
1. Introdução
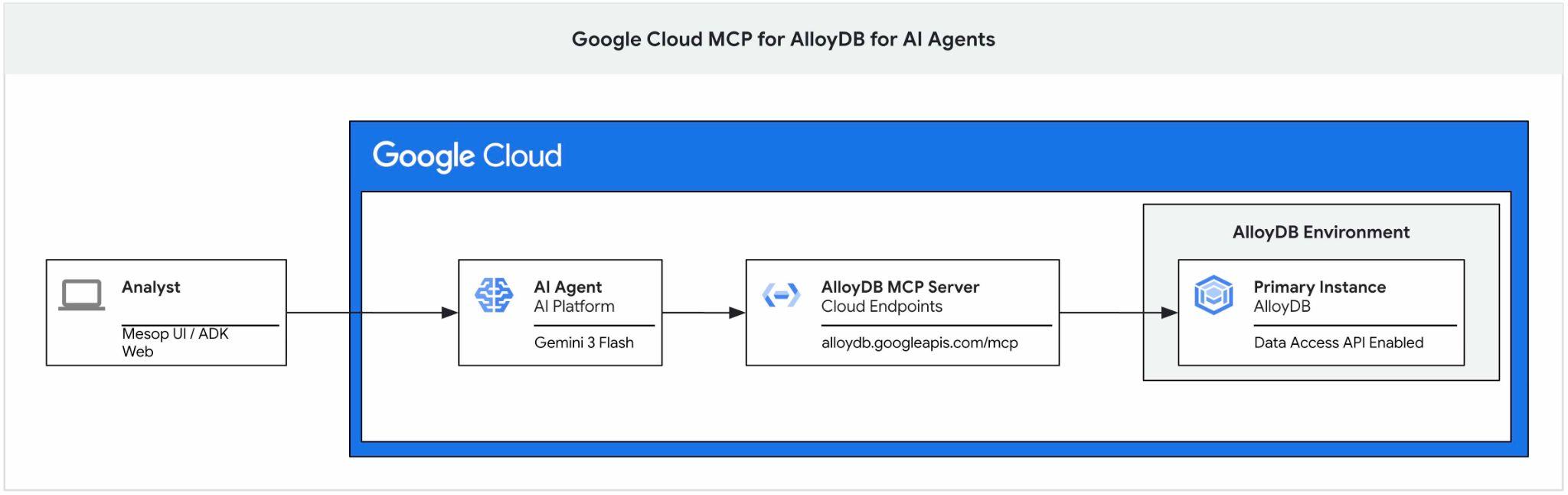
Este codelab ensina como começar a usar o servidor MCP do Google Cloud para o AlloyDB, ativá-lo como parte do conjunto de ferramentas de um agente de IA e usá-lo como parte de um aplicativo.
Pré-requisitos
- Conhecimentos básicos sobre o Google Cloud e o console
- Habilidades básicas na interface de linha de comando e no Cloud Shell
O que você vai aprender
- Como criar um cluster do AlloyDB e importar dados de amostra
- Como ativar a API de acesso aos dados do AlloyDB
- Como ativar o Google Cloud MCP para o AlloyDB NL
- Como adicionar o Google Cloud MCP para AlloyDB ao seu agente do ADK
- Como usar o MCP do Google Cloud para AlloyDB em um aplicativo
- Como usar agentes com o AlloyDBMCP para análise
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome, que seja compatível com o console do Google Cloud e o Cloud Shell
2. Configuração e requisitos
Configuração do projeto
- Faça login no Console do Google Cloud. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
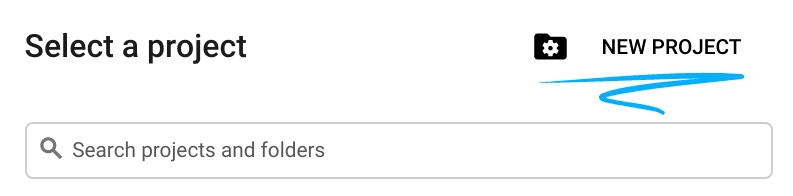
- Crie um novo projeto ou reutilize um existente. Para criar um projeto no console do Google Cloud, clique no botão "Selecionar um projeto" no cabeçalho, que vai abrir uma janela pop-up.

Na janela "Selecionar um projeto", clique no botão "Novo projeto", que vai abrir uma caixa de diálogo para o novo projeto.
Na caixa de diálogo, coloque o nome do projeto de sua preferência e escolha o local.
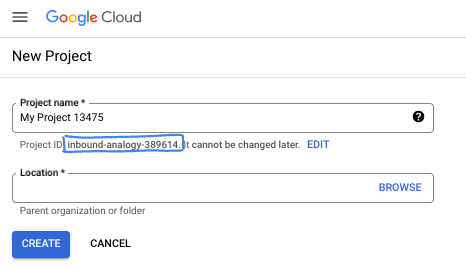
- O Nome do projeto é o nome de exibição para os participantes do projeto. O nome do projeto não é usado pelas APIs do Google e pode ser alterado a qualquer momento.
- O ID do projeto é exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Google Cloud gera automaticamente um ID exclusivo, mas você pode personalizá-lo. Se você não gostar do ID gerado, crie outro aleatório ou forneça o seu para verificar a disponibilidade. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, que normalmente é identificado com o marcador de posição PROJECT_ID.
- Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
Ativar faturamento
Configurar uma conta de faturamento pessoal
Se você configurou o faturamento usando créditos do Google Cloud, pule esta etapa.
Para configurar uma conta de faturamento pessoal, acesse este link e ative o faturamento no console do Cloud.
Algumas observações:
- A conclusão deste laboratório custa menos de US $3 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
Ou pressione G e S. Essa sequência vai ativar o Cloud Shell se você estiver no console do Google Cloud ou usar este link.
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Antes de começar
Ativar API
Para usar o AlloyDB, o Compute Engine, os serviços de rede e a Vertex AI, é necessário ativar as APIs respectivas no seu projeto do Google Cloud.
No terminal do Cloud Shell, verifique se o ID do projeto está configurado:
gcloud config get-value project
Ele vai retornar o ID do seu projeto do Google.
Defina a variável de ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Ative todos os serviços necessários:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Implantar o AlloyDB
Crie um cluster do AlloyDB e uma instância principal. Você pode implantar usando um script preparado que vai implantar todos os recursos necessários ou fazer isso etapa por etapa seguindo a documentação.
Implantar o AlloyDB usando um script automatizado
Essa abordagem usa um script automatizado para implantar o cluster do AlloyDB e fornece as informações necessárias para começar a trabalhar com os recursos implantados.
No terminal do Cloud Shell, execute o comando para clonar o script de implantação do repositório.
REPO_NAME="codelabs"
REPO_URL="https://github.com/GoogleCloudPlatform/$REPO_NAME"
SOURCE_DIR="alloydb-ai-mcp"
git clone --no-checkout --filter=blob:none --depth=1 $REPO_URL
cd $REPO_NAME
git sparse-checkout set $SOURCE_DIR
git checkout
cd $SOURCE_DIR
Execute o script de implantação.
./deploy_alloydb.sh
O script leva algum tempo para ser executado, geralmente de 5 a 7 minutos. Em seguida, como saída, ele vai fornecer informações sobre o cluster do AlloyDB implantado. A senha será diferente. Anote-a em algum lugar para uso futuro.
... <redacted> ... Creating primary instance: alloydb-aip-01-pr (8 vCPUs for TRIAL cluster) Operation ID: operation-1765988049916-646282264938a-bddce198-9f248715 Creating instance...done. ---------------------------------------- Deployment Process Completed Cluster: alloydb-aip-01 (TRIAL) Instance: alloydb-aip-01-pr Region: us-central1 Initial Password: JBBoDTgixzYwYpkF (if new cluster) ----------------------------------------
Também é possível conferir o novo cluster e a instância principal no console da Web.
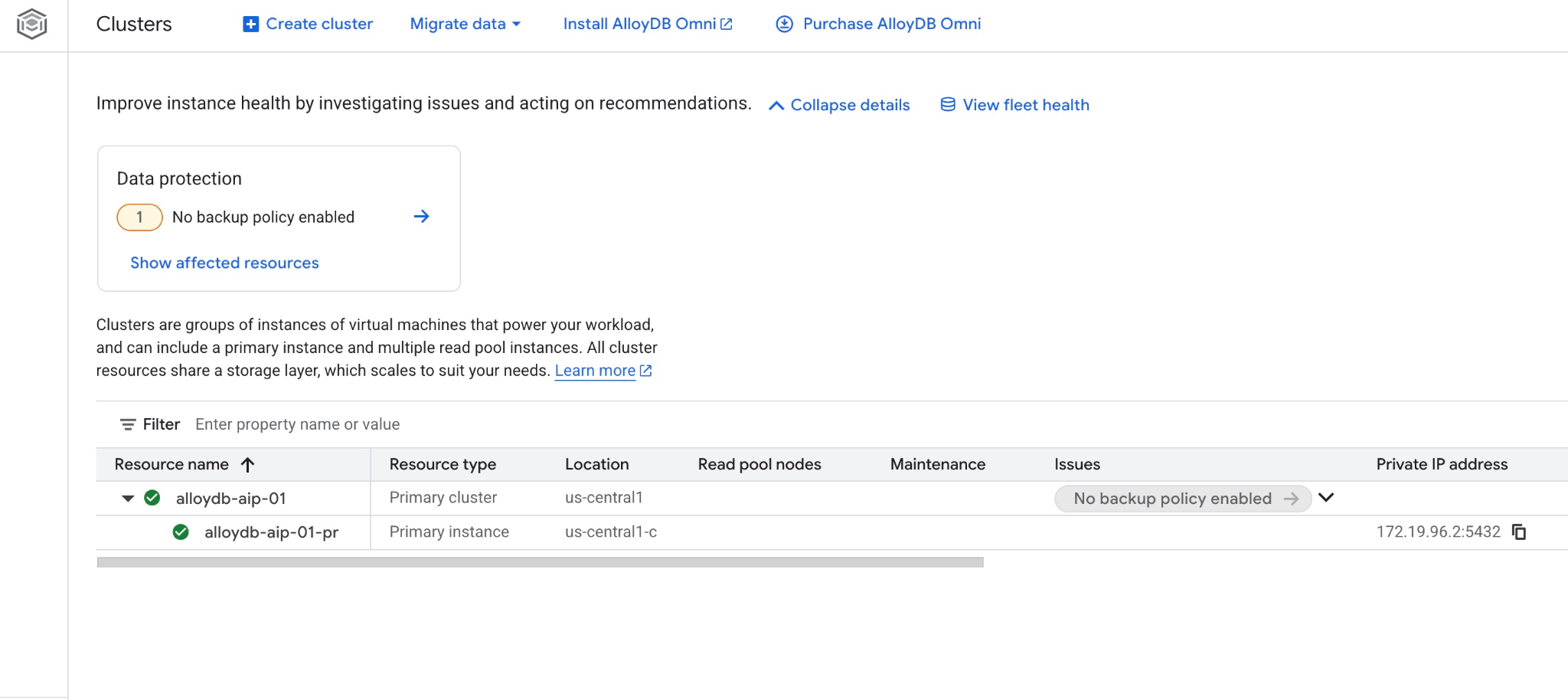
5. Preparar banco de dados
Você precisa ativar a integração da Vertex AI para usar funções e operadores de IA, ativar a API de acesso aos dados e criar um banco de dados para o conjunto de dados de exemplo.
Conceder as permissões necessárias ao AlloyDB
Adicione permissões da Vertex AI ao agente de serviço do AlloyDB.
Abra outra guia do Cloud Shell pelo sinal "+" na parte superior.
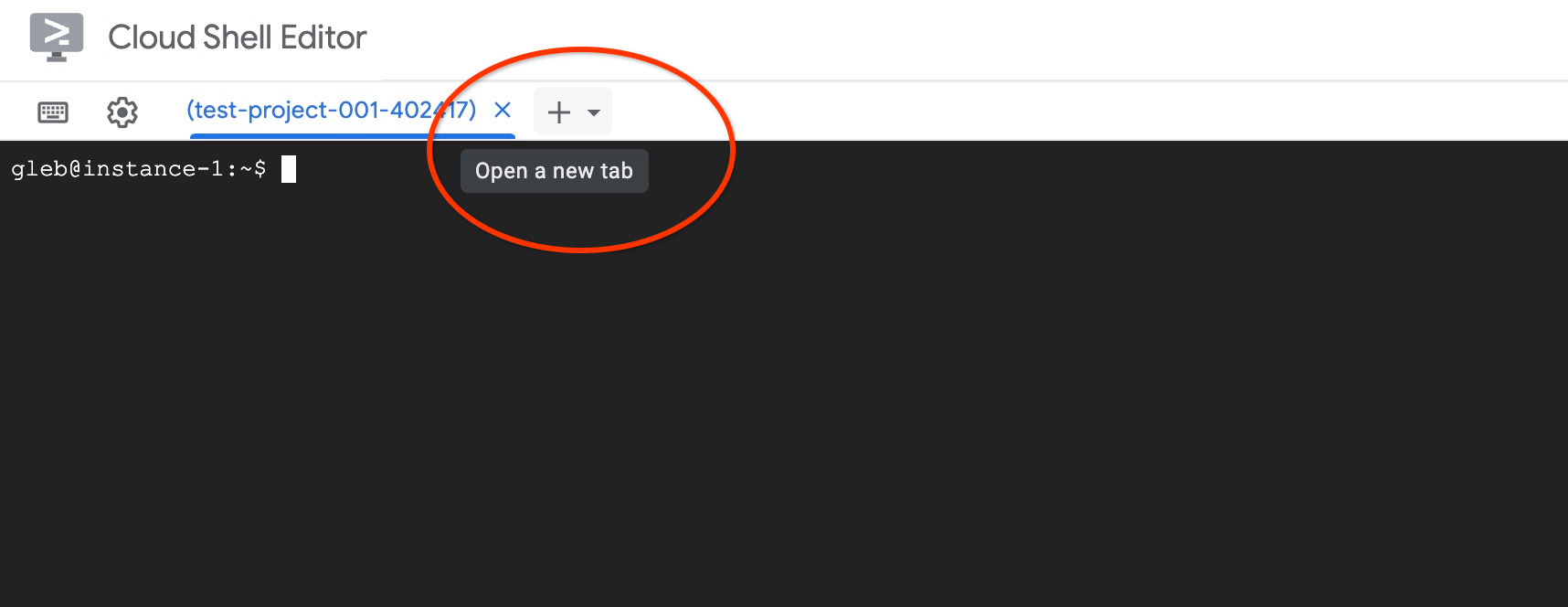
Na nova guia do Cloud Shell, execute:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/discoveryengine.viewer"
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... < redacted > etag: BwYIEbe_Z3U= version: 1
Ativar a API Data Access
É necessário ativar a API Data Access no cluster do AlloyDB para usar ferramentas do MCP, como o execute_sql.
Na mesma guia do terminal, execute.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER/instances/$ADBCLUSTER-pr?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
Atualizar flags de instância
Para usar as funções avançadas de IA no AlloyDB, precisamos ativar algumas flags de banco de dados. Depois de ativar a API Data Access, pode levar alguns minutos para que a instância fique pronta para as próximas mudanças. Consulte o status da instância no console para verificar se ela tem a marca de seleção verde.
Na mesma guia do terminal, execute.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags=google_ml_integration.enable_model_support=on,google_ml_integration.enable_ai_query_engine=on,google_ml_integration.enable_preview_ai_functions=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Ativar o MCP
A próxima etapa é ativar o servidor MCP do Google Cloud para o AlloyDB no seu projeto. Por padrão, a MCP não está ativada e é uma das várias camadas de proteção, incluindo autenticação e autorização do IAM, API de acesso aos dados e papéis no cluster.
Na mesma guia do terminal, execute.
PROJECT_ID=$(gcloud config get-value project)
gcloud beta services mcp enable alloydb.googleapis.com \
--project=$PROJECT_ID
Feche a guia pelo comando de execução "sair" na guia:
exit
Conectar-se ao AlloyDB Studio
Nos capítulos a seguir, todos os comandos SQL que exigem conexão com o banco de dados podem ser executados no AlloyDB Studio. T
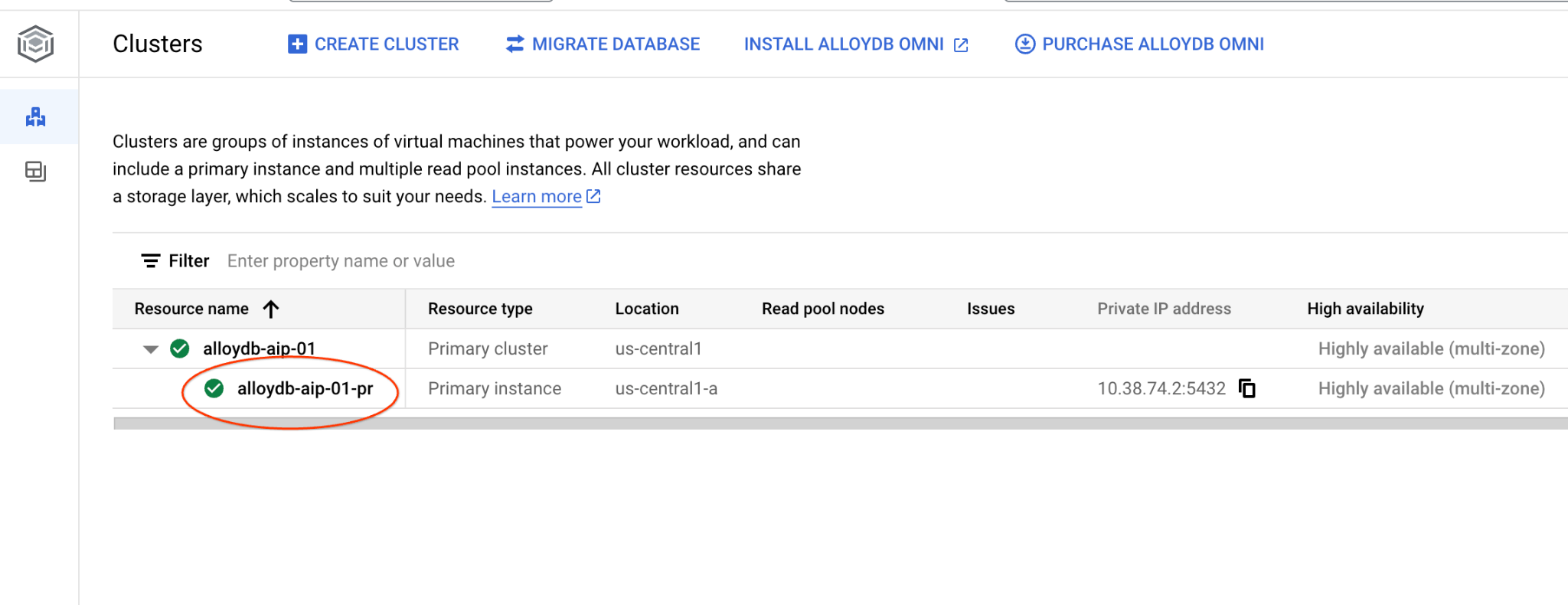
Navegue até a página "Clusters" no AlloyDB para Postgres.
Abra a interface do console da Web do cluster do AlloyDB clicando na instância principal.
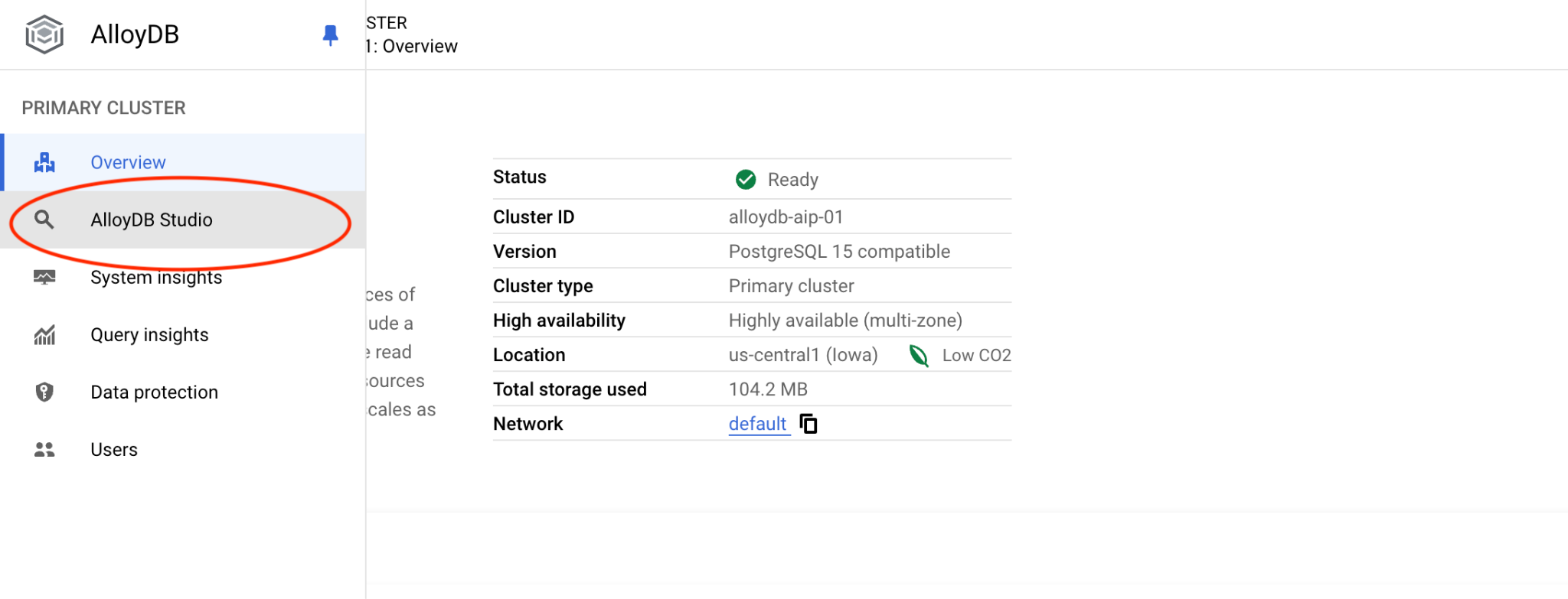
Em seguida, clique em "AlloyDB Studio" à esquerda:
Escolha o banco de dados postgres, o usuário postgres e forneça a senha anotada quando criamos o cluster. Em seguida, clique no botão "Autenticar".
Se a senha não funcionar ou você tiver esquecido de anotar, mude a senha. Confira a documentação para saber como fazer isso.
A interface do AlloyDB Studio será aberta. Para executar os comandos no banco de dados, clique na guia "Consulta sem título" à direita.
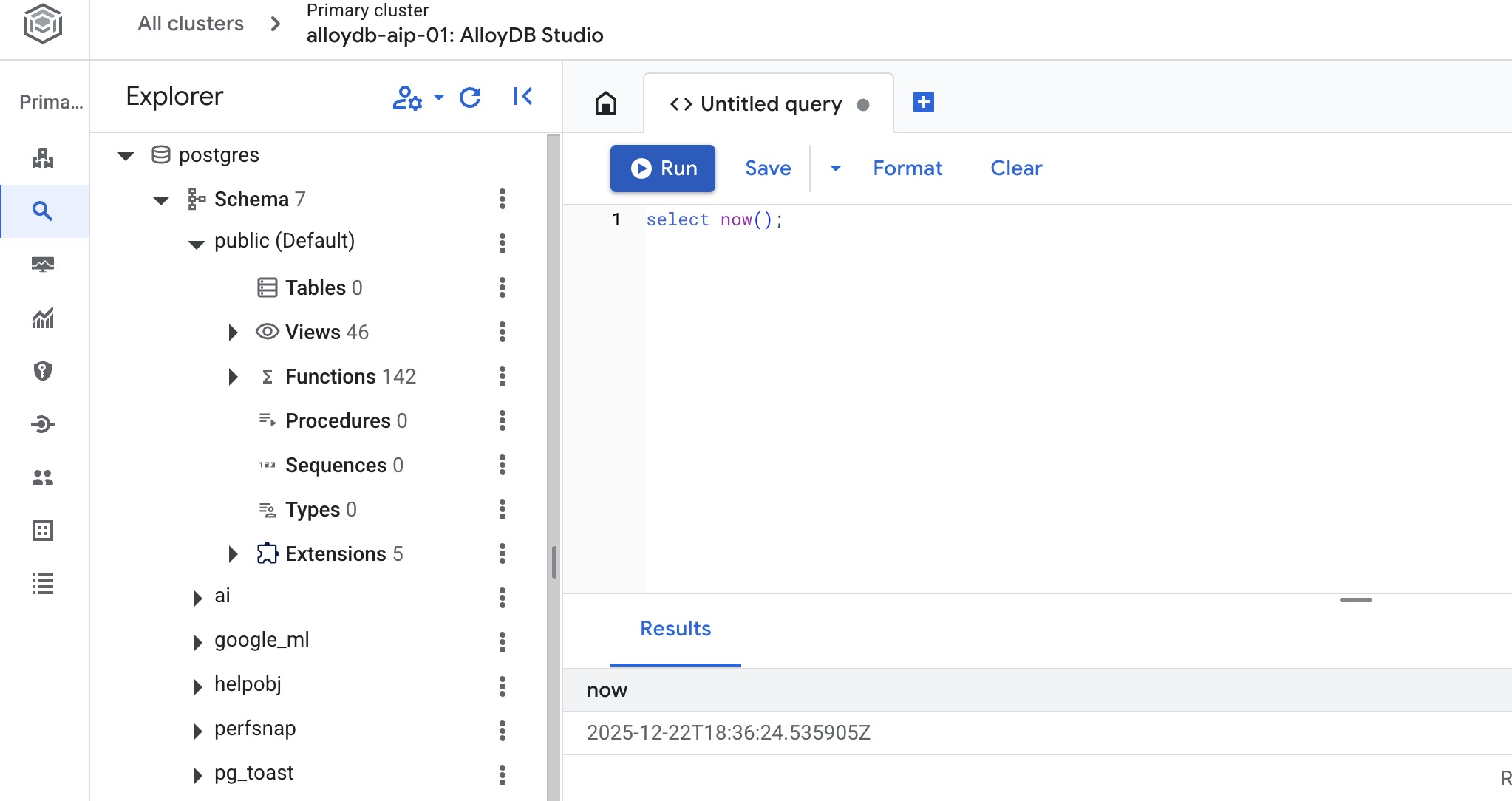
Ela abre uma interface em que é possível executar comandos SQL.
Criar banco de dados
Início rápido para criar um banco de dados.
No editor do AlloyDB Studio, execute o comando a seguir.
Crie o banco de dados:
CREATE DATABASE quickstart_db
Saída esperada:
Statement executed successfully
Conectar-se a quickstart_db
Confira se o banco de dados foi criado conectando-se a ele. Reconecte-se ao estúdio usando o botão para mudar de usuário/banco de dados.
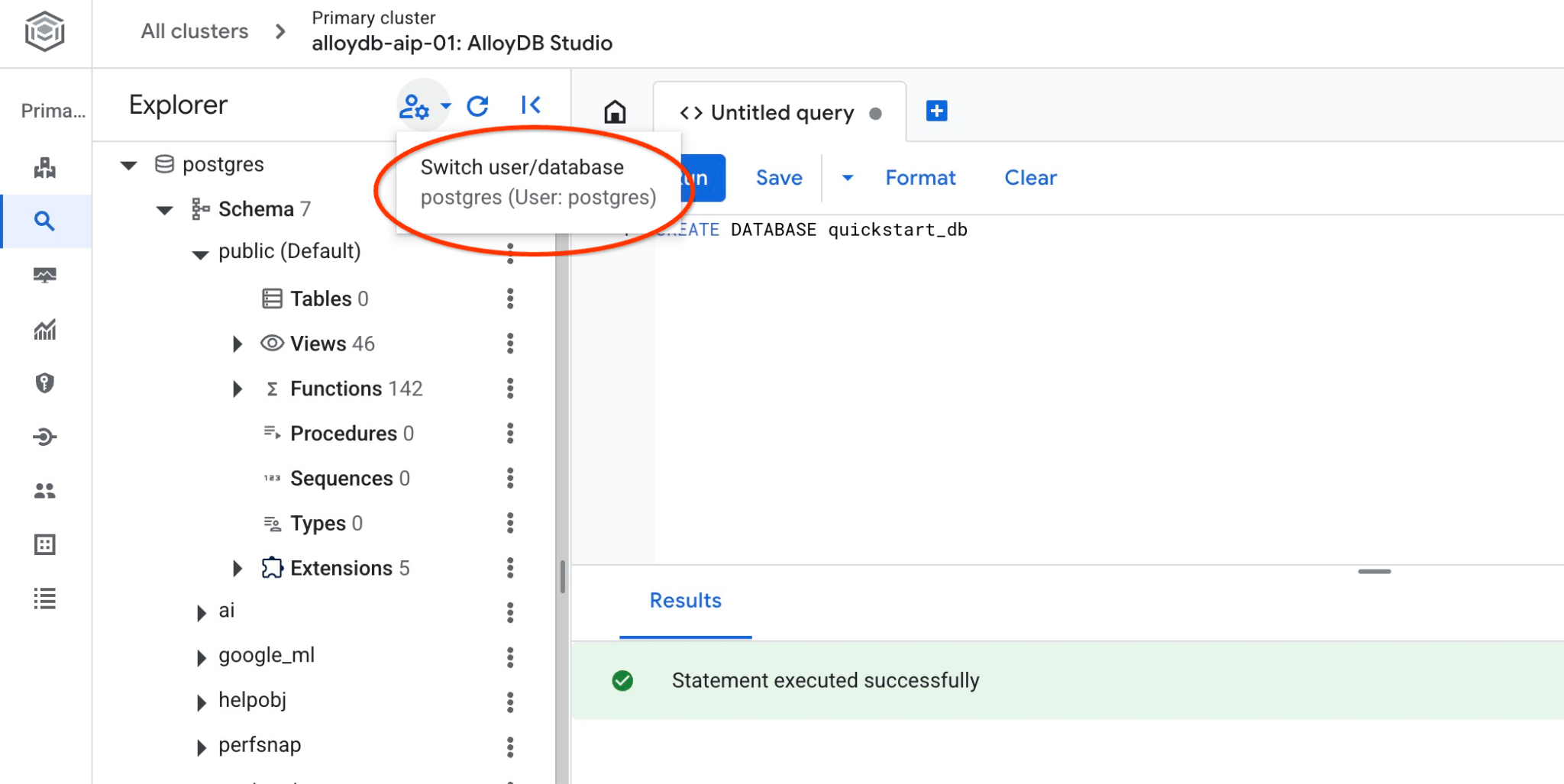
Escolha na lista suspensa o novo banco de dados quickstart_db e use o mesmo usuário e senha de antes.
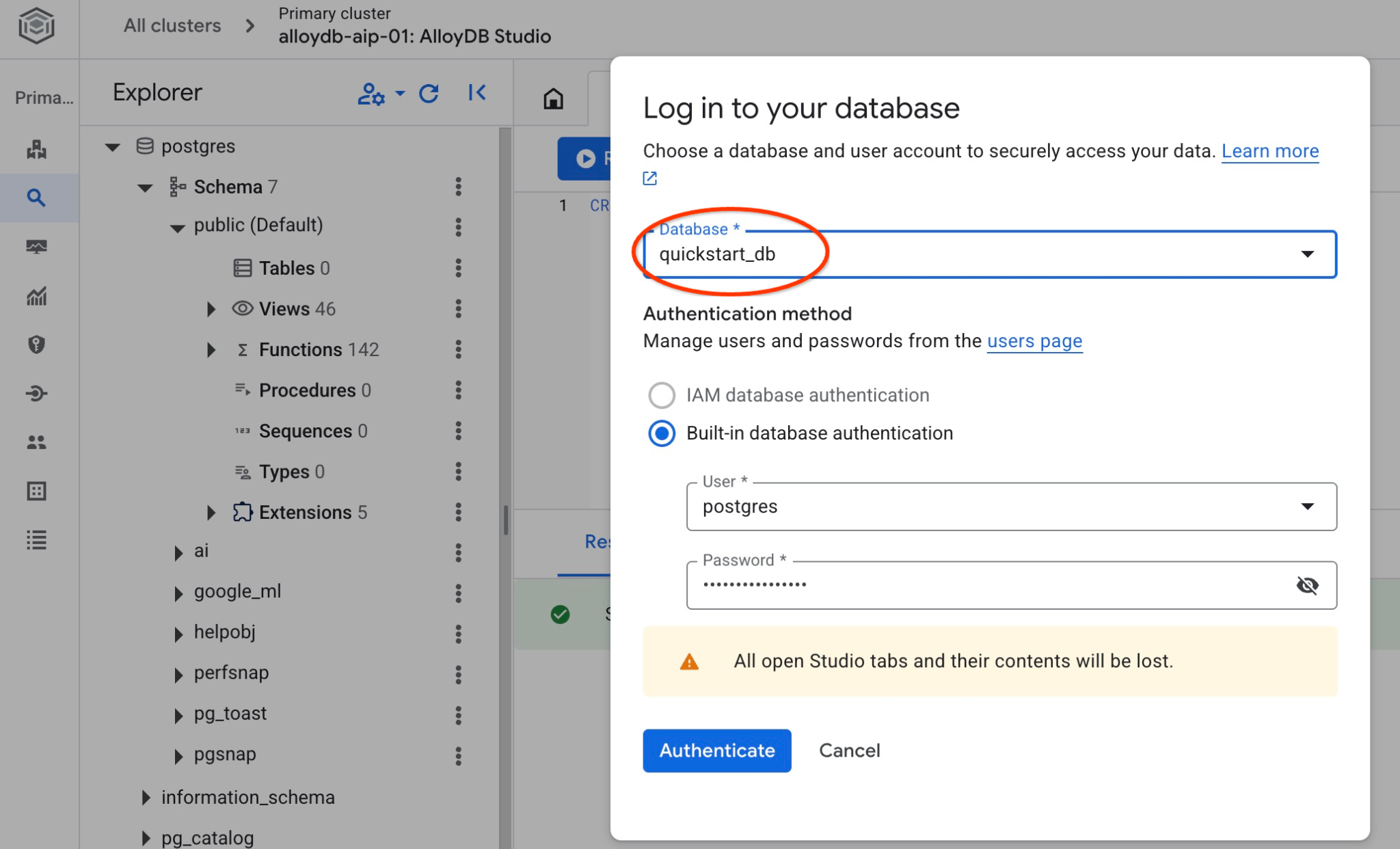
Isso vai abrir uma nova conexão em que você pode trabalhar com objetos do banco de dados quickstart_db. Lá, você poderá examinar o esquema e os dados importados.
6. Dados de amostra
Agora você precisa criar objetos no banco de dados e carregar dados. Você vai usar um conjunto de dados fictício da empresa Cymbal Shipping. Ele tem dados fictícios sobre mercadorias, caminhões, solicitações e viagens de caminhão, além de motoristas fictícios.
Criar bucket de armazenamento
Você vai usar o SDK do Google (gcloud) para importar dados do nosso repositório clonado para o banco de dados do AlloyDB. Para isso, crie um bucket de armazenamento e conceda acesso à conta de serviço do AlloyDB. Como alternativa, você sempre pode tentar fazer isso usando o console da Web, conforme descrito na documentação.
No terminal do Google Cloud Shell, execute:
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
gcloud storage buckets create gs://$PROJECT_ID-import --project=$PROJECT_ID --location=$REGION
gcloud storage buckets add-iam-policy-binding gs://$PROJECT_ID-import --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" --role=roles/storage.objectViewer
Carregar dados
A próxima etapa é carregar os dados. O despejo SQL está localizado na pasta do repositório clonado. O comando a seguir pressupõe que você usou seu diretório principal como ponto de partida ao clonar o repositório na etapa anterior durante a criação do cluster do AlloyDB.
Copie o dump SQL compactado para o novo bucket de armazenamento:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR
gcloud storage cp ~/$REPO_NAME/$SOURCE_DIR/postgres_dump.sql.gz gs://$PROJECT_ID-import
Em seguida, carregue os dados no banco de dados quickstart_db:
PROJECT_ID=$(gcloud config get-value project)
CLUSTER_NAME=alloydb-aip-01
REGION=us-central1
gcloud alloydb clusters import $CLUSTER_NAME --region=us-central1 --database=quickstart_db --gcs-uri=gs://$PROJECT_ID-import/postgres_dump.sql.gz --project=$PROJECT_ID --sql
O comando vai carregar o conjunto de dados de amostra no banco de dados quickstart_db. É possível verificar as tabelas e os registros usando o AlloyDB Studio.
7. Trabalhar com o agente de dados
Vamos começar com um agente de IA de exemplo criado usando o ADK do Google para Python e mostrar como configurá-lo para trabalhar com o servidor MCP do Google Cloud para AlloyDB.
Verificar o código-fonte do agente
No repositório clonado, revise o código do agente usando o editor do Google Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/data_agent/agent.py
No agente, há uma seção para o servidor MCP do Google Cloud para o AlloyDB. Fornecemos um endpoint como MCP_SERVER_URL, autenticação, ID do projeto e adicionamos ao conjunto de ferramentas do MCP.
# Google Cloud MCP Server for AlloyDB
MCP_SERVER_URL = "https://alloydb.googleapis.com/mcp"
creds, project_id = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
if not creds.valid:
creds.refresh(GoogleAuthRequest())
print(f"Authenticated as project: {project_id}")
# 2. Configure MCP Toolset
# We use StreamableHTTPConnectionParams to pass the auth header
headers = {
"Authorization": f"Bearer {creds.token}",
"X-Goog-User-Project": project_id
}
connection_params = StreamableHTTPConnectionParams(
url=MCP_SERVER_URL,
headers=headers,
timeout=300.0,
sse_read_timeout=600.0
)
mcp_toolset = McpToolset(connection_params=connection_params)
No código do agente, o conjunto de ferramentas do MCP é incluído como parâmetro tools. Também há nomes de cluster e instância, a região e o banco de dados como variáveis para o comando do agente.
MODEL_ID = "gemini-3-flash-preview"
cluster_name="alloydb-aip-01"
instance_name="alloydb-aip-01-pr"
location="us-central1"
database_name="quickstart_db"
# Agent configuration
root_agent = Agent(
model=MODEL_ID,
name='root_agent',
description='A helpful assistant for analyst requests.',
instruction=f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
""",
tools=[mcp_toolset],
)
O serviço MCP do Google Cloud para o AlloyDB tem um conjunto predefinido de ferramentas. Se você quiser listar todas as ferramentas disponíveis, use o comando curl no terminal do console do Cloud Shell com o seguinte comando. Você sempre pode conferir a referência mais recente do servidor MCP do Google Cloud para o AlloyDB na documentação.
curl -s -X POST http://alloydb.googleapis.com/mcp \
-H "Content-Type: application/json" \
-d @- <<EOF | jq -r '.result.tools[].name'
{
"id": "my_id_01",
"jsonrpc": "2.0",
"method": "tools/list"
}
EOF
Iniciar o agente
Agora você pode iniciar o agente no modo interativo usando a interface da web do ADK do Google. A interface da Web do ADK oferece uma maneira conveniente de testar e resolver problemas nos fluxos de trabalho dos agentes.
Primeiro, vamos instalar todos os pacotes necessários para Python usando o gerenciador de pacotes uv.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv sync
Quando todos os pacotes estiverem instalados, adicione um arquivo .env ao diretório do agente para direcioná-lo a usar a Vertex AI em todas as comunicações com os modelos de IA.
echo "GOOGLE_GENAI_USE_VERTEXAI=true" > data_agent/.env
echo "GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project -q)" >> data_agent/.env
echo "GOOGLE_CLOUD_LOCATION=global" >> data_agent/.env
Em seguida, você pode iniciar o agente
uv run adk web --allow_origins 'regex:https://.*\.cloudshell\.dev'
Você vai ver uma saída como esta, com o endpoint http://127.0.0.1:8000 .
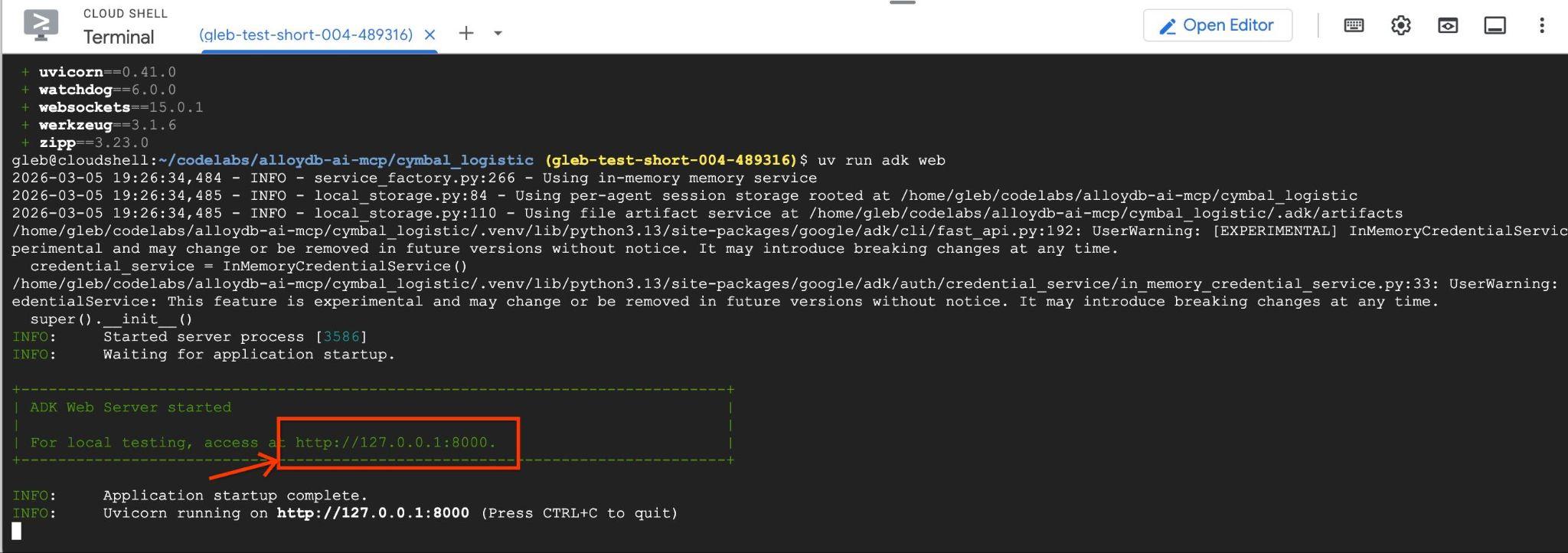
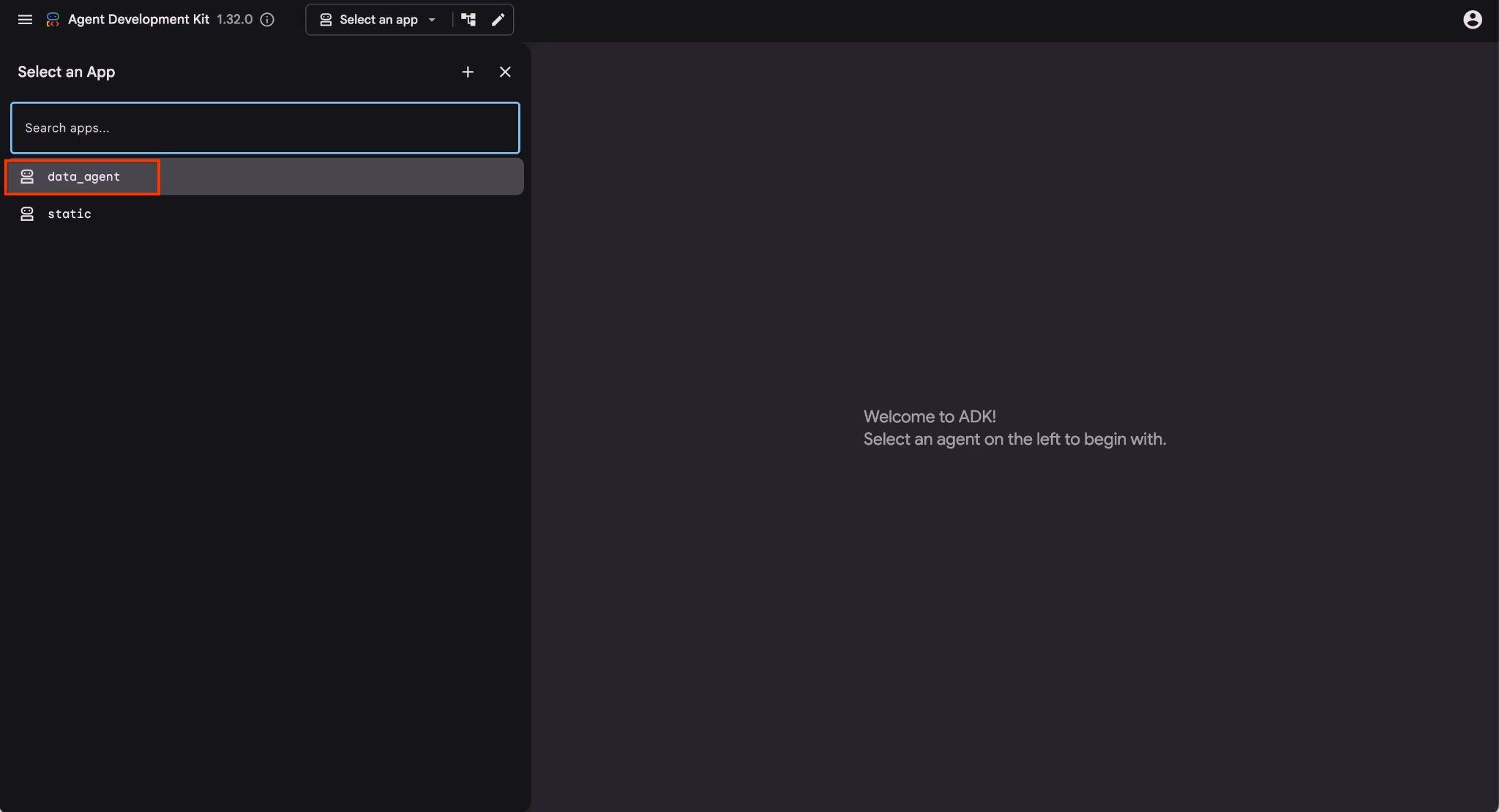
Clique nesse URL no Cloud Shell para abrir uma janela de visualização em outra guia do navegador. Nela, escolha o data_agent na lista suspensa à esquerda.
Na interface da Web do ADK, você pode postar suas perguntas no canto inferior direito e conferir o fluxo de execução completo, incluindo os rastreamentos de cada etapa no lado direito.
8. Testar o MCP do AlloyDB com o agente
Com o agente, você pode fazer perguntas em formato livre usando linguagem natural, e ele vai usar o servidor MCP do Google Cloud para o AlloyDB como uma ferramenta para responder. As perguntas são postadas na parte de baixo à direita, e a resposta com todas as chamadas para as ferramentas aparece na parte de cima.
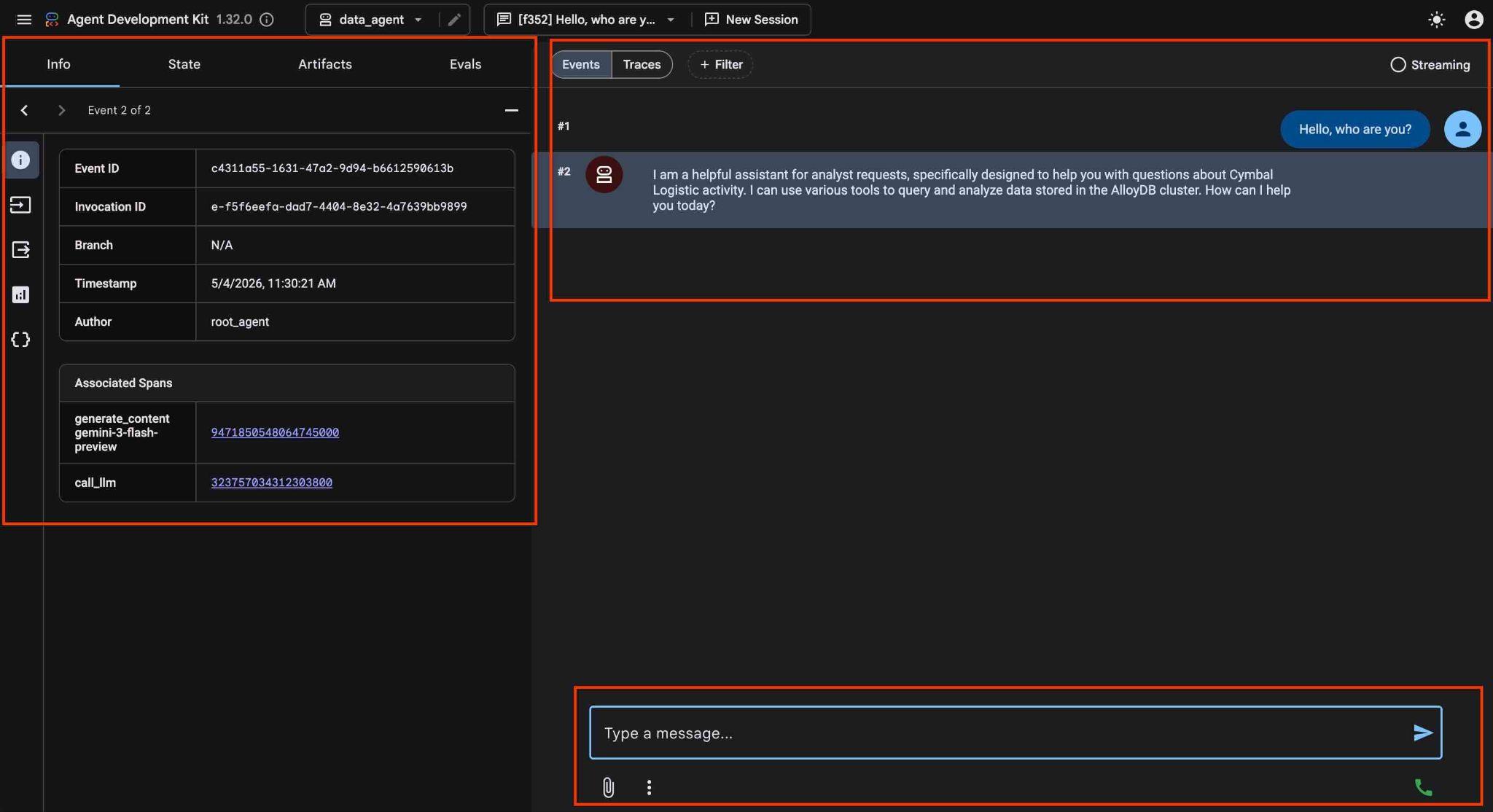
Você está trabalhando com dados operacionais de uma empresa de transporte que tem informações sobre solicitações de envio, caminhões, motoristas e viagens feitas por eles. A primeira pergunta é sobre o número de viagens realizadas em fevereiro de 2026.
No campo de entrada na parte inferior direita, digite o seguinte e pressione Enter.
Hello, can you tell me how many trips we've done in February this year?
O agente vai executar várias chamadas de ferramentas para identificar as tabelas corretas no esquema e a estrutura da tabela antes de executar a instrução SQL certa para receber os dados adequados.
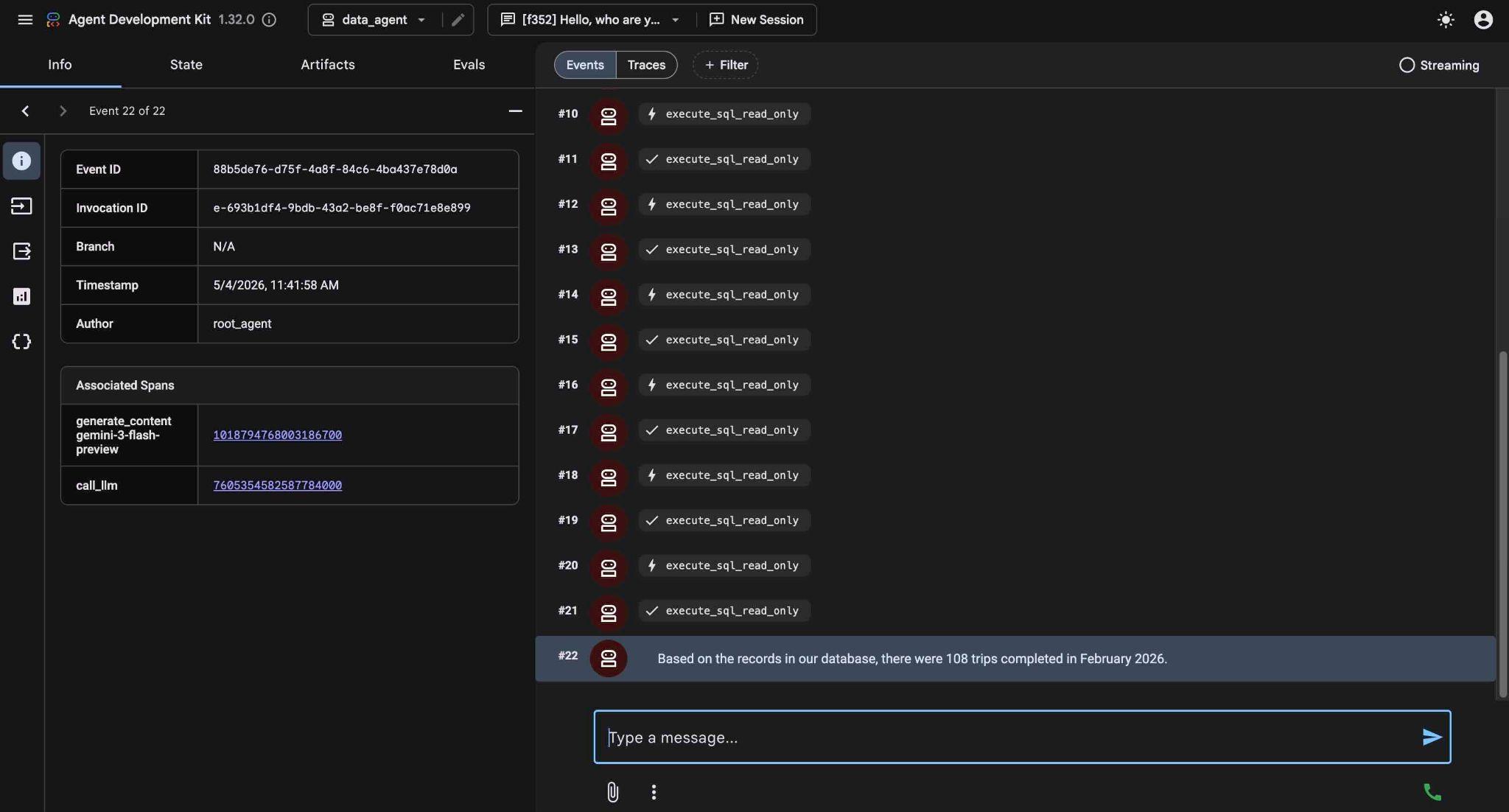
Eventualmente, ele vai produzir o resultado depois de criar e executar a consulta adequada no banco de dados.
Com base nos registros do nosso banco de dados, foram concluídas 108 viagens em fevereiro de 2026.
Para saber o que cada chamada de ferramenta faz, clique na execução dela. Por exemplo, esta é a consulta executada para receber nossos resultados.
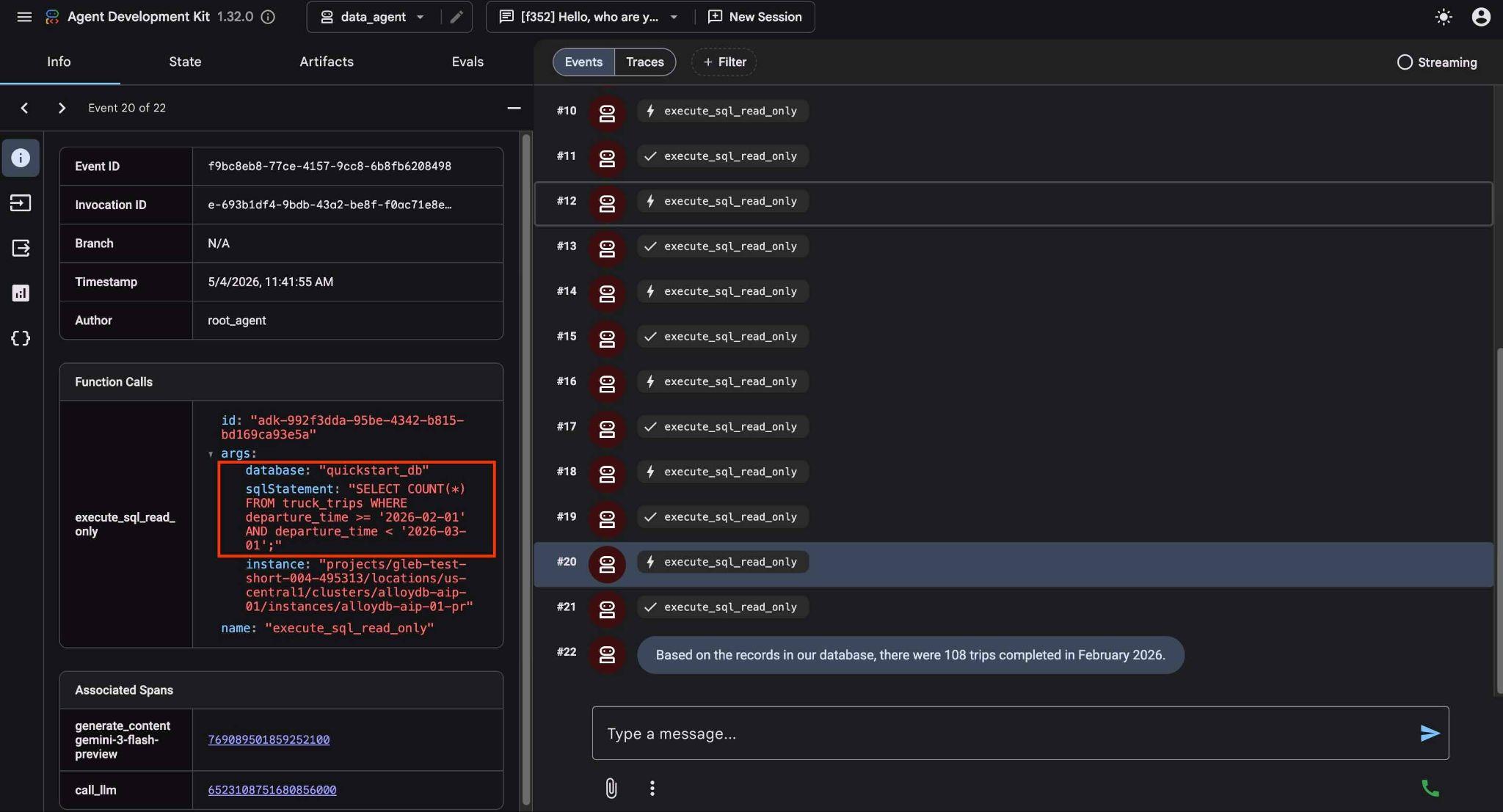
Agora, complique o pedido e peça para comparar os resultados com o mês anterior.
How is it in comparison in numbers and mileage with the January?
Ele retorna o resultado executando diferentes consultas que analisam os resultados e fornecem uma diferença no número de viagens e na quilometragem.
In comparison to January 2026, February saw a slight decrease in both the number of trips and the total mileage: January 2026: 114 trips with a total mileage of 185,597 km. February 2026: 108 trips with a total mileage of 177,893 km. This represents a decrease of 6 trips and 7,704 km in mileage for February compared to January.
Tente outros comandos simples usando a interface da Web do ADK e veja como ele executa diferentes consultas para alcançar os resultados.
Interrompa o agente pressionando ctrl+c no terminal. Você pode fechar a guia do navegador com a interface da web do ADK.
Agora você pode testar um aplicativo de exemplo e ver como ele pode ser usado como uma ferramenta para analistas de dados.
9. Aplicativo de amostra
No mesmo repositório clonado, temos um aplicativo de exemplo para nossa empresa Cymbol Logistic. O aplicativo usa o framework Python Mesop do Google .
Para analisar o código do aplicativo, abra o arquivo app.py no editor do Cloud Shell.
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
edit ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic/app.py
No código, usamos uma função para transmitir um novo comando com variáveis ao nosso agente de dados. Isso permite configurar na interface se decidirmos chamar um banco de dados ou uma instância diferente. Confira a definição da função e o comando.
def run_query_sync(request_text, cluster_name, location, instance_name, database_name, project_id, session_id, summary):
local_runner = FrontendRunner()
instruction = f"""
Answer user questions to the best of your knowledge using provided tools.
Do not try to generate non-existent data but use the grounded data from the database.
When you answer questions about Cymbal Logistic activity
use the toolset to run query in the AlloyDB cluster {cluster_name} instance {instance_name} in the location {location}
in the project {project_id} in the database {database_name}
Use ai schema to use AI functions and models like gemini-3-flash-preview with the functions from the schema.
"""
...
Depois de examinar o código, pressione o botão "terminal" para iniciar e testar o aplicativo. O aplicativo será iniciado na porta 8080. Se quiser mudar a porta, ajuste o comando alterando o valor da porta.
No Cloud Shell, execute:
REPO_NAME="codelabs"
SOURCE_DIR="alloydb-ai-mcp"
cd ~/$REPO_NAME/$SOURCE_DIR/cymbal_logistic
uv run mesop app.py --port=8080
Em seguida, use a visualização da Web no Google Cloud Shell clicando em http://localhost:8080
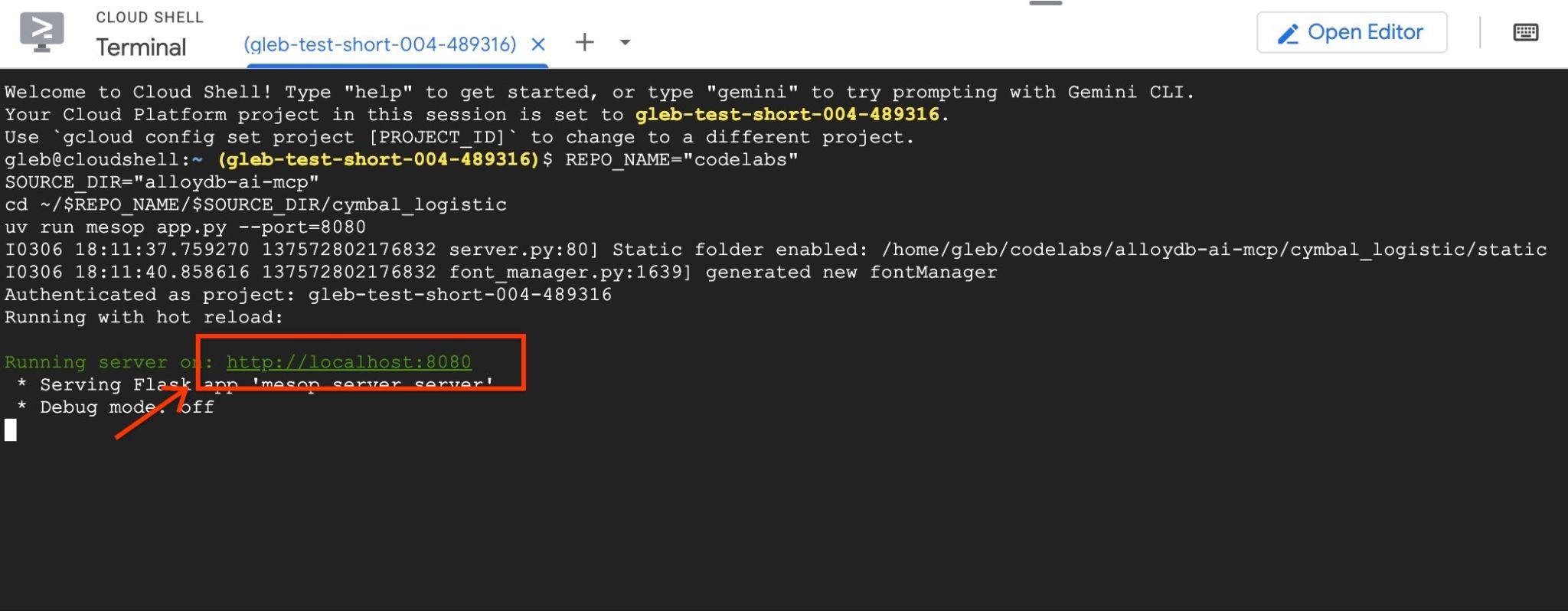
Uma nova guia será aberta no navegador com a interface do aplicativo.
Clique na caixa de seleção "Ativar saída de depuração" no canto superior direito e digite uma pergunta como a seguinte.
What was the average speed for each driver last month? List top 5 fasters drivers ranking them by the average speed. Show the name, distance and average speed for each of them.
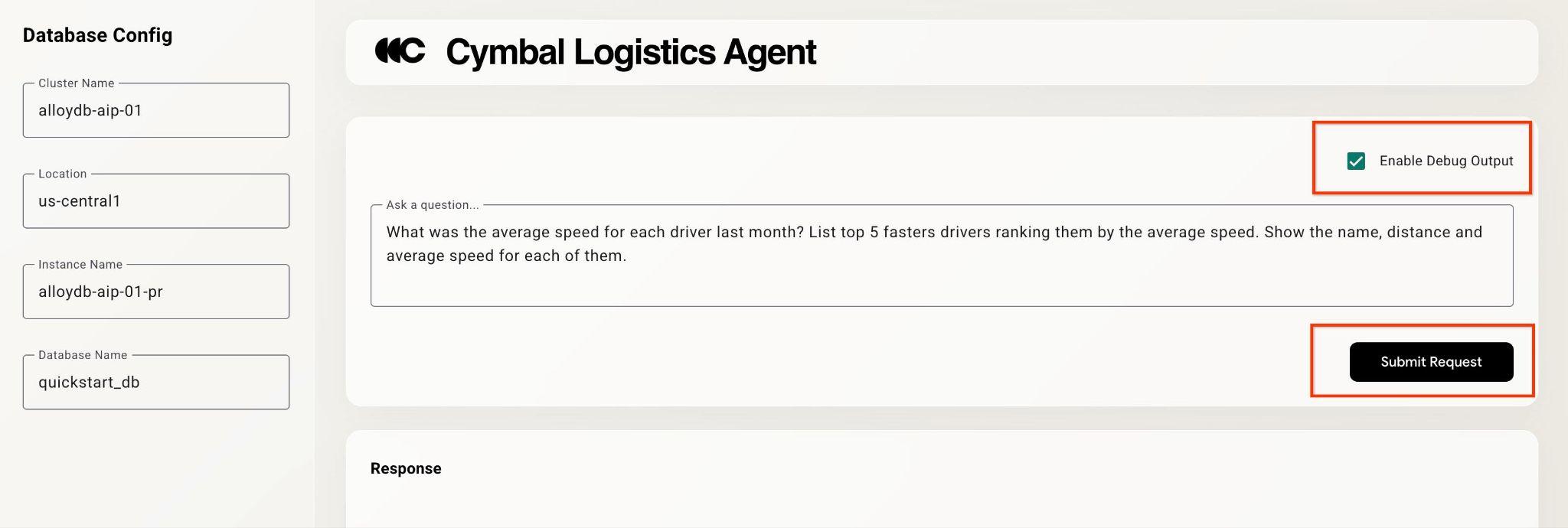
Em seguida, pressione o botão Submit Request.
O agente vai trabalhar nos bastidores e produzir a saída e as informações de depuração com todas as consultas executadas pelo nosso conjunto de ferramentas da MCP. Confira as consultas para ver o fluxo de trabalho.
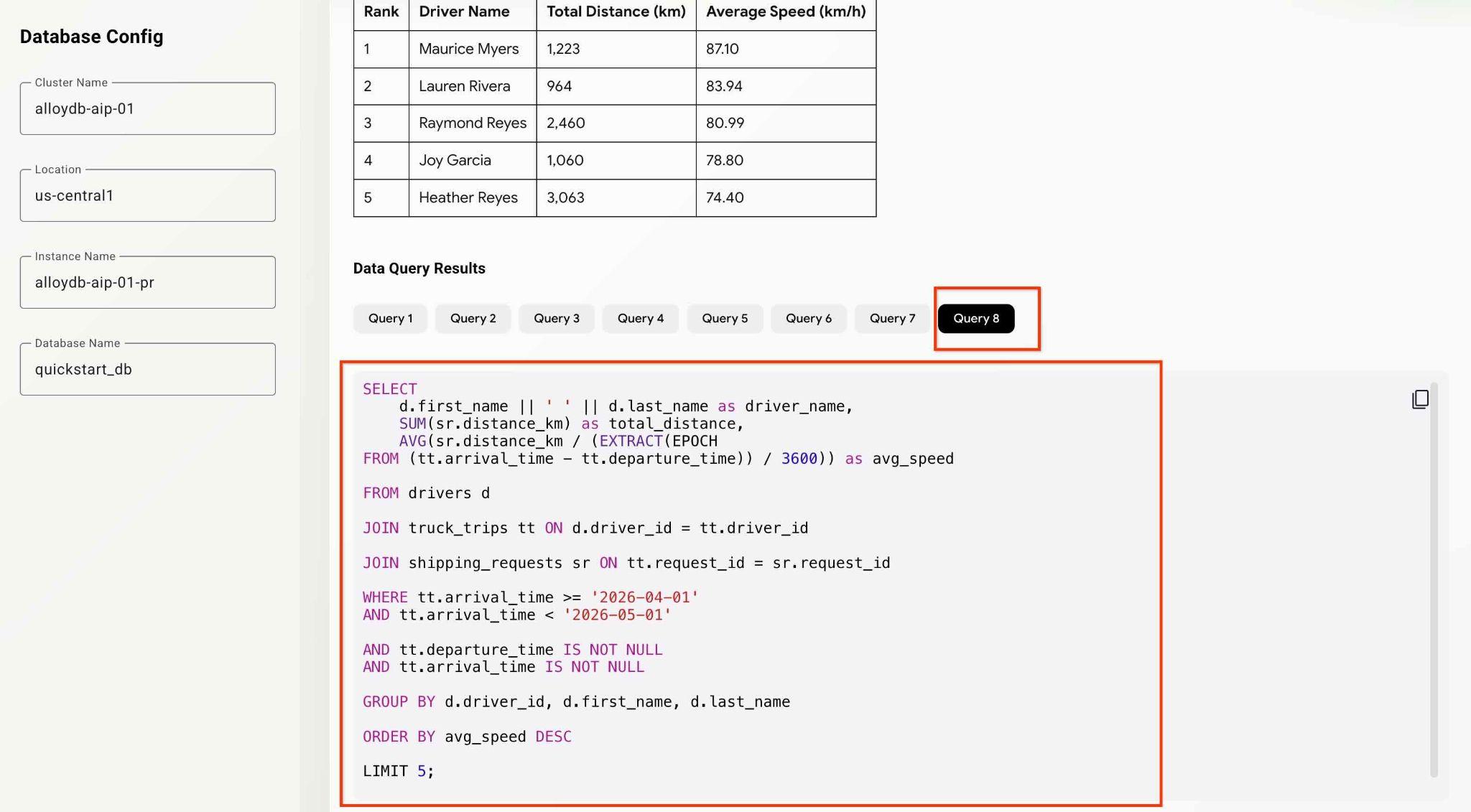
Você pode testar os agentes e os recursos do app fazendo diferentes perguntas analíticas.
Até agora, você conseguiu fazer algumas análises e descobertas básicas usando o agente com MCP. No próximo capítulo, você vai tentar usar recursos mais avançados do AlloyDB.
10. Funções da IA do AlloyDB
As funções de IA do AlloyDB permitem filtragem e classificação inteligentes de texto e dados multimodais (principalmente imagens) e trazem o poder do Gemini para suas consultas. Em particular, as funções AI.IF e AI.RANK da IA do AlloyDB podem aparecer em instruções SQL junto com operadores SQL convencionais (filtros, junções, agregação etc.).
Antes de usar as funções de IA, vamos analisar uma pesquisa e agregações usando os métodos "clássicos". Tente o comando a seguir.
Can you analyze the activity for the last 5 months and evaluate drivers for the most positive customer feedbacks. Give me top 5 drivers listing names, distance and years of experience for each driver.
Ele consegue encontrar a coluna "classificação" na tabela com feedback dos clientes e usá-la para identificar os motoristas com a melhor classificação. Em seguida, usou as informações para saber mais sobre os motoristas.
SELECT
d.first_name || ' ' || d.last_name as driver_name,
SUM(sr.distance_km) as total_distance,
d.experience_years,
COUNT(cf.feedback_id) as positive_feedback_count
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
WHERE tt.arrival_time >= '2025-12-01'
AND tt.arrival_time < '2026-05-01'
AND cf.rating >= 4
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY positive_feedback_count DESC, total_distance DESC
LIMIT 5;
Mas a classificação pode ou não incluir todos os parâmetros que queremos avaliar. Para isso, podemos usar as funções de IA do AlloyDB.
Operadores AI.RANK
A função ai.rank() pontua a qualidade da resposta de um documento a uma determinada consulta. Ela pode ser usada para classificar ou reclassificar os resultados da consulta. Leia mais sobre operadores na documentação.
Modifique a solicitação e peça explicitamente para usar AI.RANK durante a análise para avaliar os motoristas com base na performance e no profissionalismo.
Can you find the top 5 fastest drivers in the last month and rank them by the feedback using the AI.RANK function? Give me top drivers names, distance, years of experience and rank for each driver.
O comando pode levar um pouco mais de tempo, já que o agente precisa descobrir como usar a função AI.RANK, receber os dados e aplicar o AI.RANK para classificar as informações de acordo com a solicitação. No final, você vai receber a lista de motoristas classificados pelo modelo e a lista de consultas executadas.
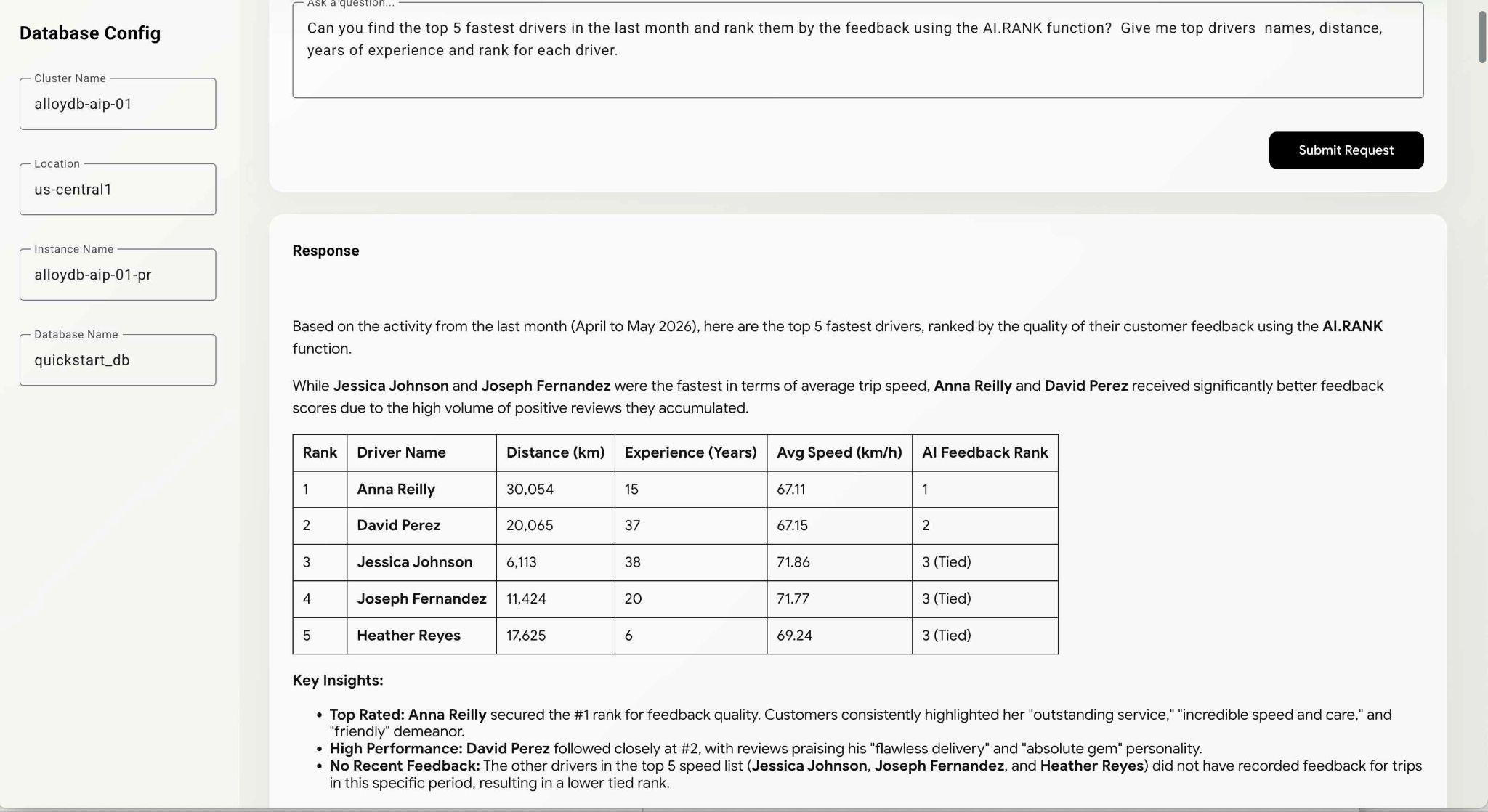
Essa consulta pode levar algum tempo para ser executada, dependendo do caminho escolhido pelo modelo. Na janela de depuração, é possível ver a consulta exata executada para receber as informações sobre os motoristas.
WITH fastest_drivers AS (
SELECT
d.driver_id,
d.first_name || ' ' || d.last_name as driver_name,
d.experience_years,
SUM(sr.distance_km) as total_distance,
AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) as avg_speed,
COALESCE(STRING_AGG(cf.feedback_text, ' | '), 'No feedback') as feedbacks,
ROW_NUMBER() OVER (
ORDER BY AVG(sr.distance_km / (NULLIF(EXTRACT(EPOCH
FROM (tt.arrival_time - tt.departure_time)), 0) / 3600)) DESC) - 1 as row_idx
FROM drivers d
JOIN truck_trips tt ON d.driver_id = tt.driver_id
JOIN shipping_requests sr ON tt.request_id = sr.request_id
LEFT
JOIN customer_feedback cf ON tt.trip_id = cf.trip_id
WHERE tt.arrival_time >= '2026-04-04'
AND tt.arrival_time IS NOT NULL
AND tt.departure_time IS NOT NULL
AND tt.arrival_time > tt.departure_time
GROUP BY d.driver_id, d.first_name, d.last_name, d.experience_years
ORDER BY avg_speed DESC
LIMIT 5
)
SELECT
f.driver_name,
f.total_distance,
f.experience_years,
f.avg_speed,
f.feedbacks,
(SELECT r.score
FROM ai.rank(
'semantic-ranker-fast-004',
'excellent customer service, professional, friendly, fast,
and reliable delivery reviews',
ARRAY[f.feedbacks],
1
) r
LIMIT 1) as feedback_score
FROM fastest_drivers f
ORDER BY feedback_score DESC;
Você pode continuar testando o aplicativo e analisando as consultas para ver como o agente chega aos resultados finais.
Isso conclui o laboratório. Espero que você tenha conseguido conferir todos os exemplos e aprender a usar o serviço MCP do Google Cloud para o AlloyDB. Para que a MCP funcione para empresas, é recomendável combinar a MCP com os recursos NL2SQL do AlloyDB descritos na documentação do AlloyDB. Você pode testar usando o codelab sobre como gerar instruções SQL para o AlloyDB.
11. Limpar o ambiente
Para evitar cobranças inesperadas, é recomendável limpar os recursos temporários. A maneira mais confiável é excluir o projeto em que você estava testando o fluxo de trabalho. Mas, se quiser, você pode se limitar excluindo recursos individuais, como o AlloyDB.
Destrua as instâncias e o cluster do AlloyDB quando terminar o laboratório.
Excluir o cluster do AlloyDB e todas as instâncias
Se você usou a versão de teste do AlloyDB. Não exclua o cluster de teste se você planeja testar outros laboratórios e recursos usando esse cluster. Não será possível criar outro cluster de teste no mesmo projeto.
O cluster é destruído com a opção "force" que também exclui todas as instâncias pertencentes.
No Cloud Shell, defina o projeto e as variáveis de ambiente se tiver ocorrido uma desconexão e todas as configurações anteriores forem perdidas:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Exclua o cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Excluir backups do AlloyDB
Exclua todos os backups do AlloyDB do cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Parabéns
Parabéns por concluir o codelab.
O que vimos
- Como criar um cluster do AlloyDB e importar dados de amostra
- Como ativar a API de acesso aos dados do AlloyDB
- Como ativar o Google Cloud MCP para o AlloyDB NL
- Como adicionar o Google Cloud MCP para AlloyDB ao seu agente do ADK
- Como usar o MCP do Google Cloud para AlloyDB em um aplicativo
- Como usar agentes com o AlloyDBMCP para análise
13. Pesquisa
Saída: