
1. 소개
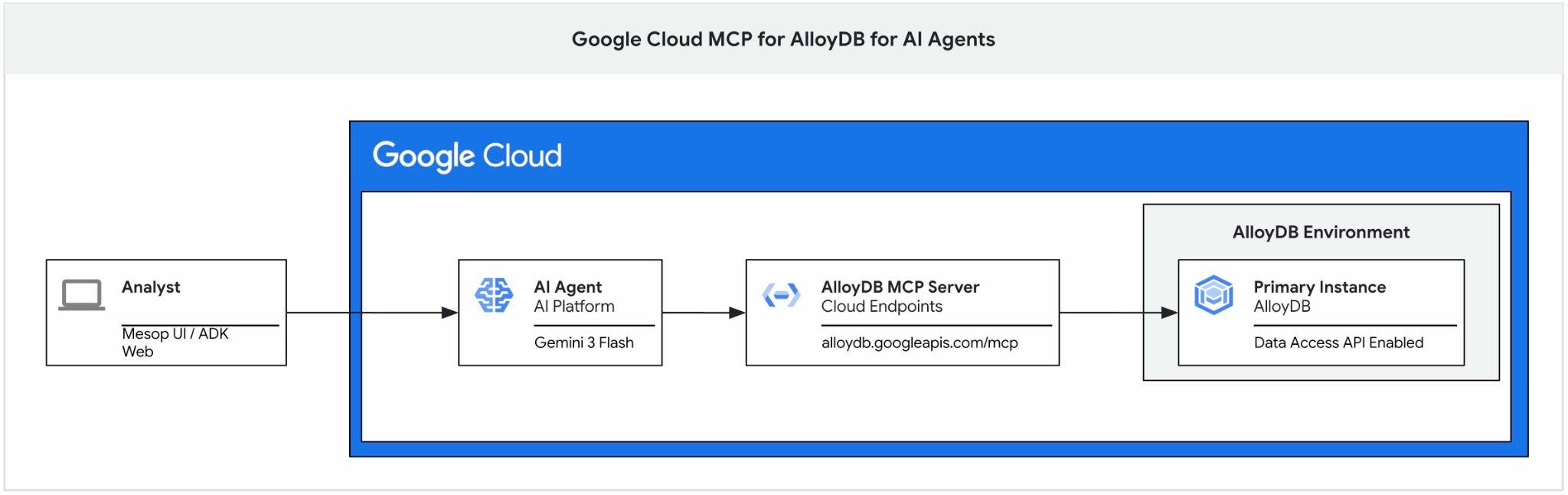
이 Codelab에서는 AlloyDB용 Google Cloud MCP 서버를 시작하고 AI 에이전트의 도구 세트의 일부로 사용 설정하고 애플리케이션의 일부로 사용하는 방법을 안내합니다.
기본 요건
- Google Cloud, 콘솔에 관한 기본적인 이해
- 명령줄 인터페이스 및 Cloud Shell의 기본 기술
학습할 내용
- AlloyDB 클러스터를 만들고 샘플 데이터를 가져오는 방법
- AlloyDB 데이터 액세스 API를 사용 설정하는 방법
- AlloyDB NL에 Google Cloud MCP를 사용 설정하는 방법
- ADK 에이전트에 AlloyDB용 Google Cloud MCP를 추가하는 방법
- 애플리케이션에서 AlloyDB용 Google Cloud MCP를 사용하는 방법
- 분석을 위해 AlloyDBMCP와 함께 에이전트를 사용하는 방법
필요한 항목
- Google Cloud 계정 및 Google Cloud 프로젝트
- Google Cloud 콘솔 및 Cloud Shell을 지원하는 웹브라우저(예: Chrome)
2. 설정 및 요구사항
프로젝트 설정
- Google Cloud 콘솔에 로그인합니다. 아직 Gmail이나 Google Workspace 계정이 없는 경우 계정을 만들어야 합니다.
직장 또는 학교 계정 대신 개인 계정을 사용하세요.
- 새 프로젝트를 만들거나 기존 프로젝트를 재사용합니다. Google Cloud 콘솔에서 새 프로젝트를 만들려면 헤더에서 프로젝트 선택 버튼을 클릭하여 팝업 창을 엽니다.

프로젝트 선택 창에서 새 프로젝트 버튼을 누르면 새 프로젝트 대화상자가 열립니다.
대화상자에서 원하는 프로젝트 이름을 입력하고 위치를 선택합니다.
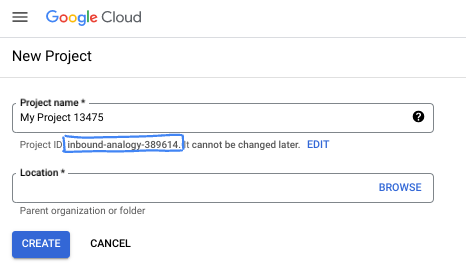
- 프로젝트 이름은 이 프로젝트 참가자의 표시 이름입니다. 프로젝트 이름은 Google API에서 사용되지 않으며 언제든지 변경할 수 있습니다.
- 프로젝트 ID는 모든 Google Cloud 프로젝트에서 고유하며, 변경할 수 없습니다 (설정된 후에는 변경할 수 없음). Google Cloud 콘솔에서 고유 ID를 자동으로 생성하지만 이를 맞춤설정할 수 있습니다. 생성된 ID가 마음에 들지 않으면 다른 무작위 ID를 생성하거나 자체 ID를 제공하여 사용 가능 여부를 확인할 수 있습니다. 대부분의 Codelab에서는 프로젝트 ID를 참조해야 하며, 이는 일반적으로 PROJECT_ID 자리표시자로 식별됩니다.
- 참고로 세 번째 값은 일부 API에서 사용하는 프로젝트 번호입니다. 이 세 가지 값에 대한 자세한 내용은 문서를 참고하세요.
결제 사용 설정
개인 결제 계정 설정
Google Cloud 크레딧을 사용하여 결제를 설정한 경우 이 단계를 건너뛸 수 있습니다.
개인 결제 계정을 설정하려면 Cloud 콘솔에서 여기에서 결제를 사용 설정하세요.
참고:
- 이 실습을 완료하는 데 드는 Cloud 리소스 비용은 미화 3달러 미만입니다.
- 이 실습이 끝나면 단계에 따라 리소스를 삭제하여 추가 요금이 발생하지 않도록 할 수 있습니다.
- 신규 사용자는 미화$300 상당의 무료 체험판을 사용할 수 있습니다.
Cloud Shell 시작
Google Cloud를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
Google Cloud Console의 오른쪽 상단 툴바에 있는 Cloud Shell 아이콘을 클릭합니다.
또는 G를 누른 다음 S를 누릅니다. Google Cloud 콘솔에 있거나 이 링크를 사용하는 경우 이 시퀀스를 통해 Cloud Shell이 활성화됩니다.
환경을 프로비저닝하고 연결하는 데 몇 분 정도 소요됩니다. 완료되면 다음과 같이 표시됩니다.

가상 머신에는 필요한 개발 도구가 모두 들어있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab의 모든 작업은 브라우저 내에서 수행할 수 있습니다. 아무것도 설치할 필요가 없습니다.
3. 시작하기 전에
API 사용 설정
AlloyDB, Compute Engine, 네트워킹 서비스, Vertex AI를 사용하려면 Google Cloud 프로젝트에서 각 API를 사용 설정해야 합니다.
Cloud Shell 터미널 내에 프로젝트 ID가 설정되어 있는지 확인합니다.
gcloud config get-value project
Google 프로젝트 ID를 반환해야 합니다.
환경 변수 PROJECT_ID를 설정합니다.
PROJECT_ID=$(gcloud config get-value project)
필요한 모든 서비스를 사용 설정합니다.
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
예상 출력
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB 배포
AlloyDB 클러스터 및 기본 인스턴스를 만듭니다. 필요한 모든 리소스를 배포하는 준비된 스크립트를 사용하여 배포하거나 문서에 따라 단계별로 직접 배포할 수 있습니다.
자동 스크립트를 사용하여 AlloyDB 배포
이 접근 방식은 자동화된 스크립트를 사용하여 AlloyDB 클러스터를 배포하고 배포된 리소스를 사용하기 시작하는 데 필요한 정보를 제공합니다.
Cloud Shell 터미널에서 명령어를 실행하여 저장소에서 배포 스크립트를 클론합니다.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-ai-mcp"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
배포 스크립트를 실행합니다.
./deploy_alloydb.sh
스크립트를 실행하는 데 시간이 걸립니다(일반적으로 5~7분). 그러면 배포된 AlloyDB 클러스터에 관한 정보가 출력으로 제공됩니다. 비밀번호가 달라지므로 나중에 사용할 수 있도록 비밀번호를 어딘가에 기록해 두세요.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
웹 콘솔에서 새 클러스터와 기본 인스턴스를 확인할 수도 있습니다.
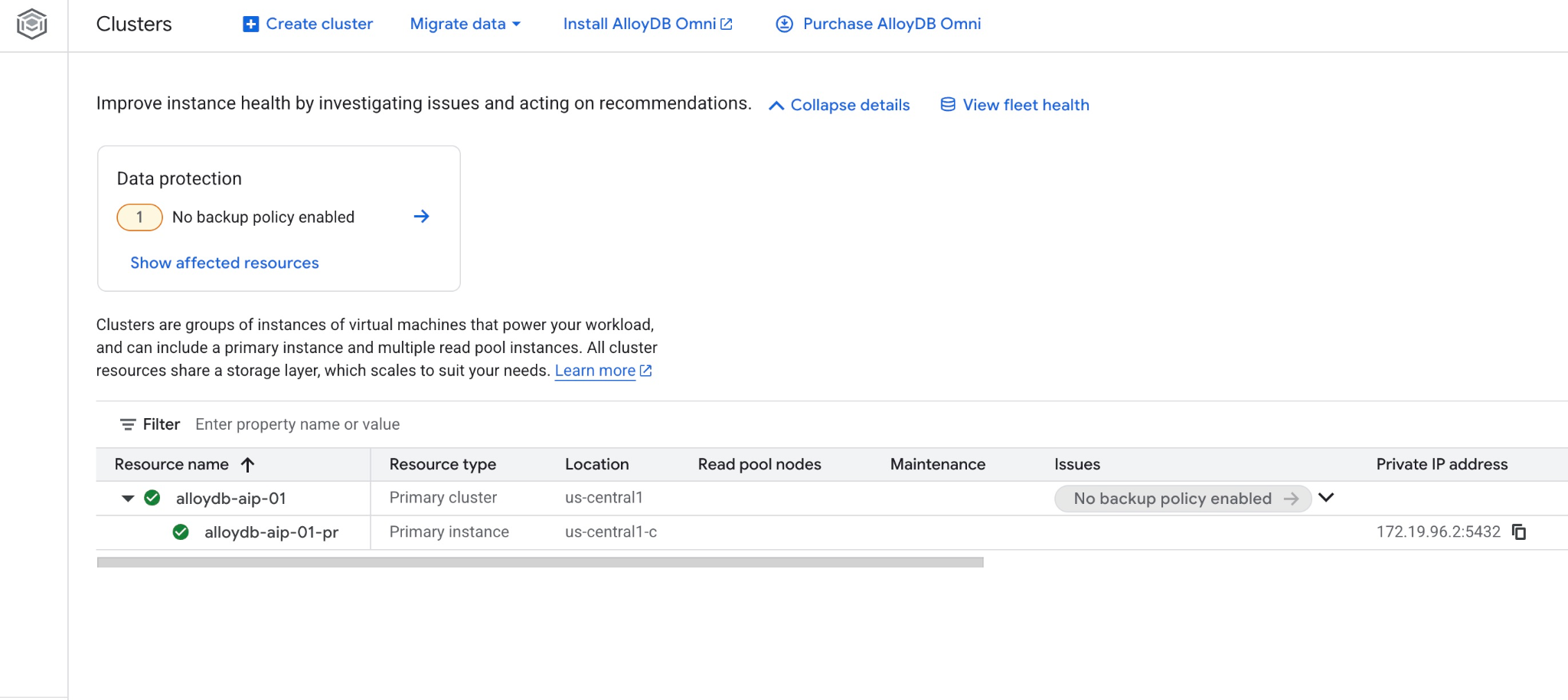
5. 데이터베이스 준비
AI 함수와 연산자를 사용하고, 데이터 액세스 API를 사용 설정하고, 샘플 데이터 세트용 데이터베이스를 만들려면 Vertex AI 통합을 사용 설정해야 합니다.
AlloyDB에 필요한 권한 부여
AlloyDB 서비스 에이전트에 Vertex AI 권한을 추가합니다.
맨 위에 있는 '+' 기호를 사용하여 다른 Cloud Shell 탭을 엽니다.
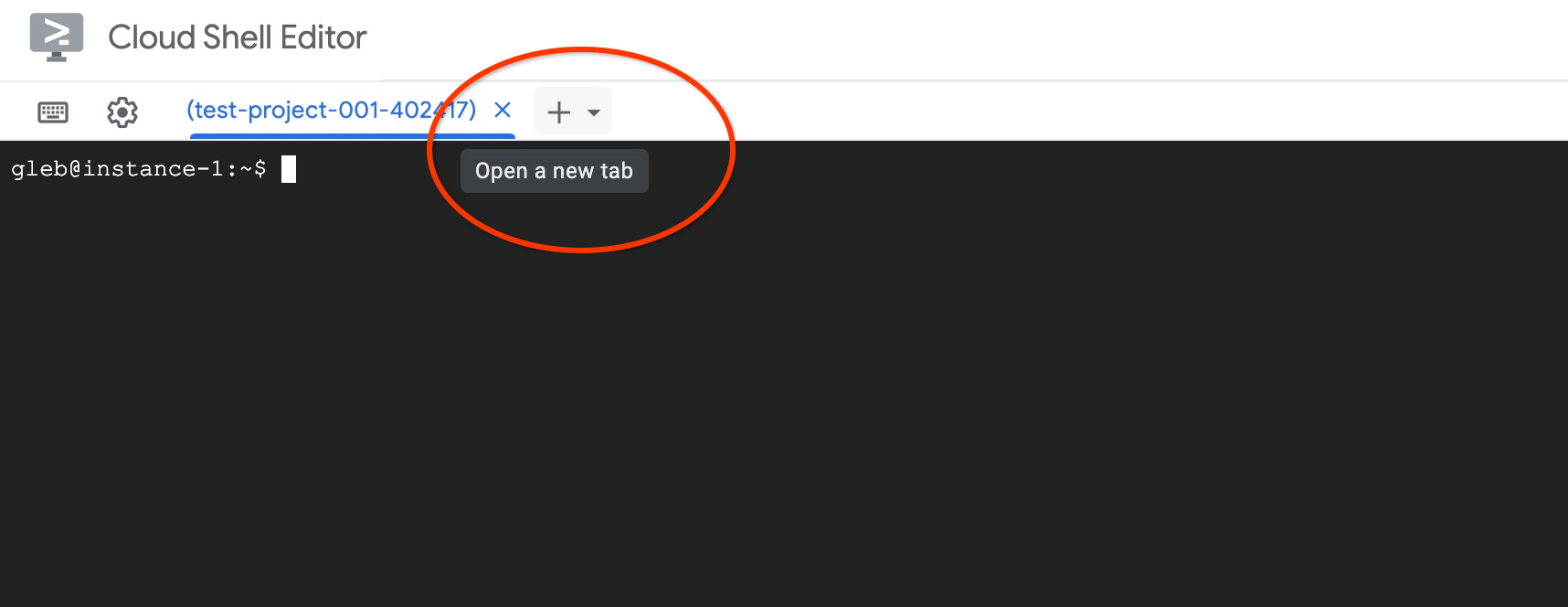
새 Cloud Shell 탭에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/discoveryengine.viewer"
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... < redacted > etag: BwYIEbe_Z3U= version: 1
데이터 액세스 API 사용 설정
execute_sql와 같은 MCP 도구를 사용하려면 AlloyDB 클러스터에서 데이터 액세스 API를 사용 설정해야 합니다.
동일한 터미널 탭에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
인스턴스 플래그 업데이트
AlloyDB에서 고급 AI 기능을 사용하려면 일부 데이터베이스 플래그를 사용 설정해야 합니다. 데이터 액세스 API를 사용 설정한 후 다음 변경사항을 적용할 준비가 된 인스턴스가 표시되기까지 몇 분 정도 걸릴 수 있습니다. 콘솔에서 인스턴스의 상태를 확인하여 녹색 체크표시가 있는지 확인하세요.
동일한 터미널 탭에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags=google_ml_integration.enable_model_support=on,google_ml_integration.enable_ai_query_engine=on,google_ml_integration.enable_preview_ai_functions=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
MCP 사용 설정
다음 단계는 프로젝트에서 AlloyDB용 Google Cloud MCP 서버를 사용 설정하는 것입니다. 기본적으로 MCP는 사용 설정되어 있지 않으며 클러스터 내 IAM 인증 및 승인, 데이터 액세스 API 및 역할을 비롯한 여러 보호 계층 중 하나입니다.
동일한 터미널 탭에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
gcloud beta services mcp enable alloydb.googleapis.com \
--project=$PROJECT_ID
탭에서 실행 명령어 'exit' 중 하나를 사용하여 탭을 닫습니다.
exit
AlloyDB Studio에 연결
다음 장에서는 데이터베이스에 연결해야 하는 모든 SQL 명령어를 AlloyDB Studio에서 실행할 수 있습니다. T
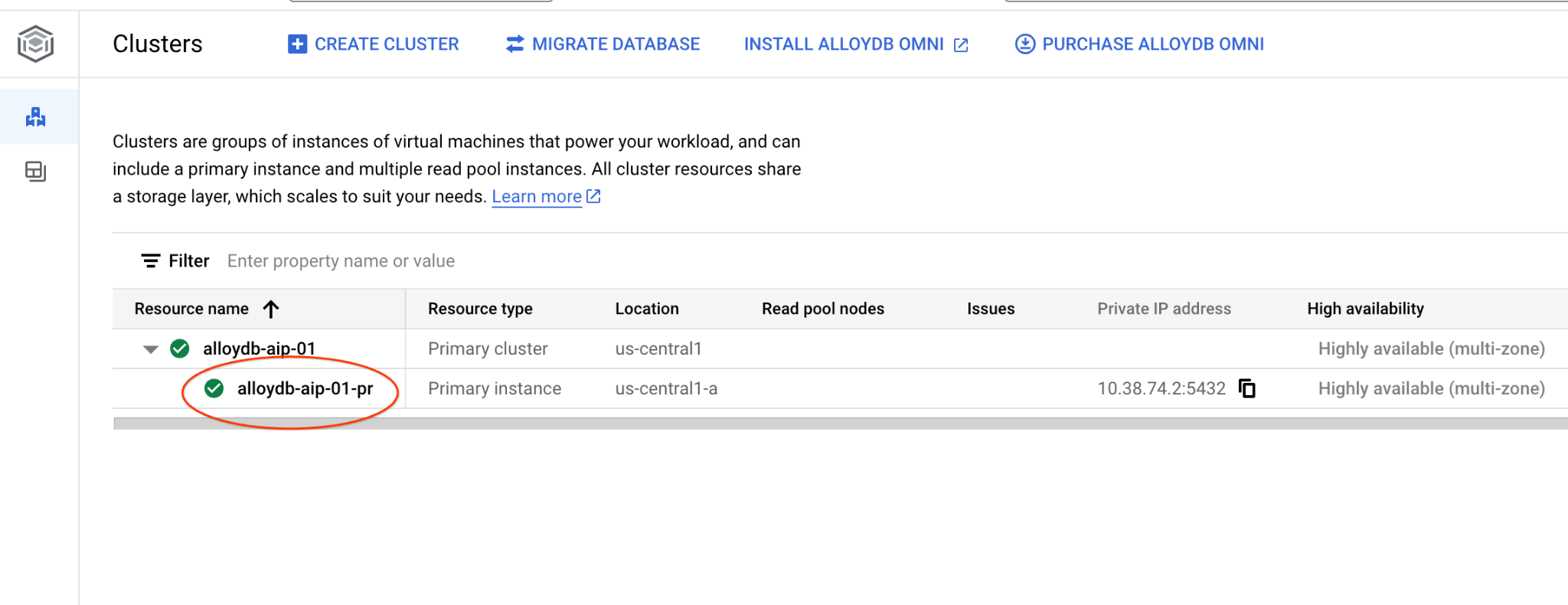
Postgres용 AlloyDB의 클러스터 페이지로 이동합니다.
기본 인스턴스를 클릭하여 AlloyDB 클러스터의 웹 콘솔 인터페이스를 엽니다.
그런 다음 왼쪽에 있는 AlloyDB Studio를 클릭합니다.
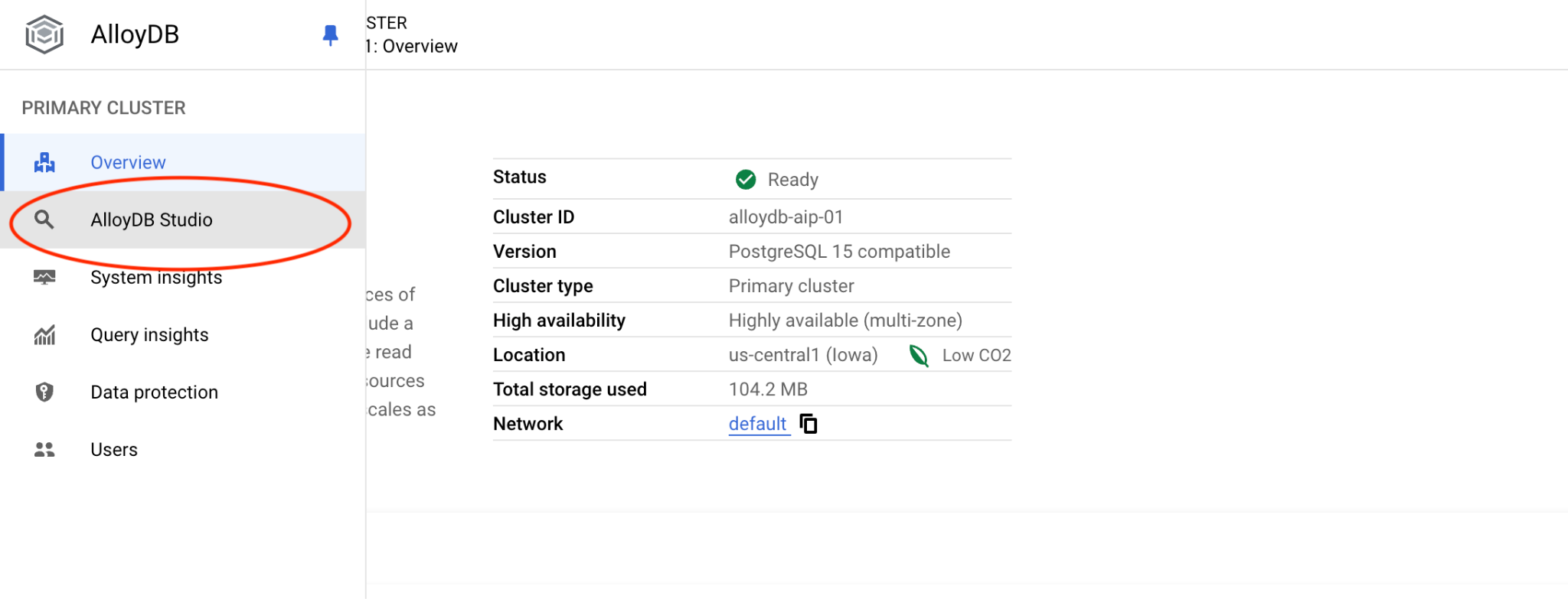
postgres 데이터베이스와 사용자 postgres를 선택하고 클러스터를 만들 때 기록해 둔 비밀번호를 입력합니다. 그런 다음 '인증' 버튼을 클릭합니다.
비밀번호가 작동하지 않거나 비밀번호를 적어 두지 않은 경우 비밀번호를 변경할 수 있습니다. 이 작업을 수행하는 방법은 문서를 참고하세요.
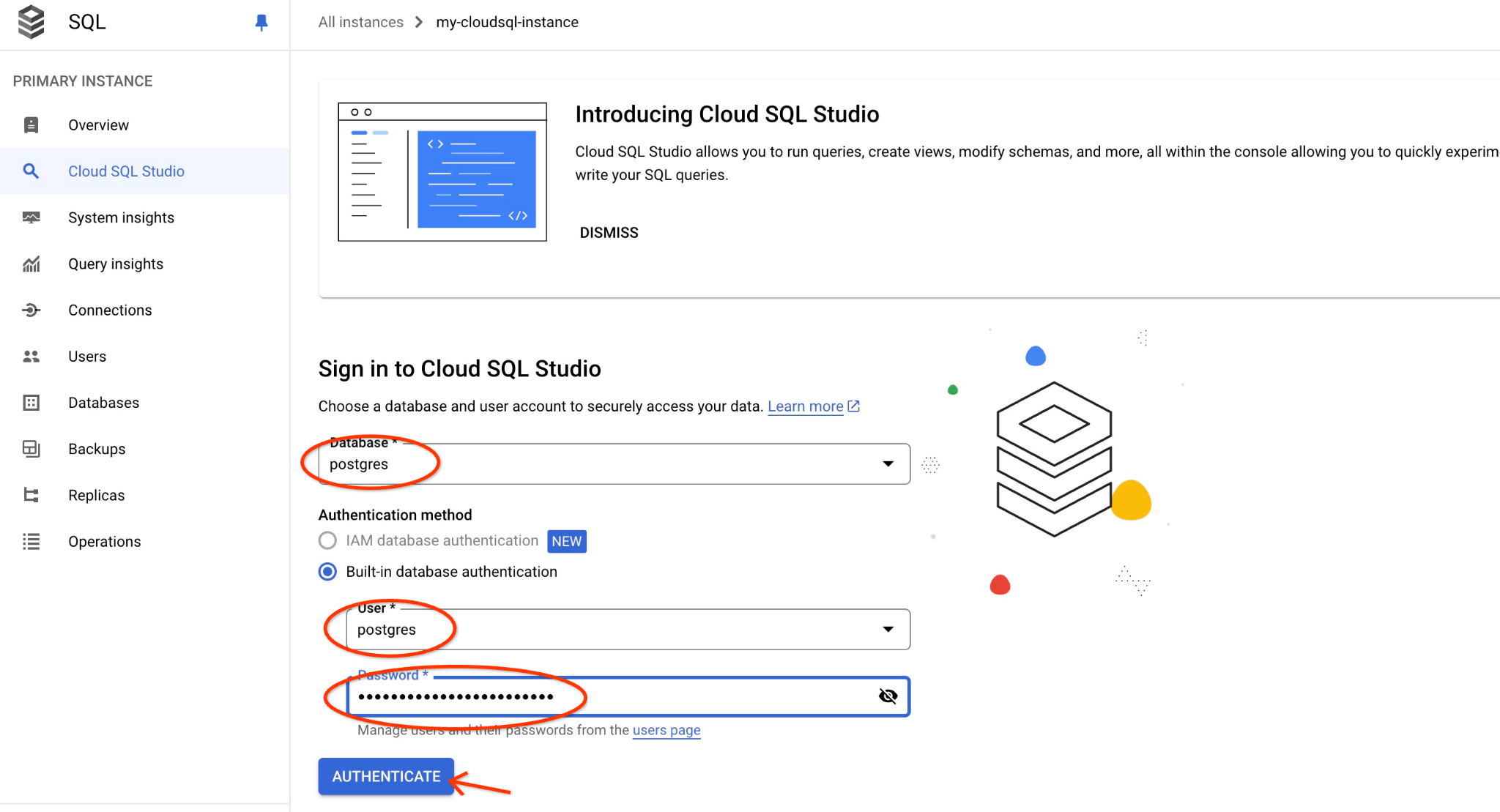
AlloyDB Studio 인터페이스가 열립니다. 데이터베이스에서 명령어를 실행하려면 오른쪽의 '제목이 없는 쿼리' 탭을 클릭합니다.
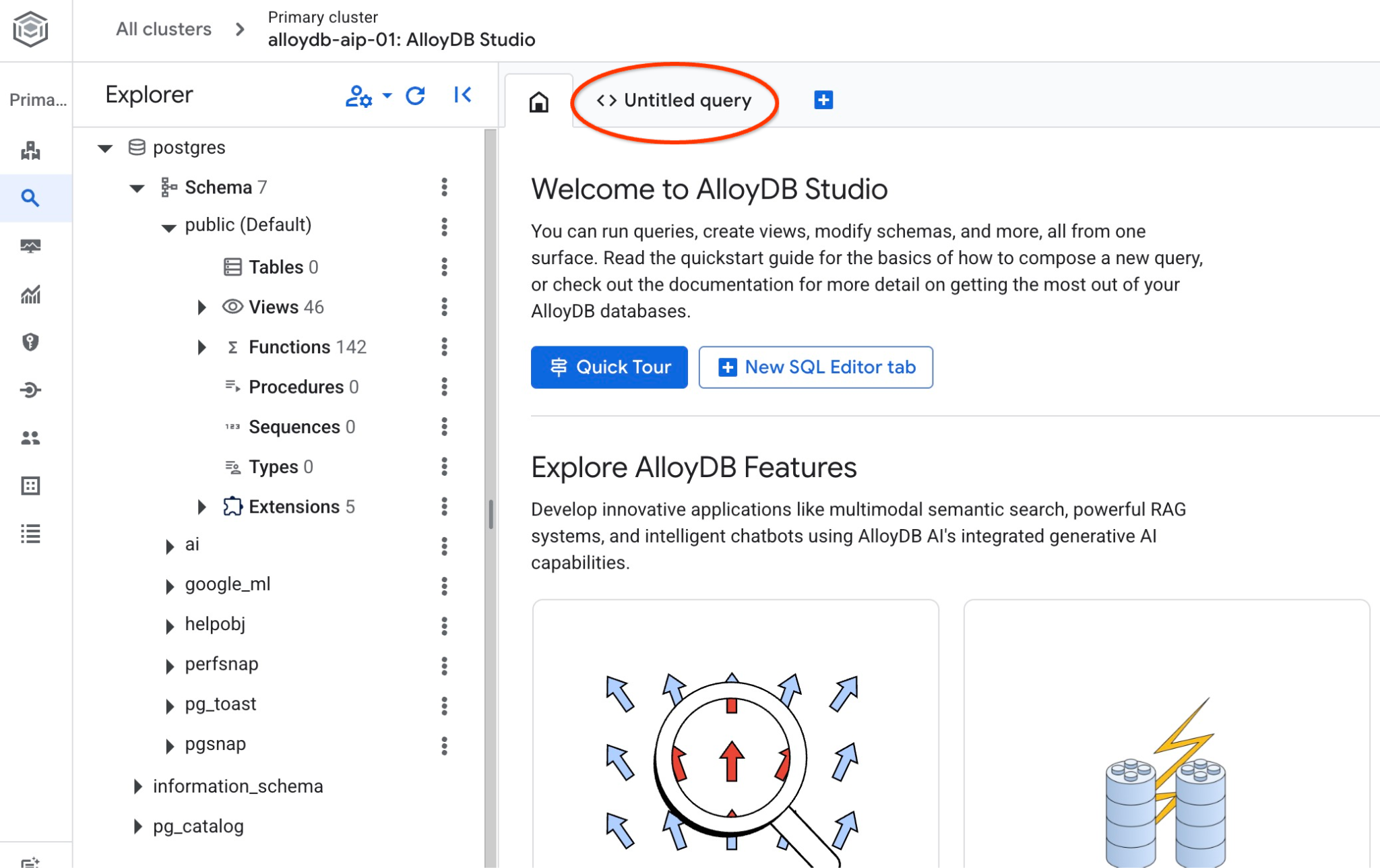
SQL 명령어를 실행할 수 있는 인터페이스가 열립니다.
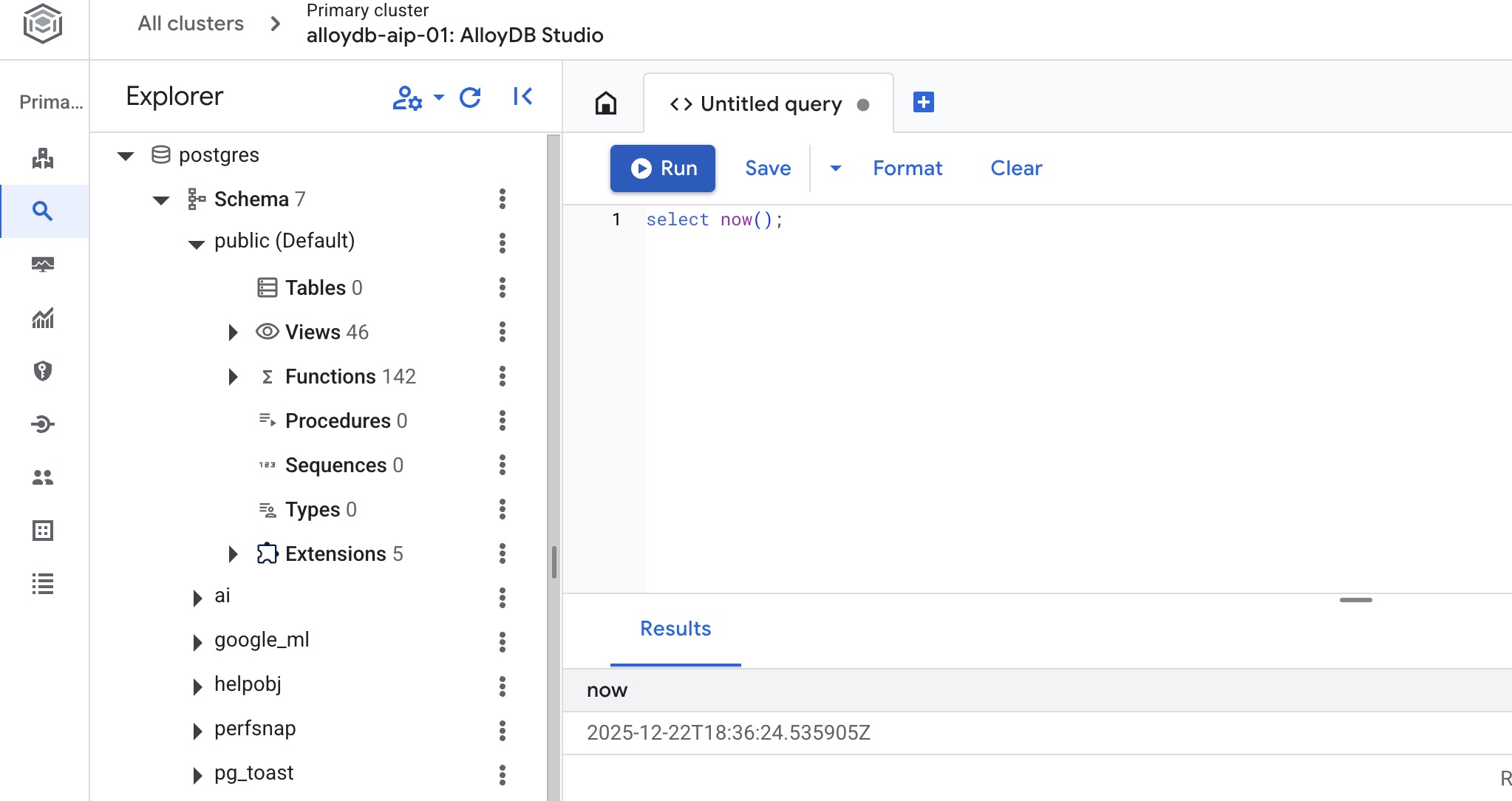
데이터베이스 만들기
데이터베이스 만들기 빠른 시작
AlloyDB Studio 편집기에서 다음 명령어를 실행합니다.
데이터베이스를 만듭니다.
CREATE DATABASE quickstart_db
예상 출력:
Statement executed successfully
quickstart_db에 연결
데이터베이스에 연결하여 데이터베이스가 생성되었는지 확인합니다. 사용자/데이터베이스 전환 버튼을 사용하여 스튜디오에 다시 연결합니다.
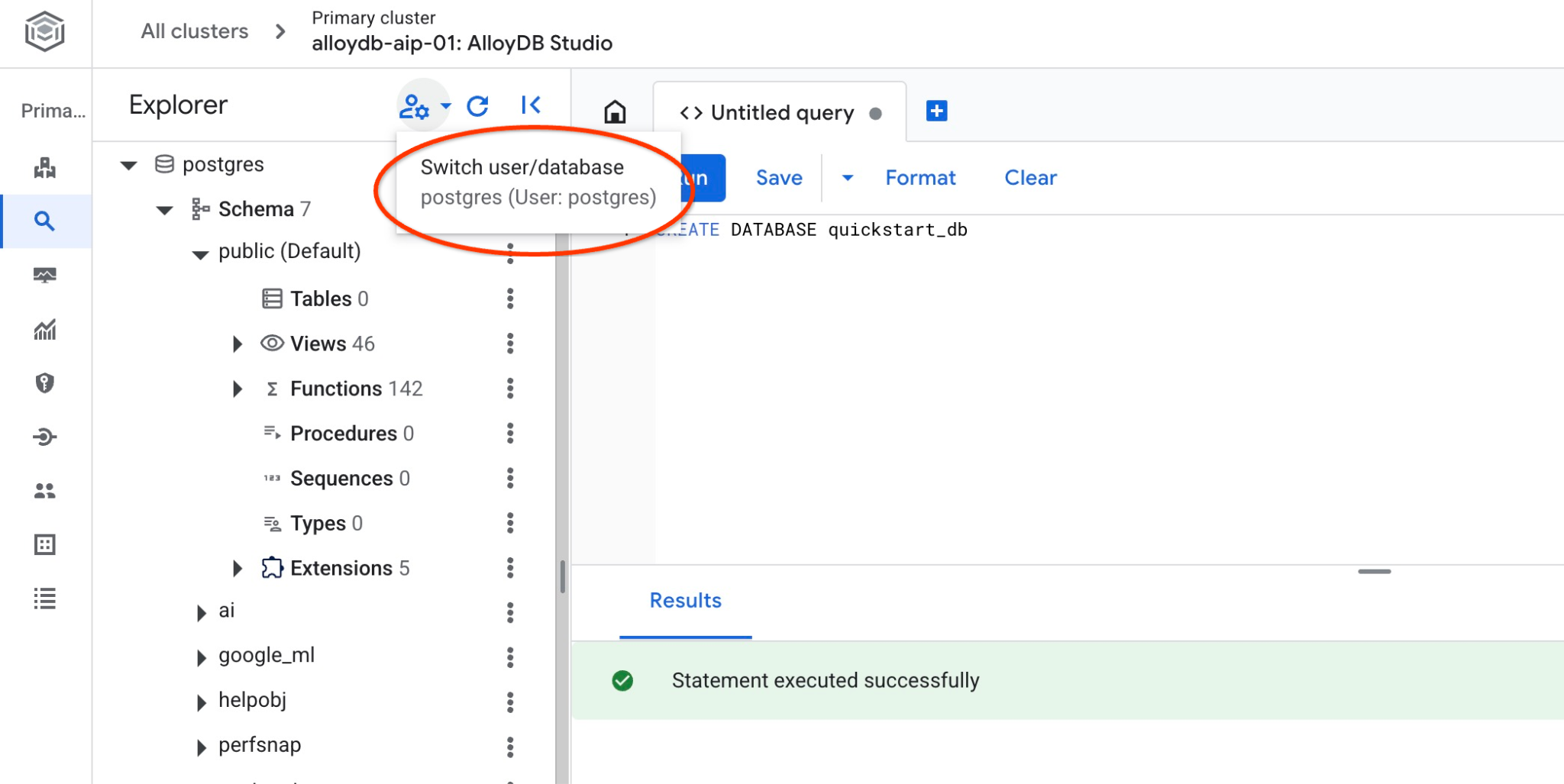
드롭다운 목록에서 새 quickstart_db 데이터베이스를 선택하고 이전과 동일한 사용자 및 비밀번호를 사용합니다.
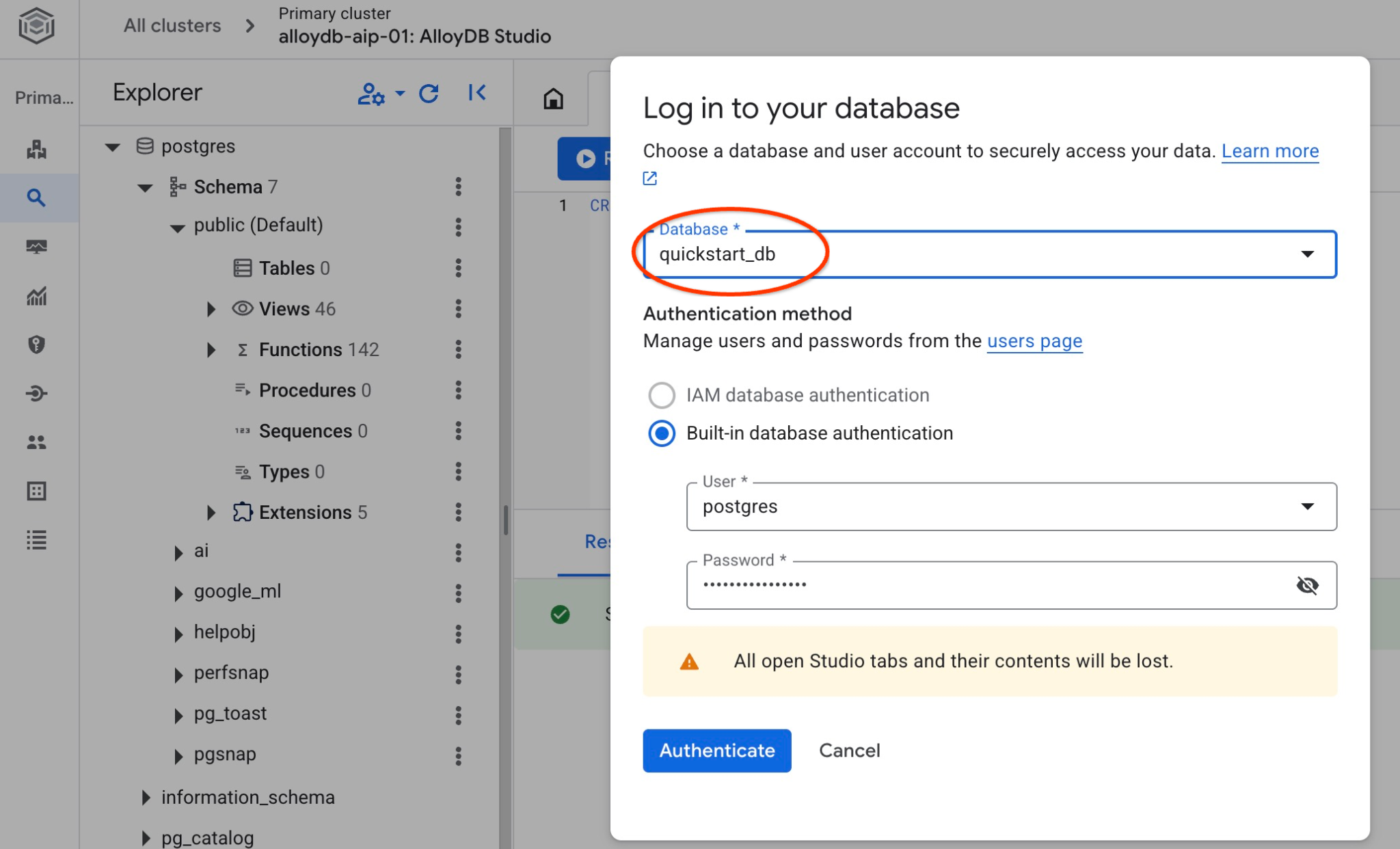
그러면 quickstart_db 데이터베이스의 객체를 사용할 수 있는 새 연결이 열립니다. 여기에서 가져온 스키마와 데이터를 검사할 수 있습니다.
6. 샘플 데이터
이제 데이터베이스에서 객체를 만들고 데이터를 로드해야 합니다. 가상의 Cymbal Shipping 회사 데이터 세트를 사용합니다. 상품, 트럭, 요청, 트럭 여정에 관한 가상 데이터와 가상 운전자가 있습니다.
스토리지 버킷 만들기
클론된 저장소에서 AlloyDB 데이터베이스로 데이터를 가져오려면 Google SDK (gcloud)를 사용해야 하며, 이를 위해 스토리지 버킷을 만들고 AlloyDB 서비스 계정에 액세스 권한을 부여해야 합니다. 또는 문서에 설명된 대로 웹 콘솔을 사용하여 항상 시도할 수 있습니다.
Google Cloud Shell 터미널에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
데이터 로드
다음 단계는 데이터를 로드하는 것입니다. SQL 덤프는 클론된 저장소 폴더에 있습니다. 다음 명령어는 AlloyDB 클러스터를 만드는 동안 이전 단계에서 저장소를 클론할 때 홈 디렉터리를 출발점으로 사용했다고 가정합니다.
압축된 SQL 덤프를 새 스토리지 버킷에 복사합니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
그런 다음 quickstart_db 데이터베이스에 데이터를 로드합니다.
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
이 명령어를 실행하면 샘플 데이터 세트가 quickstart_db 데이터베이스에 로드됩니다. AlloyDB Studio를 사용하여 테이블과 레코드를 확인할 수 있습니다.
7. 데이터 에이전트 사용
Google ADK for Python을 사용하여 만든 샘플 AI 에이전트부터 시작하여 AlloyDB용 Google Cloud MCP 서버와 함께 작동하도록 구성하는 방법을 보여드리겠습니다.
에이전트 소스 코드 확인
클론된 저장소에서 Google Cloud Shell 편집기를 사용하여 에이전트 코드를 검토합니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/data_agent/agent.py
에이전트에는 AlloyDB용 Google Cloud MCP 서버 섹션이 있습니다. 엔드포인트를 MCP_SERVER_URL로 제공하고, 인증하고, 프로젝트 ID를 추가하고, MCP 도구 모음에 추가합니다.
# Google Cloud MCP Server for AlloyDB
MCP_SERVER_URL = "https://alloydb.googleapis.com/mcp"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
# 2. Configure MCP Toolset
# We use StreamableHTTPConnectionParams to pass the auth header
headers = {
"Authorization": f"Bearer {creds.token}",
"X-Goog-User-Project": project_id
}
connection_params = StreamableHTTPConnectionParams(
url=MCP_SERVER_URL,
headers=headers,
timeout=300.0,
sse_read_timeout=600.0
)
mcp_toolset = McpToolset(connection_params=connection_params)
에이전트 코드에서 MCP 툴셋은 에이전트의 tools 매개변수로 포함됩니다. 또한 클러스터 및 인스턴스 이름, 리전, 데이터베이스가 에이전트 프롬프트의 변수로 있습니다.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
""",
tools=[mcp_toolset],
)
AlloyDB용 Google Cloud MCP 서비스에는 사전 정의된 도구 집합이 있습니다. 사용 가능한 모든 도구를 나열하려면 다음 명령어를 사용하여 Cloud Shell 콘솔 터미널에서 curl 명령어를 사용하면 됩니다. 문서에서 AlloyDB용 Google Cloud MCP 서버의 최신 참조를 항상 확인할 수 있습니다.
curl -s -X POST http://alloydb.googleapis.com/mcp \
-H "Content-Type: application/json" \
-d @- <<EOF | jq -r '.result.tools[].name'
{
"id": "my_id_01",
"jsonrpc": "2.0",
"method": "tools/list"
}
EOF
에이전트 시작
이제 Google ADK 웹 인터페이스를 사용하여 대화형 모드로 에이전트를 시작할 수 있습니다. ADK 웹 인터페이스는 에이전트의 워크플로를 테스트하고 문제를 해결하는 편리한 방법을 제공합니다.
먼저 uv 패키지 관리자를 사용하여 Python에 필요한 모든 패키지를 설치합니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv sync
모든 패키지가 설치되면 에이전트 디렉터리에 .env 파일을 추가하여 AI 모델과의 모든 통신에 Vertex AI를 사용하도록 지시해야 합니다.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
그런 다음 에이전트를 시작할 수 있습니다.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
http://127.0.0.1:8000과 같은 엔드포인트가 포함된 다음과 같은 출력이 표시됩니다 .
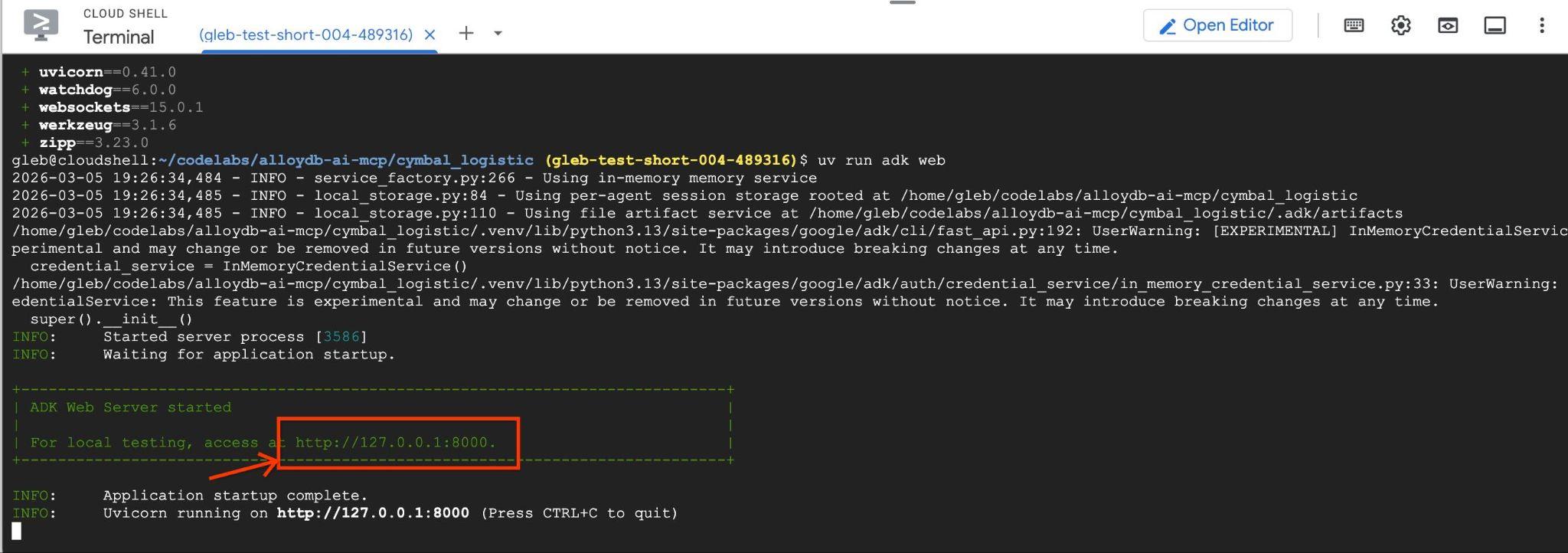
Cloud Shell에서 해당 URL을 클릭하면 별도의 브라우저 탭에서 미리보기 창이 열리고 왼쪽의 드롭다운 목록에서 data_agent을 선택할 수 있습니다.
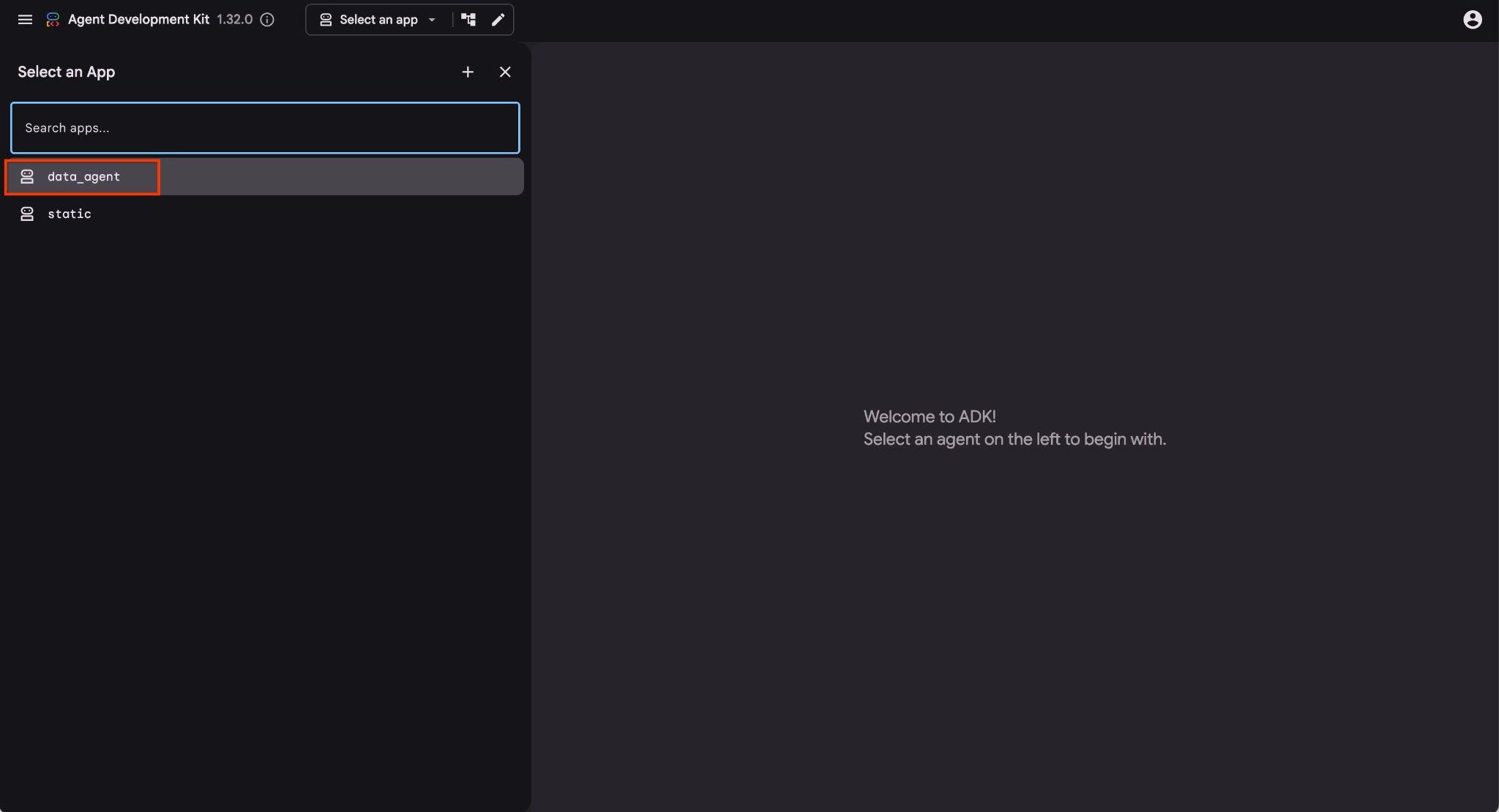
ADK 웹 인터페이스에서 오른쪽 하단에 질문을 게시하고 오른쪽에서 각 단계의 트레이스를 포함한 전체 실행 흐름을 확인할 수 있습니다.
8. 에이전트로 AlloyDB MCP 테스트
에이전트를 사용하면 자연어를 사용하여 자유 형식으로 질문할 수 있으며, 에이전트는 Google Cloud MCP 서버를 AlloyDB의 도구로 사용하여 질문에 답변합니다. 질문은 오른쪽 하단에 게시되고 도구에 대한 모든 호출이 포함된 답변은 상단에 표시됩니다.
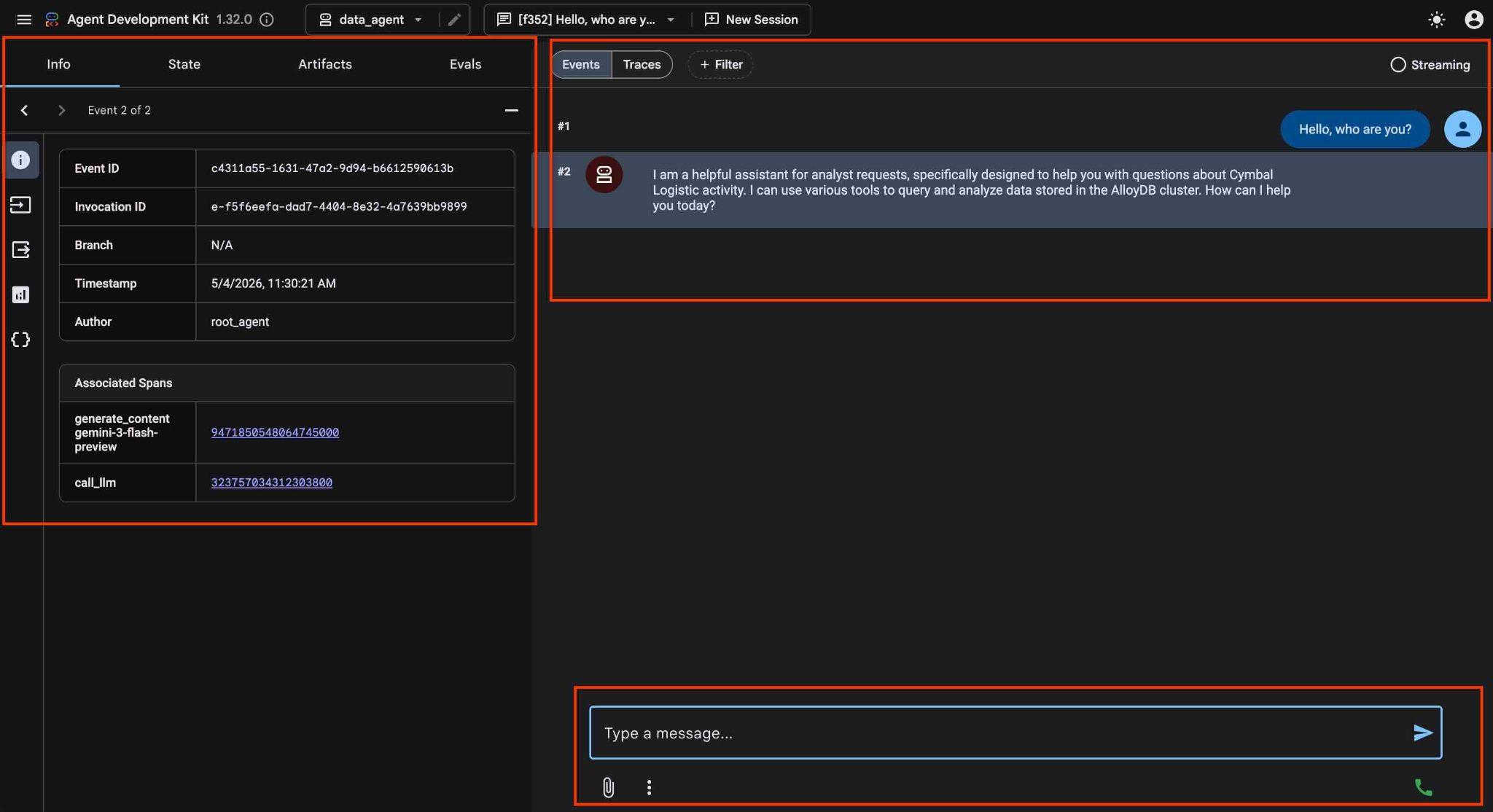
배송 요청, 트럭, 운전자, 운전자가 완료한 여정에 관한 정보가 있는 배송 회사의 운영 데이터를 사용하고 있습니다. 첫 번째 질문은 2026년 2월에 실행된 여행 수에 관한 것입니다.
오른쪽 하단의 입력 필드에 다음을 입력하고 Enter 키를 누릅니다.
Hello, can you tell me how many trips we've done in February this year?
에이전트는 여러 도구 호출을 실행하여 스키마의 올바른 테이블과 테이블 구조를 식별한 후 올바른 SQL 문을 실행하여 올바른 데이터를 가져옵니다.
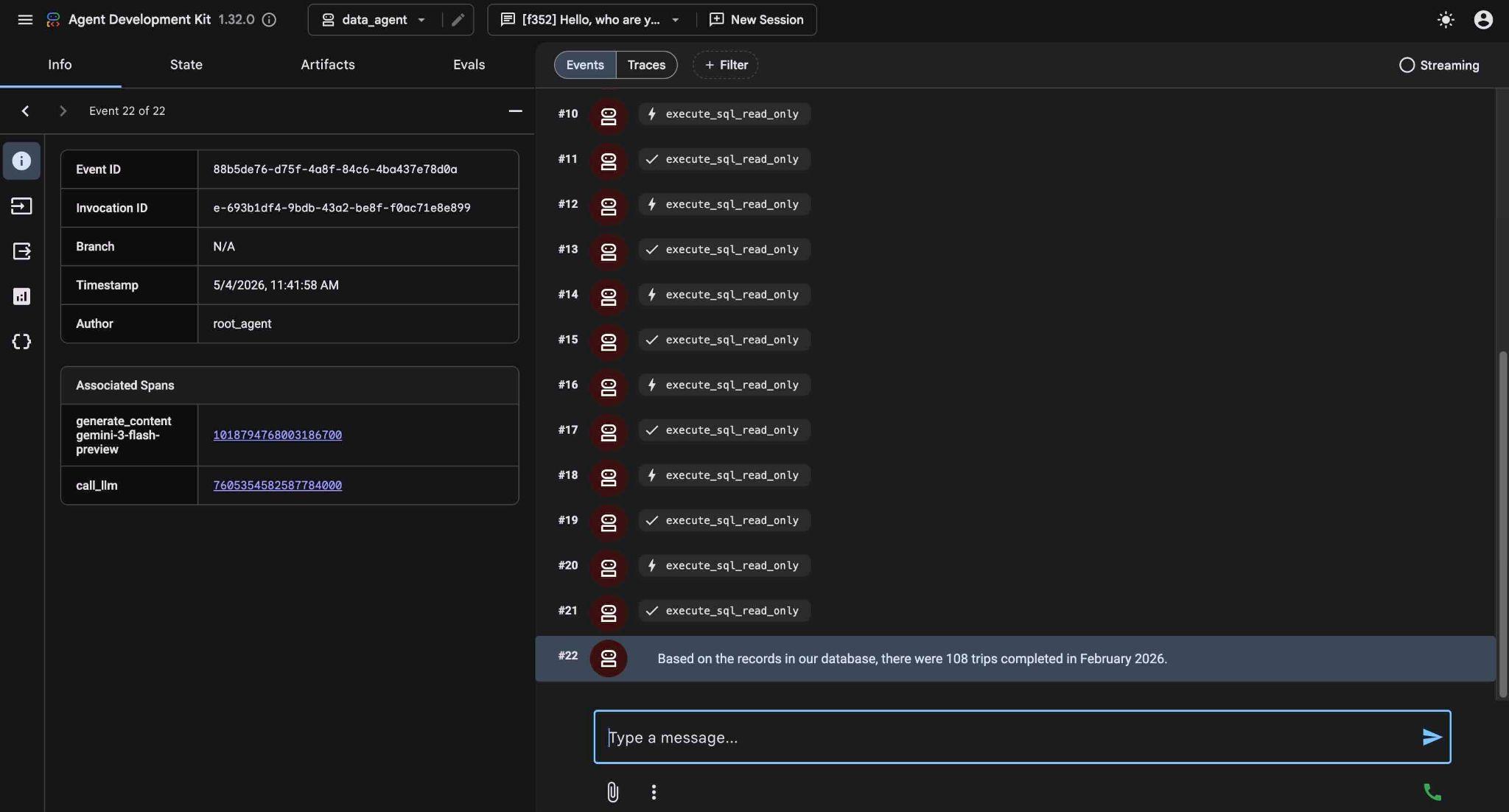
결국 적절한 쿼리를 작성하고 데이터베이스에서 실행한 후 결과를 생성합니다.
데이터베이스의 기록에 따르면 2026년 2월에 완료된 여정은 108건입니다.
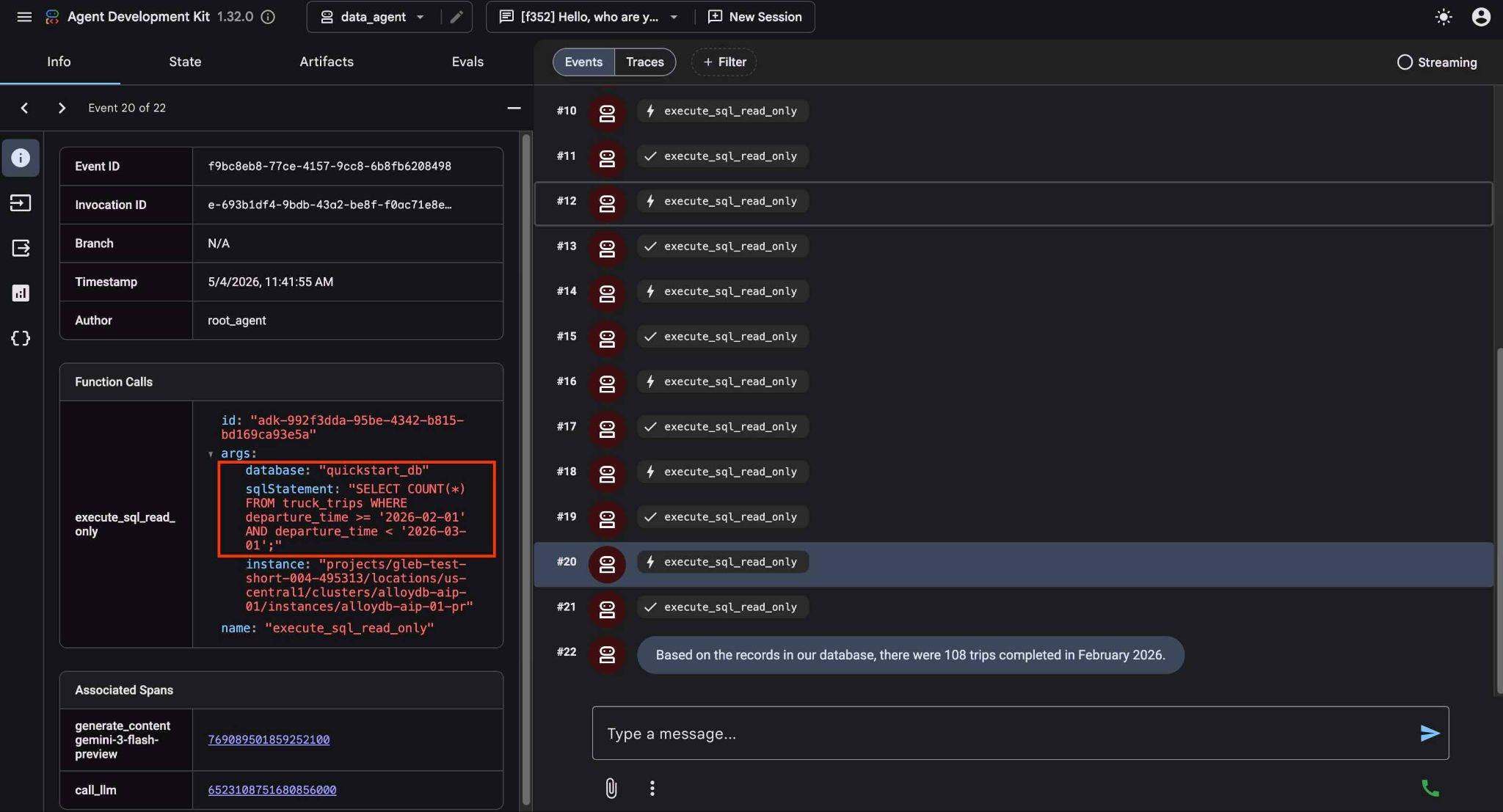
도구 실행을 클릭하면 각 도구 호출이 수행하는 작업을 확인할 수 있습니다. 예를 들어 결과를 얻기 위해 실행된 쿼리는 다음과 같습니다.
이제 지난달 결과와 비교해 달라고 요청하여 더 복잡하게 만들어 보세요.
How is it in comparison in numbers and mileage with the January?
결과를 분석하고 이동 횟수와 마일리지의 차이를 제공하는 다양한 쿼리를 실행하여 결과를 반환합니다.
In comparison to January 2026, February saw a slight decrease in both the number of trips and the total mileage: January 2026: 114 trips with a total mileage of 185,597 km. February 2026: 108 trips with a total mileage of 177,893 km. This represents a decrease of 6 trips and 7,704 km in mileage for February compared to January.
ADK 웹 인터페이스를 사용하여 다른 간단한 요청을 시도하고 결과를 얻기 위해 다양한 쿼리를 실행하는 방법을 확인합니다.
터미널에서 ctrl+c를 눌러 에이전트를 중지합니다. ADK 웹 인터페이스가 표시된 브라우저 탭을 닫아도 됩니다.
이제 샘플 애플리케이션을 사용해 보고 데이터 애널리스트를 위한 도구로 어떻게 사용할 수 있는지 확인해 보세요.
9. 샘플 애플리케이션
클론된 동일한 저장소에 Cymbol Logistic 회사의 샘플 애플리케이션이 있습니다. 애플리케이션은 Google Mesop Python 프레임워크를 사용합니다 .
Cloud Shell 편집기에서 app.py 파일을 열어 애플리케이션 코드를 분석할 수 있습니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/app.py
코드에서 함수를 사용하여 변수가 포함된 새 프롬프트를 데이터 에이전트에 전달합니다. 다른 데이터베이스나 인스턴스를 호출하기로 결정한 경우 인터페이스에서 이를 구성할 수 있어야 하기 때문입니다. 다음은 함수 정의와 프롬프트입니다.
def run_query_sync(request_text, cluster_name, location, instance_name, database_name, project_id, session_id, summary):
local_runner = FrontendRunner()
instruction = f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
"""
...
코드를 검토한 후 '터미널' 버튼을 눌러 애플리케이션을 시작하고 테스트합니다. 애플리케이션이 포트 8080에서 시작됩니다. 포트를 변경하려면 포트 값을 변경하는 명령어를 조정하세요.
Cloud Shell에서 다음을 실행합니다.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv run mesop app.py --port=8080
그런 다음 http://localhost:8080을 클릭하여 Google Cloud Shell에서 웹 미리보기를 사용합니다.
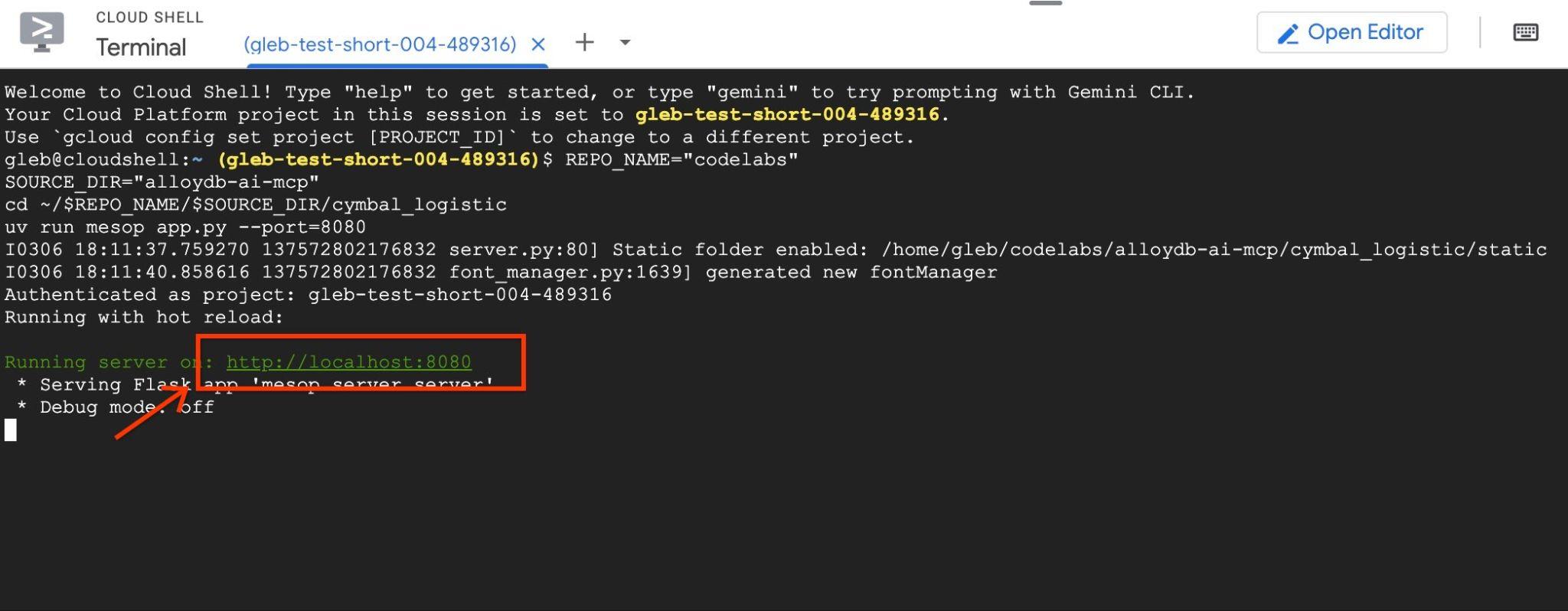
브라우저에서 애플리케이션 인터페이스가 표시된 새 탭이 열립니다.
오른쪽 상단의 '디버그 출력 사용 설정' 체크박스를 클릭하고 다음과 같은 질문을 입력합니다.
What was the average speed for each driver last month? List top 5 fasters drivers ranking them by the average speed. Show the name, distance and average speed for each of them.
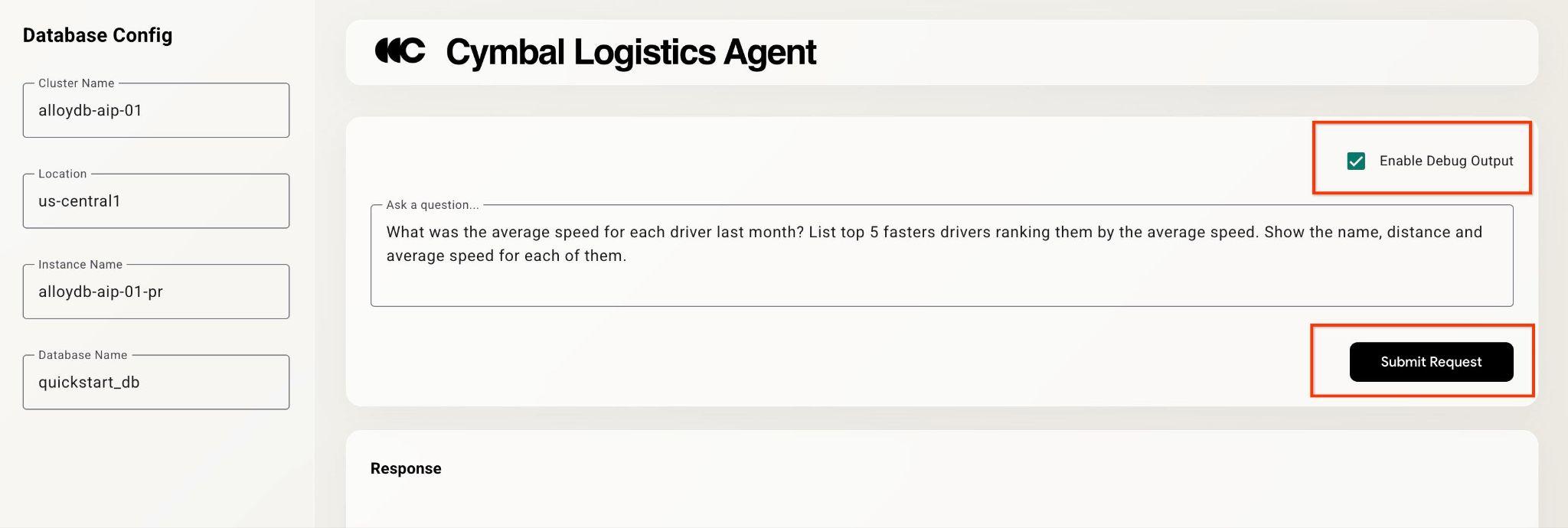
그런 다음 Submit Request 버튼을 누릅니다.
에이전트는 백그라운드에서 작업하며 Google의 MCP 도구 세트로 실행된 모든 쿼리를 사용하여 출력 및 디버깅 정보를 생성합니다. 쿼리를 확인하여 워크플로를 확인합니다.
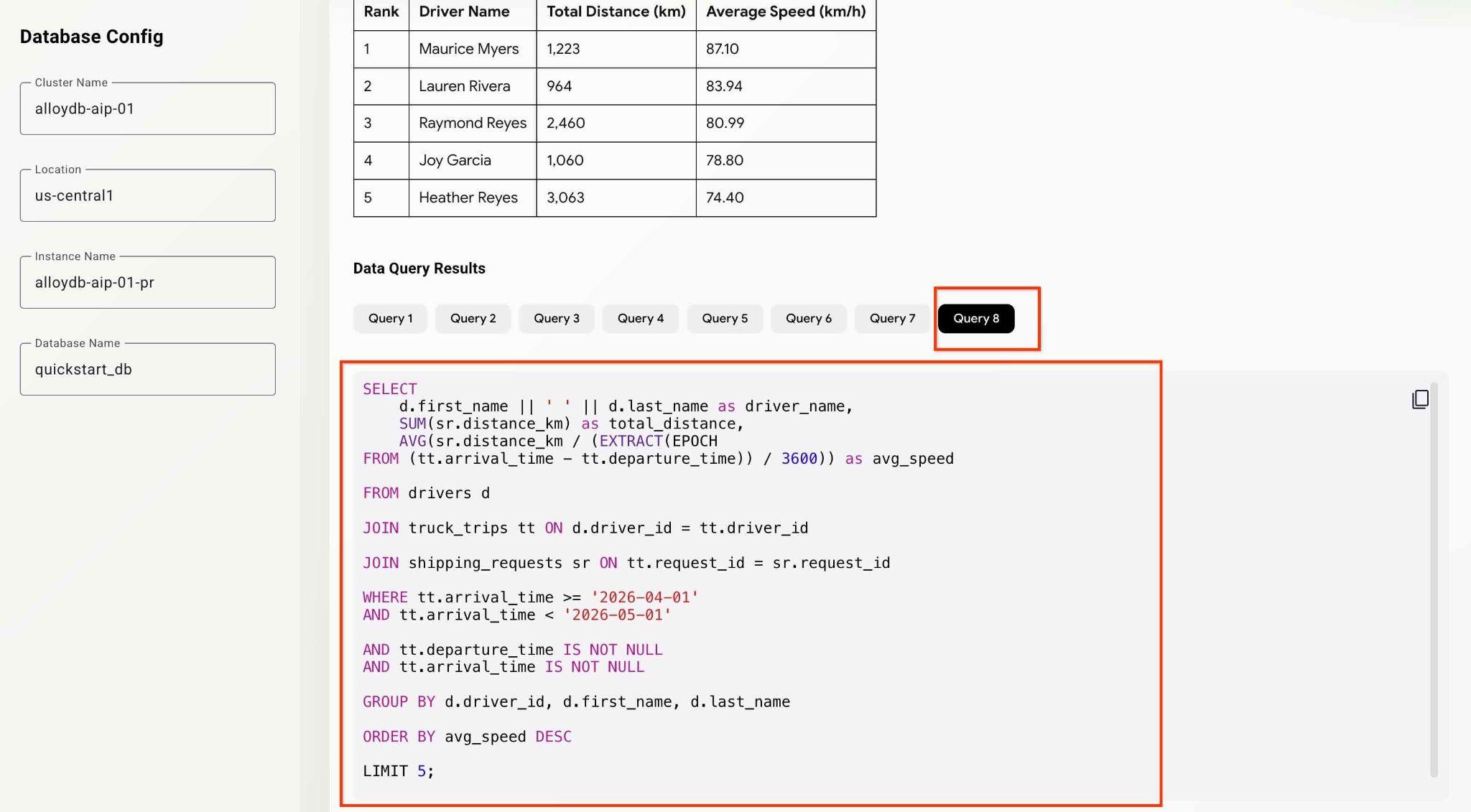
다양한 분석 질문을 시도하여 에이전트와 앱 기능을 테스트할 수 있습니다.
지금까지 MCP가 포함된 에이전트를 사용하여 기본적인 분석과 검색을 할 수 있었습니다. 다음 장에서는 더 고급 AlloyDB 기능을 사용해 봅니다.
10. AlloyDB AI 함수
AlloyDB AI 함수는 텍스트 및 멀티모달 데이터 (특히 이미지)에 대한 스마트 필터링 및 순위 지정을 지원하며 Gemini의 기능을 쿼리에 적용합니다. 특히 AlloyDB AI 함수 AI.IF 및 AI.RANK는 기존 SQL 연산자(필터, 조인, 집계 등)와 함께 SQL 문에 나타날 수 있습니다.
AI 기능을 사용하기 전에 '클래식' 메서드를 사용하여 검색 및 집계를 살펴봅니다. 다음 프롬프트를 사용해 보세요.
Can you analyze the activity for the last 5 months and evaluate drivers for the most positive customer feedbacks. Give me top 5 drivers listing names, distance and years of experience for each driver.
고객 의견이 포함된 표에서 '평점' 열을 찾아 이를 사용하여 평점이 가장 높은 운전자를 식별할 수 있습니다. 그런 다음 이 정보를 사용하여 드라이버에 관한 자세한 정보를 가져왔습니다.
SELECT
d.first_name || ' ' || d.last_name as driver_name,
SUM(sr.distance_km) as total_distance,
d.experience_years,
COUNT(cf.feedback_id) as positive_feedback_count
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
WHERE tt.arrival_time >= '2025-12-01'
AND tt.arrival_time < '2026-05-01'
AND cf.rating >= 4
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY positive_feedback_count DESC, total_distance DESC
LIMIT 5;
하지만 평가에는 Google에서 평가하려는 모든 매개변수가 포함되지 않을 수 있습니다. 이를 위해 AlloyDB AI 함수를 사용할 수 있습니다.
AI.RANK 연산자
ai.rank() 함수는 문서가 지정된 쿼리에 얼마나 잘 답변하는지에 대한 점수를 매깁니다. 쿼리 결과를 순위 지정하거나 재정렬하는 데 사용할 수 있습니다. 연산자에 관한 자세한 내용은 문서를 참고하세요.
요청을 수정하고 분석 중에 AI.RANK를 사용하여 실적과 전문성을 기반으로 운전자를 평가해 달라고 명시적으로 요청합니다.
Can you find the top 5 fastest drivers in the last month and rank them by the feedback using the AI.RANK function? Give me top drivers names, distance, years of experience and rank for each driver.
에이전트가 AI.RANK 함수를 사용하고, 데이터를 가져오고, AI.RANK를 적용하여 정보를 적절하게 정렬하는 방법을 파악해야 하므로 명령이 실행되는 데 시간이 조금 더 걸릴 수 있습니다. 마지막에 모델별로 순위가 지정된 드라이버 목록과 실행된 쿼리 목록이 표시됩니다.
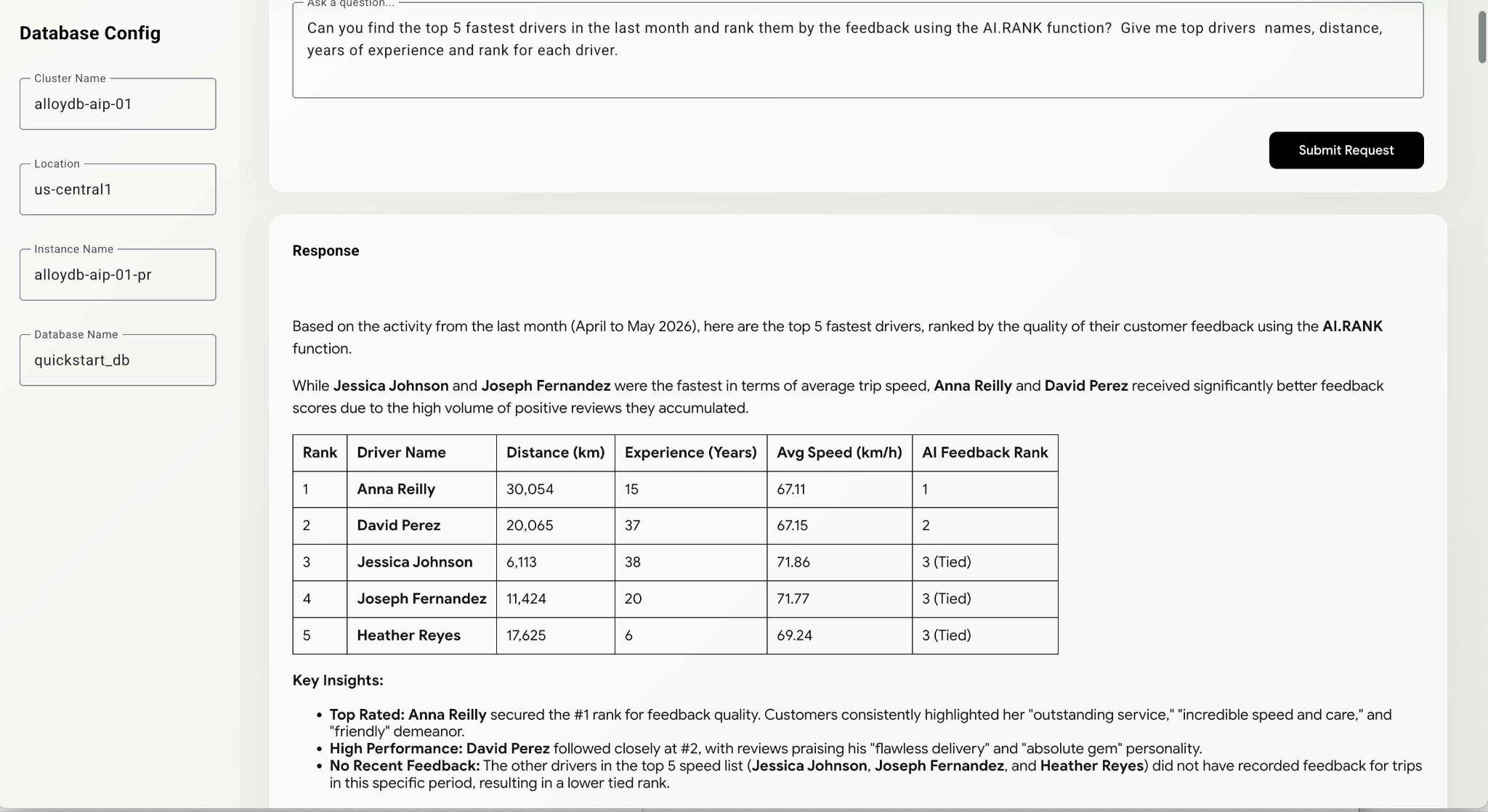
모델이 선택한 경로에 따라 쿼리를 실행하는 데 시간이 걸릴 수 있습니다. 디버그 창에서 드라이버에 관한 정보를 가져오기 위해 실행된 정확한 쿼리를 확인할 수 있습니다.
WITH fastest_drivers AS (
SELECT
d.driver_id,
d.first_name || ' ' || d.last_name as driver_name,
d.experience_years,
SUM(sr.distance_km) as total_distance,
AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) as avg_speed,
COALESCE(STRING_AGG(cf.feedback_text, ' | '), 'No feedback') as feedbacks,
ROW_NUMBER() OVER (
ORDER BY AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) DESC) - 1 as row_idx
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
LEFT
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
WHERE tt.arrival_time >= '2026-04-04'
AND tt.arrival_time IS NOT NULL
AND tt.departure_time IS NOT NULL
AND tt.arrival_time > tt.departure_time
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY avg_speed DESC
LIMIT 5
)
SELECT
f.driver_name,
f.total_distance,
f.experience_years,
f.avg_speed,
f.feedbacks,
(SELECT r.score
FROM ai.rank(
'semantic-ranker-fast-004',
'excellent customer service, professional, friendly, fast,
and reliable delivery reviews',
ARRAY[f.feedbacks],
1
) r
LIMIT 1) as feedback_score
FROM fastest_drivers f
ORDER BY feedback_score DESC;
애플리케이션을 계속 테스트하고 쿼리를 검사하여 에이전트가 최종 결과에 도달하는 방식을 확인할 수 있습니다.
이것으로 실습을 마치겠습니다. 모든 예시를 살펴보고 AlloyDB용 Google Cloud MCP 서비스를 사용하는 방법을 알아보셨기를 바랍니다. 엔터프라이즈에서 MCP를 사용하려면 AlloyDB 문서에 설명된 AlloyDB NL2SQL 기능과 MCP를 결합하는 것이 좋습니다. AlloyDB용 SQL 문 생성에 관한 Codelab을 사용하여 사용해 볼 수 있습니다.
11. 환경 정리
예기치 않은 요금이 청구되지 않도록 임시 리소스를 정리하는 것이 좋습니다. 가장 확실한 방법은 워크플로를 테스트한 프로젝트를 삭제하는 것입니다. 하지만 AlloyDB와 같은 개별 리소스를 삭제하여 직접 제한할 수도 있습니다.
실습을 마치면 AlloyDB 인스턴스와 클러스터를 폐기합니다.
AlloyDB 클러스터 및 모든 인스턴스 삭제
AlloyDB 무료 체험판을 사용한 경우 체험 클러스터를 사용하여 다른 실습과 리소스를 테스트할 계획이 있다면 체험 클러스터를 삭제하지 마세요. 동일한 프로젝트에서 다른 체험 클러스터를 만들 수 없습니다.
클러스터는 옵션 강제로 폐기되며, 클러스터에 속한 모든 인스턴스도 삭제됩니다.
연결이 끊어지고 이전 설정이 모두 손실된 경우 Cloud Shell에서 프로젝트와 환경 변수를 정의합니다.
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
다음과 같이 클러스터를 삭제합니다.
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB 백업 삭제
클러스터의 모든 AlloyDB 백업을 삭제합니다.
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. 축하합니다
축하합니다. Codelab을 완료했습니다.
학습한 내용
- AlloyDB 클러스터를 만들고 샘플 데이터를 가져오는 방법
- AlloyDB 데이터 액세스 API를 사용 설정하는 방법
- AlloyDB NL에 Google Cloud MCP를 사용 설정하는 방법
- ADK 에이전트에 AlloyDB용 Google Cloud MCP를 추가하는 방법
- 애플리케이션에서 AlloyDB용 Google Cloud MCP를 사용하는 방법
- 분석을 위해 AlloyDBMCP와 함께 에이전트를 사용하는 방법
13. 설문조사
결과: