
1. Введение
В этом практическом занятии вы научитесь создавать и развертывать планировщик диет на основе искусственного интеллекта. Для пользовательского интерфейса используется Streamlit, для модели LLM — Gemini Pro 2.5, для оркестрации Agentic AI Engine — Vertex AI, для разработки — BigQuery, а для развертывания — Cloud Run.
В ходе выполнения практического задания вы будете использовать следующий пошаговый подход:
- Подготовьте свой проект в Google Cloud и включите в него все необходимые API.
- Создайте планировщик диеты на основе Agentic AI, используя Streamlit, Vertex AI и BigQuery.
- Разверните приложение в облаке.
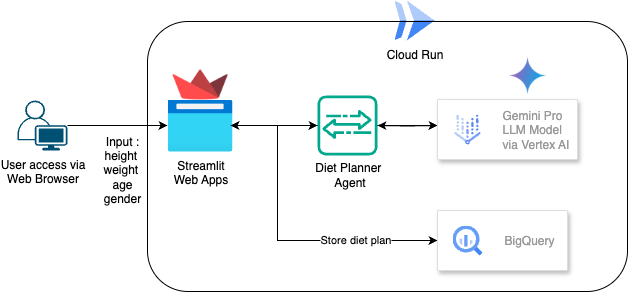
Обзор архитектуры
Предварительное условие
- Проект на платформе Google Cloud Platform (GCP) с включенной функцией выставления счетов.
- Базовые знания Python
Что вы узнаете
- Как создать планировщик диеты на основе Agentic AI с использованием Streamlit и Vertex AI и хранить данные в BigQuery
- Как развернуть приложение в облаке?
Что вам понадобится
- Веб-браузер Chrome
- Аккаунт Gmail
- Облачный проект с включенной функцией выставления счетов.
2. Основные настройки и требования
Настройка среды для самостоятельного обучения
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .

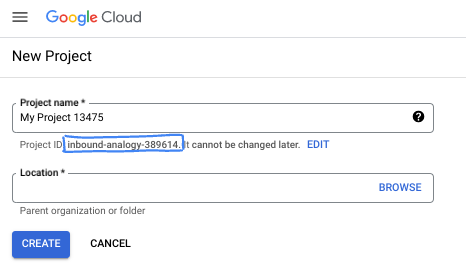
- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта, которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
3. Прежде чем начать
Настройка облачного проекта в редакторе Cloud Shell
В этом практическом задании предполагается, что у вас уже есть проект Google Cloud с включенной оплатой. Если у вас его еще нет, вы можете следовать инструкциям ниже, чтобы начать работу.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud и поставляемую с предустановленным bq. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.
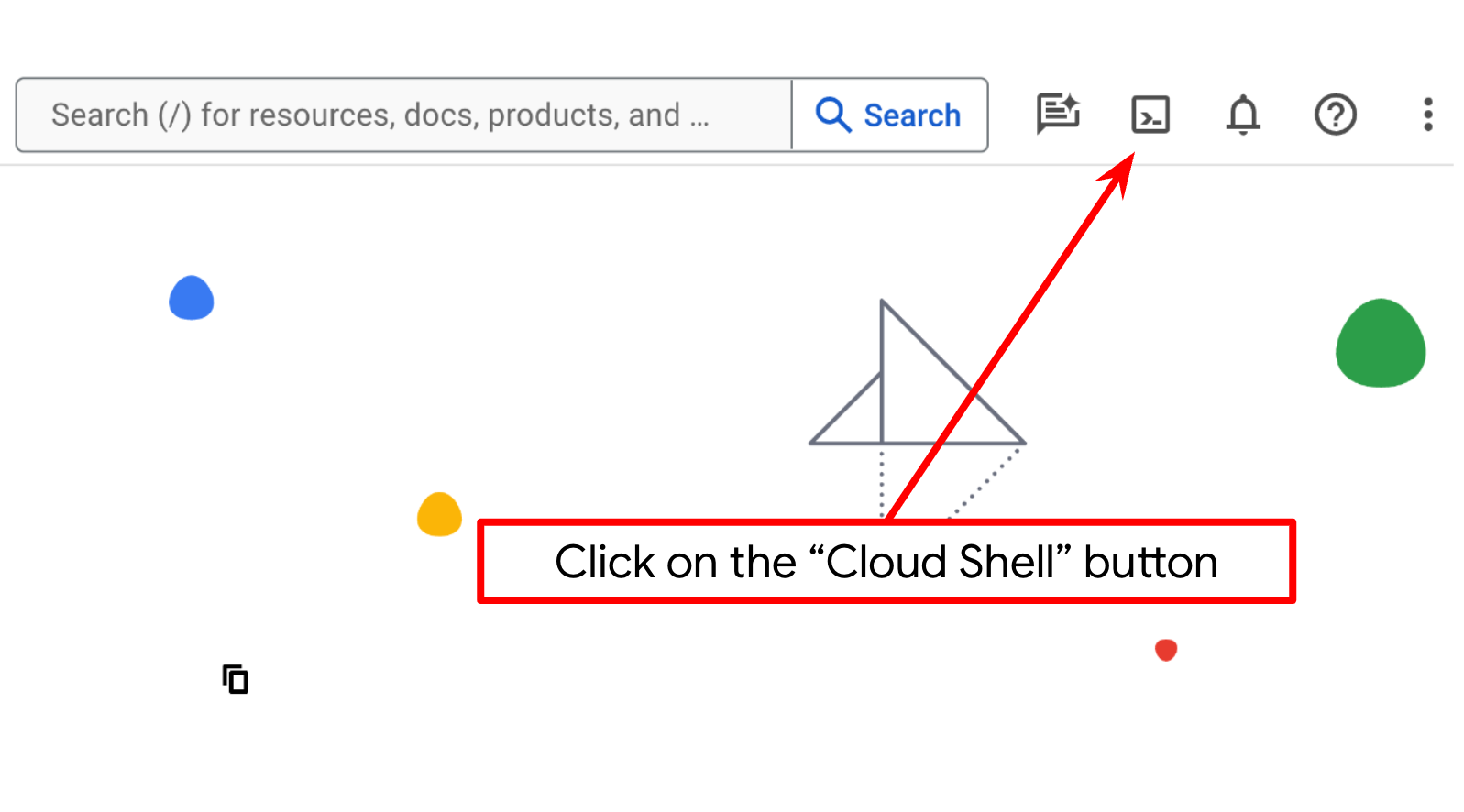
- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
В качестве альтернативы, вы также можете увидеть идентификатор PROJECT_ID в консоли.
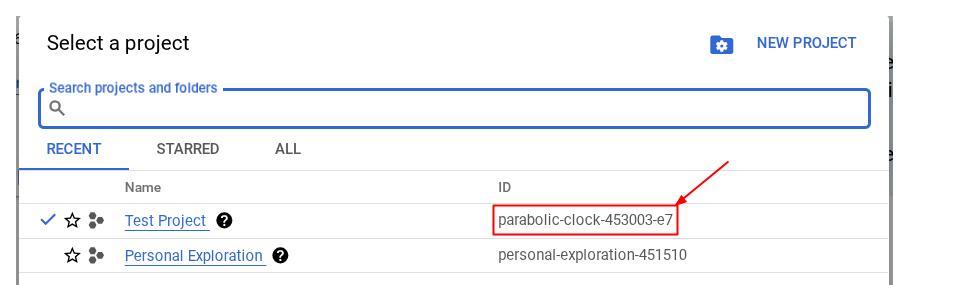
Нажмите на него, и справа отобразятся все ваши проекты и их идентификаторы.
- Включите необходимые API с помощью команды, указанной ниже. Это может занять несколько минут, поэтому, пожалуйста, наберитесь терпения.
gcloud services enable aiplatform.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
bigquery.googleapis.com
После успешного выполнения команды вы должны увидеть сообщение, похожее на показанное ниже:
Operation "operations/..." finished successfully.
Альтернативой команде gcloud является поиск каждого продукта в консоли или использование этой ссылки .
Если какой-либо API отсутствует, вы всегда можете включить его в процессе реализации.
Для получения информации о командах gcloud и их использовании обратитесь к документации .
Рабочий каталог приложения установки
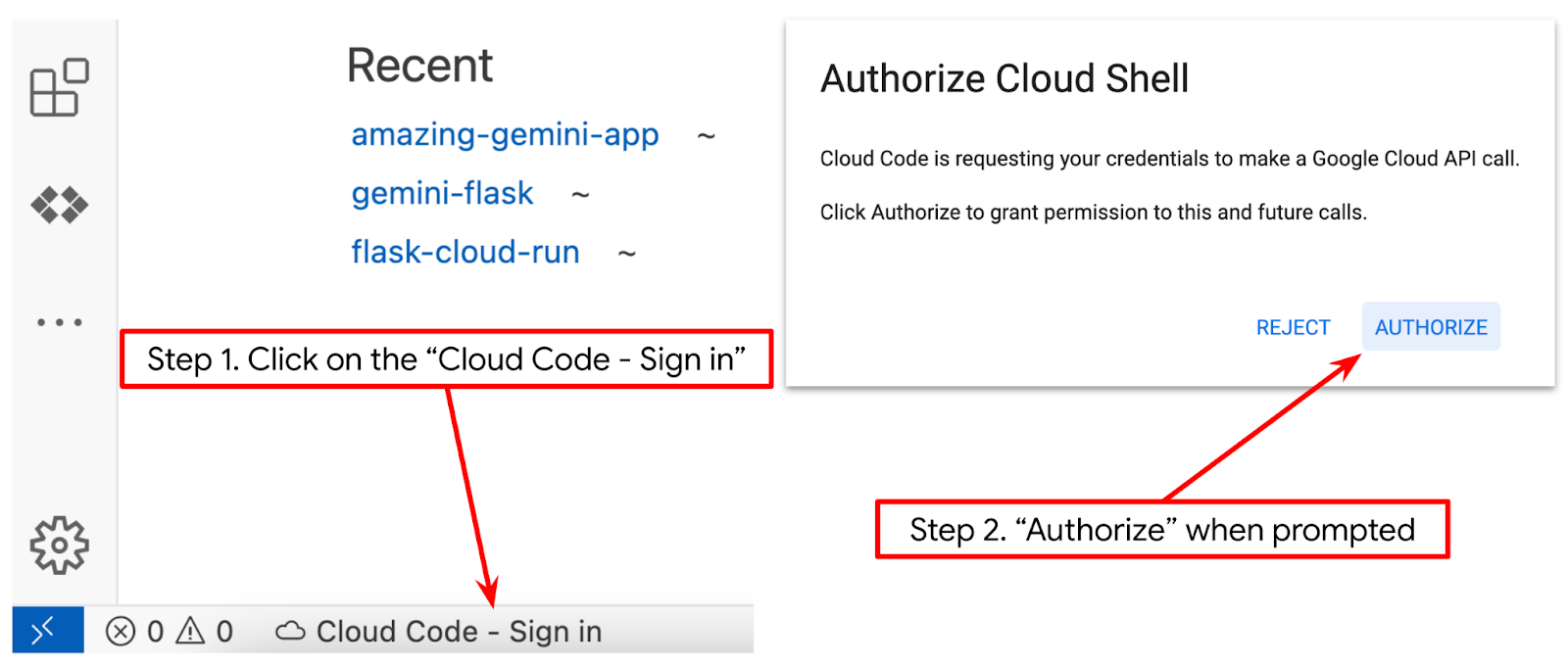
- Нажмите кнопку «Открыть редактор», это откроет редактор Cloud Shell, где мы можем писать свой код.
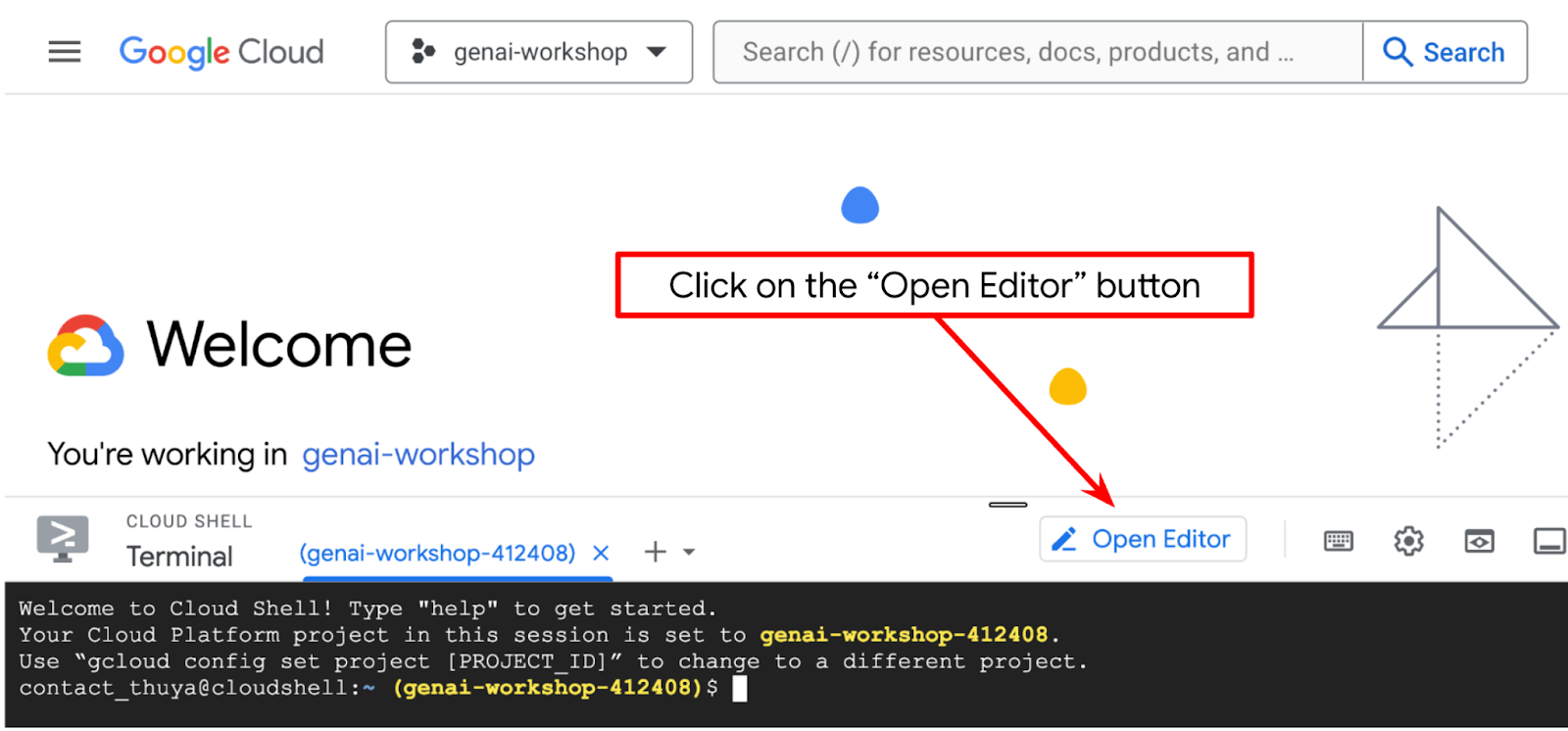
- Убедитесь, что проект Cloud Code указан в левом нижнем углу (строке состояния) редактора Cloud Shell, как показано на изображении ниже, и что он соответствует активному проекту Google Cloud, в котором включена оплата. Авторизуйтесь, если потребуется. После инициализации редактора Cloud Shell может потребоваться некоторое время, чтобы появилась кнопка «Cloud Code — Войти» , пожалуйста, подождите.
Далее мы подготовим нашу среду Python.
Настройка среды
Подготовка виртуальной среды Python
Следующий шаг — подготовка среды разработки. В этой практической работе мы будем использовать Python 3.12 и утилиту `python virtualenv`, чтобы упростить создание и управление версиями Python и виртуальными средами.
- Если вы еще не открыли терминал, откройте его, щелкнув «Терминал» -> «Новый терминал» или используя сочетание клавиш Ctrl + Shift + C.

- Создайте новую папку и перейдите в неё, выполнив следующую команду.
mkdir agent_diet_planner
cd agent_diet_planner
- Создайте новое виртуальное окружение, выполнив следующую команду.
python -m venv .env
- Активируйте виртуальное окружение с помощью следующей команды.
source .env/bin/activate
- Создайте
requirements.txt. Нажмите «Файл» → «Новый текстовый файл» и заполните его приведенным ниже содержимым. Затем сохраните его какrequirements.txt
streamlit==1.33.0
google-cloud-aiplatform
google-cloud-bigquery
pandas==2.2.2
db-dtypes==1.2.0
pyarrow==16.1.0
- Затем установите все зависимости из файла requirements.txt, выполнив следующую команду.
pip install -r requirements.txt
- Введите следующую команду, чтобы проверить, установлены ли все зависимости библиотек Python.
pip list
Настройка конфигурационных файлов
Теперь нам нужно будет настроить конфигурационные файлы для этого проекта. Конфигурационные файлы используются для хранения учетных данных переменных и сервисных учетных записей.
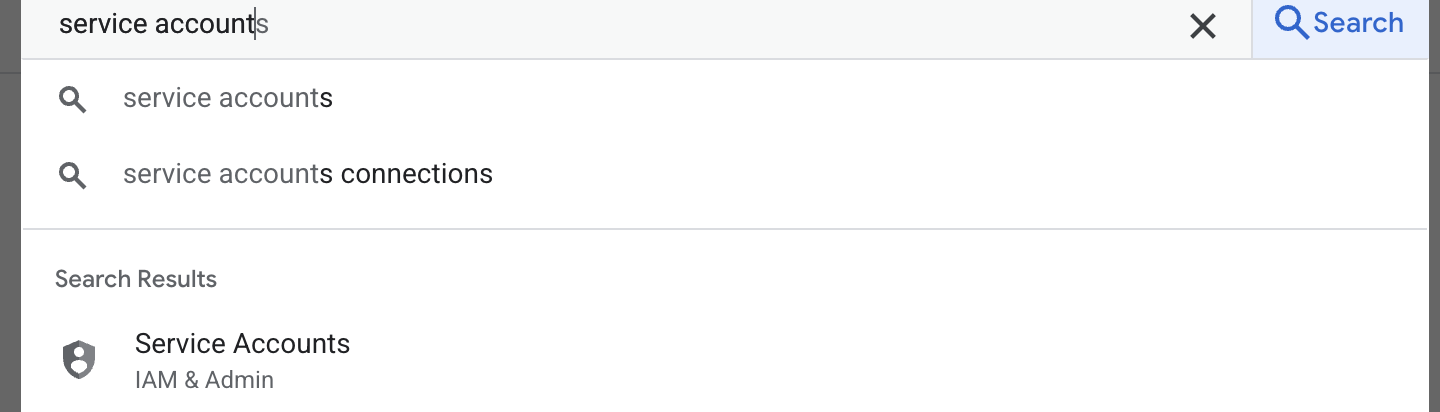
- Первый шаг — создание учетной записи службы. Введите в поиске «учетная запись службы», затем нажмите «учетная запись службы».
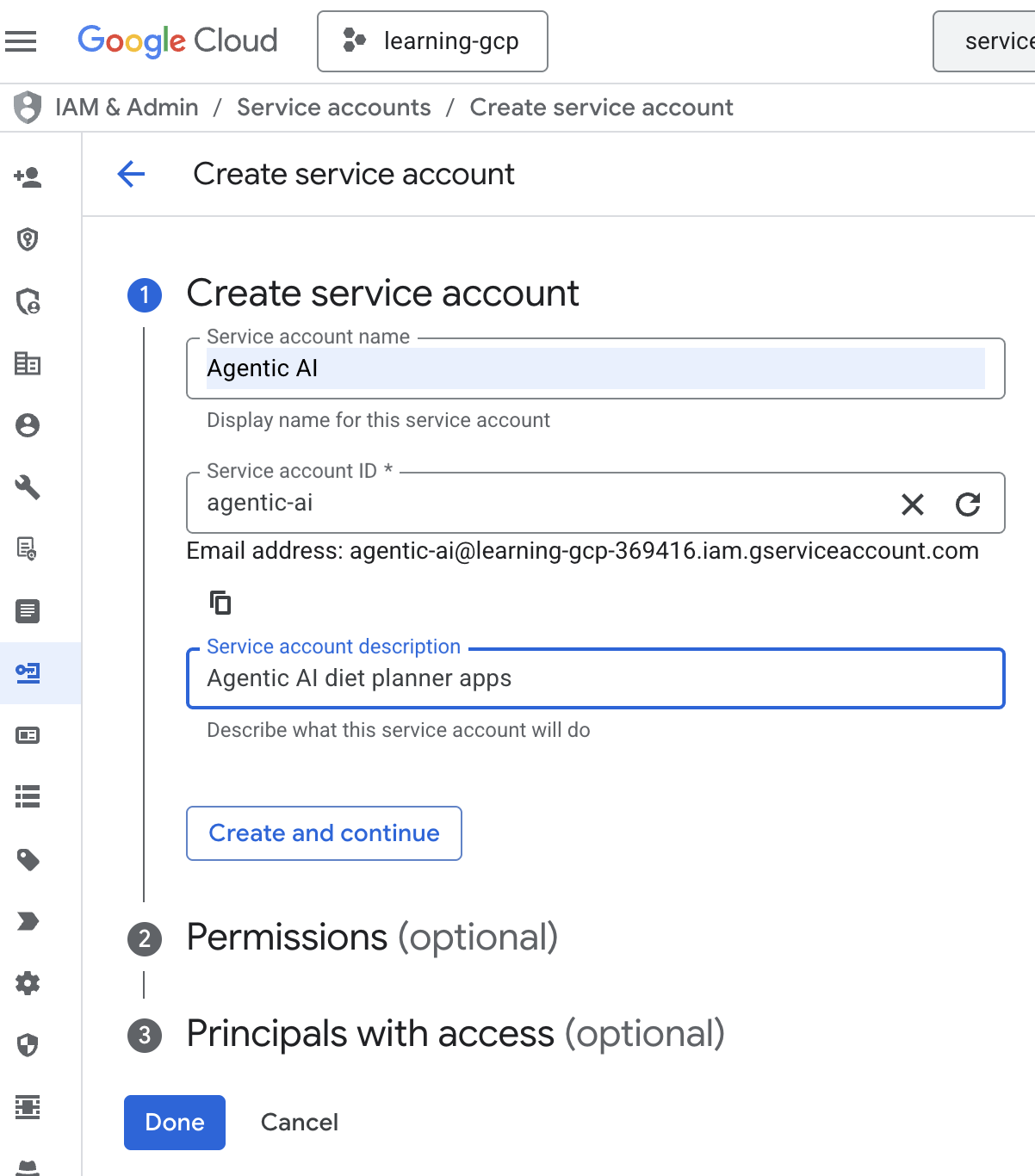
- Нажмите кнопку «+ Создать учетную запись службы». Введите имя учетной записи службы, затем нажмите «Создать» и «Продолжить».
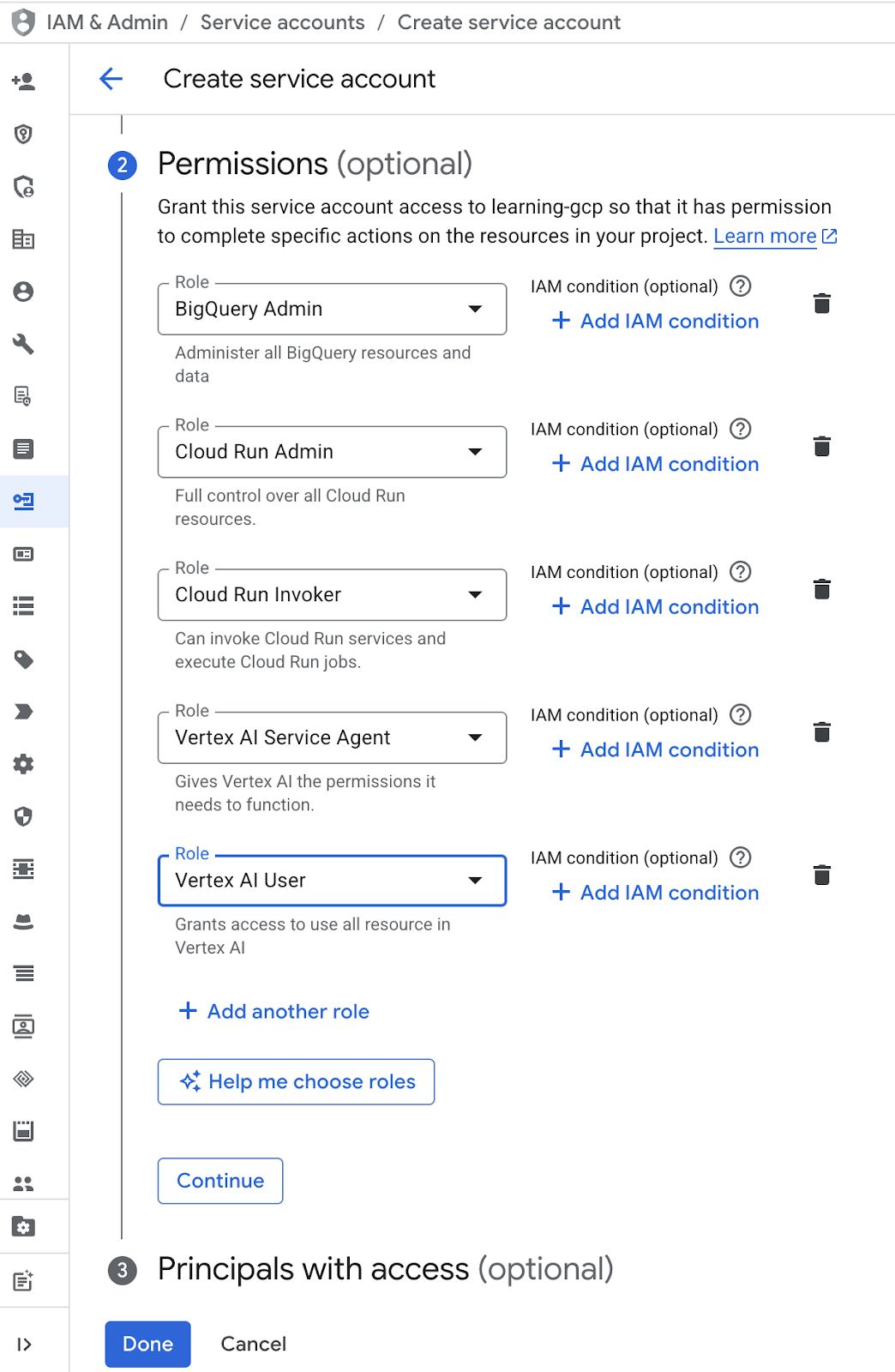
- В разделе разрешений выберите роль «Пользователь сервисной учетной записи». Нажмите «+ Добавить еще одну роль» и выберите роль IAM: «Администратор BigQuery», «Администратор Cloud Run», «Вызывающий Cloud Run», «Агент службы Vertex AI» и «Пользователь Vertex AI», затем нажмите «Готово».
- Нажмите на адрес электронной почты учетной записи службы, затем нажмите вкладку «Ключ», нажмите «Добавить ключ» → «Создать новый ключ».
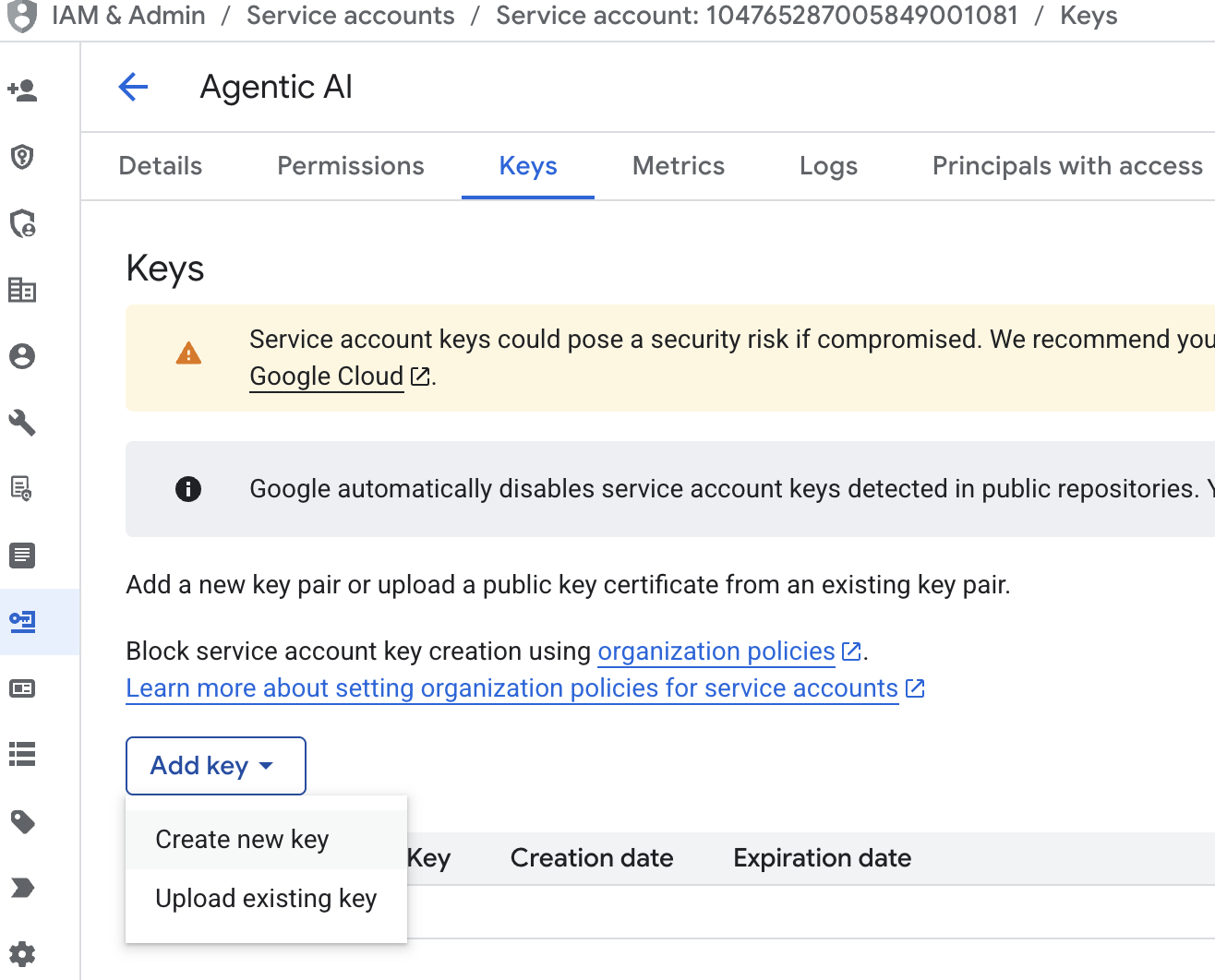
- Выберите файл json, затем нажмите «Создать». Сохраните этот файл учетной записи службы локально для следующего шага.
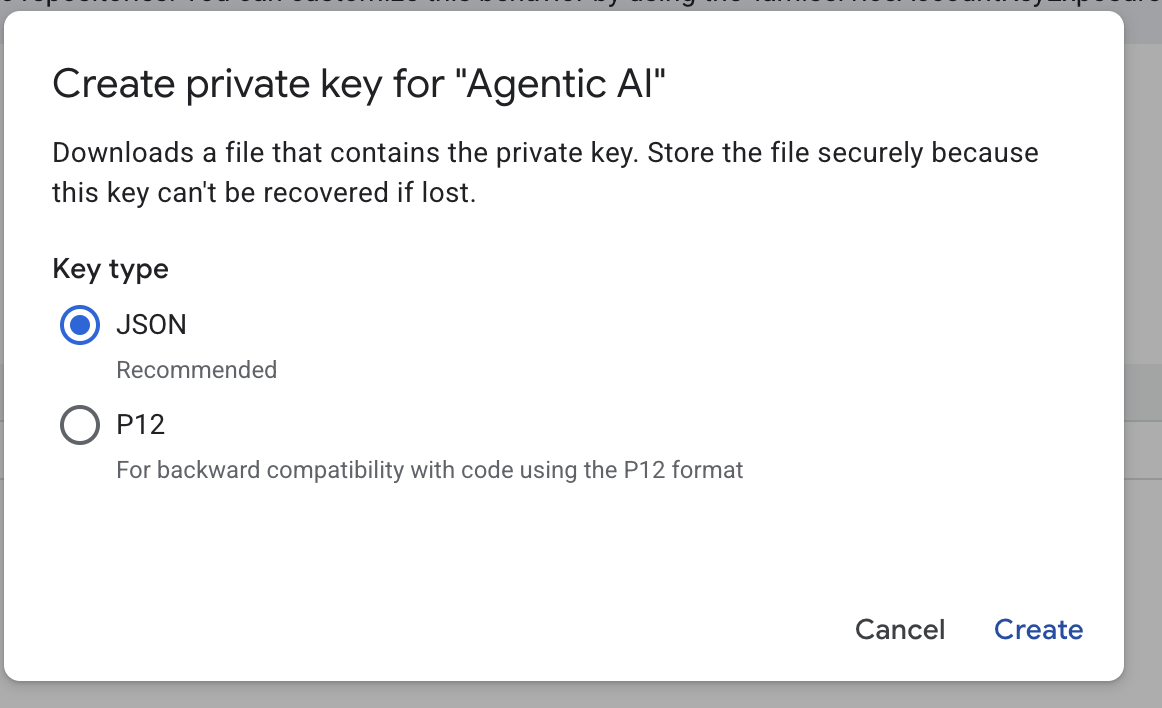
- Создайте папку с именем .streamlit со следующими настройками. Щелкните правой кнопкой мыши, выберите «Создать папку» и введите имя папки
.streamlit - Щелкните правой кнопкой мыши в папке
.streamlit, затем выберите «Создать файл» и заполните его значениями, указанными ниже. Затем сохраните файл какsecrets.toml
# secrets.toml (for Streamlit sharing)
# Store in .streamlit/secrets.toml
[gcp]
project_id = "your_gcp_project"
location = "us-central1"
[gcp_service_account]
type = "service_account"
project_id = "your-project-id"
private_key_id = "your-private-key-id"
private_key = '''-----BEGIN PRIVATE KEY-----
YOUR_PRIVATE_KEY_HERE
-----END PRIVATE KEY-----'''
client_email = "your-sa@project-id.iam.gserviceaccount.com"
client_id = "your-client-id"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "https://www.googleapis.com/robot/v1/metadata/x509/your-sa%40project-id.iam.gserviceaccount.com"
- Обновите значения для
project_id,private_key_id,private_key,client_email,client_id , and auth_provider_x509_cert_urlв соответствии с вашей учетной записью службы, созданной на предыдущем шаге.
Подготовка набора данных BigQuery
Следующий шаг — создание набора данных BigQuery для сохранения результатов генерации в BigQuery.
- Введите BigQuery в поле поиска, затем нажмите BigQuery.
- Нажмите
 затем нажмите «Создать набор данных».
затем нажмите «Создать набор данных». - Введите идентификатор набора данных
diet_planner_data, затем нажмите «Создать набор данных».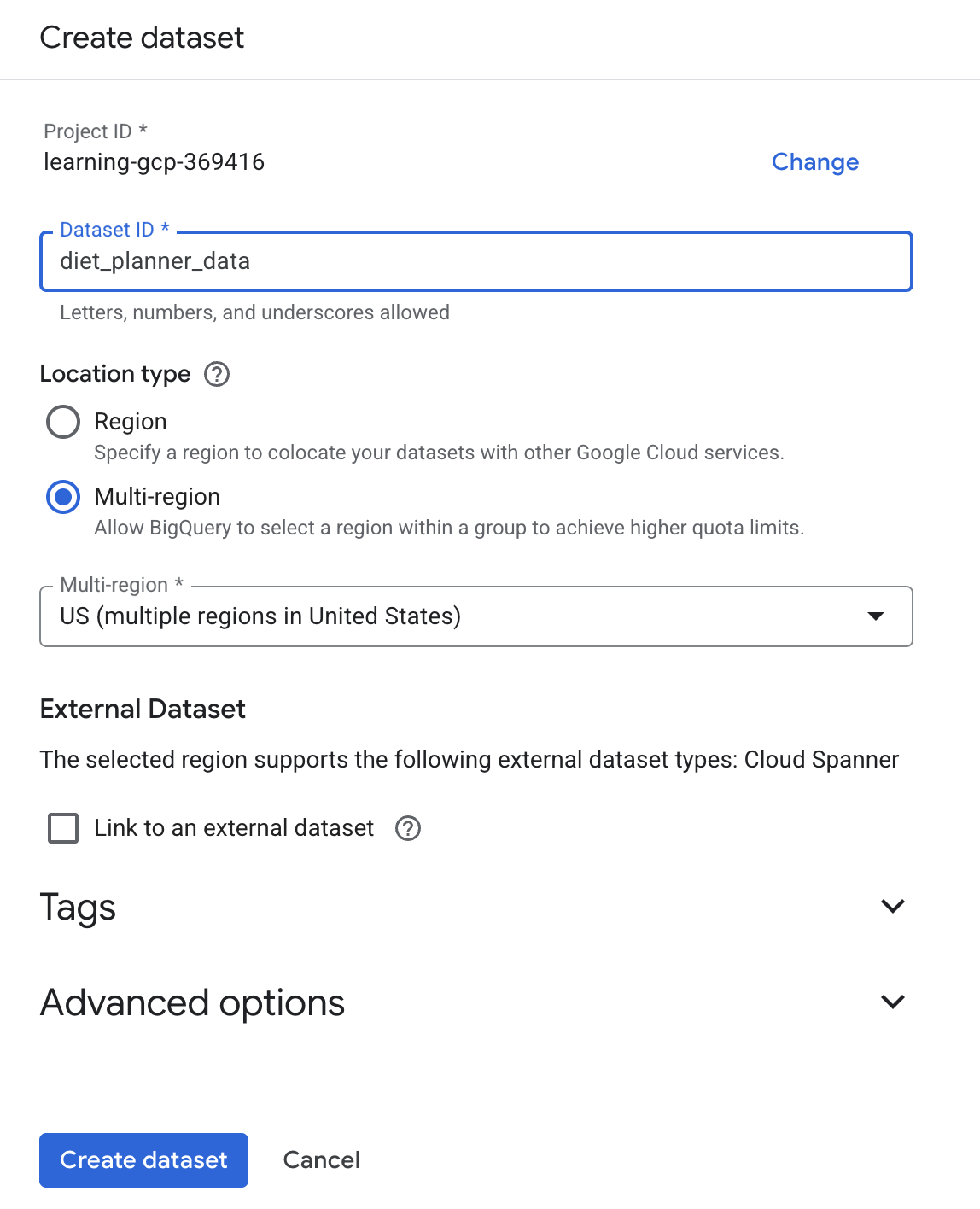
4. Создайте приложение-планировщик диеты для агентов.
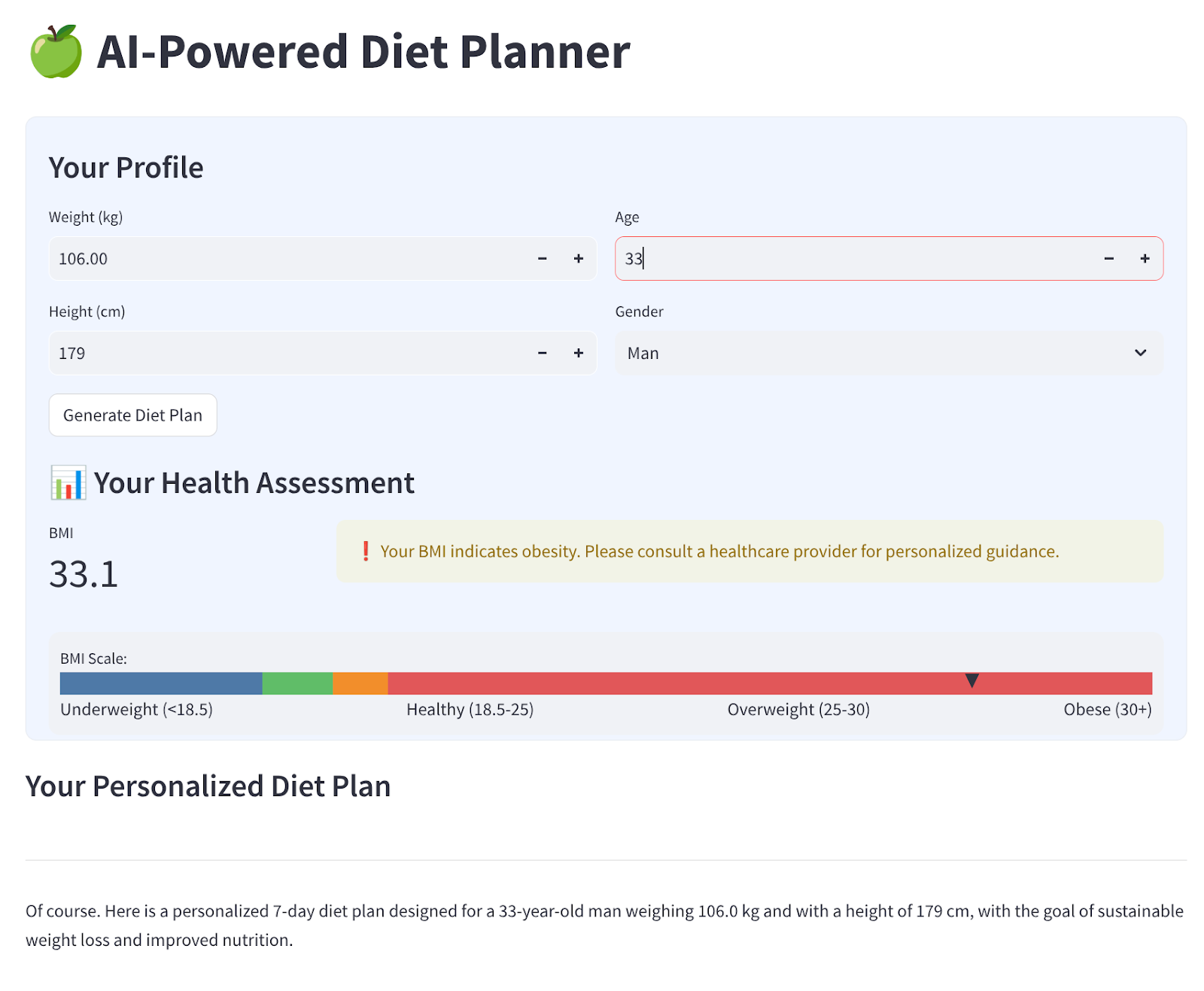
Мы создадим простой веб-интерфейс с четырьмя полями ввода, который будет выглядеть следующим образом.
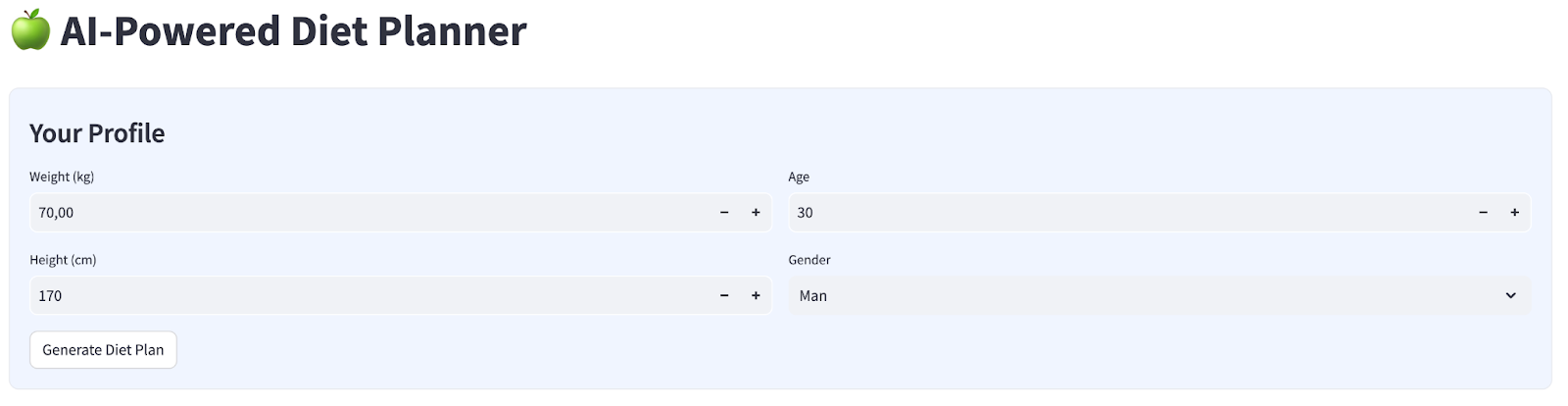
Измените вес, рост, возраст и пол в соответствии с вашим профилем, затем нажмите «Сгенерировать». Будет вызвана модель LLM Gemini Pro 2.5 из библиотеки Vertex AI, и сгенерированные результаты будут сохранены в BigQuery.
Чтобы код не был слишком длинным, он будет разделён на 6 частей.
Создать функцию для расчета статуса ИМТ
- Щелкните правой кнопкой мыши папку
agent_diet_planner→ Создать файл .. → введите имя файлаbmi_calc.pyи нажмите Enter. - Заполните код следующим содержимым.
# Add this function to calculate BMI and health status
def calculate_bmi_status(weight, height):
"""
Calculate BMI and return status message
"""
height_m = height / 100 # Convert cm to meters
bmi = weight / (height_m ** 2)
if bmi < 18.5:
status = "underweight"
message = "⚠️ Your BMI suggests you're underweight. Consider increasing calorie intake with nutrient-dense foods."
elif 18.5 <= bmi < 25:
status = "normal"
message = "✅ Your BMI is in the healthy range. Let's maintain this balance!"
elif 25 <= bmi < 30:
status = "overweight"
message = "⚠️ Your BMI suggests you're overweight. Focus on gradual weight loss through balanced nutrition."
else:
status = "obese"
message = "❗ Your BMI indicates obesity. Please consult a healthcare provider for personalized guidance."
return {
"value": round(bmi, 1),
"status": status,
"message": message
}
Создать агента, планировщик диеты, основные приложения
- Щелкните правой кнопкой мыши папку
agent_diet_planner→ Создать файл .. → введите имя файлаapp.pyи нажмите Enter. - Заполните код следующим содержимым.
import os
from google.oauth2 import service_account
import streamlit as st
from google.cloud import bigquery
from vertexai.preview.generative_models import GenerativeModel
import vertexai
import datetime
import time
import pandas as pd
from bmi_calc import calculate_bmi_status
# Get configuration from environment
PROJECT_ID = os.environ.get("GCP_PROJECT_ID", "your_gcp_project_id")
LOCATION = os.environ.get("GCP_LOCATION", "us-central1")
#CONSTANTS Dataset and table in BigQuery
DATASET = "diet_planner_data"
TABLE = "user_plans"
# Initialize Vertex AI
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Initialize BigQuery client
try:
# For Cloud Run, use default credentials
bq_client = bigquery.Client()
except:
# For local development, use service account from secrets
if "gcp_service_account" in st.secrets:
service_account_info = dict(st.secrets["gcp_service_account"])
credentials = service_account.Credentials.from_service_account_info(service_account_info)
bq_client = bigquery.Client(credentials=credentials, project=PROJECT_ID)
else:
st.error("BigQuery client initialization failed")
st.stop()
Замените значение your_gcp_project_id на идентификатор вашего проекта.
Создать основные приложения для планирования диеты агента - setup_bq_tables
В этом разделе мы создадим функцию с именем setup_bq_table с одним входным параметром bq_client . Эта функция определит схему в таблице BigQuery и создаст таблицу, если она не существует.
Вставьте следующий код в файл app.py
# Create BigQuery table if not exists
def setup_bq_table(bq_client):
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
schema = [
bigquery.SchemaField("user_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("timestamp", "TIMESTAMP", mode="REQUIRED"),
bigquery.SchemaField("weight", "FLOAT", mode="REQUIRED"),
bigquery.SchemaField("height", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("age", "INTEGER", mode="REQUIRED"),
bigquery.SchemaField("gender", "STRING", mode="REQUIRED"),
bigquery.SchemaField("diet_plan", "STRING", mode="REQUIRED")
]
try:
bq_client.get_table(table_id)
except:
table = bigquery.Table(table_id, schema=schema)
bq_client.create_table(table)
st.toast("BigQuery table created successfully")
Создать основное приложение для планирования диеты агента - generate_diet_plan
В этом разделе мы создадим функцию с именем generate_diet_plan с одним входным параметром. Эта функция будет вызывать модель LLM Gemini Pro 2.5 с параметром define prompt и генерировать результаты.
Вставьте следующий код в файл app.py
# Generate diet plan using Gemini Pro
def generate_diet_plan(params):
try:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
Create a personalized 7-day diet plan for:
- {params['gender']}, {params['age']} years old
- Weight: {params['weight']} kg
- Height: {params['height']} cm
Include:
1. Daily calorie target
2. Macronutrient breakdown (carbs, protein, fat)
3. Meal timing and frequency
4. Food recommendations
5. Hydration guidance
Make the plan:
- Nutritionally balanced
- Practical for daily use
- Culturally adaptable
- With portion size guidance
"""
response = model.generate_content(prompt)
return response.text
except Exception as e:
st.error(f"AI generation error: {str(e)}")
return None
Создать основные приложения для планирования диеты агента - save_to_bq
В этом разделе мы создадим функцию с именем save_to_bq с тремя входными параметрами: bq_client , user_id и plan . Эта функция сохранит сгенерированный результат в таблицу BigQuery.
Вставьте следующий код в файл app.py
# Save user data to BigQuery
def save_to_bq(bq_client, user_id, plan):
try:
dataset_id = f"{st.secrets['gcp']['project_id']}.{DATASET}"
table_id = f"{dataset_id}.{TABLE}"
row = {
"user_id": user_id,
"timestamp": datetime.datetime.utcnow().isoformat(),
"weight": st.session_state.user_data["weight"],
"height": st.session_state.user_data["height"],
"age": st.session_state.user_data["age"],
"gender": st.session_state.user_data["gender"],
"diet_plan": plan
}
errors = bq_client.insert_rows_json(table_id, [row])
if errors:
st.error(f"BigQuery error: {errors}")
else:
return True
except Exception as e:
st.error(f"Data saving error: {str(e)}")
return False
Создать приложение для планирования диеты от агента - основные приложения
В этом разделе мы создадим функцию с именем main без входных параметров. Эта функция в основном обрабатывает скрипты пользовательского интерфейса Streamlit, отображает сгенерированные результаты, отображает исторические сгенерированные результаты из таблицы BigQuery и предназначена для загрузки данных в файл Markdown.
Вставьте следующий код в файл app.py
# Streamlit UI
def main():
st.set_page_config(page_title="AI Diet Planner", page_icon="🍏", layout="wide")
# Initialize session state
if "user_data" not in st.session_state:
st.session_state.user_data = None
if "diet_plan" not in st.session_state:
st.session_state.diet_plan = None
# Initialize clients
#bq_client = init_clients()
setup_bq_table(bq_client)
st.title("🍏 AI-Powered Diet Planner")
st.markdown("""
<style>
.stProgress > div > div > div > div {
background-color: #4CAF50;
}
[data-testid="stForm"] {
background: #f0f5ff;
padding: 20px;
border-radius: 10px;
border: 1px solid #e6e9ef;
}
</style>
""", unsafe_allow_html=True)
# User input form
with st.form("user_profile", clear_on_submit=False):
st.subheader("Your Profile")
col1, col2 = st.columns(2)
with col1:
weight = st.number_input("Weight (kg)", min_value=30.0, max_value=200.0, value=70.0)
height = st.number_input("Height (cm)", min_value=100, max_value=250, value=170)
with col2:
age = st.number_input("Age", min_value=18, max_value=100, value=30)
gender = st.selectbox("Gender", ["Man", "Woman"])
submitted = st.form_submit_button("Generate Diet Plan")
if submitted:
user_data = {
"weight": weight,
"height": height,
"age": age,
"gender": gender
}
st.session_state.user_data = user_data
# Calculate BMI
bmi_result = calculate_bmi_status(weight, height)
# Display BMI results in a visually distinct box
with st.container():
st.subheader("📊 Your Health Assessment")
col1, col2 = st.columns([1, 3])
with col1:
st.metric("BMI", bmi_result["value"])
with col2:
if bmi_result["status"] != "normal":
st.warning(bmi_result["message"])
else:
st.success(bmi_result["message"])
# Add BMI scale visualization
st.markdown(f"""
<div style="background:#f0f2f6;padding:10px;border-radius:10px;margin-top:10px">
<small>BMI Scale:</small><br>
<div style="display:flex;height:20px;background:linear-gradient(90deg,
#4e79a7 0%,
#4e79a7 18.5%,
#60bd68 18.5%,
#60bd68 25%,
#f28e2b 25%,
#f28e2b 30%,
#e15759 30%,
#e15759 100%);position:relative">
<div style="position:absolute;left:{min(100, max(0, (bmi_result["value"]/40)*100))}%;top:-5px">
▼
</div>
</div>
<div style="display:flex;justify-content:space-between">
<span>Underweight (<18.5)</span>
<span>Healthy (18.5-25)</span>
<span>Overweight (25-30)</span>
<span>Obese (30+)</span>
</div>
</div>
""", unsafe_allow_html=True)
# Store BMI in session state
st.session_state.bmi = bmi_result
# Plan generation and display
if submitted and st.session_state.user_data:
with st.spinner("🧠 Generating your personalized diet plan using Gemini AI..."):
#diet_plan = generate_diet_plan(st.session_state.user_data)
diet_plan = generate_diet_plan({**st.session_state.user_data,"bmi": bmi_result["value"],
"bmi_status": bmi_result["status"]
})
if diet_plan:
st.session_state.diet_plan = diet_plan
# Generate unique user ID
user_id = f"user_{int(time.time())}"
# Save to BigQuery
if save_to_bq(bq_client, user_id, diet_plan):
st.toast("✅ Plan saved to database!")
# Display generated plan
if st.session_state.diet_plan:
st.subheader("Your Personalized Diet Plan")
st.markdown("---")
st.markdown(st.session_state.diet_plan)
# Download button
st.download_button(
label="Download Plan",
data=st.session_state.diet_plan,
file_name="my_diet_plan.md",
mime="text/markdown"
)
# Show history
st.subheader("Your Plan History")
try:
query = f"""
SELECT timestamp, weight, height, age, gender
FROM `{st.secrets['gcp']['project_id']}.{DATASET}.{TABLE}`
WHERE user_id LIKE 'user_%'
ORDER BY timestamp DESC
LIMIT 5
"""
history = bq_client.query(query).to_dataframe()
if not history.empty:
history["timestamp"] = pd.to_datetime(history["timestamp"])
st.dataframe(history.style.format({
"weight": "{:.1f} kg",
"height": "{:.0f} cm"
}))
else:
st.info("No previous plans found")
except Exception as e:
st.error(f"History load error: {str(e)}")
if __name__ == "__main__":
main()
Сохраните код под именем app.py.
5. Развертывание приложений с помощью Cloud Build в Cloud Run
Конечно, теперь мы хотим продемонстрировать это замечательное приложение другим. Для этого мы можем упаковать это приложение и развернуть его в Cloud Run в качестве общедоступного сервиса, к которому смогут получить доступ другие пользователи. Для этого давайте вернемся к архитектуре.
Сначала нам понадобится Dockerfile. Нажмите «Файл» -> «Создать текстовый файл», скопируйте и вставьте следующий код, затем сохраните его как Dockerfile.
# Use official Python image
FROM python:3.12-slim
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV PORT 8080
# Install system dependencies
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
libpq-dev \
&& rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /app
# Copy requirements
COPY requirements.txt .
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application files
COPY . .
# Expose port
EXPOSE $PORT
# Run the application
CMD ["streamlit", "run", "app.py", "--server.port", "8080", "--server.address", "0.0.0.0"]
Далее мы создадим файл cloudbuid.yaml для сборки приложений, чтобы они становились образами Docker, отправлялись в реестр артефактов и развертывались в CloudRun.
Нажмите «Файл» -> «Создать текстовый файл», скопируйте и вставьте следующий код, затем сохраните его как cloudbuild.yaml.
steps:
# Build Docker image
- name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID', '--no-cache',
'--progress=plain',
'.']
id: 'Build'
timeout: 1200s
waitFor: ['-']
dir: '.'
# Push to Container Registry
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID']
id: 'Push'
waitFor: ['Build']
# Deploy to Cloud Run
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args:
- 'run'
- 'deploy'
- 'diet-planner-service'
- '--image=gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
- '--port=8080'
- '--region=us-central1'
- '--platform=managed'
- '--allow-unauthenticated'
- '--set-env-vars=GCP_PROJECT_ID=$PROJECT_ID,GCP_LOCATION=us-central1'
- '--cpu=1'
- '--memory=1Gi'
- '--timeout=300'
waitFor: ['Push']
options:
logging: CLOUD_LOGGING_ONLY
machineType: 'E2_HIGHCPU_8'
diskSizeGb: 100
images:
- 'gcr.io/$PROJECT_ID/diet-planner:$BUILD_ID'
На данном этапе у нас уже есть все необходимые файлы для сборки приложений, их преобразования в образы Docker, отправки в реестр артефактов и развертывания в Cloud Run. Давайте развернем их. Перейдите в терминал Cloud Shell и убедитесь, что текущий проект настроен на ваш активный проект. Если это не так, используйте команду gcloud configure для установки идентификатора проекта:
gcloud config set project [PROJECT_ID]
Затем выполните следующую команду, чтобы создать образы Docker для сборки приложений, отправить их в реестр артефактов и развернуть в Cloud Run.
gcloud builds submit --config cloudbuild.yaml
Программа создаст контейнер Docker на основе ранее предоставленного нами Dockerfile и отправит его в реестр артефактов. После этого мы развернем созданный образ в Cloud Run. Весь этот процесс описан в шагах файла cloudbuild.yaml .
Обратите внимание, что здесь разрешен неаутентифицированный доступ, поскольку это демонстрационное приложение. Рекомендуется использовать соответствующую аутентификацию для корпоративных и производственных приложений.
После завершения развертывания можно проверить его на странице Cloud Run, введя Cloud Run в строку поиска в верхней части консоли Cloud Run и выбрав продукт Cloud Run.
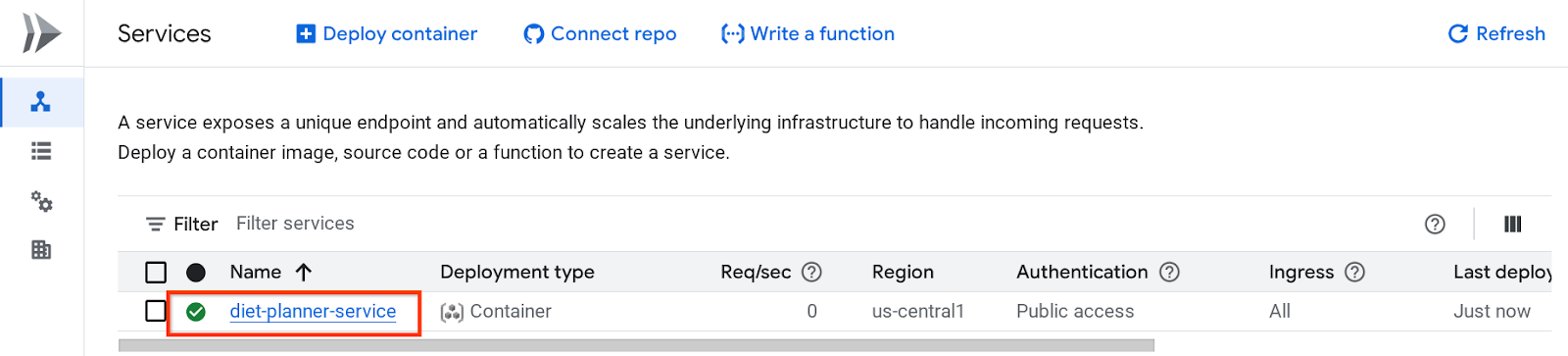
После этого вы можете проверить развернутую службу, указанную на странице Cloud Run Service. Щелкните по службе, чтобы получить URL-адрес службы.
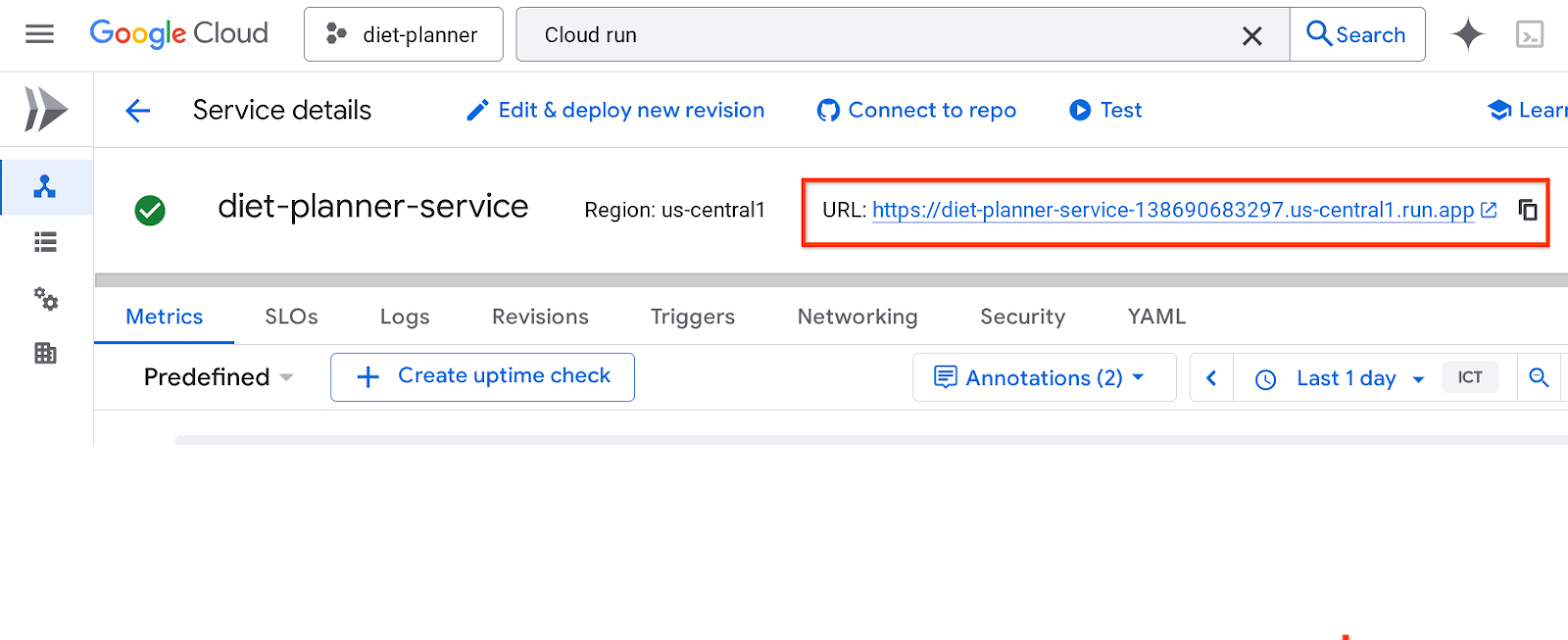
URL-адрес сервиса будет отображаться в верхней панели.
 Смело используйте приложение в режиме инкогнито или на мобильном устройстве. Оно уже должно быть запущено.
Смело используйте приложение в режиме инкогнито или на мобильном устройстве. Оно уже должно быть запущено.
6. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом практическом задании, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
- В качестве альтернативы вы можете перейти в Cloud Run в консоли, выбрать только что развернутую службу и удалить ее.