
1. Introduzione
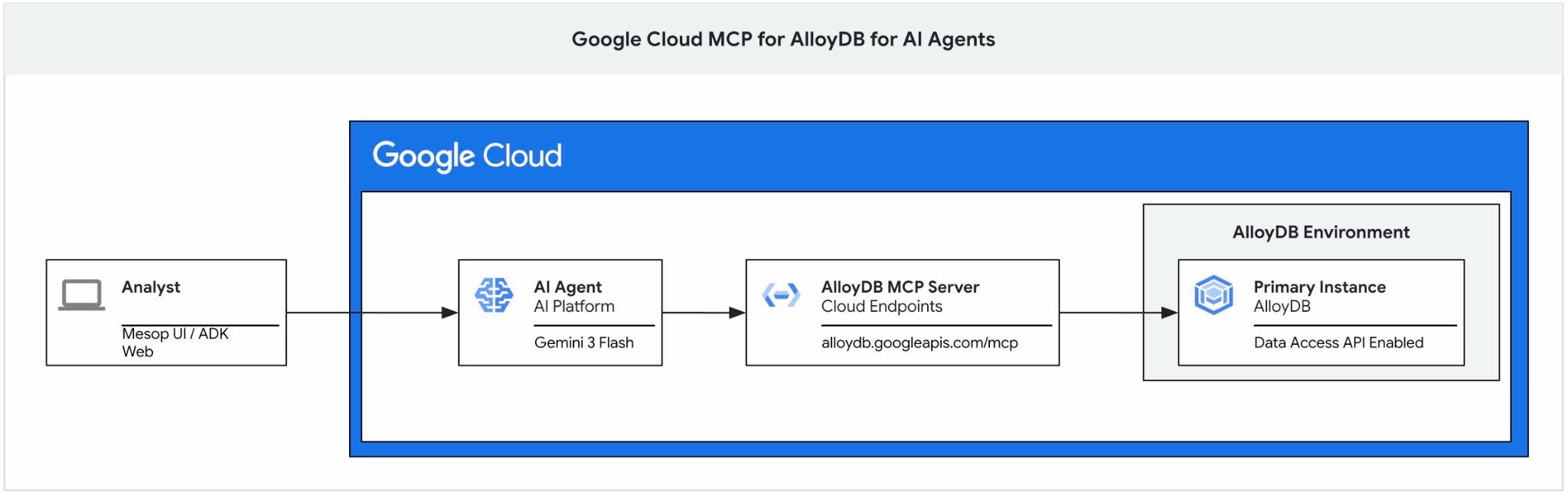
Questo codelab fornisce una guida su come iniziare a utilizzare il server Google Cloud MCP per AlloyDB e su come abilitarlo come parte del set di strumenti per un agente AI e utilizzarlo come parte dell'applicazione.
Prerequisiti
- Una conoscenza di base di Google Cloud e della console
- Competenze di base nell'interfaccia a riga di comando e in Cloud Shell
Cosa imparerai a fare
- Come creare un cluster AlloyDB e importare dati di esempio
- Come attivare l'API di accesso ai dati di AlloyDB
- Come attivare Google Cloud MCP per AlloyDB NL
- Come aggiungere Google Cloud MCP per AlloyDB all'agente ADK
- Come utilizzare Google Cloud MCP per AlloyDB in un'applicazione
- Come utilizzare gli agenti con AlloyDBMCP per l'analisi
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome che supporta la console Google Cloud e Cloud Shell
2. Configurazione e requisiti
Configurazione del progetto
- Accedi alla console Google Cloud. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
- Crea un nuovo progetto o riutilizzane uno esistente. Per creare un nuovo progetto nella console Google Cloud, fai clic sul pulsante Seleziona un progetto nell'intestazione per aprire una finestra popup.

Nella finestra Seleziona un progetto, premi il pulsante Nuovo progetto per aprire una finestra di dialogo per il nuovo progetto.
Nella finestra di dialogo, inserisci il nome del progetto che preferisci e scegli la posizione.
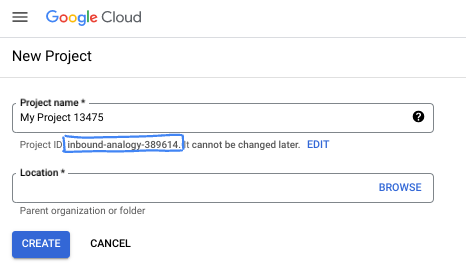
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. Il nome del progetto non viene utilizzato dalle API di Google e può essere modificato in qualsiasi momento.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Google Cloud genera automaticamente un ID univoco, ma puoi personalizzarlo. Se l'ID generato non ti piace, puoi generarne un altro casuale o fornirne uno tuo per verificarne la disponibilità. Nella maggior parte dei codelab, devi fare riferimento all'ID progetto, in genere identificato con il segnaposto PROJECT_ID.
- Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
Abilita fatturazione
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 3 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
In alternativa, puoi premere G e poi S. Questa sequenza attiverà Cloud Shell se ti trovi nella console Google Cloud o utilizza questo link.
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Prima di iniziare
Abilita l'API
Per utilizzare AlloyDB, Compute Engine, servizi di rete e Vertex AI, devi abilitare le rispettive API nel tuo progetto Google Cloud.
All'interno del terminale Cloud Shell, assicurati che l'ID progetto sia configurato:
gcloud config get-value project
Dovrebbe essere restituito l'ID progetto Google.
Imposta la variabile di ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Attiva tutti i servizi necessari:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Output previsto:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Esegui il deployment di AlloyDB
Crea il cluster AlloyDB e l'istanza principale. Puoi eseguirne il deployment utilizzando uno script preparato che eseguirà il deployment di tutte le risorse necessarie oppure puoi farlo passo dopo passo seguendo la documentazione.
Eseguire il deployment di AlloyDB utilizzando lo script automatizzato
Questo approccio utilizza uno script automatizzato per il deployment del cluster AlloyDB e fornisce le informazioni necessarie per iniziare a lavorare con le risorse di cui è stato eseguito il deployment.
Nel terminale Cloud Shell, esegui il comando per clonare lo script di deployment dal repository.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-ai-mcp"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Esegui lo script di deployment.
./deploy_alloydb.sh
L'esecuzione dello script richiede un po' di tempo, in genere circa 5-7 minuti. L'output deve fornire informazioni sul cluster AlloyDB di cui è stato eseguito il deployment. Tieni presente che la password sarà diversa. Registrala da qualche parte per un uso futuro.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
Puoi anche visualizzare il nuovo cluster e l'istanza primaria nella console web.
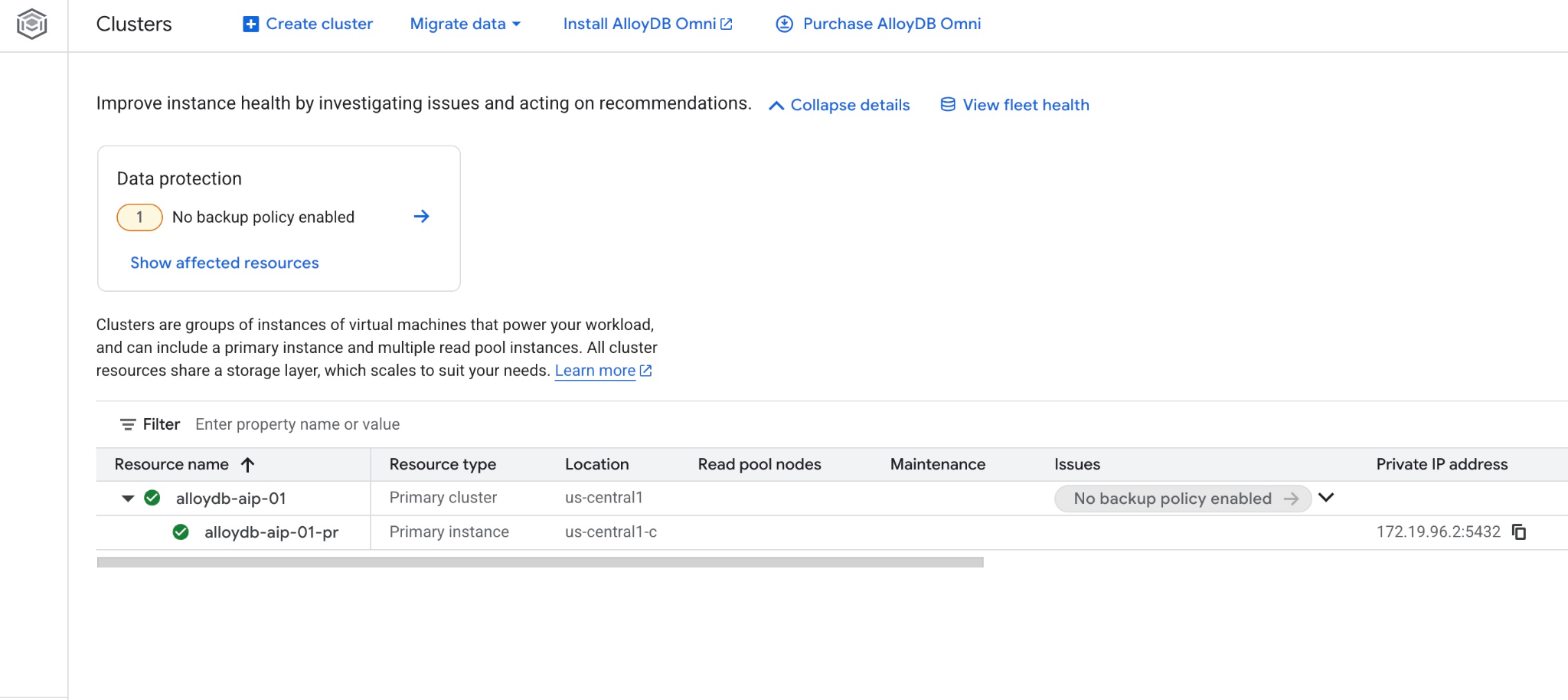
5. Prepara il database
Per utilizzare le funzioni e gli operatori di AI, devi abilitare l'integrazione di Vertex AI, l'API di accesso ai dati e creare un database per il set di dati di esempio.
Concedere le autorizzazioni necessarie ad AlloyDB
Aggiungi le autorizzazioni Vertex AI al service agent AlloyDB.
Apri un'altra scheda di Cloud Shell utilizzando il segno "+" in alto.
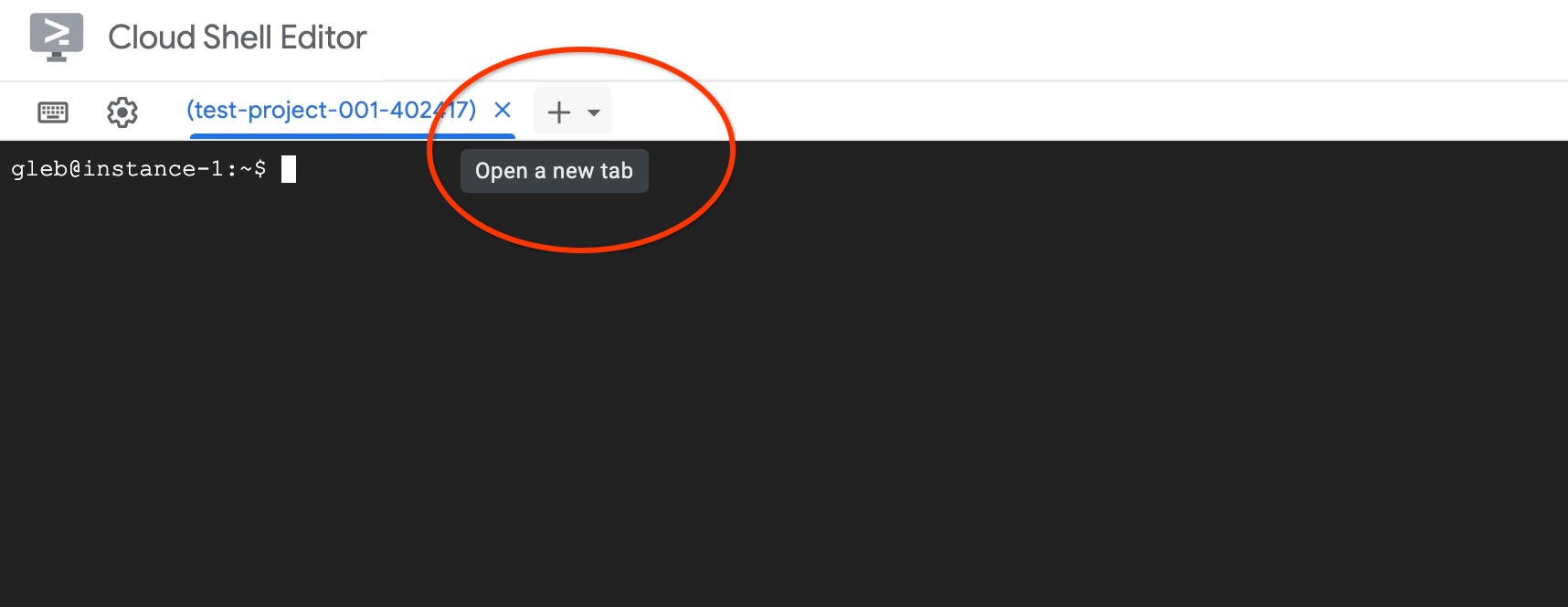
Nella nuova scheda di Cloud Shell, esegui:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/discoveryengine.viewer"
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... < redacted > etag: BwYIEbe_Z3U= version: 1
Abilita l'API Data Access
Devi abilitare l'API Data Access sul cluster AlloyDB per poter utilizzare gli strumenti MCP come execute_sql.
Nella stessa scheda del terminale, esegui.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Aggiorna flag istanza
Per utilizzare le funzioni avanzate di AI in AlloyDB, dobbiamo abilitare alcuni flag del database. Dopo aver abilitato l'API Data Access, potrebbero essere necessari alcuni minuti prima che l'istanza sia pronta per le modifiche successive. Controlla lo stato dell'istanza nella console per assicurarti che sia presente il segno di spunta verde.
Nella stessa scheda del terminale, esegui.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags=google_ml_integration.enable_model_support=on,google_ml_integration.enable_ai_query_engine=on,google_ml_integration.enable_preview_ai_functions=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Abilita MCP
Il passaggio successivo consiste nell'abilitare il server MCP di Google Cloud per AlloyDB nel tuo progetto. Per impostazione predefinita, MCP non è abilitato ed è uno dei vari livelli di protezione, tra cui autenticazione e autorizzazione IAM, API di accesso ai dati e ruoli all'interno del cluster.
Nella stessa scheda del terminale, esegui.
PROJECT_ID=$(gcloud config get-value project)
gcloud beta services mcp enable alloydb.googleapis.com \
--project=$PROJECT_ID
Chiudi la scheda con il comando di esecuzione "exit":
exit
Connettersi ad AlloyDB Studio
Nei capitoli seguenti, tutti i comandi SQL che richiedono la connessione al database possono essere eseguiti in AlloyDB Studio. T
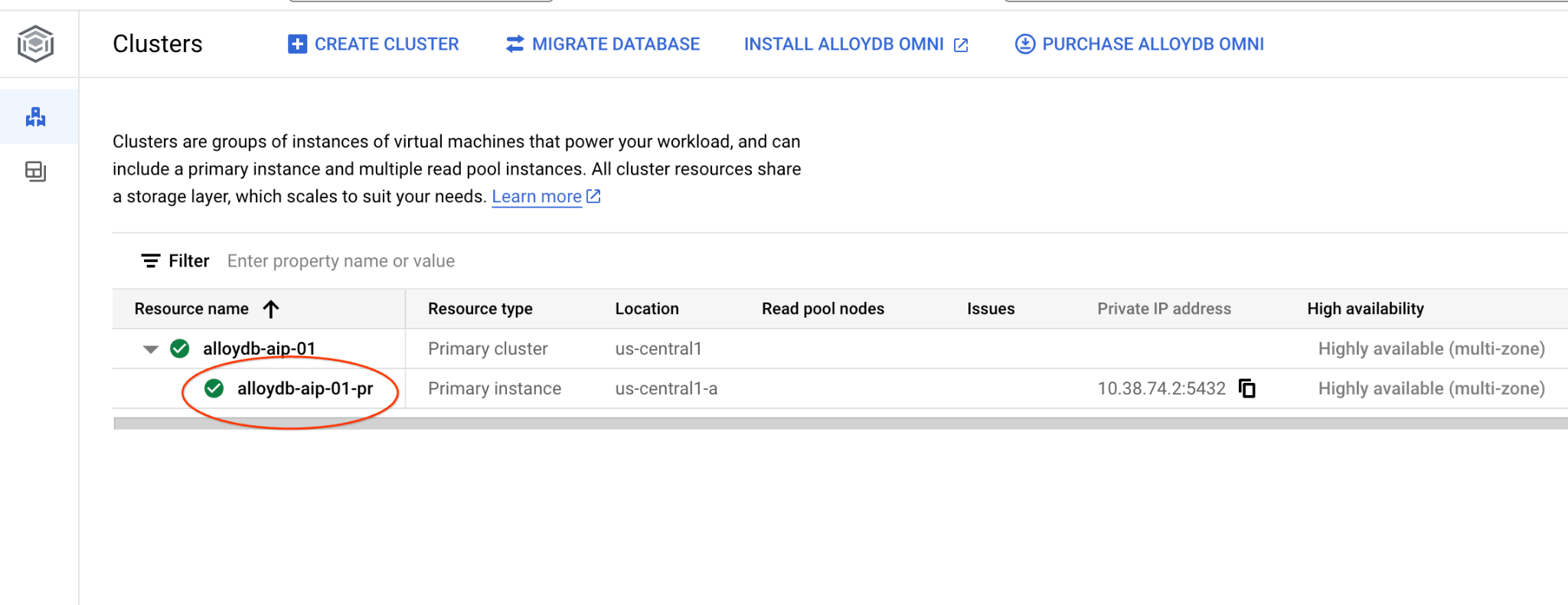
Vai alla pagina Cluster in AlloyDB per PostgreSQL.
Apri l'interfaccia della console web per il cluster AlloyDB facendo clic sull'istanza principale.
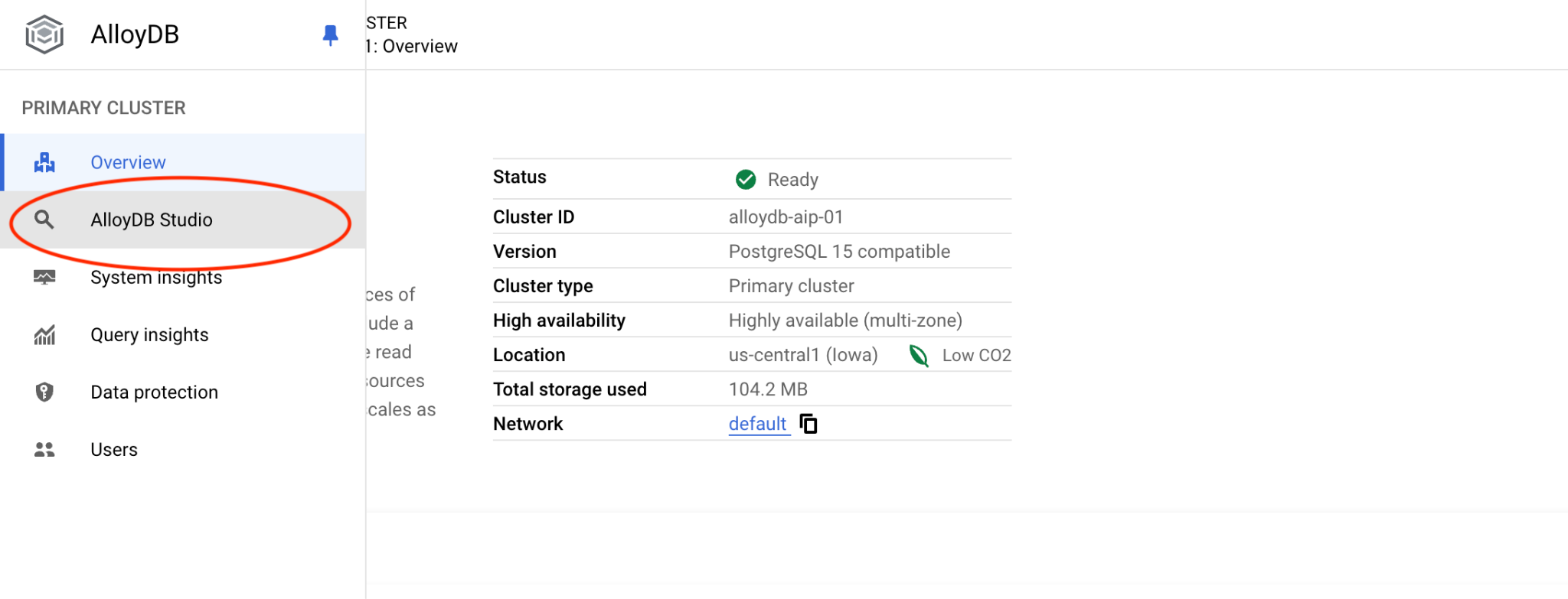
Quindi, fai clic su AlloyDB Studio a sinistra:
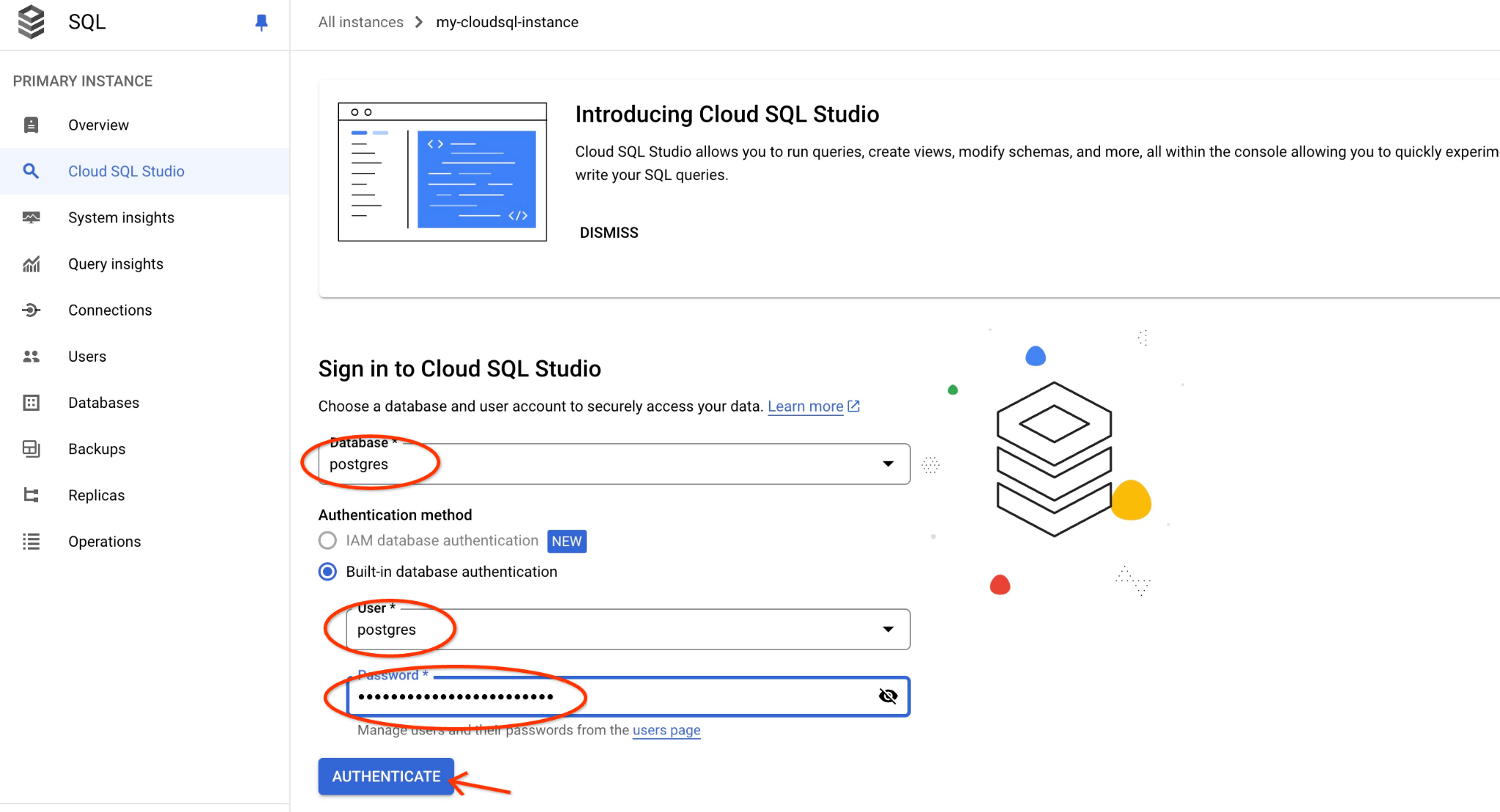
Scegli il database Postgres, l'utente Postgres e fornisci la password annotata quando abbiamo creato il cluster. A questo punto, fai clic sul pulsante "Autentica".
Se la password non funziona o hai dimenticato di annotarla, puoi cambiarla. Consulta la documentazione per scoprire come fare.
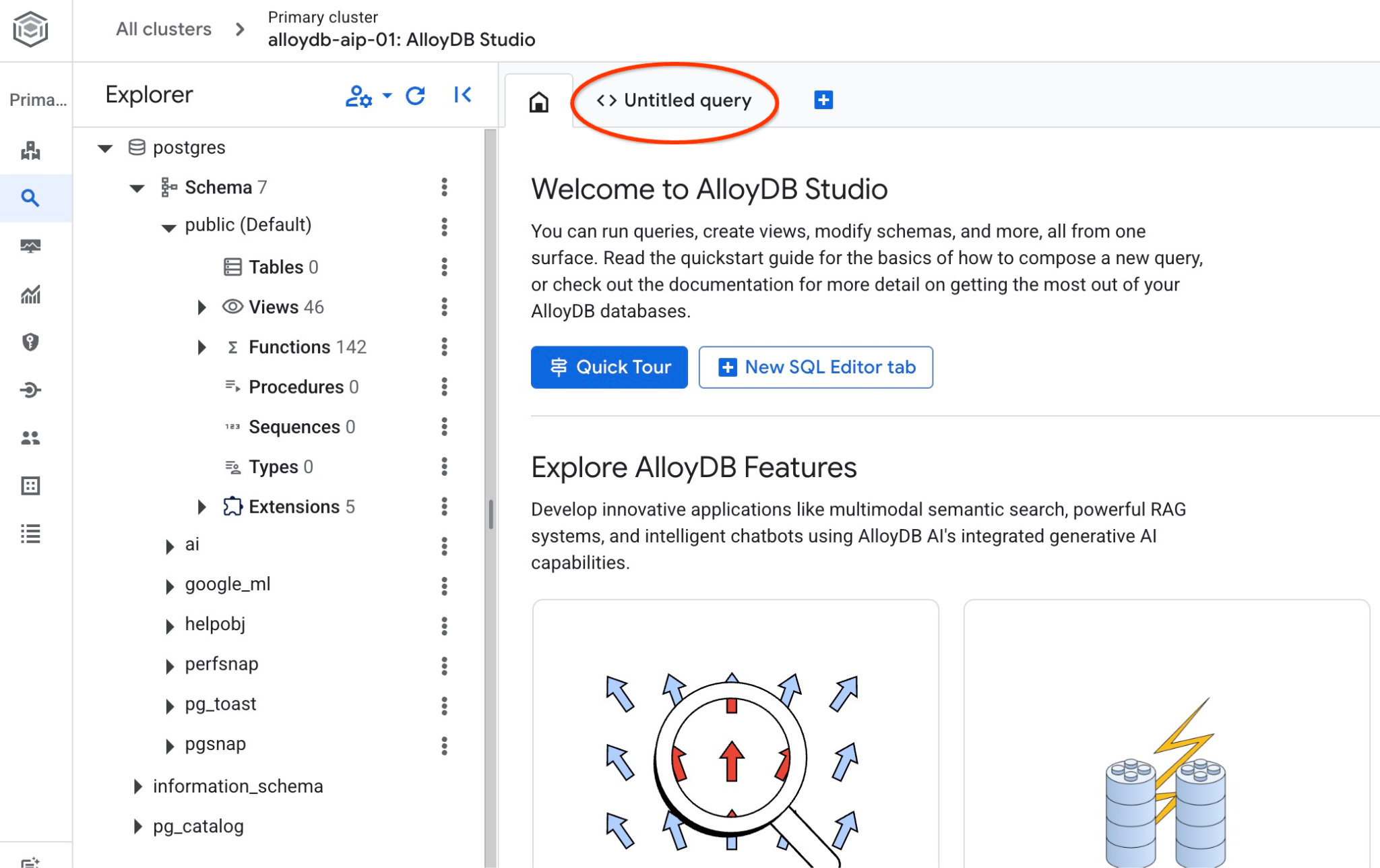
Si aprirà l'interfaccia di AlloyDB Studio. Per eseguire i comandi nel database, fai clic sulla scheda "Query senza titolo" a destra.
Si apre l'interfaccia in cui puoi eseguire i comandi SQL
Crea database
Guida rapida alla creazione di database.
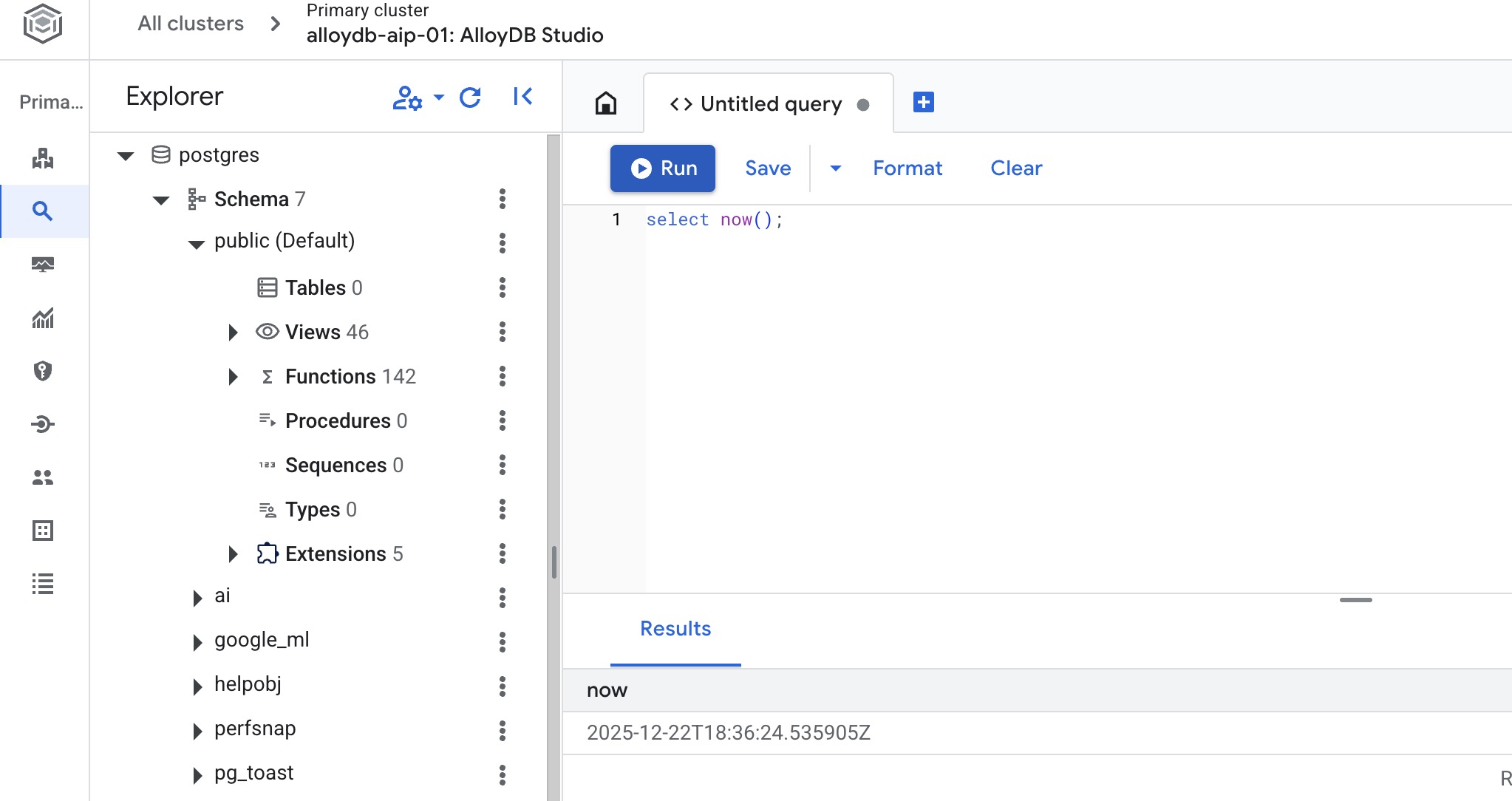
Nell'editor di AlloyDB Studio, esegui questo comando.
Crea database:
CREATE DATABASE quickstart_db
Output previsto:
Statement executed successfully
Connettiti a quickstart_db
Verifica che il database sia stato creato connettendoti. Riconnettiti allo studio utilizzando il pulsante per cambiare utente/database.
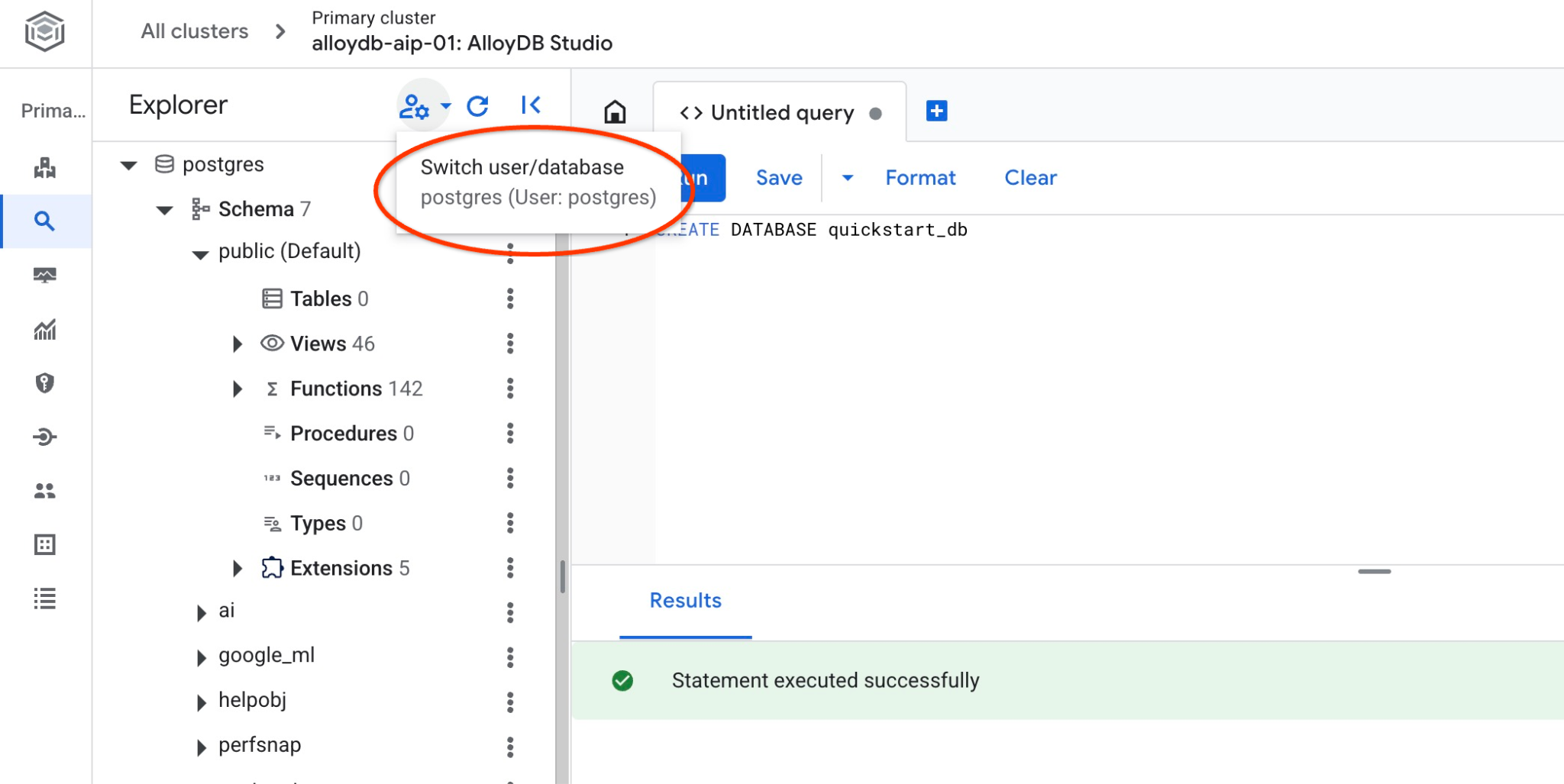
Seleziona il nuovo database quickstart_db dall'elenco a discesa e utilizza lo stesso utente e la stessa password di prima.
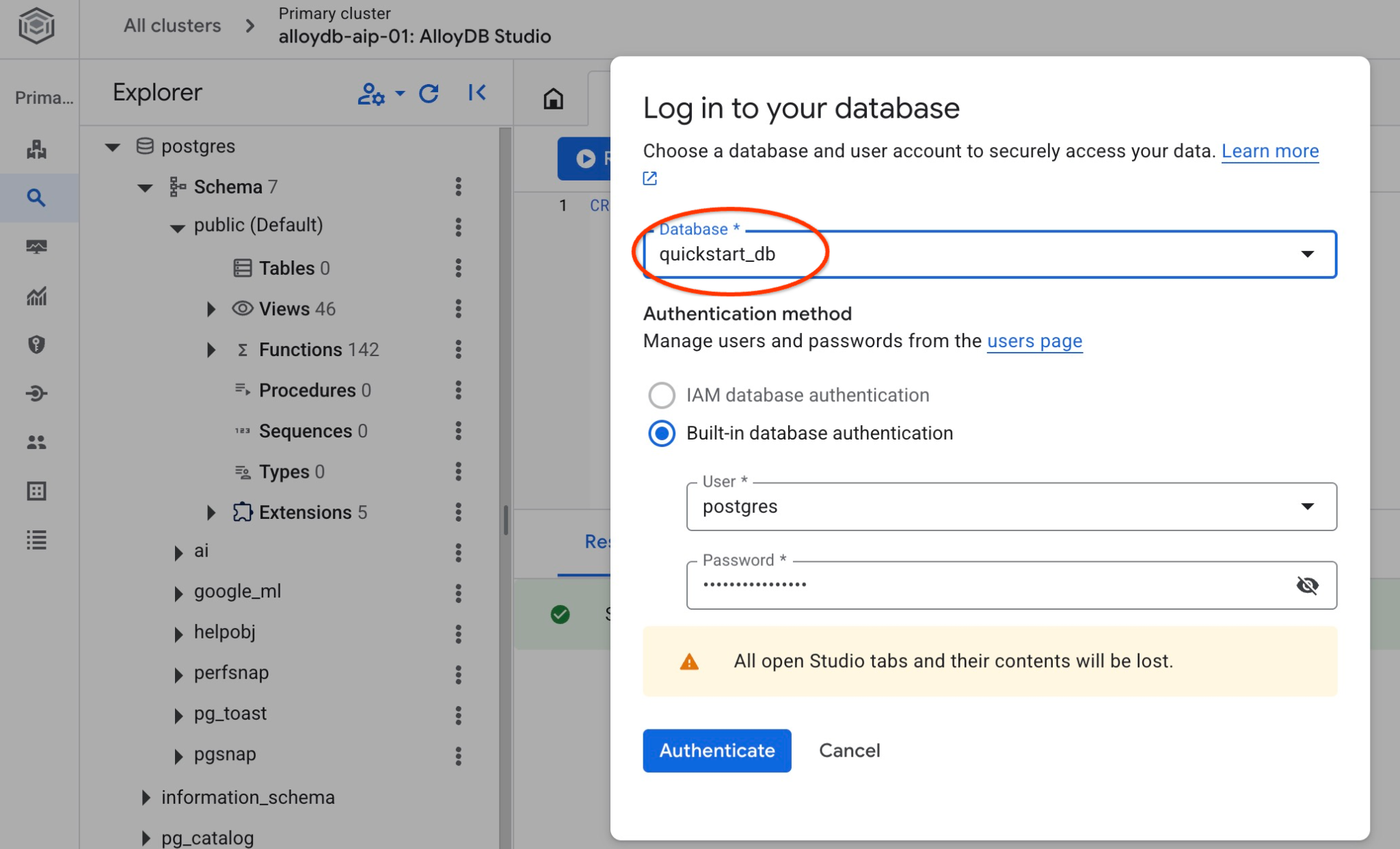
Si aprirà una nuova connessione in cui potrai lavorare con gli oggetti del database quickstart_db. Lì potrai esaminare lo schema e i dati importati.
6. Dati di esempio
Ora devi creare oggetti nel database e caricare i dati. Utilizzerai un set di dati fittizio della società di spedizioni Cymbal. Contiene dati fittizi su merci, camion, richieste e viaggi in camion, nonché su autisti fittizi.
Crea un bucket di archiviazione
Utilizzerai Google SDK (gcloud) per importare i dati dal nostro repository clonato nel database AlloyDB e devi creare un bucket di archiviazione per questo scopo e concedere l'accesso al service account AlloyDB. In alternativa, puoi sempre provare a farlo utilizzando la console web come descritto nella documentazione.
Nel terminale Google Cloud Shell esegui:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Carica dati
Il passaggio successivo consiste nel caricare i dati. Il dump SQL si trova nella cartella del repository clonato. Il seguente comando presuppone che tu abbia utilizzato la tua home directory come punto di partenza quando hai clonato il repository nel passaggio precedente durante la creazione del cluster AlloyDB.
Copia il dump SQL compresso nel nuovo bucket di archiviazione:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Quindi, carica i dati nel database quickstart_db:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
Il comando caricherà il set di dati di esempio nel database quickstart_db. Puoi verificare le tabelle e i record utilizzando AlloyDB Studio.
7. Utilizzare Data Agent
Iniziamo da un agente AI di esempio creato utilizzando Google ADK per Python e mostriamo come configurarlo per funzionare con il server MCP di Google Cloud per AlloyDB.
Controlla il codice sorgente dell'agente
Nel repository clonato, esamina il codice dell'agente utilizzando l'editor di Google Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/data_agent/agent.py
Nell'agente è presente una sezione per il server MCP di Google Cloud per AlloyDB. Forniamo un endpoint come MCP_SERVER_URL, autenticazione, ID progetto e lo aggiungiamo al set di strumenti MCP.
# Google Cloud MCP Server for AlloyDB
MCP_SERVER_URL = "https://alloydb.googleapis.com/mcp"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
# 2. Configure MCP Toolset
# We use StreamableHTTPConnectionParams to pass the auth header
headers = {
"Authorization": f"Bearer {creds.token}",
"X-Goog-User-Project": project_id
}
connection_params = StreamableHTTPConnectionParams(
url=MCP_SERVER_URL,
headers=headers,
timeout=300.0,
sse_read_timeout=600.0
)
mcp_toolset = McpToolset(connection_params=connection_params)
Nel codice dell'agente, il set di strumenti MCP è incluso come parametro tools per l'agente. Inoltre, i nomi del cluster e dell'istanza, la regione e il database sono variabili per il prompt dell'agente.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
""",
tools=[mcp_toolset],
)
Il servizio Google Cloud MCP per AlloyDB ha un insieme predefinito di strumenti. Se vuoi elencare tutti gli strumenti disponibili, puoi utilizzare il comando curl dal terminale della console Cloud Shell utilizzando il seguente comando. Puoi sempre controllare l'ultimo riferimento per il server MCP di Google Cloud per AlloyDB nella documentazione.
curl -s -X POST http://alloydb.googleapis.com/mcp \
-H "Content-Type: application/json" \
-d @- <<EOF | jq -r '.result.tools[].name'
{
"id": "my_id_01",
"jsonrpc": "2.0",
"method": "tools/list"
}
EOF
Avvia l'agente
Ora puoi avviare l'agente in modalità interattiva utilizzando l'interfaccia web di Google ADK. L'interfaccia web dell'ADK offre un modo pratico per testare e risolvere i problemi relativi ai flussi di lavoro degli agenti.
Innanzitutto, installiamo tutti i pacchetti richiesti per Python utilizzando il gestore di pacchetti uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv sync
Una volta installati tutti i pacchetti, devi aggiungere un file .env alla directory dell'agente per indicare di utilizzare Vertex AI per tutte le comunicazioni con i modelli di AI.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
A questo punto, puoi avviare l'agente.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Dovresti vedere un output simile al seguente con l'endpoint come http://127.0.0.1:8000 .
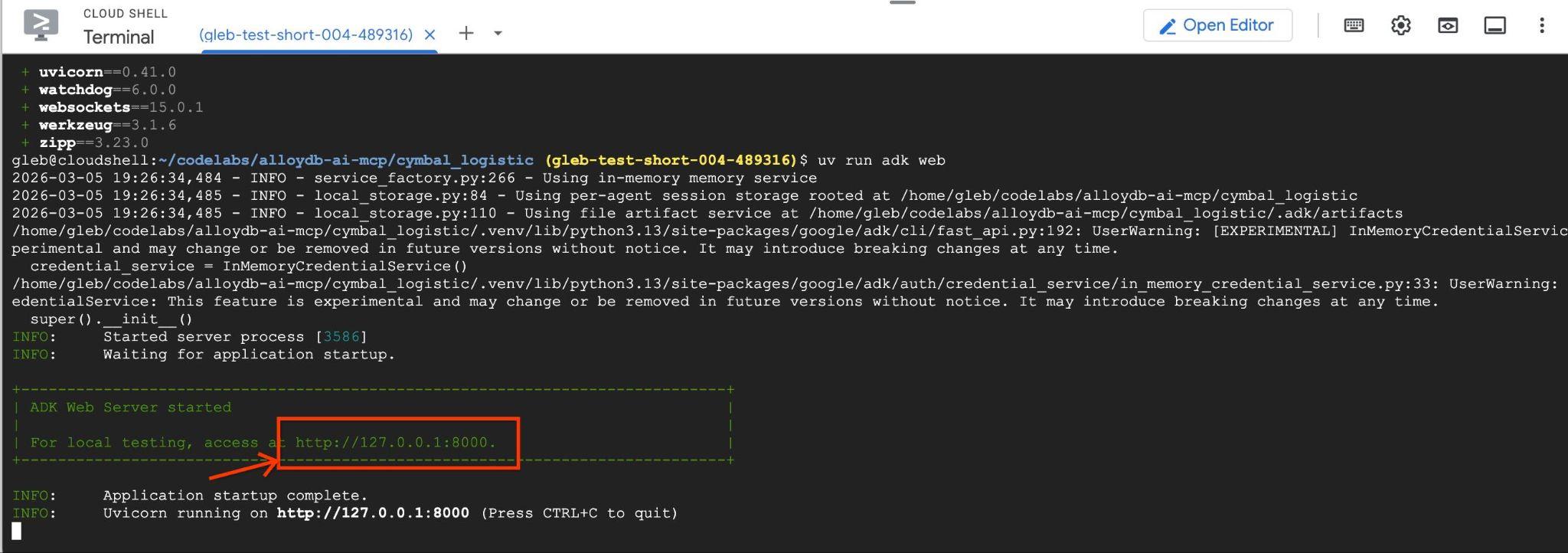
Puoi fare clic su questo URL in Cloud Shell e si aprirà una finestra di anteprima in una scheda separata del browser, in cui scegli data_agent dall'elenco a discesa a sinistra.
Nell'interfaccia web dell'ADK puoi pubblicare le tue domande in basso a destra e visualizzare il flusso di esecuzione completo, incluse le tracce per ogni passaggio sul lato destro.
8. Testa AlloyDB MCP con l'agente
L'agente ti consente di porre domande in formato libero utilizzando il linguaggio naturale e l'agente utilizzerà il server Google Cloud MCP per AlloyDB come strumento per rispondere alle domande. Le domande vengono pubblicate in basso a destra e la risposta con tutte le chiamate agli strumenti viene visualizzata in alto.
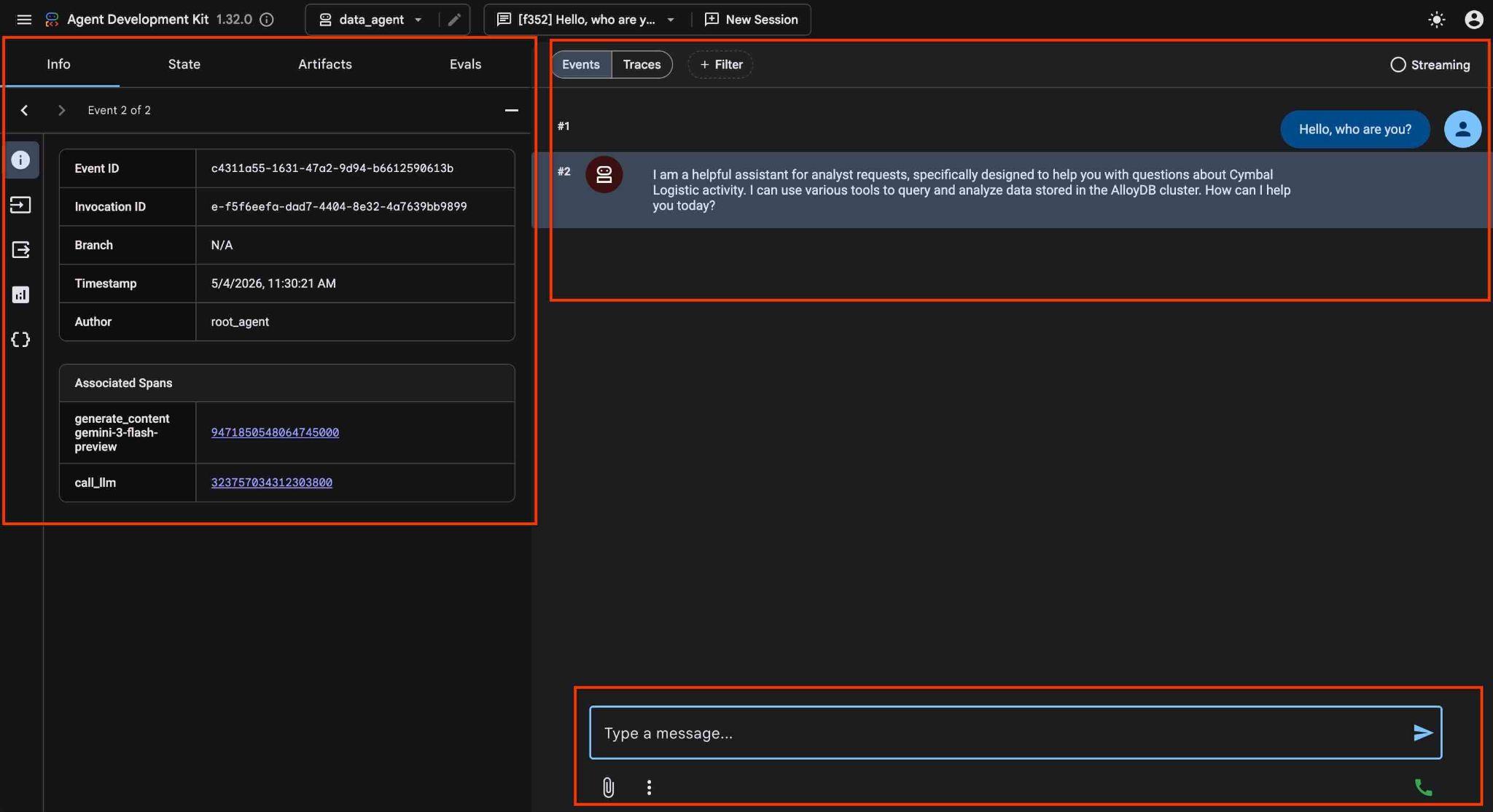
Stai lavorando con i dati operativi di una società di spedizioni che contiene informazioni su richieste di spedizione, camion, autisti e viaggi effettuati dagli autisti. La prima domanda riguarda il numero di viaggi eseguiti a febbraio 2026.
Nel campo di immissione in basso a destra, digita quanto segue e premi Invio.
Hello, can you tell me how many trips we've done in February this year?
L'agente eseguirà più chiamate di strumenti per identificare le tabelle corrette nello schema e la struttura della tabella prima di eseguire l'istruzione SQL corretta per ottenere i dati giusti.
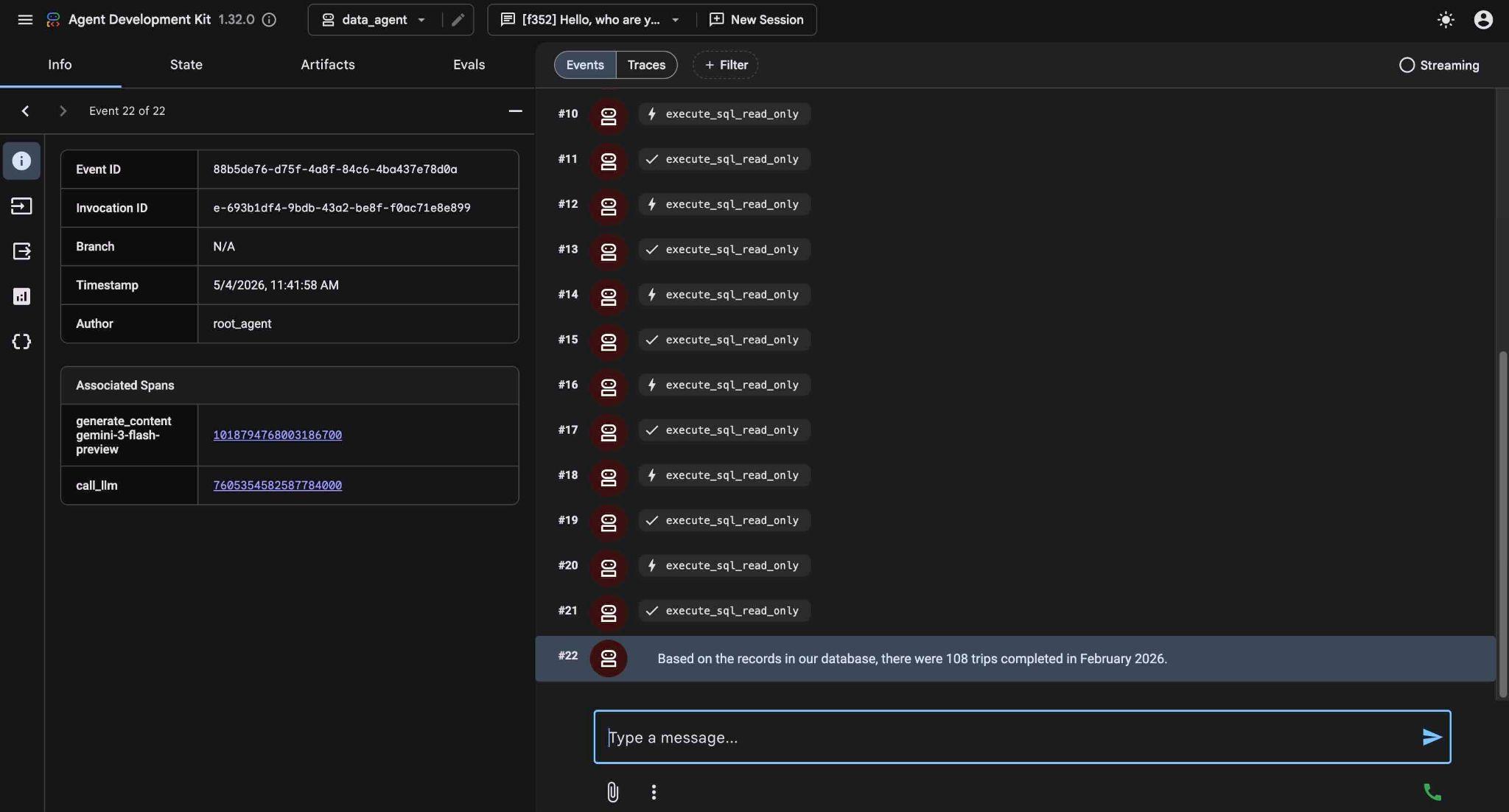
Alla fine produrrà il risultato dopo aver creato la query corretta ed eseguita sul database.
In base ai dati nel nostro database, a febbraio 2026 sono state completate 108 corse.
Puoi vedere cosa fa ogni chiamata allo strumento facendo clic sull'esecuzione dello strumento. Ad esempio, ecco la query eseguita per ottenere i risultati.
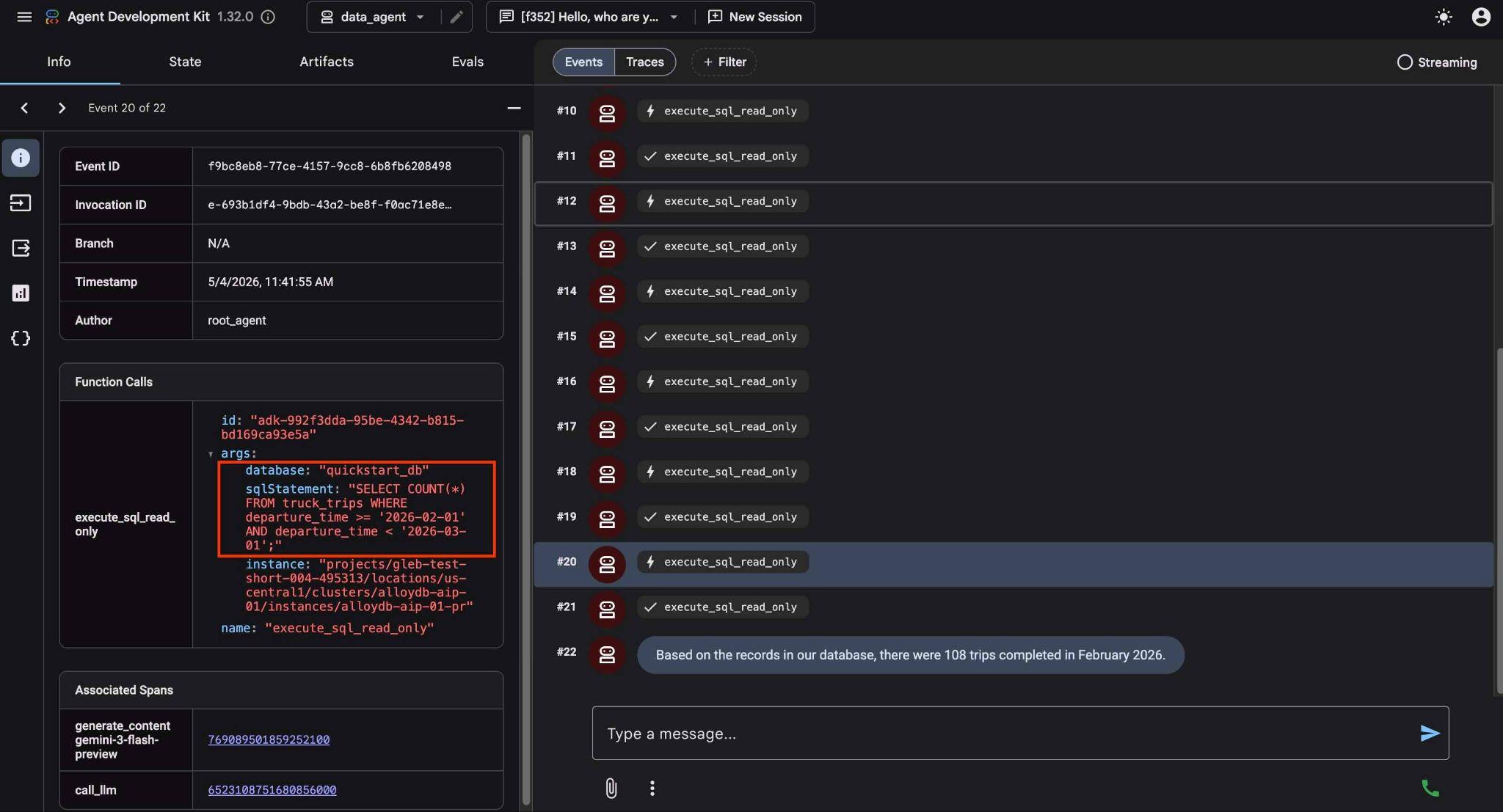
Ora rendi la richiesta più complessa chiedendo di confrontare i risultati con quelli del mese precedente.
How is it in comparison in numbers and mileage with the January?
Restituisce il risultato eseguendo query diverse che analizzano i risultati e forniscono una differenza nel numero di viaggi e nel chilometraggio.
In comparison to January 2026, February saw a slight decrease in both the number of trips and the total mileage: January 2026: 114 trips with a total mileage of 185,597 km. February 2026: 108 trips with a total mileage of 177,893 km. This represents a decrease of 6 trips and 7,704 km in mileage for February compared to January.
Prova altre richieste semplici utilizzando l'interfaccia web dell'ADK e scopri come esegue query diverse per ottenere i risultati.
Interrompi l'agente premendo ctrl+c nel terminale. Puoi chiudere la scheda del browser con l'interfaccia web dell'ADK.
Ora puoi provare un'applicazione di esempio e vedere come può essere utilizzata come strumento per gli analisti di dati.
9. Prova l'applicazione
Nello stesso repository clonato abbiamo un'applicazione di esempio per la nostra società di logistica Cymbol. L'applicazione utilizza il framework Python Mesop di Google .
Puoi analizzare il codice dell'applicazione aprendo il file app.py nell'editor di Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/app.py
Nel codice utilizziamo una funzione per passare un nuovo prompt con variabili al nostro agente dati. Il motivo è poterlo configurare nell'interfaccia se decidiamo di chiamare un database o un'istanza diversi. Ecco la definizione della funzione e il prompt.
def run_query_sync(request_text, cluster_name, location, instance_name, database_name, project_id, session_id, summary):
local_runner = FrontendRunner()
instruction = f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
"""
...
Dopo aver esaminato il codice, premi il pulsante "Terminale" per avviare e testare la nostra applicazione. L'applicazione verrà avviata sulla porta 8080. Se vuoi modificare la porta, modifica il comando cambiando il valore della porta.
In Cloud Shell, esegui.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv run mesop app.py --port=8080
Quindi, utilizza l'anteprima web in Google Cloud Shell facendo clic su http://localhost:8080
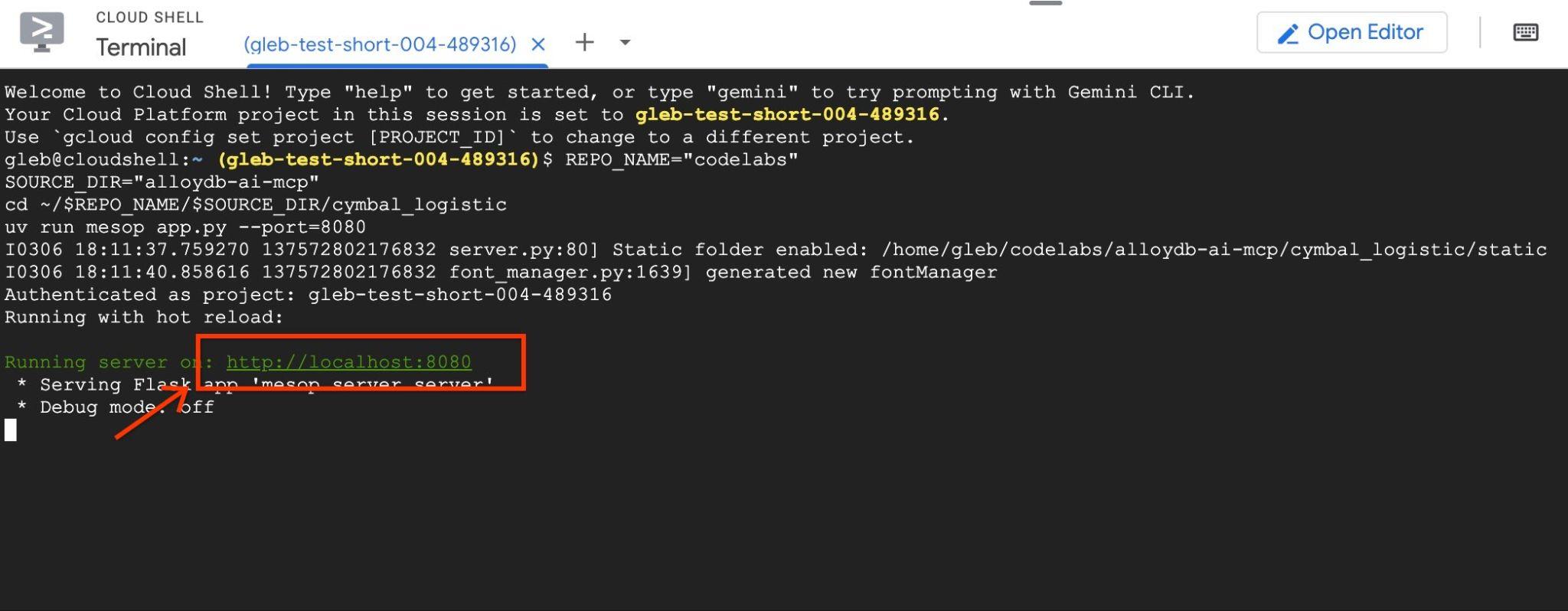
Si aprirà una nuova scheda nel browser con l'interfaccia dell'applicazione.
Fai clic sulla casella di controllo "Enable Debug Output" (Attiva output di debug) in alto a destra e digita una domanda come la seguente.
What was the average speed for each driver last month? List top 5 fasters drivers ranking them by the average speed. Show the name, distance and average speed for each of them.
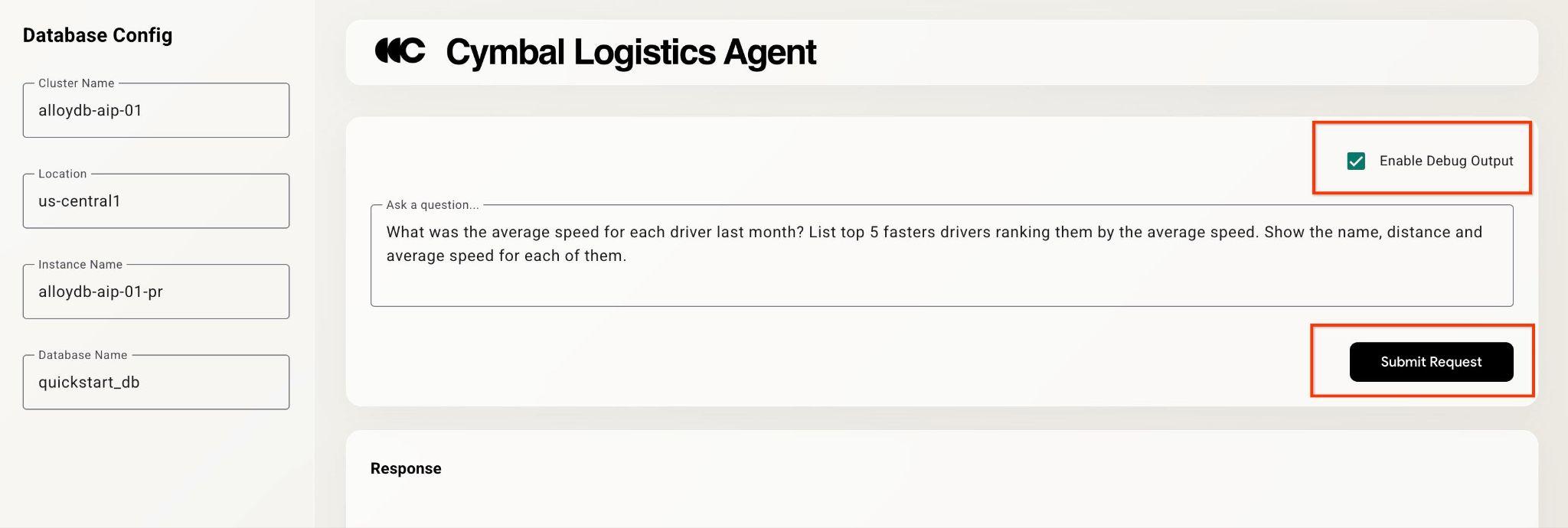
Quindi premi il pulsante Submit Request.
L'agente lavorerà in background e produrrà l'output e le informazioni di debug con tutte le query eseguite dal nostro set di strumenti MCP. Controlla le query per visualizzare il flusso di lavoro.
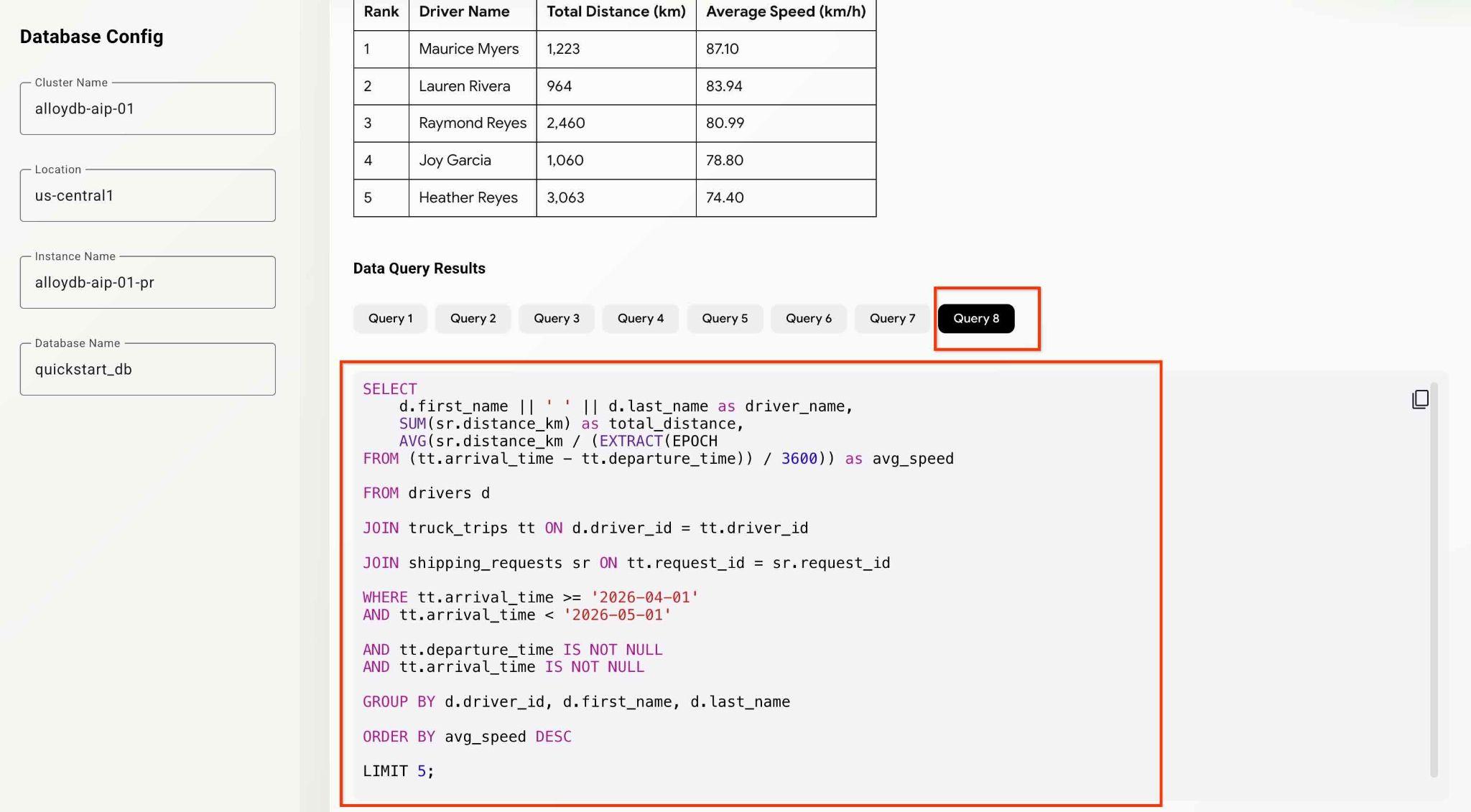
Puoi testare le funzionalità degli agenti e delle app provando diverse domande analitiche.
Finora hai potuto eseguire alcune analisi e ricerche di base utilizzando l'agente con MCP. Nel prossimo capitolo proverai a utilizzare funzionalità più avanzate di AlloyDB.
10. Funzioni di AlloyDB AI
Le funzioni di AlloyDB AI consentono il filtraggio e il ranking intelligenti di testo e dati multimodali (in particolare, immagini) e portano la potenza di Gemini nelle tue query. In particolare, le funzioni AI.IF e AI.RANK di AlloyDB AI possono essere visualizzate nelle istruzioni SQL insieme agli operatori SQL convenzionali (filtri, join, aggregazione e così via).
Prima di utilizzare le funzioni di AI, esaminiamo una ricerca e le aggregazioni utilizzando i metodi "classici". Prova il seguente prompt.
Can you analyze the activity for the last 5 months and evaluate drivers for the most positive customer feedbacks. Give me top 5 drivers listing names, distance and years of experience for each driver.
È in grado di trovare la colonna "Valutazione" nella tabella con il feedback dei clienti e utilizzarla per identificare i conducenti con la valutazione migliore. Poi ha utilizzato le informazioni per ottenere maggiori dettagli sui conducenti.
SELECT
d.first_name || ' ' || d.last_name as driver_name,
SUM(sr.distance_km) as total_distance,
d.experience_years,
COUNT(cf.feedback_id) as positive_feedback_count
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
WHERE tt.arrival_time >= '2025-12-01'
AND tt.arrival_time < '2026-05-01'
AND cf.rating >= 4
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY positive_feedback_count DESC, total_distance DESC
LIMIT 5;
Tuttavia, la classificazione potrebbe tecnicamente includere o meno tutti i parametri che vogliamo valutare. Per questo, possiamo utilizzare le funzioni AI di AlloyDB.
Operatori AI.RANK
La funzione ai.rank() assegna un punteggio in base alla pertinenza di un documento a una determinata query. Può essere utilizzato per il ranking o il riposizionamento dei risultati della query. Per saperne di più sugli operatori, consulta la documentazione.
Modifica la richiesta e chiedi esplicitamente di utilizzare AI.RANK durante l'analisi per valutare i conducenti in base alle loro prestazioni e alla loro professionalità.
Can you find the top 5 fastest drivers in the last month and rank them by the feedback using the AI.RANK function? Give me top drivers names, distance, years of experience and rank for each driver.
Il comando potrebbe richiedere un po' più di tempo, poiché l'agente deve capire come utilizzare la funzione AI.RANK, recuperare i dati e applicare AI.RANK per ordinare le informazioni di conseguenza. Alla fine dovresti ottenere l'elenco dei conducenti classificati in base al modello e l'elenco delle query eseguite.
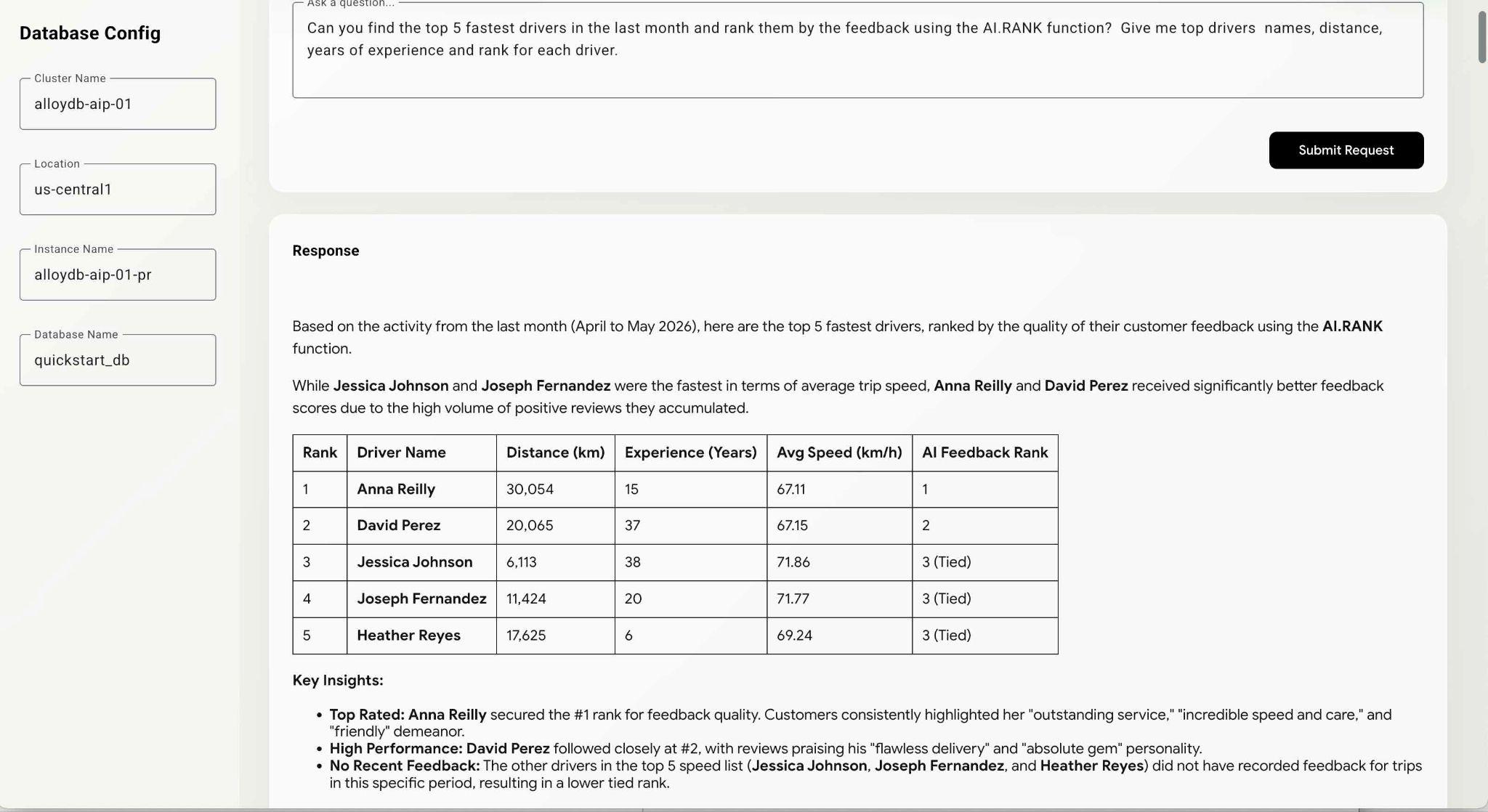
L'esecuzione di questa query potrebbe richiedere del tempo, a seconda del percorso scelto dal modello. Nella finestra di debug puoi visualizzare la query esatta eseguita per ottenere le informazioni sui conducenti.
WITH fastest_drivers AS (
SELECT
d.driver_id,
d.first_name || ' ' || d.last_name as driver_name,
d.experience_years,
SUM(sr.distance_km) as total_distance,
AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) as avg_speed,
COALESCE(STRING_AGG(cf.feedback_text, ' | '), 'No feedback') as feedbacks,
ROW_NUMBER() OVER (
ORDER BY AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) DESC) - 1 as row_idx
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
LEFT
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
WHERE tt.arrival_time >= '2026-04-04'
AND tt.arrival_time IS NOT NULL
AND tt.departure_time IS NOT NULL
AND tt.arrival_time > tt.departure_time
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY avg_speed DESC
LIMIT 5
)
SELECT
f.driver_name,
f.total_distance,
f.experience_years,
f.avg_speed,
f.feedbacks,
(SELECT r.score
FROM ai.rank(
'semantic-ranker-fast-004',
'excellent customer service, professional, friendly, fast,
and reliable delivery reviews',
ARRAY[f.feedbacks],
1
) r
LIMIT 1) as feedback_score
FROM fastest_drivers f
ORDER BY feedback_score DESC;
Puoi continuare a testare l'applicazione ed esaminare le query per vedere come l'agente arriva ai risultati finali.
Il lab è terminato. Spero che tu abbia potuto esaminare tutti gli esempi e imparare a utilizzare il servizio Google Cloud MCP per AlloyDB. Per far funzionare MCP per l'azienda, è opportuno combinare MCP con le funzionalità NL2SQL di AlloyDB descritte nella documentazione di AlloyDB. Puoi provarlo utilizzando la codelab sulla generazione di istruzioni SQL per AlloyDB.
11. Liberare spazio nell'ambiente
Per evitare addebiti imprevisti, è buona norma liberare spazio dalle risorse temporanee. Il modo più affidabile è eliminare il progetto in cui hai testato il flusso di lavoro. In alternativa, puoi limitare l'utilizzo eliminando singole risorse, come AlloyDB.
Elimina le istanze e il cluster AlloyDB al termine del lab.
Elimina il cluster AlloyDB e tutte le istanze
Se hai utilizzato la versione di prova di AlloyDB. Non eliminare il cluster di prova se prevedi di testare altri lab e risorse utilizzando il cluster di prova. Non potrai creare un altro cluster di prova nello stesso progetto.
Il cluster viene eliminato con l'opzione force, che elimina anche tutte le istanze appartenenti al cluster.
In Cloud Shell definisci le variabili di progetto e di ambiente se la connessione è stata interrotta e tutte le impostazioni precedenti sono andate perse:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Elimina il cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Elimina i backup di AlloyDB
Elimina tutti i backup AlloyDB per il cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Complimenti
Congratulazioni per aver completato il codelab.
Argomenti trattati
- Come creare un cluster AlloyDB e importare dati di esempio
- Come abilitare l'API di accesso ai dati di AlloyDB
- Come attivare Google Cloud MCP per AlloyDB NL
- Come aggiungere Google Cloud MCP per AlloyDB all'agente ADK
- Come utilizzare Google Cloud MCP per AlloyDB in un'applicazione
- Come utilizzare gli agenti con AlloyDBMCP per l'analisi
13. Sondaggio
Output: