
۱. مقدمه
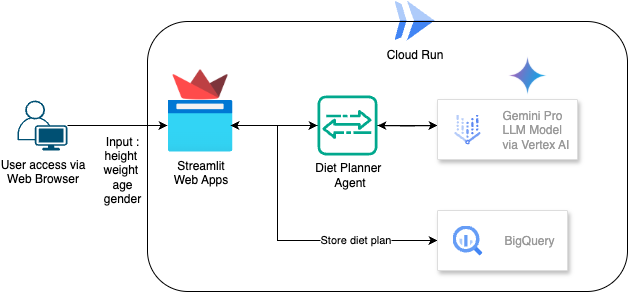
در این آزمایشگاه کد، نحوه ساخت و استقرار یک برنامهریز رژیم غذایی مبتنی بر هوش مصنوعی را خواهید آموخت. برای رابط کاربری از Streamlit، مدل LLM با استفاده از Gemini Pro 2.5، هماهنگکننده موتور هوش مصنوعی Agentic با استفاده از Vertex AI برای توسعه از Agentic AI، BigQuery برای ذخیره دادهها و Cloud Run برای استقرار.
از طریق codelab، شما یک رویکرد گام به گام به شرح زیر را به کار خواهید گرفت:
- پروژه Google Cloud خود را آماده کنید و تمام API های مورد نیاز را روی آن فعال کنید
- ساخت برنامهریز رژیم غذایی Agentic AI با استفاده از streamlit، Vertex AI و BigQuery
- برنامه را روی Cloud Run مستقر کنید
نمای کلی معماری
پیشنیاز
- یک پروژه پلتفرم ابری گوگل (GCP) با قابلیت پرداخت.
- دانش پایه پایتون
آنچه یاد خواهید گرفت
- نحوه ساخت برنامهریز رژیم غذایی Agentic AI با استفاده از streamlit و Vertex AI و ذخیره دادهها در BigQuery
- نحوه استقرار برنامه در Cloud Run
آنچه نیاز دارید
- مرورگر وب کروم
- یک حساب جیمیل
- یک پروژه ابری با قابلیت پرداخت صورتحساب
۲. تنظیمات اولیه و الزامات
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

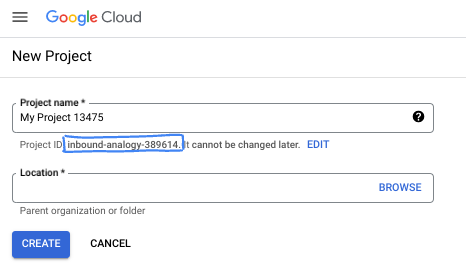
- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چه باشد. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
۳. قبل از شروع
راهاندازی پروژه ابری در ویرایشگر Cloud Shell
این آزمایشگاه کد فرض میکند که شما از قبل یک پروژه Google Cloud با قابلیت پرداخت فعال دارید. اگر هنوز آن را ندارید، میتوانید دستورالعملهای زیر را برای شروع دنبال کنید.
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود و bq از قبل روی آن بارگذاری شده است، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
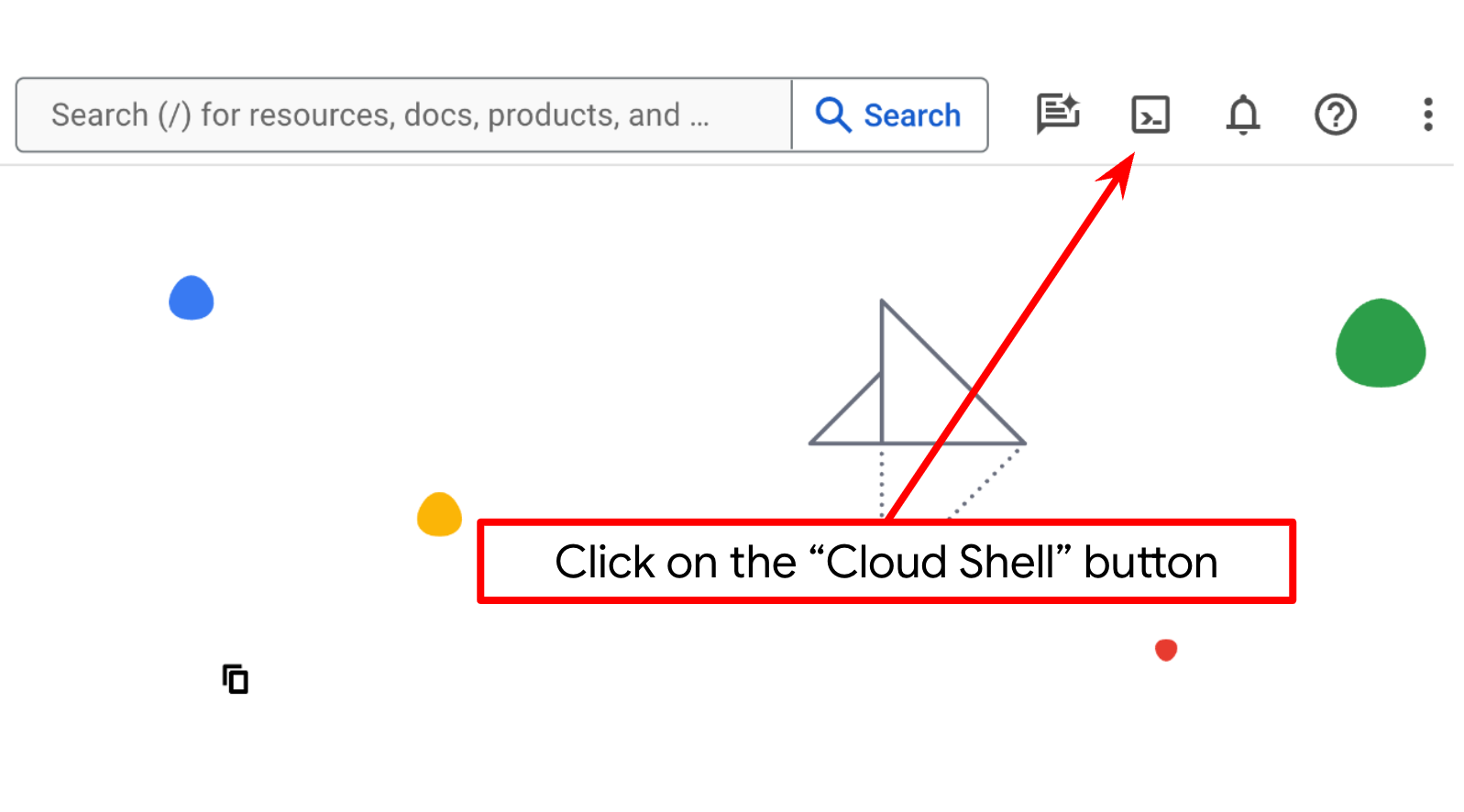
- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
از طرف دیگر، میتوانید شناسه PROJECT_ID را در کنسول نیز مشاهده کنید.
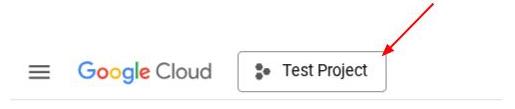
روی آن کلیک کنید تا تمام پروژه و شناسه پروژه در سمت راست نمایش داده شود.
- API های مورد نیاز را از طریق دستور زیر فعال کنید. این کار ممکن است چند دقیقه طول بکشد، پس لطفاً صبور باشید.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
bigquery.googleapis.com
در صورت اجرای موفقیتآمیز دستور، باید پیامی مشابه آنچه در زیر نشان داده شده است را مشاهده کنید:
Operation "operations/..." finished successfully.
جایگزین دستور gcloud از طریق کنسول با جستجوی هر محصول یا استفاده از این لینک است.
اگر هر API از قلم افتاده باشد، میتوانید همیشه آن را در طول پیادهسازی فعال کنید.
برای دستورات و نحوهی استفاده از gcloud به مستندات مراجعه کنید.
دایرکتوری کاری برنامه نصب
- روی دکمهی Open Editor کلیک کنید، این کار یک ویرایشگر Cloud Shell باز میکند، میتوانیم کد خود را اینجا بنویسیم
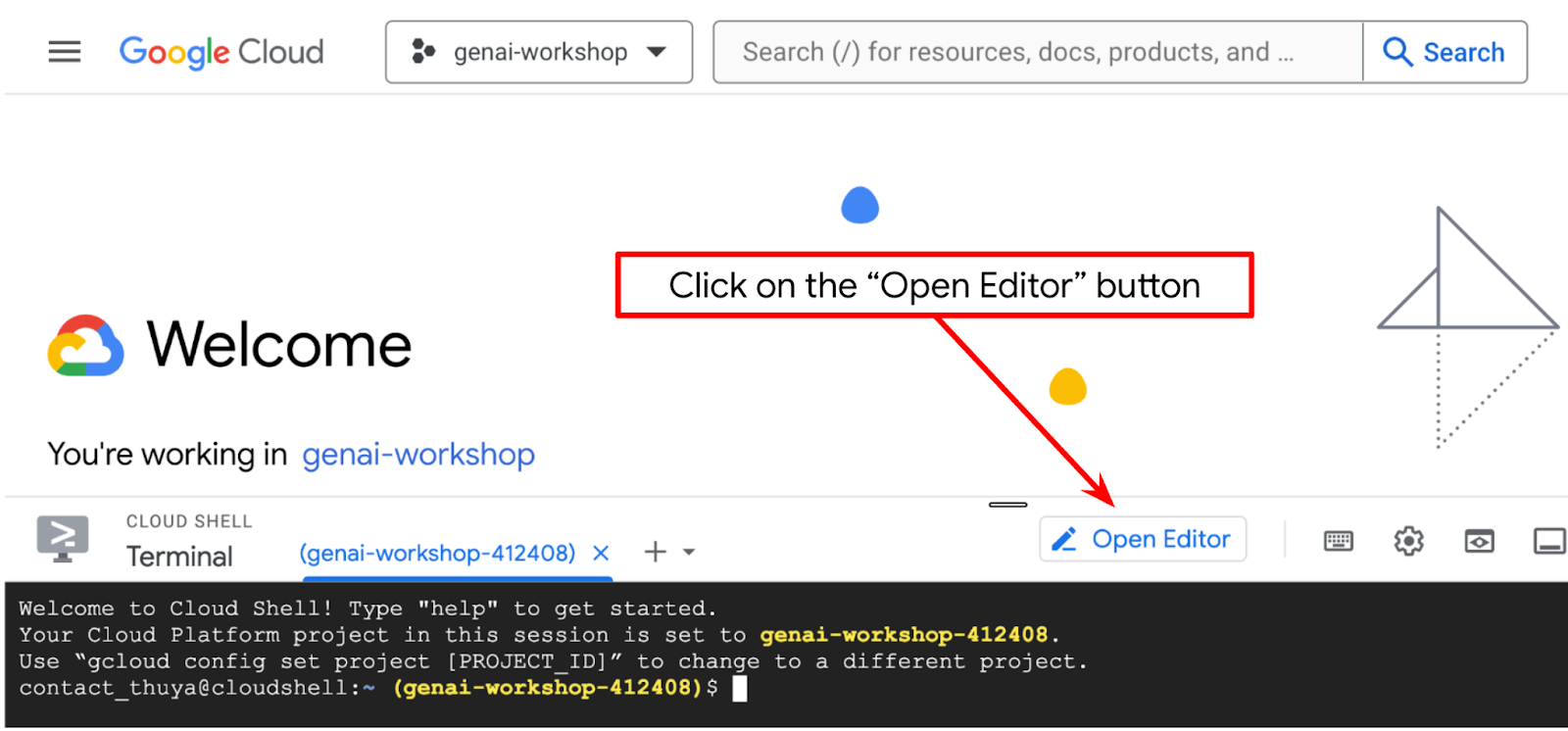
- مطمئن شوید که پروژه Cloud Code در گوشه پایین سمت چپ (نوار وضعیت) ویرایشگر Cloud Shell، همانطور که در تصویر زیر مشخص شده است، تنظیم شده باشد و روی پروژه فعال Google Cloud که در آن صورتحساب را فعال کردهاید، تنظیم شده باشد. در صورت درخواست، آن را تأیید کنید . ممکن است پس از مقداردهی اولیه ویرایشگر Cloud Shell، مدتی طول بکشد تا دکمه Cloud Code - Sign In ظاهر شود، لطفاً صبور باشید.
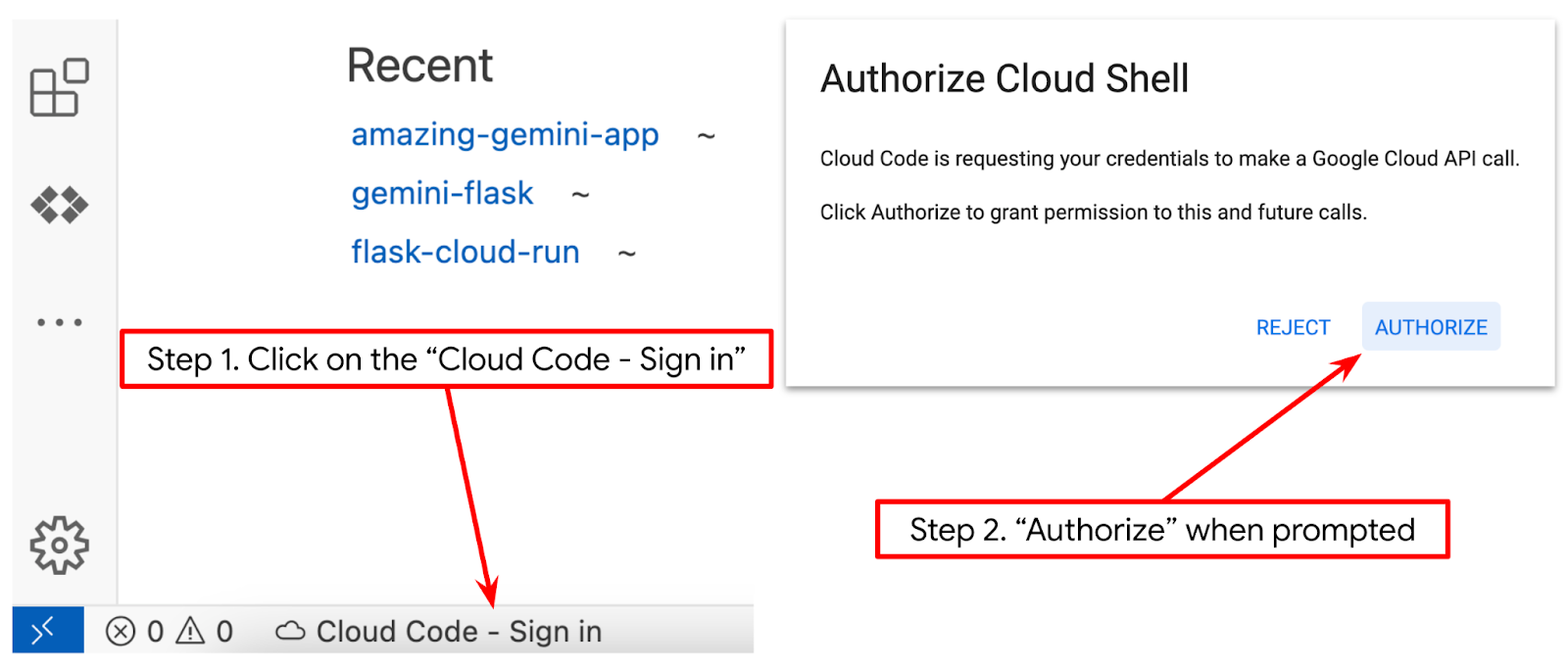
در مرحله بعد، محیط پایتون خود را آماده خواهیم کرد
تنظیمات محیط
آمادهسازی محیط مجازی پایتون
مرحله بعدی آمادهسازی محیط توسعه است. ما در این آزمایشگاه کد از پایتون ۳.۱۲ استفاده خواهیم کرد و از python virtualenv برای سادهسازی نیاز به ایجاد و مدیریت نسخه پایتون و محیط مجازی استفاده خواهیم کرد.
- اگر هنوز ترمینال را باز نکردهاید، با کلیک روی ترمینال -> ترمینال جدید ، یا با استفاده از کلیدهای Ctrl + Shift + C آن را باز کنید.

- با اجرای دستور زیر، پوشه جدیدی ایجاد کنید و مکان را به این پوشه تغییر دهید.
mkdir agent_diet_planner
cd agent_diet_planner
- با اجرای دستور زیر، virtualenv جدیدی ایجاد کنید
python -m venv .env
- با دستور زیر virtualenv را فعال کنید
source .env/bin/activate
-
requirements.txtرا ایجاد کنید. روی File → New Text File کلیک کنید و محتوای زیر را در آن وارد کنید. سپس آن را با نامrequirements.txtذخیره کنید.
streamlit==1.33.0
google-cloud-aiplatform
google-cloud-bigquery
pandas==2.2.2
db-dtypes==1.2.0
pyarrow==16.1.0
- سپس با اجرای دستور زیر، تمام وابستگیها را از requirements.txt نصب کنید.
pip install -r requirements.txt
- دستور زیر را تایپ کنید تا بررسی شود که آیا همه وابستگیهای کتابخانههای پایتون نصب شدهاند یا خیر.
pip list
فایلهای پیکربندی راهاندازی
حالا باید فایلهای پیکربندی این پروژه را تنظیم کنیم. فایلهای پیکربندی برای ذخیره اعتبارنامههای حساب کاربری متغیرها و سرویسها استفاده میشوند.
- اولین قدم ایجاد یک حساب کاربری سرویس است. در قسمت جستجو عبارت service account را تایپ کنید و سپس روی service account کلیک کنید.
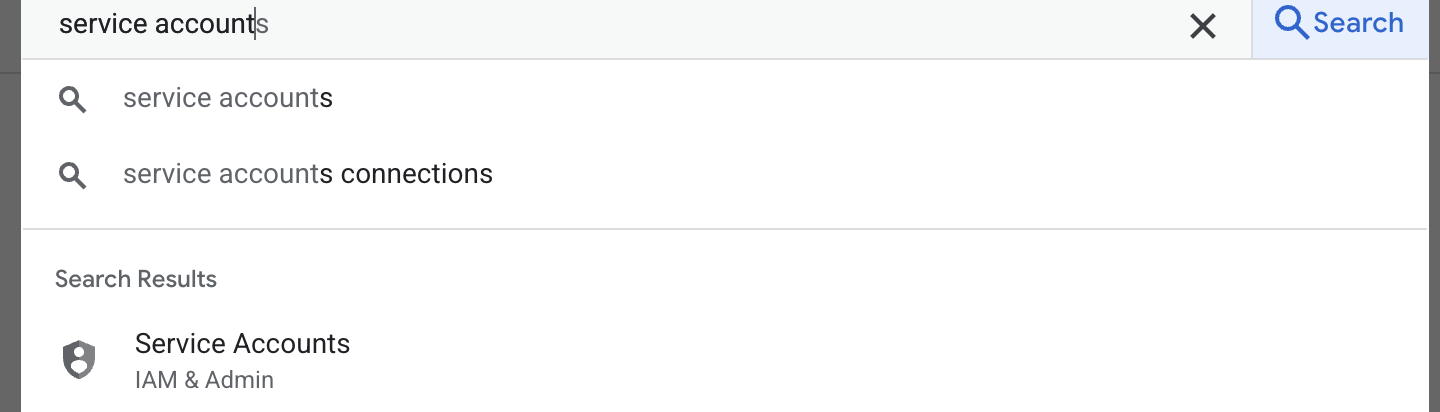
- روی + ایجاد حساب کاربری سرویس کلیک کنید. نام حساب کاربری سرویس را وارد کنید، سپس روی ایجاد و ادامه کلیک کنید.
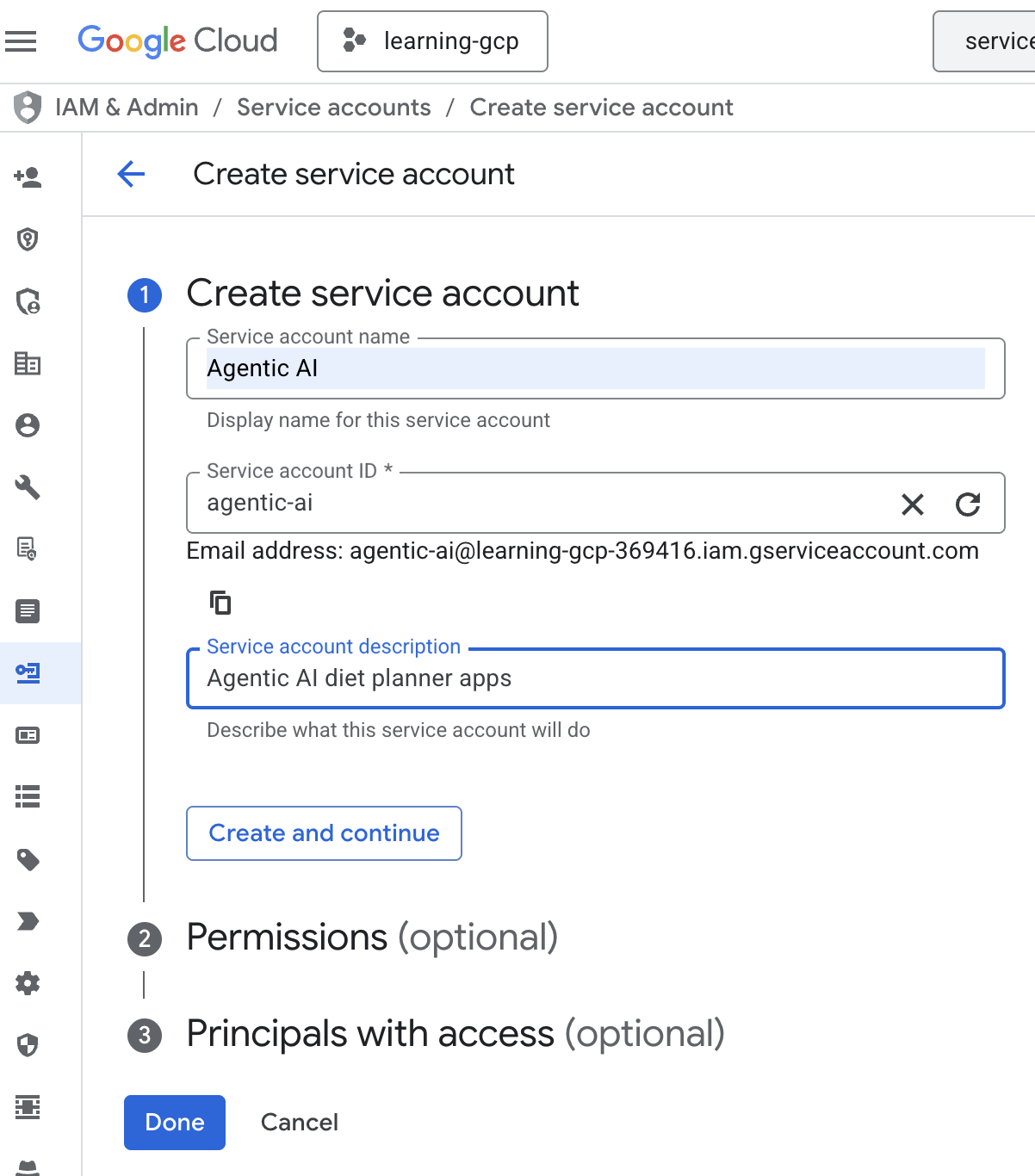
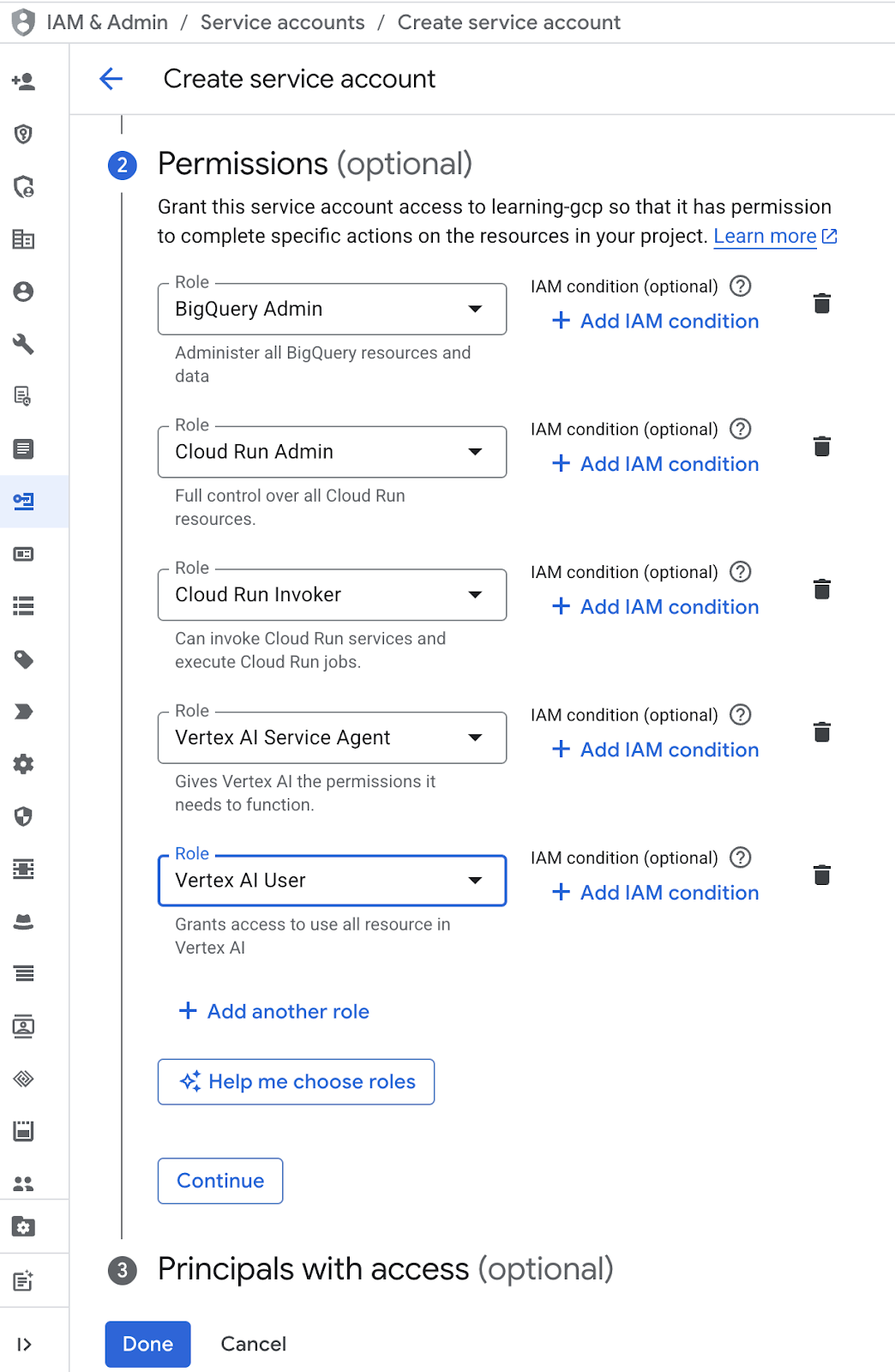
- در قسمت مجوزها، نقش «کاربر حساب کاربری سرویس» را انتخاب کنید. روی «افزودن یک نقش دیگر» کلیک کنید و نقش IAM را انتخاب کنید: BigQuery Admin، Cloud Run Admin، Cloud Run Invoker، Vertex AI Service Agent و Vertex AI User، سپس روی «انجام شد» کلیک کنید.
- روی ایمیل حساب سرویس کلیک کنید، روی کلید تب کلیک کنید، روی کلید افزودن → ایجاد کلید جدید کلیک کنید.
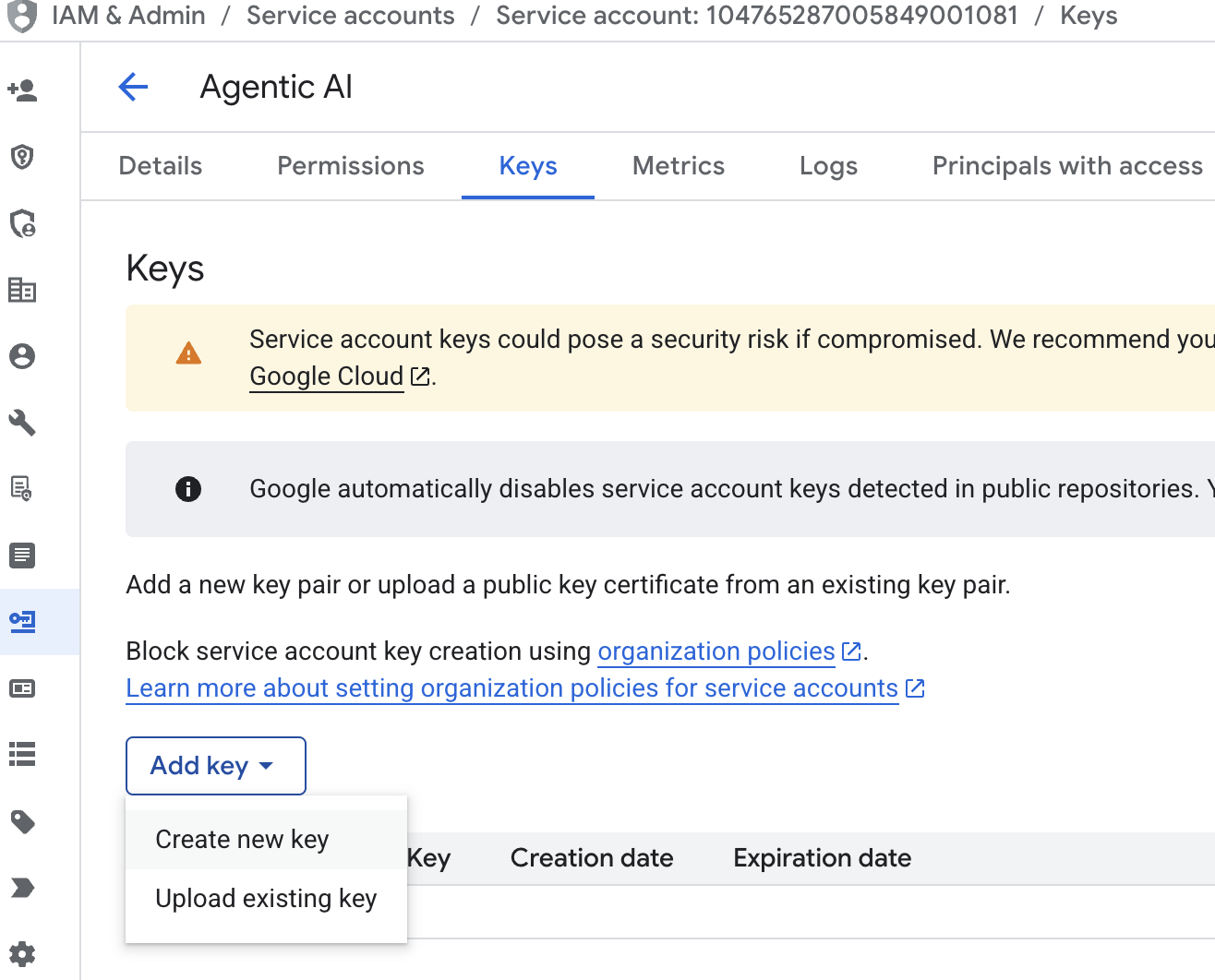
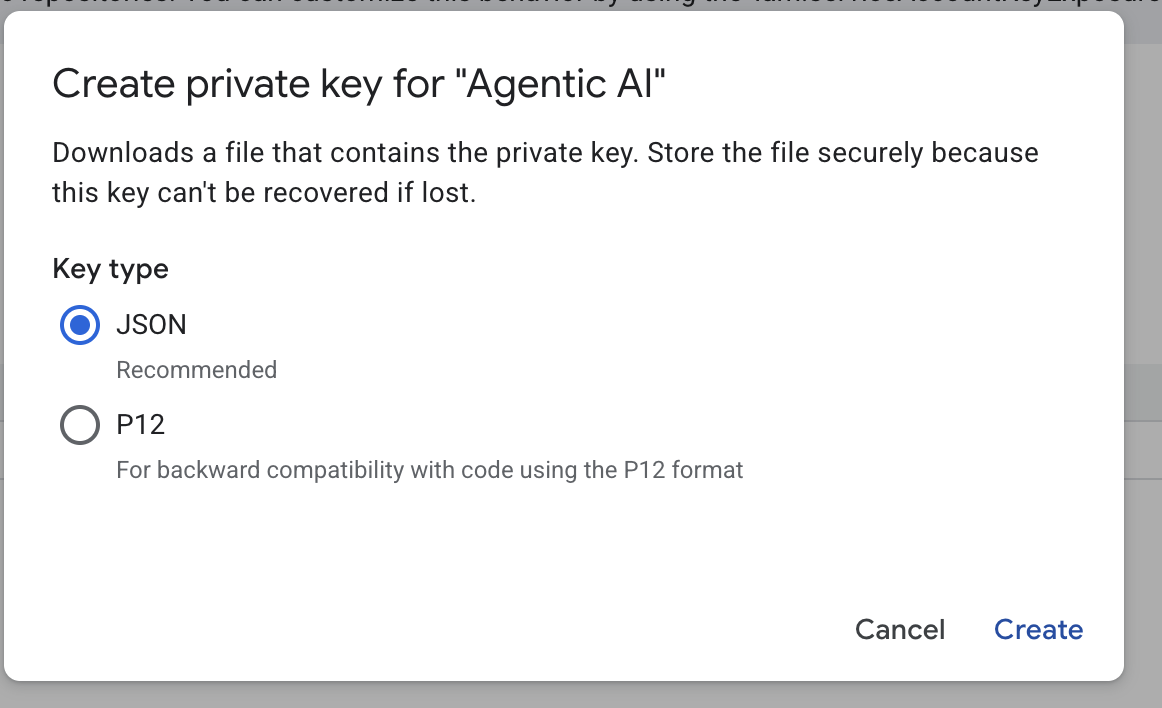
- json را انتخاب کنید و سپس روی ایجاد کلیک کنید. این فایل حساب سرویس را برای مرحله بعدی در محلی ذخیره کنید.
- یک پوشه با نام .streamlit با پیکربندی زیر ایجاد کنید. کلیک راست موس، روی New Folder کلیک کنید و نام پوشه
.streamlitرا تایپ کنید. - روی پوشه
.streamlitکلیک راست کنید، سپس روی New File کلیک کنید و مقادیر زیر را وارد کنید. سپس آن را با نامsecrets.tomlذخیره کنید.
# secrets.toml (for Streamlit sharing)
# Store in .streamlit/secrets.toml
[gcp]
project_id = "your_gcp_project"
location = "us-central1"
[gcp_service_account]
type = "service_account"
project_id = "your-project-id"
private_key_id = "your-private-key-id"
private_key = '''-----BEGIN PRIVATE KEY-----
YOUR_PRIVATE_KEY_HERE
-----END PRIVATE KEY-----'''
client_email = "your-sa@project-id.iam.gserviceaccount.com"
client_id = "your-client-id"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "https://www.googleapis.com/robot/v1/metadata/x509/your-sa%40project-id.iam.gserviceaccount.com"
- مقدار
project_id،private_key_id،private_key،client_email،client_id , and auth_provider_x509_cert_urlرا بر اساس حساب سرویس خود که در مرحله قبل ایجاد کردهاید، بهروزرسانی کنید.
آمادهسازی مجموعه داده BigQuery
مرحله بعدی ایجاد یک مجموعه داده BigQuery برای ذخیره نتایج تولید در BigQuery است.
- در قسمت جستجو عبارت BigQuery را تایپ کنید و سپس روی BigQuery کلیک کنید.
- کلیک
 سپس روی ایجاد مجموعه داده کلیک کنید
سپس روی ایجاد مجموعه داده کلیک کنید - شناسه مجموعه داده
diet_planner_dataرا وارد کنید و سپس روی ایجاد مجموعه داده کلیک کنید.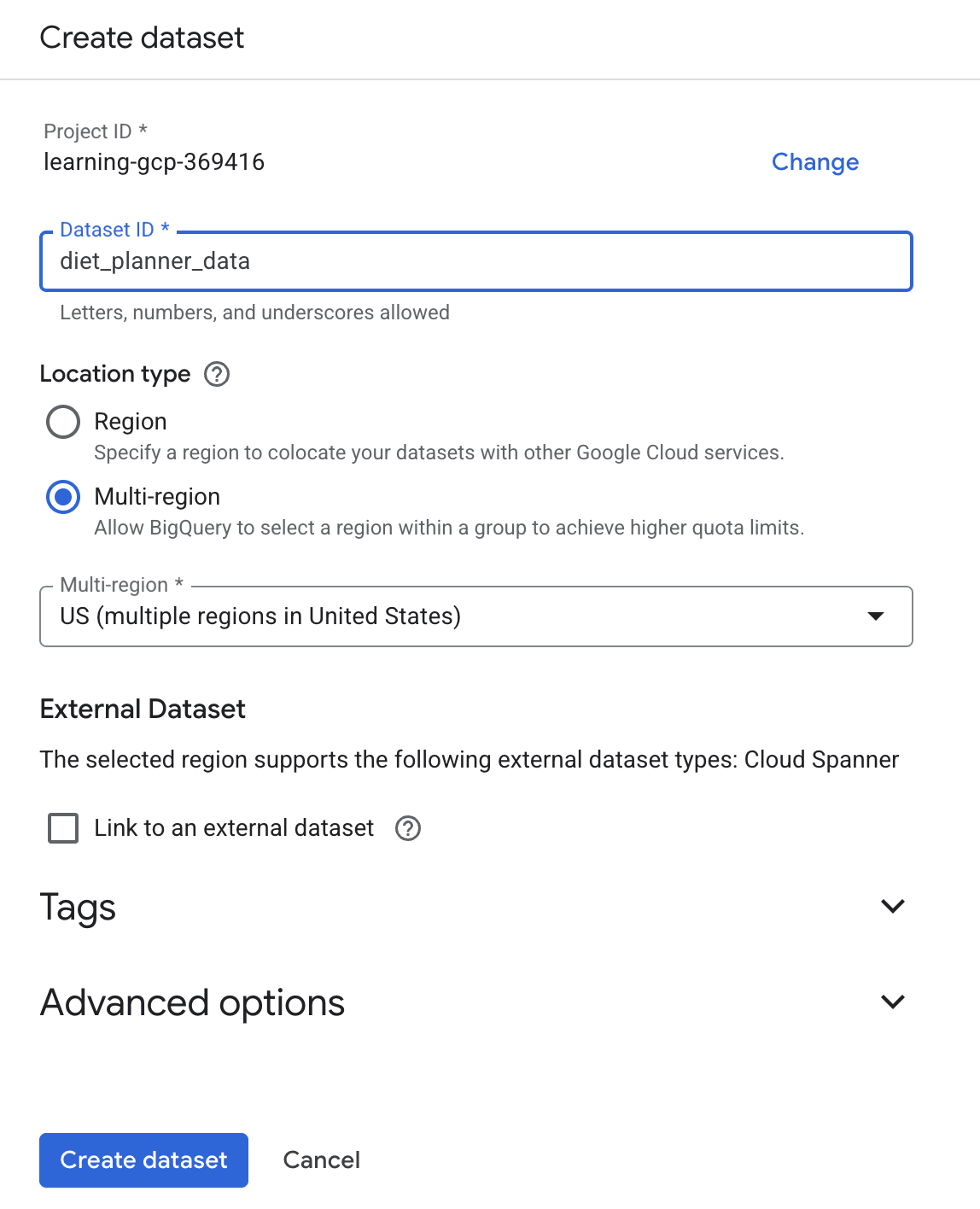
۴. یک برنامهی عامل برای برنامهریزی رژیم غذایی بسازید
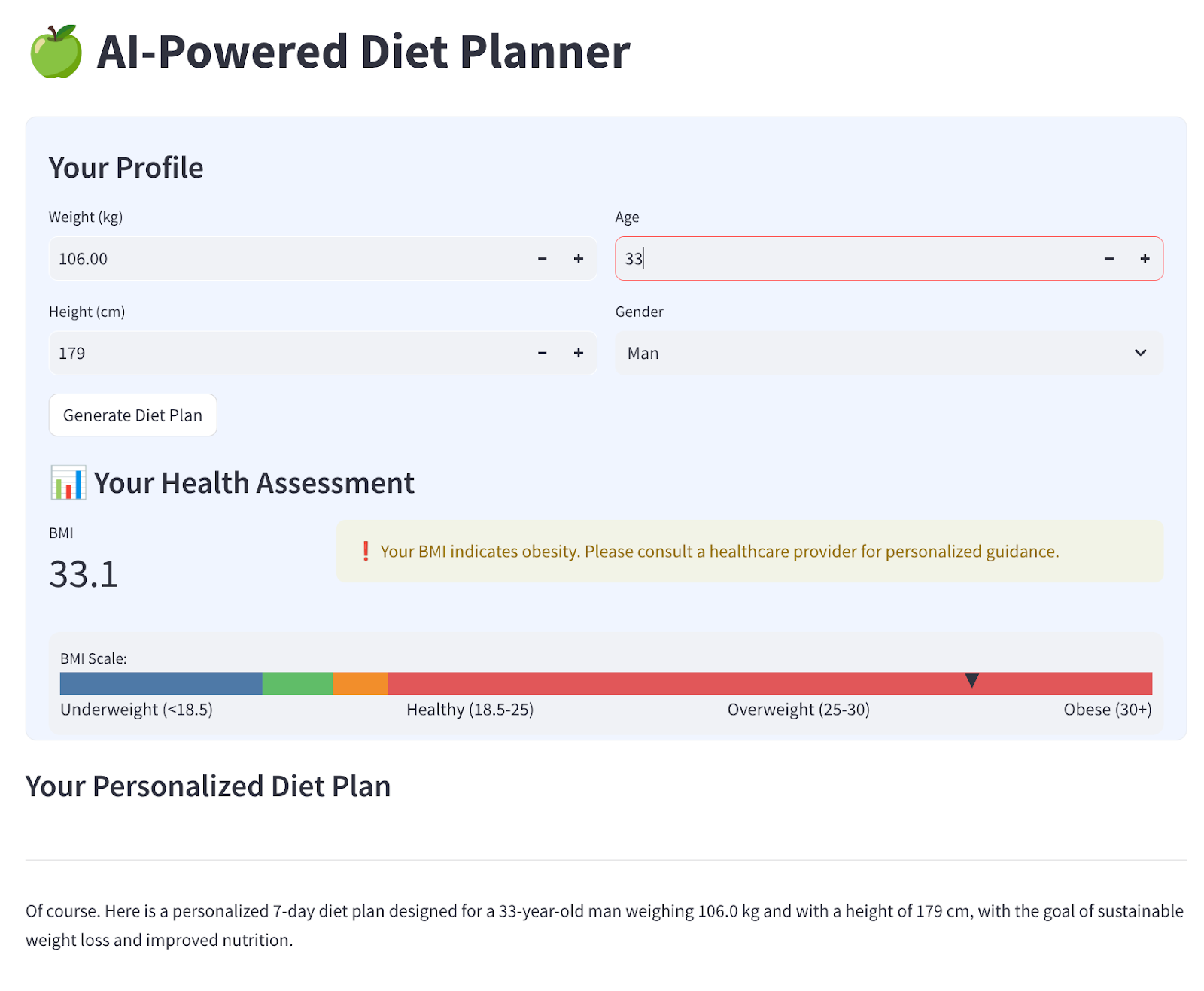
ما یک رابط وب ساده با ۴ ورودی خواهیم ساخت که به این شکل است
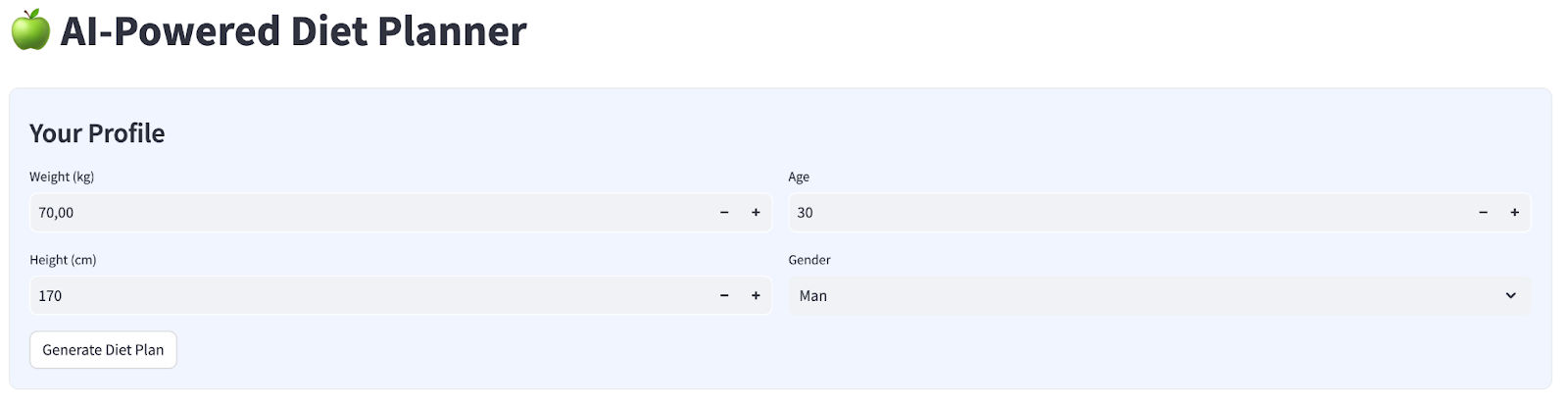
وزن، قد، سن و جنسیت را بر اساس پروفایل خود تغییر دهید و سپس روی ایجاد کلیک کنید. این مدل LLM Gemini Pro 2.5 را در کتابخانه Vertex AI فراخوانی میکند و نتایج تولید شده را در BigQuery ذخیره میکند.
کد به ۶ قسمت تقسیم میشود تا خیلی طولانی نشود.
ایجاد تابع محاسبه وضعیت BMI
- روی پوشه
agent_diet_plannerکلیک راست کنید → New File .. → filename را وارد کنیدbmi_calc.pyو سپس enter را بزنید - کد را با موارد زیر پر کنید
# Add this function to calculate BMI and health status
def calculate_bmi_status(weight, height):
"""
Calculate BMI and return status message
"""
height_m = height / 100 # Convert cm to meters
bmi = weight / (height_m ** 2)
if bmi < 18.5:
status = "underweight"
message = "⚠️ Your BMI suggests you're underweight. Consider increasing calorie intake with nutrient-dense foods."
elif 18.5 <= bmi < 25:
status = "normal"
message = "✅ Your BMI is in the healthy range. Let's maintain this balance!"
elif 25 <= bmi < 30:
status = "overweight"
message = "⚠️ Your BMI suggests you're overweight. Focus on gradual weight loss through balanced nutrition."
else:
status = "obese"
message = "❗ Your BMI indicates obesity. Please consult a healthcare provider for personalized guidance."
return {
"value": round(bmi, 1),
"status": status,
"message": message
}
ایجاد برنامه ریز رژیم غذایی عامل برنامه های اصلی
- روی پوشه
agent_diet_plannerکلیک راست کنید → New File .. → filename را وارد کنیدapp.pyو سپس Enter را بزنید. - کد را با موارد زیر پر کنید
import os
from google.oauth2 import service_account
import streamlit as st
from google.cloud import bigquery
from vertexai.preview.generative_models import GenerativeModel
import vertexai
import datetime
import time
import pandas as pd
from bmi_calc import calculate_bmi_status
# Get configuration from environment
PROJECT_ID = os.environ.get("GCP_PROJECT_ID", "your_gcp_project_id")
LOCATION = os.environ.get("GCP_LOCATION", "us-central1")
#CONSTANTS Dataset and table in BigQuery
DATASET = "diet_planner_data"
TABLE = "user_plans"
# Initialize Vertex AI
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Initialize BigQuery client
try:
# For Cloud Run, use default credentials
bq_client = bigquery.Client()
except:
# For local development, use service account from secrets
if "gcp_service_account" in st.secrets:
service_account_info = dict(st.secrets["gcp_service_account"])
credentials = service_account.Credentials.from_service_account_info(service_account_info)
bq_client = bigquery.Client(credentials=credentials, project=PROJECT_ID)
else:
st.error("BigQuery client initialization failed")
st.stop()
مقدار your_gcp_project_id را با شناسه پروژه خود تغییر دهید.
ایجاد برنامهریز رژیم غذایی عامل برنامههای اصلی - setup_bq_tables
در این بخش، تابعی به نام setup_bq_table با ۱ پارامتر ورودی bq_client ایجاد خواهیم کرد. این تابع، طرحواره (schema) را در جدول bigquery تعریف میکند و در صورت عدم وجود جدول، آن را ایجاد میکند.
کد زیر را با کد قبلی در app.py پر کنید.
# Create BigQuery table if not exists
def setup_bq_table(bq_client):
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
schema = [
bigquery.SchemaField("user_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("timestamp", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("weight", "FLOAT", mode="REQUIRED"),
bigquery.SchemaField("height", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("age", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("gender", "STRING", mode="REQUIRED"),
bigquery.SchemaField("diet_plan", "STRING", mode="REQUIRED")
]
try:
bq_client.get_table(table_id)
except:
table = bigquery.Table(table_id, schema=schema)
bq_client.create_table(table)
st.toast("BigQuery table created successfully")
برنامههای اصلی برنامهریز رژیم غذایی عامل ایجاد - generate_diet_plan
در این بخش، تابعی به نام generate_diet_plan با ۱ پارامتر ورودی ایجاد خواهیم کرد. این تابع مدل LLM در Gemini Pro 2.5 را با استفاده از define prompt فراخوانی کرده و نتایج را تولید میکند.
کد زیر را با کد قبلی در app.py پر کنید.
# Generate diet plan using Gemini Pro
def generate_diet_plan(params):
try:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
Create a personalized 7-day diet plan for:
- {params['gender']}, {params['age']} years old
- Weight: {params['weight']} kg
- Height: {params['height']} cm
Include:
1. Daily calorie target
2. Macronutrient breakdown (carbs, protein, fat)
3. Meal timing and frequency
4. Food recommendations
5. Hydration guidance
Make the plan:
- Nutritionally balanced
- Practical for daily use
- Culturally adaptable
- With portion size guidance
"""
response = model.generate_content(prompt)
return response.text
except Exception as e:
st.error(f"AI generation error: {str(e)}")
return None
ایجاد برنامهریز رژیم غذایی عامل اصلی برنامهها - save_to_bq
در این بخش، تابعی به نام save_to_bq با ۳ پارامتر ورودی bq_client ، user_id و plan ایجاد خواهیم کرد. این تابع نتیجه تولید شده را در جدول bigquery ذخیره میکند.
کد زیر را با کد قبلی در app.py پر کنید.
# Save user data to BigQuery
def save_to_bq(bq_client, user_id, plan):
try:
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
row = {
"user_id": user_id,
"timestamp": datetime.datetime.utcnow().isoformat(),
"weight": st.session_state.user_data["weight"],
"height": st.session_state.user_data["height"],
"age": st.session_state.user_data["age"],
"gender": st.session_state.user_data["gender"],
"diet_plan": plan
}
errors = bq_client.insert_rows_json(table_id, [row])
if errors:
st.error(f"BigQuery error: {errors}")
else:
return True
except Exception as e:
st.error(f"Data saving error: {str(e)}")
return False
برنامه ریز رژیم غذایی عامل ایجاد برنامه های اصلی - اصلی
در این بخش، تابعی به نام main بدون پارامتر ورودی ایجاد خواهیم کرد. این تابع عمدتاً اسکریپت رابط کاربری ساده، نمایش نتایج تولید شده، نمایش نتایج تولید شده از جدول bigquery و دانلود دادهها به فایل markdown را مدیریت میکند.
کد زیر را با کد قبلی در app.py پر کنید.
# Streamlit UI
def main():
st.set_page_config(page_title="AI Diet Planner", page_icon="🍏", layout="wide")
# Initialize session state
if "user_data" not in st.session_state:
st.session_state.user_data = None
if "diet_plan" not in st.session_state:
st.session_state.diet_plan = None
# Initialize clients
#bq_client = init_clients()
setup_bq_table(bq_client)
st.title("🍏 AI-Powered Diet Planner")
st.markdown("""
<style>
.stProgress > div > div > div > div {
background-color: #4CAF50;
}
[data-testid="stForm"] {
background: #f0f5ff;
padding: 20px;
border-radius: 10px;
border: 1px solid #e6e9ef;
}
</style>
""", unsafe_allow_html=True)
# User input form
with st.form("user_profile", clear_on_submit=False):
st.subheader("Your Profile")
col1, col2 = st.columns(2)
with col1:
weight = st.number_input("Weight (kg)", min_value=30.0, max_value=200.0, value=70.0)
height = st.number_input("Height (cm)", min_value=100, max_value=250, value=170)
with col2:
age = st.number_input("Age", min_value=18, max_value=100, value=30)
gender = st.selectbox("Gender", ["Man", "Woman"])
submitted = st.form_submit_button("Generate Diet Plan")
if submitted:
user_data = {
"weight": weight,
"height": height,
"age": age,
"gender": gender
}
st.session_state.user_data = user_data
# Calculate BMI
bmi_result = calculate_bmi_status(weight, height)
# Display BMI results in a visually distinct box
with st.container():
st.subheader("📊 Your Health Assessment")
col1, col2 = st.columns([1, 3])
with col1:
st.metric("BMI", bmi_result["value"])
with col2:
if bmi_result["status"] != "normal":
st.warning(bmi_result["message"])
else:
st.success(bmi_result["message"])
# Add BMI scale visualization
st.markdown(f"""
<div style="background:#f0f2f6;padding:10px;border-radius:10px;margin-top:10px">
<small>BMI Scale:</small><br>
<div style="display:flex;height:20px;background:linear-gradient(90deg,
#4e79a7 0%,
#4e79a7 18.5%,
#60bd68 18.5%,
#60bd68 25%,
#f28e2b 25%,
#f28e2b 30%,
#e15759 30%,
#e15759 100%);position:relative">
<div style="position:absolute;left:{min(100, max(0, (bmi_result["value"]/40)*100))}%;top:-5px">
▼
</div>
</div>
<div style="display:flex;justify-content:space-between">
<span>Underweight (<18.5)</span>
<span>Healthy (18.5-25)</span>
<span>Overweight (25-30)</span>
<span>Obese (30+)</span>
</div>
</div>
""", unsafe_allow_html=True)
# Store BMI in session state
st.session_state.bmi = bmi_result
# Plan generation and display
if submitted and st.session_state.user_data:
with st.spinner("🧠 Generating your personalized diet plan using Gemini AI..."):
#diet_plan = generate_diet_plan(st.session_state.user_data)
diet_plan = generate_diet_plan({**st.session_state.user_data,"bmi": bmi_result["value"],
"bmi_status": bmi_result["status"]
})
if diet_plan:
st.session_state.diet_plan = diet_plan
# Generate unique user ID
user_id = f"user_{int(time.time())}"
# Save to BigQuery
if save_to_bq(bq_client, user_id, diet_plan):
st.toast("✅ Plan saved to database!")
# Display generated plan
if st.session_state.diet_plan:
st.subheader("Your Personalized Diet Plan")
st.markdown("---")
st.markdown(st.session_state.diet_plan)
# Download button
st.download_button(
label="Download Plan",
data=st.session_state.diet_plan,
file_name="my_diet_plan.md",
mime="text/markdown"
)
# Show history
st.subheader("Your Plan History")
try:
query = f"""
SELECT timestamp, weight, height, age, gender
FROM `{st.secrets['gcp']['project_id']}.{DATASET}.{TABLE}`
WHERE user_id LIKE 'user_%'
ORDER BY timestamp DESC
LIMIT 5
"""
history = bq_client.query(query).to_dataframe()
if not history.empty:
history["timestamp"] = pd.to_datetime(history["timestamp"])
st.dataframe(history.style.format({
"weight": "{:.1f} kg",
"height": "{:.0f} cm"
}))
else:
st.info("No previous plans found")
except Exception as e:
st.error(f"History load error: {str(e)}")
if __name__ == "__main__":
main()
کد را با نام app.py ذخیره کنید.
۵. برنامهها را با استفاده از cloud build به Cloud Run مستقر کنید
حالا، البته که میخواهیم این برنامهی شگفتانگیز را به دیگران نشان دهیم. برای انجام این کار، میتوانیم این برنامه را بستهبندی کنیم و آن را به عنوان یک سرویس عمومی که دیگران میتوانند به آن دسترسی داشته باشند، در Cloud Run مستقر کنیم. برای انجام این کار، بیایید معماری را دوباره بررسی کنیم.
ابتدا به Dockerfile نیاز داریم، روی File->New Text File کلیک کنید و کد زیر را کپی و پیست کنید و سپس آن را با نام Dockerfile ذخیره کنید.
# Use official Python image
FROM python:3.12-slim
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV PORT 8080
# Install system dependencies
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /app
# Copy requirements
COPY requirements.txt .
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application files
COPY . .
# Expose port
EXPOSE $PORT
# Run the application
CMD ["streamlit", "run", "app.py", "--server.port", "8080", "--server.address", "0.0.0.0"]
در مرحله بعد، ما cloudbuid.yaml را برای تبدیل برنامههای ساخته شده به تصاویر داکر، ارسال به رجیستری مصنوعات و استقرار در فضای ابری ایجاد خواهیم کرد.
روی File->New Text File کلیک کنید و کد زیر را کپی و پیست کنید و سپس آن را با نام cloudbuild.yaml ذخیره کنید.
steps:
# Build Docker image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID', '--no-cache',
'--progress=plain',
'.']
id: 'Build'
timeout: 1200s
waitFor: ['-']
dir: '.'
# Push to Container Registry
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID']
id: 'Push'
waitFor: ['Build']
# Deploy to Cloud Run
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args:
- 'run'
- 'deploy'
- 'diet-planner-service'
- '--image=gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
- '--port=8080'
- '--region=us-central1'
- '--platform=managed'
- '--allow-unauthenticated'
- '--set-env-vars=GCP_PROJECT_ID=$PROJECT_ID,GCP_LOCATION=us-central1'
- '--cpu=1'
- '--memory=1Gi'
- '--timeout=300'
waitFor: ['Push']
options:
logging: CLOUD_LOGGING_ONLY
machineType: 'E2_HIGHCPU_8'
diskSizeGb: 100
images:
- 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
در این مرحله، ما تمام فایلهای مورد نیاز برای ساخت برنامهها جهت تبدیل شدن به تصاویر داکر، ارسال به رجیستری مصنوعات و استقرار آن در Cloud Run را داریم، بیایید آن را مستقر کنیم. به ترمینال Cloud Shell بروید و مطمئن شوید که پروژه فعلی با پروژه فعال شما پیکربندی شده است، در غیر این صورت از دستور gcloud configure برای تنظیم شناسه پروژه استفاده کنید:
gcloud config set project [PROJECT_ID]
سپس، دستور زیر را اجرا کنید تا برنامهها به تصاویر داکر تبدیل شوند، به رجیستری مصنوعات منتقل شوند و در Cloud Run مستقر شوند.
gcloud builds submit --config cloudbuild.yaml
این دستور، کانتینر داکر را بر اساس داکرفایلی که قبلاً ارائه دادهایم، میسازد و آن را به رجیستری مصنوعات (Artifact Registry) منتقل میکند. پس از آن، ایمیج ساختهشده را در Cloud Run مستقر میکنیم. تمام این فرآیند در مراحل cloudbuild.yaml تعریف شده است.
توجه داشته باشید که ما در اینجا به دلیل آزمایشی بودن برنامه، دسترسی غیرمجاز را مجاز میدانیم. توصیه میشود از احراز هویت مناسب برای برنامههای سازمانی و تولیدی خود استفاده کنید.
پس از اتمام استقرار، میتوانیم آن را در صفحه Cloud Run بررسی کنیم، Cloud Run را در نوار جستجوی بالای کنسول ابری جستجو کرده و روی محصول Cloud Run کلیک کنیم.
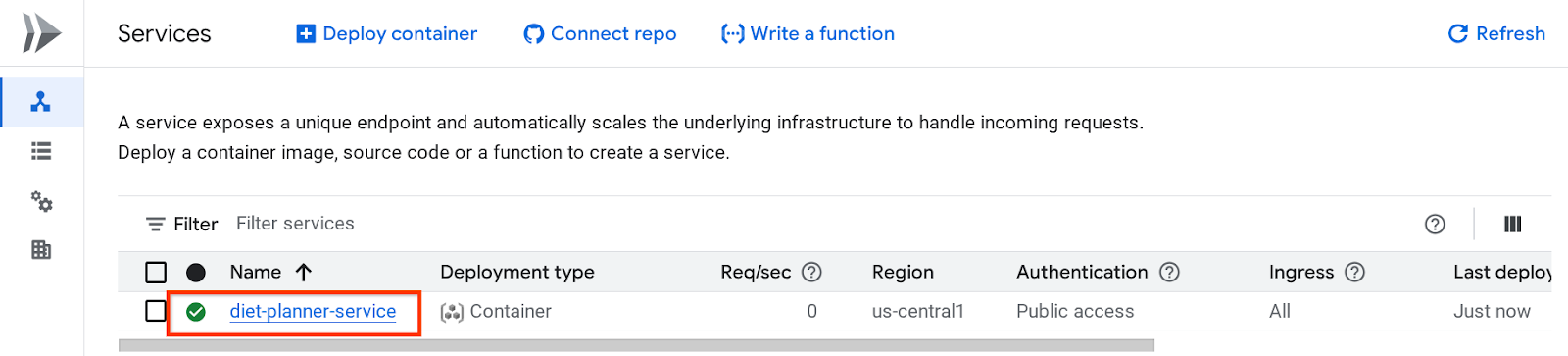
پس از آن میتوانید سرویس مستقر شده را که در صفحه Cloud Run Service فهرست شده است، بررسی کنید، روی سرویس کلیک کنید تا بتوانیم URL سرویس را دریافت کنیم.
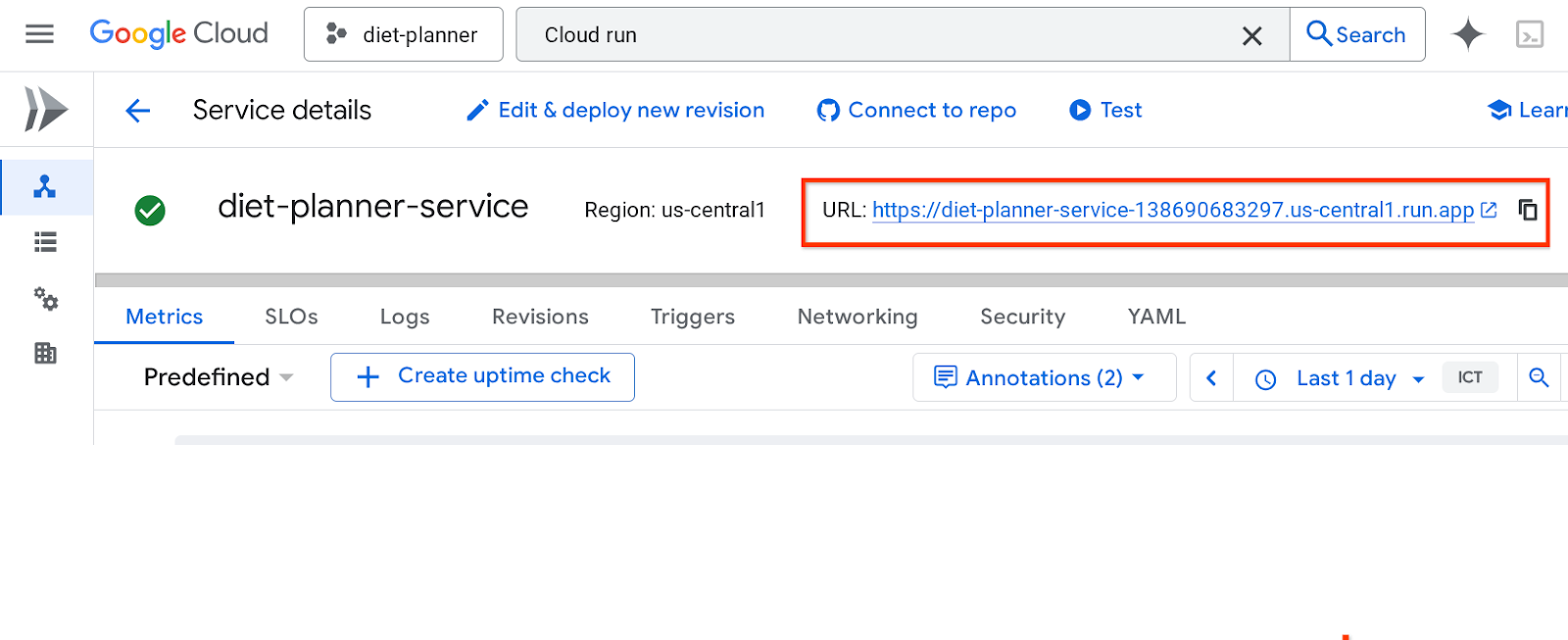
آدرس اینترنتی سرویس در نوار بالا قرار خواهد گرفت
 میتوانید از پنجره ناشناس یا دستگاه همراه خود از برنامه استفاده کنید. باید از قبل فعال باشد.
میتوانید از پنجره ناشناس یا دستگاه همراه خود از برنامه استفاده کنید. باید از قبل فعال باشد.
۶. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این آزمایشگاه کد، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
- روش دیگر این است که به Cloud Run در کنسول بروید، سرویسی را که اخیراً مستقر کردهاید انتخاب کرده و حذف کنید.