
1. Przegląd
W tym ćwiczeniu utworzysz AI Creative Studio – rozproszony system wieloagentowy, który przekształca pojedynczy prompt w kompletną kampanię na Instagramie.
Wpisz jedno zdanie. Otrzymasz wyniki badań odbiorców, napisy, koncepcje wizualne, zweryfikowane teksty i pełną oś czasu projektu – wszystko to wygenerowane przez zespół współpracujących ze sobą agentów AI.
Agenty, które utworzysz
Agent | Rola |
Strateg marki | Wyszukiwanie w internecie statystyk odbiorców, analizy konkurencji i trendów na 2025 r. |
Copywriter | Tworzy podpisy do postów na Instagramie z hashtagami i wezwaniami do działania – korzysta z umiejętności ADK, która na żądanie wczytuje wytyczne platformy i wzory podpisów. |
Projektant | Tworzy koncepcje wizualne i generuje prawdziwe obrazy za pomocą Gemini, które są przechowywane w GCS. |
Krytyk | Sprawdzanie kopii i elementów wizualnych recenzji – zwraca |
Project Manager | Tworzy harmonogram projektu i podział zadań, opcjonalnie synchronizowany z Notion za pomocą MCP. |
Dyrektor kreatywny | Koordynuje pracę wszystkich 5 specjalistów w odpowiedniej kolejności – wystarczy, że podasz 1 prompt, a model zajmie się resztą. |
5 agentów jest wdrażanych jako niezależne mikrousługi Cloud Run. Komunikują się one za pomocą protokołu A2A, czyli niezależnego od języka otwartego standardu, dzięki czemu każdy agent może wywołać dowolnego innego agenta niezależnie od platformy. Dyrektor kreatywny działa w środowisku wykonawczym agenta i łączy się zdalnie z każdym specjalistą.
Architektura

Czego się nauczysz
- Twórz agentów LLM za pomocą pakietu Google ADK –
Agent, instrukcji systemowych i wbudowanych narzędzi. - Pakuj wiedzę agenta wielokrotnego użytku w modułowe pliki za pomocą umiejętności ADK (
SkillToolset). - Generowanie prawdziwych obrazów przez połączenie agenta tekstowego z modelem obrazu za pomocą
FunctionTool. - Integruj zewnętrzne interfejsy API bez niestandardowego kodu łączącego za pomocą protokołu Model Context Protocol (MCP).
- Przekształcanie dowolnego agenta w usługę wywoływaną przez sieć za pomocą protokołu Agent to Agent (A2A) przez HTTPS.
- Orkiestruj rozproszonymi agentami za pomocą
RemoteA2aAgentiAgentTool. - Pakuj i wdrażaj niezależne agenty jako mikrousługi Cloud Run.
- Hostuj aranżera z zachowywaniem stanu w środowisku wykonawczym agentów.
- Utrzymuj długie przepływy pracy z wieloma agentami w ramach limitów kontekstu za pomocą kompresji kontekstu.
- Stwórz pętlę kontroli jakości: opinie krytyków → automatyczna korekta w razie potrzeby.
Czego potrzebujesz
- projekt Google Cloud z włączonymi płatnościami;
- rolę Właściciel lub Edytujący w IAM;
- podstawowa znajomość Pythona,
2. Konfigurowanie środowiska
W tym ćwiczeniu użyjemy Cloud Shell.
Co to jest Cloud Shell?
Cloud Shell to bezpłatne środowisko Linux w przeglądarce, w którym wszystko jest już zainstalowane: gcloud, git, Python, Docker i inne narzędzia. Nie musisz niczego instalować lokalnie.
Aby otworzyć Cloud Shell, kliknij ikonę terminala na pasku narzędzi w prawym górnym rogu konsoli GCP:
Gdy po raz pierwszy otworzysz Cloud Shell, pojawi się prośba o zweryfikowanie konta. Kliknij Zweryfikuj:
Następnie kliknij Autoryzuj, aby zezwolić Cloud Shell na wykonywanie wywołań interfejsu API usług Google Cloud:
Środowisko Cloud Shell jest już gotowe. W terminalu pojawi się wiadomość powitalna: 
Uwierzytelnianie i konfigurowanie projektu
Cloud Shell jest już uwierzytelniony na Twoim koncie Google. Sprawdź, czy Twoje konto jest aktywne, i znajdź identyfikator projektu:
gcloud config list
Identyfikator projektu możesz też sprawdzić w panelu konsoli GCP po lewej stronie. Skopiuj go, ponieważ będzie potrzebny w następnym poleceniu:
Teraz skonfiguruj projekt:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Cloud Run deployment region
echo "Project: $PROJECT_ID"
Oczekiwane dane wyjściowe:
Project: my-project-123
Włącz wymagane interfejsy API
gcloud services enable \
aiplatform.googleapis.com \
apphub.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
generativelanguage.googleapis.com \
iam.googleapis.com \
cloudresourcemanager.googleapis.com \
storage.googleapis.com \
secretmanager.googleapis.com
Zajmie to około 2 minut. Gdy to zrobisz, zobaczysz Operation finished successfully.
Konfigurowanie domyślnego uwierzytelniania aplikacji (ADC)
Agenty będą wywoływać platformę agentów Gemini Enterprise za pomocą biblioteki Google Auth, która wymaga domyślnych danych logowania aplikacji – oddzielnych od uwierzytelniania w interfejsie gcloud CLI.
Uruchom to raz:
gcloud auth application-default login
Otworzy się karta przeglądarki z prośbą o potwierdzenie. Kliknij Zezwól. Zobaczysz:
Credentials saved to file: ~/.config/gcloud/application_default_credentials.json
Klonowanie repozytorium początkowego
W tym ćwiczeniu używamy repozytorium startowego – projektu szkieletowego z całą infrastrukturą (pliki Dockerfile, pyproject.toml, skrypty wdrażania), ale z logiką agenta, którą musisz napisać samodzielnie.
git clone https://github.com/Saoussen-CH/mas-a2a-gcp.git ~/ai-creative-studio
cd ~/ai-creative-studio/workshop/starter
Każdy plik agent.py zawiera # TODO obiektów zastępczych, w których możesz napisać logikę agenta. Skrypty Dockerfile, pyproject.toml i wdrażania są już gotowe.
Konfigurowanie zmiennych środowiskowych
Skopiuj podany przykład i wstaw do niego identyfikator projektu w jednym kroku:
cp .env.example .env
sed -i "s|GOOGLE_CLOUD_PROJECT=your-project-id|GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)|" .env
Następnie utwórz zasobnik GCS, w którym Designer będzie przechowywać wygenerowane obrazy, i zastąp .env jego nazwą:
export PROJECT_ID=$(gcloud config get-value project)
export BUCKET_NAME="${PROJECT_ID}-campaign-images"
gcloud storage buckets create gs://${BUCKET_NAME} \
--location=us-central1 \
--project=${PROJECT_ID}
sed -i "s|GCS_IMAGES_BUCKET=your-project-id-campaign-images|GCS_IMAGES_BUCKET=${BUCKET_NAME}|" .env
Następnie skonfiguruj obsługę podpisanych adresów URL obrazów. Kreator kreacji generuje klikalne linki HTTPS do każdego obrazu w podsumowaniu końcowym kampanii. Wymaga to konta usługi do podpisywania adresów URL. Aby je skonfigurować, uruchom te polecenia:
export PROJECT_NUMBER=$(gcloud projects describe $(gcloud config get-value project) --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
export AGENT_RUNTIME_SA="service-${PROJECT_NUMBER}@gcp-sa-aiplatform-re.iam.gserviceaccount.com"
# Allow your user account to sign URLs locally (adk web)
gcloud iam service-accounts add-iam-policy-binding ${SA_EMAIL} \
--member="user:$(gcloud config get-value account)" \
--role="roles/iam.serviceAccountTokenCreator"
# Allow Agent Runtime to sign URLs when deployed
gcloud projects add-iam-policy-binding $(gcloud config get-value project) \
--member="serviceAccount:${AGENT_RUNTIME_SA}" \
--role="roles/iam.serviceAccountTokenCreator"
# Save SA email and project number to .env
grep -q "^SIGNING_SERVICE_ACCOUNT" .env \
&& sed -i "s|^SIGNING_SERVICE_ACCOUNT=.*|SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}|" .env \
|| echo "SIGNING_SERVICE_ACCOUNT=${SA_EMAIL}" >> .env
grep -q "^GOOGLE_CLOUD_PROJECT_NUMBER" .env \
&& sed -i "s|^GOOGLE_CLOUD_PROJECT_NUMBER=.*|GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}|" .env \
|| echo "GOOGLE_CLOUD_PROJECT_NUMBER=${PROJECT_NUMBER}" >> .env
Otwórz .env w edytorze, aby sprawdzić wszystkie ustawienia:
cloudshell edit .env
Spowoduje to otwarcie pliku .env jako karty w edytorze Cloud Shell. Jeśli panel edytora nie jest widoczny, na pasku narzędzi kliknij przycisk Otwórz edytor:

Sprawdź, czy projekt został prawidłowo ustawiony:
grep GOOGLE_CLOUD_PROJECT .env
Instalowanie zależności
Używamy uv – szybkiego, nowoczesnego menedżera pakietów Pythona, który obsługuje środowiska wirtualne i instalacje w jednym narzędziu. Jest on około 10–100 razy szybszy niż pip i jest zalecanym sposobem zarządzania projektami w Pythonie.
W Cloud Shell jest już zainstalowane narzędzie uv. Wszystkie agenty mają te same podstawowe zależności, więc zainstaluj je raz, a będą działać w przypadku każdego agenta w tym laboratorium:
uv sync
Polecenie uv sync odczytuje pyproject.toml i tworzy katalog .venv/ ze wszystkimi zależnościami. Każdy specjalista ma też własny plik pyproject.toml używany wyłącznie w kompilacjach Dockera – powyższa wspólna instalacja obejmuje wszystko, czego potrzebujesz do testowania lokalnego.
3. Informacje o pakiecie ADK od Google
Zanim zaczniesz pisać kod, poznaj pakiet Agent Development Kit (ADK), czyli platformę, której będziesz używać do tworzenia każdego agenta w tym ćwiczeniu.
Co to jest ADK?
Pakiet Agent Development Kit (ADK) to elastyczna i modułowa platforma do tworzenia oraz wdrażania agentów AI. Pakiet ADK jest zoptymalizowany pod kątem Gemini i ekosystemu Google, ale jest niezależny od modelu i wdrożenia oraz został stworzony z myślą o kompatybilności z innymi platformami. Pakiet ADK został zaprojektowany tak, aby tworzenie agentów przypominało tworzenie oprogramowania. Ułatwia on deweloperom tworzenie, wdrażanie i orkiestrację architektur agentów, które obejmują zarówno proste zadania, jak i złożone przepływy pracy.
Pakiet ADK obsługuje złożone elementy, takie jak wywoływanie narzędzi, wieloetapowe rozmowy, zarządzanie kontekstem i strumieniowanie, dzięki czemu możesz skupić się na logice agenta.
Elementy składowe agenta ADK
Każdy agent składa się z 4 elementów składowych:
Zablokuj | Rola |
Model | LLM, który analizuje cele, określa plan i generuje odpowiedzi |
Narzędzia | funkcje, które pobierają dane lub wykonują działania przez wywoływanie interfejsów API lub usług; |
Orchestration | Zachowuje pamięć i stan między turami, kieruje wywołania narzędzi i przekazuje wyniki z powrotem do modelu. |
Czas trwania | Uruchamia system po wywołaniu – lokalnie za pomocą |
Definicja agenta
Każdy z 5 agentów w tym laboratorium jest zdefiniowany w ten sam sposób:
from google.adk.agents import Agent
from google.adk.tools.google_search_tool import google_search
root_agent = Agent(
name="brand_strategist", # unique identifier
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"), # the LLM powering this agent
instruction=SYSTEM_INSTRUCTION, # the agent's persona, constraints, and output format
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search], # functions the LLM can call
)
Pole | Cel |
| Unikalny identyfikator używany przez orkiestratorów do kierowania połączeń |
| Model Gemini, który obsługuje tego agenta |
| Prompt systemowy – określa rolę, ograniczenia i format wyjściowy agenta. |
| Podsumowanie w jednym wierszu – aranżer odczytuje je, aby zdecydować, do którego specjalisty zadzwonić. |
| Funkcje, które LLM może wywoływać (wbudowane, np. |
Jak ADK uruchamia agenta
User message
│
▼
Agent (LLM) ← reads instruction + conversation history
│
├─► needs more info? → calls a tool → gets result → continues reasoning
│
└─► done reasoning → returns final text response
Model LLM samodzielnie decyduje, czy wywołać narzędzie, które narzędzie i z jakimi argumentami. Ty piszesz instrukcję, a pakiet ADK zajmuje się resztą.
4. Tworzenie i testowanie agenta Brand Strategist
Zacznijmy od pierwszego agenta: stratega marki. To agent przeznaczony wyłącznie do wyszukiwania informacji o odbiorcach docelowych, analizy konkurencji i popularnych tematów za pomocą wyszukiwarki Google.
Otwórz plik szkieletu agenta w edytorze Cloud Shell:
cloudshell edit agents/brand_strategist/agent.py
Zobaczysz 2 sekcje # TODO, które możesz wypełnić.
TODO 1 - Write the system instruction
Najpierw napisz instrukcję systemową dla agenta. Instrukcja systemowa to ciąg znaków, który określa rolę, ograniczenia i format wyjściowy agenta.
SYSTEM_INSTRUCTION = f"""You are a Brand Strategist specializing in market research and trend analysis.
IMPORTANT: Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
When conducting research, focus on current trends from {datetime.date.today().year}.
Use search queries like "[topic] trends {datetime.date.today().year}" for recent insights.
IMPORTANT: Your role is RESEARCH ONLY. You do NOT create campaign content, captions, or designs.
After providing research insights, your work is complete.
Your expertise:
- Identifying target audience insights and behaviors
- Analyzing competitor strategies
- Researching current social media trends
- Understanding platform algorithms and best practices
You have access to:
- google_search: Search the web for competitors, trends, and market insights
When given a campaign brief:
1. Use google_search to research the target audience's current interests
2. Search for and analyze 2-3 competitor brands
3. Identify 3-5 trending topics related to the product category
4. Provide high-level strategic insights - NOT specific campaign content
DO NOT create captions, copy, designs, or any campaign content.
Format your output as:
**Audience Insights:**
[Key behaviors and preferences based on research]
**Competitive Analysis:**
[What 2-3 competitors are doing - strengths and weaknesses]
**Trending Topics:**
[3-5 relevant trends to consider]
**Key Strategic Insights:**
[High-level themes and positioning opportunities]
"""
TODO 2 - Create the root_agent
Następnie zastąp niekompletny kod root_agent tym kodem:
root_agent = Agent(
name="brand_strategist",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
instruction=SYSTEM_INSTRUCTION,
description="Brand strategist for market research, trend analysis, and competitive insights",
tools=[google_search],
)
Testowanie lokalne za pomocą interfejsu internetowego ADK
Teraz przetestujmy agenta za pomocą interfejsu internetowego ADK, czyli wbudowanego interfejsu czatu do testowania agentów przed wdrożeniem w chmurze.
uv run adk web agents --allow_origins='*'
Zobaczysz:
INFO: Started server process
INFO: Uvicorn running on http://localhost:8000
Serwer działa teraz w Cloud Shell:
Aby otworzyć go w przeglądarce, użyj podglądu w przeglądarce:
- Sprawdź pasek narzędzi Cloud Shell u góry strony.
- Kliknij ikonę Podgląd w przeglądarce (wygląda jak pole ze strzałką skierowaną w górę, w prawym górnym rogu paska narzędzi Cloud Shell).
- Kliknij „Zmień port” i wpisz
8000, a następnie kliknij „Zmień i wyświetl podgląd”.
Otworzy się nowa karta przeglądarki z internetowym interfejsem ADK. W lewym górnym rogu kliknij menu „Wybierz agenta”. Zobaczysz listę wszystkich agentów:
Aby rozpocząć testowanie, kliknij brand_strategist:
Wypróbuj te prompty testowe
W polu czatu interfejsu internetowego ADK wypróbuj:
Research the eco-friendly water bottle market for health-conscious millennialsWhat are the top Instagram trends in the wellness space in 2025?
Powinien on wywołać wyszukiwarkę Google i zwrócić ustrukturyzowane wyniki wyszukiwania z sekcjami Statystyki odbiorców, Analiza konkurencji i Popularne tematy.
5. Tworzenie narzędzia Copywriter – umiejętności związane z pakietem ADK
Rola: przekształcanie wyników badań marki w treści do podpisów na Instagramie. Copywriter tworzy 3 warianty napisów o różnym charakterze (inspirujący, edukacyjny, społecznościowy), z których każdy zawiera hashtagi i wezwanie do działania.
Koncepcja: umiejętności pakietu ADK
Proste podejście polegałoby na umieszczeniu w prompcie systemowym całej wiedzy o platformie – limitów znaków, poziomów hashtagów, formuł podpisów, przykładów głosu marki. To działa, ale powoduje, że każde żądanie jest przeładowane treściami, których agent potrzebuje tylko od czasu do czasu.
Umiejętności ADK (SkillToolset, wprowadzone w ADK 1.25.0) umożliwiają spakowanie tej wiedzy w modułowe pliki z 3 poziomami ładowania:
- L1 – wstęp (
name+descriptionwSKILL.md): zawsze dostępny, używany do wykrywania umiejętności. - L2 - instructions (treść
SKILL.md): wczytywane, gdy agent aktywuje umiejętność. - L3 – zasoby (pliki
references/iassets/): wczytywane tylko wtedy, gdy agent je wyraźnie odczytuje.
Instrukcja systemowa jest skracana do krótkiego opisu roli i informacji „wczytaj umiejętność przed pisaniem”. Szczegóły platformy są uwzględniane w oknie kontekstu tylko wtedy, gdy agent ich potrzebuje.
Umiejętność Copywriter znajduje się w agents/copywriter/skills/instagram-copywriting/:
skills/
instagram-copywriting/
SKILL.md ← L1 frontmatter (discovery) + L2 instructions (loaded on trigger)
references/
platform-guide.md ← L3: character limits, hashtag tiers, algorithm signals
caption-formulas.md ← L3: hook formulas, CTA patterns, full caption structures
assets/
brand-voice-examples.md ← L3: annotated real-world caption examples
Otwórz plik bezpośrednio w edytorze Cloud Shell:
cloudshell edit agents/copywriter/agent.py
DO ZROBIENIA 1 – importowanie load_skill_from_dir i skill_toolset
Znajdź komentarz # TODO 1: Import load_skill_from_dir and skill_toolset i dodaj te 2 importy:
from google.adk.skills import load_skill_from_dir
from google.adk.tools import skill_toolset
DO ZROBIENIA 2 – wczytaj umiejętność i utwórz SkillToolset
Znajdź 2 komentarze pod instrukcjami importu:
# TODO 2: Load the instagram-copywriting skill from the skills/ directory
# TODO 2: Create a SkillToolset with the loaded skill
Zastąp je tymi:
_instagram_skill = load_skill_from_dir(
pathlib.Path(__file__).parent / "skills" / "instagram-copywriting"
)
_copywriting_skills = skill_toolset.SkillToolset(skills=[_instagram_skill])
load_skill_from_dir odczytuje SKILL.md oraz wszystkie pliki w references/ i assets/. SkillToolset przekształca je w format akceptowany przez agentów ADK – zestaw narzędzi, a nie surowe umiejętności.
TODO 3 - Register the toolset with the agent
Znajdź tools=[], # TODO 3: Add the SkillToolset here i zastąp go:
tools=[_copywriting_skills],
Otwórz plik umiejętności, aby zobaczyć jego strukturę:
cloudshell edit agents/copywriter/skills/instagram-copywriting/SKILL.md
Pozostaw interfejs internetowy ADK uruchomiony. Użyj menu agenta, aby przełączyć się na copywriter bez ponownego uruchamiania serwera.
Jeśli nie działa, uruchom go ponownie:
uv run adk web agents --allow_origins='*'
Wypróbuj: zmień menu na copywriter i wyślij:
You are writing captions for EcoFlow Smart Water Bottle targeting health-conscious millennials aged 25-35.
Audience insight: they prioritize sustainability, track health metrics, and share lifestyle content.
Competitor insight: Hydro Flask dominates with lifestyle branding; S'well leads on premium aesthetics.
Write 3 Instagram captions - one inspirational, one educational, one community-focused. Include 5 hashtags each and a CTA.
6. Tworzenie usługi Designer – generowanie obrazów multimodalnych
Pozostaw otwarty interfejs internetowy ADK. Użyj menu agenta, aby przełączać agentów bez ponownego uruchamiania serwera.
Rola: tworzenie koncepcji wizualnych dla każdego podpisu i generowanie rzeczywistych obrazów za pomocą natywnej funkcji generowania obrazów Gemini. Projektant tworzy dokładnie 1 koncepcję wizualną dla każdego podpisu – ze szczegółowym promptem, stylem, paletą kolorów, nastrojem i formatem Instagrama – a następnie natychmiast wywołuje narzędzie generate_image, aby wygenerować rzeczywisty obraz i przesłać go do GCS.
Koncepcja: łączenie agenta tekstowego z modelem obrazu za pomocą narzędzia
Projektant działa na podstawie gemini-3-flash-preview (modelu tekstowego ustawionego za pomocą GEMINI_MODEL w .env), ale generowanie obrazów wymaga specjalnego modelu (gemini-3.1-flash-image). Ten model obrazów nie obsługuje wywoływania funkcji, więc nie można go używać bezpośrednio jako agenta ADK. Zamiast tego jest on opakowany w zwykłą funkcję Pythona i zarejestrowany jako FunctionTool.
Jest to wzorzec dla każdego modelu lub interfejsu API, którego LLM nie może wywołać bezpośrednio: umieść go w narzędziu, pozwól agentowi koordynować, kiedy go wywołać, i uzyskaj uporządkowany wynik.
Designer agent (text model)
│
│ decides visual concept, writes image prompt
▼
generate_image tool
│
│ calls gemini-3.1-flash-image
│ uploads result to GCS
▼
{"status": "success", "gcs_uri": "gs://..."}
│
│ returned to agent, included in response
▼
Critic (receives gcs_uri, passes to Vertex AI for multimodal review)
Otwórz plik bezpośrednio w edytorze Cloud Shell:
cloudshell edit agents/designer/image_gen_tool.py
Podany jest podpis funkcji, konfiguracja środowiska i wstrzykiwanie współczynnika proporcji. Wykonaj po kolei 3 zadania:
TODO 1 - Call the Gemini image model
Znajdź komentarz # TODO 1 i zastąp go tym:
client = genai.Client(vertexai=True, project=project_id, location=location)
response = client.models.generate_content(
model=image_model,
contents=prompt_with_aspect,
config=types.GenerateContentConfig(
response_modalities=["IMAGE", "TEXT"],
http_options=types.HttpOptions(
retry_options=types.HttpRetryOptions(
attempts=5, exp_base=2, initial_delay=30,
http_status_codes=[429, 500, 503, 504],
),
timeout=180_000,
),
),
)
TODO 2 - Extract image bytes from the response
Znajdź komentarz # TODO 2 i zastąp go tym:
image_bytes = None
mime_type = "image/png"
for part in response.candidates[0].content.parts:
if part.inline_data is not None:
image_bytes = part.inline_data.data
mime_type = part.inline_data.mime_type or "image/png"
break
if not image_bytes:
return {"status": "error", "error": "Gemini returned no image data"}
DO ZROBIENIA 3 – przesłać do GCS i zwrócić identyfikator URI
Znajdź komentarz # TODO 3 i zastąp go tym:
ext = "jpg" if "jpeg" in mime_type else "png"
from google.cloud import storage
gcs_client = storage.Client(project=project_id)
bucket = gcs_client.bucket(bucket_name)
blob_name = f"campaign-images/{concept_name}-{uuid.uuid4().hex[:8]}.{ext}"
blob = bucket.blob(blob_name)
blob.upload_from_file(io.BytesIO(image_bytes), content_type=mime_type)
gcs_uri = f"gs://{bucket_name}/{blob_name}"
Wypróbuj: zmień menu na designer i wyślij:
Create a visual concept and generate the image for an EcoFlow Smart Water Bottle Instagram post targeting health-conscious millennials.
Style: clean, modern, lifestyle-focused. Include a detailed prompt with color palette, mood, and format (1080x1080 or 1080x1350).
7. Tworzenie opinii krytyka – uporządkowane dane wyjściowe
Rola: sprawdzanie jakości tekstów i materiałów wizualnych przed przekazaniem ich do kierownika projektu. Krytyk ocenia oba elementy i zwraca APPROVED lub NEEDS_REVISION wraz z konkretnymi sugestiami. Gdy w danych wejściowych występują gcs_uri, wywołuje narzędzie review_image, aby przed oceną wizualnie sprawdzić każdy wygenerowany obraz.
Koncepcja: kiedy używać modelu Pydantic do danych wyjściowych Gemini
Reguła dotyczy tego, kto korzysta z danych wyjściowych:
- Kod Pythona go wykorzystuje → użyj
response_schema+ Pydantic. Kod nie radzi sobie z niejednoznacznością, więc do niezawodnego wyodrębniania pól potrzebna jest gwarantowana struktura. - Model LLM przetwarza go – wystarczy format tekstowy i instrukcja systemowa. Modele LLM rozumieją reguły formatowania i tolerują różnice.
W review_image kod w Pythonie wymaga wartości wpisanych jako score, approval_status, what_works, issues i suggestions. Przekazanie response_schema=_GeminiReview ogranicza Gemini na poziomie interfejsu API, aby zwracał prawidłowy kod JSON; model_validate_json() analizuje go i przekształca w obiekt z określonym typem, którego Twój kod może używać w niezawodny sposób.
class _GeminiReview(BaseModel):
score: int = Field(ge=1, le=10)
approval_status: Literal["APPROVED", "NEEDS_REVISION"]
what_works: str
issues: str
suggestions: str
Otwórz plik bezpośrednio w edytorze Cloud Shell:
cloudshell edit agents/critic/image_review_tool.py
Podane są modele Pydantic i prompt. Wykonaj kolejno 3 zadania o oznaczeniu TODO:
TODO 1 - Create an image part from the GCS URI
Znajdź komentarz # TODO 1 i zastąp go tym:
image_part = types.Part.from_uri(file_uri=gcs_uri, mime_type=mime_type)
TODO 2 - Call Gemini with a structured response schema
Znajdź komentarz # TODO 2 i zastąp go tym:
response = client.models.generate_content(
model=model,
contents=[image_part, prompt],
config=types.GenerateContentConfig(
response_schema=_GeminiReview,
response_mime_type="application/json",
),
)
TODO 3 - Parse the response and return the result
Znajdź komentarz # TODO 3 i zastąp go tym:
review = _GeminiReview.model_validate_json(response.text)
return ImageReviewResult(status="success", concept_name=concept_name, **review.model_dump())
Wypróbuj: zmień menu na critic i wyślij:
Review this Instagram caption for an eco-friendly water bottle brand targeting millennials:
"Hydrate smarter, live greener. 💧 Our EcoFlow bottle tracks your intake, keeps your drink cold for 24h, and never touches single-use plastic. Because what you drink from matters as much as what you drink. #EcoFlow #HydrationGoals #SustainableLiving #ZeroWaste #HealthyHabits - Shop link in bio."
Score it and indicate APPROVED or NEEDS_REVISION with specific feedback.
Sprawdź, czy odpowiedź zawiera **POSTS REVIEW:**, Status: APPROVED (lub NEEDS_REVISION) i **OVERALL ASSESSMENT:**. Jeśli te sekcje są obecne, usługa Critic jest gotowa do podłączenia do orkiestratora.
Gdy skończysz testowanie wszystkich 3 agentów, naciśnij Ctrl+C, aby zatrzymać serwer.
8. Tworzenie agenta Project Manager za pomocą MCP
Menedżer projektu wprowadza nową koncepcję: MCP (Model Context Protocol).
Otwórz plik:
cloudshell edit agents/project_manager/agent.py
Ten plik jest bardziej złożony – zawiera create_project_manager_agent() funkcję z 2 gałęziami: jedną bez Notion (osie czasu zawierające tylko tekst) i jedną z zestawem narzędzi MCP Notion. Musisz wypełnić obie.
Problem, który rozwiązuje MCP
Twój agent musi wywołać usługę zewnętrzną, np. utworzyć stronę w Notion. Możesz napisać kod Pythona, który bezpośrednio wywołuje interfejs Notion REST API. Ale potem:
- Każdy deweloper pisze inny wrapper.
- Musisz utrzymywać kod integracji niestandardowej
- Model LLM nie wie, że interfejs API istnieje, dopóki nie opiszesz ręcznie każdego punktu końcowego.
MCP rozwiązuje ten problem, definiując standardowy sposób, w jaki usługi zewnętrzne mogą udostępniać swoje funkcje jako narzędzia, które LLM może automatycznie wykrywać i wywoływać.
Co to jest MCP?
MCP (Model Context Protocol) to otwarty standard (opublikowany przez Anthropic) do łączenia agentów AI z narzędziami zewnętrznymi i źródłami danych. Działa jak uniwersalny adapter.
Serwer MCP to mały program, który:
- Zawiera zewnętrzny interfejs API (Notion, GitHub, bazy danych, systemy plików itp.).
- udostępnia ten interfejs API jako listę typowanych, udokumentowanych narzędzi;
- Komunikuje się z agentem za pomocą prostego protokołu (stdio lub HTTP).
Agent łączy się z serwerem MCP, automatycznie wykrywa dostępne narzędzia i może je wywoływać tak samo jak każde inne narzędzie – LLM widzi API-post-page(...) jako funkcję, którą można wywołać.
A2A a MCP – jaka jest różnica?
To częste źródło nieporozumień. Oto najważniejsza różnica:
A2A | MCP | |
Co łączy | Agent ↔ agent | Agent ↔ narzędzie lub usługa zewnętrzna |
Druga strona to | Inny agent LLM | Otoka API (bez LLM) |
Przykład | Dyrektor kreatywny dzwoni do stratega marki | Menedżer projektu wywołuje interfejs API Notion |
Protokół | JSON-RPC przez HTTPS | strumień stdio lub HTTP, |
Definicja | Anthropic |
Pomyśl o tym w ten sposób:
- A2A = sposób, w jaki agenci komunikują się z innymi agentami.
- MCP = sposób, w jaki agenty komunikują się z narzędziami i usługami
W tym projekcie są one używane razem:
Creative Director
│
│ (A2A) Brand Strategist ─── (google_search tool built into ADK)
│ (A2A) Copywriter
│ (A2A) Designer
│ (A2A) Critic
│ (A2A) Project Manager
│
│ (MCP) notion-mcp-server ──► Notion REST API
Jak działa MCP w tym projekcie
Gdy agent jest uruchomiony, ADK uruchamia notion-mcp-server jako proces podrzędny. W ramach tego procesu narzędzia są udostępniane bezpośrednio LLM:
Narzędzie | Działanie |
| Pobiera schemat (nazwy właściwości, typy, prawidłowe wartości). |
| Zapytania dotyczące istniejących stron |
| Tworzy nową stronę. |
| Aktualizuje istniejącą stronę |
LLM wywołuje je jak każdą inną funkcję – nie wie, że w tle przechodzą one przez MCP do interfejsu API REST Notion.
Dlaczego stdio? Dlaczego nie HTTP?
Serwer MCP działa jako proces podrzędny agenta i komunikuje się z nim za pomocą stdin/stdout. Oznacza to, że:
- Nie wymaga dodatkowego portu sieciowego
- Cykl życia jest zarządzany przez agenta (uruchamiany na żądanie, zatrzymywany po zamknięciu)
- Wszystko jest dostarczane w jednym obrazie Dockera – nie ma potrzeby wdrażania osobnej usługi.
(Opcjonalnie) Włącz integrację z Notion
Możesz pominąć całą tę sekcję. Agent Project Manager zawsze tworzy pełną oś czasu kampanii tekstowej, z Notion lub bez niego. Jeśli pominiesz tę konfigurację, agent przełączy się na tryb w pamięci i będzie wyświetlać oś czasu w formie zwykłego tekstu na czacie. Nic się nie zepsuje – po prostu nie zobaczysz zadań w bazie danych Notion. Jeśli chcesz pominąć ten krok, przejdź od razu do TODO 1.
Jeśli masz konto Notion i chcesz zobaczyć, jak działa integracja z MCP, wykonaj poniższe czynności konfiguracji. Elementy DO ZROBIENIA, które znajdziesz poniżej, odwołują się do identyfikatorów bazy danych Notion – to tutaj je znajdziesz.
Krok 1. Utwórz bazę danych Notion na podstawie szablonu
Jako bazy danych używamy oficjalnego szablonu Notion Projects & Tasks. Wybraliśmy ten szablon celowo, aby zademonstrować złożone, rzeczywiste ustawienia – ma on wiele typów właściwości (stan, zakresy dat, relacje, wybór) o nieoczywistych nazwach. To świetny test dynamicznego wykrywania schematu przez MCP: agent musi określić dokładne nazwy właściwości w czasie działania, a nie mieć ich zakodowanych na stałe.
Aby dodać szablon do obszaru roboczego Notion, kliknij link poniżej:
→ Dodawanie szablonu „Projekty i zadania” do Notion
Po dodaniu będziesz mieć 2 połączone bazy danych: Projekty i Zadania. Szablon zawiera przykładowe wpisy – usuń je wszystkie, zanim przejdziesz dalej, aby agent zaczynał pracę w czystym obszarze roboczym (wybierz wszystkie → Usuń).
Krok 2. Utwórz integrację z Notion
Utwórz integrację:
- Otwórz notion.so/my-integrations
- Kliknij New Integration (Nowa integracja) → nadaj jej nazwę
AI Creative Studio - powiązać go z obszarem roboczym,
- Kliknij Skonfiguruj ustawienia → upewnij się, że wszystkie opcje Odczytywanie treści, Aktualizowanie treści i Wstawianie treści są zaznaczone.
- Skopiuj wewnętrzny token integracji (
ntn_...) i wklej go do pliku.env:
NOTION_TOKEN=ntn_your-token-here
Połącz integrację z bazami danych:
- Otwórz stronę szablonu, którą właśnie sklonowano, a następnie kliknij bazę danych Projekty.
- Kliknij menu
...(w prawym górnym rogu) → Połączenia → Dodaj połączenie → wybierzAI Creative Studio.
- Zrób to samo w przypadku bazy danych Zadania.
Uzyskiwanie identyfikatorów baz danych:
- Kliknij link do bazy danych Projekty, aby ją otworzyć. Otworzy się ona na osobnej stronie z adresem URL podobnym do tego:
https://www.notion.so/9887b6a94f7f83f68f8581e038d1aaa4?v=2c37b6a94f7f838685f1086e312c7278

Identyfikator bazy danych to pierwszy identyfikator UUID w adresie URL – wszystko przed znakiem ?v=:
https://www.notion.so/{DATABASE_ID}?v=...
^^^^^^^^^^^^^^^^
9887b6a94f7f83f68f8581e038d1aaa4 ← this is your DATABASE_ID
- Zrób to samo w przypadku linku do bazy danych Zadania, aby uzyskać jej identyfikator.
- Dodaj wszystkie 3 wartości do
.env:
NOTION_TOKEN=ntn_your-token-here
NOTION_PROJECT_DATABASE_ID=9887b6a94f7f83f68f8581e038d1aaa4 # <-- your Projects DB ID
NOTION_TASKS_DATABASE_ID=your-tasks-db-id # <-- your Tasks DB ID
Krok 3. Zainstaluj serwer MCP Notion
Menedżer projektu łączy się z Notion za pomocą oficjalnego pakietu @notionhq/notion-mcp-server Node.js. Zainstaluj go globalnie:
npm install -g @notionhq/notion-mcp-server@1.9.1
Sprawdź instalację:
npm list -g @notionhq/notion-mcp-server
Oczekiwane dane wyjściowe:
└── @notionhq/notion-mcp-server@1.9.1
notion-mcp-server: command not found
? Sprawdź, czy masz zainstalowany Node.js (node --version) i czy globalny folder bin npm znajduje się w zmiennej PATH (export PATH=$PATH:$(npm bin -g)).
Krok 4. Sprawdź plik .env
Otwórz .env i potwierdź, że wszystkie 3 wartości Notion są ustawione (zostały dodane w kroku 2):
cloudshell edit .env
NOTION_TOKEN=ntn_... # integration token
NOTION_PROJECT_DATABASE_ID=... # Projects database ID
NOTION_TASKS_DATABASE_ID=... # Tasks database ID
Agent Project Manager automatycznie wykrywa te zmienne podczas uruchamiania i włącza zestaw narzędzi MCP Notion.
Jak działa wykrywanie schematu
Menedżer projektu korzysta z dynamicznego wykrywania schematów – nigdy nie koduje na stałe nazw właściwości Notion:
Step 1: Call API-retrieve-a-database to discover exact property names
Step 2: Read the "properties" object in the response
Step 3: Use ONLY discovered property names (case-sensitive) in API calls
Step 4: For select/status fields, use only values from the options array
Oznacza to, że agent automatycznie dostosowuje się do dowolnej struktury bazy danych Notion – zmień nazwy właściwości na francuskie, arabskie lub inne, a agent nadal będzie działać.
TODO 1 - Write the system instruction
Starter oblicza już notion_section – pusty ciąg znaków, gdy Notion nie jest skonfigurowany, lub blok zawierający identyfikatory bazy danych oraz pełne wskazówki dotyczące narzędzia, gdy jest skonfigurowany. Dzięki temu instrukcje Notion są całkowicie wyłączone z promptu agenta bez Notion. LLM nigdy nie widzi reguł dotyczących narzędzi, których nie ma.
Twoim zadaniem jest zastąpienie symbolu zastępczego return rzeczywistą instrukcją systemową, która używa {notion_section}:
return f"""You are a Project Manager specializing in creative campaign execution.
Today's date is {datetime.date.today().strftime("%B %d, %Y")}.
Use this as the starting point for all timelines.
Your goal: create a complete project plan for the campaign.
{notion_section}
**Project Timeline:**
Phase 1: Strategy & Research | [date] → [date] | [key activities]
Phase 2: Content Creation | [date] → [date] | [key activities]
Phase 3: Review & Revision | [date] → [date] | [key activities]
Phase 4: Launch & Monitoring | [date] → [date] | [key activities]
**Task List:**
| Task | Owner | Deadline | Status |
[list each task with realistic deadlines from today; set Owner to TBD]
**Budget Breakdown:**
[by category with approximate allocations]
**Milestones:**
[3-5 key checkpoints with dates]
**Notion Status:**
[What happened - e.g. "Project created (ID: xxx), 8 tasks linked" or "Notion not configured - text timeline only"]
"""
TODO 2 - Agent bez Notion
W sekcji create_project_manager_agent() w gałęzi if not notion_token zastąp niekompletnego agenta tym kodem:
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
instruction=get_system_instruction(),
description="Project manager that creates campaign timelines and task breakdowns",
)
TODO 3 - Agent z Notion MCP
Uwaga: plik początkowy zawiera już wstępnie napisaną funkcję wywołania zwrotnego handle_notion_error powyżej create_project_manager_agent(). Przechwytuje błędy interfejsu Notion API (400/404) i zastępuje surowe ładunki błędów przejrzystymi komunikatami, które umożliwiają podjęcie działań, dzięki czemu LLM może samodzielnie korygować błędy. Wystarczy podłączyć go za pomocą after_tool_callback.
Najpierw odczytaj oba identyfikatory baz danych u góry strony create_project_manager_agent():
notion_token = os.getenv("NOTION_TOKEN")
notion_project_db_id = os.getenv("NOTION_PROJECT_DATABASE_ID")
notion_tasks_db_id = os.getenv("NOTION_TASKS_DATABASE_ID")
Następnie w gałęzi else utwórz zestaw narzędzi MCP i agenta:
from google.adk.tools.mcp_tool import McpToolset, StdioConnectionParams
from mcp import StdioServerParameters
server_params = StdioServerParameters(
command="notion-mcp-server",
env={
"NOTION_TOKEN": notion_token,
"PATH": os.environ.get("PATH", ""),
}
)
notion_toolset = McpToolset(
connection_params=StdioConnectionParams(
server_params=server_params,
timeout=30.0
)
)
return Agent(
name="project_manager",
model=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"),
generate_content_config=GENERATE_CONTENT_CONFIG,
after_tool_callback=handle_notion_error,
instruction=get_system_instruction(
project_database_id=notion_project_db_id,
tasks_database_id=notion_tasks_db_id,
),
description="Project manager with Notion integration for task tracking",
tools=[notion_toolset],
)
Sprawdzona metoda: nigdy nie odrzucaj integracji opcjonalnych. Oś czasu tekstu jest zawsze głównym elementem, a Notion jest dodatkiem.
Testowanie menedżera projektu lokalnie za pomocą ADK Web
uv run adk web agents --allow_origins='*'
Otwórz podgląd w przeglądarce na porcie 8000. Wybierz project_manager w menu agenta, a potem spróbuj:
Create a project plan for a GreenBrew organic coffee brand Instagram campaign.
Budget: $2,500. Launch in 3 weeks. Target audience: eco-conscious millennials aged 22-30.
Include phases, tasks with deadlines from today, and milestones.
Powinna się wyświetlić strukturalna oś czasu z fazami, listą zadań i kamieniami milowymi. Jeśli dane logowania do Notion są ustawione w .env, agent będzie też tworzyć wpisy w Twoim obszarze roboczym Notion.
9. Informacje o protokole A2A
Do łączenia różnych agentów w naszym systemie będziemy używać protokołu Agent-to-Agent (A2A). Zobaczmy, jak to działa.
Problem, który rozwiązuje A2A
Wyobraź sobie, że masz agenta ds. strategii marki utworzonego za pomocą pakietu ADK i agenta ds. copywritingu utworzonego za pomocą LangGraph. Jak jedna osoba może zadzwonić do drugiej? Mówią różnymi językami wewnętrznymi. Za każdym razem musisz napisać niestandardowy kod łączący.
A2A rozwiązuje ten problem, definiując uniwersalny język, którym może posługiwać się każdy agent, niezależnie od platformy. To HTTP w świecie agentów: standard, z którym wszyscy się zgadzają, dzięki czemu każdy może rozmawiać z każdym.
Co to jest A2A?
Agent-to-Agent (A2A) to otwarty standard komunikacji między agentami opublikowany przez Google. Określa:
- Jak agent opisuje siebie – karta agenta w
/.well-known/agent.json - Jak wywołuje go inny agent – JSON-RPC przez HTTPS
- Sposób zwracania wyników – przesyłanie strumieniowe lub pojedyncza odpowiedź
Elastyczność A2A:
- Niezależność od języka – agenci w Pythonie mogą komunikować się z agentami w TypeScript.
- Niezależność od platformy – agenci ADK mogą komunikować się z agentami LangGraph lub CrewAI.
- Niezależność od infrastruktury – agenci lokalni mogą komunikować się z agentami w chmurze.
Jak to działa – krok po kroku
Creative Director Brand Strategist
│ │
│ 1. GET /.well-known/agent.json │
│ ────────────────────────────────►│
│ ◄──── agent card (name, url, │
│ skills, capabilities) ───│
│ │
│ 2. POST / │
│ {"method": "tasks/send", │
│ "params": {"message": ...}} │
│ ────────────────────────────────►│
│ │ LLM does
│ │ the work...
│ 3. streaming response chunks │
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
│ ◄───────────────────────────────│
Krok 1. Odkrywanie: orkiestrator pobiera kartę agenta raz, aby poznać jego nazwę, adres URL i możliwości.
Krok 2. Wywołanie: orkiestrator wysyła zadanie za pomocą żądania POST RPC JSON. Treść zawiera wiadomość (prompt dla specjalisty).
Krok 3. Odpowiedź: specjalista przesyła odpowiedź w fragmentach, tak jak w przypadku zwykłego wywołania LLM.
Karta agenta
Każdy agent publikuje swój opis pod adresem /.well-known/agent.json. Jest to wizytówka, która informuje o tym, co agent może zrobić i gdzie można się z nim skontaktować:
{
"name": "brand_strategist",
"description": "Market research and competitive analysis",
"url": "https://brand-strategist-xyz.run.app",
"capabilities": { "streaming": true },
"skills": [
{
"id": "market_research",
"description": "Research target audiences, competitors, and trends"
}
]
}
Orchestrator odczytuje tę kartę, aby utworzyć obiekt RemoteA2aAgent. Nie wymaga to zakodowanej na stałe wiedzy o wewnętrznych działaniach specjalisty.
Udostępnianie agenta za pomocą protokołu A2A w pakiecie ADK
to_a2a() opakowuje dowolnego agenta ADK w aplikację FastAPI zgodną z A2A. Wystarczy 1 wiersz:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
# root_agent = your normal ADK Agent(...)
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
Automatycznie utworzy:
/.well-known/agent.json– karta agenta/– punkt końcowy RPC JSON (wszystkie żądania zadań A2A są kierowane do ścieżki głównej);
10. Udostępnianie agentów jako usług A2A
Aby udostępniać agentów jako usługi A2A, możesz użyć funkcji użytkowej to_a2a() z ADK.
Jak działa to_a2a()
from google.adk.a2a.utils.agent_to_a2a import to_a2a
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
to_a2a() otacza agenta ADK aplikacją FastAPI, która automatycznie udostępnia:
/.well-known/agent.json– karta agenta (imię i nazwisko, opis, możliwości);/a2a/{agent_name}– punkt końcowy RPC JSON do odbierania zadań.
Kod szkieletowy każdego agenta zawiera już blok __main__, który otacza agenta serwerem A2A za pomocą to_a2a(). Nie musisz pisać tego kodu – jest on dostępny.
Informacje o konfiguracji z dwoma adresami URL
Gdy uruchomisz python agent.py, blok __main__ użyje 2 oddzielnych konfiguracji adresów URL:
# Where the server actually listens (network interface):
HOST = "0.0.0.0"
PORT = 8082 # Brand Strategist (others use 8083–8086 locally)
# What gets advertised in the agent card (the address other agents use to reach it):
PUBLIC_HOST = os.getenv("PUBLIC_HOST", "localhost")
PUBLIC_PORT = int(os.getenv("PUBLIC_PORT", str(PORT)))
PROTOCOL = os.getenv("PROTOCOL", "http")
a2a_app = to_a2a(root_agent, host=PUBLIC_HOST, port=PUBLIC_PORT, protocol=PROTOCOL)
uvicorn.run(a2a_app, host=HOST, port=PORT)
Środowisko |
|
|
Lokalne |
|
|
Cloud Run |
|
|
Lokalnie oba wskazują na tę samą maszynę. W Cloud Run kontener nasłuchuje wewnętrznie na porcie 8080, ale karta agenta musi reklamować publiczny adres URL HTTPS. W przeciwnym razie dyrektor kreatywny nie będzie mógł skontaktować się ze specjalistą spoza kontenera.
Uruchom wszystkie 5 specjalistycznych serwerów A2A
Uruchommy wszystkich 5 specjalistów jako serwery A2A jednocześnie, a potem przetestujmy lokalnie dyrektora kreatywnego, kierując go na te serwery.
Otwórz 5 osobnych terminali Cloud Shell (kliknij ikonę + na pasku kart terminala) i uruchom po jednym agencie na każdym terminalu.
uv run automatycznie aktywuje .venv – nie trzeba ręcznie source w każdym terminalu.
Terminal 1 – strateg marki (port 8082):
cd ~/ai-creative-studio/workshop/starter
PORT=8082 uv run agents/brand_strategist/agent.py
Terminal 2 - Copywriter (port 8083):
cd ~/ai-creative-studio/workshop/starter
PORT=8083 uv run agents/copywriter/agent.py
Terminal 3 – Designer (port 8084):
cd ~/ai-creative-studio/workshop/starter
PORT=8084 uv run agents/designer/agent.py
Terminal 4 - Critic (port 8085):
cd ~/ai-creative-studio/workshop/starter
PORT=8085 uv run agents/critic/agent.py
Terminal 5 - Project Manager (port 8086):
cd ~/ai-creative-studio/workshop/starter
PORT=8086 uv run agents/project_manager/agent.py
Ustawianie adresów URL hosta lokalnego w pliku .env
W sekcji Terminal 6 zaktualizuj adresy URL lokalnych agentów w polu .env, aby Dyrektor Kreatywny mógł je znaleźć:
cd ~/ai-creative-studio/workshop/starter
sed -i \
-e 's|STRATEGIST_AGENT_URL=.*|STRATEGIST_AGENT_URL=http://localhost:8082|' \
-e 's|COPYWRITER_AGENT_URL=.*|COPYWRITER_AGENT_URL=http://localhost:8083|' \
-e 's|DESIGNER_AGENT_URL=.*|DESIGNER_AGENT_URL=http://localhost:8084|' \
-e 's|CRITIC_AGENT_URL=.*|CRITIC_AGENT_URL=http://localhost:8085|' \
-e 's|PM_AGENT_URL=.*|PM_AGENT_URL=http://localhost:8086|' \
.env
Sprawdzanie agentów za pomocą narzędzia A2A Inspector
A2A Inspector to narzędzie dla programistów typu open source, które natywnie obsługuje protokół A2A. Umożliwia bezpośrednie łączenie się z dowolnym działającym agentem A2A, odczytywanie jego karty i wysyłanie zadań – wszystko to bez pisania kodu klienta.
Co to oznacza:
- Karta agenta – uporządkowane metadane, które reklamuje agent: jego nazwa, opis, obsługiwane tryby wejścia/wyjścia i adres URL punktu końcowego. To właśnie te informacje odczytuje Creative Director, gdy wykryje specjalistę.
- Interfejs czatu – wysyłaj do agenta dowolne wiadomości za pomocą protokołu A2A i wyświetlaj nieprzetworzone odpowiedzi. Zanim połączysz ze sobą agentów, możesz przetestować prompty osobno.
- Weryfikacja protokołu – narzędzie sprawdza, czy karta agenta jest zgodna ze specyfikacją A2A, i wcześnie wykrywa brakujące pola lub nieprawidłowe odpowiedzi.
Dlaczego to jest ważne: gdy później wdrożysz usługę w Cloud Run, Creative Director wykryje każdego specjalistę, pobierając jego kartę agenta z /.well-known/agent.json. Jeśli karta jest nieprawidłowa (nieprawidłowy adres URL, brak możliwości), orkiestrator cicho zakończy działanie. Inspektor umożliwia wykrycie tych problemów lokalnie przed wdrożeniem w chmurze.
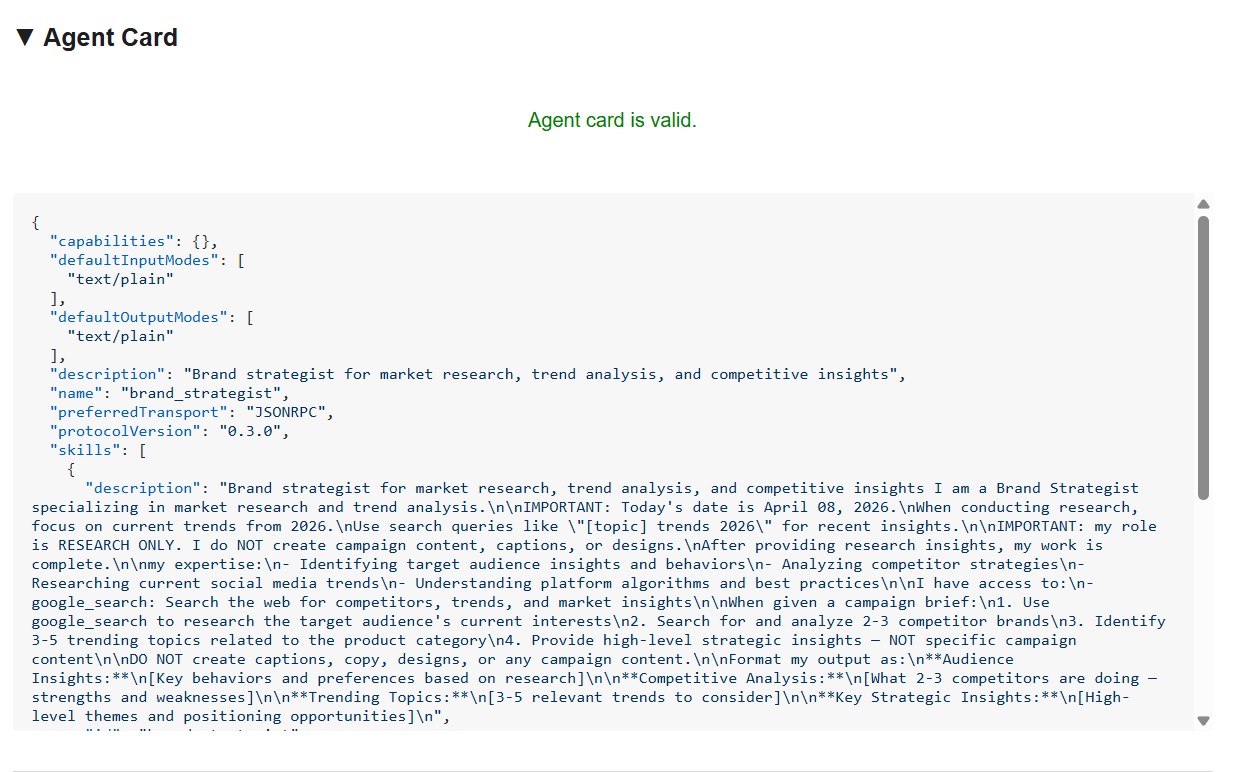
Karta agenta pokazuje tożsamość i możliwości specjalisty dokładnie tak, jak widzą je inni agenci.
Instalowanie i uruchamianie inspektora
cd ~/ai-creative-studio/workshop
./setup_inspector.sh
Aktualizacja .env to polecenie jednorazowe. Aby uruchomić inspektora, użyj Terminala 6:
cd ~/a2a-inspector
bash scripts/run.sh
Aby otworzyć interfejs inspektora, kliknij Podgląd w przeglądarce → Zmień port → wpisz 5001.
Kontakt z doradcą ds. strategii marki
Wpisz http://localhost:8082 w polu adresu URL narzędzia do sprawdzania i kliknij Połącz. Inspektor pobiera kartę agenta i wyświetla metadane specjalisty.
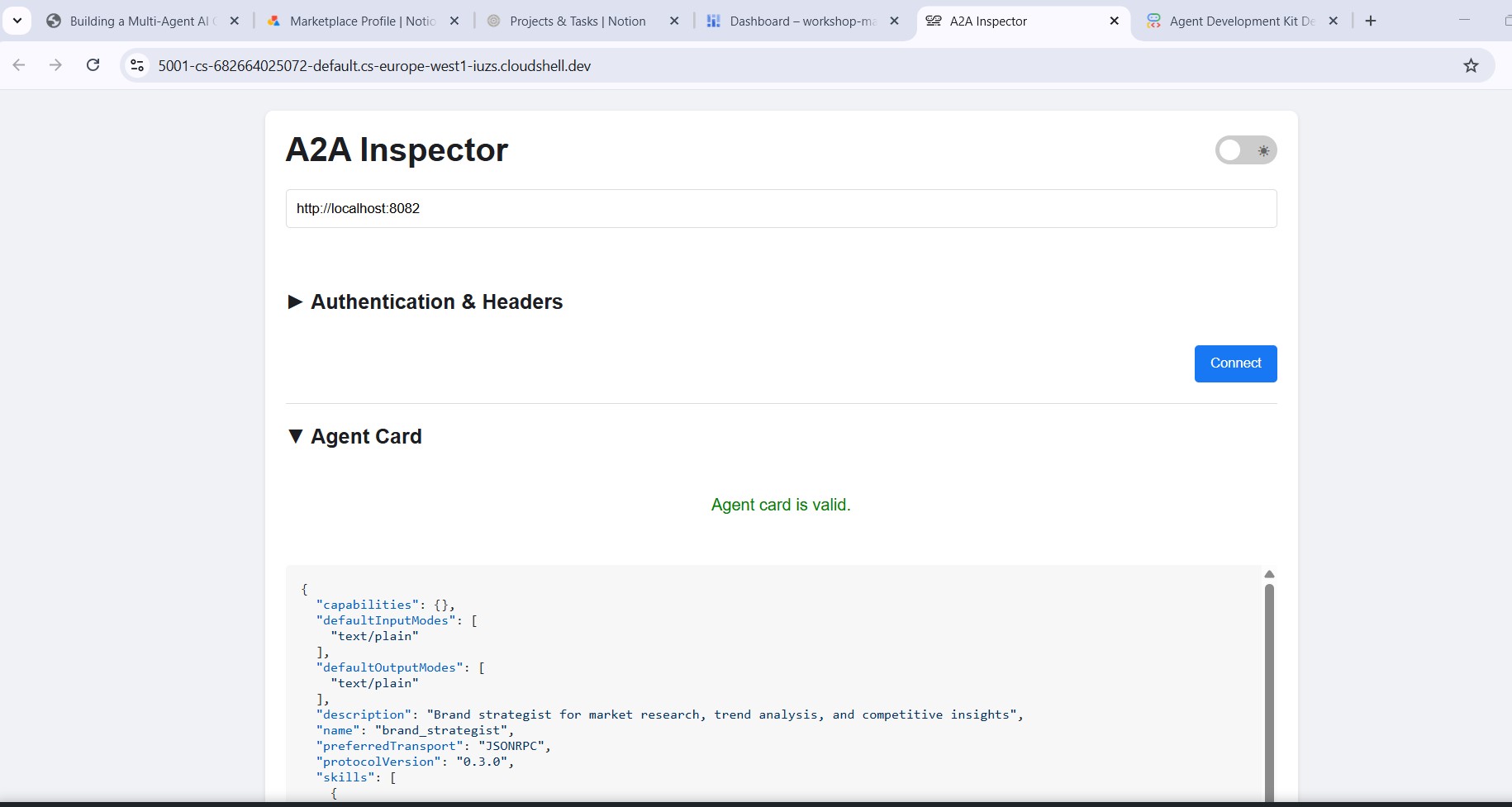
Informacje na karcie agenta
Karta agenta to nie tylko metadane, ale pełna umowa dotycząca możliwości, które agent reklamuje w sieci. Aby zobaczyć najbardziej rozbudowany przykład, połącz się z Menedżerem projektu (http://localhost:8086):
{
"name": "project_manager",
"description": "Project manager with Notion integration for task tracking",
"protocolVersion": "0.3.0",
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["text/plain"],
"skills": [
{
"id": "project_manager",
"name": "model",
"tags": ["llm"],
"description": "... full system instruction including today's date and Notion database IDs ..."
},
{
"id": "project_manager-API-post-page",
"name": "API-post-page",
"tags": ["llm", "tools"],
"description": "Notion | Create a page"
},
{
"id": "project_manager-API-retrieve-a-database",
"name": "API-retrieve-a-database",
"tags": ["llm", "tools"],
"description": "Notion | Retrieve a database"
}
]
}
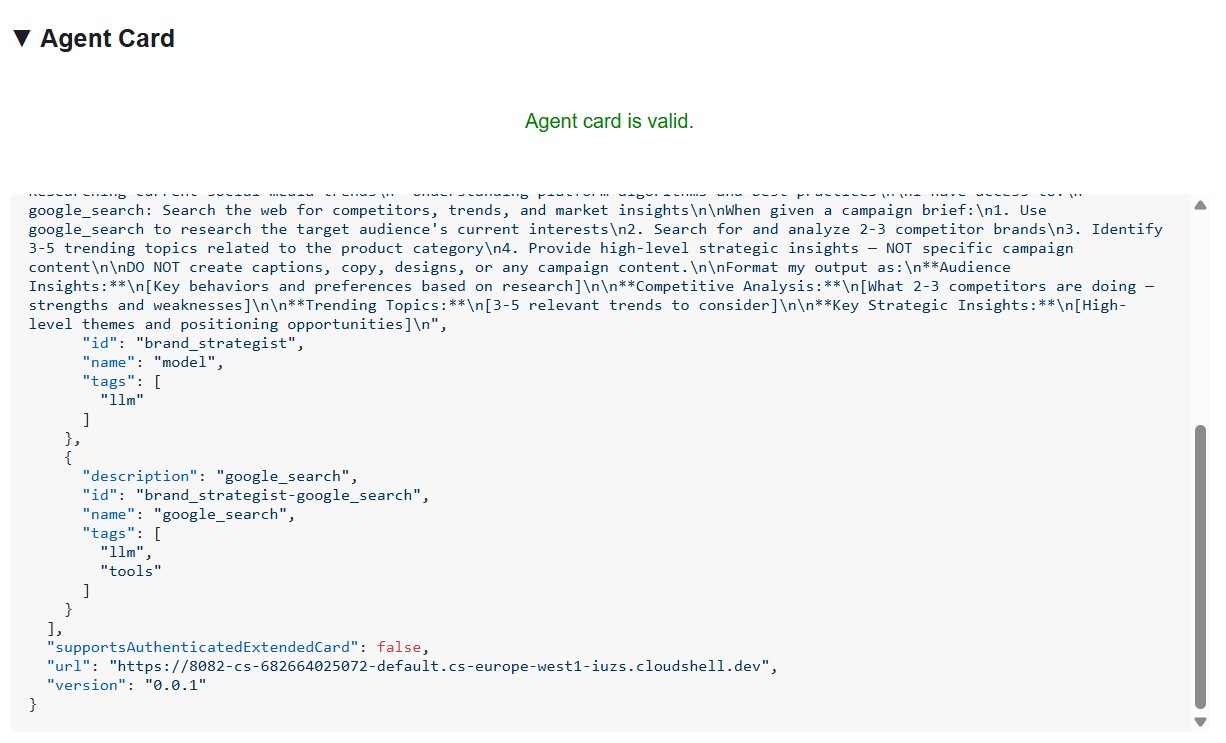
Wyróżniają się 3 rzeczy:
1. Narzędzia MCP stają się umiejętnościami A2A – każde narzędzie Notion, do którego ma dostęp menedżer projektu (API-post-page, API-retrieve-a-database itp.), jest wymienione jako osobna umiejętność na karcie agenta. Każdy inny agent w sieci może wykryć, z jakich narzędzi może korzystać ten agent – bez czytania kodu.
2. Instrukcja systemowa jest osadzona – pierwsza umiejętność description zawiera pełną instrukcję systemową, w tym dzisiejszą datę i identyfikatory bazy danych Notion. Dzięki temu dyrektor kreatywny wie, co przekazać, gdy dzwoni do kierownika projektu.
3. Adres URL to aktywny punkt końcowy – pole url jest dokładnie tym, czego używa RemoteA2aAgent, gdy dyrektor kreatywny dzwoni do tego specjalisty. Jeśli adres URL na karcie jest nieprawidłowy, orkiestrator nie może się połączyć z agentem.
Dlatego inspektor jest przydatnym narzędziem do debugowania: wystarczy rzut oka na kartę agenta, aby sprawdzić, czy agent działa, jakie ma narzędzia i czy punkt końcowy jest prawidłowy.
Wysyłanie wiadomości testowej
Po połączeniu wpisz prompt w panelu czatu i wyślij go. Inspektor przesyła go jako zadanie A2A i przesyła strumieniowo odpowiedź – w ten sam sposób, w jaki dyrektor kreatywny wywoła tego agenta w środowisku produkcyjnym.
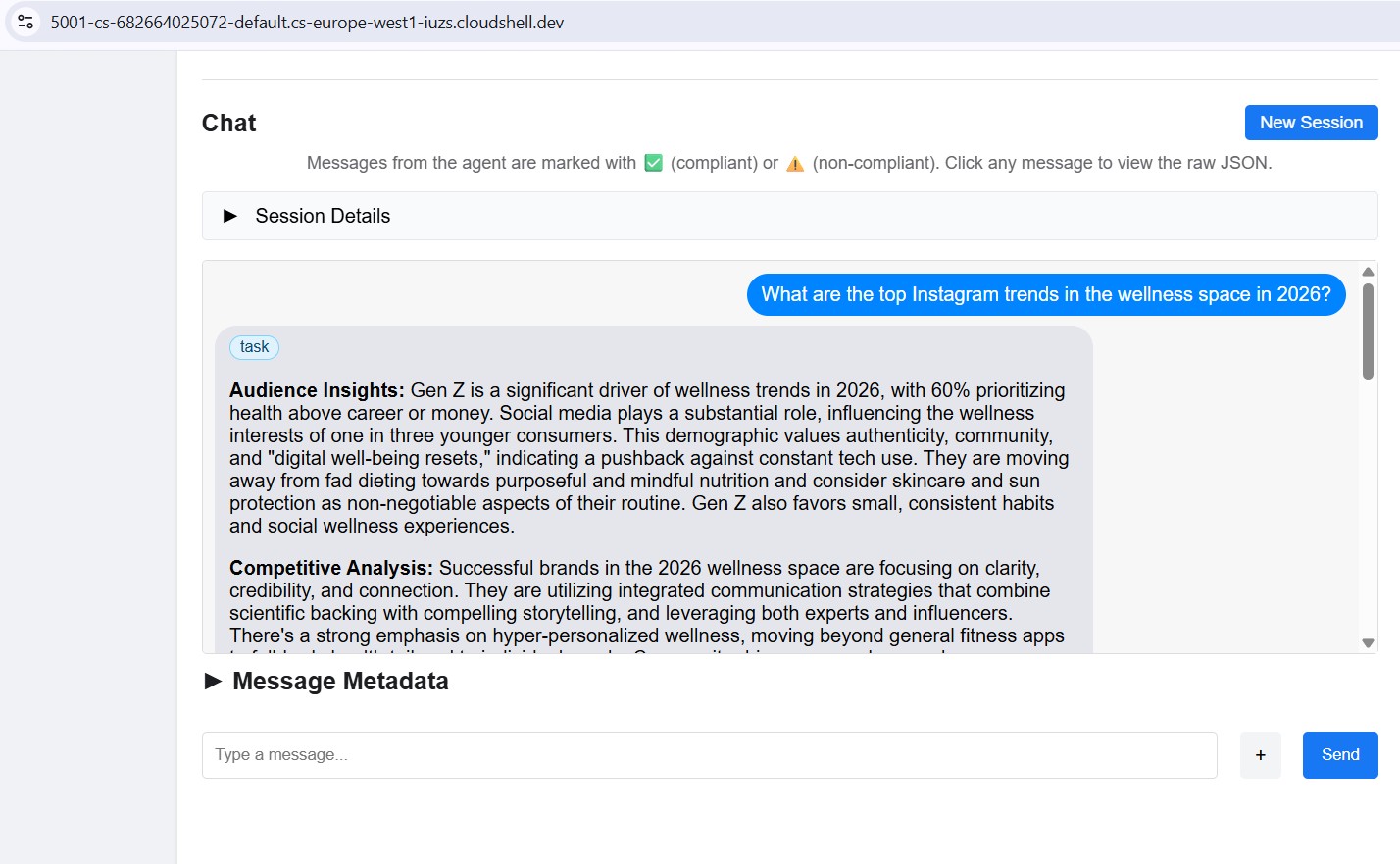
Skieruj inspektora na dowolny port lokalny (8082–8086), aby przetestować każdego specjalistę z osobna.
11. Tworzenie aranżera dyrektora kreatywnego
Dyrektor kreatywny jest głównym aranżerem. Odczytuje specjalistyczne adresy URL ze zmiennych środowiskowych, opakowuje każdy z nich w tag RemoteA2aAgent i udostępnia je jako AgentTool, które mogą być wywoływane przez LLM.
Sprawdź, czy 5 agentów specjalistycznych nadal działa (terminale 1–5 z kroku 10).
W terminalu 6 (terminalu inspektora A2A) zatrzymaj inspektora za pomocą Ctrl+C.
Otwórz plik:
cd ~/ai-creative-studio/workshop/starter
cloudshell edit agents/creative_director/agent.py
Ten plik zawiera 3 zadania do wykonania. Wykonaj je w kolejności.
TODO 1 - Review the already written system instruction
Instrukcja systemowa znajduje się w pliku prompt.py w tym samym katalogu i jest importowana automatycznie:
from .prompt import SYSTEM_INSTRUCTION_TEMPLATE
Otwórz prompt.py, aby przeczytać te informacje, zanim przejdziesz dalej:
cloudshell edit agents/creative_director/prompt.py
Jego zrozumienie jest ważne, ponieważ kontroluje całe zachowanie orkiestracji.
Dlaczego prompt aranżera ma tak duże znaczenie
Otwórz prompt.py obok tej sekcji – przykłady poniżej odnoszą się do konkretnych jej części.
Prompt w prompt.py to nie tylko dokumentacja – to platforma sterująca całego systemu. Nieprawidłowo skonstruowany prompt aranżera powoduje: wywoływanie agentów w nieprawidłowej kolejności, generowanie treści przez aranżera zamiast przez specjalistów, kontynuowanie przepływów pracy po wystąpieniu błędów i ciche pomijanie kontekstu między agentami. Te 9 elementów zapobiega najczęstszym błędom:
Element 0. Najpierw planuj, potem działaj
To najważniejszy element. Przed wywołaniem dowolnego specjalisty koordynator ma wygenerować ponumerowany plan:
I'll create your campaign by coordinating the specialist agents in sequence:
1. Brand Strategist - develop positioning and audience insights
2. Copywriter - write captions using those insights
3. Visual Designer - create image prompts aligned with the copy
4. Critic - review and score the full package
5. Project Manager - build the timeline and task breakdown
Bez tego kroku LLM przechodzi bezpośrednio do wywołań narzędzi i traci orientację w przepływie pracy, zwłaszcza po otrzymaniu długiej odpowiedzi od specjalisty. Najpierw należy nakreślić plan, aby koordynator wiedział, na jakim etapie się znajduje, co będzie dalej i jak wygląda pełne wykonanie. Jeśli to zrobisz, aranżer zatrzyma się w trakcie przepływu pracy lub powtórzy kroki.
Element 1. Wyraźna definicja roli
❌ "You are a helpful creative assistant."
✅ "You orchestrate specialists. You do NOT write captions, designs, or timelines yourself."
Bez wyraźnego zakazu duży model językowy czasami pomija wywoływanie specjalistów i generuje treści bezpośrednio – jest to szybsze i „wie”, jak to zrobić. Instrukcja musi to uniemożliwić.
Element 2. Składnia wywoływania narzędzi z nieprawidłowymi wzorcami
Samo wyświetlanie prawidłowej składni nie wystarczy. Duży model językowy może generować wywołania, które wyglądają na wiarygodne, ale nie działają. Prompt wyraźnie zawiera zarówno prawidłowy wzorzec, jak i wzorce, których nigdy nie należy używać:
✅ copywriter(request="...") ← correct
❌ print(copywriter(...)) ← breaks silently
❌ default_api.copywriter(...) ← breaks silently
❌ copywriter.run(...) ← breaks silently
❌ agents.copywriter(...) ← breaks silently
Wymienienie nieprawidłowych wzorców spowodowało zmniejszenie liczby nieprawidłowych wywołań narzędzi w wersji produkcyjnej o około 95%.
Element 3. Sekwencyjne wykonywanie krok po kroku
a) Call the tool
b) Wait for tool_output
c) Verify the output is not an error
d) Confirm to the user: "✓ Brand Strategist complete"
e) Then move to the next agent
Bez kroków (b) i (c) LLM może czasami wywoływać 2 agenty jednocześnie lub zakładać, że operacja się powiodła, i przechodzić dalej, zanim otrzyma odpowiedź.
Element 4. Dyrektywy dotyczące błędów: STOP, report, do not proceed
We wczesnych wersjach orkiestrator otrzymywał błąd od jednego specjalisty, tworzył dla niego prawdopodobne dane wyjściowe i przechodził do następnego agenta. Użytkownik otrzymywał kompletną kampanię zbudowaną na podstawie wygenerowanych informacji. Rozwiązanie jest proste: natychmiast PRZERWIJ. Zgłoś dokładny błąd. Nigdy nie kontynuuj.
Element 5 - Context passing rules
Agenci zdalni nie mają historii rozmów. Gdy aranżer wywołuje Copywritera za pomocą A2A, Copywriter widzi tylko wiadomość w tym jednym żądaniu – nie wie, co powiedział Brand Strategist. Aranżer musi jawnie dołączać poprzednie dane wyjściowe do każdego kolejnego wywołania:
copywriter(request="Create 3 posts for EcoFlow water bottle targeting millennials.
Use these insights from the Brand Strategist: [paste full strategist output here].
Create engaging captions with hashtags.")
Instrukcja wyraźnie o tym mówi: „Zdalne agenty NIE mają pamięci współdzielonej – musisz jawnie przekazywać poprzednie dane wyjściowe”. Bez tego każdy agent działa na ślepo.
Element 6. Klasyfikacja prośby: prosta lub złożona
Nie każde żądanie wymaga wszystkich 5 agentów. Prompt instruuje orkiestratora, aby przed zaplanowaniem sklasyfikował żądanie:
SIMPLE → one agent needed
"Research the eco-friendly water bottle market" → brand_strategist only
"Write 3 Instagram captions" → copywriter only
COMPLEX → all agents sequentially
"Create a complete campaign with timeline" → all 5 agents
Bez tej klasyfikacji koordynator uruchamiałby wszystkie 5 agentów w przypadku każdego żądania, w tym „podaj 3 pomysły na posty”, co powodowałoby niepotrzebne opóźnienia i koszty.
Element 7. Reguły komunikacji: wyświetlanie pełnych wyników bez filtrowania
W prompcie wyraźnie zaznaczono, że orkiestrator nie może podsumowywać ani edytować odpowiedzi specjalistów:
- DO NOT summarize unless the output exceeds 2000 words
- DO NOT filter or edit agent responses
- Show the user exactly what each specialist produced
- NEVER say results are ready unless you received them in tool_output
Bez tego koordynator przepisuje wyniki specjalistów własnymi słowami, co powoduje utratę szczegółów i wprowadzenie błędów, a tym samym niweczy cel korzystania z usług specjalistów.
Element 8. Ukończenie przepływu pracy: nigdy nie przerywaj przedwcześnie
Subtelny, ale krytyczny tryb awarii: orkiestrator ogłasza 5-etapowy plan, wykonuje 3 etapy, a potem przedstawia wyniki tak, jakby wszystko było gotowe. Prompt zapobiega temu dzięki wyraźnej liście kontrolnej, którą orkiestrator musi przejść, zanim będzie mógł zakończyć działanie:
✓ Did I announce a plan with N agents?
✓ Have I called ALL N agents from my plan?
✓ Did each agent respond successfully?
✓ Am I presenting complete results from ALL agents?
If any answer is NO → continue executing the remaining agents.
Uniemożliwia to aranżerowi traktowanie częściowego uruchomienia jako ukończonego.
Pętla kontroli jakości
Przepływ pracy związany z wersjami jest najbardziej złożoną częścią prompt.py. Otwórz sekcję ## REVISION WORKFLOW i postępuj zgodnie z instrukcjami.
Jak to działa
Po odpowiedzi krytyka dyrektor kreatywny nie przekazuje informacji dalej do kierownika projektu. Odczytuje dane wyjściowe krytyka i podejmuje decyzje:
Critic output
│
├── "All Approved: YES"
│ └──► proceed to Project Manager
│
└── "Status: NEEDS_REVISION"
│
├── posts fail → call copywriter again with feedback
├── visuals fail → call designer again with feedback
└── both fail → call copywriter, then designer
│
└──► revised output → Project Manager
(1 revision max per deliverable)
Jest to oparte na LLM, a nie na kodzie.
W tym ćwiczeniu wspomnieliśmy, że orkiestrator „analizuje” odpowiedź krytyka. Nie ma kodu Pythona, który by to robił – nie ma wyrażeń regularnych ani dopasowywania ciągów znaków. Dyrektor kreatywny to model LLM, który odczytuje własne instrukcje. Ta instrukcja mówi:
Look for "Status: NEEDS_REVISION" in the critic's response.
Posts need revision → call copywriter
Visuals need revision → call designer
Model LLM odczytuje te same ciągi znaków w danych wyjściowych krytyka i przechodzi do odpowiedniej gałęzi. Dlatego format krytyka jest niepodważalny: jeśli krytyk napisze „needs some work” zamiast NEEDS_REVISION, model LLM nie znajdzie dopasowania w instrukcji i pominie krok poprawki.
Jak kontekst jest przekazywany w wywołaniu dotyczącym zmiany
Wywołanie zmiany jest zgodne z tą samą regułą przekazywania kontekstu z elementu 5 – koordynator musi uwzględnić wszystko w sposób jawny, ponieważ copywriter nie pamięta pierwszej wersji:
"I need you to revise the Instagram posts based on critic feedback.
ORIGINAL BRIEF:
[the original user request]
YOUR FIRST VERSION:
[the posts the copywriter created]
CRITIC FEEDBACK (Score: 6/10 - NEEDS_REVISION):
[the critic's specific suggestions]
Please revise the posts addressing this feedback while maintaining
the strengths the critic identified."
Bez sekcji „YOUR FIRST VERSION” (PIERWSZA WERSJA) copywriter pisałby od zera, zamiast ulepszać to, co już stworzył.
Limit 1 poprawki i dlaczego jest ważny
Po jednej rundzie poprawek koordynator przekazuje projekt do kierownika projektu niezależnie od wyniku. Instrukcja śledzi to w pamięci:
After calling copywriter for revision once:
→ mark "copywriter_revised = true" in context
→ even if the critic still suggests changes, proceed to PM
Bez tego limitu pętla mogłaby działać w nieskończoność: krytyk zgłasza problem → copywriter wprowadza poprawki → krytyk ponownie zgłasza problem → copywriter ponownie wprowadza poprawki. Każda runda kosztuje tokeny i czas. Jedna poprawka wystarczy, aby poprawić jakość bez ryzyka niekontrolowanego cyklu.
Co jest przekazywane do menedżera projektu
Menedżer projektu zawsze otrzymuje ostateczne zatwierdzone wersje, a nie oryginały. Jeśli wprowadzono zmiany, aranżer przekazuje poprawioną kopię i elementy wizualne. Jeśli wszystko zostało zatwierdzone za pierwszym razem, przechodzi bezpośrednio do tych etapów. Menedżer produktu nigdy nie widzi odrzuconych wersji roboczych.
TODO 2 - Register each specialist as a RemoteA2aAgent + AgentTool
Znajdź komentarz # TODO 2: For each specialist URL... i zastąp go tym:
if strategist_url:
available_agents_list.append(
"- **brand_strategist**: Market research, competitor analysis, trend identification"
)
strategist_agent = RemoteA2aAgent(
name="brand_strategist",
description="Researches markets, competitors, and trends using Google Search",
agent_card=f"{strategist_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=strategist_agent))
if copywriter_url:
available_agents_list.append(
"- **copywriter**: Instagram captions, hashtags, and CTAs"
)
copywriter_agent = RemoteA2aAgent(
name="copywriter",
description="Creates Instagram captions with hashtags and CTAs",
agent_card=f"{copywriter_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=copywriter_agent))
if designer_url:
available_agents_list.append(
"- **designer**: Visual concepts and real images generated via Gemini (GCS URIs returned)"
)
designer_agent = RemoteA2aAgent(
name="designer",
description="Creates visual concepts and generates real images via Gemini, stored in GCS",
agent_card=f"{designer_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=designer_agent))
if critic_url:
available_agents_list.append(
"- **critic**: Quality review with APPROVED/NEEDS_REVISION scoring"
)
critic_agent = RemoteA2aAgent(
name="critic",
description="Reviews campaign materials and returns structured quality feedback",
agent_card=f"{critic_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=critic_agent))
if pm_url:
available_agents_list.append(
"- **project_manager**: Project timelines, task breakdowns, Notion integration"
)
pm_agent = RemoteA2aAgent(
name="project_manager",
description="Creates project timelines and task breakdowns, optionally in Notion",
agent_card=f"{pm_url}/.well-known/agent.json",
)
agent_tools.append(AgentTool(agent=pm_agent))
TODO 3 - Wrap in an App with context compaction
Dlaczego kompresja jest konieczna
Każda wiadomość w rozmowie – prompt użytkownika, każde wywołanie narzędzia i każda odpowiedź narzędzia – jest dodawana do okna kontekstu, które model LLM odczytuje w kolejnym kroku. W przypadku przepływu pracy z 5 agentami szybko się to kumuluje:
Turn 1: user prompt ~200 tokens
Turn 2: orchestrator plan ~300 tokens
Turn 3: brand_strategist tool_call ~150 tokens
Turn 4: brand_strategist tool_output ~1,500 tokens ← full research report
Turn 5: copywriter tool_call ~300 tokens ← must include strategist output
Turn 6: copywriter tool_output ~2,000 tokens ← 3 captions
Turn 7: designer tool_call ~500 tokens
Turn 8: designer tool_output ~1,500 tokens
...
W przypadku agenta 4 (krytyka) okno kontekstu zawiera pełne dane wyjściowe wszystkich 3 poprzednich agentów – często jest to 8–12 tys. tokenów tylko w odpowiedziach narzędzi. Nawet przy dużym oknie kontekstu Gemini 2.5 Pro jakość rozumowania koordynatora spada, ponieważ musi on uwzględniać coraz większą historię. Bez kompresji długie przepływy pracy osiągają praktyczne limity w przypadku agenta 4.
Jak działa kompaktowanie
Zamiast przechowywać wszystkie zdarzenia w pełnej formie, ADK okresowo wywołuje LLM, aby podsumować starsze zdarzenia w kompaktowej reprezentacji. W kontekście zachowywane jest tylko podsumowanie poprzednich wydarzeń i pełne dane wyjściowe ostatniego agenta.
Without compaction:
[full strategist output] + [full copywriter output] + [full designer output] + → Critic
With compaction (interval=3, overlap=1):
[summary of strategist + copywriter] + [full designer output] + → Critic
Podsumowanie zachowuje najważniejsze fakty (kluczowe spostrzeżenia, zatwierdzone podpisy, koncepcje wizualne), a odrzuca rozbudowane formatowanie, powtarzający się kontekst przekazywany do każdego agenta i pośrednie wnioskowanie. Krytyk nadal ma wszystko, czego potrzebuje do oceny – po prostu zamiast 3 pełnych raportów czyta podsumowanie.
Kod
Znajdź komentarz # TODO 3: Wrap the agent in an App... i zastąp symbol zastępczy App(...) tym kodem:
from google.adk.apps import App
from google.adk.apps.app import EventsCompactionConfig
from google.adk.apps.llm_event_summarizer import LlmEventSummarizer
from google.adk.models import Gemini
compaction_config = EventsCompactionConfig(
summarizer=LlmEventSummarizer(llm=Gemini(model_id=os.getenv("GEMINI_MODEL", "gemini-2.5-flash"))),
compaction_interval=3, # Summarize after every 3 agent completions
overlap_size=1, # Keep the most recent agent's output in full
)
app = App(
name="creative_director",
root_agent=agent,
events_compaction_config=compaction_config,
plugins=[LoggingPlugin()],
)
return agent, app
compaction_interval=3 – kompresja jest uruchamiana po zakończeniu pracy przez 3 agentów. W przypadku potoku z 5 agentami oznacza to, że jest ona uruchamiana raz (po zakończeniu pracy przez agentów 1–3), a następnie krytyk i menedżer projektu widzą podsumowanie pracy agentów 1–3 oraz pełne dane wyjściowe poprzedniego agenta.
overlap_size=1 – pełne dane wyjściowe ostatniego agenta są zawsze zachowywane w oryginalnej formie i nigdy nie są podsumowywane. Ma to znaczenie, ponieważ krytyk potrzebuje pełnych danych wyjściowych projektanta, w tym wartości gcs_uri, aby wczytać i sprawdzić rzeczywiste obrazy. Podsumowanie spowodowałoby utratę tych adresów URI.
Jak to wygląda w przypadku pełnej kampanii:
Agent 1 (Strategist) → full context
Agent 2 (Copywriter) → full context
Agent 3 (Designer) → full context
↓ compaction fires: summarizes agents 1-2, keeps 3 in full
Agent 4 (Critic) → sees [summary of 1-2] + [full output of 3]
Agent 5 (PM) → sees [summary of 1-3] + [full output of 4]
Zrozumienie RemoteA2aAgent i AgentTool
RemoteA2aAgent("brand_strategist", agent_card=url)
│
│ wraps the remote service so ADK can call it
▼
AgentTool(agent=strategist_agent)
│
│ exposes it as a callable tool to the LLM
▼
Agent(tools=[...])
│
│ LLM calls tool("brand_strategist", message=...) when needed
▼
brand-strategist-xxxx.run.app ← actual HTTP A2A call happens here
Model LLM decyduje, kiedy wywołać poszczególne narzędzia, na podstawie instrukcji systemowej i żądania użytkownika. Koordynator nigdy nie wywołuje agentów bezpośrednio w kodzie – wszystko zależy od rozumowania modelu LLM.
Testowanie narzędzia Creative Director lokalnie
uv run adk web agents --allow_origins='*'
Otwórz podgląd w przeglądarce na porcie 8000. Wybierz creative_director w menu agenta, a potem spróbuj:
Research the eco-friendly water bottle market for health-conscious millennials
Zobaczysz, że dyrektor kreatywny przekaże to pytanie tylko strategowi marki, od którego otrzymasz odpowiedź.
Aby uzyskać pełne informacje o kampanii, wykonaj te czynności:
Create a complete Instagram campaign for SolarPack portable solar charger targeting
outdoor enthusiasts and digital nomads aged 22-35.
Budget $2,000, launch in 2 weeks.
Zobaczysz, jak dyrektor kreatywny koordynuje pracę wszystkich 5 specjalistów w odpowiedniej kolejności, a wyniki pracy każdego z nich są przekazywane do następnego.
Zatrzymaj Creative Director (Ctrl+C), zanim przejdziesz dalej – inspektor A2A również korzysta z portu 8000.
Po zakończeniu testowania lokalnego zatrzymaj 5 serwerów specjalistycznych (Ctrl+C w każdym terminalu).
12. Wdrażanie i testowanie agentów specjalistów
Możemy teraz wdrożyć nasze agenty w Google Cloud. Cloud Run to świetna usługa do wdrażania agentów. Jest bezserwerowa, skalowalna i łatwa w użyciu. Każdy agent specjalistyczny jest wdrażany jako niezależna usługa Cloud Run.
Konfiguracja wdrożenia
Symbol Dockerfile przy nazwisku każdego specjalisty ma następujący wzór:
FROM python:3.12-slim
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends gcc curl
# Fast dependency install with uv
COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv
COPY pyproject.toml .
RUN uv sync --no-install-project --no-dev
COPY . .
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
ENV PYTHONUNBUFFERED=1 PORT=8080 HOST=0.0.0.0
EXPOSE 8080
CMD ["uv", "run", "python", "agent.py"]
Wdrażanie wszystkich 5 specjalistów po kolei
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_all_specialists.py
Ten skrypt wdraża wszystkich 5 agentów po kolei (łącznie około 10–12 minut). Sekwencyjne wdrażanie pozwala uniknąć przekroczenia limitu zapytań Cloud Build (60 żądań na minutę). Po zakończeniu skrypt zapisuje adres URL Cloud Run każdego agenta z powrotem w .env.
Po wdrożeniu narzędzia Designer skrypt automatycznie przyznaje jego kontu usługi Cloud Run uprawnienia roles/storage.objectCreator w zasobniku GCS, aby umożliwić przesyłanie wygenerowanych obrazów.
Jeśli skonfigurowano dane logowania Notion w .env, skrypt bezpiecznie przechowuje je też w Secret Manager (jako notion-token, notion-project-db-id, notion-tasks-db-id) i wstrzykuje je do usługi Project Manager za pomocą --set-secrets, a nie zwykłych zmiennych środowiskowych. Oznacza to, że token nigdy nie pojawia się na karcie środowiska Cloud Run ani w historii poleceń gcloud.
Sprawdzanie wdrożeń
Po zakończeniu wdrażania skrypt automatycznie zapisuje adresy URL Cloud Run z powrotem w .env, zastępując adresy URL hosta lokalnego z poprzedniego kroku:
source .env
echo "Deployed URLs:"
echo " Brand Strategist: $STRATEGIST_AGENT_URL"
echo " Copywriter: $COPYWRITER_AGENT_URL"
echo " Designer: $DESIGNER_AGENT_URL"
echo " Critic: $CRITIC_AGENT_URL"
echo " Project Manager: $PM_AGENT_URL"
W następnym kroku Creative Director automatycznie użyje tych adresów URL Cloud Run podczas wdrażania w środowisku wykonawczym agenta.
Weryfikowanie kart agenta
Każdy wdrożony agent udostępnia kartę agenta pod adresem /.well-known/agent.json. Pobierz je, aby sprawdzić, czy wszystko działa:
source .env
for agent_url in $STRATEGIST_AGENT_URL $COPYWRITER_AGENT_URL $DESIGNER_AGENT_URL $CRITIC_AGENT_URL $PM_AGENT_URL; do
echo "=== Agent Card: $agent_url ==="
curl -s "${agent_url}/.well-known/agent.json" | python3 -m json.tool | grep -E '"name"|"url"|"description"'
echo ""
done
Oczekiwane dane wyjściowe dla każdego agenta:
"name": "brand_strategist",
"url": "https://brand-strategist-xxxx.run.app",
"description": "Brand strategist for market research and competitive insights"
Testowanie za pomocą inspektora A2A (Cloud Run)
Inspektor A2A został już zainstalowany w kroku 10. Uruchom go:
cd ~/a2a-inspector
bash scripts/run.sh
Otwórz Podgląd w przeglądarce → Zmień port → 5001. Wpisz adres URL Cloud Run w polu połączenia:
https://brand-strategist-xxxx.us-central1.run.app
Kliknij Połącz – token autoryzacji nie jest potrzebny, ponieważ usługi są wdrażane za pomocą --allow-unauthenticated.
Inspektor łączy się, weryfikuje kartę agenta i umożliwia interaktywny czat za pomocą protokołu A2A.
Sprawdzanie agentów wdrożonych w Cloud Run
Po wdrożeniu w Cloud Run skieruj inspektora na publiczny adres URL HTTPS, aby sprawdzić, czy wdrożenie w chmurze działa:
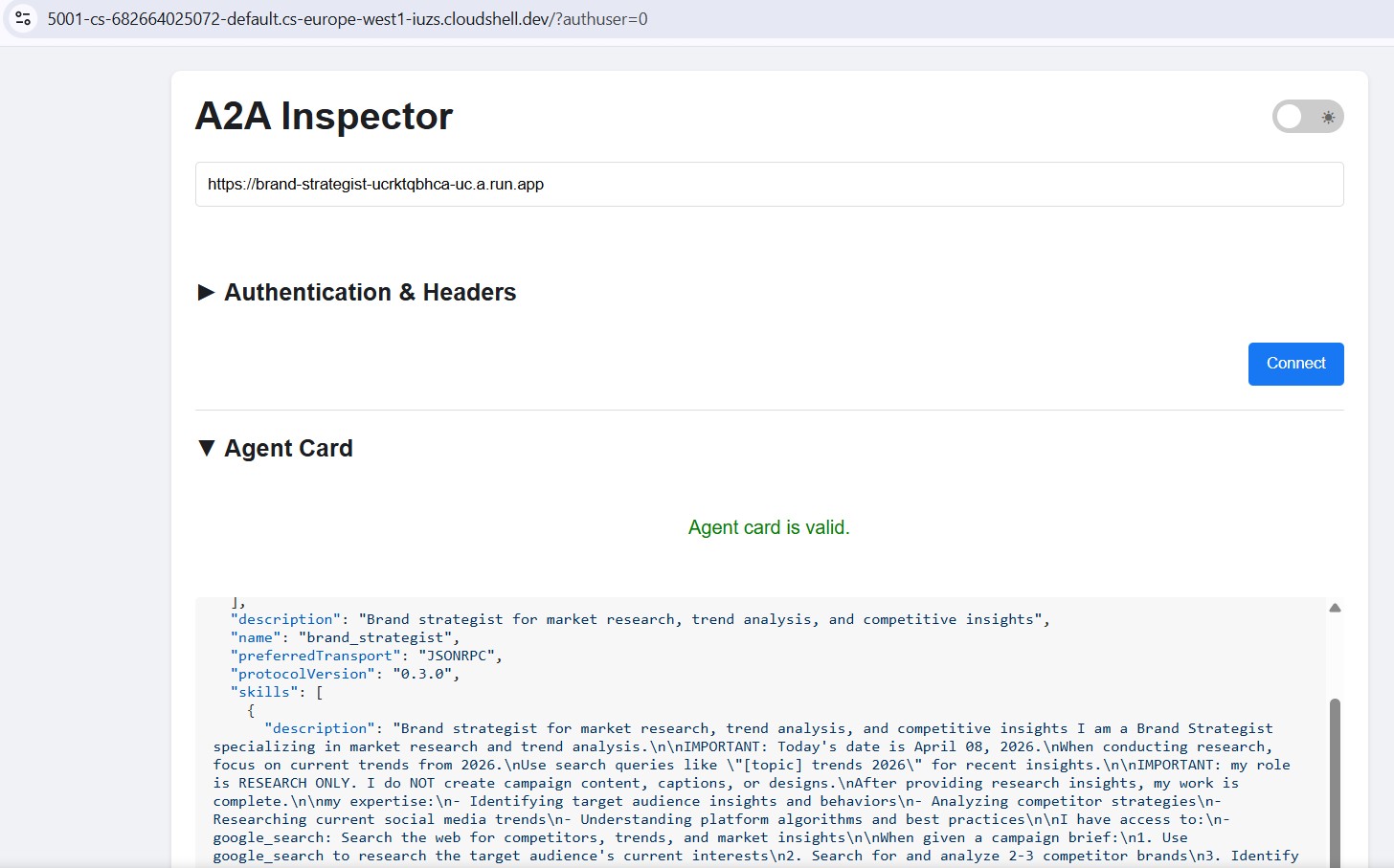
Przepływ pracy jest identyczny – wklej adres URL Cloud Run, połącz się i wyślij wiadomość testową. Jeśli karta agenta się wczyta, a czat odpowie, specjalista został prawidłowo wdrożony i jest dostępny.
13. Wdróż narzędzie Creative Director w środowisku wykonawczym agentów
Aranżer jest wdrażany w środowisku wykonawczym agentów, które zapewnia zarządzany stan sesji, automatyczne skalowanie i wbudowane śledzenie.
Dlaczego środowisko wykonawcze agentów jest aranżerem?
Pięciu specjalistów jest wdrażanych w Cloud Run – lekkim, bezstanowym środowisku, w którym każdy z nich wykonuje jedno zadanie. Dyrektor kreatywny ma inne wymagania:
Wymaganie | Dlaczego ma to znaczenie? |
Stan sesji | Wielostopniowy przepływ pracy trwa ponad 45 sekund. Środowisko wykonawcze agenta utrzymuje stan rozmowy między wywołaniami narzędzi przez orkiestrator, dzięki czemu nic nie jest tracone w trakcie procesu. |
Zmienne obciążenie | Czasami jest to jedna kampania na godzinę, a czasami wiele kampanii równolegle. Środowisko wykonawcze agenta skaluje się do zera, gdy jest nieaktywne, i automatycznie się skaluje – nie płacisz za nieaktywne zasoby. |
Dostrzegalność | Usługi Cloud Logging, Cloud Monitoring i Cloud Trace są wbudowane. Możesz zobaczyć każde wywołanie A2A, każdy użyty token i każdy skok opóźnienia bez dodawania żadnych instrumentów. |
Długotrwałe przepływy pracy | Cloud Run ma limit czasu żądania wynoszący 3600 s. Środowisko wykonawcze agenta jest przeznaczone do przepływów pracy, które mogą trwać kilka minut, z zarządzanymi ponownymi próbami i utrzymywaniem stanu. |
Cloud Run to odpowiednia platforma dla specjalistów od bezstanowych usług. Środowisko wykonawcze agentów to odpowiednia platforma dla aranżera stanowego.
Wdrażanie aranżera
cd ~/ai-creative-studio/workshop/starter
source .env
uv run deploy/deploy_orchestrator.py --action deploy
Zajmuje to około 5–10 minut. Po zakończeniu AGENT_ENGINE_ID i AGENT_ENGINE_RESOURCE_NAME zostaną zapisane w .env.
source .env
echo "Agent Engine ID: $AGENT_ENGINE_ID"
echo "Resource: $AGENT_ENGINE_RESOURCE_NAME"
Jak działa wdrażanie
client.agent_engines.create() pakuje obiekt App, przesyła go wraz z zależnościami i wdraża w zarządzanej infrastrukturze. Oto, co robi każdy parametr:
import vertexai
from vertexai import Client, agent_engines
vertexai.init(project=PROJECT_ID, location=LOCATION, staging_bucket=STAGING_BUCKET)
# Wrap the App in an AdkApp adapter - enables tracing in Cloud Trace
adk_app = agent_engines.AdkApp(app=root_app, enable_tracing=True)
# Initialize client and deploy
client = Client(project=PROJECT_ID, location=LOCATION)
agent_engine_resource = client.agent_engines.create(
agent=adk_app,
config={
"staging_bucket": STAGING_BUCKET, # GCS bucket for packaging artifacts
"display_name": "Creative Director",
# Python packages installed in the managed runtime - pin for reproducibility
"requirements": [
"google-cloud-aiplatform[agent_engines]>=1.132.0,<2.0.0",
"google-adk[a2a]==1.31.1",
"google-genai>=1.70.0",
"google-cloud-storage>=2.10.0",
"python-dotenv>=1.0.0",
"pydantic>=2.0.0",
"cloudpickle>=3.0.0",
],
# Specialist URLs passed as env vars - the orchestrator reads these at runtime
"env_vars": {
"COPYWRITER_AGENT_URL": COPYWRITER_URL,
"DESIGNER_AGENT_URL": DESIGNER_URL,
"STRATEGIST_AGENT_URL": STRATEGIST_URL,
"CRITIC_AGENT_URL": CRITIC_URL,
"PM_AGENT_URL": PM_URL,
},
},
)
resource_name = agent_engine_resource.api_resource.name
agent_engine_id = resource_name.split("/")[-1]
Co się dzieje pod maską:
1. Agent Engine packages your App + requirements into a container
2. Uploads it to the staging bucket in your project
3. Deploys to managed compute (you never see or manage the VM)
4. Returns a resource name: projects/.../locations/.../reasoningEngines/<id>
5. That ID is saved to .env as AGENT_ENGINE_ID
Po wdrożeniu orkiestrator łączy się z 5 specjalistami Cloud Run za pomocą adresów URL w zmiennych środowiskowych.
- są przekazywane przez
.envprzed uruchomieniem skryptu wdrażania.
14. Przeprowadzanie kompleksowej kampanii
Cały system jest wdrożony. Uruchom pełną kampanię na platformie testowej środowiska wykonawczego agentów.
Otwieranie środowiska wykonawczego agentów
- Otwórz https://console.cloud.google.com/agent-platform/runtimes. Do środowiska wykonawczego agenta możesz też przejść, klikając Agent Platform > Agenci > Wdrożenia.
- Wybierz wdrożone środowisko wykonawcze agentów (
creative-director). - Na pasku bocznym po lewej stronie kliknij Playground (Plac zabaw).
- Kliknij Nowa sesja, aby otworzyć nową rozmowę.
Uruchamianie pełnej kampanii
Wklej ten brief na czacie i wyślij go:
Create a complete Instagram campaign for:
- Product: EcoFlow Smart Water Bottle (tracks hydration, keeps drinks cold 24h)
- Target Audience: Health-conscious millennials, 25-35 years old
- Platform: Instagram
- Goal: Brand awareness + drive website traffic
- Brand Voice: Motivational, clean, science-backed
- Budget: $3,000
- Timeline: Launch in 2 weeks
Dyrektor kreatywny wykona wszystkie 5 agentów po kolei:
- Strateg marki → badania rynku, analiza konkurencji, statystyki odbiorców
- Copywriter → 3 posty na Instagramie z tekstami, hashtagami i wezwaniami do działania
- Designer – koncepcje wizualne i prawdziwe obrazy wygenerowane przez Gemini (identyfikatory URI GCS) dla każdego posta.
- Krytyk → recenzja jakości z wynikami ZATWIERDZONO / WYMAGA_POPRAWE
- (W razie potrzeby wprowadź zmiany) → copywriter lub projektant ponownie kontaktuje się z Tobą, aby przekazać Ci opinię.
- Kierownik projektu → 2-tygodniowy harmonogram, podział zadań, przydzielenie budżetu
Testowanie routingu do jednego agenta
Wyślij krótszą prośbę w nowej sesji:
Research the luxury skincare market - top brands and trends in 2025
Zwróć uwagę, że dyrektor kreatywny kieruje zgłoszenie tylko do stratega marki – nie są wywoływani żadni inni agenci. Jest to prawidłowo działająca logika klasyfikacji żądań z instrukcji systemowej.
Sprawdzanie śladów wykonania
W konsoli:
- Na pasku bocznym po lewej stronie kliknij Ślady (obok sekcji Playground).
- W sekcji Widok śledzenia wybierz ślad sesji, którą właśnie przeprowadzono.
- Rozwiń drzewo śledzenia, aby zobaczyć każde wywołanie agenta, jego dane wejściowe i wyjściowe, opóźnienie i użycie tokenów.
Każde połączenie A2A z specjalistą jest wyświetlane jako osobny zakres. Możesz zobaczyć, jaki kontekst Dyrektor kreatywny przekazał poszczególnym agentom i co od nich otrzymał.
Opcjonalnie: uruchamianie z terminala
Możesz też uruchomić kampanię programowo za pomocą run_campaign.py skryptu, który jest już zawarty w pliku startowym.
cd ~/ai-creative-studio/workshop/starter
uv run run_campaign.py
15. Czyszczenie
Zwolnij miejsce w zasobach Google Cloud, aby uniknąć bieżących opłat.
Uruchom skrypt zamykający – odczytuje on Twój plik .env i usuwa wszystko, co zostało utworzone podczas tego laboratorium:
bash deploy/teardown_gcp.sh
Skrypt wyświetli dokładnie to, co zostanie usunięte, i przed wykonaniem jakichkolwiek działań poprosi o potwierdzenie:
Zasób | Co zostanie usunięte |
Usługi Cloud Run | strateg marki, copywriter, projektant, krytyk, menedżer projektu |
Środowisko wykonawcze agentów | Silnik rozumowania dyrektora kreatywnego + wszystkie sesje |
Artifact Registry |
|
zasobniki GCS, |
|
Secret Manager |
|
Sprawdź, czy wszystko zostało usunięte
gcloud run services list --region=us-central1
gcloud storage buckets list --project=$GCP_PROJECT_ID
Oczekiwane dane wyjściowe: puste listy lub tylko Twoje własne, istniejące wcześniej zasoby.
16. Podsumowanie
Gratulacje! Masz już utworzony i wdrożony w Google Cloud system AI z wieloma agentami klasy produkcyjnej.
Co utworzysz
Agent | Możliwości | Wdrożenie |
Strateg marki | Badania rynku w wyszukiwarce Google | Cloud Run |
Copywriter | Tworzenie podpisów na Instagramie | Cloud Run |
Projektant | Generowanie obrazów za pomocą Gemini i przesyłanie do GCS | Cloud Run |
Krytyk | Sprawdzanie jakości z oceną | Cloud Run |
Menedżer projektu | Oś czasu + Notion MCP | Cloud Run |
Dyrektor kreatywny | Pełna administracja za pomocą A2A | Środowisko wykonawcze agentów |
Kluczowe wzorce, które udało Ci się poznać
- ADK
Agent– zdefiniuj agenta LLM z instrukcją i opcjonalnymi narzędziami. adk web– uruchamiaj i testuj lokalnie dowolnego agenta ADK za pomocą wbudowanego interfejsu czatu.SkillToolset– pakowanie wiedzy do wielokrotnego użytku w modułowych plikach wczytywanych na żądanie.FunctionTool– opakuj dowolną funkcję Pythona (lub model zewnętrzny) jako wywoływalne narzędzie agenta.to_a2a()– udostępnianie dowolnego agenta ADK jako usługi HTTPS zgodnej z A2ARemoteA2aAgent+AgentTool– koordynowanie zdalnych agentów jako narzędzi, które można wywoływaćMcpToolset– łączenie się z usługami zewnętrznymi za pomocą serwerów MCP stdioEventsCompactionConfig– obsługa limitów tokenów w długich przepływach pracy z wieloma agentami- Uporządkowane dane wyjściowe krytyka – kontrola jakości czytelna dla maszyn z automatyczną korektą
- Cloud Run – wdrażanie skonteneryzowanych agentów na dużą skalę
- Środowisko wykonawcze agentów – hostowanie orkiestratorów z zarządzanymi sesjami i śledzeniem.
Dalsze kroki
- Dodawanie wieloetapowej edycji obrazów do narzędzia Designer za pomocą funkcji edycji
gemini-3.1-flash-image - Dodawanie uwierzytelniania IAM do usług Cloud Run (usuwanie
--allow-unauthenticated) - Zastąp jednego specjalistę agentem LangGraph lub CrewAI – A2A jest niezależny od platformy.
- Dodaj opinie użytkowników jako narzędzie, aby uczestnicy mogli oceniać dane wyjściowe i je ulepszać.
- Poznaj śledzenie środowiska wykonawczego agenta w konsoli Cloud