
1. Giriş
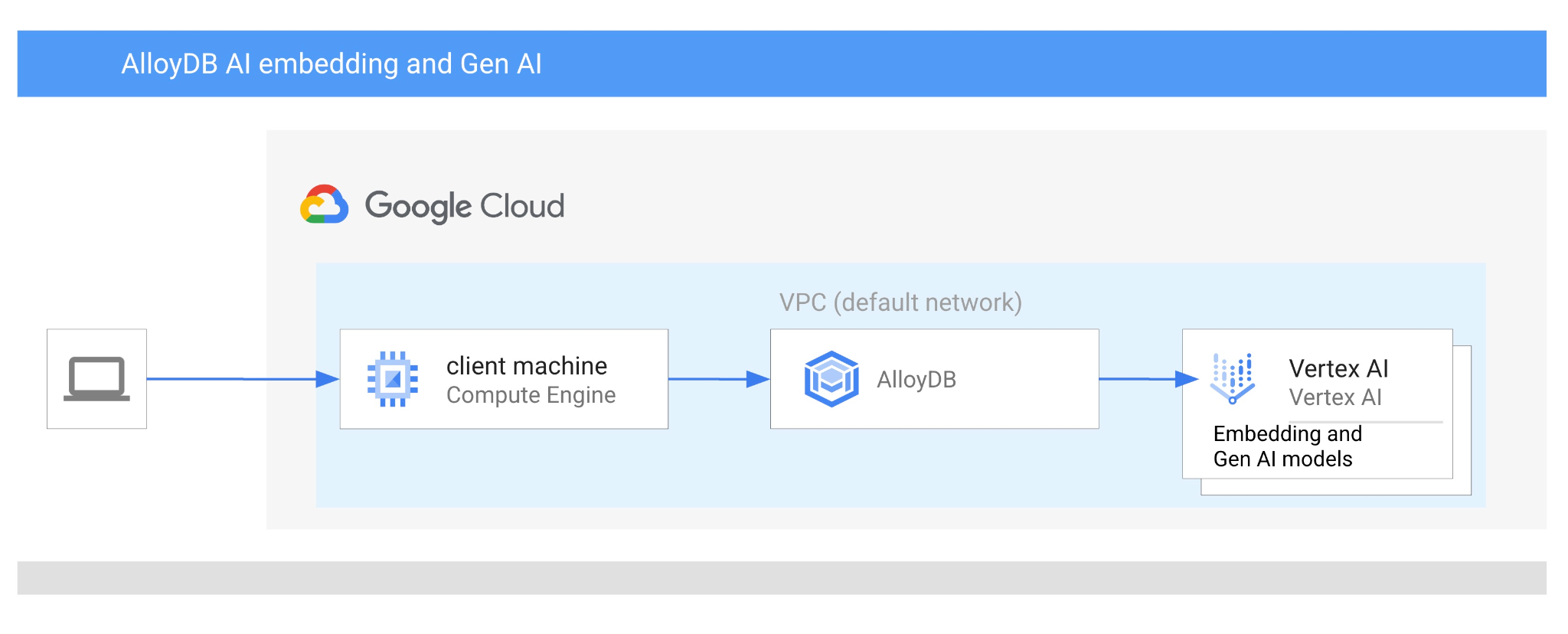
Bu codelab'de, vektör aramayı Vertex AI yerleştirmeleriyle birleştirerek AlloyDB AI'ı kullanmayı öğreneceksiniz. Bu laboratuvar, AlloyDB AI özelliklerine ayrılmış bir laboratuvar koleksiyonunun parçasıdır. Belgelerdeki AlloyDB AI sayfasında daha fazla bilgi edinebilirsiniz.
Ön koşullar
- Google Cloud Console hakkında temel bilgiler
- Komut satırı arayüzü ve Google Shell'de temel beceriler
Neler öğreneceksiniz?
- AlloyDB kümesi ve birincil örneği dağıtma
- Google Compute Engine sanal makinesinden AlloyDB'ye bağlanma
- Veritabanı oluşturma ve AlloyDB AI'yı etkinleştirme
- Veritabanına veri yükleme
- AlloyDB Studio'yu kullanma
- AlloyDB'de Vertex AI yerleştirme modelini kullanma
- Vertex AI Studio'yu kullanma
- Vertex AI üretken modelini kullanarak sonucu zenginleştirme
- Vektör dizini kullanarak performansı artırma
Gerekenler
- Google Cloud hesabı ve Google Cloud projesi
- Chrome gibi bir web tarayıcısı
2. Kurulum ve Gereksinimler
Proje Kurulumu
- Google Cloud Console'da oturum açın. Gmail veya Google Workspace hesabınız yoksa oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
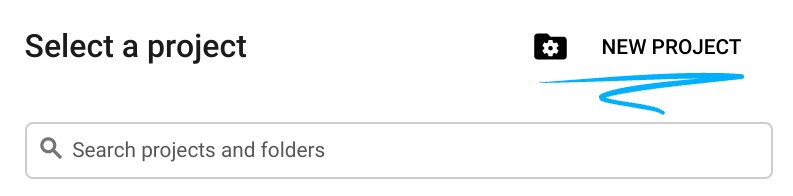
- Yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. Google Cloud Console'da yeni bir proje oluşturmak için üstbilgide "Bir proje seçin" düğmesini tıklayın. Bu işlem, bir pop-up pencere açar.

Proje seçin penceresinde Yeni Proje düğmesini tıklayın. Bu işlem, yeni proje için bir iletişim kutusu açar.
İletişim kutusunda tercih ettiğiniz proje adını girin ve konumu seçin.
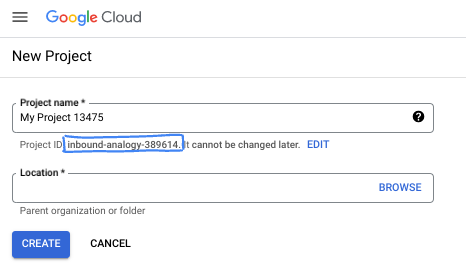
- Proje adı, bu projenin katılımcıları için görünen addır. Proje adı, Google API'leri tarafından kullanılmaz ve istediğiniz zaman değiştirilebilir.
- Proje kimliği, tüm Google Cloud projelerinde benzersizdir ve sabittir (ayarlandıktan sonra değiştirilemez). Google Cloud Console, benzersiz bir kimliği otomatik olarak oluşturur ancak bu kimliği özelleştirebilirsiniz. Oluşturulan kimliği beğenmediyseniz başka bir rastgele kimlik oluşturabilir veya kendi kimliğinizi girerek kullanılabilirliğini kontrol edebilirsiniz. Çoğu codelab'de, genellikle PROJECT_ID yer tutucusuyla tanımlanan proje kimliğinize başvurmanız gerekir.
- Bazı API'lerin kullandığı üçüncü bir değer olan Proje Numarası da vardır. Bu üç değer hakkında daha fazla bilgiyi belgelerde bulabilirsiniz.
Faturalandırmayı etkinleştirme
Faturalandırmayı etkinleştirmek için iki seçeneğiniz vardır. Kişisel faturalandırma hesabınızı kullanabilir veya aşağıdaki adımları uygulayarak kredileri kullanabilirsiniz.
5 ABD doları değerindeki Google Cloud kredilerini kullanma (isteğe bağlı)
Bu atölyeyi düzenlemek için bir miktar kredisi olan bir faturalandırma hesabına ihtiyacınız vardır. Kendi faturalandırmanızı kullanmayı planlıyorsanız bu adımı atlayabilirsiniz.
- Bu bağlantıyı tıklayın ve kişisel bir Google Hesabı ile oturum açın.
- Aşağıdakine benzer bir ifade görürsünüz:

- KREDİLERİNİZE ERİŞMEK İÇİN BURAYI TIKLAYIN düğmesini tıklayın. Bu işlem sizi faturalandırma profilinizi oluşturacağınız sayfaya yönlendirir. Ücretsiz deneme kaydı ekranı gösterilirse iptal'i tıklayın ve faturalandırmayı bağlamaya devam edin.
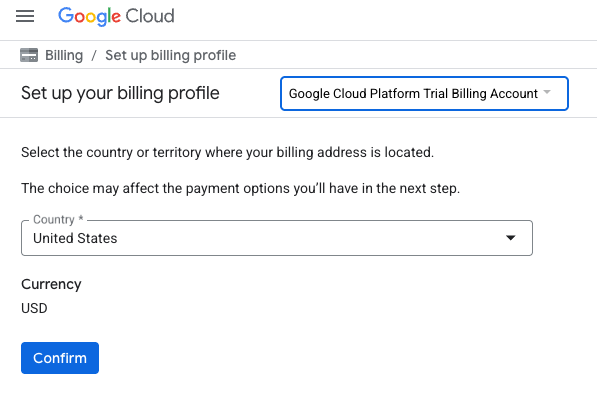
- "Artık bir Google Cloud Platform deneme sürümü faturalandırma hesabına bağlısınız" seçeneğini tıklayın.
Kişisel faturalandırma hesabı oluşturma
Faturalandırmayı Google Cloud kredilerini kullanarak ayarladıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturmak için Cloud Console'da faturalandırmayı etkinleştirmek üzere buraya gidin.
Bazı notlar:
- Bu laboratuvarın tamamlanması için 3 ABD dolarından daha az bir tutarda bulut kaynağı kullanılması gerekir.
- Daha fazla ödeme alınmaması için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerindeki ücretsiz denemeden yararlanabilir.
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir. Ancak bu codelab'de, Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Google Cloud Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:
Alternatif olarak G, ardından S tuşuna basabilirsiniz. Bu sıra, Google Cloud Console'da veya bu bağlantıyı kullanıyorsanız Cloud Shell'i etkinleştirir.
Ortamın sağlanması ve bağlantının kurulması yalnızca birkaç saniye sürer. İşlem tamamlandığında aşağıdakine benzer bir sonuç görürsünüz:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde iyileştirilir. Bu codelab'deki tüm çalışmalarınızı tarayıcıda yapabilirsiniz. Herhangi bir yazılım yüklemeniz gerekmez.
3. Başlamadan önce
API'yi etkinleştirme
Çıkış:
AlloyDB, Compute Engine, Networking Services ve Vertex AI'ı kullanmak için Google Cloud projenizde ilgili API'leri etkinleştirmeniz gerekir.
API'leri etkinleştirme
Terminaldeki Cloud Shell'de proje kimliğinizin ayarlandığından emin olun:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID ortam değişkenini ayarlayın:
PROJECT_ID=$(gcloud config get-value project)
Gerekli tüm API'leri etkinleştirin:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Beklenen çıktı
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
API'lerle tanışın
- AlloyDB API (
alloydb.googleapis.com), PostgreSQL için AlloyDB kümeleri oluşturmanıza, yönetmenize ve ölçeklendirmenize olanak tanır. Talepkar kurumsal işlemsel ve analitik iş yükleri için tasarlanmış, tümüyle yönetilen ve PostgreSQL ile uyumlu bir veritabanı hizmeti sunar. - Compute Engine API (
compute.googleapis.com), sanal makineler (VM'ler), kalıcı diskler ve ağ ayarları oluşturup yönetmenize olanak tanır. İş yüklerinizi çalıştırmak ve birçok yönetilen hizmetin temel altyapısını barındırmak için gereken temel hizmet olarak altyapı (IaaS) temelini sağlar. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com), Google Cloud projenizin meta verilerini ve yapılandırmasını programatik olarak yönetmenize olanak tanır. Kaynakları düzenlemenize, Identity and Access Management (IAM) politikalarını yönetmenize ve proje hiyerarşisi genelinde izinleri doğrulamanıza olanak tanır. - Service Networking API (
servicenetworking.googleapis.com), sanal özel bulut (VPC) ağınız ile Google'ın yönetilen hizmetleri arasındaki özel bağlantının kurulumunu otomatikleştirmenize olanak tanır. AlloyDB gibi hizmetler için özel IP erişimi oluşturmak ve bu hizmetlerin diğer kaynaklarınızla güvenli bir şekilde iletişim kurmasını sağlamak için özellikle gereklidir. - Vertex AI API (
aiplatform.googleapis.com), uygulamalarınızın makine öğrenimi modelleri oluşturmasına, dağıtmasına ve ölçeklendirmesine olanak tanır. Üretken yapay zeka modellerine (ör. Gemini) erişim ve özel model eğitimi de dahil olmak üzere Google Cloud'un tüm yapay zeka hizmetleri için birleşik bir arayüz sağlar.
İsteğe bağlı olarak, varsayılan bölgenizi Vertex AI yerleştirme modellerini kullanacak şekilde yapılandırabilirsiniz. Vertex AI'ın kullanılabildiği konumlar hakkında daha fazla bilgi edinin. Örnekte us-central1 bölgesi kullanılmaktadır.
gcloud config set compute/region us-central1
4. AlloyDB'yi dağıtma
AlloyDB kümesi oluşturmadan önce, gelecekteki AlloyDB örneği tarafından kullanılacak VPC'mizde kullanılabilir bir özel IP aralığına ihtiyacımız var. Bu kimlik yoksa oluşturmamız, dahili Google hizmetleri tarafından kullanılacak şekilde atamamız ve ardından küme ile örneği oluşturabilmemiz gerekir.
Özel IP aralığı oluşturma
AlloyDB için VPC'mizde özel hizmet erişimi yapılandırması yapmamız gerekiyor. Buradaki varsayım, projede "varsayılan" VPC ağının olduğu ve tüm işlemler için bu ağın kullanılacağıdır.
Özel IP aralığını oluşturun:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Ayrılan IP aralığını kullanarak özel bağlantı oluşturma:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB kümesi oluşturma
Bu bölümde, us-central1 bölgesinde bir AlloyDB kümesi oluşturuyoruz.
Postgres kullanıcısı için şifre tanımlayın. Kendi şifrenizi tanımlayabilir veya rastgele bir işlev kullanarak şifre oluşturabilirsiniz.
export PGPASSWORD=`openssl rand -hex 12`
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
PostgreSQL şifresini ileride kullanmak üzere not edin.
echo $PGPASSWORD
Gelecekte postgres kullanıcısı olarak örneğe bağlanmak için bu şifreye ihtiyacınız olacaktır. Daha sonra kullanabilmek için bu kodu bir yere yazmanızı veya kopyalamanızı öneririz.
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Ücretsiz deneme kümesi oluşturma
AlloyDB'yi daha önce kullanmadıysanız ücretsiz bir deneme kümesi oluşturabilirsiniz:
Bölgeyi ve AlloyDB küme adını tanımlayın. us-central1 bölgesini ve alloydb-aip-01'i küme adı olarak kullanacağız:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Kümeyi oluşturmak için komutu çalıştırın:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Beklenen konsol çıkışı:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Aynı Cloud Shell oturumunda kümemiz için bir AlloyDB birincil örneği oluşturun. Bağlantınız kesilirse bölge ve küme adı ortam değişkenlerini tekrar tanımlamanız gerekir.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard kümesi oluşturma
Projedeki ilk AlloyDB kümeniz değilse standart küme oluşturma işlemine devam edin.
Bölgeyi ve AlloyDB küme adını tanımlayın. us-central1 bölgesini ve alloydb-aip-01'i küme adı olarak kullanacağız:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Kümeyi oluşturmak için komutu çalıştırın:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Beklenen konsol çıkışı:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Aynı Cloud Shell oturumunda kümemiz için bir AlloyDB birincil örneği oluşturun. Bağlantınız kesilirse bölge ve küme adı ortam değişkenlerini tekrar tanımlamanız gerekir.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. AlloyDB'ye bağlanma
AlloyDB yalnızca özel bağlantı kullanılarak dağıtıldığından veritabanıyla çalışmak için PostgreSQL istemcisinin yüklü olduğu bir VM'ye ihtiyacımız var.
GCE sanal makinesi dağıtma
AlloyDB kümesiyle aynı bölgede ve VPC'de bir GCE VM oluşturun.
Cloud Shell'de şunu çalıştırın:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
Postgres istemcisini yükleme
Dağıtılan sanal makineye PostgreSQL istemci yazılımını yükleyin.
Sanal makineye bağlanın:
gcloud compute ssh instance-1 --zone=us-central1-a
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
Sanal makinenin içinde aşağıdaki komutu çalıştırarak yazılımı yükleyin:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Beklenen konsol çıkışı:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
Örneğe bağlanma
psql kullanarak sanal makineden birincil örneğe bağlanın.
instance-1 sanal makinenize açılan SSH oturumunun bulunduğu Cloud Shell sekmesinde.
GCE sanal makinesinden AlloyDB'ye bağlanmak için belirtilen AlloyDB şifresi (PGPASSWORD) değerini ve AlloyDB küme kimliğini kullanın:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Beklenen konsol çıkışı:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
psql oturumunu kapatın:
exit
6. Veritabanını Hazırlama
Veritabanı oluşturmamız, Vertex AI entegrasyonunu etkinleştirmemiz, veritabanı nesneleri oluşturmamız ve verileri içe aktarmamız gerekiyor.
AlloyDB'ye Gerekli İzinleri Verme
AlloyDB hizmet aracısına Vertex AI izinleri ekleyin.
En üstteki "+" işaretini kullanarak başka bir Cloud Shell sekmesi açın.
Yeni Cloud Shell sekmesinde şunu çalıştırın:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Sekmede "exit" yürütme komutunu kullanarak sekmeyi kapatın:
exit
Veritabanı Oluşturma
Veritabanı oluşturma hızlı başlangıç kılavuzu.
GCE sanal makine oturumunda şunu çalıştırın:
Veritabanı oluşturma:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
Beklenen konsol çıkışı:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
Vertex AI entegrasyonunu etkinleştirme
Veritabanında Vertex AI entegrasyonunu ve pgvector uzantılarını etkinleştirin.
GCE sanal makinesinde şunu çalıştırın:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
Beklenen konsol çıkışı:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
Verileri İçe Aktarma
Hazırlanan verileri indirip yeni veritabanına aktarın.
GCE sanal makinesinde şunu çalıştırın:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
Beklenen konsol çıkışı:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. Yerleştirmeleri hesaplama
Verileri içe aktardıktan sonra ürün verilerimizi cymbal_products tablosunda, her mağazadaki mevcut ürün sayısını gösteren envanteri cymbal_inventory tablosunda ve mağaza listesini cymbal_stores tablosunda aldık. Ürünlerimizin açıklamalarına göre vektör verilerini hesaplamamız gerekiyor ve bu amaçla embedding işlevini kullanacağız. Kullanacağımız işlevi kullanarak ürün açıklamalarımıza göre vektör verilerini hesaplamak ve tabloya eklemek için Vertex AI entegrasyonunu kullanacağız. Kullanılan teknoloji hakkında daha fazla bilgiyi belgelerde bulabilirsiniz.
Birkaç satır için oluşturmak kolaydır ancak binlerce satır varsa nasıl verimli hale getirebiliriz? Burada, büyük tablolar için yerleştirmelerin nasıl oluşturulacağını ve yönetileceğini göstereceğim. Farklı seçenekler ve teknikler hakkında daha fazla bilgiyi rehberde bulabilirsiniz.
Hızlı yerleştirme oluşturmayı etkinleştirme
AlloyDB örneği IP'sini ve postgres şifresini kullanarak sanal makinenizden psql ile veritabanına bağlanın:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
google_ml_integration uzantısının sürümünü doğrulayın.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Sürüm 1.5.2 veya daha yeni olmalıdır. Çıkış örneğini aşağıda görebilirsiniz:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
Varsayılan sürüm 1.5.2 veya daha yeni olmalıdır. Ancak örneğinizde daha eski bir sürüm gösteriliyorsa muhtemelen güncellenmesi gerekir. Örnek için bakımın devre dışı bırakılıp bırakılmadığını kontrol edin.
Ardından veritabanı işaretini doğrulamamız gerekir. google_ml_integration.enable_faster_embedding_generation işaretinin etkinleştirilmesi gerekir. Aynı psql oturumunda işaretin değerini kontrol edin.
show google_ml_integration.enable_faster_embedding_generation;
İşaret doğru konumdaysa beklenen çıkış şu şekilde görünür:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
Ancak "kapalı" gösteriyorsa örneği güncellememiz gerekir. Bu işlemi, dokümanlarda açıklandığı gibi web konsolunu veya gcloud komutunu kullanarak yapabilirsiniz. Burada, gcloud komutu kullanılarak bu işlemin nasıl yapılacağı gösterilmektedir:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Bu işlem birkaç dakika sürebilir ancak sonunda işaret değeri "açık" olarak değiştirilir. Ardından, sonraki adımlara geçebilirsiniz.
Yerleştirme sütunu oluşturma
psql kullanarak veritabanına bağlanın ve cymbal_products tablosundaki yerleştirme işlevini kullanarak vektör verileri içeren bir sanal sütun oluşturun. Yerleştirme işlevi, product_description sütunundan sağlanan verilere göre Vertex AI'dan vektör verileri döndürür.
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Veritabanına bağlandıktan sonra psql oturumunda şunu çalıştırın:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
Komut, sanal sütunu oluşturur ve vektör verileriyle doldurur.
Beklenen konsol çıkışı:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
Artık her biri 50 satırlık gruplar kullanarak yerleştirmeler oluşturabiliriz. Farklı toplu iş boyutlarıyla denemeler yapabilir ve yürütme süresinin değişip değişmediğini görebilirsiniz. Aynı psql oturumunda şunu çalıştırın:
Ne kadar süreceğini ölçmek için zamanlamayı etkinleştirin:
\timing
Komutu çalıştırın:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
Yerleştirme oluşturma işlemi için konsol çıkışı 2 saniyeden kısa sürede gösterilir:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
Varsayılan olarak, ilgili product_description sütunu güncellenirse veya tamamen yeni bir satır eklenirse yerleştirmeler yenilenmez. Ancak incremental_refresh_mode parametresini tanımlayarak bunu yapabilirsiniz. "product_embeddings" adlı bir sütun oluşturalım ve bu sütunun otomatik olarak güncellenmesini sağlayalım.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
Şimdi tabloya yeni bir satır eklersek.
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
Sütunlardaki farkı şu sorguyu kullanarak karşılaştırabiliriz:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
Çıktıda, embedding sütunu boş kalırken product_embedding sütununun otomatik olarak güncellendiğini görüyoruz.
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. Benzerlik Arama'yı çalıştırma
Artık açıklamalar için hesaplanan vektör değerlerine ve isteğimiz için aldığımız vektör değerine dayalı benzerlik araması kullanarak aramamızı çalıştırabiliriz.
SQL sorgusu aynı psql komut satırı arayüzünden veya alternatif olarak AlloyDB Studio'dan yürütülebilir. Çok satırlı ve karmaşık tüm çıkışlar AlloyDB Studio'da daha iyi görünebilir.
AlloyDB Studio'ya bağlanma
Aşağıdaki bölümlerde, veritabanına bağlantı gerektiren tüm SQL komutları alternatif olarak AlloyDB Studio'da yürütülebilir. Komutu çalıştırmak için birincil örneği tıklayarak AlloyDB kümenizin web konsolu arayüzünü açmanız gerekir.
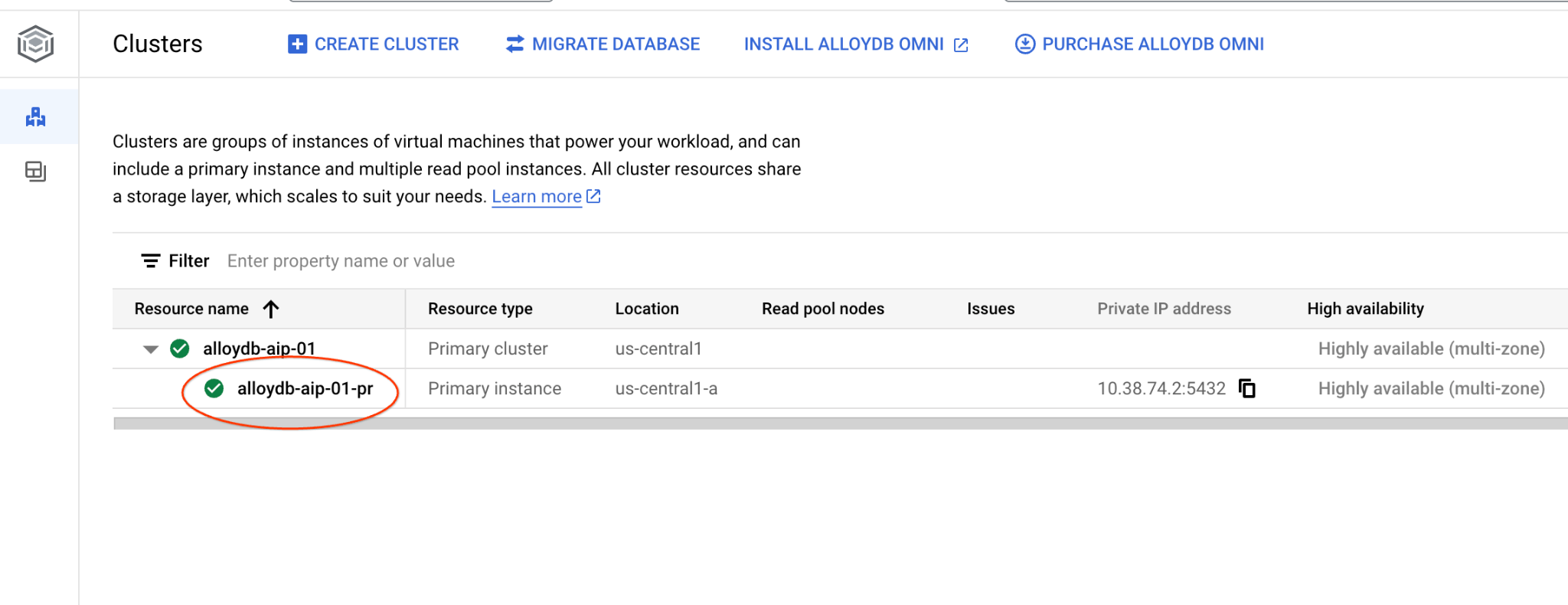
Ardından solda AlloyDB Studio'yu tıklayın:
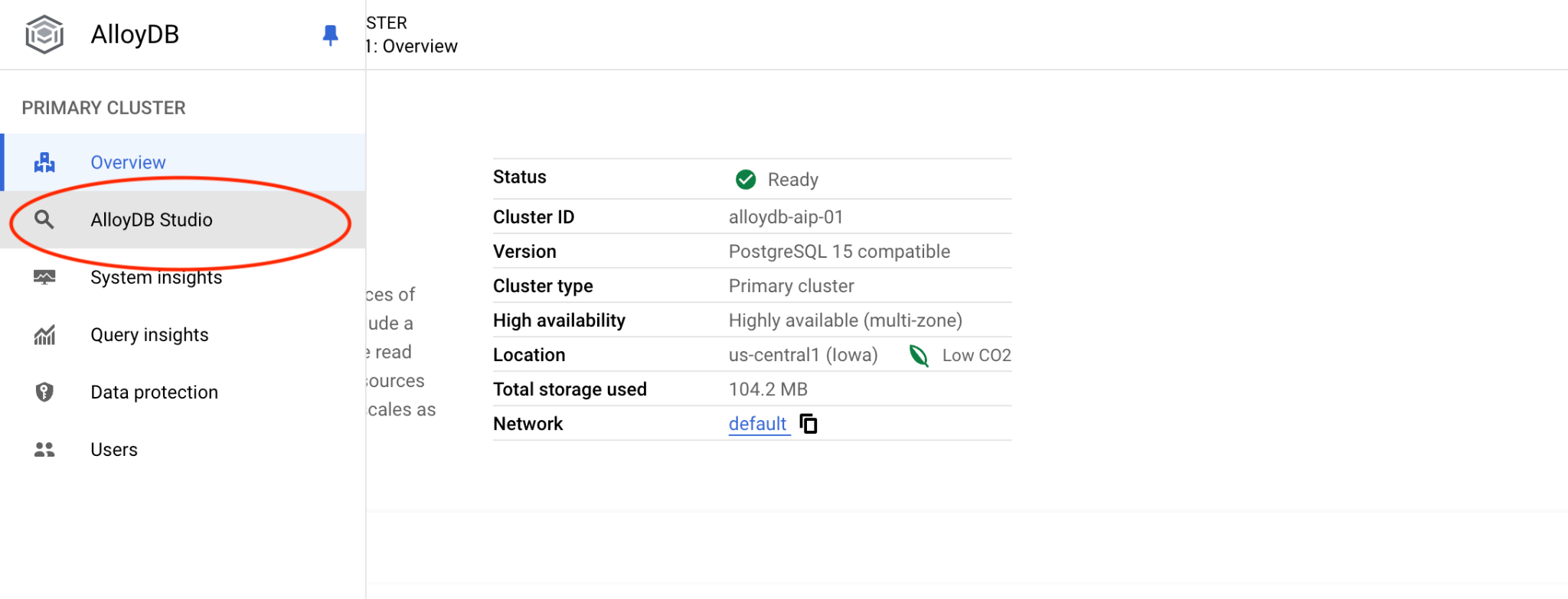
quickstart_db veritabanını ve postgres kullanıcısını seçin. Küme oluşturulurken not edilen şifreyi girin. Ardından "Kimlik doğrulama" düğmesini tıklayın.
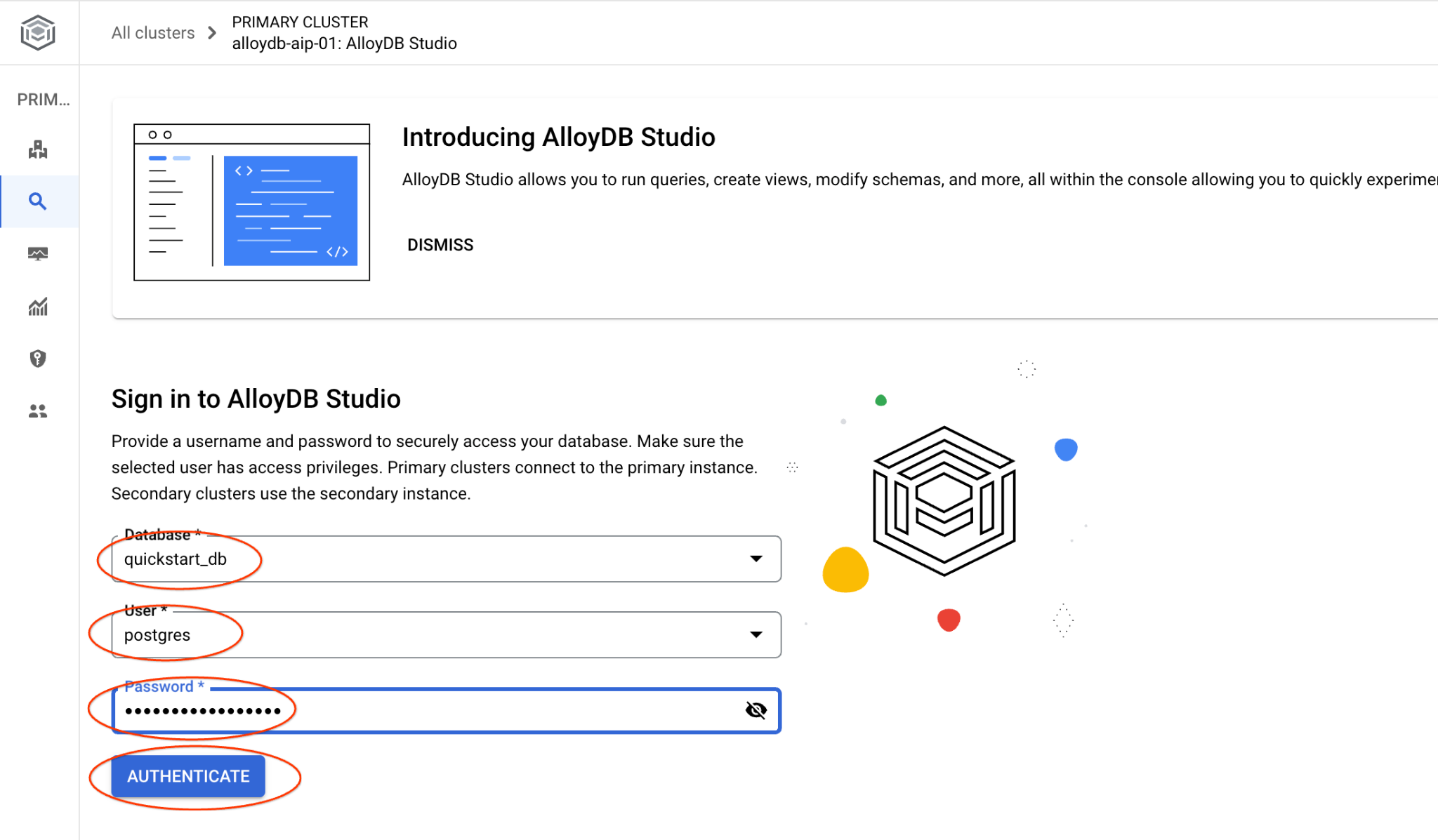
AlloyDB Studio arayüzü açılır. Veritabanındaki komutları çalıştırmak için sağdaki "Editor 1" sekmesini tıklayın.
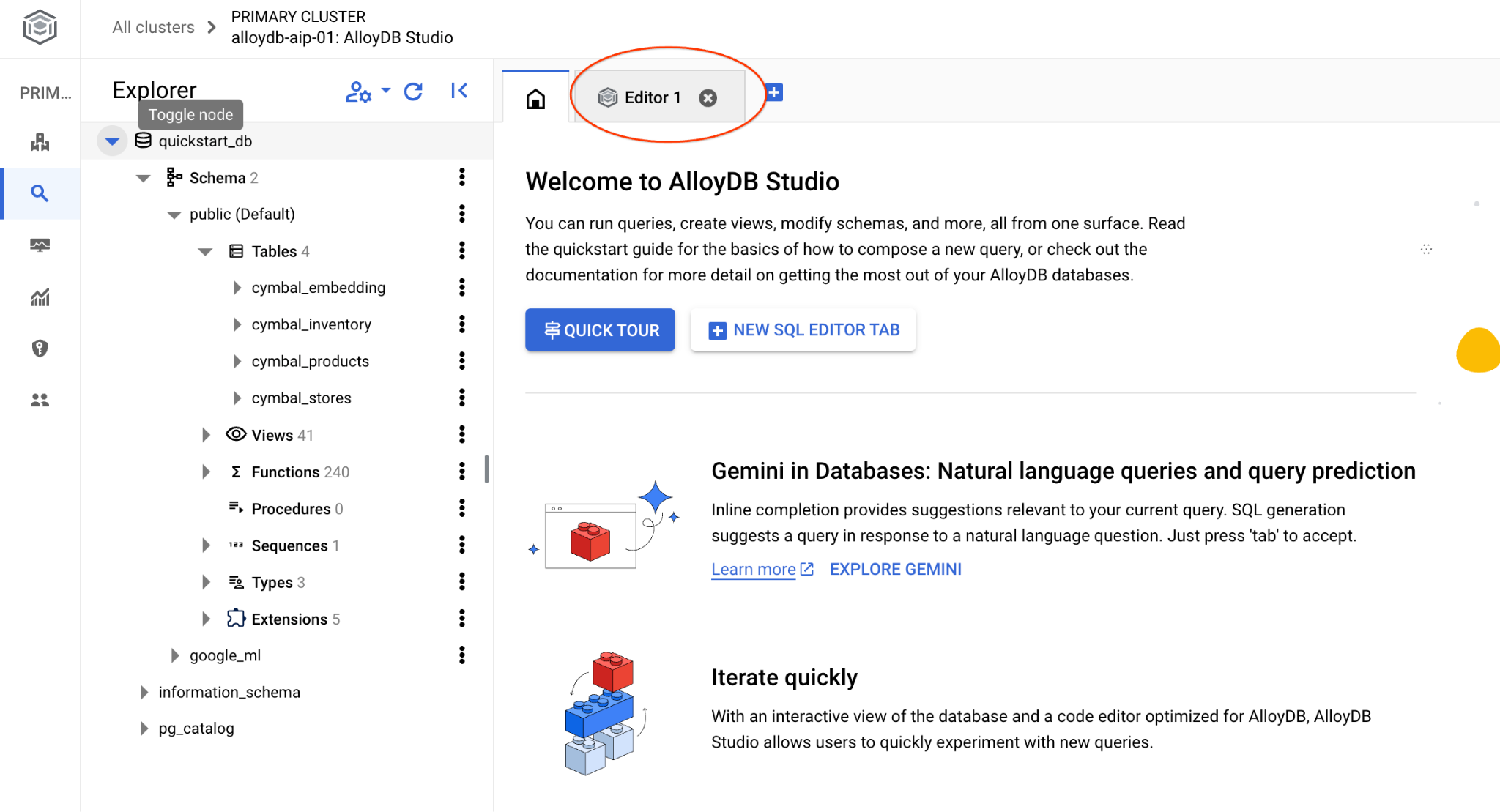
SQL komutlarını çalıştırabileceğiniz arayüz açılır.
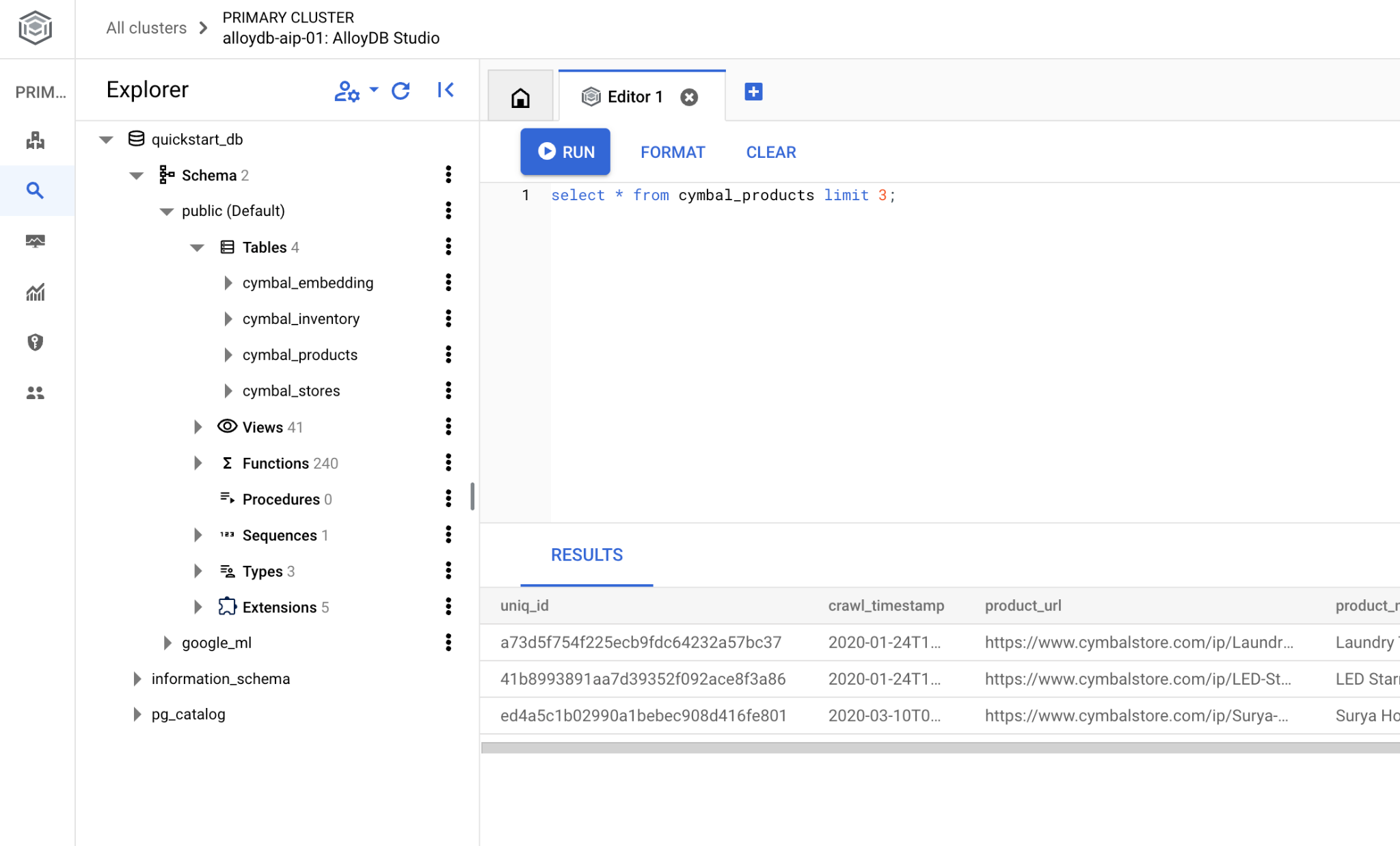
psql komut satırını kullanmayı tercih ederseniz alternatif yolu izleyin ve önceki bölümlerde açıklandığı gibi sanal makinenizin SSH oturumundan veritabanına bağlanın.
psql'den benzerlik araması çalıştırma
Veritabanı oturumunuzun bağlantısı kesildiyse psql veya AlloyDB Studio'yu kullanarak veritabanına tekrar bağlanın.
Veritabanına bağlanın:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Bir sorgu çalıştırarak müşterinin isteğiyle en alakalı olan mevcut ürünlerin listesini alın. Vektör değerini almak için Vertex AI'a ileteceğimiz istek "Burada hangi tür meyve ağaçları iyi yetişir?" gibi bir soruya benziyor.
İsteğimize en uygun ilk 10 öğeyi seçmek için çalıştırabileceğiniz sorguyu aşağıda bulabilirsiniz:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Beklenen çıktı:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. Yanıtı İyileştir
Sorgunun sonucunu kullanarak bir istemci uygulamasına verilen yanıtı iyileştirebilir ve sağlanan sorgu sonuçlarını Vertex AI üretken temel dil modeline gönderilen istemin bir parçası olarak kullanarak anlamlı bir çıkış hazırlayabilirsiniz.
Bunu yapmak için vektör aramasından elde ettiğimiz sonuçları içeren bir JSON oluşturmayı ve ardından anlamlı bir çıkış oluşturmak üzere Vertex AI'daki bir metin LLM modeli için isteme ek olarak bu JSON'u kullanmayı planlıyoruz. İlk adımda JSON'ı oluştururuz, ardından Vertex AI Studio'da test ederiz ve son adımda bir uygulamada kullanılabilecek bir SQL ifadesine dahil ederiz.
JSON biçiminde çıktı oluşturma
Çıkışı JSON biçiminde oluşturmak ve Vertex AI'a iletilecek yalnızca bir satır döndürmek için sorguyu değiştirin.
Sorgu örneği:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Çıktıda beklenen JSON:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
İstemi Vertex AI Studio'da çalıştırma
Oluşturulan JSON'u, Vertex AI Studio'daki üretken yapay zeka metin modeline istemin bir parçası olarak sağlamak için kullanabiliriz.
Cloud Console'da Vertex AI Studio'yu açın.
Daha önce kullanmadıysanız kullanım şartlarını kabul etmeniz istenebilir. "Kabul et ve devam et" düğmesine basın.
İsteminizi arayüze yazın.
Ek API'leri etkinleştirmenizi isteyebilir ancak bu isteği yoksayabilirsiniz. Laboratuvarımızı tamamlamak için ek API'lere ihtiyacımız yok.
Ağaçlarla ilgili ilk sorgunun JSON çıkışıyla birlikte kullanacağımız istemi aşağıda bulabilirsiniz:
Müşterinin ihtiyaçlarına göre ürün bulmasına yardımcı olan samimi bir danışmansın.
Müşteri isteğine göre, aramayla yakından ilişkili ürünlerin listesini yükledik.
JSON biçiminde, değer listesi içeren liste. Örneğin: {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Ürünlerin listesini aşağıda bulabilirsiniz:
{"product_name":"Kiraz Ağacı","description":"Bu, lezzetli kirazlar verecek güzel bir kiraz ağacıdır. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
Müşteri, "Burada en iyi yetişen ağaç hangisi?" diye sordu.
Ürün, fiyat ve bazı ek bilgiler hakkında bilgi vermelisiniz
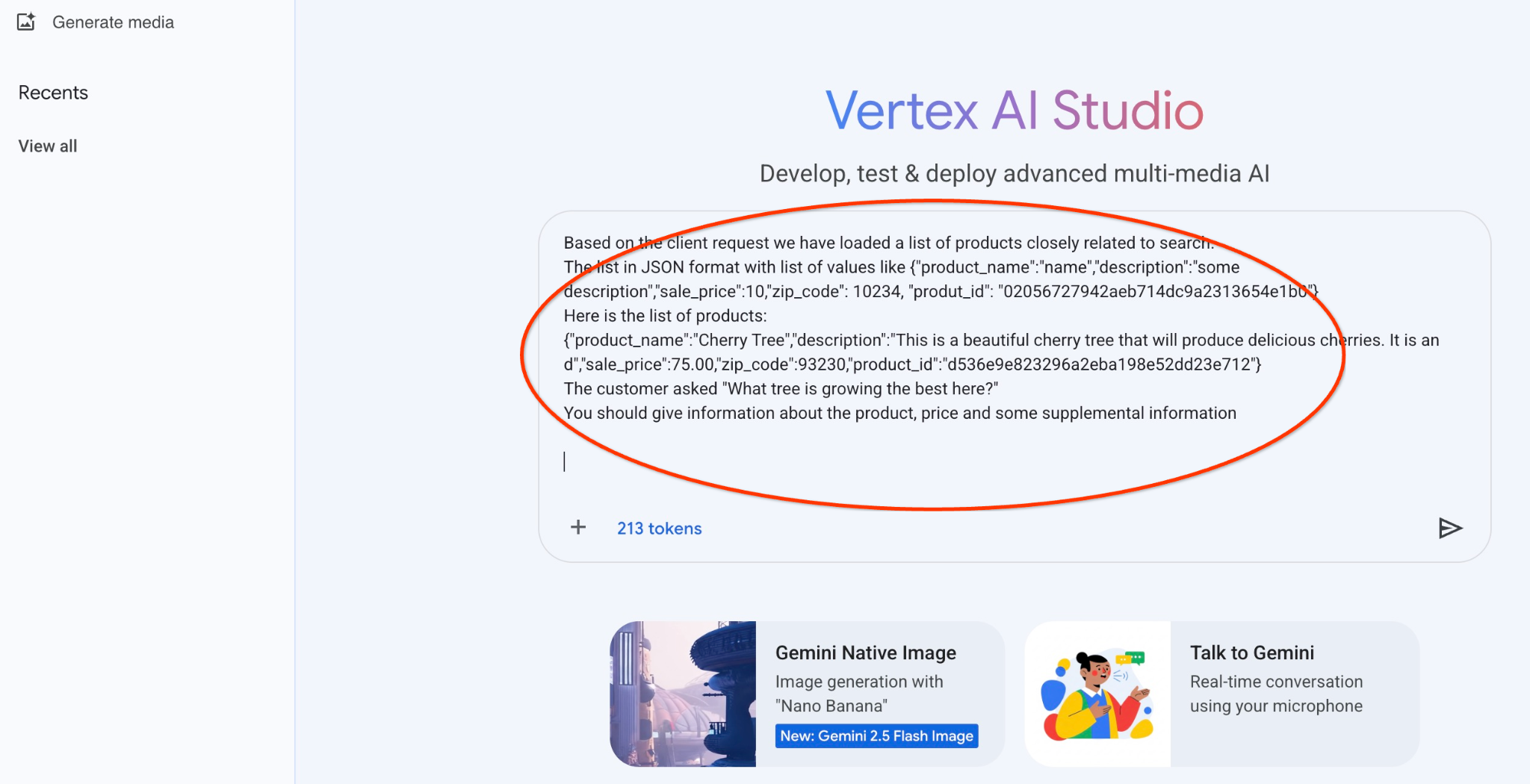
İstem, JSON değerlerimizle ve gemini-2.5-flash-light modeli kullanılarak çalıştırıldığında elde edilen sonuç:
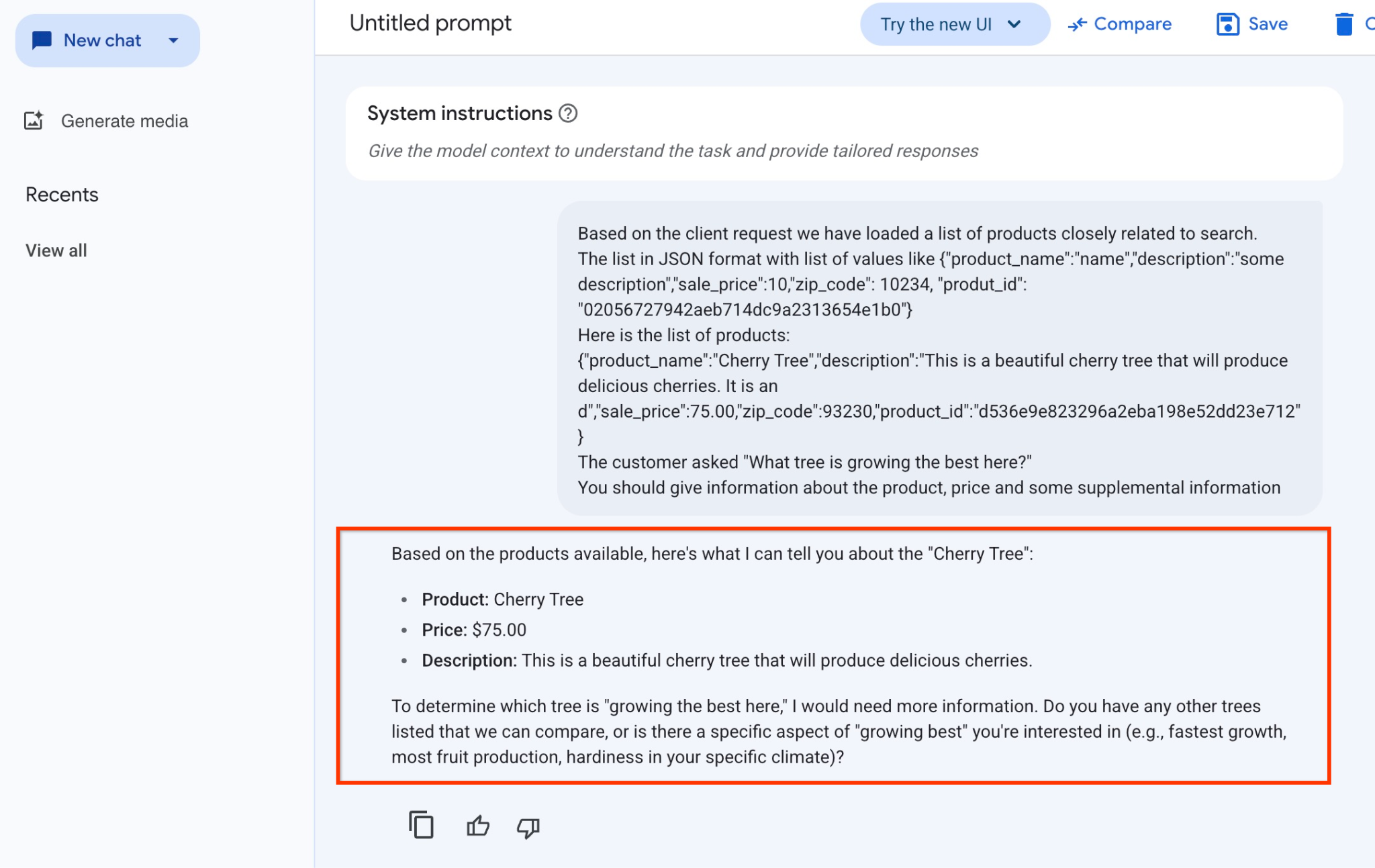
Bu örnekte modelden aldığımız yanıtı aşağıda bulabilirsiniz. Model ve parametrelerde zaman içinde yapılan değişiklikler nedeniyle yanıtınızın farklı olabileceğini unutmayın:
"Based on the products available, here's what I can tell you about the "Cherry Tree":
Ürün: Cherry Tree
Fiyat: 75,00 ABD doları
Açıklama: Bu, lezzetli kirazlar veren güzel bir kiraz ağacıdır.
Hangi ağacın "burada en iyi şekilde büyüdüğünü" belirlemek için daha fazla bilgiye ihtiyacım var. Karşılaştırabileceğimiz başka ağaçlar var mı veya "en iyi şekilde büyüme"nin ilgilendiğiniz belirli bir yönü var mı (ör. en hızlı büyüme, en fazla meyve üretimi, belirli ikliminizde dayanıklılık)?"
İstemi PSQL'de çalıştırma
Doğrudan veritabanında SQL kullanarak üretken bir modelden aynı yanıtı almak için AlloyDB AI'ın Vertex AI ile entegrasyonunu kullanabiliriz. Ancak gemini-1.5-flash modelini kullanmak için önce kaydetmemiz gerekir.
google_ml_integration uzantısını doğrulayın. 1.4.2 veya daha yeni bir sürüm yüklü olmalıdır.
Daha önce gösterildiği gibi psql'den quickstart_db veritabanına bağlanın (veya AlloyDB Studio'yu kullanın) ve şu komutu çalıştırın:
SELECT extversion from pg_extension where extname='google_ml_integration';
google_ml_integration.enable_model_support veritabanı işaretini kontrol edin.
show google_ml_integration.enable_model_support;
psql oturumundan beklenen çıktı "on"dur:
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
"Kapalı" gösteriliyorsa google_ml_integration.enable_model_support veritabanı işaretini "açık" olarak ayarlamamız gerekir. Bunu yapmak için AlloyDB web konsolu arayüzünü kullanabilir veya aşağıdaki gcloud komutunu çalıştırabilirsiniz.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Komutun arka planda yürütülmesi yaklaşık 1-3 dakika sürer. Ardından, işareti tekrar doğrulayabilirsiniz.
Sorgumuz için iki modele ihtiyacımız var. Birincisi, zaten kullanılan text-embedding-005 modeli, ikincisi ise genel Google Gemini modellerinden biridir.
Metin yerleştirme modelinden başlıyoruz. Model çalıştırmasını kaydetmek için psql veya AlloyDB Studio'da aşağıdaki kodu çalıştırın:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Kaydetmemiz gereken bir sonraki model ise kullanıcı dostu çıktı oluşturmak için kullanılacak olan gemini-2.0-flash-001.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
Kayıtlı modellerin listesini, google_ml.model_info_view'dan bilgi seçerek istediğiniz zaman doğrulayabilirsiniz.
select model_id,model_type from google_ml.model_info_view;
Örnek çıktı
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
Artık SQL kullanarak üretken yapay zeka metin modeline istemin bir parçası olarak sağlamak için alt sorguda oluşturulan JSON'u kullanabiliriz.
Veritabanına yönelik psql veya AlloyDB Studio oturumunda sorguyu çalıştırın.
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Beklenen çıktı aşağıda verilmiştir. Çıkışınız, model sürümüne ve parametrelere bağlı olarak farklı olabilir:
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. Vektör dizini oluşturma
Veri kümemiz oldukça küçüktür ve yanıt süresi öncelikle yapay zeka modelleriyle etkileşime bağlıdır. Ancak milyonlarca vektörünüz olduğunda vektör arama kısmı, yanıt süremizin önemli bir bölümünü alabilir ve sisteme yüksek yük bindirebilir. Bunu iyileştirmek için vektörlerimizin üzerinde bir dizin oluşturabiliriz.
ScaNN dizini oluşturma
SCANN dizinini oluşturmak için bir uzantı daha etkinleştirmemiz gerekiyor. alloydb_scann uzantısı, Google ScaNN algoritmasını kullanarak ANN türü vektör diziniyle çalışmak için bir arayüz sağlar.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Beklenen çıktı:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
Dizin, MANUAL (MANUEL) veya AUTO (OTOMATİK) modda oluşturulabilir. MANUEL modu varsayılan olarak etkindir ve diğer tüm dizinler gibi bir dizin oluşturup bunu koruyabilirsiniz. Ancak AUTO modunu etkinleştirirseniz sizden herhangi bir bakım gerektirmeyen dizin oluşturabilirsiniz. Tüm seçenekler hakkında ayrıntılı bilgiyi belgelerde bulabilirsiniz. Burada ise AUTO modunu etkinleştirme ve dizin oluşturma işlemlerini göstereceğiz. Bizim durumumuzda, AUTO modunda dizin oluşturmak için yeterli satır yok. Bu nedenle, dizini MANUAL olarak oluşturacağız.
Aşağıdaki örnekte çoğu parametreyi varsayılan olarak bırakıyorum ve dizin için yalnızca bir bölüm sayısı (num_leaves) sağlıyorum:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
Dizin parametrelerini ayarlama hakkında bilgiyi belgelerde bulabilirsiniz.
Beklenen çıktı:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
Yanıtı Karşılaştır
Artık vektör arama sorgusunu EXPLAIN (AÇIKLA) modunda çalıştırabilir ve dizinin kullanılıp kullanılmadığını doğrulayabiliriz.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Beklenen çıktı (netlik için sansürlenmiştir):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
Çıktıdan, sorgunun "cymbal_products_embeddings_scann üzerinde cymbal_products kullanılarak yapılan dizin taraması" kullandığı açıkça görülüyor.
Sorguyu explain olmadan çalıştırırsak:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Beklenen çıktı:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Sonucun, dizin oluşturulmamış arama sonuçlarımızda en üstte yer alan aynı kiraz ağacı olduğunu görüyoruz. Bazen bu durum geçerli olmayabilir ve yanıt, aynı ağacı değil, üst kısımdaki diğer ağaçları döndürebilir. Bu nedenle, dizin bize performans sağlıyor ancak yine de iyi sonuçlar verecek kadar doğru.
Vektörler için kullanılabilen farklı dizinleri ve dokümanlar sayfasında langchain entegrasyonuyla ilgili daha fazla laboratuvar ve örneği deneyebilirsiniz.
11. Ortamı temizleme
Laboratuvarı tamamladığınızda AlloyDB örneklerini ve kümeyi yok edin.
AlloyDB kümesini ve tüm örnekleri silme
AlloyDB'nin deneme sürümünü kullandıysanız Deneme kümesini kullanarak diğer laboratuvarları ve kaynakları test etmeyi planlıyorsanız deneme kümesini silmeyin. Aynı projede başka bir deneme kümesi oluşturamazsınız.
Küme, zorlama seçeneğiyle yok edilir. Bu seçenek, kümeye ait tüm örnekleri de siler.
Bağlantınız kesildiyse ve önceki tüm ayarlar kaybolduysa Cloud Shell'de proje ve ortam değişkenlerini tanımlayın:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Kümeyi silme:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB Yedeklemelerini Silme
Kümenin tüm AlloyDB yedeklerini silin:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
Artık VM'mizi yok edebiliriz.
GCE sanal makinesini silme
Cloud Shell'de şunu çalıştırın:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. Tebrikler
Codelab'i tamamladığınız için tebrik ederiz.
Bu laboratuvar, Google Cloud ile Üretime Hazır Yapay Zeka öğrenme rotasının bir parçasıdır.
- Prototip aşamasından üretim aşamasına geçiş yapmak için tüm müfredatı inceleyin.
- İlerleme durumunuzu
#ProductionReadyAIhashtag'iyle paylaşın.
İşlediğimiz konular
- AlloyDB kümesi ve birincil örneği dağıtma
- Google Compute Engine sanal makinesinden AlloyDB'ye bağlanma
- Veritabanı oluşturma ve AlloyDB AI'yı etkinleştirme
- Veritabanına veri yükleme
- AlloyDB Studio'yu kullanma
- AlloyDB'de Vertex AI yerleştirme modelini kullanma
- Vertex AI Studio'yu kullanma
- Vertex AI üretken modelini kullanarak sonucu zenginleştirme
- Vektör dizini kullanarak performansı artırma
13. Anket
Çıkış: