
1. Einführung
Hallo! Sie finden die Idee von KI-Agenten gut – kleinen Helfern, die Dinge für Sie erledigen können, ohne dass Sie einen Finger rühren müssen, oder? Sehr gut! Aber seien wir ehrlich: Ein Agent reicht nicht immer aus, insbesondere wenn Sie größere, komplexere Projekte in Angriff nehmen. Wahrscheinlich brauchen Sie ein ganzes Team von ihnen! Hier kommen Multi-Agenten-Systeme ins Spiel.
Agents, die auf LLMs basieren, bieten Ihnen im Vergleich zum herkömmlichen Hardcoding eine unglaubliche Flexibilität. Aber, und es gibt immer ein Aber, sie bringen auch einige knifflige Herausforderungen mit sich. Genau darum geht es in diesem Workshop.

Das erwartet Sie:
Ersten Agent mit LangGraph erstellen: Wir erstellen einen eigenen Agent mit LangGraph, einem beliebten Framework. Sie erfahren, wie Sie Tools erstellen, die eine Verbindung zu Datenbanken herstellen, die neueste Gemini 2 API für die Internetsuche nutzen und die Prompts und Antworten optimieren, damit Ihr Agent nicht nur mit LLMs, sondern auch mit vorhandenen Diensten interagieren kann. Außerdem zeigen wir Ihnen, wie Funktionsaufrufe funktionieren.
Agent-Orchestration nach Ihren Wünschen: Wir sehen uns verschiedene Möglichkeiten an, Ihre Agenten zu orchestrieren – von einfachen geraden Pfaden bis hin zu komplexeren Szenarien mit mehreren Pfaden. Sie können sich das so vorstellen, dass Sie den Ablauf Ihres Agententeams steuern.
Multi-Agent-Systeme: Sie erfahren, wie Sie ein System einrichten, in dem Ihre Agents zusammenarbeiten und gemeinsam Aufgaben erledigen können – alles dank einer ereignisgesteuerten Architektur.
LLM-Freiheit: Das beste Tool für die jeweilige Aufgabe: Wir sind nicht auf ein einziges LLM beschränkt. Sie erfahren, wie Sie mehrere LLMs verwenden und ihnen verschiedene Rollen zuweisen können, um die Problemlösungsfähigkeit mithilfe von „Denkmodellen“ zu steigern.
Dynamischer Content? Kein Problem!: Stellen Sie sich vor, Ihr Agent erstellt dynamische Inhalte, die in Echtzeit speziell auf jeden Nutzer zugeschnitten sind. Wir zeigen Ihnen, wie das geht.
Taking it to the Cloud with Google Cloud: Hier geht es nicht nur darum, in einem Notebook zu spielen. Wir zeigen Ihnen, wie Sie Ihr Multi-Agent-System in Google Cloud entwerfen und bereitstellen, damit es für die reale Welt gerüstet ist.
Dieses Projekt ist ein gutes Beispiel dafür, wie Sie alle Techniken anwenden können, über die wir gesprochen haben.
2. Architektur
Lehrer zu sein oder im Bildungsbereich zu arbeiten, kann sehr erfüllend sein. Aber die Arbeitsbelastung, insbesondere die ganze Vorbereitung, kann eine Herausforderung sein. Außerdem gibt es oft nicht genügend Personal und Nachhilfe kann teuer sein. Deshalb schlagen wir einen KI-basierten Lehrassistenten vor. Dieses Tool kann Lehrkräfte entlasten und dazu beitragen, die Lücke zu schließen, die durch Personalmangel und den Mangel an erschwinglichen Nachhilfeangeboten entsteht.
Unser KI-Lehrassistent kann detaillierte Unterrichtspläne, unterhaltsame Quizze, leicht verständliche Audio-Zusammenfassungen und personalisierte Aufgaben erstellen. So können sich Lehrkräfte auf das konzentrieren, was sie am besten können: mit Schülern in Kontakt treten und ihnen helfen, Spaß am Lernen zu entwickeln.
Das System hat zwei Websites: eine für Lehrkräfte, um Unterrichtspläne für die kommenden Wochen zu erstellen,

und eine für Schüler und Studenten, um auf Quizze, Audiozusammenfassungen und Aufgaben zuzugreifen. 
Sehen wir uns die Architektur an, die unserem Lehrassistenten Aidemy zugrunde liegt. Wie Sie sehen, haben wir die Funktion in mehrere Schlüsselkomponenten unterteilt, die alle zusammenarbeiten, um dies zu ermöglichen.

Wichtige Architekturelemente und Technologien:
Google Cloud Platform (GCP): Zentral für das gesamte System:
- Vertex AI: Greift auf die Gemini-LLMs von Google zu.
- Cloud Run: Serverlose Plattform zum Bereitstellen von containerisierten Agents und Funktionen.
- Cloud SQL: PostgreSQL-Datenbank für Lehrplandaten.
- Pub/Sub und Eventarc: Grundlage der ereignisgesteuerten Architektur, die die asynchrone Kommunikation zwischen Komponenten ermöglicht.
- Cloud Storage: Hier werden Audiozusammenfassungen und Aufgaben-Dateien gespeichert.
- Secret Manager: Verwaltet Datenbankanmeldedaten sicher.
- Artifact Registry: Speichert Docker-Images für die Agents.
- Compute Engine: Zum Bereitstellen selbst gehosteter LLMs anstelle von Anbieterlösungen
LLMs: Das „Gehirn“ des Systems:
- Gemini-Modelle von Google: (Gemini x Pro, Gemini x Flash, Gemini x Flash Thinking) Werden für die Unterrichtsplanung, die Erstellung von Inhalten, die dynamische HTML-Erstellung, die Erklärung von Quizfragen und die Kombination der Aufgaben verwendet.
- DeepSeek: Wird für die spezielle Aufgabe verwendet, Aufgaben zum Selbststudium zu generieren.
LangChain und LangGraph: Frameworks für die Entwicklung von LLM-Anwendungen
- Erleichtert die Erstellung komplexer Multi-Agent-Workflows.
- Ermöglicht die intelligente Orchestrierung von Tools (API-Aufrufe, Datenbankabfragen, Websuchen).
- Implementiert eine ereignisgesteuerte Architektur für Systemskalierbarkeit und ‑flexibilität.
Im Wesentlichen kombiniert unsere Architektur die Leistungsfähigkeit von LLMs mit strukturierten Daten und ereignisgesteuerter Kommunikation, die alle in Google Cloud ausgeführt werden. So können wir einen skalierbaren, zuverlässigen und effektiven Lehrassistenten entwickeln.
3. Hinweis
Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines. Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Gemini Code Assist in der Cloud Shell-IDE aktivieren
👉 Rufen Sie in der Google Cloud Console die Gemini Code Assist-Tools auf und aktivieren Sie Gemini Code Assist kostenlos, indem Sie den Nutzungsbedingungen zustimmen.
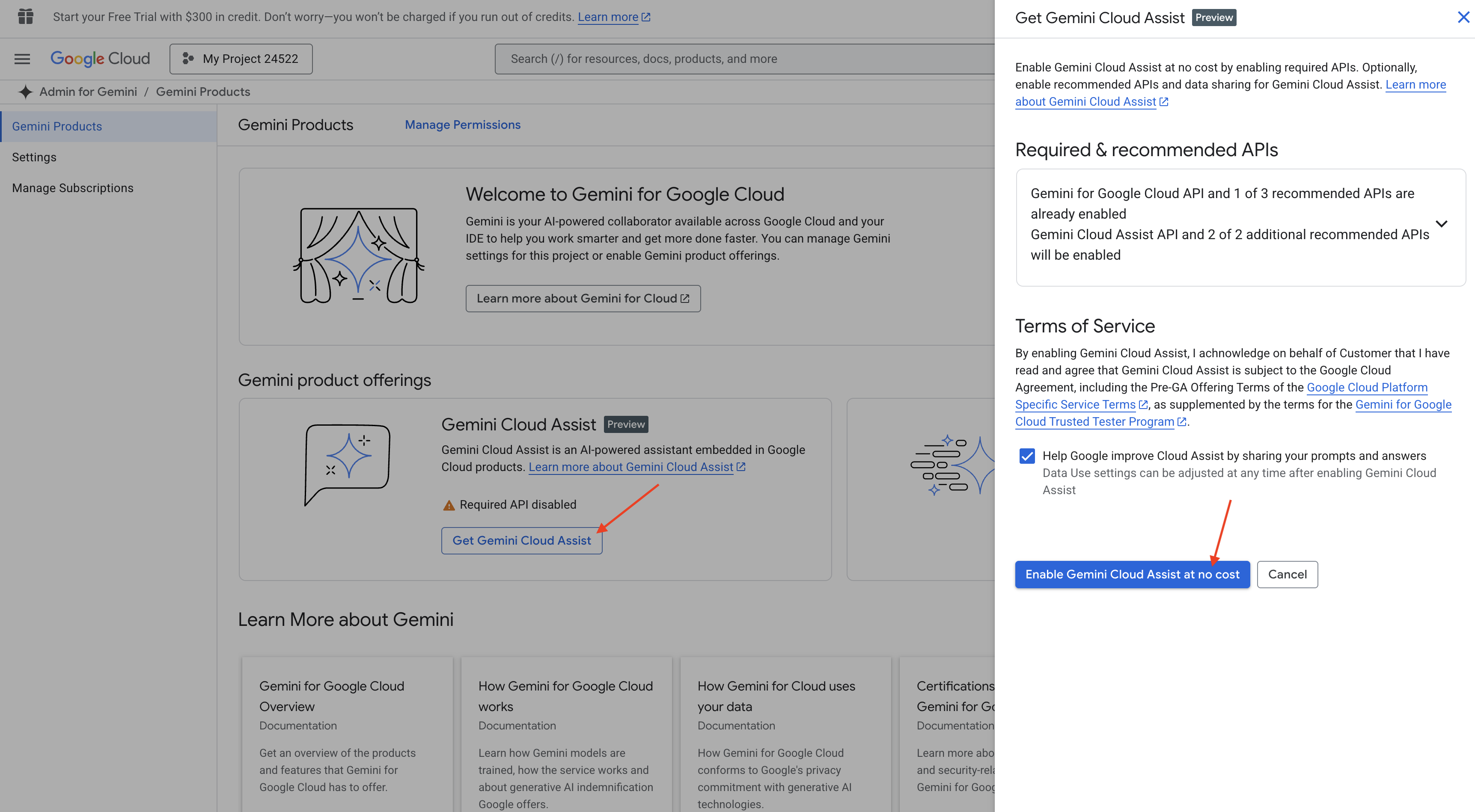
Ignorieren Sie die Einrichtung der Berechtigungen und verlassen Sie diese Seite.
Mit dem Cloud Shell-Editor arbeiten
👉 Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren (das Symbol für das Terminal oben im Cloud Shell-Bereich). Klicken Sie dann auf die Schaltfläche Editor öffnen (sieht aus wie ein geöffneter Ordner mit einem Bleistift). Dadurch wird der Cloud Shell-Code-Editor im Fenster geöffnet. Auf der linken Seite sehen Sie einen Datei-Explorer.

👉 Klicken Sie in der unteren Statusleiste auf den Button Cloud Code-Anmeldung, wie dargestellt. Autorisieren Sie das Plug-in wie beschrieben. Wenn in der Statusleiste Cloud Code – kein Projekt angezeigt wird, wählen Sie diese Option im Drop-down-Menü „Google Cloud-Projekt auswählen“ aus und wählen Sie dann das gewünschte Google Cloud-Projekt aus der Liste der Projekte aus, die Sie erstellt haben.

👉 Öffnen Sie das Terminal in der Cloud-IDE  oder
oder  .
.
👉 Prüfen Sie im Terminal mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und das Projekt auf Ihre Projekt-ID festgelegt ist:
gcloud auth list
👉 Ersetzen Sie <YOUR_PROJECT_ID> durch Ihre Projekt-ID:
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉 Führen Sie den folgenden Befehl aus, um die erforderlichen Google Cloud APIs zu aktivieren:
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Das kann einige Minuten dauern.
Berechtigung einrichten
👉 Dienstkontoberechtigungen einrichten Führen Sie im Terminal folgenden Befehl aus :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 Berechtigungen erteilen Führen Sie im Terminal folgenden Befehl aus :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
👉 Ergebnis in der IAM-Konsole prüfen
prüfen
👉 Führen Sie die folgenden Befehle im Terminal aus, um eine Cloud SQL-Instanz mit dem Namen aidemy zu erstellen. Wir benötigen diese Informationen später, aber da dieser Vorgang einige Zeit in Anspruch nehmen kann, führen wir ihn jetzt durch.
gcloud sql instances create aidemy \
--database-version=POSTGRES_14 \
--cpu=2 \
--memory=4GB \
--region=us-central1 \
--root-password=1234qwer \
--storage-size=10GB \
--storage-auto-increase
4. Ersten Agenten erstellen
Bevor wir uns mit komplexen Multi-Agenten-Systemen befassen, müssen wir einen grundlegenden Baustein festlegen: einen einzelnen, funktionalen Agenten. In diesem Abschnitt erstellen wir einen einfachen Agenten für Buchanbieter. Der Buchanbieter-Agent nimmt eine Kategorie als Eingabe entgegen und verwendet ein Gemini-LLM, um eine JSON-Darstellung eines Buchs in dieser Kategorie zu generieren. Anschließend werden diese Buchempfehlungen als REST API-Endpunkt bereitgestellt .

👉 Öffnen Sie in einem anderen Browser-Tab die Google Cloud Console in Ihrem Webbrowser. Rufen Sie im Navigationsmenü (☰) „Cloud Run“ auf. Klicken Sie auf die Schaltfläche „+ … FUNKTION SCHREIBEN“.

👉 Als Nächstes konfigurieren wir die Grundeinstellungen der Cloud Run-Funktion:
- Dienstname:
book-provider - Region:
us-central1 - Laufzeit:
Python 3.12 - Authentifizierung:
Allow unauthenticated invocationsauf „Aktiviert“ setzen.
👉 Übernehmen Sie die anderen Standardeinstellungen und klicken Sie auf Erstellen. Dadurch gelangen Sie zum Quellcode-Editor.
Sie sehen die vorab ausgefüllten Dateien main.py und requirements.txt.
main.py enthält die Geschäftslogik der Funktion, requirements.txt die erforderlichen Pakete.
👉 Jetzt können wir Code schreiben. Bevor wir uns das genauer ansehen, wollen wir prüfen, ob Gemini Code Assist uns einen Vorsprung verschaffen kann. Kehren Sie zum Cloud Shell-Editor zurück und klicken Sie oben auf das Gemini Code Assist-Symbol, um den Gemini Code Assist-Chat zu öffnen.

👉 Fügen Sie die folgende Anfrage in das Prompt-Feld ein:
Use the functions_framework library to be deployable as an HTTP function.
Accept a request with category and number_of_book parameters (either in JSON body or query string).
Use langchain and gemini to generate the data for book with fields bookname, author, publisher, publishing_date.
Use pydantic to define a Book model with the fields: bookname (string, description: "Name of the book"), author (string, description: "Name of the author"), publisher (string, description: "Name of the publisher"), and publishing_date (string, description: "Date of publishing").
Use langchain and gemini model to generate book data. the output should follow the format defined in Book model.
The logic should use JsonOutputParser from langchain to enforce output format defined in Book Model.
Have a function get_recommended_books(category) that internally uses langchain and gemini to return a single book object.
The main function, exposed as the Cloud Function, should call get_recommended_books() multiple times (based on number_of_book) and return a JSON list of the generated book objects.
Handle the case where category or number_of_book are missing by returning an error JSON response with a 400 status code.
return a JSON string representing the recommended books. use os library to retrieve GOOGLE_CLOUD_PROJECT env var. Use ChatVertexAI from langchain for the LLM call
Code Assist generiert dann eine mögliche Lösung und stellt sowohl den Quellcode als auch eine Datei „requirements.txt“ mit den Abhängigkeiten bereit. (DIESEN CODE NICHT VERWENDEN)
Wir empfehlen Ihnen, den von Code Assist generierten Code mit der unten bereitgestellten getesteten, korrekten Lösung zu vergleichen. So können Sie die Effektivität des Tools bewerten und potenzielle Abweichungen erkennen. LLMs sollten zwar nie blind vertraut werden, aber Code Assist kann ein hervorragendes Tool für schnelles Prototyping und das Generieren von anfänglichen Codestrukturen sein und sollte für einen guten Start verwendet werden.
Da es sich um einen Workshop handelt, verwenden wir den unten angegebenen bestätigten Code. Sie können den von Code Assist generierten Code jedoch jederzeit selbst ausprobieren, um ein besseres Verständnis der Funktionen und Einschränkungen zu erhalten.
👉 Kehren Sie zum Quellcode-Editor der Cloud Run-Funktion zurück (auf dem anderen Browser-Tab). Ersetzen Sie den vorhandenen Inhalt von main.py sorgfältig durch den unten stehenden Code:
import functions_framework
import json
from flask import Flask, jsonify, request
from langchain_google_vertexai import ChatVertexAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field
import os
class Book(BaseModel):
bookname: str = Field(description="Name of the book")
author: str = Field(description="Name of the author")
publisher: str = Field(description="Name of the publisher")
publishing_date: str = Field(description="Date of publishing")
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT")
llm = ChatVertexAI(model_name="gemini-2.0-flash-lite-001")
def get_recommended_books(category):
"""
A simple book recommendation function.
Args:
category (str): category
Returns:
str: A JSON string representing the recommended books.
"""
parser = JsonOutputParser(pydantic_object=Book)
question = f"Generate a random made up book on {category} with bookname, author and publisher and publishing_date"
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | llm | parser
response = chain.invoke({"query": question})
return json.dumps(response)
@functions_framework.http
def recommended(request):
request_json = request.get_json(silent=True) # Get JSON data
if request_json and 'category' in request_json and 'number_of_book' in request_json:
category = request_json['category']
number_of_book = int(request_json['number_of_book'])
elif request.args and 'category' in request.args and 'number_of_book' in request.args:
category = request.args.get('category')
number_of_book = int(request.args.get('number_of_book'))
else:
return jsonify({'error': 'Missing category or number_of_book parameters'}), 400
recommendations_list = []
for i in range(number_of_book):
book_dict = json.loads(get_recommended_books(category))
print(f"book_dict=======>{book_dict}")
recommendations_list.append(book_dict)
return jsonify(recommendations_list)
👉 Ersetzen Sie den Inhalt von „requirements.txt“ durch Folgendes:
functions-framework==3.*
google-genai==1.0.0
flask==3.1.0
jsonify==0.5
langchain_google_vertexai==2.0.13
langchain_core==0.3.34
pydantic==2.10.5
👉 Wir legen den Funktionseinstiegspunkt fest: recommended

👉 Klicken Sie auf SPEICHERN UND BEREITSTELLEN (oder SPEICHERN UND WIEDER BEREITSTELLEN), um die Funktion bereitzustellen. Warten Sie, bis der Bereitstellungsvorgang abgeschlossen ist. In der Cloud Console wird der Status angezeigt. Dieser Vorgang kann einige Minuten dauern.
 👉 Kehren Sie nach der Bereitstellung zum Cloud Shell-Editor zurück und führen Sie im Terminal Folgendes aus:
👉 Kehren Sie nach der Bereitstellung zum Cloud Shell-Editor zurück und führen Sie im Terminal Folgendes aus:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
curl -X POST -H "Content-Type: application/json" -d '{"category": "Science Fiction", "number_of_book": 2}' $BOOK_PROVIDER_URL
Es sollten einige Buchdaten im JSON-Format angezeigt werden.
[
{"author":"Anya Sharma","bookname":"Echoes of the Singularity","publisher":"NovaLight Publishing","publishing_date":"2077-03-15"},
{"author":"Anya Sharma","bookname":"Echoes of the Quantum Dawn","publisher":"Nova Genesis Publishing","publishing_date":"2077-03-15"}
]
Glückwunsch! Sie haben eine Cloud Run-Funktion bereitgestellt. Dies ist einer der Dienste, die wir bei der Entwicklung unseres Aidemy-Agents integrieren werden.
5. Tools erstellen: Agents mit RESTFUL-Diensten und Daten verbinden
Laden wir das Bootstrap-Skelettprojekt herunter. Achten Sie darauf, dass Sie sich im Cloud Shell-Editor befinden. Führen Sie im Terminal folgenden Befehl aus:
git clone https://github.com/weimeilin79/aidemy-bootstrap.git
Nachdem Sie diesen Befehl ausgeführt haben, wird in Ihrer Cloud Shell-Umgebung ein neuer Ordner mit dem Namen aidemy-bootstrap erstellt.
Im Bereich „Explorer“ des Cloud Shell-Editors (normalerweise auf der linken Seite) sollte jetzt der Ordner angezeigt werden, der beim Klonen des Git-Repositorys aidemy-bootstrap erstellt wurde. Öffnen Sie den Stammordner Ihres Projekts im Explorer. Darin finden Sie den Unterordner planner. Öffnen Sie auch diesen. 
Lassen Sie uns mit der Entwicklung der Tools beginnen, die unsere KI-Agenten benötigen, um wirklich hilfreich zu sein. Wie Sie wissen, sind LLMs hervorragend darin, Schlussfolgerungen zu ziehen und Text zu generieren. Sie benötigen jedoch Zugriff auf externe Ressourcen, um praktische Aufgaben auszuführen und genaue, aktuelle Informationen bereitzustellen. Stellen Sie sich diese Tools als das „Schweizer Taschenmesser“ des Agenten vor, mit dem er mit der Welt interagieren kann.
Beim Erstellen eines Agents ist es leicht, viele Details fest zu codieren. Dadurch wird ein Agent erstellt, der nicht flexibel ist. Stattdessen hat der Agent durch das Erstellen und Verwenden von Tools Zugriff auf externe Logik oder Systeme, was ihm die Vorteile sowohl des LLM als auch der herkömmlichen Programmierung bietet.
In diesem Abschnitt legen wir die Grundlage für den Planer-Agenten, mit dem Lehrkräfte Unterrichtspläne erstellen können. Bevor der Agent einen Plan generiert, möchten wir Grenzen festlegen, indem wir weitere Details zum Fach und Thema angeben. Wir erstellen drei Tools:
- Restful-API-Aufruf:Interaktion mit einer vorhandenen API zum Abrufen von Daten.
- Datenbankabfrage:Abrufen strukturierter Daten aus einer Cloud SQL-Datenbank.
- Google Suche:Zugriff auf Echtzeitinformationen aus dem Web.
Buchempfehlungen über eine API abrufen
Zuerst erstellen wir ein Tool, das Buchempfehlungen von der book-provider-API abruft, die wir im vorherigen Abschnitt bereitgestellt haben. Hier wird gezeigt, wie ein Agent vorhandene Dienste nutzen kann.

Öffnen Sie im Cloud Shell-Editor das Projekt aidemy-bootstrap, das Sie im vorherigen Abschnitt geklont haben.
👉 Bearbeiten Sie die Datei book.py im Ordner planner und fügen Sie den folgenden Code am Ende der Datei ein:
def recommend_book(query: str):
"""
Get a list of recommended book from an API endpoint
Args:
query: User's request string
"""
region = get_next_region();
llm = VertexAI(model_name="gemini-1.5-pro", location=region)
query = f"""The user is trying to plan a education course, you are the teaching assistant. Help define the category of what the user requested to teach, respond the categroy with no more than two word.
user request: {query}
"""
print(f"-------->{query}")
response = llm.invoke(query)
print(f"CATEGORY RESPONSE------------>: {response}")
# call this using python and parse the json back to dict
category = response.strip()
headers = {"Content-Type": "application/json"}
data = {"category": category, "number_of_book": 2}
books = requests.post(BOOK_PROVIDER_URL, headers=headers, json=data)
return books.text
if __name__ == "__main__":
print(recommend_book("I'm doing a course for my 5th grade student on Math Geometry, I'll need to recommend few books come up with a teach plan, few quizes and also a homework assignment."))
Erklärung:
- recommend_book(query: str): Diese Funktion verwendet die Anfrage eines Nutzers als Eingabe.
- LLM-Interaktion: Das LLM wird verwendet, um die Kategorie aus der Anfrage zu extrahieren. Hier wird gezeigt, wie Sie das LLM verwenden können, um Parameter für Tools zu erstellen.
- API-Aufruf: Es wird eine POST-Anfrage an die Book-Provider API gesendet, wobei die Kategorie und die gewünschte Anzahl von Büchern übergeben werden.
👉 Um diese neue Funktion zu testen, legen Sie die Umgebungsvariable fest und führen Sie Folgendes aus :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
cd ~/aidemy-bootstrap/planner/
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
👉 Installieren Sie die Abhängigkeiten und führen Sie den Code aus, um sicherzustellen, dass er funktioniert:
cd ~/aidemy-bootstrap/planner/
python -m venv env
source env/bin/activate
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python book.py
Sie sollten einen JSON-String mit Buchempfehlungen sehen, die über die Buchanbieter-API abgerufen wurden. Die Ergebnisse werden zufällig generiert. Ihre Bücher sind möglicherweise nicht identisch, aber Sie sollten zwei Buchempfehlungen im JSON-Format erhalten.
[{"author":"Anya Sharma","bookname":"Echoes of the Singularity","publisher":"NovaLight Publishing","publishing_date":"2077-03-15"},{"author":"Anya Sharma","bookname":"Echoes of the Quantum Dawn","publisher":"Nova Genesis Publishing","publishing_date":"2077-03-15"}]
Wenn Sie das sehen, funktioniert das erste Tool richtig.
Anstatt einen RESTful API-Aufruf mit bestimmten Parametern explizit zu erstellen, verwenden wir natürliche Sprache („I'm doing a course...“). Der Agent extrahiert dann intelligent die erforderlichen Parameter (z. B. die Kategorie) mithilfe von NLP und zeigt so, wie der Agent Natural Language Understanding nutzt, um mit der API zu interagieren.

👉Entfernen Sie den folgenden Testcode aus book.py.
if __name__ == "__main__":
print(recommend_book("I'm doing a course for my 5th grade student on Math Geometry, I'll need to recommend few books come up with a teach plan, few quizes and also a homework assignment."))
Curriculum-Daten aus einer Datenbank abrufen
Als Nächstes erstellen wir ein Tool, mit dem strukturierte Lehrplandaten aus einer Cloud SQL PostgreSQL-Datenbank abgerufen werden. So kann der Agent auf eine zuverlässige Informationsquelle für die Unterrichtsplanung zugreifen.

Erinnern Sie sich an die Cloud SQL-Instanz aidemy, die Sie im vorherigen Schritt erstellt haben? Hier wird sie verwendet.
👉 Führen Sie im Terminal den folgenden Befehl aus, um in der neuen Instanz eine Datenbank mit dem Namen aidemy-db zu erstellen.
gcloud sql databases create aidemy-db \
--instance=aidemy
Sehen wir uns die Instanz in Cloud SQL in der Google Cloud Console an. Dort sollte eine Cloud SQL-Instanz mit dem Namen aidemy aufgeführt sein.
👉 Klicken Sie auf den Instanznamen, um die Details aufzurufen. 👉 Klicken Sie auf der Detailseite der Cloud SQL-Instanz im linken Navigationsmenü auf Cloud SQL Studio. Damit wird ein neuer Tab geöffnet.
Wählen Sie aidemy-db als Datenbank aus, geben Sie postgres als Nutzer und 1234qwer als Passwort ein.
Klicken Sie auf Authentifizieren.

👉 Rufen Sie im Abfrageeditor von SQL Studio den Tab Editor 1 auf und fügen Sie den folgenden SQL-Code ein:
CREATE TABLE curriculums (
id SERIAL PRIMARY KEY,
year INT,
subject VARCHAR(255),
description TEXT
);
-- Inserting detailed curriculum data for different school years and subjects
INSERT INTO curriculums (year, subject, description) VALUES
-- Year 5
(5, 'Mathematics', 'Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.'),
(5, 'English', 'Developing reading comprehension, creative writing, and basic grammar, with a focus on storytelling and poetry.'),
(5, 'Science', 'Exploring basic physics, chemistry, and biology concepts, including forces, materials, and ecosystems.'),
(5, 'Computer Science', 'Basic coding concepts using block-based programming and an introduction to digital literacy.'),
-- Year 6
(6, 'Mathematics', 'Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.'),
(6, 'English', 'Introduction to persuasive writing, character analysis, and deeper comprehension of literary texts.'),
(6, 'Science', 'Forces and motion, the human body, and introductory chemical reactions with hands-on experiments.'),
(6, 'Computer Science', 'Introduction to algorithms, logical reasoning, and basic text-based programming (Python, Scratch).'),
-- Year 7
(7, 'Mathematics', 'Algebraic expressions, geometry, and introduction to statistics and probability.'),
(7, 'English', 'Analytical reading of classic and modern literature, essay writing, and advanced grammar skills.'),
(7, 'Science', 'Introduction to cells and organisms, chemical reactions, and energy transfer in physics.'),
(7, 'Computer Science', 'Building on programming skills with Python, introduction to web development, and cyber safety.');
Mit diesem SQL-Code wird eine Tabelle mit dem Namen curriculums erstellt und es werden einige Beispieldaten eingefügt.
👉 Klicken Sie auf Ausführen, um den SQL-Code auszuführen. Sie sollten eine Bestätigungsmeldung sehen, dass die Anweisungen erfolgreich ausgeführt wurden.
👉 Maximieren Sie den Explorer, suchen Sie die neu erstellte Tabelle curriculums und klicken Sie auf Abfrage. Ein neuer Editor-Tab mit für Sie generiertem SQL sollte geöffnet werden.

SELECT * FROM
"public"."curriculums" LIMIT 1000;
👉 Klicken Sie auf Ausführen.
In der Ergebnistabelle sollten die Datenzeilen angezeigt werden, die Sie im vorherigen Schritt eingefügt haben. So wird bestätigt, dass die Tabelle und die Daten korrekt erstellt wurden.
Nachdem Sie nun eine Datenbank mit Beispieldaten für den Lehrplan erstellt haben, entwickeln wir ein Tool, mit dem Sie die Daten abrufen können.
👉 Bearbeiten Sie im Cloud Code-Editor die Datei curriculums.py im Ordner aidemy-bootstrap und fügen Sie den folgenden Code am Ende der Datei ein:
def connect_with_connector() -> sqlalchemy.engine.base.Engine:
db_user = os.environ["DB_USER"]
db_pass = os.environ["DB_PASS"]
db_name = os.environ["DB_NAME"]
print(f"--------------------------->db_user: {db_user!r}")
print(f"--------------------------->db_pass: {db_pass!r}")
print(f"--------------------------->db_name: {db_name!r}")
connector = Connector()
pool = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=lambda: connector.connect(
instance_connection_name,
"pg8000",
user=db_user,
password=db_pass,
db=db_name,
),
pool_size=2,
max_overflow=2,
pool_timeout=30, # 30 seconds
pool_recycle=1800, # 30 minutes
)
return pool
def get_curriculum(year: int, subject: str):
"""
Get school curriculum
Args:
subject: User's request subject string
year: User's request year int
"""
try:
stmt = sqlalchemy.text(
"SELECT description FROM curriculums WHERE year = :year AND subject = :subject"
)
with db.connect() as conn:
result = conn.execute(stmt, parameters={"year": year, "subject": subject})
row = result.fetchone()
if row:
return row[0]
else:
return None
except Exception as e:
print(e)
return None
db = connect_with_connector()
Erklärung:
- Umgebungsvariablen: Der Code ruft Datenbankanmeldedaten und Verbindungsinformationen aus Umgebungsvariablen ab (siehe unten).
- connect_with_connector(): Diese Funktion stellt mithilfe des Cloud SQL-Connectors eine sichere Verbindung zur Datenbank her.
- get_curriculum(year: int, subject: str): Diese Funktion verwendet das Jahr und das Fach als Eingabe, fragt die Tabelle „curriculums“ ab und gibt die entsprechende Lehrplanbeschreibung zurück.
👉 Bevor wir den Code ausführen können, müssen wir einige Umgebungsvariablen festlegen. Führen Sie dazu im Terminal Folgendes aus:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 Fügen Sie zum Testen den folgenden Code am Ende von curriculums.py ein:
if __name__ == "__main__":
print(get_curriculum(6, "Mathematics"))
👉 Code ausführen:
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python curriculums.py
Auf der Konsole sollte die Lehrplanbeschreibung für Mathematik der 6. Klasse angezeigt werden.
Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.
Wenn Sie die Lehrplanbeschreibung sehen, funktioniert das Datenbanktool richtig. Beenden Sie das Skript durch Drücken von Ctrl+C, falls es noch ausgeführt wird.
👉Entfernen Sie den folgenden Testcode aus curriculums.py.
if __name__ == "__main__":
print(get_curriculum(6, "Mathematics"))
👉 Beenden Sie die virtuelle Umgebung, indem Sie im Terminal Folgendes ausführen:
deactivate
6. Tools erstellen: Auf Echtzeitinformationen aus dem Web zugreifen
Zum Schluss entwickeln wir ein Tool, das die Integration von Gemini 2 und der Google Suche nutzt, um auf Echtzeitinformationen aus dem Web zuzugreifen. So kann der Agent auf dem neuesten Stand bleiben und relevante Ergebnisse liefern.
Die Integration von Gemini 2 in die Google Search API verbessert die Funktionen von Agenten, da genauere und kontextbezogenere Suchergebnisse bereitgestellt werden. So können Agents auf aktuelle Informationen zugreifen und ihre Antworten auf realen Daten basieren, wodurch Halluzinationen minimiert werden. Die verbesserte API-Integration ermöglicht auch natürlichere Suchanfragen, sodass Kundenservicemitarbeiter komplexe und differenzierte Suchanfragen formulieren können.

Diese Funktion verwendet eine Suchanfrage, einen Lehrplan, ein Fach und ein Jahr als Eingabe und ruft mit der Gemini API und dem Google-Suchtool relevante Informationen aus dem Internet ab. Bei genauerer Betrachtung wird deutlich, dass das Google Generative AI SDK für Funktionsaufrufe verwendet wird, ohne dass ein anderes Framework zum Einsatz kommt.
👉 Bearbeiten Sie search.py im Ordner aidemy-bootstrap und fügen Sie den folgenden Code am Ende der Datei ein:
model_id = "gemini-2.0-flash-001"
google_search_tool = Tool(
google_search = GoogleSearch()
)
def search_latest_resource(search_text: str, curriculum: str, subject: str, year: int):
"""
Get latest information from the internet
Args:
search_text: User's request category string
subject: "User's request subject" string
year: "User's request year" integer
"""
search_text = "%s in the context of year %d and subject %s with following curriculum detail %s " % (search_text, year, subject, curriculum)
region = get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
print(f"search_latest_resource text-----> {search_text}")
response = client.models.generate_content(
model=model_id,
contents=search_text,
config=GenerateContentConfig(
tools=[google_search_tool],
response_modalities=["TEXT"],
)
)
print(f"search_latest_resource response-----> {response}")
return response
if __name__ == "__main__":
response = search_latest_resource("What are the syllabus for Year 6 Mathematics?", "Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.", "Mathematics", 6)
for each in response.candidates[0].content.parts:
print(each.text)
Erklärung:
- Tool definieren – google_search_tool: Das GoogleSearch-Objekt in ein Tool einbetten
- search_latest_resource(search_text: str, subject: str, year: int): Diese Funktion verwendet eine Suchanfrage, ein Thema und ein Jahr als Eingabe und führt mit der Gemini API eine Google-Suche durch.
- GenerateContentConfig: Definieren, dass es Zugriff auf das GoogleSearch-Tool hat
Das Gemini-Modell analysiert intern den search_text und ermittelt, ob es die Frage direkt beantworten kann oder ob es das GoogleSearch-Tool verwenden muss. Dies ist ein wichtiger Schritt im Logikprozess des LLM. Das Modell wurde darauf trainiert, Situationen zu erkennen, in denen externe Tools erforderlich sind. Wenn das Modell entscheidet, das GoogleSearch-Tool zu verwenden, übernimmt das Google Generative AI SDK den eigentlichen Aufruf. Das SDK übernimmt die Entscheidung des Modells und die von ihm generierten Parameter und sendet sie an die Google Search API. Dieser Teil ist im Code für den Nutzer ausgeblendet.
Das Gemini-Modell bezieht die Suchergebnisse dann in seine Antwort ein. Sie kann die Informationen verwenden, um die Frage des Nutzers zu beantworten, eine Zusammenfassung zu erstellen oder eine andere Aufgabe auszuführen.
👉 So testen Sie den Code:
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
source env/bin/activate
python search.py
Sie sollten die Antwort der Gemini Search API mit Suchergebnissen zum Thema „Lehrplan für Mathematik in der 5. Klasse“ sehen. Die genaue Ausgabe hängt von den Suchergebnissen ab, ist aber ein JSON-Objekt mit Informationen zur Suche.
Wenn Sie Suchergebnisse sehen, funktioniert das Google Suche-Tool richtig. Beenden Sie das Skript durch Drücken von Ctrl+C, falls es noch ausgeführt wird.
👉 Entfernen Sie den letzten Teil des Codes.
if __name__ == "__main__":
response = search_latest_resource("What are the syllabus for Year 6 Mathematics?", "Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.", "Mathematics", 6)
for each in response.candidates[0].content.parts:
print(each.text)
👉 Beenden Sie die virtuelle Umgebung, indem Sie im Terminal Folgendes ausführen:
deactivate
Glückwunsch! Sie haben jetzt drei leistungsstarke Tools für Ihren Planer-Agenten erstellt: einen API-Connector, einen Datenbank-Connector und ein Google Suche-Tool. Mit diesen Tools kann der Agent auf die Informationen und Funktionen zugreifen, die er zum Erstellen effektiver Lehrpläne benötigt.
7. Orchestrierung mit LangGraph
Nachdem wir unsere einzelnen Tools erstellt haben, ist es an der Zeit, sie mit LangGraph zu orchestrieren. So können wir einen ausgefeilteren „Planner“-Agenten erstellen, der basierend auf der Anfrage des Nutzers intelligent entscheiden kann, welche Tools wann verwendet werden sollen.
LangGraph ist eine Python-Bibliothek, mit der sich zustandsbehaftete Anwendungen mit mehreren Akteuren, die Large Language Models (LLMs) verwenden, einfacher erstellen lassen. Stellen Sie sich das als Framework für die Orchestrierung komplexer Unterhaltungen und Workflows vor, an denen LLMs, Tools und andere Agents beteiligt sind.
Schlüsselkonzepte:
- Diagrammstruktur:LangGraph stellt die Logik Ihrer Anwendung als gerichteten Graphen dar. Jeder Knoten im Diagramm stellt einen Schritt im Prozess dar, z.B. einen Aufruf eines LLM, einen Toolaufruf oder eine bedingte Prüfung. Kanten definieren den Ausführungsfluss zwischen Knoten.
- Status:LangGraph verwaltet den Status Ihrer Anwendung, während sie sich durch den Graphen bewegt. Dieser Status kann Variablen wie die Eingabe des Nutzers, die Ergebnisse von Tool-Aufrufen, Zwischenausgaben von LLMs und alle anderen Informationen enthalten, die zwischen den Schritten beibehalten werden müssen.
- Knoten:Jeder Knoten steht für eine Berechnung oder Interaktion. Mögliche Werte:
- Tool-Knoten:Ein Tool verwenden (z.B. eine Websuche durchführen, eine Datenbank abfragen)
- Funktionsknoten:Führen eine Python-Funktion aus.
- Kanten:Verbinden Knoten und definieren den Ausführungsablauf. Mögliche Werte:
- Direkte Kanten:Ein einfacher, bedingungsloser Fluss von einem Knoten zum nächsten.
- Bedingte Kanten:Der Ablauf hängt vom Ergebnis eines bedingten Knotens ab.

Wir verwenden LangGraph, um die Orchestrierung zu implementieren. Bearbeiten wir die Datei aidemy.py im Ordner aidemy-bootstrap, um unsere LangGraph-Logik zu definieren.
👉 Fügen Sie den folgenden Code am Ende von ein.
aidemy.py:
tools = [get_curriculum, search_latest_resource, recommend_book]
def determine_tool(state: MessagesState):
llm = ChatVertexAI(model_name="gemini-2.0-flash-001", location=get_next_region())
sys_msg = SystemMessage(
content=(
f"""You are a helpful teaching assistant that helps gather all needed information.
Your ultimate goal is to create a detailed 3-week teaching plan.
You have access to tools that help you gather information.
Based on the user request, decide which tool(s) are needed.
"""
)
)
llm_with_tools = llm.bind_tools(tools)
return {"messages": llm_with_tools.invoke([sys_msg] + state["messages"])}
Diese Funktion ist dafür zuständig, den aktuellen Status der Unterhaltung zu erfassen, dem LLM eine Systemnachricht zu senden und das LLM dann aufzufordern, eine Antwort zu generieren. Das LLM kann entweder direkt auf den Nutzer reagieren oder eines der verfügbaren Tools verwenden.
tools : Diese Liste enthält die Tools, die dem Agent zur Verfügung stehen. Sie enthält drei Tool-Funktionen, die wir in den vorherigen Schritten definiert haben: get_curriculum, search_latest_resource und recommend_book. llm.bind_tools(tools): Die Tool-Liste wird an das LLM-Objekt „gebunden“. Durch das Binden der Tools wird dem LLM mitgeteilt, dass diese Tools verfügbar sind, und es erhält Informationen dazu, wie sie verwendet werden (z.B. die Namen der Tools, die Parameter, die sie akzeptieren, und was sie tun).
Wir verwenden LangGraph, um die Orchestrierung zu implementieren.
👉 Fügen Sie den folgenden Code am Ende von ein.
aidemy.py:
def prep_class(prep_needs):
builder = StateGraph(MessagesState)
builder.add_node("determine_tool", determine_tool)
builder.add_node("tools", ToolNode(tools))
builder.add_edge(START, "determine_tool")
builder.add_conditional_edges("determine_tool",tools_condition)
builder.add_edge("tools", "determine_tool")
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "1"}}
messages = graph.invoke({"messages": prep_needs},config)
print(messages)
for m in messages['messages']:
m.pretty_print()
teaching_plan_result = messages["messages"][-1].content
return teaching_plan_result
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, , get school curriculum, and come up with few books recommendation plus search latest resources on the internet base on the curriculum outcome. And come up with a 3 week teaching plan")
Erklärung:
StateGraph(MessagesState):Erstellt einStateGraph-Objekt. EinStateGraphist ein Kernkonzept in LangGraph. Er stellt den Workflow Ihres Agents als Diagramm dar, wobei jeder Knoten im Diagramm einen Schritt im Prozess darstellt. Damit legen Sie fest, wie der Agent argumentiert und handelt.- Bedingte Kante:Das Argument
tools_conditionstammt vom Knoten"determine_tool"und ist wahrscheinlich eine Funktion, die anhand der Ausgabe der Funktiondetermine_toolbestimmt, welcher Kante gefolgt werden soll. Mit bedingten Kanten kann der Graph verzweigen, je nachdem, welches Tool das LLM verwendet (oder ob es direkt auf den Nutzer antwortet). Hier kommt die „Intelligenz“ des Agents ins Spiel – er kann sein Verhalten dynamisch an die Situation anpassen. - Schleife:Fügt dem Diagramm eine Kante hinzu, die den Knoten
"tools"mit dem Knoten"determine_tool"verbindet. Dadurch entsteht eine Schleife im Diagramm, sodass der Agent Tools wiederholt verwenden kann, bis er genügend Informationen gesammelt hat, um die Aufgabe zu erledigen und eine zufriedenstellende Antwort zu geben. Diese Schleife ist für komplexe Aufgaben, die mehrere Schritte für die Argumentation und das Sammeln von Informationen erfordern, von entscheidender Bedeutung.
Sehen wir uns nun an, wie unser Planner-Agent die verschiedenen Tools orchestriert.
Mit diesem Code wird die Funktion „prep_class“ mit einer bestimmten Nutzereingabe ausgeführt. Dabei wird eine Anfrage simuliert, einen Unterrichtsplan für Mathematik in der 5. Klasse im Bereich Geometrie zu erstellen, wobei der Lehrplan, Buchempfehlungen und die neuesten Internetressourcen verwendet werden.
👉 Wenn Sie Ihr Terminal geschlossen haben oder die Umgebungsvariablen nicht mehr festgelegt sind, führen Sie die folgenden Befehle noch einmal aus:
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 Code ausführen:
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
pip install -r requirements.txt
python aidemy.py
Sehen Sie sich das Log im Terminal an. Sie sollten sehen, dass der Agent alle drei Tools aufruft (Abrufen des Lehrplans, Abrufen von Buchempfehlungen und Suchen nach den neuesten Ressourcen), bevor er den endgültigen Lehrplan bereitstellt. Das zeigt, dass die LangGraph-Orchestrierung korrekt funktioniert und der Agent alle verfügbaren Tools intelligent nutzt, um die Anfrage des Nutzers zu erfüllen.
================================ Human Message =================================
I'm doing a course for year 5 on subject Mathematics in Geometry, , get school curriculum, and come up with few books recommendation plus search latest resources on the internet base on the curriculum outcome. And come up with a 3 week teaching plan
================================== Ai Message ==================================
Tool Calls:
get_curriculum (xxx)
Call ID: xxx
Args:
year: 5.0
subject: Mathematics
================================= Tool Message =================================
Name: get_curriculum
Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.
================================== Ai Message ==================================
Tool Calls:
search_latest_resource (xxxx)
Call ID: xxxx
Args:
year: 5.0
search_text: Geometry
curriculum: {"content": "Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques."}
subject: Mathematics
================================= Tool Message =================================
Name: search_latest_resource
candidates=[Candidate(content=Content(parts=[Part(.....) automatic_function_calling_history=[] parsed=None
================================== Ai Message ==================================
Tool Calls:
recommend_book (93b48189-4d69-4c09-a3bd-4e60cdc5f1c6)
Call ID: 93b48189-4d69-4c09-a3bd-4e60cdc5f1c6
Args:
query: Mathematics Geometry Year 5
================================= Tool Message =================================
Name: recommend_book
[{.....}]
================================== Ai Message ==================================
Based on the curriculum outcome, here is a 3-week teaching plan for year 5 Mathematics Geometry:
**Week 1: Introduction to Shapes and Properties**
.........
Beenden Sie das Skript durch Drücken von Ctrl+C, falls es noch ausgeführt wird.
👉 (DIESER SCHRITT IST OPTIONAL) Ersetzen Sie den Testcode durch einen anderen Prompt, für den andere Tools aufgerufen werden müssen.
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan")
👉 Wenn Sie das Terminal geschlossen haben oder die Umgebungsvariablen nicht mehr festgelegt sind, führen Sie die folgenden Befehle noch einmal aus.
gcloud config set project $(cat ~/project_id.txt)
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 (DIESER SCHRITT IST OPTIONAL und muss NUR ausgeführt werden, wenn Sie den vorherigen Schritt ausgeführt haben): Führen Sie den Code noch einmal aus:
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python aidemy.py
Was ist dir dieses Mal aufgefallen? Welche Tools hat der Kundenservicemitarbeiter aufgerufen? Sie sollten sehen, dass der Agent dieses Mal nur das Tool „search_latest_resource“ aufruft. Das liegt daran, dass im Prompt nicht angegeben ist, dass die beiden anderen Tools benötigt werden, und unser LLM intelligent genug ist, die anderen Tools nicht aufzurufen.
================================ Human Message =================================
I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan
================================== Ai Message ==================================
Tool Calls:
get_curriculum (xxx)
Call ID: xxx
Args:
year: 5.0
subject: Mathematics
================================= Tool Message =================================
Name: get_curriculum
Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.
================================== Ai Message ==================================
Tool Calls:
search_latest_resource (xxx)
Call ID: xxxx
Args:
year: 5.0
subject: Mathematics
curriculum: {"content": "Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques."}
search_text: Geometry
================================= Tool Message =================================
Name: search_latest_resource
candidates=[Candidate(content=Content(parts=[Part(.......token_count=40, total_token_count=772) automatic_function_calling_history=[] parsed=None
================================== Ai Message ==================================
Based on the information provided, a 3-week teaching plan for Year 5 Mathematics focusing on Geometry could look like this:
**Week 1: Introducing 2D Shapes**
........
* Use visuals, manipulatives, and real-world examples to make the learning experience engaging and relevant.
Beenden Sie das Skript durch Druck auf Ctrl+C.
👉 (DIESEN SCHRITT NICHT ÜBERSPRINGEN!) Entfernen Sie den Testcode, damit die Datei „aidemy.py“ übersichtlich bleibt :
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan")
Nachdem wir die Agent-Logik definiert haben, starten wir die Flask-Webanwendung. So erhalten Lehrkräfte eine vertraute formularbasierte Oberfläche für die Interaktion mit dem Agenten. Chatbot-Interaktionen sind zwar bei LLMs üblich, wir haben uns jedoch für eine herkömmliche Benutzeroberfläche zur Formularübermittlung entschieden, da sie für viele Lehrkräfte möglicherweise intuitiver ist.
👉 Wenn Sie das Terminal geschlossen haben oder die Umgebungsvariablen nicht mehr festgelegt sind, führen Sie die folgenden Befehle noch einmal aus.
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 Starten Sie jetzt die Web-UI.
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python app.py
Suchen Sie in der Cloud Shell-Terminalausgabe nach Startmeldungen. Flask gibt normalerweise Meldungen aus, die angeben, dass es ausgeführt wird und auf welchem Port.
Running on http://127.0.0.1:8080
Running on http://127.0.0.1:8080
The application needs to keep running to serve requests.
👉 Wählen Sie rechts oben im Menü „Webvorschau“ die Option Vorschau auf Port 8080 aus. In Cloud Shell wird ein neuer Browsertab oder ein neues Browserfenster mit der Webvorschau Ihrer Anwendung geöffnet.

Wählen Sie in der Anwendungsoberfläche 5 für „Year“ (Jahr) aus, wählen Sie das Thema Mathematics aus und geben Sie Geometry in die Add-on-Anfrage ein.
👉 Wenn Sie die Benutzeroberfläche Ihrer Anwendung verlassen haben, kehren Sie zurück. Die generierte Ausgabe sollte dann angezeigt werden.
👉 Beenden Sie das Skript im Terminal durch Drücken von Ctrl+C.
👉 Beenden Sie die virtuelle Umgebung in Ihrem Terminal:
deactivate
8. Planner-Agent in der Cloud bereitstellen
Image erstellen und per Push in die Registry übertragen

Zeit, das in der Cloud bereitzustellen.
👉 Erstellen Sie im Terminal ein Artifacts-Repository zum Speichern des Docker-Images, das wir erstellen werden.
gcloud artifacts repositories create agent-repository \
--repository-format=docker \
--location=us-central1 \
--description="My agent repository"
Sie sollten die Meldung „Created repository [agent-repository]“ (Repository [agent-repository] wurde erstellt) sehen.
👉 Führen Sie den folgenden Befehl aus, um das Docker-Image zu erstellen.
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-planner .
👉 Wir müssen das Image neu taggen, damit es in Artifact Registry anstelle von GCR gehostet wird, und das getaggte Image in Artifact Registry übertragen:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-planner us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
Nachdem das Push abgeschlossen ist, können Sie prüfen, ob das Image erfolgreich in Artifact Registry gespeichert wurde.
👉 Rufen Sie in der Google Cloud Console Artifact Registry auf. Das aidemy-planner-Image sollte sich im Repository agent-repository befinden. 
Datenbankanmeldedaten mit Secret Manager sichern
Wir verwenden Google Cloud Secret Manager, um Datenbankanmeldedaten sicher zu verwalten und darauf zuzugreifen. So wird verhindert, dass vertrauliche Informationen in unserem Anwendungscode hartcodiert werden, und die Sicherheit wird erhöht.
Wir erstellen separate Secrets für den Datenbanknutzernamen, das Passwort und den Datenbanknamen. So können wir jede Anmeldedaten unabhängig verwalten.
👉 Führen Sie im Terminal Folgendes aus:
gcloud secrets create db-user
printf "postgres" | gcloud secrets versions add db-user --data-file=-
gcloud secrets create db-pass
printf "1234qwer" | gcloud secrets versions add db-pass --data-file=-
gcloud secrets create db-name
printf "aidemy-db" | gcloud secrets versions add db-name --data-file=-
Die Verwendung von Secret Manager ist ein wichtiger Schritt, um Ihre Anwendung zu schützen und die versehentliche Offenlegung vertraulicher Anmeldedaten zu verhindern. Es werden Best Practices für die Sicherheit von Cloud-Bereitstellungen eingehalten.
In Cloud Run bereitstellen
Cloud Run ist eine vollständig verwaltete serverlose Plattform, mit der Sie containerisierte Anwendungen schnell und einfach bereitstellen können. Die Infrastrukturverwaltung wird abstrahiert, sodass Sie sich auf das Schreiben und Bereitstellen von Code konzentrieren können. Wir stellen unseren Planer als Cloud Run-Dienst bereit.
👉 Rufen Sie in der Google Cloud Console Cloud Run auf. Klicken Sie auf CONTAINER BEREITSTELLEN und wählen Sie SERVICE aus. Cloud Run-Dienst konfigurieren:

- Container-Image: Klicken Sie im URL-Feld auf „Auswählen“. Suchen Sie die Bild-URL, die Sie in Artifact Registry hochgeladen haben (z.B. us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repository/aidemy-planner/YOUR_IMG).
- Service name:
aidemy-planner - Region: Wählen Sie die Region
us-central1aus. - Authentifizierung: Für diesen Workshop können Sie „Nicht authentifizierte Aufrufe zulassen“ aktivieren. In der Produktion sollten Sie den Zugriff wahrscheinlich einschränken.
- Maximieren Sie den Bereich „Container, Volumes, Netzwerk, Sicherheit“ und legen Sie auf dem Tab Container Folgendes fest:
- Tab „Einstellungen“:
- Ressourcen
- memory : 2GiB
- Ressourcen
- Tab „Variablen und Secrets“:
- Umgebungsvariablen: Fügen Sie die folgenden Variablen hinzu, indem Sie auf die Schaltfläche + Variable hinzufügen klicken:
- Fügen Sie den Namen
GOOGLE_CLOUD_PROJECTund den Wert <YOUR_PROJECT_ID> hinzu. - Fügen Sie den Namen
BOOK_PROVIDER_URLhinzu und legen Sie den Wert auf die URL Ihrer Buchanbieterfunktion fest. Diese können Sie mit dem folgenden Befehl im Terminal ermitteln:gcloud config set project $(cat ~/project_id.txt) gcloud run services describe book-provider \ --region=us-central1 \ --project=$PROJECT_ID \ --format="value(status.url)"
- Fügen Sie den Namen
- Fügen Sie im Abschnitt Secrets, die als Umgebungsvariablen bereitgestellt werden, die folgenden Secrets hinzu, indem Sie auf die Schaltfläche + Als Secret referenzieren klicken:
- Name hinzufügen:
DB_USER, Secret:db-userauswählen und Version:latest - Name hinzufügen:
DB_PASS, Secret:db-passauswählen und Version:latest - Name hinzufügen:
DB_NAME, Secret:db-nameauswählen und Version:latest
- Name hinzufügen:
- Umgebungsvariablen: Fügen Sie die folgenden Variablen hinzu, indem Sie auf die Schaltfläche + Variable hinzufügen klicken:
- Tab „Einstellungen“:

Übernehmen Sie für die anderen Werte die Standardeinstellung.
👉 Klicke auf ERSTELLEN.
Cloud Run stellt Ihren Dienst bereit.
Wenn der Dienst bereitgestellt wurde und Sie sich noch nicht auf der Detailseite befinden, klicken Sie auf den Dienstnamen, um die Detailseite aufzurufen. Die bereitgestellte URL finden Sie oben.

👉 Wählen Sie in der Anwendungsoberfläche 7 für das Jahr und Mathematics als Betreff aus und geben Sie Algebra in das Feld „Add-on-Anfrage“ ein.
👉 Klicken Sie auf Plan erstellen. So erhält der KI-Agent den erforderlichen Kontext, um einen maßgeschneiderten Lehrplan zu erstellen.
Glückwunsch! Sie haben erfolgreich einen Lehrplan mit unserem leistungsstarken KI-Agenten erstellt. Das zeigt, wie KI-Agenten die Arbeitsbelastung erheblich reduzieren und Aufgaben optimieren können, was letztendlich die Effizienz steigert und das Leben von Lehrkräften erleichtert.
9. Multi-Agenten-Systeme
Nachdem wir das Tool zum Erstellen von Unterrichtsplänen erfolgreich implementiert haben, konzentrieren wir uns nun auf die Entwicklung des Schülerportals. Über dieses Portal erhalten Schüler und Studenten Zugriff auf Quizze, Audiozusammenfassungen und Aufgaben im Zusammenhang mit ihren Kursen. Angesichts des Umfangs dieser Funktion nutzen wir die Leistungsfähigkeit von Multi-Agent-Systemen, um eine modulare und skalierbare Lösung zu schaffen.
Wie bereits erwähnt, können wir die Arbeitslast in einem Multi-Agent-System in kleinere, spezialisierte Aufgaben aufteilen, die jeweils von einem dedizierten Agenten ausgeführt werden, anstatt uns auf einen einzelnen Agenten zu verlassen, der alles erledigt. Dieser Ansatz bietet mehrere wichtige Vorteile:
Modularität und Wartungsfreundlichkeit: Anstatt einen einzelnen Agenten zu erstellen, der alles erledigt, sollten Sie kleinere, spezialisierte Agenten mit klar definierten Verantwortlichkeiten entwickeln. Durch diese Modularität ist das System leichter zu verstehen, zu warten und zu debuggen. Wenn ein Problem auftritt, können Sie es auf einen bestimmten Agent eingrenzen, anstatt eine riesige Codebasis durchsuchen zu müssen.
Skalierbarkeit: Die Skalierung eines einzelnen, komplexen Agents kann einen Engpass darstellen. Mit einem Multi-Agent-System können Sie einzelne Agents entsprechend ihren spezifischen Anforderungen skalieren. Wenn beispielsweise ein Agent eine große Anzahl von Anfragen verarbeitet, können Sie problemlos weitere Instanzen dieses Agents hochfahren, ohne den Rest des Systems zu beeinträchtigen.
Teamspezialisierung: Stellen Sie sich vor, Sie würden einen einzelnen Entwickler bitten, eine ganze Anwendung von Grund auf zu entwickeln. Stattdessen stellen Sie ein Team von Spezialisten zusammen, die jeweils über Fachwissen in einem bestimmten Bereich verfügen. Mit einem Multi-Agent-System können Sie die Stärken verschiedener LLMs und Tools nutzen und sie Agenten zuweisen, die am besten für bestimmte Aufgaben geeignet sind.
Parallele Entwicklung: Verschiedene Teams können gleichzeitig an unterschiedlichen Agents arbeiten, was den Entwicklungsprozess beschleunigt. Da Agents unabhängig sind, wirken sich Änderungen an einem Agent weniger wahrscheinlich auf andere Agents aus.
Ereignisgesteuerte Architektur
Um eine effektive Kommunikation und Koordination zwischen diesen Agenten zu ermöglichen, verwenden wir eine ereignisgesteuerte Architektur. Das bedeutet, dass Agents auf „Ereignisse“ reagieren, die im System stattfinden.
Agents abonnieren bestimmte Ereignistypen, z.B. „Unterrichtsplan erstellt“ oder „Aufgabe erstellt“. Wenn ein Ereignis eintritt, werden die entsprechenden Kundenservicemitarbeiter benachrichtigt und können entsprechend reagieren. Diese Entkopplung fördert Flexibilität, Skalierbarkeit und Reaktionsfähigkeit in Echtzeit.

Zuerst brauchen wir eine Möglichkeit, diese Ereignisse zu übertragen. Dazu richten wir ein Pub/Sub-Thema ein. Erstellen wir zuerst ein Thema namens plan.
👉 Zur Google Cloud Console – Pub/Sub
👉 Klicken Sie auf den Button Thema erstellen.
👉 Konfigurieren Sie das Thema mit der ID/dem Namen plan und entfernen Sie das Häkchen bei Add a default subscription. Belassen Sie die restlichen Einstellungen als Standard und klicken Sie auf Erstellen.
Die Pub/Sub-Seite wird aktualisiert und das neu erstellte Thema sollte jetzt in der Tabelle aufgeführt sein. 
Wir integrieren nun die Funktion zum Veröffentlichen von Pub/Sub-Ereignissen in unseren Planner-Agenten. Wir fügen ein neues Tool hinzu, das ein „plan“-Ereignis an das gerade erstellte Pub/Sub-Thema sendet. Dieses Ereignis signalisiert anderen Komponenten im System (z. B. im Lernendenportal), dass ein neuer Lehrplan verfügbar ist.
👉 Kehren Sie zum Cloud Code-Editor zurück und öffnen Sie die Datei app.py im Ordner planner. Wir werden eine Funktion hinzufügen, mit der das Event veröffentlicht wird. Ersetzen:
##ADD SEND PLAN EVENT FUNCTION HERE
mit dem folgenden Code
def send_plan_event(teaching_plan:str):
"""
Send the teaching event to the topic called plan
Args:
teaching_plan: teaching plan
"""
publisher = pubsub_v1.PublisherClient()
print(f"-------------> Sending event to topic plan: {teaching_plan}")
topic_path = publisher.topic_path(PROJECT_ID, "plan")
message_data = {"teaching_plan": teaching_plan}
data = json.dumps(message_data).encode("utf-8")
future = publisher.publish(topic_path, data)
return f"Published message ID: {future.result()}"
- send_plan_event: Diese Funktion verwendet den generierten Lehrplan als Eingabe, erstellt einen Pub/Sub-Publisher-Client, erstellt den Themapfad, konvertiert den Lehrplan in einen JSON-String und veröffentlicht die Nachricht im Thema.
In derselben app.py-Datei
👉 Aktualisieren Sie den Prompt, damit der Agent das Ereignis für den Lehrplan nach der Generierung des Lehrplans an das Pub/Sub-Thema sendet. *Ersetzen
### ADD send_plan_event CALL
mit Folgendem:
send_plan_event(teaching_plan)
Durch Hinzufügen des Tools „send_plan_event“ und Ändern des Prompts haben wir unserem Planner-Agent ermöglicht, Ereignisse in Pub/Sub zu veröffentlichen, sodass andere Komponenten unseres Systems auf die Erstellung neuer Lehrpläne reagieren können. In den folgenden Abschnitten haben wir nun ein funktionales Multi-Agenten-System.
10. Lernende mit On-Demand-Quizzen motivieren
Stellen Sie sich eine Lernumgebung vor, in der Schüler und Studenten Zugriff auf eine unendliche Anzahl von Quizfragen haben, die auf ihre spezifischen Lernpläne zugeschnitten sind. Diese Quizfragen bieten sofortiges Feedback, einschließlich Antworten und Erklärungen, und fördern so ein tieferes Verständnis des Materials. Das ist das Potenzial, das wir mit unserem KI-basierten Quizportal erschließen möchten.
Um diese Vision zu verwirklichen, entwickeln wir eine Komponente zur Quizgenerierung, mit der Multiple-Choice-Fragen auf Grundlage des Inhalts des Lehrplans erstellt werden können.

👉 Rufen Sie im Explorer-Bereich des Cloud Code-Editors den Ordner portal auf. Öffnen Sie die Datei quiz.py und fügen Sie den folgenden Code am Ende der Datei ein.
def generate_quiz_question(file_name: str, difficulty: str, region:str ):
"""Generates a single multiple-choice quiz question using the LLM.
```json
{
"question": "The question itself",
"options": ["Option A", "Option B", "Option C", "Option D"],
"answer": "The correct answer letter (A, B, C, or D)"
}
```
"""
print(f"region: {region}")
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.5-flash-preview-04-17", location=region)
plan=None
#load the file using file_name and read content into string call plan
with open(file_name, 'r') as f:
plan = f.read()
parser = JsonOutputParser(pydantic_object=QuizQuestion)
instruction = f"You'll provide one question with difficulty level of {difficulty}, 4 options as multiple choices and provide the anwsers, the quiz needs to be related to the teaching plan {plan}"
prompt = PromptTemplate(
template="Generates a single multiple-choice quiz question\n {format_instructions}\n {instruction}\n",
input_variables=["instruction"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | llm | parser
response = chain.invoke({"instruction": instruction})
print(f"{response}")
return response
Im Agent wird ein JSON-Ausgabe-Parser erstellt, der speziell darauf ausgelegt ist, die Ausgabe des LLM zu verstehen und zu strukturieren. Dabei wird das zuvor definierte Modell QuizQuestion verwendet, um sicherzustellen, dass die geparste Ausgabe dem richtigen Format entspricht (Frage, Optionen und Antwort).
👉 Führen Sie im Terminal die folgenden Befehle aus, um eine virtuelle Umgebung einzurichten, Abhängigkeiten zu installieren und den Agent zu starten:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
python -m venv env
source env/bin/activate
pip install -r requirements.txt
python app.py
👉 Wählen Sie rechts oben im Menü „Webvorschau“ die Option Vorschau auf Port 8080 aus. In Cloud Shell wird ein neuer Browsertab oder ein neues Browserfenster mit der Webvorschau Ihrer Anwendung geöffnet.
👉 Klicken Sie in der Webanwendung entweder in der oberen Navigationsleiste oder auf der Karte auf der Indexseite auf den Link Quizze. Dem Schüler sollten drei zufällig generierte Quizze angezeigt werden. Diese Quizze basieren auf dem Lehrplan und zeigen die Leistungsfähigkeit unseres KI-basierten Quizgenerierungssystems.

👉 Drücken Sie im Terminal Ctrl+C, um den lokal ausgeführten Prozess zu beenden.
Gemini 2 Thinking für Erklärungen
Okay, wir haben also Quizze. Das ist schon mal ein guter Anfang. Was passiert, wenn Schüler oder Studenten etwas falsch machen? Das ist doch der Ort, an dem wirklich gelernt wird, oder? Wenn wir erklären können, warum ihre Antwort falsch war und wie sie zur richtigen Antwort gelangen, ist es viel wahrscheinlicher, dass sie sich daran erinnern. Außerdem können Sie so Unklarheiten beseitigen und das Vertrauen der Kunden stärken.
Deshalb werden wir das „Thinking“-Modell von Gemini 2 einsetzen. So geben Sie der KI etwas mehr Zeit, um sich die Dinge zu überlegen, bevor sie sie erklärt. So kann es detaillierteres und besseres Feedback geben.
Wir möchten herausfinden, ob es Schülern helfen kann, indem es sie unterstützt, Fragen beantwortet und Dinge detailliert erklärt. Um das zu testen, beginnen wir mit einem notorisch schwierigen Thema: der Analysis.

👉 Rufen Sie zuerst den Cloud Code-Editor in answer.py im Ordner portal auf. Funktionscode ersetzen
def answer_thinking(question, options, user_response, answer, region):
return ""
mit dem folgenden Code-Snippet:
def answer_thinking(question, options, user_response, answer, region):
try:
llm = VertexAI(model_name="gemini-2.0-flash-001",location=region)
input_msg = HumanMessage(content=[f"Here the question{question}, here are the available options {options}, this student's answer {user_response}, whereas the correct answer is {answer}"])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful teacher trying to teach the student on question, you were given the question and a set of multiple choices "
"what's the correct answer. use friendly tone"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
if __name__ == "__main__":
question = "Evaluate the limit: lim (x→0) [(sin(5x) - 5x) / x^3]"
options = ["A) -125/6", "B) -5/3 ", "C) -25/3", "D) -5/6"]
user_response = "B"
answer = "A"
region = "us-central1"
result = answer_thinking(question, options, user_response, answer, region)
Dies ist eine sehr einfache Langchain-App, in der das Gemini 2 Flash-Modell initialisiert wird. Wir weisen es an, als hilfreicher Lehrer zu fungieren und Erklärungen zu liefern.
👉 Führen Sie im Terminal den folgenden Befehl aus:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python answer.py
Die Ausgabe sollte in etwa wie im Beispiel in der ursprünglichen Anleitung aussehen. Das aktuelle Modell liefert möglicherweise keine so ausführliche Erklärung.
Okay, I see the question and the choices. The question is to evaluate the limit:
lim (x→0) [(sin(5x) - 5x) / x^3]
You chose option B, which is -5/3, but the correct answer is A, which is -125/6.
It looks like you might have missed a step or made a small error in your calculations. This type of limit often involves using L'Hôpital's Rule or Taylor series expansion. Since we have the form 0/0, L'Hôpital's Rule is a good way to go! You need to apply it multiple times. Alternatively, you can use the Taylor series expansion of sin(x) which is:
sin(x) = x - x^3/3! + x^5/5! - ...
So, sin(5x) = 5x - (5x)^3/3! + (5x)^5/5! - ...
Then, (sin(5x) - 5x) = - (5x)^3/3! + (5x)^5/5! - ...
Finally, (sin(5x) - 5x) / x^3 = - 5^3/3! + (5^5 * x^2)/5! - ...
Taking the limit as x approaches 0, we get -125/6.
Keep practicing, you'll get there!
👉 Ersetzen Sie in der Datei answer.py
model_name von gemini-2.0-flash-001 zu gemini-2.0-flash-thinking-exp-01-21 in der Funktion answer_thinking geändert.
Dadurch wird das LLM in ein anderes geändert, das besser für das Reasoning geeignet ist. So kann das Modell bessere Erklärungen generieren.
👉 Führen Sie das answer.py-Skript noch einmal aus, um das neue Thinking-Modell zu testen:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python answer.py
Hier ist ein Beispiel für die Antwort des Denkmodells, die viel gründlicher und detaillierter ist und eine Schritt-für-Schritt-Anleitung zum Lösen der Rechenaufgabe enthält. Das zeigt, wie leistungsstark „Denkmodelle“ bei der Generierung hochwertiger Erklärungen sind. Die Ausgabe sollte in etwa so aussehen:
Hey there! Let's take a look at this limit problem together. You were asked to evaluate:
lim (x→0) [(sin(5x) - 5x) / x^3]
and you picked option B, -5/3, but the correct answer is actually A, -125/6. Let's figure out why!
It's a tricky one because if we directly substitute x=0, we get (sin(0) - 0) / 0^3 = (0 - 0) / 0 = 0/0, which is an indeterminate form. This tells us we need to use a more advanced technique like L'Hopital's Rule or Taylor series expansion.
Let's use the Taylor series expansion for sin(y) around y=0. Do you remember it? It looks like this:
sin(y) = y - y^3/3! + y^5/5! - ...
where 3! (3 factorial) is 3 × 2 × 1 = 6, 5! is 5 × 4 × 3 × 2 × 1 = 120, and so on.
In our problem, we have sin(5x), so we can substitute y = 5x into the Taylor series:
sin(5x) = (5x) - (5x)^3/3! + (5x)^5/5! - ...
sin(5x) = 5x - (125x^3)/6 + (3125x^5)/120 - ...
Now let's plug this back into our limit expression:
[(sin(5x) - 5x) / x^3] = [ (5x - (125x^3)/6 + (3125x^5)/120 - ...) - 5x ] / x^3
Notice that the '5x' and '-5x' cancel out! So we are left with:
= [ - (125x^3)/6 + (3125x^5)/120 - ... ] / x^3
Now, we can divide every term in the numerator by x^3:
= -125/6 + (3125x^2)/120 - ...
Finally, let's take the limit as x approaches 0. As x gets closer and closer to zero, terms with x^2 and higher powers will become very, very small and approach zero. So, we are left with:
lim (x→0) [ -125/6 + (3125x^2)/120 - ... ] = -125/6
Therefore, the correct answer is indeed **A) -125/6**.
It seems like your answer B, -5/3, might have come from perhaps missing a factor somewhere during calculation or maybe using an incorrect simplification. Double-check your steps when you were trying to solve it!
Don't worry, these limit problems can be a bit tricky sometimes! Keep practicing and you'll get the hang of it. Let me know if you want to go through another similar example or if you have any more questions! 😊
Now that we have confirmed it works, let's use the portal.
👉ENTFERNEN Sie den folgenden Testcode aus answer.py:
if __name__ == "__main__":
question = "Evaluate the limit: lim (x→0) [(sin(5x) - 5x) / x^3]"
options = ["A) -125/6", "B) -5/3 ", "C) -25/3", "D) -5/6"]
user_response = "B"
answer = "A"
region = "us-central1"
result = answer_thinking(question, options, user_response, answer, region)
👉 Führen Sie die folgenden Befehle im Terminal aus, um eine virtuelle Umgebung einzurichten, Abhängigkeiten zu installieren und den Agenten zu starten:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python app.py
👉 Wählen Sie rechts oben im Menü „Webvorschau“ die Option Vorschau auf Port 8080 aus. In Cloud Shell wird ein neuer Browsertab oder ein neues Browserfenster mit der Webvorschau Ihrer Anwendung geöffnet.
👉 Klicken Sie in der Webanwendung entweder in der oberen Navigationsleiste oder auf der Karte auf der Indexseite auf den Link Quizze.
👉 Beantworte alle Quizfragen und sorge dafür, dass mindestens eine Antwort falsch ist. Klicke dann auf Senden.

Anstatt nur auf die Antwort zu warten, können Sie zum Terminal des Cloud-Editors wechseln. Sie können den Fortschritt und alle Ausgaben oder Fehlermeldungen, die von Ihrer Funktion generiert werden, im Terminal des Emulators beobachten. 😁
👉 Beenden Sie den lokal ausgeführten Prozess in Ihrem Terminal, indem Sie Ctrl+C im Terminal drücken.
11. OPTIONAL: Agents mit Eventarc orchestrieren
Bisher wurden im Schülerportal Quizze auf Grundlage einer Standardgruppe von Lehrplänen erstellt. Das ist zwar hilfreich, aber es bedeutet, dass unser Planungs- und unser Quiz-Agent im Portal nicht wirklich miteinander kommunizieren. Erinnern Sie sich, wie wir die Funktion hinzugefügt haben, mit der der Planner-Agent seine neu generierten Unterrichtspläne in einem Pub/Sub-Thema veröffentlicht? Jetzt ist es an der Zeit, die Verbindung zu unserem Portal-Agent herzustellen.

Wir möchten, dass die Quizinhalte des Portals automatisch aktualisiert werden, wenn ein neuer Lehrplan generiert wird. Dazu erstellen wir im Portal einen Endpunkt, der diese neuen Pläne empfangen kann.
👉 Gehen Sie im Explorer-Bereich des Cloud Code-Editors zum Ordner portal.
👉 Öffnen Sie die Datei app.py zur Bearbeitung. ERSETZEN Sie die Zeile ## REPLACE ME! NEW TEACHING PLAN durch den folgenden Code:
@app.route('/new_teaching_plan', methods=['POST'])
def new_teaching_plan():
try:
# Get data from Pub/Sub message delivered via Eventarc
envelope = request.get_json()
if not envelope:
return jsonify({'error': 'No Pub/Sub message received'}), 400
if not isinstance(envelope, dict) or 'message' not in envelope:
return jsonify({'error': 'Invalid Pub/Sub message format'}), 400
pubsub_message = envelope['message']
print(f"data: {pubsub_message['data']}")
data = pubsub_message['data']
data_str = base64.b64decode(data).decode('utf-8')
data = json.loads(data_str)
teaching_plan = data['teaching_plan']
print(f"File content: {teaching_plan}")
with open("teaching_plan.txt", "w") as f:
f.write(teaching_plan)
print(f"Teaching plan saved to local file: teaching_plan.txt")
return jsonify({'message': 'File processed successfully'})
except Exception as e:
print(f"Error processing file: {e}")
return jsonify({'error': 'Error processing file'}), 500
Neu erstellen und in Cloud Run bereitstellen
Sie müssen sowohl den Planner- als auch den Portal-Agent aktualisieren und in Cloud Run neu bereitstellen. So wird dafür gesorgt, dass sie den neuesten Code haben und für die Kommunikation über Ereignisse konfiguriert sind.

👉 Zuerst erstellen wir das Agent-Image planner neu und übertragen es per Push. Führen Sie dazu im Terminal Folgendes aus:
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-planner .
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-planner us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
👉 Wir erstellen und übertragen das Agent-Image für das Portal:
cd ~/aidemy-bootstrap/portal/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-portal .
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-portal us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
👉 Rufen Sie Artifact Registry auf. Dort sollten die Container-Images aidemy-planner und aidemy-portal unter agent-repository aufgeführt sein.

👉 Führen Sie im Terminal den folgenden Befehl aus, um das Cloud Run-Image für den Planer-Agenten zu aktualisieren:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services update aidemy-planner \
--region=us-central1 \
--image=us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner:latest
Die Ausgabe sollte in etwa so aussehen:
OK Deploying... Done.
OK Creating Revision...
OK Routing traffic...
Done.
Service [aidemy-planner] revision [aidemy-planner-xxxxx] has been deployed and is serving 100 percent of traffic.
Service URL: https://aidemy-planner-xxx.us-central1.run.app
Notieren Sie sich die Dienst-URL. Das ist der Link zu Ihrem bereitgestellten Planner-Agent. Wenn Sie die Dienst-URL des Planner-Agents später ermitteln müssen, verwenden Sie diesen Befehl:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services describe aidemy-planner \
--region=us-central1 \
--format 'value(status.url)'
👉 Führen Sie diesen Befehl aus, um die Cloud Run-Instanz für den portal-Agent zu erstellen.
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy aidemy-portal \
--image=us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal:latest \
--region=us-central1 \
--platform=managed \
--allow-unauthenticated \
--memory=2Gi \
--cpu=2 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID}
Die Ausgabe sollte in etwa so aussehen:
Deploying container to Cloud Run service [aidemy-portal] in project [xxxx] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [aidemy-portal] revision [aidemy-portal-xxxx] has been deployed and is serving 100 percent of traffic.
Service URL: https://aidemy-portal-xxxx.us-central1.run.app
Notieren Sie sich die Dienst-URL. Das ist der Link zu Ihrem bereitgestellten Schüler-/Studentenportal. Wenn Sie die Dienst-URL des Schülerportals später ermitteln müssen, verwenden Sie diesen Befehl:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services describe aidemy-portal \
--region=us-central1 \
--format 'value(status.url)'
Eventarc-Trigger erstellen
Aber wie wird dieser Endpunkt benachrichtigt, wenn im Pub/Sub-Thema ein neuer Plan wartet? Hier kommt Eventarc ins Spiel.
Eventarc fungiert als Brücke, die auf bestimmte Ereignisse wartet (z. B. eine neue Nachricht in unserem Pub/Sub-Thema) und automatisch Aktionen als Reaktion darauf auslöst. In unserem Fall wird erkannt, wenn ein neuer Lehrplan veröffentlicht wird, und dann wird ein Signal an den Endpunkt unseres Portals gesendet, um ihn darüber zu informieren, dass es Zeit für ein Update ist.
Da Eventarc die ereignisgesteuerte Kommunikation übernimmt, können wir unseren Planer- und Portal-Agenten nahtlos verbinden und so ein wirklich dynamisches und reaktionsfähiges Lernsystem schaffen. Es ist, als hätten Sie einen intelligenten Messenger, der automatisch die neuesten Unterrichtspläne an den richtigen Ort liefert.
👉 Rufen Sie in der Console Eventarc auf.
👉 Klicken Sie auf die Schaltfläche „+ TRIGGER ERSTELLEN“.
Trigger konfigurieren (Grundlagen):
- Trigger name:
plan-topic-trigger - Triggertyp: Google-Quellen
- Ereignisanbieter: Cloud Pub/Sub
- Ereignistyp:
google.cloud.pubsub.topic.v1.messagePublished - Cloud Pub/Sub-Thema: Wählen Sie
projects/PROJECT_ID/topics/planaus. - Region:
us-central1. - Dienstkonto:
- GRANT dem Dienstkonto die Rolle
roles/iam.serviceAccountTokenCreator - Standardwert verwenden: Standarddienstkonto von Compute
- GRANT dem Dienstkonto die Rolle
- Ereignisziel: Cloud Run
- Cloud Run-Dienst:
aidemy-portal - Fehlermeldung ignorieren: Berechtigung für „locations/me-central2“ verweigert (oder sie ist möglicherweise nicht vorhanden).
- Dienst-URL-Pfad:
/new_teaching_plan
👉 Klicken Sie auf „Erstellen“.
Die Seite „Eventarc-Trigger“ wird aktualisiert und der neu erstellte Trigger sollte jetzt in der Tabelle aufgeführt sein.
Greifen Sie jetzt über die Dienst-URL auf den Planner-Agent zu, um einen neuen Lehrplan anzufordern.
👉 Führen Sie diesen Befehl im Terminal aus, um die Dienst-URL des Planner-Agents zu ermitteln:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep planner
👉 Rufen Sie die ausgegebene URL auf und versuchen Sie es diesmal mit „Year“ (Jahr) 5, „Subject“ (Thema) Science und „Add-on Request“ (Add-on-Anfrage) atoms.
Warten Sie dann ein oder zwei Minuten. Diese Verzögerung wurde aufgrund der Abrechnungsbeschränkung dieses Labs eingeführt. Unter normalen Umständen sollte es keine Verzögerung geben.
Rufen Sie schließlich über die Dienst-URL auf das Schülerportal zu.
Führen Sie diesen Befehl im Terminal aus, um die Dienst-URL des Student Portal-Agents zu ermitteln:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep portal
Die Quizze sollten jetzt aktualisiert sein und dem neuen Lehrplan entsprechen, den Sie gerade erstellt haben. Das zeigt, dass Eventarc erfolgreich in das Aidemy-System integriert wurde.

Glückwunsch! Sie haben erfolgreich ein Multi-Agenten-System in Google Cloud erstellt und dabei eine ereignisgesteuerte Architektur für mehr Skalierbarkeit und Flexibilität genutzt. Sie haben eine solide Grundlage geschaffen, aber es gibt noch viel mehr zu entdecken. Wenn Sie mehr über die tatsächlichen Vorteile dieser Architektur erfahren möchten, die Leistungsfähigkeit der multimodalen Live-API von Gemini 2 kennenlernen und erfahren möchten, wie Sie die Single-Path-Orchestration mit LangGraph implementieren, können Sie mit den nächsten beiden Kapiteln fortfahren.
12. OPTIONAL: Audio-Zusammenfassungen mit Gemini
Gemini kann Informationen aus verschiedenen Quellen wie Text, Bildern und sogar Audio verstehen und verarbeiten. Das eröffnet ganz neue Möglichkeiten für das Lernen und die Erstellung von Inhalten. Die Fähigkeit von Gemini, zu „sehen“, zu „hören“ und zu „lesen“, eröffnet wirklich kreative und ansprechende Nutzererlebnisse.
Neben der Erstellung von Bildern oder Text ist ein weiterer wichtiger Schritt beim Lernen die effektive Zusammenfassung und Wiederholung. Denken Sie darüber nach: Wie oft erinnern Sie sich leichter an einen eingängigen Songtext als an etwas, das Sie in einem Lehrbuch gelesen haben? Sound kann unglaublich einprägsam sein. Deshalb werden wir die multimodalen Funktionen von Gemini nutzen, um Audio-Zusammenfassungen unserer Unterrichtspläne zu erstellen. So können Schüler das Material auf bequeme und ansprechende Weise wiederholen, was durch die Kraft des auditiven Lernens möglicherweise die Behaltens- und Verständnisfähigkeit steigert.

Wir benötigen einen Ort, an dem die generierten Audiodateien gespeichert werden können. Cloud Storage bietet eine skalierbare und zuverlässige Lösung.
👉 Rufen Sie in der Console Storage auf. Klicken Sie im Menü auf der linken Seite auf „Buckets“. Klicken Sie oben auf die Schaltfläche „+ ERSTELLEN“.
👉 Neuen Bucket konfigurieren:
- Bucket-Name:
aidemy-recap-UNIQUE_NAME.- WICHTIG: Achten Sie darauf, dass Sie einen eindeutigen Bucket-Namen definieren, der mit
aidemy-recap-beginnt. Dieses eindeutige Präfix ist wichtig, um Namenskonflikte beim Erstellen Ihres Cloud Storage-Buckets zu vermeiden.
- WICHTIG: Achten Sie darauf, dass Sie einen eindeutigen Bucket-Namen definieren, der mit
- Region:
us-central1. - Speicherklasse: „Standard“ Standard eignet sich für Daten, auf die häufig zugegriffen wird.
- Zugriffssteuerung: Lassen Sie die standardmäßige Zugriffssteuerung „Einheitlich“ ausgewählt. Dies ermöglicht eine einheitliche Zugriffssteuerung auf Bucket-Ebene.
- Erweiterte Optionen: Für diesen Workshop sind die Standardeinstellungen in der Regel ausreichend.
Klicken Sie auf die Schaltfläche ERSTELLEN, um den Bucket zu erstellen.
- Möglicherweise wird ein Pop-up-Fenster zur Verhinderung des öffentlichen Zugriffs angezeigt. Lassen Sie das Kästchen „Verhinderung des öffentlichen Zugriffs für diesen Bucket erzwingen“ aktiviert und klicken Sie auf
Confirm.
Der neu erstellte Bucket wird jetzt in der Liste „Buckets“ angezeigt. Merken Sie sich den Bucket-Namen, da Sie ihn später benötigen.
👉 Führen Sie im Terminal des Cloud Code-Editors die folgenden Befehle aus, um dem Dienstkonto Zugriff auf den Bucket zu gewähren:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gcloud storage buckets add-iam-policy-binding gs://$COURSE_BUCKET_NAME \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectViewer"
gcloud storage buckets add-iam-policy-binding gs://$COURSE_BUCKET_NAME \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectCreator"
👉 Öffnen Sie im Cloud Code-Editor die Datei audio.py im Ordner courses. Fügen Sie am Ende der Datei den folgenden Code ein:
config = LiveConnectConfig(
response_modalities=["AUDIO"],
speech_config=SpeechConfig(
voice_config=VoiceConfig(
prebuilt_voice_config=PrebuiltVoiceConfig(
voice_name="Charon",
)
)
),
)
async def process_weeks(teaching_plan: str):
region = "us-east5" #To workaround onRamp quota limits
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
clientAudio = genai.Client(vertexai=True, project=PROJECT_ID, location="us-central1")
async with clientAudio.aio.live.connect(
model=MODEL_ID,
config=config,
) as session:
for week in range(1, 4):
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Given the following teaching plan: {teaching_plan}, Extrace content plan for week {week}. And return just the plan, nothingh else " # Clarified prompt
)
prompt = f"""
Assume you are the instructor.
Prepare a concise and engaging recap of the key concepts and topics covered.
This recap should be suitable for generating a short audio summary for students.
Focus on the most important learnings and takeaways, and frame it as a direct address to the students.
Avoid overly formal language and aim for a conversational tone, tell a few jokes.
Teaching plan: {response.text} """
print(f"prompt --->{prompt}")
await session.send(input=prompt, end_of_turn=True)
with open(f"temp_audio_week_{week}.raw", "wb") as temp_file:
async for message in session.receive():
if message.server_content.model_turn:
for part in message.server_content.model_turn.parts:
if part.inline_data:
temp_file.write(part.inline_data.data)
data, samplerate = sf.read(f"temp_audio_week_{week}.raw", channels=1, samplerate=24000, subtype='PCM_16', format='RAW')
sf.write(f"course-week-{week}.wav", data, samplerate)
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
blob = bucket.blob(f"course-week-{week}.wav") # Or give it a more descriptive name
blob.upload_from_filename(f"course-week-{week}.wav")
print(f"Audio saved to GCS: gs://{BUCKET_NAME}/course-week-{week}.wav")
await session.close()
def breakup_sessions(teaching_plan: str):
asyncio.run(process_weeks(teaching_plan))
- Streaming-Verbindung: Zuerst wird eine dauerhafte Verbindung zum Live API-Endpunkt hergestellt. Im Gegensatz zu einem Standard-API-Aufruf, bei dem Sie eine Anfrage senden und eine Antwort erhalten, bleibt diese Verbindung für einen kontinuierlichen Datenaustausch geöffnet.
- Multimodale Konfiguration: Mit der Konfiguration können Sie angeben, welche Art von Ausgabe Sie wünschen (in diesem Fall Audio). Sie können sogar angeben, welche Parameter Sie verwenden möchten (z. B. Sprachauswahl, Audiocodierung).
- Asynchrone Verarbeitung: Diese API funktioniert asynchron. Das bedeutet, dass der Hauptthread nicht blockiert wird, während auf die Fertigstellung der Audiogenerierung gewartet wird. Da Daten in Echtzeit verarbeitet und die Ausgabe in Chunks gesendet wird, ist die Reaktion nahezu sofort.
Die entscheidende Frage ist nun: Wann sollte dieser Prozess zur Audiogenerierung ausgeführt werden? Im Idealfall sollen die Audiozusammenfassungen verfügbar sein, sobald ein neuer Lehrplan erstellt wird. Da wir bereits eine ereignisgesteuerte Architektur implementiert haben, indem wir den Lehrplan in einem Pub/Sub-Thema veröffentlicht haben, können wir dieses Thema einfach abonnieren.
Wir erstellen jedoch nicht sehr oft neue Unterrichtspläne. Es wäre nicht effizient, einen Agenten ständig auszuführen und auf neue Pläne warten zu lassen. Daher ist es sinnvoll, diese Logik zur Audiogenerierung als Cloud Run-Funktion bereitzustellen.
Wenn Sie sie als Funktion bereitstellen, bleibt sie inaktiv, bis eine neue Nachricht im Pub/Sub-Thema veröffentlicht wird. In diesem Fall wird die Funktion automatisch ausgelöst, die die Audiozusammenfassungen generiert und in unserem Bucket speichert.
👉 Diese Datei definiert die Cloud Run-Funktion, die ausgelöst wird, wenn ein neuer Lehrplan verfügbar ist. Sie befindet sich im Ordner courses in der Datei main.py. Es empfängt den Plan und startet die Generierung der Audiozusammenfassung. Fügen Sie am Ende der Datei das folgende Code-Snippet ein.
@functions_framework.cloud_event
def process_teaching_plan(cloud_event):
print(f"CloudEvent received: {cloud_event.data}")
time.sleep(60)
try:
if isinstance(cloud_event.data.get('message', {}).get('data'), str): # Check for base64 encoding
data = json.loads(base64.b64decode(cloud_event.data['message']['data']).decode('utf-8'))
teaching_plan = data.get('teaching_plan') # Get the teaching plan
elif 'teaching_plan' in cloud_event.data: # No base64
teaching_plan = cloud_event.data["teaching_plan"]
else:
raise KeyError("teaching_plan not found") # Handle error explicitly
#Load the teaching_plan as string and from cloud event, call audio breakup_sessions
breakup_sessions(teaching_plan)
return "Teaching plan processed successfully", 200
except (json.JSONDecodeError, AttributeError, KeyError) as e:
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500
except Exception as e:
print(f"Error processing teaching plan: {e}")
return "Error processing teaching plan", 500
@functions_framework.cloud_event: Dieser Decorator kennzeichnet die Funktion als Cloud Run-Funktion, die durch CloudEvents ausgelöst wird.
Anwendung lokal testen
👉 Wir führen diesen Code in einer virtuellen Umgebung aus und installieren die erforderlichen Python-Bibliotheken für die Cloud Run-Funktion.
cd ~/aidemy-bootstrap/courses
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Mit dem Cloud Run Functions-Emulator können wir unsere Funktion lokal testen, bevor wir sie in Google Cloud bereitstellen. Starten Sie einen lokalen Emulator mit folgendem Befehl:
functions-framework --target process_teaching_plan --signature-type=cloudevent --source main.py
👉 Während der Emulator ausgeführt wird, können Sie Test-CloudEvents an den Emulator senden, um die Veröffentlichung eines neuen Lehrplans zu simulieren. In einem neuen Terminal:

👉 Ausführen:
curl -X POST \
http://localhost:8080/ \
-H "Content-Type: application/json" \
-H "ce-id: event-id-01" \
-H "ce-source: planner-agent" \
-H "ce-specversion: 1.0" \
-H "ce-type: google.cloud.pubsub.topic.v1.messagePublished" \
-d '{
"message": {
"data": "eyJ0ZWFjaGluZ19wbGFuIjogIldlZWsgMTogMkQgU2hhcGVzIGFuZCBBbmdsZXMgLSBEYXkgMTogUmV2aWV3IG9mIGJhc2ljIDJEIHNoYXBlcyAoc3F1YXJlcywgcmVjdGFuZ2xlcywgdHJpYW5nbGVzLCBjaXJjbGVzKS4gRGF5IDI6IEV4cGxvcmluZyBkaWZmZXJlbnQgdHlwZXMgb2YgdHJpYW5nbGVzIChlcXVpbGF0ZXJhbCwgaXNvc2NlbGVzLCBzY2FsZW5lLCByaWdodC1hbmdsZWQpLiBEYXkgMzogRXhwbG9yaW5nIHF1YWRyaWxhdGVyYWxzIChzcXVhcmUsIHJlY3RhbmdsZSwgcGFyYWxsZWxvZ3JhbSwgcmhvbWJ1cywgdHJhcGV6aXVtKS4gRGF5IDQ6IEludHJvZHVjdGlvbiB0byBhbmdsZXM6IHJpZ2h0IGFuZ2xlcywgYWN1dGUgYW5nbGVzLCBhbmQgb2J0dXNlIGFuZ2xlcy4gRGF5IDU6IE1lYXN1cmluZyBhbmdsZXMgdXNpbmcgYSBwcm90cmFjdG9yLiBXZWVrIDI6IDNEIFNoYXBlcyBhbmQgU3ltbWV0cnkgLSBEYXkgNjogSW50cm9kdWN0aW9uIHRvIDNEIHNoYXBlczogY3ViZXMsIGN1Ym9pZHMsIHNwaGVyZXMsIGN5bGluZGVycywgY29uZXMsIGFuZCBweXJhbWlkcy4gRGF5IDc6IERlc2NyaWJpbmcgM0Qgc2hhcGVzIHVzaW5nIGZhY2VzLCBlZGdlcywgYW5kIHZlcnRpY2VzLiBEYXkgODogUmVsYXRpbmcgMkQgc2hhcGVzIHRvIDNEIHNoYXBlcy4gRGF5IDk6IElkZW50aWZ5aW5nIGxpbmVzIG9mIHN5bW1ldHJ5IGluIDJEIHNoYXBlcy4gRGF5IDEwOiBDb21wbGV0aW5nIHN5bW1ldHJpY2FsIGZpZ3VyZXMuIFdlZWsgMzogUG9zaXRpb24sIERpcmVjdGlvbiwgYW5kIFByb2JsZW0gU29sdmluZyAtIERheSAxMTogRGVzY3JpYmluZyBwb3NpdGlvbiB1c2luZyBjb29yZGluYXRlcyBpbiB0aGUgZmlyc3QgcXVhZHJhbnQuIERheSAxMjogUGxvdHRpbmcgY29vcmRpbmF0ZXMgdG8gZHJhdyBzaGFwZXMuIERheSAxMzogVW5kZXJzdGFuZGluZyB0cmFuc2xhdGlvbiAoc2xpZGluZyBhIHNoYXBlKS4gRGF5IDE0OiBVbmRlcnN0YW5kaW5nIHJlZmxlY3Rpb24gKGZsaXBwaW5nIGEgc2hhcGUpLiBEYXkgMTU6IFByb2JsZW0tc29sdmluZyBhY3Rpdml0aWVzIGludm9sdmluZyBwZXJpbWV0ZXIsIGFyZWEsIGFuZCBtaXNzaW5nIGFuZ2xlcy4ifQ=="
}
}'
Anstatt nur auf die Antwort zu warten, wechseln Sie zum anderen Cloud Shell-Terminal. Sie können den Fortschritt und alle Ausgaben oder Fehlermeldungen, die von Ihrer Funktion generiert werden, im Terminal des Emulators beobachten. 😁
Im zweiten Terminal sollte OK zurückgegeben werden.
👉 Sie müssen die Daten im Bucket bestätigen. Rufen Sie dazu Cloud Storage auf, wählen Sie den Tab „Bucket“ und dann aidemy-recap-UNIQUE_NAME aus.

👉 Geben Sie im Terminal, in dem der Emulator ausgeführt wird, ctrl+c ein, um den Emulator zu beenden. Schließen Sie das zweite Terminal. Schließen Sie das zweite Terminal und führen Sie „deactivate“ aus, um die virtuelle Umgebung zu beenden.
deactivate
In Google Cloud bereitstellen
 👉 Nachdem Sie den Kurs-Agenten lokal getestet haben, können Sie ihn in Google Cloud bereitstellen. Führen Sie im Terminal die folgenden Befehle aus:
👉 Nachdem Sie den Kurs-Agenten lokal getestet haben, können Sie ihn in Google Cloud bereitstellen. Führen Sie im Terminal die folgenden Befehle aus:
cd ~/aidemy-bootstrap/courses
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud functions deploy courses-agent \
--region=us-central1 \
--gen2 \
--source=. \
--runtime=python312 \
--trigger-topic=plan \
--entry-point=process_teaching_plan \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
Prüfen Sie die Bereitstellung, indem Sie in der Google Cloud Console zu Cloud Run wechseln.Dort sollte ein neuer Dienst mit dem Namen „courses-agent“ aufgeführt sein.

Wenn Sie die Triggerkonfiguration prüfen möchten, klicken Sie auf den Dienst „courses-agent“, um die zugehörigen Details aufzurufen. Rufen Sie den Tab „TRIGGERS“ (TRIGGERS) auf.
Sie sollten einen Trigger sehen, der so konfiguriert ist, dass er auf Nachrichten wartet, die im Plan-Thema veröffentlicht werden.

Sehen wir uns zum Schluss an, wie das Ganze in der Praxis aussieht.
👉 Wir müssen den Portal-Agent so konfigurieren, dass er weiß, wo die generierten Audiodateien zu finden sind. Führen Sie im Terminal folgenden Befehl aus:
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services update aidemy-portal \
--region=us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
👉 Erstellen Sie einen neuen Lehrplan über die Webseite des Planner-KI-Agenten. Es kann einige Minuten dauern, bis der Dienst gestartet wird. Das ist normal, da es sich um einen serverlosen Dienst handelt.
Um auf den Planner-Agent zuzugreifen, rufen Sie seine Dienst-URL ab, indem Sie Folgendes im Terminal ausführen:
gcloud run services list \
--platform=managed \
--region=us-central1 \
--format='value(URL)' | grep planner
Warten Sie nach dem Generieren des neuen Plans 2 bis 3 Minuten, bis die Audioausgabe generiert wurde. Dies dauert aufgrund der Abrechnungsbeschränkung für dieses Lab-Konto einige Minuten.
Sie können prüfen, ob die Funktion courses-agent den Lehrplan erhalten hat, indem Sie den Tab „TRIGGERS“ (Auslöser) der Funktion aufrufen. Aktualisieren Sie die Seite regelmäßig. Sie sollten schließlich sehen, dass die Funktion aufgerufen wurde. Wenn die Funktion nach mehr als zwei Minuten nicht aufgerufen wurde, können Sie versuchen, den Lehrplan noch einmal zu generieren. Vermeiden Sie es jedoch, Pläne wiederholt in schneller Folge zu generieren, da jeder generierte Plan sequenziell vom Agenten verarbeitet wird, was zu einem Rückstand führen kann.

👉 Rufen Sie das Portal auf und klicken Sie auf „Kurse“. Sie sollten drei Karten sehen, auf denen jeweils eine Audiozusammenfassung angezeigt wird. So finden Sie die URL Ihres Portal-Agents:
gcloud run services list \
--platform=managed \
--region=us-central1 \
--format='value(URL)' | grep portal
Klicken Sie bei jedem Kurs auf „Wiedergabe“, um sicherzustellen, dass die Audiozusammenfassungen mit dem gerade erstellten Lehrplan übereinstimmen. 
Beenden Sie die virtuelle Umgebung.
deactivate
13. OPTIONAL: Rollenbasierte Zusammenarbeit mit Gemini und DeepSeek
Mehrere Perspektiven sind von unschätzbarem Wert, insbesondere wenn es darum geht, ansprechende und durchdachte Aufgaben zu erstellen. Wir erstellen jetzt ein Multi-Agent-System, das zwei verschiedene Modelle mit unterschiedlichen Rollen nutzt, um Aufgaben zu generieren: eines fördert die Zusammenarbeit und das andere das Selbststudium. Wir verwenden eine „Single-Shot“-Architektur, bei der der Workflow einem festen Pfad folgt.
Gemini Assignment Generator
 Zuerst richten wir die Gemini-Funktion ein, um Aufgaben mit Schwerpunkt auf Zusammenarbeit zu erstellen. Bearbeiten Sie die Datei
Zuerst richten wir die Gemini-Funktion ein, um Aufgaben mit Schwerpunkt auf Zusammenarbeit zu erstellen. Bearbeiten Sie die Datei gemini.py im Ordner assignment.
👉 Fügen Sie den folgenden Code am Ende der gemini.py-Datei ein:
def gen_assignment_gemini(state):
region=get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
print(f"---------------gen_assignment_gemini")
response = client.models.generate_content(
model=MODEL_ID, contents=f"""
You are an instructor
Develop engaging and practical assignments for each week, ensuring they align with the teaching plan's objectives and progressively build upon each other.
For each week, provide the following:
* **Week [Number]:** A descriptive title for the assignment (e.g., "Data Exploration Project," "Model Building Exercise").
* **Learning Objectives Assessed:** List the specific learning objectives from the teaching plan that this assignment assesses.
* **Description:** A detailed description of the task, including any specific requirements or constraints. Provide examples or scenarios if applicable.
* **Deliverables:** Specify what students need to submit (e.g., code, report, presentation).
* **Estimated Time Commitment:** The approximate time students should dedicate to completing the assignment.
* **Assessment Criteria:** Briefly outline how the assignment will be graded (e.g., correctness, completeness, clarity, creativity).
The assignments should be a mix of individual and collaborative work where appropriate. Consider different learning styles and provide opportunities for students to apply their knowledge creatively.
Based on this teaching plan: {state["teaching_plan"]}
"""
)
print(f"---------------gen_assignment_gemini answer {response.text}")
state["model_one_assignment"] = response.text
return state
import unittest
class TestGenAssignmentGemini(unittest.TestCase):
def test_gen_assignment_gemini(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assigmodel_one_assignmentnment": "", "final_assignment": ""}
updated_state = gen_assignment_gemini(initial_state)
self.assertIn("model_one_assignment", updated_state)
self.assertIsNotNone(updated_state["model_one_assignment"])
self.assertIsInstance(updated_state["model_one_assignment"], str)
self.assertGreater(len(updated_state["model_one_assignment"]), 0)
print(updated_state["model_one_assignment"])
if __name__ == '__main__':
unittest.main()
Dabei wird das Gemini-Modell verwendet, um Aufgaben zu generieren.
Wir sind bereit, den Gemini-Agenten zu testen.
👉 Führen Sie diese Befehle im Terminal aus, um die Umgebung einzurichten:
cd ~/aidemy-bootstrap/assignment
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Sie können den folgenden Befehl ausführen, um die Funktion zu testen:
python gemini.py
In der Ausgabe sollte eine Aufgabe mit mehr Gruppenarbeit angezeigt werden. Am Ende werden auch die Ergebnisse des Assert-Tests ausgegeben.
Here are some engaging and practical assignments for each week, designed to build progressively upon the teaching plan's objectives:
**Week 1: Exploring the World of 2D Shapes**
* **Learning Objectives Assessed:**
* Identify and name basic 2D shapes (squares, rectangles, triangles, circles).
* .....
* **Description:**
* **Shape Scavenger Hunt:** Students will go on a scavenger hunt in their homes or neighborhoods, taking pictures of objects that represent different 2D shapes. They will then create a presentation or poster showcasing their findings, classifying each shape and labeling its properties (e.g., number of sides, angles, etc.).
* **Triangle Trivia:** Students will research and create a short quiz or presentation about different types of triangles, focusing on their properties and real-world examples.
* **Angle Exploration:** Students will use a protractor to measure various angles in their surroundings, such as corners of furniture, windows, or doors. They will record their measurements and create a chart categorizing the angles as right, acute, or obtuse.
....
**Week 2: Delving into the World of 3D Shapes and Symmetry**
* **Learning Objectives Assessed:**
* Identify and name basic 3D shapes.
* ....
* **Description:**
* **3D Shape Construction:** Students will work in groups to build 3D shapes using construction paper, cardboard, or other materials. They will then create a presentation showcasing their creations, describing the number of faces, edges, and vertices for each shape.
* **Symmetry Exploration:** Students will investigate the concept of symmetry by creating a visual representation of various symmetrical objects (e.g., butterflies, leaves, snowflakes) using drawing or digital tools. They will identify the lines of symmetry and explain their findings.
* **Symmetry Puzzles:** Students will be given a half-image of a symmetrical figure and will be asked to complete the other half, demonstrating their understanding of symmetry. This can be done through drawing, cut-out activities, or digital tools.
**Week 3: Navigating Position, Direction, and Problem Solving**
* **Learning Objectives Assessed:**
* Describe position using coordinates in the first quadrant.
* ....
* **Description:**
* **Coordinate Maze:** Students will create a maze using coordinates on a grid paper. They will then provide directions for navigating the maze using a combination of coordinate movements and translation/reflection instructions.
* **Shape Transformations:** Students will draw shapes on a grid paper and then apply transformations such as translation and reflection, recording the new coordinates of the transformed shapes.
* **Geometry Challenge:** Students will solve real-world problems involving perimeter, area, and angles. For example, they could be asked to calculate the perimeter of a room, the area of a garden, or the missing angle in a triangle.
....
Beenden Sie mit ctl+c und bereinigen Sie den Testcode. ENTFERNEN Sie den folgenden Code aus gemini.py:
import unittest
class TestGenAssignmentGemini(unittest.TestCase):
def test_gen_assignment_gemini(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assigmodel_one_assignmentnment": "", "final_assignment": ""}
updated_state = gen_assignment_gemini(initial_state)
self.assertIn("model_one_assignment", updated_state)
self.assertIsNotNone(updated_state["model_one_assignment"])
self.assertIsInstance(updated_state["model_one_assignment"], str)
self.assertGreater(len(updated_state["model_one_assignment"]), 0)
print(updated_state["model_one_assignment"])
if __name__ == '__main__':
unittest.main()
DeepSeek Assignment Generator konfigurieren
Cloudbasierte KI-Plattformen sind zwar praktisch, aber das Self-Hosting von LLMs kann entscheidend sein, um den Datenschutz zu gewährleisten und die Datenhoheit zu sichern. Wir stellen das kleinste DeepSeek-Modell (1,5 Milliarden Parameter) auf einer Cloud Compute Engine-Instanz bereit. Es gibt auch andere Möglichkeiten, z. B. das Hosting auf der Vertex AI-Plattform von Google oder auf Ihrer GKE-Instanz. Da es sich hier aber nur um einen Workshop zu KI-Agenten handelt und ich Sie nicht ewig aufhalten möchte, verwenden wir einfach die einfachste Methode. Wenn Sie sich für andere Optionen interessieren, finden Sie in der Datei deepseek-vertexai.py im Zuweisungsordner Beispielcode für die Interaktion mit Modellen, die in Vertex AI bereitgestellt werden.

👉 Führen Sie diesen Befehl im Terminal aus, um die selbst gehostete LLM-Plattform Ollama zu erstellen:
cd ~/aidemy-bootstrap/assignment
gcloud config set project $(cat ~/project_id.txt)
gcloud compute instances create ollama-instance \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--machine-type=e2-standard-4 \
--zone=us-central1-a \
--metadata-from-file startup-script=startup.sh \
--boot-disk-size=50GB \
--tags=ollama \
--scopes=https://www.googleapis.com/auth/cloud-platform
So prüfen Sie, ob die Compute Engine-Instanz ausgeführt wird:
Rufen Sie in der Google Cloud Console Compute Engine > „VM-Instanzen“ auf. Die ollama-instance sollte mit einem grünen Häkchen angezeigt werden, das darauf hinweist, dass sie ausgeführt wird. Wenn Sie sie nicht sehen, prüfen Sie, ob die Zone „us-central1“ ist. Falls nicht, müssen Sie möglicherweise danach suchen.

👉 Wir installieren das kleinste DeepSeek-Modell und testen es. Führen Sie dazu im Cloud Shell-Editor in einem New-Terminal den folgenden Befehl aus, um eine SSH-Verbindung zur GCE-Instanz herzustellen.
gcloud compute ssh ollama-instance --zone=us-central1-a
Nachdem Sie die SSH-Verbindung hergestellt haben, werden Sie möglicherweise aufgefordert, Folgendes einzugeben:
„Do you want to continue (Y/n)?“
Geben Sie einfach Y ein(Groß-/Kleinschreibung wird nicht beachtet) und drücken Sie die Eingabetaste, um fortzufahren.
Als Nächstes werden Sie möglicherweise aufgefordert, eine Passphrase für den SSH-Schlüssel zu erstellen. Wenn Sie keine Passphrase verwenden möchten, drücken Sie einfach zweimal die Eingabetaste, um die Standardeinstellung (keine Passphrase) zu übernehmen.
👉 Rufen Sie nun das kleinste DeepSeek R1-Modell ab und testen Sie, ob es funktioniert.
ollama pull deepseek-r1:1.5b
ollama run deepseek-r1:1.5b "who are you?"
👉 Geben Sie im SSH-Terminal Folgendes ein, um die GCE-Instanz zu beenden:
exit
👉 Richten Sie als Nächstes die Netzwerkrichtlinie ein, damit andere Dienste auf das LLM zugreifen können. Beschränken Sie den Zugriff auf die Instanz, wenn Sie dies für die Produktion tun möchten. Implementieren Sie entweder die Sicherheitsanmeldung für den Dienst oder schränken Sie den IP-Zugriff ein. Ausführen:
gcloud compute firewall-rules create allow-ollama-11434 \
--allow=tcp:11434 \
--target-tags=ollama \
--description="Allow access to Ollama on port 11434"
👉 So prüfen Sie, ob Ihre Firewallrichtlinie ordnungsgemäß funktioniert:
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
curl -X POST "${OLLAMA_HOST}/api/generate" \
-H "Content-Type: application/json" \
-d '{
"prompt": "Hello, what are you?",
"model": "deepseek-r1:1.5b",
"stream": false
}'
Als Nächstes arbeiten wir an der Deepseek-Funktion im Zuweisungs-Agent, um Aufgaben mit individuellen Arbeitsschwerpunkten zu generieren.
👉 Bearbeiten Sie deepseek.py im Ordner assignment und fügen Sie am Ende das folgende Snippet hinzu:
def gen_assignment_deepseek(state):
print(f"---------------gen_assignment_deepseek")
template = """
You are an instructor who favor student to focus on individual work.
Develop engaging and practical assignments for each week, ensuring they align with the teaching plan's objectives and progressively build upon each other.
For each week, provide the following:
* **Week [Number]:** A descriptive title for the assignment (e.g., "Data Exploration Project," "Model Building Exercise").
* **Learning Objectives Assessed:** List the specific learning objectives from the teaching plan that this assignment assesses.
* **Description:** A detailed description of the task, including any specific requirements or constraints. Provide examples or scenarios if applicable.
* **Deliverables:** Specify what students need to submit (e.g., code, report, presentation).
* **Estimated Time Commitment:** The approximate time students should dedicate to completing the assignment.
* **Assessment Criteria:** Briefly outline how the assignment will be graded (e.g., correctness, completeness, clarity, creativity).
The assignments should be a mix of individual and collaborative work where appropriate. Consider different learning styles and provide opportunities for students to apply their knowledge creatively.
Based on this teaching plan: {teaching_plan}
"""
prompt = ChatPromptTemplate.from_template(template)
model = OllamaLLM(model="deepseek-r1:1.5b",
base_url=OLLAMA_HOST)
chain = prompt | model
response = chain.invoke({"teaching_plan":state["teaching_plan"]})
state["model_two_assignment"] = response
return state
import unittest
class TestGenAssignmentDeepseek(unittest.TestCase):
def test_gen_assignment_deepseek(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = gen_assignment_deepseek(initial_state)
self.assertIn("model_two_assignment", updated_state)
self.assertIsNotNone(updated_state["model_two_assignment"])
self.assertIsInstance(updated_state["model_two_assignment"], str)
self.assertGreater(len(updated_state["model_two_assignment"]), 0)
print(updated_state["model_two_assignment"])
if __name__ == '__main__':
unittest.main()
👉 Testen wir das mit folgendem Befehl:
cd ~/aidemy-bootstrap/assignment
source env/bin/activate
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
python deepseek.py
Sie sollten eine Aufgabe sehen, die mehr Selbststudium erfordert.
**Assignment Plan for Each Week**
---
### **Week 1: 2D Shapes and Angles**
- **Week Title:** "Exploring 2D Shapes"
Assign students to research and present on various 2D shapes. Include a project where they create models using straws and tape for triangles, draw quadrilaterals with specific measurements, and compare their properties.
### **Week 2: 3D Shapes and Symmetry**
Assign students to create models or nets for cubes and cuboids. They will also predict how folding these nets form the 3D shapes. Include a project where they identify symmetrical properties using mirrors or folding techniques.
### **Week 3: Position, Direction, and Problem Solving**
Assign students to use mirrors or folding techniques for reflections. Include activities where they measure angles, use a protractor, solve problems involving perimeter/area, and create symmetrical designs.
....
👉 Beenden Sie die ctl+c und bereinigen Sie den Testcode. ENTFERNEN Sie den folgenden Code aus deepseek.py:
import unittest
class TestGenAssignmentDeepseek(unittest.TestCase):
def test_gen_assignment_deepseek(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = gen_assignment_deepseek(initial_state)
self.assertIn("model_two_assignment", updated_state)
self.assertIsNotNone(updated_state["model_two_assignment"])
self.assertIsInstance(updated_state["model_two_assignment"], str)
self.assertGreater(len(updated_state["model_two_assignment"]), 0)
print(updated_state["model_two_assignment"])
if __name__ == '__main__':
unittest.main()
Jetzt verwenden wir dasselbe Gemini-Modell, um beide Aufgaben zu einer neuen Aufgabe zu kombinieren. Bearbeiten Sie die Datei gemini.py im Ordner assignment.
👉 Fügen Sie den folgenden Code am Ende der gemini.py-Datei ein:
def combine_assignments(state):
print(f"---------------combine_assignments ")
region=get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
response = client.models.generate_content(
model=MODEL_ID, contents=f"""
Look at all the proposed assignment so far {state["model_one_assignment"]} and {state["model_two_assignment"]}, combine them and come up with a final assignment for student.
"""
)
state["final_assignment"] = response.text
return state
Um die Stärken beider Modelle zu kombinieren, orchestrieren wir einen definierten Workflow mit LangGraph. Dieser Workflow besteht aus drei Schritten: Zuerst generiert das Gemini-Modell eine Aufgabe mit Schwerpunkt auf Zusammenarbeit. Zweitens generiert das DeepSeek-Modell eine Aufgabe mit Schwerpunkt auf individueller Arbeit. Schließlich fasst Gemini diese beiden Aufgaben zu einer einzigen, umfassenden Aufgabe zusammen. Da wir die Reihenfolge der Schritte ohne LLM-Entscheidungsfindung vordefinieren, handelt es sich um eine benutzerdefinierte Orchestrierung mit einem einzigen Pfad.

👉 Fügen Sie den folgenden Code am Ende der Datei main.py im Ordner assignment ein:
def create_assignment(teaching_plan: str):
print(f"create_assignment---->{teaching_plan}")
builder = StateGraph(State)
builder.add_node("gen_assignment_gemini", gen_assignment_gemini)
builder.add_node("gen_assignment_deepseek", gen_assignment_deepseek)
builder.add_node("combine_assignments", combine_assignments)
builder.add_edge(START, "gen_assignment_gemini")
builder.add_edge("gen_assignment_gemini", "gen_assignment_deepseek")
builder.add_edge("gen_assignment_deepseek", "combine_assignments")
builder.add_edge("combine_assignments", END)
graph = builder.compile()
state = graph.invoke({"teaching_plan": teaching_plan})
return state["final_assignment"]
import unittest
class TestCreateAssignment(unittest.TestCase):
def test_create_assignment(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = create_assignment(initial_state)
print(updated_state)
if __name__ == '__main__':
unittest.main()
👉 Führen Sie den folgenden Befehl aus, um die Funktion create_assignment zu testen und zu bestätigen, dass der Workflow, in dem Gemini und DeepSeek kombiniert werden, funktioniert:
cd ~/aidemy-bootstrap/assignment
source env/bin/activate
pip install -r requirements.txt
python main.py
Sie sollten etwas sehen, das beide Modelle mit ihrer individuellen Perspektive für das Lernen von Schülern und für Gruppenarbeiten kombiniert.
**Tasks:**
1. **Clue Collection:** Gather all the clues left by the thieves. These clues will include:
* Descriptions of shapes and their properties (angles, sides, etc.)
* Coordinate grids with hidden messages
* Geometric puzzles requiring transformation (translation, reflection, rotation)
* Challenges involving area, perimeter, and angle calculations
2. **Clue Analysis:** Decipher each clue using your geometric knowledge. This will involve:
* Identifying the shape and its properties
* Plotting coordinates and interpreting patterns on the grid
* Solving geometric puzzles by applying transformations
* Calculating area, perimeter, and missing angles
3. **Case Report:** Create a comprehensive case report outlining your findings. This report should include:
* A detailed explanation of each clue and its solution
* Sketches and diagrams to support your explanations
* A step-by-step account of how you followed the clues to locate the artifact
* A final conclusion about the thieves and their motives
👉 Beenden Sie die ctl+c und bereinigen Sie den Testcode. ENTFERNEN Sie den folgenden Code aus main.py:
import unittest
class TestCreateAssignment(unittest.TestCase):
def test_create_assignment(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = create_assignment(initial_state)
print(updated_state)
if __name__ == '__main__':
unittest.main()

Um die Erstellung von Aufgaben zu automatisieren und auf neue Lehrpläne zu reagieren, nutzen wir die vorhandene ereignisgesteuerte Architektur. Der folgende Code definiert eine Cloud Run-Funktion (generate_assignment), die ausgelöst wird, wenn ein neuer Lehrplan im Pub/Sub-Thema plan veröffentlicht wird.
👉 Fügen Sie am Ende von main.py im Ordner assignment den folgenden Code ein:
@functions_framework.cloud_event
def generate_assignment(cloud_event):
print(f"CloudEvent received: {cloud_event.data}")
try:
if isinstance(cloud_event.data.get('message', {}).get('data'), str):
data = json.loads(base64.b64decode(cloud_event.data['message']['data']).decode('utf-8'))
teaching_plan = data.get('teaching_plan')
elif 'teaching_plan' in cloud_event.data:
teaching_plan = cloud_event.data["teaching_plan"]
else:
raise KeyError("teaching_plan not found")
assignment = create_assignment(teaching_plan)
print(f"Assignment---->{assignment}")
#Store the return assignment into bucket as a text file
storage_client = storage.Client()
bucket = storage_client.bucket(ASSIGNMENT_BUCKET)
file_name = f"assignment-{random.randint(1, 1000)}.txt"
blob = bucket.blob(file_name)
blob.upload_from_string(assignment)
return f"Assignment generated and stored in {ASSIGNMENT_BUCKET}/{file_name}", 200
except (json.JSONDecodeError, AttributeError, KeyError) as e:
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500
except Exception as e:
print(f"Error generate assignment: {e}")
return "Error generate assignment", 500
Anwendung lokal testen
Bevor Sie die Cloud Run Function in Google Cloud bereitstellen, sollten Sie sie lokal testen. Das ermöglicht eine schnellere Iteration und einfachere Fehlerbehebung.
Erstellen Sie zuerst einen Cloud Storage-Bucket zum Speichern der generierten Zuweisungsdateien und gewähren Sie dem Dienstkonto Zugriff auf den Bucket. Führen Sie im Terminal die folgenden Befehle aus:
👉WICHTIG: Achten Sie darauf, dass Sie einen eindeutigen ASSIGNMENT_BUCKET-Namen definieren, der mit „aidemy-assignment-“ beginnt. Dieser eindeutige Name ist wichtig, um Namenskonflikte beim Erstellen Ihres Cloud Storage-Buckets zu vermeiden. Ersetzen Sie <YOUR_NAME> durch ein beliebiges zufälliges Wort.
export ASSIGNMENT_BUCKET=aidemy-assignment-<YOUR_NAME> #Name must be unqiue
👉 Führen Sie dann diesen Befehl aus:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gsutil mb -p $PROJECT_ID -l us-central1 gs://$ASSIGNMENT_BUCKET
gcloud storage buckets add-iam-policy-binding gs://$ASSIGNMENT_BUCKET \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectViewer"
gcloud storage buckets add-iam-policy-binding gs://$ASSIGNMENT_BUCKET \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectCreator"
👉 Starten Sie jetzt den Emulator für Cloud Run Functions:
cd ~/aidemy-bootstrap/assignment
functions-framework \
--target generate_assignment \
--signature-type=cloudevent \
--source main.py
👉 Während der Emulator in einem Terminal ausgeführt wird, öffnen Sie ein zweites Terminal in Cloud Shell. Senden Sie in diesem zweiten Terminal ein Test-CloudEvent an den Emulator, um die Veröffentlichung eines neuen Lehrplans zu simulieren:
curl -X POST \
http://localhost:8080/ \
-H "Content-Type: application/json" \
-H "ce-id: event-id-01" \
-H "ce-source: planner-agent" \
-H "ce-specversion: 1.0" \
-H "ce-type: google.cloud.pubsub.topic.v1.messagePublished" \
-d '{
"message": {
"data": "eyJ0ZWFjaGluZ19wbGFuIjogIldlZWsgMTogMkQgU2hhcGVzIGFuZCBBbmdsZXMgLSBEYXkgMTogUmV2aWV3IG9mIGJhc2ljIDJEIHNoYXBlcyAoc3F1YXJlcywgcmVjdGFuZ2xlcywgdHJpYW5nbGVzLCBjaXJjbGVzKS4gRGF5IDI6IEV4cGxvcmluZyBkaWZmZXJlbnQgdHlwZXMgb2YgdHJpYW5nbGVzIChlcXVpbGF0ZXJhbCwgaXNvc2NlbGVzLCBzY2FsZW5lLCByaWdodC1hbmdsZWQpLiBEYXkgMzogRXhwbG9yaW5nIHF1YWRyaWxhdGVyYWxzIChzcXVhcmUsIHJlY3RhbmdsZSwgcGFyYWxsZWxvZ3JhbSwgcmhvbWJ1cywgdHJhcGV6aXVtKS4gRGF5IDQ6IEludHJvZHVjdGlvbiB0byBhbmdsZXM6IHJpZ2h0IGFuZ2xlcywgYWN1dGUgYW5nbGVzLCBhbmQgb2J0dXNlIGFuZ2xlcy4gRGF5IDU6IE1lYXN1cmluZyBhbmdsZXMgdXNpbmcgYSBwcm90cmFjdG9yLiBXZWVrIDI6IDNEIFNoYXBlcyBhbmQgU3ltbWV0cnkgLSBEYXkgNjogSW50cm9kdWN0aW9uIHRvIDNEIHNoYXBlczogY3ViZXMsIGN1Ym9pZHMsIHNwaGVyZXMsIGN5bGluZGVycywgY29uZXMsIGFuZCBweXJhbWlkcy4gRGF5IDc6IERlc2NyaWJpbmcgM0Qgc2hhcGVzIHVzaW5nIGZhY2VzLCBlZGdlcywgYW5kIHZlcnRpY2VzLiBEYXkgODogUmVsYXRpbmcgMkQgc2hhcGVzIHRvIDNEIHNoYXBlcy4gRGF5IDk6IElkZW50aWZ5aW5nIGxpbmVzIG9mIHN5bW1ldHJ5IGluIDJEIHNoYXBlcy4gRGF5IDEwOiBDb21wbGV0aW5nIHN5bW1ldHJpY2FsIGZpZ3VyZXMuIFdlZWsgMzogUG9zaXRpb24sIERpcmVjdGlvbiwgYW5kIFByb2JsZW0gU29sdmluZyAtIERheSAxMTogRGVzY3JpYmluZyBwb3NpdGlvbiB1c2luZyBjb29yZGluYXRlcyBpbiB0aGUgZmlyc3QgcXVhZHJhbnQuIERheSAxMjogUGxvdHRpbmcgY29vcmRpbmF0ZXMgdG8gZHJhdyBzaGFwZXMuIERheSAxMzogVW5kZXJzdGFuZGluZyB0cmFuc2xhdGlvbiAoc2xpZGluZyBhIHNoYXBlKS4gRGF5IDE0OiBVbmRlcnN0YW5kaW5nIHJlZmxlY3Rpb24gKGZsaXBwaW5nIGEgc2hhcGUpLiBEYXkgMTU6IFByb2JsZW0tc29sdmluZyBhY3Rpdml0aWVzIGludm9sdmluZyBwZXJpbWV0ZXIsIGFyZWEsIGFuZCBtaXNzaW5nIGFuZ2xlcy4ifQ=="
}
}'
Anstatt nur auf die Antwort zu warten, wechseln Sie zum anderen Cloud Shell-Terminal. Sie können den Fortschritt und alle Ausgaben oder Fehlermeldungen, die von Ihrer Funktion generiert werden, im Terminal des Emulators beobachten. 😁
Der curl-Befehl sollte „OK“ ausgeben (ohne Zeilenumbruch, sodass „OK“ möglicherweise in derselben Zeile wie die Eingabeaufforderung des Terminals angezeigt wird).
Wenn Sie prüfen möchten, ob die Zuweisung erfolgreich generiert und gespeichert wurde, rufen Sie die Google Cloud Console auf und wechseln Sie zu Storage > „Cloud Storage“. Wählen Sie den von Ihnen erstellten aidemy-assignment-Bucket aus. Im Bucket sollte eine Textdatei namens assignment-{random number}.txt angezeigt werden. Klicken Sie auf die Datei, um sie herunterzuladen und ihren Inhalt zu prüfen. So wird überprüft, ob eine neue Datei die gerade generierte neue Zuweisung enthält.

👉 Geben Sie im Terminal, in dem der Emulator ausgeführt wird, ctrl+c ein, um den Emulator zu beenden. Schließen Sie das zweite Terminal. 👉 Beenden Sie außerdem die virtuelle Umgebung im Terminal, in dem der Emulator ausgeführt wird.
deactivate
👉 Als Nächstes stellen wir den Aufgaben-Agent in der Cloud bereit.
cd ~/aidemy-bootstrap/assignment
export ASSIGNMENT_BUCKET=$(gcloud storage buckets list --format="value(name)" | grep aidemy-assignment)
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud functions deploy assignment-agent \
--gen2 \
--timeout=540 \
--memory=2Gi \
--cpu=1 \
--set-env-vars="ASSIGNMENT_BUCKET=${ASSIGNMENT_BUCKET}" \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--set-env-vars=OLLAMA_HOST=${OLLAMA_HOST} \
--region=us-central1 \
--runtime=python312 \
--source=. \
--entry-point=generate_assignment \
--trigger-topic=plan
Rufen Sie die Google Cloud Console auf und gehen Sie zu Cloud Run, um die Bereitstellung zu überprüfen. Sie sollten einen neuen Dienst mit dem Namen „courses-agent“ sehen. 
Nachdem der Workflow für die Aufgabenerstellung implementiert, getestet und bereitgestellt wurde, können wir mit dem nächsten Schritt fortfahren: den Zugriff auf diese Aufgaben im Lernendenportal ermöglichen.
14. OPTIONAL: Rollenbasierte Zusammenarbeit mit Gemini und DeepSeek – Fortsetzung
Generierung dynamischer Websites
Um das Lernportal zu optimieren und ansprechender zu gestalten, werden wir die dynamische HTML-Generierung für Aufgabenseiten implementieren. Das Ziel ist, das Portal automatisch mit einem neuen, ansprechenden Design zu aktualisieren, wenn eine neue Aufgabe generiert wird. Dabei werden die Programmierfunktionen des LLM genutzt, um eine dynamischere und interessantere Nutzererfahrung zu schaffen.

👉 Bearbeiten Sie im Cloud Shell-Editor die Datei render.py im Ordner portal und ersetzen Sie
def render_assignment_page():
return ""
mit dem folgenden Code-Snippet:
def render_assignment_page(assignment: str):
try:
region=get_next_region()
llm = VertexAI(model_name="gemini-2.0-flash-001", location=region)
input_msg = HumanMessage(content=[f"Here the assignment {assignment}"])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"""
As a frontend developer, create HTML to display a student assignment with a creative look and feel. Include the following navigation bar at the top:
```
<nav>
<a href="/">Home</a>
<a href="/quiz">Quizzes</a>
<a href="/courses">Courses</a>
<a href="/assignment">Assignments</a>
</nav>
```
Also include these links in the <head> section:
```
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Roboto:wght@400;500&display=swap" rel="stylesheet">
```
Do not apply inline styles to the navigation bar.
The HTML should display the full assignment content. In its CSS, be creative with the rainbow colors and aesthetic.
Make it creative and pretty
The assignment content should be well-structured and easy to read.
respond with JUST the html file
"""
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
response = response.replace("```html", "")
response = response.replace("```", "")
with open("templates/assignment.html", "w") as f:
f.write(response)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
Es verwendet das Gemini-Modell, um dynamisch HTML für die Aufgabe zu generieren. Die Aufgabe wird als Eingabe verwendet und Gemini wird mit einem Prompt angewiesen, eine ansprechende HTML-Seite mit einem kreativen Stil zu erstellen.
Als Nächstes erstellen wir einen Endpunkt, der immer dann ausgelöst wird, wenn dem Zuweisungs-Bucket ein neues Dokument hinzugefügt wird:
👉 Bearbeiten Sie im Portalordner die Datei app.py und ERSETZEN Sie die Zeile ## REPLACE ME! RENDER ASSIGNMENT durch den folgenden Code:
@app.route('/render_assignment', methods=['POST'])
def render_assignment():
try:
data = request.get_json()
file_name = data.get('name')
bucket_name = data.get('bucket')
if not file_name or not bucket_name:
return jsonify({'error': 'Missing file name or bucket name'}), 400
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
content = blob.download_as_text()
print(f"File content: {content}")
render_assignment_page(content)
return jsonify({'message': 'Assignment rendered successfully'})
except Exception as e:
print(f"Error processing file: {e}")
return jsonify({'error': 'Error processing file'}), 500
Wenn die Funktion ausgelöst wird, ruft sie den Dateinamen und den Bucket-Namen aus den Anforderungsdaten ab, lädt die Aufgabeninhalte aus Cloud Storage herunter und ruft die render_assignment_page-Funktion auf, um den HTML-Code zu generieren.
👉 Wir führen sie lokal aus:
cd ~/aidemy-bootstrap/portal
source env/bin/activate
python app.py
👉 Wählen Sie im Menü „Webvorschau“ oben im Cloud Shell-Fenster „Vorschau auf Port 8080“ aus. Daraufhin wird Ihre Anwendung in einem neuen Browsertab geöffnet. Klicken Sie in der Navigationsleiste auf den Link Aufgabe. An dieser Stelle sollte eine leere Seite angezeigt werden. Das ist normal, da wir noch keine Kommunikationsbrücke zwischen dem Zuweisungs-Agent und dem Portal eingerichtet haben, um die Inhalte dynamisch zu generieren.

Beenden Sie das Skript durch Drücken von Ctrl+C.
👉 Um diese Änderungen zu übernehmen und den aktualisierten Code bereitzustellen, müssen Sie das Portal-Agent-Image neu erstellen und per Push übertragen:
cd ~/aidemy-bootstrap/portal/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-portal .
docker tag gcr.io/${PROJECT_ID}/aidemy-portal us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
👉 Nachdem Sie das neue Image per Push übertragen haben, stellen Sie den Cloud Run-Dienst noch einmal bereit. Führen Sie das folgende Skript aus, um das Cloud Run-Update zu erzwingen:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud run services update aidemy-portal \
--region=us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
👉 Als Nächstes stellen wir einen Eventarc-Trigger bereit, der auf alle neuen Objekte wartet, die im Zuweisungs-Bucket erstellt (abgeschlossen) werden. Dieser Trigger ruft automatisch den Endpunkt /render_assignment im Portaldienst auf, wenn eine neue Zuweisungsdatei erstellt wird.
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$(gcloud storage service-agent --project $PROJECT_ID)" \
--role="roles/pubsub.publisher"
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gcloud eventarc triggers create portal-assignment-trigger \
--location=us-central1 \
--service-account=$SERVICE_ACCOUNT_NAME \
--destination-run-service=aidemy-portal \
--destination-run-region=us-central1 \
--destination-run-path="/render_assignment" \
--event-filters="bucket=$ASSIGNMENT_BUCKET" \
--event-filters="type=google.cloud.storage.object.v1.finalized"
Rufen Sie in der Google Cloud Console die Seite Eventarc-Trigger auf, um zu prüfen, ob der Trigger erfolgreich erstellt wurde. portal-assignment-trigger sollte in der Tabelle aufgeführt sein. Klicken Sie auf den Triggernamen, um die Details aufzurufen. 
Es kann bis zu 2–3 Minuten dauern, bis der neue Trigger aktiv wird.
Führen Sie den folgenden Befehl aus, um die dynamische Zuweisung in Aktion zu sehen und die URL Ihres Planner-Agents zu ermitteln (falls Sie sie nicht zur Hand haben):
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep planner
So finden Sie die URL Ihres Portal-Agents:
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep portal
Generieren Sie im Planner-Agent einen neuen Lehrplan.

Nach einigen Minuten (damit die Audio- und Aufgabenstellung generiert und das HTML gerendert werden kann) rufen Sie das Schülerportal auf.
👉 Klicken Sie in der Navigationsleiste auf den Link „Aufgabe“. Sie sollten eine neu erstellte Aufgabe mit dynamisch generiertem HTML sehen. Jedes Mal, wenn ein Lehrplan generiert wird, sollte es sich um eine dynamische Aufgabe handeln.

Herzlichen Glückwunsch zum Abschluss des Aidemy-Multi-Agent-Systems! Sie haben praktische Erfahrungen gesammelt und wertvolle Einblicke in die folgenden Bereiche erhalten:
- Die Vorteile von Multi-Agent-Systemen, darunter Modularität, Skalierbarkeit, Spezialisierung und vereinfachte Wartung.
- Die Bedeutung ereignisgesteuerter Architekturen für die Entwicklung responsiver und lose gekoppelter Anwendungen.
- Der strategische Einsatz von LLMs, die Auswahl des richtigen Modells für die jeweilige Aufgabe und die Integration von Tools für reale Auswirkungen.
- Cloudnative Entwicklungspraktiken mit Google Cloud-Diensten zur Erstellung skalierbarer und zuverlässiger Lösungen.
- Die Bedeutung von Datenschutz und Self-Hosting-Modellen als Alternative zu Anbieterlösungen.
Sie haben jetzt eine solide Grundlage für die Entwicklung anspruchsvoller KI-basierter Anwendungen in Google Cloud.
15. Herausforderungen und nächste Schritte
Herzlichen Glückwunsch zur Entwicklung des Aidemy-Multi-Agenten-Systems! Sie haben eine solide Grundlage für KI-basierte Bildung geschaffen. Sehen wir uns nun einige Herausforderungen und mögliche zukünftige Verbesserungen an, um die Funktionen weiter auszubauen und auf die Bedürfnisse der realen Welt einzugehen:
Interaktives Lernen mit Live-Fragerunden:
- Challenge: Kannst du die Live API von Gemini 2 nutzen, um eine Echtzeit-Funktion für Fragen und Antworten für Schüler und Studenten zu erstellen? Stellen Sie sich ein virtuelles Klassenzimmer vor, in dem Lernende Fragen stellen und sofort KI-basierte Antworten erhalten können.
Automatisches Einreichen und Bewerten von Aufgaben:
- Herausforderung: Entwerfen und implementieren Sie ein System, mit dem Schüler und Studenten Aufgaben digital einreichen und automatisch von KI bewerten lassen können. Das System soll außerdem Plagiate erkennen und verhindern. Diese Challenge bietet eine hervorragende Gelegenheit, Retrieval-Augmented Generation (RAG) zu nutzen, um die Genauigkeit und Zuverlässigkeit der Prozesse für die Notengebung und die Plagiatserkennung zu verbessern.

16. Bereinigen
Nachdem wir unser Aidemy-Multi-Agenten-System erstellt und untersucht haben, ist es an der Zeit, unsere Google Cloud-Umgebung aufzuräumen.
👉 Cloud Run-Dienste löschen
gcloud run services delete aidemy-planner --region=us-central1 --quiet
gcloud run services delete aidemy-portal --region=us-central1 --quiet
gcloud run services delete courses-agent --region=us-central1 --quiet
gcloud run services delete book-provider --region=us-central1 --quiet
gcloud run services delete assignment-agent --region=us-central1 --quiet
👉 Eventarc-Trigger löschen
gcloud eventarc triggers delete portal-assignment-trigger --location=us --quiet
gcloud eventarc triggers delete plan-topic-trigger --location=us-central1 --quiet
gcloud eventarc triggers delete portal-assignment-trigger --location=us-central1 --quiet
ASSIGNMENT_AGENT_TRIGGER=$(gcloud eventarc triggers list --project="$PROJECT_ID" --location=us-central1 --filter="name:assignment-agent" --format="value(name)")
COURSES_AGENT_TRIGGER=$(gcloud eventarc triggers list --project="$PROJECT_ID" --location=us-central1 --filter="name:courses-agent" --format="value(name)")
gcloud eventarc triggers delete $ASSIGNMENT_AGENT_TRIGGER --location=us-central1 --quiet
gcloud eventarc triggers delete $COURSES_AGENT_TRIGGER --location=us-central1 --quiet
👉 Pub/Sub-Thema löschen
gcloud pubsub topics delete plan --project="$PROJECT_ID" --quiet
👉 Cloud SQL-Instanz löschen
gcloud sql instances delete aidemy --quiet
👉 Artifact Registry-Repository löschen
gcloud artifacts repositories delete agent-repository --location=us-central1 --quiet
👉 Secret Manager-Secrets löschen
gcloud secrets delete db-user --quiet
gcloud secrets delete db-pass --quiet
gcloud secrets delete db-name --quiet
👉 Compute Engine-Instanz löschen (falls für Deepseek erstellt)
gcloud compute instances delete ollama-instance --zone=us-central1-a --quiet
👉 Firewallregel für Deepseek-Instanz löschen
gcloud compute firewall-rules delete allow-ollama-11434 --quiet
👉 Cloud Storage-Buckets löschen
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
export ASSIGNMENT_BUCKET=$(gcloud storage buckets list --format="value(name)" | grep aidemy-assignment)
gsutil rm -r gs://$COURSE_BUCKET_NAME
gsutil rm -r gs://$ASSIGNMENT_BUCKET
