
1. परिचय
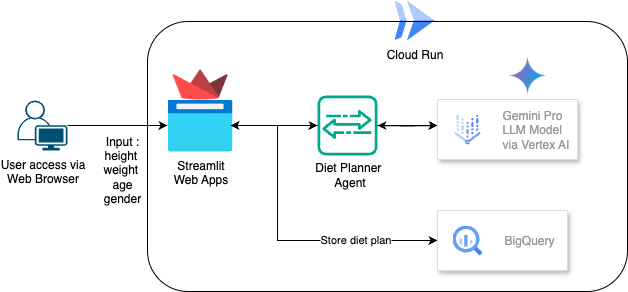
इस कोडलैब में, आपको एआई की मदद से काम करने वाले एजेंट डाइट प्लानर को बनाने और उसे डिप्लॉय करने का तरीका बताया जाएगा. Streamlit का इस्तेमाल करने वाले यूज़र इंटरफ़ेस (यूआई), Gemini Pro 2.5 का इस्तेमाल करने वाले एलएलएम मॉडल, Agentic AI को डेवलप करने के लिए Vertex AI का इस्तेमाल करने वाले Agentic AI Engine Orchestrator, डेटा को सेव करने के लिए BigQuery, और डिप्लॉयमेंट के लिए Cloud Run का इस्तेमाल किया जाता है.
कोडलैब के ज़रिए, आपको यहां दिया गया तरीका अपनाना होगा:
- अपना Google Cloud प्रोजेक्ट तैयार करें और उस पर सभी ज़रूरी एपीआई चालू करें
- streamlit, Vertex AI, और BigQuery का इस्तेमाल करके, एजेंटिक एआई डाइट प्लानर बनाना
- ऐप्लिकेशन को Cloud Run पर डिप्लॉय करना
आर्किटेक्चर की खास जानकारी
ज़रूरी शर्त
- बिलिंग की सुविधा वाला Google Cloud Platform (GCP) प्रोजेक्ट.
- Python की बुनियादी जानकारी
आपको क्या सीखने को मिलेगा
- Streamlit और Vertex AI का इस्तेमाल करके, डाइट प्लानर के तौर पर काम करने वाला एआई कैसे बनाया जाए और BigQuery में डेटा कैसे सेव किया जाए
- ऐप्लिकेशन को Cloud Run पर डिप्लॉय करने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Chrome वेब ब्राउज़र
- Gmail खाता
- ऐसा Cloud प्रोजेक्ट जिसमें बिलिंग की सुविधा चालू हो
2. बुनियादी सेटअप और ज़रूरी शर्तें
अपनी स्पीड से एनवायरमेंट सेट अप करना
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.

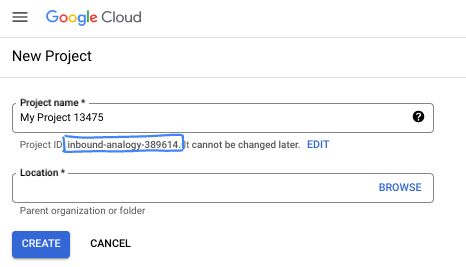
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग को अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता कि यह क्या है. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी (आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है) का रेफ़रंस देना होगा. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहता है. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, आपको Cloud Console में बिलिंग चालू करनी होगी, ताकि Cloud संसाधनों/एपीआई का इस्तेमाल किया जा सके. इस कोडलैब को पूरा करने में ज़्यादा समय नहीं लगेगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, संसाधनों को बंद किया जा सकता है. इसके लिए, बनाए गए संसाधनों को मिटाएं या प्रोजेक्ट को मिटाएं. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मिलेगा. वे इसे मुफ़्त में आज़मा सकते हैं.
3. शुरू करने से पहले
Cloud Shell Editor में Cloud Project सेट अप करना
इस कोडलैब में यह माना गया है कि आपके पास पहले से ही बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट है. अगर आपके पास यह सुविधा अभी तक नहीं है, तो इसे इस्तेमाल करने के लिए यहां दिया गया तरीका अपनाएं.
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें .
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. इसमें bq पहले से लोड होता है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
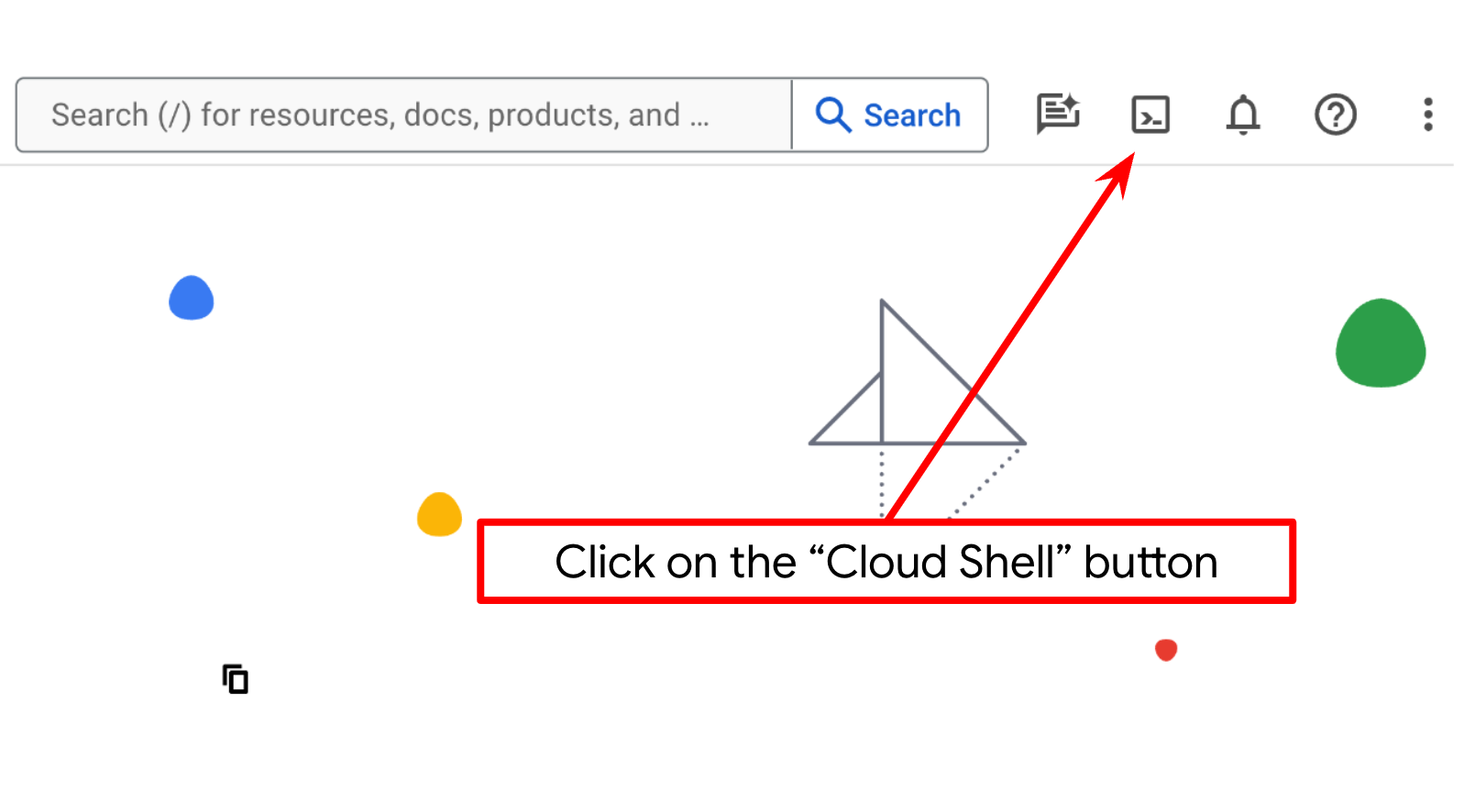
- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
इसके अलावा, PROJECT_ID आईडी को कंसोल में भी देखा जा सकता है
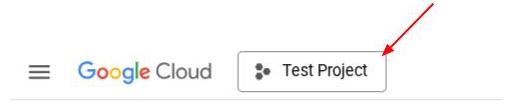
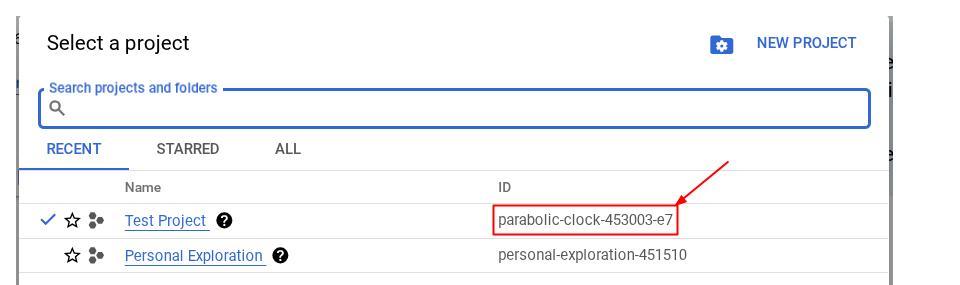
इस पर क्लिक करने से, आपको अपने सभी प्रोजेक्ट और प्रोजेक्ट आईडी दाईं ओर दिखेंगे
- नीचे दिए गए निर्देश का इस्तेमाल करके, ज़रूरी एपीआई चालू करें. इसमें कुछ मिनट लग सकते हैं. इसलिए, कृपया इंतज़ार करें.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
bigquery.googleapis.com
कमांड के सही तरीके से लागू होने पर, आपको यहां दिखाए गए मैसेज जैसा मैसेज दिखेगा:
Operation "operations/..." finished successfully.
gcloud कमांड के बजाय, कंसोल का इस्तेमाल करके भी ऐसा किया जा सकता है. इसके लिए, हर प्रॉडक्ट को खोजें या इस लिंक का इस्तेमाल करें.
अगर कोई एपीआई छूट जाता है, तो उसे लागू करने के दौरान कभी भी चालू किया जा सकता है.
gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
ऐप्लिकेशन की वर्किंग डायरेक्ट्री सेट अप करना
- 'एडिटर खोलें' बटन पर क्लिक करें. इससे Cloud Shell Editor खुल जाएगा. यहां हम अपना कोड लिख सकते हैं
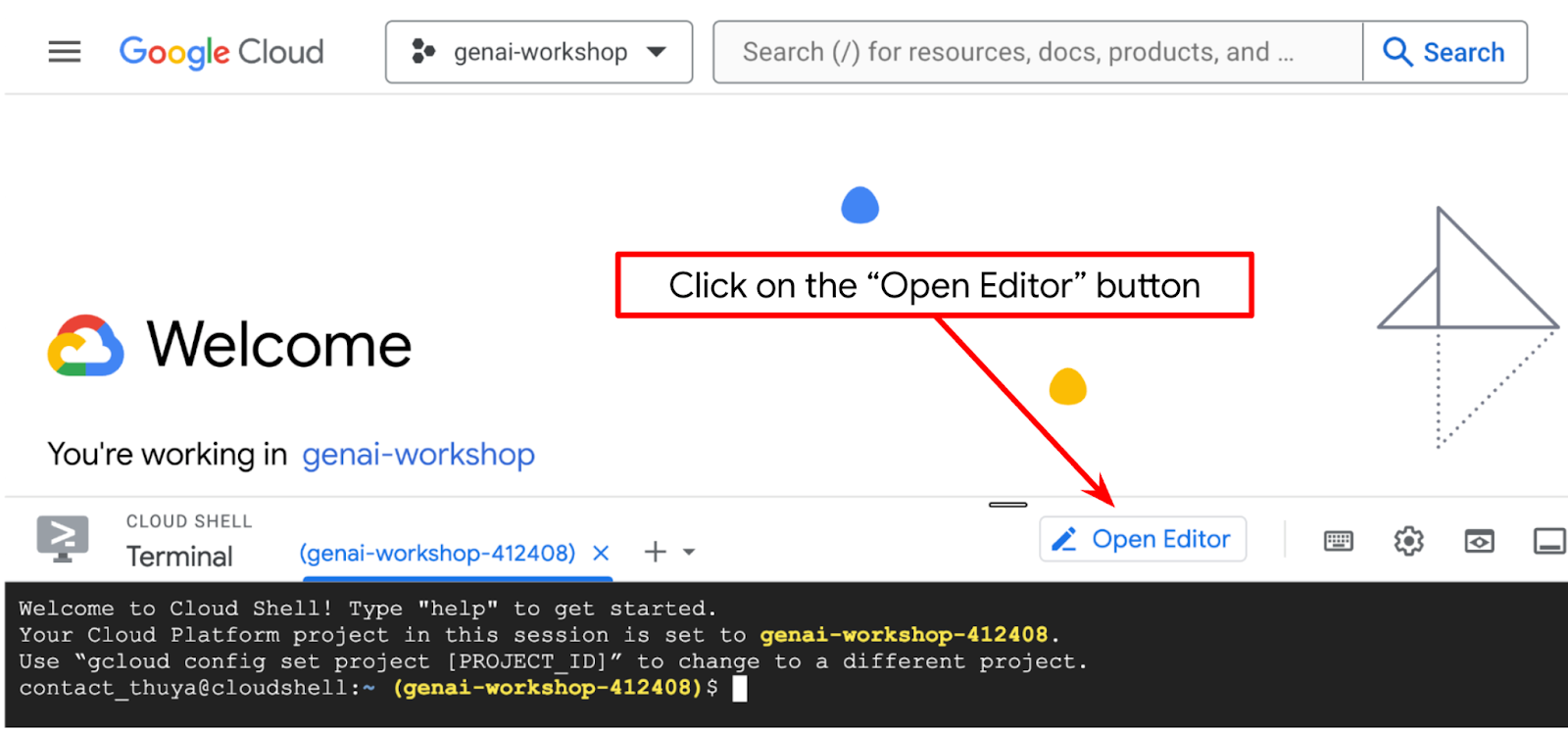
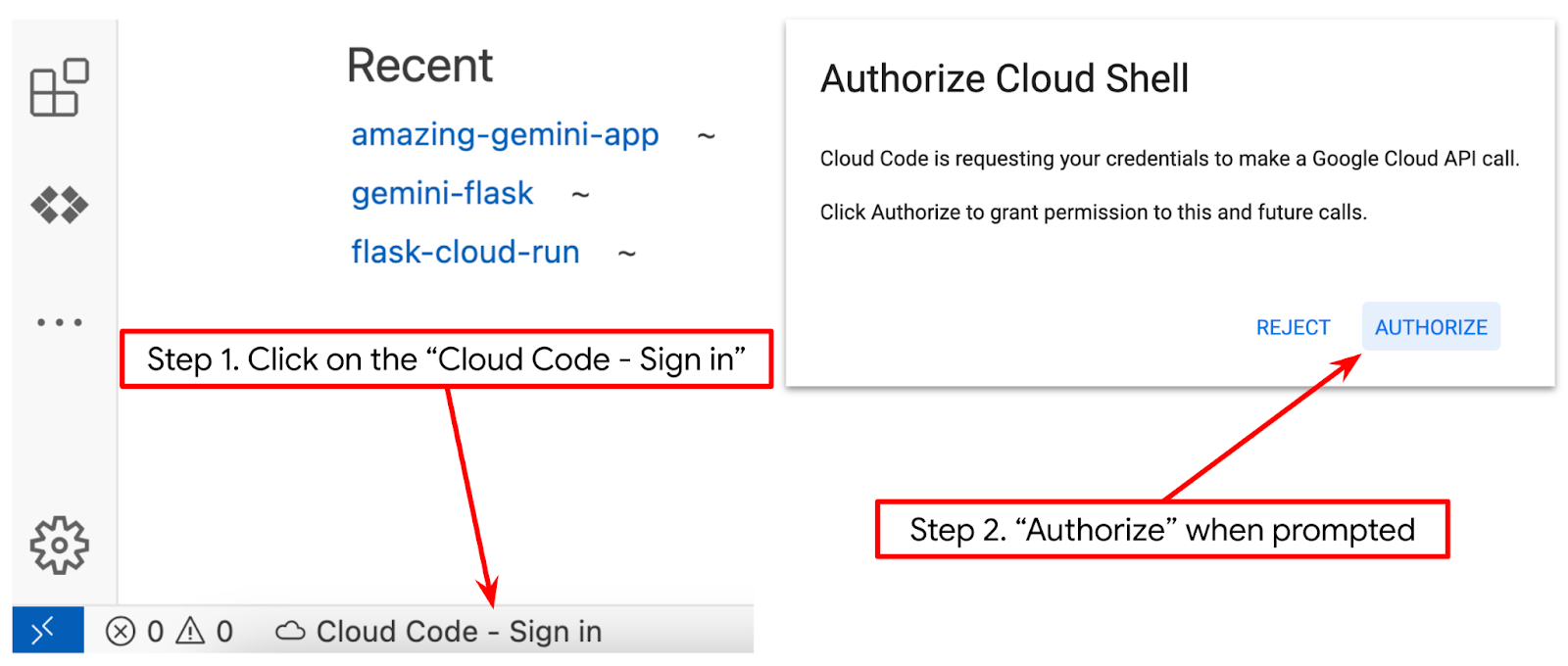
- पक्का करें कि Cloud Code प्रोजेक्ट, Cloud Shell एडिटर के सबसे नीचे बाईं ओर (स्टेटस बार) में सेट हो. जैसा कि नीचे दी गई इमेज में हाइलाइट किया गया है. साथ ही, यह उस चालू Google Cloud प्रोजेक्ट पर सेट हो जिसमें आपने बिलिंग चालू की है. अगर कहा जाए, तो अनुमति दें पर क्लिक करें. Cloud Shell Editor को शुरू करने के बाद, Cloud Code - Sign In बटन दिखने में थोड़ा समय लग सकता है. कृपया इंतज़ार करें.
इसके बाद, हम अपना Python एनवायरमेंट तैयार करेंगे
एनवायरमेंट सेटअप करना
Python वर्चुअल एनवायरमेंट तैयार करना
अगला चरण, डेवलपमेंट एनवायरमेंट तैयार करना है. इस कोडलैब में, हम Python 3.12 का इस्तेमाल करेंगे. साथ ही, Python के वर्शन और वर्चुअल एनवायरमेंट को बनाने और मैनेज करने की ज़रूरत को आसान बनाने के लिए, हम python virtualenv का इस्तेमाल करेंगे
- अगर आपने अब तक टर्मिनल नहीं खोला है, तो टर्मिनल -> नया टर्मिनल पर क्लिक करके इसे खोलें. इसके अलावा , Ctrl + Shift + C का इस्तेमाल करें

- नया फ़ोल्डर बनाएं और इस फ़ोल्डर में जगह बदलें. इसके लिए, यह कमांड चलाएं
mkdir agent_diet_planner
cd agent_diet_planner
- नीचे दिए गए कमांड का इस्तेमाल करके, नया virtualenv बनाएं
python -m venv .env
- इस कमांड का इस्तेमाल करके virtualenv को चालू करें
source .env/bin/activate
requirements.txtबनाएं. फ़ाइल → नई टेक्स्ट फ़ाइल पर क्लिक करें और नीचे दिया गया कॉन्टेंट डालें. इसके बाद, इसेrequirements.txtके तौर पर सेव करें
streamlit==1.33.0
google-cloud-aiplatform
google-cloud-bigquery
pandas==2.2.2
db-dtypes==1.2.0
pyarrow==16.1.0
- इसके बाद, requirements.txt फ़ाइल से सभी ज़रूरी सॉफ़्टवेयर इंस्टॉल करें. इसके लिए, यह कमांड चलाएं
pip install -r requirements.txt
- नीचे दी गई कमांड टाइप करके देखें कि Python लाइब्रेरी की सभी डिपेंडेंसी इंस्टॉल हैं या नहीं
pip list
कॉन्फ़िगरेशन फ़ाइलें सेट अप करना
अब हमें इस प्रोजेक्ट के लिए कॉन्फ़िगरेशन फ़ाइलें सेट अप करनी होंगी. कॉन्फ़िगरेशन फ़ाइलों का इस्तेमाल, वैरिएबल और सेवा खाते के क्रेडेंशियल को सेव करने के लिए किया जाता है.
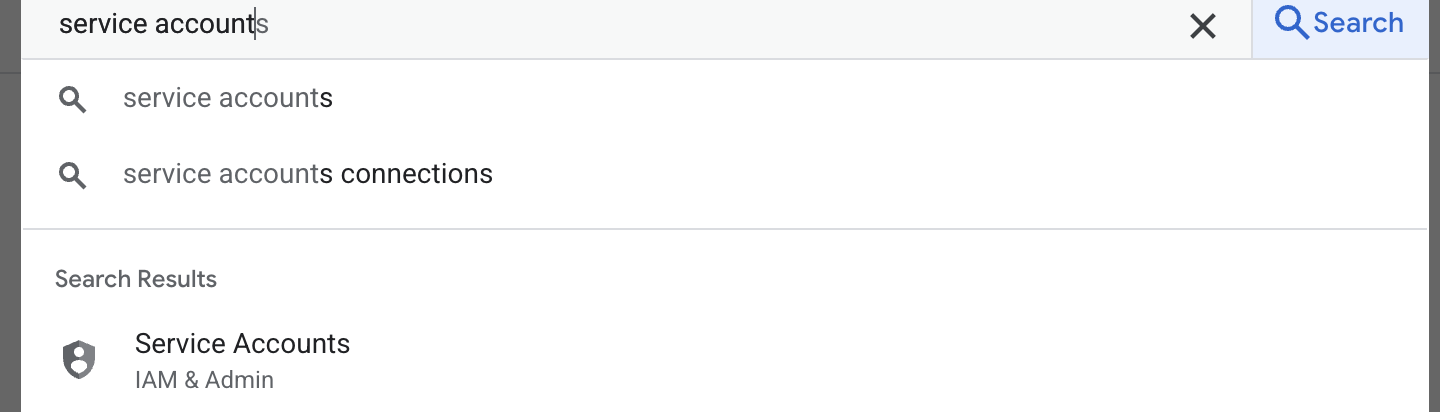
- पहला चरण, सेवा खाता बनाना है. खोज बार में सेवा खाता टाइप करें. इसके बाद, सेवा खाता पर क्लिक करें.
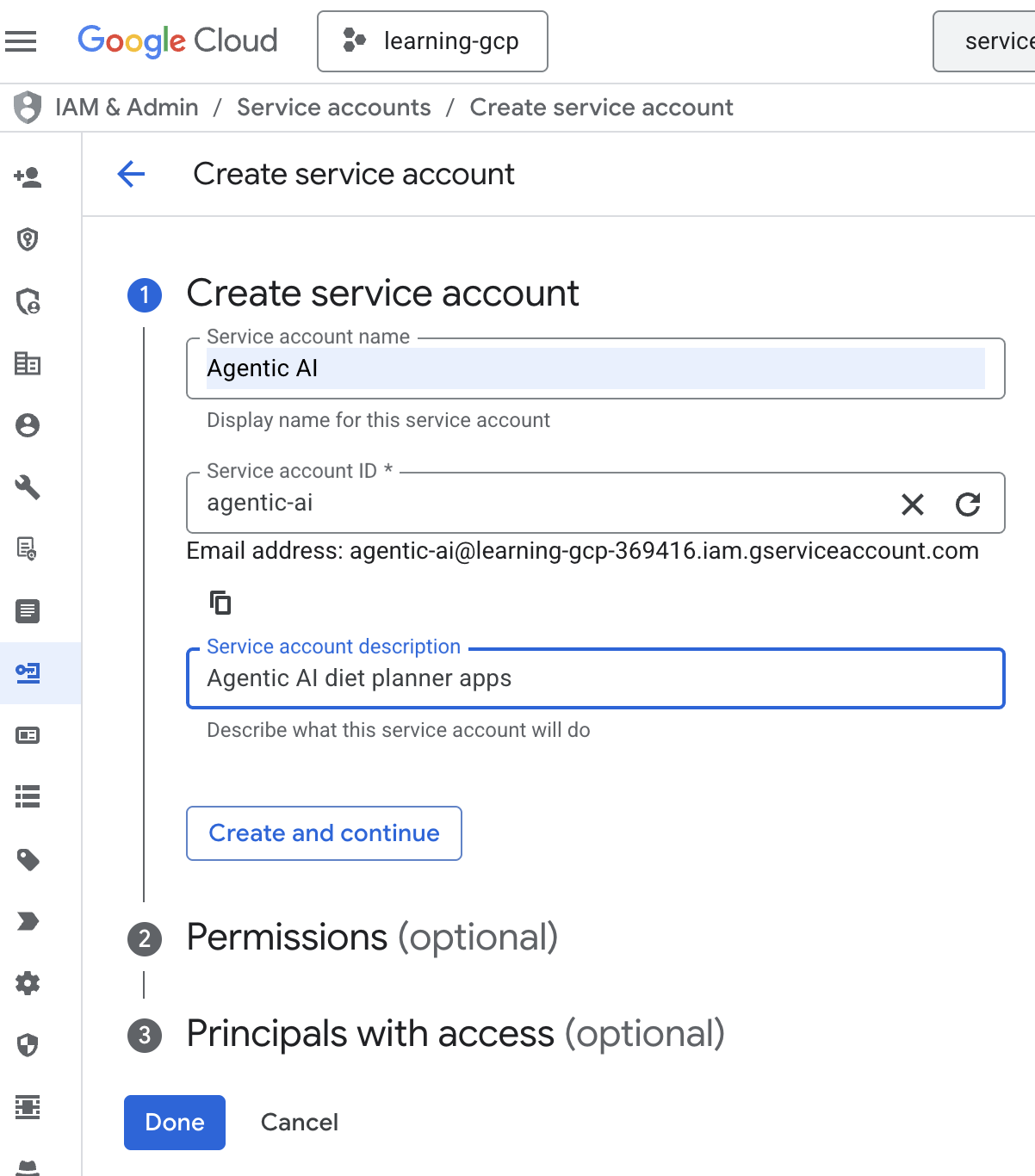
- + सेवा खाता बनाएं पर क्लिक करें. सेवा खाते का नाम डालें. इसके बाद, बनाएं और जारी रखें पर क्लिक करें.
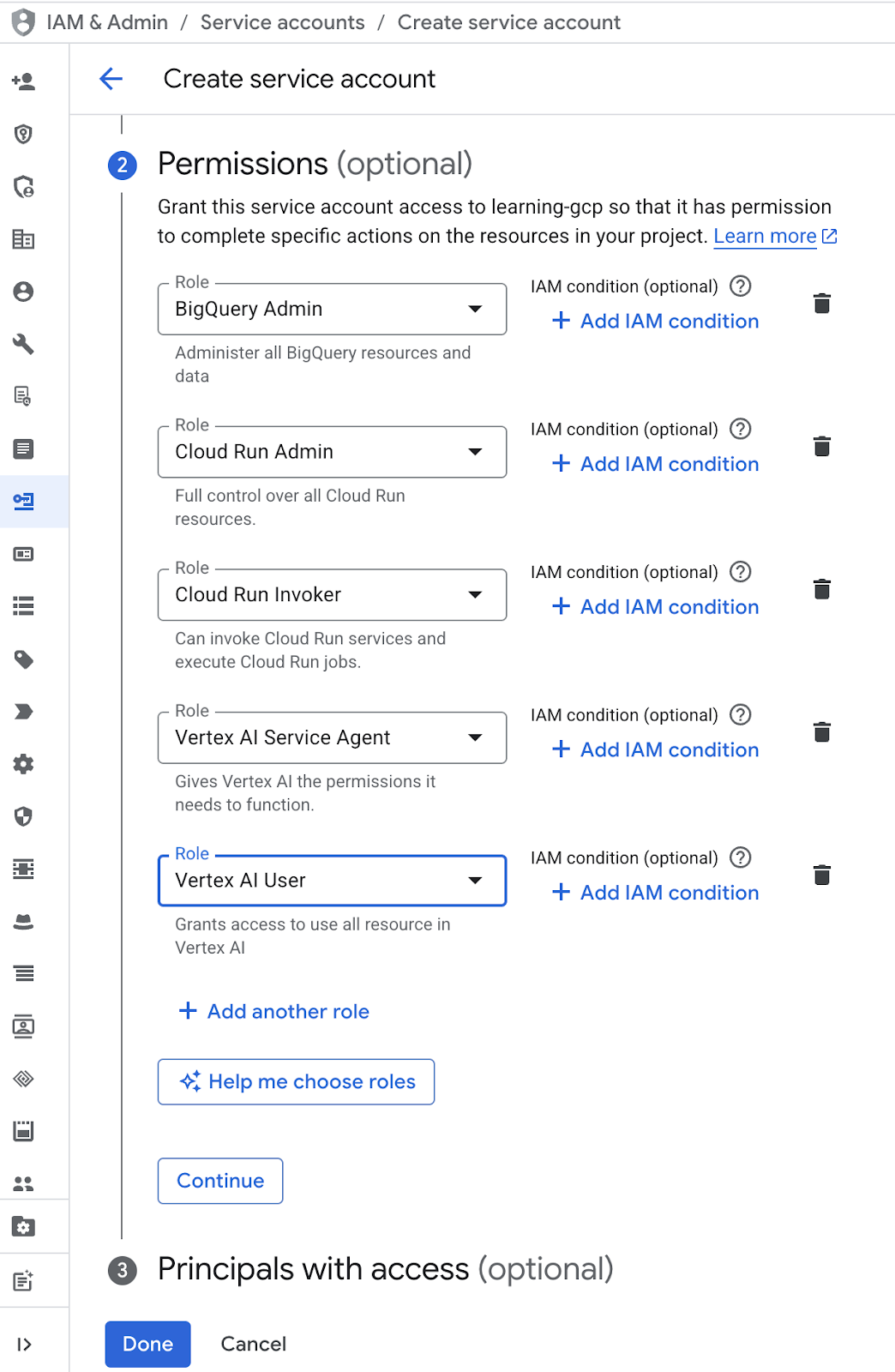
- अनुमति में, सेवा खाते के उपयोगकर्ता की भूमिका चुनें. 'कोई और भूमिका जोड़ें' पर क्लिक करें. इसके बाद, IAM की भूमिका चुनें : BigQuery एडमिन, Cloud Run एडमिन, Cloud Run Invoker, Vertex AI सेवा एजेंट, और Vertex AI उपयोगकर्ता. इसके बाद, हो गया
 पर क्लिक करें
पर क्लिक करें - सेवा खाते के ईमेल पर क्लिक करें, टैब कुंजी पर क्लिक करें, कुंजी जोड़ें → नई कुंजी बनाएं पर क्लिक करें.
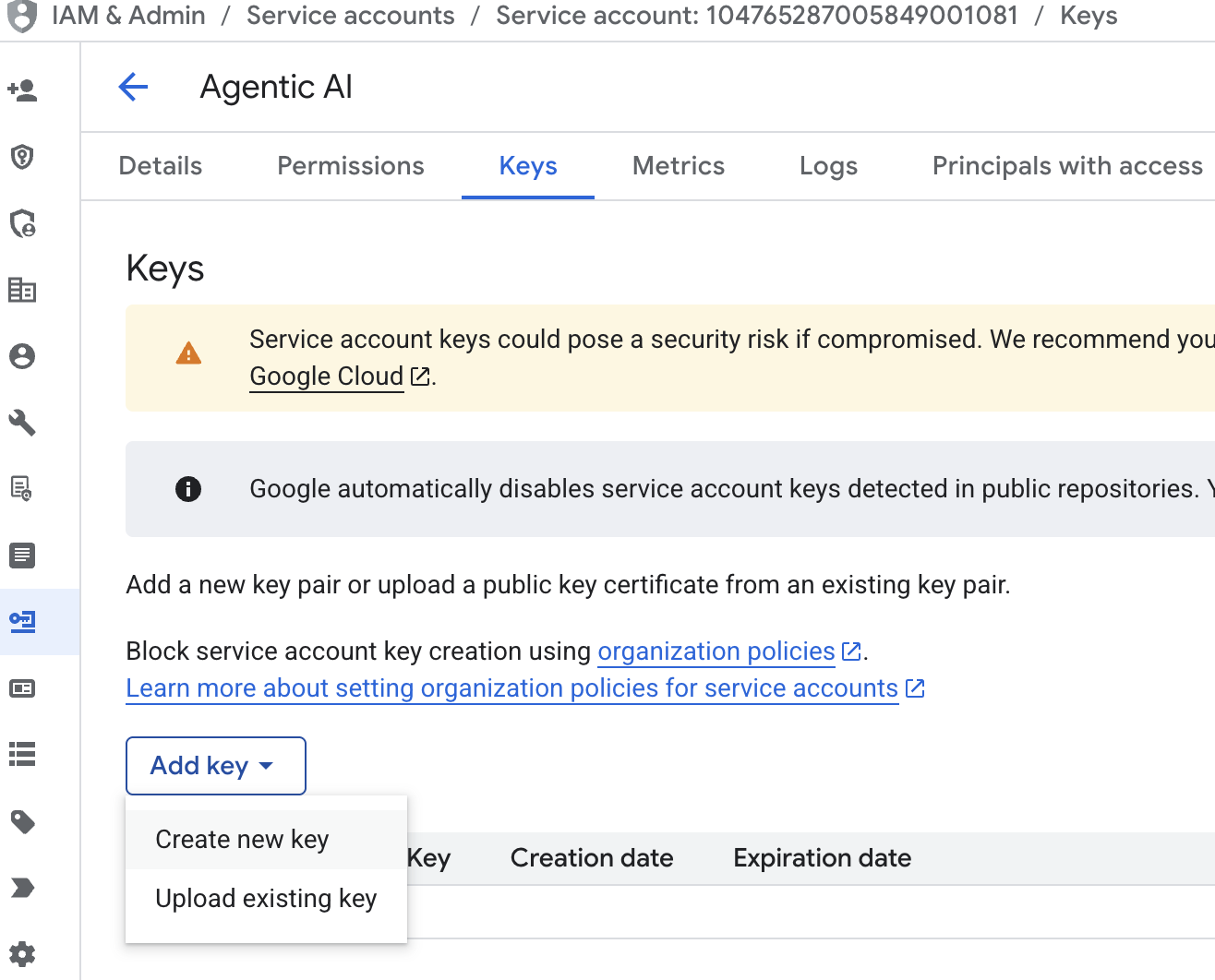
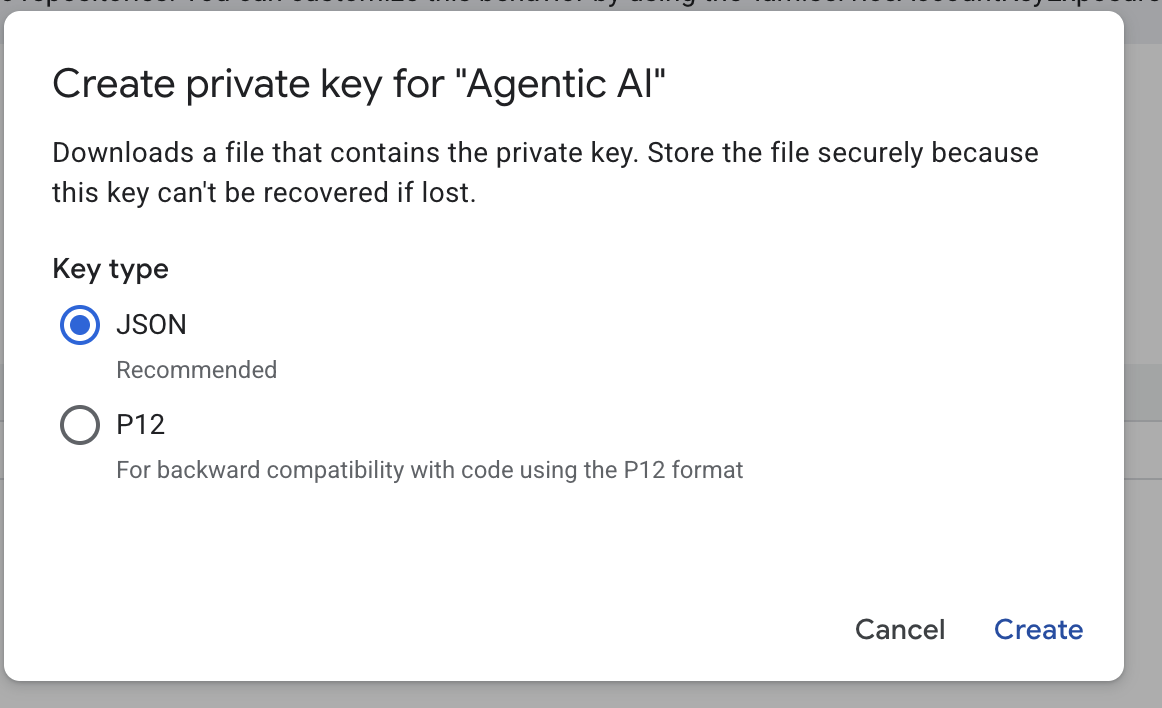
- json चुनें. इसके बाद, बनाएं पर क्लिक करें. इस सेवा खाते की फ़ाइल को अगले चरण के लिए लोकल में सेव करें
- नीचे दिए गए कॉन्फ़िगरेशन के साथ .streamlit नाम का फ़ोल्डर बनाएं. माउस पर राइट क्लिक करें. इसके बाद, नया फ़ोल्डर पर क्लिक करें और फ़ोल्डर का नाम टाइप करें
.streamlit - फ़ोल्डर
.streamlitमें राइट क्लिक करें. इसके बाद, नई फ़ाइल पर क्लिक करें और नीचे दी गई वैल्यू डालें. इसके बाद, इसेsecrets.tomlके तौर पर सेव करें
# secrets.toml (for Streamlit sharing)
# Store in .streamlit/secrets.toml
[gcp]
project_id = "your_gcp_project"
location = "us-central1"
[gcp_service_account]
type = "service_account"
project_id = "your-project-id"
private_key_id = "your-private-key-id"
private_key = '''-----BEGIN PRIVATE KEY-----
YOUR_PRIVATE_KEY_HERE
-----END PRIVATE KEY-----'''
client_email = "your-sa@project-id.iam.gserviceaccount.com"
client_id = "your-client-id"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "https://www.googleapis.com/robot/v1/metadata/x509/your-sa%40project-id.iam.gserviceaccount.com"
- पिछले चरण में बनाए गए सेवा खाते के आधार पर,
project_id,private_key_id,private_key,client_email,client_id , and auth_provider_x509_cert_urlकी वैल्यू अपडेट करें
BigQuery डेटासेट तैयार करना
अगला चरण, BigQuery में जनरेशन के नतीजों को सेव करने के लिए, BigQuery डेटासेट बनाना है.
- खोज बार में BigQuery टाइप करें. इसके बाद, BigQuery पर क्लिक करें.
 पर क्लिक करें. इसके बाद, डेटासेट बनाएं पर क्लिक करें
पर क्लिक करें. इसके बाद, डेटासेट बनाएं पर क्लिक करें- डेटासेट का आईडी डालें
diet_planner_data. इसके बाद, डेटासेट बनाएं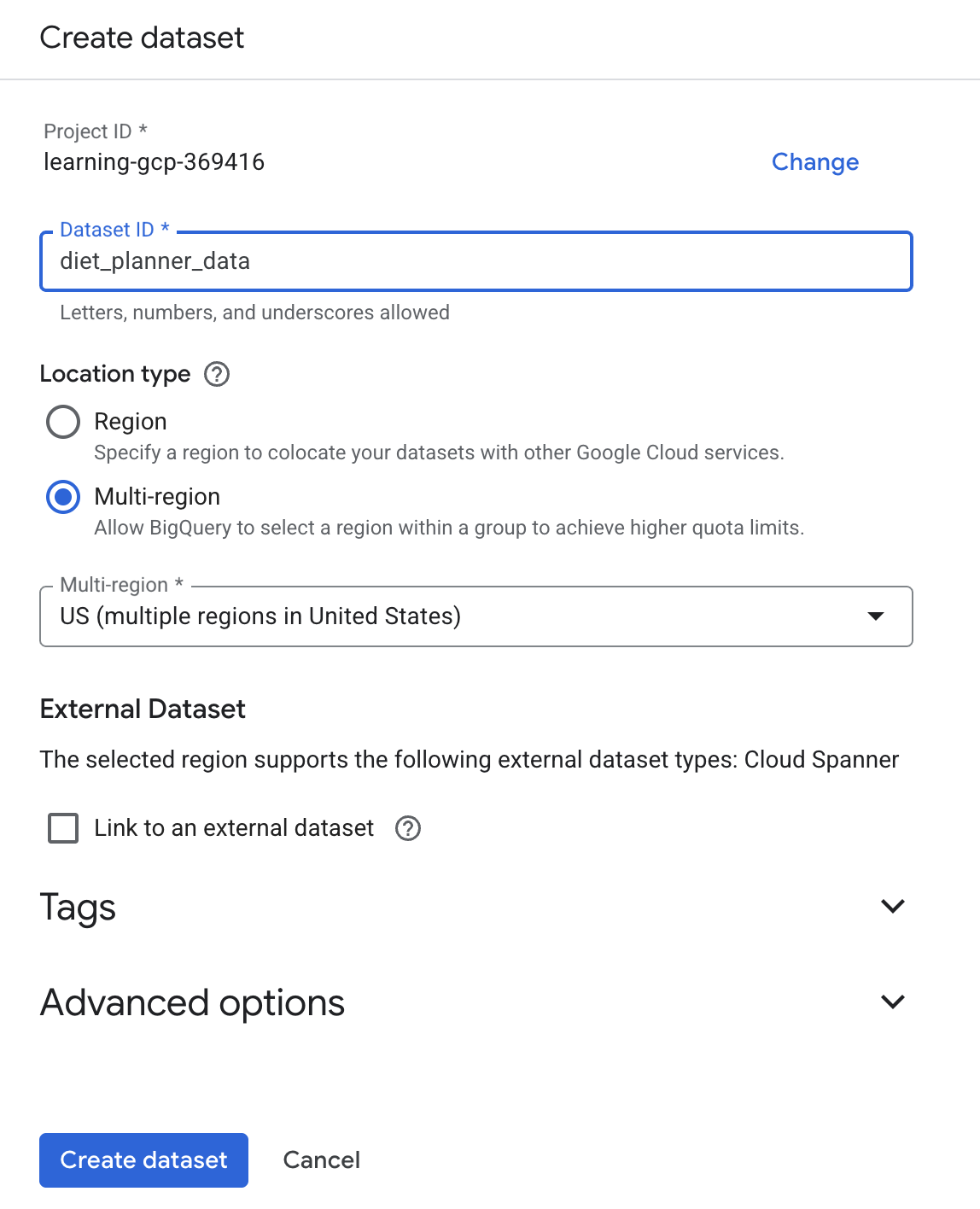 पर क्लिक करें
पर क्लिक करें
4. एजेंट डाइट प्लानर ऐप्लिकेशन बनाना
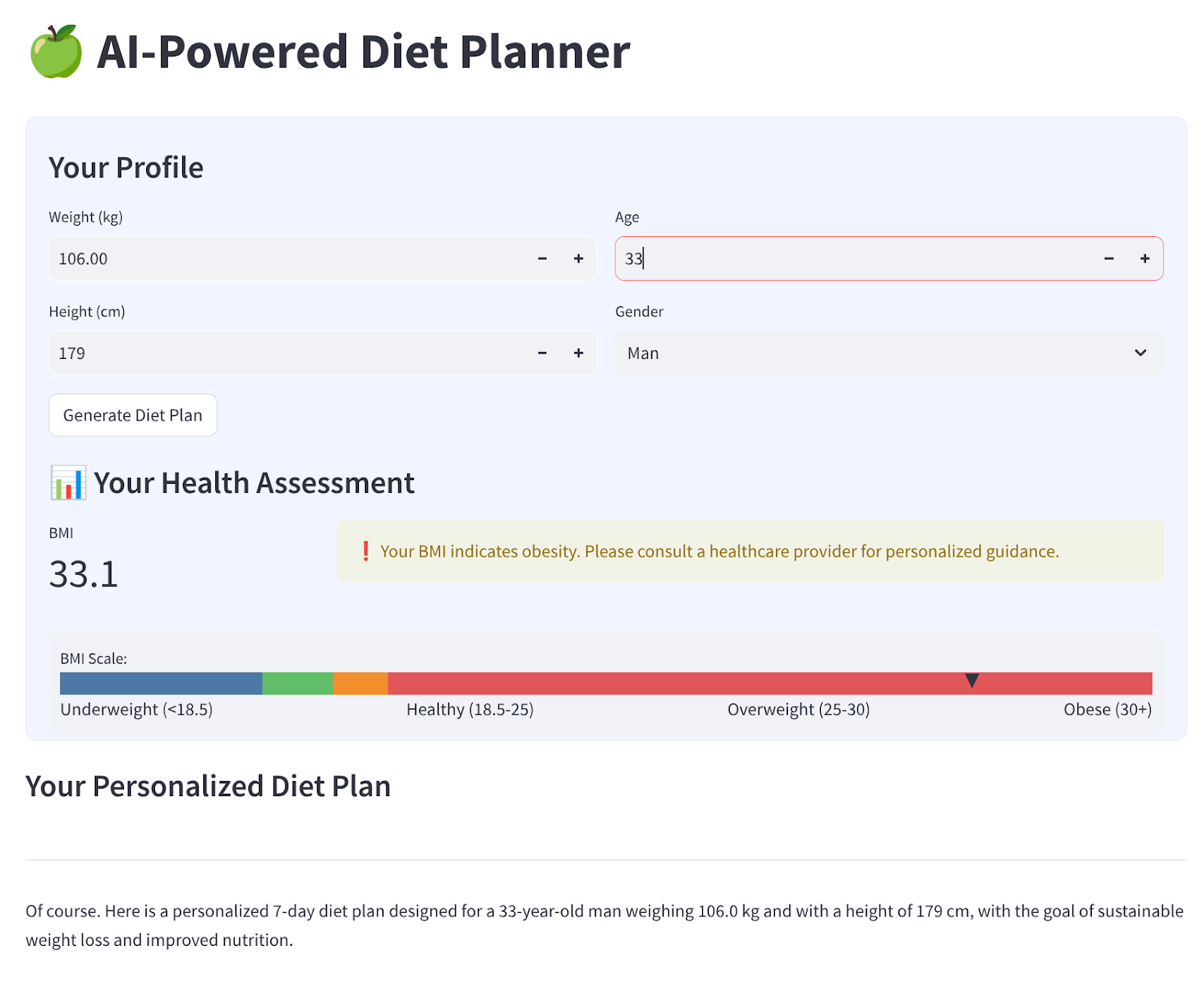
हम चार इनपुट वाला एक आसान वेब इंटरफ़ेस बनाएंगे, जो इस तरह दिखेगा
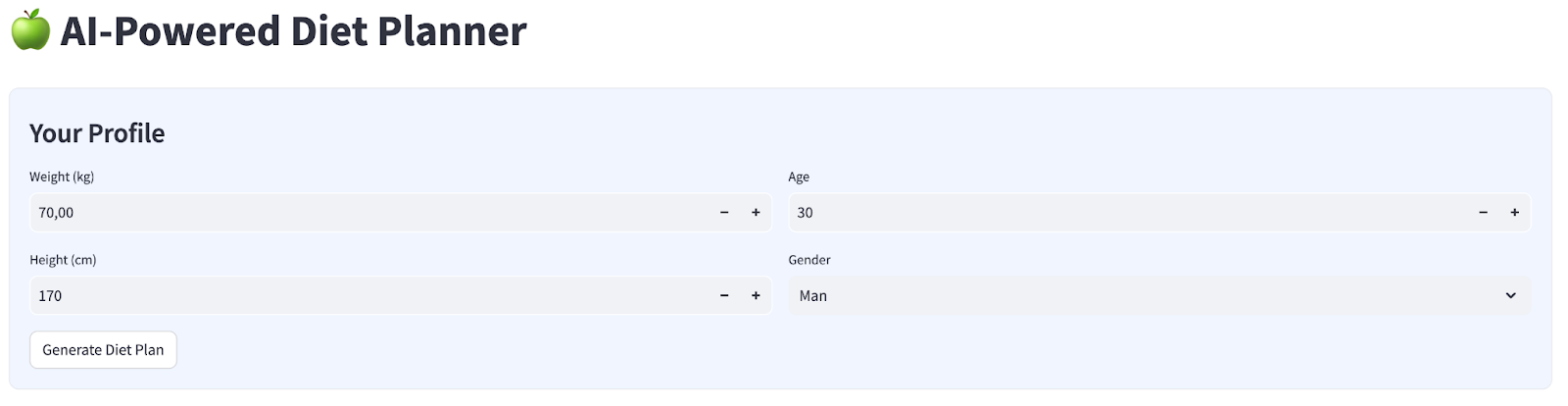
अपनी प्रोफ़ाइल के हिसाब से वज़न, लंबाई, उम्र, और लिंग की जानकारी बदलें. इसके बाद, जनरेट करें पर क्लिक करें. यह Vertex AI लाइब्रेरी में Gemini Pro 2.5 एलएलएम मॉडल को कॉल करेगा और जनरेट किए गए नतीजों को BigQuery में सेव करेगा.
कोड को छह हिस्सों में बांटा जाएगा, ताकि यह बहुत लंबा न हो.
Create function calculate bmi status
agent_diet_plannerफ़ोल्डर पर राइट क्लिक करें → नई फ़ाइल .. → फ़ाइल का नाम डालेंbmi_calc.pyइसके बाद, Enter दबाएं- कोड में यह जानकारी भरो
# Add this function to calculate BMI and health status
def calculate_bmi_status(weight, height):
"""
Calculate BMI and return status message
"""
height_m = height / 100 # Convert cm to meters
bmi = weight / (height_m ** 2)
if bmi < 18.5:
status = "underweight"
message = "⚠️ Your BMI suggests you're underweight. Consider increasing calorie intake with nutrient-dense foods."
elif 18.5 <= bmi < 25:
status = "normal"
message = "✅ Your BMI is in the healthy range. Let's maintain this balance!"
elif 25 <= bmi < 30:
status = "overweight"
message = "⚠️ Your BMI suggests you're overweight. Focus on gradual weight loss through balanced nutrition."
else:
status = "obese"
message = "❗ Your BMI indicates obesity. Please consult a healthcare provider for personalized guidance."
return {
"value": round(bmi, 1),
"status": status,
"message": message
}
डाइट प्लानर के मुख्य ऐप्लिकेशन के लिए एजेंट बनाना
agent_diet_plannerफ़ोल्डर पर राइट क्लिक करें → नई फ़ाइल .. → फ़ाइल का नाम डालेंapp.pyइसके बाद, Enter दबाएं.- कोड में यह जानकारी भरें
import os
from google.oauth2 import service_account
import streamlit as st
from google.cloud import bigquery
from vertexai.preview.generative_models import GenerativeModel
import vertexai
import datetime
import time
import pandas as pd
from bmi_calc import calculate_bmi_status
# Get configuration from environment
PROJECT_ID = os.environ.get("GCP_PROJECT_ID", "your_gcp_project_id")
LOCATION = os.environ.get("GCP_LOCATION", "us-central1")
#CONSTANTS Dataset and table in BigQuery
DATASET = "diet_planner_data"
TABLE = "user_plans"
# Initialize Vertex AI
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Initialize BigQuery client
try:
# For Cloud Run, use default credentials
bq_client = bigquery.Client()
except:
# For local development, use service account from secrets
if "gcp_service_account" in st.secrets:
service_account_info = dict(st.secrets["gcp_service_account"])
credentials = service_account.Credentials.from_service_account_info(service_account_info)
bq_client = bigquery.Client(credentials=credentials, project=PROJECT_ID)
else:
st.error("BigQuery client initialization failed")
st.stop()
your_gcp_project_id की जगह अपना प्रोजेक्ट आईडी डालें.
Create agent diet planner main apps - setup_bq_tables
इस सेक्शन में, हम bq_client नाम का एक फ़ंक्शन बनाएंगे, जिसमें एक इनपुट पैरामीटर setup_bq_table होगा. यह फ़ंक्शन, BigQuery टेबल में स्कीमा तय करेगा. साथ ही, अगर टेबल मौजूद नहीं है, तो उसे बनाएगा.
app.py में, पिछले कोड के नीचे दिया गया कोड डालें
# Create BigQuery table if not exists
def setup_bq_table(bq_client):
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
schema = [
bigquery.SchemaField("user_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("timestamp", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("weight", "FLOAT", mode="REQUIRED"),
bigquery.SchemaField("height", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("age", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("gender", "STRING", mode="REQUIRED"),
bigquery.SchemaField("diet_plan", "STRING", mode="REQUIRED")
]
try:
bq_client.get_table(table_id)
except:
table = bigquery.Table(table_id, schema=schema)
bq_client.create_table(table)
st.toast("BigQuery table created successfully")
Create agent diet planner main apps - generate_diet_plan
इस सेक्शन में, हम generate_diet_plan नाम का एक फ़ंक्शन बनाएंगे. इसमें एक इनपुट पैरामीटर होगा. यह फ़ंक्शन, Gemini Pro 2.5 एलएलएम मॉडल को कॉल करेगा. साथ ही, प्रॉम्प्ट को तय करेगा और नतीजे जनरेट करेगा.
app.py में, पिछले कोड के नीचे दिया गया कोड डालें
# Generate diet plan using Gemini Pro
def generate_diet_plan(params):
try:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
Create a personalized 7-day diet plan for:
- {params['gender']}, {params['age']} years old
- Weight: {params['weight']} kg
- Height: {params['height']} cm
Include:
1. Daily calorie target
2. Macronutrient breakdown (carbs, protein, fat)
3. Meal timing and frequency
4. Food recommendations
5. Hydration guidance
Make the plan:
- Nutritionally balanced
- Practical for daily use
- Culturally adaptable
- With portion size guidance
"""
response = model.generate_content(prompt)
return response.text
except Exception as e:
st.error(f"AI generation error: {str(e)}")
return None
Create agent diet planner main apps - save_to_bq
इस सेक्शन में, हम save_to_bq नाम का एक फ़ंक्शन बनाएंगे. इसमें तीन इनपुट पैरामीटर होंगे : bq_client, user_id, और plan. यह फ़ंक्शन, जनरेट किए गए नतीजे को BigQuery टेबल में सेव करेगा
app.py में, पिछले कोड के नीचे दिया गया कोड डालें
# Save user data to BigQuery
def save_to_bq(bq_client, user_id, plan):
try:
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
row = {
"user_id": user_id,
"timestamp": datetime.datetime.utcnow().isoformat(),
"weight": st.session_state.user_data["weight"],
"height": st.session_state.user_data["height"],
"age": st.session_state.user_data["age"],
"gender": st.session_state.user_data["gender"],
"diet_plan": plan
}
errors = bq_client.insert_rows_json(table_id, [row])
if errors:
st.error(f"BigQuery error: {errors}")
else:
return True
except Exception as e:
st.error(f"Data saving error: {str(e)}")
return False
Create agent diet planner main apps - main
इस सेक्शन में, हम main नाम का एक फ़ंक्शन बनाएंगे. इसमें कोई इनपुट पैरामीटर नहीं होगा. यह फ़ंक्शन, ज़्यादातर Streamlit यूज़र इंटरफ़ेस (यूआई) स्क्रिप्ट को मैनेज करता है. साथ ही, जनरेट किए गए नतीजे दिखाता है. इसके अलावा, यह BigQuery टेबल से जनरेट किए गए पिछले नतीजे दिखाता है और डेटा को Markdown फ़ाइल में डाउनलोड करने की सुविधा देता है.
app.py में, पिछले कोड के नीचे दिया गया कोड डालें
# Streamlit UI
def main():
st.set_page_config(page_title="AI Diet Planner", page_icon="🍏", layout="wide")
# Initialize session state
if "user_data" not in st.session_state:
st.session_state.user_data = None
if "diet_plan" not in st.session_state:
st.session_state.diet_plan = None
# Initialize clients
#bq_client = init_clients()
setup_bq_table(bq_client)
st.title("🍏 AI-Powered Diet Planner")
st.markdown("""
<style>
.stProgress > div > div > div > div {
background-color: #4CAF50;
}
[data-testid="stForm"] {
background: #f0f5ff;
padding: 20px;
border-radius: 10px;
border: 1px solid #e6e9ef;
}
</style>
""", unsafe_allow_html=True)
# User input form
with st.form("user_profile", clear_on_submit=False):
st.subheader("Your Profile")
col1, col2 = st.columns(2)
with col1:
weight = st.number_input("Weight (kg)", min_value=30.0, max_value=200.0, value=70.0)
height = st.number_input("Height (cm)", min_value=100, max_value=250, value=170)
with col2:
age = st.number_input("Age", min_value=18, max_value=100, value=30)
gender = st.selectbox("Gender", ["Man", "Woman"])
submitted = st.form_submit_button("Generate Diet Plan")
if submitted:
user_data = {
"weight": weight,
"height": height,
"age": age,
"gender": gender
}
st.session_state.user_data = user_data
# Calculate BMI
bmi_result = calculate_bmi_status(weight, height)
# Display BMI results in a visually distinct box
with st.container():
st.subheader("📊 Your Health Assessment")
col1, col2 = st.columns([1, 3])
with col1:
st.metric("BMI", bmi_result["value"])
with col2:
if bmi_result["status"] != "normal":
st.warning(bmi_result["message"])
else:
st.success(bmi_result["message"])
# Add BMI scale visualization
st.markdown(f"""
<div style="background:#f0f2f6;padding:10px;border-radius:10px;margin-top:10px">
<small>BMI Scale:</small><br>
<div style="display:flex;height:20px;background:linear-gradient(90deg,
#4e79a7 0%,
#4e79a7 18.5%,
#60bd68 18.5%,
#60bd68 25%,
#f28e2b 25%,
#f28e2b 30%,
#e15759 30%,
#e15759 100%);position:relative">
<div style="position:absolute;left:{min(100, max(0, (bmi_result["value"]/40)*100))}%;top:-5px">
▼
</div>
</div>
<div style="display:flex;justify-content:space-between">
<span>Underweight (<18.5)</span>
<span>Healthy (18.5-25)</span>
<span>Overweight (25-30)</span>
<span>Obese (30+)</span>
</div>
</div>
""", unsafe_allow_html=True)
# Store BMI in session state
st.session_state.bmi = bmi_result
# Plan generation and display
if submitted and st.session_state.user_data:
with st.spinner("🧠 Generating your personalized diet plan using Gemini AI..."):
#diet_plan = generate_diet_plan(st.session_state.user_data)
diet_plan = generate_diet_plan({**st.session_state.user_data,"bmi": bmi_result["value"],
"bmi_status": bmi_result["status"]
})
if diet_plan:
st.session_state.diet_plan = diet_plan
# Generate unique user ID
user_id = f"user_{int(time.time())}"
# Save to BigQuery
if save_to_bq(bq_client, user_id, diet_plan):
st.toast("✅ Plan saved to database!")
# Display generated plan
if st.session_state.diet_plan:
st.subheader("Your Personalized Diet Plan")
st.markdown("---")
st.markdown(st.session_state.diet_plan)
# Download button
st.download_button(
label="Download Plan",
data=st.session_state.diet_plan,
file_name="my_diet_plan.md",
mime="text/markdown"
)
# Show history
st.subheader("Your Plan History")
try:
query = f"""
SELECT timestamp, weight, height, age, gender
FROM `{st.secrets['gcp']['project_id']}.{DATASET}.{TABLE}`
WHERE user_id LIKE 'user_%'
ORDER BY timestamp DESC
LIMIT 5
"""
history = bq_client.query(query).to_dataframe()
if not history.empty:
history["timestamp"] = pd.to_datetime(history["timestamp"])
st.dataframe(history.style.format({
"weight": "{:.1f} kg",
"height": "{:.0f} cm"
}))
else:
st.info("No previous plans found")
except Exception as e:
st.error(f"History load error: {str(e)}")
if __name__ == "__main__":
main()
कोड को app.py नाम से सेव करें.
5. Cloud Run पर ऐप्लिकेशन डिप्लॉय करने के लिए, Cloud Build का इस्तेमाल करना
अब हम इस बेहतरीन ऐप्लिकेशन को दूसरों को दिखाना चाहते हैं. इसके लिए, हम इस ऐप्लिकेशन को पैकेज कर सकते हैं और इसे Cloud Run पर एक सार्वजनिक सेवा के तौर पर डिप्लॉय कर सकते हैं. इससे दूसरे लोग इसे ऐक्सेस कर पाएंगे. इसके लिए, आइए आर्किटेक्चर पर फिर से नज़र डालें
सबसे पहले हमें Dockerfile की ज़रूरत होगी. File->New Text File पर क्लिक करें. इसके बाद, यहां दिया गया कोड कॉपी करके चिपकाएं. फिर,इसे Dockerfile के तौर पर सेव करें
# Use official Python image
FROM python:3.12-slim
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV PORT 8080
# Install system dependencies
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /app
# Copy requirements
COPY requirements.txt .
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application files
COPY . .
# Expose port
EXPOSE $PORT
# Run the application
CMD ["streamlit", "run", "app.py", "--server.port", "8080", "--server.address", "0.0.0.0"]
इसके बाद, हम ऐप्लिकेशन को डॉकर इमेज बनाने, आर्टफ़ैक्ट रजिस्ट्री में पुश करने, और Cloud Run पर डिप्लॉय करने के लिए, cloudbuild.yaml फ़ाइल बनाएंगे.
File->New Text File पर क्लिक करें. इसके बाद, यहां दिया गया कोड कॉपी करके चिपकाएं. इसके बाद, इसे cloudbuild.yaml के तौर पर सेव करें
steps:
# Build Docker image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID', '--no-cache',
'--progress=plain',
'.']
id: 'Build'
timeout: 1200s
waitFor: ['-']
dir: '.'
# Push to Container Registry
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID']
id: 'Push'
waitFor: ['Build']
# Deploy to Cloud Run
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args:
- 'run'
- 'deploy'
- 'diet-planner-service'
- '--image=gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
- '--port=8080'
- '--region=us-central1'
- '--platform=managed'
- '--allow-unauthenticated'
- '--set-env-vars=GCP_PROJECT_ID=$PROJECT_ID,GCP_LOCATION=us-central1'
- '--cpu=1'
- '--memory=1Gi'
- '--timeout=300'
waitFor: ['Push']
options:
logging: CLOUD_LOGGING_ONLY
machineType: 'E2_HIGHCPU_8'
diskSizeGb: 100
images:
- 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
इस समय, हमारे पास ऐप्लिकेशन बनाने के लिए ज़रूरी सभी फ़ाइलें मौजूद हैं. इन फ़ाइलों का इस्तेमाल करके, डॉकर इमेज बनाई जा सकती हैं. साथ ही, इन्हें आर्टफ़ैक्ट रजिस्ट्री में पुश किया जा सकता है और Cloud Run पर डिप्लॉय किया जा सकता है. आइए, इसे डिप्लॉय करें. Cloud Shell टर्मिनल पर जाएं और पक्का करें कि मौजूदा प्रोजेक्ट, आपके एक्टिव प्रोजेक्ट के लिए कॉन्फ़िगर किया गया हो. अगर ऐसा नहीं है, तो प्रोजेक्ट आईडी सेट करने के लिए, gcloud configure कमांड का इस्तेमाल करें:
gcloud config set project [PROJECT_ID]
इसके बाद, ऐप्लिकेशन को Docker इमेज में बदलने, आर्टफ़ैक्ट रजिस्ट्री में पुश करने, और Cloud Run पर डिप्लॉय करने के लिए, यह कमांड चलाएँ
gcloud builds submit --config cloudbuild.yaml
यह हमारे पहले से दिए गए Dockerfile के आधार पर, Docker कंटेनर बनाएगा और उसे Artifact Registry में पुश करेगा. इसके बाद, हम बनाई गई इमेज को Cloud Run पर डिप्लॉय करेंगे. इस पूरी प्रोसेस के बारे में cloudbuild.yaml चरणों में बताया गया है.
ध्यान दें कि हम यहां बिना पुष्टि किए ऐक्सेस करने की अनुमति दे रहे हैं, क्योंकि यह एक डेमो ऐप्लिकेशन है. हमारा सुझाव है कि आप अपने एंटरप्राइज़ और प्रोडक्शन ऐप्लिकेशन के लिए, पुष्टि करने के सही तरीके का इस्तेमाल करें.
डिप्लॉयमेंट पूरा होने के बाद, हम इसे Cloud Run पेज में देख सकते हैं. इसके लिए, क्लाउड कंसोल के सबसे ऊपर मौजूद खोज बार में Cloud Run खोजें और Cloud Run प्रॉडक्ट पर क्लिक करें
इसके बाद, Cloud Run सेवा पेज पर जाकर, डिप्लॉय की गई सेवा की जांच की जा सकती है. सेवा पर क्लिक करें, ताकि हमें सेवा का यूआरएल मिल सके
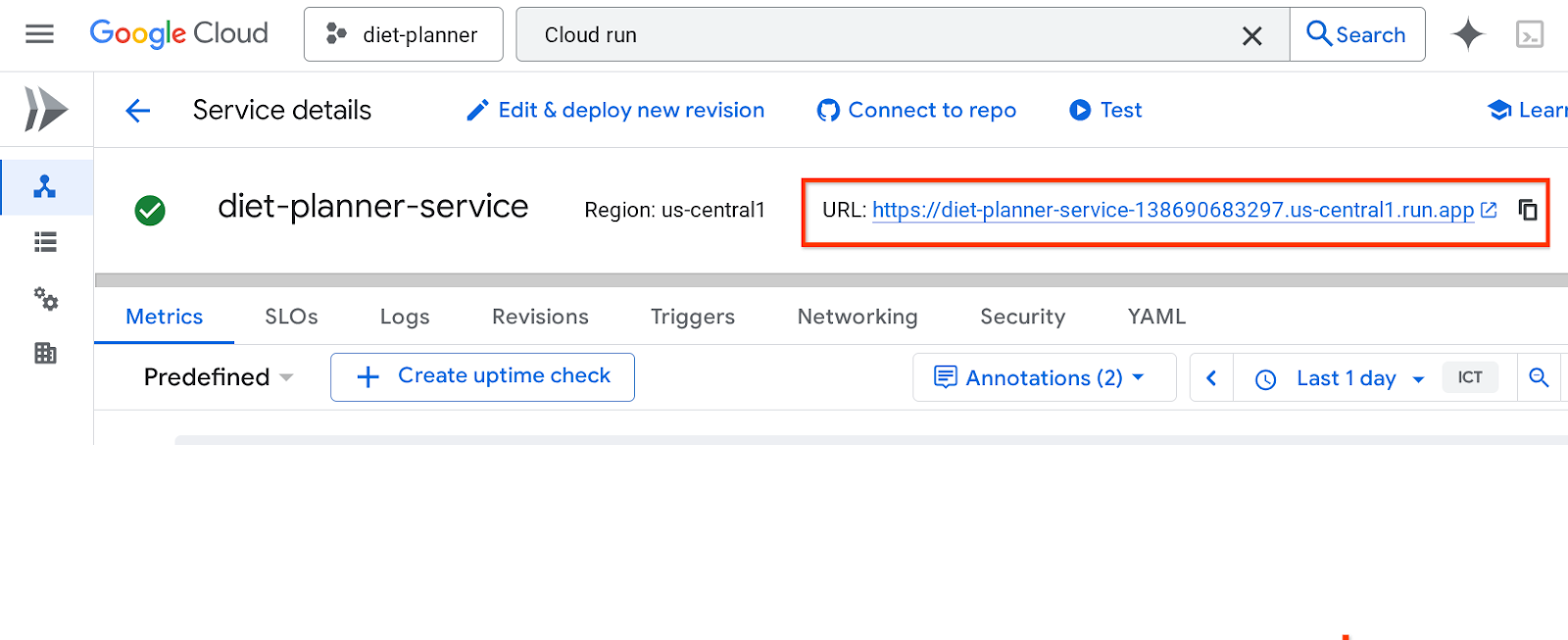
सेवा का यूआरएल, सबसे ऊपर मौजूद बार में दिखेगा
 अब गुप्त विंडो या अपने फ़ोन या टैबलेट पर ऐप्लिकेशन का इस्तेमाल करें. यह पहले से ही लाइव होना चाहिए.
अब गुप्त विंडो या अपने फ़ोन या टैबलेट पर ऐप्लिकेशन का इस्तेमाल करें. यह पहले से ही लाइव होना चाहिए.
6. व्यवस्थित करें
इस कोडलैब में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेज करें पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
- इसके अलावा, कंसोल पर Cloud Run पर जाकर, अभी-अभी डिप्लॉय की गई सेवा को चुनें और उसे मिटाएं.