
1. Wprowadzenie
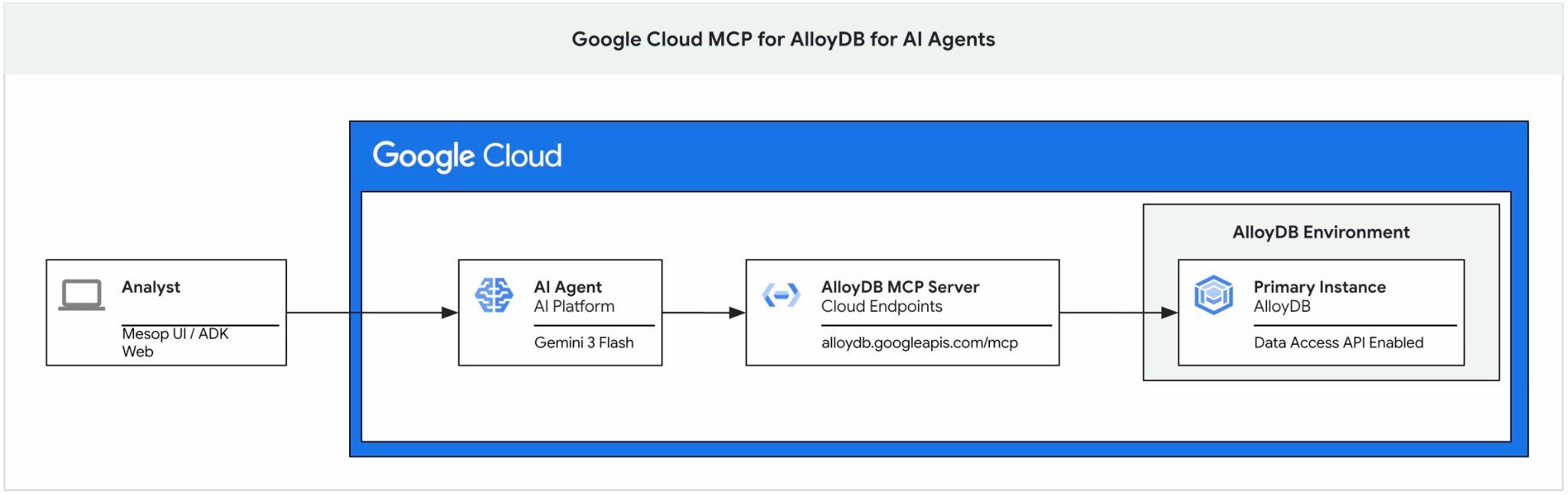
To ćwiczenie zawiera przewodnik po rozpoczęciu korzystania z serwera MCP Google Cloud dla AlloyDB, włączeniu go jako części zestawu narzędzi dla agenta AI i używaniu go jako części aplikacji.
Wymagania wstępne
- Podstawowa wiedza o Google Cloud i konsoli
- Podstawowe umiejętności w zakresie interfejsu wiersza poleceń i Cloud Shell
Czego się nauczysz
- Jak utworzyć klaster AlloyDB i zaimportować przykładowe dane
- Jak włączyć interfejs API dostępu do danych AlloyDB
- Jak włączyć MCP w Google Cloud dla AlloyDB NL
- Dodawanie narzędzia Google Cloud MCP dla AlloyDB do agenta ADK
- Jak używać Google Cloud MCP w przypadku AlloyDB w aplikacji
- Jak używać agentów z usługą AlloyDBMCP na potrzeby analizy
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- przeglądarka internetowa, np. Chrome, obsługująca konsolę Google Cloud i Cloud Shell;
2. Konfiguracja i wymagania
Konfiguracja projektu
- Zaloguj się w konsoli Google Cloud. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
- Utwórz nowy projekt lub użyj istniejącego. Aby utworzyć nowy projekt w konsoli Google Cloud, w nagłówku kliknij przycisk Wybierz projekt. Otworzy się okno wyskakujące.

W oknie Wybierz projekt kliknij przycisk Nowy projekt, który otworzy okno dialogowe nowego projektu.
W oknie dialogowym wpisz preferowaną nazwę projektu i wybierz lokalizację.
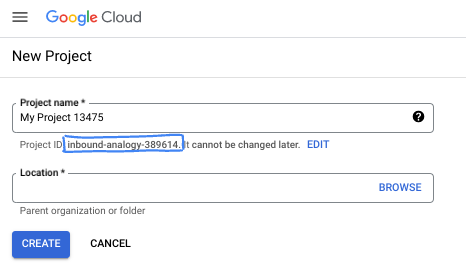
- Nazwa projektu to wyświetlana nazwa dla uczestników tego projektu. Nazwa projektu nie jest używana przez interfejsy API Google i można ją w każdej chwili zmienić.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Google Cloud automatycznie generuje unikalny identyfikator, ale możesz go dostosować. Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować kolejny losowy identyfikator lub podać własny, aby sprawdzić jego dostępność. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu, który jest zwykle oznaczony symbolem zastępczym PROJECT_ID.
- Warto wiedzieć, że istnieje też trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
Włącz płatności
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w konsoli Google Cloud.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 3 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Możesz też nacisnąć G, a potem S. Ta sekwencja aktywuje Cloud Shell, jeśli korzystasz z konsoli Google Cloud. Możesz też użyć tego linku.
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Zanim zaczniesz
Włącz API
Aby korzystać z AlloyDB, Compute Engine, usług sieciowych i Vertex AI, musisz włączyć odpowiednie interfejsy API w projekcie Google Cloud.
W terminalu Cloud Shell sprawdź, czy identyfikator projektu jest skonfigurowany:
gcloud config get-value project
Powinien zwrócić identyfikator Twojego projektu Google.
Ustaw zmienną środowiskową PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Włącz wszystkie niezbędne usługi:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Oczekiwane dane wyjściowe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Wdrażanie AlloyDB
Utwórz klaster AlloyDB i instancję główną. Możesz wdrożyć go za pomocą gotowego skryptu, który wdroży wszystkie niezbędne zasoby, lub samodzielnie, wykonując czynności opisane w dokumentacji.
Wdrażanie AlloyDB za pomocą automatycznego skryptu
W tym podejściu używamy automatycznego skryptu do wdrożenia klastra AlloyDB i podajemy niezbędne informacje, aby rozpocząć pracę z wdrożonymi zasobami.
W terminalu Cloud Shell wykonaj polecenie, aby sklonować skrypt wdrożenia z repozytorium.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-ai-mcp"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Uruchom skrypt wdrażania.
./deploy_alloydb.sh
Wykonanie skryptu zajmie trochę czasu – zwykle około 5–7 minut. Następnie powinna wyświetlić informacje o wdrożonym klastrze AlloyDB. Pamiętaj, że hasło będzie inne. Zapisz je w bezpiecznym miejscu, aby móc z niego korzystać w przyszłości.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
Nowy klaster i instancję podstawową możesz też zobaczyć w konsoli internetowej.
5. Przygotowywanie bazy danych
Aby korzystać z funkcji i operatorów AI, musisz włączyć integrację z Vertex AI, włączyć interfejs API dostępu do danych i utworzyć bazę danych dla przykładowego zbioru danych.
Przyznawanie AlloyDB niezbędnych uprawnień
Dodaj uprawnienia Vertex AI do agenta usługi AlloyDB.
Otwórz kolejną kartę Cloud Shell, klikając znak „+” u góry.
Na nowej karcie Cloud Shell wykonaj to polecenie:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/discoveryengine.viewer"
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... < redacted > etag: BwYIEbe_Z3U= version: 1
Włączanie interfejsu Data Access API
Aby móc korzystać z narzędzi MCP, takich jak execute_sql, musisz włączyć interfejs Data Access API w klastrze AlloyDB.
W tej samej karcie terminala wykonaj to polecenie.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Aktualizowanie flag instancji
Aby korzystać z zaawansowanych funkcji AI w AlloyDB, musimy włączyć niektóre flagi bazy danych. Po włączeniu interfejsu Data Access API może minąć kilka minut, zanim instancja będzie gotowa na kolejne zmiany. Sprawdź stan instancji w konsoli, aby upewnić się, że ma zielony znacznik wyboru.
W tej samej karcie terminala wykonaj to polecenie.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags=google_ml_integration.enable_model_support=on,google_ml_integration.enable_ai_query_engine=on,google_ml_integration.enable_preview_ai_functions=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Włącz MCP
Następnym krokiem jest włączenie serwera Google Cloud MCP dla AlloyDB w projekcie. Domyślnie MCP nie jest włączony. Jest to jedna z wielu warstw ochrony, w tym uwierzytelnianie i autoryzacja IAM, interfejs API dostępu do danych i role w klastrze.
W tej samej karcie terminala wykonaj to polecenie.
PROJECT_ID=$(gcloud config get-value project)
gcloud beta services mcp enable alloydb.googleapis.com \
--project=$PROJECT_ID
Zamknij kartę, wpisując na niej polecenie „exit”:
exit
Łączenie się z AlloyDB Studio
W kolejnych rozdziałach wszystkie polecenia SQL wymagające połączenia z bazą danych można wykonywać w AlloyDB Studio. T
Otwórz stronę Klastry w AlloyDB for Postgres.
Otwórz interfejs konsoli internetowej klastra AlloyDB, klikając instancję główną.
Następnie po lewej stronie kliknij AlloyDB Studio:
Wybierz bazę danych postgres, użytkownika postgres i podaj hasło zanotowane podczas tworzenia klastra. Następnie kliknij przycisk „Uwierzytelnij”.
Jeśli hasło nie działa lub nie pamiętasz, aby je zapisać, możesz je zmienić. Instrukcje znajdziesz w dokumentacji.
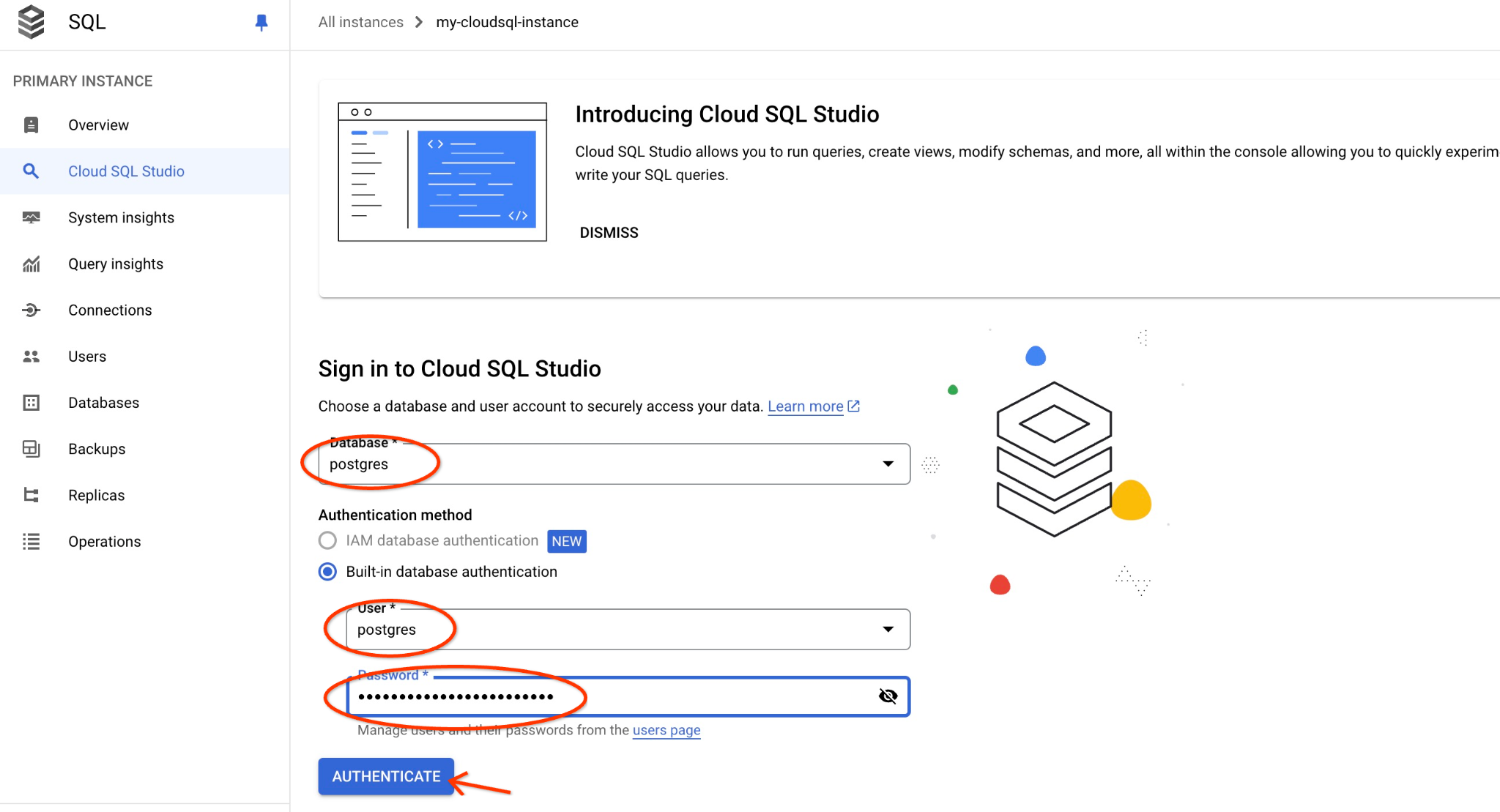
Otworzy się interfejs AlloyDB Studio. Aby uruchomić polecenia w bazie danych, kliknij kartę „Untitled Query” (Nienazwane zapytanie) po prawej stronie.
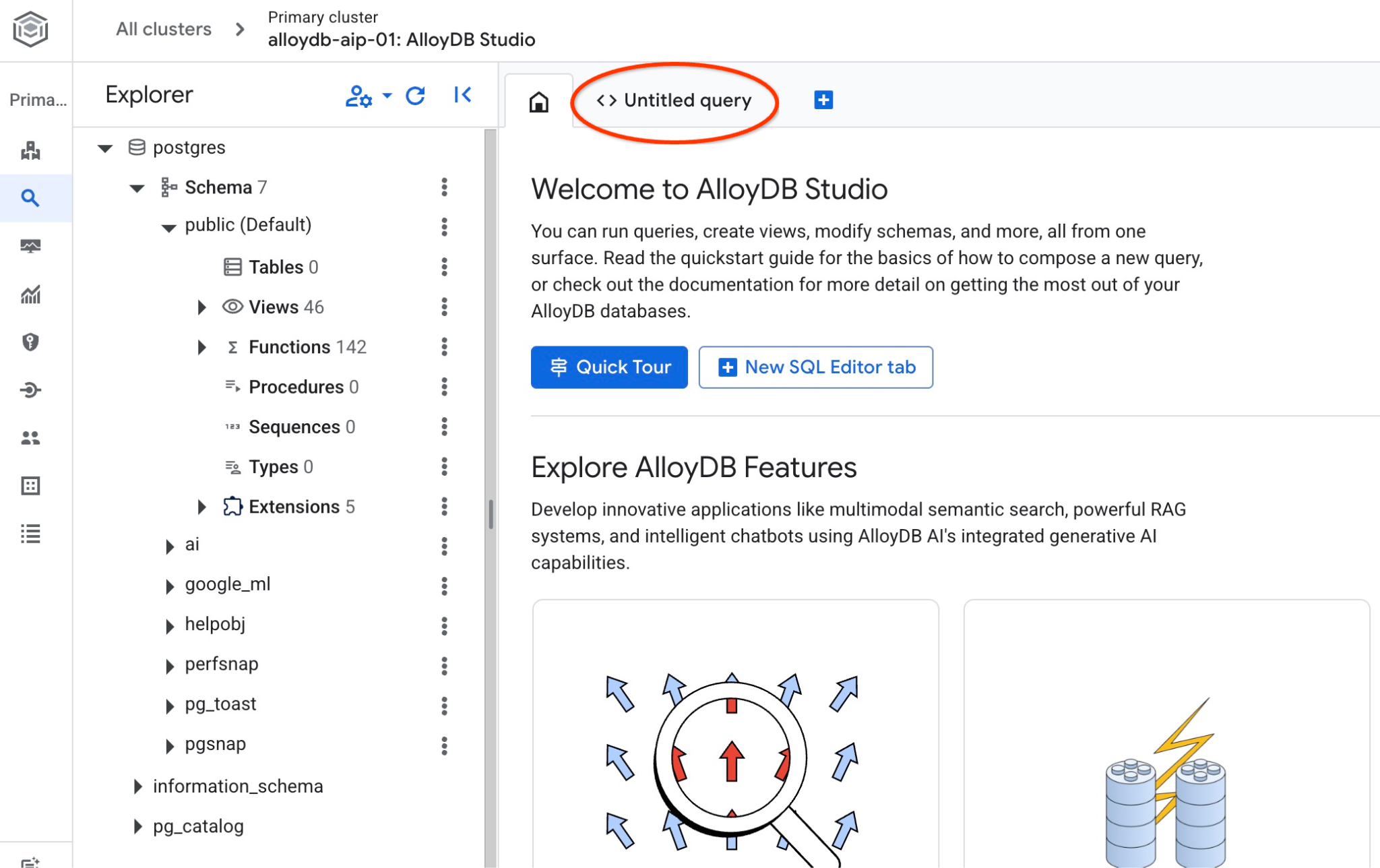
Otworzy się interfejs, w którym możesz uruchamiać polecenia SQL.
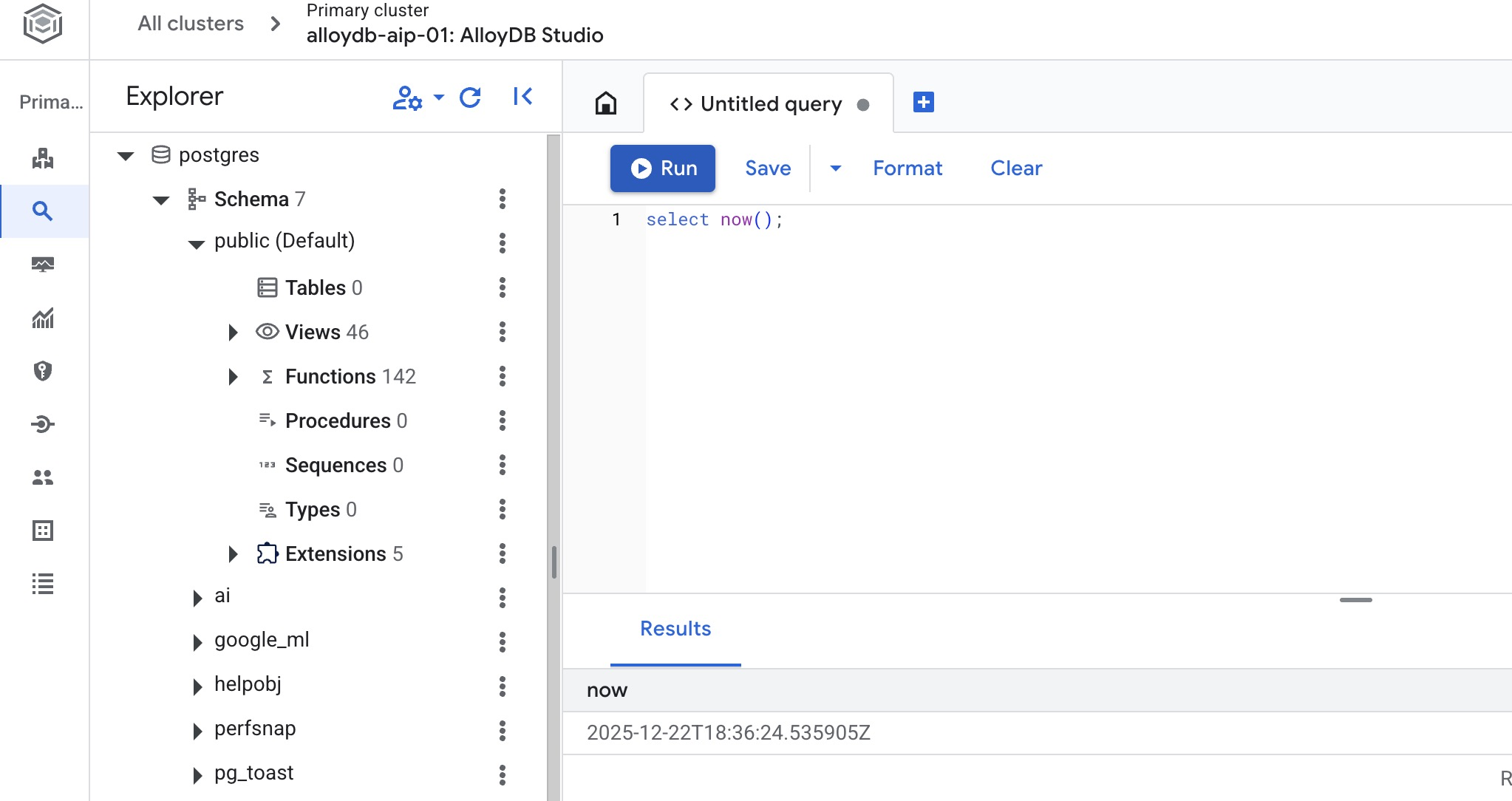
Utwórz bazę danych
Szybki start dotyczący tworzenia bazy danych.
W edytorze AlloyDB Studio wykonaj to polecenie.
Utwórz bazę danych:
CREATE DATABASE quickstart_db
Oczekiwane dane wyjściowe:
Statement executed successfully
Połącz się z bazą danych quickstart_db
Sprawdź, czy baza danych została utworzona, łącząc się z nią. Połącz się ponownie ze studiem, używając przycisku przełączania użytkownika lub bazy danych.
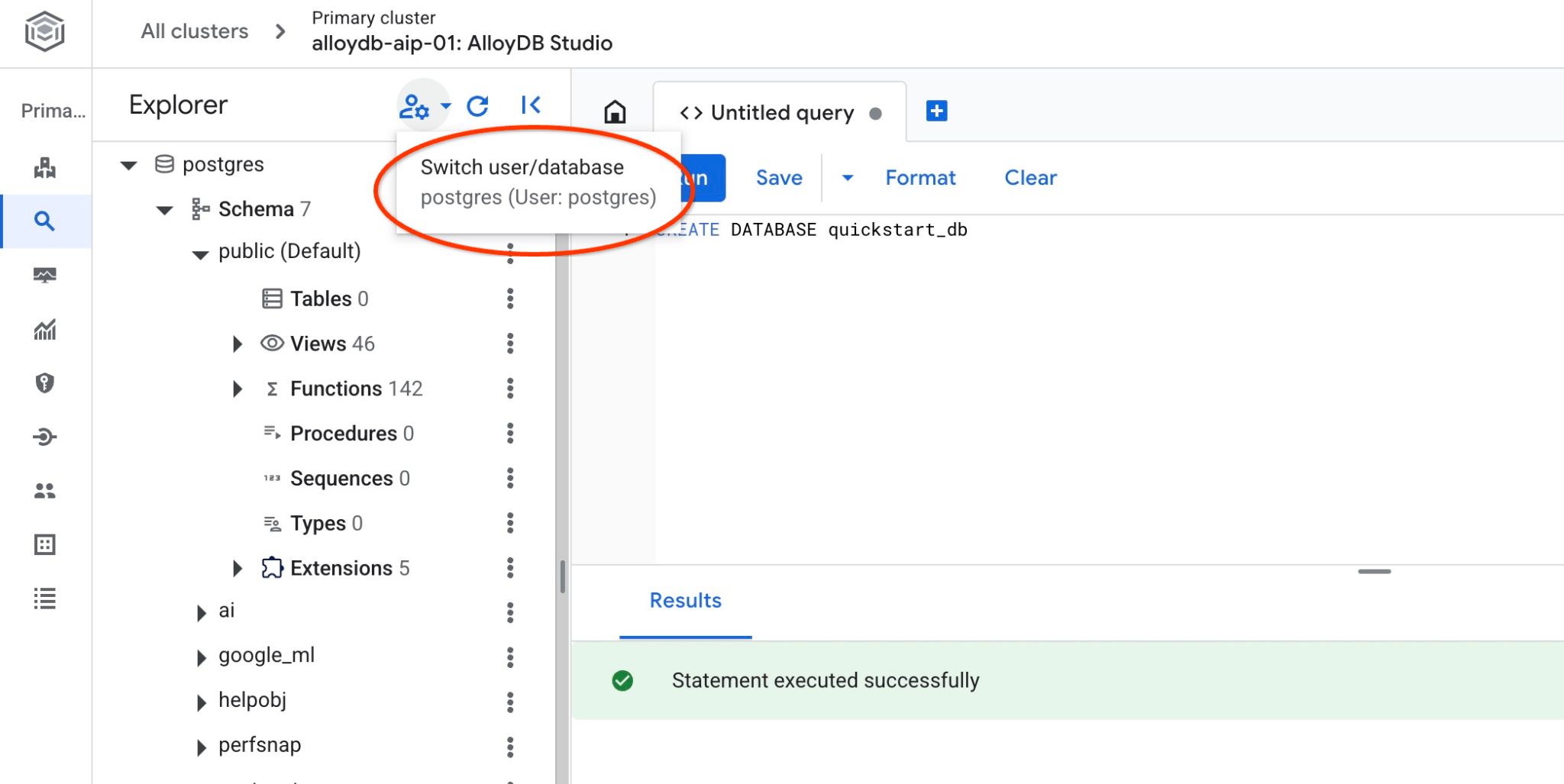
Na liście wybierz nową bazę danych quickstart_db i użyj tych samych nazwy użytkownika i hasła co wcześniej.
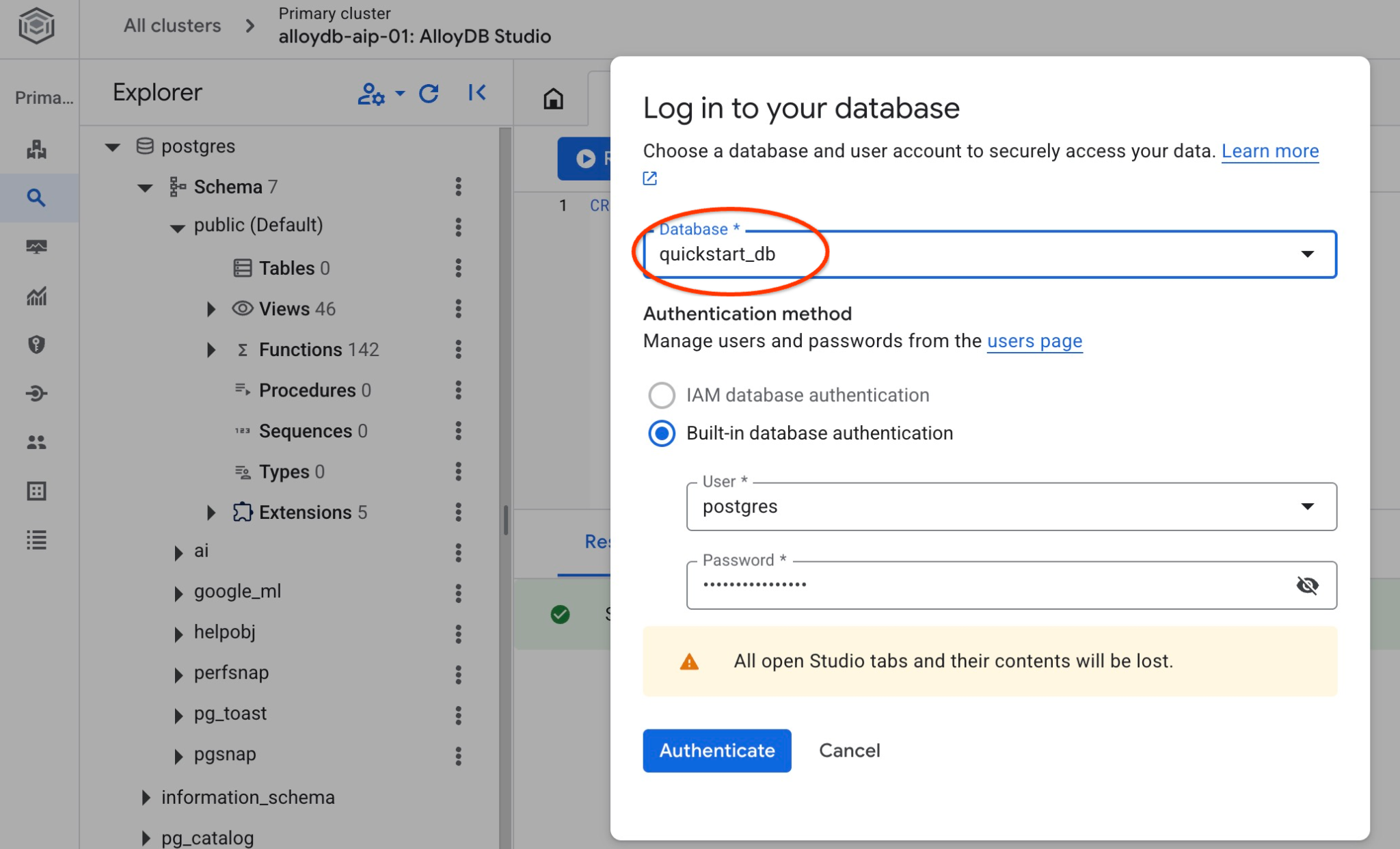
Otworzy się nowe połączenie, w którym możesz pracować z obiektami z bazy danych quickstart_db. Możesz tam sprawdzić zaimportowany schemat i dane.
6. Przykładowe dane
Teraz musisz utworzyć obiekty w bazie danych i wczytać dane. Użyjesz fikcyjnego zbioru danych firmy transportowej Cymbal Shipping. Zawiera fikcyjne dane o towarach, ciężarówkach, żądaniach i przejazdach ciężarówek, a także fikcyjnych kierowcach.
Tworzenie zasobnika na dane
Do zaimportowania danych ze sklonowanego repozytorium do bazy danych AlloyDB użyjesz pakietu Google SDK (gcloud). W tym celu musisz utworzyć zasobnik pamięci i przyznać dostęp do konta usługi AlloyDB. Możesz też spróbować zrobić to za pomocą konsoli internetowej, zgodnie z opisem w dokumentacji.
W terminalu Google Cloud Shell wykonaj to polecenie:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Wczytywanie danych
Następnym krokiem jest wczytanie danych. Nasz zrzut SQL znajduje się w sklonowanym folderze repozytorium. Poniższe polecenie zakłada, że podczas klonowania repozytorium w poprzednim kroku (podczas tworzenia klastra AlloyDB) jako punktu początkowego użyto katalogu domowego.
Skopiuj skompresowany zrzut SQL do nowego zasobnika pamięci:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Następnie wczytaj dane do bazy danych quickstart_db:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
Polecenie wczyta przykładowy zbiór danych do bazy danych quickstart_db. Tabele i rekordy możesz sprawdzić za pomocą AlloyDB Studio.
7. Praca z agentem danych
Zacznijmy od przykładowego agenta AI utworzonego za pomocą pakietu Google ADK dla Pythona i pokażmy, jak skonfigurować go do pracy z serwerem MCP Google Cloud dla AlloyDB.
Sprawdzanie kodu źródłowego agenta
W sklonowanym repozytorium sprawdź kod agenta za pomocą edytora Google Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/data_agent/agent.py
W agencie znajduje się sekcja serwera MCP Google Cloud dla AlloyDB. Podajemy punkt końcowy jako MCP_SERVER_URL, uwierzytelnianie, identyfikator projektu i dodajemy go do zestawu narzędzi MCP.
# Google Cloud MCP Server for AlloyDB
MCP_SERVER_URL = "https://alloydb.googleapis.com/mcp"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
# 2. Configure MCP Toolset
# We use StreamableHTTPConnectionParams to pass the auth header
headers = {
"Authorization": f"Bearer {creds.token}",
"X-Goog-User-Project": project_id
}
connection_params = StreamableHTTPConnectionParams(
url=MCP_SERVER_URL,
headers=headers,
timeout=300.0,
sse_read_timeout=600.0
)
mcp_toolset = McpToolset(connection_params=connection_params)
W kodzie agenta zestaw narzędzi MCP jest uwzględniony jako parametr tools agenta. W prompcie agenta znajdują się też nazwy klastra i instancji, region oraz baza danych jako zmienne.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
""",
tools=[mcp_toolset],
)
Usługa Google Cloud MCP dla AlloyDB ma wstępnie zdefiniowany zestaw narzędzi. Aby wyświetlić listę wszystkich dostępnych narzędzi, możesz użyć polecenia curl w terminalu konsoli Cloud Shell. Najnowsze informacje o serwerze MCP Google Cloud dla AlloyDB znajdziesz w dokumentacji.
curl -s -X POST http://alloydb.googleapis.com/mcp \
-H "Content-Type: application/json" \
-d @- <<EOF | jq -r '.result.tools[].name'
{
"id": "my_id_01",
"jsonrpc": "2.0",
"method": "tools/list"
}
EOF
Uruchamianie agenta
Teraz możesz uruchomić agenta w trybie interaktywnym za pomocą interfejsu internetowego Google ADK. Interfejs internetowy ADK to wygodny sposób na testowanie i rozwiązywanie problemów z przepływami pracy agentów.
Najpierw zainstaluj wszystkie wymagane pakiety dla Pythona za pomocą menedżera pakietów uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv sync
Po zainstalowaniu wszystkich pakietów musisz dodać do katalogu agenta plik .env, aby nakierować go na korzystanie z Vertex AI we wszystkich komunikatach z modelami AI.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Następnie możesz uruchomić agenta.
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Powinny się wyświetlić dane wyjściowe podobne do tych z punktem końcowym, np. http://127.0.0.1:8000.
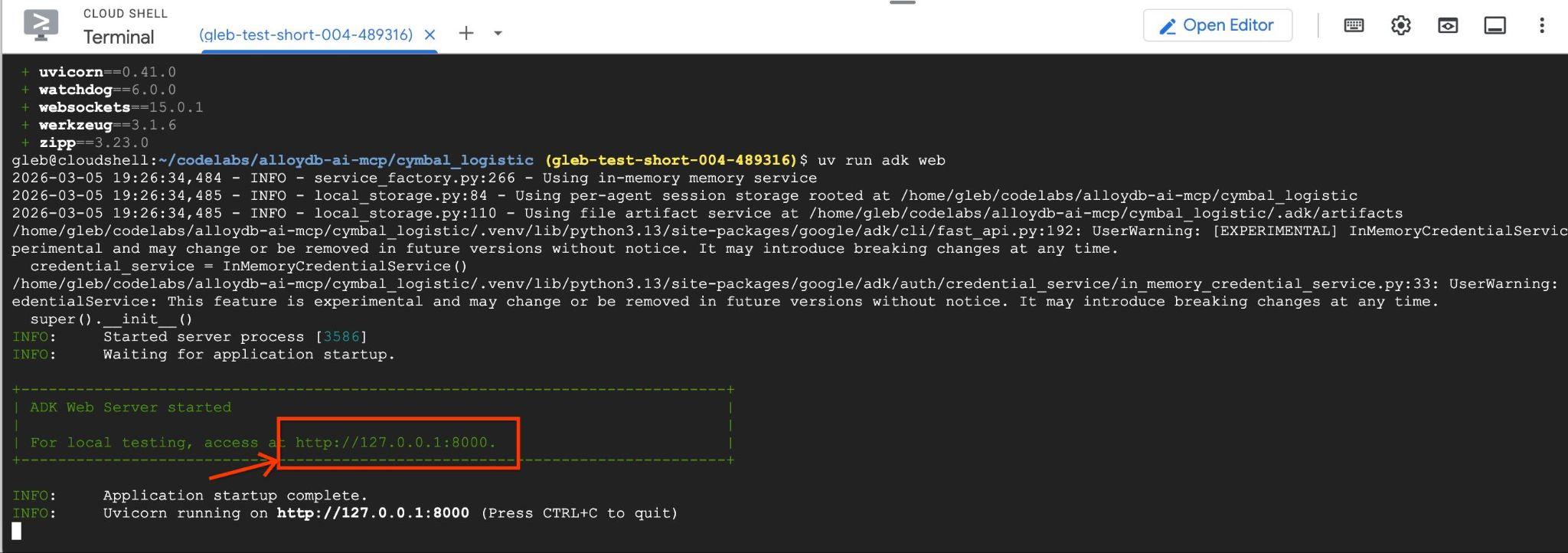
Możesz kliknąć ten adres URL w powłoce w chmurze. Spowoduje to otwarcie okna podglądu na osobnej karcie przeglądarki, w którym możesz wybrać data_agent z listy rozwijanej po lewej stronie.
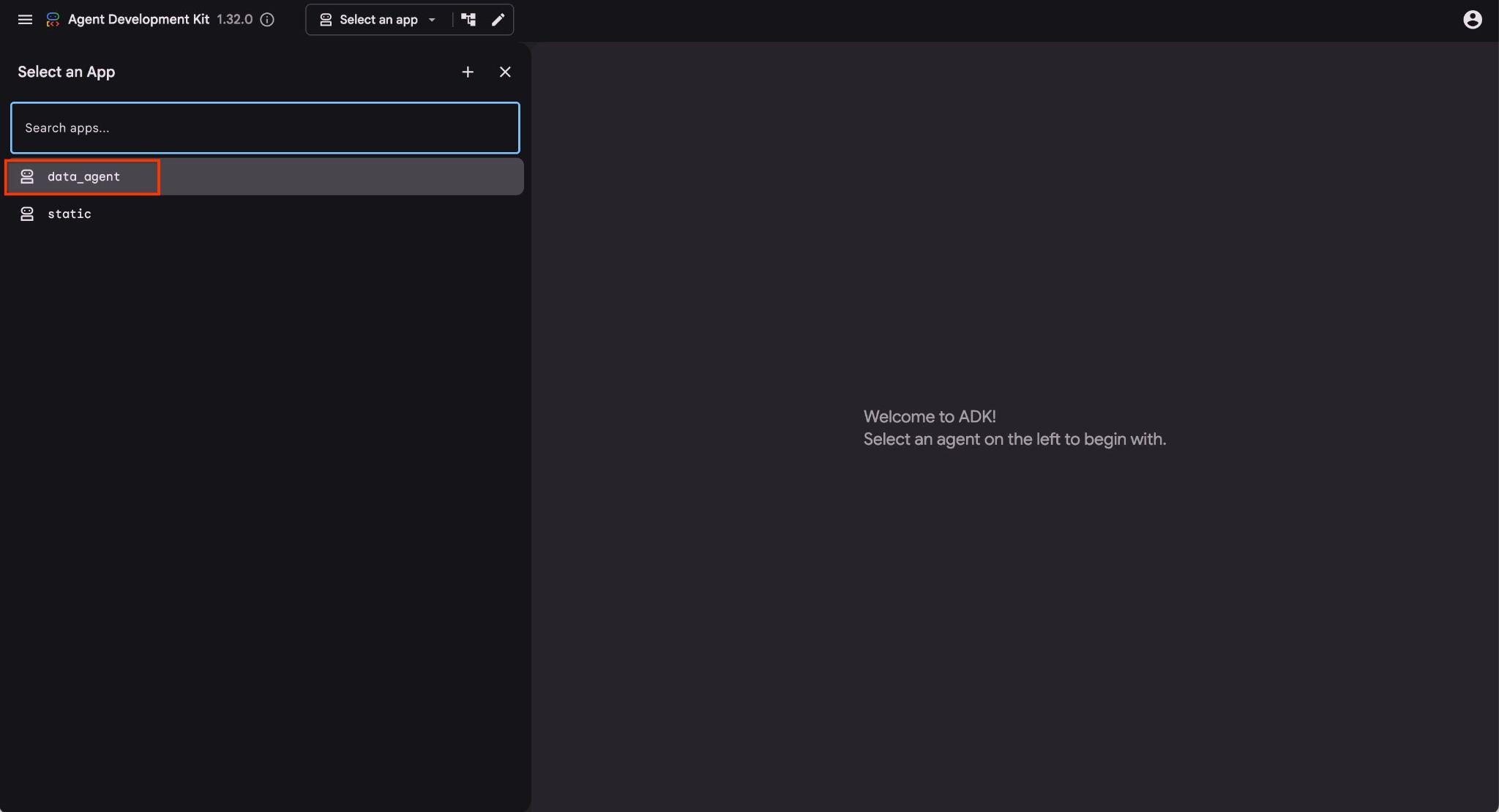
W interfejsie ADK możesz zadawać pytania w prawym dolnym rogu i wyświetlać pełny przepływ wykonania, w tym ślady każdego kroku po prawej stronie.
8. Testowanie narzędzia MCP AlloyDB za pomocą agenta
Agent umożliwia zadawanie pytań w eksploracji swobodnej w języku naturalnym, a do udzielania odpowiedzi wykorzystuje serwer Google Cloud MCP dla AlloyDB. Pytania są publikowane w prawym dolnym rogu, a odpowiedź ze wszystkimi wywołaniami narzędzi pojawia się u góry.
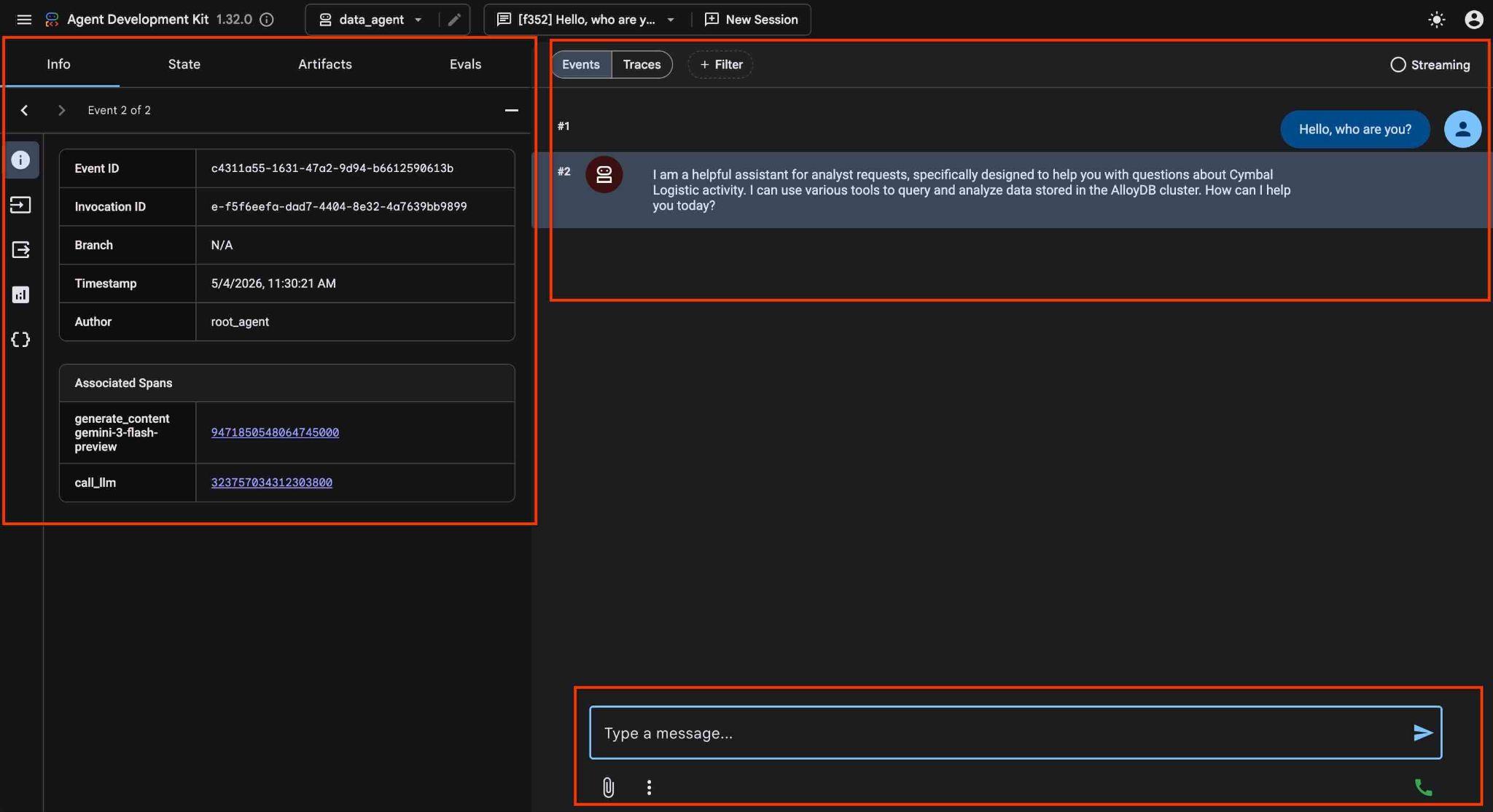
Pracujesz z danymi operacyjnymi firmy kurierskiej, które zawierają informacje o prośbach o dostawę, ciężarówkach, kierowcach i trasach pokonywanych przez kierowców. Pierwsze pytanie dotyczy liczby przejazdów zrealizowanych w lutym 2026 r.
W polu do wprowadzania danych w prawym dolnym rogu wpisz poniższy tekst i naciśnij Enter.
Hello, can you tell me how many trips we've done in February this year?
Agent będzie wykonywać wiele wywołań narzędzi, aby zidentyfikować odpowiednie tabele w schemacie i strukturę tabeli, zanim wykona prawidłowe instrukcje SQL w celu uzyskania właściwych danych.
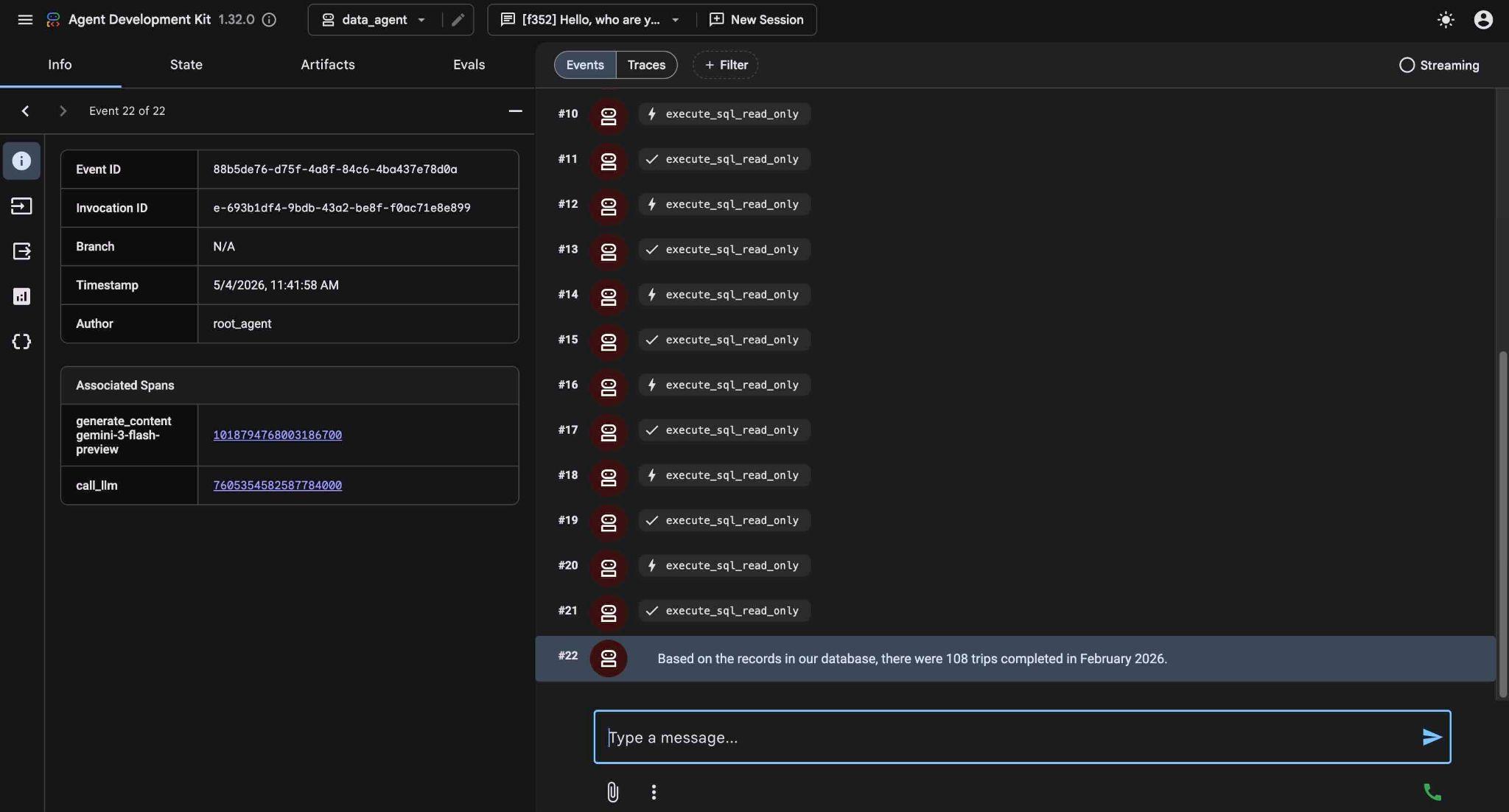
Ostatecznie zwróci wynik po utworzeniu odpowiedniego zapytania i wykonaniu go w bazie danych.
Z naszych danych wynika, że w lutym 2026 r. zrealizowano 108 przejazdów.
Aby sprawdzić, co robi każde wywołanie narzędzia, kliknij jego wykonanie. Na przykład oto zapytanie, które zostało wykonane, aby uzyskać nasze wyniki.
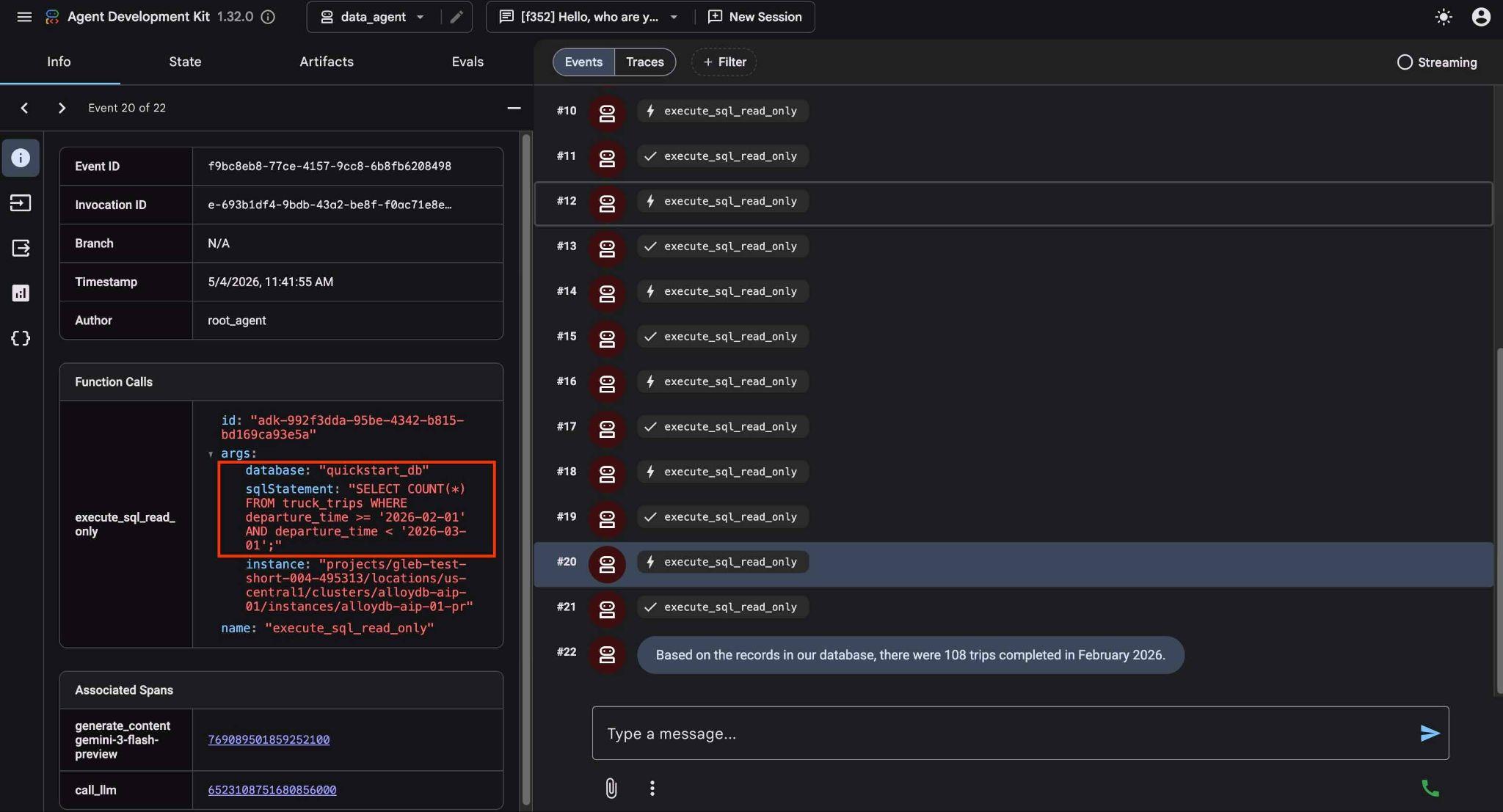
Teraz skomplikuj prośbę, prosząc o porównanie wyników z poprzednim miesiącem.
How is it in comparison in numbers and mileage with the January?
Zwraca wynik, wykonując różne zapytania, analizując wyniki i podając różnicę w liczbie przejazdów i przebiegu.
In comparison to January 2026, February saw a slight decrease in both the number of trips and the total mileage: January 2026: 114 trips with a total mileage of 185,597 km. February 2026: 108 trips with a total mileage of 177,893 km. This represents a decrease of 6 trips and 7,704 km in mileage for February compared to January.
Wypróbuj inne proste żądania za pomocą interfejsu internetowego ADK i zobacz, jak wykonuje on różne zapytania, aby uzyskać wyniki.
Zatrzymaj agenta, naciskając ctrl+c w terminalu. Możesz zamknąć kartę przeglądarki z interfejsem internetowym ADK.
Teraz możesz wypróbować przykładową aplikację i sprawdzić, jak może ona służyć jako narzędzie dla analityków danych.
9. Przykładowa aplikacja
W tym samym sklonowanym repozytorium mamy przykładową aplikację dla naszej firmy logistycznej Cymbol Logistic. Aplikacja korzysta z platformy Python Mesop od Google .
Możesz przeanalizować kod aplikacji, otwierając plik app.py w edytorze Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/app.py
W kodzie używamy funkcji, aby przekazać do agenta danych nowy prompt ze zmiennymi. Dzięki temu w interfejsie można skonfigurować wywołanie innej bazy danych lub instancji. Oto definicja funkcji i prompt.
def run_query_sync(request_text, cluster_name, location, instance_name, database_name, project_id, session_id, summary):
local_runner = FrontendRunner()
instruction = f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
"""
...
Po sprawdzeniu kodu naciśnij przycisk „terminal”, aby uruchomić i przetestować aplikację. Aplikacja zostanie uruchomiona na porcie 8080. Jeśli chcesz zmienić port, dostosuj polecenie, zmieniając wartość portu.
Uruchom w Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv run mesop app.py --port=8080
Następnie użyj podglądu w przeglądarce w Google Cloud Shell, klikając http://localhost:8080.
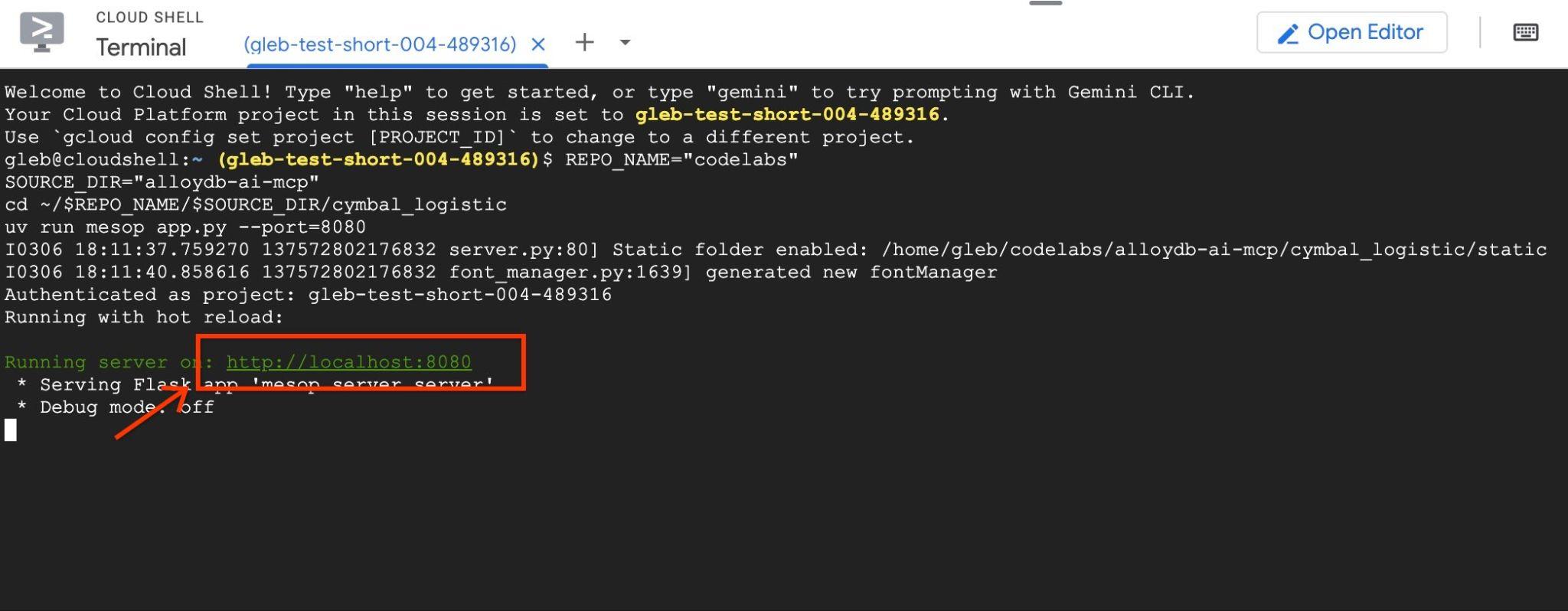
Otworzy się nowa karta przeglądarki z interfejsem aplikacji.
W prawym górnym rogu kliknij pole wyboru „Włącz dane wyjściowe debugowania” i wpisz pytanie podobne do tego poniżej.
What was the average speed for each driver last month? List top 5 fasters drivers ranking them by the average speed. Show the name, distance and average speed for each of them.
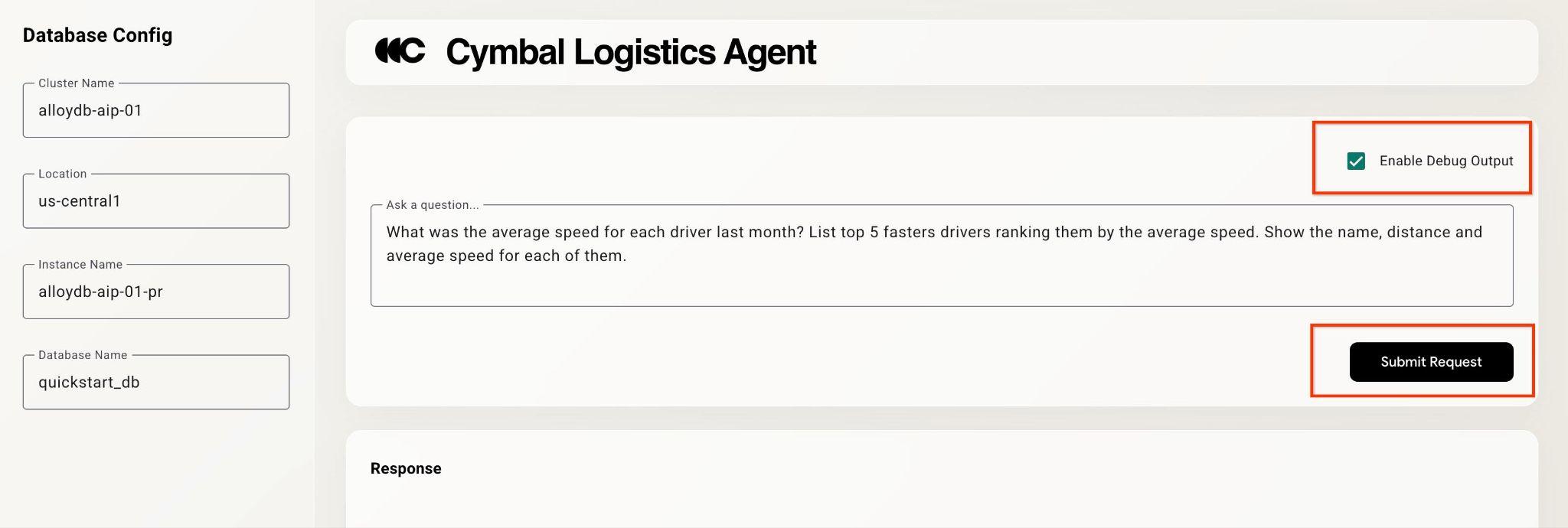
Następnie naciśnij przycisk Submit Request.
Agent będzie działać za kulisami i generować dane wyjściowe oraz informacje na potrzeby debugowania ze wszystkimi zapytaniami wykonywanymi przez nasz zestaw narzędzi MCP. Sprawdź zapytania, aby zobaczyć przepływ pracy.
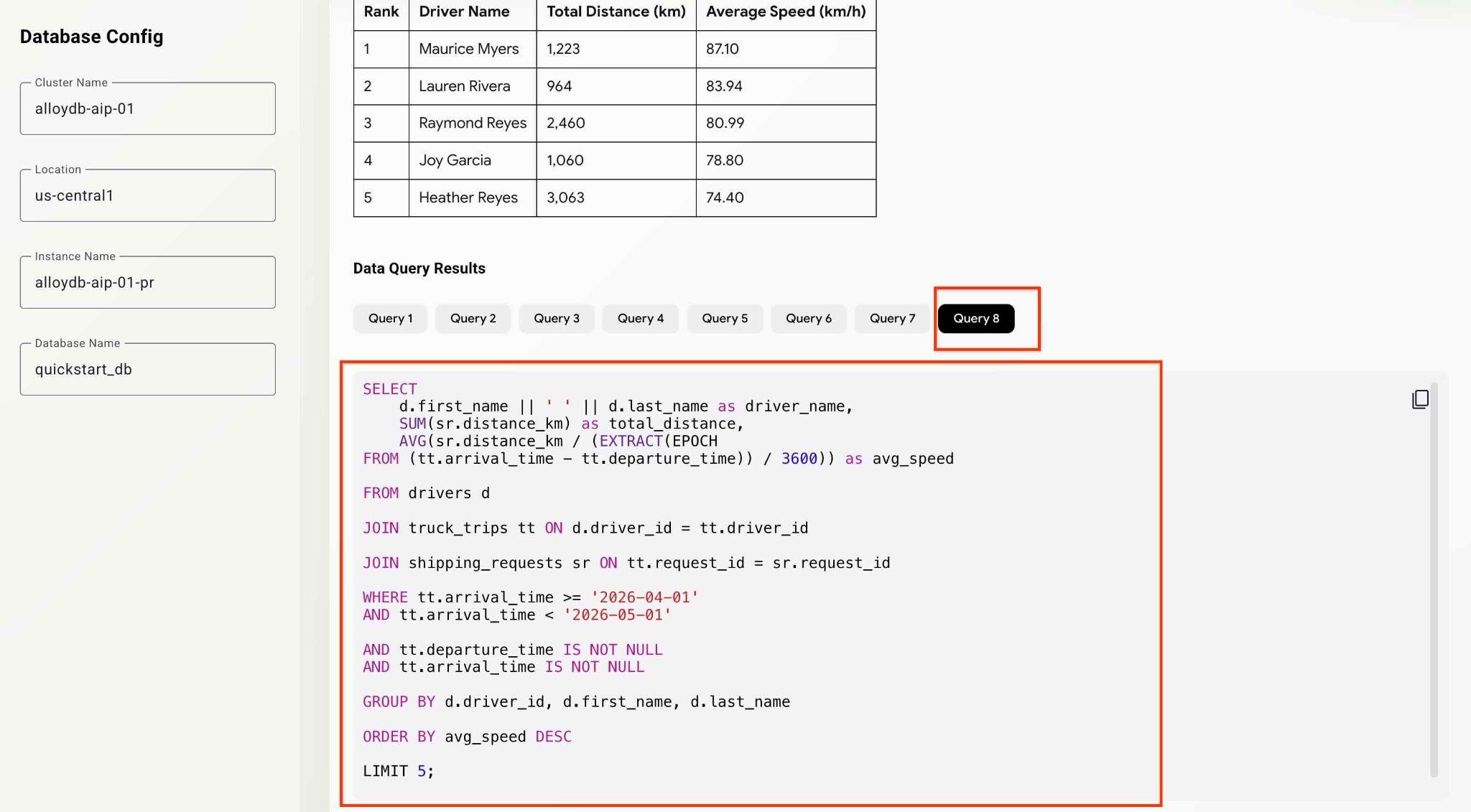
Możesz przetestować agentów i funkcje aplikacji, zadając różne pytania analityczne.
Do tej pory udało Ci się przeprowadzić podstawowe analizy i odkrywanie za pomocą agenta z MCP. W następnym rozdziale spróbujesz użyć bardziej zaawansowanych funkcji AlloyDB.
10. Funkcje AlloyDB AI
Funkcje AI w AlloyDB umożliwiają inteligentne filtrowanie i rankingowanie danych tekstowych i multimodalnych (zwłaszcza obrazów) oraz wykorzystują możliwości Gemini w zapytaniach. W szczególności funkcje AlloyDB AI AI.IF i AI.RANK mogą występować w instrukcjach SQL wraz z konwencjonalnymi operatorami SQL (filtrami, złączeniami, agregacją itp.).
Zanim użyjemy funkcji AI, sprawdzamy wyszukiwanie i agregacje za pomocą „klasycznych” metod. Wypróbuj ten prompt:
Can you analyze the activity for the last 5 months and evaluate drivers for the most positive customer feedbacks. Give me top 5 drivers listing names, distance and years of experience for each driver.
Potrafi znaleźć w tabeli z opiniami klientów kolumnę „ocena” i na jej podstawie określić kierowców z najwyższą oceną. Następnie wykorzystała te informacje, aby uzyskać więcej danych o kierowcach.
SELECT
d.first_name || ' ' || d.last_name as driver_name,
SUM(sr.distance_km) as total_distance,
d.experience_years,
COUNT(cf.feedback_id) as positive_feedback_count
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
WHERE tt.arrival_time >= '2025-12-01'
AND tt.arrival_time < '2026-05-01'
AND cf.rating >= 4
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY positive_feedback_count DESC, total_distance DESC
LIMIT 5;
Ocena może jednak obejmować wszystkie parametry, które chcemy ocenić, lub nie. W tym celu możemy użyć funkcji AI w AlloyDB.
Operatory AI.RANK
Funkcja ai.rank() ocenia, jak dobrze dokument odpowiada na dane zapytanie. Może być używany do określania lub ponownego określania rankingu wyników zapytania. Więcej informacji o operatorach znajdziesz w dokumentacji.
Zmodyfikuj prośbę i poproś o wykorzystanie podczas analizy funkcji AI.RANK, aby ocenić kierowców na podstawie ich skuteczności i profesjonalizmu.
Can you find the top 5 fastest drivers in the last month and rank them by the feedback using the AI.RANK function? Give me top drivers names, distance, years of experience and rank for each driver.
Wykonanie polecenia może zająć nieco więcej czasu, ponieważ agent musi dowiedzieć się, jak używać funkcji AI.RANK, pobrać dane i zastosować funkcję AI.RANK, aby odpowiednio posortować informacje. Na końcu powinna pojawić się lista kierowców uszeregowanych według modelu oraz lista wykonanych zapytań.
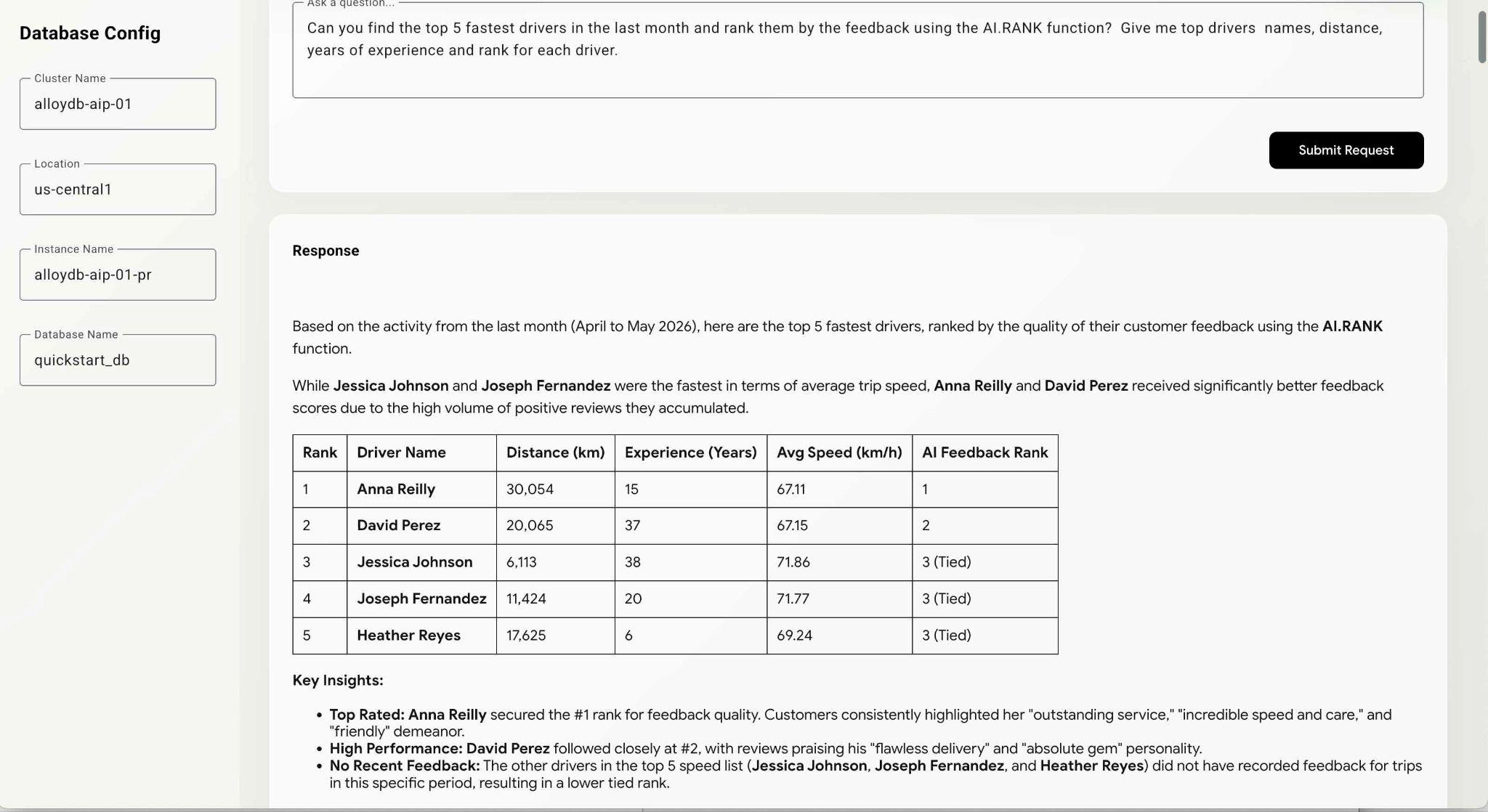
Wykonanie tego zapytania może zająć trochę czasu w zależności od ścieżki wybranej przez model. W oknie debugowania możesz zobaczyć dokładne zapytanie wykonane w celu uzyskania informacji o kierowcach.
WITH fastest_drivers AS (
SELECT
d.driver_id,
d.first_name || ' ' || d.last_name as driver_name,
d.experience_years,
SUM(sr.distance_km) as total_distance,
AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) as avg_speed,
COALESCE(STRING_AGG(cf.feedback_text, ' | '), 'No feedback') as feedbacks,
ROW_NUMBER() OVER (
ORDER BY AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) DESC) - 1 as row_idx
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
LEFT
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
WHERE tt.arrival_time >= '2026-04-04'
AND tt.arrival_time IS NOT NULL
AND tt.departure_time IS NOT NULL
AND tt.arrival_time > tt.departure_time
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY avg_speed DESC
LIMIT 5
)
SELECT
f.driver_name,
f.total_distance,
f.experience_years,
f.avg_speed,
f.feedbacks,
(SELECT r.score
FROM ai.rank(
'semantic-ranker-fast-004',
'excellent customer service, professional, friendly, fast,
and reliable delivery reviews',
ARRAY[f.feedbacks],
1
) r
LIMIT 1) as feedback_score
FROM fastest_drivers f
ORDER BY feedback_score DESC;
Możesz nadal testować aplikację i sprawdzać zapytania, aby zobaczyć, jak agent dochodzi do ostatecznych wyników.
To koniec modułu. Mam nadzieję, że udało Ci się zapoznać ze wszystkimi przykładami i dowiedzieć się, jak używać usługi Google Cloud MCP w przypadku AlloyDB. Aby MCP działał w przypadku przedsiębiorstw, warto połączyć go z funkcjami AlloyDB NL2SQL opisanymi w dokumentacji AlloyDB. Możesz wypróbować tę funkcję, korzystając z ćwiczeń z programowania dotyczących generowania instrukcji SQL dla AlloyDB.
11. Zwalnianie miejsca w środowisku
Aby uniknąć nieoczekiwanych opłat, warto usunąć zasoby tymczasowe. Najbardziej niezawodnym sposobem jest usunięcie projektu, w którym testowano przepływ pracy. Możesz jednak ograniczyć się, usuwając poszczególne zasoby, np. AlloyDB.
Po zakończeniu modułu zniszcz instancje i klaster AlloyDB.
Usuwanie klastra AlloyDB i wszystkich instancji
Jeśli korzystasz z wersji próbnej AlloyDB. Nie usuwaj klastra próbnego, jeśli planujesz testować inne laboratoria i zasoby przy użyciu tego klastra. Nie będzie można utworzyć kolejnego klastra próbnego w tym samym projekcie.
Klaster zostanie zniszczony z opcją force, która powoduje też usunięcie wszystkich instancji należących do klastra.
W Cloud Shell zdefiniuj projekt i zmienne środowiskowe, jeśli połączenie zostało przerwane i wszystkie poprzednie ustawienia zostały utracone:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Usuń klaster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Usuwanie kopii zapasowych AlloyDB
Usuń wszystkie kopie zapasowe AlloyDB dla klastra:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Gratulacje
Gratulujemy ukończenia ćwiczenia.
Omówione zagadnienia
- Jak utworzyć klaster AlloyDB i zaimportować przykładowe dane
- Jak włączyć interfejs API dostępu do danych AlloyDB
- Jak włączyć MCP w Google Cloud dla AlloyDB NL
- Dodawanie narzędzia Google Cloud MCP dla AlloyDB do agenta ADK
- Jak używać Google Cloud MCP w przypadku AlloyDB w aplikacji
- Jak używać agentów z usługą AlloyDBMCP na potrzeby analizy
13. Ankieta
Dane wyjściowe: