
1. Introduction
In this codelab you will learn how to use AlloyDB AI by combining vector search with Vertex AI embeddings. This lab is part of a lab collection dedicated to AlloyDB AI features. You can read more on the AlloyDB AI page in documentation.
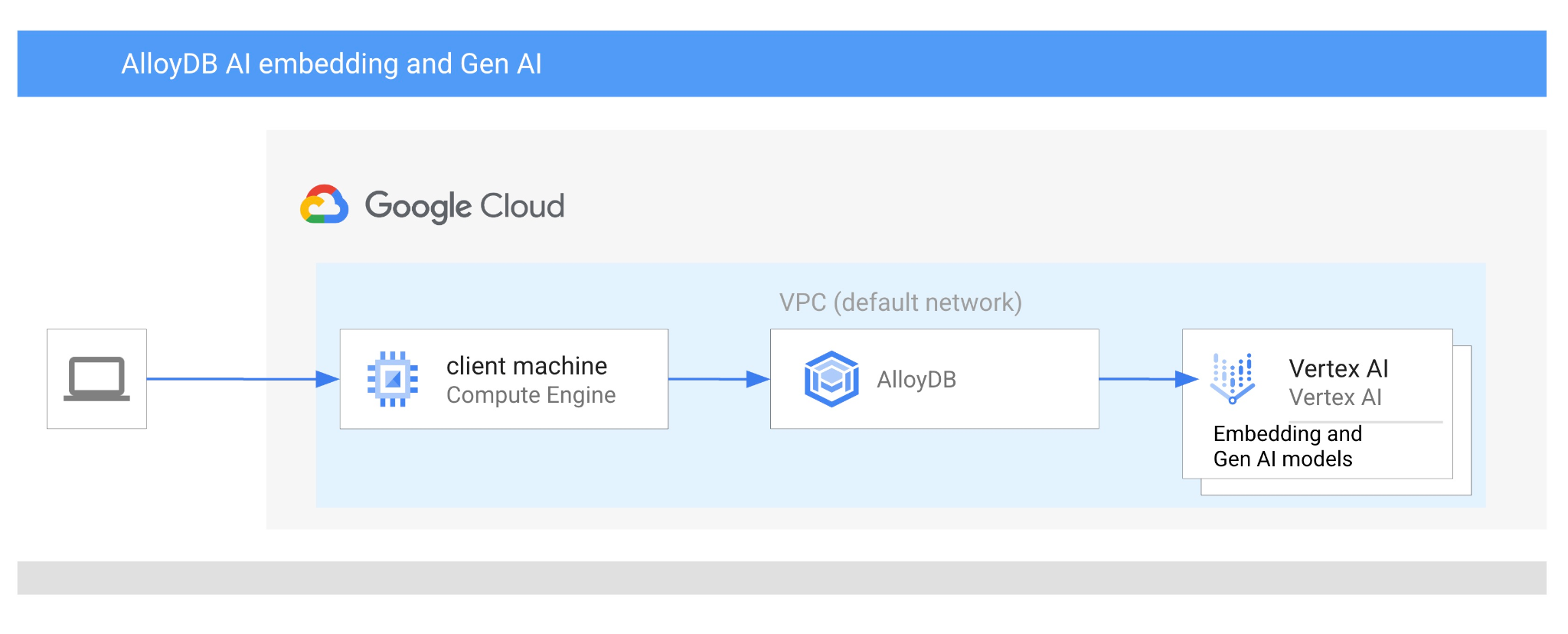
Prerequisites
- A basic understanding of the Google Cloud, Console
- Basic skills in command line interface and google shell
What you'll learn
- How to deploy AlloyDB cluster and primary instance
- How to connect to the AlloyDB from Google Compute Engine VM
- How to create database and enable AlloyDB AI
- How to load data to the database
- How to use AlloyDB Studio
- How to use Vertex AI embedding model in AlloyDB
- How to use Vertex AI Studio
- How to enrich the result using Vertex AI generative model
- How to improve performance using vector index
What you'll need
- A Google Cloud Account and Google Cloud Project
- A web browser such as Chrome
2. Setup and Requirements
Project Setup
- Sign-in to the Google Cloud Console. If you don't already have a Gmail or Google Workspace account, you must create one.
Use a personal account instead of a work or school account.
- Create a new project or reuse an existing one. To create a new project in the Google Cloud console, in the header, click the Select a project button which will open a popup window.

In the Select a project window push the button New Project which will open a dialog box for the new project.
In the dialog box put your preferable Project name and choose the location.
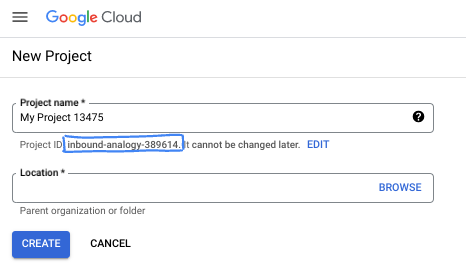
- The Project name is the display name for this project's participants. The project name isn't used by Google APIs, and it can be changed at any time.
- The Project ID is unique across all Google Cloud projects and is immutable (it can't be changed after it has been set). The Google Cloud console automatically generates a unique ID, but you can customize it. If you don't like the generated ID, you can generate another random one or provide your own to check its availability. In most codelabs, you'll need to reference your project ID, which is typically identified with the placeholder PROJECT_ID.
- For your information, there is a third value, a Project Number, which some APIs use. Learn more about all three of these values in the documentation.
Enable Billing
To enable billing, you have two options. You can either use your personal billing account or you can redeem credits with the following steps.
Redeem Google Cloud credits (optional)
To run this workshop, you need a billing account with some credit. Use the credits from the banner at the top of this codelab to get started. If you are already connected to a billing account, you can skip this step.
Set up a personal billing account
If you set up billing using Google Cloud credits, you can skip this step.
To set up a personal billing account, go here to enable billing in the Cloud Console.
Some Notes:
- Completing this lab should cost less than $3 USD in Cloud resources.
- You can follow the steps at the end of this lab to delete resources to avoid further charges.
- New users are eligible for the $300 USD Free Trial.
Start Cloud Shell
While Google Cloud can be operated remotely from your laptop, in this codelab you will be using Google Cloud Shell, a command line environment running in the Cloud.
From the Google Cloud Console, click the Cloud Shell icon on the top right toolbar:
Alternatively you can press G then S. This sequence will activate Cloud Shell if you are within the Google Cloud Console or use this link.
It should only take a few moments to provision and connect to the environment. When it is finished, you should see something like this:

This virtual machine is loaded with all the development tools you'll need. It offers a persistent 5GB home directory, and runs on Google Cloud, greatly enhancing network performance and authentication. All of your work in this codelab can be done within a browser. You do not need to install anything.
3. Before you begin
Enable API
Output:
To use AlloyDB, Compute Engine, Networking services, and Vertex AI, you need to enable their respective APIs in your Google Cloud project.
Enabling the APIs
Inside Cloud Shell in the terminal, make sure that your project ID is setup:
gcloud config set project [YOUR-PROJECT-ID]
Set environment variable PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Enable all necessary APIs:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Expected output
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Introducing the APIs
- AlloyDB API (
alloydb.googleapis.com) allows you to create, manage, and scale AlloyDB for PostgreSQL clusters. It provides a fully managed, PostgreSQL-compatible database service designed for demanding enterprise transactional and analytical workloads. - Compute Engine API (
compute.googleapis.com) allows you to create and manage virtual machines (VMs), persistent disks, and network settings. It provides the core Infrastructure-as-a-Service (IaaS) foundation required to run your workloads and host the underlying infrastructure for many managed services. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) allows you to programmatically manage the metadata and configuration of your Google Cloud project. It enables you to organize resources, handle Identity and Access Management (IAM) policies, and validate permissions across the project hierarchy. - Service Networking API (
servicenetworking.googleapis.com) allows you to automate the setup of private connectivity between your Virtual Private Cloud (VPC) network and Google's managed services. It is specifically required to establish private IP access for services like AlloyDB so they can communicate securely with your other resources. - Vertex AI API (
aiplatform.googleapis.com) enables your applications to build, deploy, and scale machine learning models. It provides the unified interface for all of Google Cloud's AI services, including access to Generative AI models (like Gemini) and custom model training.
Optionally you can configure your default region to use the Vertex AI embedding models. Read more about available locations for Vertex AI. In the example we are using the us-central1 region.
gcloud config set compute/region us-central1
4. Deploy AlloyDB
Before creating an AlloyDB cluster we need an available private IP range in our VPC to be used by the future AlloyDB instance. If we don't have it then we need to create it, assign it to be used by internal Google services and after that we will be able to create the cluster and instance.
Create private IP range
We need to configure Private Service Access configuration in our VPC for AlloyDB. The assumption here is that we have the "default" VPC network in the project and it is going to be used for all actions.
Create the private IP range:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Create private connection using the allocated IP range:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Expected console output:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Create AlloyDB Cluster
In this section we are creating an AlloyDB cluster in the us-central1 region.
Define password for the postgres user. You can define your own password or use a random function to generate one
export PGPASSWORD=`openssl rand -hex 12`
Expected console output:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Note the PostgreSQL password for future use.
echo $PGPASSWORD
You will need that password in the future to connect to the instance as the postgres user. I suggest writing it down or copying it somewhere to be able to use later.
Expected console output:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Create a Free Trial Cluster
If you haven't been using AlloyDB before you can create a free trial cluster:
Define region and AlloyDB cluster name. We are going to use us-central1 region and alloydb-aip-01 as a cluster name:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Run command to create the cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Expected console output:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Create an AlloyDB primary instance for our cluster in the same cloud shell session. If you are disconnected you will need to define the region and cluster name environment variables again.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Expected console output:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Create AlloyDB Standard Cluster
If it is not your first AlloyDB cluster in the project proceed with creation of a standard cluster.
Define region and AlloyDB cluster name. We are going to use us-central1 region and alloydb-aip-01 as a cluster name:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Run command to create the cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Expected console output:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Create an AlloyDB primary instance for our cluster in the same cloud shell session. If you are disconnected you will need to define the region and cluster name environment variables again.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Expected console output:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Connect to AlloyDB
AlloyDB is deployed using a private-only connection, so we need a VM with PostgreSQL client installed to work with the database.
Deploy GCE VM
Create a GCE VM in the same region and VPC as the AlloyDB cluster.
In Cloud Shell execute:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Expected console output:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
Install Postgres Client
Install the PostgreSQL client software on the deployed VM
Connect to the VM:
gcloud compute ssh instance-1 --zone=us-central1-a
Expected console output:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
Install the software running command inside the VM:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Expected console output:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
Connect to the Instance
Connect to the primary instance from the VM using psql.
In the same Cloud Shell tab with the opened SSH session to your instance-1 VM.
Use the noted AlloyDB password (PGPASSWORD) value and the AlloyDB cluster id to connect to AlloyDB from the GCE VM:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Expected console output:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
Close the psql session:
exit
6. Prepare Database
We need to create a database, enable Vertex AI integration, create database objects and import the data.
Grant Necessary Permissions to AlloyDB
Add Vertex AI permissions to the AlloyDB service agent.
Open another Cloud Shell tab using the sign "+" at the top.
In the new cloud shell tab execute:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Close the tab by either execution command "exit" in the tab:
exit
Create Database
Create database quickstart.
In the GCE VM session execute:
Create database:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
Expected console output:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
Enable Vertex AI Integration
Enable Vertex AI integration and the pgvector extensions in the database.
In the GCE VM execute:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
Expected console output:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
Import Data
Download the prepared data and import it into the new database.
In the GCE VM execute:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
Expected console output:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. Calculate embeddings
After importing the data we got our product data in the cymbal_products table, inventory showing the number of available products in each store in the cymbal_inventory table and list of the stores in the cymbal_stores table. We need to calculate the vector data based on descriptions for our products and we are going to use function embedding for that. Using the function we are going to use Vertex AI integration to calculate vector data based on our products descriptions and add it to the table. You can read more about the used technology in the documentation.
It is easy to generate it for a few rows but how to make it efficient if we have thousands? Here I will show how to generate and manage embeddings for large tables. You can also read more about different options and techniques in the guide.
Enable Fast Embedding Generation
Connect to the database using psql from your VM using the AlloyDB instance IP and postgres password:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Verify the version of the google_ml_integration extension.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
The version should be 1.5.2 or higher. Here is example of the output:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
The default version should be 1.5.2 or higher but if your instance shows an older version it probably needs to be updated. Check if maintenance was disabled for the instance.
Then we need to verify the database flag. We need the google_ml_integration.enable_faster_embedding_generation flag to be turned on. In the same psql session check the value for the flag.
show google_ml_integration.enable_faster_embedding_generation;
If the flag is in correct position then the expected output looks like this:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
But if it shows "off" then we need to update the instance. You can do it using the web console or gcloud command as it is described in the documentation. Here I show how to do that using gcloud command:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
It can take a few minutes but eventually the flag value should be switched to "on". After that you can proceed with the next steps.
Create embedding column
Connect to the database using psql and create a virtual column with the vector data using the embedding function in the cymbal_products table. The embedding function returns vector data from Vertex AI based on the data supplied from the product_description column.
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
In the psql session after connecting to the database execute:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
The command will create the virtual column and populate it with vector data.
Expected console output:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
Now we can generate embeddings using batches with 50 rows each. You can experiment with different batch sizes and see if it changes the time for the execution. In the same psql session execute:
Enable timing to measure how much time it will take:
\timing
Run the command:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
And the console output shown less than 2 seconds for the embedding generation:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
By default the embeddings are not going to be refreshed if the corresponding product_description column is getting updated or an entire new row is inserted. But you can do it by defining parameter incremental_refresh_mode. Let's create a column "product_embeddings" and make it automatically updatable.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
And now if we insert a new row to the table.
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
We can compare the difference in the columns using the query:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
And in the output we can see that while the embedding column stays empty the product_embedding column is automatically updated
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. Run Similarity Search
We can now run our search using similarity search based on vector values calculated for the descriptions and the vector value we get for our request.
The SQL query can be executed from the same psql command line interface or, as alternative, from AlloyDB Studio. Any multirow and complex output might look better in the AlloyDB Studio.
Connect to AlloyDB Studio
In the following chapters all the SQL commands requiring connection to the database can be alternatively executed in the AlloyDB Studio. To run the command you need to open the web console interface for your AlloyDB cluster by clicking on the primary instance.
Then click on AlloyDB Studio on the left:
Choose the quickstart_db database, user postgres and provide the password noted when we created the cluster. Then click on the "Authenticate" button.
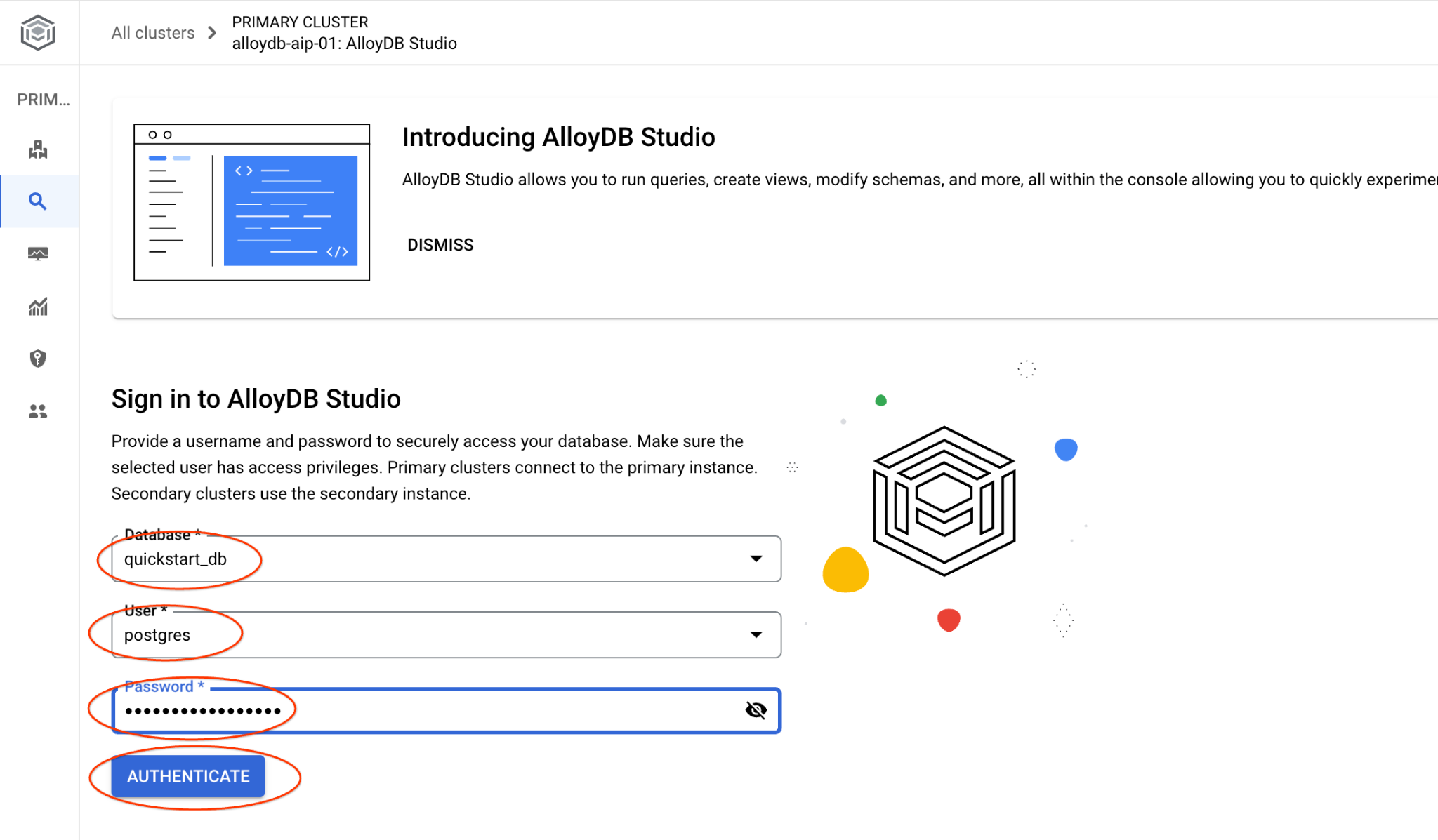
It will open the AlloyDB Studio interface. To run the commands in the database you click on the "Editor 1" tab on the right.
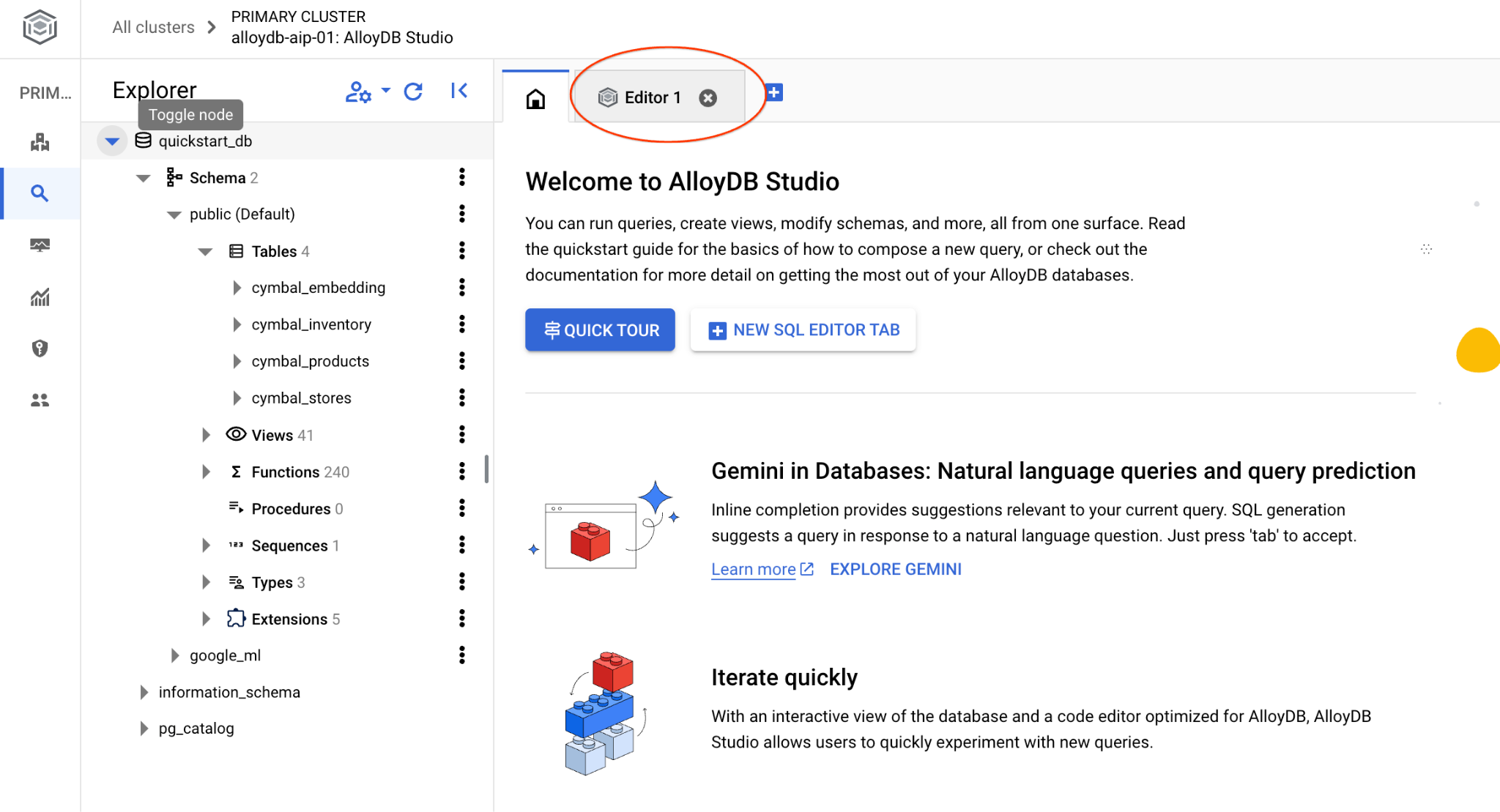
It opens interface where you can run SQL commands
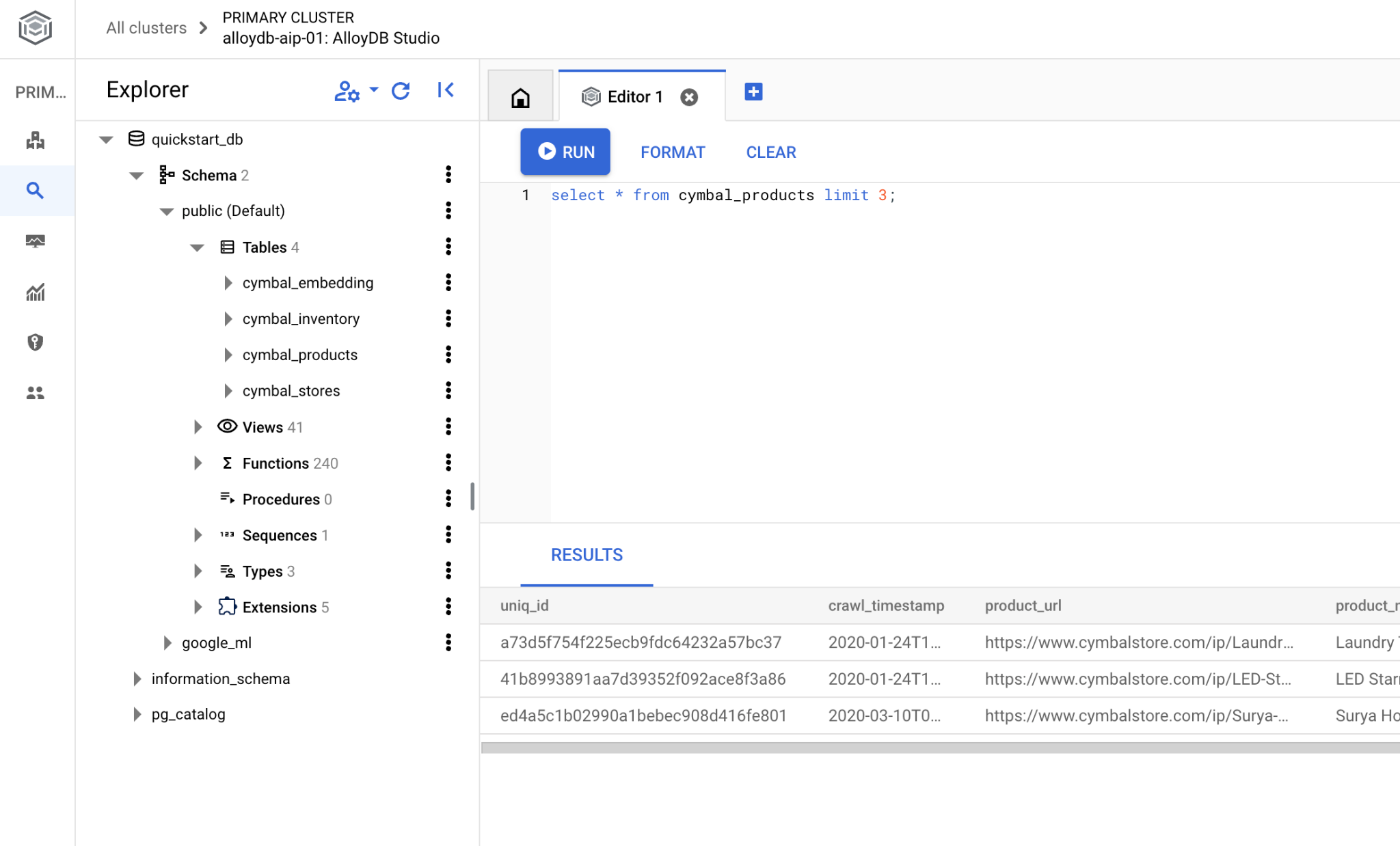
If you prefer to use command line psql then follow the alternative route and connect to the database from your VM SSH session as it has been described in the previous chapters.
Run Similarity Search from psql
If your database session was disconnected then connect to the database again using psql or the AlloyDB Studio.
Connect to the database:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Run a query to get a list of available products most closely related to a client's request. The request we are going to pass to Vertex AI to get the vector value sounds like "What kind of fruit trees grow well here?"
Here is the query you can run to choose first 10 items most suitable for our request:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
And here is the expected output:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. Improve Response
You can improve the response to a client application using the result of the query and prepare a meaningful output using the supplied query results as part of the prompt to the Vertex AI generative foundation language model.
To achieve that we plan to generate a JSON with our results from the vector search, then use that generated JSON as addition to a prompt for a text LLM model in Vertex AI to create a meaningful output. In the first step we generate the JSON, then we test it in the Vertex AI Studio and in the last step we incorporate it into a SQL statement which can be used in an application.
Generate output in JSON format
Modify the query to generate the output in JSON format and return only one row to pass to Vertex AI
Here is the example of the query:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
And here is the expected JSON in the output:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Run the prompt in Vertex AI Studio
We can use the generated JSON to supply it as a part of the prompt to generative AI text model in the Vertex AI Studio
Open the Vertex AI Studio in the cloud console.

It might ask to agree with terms of usage if you haven't used it before. Push the button "Agree & continue"
Write your prompt in the interface.
It may ask you to enable additional APIs but you can ignore the request. We don't need any additional APIs to finish our lab.
Here is the prompt we are going to use with the JSON output of the early query about the trees:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information
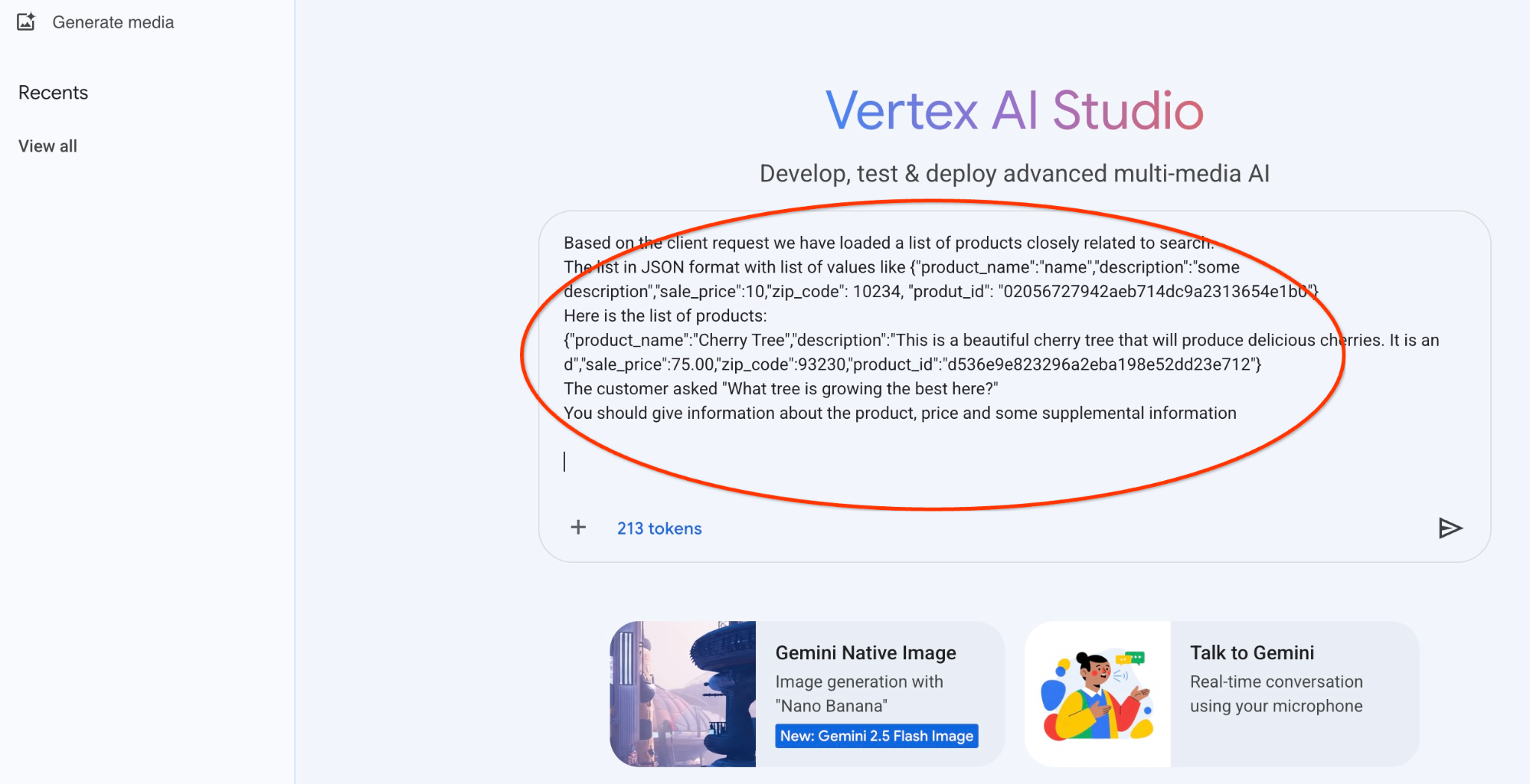
And here is the result when we run the prompt with our JSON values and using the gemini-2.5-flash-light model:
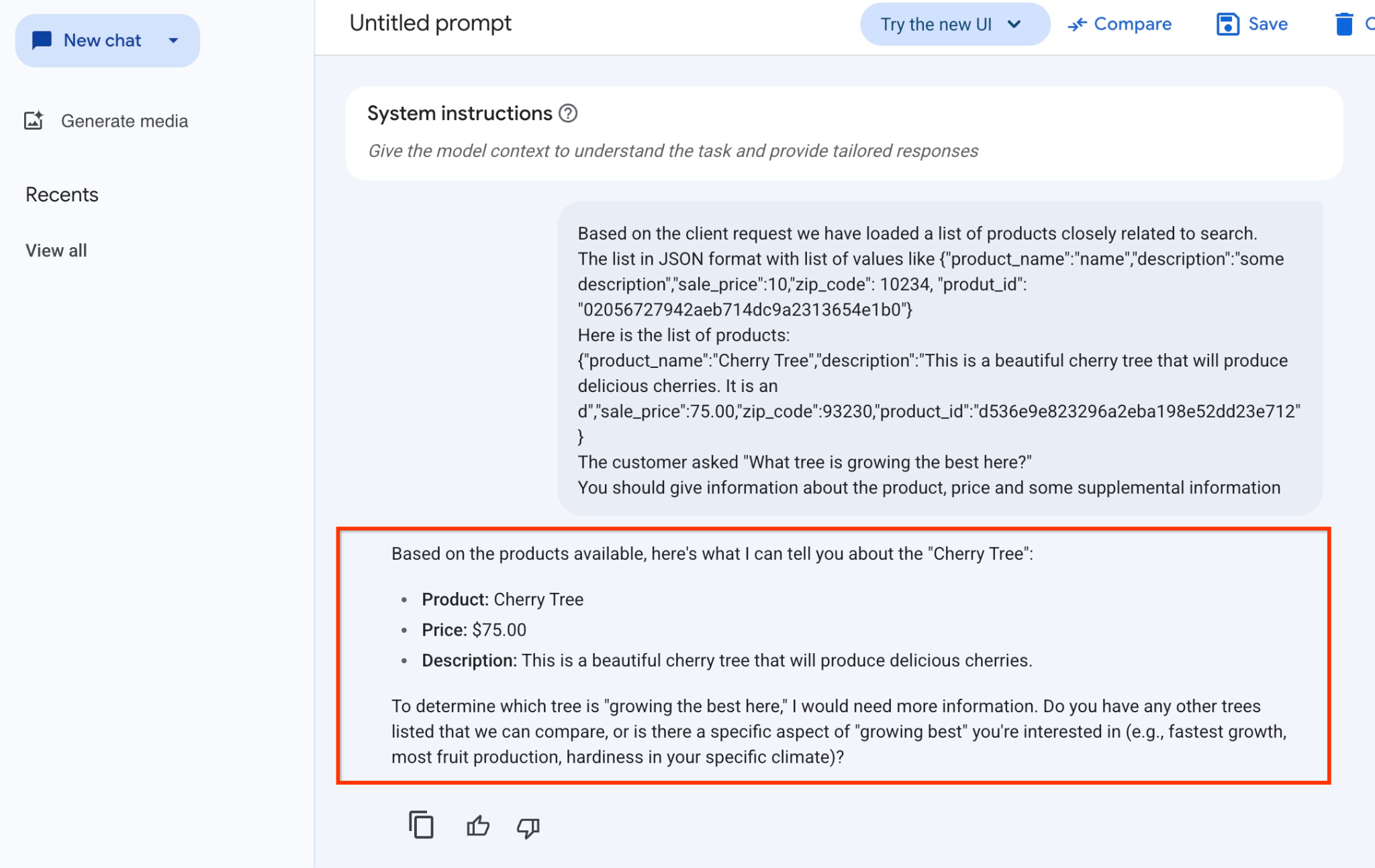
The answer we got from the model in this example follows. Note that your answer may be different because of model and parameters changes over time:
"Based on the products available, here's what I can tell you about the "Cherry Tree":
Product: Cherry Tree
Price: $75.00
Description: This is a beautiful cherry tree that will produce delicious cherries.
To determine which tree is "growing the best here," I would need more information. Do you have any other trees listed that we can compare, or is there a specific aspect of "growing best" you're interested in (e.g., fastest growth, most fruit production, hardiness in your specific climate)?"
Run the prompt in PSQL
We can use the AlloyDB AI integration with Vertex AI to get the same response from a generative model using SQL directly in the database. But to use the gemini-1.5-flash model we need to register it first.
Verify the google_ml_integration extension. It should have version 1.4.2 or newer.
Connect to the quickstart_db database from psql as it has been shown before (or use AlloyDB Studio) and execute:
SELECT extversion from pg_extension where extname='google_ml_integration';
Check google_ml_integration.enable_model_support database flag.
show google_ml_integration.enable_model_support;
The expected output from the psql session is "on":
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
If it shows "off" then we need to set google_ml_integration.enable_model_support database flag to "on". To perform that you can use the AlloyDB web console interface or run the following gcloud command.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
The command takes around 1-3 min to execute in the background. Then you can verify the flag again.
For our query we need two models. The first one is the already used text-embedding-005 model and the second is one of the generic Google gemini models.
We start from the text embedding model. To register the model run in psql or AlloyDB Studio the following code:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
And the next model we need to register is gemini-2.0-flash-001 which will be used to generate the user-friendly output.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
You can always verify the list of registered models by selecting information from the google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Here is sample output
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
Now we can use the generated in a subquery JSON to supply it as a part of the prompt to generative AI text model using SQL.
In the psql or AlloyDB Studio session to the database run the query
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
And here is the expected output. Your output might be different depending on the model version and parameters.:
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. Create vector index
Our dataset is quite small and response time primarily depends on interaction with AI models. But when you have millions of vectors the vector search part can take a significant portion of our response time and put a high load on the system. To improve that we can build an index on top of our vectors.
Create ScaNN index
To build the SCANN index we need to enable one more extension. The extension alloydb_scann provides an interface to work with the ANN type vector index using Google ScaNN algorithm.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Expected output:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
The index can be created in MANUAL or AUTO mode. The MANUAL mode is enabled by default and you can create an index and maintain it as any other index. But if you enable AUTO mode then you are able to create the index which doesn't require any maintenance from your side. You can read in detail about all options in the documentation and here I will show you how to enable the AUTO mode and create the index. In our case we don't have enough rows to create the index in AUTO mode - so we will create it as MANUAL.
In the following example I am leaving most parameters as default and providing only a number of partitions (num_leaves) for the index:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
You can read about tuning index parameters in the documentation.
Expected output:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
Compare Response
Now we can run the vector search query in EXPLAIN mode and verify if the index has been used.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Expected output (redacted for clarity):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
From the output we can clearly see that the query was using "Index Scan using cymbal_products_embeddings_scann on cymbal_products".
And if we run the query without explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Expected output:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
We can see that the result is the same Cherry tree which was on the top in our search without index. Sometimes it might not be the case and the response can return not the same tree but some other trees from the top. So the index is giving us performance but still accurate enough to deliver good results.
You can try different indexes available for the vectors and more labs and examples with langchain integration available on the documentation page.
11. Clean up environment
Destroy the AlloyDB instances and cluster when you are done with the lab.
Delete AlloyDB cluster and all instances
If you've used the trial version of AlloyDB. Do not delete the trial cluster if you have plans to test other labs and resources using the trial cluster. You will not be able to create another trial cluster in the same project.
The cluster is destroyed with option force which also deletes all the instances belonging to the cluster.
In the cloud shell define the project and environment variables if you've been disconnected and all the previous settings are lost:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Delete the cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Delete AlloyDB Backups
Delete all AlloyDB backups for the cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
Now we can destroy our VM
Delete GCE VM
In Cloud Shell execute:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Expected console output:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. Congratulations
Congratulations for completing the codelab.
This lab is part of the Production-Ready AI with Google Cloud Learning Path.
- Explore the full curriculum to bridge the gap from prototype to production.
- Share your progress with the hashtag
#ProductionReadyAI.
What we've covered
- How to deploy AlloyDB cluster and primary instance
- How to connect to the AlloyDB from Google Compute Engine VM
- How to create database and enable AlloyDB AI
- How to load data to the database
- How to use AlloyDB Studio
- How to use Vertex AI embedding model in AlloyDB
- How to use Vertex AI Studio
- How to enrich the result using Vertex AI generative model
- How to improve performance using vector index
13. Survey
Output: