
1. परिचय
नमस्ते! इसलिए, आपको एजेंट का कॉन्सेप्ट पसंद आया. ये छोटे-छोटे हेल्पर होते हैं, जो बिना आपकी मदद के आपके काम पूरे कर सकते हैं, है न? बहुत बढ़िया! हालांकि, एक एजेंट से हमेशा काम नहीं चलेगा. खास तौर पर, जब आपको बड़े और ज़्यादा मुश्किल प्रोजेक्ट पर काम करना हो. आपको शायद इन सभी की एक टीम की ज़रूरत पड़ेगी! ऐसे में, मल्टी-एजेंट सिस्टम काम आते हैं.
एलएलएम की मदद से काम करने वाले एजेंट, आपको हार्ड कोडिंग की तुलना में ज़्यादा सुविधाएं देते हैं. हालांकि, इनके साथ कुछ चुनौतियां भी जुड़ी होती हैं. इस वर्कशॉप में, हम इसी के बारे में विस्तार से जानेंगे!

यहां बताया गया है कि आपको क्या सीखने को मिलेगा. इसे एजेंट के तौर पर अपनी परफ़ॉर्मेंस को बेहतर बनाने के तौर पर देखें:
LangGraph की मदद से अपना पहला एजेंट बनाना: हम LangGraph का इस्तेमाल करके, आपका एजेंट बनाएंगे. LangGraph एक लोकप्रिय फ़्रेमवर्क है. आपको ऐसे टूल बनाने का तरीका बताया जाएगा जो डेटाबेस से कनेक्ट होते हैं. साथ ही, इंटरनेट पर कुछ खोजने के लिए, Gemini 2 API का इस्तेमाल करने का तरीका भी बताया जाएगा. इसके अलावा, प्रॉम्प्ट और जवाब को ऑप्टिमाइज़ करने का तरीका भी बताया जाएगा, ताकि आपका एजेंट न सिर्फ़ एलएलएम, बल्कि मौजूदा सेवाओं के साथ भी इंटरैक्ट कर सके. हम आपको यह भी दिखाएंगे कि फ़ंक्शन कॉलिंग कैसे काम करती है.
एजेंट ऑर्केस्ट्रेशन, अपने हिसाब से: हम आपके एजेंटों को ऑर्केस्ट्रेट करने के अलग-अलग तरीकों के बारे में जानेंगे. इनमें आसान पाथ से लेकर ज़्यादा जटिल मल्टी-पाथ वाले परिदृश्य शामिल हैं. इसे अपनी एजेंट टीम के काम करने के तरीके को मैनेज करने के तौर पर समझें.
मल्टी-एजेंट सिस्टम: आपको यह पता चलेगा कि ऐसा सिस्टम कैसे सेट अप किया जाए जिसमें आपके एजेंट एक साथ मिलकर काम कर सकें और एक साथ मिलकर काम पूरा कर सकें. यह सब इवेंट-ड्रिवन आर्किटेक्चर की वजह से होता है.
एलएलएम की स्वतंत्रता: काम के हिसाब से सबसे सही एलएलएम का इस्तेमाल करें: हम सिर्फ़ एक एलएलएम पर निर्भर नहीं हैं! आपको यह भी पता चलेगा कि एक से ज़्यादा एलएलएम का इस्तेमाल कैसे किया जाता है. साथ ही, उन्हें अलग-अलग भूमिकाएं असाइन करके, "थिंकिंग मॉडल" का इस्तेमाल करके समस्या हल करने की क्षमता को कैसे बढ़ाया जाता है.
डाइनैमिक कॉन्टेंट क्या होता है? कोई बात नहीं!: कल्पना करें कि आपका एजेंट, हर उपयोगकर्ता के लिए रीयल-टाइम में डाइनैमिक कॉन्टेंट बना रहा है. हम आपको इसका तरीका बताएंगे!
Google Cloud की मदद से इसे क्लाउड पर ले जाना: सिर्फ़ नोटबुक में काम करने की ज़रूरत नहीं है. हम आपको Google Cloud पर मल्टी-एजेंट सिस्टम को डिज़ाइन और डिप्लॉय करने का तरीका बताएंगे, ताकि यह असल दुनिया के लिए तैयार हो सके!
यह प्रोजेक्ट, उन सभी तकनीकों को इस्तेमाल करने का एक अच्छा उदाहरण होगा जिनके बारे में हमने बात की है.
2. आर्किटेक्चर
शिक्षक होना या शिक्षा के क्षेत्र में काम करना बहुत अच्छा अनुभव हो सकता है. हालांकि, हमें यह भी मानना होगा कि काम का बोझ, खास तौर पर तैयारी से जुड़ा काम बहुत मुश्किल हो सकता है! इसके अलावा, अक्सर ऐसा होता है कि स्कूल में स्टाफ़ की कमी होती है और ट्यूशन लेना महंगा पड़ सकता है. इसलिए, हम एआई की मदद से काम करने वाले एक टीचिंग असिस्टेंट का सुझाव दे रहे हैं. इस टूल से, शिक्षकों का काम आसान हो सकता है. साथ ही, यह स्टाफ़ की कमी और कम कीमत पर ट्यूशन की सुविधा न होने की वजह से होने वाली समस्याओं को दूर करने में मदद कर सकता है.
एआई की मदद से काम करने वाला हमारा टीचिंग असिस्टेंट, लेसन प्लान, मज़ेदार क्विज़, आसानी से समझ में आने वाले ऑडियो रीकैप, और ज़रूरत के हिसाब से असाइनमेंट तैयार कर सकता है. इससे शिक्षकों को उन कामों पर ध्यान देने में मदद मिलती है जो वे सबसे अच्छी तरह से करते हैं: छात्र-छात्राओं से जुड़ना और उन्हें सीखने में दिलचस्पी पैदा करने में मदद करना.
सिस्टम में दो साइटें हैं: एक शिक्षकों के लिए, ताकि वे आने वाले हफ़्तों के लिए लेसन प्लान बना सकें.
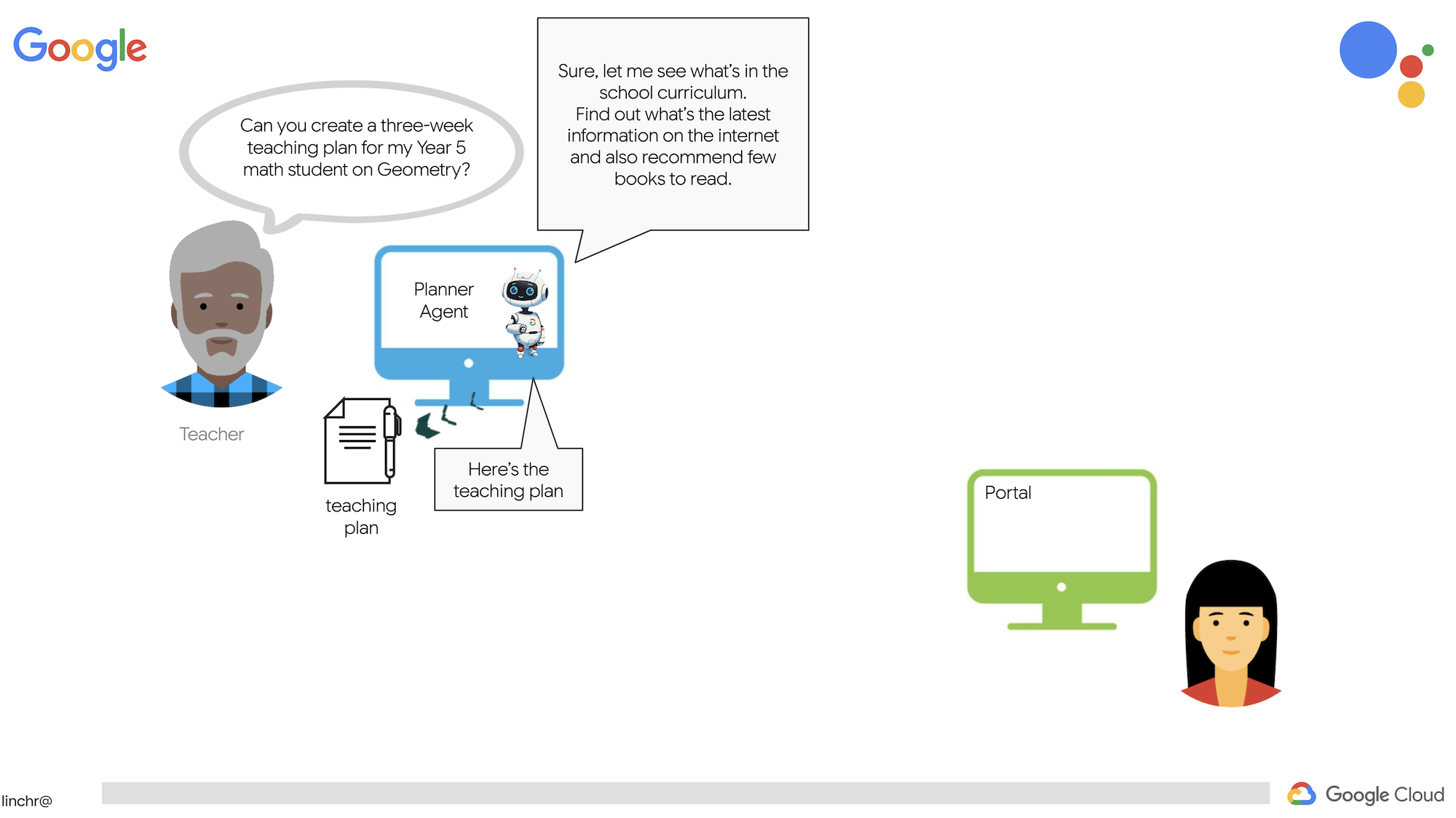
और दूसरा, छात्र-छात्राओं के लिए होता है. इससे वे क्विज़, ऑडियो रीकैप, और असाइनमेंट ऐक्सेस कर सकते हैं. 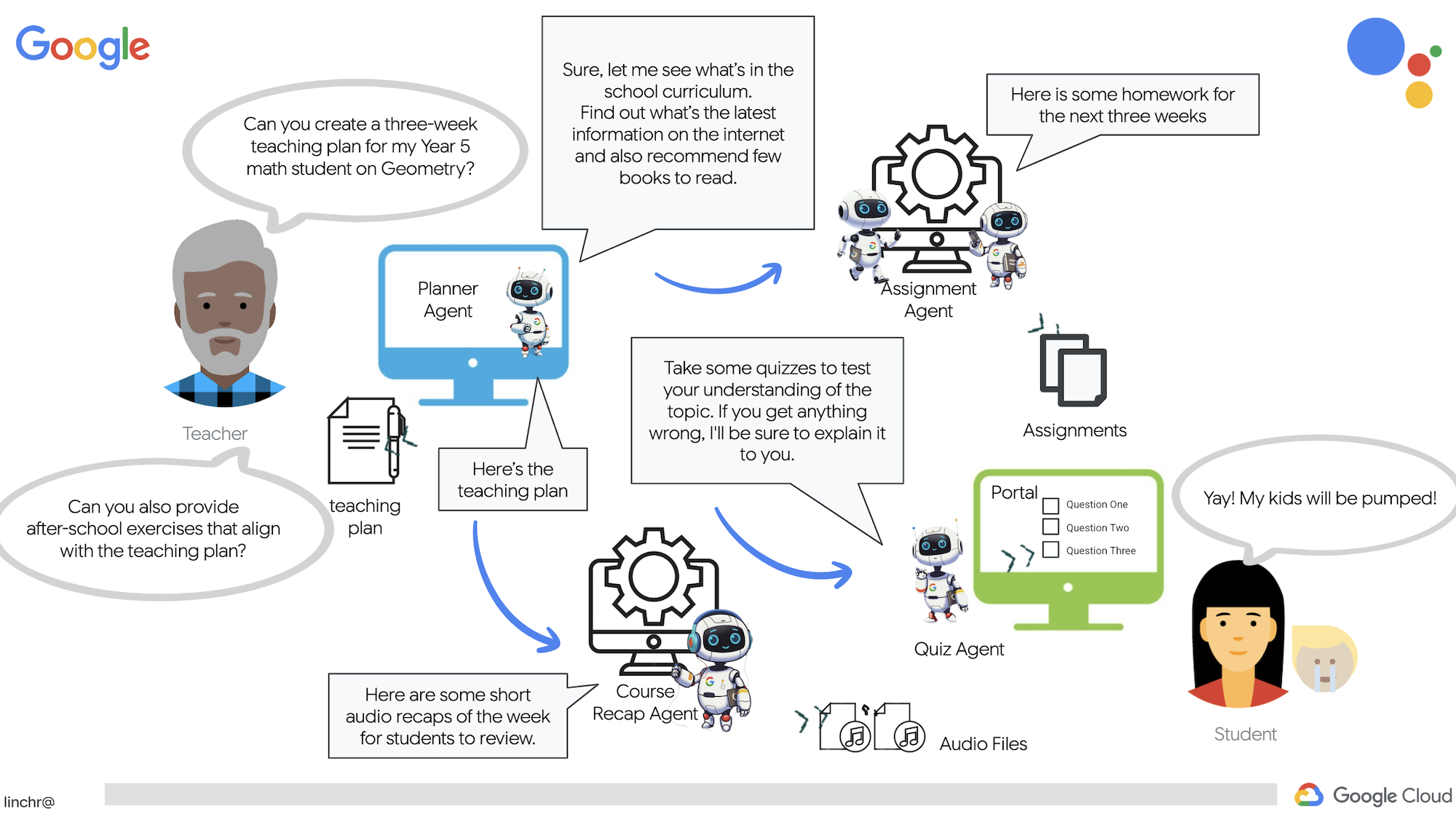
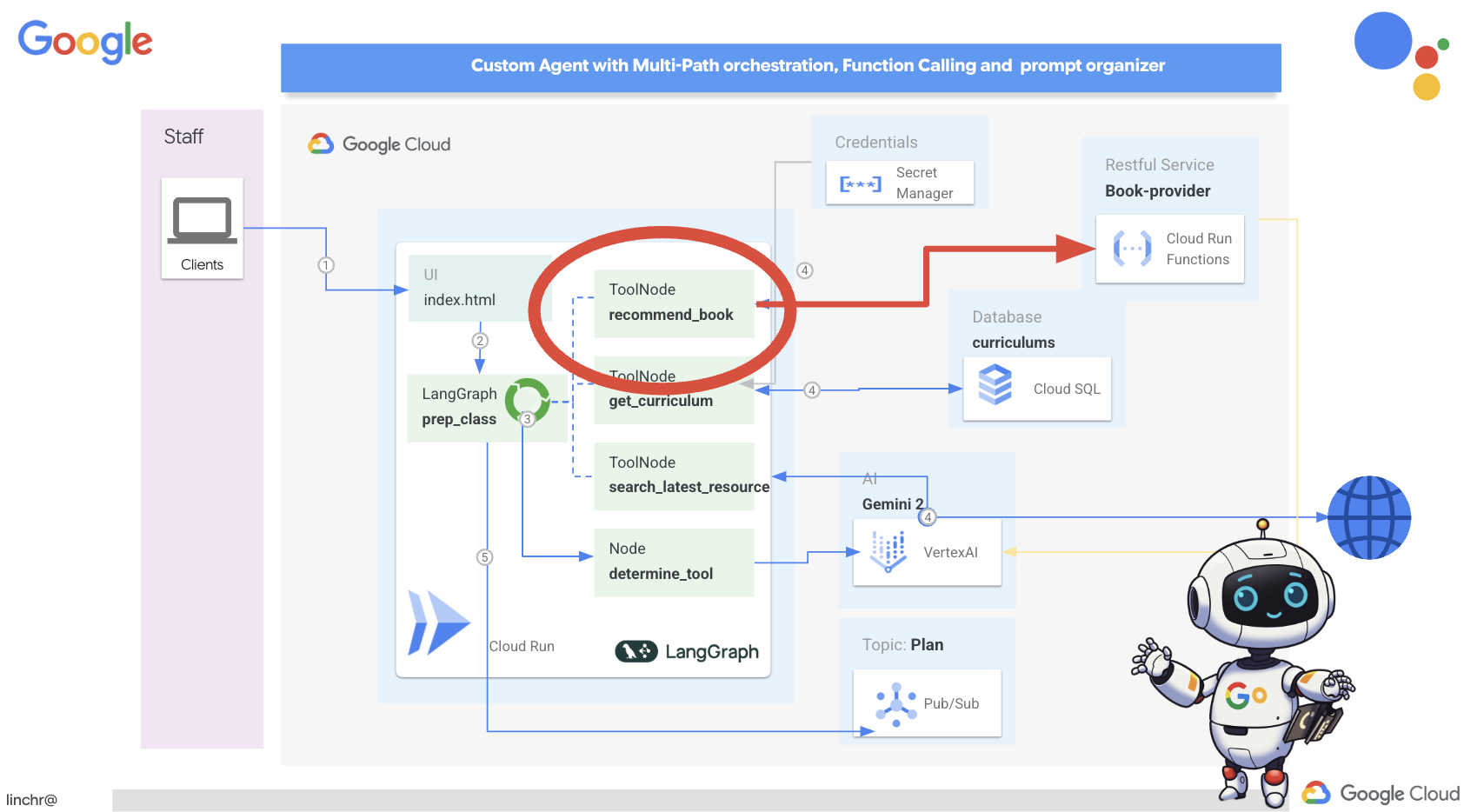
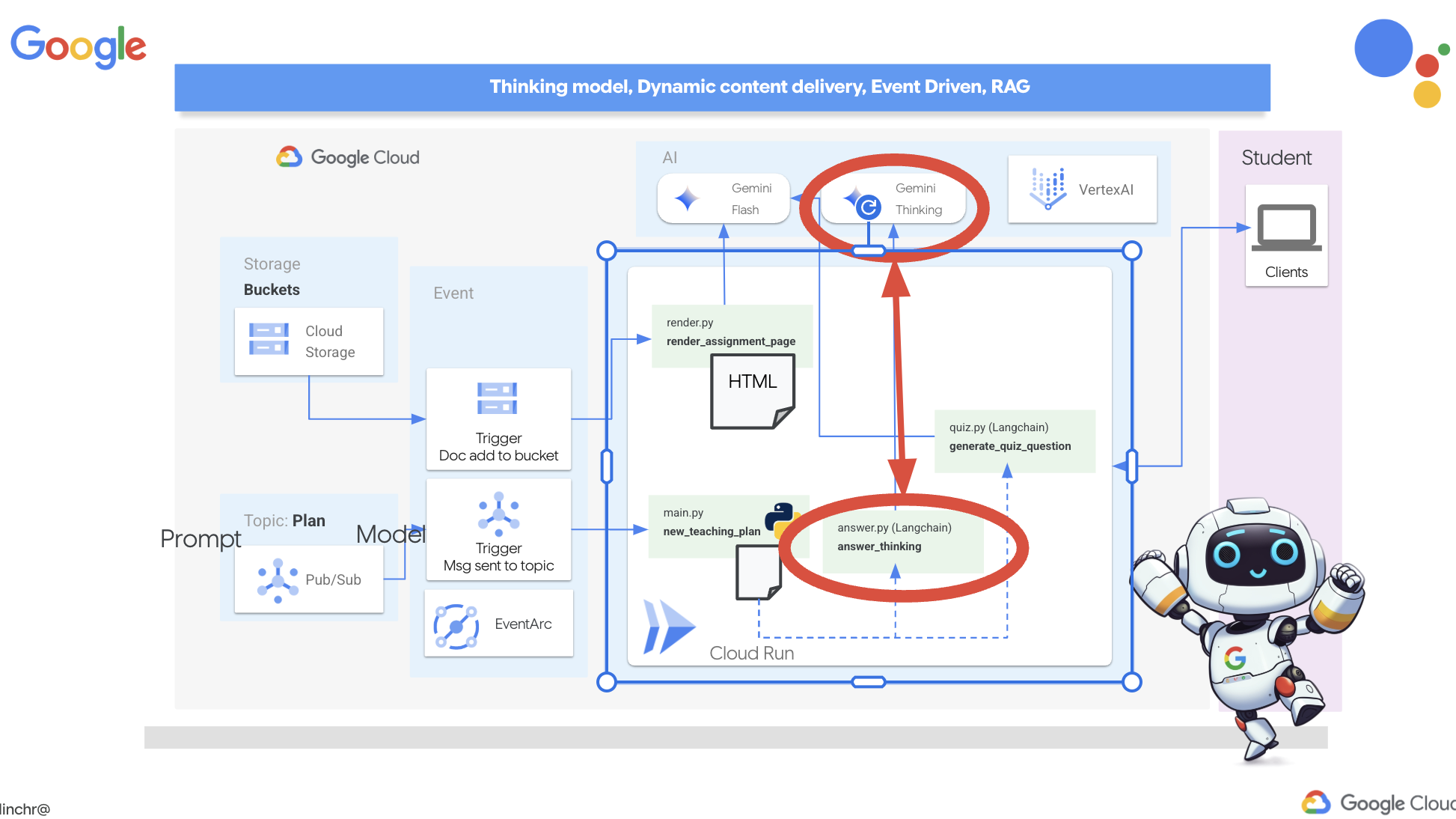
ठीक है, आइए हम आपको Aidemy के आर्किटेक्चर के बारे में बताते हैं. यह आर्किटेक्चर, हमारी टीचिंग असिस्टेंट को बेहतर तरीके से काम करने में मदद करता है. जैसा कि आप देख सकते हैं, हमने इसे कई मुख्य कॉम्पोनेंट में बांटा है. ये सभी कॉम्पोनेंट एक साथ काम करते हैं, ताकि यह प्रोसेस पूरी हो सके.
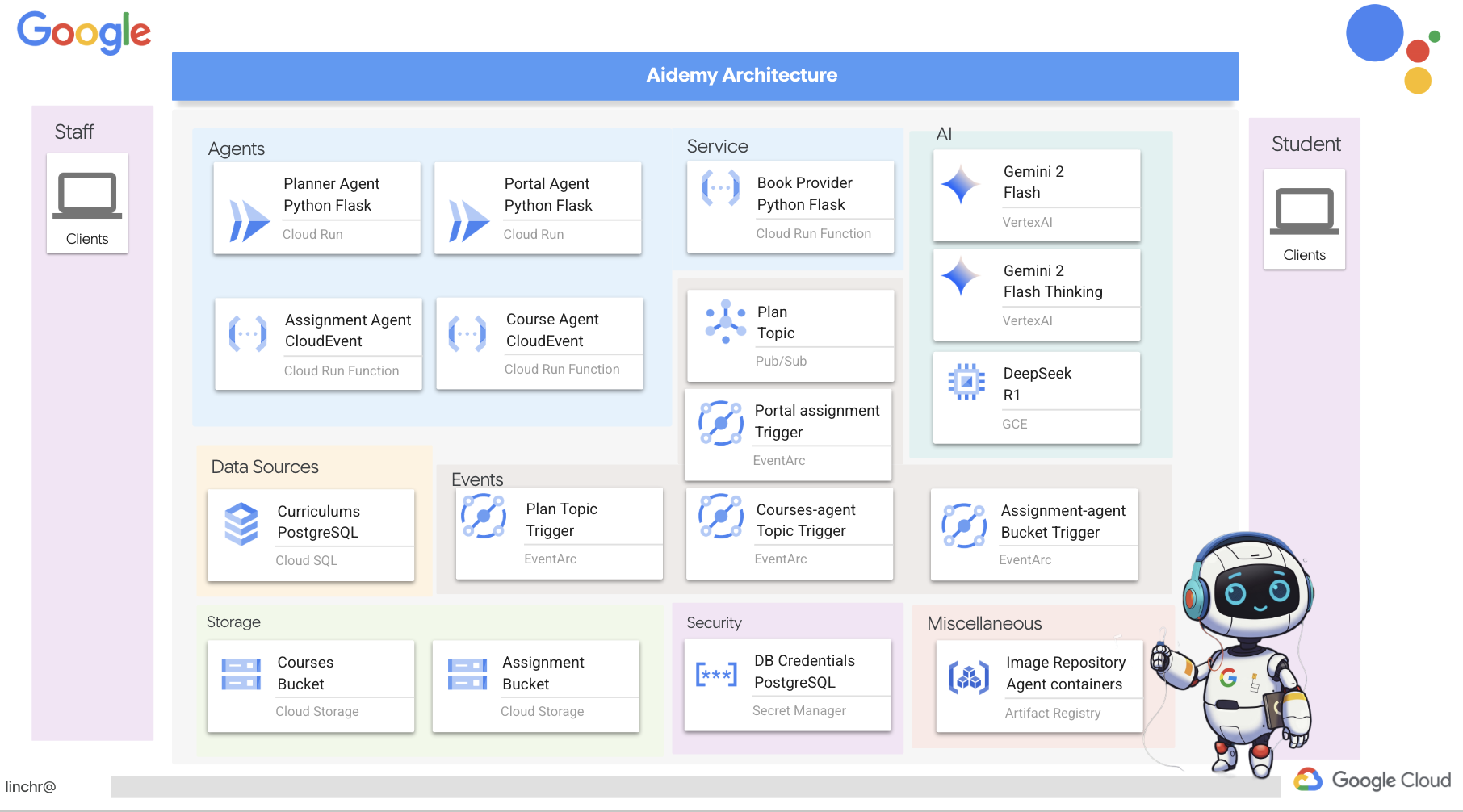
मुख्य आर्किटेक्चरल एलिमेंट और टेक्नोलॉजी:
Google Cloud Platform (GCP): यह पूरे सिस्टम के लिए ज़रूरी है:
- Vertex AI: यह Google के Gemini LLM को ऐक्सेस करता है.
- Cloud Run: कंटेनर वाले एजेंट और फ़ंक्शन डिप्लॉय करने के लिए, बिना सर्वर वाला प्लैटफ़ॉर्म.
- Cloud SQL: पाठ्यक्रम के डेटा के लिए PostgreSQL डेटाबेस.
- Pub/Sub और Eventarc: ये इवेंट-ड्रिवन आर्किटेक्चर के बुनियादी सिद्धांत हैं. इनसे कॉम्पोनेंट के बीच एसिंक्रोनस कम्यूनिकेशन किया जा सकता है.
- Cloud Storage: इसमें ऑडियो रीकैप और असाइनमेंट की फ़ाइलें सेव होती हैं.
- Secret Manager: यह डेटाबेस क्रेडेंशियल को सुरक्षित तरीके से मैनेज करता है.
- Artifact Registry: यह एजेंट के लिए Docker इमेज सेव करता है.
- Compute Engine: वेंडर के समाधानों पर भरोसा करने के बजाय, खुद होस्ट किए गए एलएलएम को डिप्लॉय करने के लिए
एलएलएम: ये सिस्टम के "दिमाग" होते हैं:
- Google के Gemini मॉडल: (Gemini x Pro, Gemini x Flash, Gemini x Flash Thinking) इनका इस्तेमाल लेसन प्लान बनाने, कॉन्टेंट जनरेट करने, डाइनैमिक एचटीएमएल बनाने, क्विज़ के बारे में जानकारी देने, और असाइनमेंट को एक साथ जोड़ने के लिए किया जाता है.
- DeepSeek: इसका इस्तेमाल, खुद से पढ़ाई करने के लिए असाइनमेंट जनरेट करने के खास काम के लिए किया जाता है
LangChain और LangGraph: एलएलएम ऐप्लिकेशन डेवलपमेंट के लिए फ़्रेमवर्क
- इससे, मल्टी-एजेंट वाले मुश्किल वर्कफ़्लो बनाने में मदद मिलती है.
- यह टूल के बेहतर तरीके से काम करने की सुविधा चालू करता है. जैसे, एपीआई कॉल, डेटाबेस क्वेरी, और वेब खोज.
- यह सिस्टम को ज़्यादा बेहतर बनाने और उसे ज़्यादा सुविधाजनक बनाने के लिए, इवेंट-ड्रिवन आर्किटेक्चर को लागू करता है.
कुल मिलाकर, हमारे आर्किटेक्चर में एलएलएम की क्षमता को स्ट्रक्चर्ड डेटा और इवेंट-ड्रिवन कम्यूनिकेशन के साथ जोड़ा गया है. यह सब Google Cloud पर काम करता है. इससे हमें एक ऐसा टीचिंग असिस्टेंट बनाने में मदद मिलती है जो भरोसेमंद हो, असरदार हो, और जिसे ज़रूरत के हिसाब से बढ़ाया जा सके.
3. शुरू करने से पहले
Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं. पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. यह देखने का तरीका जानें कि किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं.
Cloud Shell IDE में Gemini Code Assist की सुविधा चालू करना
👉 Google Cloud Console में, Gemini Code Assist के टूल पर जाएं. इसके बाद, बिना किसी शुल्क के Gemini Code Assist को चालू करें. इसके लिए, आपको शर्तों और नियमों से सहमत होना होगा.
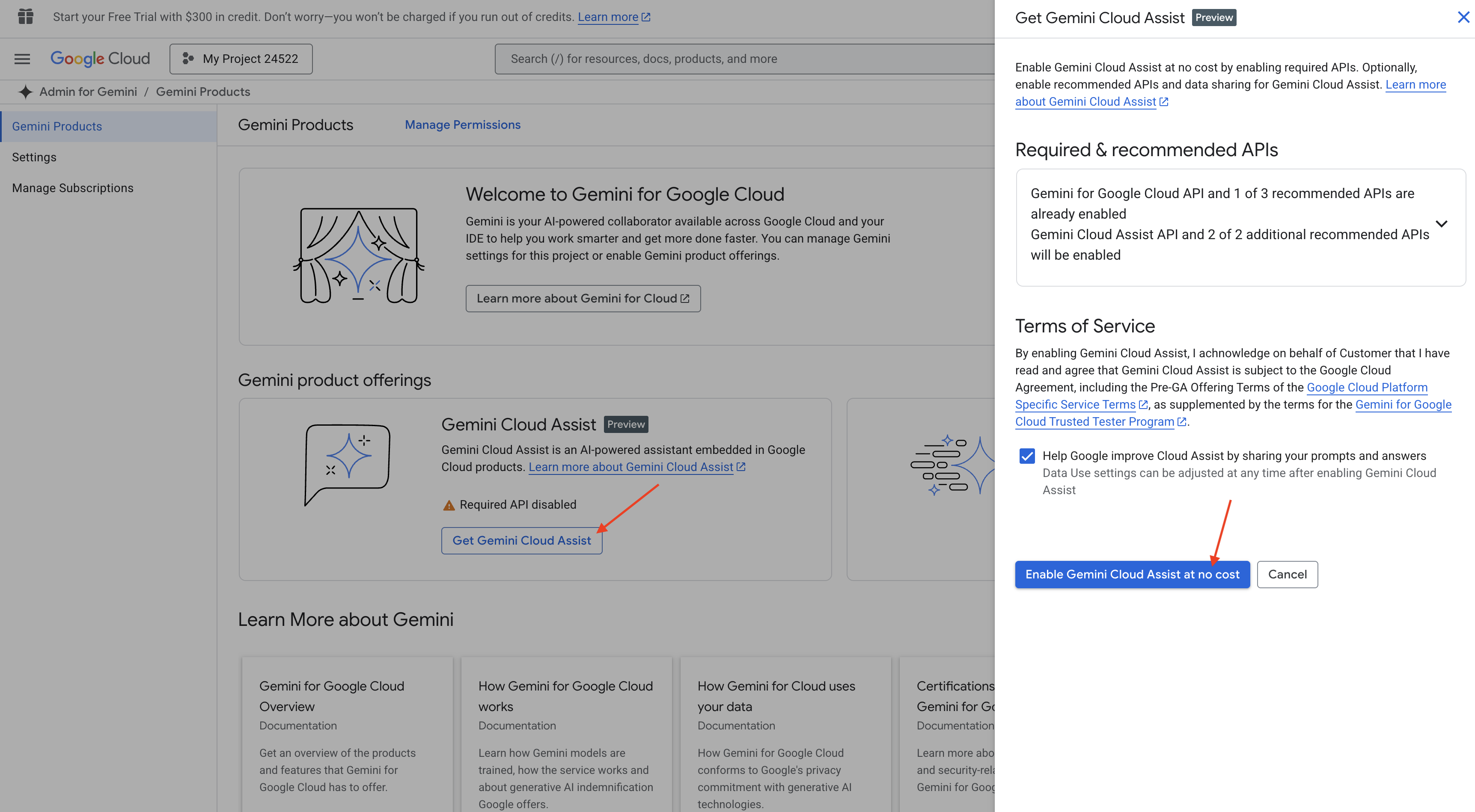
अनुमति सेटअप करने की प्रोसेस को अनदेखा करें और इस पेज को छोड़ दें.
Cloud Shell Editor पर काम करना
👉Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें. यह Cloud Shell पैनल में सबसे ऊपर मौजूद टर्मिनल के आकार का आइकॉन है. इसके बाद, "एडिटर खोलें" बटन पर क्लिक करें. यह पेंसिल वाले खुले फ़ोल्डर जैसा दिखता है. इससे विंडो में Cloud Shell Code Editor खुल जाएगा. आपको बाईं ओर फ़ाइल एक्सप्लोरर दिखेगा.
👉नीचे दिए गए स्टेटस बार में, क्लाउड कोड से साइन इन करें बटन पर क्लिक करें. दिए गए निर्देशों के मुताबिक, प्लगिन को अनुमति दें. अगर आपको स्टेटस बार में Cloud Code - no project दिखता है, तो उसे चुनें. इसके बाद, ड्रॉप-डाउन में ‘Select a Google Cloud Project' को चुनें. इसके बाद, बनाए गए प्रोजेक्ट की सूची से कोई Google Cloud प्रोजेक्ट चुनें.
👉क्लाउड आईडीई में टर्मिनल खोलें,  या
या 
👉टर्मिनल में, पुष्टि करें कि आपने पहले ही पुष्टि कर ली है और प्रोजेक्ट को अपने प्रोजेक्ट आईडी पर सेट किया गया है. इसके लिए, यह कमांड इस्तेमाल करें:
gcloud auth list
👉इसके बाद, यह कमांड चलाएं. <YOUR_PROJECT_ID> की जगह अपना प्रोजेक्ट आईडी डालना न भूलें:
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉ज़रूरी Google Cloud API चालू करने के लिए, यह कमांड चलाएं:
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
इसमें कुछ मिनट लग सकते हैं..
अनुमति सेट अप करना
👉सेवा खाते की अनुमति सेट अप करें. टर्मिनल में, यह कमांड चलाएं :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 अनुमतियां दें. टर्मिनल में, यह कमांड चलाएं :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
👉अपनी IAM console में जाकर, नतीजे की पुष्टि करें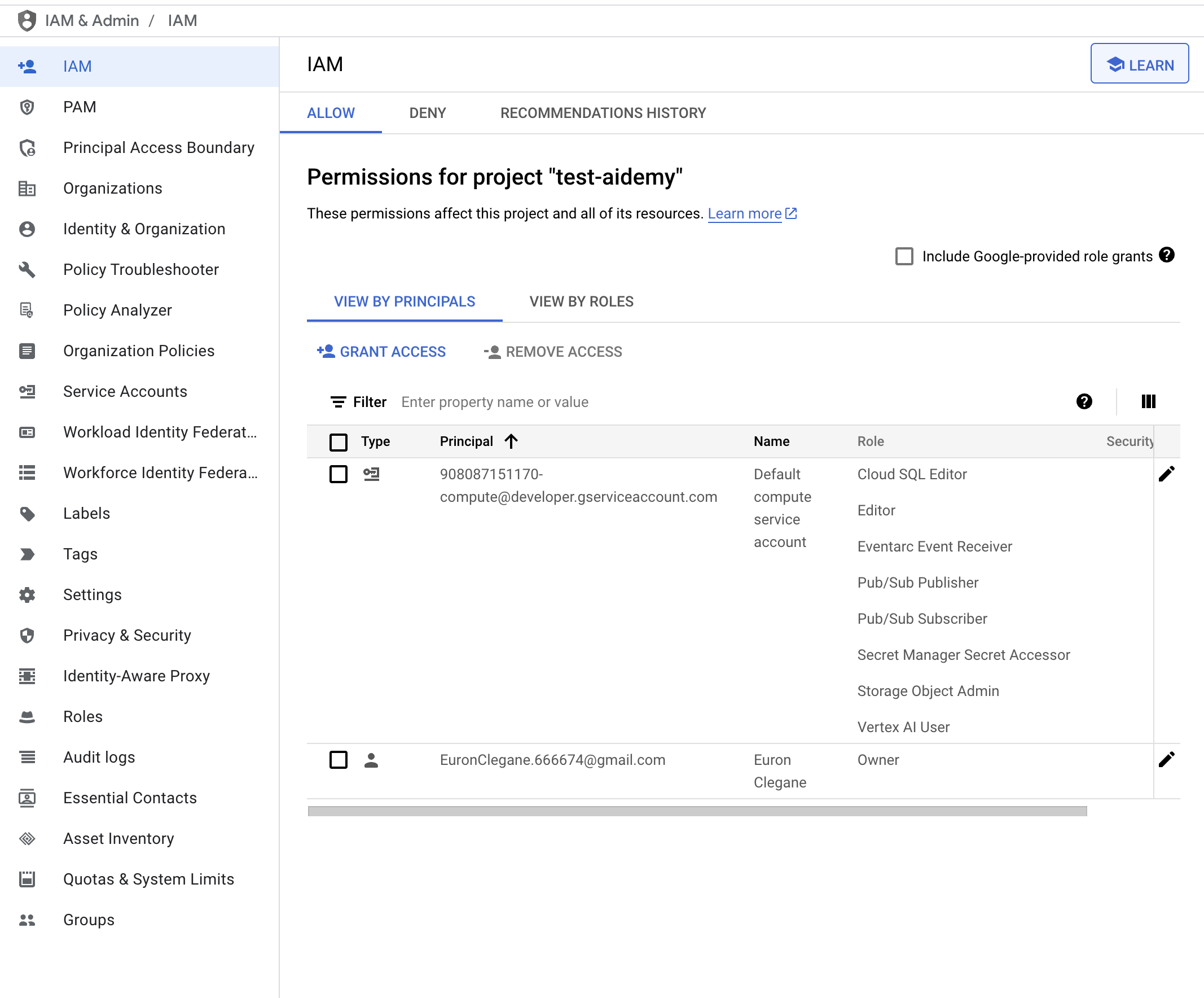
👉aidemy नाम का Cloud SQL इंस्टेंस बनाने के लिए, टर्मिनल में यहां दी गई कमांड चलाएं. हमें इसकी ज़रूरत बाद में पड़ेगी. हालांकि, इस प्रोसेस में कुछ समय लग सकता है. इसलिए, हम इसे अभी पूरा करेंगे.
gcloud sql instances create aidemy \
--database-version=POSTGRES_14 \
--cpu=2 \
--memory=4GB \
--region=us-central1 \
--root-password=1234qwer \
--storage-size=10GB \
--storage-auto-increase
4. पहला एजेंट बनाना
हम मल्टी-एजेंट सिस्टम के बारे में विस्तार से जानने से पहले, एक बुनियादी बिल्डिंग ब्लॉक के बारे में जानेंगे: एक ऐसा एजेंट जो काम कर सकता हो. इस सेक्शन में, हम "किताब उपलब्ध कराने वाला" एक सामान्य एजेंट बनाकर शुरुआत करेंगे. किताब उपलब्ध कराने वाली कंपनी का एजेंट, कैटगरी को इनपुट के तौर पर लेता है. इसके बाद, Gemini LLM का इस्तेमाल करके, उस कैटगरी में मौजूद किताब को JSON फ़ॉर्मैट में जनरेट करता है. इसके बाद, यह इन किताबों के सुझावों को REST API एंडपॉइंट के तौर पर दिखाता है .
👉ब्राउज़र के दूसरे टैब में, अपने वेब ब्राउज़र में Google Cloud Console खोलें. नेविगेशन मेन्यू (☰) में, "Cloud Run" पर जाएं. "+ ... WRITE A FUNCTION" बटन पर क्लिक करें.
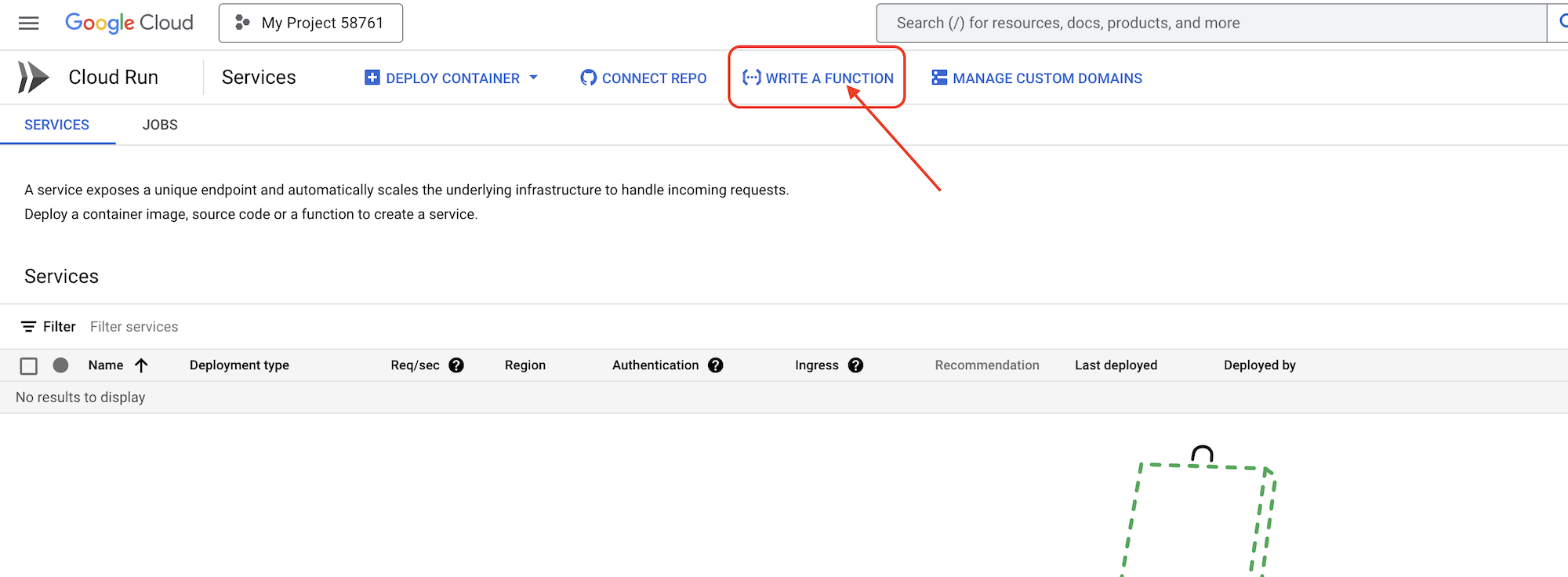
👉इसके बाद, हम Cloud Run फ़ंक्शन की बुनियादी सेटिंग कॉन्फ़िगर करेंगे:
- सेवा का नाम:
book-provider - क्षेत्र:
us-central1 - रनटाइम:
Python 3.12 - पुष्टि करने की सुविधा:
Allow unauthenticated invocationsसे Enabled पर सेट करें.
👉अन्य सेटिंग को डिफ़ॉल्ट पर रहने दें और बनाएं पर क्लिक करें. इससे आपको सोर्स कोड एडिटर पर ले जाया जाएगा.
आपको पहले से भरी हुई main.py और requirements.txt फ़ाइलें दिखेंगी.
main.py में फ़ंक्शन का बिज़नेस लॉजिक होगा और requirements.txt में ज़रूरी पैकेज होंगे.
👉अब हम कुछ कोड लिखने के लिए तैयार हैं! लेकिन आगे बढ़ने से पहले, आइए देखें कि क्या Gemini Code Assist हमारी मदद कर सकता है. Cloud Shell Editor पर वापस जाएं. इसके बाद, सबसे ऊपर मौजूद Gemini Code Assist आइकॉन पर क्लिक करें. इससे Gemini Code Assist चैट खुल जाएगी.
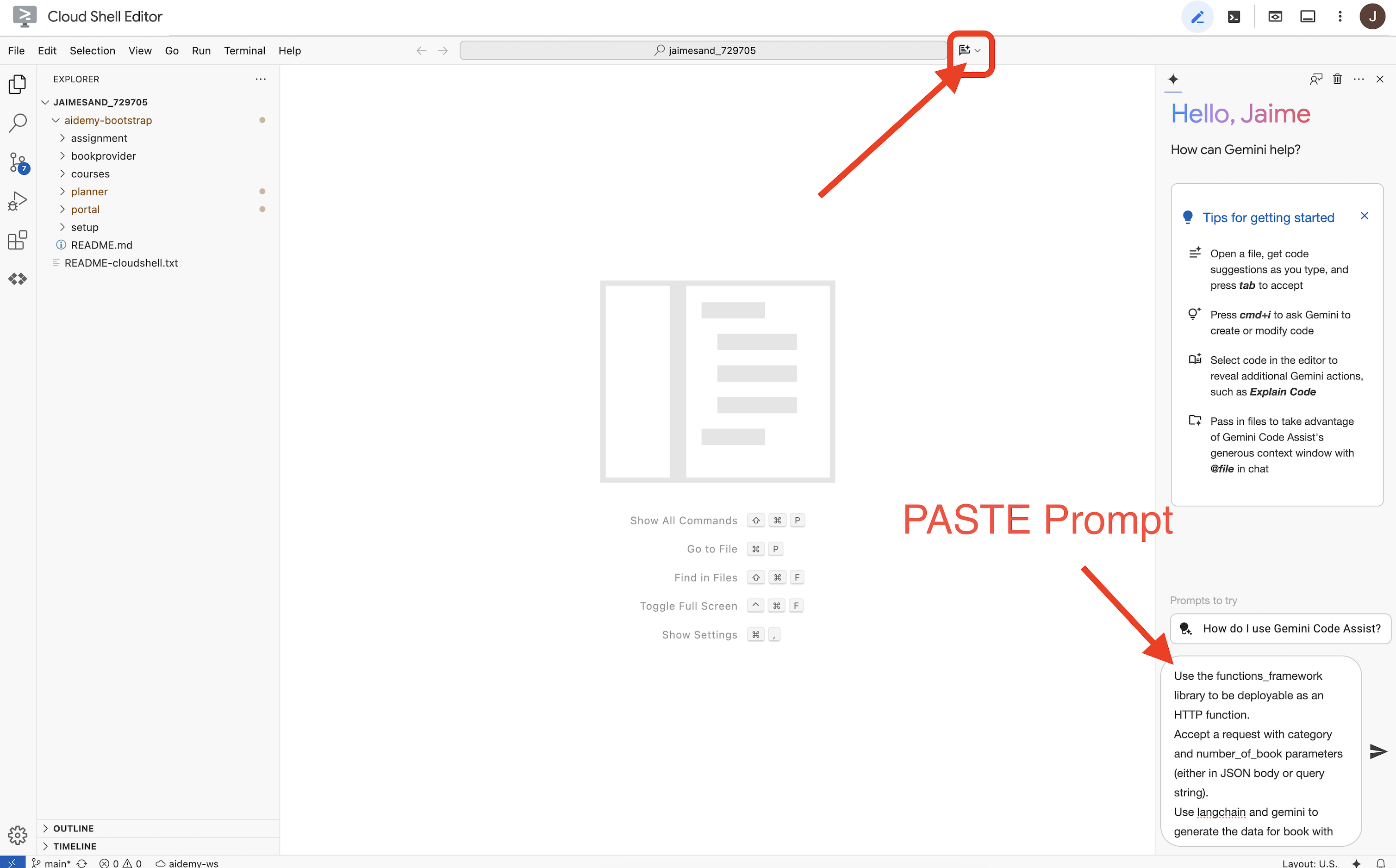
👉 यहां दिए गए अनुरोध को प्रॉम्प्ट बॉक्स में चिपकाएं:
Use the functions_framework library to be deployable as an HTTP function.
Accept a request with category and number_of_book parameters (either in JSON body or query string).
Use langchain and gemini to generate the data for book with fields bookname, author, publisher, publishing_date.
Use pydantic to define a Book model with the fields: bookname (string, description: "Name of the book"), author (string, description: "Name of the author"), publisher (string, description: "Name of the publisher"), and publishing_date (string, description: "Date of publishing").
Use langchain and gemini model to generate book data. the output should follow the format defined in Book model.
The logic should use JsonOutputParser from langchain to enforce output format defined in Book Model.
Have a function get_recommended_books(category) that internally uses langchain and gemini to return a single book object.
The main function, exposed as the Cloud Function, should call get_recommended_books() multiple times (based on number_of_book) and return a JSON list of the generated book objects.
Handle the case where category or number_of_book are missing by returning an error JSON response with a 400 status code.
return a JSON string representing the recommended books. use os library to retrieve GOOGLE_CLOUD_PROJECT env var. Use ChatVertexAI from langchain for the LLM call
इसके बाद, कोड असिस्ट एक संभावित समाधान जनरेट करेगा. इसमें सोर्स कोड और requirements.txt डिपेंडेंसी फ़ाइल, दोनों शामिल होंगी. (इस कोड का इस्तेमाल न करें)
हमारा सुझाव है कि आप कोड असिस्ट की मदद से जनरेट किए गए कोड की तुलना, नीचे दिए गए टेस्ट किए गए सही समाधान से करें. इससे आपको टूल के असर का आकलन करने और संभावित अंतरों का पता लगाने में मदद मिलती है. एलएलएम पर कभी भी पूरी तरह से भरोसा नहीं करना चाहिए. हालांकि, कोड असिस्ट, रैपिड प्रोटोटाइपिंग और शुरुआती कोड स्ट्रक्चर जनरेट करने के लिए एक बेहतरीन टूल हो सकता है. इसलिए, इसका इस्तेमाल शुरुआती तौर पर किया जाना चाहिए.
यह एक वर्कशॉप है. इसलिए, हम यहां दिए गए पुष्टि किए गए कोड का इस्तेमाल करेंगे. हालांकि, कोड की मदद से काम करने की सुविधा से जनरेट किए गए कोड को अपनी सुविधा के हिसाब से आज़माएं. इससे आपको इस सुविधा की क्षमताओं और सीमाओं के बारे में ज़्यादा जानकारी मिलेगी.
👉दूसरे ब्राउज़र टैब में, Cloud Run फ़ंक्शन के सोर्स कोड एडिटर पर वापस जाएं. main.py के मौजूदा कॉन्टेंट को नीचे दिए गए कोड से ध्यान से बदलें:
import functions_framework
import json
from flask import Flask, jsonify, request
from langchain_google_vertexai import ChatVertexAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field
import os
class Book(BaseModel):
bookname: str = Field(description="Name of the book")
author: str = Field(description="Name of the author")
publisher: str = Field(description="Name of the publisher")
publishing_date: str = Field(description="Date of publishing")
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT")
llm = ChatVertexAI(model_name="gemini-2.0-flash-lite-001")
def get_recommended_books(category):
"""
A simple book recommendation function.
Args:
category (str): category
Returns:
str: A JSON string representing the recommended books.
"""
parser = JsonOutputParser(pydantic_object=Book)
question = f"Generate a random made up book on {category} with bookname, author and publisher and publishing_date"
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | llm | parser
response = chain.invoke({"query": question})
return json.dumps(response)
@functions_framework.http
def recommended(request):
request_json = request.get_json(silent=True) # Get JSON data
if request_json and 'category' in request_json and 'number_of_book' in request_json:
category = request_json['category']
number_of_book = int(request_json['number_of_book'])
elif request.args and 'category' in request.args and 'number_of_book' in request.args:
category = request.args.get('category')
number_of_book = int(request.args.get('number_of_book'))
else:
return jsonify({'error': 'Missing category or number_of_book parameters'}), 400
recommendations_list = []
for i in range(number_of_book):
book_dict = json.loads(get_recommended_books(category))
print(f"book_dict=======>{book_dict}")
recommendations_list.append(book_dict)
return jsonify(recommendations_list)
👉requirements.txt के कॉन्टेंट को इससे बदलें:
functions-framework==3.*
google-genai==1.0.0
flask==3.1.0
jsonify==0.5
langchain_google_vertexai==2.0.13
langchain_core==0.3.34
pydantic==2.10.5
👉हम फ़ंक्शन एंट्री पॉइंट को इस तरह सेट करेंगे: recommended
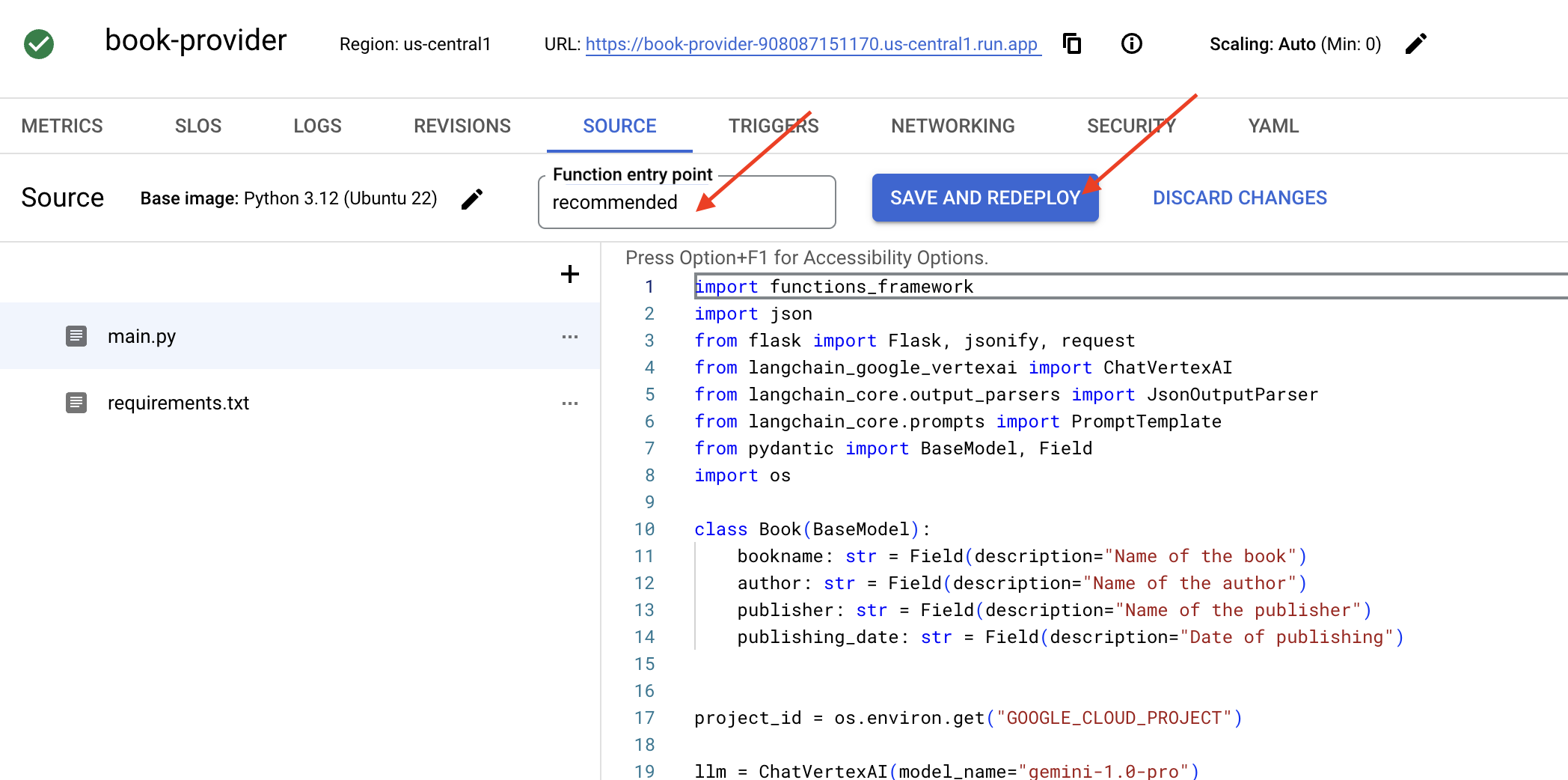
👉फ़ंक्शन को डिप्लॉय करने के लिए, सेव करें और डिप्लॉय करें (या सेव करें और फिर से डिप्लॉय करें) पर क्लिक करें. डप्लॉयमेंट की प्रोसेस पूरी होने तक इंतज़ार करें. Cloud Console में स्टेटस दिखेगा. इसमें कुछ मिनट लग सकते हैं.
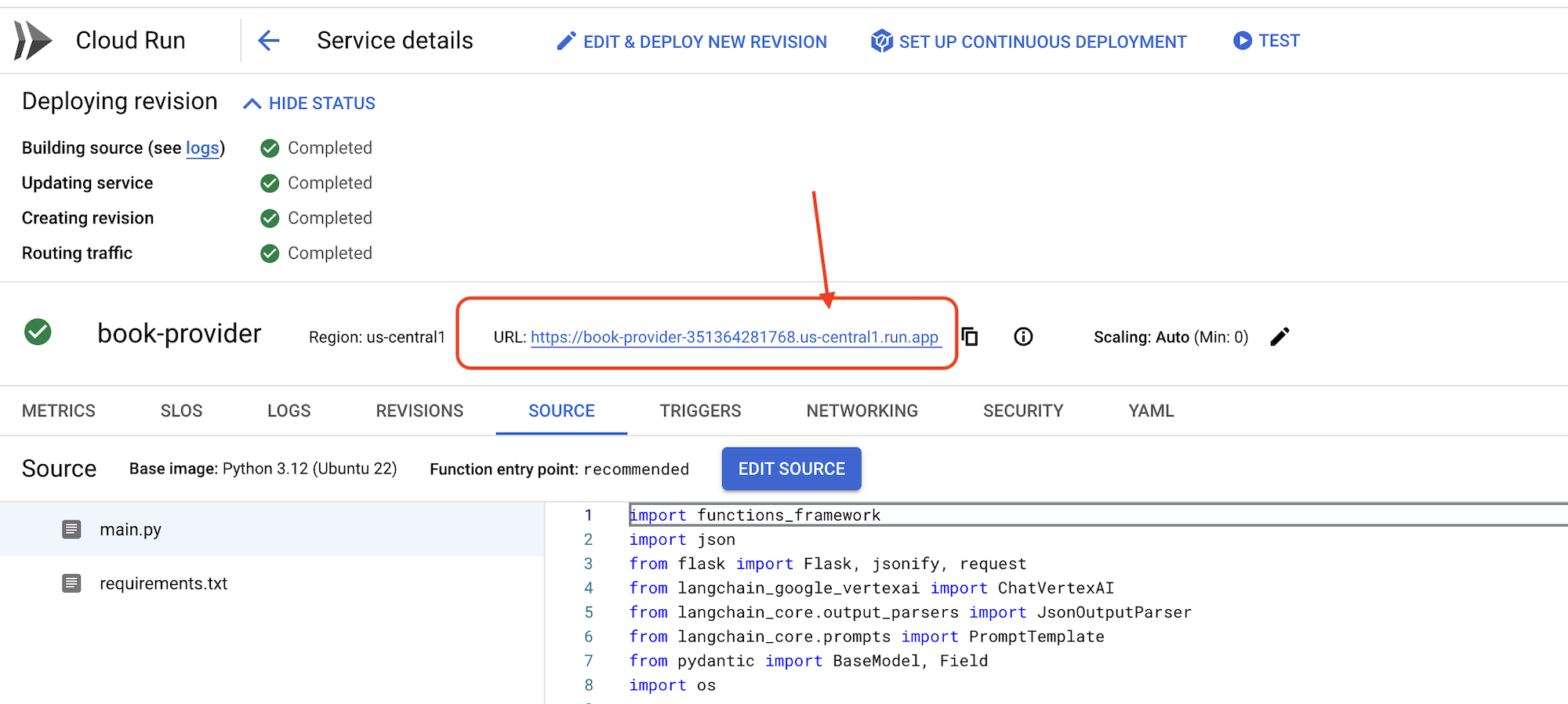 👉डप्लॉय होने के बाद, क्लाउड शेल एडिटर में वापस जाएं. टर्मिनल में यह कमांड चलाएं:
👉डप्लॉय होने के बाद, क्लाउड शेल एडिटर में वापस जाएं. टर्मिनल में यह कमांड चलाएं:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
curl -X POST -H "Content-Type: application/json" -d '{"category": "Science Fiction", "number_of_book": 2}' $BOOK_PROVIDER_URL
इसमें JSON फ़ॉर्मैट में किताब का कुछ डेटा दिखना चाहिए.
[
{"author":"Anya Sharma","bookname":"Echoes of the Singularity","publisher":"NovaLight Publishing","publishing_date":"2077-03-15"},
{"author":"Anya Sharma","bookname":"Echoes of the Quantum Dawn","publisher":"Nova Genesis Publishing","publishing_date":"2077-03-15"}
]
बधाई हो! आपने Cloud Run फ़ंक्शन को डिप्लॉय कर लिया है. यह एक ऐसी सेवा है जिसे हम Aidemy एजेंट को डेवलप करते समय इंटिग्रेट करेंगे.
5. बिल्डिंग टूल: एजेंट को RESTFUL सेवा और डेटा से कनेक्ट करना
चलिए, Bootstrap Skeleton Project को डाउनलोड करते हैं. पक्का करें कि आप Cloud Shell Editor में हों. टर्मिनल रन में,
git clone https://github.com/weimeilin79/aidemy-bootstrap.git
इस कमांड को चलाने के बाद, आपके Cloud Shell एनवायरमेंट में aidemy-bootstrap नाम का एक नया फ़ोल्डर बन जाएगा.
Cloud Shell Editor के एक्सप्लोरर पैनल में (आम तौर पर बाईं ओर), अब आपको वह फ़ोल्डर दिखेगा जो Git रिपॉज़िटरी aidemy-bootstrap को क्लोन करते समय बनाया गया था. एक्सप्लोरर में अपने प्रोजेक्ट का रूट फ़ोल्डर खोलें. आपको इसमें planner सबफ़ोल्डर दिखेगा. इसे भी खोलें. 
आइए, ऐसे टूल बनाना शुरू करें जिनका इस्तेमाल करके हमारे एजेंट, लोगों की बेहतर तरीके से मदद कर पाएंगे. जैसा कि आपको पता है, एलएलएम तर्क करने और टेक्स्ट जनरेट करने में बहुत अच्छे होते हैं. हालाँकि, असल दुनिया के कामों को पूरा करने और सटीक, अप-टू-डेट जानकारी देने के लिए, उन्हें बाहरी संसाधनों का ऐक्सेस चाहिए. इन टूल को एजेंट का "स्विस आर्मी नाइफ़" माना जाता है. इनकी मदद से, एजेंट दुनिया के साथ इंटरैक्ट कर पाता है.
एजेंट बनाते समय, कई सारी जानकारी को हार्ड-कोड करना आसान होता है. इससे एक ऐसा एजेंट बनता है जो लचीला नहीं होता. इसके बजाय, टूल बनाकर और उनका इस्तेमाल करके, एजेंट को बाहरी लॉजिक या सिस्टम का ऐक्सेस मिलता है. इससे उसे एलएलएम और ट्रेडिशनल प्रोग्रामिंग, दोनों के फ़ायदे मिलते हैं.
इस सेक्शन में, हम प्लानर एजेंट के लिए बुनियादी जानकारी तैयार करेंगे. शिक्षक इसका इस्तेमाल, लेसन प्लान जनरेट करने के लिए करेंगे. एजेंट के प्लान जनरेट करने से पहले, हम विषय और टॉपिक के बारे में ज़्यादा जानकारी देकर सीमाएं तय करना चाहते हैं. हम तीन टूल बनाएंगे:
- Restful API कॉल: डेटा वापस पाने के लिए, पहले से मौजूद एपीआई के साथ इंटरैक्ट करना.
- डेटाबेस क्वेरी: Cloud SQL डेटाबेस से स्ट्रक्चर्ड डेटा फ़ेच करना.
- Google Search: वेब से रीयल-टाइम में जानकारी ऐक्सेस करना.
किसी एपीआई से किताबों के सुझाव पाना
सबसे पहले, एक ऐसा टूल बनाते हैं जो पिछले सेक्शन में डिप्लॉय किए गए book-provider API से किताबों के सुझाव वापस लाता है. इससे पता चलता है कि कोई एजेंट, मौजूदा सेवाओं का फ़ायदा कैसे पा सकता है.
Cloud Shell Editor में, उस aidemy-bootstrap प्रोजेक्ट को खोलें जिसे आपने पिछले सेक्शन में क्लोन किया था.
👉planner फ़ोल्डर में मौजूद book.py में बदलाव करें. इसके बाद, फ़ाइल के आखिर में यह कोड चिपकाएं:
def recommend_book(query: str):
"""
Get a list of recommended book from an API endpoint
Args:
query: User's request string
"""
region = get_next_region();
llm = VertexAI(model_name="gemini-1.5-pro", location=region)
query = f"""The user is trying to plan a education course, you are the teaching assistant. Help define the category of what the user requested to teach, respond the categroy with no more than two word.
user request: {query}
"""
print(f"-------->{query}")
response = llm.invoke(query)
print(f"CATEGORY RESPONSE------------>: {response}")
# call this using python and parse the json back to dict
category = response.strip()
headers = {"Content-Type": "application/json"}
data = {"category": category, "number_of_book": 2}
books = requests.post(BOOK_PROVIDER_URL, headers=headers, json=data)
return books.text
if __name__ == "__main__":
print(recommend_book("I'm doing a course for my 5th grade student on Math Geometry, I'll need to recommend few books come up with a teach plan, few quizes and also a homework assignment."))
व्याख्या:
- recommend_book(query: str): यह फ़ंक्शन, उपयोगकर्ता की क्वेरी को इनपुट के तौर पर लेता है.
- एलएलएम इंटरैक्शन: यह क्वेरी से कैटगरी निकालने के लिए, एलएलएम का इस्तेमाल करता है. इसमें दिखाया गया है कि टूल के लिए पैरामीटर बनाने में, एलएलएम का इस्तेमाल कैसे किया जा सकता है.
- एपीआई कॉल: यह बुक-प्रोवाइडर एपीआई को POST अनुरोध करता है. इसमें कैटगरी और किताबों की ज़रूरी संख्या पास की जाती है.
👉इस नए फ़ंक्शन को आज़माने के लिए, एनवायरमेंट वैरिएबल सेट करें और यह कमांड चलाएं :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
cd ~/aidemy-bootstrap/planner/
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
👉डिपेंडेंसी इंस्टॉल करें और कोड चलाएं, ताकि यह पक्का किया जा सके कि कोड काम कर रहा है. इसके लिए, यह कमांड चलाएं:
cd ~/aidemy-bootstrap/planner/
python -m venv env
source env/bin/activate
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python book.py
आपको एक JSON स्ट्रिंग दिखेगी. इसमें, किताब उपलब्ध कराने वाली कंपनी के एपीआई से मिली किताबों के सुझाव होंगे. नतीजे रैंडम तरीके से जनरेट किए जाते हैं. ऐसा हो सकता है कि आपकी किताबें एक जैसी न हों, लेकिन आपको JSON फ़ॉर्मैट में किताबों के दो सुझाव मिलने चाहिए.
[{"author":"Anya Sharma","bookname":"Echoes of the Singularity","publisher":"NovaLight Publishing","publishing_date":"2077-03-15"},{"author":"Anya Sharma","bookname":"Echoes of the Quantum Dawn","publisher":"Nova Genesis Publishing","publishing_date":"2077-03-15"}]
अगर आपको यह दिखता है, तो इसका मतलब है कि पहला टूल सही तरीके से काम कर रहा है!
यहां हम खास पैरामीटर के साथ RESTful API कॉल बनाने के बजाय, सामान्य भाषा ("मैं एक कोर्स कर रहा हूं...") का इस्तेमाल कर रहे हैं. इसके बाद, एजेंट एनएलपी का इस्तेमाल करके ज़रूरी पैरामीटर (जैसे, कैटगरी) को समझदारी से निकालता है. इससे यह पता चलता है कि एजेंट, एपीआई के साथ इंटरैक्ट करने के लिए, आम बोलचाल की भाषा को समझने की सुविधा का इस्तेमाल कैसे करता है.
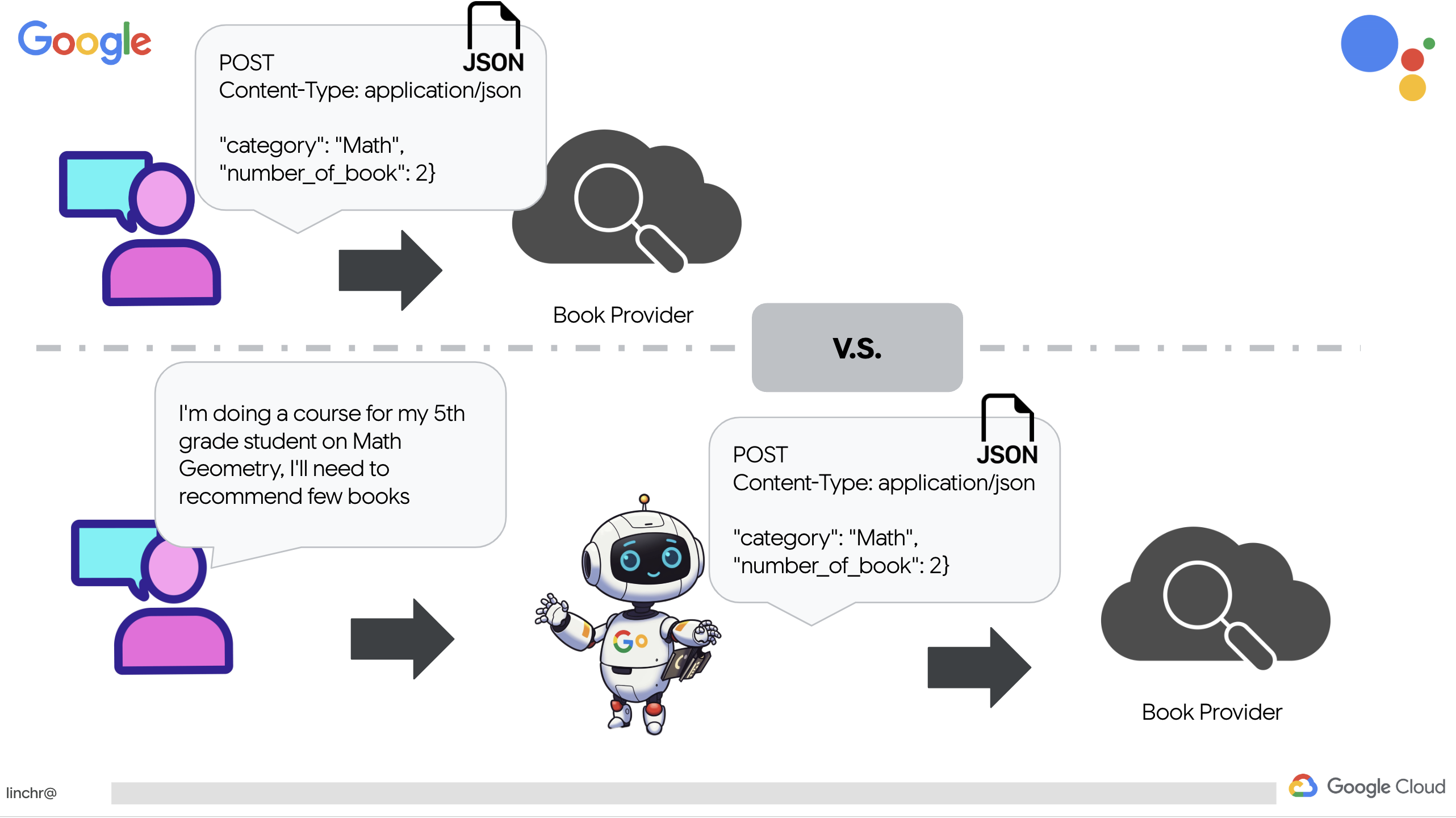
👉हटाएं book.py से यह टेस्टिंग कोड
if __name__ == "__main__":
print(recommend_book("I'm doing a course for my 5th grade student on Math Geometry, I'll need to recommend few books come up with a teach plan, few quizes and also a homework assignment."))
डेटाबेस से पाठ्यक्रम का डेटा पाना
इसके बाद, हम एक ऐसा टूल बनाएंगे जो Cloud SQL PostgreSQL डेटाबेस से, स्ट्रक्चर्ड करिकुलम डेटा को फ़ेच करेगा. इससे एजेंट को, लेसन प्लान बनाने के लिए भरोसेमंद सोर्स से जानकारी ऐक्सेस करने की अनुमति मिलती है.
क्या आपको पिछले चरण में बनाया गया aidemy Cloud SQL इंस्टेंस याद है? इसका इस्तेमाल यहां किया जाएगा.
👉 नए इंस्टेंस में aidemy-db नाम का डेटाबेस बनाने के लिए, टर्मिनल में यह कमांड चलाएं.
gcloud sql databases create aidemy-db \
--instance=aidemy
आइए, Google Cloud Console में Cloud SQL में जाकर इंस्टेंस की पुष्टि करें. आपको aidemy नाम का Cloud SQL इंस्टेंस दिखेगा.
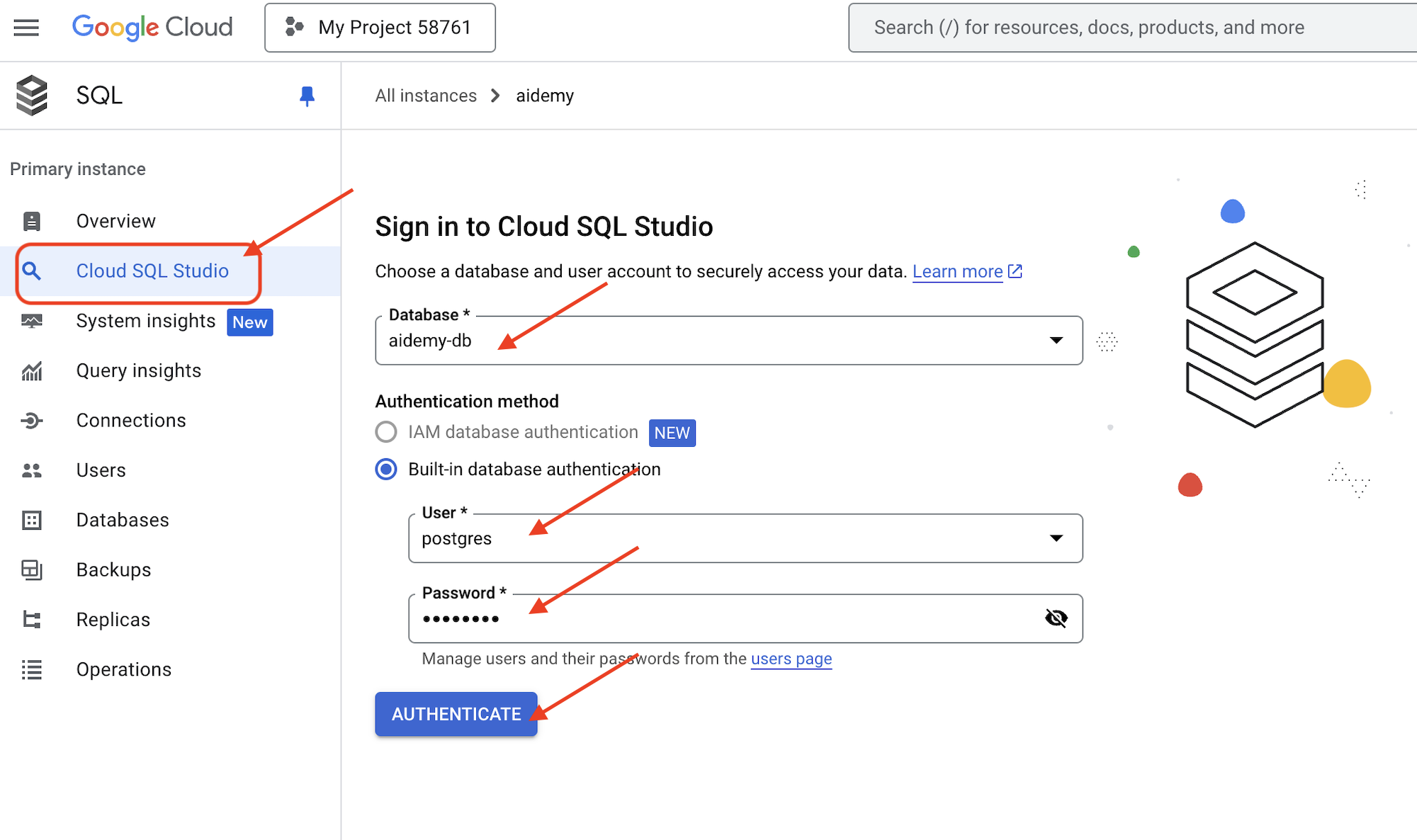
👉 इंस्टेंस की जानकारी देखने के लिए, उसके नाम पर क्लिक करें. 👉 Cloud SQL इंस्टेंस की जानकारी वाले पेज पर, बाईं ओर दिए गए नेविगेशन मेन्यू में जाकर, Cloud SQL Studio पर क्लिक करें. इससे एक नया टैब खुलेगा.
डेटाबेस के तौर पर aidemy-db चुनें. उपयोगकर्ता के तौर पर postgres और पासवर्ड के तौर पर 1234qwer डालें.
पुष्टि करें पर क्लिक करें
👉SQL Studio के क्वेरी एडिटर में, Editor 1 टैब पर जाएं और यह एसक्यूएल कोड चिपकाएं:
CREATE TABLE curriculums (
id SERIAL PRIMARY KEY,
year INT,
subject VARCHAR(255),
description TEXT
);
-- Inserting detailed curriculum data for different school years and subjects
INSERT INTO curriculums (year, subject, description) VALUES
-- Year 5
(5, 'Mathematics', 'Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.'),
(5, 'English', 'Developing reading comprehension, creative writing, and basic grammar, with a focus on storytelling and poetry.'),
(5, 'Science', 'Exploring basic physics, chemistry, and biology concepts, including forces, materials, and ecosystems.'),
(5, 'Computer Science', 'Basic coding concepts using block-based programming and an introduction to digital literacy.'),
-- Year 6
(6, 'Mathematics', 'Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.'),
(6, 'English', 'Introduction to persuasive writing, character analysis, and deeper comprehension of literary texts.'),
(6, 'Science', 'Forces and motion, the human body, and introductory chemical reactions with hands-on experiments.'),
(6, 'Computer Science', 'Introduction to algorithms, logical reasoning, and basic text-based programming (Python, Scratch).'),
-- Year 7
(7, 'Mathematics', 'Algebraic expressions, geometry, and introduction to statistics and probability.'),
(7, 'English', 'Analytical reading of classic and modern literature, essay writing, and advanced grammar skills.'),
(7, 'Science', 'Introduction to cells and organisms, chemical reactions, and energy transfer in physics.'),
(7, 'Computer Science', 'Building on programming skills with Python, introduction to web development, and cyber safety.');
यह SQL कोड, curriculums नाम की एक टेबल बनाता है और उसमें कुछ सैंपल डेटा डालता है.
👉 एसक्यूएल कोड को लागू करने के लिए, चलाएं पर क्लिक करें. आपको एक मैसेज दिखेगा. इसमें पुष्टि की जाएगी कि स्टेटमेंट को सही तरीके से लागू किया गया है.
👉 एक्सप्लोरर को बड़ा करें. इसके बाद, नई बनाई गई टेबल curriculums ढूंढें और क्वेरी पर क्लिक करें. इससे एक नया एडिटर टैब खुलना चाहिए, जिसमें आपके लिए जनरेट किया गया एसक्यूएल मौजूद हो,
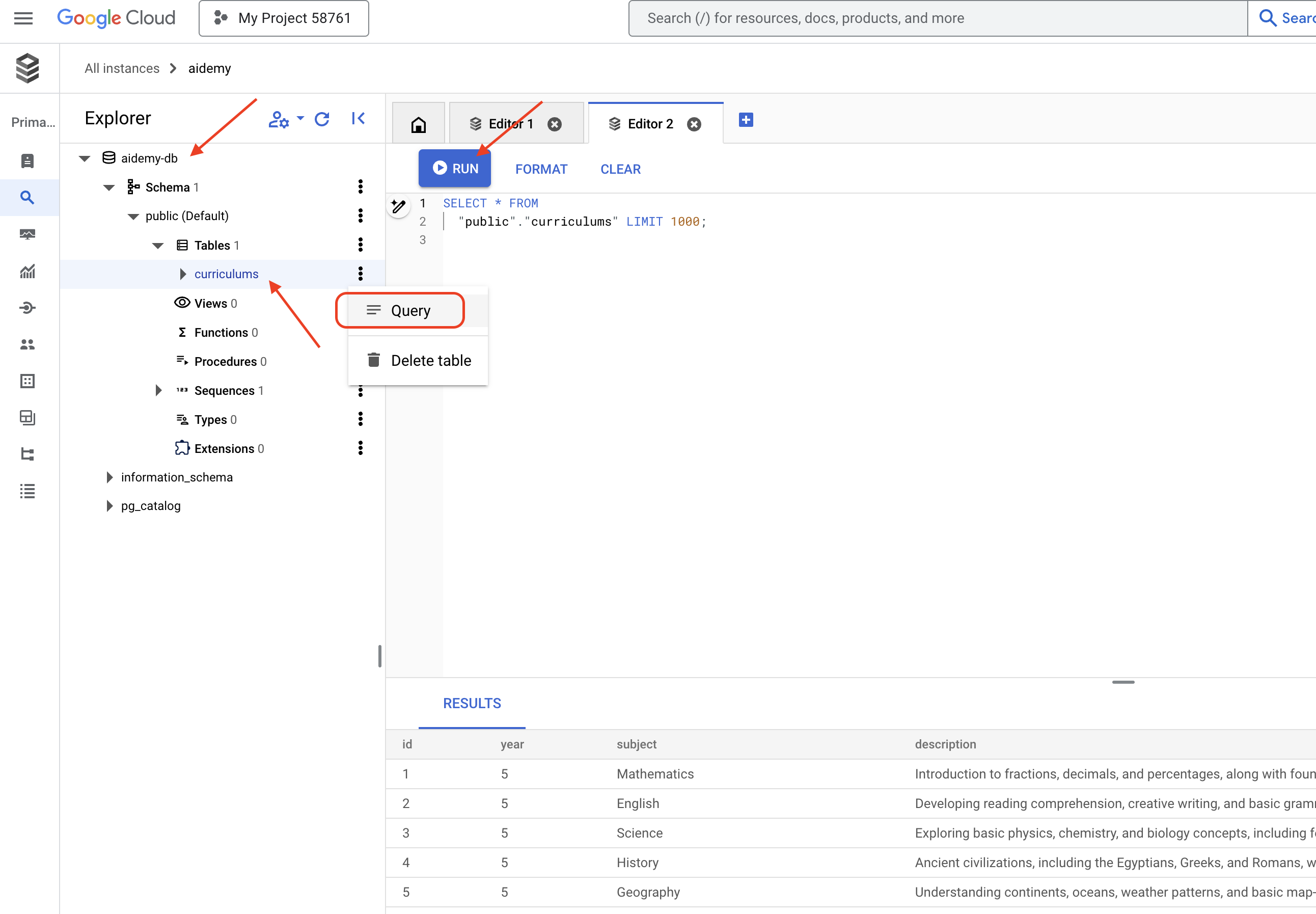
SELECT * FROM
"public"."curriculums" LIMIT 1000;
👉चलाएं पर क्लिक करें.
नतीजों की टेबल में, पिछले चरण में डाला गया डेटा दिखना चाहिए. इससे यह पुष्टि होती है कि टेबल और डेटा सही तरीके से बनाया गया है.
आपने सैंपल पाठ्यक्रम के डेटा के साथ डेटाबेस बना लिया है. अब हम इसे वापस पाने के लिए एक टूल बनाएंगे.
👉क्लाउड कोड एडिटर में, aidemy-bootstrap फ़ोल्डर में मौजूद curriculums.py फ़ाइल में बदलाव करें. इसके बाद, फ़ाइल के आखिर में यह कोड चिपकाएं:
def connect_with_connector() -> sqlalchemy.engine.base.Engine:
db_user = os.environ["DB_USER"]
db_pass = os.environ["DB_PASS"]
db_name = os.environ["DB_NAME"]
print(f"--------------------------->db_user: {db_user!r}")
print(f"--------------------------->db_pass: {db_pass!r}")
print(f"--------------------------->db_name: {db_name!r}")
connector = Connector()
pool = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=lambda: connector.connect(
instance_connection_name,
"pg8000",
user=db_user,
password=db_pass,
db=db_name,
),
pool_size=2,
max_overflow=2,
pool_timeout=30, # 30 seconds
pool_recycle=1800, # 30 minutes
)
return pool
def get_curriculum(year: int, subject: str):
"""
Get school curriculum
Args:
subject: User's request subject string
year: User's request year int
"""
try:
stmt = sqlalchemy.text(
"SELECT description FROM curriculums WHERE year = :year AND subject = :subject"
)
with db.connect() as conn:
result = conn.execute(stmt, parameters={"year": year, "subject": subject})
row = result.fetchone()
if row:
return row[0]
else:
return None
except Exception as e:
print(e)
return None
db = connect_with_connector()
व्याख्या:
- एनवायरमेंट वैरिएबल: कोड, एनवायरमेंट वैरिएबल से डेटाबेस क्रेडेंशियल और कनेक्शन की जानकारी को फिर से हासिल करता है. इसके बारे में यहां ज़्यादा जानकारी दी गई है.
- connect_with_connector(): यह फ़ंक्शन, Cloud SQL कनेक्टर का इस्तेमाल करके डेटाबेस से सुरक्षित कनेक्शन बनाता है.
- get_curriculum(year: int, subject: str): यह फ़ंक्शन, साल और विषय को इनपुट के तौर पर लेता है. साथ ही, यह पाठ्यक्रम की टेबल से क्वेरी करता है और उससे जुड़ी जानकारी दिखाता है.
👉कोड चलाने से पहले, हमें कुछ एनवायरमेंट वैरिएबल सेट करने होंगे. इसके लिए, टर्मिनल में यह कमांड चलाएं:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉जांच करने के लिए, curriculums.py के आखिर में यह कोड जोड़ें:
if __name__ == "__main__":
print(get_curriculum(6, "Mathematics"))
👉कोड चलाएं:
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python curriculums.py
आपको कंसोल पर, छठी कक्षा के गणित के पाठ्यक्रम की जानकारी दिखेगी.
Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.
अगर आपको पाठ्यक्रम का ब्यौरा दिखता है, तो इसका मतलब है कि डेटाबेस टूल ठीक से काम कर रहा है! अगर स्क्रिप्ट अब भी चल रही है, तो Ctrl+C दबाकर उसे रोकें.
👉हटाएं curriculums.py से यह टेस्टिंग कोड
if __name__ == "__main__":
print(get_curriculum(6, "Mathematics"))
👉वर्चुअल एनवायरमेंट से बाहर निकलने के लिए, टर्मिनल में यह कमांड चलाएं:
deactivate
6. बिल्डिंग टूल: वेब से रीयल-टाइम में जानकारी ऐक्सेस करना
आखिर में, हम एक ऐसा टूल बनाएंगे जो Gemini 2 और Google Search इंटिग्रेशन का इस्तेमाल करके, वेब से रीयल-टाइम में जानकारी ऐक्सेस करेगा. इससे एजेंट को अप-टू-डेट रहने और काम के नतीजे देने में मदद मिलती है.
Google Search API के साथ Gemini 2 के इंटिग्रेशन से, एजेंट की क्षमताओं को बेहतर बनाया जा सकता है. इससे, खोज के ज़्यादा सटीक और कॉन्टेक्स्ट के हिसाब से काम के नतीजे मिलते हैं. इससे एजेंट, अप-टू-डेट जानकारी ऐक्सेस कर पाते हैं. साथ ही, वे अपने जवाबों में असल दुनिया के डेटा को शामिल कर पाते हैं. इससे, गलत जानकारी देने की संभावना कम हो जाती है. एपीआई इंटिग्रेशन को बेहतर बनाने से, आम भाषा में क्वेरी करने की सुविधा भी मिलती है. इससे एजेंट, खोज के लिए मुश्किल और बारीकी से तैयार किए गए अनुरोध कर पाते हैं.
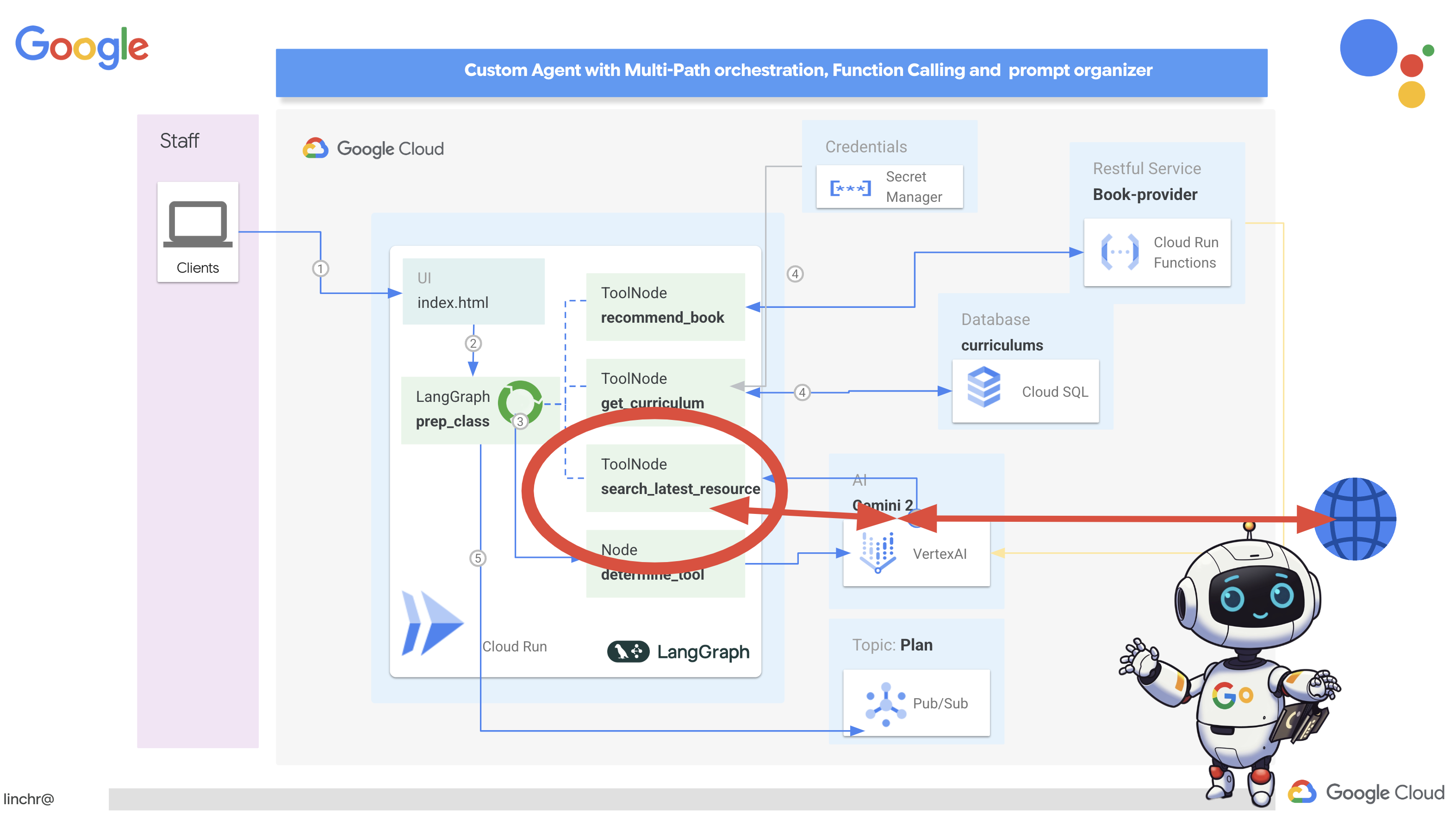
यह फ़ंक्शन, खोज क्वेरी, पाठ्यक्रम, विषय, और साल को इनपुट के तौर पर लेता है. इसके बाद, Gemini API और Google Search टूल का इस्तेमाल करके, इंटरनेट से काम की जानकारी हासिल करता है. ध्यान से देखने पर पता चलता है कि यह फ़ंक्शन कॉलिंग के लिए, Google Generative AI SDK का इस्तेमाल कर रहा है. इसके लिए, किसी अन्य फ़्रेमवर्क का इस्तेमाल नहीं किया जा रहा है.
👉aidemy-bootstrap फ़ोल्डर में मौजूद search.py में बदलाव करें और फ़ाइल के आखिर में यह कोड चिपकाएं:
model_id = "gemini-2.0-flash-001"
google_search_tool = Tool(
google_search = GoogleSearch()
)
def search_latest_resource(search_text: str, curriculum: str, subject: str, year: int):
"""
Get latest information from the internet
Args:
search_text: User's request category string
subject: "User's request subject" string
year: "User's request year" integer
"""
search_text = "%s in the context of year %d and subject %s with following curriculum detail %s " % (search_text, year, subject, curriculum)
region = get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
print(f"search_latest_resource text-----> {search_text}")
response = client.models.generate_content(
model=model_id,
contents=search_text,
config=GenerateContentConfig(
tools=[google_search_tool],
response_modalities=["TEXT"],
)
)
print(f"search_latest_resource response-----> {response}")
return response
if __name__ == "__main__":
response = search_latest_resource("What are the syllabus for Year 6 Mathematics?", "Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.", "Mathematics", 6)
for each in response.candidates[0].content.parts:
print(each.text)
व्याख्या:
- टूल को तय करना - google_search_tool: GoogleSearch ऑब्जेक्ट को टूल में रैप करना
- search_latest_resource(search_text: str, subject: str, year: int): यह फ़ंक्शन, खोज क्वेरी, विषय, और साल को इनपुट के तौर पर लेता है. साथ ही, Google पर खोज करने के लिए Gemini API का इस्तेमाल करता है.
- GenerateContentConfig: यह तय करें कि इसके पास GoogleSearch टूल का ऐक्सेस है
Gemini मॉडल, search_text का अंदरूनी तौर पर विश्लेषण करता है. इससे यह तय होता है कि वह सवाल का जवाब सीधे तौर पर दे सकता है या उसे GoogleSearch टूल का इस्तेमाल करना होगा. यह एक अहम चरण है, जो एलएलएम की तर्क करने की प्रोसेस के दौरान होता है. मॉडल को इस तरह से ट्रेन किया गया है कि वह उन स्थितियों को पहचान सके जहां बाहरी टूल का इस्तेमाल करना ज़रूरी है. अगर मॉडल, GoogleSearch टूल का इस्तेमाल करने का फ़ैसला लेता है, तो Google Generative AI SDK, टूल को चालू करने की प्रोसेस को मैनेज करता है. एसडीके, मॉडल के फ़ैसले और जनरेट किए गए पैरामीटर को लेता है. इसके बाद, उन्हें Google Search API को भेजता है. कोड में, इस हिस्से को उपयोगकर्ता से छिपाया गया है.
इसके बाद, Gemini मॉडल, खोज के नतीजों को अपने जवाब में शामिल करता है. यह जानकारी का इस्तेमाल, उपयोगकर्ता के सवाल का जवाब देने, खास जानकारी जनरेट करने या कोई अन्य काम करने के लिए कर सकता है.
👉जांच करने के लिए, यह कोड चलाएं:
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
source env/bin/activate
python search.py
आपको Gemini Search API से मिला जवाब दिखेगा. इसमें "पांचवीं कक्षा के गणित का सिलेबस" से जुड़े खोज नतीजे शामिल होंगे. सटीक आउटपुट, खोज के नतीजों पर निर्भर करेगा. हालांकि, यह खोज के बारे में जानकारी देने वाला JSON ऑब्जेक्ट होगा.
अगर आपको खोज के नतीजे दिखते हैं, तो इसका मतलब है कि Google Search टूल ठीक से काम कर रहा है! अगर स्क्रिप्ट अब भी चल रही है, तो Ctrl+C दबाकर उसे रोकें.
👉इसके बाद, कोड का आखिरी हिस्सा हटाएं.
if __name__ == "__main__":
response = search_latest_resource("What are the syllabus for Year 6 Mathematics?", "Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.", "Mathematics", 6)
for each in response.candidates[0].content.parts:
print(each.text)
👉वर्चुअल एनवायरमेंट से बाहर निकलने के लिए, टर्मिनल में यह कमांड चलाएं:
deactivate
बधाई हो! आपने अब प्लानर एजेंट के लिए तीन बेहतरीन टूल बना लिए हैं: एपीआई कनेक्टर, डेटाबेस कनेक्टर, और Google Search टूल. इन टूल की मदद से एजेंट, ज़रूरी जानकारी और सुविधाओं को ऐक्सेस कर पाएगा. इससे वह बेहतर तरीके से पढ़ाने के प्लान बना पाएगा.
7. LangGraph की मदद से ऑर्केस्ट्रेशन करना
अब जब हमने अपने अलग-अलग टूल बना लिए हैं, तो अब समय है कि हम LangGraph का इस्तेमाल करके उन्हें व्यवस्थित करें. इससे हमें ज़्यादा बेहतर "प्लानर" एजेंट बनाने में मदद मिलेगी. यह एजेंट, उपयोगकर्ता के अनुरोध के आधार पर यह तय कर पाएगा कि कौनसे टूल का इस्तेमाल कब करना है.
LangGraph, Python लाइब्रेरी है. इसे लार्ज लैंग्वेज मॉडल (एलएलएम) का इस्तेमाल करके, स्टेटफ़ुल और मल्टी-ऐक्टर ऐप्लिकेशन को आसानी से बनाने के लिए डिज़ाइन किया गया है. इसे एलएलएम, टूल, और अन्य एजेंटों को शामिल करके, जटिल बातचीत और वर्कफ़्लो को व्यवस्थित करने के लिए एक फ़्रेमवर्क के तौर पर देखें.
मुख्य सिद्धांत:
- ग्राफ़ स्ट्रक्चर: LangGraph, आपके ऐप्लिकेशन के लॉजिक को डायरेक्टेड ग्राफ़ के तौर पर दिखाता है. ग्राफ़ में मौजूद हर नोड, प्रोसेस के एक चरण को दिखाता है. जैसे, एलएलएम को कॉल करना, टूल शुरू करना, शर्त की जांच करना. किनारे, नोड के बीच एक्ज़ीक्यूशन के फ़्लो को तय करते हैं.
- स्टेट: LangGraph, आपके ऐप्लिकेशन की स्टेट को मैनेज करता है, ताकि वह ग्राफ़ में आगे बढ़ सके. इस स्थिति में, कई तरह के वैरिएबल शामिल हो सकते हैं. जैसे, उपयोगकर्ता का इनपुट, टूल कॉल के नतीजे, एलएलएम से मिले इंटरमीडिएट आउटपुट, और कोई भी ऐसी जानकारी जिसे चरणों के बीच सुरक्षित रखना ज़रूरी है.
- नोड: हर नोड, कंप्यूटेशन या इंटरैक्शन को दिखाता है. ये हो सकते हैं:
- टूल नोड: किसी टूल का इस्तेमाल करना. जैसे, वेब खोज करना, डेटाबेस से क्वेरी करना
- फ़ंक्शन नोड: Python फ़ंक्शन को लागू करता है.
- एज: ये नोड को कनेक्ट करते हैं और प्रोग्राम के चलने का क्रम तय करते हैं. ये हो सकते हैं:
- सीधे तौर पर जुड़े एज: एक नोड से दूसरे नोड तक बिना किसी शर्त के फ़्लो.
- शर्त के आधार पर तय होने वाले एज: फ़्लो, शर्त के आधार पर तय होने वाले नोड के नतीजे पर निर्भर करता है.
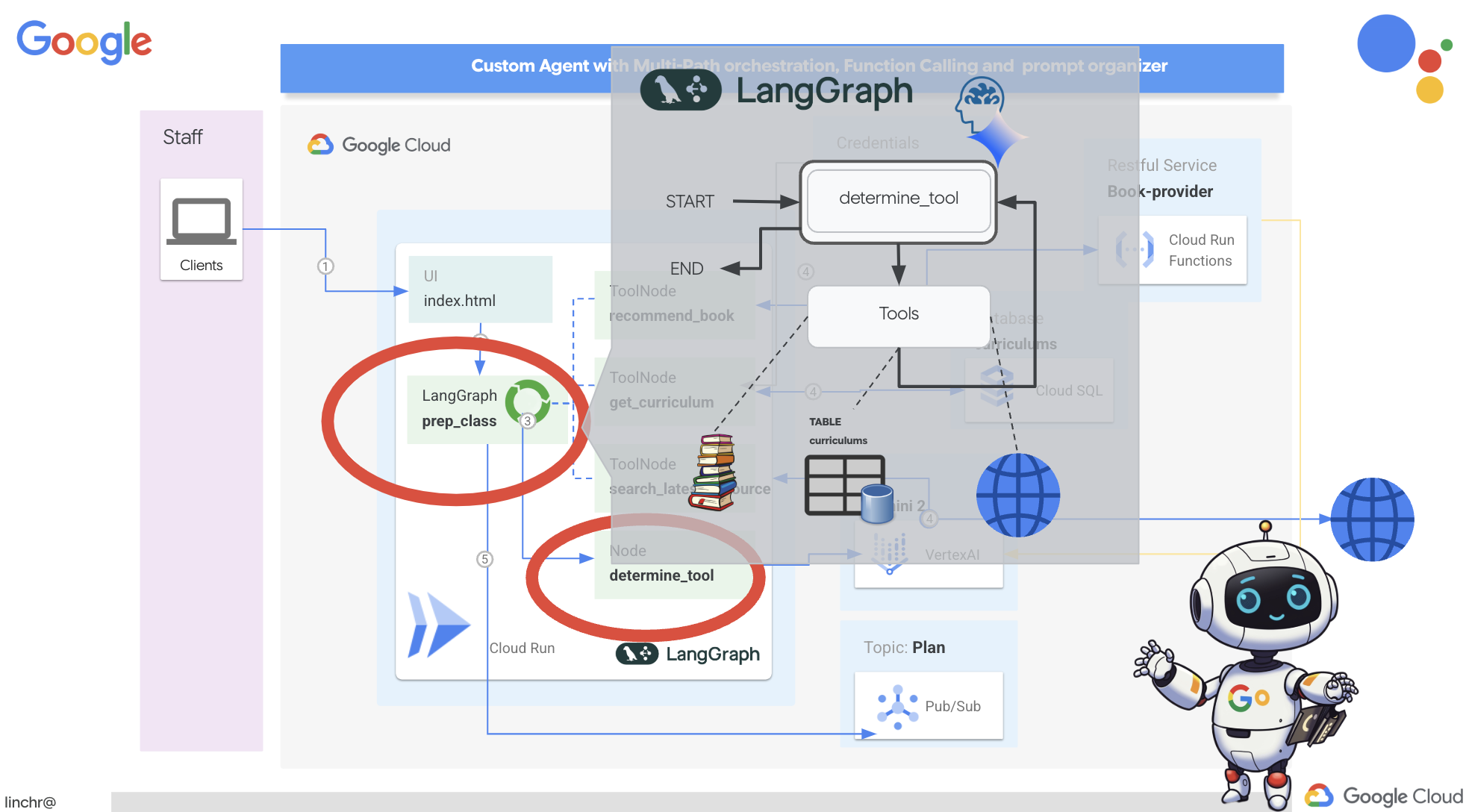
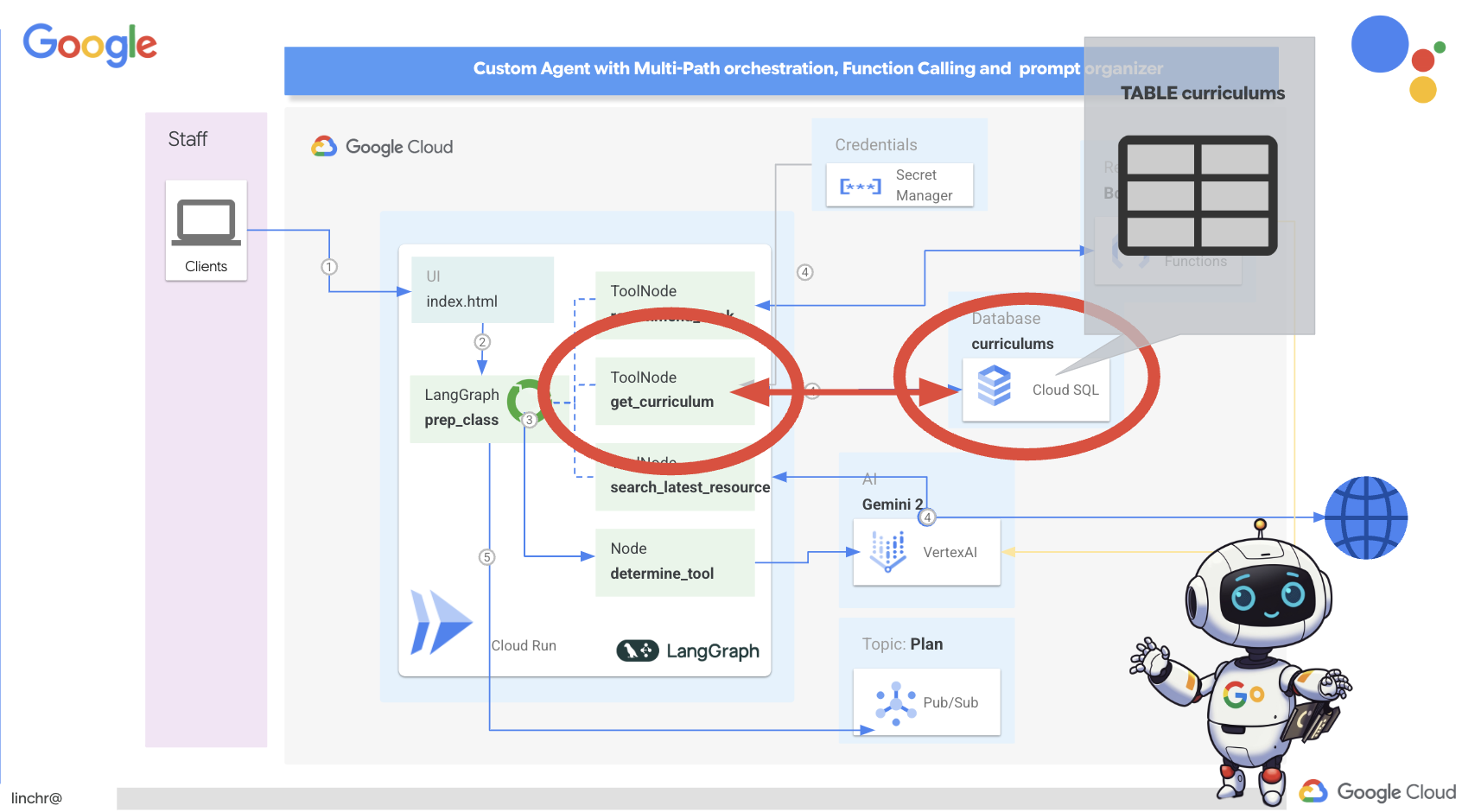
हम ऑर्केस्ट्रेशन को लागू करने के लिए, LangGraph का इस्तेमाल करेंगे. LangGraph लॉजिक को तय करने के लिए, aidemy.py फ़ोल्डर में मौजूद aidemy.py फ़ाइल में बदलाव करते हैं.aidemy-bootstrap
👉 नीचे दिए गए कोड को के आखिर में जोड़ें
aidemy.py:
tools = [get_curriculum, search_latest_resource, recommend_book]
def determine_tool(state: MessagesState):
llm = ChatVertexAI(model_name="gemini-2.0-flash-001", location=get_next_region())
sys_msg = SystemMessage(
content=(
f"""You are a helpful teaching assistant that helps gather all needed information.
Your ultimate goal is to create a detailed 3-week teaching plan.
You have access to tools that help you gather information.
Based on the user request, decide which tool(s) are needed.
"""
)
)
llm_with_tools = llm.bind_tools(tools)
return {"messages": llm_with_tools.invoke([sys_msg] + state["messages"])}
यह फ़ंक्शन, बातचीत की मौजूदा स्थिति को समझने, एलएलएम को सिस्टम मैसेज देने, और फिर एलएलएम से जवाब जनरेट करने के लिए कहता है. एलएलएम, सीधे तौर पर उपयोगकर्ता को जवाब दे सकता है या उपलब्ध टूल में से किसी एक का इस्तेमाल कर सकता है.
टूल : इस सूची में, एजेंट के लिए उपलब्ध टूल का सेट दिखाया गया है. इसमें तीन टूल फ़ंक्शन शामिल हैं, जिन्हें हमने पिछले चरणों में तय किया था: get_curriculum, search_latest_resource, और recommend_book. llm.bind_tools(tools): यह टूल की सूची को llm ऑब्जेक्ट से "बाइंड" करता है. टूल को बाइंड करने से, एलएलएम को यह पता चलता है कि ये टूल उपलब्ध हैं.साथ ही, एलएलएम को यह जानकारी मिलती है कि इनका इस्तेमाल कैसे किया जाए. जैसे, टूल के नाम, वे पैरामीटर जिन्हें वे स्वीकार करते हैं, और वे क्या करते हैं.
हम ऑर्केस्ट्रेशन को लागू करने के लिए, LangGraph का इस्तेमाल करेंगे.
👉 नीचे दिए गए कोड को के आखिर में जोड़ें
aidemy.py:
def prep_class(prep_needs):
builder = StateGraph(MessagesState)
builder.add_node("determine_tool", determine_tool)
builder.add_node("tools", ToolNode(tools))
builder.add_edge(START, "determine_tool")
builder.add_conditional_edges("determine_tool",tools_condition)
builder.add_edge("tools", "determine_tool")
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "1"}}
messages = graph.invoke({"messages": prep_needs},config)
print(messages)
for m in messages['messages']:
m.pretty_print()
teaching_plan_result = messages["messages"][-1].content
return teaching_plan_result
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, , get school curriculum, and come up with few books recommendation plus search latest resources on the internet base on the curriculum outcome. And come up with a 3 week teaching plan")
व्याख्या:
StateGraph(MessagesState): यहStateGraphऑब्जेक्ट बनाता है. LangGraph मेंStateGraphएक मुख्य कॉन्सेप्ट है. यह आपके एजेंट के वर्कफ़्लो को ग्राफ़ के तौर पर दिखाता है. ग्राफ़ में मौजूद हर नोड, प्रोसेस के एक चरण को दिखाता है. इसे इस तरह समझें कि यह एजेंट के काम करने के तरीके का ब्लूप्रिंट तय करता है.- शर्त के हिसाब से तय होने वाला किनारा:
"determine_tool"नोड से शुरू होने वालाtools_conditionआर्ग्युमेंट, ऐसा फ़ंक्शन हो सकता है जोdetermine_toolफ़ंक्शन के आउटपुट के आधार पर यह तय करता है कि किस किनारे को फ़ॉलो करना है. शर्त के हिसाब से तय होने वाले एज, ग्राफ़ को इस आधार पर ब्रांच करने की अनुमति देते हैं कि एलएलएम को कौनसे टूल का इस्तेमाल करना है या उपयोगकर्ता को सीधे जवाब देना है या नहीं. यहां एजेंट की "इंटेलिजेंस" काम आती है. यह स्थिति के हिसाब से अपने व्यवहार को डाइनैमिक तरीके से बदल सकता है. - लूप: यह ग्राफ़ में एक ऐसा किनारा जोड़ता है जो
"tools"नोड को वापस"determine_tool"नोड से कनेक्ट करता है. इससे ग्राफ़ में एक लूप बन जाता है. इससे एजेंट, टास्क पूरा करने और संतोषजनक जवाब देने के लिए ज़रूरी जानकारी इकट्ठा होने तक, बार-बार टूल का इस्तेमाल कर सकता है. यह लूप, मुश्किल कामों के लिए ज़रूरी है. इसके लिए, कई चरणों में रीज़निंग और जानकारी इकट्ठा करने की ज़रूरत होती है.
अब, हम अपने प्लानर एजेंट को टेस्ट करते हैं, ताकि यह देखा जा सके कि वह अलग-अलग टूल को कैसे व्यवस्थित करता है.
यह कोड, prep_class फ़ंक्शन को किसी खास उपयोगकर्ता के इनपुट के साथ चलाएगा. इससे, पांचवीं कक्षा के गणित के लिए ज्यामिति का टीचिंग प्लान बनाने के अनुरोध का सिम्युलेशन किया जाएगा. इसके लिए, पाठ्यक्रम, किताबों के सुझाव, और इंटरनेट पर उपलब्ध नए संसाधनों का इस्तेमाल किया जाएगा.
👉 अगर आपने टर्मिनल बंद कर दिया है या एनवायरमेंट वैरिएबल अब सेट नहीं हैं, तो अपने टर्मिनल में जाकर ये कमांड फिर से चलाएं
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉कोड चलाएं:
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
pip install -r requirements.txt
python aidemy.py
टर्मिनल में लॉग इन करें. आपको इस बात का सबूत दिखना चाहिए कि एजेंट, पढ़ाने का प्लान बनाने से पहले तीनों टूल का इस्तेमाल कर रहा है. जैसे, स्कूल का पाठ्यक्रम, किताबों के सुझाव, और नए संसाधन ढूंढना. इससे पता चलता है कि LangGraph ऑर्केस्ट्रेशन सही तरीके से काम कर रहा है. साथ ही, एजेंट, उपयोगकर्ता के अनुरोध को पूरा करने के लिए, उपलब्ध सभी टूल का समझदारी से इस्तेमाल कर रहा है.
================================ Human Message =================================
I'm doing a course for year 5 on subject Mathematics in Geometry, , get school curriculum, and come up with few books recommendation plus search latest resources on the internet base on the curriculum outcome. And come up with a 3 week teaching plan
================================== Ai Message ==================================
Tool Calls:
get_curriculum (xxx)
Call ID: xxx
Args:
year: 5.0
subject: Mathematics
================================= Tool Message =================================
Name: get_curriculum
Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.
================================== Ai Message ==================================
Tool Calls:
search_latest_resource (xxxx)
Call ID: xxxx
Args:
year: 5.0
search_text: Geometry
curriculum: {"content": "Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques."}
subject: Mathematics
================================= Tool Message =================================
Name: search_latest_resource
candidates=[Candidate(content=Content(parts=[Part(.....) automatic_function_calling_history=[] parsed=None
================================== Ai Message ==================================
Tool Calls:
recommend_book (93b48189-4d69-4c09-a3bd-4e60cdc5f1c6)
Call ID: 93b48189-4d69-4c09-a3bd-4e60cdc5f1c6
Args:
query: Mathematics Geometry Year 5
================================= Tool Message =================================
Name: recommend_book
[{.....}]
================================== Ai Message ==================================
Based on the curriculum outcome, here is a 3-week teaching plan for year 5 Mathematics Geometry:
**Week 1: Introduction to Shapes and Properties**
.........
अगर स्क्रिप्ट अब भी चल रही है, तो Ctrl+C दबाकर उसे रोकें.
👉 (यह चरण ज़रूरी नहीं है) टेस्टिंग कोड को किसी दूसरे प्रॉम्प्ट से बदलें. इसके लिए, अलग-अलग टूल को कॉल करने की ज़रूरत होती है.
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan")
👉 अगर आपने अपना टर्मिनल बंद कर दिया है या एनवायरमेंट वैरिएबल अब सेट नहीं हैं, तो इन कमांड को फिर से चलाएं
gcloud config set project $(cat ~/project_id.txt)
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 (यह चरण ज़रूरी नहीं है. इसे सिर्फ़ तब करें, जब आपने पिछला चरण पूरा कर लिया हो) कोड को फिर से चलाएं:
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python aidemy.py
इस बार आपको क्या गड़बड़ी देखने को मिली? एजेंट ने किन टूल को कॉल किया? आपको दिखेगा कि एजेंट ने इस बार सिर्फ़ search_latest_resource टूल को कॉल किया है. ऐसा इसलिए है, क्योंकि प्रॉम्प्ट में यह नहीं बताया गया है कि उसे अन्य दो टूल की ज़रूरत है. साथ ही, हमारा एलएलएम इतना स्मार्ट है कि वह अन्य टूल को कॉल नहीं करता.
================================ Human Message =================================
I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan
================================== Ai Message ==================================
Tool Calls:
get_curriculum (xxx)
Call ID: xxx
Args:
year: 5.0
subject: Mathematics
================================= Tool Message =================================
Name: get_curriculum
Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.
================================== Ai Message ==================================
Tool Calls:
search_latest_resource (xxx)
Call ID: xxxx
Args:
year: 5.0
subject: Mathematics
curriculum: {"content": "Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques."}
search_text: Geometry
================================= Tool Message =================================
Name: search_latest_resource
candidates=[Candidate(content=Content(parts=[Part(.......token_count=40, total_token_count=772) automatic_function_calling_history=[] parsed=None
================================== Ai Message ==================================
Based on the information provided, a 3-week teaching plan for Year 5 Mathematics focusing on Geometry could look like this:
**Week 1: Introducing 2D Shapes**
........
* Use visuals, manipulatives, and real-world examples to make the learning experience engaging and relevant.
Ctrl+C दबाकर स्क्रिप्ट को रोकें.
👉 (यह चरण न छोड़ें!) अपनी aidemy.py फ़ाइल को साफ़ रखने के लिए, टेस्टिंग कोड हटाएं :
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan")
अब हमने एजेंट लॉजिक तय कर लिया है. इसलिए, चलिए Flask वेब ऐप्लिकेशन लॉन्च करते हैं. इससे शिक्षकों को, एजेंट के साथ इंटरैक्ट करने के लिए फ़ॉर्म जैसा इंटरफ़ेस मिलेगा. एलएलएम के साथ चैटबॉट इंटरैक्शन आम बात है. हालांकि, हम फ़ॉर्म सबमिट करने के लिए पारंपरिक यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल कर रहे हैं, क्योंकि यह कई शिक्षकों के लिए ज़्यादा आसान हो सकता है.
👉 अगर आपने अपना टर्मिनल बंद कर दिया है या एनवायरमेंट वैरिएबल अब सेट नहीं हैं, तो इन कमांड को फिर से चलाएं
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 अब वेब यूज़र इंटरफ़ेस (यूआई) शुरू करें.
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python app.py
Cloud Shell टर्मिनल के आउटपुट में स्टार्टअप मैसेज देखें. Flask आम तौर पर ऐसे मैसेज प्रिंट करता है जिनसे पता चलता है कि यह चल रहा है और किस पोर्ट पर चल रहा है.
Running on http://127.0.0.1:8080
Running on http://127.0.0.1:8080
The application needs to keep running to serve requests.
👉 सबसे ऊपर दाएं कोने में मौजूद "वेब पर झलक देखें" मेन्यू में जाकर, पोर्ट 8080 पर झलक देखें को चुनें. Cloud Shell, आपके ऐप्लिकेशन की वेब झलक के साथ एक नया ब्राउज़र टैब या विंडो खोलेगा.
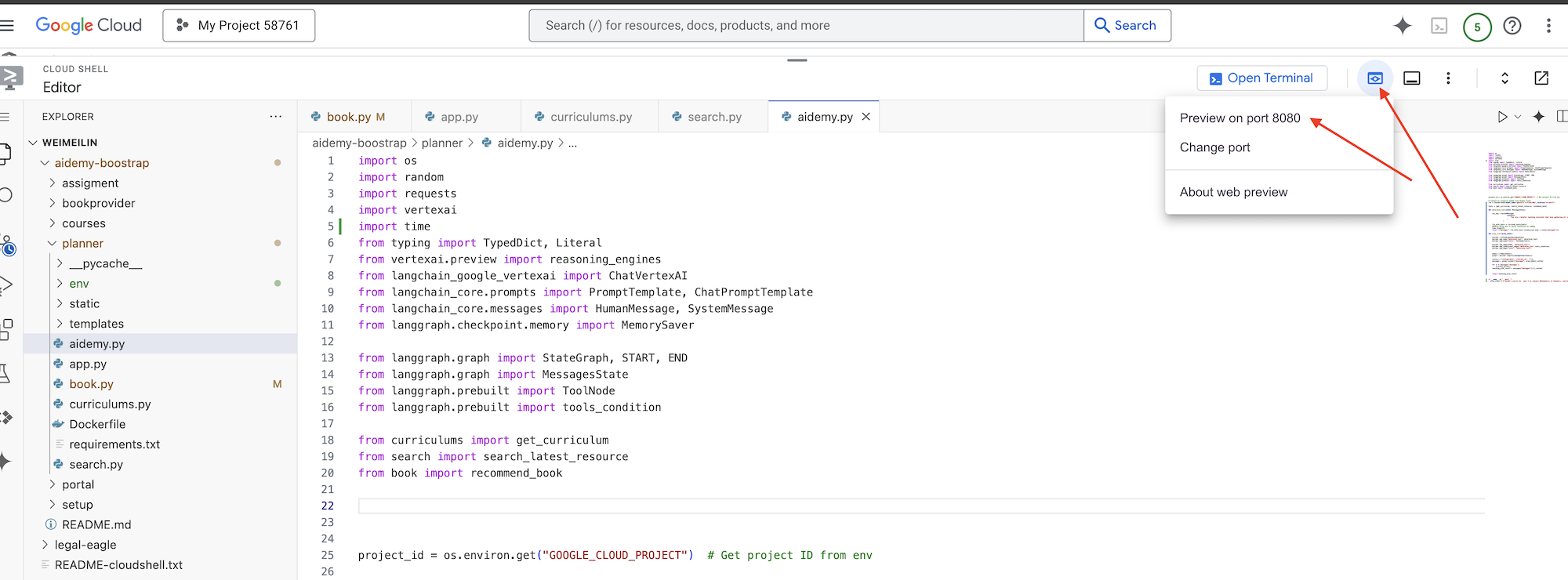
ऐप्लिकेशन इंटरफ़ेस में, साल के लिए 5 चुनें. इसके बाद, विषय Mathematics चुनें और ऐड-ऑन के अनुरोध में Geometry टाइप करें
👉 अगर आपने ऐप्लिकेशन के यूज़र इंटरफ़ेस (यूआई) से किसी और पेज पर नेविगेट किया है, तो वापस जाएं. आपको जनरेट किया गया आउटपुट दिखेगा.
👉 अपने टर्मिनल में, स्क्रिप्ट को रोकने के लिए Ctrl+C दबाएं.
👉 अपने टर्मिनल में, वर्चुअल एनवायरमेंट से बाहर निकलें:
deactivate
8. प्लानर एजेंट को क्लाउड पर डिप्लॉय करना
इमेज बनाना और उसे रजिस्ट्री में पुश करना
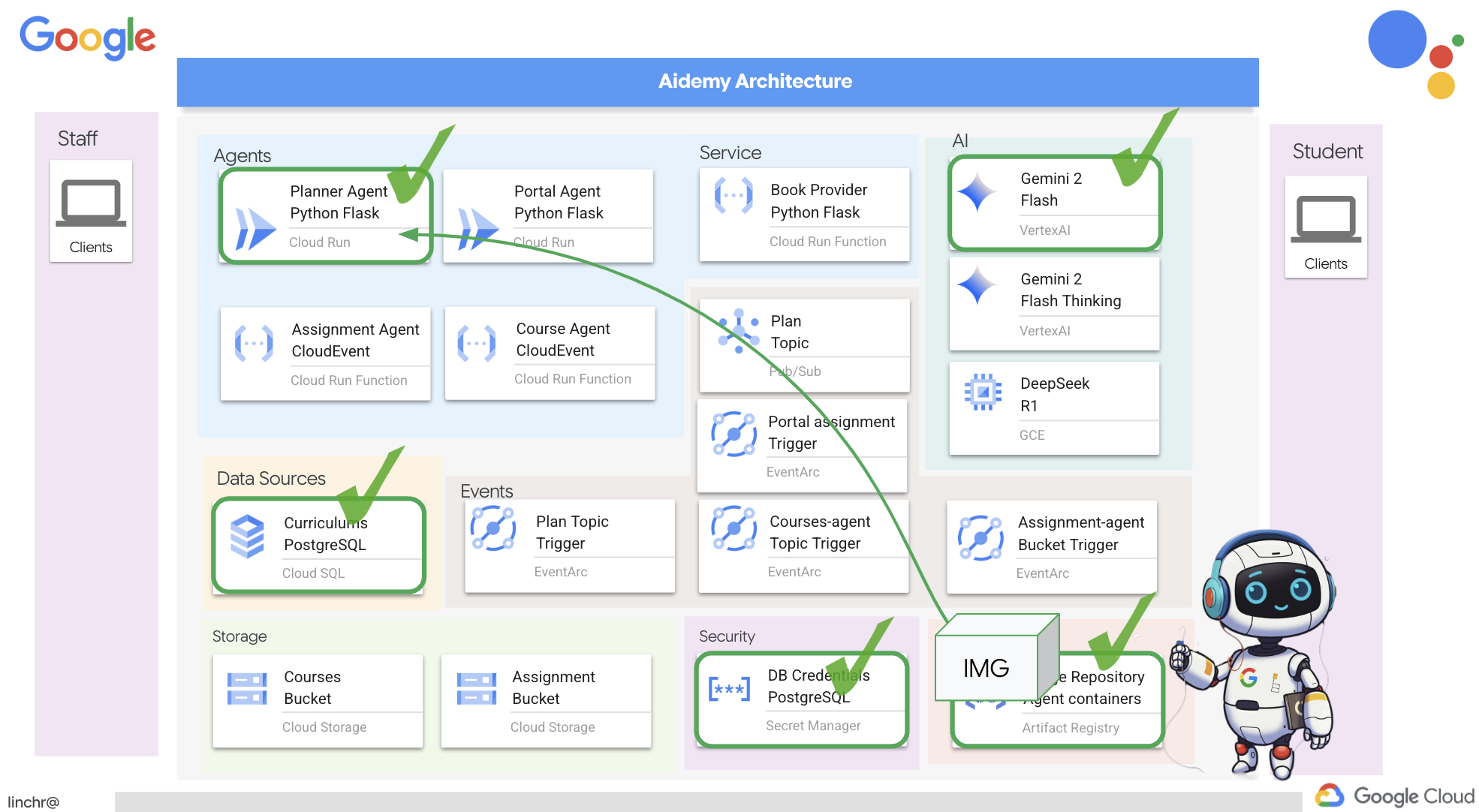
इसे क्लाउड पर डिप्लॉय करने का समय आ गया है.
👉 टर्मिनल में, आर्टफ़ैक्ट रिपॉज़िटरी बनाएं. इसमें हम डॉकर इमेज को सेव करेंगे.
gcloud artifacts repositories create agent-repository \
--repository-format=docker \
--location=us-central1 \
--description="My agent repository"
आपको Created repository [agent-repository] दिखेगा.
👉 Docker इमेज बनाने के लिए, यह कमांड चलाएं.
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-planner .
👉 हमें इमेज को फिर से टैग करना होगा, ताकि इसे GCR के बजाय Artifact Registry में होस्ट किया जा सके. साथ ही, टैग की गई इमेज को Artifact Registry में पुश किया जा सके:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-planner us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
पुश पूरा होने के बाद, पुष्टि करें कि इमेज को Artifact Registry में सेव कर लिया गया है.
👉 Google Cloud Console में Artifact Registry पर जाएं. आपको aidemy-planner इमेज, agent-repository रिपॉज़िटरी में दिखनी चाहिए. 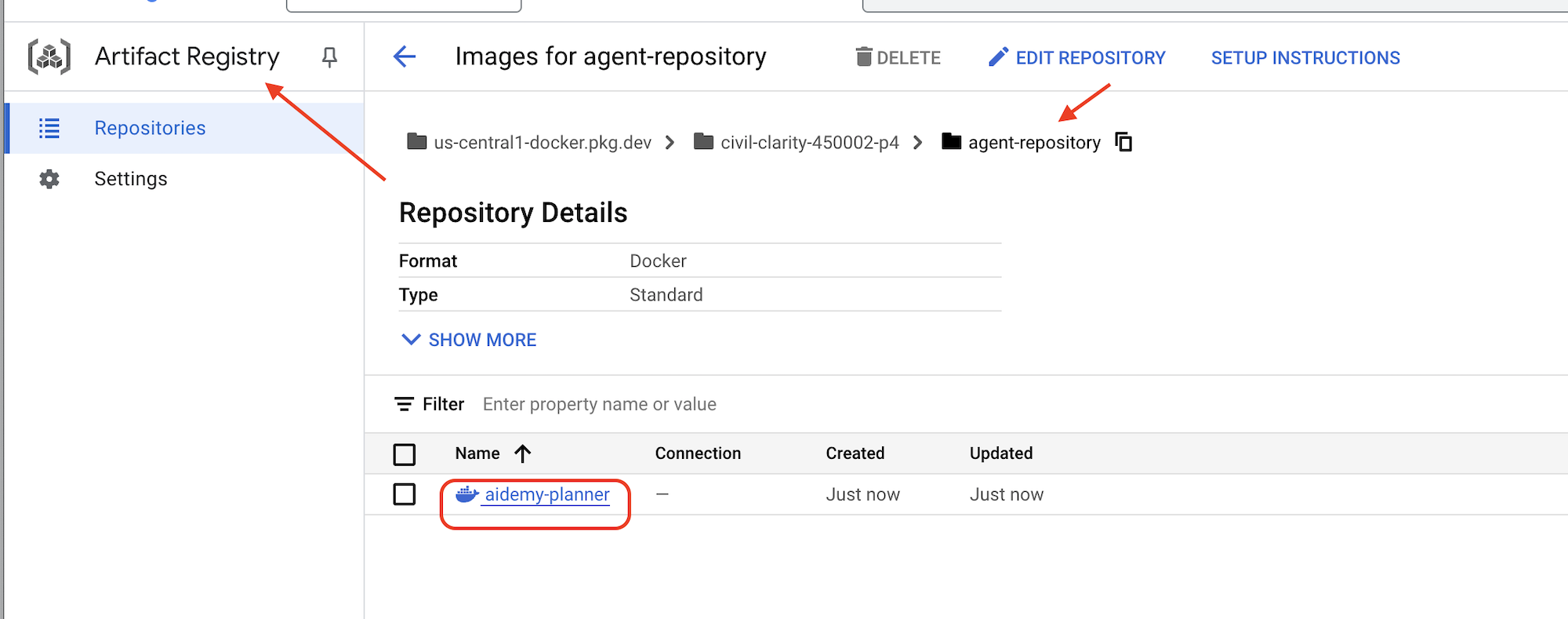
Secret Manager की मदद से डेटाबेस क्रेडेंशियल को सुरक्षित करना
डेटाबेस क्रेडेंशियल को सुरक्षित तरीके से मैनेज करने और ऐक्सेस करने के लिए, हम Google Cloud Secret Manager का इस्तेमाल करेंगे. इससे हमारे ऐप्लिकेशन कोड में संवेदनशील जानकारी को हार्डकोड करने से रोका जा सकता है. साथ ही, इससे सुरक्षा को बेहतर बनाया जा सकता है.
हम डेटाबेस के उपयोगकर्ता नाम, पासवर्ड, और डेटाबेस के नाम के लिए अलग-अलग सीक्रेट बनाएंगे. इस तरीके से, हम हर क्रेडेंशियल को अलग-अलग मैनेज कर पाते हैं.
👉 टर्मिनल में यह कमांड चलाएं:
gcloud secrets create db-user
printf "postgres" | gcloud secrets versions add db-user --data-file=-
gcloud secrets create db-pass
printf "1234qwer" | gcloud secrets versions add db-pass --data-file=-
gcloud secrets create db-name
printf "aidemy-db" | gcloud secrets versions add db-name --data-file=-
Secret Manager का इस्तेमाल करना, आपके ऐप्लिकेशन को सुरक्षित रखने और संवेदनशील क्रेडेंशियल को गलती से सार्वजनिक होने से रोकने के लिए एक ज़रूरी कदम है. यह क्लाउड डिप्लॉयमेंट के लिए, सुरक्षा के सबसे सही तरीकों का पालन करता है.
Cloud Run पर डिप्लॉय करें
Cloud Run, पूरी तरह से मैनेज किया गया सर्वरलेस प्लैटफ़ॉर्म है. इसकी मदद से, कंटेनर वाले ऐप्लिकेशन को आसानी से और तुरंत डिप्लॉय किया जा सकता है. यह इन्फ़्रास्ट्रक्चर मैनेजमेंट को अलग कर देता है, ताकि आप कोड लिखने और उसे डिप्लॉय करने पर फ़ोकस कर सकें. हम अपने प्लानर को Cloud Run सेवा के तौर पर डिप्लॉय करेंगे.
👉Google Cloud Console में, "Cloud Run" पर जाएं. कंटेनर डिप्लॉय करें पर क्लिक करें और SERVICE चुनें. Cloud Run सेवा को कॉन्फ़िगर करें:
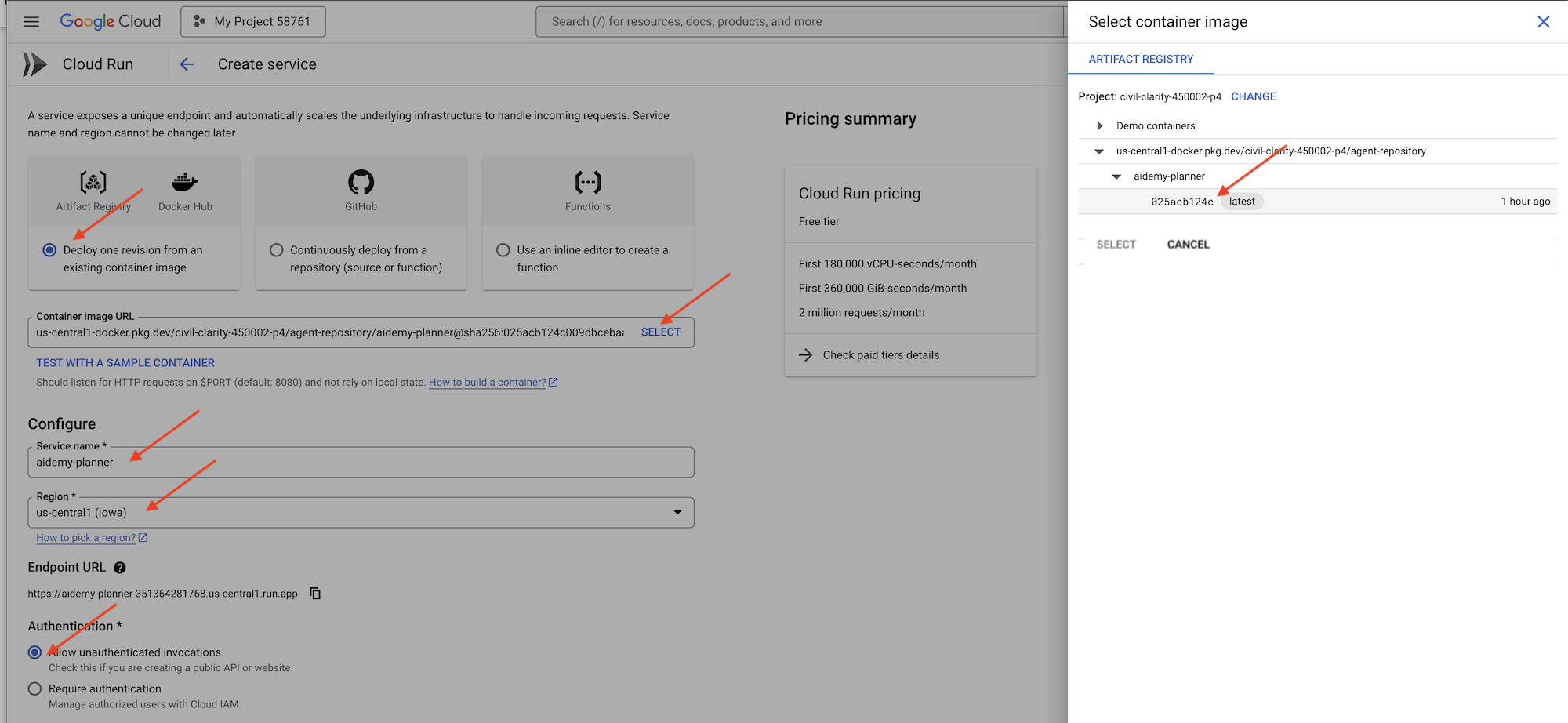
- कंटेनर इमेज: यूआरएल फ़ील्ड में "चुनें" पर क्लिक करें. Artifact Registry में पुश की गई इमेज का यूआरएल ढूंढें. उदाहरण के लिए, us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repository/aidemy-planner/YOUR_IMG.
- सेवा का नाम:
aidemy-planner - क्षेत्र:
us-central1क्षेत्र चुनें. - पुष्टि करना: इस वर्कशॉप के लिए, "बिना पुष्टि किए गए अनुरोधों को अनुमति दें" विकल्प को चुना जा सकता है. प्रोडक्शन के लिए, आपको ऐक्सेस सीमित करना पड़ सकता है.
- कंटेनर, वॉल्यूम, नेटवर्किंग, सुरक्षा सेक्शन को बड़ा करें. इसके बाद, कंटेनर टैब में जाकर, ये सेटिंग सेट करें (:
- सेटिंग टैब:
- संसाधन
- memory : 2GiB
- संसाधन
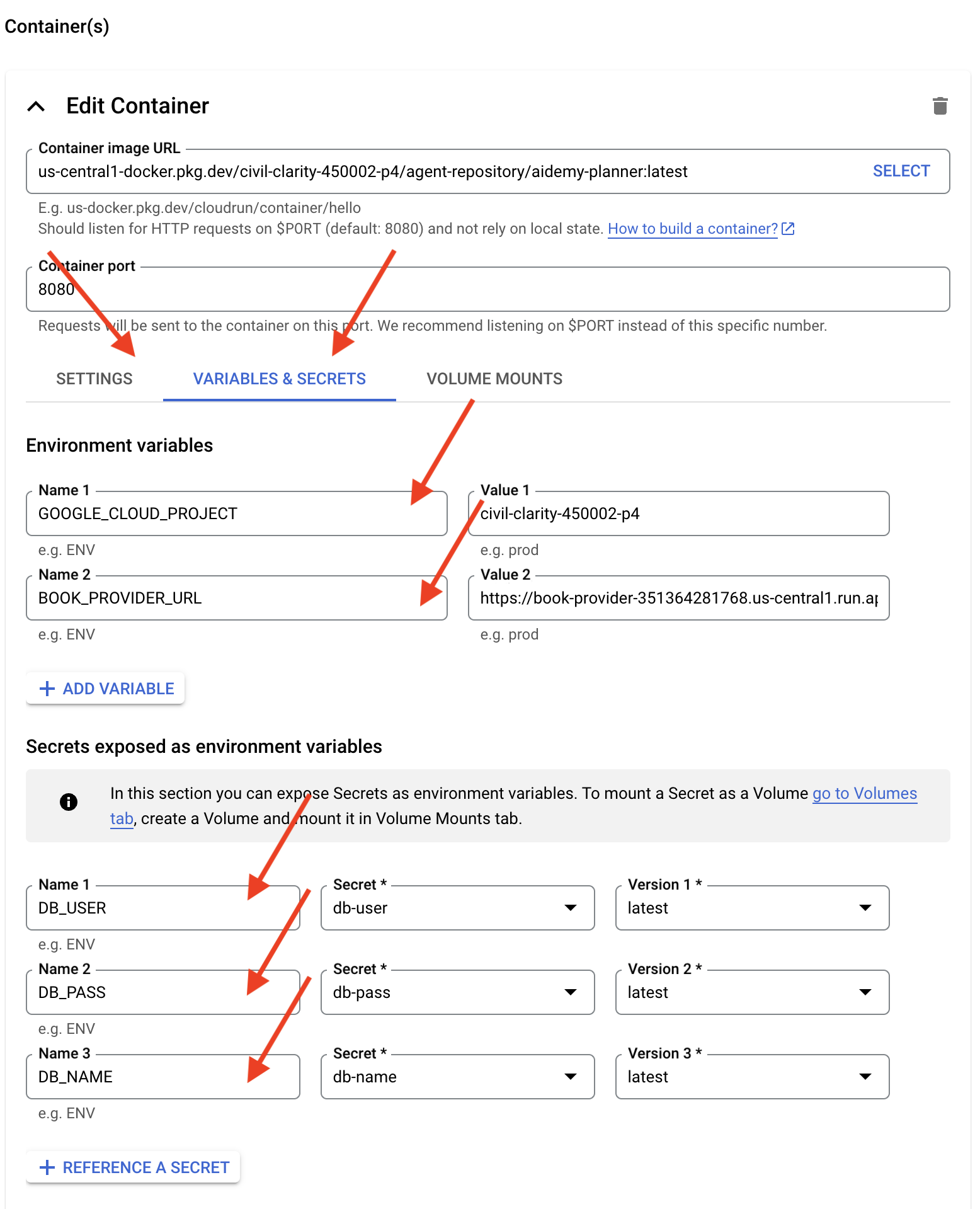
- वैरिएबल और सीक्रेट टैब:
- एनवायरमेंट वैरिएबल, + वैरिएबल जोड़ें बटन पर क्लिक करके, ये वैरिएबल जोड़ें:
- नाम जोड़ें:
GOOGLE_CLOUD_PROJECTऔर वैल्यू जोड़ें: <YOUR_PROJECT_ID> - नाम जोड़ें:
BOOK_PROVIDER_URL. इसके बाद, वैल्यू को अपनी बुक-प्रोवाइडर फ़ंक्शन यूआरएल पर सेट करें. इसे टर्मिनल में इस कमांड का इस्तेमाल करके तय किया जा सकता है:gcloud config set project $(cat ~/project_id.txt) gcloud run services describe book-provider \ --region=us-central1 \ --project=$PROJECT_ID \ --format="value(status.url)"
- नाम जोड़ें:
- Environment variable के तौर पर दिखाए गए सीक्रेट सेक्शन में जाकर, + सीक्रेट के तौर पर रेफ़रंस दें बटन पर क्लिक करके, ये सीक्रेट जोड़ें:
- नाम जोड़ें:
DB_USER, सीक्रेट:db-userचुनें, और वर्शन:latest - नाम जोड़ें:
DB_PASS, सीक्रेट:db-passचुनें, और वर्शन:latest - नाम जोड़ें:
DB_NAME, सीक्रेट:db-nameचुनें, और वर्शन:latest
- नाम जोड़ें:
- एनवायरमेंट वैरिएबल, + वैरिएबल जोड़ें बटन पर क्लिक करके, ये वैरिएबल जोड़ें:
- सेटिंग टैब:
अन्य वैल्यू को डिफ़ॉल्ट के तौर पर छोड़ दें.
👉 बनाएं पर क्लिक करें.
Cloud Run आपकी सेवा को डिप्लॉय करेगा.
डेटा सोर्स को डिप्लॉय करने के बाद, अगर आप ज़्यादा जानकारी वाले पेज पर नहीं हैं, तो सेवा के नाम पर क्लिक करके ज़्यादा जानकारी वाले पेज पर जाएं. आपको सबसे ऊपर, डिप्लॉय किया गया यूआरएल दिखेगा.
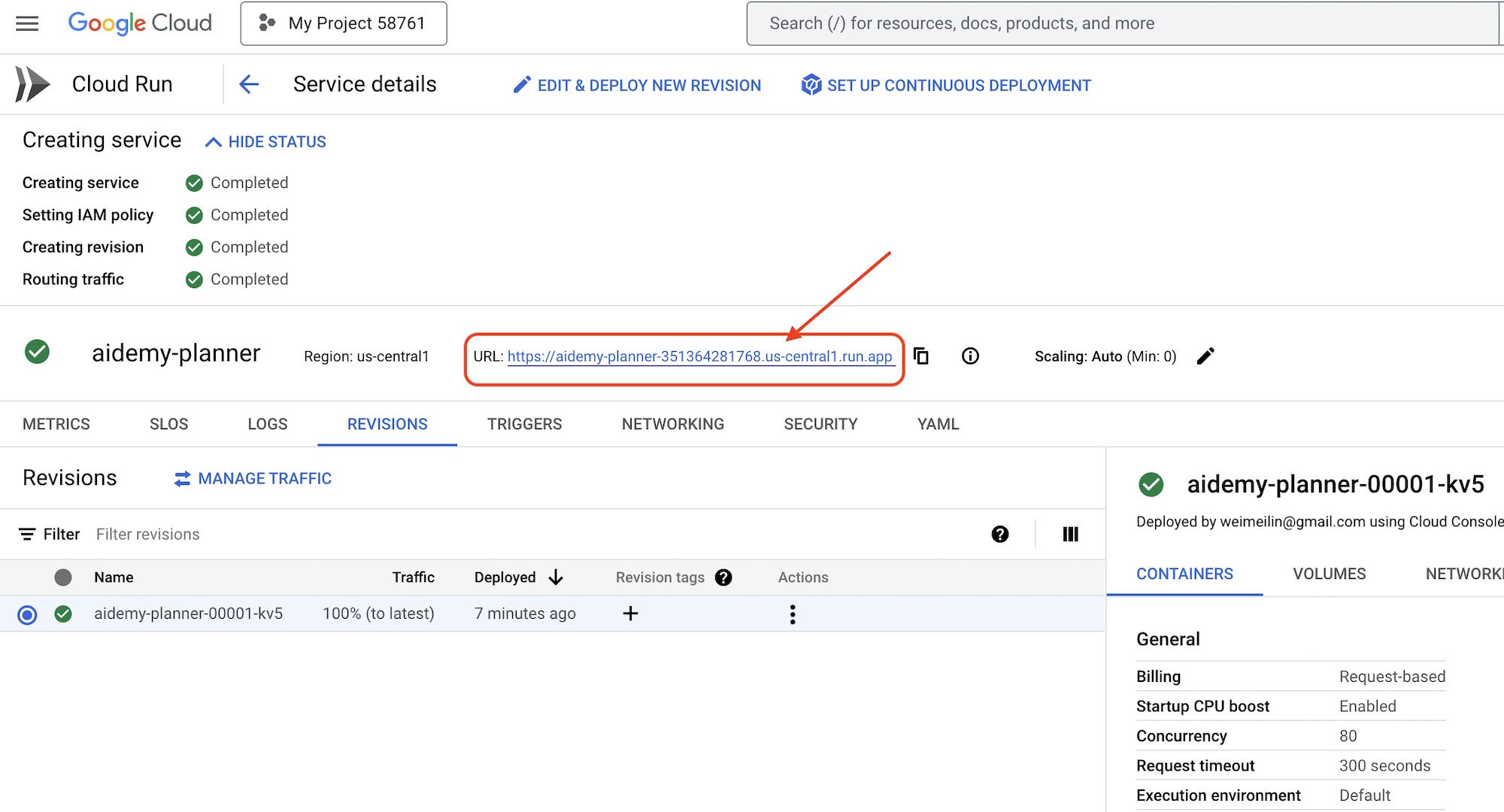
👉 ऐप्लिकेशन इंटरफ़ेस में, साल के लिए 7 चुनें. इसके बाद, विषय के तौर पर Mathematics चुनें. इसके बाद, ऐड-ऑन के अनुरोध वाले फ़ील्ड में Algebra डालें.
👉 प्लान जनरेट करें पर क्लिक करें. इससे एजेंट को ज़रूरी संदर्भ मिलेगा, ताकि वह आपकी ज़रूरतों के हिसाब से लेसन प्लान जनरेट कर सके.
बधाई हो! आपने हमारे दमदार एआई एजेंट का इस्तेमाल करके, पढ़ाने का प्लान बना लिया है. इससे पता चलता है कि एजेंट, शिक्षकों के काम को काफ़ी हद तक कम कर सकते हैं और उनके कामों को आसान बना सकते हैं. इससे शिक्षकों की परफ़ॉर्मेंस बेहतर होती है और उनकी ज़िंदगी आसान हो जाती है.
9. मल्टी-एजेंट सिस्टम
हमने शिक्षण योजना बनाने वाले टूल को लागू कर दिया है. अब हम छात्र-छात्राओं के लिए पोर्टल बनाने पर ध्यान देंगे. इस पोर्टल पर, छात्र-छात्राओं को उनके कोर्स से जुड़ी क्विज़, ऑडियो रीकैप, और असाइनमेंट का ऐक्सेस मिलेगा. इस सुविधा के दायरे को देखते हुए, हम मल्टी-एजेंट सिस्टम का इस्तेमाल करेंगे, ताकि मॉड्यूलर और स्केलेबल समाधान तैयार किया जा सके.
जैसा कि हमने पहले बताया था, किसी एक एजेंट पर पूरी तरह से भरोसा करने के बजाय, मल्टी-एजेंट सिस्टम की मदद से काम को छोटे-छोटे, खास टास्क में बांटा जा सकता है. हर टास्क को एक खास एजेंट हैंडल करता है. इस तरीके के कई मुख्य फ़ायदे हैं:
मॉड्यूलरिटी और रखरखाव: एक ऐसा एजेंट बनाने के बजाय जो सभी काम करता है, छोटे और खास एजेंट बनाएं. साथ ही, उनकी ज़िम्मेदारियां तय करें. मॉड्यूलरिटी की वजह से, सिस्टम को समझना, उसे बनाए रखना, और उसमें मौजूद गड़बड़ियों को ठीक करना आसान हो जाता है. कोई समस्या आने पर, उसे किसी खास एजेंट से अलग किया जा सकता है. इसके लिए, आपको बड़े कोडबेस को खंगालने की ज़रूरत नहीं होती.
स्केलेबिलिटी: एक जटिल एजेंट को स्केल करना मुश्किल हो सकता है. मल्टी-एजेंट सिस्टम की मदद से, अलग-अलग एजेंट को उनकी ज़रूरतों के हिसाब से बढ़ाया जा सकता है. उदाहरण के लिए, अगर कोई एजेंट बड़ी संख्या में अनुरोधों को हैंडल कर रहा है, तो सिस्टम के बाकी हिस्सों पर असर डाले बिना, उस एजेंट के ज़्यादा इंस्टेंस आसानी से बनाए जा सकते हैं.
टीम की विशेषज्ञता: इसे ऐसे समझें: आप किसी एक इंजीनियर से पूरा ऐप्लिकेशन बनाने के लिए नहीं कहेंगे. इसके बजाय, विशेषज्ञों की एक टीम बनाएं. हर विशेषज्ञ को किसी खास क्षेत्र में महारत हासिल हो. इसी तरह, मल्टी-एजेंट सिस्टम की मदद से, अलग-अलग एलएलएम और टूल की क्षमताओं का फ़ायदा उठाया जा सकता है. साथ ही, उन्हें ऐसे एजेंट को असाइन किया जा सकता है जो किसी खास टास्क के लिए सबसे सही हो.
पैरलल डेवलपमेंट: अलग-अलग टीमें एक साथ अलग-अलग एजेंट पर काम कर सकती हैं. इससे डेवलपमेंट की प्रोसेस तेज़ हो जाती है. एजेंट स्वतंत्र होते हैं. इसलिए, एक एजेंट में किए गए बदलावों का असर दूसरे एजेंटों पर कम पड़ता है.
इवेंट ड्रिवन आर्किटेक्चर
इन एजेंट के बीच बेहतर तरीके से बातचीत और तालमेल बनाए रखने के लिए, हम इवेंट-ड्रिवन आर्किटेक्चर का इस्तेमाल करेंगे. इसका मतलब है कि एजेंट, सिस्टम में होने वाले "इवेंट" पर प्रतिक्रिया देंगे.
एजेंट, खास तरह के इवेंट टाइप के लिए सदस्यता लेते हैं. जैसे, "टीचिंग प्लान जनरेट किया गया", "असाइनमेंट बनाया गया"). जब कोई इवेंट होता है, तो इससे जुड़े एजेंट को इसकी सूचना दी जाती है. इसके बाद, वे ज़रूरी कार्रवाई कर सकते हैं. इससे सिस्टम को ज़्यादा विकल्प मिलते हैं, उसे आसानी से बढ़ाया जा सकता है, और वह रीयल-टाइम में रिस्पॉन्स दे पाता है.
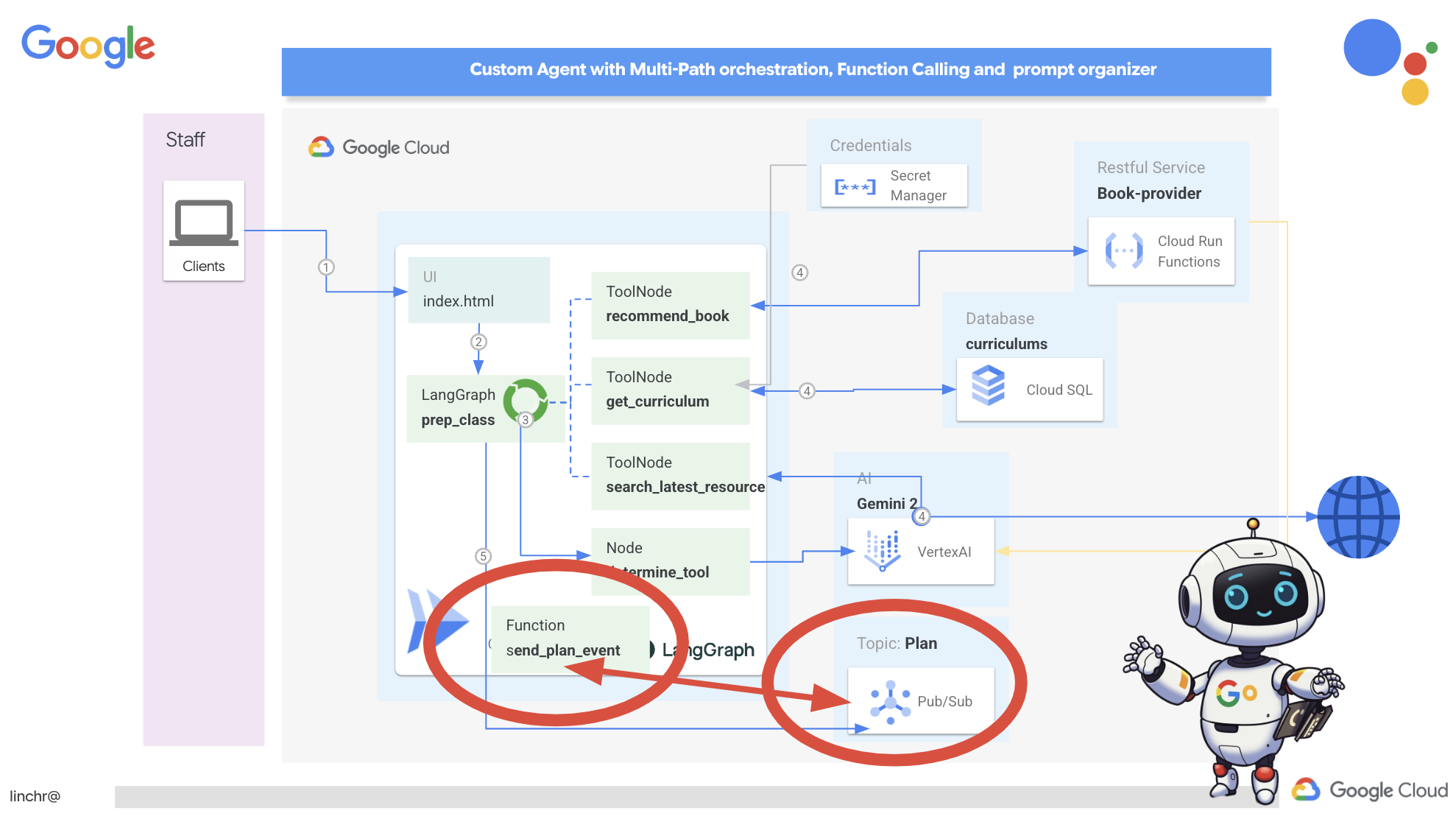
अब इन इवेंट को ब्रॉडकास्ट करने के लिए, हमें एक तरीके की ज़रूरत होगी. इसके लिए, हम Pub/Sub विषय सेट अप करेंगे. आइए, प्लान नाम का विषय बनाकर शुरू करें.
👉 Google Cloud Console pub/sub पर जाएं.
👉 विषय बनाएं बटन पर क्लिक करें.
👉 आईडी/नाम plan के साथ विषय को कॉन्फ़िगर करें और अनचेक करें Add a default subscription. बाकी को डिफ़ॉल्ट के तौर पर छोड़ दें और बनाएं पर क्लिक करें.
Pub/Sub पेज रीफ़्रेश होगा. इसके बाद, आपको टेबल में नया विषय दिखेगा. 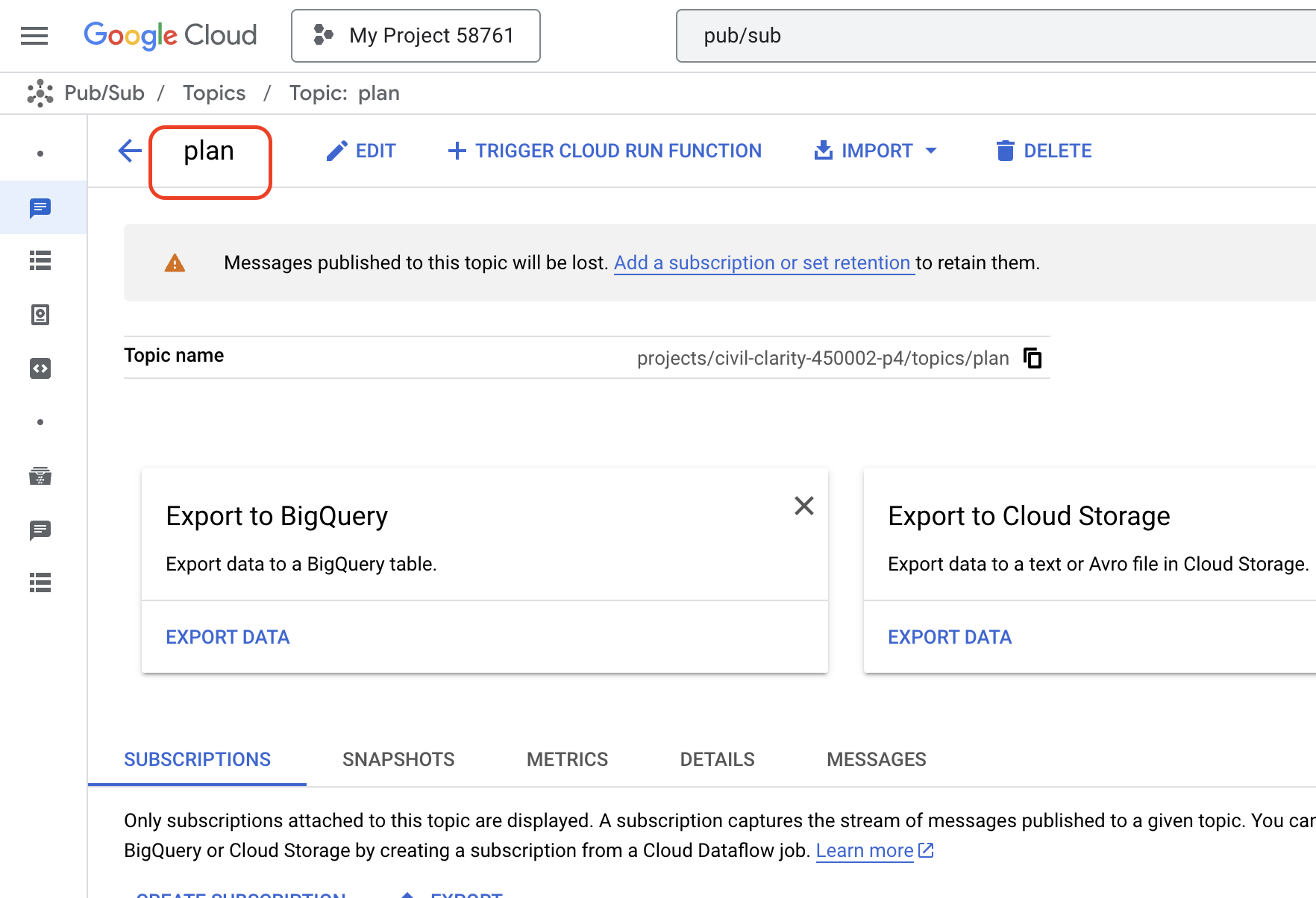
अब हम Pub/Sub इवेंट पब्लिश करने की सुविधा को, अपने प्लानर एजेंट में इंटिग्रेट करेंगे. हम एक नया टूल जोड़ेंगे. यह टूल, "प्लान" इवेंट को उस Pub/Sub विषय पर भेजेगा जिसे हमने अभी बनाया है. इस इवेंट से, सिस्टम में मौजूद अन्य एजेंट (जैसे कि छात्र-छात्राओं के पोर्टल में मौजूद एजेंट) को यह सूचना मिलेगी कि नया टीचिंग प्लान उपलब्ध है.
👉Cloud Code Editor पर वापस जाएं और planner फ़ोल्डर में मौजूद app.py फ़ाइल खोलें. हम एक ऐसा फ़ंक्शन जोड़ेंगे जो इवेंट को पब्लिश करता है. बदलें:
##ADD SEND PLAN EVENT FUNCTION HERE
इस कोड के साथ
def send_plan_event(teaching_plan:str):
"""
Send the teaching event to the topic called plan
Args:
teaching_plan: teaching plan
"""
publisher = pubsub_v1.PublisherClient()
print(f"-------------> Sending event to topic plan: {teaching_plan}")
topic_path = publisher.topic_path(PROJECT_ID, "plan")
message_data = {"teaching_plan": teaching_plan}
data = json.dumps(message_data).encode("utf-8")
future = publisher.publish(topic_path, data)
return f"Published message ID: {future.result()}"
- send_plan_event: यह फ़ंक्शन, जनरेट किए गए टीचिंग प्लान को इनपुट के तौर पर लेता है. साथ ही, Pub/Sub पब्लिशर क्लाइंट बनाता है, विषय का पाथ बनाता है, टीचिंग प्लान को JSON स्ट्रिंग में बदलता है, और मैसेज को विषय पर पब्लिश करता है.
एक ही app.py फ़ाइल में
👉प्रॉम्प्ट को अपडेट करें, ताकि एजेंट को निर्देश दिया जा सके कि वह टीचिंग प्लान जनरेट करने के बाद, टीचिंग प्लान इवेंट को Pub/Sub विषय पर भेजे. *बदलें
### ADD send_plan_event CALL
इनके साथ:
send_plan_event(teaching_plan)
send_plan_event टूल को जोड़कर और प्रॉम्प्ट में बदलाव करके, हमने अपने प्लानर एजेंट को Pub/Sub पर इवेंट पब्लिश करने की सुविधा दी है. इससे हमारे सिस्टम के अन्य कॉम्पोनेंट, नए टीचिंग प्लान के हिसाब से काम कर सकेंगे. अब हमारे पास इन सेक्शन में, एक से ज़्यादा एजेंट वाला सिस्टम होगा.
10. मांग पर उपलब्ध क्विज़ की मदद से छात्र-छात्राओं को सशक्त बनाना
कल्पना करें कि सीखने के माहौल में छात्र-छात्राओं को उनके लर्निंग प्लान के हिसाब से, अनगिनत क्विज़ का ऐक्सेस मिलता है. इन क्विज़ से उन्हें तुरंत फ़ीडबैक मिलता है. इसमें जवाब और उनके बारे में जानकारी भी शामिल होती है. इससे उन्हें कॉन्टेंट को बेहतर तरीके से समझने में मदद मिलती है. हमारा लक्ष्य, एआई की मदद से काम करने वाले क्विज़ पोर्टल के ज़रिए इस क्षमता को अनलॉक करना है.
इस विज़न को साकार करने के लिए, हम क्विज़ जनरेट करने वाला एक ऐसा कॉम्पोनेंट बनाएंगे जो शिक्षण योजना के कॉन्टेंट के आधार पर, जवाब के कई विकल्पों वाले सवाल बना सके.
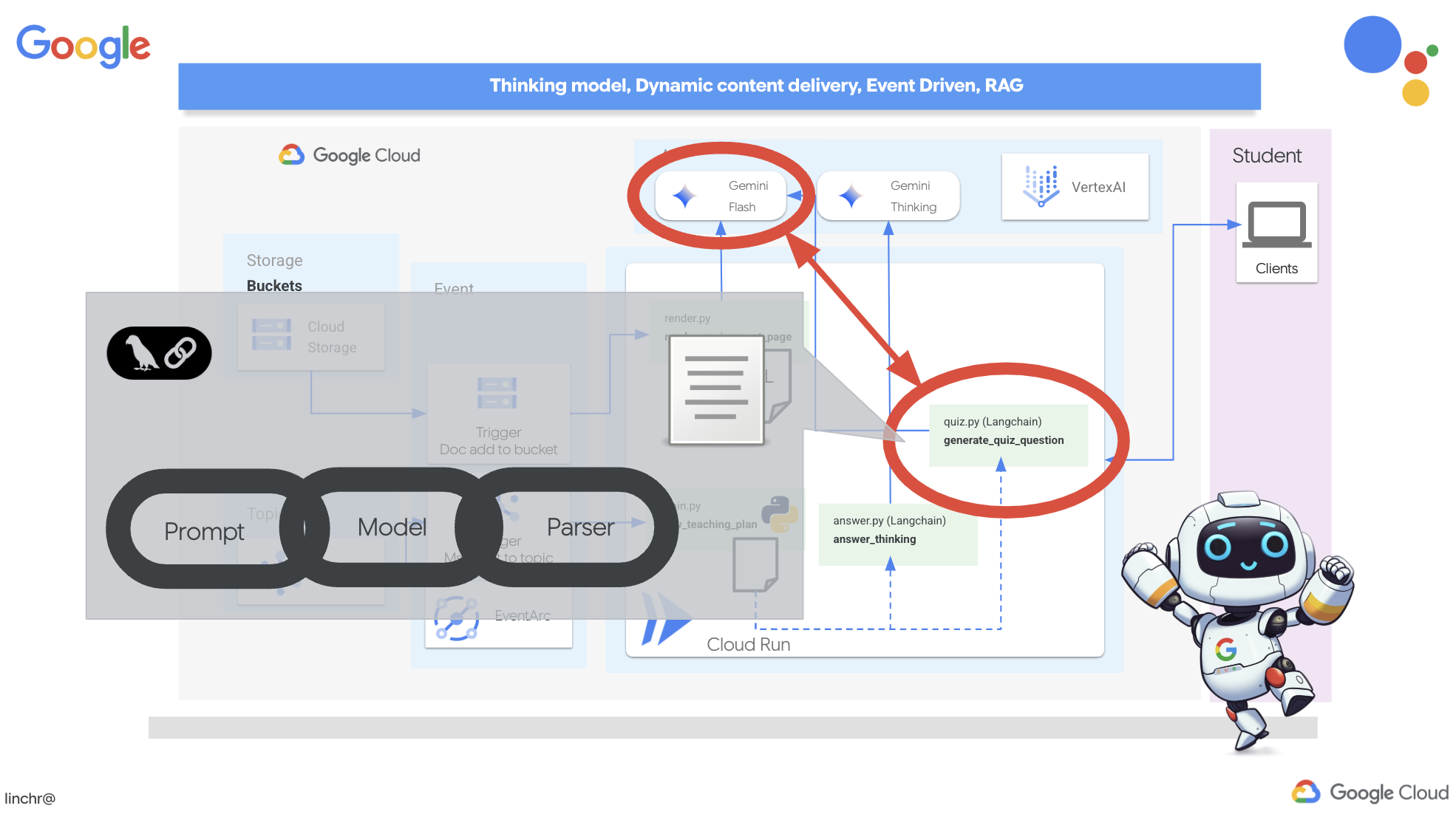
👉 Cloud Code Editor के एक्सप्लोरर पैन में, portal फ़ोल्डर पर जाएं. quiz.py फ़ाइल की कॉपी खोलें और इस कोड को फ़ाइल के आखिर में चिपकाएं.
def generate_quiz_question(file_name: str, difficulty: str, region:str ):
"""Generates a single multiple-choice quiz question using the LLM.
```json
{
"question": "The question itself",
"options": ["Option A", "Option B", "Option C", "Option D"],
"answer": "The correct answer letter (A, B, C, or D)"
}
```
"""
print(f"region: {region}")
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.5-flash-preview-04-17", location=region)
plan=None
#load the file using file_name and read content into string call plan
with open(file_name, 'r') as f:
plan = f.read()
parser = JsonOutputParser(pydantic_object=QuizQuestion)
instruction = f"You'll provide one question with difficulty level of {difficulty}, 4 options as multiple choices and provide the anwsers, the quiz needs to be related to the teaching plan {plan}"
prompt = PromptTemplate(
template="Generates a single multiple-choice quiz question\n {format_instructions}\n {instruction}\n",
input_variables=["instruction"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | llm | parser
response = chain.invoke({"instruction": instruction})
print(f"{response}")
return response
यह एजेंट में एक JSON आउटपुट पार्सर बनाता है. इसे खास तौर पर एलएलएम के आउटपुट को समझने और उसे स्ट्रक्चर करने के लिए डिज़ाइन किया गया है. यह QuizQuestion मॉडल का इस्तेमाल करता है. हमने इस मॉडल को पहले ही तय कर लिया था. इससे यह पक्का किया जाता है कि पार्स किया गया आउटपुट सही फ़ॉर्मैट (सवाल, विकल्प, और जवाब) के मुताबिक हो.
👉 अपने टर्मिनल में, वर्चुअल एनवायरमेंट सेट अप करने, ज़रूरी सॉफ़्टवेयर इंस्टॉल करने, और एजेंट शुरू करने के लिए, यहां दिए गए कमांड चलाएं:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
python -m venv env
source env/bin/activate
pip install -r requirements.txt
python app.py
👉 सबसे ऊपर दाएं कोने में मौजूद "वेब पर झलक देखें" मेन्यू में जाकर, पोर्ट 8080 पर झलक देखें को चुनें. Cloud Shell, आपके ऐप्लिकेशन की वेब झलक के साथ एक नया ब्राउज़र टैब या विंडो खोलेगा.
👉 वेब ऐप्लिकेशन में, "क्विज़" पर क्लिक करें. यह लिंक, ऊपर मौजूद नेविगेशन बार में या इंडेक्स पेज पर मौजूद कार्ड में होता है. आपको छात्र या छात्रा के लिए, रैंडम तरीके से जनरेट की गई तीन क्विज़ दिखेंगी. ये क्विज़, टीचिंग प्लान पर आधारित हैं. साथ ही, इनसे एआई की मदद से क्विज़ जनरेट करने वाले हमारे सिस्टम की क्षमता का पता चलता है.
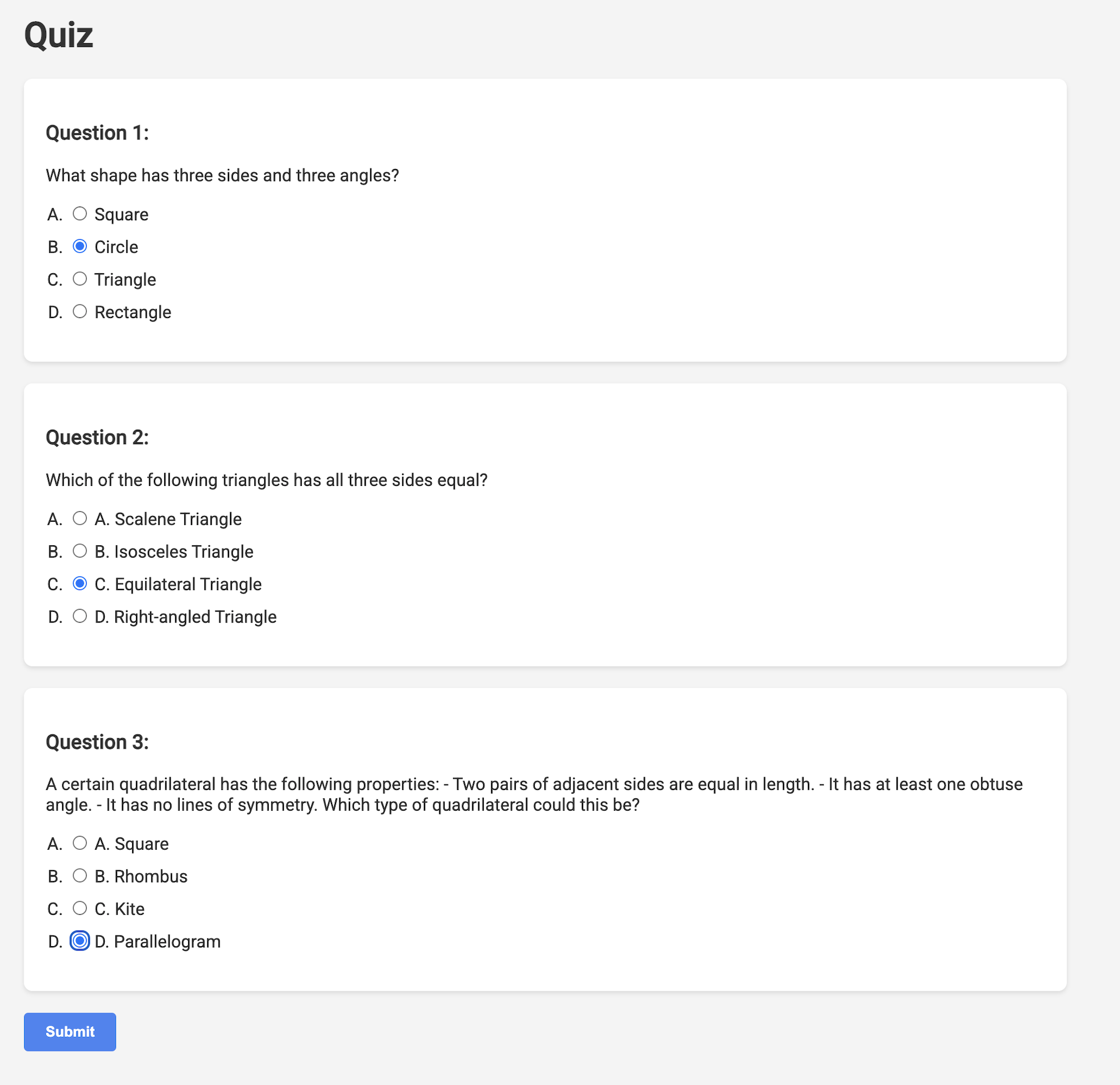
👉स्थानीय तौर पर चल रही प्रोसेस को रोकने के लिए, टर्मिनल में Ctrl+C दबाएं.
Gemini 2 Thinking for Explanations
ठीक है, तो हमारे पास क्विज़ हैं, जो एक अच्छी शुरुआत है! लेकिन, अगर छात्र-छात्राओं को कोई जानकारी गलत मिलती है, तो क्या होगा? असल में, सीखने की प्रक्रिया यहीं से शुरू होती है, है न? अगर हम उन्हें यह बता पाएं कि उनका जवाब गलत क्यों था और सही जवाब कैसे पाया जा सकता है, तो वे उसे ज़्यादा समय तक याद रख पाएंगे. साथ ही, इससे उन्हें किसी भी तरह की उलझन को दूर करने और आत्मविश्वास बढ़ाने में मदद मिलती है.
इसलिए, हम Gemini 2 के "सोचने" वाले मॉडल का इस्तेमाल करने जा रहे हैं! इसे ऐसे समझें कि एआई को जवाब देने से पहले, कुछ और समय दिया जा रहा है, ताकि वह सोच-विचार कर सके. इससे, उसे ज़्यादा जानकारी के साथ बेहतर सुझाव देने में मदद मिलती है.
हम यह देखना चाहते हैं कि यह सुविधा, छात्र-छात्राओं की मदद कर सकती है या नहीं. जैसे, उनके सवालों के जवाब देना, उन्हें जानकारी देना, और उन्हें विस्तार से समझाना. इसे आज़माने के लिए, हम एक ऐसे विषय से शुरुआत करेंगे जिसे समझना बहुत मुश्किल माना जाता है. यह विषय है, कैलकुलस.
👉सबसे पहले, portal फ़ोल्डर में मौजूद answer.py में जाकर, Cloud Code Editor पर जाएं. फ़ंक्शन के इस कोड की जगह यह कोड डालें
def answer_thinking(question, options, user_response, answer, region):
return ""
इस कोड स्निपेट का इस्तेमाल करके:
def answer_thinking(question, options, user_response, answer, region):
try:
llm = VertexAI(model_name="gemini-2.0-flash-001",location=region)
input_msg = HumanMessage(content=[f"Here the question{question}, here are the available options {options}, this student's answer {user_response}, whereas the correct answer is {answer}"])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful teacher trying to teach the student on question, you were given the question and a set of multiple choices "
"what's the correct answer. use friendly tone"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
if __name__ == "__main__":
question = "Evaluate the limit: lim (x→0) [(sin(5x) - 5x) / x^3]"
options = ["A) -125/6", "B) -5/3 ", "C) -25/3", "D) -5/6"]
user_response = "B"
answer = "A"
region = "us-central1"
result = answer_thinking(question, options, user_response, answer, region)
यह एक बहुत ही सामान्य लैंगचैन ऐप्लिकेशन है. इसमें Gemini 2 Flash मॉडल को शुरू किया जाता है. इसमें हम इसे एक मददगार शिक्षक के तौर पर काम करने और जवाबों के बारे में जानकारी देने का निर्देश दे रहे हैं
👉टर्मिनल में यह कमांड चलाएं:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python answer.py
आपको ओरिजनल निर्देशों में दिए गए उदाहरण जैसा आउटपुट दिखेगा. मौजूदा मॉडल से आपको पूरी जानकारी नहीं मिल सकती.
Okay, I see the question and the choices. The question is to evaluate the limit:
lim (x→0) [(sin(5x) - 5x) / x^3]
You chose option B, which is -5/3, but the correct answer is A, which is -125/6.
It looks like you might have missed a step or made a small error in your calculations. This type of limit often involves using L'Hôpital's Rule or Taylor series expansion. Since we have the form 0/0, L'Hôpital's Rule is a good way to go! You need to apply it multiple times. Alternatively, you can use the Taylor series expansion of sin(x) which is:
sin(x) = x - x^3/3! + x^5/5! - ...
So, sin(5x) = 5x - (5x)^3/3! + (5x)^5/5! - ...
Then, (sin(5x) - 5x) = - (5x)^3/3! + (5x)^5/5! - ...
Finally, (sin(5x) - 5x) / x^3 = - 5^3/3! + (5^5 * x^2)/5! - ...
Taking the limit as x approaches 0, we get -125/6.
Keep practicing, you'll get there!
👉 answer.py फ़ाइल में, बदलाव करें
answer_thinking फ़ंक्शन में, gemini-2.0-flash-001 से gemini-2.0-flash-thinking-exp-01-21 तक model_name.
इससे एलएलएम को ऐसे एलएलएम में बदल दिया जाता है जो तर्क के साथ बेहतर जवाब देता है. इससे मॉडल को बेहतर जवाब जनरेट करने में मदद मिलेगी.
👉 नए थिंकिंग मॉडल को आज़माने के लिए, answer.py स्क्रिप्ट को फिर से चलाएं:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python answer.py
यहां थिंकिंग मॉडल से मिले जवाब का एक उदाहरण दिया गया है. यह जवाब, ज़्यादा जानकारी वाला और सिलसिलेवार तरीके से दिया गया है. इसमें कैलकुलस की समस्या को हल करने के तरीके के बारे में सिलसिलेवार तरीके से बताया गया है. इससे पता चलता है कि "सोचने" वाले मॉडल, अच्छी क्वालिटी के जवाब जनरेट करने में कितने असरदार होते हैं. आपको इससे मिलता-जुलता आउटपुट दिखेगा:
Hey there! Let's take a look at this limit problem together. You were asked to evaluate:
lim (x→0) [(sin(5x) - 5x) / x^3]
and you picked option B, -5/3, but the correct answer is actually A, -125/6. Let's figure out why!
It's a tricky one because if we directly substitute x=0, we get (sin(0) - 0) / 0^3 = (0 - 0) / 0 = 0/0, which is an indeterminate form. This tells us we need to use a more advanced technique like L'Hopital's Rule or Taylor series expansion.
Let's use the Taylor series expansion for sin(y) around y=0. Do you remember it? It looks like this:
sin(y) = y - y^3/3! + y^5/5! - ...
where 3! (3 factorial) is 3 × 2 × 1 = 6, 5! is 5 × 4 × 3 × 2 × 1 = 120, and so on.
In our problem, we have sin(5x), so we can substitute y = 5x into the Taylor series:
sin(5x) = (5x) - (5x)^3/3! + (5x)^5/5! - ...
sin(5x) = 5x - (125x^3)/6 + (3125x^5)/120 - ...
Now let's plug this back into our limit expression:
[(sin(5x) - 5x) / x^3] = [ (5x - (125x^3)/6 + (3125x^5)/120 - ...) - 5x ] / x^3
Notice that the '5x' and '-5x' cancel out! So we are left with:
= [ - (125x^3)/6 + (3125x^5)/120 - ... ] / x^3
Now, we can divide every term in the numerator by x^3:
= -125/6 + (3125x^2)/120 - ...
Finally, let's take the limit as x approaches 0. As x gets closer and closer to zero, terms with x^2 and higher powers will become very, very small and approach zero. So, we are left with:
lim (x→0) [ -125/6 + (3125x^2)/120 - ... ] = -125/6
Therefore, the correct answer is indeed **A) -125/6**.
It seems like your answer B, -5/3, might have come from perhaps missing a factor somewhere during calculation or maybe using an incorrect simplification. Double-check your steps when you were trying to solve it!
Don't worry, these limit problems can be a bit tricky sometimes! Keep practicing and you'll get the hang of it. Let me know if you want to go through another similar example or if you have any more questions! 😊
Now that we have confirmed it works, let's use the portal.
👉answer.py से, नीचे दिया गया टेस्ट कोड हटाएं:
if __name__ == "__main__":
question = "Evaluate the limit: lim (x→0) [(sin(5x) - 5x) / x^3]"
options = ["A) -125/6", "B) -5/3 ", "C) -25/3", "D) -5/6"]
user_response = "B"
answer = "A"
region = "us-central1"
result = answer_thinking(question, options, user_response, answer, region)
👉वर्चुअल एनवायरमेंट सेट अप करने, ज़रूरी सॉफ़्टवेयर इंस्टॉल करने, और एजेंट शुरू करने के लिए, टर्मिनल में ये कमांड चलाएं:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python app.py
👉 सबसे ऊपर दाएं कोने में मौजूद "वेब पर झलक देखें" मेन्यू में जाकर, पोर्ट 8080 पर झलक देखें को चुनें. Cloud Shell, आपके ऐप्लिकेशन की वेब झलक के साथ एक नया ब्राउज़र टैब या विंडो खोलेगा.
👉 वेब ऐप्लिकेशन में, "क्विज़" पर क्लिक करें. यह लिंक, ऊपर मौजूद नेविगेशन बार में या इंडेक्स पेज पर मौजूद कार्ड में होता है.
👉 सभी क्विज़ के जवाब दें. पक्का करें कि कम से कम एक जवाब गलत हो. इसके बाद, सबमिट करें पर क्लिक करें.
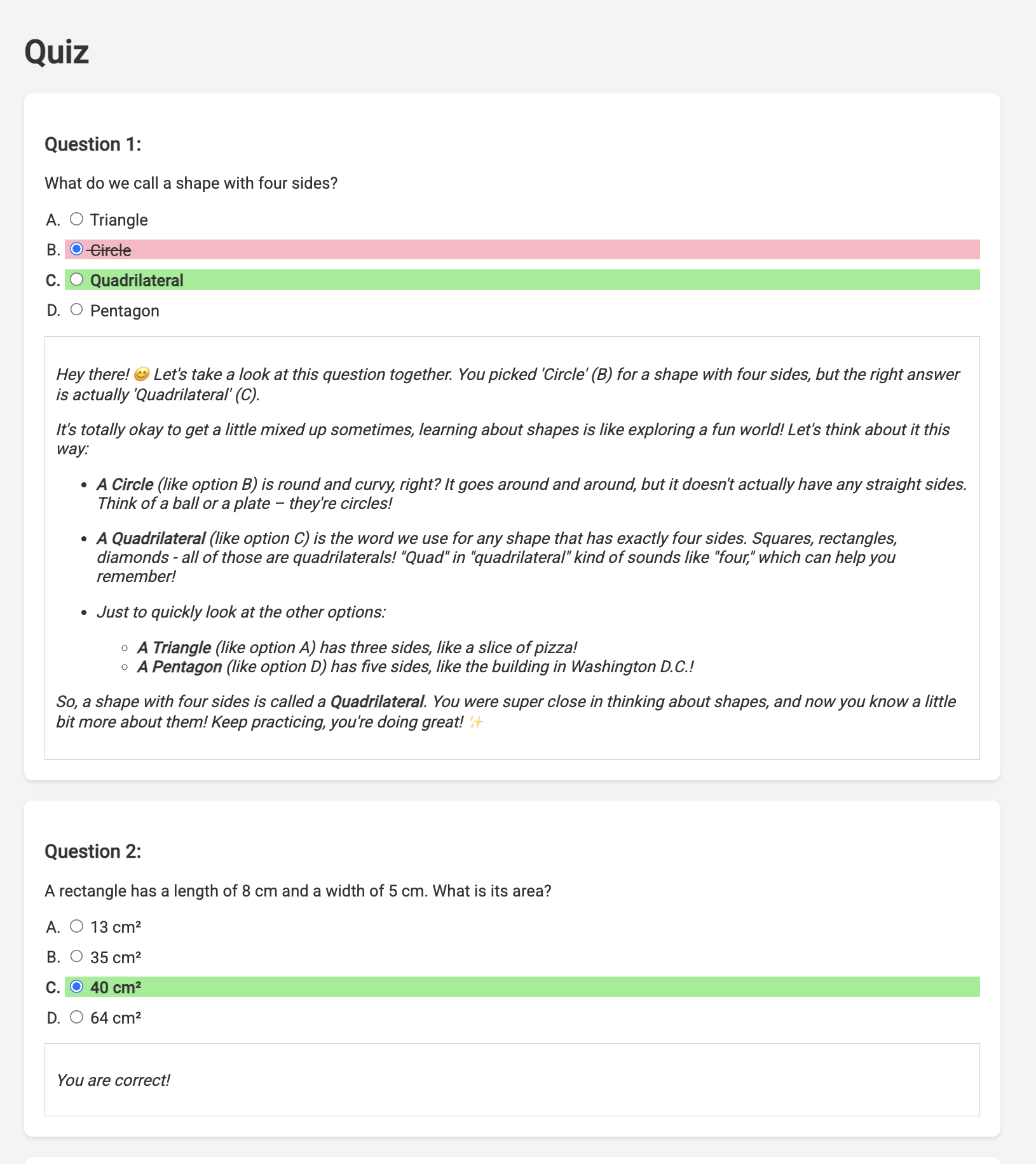
जवाब का इंतज़ार करते समय, Cloud Editor के टर्मिनल पर स्विच करें. एम्युलेटर के टर्मिनल में, अपने फ़ंक्शन की प्रोग्रेस और उससे जनरेट हुए किसी भी आउटपुट या गड़बड़ी के मैसेज को देखा जा सकता है. 😁
👉 अपने टर्मिनल में, Ctrl+C दबाकर स्थानीय तौर पर चल रही प्रोसेस को रोकें.
11. ज़रूरी नहीं: Eventarc की मदद से एजेंटों को व्यवस्थित करना
अब तक, छात्र-छात्राओं के पोर्टल पर, डिफ़ॉल्ट रूप से सेट किए गए टीचिंग प्लान के आधार पर क्विज़ जनरेट किए जा रहे थे. यह मददगार है, लेकिन इसका मतलब है कि हमारा प्लानर एजेंट और पोर्टल का क्विज़ एजेंट, एक-दूसरे से बात नहीं कर रहे हैं. आपको याद है कि हमने एक ऐसी सुविधा जोड़ी थी जिसमें प्लानर एजेंट, Pub/Sub विषय पर अपने नए जनरेट किए गए टीचिंग प्लान पब्लिश करता है? अब इसे हमारे पोर्टल एजेंट से कनेक्ट करने का समय है!

हम चाहते हैं कि जब भी कोई नया टीचिंग प्लान जनरेट हो, तो पोर्टल पर क्विज़ का कॉन्टेंट अपने-आप अपडेट हो जाए. इसके लिए, हम पोर्टल में एक ऐसा एंडपॉइंट बनाएंगे जो इन नए प्लान को स्वीकार कर सके.
👉 Cloud Code Editor के एक्सप्लोरर पैन में, portal फ़ोल्डर पर जाएं.
👉 बदलाव करने के लिए, app.py फ़ाइल खोलें. REPLACE ## REPLACE ME! NEW TEACHING PLAN लाइन की जगह यह कोड डालें:
@app.route('/new_teaching_plan', methods=['POST'])
def new_teaching_plan():
try:
# Get data from Pub/Sub message delivered via Eventarc
envelope = request.get_json()
if not envelope:
return jsonify({'error': 'No Pub/Sub message received'}), 400
if not isinstance(envelope, dict) or 'message' not in envelope:
return jsonify({'error': 'Invalid Pub/Sub message format'}), 400
pubsub_message = envelope['message']
print(f"data: {pubsub_message['data']}")
data = pubsub_message['data']
data_str = base64.b64decode(data).decode('utf-8')
data = json.loads(data_str)
teaching_plan = data['teaching_plan']
print(f"File content: {teaching_plan}")
with open("teaching_plan.txt", "w") as f:
f.write(teaching_plan)
print(f"Teaching plan saved to local file: teaching_plan.txt")
return jsonify({'message': 'File processed successfully'})
except Exception as e:
print(f"Error processing file: {e}")
return jsonify({'error': 'Error processing file'}), 500
Cloud Run पर फिर से बनाना और डिप्लॉय करना
आपको हमारे प्लानर और पोर्टल एजेंट, दोनों को Cloud Run पर अपडेट और फिर से डिप्लॉय करना होगा. इससे यह पक्का होता है कि उनके पास नया कोड है और वे इवेंट के ज़रिए कम्यूनिकेट करने के लिए कॉन्फ़िगर किए गए हैं.
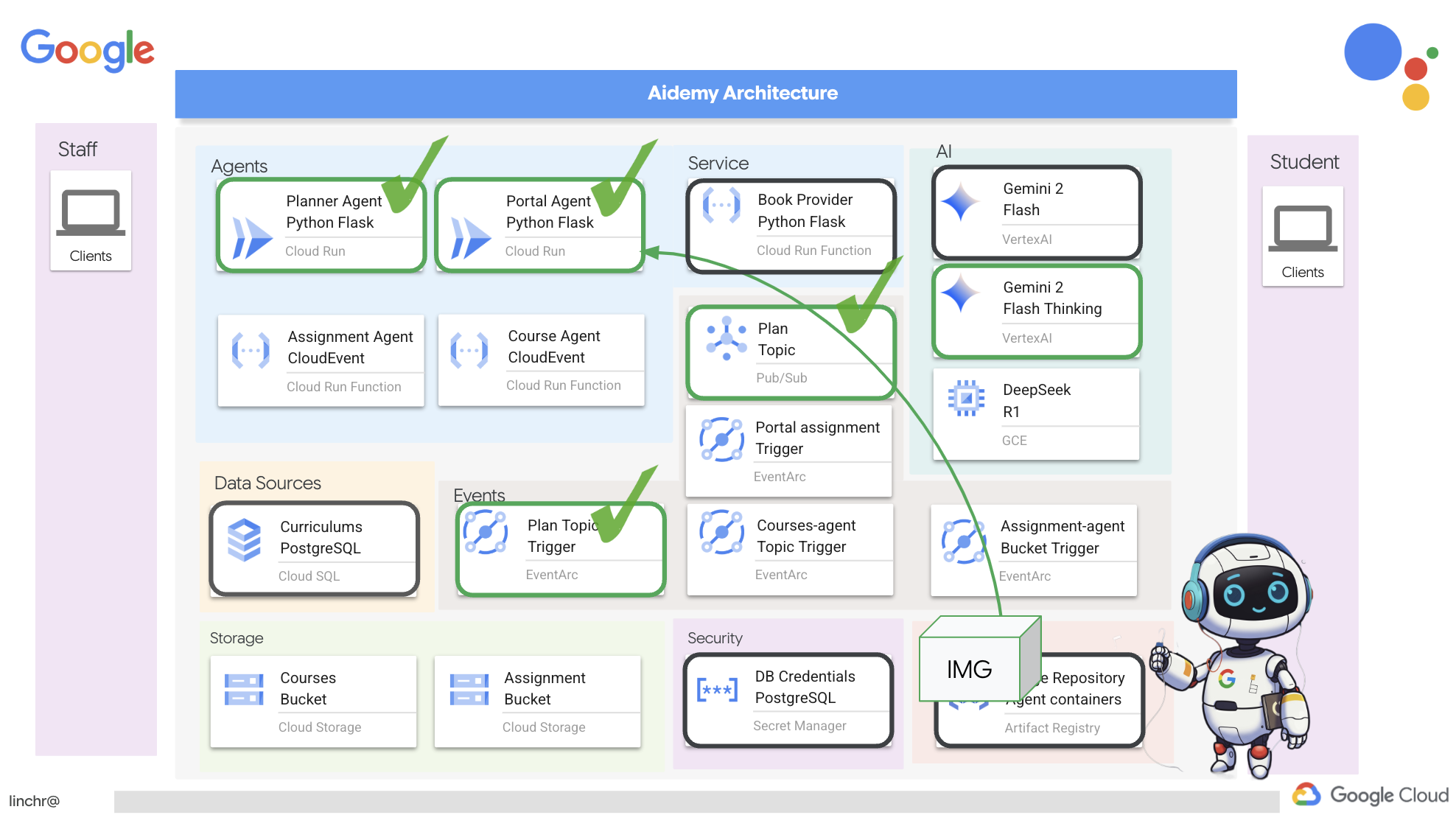
👉सबसे पहले, हम planner एजेंट की इमेज को फिर से बनाएंगे और पुश करेंगे. इसके लिए, टर्मिनल रन का इस्तेमाल किया जाएगा:
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-planner .
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-planner us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
👉हम भी ऐसा ही करेंगे. पोर्टल एजेंट की इमेज बनाएंगे और उसे पुश करेंगे:
cd ~/aidemy-bootstrap/portal/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-portal .
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-portal us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
👉 Artifact Registry पर जाएं. आपको agent-repository में, aidemy-planner और aidemy-portal, दोनों कंटेनर इमेज दिखेंगी.
👉टर्मिनल पर वापस जाकर, प्लानर एजेंट के लिए Cloud Run इमेज को अपडेट करने के लिए, यह कमांड चलाएँ:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services update aidemy-planner \
--region=us-central1 \
--image=us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner:latest
आपको इससे मिलता-जुलता आउटपुट दिखेगा:
OK Deploying... Done.
OK Creating Revision...
OK Routing traffic...
Done.
Service [aidemy-planner] revision [aidemy-planner-xxxxx] has been deployed and is serving 100 percent of traffic.
Service URL: https://aidemy-planner-xxx.us-central1.run.app
सेवा के यूआरएल को नोट कर लें. यह आपके डिप्लॉय किए गए प्लानर एजेंट का लिंक है. अगर आपको बाद में प्लानर एजेंट के सेवा यूआरएल का पता लगाना है, तो इस कमांड का इस्तेमाल करें:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services describe aidemy-planner \
--region=us-central1 \
--format 'value(status.url)'
👉पोर्टल एजेंट के लिए Cloud Run इंस्टेंस बनाने के लिए, इस कमांड को चलाएं
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy aidemy-portal \
--image=us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal:latest \
--region=us-central1 \
--platform=managed \
--allow-unauthenticated \
--memory=2Gi \
--cpu=2 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID}
आपको इससे मिलता-जुलता आउटपुट दिखेगा:
Deploying container to Cloud Run service [aidemy-portal] in project [xxxx] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [aidemy-portal] revision [aidemy-portal-xxxx] has been deployed and is serving 100 percent of traffic.
Service URL: https://aidemy-portal-xxxx.us-central1.run.app
सेवा के यूआरएल को नोट करें. यह आपके डिप्लॉय किए गए छात्र-छात्राओं के पोर्टल का लिंक है. अगर आपको बाद में छात्र-छात्राओं के पोर्टल का सेवा यूआरएल तय करना है, तो इस कमांड का इस्तेमाल करें:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services describe aidemy-portal \
--region=us-central1 \
--format 'value(status.url)'
Eventarc ट्रिगर बनाना
हालांकि, यहां सबसे बड़ा सवाल यह है कि जब Pub/Sub विषय में कोई नया प्लान उपलब्ध होता है, तो इस एंडपॉइंट को इसकी सूचना कैसे मिलती है? ऐसे में, Eventarc आपकी मदद कर सकता है!
Eventarc एक ब्रिज की तरह काम करता है. यह कुछ इवेंट (जैसे, हमारे Pub/Sub विषय में नया मैसेज आना) को सुनता है और उनके जवाब में कार्रवाइयों को अपने-आप ट्रिगर करता है. हमारे मामले में, यह सुविधा यह पता लगाएगी कि नया टीचिंग प्लान कब पब्लिश किया गया है. इसके बाद, यह हमारे पोर्टल के एंडपॉइंट को एक सिग्नल भेजेगी. इससे उसे पता चल जाएगा कि अपडेट करने का समय आ गया है.
Eventarc की मदद से, इवेंट के हिसाब से कम्यूनिकेशन को मैनेज किया जा सकता है. इससे हम अपने प्लानर एजेंट और पोर्टल एजेंट को आसानी से कनेक्ट कर सकते हैं. इससे हमें एक ऐसा लर्निंग सिस्टम बनाने में मदद मिलती है जो डाइनैमिक और रिस्पॉन्सिव हो. यह एक स्मार्ट मैसेंजर की तरह है, जो अपने-आप सही जगह पर नए लेसन प्लान डिलीवर करता है!
👉कंसोल में, Eventarc पर जाएं.
👉 "+ ट्रिगर बनाएं" बटन पर क्लिक करें.
ट्रिगर कॉन्फ़िगर करना (बुनियादी बातें):
- ट्रिगर का नाम:
plan-topic-trigger - ट्रिगर टाइप: Google के सोर्स
- इवेंट प्रोवाइडर: Cloud Pub/Sub
- इवेंट टाइप:
google.cloud.pubsub.topic.v1.messagePublished - Cloud Pub/Sub विषय:
projects/PROJECT_ID/topics/planचुनें - देश या इलाका:
us-central1. - सेवा खाता:
- GRANT the service account with role
roles/iam.serviceAccountTokenCreator - डिफ़ॉल्ट वैल्यू का इस्तेमाल करें: डिफ़ॉल्ट कंप्यूट सेवा खाता
- GRANT the service account with role
- इवेंट डेस्टिनेशन: Cloud Run
- Cloud Run सेवा:
aidemy-portal - गड़बड़ी के इस मैसेज को अनदेखा करें: ‘locations/me-central2' के लिए अनुमति नहीं दी गई (या हो सकता है कि यह मौजूद ही न हो).
- सेवा के यूआरएल का पाथ:
/new_teaching_plan
👉 "बनाएं" पर क्लिक करें.
Eventarc ट्रिगर पेज रीफ़्रेश होगा. अब आपको टेबल में, नया ट्रिगर दिखेगा.
अब, प्लानर एजेंट को उसके सेवा यूआरएल का इस्तेमाल करके ऐक्सेस करें, ताकि नया टीचिंग प्लान मांगा जा सके.
👉 प्लानर एजेंट के सेवा यूआरएल का पता लगाने के लिए, इसे टर्मिनल में चलाएं:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep planner
👉 आउटपुट में दिए गए यूआरएल पर जाएं. इस बार, साल 5, विषय Science, और ऐड-ऑन का अनुरोध atoms आज़माएं.
इसके बाद, एक या दो मिनट इंतज़ार करें. इस लैब की बिलिंग की सीमा की वजह से, इसमें देरी हो रही है. आम तौर पर, इसमें देरी नहीं होनी चाहिए.
आखिर में, छात्र-छात्रा के पोर्टल को उसके सेवा यूआरएल का इस्तेमाल करके ऐक्सेस करें.
छात्र पोर्टल एजेंट सेवा का यूआरएल पता करने के लिए, इसे टर्मिनल में चलाएं:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep portal
आपको दिखेगा कि क्विज़ अपडेट हो गए हैं और अब वे आपके जनरेट किए गए नए टीचिंग प्लान के मुताबिक हैं! इससे पता चलता है कि Aidemy सिस्टम में Eventarc को इंटिग्रेट कर दिया गया है!

बधाई हो! आपने Google Cloud पर एक मल्टी-एजेंट सिस्टम बना लिया है. इसमें इवेंट-ड्रिवन आर्किटेक्चर का इस्तेमाल किया गया है, ताकि इसे बड़े पैमाने पर इस्तेमाल किया जा सके और यह ज़्यादा लचीला हो! आपने बुनियादी बातें जान ली हैं, लेकिन एक्सप्लोर करने के लिए और भी बहुत कुछ है. इस आर्किटेक्चर के फ़ायदों के बारे में ज़्यादा जानने के लिए, Gemini 2 के मल्टीमॉडल Live API की क्षमताओं के बारे में जानें. साथ ही, LangGraph की मदद से सिंगल-पाथ ऑर्केस्ट्रेशन को लागू करने का तरीका जानें. इसके लिए, अगले दो चैप्टर पढ़ें.
12. वैकल्पिक: Gemini की मदद से ऑडियो रीकैप
Gemini, टेक्स्ट, इमेज, और ऑडियो जैसे अलग-अलग सोर्स से मिली जानकारी को समझकर प्रोसेस कर सकता है. इससे, सीखने और कॉन्टेंट बनाने के लिए कई नए विकल्प मिलते हैं. Gemini की "देखने", "सुनने", और "पढ़ने" की क्षमता, उपयोगकर्ताओं को क्रिएटिव और दिलचस्प अनुभव देती है.
सिर्फ़ विज़ुअल या टेक्स्ट बनाने के अलावा, सीखने का एक और अहम तरीका है कि जानकारी को असरदार तरीके से कम शब्दों में बताया जाए और उसे दोहराया जाए. सोचकर देखें: आपको किसी किताब में पढ़ी गई बात की तुलना में, किसी गाने के बोल ज़्यादा आसानी से कितनी बार याद रहते हैं? आवाज़ से किसी चीज़ को आसानी से याद रखा जा सकता है! इसलिए, हम Gemini की मल्टीमॉडल सुविधाओं का इस्तेमाल करके, अपने टीचिंग प्लान के ऑडियो रीकैप जनरेट करेंगे. इससे छात्र-छात्राओं को कॉन्टेंट की समीक्षा करने का एक आसान और दिलचस्प तरीका मिलेगा. साथ ही, सुनकर सीखने की सुविधा की मदद से, उन्हें कॉन्टेंट को ज़्यादा समय तक याद रखने और उसे बेहतर तरीके से समझने में मदद मिलेगी.
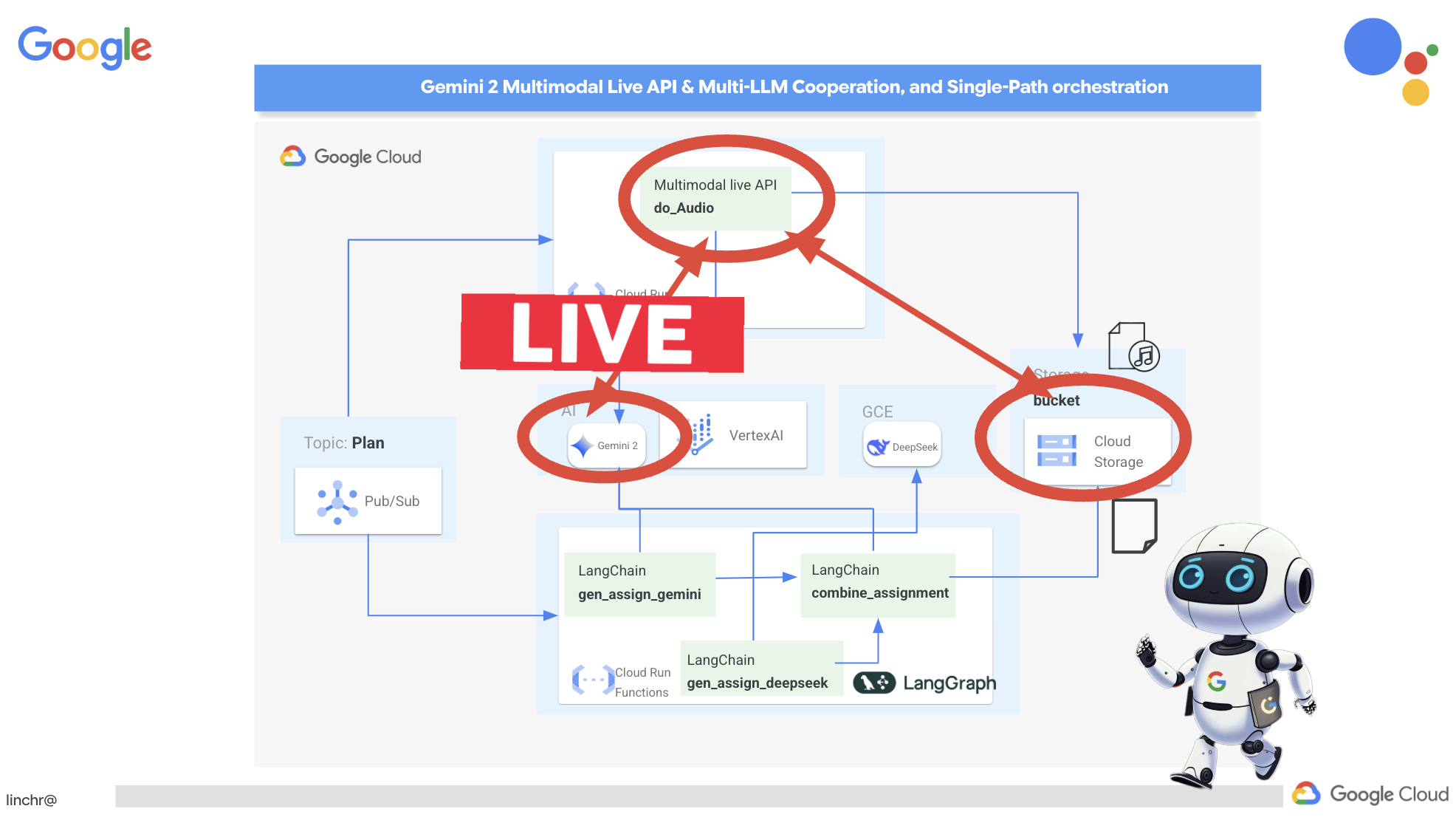
हमें जनरेट की गई ऑडियो फ़ाइलों को सेव करने के लिए, किसी जगह की ज़रूरत होती है. Cloud Storage, बड़े पैमाने पर इस्तेमाल किए जा सकने वाला और भरोसेमंद समाधान उपलब्ध कराता है.
👉कंसोल में स्टोरेज पर जाएं. बाईं ओर मौजूद मेन्यू में, "बकेट" पर क्लिक करें. सबसे ऊपर मौजूद, "+ बनाएं" बटन पर क्लिक करें.
👉अपने नए बकेट को कॉन्फ़िगर करें:
- बकेट का नाम:
aidemy-recap-UNIQUE_NAME.- अहम जानकारी: पक्का करें कि आपने बकेट का ऐसा नाम तय किया हो जो पहले से मौजूद न हो और
aidemy-recap-से शुरू होता हो. Cloud Storage बकेट बनाते समय, नाम से जुड़ी समस्याओं से बचने के लिए यह यूनीक प्रीफ़िक्स ज़रूरी है.
- अहम जानकारी: पक्का करें कि आपने बकेट का ऐसा नाम तय किया हो जो पहले से मौजूद न हो और
- देश या इलाका:
us-central1. - स्टोरेज क्लास: "स्टैंडर्ड". स्टैंडर्ड, अक्सर ऐक्सेस किए जाने वाले डेटा के लिए सही है.
- ऐक्सेस कंट्रोल: डिफ़ॉल्ट रूप से चुने गए "यूनिफ़ॉर्म" ऐक्सेस कंट्रोल को ही रहने दें. इससे बकेट के लेवल पर ऐक्सेस कंट्रोल करने की सुविधा मिलती है.
- ऐडवांस विकल्प: इस वर्कशॉप के लिए, डिफ़ॉल्ट सेटिंग आम तौर पर काफ़ी होती हैं.
बकेट बनाने के लिए, बनाएं बटन पर क्लिक करें.
- आपको सार्वजनिक ऐक्सेस को रोकने की सुविधा के बारे में एक पॉप-अप दिख सकता है. "इस बकेट पर सार्वजनिक ऐक्सेस को रोकने की सुविधा लागू करें" बॉक्स को चुने हुए रहने दें. इसके बाद,
Confirmपर क्लिक करें.
अब आपको बकेट की सूची में, अपनी नई बकेट दिखेगी. बकेट का नाम याद रखें. आपको इसकी ज़रूरत बाद में पड़ेगी.
👉क्लाउड कोड एडिटर के टर्मिनल में, सेवा खाते को बकेट का ऐक्सेस देने के लिए, ये कमांड चलाएं:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gcloud storage buckets add-iam-policy-binding gs://$COURSE_BUCKET_NAME \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectViewer"
gcloud storage buckets add-iam-policy-binding gs://$COURSE_BUCKET_NAME \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectCreator"
👉Cloud Code Editor में, courses फ़ोल्डर के अंदर audio.py खोलें. इस कोड को फ़ाइल के आखिर में चिपकाएं:
config = LiveConnectConfig(
response_modalities=["AUDIO"],
speech_config=SpeechConfig(
voice_config=VoiceConfig(
prebuilt_voice_config=PrebuiltVoiceConfig(
voice_name="Charon",
)
)
),
)
async def process_weeks(teaching_plan: str):
region = "us-east5" #To workaround onRamp quota limits
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
clientAudio = genai.Client(vertexai=True, project=PROJECT_ID, location="us-central1")
async with clientAudio.aio.live.connect(
model=MODEL_ID,
config=config,
) as session:
for week in range(1, 4):
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Given the following teaching plan: {teaching_plan}, Extrace content plan for week {week}. And return just the plan, nothingh else " # Clarified prompt
)
prompt = f"""
Assume you are the instructor.
Prepare a concise and engaging recap of the key concepts and topics covered.
This recap should be suitable for generating a short audio summary for students.
Focus on the most important learnings and takeaways, and frame it as a direct address to the students.
Avoid overly formal language and aim for a conversational tone, tell a few jokes.
Teaching plan: {response.text} """
print(f"prompt --->{prompt}")
await session.send(input=prompt, end_of_turn=True)
with open(f"temp_audio_week_{week}.raw", "wb") as temp_file:
async for message in session.receive():
if message.server_content.model_turn:
for part in message.server_content.model_turn.parts:
if part.inline_data:
temp_file.write(part.inline_data.data)
data, samplerate = sf.read(f"temp_audio_week_{week}.raw", channels=1, samplerate=24000, subtype='PCM_16', format='RAW')
sf.write(f"course-week-{week}.wav", data, samplerate)
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
blob = bucket.blob(f"course-week-{week}.wav") # Or give it a more descriptive name
blob.upload_from_filename(f"course-week-{week}.wav")
print(f"Audio saved to GCS: gs://{BUCKET_NAME}/course-week-{week}.wav")
await session.close()
def breakup_sessions(teaching_plan: str):
asyncio.run(process_weeks(teaching_plan))
- स्ट्रीमिंग कनेक्शन: सबसे पहले, Live API एंडपॉइंट के साथ एक परसिस्टेंट कनेक्शन बनाया जाता है. स्टैंडर्ड एपीआई कॉल में, अनुरोध भेजा जाता है और जवाब मिलता है. हालांकि, इस कनेक्शन में डेटा का लगातार आदान-प्रदान होता रहता है.
- कॉन्फ़िगरेशन मल्टीमॉडल: कॉन्फ़िगरेशन का इस्तेमाल करके यह तय किया जा सकता है कि आपको किस तरह का आउटपुट चाहिए. इस मामले में, ऑडियो. इसके अलावा, यह भी तय किया जा सकता है कि आपको किन पैरामीटर का इस्तेमाल करना है. जैसे, आवाज़ चुनना, ऑडियो एन्कोडिंग
- एसिंक्रोनस प्रोसेसिंग: यह एपीआई एसिंक्रोनस तरीके से काम करता है. इसका मतलब है कि ऑडियो जनरेट होने का इंतज़ार करते समय, यह मुख्य थ्रेड को ब्लॉक नहीं करता. डेटा को रीयल-टाइम में प्रोसेस करके और आउटपुट को छोटे-छोटे हिस्सों में भेजकर, यह तुरंत जवाब देने का अनुभव देता है.
अब सबसे अहम सवाल यह है कि ऑडियो जनरेट करने की यह प्रोसेस कब चलनी चाहिए? हम चाहते हैं कि नया टीचिंग प्लान बनाने के तुरंत बाद, ऑडियो रीकैप उपलब्ध हो जाएं. हमने Pub/Sub विषय पर शिक्षण योजना पब्लिश करके, इवेंट-ड्रिवन आर्किटेक्चर को पहले ही लागू कर दिया है. इसलिए, हम उस विषय की सदस्यता ले सकते हैं.
हालांकि, हम नए टीचिंग प्लान बहुत बार जनरेट नहीं करते. किसी एजेंट को लगातार चालू रखना और नए प्लान का इंतज़ार करना सही नहीं होगा. इसलिए, ऑडियो जनरेट करने के इस लॉजिक को Cloud Run फ़ंक्शन के तौर पर डिप्लॉय करना सही है.
इसे फ़ंक्शन के तौर पर डिप्लॉय करने पर, यह तब तक काम नहीं करता, जब तक Pub/Sub टॉपिक पर कोई नया मैसेज पब्लिश नहीं किया जाता. ऐसा होने पर, यह फ़ंक्शन अपने-आप ट्रिगर हो जाता है. यह फ़ंक्शन, ऑडियो रीकैप जनरेट करता है और उन्हें हमारे बकेट में सेव करता है.
👉main.py फ़ाइल में मौजूद courses फ़ोल्डर में, यह फ़ाइल Cloud Run फ़ंक्शन को तय करती है. यह फ़ंक्शन तब ट्रिगर होगा, जब कोई नया टीचिंग प्लान उपलब्ध होगा. इसे प्लान मिलता है और यह ऑडियो रीकैप जनरेट करने की प्रोसेस शुरू करता है. इस कोड स्निपेट को फ़ाइल के आखिर में जोड़ें.
@functions_framework.cloud_event
def process_teaching_plan(cloud_event):
print(f"CloudEvent received: {cloud_event.data}")
time.sleep(60)
try:
if isinstance(cloud_event.data.get('message', {}).get('data'), str): # Check for base64 encoding
data = json.loads(base64.b64decode(cloud_event.data['message']['data']).decode('utf-8'))
teaching_plan = data.get('teaching_plan') # Get the teaching plan
elif 'teaching_plan' in cloud_event.data: # No base64
teaching_plan = cloud_event.data["teaching_plan"]
else:
raise KeyError("teaching_plan not found") # Handle error explicitly
#Load the teaching_plan as string and from cloud event, call audio breakup_sessions
breakup_sessions(teaching_plan)
return "Teaching plan processed successfully", 200
except (json.JSONDecodeError, AttributeError, KeyError) as e:
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500
except Exception as e:
print(f"Error processing teaching plan: {e}")
return "Error processing teaching plan", 500
@functions_framework.cloud_event: यह डेकोरेटर, फ़ंक्शन को Cloud Run फ़ंक्शन के तौर पर मार्क करता है. इसे CloudEvents से ट्रिगर किया जाएगा.
स्थानीय तौर पर टेस्टिंग करना
👉हम इसे वर्चुअल एनवायरमेंट में चलाएंगे और Cloud Run फ़ंक्शन के लिए ज़रूरी Python लाइब्रेरी इंस्टॉल करेंगे.
cd ~/aidemy-bootstrap/courses
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉Cloud Run फ़ंक्शन एम्युलेटर की मदद से, हम अपने फ़ंक्शन को Google Cloud पर डिप्लॉय करने से पहले, स्थानीय तौर पर उसकी जांच कर सकते हैं. यह कमांड चलाकर, लोकल एम्युलेटर शुरू करें:
functions-framework --target process_teaching_plan --signature-type=cloudevent --source main.py
👉एम्युलेटर के चालू होने पर, एम्युलेटर को CloudEvents के टेस्ट भेजे जा सकते हैं. इससे, पब्लिश किए जा रहे नए टीचिंग प्लान का सिम्युलेशन किया जा सकता है. नए टर्मिनल में:

👉रन करें:
curl -X POST \
http://localhost:8080/ \
-H "Content-Type: application/json" \
-H "ce-id: event-id-01" \
-H "ce-source: planner-agent" \
-H "ce-specversion: 1.0" \
-H "ce-type: google.cloud.pubsub.topic.v1.messagePublished" \
-d '{
"message": {
"data": "eyJ0ZWFjaGluZ19wbGFuIjogIldlZWsgMTogMkQgU2hhcGVzIGFuZCBBbmdsZXMgLSBEYXkgMTogUmV2aWV3IG9mIGJhc2ljIDJEIHNoYXBlcyAoc3F1YXJlcywgcmVjdGFuZ2xlcywgdHJpYW5nbGVzLCBjaXJjbGVzKS4gRGF5IDI6IEV4cGxvcmluZyBkaWZmZXJlbnQgdHlwZXMgb2YgdHJpYW5nbGVzIChlcXVpbGF0ZXJhbCwgaXNvc2NlbGVzLCBzY2FsZW5lLCByaWdodC1hbmdsZWQpLiBEYXkgMzogRXhwbG9yaW5nIHF1YWRyaWxhdGVyYWxzIChzcXVhcmUsIHJlY3RhbmdsZSwgcGFyYWxsZWxvZ3JhbSwgcmhvbWJ1cywgdHJhcGV6aXVtKS4gRGF5IDQ6IEludHJvZHVjdGlvbiB0byBhbmdsZXM6IHJpZ2h0IGFuZ2xlcywgYWN1dGUgYW5nbGVzLCBhbmQgb2J0dXNlIGFuZ2xlcy4gRGF5IDU6IE1lYXN1cmluZyBhbmdsZXMgdXNpbmcgYSBwcm90cmFjdG9yLiBXZWVrIDI6IDNEIFNoYXBlcyBhbmQgU3ltbWV0cnkgLSBEYXkgNjogSW50cm9kdWN0aW9uIHRvIDNEIHNoYXBlczogY3ViZXMsIGN1Ym9pZHMsIHNwaGVyZXMsIGN5bGluZGVycywgY29uZXMsIGFuZCBweXJhbWlkcy4gRGF5IDc6IERlc2NyaWJpbmcgM0Qgc2hhcGVzIHVzaW5nIGZhY2VzLCBlZGdlcywgYW5kIHZlcnRpY2VzLiBEYXkgODogUmVsYXRpbmcgMkQgc2hhcGVzIHRvIDNEIHNoYXBlcy4gRGF5IDk6IElkZW50aWZ5aW5nIGxpbmVzIG9mIHN5bW1ldHJ5IGluIDJEIHNoYXBlcy4gRGF5IDEwOiBDb21wbGV0aW5nIHN5bW1ldHJpY2FsIGZpZ3VyZXMuIFdlZWsgMzogUG9zaXRpb24sIERpcmVjdGlvbiwgYW5kIFByb2JsZW0gU29sdmluZyAtIERheSAxMTogRGVzY3JpYmluZyBwb3NpdGlvbiB1c2luZyBjb29yZGluYXRlcyBpbiB0aGUgZmlyc3QgcXVhZHJhbnQuIERheSAxMjogUGxvdHRpbmcgY29vcmRpbmF0ZXMgdG8gZHJhdyBzaGFwZXMuIERheSAxMzogVW5kZXJzdGFuZGluZyB0cmFuc2xhdGlvbiAoc2xpZGluZyBhIHNoYXBlKS4gRGF5IDE0OiBVbmRlcnN0YW5kaW5nIHJlZmxlY3Rpb24gKGZsaXBwaW5nIGEgc2hhcGUpLiBEYXkgMTU6IFByb2JsZW0tc29sdmluZyBhY3Rpdml0aWVzIGludm9sdmluZyBwZXJpbWV0ZXIsIGFyZWEsIGFuZCBtaXNzaW5nIGFuZ2xlcy4ifQ=="
}
}'
जवाब का इंतज़ार करते समय, Cloud Shell के दूसरे टर्मिनल पर स्विच करें. एम्युलेटर के टर्मिनल में, अपने फ़ंक्शन की प्रोग्रेस और उससे जनरेट हुए किसी भी आउटपुट या गड़बड़ी के मैसेज को देखा जा सकता है. 😁
दूसरे टर्मिनल में वापस जाने पर, आपको दिखेगा कि यह OK पर वापस आ गया है.
👉आपको बकेट में मौजूद डेटा की पुष्टि करनी होगी. इसके लिए, Cloud Storage पर जाएं. इसके बाद, "बकेट" टैब और फिर aidemy-recap-UNIQUE_NAME चुनें
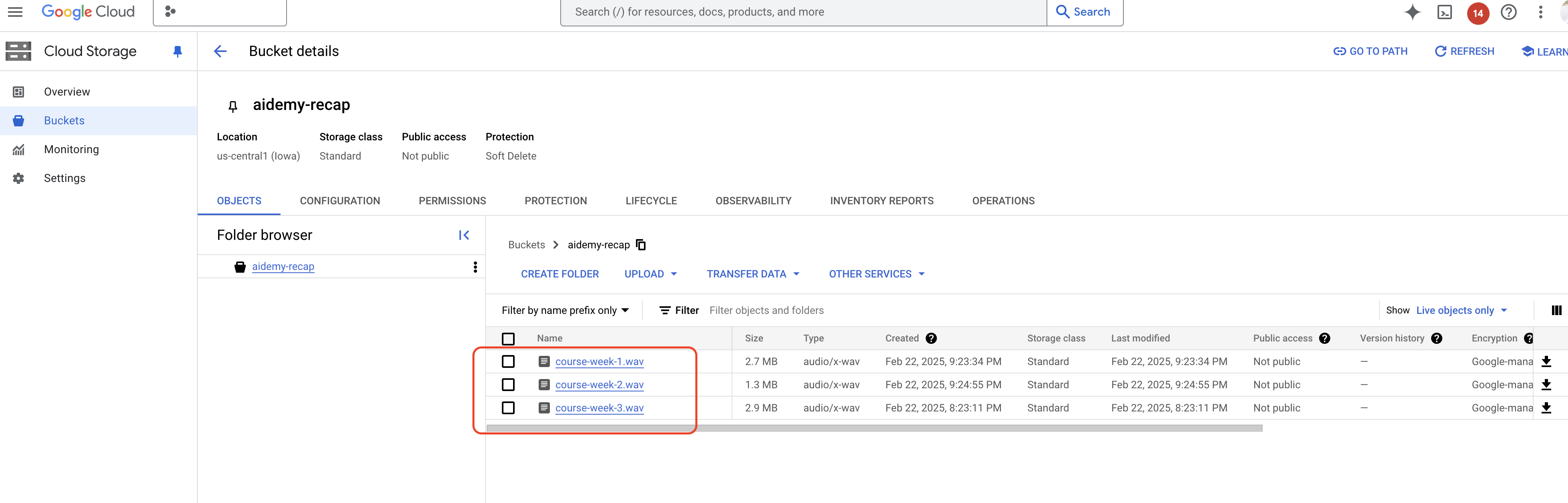
👉एम्युलेटर चलाने वाले टर्मिनल में, बंद करने के लिए ctrl+c टाइप करें. इसके बाद, दूसरे टर्मिनल को बंद करें. इसके बाद, दूसरे टर्मिनल को बंद करें. साथ ही, वर्चुअल एनवायरमेंट से बाहर निकलने के लिए, deactivate कमांड चलाएं.
deactivate
Google Cloud पर डिप्लॉय करना
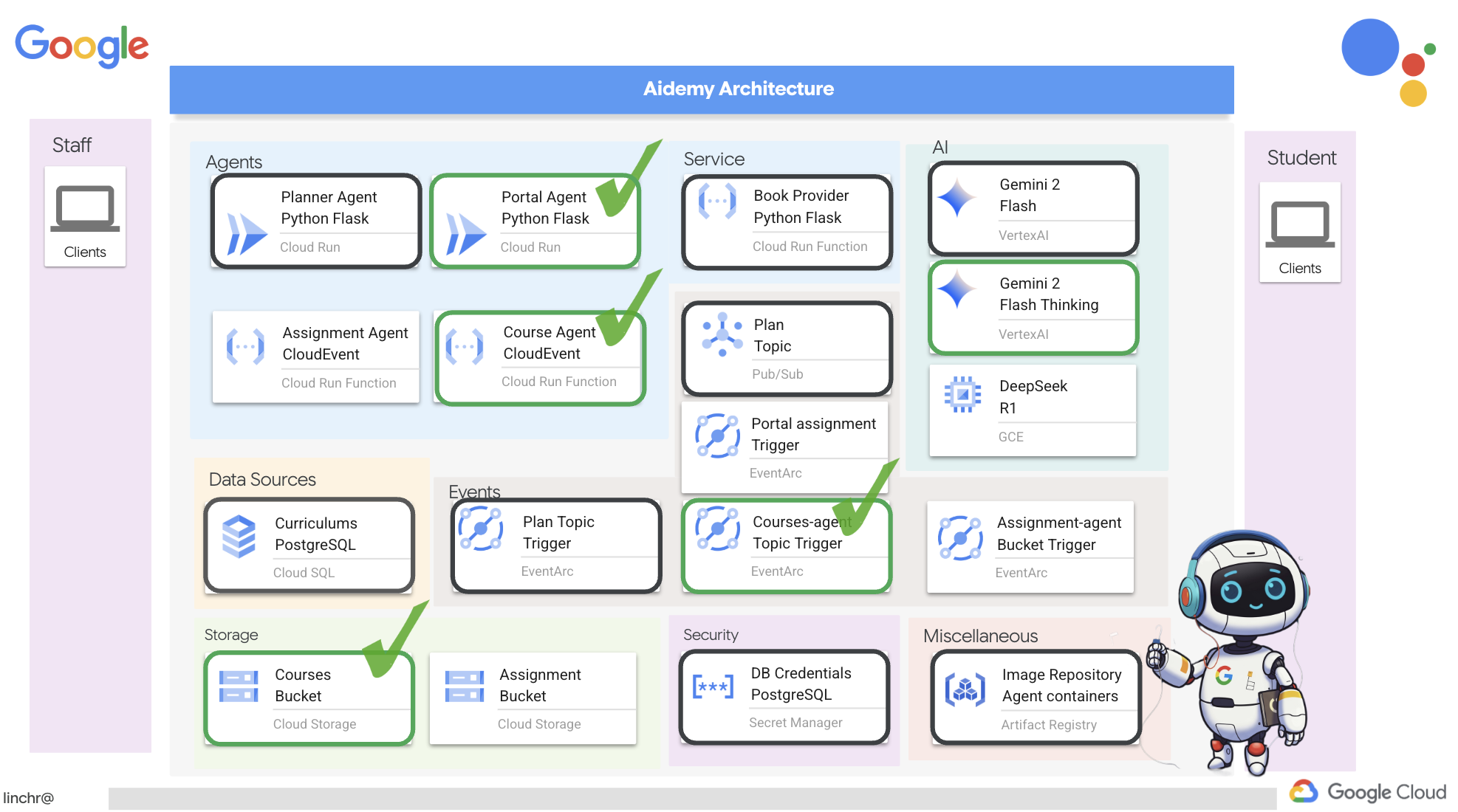 👉स्थानीय तौर पर जांच करने के बाद, अब कोर्स एजेंट को Google Cloud पर डिप्लॉय करने का समय है. टर्मिनल में, ये कमांड चलाएं:
👉स्थानीय तौर पर जांच करने के बाद, अब कोर्स एजेंट को Google Cloud पर डिप्लॉय करने का समय है. टर्मिनल में, ये कमांड चलाएं:
cd ~/aidemy-bootstrap/courses
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud functions deploy courses-agent \
--region=us-central1 \
--gen2 \
--source=. \
--runtime=python312 \
--trigger-topic=plan \
--entry-point=process_teaching_plan \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
Google Cloud Console में Cloud Run पर जाकर, डिप्लॉयमेंट की पुष्टि करें.आपको courses-agent नाम की एक नई सेवा दिखेगी.
ट्रिगर कॉन्फ़िगरेशन देखने के लिए, courses-agent सेवा पर क्लिक करें. इससे आपको इसकी जानकारी दिखेगी. "ट्रिगर" टैब पर जाएं.
आपको प्लान के विषय पर पब्लिश किए गए मैसेज सुनने के लिए कॉन्फ़िगर किया गया ट्रिगर दिखेगा.
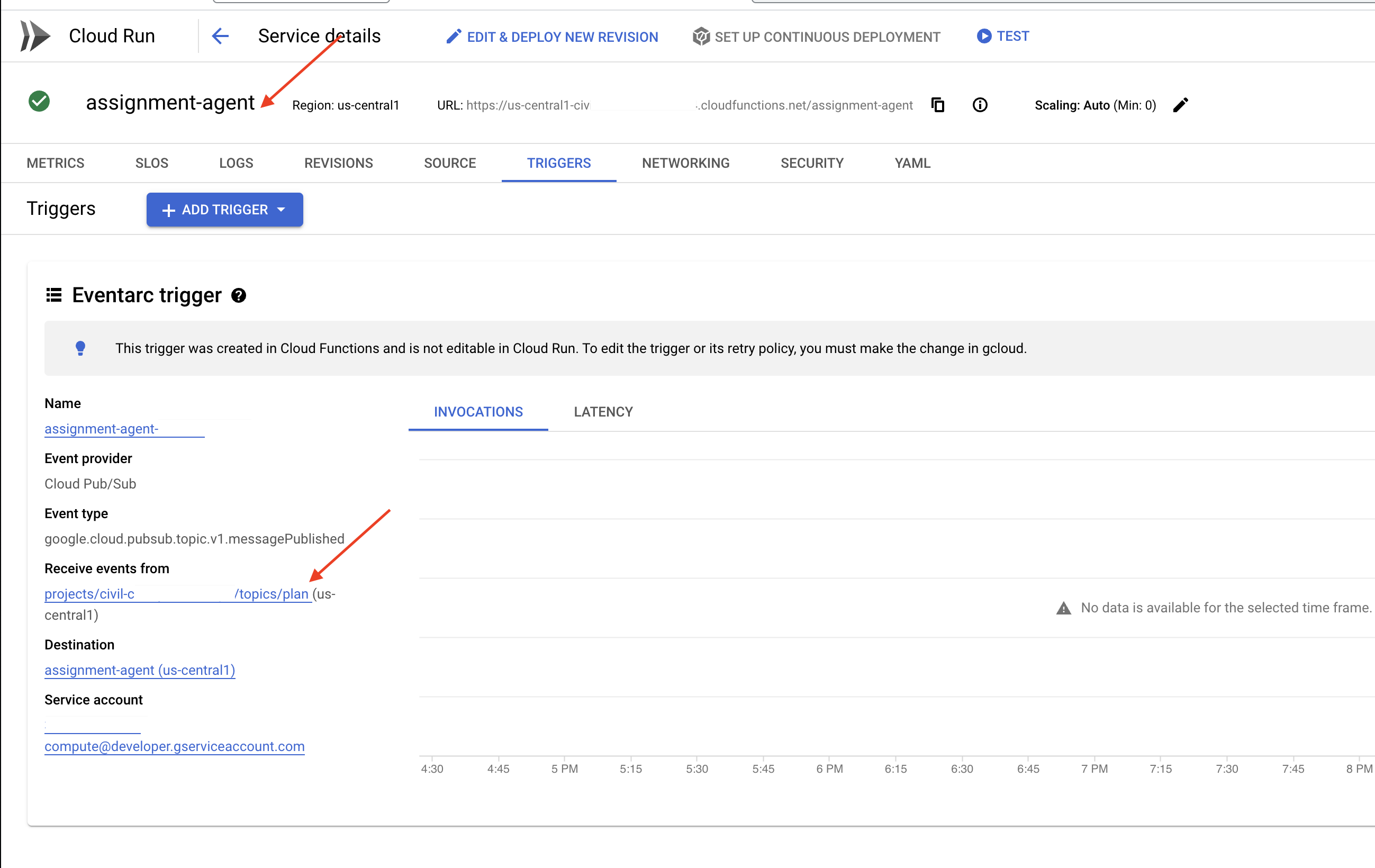
आखिर में, इसे शुरू से आखिर तक चलते हुए देखते हैं.
👉हमें पोर्टल एजेंट को कॉन्फ़िगर करना होगा, ताकि उसे पता चल सके कि जनरेट की गई ऑडियो फ़ाइलें कहां मिलेंगी. टर्मिनल में यह कमांड चलाएं:
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services update aidemy-portal \
--region=us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
👉प्लानर एजेंट के वेब पेज का इस्तेमाल करके, नया टीचिंग प्लान जनरेट करने की कोशिश करें. इसे शुरू होने में कुछ मिनट लग सकते हैं. चिंता न करें, यह सर्वरलेस सेवा है.
प्लानर एजेंट को ऐक्सेस करने के लिए, टर्मिनल में यह कमांड चलाकर इसका सेवा यूआरएल पाएं:
gcloud run services list \
--platform=managed \
--region=us-central1 \
--format='value(URL)' | grep planner
नया प्लान जनरेट करने के बाद, ऑडियो जनरेट होने में दो से तीन मिनट लगेंगे. इस लैब खाते के लिए बिलिंग की सीमा तय होने की वजह से, इसमें कुछ और मिनट लग सकते हैं.
courses-agent फ़ंक्शन को ट्रेनिंग प्लान मिला है या नहीं, यह देखने के लिए फ़ंक्शन के "ट्रिगर" टैब पर जाएं. पेज को समय-समय पर रीफ़्रेश करें. कुछ समय बाद, आपको दिखेगा कि फ़ंक्शन शुरू हो गया है. अगर दो मिनट से ज़्यादा समय बीत जाने के बाद भी फ़ंक्शन चालू नहीं होता है, तो टीचिंग प्लान को फिर से जनरेट करने की कोशिश करें. हालांकि, प्लान को बार-बार जनरेट करने से बचें. ऐसा इसलिए, क्योंकि जनरेट किए गए हर प्लान को एजेंट क्रम से इस्तेमाल और प्रोसेस करेगा. इससे बैकलॉग बन सकता है.
👉पोर्टल पर जाएं और "कोर्स" पर क्लिक करें. आपको तीन कार्ड दिखेंगे. हर कार्ड में ऑडियो रीकैप दिखेगा. अपने पोर्टल एजेंट का यूआरएल ढूंढने के लिए:
gcloud run services list \
--platform=managed \
--region=us-central1 \
--format='value(URL)' | grep portal
हर कोर्स पर "चलाएं" पर क्लिक करके पक्का करें कि ऑडियो रीकैप, आपके जनरेट किए गए टीचिंग प्लान के मुताबिक हों! 
वर्चुअल एनवायरमेंट से बाहर निकलें.
deactivate
13. ज़रूरी नहीं: Gemini और DeepSeek के साथ भूमिका के आधार पर मिलकर काम करना
अलग-अलग नज़रियों से देखने पर, कई अहम बातें पता चलती हैं. खास तौर पर, दिलचस्प और सोच-समझकर असाइनमेंट तैयार करने के लिए ऐसा करना ज़रूरी है. अब हम एक मल्टी-एजेंट सिस्टम बनाएंगे. यह सिस्टम, असाइनमेंट जनरेट करने के लिए, अलग-अलग भूमिकाओं वाले दो मॉडल का इस्तेमाल करेगा. इनमें से एक मॉडल, साथ मिलकर काम करने को बढ़ावा देगा और दूसरा मॉडल, खुद से पढ़ाई करने को बढ़ावा देगा. हम "सिंगल-शॉट" आर्किटेक्चर का इस्तेमाल करेंगे. इसमें वर्कफ़्लो एक तय रूट को फ़ॉलो करता है.
Gemini की मदद से असाइनमेंट जनरेट करने की सुविधा
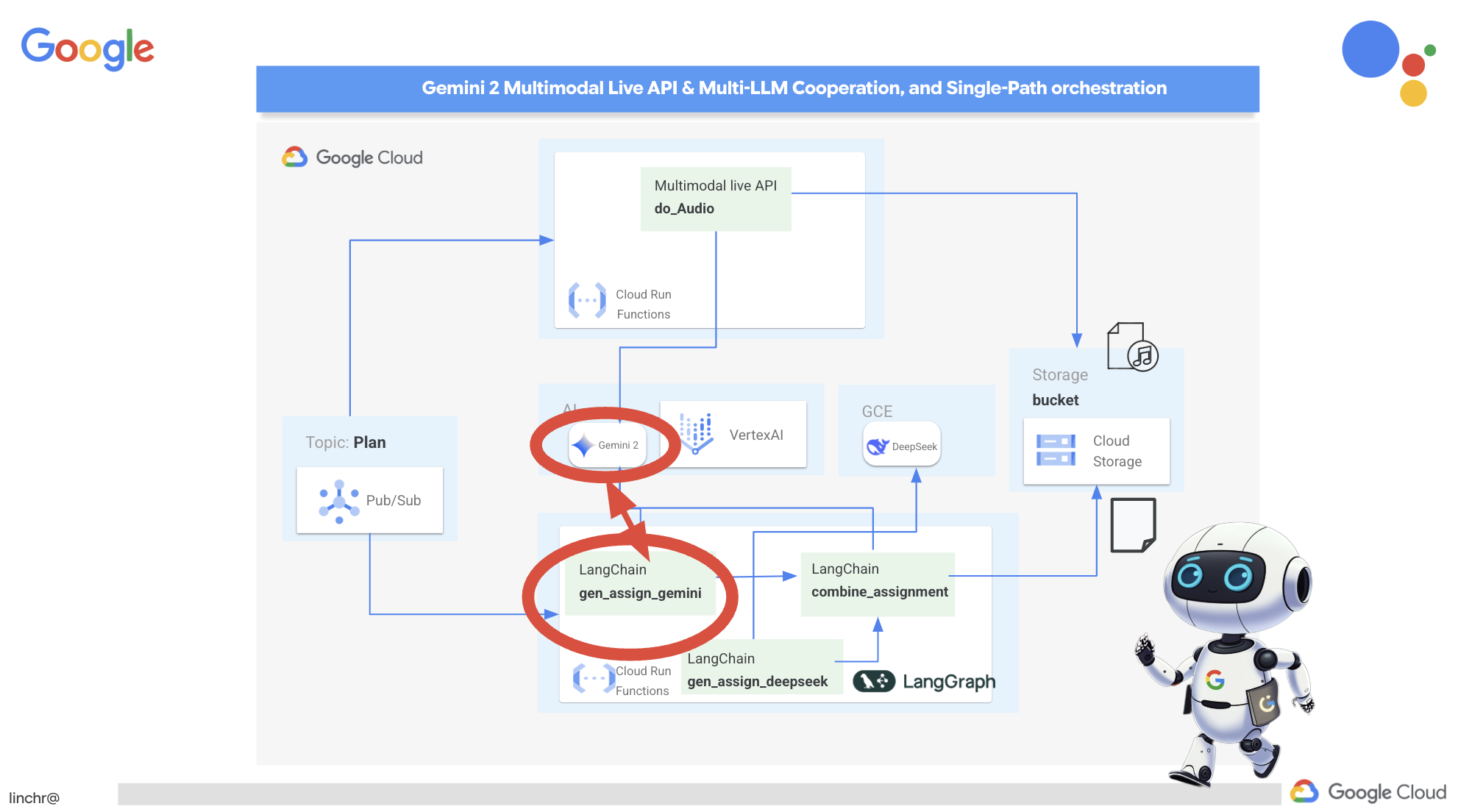 हम Gemini के फ़ंक्शन को सेट अप करके शुरुआत करेंगे, ताकि मिलकर काम करने पर ज़ोर देने वाले असाइनमेंट जनरेट किए जा सकें.
हम Gemini के फ़ंक्शन को सेट अप करके शुरुआत करेंगे, ताकि मिलकर काम करने पर ज़ोर देने वाले असाइनमेंट जनरेट किए जा सकें. assignment फ़ोल्डर में मौजूद gemini.py फ़ाइल में बदलाव करें.
👉gemini.py फ़ाइल के आखिर में यह कोड चिपकाएं:
def gen_assignment_gemini(state):
region=get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
print(f"---------------gen_assignment_gemini")
response = client.models.generate_content(
model=MODEL_ID, contents=f"""
You are an instructor
Develop engaging and practical assignments for each week, ensuring they align with the teaching plan's objectives and progressively build upon each other.
For each week, provide the following:
* **Week [Number]:** A descriptive title for the assignment (e.g., "Data Exploration Project," "Model Building Exercise").
* **Learning Objectives Assessed:** List the specific learning objectives from the teaching plan that this assignment assesses.
* **Description:** A detailed description of the task, including any specific requirements or constraints. Provide examples or scenarios if applicable.
* **Deliverables:** Specify what students need to submit (e.g., code, report, presentation).
* **Estimated Time Commitment:** The approximate time students should dedicate to completing the assignment.
* **Assessment Criteria:** Briefly outline how the assignment will be graded (e.g., correctness, completeness, clarity, creativity).
The assignments should be a mix of individual and collaborative work where appropriate. Consider different learning styles and provide opportunities for students to apply their knowledge creatively.
Based on this teaching plan: {state["teaching_plan"]}
"""
)
print(f"---------------gen_assignment_gemini answer {response.text}")
state["model_one_assignment"] = response.text
return state
import unittest
class TestGenAssignmentGemini(unittest.TestCase):
def test_gen_assignment_gemini(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assigmodel_one_assignmentnment": "", "final_assignment": ""}
updated_state = gen_assignment_gemini(initial_state)
self.assertIn("model_one_assignment", updated_state)
self.assertIsNotNone(updated_state["model_one_assignment"])
self.assertIsInstance(updated_state["model_one_assignment"], str)
self.assertGreater(len(updated_state["model_one_assignment"]), 0)
print(updated_state["model_one_assignment"])
if __name__ == '__main__':
unittest.main()
यह असाइनमेंट जनरेट करने के लिए, Gemini मॉडल का इस्तेमाल करता है.
हम Gemini Agent को टेस्ट करने के लिए तैयार हैं.
👉एनवायरमेंट सेट अप करने के लिए, टर्मिनल में ये कमांड चलाएं:
cd ~/aidemy-bootstrap/assignment
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉इसे आज़माने के लिए, यह कमांड चलाएँ:
python gemini.py
आपको ऐसा असाइनमेंट दिखेगा जिसमें आउटपुट में ग्रुप वर्क ज़्यादा होगा. आखिर में, Assert टेस्ट भी नतीजे दिखाएगा.
Here are some engaging and practical assignments for each week, designed to build progressively upon the teaching plan's objectives:
**Week 1: Exploring the World of 2D Shapes**
* **Learning Objectives Assessed:**
* Identify and name basic 2D shapes (squares, rectangles, triangles, circles).
* .....
* **Description:**
* **Shape Scavenger Hunt:** Students will go on a scavenger hunt in their homes or neighborhoods, taking pictures of objects that represent different 2D shapes. They will then create a presentation or poster showcasing their findings, classifying each shape and labeling its properties (e.g., number of sides, angles, etc.).
* **Triangle Trivia:** Students will research and create a short quiz or presentation about different types of triangles, focusing on their properties and real-world examples.
* **Angle Exploration:** Students will use a protractor to measure various angles in their surroundings, such as corners of furniture, windows, or doors. They will record their measurements and create a chart categorizing the angles as right, acute, or obtuse.
....
**Week 2: Delving into the World of 3D Shapes and Symmetry**
* **Learning Objectives Assessed:**
* Identify and name basic 3D shapes.
* ....
* **Description:**
* **3D Shape Construction:** Students will work in groups to build 3D shapes using construction paper, cardboard, or other materials. They will then create a presentation showcasing their creations, describing the number of faces, edges, and vertices for each shape.
* **Symmetry Exploration:** Students will investigate the concept of symmetry by creating a visual representation of various symmetrical objects (e.g., butterflies, leaves, snowflakes) using drawing or digital tools. They will identify the lines of symmetry and explain their findings.
* **Symmetry Puzzles:** Students will be given a half-image of a symmetrical figure and will be asked to complete the other half, demonstrating their understanding of symmetry. This can be done through drawing, cut-out activities, or digital tools.
**Week 3: Navigating Position, Direction, and Problem Solving**
* **Learning Objectives Assessed:**
* Describe position using coordinates in the first quadrant.
* ....
* **Description:**
* **Coordinate Maze:** Students will create a maze using coordinates on a grid paper. They will then provide directions for navigating the maze using a combination of coordinate movements and translation/reflection instructions.
* **Shape Transformations:** Students will draw shapes on a grid paper and then apply transformations such as translation and reflection, recording the new coordinates of the transformed shapes.
* **Geometry Challenge:** Students will solve real-world problems involving perimeter, area, and angles. For example, they could be asked to calculate the perimeter of a room, the area of a garden, or the missing angle in a triangle.
....
ctl+c के साथ बंद करें और टेस्ट कोड को साफ़ करें. gemini.py से यह कोड हटाएं
import unittest
class TestGenAssignmentGemini(unittest.TestCase):
def test_gen_assignment_gemini(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assigmodel_one_assignmentnment": "", "final_assignment": ""}
updated_state = gen_assignment_gemini(initial_state)
self.assertIn("model_one_assignment", updated_state)
self.assertIsNotNone(updated_state["model_one_assignment"])
self.assertIsInstance(updated_state["model_one_assignment"], str)
self.assertGreater(len(updated_state["model_one_assignment"]), 0)
print(updated_state["model_one_assignment"])
if __name__ == '__main__':
unittest.main()
DeepSeek Assignment Generator को कॉन्फ़िगर करना
क्लाउड पर आधारित एआई प्लैटफ़ॉर्म इस्तेमाल करने में आसान होते हैं. हालांकि, डेटा की निजता और डेटा का कंट्रोल बनाए रखने के लिए, एलएलएम को खुद होस्ट करना ज़रूरी हो सकता है. हम Cloud Compute Engine इंस्टेंस पर, DeepSeek का सबसे छोटा मॉडल (1.5B पैरामीटर) डिप्लॉय करेंगे. इसे Google के Vertex AI प्लैटफ़ॉर्म पर होस्ट करने या इसे अपने GKE इंस्टेंस पर होस्ट करने जैसे अन्य तरीके भी हैं. हालांकि, यह सिर्फ़ एआई एजेंट पर आधारित वर्कशॉप है और हम आपको यहां ज़्यादा देर तक नहीं रखना चाहते. इसलिए, हम सबसे आसान तरीका इस्तेमाल करेंगे. हालांकि, अगर आपको इसमें दिलचस्पी है और आपको अन्य विकल्पों के बारे में ज़्यादा जानना है, तो असाइनमेंट फ़ोल्डर में मौजूद deepseek-vertexai.py फ़ाइल देखें. इसमें, VertexAI पर डिप्लॉय किए गए मॉडल के साथ इंटरैक्ट करने का सैंपल कोड दिया गया है.
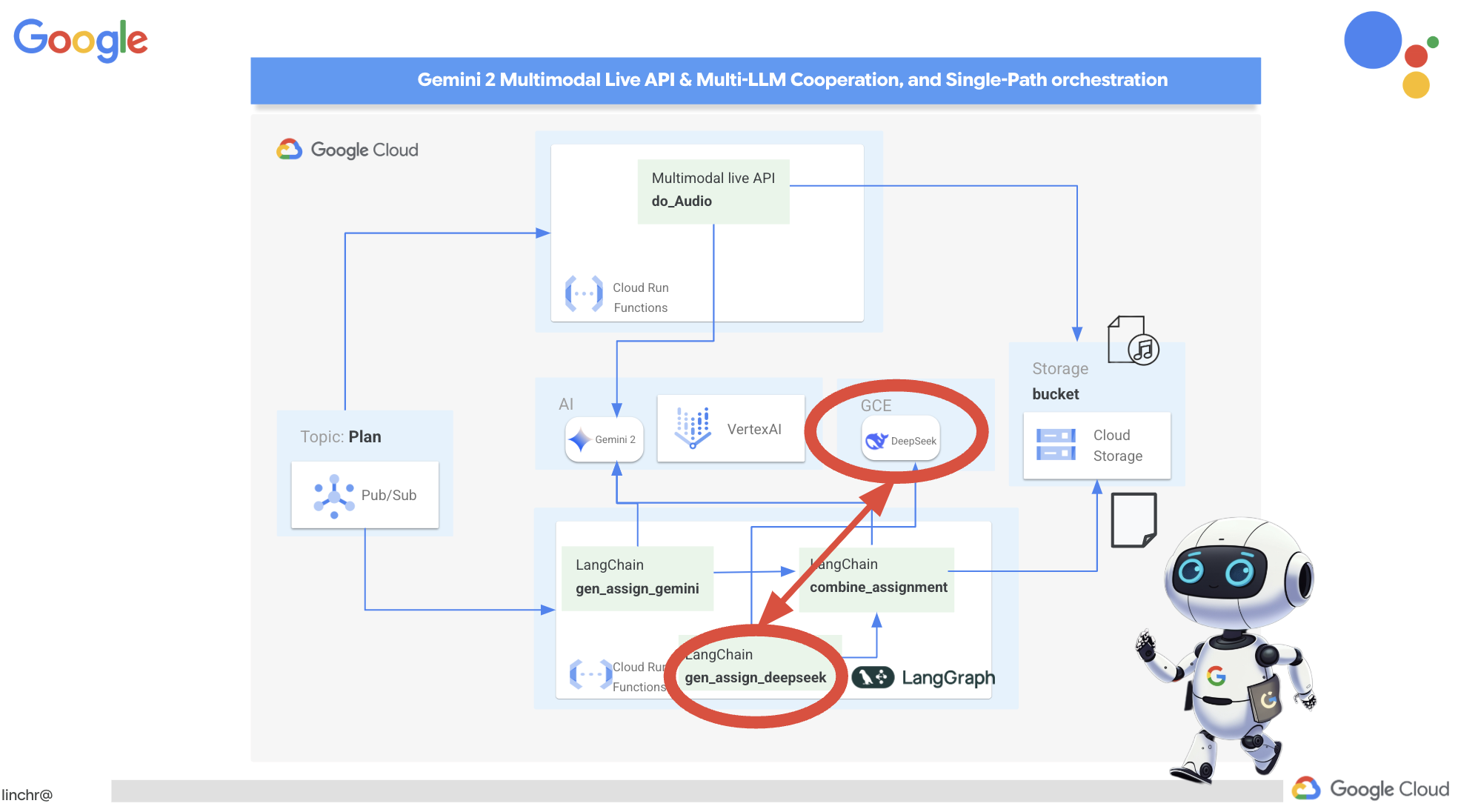
👉सेल्फ़-होस्ट किया गया एलएलएम प्लैटफ़ॉर्म Ollama बनाने के लिए, टर्मिनल में यह कमांड चलाएं:
cd ~/aidemy-bootstrap/assignment
gcloud config set project $(cat ~/project_id.txt)
gcloud compute instances create ollama-instance \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--machine-type=e2-standard-4 \
--zone=us-central1-a \
--metadata-from-file startup-script=startup.sh \
--boot-disk-size=50GB \
--tags=ollama \
--scopes=https://www.googleapis.com/auth/cloud-platform
यह पुष्टि करने के लिए कि Compute Engine इंस्टेंस चल रहा है:
Google Cloud Console में, Compute Engine > "VM इंस्टेंस" पर जाएं. आपको ollama-instance के बगल में हरे रंग का सही का निशान दिखेगा. इससे पता चलता है कि यह चालू है. अगर आपको यह नहीं दिख रहा है, तो पक्का करें कि ज़ोन us-central1 हो. अगर ऐसा नहीं है, तो आपको इसे खोजना पड़ सकता है.
👉हम सबसे छोटा DeepSeek मॉडल इंस्टॉल करेंगे और Cloud Shell Editor में वापस जाकर, नए टर्मिनल में इसकी जांच करेंगे. GCE इंस्टेंस में एसएसएच करने के लिए, यह कमांड चलाएं.
gcloud compute ssh ollama-instance --zone=us-central1-a
एसएसएच कनेक्शन सेट अप करने के बाद, आपको यह मैसेज दिख सकता है:
"क्या आपको जारी रखना है (Y/n)?"
आगे बढ़ने के लिए, Y टाइप करें और Enter दबाएं. इसमें केस-सेंसिटिविटी का ध्यान रखने की ज़रूरत नहीं है.
इसके बाद, आपसे एसएसएच कुंजी के लिए लंबा पासवर्ड बनाने के लिए कहा जा सकता है. अगर आपको पासफ़्रेज़ का इस्तेमाल नहीं करना है, तो डिफ़ॉल्ट (कोई पासफ़्रेज़ नहीं) को स्वीकार करने के लिए, बस दो बार Enter दबाएं.
👉अब आप वर्चुअल मशीन में हैं. सबसे छोटे DeepSeek R1 मॉडल को पुल करें और देखें कि क्या यह काम करता है?
ollama pull deepseek-r1:1.5b
ollama run deepseek-r1:1.5b "who are you?"
👉GCE इंस्टेंस से बाहर निकलें और एसएसएच टर्मिनल में यह डालें:
exit
👉इसके बाद, नेटवर्क की नीति सेट अप करें, ताकि अन्य सेवाएं एलएलएम को ऐक्सेस कर सकें. अगर आपको प्रोडक्शन के लिए ऐसा करना है, तो कृपया इंस्टेंस के ऐक्सेस को सीमित करें. इसके लिए, सेवा के लिए सुरक्षा लॉगिन लागू करें या आईपी ऐक्सेस को सीमित करें. रन:
gcloud compute firewall-rules create allow-ollama-11434 \
--allow=tcp:11434 \
--target-tags=ollama \
--description="Allow access to Ollama on port 11434"
👉यह पुष्टि करने के लिए कि आपकी फ़ायरवॉल नीति सही तरीके से काम कर रही है, यह कमांड चलाकर देखें:
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
curl -X POST "${OLLAMA_HOST}/api/generate" \
-H "Content-Type: application/json" \
-d '{
"prompt": "Hello, what are you?",
"model": "deepseek-r1:1.5b",
"stream": false
}'
इसके बाद, हम असाइनमेंट एजेंट में Deepseek फ़ंक्शन पर काम करेंगे, ताकि ऐसे असाइनमेंट जनरेट किए जा सकें जिनमें हर छात्र-छात्रा के काम पर ज़ोर दिया गया हो.
👉assignment फ़ोल्डर में जाकर, deepseek.py में बदलाव करें. इसके आखिर में यह स्निपेट जोड़ें:
def gen_assignment_deepseek(state):
print(f"---------------gen_assignment_deepseek")
template = """
You are an instructor who favor student to focus on individual work.
Develop engaging and practical assignments for each week, ensuring they align with the teaching plan's objectives and progressively build upon each other.
For each week, provide the following:
* **Week [Number]:** A descriptive title for the assignment (e.g., "Data Exploration Project," "Model Building Exercise").
* **Learning Objectives Assessed:** List the specific learning objectives from the teaching plan that this assignment assesses.
* **Description:** A detailed description of the task, including any specific requirements or constraints. Provide examples or scenarios if applicable.
* **Deliverables:** Specify what students need to submit (e.g., code, report, presentation).
* **Estimated Time Commitment:** The approximate time students should dedicate to completing the assignment.
* **Assessment Criteria:** Briefly outline how the assignment will be graded (e.g., correctness, completeness, clarity, creativity).
The assignments should be a mix of individual and collaborative work where appropriate. Consider different learning styles and provide opportunities for students to apply their knowledge creatively.
Based on this teaching plan: {teaching_plan}
"""
prompt = ChatPromptTemplate.from_template(template)
model = OllamaLLM(model="deepseek-r1:1.5b",
base_url=OLLAMA_HOST)
chain = prompt | model
response = chain.invoke({"teaching_plan":state["teaching_plan"]})
state["model_two_assignment"] = response
return state
import unittest
class TestGenAssignmentDeepseek(unittest.TestCase):
def test_gen_assignment_deepseek(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = gen_assignment_deepseek(initial_state)
self.assertIn("model_two_assignment", updated_state)
self.assertIsNotNone(updated_state["model_two_assignment"])
self.assertIsInstance(updated_state["model_two_assignment"], str)
self.assertGreater(len(updated_state["model_two_assignment"]), 0)
print(updated_state["model_two_assignment"])
if __name__ == '__main__':
unittest.main()
👉इसे आज़माने के लिए, यह कमांड चलाएं:
cd ~/aidemy-bootstrap/assignment
source env/bin/activate
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
python deepseek.py
आपको एक ऐसा असाइनमेंट दिखेगा जिसमें ज़्यादातर काम खुद से करना होगा.
**Assignment Plan for Each Week**
---
### **Week 1: 2D Shapes and Angles**
- **Week Title:** "Exploring 2D Shapes"
Assign students to research and present on various 2D shapes. Include a project where they create models using straws and tape for triangles, draw quadrilaterals with specific measurements, and compare their properties.
### **Week 2: 3D Shapes and Symmetry**
Assign students to create models or nets for cubes and cuboids. They will also predict how folding these nets form the 3D shapes. Include a project where they identify symmetrical properties using mirrors or folding techniques.
### **Week 3: Position, Direction, and Problem Solving**
Assign students to use mirrors or folding techniques for reflections. Include activities where they measure angles, use a protractor, solve problems involving perimeter/area, and create symmetrical designs.
....
👉ctl+c को बंद करें और टेस्ट कोड को क्लीन अप करें. deepseek.py से यह कोड हटाएं
import unittest
class TestGenAssignmentDeepseek(unittest.TestCase):
def test_gen_assignment_deepseek(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = gen_assignment_deepseek(initial_state)
self.assertIn("model_two_assignment", updated_state)
self.assertIsNotNone(updated_state["model_two_assignment"])
self.assertIsInstance(updated_state["model_two_assignment"], str)
self.assertGreater(len(updated_state["model_two_assignment"]), 0)
print(updated_state["model_two_assignment"])
if __name__ == '__main__':
unittest.main()
अब हम दोनों असाइनमेंट को एक नए असाइनमेंट में जोड़ने के लिए, उसी Gemini मॉडल का इस्तेमाल करेंगे. assignment फ़ोल्डर में मौजूद gemini.py फ़ाइल में बदलाव करें.
👉इस कोड को gemini.py फ़ाइल के आखिर में चिपकाएं:
def combine_assignments(state):
print(f"---------------combine_assignments ")
region=get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
response = client.models.generate_content(
model=MODEL_ID, contents=f"""
Look at all the proposed assignment so far {state["model_one_assignment"]} and {state["model_two_assignment"]}, combine them and come up with a final assignment for student.
"""
)
state["final_assignment"] = response.text
return state
दोनों मॉडल की खूबियों को एक साथ इस्तेमाल करने के लिए, हम LangGraph का इस्तेमाल करके तय किए गए वर्कफ़्लो को व्यवस्थित करेंगे. इस वर्कफ़्लो में तीन चरण होते हैं: पहले चरण में, Gemini मॉडल मिलकर काम करने पर फ़ोकस करने वाला असाइनमेंट जनरेट करता है. दूसरे चरण में, DeepSeek मॉडल ऐसा असाइनमेंट जनरेट करता है जिसमें व्यक्तिगत तौर पर काम करने पर ज़ोर दिया गया हो. आखिर में, Gemini इन दोनों असाइनमेंट को मिलाकर एक ऐसा असाइनमेंट तैयार करता है जिसमें दोनों तरह के काम शामिल हों. हम एलएलएम के फ़ैसले लेने से पहले ही, चरणों का क्रम तय कर देते हैं. इसलिए, यह उपयोगकर्ता के तय किए गए सिंगल-पाथ ऑर्केस्ट्रेशन का हिस्सा है.
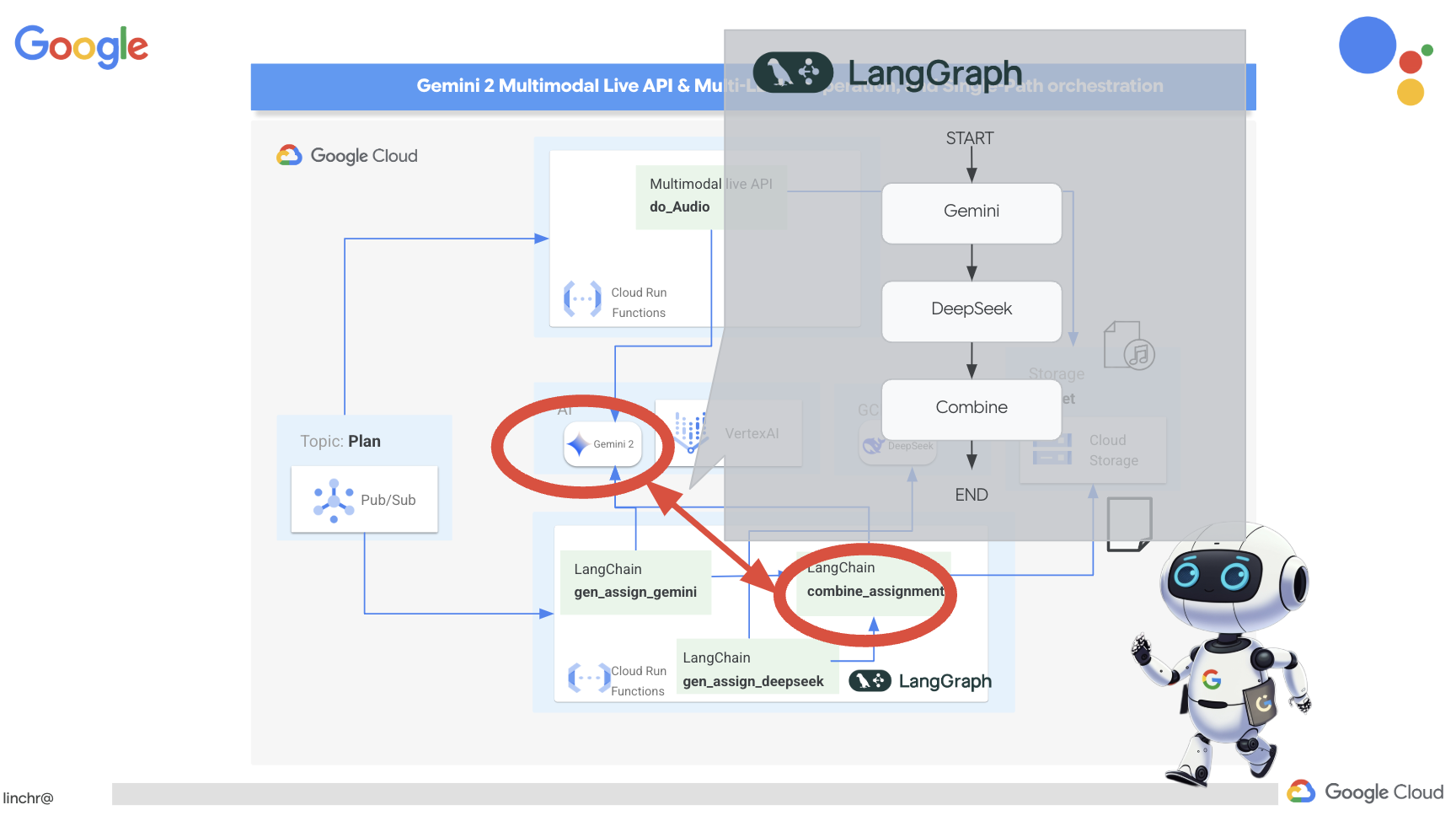
👉इस कोड को main.pyफ़ोल्डर में मौजूद assignment फ़ाइल के आखिर में चिपकाएं:
def create_assignment(teaching_plan: str):
print(f"create_assignment---->{teaching_plan}")
builder = StateGraph(State)
builder.add_node("gen_assignment_gemini", gen_assignment_gemini)
builder.add_node("gen_assignment_deepseek", gen_assignment_deepseek)
builder.add_node("combine_assignments", combine_assignments)
builder.add_edge(START, "gen_assignment_gemini")
builder.add_edge("gen_assignment_gemini", "gen_assignment_deepseek")
builder.add_edge("gen_assignment_deepseek", "combine_assignments")
builder.add_edge("combine_assignments", END)
graph = builder.compile()
state = graph.invoke({"teaching_plan": teaching_plan})
return state["final_assignment"]
import unittest
class TestCreateAssignment(unittest.TestCase):
def test_create_assignment(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = create_assignment(initial_state)
print(updated_state)
if __name__ == '__main__':
unittest.main()
👉शुरुआत में create_assignment फ़ंक्शन की जांच करने के लिए, यह पुष्टि करें कि Gemini और DeepSeek को एक साथ इस्तेमाल करने वाला वर्कफ़्लो काम कर रहा है. इसके लिए, यह कमांड चलाएँ:
cd ~/aidemy-bootstrap/assignment
source env/bin/activate
pip install -r requirements.txt
python main.py
आपको ऐसा जवाब दिखेगा जिसमें दोनों मॉडल को मिलाकर जानकारी दी गई होगी. इसमें छात्र-छात्राओं की पढ़ाई और ग्रुप में किए जाने वाले काम के बारे में अलग-अलग जानकारी दी गई होगी.
**Tasks:**
1. **Clue Collection:** Gather all the clues left by the thieves. These clues will include:
* Descriptions of shapes and their properties (angles, sides, etc.)
* Coordinate grids with hidden messages
* Geometric puzzles requiring transformation (translation, reflection, rotation)
* Challenges involving area, perimeter, and angle calculations
2. **Clue Analysis:** Decipher each clue using your geometric knowledge. This will involve:
* Identifying the shape and its properties
* Plotting coordinates and interpreting patterns on the grid
* Solving geometric puzzles by applying transformations
* Calculating area, perimeter, and missing angles
3. **Case Report:** Create a comprehensive case report outlining your findings. This report should include:
* A detailed explanation of each clue and its solution
* Sketches and diagrams to support your explanations
* A step-by-step account of how you followed the clues to locate the artifact
* A final conclusion about the thieves and their motives
👉ctl+c को बंद करें और टेस्ट कोड को क्लीन अप करें. main.py से यह कोड हटाएं
import unittest
class TestCreateAssignment(unittest.TestCase):
def test_create_assignment(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = create_assignment(initial_state)
print(updated_state)
if __name__ == '__main__':
unittest.main()
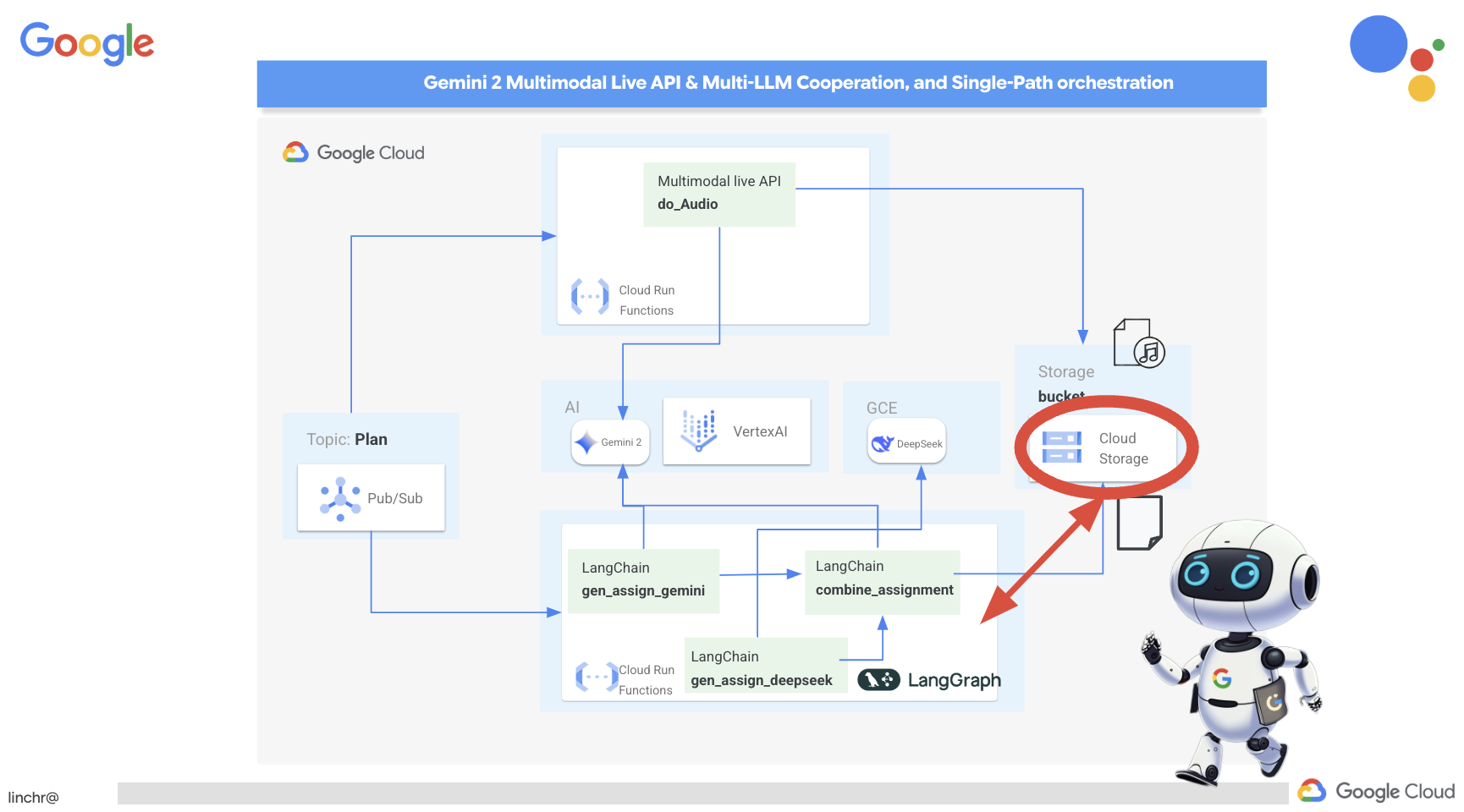
असाइनमेंट जनरेट करने की प्रोसेस को अपने-आप होने वाली और नए शिक्षण प्लान के हिसाब से बनाने के लिए, हम इवेंट-ड्रिवन आर्किटेक्चर का इस्तेमाल करेंगे. यहां दिए गए कोड में, Cloud Run फ़ंक्शन (generate_assignment) के बारे में बताया गया है. यह फ़ंक्शन तब ट्रिगर होगा, जब Pub/Sub विषय ‘plan' पर कोई नया टीचिंग प्लान पब्लिश किया जाएगा.
👉assignment फ़ोल्डर में मौजूद main.py के आखिर में यह कोड जोड़ें:
@functions_framework.cloud_event
def generate_assignment(cloud_event):
print(f"CloudEvent received: {cloud_event.data}")
try:
if isinstance(cloud_event.data.get('message', {}).get('data'), str):
data = json.loads(base64.b64decode(cloud_event.data['message']['data']).decode('utf-8'))
teaching_plan = data.get('teaching_plan')
elif 'teaching_plan' in cloud_event.data:
teaching_plan = cloud_event.data["teaching_plan"]
else:
raise KeyError("teaching_plan not found")
assignment = create_assignment(teaching_plan)
print(f"Assignment---->{assignment}")
#Store the return assignment into bucket as a text file
storage_client = storage.Client()
bucket = storage_client.bucket(ASSIGNMENT_BUCKET)
file_name = f"assignment-{random.randint(1, 1000)}.txt"
blob = bucket.blob(file_name)
blob.upload_from_string(assignment)
return f"Assignment generated and stored in {ASSIGNMENT_BUCKET}/{file_name}", 200
except (json.JSONDecodeError, AttributeError, KeyError) as e:
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500
except Exception as e:
print(f"Error generate assignment: {e}")
return "Error generate assignment", 500
स्थानीय तौर पर टेस्टिंग करना
Google Cloud पर डिप्लॉय करने से पहले, Cloud Run फ़ंक्शन को स्थानीय तौर पर टेस्ट करना अच्छा होता है. इससे, गड़बड़ियों को तेज़ी से ठीक किया जा सकता है और बार-बार होने वाली गड़बड़ियों को आसानी से डीबग किया जा सकता है.
सबसे पहले, जनरेट की गई असाइनमेंट फ़ाइलों को सेव करने के लिए, Cloud Storage बकेट बनाएं. इसके बाद, सेवा खाते को बकेट का ऐक्सेस दें. टर्मिनल में ये कमांड चलाएं:
👉अहम जानकारी: पक्का करें कि आपने ASSIGNMENT_BUCKET का यूनीक नाम तय किया हो. यह नाम "aidemy-assignment-" से शुरू होना चाहिए. Cloud Storage बकेट बनाते समय, नाम से जुड़ी समस्याओं से बचने के लिए यह यूनीक नाम ज़रूरी है. (<YOUR_NAME> की जगह कोई भी शब्द डालें)
export ASSIGNMENT_BUCKET=aidemy-assignment-<YOUR_NAME> #Name must be unqiue
👉इसके बाद, यह कमांड चलाएं:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gsutil mb -p $PROJECT_ID -l us-central1 gs://$ASSIGNMENT_BUCKET
gcloud storage buckets add-iam-policy-binding gs://$ASSIGNMENT_BUCKET \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectViewer"
gcloud storage buckets add-iam-policy-binding gs://$ASSIGNMENT_BUCKET \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectCreator"
👉अब, Cloud Run फ़ंक्शन एम्युलेटर शुरू करें:
cd ~/aidemy-bootstrap/assignment
functions-framework \
--target generate_assignment \
--signature-type=cloudevent \
--source main.py
👉जब एम्युलेटर एक टर्मिनल में चल रहा हो, तब Cloud Shell में दूसरा टर्मिनल खोलें. दूसरे टर्मिनल में, एम्युलेटर को एक टेस्ट CloudEvent भेजें, ताकि यह पता चल सके कि नया टीचिंग प्लान पब्लिश किया जा रहा है या नहीं:
curl -X POST \
http://localhost:8080/ \
-H "Content-Type: application/json" \
-H "ce-id: event-id-01" \
-H "ce-source: planner-agent" \
-H "ce-specversion: 1.0" \
-H "ce-type: google.cloud.pubsub.topic.v1.messagePublished" \
-d '{
"message": {
"data": "eyJ0ZWFjaGluZ19wbGFuIjogIldlZWsgMTogMkQgU2hhcGVzIGFuZCBBbmdsZXMgLSBEYXkgMTogUmV2aWV3IG9mIGJhc2ljIDJEIHNoYXBlcyAoc3F1YXJlcywgcmVjdGFuZ2xlcywgdHJpYW5nbGVzLCBjaXJjbGVzKS4gRGF5IDI6IEV4cGxvcmluZyBkaWZmZXJlbnQgdHlwZXMgb2YgdHJpYW5nbGVzIChlcXVpbGF0ZXJhbCwgaXNvc2NlbGVzLCBzY2FsZW5lLCByaWdodC1hbmdsZWQpLiBEYXkgMzogRXhwbG9yaW5nIHF1YWRyaWxhdGVyYWxzIChzcXVhcmUsIHJlY3RhbmdsZSwgcGFyYWxsZWxvZ3JhbSwgcmhvbWJ1cywgdHJhcGV6aXVtKS4gRGF5IDQ6IEludHJvZHVjdGlvbiB0byBhbmdsZXM6IHJpZ2h0IGFuZ2xlcywgYWN1dGUgYW5nbGVzLCBhbmQgb2J0dXNlIGFuZ2xlcy4gRGF5IDU6IE1lYXN1cmluZyBhbmdsZXMgdXNpbmcgYSBwcm90cmFjdG9yLiBXZWVrIDI6IDNEIFNoYXBlcyBhbmQgU3ltbWV0cnkgLSBEYXkgNjogSW50cm9kdWN0aW9uIHRvIDNEIHNoYXBlczogY3ViZXMsIGN1Ym9pZHMsIHNwaGVyZXMsIGN5bGluZGVycywgY29uZXMsIGFuZCBweXJhbWlkcy4gRGF5IDc6IERlc2NyaWJpbmcgM0Qgc2hhcGVzIHVzaW5nIGZhY2VzLCBlZGdlcywgYW5kIHZlcnRpY2VzLiBEYXkgODogUmVsYXRpbmcgMkQgc2hhcGVzIHRvIDNEIHNoYXBlcy4gRGF5IDk6IElkZW50aWZ5aW5nIGxpbmVzIG9mIHN5bW1ldHJ5IGluIDJEIHNoYXBlcy4gRGF5IDEwOiBDb21wbGV0aW5nIHN5bW1ldHJpY2FsIGZpZ3VyZXMuIFdlZWsgMzogUG9zaXRpb24sIERpcmVjdGlvbiwgYW5kIFByb2JsZW0gU29sdmluZyAtIERheSAxMTogRGVzY3JpYmluZyBwb3NpdGlvbiB1c2luZyBjb29yZGluYXRlcyBpbiB0aGUgZmlyc3QgcXVhZHJhbnQuIERheSAxMjogUGxvdHRpbmcgY29vcmRpbmF0ZXMgdG8gZHJhdyBzaGFwZXMuIERheSAxMzogVW5kZXJzdGFuZGluZyB0cmFuc2xhdGlvbiAoc2xpZGluZyBhIHNoYXBlKS4gRGF5IDE0OiBVbmRlcnN0YW5kaW5nIHJlZmxlY3Rpb24gKGZsaXBwaW5nIGEgc2hhcGUpLiBEYXkgMTU6IFByb2JsZW0tc29sdmluZyBhY3Rpdml0aWVzIGludm9sdmluZyBwZXJpbWV0ZXIsIGFyZWEsIGFuZCBtaXNzaW5nIGFuZ2xlcy4ifQ=="
}
}'
जवाब का इंतज़ार करते समय, Cloud Shell के दूसरे टर्मिनल पर स्विच करें. एम्युलेटर के टर्मिनल में, अपने फ़ंक्शन की प्रोग्रेस और उससे जनरेट हुए किसी भी आउटपुट या गड़बड़ी के मैसेज को देखा जा सकता है. 😁
curl कमांड से "OK" प्रिंट होना चाहिए. इसमें नई लाइन नहीं होनी चाहिए, इसलिए "OK" आपके टर्मिनल शेल प्रॉम्प्ट वाली लाइन पर दिख सकता है.
असाइनमेंट जनरेट होने और सेव होने की पुष्टि करने के लिए, Google Cloud Console पर जाएं. इसके बाद, Storage > "Cloud Storage" पर जाएं. आपने जो aidemy-assignment बकेट बनाया है उसे चुनें. आपको बकेट में assignment-{random number}.txt नाम की टेक्स्ट फ़ाइल दिखेगी. फ़ाइल को डाउनलोड करने और उसके कॉन्टेंट की पुष्टि करने के लिए, उस पर क्लिक करें. इससे यह पुष्टि होती है कि नई फ़ाइल में, अभी-अभी जनरेट किया गया नया असाइनमेंट मौजूद है.
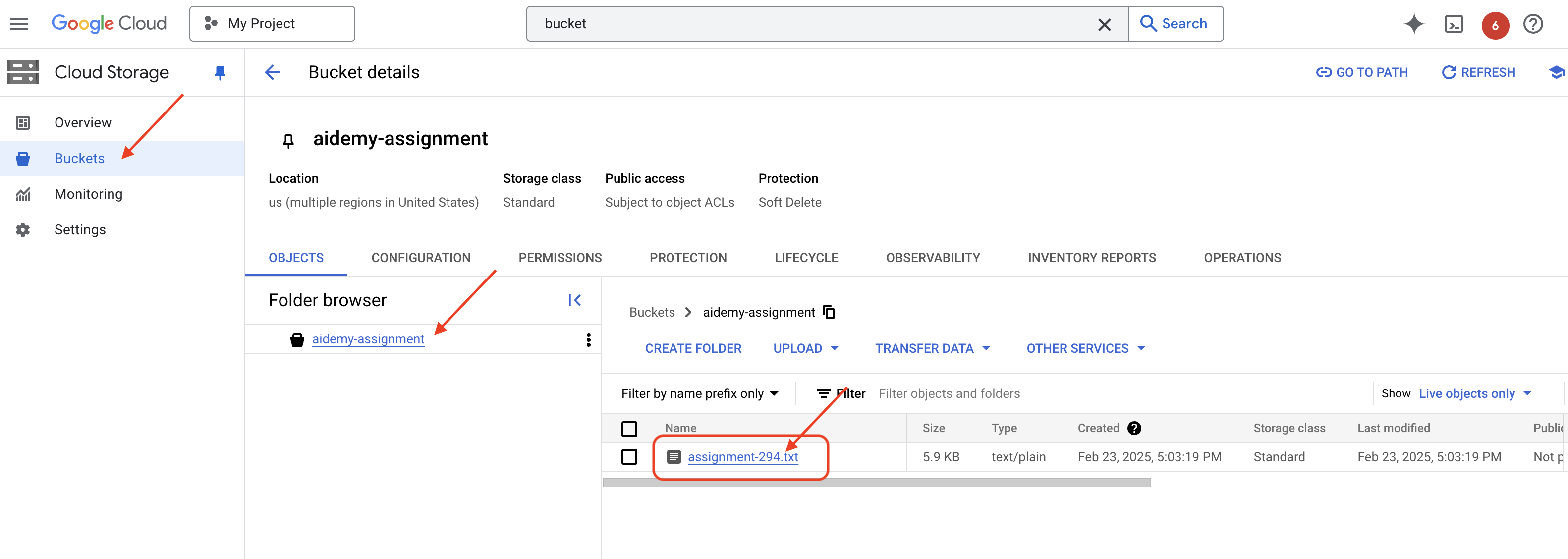
👉एम्युलेटर चलाने वाले टर्मिनल में, बंद करने के लिए ctrl+c टाइप करें. इसके बाद, दूसरे टर्मिनल को बंद करें. 👉साथ ही, एम्युलेटर चलाने वाले टर्मिनल में, वर्चुअल एनवायरमेंट से बाहर निकलें.
deactivate
👉इसके बाद, हम असाइनमेंट एजेंट को क्लाउड पर डिप्लॉय करेंगे
cd ~/aidemy-bootstrap/assignment
export ASSIGNMENT_BUCKET=$(gcloud storage buckets list --format="value(name)" | grep aidemy-assignment)
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud functions deploy assignment-agent \
--gen2 \
--timeout=540 \
--memory=2Gi \
--cpu=1 \
--set-env-vars="ASSIGNMENT_BUCKET=${ASSIGNMENT_BUCKET}" \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--set-env-vars=OLLAMA_HOST=${OLLAMA_HOST} \
--region=us-central1 \
--runtime=python312 \
--source=. \
--entry-point=generate_assignment \
--trigger-topic=plan
Google Cloud Console पर जाकर, Cloud Run पर जाएं और डिप्लॉयमेंट की पुष्टि करें. आपको courses-agent नाम की एक नई सेवा दिखेगी. 
असाइनमेंट जनरेट करने की सुविधा को लागू कर दिया गया है. साथ ही, इसकी जांच और इसे डिप्लॉय भी कर दिया गया है. अब हम अगले चरण पर जा सकते हैं: इन असाइनमेंट को छात्र-छात्राओं के पोर्टल में उपलब्ध कराना.
14. वैकल्पिक: Gemini और DeepSeek के साथ भूमिका के आधार पर मिलकर काम करना - जारी है.
डाइनैमिक वेबसाइट जनरेशन
छात्र-छात्राओं के पोर्टल को बेहतर बनाने और उसे ज़्यादा दिलचस्प बनाने के लिए, हम असाइनमेंट पेजों के लिए डाइनैमिक एचटीएमएल जनरेशन लागू करेंगे. इसका मकसद, नया असाइनमेंट जनरेट होने पर, पोर्टल को नए और देखने में अच्छे डिज़ाइन के साथ अपने-आप अपडेट करना है. इससे एलएलएम की कोडिंग क्षमताओं का इस्तेमाल करके, लोगों को ज़्यादा दिलचस्प और बेहतर अनुभव मिलता है.
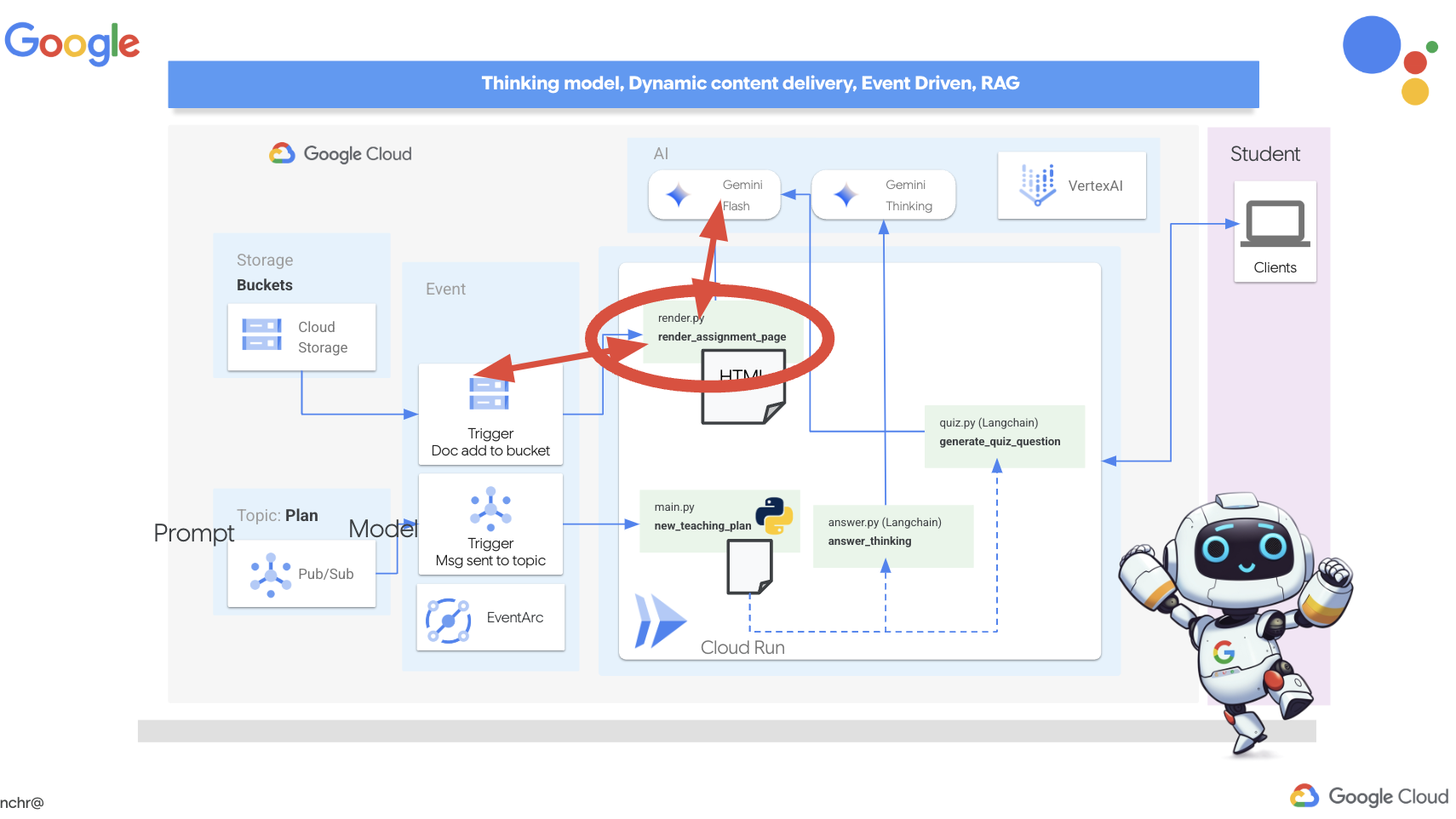
👉Cloud Shell Editor में, portal फ़ोल्डर में मौजूद render.py फ़ाइल में बदलाव करें. इसके बाद,
def render_assignment_page():
return ""
इस कोड स्निपेट के साथ:
def render_assignment_page(assignment: str):
try:
region=get_next_region()
llm = VertexAI(model_name="gemini-2.0-flash-001", location=region)
input_msg = HumanMessage(content=[f"Here the assignment {assignment}"])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"""
As a frontend developer, create HTML to display a student assignment with a creative look and feel. Include the following navigation bar at the top:
```
<nav>
<a href="/">Home</a>
<a href="/quiz">Quizzes</a>
<a href="/courses">Courses</a>
<a href="/assignment">Assignments</a>
</nav>
```
Also include these links in the <head> section:
```
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Roboto:wght@400;500&display=swap" rel="stylesheet">
```
Do not apply inline styles to the navigation bar.
The HTML should display the full assignment content. In its CSS, be creative with the rainbow colors and aesthetic.
Make it creative and pretty
The assignment content should be well-structured and easy to read.
respond with JUST the html file
"""
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
response = response.replace("```html", "")
response = response.replace("```", "")
with open("templates/assignment.html", "w") as f:
f.write(response)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
यह असाइनमेंट के लिए, Gemini मॉडल का इस्तेमाल करके डाइनैमिक तौर पर एचटीएमएल जनरेट करता है. यह असाइनमेंट के कॉन्टेंट को इनपुट के तौर पर लेता है. साथ ही, Gemini को निर्देश देने के लिए प्रॉम्प्ट का इस्तेमाल करता है, ताकि वह क्रिएटिव स्टाइल वाला, दिखने में आकर्षक एचटीएमएल पेज बना सके.
इसके बाद, हम एक ऐसा एंडपॉइंट बनाएंगे जो असाइनमेंट बकेट में कोई नया दस्तावेज़ जोड़े जाने पर ट्रिगर होगा:
👉पोर्टल फ़ोल्डर में, app.py फ़ाइल में बदलाव करें. साथ ही, ## REPLACE ME! RENDER ASSIGNMENT लाइन को इस कोड से बदलें:
@app.route('/render_assignment', methods=['POST'])
def render_assignment():
try:
data = request.get_json()
file_name = data.get('name')
bucket_name = data.get('bucket')
if not file_name or not bucket_name:
return jsonify({'error': 'Missing file name or bucket name'}), 400
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
content = blob.download_as_text()
print(f"File content: {content}")
render_assignment_page(content)
return jsonify({'message': 'Assignment rendered successfully'})
except Exception as e:
print(f"Error processing file: {e}")
return jsonify({'error': 'Error processing file'}), 500
ट्रिगर होने पर, यह फ़ंक्शन अनुरोध के डेटा से फ़ाइल का नाम और बकेट का नाम वापस पाता है. साथ ही, Cloud Storage से असाइनमेंट का कॉन्टेंट डाउनलोड करता है. इसके बाद, एचटीएमएल जनरेट करने के लिए render_assignment_page फ़ंक्शन को कॉल करता है.
👉हम इसे स्थानीय तौर पर चलाएंगे:
cd ~/aidemy-bootstrap/portal
source env/bin/activate
python app.py
👉Cloud Shell विंडो में सबसे ऊपर मौजूद "वेब प्रीव्यू" मेन्यू से, "पोर्ट 8080 पर प्रीव्यू करें" चुनें. इससे आपका ऐप्लिकेशन, ब्राउज़र के नए टैब में खुलेगा. नेविगेशन बार में, असाइनमेंट लिंक पर जाएं. इस समय आपको खाली पेज दिखेगा. ऐसा इसलिए है, क्योंकि हमने असाइनमेंट एजेंट और पोर्टल के बीच कम्यूनिकेशन ब्रिज सेट अप नहीं किया है, ताकि कॉन्टेंट को डाइनैमिक तौर पर भरा जा सके.
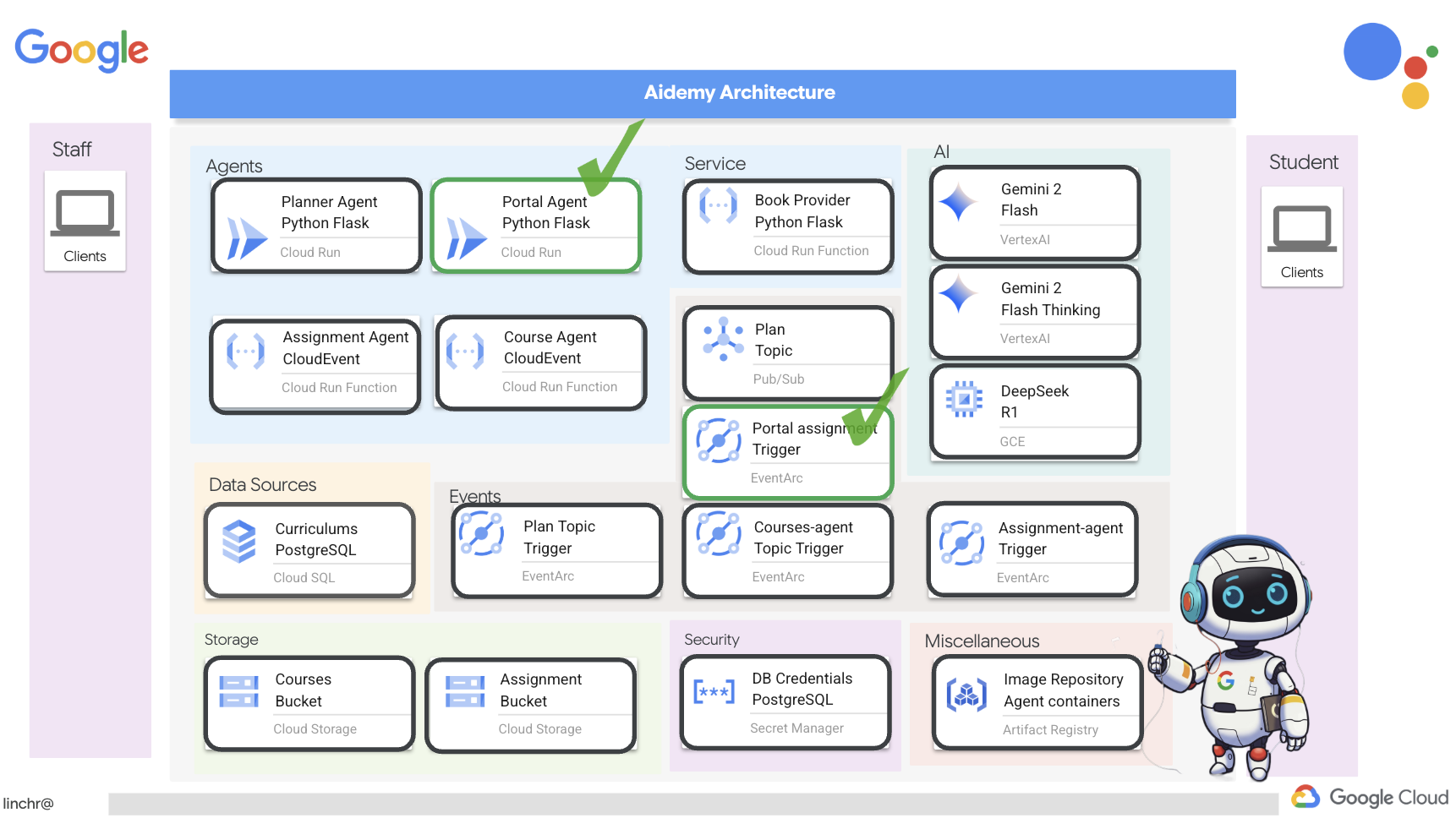
आगे बढ़ें और Ctrl+C दबाकर स्क्रिप्ट को रोकें.
👉इन बदलावों को शामिल करने और अपडेट किए गए कोड को डिप्लॉय करने के लिए, पोर्टल एजेंट की इमेज को फिर से बनाएं और पुश करें:
cd ~/aidemy-bootstrap/portal/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-portal .
docker tag gcr.io/${PROJECT_ID}/aidemy-portal us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
👉नई इमेज को पुश करने के बाद, Cloud Run सेवा को फिर से डिप्लॉय करें. Cloud Run को अपडेट करने के लिए, यह स्क्रिप्ट चलाएं:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud run services update aidemy-portal \
--region=us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
👉अब हम एक Eventarc ट्रिगर डिप्लॉय करेंगे. यह ट्रिगर, असाइनमेंट बकेट में बनाए गए (फ़ाइनल किए गए) किसी भी नए ऑब्जेक्ट के बारे में सूचना देगा. नई असाइनमेंट फ़ाइल बनने पर, यह ट्रिगर पोर्टल सेवा पर /render_assignment एंडपॉइंट को अपने-आप चालू कर देगा.
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$(gcloud storage service-agent --project $PROJECT_ID)" \
--role="roles/pubsub.publisher"
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gcloud eventarc triggers create portal-assignment-trigger \
--location=us-central1 \
--service-account=$SERVICE_ACCOUNT_NAME \
--destination-run-service=aidemy-portal \
--destination-run-region=us-central1 \
--destination-run-path="/render_assignment" \
--event-filters="bucket=$ASSIGNMENT_BUCKET" \
--event-filters="type=google.cloud.storage.object.v1.finalized"
ट्रिगर के सही तरीके से बनने की पुष्टि करने के लिए, Google Cloud Console में Eventarc ट्रिगर पेज पर जाएं. आपको टेबल में portal-assignment-trigger दिखना चाहिए. ट्रिगर की जानकारी देखने के लिए, उसके नाम पर क्लिक करें. 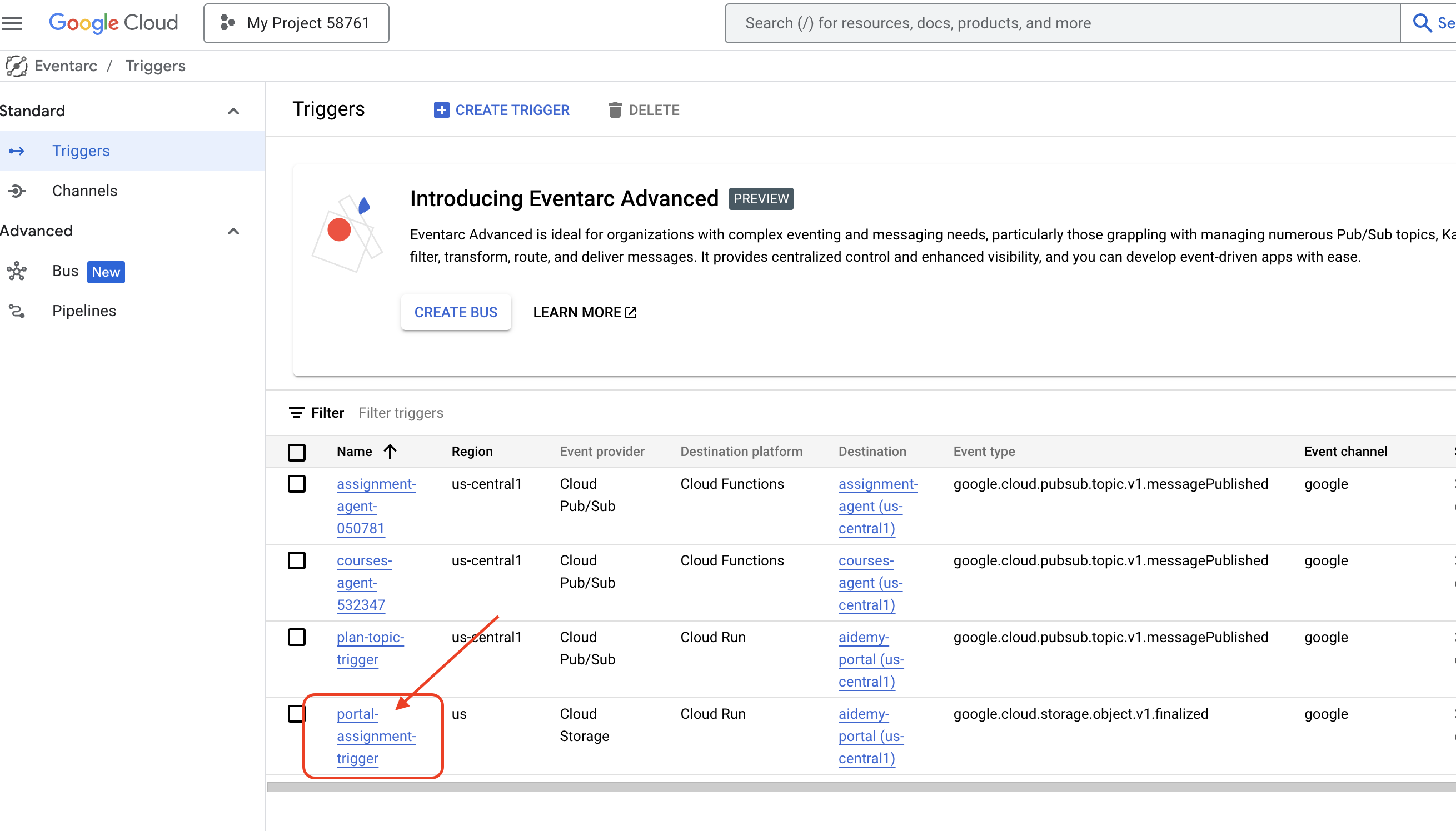
नए ट्रिगर को चालू होने में दो से तीन मिनट लग सकते हैं.
डाइनैमिक असाइनमेंट जनरेशन की सुविधा को काम करते हुए देखने के लिए, यहां दिया गया निर्देश चलाएं. इससे आपको अपने प्लानर एजेंट का यूआरएल मिलेगा. अगर आपके पास यह यूआरएल पहले से है, तो आपको यह निर्देश चलाने की ज़रूरत नहीं है:
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep planner
अपने पोर्टल एजेंट का यूआरएल ढूंढें:
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep portal
प्लानर एजेंट में, नया टीचिंग प्लान जनरेट करें.
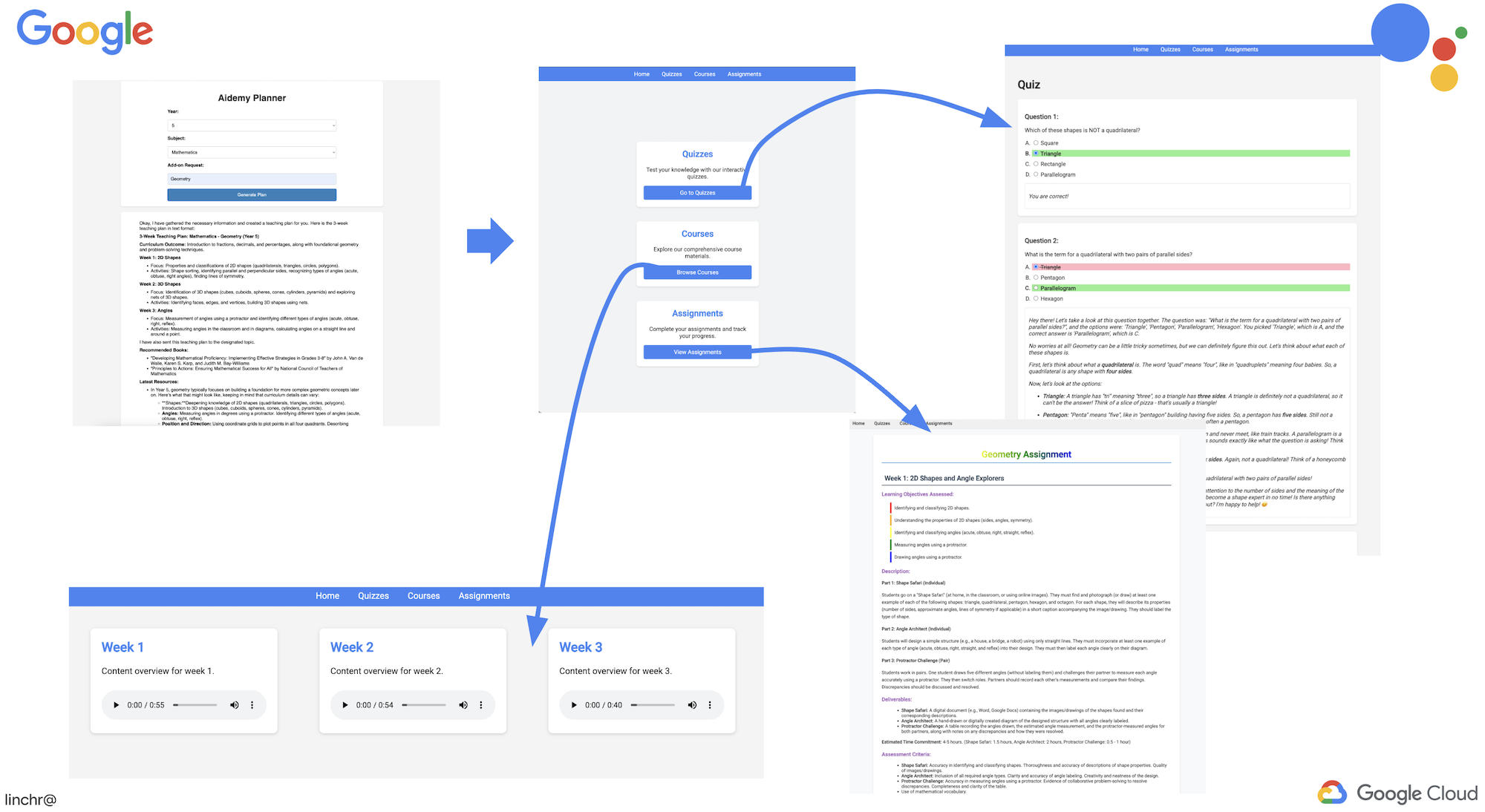
कुछ मिनट बाद, छात्र-छात्रा के पोर्टल पर जाएं. ऐसा इसलिए, ताकि ऑडियो जनरेट होने, असाइनमेंट जनरेट होने, और एचटीएमएल रेंडर होने की प्रोसेस पूरी हो सके.
👉नेविगेशन बार में मौजूद "असाइनमेंट" लिंक पर क्लिक करें. आपको डाइनैमिक तौर पर जनरेट किए गए एचटीएमएल के साथ, नया असाइनमेंट दिखेगा. हर बार टीचिंग प्लान जनरेट होने पर, उसे डाइनैमिक असाइनमेंट के तौर पर जनरेट किया जाना चाहिए.
Aidemy मल्टी-एजेंट सिस्टम पूरा करने के लिए बधाई! आपको इन विषयों के बारे में व्यावहारिक अनुभव और अहम जानकारी मिली है:
- मल्टी-एजेंट सिस्टम के फ़ायदे, जिनमें मॉड्यूलरिटी, स्केलेबिलिटी, विशेषज्ञता, और रखरखाव को आसान बनाना शामिल है.
- रिस्पॉन्सिव और लूज़ली कपल्ड ऐप्लिकेशन बनाने के लिए, इवेंट-ड्रिवन आर्किटेक्चर की अहमियत.
- एलएलएम का रणनीतिक इस्तेमाल, टास्क के हिसाब से सही मॉडल चुनना, और उन्हें असल दुनिया में असर डालने वाले टूल के साथ इंटिग्रेट करना.
- बड़े पैमाने पर और भरोसेमंद समाधान बनाने के लिए, Google Cloud सेवाओं का इस्तेमाल करके क्लाउड-नेटिव डेवलपमेंट के तरीके.
- वेंडर के समाधानों के विकल्प के तौर पर, डेटा की निजता और सेल्फ-होस्टिंग मॉडल पर विचार करना कितना ज़रूरी है.
अब आपके पास Google Cloud पर, एआई की मदद से काम करने वाले बेहतर ऐप्लिकेशन बनाने के लिए एक मज़बूत आधार है!
15. चैलेंज और अगले चरण
Aidemy का मल्टी-एजेंट सिस्टम बनाने के लिए बधाई! आपने एआई की मदद से शिक्षा देने के लिए, एक मज़बूत नींव तैयार कर ली है. अब, आइए कुछ चुनौतियों और आने वाले समय में होने वाले संभावित सुधारों के बारे में जानते हैं, ताकि इसकी क्षमताओं को और बढ़ाया जा सके और असल दुनिया की ज़रूरतों को पूरा किया जा सके:
सवाल-जवाब के लाइव सेशन की मदद से इंटरैक्टिव लर्निंग:
- चैलेंज: क्या Gemini 2 के Live API का इस्तेमाल करके, छात्र-छात्राओं के लिए रीयल-टाइम में सवाल-जवाब की सुविधा बनाई जा सकती है? एक ऐसे वर्चुअल क्लासरूम की कल्पना करें जहां छात्र-छात्राएं सवाल पूछ सकें और उन्हें एआई की मदद से तुरंत जवाब मिल सकें.
असाइनमेंट अपने-आप सबमिट होने और ग्रेडिंग की सुविधा:
- चुनौती: ऐसा सिस्टम डिज़ाइन और लागू करें जिसकी मदद से छात्र-छात्राएं, असाइनमेंट को डिजिटल तरीके से सबमिट कर सकें. साथ ही, एआई की मदद से उन्हें अपने-आप ग्रेड मिल सकें. इस सिस्टम में, नकल का पता लगाने और उसे रोकने का तरीका भी शामिल होना चाहिए. इस चैलेंज में, Retrieval Augmented Generation (RAG) को एक्सप्लोर करने का बेहतरीन मौका मिलता है. इससे ग्रेडिंग और साहित्यिक चोरी का पता लगाने की प्रोसेस को ज़्यादा सटीक और भरोसेमंद बनाया जा सकता है.

16. व्यवस्थित करें
हमने Aidemy के मल्टी-एजेंट सिस्टम को बना लिया है और इसके बारे में जान लिया है. अब हमें Google Cloud एनवायरमेंट को क्लीन अप करना है.
👉Cloud Run की सेवाएं मिटाना
gcloud run services delete aidemy-planner --region=us-central1 --quiet
gcloud run services delete aidemy-portal --region=us-central1 --quiet
gcloud run services delete courses-agent --region=us-central1 --quiet
gcloud run services delete book-provider --region=us-central1 --quiet
gcloud run services delete assignment-agent --region=us-central1 --quiet
👉Eventarc ट्रिगर मिटाना
gcloud eventarc triggers delete portal-assignment-trigger --location=us --quiet
gcloud eventarc triggers delete plan-topic-trigger --location=us-central1 --quiet
gcloud eventarc triggers delete portal-assignment-trigger --location=us-central1 --quiet
ASSIGNMENT_AGENT_TRIGGER=$(gcloud eventarc triggers list --project="$PROJECT_ID" --location=us-central1 --filter="name:assignment-agent" --format="value(name)")
COURSES_AGENT_TRIGGER=$(gcloud eventarc triggers list --project="$PROJECT_ID" --location=us-central1 --filter="name:courses-agent" --format="value(name)")
gcloud eventarc triggers delete $ASSIGNMENT_AGENT_TRIGGER --location=us-central1 --quiet
gcloud eventarc triggers delete $COURSES_AGENT_TRIGGER --location=us-central1 --quiet
👉Pub/Sub विषय मिटाना
gcloud pubsub topics delete plan --project="$PROJECT_ID" --quiet
👉Cloud SQL इंस्टेंस मिटाना
gcloud sql instances delete aidemy --quiet
👉Artifact Registry में मौजूद डेटाबेस मिटाना
gcloud artifacts repositories delete agent-repository --location=us-central1 --quiet
👉Secret Manager के सीक्रेट मिटाना
gcloud secrets delete db-user --quiet
gcloud secrets delete db-pass --quiet
gcloud secrets delete db-name --quiet
👉Compute Engine इंस्टेंस मिटाएं (अगर इसे Deepseek के लिए बनाया गया है)
gcloud compute instances delete ollama-instance --zone=us-central1-a --quiet
👉Deepseek इंस्टेंस के लिए फ़ायरवॉल का नियम मिटाना
gcloud compute firewall-rules delete allow-ollama-11434 --quiet
👉Cloud Storage बकेट मिटाना
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
export ASSIGNMENT_BUCKET=$(gcloud storage buckets list --format="value(name)" | grep aidemy-assignment)
gsutil rm -r gs://$COURSE_BUCKET_NAME
gsutil rm -r gs://$ASSIGNMENT_BUCKET
