
1. परिचय
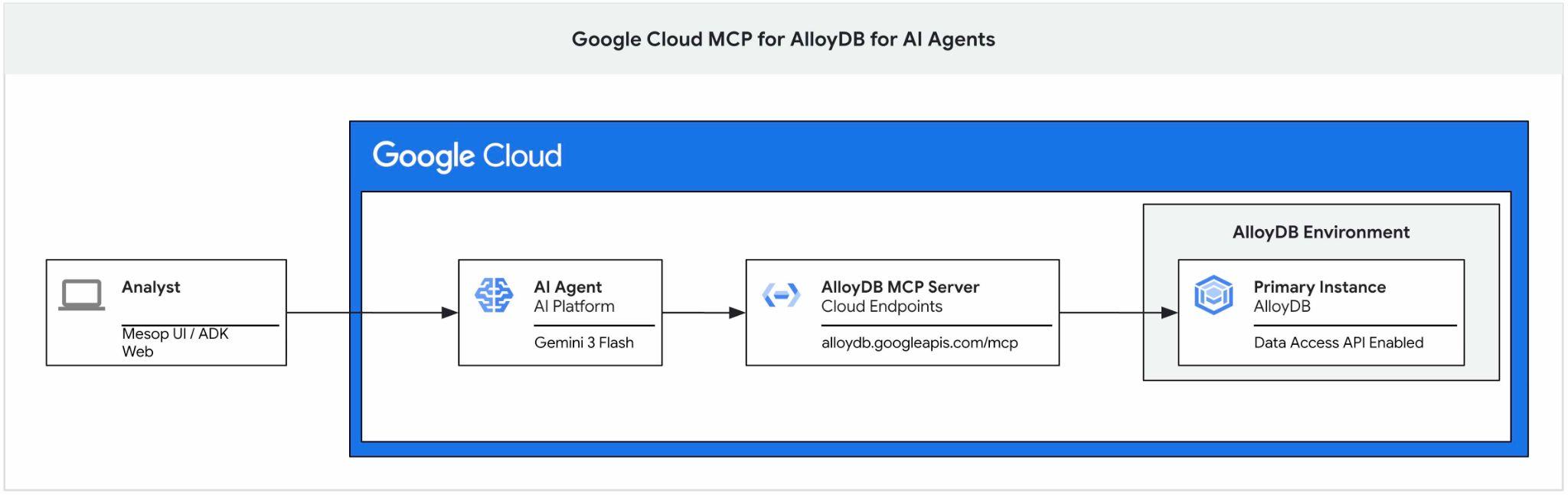
इस कोडलैब में, AlloyDB के लिए Google Cloud MCP सर्वर का इस्तेमाल शुरू करने के बारे में जानकारी दी गई है. साथ ही, इसे एआई एजेंट के टूलसेट के हिस्से के तौर पर चालू करने और ऐप्लिकेशन के हिस्से के तौर पर इस्तेमाल करने का तरीका बताया गया है.
ज़रूरी शर्तें
- Google Cloud और Console की बुनियादी जानकारी
- कमांड लाइन इंटरफ़ेस और Cloud Shell में बुनियादी कौशल
आपको क्या सीखने को मिलेगा
- AlloyDB क्लस्टर बनाने और सैंपल डेटा इंपोर्ट करने का तरीका
- AlloyDB Data access API को चालू करने का तरीका
- AlloyDB NL के लिए, Google Cloud MCP को चालू करने का तरीका
- अपने ADK एजेंट में, AlloyDB के लिए Google Cloud MCP को कैसे जोड़ें
- किसी ऐप्लिकेशन में, AlloyDB के लिए Google Cloud MCP का इस्तेमाल कैसे करें
- Analytics के लिए AlloyDBMCP के साथ एजेंट इस्तेमाल करने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- Google Cloud Console और Cloud Shell के साथ काम करने वाला वेब ब्राउज़र, जैसे कि Chrome
2. सेटअप और ज़रूरी शर्तें
प्रोजेक्ट सेटअप करना
- Google Cloud Console में साइन इन करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
- कोई नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. Google Cloud Console में नया प्रोजेक्ट बनाने के लिए, हेडर में मौजूद 'कोई प्रोजेक्ट चुनें' बटन पर क्लिक करें. इससे एक पॉप-अप विंडो खुलेगी.

'कोई प्रोजेक्ट चुनें' विंडो में, 'नया प्रोजेक्ट' बटन दबाएं. इससे नए प्रोजेक्ट के लिए एक डायलॉग बॉक्स खुलेगा.
डायलॉग बॉक्स में, प्रोजेक्ट का पसंदीदा नाम डालें और जगह चुनें.
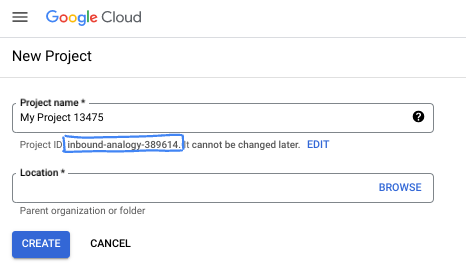
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. प्रोजेक्ट के नाम का इस्तेमाल Google API नहीं करते हैं. इसे कभी भी बदला जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Google Cloud Console, यूनीक आईडी अपने-आप जनरेट करता है. हालांकि, इसे अपनी पसंद के मुताबिक बनाया जा सकता है. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा आईडी जनरेट करें. इसके अलावा, अपने हिसाब से कोई आईडी डालें और देखें कि वह उपलब्ध है या नहीं. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी का रेफ़रंस देना होगा. इसे आम तौर पर, PROJECT_ID प्लेसहोल्डर से पहचाना जाता है.
- आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
बिलिंग चालू करना
निजी बिलिंग खाता सेट अप करना
अगर आपने Google Cloud क्रेडिट का इस्तेमाल करके बिलिंग सेट अप की है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करने के लिए, Cloud Console में बिलिंग की सुविधा चालू करने के लिए यहां जाएं.
ध्यान दें:
- इस लैब को पूरा करने में, क्लाउड संसाधनों पर 3 डॉलर से कम खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करके संसाधनों को मिटाया जा सकता है.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त क्रेडिट का इस्तेमाल कर सकते हैं.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसके अलावा, G और फिर S दबाएं. इस क्रम से, Cloud Shell चालू हो जाएगा. इसके लिए, आपको Google Cloud Console में होना चाहिए या इस लिंक का इस्तेमाल करना होगा.
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद होते हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. शुरू करने से पहले
एपीआई चालू करना
AlloyDB, Compute Engine, नेटवर्किंग सेवाएं, और Vertex AI का इस्तेमाल करने के लिए, आपको अपने Google Cloud प्रोजेक्ट में इनसे जुड़े एपीआई चालू करने होंगे.
Cloud Shell टर्मिनल में, पक्का करें कि आपका प्रोजेक्ट आईडी सेट अप हो:
gcloud config get-value project
इससे आपको अपना Google प्रोजेक्ट आईडी दिखेगा.
PROJECT_ID एनवायरमेंट वैरिएबल सेट करें:
PROJECT_ID=$(gcloud config get-value project)
सभी ज़रूरी सेवाएं चालू करें:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
अनुमानित आउटपुट
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB डिप्लॉय करना
AlloyDB क्लस्टर और प्राइमरी इंस्टेंस बनाएं. इसे डिप्लॉय करने के लिए, तैयार की गई स्क्रिप्ट का इस्तेमाल किया जा सकता है. इससे सभी ज़रूरी संसाधन डिप्लॉय हो जाएंगे. इसके अलावा, दस्तावेज़ में दिए गए तरीके का पालन करके, इसे चरण-दर-चरण खुद भी डिप्लॉय किया जा सकता है.
ऑटोमेटेड स्क्रिप्ट का इस्तेमाल करके AlloyDB को डिप्लॉय करना
इस तरीके में, AlloyDB क्लस्टर को डिप्लॉय करने के लिए, अपने-आप काम करने वाली स्क्रिप्ट का इस्तेमाल किया जा रहा है. साथ ही, डिप्लॉय किए गए संसाधनों का इस्तेमाल शुरू करने के लिए ज़रूरी जानकारी दी जा रही है.
डिपार्टमेंट स्क्रिप्ट को रिपॉज़िटरी से क्लोन करने के लिए, Cloud Shell टर्मिनल में कमांड चलाएं.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-ai-mcp"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
डिप्लॉयमेंट स्क्रिप्ट चलाएं.
./deploy_alloydb.sh
स्क्रिप्ट को चलने में कुछ समय लगेगा. आम तौर पर, इसमें 5 से 7 मिनट लगते हैं. इसके बाद, आउटपुट के तौर पर इसे आपके डिप्लॉय किए गए AlloyDB क्लस्टर के बारे में जानकारी देनी चाहिए. कृपया ध्यान दें कि आपका पासवर्ड अलग होगा. इसे कहीं लिख लें, ताकि आने वाले समय में इसका इस्तेमाल किया जा सके.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
साथ ही, वेब कंसोल में नया क्लस्टर और प्राइमरी इंस्टेंस भी देखा जा सकता है
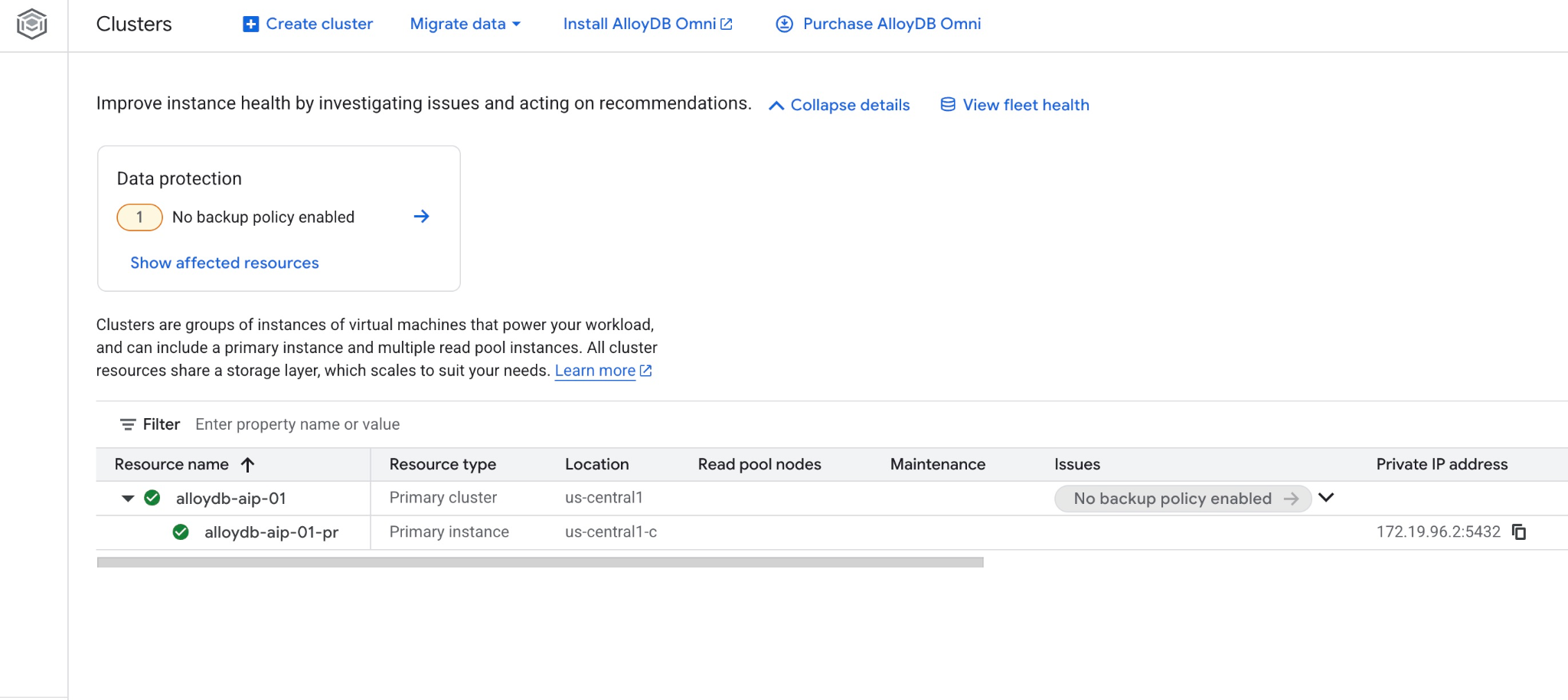
5. डेटाबेस तैयार करना
एआई फ़ंक्शन और ऑपरेटर इस्तेमाल करने के लिए, आपको Vertex AI इंटिग्रेशन चालू करना होगा. साथ ही, डेटा ऐक्सेस एपीआई चालू करना होगा और सैंपल डेटासेट के लिए डेटाबेस बनाना होगा.
AlloyDB को ज़रूरी अनुमतियां देना
AlloyDB के सर्विस एजेंट को Vertex AI की अनुमतियां दें.
सबसे ऊपर मौजूद "+" साइन का इस्तेमाल करके, Cloud Shell का कोई दूसरा टैब खोलें.
नए क्लाउड शेल टैब में यह कमांड चलाएं:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/discoveryengine.viewer"
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... < redacted > etag: BwYIEbe_Z3U= version: 1
Data Access API चालू करना
execute_sql जैसे एमसीपी टूल का इस्तेमाल करने के लिए, आपको AlloyDB क्लस्टर पर Data Access API चालू करना होगा.
उसी टर्मिनल टैब में एक्ज़ीक्यूट करें.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
इंस्टेंस के फ़्लैग अपडेट करना
AlloyDB में एआई के ऐडवांस फ़ंक्शन इस्तेमाल करने के लिए, हमें कुछ डेटाबेस फ़्लैग चालू करने होंगे. डेटा ऐक्सेस करने वाले एपीआई को चालू करने के बाद, इंस्टेंस को अगले बदलावों के लिए तैयार होने में कुछ मिनट लग सकते हैं. कृपया कंसोल में जाकर, इंस्टेंस की स्थिति देखें. इससे यह पक्का किया जा सकेगा कि उस पर हरे रंग का सही का निशान लगा हो.
उसी टर्मिनल टैब में एक्ज़ीक्यूट करें.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags=google_ml_integration.enable_model_support=on,google_ml_integration.enable_ai_query_engine=on,google_ml_integration.enable_preview_ai_functions=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
एमसीपी चालू करना
अगले चरण में, अपने प्रोजेक्ट में AlloyDB के लिए Google Cloud MCP सर्वर चालू करें. एमसीपी डिफ़ॉल्ट रूप से चालू नहीं होता है. यह सुरक्षा की कई लेयर में से एक है. इसमें IAM की पुष्टि और अनुमति, डेटा ऐक्सेस एपीआई, और आपके क्लस्टर में मौजूद भूमिकाएं शामिल हैं.
उसी टर्मिनल टैब में एक्ज़ीक्यूट करें.
PROJECT_ID=$(gcloud config get-value project)
gcloud beta services mcp enable alloydb.googleapis.com \
--project=$PROJECT_ID
टैब में "exit" कमांड डालकर टैब बंद करें:
exit
AlloyDB Studio से कनेक्ट करना
यहां दिए गए अध्यायों में, डेटाबेस से कनेक्ट करने के लिए ज़रूरी सभी SQL कमांड, AlloyDB Studio में एक्ज़ीक्यूट की जा सकती हैं. T
AlloyDB for Postgres में क्लस्टर पेज पर जाएं.
प्राइमरी इंस्टेंस पर क्लिक करके, अपने AlloyDB क्लस्टर के लिए वेब कंसोल इंटरफ़ेस खोलें.
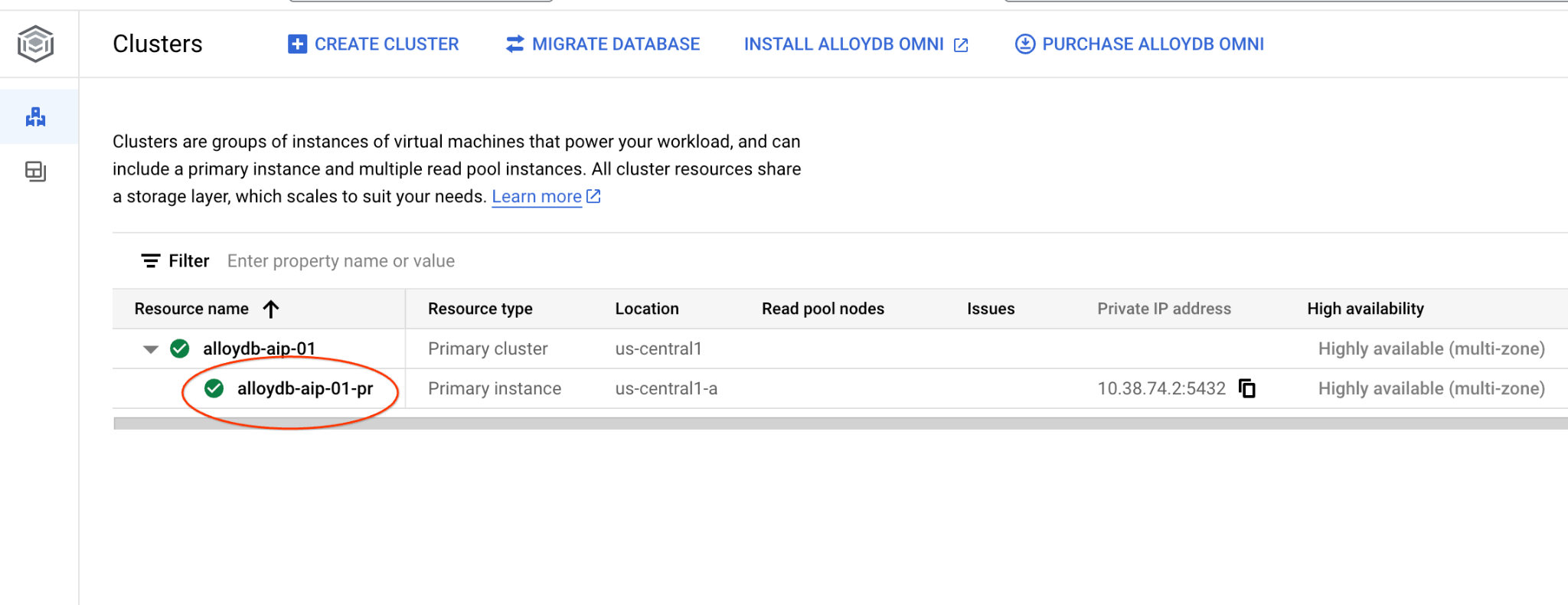
इसके बाद, बाईं ओर मौजूद AlloyDB Studio पर क्लिक करें:
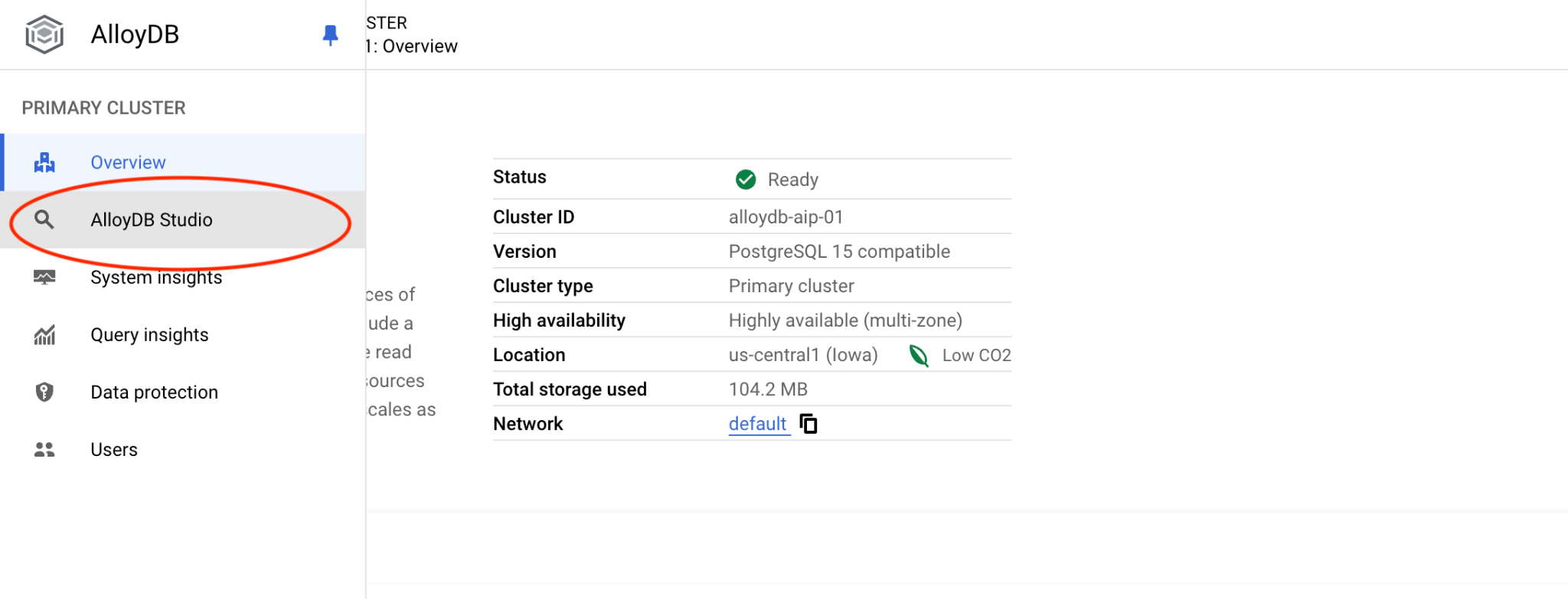
postgres डेटाबेस और postgres उपयोगकर्ता चुनें. साथ ही, क्लस्टर बनाते समय नोट किया गया पासवर्ड डालें. इसके बाद, "Authenticate" बटन पर क्लिक करें.
अगर पासवर्ड काम नहीं करता है या आपने पासवर्ड नोट नहीं किया है, तो पासवर्ड बदला जा सकता है. ऐसा करने का तरीका जानने के लिए, दस्तावेज़ देखें.
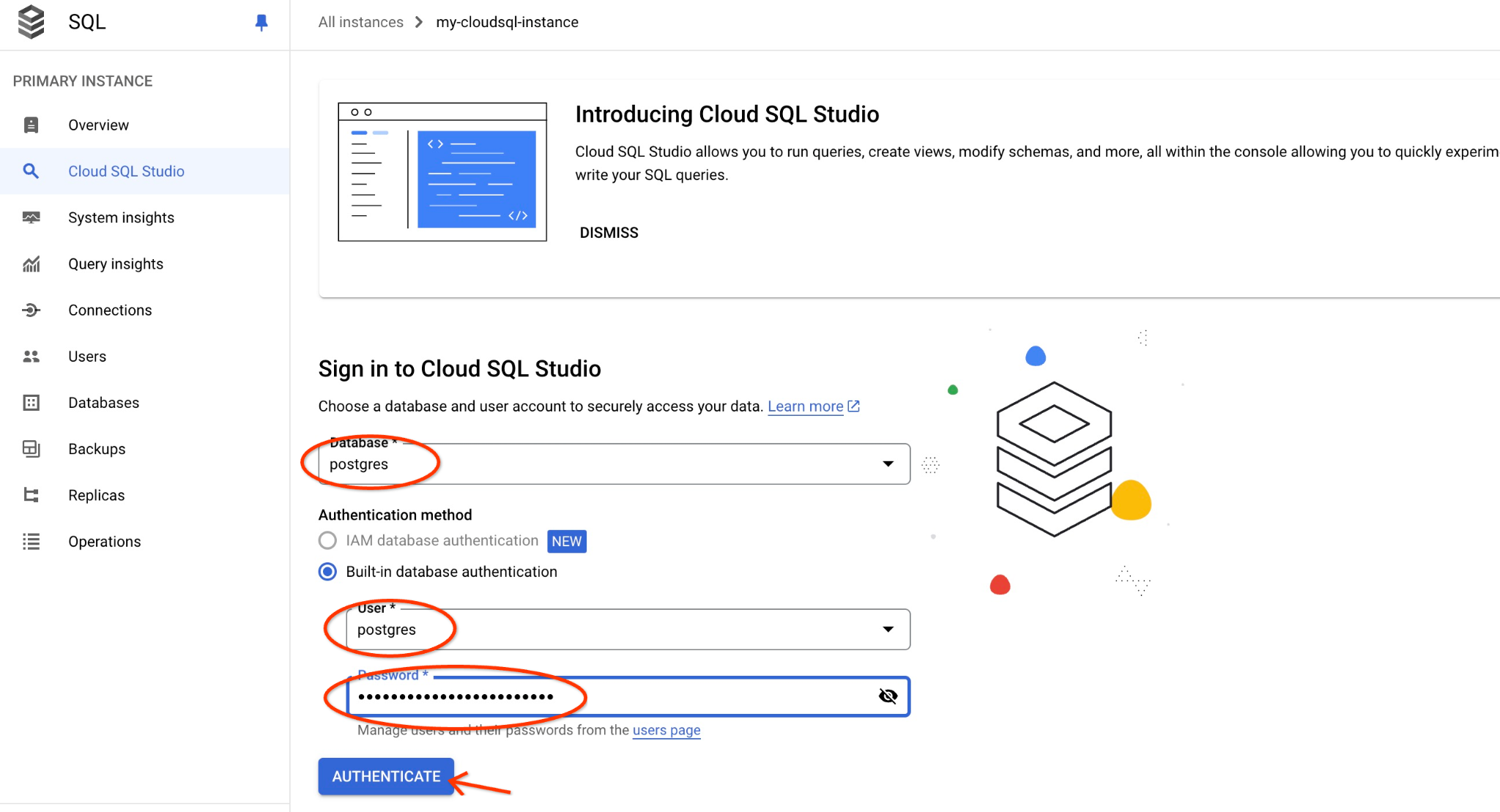
इससे AlloyDB Studio का इंटरफ़ेस खुल जाएगा. डेटाबेस में कमांड चलाने के लिए, दाईं ओर मौजूद "Untitled Query" टैब पर क्लिक करें.
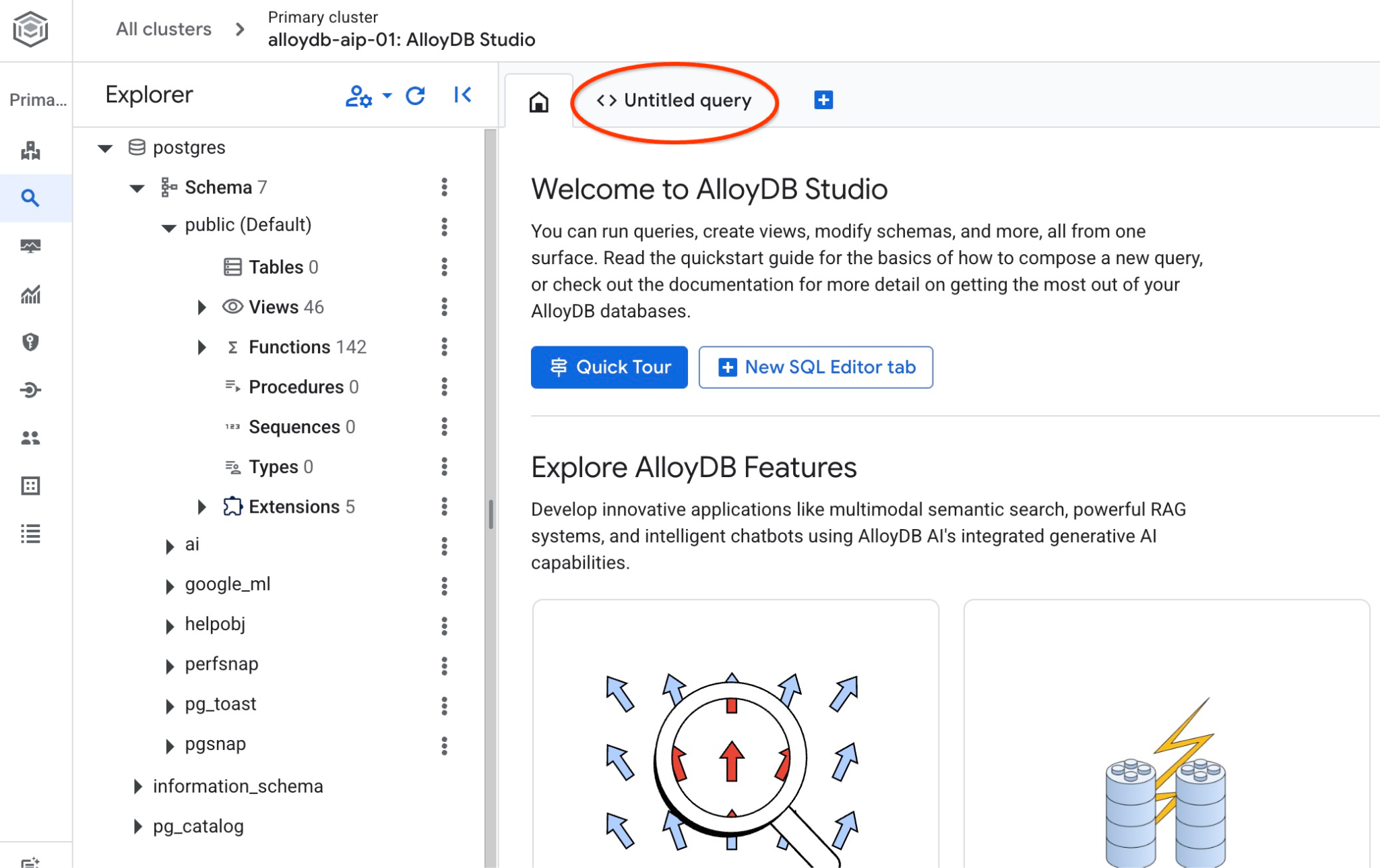
इससे एक इंटरफ़ेस खुलता है, जहां एसक्यूएल कमांड चलाई जा सकती हैं
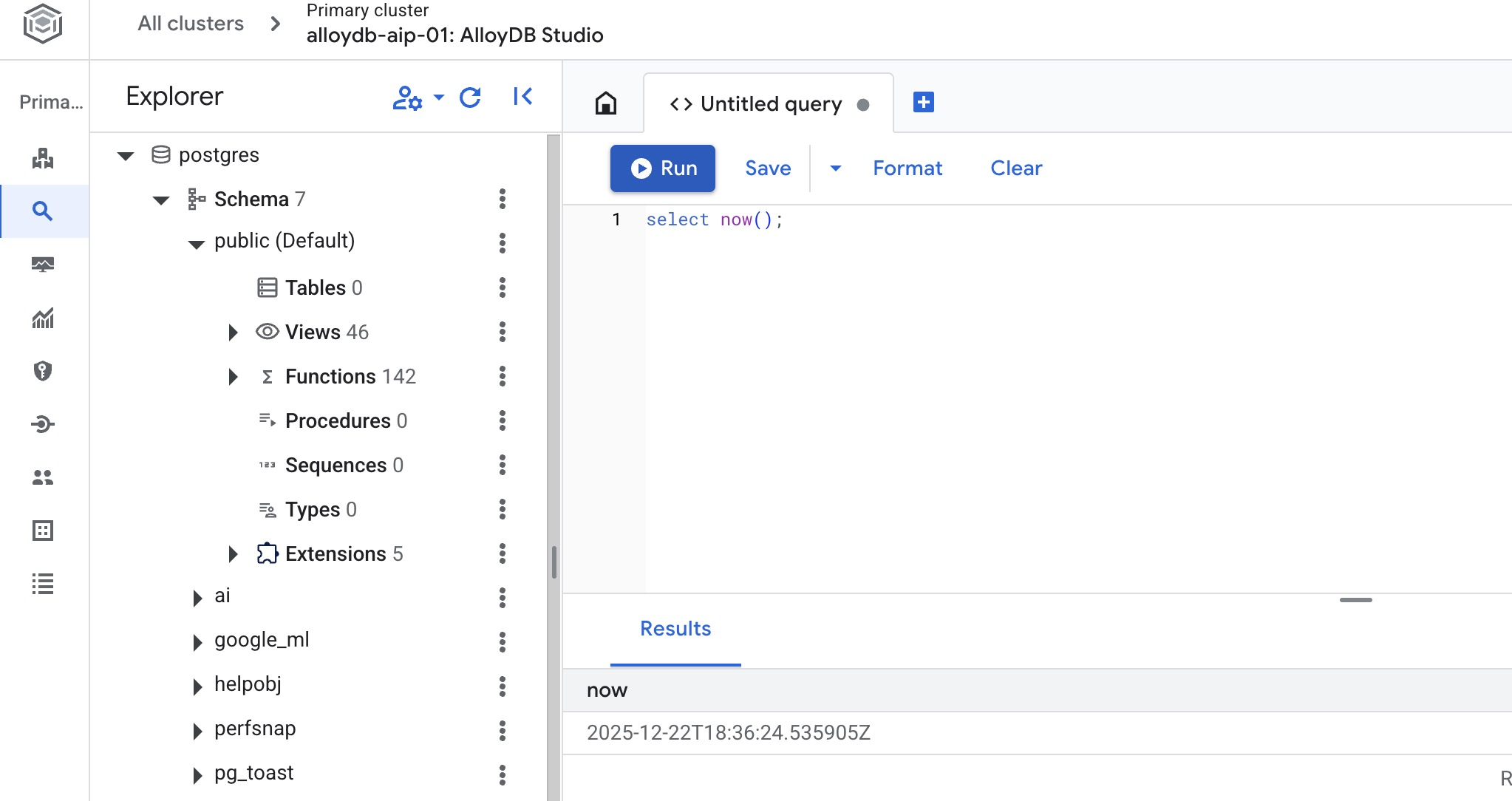
डेटाबेस बनाएं
डेटाबेस बनाने के बारे में क्विकस्टार्ट गाइड.
AlloyDB Studio Editor में, यह कमांड चलाएं.
डेटाबेस बनाएं:
CREATE DATABASE quickstart_db
अनुमानित आउटपुट:
Statement executed successfully
quickstart_db से कनेक्ट करें
देखें कि डेटाबेस, उससे कनेक्ट करके बनाया गया हो. उपयोगकर्ता/डेटाबेस बदलने के बटन का इस्तेमाल करके, स्टूडियो से फिर से कनेक्ट करें.
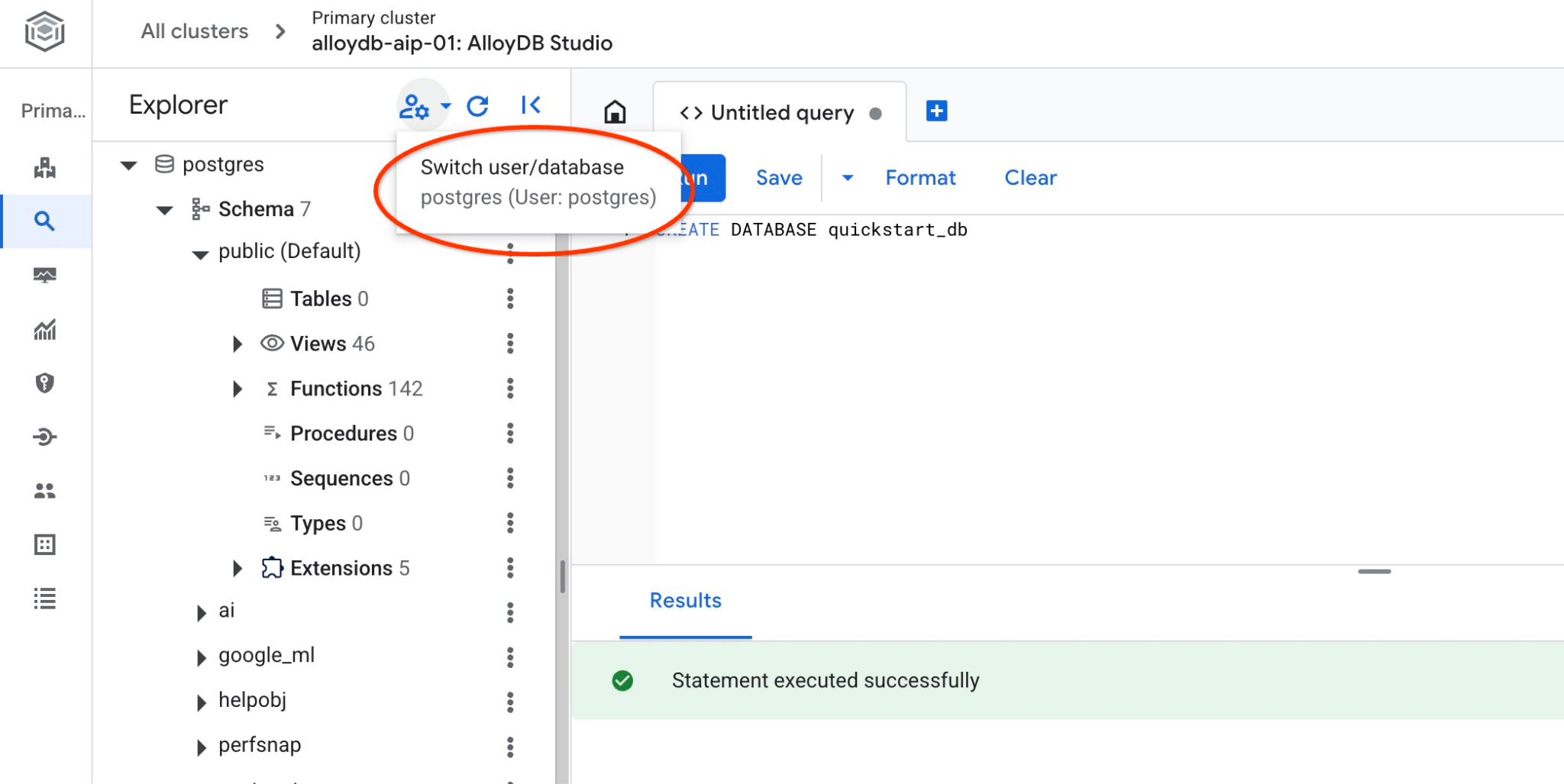
ड्रॉपडाउन सूची से नई quickstart_db डेटाबेस चुनें. साथ ही, पहले की तरह ही उपयोगकर्ता नाम और पासवर्ड का इस्तेमाल करें.
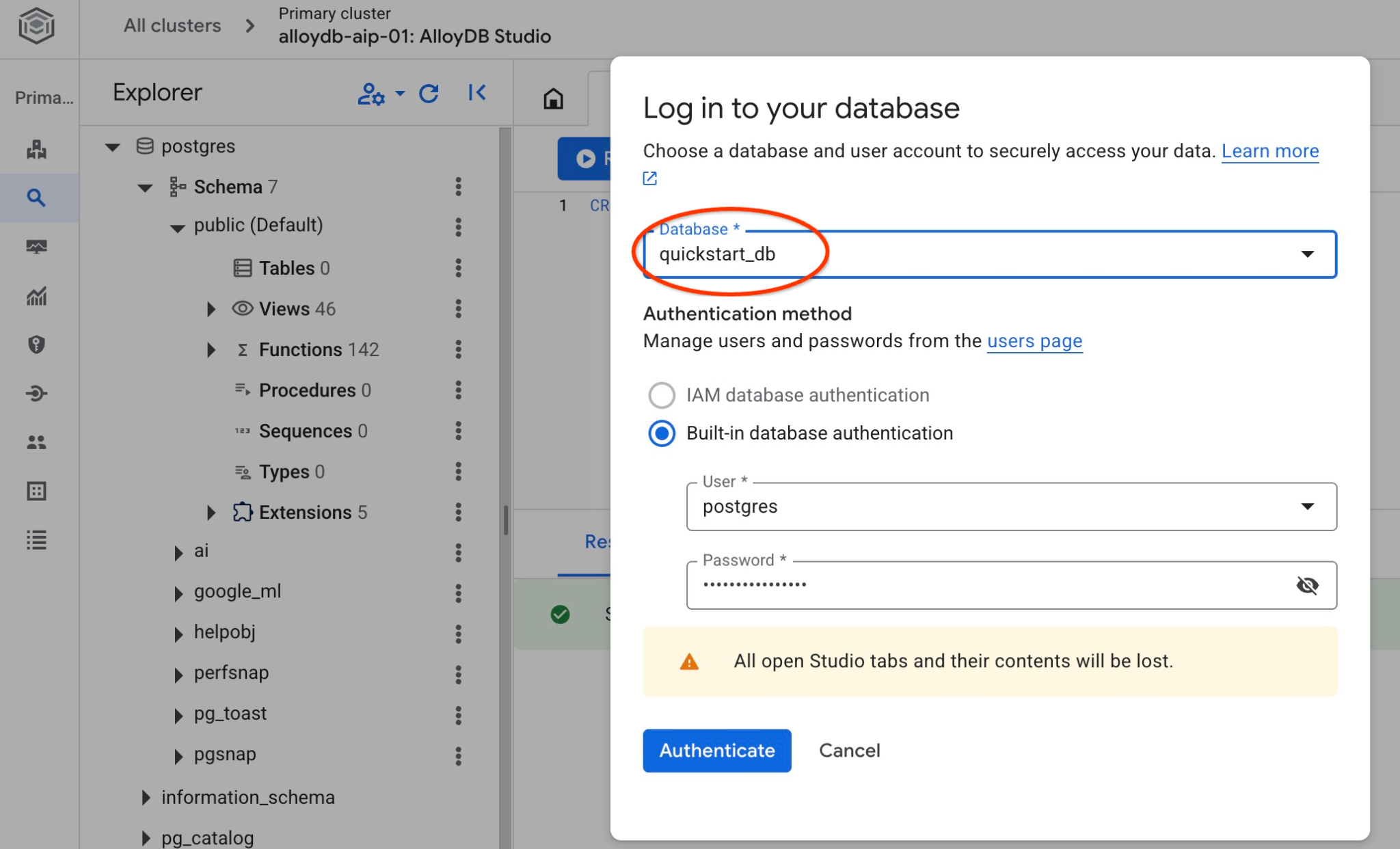
इससे एक नया कनेक्शन खुलेगा. यहां quickstart_db डेटाबेस के ऑब्जेक्ट के साथ काम किया जा सकता है. यहां इंपोर्ट किए गए स्कीमा और डेटा की जांच की जा सकती है.
6. सैंपल डेटा
अब आपको डेटाबेस में ऑब्जेक्ट बनाने और डेटा लोड करने की ज़रूरत है. आपको काल्पनिक Cymbal Shipping कंपनी के डेटासेट का इस्तेमाल करना है. इसमें सामान, ट्रक, अनुरोधों, और ट्रक की यात्राओं के साथ-साथ काल्पनिक ड्राइवरों के बारे में काल्पनिक डेटा होता है.
स्टोरेज बकेट बनाना
आपको Google SDK (gcloud) का इस्तेमाल करके, क्लोन की गई हमारी रिपॉज़िटरी से AlloyDB डेटाबेस में डेटा इंपोर्ट करना होगा. इसके लिए, आपको एक स्टोरेज बकेट बनानी होगी और AlloyDB सेवा खाते को ऐक्सेस देना होगा. इसके अलावा, वेब कंसोल का इस्तेमाल करके भी ऐसा किया जा सकता है. इसके बारे में दस्तावेज़ में बताया गया है.
Google Cloud Shell टर्मिनल में यह कमांड चलाएं:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
डेटा लोड करें
अगला चरण, डेटा लोड करना है. हमारा एसक्यूएल डंप, क्लोन किए गए रिपॉज़िटरी फ़ोल्डर में मौजूद है. नीचे दिए गए कमांड से यह माना जाता है कि आपने AlloyDB क्लस्टर बनाते समय, पिछले चरण में रिपॉज़िटरी को क्लोन करते समय अपनी होम डायरेक्ट्री का इस्तेमाल शुरुआती पॉइंट के तौर पर किया था.
कंप्रेस किए गए SQL डंप को नए स्टोरेज बकेट में कॉपी करें:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
इसके बाद, डेटा को quickstart_db डेटाबेस में लोड करें:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
इस कमांड से, सैंपल डेटासेट को quickstart_db डेटाबेस में लोड किया जाएगा. AlloyDB Studio का इस्तेमाल करके, टेबल और रिकॉर्ड की पुष्टि की जा सकती है.
7. डेटा एजेंट का इस्तेमाल करना
हम Python के लिए Google ADK का इस्तेमाल करके बनाए गए एक सैंपल एआई एजेंट से शुरुआत करते हैं. साथ ही, हम आपको इसे AlloyDB के लिए Google Cloud MCP सर्वर के साथ काम करने के लिए कॉन्फ़िगर करने का तरीका दिखाएंगे.
एजेंट के सोर्स कोड की जांच करना
क्लोन की गई रिपॉज़िटरी में, Google Cloud Shell Editor का इस्तेमाल करके एजेंट कोड की समीक्षा करें.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/data_agent/agent.py
एजेंट में, AlloyDB के लिए Google Cloud MCP सर्वर का सेक्शन मौजूद है. हम एमसीपी_SERVER_URL, पुष्टि करने की सुविधा, प्रोजेक्ट आईडी के तौर पर एक एंडपॉइंट उपलब्ध कराते हैं. साथ ही, इसे एमसीपी टूलसेट में जोड़ने की सुविधा भी देते हैं.
# Google Cloud MCP Server for AlloyDB
MCP_SERVER_URL = "https://alloydb.googleapis.com/mcp"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
# 2. Configure MCP Toolset
# We use StreamableHTTPConnectionParams to pass the auth header
headers = {
"Authorization": f"Bearer {creds.token}",
"X-Goog-User-Project": project_id
}
connection_params = StreamableHTTPConnectionParams(
url=MCP_SERVER_URL,
headers=headers,
timeout=300.0,
sse_read_timeout=600.0
)
mcp_toolset = McpToolset(connection_params=connection_params)
साथ ही, एजेंट कोड में एमसीपी टूलसेट को एजेंट के लिए tools पैरामीटर के तौर पर शामिल किया जाता है. इसके अलावा, एजेंट प्रॉम्प्ट के लिए क्लस्टर और इंस्टेंस के नाम, क्षेत्र, और डेटाबेस को वैरिएबल के तौर पर इस्तेमाल किया जाता है.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
""",
tools=[mcp_toolset],
)
AlloyDB के लिए Google Cloud MCP सेवा में, टूल का पहले से तय किया गया सेट होता है. अगर आपको सभी उपलब्ध टूल की सूची बनानी है, तो Cloud Shell कंसोल टर्मिनल में curl कमांड का इस्तेमाल करें. इसके लिए, यहां दिया गया निर्देश इस्तेमाल करें. साथ ही, दस्तावेज़ में जाकर, AlloyDB के लिए Google Cloud MCP सर्वर का नया रेफ़रंस देखा जा सकता है.
curl -s -X POST http://alloydb.googleapis.com/mcp \
-H "Content-Type: application/json" \
-d @- <<EOF | jq -r '.result.tools[].name'
{
"id": "my_id_01",
"jsonrpc": "2.0",
"method": "tools/list"
}
EOF
एजेंट शुरू करना
अब Google ADK के वेब इंटरफ़ेस का इस्तेमाल करके, एजेंट को इंटरैक्टिव मोड में शुरू किया जा सकता है. ADK का वेब इंटरफ़ेस, एजेंट के वर्कफ़्लो की जांच करने और समस्याओं को हल करने का आसान तरीका उपलब्ध कराता है.
सबसे पहले, uv पैकेज मैनेजर का इस्तेमाल करके Python के लिए ज़रूरी सभी पैकेज इंस्टॉल करें.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv sync
सभी पैकेज इंस्टॉल हो जाने के बाद, आपको एजेंट डायरेक्ट्री में एक .env फ़ाइल जोड़नी होगी. इससे एजेंट को यह निर्देश मिलेगा कि वह एआई मॉडल के साथ सभी कम्यूनिकेशन के लिए Vertex AI का इस्तेमाल करे.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
इसके बाद, एजेंट को शुरू किया जा सकता है
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
आपको http://127.0.0.1:8000 जैसे एंडपॉइंट के साथ, इस तरह का आउटपुट दिखेगा .
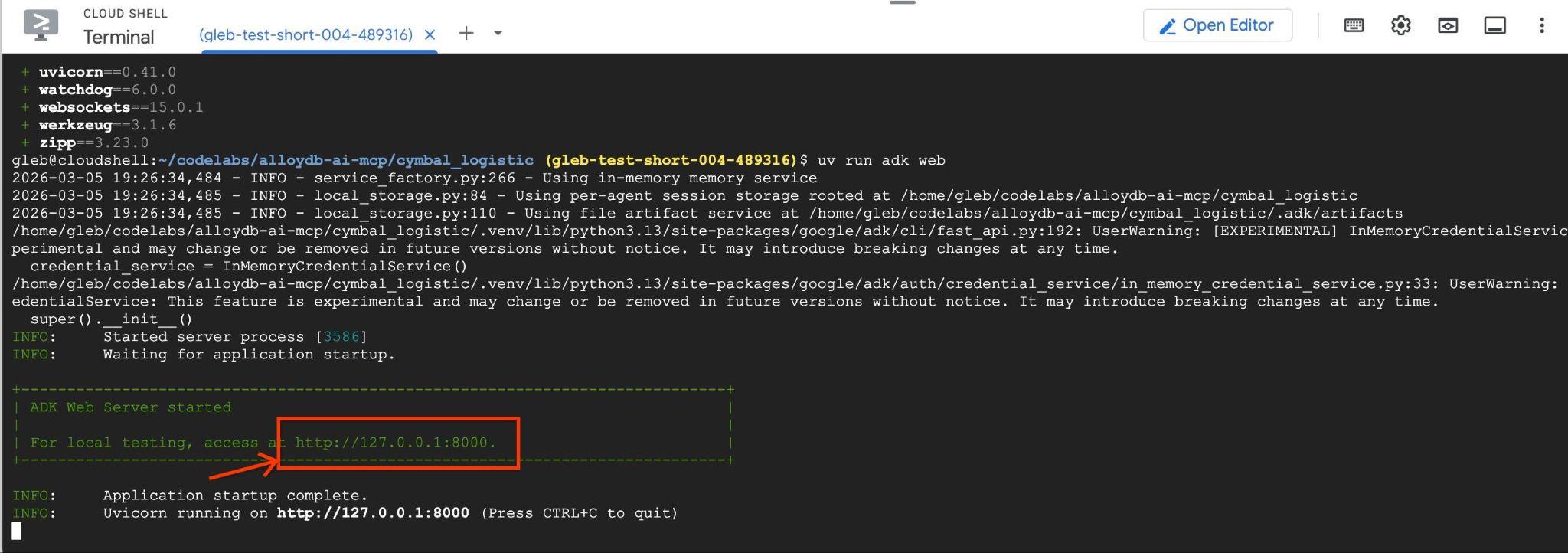
क्लाउड शेल में मौजूद उस यूआरएल पर क्लिक करें. इससे, एक अलग ब्राउज़र टैब में झलक वाली विंडो खुलेगी. इसमें, बाईं ओर मौजूद ड्रॉप-डाउन सूची से data_agent चुनें.
ADK के वेब इंटरफ़ेस में, सबसे नीचे दाईं ओर अपने सवाल पोस्ट किए जा सकते हैं. साथ ही, पूरे एक्ज़ीक्यूशन फ़्लो को देखा जा सकता है. इसमें हर चरण के लिए ट्रेस शामिल होते हैं, जो दाईं ओर दिखते हैं.
8. एजेंट के साथ AlloyDB MCP की जांच करना
एजेंट की मदद से, नैचुरल लैंग्वेज का इस्तेमाल करके फ़्री फ़ॉर्म में सवाल पूछे जा सकते हैं. एजेंट, सवालों के जवाब देने के लिए, AlloyDB के लिए Google Cloud MCP सर्वर का इस्तेमाल करेगा. सवाल, सबसे नीचे दाईं ओर पोस्ट किए जाते हैं. साथ ही, टूल के सभी कॉल के साथ जवाब सबसे ऊपर दिखेगा.
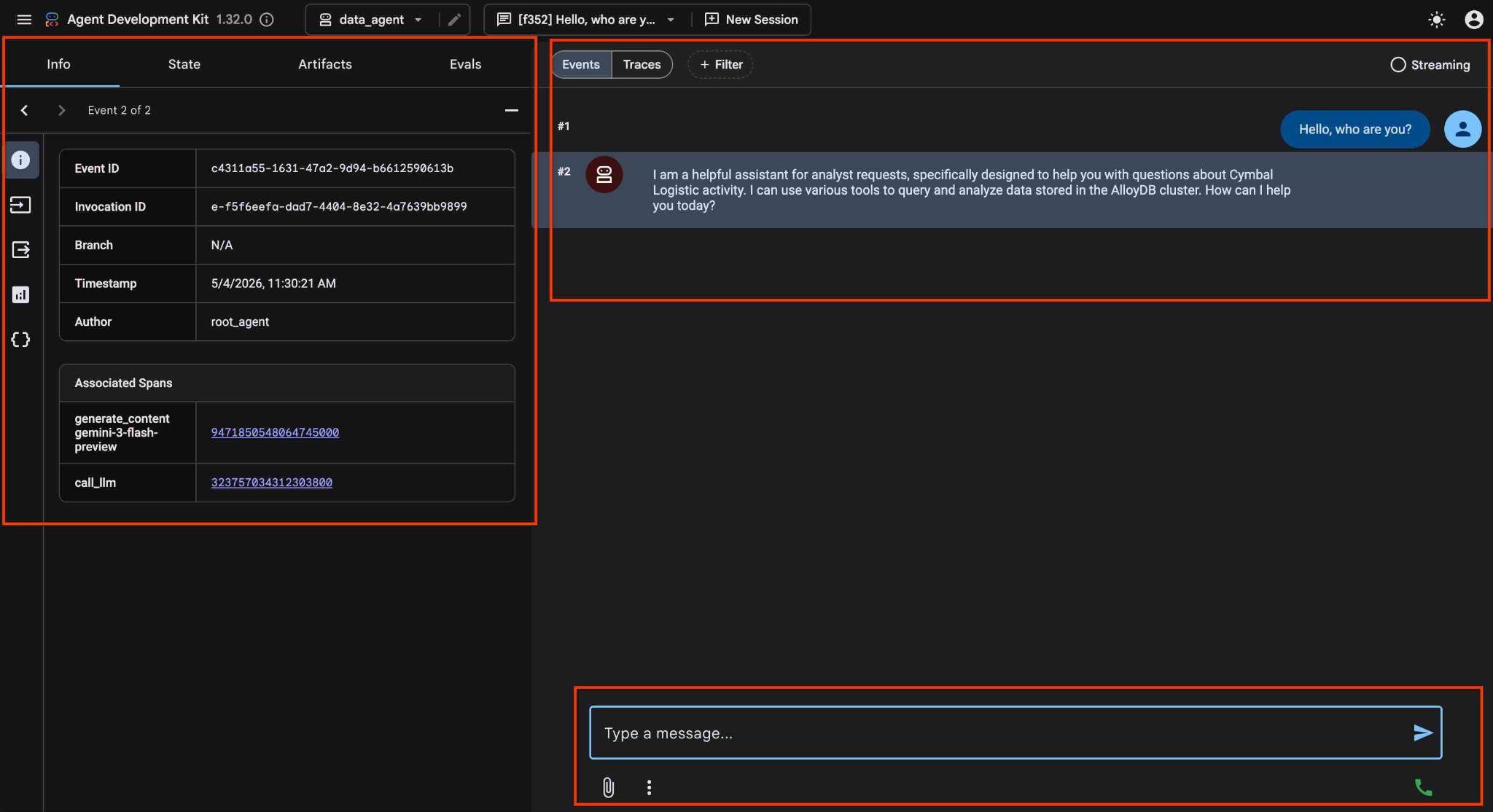
आपको शिपिंग कंपनी के ऑपरेशनल डेटा पर काम करना है. इसमें शिपिंग के अनुरोधों, ट्रकों, ड्राइवरों, और ड्राइवरों की यात्राओं के बारे में जानकारी होती है. पहला सवाल, फ़रवरी 2026 में की गई यात्राओं की संख्या के बारे में है.
सबसे नीचे दाईं ओर मौजूद इनपुट फ़ील्ड में, यह टाइप करें और Enter दबाएं.
Hello, can you tell me how many trips we've done in February this year?
सही डेटा पाने के लिए, एजेंट कई टूल कॉल को एक्ज़ीक्यूट करेगा. इससे वह स्कीमा में मौजूद सही टेबल और टेबल स्ट्रक्चर की पहचान कर पाएगा. इसके बाद, वह सही एसक्यूएल स्टेटमेंट को एक्ज़ीक्यूट करेगा.
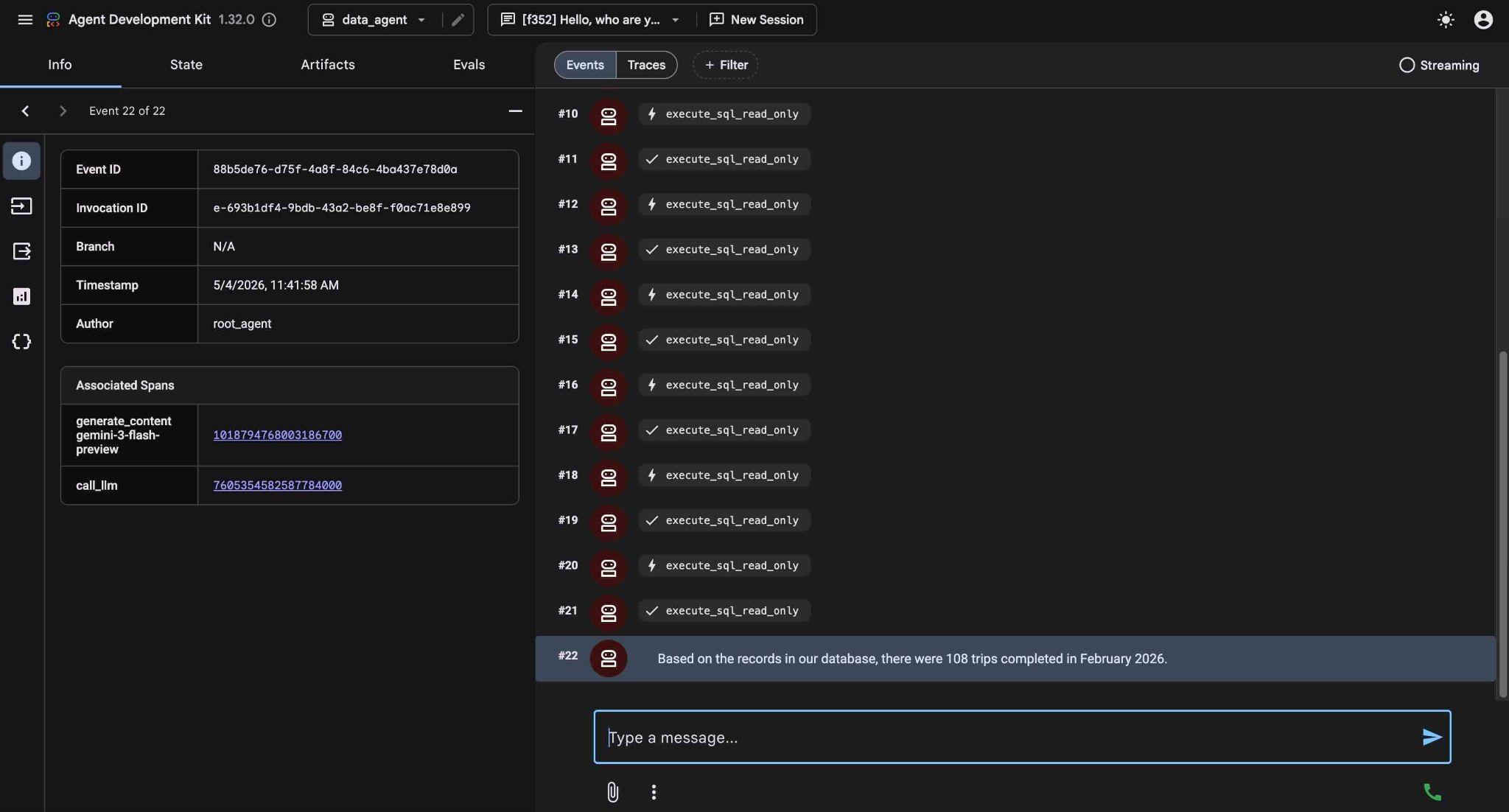
सही क्वेरी बनाने और उसे डेटाबेस पर लागू करने के बाद, यह आखिर में नतीजा देगा.
हमारे डेटाबेस में मौजूद रिकॉर्ड के मुताबिक, फ़रवरी 2026 में 108 यात्राएं पूरी की गईं.
टूल के इस्तेमाल पर क्लिक करके, यह देखा जा सकता है कि हर टूल कॉल क्या करता है. उदाहरण के लिए, हमारे नतीजे पाने के लिए यहां क्वेरी दी गई है.
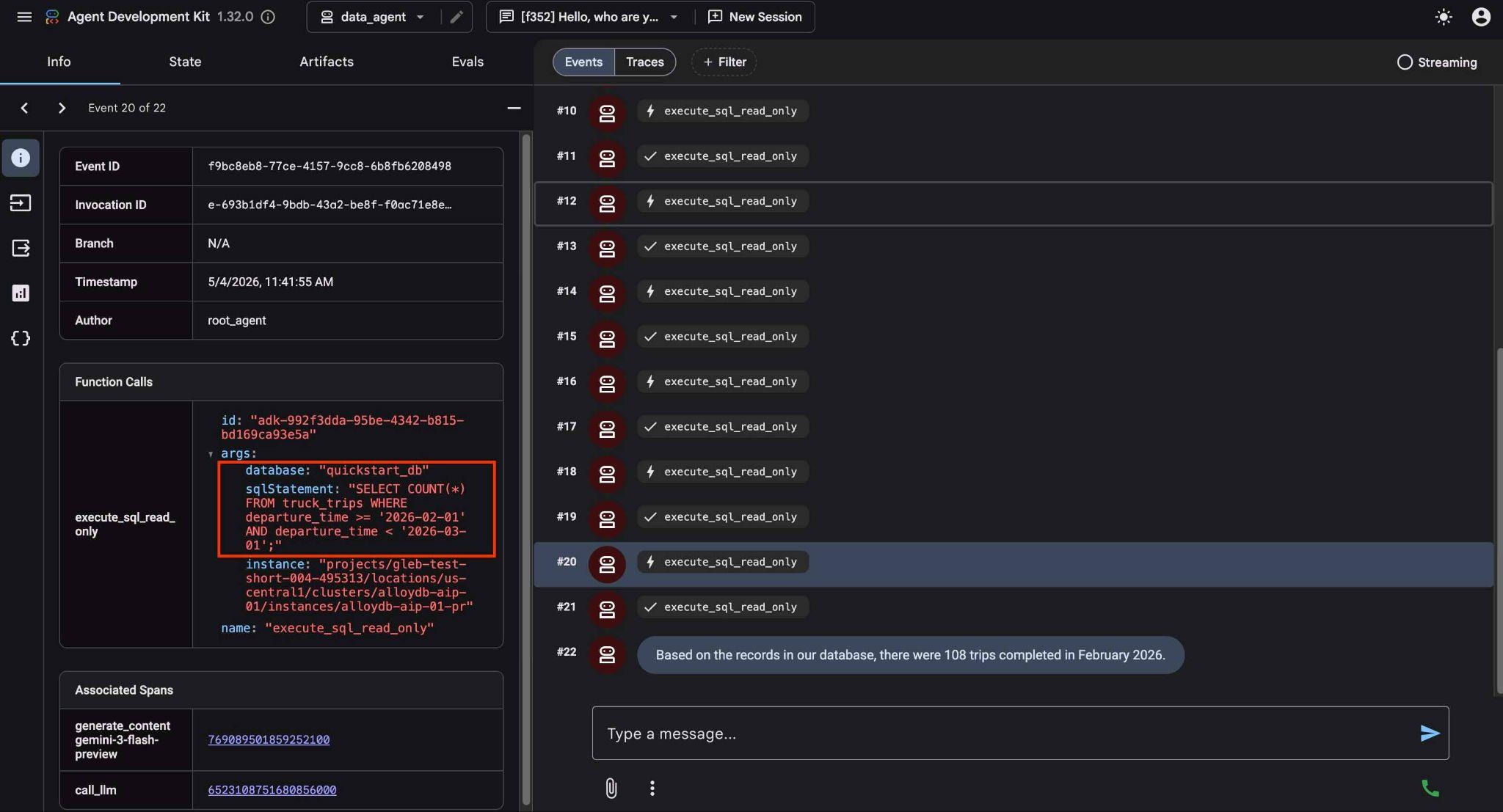
अब अनुरोध को और मुश्किल बनाओ. इसमें पिछले महीने के नतीजों से तुलना करने के लिए कहो.
How is it in comparison in numbers and mileage with the January?
यह अलग-अलग क्वेरी को एक्ज़ीक्यूट करके नतीजे दिखाता है. साथ ही, नतीजों का विश्लेषण करके, यात्राओं की संख्या और माइलेज में अंतर दिखाता है.
In comparison to January 2026, February saw a slight decrease in both the number of trips and the total mileage: January 2026: 114 trips with a total mileage of 185,597 km. February 2026: 108 trips with a total mileage of 177,893 km. This represents a decrease of 6 trips and 7,704 km in mileage for February compared to January.
ADK के वेब इंटरफ़ेस का इस्तेमाल करके, अन्य सामान्य अनुरोध आज़माएं. साथ ही, देखें कि नतीजे पाने के लिए, यह अलग-अलग क्वेरी कैसे पूरी करता है.
टर्मिनल में ctrl+c दबाकर, एजेंट को रोकें. ADK के वेब इंटरफ़ेस वाले ब्राउज़र टैब को बंद किया जा सकता है.
अब सैंपल ऐप्लिकेशन आज़माएं और देखें कि इसका इस्तेमाल डेटा विश्लेषक के लिए टूल के तौर पर कैसे किया जा सकता है.
9. नमूना एप्लिकेशन
क्लोन की गई उसी रिपॉज़िटरी में, हमारी Cymbol Logistic कंपनी के लिए एक सैंपल ऐप्लिकेशन है. यह ऐप्लिकेशन, Google के Mesop Python फ़्रेमवर्क का इस्तेमाल कर रहा है .
क्लाउड शेल एडिटर में app.py फ़ाइल खोलकर, ऐप्लिकेशन कोड का विश्लेषण किया जा सकता है.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/app.py
कोड में, हम एक फ़ंक्शन का इस्तेमाल करके, अपने डेटा एजेंट को वैरिएबल के साथ एक नया प्रॉम्प्ट पास करते हैं. ऐसा इसलिए किया जाता है, ताकि अगर हमें किसी दूसरे डेटाबेस या इंस्टेंस को कॉल करना हो, तो हम उसे इंटरफ़ेस में कॉन्फ़िगर कर सकें. यहां फ़ंक्शन की परिभाषा और प्रॉम्प्ट दिया गया है.
def run_query_sync(request_text, cluster_name, location, instance_name, database_name, project_id, session_id, summary):
local_runner = FrontendRunner()
instruction = f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
"""
...
कोड की जांच करने के बाद, हमारे ऐप्लिकेशन को शुरू करने और उसकी जांच करने के लिए, "टर्मिनल" बटन दबाएं. ऐप्लिकेशन, पोर्ट 8080 पर शुरू होगा. अगर आपको पोर्ट बदलना है, तो पोर्ट की वैल्यू बदलने वाले कमांड में बदलाव करें.
क्लाउड शेल में यह कमांड चलाएं.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv run mesop app.py --port=8080
इसके बाद, Google Cloud Shell में वेब प्रीव्यू का इस्तेमाल करें. इसके लिए, http://localhost:8080 पर क्लिक करें
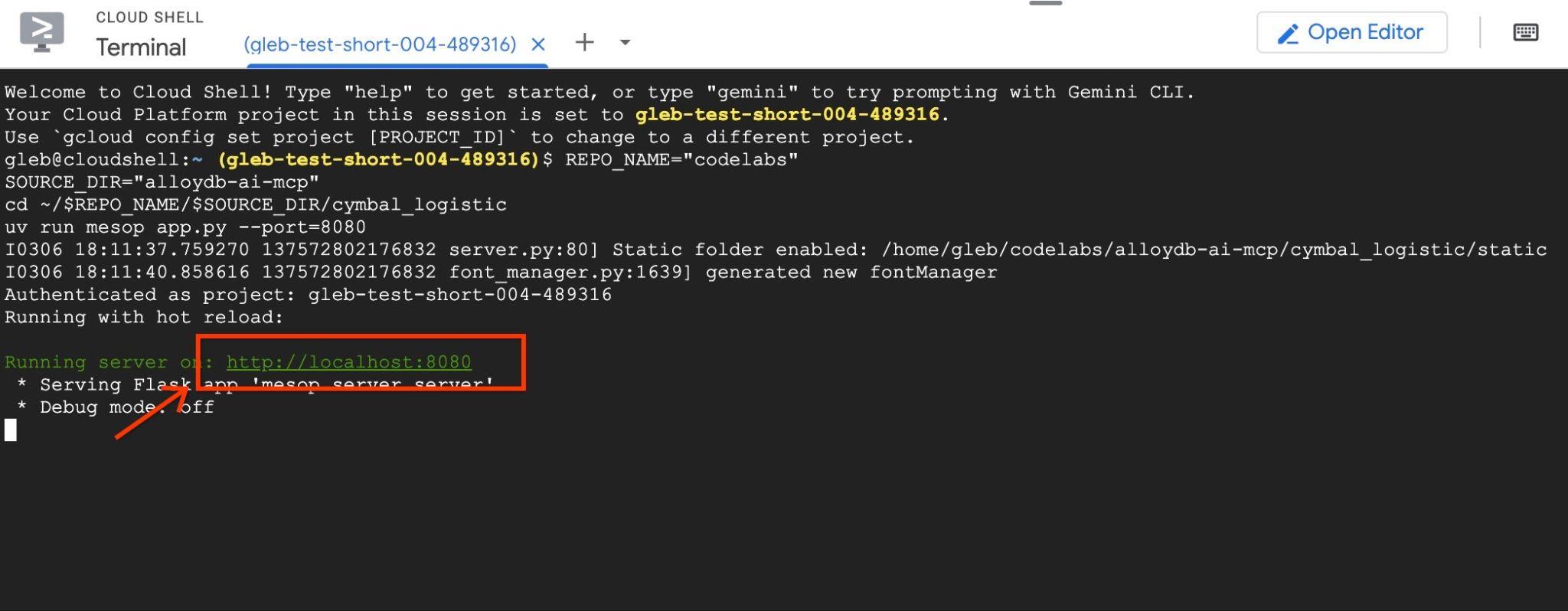
इससे ब्राउज़र में एक नया टैब खुलेगा. इसमें ऐप्लिकेशन का इंटरफ़ेस दिखेगा.
सबसे ऊपर दाईं ओर मौजूद, "डीबग आउटपुट चालू करें" चेकबॉक्स पर क्लिक करें. इसके बाद, यहां दिया गया सवाल टाइप करें.
What was the average speed for each driver last month? List top 5 fasters drivers ranking them by the average speed. Show the name, distance and average speed for each of them.
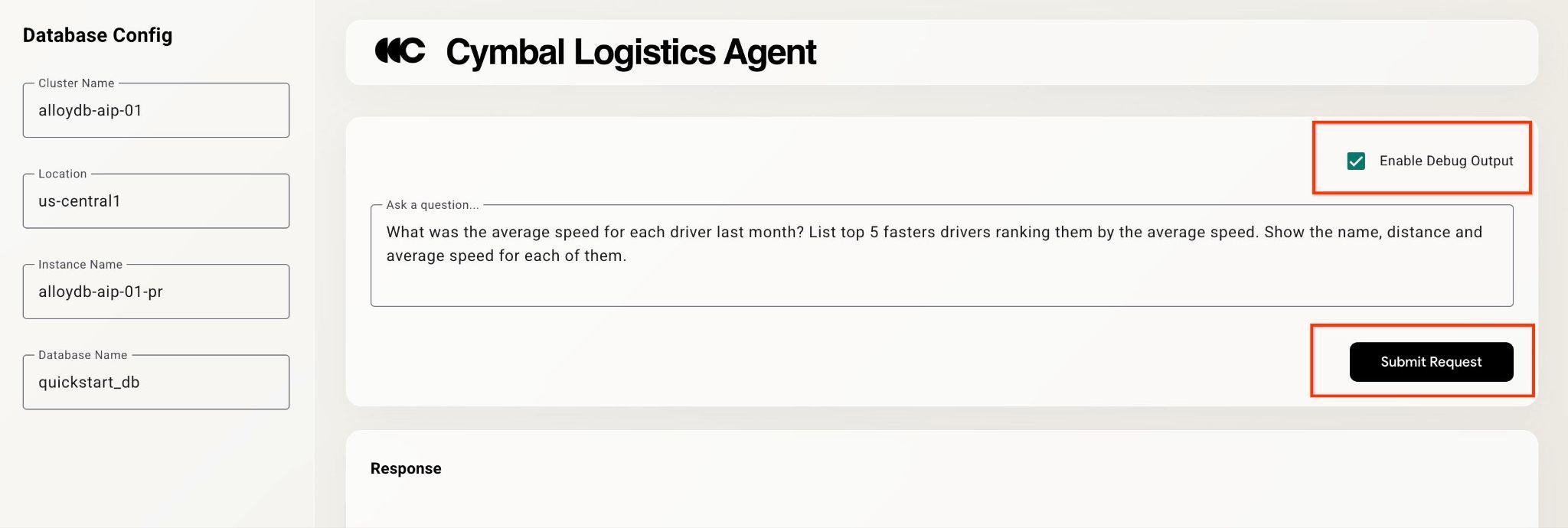
इसके बाद, Submit Request बटन दबाएं.
यह एजेंट, बैकग्राउंड में काम करेगा. साथ ही, हमारे MCP टूलसेट से की गई सभी क्वेरी के लिए आउटपुट और डीबग करने से जुड़ी जानकारी देगा. वर्कफ़्लो देखने के लिए, क्वेरी देखें.
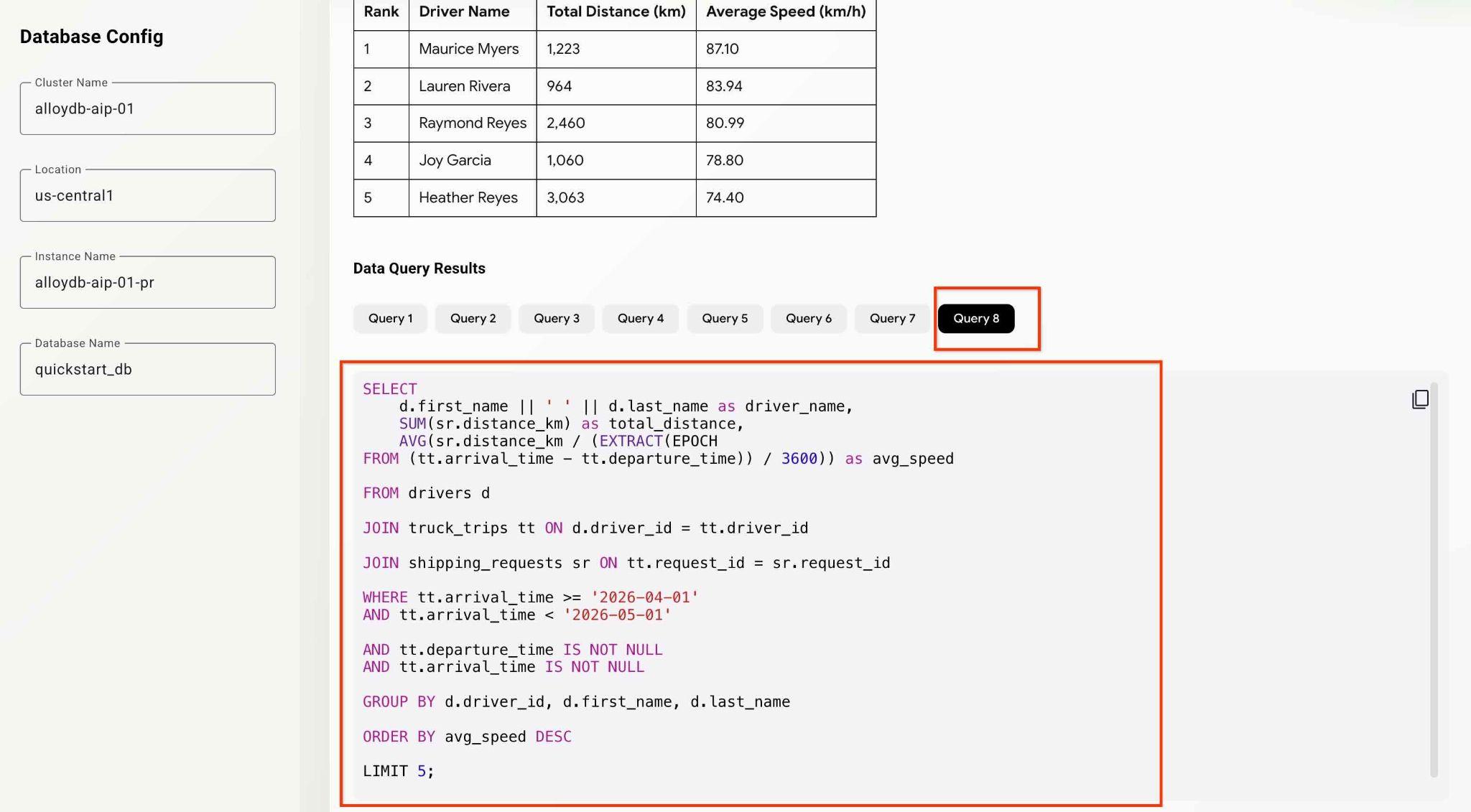
अलग-अलग तरह के विश्लेषण वाले सवाल पूछकर, एजेंट और ऐप्लिकेशन की क्षमताओं को टेस्ट किया जा सकता है.
अब तक, एमसीपी के साथ एजेंट का इस्तेमाल करके, कुछ बुनियादी विश्लेषण और खोज की जा सकती थी. अगले चैप्टर में, AlloyDB की ज़्यादा बेहतर सुविधाओं का इस्तेमाल करने की कोशिश की जाएगी.
10. AlloyDB AI फ़ंक्शन
AlloyDB में एआई फ़ंक्शन की मदद से, टेक्स्ट और मल्टीमॉडल डेटा (खास तौर पर, इमेज) को स्मार्ट तरीके से फ़िल्टर और रैंक किया जा सकता है. साथ ही, ये फ़ंक्शन आपकी क्वेरी के लिए Gemini की सुविधाओं को उपलब्ध कराते हैं. खास तौर पर, AlloyDB AI के फ़ंक्शन AI.IF और AI.RANK, एसक्यूएल स्टेटमेंट में पारंपरिक एसक्यूएल ऑपरेटर (फ़िल्टर, जॉइन, एग्रीगेशन वगैरह) के साथ दिख सकते हैं.
एआई फ़ंक्शन का इस्तेमाल करने से पहले, हम "क्लासिक" तरीकों का इस्तेमाल करके खोज और एग्रीगेशन की जांच करते हैं. यह प्रॉम्प्ट आज़माएं.
Can you analyze the activity for the last 5 months and evaluate drivers for the most positive customer feedbacks. Give me top 5 drivers listing names, distance and years of experience for each driver.
यह टेबल में मौजूद "रेटिंग" कॉलम का पता लगा सकता है. इस कॉलम में ग्राहक की राय होती है. साथ ही, यह इसका इस्तेमाल करके सबसे अच्छी रेटिंग वाले ड्राइवर की पहचान कर सकता है. इसके बाद, इस जानकारी का इस्तेमाल करके ड्राइवरों के बारे में ज़्यादा जानकारी इकट्ठा की गई.
SELECT
d.first_name || ' ' || d.last_name as driver_name,
SUM(sr.distance_km) as total_distance,
d.experience_years,
COUNT(cf.feedback_id) as positive_feedback_count
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
WHERE tt.arrival_time >= '2025-12-01'
AND tt.arrival_time < '2026-05-01'
AND cf.rating >= 4
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY positive_feedback_count DESC, total_distance DESC
LIMIT 5;
हालांकि, तकनीकी तौर पर ऐसा हो सकता है कि रेटिंग में उन सभी पैरामीटर को शामिल न किया गया हो जिनका हमें आकलन करना है. इसके लिए, हम AlloyDB के एआई फ़ंक्शन का इस्तेमाल कर सकते हैं.
AI.RANK ऑपरेटर
ai.rank() फ़ंक्शन, यह स्कोर करता है कि कोई दस्तावेज़ किसी क्वेरी का जवाब कितनी अच्छी तरह से देता है. इसका इस्तेमाल, क्वेरी के नतीजों को रैंक करने या फिर से रैंक करने के लिए किया जा सकता है. दस्तावेज़ में जाकर, ऑपरेटर के बारे में ज़्यादा जानें.
अनुरोध में बदलाव करें और विश्लेषण के दौरान, एआई.रैंक का इस्तेमाल करने के लिए साफ़ तौर पर कहें. इससे, ड्राइवर की परफ़ॉर्मेंस और उनके पेशेवर रवैये के आधार पर उनका आकलन किया जा सकेगा.
Can you find the top 5 fastest drivers in the last month and rank them by the feedback using the AI.RANK function? Give me top drivers names, distance, years of experience and rank for each driver.
इस कमांड को पूरा होने में थोड़ा ज़्यादा समय लग सकता है, क्योंकि एजेंट को यह पता लगाना होगा कि AI.RANK फ़ंक्शन का इस्तेमाल कैसे किया जाए. साथ ही, उसे डेटा पाना होगा और जानकारी को क्रम से लगाने के लिए, AI.RANK फ़ंक्शन को लागू करना होगा. आखिर में, आपको मॉडल के हिसाब से रैंक किए गए ड्राइवर की सूची और एक्ज़ीक्यूट की गई क्वेरी की सूची मिलेगी.
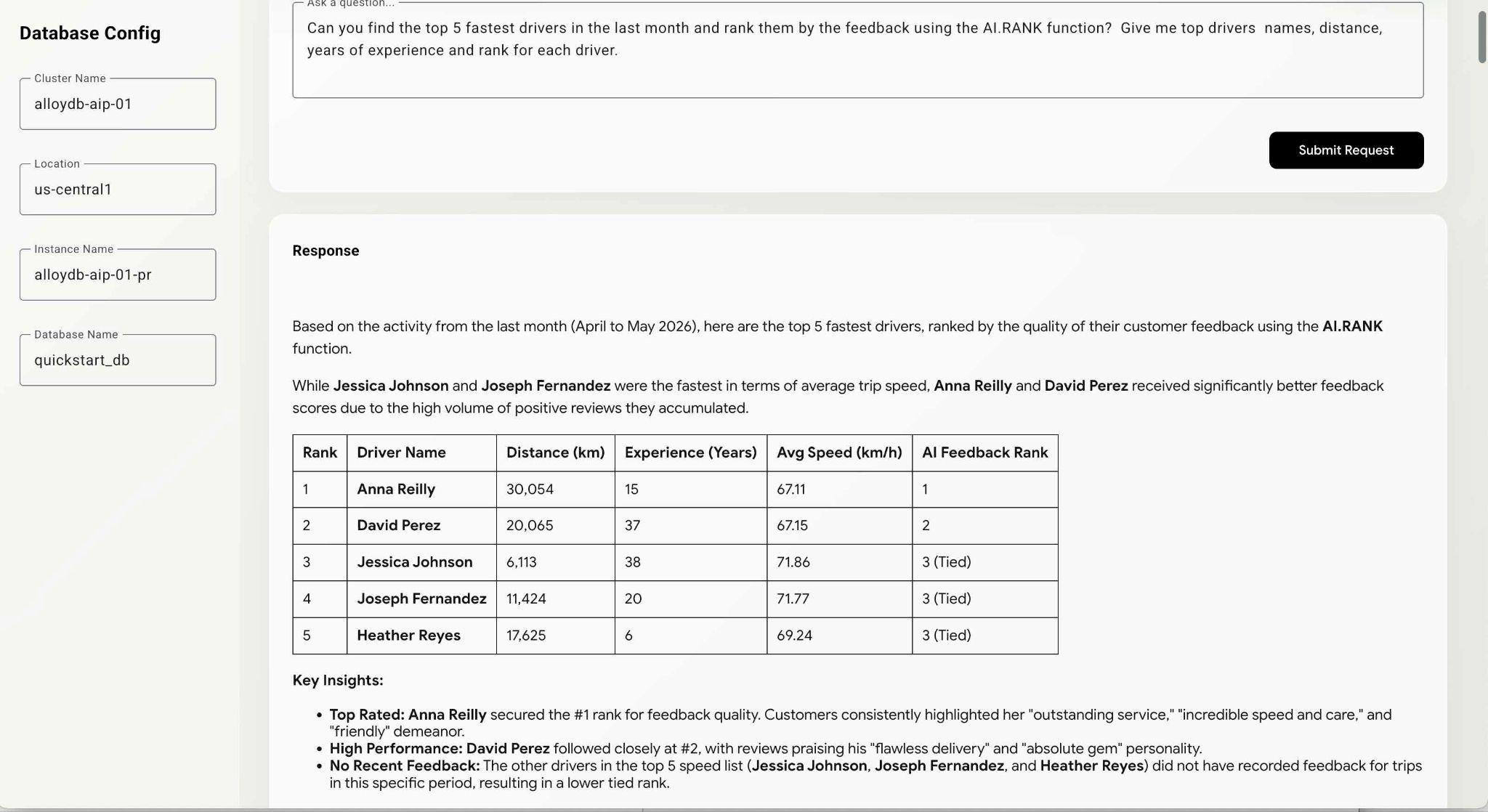
मॉडल के चुने गए पाथ के आधार पर, उस क्वेरी को पूरा होने में कुछ समय लग सकता है. साथ ही, डीबग विंडो में ड्राइवर की जानकारी पाने के लिए, चलाई गई क्वेरी को देखा जा सकता है.
WITH fastest_drivers AS (
SELECT
d.driver_id,
d.first_name || ' ' || d.last_name as driver_name,
d.experience_years,
SUM(sr.distance_km) as total_distance,
AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) as avg_speed,
COALESCE(STRING_AGG(cf.feedback_text, ' | '), 'No feedback') as feedbacks,
ROW_NUMBER() OVER (
ORDER BY AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) DESC) - 1 as row_idx
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
LEFT
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
WHERE tt.arrival_time >= '2026-04-04'
AND tt.arrival_time IS NOT NULL
AND tt.departure_time IS NOT NULL
AND tt.arrival_time > tt.departure_time
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY avg_speed DESC
LIMIT 5
)
SELECT
f.driver_name,
f.total_distance,
f.experience_years,
f.avg_speed,
f.feedbacks,
(SELECT r.score
FROM ai.rank(
'semantic-ranker-fast-004',
'excellent customer service, professional, friendly, fast,
and reliable delivery reviews',
ARRAY[f.feedbacks],
1
) r
LIMIT 1) as feedback_score
FROM fastest_drivers f
ORDER BY feedback_score DESC;
आपके पास ऐप्लिकेशन को टेस्ट करने और क्वेरी की जांच करने का विकल्प होता है. इससे यह पता चलता है कि एजेंट को फ़ाइनल नतीजे कैसे मिलते हैं.
हमारी लैब यहीं खत्म होती है. हमें उम्मीद है कि आपने सभी उदाहरण देख लिए होंगे और आपको AlloyDB के लिए Google Cloud MCP सेवा का इस्तेमाल करने का तरीका पता चल गया होगा. अगर आपको एंटरप्राइज़ के लिए एमसीपी का इस्तेमाल करना है, तो इसे AlloyDB के दस्तावेज़ में बताई गई AlloyDB की NL2SQL सुविधाओं के साथ इस्तेमाल करें. AlloyDB के लिए एसक्यूएल स्टेटमेंट जनरेट करने के बारे में जानकारी देने वाले कोडलैब का इस्तेमाल करके, इसे आज़माया जा सकता है.
11. पर्यावरण को साफ़-सुथरा रखना
अचानक लगने वाले शुल्क से बचने के लिए, अस्थायी संसाधनों को हटा देना चाहिए. सबसे भरोसेमंद तरीका यह है कि उस प्रोजेक्ट को मिटा दिया जाए जिसमें वर्कफ़्लो की टेस्टिंग की जा रही थी. हालांकि, AlloyDB जैसे अलग-अलग संसाधनों को मिटाकर, अपने इस्तेमाल को सीमित किया जा सकता है.
लैब का काम पूरा हो जाने के बाद, AlloyDB इंस्टेंस और क्लस्टर मिटा दें.
AlloyDB क्लस्टर और सभी इंस्टेंस मिटाना
अगर आपने AlloyDB का मुफ़्त में आज़माने की सुविधा वाला वर्शन इस्तेमाल किया है. अगर आपको ट्रायल क्लस्टर का इस्तेमाल करके अन्य लैब और संसाधनों की जांच करनी है, तो ट्रायल क्लस्टर को न मिटाएं. आपके पास एक ही प्रोजेक्ट में, दूसरा ट्रायल क्लस्टर बनाने का विकल्प नहीं होगा.
फ़ोर्स विकल्प का इस्तेमाल करके क्लस्टर को डिस्ट्रॉय किया जाता है. इससे क्लस्टर से जुड़े सभी इंस्टेंस भी मिट जाते हैं.
अगर आपका कनेक्शन बंद हो गया है और पिछली सभी सेटिंग मिट गई हैं, तो क्लाउड शेल में प्रोजेक्ट और एनवायरमेंट वैरिएबल तय करें:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
क्लस्टर मिटाने के लिए:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB के बैकअप मिटाना
क्लस्टर के सभी AlloyDB बैकअप मिटाने के लिए:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. बधाई हो
कोडलैब पूरा करने के लिए बधाई.
हमने क्या-क्या बताया
- AlloyDB क्लस्टर बनाने और सैंपल डेटा इंपोर्ट करने का तरीका
- AlloyDB डेटा ऐक्सेस एपीआई को चालू करने का तरीका
- AlloyDB NL के लिए, Google Cloud MCP को चालू करने का तरीका
- अपने ADK एजेंट में, AlloyDB के लिए Google Cloud MCP को कैसे जोड़ें
- किसी ऐप्लिकेशन में, AlloyDB के लिए Google Cloud MCP का इस्तेमाल कैसे करें
- Analytics के लिए AlloyDBMCP के साथ एजेंट इस्तेमाल करने का तरीका
13. सर्वे
आउटपुट: