
1. Wprowadzenie
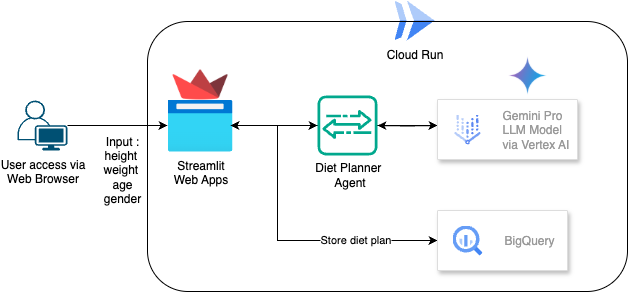
Z tego ćwiczenia dowiesz się, jak utworzyć i wdrożyć opartego na AI agenta do planowania diety. Interfejs użytkownika korzysta z Streamlit, model LLM z Gemini Pro 2.5, a orkiestrator silnika agentowej AI z Vertex AI do tworzenia agentowej AI. BigQuery służy do przechowywania danych, a Cloud Run do wdrażania.
W ramach ćwiczeń z programowania będziesz wykonywać kolejne czynności:
- Przygotowywanie projektu Google Cloud i włączanie w nim wszystkich wymaganych interfejsów API
- Tworzenie agentowej AI do planowania diety z użyciem Streamlit, Vertex AI i BigQuery
- Wdrażanie aplikacji w Cloud Run
Omówienie architektury
Wymagania wstępne
- Projekt Google Cloud Platform (GCP) z włączonymi płatnościami.
- Podstawowa znajomość Pythona
Czego się nauczysz
- Jak utworzyć agentową AI do planowania diety za pomocą Streamlit i Vertex AI oraz przechowywać dane w BigQuery
- Jak wdrożyć aplikację w Cloud Run
Czego potrzebujesz
- przeglądarki Chrome,
- konto Gmail,
- Projekt w chmurze z włączonymi płatnościami
2. Konfiguracja podstawowa i wymagania
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.

- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Jest to ciąg znaków, który nie jest używany przez interfejsy API Google. Zawsze możesz ją zaktualizować.
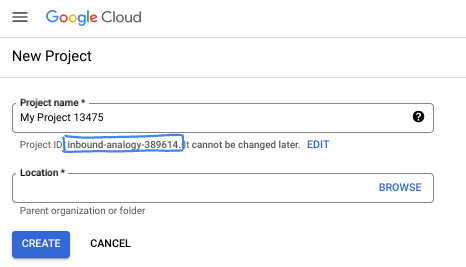
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie musisz się tym przejmować. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu (zwykle oznaczanego jako
PROJECT_ID). Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować inny losowy identyfikator. Możesz też spróbować własnej nazwy i sprawdzić, czy jest dostępna. Po tym kroku nie można go zmienić i pozostaje on taki przez cały czas trwania projektu. - Warto wiedzieć, że istnieje trzecia wartość, czyli numer projektu, którego używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
- Następnie musisz włączyć płatności w konsoli Cloud, aby korzystać z zasobów i interfejsów API Google Cloud. Wykonanie tego laboratorium nie będzie kosztować dużo, a może nawet nic. Aby wyłączyć zasoby i uniknąć naliczania opłat po zakończeniu tego samouczka, możesz usunąć utworzone zasoby lub projekt. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
3. Zanim zaczniesz
Konfigurowanie projektu w Cloud Shell Editor
W tym samouczku zakładamy, że masz już projekt Google Cloud z włączonymi płatnościami. Jeśli jeszcze go nie masz, możesz zacząć, wykonując czynności opisane poniżej.
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności .
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud, które jest wstępnie załadowane narzędziem bq. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.
- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
Możesz też zobaczyć PROJECT_ID id w konsoli.
Kliknij go, a po prawej stronie zobaczysz wszystkie swoje projekty i identyfikator projektu.
- Włącz wymagane interfejsy API za pomocą polecenia pokazanego poniżej. Może to potrwać kilka minut, więc zachowaj cierpliwość.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
bigquery.googleapis.com
Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
Alternatywą dla polecenia gcloud jest wyszukanie poszczególnych usług w konsoli lub skorzystanie z tego linku.
Jeśli pominiesz jakiś interfejs API, możesz go włączyć w trakcie wdrażania.
Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
Konfigurowanie katalogu roboczego aplikacji
- Kliknij przycisk Otwórz edytor. Spowoduje to otwarcie edytora Cloud Shell, w którym możesz pisać kod.
- Sprawdź, czy projekt Cloud Code jest ustawiony w lewym dolnym rogu (na pasku stanu) edytora Cloud Shell, jak pokazano na ilustracji poniżej, i czy jest ustawiony jako aktywny projekt Google Cloud, w którym masz włączone płatności. W razie potrzeby kliknij Autoryzuj. Po zainicjowaniu edytora Cloud Shell może minąć trochę czasu, zanim pojawi się przycisk Cloud Code – zaloguj się. Prosimy o cierpliwość.
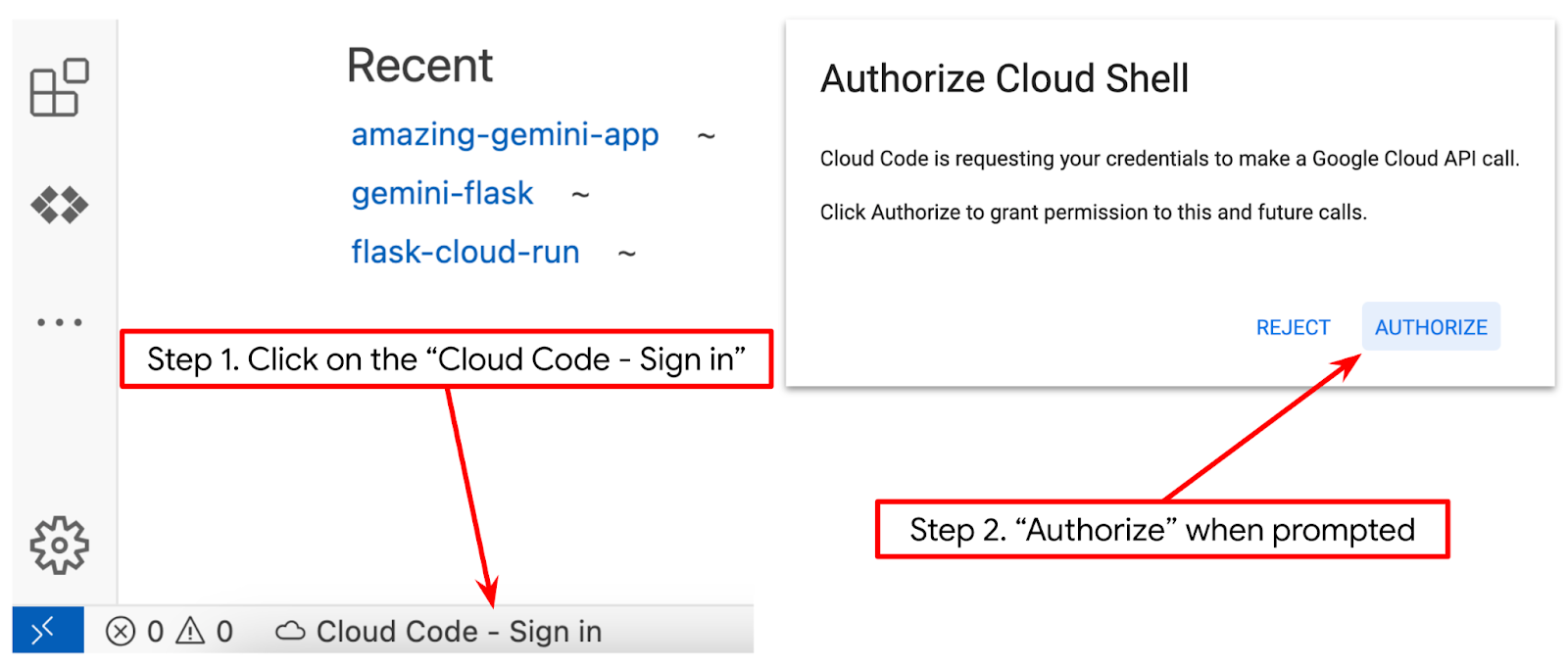
Następnie przygotujemy środowisko Pythona.
Konfiguracja środowiska
Przygotuj środowisko wirtualne Pythona
Następnym krokiem jest przygotowanie środowiska programistycznego. W tym ćwiczeniu użyjemy Pythona 3.12 i narzędzia virtualenv, aby uprościć tworzenie środowiska wirtualnego i zarządzanie nim oraz wersją Pythona.
- Jeśli terminal nie jest jeszcze otwarty, otwórz go , klikając Terminal –> Nowy terminal lub używając skrótu Ctrl + Shift + C.

- Utwórz nowy folder i zmień lokalizację na ten folder, uruchamiając to polecenie:
mkdir agent_diet_planner
cd agent_diet_planner
- Utwórz nowe środowisko wirtualne, uruchamiając to polecenie:
python -m venv .env
- Aktywuj środowisko wirtualne za pomocą tego polecenia:
source .env/bin/activate
- Utwórz
requirements.txt. Kliknij Plik → Nowy plik tekstowy i wypełnij go treścią poniżej. Następnie zapisz go jakorequirements.txt
streamlit==1.33.0
google-cloud-aiplatform
google-cloud-bigquery
pandas==2.2.2
db-dtypes==1.2.0
pyarrow==16.1.0
- Następnie zainstaluj wszystkie zależności z pliku requirements.txt, uruchamiając to polecenie:
pip install -r requirements.txt
- Aby sprawdzić, czy wszystkie zależności bibliotek Pythona są zainstalowane, wpisz poniższe polecenie:
pip list
Konfigurowanie plików konfiguracji
Teraz musimy skonfigurować pliki konfiguracji dla tego projektu. Pliki konfiguracyjne służą do przechowywania zmiennych i danych logowania do konta usługi.
- Pierwszym krokiem jest utworzenie konta usługi. Wpisz w wyszukiwarce „konto usługi”, a następnie kliknij „konto usługi”.
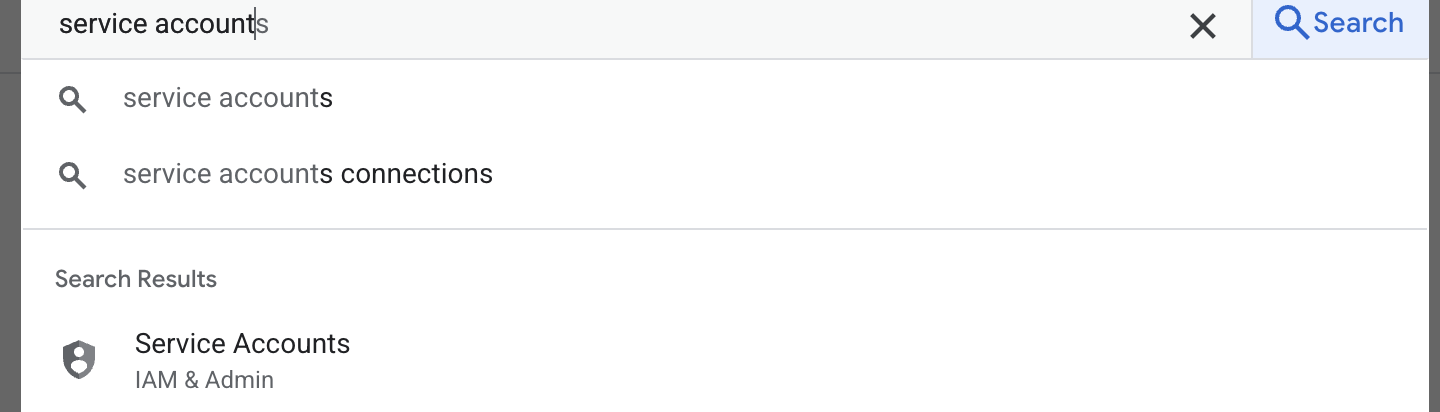
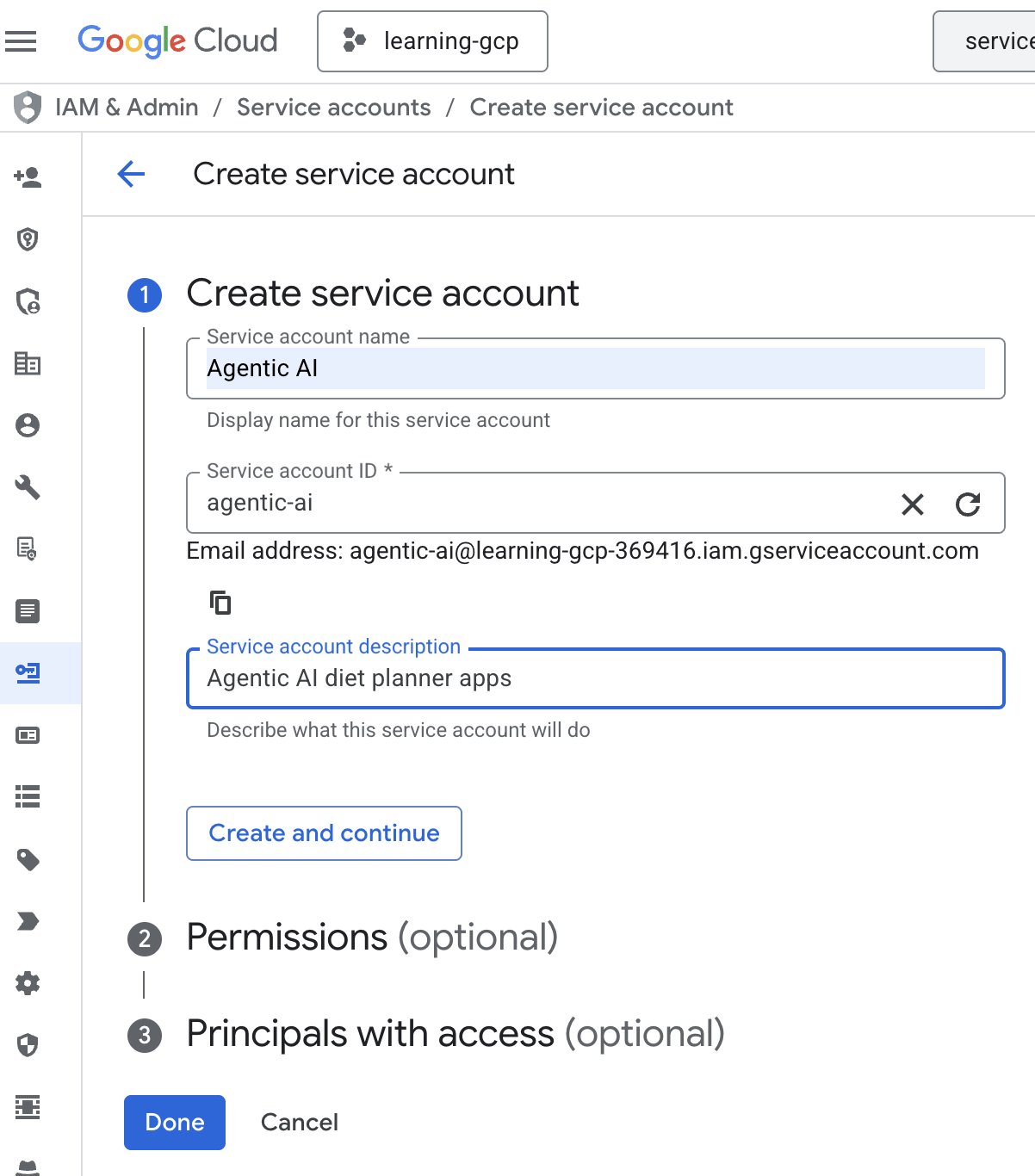
- Kliknij + Utwórz konto usługi. Wpisz nazwę konta usługi, a potem kliknij Utwórz i kontynuuj.
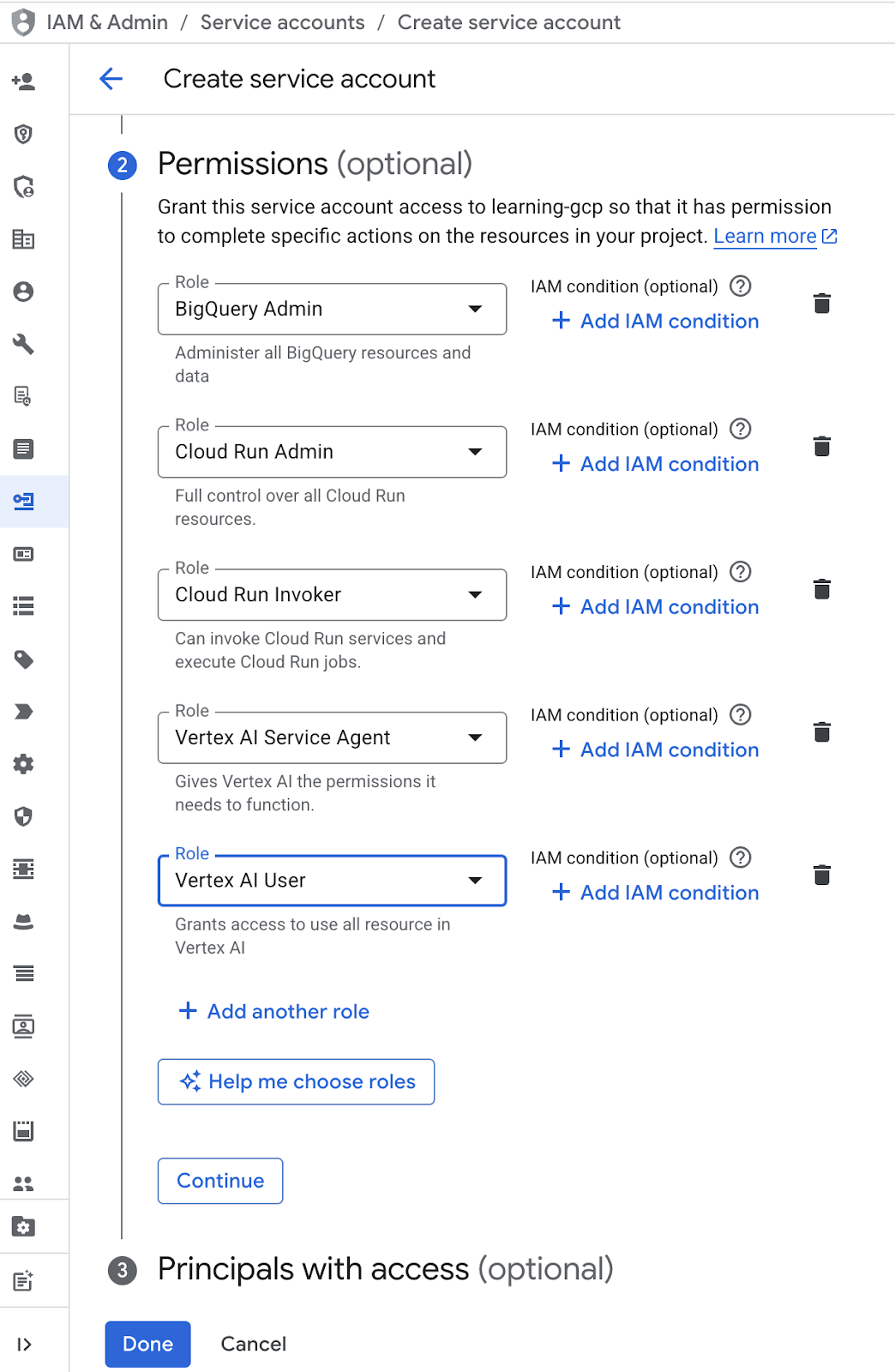
- W sekcji Uprawnienia wybierz rolę Użytkownik kont usługi. Kliknij + Dodaj kolejną rolę i wybierz rolę uprawnień : Administrator BigQuery, Administrator Cloud Run, Wywołujący Cloud Run, Agent usługi Vertex AI i Użytkownik Vertex AI, a następnie kliknij Gotowe
 .
. - Kliknij kolejno Adres e-mail konta usługi, klawisz Tab, Dodaj klucz → Utwórz nowy klucz.
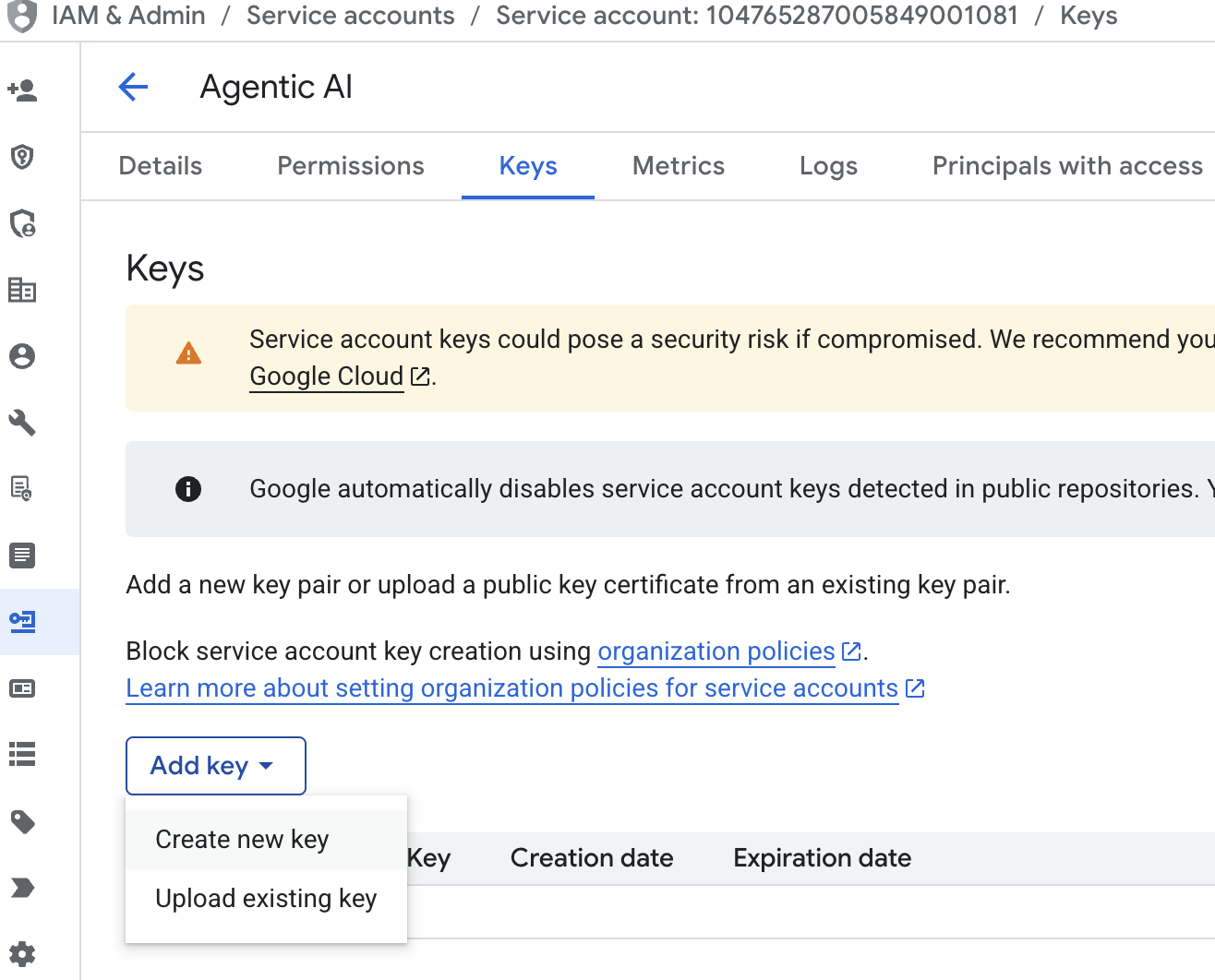
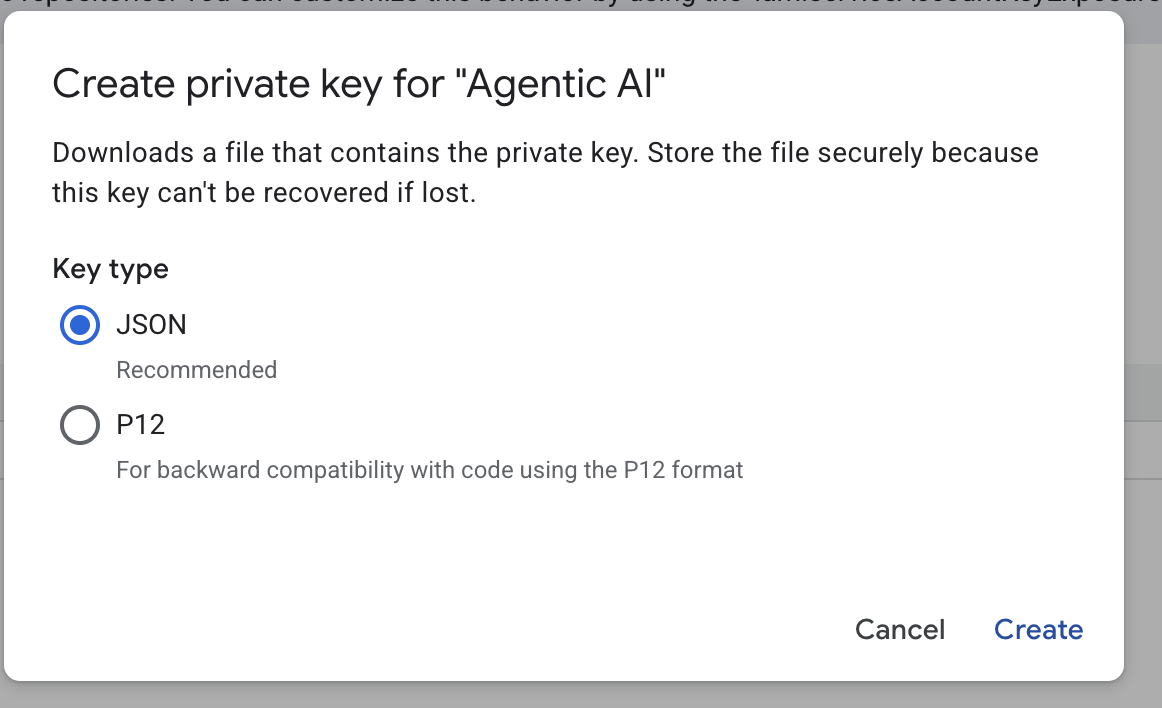
- Wybierz json, a następnie kliknij Utwórz. Zapisz ten plik konta usługi lokalnie, aby przejść do następnego kroku.
- Utwórz folder o nazwie .streamlit z tą konfiguracją: Kliknij prawym przyciskiem myszy, wybierz Nowy folder i wpisz nazwę folderu
.streamlit. - Kliknij prawym przyciskiem myszy folder
.streamlit, a następnie kliknij Nowy plik i wpisz poniższą wartość. Następnie zapisz go jakosecrets.toml
# secrets.toml (for Streamlit sharing)
# Store in .streamlit/secrets.toml
[gcp]
project_id = "your_gcp_project"
location = "us-central1"
[gcp_service_account]
type = "service_account"
project_id = "your-project-id"
private_key_id = "your-private-key-id"
private_key = '''-----BEGIN PRIVATE KEY-----
YOUR_PRIVATE_KEY_HERE
-----END PRIVATE KEY-----'''
client_email = "your-sa@project-id.iam.gserviceaccount.com"
client_id = "your-client-id"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "https://www.googleapis.com/robot/v1/metadata/x509/your-sa%40project-id.iam.gserviceaccount.com"
- Zaktualizuj wartości
project_id,private_key_id,private_key,client_emailiclient_id , and auth_provider_x509_cert_urlna podstawie konta usługi utworzonego w poprzednim kroku.
Przygotowywanie zbioru danych BigQuery
Następnym krokiem jest utworzenie zbioru danych BigQuery, w którym będą zapisywane wyniki generowania.
- Wpisz BigQuery w polu wyszukiwania, a następnie kliknij BigQuery.
- Kliknij
 , a następnie Utwórz zbiór danych.
, a następnie Utwórz zbiór danych. - Wpisz identyfikator zbioru danych
diet_planner_data, a następnie kliknij Utwórz zbiór danych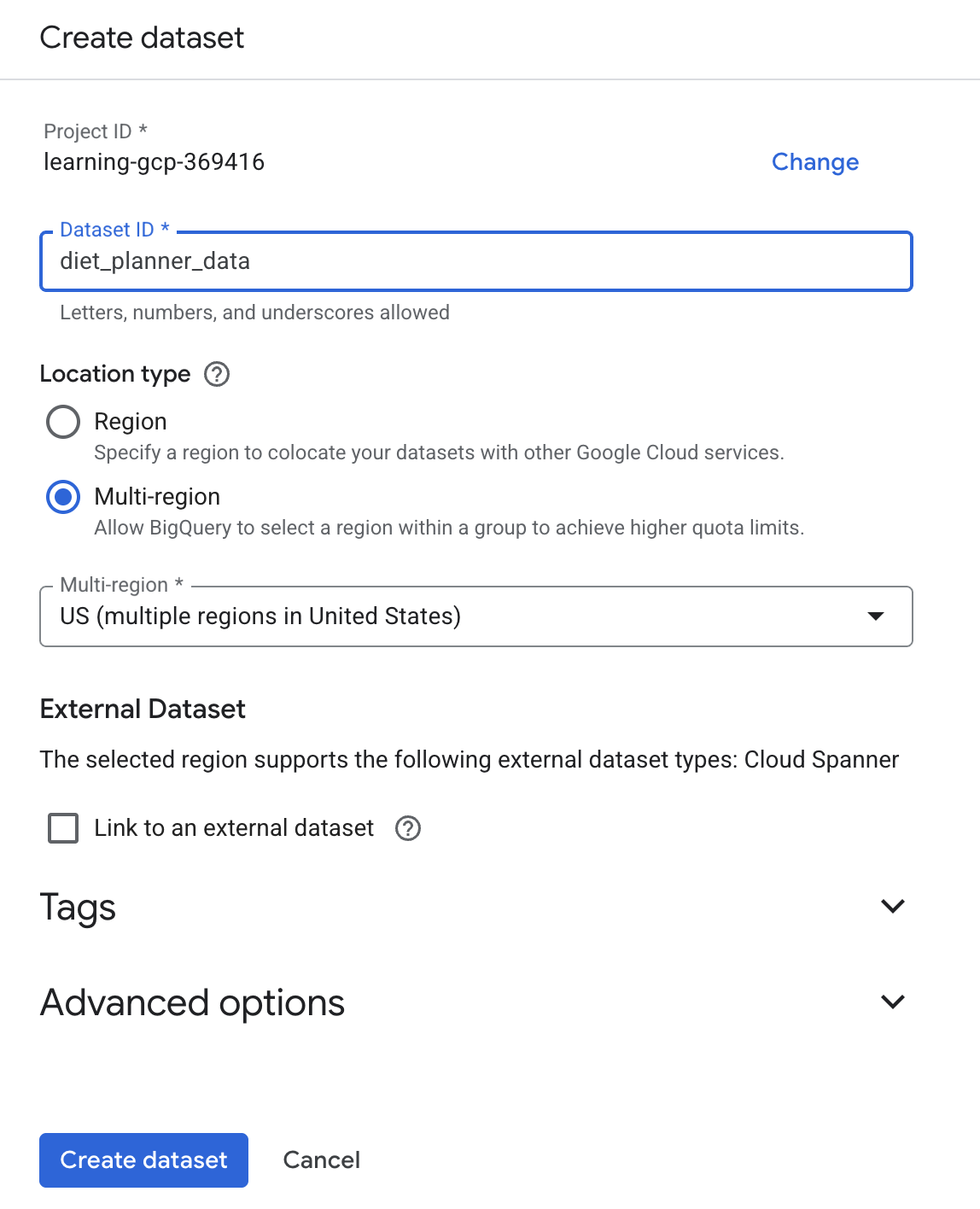 .
.
4. Tworzenie aplikacji do planowania diety agenta
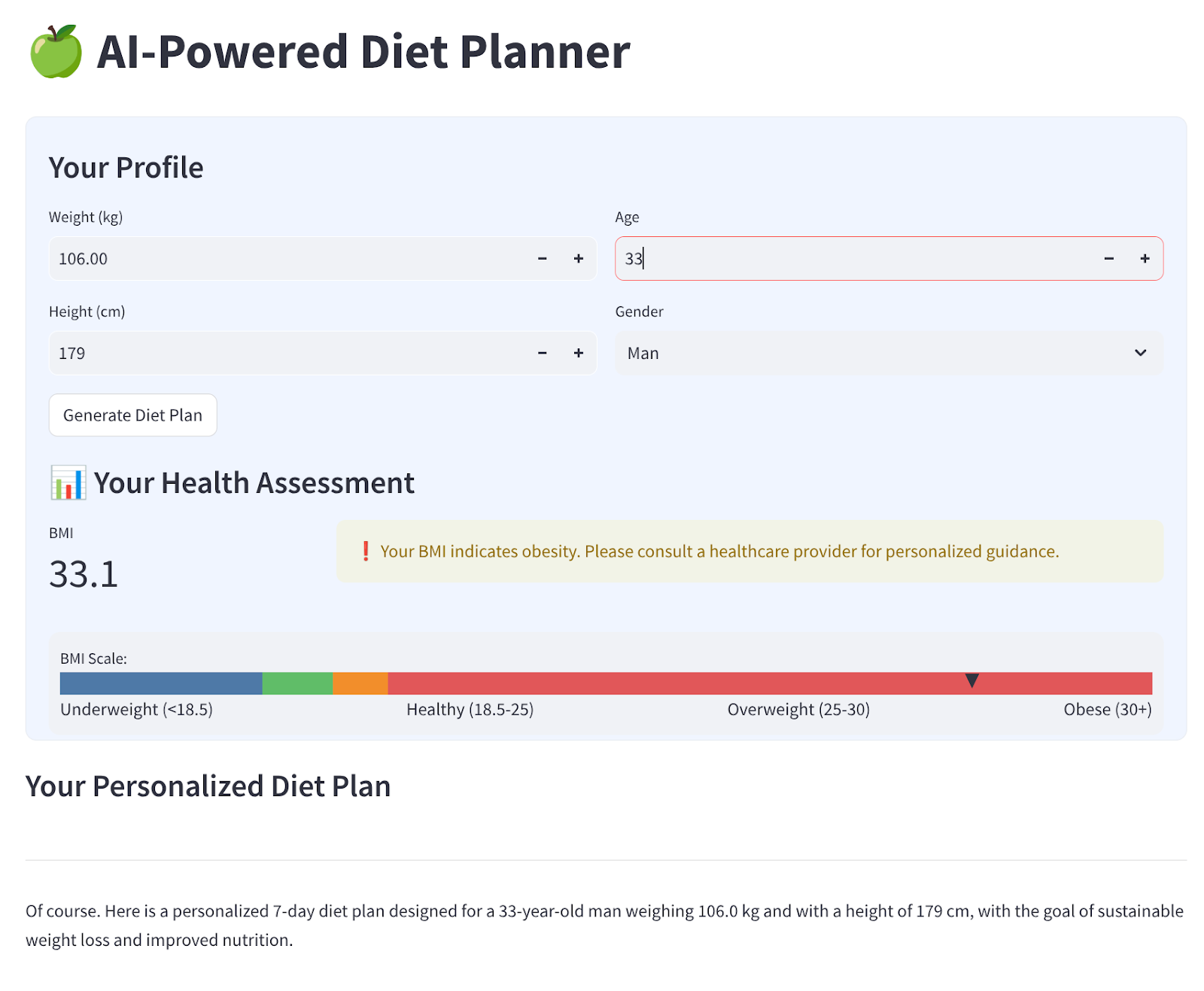
Utworzymy prosty interfejs internetowy z 4 polami wejściowymi, który będzie wyglądać tak:
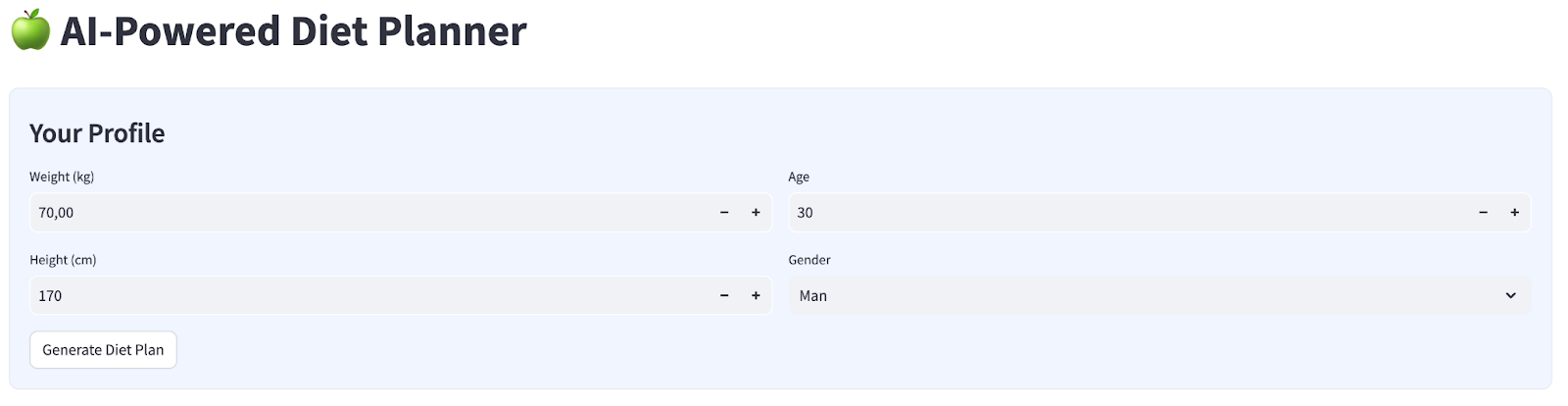
Zmień wagę, wzrost, wiek i płeć na podstawie swojego profilu, a potem kliknij Wygeneruj. Wywoła model LLM Gemini Pro 2.5 z biblioteki Vertex AI i zapisze wygenerowane wyniki w BigQuery.
Kod zostanie podzielony na 6 części, aby nie był zbyt długi.
Utwórz funkcję obliczania stanu BMI
- Kliknij prawym przyciskiem myszy
agent_diet_plannerfolder → Nowy plik → wpisz nazwę plikubmi_calc.py, a następnie naciśnij Enter. - Wypełnij kod tymi informacjami:
# Add this function to calculate BMI and health status
def calculate_bmi_status(weight, height):
"""
Calculate BMI and return status message
"""
height_m = height / 100 # Convert cm to meters
bmi = weight / (height_m ** 2)
if bmi < 18.5:
status = "underweight"
message = "⚠️ Your BMI suggests you're underweight. Consider increasing calorie intake with nutrient-dense foods."
elif 18.5 <= bmi < 25:
status = "normal"
message = "✅ Your BMI is in the healthy range. Let's maintain this balance!"
elif 25 <= bmi < 30:
status = "overweight"
message = "⚠️ Your BMI suggests you're overweight. Focus on gradual weight loss through balanced nutrition."
else:
status = "obese"
message = "❗ Your BMI indicates obesity. Please consult a healthcare provider for personalized guidance."
return {
"value": round(bmi, 1),
"status": status,
"message": message
}
Tworzenie głównych aplikacji do planowania diety agenta
- Kliknij prawym przyciskiem myszy
agent_diet_plannerfolder → Nowy plik → wpisz nazwę plikuapp.py, a następnie naciśnij Enter. - Wypełnij kod tymi informacjami:
import os
from google.oauth2 import service_account
import streamlit as st
from google.cloud import bigquery
from vertexai.preview.generative_models import GenerativeModel
import vertexai
import datetime
import time
import pandas as pd
from bmi_calc import calculate_bmi_status
# Get configuration from environment
PROJECT_ID = os.environ.get("GCP_PROJECT_ID", "your_gcp_project_id")
LOCATION = os.environ.get("GCP_LOCATION", "us-central1")
#CONSTANTS Dataset and table in BigQuery
DATASET = "diet_planner_data"
TABLE = "user_plans"
# Initialize Vertex AI
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Initialize BigQuery client
try:
# For Cloud Run, use default credentials
bq_client = bigquery.Client()
except:
# For local development, use service account from secrets
if "gcp_service_account" in st.secrets:
service_account_info = dict(st.secrets["gcp_service_account"])
credentials = service_account.Credentials.from_service_account_info(service_account_info)
bq_client = bigquery.Client(credentials=credentials, project=PROJECT_ID)
else:
st.error("BigQuery client initialization failed")
st.stop()
Zastąp wartość your_gcp_project_id identyfikatorem projektu.
Create agent diet planner main apps - setup_bq_tables
W tej sekcji utworzymy funkcję o nazwie setup_bq_table z 1 parametrem wejściowym bq_client. Ta funkcja zdefiniuje schemat w tabeli BigQuery i utworzy tabelę, jeśli nie istnieje.
Wypełnij kod poniższym kodem w pliku app.py
# Create BigQuery table if not exists
def setup_bq_table(bq_client):
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
schema = [
bigquery.SchemaField("user_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("timestamp", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("weight", "FLOAT", mode="REQUIRED"),
bigquery.SchemaField("height", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("age", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("gender", "STRING", mode="REQUIRED"),
bigquery.SchemaField("diet_plan", "STRING", mode="REQUIRED")
]
try:
bq_client.get_table(table_id)
except:
table = bigquery.Table(table_id, schema=schema)
bq_client.create_table(table)
st.toast("BigQuery table created successfully")
Tworzenie głównych aplikacji do planowania diety agenta – generate_diet_plan
W tej sekcji utworzymy funkcję o nazwie generate_diet_plan z 1 parametrem wejściowym. Ta funkcja wywoła model LLM Gemini Pro 2.5 z promptem definicji i wygeneruje wyniki.
Wypełnij kod poniższym kodem w pliku app.py
# Generate diet plan using Gemini Pro
def generate_diet_plan(params):
try:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
Create a personalized 7-day diet plan for:
- {params['gender']}, {params['age']} years old
- Weight: {params['weight']} kg
- Height: {params['height']} cm
Include:
1. Daily calorie target
2. Macronutrient breakdown (carbs, protein, fat)
3. Meal timing and frequency
4. Food recommendations
5. Hydration guidance
Make the plan:
- Nutritionally balanced
- Practical for daily use
- Culturally adaptable
- With portion size guidance
"""
response = model.generate_content(prompt)
return response.text
except Exception as e:
st.error(f"AI generation error: {str(e)}")
return None
Create agent diet planner main apps - save_to_bq
W tej sekcji utworzymy funkcję o nazwie save_to_bq z 3 parametrami wejściowymi : bq_client, user_id i plan. Ta funkcja zapisze wygenerowany wynik w tabeli BigQuery.
Wypełnij kod poniższym kodem w pliku app.py
# Save user data to BigQuery
def save_to_bq(bq_client, user_id, plan):
try:
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
row = {
"user_id": user_id,
"timestamp": datetime.datetime.utcnow().isoformat(),
"weight": st.session_state.user_data["weight"],
"height": st.session_state.user_data["height"],
"age": st.session_state.user_data["age"],
"gender": st.session_state.user_data["gender"],
"diet_plan": plan
}
errors = bq_client.insert_rows_json(table_id, [row])
if errors:
st.error(f"BigQuery error: {errors}")
else:
return True
except Exception as e:
st.error(f"Data saving error: {str(e)}")
return False
Tworzenie głównych aplikacji do planowania diety agenta – główne
W tej sekcji utworzymy funkcję o nazwie main bez parametru wejściowego. Ta funkcja obsługuje głównie skrypt interfejsu Streamlit, wyświetla wygenerowane wyniki i historyczne wygenerowane wyniki z tabeli BigQuery oraz umożliwia pobieranie danych do pliku Markdown.
Wypełnij kod poniższym kodem w pliku app.py
# Streamlit UI
def main():
st.set_page_config(page_title="AI Diet Planner", page_icon="🍏", layout="wide")
# Initialize session state
if "user_data" not in st.session_state:
st.session_state.user_data = None
if "diet_plan" not in st.session_state:
st.session_state.diet_plan = None
# Initialize clients
#bq_client = init_clients()
setup_bq_table(bq_client)
st.title("🍏 AI-Powered Diet Planner")
st.markdown("""
<style>
.stProgress > div > div > div > div {
background-color: #4CAF50;
}
[data-testid="stForm"] {
background: #f0f5ff;
padding: 20px;
border-radius: 10px;
border: 1px solid #e6e9ef;
}
</style>
""", unsafe_allow_html=True)
# User input form
with st.form("user_profile", clear_on_submit=False):
st.subheader("Your Profile")
col1, col2 = st.columns(2)
with col1:
weight = st.number_input("Weight (kg)", min_value=30.0, max_value=200.0, value=70.0)
height = st.number_input("Height (cm)", min_value=100, max_value=250, value=170)
with col2:
age = st.number_input("Age", min_value=18, max_value=100, value=30)
gender = st.selectbox("Gender", ["Man", "Woman"])
submitted = st.form_submit_button("Generate Diet Plan")
if submitted:
user_data = {
"weight": weight,
"height": height,
"age": age,
"gender": gender
}
st.session_state.user_data = user_data
# Calculate BMI
bmi_result = calculate_bmi_status(weight, height)
# Display BMI results in a visually distinct box
with st.container():
st.subheader("📊 Your Health Assessment")
col1, col2 = st.columns([1, 3])
with col1:
st.metric("BMI", bmi_result["value"])
with col2:
if bmi_result["status"] != "normal":
st.warning(bmi_result["message"])
else:
st.success(bmi_result["message"])
# Add BMI scale visualization
st.markdown(f"""
<div style="background:#f0f2f6;padding:10px;border-radius:10px;margin-top:10px">
<small>BMI Scale:</small><br>
<div style="display:flex;height:20px;background:linear-gradient(90deg,
#4e79a7 0%,
#4e79a7 18.5%,
#60bd68 18.5%,
#60bd68 25%,
#f28e2b 25%,
#f28e2b 30%,
#e15759 30%,
#e15759 100%);position:relative">
<div style="position:absolute;left:{min(100, max(0, (bmi_result["value"]/40)*100))}%;top:-5px">
▼
</div>
</div>
<div style="display:flex;justify-content:space-between">
<span>Underweight (<18.5)</span>
<span>Healthy (18.5-25)</span>
<span>Overweight (25-30)</span>
<span>Obese (30+)</span>
</div>
</div>
""", unsafe_allow_html=True)
# Store BMI in session state
st.session_state.bmi = bmi_result
# Plan generation and display
if submitted and st.session_state.user_data:
with st.spinner("🧠 Generating your personalized diet plan using Gemini AI..."):
#diet_plan = generate_diet_plan(st.session_state.user_data)
diet_plan = generate_diet_plan({**st.session_state.user_data,"bmi": bmi_result["value"],
"bmi_status": bmi_result["status"]
})
if diet_plan:
st.session_state.diet_plan = diet_plan
# Generate unique user ID
user_id = f"user_{int(time.time())}"
# Save to BigQuery
if save_to_bq(bq_client, user_id, diet_plan):
st.toast("✅ Plan saved to database!")
# Display generated plan
if st.session_state.diet_plan:
st.subheader("Your Personalized Diet Plan")
st.markdown("---")
st.markdown(st.session_state.diet_plan)
# Download button
st.download_button(
label="Download Plan",
data=st.session_state.diet_plan,
file_name="my_diet_plan.md",
mime="text/markdown"
)
# Show history
st.subheader("Your Plan History")
try:
query = f"""
SELECT timestamp, weight, height, age, gender
FROM `{st.secrets['gcp']['project_id']}.{DATASET}.{TABLE}`
WHERE user_id LIKE 'user_%'
ORDER BY timestamp DESC
LIMIT 5
"""
history = bq_client.query(query).to_dataframe()
if not history.empty:
history["timestamp"] = pd.to_datetime(history["timestamp"])
st.dataframe(history.style.format({
"weight": "{:.1f} kg",
"height": "{:.0f} cm"
}))
else:
st.info("No previous plans found")
except Exception as e:
st.error(f"History load error: {str(e)}")
if __name__ == "__main__":
main()
Zapisz kod pod nazwą app.py.
5. Wdrażanie aplikacji w Cloud Run za pomocą Cloud Build
Oczywiście chcemy pokazać tę niesamowitą aplikację innym. Aby to zrobić, możemy spakować tę aplikację i wdrożyć ją w Cloud Run jako usługę publiczną, do której inni użytkownicy będą mieli dostęp. Aby to zrobić, wróćmy do architektury
Najpierw potrzebujemy pliku Dockerfile. Kliknij Plik –> Nowy plik tekstowy, skopiuj i wklej poniższy kod,a następnie zapisz go jako Dockerfile.
# Use official Python image
FROM python:3.12-slim
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV PORT 8080
# Install system dependencies
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /app
# Copy requirements
COPY requirements.txt .
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application files
COPY . .
# Expose port
EXPOSE $PORT
# Run the application
CMD ["streamlit", "run", "app.py", "--server.port", "8080", "--server.address", "0.0.0.0"]
Następnie utworzymy plik cloudbuild.yaml, aby skompilować aplikacje w obrazy Dockera, przesłać je do Artifact Registry i wdrożyć w Cloud Run.
Kliknij Plik –> Nowy plik tekstowy, skopiuj i wklej poniższy kod, a następnie zapisz go jako cloudbuild.yaml.
steps:
# Build Docker image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID', '--no-cache',
'--progress=plain',
'.']
id: 'Build'
timeout: 1200s
waitFor: ['-']
dir: '.'
# Push to Container Registry
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID']
id: 'Push'
waitFor: ['Build']
# Deploy to Cloud Run
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args:
- 'run'
- 'deploy'
- 'diet-planner-service'
- '--image=gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
- '--port=8080'
- '--region=us-central1'
- '--platform=managed'
- '--allow-unauthenticated'
- '--set-env-vars=GCP_PROJECT_ID=$PROJECT_ID,GCP_LOCATION=us-central1'
- '--cpu=1'
- '--memory=1Gi'
- '--timeout=300'
waitFor: ['Push']
options:
logging: CLOUD_LOGGING_ONLY
machineType: 'E2_HIGHCPU_8'
diskSizeGb: 100
images:
- 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
Mamy już wszystkie pliki potrzebne do utworzenia obrazów Dockera z aplikacji, przesłania ich do Artifact Registry i wdrożenia w Cloud Run. Możemy więc rozpocząć wdrażanie. Otwórz terminal Cloud Shell i sprawdź, czy bieżący projekt jest skonfigurowany jako aktywny. Jeśli nie, użyj polecenia gcloud configure, aby ustawić identyfikator projektu:
gcloud config set project [PROJECT_ID]
Następnie uruchom to polecenie, aby utworzyć aplikacje jako obrazy Dockera, przenieść je do Artifact Registry i wdrożyć w Cloud Run:
gcloud builds submit --config cloudbuild.yaml
Utworzy on kontener Dockera na podstawie wcześniej podanego pliku Dockerfile i prześle go do Artifact Registry. Następnie wdrożymy utworzony obraz w Cloud Run. Cały ten proces jest opisany w cloudbuild.yaml krokach.
Pamiętaj, że w tym przypadku zezwalamy na nieuwierzytelniony dostęp, ponieważ jest to aplikacja demonstracyjna. Zalecamy stosowanie odpowiedniego uwierzytelniania w przypadku aplikacji firmowych i produkcyjnych.
Po zakończeniu wdrażania możemy sprawdzić je na stronie Cloud Run. W tym celu wpisz „Cloud Run” na pasku wyszukiwania u góry konsoli Cloud i kliknij usługę Cloud Run.
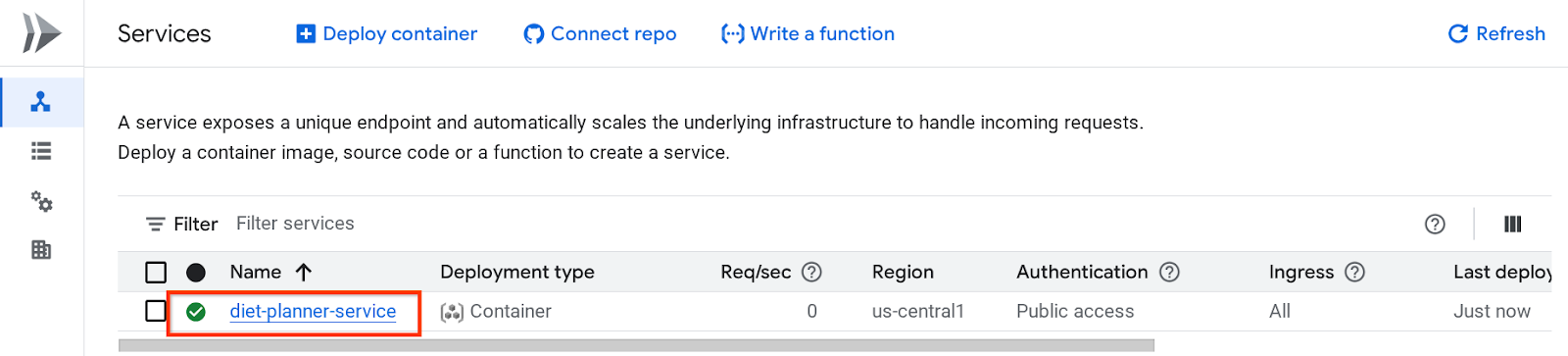
Następnie możesz sprawdzić wdrożoną usługę na stronie Usługa Cloud Run. Kliknij usługę, aby uzyskać jej adres URL.
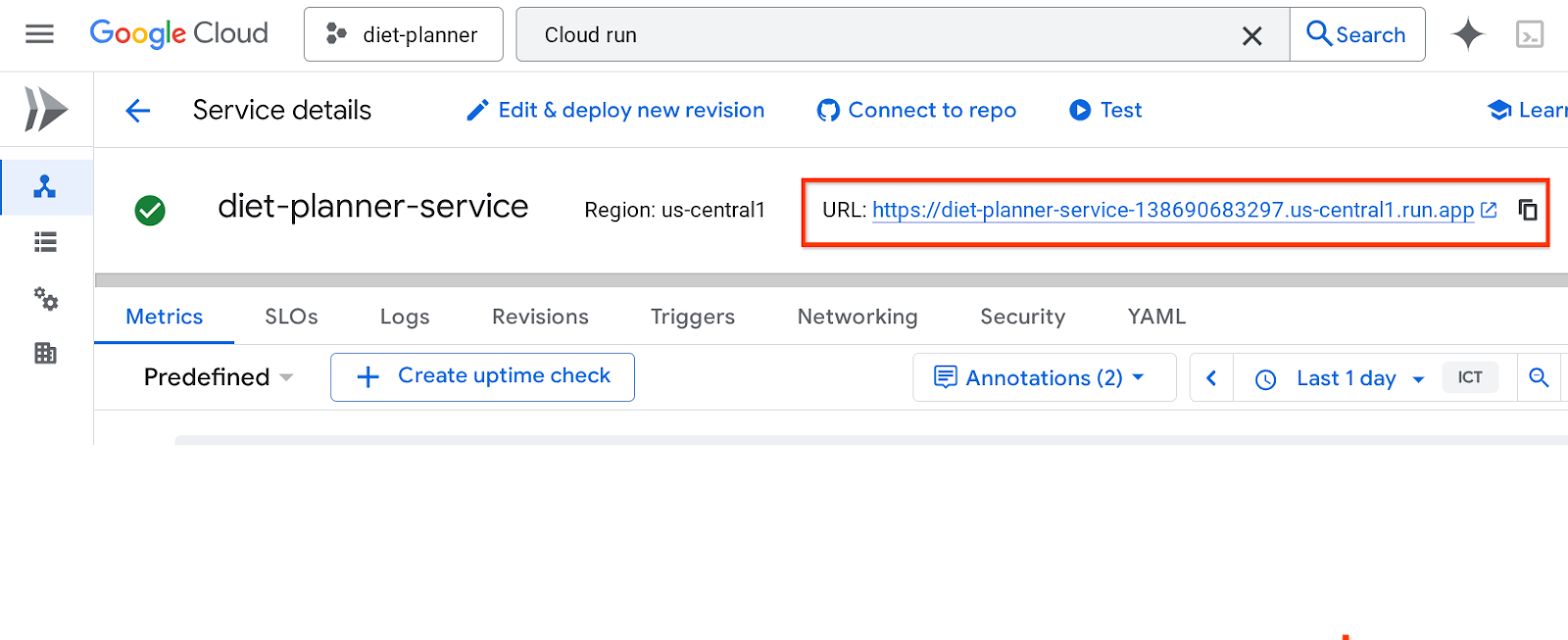
Adres URL usługi będzie widoczny na górnym pasku.
 Możesz teraz korzystać z aplikacji w oknie incognito lub na urządzeniu mobilnym. Powinien być już widoczny.
Możesz teraz korzystać z aplikacji w oknie incognito lub na urządzeniu mobilnym. Powinien być już widoczny.
6. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym laboratorium, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Zarządzanie zasobami.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
- Możesz też otworzyć Cloud Run w konsoli, wybrać wdrożoną usługę i ją usunąć.