
1. Einführung
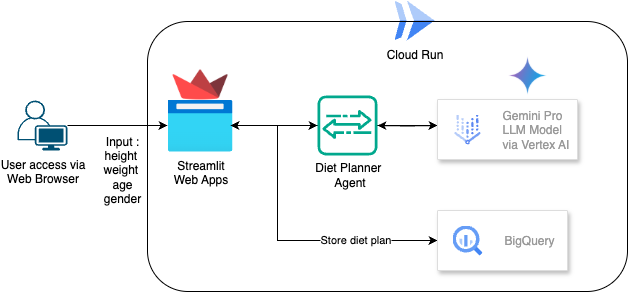
In diesem Codelab erfahren Sie, wie Sie einen KI-basierten Agenten für die Ernährungsplanung erstellen und bereitstellen. Für die Benutzeroberfläche wird Streamlit verwendet, für das LLM-Modell Gemini Pro 2.5, für den Orchestrator der Agentic AI Engine Vertex AI für die Entwicklung von Agentic AI, für die Datenspeicherung BigQuery und für die Bereitstellung Cloud Run.
In diesem Codelab gehen Sie schrittweise so vor:
- Google Cloud-Projekt vorbereiten und alle erforderlichen APIs aktivieren
- Agentic AI Diet Planner mit Streamlit, Vertex AI und BigQuery erstellen
- Anwendung in Cloud Run bereitstellen
Architekturübersicht
Voraussetzung
- Ein Google Cloud-Projekt mit aktivierter Abrechnung.
- Grundlegende Python-Kenntnisse
Lerninhalte
- So erstellen Sie einen Agentic AI-Ernährungsplaner mit Streamlit, Vertex AI und speichern Daten in BigQuery
- Anwendung in Cloud Run bereitstellen
Voraussetzungen
- Chrome-Webbrowser
- Ein Gmail-Konto
- Ein Cloud-Projekt mit aktivierter Abrechnung
2. Grundlegende Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

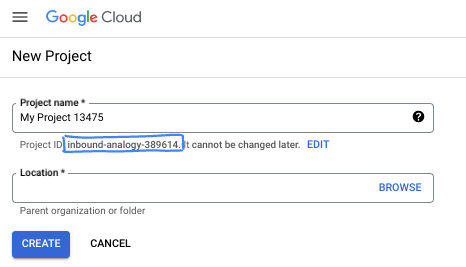
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie es mit einem eigenen Namen versuchen und sehen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, eine Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/-APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um Kosten zu vermeiden, die über diese Anleitung hinausgehen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am kostenlosen Testzeitraum mit einem Guthaben von 300$ teilnehmen.
3. Hinweis
Cloud-Projekt im Cloud Shell-Editor einrichten
In diesem Codelab wird davon ausgegangen, dass Sie bereits ein Google Cloud-Projekt mit aktivierter Abrechnung haben. Wenn Sie noch kein Konto haben, können Sie der Anleitung unten folgen, um eines zu erstellen.
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist .
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und in der bq vorinstalliert ist. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.
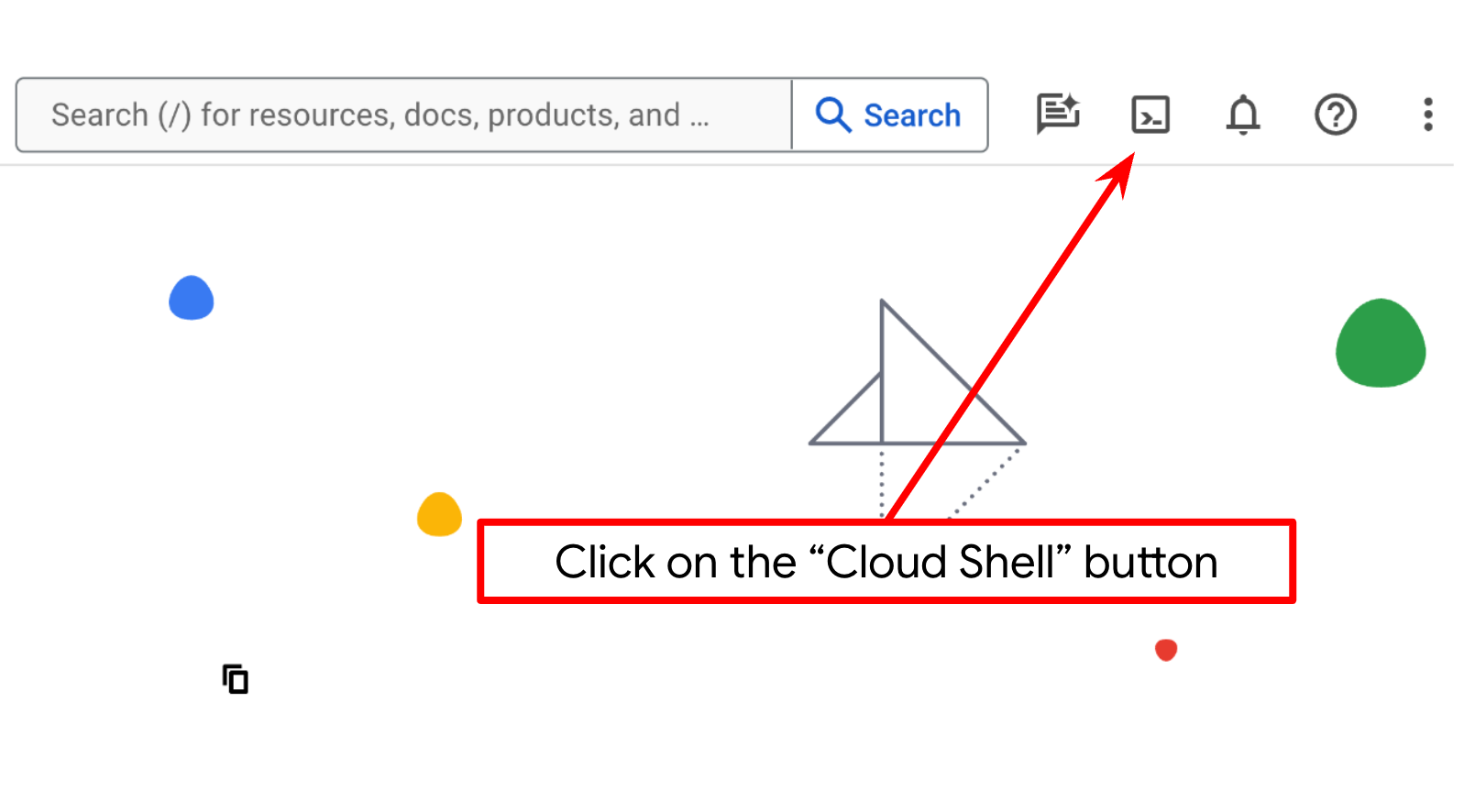
- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
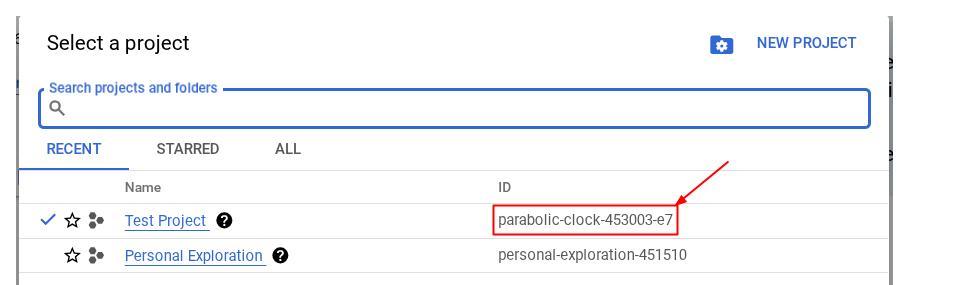
Alternativ können Sie die PROJECT_ID-ID auch in der Console sehen.
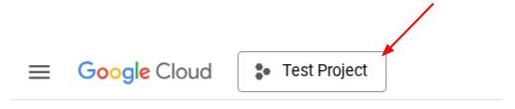
Klicken Sie darauf. Rechts sehen Sie dann alle Ihre Projekte und die Projekt-ID.
- Aktivieren Sie die erforderlichen APIs mit dem unten gezeigten Befehl. Das kann einige Minuten dauern.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
bigquery.googleapis.com
Bei erfolgreicher Ausführung des Befehls sollte eine Meldung wie die unten gezeigte angezeigt werden:
Operation "operations/..." finished successfully.
Alternativ zum gcloud-Befehl können Sie in der Konsole nach den einzelnen Produkten suchen oder diesen Link verwenden.
Wenn eine API fehlt, können Sie sie jederzeit während der Implementierung aktivieren.
Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
Arbeitsverzeichnis der Anwendung einrichten
- Klicken Sie auf die Schaltfläche „Editor öffnen“, um den Cloud Shell-Editor zu öffnen. Hier können Sie Ihren Code schreiben
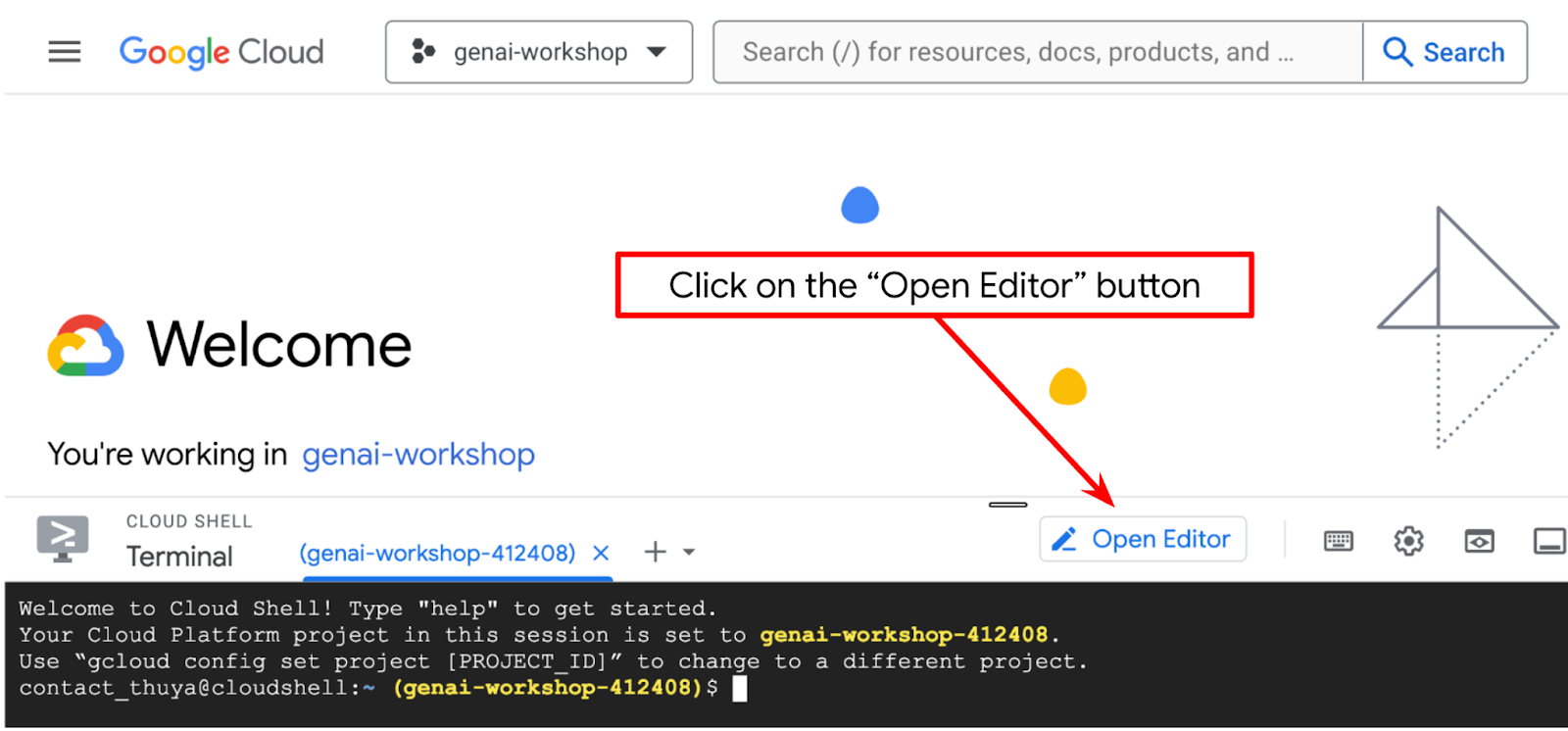 .
. - Achten Sie darauf, dass das Cloud Code-Projekt in der Statusleiste unten links im Cloud Shell-Editor festgelegt ist, wie im Bild unten dargestellt, und auf das aktive Google Cloud-Projekt festgelegt ist, in dem die Abrechnung aktiviert ist. Autorisieren, wenn Sie dazu aufgefordert werden. Nach der Initialisierung des Cloud Shell-Editors kann es eine Weile dauern, bis die Schaltfläche Cloud Code – Anmelden angezeigt wird.
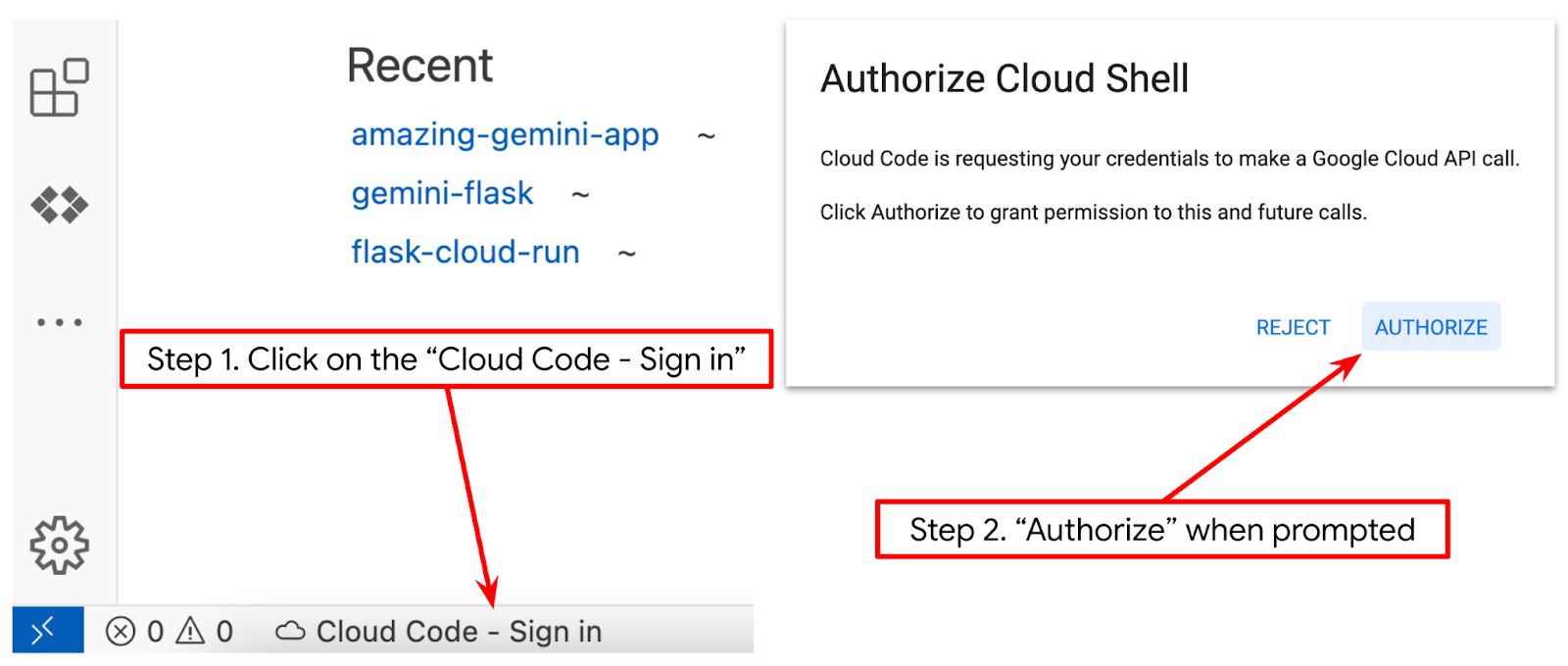
Als Nächstes bereiten wir unsere Python-Umgebung vor.
Umgebung einrichten
Virtuelle Python-Umgebung vorbereiten
Im nächsten Schritt bereiten Sie die Entwicklungsumgebung vor. In diesem Codelab verwenden wir Python 3.12 und python virtualenv, um das Erstellen und Verwalten von Python-Versionen und virtuellen Umgebungen zu vereinfachen.
- Wenn Sie das Terminal noch nicht geöffnet haben, klicken Sie auf Terminal -> Neues Terminal oder verwenden Sie Strg + Umschalt + C.

- Erstellen Sie einen neuen Ordner und wechseln Sie mit dem folgenden Befehl zu diesem Ordner.
mkdir agent_diet_planner
cd agent_diet_planner
- Erstellen Sie mit dem folgenden Befehl eine neue virtuelle Umgebung:
python -m venv .env
- Aktivieren Sie virtualenv mit dem folgenden Befehl:
source .env/bin/activate
- Erstellen Sie
requirements.txt. Klicken Sie auf „Datei“ → „Neue Textdatei“ und fügen Sie den folgenden Inhalt ein. Speichern Sie es dann alsrequirements.txt.
streamlit==1.33.0
google-cloud-aiplatform
google-cloud-bigquery
pandas==2.2.2
db-dtypes==1.2.0
pyarrow==16.1.0
- Installieren Sie dann alle Abhängigkeiten aus „requirements.txt“ mit dem folgenden Befehl:
pip install -r requirements.txt
- Geben Sie den folgenden Befehl ein, um zu prüfen, ob alle Python-Bibliotheksabhängigkeiten installiert sind.
pip list
Konfigurationsdateien einrichten
Als Nächstes müssen wir Konfigurationsdateien für dieses Projekt einrichten. Konfigurationsdateien werden zum Speichern von Variablen und Anmeldedaten für Dienstkonten verwendet.
- Im ersten Schritt erstellen Sie ein Dienstkonto. Geben Sie „Dienstkonto“ in die Suche ein und klicken Sie auf „Dienstkonto“.
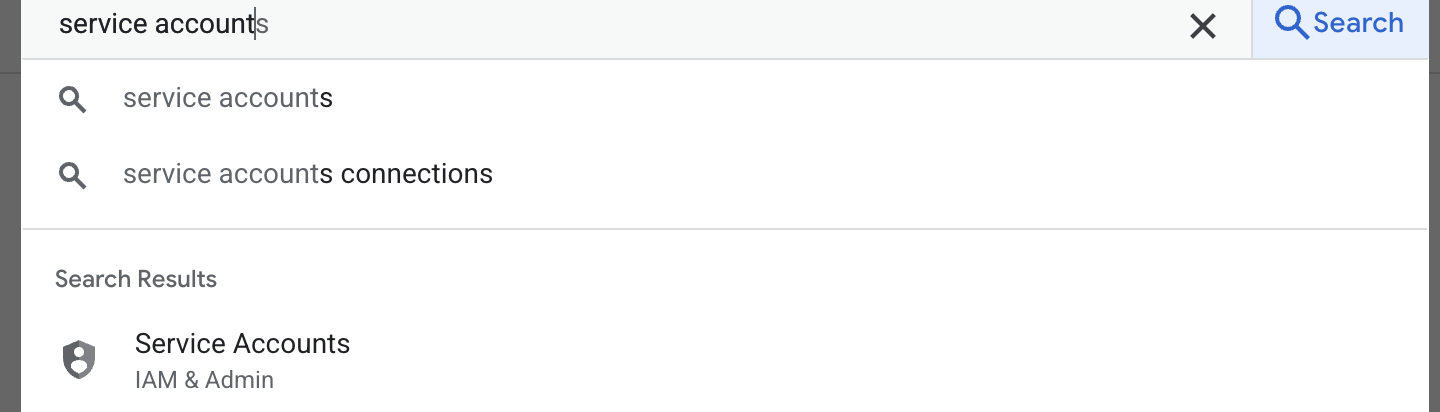
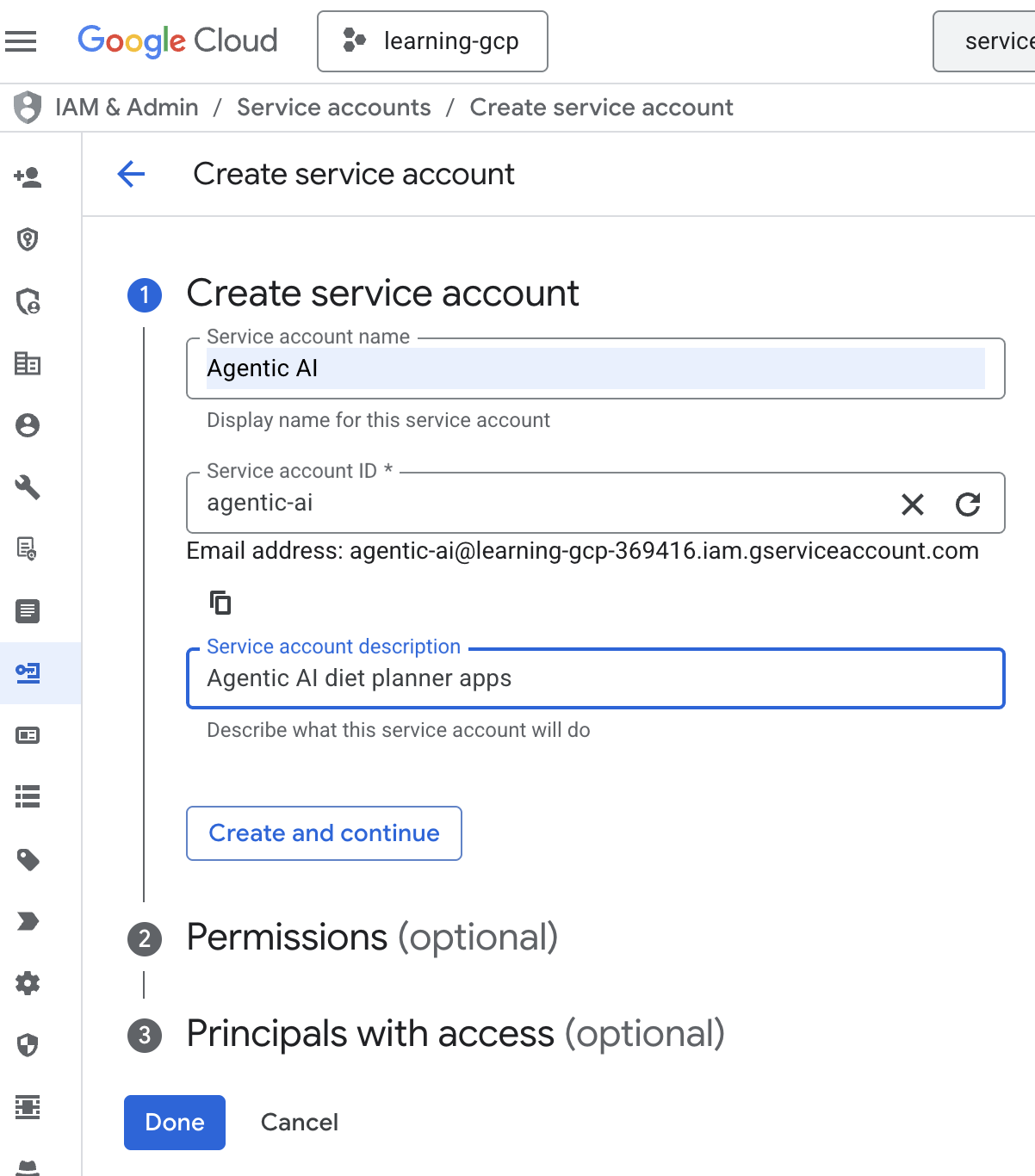
- Klicken Sie auf „+ Dienstkonto erstellen“. Geben Sie den Namen des Dienstkontos ein und klicken Sie auf „Erstellen und fortfahren“.
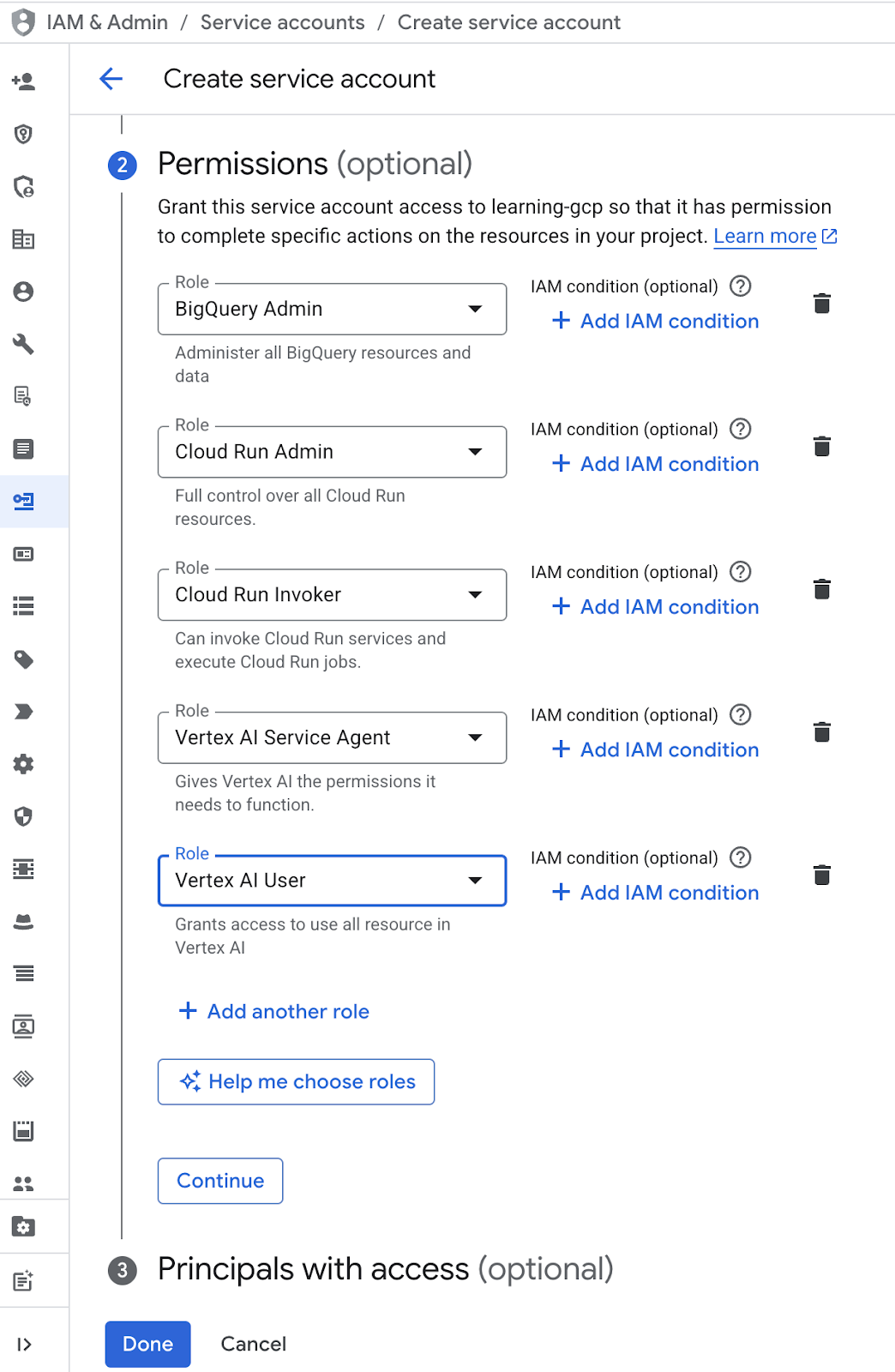
- Wählen Sie unter „Berechtigung“ die Rolle „Dienstkontonutzer“ aus. Klicken Sie auf „+ Weitere Rolle hinzufügen“ und wählen Sie die IAM-Rollen „BigQuery-Administrator“, „Cloud Run-Administrator“, „Cloud Run-Aufrufer“, „Vertex AI-Dienst-Agent“ und „Vertex AI-Nutzer“ aus. Klicken Sie dann auf „Fertig“
 .
. - Klicken Sie auf die E-Mail-Adresse des Dienstkontos, drücken Sie die Tabulatortaste und klicken Sie auf „Schlüssel hinzufügen“ → „Neuen Schlüssel erstellen“.
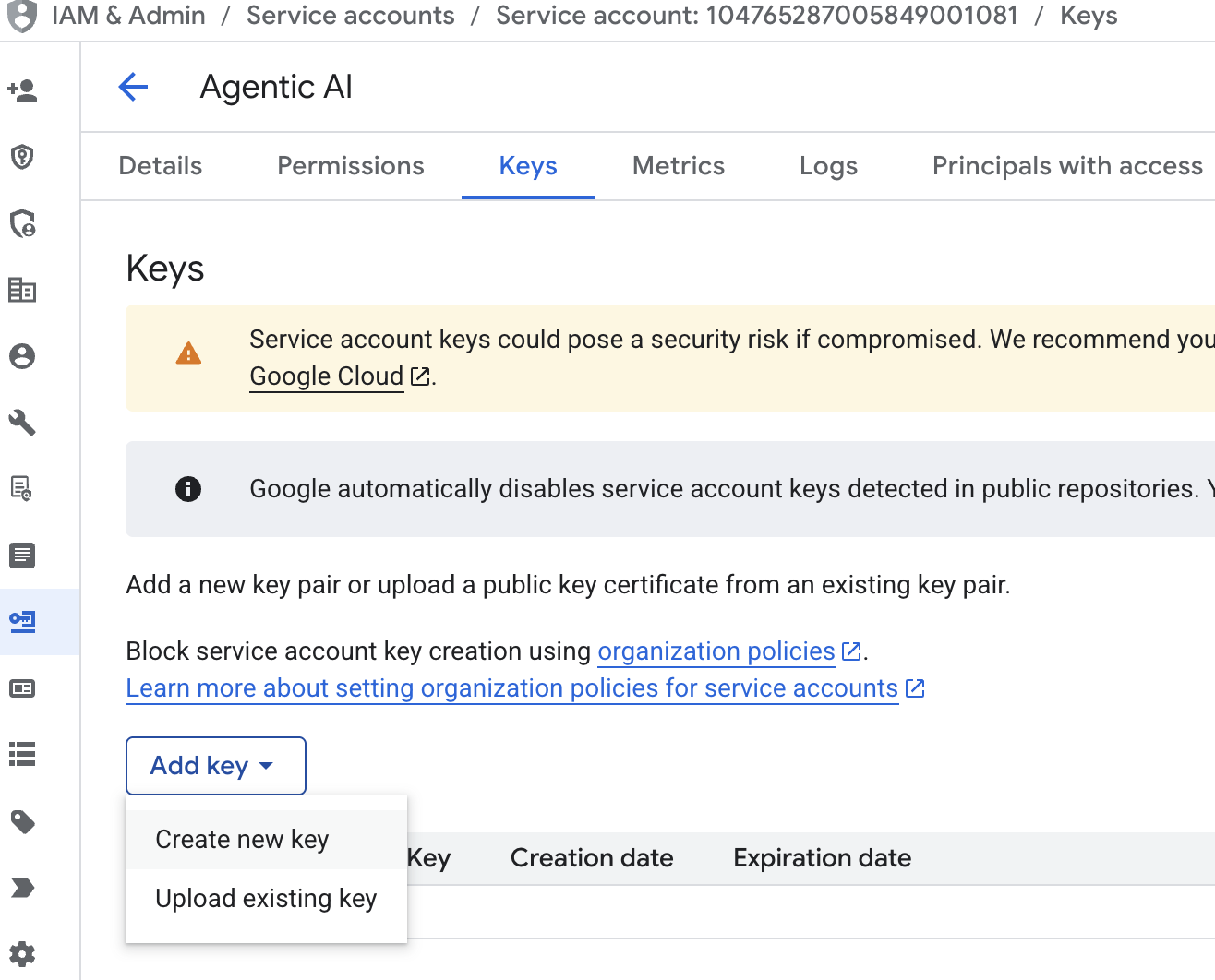
- Wählen Sie „json“ aus und klicken Sie auf „Erstellen“. Speichern Sie diese Dienstkontodatei lokal für den nächsten Schritt
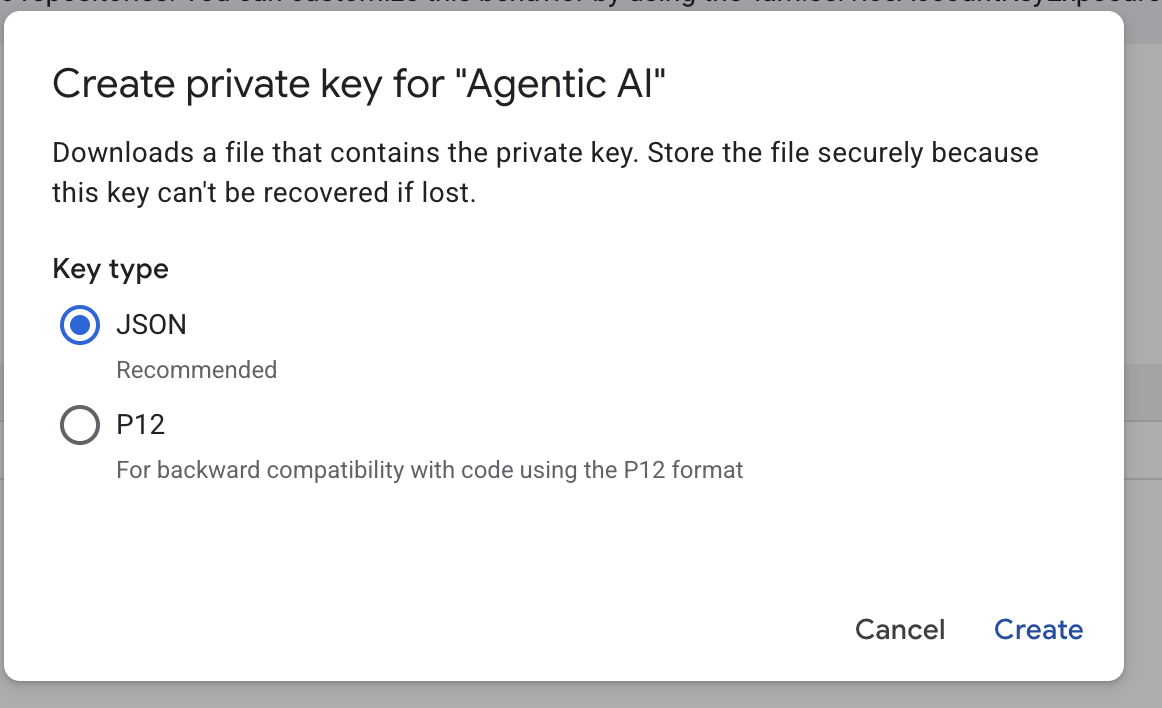 .
. - Erstellen Sie einen Ordner mit dem Namen „.streamlit“ mit der folgenden Konfiguration. Klicken Sie mit der rechten Maustaste, klicken Sie auf „Neuer Ordner“ und geben Sie den Ordnernamen
.streamlitein. - Klicken Sie mit der rechten Maustaste auf den Ordner
.streamlitund dann auf „Neue Datei“. Füllen Sie die Datei mit dem folgenden Wert aus. Speichern Sie es dann alssecrets.toml.
# secrets.toml (for Streamlit sharing)
# Store in .streamlit/secrets.toml
[gcp]
project_id = "your_gcp_project"
location = "us-central1"
[gcp_service_account]
type = "service_account"
project_id = "your-project-id"
private_key_id = "your-private-key-id"
private_key = '''-----BEGIN PRIVATE KEY-----
YOUR_PRIVATE_KEY_HERE
-----END PRIVATE KEY-----'''
client_email = "your-sa@project-id.iam.gserviceaccount.com"
client_id = "your-client-id"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "https://www.googleapis.com/robot/v1/metadata/x509/your-sa%40project-id.iam.gserviceaccount.com"
- Aktualisieren Sie die Werte für
project_id,private_key_id,private_key,client_emailundclient_id , and auth_provider_x509_cert_urlbasierend auf dem Dienstkonto , das Sie im vorherigen Schritt erstellt haben.
BigQuery-Dataset vorbereiten
Als Nächstes erstellen Sie ein BigQuery-Dataset, um die Generierungsergebnisse in BigQuery zu speichern.
- Geben Sie „BigQuery“ in die Suche ein und klicken Sie auf „BigQuery“.
- Klicken Sie auf
 und dann auf „Dataset erstellen“.
und dann auf „Dataset erstellen“. - Geben Sie die Dataset-ID
diet_planner_dataein und klicken Sie auf „Dataset erstellen“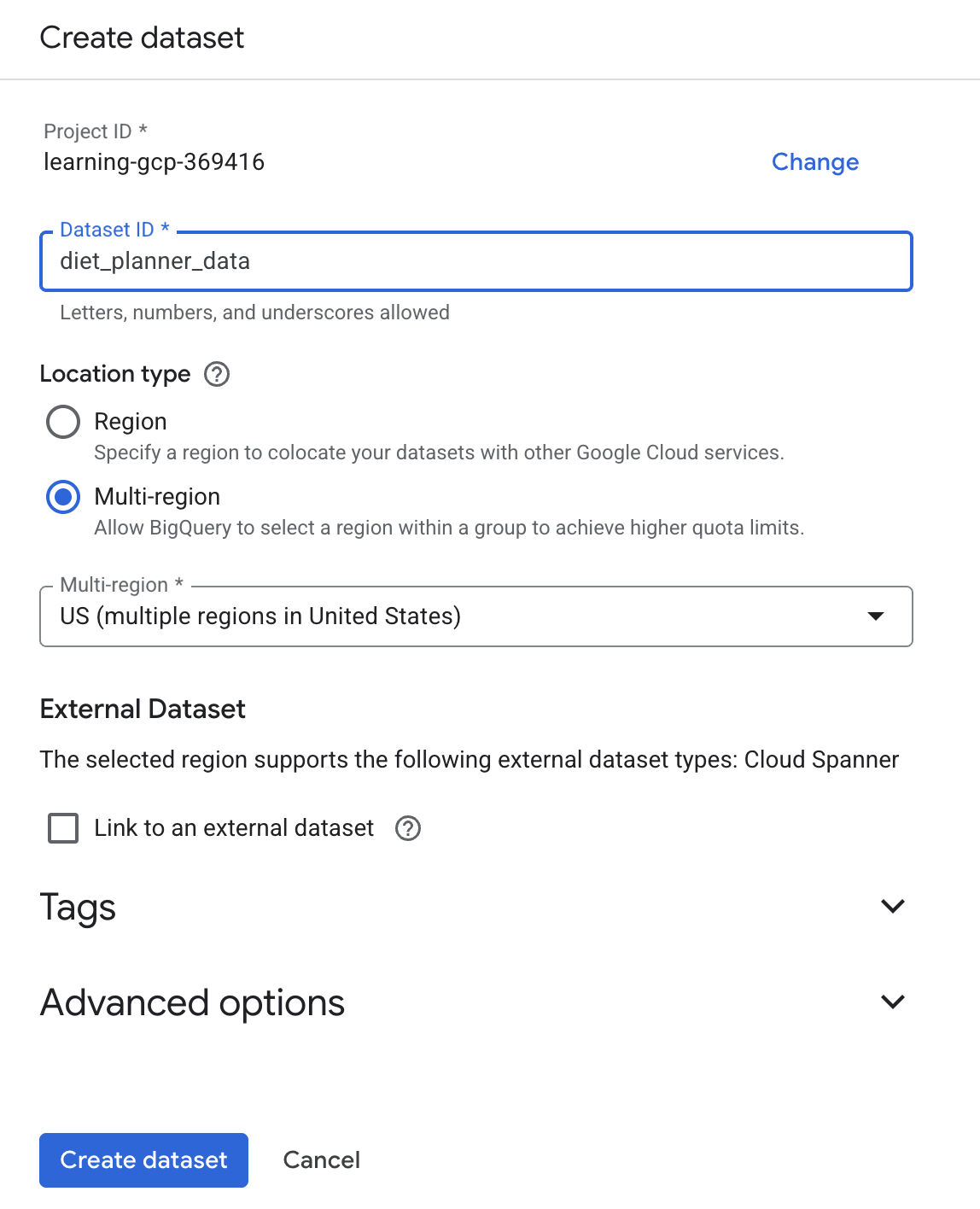 .
.
4. Agent-Apps für die Ernährungsplanung erstellen
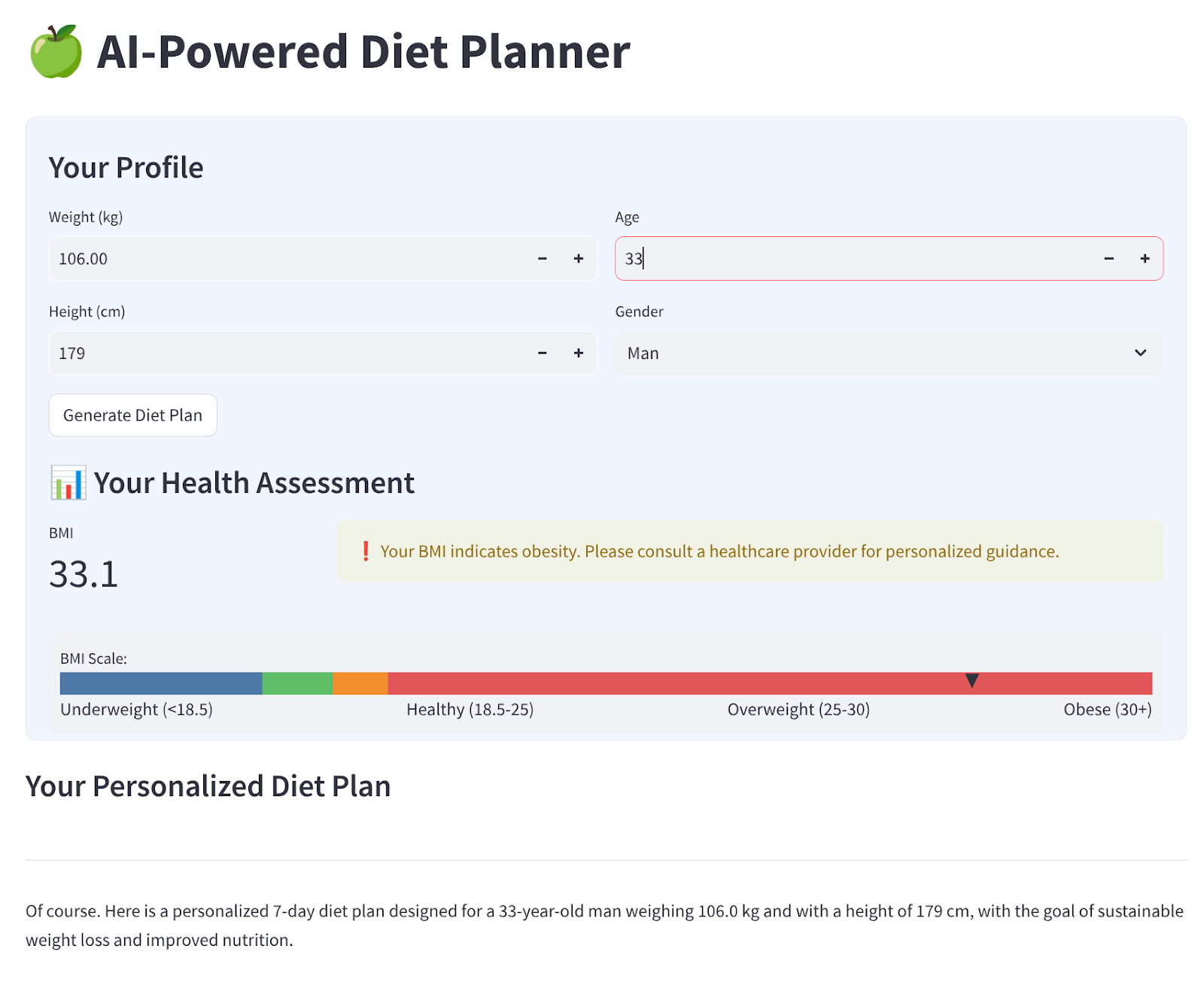
Wir erstellen eine einfache Weboberfläche mit vier Eingaben, die so aussieht:
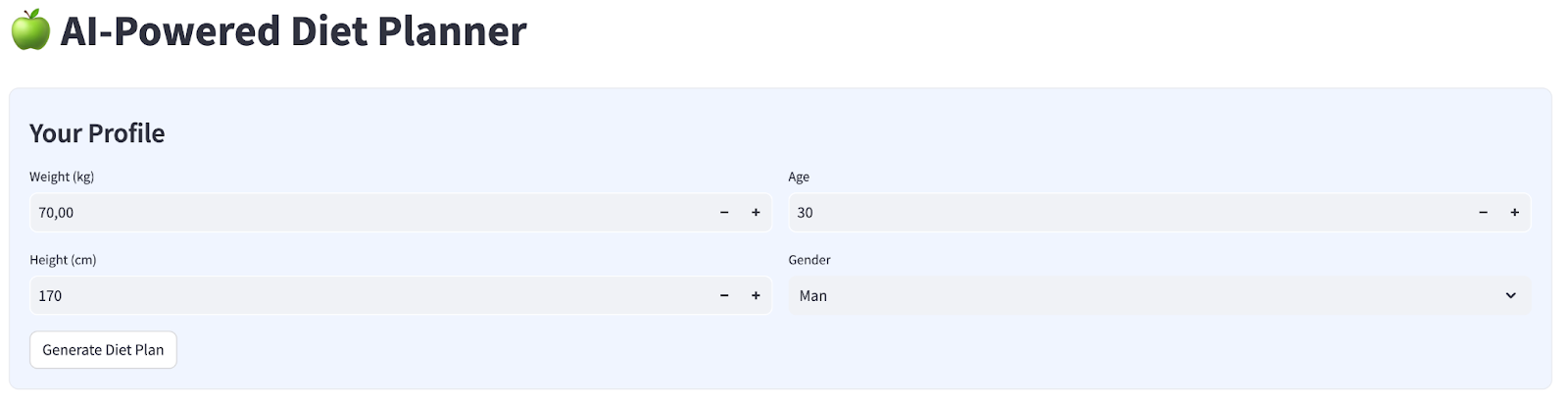
Ändern Sie Gewicht, Größe, Alter und Geschlecht entsprechend Ihrem Profil und klicken Sie dann auf „Generieren“. Das LLM-Modell Gemini Pro 2.5 wird in der Vertex AI-Bibliothek aufgerufen und die generierten Ergebnisse werden in BigQuery gespeichert.
Der Code wird in sechs Teile unterteilt, damit er nicht zu lang ist.
Funktion „calculate bmi status“ erstellen
- Klicken Sie mit der rechten Maustaste auf den Ordner
agent_diet_planner→ „Neue Datei“ → geben Sie den Dateinamenbmi_calc.pyein und drücken Sie die Eingabetaste. - Fülle den Code mit Folgendem aus
# Add this function to calculate BMI and health status
def calculate_bmi_status(weight, height):
"""
Calculate BMI and return status message
"""
height_m = height / 100 # Convert cm to meters
bmi = weight / (height_m ** 2)
if bmi < 18.5:
status = "underweight"
message = "⚠️ Your BMI suggests you're underweight. Consider increasing calorie intake with nutrient-dense foods."
elif 18.5 <= bmi < 25:
status = "normal"
message = "✅ Your BMI is in the healthy range. Let's maintain this balance!"
elif 25 <= bmi < 30:
status = "overweight"
message = "⚠️ Your BMI suggests you're overweight. Focus on gradual weight loss through balanced nutrition."
else:
status = "obese"
message = "❗ Your BMI indicates obesity. Please consult a healthcare provider for personalized guidance."
return {
"value": round(bmi, 1),
"status": status,
"message": message
}
Haupt-Apps für KI-Agenten zur Ernährungsplanung erstellen
- Klicken Sie mit der rechten Maustaste auf den Ordner
agent_diet_planner→ „Neue Datei“ → geben Sie den Dateinamenapp.pyein und drücken Sie die Eingabetaste. - Fülle den Code mit Folgendem aus
import os
from google.oauth2 import service_account
import streamlit as st
from google.cloud import bigquery
from vertexai.preview.generative_models import GenerativeModel
import vertexai
import datetime
import time
import pandas as pd
from bmi_calc import calculate_bmi_status
# Get configuration from environment
PROJECT_ID = os.environ.get("GCP_PROJECT_ID", "your_gcp_project_id")
LOCATION = os.environ.get("GCP_LOCATION", "us-central1")
#CONSTANTS Dataset and table in BigQuery
DATASET = "diet_planner_data"
TABLE = "user_plans"
# Initialize Vertex AI
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Initialize BigQuery client
try:
# For Cloud Run, use default credentials
bq_client = bigquery.Client()
except:
# For local development, use service account from secrets
if "gcp_service_account" in st.secrets:
service_account_info = dict(st.secrets["gcp_service_account"])
credentials = service_account.Credentials.from_service_account_info(service_account_info)
bq_client = bigquery.Client(credentials=credentials, project=PROJECT_ID)
else:
st.error("BigQuery client initialization failed")
st.stop()
Ersetzen Sie den Wert your_gcp_project_id durch Ihre Projekt-ID.
Create agent diet planner main apps - setup_bq_tables
In diesem Abschnitt erstellen wir eine Funktion mit dem Namen setup_bq_table mit dem Eingabeparameter bq_client. Mit dieser Funktion wird das Schema in der BigQuery-Tabelle definiert und eine Tabelle erstellt, sofern sie nicht vorhanden ist.
Füllen Sie den Code mit dem folgenden Code in app.py aus.
# Create BigQuery table if not exists
def setup_bq_table(bq_client):
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
schema = [
bigquery.SchemaField("user_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("timestamp", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("weight", "FLOAT", mode="REQUIRED"),
bigquery.SchemaField("height", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("age", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("gender", "STRING", mode="REQUIRED"),
bigquery.SchemaField("diet_plan", "STRING", mode="REQUIRED")
]
try:
bq_client.get_table(table_id)
except:
table = bigquery.Table(table_id, schema=schema)
bq_client.create_table(table)
st.toast("BigQuery table created successfully")
Haupt-Apps für KI-Agenten zur Ernährungsplanung erstellen – generate_diet_plan
In diesem Abschnitt erstellen wir eine Funktion mit dem Namen generate_diet_plan mit einem Eingabeparameter. Mit dieser Funktion wird das LLM-Modell Gemini Pro 2.5 mit dem Prompt „define“ aufgerufen und es werden Ergebnisse generiert.
Füllen Sie den Code mit dem folgenden Code in app.py aus.
# Generate diet plan using Gemini Pro
def generate_diet_plan(params):
try:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
Create a personalized 7-day diet plan for:
- {params['gender']}, {params['age']} years old
- Weight: {params['weight']} kg
- Height: {params['height']} cm
Include:
1. Daily calorie target
2. Macronutrient breakdown (carbs, protein, fat)
3. Meal timing and frequency
4. Food recommendations
5. Hydration guidance
Make the plan:
- Nutritionally balanced
- Practical for daily use
- Culturally adaptable
- With portion size guidance
"""
response = model.generate_content(prompt)
return response.text
except Exception as e:
st.error(f"AI generation error: {str(e)}")
return None
Create agent diet planner main apps - save_to_bq
In diesem Abschnitt erstellen wir eine Funktion mit dem Namen save_to_bq mit drei Eingabeparametern : bq_client, user_id und plan. Mit dieser Funktion wird das Ergebnis in einer BigQuery-Tabelle gespeichert.
Füllen Sie den Code mit dem folgenden Code in app.py aus.
# Save user data to BigQuery
def save_to_bq(bq_client, user_id, plan):
try:
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
row = {
"user_id": user_id,
"timestamp": datetime.datetime.utcnow().isoformat(),
"weight": st.session_state.user_data["weight"],
"height": st.session_state.user_data["height"],
"age": st.session_state.user_data["age"],
"gender": st.session_state.user_data["gender"],
"diet_plan": plan
}
errors = bq_client.insert_rows_json(table_id, [row])
if errors:
st.error(f"BigQuery error: {errors}")
else:
return True
except Exception as e:
st.error(f"Data saving error: {str(e)}")
return False
Haupt-Apps für KI-Agenten-Diätplaner erstellen – main
In diesem Abschnitt erstellen wir eine Funktion mit dem Namen main ohne Eingabeparameter. Diese Funktion verarbeitet hauptsächlich das Streamlit-UI-Skript, zeigt das generierte Ergebnis an, zeigt das bisherige generierte Ergebnis aus der BigQuery-Tabelle an und lädt Daten in eine Markdown-Datei herunter.
Füllen Sie den Code mit dem folgenden Code in app.py aus.
# Streamlit UI
def main():
st.set_page_config(page_title="AI Diet Planner", page_icon="🍏", layout="wide")
# Initialize session state
if "user_data" not in st.session_state:
st.session_state.user_data = None
if "diet_plan" not in st.session_state:
st.session_state.diet_plan = None
# Initialize clients
#bq_client = init_clients()
setup_bq_table(bq_client)
st.title("🍏 AI-Powered Diet Planner")
st.markdown("""
<style>
.stProgress > div > div > div > div {
background-color: #4CAF50;
}
[data-testid="stForm"] {
background: #f0f5ff;
padding: 20px;
border-radius: 10px;
border: 1px solid #e6e9ef;
}
</style>
""", unsafe_allow_html=True)
# User input form
with st.form("user_profile", clear_on_submit=False):
st.subheader("Your Profile")
col1, col2 = st.columns(2)
with col1:
weight = st.number_input("Weight (kg)", min_value=30.0, max_value=200.0, value=70.0)
height = st.number_input("Height (cm)", min_value=100, max_value=250, value=170)
with col2:
age = st.number_input("Age", min_value=18, max_value=100, value=30)
gender = st.selectbox("Gender", ["Man", "Woman"])
submitted = st.form_submit_button("Generate Diet Plan")
if submitted:
user_data = {
"weight": weight,
"height": height,
"age": age,
"gender": gender
}
st.session_state.user_data = user_data
# Calculate BMI
bmi_result = calculate_bmi_status(weight, height)
# Display BMI results in a visually distinct box
with st.container():
st.subheader("📊 Your Health Assessment")
col1, col2 = st.columns([1, 3])
with col1:
st.metric("BMI", bmi_result["value"])
with col2:
if bmi_result["status"] != "normal":
st.warning(bmi_result["message"])
else:
st.success(bmi_result["message"])
# Add BMI scale visualization
st.markdown(f"""
<div style="background:#f0f2f6;padding:10px;border-radius:10px;margin-top:10px">
<small>BMI Scale:</small><br>
<div style="display:flex;height:20px;background:linear-gradient(90deg,
#4e79a7 0%,
#4e79a7 18.5%,
#60bd68 18.5%,
#60bd68 25%,
#f28e2b 25%,
#f28e2b 30%,
#e15759 30%,
#e15759 100%);position:relative">
<div style="position:absolute;left:{min(100, max(0, (bmi_result["value"]/40)*100))}%;top:-5px">
▼
</div>
</div>
<div style="display:flex;justify-content:space-between">
<span>Underweight (<18.5)</span>
<span>Healthy (18.5-25)</span>
<span>Overweight (25-30)</span>
<span>Obese (30+)</span>
</div>
</div>
""", unsafe_allow_html=True)
# Store BMI in session state
st.session_state.bmi = bmi_result
# Plan generation and display
if submitted and st.session_state.user_data:
with st.spinner("🧠 Generating your personalized diet plan using Gemini AI..."):
#diet_plan = generate_diet_plan(st.session_state.user_data)
diet_plan = generate_diet_plan({**st.session_state.user_data,"bmi": bmi_result["value"],
"bmi_status": bmi_result["status"]
})
if diet_plan:
st.session_state.diet_plan = diet_plan
# Generate unique user ID
user_id = f"user_{int(time.time())}"
# Save to BigQuery
if save_to_bq(bq_client, user_id, diet_plan):
st.toast("✅ Plan saved to database!")
# Display generated plan
if st.session_state.diet_plan:
st.subheader("Your Personalized Diet Plan")
st.markdown("---")
st.markdown(st.session_state.diet_plan)
# Download button
st.download_button(
label="Download Plan",
data=st.session_state.diet_plan,
file_name="my_diet_plan.md",
mime="text/markdown"
)
# Show history
st.subheader("Your Plan History")
try:
query = f"""
SELECT timestamp, weight, height, age, gender
FROM `{st.secrets['gcp']['project_id']}.{DATASET}.{TABLE}`
WHERE user_id LIKE 'user_%'
ORDER BY timestamp DESC
LIMIT 5
"""
history = bq_client.query(query).to_dataframe()
if not history.empty:
history["timestamp"] = pd.to_datetime(history["timestamp"])
st.dataframe(history.style.format({
"weight": "{:.1f} kg",
"height": "{:.0f} cm"
}))
else:
st.info("No previous plans found")
except Exception as e:
st.error(f"History load error: {str(e)}")
if __name__ == "__main__":
main()
Speichern Sie den Code unter dem Namen app.py.
5. Apps mit Cloud Build in Cloud Run bereitstellen
Natürlich möchten wir diese tolle App auch anderen vorstellen. Dazu können wir diese Anwendung packen und als öffentlichen Dienst in Cloud Run bereitstellen, auf den andere zugreifen können. Sehen wir uns dazu noch einmal die Architektur an.
Zuerst benötigen wir ein Dockerfile. Klicken Sie auf Datei > Neue Textdatei, kopieren Sie den folgenden Code und fügen Sie ihn ein. Speichern Sie die Datei dann als Dockerfile.
# Use official Python image
FROM python:3.12-slim
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV PORT 8080
# Install system dependencies
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /app
# Copy requirements
COPY requirements.txt .
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application files
COPY . .
# Expose port
EXPOSE $PORT
# Run the application
CMD ["streamlit", "run", "app.py", "--server.port", "8080", "--server.address", "0.0.0.0"]
Als Nächstes erstellen wir cloudbuild.yaml, um Apps in Docker-Images zu erstellen, per Push in Artifact Registry zu übertragen und in Cloud Run bereitzustellen.
Klicken Sie auf Datei > Neue Textdatei,kopieren Sie den folgenden Code und fügen Sie ihn ein. Speichern Sie die Datei dann als cloudbuild.yaml.
steps:
# Build Docker image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID', '--no-cache',
'--progress=plain',
'.']
id: 'Build'
timeout: 1200s
waitFor: ['-']
dir: '.'
# Push to Container Registry
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID']
id: 'Push'
waitFor: ['Build']
# Deploy to Cloud Run
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args:
- 'run'
- 'deploy'
- 'diet-planner-service'
- '--image=gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
- '--port=8080'
- '--region=us-central1'
- '--platform=managed'
- '--allow-unauthenticated'
- '--set-env-vars=GCP_PROJECT_ID=$PROJECT_ID,GCP_LOCATION=us-central1'
- '--cpu=1'
- '--memory=1Gi'
- '--timeout=300'
waitFor: ['Push']
options:
logging: CLOUD_LOGGING_ONLY
machineType: 'E2_HIGHCPU_8'
diskSizeGb: 100
images:
- 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
An diesem Punkt haben wir bereits alle Dateien, die zum Erstellen von Apps als Docker-Images, zum Übertragen per Push an Artifact Registry und zum Bereitstellen in Cloud Run erforderlich sind. Stellen wir die App jetzt bereit. Rufen Sie das Cloud Shell-Terminal auf und prüfen Sie, ob das aktuelle Projekt für Ihr aktives Projekt konfiguriert ist. Falls nicht, müssen Sie die Projekt-ID mit dem Befehl „gcloud configure“ festlegen:
gcloud config set project [PROJECT_ID]
Führen Sie dann den folgenden Befehl aus, um Apps als Docker-Images zu erstellen, per Push an Artifact Registry zu senden und in Cloud Run bereitzustellen.
gcloud builds submit --config cloudbuild.yaml
Der Docker-Container wird auf Grundlage des zuvor bereitgestellten Dockerfile erstellt und per Push in die Artifact Registry übertragen. Danach stellen wir das erstellte Image in Cloud Run bereit. Der gesamte Prozess ist in den cloudbuild.yaml-Schritten definiert.
Hinweis: Wir erlauben hier den nicht authentifizierten Zugriff, da es sich um eine Demoanwendung handelt. Wir empfehlen, für Ihre Unternehmens- und Produktionsanwendungen eine geeignete Authentifizierung zu verwenden.
Nach Abschluss der Bereitstellung können wir sie auf der Cloud Run-Seite prüfen. Suchen Sie dazu in der Suchleiste oben in der Cloud Console nach „Cloud Run“ und klicken Sie auf das Cloud Run-Produkt.
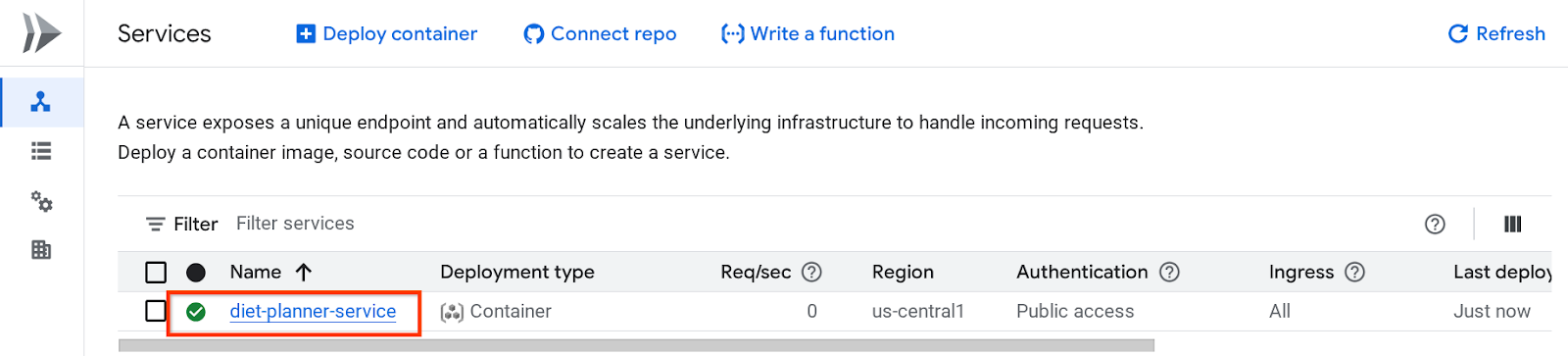
Danach können Sie den bereitgestellten Dienst auf der Seite „Cloud Run-Dienst“ prüfen. Klicken Sie auf den Dienst, um die Dienst-URL abzurufen.
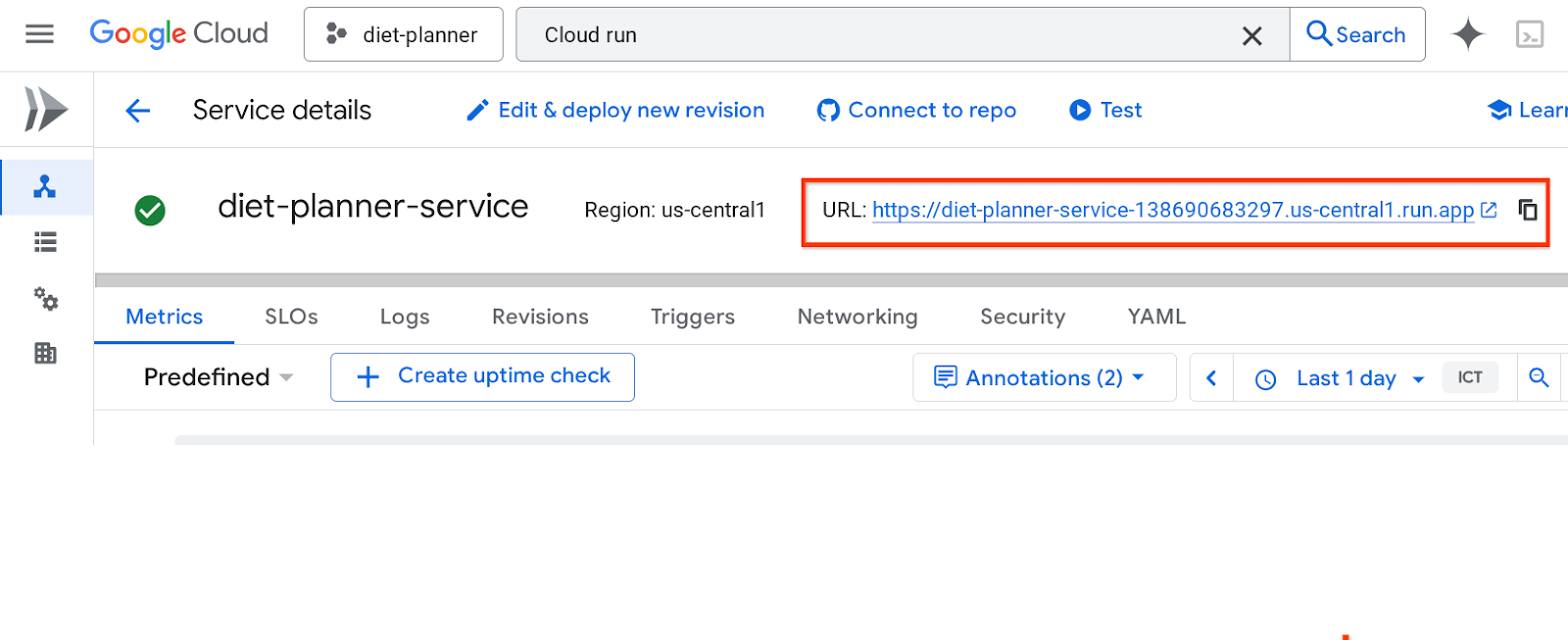
Die Dienst-URL befindet sich in der oberen Leiste.
 Sie können Ihre Anwendung nun im Inkognitomodus oder auf Ihrem Mobilgerät verwenden. Sie sollte bereits aktiv sein.
Sie können Ihre Anwendung nun im Inkognitomodus oder auf Ihrem Mobilgerät verwenden. Sie sollte bereits aktiv sein.
6. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
- Alternativ können Sie in der Console zu Cloud Run wechseln, den gerade bereitgestellten Dienst auswählen und löschen.