
1. はじめに
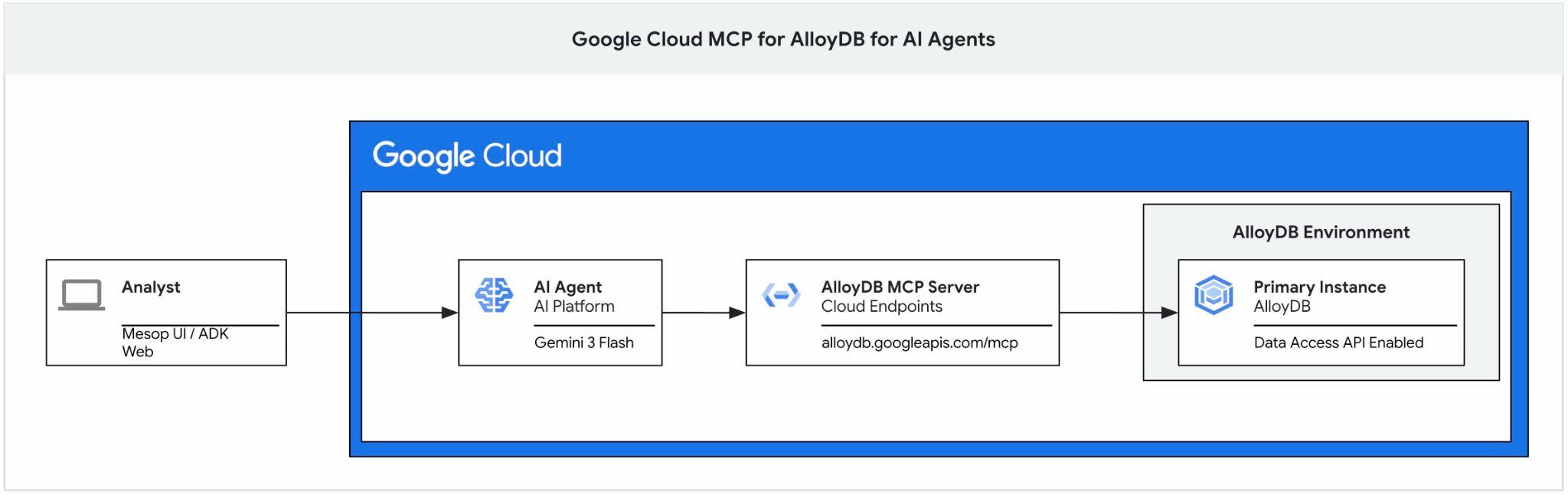
この Codelab では、AlloyDB 用 Google Cloud MCP サーバーを使い始める方法と、AI エージェントのツールセットの一部として有効にしてアプリケーションの一部として使用する方法について説明します。
前提条件
- Google Cloud とコンソールの基本的な知識
- コマンドライン インターフェースと Cloud Shell の基本的なスキル
学習内容
- AlloyDB クラスタを作成してサンプルデータをインポートする方法
- AlloyDB Data access API を有効にする方法
- AlloyDB NL で Google Cloud MCP を有効にする方法
- AlloyDB 用 Google Cloud MCP を ADK エージェントに追加する方法
- アプリケーションで AlloyDB 用 Google Cloud MCP を使用する方法
- 分析に AlloyDBMCP でエージェントを使用する方法
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- Google Cloud コンソールと Cloud Shell をサポートするウェブブラウザ(Chrome など)
2. 設定と要件
プロジェクトのセットアップ
- Google Cloud コンソールにログインします。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。
仕事用または学校用アカウントではなく、個人アカウントを使用する。
- 新しいプロジェクトを作成するか、既存のプロジェクトを再利用します。Google Cloud コンソールで新しいプロジェクトを作成するには、ヘッダーで [プロジェクトを選択] ボタンをクリックします。ポップアップ ウィンドウが開きます。

[プロジェクトを選択] ウィンドウで [新しいプロジェクト] ボタンを押すと、新しいプロジェクトのダイアログ ボックスが開きます。
ダイアログ ボックスで、任意のプロジェクト名を入力し、ロケーションを選択します。
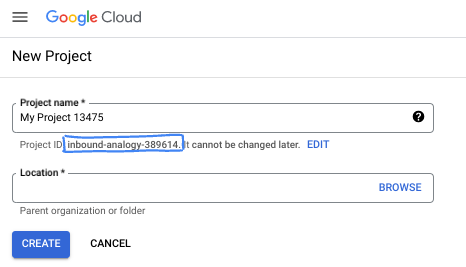
- プロジェクト名は、このプロジェクトの参加者に表示される名称です。プロジェクト名は Google API では使用されず、いつでも変更できます。
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Google Cloud コンソールでは一意の ID が自動的に生成されますが、カスタマイズすることもできます。生成された ID が気に入らない場合は、別のランダムな ID を生成するか、独自の ID を指定して使用可能かどうかを確認できます。ほとんどの Codelab では、プロジェクト ID を参照する必要があります。通常、プロジェクト ID はプレースホルダ PROJECT_ID で識別されます。
- なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
課金を有効にする
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 3 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud Console で、右上のツールバーにある Cloud Shell アイコンをクリックします。
または、G キーを押してから S キーを押します。このシーケンスは、Google Cloud コンソール内からアクセスした場合、またはこのリンクを使用した場合に Cloud Shell をアクティブにします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
3. はじめに
API を有効にする
AlloyDB、Compute Engine、ネットワーキング サービス、Vertex AI を使用するには、Google Cloud プロジェクトでそれぞれの API を有効にする必要があります。
Cloud Shell ターミナルで、プロジェクト ID が設定されていることを確認します。
gcloud config get-value project
Google プロジェクト ID が返されます。
環境変数 PROJECT_ID を設定します。
PROJECT_ID=$(gcloud config get-value project)
必要なサービスをすべて有効にします。
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
想定される出力
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB をデプロイする
AlloyDB クラスタとプライマリ インスタンスを作成します。必要なリソースをすべてデプロイする準備済みのスクリプトを使用してデプロイすることも、ドキュメントに沿って手順ごとに自分でデプロイすることもできます。
自動化スクリプトを使用して AlloyDB をデプロイする
このアプローチでは、自動化されたスクリプトを使用して AlloyDB クラスタをデプロイし、デプロイされたリソースの操作を開始するために必要な情報を提供します。
Cloud Shell ターミナルでコマンドを実行して、リポジトリからデプロイ スクリプトのクローンを作成します。
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-ai-mcp"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
デプロイ スクリプトを実行します。
./deploy_alloydb.sh
スクリプトの実行には時間がかかります(通常は 5 ~ 7 分ほど)。出力として、デプロイされた AlloyDB クラスタに関する情報が表示されます。パスワードは異なります。後で使用できるように、パスワードをどこかに記録しておいてください。
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
新しいクラスタとプライマリ インスタンスは、ウェブ コンソールでも確認できます。
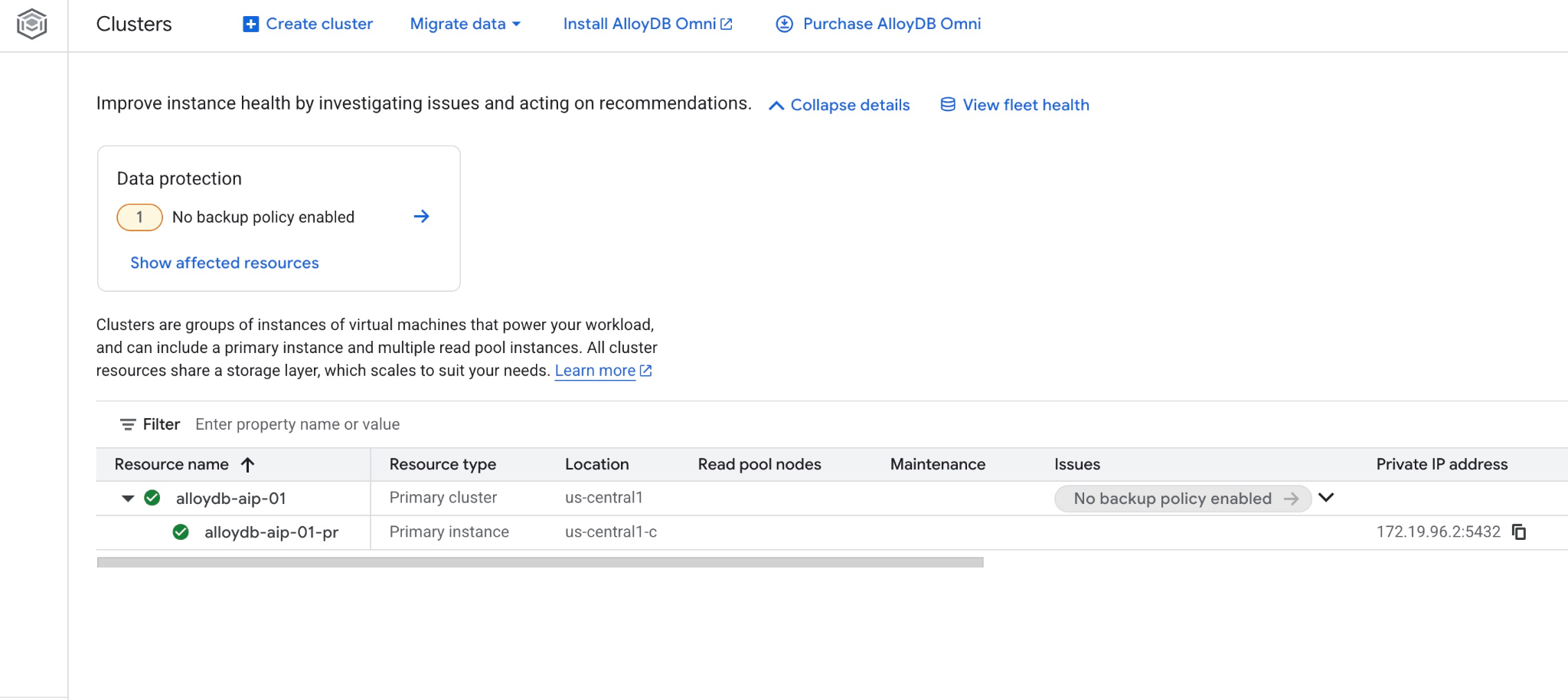
5. データベースを準備する
AI 関数と演算子を使用するには、Vertex AI インテグレーションを有効にし、データアクセス API を有効にして、サンプル データセットのデータベースを作成する必要があります。
AlloyDB に必要な権限を付与する
AlloyDB サービス エージェントに Vertex AI 権限を追加します。
上部の「+」記号を選択して、別の Cloud Shell タブを開きます。
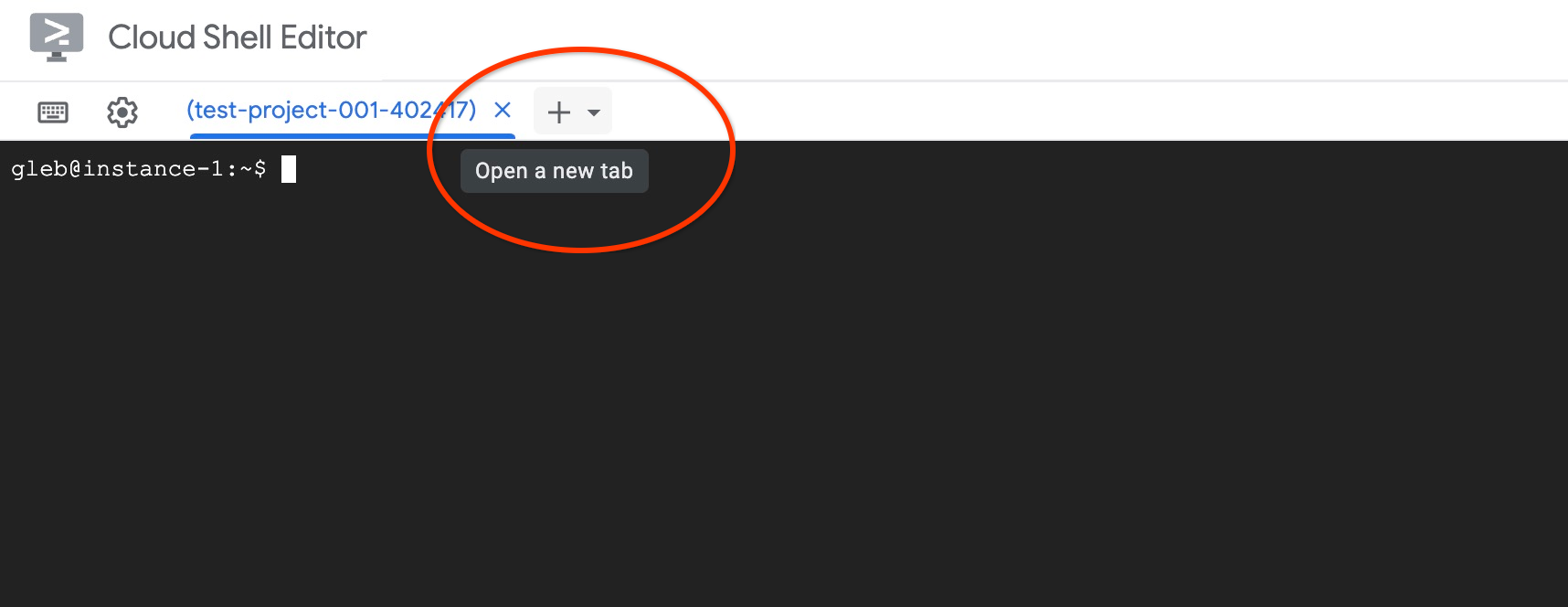
新しい Cloud Shell タブで、次のコマンドを実行します。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/discoveryengine.viewer"
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... < redacted > etag: BwYIEbe_Z3U= version: 1
データアクセス API を有効にする
execute_sql などの MCP ツールを使用するには、AlloyDB クラスタで Data Access API を有効にする必要があります。
同じターミナル タブで実行します。
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
インスタンス フラグを更新
AlloyDB で高度な AI 関数を使用するには、一部のデータベース フラグを有効にする必要があります。Data Access API を有効にしてから、次の変更の準備ができたインスタンスが表示されるまでに数分かかることがあります。コンソールでインスタンスのステータスを確認し、緑色のチェックマークが表示されていることを確認してください。
同じターミナル タブで実行します。
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags=google_ml_integration.enable_model_support=on,google_ml_integration.enable_ai_query_engine=on,google_ml_integration.enable_preview_ai_functions=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
MCP を有効にする
次のステップでは、プロジェクトで AlloyDB 用の Google Cloud MCP サーバーを有効にします。デフォルトでは MCP は有効になっていません。MCP は、IAM 認証と認可、データアクセス API、クラスタ内のロールなど、複数の保護レイヤの 1 つです。
同じターミナル タブで実行します。
PROJECT_ID=$(gcloud config get-value project)
gcloud beta services mcp enable alloydb.googleapis.com \
--project=$PROJECT_ID
タブに実行コマンド「exit」を入力して、タブを閉じます。
exit
AlloyDB Studio に接続する
以降の章では、データベースへの接続を必要とするすべての SQL コマンドを AlloyDB Studio で実行できます。T
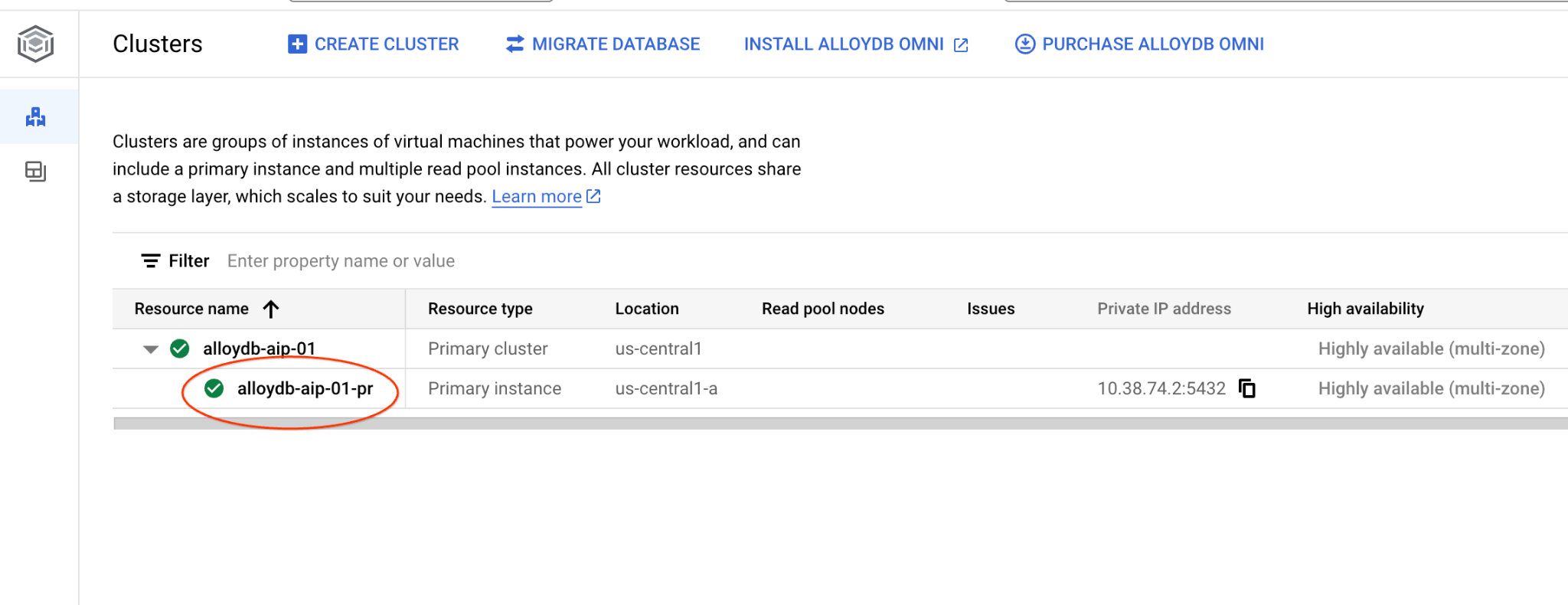
AlloyDB for Postgres の [クラスタ] ページに移動します。
プライマリ インスタンスをクリックして、AlloyDB クラスタのウェブ コンソール インターフェースを開きます。
次に、左側の [AlloyDB Studio] をクリックします。
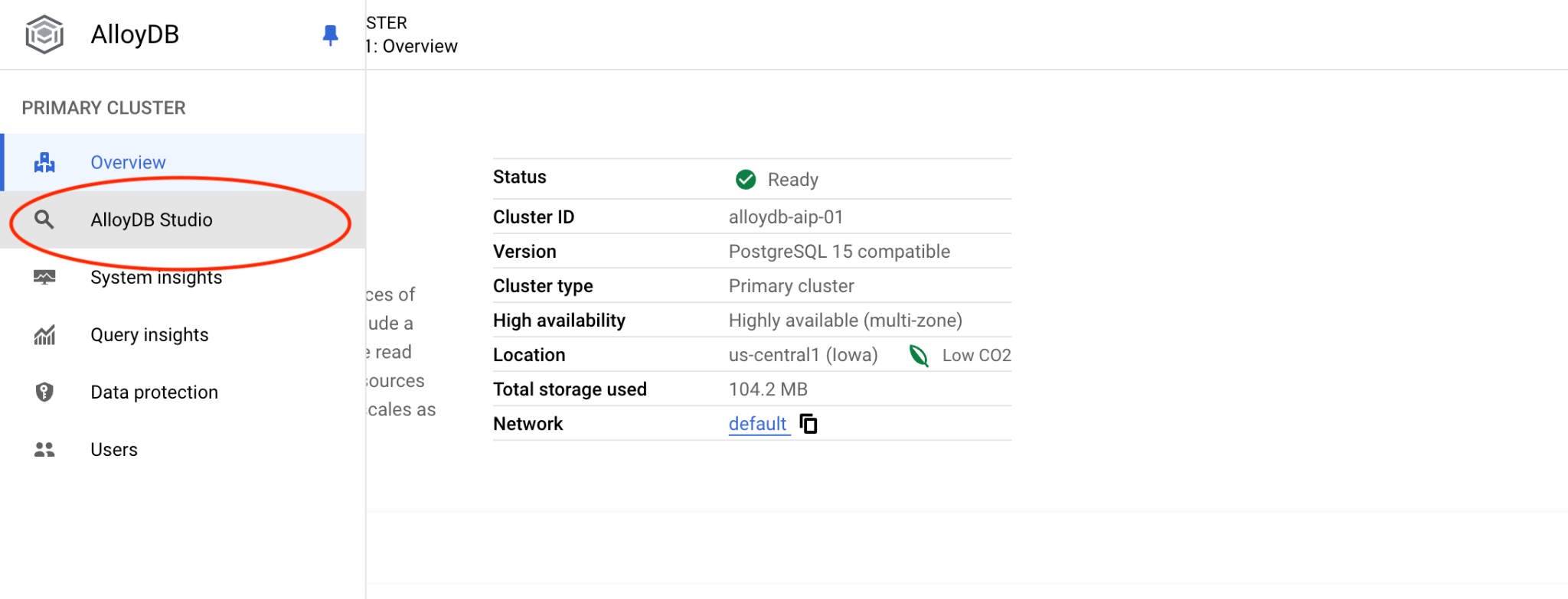
postgres データベースとユーザー postgres を選択し、クラスタの作成時にメモしたパスワードを入力します。[認証] ボタンをクリックします。
パスワードが機能しない場合や、パスワードをメモし忘れた場合は、パスワードを変更できます。方法については、ドキュメントをご覧ください。
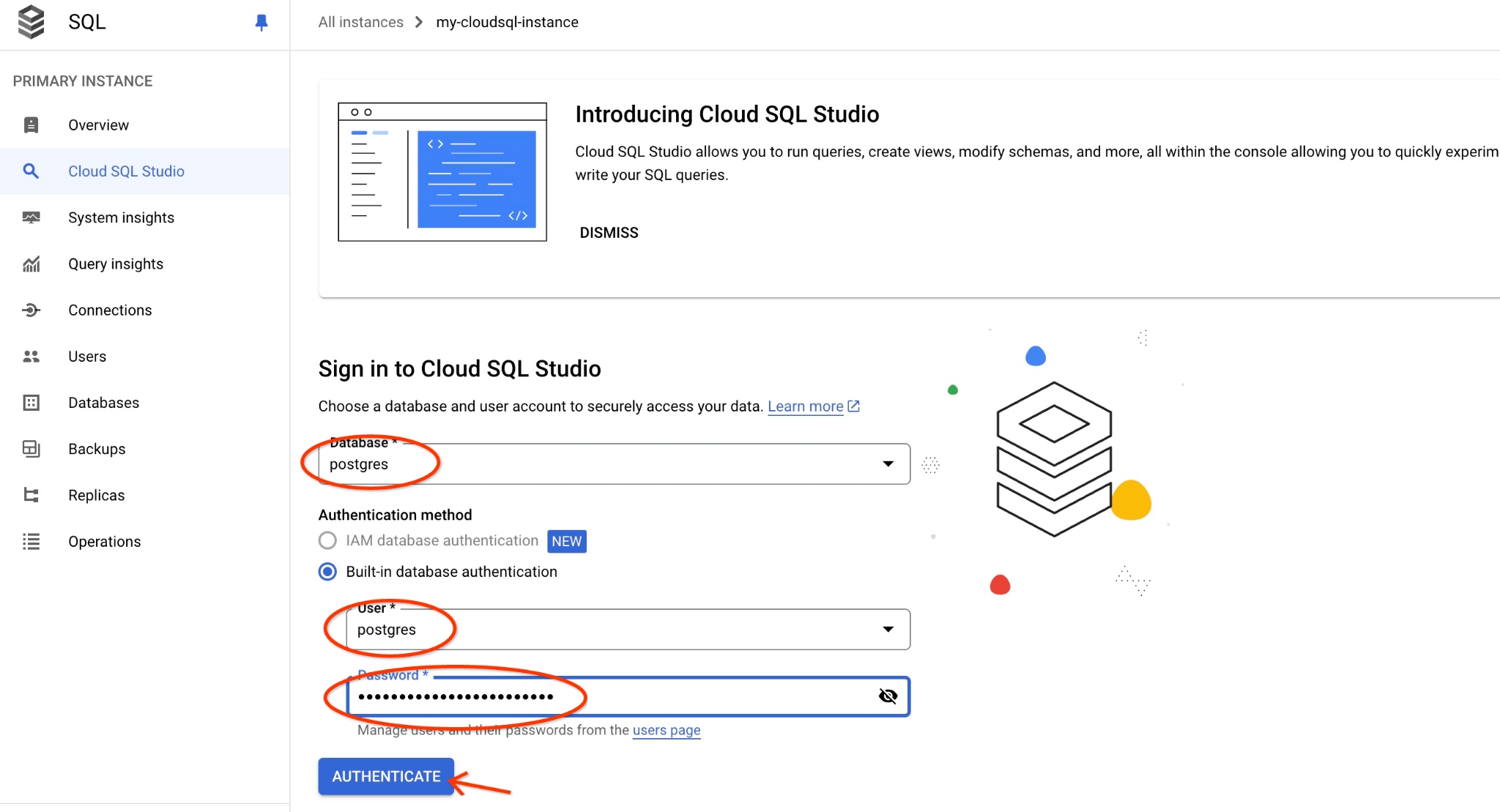
AlloyDB Studio インターフェースが開きます。データベースでコマンドを実行するには、右側の [無題のクエリ] タブをクリックします。
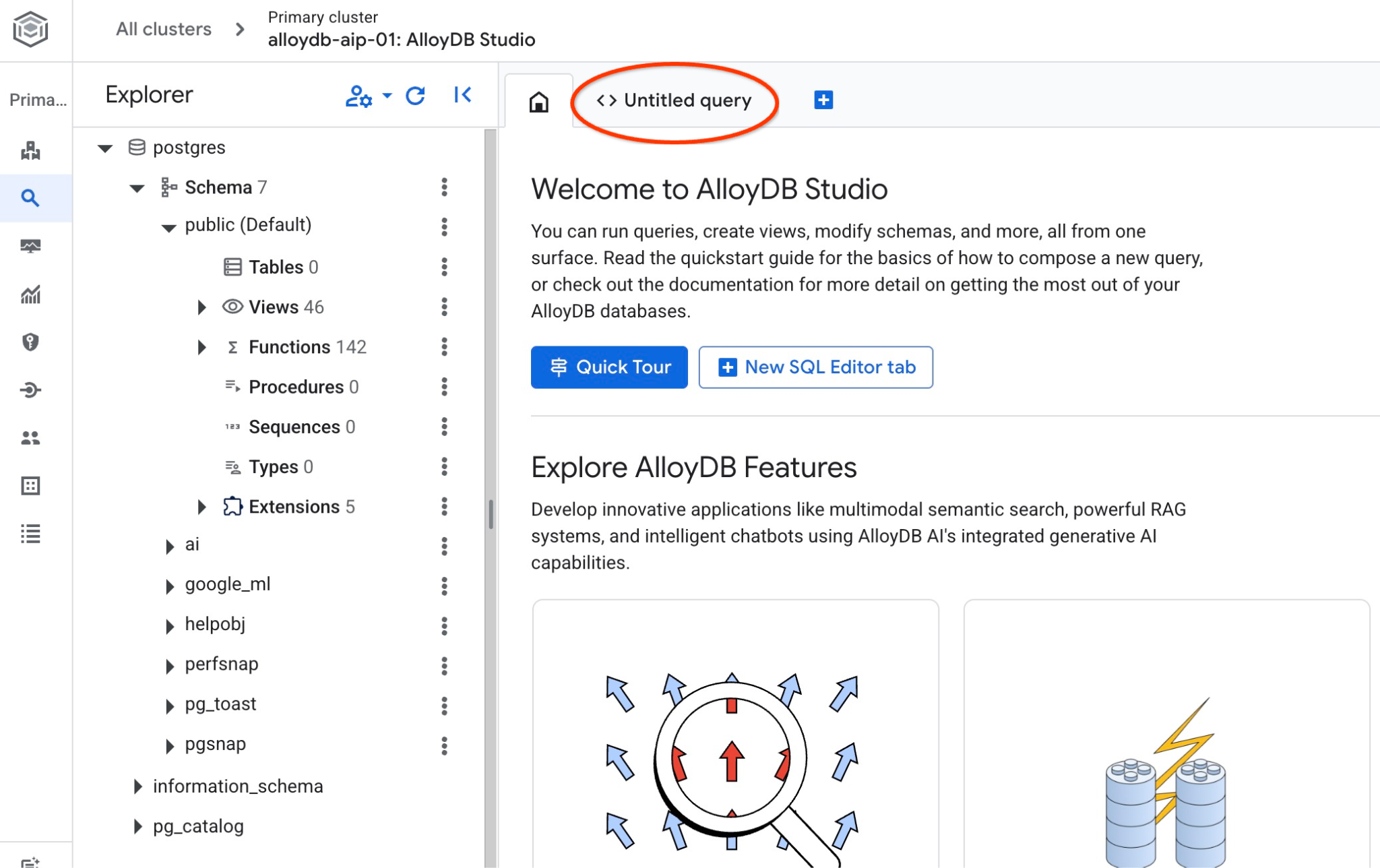
SQL コマンドを実行できるインターフェースが開きます。
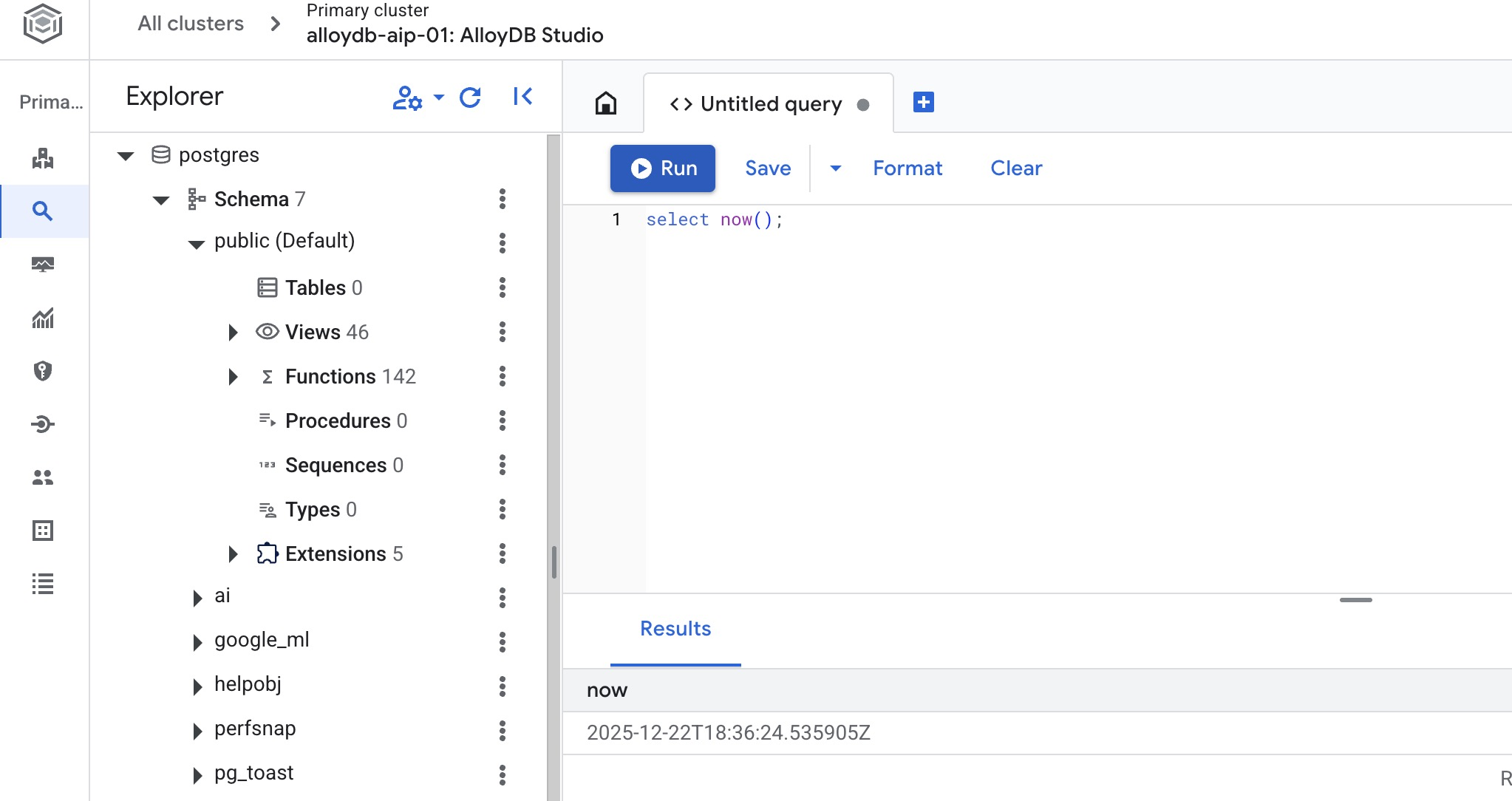
データベースを作成する
データベース作成のクイックスタート。
AlloyDB Studio エディタで、次のコマンドを実行します。
データベースを作成します。
CREATE DATABASE quickstart_db
予想される出力:
Statement executed successfully
quickstart_db に接続する
データベースに接続して、データベースが作成されているかどうかを確認します。ユーザー/データベースを切り替えるボタンを使用して、スタジオに再接続します。
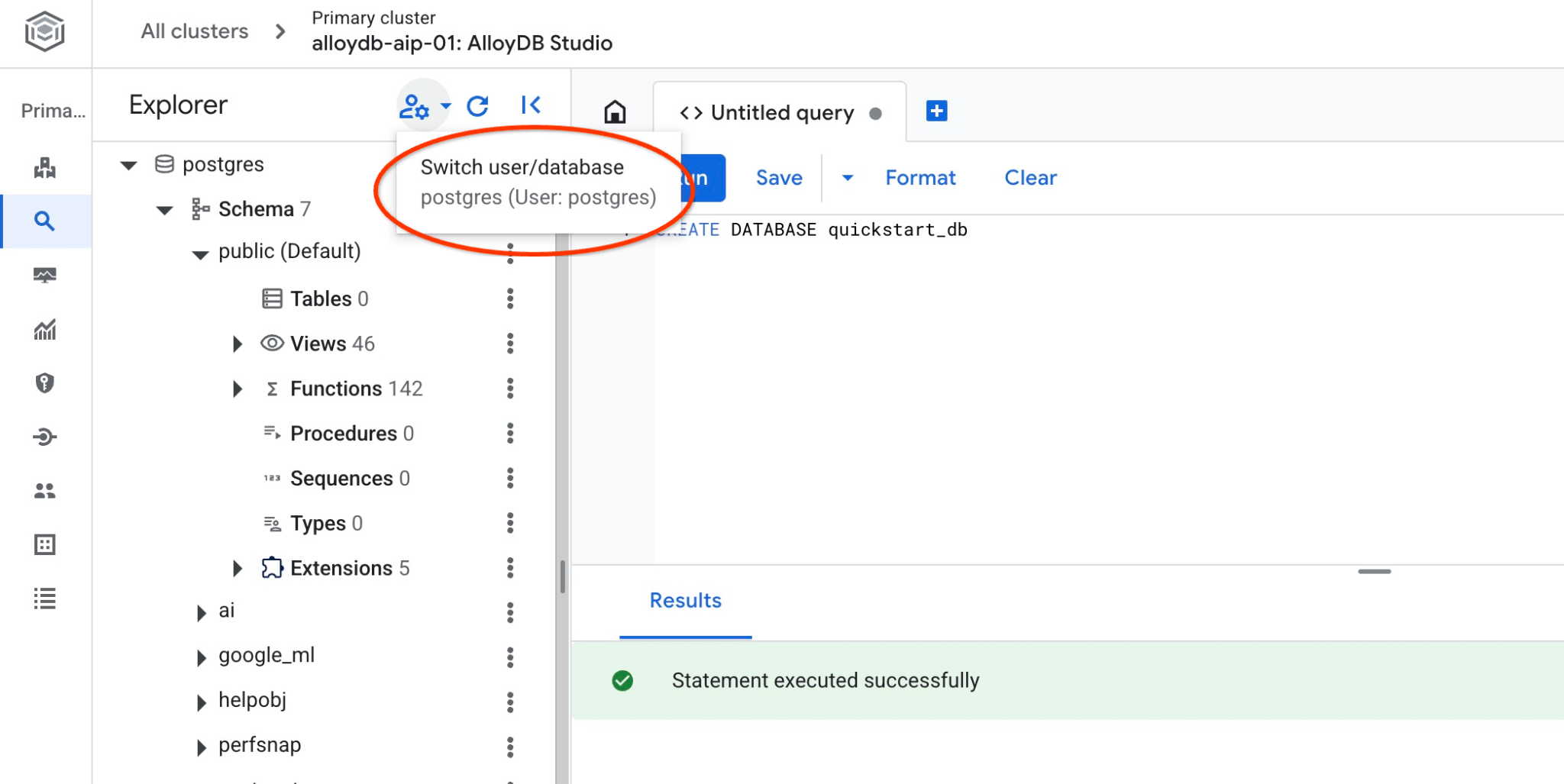
プルダウン リストから新しい quickstart_db データベースを選択し、以前と同じユーザーとパスワードを使用します。
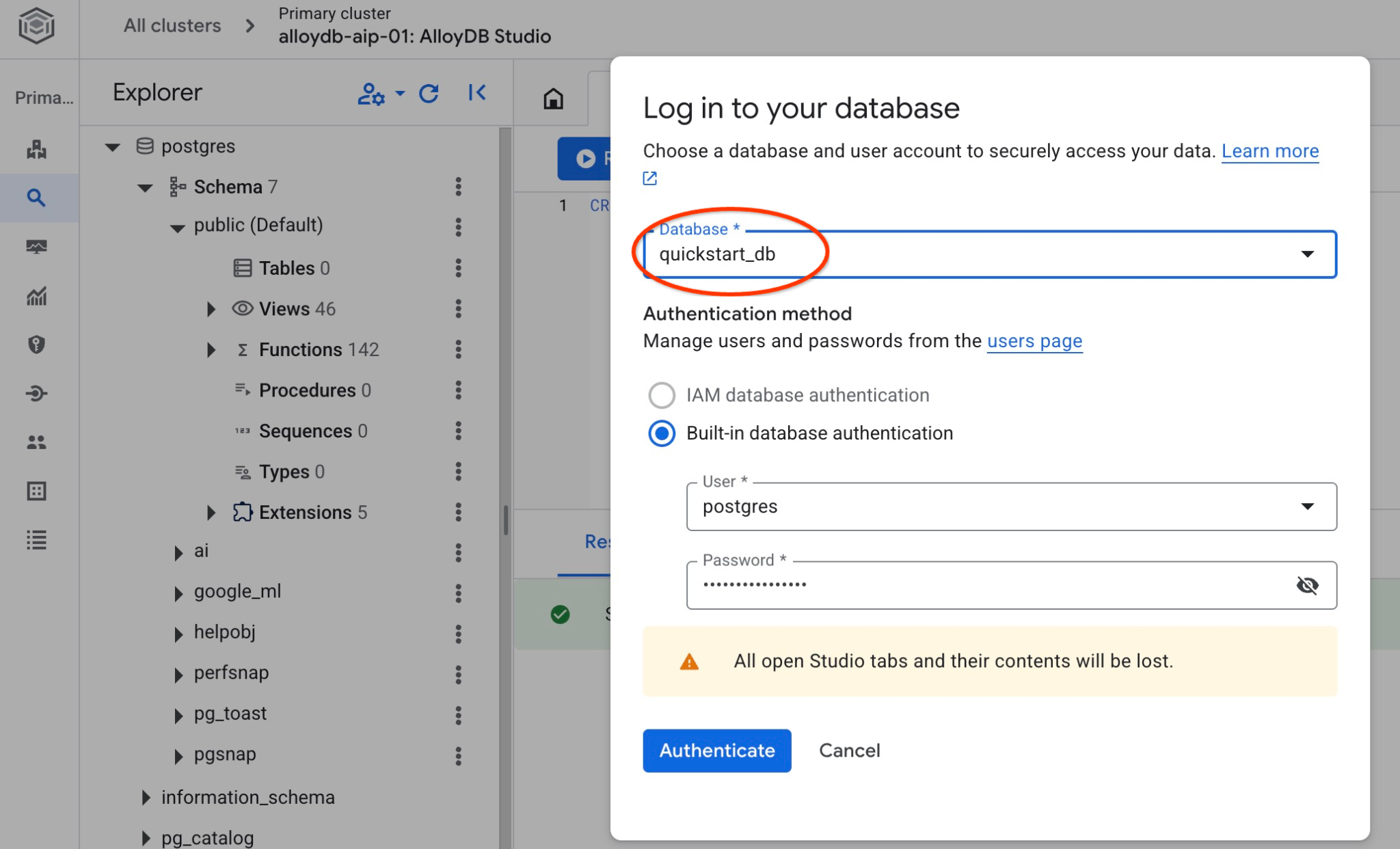
新しい接続が開き、quickstart_db データベースのオブジェクトを操作できます。ここで、インポートしたスキーマとデータを確認できます。
6. サンプルデータ
次に、データベースにオブジェクトを作成してデータを読み込む必要があります。架空の Cymbal Shipping 社のデータセットを使用します。商品、トラック、リクエスト、トラックの走行に関する架空のデータと、架空のドライバーが含まれています。
ストレージ バケットを作成する
Google SDK(gcloud)を使用して、クローンされたリポジトリから AlloyDB データベースにデータをインポートします。そのため、ストレージ バケットを作成し、AlloyDB サービス アカウントにアクセス権を付与する必要があります。また、ドキュメントに記載されているように、ウェブ コンソールを使用していつでも実行できます。
Google Cloud Shell ターミナルで、次のコマンドを実行します。
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
データの読み込み
次のステップは、データを読み込むことです。SQL ダンプは、クローン作成されたリポジトリ フォルダにあります。次のコマンドは、AlloyDB クラスタの作成時に前の手順でリポジトリをクローンしたときに、ホーム ディレクトリを開始点として使用したことを前提としています。
圧縮された SQL ダンプを新しいストレージ バケットにコピーします。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
次に、データを quickstart_db データベースに読み込みます。
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
このコマンドは、サンプル データセットを quickstart_db データベースに読み込みます。AlloyDB Studio を使用して、テーブルとレコードを確認できます。
7. Data Agent を操作する
まず、Python 用 Google ADK を使用して作成された AI エージェントのサンプルから始め、AlloyDB 用 Google Cloud MCP サーバーで動作するように構成する方法を説明します。
エージェントのソースコードを確認する
クローンされたリポジトリで、Google Cloud Shell エディタを使用してエージェント コードを確認します。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/data_agent/agent.py
エージェントには、AlloyDB 用の Google Cloud MCP サーバーのセクションがあります。エンドポイントを MCP_SERVER_URL として提供し、認証、プロジェクト ID を MCP ツールセットに追加します。
# Google Cloud MCP Server for AlloyDB
MCP_SERVER_URL = "https://alloydb.googleapis.com/mcp"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
# 2. Configure MCP Toolset
# We use StreamableHTTPConnectionParams to pass the auth header
headers = {
"Authorization": f"Bearer {creds.token}",
"X-Goog-User-Project": project_id
}
connection_params = StreamableHTTPConnectionParams(
url=MCP_SERVER_URL,
headers=headers,
timeout=300.0,
sse_read_timeout=600.0
)
mcp_toolset = McpToolset(connection_params=connection_params)
エージェント コードでは、MCP ツールセットはエージェントの tools パラメータとして含まれています。また、エージェント プロンプトの変数として、クラスタ名、インスタンス名、リージョン、データベースもあります。
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
""",
tools=[mcp_toolset],
)
AlloyDB 用の Google Cloud MCP サービスには、事前定義されたツールセットがあります。使用可能なすべてのツールを一覧表示するには、Cloud Shell コンソール ターミナルから次のコマンドを使用して curl コマンドを実行します。AlloyDB 用 Google Cloud MCP サーバーの最新のリファレンスは、常にドキュメントで確認できます。
curl -s -X POST http://alloydb.googleapis.com/mcp \
-H "Content-Type: application/json" \
-d @- <<EOF | jq -r '.result.tools[].name'
{
"id": "my_id_01",
"jsonrpc": "2.0",
"method": "tools/list"
}
EOF
エージェントを起動する
Google ADK ウェブ インターフェースを使用して、エージェントをインタラクティブ モードで起動できるようになりました。ADK のウェブ インターフェースを使用すると、エージェントのワークフローを簡単にテストしてトラブルシューティングできます。
まず、uv パッケージ マネージャーを使用して、Python に必要なパッケージをすべてインストールします。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv sync
すべてのパッケージがインストールされたら、.env ファイルをエージェント ディレクトリに追加して、AI モデルとのすべての通信に Vertex AI を使用するように指示する必要があります。
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
その後、エージェントを起動できます。
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
次のような出力が表示されます。エンドポイントは http://127.0.0.1:8000 のようになります。
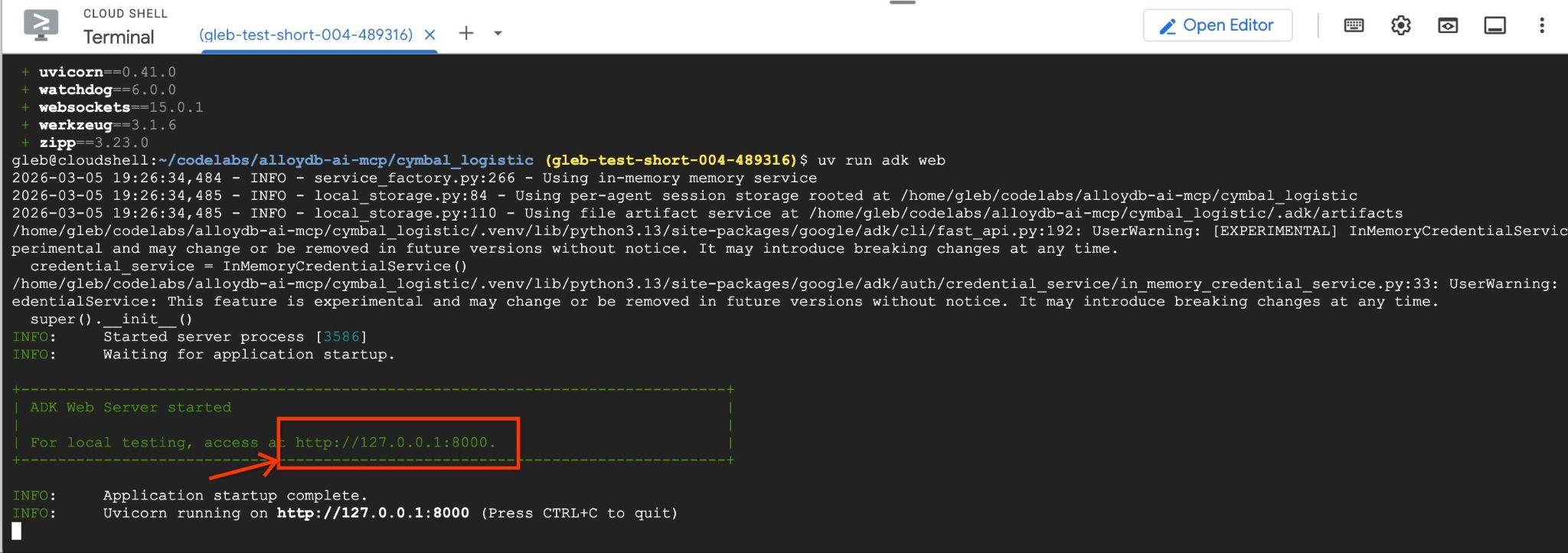
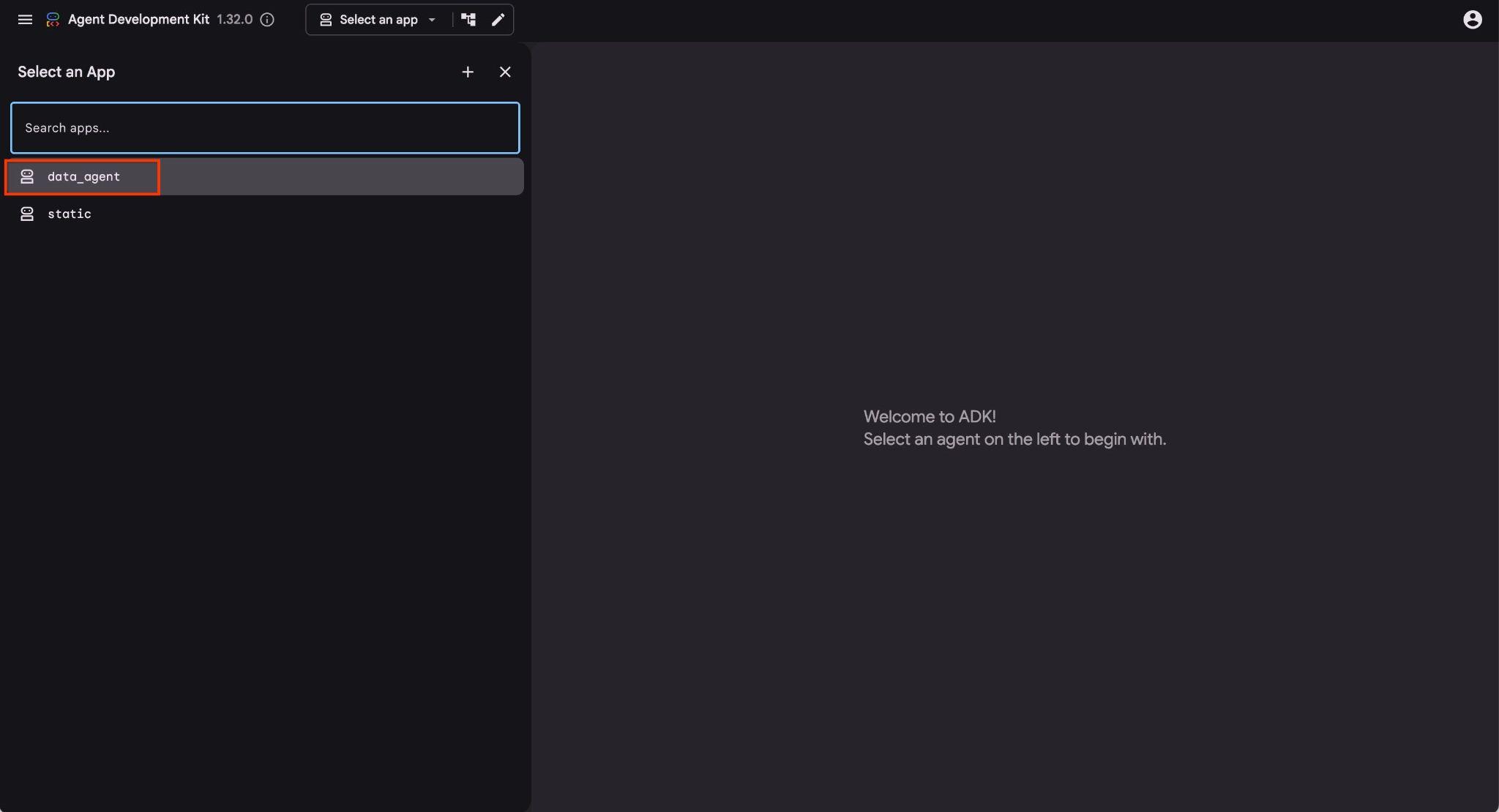
クラウド シェルでその URL をクリックすると、別のブラウザタブでプレビュー ウィンドウが開き、左側のプルダウン リストから data_agent を選択できます。
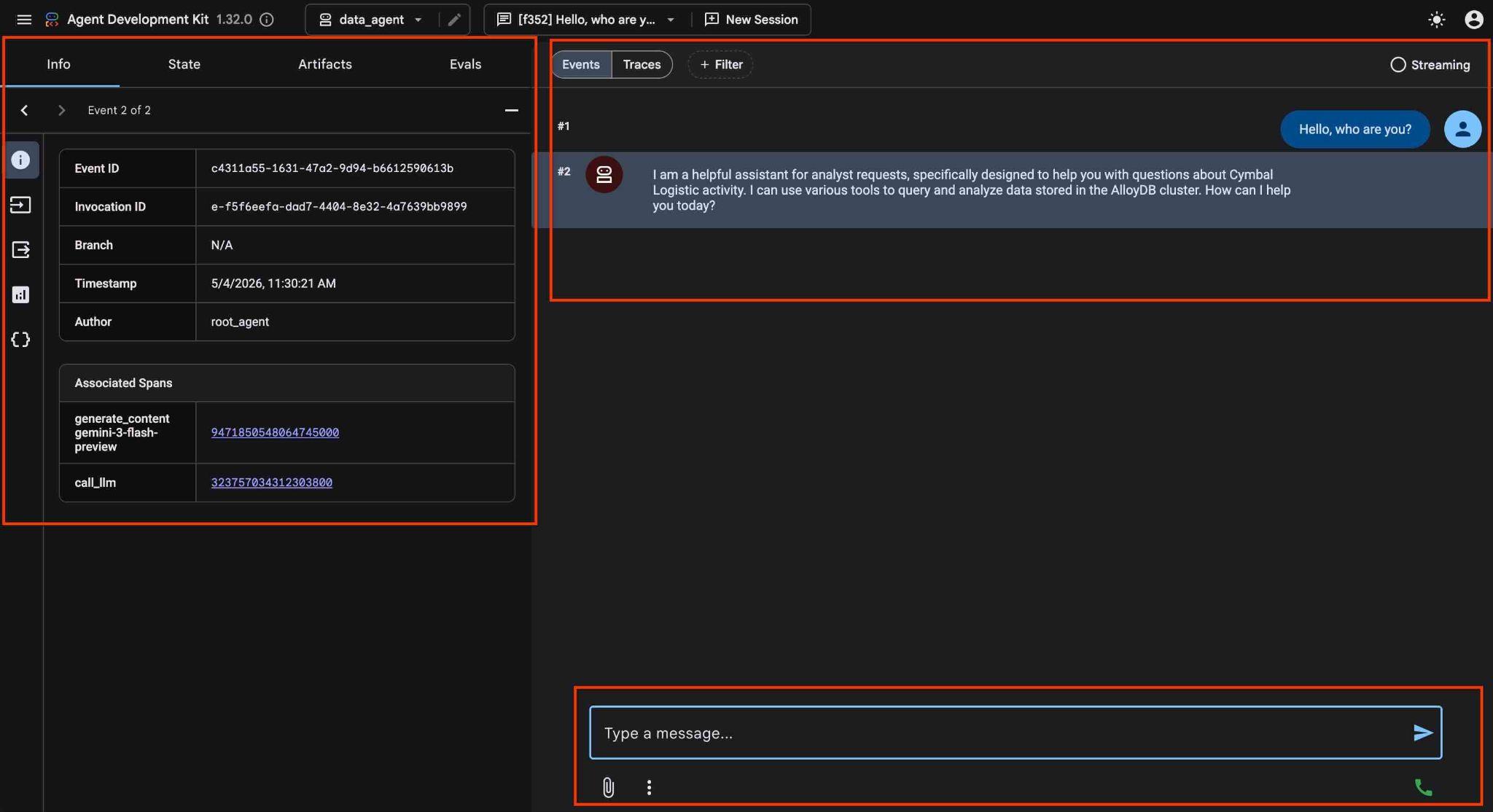
ADK ウェブ インターフェースでは、右下に質問を投稿できます。右側には、各ステップのトレースを含む実行フロー全体が表示されます。
8. エージェントで AlloyDB MCP をテストする
エージェントを使用すると、自然言語を使用して自由形式で質問できます。エージェントは、Google Cloud MCP サーバー for AlloyDB をツールとして使用して質問に回答します。質問は右下に投稿され、ツールへのすべての呼び出しを含む回答が上部に表示されます。
あなたは、配送リクエスト、トラック、ドライバー、ドライバーによる配送に関する情報を含む運送会社の運用データを扱っています。最初の質問は、2026 年 2 月に実行された乗車回数に関するものです。
右下の入力フィールドに次のように入力して、Enter キーを押します。
Hello, can you tell me how many trips we've done in February this year?
エージェントは、複数のツール呼び出しを実行してスキーマ内の正しいテーブルとテーブル構造を特定してから、正しい SQL ステートメントを実行して正しいデータを取得します。
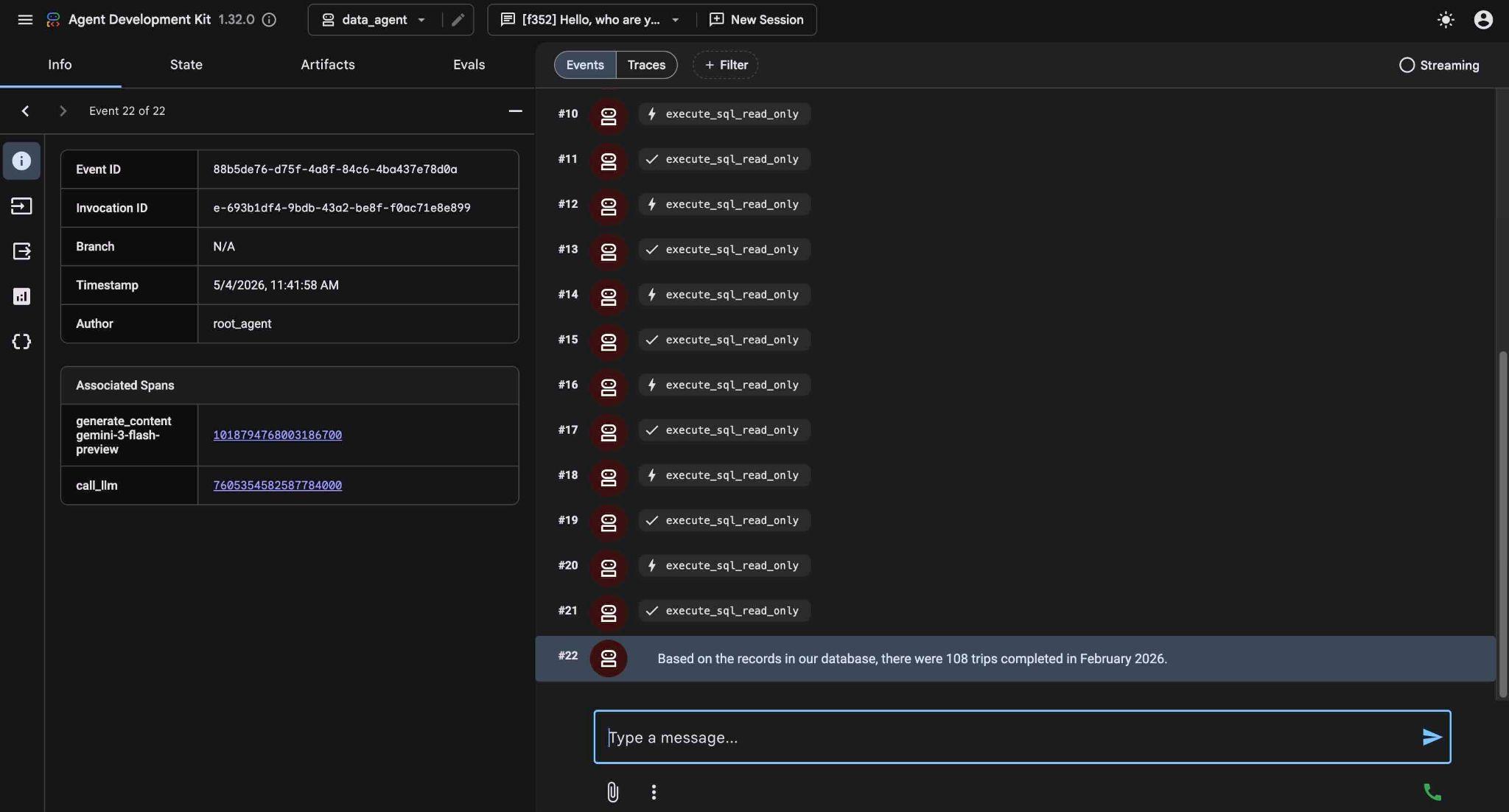
最終的に、適切なクエリを作成してデータベースで実行した後、結果が生成されます。
データベースの記録によると、2026 年 2 月に完了した乗車は 108 回でした。
ツール実行をクリックすると、各ツール呼び出しの処理内容を確認できます。たとえば、結果を取得するために実行されたクエリは次のとおりです。
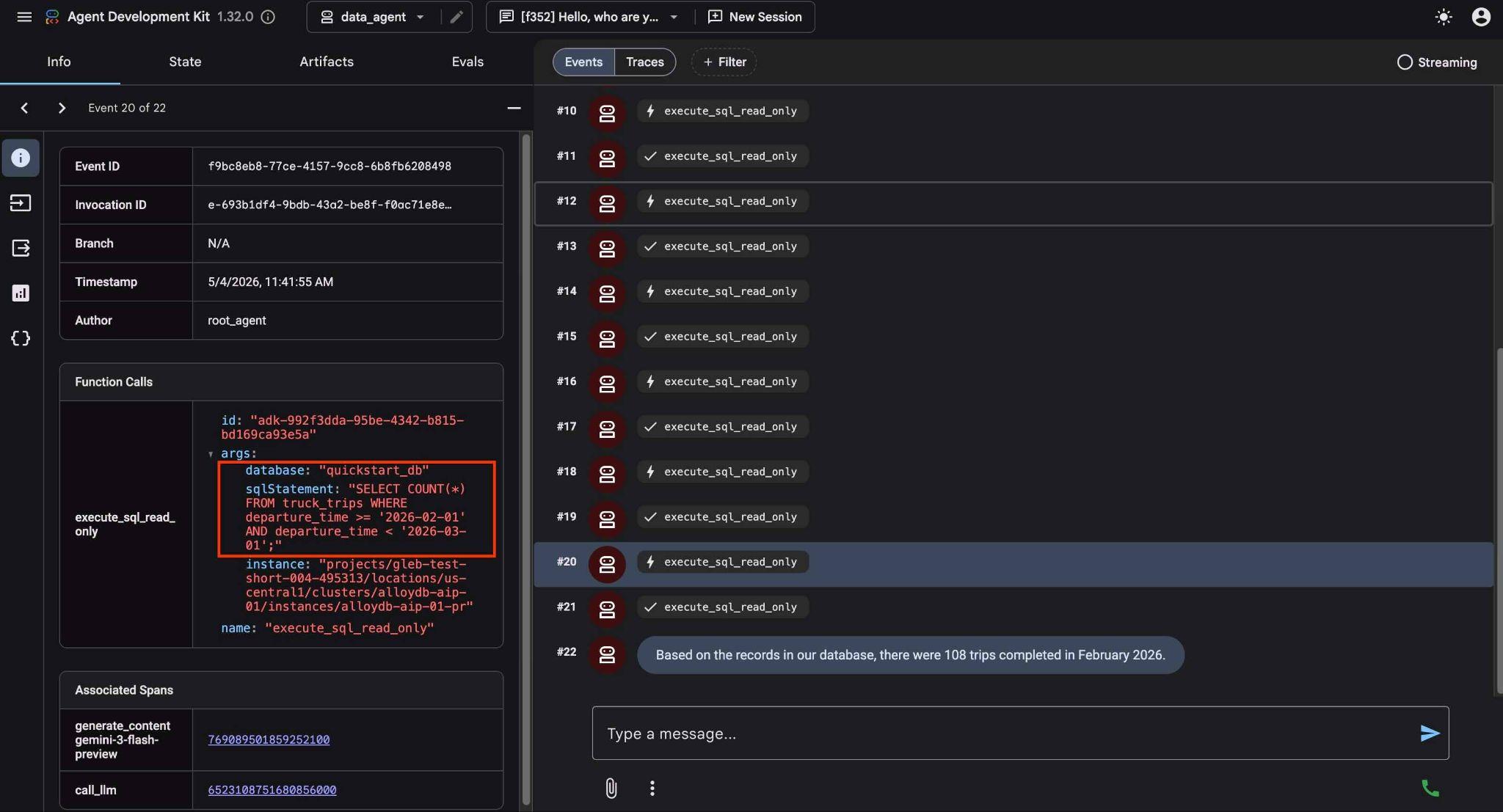
次に、前月との結果を比較するようリクエストを複雑にします。
How is it in comparison in numbers and mileage with the January?
結果を分析し、乗車回数と走行距離の差を求めるさまざまなクエリを実行して、結果を返します。
In comparison to January 2026, February saw a slight decrease in both the number of trips and the total mileage: January 2026: 114 trips with a total mileage of 185,597 km. February 2026: 108 trips with a total mileage of 177,893 km. This represents a decrease of 6 trips and 7,704 km in mileage for February compared to January.
ADK ウェブ インターフェースを使用して他の簡単なリクエストを試し、さまざまなクエリを実行して結果を取得する方法を確認します。
ターミナルで ctrl+c を押してエージェントを停止します。ADK ウェブ インターフェースのブラウザタブを閉じます。
サンプル アプリケーションを試して、データ アナリストのツールとしてどのように使用できるかを確認してみましょう。
9. サンプル アプリケーション
同じクローン作成されたリポジトリに、Cymbol Logistic 社のサンプル アプリケーションがあります。このアプリケーションは、Google Mesop Python フレームワークを使用しています。
Cloud Shell エディタで app.py ファイルを開いて、アプリケーション コードを分析できます。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/app.py
コードでは、関数を使用して、変数を含む新しいプロンプトをデータ エージェントに渡します。これは、別のデータベースやインスタンスを呼び出す場合に、インターフェースで構成できるようにするためです。関数定義とプロンプトは次のとおりです。
def run_query_sync(request_text, cluster_name, location, instance_name, database_name, project_id, session_id, summary):
local_runner = FrontendRunner()
instruction = f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
"""
...
コードを確認したら、[terminal] ボタンを押してアプリケーションを起動し、テストします。アプリケーションがポート 8080 で起動します。ポートを変更する場合は、ポート値を変更してコマンドを調整します。
Cloud Shell で実行します。
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv run mesop app.py --port=8080
次に、http://localhost:8080 をクリックして、Google Cloud Shell でウェブ プレビューを使用します。
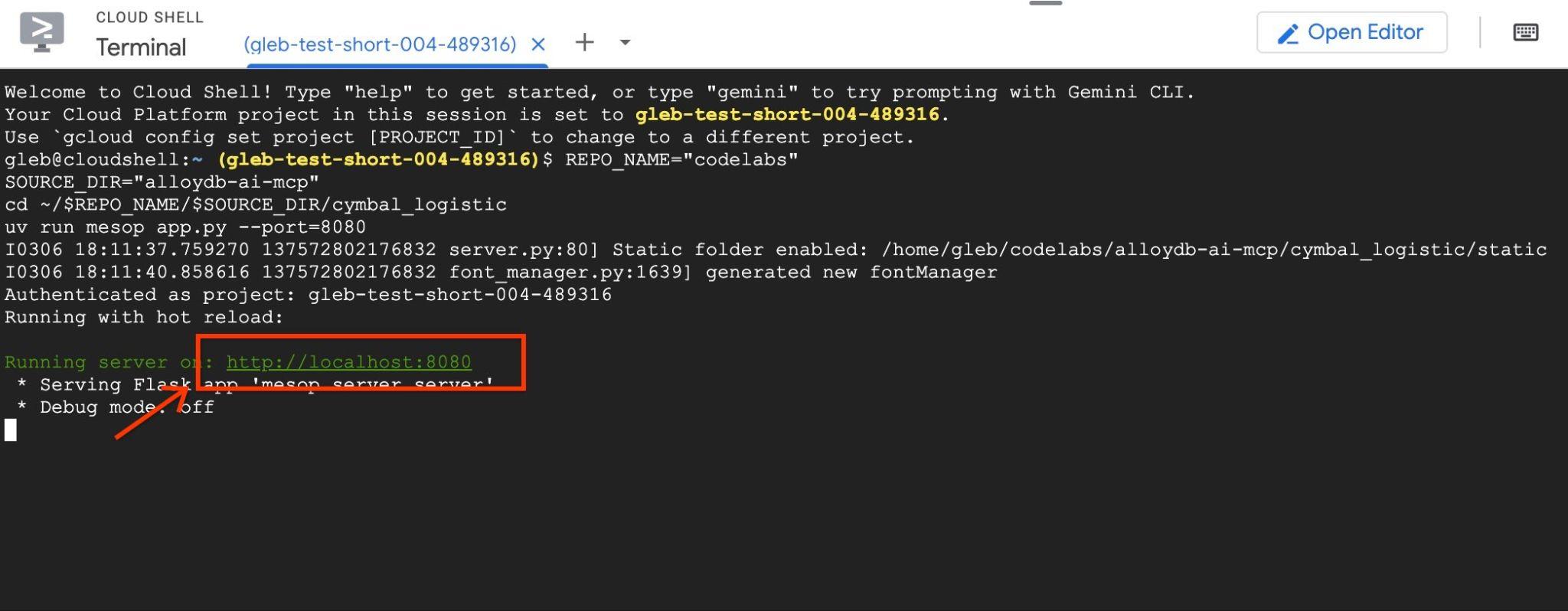
ブラウザで新しいタブが開き、アプリケーションのインターフェースが表示されます。
右上の [デバッグ出力を有効にする] チェックボックスをオンにして、次のような質問を入力します。
What was the average speed for each driver last month? List top 5 fasters drivers ranking them by the average speed. Show the name, distance and average speed for each of them.
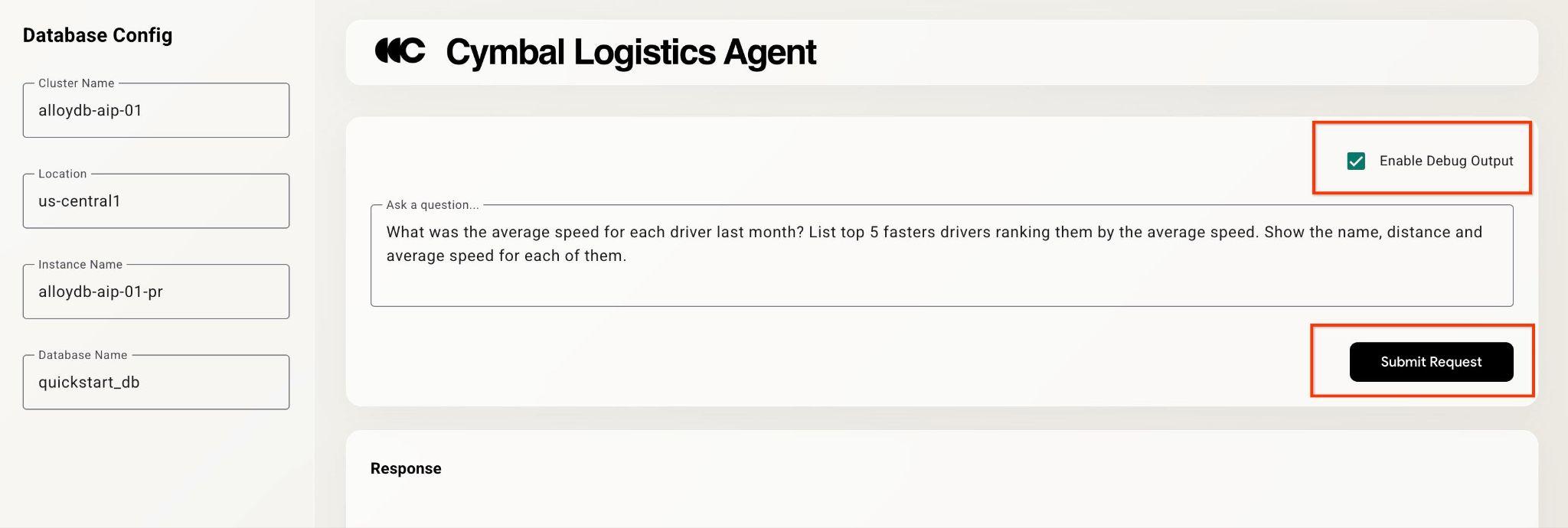
[Submit Request] ボタンを押します。
エージェントは舞台裏で動作し、MCP ツールセットによって実行されたすべてのクエリを含む出力とデバッグ情報を生成します。クエリをチェックして、ワークフローを確認します。
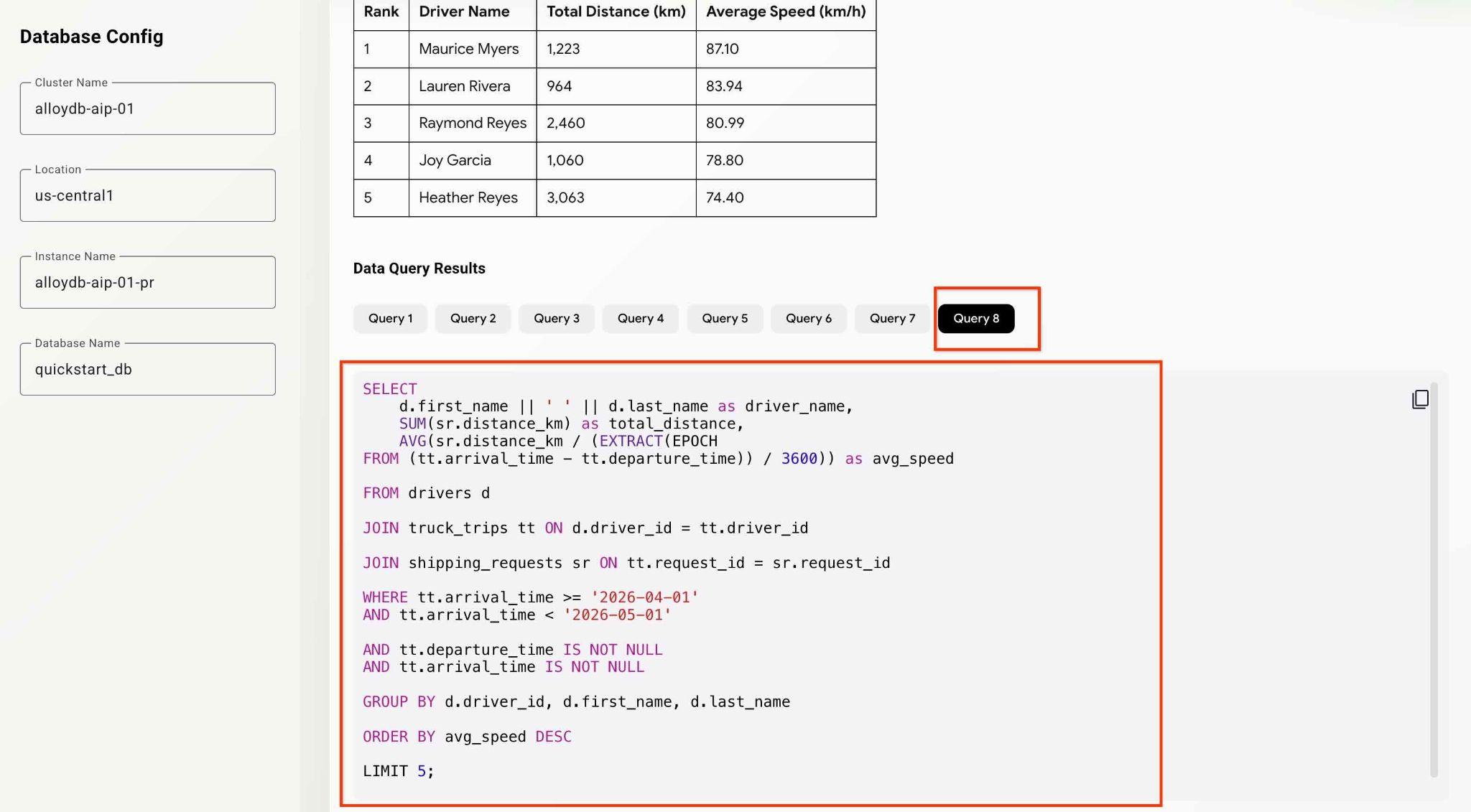
さまざまな分析質問を試すことで、エージェントとアプリの機能をテストできます。
これまで、MCP を使用したエージェントを使用して、基本的な分析と検出を行うことができました。次の章では、AlloyDB のより高度な機能を使用してみます。
10. AlloyDB AI 関数
AlloyDB AI 関数を使用すると、テキストやマルチモーダル データ(特に画像)に対するスマートなフィルタやランク付けが可能となり、Gemini の能力をクエリに活用できます。特に、AlloyDB AI 関数 AI.IF と AI.RANK は、従来の SQL 演算子(フィルタ、結合、集計など)と一緒に SQL ステートメントで使用できます。
AI 関数を使用する前に、「従来」の方法を使用して検索と集計を調べます。次のプロンプトを試してください。
Can you analyze the activity for the last 5 months and evaluate drivers for the most positive customer feedbacks. Give me top 5 drivers listing names, distance and years of experience for each driver.
顧客フィードバックを含むテーブルから「評価」列を見つけ、それを使用して評価の高いドライバーを特定できます。次に、この情報を使用して、ドライバに関する詳細情報を取得しました。
SELECT
d.first_name || ' ' || d.last_name as driver_name,
SUM(sr.distance_km) as total_distance,
d.experience_years,
COUNT(cf.feedback_id) as positive_feedback_count
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
WHERE tt.arrival_time >= '2025-12-01'
AND tt.arrival_time < '2026-05-01'
AND cf.rating >= 4
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY positive_feedback_count DESC, total_distance DESC
LIMIT 5;
ただし、評価には、評価対象のすべてのパラメータが含まれている場合と、そうでない場合があります。これには、AlloyDB AI 関数を使用できます。
AI.RANK 演算子
ai.rank() 関数は、ドキュメントが特定のクエリにどの程度適切に回答しているかをスコア付けします。クエリの結果のランキングまたは再ランキングに使用できます。演算子の詳細については、ドキュメントをご覧ください。
リクエストを変更し、分析中に AI.RANK を使用して、パフォーマンスとプロフェッショナリズムに基づいてドライバーを評価するよう明示的に依頼します。
Can you find the top 5 fastest drivers in the last month and rank them by the feedback using the AI.RANK function? Give me top drivers names, distance, years of experience and rank for each driver.
エージェントは AI.RANK 関数の使用方法を把握し、データを取得して AI.RANK を適用して情報を並べ替える必要があるため、コマンドの実行に時間がかかることがあります。最後に、モデルによってランク付けされたドライバのリストと、実行されたクエリのリストが表示されます。
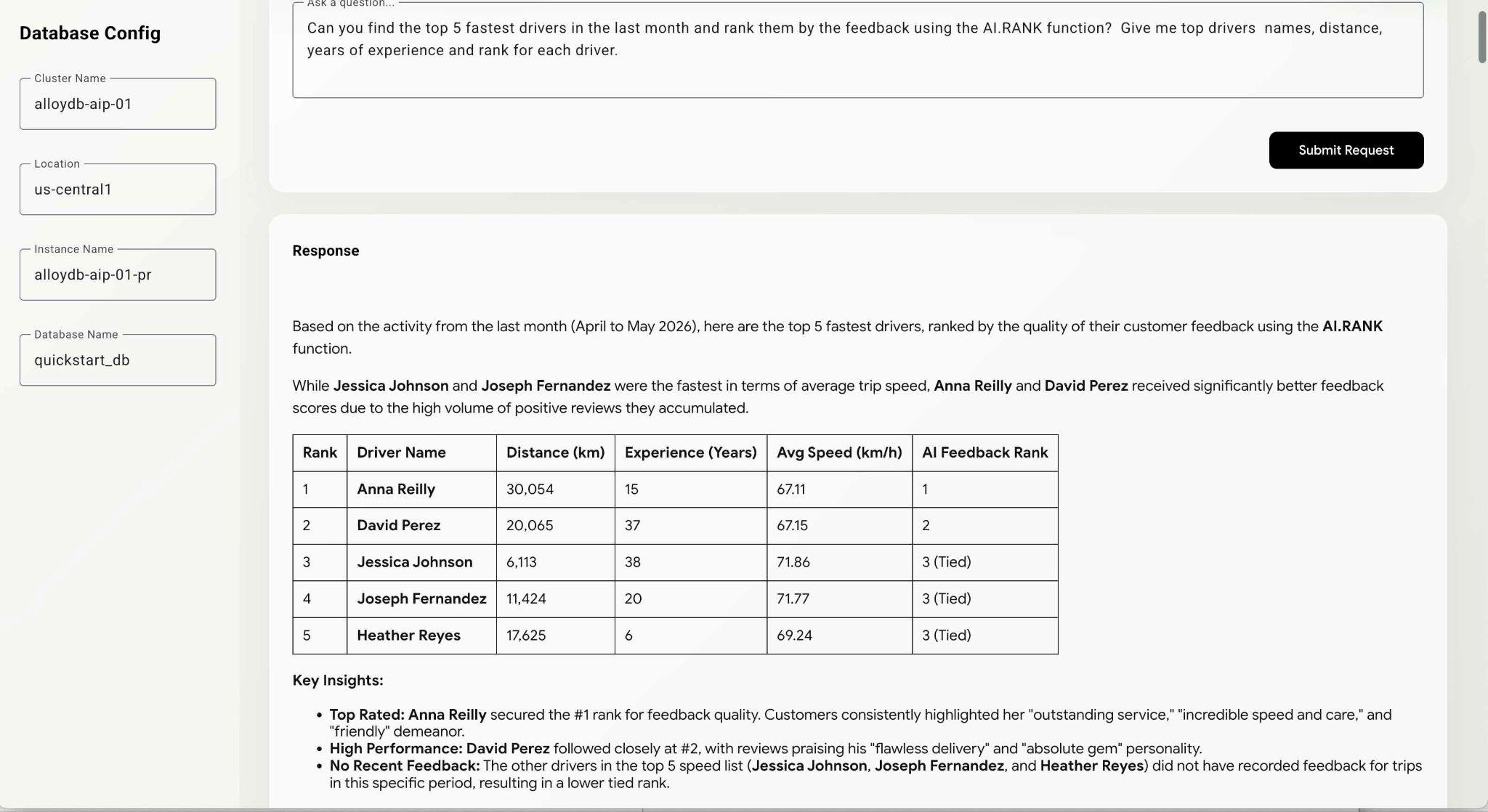
モデルが選択するパスによっては、このクエリの実行に時間がかかることがあります。デバッグ ウィンドウで、ドライバーに関する情報を取得するために実行された正確なクエリを確認できます。
WITH fastest_drivers AS (
SELECT
d.driver_id,
d.first_name || ' ' || d.last_name as driver_name,
d.experience_years,
SUM(sr.distance_km) as total_distance,
AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) as avg_speed,
COALESCE(STRING_AGG(cf.feedback_text, ' | '), 'No feedback') as feedbacks,
ROW_NUMBER() OVER (
ORDER BY AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) DESC) - 1 as row_idx
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
LEFT
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
WHERE tt.arrival_time >= '2026-04-04'
AND tt.arrival_time IS NOT NULL
AND tt.departure_time IS NOT NULL
AND tt.arrival_time > tt.departure_time
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY avg_speed DESC
LIMIT 5
)
SELECT
f.driver_name,
f.total_distance,
f.experience_years,
f.avg_speed,
f.feedbacks,
(SELECT r.score
FROM ai.rank(
'semantic-ranker-fast-004',
'excellent customer service, professional, friendly, fast,
and reliable delivery reviews',
ARRAY[f.feedbacks],
1
) r
LIMIT 1) as feedback_score
FROM fastest_drivers f
ORDER BY feedback_score DESC;
アプリケーションのテストを続行し、クエリを調べて、エージェントが最終結果に到達するまでの過程を確認できます。
これでラボは終了です。すべての例を確認し、AlloyDB に Google Cloud MCP サービスを使用する方法を理解していただけたでしょうか。MCP を企業向けに機能させるには、AlloyDB のドキュメントで説明されている AlloyDB NL2SQL 機能と MCP を組み合わせることをおすすめします。AlloyDB の SQL ステートメントの生成に関する Codelab を使用して試すことができます。
11. 環境をクリーンアップする
予期しない請求が発生しないように、一時リソースをクリーンアップすることをおすすめします。最も確実な方法は、ワークフローをテストしていたプロジェクトを削除することです。ただし、AlloyDB などの個々のリソースを削除することで、必要に応じて制限できます。
ラボの終了時に AlloyDB インスタンスとクラスタを破棄します。
AlloyDB クラスタとすべてのインスタンスを削除する
AlloyDB の試用版を使用した場合。トライアル クラスタを使用して他のラボやリソースをテストする予定がある場合は、トライアル クラスタを削除しないでください。同じプロジェクトに別のトライアル クラスタを作成することはできません。
クラスタは force オプションで破棄され、クラスタに属するすべてのインスタンスも削除されます。
接続が切断され、以前の設定がすべて失われた場合は、Cloud Shell でプロジェクトと環境変数を定義します。
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
クラスタを削除します。
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB バックアップを削除する
クラスタの AlloyDB バックアップをすべて削除します。
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. 完了
以上で、この Codelab は完了です。
学習した内容
- AlloyDB クラスタを作成してサンプルデータをインポートする方法
- AlloyDB データアクセス API を有効にする方法
- AlloyDB NL で Google Cloud MCP を有効にする方法
- AlloyDB 用 Google Cloud MCP を ADK エージェントに追加する方法
- アプリケーションで AlloyDB 用 Google Cloud MCP を使用する方法
- 分析に AlloyDBMCP でエージェントを使用する方法
13. アンケート
出力: