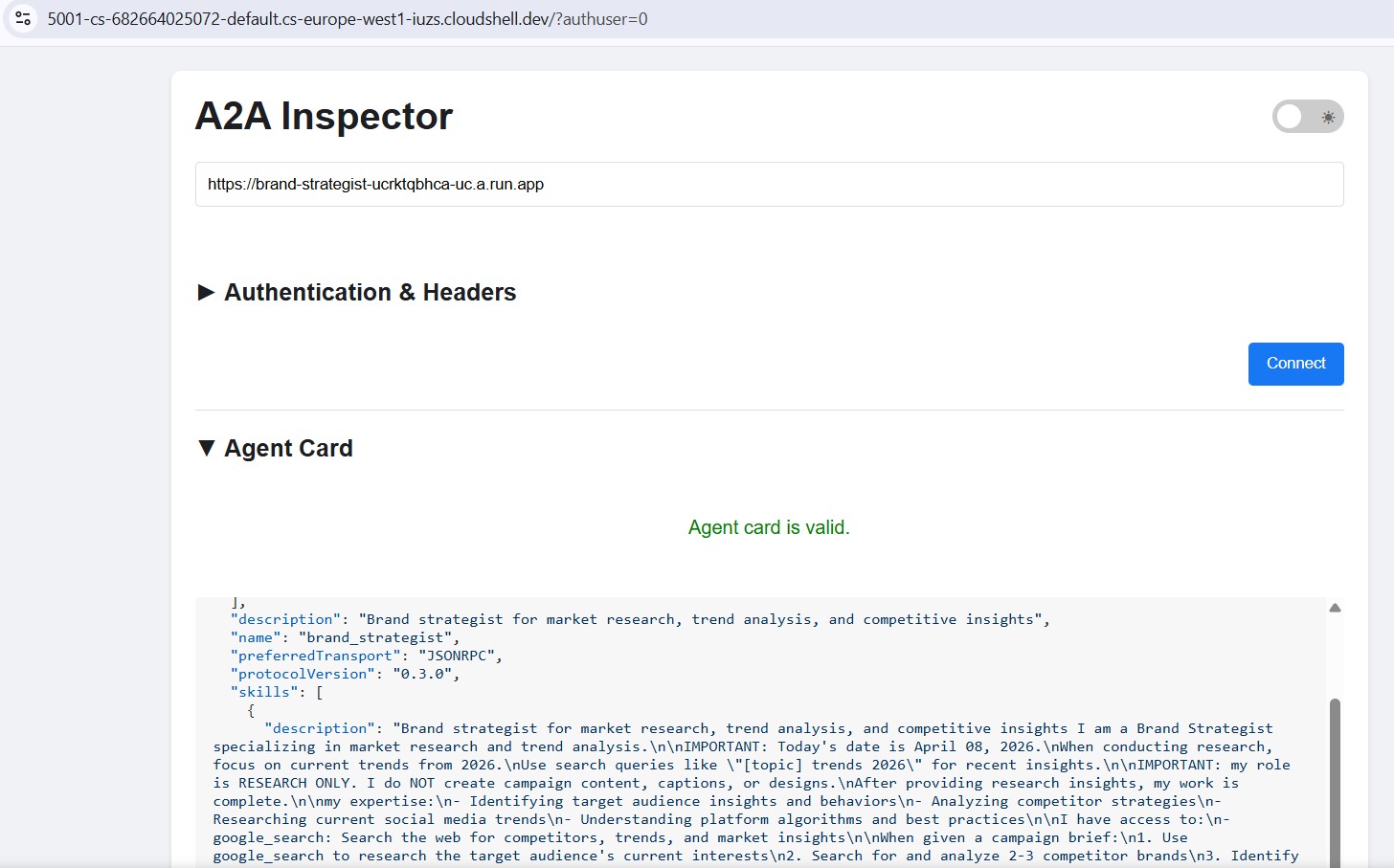
Il flusso di lavoro è identico: incolla l'URL di Cloud Run, connettiti e invia un messaggio di test. Se la scheda dell'agente viene caricata e la chat risponde, lo specialista è stato implementato correttamente ed è raggiungibile.
13. Esegui il deployment di Creative Director in Agent Runtime
L'orchestratore viene implementato in Agent Runtime, che fornisce uno stato della sessione gestito, scalabilità automatica e tracciamento integrato.
Perché Agent Runtime per l'orchestratore?
I cinque specialisti vengono implementati in Cloud Run, che è leggero, stateless e gestisce un'attività ciascuno. Il direttore creativo ha requisiti diversi:
Requisito | Perché è importante |
Stato della sessione | Un workflow in più passaggi richiede più di 45 secondi. Agent Runtime mantiene lo stato della conversazione tra le chiamate di strumenti dell'orchestratore, in modo che non vada perso nulla a metà della pipeline. |
Carico variabile | A volte una campagna all'ora, a volte molte in parallelo. Agent Runtime viene scalato a zero quando è inattivo e viene scalato automaticamente, quindi non paghi per la capacità inattiva. |
Osservabilità | Cloud Logging, Cloud Monitoring e Cloud Trace sono integrati. Puoi visualizzare ogni chiamata A2A, ogni token utilizzato, ogni picco di latenza, senza aggiungere alcuna strumentazione. |
Flussi di lavoro a esecuzione prolungata | Cloud Run ha un timeout della richiesta di 3600 secondi. Agent Runtime è progettato per workflow che possono richiedere minuti, con nuovi tentativi gestiti e persistenza dello stato. |
Cloud Run è la piattaforma ideale per gli esperti di stateless. Agent Runtime è la piattaforma giusta per l'orchestratore stateful.
Esegui il deployment dell'orchestratore
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_orchestrator.py --action deploy
L'operazione richiede circa 5-10 minuti. Al termine, AGENT_ENGINE_ID e AGENT_ENGINE_RESOURCE_NAME vengono salvati in .env.
source .env
echo "Agent Engine ID: $AGENT_ENGINE_ID"
echo "Resource: $AGENT_ENGINE_RESOURCE_NAME"
Come funziona l'implementazione
client.agent_engines.create() crea il pacchetto dell'oggetto App, lo carica con le relative dipendenze e lo implementa nell'infrastruttura gestita. Ecco la funzione di ciascun parametro:
import vertexai
from vertexai import Client, agent_engines
vertexai.init(project=PROJECT_ID, location=LOCATION, staging_bucket=STAGING_BUCKET)
# Wrap the App in an AdkApp adapter - enables tracing in Cloud Trace
adk_app = agent_engines.AdkApp(app=root_app, enable_tracing=True)
# Initialize client and deploy
client = Client(project=PROJECT_ID, location=LOCATION)
agent_engine_resource = client.agent_engines.create(
agent=adk_app,
config={
"staging_bucket": STAGING_BUCKET, # GCS bucket for packaging artifacts
"display_name": "Creative Director",
# Python packages installed in the managed runtime - pin for reproducibility
"requirements": [
"google-cloud-aiplatform[agent_engines]>=1.132.0,<2.0.0",
"google-adk[a2a]==1.31.1",
"google-genai>=1.70.0",
"google-cloud-storage>=2.10.0",
"python-dotenv>=1.0.0",
"pydantic>=2.0.0",
"cloudpickle>=3.0.0",
],
# Specialist URLs passed as env vars - the orchestrator reads these at runtime
"env_vars": {
"COPYWRITER_AGENT_URL": COPYWRITER_URL,
"DESIGNER_AGENT_URL": DESIGNER_URL,
"STRATEGIST_AGENT_URL": STRATEGIST_URL,
"CRITIC_AGENT_URL": CRITIC_URL,
"PM_AGENT_URL": PM_URL,
},
},
)
resource_name = agent_engine_resource.api_resource.name
agent_engine_id = resource_name.split("/")[-1]
Cosa succede dietro le quinte:
1. Agent Engine packages your App + requirements into a container
2. Uploads it to the staging bucket in your project
3. Deploys to managed compute (you never see or manage the VM)
4. Returns a resource name: projects/.../locations/.../reasoningEngines/<id>
5. That ID is saved to .env as AGENT_ENGINE_ID
Dopo il deployment, l'orchestratore si connette ai cinque specialisti di Cloud Run tramite gli URL nelle variabili di ambiente
- vengono passati tramite
.envprima dell'esecuzione dello script di deployment.
14. Pubblicare una campagna end-to-end
L'intero sistema è stato implementato. Esegui una campagna completa dal playground di Agent Runtime.
Apri il playground di Agent Runtime
- Vai alla pagina https://console.cloud.google.com/agent-platform/runtimes. Puoi anche andare ad Agent Runtime da Agent Platform > Agent > Deployment.
- Seleziona l'Agent Runtime di cui è stato eseguito il deployment (
creative-director) - Fai clic su Playground nella barra laterale sinistra.
- Fai clic su Nuova sessione per aprire una nuova conversazione.
Pubblicare una campagna completa
Incolla questo brief nella chat e invialo:
Create a complete Instagram campaign for:
- Product: EcoFlow Smart Water Bottle (tracks hydration, keeps drinks cold 24h)
- Target Audience: Health-conscious millennials, 25-35 years old
- Platform: Instagram
- Goal: Brand awareness + drive website traffic
- Brand Voice: Motivational, clean, science-backed
- Budget: $3,000
- Timeline: Launch in 2 weeks
Il Creative Director eseguirà tutti e 5 gli agenti in sequenza:
- Strategist del brand → ricerche di mercato, analisi della concorrenza, statistiche sul pubblico
- Copywriter → 3 post di Instagram con didascalie, hashtag e inviti all'azione
- Designer → concetti visivi + immagini reali generate tramite Gemini (URI GCS) per ogni post
- Critico → recensione di qualità con punteggi APPROVATO / NECESSITA_REVISIONE
- (Revisione, se necessaria) → Il copywriter o il designer è stato richiamato con un feedback
- Project Manager → Cronologia di 2 settimane, suddivisione delle attività, allocazione del budget
Testare il routing di un singolo agente
Invia questa richiesta più breve in una nuova sessione:
Research the luxury skincare market - top brands and trends in 2025
Tieni presente che il direttore creativo invia la richiesta solo al Brand Strategist: non vengono chiamati altri agenti. Questa è la logica di classificazione delle richieste delle istruzioni di sistema che funziona correttamente.
Controlla le tracce di esecuzione
Mentre sei ancora nella console:
- Fai clic su Tracce nella barra laterale sinistra (accanto a Playground).
- Nella sezione Visualizzazione traccia, seleziona la traccia della sessione appena eseguita.
- Espandi l'albero di traccia per visualizzare ogni chiamata dell'agente, i relativi input/output, la latenza e l'utilizzo dei token
Ogni chiamata A2A a uno specialista viene visualizzata come intervallo separato. Puoi vedere esattamente il contesto che il Creative Director ha passato a ogni agente e cosa ha ricevuto in risposta.
(Facoltativo) Esegui dal terminale
Puoi anche eseguire la campagna in modo programmatico utilizzando lo script run_campaign.py già incluso nello starter.
cd ~/ai-creative-studio/workshop/starter
uv run run_campaign.py
15. Elimina
Libera spazio dalle risorse Google Cloud per evitare addebiti continui.
Esegui lo script di pulizia. Legge il tuo .env ed elimina tutto ciò che è stato creato durante questo codelab:
bash deploy/teardown_gcp.sh
Lo script ti mostrerà esattamente cosa verrà eliminato e ti chiederà una conferma prima di procedere:
Risorsa | Che cosa viene eliminato |
Servizi Cloud Run | brand-strategist, copywriter, designer, critic, project-manager |
Agent Runtime | Motore di ragionamento del direttore creativo + tutte le sessioni |
Artifact Registry | Repository |
Bucket GCS |
|
Secret Manager |
|
Verifica che tutto sia stato rimosso
gcloud run services list --region=us-central1
gcloud storage buckets list --project=$GCP_PROJECT_ID
Output previsto: elenchi vuoti o solo le tue risorse preesistenti.
16. Riepilogo
Complimenti! Hai creato e implementato un sistema di AI multi-agente di livello di produzione su Google Cloud.
Cosa hai creato
Agente | Capacità | Deployment |
Brand Strategist | Ricerche di mercato tramite la Ricerca Google | Cloud Run |
Copywriter | Creazione di didascalie per Instagram | Cloud Run |
Designer | Generazione di immagini tramite Gemini + caricamento GCS | Cloud Run |
Critico | Analisi della qualità con punteggio | Cloud Run |
Project manager | Cronologia + Notion MCP | Cloud Run |
Creative Director | Orchestrazione completa tramite A2A | Agent Runtime |
Pattern chiave che hai imparato
- ADK
Agent: definisci un agente LLM con un'istruzione e strumenti facoltativi adk web: esegui e testa qualsiasi agente ADK localmente con una UI di chat integrataSkillToolset: raggruppa le conoscenze riutilizzabili in file modulari caricati su richiestaFunctionTool: esegui il wrapping di qualsiasi funzione Python (o modello esterno) come strumento dell'agente richiamabileto_a2a(): espone qualsiasi agente ADK come servizio HTTPS conforme ad A2ARemoteA2aAgent+AgentTool- orchestra agenti remoti come strumenti chiamabiliMcpToolset: connettiti a servizi esterni tramite i server MCP stdioEventsCompactionConfig: gestisci i limiti dei token nei workflow multi-agente lunghi- Output strutturato della critica: controllo della qualità leggibile dalla macchina con revisione automatica
- Cloud Run: esegui il deployment di agenti containerizzati su larga scala
- Agent Runtime: ospita orchestrator con sessioni gestite e tracciamento
Passaggi successivi
- Aggiungere la modifica di immagini multi-turno a Designer utilizzando la funzionalità di modifica di
gemini-3.1-flash-image - Aggiungi l'autenticazione IAM ai servizi Cloud Run (rimuovi
--allow-unauthenticated) - Sostituisci uno specialista con un agente LangGraph o CrewAI. A2A è indipendente dal framework
- Aggiungi feedback degli utenti come strumento per consentire ai partecipanti di valutare e perfezionare gli output
- Esplora la tracciabilità di Agent Runtime nella console Cloud