
1. Introduction
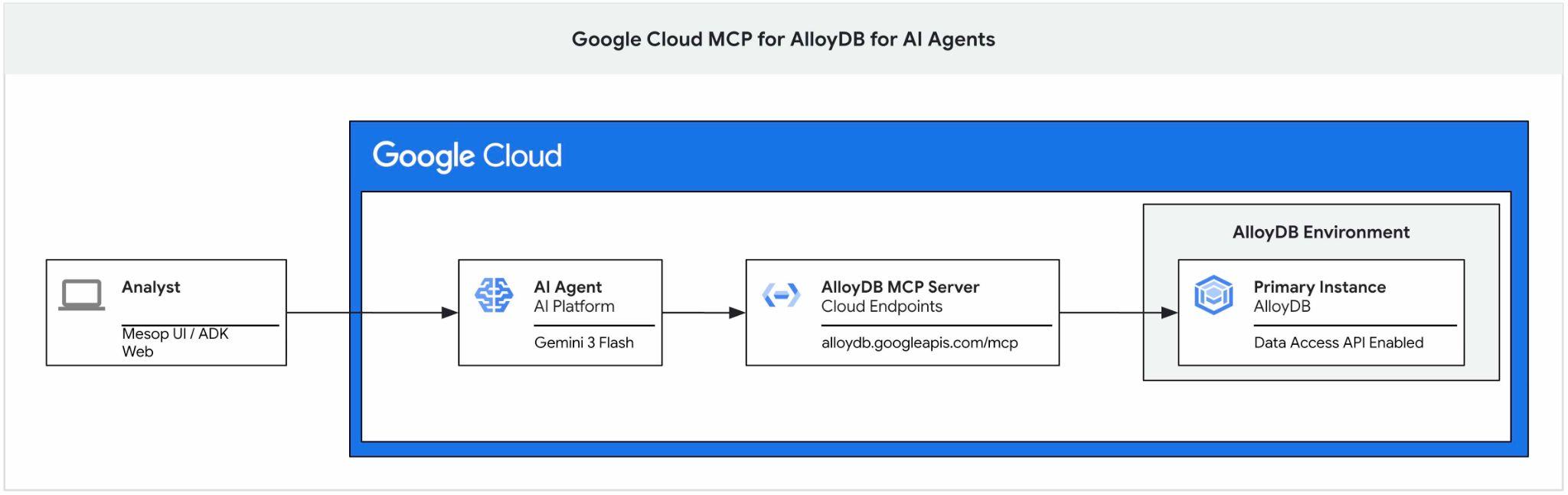
Cet atelier de programmation explique comment commencer à utiliser le serveur MCP Google Cloud pour AlloyDB, l'activer dans l'ensemble d'outils d'un agent d'IA et l'utiliser dans une application.
Prérequis
- Connaissances de base concernant la console Google Cloud
- Compétences de base concernant l'interface de ligne de commande et Cloud Shell
Points abordés
- Créer un cluster AlloyDB et importer des exemples de données
- Activer l'API d'accès aux données AlloyDB
- Activer Google Cloud MCP pour AlloyDB NL
- Ajouter Google Cloud MCP pour AlloyDB à votre agent ADK
- Utiliser Google Cloud MCP pour AlloyDB dans une application
- Utiliser des agents avec AlloyDBMCP pour l'analyse
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome, compatible avec la console Google Cloud et Cloud Shell
2. Préparation
Configuration du projet
- Connectez-vous à la console Google Cloud. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
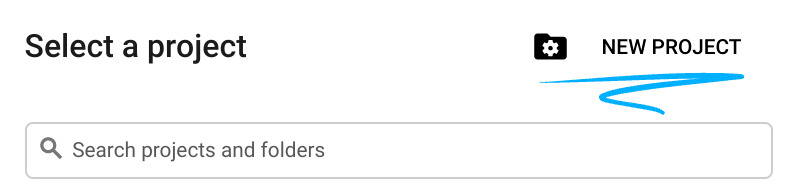
- Créez un projet ou réutilisez-en un existant. Pour créer un projet dans la console Google Cloud, cliquez sur le bouton "Sélectionner un projet" dans l'en-tête. Une fenêtre pop-up s'ouvre.

Dans la fenêtre "Sélectionner un projet", cliquez sur le bouton "Nouveau projet" pour ouvrir une boîte de dialogue pour le nouveau projet.
Dans la boîte de dialogue, saisissez le nom de projet de votre choix et sélectionnez l'emplacement.
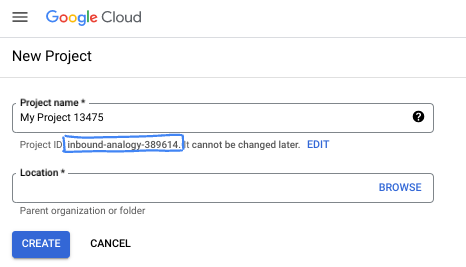
- Le nom du projet est le nom à afficher pour les participants au projet. Le nom du projet n'est pas utilisé par les API Google et peut être modifié à tout moment.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Google Cloud génère automatiquement un ID unique, mais vous pouvez le personnaliser. Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire ou fournir le vôtre pour vérifier sa disponibilité. Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet, généralement identifié par l'espace réservé PROJECT_ID.
- Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
Activer la facturation
Configurer un compte de facturation personnel
Si vous configurez la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, cliquez ici pour activer la facturation dans la console Cloud.
Remarques :
- Cet atelier devrait vous coûter moins de 3 USD en ressources cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour profiter d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Vous pouvez également appuyer sur G, puis sur S. Cette séquence activera Cloud Shell si vous êtes dans la console Google Cloud ou si vous utilisez ce lien.
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Activer l'API
Pour utiliser AlloyDB, Compute Engine, les services réseau et Vertex AI, vous devez activer leurs API respectives dans votre projet Google Cloud.
Dans le terminal Cloud Shell, assurez-vous que l'ID de votre projet est configuré :
gcloud config get-value project
Il devrait renvoyer l'ID de votre projet Google.
Définissez la variable d'environnement PROJECT_ID :
PROJECT_ID=$(gcloud config get-value project)
Activez tous les services nécessaires :
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Résultat attendu
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Déployer AlloyDB
Créez un cluster AlloyDB et une instance principale. Vous pouvez le déployer à l'aide d'un script préparé qui déploiera toutes les ressources nécessaires, ou le faire vous-même étape par étape en suivant la documentation.
Déployer AlloyDB à l'aide d'un script automatisé
Cette approche utilise un script automatisé pour déployer le cluster AlloyDB et fournit les informations nécessaires pour commencer à utiliser les ressources déployées.
Dans le terminal Cloud Shell, exécutez la commande permettant de cloner le script de déploiement à partir du dépôt.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-ai-mcp"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Exécutez le script de déploiement.
./deploy_alloydb.sh
L'exécution du script prendra un certain temps (environ cinq à sept minutes). La sortie doit ensuite fournir des informations sur votre cluster AlloyDB déployé. Veuillez noter que votre mot de passe sera différent. Enregistrez-le quelque part pour une utilisation ultérieure.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
Vous pouvez également voir le nouveau cluster et l'instance principale dans la console Web.
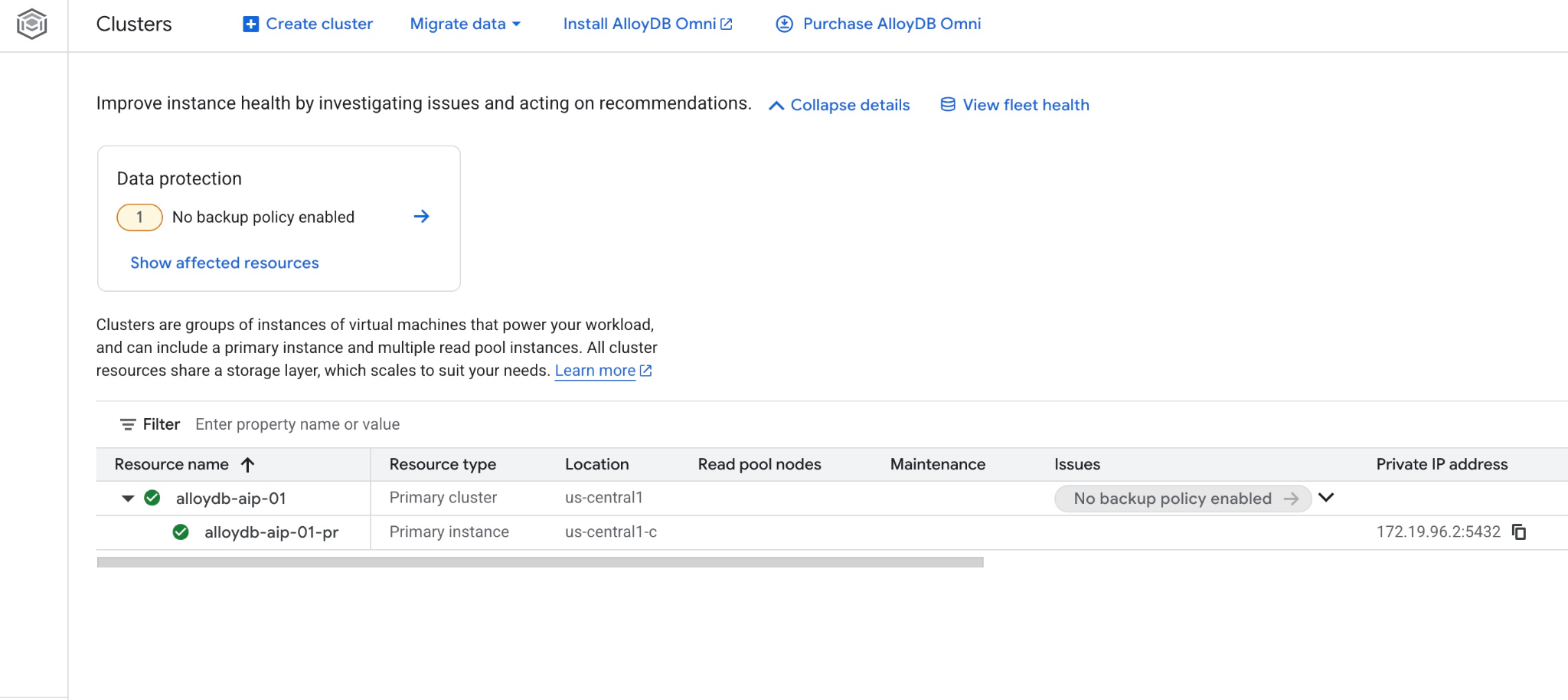
5. Préparer la base de données
Pour utiliser les fonctions et opérateurs d'IA, vous devez activer l'intégration de Vertex AI, activer l'API d'accès aux données et créer une base de données pour l'ensemble de données exemple.
Accorder les autorisations nécessaires à AlloyDB
Ajoutez des autorisations Vertex AI à l'agent de service AlloyDB.
Ouvrez un autre onglet Cloud Shell à l'aide du signe "+" situé en haut.
Dans le nouvel onglet Cloud Shell, exécutez :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/discoveryengine.viewer"
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... < redacted > etag: BwYIEbe_Z3U= version: 1
Activer l'API Data Access
Vous devez activer l'API Data Access sur le cluster AlloyDB pour pouvoir utiliser les outils MCP tels que execute_sql.
Dans le même onglet de terminal, exécutez la commande suivante :
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Mettre à jour les indicateurs d'instance
Pour utiliser les fonctions d'IA avancées dans AlloyDB, nous devons activer certains indicateurs de base de données. Une fois l'API Data Access activée, l'instance peut mettre quelques minutes à être prête pour les prochaines modifications. Veuillez consulter l'état de l'instance dans la console pour vous assurer qu'elle est accompagnée d'une coche verte.
Dans le même onglet de terminal, exécutez la commande suivante :
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags=google_ml_integration.enable_model_support=on,google_ml_integration.enable_ai_query_engine=on,google_ml_integration.enable_preview_ai_functions=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Activer MCP
L'étape suivante consiste à activer le serveur MCP Google Cloud pour AlloyDB dans votre projet. Par défaut, le MCP n'est pas activé. Il s'agit de l'une des nombreuses couches de protection, y compris l'authentification et l'autorisation IAM, l'API d'accès aux données et les rôles dans votre cluster.
Dans le même onglet de terminal, exécutez la commande suivante :
PROJECT_ID=$(gcloud config get-value project)
gcloud beta services mcp enable alloydb.googleapis.com \
--project=$PROJECT_ID
Fermez l'onglet en exécutant la commande "exit" dans l'onglet :
exit
Se connecter à AlloyDB Studio
Dans les chapitres suivants, toutes les commandes SQL nécessitant une connexion à la base de données peuvent être exécutées dans AlloyDB Studio. T
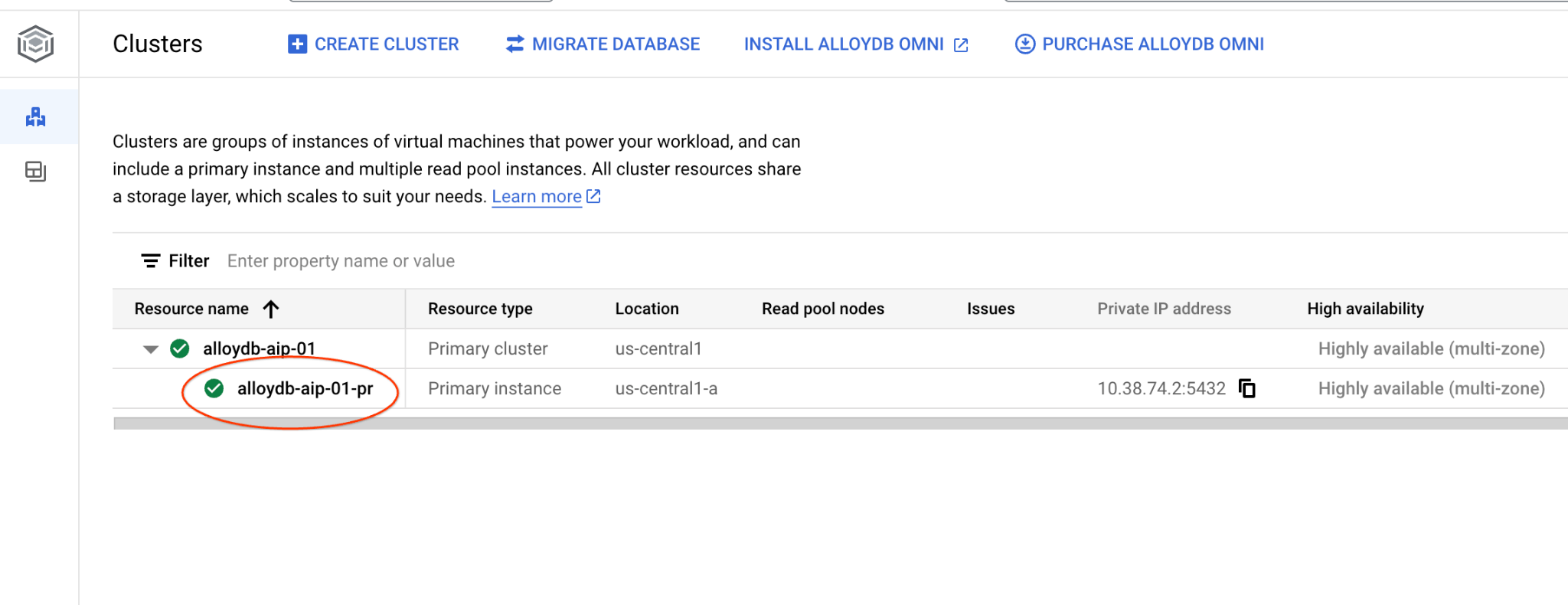
Accédez à la page "Clusters" dans AlloyDB pour PostgreSQL.
Ouvrez l'interface de la console Web pour votre cluster AlloyDB en cliquant sur l'instance principale.
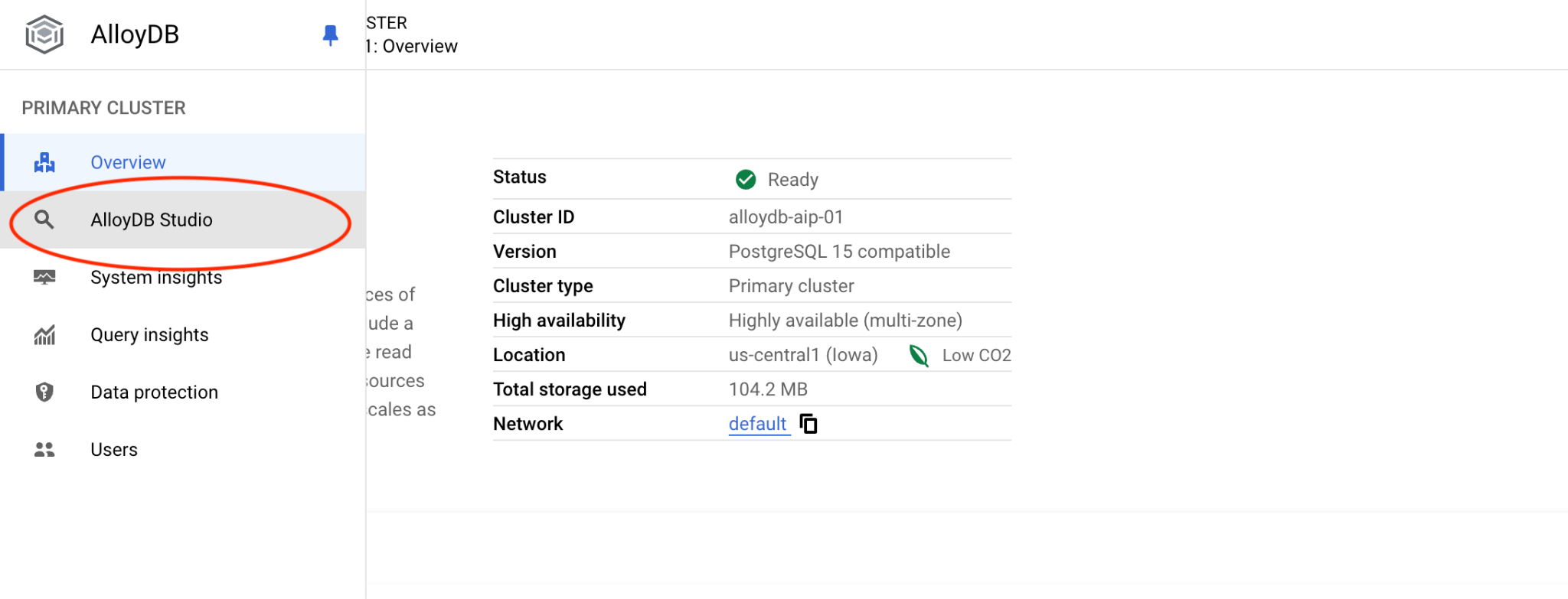
Cliquez ensuite sur AlloyDB Studio à gauche :
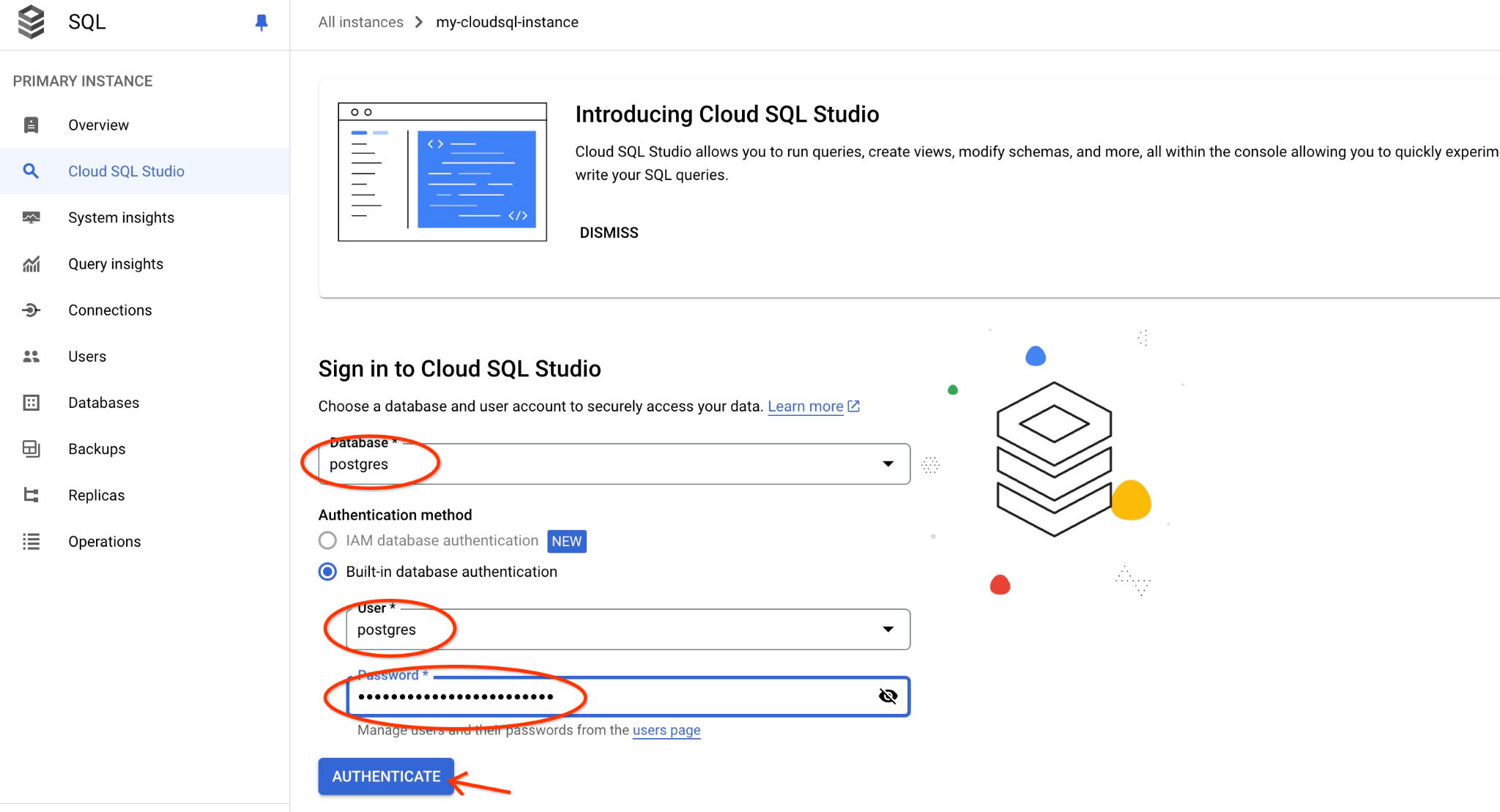
Choisissez la base de données postgres et l'utilisateur postgres, puis fournissez le mot de passe indiqué lors de la création du cluster. Cliquez ensuite sur le bouton "Authenticate" (S'authentifier).
Si le mot de passe ne fonctionne pas ou si vous avez oublié de le noter, vous pouvez le modifier. Pour savoir comment procéder, consultez la documentation.
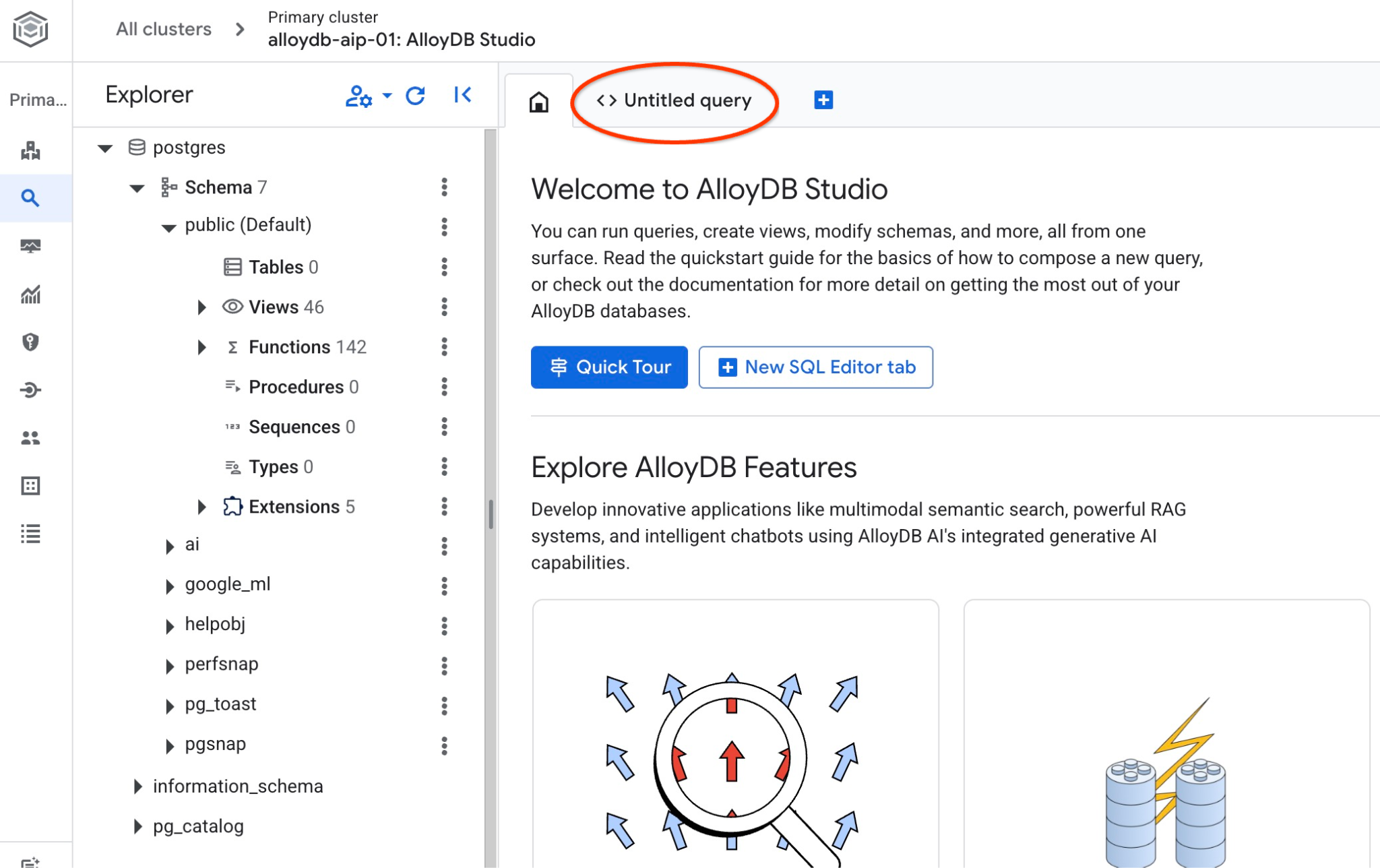
L'interface AlloyDB Studio s'ouvre. Pour exécuter les commandes dans la base de données, cliquez sur l'onglet "Requête sans titre" à droite.
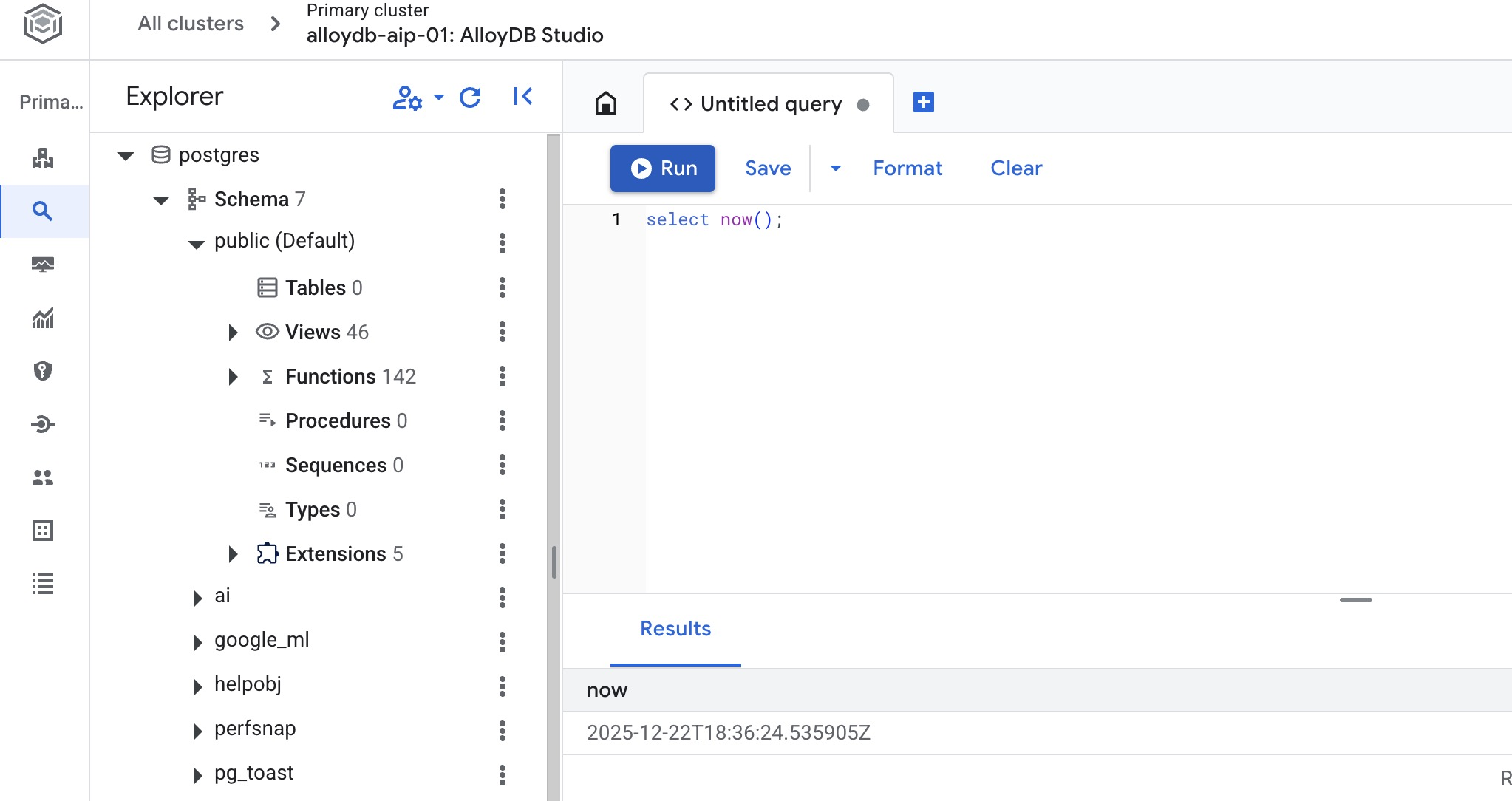
L'interface qui s'ouvre vous permet d'exécuter des commandes SQL.
Créer une base de données
Créez un démarrage rapide de base de données.
Dans l'éditeur AlloyDB Studio, exécutez la commande suivante.
Créez une base de données :
CREATE DATABASE quickstart_db
Résultat attendu :
Statement executed successfully
Se connecter à quickstart_db
Vérifiez si votre base de données a été créée en vous y connectant. Reconnectez-vous au studio à l'aide du bouton permettant de changer d'utilisateur ou de base de données.
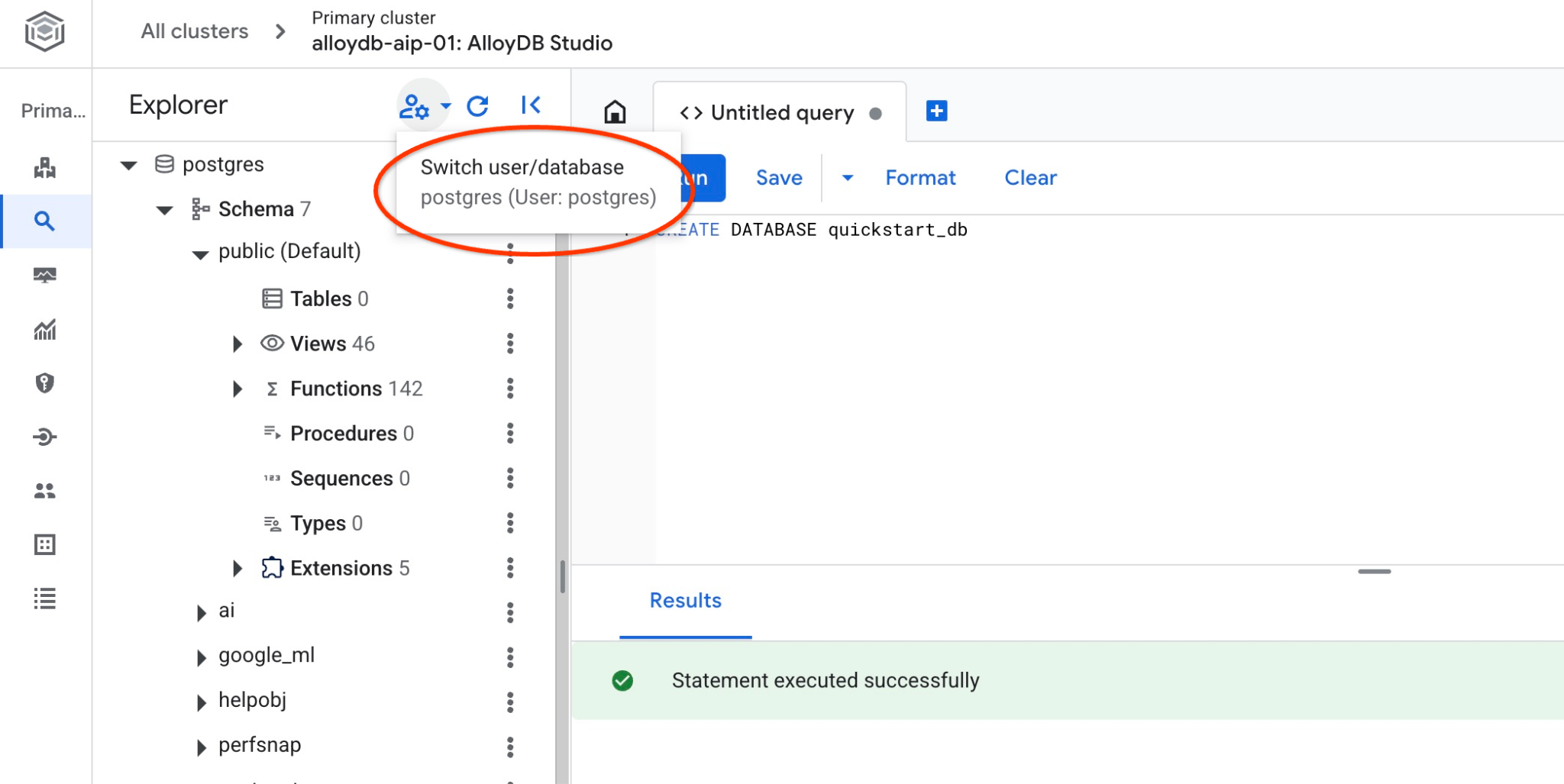
Dans la liste déroulante, sélectionnez la nouvelle base de données quickstart_db et utilisez les mêmes nom d'utilisateur et mot de passe qu'avant.
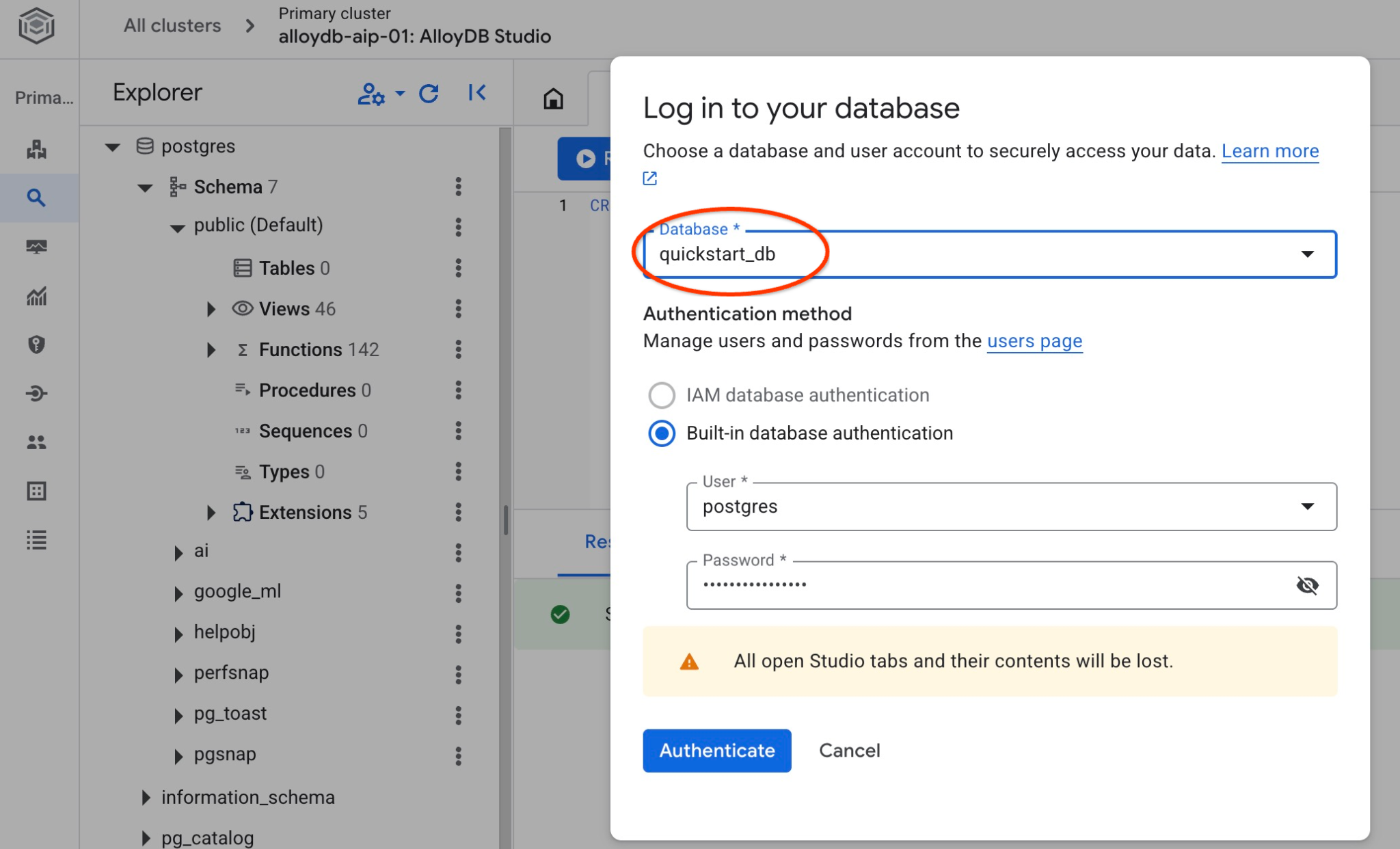
Une nouvelle connexion s'ouvre, vous permettant de travailler avec des objets de la base de données quickstart_db. Vous pourrez y examiner le schéma et les données que vous avez importés.
6. Exemples de données
Vous devez maintenant créer des objets dans la base de données et charger des données. Vous allez utiliser un ensemble de données fictif de l'entreprise Cymbal Shipping. Il contient des données fictives sur les marchandises, les camions, les demandes et les trajets de camions, ainsi que sur les conducteurs fictifs.
Créer un bucket Storage
Vous allez utiliser le SDK Google (gcloud) pour importer des données de notre dépôt cloné dans la base de données AlloyDB. Pour cela, vous devez créer un bucket de stockage et accorder l'accès au compte de service AlloyDB. Vous pouvez également essayer de le faire à l'aide de la console Web, comme décrit dans la documentation.
Dans le terminal Google Cloud Shell, exécutez :
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Charger des données
L'étape suivante consiste à charger les données. Notre vidage SQL se trouve dans le dossier du dépôt cloné. La commande suivante suppose que vous avez utilisé votre répertoire personnel comme point de départ lorsque vous avez cloné le dépôt à l'étape précédente lors de la création du cluster AlloyDB.
Copiez le vidage SQL compressé dans le nouveau bucket de stockage :
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Chargez ensuite les données dans la base de données quickstart_db :
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
La commande chargera l'ensemble de données exemple dans la base de données quickstart_db. Vous pouvez vérifier les tables et les enregistrements à l'aide d'AlloyDB Studio.
7. Utiliser l'agent de données
Commençons par un exemple d'agent d'IA créé à l'aide du kit de développement d'agents Google pour Python et montrons comment le configurer pour qu'il fonctionne avec le serveur MCP Google Cloud pour AlloyDB.
Vérifier le code source de l'agent
Dans le dépôt cloné, examinez le code de l'agent à l'aide de l'éditeur Google Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/data_agent/agent.py
Vous pouvez voir dans l'agent que nous avons une section pour le serveur MCP Google Cloud pour AlloyDB. Nous fournissons un point de terminaison en tant que MCP_SERVER_URL, une authentification, un ID de projet et l'ajoutons à l'ensemble d'outils MCP.
# Google Cloud MCP Server for AlloyDB
MCP_SERVER_URL = "https://alloydb.googleapis.com/mcp"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
# 2. Configure MCP Toolset
# We use StreamableHTTPConnectionParams to pass the auth header
headers = {
"Authorization": f"Bearer {creds.token}",
"X-Goog-User-Project": project_id
}
connection_params = StreamableHTTPConnectionParams(
url=MCP_SERVER_URL,
headers=headers,
timeout=300.0,
sse_read_timeout=600.0
)
mcp_toolset = McpToolset(connection_params=connection_params)
Dans le code de l'agent, l'ensemble d'outils MCP est inclus en tant que paramètre tools pour l'agent. Le nom du cluster et de l'instance, la région et la base de données sont également disponibles en tant que variables pour la requête de l'agent.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
""",
tools=[mcp_toolset],
)
Le service MCP Google Cloud pour AlloyDB dispose d'un ensemble d'outils prédéfini. Si vous souhaitez lister tous les outils disponibles, vous pouvez utiliser la commande curl à partir du terminal de la console Cloud Shell à l'aide de la commande suivante. Vous pouvez toujours consulter la dernière référence du serveur MCP Google Cloud pour AlloyDB dans la documentation.
curl -s -X POST http://alloydb.googleapis.com/mcp \
-H "Content-Type: application/json" \
-d @- <<EOF | jq -r '.result.tools[].name'
{
"id": "my_id_01",
"jsonrpc": "2.0",
"method": "tools/list"
}
EOF
Démarrer l'agent
Vous pouvez maintenant démarrer l'agent en mode interactif à l'aide de l'interface Web Google ADK. L'interface Web d'ADK permet de tester et de dépanner facilement les workflows des agents.
Commençons par installer tous les packages Python requis à l'aide du gestionnaire de packages uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv sync
Une fois tous les packages installés, vous devez ajouter un fichier .env au répertoire de l'agent pour lui indiquer d'utiliser Vertex AI pour toutes les communications avec les modèles d'IA.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Vous pouvez ensuite démarrer l'agent.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Un résultat semblable à celui-ci doit s'afficher, avec le point de terminaison http://127.0.0.1:8000 .
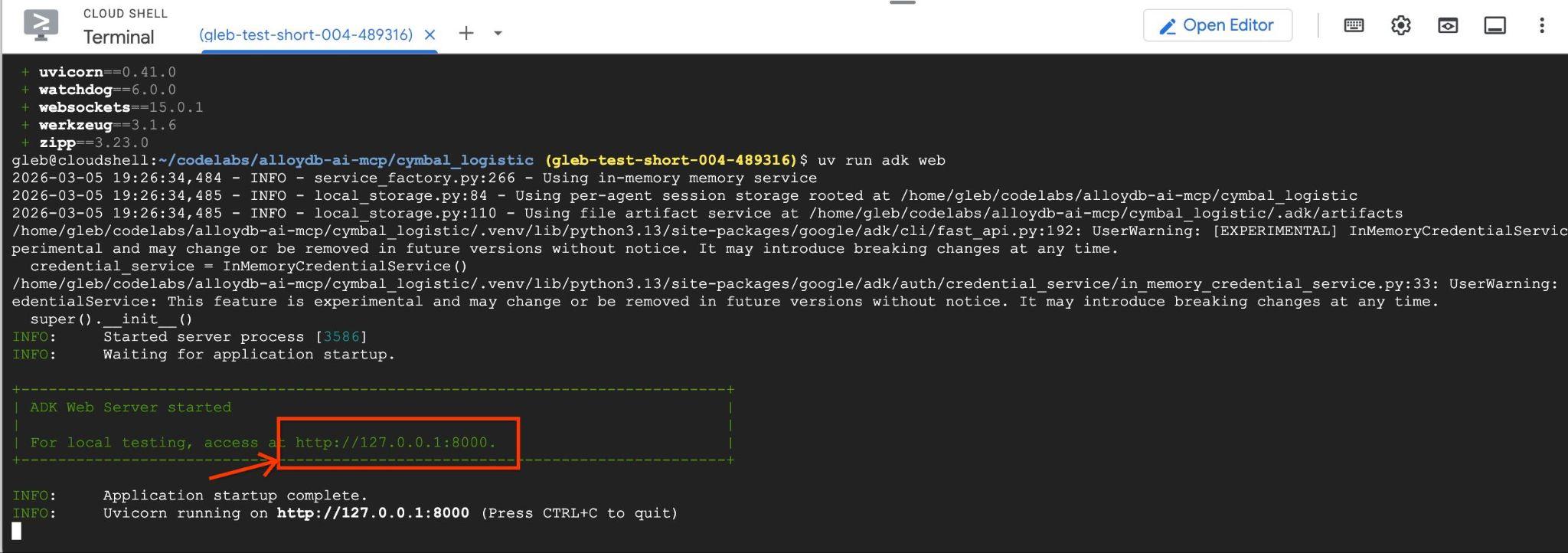
Vous pouvez cliquer sur cette URL dans Cloud Shell. Une fenêtre d'aperçu s'ouvre alors dans un onglet de navigateur distinct. Vous pouvez y sélectionner data_agent dans la liste déroulante de gauche.
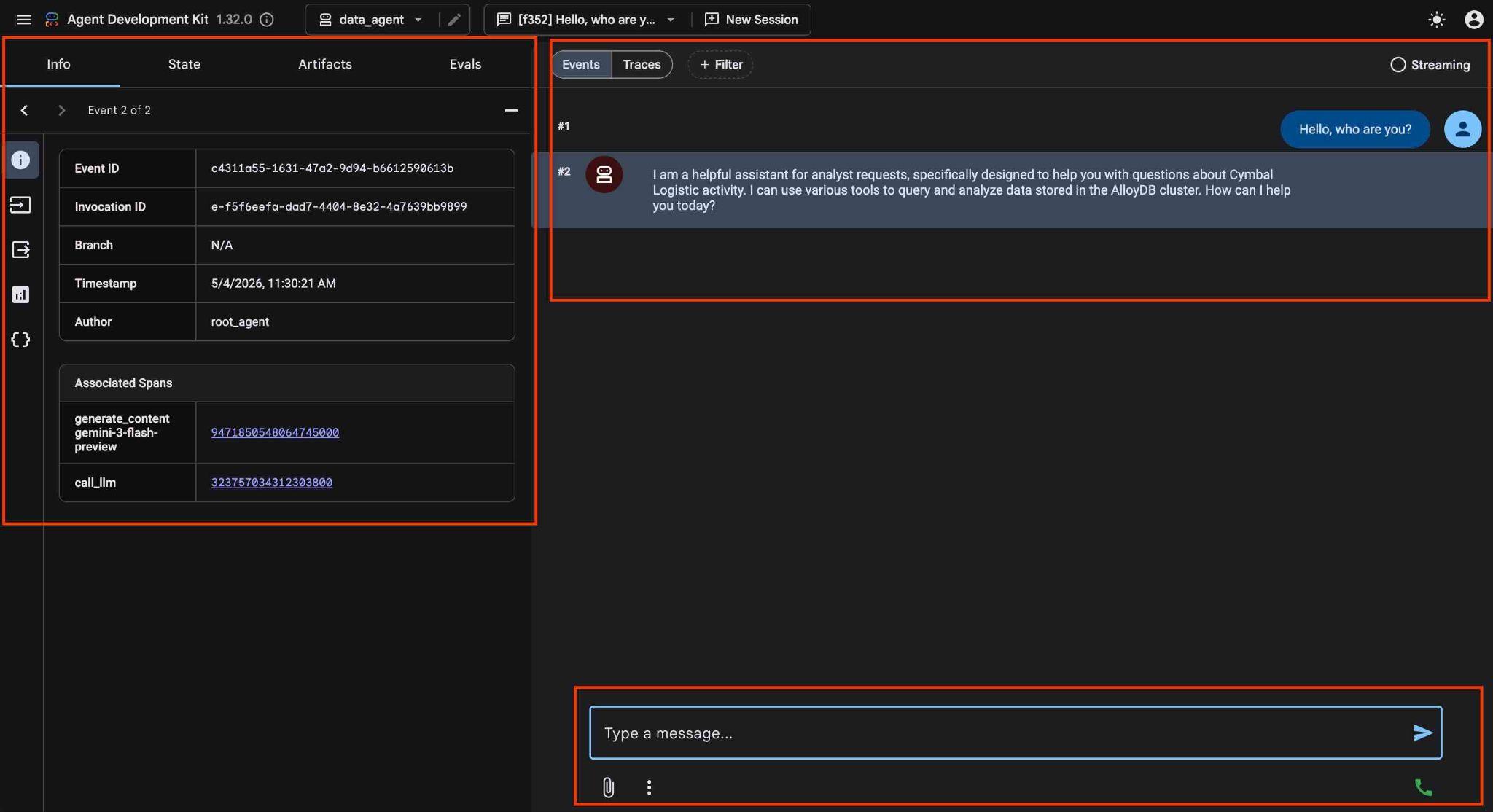
Dans l'interface Web de l'ADK, vous pouvez poser vos questions en bas à droite et voir le flux d'exécution complet, y compris les traces de chaque étape sur la droite.
8. Tester AlloyDB MCP avec l'agent
L'agent vous permet de poser des questions en format libre en langage naturel. Il utilise le serveur MCP Google Cloud pour AlloyDB comme outil pour y répondre. Les questions sont publiées en bas à droite et la réponse avec tous les appels aux outils s'affiche en haut.
Vous travaillez avec des données opérationnelles pour une entreprise de transport maritime qui dispose d'informations sur les demandes d'expédition, les camions, les chauffeurs et les trajets effectués par les chauffeurs. La première question porte sur le nombre de trajets effectués en février 2026.
Dans le champ de saisie en bas à droite, saisissez ce qui suit, puis appuyez sur Entrée.
Hello, can you tell me how many trips we've done in February this year?
L'agent exécutera plusieurs appels d'outils pour identifier les tables appropriées dans le schéma et la structure des tables avant d'exécuter l'instruction SQL correcte pour obtenir les bonnes données.
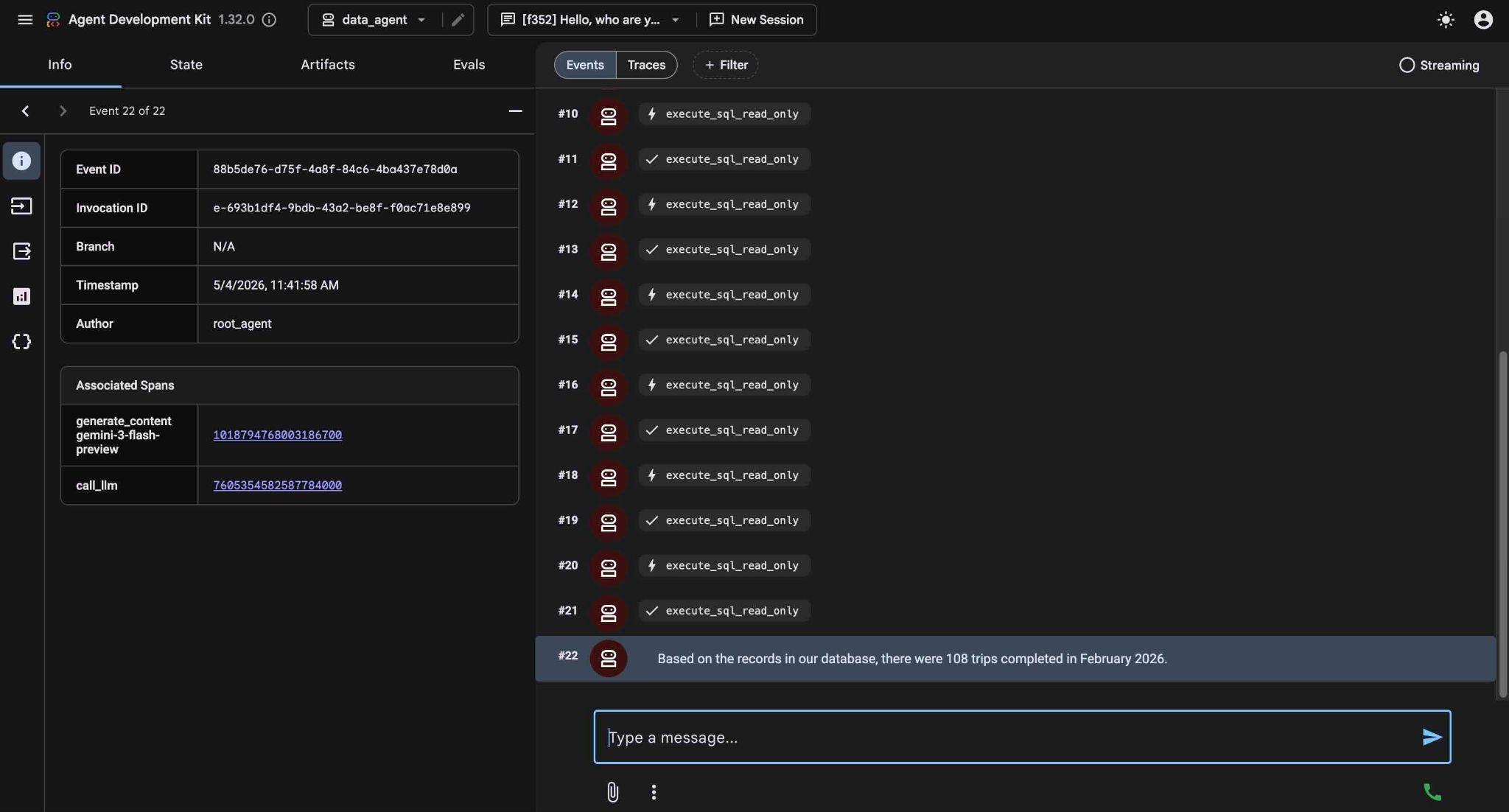
Il finira par produire le résultat après avoir créé la requête appropriée et l'avoir exécutée sur la base de données.
D'après les informations de notre base de données, 108 trajets ont été effectués en février 2026.
Vous pouvez voir ce que fait chaque appel d'outil en cliquant sur l'exécution de l'outil. Par exemple, voici la requête exécutée pour obtenir nos résultats.
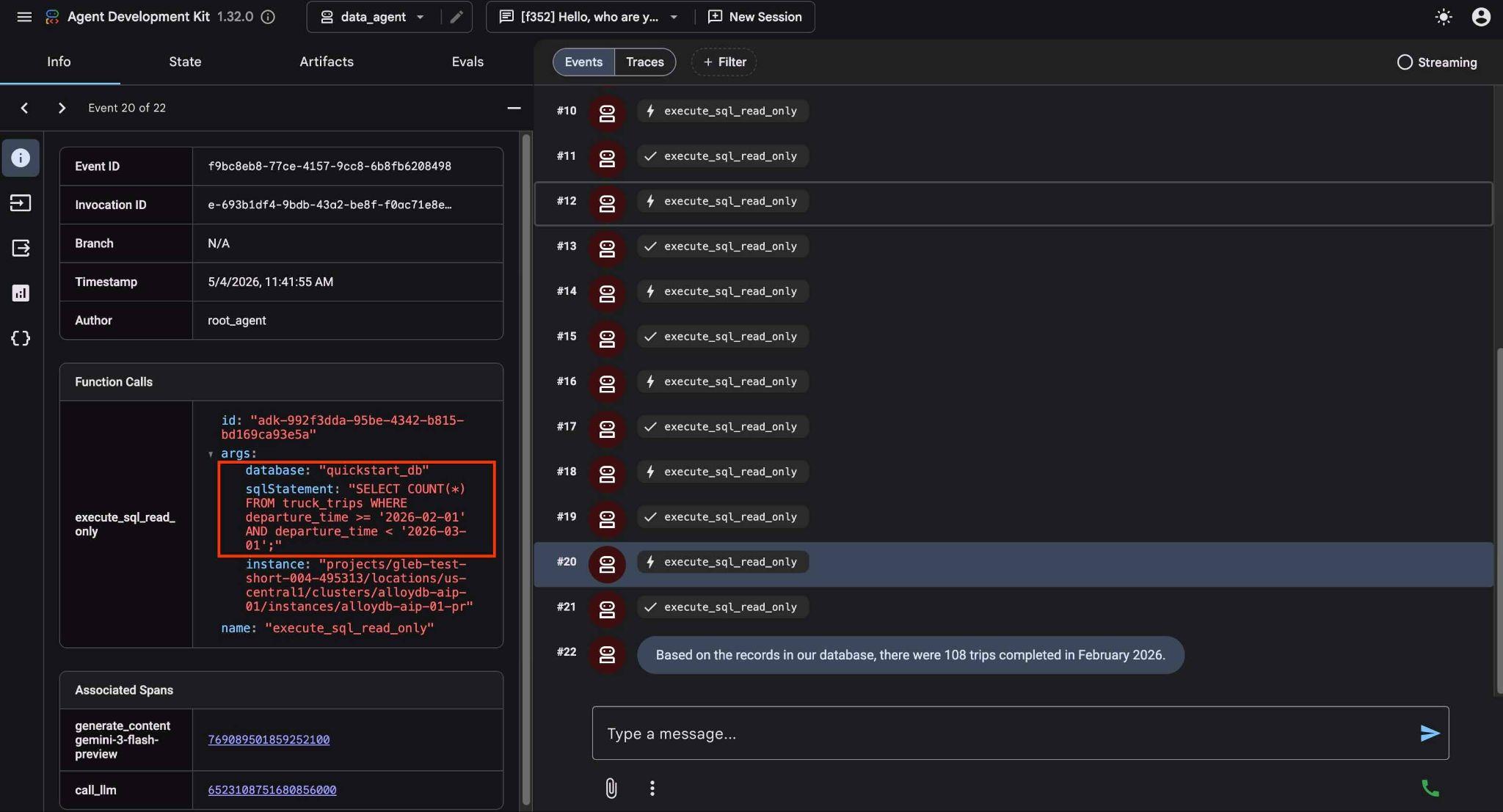
Complexifiez maintenant la demande en demandant de comparer les résultats avec ceux du mois précédent.
How is it in comparison in numbers and mileage with the January?
Il renvoie le résultat en exécutant différentes requêtes qui analysent les résultats et fournissent une différence dans le nombre de trajets et le kilométrage.
In comparison to January 2026, February saw a slight decrease in both the number of trips and the total mileage: January 2026: 114 trips with a total mileage of 185,597 km. February 2026: 108 trips with a total mileage of 177,893 km. This represents a decrease of 6 trips and 7,704 km in mileage for February compared to January.
Essayez d'autres requêtes simples à l'aide de l'interface Web ADK et voyez comment il exécute différentes requêtes pour obtenir les résultats.
Arrêtez l'agent en appuyant sur ctrl+c dans le terminal. Vous pouvez fermer l'onglet du navigateur contenant l'interface Web ADK.
Vous pouvez maintenant essayer un exemple d'application et voir comment elle peut être utilisée comme outil pour les analystes de données.
9. Exemple d'application
Dans le même dépôt cloné, nous avons un exemple d'application pour notre entreprise Cymbol Logistic. L'application utilise le framework Python Mesop de Google .
Vous pouvez analyser le code de l'application en ouvrant le fichier app.py dans l'éditeur Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/app.py
Dans le code, nous utilisons une fonction pour transmettre une nouvelle requête avec des variables à notre agent de données. Cela permet de le configurer dans l'interface si nous décidons d'appeler une autre base de données ou instance. Voici la définition de la fonction et l'invite.
def run_query_sync(request_text, cluster_name, location, instance_name, database_name, project_id, session_id, summary):
local_runner = FrontendRunner()
instruction = f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
"""
...
Après avoir examiné le code, appuyez sur le bouton "Terminal" pour démarrer et tester notre application. L'application démarre sur le port 8080. Si vous souhaitez modifier le port, ajustez la commande en changeant la valeur du port.
Dans Cloud Shell, exécutez la commande suivante :
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv run mesop app.py --port=8080
Utilisez ensuite l'aperçu Web dans Google Cloud Shell en cliquant sur http://localhost:8080.
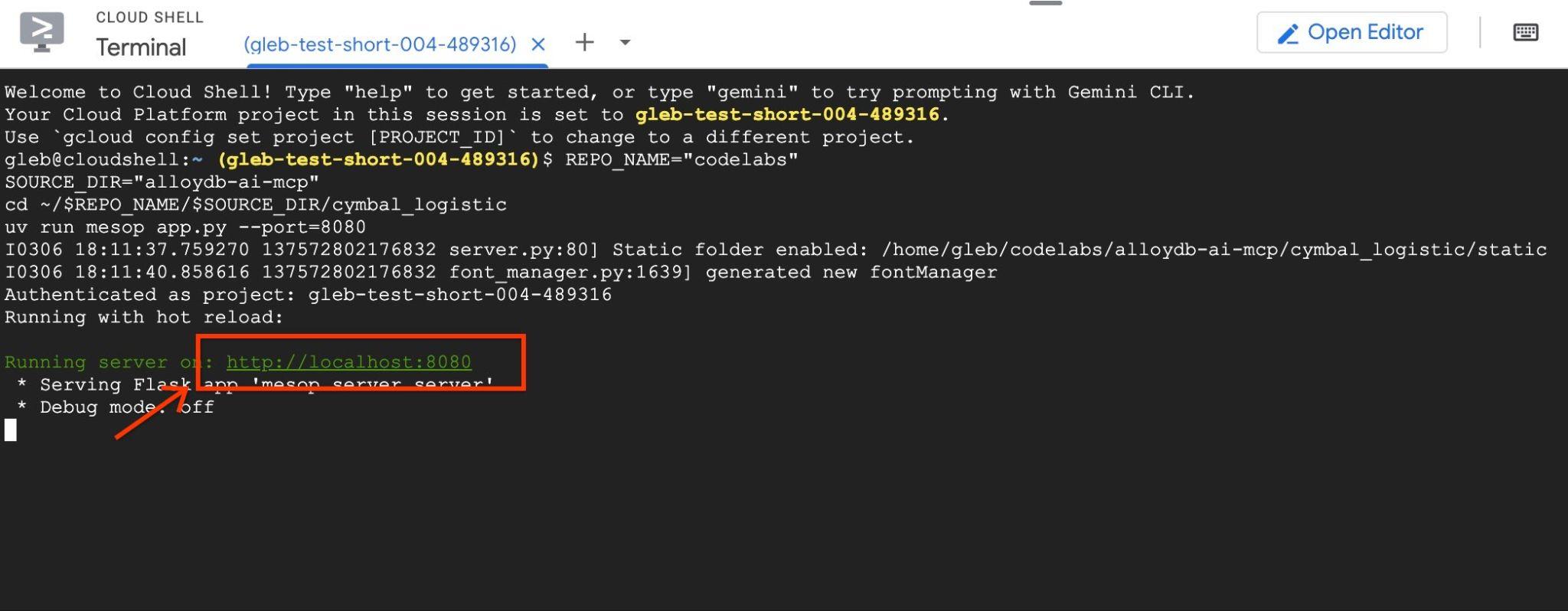
Un nouvel onglet affichant l'interface de l'application s'ouvre dans le navigateur.
Cochez la case "Enable Debug Output" (Activer la sortie de débogage) en haut à droite, puis saisissez une question comme celle ci-dessous.
What was the average speed for each driver last month? List top 5 fasters drivers ranking them by the average speed. Show the name, distance and average speed for each of them.
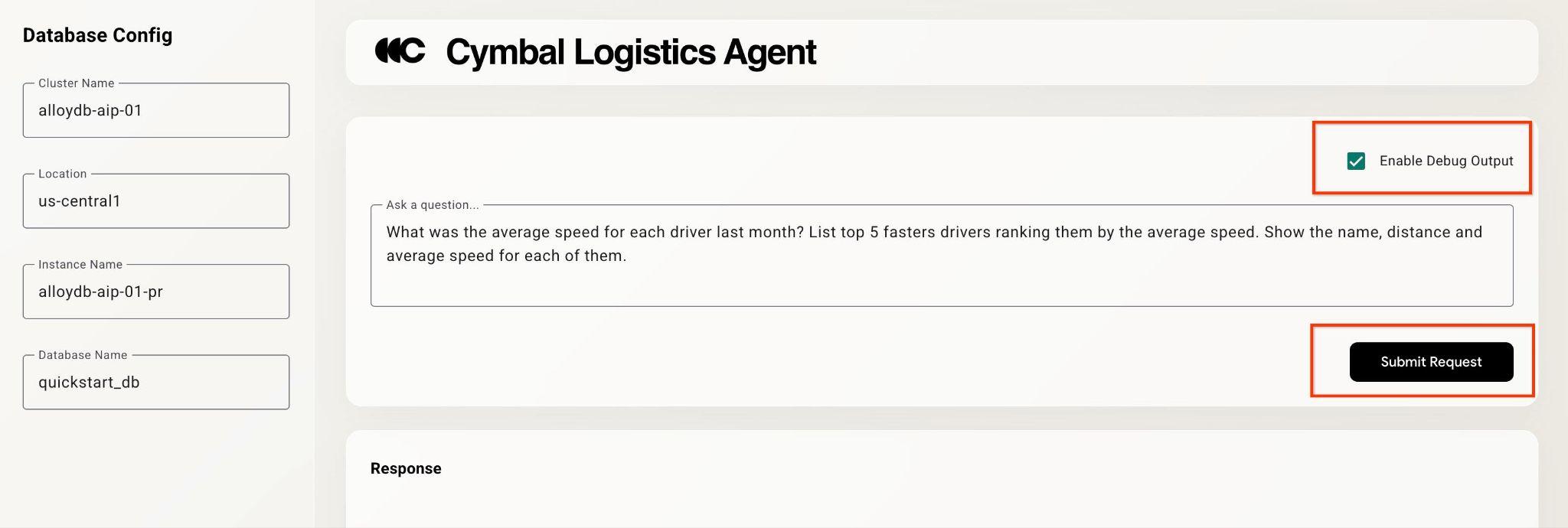
Appuyez ensuite sur le bouton Submit Request.
L'agent travaillera en arrière-plan et générera les informations de sortie et de débogage avec toutes les requêtes exécutées par notre ensemble d'outils MCP. Consultez les requêtes pour voir le workflow.
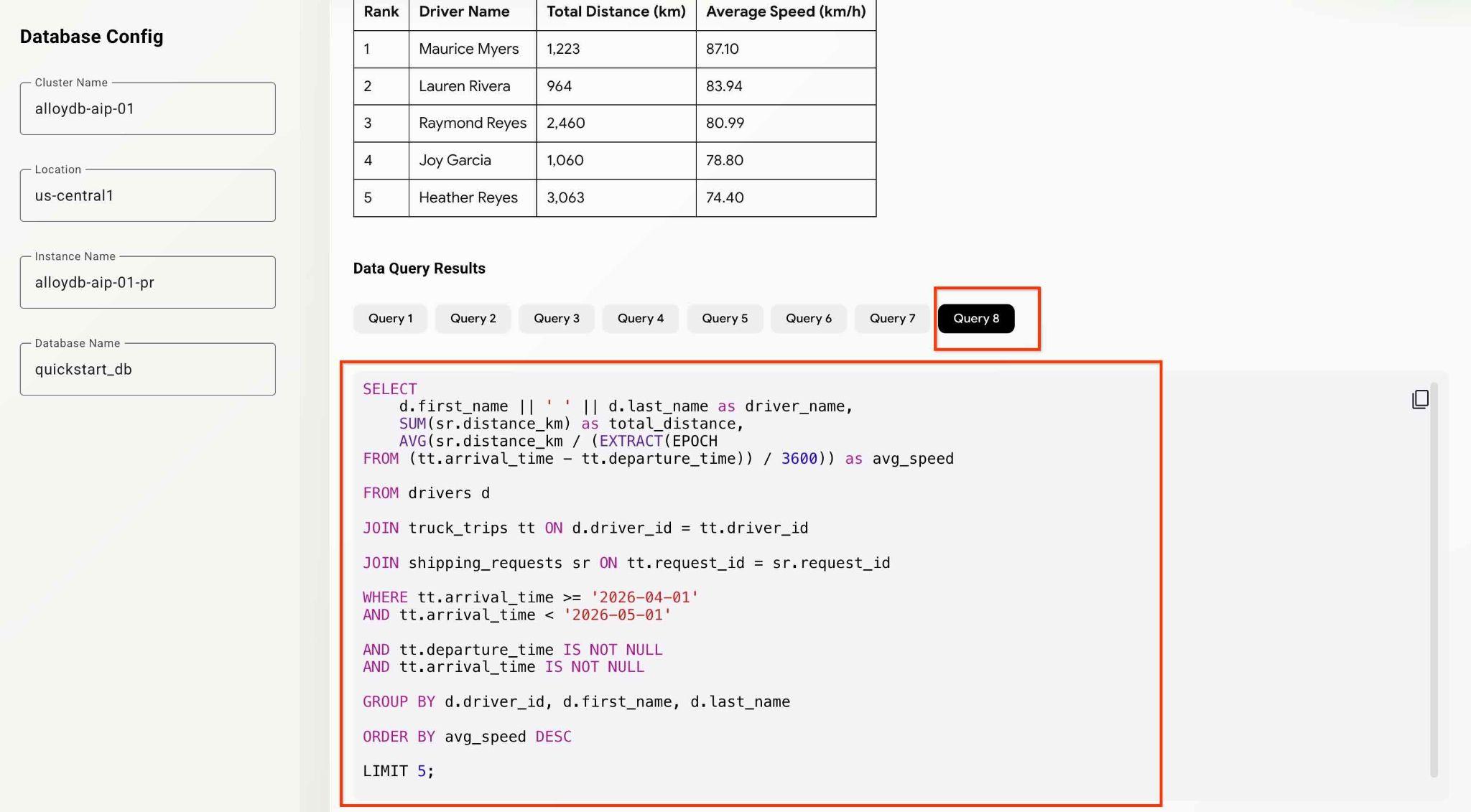
Vous pouvez tester les capacités des agents et de l'application en posant différentes questions analytiques.
Jusqu'à présent, vous avez pu effectuer des analyses et des découvertes de base à l'aide de l'agent avec MCP. Dans le chapitre suivant, vous allez essayer d'utiliser des fonctionnalités AlloyDB plus avancées.
10. Fonctions AlloyDB AI
Les fonctions AlloyDB AI permettent de filtrer et de classer intelligemment les données textuelles et multimodales (notamment les images), et d'exploiter la puissance de Gemini dans vos requêtes. Plus précisément, les fonctions AlloyDB AI AI.IF et AI.RANK peuvent apparaître dans des instructions SQL avec des opérateurs SQL conventionnels (filtres, jointures, agrégation, etc.).
Avant d'utiliser les fonctions d'IA, nous allons examiner une recherche et des agrégations à l'aide des méthodes "classiques". Essayez le prompt suivant.
Can you analyze the activity for the last 5 months and evaluate drivers for the most positive customer feedbacks. Give me top 5 drivers listing names, distance and years of experience for each driver.
Il est capable de trouver la colonne "Note" dans le tableau contenant les commentaires des clients et de l'utiliser pour identifier les chauffeurs ayant la meilleure note. Il a ensuite utilisé ces informations pour en savoir plus sur les conducteurs.
SELECT
d.first_name || ' ' || d.last_name as driver_name,
SUM(sr.distance_km) as total_distance,
d.experience_years,
COUNT(cf.feedback_id) as positive_feedback_count
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
WHERE tt.arrival_time >= '2025-12-01'
AND tt.arrival_time < '2026-05-01'
AND cf.rating >= 4
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY positive_feedback_count DESC, total_distance DESC
LIMIT 5;
Toutefois, la note peut techniquement inclure ou non tous les paramètres que nous souhaitons évaluer. Pour ce faire, nous pouvons utiliser les fonctions AlloyDB/AI.
Opérateurs AI.RANK
La fonction ai.rank() évalue la pertinence d'un document par rapport à une requête donnée. Elle peut être utilisée pour classer ou reclasser les résultats de la requête. Pour en savoir plus sur les opérateurs, consultez la documentation.
Modifiez la demande et demandez explicitement d'utiliser AI.RANK lors de l'analyse pour évaluer les facteurs en fonction de leurs performances et de leur professionnalisme.
Can you find the top 5 fastest drivers in the last month and rank them by the feedback using the AI.RANK function? Give me top drivers names, distance, years of experience and rank for each driver.
La commande peut prendre un peu plus de temps, car l'agent doit trouver comment utiliser la fonction AI.RANK, obtenir les données et appliquer AI.RANK pour trier les informations en conséquence. À la fin, vous devriez obtenir la liste des pilotes classés par le modèle et la liste des requêtes exécutées.
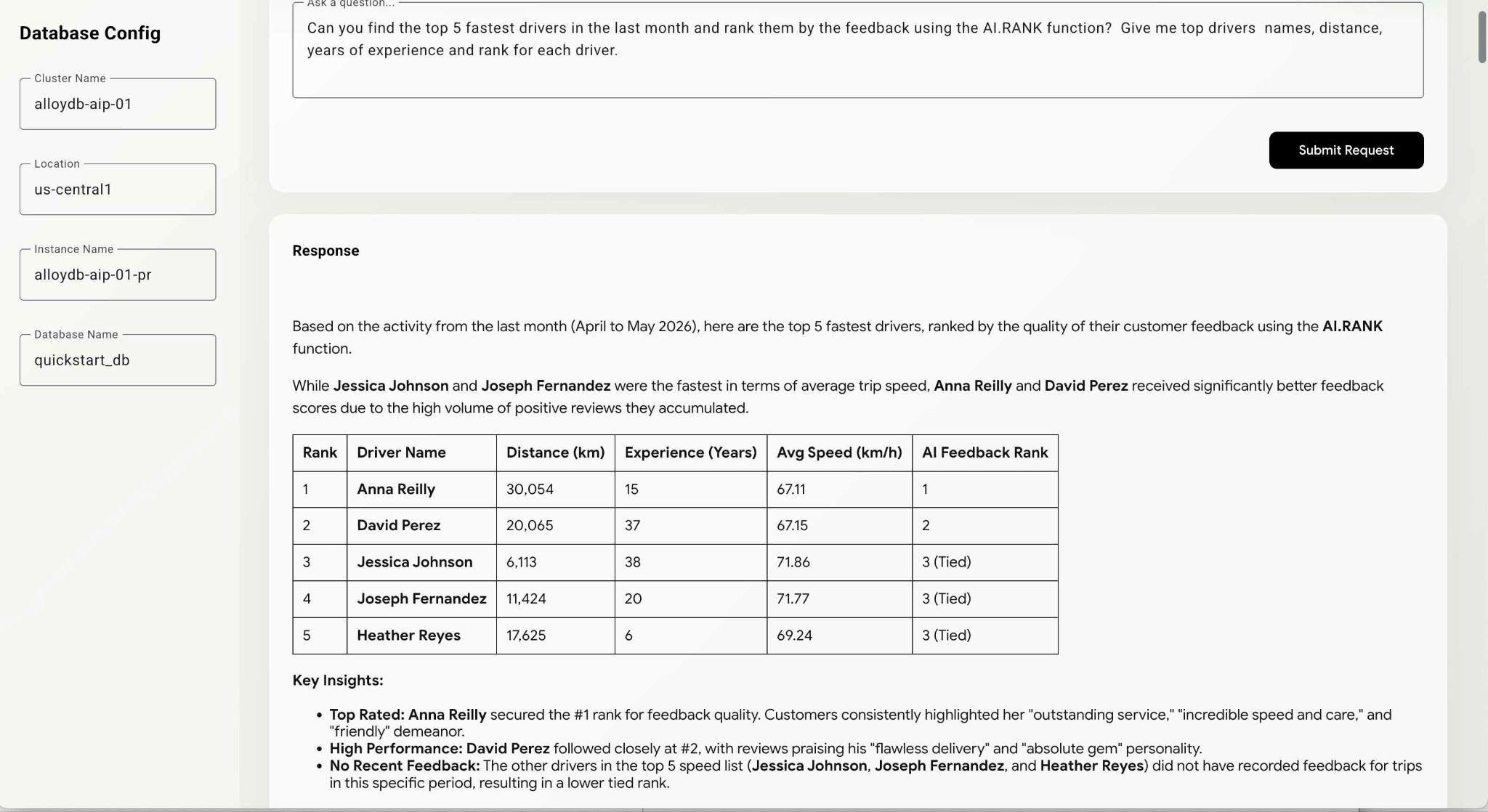
L'exécution de cette requête peut prendre un certain temps en fonction du chemin choisi par le modèle. Vous pouvez voir la requête exacte exécutée pour obtenir des informations sur les pilotes dans la fenêtre de débogage.
WITH fastest_drivers AS (
SELECT
d.driver_id,
d.first_name || ' ' || d.last_name as driver_name,
d.experience_years,
SUM(sr.distance_km) as total_distance,
AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) as avg_speed,
COALESCE(STRING_AGG(cf.feedback_text, ' | '), 'No feedback') as feedbacks,
ROW_NUMBER() OVER (
ORDER BY AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) DESC) - 1 as row_idx
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
LEFT
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
WHERE tt.arrival_time >= '2026-04-04'
AND tt.arrival_time IS NOT NULL
AND tt.departure_time IS NOT NULL
AND tt.arrival_time > tt.departure_time
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY avg_speed DESC
LIMIT 5
)
SELECT
f.driver_name,
f.total_distance,
f.experience_years,
f.avg_speed,
f.feedbacks,
(SELECT r.score
FROM ai.rank(
'semantic-ranker-fast-004',
'excellent customer service, professional, friendly, fast,
and reliable delivery reviews',
ARRAY[f.feedbacks],
1
) r
LIMIT 1) as feedback_score
FROM fastest_drivers f
ORDER BY feedback_score DESC;
Vous pouvez continuer à tester l'application et à examiner les requêtes pour voir comment l'agent arrive aux résultats finaux.
Cet atelier est maintenant terminé. J'espère que vous avez pu parcourir tous les exemples et apprendre à utiliser le service MCP Google Cloud pour AlloyDB. Pour que votre MCP fonctionne pour les entreprises, il est judicieux de le combiner avec les fonctionnalités NL2SQL d'AlloyDB décrites dans la documentation AlloyDB. Vous pouvez l'essayer à l'aide de l'atelier de programmation sur la génération d'instructions SQL pour AlloyDB.
11. Nettoyer l'environnement
Pour éviter des frais inattendus, il est recommandé de nettoyer les ressources temporaires. Le moyen le plus fiable consiste à supprimer le projet dans lequel vous avez testé le workflow. Toutefois, vous pouvez également vous limiter en supprimant des ressources individuelles, telles qu'AlloyDB.
Détruisez les instances et le cluster AlloyDB une fois l'atelier terminé.
Supprimer le cluster AlloyDB et toutes les instances
Si vous avez utilisé la version d'essai d'AlloyDB. Ne supprimez pas le cluster d'essai si vous prévoyez de tester d'autres ateliers et ressources à l'aide de ce cluster. Vous ne pourrez pas créer d'autre cluster d'essai dans le même projet.
Le cluster est détruit avec l'option "force", qui supprime également toutes les instances appartenant au cluster.
Dans Cloud Shell, définissez le projet et les variables d'environnement si vous avez été déconnecté et que tous les paramètres précédents sont perdus :
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Supprimez le cluster :
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Supprimer les sauvegardes AlloyDB
Supprimez toutes les sauvegardes AlloyDB du cluster :
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation.
Points abordés
- Créer un cluster AlloyDB et importer des exemples de données
- Activer l'API d'accès aux données AlloyDB
- Activer Google Cloud MCP pour AlloyDB NL
- Ajouter Google Cloud MCP pour AlloyDB à votre agent ADK
- Utiliser Google Cloud MCP pour AlloyDB dans une application
- Utiliser des agents avec AlloyDBMCP pour l'analyse
13. Enquête
Résultat :