
1. Introduction
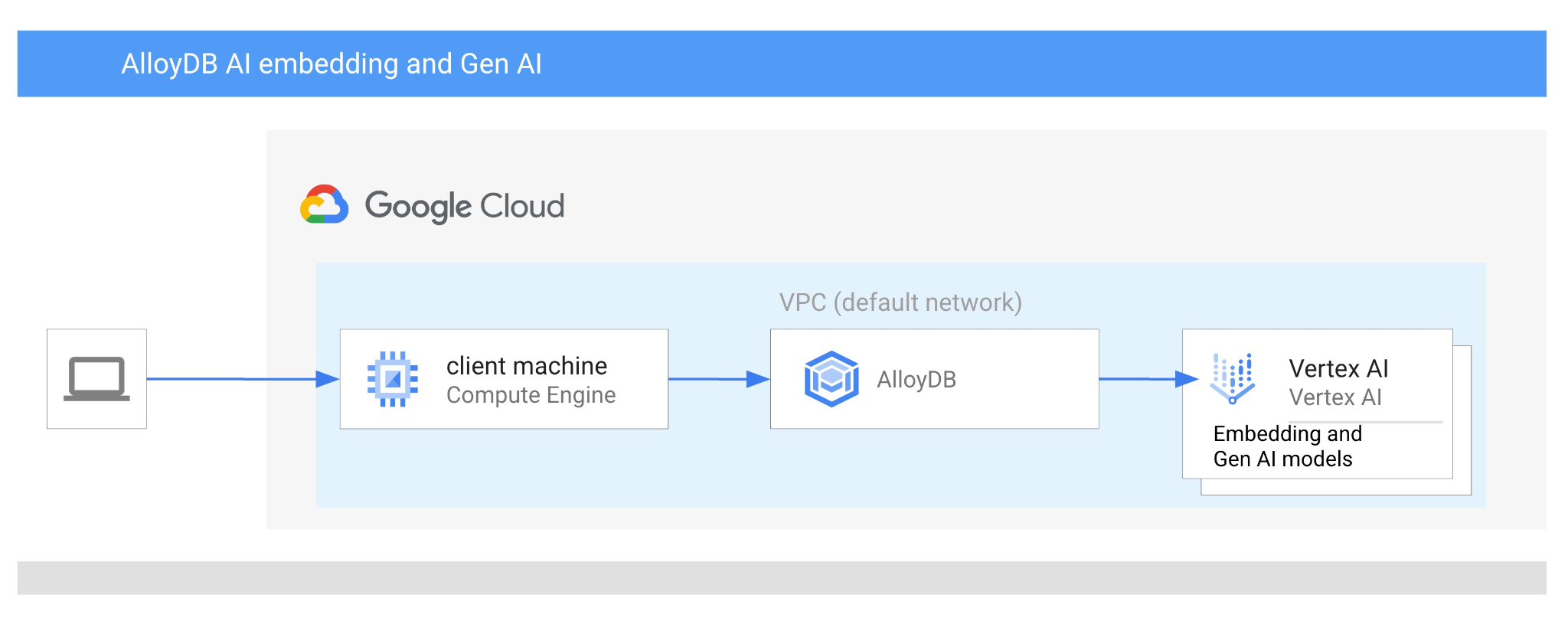
Dans cet atelier de programmation, vous allez apprendre à utiliser AlloyDB AI en combinant la recherche vectorielle avec les embeddings Vertex AI. Cet atelier fait partie d'une collection d'ateliers consacrés aux fonctionnalités d'AlloyDB AI. Pour en savoir plus, consultez la page AlloyDB AI dans la documentation.
Prérequis
- Connaissances de base concernant la console Google Cloud
- Compétences de base concernant l'interface de ligne de commande et Google Shell
Points abordés
- Déployer un cluster AlloyDB et une instance principale
- Se connecter à AlloyDB depuis une VM Google Compute Engine
- Créer une base de données et activer AlloyDB AI
- Charger des données dans la base de données
- Utiliser AlloyDB Studio
- Utiliser le modèle d'embedding Vertex AI dans AlloyDB
- Utiliser Vertex AI Studio
- Enrichir les résultats à l'aide du modèle génératif Vertex AI
- Améliorer les performances à l'aide de l'index vectoriel
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome
2. Préparation
Configuration du projet
- Connectez-vous à la console Google Cloud. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
- Créez un projet ou réutilisez-en un existant. Pour créer un projet dans la console Google Cloud, cliquez sur le bouton "Sélectionner un projet" dans l'en-tête pour ouvrir une fenêtre pop-up.

Dans la fenêtre "Sélectionner un projet", cliquez sur le bouton "Nouveau projet" pour ouvrir une boîte de dialogue pour le nouveau projet.
Dans la boîte de dialogue, saisissez le nom de projet de votre choix et sélectionnez l'emplacement.
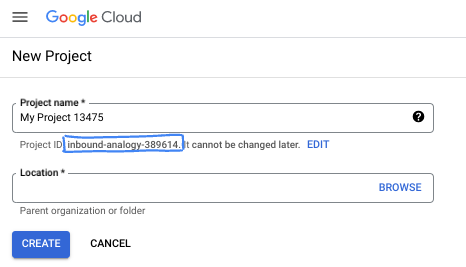
- Le nom du projet est le nom à afficher pour les participants au projet. Le nom de projet n'est utilisé par aucune API Google et peut être modifié à tout moment.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Google Cloud génère automatiquement un ID unique, mais vous pouvez le personnaliser. Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire ou en fournir un pour vérifier sa disponibilité. Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet, généralement identifié par l'espace réservé PROJECT_ID.
- Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
Activer la facturation
Pour activer la facturation, vous avez deux options. Vous pouvez utiliser votre compte de facturation personnel ou suivre les étapes ci-dessous pour utiliser des crédits.
Utiliser des crédits Google Cloud (facultatif)
Pour suivre cet atelier, vous avez besoin d'un compte de facturation avec un certain crédit. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà associé à un compte de facturation, vous pouvez ignorer cette étape.
Configurer un compte de facturation personnel
Si vous configurez la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, cliquez ici pour activer la facturation dans la console Cloud.
Remarques :
- Cet atelier devrait vous coûter moins de 3 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Vous pouvez également appuyer sur G, puis sur S. Cette séquence activera Cloud Shell si vous êtes dans la console Google Cloud ou si vous utilisez ce lien.
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Activer l'API
Résultat :
Pour utiliser AlloyDB, Compute Engine, les services réseau et Vertex AI, vous devez activer leurs API respectives dans votre projet Google Cloud.
Activer les API
Dans Cloud Shell, dans le terminal, assurez-vous que l'ID de votre projet est configuré :
gcloud config set project [YOUR-PROJECT-ID]
Définissez la variable d'environnement PROJECT_ID :
PROJECT_ID=$(gcloud config get-value project)
Activez toutes les API nécessaires :
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Résultat attendu
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Présentation des API
- L'API AlloyDB (
alloydb.googleapis.com) vous permet de créer, de gérer et de mettre à l'échelle des clusters AlloyDB pour PostgreSQL. Il s'agit d'un service de base de données entièrement géré compatible avec PostgreSQL, conçu pour les charges de travail transactionnelles et analytiques d'entreprise exigeantes. - L'API Compute Engine (
compute.googleapis.com) vous permet de créer et de gérer des machines virtuelles (VM), des disques persistants et des paramètres réseau. Elle fournit les bases IaaS (Infrastructure as a Service) nécessaires pour exécuter vos charges de travail et héberger l'infrastructure sous-jacente de nombreux services gérés. - L'API Cloud Resource Manager (
cloudresourcemanager.googleapis.com) vous permet de gérer de façon programmatique les métadonnées et la configuration de votre projet Google Cloud. Il vous permet d'organiser les ressources, de gérer les stratégies IAM (Identity and Access Management) et de valider les autorisations dans la hiérarchie des projets. - L'API Service Networking (
servicenetworking.googleapis.com) vous permet d'automatiser la configuration de la connectivité privée entre votre réseau Virtual Private Cloud (VPC) et les services gérés de Google. Il est spécifiquement requis pour établir un accès par adresse IP privée pour des services tels qu'AlloyDB, afin qu'ils puissent communiquer de manière sécurisée avec vos autres ressources. - L'API Vertex AI (
aiplatform.googleapis.com) permet à vos applications de créer, de déployer et de mettre à l'échelle des modèles de machine learning. Elle fournit une interface unifiée pour tous les services d'IA de Google Cloud, y compris l'accès aux modèles d'IA générative (comme Gemini) et l'entraînement de modèles personnalisés.
Vous pouvez également configurer votre région par défaut pour utiliser les modèles d'embedding Vertex AI. En savoir plus sur les emplacements disponibles pour Vertex AI Dans l'exemple, nous utilisons la région "us-central1".
gcloud config set compute/region us-central1
4. Déployer AlloyDB
Avant de créer un cluster AlloyDB, nous avons besoin d'une plage d'adresses IP privées disponible dans notre VPC, qui sera utilisée par la future instance AlloyDB. Si nous ne l'avons pas, nous devons le créer, l'attribuer pour qu'il soit utilisé par les services Google internes, après quoi nous pourrons créer le cluster et l'instance.
Créer une plage d'adresses IP privées
Nous devons configurer l'accès au service privé dans notre VPC pour AlloyDB. L'hypothèse ici est que nous avons le réseau VPC "par défaut" dans le projet et qu'il sera utilisé pour toutes les actions.
Créez la plage d'adresses IP privées :
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Créez une connexion privée à l'aide de la plage d'adresses IP allouée :
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Créer un cluster AlloyDB
Dans cette section, nous allons créer un cluster AlloyDB dans la région us-central1.
Définissez le mot de passe de l'utilisateur postgres. Vous pouvez définir votre propre mot de passe ou utiliser une fonction aléatoire pour en générer un.
export PGPASSWORD=`openssl rand -hex 12`
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Notez le mot de passe PostgreSQL (il vous servira plus tard).
echo $PGPASSWORD
Vous aurez besoin de ce mot de passe à l'avenir pour vous connecter à l'instance en tant qu'utilisateur postgres. Je vous suggère de l'écrire ou de le copier quelque part pour pouvoir l'utiliser plus tard.
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Créer un cluster d'essai sans frais
Si vous n'avez jamais utilisé AlloyDB, vous pouvez créer un cluster d'essai sans frais :
Définissez la région et le nom du cluster AlloyDB. Nous allons utiliser la région us-central1 et alloydb-aip-01 comme nom de cluster :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Exécutez la commande pour créer le cluster :
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Résultat attendu sur la console :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Créez une instance principale AlloyDB pour le cluster dans la même session Cloud Shell. Si vous êtes déconnecté, vous devrez définir à nouveau les variables d'environnement pour la région et le nom du cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Créer un cluster AlloyDB Standard
Si ce n'est pas votre premier cluster AlloyDB dans le projet, créez un cluster standard.
Définissez la région et le nom du cluster AlloyDB. Nous allons utiliser la région us-central1 et alloydb-aip-01 comme nom de cluster :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Exécutez la commande pour créer le cluster :
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Résultat attendu sur la console :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Créez une instance principale AlloyDB pour le cluster dans la même session Cloud Shell. Si vous êtes déconnecté, vous devrez définir à nouveau les variables d'environnement pour la région et le nom du cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. vous connecter à AlloyDB ;
AlloyDB est déployé à l'aide d'une connexion privée uniquement. Nous avons donc besoin d'une VM avec le client PostgreSQL installé pour pouvoir utiliser la base de données.
Déployer une VM GCE
Créez une VM GCE dans la même région et dans le même VPC que le cluster AlloyDB.
Dans Cloud Shell, exécutez :
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
Installer le client Postgres
Installez le logiciel client PostgreSQL sur la VM déployée.
Connectez-vous à la VM.
gcloud compute ssh instance-1 --zone=us-central1-a
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
Installez la commande logicielle en cours d'exécution dans la VM :
sudo apt-get update
sudo apt-get install --yes postgresql-client
Résultat attendu sur la console :
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
Se connecter à l'instance
Connectez-vous à l'instance principale depuis la VM à l'aide de psql.
Dans le même onglet Cloud Shell que la session SSH ouverte sur votre VM instance-1.
Utilisez la valeur du mot de passe AlloyDB (PGPASSWORD) notée et l'ID du cluster AlloyDB pour vous connecter à AlloyDB depuis la VM GCE :
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Résultat attendu sur la console :
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
Fermez la session psql :
exit
6. Préparer la base de données
Nous devons créer une base de données, activer l'intégration de Vertex AI, créer des objets de base de données et importer les données.
Accorder les autorisations nécessaires à AlloyDB
Ajoutez des autorisations Vertex AI à l'agent de service AlloyDB.
Ouvrez un autre onglet Cloud Shell à l'aide du signe "+" situé en haut.
Dans le nouvel onglet Cloud Shell, exécutez :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Fermez l'onglet en exécutant la commande "exit" dans l'onglet :
exit
Créer une base de données
Démarrage rapide pour la création d'une base de données
Dans la session de la VM GCE, exécutez :
Créez une base de données :
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
Résultat attendu sur la console :
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
Activer l'intégration à Vertex AI
Activez l'intégration Vertex AI et les extensions pgvector dans la base de données.
Dans la VM GCE, exécutez :
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
Résultat attendu sur la console :
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
Importer des données
Téléchargez les données préparées et importez-les dans la nouvelle base de données.
Dans la VM GCE, exécutez :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
Résultat attendu sur la console :
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. Calculer des embeddings
Après avoir importé les données, nous avons obtenu les données produit dans la table "cymbal_products", l'inventaire indiquant le nombre de produits disponibles dans chaque magasin dans la table "cymbal_inventory" et la liste des magasins dans la table "cymbal_stores". Nous devons calculer les données vectorielles en fonction des descriptions de nos produits. Pour ce faire, nous allons utiliser la fonction embedding. À l'aide de la fonction, nous allons utiliser l'intégration Vertex AI pour calculer les données vectorielles en fonction des descriptions de nos produits et les ajouter au tableau. Pour en savoir plus sur la technologie utilisée, consultez la documentation.
Il est facile de le générer pour quelques lignes, mais comment le rendre efficace si nous en avons des milliers ? Je vais vous montrer comment générer et gérer des embeddings pour les grandes tables. Pour en savoir plus sur les différentes options et techniques, consultez le guide.
Activer la génération rapide d'embeddings
Connectez-vous à la base de données à l'aide de psql depuis votre VM en utilisant l'adresse IP de l'instance AlloyDB et le mot de passe postgres :
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Vérifiez la version de l'extension google_ml_integration.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
La version doit être 1.5.2 ou ultérieure. Voici un exemple de résultat :
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
La version par défaut doit être la version 1.5.2 ou une version ultérieure. Si votre instance affiche une version antérieure, vous devrez probablement la mettre à jour. Vérifiez si la maintenance a été désactivée pour l'instance.
Nous devons ensuite vérifier l'indicateur de base de données. Nous devons activer le flag google_ml_integration.enable_faster_embedding_generation. Dans la même session psql, vérifiez la valeur du flag.
show google_ml_integration.enable_faster_embedding_generation;
Si l'indicateur est dans la bonne position, le résultat attendu ressemble à ceci :
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
Si l'état est "Désactivé", vous devez mettre à jour l'instance. Vous pouvez le faire à l'aide de la console Web ou de la commande gcloud, comme décrit dans la documentation. Voici comment procéder à l'aide de la commande gcloud :
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Cela peut prendre quelques minutes, mais la valeur du flag devrait finir par passer sur "on". Vous pouvez ensuite passer aux étapes suivantes.
Créer une colonne d'embedding
Connectez-vous à la base de données à l'aide de psql et créez une colonne virtuelle avec les données vectorielles à l'aide de la fonction d'embedding dans la table cymbal_products. La fonction d'embedding renvoie des données vectorielles de Vertex AI en fonction des données fournies par la colonne "product_description".
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Dans la session psql, après vous être connecté à la base de données, exécutez la commande suivante :
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
La commande crée la colonne virtuelle et la remplit avec des données vectorielles.
Résultat attendu sur la console :
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
Nous pouvons maintenant générer des embeddings à l'aide de lots de 50 lignes chacun. Vous pouvez tester différentes tailles de lot et voir si cela modifie le temps d'exécution. Dans la même session psql, exécutez :
Activez le timing pour mesurer le temps nécessaire :
\timing
Exécutez la commande suivante :
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
La sortie de la console indique que la génération de l'embedding a pris moins de deux secondes :
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
Par défaut, les embeddings ne sont pas actualisés si la colonne product_description correspondante est mise à jour ou si une ligne entièrement nouvelle est insérée. Toutefois, vous pouvez le faire en définissant le paramètre incremental_refresh_mode. Créons une colonne product_embeddings et rendons-la automatiquement modifiable.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
Et maintenant, si nous insérons une nouvelle ligne dans le tableau.
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
Nous pouvons comparer la différence entre les colonnes à l'aide de la requête suivante :
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
Dans le résultat, nous pouvons voir que la colonne embedding reste vide, tandis que la colonne product_embedding est automatiquement mise à jour.
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. Exécuter une recherche de similarités
Nous pouvons maintenant exécuter notre recherche à l'aide de la recherche par similarité basée sur les valeurs vectorielles calculées pour les descriptions et la valeur vectorielle que nous obtenons pour notre requête.
La requête SQL peut être exécutée à partir de la même interface de ligne de commande psql ou, en alternative, à partir d'AlloyDB Studio. Les résultats complexes et sur plusieurs lignes peuvent être plus lisibles dans AlloyDB Studio.
Se connecter à AlloyDB Studio
Dans les chapitres suivants, toutes les commandes SQL nécessitant une connexion à la base de données peuvent également être exécutées dans AlloyDB Studio. Pour exécuter la commande, vous devez ouvrir l'interface de la console Web de votre cluster AlloyDB en cliquant sur l'instance principale.
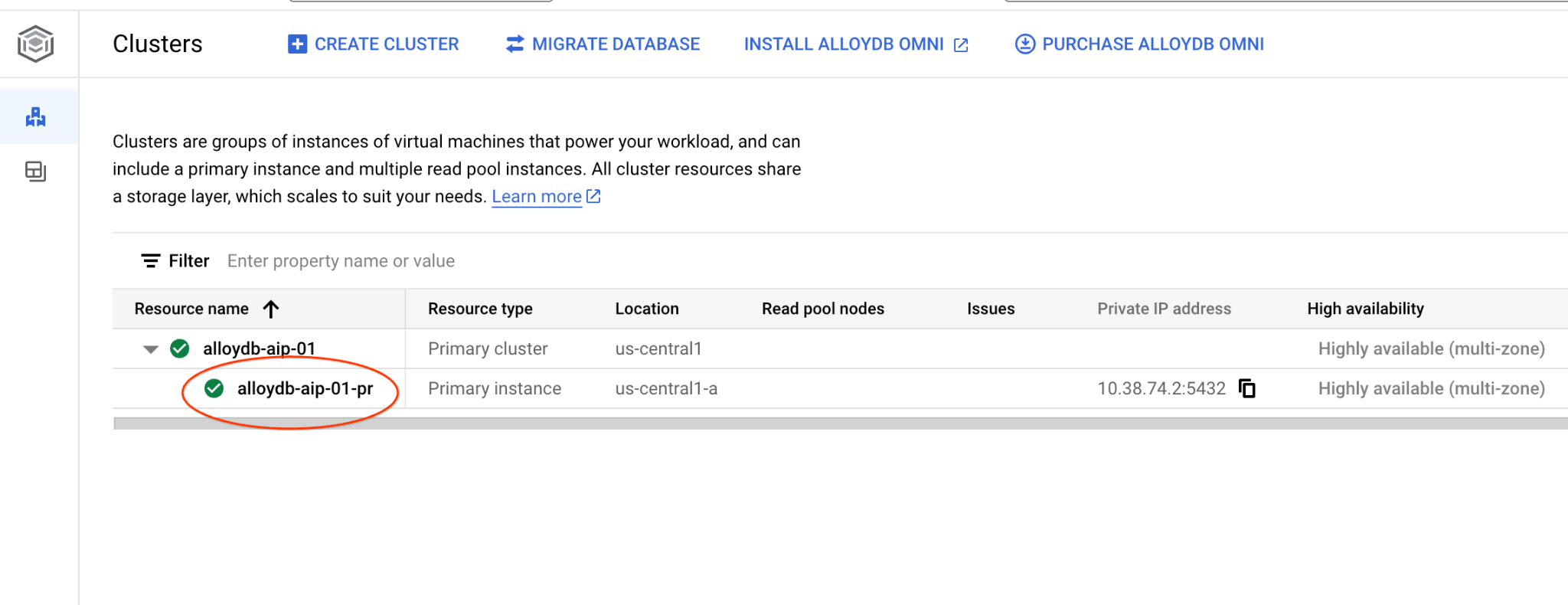
Cliquez ensuite sur AlloyDB Studio à gauche :
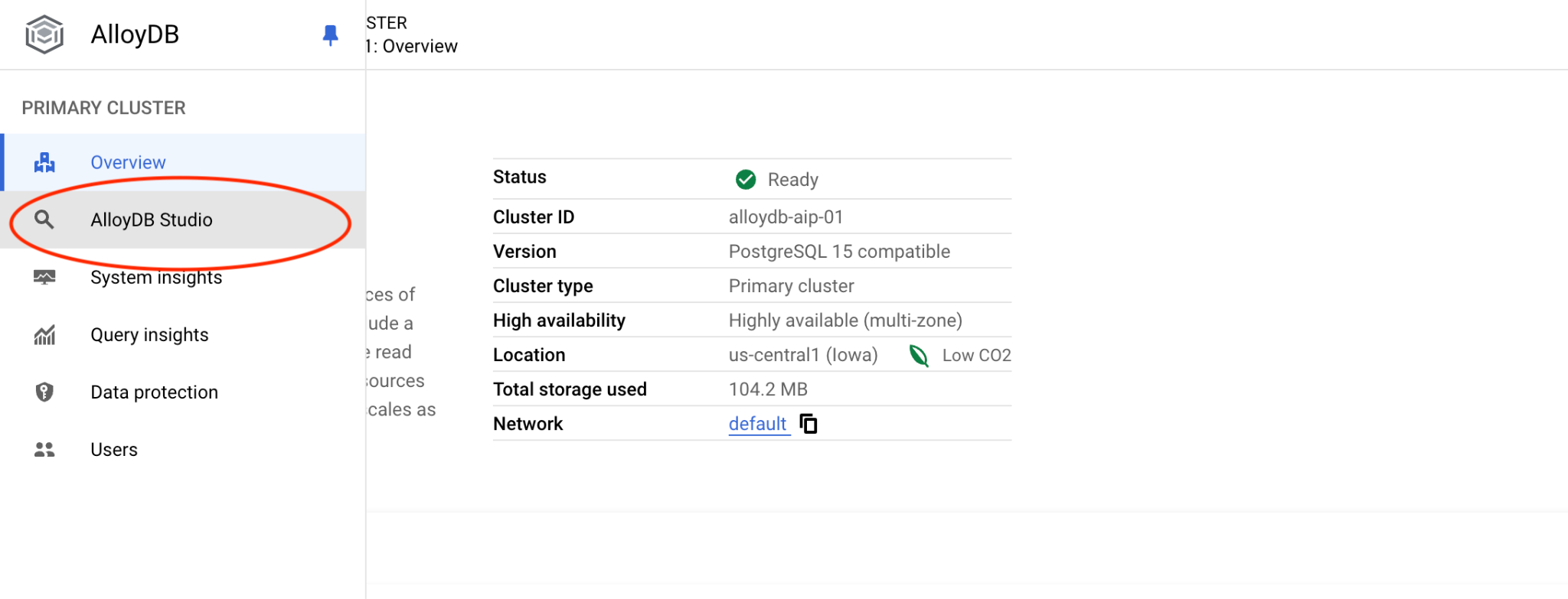
Choisissez la base de données quickstart_db et l'utilisateur postgres, puis fournissez le mot de passe indiqué lors de la création du cluster. Cliquez ensuite sur le bouton "Authenticate" (S'authentifier).
L'interface AlloyDB Studio s'ouvre. Pour exécuter les commandes dans la base de données, cliquez sur l'onglet "Editor 1" (Éditeur 1) à droite.
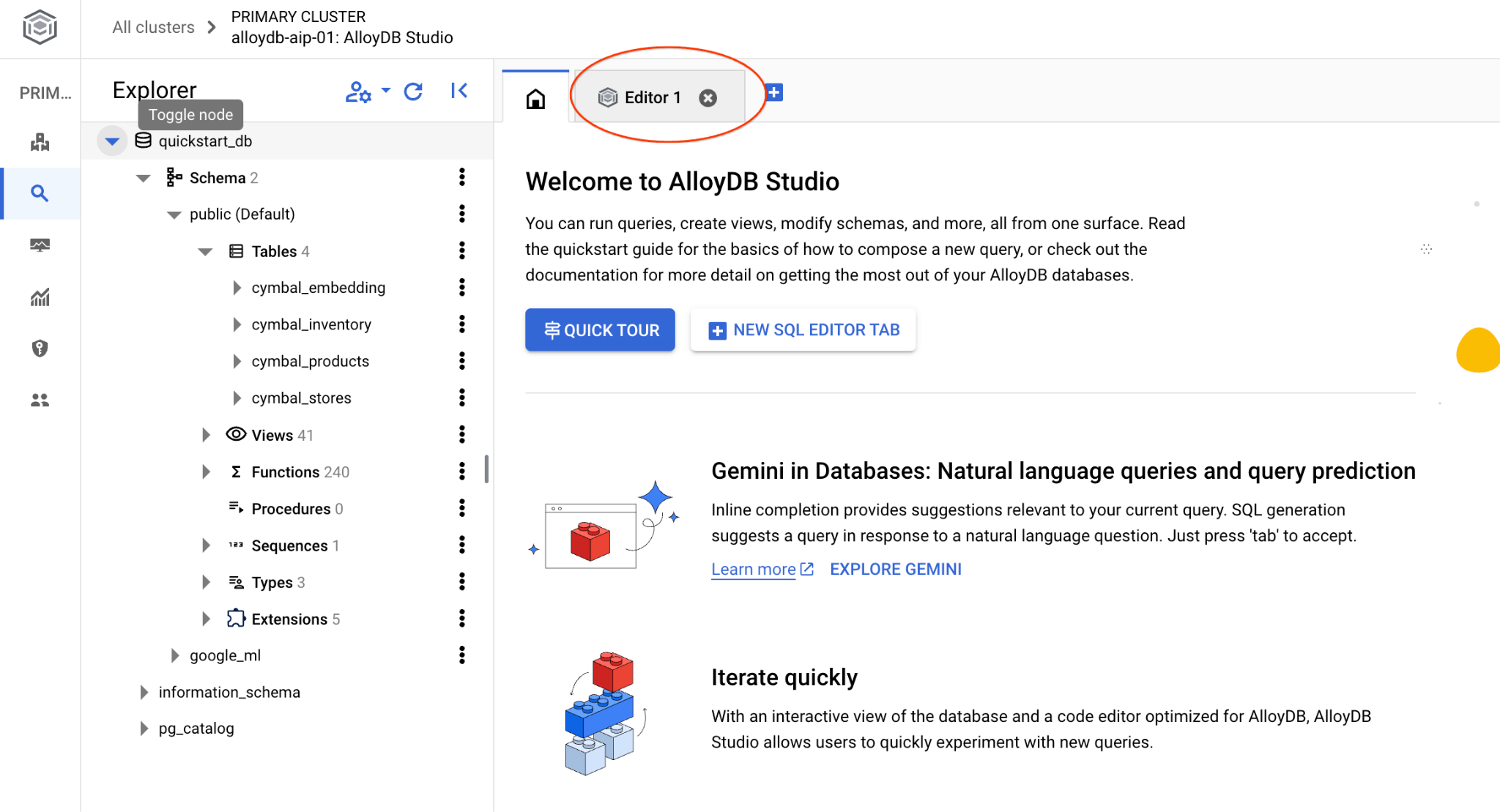
L'interface qui s'ouvre vous permet d'exécuter des commandes SQL.
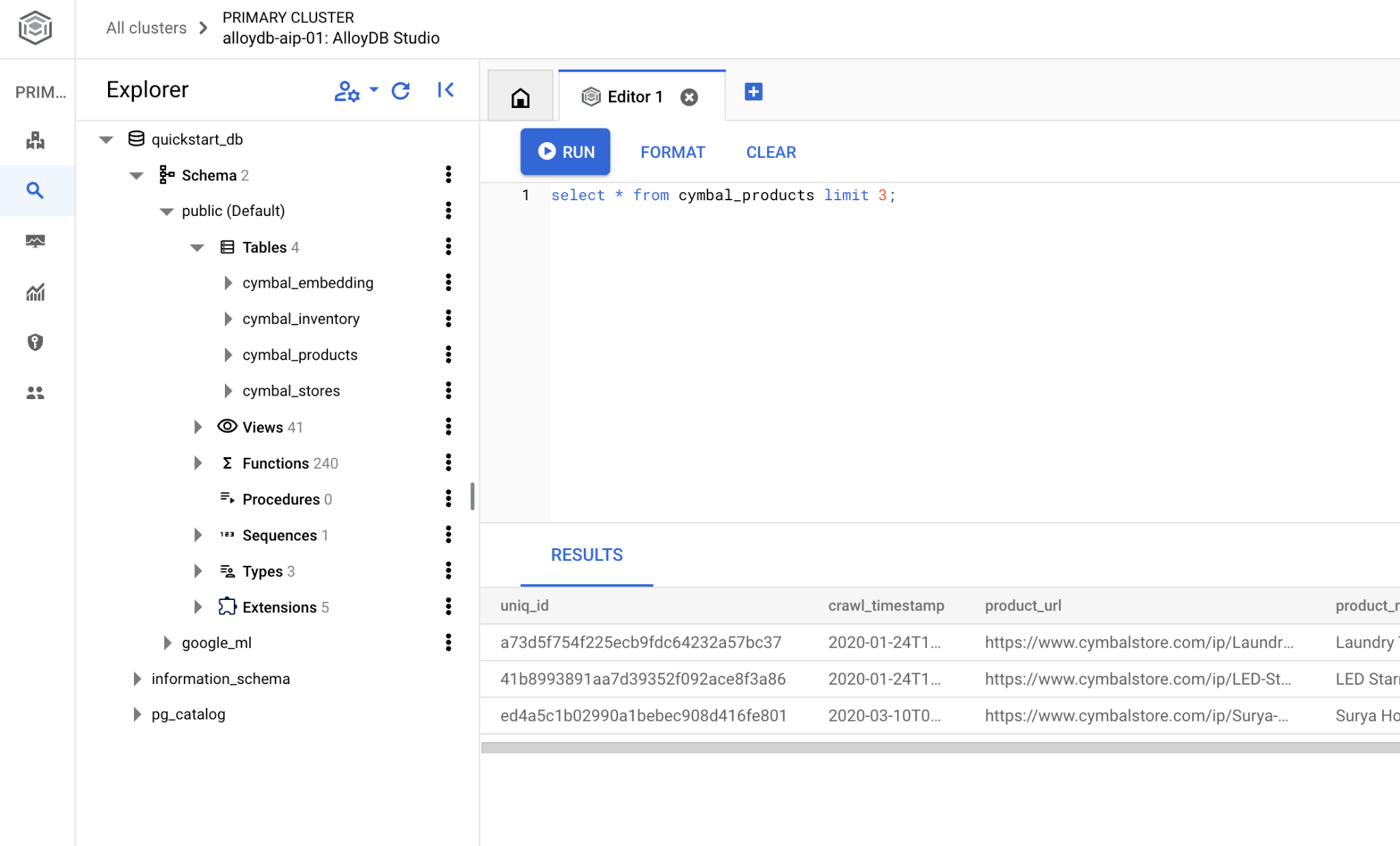
Si vous préférez utiliser la ligne de commande psql, suivez l'autre méthode et connectez-vous à la base de données depuis la session SSH de votre VM, comme décrit dans les chapitres précédents.
Exécuter une recherche de similarités à partir de psql
Si votre session de base de données a été déconnectée, reconnectez-vous à la base de données à l'aide de psql ou d'AlloyDB Studio.
Connectez-vous à la base de données :
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Exécutez une requête pour obtenir la liste des produits disponibles qui correspondent le mieux à la demande d'un client. La requête que nous allons transmettre à Vertex AI pour obtenir la valeur vectorielle ressemble à "Quels types d'arbres fruitiers poussent bien ici ?"
Voici la requête que vous pouvez exécuter pour choisir les 10 premiers éléments les plus adaptés à votre demande :
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Voici le résultat attendu :
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. Améliorer la réponse
Vous pouvez améliorer la réponse à une application cliente en utilisant le résultat de la requête et préparer une sortie pertinente en utilisant les résultats de la requête fournie dans le cadre de l'invite au modèle de langage de fondation générative Vertex AI.
Pour ce faire, nous prévoyons de générer un fichier JSON contenant les résultats de la recherche vectorielle, puis d'utiliser ce fichier JSON généré en complément d'un prompt pour un modèle LLM de texte dans Vertex AI afin de créer un résultat pertinent. Dans la première étape, nous générons le JSON, puis nous le testons dans Vertex AI Studio. Dans la dernière étape, nous l'intégrons à une instruction SQL qui peut être utilisée dans une application.
Générer le résultat au format JSON
Modifiez la requête pour générer la sortie au format JSON et ne renvoyer qu'une seule ligne à transmettre à Vertex AI.
Voici un exemple de requête :
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Voici le JSON attendu dans le résultat :
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Exécuter la requête dans Vertex AI Studio
Nous pouvons utiliser le fichier JSON généré pour l'inclure dans le prompt du modèle de texte d'IA générative dans Vertex AI Studio.
Ouvrez Vertex AI Studio dans la console cloud.
Si vous ne l'avez jamais utilisé, il peut vous demander d'accepter les conditions d'utilisation. Appuyez sur le bouton "Accepter et continuer".
Rédigez votre requête dans l'interface.
Il peut vous demander d'activer d'autres API, mais vous pouvez ignorer la demande. Nous n'avons besoin d'aucune API supplémentaire pour terminer notre atelier.
Voici la requête que nous allons utiliser avec la sortie JSON de la première requête sur les arbres :
Vous êtes un conseiller amical qui aide les clients à trouver un produit en fonction de leurs besoins.
En fonction de la demande du client, nous avons chargé une liste de produits étroitement liés à la recherche.
Liste au format JSON avec des valeurs telles que {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Voici la liste des produits :
{"product_name":"Cerisier","description":"Il s'agit d'un magnifique cerisier qui produira de délicieuses cerises. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
Le client a demandé : "Quel est l'arbre qui pousse le mieux ici ?"
Vous devez fournir des informations sur le produit, son prix et des informations supplémentaires.
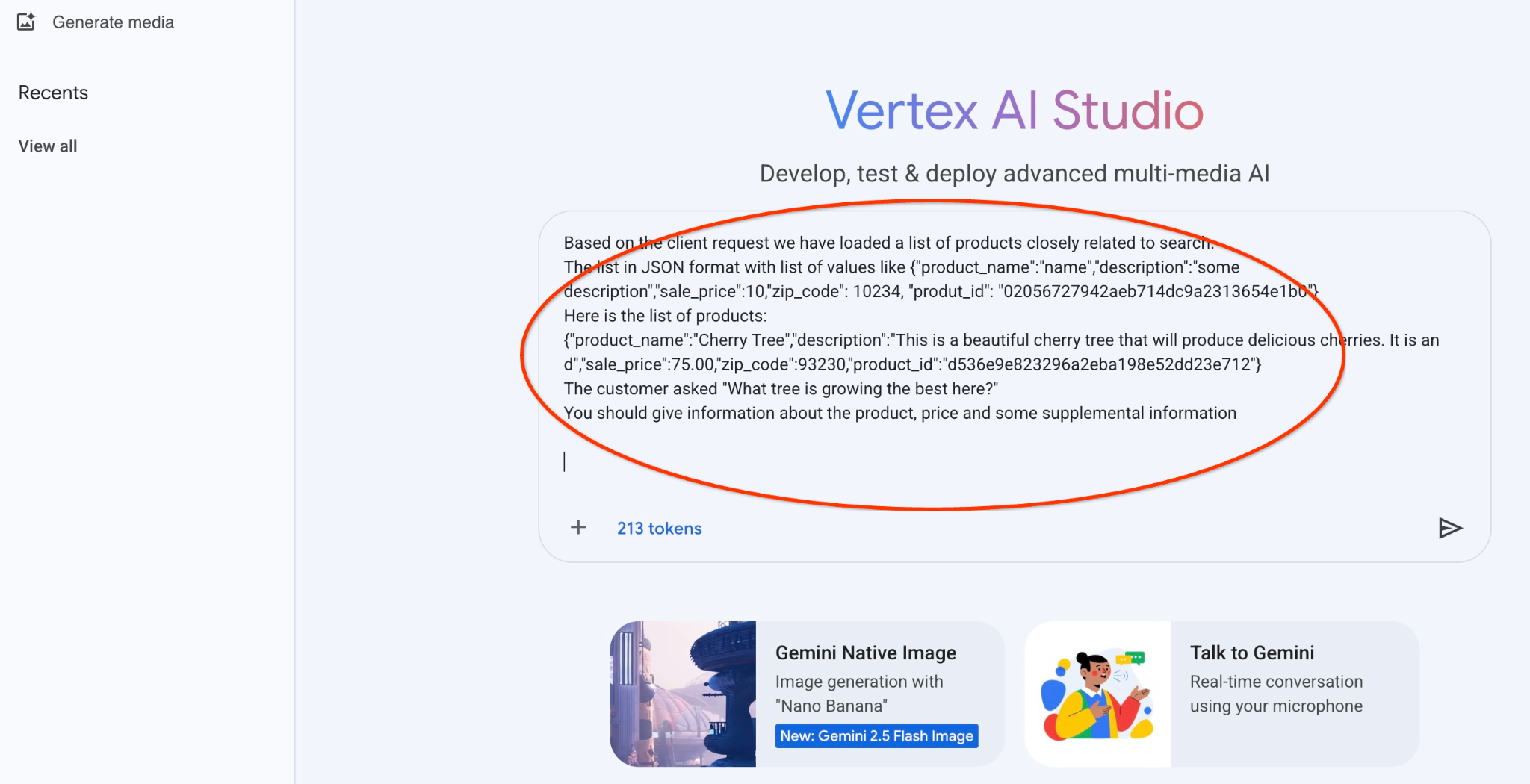
Voici le résultat lorsque nous exécutons le prompt avec nos valeurs JSON et en utilisant le modèle gemini-2.5-flash-light :
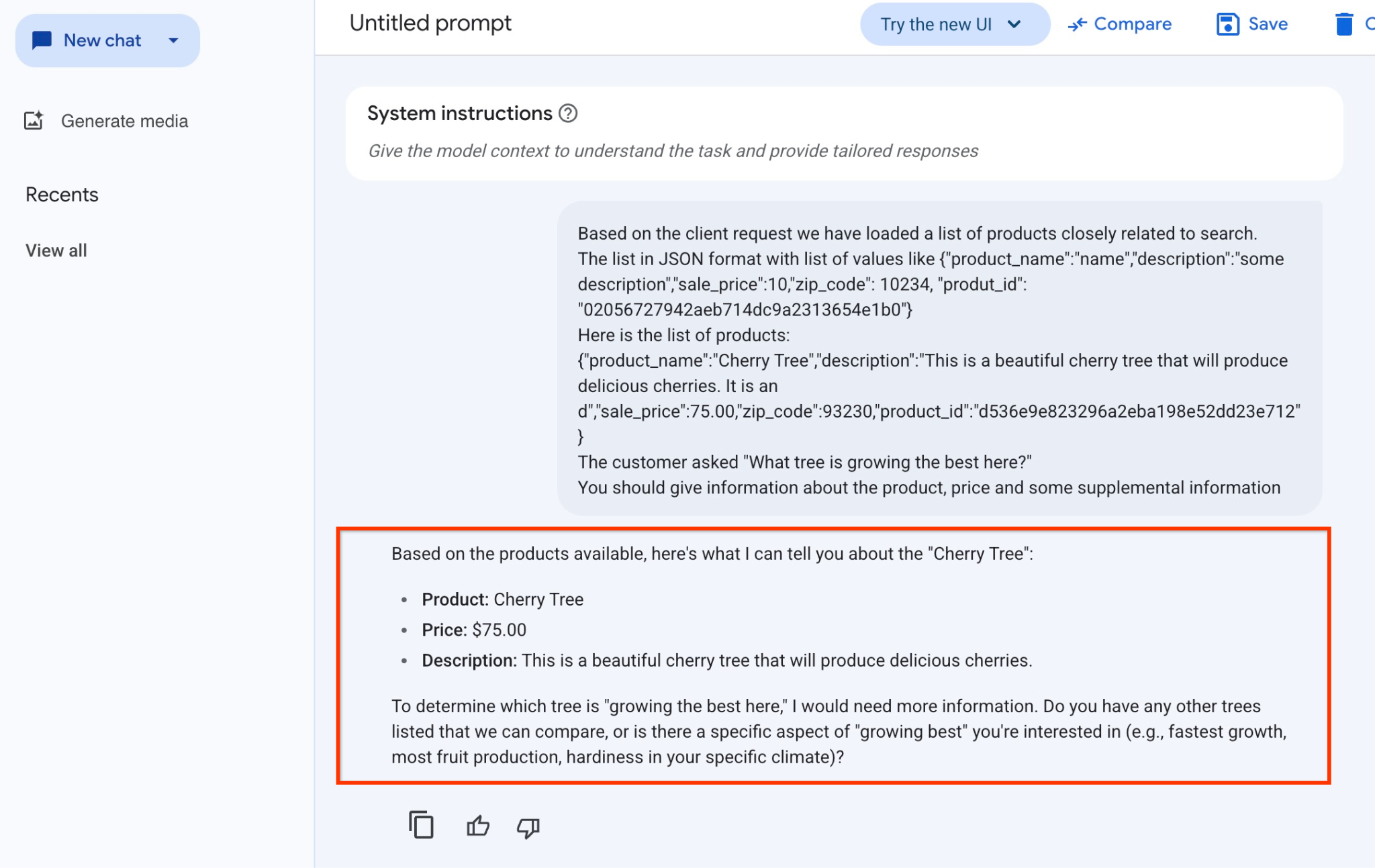
Voici la réponse que nous avons obtenue du modèle dans cet exemple. Notez que votre réponse peut être différente en raison des modifications apportées au modèle et aux paramètres au fil du temps :
"Voici ce que je peux vous dire sur le produit "Cerisier" en fonction des produits disponibles :
Produit : Cherry Tree
Prix : 75,00 $
Description : Ce magnifique cerisier produira de délicieuses cerises.
Pour déterminer quel arbre "pousse le mieux ici", j'aurais besoin de plus d'informations. Avez-vous d'autres arbres listés que nous pouvons comparer, ou y a-t-il un aspect spécifique de la"meilleure croissance" qui vous intéresse (par exemple, la croissance la plus rapide, la production de fruits la plus importante, la rusticité dans votre climat spécifique) ?"
Exécuter le prompt dans PSQL
Nous pouvons utiliser l'intégration d'AlloyDB AI à Vertex AI pour obtenir la même réponse d'un modèle génératif à l'aide de SQL directement dans la base de données. Mais pour utiliser le modèle gemini-1.5-flash, nous devons d'abord l'enregistrer.
Vérifiez l'extension google_ml_integration. Elle doit être de version 1.4.2 ou ultérieure.
Connectez-vous à la base de données quickstart_db depuis psql comme indiqué précédemment (ou utilisez AlloyDB Studio), puis exécutez la commande suivante :
SELECT extversion from pg_extension where extname='google_ml_integration';
Vérifiez l'indicateur de base de données google_ml_integration.enable_model_support.
show google_ml_integration.enable_model_support;
Le résultat attendu de la session psql est "on" :
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Si la valeur "off" (désactivé) s'affiche, vous devez définir l'indicateur de base de données google_ml_integration.enable_model_support sur "on" (activé). Pour ce faire, vous pouvez utiliser l'interface de la console Web AlloyDB ou exécuter la commande gcloud suivante.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
L'exécution de la commande en arrière-plan prend environ une à trois minutes. Vous pourrez ensuite valider à nouveau le signalement.
Pour notre requête, nous avons besoin de deux modèles. Le premier est le modèle text-embedding-005 déjà utilisé, et le second est l'un des modèles Gemini génériques de Google.
Nous commençons par le modèle d'embedding textuel. Pour enregistrer l'exécution du modèle dans psql ou AlloyDB Studio, exécutez le code suivant :
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Le prochain modèle que nous devons enregistrer est gemini-2.0-flash-001, qui sera utilisé pour générer la sortie conviviale.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
Vous pouvez toujours vérifier la liste des modèles enregistrés en sélectionnant des informations dans google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Voici un exemple de résultat :
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
Nous pouvons maintenant utiliser le JSON généré dans une sous-requête pour le fournir dans le prompt au modèle de texte d'IA générative à l'aide de SQL.
Dans la session psql ou AlloyDB Studio de la base de données, exécutez la requête.
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Voici le résultat attendu. Votre résultat peut être différent selon la version et les paramètres du modèle :
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. Créer un index vectoriel
Notre ensemble de données est assez petit et le temps de réponse dépend principalement de l'interaction avec les modèles d'IA. Toutefois, lorsque vous avez des millions de vecteurs, la partie de recherche vectorielle peut prendre une partie importante de notre temps de réponse et exercer une forte charge sur le système. Pour améliorer cela, nous pouvons créer un index sur nos vecteurs.
Créer un index ScaNN
Pour créer l'index SCANN, nous devons activer une extension supplémentaire. L'extension alloydb_scann fournit une interface permettant d'utiliser l'index vectoriel de type ANN à l'aide de l'algorithme ScaNN de Google.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Résultat attendu :
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
L'index peut être créé en mode MANUEL ou AUTO. Le mode MANUEL est activé par défaut. Vous pouvez créer un index et le gérer comme n'importe quel autre index. Toutefois, si vous activez le mode AUTO, vous pouvez créer l'index sans avoir à l'entretenir. Pour en savoir plus sur toutes les options, consultez la documentation. Je vais vous montrer comment activer le mode AUTO et créer l'index. Dans notre cas, nous n'avons pas assez de lignes pour créer l'index en mode AUTO. Nous allons donc le créer en mode MANUAL.
Dans l'exemple suivant, je laisse la plupart des paramètres par défaut et ne fournis qu'un nombre de partitions (num_leaves) pour l'index :
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
Pour en savoir plus sur l'ajustement des paramètres d'index, consultez la documentation.
Résultat attendu :
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
Comparer la réponse
Nous pouvons maintenant exécuter la requête de recherche vectorielle en mode EXPLAIN et vérifier si l'index a été utilisé.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Résultat attendu (masqué par souci de clarté) :
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
La sortie indique clairement que la requête utilisait "Index Scan using cymbal_products_embeddings_scann on cymbal_products".
Et si nous exécutons la requête sans l'expliquer :
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Résultat attendu :
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Nous pouvons voir que le résultat est le même cerisier qui était en tête de notre recherche sans index. Il peut arriver que la réponse renvoie d'autres arbres en haut de la liste. L'index nous donne donc des performances tout en restant suffisamment précis pour fournir de bons résultats.
Vous pouvez essayer différents index disponibles pour les vecteurs, ainsi que d'autres ateliers et exemples avec l'intégration de LangChain sur la page de documentation.
11. Nettoyer l'environnement
Détruisez les instances et le cluster AlloyDB une fois l'atelier terminé.
Supprimer le cluster AlloyDB et toutes les instances
Si vous avez utilisé la version d'essai d'AlloyDB. Ne supprimez pas le cluster d'essai si vous prévoyez de tester d'autres ateliers et ressources à l'aide de ce cluster. Vous ne pourrez pas créer d'autre cluster d'essai dans le même projet.
Le cluster est détruit avec l'option "force", qui supprime également toutes les instances appartenant au cluster.
Dans Cloud Shell, définissez le projet et les variables d'environnement si vous avez été déconnecté et que tous les paramètres précédents sont perdus :
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Supprimez le cluster :
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Supprimer les sauvegardes AlloyDB
Supprimez toutes les sauvegardes AlloyDB du cluster :
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
Nous pouvons maintenant détruire notre VM.
Supprimer la VM GCE
Dans Cloud Shell, exécutez :
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation.
Cet atelier fait partie du parcours de formation "L'IA prête pour la production avec Google Cloud".
- Explorez le programme complet pour combler le fossé entre le prototype et la production.
- Partagez votre progression avec le hashtag
#ProductionReadyAI.
Points abordés
- Déployer un cluster AlloyDB et une instance principale
- Se connecter à AlloyDB depuis une VM Google Compute Engine
- Créer une base de données et activer AlloyDB AI
- Charger des données dans la base de données
- Utiliser AlloyDB Studio
- Utiliser le modèle d'embedding Vertex AI dans AlloyDB
- Utiliser Vertex AI Studio
- Enrichir les résultats à l'aide du modèle génératif Vertex AI
- Améliorer les performances à l'aide de l'index vectoriel
13. Enquête
Résultat :