
1. Wprowadzenie
Cześć! Podoba Ci się pomysł agentów – małych pomocników, którzy mogą załatwiać różne sprawy bez Twojego udziału, prawda? Świetnie! Ale bądźmy szczerzy, jeden agent nie zawsze wystarczy, zwłaszcza gdy pracujesz nad większymi i bardziej złożonymi projektami. Prawdopodobnie będziesz potrzebować całego zespołu takich osób. Właśnie dlatego powstały systemy wieloagentowe.
Agenty oparte na LLM-ach zapewniają niesamowitą elastyczność w porównaniu z tradycyjnym kodowaniem. Ale, jak to zwykle bywa, wiążą się one z pewnymi trudnościami. Właśnie tym zajmiemy się na tych warsztatach.

Oto czego możesz się nauczyć – potraktuj to jako sposób na podniesienie swoich umiejętności:
Tworzenie pierwszego agenta za pomocą LangGraph: stworzymy własnego agenta za pomocą LangGraph, popularnej platformy. Dowiesz się, jak tworzyć narzędzia, które łączą się z bazami danych, korzystają z najnowszego interfejsu Gemini 2 API do wyszukiwania w internecie oraz optymalizują prompty i odpowiedzi, aby Twój agent mógł wchodzić w interakcje nie tylko z modelami LLM, ale też z dotychczasowymi usługami. Pokażemy Ci też, jak działa wywoływanie funkcji.
Orkiestracja agentów na Twój sposób: omówimy różne sposoby orkiestracji agentów, od prostych ścieżek bezpośrednich po bardziej złożone scenariusze wielościeżkowe. Możesz to traktować jako kierowanie pracą zespołu agentów.
Systemy wieloagentowe: dowiesz się, jak skonfigurować system, w którym agenci mogą współpracować i wspólnie wykonywać zadania – wszystko dzięki architekturze opartej na zdarzeniach.
LLM Freedom: używaj najlepszego narzędzia do danego zadania. Nie ograniczamy się do jednego modelu LLM. Dowiesz się, jak używać wielu dużych modeli językowych, przypisując im różne role, aby zwiększyć możliwości rozwiązywania problemów za pomocą ciekawych „modeli myślenia”.
Treści dynamiczne? Żaden problem! Wyobraź sobie, że Twój agent tworzy dynamiczne treści dostosowane do każdego użytkownika w czasie rzeczywistym. Pokażemy Ci, jak to zrobić.
Przenoszenie do chmury za pomocą Google Cloud: zapomnij o zabawie w notatniku. Pokażemy Ci, jak zaprojektować i wdrożyć system wielu agentów w Google Cloud, aby był gotowy do działania w rzeczywistym świecie.
Ten projekt będzie dobrym przykładem wykorzystania wszystkich omówionych technik.
2. Architektura
Praca nauczyciela lub nauczycielki może być bardzo satysfakcjonująca, ale nie da się ukryć, że nakład pracy, zwłaszcza przygotowawczej, może być spory. Poza tym często brakuje personelu, a korepetycje mogą być drogie. Dlatego proponujemy asystenta nauczyciela opartego na AI. To narzędzie może odciążyć nauczycieli i pomóc w przezwyciężeniu problemów wynikających z niedoboru personelu i braku niedrogich korepetycji.
Nasz asystent nauczania AI może tworzyć szczegółowe konspekty lekcji, ciekawe quizy, łatwe do zrozumienia podsumowania audio i spersonalizowane zadania. Dzięki temu nauczyciele mogą skupić się na tym, co robią najlepiej: nawiązywaniu kontaktu z uczniami i pomaganiu im w polubieniu nauki.
System składa się z 2 witryn: jednej dla nauczycieli, w której mogą tworzyć plany lekcji na najbliższe tygodnie,

i jedna dla uczniów, w której mogą oni uzyskać dostęp do quizów, podsumowań audio i projektów. 
Przyjrzyjmy się architekturze, która zasila naszego asystenta nauczyciela Aidemy. Jak widzisz, podzieliliśmy go na kilka kluczowych komponentów, które współpracują ze sobą, aby to osiągnąć.

Kluczowe elementy architektury i technologie:
Google Cloud Platform (GCP): kluczowa dla całego systemu:
- Vertex AI: dostęp do modeli LLM Gemini od Google.
- Cloud Run: bezserwerowa platforma do wdrażania agentów i funkcji w kontenerach.
- Cloud SQL: baza danych PostgreSQL na potrzeby danych o programie nauczania.
- Pub/Sub i Eventarc: podstawa architektury opartej na zdarzeniach, umożliwiająca asynchroniczną komunikację między komponentami.
- Cloud Storage: przechowuje podsumowania audio i pliki projektów.
- Secret Manager: bezpiecznie zarządza danymi logowania do bazy danych.
- Artifact Registry: przechowuje obrazy Dockera dla agentów.
- Compute Engine: do wdrażania samodzielnie hostowanego LLM zamiast korzystania z rozwiązań dostawców.
LLM: „mózg” systemu:
- Modele Gemini od Google: (Gemini x Pro, Gemini x Flash, Gemini x Flash Thinking) używane do planowania lekcji, generowania treści, tworzenia dynamicznego kodu HTML, wyjaśniania quizów i łączenia zadań.
- DeepSeek: wykorzystywany do specjalistycznego zadania generowania zadań do samodzielnej nauki.
LangChain i LangGraph: platformy do tworzenia aplikacji LLM
- Ułatwia tworzenie złożonych przepływów pracy z wieloma agentami.
- Umożliwia inteligentne zarządzanie narzędziami (wywołaniami interfejsu API, zapytaniami do bazy danych, wyszukiwaniami w internecie).
- Wdraża architekturę opartą na zdarzeniach, aby zapewnić skalowalność i elastyczność systemu.
Nasza architektura łączy moc dużych modeli językowych z danymi strukturalnymi i komunikacją opartą na zdarzeniach, a wszystko to działa w Google Cloud. Dzięki temu możemy stworzyć skalowalnego, niezawodnego i skutecznego asystenta nauczania.
3. Zanim zaczniesz
W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud. Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności
Włączanie Gemini Code Assist w środowisku IDE Cloud Shell
👉 W konsoli Google Cloud otwórz Narzędzia Gemini Code Assist i włącz Gemini Code Assist bezpłatnie, akceptując warunki.
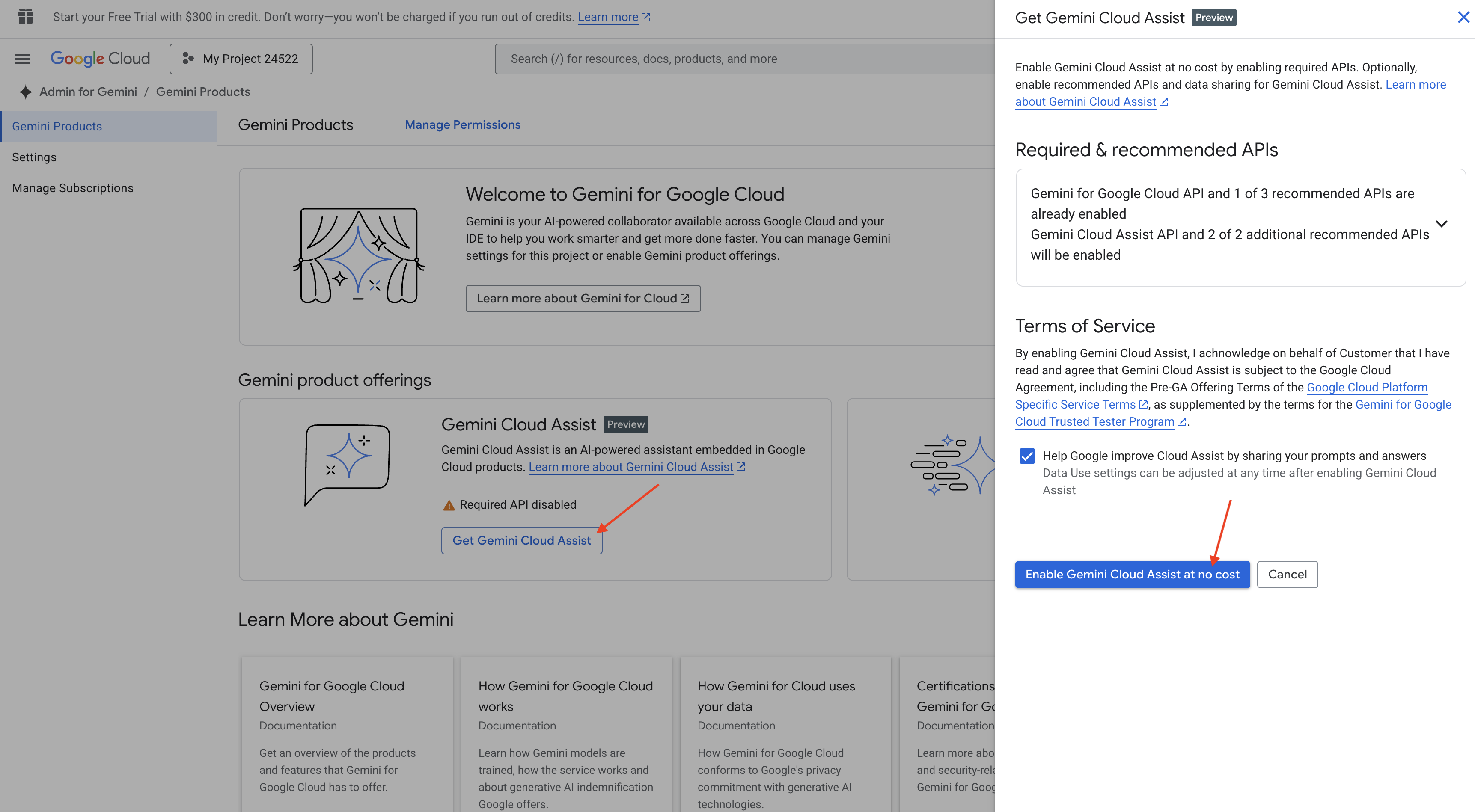
Zignoruj konfigurację uprawnień i opuść tę stronę.
Praca w edytorze Cloud Shell
👉 U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell (ikona terminala u góry panelu Cloud Shell), a następnie kliknij przycisk „Otwórz edytor” (ikona otwartego folderu z ołówkiem). W oknie otworzy się edytor kodu Cloud Shell. Po lewej stronie zobaczysz eksplorator plików.

👉 Na pasku stanu u dołu kliknij przycisk Zaloguj się w Cloud Code, jak pokazano na ilustracji. Autoryzuj wtyczkę zgodnie z instrukcjami. Jeśli na pasku stanu widzisz Cloud Code – brak projektu, wybierz tę opcję, a następnie w menu „Wybierz projekt Google Cloud” wybierz konkretny projekt Google Cloud z listy utworzonych projektów.

👉Otwórz terminal w chmurowym IDE 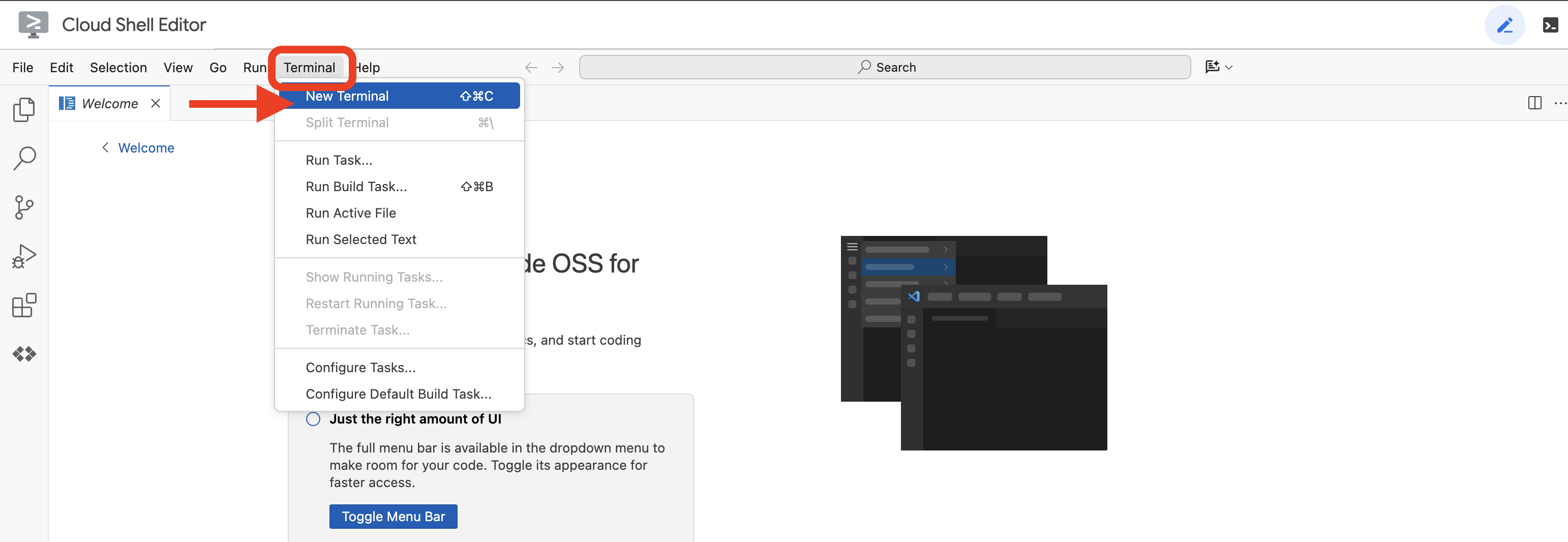 lub
lub  .
.
👉W terminalu sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu. Użyj tego polecenia:
gcloud auth list
👉 Zastąp <YOUR_PROJECT_ID> identyfikatorem projektu:
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉Aby włączyć niezbędne interfejsy Google Cloud API, uruchom to polecenie:
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Może to potrwać kilka minut.
Konfigurowanie uprawnień
👉Skonfiguruj uprawnienia konta usługi. W terminalu uruchom :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 Przyznaj uprawnienia. W terminalu uruchom :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
👉Sprawdź wynik w konsoli IAM
👉 Aby utworzyć instancję Cloud SQL o nazwie aidemy, uruchom w terminalu te polecenia: Będziemy tego potrzebować później, ale ponieważ ten proces może zająć trochę czasu, zrobimy to teraz.
gcloud sql instances create aidemy \
--database-version=POSTGRES_14 \
--cpu=2 \
--memory=4GB \
--region=us-central1 \
--root-password=1234qwer \
--storage-size=10GB \
--storage-auto-increase
4. Tworzenie pierwszego agenta
Zanim przejdziemy do złożonych systemów wieloagentowych, musimy stworzyć podstawowy element składowy: pojedynczego, funkcjonalnego agenta. W tej sekcji wykonamy pierwsze kroki, tworząc prostego agenta „dostawcy książek”. Agent dostawcy książek przyjmuje kategorię jako dane wejściowe i używa modelu LLM Gemini do generowania reprezentacji książki w formacie JSON w tej kategorii. Następnie udostępnia te rekomendacje książek jako punkt końcowy interfejsu API REST .

👉 Na innej karcie przeglądarki otwórz konsolę Google Cloud. W menu nawigacyjnym (☰) kliknij „Cloud Run”. Kliknij przycisk „+ … NAPISZ FUNKCJĘ”.

👉Następnie skonfigurujemy podstawowe ustawienia funkcji Cloud Run:
- Nazwa usługi:
book-provider - Region:
us-central1 - Środowisko wykonawcze:
Python 3.12 - Uwierzytelnianie: ustaw przełącznik
Allow unauthenticated invocationsna Włączone.
👉 Pozostaw inne ustawienia domyślne i kliknij Utwórz. Spowoduje to przejście do edytora kodu źródłowego.
Zobaczysz wstępnie wypełnione pliki main.py i requirements.txt.
main.py będzie zawierać logikę biznesową funkcji, a requirements.txt – potrzebne pakiety.
👉 Teraz możemy napisać kod. Zanim jednak zaczniemy, sprawdźmy, czy Gemini Code Assist może nam pomóc na początek. Wróć do edytora Cloud Shell i kliknij ikonę Gemini Code Assist u góry. Powinien otworzyć się czat Gemini Code Assist.

👉 Wklej do pola prompta to żądanie:
Use the functions_framework library to be deployable as an HTTP function.
Accept a request with category and number_of_book parameters (either in JSON body or query string).
Use langchain and gemini to generate the data for book with fields bookname, author, publisher, publishing_date.
Use pydantic to define a Book model with the fields: bookname (string, description: "Name of the book"), author (string, description: "Name of the author"), publisher (string, description: "Name of the publisher"), and publishing_date (string, description: "Date of publishing").
Use langchain and gemini model to generate book data. the output should follow the format defined in Book model.
The logic should use JsonOutputParser from langchain to enforce output format defined in Book Model.
Have a function get_recommended_books(category) that internally uses langchain and gemini to return a single book object.
The main function, exposed as the Cloud Function, should call get_recommended_books() multiple times (based on number_of_book) and return a JSON list of the generated book objects.
Handle the case where category or number_of_book are missing by returning an error JSON response with a 400 status code.
return a JSON string representing the recommended books. use os library to retrieve GOOGLE_CLOUD_PROJECT env var. Use ChatVertexAI from langchain for the LLM call
Asystent kodu wygeneruje wtedy potencjalne rozwiązanie, udostępniając zarówno kod źródłowy, jak i plik zależności requirements.txt. (NIE UŻYWAJ TEGO KODU)
Zachęcamy do porównania wygenerowanego przez Asystenta kodu z przetestowanym, prawidłowym rozwiązaniem podanym poniżej. Dzięki temu możesz ocenić skuteczność narzędzia i wykryć ewentualne rozbieżności. Chociaż LLM nie należy nigdy ślepo ufać, Code Assist może być świetnym narzędziem do szybkiego tworzenia prototypów i generowania początkowych struktur kodu. Warto go używać, aby zyskać dobry start.
Ponieważ są to warsztaty, użyjemy zweryfikowanego kodu podanego poniżej. Możesz jednak w wolnym czasie eksperymentować z kodem wygenerowanym przez Asystenta kodu, aby lepiej poznać jego możliwości i ograniczenia.
👉Wróć do edytora kodu źródłowego funkcji Cloud Run (na innej karcie przeglądarki). Ostrożnie zastąp dotychczasową zawartość pliku main.py kodem podanym poniżej:
import functions_framework
import json
from flask import Flask, jsonify, request
from langchain_google_vertexai import ChatVertexAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field
import os
class Book(BaseModel):
bookname: str = Field(description="Name of the book")
author: str = Field(description="Name of the author")
publisher: str = Field(description="Name of the publisher")
publishing_date: str = Field(description="Date of publishing")
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT")
llm = ChatVertexAI(model_name="gemini-2.0-flash-lite-001")
def get_recommended_books(category):
"""
A simple book recommendation function.
Args:
category (str): category
Returns:
str: A JSON string representing the recommended books.
"""
parser = JsonOutputParser(pydantic_object=Book)
question = f"Generate a random made up book on {category} with bookname, author and publisher and publishing_date"
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | llm | parser
response = chain.invoke({"query": question})
return json.dumps(response)
@functions_framework.http
def recommended(request):
request_json = request.get_json(silent=True) # Get JSON data
if request_json and 'category' in request_json and 'number_of_book' in request_json:
category = request_json['category']
number_of_book = int(request_json['number_of_book'])
elif request.args and 'category' in request.args and 'number_of_book' in request.args:
category = request.args.get('category')
number_of_book = int(request.args.get('number_of_book'))
else:
return jsonify({'error': 'Missing category or number_of_book parameters'}), 400
recommendations_list = []
for i in range(number_of_book):
book_dict = json.loads(get_recommended_books(category))
print(f"book_dict=======>{book_dict}")
recommendations_list.append(book_dict)
return jsonify(recommendations_list)
👉Zastąp zawartość pliku requirements.txt tymi elementami:
functions-framework==3.*
google-genai==1.0.0
flask==3.1.0
jsonify==0.5
langchain_google_vertexai==2.0.13
langchain_core==0.3.34
pydantic==2.10.5
👉ustawimy Punkt wejścia funkcji: recommended

👉 Aby wdrożyć funkcję, kliknij ZAPISZ I WDROŻ (lub ZAPISZ I WDROŻ PONOWNIE). Poczekaj na zakończenie procesu wdrażania. W konsoli Cloud pojawi się stan. Może to potrwać kilka minut.
 👉Po wdrożeniu wróć do edytora Cloud Shell i uruchom w terminalu to polecenie:
👉Po wdrożeniu wróć do edytora Cloud Shell i uruchom w terminalu to polecenie:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
curl -X POST -H "Content-Type: application/json" -d '{"category": "Science Fiction", "number_of_book": 2}' $BOOK_PROVIDER_URL
Powinny się w nim wyświetlić dane książki w formacie JSON.
[
{"author":"Anya Sharma","bookname":"Echoes of the Singularity","publisher":"NovaLight Publishing","publishing_date":"2077-03-15"},
{"author":"Anya Sharma","bookname":"Echoes of the Quantum Dawn","publisher":"Nova Genesis Publishing","publishing_date":"2077-03-15"}
]
Gratulacje! Udało Ci się wdrożyć funkcję Cloud Run. Jest to jedna z usług, które zintegrujemy podczas tworzenia naszego agenta Aidemy.
5. Narzędzia do tworzenia: łączenie agentów z usługą RESTFUL i danymi
Pobierz projekt szkieletowy Bootstrap. Upewnij się, że jesteś w edytorze Cloud Shell. W terminalu uruchom
git clone https://github.com/weimeilin79/aidemy-bootstrap.git
Po uruchomieniu tego polecenia w środowisku Cloud Shell zostanie utworzony nowy folder o nazwie aidemy-bootstrap.
W panelu Eksplorator w edytorze Cloud Shell (zwykle po lewej stronie) powinien być widoczny folder utworzony podczas klonowania repozytorium Git aidemy-bootstrap. Otwórz folder główny projektu w Eksploratorze. Znajdziesz w nim podfolder planner, który też otwórz. 
Zacznijmy tworzyć narzędzia, których będą używać nasi agenci, aby stać się naprawdę pomocni. Jak wiesz, duże modele językowe doskonale sprawdzają się w rozumowaniu i generowaniu tekstu, ale do wykonywania zadań w rzeczywistym świecie i podawania dokładnych, aktualnych informacji potrzebują dostępu do zewnętrznych zasobów. Pomyśl o nich jak o „szwajcarskim scyzoryku” agenta, który umożliwia mu interakcję ze światem.
Podczas tworzenia agenta łatwo jest zakodować na stałe wiele szczegółów. Spowoduje to utworzenie agenta, który nie jest elastyczny. Zamiast tego, tworząc i używając narzędzi, agent ma dostęp do zewnętrznej logiki lub systemów, co daje mu korzyści zarówno z LLM, jak i z tradycyjnego programowania.
W tej sekcji stworzymy podstawy agenta planującego, którego nauczyciele będą używać do generowania konspektów lekcji. Zanim agent zacznie generować plan, chcemy wyznaczyć granice, podając więcej szczegółów na temat przedmiotu i tematu. Stworzymy 3 narzędzia:
- Wywołanie interfejsu API RESTful: interakcja z istniejącym interfejsem API w celu pobrania danych.
- Zapytanie do bazy danych: pobieranie danych strukturalnych z bazy danych Cloud SQL.
- Wyszukiwarka Google: dostęp do informacji w czasie rzeczywistym z internetu.
Pobieranie rekomendacji książek z interfejsu API
Najpierw utwórzmy narzędzie, które pobiera rekomendacje książek z interfejsu API book-provider wdrożonego w poprzedniej sekcji. Pokazuje, jak agent może korzystać z dotychczasowych usług.

W edytorze Cloud Shell otwórz projekt aidemy-bootstrap, który został sklonowany w poprzedniej sekcji.
👉Edytuj plik book.py w folderze planner i wklej ten kod na końcu pliku:
def recommend_book(query: str):
"""
Get a list of recommended book from an API endpoint
Args:
query: User's request string
"""
region = get_next_region();
llm = VertexAI(model_name="gemini-1.5-pro", location=region)
query = f"""The user is trying to plan a education course, you are the teaching assistant. Help define the category of what the user requested to teach, respond the categroy with no more than two word.
user request: {query}
"""
print(f"-------->{query}")
response = llm.invoke(query)
print(f"CATEGORY RESPONSE------------>: {response}")
# call this using python and parse the json back to dict
category = response.strip()
headers = {"Content-Type": "application/json"}
data = {"category": category, "number_of_book": 2}
books = requests.post(BOOK_PROVIDER_URL, headers=headers, json=data)
return books.text
if __name__ == "__main__":
print(recommend_book("I'm doing a course for my 5th grade student on Math Geometry, I'll need to recommend few books come up with a teach plan, few quizes and also a homework assignment."))
Wyjaśnienie:
- recommend_book(query: str): ta funkcja przyjmuje zapytanie użytkownika jako dane wejściowe.
- Interakcja z LLM: używa modelu LLM do wyodrębniania kategorii z zapytania. Pokazuje to, jak można używać modelu LLM do tworzenia parametrów narzędzi.
- Wywołanie interfejsu API: wysyła żądanie POST do interfejsu API dostawcy książek, przekazując kategorię i żądaną liczbę książek.
👉 Aby przetestować tę nową funkcję, ustaw zmienną środowiskową i uruchom :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
cd ~/aidemy-bootstrap/planner/
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
👉Aby zainstalować zależności i uruchomić kod, aby sprawdzić, czy działa, wpisz:
cd ~/aidemy-bootstrap/planner/
python -m venv env
source env/bin/activate
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python book.py
Powinien pojawić się ciąg znaków JSON zawierający rekomendacje książek pobrane z interfejsu API dostawcy książek. Wyniki są generowane losowo. Książki mogą się różnić, ale powinny być to 2 rekomendacje w formacie JSON.
[{"author":"Anya Sharma","bookname":"Echoes of the Singularity","publisher":"NovaLight Publishing","publishing_date":"2077-03-15"},{"author":"Anya Sharma","bookname":"Echoes of the Quantum Dawn","publisher":"Nova Genesis Publishing","publishing_date":"2077-03-15"}]
Jeśli widzisz ten komunikat, pierwsze narzędzie działa prawidłowo.
Zamiast tworzyć wywołanie interfejsu API REST z określonymi parametrami, używamy języka naturalnego („I'm doing a course...”). Następnie agent inteligentnie wyodrębnia niezbędne parametry (np. kategorię) za pomocą NLP, co pokazuje, jak wykorzystuje on rozumienie języka naturalnego do interakcji z API.

👉Usuń z pliku book.py ten kod testowy:
if __name__ == "__main__":
print(recommend_book("I'm doing a course for my 5th grade student on Math Geometry, I'll need to recommend few books come up with a teach plan, few quizes and also a homework assignment."))
Pobieranie danych o programie nauczania z bazy danych
Następnie utworzymy narzędzie, które pobiera ustrukturyzowane dane programu nauczania z bazy danych Cloud SQL PostgreSQL. Dzięki temu agent może korzystać z wiarygodnego źródła informacji do planowania lekcji.

Pamiętasz instancję Cloud SQL aidemy utworzoną w poprzednim kroku? Oto gdzie będzie używana.
👉 W terminalu uruchom to polecenie, aby utworzyć w nowej instancji bazę danych o nazwie aidemy-db.
gcloud sql databases create aidemy-db \
--instance=aidemy
Sprawdźmy instancję w Cloud SQL w konsoli Google Cloud. Powinna być tam widoczna instancja Cloud SQL o nazwie aidemy.
👉 Kliknij nazwę instancji, aby wyświetlić jej szczegóły. 👉 Na stronie z informacjami o instancji Cloud SQL w menu nawigacyjnym po lewej stronie kliknij Cloud SQL Studio. Otworzy się nowa karta.
Wybierz bazę danych aidemy-db, wpisz postgres jako użytkownika i 1234qwer jako hasło.
Kliknij Uwierzytelnij.

👉W edytorze zapytań SQL Studio otwórz kartę Edytor 1 i wklej ten kod SQL:
CREATE TABLE curriculums (
id SERIAL PRIMARY KEY,
year INT,
subject VARCHAR(255),
description TEXT
);
-- Inserting detailed curriculum data for different school years and subjects
INSERT INTO curriculums (year, subject, description) VALUES
-- Year 5
(5, 'Mathematics', 'Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.'),
(5, 'English', 'Developing reading comprehension, creative writing, and basic grammar, with a focus on storytelling and poetry.'),
(5, 'Science', 'Exploring basic physics, chemistry, and biology concepts, including forces, materials, and ecosystems.'),
(5, 'Computer Science', 'Basic coding concepts using block-based programming and an introduction to digital literacy.'),
-- Year 6
(6, 'Mathematics', 'Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.'),
(6, 'English', 'Introduction to persuasive writing, character analysis, and deeper comprehension of literary texts.'),
(6, 'Science', 'Forces and motion, the human body, and introductory chemical reactions with hands-on experiments.'),
(6, 'Computer Science', 'Introduction to algorithms, logical reasoning, and basic text-based programming (Python, Scratch).'),
-- Year 7
(7, 'Mathematics', 'Algebraic expressions, geometry, and introduction to statistics and probability.'),
(7, 'English', 'Analytical reading of classic and modern literature, essay writing, and advanced grammar skills.'),
(7, 'Science', 'Introduction to cells and organisms, chemical reactions, and energy transfer in physics.'),
(7, 'Computer Science', 'Building on programming skills with Python, introduction to web development, and cyber safety.');
Ten kod SQL tworzy tabelę o nazwie curriculums i wstawia do niej przykładowe dane.
👉 Aby uruchomić kod SQL, kliknij Uruchom. Powinien pojawić się komunikat z potwierdzeniem, że instrukcje zostały wykonane.
👉 Rozwiń eksplorator, znajdź nowo utworzoną tabelę curriculums i kliknij zapytanie. Powinna otworzyć się nowa karta edytora z wygenerowanym dla Ciebie kodem SQL.

SELECT * FROM
"public"."curriculums" LIMIT 1000;
👉 Kliknij Uruchom.
W tabeli wyników powinny być widoczne wiersze danych wstawione w poprzednim kroku. Potwierdza to, że tabela i dane zostały utworzone prawidłowo.
Po utworzeniu bazy danych z przykładowymi danymi dotyczącymi programu nauczania zbudujemy narzędzie do ich pobierania.
👉 W edytorze kodu Cloud zmodyfikuj plik curriculums.py w folderze aidemy-bootstrap i wklej na końcu pliku ten kod:
def connect_with_connector() -> sqlalchemy.engine.base.Engine:
db_user = os.environ["DB_USER"]
db_pass = os.environ["DB_PASS"]
db_name = os.environ["DB_NAME"]
print(f"--------------------------->db_user: {db_user!r}")
print(f"--------------------------->db_pass: {db_pass!r}")
print(f"--------------------------->db_name: {db_name!r}")
connector = Connector()
pool = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=lambda: connector.connect(
instance_connection_name,
"pg8000",
user=db_user,
password=db_pass,
db=db_name,
),
pool_size=2,
max_overflow=2,
pool_timeout=30, # 30 seconds
pool_recycle=1800, # 30 minutes
)
return pool
def get_curriculum(year: int, subject: str):
"""
Get school curriculum
Args:
subject: User's request subject string
year: User's request year int
"""
try:
stmt = sqlalchemy.text(
"SELECT description FROM curriculums WHERE year = :year AND subject = :subject"
)
with db.connect() as conn:
result = conn.execute(stmt, parameters={"year": year, "subject": subject})
row = result.fetchone()
if row:
return row[0]
else:
return None
except Exception as e:
print(e)
return None
db = connect_with_connector()
Wyjaśnienie:
- Zmienne środowiskowe: kod pobiera dane logowania do bazy danych i informacje o połączeniu ze zmiennych środowiskowych (więcej informacji poniżej).
- connect_with_connector(): ta funkcja używa Cloud SQL Connector do nawiązania bezpiecznego połączenia z bazą danych.
- get_curriculum(year: int, subject: str): ta funkcja przyjmuje rok i przedmiot jako dane wejściowe, wysyła zapytanie do tabeli programów nauczania i zwraca odpowiedni opis programu.
👉Zanim uruchomimy kod, musimy ustawić kilka zmiennych środowiskowych. W terminalu uruchom:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉Aby przetestować, dodaj ten kod na końcu pliku curriculums.py:
if __name__ == "__main__":
print(get_curriculum(6, "Mathematics"))
👉 Uruchom kod:
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python curriculums.py
W konsoli powinien pojawić się opis programu nauczania matematyki w klasie 6.
Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.
Jeśli widzisz opis programu nauczania, narzędzie bazy danych działa prawidłowo. Jeśli skrypt nadal działa, zatrzymaj go, naciskając Ctrl+C.
👉Usuń z pliku curriculums.py ten kod testowy:
if __name__ == "__main__":
print(get_curriculum(6, "Mathematics"))
👉 Aby zamknąć środowisko wirtualne, w terminalu uruchom polecenie:
deactivate
6. Narzędzia do tworzenia: dostęp do informacji w czasie rzeczywistym z internetu
Na koniec stworzymy narzędzie, które wykorzystuje integrację Gemini 2 i wyszukiwarki Google, aby uzyskiwać dostęp do informacji w czasie rzeczywistym z internetu. Dzięki temu agent może być na bieżąco i wyświetlać trafne wyniki.
Integracja Gemini 2 z interfejsem Google Search API zwiększa możliwości agenta, ponieważ zapewnia dokładniejsze i bardziej dopasowane do kontekstu wyniki wyszukiwania. Dzięki temu agenty mają dostęp do aktualnych informacji i mogą opierać swoje odpowiedzi na danych z rzeczywistego świata, co minimalizuje halucynacje. Ulepszona integracja interfejsu API ułatwia też formułowanie zapytań w języku naturalnym, dzięki czemu agenci mogą tworzyć złożone i zniuansowane żądania wyszukiwania.

Ta funkcja przyjmuje jako dane wejściowe zapytanie, program nauczania, przedmiot i rok, a następnie używa interfejsu Gemini API i narzędzia wyszukiwarki Google do pobierania z internetu odpowiednich informacji. Jeśli przyjrzysz się bliżej, zobaczysz, że do wywoływania funkcji używa pakietu Google Generatywna AI SDK bez korzystania z innych platform.
👉Edytuj plik search.py w folderze aidemy-bootstrap i wklej ten kod na końcu pliku:
model_id = "gemini-2.0-flash-001"
google_search_tool = Tool(
google_search = GoogleSearch()
)
def search_latest_resource(search_text: str, curriculum: str, subject: str, year: int):
"""
Get latest information from the internet
Args:
search_text: User's request category string
subject: "User's request subject" string
year: "User's request year" integer
"""
search_text = "%s in the context of year %d and subject %s with following curriculum detail %s " % (search_text, year, subject, curriculum)
region = get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
print(f"search_latest_resource text-----> {search_text}")
response = client.models.generate_content(
model=model_id,
contents=search_text,
config=GenerateContentConfig(
tools=[google_search_tool],
response_modalities=["TEXT"],
)
)
print(f"search_latest_resource response-----> {response}")
return response
if __name__ == "__main__":
response = search_latest_resource("What are the syllabus for Year 6 Mathematics?", "Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.", "Mathematics", 6)
for each in response.candidates[0].content.parts:
print(each.text)
Wyjaśnienie:
- Narzędzie do definiowania – google_search_tool: opakowanie obiektu GoogleSearch w narzędzie.
- search_latest_resource(search_text: str, subject: str, year: int): ta funkcja przyjmuje jako dane wejściowe zapytanie, temat i rok, a następnie używa interfejsu Gemini API do przeprowadzenia wyszukiwania w Google.
- GenerateContentConfig: określ, że ma dostęp do narzędzia GoogleSearch.
Model Gemini wewnętrznie analizuje tekst wyszukiwania i określa, czy może bezpośrednio odpowiedzieć na pytanie, czy też musi użyć narzędzia GoogleSearch. To kluczowy etap, który odbywa się w ramach procesu rozumowania LLM. Model został wytrenowany tak, aby rozpoznawać sytuacje, w których konieczne jest użycie narzędzi zewnętrznych. Jeśli model zdecyduje się użyć narzędzia GoogleSearch, wywołanie jest obsługiwane przez pakiet Google Generative AI SDK. Pakiet SDK pobiera decyzję modelu i wygenerowane przez niego parametry i wysyła je do interfejsu Google Search API. Ta część jest ukryta przed użytkownikiem w kodzie.
Model Gemini integruje następnie wyniki wyszukiwania w swojej odpowiedzi. Może wykorzystać te informacje, aby odpowiedzieć na pytanie użytkownika, wygenerować podsumowanie lub wykonać inne zadanie.
👉 Aby przetestować kod, uruchom go:
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
source env/bin/activate
python search.py
Powinna się wyświetlić odpowiedź interfejsu Gemini Search API zawierająca wyniki wyszukiwania związane z „Syllabus for Year 5 Mathematics”. Dokładny wynik zależy od wyników wyszukiwania, ale będzie to obiekt JSON z informacjami o wyszukiwaniu.
Jeśli widzisz wyniki wyszukiwania, narzędzie wyszukiwarki Google działa prawidłowo. Jeśli skrypt nadal działa, zatrzymaj go, naciskając Ctrl+C.
👉 Usuń ostatnią część kodu.
if __name__ == "__main__":
response = search_latest_resource("What are the syllabus for Year 6 Mathematics?", "Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.", "Mathematics", 6)
for each in response.candidates[0].content.parts:
print(each.text)
👉 Aby zamknąć środowisko wirtualne, w terminalu uruchom polecenie:
deactivate
Gratulacje! Masz teraz 3 zaawansowane narzędzia dla agenta planującego: łącznik API, łącznik bazy danych i narzędzie wyszukiwarki Google. Dzięki tym narzędziom agent będzie mieć dostęp do informacji i funkcji potrzebnych do tworzenia skutecznych planów nauczania.
7. Administrowanie za pomocą LangGraph
Po utworzeniu poszczególnych narzędzi czas je skoordynować za pomocą LangGraph. Dzięki temu będziemy mogli stworzyć bardziej zaawansowanego agenta „planującego”, który na podstawie prośby użytkownika będzie inteligentnie decydować, których narzędzi użyć i kiedy.
LangGraph to biblioteka Pythona, która ułatwia tworzenie aplikacji stanowych z wieloma aktorami przy użyciu dużych modeli językowych (LLM). To platforma do zarządzania złożonymi rozmowami i przepływami pracy z udziałem LLM, narzędzi i innych agentów.
Kluczowe pojęcia:
- Struktura grafu: LangGraph reprezentuje logikę aplikacji jako graf skierowany. Każdy węzeł na wykresie reprezentuje krok w procesie (np. wywołanie LLM, wywołanie narzędzia, sprawdzenie warunkowe). Krawędzie określają przepływ wykonywania między węzłami.
- Stan: LangGraph zarządza stanem aplikacji w miarę jej przechodzenia przez graf. Ten stan może obejmować zmienne takie jak dane wejściowe użytkownika, wyniki wywołań narzędzi, dane wyjściowe pośrednie z LLM i wszelkie inne informacje, które muszą być zachowane między krokami.
- Węzły: każdy węzeł reprezentuje obliczenie lub interakcję. Mogą to być:
- Węzły narzędzi: używaj narzędzia (np.wyszukiwarki internetowej lub bazy danych).
- Węzły funkcji: wykonują funkcję Pythona.
- Krawędzie: łączą węzły i określają przepływ wykonania. Mogą to być:
- Krawędzie bezpośrednie: proste, bezwarunkowe przejście z jednego węzła do drugiego.
- Krawędzie warunkowe: przepływ zależy od wyniku węzła warunkowego.

Do wdrożenia orkiestracji użyjemy LangGraph. Edytujmy plik aidemy.py w folderze aidemy-bootstrap, aby zdefiniować logikę LangGraph.
👉 Dodaj ten kod na końcu
aidemy.py:
tools = [get_curriculum, search_latest_resource, recommend_book]
def determine_tool(state: MessagesState):
llm = ChatVertexAI(model_name="gemini-2.0-flash-001", location=get_next_region())
sys_msg = SystemMessage(
content=(
f"""You are a helpful teaching assistant that helps gather all needed information.
Your ultimate goal is to create a detailed 3-week teaching plan.
You have access to tools that help you gather information.
Based on the user request, decide which tool(s) are needed.
"""
)
)
llm_with_tools = llm.bind_tools(tools)
return {"messages": llm_with_tools.invoke([sys_msg] + state["messages"])}
Ta funkcja odpowiada za pobieranie bieżącego stanu rozmowy, przekazywanie do modelu LLM wiadomości systemowej, a następnie proszenie go o wygenerowanie odpowiedzi. Model LLM może bezpośrednio odpowiedzieć użytkownikowi lub użyć jednego z dostępnych narzędzi.
tools : ta lista zawiera zestaw narzędzi dostępnych dla agenta. Zawiera 3 funkcje narzędziowe zdefiniowane w poprzednich krokach: get_curriculum, search_latest_resource i recommend_book. llm.bind_tools(tools): „wiąże” listę narzędzi z obiektem llm. Powiązanie narzędzi informuje model LLM, że są one dostępne, i dostarcza mu informacji o sposobie ich używania (np. nazwy narzędzi, parametry, które akceptują, i działania, które wykonują).
Do wdrożenia orkiestracji użyjemy LangGraph.
👉 Dodaj ten kod na końcu
aidemy.py:
def prep_class(prep_needs):
builder = StateGraph(MessagesState)
builder.add_node("determine_tool", determine_tool)
builder.add_node("tools", ToolNode(tools))
builder.add_edge(START, "determine_tool")
builder.add_conditional_edges("determine_tool",tools_condition)
builder.add_edge("tools", "determine_tool")
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "1"}}
messages = graph.invoke({"messages": prep_needs},config)
print(messages)
for m in messages['messages']:
m.pretty_print()
teaching_plan_result = messages["messages"][-1].content
return teaching_plan_result
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, , get school curriculum, and come up with few books recommendation plus search latest resources on the internet base on the curriculum outcome. And come up with a 3 week teaching plan")
Wyjaśnienie:
StateGraph(MessagesState): tworzy obiektStateGraph.StateGraphto podstawowe pojęcie w LangGraph. Przedstawia przepływ pracy agenta w postaci wykresu, w którym każdy węzeł reprezentuje krok w procesie. To jakby określenie planu działania agenta.- Krawędź warunkowa: wychodząca z węzła
"determine_tool", argumenttools_conditionjest prawdopodobnie funkcją, która na podstawie wyniku funkcjidetermine_toolokreśla, którą krawędzią należy podążać. Krawędzie warunkowe umożliwiają rozgałęzienie grafu na podstawie decyzji LLM o tym, którego narzędzia użyć (lub czy odpowiedzieć użytkownikowi bezpośrednio). W tym momencie ujawnia się „inteligencja” agenta – może on dynamicznie dostosowywać swoje zachowanie do sytuacji. - Pętla: dodaje do wykresu krawędź, która łączy węzeł
"tools"z węzłem"determine_tool". Tworzy to pętlę w grafie, dzięki czemu agent może wielokrotnie korzystać z narzędzi, dopóki nie zbierze wystarczającej ilości informacji, aby wykonać zadanie i udzielić satysfakcjonującej odpowiedzi. Ta pętla ma kluczowe znaczenie w przypadku złożonych zadań, które wymagają wielu etapów rozumowania i zbierania informacji.
Teraz przetestujmy agenta planującego, aby sprawdzić, jak koordynuje różne narzędzia.
Ten kod uruchomi funkcję prep_class z określonymi danymi wejściowymi użytkownika, symulując żądanie utworzenia planu nauczania matematyki w klasie 5 w zakresie geometrii z wykorzystaniem programu nauczania, rekomendacji książek i najnowszych zasobów internetowych.
👉 Jeśli terminal został zamknięty lub zmienne środowiskowe nie są już ustawione, uruchom ponownie te polecenia:
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 Uruchom kod:
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
pip install -r requirements.txt
python aidemy.py
Obserwuj dziennik w terminalu. Zanim podasz ostateczny plan nauczania, sprawdź, czy agent korzysta ze wszystkich 3 narzędzi (pobiera program nauczania, rekomendacje książek i najnowsze zasoby). Pokazuje to, że orkiestracja LangGraph działa prawidłowo, a agent inteligentnie korzysta ze wszystkich dostępnych narzędzi, aby spełnić prośbę użytkownika.
================================ Human Message =================================
I'm doing a course for year 5 on subject Mathematics in Geometry, , get school curriculum, and come up with few books recommendation plus search latest resources on the internet base on the curriculum outcome. And come up with a 3 week teaching plan
================================== Ai Message ==================================
Tool Calls:
get_curriculum (xxx)
Call ID: xxx
Args:
year: 5.0
subject: Mathematics
================================= Tool Message =================================
Name: get_curriculum
Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.
================================== Ai Message ==================================
Tool Calls:
search_latest_resource (xxxx)
Call ID: xxxx
Args:
year: 5.0
search_text: Geometry
curriculum: {"content": "Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques."}
subject: Mathematics
================================= Tool Message =================================
Name: search_latest_resource
candidates=[Candidate(content=Content(parts=[Part(.....) automatic_function_calling_history=[] parsed=None
================================== Ai Message ==================================
Tool Calls:
recommend_book (93b48189-4d69-4c09-a3bd-4e60cdc5f1c6)
Call ID: 93b48189-4d69-4c09-a3bd-4e60cdc5f1c6
Args:
query: Mathematics Geometry Year 5
================================= Tool Message =================================
Name: recommend_book
[{.....}]
================================== Ai Message ==================================
Based on the curriculum outcome, here is a 3-week teaching plan for year 5 Mathematics Geometry:
**Week 1: Introduction to Shapes and Properties**
.........
Jeśli skrypt nadal działa, zatrzymaj go, naciskając Ctrl+C.
👉 (TEN KROK JEST OPCJONALNY) zastąp kod testowy innym promptem, który wymaga wywołania innych narzędzi.
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan")
👉 Jeśli terminal został zamknięty lub zmienne środowiskowe nie są już ustawione, ponownie uruchom te polecenia.
gcloud config set project $(cat ~/project_id.txt)
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 (TEN KROK JEST OPCJONALNY. WYKONAJ GO TYLKO WTEDY, GDY ZREALIZOWANO POPRZEDNI KROK) Uruchom kod ponownie:
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python aidemy.py
Co tym razem zauważasz? Które narzędzia zostały wywołane przez agenta? Powinno być widać, że tym razem agent wywołuje tylko narzędzie search_latest_resource. Dzieje się tak, ponieważ prompt nie określa, że potrzebuje pozostałych 2 narzędzi, a nasz LLM jest wystarczająco inteligentny, aby ich nie wywoływać.
================================ Human Message =================================
I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan
================================== Ai Message ==================================
Tool Calls:
get_curriculum (xxx)
Call ID: xxx
Args:
year: 5.0
subject: Mathematics
================================= Tool Message =================================
Name: get_curriculum
Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.
================================== Ai Message ==================================
Tool Calls:
search_latest_resource (xxx)
Call ID: xxxx
Args:
year: 5.0
subject: Mathematics
curriculum: {"content": "Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques."}
search_text: Geometry
================================= Tool Message =================================
Name: search_latest_resource
candidates=[Candidate(content=Content(parts=[Part(.......token_count=40, total_token_count=772) automatic_function_calling_history=[] parsed=None
================================== Ai Message ==================================
Based on the information provided, a 3-week teaching plan for Year 5 Mathematics focusing on Geometry could look like this:
**Week 1: Introducing 2D Shapes**
........
* Use visuals, manipulatives, and real-world examples to make the learning experience engaging and relevant.
Zatrzymaj skrypt, naciskając Ctrl+C.
👉 (NIE POMIJAJ TEGO KROKU!) Usuń kod testowy, aby zachować przejrzystość pliku aidemy.py :
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan")
Zdefiniowaliśmy już logikę agenta, więc uruchommy aplikację internetową Flask. Dzięki temu nauczyciele będą mogli korzystać z agenta za pomocą znanego interfejsu opartego na formularzach. Interakcje z chatbotem są powszechne w przypadku modeli LLM, ale my wybraliśmy tradycyjny interfejs przesyłania formularzy, ponieważ może być bardziej intuicyjny dla wielu nauczycieli.
👉 Jeśli terminal został zamknięty lub zmienne środowiskowe nie są już ustawione, ponownie uruchom te polecenia.
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 Teraz uruchom interfejs internetowy.
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python app.py
Poszukaj komunikatów startowych w danych wyjściowych terminala Cloud Shell. Flask zwykle wyświetla komunikaty informujące o tym, że działa i na jakim porcie.
Running on http://127.0.0.1:8080
Running on http://127.0.0.1:8080
The application needs to keep running to serve requests.
👉 W menu „Podgląd w przeglądarce” w prawym górnym rogu wybierz Podejrzyj na porcie 8080. Cloud Shell otworzy nową kartę przeglądarki lub okno z podglądem internetowym aplikacji.

W interfejsie aplikacji wybierz 5 dla roku, wybierz temat Mathematics i wpisz Geometry w prośbie o dodatek.
👉 Jeśli opuścisz interfejs aplikacji, wróć do niego. Powinien się w nim wyświetlić wygenerowany wynik.
👉 W terminalu zatrzymaj skrypt, naciskając Ctrl+C.
👉 W terminalu zamknij środowisko wirtualne:
deactivate
8. Wdrażanie agenta planującego w chmurze
Tworzenie obrazu i przesyłanie go do rejestru

Czas wdrożyć to w chmurze.
👉 W terminalu utwórz repozytorium artefaktów, w którym zapiszesz obraz Dockera, który zamierzamy utworzyć.
gcloud artifacts repositories create agent-repository \
--repository-format=docker \
--location=us-central1 \
--description="My agent repository"
Powinien wyświetlić się komunikat Utworzono repozytorium [agent-repository].
👉 Aby utworzyć obraz Dockera, uruchom to polecenie.
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-planner .
👉 Musimy ponownie otagować obraz, aby był hostowany w Artifact Registry zamiast w GCR, i przesłać otagowany obraz do Artifact Registry:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-planner us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
Po zakończeniu przesyłania możesz sprawdzić, czy obraz został zapisany w Artifact Registry.
👉 W konsoli Google Cloud otwórz Artifact Registry. Obraz aidemy-planner powinien znajdować się w repozytorium agent-repository. 
Zabezpieczanie danych logowania do bazy danych za pomocą usługi Secret Manager
Do bezpiecznego zarządzania danymi logowania do bazy danych i uzyskiwania do nich dostępu użyjemy Google Cloud Secret Managera. Zapobiega to zakodowaniu na stałe informacji poufnych w kodzie aplikacji i zwiększa bezpieczeństwo.
Utworzymy osobne klucze tajne dla nazwy użytkownika bazy danych, hasła i nazwy bazy danych. Dzięki temu możemy zarządzać każdym rodzajem danych logowania osobno.
👉 W terminalu uruchom to polecenie:
gcloud secrets create db-user
printf "postgres" | gcloud secrets versions add db-user --data-file=-
gcloud secrets create db-pass
printf "1234qwer" | gcloud secrets versions add db-pass --data-file=-
gcloud secrets create db-name
printf "aidemy-db" | gcloud secrets versions add db-name --data-file=-
Korzystanie z usługi Secret Manager to ważny krok w zabezpieczaniu aplikacji i zapobieganiu przypadkowemu ujawnieniu poufnych danych logowania. Jest zgodny ze sprawdzonymi metodami dotyczącymi bezpieczeństwa wdrożeń w chmurze.
Wdrożenie w Cloud Run
Cloud Run to w pełni zarządzana platforma bezserwerowa, która umożliwia szybkie i łatwe wdrażanie aplikacji w kontenerach. Usługa nie wymaga zarządzania infrastrukturą, dzięki czemu możesz skupić się na pisaniu i wdrażaniu kodu. Wdrożymy nasz planer jako usługę Cloud Run.
👉 W konsoli Google Cloud otwórz „Cloud Run”. Kliknij WDRÓŻ KONTENER i wybierz SERVICE. Skonfiguruj usługę Cloud Run:

- Obraz kontenera: w polu adresu URL kliknij „Wybierz”. Znajdź adres URL obrazu przesłanego do Artifact Registry (np. us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repository/aidemy-planner/YOUR_IMG).
- Nazwa usługi:
aidemy-planner - Region: wybierz region
us-central1. - Uwierzytelnianie: na potrzeby tych warsztatów możesz zezwolić na „Zezwalaj na nieuwierzytelnione wywołania”. W przypadku wersji produkcyjnej prawdopodobnie zechcesz ograniczyć dostęp.
- Rozwiń sekcję Kontenery, woluminy, sieć, zabezpieczenia i na karcie Kontenery ustaw te wartości:
- Karta Ustawienia:
- Zasoby
- pamięć : 2 GiB
- Zasoby
- Karta Zmienne i obiekty tajne:
- Zmienne środowiskowe: dodaj te zmienne, klikając przycisk + Dodaj zmienną:
- Dodaj nazwę:
GOOGLE_CLOUD_PROJECTi wartość: <YOUR_PROJECT_ID> - Dodaj nazwę:
BOOK_PROVIDER_URLi ustaw wartość na adres URL funkcji dostawcy książek, który możesz określić za pomocą tego polecenia w terminalu:gcloud config set project $(cat ~/project_id.txt) gcloud run services describe book-provider \ --region=us-central1 \ --project=$PROJECT_ID \ --format="value(status.url)"
- Dodaj nazwę:
- W sekcji Obiekty tajne ujawnione jako zmienne środowiskowe dodaj te obiekty tajne, klikając przycisk + Odwołaj się do obiektu tajnego:
- Dodaj nazwę:
DB_USER, obiekt tajny: wybierzdb-useri wersję:latest - Dodaj nazwę:
DB_PASS, obiekt tajny: wybierzdb-passi wersję:latest - Dodaj nazwę:
DB_NAME, obiekt tajny: wybierzdb-namei wersję:latest
- Dodaj nazwę:
- Zmienne środowiskowe: dodaj te zmienne, klikając przycisk + Dodaj zmienną:
- Karta Ustawienia:

W pozostałych polach pozostaw wartości domyślne.
👉 Kliknij UTWÓRZ.
Cloud Run wdroży Twoją usługę.
Po wdrożeniu, jeśli nie jesteś jeszcze na stronie szczegółów, kliknij nazwę usługi, aby przejść na stronę szczegółów. Wdrożony adres URL znajdziesz u góry.

👉 W interfejsie aplikacji wybierz 7 w polu Rok, wybierz Mathematics jako temat i wpisz Algebra w polu Prośba o dodatek.
👉 Kliknij Wygeneruj plan. Dzięki temu agent będzie miał kontekst niezbędny do wygenerowania dostosowanego konspektu lekcji.
Gratulacje! Udało Ci się utworzyć plan nauczania za pomocą naszego zaawansowanego agenta AI. Pokazuje to potencjał agentów w zakresie znacznego zmniejszenia nakładu pracy i usprawnienia zadań, co w efekcie zwiększa wydajność i ułatwia życie nauczycielom.
9. Systemy wieloagentowe
Narzędzie do tworzenia planów nauczania zostało już wdrożone. Teraz skupmy się na budowaniu portalu dla uczniów. Ten portal zapewni uczniom dostęp do testów, podsumowań audio i projektów związanych z ich materiałami dydaktycznymi. Ze względu na zakres tej funkcji wykorzystamy możliwości systemów wieloagentowych, aby stworzyć modułowe i skalowalne rozwiązanie.
Jak wspomnieliśmy wcześniej, zamiast polegać na jednym agencie, który zajmuje się wszystkim, system wielu agentów pozwala nam podzielić zadania na mniejsze, wyspecjalizowane części, z których każda jest obsługiwana przez dedykowanego agenta. Takie podejście ma kilka kluczowych zalet:
Modułowość i łatwość konserwacji: zamiast tworzyć jednego agenta, który robi wszystko, buduj mniejsze, wyspecjalizowane agenty o dobrze zdefiniowanych obowiązkach. Dzięki modułowości system jest łatwiejszy do zrozumienia, utrzymania i debugowania. Gdy pojawi się problem, możesz go przypisać do konkretnego agenta, zamiast przeszukiwać ogromną bazę kodu.
Skalowalność: skalowanie pojedynczego, złożonego agenta może być wąskim gardłem. Dzięki systemowi wielu agentów możesz skalować poszczególnych agentów w zależności od ich konkretnych potrzeb. Jeśli na przykład jeden agent obsługuje dużą liczbę żądań, możesz łatwo uruchomić więcej jego instancji bez wpływu na resztę systemu.
Specjalizacja zespołu: pomyśl o tym w ten sposób: nie poprosisz jednego inżyniera o zbudowanie całej aplikacji od podstaw. Zamiast tego zbierasz zespół specjalistów, z których każdy ma wiedzę w określonej dziedzinie. Podobnie system wielu agentów pozwala wykorzystać zalety różnych dużych modeli językowych i narzędzi, przypisując je do agentów, którzy najlepiej nadają się do konkretnych zadań.
Równoległe tworzenie: różne zespoły mogą pracować nad różnymi agentami jednocześnie, co przyspiesza proces tworzenia. Agenci są niezależni, więc zmiany w przypadku jednego z nich rzadziej wpływają na innych.
Architektura oparta na zdarzeniach
Aby umożliwić skuteczną komunikację i koordynację między tymi agentami, zastosujemy architekturę opartą na zdarzeniach. Oznacza to, że agenci będą reagować na „zdarzenia” zachodzące w systemie.
Agenci subskrybują określone typy zdarzeń (np. „wygenerowano plan nauczania”, „utworzono zadanie”). Gdy wystąpi zdarzenie, odpowiedni agenci otrzymają powiadomienie i będą mogli odpowiednio zareagować. Takie rozdzielenie zwiększa elastyczność, skalowalność i szybkość reakcji w czasie rzeczywistym.

Aby zacząć, musimy mieć możliwość transmitowania tych wydarzeń. W tym celu skonfigurujemy temat Pub/Sub. Zacznijmy od utworzenia tematu o nazwie plan.
👉 Otwórz konsolę Google Cloud Pub/Sub.
👉 Kliknij przycisk Utwórz temat.
👉 Skonfiguruj temat o identyfikatorze lub nazwie plan i odznaczAdd a default subscription. Pozostałe ustawienia pozostaw bez zmian i kliknij Utwórz.
Strona Pub/Sub zostanie odświeżona i w tabeli powinien być widoczny nowo utworzony temat. 
Teraz zintegrujmy funkcję publikowania zdarzeń Pub/Sub z naszym agentem planującym. Dodamy nowe narzędzie, które będzie wysyłać zdarzenie „plan” do utworzonego właśnie tematu Pub/Sub. To zdarzenie poinformuje inne komponenty systemu (np. te w portalu dla uczniów), że dostępny jest nowy plan nauczania.
👉 Wróć do edytora Cloud Code i otwórz plik app.py znajdujący się w folderze planner. Dodamy funkcję publikowania wydarzenia. Zastąp:
##ADD SEND PLAN EVENT FUNCTION HERE
z tym kodem
def send_plan_event(teaching_plan:str):
"""
Send the teaching event to the topic called plan
Args:
teaching_plan: teaching plan
"""
publisher = pubsub_v1.PublisherClient()
print(f"-------------> Sending event to topic plan: {teaching_plan}")
topic_path = publisher.topic_path(PROJECT_ID, "plan")
message_data = {"teaching_plan": teaching_plan}
data = json.dumps(message_data).encode("utf-8")
future = publisher.publish(topic_path, data)
return f"Published message ID: {future.result()}"
- send_plan_event: ta funkcja przyjmuje wygenerowany plan nauczania jako dane wejściowe, tworzy klienta publikującego Pub/Sub, konstruuje ścieżkę tematu, przekształca plan nauczania w ciąg znaków JSON i publikuje wiadomość w temacie.
W tym samym pliku app.py
👉Zaktualizuj prompt, aby po wygenerowaniu planu nauczania agent wysyłał zdarzenie planu nauczania do tematu Pub/Sub. *Zastąp
### ADD send_plan_event CALL
z tymi informacjami:
send_plan_event(teaching_plan)
Dodając narzędzie send_plan_event i modyfikując prompt, umożliwiliśmy naszemu agentowi planującemu publikowanie zdarzeń w Pub/Sub, dzięki czemu inne komponenty naszego systemu mogą reagować na tworzenie nowych planów nauczania. W kolejnych sekcjach będziemy mieć funkcjonalny system wieloagentowy.
10. Umożliwianie uczniom rozwiązywania testów na żądanie
Wyobraź sobie środowisko do nauki, w którym uczniowie mają dostęp do nieograniczonej liczby quizów dostosowanych do ich indywidualnych planów nauki. Quizy te zapewniają natychmiastową informację zwrotną, w tym odpowiedzi i wyjaśnienia, co sprzyja głębszemu zrozumieniu materiału. To potencjał, który chcemy wykorzystać dzięki naszemu portalowi z quizami opartemu na AI.
Aby zrealizować tę wizję, stworzymy komponent do generowania quizów, który będzie tworzyć pytania wielokrotnego wyboru na podstawie treści planu nauczania.

👉 W panelu Eksplorator edytora Cloud Code otwórz folder portal. Otwórz kopię pliku quiz.py i wklej ten kod na końcu pliku.
def generate_quiz_question(file_name: str, difficulty: str, region:str ):
"""Generates a single multiple-choice quiz question using the LLM.
```json
{
"question": "The question itself",
"options": ["Option A", "Option B", "Option C", "Option D"],
"answer": "The correct answer letter (A, B, C, or D)"
}
```
"""
print(f"region: {region}")
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.5-flash-preview-04-17", location=region)
plan=None
#load the file using file_name and read content into string call plan
with open(file_name, 'r') as f:
plan = f.read()
parser = JsonOutputParser(pydantic_object=QuizQuestion)
instruction = f"You'll provide one question with difficulty level of {difficulty}, 4 options as multiple choices and provide the anwsers, the quiz needs to be related to the teaching plan {plan}"
prompt = PromptTemplate(
template="Generates a single multiple-choice quiz question\n {format_instructions}\n {instruction}\n",
input_variables=["instruction"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | llm | parser
response = chain.invoke({"instruction": instruction})
print(f"{response}")
return response
W agencie tworzy parser danych wyjściowych w formacie JSON, który jest specjalnie zaprojektowany do rozumienia i strukturyzowania danych wyjściowych LLM. Korzysta z modelu QuizQuestion, który został zdefiniowany wcześniej, aby mieć pewność, że przeanalizowane dane wyjściowe są zgodne z prawidłowym formatem (pytanie, opcje i odpowiedź).
👉 W terminalu wykonaj te polecenia, aby skonfigurować środowisko wirtualne, zainstalować zależności i uruchomić agenta:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
python -m venv env
source env/bin/activate
pip install -r requirements.txt
python app.py
👉 W menu „Podgląd w przeglądarce” w prawym górnym rogu wybierz Podejrzyj na porcie 8080. Cloud Shell otworzy nową kartę przeglądarki lub okno z podglądem internetowym aplikacji.
👉 W aplikacji internetowej kliknij link „Quizy” na górnym pasku nawigacyjnym lub na karcie na stronie indeksu. Uczeń powinien zobaczyć 3 losowo wygenerowane quizy. Te quizy są oparte na planie nauczania i pokazują możliwości naszego systemu generowania quizów opartego na AI.

👉 Aby zatrzymać proces uruchomiony lokalnie, naciśnij Ctrl+C w terminalu.
Gemini 2 Thinking do wyjaśnień
OK, mamy quizy, co jest świetnym początkiem. Ale co się stanie, jeśli uczniowie się pomylą? To właśnie wtedy następuje prawdziwa nauka, prawda? Jeśli wyjaśnimy, dlaczego odpowiedź była nieprawidłowa i jak uzyskać prawidłową, jest większe prawdopodobieństwo, że zapamiętają ją na dłużej. Pomaga to też rozwiać wszelkie wątpliwości i zwiększyć pewność siebie.
Dlatego sięgniemy po ciężką artylerię: model myślący Gemini 2. To tak, jakby dać AI trochę więcej czasu na przemyślenie sprawy przed wyjaśnieniem. Dzięki temu może ona przekazywać bardziej szczegółowe i lepsze opinie.
Chcemy sprawdzić, czy może pomóc uczniom, udzielając odpowiedzi i szczegółowych wyjaśnień. Aby to sprawdzić, zaczniemy od notorycznie trudnego tematu, czyli rachunku różniczkowego i całkowego.

👉Najpierw otwórz edytor Cloud Code w pliku answer.py w folderze portal. Zastąp ten kod funkcji
def answer_thinking(question, options, user_response, answer, region):
return ""
z tym fragmentem kodu:
def answer_thinking(question, options, user_response, answer, region):
try:
llm = VertexAI(model_name="gemini-2.0-flash-001",location=region)
input_msg = HumanMessage(content=[f"Here the question{question}, here are the available options {options}, this student's answer {user_response}, whereas the correct answer is {answer}"])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful teacher trying to teach the student on question, you were given the question and a set of multiple choices "
"what's the correct answer. use friendly tone"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
if __name__ == "__main__":
question = "Evaluate the limit: lim (x→0) [(sin(5x) - 5x) / x^3]"
options = ["A) -125/6", "B) -5/3 ", "C) -25/3", "D) -5/6"]
user_response = "B"
answer = "A"
region = "us-central1"
result = answer_thinking(question, options, user_response, answer, region)
Jest to bardzo prosta aplikacja Langchain, która inicjuje model Gemini 2 Flash. Instruujemy ją, aby działała jak pomocny nauczyciel i wyjaśniała różne kwestie.
👉 W terminalu wykonaj to polecenie:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python answer.py
Dane wyjściowe powinny być podobne do przykładu podanego w oryginalnych instrukcjach. Obecny model może nie zapewniać tak dokładnego wyjaśnienia.
Okay, I see the question and the choices. The question is to evaluate the limit:
lim (x→0) [(sin(5x) - 5x) / x^3]
You chose option B, which is -5/3, but the correct answer is A, which is -125/6.
It looks like you might have missed a step or made a small error in your calculations. This type of limit often involves using L'Hôpital's Rule or Taylor series expansion. Since we have the form 0/0, L'Hôpital's Rule is a good way to go! You need to apply it multiple times. Alternatively, you can use the Taylor series expansion of sin(x) which is:
sin(x) = x - x^3/3! + x^5/5! - ...
So, sin(5x) = 5x - (5x)^3/3! + (5x)^5/5! - ...
Then, (sin(5x) - 5x) = - (5x)^3/3! + (5x)^5/5! - ...
Finally, (sin(5x) - 5x) / x^3 = - 5^3/3! + (5^5 * x^2)/5! - ...
Taking the limit as x approaches 0, we get -125/6.
Keep practicing, you'll get there!
👉 W pliku answer.py zastąp
model_name od gemini-2.0-flash-001 do gemini-2.0-flash-thinking-exp-01-21 w funkcji answer_thinking.
Spowoduje to zmianę modelu LLM na inny, który lepiej radzi sobie z rozumowaniem. Pomoże to modelowi generować lepsze wyjaśnienia.
👉 Ponownie uruchom answer.py skrypt, aby przetestować nowy model myślenia:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python answer.py
Oto przykład odpowiedzi modelu myślącego, która jest znacznie bardziej szczegółowa i zawiera wyjaśnienie krok po kroku, jak rozwiązać zadanie z rachunku różniczkowego. Podkreśla to możliwości modeli „myślących” w generowaniu wysokiej jakości wyjaśnień. Dane wyjściowe powinny być podobne do tych:
Hey there! Let's take a look at this limit problem together. You were asked to evaluate:
lim (x→0) [(sin(5x) - 5x) / x^3]
and you picked option B, -5/3, but the correct answer is actually A, -125/6. Let's figure out why!
It's a tricky one because if we directly substitute x=0, we get (sin(0) - 0) / 0^3 = (0 - 0) / 0 = 0/0, which is an indeterminate form. This tells us we need to use a more advanced technique like L'Hopital's Rule or Taylor series expansion.
Let's use the Taylor series expansion for sin(y) around y=0. Do you remember it? It looks like this:
sin(y) = y - y^3/3! + y^5/5! - ...
where 3! (3 factorial) is 3 × 2 × 1 = 6, 5! is 5 × 4 × 3 × 2 × 1 = 120, and so on.
In our problem, we have sin(5x), so we can substitute y = 5x into the Taylor series:
sin(5x) = (5x) - (5x)^3/3! + (5x)^5/5! - ...
sin(5x) = 5x - (125x^3)/6 + (3125x^5)/120 - ...
Now let's plug this back into our limit expression:
[(sin(5x) - 5x) / x^3] = [ (5x - (125x^3)/6 + (3125x^5)/120 - ...) - 5x ] / x^3
Notice that the '5x' and '-5x' cancel out! So we are left with:
= [ - (125x^3)/6 + (3125x^5)/120 - ... ] / x^3
Now, we can divide every term in the numerator by x^3:
= -125/6 + (3125x^2)/120 - ...
Finally, let's take the limit as x approaches 0. As x gets closer and closer to zero, terms with x^2 and higher powers will become very, very small and approach zero. So, we are left with:
lim (x→0) [ -125/6 + (3125x^2)/120 - ... ] = -125/6
Therefore, the correct answer is indeed **A) -125/6**.
It seems like your answer B, -5/3, might have come from perhaps missing a factor somewhere during calculation or maybe using an incorrect simplification. Double-check your steps when you were trying to solve it!
Don't worry, these limit problems can be a bit tricky sometimes! Keep practicing and you'll get the hang of it. Let me know if you want to go through another similar example or if you have any more questions! 😊
Now that we have confirmed it works, let's use the portal.
👉USUŃ z pliku answer.py ten kod testowy:
if __name__ == "__main__":
question = "Evaluate the limit: lim (x→0) [(sin(5x) - 5x) / x^3]"
options = ["A) -125/6", "B) -5/3 ", "C) -25/3", "D) -5/6"]
user_response = "B"
answer = "A"
region = "us-central1"
result = answer_thinking(question, options, user_response, answer, region)
👉Aby skonfigurować środowisko wirtualne, zainstalować zależności i uruchomić agenta, wykonaj w terminalu te polecenia:
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python app.py
👉 W menu „Podgląd w przeglądarce” w prawym górnym rogu wybierz Podejrzyj na porcie 8080. Cloud Shell otworzy nową kartę przeglądarki lub okno z podglądem internetowym aplikacji.
👉 W aplikacji internetowej kliknij link „Quizy” na górnym pasku nawigacyjnym lub na karcie na stronie indeksu.
👉 Odpowiedz na wszystkie quizy i upewnij się, że przynajmniej jedna odpowiedź jest błędna, a następnie kliknij Prześlij.

Zamiast czekać na odpowiedź, przełącz się na terminal edytora Cloud. Postęp i wszelkie dane wyjściowe lub komunikaty o błędach generowane przez funkcję możesz obserwować w terminalu emulatora. 😁
👉 W terminalu zatrzymaj lokalnie działający proces, naciskając Ctrl+C.
11. OPCJONALNIE: koordynowanie agentów za pomocą Eventarc
Do tej pory portal dla uczniów generował quizy na podstawie domyślnego zestawu planów nauczania. Jest to przydatne, ale oznacza, że nasz agent planujący i agent quizów w portalu nie komunikują się ze sobą. Pamiętasz, jak dodaliśmy funkcję, dzięki której agent planujący publikuje nowo wygenerowane plany nauczania w temacie Pub/Sub? Teraz musimy połączyć go z agentem portalu.

Chcemy, aby portal automatycznie aktualizował treści quizu za każdym razem, gdy zostanie wygenerowany nowy plan nauczania. W tym celu utworzymy w portalu punkt końcowy, który będzie mógł odbierać te nowe plany.
👉 W panelu Eksplorator edytora Cloud Code otwórz folder portal.
👉 Otwórz plik app.py do edycji. Zastąp wiersz REPLACE ## REPLACE ME! NEW TEACHING PLAN tym kodem:
@app.route('/new_teaching_plan', methods=['POST'])
def new_teaching_plan():
try:
# Get data from Pub/Sub message delivered via Eventarc
envelope = request.get_json()
if not envelope:
return jsonify({'error': 'No Pub/Sub message received'}), 400
if not isinstance(envelope, dict) or 'message' not in envelope:
return jsonify({'error': 'Invalid Pub/Sub message format'}), 400
pubsub_message = envelope['message']
print(f"data: {pubsub_message['data']}")
data = pubsub_message['data']
data_str = base64.b64decode(data).decode('utf-8')
data = json.loads(data_str)
teaching_plan = data['teaching_plan']
print(f"File content: {teaching_plan}")
with open("teaching_plan.txt", "w") as f:
f.write(teaching_plan)
print(f"Teaching plan saved to local file: teaching_plan.txt")
return jsonify({'message': 'File processed successfully'})
except Exception as e:
print(f"Error processing file: {e}")
return jsonify({'error': 'Error processing file'}), 500
Ponowne kompilowanie i wdrażanie w Cloud Run
Musisz zaktualizować i ponownie wdrożyć w Cloud Run zarówno agenta planującego, jak i agenta portalu. Dzięki temu będą one miały najnowszy kod i będą skonfigurowane do komunikacji za pomocą zdarzeń.

👉Najpierw ponownie skompilujemy i prześlemy obraz agenta planner, wykonując w terminalu to polecenie:
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-planner .
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-planner us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
👉 Zrobimy to samo, czyli utworzymy i prześlemy obraz agenta portal:
cd ~/aidemy-bootstrap/portal/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-portal .
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-portal us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
👉 Przejdź do Artifact Registry. W sekcji agent-repository powinny być widoczne obrazy kontenerów aidemy-planner i aidemy-portal.

👉Wróć do terminala i uruchom to polecenie, aby zaktualizować obraz Cloud Run dla agenta planującego:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services update aidemy-planner \
--region=us-central1 \
--image=us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner:latest
Dane wyjściowe powinny być podobne do tych:
OK Deploying... Done.
OK Creating Revision...
OK Routing traffic...
Done.
Service [aidemy-planner] revision [aidemy-planner-xxxxx] has been deployed and is serving 100 percent of traffic.
Service URL: https://aidemy-planner-xxx.us-central1.run.app
Zanotuj adres URL usługi. Jest to link do wdrożonego agenta planującego. Jeśli później będziesz potrzebować adresu URL usługi agenta planującego, użyj tego polecenia:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services describe aidemy-planner \
--region=us-central1 \
--format 'value(status.url)'
👉 Uruchom to polecenie, aby utworzyć instancję Cloud Run dla agenta portalu.
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy aidemy-portal \
--image=us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal:latest \
--region=us-central1 \
--platform=managed \
--allow-unauthenticated \
--memory=2Gi \
--cpu=2 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID}
Dane wyjściowe powinny być podobne do tych:
Deploying container to Cloud Run service [aidemy-portal] in project [xxxx] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [aidemy-portal] revision [aidemy-portal-xxxx] has been deployed and is serving 100 percent of traffic.
Service URL: https://aidemy-portal-xxxx.us-central1.run.app
Zanotuj adres URL usługi. Jest to link do wdrożonego portalu dla uczniów. Jeśli później będziesz potrzebować adresu URL usługi portalu dla uczniów, użyj tego polecenia:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services describe aidemy-portal \
--region=us-central1 \
--format 'value(status.url)'
Tworzenie aktywatora Eventarc
Pojawia się jednak ważne pytanie: jak ten punkt końcowy otrzymuje powiadomienie, gdy w temacie Pub/Sub pojawi się nowy plan? W takich sytuacjach Eventarc przychodzi z pomocą.
Eventarc działa jak pomost, nasłuchując określonych zdarzeń (np. pojawienia się nowej wiadomości w temacie Pub/Sub) i automatycznie wywołując działania w odpowiedzi na nie. W naszym przypadku wykryje on opublikowanie nowego planu nauczania, a następnie wyśle sygnał do punktu końcowego portalu, informując go, że nadszedł czas na aktualizację.
Dzięki Eventarc, który obsługuje komunikację opartą na zdarzeniach, możemy bezproblemowo połączyć agenta planującego i agenta portalu, tworząc dynamiczny i elastyczny system nauczania. To jak inteligentny posłaniec, który automatycznie dostarcza najnowsze plany lekcji we właściwe miejsce.
👉 W konsoli otwórz Eventarc.
👉 Kliknij przycisk „+ UTWÓRZ WYWOŁYWACZ”.
Skonfiguruj regułę (podstawowe ustawienia):
- Nazwa aktywatora:
plan-topic-trigger - Typ aktywatora: źródła Google
- Dostawca zdarzeń: Cloud Pub/Sub
- Typ zdarzenia:
google.cloud.pubsub.topic.v1.messagePublished - Temat Cloud Pub/Sub: wybierz
projects/PROJECT_ID/topics/plan. - Region:
us-central1. - Konto usługi:
- PRZYPISZ do konta usługi rolę
roles/iam.serviceAccountTokenCreator - Użyj wartości domyślnej: domyślne konto usługi Compute.
- PRZYPISZ do konta usługi rolę
- Miejsce docelowe zdarzenia: Cloud Run
- Usługa Cloud Run:
aidemy-portal - Zignoruj komunikat o błędzie: Odmowa uprawnień w odniesieniu do „locations/me-central2” (lub może on nie istnieć).
- Ścieżka adresu URL usługi:
/new_teaching_plan
👉 Kliknij „Utwórz”.
Strona Aktywatory Eventarc zostanie odświeżona i w tabeli powinien być widoczny nowo utworzony aktywator.
Teraz uzyskaj dostęp do agenta planowania za pomocą jego adresu URL usługi, aby poprosić o nowy plan nauczania.
👉 Aby określić adres URL usługi agenta planującego, uruchom to polecenie w terminalu:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep planner
👉 Przejdź do wygenerowanego adresu URL i tym razem wypróbuj opcje Year 5, Subject Science i Add-on Request atoms.
Następnie odczekaj minutę lub dwie. To opóźnienie zostało wprowadzone ze względu na ograniczenia rozliczeniowe tego modułu. W normalnych warunkach nie powinno go być.
Na koniec otwórz portal ucznia, korzystając z adresu URL usługi.
Aby określić adres URL usługi agenta portalu dla uczniów, uruchom w terminalu to polecenie:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep portal
Powinny być widoczne zaktualizowane quizy, które są teraz zgodne z nowym planem nauczania. To pokazuje, że integracja Eventarc z systemem Aidemy przebiegła pomyślnie.

Gratulacje! Udało Ci się utworzyć w Google Cloud system z wieloma agentami, który wykorzystuje architekturę opartą na zdarzeniach, aby zwiększyć skalowalność i elastyczność. Masz już solidne podstawy, ale to nie wszystko. Aby dowiedzieć się więcej o prawdziwych korzyściach tej architektury, poznać możliwości interfejsu Gemini 2 Multimodal Live API i nauczyć się wdrażać orkiestrację pojedynczej ścieżki za pomocą LangGraph, przejdź do kolejnych dwóch rozdziałów.
12. OPCJONALNIE: podsumowania audio z Gemini
Gemini potrafi rozumieć i przetwarzać informacje z różnych źródeł, takich jak tekst, obrazy, a nawet dźwięk, co otwiera zupełnie nowe możliwości uczenia się i tworzenia treści. Dzięki temu, że Gemini „widzi”, „słyszy” i „czyta”, możesz tworzyć kreatywne i angażujące doświadczenia użytkowników.
Oprócz tworzenia wizualizacji i tekstu ważnym krokiem w procesie uczenia się jest skuteczne podsumowywanie i powtarzanie informacji. Zastanów się: jak często łatwiej zapamiętujesz chwytliwy tekst piosenki niż coś, co przeczytałeś(-aś) w podręczniku? Dźwięk może być niezwykle zapadający w pamięć. Dlatego wykorzystamy multimodalne możliwości Gemini do generowania podsumowań audio naszych planów nauczania. Dzięki temu uczniowie będą mogli w wygodny i angażujący sposób powtarzać materiał, co może zwiększyć zapamiętywanie i zrozumienie dzięki nauce słuchowej.

Potrzebujemy miejsca do przechowywania wygenerowanych plików audio. Cloud Storage to skalowalne i niezawodne rozwiązanie.
👉 W konsoli otwórz Miejsce na dane. W menu po lewej stronie kliknij „Buckets” (Kosz). U góry kliknij przycisk „+ UTWÓRZ”.
👉Skonfiguruj nowy zasobnik:
- nazwa zasobnika:
aidemy-recap-UNIQUE_NAME.- WAŻNE: określ unikalną nazwę zasobnika, która zaczyna się od znaku
aidemy-recap-. Ten unikalny prefiks jest niezbędny, aby uniknąć konfliktów nazw podczas tworzenia zasobnika Cloud Storage.
- WAŻNE: określ unikalną nazwę zasobnika, która zaczyna się od znaku
- region:
us-central1. - Klasa pamięci masowej: „Standard”. Standardowa klasa pamięci jest odpowiednia w przypadku danych, do których często sięga się użytkownik.
- Kontrola dostępu: pozostaw domyślną opcję „Jednolita”. Zapewnia to spójną kontrolę dostępu na poziomie zasobnika.
- Opcje zaawansowane: w przypadku tych warsztatów ustawienia domyślne są zwykle wystarczające.
Aby utworzyć zasobnik, kliknij przycisk UTWÓRZ.
- Może pojawić się okienko z informacją o blokadzie dostępu publicznego. Pozostaw zaznaczone pole „Wyegzekwuj blokadę dostępu publicznego do tego zasobnika” i kliknij
Confirm.
Nowo utworzony zasobnik pojawi się na liście Zasobniki. Zapamiętaj nazwę zasobnika, będzie Ci później potrzebna.
👉 W terminalu edytora Cloud Code uruchom te polecenia, aby przyznać kontu usługi dostęp do zasobnika:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gcloud storage buckets add-iam-policy-binding gs://$COURSE_BUCKET_NAME \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectViewer"
gcloud storage buckets add-iam-policy-binding gs://$COURSE_BUCKET_NAME \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectCreator"
👉 W edytorze Cloud Code otwórz plik audio.py w folderze courses. Wklej na końcu pliku ten kod:
config = LiveConnectConfig(
response_modalities=["AUDIO"],
speech_config=SpeechConfig(
voice_config=VoiceConfig(
prebuilt_voice_config=PrebuiltVoiceConfig(
voice_name="Charon",
)
)
),
)
async def process_weeks(teaching_plan: str):
region = "us-east5" #To workaround onRamp quota limits
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
clientAudio = genai.Client(vertexai=True, project=PROJECT_ID, location="us-central1")
async with clientAudio.aio.live.connect(
model=MODEL_ID,
config=config,
) as session:
for week in range(1, 4):
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Given the following teaching plan: {teaching_plan}, Extrace content plan for week {week}. And return just the plan, nothingh else " # Clarified prompt
)
prompt = f"""
Assume you are the instructor.
Prepare a concise and engaging recap of the key concepts and topics covered.
This recap should be suitable for generating a short audio summary for students.
Focus on the most important learnings and takeaways, and frame it as a direct address to the students.
Avoid overly formal language and aim for a conversational tone, tell a few jokes.
Teaching plan: {response.text} """
print(f"prompt --->{prompt}")
await session.send(input=prompt, end_of_turn=True)
with open(f"temp_audio_week_{week}.raw", "wb") as temp_file:
async for message in session.receive():
if message.server_content.model_turn:
for part in message.server_content.model_turn.parts:
if part.inline_data:
temp_file.write(part.inline_data.data)
data, samplerate = sf.read(f"temp_audio_week_{week}.raw", channels=1, samplerate=24000, subtype='PCM_16', format='RAW')
sf.write(f"course-week-{week}.wav", data, samplerate)
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
blob = bucket.blob(f"course-week-{week}.wav") # Or give it a more descriptive name
blob.upload_from_filename(f"course-week-{week}.wav")
print(f"Audio saved to GCS: gs://{BUCKET_NAME}/course-week-{week}.wav")
await session.close()
def breakup_sessions(teaching_plan: str):
asyncio.run(process_weeks(teaching_plan))
- Połączenie transmisji strumieniowej: najpierw nawiązywane jest trwałe połączenie z punktem końcowym Live API. W przeciwieństwie do standardowego wywołania interfejsu API, w którym wysyłasz żądanie i otrzymujesz odpowiedź, to połączenie pozostaje otwarte w celu ciągłej wymiany danych.
- Configuration Multimodal: Use configuration to specifying what type of output you want (in this case, audio), and you can even specify what parameters you'd like to use (e.g., voice selection, audio encoding)
- Przetwarzanie asynchroniczne: ten interfejs API działa asynchronicznie, co oznacza, że nie blokuje wątku głównego podczas oczekiwania na zakończenie generowania dźwięku. Przetwarzając dane w czasie rzeczywistym i wysyłając wyniki w częściach, zapewnia niemal natychmiastowe działanie.
Kluczowe pytanie brzmi: kiedy powinien być uruchamiany proces generowania dźwięku? Zależy nam na tym, aby podsumowania audio były dostępne od razu po utworzeniu nowego planu nauczania. Ponieważ wdrożyliśmy już architekturę opartą na zdarzeniach, publikując plan nauczania w temacie Pub/Sub, możemy po prostu zasubskrybować ten temat.
Nie generujemy jednak nowych planów nauczania zbyt często. Nie byłoby wydajne, gdyby agent stale działał i czekał na nowe plany. Dlatego idealnym rozwiązaniem jest wdrożenie tej logiki generowania dźwięku jako funkcji Cloud Run.
Dzięki wdrożeniu go jako funkcji pozostaje on w stanie uśpienia do momentu opublikowania nowej wiadomości w temacie Pub/Sub. W takim przypadku automatycznie uruchamia się funkcja, która generuje podsumowania audio i zapisuje je w naszym zasobniku.
👉W folderze courses w pliku main.py ten plik definiuje funkcję Cloud Run, która zostanie uruchomiona, gdy będzie dostępny nowy plan nauczania. Otrzymuje plan i rozpoczyna generowanie podsumowania audio. Na końcu pliku dodaj ten fragment kodu.
@functions_framework.cloud_event
def process_teaching_plan(cloud_event):
print(f"CloudEvent received: {cloud_event.data}")
time.sleep(60)
try:
if isinstance(cloud_event.data.get('message', {}).get('data'), str): # Check for base64 encoding
data = json.loads(base64.b64decode(cloud_event.data['message']['data']).decode('utf-8'))
teaching_plan = data.get('teaching_plan') # Get the teaching plan
elif 'teaching_plan' in cloud_event.data: # No base64
teaching_plan = cloud_event.data["teaching_plan"]
else:
raise KeyError("teaching_plan not found") # Handle error explicitly
#Load the teaching_plan as string and from cloud event, call audio breakup_sessions
breakup_sessions(teaching_plan)
return "Teaching plan processed successfully", 200
except (json.JSONDecodeError, AttributeError, KeyError) as e:
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500
except Exception as e:
print(f"Error processing teaching plan: {e}")
return "Error processing teaching plan", 500
@functions_framework.cloud_event: ten dekorator oznacza funkcję jako funkcję Cloud Run, która będzie wywoływana przez CloudEvents.
Testowanie lokalne
👉 Uruchomimy to w środowisku wirtualnym i zainstalujemy niezbędne biblioteki Pythona dla funkcji Cloud Run.
cd ~/aidemy-bootstrap/courses
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉Emulator funkcji Cloud Run umożliwia przetestowanie funkcji lokalnie przed wdrożeniem jej w Google Cloud. Uruchom emulator lokalny, wpisując:
functions-framework --target process_teaching_plan --signature-type=cloudevent --source main.py
👉Gdy emulator jest uruchomiony, możesz wysyłać do niego testowe zdarzenia CloudEvents, aby symulować publikowanie nowego planu nauczania. W nowym terminalu:

👉Uruchom:
curl -X POST \
http://localhost:8080/ \
-H "Content-Type: application/json" \
-H "ce-id: event-id-01" \
-H "ce-source: planner-agent" \
-H "ce-specversion: 1.0" \
-H "ce-type: google.cloud.pubsub.topic.v1.messagePublished" \
-d '{
"message": {
"data": "eyJ0ZWFjaGluZ19wbGFuIjogIldlZWsgMTogMkQgU2hhcGVzIGFuZCBBbmdsZXMgLSBEYXkgMTogUmV2aWV3IG9mIGJhc2ljIDJEIHNoYXBlcyAoc3F1YXJlcywgcmVjdGFuZ2xlcywgdHJpYW5nbGVzLCBjaXJjbGVzKS4gRGF5IDI6IEV4cGxvcmluZyBkaWZmZXJlbnQgdHlwZXMgb2YgdHJpYW5nbGVzIChlcXVpbGF0ZXJhbCwgaXNvc2NlbGVzLCBzY2FsZW5lLCByaWdodC1hbmdsZWQpLiBEYXkgMzogRXhwbG9yaW5nIHF1YWRyaWxhdGVyYWxzIChzcXVhcmUsIHJlY3RhbmdsZSwgcGFyYWxsZWxvZ3JhbSwgcmhvbWJ1cywgdHJhcGV6aXVtKS4gRGF5IDQ6IEludHJvZHVjdGlvbiB0byBhbmdsZXM6IHJpZ2h0IGFuZ2xlcywgYWN1dGUgYW5nbGVzLCBhbmQgb2J0dXNlIGFuZ2xlcy4gRGF5IDU6IE1lYXN1cmluZyBhbmdsZXMgdXNpbmcgYSBwcm90cmFjdG9yLiBXZWVrIDI6IDNEIFNoYXBlcyBhbmQgU3ltbWV0cnkgLSBEYXkgNjogSW50cm9kdWN0aW9uIHRvIDNEIHNoYXBlczogY3ViZXMsIGN1Ym9pZHMsIHNwaGVyZXMsIGN5bGluZGVycywgY29uZXMsIGFuZCBweXJhbWlkcy4gRGF5IDc6IERlc2NyaWJpbmcgM0Qgc2hhcGVzIHVzaW5nIGZhY2VzLCBlZGdlcywgYW5kIHZlcnRpY2VzLiBEYXkgODogUmVsYXRpbmcgMkQgc2hhcGVzIHRvIDNEIHNoYXBlcy4gRGF5IDk6IElkZW50aWZ5aW5nIGxpbmVzIG9mIHN5bW1ldHJ5IGluIDJEIHNoYXBlcy4gRGF5IDEwOiBDb21wbGV0aW5nIHN5bW1ldHJpY2FsIGZpZ3VyZXMuIFdlZWsgMzogUG9zaXRpb24sIERpcmVjdGlvbiwgYW5kIFByb2JsZW0gU29sdmluZyAtIERheSAxMTogRGVzY3JpYmluZyBwb3NpdGlvbiB1c2luZyBjb29yZGluYXRlcyBpbiB0aGUgZmlyc3QgcXVhZHJhbnQuIERheSAxMjogUGxvdHRpbmcgY29vcmRpbmF0ZXMgdG8gZHJhdyBzaGFwZXMuIERheSAxMzogVW5kZXJzdGFuZGluZyB0cmFuc2xhdGlvbiAoc2xpZGluZyBhIHNoYXBlKS4gRGF5IDE0OiBVbmRlcnN0YW5kaW5nIHJlZmxlY3Rpb24gKGZsaXBwaW5nIGEgc2hhcGUpLiBEYXkgMTU6IFByb2JsZW0tc29sdmluZyBhY3Rpdml0aWVzIGludm9sdmluZyBwZXJpbWV0ZXIsIGFyZWEsIGFuZCBtaXNzaW5nIGFuZ2xlcy4ifQ=="
}
}'
Zamiast czekać na odpowiedź, przełącz się na drugi terminal Cloud Shell. Postęp i wszelkie dane wyjściowe lub komunikaty o błędach generowane przez funkcję możesz obserwować w terminalu emulatora. 😁
W drugim terminalu powinna pojawić się wartość OK.
👉Sprawdź dane w zasobniku. W tym celu otwórz Cloud Storage, wybierz kartę „Zasobnik”, a następnie kliknij aidemy-recap-UNIQUE_NAME.

👉 W terminalu, w którym działa emulator, wpisz ctrl+c, aby zamknąć emulator. Zamknij drugi terminal. Zamknij drugi terminal i uruchom polecenie deactivate, aby zamknąć środowisko wirtualne.
deactivate
Wdrażanie w Google Cloud
 👉Po przetestowaniu agenta lokalnie możesz wdrożyć go w Google Cloud. W terminalu uruchom te polecenia:
👉Po przetestowaniu agenta lokalnie możesz wdrożyć go w Google Cloud. W terminalu uruchom te polecenia:
cd ~/aidemy-bootstrap/courses
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud functions deploy courses-agent \
--region=us-central1 \
--gen2 \
--source=. \
--runtime=python312 \
--trigger-topic=plan \
--entry-point=process_teaching_plan \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
Sprawdź wdrożenie, otwierając Cloud Run w konsoli Google Cloud.Powinna się tam pojawić nowa usługa o nazwie courses-agent.

Aby sprawdzić konfigurację wyzwalacza, kliknij usługę courses-agent, aby wyświetlić jej szczegóły. Otwórz kartę „WYWOŁYWACZE”.
Powinien pojawić się wyzwalacz skonfigurowany do nasłuchiwania wiadomości publikowanych w temacie planu.

Na koniec zobaczmy, jak to działa w praktyce.
👉Musimy skonfigurować agenta portalu, aby wiedział, gdzie znaleźć wygenerowane pliki audio. W terminalu uruchom:
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services update aidemy-portal \
--region=us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
👉 Spróbuj wygenerować nowy plan nauczania na stronie internetowej agenta planującego. Uruchomienie może potrwać kilka minut. Nie martw się, to usługa bezserwerowa.
Aby uzyskać dostęp do agenta planowania, pobierz jego adres URL usługi, uruchamiając w terminalu to polecenie:
gcloud run services list \
--platform=managed \
--region=us-central1 \
--format='value(URL)' | grep planner
Po wygenerowaniu nowego planu poczekaj 2–3 minuty na wygenerowanie dźwięku. Ze względu na ograniczenia rozliczeniowe tego konta laboratoryjnego potrwa to kilka minut.
Aby sprawdzić, czy funkcja courses-agent otrzymała plan nauczania, otwórz kartę „TRIGGERS” (WYWOŁANIA) funkcji. Odświeżaj stronę okresowo. W końcu zobaczysz, że funkcja została wywołana. Jeśli funkcja nie została wywołana po upływie 2 minut, możesz spróbować ponownie wygenerować plan nauczania. Unikaj jednak wielokrotnego generowania planów w szybkim tempie, ponieważ każdy wygenerowany plan będzie kolejno wykorzystywany i przetwarzany przez agenta, co może spowodować zaległości.

👉 Odwiedź portal i kliknij „Courses” (Kursy). Powinny pojawić się 3 karty, na których wyświetlają się podsumowania audio. Aby znaleźć adres URL agenta portalu:
gcloud run services list \
--platform=managed \
--region=us-central1 \
--format='value(URL)' | grep portal
Kliknij „Odtwórz” przy każdym szkoleniu, aby sprawdzić, czy podsumowania audio są zgodne z wygenerowanym właśnie planem nauczania. 
Zamknij środowisko wirtualne.
deactivate
13. OPCJONALNIE: współpraca oparta na rolach z Gemini i DeepSeek
Różne perspektywy są nieocenione, zwłaszcza podczas tworzenia angażujących i przemyślanych zadań. Teraz zbudujemy system z wieloma agentami, który wykorzystuje 2 różne modele o odmiennych rolach do generowania zadań: jeden promuje współpracę, a drugi zachęca do samodzielnej nauki. Użyjemy architektury „jednorazowej”, w której przepływ pracy przebiega stałą trasą.
Generator zadań Gemini
 Zaczniemy od skonfigurowania funkcji Gemini, aby generować projekty z naciskiem na współpracę. Edytuj plik
Zaczniemy od skonfigurowania funkcji Gemini, aby generować projekty z naciskiem na współpracę. Edytuj plik gemini.py znajdujący się w folderze assignment.
👉 Wklej ten kod na końcu pliku gemini.py:
def gen_assignment_gemini(state):
region=get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
print(f"---------------gen_assignment_gemini")
response = client.models.generate_content(
model=MODEL_ID, contents=f"""
You are an instructor
Develop engaging and practical assignments for each week, ensuring they align with the teaching plan's objectives and progressively build upon each other.
For each week, provide the following:
* **Week [Number]:** A descriptive title for the assignment (e.g., "Data Exploration Project," "Model Building Exercise").
* **Learning Objectives Assessed:** List the specific learning objectives from the teaching plan that this assignment assesses.
* **Description:** A detailed description of the task, including any specific requirements or constraints. Provide examples or scenarios if applicable.
* **Deliverables:** Specify what students need to submit (e.g., code, report, presentation).
* **Estimated Time Commitment:** The approximate time students should dedicate to completing the assignment.
* **Assessment Criteria:** Briefly outline how the assignment will be graded (e.g., correctness, completeness, clarity, creativity).
The assignments should be a mix of individual and collaborative work where appropriate. Consider different learning styles and provide opportunities for students to apply their knowledge creatively.
Based on this teaching plan: {state["teaching_plan"]}
"""
)
print(f"---------------gen_assignment_gemini answer {response.text}")
state["model_one_assignment"] = response.text
return state
import unittest
class TestGenAssignmentGemini(unittest.TestCase):
def test_gen_assignment_gemini(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assigmodel_one_assignmentnment": "", "final_assignment": ""}
updated_state = gen_assignment_gemini(initial_state)
self.assertIn("model_one_assignment", updated_state)
self.assertIsNotNone(updated_state["model_one_assignment"])
self.assertIsInstance(updated_state["model_one_assignment"], str)
self.assertGreater(len(updated_state["model_one_assignment"]), 0)
print(updated_state["model_one_assignment"])
if __name__ == '__main__':
unittest.main()
Do generowania zadań wykorzystuje model Gemini.
Możemy przetestować agenta Gemini.
👉 Aby skonfigurować środowisko, uruchom w terminalu te polecenia:
cd ~/aidemy-bootstrap/assignment
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉Aby to sprawdzić, możesz uruchomić:
python gemini.py
W danych wyjściowych powinno się pojawić zadanie, które zawiera więcej pracy w grupach. Test asercji na końcu również wyświetli wyniki.
Here are some engaging and practical assignments for each week, designed to build progressively upon the teaching plan's objectives:
**Week 1: Exploring the World of 2D Shapes**
* **Learning Objectives Assessed:**
* Identify and name basic 2D shapes (squares, rectangles, triangles, circles).
* .....
* **Description:**
* **Shape Scavenger Hunt:** Students will go on a scavenger hunt in their homes or neighborhoods, taking pictures of objects that represent different 2D shapes. They will then create a presentation or poster showcasing their findings, classifying each shape and labeling its properties (e.g., number of sides, angles, etc.).
* **Triangle Trivia:** Students will research and create a short quiz or presentation about different types of triangles, focusing on their properties and real-world examples.
* **Angle Exploration:** Students will use a protractor to measure various angles in their surroundings, such as corners of furniture, windows, or doors. They will record their measurements and create a chart categorizing the angles as right, acute, or obtuse.
....
**Week 2: Delving into the World of 3D Shapes and Symmetry**
* **Learning Objectives Assessed:**
* Identify and name basic 3D shapes.
* ....
* **Description:**
* **3D Shape Construction:** Students will work in groups to build 3D shapes using construction paper, cardboard, or other materials. They will then create a presentation showcasing their creations, describing the number of faces, edges, and vertices for each shape.
* **Symmetry Exploration:** Students will investigate the concept of symmetry by creating a visual representation of various symmetrical objects (e.g., butterflies, leaves, snowflakes) using drawing or digital tools. They will identify the lines of symmetry and explain their findings.
* **Symmetry Puzzles:** Students will be given a half-image of a symmetrical figure and will be asked to complete the other half, demonstrating their understanding of symmetry. This can be done through drawing, cut-out activities, or digital tools.
**Week 3: Navigating Position, Direction, and Problem Solving**
* **Learning Objectives Assessed:**
* Describe position using coordinates in the first quadrant.
* ....
* **Description:**
* **Coordinate Maze:** Students will create a maze using coordinates on a grid paper. They will then provide directions for navigating the maze using a combination of coordinate movements and translation/reflection instructions.
* **Shape Transformations:** Students will draw shapes on a grid paper and then apply transformations such as translation and reflection, recording the new coordinates of the transformed shapes.
* **Geometry Challenge:** Students will solve real-world problems involving perimeter, area, and angles. For example, they could be asked to calculate the perimeter of a room, the area of a garden, or the missing angle in a triangle.
....
Zatrzymaj się na ctl+c i wyczyść kod testowy. USUŃ ten kod z gemini.py
import unittest
class TestGenAssignmentGemini(unittest.TestCase):
def test_gen_assignment_gemini(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assigmodel_one_assignmentnment": "", "final_assignment": ""}
updated_state = gen_assignment_gemini(initial_state)
self.assertIn("model_one_assignment", updated_state)
self.assertIsNotNone(updated_state["model_one_assignment"])
self.assertIsInstance(updated_state["model_one_assignment"], str)
self.assertGreater(len(updated_state["model_one_assignment"]), 0)
print(updated_state["model_one_assignment"])
if __name__ == '__main__':
unittest.main()
Konfigurowanie generatora zadań DeepSeek
Platformy AI oparte na chmurze są wygodne, ale samodzielne hostowanie dużych modeli językowych może mieć kluczowe znaczenie dla ochrony prywatności danych i zapewnienia suwerenności danych. Wdrożymy najmniejszy model DeepSeek (1,5 mld parametrów) na instancji Cloud Compute Engine. Istnieją inne sposoby, takie jak hostowanie na platformie Vertex AI od Google lub hostowanie na instancji GKE, ale ponieważ są to tylko warsztaty dotyczące agentów AI i nie chcę Cię tu zatrzymywać na zawsze, użyjmy najprostszego sposobu. Jeśli jednak interesuje Cię to zagadnienie i chcesz poznać inne opcje, zajrzyj do pliku deepseek-vertexai.py w folderze z zadaniem. Znajdziesz tam przykładowy kod pokazujący, jak korzystać z modeli wdrożonych w Vertex AI.

👉Uruchom w terminalu to polecenie, aby utworzyć samodzielnie hostowaną platformę LLM Ollama:
cd ~/aidemy-bootstrap/assignment
gcloud config set project $(cat ~/project_id.txt)
gcloud compute instances create ollama-instance \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--machine-type=e2-standard-4 \
--zone=us-central1-a \
--metadata-from-file startup-script=startup.sh \
--boot-disk-size=50GB \
--tags=ollama \
--scopes=https://www.googleapis.com/auth/cloud-platform
Aby sprawdzić, czy instancja Compute Engine jest uruchomiona:
W konsoli Google Cloud otwórz Compute Engine > „Instancje maszyn wirtualnych”. Powinna być widoczna ikona ollama-instance z zielonym znacznikiem wyboru, co oznacza, że jest uruchomiona. Jeśli nie widzisz tej opcji, sprawdź, czy strefa to us-central1. Jeśli nie, może być konieczne wyszukanie tej opcji.

👉Zainstalujemy najmniejszy model DeepSeek i go przetestujemy. W tym celu w edytorze Cloud Shell w nowym terminalu uruchom to polecenie, aby połączyć się z instancją GCE za pomocą SSH.
gcloud compute ssh ollama-instance --zone=us-central1-a
Po nawiązaniu połączenia SSH może pojawić się ten komunikat:
„Czy chcesz kontynuować (T/n)?”.
Aby przejść dalej, wpisz Y(bez rozróżniania wielkości liter) i naciśnij Enter.
Następnie może pojawić się prośba o utworzenie hasła do klucza SSH. Jeśli nie chcesz używać hasła, dwukrotnie naciśnij Enter, aby zaakceptować wartość domyślną (brak hasła).
👉Teraz jesteś na maszynie wirtualnej. Pobierz najmniejszy model DeepSeek R1 i sprawdź, czy działa.
ollama pull deepseek-r1:1.5b
ollama run deepseek-r1:1.5b "who are you?"
👉Aby zamknąć instancję GCE, wpisz w terminalu SSH:
exit
👉Następnie skonfiguruj zasady sieci, aby inne usługi mogły uzyskać dostęp do LLM. Jeśli chcesz to zrobić w przypadku środowiska produkcyjnego, ogranicz dostęp do instancji, wdrażając logowanie zabezpieczające dla usługi lub ograniczając dostęp do IP. Uruchomienie:
gcloud compute firewall-rules create allow-ollama-11434 \
--allow=tcp:11434 \
--target-tags=ollama \
--description="Allow access to Ollama on port 11434"
👉Aby sprawdzić, czy zasady zapory sieciowej działają prawidłowo, uruchom to polecenie:
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
curl -X POST "${OLLAMA_HOST}/api/generate" \
-H "Content-Type: application/json" \
-d '{
"prompt": "Hello, what are you?",
"model": "deepseek-r1:1.5b",
"stream": false
}'
Następnie zajmiemy się funkcją Deepseek w agencie projektów, aby generować projekty z naciskiem na indywidualną pracę.
👉Edytuj deepseek.py w folderze assignment i dodaj na końcu ten fragment kodu:
def gen_assignment_deepseek(state):
print(f"---------------gen_assignment_deepseek")
template = """
You are an instructor who favor student to focus on individual work.
Develop engaging and practical assignments for each week, ensuring they align with the teaching plan's objectives and progressively build upon each other.
For each week, provide the following:
* **Week [Number]:** A descriptive title for the assignment (e.g., "Data Exploration Project," "Model Building Exercise").
* **Learning Objectives Assessed:** List the specific learning objectives from the teaching plan that this assignment assesses.
* **Description:** A detailed description of the task, including any specific requirements or constraints. Provide examples or scenarios if applicable.
* **Deliverables:** Specify what students need to submit (e.g., code, report, presentation).
* **Estimated Time Commitment:** The approximate time students should dedicate to completing the assignment.
* **Assessment Criteria:** Briefly outline how the assignment will be graded (e.g., correctness, completeness, clarity, creativity).
The assignments should be a mix of individual and collaborative work where appropriate. Consider different learning styles and provide opportunities for students to apply their knowledge creatively.
Based on this teaching plan: {teaching_plan}
"""
prompt = ChatPromptTemplate.from_template(template)
model = OllamaLLM(model="deepseek-r1:1.5b",
base_url=OLLAMA_HOST)
chain = prompt | model
response = chain.invoke({"teaching_plan":state["teaching_plan"]})
state["model_two_assignment"] = response
return state
import unittest
class TestGenAssignmentDeepseek(unittest.TestCase):
def test_gen_assignment_deepseek(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = gen_assignment_deepseek(initial_state)
self.assertIn("model_two_assignment", updated_state)
self.assertIsNotNone(updated_state["model_two_assignment"])
self.assertIsInstance(updated_state["model_two_assignment"], str)
self.assertGreater(len(updated_state["model_two_assignment"]), 0)
print(updated_state["model_two_assignment"])
if __name__ == '__main__':
unittest.main()
👉sprawdźmy to, uruchamiając:
cd ~/aidemy-bootstrap/assignment
source env/bin/activate
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
python deepseek.py
Powinien pojawić się projekt, który zawiera więcej materiałów do samodzielnej nauki.
**Assignment Plan for Each Week**
---
### **Week 1: 2D Shapes and Angles**
- **Week Title:** "Exploring 2D Shapes"
Assign students to research and present on various 2D shapes. Include a project where they create models using straws and tape for triangles, draw quadrilaterals with specific measurements, and compare their properties.
### **Week 2: 3D Shapes and Symmetry**
Assign students to create models or nets for cubes and cuboids. They will also predict how folding these nets form the 3D shapes. Include a project where they identify symmetrical properties using mirrors or folding techniques.
### **Week 3: Position, Direction, and Problem Solving**
Assign students to use mirrors or folding techniques for reflections. Include activities where they measure angles, use a protractor, solve problems involving perimeter/area, and create symmetrical designs.
....
👉Zatrzymaj ctl+c i wyczyść kod testowy. USUŃ ten kod z deepseek.py
import unittest
class TestGenAssignmentDeepseek(unittest.TestCase):
def test_gen_assignment_deepseek(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = gen_assignment_deepseek(initial_state)
self.assertIn("model_two_assignment", updated_state)
self.assertIsNotNone(updated_state["model_two_assignment"])
self.assertIsInstance(updated_state["model_two_assignment"], str)
self.assertGreater(len(updated_state["model_two_assignment"]), 0)
print(updated_state["model_two_assignment"])
if __name__ == '__main__':
unittest.main()
Teraz użyjemy tego samego modelu Gemini, aby połączyć oba zadania w jedno nowe. Edytuj plik gemini.py znajdujący się w folderze assignment.
👉 Wklej ten kod na końcu pliku gemini.py:
def combine_assignments(state):
print(f"---------------combine_assignments ")
region=get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
response = client.models.generate_content(
model=MODEL_ID, contents=f"""
Look at all the proposed assignment so far {state["model_one_assignment"]} and {state["model_two_assignment"]}, combine them and come up with a final assignment for student.
"""
)
state["final_assignment"] = response.text
return state
Aby połączyć zalety obu modeli, zorganizujemy zdefiniowany przepływ pracy za pomocą LangGraph. Ten proces składa się z 3 etapów: najpierw model Gemini generuje zadanie skupione na współpracy, następnie model DeepSeek generuje zadanie podkreślające pracę indywidualną, a na koniec Gemini łączy te 2 zadania w jedno kompleksowe zadanie. Ponieważ wstępnie definiujemy sekwencję kroków bez podejmowania decyzji przez LLM, jest to orkiestracja zdefiniowana przez użytkownika, która przebiega jedną ścieżką.

👉Wklej ten kod na końcu pliku main.py w folderze assignment:
def create_assignment(teaching_plan: str):
print(f"create_assignment---->{teaching_plan}")
builder = StateGraph(State)
builder.add_node("gen_assignment_gemini", gen_assignment_gemini)
builder.add_node("gen_assignment_deepseek", gen_assignment_deepseek)
builder.add_node("combine_assignments", combine_assignments)
builder.add_edge(START, "gen_assignment_gemini")
builder.add_edge("gen_assignment_gemini", "gen_assignment_deepseek")
builder.add_edge("gen_assignment_deepseek", "combine_assignments")
builder.add_edge("combine_assignments", END)
graph = builder.compile()
state = graph.invoke({"teaching_plan": teaching_plan})
return state["final_assignment"]
import unittest
class TestCreateAssignment(unittest.TestCase):
def test_create_assignment(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = create_assignment(initial_state)
print(updated_state)
if __name__ == '__main__':
unittest.main()
👉Aby wstępnie przetestować funkcję create_assignment i sprawdzić, czy przepływ pracy łączący Gemini i DeepSeek działa prawidłowo, uruchom to polecenie:
cd ~/aidemy-bootstrap/assignment
source env/bin/activate
pip install -r requirements.txt
python main.py
Powinny one łączyć oba modele z ich indywidualną perspektywą dotyczącą nauki uczniów, a także pracy w grupie uczniów.
**Tasks:**
1. **Clue Collection:** Gather all the clues left by the thieves. These clues will include:
* Descriptions of shapes and their properties (angles, sides, etc.)
* Coordinate grids with hidden messages
* Geometric puzzles requiring transformation (translation, reflection, rotation)
* Challenges involving area, perimeter, and angle calculations
2. **Clue Analysis:** Decipher each clue using your geometric knowledge. This will involve:
* Identifying the shape and its properties
* Plotting coordinates and interpreting patterns on the grid
* Solving geometric puzzles by applying transformations
* Calculating area, perimeter, and missing angles
3. **Case Report:** Create a comprehensive case report outlining your findings. This report should include:
* A detailed explanation of each clue and its solution
* Sketches and diagrams to support your explanations
* A step-by-step account of how you followed the clues to locate the artifact
* A final conclusion about the thieves and their motives
👉Zatrzymaj ctl+c i wyczyść kod testowy. USUŃ ten kod z main.py
import unittest
class TestCreateAssignment(unittest.TestCase):
def test_create_assignment(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = create_assignment(initial_state)
print(updated_state)
if __name__ == '__main__':
unittest.main()

Aby proces generowania zadań był automatyczny i reagował na nowe plany nauczania, wykorzystamy istniejącą architekturę opartą na zdarzeniach. Poniższy kod definiuje funkcję Cloud Run (generate_assignment), która będzie wywoływana za każdym razem, gdy nowy plan nauczania zostanie opublikowany w temacie Pub/Sub „plan”.
👉Na końcu pliku main.py w folderze assignment dodaj ten kod:
@functions_framework.cloud_event
def generate_assignment(cloud_event):
print(f"CloudEvent received: {cloud_event.data}")
try:
if isinstance(cloud_event.data.get('message', {}).get('data'), str):
data = json.loads(base64.b64decode(cloud_event.data['message']['data']).decode('utf-8'))
teaching_plan = data.get('teaching_plan')
elif 'teaching_plan' in cloud_event.data:
teaching_plan = cloud_event.data["teaching_plan"]
else:
raise KeyError("teaching_plan not found")
assignment = create_assignment(teaching_plan)
print(f"Assignment---->{assignment}")
#Store the return assignment into bucket as a text file
storage_client = storage.Client()
bucket = storage_client.bucket(ASSIGNMENT_BUCKET)
file_name = f"assignment-{random.randint(1, 1000)}.txt"
blob = bucket.blob(file_name)
blob.upload_from_string(assignment)
return f"Assignment generated and stored in {ASSIGNMENT_BUCKET}/{file_name}", 200
except (json.JSONDecodeError, AttributeError, KeyError) as e:
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500
except Exception as e:
print(f"Error generate assignment: {e}")
return "Error generate assignment", 500
Testowanie lokalne
Przed wdrożeniem w Google Cloud warto przetestować funkcję Cloud Run lokalnie. Umożliwia to szybsze iteracje i łatwiejsze debugowanie.
Najpierw utwórz zasobnik Cloud Storage, w którym będą przechowywane wygenerowane pliki zadań, i przyznaj kontu usługi dostęp do tego zasobnika. Uruchom w terminalu te polecenia:
👉WAŻNE: określ unikalną nazwę ASSIGNMENT_BUCKET, która zaczyna się od „aidemy-assignment-”. Ta unikalna nazwa jest niezbędna, aby uniknąć konfliktów nazw podczas tworzenia zasobnika Cloud Storage. (Zastąp <YOUR_NAME> dowolnym losowym słowem)
export ASSIGNMENT_BUCKET=aidemy-assignment-<YOUR_NAME> #Name must be unqiue
👉Następnie uruchom:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gsutil mb -p $PROJECT_ID -l us-central1 gs://$ASSIGNMENT_BUCKET
gcloud storage buckets add-iam-policy-binding gs://$ASSIGNMENT_BUCKET \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectViewer"
gcloud storage buckets add-iam-policy-binding gs://$ASSIGNMENT_BUCKET \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectCreator"
👉Teraz uruchom emulator funkcji Cloud Run:
cd ~/aidemy-bootstrap/assignment
functions-framework \
--target generate_assignment \
--signature-type=cloudevent \
--source main.py
👉Gdy emulator działa w jednym terminalu, otwórz drugi terminal w Cloud Shell. W drugim terminalu wyślij do emulatora testowe zdarzenie CloudEvent, aby zasymulować opublikowanie nowego planu nauczania:
curl -X POST \
http://localhost:8080/ \
-H "Content-Type: application/json" \
-H "ce-id: event-id-01" \
-H "ce-source: planner-agent" \
-H "ce-specversion: 1.0" \
-H "ce-type: google.cloud.pubsub.topic.v1.messagePublished" \
-d '{
"message": {
"data": "eyJ0ZWFjaGluZ19wbGFuIjogIldlZWsgMTogMkQgU2hhcGVzIGFuZCBBbmdsZXMgLSBEYXkgMTogUmV2aWV3IG9mIGJhc2ljIDJEIHNoYXBlcyAoc3F1YXJlcywgcmVjdGFuZ2xlcywgdHJpYW5nbGVzLCBjaXJjbGVzKS4gRGF5IDI6IEV4cGxvcmluZyBkaWZmZXJlbnQgdHlwZXMgb2YgdHJpYW5nbGVzIChlcXVpbGF0ZXJhbCwgaXNvc2NlbGVzLCBzY2FsZW5lLCByaWdodC1hbmdsZWQpLiBEYXkgMzogRXhwbG9yaW5nIHF1YWRyaWxhdGVyYWxzIChzcXVhcmUsIHJlY3RhbmdsZSwgcGFyYWxsZWxvZ3JhbSwgcmhvbWJ1cywgdHJhcGV6aXVtKS4gRGF5IDQ6IEludHJvZHVjdGlvbiB0byBhbmdsZXM6IHJpZ2h0IGFuZ2xlcywgYWN1dGUgYW5nbGVzLCBhbmQgb2J0dXNlIGFuZ2xlcy4gRGF5IDU6IE1lYXN1cmluZyBhbmdsZXMgdXNpbmcgYSBwcm90cmFjdG9yLiBXZWVrIDI6IDNEIFNoYXBlcyBhbmQgU3ltbWV0cnkgLSBEYXkgNjogSW50cm9kdWN0aW9uIHRvIDNEIHNoYXBlczogY3ViZXMsIGN1Ym9pZHMsIHNwaGVyZXMsIGN5bGluZGVycywgY29uZXMsIGFuZCBweXJhbWlkcy4gRGF5IDc6IERlc2NyaWJpbmcgM0Qgc2hhcGVzIHVzaW5nIGZhY2VzLCBlZGdlcywgYW5kIHZlcnRpY2VzLiBEYXkgODogUmVsYXRpbmcgMkQgc2hhcGVzIHRvIDNEIHNoYXBlcy4gRGF5IDk6IElkZW50aWZ5aW5nIGxpbmVzIG9mIHN5bW1ldHJ5IGluIDJEIHNoYXBlcy4gRGF5IDEwOiBDb21wbGV0aW5nIHN5bW1ldHJpY2FsIGZpZ3VyZXMuIFdlZWsgMzogUG9zaXRpb24sIERpcmVjdGlvbiwgYW5kIFByb2JsZW0gU29sdmluZyAtIERheSAxMTogRGVzY3JpYmluZyBwb3NpdGlvbiB1c2luZyBjb29yZGluYXRlcyBpbiB0aGUgZmlyc3QgcXVhZHJhbnQuIERheSAxMjogUGxvdHRpbmcgY29vcmRpbmF0ZXMgdG8gZHJhdyBzaGFwZXMuIERheSAxMzogVW5kZXJzdGFuZGluZyB0cmFuc2xhdGlvbiAoc2xpZGluZyBhIHNoYXBlKS4gRGF5IDE0OiBVbmRlcnN0YW5kaW5nIHJlZmxlY3Rpb24gKGZsaXBwaW5nIGEgc2hhcGUpLiBEYXkgMTU6IFByb2JsZW0tc29sdmluZyBhY3Rpdml0aWVzIGludm9sdmluZyBwZXJpbWV0ZXIsIGFyZWEsIGFuZCBtaXNzaW5nIGFuZ2xlcy4ifQ=="
}
}'
Zamiast czekać na odpowiedź, przełącz się na drugi terminal Cloud Shell. Postęp i wszelkie dane wyjściowe lub komunikaty o błędach generowane przez funkcję możesz obserwować w terminalu emulatora. 😁
Polecenie curl powinno wyświetlić „OK” (bez znaku nowego wiersza, więc „OK” może pojawić się w tym samym wierszu co prompt powłoki terminala).
Aby sprawdzić, czy przypisanie zostało wygenerowane i zapisane, otwórz konsolę Google Cloud i wybierz Storage > „Cloud Storage”. Wybierz utworzony aidemy-assignment zasobnik. W zasobniku powinien być widoczny plik tekstowy o nazwie assignment-{random number}.txt. Kliknij plik, aby go pobrać i sprawdzić jego zawartość. Sprawdza to, czy nowy plik zawiera właśnie wygenerowane nowe zadanie.

👉 W terminalu, w którym działa emulator, wpisz ctrl+c, aby zamknąć emulator. Zamknij drugi terminal. 👉 W terminalu, w którym działa emulator, zamknij środowisko wirtualne.
deactivate
👉Następnie wdrożymy agenta przypisywania w chmurze.
cd ~/aidemy-bootstrap/assignment
export ASSIGNMENT_BUCKET=$(gcloud storage buckets list --format="value(name)" | grep aidemy-assignment)
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud functions deploy assignment-agent \
--gen2 \
--timeout=540 \
--memory=2Gi \
--cpu=1 \
--set-env-vars="ASSIGNMENT_BUCKET=${ASSIGNMENT_BUCKET}" \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--set-env-vars=OLLAMA_HOST=${OLLAMA_HOST} \
--region=us-central1 \
--runtime=python312 \
--source=. \
--entry-point=generate_assignment \
--trigger-topic=plan
Sprawdź wdrożenie, otwierając konsolę Google Cloud i przechodząc do Cloud Run. Powinna być widoczna nowa usługa o nazwie courses-agent. 
Po wdrożeniu, przetestowaniu i wdrożeniu przepływu pracy związanego z generowaniem projektów możemy przejść do kolejnego kroku: udostępnienia tych projektów w portalu dla uczniów.
14. OPCJONALNIE: Współpraca z Gemini i DeepSeek oparta na rolach – ciąg dalszy
Generowanie dynamicznych witryn
Aby ulepszyć portal dla uczniów i zwiększyć jego atrakcyjność, wdrożymy dynamiczne generowanie kodu HTML na stronach zadań. Celem jest automatyczne aktualizowanie portalu za pomocą nowego, atrakcyjnego wizualnie projektu za każdym razem, gdy generowane jest nowe zadanie. Wykorzystuje to możliwości LLM w zakresie kodowania, aby zapewnić bardziej dynamiczne i interesujące wrażenia użytkownika.

👉W edytorze Cloud Shell zmodyfikuj plik render.py w folderze portal, zastępując
def render_assignment_page():
return ""
z tym fragmentem kodu:
def render_assignment_page(assignment: str):
try:
region=get_next_region()
llm = VertexAI(model_name="gemini-2.0-flash-001", location=region)
input_msg = HumanMessage(content=[f"Here the assignment {assignment}"])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"""
As a frontend developer, create HTML to display a student assignment with a creative look and feel. Include the following navigation bar at the top:
```
<nav>
<a href="/">Home</a>
<a href="/quiz">Quizzes</a>
<a href="/courses">Courses</a>
<a href="/assignment">Assignments</a>
</nav>
```
Also include these links in the <head> section:
```
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Roboto:wght@400;500&display=swap" rel="stylesheet">
```
Do not apply inline styles to the navigation bar.
The HTML should display the full assignment content. In its CSS, be creative with the rainbow colors and aesthetic.
Make it creative and pretty
The assignment content should be well-structured and easy to read.
respond with JUST the html file
"""
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
response = response.replace("```html", "")
response = response.replace("```", "")
with open("templates/assignment.html", "w") as f:
f.write(response)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
Wykorzystuje model Gemini do dynamicznego generowania kodu HTML dla zadania. Wykorzystuje ona treść zadania jako dane wejściowe i za pomocą prompta instruuje Gemini, aby utworzyła atrakcyjną wizualnie stronę HTML o kreatywnym stylu.
Następnie utworzymy punkt końcowy, który będzie wywoływany za każdym razem, gdy do zasobnika zadania zostanie dodany nowy dokument:
👉W folderze portalu otwórz plik app.py i ZASTĄP wiersz ## REPLACE ME! RENDER ASSIGNMENT tym kodem:
@app.route('/render_assignment', methods=['POST'])
def render_assignment():
try:
data = request.get_json()
file_name = data.get('name')
bucket_name = data.get('bucket')
if not file_name or not bucket_name:
return jsonify({'error': 'Missing file name or bucket name'}), 400
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
content = blob.download_as_text()
print(f"File content: {content}")
render_assignment_page(content)
return jsonify({'message': 'Assignment rendered successfully'})
except Exception as e:
print(f"Error processing file: {e}")
return jsonify({'error': 'Error processing file'}), 500
Po wywołaniu pobiera nazwę pliku i nazwę zasobnika z danych żądania, pobiera zawartość zadania z Cloud Storage i wywołuje funkcję render_assignment_page, aby wygenerować kod HTML.
👉Uruchomimy go lokalnie:
cd ~/aidemy-bootstrap/portal
source env/bin/activate
python app.py
👉 W menu „Podgląd w przeglądarce” u góry okna Cloud Shell wybierz „Podejrzyj na porcie 8080”. Aplikacja otworzy się w nowej karcie przeglądarki. Na pasku nawigacyjnym kliknij link Przypisanie. W tym momencie powinna pojawić się pusta strona. Jest to oczekiwane zachowanie, ponieważ nie utworzyliśmy jeszcze mostu komunikacyjnego między agentem przypisania a portalem, który dynamicznie wypełniałby treści.

o ahead and stop the script by pressing Ctrl+C.
👉Aby wprowadzić te zmiany i wdrożyć zaktualizowany kod, ponownie skompiluj i prześlij obraz agenta portalu:
cd ~/aidemy-bootstrap/portal/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-portal .
docker tag gcr.io/${PROJECT_ID}/aidemy-portal us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
👉Po przesłaniu nowego obrazu wdróż ponownie usługę Cloud Run. Aby wymusić aktualizację Cloud Run, uruchom ten skrypt:
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud run services update aidemy-portal \
--region=us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
👉Teraz wdrożymy aktywator Eventarc, który będzie nasłuchiwać wszystkich nowych obiektów utworzonych (sfinalizowanych) w zasobniku przypisań. Ten aktywator automatycznie wywoła punkt końcowy /render_assignment w usłudze portalu, gdy zostanie utworzony nowy plik przypisania.
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$(gcloud storage service-agent --project $PROJECT_ID)" \
--role="roles/pubsub.publisher"
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gcloud eventarc triggers create portal-assignment-trigger \
--location=us-central1 \
--service-account=$SERVICE_ACCOUNT_NAME \
--destination-run-service=aidemy-portal \
--destination-run-region=us-central1 \
--destination-run-path="/render_assignment" \
--event-filters="bucket=$ASSIGNMENT_BUCKET" \
--event-filters="type=google.cloud.storage.object.v1.finalized"
Aby sprawdzić, czy aktywator został utworzony, otwórz stronę Aktywatory Eventarc w konsoli Google Cloud. W tabeli powinna pojawić się wartość portal-assignment-trigger. Kliknij nazwę aktywatora, aby wyświetlić jego szczegóły. 
Aktywowanie nowego aktywatora może potrwać 2–3 minuty.
Aby zobaczyć, jak działa dynamiczne generowanie przypisań, uruchom to polecenie, aby znaleźć adres URL agenta planującego (jeśli go nie masz):
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep planner
Znajdź adres URL agenta portalu:
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep portal
W agencie planowania wygeneruj nowy plan nauczania.

Po kilku minutach (na wygenerowanie dźwięku, projektu i wyrenderowanie kodu HTML) otwórz portal ucznia.
👉 Na pasku nawigacyjnym kliknij link „Zadanie”. Powinien wyświetlić się nowo utworzony projekt z dynamicznie wygenerowanym kodem HTML. Za każdym razem, gdy generowany jest plan nauczania, powinien on być dynamicznym zadaniem.

Gratulujemy ukończenia systemu wieloagentowego Aidemy. Zdobędziesz praktyczne doświadczenie i cenne informacje na temat:
- Korzyści z systemów wieloagentowych, w tym modułowość, skalowalność, specjalizacja i uproszczona konserwacja.
- Znaczenie architektur opartych na zdarzeniach w tworzeniu elastycznych i luźno powiązanych aplikacji.
- Strategiczne wykorzystanie modeli LLM, dopasowywanie odpowiedniego modelu do zadania i integrowanie ich z narzędziami w celu uzyskania rzeczywistego wpływu.
- praktyki tworzenia aplikacji w chmurze przy użyciu usług Google Cloud, aby tworzyć skalowalne i niezawodne rozwiązania;
- Znaczenie uwzględniania ochrony prywatności danych i modeli hostingu własnego jako alternatywy dla rozwiązań dostawców.
Masz teraz solidne podstawy do tworzenia zaawansowanych aplikacji opartych na AI w Google Cloud.
15. Wyzwania i dalsze kroki
Gratulujemy stworzenia systemu wieloagentowego Aidemy. Masz solidne podstawy do korzystania z edukacji opartej na AI. Teraz przyjrzyjmy się niektórym wyzwaniom i potencjalnym przyszłym ulepszeniom, które pozwolą jeszcze bardziej rozwinąć możliwości tej technologii i zaspokoić rzeczywiste potrzeby:
Interaktywne uczenie się dzięki sesjom pytań i odpowiedzi na żywo:
- Wyzwanie: czy możesz wykorzystać interfejs Gemini 2 Live API do utworzenia funkcji pytań i odpowiedzi w czasie rzeczywistym dla uczniów? Wyobraź sobie wirtualną klasę, w której uczniowie mogą zadawać pytania i otrzymywać natychmiastowe odpowiedzi oparte na AI.
Automatyczne przesyłanie i ocenianie projektów:
- Wyzwanie: zaprojektowanie i wdrożenie systemu, który umożliwia uczniom przesyłanie zadań w formie cyfrowej i automatyczne ocenianie ich przez AI, z mechanizmem wykrywania plagiatów i zapobiegania im. To wyzwanie stwarza doskonałą okazję do zbadania generowania wspomaganego wyszukiwaniem (RAG) w celu zwiększenia dokładności i niezawodności procesu oceniania i wykrywania plagiatów.

16. Czyszczenie danych
Po utworzeniu i przetestowaniu systemu wieloagentowego Aidemy czas zwolnić miejsce w środowisku Google Cloud.
👉Usuń usługi Cloud Run
gcloud run services delete aidemy-planner --region=us-central1 --quiet
gcloud run services delete aidemy-portal --region=us-central1 --quiet
gcloud run services delete courses-agent --region=us-central1 --quiet
gcloud run services delete book-provider --region=us-central1 --quiet
gcloud run services delete assignment-agent --region=us-central1 --quiet
👉Usuwanie aktywatora Eventarc
gcloud eventarc triggers delete portal-assignment-trigger --location=us --quiet
gcloud eventarc triggers delete plan-topic-trigger --location=us-central1 --quiet
gcloud eventarc triggers delete portal-assignment-trigger --location=us-central1 --quiet
ASSIGNMENT_AGENT_TRIGGER=$(gcloud eventarc triggers list --project="$PROJECT_ID" --location=us-central1 --filter="name:assignment-agent" --format="value(name)")
COURSES_AGENT_TRIGGER=$(gcloud eventarc triggers list --project="$PROJECT_ID" --location=us-central1 --filter="name:courses-agent" --format="value(name)")
gcloud eventarc triggers delete $ASSIGNMENT_AGENT_TRIGGER --location=us-central1 --quiet
gcloud eventarc triggers delete $COURSES_AGENT_TRIGGER --location=us-central1 --quiet
👉Usuwanie tematu Pub/Sub
gcloud pubsub topics delete plan --project="$PROJECT_ID" --quiet
👉Usuń instancję Cloud SQL
gcloud sql instances delete aidemy --quiet
👉Usuwanie repozytorium Artifact Registry
gcloud artifacts repositories delete agent-repository --location=us-central1 --quiet
👉Usuwanie obiektów tajnych usługi Secret Manager
gcloud secrets delete db-user --quiet
gcloud secrets delete db-pass --quiet
gcloud secrets delete db-name --quiet
👉Usuń instancję Compute Engine (jeśli została utworzona na potrzeby Deepseek)
gcloud compute instances delete ollama-instance --zone=us-central1-a --quiet
👉Usuń regułę zapory sieciowej dla instancji Deepseek
gcloud compute firewall-rules delete allow-ollama-11434 --quiet
👉Usuwanie zasobników Cloud Storage
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
export ASSIGNMENT_BUCKET=$(gcloud storage buckets list --format="value(name)" | grep aidemy-assignment)
gsutil rm -r gs://$COURSE_BUCKET_NAME
gsutil rm -r gs://$ASSIGNMENT_BUCKET
