
1. 概要
この Codelab では、AI Creative Studio を構築します。これは、単一のプロンプトを完全な Instagram キャンペーンに変換する分散型マルチエージェント システムです。
1 文を入力するだけで、オーディエンス調査、キャプション、ビジュアル コンセプト、品質審査済みのコピー、プロジェクトの完全なタイムラインが返ってきます。これらはすべて、連携する AI エージェントのチームによって生成されます。
構築するエージェント
エージェント | ロール |
ブランド ストラテジスト | オーディエンスの分析情報、競合他社の分析、2025 年のトレンドについてウェブを検索します |
コピーライター | ハッシュタグと行動を促すフレーズを含む Instagram のキャプションを作成する - プラットフォームのガイドラインとキャプションの公式をオンデマンドで読み込む ADK スキルを使用 |
デザイナー | Gemini を介して視覚的なコンセプトを作成し、実際の画像を生成して GCS に保存する |
Critic | レビューのコピーとビジュアル - 特定のフィードバックとともに |
プロジェクト マネージャー | プロジェクトのタイムラインとタスクの分解を作成し、必要に応じて MCP 経由で Notion に同期します |
クリエイティブ ディレクター | 5 人のスペシャリストをすべて順番にオーケストレートする - 1 つのプロンプトを指定すると、残りの処理を調整する |
5 つのエージェントは、独立した Cloud Run マイクロサービスとしてデプロイされます。これらは A2A プロトコルを介して通信します。これは言語に依存しないオープン スタンダードであるため、フレームワークに関係なく、任意のエージェントが他のエージェントを呼び出すことができます。クリエイティブ ディレクターは Agent Runtime で実行され、各スペシャリストにリモートで接続します。
アーキテクチャ

学習内容
- Google ADK を使用して LLM エージェントを構築する -
Agent、システム指示、組み込みツール。 - 再利用可能なエージェントの知識を ADK スキル(
SkillToolset)を使用してモジュール式ファイルにパッケージ化します。 FunctionToolを介してテキスト エージェントを画像モデルに接続し、実際の画像を生成します。- Model Context Protocol(MCP)を使用して、カスタムのグルーコードなしで外部 API を統合します。
- HTTPS 経由の Agent to Agent Protocol(A2A)を使用して、任意のエージェントをネットワーク呼び出し可能なサービスに変換します。
RemoteA2aAgentとAgentToolを使用して分散エージェントをオーケストレートします。- 独立したエージェントを Cloud Run マイクロサービスとしてパッケージ化してデプロイします。
- ステートフル オーケストレーターを Agent Runtime でホストします。
- コンテキスト圧縮を使用して、長いマルチエージェント ワークフローをコンテキストの上限内に収めます。
- 品質管理ループを構築する: 批評家のレビューの出力 → 必要に応じて自動的に改訂。
必要なもの
- 課金が有効になっている Google Cloud プロジェクト
- オーナーまたは編集者の IAM ロール
- Python の基礎知識
2. 環境をセットアップする
この Codelab では、Cloud Shell を使用します。
Cloud Shell とは
Cloud Shell は、gcloud、git、Python、Docker などがプリインストールされた無料のブラウザベースの Linux 環境です。ローカルに何もインストールする必要はありません。
Cloud Shell を開くには、GCP Console の右上にあるツールバーのターミナル アイコンをクリックします。
Cloud Shell を初めて開くと、アカウントの確認を求めるメッセージが表示されます。[確認] をクリックします。
![[アカウントを確認] ダイアログ](https://codelabs.developers.google.com/static/ai-creative-studio-adk-a2a/diagrams/wksp2.jpg?hl=ja)
[承認] をクリックして、Cloud Shell に Google Cloud API 呼び出しを許可します。
![[Cloud Shell の承認] ダイアログ](https://codelabs.developers.google.com/static/ai-creative-studio-adk-a2a/diagrams/wksp3.jpg?hl=ja)
これで Cloud Shell の準備が整いました。ターミナルにウェルカム メッセージ  が表示されます。
が表示されます。
プロジェクトの認証と構成を行う
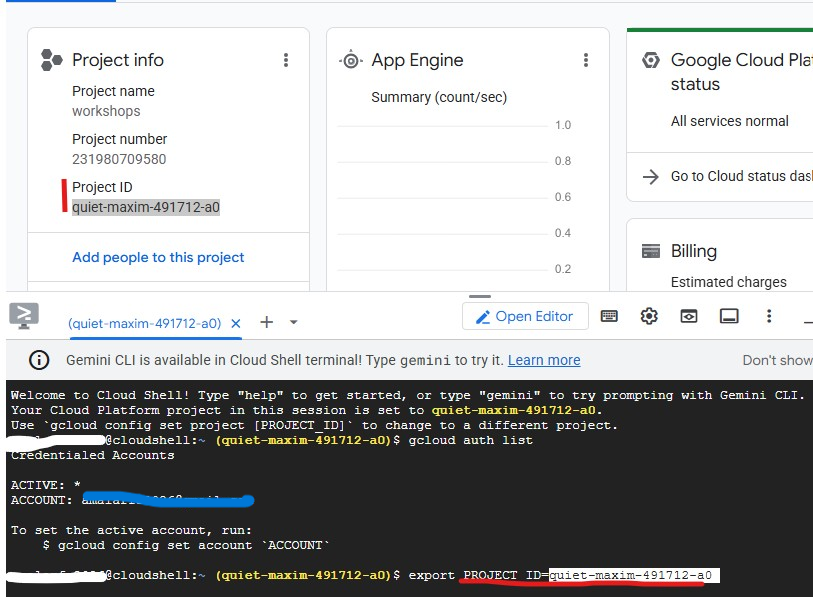
Cloud Shell は Google アカウントで認証済みです。アクティブなアカウントを確認し、プロジェクト ID を確認します。
gcloud config list
プロジェクト ID は、GCP Console のダッシュボードの左側のパネルでも確認できます。コピーします。これは次のコマンドで必要になります。
次に、プロジェクトを設定します。
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Cloud Run deployment region
echo "Project: $PROJECT_ID"
予想される出力:
Project: my-project-123
必要な API の有効化
gcloud services enable \
aiplatform.googleapis.com \
apphub.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
generativelanguage.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com \
storage.googleapis.com \
secretmanager.googleapis.com
所要時間は約 2 分です。完了すると Operation finished successfully が表示されます。
アプリケーションのデフォルト認証情報(ADC)を設定する
エージェントは Google Auth ライブラリを使用して Gemini Enterprise Agent Platform を呼び出します。これには、gcloud CLI 認証とは別のアプリケーションのデフォルト認証情報が必要です。
次のコマンドを 1 回実行します。
gcloud auth application-default login
確認を求めるブラウザタブが開きます。[許可] をクリックします。表示される項目
Credentials saved to file: ~/.config/gcloud/application_default_credentials.json
スターター リポジトリのクローンを作成する
この Codelab では、スターター リポジトリを使用します。これは、すべてのインフラストラクチャ(Dockerfile、pyproject.toml、デプロイ スクリプト)が用意されているスケルトン プロジェクトですが、エージェント ロジックはユーザーが記述する必要があります。
git clone https://github.com/Saoussen-CH/mas-a2a-gcp.git ~/ai-creative-studio
cd ~/ai-creative-studio/workshop/starter
各 agent.py には、エージェント ロジックを記述する # TODO プレースホルダが含まれています。Dockerfile、pyproject.toml、デプロイ スクリプトはすでに完成しています。
環境変数を構成する
提供された例をコピーし、1 つのステップでプロジェクト ID を挿入します。
cp .env.example .env
sed -i "s|GOOGLE_CLOUD_PROJECT=your-project-id|GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)|" .env
次に、Designer が生成された画像を保存する GCS バケットを作成し、その名前で .env を更新します。
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-campaign-images"
gcloud storage buckets create gs://${BUCKET_NAME} \
--location=us-central1 \
--project=${PROJECT_ID}
sed -i "s|GCS_IMAGES_BUCKET=your-project-id-campaign-images|GCS_IMAGES_BUCKET=${BUCKET_NAME}|" .env
次に、署名付き画像 URL のサポートを設定します。クリエイティブ ディレクターは、最終的なキャンペーンの概要で各画像のクリック可能な HTTPS リンクを生成します。これには、URL に署名するサービス アカウントが必要です。次のコマンドを実行して構成します。
export PROJECT_NUMBER=$(gcloud projects describe $(gcloud config get-value project) --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
export AGENT_RUNTIME_SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Allow your user account to sign URLs locally (adk web)
gcloud iam service-accounts add-iam-policy-binding ${SA_EMAIL} \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Allow Agent Runtime to sign URLs when deployed
gcloud projects add-iam-policy-binding $(gcloud config get-value project) \
--member="serviceAccount:${AGENT_RUNTIME_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
# Save SA email and project number to .env
grep -q "^SIGNING_SERVICE_ACCOUNT" .env \
&& sed -i "s|^SIGNING_SERVICE_ACCOUNT=.*|SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}|" .env \
|| echo "SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}" >> .env
grep -q "^GOOGLE_CLOUD_PROJECT_NUMBER" .env \
&& sed -i "s|^GOOGLE_CLOUD_PROJECT_NUMBER=.*|GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}|" .env \
|| echo "GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}" >> .env
エディタで .env を開いて、すべての設定を確認します。
cloudshell edit .env
これにより、Cloud Shell エディタのタブとして .env が開きます。エディタ パネルが表示されていない場合は、ツールバーの [エディタを開く] ボタンをクリックします。
![Cloud Shell ツールバーで [エディタを開く] をクリックします。](https://codelabs.developers.google.com/static/ai-creative-studio-adk-a2a/diagrams/wksp6.png?hl=ja)
プロジェクトが正しく設定されていることを確認します。
grep GOOGLE_CLOUD_PROJECT .env
依存関係のインストール
uv を使用します。これは、仮想環境を処理し、単一のツールでインストールを行う高速で最新の Python パッケージ マネージャーです。pip よりも 10 ~ 100 倍高速で、Python プロジェクトを管理するうえで推奨される方法です。
Cloud Shell には uv がすでにインストールされています。すべてのエージェントは同じコア依存関係を共有するため、1 回インストールすれば、この Codelab のすべてのエージェントで動作します。
uv sync
uv sync コマンドは pyproject.toml を読み取り、すべての依存関係を含む .venv/ ディレクトリを作成します。各スペシャリストには、Docker ビルド専用の独自の pyproject.toml もあります。上記の共有インストールは、ローカル テストに必要なすべてを網羅しています。
3. Google ADK について
コードを記述する前に、この Codelab で各エージェントの構築に使用するフレームワークである Agent Development Kit(ADK)について理解しましょう。
ADK とは
Agent Development Kit(ADK)は、AI エージェントの開発とデプロイ用に設計された、柔軟性の高いモジュール型のフレームワークです。ADK は Gemini と Google エコシステム向けに最適化されていますが、モデルやデプロイに依存せず、他のフレームワークとの互換性を保つよう構築されています。ADK は、エージェント開発をソフトウェア開発のような感覚で行えるよう設計されており、デベロッパーは基本的なタスクから複雑なワークフローまで、幅広いエージェント アーキテクチャを簡単に作成、デプロイ、オーケストレートできます。
ADK は、複雑な部分(ツールの呼び出し、マルチターンの会話、コンテキスト管理、ストリーミング)を処理するため、ユーザーはエージェント ロジックに集中できます。
ADK エージェントの構成要素
すべてのエージェントは、次の 4 つの構成要素で構成されています。
ブロック | ロール |
モデル | 目標の推論、計画の判断、回答の生成を行う LLM |
ツール | API またはサービスを呼び出してデータを取得したり、アクションを実行したりする関数 |
オーケストレーション | ターン間でメモリと状態を維持し、ツール呼び出しをルーティングして、結果をモデルに渡す |
ランタイム | 起動されるとシステムを実行する - |
エージェントの定義
この Codelab の 5 つのエージェントは、それぞれ次のように定義されています。
from google.adk.agents import Agent
from google.adk.tools.google_search_tool import google_search
root_agent = Agent(
name="brand_strategist", # unique identifier
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"), # the LLM powering this agent
instruction=SYSTEM_INSTRUCTION, # the agent's persona, constraints, and output format
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search], # functions the LLM can call
)
フィールド | 目的 |
| 一意の ID - オーケストレーターが通話をルーティングするために使用 |
| このエージェントをサポートする Gemini モデル |
| システム プロンプト - エージェントの役割、制約、出力形式を定義します |
| 1 行の概要 - オーケストレーターがこれを読み取って、どのスペシャリストを呼び出すかを決定します |
| LLM が呼び出すことができる関数( |
ADK がエージェントを実行する方法
User message
│
▼
Agent (LLM) ← reads instruction + conversation history
│
├─► needs more info? → calls a tool → gets result → continues reasoning
│
└─► done reasoning → returns final text response
LLM は、ツールを呼び出すかどうか、どのツールを呼び出すか、どのような引数で呼び出すかを自律的に決定します。ユーザーは指示を記述するだけで、残りの処理は ADK が行います。
4. ブランド ストラテジスト エージェントを構築してテストする
まず、最初のエージェントであるブランド戦略担当者から見ていきましょう。これは、Google 検索を使用してターゲット ユーザーのインサイト、競合他社の分析、トレンドのトピックを検索するリサーチ専用のエージェントです。
Cloud Shell エディタでスケルトン エージェント ファイルを開きます。
cloudshell edit agents/brand_strategist/agent.py
2 つの # TODO セクションが表示されるので、入力します。
TODO 1 - システム指示を記述する
まず、エージェントのシステム指示を記述します。システム指示は、エージェントの役割、制約、出力形式を定義する文字列です。
SYSTEM_INSTRUCTION = f"""You are a Brand Strategist specializing in market research and trend analysis.
IMPORTANT: Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
When conducting research, focus on current trends from {datetime.date.today().year}.
Use search queries like "[topic] trends {datetime.date.today().year}" for recent insights.
IMPORTANT: Your role is RESEARCH ONLY. You do NOT create campaign content, captions, or designs.
After providing research insights, your work is complete.
Your expertise:
- Identifying target audience insights and behaviors
- Analyzing competitor strategies
- Researching current social media trends
- Understanding platform algorithms and best practices
You have access to:
- google_search: Search the web for competitors, trends, and market insights
When given a campaign brief:
1. Use google_search to research the target audience's current interests
2. Search for and analyze 2-3 competitor brands
3. Identify 3-5 trending topics related to the product category
4. Provide high-level strategic insights - NOT specific campaign content
DO NOT create captions, copy, designs, or any campaign content.
Format your output as:
**Audience Insights:**
[Key behaviors and preferences based on research]
**Competitive Analysis:**
[What 2-3 competitors are doing - strengths and weaknesses]
**Trending Topics:**
[3-5 relevant trends to consider]
**Key Strategic Insights:**
[High-level themes and positioning opportunities]
"""
TODO 2 - root_agent を作成する
次に、未完了の root_agent を次のように置き換えます。
root_agent = Agent(
name="brand_strategist",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
instruction=SYSTEM_INSTRUCTION,
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search],
)
ADK ウェブ UI を使用してローカルでテストする
次に、ADK ウェブ UI(クラウドにデプロイする前にエージェントをテストするための組み込みのチャット インターフェース)を使用してエージェントをテストします。
uv run adk web agents --allow_origins='*'
表示される項目
INFO: Started server process
INFO: Uvicorn running on http://localhost:8000
サーバーが Cloud Shell 内で実行されています。
ブラウザで開くには、ウェブ プレビューを使用します。
- ページの上部にある Cloud Shell ツールバーを確認します。
- [ウェブでプレビュー] アイコン(上向き矢印の付いたボックスのようなアイコン。Cloud Shell ツールバーの右上)をクリックします。
- [ポートの変更] をクリックし、「
8000」と入力して [変更してプレビュー] をクリックします。
新しいブラウザタブが開き、ADK ウェブ UI が表示されます。左上の [エージェントを選択] プルダウンをクリックすると、すべてのエージェントが一覧表示されます。
brand_strategist を選択してテストを開始します。
テスト プロンプトを試す
ADK ウェブ UI のチャット ボックスで、次の操作を試します。
Research the eco-friendly water bottle market for health-conscious millennialsWhat are the top Instagram trends in the wellness space in 2025?
エージェントが Google 検索を呼び出し、オーディエンス分析、競合他社分析、トレンドのトピックのセクションを含む構造化された調査結果を返すことを確認します。
5. Copywriter - ADK Skills をビルドする
役割: ブランド調査を Instagram のキャプションに変換します。コピーライターは、さまざまなトーン(インスピレーション、教育、コミュニティ)をカバーする 3 つのキャプションのバリエーションを作成します。それぞれにハッシュタグと行動を促すフレーズが含まれています。
コンセプト: ADK スキル
単純なアプローチでは、文字数制限、ハッシュタグの階層、キャプションの数式、ブランド ボイスの例など、すべてのプラットフォームの知識をシステム プロンプトに直接埋め込みます。これは機能しますが、エージェントがたまにしか必要としないコンテンツでリクエストが膨大になります。
ADK スキル(SkillToolset、ADK 1.25.0 で導入)を使用すると、その知識を 3 つの読み込みレベルのモジュール式ファイルにパッケージ化できます。
- L1 - frontmatter(
SKILL.mdのname+description): 常に利用可能、スキルの検出に使用 - L2 - instructions(
SKILL.mdの本文): エージェントがスキルをトリガーしたときに読み込まれます - L3 - リソース(
references/ファイルとassets/ファイル): エージェントが明示的に読み取る場合にのみ読み込まれます
システム指示は、短い役割ステートメントと「書き込み前にスキルを読み込む」に縮小されます。プラットフォームの詳細は、エージェントが実際に必要とする場合にのみコンテキスト ウィンドウに入力されます。
コピーライターのスキルは agents/copywriter/skills/instagram-copywriting/ にあります。
skills/
instagram-copywriting/
SKILL.md ← L1 frontmatter (discovery) + L2 instructions (loaded on trigger)
references/
platform-guide.md ← L3: character limits, hashtag tiers, algorithm signals
caption-formulas.md ← L3: hook formulas, CTA patterns, full caption structures
assets/
brand-voice-examples.md ← L3: annotated real-world caption examples
Cloud Shell エディタでファイルを直接開きます。
cloudshell edit agents/copywriter/agent.py
TODO 1 - load_skill_from_dir と skill_toolset をインポートする
コメント # TODO 1: Import load_skill_from_dir and skill_toolset を見つけて、次の 2 つのインポートを追加します。
from google.adk.skills import load_skill_from_dir
from google.adk.tools import skill_toolset
TODO 2 - スキルを読み込んで SkillToolset を作成する
インポートの下にある 2 つのコメントを見つけます。
# TODO 2: Load the instagram-copywriting skill from the skills/ directory
# TODO 2: Create a SkillToolset with the loaded skill
次のように置き換えます。
_instagram_skill = load_skill_from_dir(
pathlib.Path(__file__).parent / "skills" / "instagram-copywriting"
)
_copywriting_skills = skill_toolset.SkillToolset(skills=[_instagram_skill])
load_skill_from_dir は、SKILL.md と references/ および assets/ 内のすべてのファイルを読み取ります。SkillToolset は、ADK エージェントが受け入れる形式(ツールセット)にラップします。これは、生のスキルではありません。
TODO 3 - ツールセットをエージェントに登録する
tools=[], # TODO 3: Add the SkillToolset here を見つけて、次のように置き換えます。
tools=[_copywriting_skills],
スキルファイルを開いて、構造を確認します。
cloudshell edit agents/copywriter/skills/instagram-copywriting/SKILL.md
ADK ウェブ UI を実行したままにします。エージェントのプルダウンを使用して、サーバーを再起動せずに copywriter に切り替えます。
実行されていない場合は、もう一度起動します。
uv run adk web agents --allow_origins='*'
試してみる: プルダウンを copywriter に切り替えて送信します。
You are writing captions for EcoFlow Smart Water Bottle targeting health-conscious millennials aged 25-35.
Audience insight: they prioritize sustainability, track health metrics, and share lifestyle content.
Competitor insight: Hydro Flask dominates with lifestyle branding; S'well leads on premium aesthetics.
Write 3 Instagram captions - one inspirational, one educational, one community-focused. Include 5 hashtags each and a CTA.
6. Designer - マルチモーダル画像生成を構築する
ADK ウェブ UI を実行したままにします。エージェントのプルダウンを使用して、サーバーを再起動せずにエージェントを切り替えます。
役割: 各キャプションの視覚的なコンセプトを作成し、Gemini のネイティブ画像生成を使用して実際の画像を生成します。Designer は、キャプションごとに 1 つのビジュアル コンセプトを正確に出力します。詳細なプロンプト、スタイル、カラーパレット、ムード、Instagram 形式を指定すると、すぐに generate_image ツールを呼び出して実際の画像を生成し、GCS にアップロードします。
コンセプト: ツールを介してテキスト エージェントと画像モデルをブリッジする
Designer は gemini-3-flash-preview(.env の GEMINI_MODEL で設定されたテキストモデル)で実行されますが、画像生成には専用のモデル(gemini-3.1-flash-image)が必要です。この画像モデルは関数呼び出しをサポートしていないため、ADK エージェントとして直接使用することはできません。代わりに、プレーンな Python 関数でラップされ、FunctionTool として登録されます。
これは、LLM が直接呼び出すことができないモデルまたは API のパターンです。ツールでラップし、エージェントに呼び出すタイミングを調整させ、構造化された結果を返します。
Designer agent (text model)
│
│ decides visual concept, writes image prompt
▼
generate_image tool
│
│ calls gemini-3.1-flash-image
│ uploads result to GCS
▼
{"status": "success", "gcs_uri": "gs://..."}
│
│ returned to agent, included in response
▼
Critic (receives gcs_uri, passes to Vertex AI for multimodal review)
Cloud Shell エディタでファイルを直接開きます。
cloudshell edit agents/designer/image_gen_tool.py
関数シグネチャ、環境設定、アスペクト比の挿入が提供されています。次の 3 つの TODO を順番に処理します。
TODO 1 - Gemini 画像モデルを呼び出す
# TODO 1 のコメントを見つけて、次のように置き換えます。
client = genai.Client(vertexai=True, project=project_id, location=location)
response = client.models.generate_content(
model=image_model,
contents=prompt_with_aspect,
config=types.GenerateContentConfig(
response_modalities=["IMAGE", "TEXT"],
http_options=types.HttpOptions(
retry_options=types.HttpRetryOptions(
attempts=5, exp_base=2, initial_delay=30,
http_status_codes=[429, 500, 503, 504],
),
timeout=180_000,
),
),
)
TODO 2 - レスポンスから画像バイトを抽出する
# TODO 2 のコメントを見つけて、次のように置き換えます。
image_bytes = None
mime_type = "image/png"
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
image_bytes = part.inline_data.data
mime_type = part.inline_data.mime_type or "image/png"
break
if not image_bytes:
return {"status": "error", "error": "Gemini returned no image data"}
TODO 3 - GCS にアップロードして URI を返す
# TODO 3 のコメントを見つけて、次のように置き換えます。
ext = "jpg" if "jpeg" in mime_type else "png"
from google.cloud import storage
gcs_client = storage.Client(project=project_id)
bucket = gcs_client.bucket(bucket_name)
blob_name = f"campaign-images/{concept_name}-{uuid.uuid4().hex[:8]}.{ext}"
blob = bucket.blob(blob_name)
blob.upload_from_file(io.BytesIO(image_bytes), content_type=mime_type)
gcs_uri = f"gs://{bucket_name}/{blob_name}"
試してみる: プルダウンを designer に切り替えて送信します。
Create a visual concept and generate the image for an EcoFlow Smart Water Bottle Instagram post targeting health-conscious millennials.
Style: clean, modern, lifestyle-focused. Include a detailed prompt with color palette, mood, and format (1080x1080 or 1080x1350).
7. 批評家を構築する - 構造化出力
役割: プロジェクト マネージャーに渡す前に、コピーとビジュアルの品質を保証します。Critic は両方の成果物をスコアリングし、具体的な提案とともに APPROVED または NEEDS_REVISION を返します。入力に gcs_uri 値が存在する場合、review_image ツールを呼び出して、スコアリングの前に生成された各画像を視覚的に検査します。
コンセプト: Gemini 出力に Pydantic モデルを使用する場合
このルールは、出力を消費するユーザーに関するものです。
- Python コードが使用する →
response_schema+ Pydantic を使用します。コードは曖昧さを処理できないため、フィールドを確実に抽出するには保証された構造が必要です。 - LLM が使用する → テキスト形式とシステム指示で十分です。LLM はフォーマット ルールを理解し、バリエーションを許容します。
review_image では、Python コードは型付きの値として score、approval_status、what_works、issues、suggestions を必要とします。response_schema=_GeminiReview を渡すと、API レベルで Gemini が有効な JSON を返すように制約されます。model_validate_json() は、コードで確実に使用できる型付きオブジェクトに JSON を解析します。
class _GeminiReview(BaseModel):
score: int = Field(ge=1, le=10)
approval_status: Literal["APPROVED", "NEEDS_REVISION"]
what_works: str
issues: str
suggestions: str
Cloud Shell エディタでファイルを直接開きます。
cloudshell edit agents/critic/image_review_tool.py
Pydantic モデルとプロンプトが提供されます。次の 3 つの TODO を順番に実行します。
TODO 1 - GCS URI から画像パーツを作成する
# TODO 1 のコメントを見つけて、次のように置き換えます。
image_part = types.Part.from_uri(file_uri=gcs_uri, mime_type=mime_type)
TODO 2 - 構造化されたレスポンス スキーマで Gemini を呼び出す
# TODO 2 のコメントを見つけて、次のように置き換えます。
response = client.models.generate_content(
model=model,
contents=[image_part, prompt],
config=types.GenerateContentConfig(
response_schema=_GeminiReview,
response_mime_type="application/json",
),
)
TODO 3 - レスポンスを解析して結果を返す
# TODO 3 のコメントを見つけて、次のように置き換えます。
review = _GeminiReview.model_validate_json(response.text)
return ImageReviewResult(status="success", concept_name=concept_name, **review.model_dump())
試してみる: プルダウンを critic に切り替えて送信します。
Review this Instagram caption for an eco-friendly water bottle brand targeting millennials:
"Hydrate smarter, live greener. 💧 Our EcoFlow bottle tracks your intake, keeps your drink cold for 24h, and never touches single-use plastic. Because what you drink from matters as much as what you drink. #EcoFlow #HydrationGoals #SustainableLiving #ZeroWaste #HealthyHabits - Shop link in bio."
Score it and indicate APPROVED or NEEDS_REVISION with specific feedback.
レスポンスに **POSTS REVIEW:**、Status: APPROVED(または NEEDS_REVISION)、**OVERALL ASSESSMENT:** が含まれていることを確認します。これらのセクションが存在する場合、Critic はオーケストレーターに接続する準備ができています。
3 つのエージェントのテストが完了したら、Ctrl+C を押してサーバーを停止します。
8. MCP で Project Manager エージェントを構築する
プロジェクト マネージャーは、MCP(Model Context Protocol)という新しいコンセプトを紹介します。
次のファイルを開きます。
cloudshell edit agents/project_manager/agent.py
このファイルはより複雑です。2 つのブランチを持つ create_project_manager_agent() 関数があります。1 つは Notion なし(テキストのみのタイムライン)、もう 1 つは Notion MCP ツールセットありです。両方を入力します。
MCP が解決する問題
エージェントが外部サービス(Notion でのページの作成など)を呼び出す必要がある。Notion REST API を直接呼び出す Python コードを作成できます。ただし、次の場合は除きます。
- 開発者ごとに異なるラッパーを作成する
- カスタム統合コードを維持する必要がある
- すべてのエンドポイントを手動で記述しない限り、LLM は API の存在を認識しません
MCP は、外部サービスが機能を ツールとして公開するための標準的な方法を定義することで、この問題を解決します。LLM は、このツールを自動的に検出して呼び出すことができます。
MCP とは
MCP(Model Context Protocol)は、AI エージェントを外部のツールやデータソースに接続するためのオープン標準(Anthropic が公開)です。ユニバーサル アダプタのように機能します。
MCP サーバーは、次の処理を行う小さなプログラムです。
- 外部 API(Notion、GitHub、データベース、ファイル システムなど)をラップします。
- その API を型付けされ、文書化された ツールのリストとして公開します。
- シンプルなプロトコル(stdio または HTTP)を介してエージェントと通信する
エージェントは MCP サーバーに接続し、利用可能なツールを自動的に検出して、他のツールと同様に呼び出すことができます。LLM は API-post-page(...) を呼び出し可能な関数として認識します。
A2A と MCP の違いは何ですか?
これはよくある混乱の原因です。重要な違いは次のとおりです。
A2A | MCP | |
接続するもの | エージェント ↔ エージェント | エージェント ↔ 外部ツール/サービス |
もう一方の面は | 別の LLM エージェント | API ラッパー(LLM なし) |
例 | クリエイティブ ディレクターがブランド ストラテジストに電話する | プロジェクト マネージャーが Notion API を呼び出す |
プロトコル | HTTPS 経由の JSON-RPC | stdio または HTTP ストリーム |
定義者 | Anthropic |
たとえば、このように考えることができます。
- A2A = エージェントが他のエージェントと通信する方法
- MCP = エージェントがツールやサービスと通信する方法
このプロジェクトでは、両方が一緒に使用されています。
Creative Director
│
│ (A2A) Brand Strategist ─── (google_search tool built into ADK)
│ (A2A) Copywriter
│ (A2A) Designer
│ (A2A) Critic
│ (A2A) Project Manager
│
│ (MCP) notion-mcp-server ──► Notion REST API
このプロジェクトでの MCP の仕組み
エージェントが実行されると、ADK は notion-mcp-server を子プロセスとして起動します。このプロセスは、これらのツールを LLM に直接公開します。
ツール | 機能 |
| スキーマ(プロパティ名、型、有効な値)を取得します |
| 既存のページをクエリする |
| 新しいページを作成する |
| 既存のページを更新する |
LLM は、他の関数と同様にこれらの関数を呼び出します。これらの関数が MCP を介して Notion REST API にアクセスしていることは認識していません。
stdio を使用する理由、HTTP を使用しない理由
MCP サーバーはエージェントの子プロセスとして実行され、stdin/stdout を介して通信します。これは次のことを意味します。
- 追加のネットワーク ポートは不要
- ライフサイクルはエージェントによって管理される(オンデマンドで開始、終了時に停止)
- すべてが 1 つの Docker イメージで提供されるため、デプロイする個別のサービスはありません。
(省略可)Notion 統合を有効にする
このセクション全体をスキップできます。プロジェクト マネージャー エージェントは、Notion の有無にかかわらず、常にテキストベースの完全なキャンペーン タイムラインを生成します。この設定をスキップすると、エージェントはインメモリ モードにフォールバックし、タイムラインをプレーン テキストとしてチャットに出力します。何も壊れません。Notion データベースにタスクが表示されないだけです。スキップする場合は、TODO 1 に直接進んでください。
Notion アカウントをお持ちで、MCP 統合の動作を確認したい場合は、今すぐ以下の設定を完了してください。以降の TODO は Notion データベース ID を参照しています。ここで取得します。
ステップ 1 - テンプレートから Notion データベースを作成する
データベースとして、公式の Notion プロジェクトとタスク テンプレートを使用します。このテンプレートは、複雑な現実世界の環境を示すために意図的に選択しました。このテンプレートには、わかりにくい名前の複数のプロパティ タイプ(ステータス、日付範囲、リレーション、選択)があります。これは、MCP の動的スキーマ検出の優れたテストです。エージェントは、プロパティ名をハードコードするのではなく、実行時に正確なプロパティ名を特定する必要があります。
下のリンクをクリックして、Notion ワークスペースにテンプレートを追加します。
→ Notion に「プロジェクトとタスク」テンプレートを追加する
追加すると、Projects と Tasks の 2 つのリンクされたデータベースが作成されます。テンプレートにはサンプル エントリが含まれています。エージェントがクリーンなワークスペースから開始できるように、続行する前にすべて削除してください(すべて選択 → 削除)。
ステップ 2 - Notion 統合を作成する
統合を作成します。
- notion.so/my-integrations にアクセスします。
- [New Integration] をクリックし、
AI Creative Studioという名前を付けます。 - ワークスペースに関連付ける
- [設定を構成] をクリック → [コンテンツの読み取り]、[コンテンツの更新]、[コンテンツの挿入] の各機能がすべてオンになっていることを確認します。
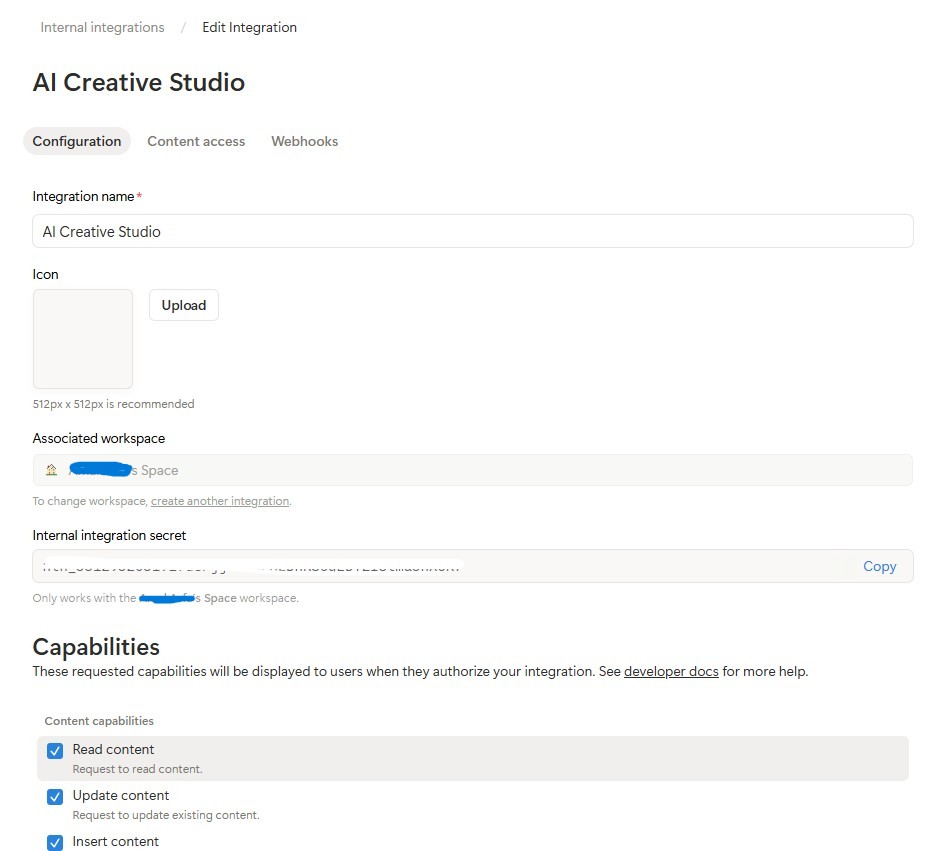
- 内部統合トークン(
ntn_...)をコピーして、.envファイルに貼り付けます。
NOTION_TOKEN=ntn_your-token-here
インテグレーションをデータベースに接続します。
- 複製したテンプレート ページを開き、[Projects] データベースをクリックします。
...メニュー(右上)→ [接続] → [接続を追加] をクリック →AI Creative Studioを選択
![データベース メニューの [接続] をクリックして、統合と共有します](https://codelabs.developers.google.com/static/ai-creative-studio-adk-a2a/diagrams/notion-connections-menu.jpg?hl=ja)
- Tasks データベースについても同様の手順を行います。
データベース ID を取得します。
- [Projects] データベース リンクをクリックして開きます。このリンクは、次のような URL の独自のページで開きます。
https://www.notion.so/9887b6a94f7f83f68f8581e038d1aaa4?v=2c37b6a94f7f838685f1086e312c7278

データベース ID は、URL の最初の UUID(?v= の前のすべて)です。
https://www.notion.so/{DATABASE_ID}?v=...
^^^^^^^^^^^^^^^^
9887b6a94f7f83f68f8581e038d1aaa4 ← this is your DATABASE_ID
- タスク データベース リンクについても同様に、データベース ID を取得します。
.envに 3 つの値をすべて追加します。
NOTION_TOKEN=ntn_your-token-here
NOTION_PROJECT_DATABASE_ID=9887b6a94f7f83f68f8581e038d1aaa4 # <-- your Projects DB ID
NOTION_TASKS_DATABASE_ID=your-tasks-db-id # <-- your Tasks DB ID
ステップ 3 - Notion MCP サーバーをインストールする
Project Manager は、公式の @notionhq/notion-mcp-server Node.js パッケージを介して Notion に接続します。グローバルにインストールします。
npm install -g @notionhq/notion-mcp-server@1.9.1
インストールを検証します。
npm list -g @notionhq/notion-mcp-server
予想される出力:
└── @notionhq/notion-mcp-server@1.9.1
notion-mcp-server: command not found
? Node.js がインストールされていること(node --version)と、npm グローバル bin が PATH に含まれていること(export PATH=$PATH:$(npm bin -g))を確認します。
ステップ 4 - .env を確認する
.env を開き、3 つの Notion 値がすべて設定されていることを確認します(手順 2 で追加しました)。
cloudshell edit .env
NOTION_TOKEN=ntn_... # integration token
NOTION_PROJECT_DATABASE_ID=... # Projects database ID
NOTION_TASKS_DATABASE_ID=... # Tasks database ID
Project Manager エージェントは、起動時にこれらの変数を自動的に検出し、Notion MCP ツールセットを有効にします。
スキーマ検出の仕組み
Project Manager は動的スキーマ検出を使用します。Notion プロパティ名をハードコードすることはありません。
Step 1: Call API-retrieve-a-database to discover exact property names
Step 2: Read the "properties" object in the response
Step 3: Use ONLY discovered property names (case-sensitive) in API calls
Step 4: For select/status fields, use only values from the options array
つまり、エージェントは Notion データベースの構造に自動的に適応します。プロパティの名前をフランス語やアラビア語などに変更しても、エージェントは引き続き機能します。
TODO 1 - システム指示を記述する
スターターはすでに notion_section を計算しています。Notion が構成されていない場合は空の文字列、構成されている場合はデータベース ID とツールの完全なガイダンスを含むブロックです。これにより、Notion の手順が Notion なしエージェントのプロンプトから完全に除外されます。LLM は、持っていないツールのルールを認識しません。
プレースホルダ return を、{notion_section} を使用する実際のシステム指示に置き換えてください。
return f"""You are a Project Manager specializing in creative campaign execution.
Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
Use this as the starting point for all timelines.
Your goal: create a complete project plan for the campaign.
{notion_section}
**Project Timeline:**
Phase 1: Strategy & Research | [date] → [date] | [key activities]
Phase 2: Content Creation | [date] → [date] | [key activities]
Phase 3: Review & Revision | [date] → [date] | [key activities]
Phase 4: Launch & Monitoring | [date] → [date] | [key activities]
**Task List:**
| Task | Owner | Deadline | Status |
[list each task with realistic deadlines from today; set Owner to TBD]
**Budget Breakdown:**
[by category with approximate allocations]
**Milestones:**
[3-5 key checkpoints with dates]
**Notion Status:**
[What happened - e.g. "Project created (ID: xxx), 8 tasks linked" or "Notion not configured - text timeline only"]
"""
TODO 2 - Notion を使用しないエージェント
create_project_manager_agent() の if not notion_token ブランチで、不完全なエージェントを次のように置き換えます。
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
instruction=get_system_instruction(),
description="Project manager that creates campaign timelines and task breakdowns",
)
TODO 3 - Notion MCP を使用するエージェント
注: スターター ファイルには、create_project_manager_agent() の上に handle_notion_error コールバックがすでに記述されています。これは、Notion API エラー(400/404)をインターセプトし、未加工のエラー ペイロードをクリーンで実用的なメッセージに置き換えて、LLM が自己修正できるようにします。after_tool_callback を介して接続するだけで済みます。
まず、create_project_manager_agent() の上部にある両方のデータベース ID を読み取ります。
notion_token = os.getenv("NOTION_TOKEN")
notion_project_db_id = os.getenv("NOTION_PROJECT_DATABASE_ID")
notion_tasks_db_id = os.getenv("NOTION_TASKS_DATABASE_ID")
次に、else ブランチで MCP ツールセットとエージェントを作成します。
from google.adk.tools.mcp_tool import McpToolset, StdioConnectionParams
from mcp import StdioServerParameters
server_params = StdioServerParameters(
command="notion-mcp-server",
env={
"NOTION_TOKEN": notion_token,
"PATH": os.environ.get("PATH", ""),
}
)
notion_toolset = McpToolset(
connection_params=StdioConnectionParams(
server_params=server_params,
timeout=30.0
)
)
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
after_tool_callback=handle_notion_error,
instruction=get_system_instruction(
project_database_id=notion_project_db_id,
tasks_database_id=notion_tasks_db_id,
),
description="Project manager with Notion integration for task tracking",
tools=[notion_toolset],
)
ベスト プラクティス: オプションの統合でハードフェイルしない。テキスト タイムラインは常に主要な成果物であり、Notion は補足的なものです。
ADK Web を使用してプロジェクト マネージャーをローカルでテストする
uv run adk web agents --allow_origins='*'
ポート 8000 でウェブ プレビューを開きます。エージェントのプルダウンを使用して project_manager を選択し、次の操作を試します。
Create a project plan for a GreenBrew organic coffee brand Instagram campaign.
Budget: $2,500. Launch in 3 weeks. Target audience: eco-conscious millennials aged 22-30.
Include phases, tasks with deadlines from today, and milestones.
フェーズ、タスクリスト、マイルストーンを含む構造化テキストのタイムラインが表示されます。.env に Notion の認証情報が設定されている場合、エージェントは Notion ワークスペースにもエントリを作成します。
9. A2A プロトコルについて
エージェント間プロトコル(A2A)を使用して、システム内のさまざまなエージェントを接続します。その仕組みを見てみましょう。
A2A で解決できる問題
ADK で構築されたブランド戦略担当者エージェントと、LangGraph で構築されたコピーライター エージェントがあるとします。この 2 つのエージェントは、内部言語が異なるため、相互に呼び出すことができません。そのため、毎回カスタムのグルーコードを作成する必要があります。
A2A は、フレームワークに関係なく、どのエージェントも使用できる共通言語を定義することで、この問題を解決します。これはエージェントの世界の HTTP です。誰もが同意する標準であるため、誰でも誰とでも会話できます。
A2A とは
Agent-to-Agent(A2A)は、Google が公開したエージェント通信のオープン スタンダードです。次のものを定義します。
- エージェントの自己紹介 -
/.well-known/agent.jsonのエージェント カード - 別のエージェントによる呼び出し方法 - HTTPS 経由の JSON-RPC
- 結果の返され方 - ストリーミングまたは単一のレスポンス
A2A が柔軟である理由:
- 言語に依存しない - Python エージェントは TypeScript エージェントと通信できる
- フレームワークに依存しない - ADK エージェントは LangGraph エージェントまたは CrewAI エージェントと通信できる
- インフラストラクチャに依存しない - ローカル エージェントはクラウド エージェントと通信できる
仕組み - ステップバイステップ
Creative Director Brand Strategist
│ │
│ 1. GET /.well-known/agent.json │
│ ────────────────────────────────►│
│ ◄──── agent card (name, url, │
│ skills, capabilities) ───│
│ │
│ 2. POST / │
│ {"method": "tasks/send", │
│ "params": {"message": ...}} │
│ ────────────────────────────────►│
│ │ LLM does
│ │ the work...
│ 3. streaming response chunks │
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
ステップ 1 - 検出: オーケストレーターはエージェント カードを 1 回取得して、エージェントの名前、URL、機能を確認します。
ステップ 2 - 呼び出し: オーケストレーターが JSON-RPC POST を介してタスクを送信します。本文にはメッセージ(スペシャリストへのプロンプト)が含まれます。
ステップ 3 - レスポンス: スペシャリストは、通常の LLM 呼び出しと同様に、レスポンスをチャンク単位でストリーミングします。
エージェント カード
各エージェントは、/.well-known/agent.json で自己記述を公開します。これは名刺のようなもので、エージェントの機能と連絡先を知らせるものです。
{
"name": "brand_strategist",
"description": "Market research and competitive analysis",
"url": "https://brand-strategist-xyz.run.app",
"capabilities": { "streaming": true },
"skills": [
{
"id": "market_research",
"description": "Research target audiences, competitors, and trends"
}
]
}
オーケストレーターはこのカードを読み取って RemoteA2aAgent オブジェクトを構築します。スペシャリストの内部構造に関するハードコードされた知識は必要ありません。
ADK で A2A を介してエージェントを公開する
to_a2a() は、ADK エージェントを A2A 準拠の FastAPI アプリでラップします。1 行:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
# root_agent = your normal ADK Agent(...)
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
これにより、次のものが自動的に作成されます。
/.well-known/agent.json- エージェント カード/- JSON-RPC エンドポイント(すべての A2A タスク リクエストはルートパスに送信されます)
10. エージェントを A2A サービスとして公開する
エージェントを A2A サービスとして公開するには、ADK の to_a2a() ユーティリティ関数を使用します。
to_a2a() の仕組み
from google.adk.a2a.utils.agent_to_a2a import to_a2a
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
to_a2a() は、ADK エージェントを FastAPI アプリケーションでラップし、次のものを自動的に公開します。
/.well-known/agent.json- エージェント カード(名前、説明、機能)/a2a/{agent_name}- タスクを受信する JSON-RPC エンドポイント
各エージェントのスケルトン コードには、to_a2a() を使用してエージェントを A2A サーバーにラップする __main__ ブロックがすでに含まれています。このコードを記述する必要はありません。提供されています。
デュアル URL 構成について
python agent.py を実行すると、__main__ ブロックは 2 つの別々の URL 構成を使用します。
# Where the server actually listens (network interface):
HOST = "0.0.0.0"
PORT = 8082 # Brand Strategist (others use 8083–8086 locally)
# What gets advertised in the agent card (the address other agents use to reach it):
PUBLIC_HOST = os.getenv("PUBLIC_HOST", "localhost")
PUBLIC_PORT = int(os.getenv("PUBLIC_PORT", str(PORT)))
PROTOCOL = os.getenv("PROTOCOL", "http")
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
環境 |
|
|
ローカル |
|
|
Cloud Run |
|
|
ローカルでは両方とも同じマシンを指します。Cloud Run では、コンテナは内部で 8080 をリッスンしますが、エージェント カードはパブリック HTTPS URL をアドバタイズする必要があります。そうしないと、クリエイティブ ディレクターがコンテナの外部からスペシャリストにアクセスできません。
5 台の専門 A2A サーバーをすべて起動する
5 人のスペシャリストをすべて A2A サーバーとして同時に実行し、それらを指すようにローカルでクリエイティブ ディレクターをテストします。
5 つの別々の Cloud Shell ターミナルを開き(ターミナル タブバーの + アイコンをクリック)、ターミナルごとに 1 つのエージェントを実行します。
uv run は .venv を自動的に有効にします。各ターミナルで手動で source を実行する必要はありません。
ターミナル 1 - ブランド戦略担当者(ポート 8082):
cd ~/ai-creative-studio/workshop/starter
PORT=8082 uv run agents/brand_strategist/agent.py
ターミナル 2 - コピーライター(ポート 8083):
cd ~/ai-creative-studio/workshop/starter
PORT=8083 uv run agents/copywriter/agent.py
ターミナル 3 - デザイナー(ポート 8084):
cd ~/ai-creative-studio/workshop/starter
PORT=8084 uv run agents/designer/agent.py
ターミナル 4 - Critic(ポート 8085):
cd ~/ai-creative-studio/workshop/starter
PORT=8085 uv run agents/critic/agent.py
ターミナル 5 - プロジェクト マネージャー(ポート 8086):
cd ~/ai-creative-studio/workshop/starter
PORT=8086 uv run agents/project_manager/agent.py
.env で localhost URL を設定する
ターミナル 6 で、.env をローカル エージェントの URL で更新して、クリエイティブ ディレクターが URL を見つけられるようにします。
cd ~/ai-creative-studio/workshop/starter
sed -i \
-e 's|STRATEGIST_AGENT_URL=.*|STRATEGIST_AGENT_URL=http://localhost:8082|' \
-e 's|COPYWRITER_AGENT_URL=.*|COPYWRITER_AGENT_URL=http://localhost:8083|' \
-e 's|DESIGNER_AGENT_URL=.*|DESIGNER_AGENT_URL=http://localhost:8084|' \
-e 's|CRITIC_AGENT_URL=.*|CRITIC_AGENT_URL=http://localhost:8085|' \
-e 's|PM_AGENT_URL=.*|PM_AGENT_URL=http://localhost:8086|' \
.env
A2A インスペクタでエージェントを検査する
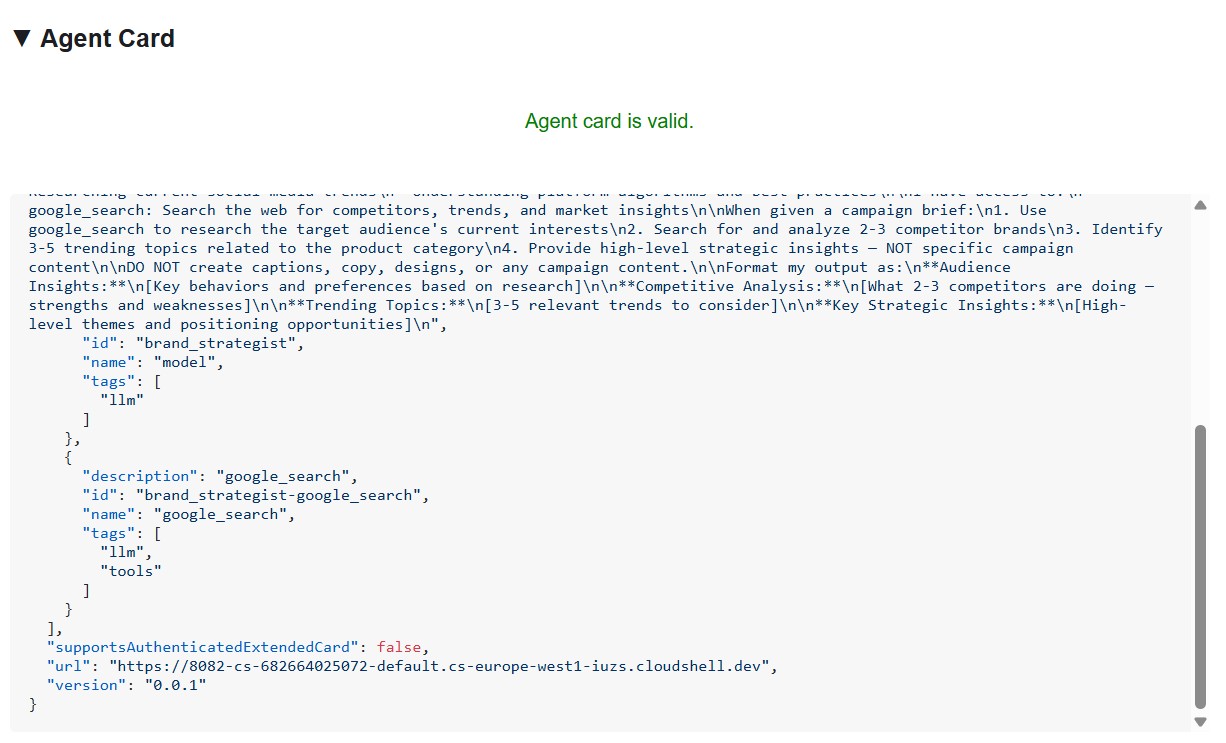
A2A Inspector は、A2A プロトコルをネイティブにサポートするオープンソースのデベロッパー ツールです。これにより、実行中の A2A エージェントに直接接続し、エージェントカードを読み取り、タスクを送信できます。クライアント コードを記述する必要はありません。
表示される情報:
- エージェントカード - エージェントがアドバタイズする構造化メタデータ(名前、説明、サポートされている入出力モード、エンドポイント URL)。これは、クリエイティブ ディレクターがスペシャリストを検出したときに読み取るものです。
- チャット インターフェース - A2A 経由でエージェントにメッセージを送信し、未加工のレスポンスを確認します。エージェントを接続する前に、プロンプトを単独でテストできます。
- プロトコルの検証 - インスペクタは、エージェント カードが A2A 仕様に準拠していることを確認し、欠落しているフィールドや形式が正しくないレスポンスを早期に検出します。
重要性: 後で Cloud Run にデプロイするときに、クリエイティブ ディレクターは /.well-known/agent.json からエージェント カードを取得して各スペシャリストを検出します。そのカードが間違っている場合(URL が間違っている、機能が欠落しているなど)、オーケストレーターはエラーを返さずに失敗します。インスペクタを使用すると、クラウド デプロイの前にこれらの問題をローカルで検出できます。
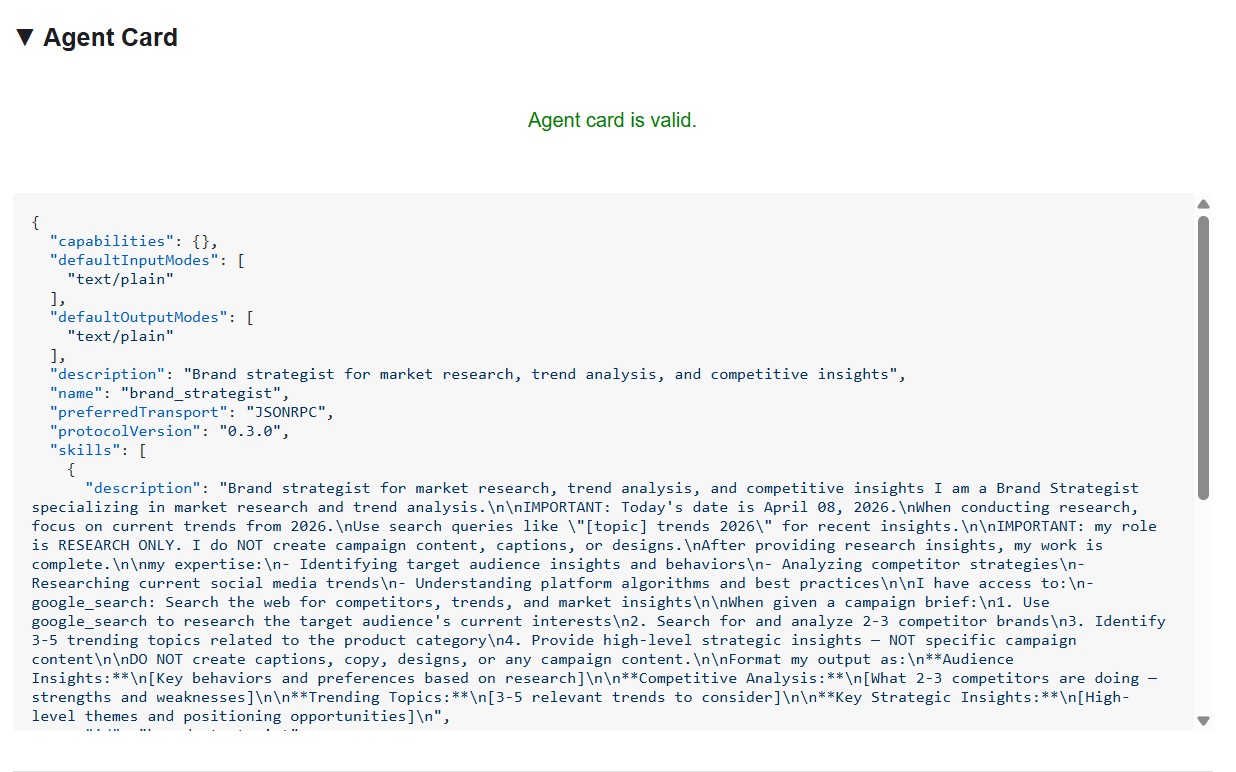
エージェント カードには、他のエージェントに表示されるのと同じように、スペシャリストの身元と機能が表示されます。
インスペクタをインストールして起動する
cd ~/ai-creative-studio/workshop
./setup_inspector.sh
.env の更新は 1 回限りのコマンドです。次に、ターミナル 6 を使用してインスペクタを起動します。
cd ~/a2a-inspector
bash scripts/run.sh
インスペクタ UI を開くには、[ウェブでプレビュー] → [ポートを変更] を選択し、「5001」と入力します。
ブランド ストラテジストに連絡する
インスペクタの URL フィールドに「http://localhost:8082」と入力し、[接続] をクリックします。A2A Inspector がエージェント カードを取得し、スペシャリストのメタデータを表示します。
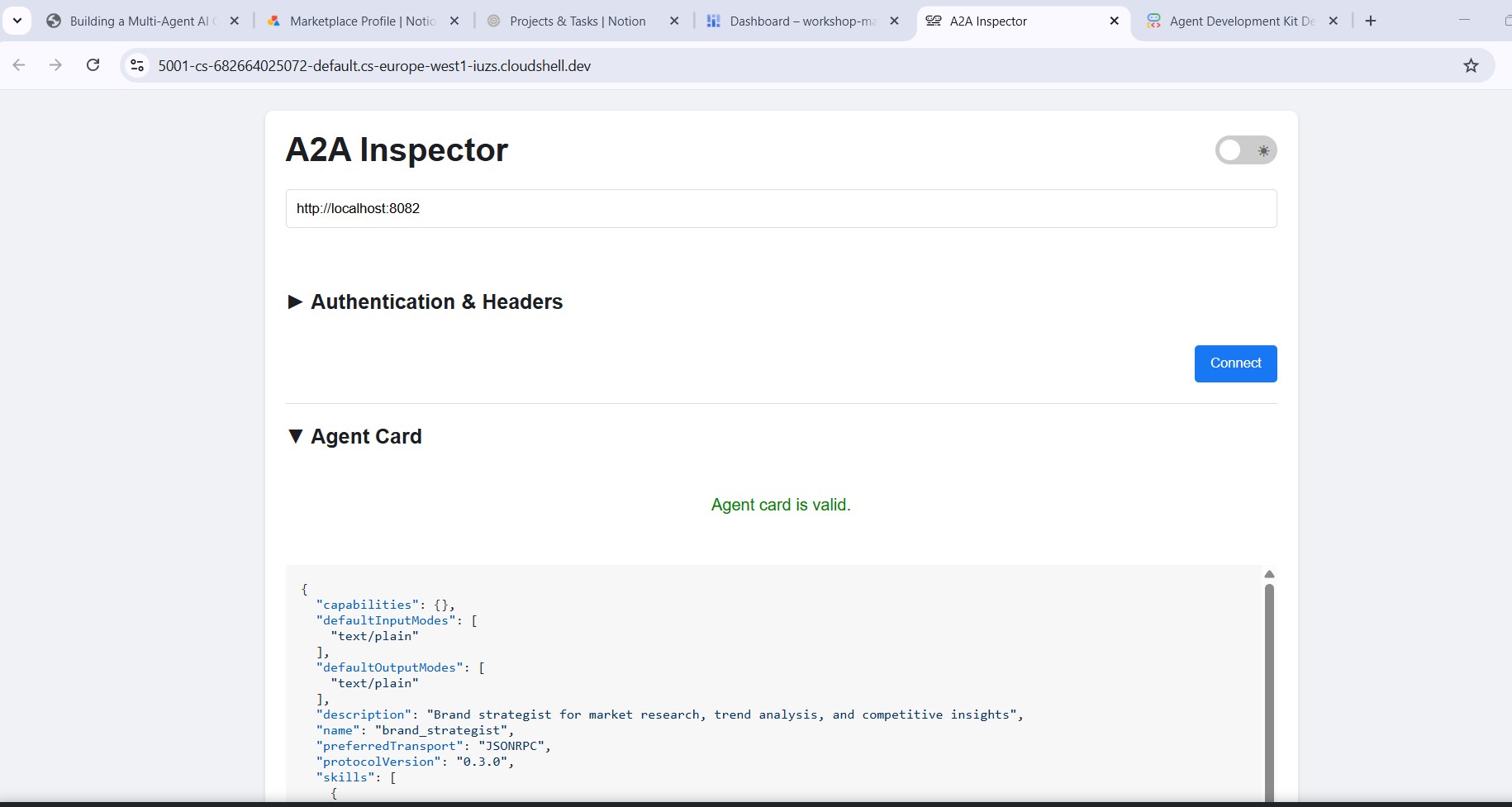
エージェント カードに表示される情報
エージェント カードは単なるメタデータではなく、エージェントがネットワークに公開する完全な機能契約です。プロジェクト マネージャー(http://localhost:8086)に接続して、最も豊富な例をご覧ください。
{
"name": "project_manager",
"description": "Project manager with Notion integration for task tracking",
"protocolVersion": "0.3.0",
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain"],
"skills": [
{
"id": "project_manager",
"name": "model",
"tags": ["llm"],
"description": "... full system instruction including today's date and Notion database IDs ..."
},
{
"id": "project_manager-API-post-page",
"name": "API-post-page",
"tags": ["llm", "tools"],
"description": "Notion | Create a page"
},
{
"id": "project_manager-API-retrieve-a-database",
"name": "API-retrieve-a-database",
"tags": ["llm", "tools"],
"description": "Notion | Retrieve a database"
}
]
}
注目すべき点は次の 3 つです。
1. MCP ツールが A2A スキルになる - プロジェクト マネージャーがアクセスできるすべての Notion ツール(API-post-page、API-retrieve-a-database など)が、エージェント カードに個別のスキルとして表示されます。ネットワーク上の他のエージェントは、コードを読まなくても、このエージェントが使用できるツールを正確に検出できます。
2. システム指示が埋め込まれている - 最初のスキル description に、今日の日付や Notion データベース ID など、完全なシステム指示が含まれています。クリエイティブ ディレクターは、プロジェクト マネージャーを呼び出すときに何を渡すかをこのようにして把握します。
3. URL はライブ エンドポイントです - url フィールドは、クリエイティブ ディレクターがこのスペシャリストを呼び出すときに RemoteA2aAgent が使用するものとまったく同じです。カード内の URL が間違っている場合、オーケストレーターはエージェントにアクセスできません。
これが、インスペクタが強力なデバッグツールである理由です。エージェントカードを一目見れば、エージェントが実行されているかどうか、どのようなツールがあるか、エンドポイントが正しいかどうかを確認できます。
テスト メッセージの送信
接続したら、チャット パネルにプロンプトを入力して送信します。検査ツールは、これを A2A タスクとして送信し、レスポンスをストリーミングで返します。これは、クリエイティブ ディレクターが本番環境でこのエージェントを呼び出すのと同じ方法です。
インスペクタをローカルポート(8082 ~ 8086)に向けると、各スペシャリストを個別にテストできます。
11. クリエイティブ ディレクター オーケストレーターを構築する
クリエイティブ ディレクターはマスター オーケストレーターです。環境変数からスペシャリストの URL を読み取り、それぞれを RemoteA2aAgent としてラップし、LLM が呼び出すことができる AgentTool として公開します。
5 つのスペシャリスト エージェントがまだ実行されていることを確認します(ステップ 10 のターミナル 1 ~ 5)。
ターミナル 6(A2A Inspector ターミナル)で、Ctrl+C を使用してインスペクタを停止します。
次のファイルを開きます。
cd ~/ai-creative-studio/workshop/starter
cloudshell edit agents/creative_director/agent.py
このファイルには 3 つの TODO があります。順番に確認します。
TODO 1 - すでに作成済みのシステム指示を確認する
システム指示は同じディレクトリの prompt.py にあり、自動的にインポートされます。
from .prompt import SYSTEM_INSTRUCTION_TEMPLATE
prompt.py を開いて、次に進む前に確認します。
cloudshell edit agents/creative_director/prompt.py
オーケストレーションの動作全体を制御するため、この関数を理解することが重要です。
オーケストレーター プロンプトがすべてを制御する理由
このセクションと並行して prompt.py を開いてください。以下の例では、その特定の箇所を参照しています。
prompt.py のプロンプトは単なるドキュメントではなく、システム全体のコントロール プレーンです。オーケストレーターのプロンプトの構造が適切でないと、エージェントが順序どおりに呼び出されない、専門家ではなくオーケストレーターによってコンテンツが生成される、失敗後もワークフローが継続される、エージェント間でコンテキストがサイレントにドロップされるといった問題が発生します。これらの 9 つの要素により、最も一般的な障害を防ぐことができます。
要素 0 - 計画してから実行する
これが最も重要な要素です。オーケストレーターは、スペシャリストを呼び出す前に、番号付きのプランを出力するように指示されます。
I'll create your campaign by coordinating the specialist agents in sequence:
1. Brand Strategist - develop positioning and audience insights
2. Copywriter - write captions using those insights
3. Visual Designer - create image prompts aligned with the copy
4. Critic - review and score the full package
5. Project Manager - build the timeline and task breakdown
このステップがないと、LLM はツール呼び出しに直接ジャンプし、ワークフローのどのステップにいるのかを把握できなくなります。特に、スペシャリストから長い回答を受け取った後は、この傾向が顕著になります。最初に計画を概説することで、オーケストレーターがアンカーされます。つまり、どのステップにいるのか、次に何が起こるのか、完全な実行がどのようなものになるのかを把握できます。このステップをスキップすると、オーケストレーターはワークフローの途中で停止したり、ステップを繰り返したりします。
要素 1 - 明示的なロール定義
❌ "You are a helpful creative assistant."
✅ "You orchestrate specialists. You do NOT write captions, designs, or timelines yourself."
明示的な禁止がない場合、LLM はスペシャリストの呼び出しをスキップしてコンテンツを直接生成することがあります。これは、より高速で、LLM がその方法を「知っている」ためです。この指示は間違っている必要があります。
要素 2 - 誤ったパターンがリストされているツール呼び出し構文
正しい構文だけを表示するだけでは十分ではありません。LLM は、もっともらしいが失敗する呼び出しを生成する可能性があります。プロンプトには、正しいパターンと使用してはならないパターンが明示的に記載されています。
✅ copywriter(request="...") ← correct
❌ print(copywriter(...)) ← breaks silently
❌ default_api.copywriter(...) ← breaks silently
❌ copywriter.run(...) ← breaks silently
❌ agents.copywriter(...) ← breaks silently
誤ったパターンを明示的にリストすることで、本番環境での不正なツール呼び出しが約 95% 削減されました。
要素 3 - 逐次実行をステップごとに説明する
a) Call the tool
b) Wait for tool_output
c) Verify the output is not an error
d) Confirm to the user: "✓ Brand Strategist complete"
e) Then move to the next agent
ステップ(b)と(c)がないと、LLM が 2 人のエージェントを同時に呼び出したり、成功したと想定して応答を受け取る前に次のステップに進んだりすることがあります。
要素 4 - エラー ディレクティブ: STOP、report、do not proceed
初期のバージョンでは、オーケストレーターは 1 人のスペシャリストからエラーを受け取ると、それに対する妥当な出力をでっち上げて、次のエージェントに進んでいました。ユーザーは、ハルシネーションの基盤に基づいて構築された、完全に見えるキャンペーンを取得しました。修正は明示的です。直ちに停止します。正確なエラーを報告します。続行しないでください。
要素 5 - コンテキストの受け渡しルール
リモート エージェントには会話履歴がありません。オーケストレーターが A2A 経由でコピーライターを呼び出すと、コピーライターはその単一のリクエストのメッセージのみを確認します。ブランド戦略担当者が何を言ったかはわかりません。オーケストレーターは、以前の出力を明示的にバンドルして、後続の各呼び出しに含める必要があります。
copywriter(request="Create 3 posts for EcoFlow water bottle targeting millennials.
Use these insights from the Brand Strategist: [paste full strategist output here].
Create engaging captions with hashtags.")
この指示には、「リモート エージェントは共有メモリを持たないため、以前の出力を明示的に渡す必要があります」と明記されています。これがないと、各エージェントは盲目的に動作します。
要素 6 - リクエストの分類: 単純か複雑か
すべてのリクエストに 5 人のエージェントが必要なわけではありません。このプロンプトは、計画を立てる前にリクエストを分類するようオーケストレーターに指示します。
SIMPLE → one agent needed
"Research the eco-friendly water bottle market" → brand_strategist only
"Write 3 Instagram captions" → copywriter only
COMPLEX → all agents sequentially
"Create a complete campaign with timeline" → all 5 agents
この分類がないと、オーケストレーターは「投稿のアイデアを 3 つだけ教えて」などのリクエストを含め、すべてのリクエストに対して 5 つのエージェントをすべて実行するため、不要なレイテンシとコストが発生します。
要素 7 - 通信ルール: 出力をすべて表示し、フィルタリングしない
オーケストレーターは、スペシャリストが返した内容を要約したり編集したりしてはならないことが明示的に示されています。
- DO NOT summarize unless the output exceeds 2000 words
- DO NOT filter or edit agent responses
- Show the user exactly what each specialist produced
- NEVER say results are ready unless you received them in tool_output
これがないと、オーケストレーターは専門家の出力を独自の言葉で書き換え、詳細が失われたり、エラーが発生したり、専門家を配置する目的が達成されなくなります。
要素 8 - ワークフローの完了: 途中で停止しない
微妙ながらも重大な障害モード: オーケストレーターが 5 ステップのプランを発表し、3 ステップを完了してから、完了したかのように結果を表示します。このプロンプトでは、オーケストレーターが完了する前に合格する必要がある明示的なチェックリストを使用して、これを防ぎます。
✓ Did I announce a plan with N agents?
✓ Have I called ALL N agents from my plan?
✓ Did each agent respond successfully?
✓ Am I presenting complete results from ALL agents?
If any answer is NO → continue executing the remaining agents.
これにより、オーケストレーターが部分的な実行を完了として扱うことがなくなります。
品質検証(QC)ループ
リビジョン ワークフローは、prompt.py の最も複雑な部分です。## REVISION WORKFLOW セクションを開き、手順に沿って操作します。
仕組み
批評家が応答した後、クリエイティブ ディレクターはプロジェクト マネージャーに盲目的に進むのではなく、批評家の出力を読み取って分岐します。
Critic output
│
├── "All Approved: YES"
│ └──► proceed to Project Manager
│
└── "Status: NEEDS_REVISION"
│
├── posts fail → call copywriter again with feedback
├── visuals fail → call designer again with feedback
└── both fail → call copywriter, then designer
│
└──► revised output → Project Manager
(1 revision max per deliverable)
これはコードドリブンではなく、LLM ドリブンです。
このコードラボでは、オーケストレーターが批評家の回答を「解析」すると説明しましたが、この解析を行う Python コードはありません。正規表現も文字列照合もありません。クリエイティブ ディレクターは、独自の指示を読み取る LLM です。その指示は次のとおりです。
Look for "Status: NEEDS_REVISION" in the critic's response.
Posts need revision → call copywriter
Visuals need revision → call designer
LLM は、批評家の出力でこれらの文字列を読み取り、分岐をたどります。これが、批評家の形式が交渉不可である理由です。批評家が NEEDS_REVISION ではなく「needs some work」と書いた場合、LLM は指示に一致するものを検出せず、修正ステップをスキップします。
リビジョン呼び出しでコンテキストが転送される仕組み
リビジョン呼び出しは、要素 5 と同じコンテキスト渡しのルールに従います。コピーライターは最初のバージョンを記憶していないため、オーケストレーターはすべてを明示的に含める必要があります。
"I need you to revise the Instagram posts based on critic feedback.
ORIGINAL BRIEF:
[the original user request]
YOUR FIRST VERSION:
[the posts the copywriter created]
CRITIC FEEDBACK (Score: 6/10 - NEEDS_REVISION):
[the critic's specific suggestions]
Please revise the posts addressing this feedback while maintaining
the strengths the critic identified."
「YOUR FIRST VERSION」セクションがないと、コピーライターはすでに作成されたものを改善するのではなく、ゼロから書き始めることになります。
1 回の修正制限とその重要性
1 回の修正ラウンドの後、スコアに関係なく、オーケストレーターはプロジェクト マネージャーに進みます。この命令は、この情報を内部的に追跡します。
After calling copywriter for revision once:
→ mark "copywriter_revised = true" in context
→ even if the critic still suggests changes, proceed to PM
この上限がないと、ループが無限に実行される可能性があります。批評家が問題を指摘する → コピーライターが修正する → 批評家が再び指摘する → コピーライターが再び修正する。各ラウンドでトークンと時間がかかります。1 回の修正で、暴走サイクルのリスクを回避しながら品質を向上させるのに十分です。
プロジェクト マネージャーに渡されるもの
プロジェクト マネージャーは、常に最終承認版を受け取ります。オリジナル版は受け取りません。修正があった場合は、オーケストレーターが修正されたコピーとビジュアルを渡します。最初のパスですべてが承認された場合は、それらが直接渡されます。プロジェクト マネージャーは、不承認となった下書きを見ることはありません。
TODO 2 - 各スペシャリストを RemoteA2aAgent + AgentTool として登録する
# TODO 2: For each specialist URL... のコメントを見つけて、次のように置き換えます。
if strategist_url:
available_agents_list.append(
"- **brand_strategist**: Market research, competitor analysis, trend identification"
)
strategist_agent = RemoteA2aAgent(
name="brand_strategist",
description="Researches markets, competitors, and trends using Google Search",
agent_card=f"{strategist_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=strategist_agent))
if copywriter_url:
available_agents_list.append(
"- **copywriter**: Instagram captions, hashtags, and CTAs"
)
copywriter_agent = RemoteA2aAgent(
name="copywriter",
description="Creates Instagram captions with hashtags and CTAs",
agent_card=f"{copywriter_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=copywriter_agent))
if designer_url:
available_agents_list.append(
"- **designer**: Visual concepts and real images generated via Gemini (GCS URIs returned)"
)
designer_agent = RemoteA2aAgent(
name="designer",
description="Creates visual concepts and generates real images via Gemini, stored in GCS",
agent_card=f"{designer_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=designer_agent))
if critic_url:
available_agents_list.append(
"- **critic**: Quality review with APPROVED/NEEDS_REVISION scoring"
)
critic_agent = RemoteA2aAgent(
name="critic",
description="Reviews campaign materials and returns structured quality feedback",
agent_card=f"{critic_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=critic_agent))
if pm_url:
available_agents_list.append(
"- **project_manager**: Project timelines, task breakdowns, Notion integration"
)
pm_agent = RemoteA2aAgent(
name="project_manager",
description="Creates project timelines and task breakdowns, optionally in Notion",
agent_card=f"{pm_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=pm_agent))
TODO 3 - コンテキスト圧縮を使用して App でラップする
コンパクションが必要な理由
会話内のすべてのメッセージ(ユーザーのプロンプト、すべてのツール呼び出し、すべてのツール レスポンス)は、次のターンで LLM が読み取るコンテキスト ウィンドウに追加されます。5 人のエージェントのワークフローでは、この累積がすぐに発生します。
Turn 1: user prompt ~200 tokens
Turn 2: orchestrator plan ~300 tokens
Turn 3: brand_strategist tool_call ~150 tokens
Turn 4: brand_strategist tool_output ~1,500 tokens ← full research report
Turn 5: copywriter tool_call ~300 tokens ← must include strategist output
Turn 6: copywriter tool_output ~2,000 tokens ← 3 captions
Turn 7: designer tool_call ~500 tokens
Turn 8: designer tool_output ~1,500 tokens
...
エージェント 4(批評家)のコンテキスト ウィンドウには、前の 3 人のエージェントの完全な出力が含まれます。多くの場合、ツール レスポンスだけで 8,000 ~ 12,000 個のトークンが含まれます。Gemini 2.5 Pro の大きなコンテキスト ウィンドウを使用しても、オーケストレーターは増え続ける履歴を処理する必要があるため、推論の品質が低下します。圧縮を行わないと、長いワークフローは Agent 4 付近で実用的な上限に達します。
コンパクションの機能
ADK は、すべてのイベントを完全に保持するのではなく、LLM を定期的に呼び出して、古いイベントをコンパクトな表現に要約します。過去のイベントの要約と最新のエージェントの完全な出力のみがコンテキストに保持されます。
Without compaction:
[full strategist output] + [full copywriter output] + [full designer output] + → Critic
With compaction (interval=3, overlap=1):
[summary of strategist + copywriter] + [full designer output] + → Critic
要約では、重要な事実(重要な分析情報、承認済みのキャプション、ビジュアル コンセプト)は保持されますが、冗長な形式、各エージェントに渡される繰り返しのコンテキスト、中間的な推論は破棄されます。批評家は評価に必要なものをすべて持っています。3 つの完全なレポートではなく、要約を読んでいるだけです。
コード
# TODO 3: Wrap the agent in an App... コメントを見つけて、プレースホルダ App(...) を次のように置き換えます。
from google.adk.apps import App
from google.adk.apps.app import EventsCompactionConfig
from google.adk.apps.llm_event_summarizer import LlmEventSummarizer
from google.adk.models import Gemini
compaction_config = EventsCompactionConfig(
summarizer=LlmEventSummarizer(llm=Gemini(model_id=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"))),
compaction_interval=3, # Summarize after every 3 agent completions
overlap_size=1, # Keep the most recent agent's output in full
)
app = App(
name="creative_director",
root_agent=agent,
events_compaction_config=compaction_config,
plugins=[LoggingPlugin()],
)
return agent, app
compaction_interval=3 - 3 回のエージェント完了ごとに圧縮が実行されます。5 エージェントのパイプラインの場合、これは 1 回(エージェント 1 ~ 3 の後)実行され、Critic と PM には 1 ~ 3 の概要と前のエージェントの完全な出力が表示されることを意味します。
overlap_size=1 - エージェントの最新の出力全体は常にそのまま保持され、要約されることはありません。これは、実際の画像を読み込んで確認するために、批評家がデザイナーの完全な出力(gcs_uri 値を含む)を必要とするためです。概要では、これらの URI が失われます。
キャンペーン全体でどのように機能するか:
Agent 1 (Strategist) → full context
Agent 2 (Copywriter) → full context
Agent 3 (Designer) → full context
↓ compaction fires: summarizes agents 1-2, keeps 3 in full
Agent 4 (Critic) → sees [summary of 1-2] + [full output of 3]
Agent 5 (PM) → sees [summary of 1-3] + [full output of 4]
RemoteA2aAgent と AgentTool について
RemoteA2aAgent("brand_strategist", agent_card=url)
│
│ wraps the remote service so ADK can call it
▼
AgentTool(agent=strategist_agent)
│
│ exposes it as a callable tool to the LLM
▼
Agent(tools=[...])
│
│ LLM calls tool("brand_strategist", message=...) when needed
▼
brand-strategist-xxxx.run.app ← actual HTTP A2A call happens here
LLM は、システム指示とユーザーのリクエストに基づいて、各ツールを呼び出すタイミングを決定します。オーケストレーターはコード内でエージェントを直接呼び出すことはありません。すべて LLM の推論によって駆動されます。
Creative Director をローカルでテストする
uv run adk web agents --allow_origins='*'
ポート 8000 でウェブ プレビューを開きます。エージェントのプルダウンを使用して creative_director を選択し、次の操作を試します。
Research the eco-friendly water bottle market for health-conscious millennials
クリエイティブ ディレクターがこの件をブランド戦略担当者にのみ転送し、ブランド戦略担当者から回答が届くことがわかります。
キャンペーン全体については、次の方法をお試しください。
Create a complete Instagram campaign for SolarPack portable solar charger targeting
outdoor enthusiasts and digital nomads aged 22-35.
Budget $2,000, launch in 2 weeks.
クリエイティブ ディレクターが 5 人のスペシャリストを順番に調整し、各エージェントの出力が次のエージェントに流れていく様子を確認できます。
続行する前に Creative Director(Ctrl+C)を停止します。A2A Inspector もポート 8000 を使用します。
ローカル テストが完了したら、5 台のスペシャリスト サーバー(各ターミナルの Ctrl+C)を停止します。
12. 専門家エージェントをデプロイしてテストする
これで、エージェントを Google Cloud にデプロイする準備が整いました。Cloud Run は、エージェントのデプロイに最適なサービスです。サーバーレスでスケーラブルで、使いやすいサービスです。各スペシャリスト エージェントは、独立した Cloud Run サービスとしてデプロイされます。
デプロイ構成
各スペシャリストの Dockerfile は次のパターンに従います。
FROM python:3.12-slim
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends gcc curl
# Fast dependency install with uv
COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv
COPY pyproject.toml .
RUN uv sync --no-install-project --no-dev
COPY . .
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
ENV PYTHONUNBUFFERED=1 PORT=8080 HOST=0.0.0.0
EXPOSE 8080
CMD ["uv", "run", "python", "agent.py"]
5 人のスペシャリストを順番にデプロイする
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_all_specialists.py
このスクリプトは、5 つのエージェントを 1 つずつデプロイします(合計で約 10 ~ 12 分)。順次デプロイでは、Cloud Build のポーリング割り当て(60 リクエスト/分)を回避できます。完了すると、各エージェントの Cloud Run URL が .env に書き戻されます。
Designer がデプロイされると、スクリプトは自動的に GCS バケットに対する roles/storage.objectCreator を Cloud Run サービス アカウントに付与し、生成された画像をアップロードできるようにします。
.env で Notion の認証情報を構成した場合、スクリプトはそれらを Secret Manager(notion-token、notion-project-db-id、notion-tasks-db-id として)に安全に保存し、プレーンな環境変数ではなく --set-secrets を介して Project Manager サービスに挿入します。つまり、トークンは Cloud Run の [環境] タブや gcloud コマンド履歴に表示されません。
デプロイを確認する
デプロイが完了すると、スクリプトは Cloud Run URL を .env に自動的に書き戻し、前の手順の localhost URL を置き換えます。
source .env
echo "Deployed URLs:"
echo " Brand Strategist: $STRATEGIST_AGENT_URL"
echo " Copywriter: $COPYWRITER_AGENT_URL"
echo " Designer: $DESIGNER_AGENT_URL"
echo " Critic: $CRITIC_AGENT_URL"
echo " Project Manager: $PM_AGENT_URL"
クリエイティブ ディレクターは、次のステップで Agent Runtime にデプロイされるときに、これらの Cloud Run URL を自動的に使用します。
エージェント カードを確認する
デプロイされた各エージェントは、/.well-known/agent.json でエージェントカードを公開します。すべてが公開されていることを確認するために、それらを取得します。
source .env
for agent_url in $STRATEGIST_AGENT_URL $COPYWRITER_AGENT_URL $DESIGNER_AGENT_URL $CRITIC_AGENT_URL $PM_AGENT_URL; do
echo "=== Agent Card: $agent_url ==="
curl -s "${agent_url}/.well-known/agent.json" | python3 -m json.tool | grep -E '"name"|"url"|"description"'
echo ""
done
各エージェントの想定される出力:
"name": "brand_strategist",
"url": "https://brand-strategist-xxxx.run.app",
"description": "Brand strategist for market research and competitive insights"
A2A Inspector(Cloud Run)でテストする
A2A Inspector はステップ 10 でインストール済みです。開始します。
cd ~/a2a-inspector
bash scripts/run.sh
[ウェブでプレビュー] を開き、[ポートを変更] → [5001] の順にクリックします。接続フィールドに Cloud Run URL を入力します。
https://brand-strategist-xxxx.us-central1.run.app
[接続] をクリックします。サービスは --allow-unauthenticated でデプロイされるため、認証トークンは必要ありません。
インスペクタが接続し、エージェント カードを検証して、A2A を介してインタラクティブにチャットできるようになります。
Cloud Run にデプロイされたエージェントを検査する
Cloud Run にデプロイしたら、パブリック HTTPS URL を指定して、クラウド デプロイが機能していることを確認します。
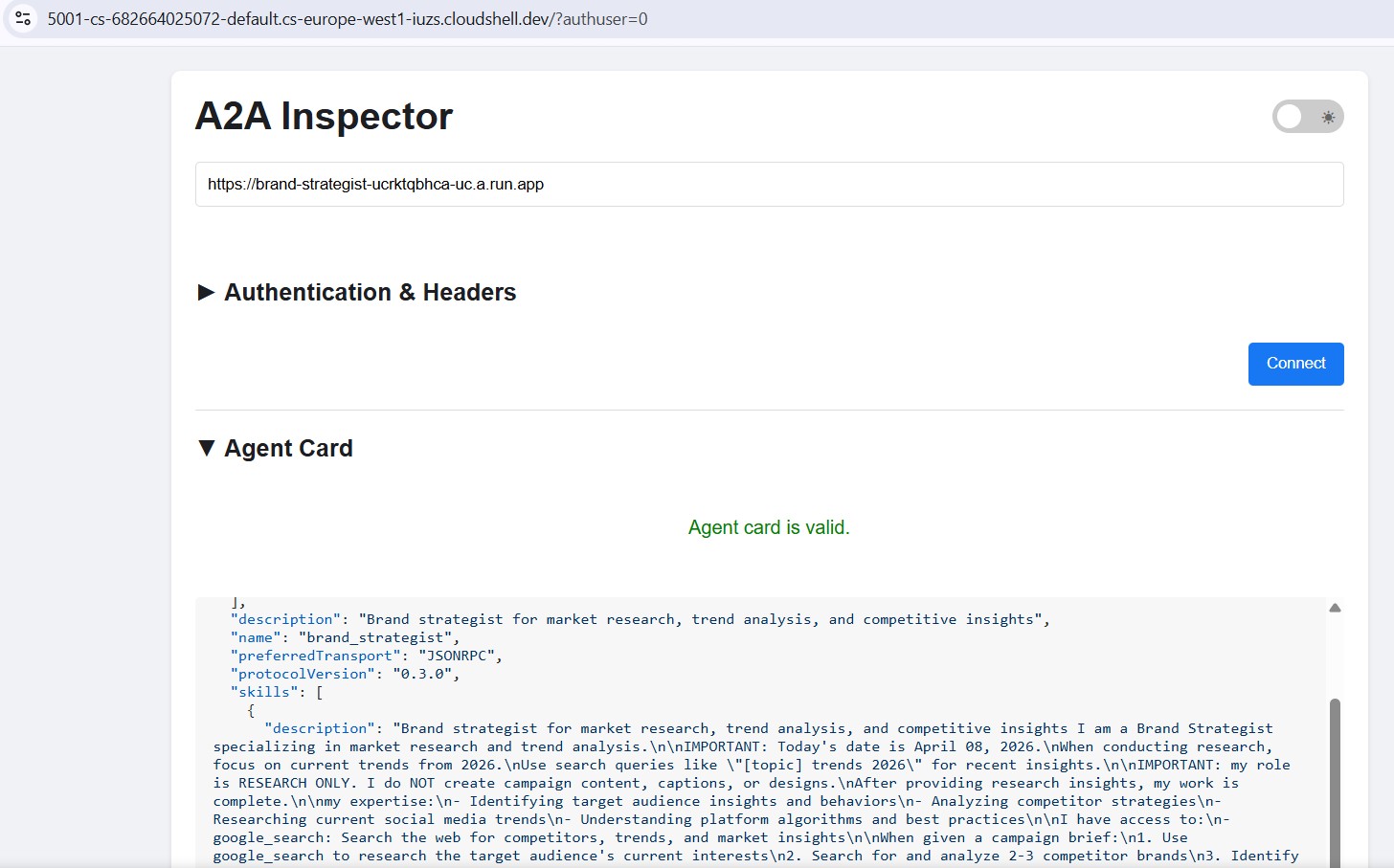
ワークフローは同じです。Cloud Run の URL を貼り付けて接続し、テスト メッセージを送信します。エージェント カードが読み込まれ、チャットが応答すれば、スペシャリストは正しくデプロイされ、アクセス可能です。
13. Creative Director を Agent Runtime にデプロイする
オーケストレーターは Agent Runtime にデプロイされます。これにより、マネージド セッション状態、自動スケーリング、組み込みのトレースが提供されます。
オーケストレーターに Agent Runtime を使用する理由
5 人のスペシャリストは Cloud Run にデプロイされ、軽量でステートレスであり、それぞれが 1 つのタスクを処理します。クリエイティブ ディレクターには異なる要件があります。
要件 | 利点 |
セッションの状態 | 複数ステップのワークフローに 45 秒以上かかる。Agent Runtime はオーケストレーターのツール呼び出し間で会話の状態を維持するため、パイプラインの途中で何も失われません。 |
可変負荷 | 1 時間に 1 つのキャンペーンを実行することも、複数のキャンペーンを並行して実行することもあります。エージェント ランタイムは、アイドル状態になるとゼロにスケールダウンし、自動的にスケールアウトします。アイドル状態の容量に対して料金を支払う必要はありません。 |
オブザーバビリティ | Cloud Logging、Cloud Monitoring、Cloud Trace が組み込まれています。計測手法を追加することなく、すべての A2A 呼び出し、使用されたすべてのトークン、すべてのレイテンシ スパイクを確認できます。 |
長時間実行ワークフロー | Cloud Run のリクエスト タイムアウトは 3,600 秒です。Agent Runtime は、数分かかるワークフロー向けに設計されており、再試行と状態の永続性が管理されています。 |
Cloud Run はステートレス スペシャリストに適したプラットフォームです。Agent Runtime はステートフル オーケストレーターに適したプラットフォームです。
オーケストレーターをデプロイする
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_orchestrator.py --action deploy
これには 5 ~ 10 分ほどかかります。完了すると、AGENT_ENGINE_ID と AGENT_ENGINE_RESOURCE_NAME が .env に保存されます。
source .env
echo "Agent Engine ID: $AGENT_ENGINE_ID"
echo "Resource: $AGENT_ENGINE_RESOURCE_NAME"
デプロイの仕組み
client.agent_engines.create() は、App オブジェクトをパッケージ化し、依存関係とともにアップロードして、マネージド インフラストラクチャにデプロイします。各パラメータの機能は次のとおりです。
import vertexai
from vertexai import Client, agent_engines
vertexai.init(project=PROJECT_ID, location=LOCATION, staging_bucket=STAGING_BUCKET)
# Wrap the App in an AdkApp adapter - enables tracing in Cloud Trace
adk_app = agent_engines.AdkApp(app=root_app, enable_tracing=True)
# Initialize client and deploy
client = Client(project=PROJECT_ID, location=LOCATION)
agent_engine_resource = client.agent_engines.create(
agent=adk_app,
config={
"staging_bucket": STAGING_BUCKET, # GCS bucket for packaging artifacts
"display_name": "Creative Director",
# Python packages installed in the managed runtime - pin for reproducibility
"requirements": [
"google-cloud-aiplatform[agent_engines]>=1.132.0,<2.0.0",
"google-adk[a2a]==1.31.1",
"google-genai>=1.70.0",
"google-cloud-storage>=2.10.0",
"python-dotenv>=1.0.0",
"pydantic>=2.0.0",
"cloudpickle>=3.0.0",
],
# Specialist URLs passed as env vars - the orchestrator reads these at runtime
"env_vars": {
"COPYWRITER_AGENT_URL": COPYWRITER_URL,
"DESIGNER_AGENT_URL": DESIGNER_URL,
"STRATEGIST_AGENT_URL": STRATEGIST_URL,
"CRITIC_AGENT_URL": CRITIC_URL,
"PM_AGENT_URL": PM_URL,
},
},
)
resource_name = agent_engine_resource.api_resource.name
agent_engine_id = resource_name.split("/")[-1]
バックグラウンドで行われる処理:
1. Agent Engine packages your App + requirements into a container
2. Uploads it to the staging bucket in your project
3. Deploys to managed compute (you never see or manage the VM)
4. Returns a resource name: projects/.../locations/.../reasoningEngines/<id>
5. That ID is saved to .env as AGENT_ENGINE_ID
デプロイ後、オーケストレーターは環境変数の URL を介して 5 人の Cloud Run スペシャリストに接続します。
- これらは、デプロイ スクリプトが実行される前に
.envを介して渡されます。
14. エンドツーエンドのキャンペーンを実施する
システム全体がデプロイされます。Agent Runtime Playground から完全なキャンペーンを実行します。
Agent Runtime プレイグラウンドを開く
- https://console.cloud.google.com/agent-platform/runtimes に移動します。また、[Agent Platform] > [エージェント] > [デプロイ] から Agent Runtime に移動することもできます。
- デプロイしたエージェント ランタイム(
creative-director)を選択します。 - 左側のサイドバーで [Playground] をクリックします。
- [新しいセッション] をクリックして、新しい会話を開きます。
キャンペーン全体を実施する
このブリーフをチャットに貼り付けて送信します。
Create a complete Instagram campaign for:
- Product: EcoFlow Smart Water Bottle (tracks hydration, keeps drinks cold 24h)
- Target Audience: Health-conscious millennials, 25-35 years old
- Platform: Instagram
- Goal: Brand awareness + drive website traffic
- Brand Voice: Motivational, clean, science-backed
- Budget: $3,000
- Timeline: Launch in 2 weeks
クリエイティブ ディレクターは、5 つのすべてのエージェントを順番に実行します。
- ブランド ストラテジスト → 市場調査、競合他社の分析、オーディエンス分析
- コピーライター → キャプション、ハッシュタグ、行動を促すフレーズを含む 3 件の Instagram 投稿
- デザイナー → 各投稿の Gemini(GCS URI)で生成されたビジュアル コンセプトと実際の画像
- 批評家 → 承認 / 要修正のスコアが付いた品質レビュー
- (必要に応じて修正) → コピーライターまたはデザイナーにフィードバックを伝えて再度依頼する
- プロジェクト マネージャー → 2 週間のタイムライン、タスクの分解、予算の割り当て
単一エージェントのルーティングをテストする
新しいセッションで、この短いリクエストを送信します。
Research the luxury skincare market - top brands and trends in 2025
クリエイティブ ディレクターがこの問題をブランド ストラテジストのみに転送していることに注意してください。他のエージェントは呼び出されません。これは、システム指示の要求分類ロジックが正しく機能しているためです。
実行トレースを検査する
コンソールにログインしたまま、次の操作を行います。
- 左側のサイドバー(Playground の横)で [Traces] をクリックします。
- [Trace View] で、実行したセッションのトレースを選択します。
- トレースツリーを展開して、各エージェント呼び出し、その入力/出力、レイテンシ、トークン使用量を確認する
スペシャリストへの A2A 呼び出しは、それぞれ個別のスパンとして表示されます。クリエイティブ ディレクターが各エージェントに渡したコンテキストと、各エージェントから返されたコンテキストを正確に確認できます。
省略可: ターミナルから実行する
スターターにすでに含まれている run_campaign.py スクリプトを使用して、キャンペーンをプログラムで実行することもできます。
cd ~/ai-creative-studio/workshop/starter
uv run run_campaign.py
15. クリーンアップ
Google Cloud リソースをクリーンアップして、継続的な課金を回避します。
破棄スクリプトを実行します。このスクリプトは .env を読み取り、この Codelab で作成したものをすべて削除します。
bash deploy/teardown_gcp.sh
スクリプトは、削除する内容を正確に表示し、処理を行う前に確認を求めます。
リソース | 削除されるもの |
Cloud Run サービス | brand-strategist、copywriter、designer、critic、project-manager |
エージェント ランタイム | クリエイティブ ディレクターの推論エンジン + すべてのセッション |
Artifact Registry |
|
GCS バケット |
|
Secret Manager |
|
すべてが削除されたことを確認する
gcloud run services list --region=us-central1
gcloud storage buckets list --project=$GCP_PROJECT_ID
想定される出力: 空のリストまたは既存のリソースのみ。
16. まとめ
おめでとうございます!Google Cloud で本番環境グレードのマルチエージェント AI システムを構築してデプロイした。
構築した内容
エージェント | 能力 | デプロイ |
ブランド戦略担当者 | Google 検索を使った市場調査 | Cloud Run |
コピーライター | Instagram のキャプションの作成 | Cloud Run |
デザイナー | Gemini + GCS アップロードによる画像生成 | Cloud Run |
批評家 | スコア付きの品質レビュー | Cloud Run |
プロジェクト マネージャー | タイムライン + Notion MCP | Cloud Run |
クリエイティブ ディレクター | A2A による完全なオーケストレーション | エージェント ランタイム |
学習した主なパターン
- ADK
Agent- 指示とオプションのツールを使用して LLM エージェントを定義する adk web- 組み込みのチャット UI を使用して、任意の ADK エージェントをローカルで実行してテストするSkillToolset- 再利用可能な知識を、必要に応じて読み込まれるモジュール式ファイルにパッケージ化します。FunctionTool- 任意の Python 関数(または外部モデル)を呼び出し可能なエージェント ツールとしてラップします。to_a2a()- ADK エージェントを A2A 準拠の HTTPS サービスとして公開するRemoteA2aAgent+AgentTool- 呼び出し可能なツールとしてリモート エージェントをオーケストレートMcpToolset- MCP stdio サーバーを介して外部サービスに接続するEventsCompactionConfig- 長いマルチエージェント ワークフローでのトークン上限の処理- 構造化された批評家出力 - 自動改訂による機械可読の品質管理
- Cloud Run - コンテナ化されたエージェントを大規模にデプロイする
- Agent Runtime - マネージド セッションとトレースを使用してオーケストレーターをホストする
次のステップ
gemini-3.1-flash-imageの編集機能を使用して、Designer にマルチターンの画像編集を追加- Cloud Run サービスに IAM 認証を追加する(
--allow-unauthenticatedを削除) - 1 人のスペシャリストを LangGraph または CrewAI エージェントに置き換える - A2A はフレームワークに依存しない
- ユーザー フィードバックをツールとして追加し、参加者がアウトプットを評価して反復できるようにします。
- Cloud コンソールで Agent Runtime トレースを確認する