
۱. مقدمه
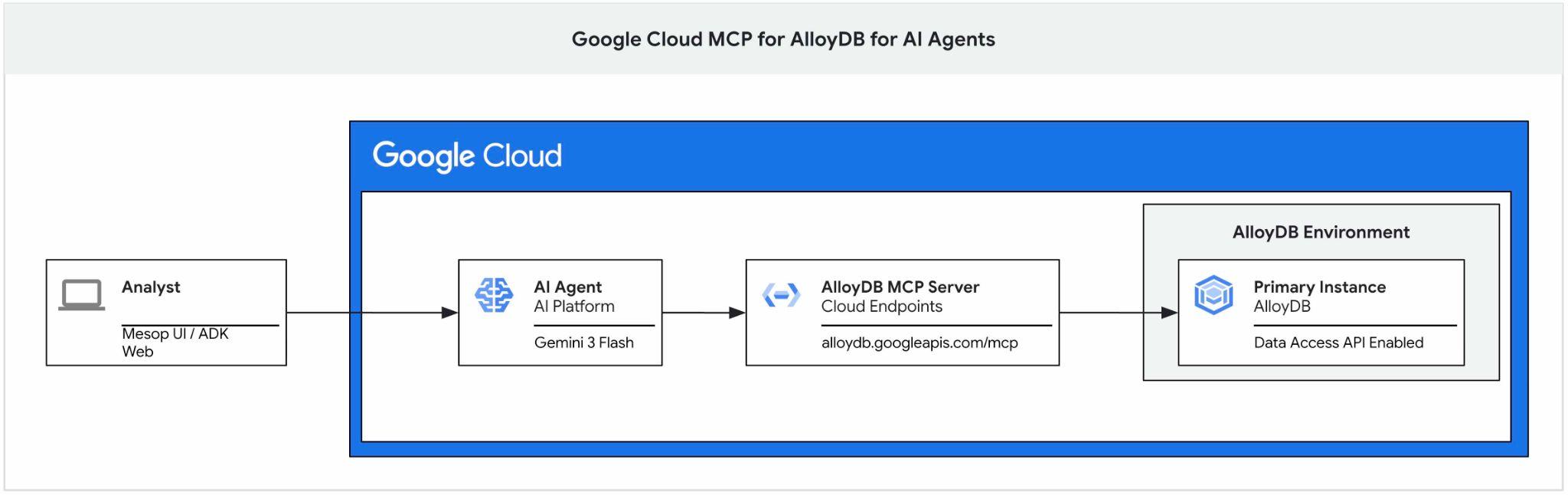
این آزمایشگاه کد، راهنمایی در مورد نحوه شروع به کار با سرور Google Cloud MCP برای AlloyDB و فعال کردن آن به عنوان بخشی از مجموعه ابزارهای یک عامل هوش مصنوعی و استفاده از آن به عنوان بخشی از برنامه ارائه میدهد.
پیشنیازها
- درک اولیه از گوگل کلود، کنسول
- مهارتهای پایه در رابط خط فرمان و Cloud Shell
آنچه یاد خواهید گرفت
- نحوه ایجاد یک کلاستر AlloyDB و وارد کردن دادههای نمونه
- نحوه فعال کردن API دسترسی به داده AlloyDB
- نحوه فعال کردن Google Cloud MCP برای AlloyDB NL
- نحوه اضافه کردن Google Cloud MCP برای AlloyDB به عامل ADK شما
- نحوه استفاده از Google Cloud MCP برای AlloyDB در یک برنامه
- نحوه استفاده از عاملها با AlloyDBMCP برای تجزیه و تحلیل
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم که از کنسول گوگل کلود و کلود شل پشتیبانی میکند
۲. تنظیمات و الزامات
راهاندازی پروژه
- وارد کنسول ابری گوگل شوید. اگر از قبل حساب جیمیل یا گوگل ورکاسپیس ندارید، باید یکی ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید.
- یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. برای ایجاد یک پروژه جدید در کنسول Google Cloud، در سربرگ، روی دکمه «انتخاب پروژه» کلیک کنید که یک پنجره بازشو باز میشود.

در پنجره انتخاب پروژه، دکمه «پروژه جدید» را فشار دهید که یک کادر محاورهای برای پروژه جدید باز میکند.
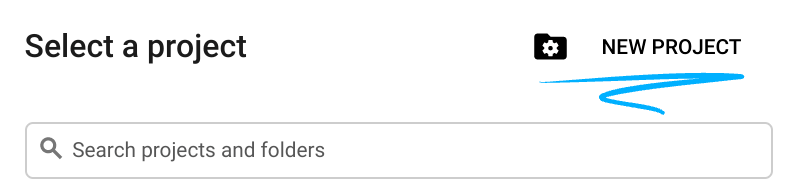
در کادر محاورهای، نام پروژه مورد نظر خود را وارد کرده و مکان را انتخاب کنید.
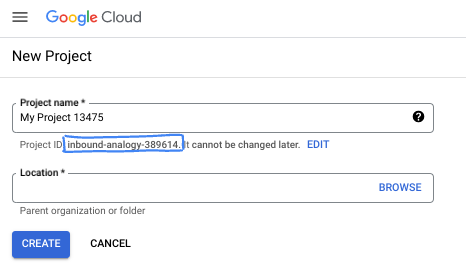
- نام پروژه ، نام نمایشی برای شرکتکنندگان این پروژه است. نام پروژه توسط APIهای گوگل استفاده نمیشود و میتوان آن را در هر زمانی تغییر داد.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد و غیرقابل تغییر است (پس از تنظیم، دیگر قابل تغییر نیست). کنسول گوگل کلود به طور خودکار یک شناسه منحصر به فرد تولید میکند، اما میتوانید آن را سفارشی کنید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید یا شناسه خودتان را برای بررسی در دسترس بودن آن ارائه دهید. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را که معمولاً با عبارت PROJECT_ID مشخص میشود، ارجاع دهید.
- برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
فعال کردن صورتحساب
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۳ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
همچنین میتوانید دکمههای G و سپس S را فشار دهید. اگر در کنسول ابری گوگل باشید یا از این لینک استفاده کنید، این توالی، Cloud Shell را فعال میکند.
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. قبل از شروع
فعال کردن API
برای استفاده از AlloyDB ، Compute Engine ، Networking services و Vertex AI ، باید API های مربوط به آنها را در پروژه Google Cloud خود فعال کنید.
در داخل ترمینال Cloud Shell، مطمئن شوید که شناسه پروژه شما تنظیم شده است:
gcloud config get-value project
باید شناسه پروژه گوگل شما را برگرداند.
متغیر محیطی PROJECT_ID را تنظیم کنید:
PROJECT_ID=$(gcloud config get-value project)
فعال کردن تمام سرویسهای لازم:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
خروجی مورد انتظار
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
۴. استقرار AlloyDB
کلاستر AlloyDB و نمونه اولیه آن را ایجاد کنید. میتوانید آن را با استفاده از یک اسکریپت آماده که تمام منابع لازم را مستقر میکند، مستقر کنید یا میتوانید این کار را گام به گام خودتان با دنبال کردن مستندات انجام دهید.
استقرار AlloyDB با استفاده از اسکریپت خودکار
این رویکرد با استفاده از یک اسکریپت خودکار، کلاستر AlloyDB را مستقر میکند و اطلاعات لازم را برای شروع کار با منابع مستقر شده فراهم میکند.
در ترمینال Cloud Shell، دستور را اجرا کنید تا اسکریپت استقرار از مخزن کلون شود.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-ai-mcp"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
اسکریپت استقرار را اجرا کنید.
./deploy_alloydb.sh
اجرای اسکریپت مدتی طول میکشد - معمولاً حدود ۵ تا ۷ دقیقه. سپس به عنوان خروجی، اطلاعاتی در مورد کلاستر AlloyDB مستقر شده شما ارائه میدهد. لطفاً توجه داشته باشید که رمز عبور شما متفاوت خواهد بود - رمز عبور را برای استفادههای بعدی در جایی یادداشت کنید .
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
و همچنین میتوانید کلاستر جدید و نمونه اصلی را در کنسول وب مشاهده کنید.
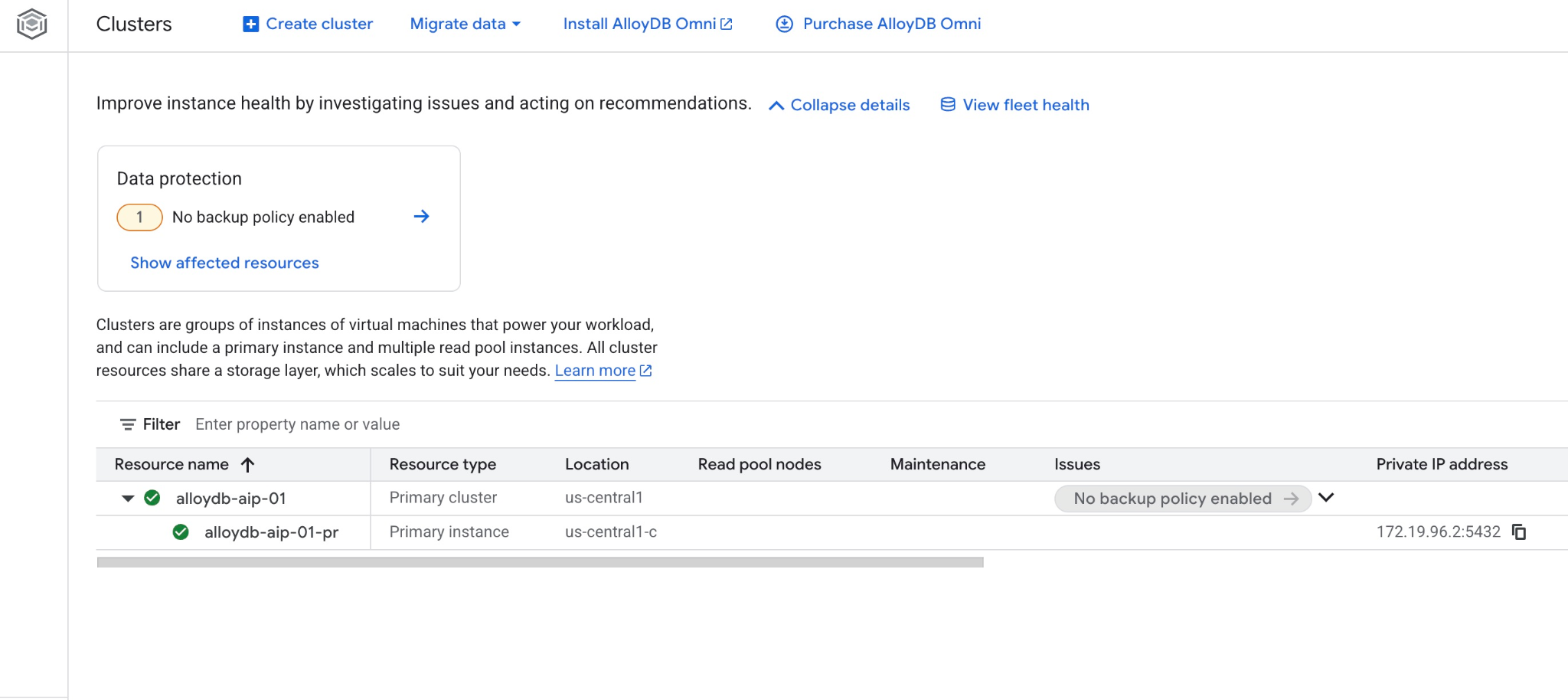
۵. آمادهسازی پایگاه داده
برای استفاده از توابع و عملگرهای هوش مصنوعی، باید ادغام هوش مصنوعی Vertex را فعال کنید، API دسترسی به داده را فعال کنید و یک پایگاه داده برای مجموعه دادههای نمونه ایجاد کنید.
مجوزهای لازم را به AlloyDB اعطا کنید
مجوزهای Vertex AI را به عامل سرویس AlloyDB اضافه کنید.
با استفاده از علامت "+" در بالا، یک تب Cloud Shell دیگر باز کنید.
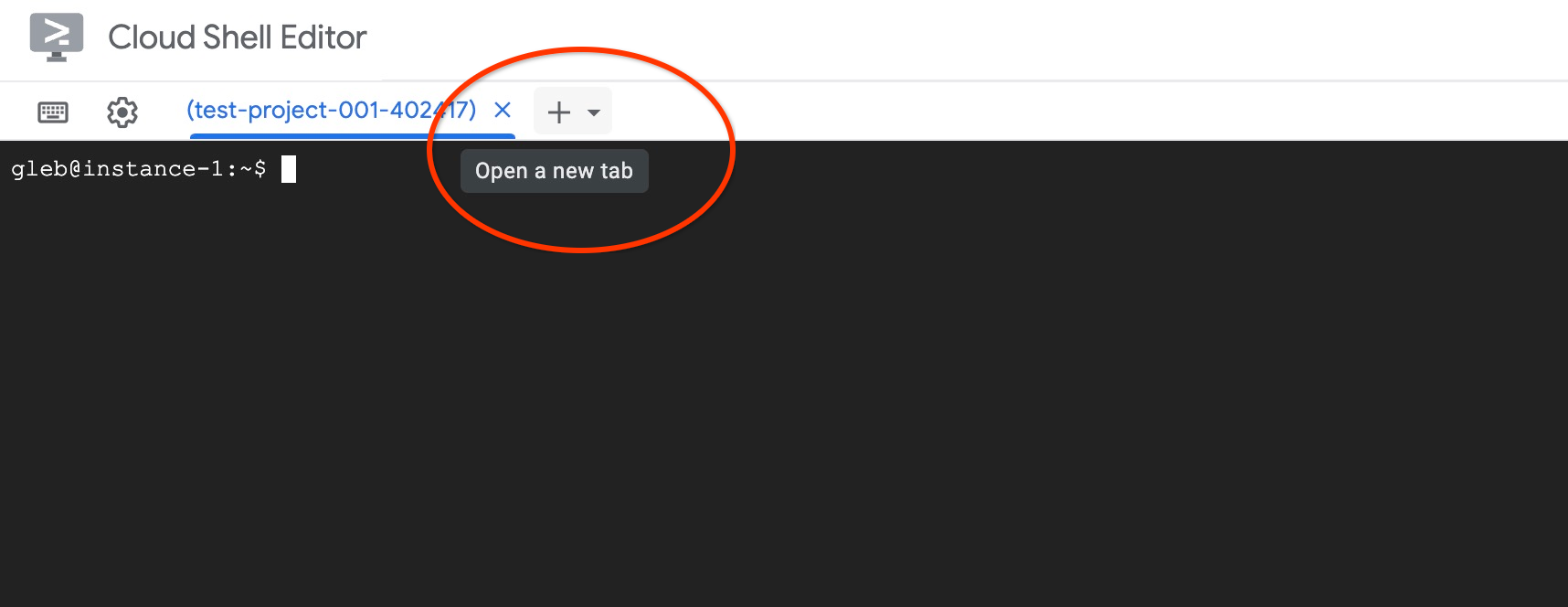
در تب جدید cloud shell دستور زیر را اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/discoveryengine.viewer"
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... < redacted > etag: BwYIEbe_Z3U= version: 1
فعال کردن API دسترسی به داده
برای اینکه بتوانید از ابزارهای MCP مانند execute_sql استفاده کنید، باید API دسترسی به داده (Data Access API) را در کلاستر AlloyDB فعال کنید.
در همان تب ترمینال، دستور زیر را اجرا کنید.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
بهروزرسانی پرچمهای نمونه
برای استفاده از توابع پیشرفته هوش مصنوعی در AlloyDB، باید برخی از پرچمهای پایگاه داده را فعال کنیم. پس از فعال کردن API دسترسی به داده، ممکن است چند دقیقه طول بکشد تا نمونه برای تغییرات بعدی آماده شود. لطفاً وضعیت نمونه را در کنسول بررسی کنید تا مطمئن شوید که علامت سبز دارد.
در همان تب ترمینال، دستور زیر را اجرا کنید.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags=google_ml_integration.enable_model_support=on,google_ml_integration.enable_ai_query_engine=on,google_ml_integration.enable_preview_ai_functions=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
فعال کردن MCP
مرحله بعدی فعال کردن سرور Google Cloud MCP برای AlloyDB در پروژه شماست. به طور پیشفرض MCP فعال نیست و یکی از چندین لایه حفاظتی شامل احراز هویت و مجوز IAM، API دسترسی به دادهها و نقشها در داخل کلاستر شما است.
در همان تب ترمینال، دستور زیر را اجرا کنید.
PROJECT_ID=$(gcloud config get-value project)
gcloud beta services mcp enable alloydb.googleapis.com \
--project=$PROJECT_ID
با اجرای هر یک از دستورهای "exit" در تب، تب را ببندید:
exit
اتصال به استودیوی AlloyDB
در فصلهای بعدی، تمام دستورات SQL که نیاز به اتصال به پایگاه داده دارند، میتوانند در AlloyDB Studio اجرا شوند.
به صفحه خوشهها در AlloyDB برای Postgres بروید.
با کلیک روی نمونه اصلی، رابط کنسول وب را برای خوشه AlloyDB خود باز کنید.
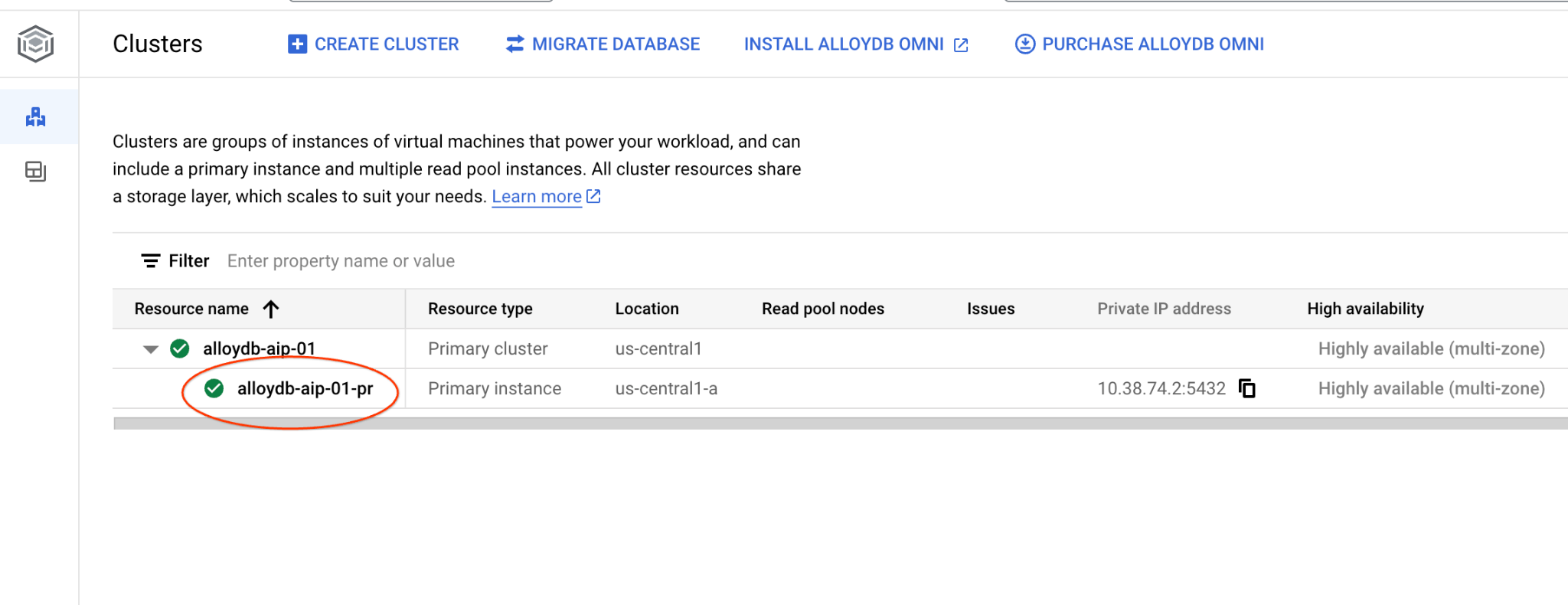
سپس در سمت چپ روی AlloyDB Studio کلیک کنید:
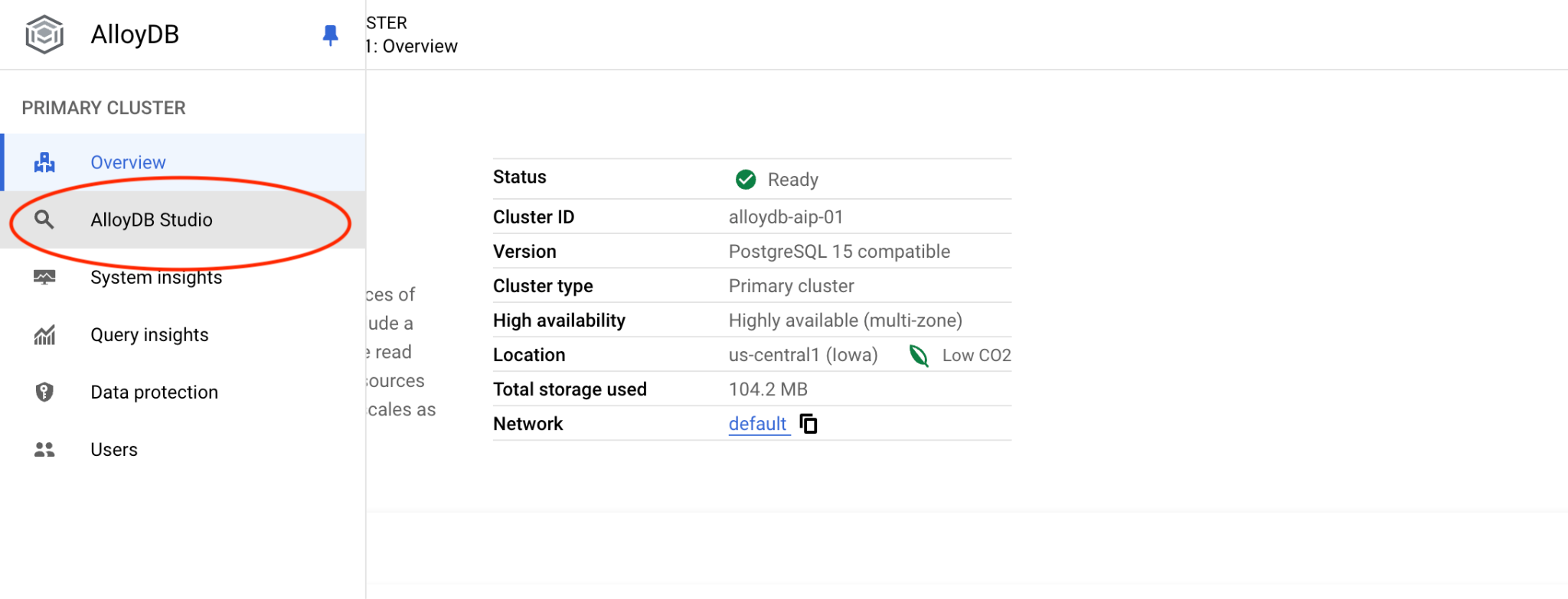
پایگاه داده postgres، نام کاربری postgres و رمز عبوری که هنگام ایجاد کلاستر یادداشت کردیم را انتخاب کنید. سپس روی دکمه "Authenticate" کلیک کنید.
اگر رمز عبور کار نمیکند یا فراموش کردهاید که آن را یادداشت کنید، میتوانید رمز عبور را تغییر دهید. برای نحوه انجام این کار، مستندات را بررسی کنید.
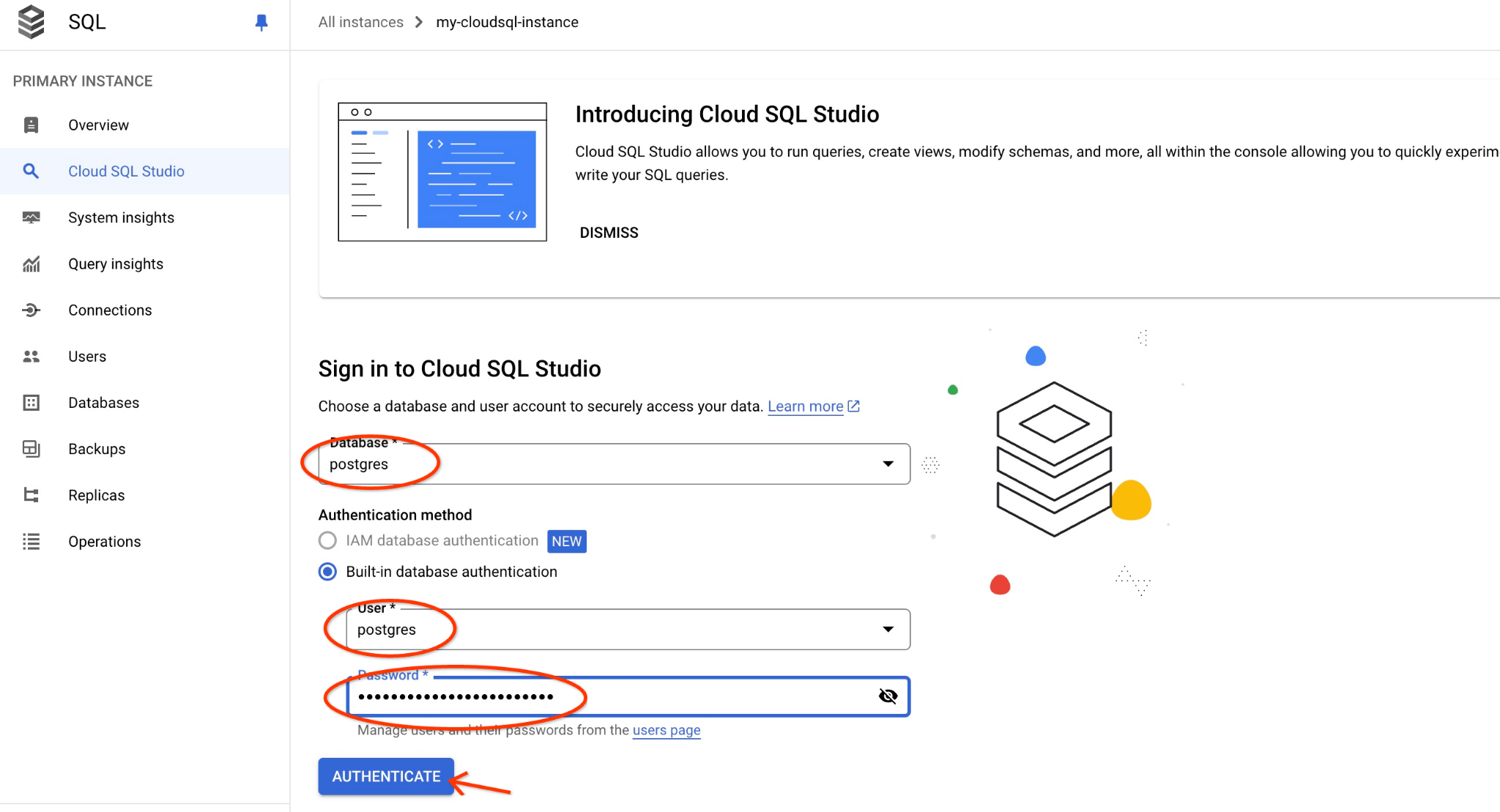
رابط کاربری AlloyDB Studio باز خواهد شد. برای اجرای دستورات در پایگاه داده، روی تب "Untitled Query" در سمت راست کلیک کنید.
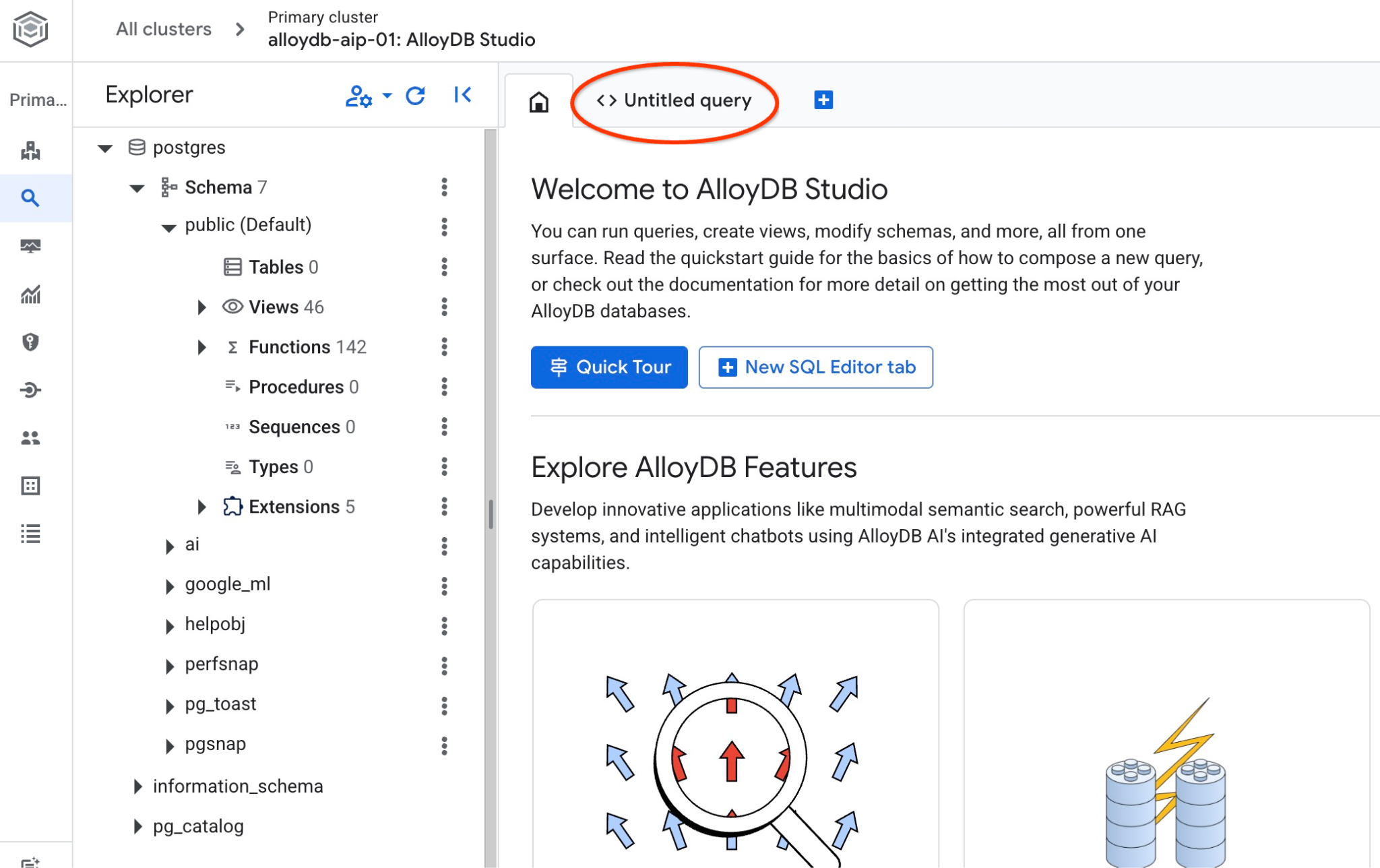
رابطی را باز میکند که میتوانید دستورات SQL را در آن اجرا کنید
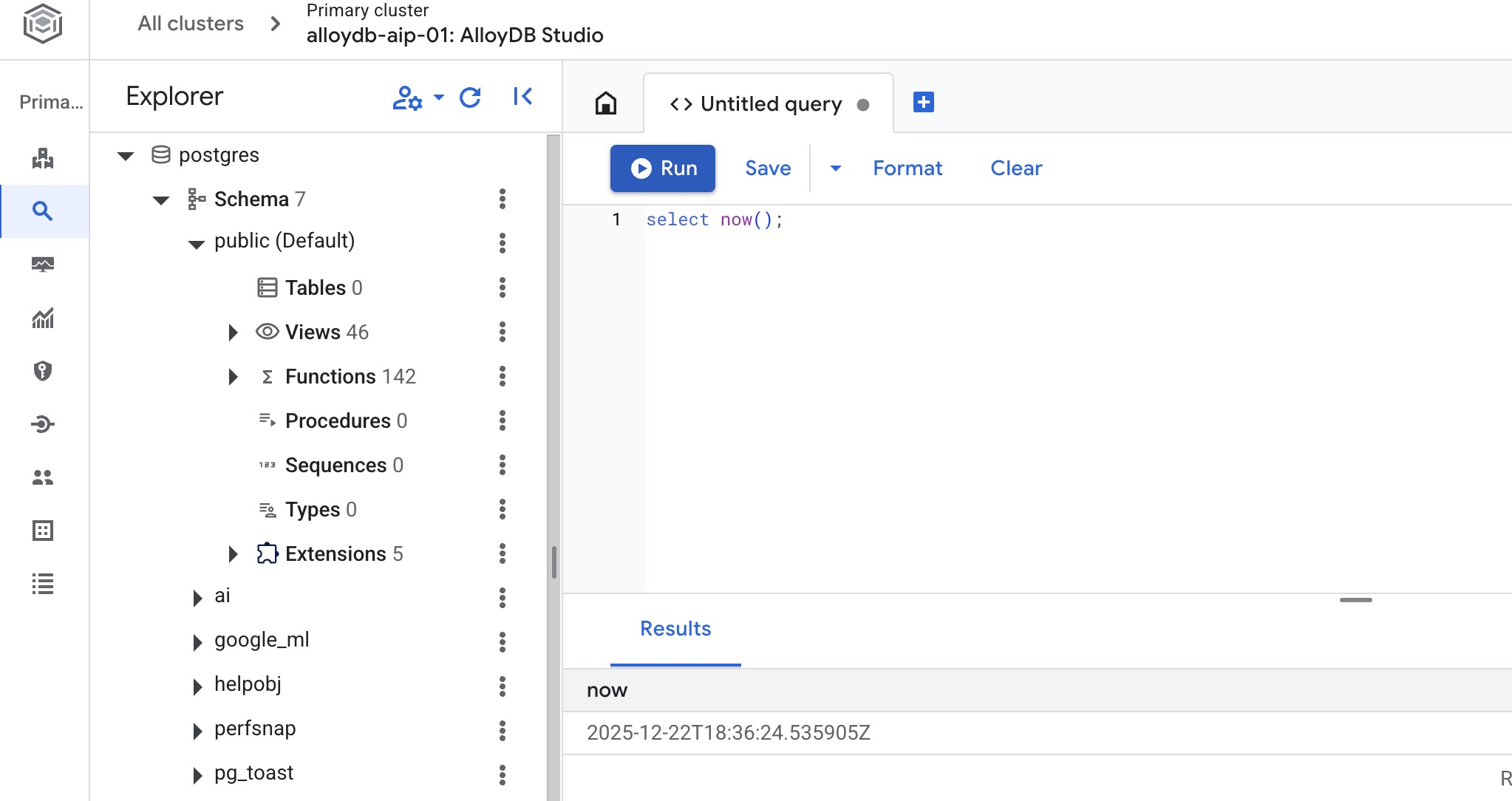
ایجاد پایگاه داده
ایجاد پایگاه داده با شروع سریع
در ویرایشگر استودیوی AlloyDB، دستور زیر را اجرا کنید.
ایجاد پایگاه داده:
CREATE DATABASE quickstart_db
خروجی مورد انتظار:
Statement executed successfully
اتصال به پایگاه دادهی quickstart_db
با اتصال به پایگاه داده، بررسی کنید که آیا پایگاه داده شما ایجاد شده است یا خیر. با استفاده از دکمه تغییر کاربر/پایگاه داده، دوباره به استودیو متصل شوید.
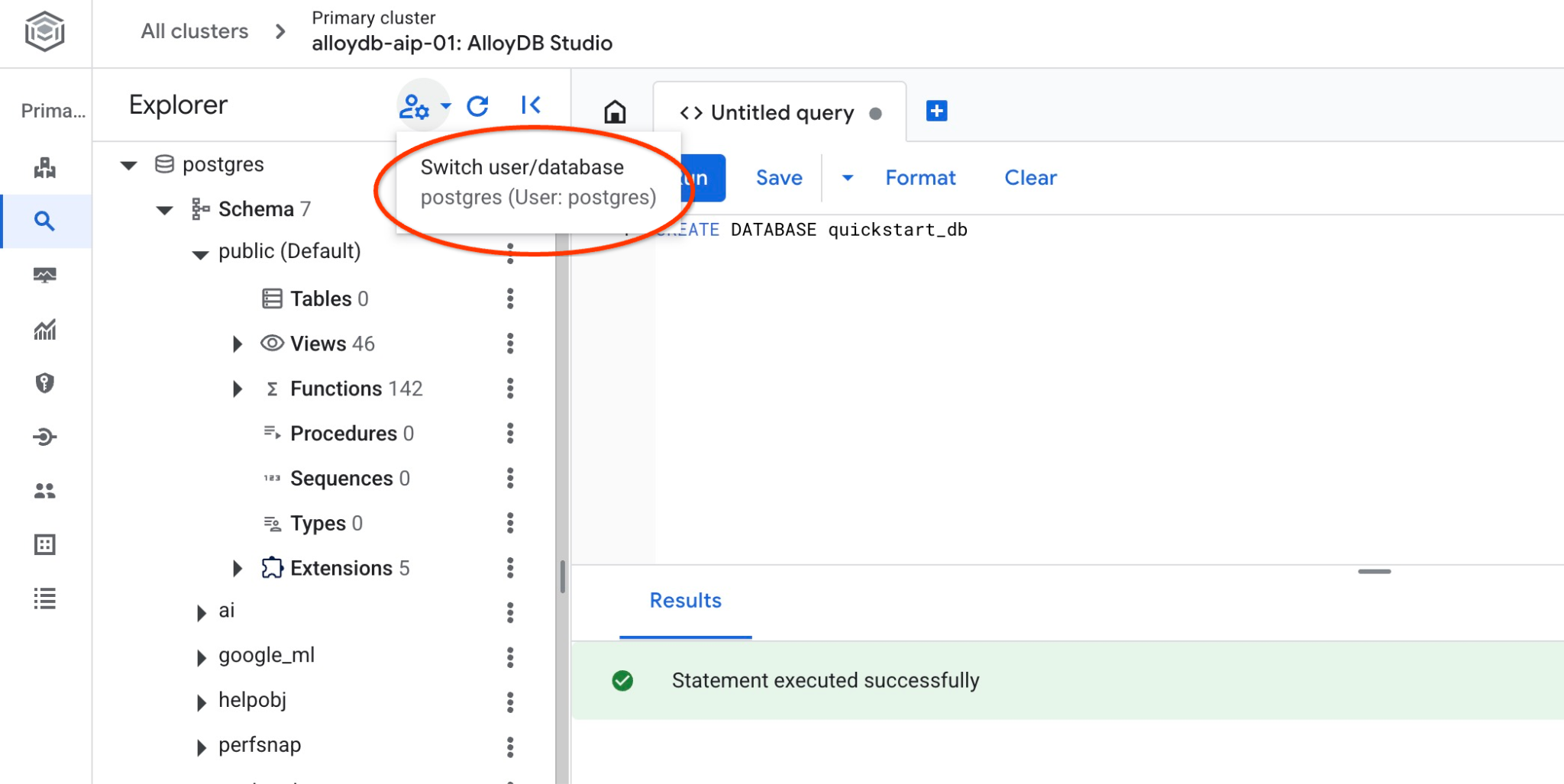
از لیست کشویی، پایگاه داده جدید quickstart_db را انتخاب کنید و از همان نام کاربری و رمز عبور قبلی استفاده کنید.
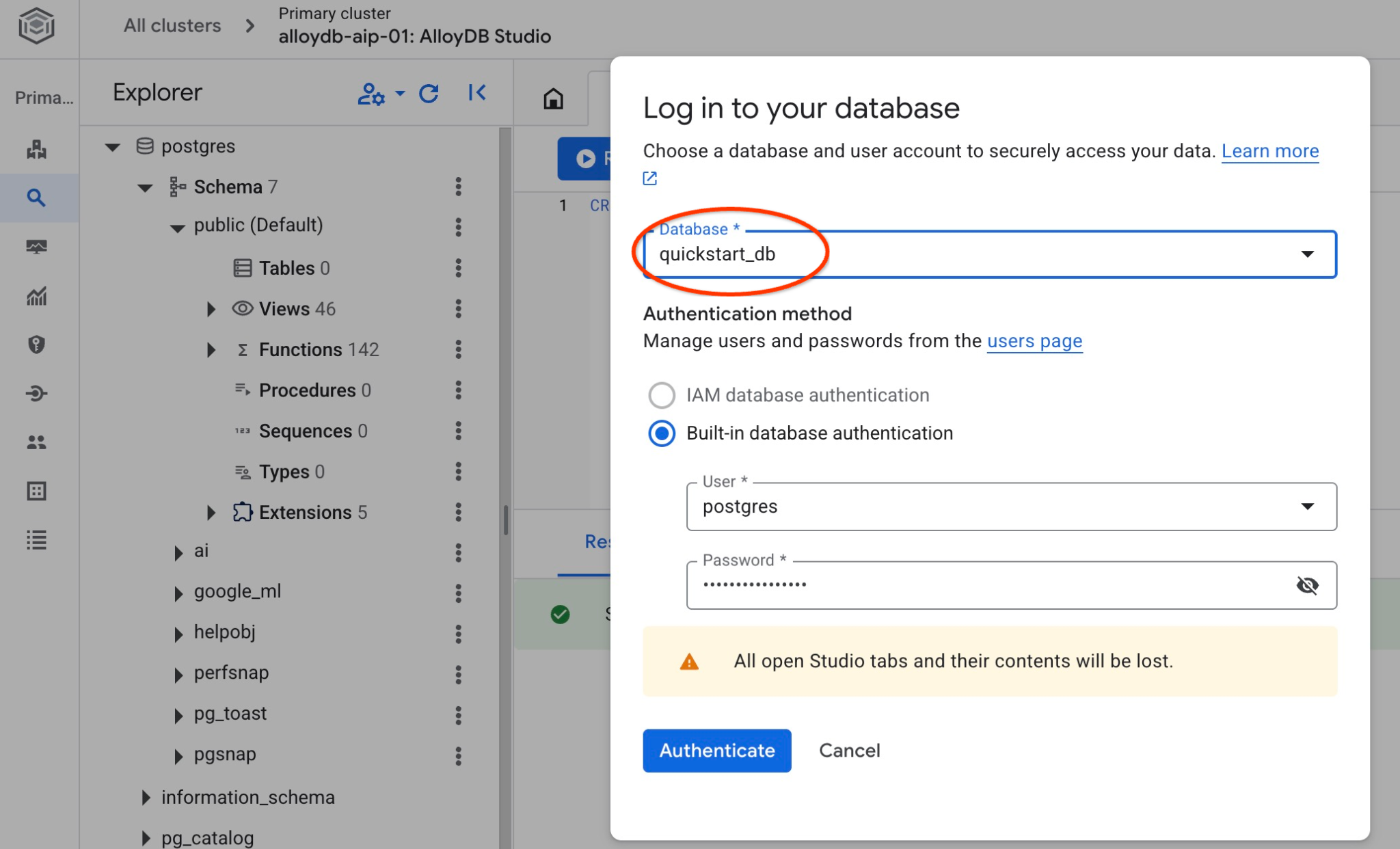
این یک اتصال جدید باز میکند که در آن میتوانید با اشیاء پایگاه داده quickstart_db کار کنید. در آنجا میتوانید طرحواره و دادههای وارد شده خود را بررسی کنید.
۶. دادههای نمونه
حالا باید اشیاء را در پایگاه داده ایجاد کرده و دادهها را بارگذاری کنید. شما قصد دارید از یک مجموعه داده فرضی شرکت حمل و نقل Cymbal استفاده کنید. این مجموعه داده شامل دادههای فرضی در مورد کالاها، کامیونها، درخواستها و سفرهای کامیون به همراه رانندگان فرضی است.
ایجاد سطل ذخیرهسازی
شما قرار است از Google SDK (gcloud) برای وارد کردن دادهها از مخزن کلونشده ما به پایگاه داده AlloyDB استفاده کنید و باید یک مخزن ذخیرهسازی برای آن ایجاد کنید و به حساب سرویس AlloyDB دسترسی بدهید. به عنوان یک روش جایگزین، همیشه میتوانید این کار را با استفاده از کنسول وب، همانطور که در مستندات توضیح داده شده است، انجام دهید.
در ترمینال Google Cloud Shell دستور زیر را اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
بارگذاری داده
مرحله بعدی بارگذاری دادهها است. فایل SQL dump ما در پوشه مخزن کلون شده قرار دارد. دستور زیر فرض میکند که شما هنگام کلون کردن مخزن در مرحله قبل هنگام ایجاد خوشه AlloyDB، از دایرکتوری خانگی خود به عنوان نقطه شروع استفاده کردهاید.
فایل فشرده SQL dump را در حافظه جدید کپی کنید:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
سپس دادهها را در پایگاه داده quickstart_db بارگذاری کنید:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
این دستور، مجموعه دادههای نمونه را در پایگاه داده quickstart_db بارگذاری میکند. میتوانید جداول و رکوردها را با استفاده از AlloyDB Studio تأیید کنید.
۷. کار با عامل داده
بیایید از یک عامل هوش مصنوعی نمونه که با استفاده از Google ADK برای پایتون ایجاد شده است شروع کنیم و نحوه پیکربندی آن را برای کار با سرور Google Cloud MCP برای AlloyDB نشان دهیم.
کد منبع عامل را بررسی کنید
در مخزن کلون شده، کد عامل را با استفاده از ویرایشگر Google Cloud Shell بررسی کنید.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/data_agent/agent.py
میتوانید در agent ببینید که ما بخشی برای سرور Google Cloud MCP برای AlloyDB داریم. ما یک نقطه پایانی به عنوان MCP_SERVER_URL، احراز هویت، شناسه پروژه و اضافه کردن آن به مجموعه ابزار MCP ارائه میدهیم.
# Google Cloud MCP Server for AlloyDB
MCP_SERVER_URL = "https://alloydb.googleapis.com/mcp"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
# 2. Configure MCP Toolset
# We use StreamableHTTPConnectionParams to pass the auth header
headers = {
"Authorization": f"Bearer {creds.token}",
"X-Goog-User-Project": project_id
}
connection_params = StreamableHTTPConnectionParams(
url=MCP_SERVER_URL,
headers=headers,
timeout=300.0,
sse_read_timeout=600.0
)
mcp_toolset = McpToolset(connection_params=connection_params)
و در کد عامل، مجموعه ابزار MCP به عنوان پارامتر tools برای عامل گنجانده شده است. همچنین نامهای خوشه و نمونه، منطقه و پایگاه داده به عنوان متغیرهایی برای اعلان عامل وجود دارد.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
""",
tools=[mcp_toolset],
)
سرویس Google Cloud MCP برای AlloyDB مجموعهای از ابزارهای از پیش تعریف شده دارد. اگر میخواهید تمام ابزارهای موجود را فهرست کنید، میتوانید از دستور curl از ترمینال کنسول Cloud Shell با استفاده از دستور زیر استفاده کنید. و همیشه میتوانید آخرین مرجع برای سرور Google Cloud MCP برای alloydb را در مستندات بررسی کنید.
curl -s -X POST http://alloydb.googleapis.com/mcp \
-H "Content-Type: application/json" \
-d @- <<EOF | jq -r '.result.tools[].name'
{
"id": "my_id_01",
"jsonrpc": "2.0",
"method": "tools/list"
}
EOF
عامل را شروع کنید
اکنون میتوانید با استفاده از رابط وب Google ADK، عامل را در حالت تعاملی راهاندازی کنید. رابط وب ADK روشی مناسب برای آزمایش و عیبیابی گردش کار عاملها فراهم میکند.
ابتدا اجازه دهید تمام بستههای مورد نیاز برای پایتون را با استفاده از مدیر بسته uv نصب کنیم.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv sync
وقتی همه بستهها نصب شدند، باید یک فایل .env را به دایرکتوری agent اضافه کنید تا آن را طوری هدایت کنید که برای همه ارتباطات با مدلهای هوش مصنوعی از Vertex AI استفاده کند.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
سپس میتوانید عامل را شروع کنید
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
شما باید خروجی مانند زیر را با نقطه پایانی مانند http://127.0.0.1:8000 ببینید.
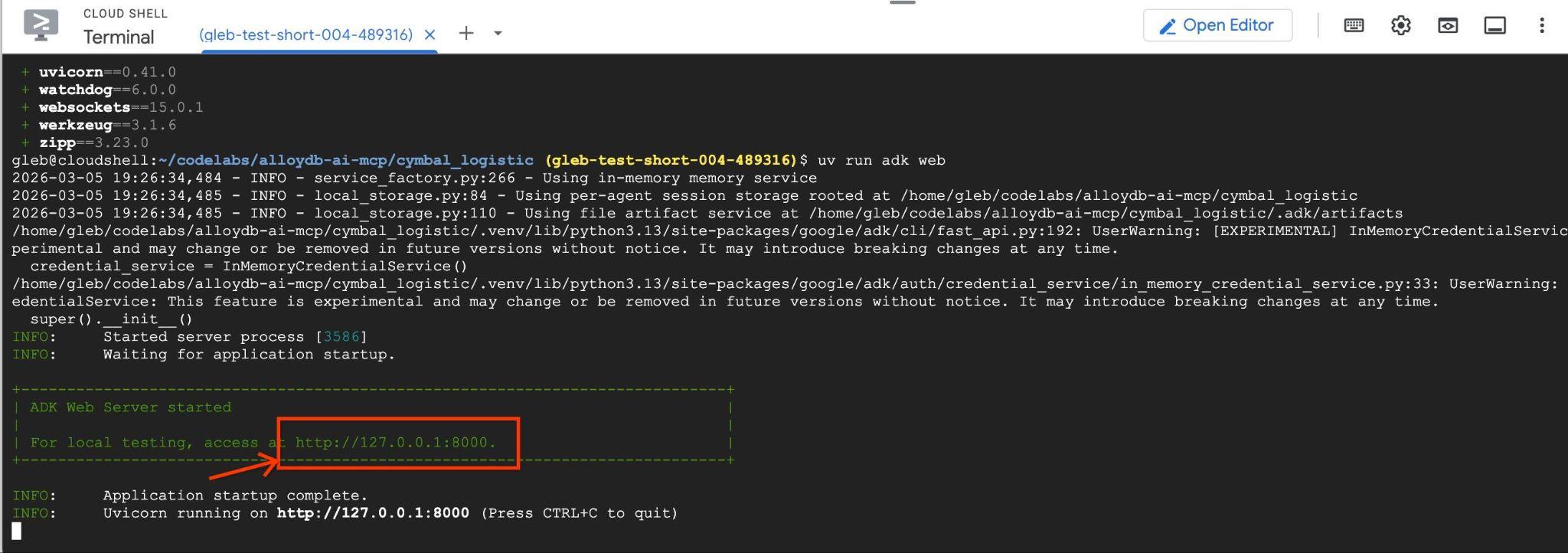
میتوانید روی آن URL در پوسته ابری کلیک کنید و یک پنجره پیشنمایش در یک برگه مرورگر جداگانه باز میشود که در آن میتوانید data_agent از لیست کشویی سمت چپ انتخاب کنید.
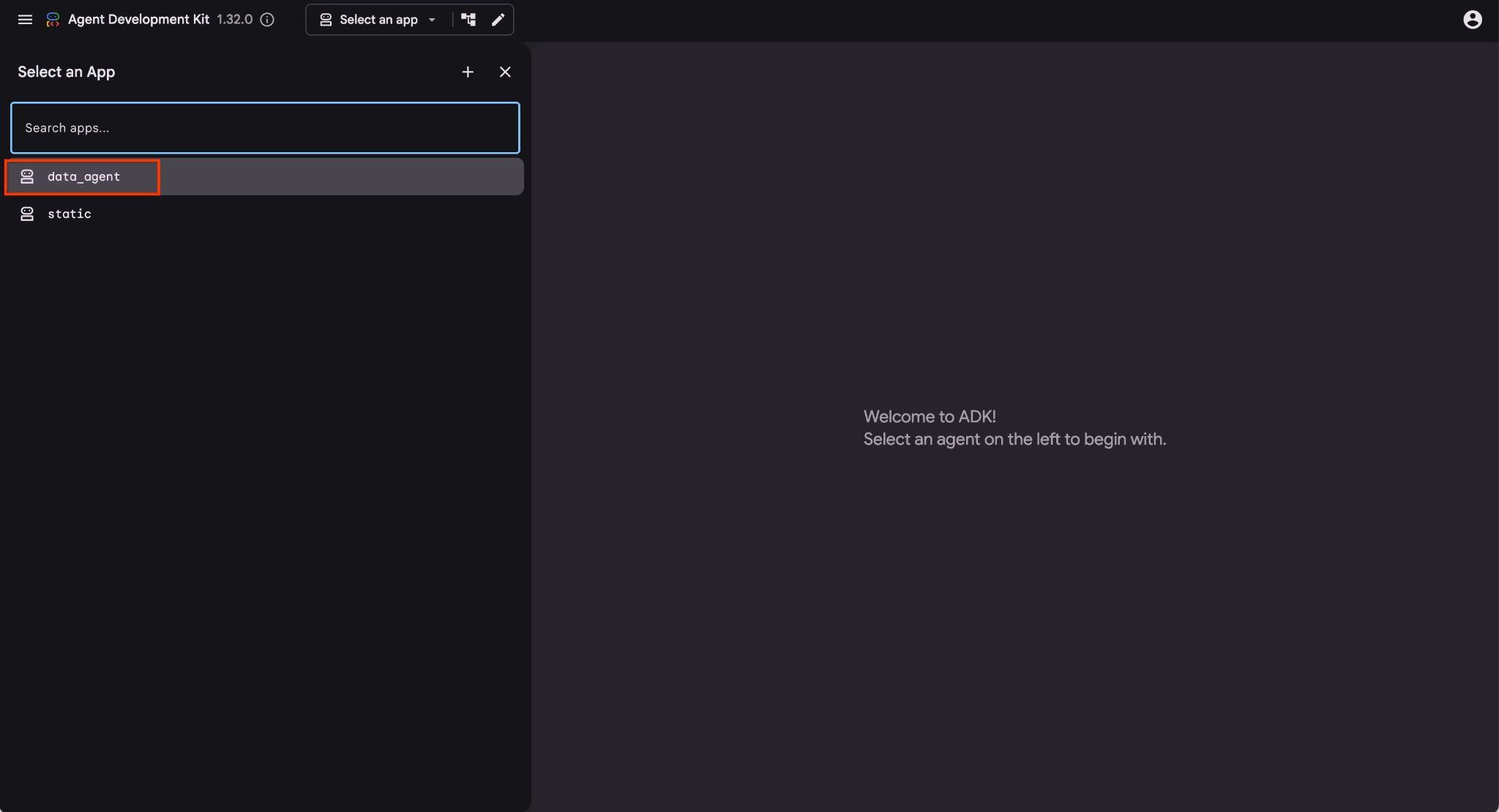
در رابط وب ADK میتوانید سوالات خود را در پایین سمت راست پست کنید و جریان کامل اجرا، شامل ردپاهای هر مرحله را در سمت راست مشاهده کنید.
۸. AlloyDB MCP را با Agent تست کنید
نماینده به شما امکان میدهد تا با استفاده از زبان طبیعی، سوالات خود را به صورت رایگان بپرسید و نماینده از سرور Google Cloud MCP برای AlloyDB به عنوان ابزاری برای پاسخ به سوالات استفاده خواهد کرد. سوالات در پایین سمت راست قرار میگیرند و پاسخ به همراه تمام فراخوانیهای ابزارها در بالا ظاهر میشود.
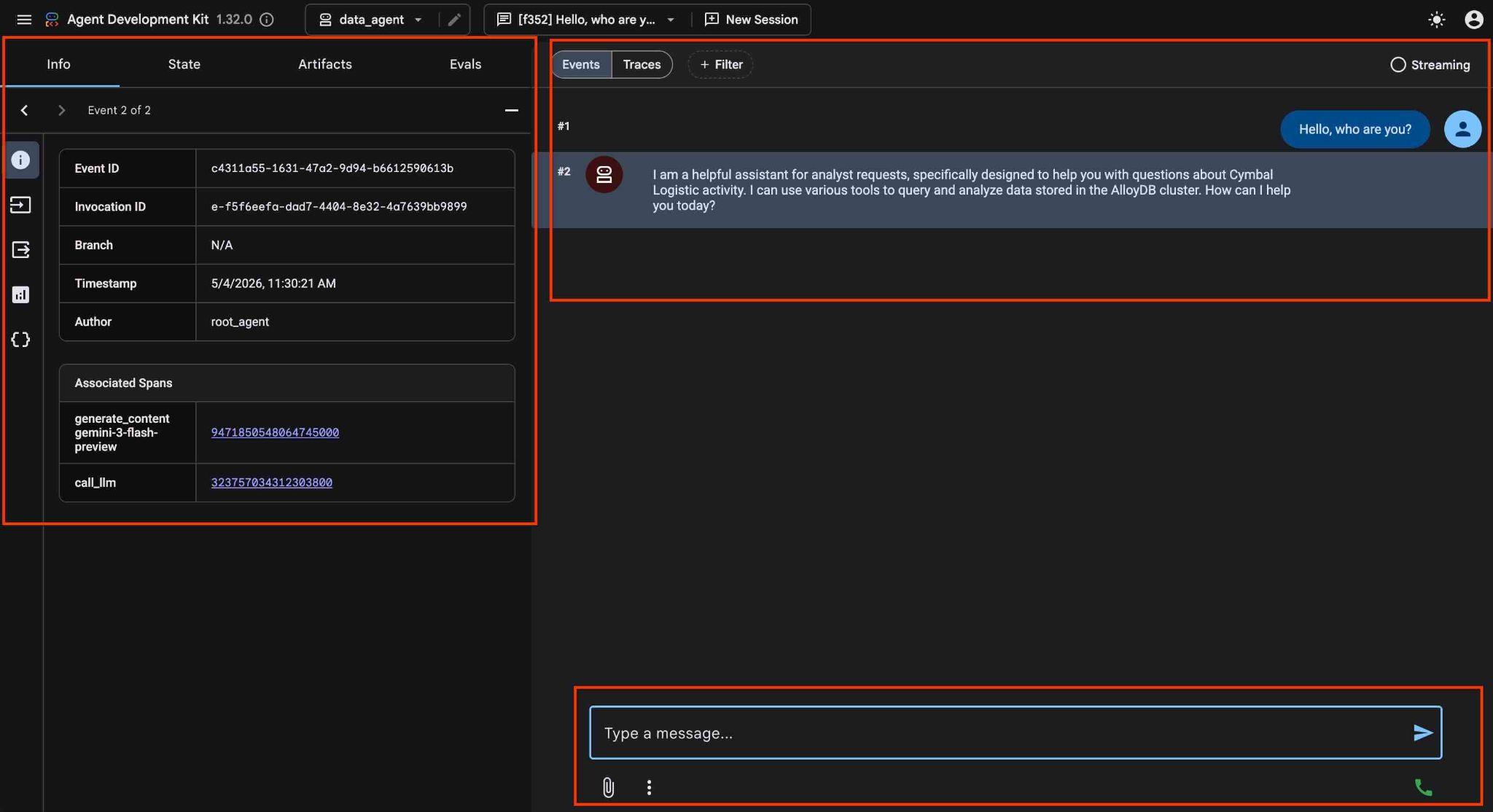
شما با دادههای عملیاتی یک شرکت حمل و نقل کار میکنید که اطلاعاتی در مورد درخواستهای حمل و نقل، کامیونها، رانندگان و سفرهای انجام شده توسط رانندگان دارد. اولین سوال در مورد تعداد سفرهای انجام شده در فوریه 2026 است.
در قسمت ورودی در پایین سمت راست، عبارت زیر را تایپ کنید و اینتر را بزنید.
Hello, can you tell me how many trips we've done in February this year?
این عامل، قبل از اجرای دستور SQL صحیح برای دریافت دادههای صحیح، با اجرای فراخوانیهای ابزارهای متعدد، جداول مناسب در طرحواره و ساختار جدول را شناسایی خواهد کرد.
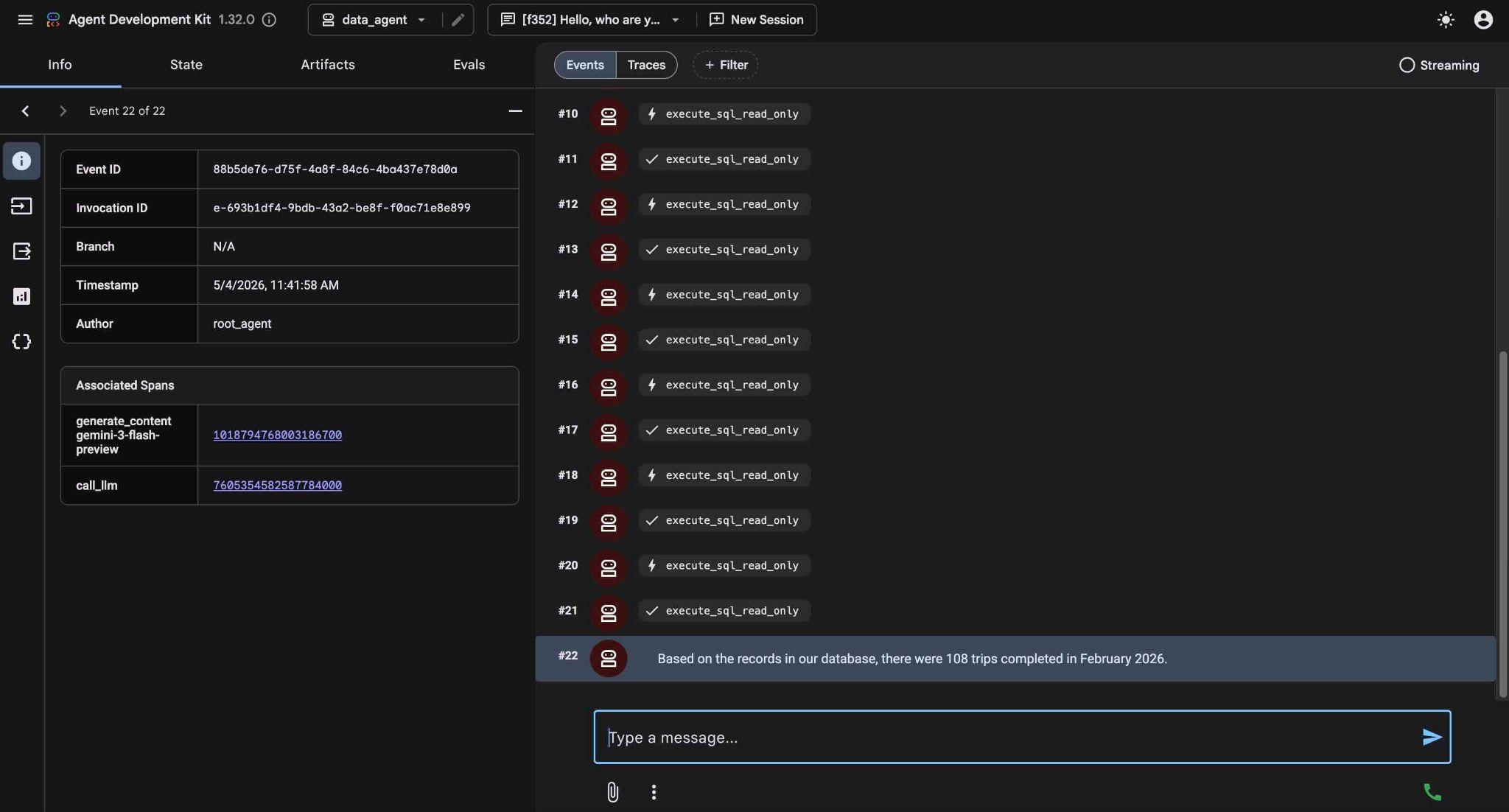
در نهایت، پس از ساخت کوئری مناسب و اجرای آن روی پایگاه داده، نتیجه را تولید خواهد کرد.
بر اساس سوابق موجود در پایگاه داده ما، در فوریه ۲۰۲۶، ۱۰۸ سفر انجام شده است.
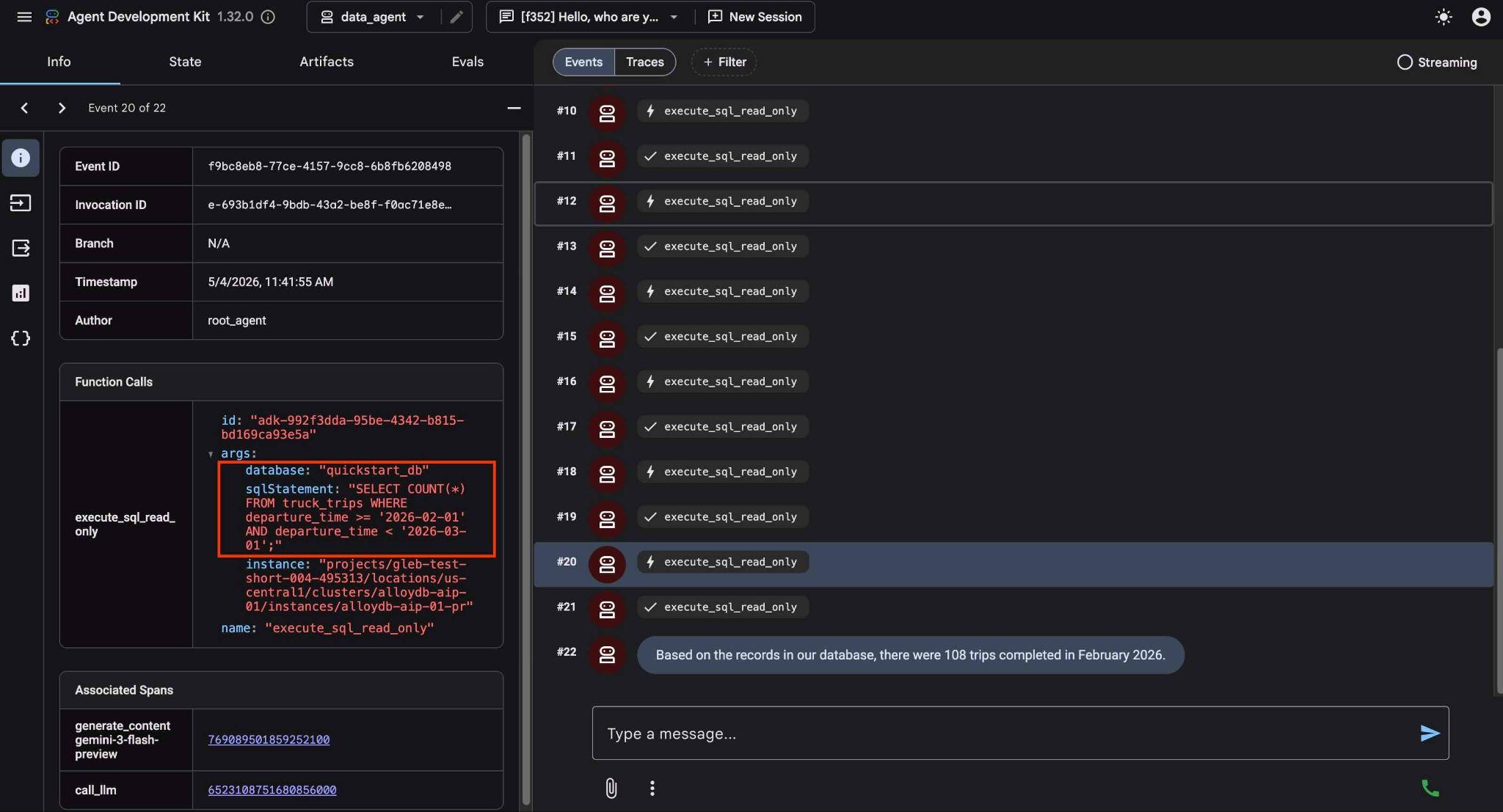
شما میتوانید با کلیک روی اجرای ابزار، ببینید که هر فراخوانی ابزار چه کاری انجام میدهد. برای مثال، در اینجا کوئری اجرا شده برای دریافت نتایج ما آمده است.
حالا درخواست را پیچیدهتر کنید و بخواهید نتایج را با ماه قبل مقایسه کنید.
How is it in comparison in numbers and mileage with the January?
این تابع با اجرای کوئریهای مختلف و تجزیه و تحلیل نتایج و ارائه تفاوت در تعداد سفرها و مسافت پیموده شده، نتیجه را برمیگرداند.
In comparison to January 2026, February saw a slight decrease in both the number of trips and the total mileage: January 2026: 114 trips with a total mileage of 185,597 km. February 2026: 108 trips with a total mileage of 177,893 km. This represents a decrease of 6 trips and 7,704 km in mileage for February compared to January.
درخواستهای سادهی دیگری را با استفاده از رابط وب ADK امتحان کنید و ببینید که چگونه کوئریهای مختلف را برای دستیابی به نتایج اجرا میکند.
با فشردن ctrl+c در ترمینال، عامل را متوقف کنید. میتوانید با رابط وب ADK، تب مرورگر را ببندید.
حالا میتوانید یک نمونه برنامه را امتحان کنید و ببینید که چگونه میتوان از آن به عنوان ابزاری برای تحلیلگران داده استفاده کرد.
۹. نمونه درخواست
در همان مخزن کلون شده، ما یک برنامه نمونه برای شرکت Cymbol Logistic خود داریم. این برنامه از چارچوب پایتون Google Mesop استفاده میکند.
شما میتوانید با باز کردن فایل app.py در ویرایشگر پوسته ابری، کد برنامه را تجزیه و تحلیل کنید.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/app.py
در کد، ما از یک تابع برای ارسال یک اعلان جدید به همراه متغیرها به عامل داده خود استفاده میکنیم. دلیل این کار این است که اگر تصمیم به فراخوانی یک پایگاه داده یا نمونه متفاوت گرفتیم، بتوانیم آن را در رابط پیکربندی کنیم. در اینجا تعریف تابع و اعلان آمده است.
def run_query_sync(request_text, cluster_name, location, instance_name, database_name, project_id, session_id, summary):
local_runner = FrontendRunner()
instruction = f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
"""
...
پس از بررسی کد، دکمه "ترمینال" را برای شروع و آزمایش برنامه فشار دهید. برنامه روی پورت ۸۰۸۰ اجرا خواهد شد. اگر میخواهید پورت را تغییر دهید، دستور تغییر مقدار پورت را تنظیم کنید.
در پوسته ابری اجرا کنید.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv run mesop app.py --port=8080
سپس با کلیک روی http://localhost:8080 از پیشنمایش وب در Google Cloud Shell استفاده کنید.
این یک برگه جدید در مرورگر با رابط برنامه باز میکند.
روی کادر انتخاب «فعال کردن خروجی اشکالزدایی» در بالا سمت راست کلیک کنید و سوالی مانند زیر تایپ کنید.
What was the average speed for each driver last month? List top 5 fasters drivers ranking them by the average speed. Show the name, distance and average speed for each of them.
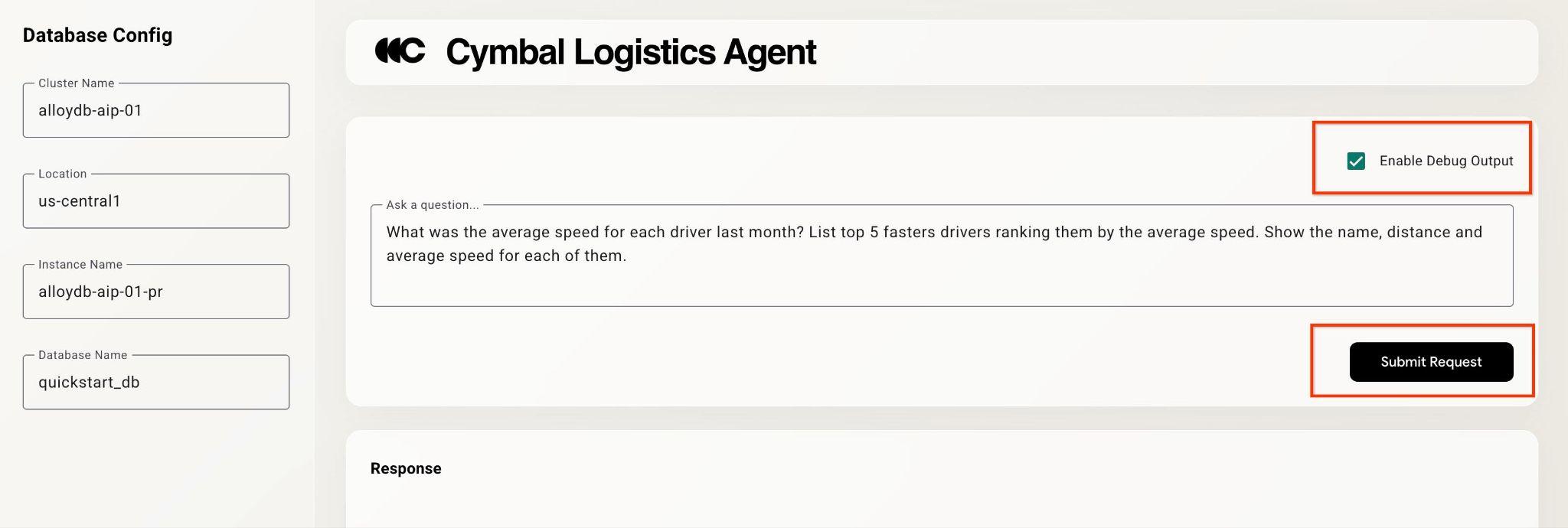
سپس دکمه Submit Request را فشار دهید.
این عامل در پشت صحنه کار خواهد کرد و خروجی را تولید کرده و اطلاعات اشکالزدایی را با تمام پرسوجوهای اجرا شده توسط مجموعه ابزار MCP ما، اشکالزدایی میکند. برای مشاهده گردش کار، پرسوجوها را بررسی کنید.
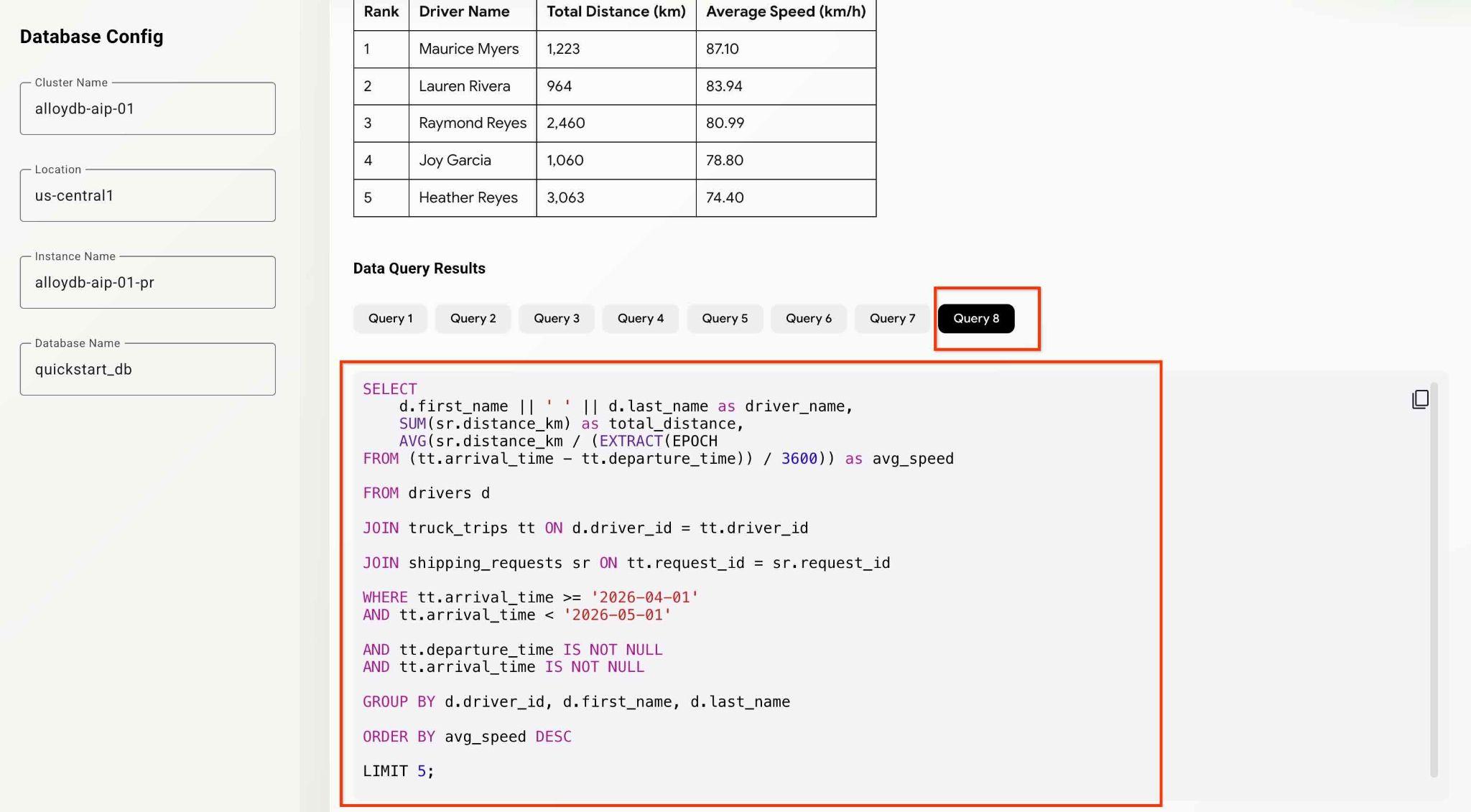
شما میتوانید با پرسیدن سوالات تحلیلی مختلف، قابلیتها و قابلیتهای برنامه را آزمایش کنید.
تاکنون شما توانستید با استفاده از عامل MCP، برخی تجزیه و تحلیلها و کشفهای اولیه را انجام دهید. در فصل بعدی سعی خواهید کرد از ویژگیهای پیشرفتهتر AlloyDB استفاده کنید.
۱۰. توابع هوش مصنوعی AlloyDB
توابع هوش مصنوعی AlloyDB امکان فیلتر کردن و رتبهبندی هوشمند روی متن و دادههای چندوجهی (بهویژه تصاویر) را فراهم میکنند و قدرت Gemini را به پرسوجوهای شما میآورند. بهطور خاص، توابع هوش مصنوعی AlloyDB، AI.IF و AI.RANK، میتوانند در دستورات SQL همراه با عملگرهای SQL مرسوم (فیلترها، پیوندها، تجمیع و غیره) ظاهر شوند.
قبل از استفاده از توابع هوش مصنوعی، جستجو و تجمیع دادهها را با استفاده از روشهای «کلاسیک» بررسی میکنیم. دستور زیر را امتحان کنید.
Can you analyze the activity for the last 5 months and evaluate drivers for the most positive customer feedbacks. Give me top 5 drivers listing names, distance and years of experience for each driver.
این نرمافزار میتواند ستون «رتبهبندی» را در جدول حاوی بازخورد مشتری پیدا کند و از آن برای شناسایی رانندگانی که بهترین رتبه را دارند استفاده کند. سپس از این اطلاعات برای کسب اطلاعات بیشتر در مورد رانندگان استفاده میکند.
SELECT
d.first_name || ' ' || d.last_name as driver_name,
SUM(sr.distance_km) as total_distance,
d.experience_years,
COUNT(cf.feedback_id) as positive_feedback_count
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
WHERE tt.arrival_time >= '2025-12-01'
AND tt.arrival_time < '2026-05-01'
AND cf.rating >= 4
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY positive_feedback_count DESC, total_distance DESC
LIMIT 5;
اما از نظر فنی، این رتبهبندی ممکن است شامل تمام پارامترهایی باشد که میخواهیم ارزیابی کنیم یا نباشد. برای این کار میتوانیم از توابع هوش مصنوعی AlloyDB استفاده کنیم.
اپراتورهای AI.RANK
تابع ai.rank() به میزان خوبی پاسخ یک سند به یک پرسوجوی داده شده امتیاز میدهد. میتوان از آن برای رتبهبندی یا تغییر رتبهبندی نتایج پرسوجو استفاده کرد. میتوانید اطلاعات بیشتر در مورد عملگرها را در مستندات بخوانید.
درخواست را اصلاح کنید و صریحاً درخواست کنید که در طول تحلیل از AI.RANK برای ارزیابی رانندگان بر اساس عملکرد و حرفهای بودنشان استفاده شود.
Can you find the top 5 fastest drivers in the last month and rank them by the feedback using the AI.RANK function? Give me top drivers names, distance, years of experience and rank for each driver.
این دستور ممکن است کمی بیشتر طول بکشد زیرا عامل باید نحوه استفاده از تابع AI.RANK را بفهمد، دادهها را دریافت کند و AI.RANK را برای مرتبسازی اطلاعات بر اساس آن اعمال کند. در پایان باید لیست درایورهای رتبهبندی شده بر اساس مدل و لیست کوئریهای اجرا شده را دریافت کنید.
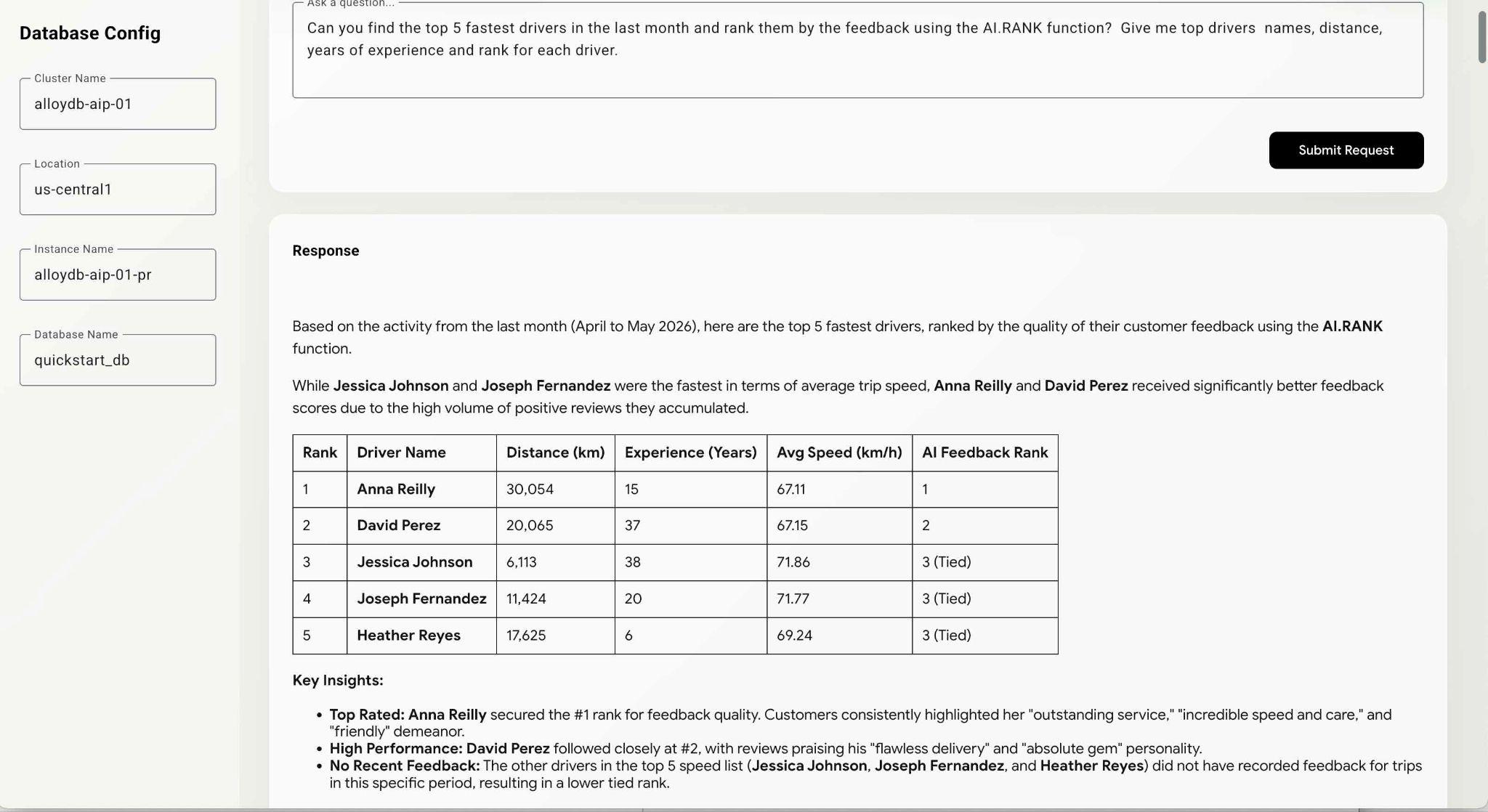
بسته به مسیری که مدل انتخاب میکند، ممکن است اجرای آن پرسوجو کمی زمان ببرد. و میتوانید پرسوجوی دقیقی که برای دریافت اطلاعات مربوط به درایورها اجرا شده است را در پنجره اشکالزدایی مشاهده کنید.
WITH fastest_drivers AS (
SELECT
d.driver_id,
d.first_name || ' ' || d.last_name as driver_name,
d.experience_years,
SUM(sr.distance_km) as total_distance,
AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) as avg_speed,
COALESCE(STRING_AGG(cf.feedback_text, ' | '), 'No feedback') as feedbacks,
ROW_NUMBER() OVER (
ORDER BY AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) DESC) - 1 as row_idx
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
LEFT
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
WHERE tt.arrival_time >= '2026-04-04'
AND tt.arrival_time IS NOT NULL
AND tt.departure_time IS NOT NULL
AND tt.arrival_time > tt.departure_time
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY avg_speed DESC
LIMIT 5
)
SELECT
f.driver_name,
f.total_distance,
f.experience_years,
f.avg_speed,
f.feedbacks,
(SELECT r.score
FROM ai.rank(
'semantic-ranker-fast-004',
'excellent customer service, professional, friendly, fast,
and reliable delivery reviews',
ARRAY[f.feedbacks],
1
) r
LIMIT 1) as feedback_score
FROM fastest_drivers f
ORDER BY feedback_score DESC;
شما میتوانید به آزمایش برنامه ادامه دهید و پرسوجوها را بررسی کنید تا ببینید که اپراتور چگونه به نتایج نهایی میرسد.
این پایان آزمایش ماست. امیدوارم توانسته باشید تمام مثالها را مرور کنید و نحوه استفاده از سرویس Google Cloud MCP برای AlloyDB را یاد بگیرید. برای اینکه MCP شما برای سازمانها قابل استفاده باشد، منطقی است که MCP را با ویژگیهای AlloyDB NL2SQL که در مستندات AlloyDB توضیح داده شده است، ترکیب کنید. میتوانید آن را با استفاده از codelab مربوط به تولید دستورات SQL برای AlloyDB امتحان کنید.
۱۱. محیط را تمیز کنید
برای جلوگیری از هزینههای غیرمنتظره، پاکسازی منابع موقت روش خوبی است. مطمئنترین راه، حذف پروژهای است که در آن گردش کار را آزمایش میکردید. اما به صورت اختیاری میتوانید با حذف منابع منفرد، مانند AlloyDB، خود را محدود کنید.
وقتی کار آزمایشگاهیتان تمام شد، نمونهها و کلاستر AlloyDB را از بین ببرید.
کلاستر AlloyDB و تمام نمونههای آن را حذف کنید.
اگر از نسخه آزمایشی AlloyDB استفاده کردهاید. اگر قصد دارید آزمایشگاهها و منابع دیگری را با استفاده از خوشه آزمایشی آزمایش کنید، خوشه آزمایشی را حذف نکنید. شما قادر به ایجاد خوشه آزمایشی دیگری در همان پروژه نخواهید بود.
خوشه با استفاده از گزینهی Force از بین میرود که تمام نمونههای متعلق به خوشه را نیز حذف میکند.
در پوسته ابری، اگر اتصال شما قطع شده و تمام تنظیمات قبلی از بین رفته است، متغیرهای پروژه و محیط را تعریف کنید:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
حذف خوشه:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
حذف پشتیبانهای AlloyDB
تمام پشتیبانهای AlloyDB را برای کلاستر حذف کنید:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
۱۲. تبریک
تبریک میگویم که آزمایشگاه کد را تمام کردی.
آنچه ما پوشش دادهایم
- نحوه ایجاد یک کلاستر AlloyDB و وارد کردن دادههای نمونه
- نحوه فعال کردن API دسترسی به داده AlloyDB
- نحوه فعال کردن Google Cloud MCP برای AlloyDB NL
- نحوه اضافه کردن Google Cloud MCP برای AlloyDB به عامل ADK شما
- نحوه استفاده از Google Cloud MCP برای AlloyDB در یک برنامه
- نحوه استفاده از عاملها با AlloyDBMCP برای تجزیه و تحلیل
۱۳. نظرسنجی
خروجی: