
1. はじめに
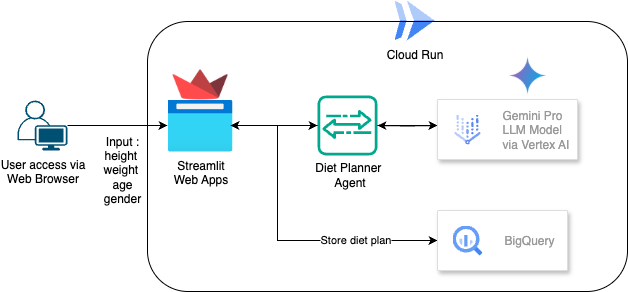
この Codelab では、AI を活用したエージェント ダイエット プランナーを作成してデプロイする方法を学びます。Streamlit を使用する UI、Gemini Pro 2.5 を使用する LLM モデル、Vertex AI を使用してエージェント型 AI を開発するエージェント型 AI エンジン オーケストレーター、データを保存する BigQuery、デプロイする Cloud Run。
この Codelab では、次の手順でアプローチします。
- Google Cloud プロジェクトを準備し、必要な API をすべて有効にする
- streamlit、Vertex AI、BigQuery を使用してエージェント AI ダイエット プランナーを構築する
- アプリケーションを Cloud Run にデプロイする
アーキテクチャの概要
要件
- 課金が有効になっている Google Cloud Platform(GCP)プロジェクト。
- Python の基礎知識
学習内容
- streamlit と Vertex AI を使用してエージェント AI ダイエット プランナーを構築し、BigQuery にデータを保存する方法
- アプリケーションを Cloud Run にデプロイする方法
必要なもの
- Chrome ウェブブラウザ
- Gmail アカウント
- 課金が有効になっている Cloud プロジェクト
2. 基本的な設定と要件
セルフペース型の環境設定
- Google Cloud Console にログインして、プロジェクトを新規作成するか、既存のプロジェクトを再利用します。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。

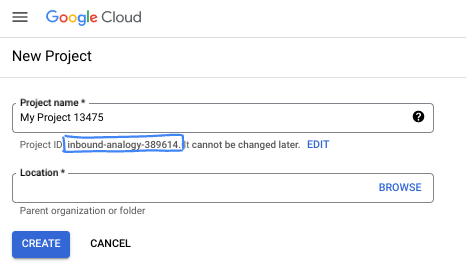
- プロジェクト名は、このプロジェクトの参加者に表示される名称です。Google API では使用されない文字列です。いつでも更新できます。
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Cloud コンソールでは一意の文字列が自動生成されます。通常は、この内容を意識する必要はありません。ほとんどの Codelab では、プロジェクト ID(通常は
PROJECT_IDと識別されます)を参照する必要があります。生成された ID が好みではない場合は、ランダムに別の ID を生成できます。または、ご自身で試して、利用可能かどうかを確認することもできます。このステップ以降は変更できず、プロジェクトを通して同じ ID になります。 - なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
- 次に、Cloud のリソースや API を使用するために、Cloud コンソールで課金を有効にする必要があります。この Codelab の操作をすべて行って、費用が生じたとしても、少額です。このチュートリアルの終了後に請求が発生しないようにリソースをシャットダウンするには、作成したリソースを削除するか、プロジェクトを削除します。Google Cloud の新規ユーザーは、300 米ドル分の無料トライアル プログラムをご利用いただけます。
3. 始める前に
Cloud Shell エディタで Cloud プロジェクトを設定する
この Codelab では、課金が有効になっている Google Cloud プロジェクトがすでにあることを前提としています。まだお持ちでない場合は、以下の手順に沿って開始してください。
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
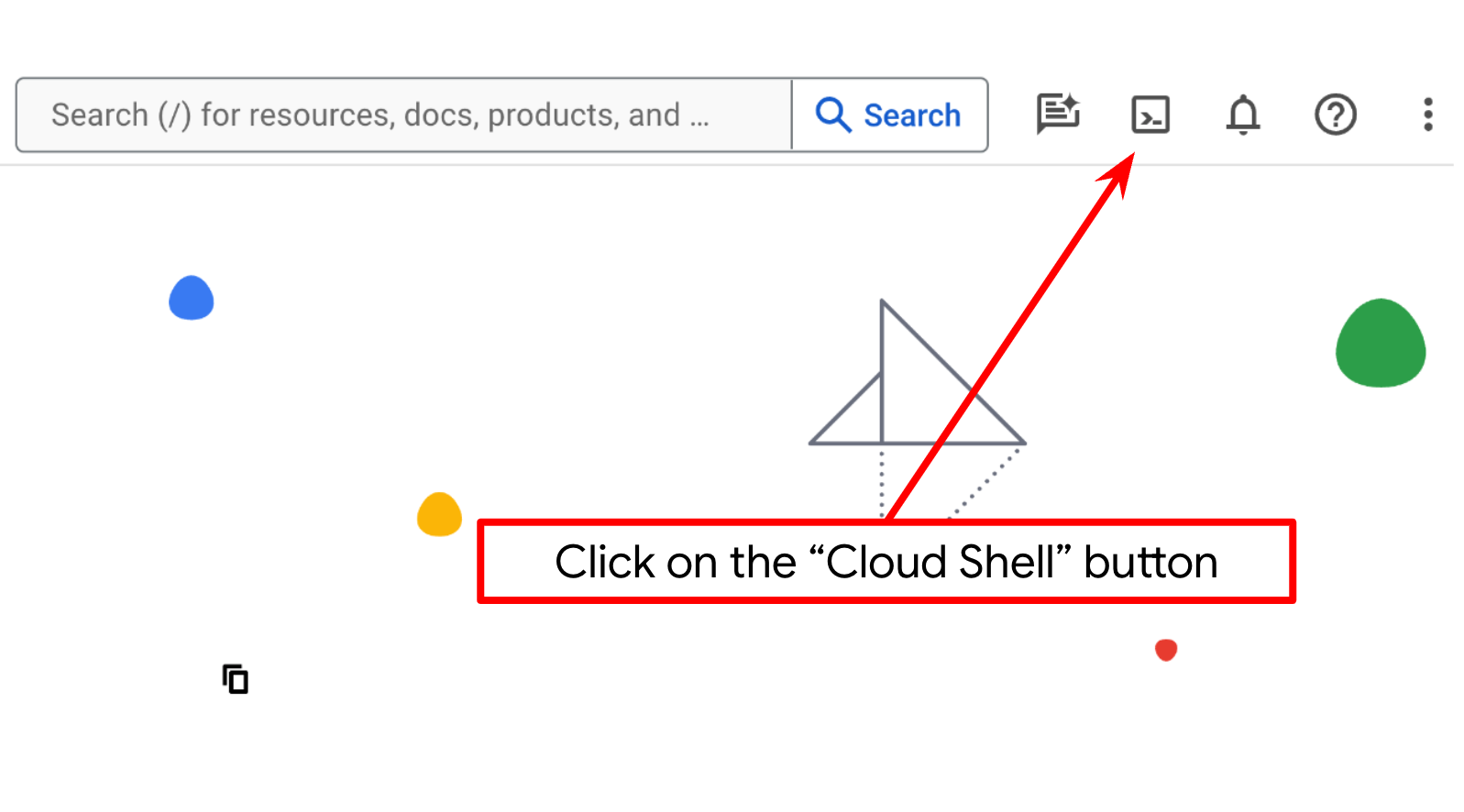
- Cloud Shell(Google Cloud で動作するコマンドライン環境)を使用します。この環境には bq がプリロードされています。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
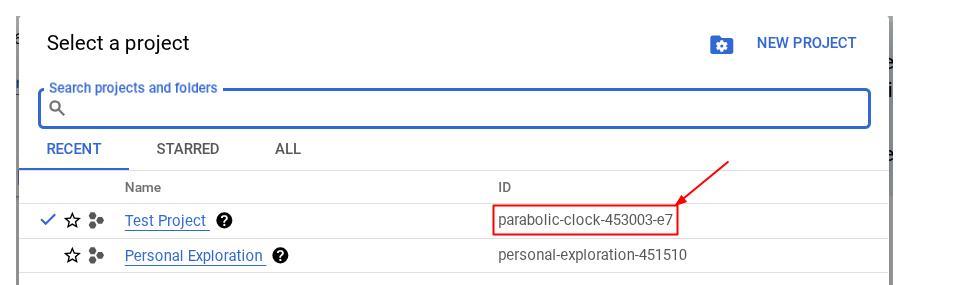
また、コンソールで PROJECT_ID ID を確認することもできます。
クリックすると、右側にすべてのプロジェクトとプロジェクト ID が表示されます。
- 次のコマンドを使用して、必要な API を有効にします。これには数分かかることがあります。
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
bigquery.googleapis.com
コマンドが正常に実行されると、次のようなメッセージが表示されます。
Operation "operations/..." finished successfully.
gcloud コマンドの代わりに、コンソールで各プロダクトを検索するか、こちらのリンクを使用することもできます。
API が見つからない場合は、実装中にいつでも有効にできます。
gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
アプリケーションの作業ディレクトリを設定する
- [エディタを開く] ボタンをクリックすると、Cloud Shell エディタが開きます。ここにコードを記述できます。
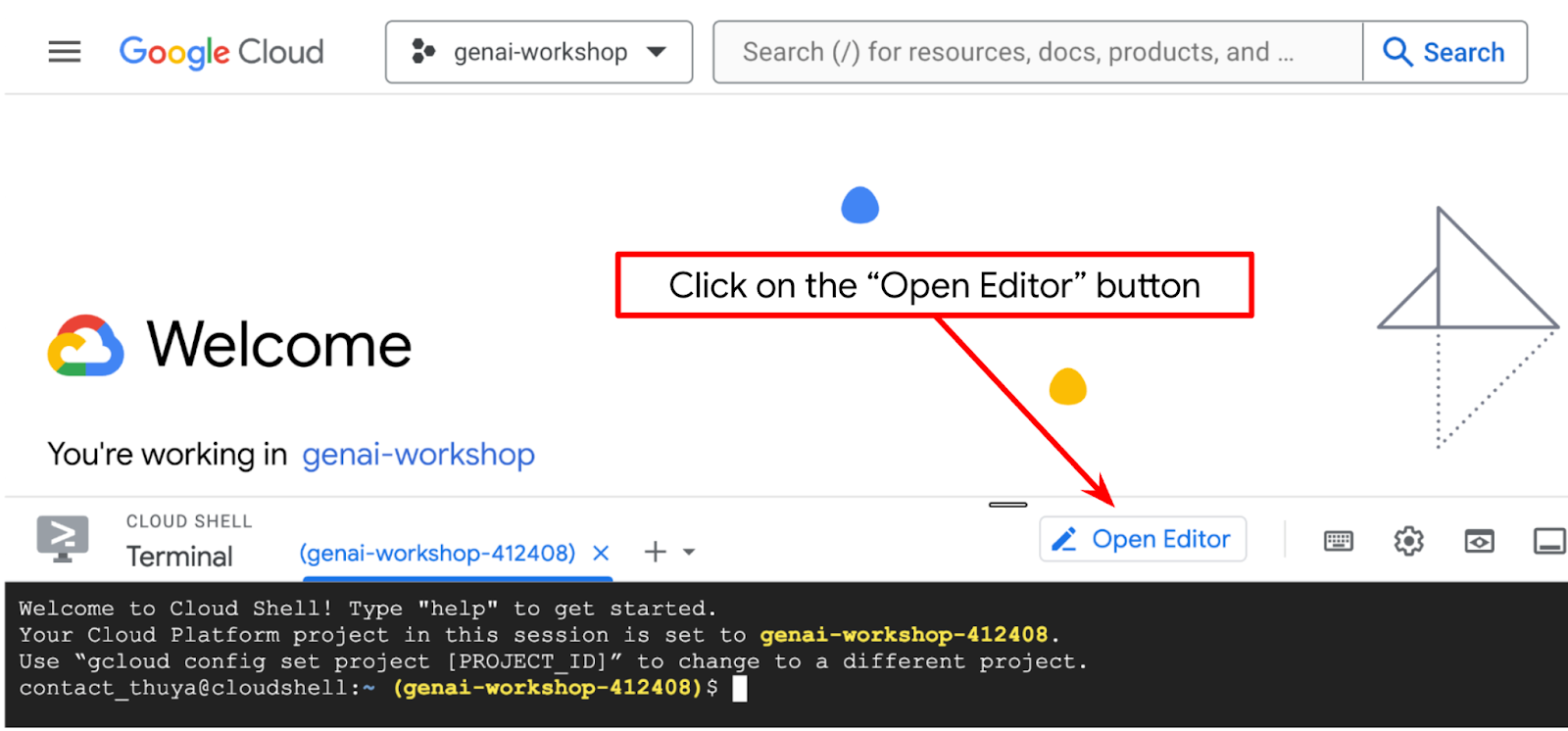
- 下の図でハイライト表示されているように、Cloud Shell エディタの左下(ステータスバー)に Cloud Code プロジェクトが設定され、請求が有効になっているアクティブな Google Cloud プロジェクトに設定されていることを確認します。プロンプトが表示されたら、[Authorize] をクリックします。Cloud Shell エディタの初期化後、[Cloud Code - Sign In] ボタンが表示されるまでに時間がかかることがあります。しばらくお待ちください。
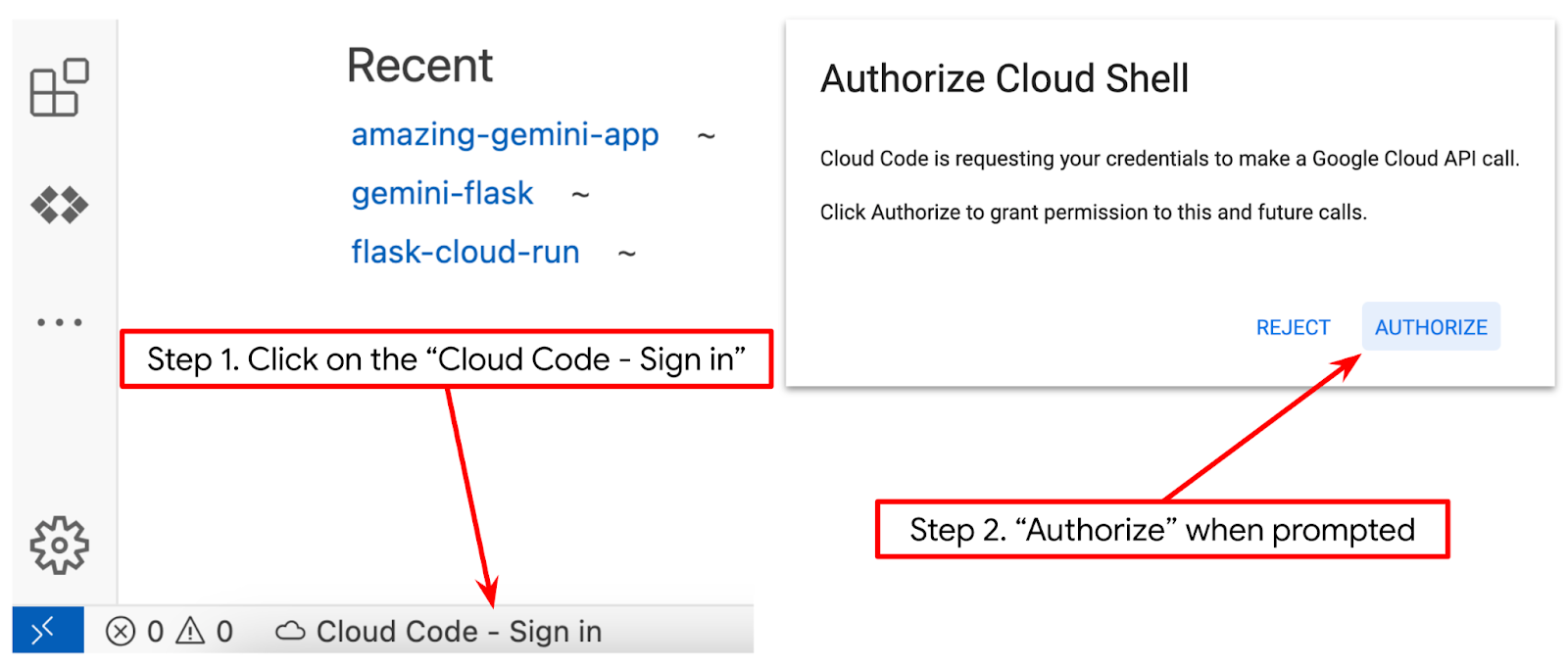
次に、Python 環境を準備します。
環境の設定
Python 仮想環境を準備する
次のステップは、開発環境を準備することです。この Codelab では Python 3.12 を使用し、python virtualenv を使用して Python のバージョンと仮想環境の作成と管理の必要性を簡素化します。
- ターミナルをまだ開いていない場合は、[ターミナル] -> [新しいターミナル] をクリックして開くか、Ctrl+Shift+C を使用します。

- 次のコマンドを実行して、新しいフォルダを作成し、そのフォルダに移動します。
mkdir agent_diet_planner
cd agent_diet_planner
- 次のコマンドを実行して、新しい virtualenv を作成します。
python -m venv .env
- 次のコマンドで virtualenv を有効にします。
source .env/bin/activate
requirements.txtを作成します。[ファイル] → [新しいテキスト ファイル] をクリックし、次の内容を入力します。requirements.txtとして保存します。
streamlit==1.33.0
google-cloud-aiplatform
google-cloud-bigquery
pandas==2.2.2
db-dtypes==1.2.0
pyarrow==16.1.0
- 次に、次のコマンドを実行して、requirements.txt からすべての依存関係をインストールします。
pip install -r requirements.txt
- 次のコマンドを入力して、すべての Python ライブラリの依存関係がインストールされているかどうかを確認します。
pip list
設定構成ファイル
次に、このプロジェクトの構成ファイルを設定する必要があります。構成ファイルは、変数とサービス アカウントの認証情報の保存に使用されます。
- まず、サービス アカウントを作成します。検索で「サービス アカウント」と入力し、[サービス アカウント] をクリックします。
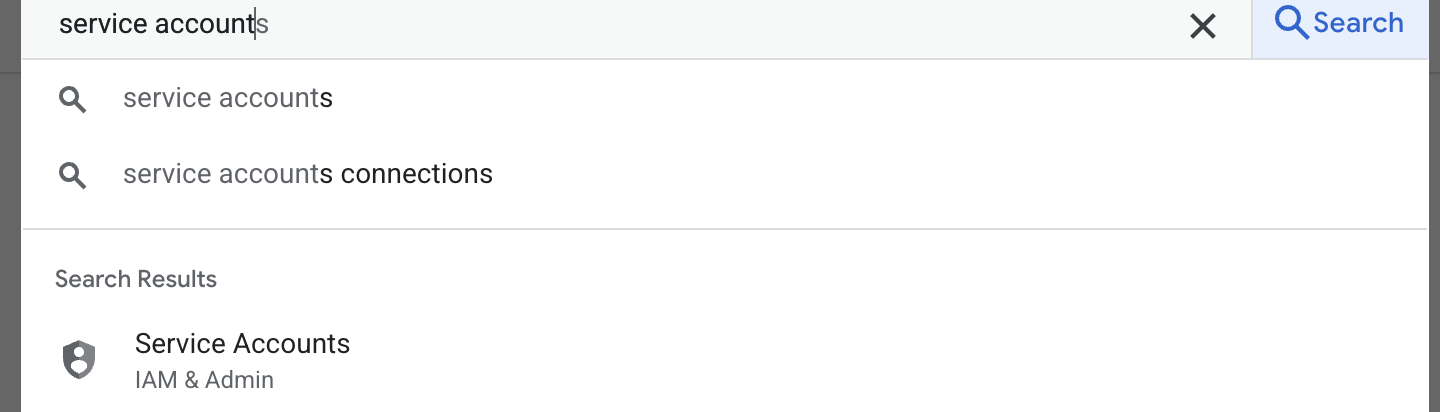
- [+ サービス アカウントを作成] をクリックします。サービス アカウント名を入力し、[作成して続行] をクリックします。
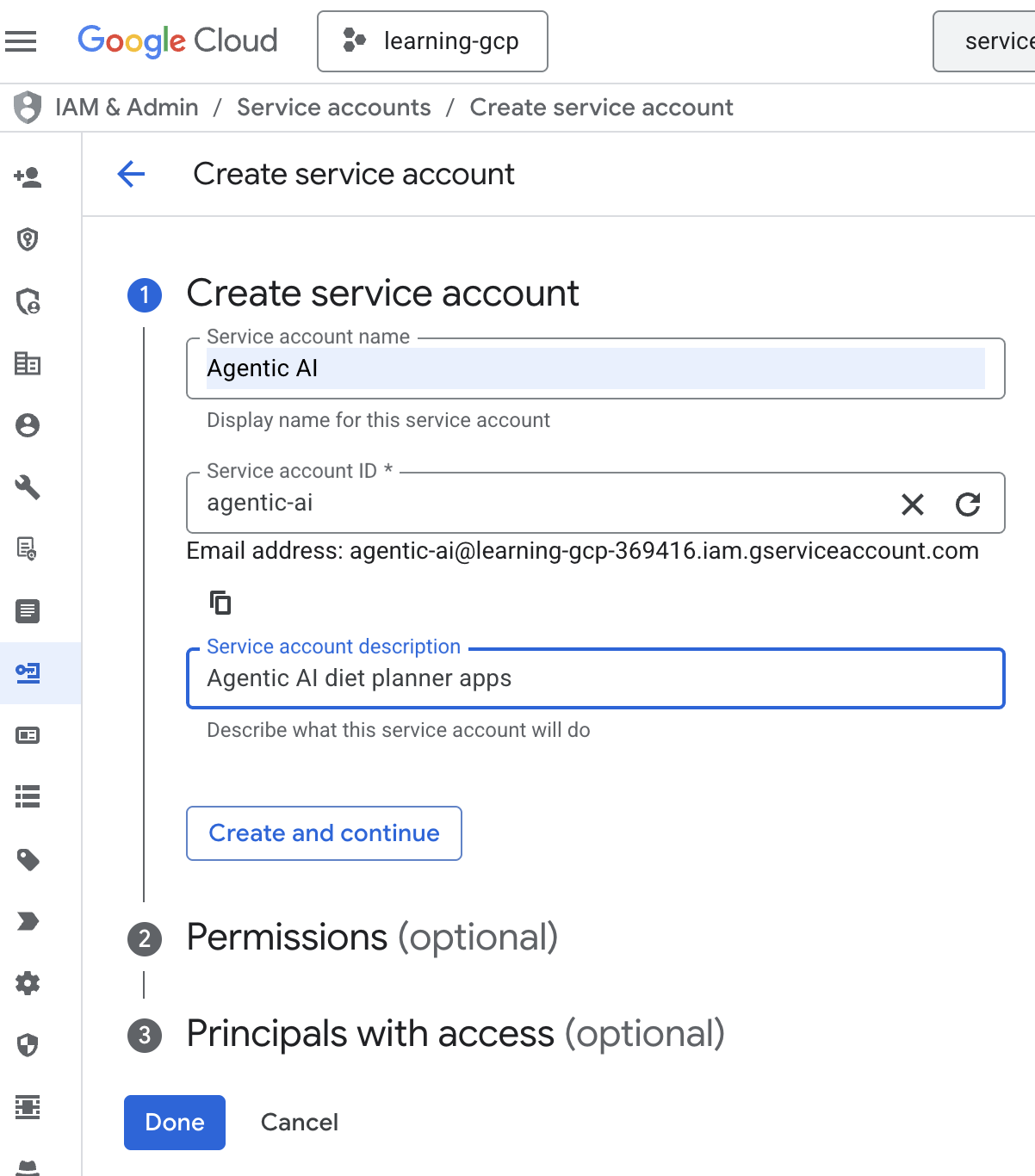
- 権限で、ロール [サービス アカウント ユーザー] を選択します。[+ 別のロールを追加] をクリックし、IAM ロールとして BigQuery 管理者、Cloud Run 管理者、Cloud Run 起動元、Vertex AI サービス エージェント、Vertex AI ユーザーを選択して、[完了]
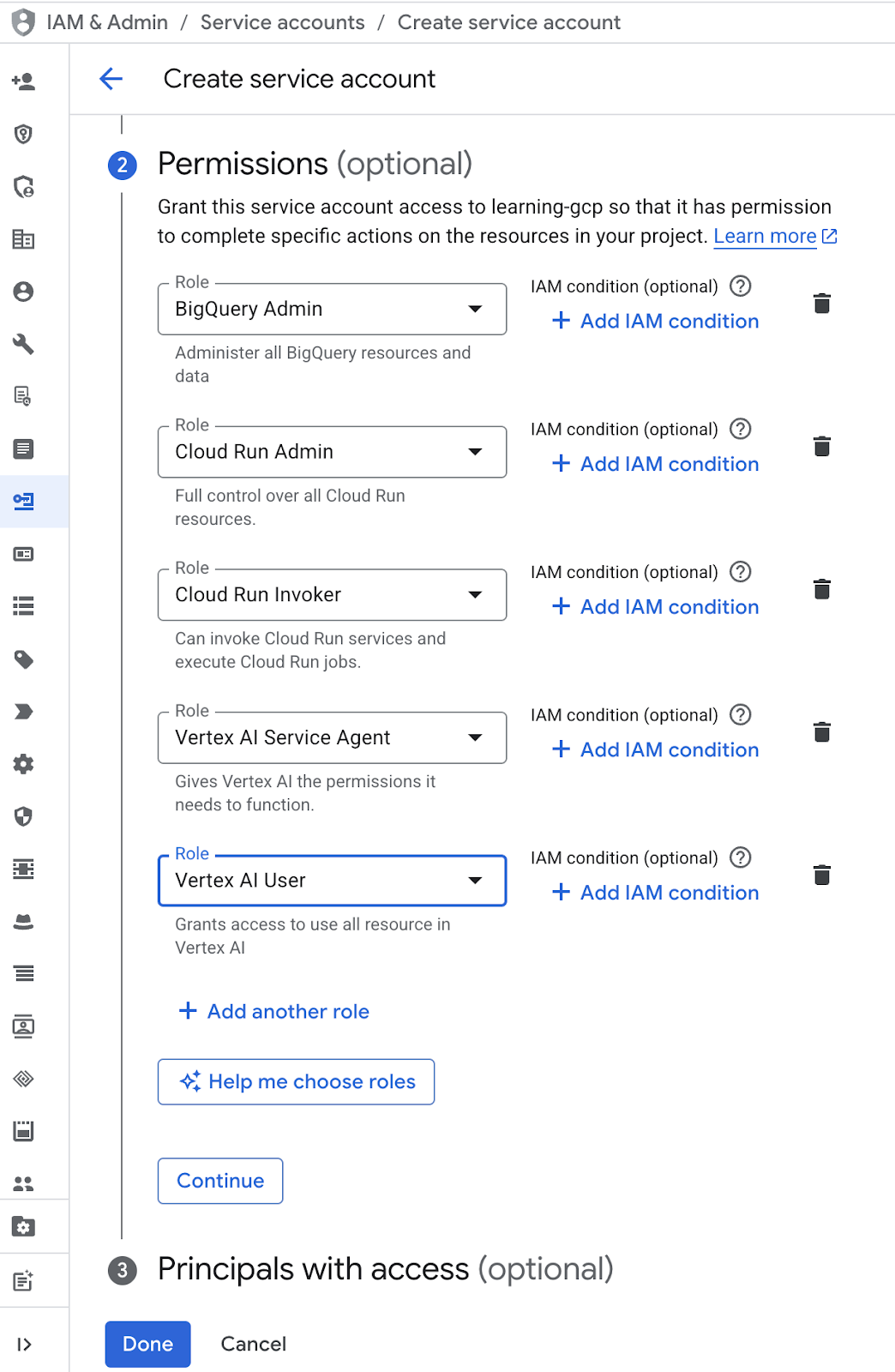 をクリックします。
をクリックします。 - [サービス アカウントのメールアドレス] をクリックし、Tab キーを押し、[キーを追加] → [新しいキーを作成] をクリックします。
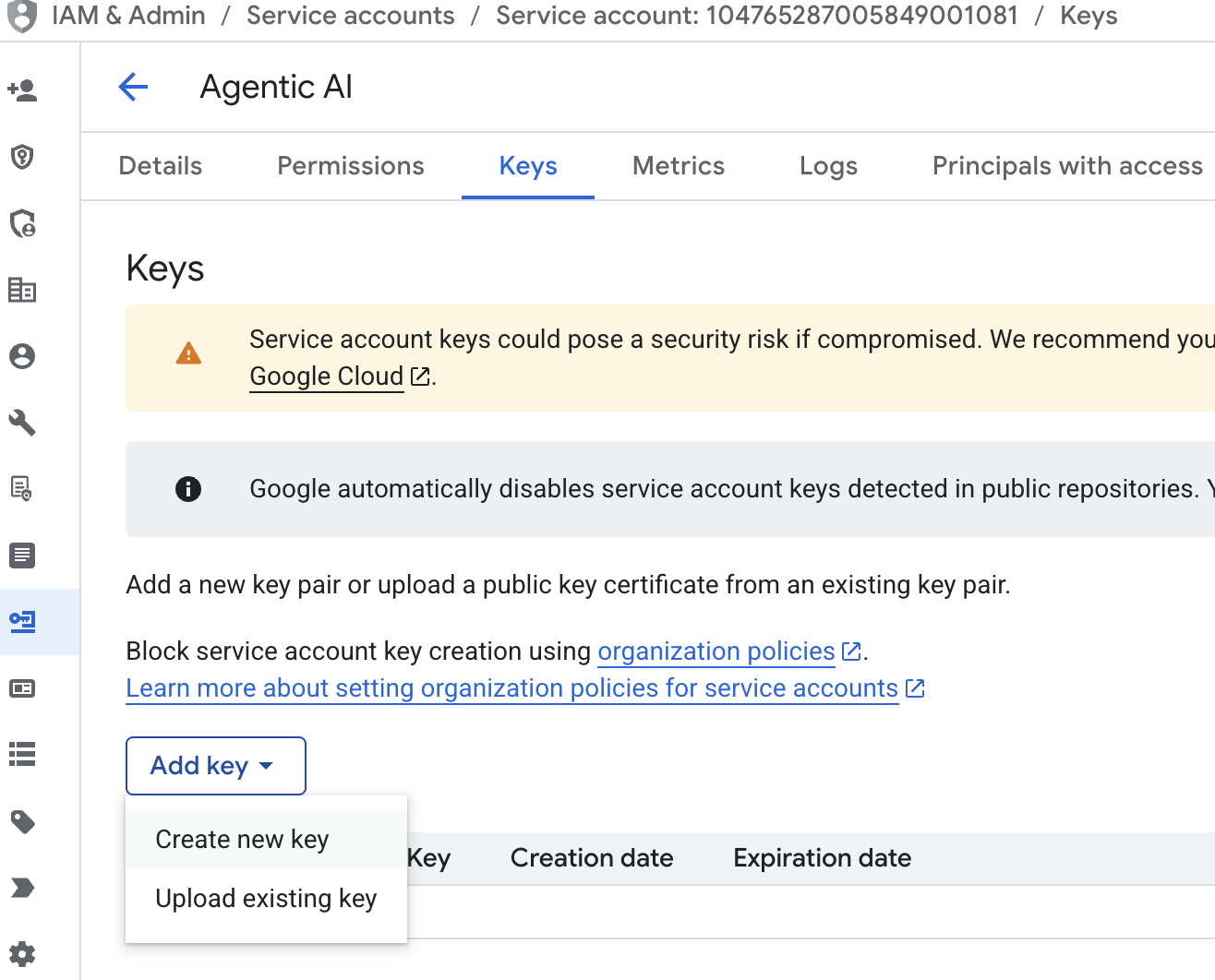
- [json] を選択して [作成] をクリックします。次のステップ
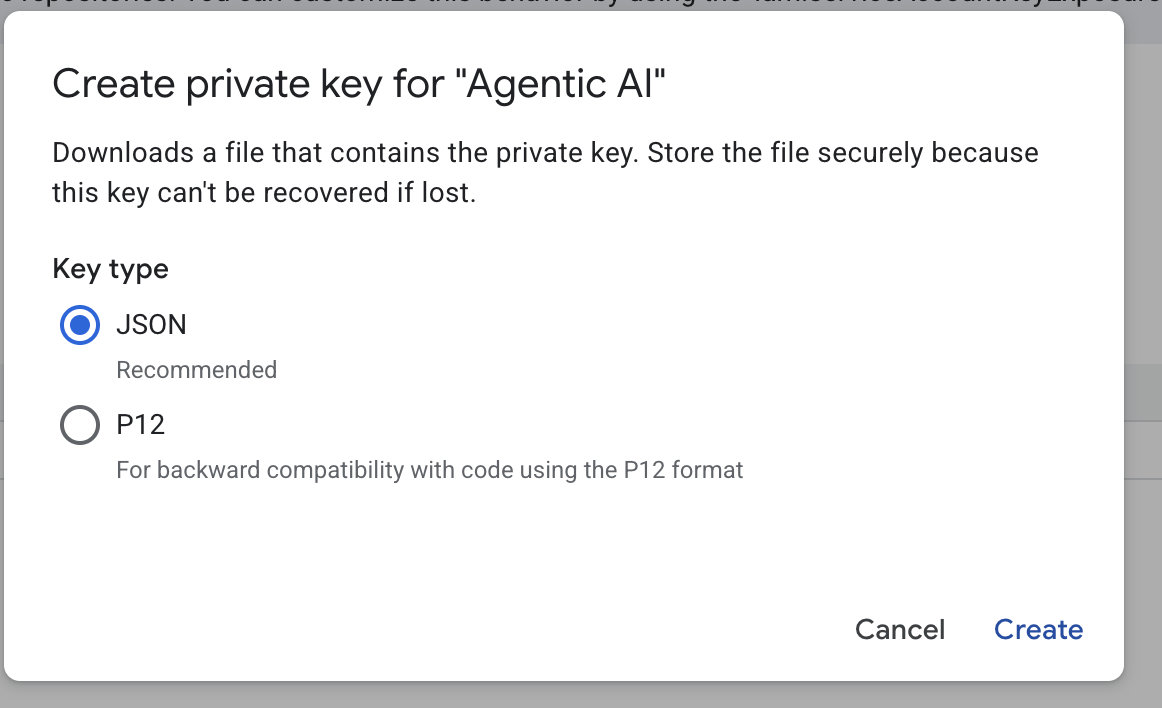 のために、このサービス アカウント ファイルをローカルに保存します
のために、このサービス アカウント ファイルをローカルに保存します - 次の構成で .streamlit という名前のフォルダを作成します。マウスを右クリックし、[新しいフォルダ] をクリックして、フォルダ名
.streamlitを入力します。 - フォルダ
.streamlitを右クリックし、[新しいファイル] をクリックして、次の値を入力します。secrets.tomlとして保存します。
# secrets.toml (for Streamlit sharing)
# Store in .streamlit/secrets.toml
[gcp]
project_id = "your_gcp_project"
location = "us-central1"
[gcp_service_account]
type = "service_account"
project_id = "your-project-id"
private_key_id = "your-private-key-id"
private_key = '''-----BEGIN PRIVATE KEY-----
YOUR_PRIVATE_KEY_HERE
-----END PRIVATE KEY-----'''
client_email = "your-sa@project-id.iam.gserviceaccount.com"
client_id = "your-client-id"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "https://www.googleapis.com/robot/v1/metadata/x509/your-sa%40project-id.iam.gserviceaccount.com"
- 前の手順で作成したサービス アカウントに基づいて、
project_id、private_key_id、private_key、client_email、client_id , and auth_provider_x509_cert_urlの値を更新します。
BigQuery データセットを準備する
次のステップでは、生成結果を BigQuery に保存するための BigQuery データセットを作成します。
- 検索で「BigQuery」と入力し、[BigQuery] をクリックします。
- [
 ] をクリックし、[データセットを作成] をクリックします。
] をクリックし、[データセットを作成] をクリックします。 - データセット ID
diet_planner_dataを入力し、[データセットを作成]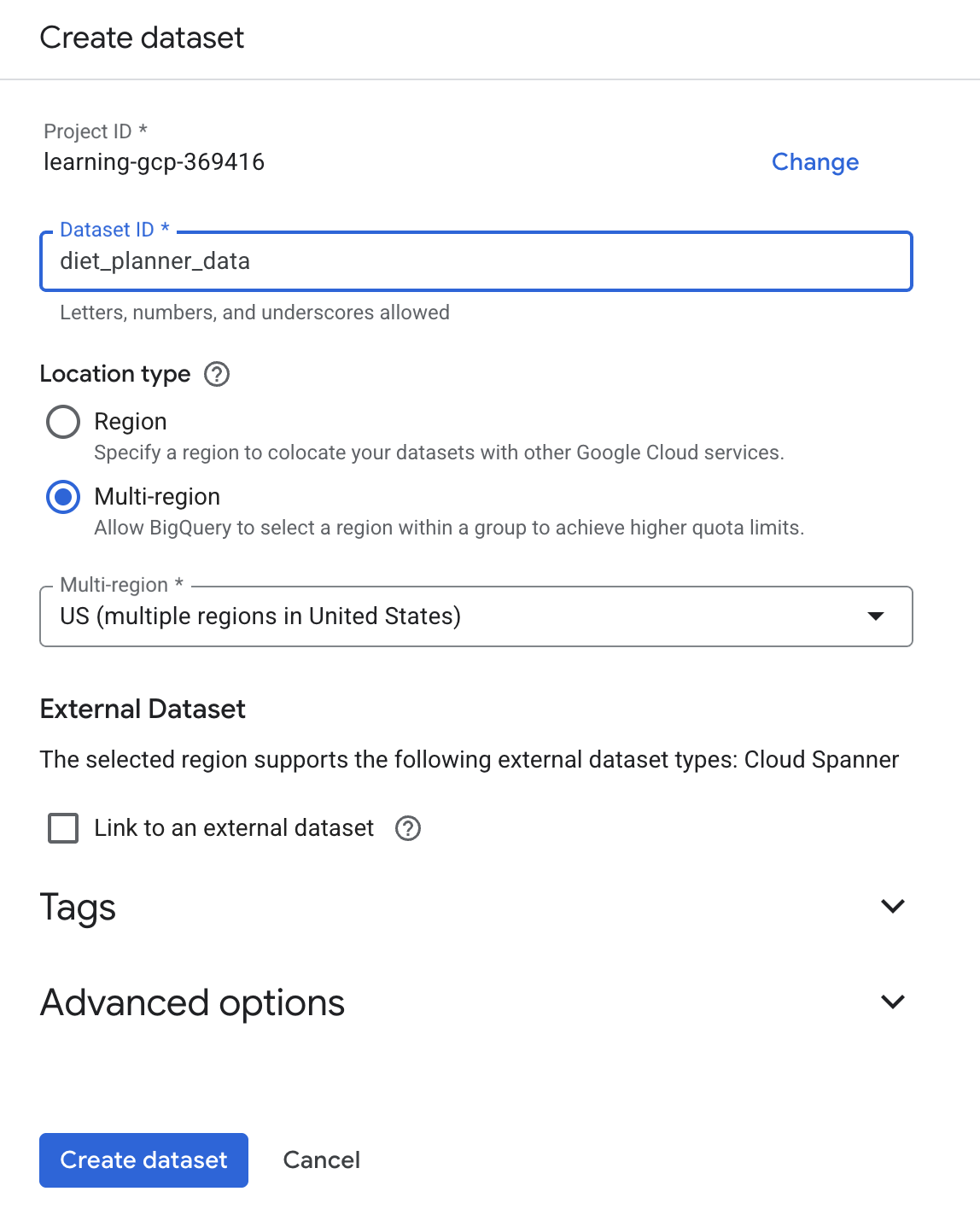 をクリックします。
をクリックします。
4. エージェントの食事プランナー アプリを構築する
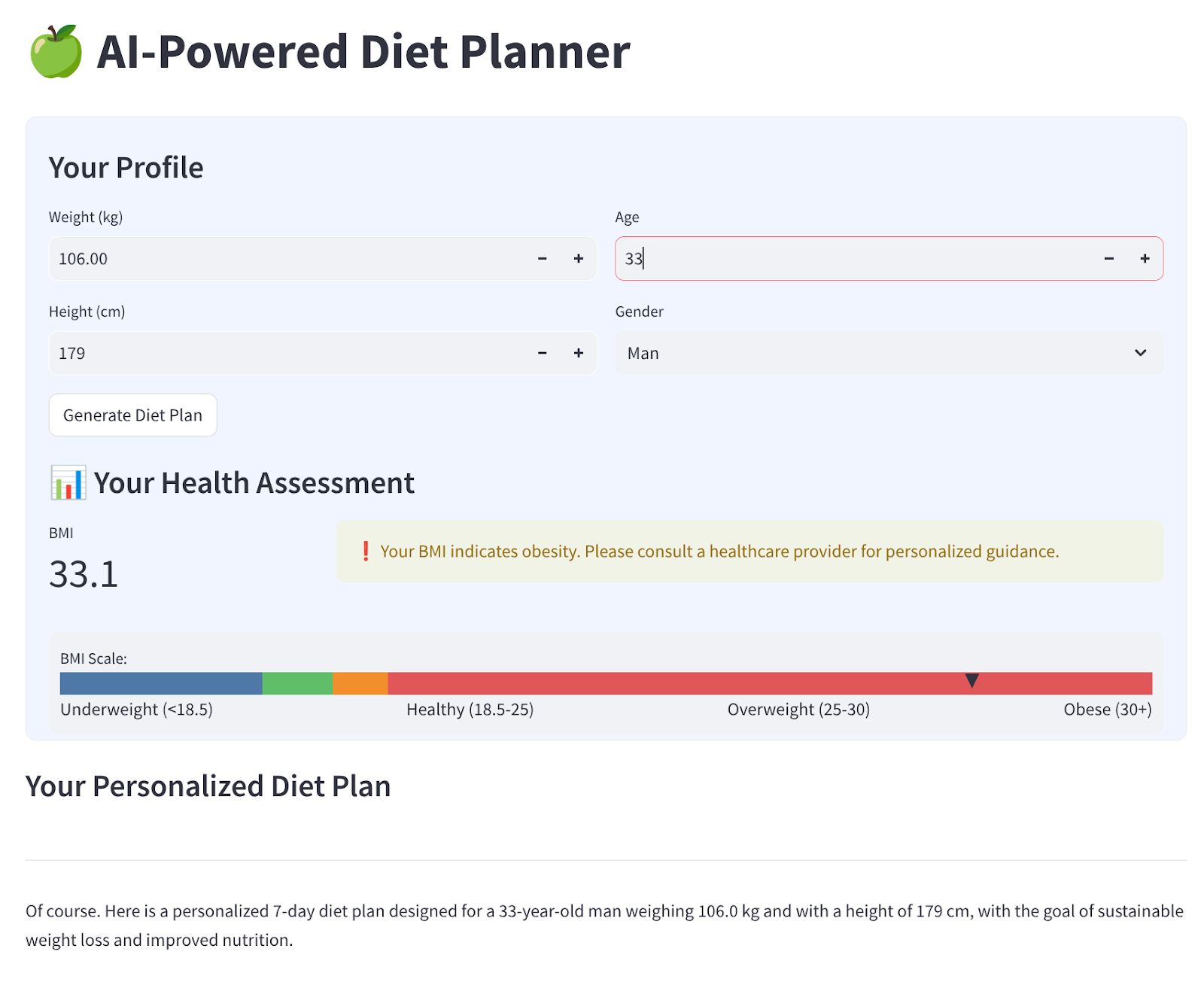
次のような 4 つの入力を持つシンプルなウェブ インターフェースを構築します。
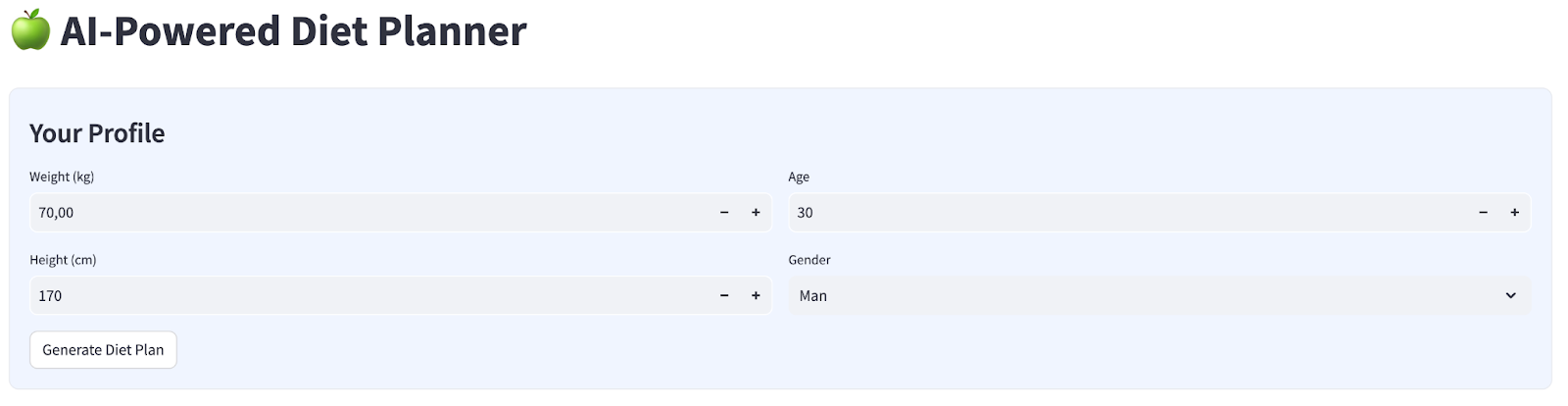
プロフィールに基づいて体重、身長、年齢、性別を変更し、[生成] をクリックします。Vertex AI ライブラリの LLM モデル Gemini Pro 2.5 を呼び出し、生成された結果を BigQuery に保存します。
コードが長くなりすぎないように、6 つの部分に分割します。
BMI ステータスを計算する関数を作成する
agent_diet_plannerフォルダを右クリック → [New File ..] → ファイル名bmi_calc.pyを入力して Enter キーを押します。- コードを次のように入力します。
# Add this function to calculate BMI and health status
def calculate_bmi_status(weight, height):
"""
Calculate BMI and return status message
"""
height_m = height / 100 # Convert cm to meters
bmi = weight / (height_m ** 2)
if bmi < 18.5:
status = "underweight"
message = "⚠️ Your BMI suggests you're underweight. Consider increasing calorie intake with nutrient-dense foods."
elif 18.5 <= bmi < 25:
status = "normal"
message = "✅ Your BMI is in the healthy range. Let's maintain this balance!"
elif 25 <= bmi < 30:
status = "overweight"
message = "⚠️ Your BMI suggests you're overweight. Focus on gradual weight loss through balanced nutrition."
else:
status = "obese"
message = "❗ Your BMI indicates obesity. Please consult a healthcare provider for personalized guidance."
return {
"value": round(bmi, 1),
"status": status,
"message": message
}
エージェントのダイエット プランナー メインアプリを作成する
agent_diet_plannerフォルダを右クリック → [New File] → ファイル名app.pyを入力して Enter キーを押します。- コードを次のように入力します。
import os
from google.oauth2 import service_account
import streamlit as st
from google.cloud import bigquery
from vertexai.preview.generative_models import GenerativeModel
import vertexai
import datetime
import time
import pandas as pd
from bmi_calc import calculate_bmi_status
# Get configuration from environment
PROJECT_ID = os.environ.get("GCP_PROJECT_ID", "your_gcp_project_id")
LOCATION = os.environ.get("GCP_LOCATION", "us-central1")
#CONSTANTS Dataset and table in BigQuery
DATASET = "diet_planner_data"
TABLE = "user_plans"
# Initialize Vertex AI
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Initialize BigQuery client
try:
# For Cloud Run, use default credentials
bq_client = bigquery.Client()
except:
# For local development, use service account from secrets
if "gcp_service_account" in st.secrets:
service_account_info = dict(st.secrets["gcp_service_account"])
credentials = service_account.Credentials.from_service_account_info(service_account_info)
bq_client = bigquery.Client(credentials=credentials, project=PROJECT_ID)
else:
st.error("BigQuery client initialization failed")
st.stop()
値 your_gcp_project_id をプロジェクト ID に変更します。
エージェントのダイエット プランナー メインアプリを作成する - setup_bq_tables
このセクションでは、1 つの入力パラメータ bq_client を持つ setup_bq_table という関数を作成します。この関数は、BigQuery テーブルでスキーマを定義し、テーブルが存在しない場合は作成します。
app.py の前のコードの下に次のコードを入力します。
# Create BigQuery table if not exists
def setup_bq_table(bq_client):
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
schema = [
bigquery.SchemaField("user_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("timestamp", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("weight", "FLOAT", mode="REQUIRED"),
bigquery.SchemaField("height", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("age", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("gender", "STRING", mode="REQUIRED"),
bigquery.SchemaField("diet_plan", "STRING", mode="REQUIRED")
]
try:
bq_client.get_table(table_id)
except:
table = bigquery.Table(table_id, schema=schema)
bq_client.create_table(table)
st.toast("BigQuery table created successfully")
エージェントの食事プランナー メインアプリを作成する - generate_diet_plan
このセクションでは、1 つの入力パラメータを持つ generate_diet_plan という名前の関数を作成します。この関数は、定義されたプロンプトを使用して LLM モデル Gemini Pro 2.5 を呼び出し、結果を生成します。
app.py の前のコードの下に次のコードを入力します。
# Generate diet plan using Gemini Pro
def generate_diet_plan(params):
try:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
Create a personalized 7-day diet plan for:
- {params['gender']}, {params['age']} years old
- Weight: {params['weight']} kg
- Height: {params['height']} cm
Include:
1. Daily calorie target
2. Macronutrient breakdown (carbs, protein, fat)
3. Meal timing and frequency
4. Food recommendations
5. Hydration guidance
Make the plan:
- Nutritionally balanced
- Practical for daily use
- Culturally adaptable
- With portion size guidance
"""
response = model.generate_content(prompt)
return response.text
except Exception as e:
st.error(f"AI generation error: {str(e)}")
return None
エージェントのダイエット プランナー メインアプリを作成する - save_to_bq
このセクションでは、bq_client、user_id、plan の 3 つの入力パラメータを持つ save_to_bq という名前の関数を作成します。この関数は、生成結果を BigQuery テーブルに保存します。
app.py の前のコードの下に次のコードを入力します。
# Save user data to BigQuery
def save_to_bq(bq_client, user_id, plan):
try:
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
row = {
"user_id": user_id,
"timestamp": datetime.datetime.utcnow().isoformat(),
"weight": st.session_state.user_data["weight"],
"height": st.session_state.user_data["height"],
"age": st.session_state.user_data["age"],
"gender": st.session_state.user_data["gender"],
"diet_plan": plan
}
errors = bq_client.insert_rows_json(table_id, [row])
if errors:
st.error(f"BigQuery error: {errors}")
else:
return True
except Exception as e:
st.error(f"Data saving error: {str(e)}")
return False
エージェントのダイエット プランナー メインアプリを作成する - メイン
このセクションでは、入力パラメータのない main という関数を作成します。この関数は主に、streamlit UI スクリプトの処理、生成された結果の表示、BigQuery テーブルからの過去の生成結果の表示、データの Markdown ファイルへのダウンロードを行います。
app.py の前のコードの下に次のコードを入力します。
# Streamlit UI
def main():
st.set_page_config(page_title="AI Diet Planner", page_icon="🍏", layout="wide")
# Initialize session state
if "user_data" not in st.session_state:
st.session_state.user_data = None
if "diet_plan" not in st.session_state:
st.session_state.diet_plan = None
# Initialize clients
#bq_client = init_clients()
setup_bq_table(bq_client)
st.title("🍏 AI-Powered Diet Planner")
st.markdown("""
<style>
.stProgress > div > div > div > div {
background-color: #4CAF50;
}
[data-testid="stForm"] {
background: #f0f5ff;
padding: 20px;
border-radius: 10px;
border: 1px solid #e6e9ef;
}
</style>
""", unsafe_allow_html=True)
# User input form
with st.form("user_profile", clear_on_submit=False):
st.subheader("Your Profile")
col1, col2 = st.columns(2)
with col1:
weight = st.number_input("Weight (kg)", min_value=30.0, max_value=200.0, value=70.0)
height = st.number_input("Height (cm)", min_value=100, max_value=250, value=170)
with col2:
age = st.number_input("Age", min_value=18, max_value=100, value=30)
gender = st.selectbox("Gender", ["Man", "Woman"])
submitted = st.form_submit_button("Generate Diet Plan")
if submitted:
user_data = {
"weight": weight,
"height": height,
"age": age,
"gender": gender
}
st.session_state.user_data = user_data
# Calculate BMI
bmi_result = calculate_bmi_status(weight, height)
# Display BMI results in a visually distinct box
with st.container():
st.subheader("📊 Your Health Assessment")
col1, col2 = st.columns([1, 3])
with col1:
st.metric("BMI", bmi_result["value"])
with col2:
if bmi_result["status"] != "normal":
st.warning(bmi_result["message"])
else:
st.success(bmi_result["message"])
# Add BMI scale visualization
st.markdown(f"""
<div style="background:#f0f2f6;padding:10px;border-radius:10px;margin-top:10px">
<small>BMI Scale:</small><br>
<div style="display:flex;height:20px;background:linear-gradient(90deg,
#4e79a7 0%,
#4e79a7 18.5%,
#60bd68 18.5%,
#60bd68 25%,
#f28e2b 25%,
#f28e2b 30%,
#e15759 30%,
#e15759 100%);position:relative">
<div style="position:absolute;left:{min(100, max(0, (bmi_result["value"]/40)*100))}%;top:-5px">
▼
</div>
</div>
<div style="display:flex;justify-content:space-between">
<span>Underweight (<18.5)</span>
<span>Healthy (18.5-25)</span>
<span>Overweight (25-30)</span>
<span>Obese (30+)</span>
</div>
</div>
""", unsafe_allow_html=True)
# Store BMI in session state
st.session_state.bmi = bmi_result
# Plan generation and display
if submitted and st.session_state.user_data:
with st.spinner("🧠 Generating your personalized diet plan using Gemini AI..."):
#diet_plan = generate_diet_plan(st.session_state.user_data)
diet_plan = generate_diet_plan({**st.session_state.user_data,"bmi": bmi_result["value"],
"bmi_status": bmi_result["status"]
})
if diet_plan:
st.session_state.diet_plan = diet_plan
# Generate unique user ID
user_id = f"user_{int(time.time())}"
# Save to BigQuery
if save_to_bq(bq_client, user_id, diet_plan):
st.toast("✅ Plan saved to database!")
# Display generated plan
if st.session_state.diet_plan:
st.subheader("Your Personalized Diet Plan")
st.markdown("---")
st.markdown(st.session_state.diet_plan)
# Download button
st.download_button(
label="Download Plan",
data=st.session_state.diet_plan,
file_name="my_diet_plan.md",
mime="text/markdown"
)
# Show history
st.subheader("Your Plan History")
try:
query = f"""
SELECT timestamp, weight, height, age, gender
FROM `{st.secrets['gcp']['project_id']}.{DATASET}.{TABLE}`
WHERE user_id LIKE 'user_%'
ORDER BY timestamp DESC
LIMIT 5
"""
history = bq_client.query(query).to_dataframe()
if not history.empty:
history["timestamp"] = pd.to_datetime(history["timestamp"])
st.dataframe(history.style.format({
"weight": "{:.1f} kg",
"height": "{:.0f} cm"
}))
else:
st.info("No previous plans found")
except Exception as e:
st.error(f"History load error: {str(e)}")
if __name__ == "__main__":
main()
コードを app.py という名前で保存します。
5. Cloud Build を使用して Cloud Run にアプリをデプロイする
この素晴らしいアプリを他のユーザーにも紹介したいところですが、そのためには、このアプリケーションをパッケージ化し、他のユーザーがアクセスできる公開サービスとして Cloud Run にデプロイします。そのため、アーキテクチャを復習しましょう。
まず Dockerfile が必要です。[ファイル] -> [新しいテキスト ファイル] をクリックし、次のコードをコピーして貼り付け、Dockerfile として保存します。
# Use official Python image
FROM python:3.12-slim
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV PORT 8080
# Install system dependencies
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /app
# Copy requirements
COPY requirements.txt .
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application files
COPY . .
# Expose port
EXPOSE $PORT
# Run the application
CMD ["streamlit", "run", "app.py", "--server.port", "8080", "--server.address", "0.0.0.0"]
次に、アプリをビルドして Docker イメージにし、Artifact Registry に push して Cloud Run にデプロイするための cloudbuid.yaml を作成します。
[ファイル] -> [新しいテキスト ファイル] をクリックし、次のコードをコピーして貼り付け、cloudbuild.yaml として保存します。
steps:
# Build Docker image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID', '--no-cache',
'--progress=plain',
'.']
id: 'Build'
timeout: 1200s
waitFor: ['-']
dir: '.'
# Push to Container Registry
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID']
id: 'Push'
waitFor: ['Build']
# Deploy to Cloud Run
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args:
- 'run'
- 'deploy'
- 'diet-planner-service'
- '--image=gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
- '--port=8080'
- '--region=us-central1'
- '--platform=managed'
- '--allow-unauthenticated'
- '--set-env-vars=GCP_PROJECT_ID=$PROJECT_ID,GCP_LOCATION=us-central1'
- '--cpu=1'
- '--memory=1Gi'
- '--timeout=300'
waitFor: ['Push']
options:
logging: CLOUD_LOGGING_ONLY
machineType: 'E2_HIGHCPU_8'
diskSizeGb: 100
images:
- 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
この時点で、アプリをビルドして Docker イメージにし、Artifact Registry に push して Cloud Run にデプロイするために必要なファイルはすべて揃っています。デプロイしましょう。Cloud Shell ターミナルに移動し、現在のプロジェクトがアクティブなプロジェクトに構成されていることを確認します。構成されていない場合は、gcloud configure コマンドを使用してプロジェクト ID を設定します。
gcloud config set project [PROJECT_ID]
次に、次のコマンドを実行して、アプリを Docker イメージにビルドし、Artifact Registry に push して、Cloud Run にデプロイします。
gcloud builds submit --config cloudbuild.yaml
これにより、以前に提供した Dockerfile に基づいて Docker コンテナがビルドされ、Artifact Registry に push されます。その後、構築したイメージを Cloud Run にデプロイします。このプロセス全体は cloudbuild.yaml ステップで定義されています。
これはデモ アプリケーションであるため、ここでは未認証のアクセスを許可しています。エンタープライズ アプリケーションと本番環境アプリケーションには適切な認証を使用することをおすすめします。
デプロイが完了したら、Cloud Run ページで確認できます。上部の Cloud コンソールの検索バーで Cloud Run を検索し、Cloud Run プロダクトをクリックします。
デプロイされたサービスは Cloud Run サービスのページに表示されます。サービスをクリックして、サービス URL を取得します。
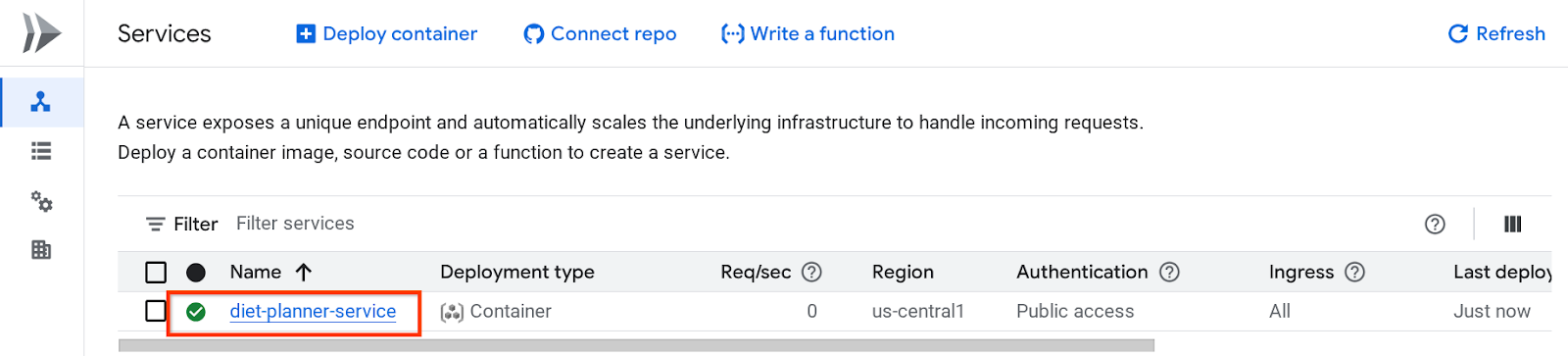
サービス URL がトップバーに表示されます
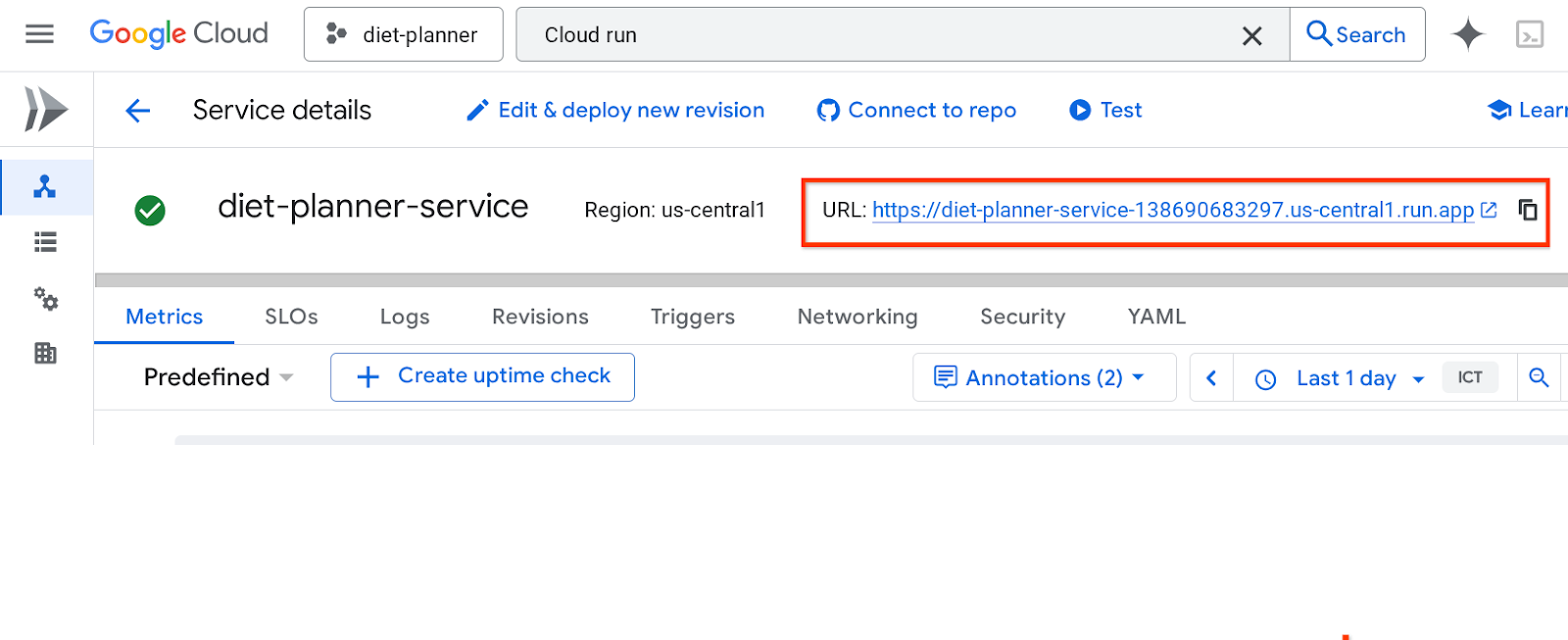 シークレット ウィンドウまたはモバイル デバイスからアプリケーションを使用します。すでに公開されているはずです。
シークレット ウィンドウまたはモバイル デバイスからアプリケーションを使用します。すでに公開されているはずです。
6. クリーンアップ
この Codelab で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順を行います。