
1. Introduction
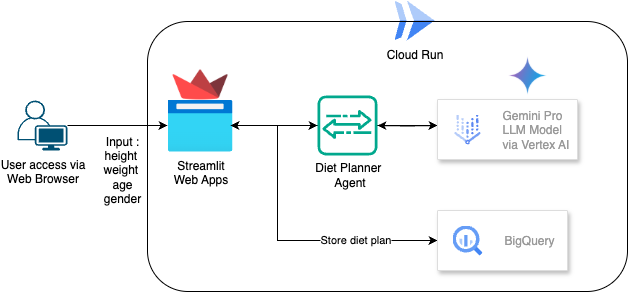
Dans cet atelier de programmation, vous allez apprendre à créer et à déployer un planificateur de régime alimentaire basé sur l'IA. Pour l'UI, utilisez Streamlit, le modèle LLM Gemini Pro 2.5, l'orchestrateur du moteur d'IA agentique Vertex AI pour l'IA agentique de développement, BigQuery pour stocker les données et Cloud Run pour le déploiement.
Au cours de cet atelier de programmation, vous allez suivre une approche par étapes :
- Préparez votre projet Google Cloud et activez toutes les API requises.
- Créer un planificateur de régime basé sur l'IA à l'aide de Streamlit, Vertex AI et BigQuery
- Déployer l'application sur Cloud Run
Présentation de l'architecture
Conditions préalables
- Un projet Google Cloud Platform (GCP) avec la facturation activée.
- Connaissances de base de Python
Points abordés
- Créer un planificateur de régime basé sur l'IA avec Streamlit, Vertex AI et stocker des données dans BigQuery
- Déployer l'application sur Cloud Run
Prérequis
- Navigateur Web Chrome
- Un compte Gmail
- Un projet Cloud pour lequel la facturation est activée
2. Configuration de base et exigences
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.

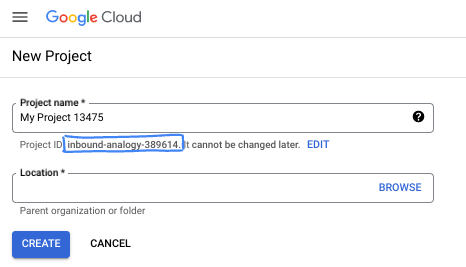
- Le nom du projet est celui que verront les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
3. Avant de commencer
Configurer un projet Cloud dans l'éditeur Cloud Shell
Cet atelier de programmation suppose que vous disposez déjà d'un projet Google Cloud pour lequel la facturation est activée. Si vous ne l'avez pas encore, vous pouvez suivre les instructions ci-dessous pour commencer.
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet .
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud et fourni avec bq. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.
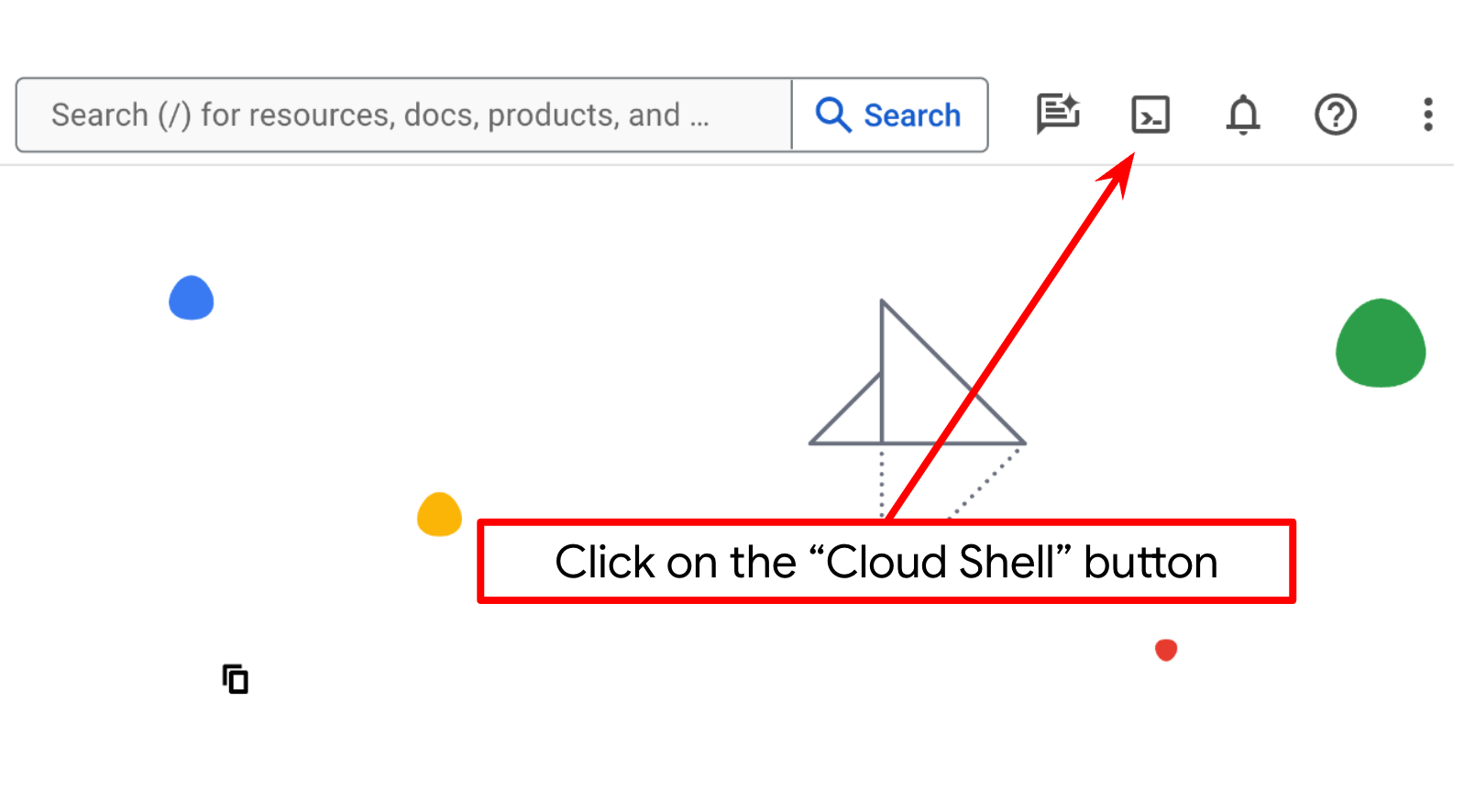
- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
Vous pouvez également voir l'ID PROJECT_ID dans la console.
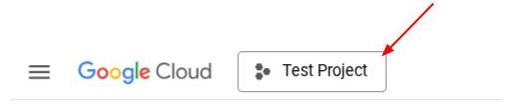
Cliquez dessus pour afficher tous vos projets et l'ID du projet sur la droite.
- Activez les API requises à l'aide de la commande ci-dessous. Cette opération peut prendre quelques minutes. Veuillez patienter.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
bigquery.googleapis.com
Si la commande s'exécute correctement, un message semblable à celui ci-dessous s'affiche :
Operation "operations/..." finished successfully.
Vous pouvez également accéder à la console en recherchant chaque produit ou en utilisant ce lien.
Si vous oubliez une API, vous pourrez toujours l'activer au cours de l'implémentation.
Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
Configurer le répertoire de travail de l'application
- Cliquez sur le bouton "Ouvrir l'éditeur". Un éditeur Cloud Shell s'ouvre. Vous pouvez y écrire votre code
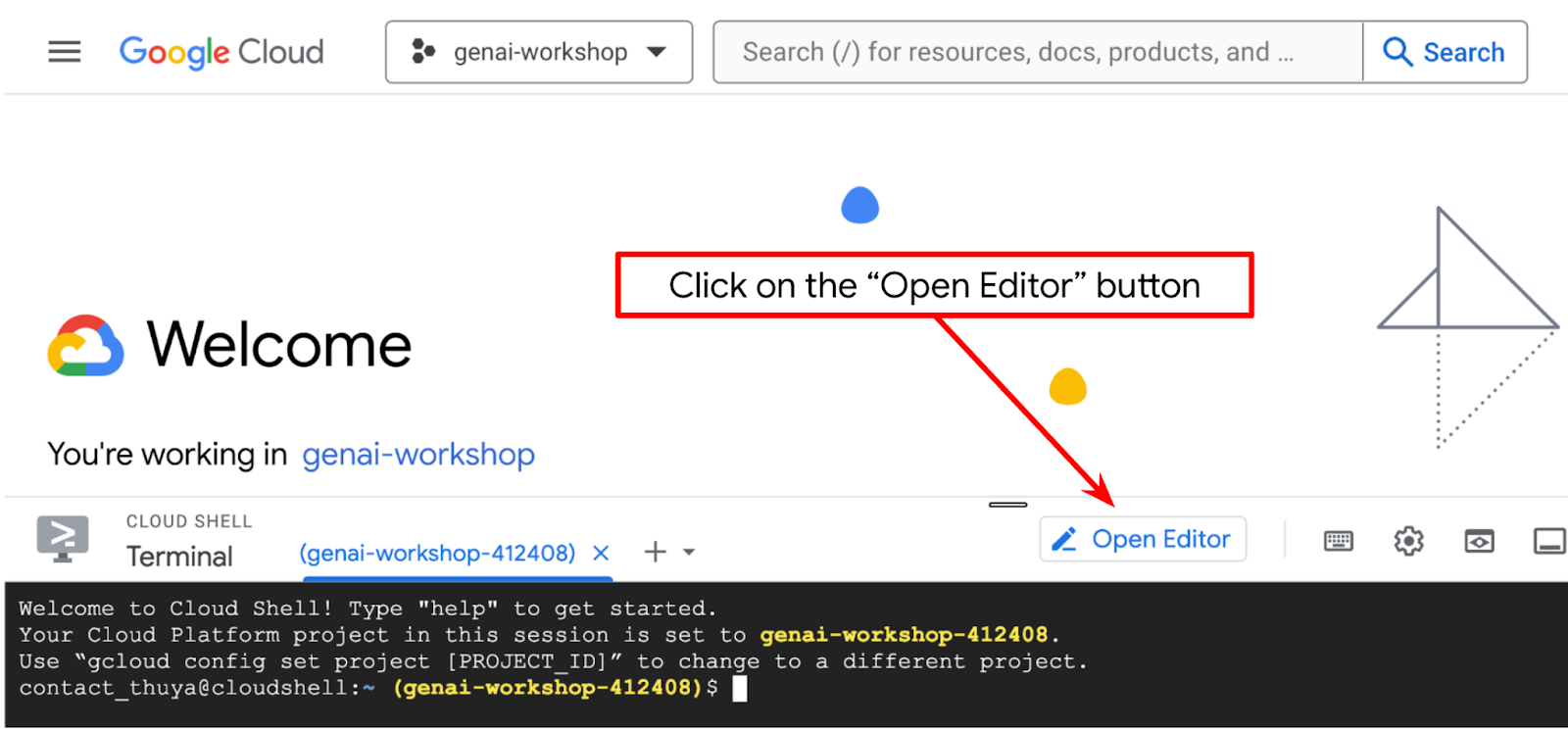 .
. - Assurez-vous que le projet Cloud Code est défini en bas à gauche (barre d'état) de l'éditeur Cloud Shell, comme indiqué dans l'image ci-dessous, et qu'il est défini sur le projet Google Cloud actif pour lequel la facturation est activée. Cliquez sur Autoriser si vous y êtes invité. L'initialisation de l'éditeur Cloud Shell peut prendre un certain temps. Soyez patient jusqu'à ce que le bouton Cloud Code – Se connecter s'affiche.
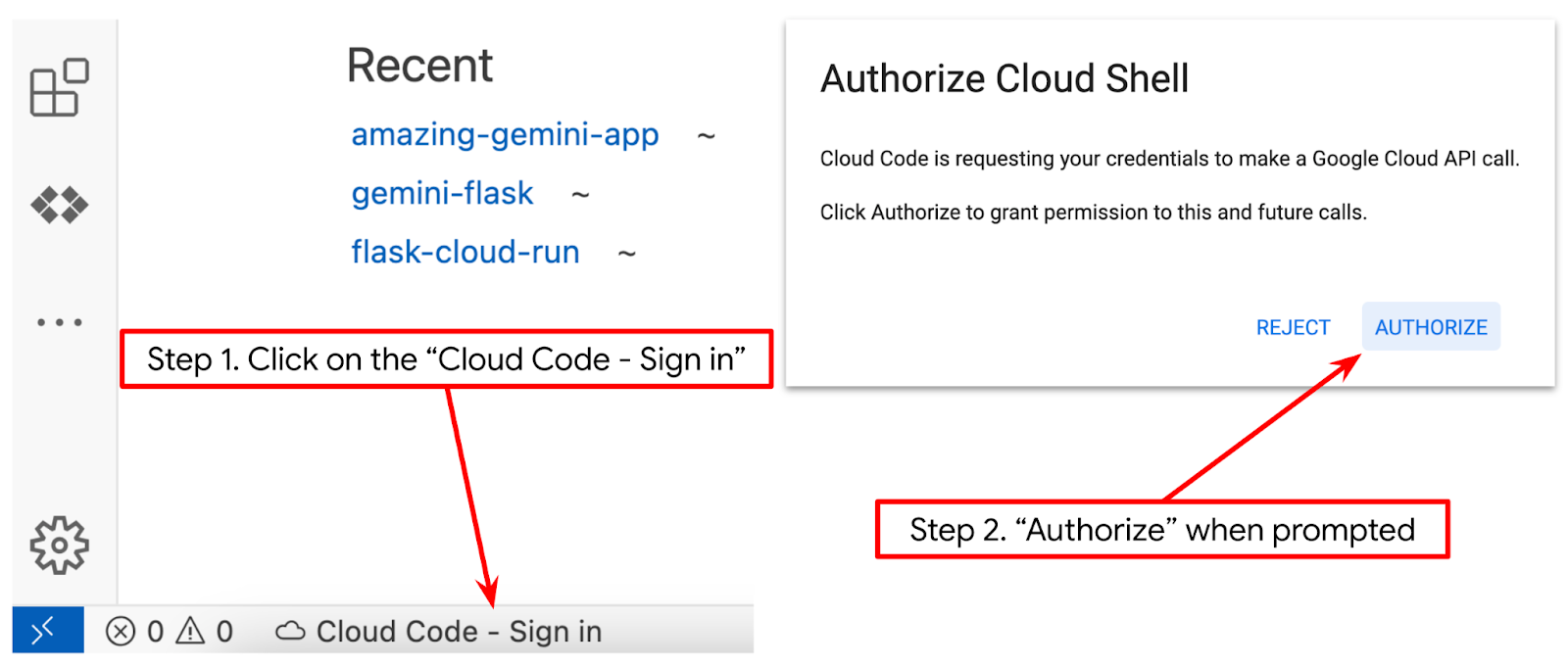
Ensuite, nous allons préparer notre environnement Python.
Configurer l'environnement
Préparer l'environnement virtuel Python
L'étape suivante consiste à préparer l'environnement de développement. Dans cet atelier de programmation, nous utiliserons Python 3.12 et python virtualenv pour simplifier la création et la gestion de la version Python et de l'environnement virtuel.
- Si vous n'avez pas encore ouvert le terminal, ouvrez-le en cliquant sur Terminal > Nouveau terminal ou en utilisant le raccourci Ctrl+Maj+C.

- Créez un dossier et accédez-y en exécutant la commande suivante :
mkdir agent_diet_planner
cd agent_diet_planner
- Créez un environnement virtuel en exécutant la commande suivante :
python -m venv .env
- Activez virtualenv avec la commande suivante :
source .env/bin/activate
- Créez des
requirements.txt. Cliquez sur Fichier → Nouveau fichier texte et renseignez-le avec le contenu ci-dessous. Ensuite, enregistrez-le au formatrequirements.txt.
streamlit==1.33.0
google-cloud-aiplatform
google-cloud-bigquery
pandas==2.2.2
db-dtypes==1.2.0
pyarrow==16.1.0
- Installez ensuite toutes les dépendances à partir de requirements.txt en exécutant la commande suivante :
pip install -r requirements.txt
- Saisissez la commande ci-dessous pour vérifier que toutes les dépendances des bibliothèques Python sont installées.
pip list
Configurer les fichiers de configuration
Nous devons maintenant configurer les fichiers de configuration pour ce projet. Les fichiers de configuration permettent de stocker les variables et les identifiants des comptes de service.
- La première étape consiste à créer un compte de service. Saisissez "compte de service" dans la recherche, puis cliquez sur "Compte de service".
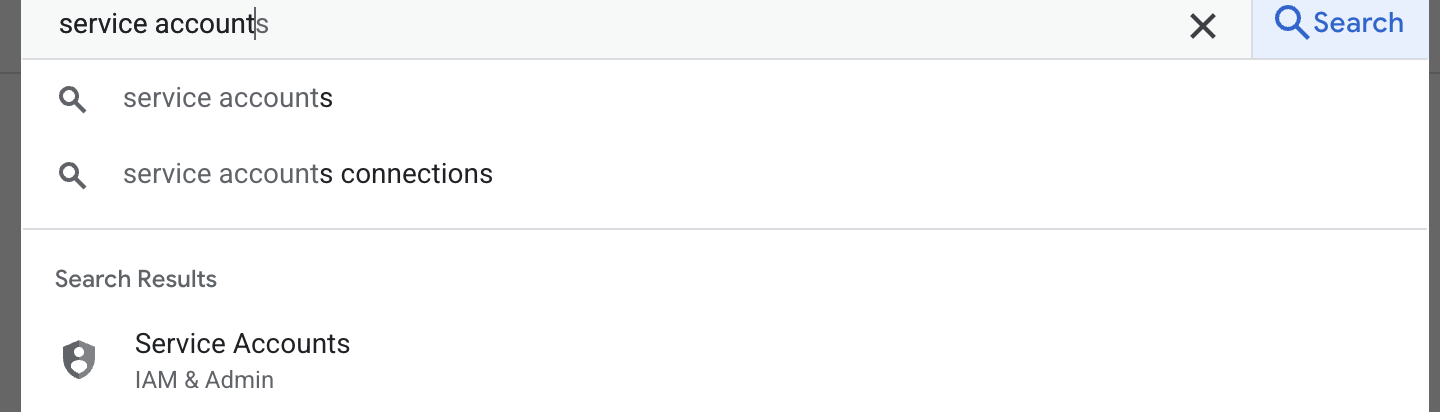
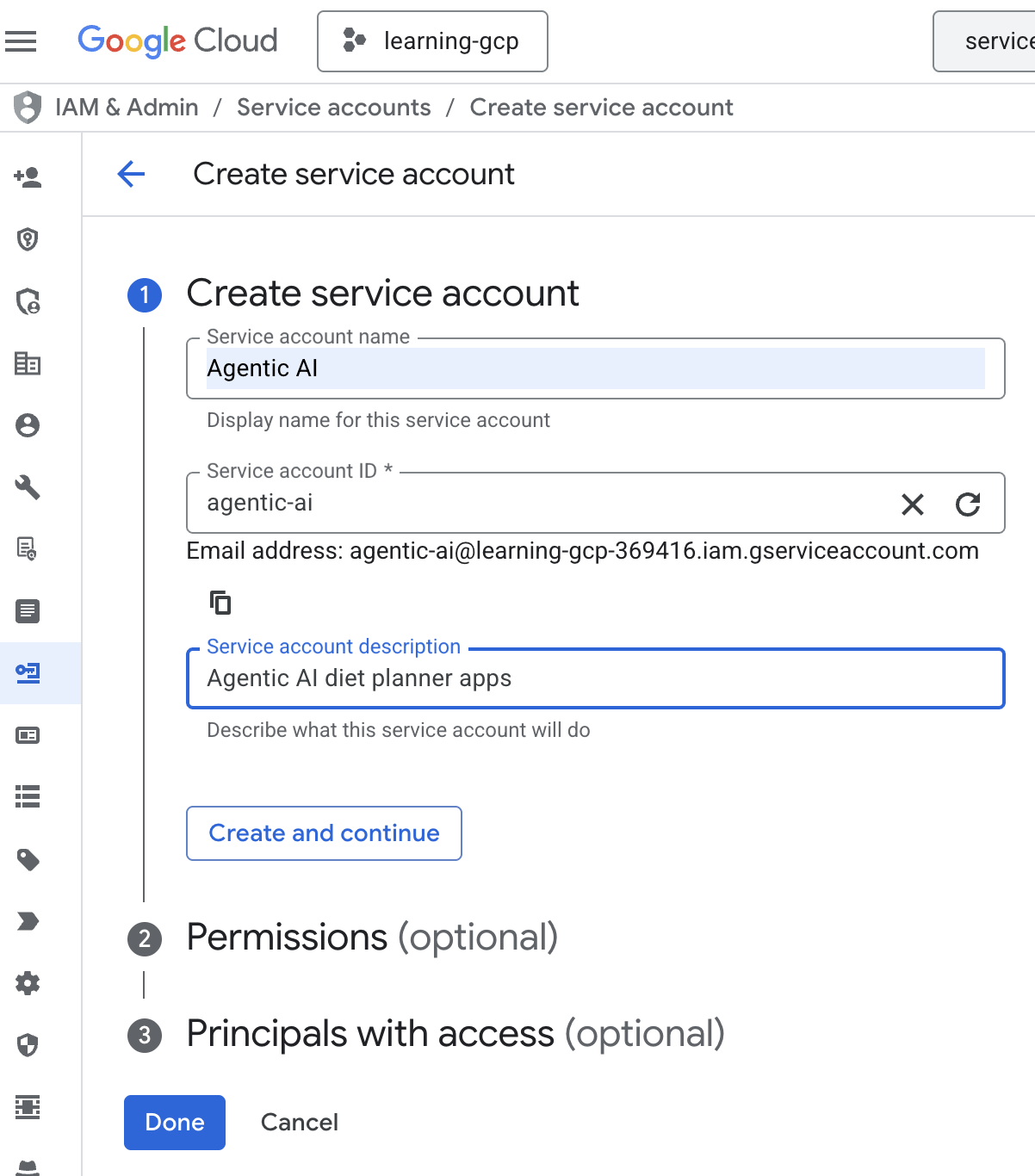
- Cliquez sur "+ Créer un compte de service". Saisissez le nom du compte de service, puis cliquez sur "Créer et continuer".
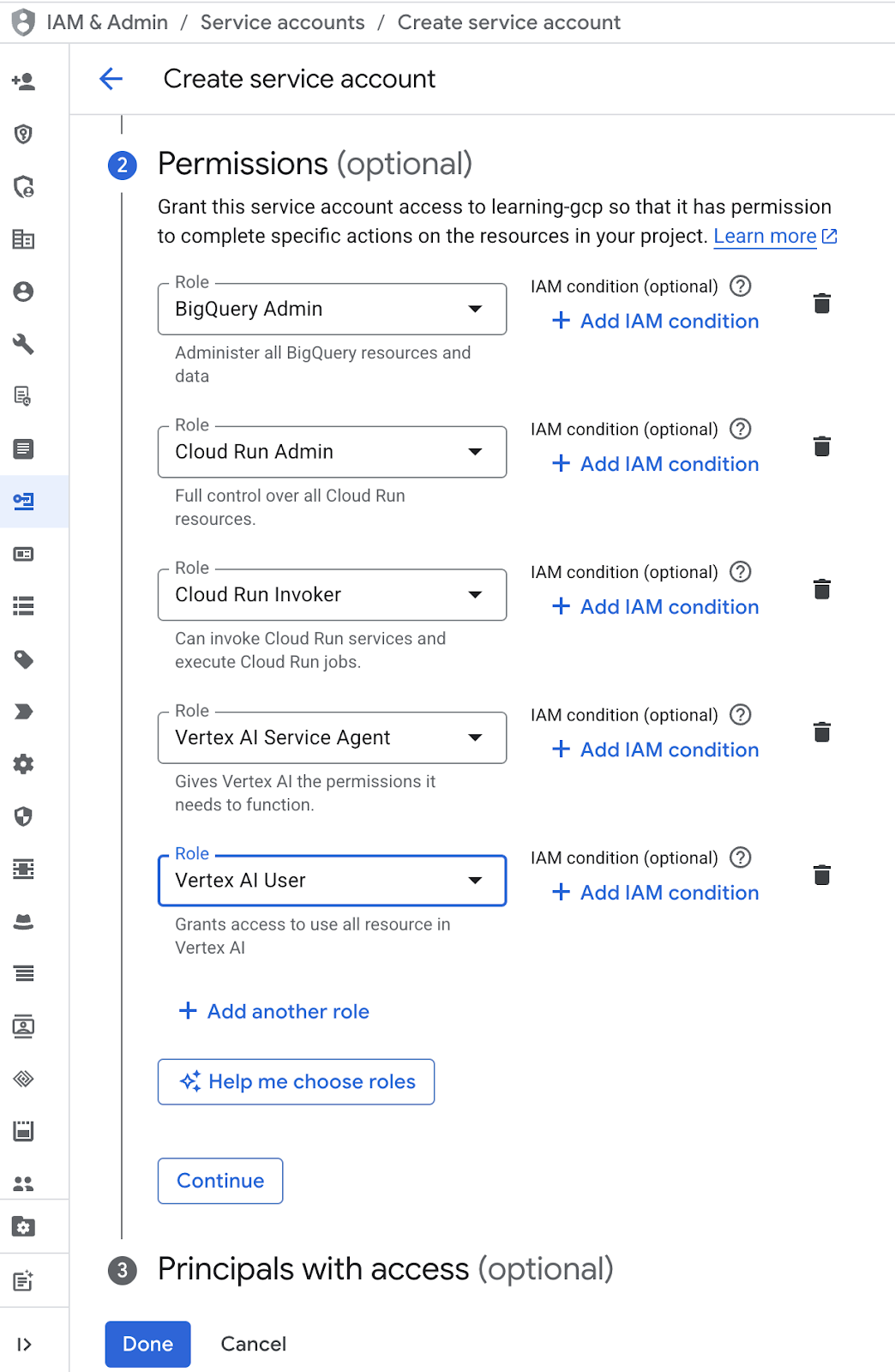
- Dans "Autorisation", sélectionnez le rôle "Utilisateur du compte de service". Cliquez sur "Ajouter un autre rôle", puis sélectionnez les rôles IAM suivants : "Administrateur BigQuery", "Administrateur Cloud Run", "Appelant Cloud Run", "Agent de service Vertex AI" et "Utilisateur Vertex AI". Cliquez ensuite sur "OK".
- Cliquez sur l'adresse e-mail du compte de service, appuyez sur la touche de tabulation, puis cliquez sur Ajouter une clé → Créer une clé.
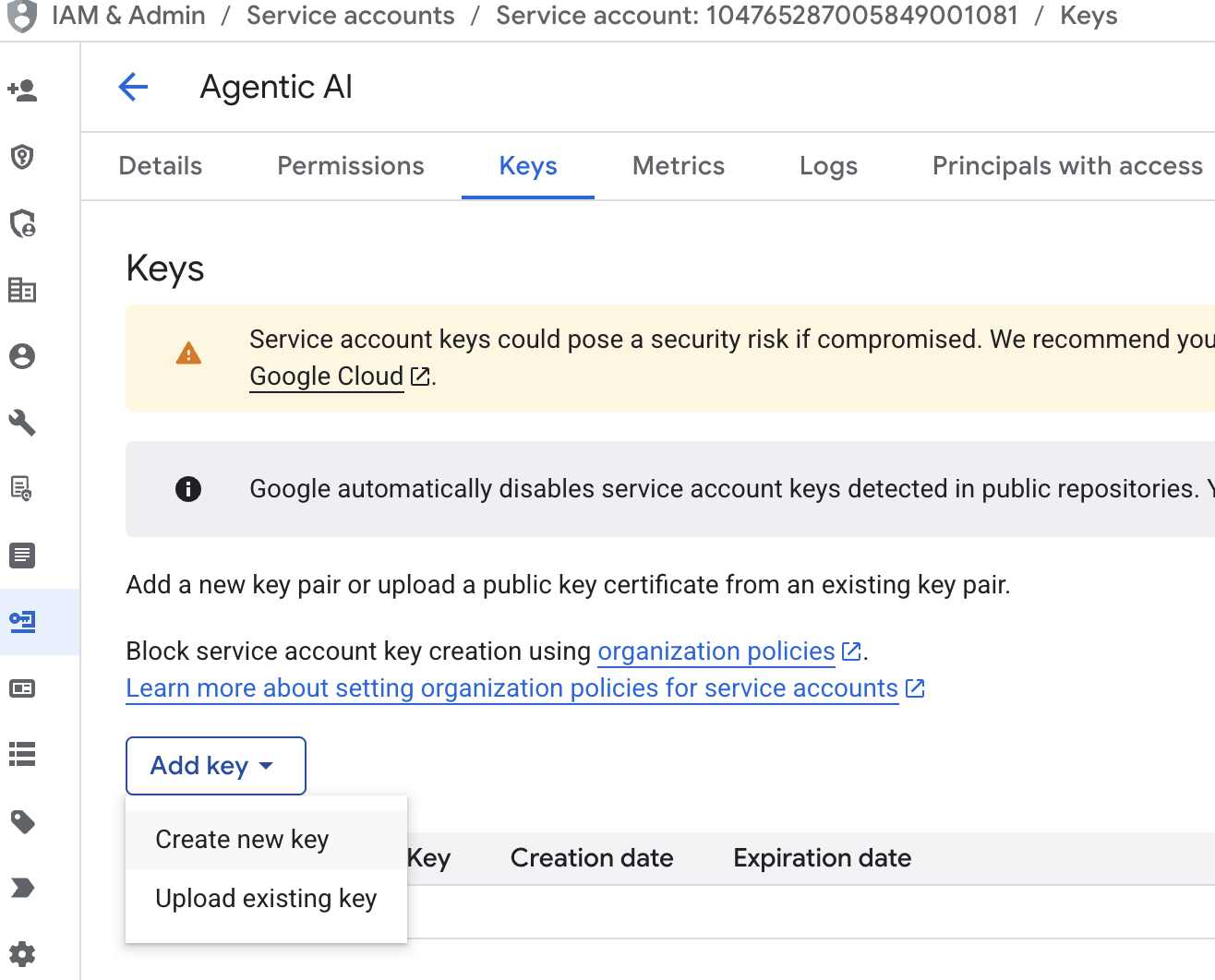
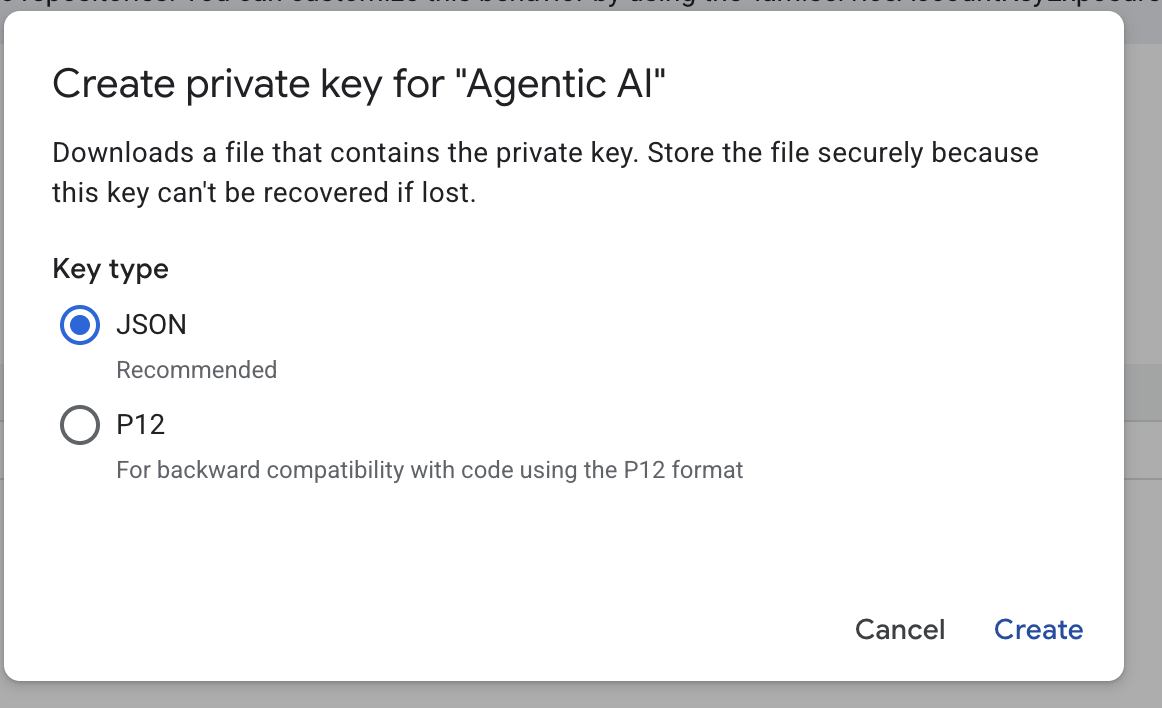
- Sélectionnez "json", puis cliquez sur "Créer". Enregistrez ce fichier de compte de service en local pour l'étape suivante :
- Créez un dossier nommé .streamlit avec la configuration suivante. Effectuez un clic droit, cliquez sur "Nouveau dossier", puis saisissez le nom du dossier
.streamlit. - Effectuez un clic droit dans le dossier
.streamlit, puis cliquez sur "Nouveau fichier" et saisissez la valeur ci-dessous. Ensuite, enregistrez-le au formatsecrets.toml.
# secrets.toml (for Streamlit sharing)
# Store in .streamlit/secrets.toml
[gcp]
project_id = "your_gcp_project"
location = "us-central1"
[gcp_service_account]
type = "service_account"
project_id = "your-project-id"
private_key_id = "your-private-key-id"
private_key = '''-----BEGIN PRIVATE KEY-----
YOUR_PRIVATE_KEY_HERE
-----END PRIVATE KEY-----'''
client_email = "your-sa@project-id.iam.gserviceaccount.com"
client_id = "your-client-id"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "https://www.googleapis.com/robot/v1/metadata/x509/your-sa%40project-id.iam.gserviceaccount.com"
- Mettez à jour les valeurs de
project_id,private_key_id,private_key,client_emailetclient_id , and auth_provider_x509_cert_urlen fonction du compte de service que vous avez créé à l'étape précédente.
Préparer l'ensemble de données BigQuery
L'étape suivante consiste à créer un ensemble de données BigQuery pour enregistrer les résultats de la génération dans BigQuery.
- Saisissez "BigQuery" dans la recherche, puis cliquez sur BigQuery.
- Cliquez sur
 , puis sur "Créer un ensemble de données".
, puis sur "Créer un ensemble de données". - Saisissez l'ID de l'ensemble de données
diet_planner_data, puis cliquez sur Créer un ensemble de données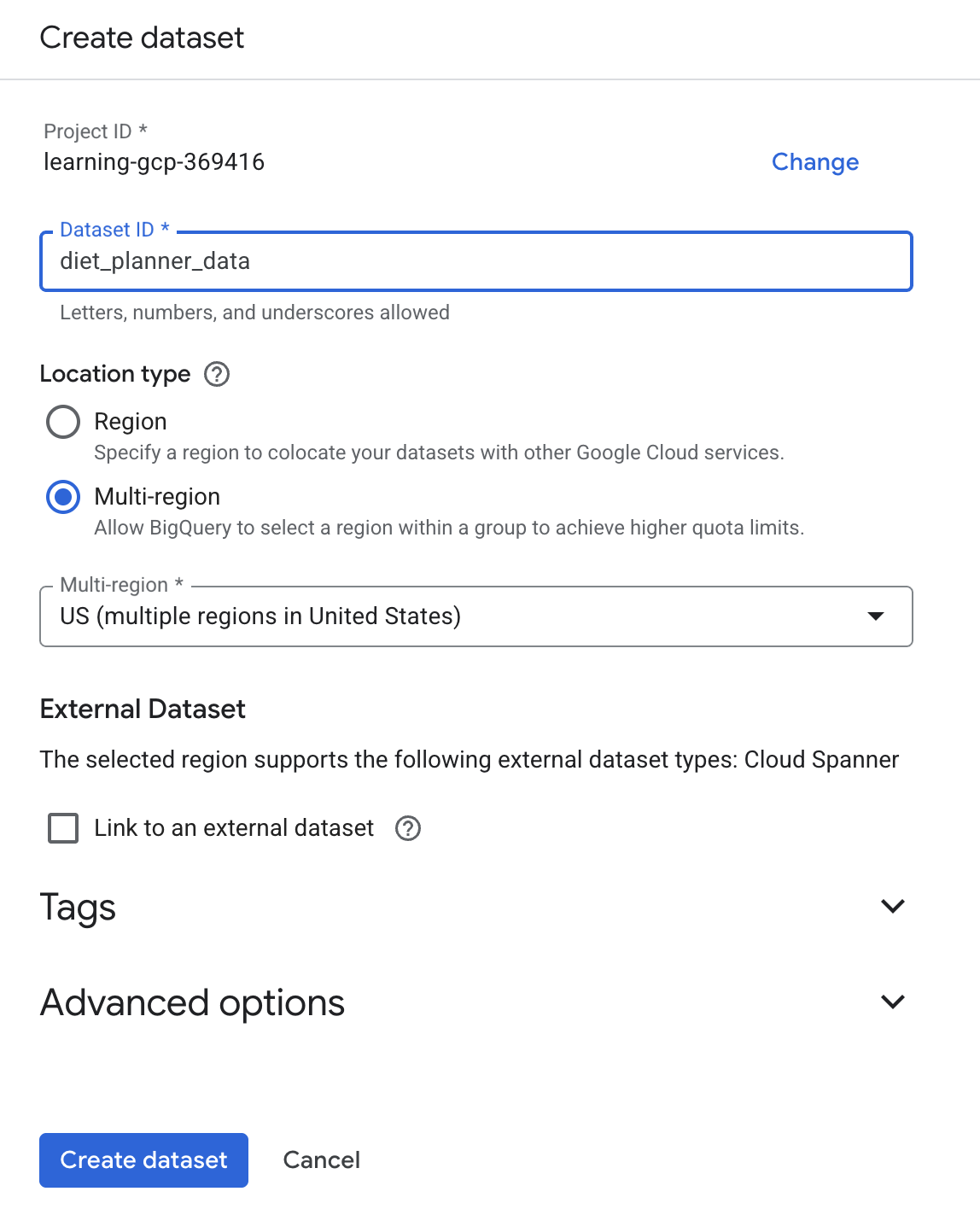 .
.
4. Créer des applications Agent Diet Planner
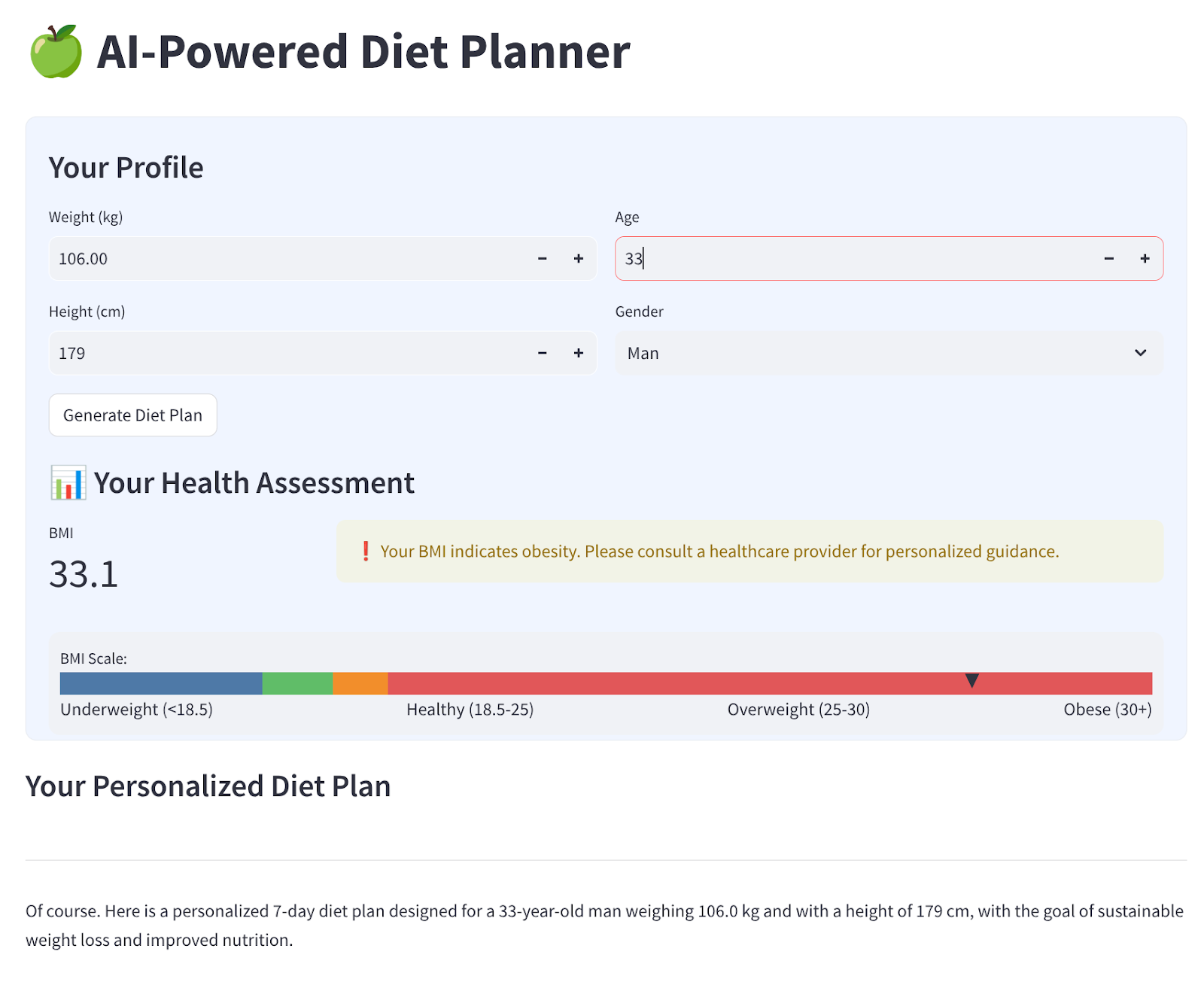
Nous allons créer une interface Web simple avec quatre entrées, qui ressemble à ceci :
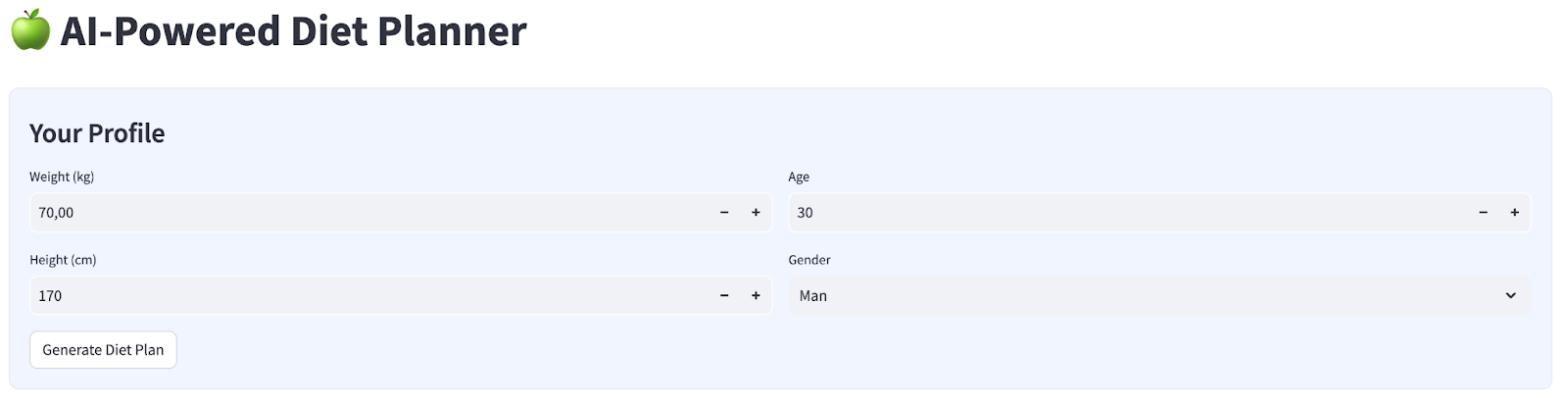
Modifiez le poids, la taille, l'âge et le genre en fonction de votre profil, puis cliquez sur "Générer". Il appellera le modèle LLM Gemini Pro 2.5 dans la bibliothèque Vertex AI et stockera les résultats générés dans BigQuery.
Le code sera divisé en six parties pour ne pas être trop long.
Créer une fonction pour calculer l'état de l'IMC
- Effectuez un clic droit sur le dossier
agent_diet_planner→ Nouveau fichier → saisissez le nom de fichierbmi_calc.py, puis appuyez sur Entrée. - Remplissez le code avec ce qui suit
# Add this function to calculate BMI and health status
def calculate_bmi_status(weight, height):
"""
Calculate BMI and return status message
"""
height_m = height / 100 # Convert cm to meters
bmi = weight / (height_m ** 2)
if bmi < 18.5:
status = "underweight"
message = "⚠️ Your BMI suggests you're underweight. Consider increasing calorie intake with nutrient-dense foods."
elif 18.5 <= bmi < 25:
status = "normal"
message = "✅ Your BMI is in the healthy range. Let's maintain this balance!"
elif 25 <= bmi < 30:
status = "overweight"
message = "⚠️ Your BMI suggests you're overweight. Focus on gradual weight loss through balanced nutrition."
else:
status = "obese"
message = "❗ Your BMI indicates obesity. Please consult a healthcare provider for personalized guidance."
return {
"value": round(bmi, 1),
"status": status,
"message": message
}
Créer des applications principales de planification de régime alimentaire par agent
- Effectuez un clic droit sur le dossier
agent_diet_planner→ Nouveau fichier … → saisissez le nom de fichierapp.py, puis appuyez sur Entrée. - Remplissez le code avec ce qui suit
import os
from google.oauth2 import service_account
import streamlit as st
from google.cloud import bigquery
from vertexai.preview.generative_models import GenerativeModel
import vertexai
import datetime
import time
import pandas as pd
from bmi_calc import calculate_bmi_status
# Get configuration from environment
PROJECT_ID = os.environ.get("GCP_PROJECT_ID", "your_gcp_project_id")
LOCATION = os.environ.get("GCP_LOCATION", "us-central1")
#CONSTANTS Dataset and table in BigQuery
DATASET = "diet_planner_data"
TABLE = "user_plans"
# Initialize Vertex AI
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Initialize BigQuery client
try:
# For Cloud Run, use default credentials
bq_client = bigquery.Client()
except:
# For local development, use service account from secrets
if "gcp_service_account" in st.secrets:
service_account_info = dict(st.secrets["gcp_service_account"])
credentials = service_account.Credentials.from_service_account_info(service_account_info)
bq_client = bigquery.Client(credentials=credentials, project=PROJECT_ID)
else:
st.error("BigQuery client initialization failed")
st.stop()
Remplacez la valeur your_gcp_project_id par l'ID de votre projet.
Créer les applications principales de planification de régime alimentaire de l'agent : setup_bq_tables
Dans cette section, nous allons créer une fonction nommée setup_bq_table avec un paramètre d'entrée bq_client. Cette fonction définit le schéma dans la table BigQuery et crée une table si elle n'existe pas.
Remplissez le code avec le code suivant sous le code précédent dans app.py.
# Create BigQuery table if not exists
def setup_bq_table(bq_client):
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
schema = [
bigquery.SchemaField("user_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("timestamp", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("weight", "FLOAT", mode="REQUIRED"),
bigquery.SchemaField("height", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("age", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("gender", "STRING", mode="REQUIRED"),
bigquery.SchemaField("diet_plan", "STRING", mode="REQUIRED")
]
try:
bq_client.get_table(table_id)
except:
table = bigquery.Table(table_id, schema=schema)
bq_client.create_table(table)
st.toast("BigQuery table created successfully")
Créer des applications principales de planification de régime alimentaire par agent : generate_diet_plan
Dans cette section, nous allons créer une fonction nommée generate_diet_plan avec un paramètre d'entrée. Cette fonction appellera le modèle LLM Gemini Pro 2.5 avec un prompt de définition et générera des résultats.
Remplissez le code avec le code suivant sous le code précédent dans app.py.
# Generate diet plan using Gemini Pro
def generate_diet_plan(params):
try:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
Create a personalized 7-day diet plan for:
- {params['gender']}, {params['age']} years old
- Weight: {params['weight']} kg
- Height: {params['height']} cm
Include:
1. Daily calorie target
2. Macronutrient breakdown (carbs, protein, fat)
3. Meal timing and frequency
4. Food recommendations
5. Hydration guidance
Make the plan:
- Nutritionally balanced
- Practical for daily use
- Culturally adaptable
- With portion size guidance
"""
response = model.generate_content(prompt)
return response.text
except Exception as e:
st.error(f"AI generation error: {str(e)}")
return None
Créer des applications principales de planification de régime alimentaire pour l'agent : save_to_bq
Dans cette section, nous allons créer une fonction nommée save_to_bq avec trois paramètres d'entrée : bq_client, user_id et plan. Cette fonction enregistre le résultat de la génération dans une table BigQuery.
Remplissez le code avec le code suivant sous le code précédent dans app.py.
# Save user data to BigQuery
def save_to_bq(bq_client, user_id, plan):
try:
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
row = {
"user_id": user_id,
"timestamp": datetime.datetime.utcnow().isoformat(),
"weight": st.session_state.user_data["weight"],
"height": st.session_state.user_data["height"],
"age": st.session_state.user_data["age"],
"gender": st.session_state.user_data["gender"],
"diet_plan": plan
}
errors = bq_client.insert_rows_json(table_id, [row])
if errors:
st.error(f"BigQuery error: {errors}")
else:
return True
except Exception as e:
st.error(f"Data saving error: {str(e)}")
return False
Créer les applications principales du planificateur de régime de l'agent : main
Dans cette section, nous allons créer une fonction nommée main sans paramètre d'entrée. Cette fonction gère principalement le script de l'interface utilisateur Streamlit, affiche le résultat généré, affiche l'historique des résultats générés à partir de la table BigQuery et permet de télécharger les données dans un fichier Markdown.
Remplissez le code avec le code suivant sous le code précédent dans app.py.
# Streamlit UI
def main():
st.set_page_config(page_title="AI Diet Planner", page_icon="🍏", layout="wide")
# Initialize session state
if "user_data" not in st.session_state:
st.session_state.user_data = None
if "diet_plan" not in st.session_state:
st.session_state.diet_plan = None
# Initialize clients
#bq_client = init_clients()
setup_bq_table(bq_client)
st.title("🍏 AI-Powered Diet Planner")
st.markdown("""
<style>
.stProgress > div > div > div > div {
background-color: #4CAF50;
}
[data-testid="stForm"] {
background: #f0f5ff;
padding: 20px;
border-radius: 10px;
border: 1px solid #e6e9ef;
}
</style>
""", unsafe_allow_html=True)
# User input form
with st.form("user_profile", clear_on_submit=False):
st.subheader("Your Profile")
col1, col2 = st.columns(2)
with col1:
weight = st.number_input("Weight (kg)", min_value=30.0, max_value=200.0, value=70.0)
height = st.number_input("Height (cm)", min_value=100, max_value=250, value=170)
with col2:
age = st.number_input("Age", min_value=18, max_value=100, value=30)
gender = st.selectbox("Gender", ["Man", "Woman"])
submitted = st.form_submit_button("Generate Diet Plan")
if submitted:
user_data = {
"weight": weight,
"height": height,
"age": age,
"gender": gender
}
st.session_state.user_data = user_data
# Calculate BMI
bmi_result = calculate_bmi_status(weight, height)
# Display BMI results in a visually distinct box
with st.container():
st.subheader("📊 Your Health Assessment")
col1, col2 = st.columns([1, 3])
with col1:
st.metric("BMI", bmi_result["value"])
with col2:
if bmi_result["status"] != "normal":
st.warning(bmi_result["message"])
else:
st.success(bmi_result["message"])
# Add BMI scale visualization
st.markdown(f"""
<div style="background:#f0f2f6;padding:10px;border-radius:10px;margin-top:10px">
<small>BMI Scale:</small><br>
<div style="display:flex;height:20px;background:linear-gradient(90deg,
#4e79a7 0%,
#4e79a7 18.5%,
#60bd68 18.5%,
#60bd68 25%,
#f28e2b 25%,
#f28e2b 30%,
#e15759 30%,
#e15759 100%);position:relative">
<div style="position:absolute;left:{min(100, max(0, (bmi_result["value"]/40)*100))}%;top:-5px">
▼
</div>
</div>
<div style="display:flex;justify-content:space-between">
<span>Underweight (<18.5)</span>
<span>Healthy (18.5-25)</span>
<span>Overweight (25-30)</span>
<span>Obese (30+)</span>
</div>
</div>
""", unsafe_allow_html=True)
# Store BMI in session state
st.session_state.bmi = bmi_result
# Plan generation and display
if submitted and st.session_state.user_data:
with st.spinner("🧠 Generating your personalized diet plan using Gemini AI..."):
#diet_plan = generate_diet_plan(st.session_state.user_data)
diet_plan = generate_diet_plan({**st.session_state.user_data,"bmi": bmi_result["value"],
"bmi_status": bmi_result["status"]
})
if diet_plan:
st.session_state.diet_plan = diet_plan
# Generate unique user ID
user_id = f"user_{int(time.time())}"
# Save to BigQuery
if save_to_bq(bq_client, user_id, diet_plan):
st.toast("✅ Plan saved to database!")
# Display generated plan
if st.session_state.diet_plan:
st.subheader("Your Personalized Diet Plan")
st.markdown("---")
st.markdown(st.session_state.diet_plan)
# Download button
st.download_button(
label="Download Plan",
data=st.session_state.diet_plan,
file_name="my_diet_plan.md",
mime="text/markdown"
)
# Show history
st.subheader("Your Plan History")
try:
query = f"""
SELECT timestamp, weight, height, age, gender
FROM `{st.secrets['gcp']['project_id']}.{DATASET}.{TABLE}`
WHERE user_id LIKE 'user_%'
ORDER BY timestamp DESC
LIMIT 5
"""
history = bq_client.query(query).to_dataframe()
if not history.empty:
history["timestamp"] = pd.to_datetime(history["timestamp"])
st.dataframe(history.style.format({
"weight": "{:.1f} kg",
"height": "{:.0f} cm"
}))
else:
st.info("No previous plans found")
except Exception as e:
st.error(f"History load error: {str(e)}")
if __name__ == "__main__":
main()
Enregistrez le code sous le nom app.py.
5. Déployer des applications à l'aide de Cloud Build sur Cloud Run
Bien sûr, nous voulons présenter cette application incroyable aux autres. Pour ce faire, nous pouvons empaqueter cette application et la déployer sur Cloud Run en tant que service public accessible à d'autres utilisateurs. Pour ce faire, revenons à l'architecture
Nous avons d'abord besoin de Dockerfile. Cliquez sur File->New Text File (Fichier > Nouveau fichier texte), copiez et collez le code suivant,puis enregistrez-le sous le nom Dockerfile.
# Use official Python image
FROM python:3.12-slim
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV PORT 8080
# Install system dependencies
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /app
# Copy requirements
COPY requirements.txt .
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application files
COPY . .
# Expose port
EXPOSE $PORT
# Run the application
CMD ["streamlit", "run", "app.py", "--server.port", "8080", "--server.address", "0.0.0.0"]
Ensuite, nous allons créer cloudbuild.yaml pour compiler les applications afin qu'elles deviennent des images Docker, les transférer vers Artifact Registry et les déployer sur Cloud Run.
Cliquez sur Fichier > Nouveau fichier texte, copiez et collez le code suivant, puis enregistrez-le sous le nom cloudbuild.yaml.
steps:
# Build Docker image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID', '--no-cache',
'--progress=plain',
'.']
id: 'Build'
timeout: 1200s
waitFor: ['-']
dir: '.'
# Push to Container Registry
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID']
id: 'Push'
waitFor: ['Build']
# Deploy to Cloud Run
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args:
- 'run'
- 'deploy'
- 'diet-planner-service'
- '--image=gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
- '--port=8080'
- '--region=us-central1'
- '--platform=managed'
- '--allow-unauthenticated'
- '--set-env-vars=GCP_PROJECT_ID=$PROJECT_ID,GCP_LOCATION=us-central1'
- '--cpu=1'
- '--memory=1Gi'
- '--timeout=300'
waitFor: ['Push']
options:
logging: CLOUD_LOGGING_ONLY
machineType: 'E2_HIGHCPU_8'
diskSizeGb: 100
images:
- 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
À ce stade, nous disposons déjà de tous les fichiers nécessaires pour compiler les applications en images Docker, les transférer vers Artifact Registry et les déployer sur Cloud Run. Déployons-les. Accédez au terminal Cloud Shell et assurez-vous que le projet actuel est configuré sur votre projet actif. Si ce n'est pas le cas, utilisez la commande gcloud configure pour définir l'ID du projet :
gcloud config set project [PROJECT_ID]
Exécutez ensuite la commande suivante pour compiler les applications afin qu'elles deviennent des images Docker, les transférer vers Artifact Registry et les déployer sur Cloud Run.
gcloud builds submit --config cloudbuild.yaml
Il créera le conteneur Docker en fonction du Dockerfile que nous avons fourni précédemment et le transférera vers Artifact Registry. Nous déploierons ensuite l'image construite sur Cloud Run. L'ensemble de ce processus est défini dans les étapes cloudbuild.yaml.
Notez que nous autorisons ici l'accès non authentifié, car il s'agit d'une application de démonstration. Nous vous recommandons d'utiliser une authentification appropriée pour vos applications d'entreprise et de production.
Une fois le déploiement terminé, nous pouvons le vérifier sur la page Cloud Run. Pour cela, recherchez Cloud Run dans la barre de recherche en haut de la console Cloud, puis cliquez sur le produit Cloud Run.
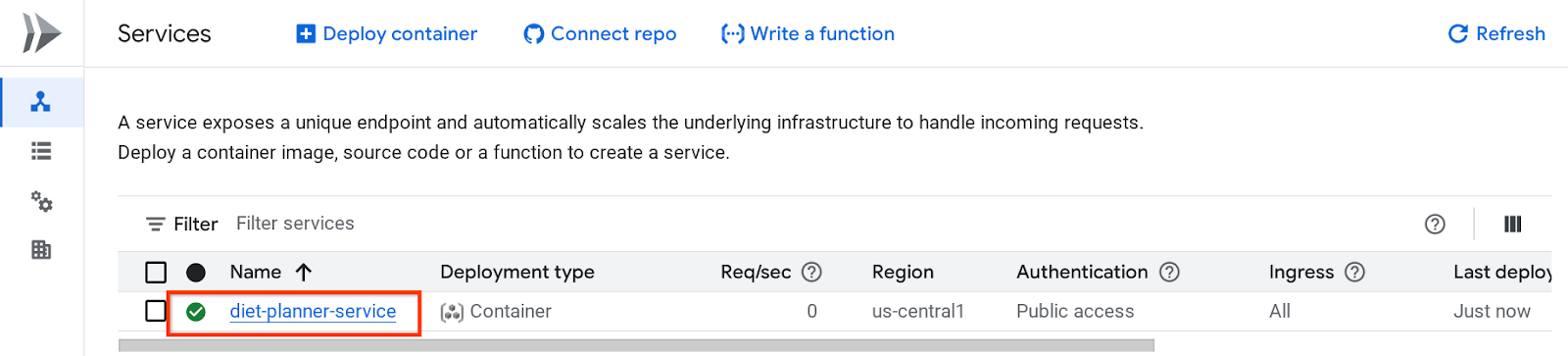
Vous pouvez ensuite inspecter le service déployé listé sur la page "Services Cloud Run". Cliquez sur le service pour obtenir son URL.
L'URL du service se trouve dans la barre supérieure.
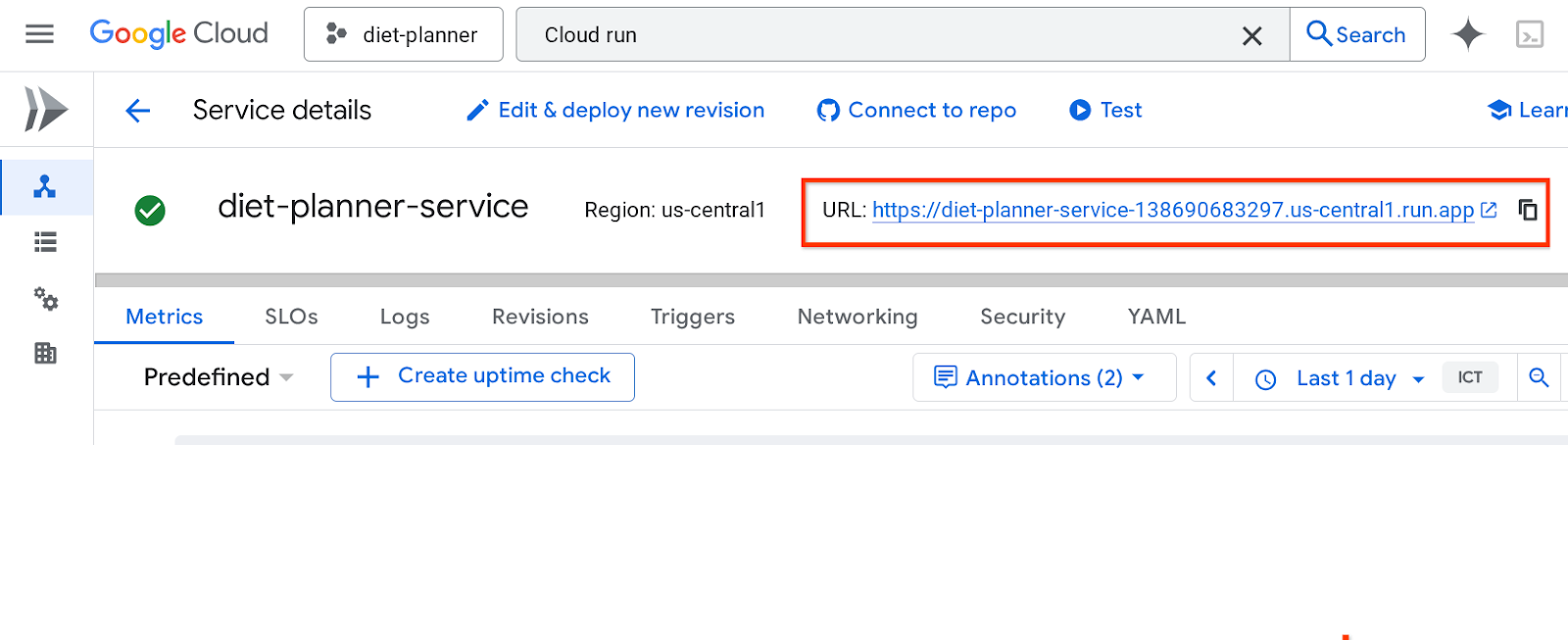 Utilisez votre application depuis la fenêtre de navigation privée ou votre appareil mobile. Il devrait déjà être en ligne.
Utilisez votre application depuis la fenêtre de navigation privée ou votre appareil mobile. Il devrait déjà être en ligne.
6. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet atelier de programmation soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
- Vous pouvez également accéder à Cloud Run dans la console, sélectionner le service que vous venez de déployer, puis le supprimer.