
1. 简介
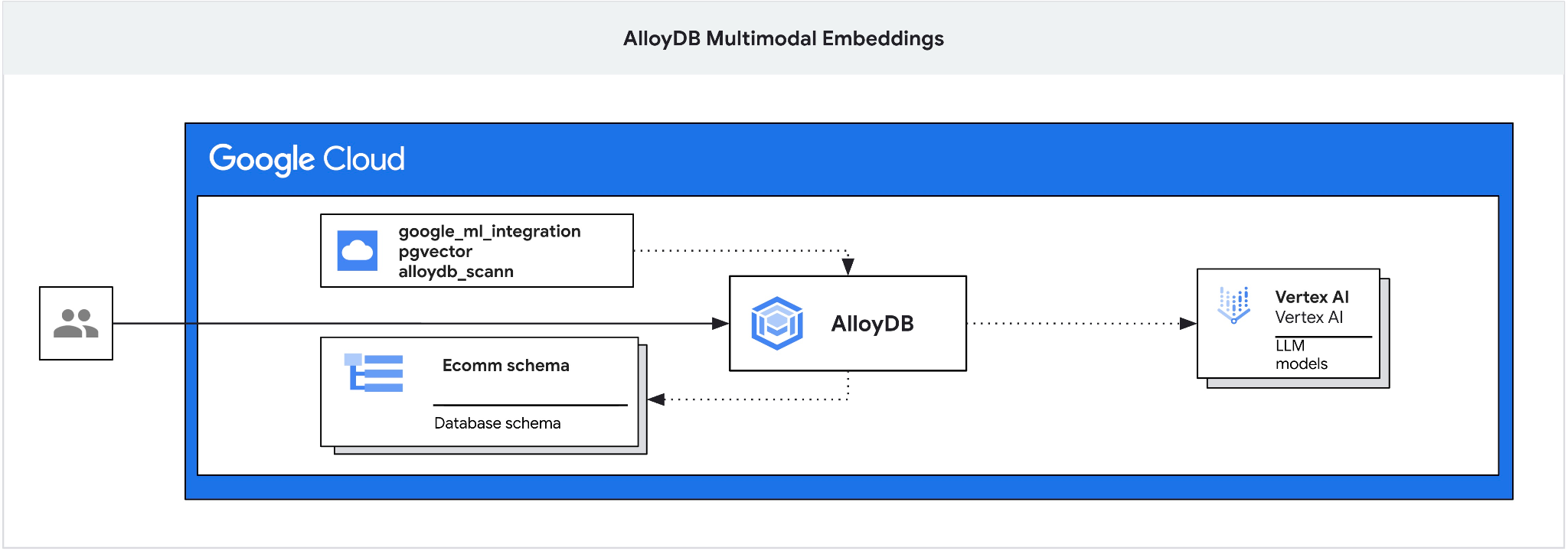
此 Codelab 提供了有关如何部署 AlloyDB 并利用 AI 集成通过多模态嵌入进行语义搜索的指南。本实验是专门介绍 AlloyDB AI 功能的实验合集中的一个实验。如需了解详情,请参阅文档中的 AlloyDB AI 页面。
前提条件
- 对 Google Cloud 控制台有基本的了解
- 具备命令行界面和 Cloud Shell 方面的基本技能
学习内容
- 如何部署 AlloyDB for Postgres
- 如何使用 AlloyDB Studio
- 如何使用多模态向量搜索
- 如何启用 AlloyDB AI 运算符
- 如何使用不同的 AlloyDB AI 运算符进行多模态搜索
- 如何使用 AlloyDB AI 合并文本和图片搜索结果
所需条件
- Google Cloud 账号和 Google Cloud 项目
- 支持 Google Cloud 控制台和 Cloud Shell 的网络浏览器,例如 Chrome
2. 设置和要求
项目设置
- 登录 Google Cloud 控制台。如果您还没有 Gmail 或 Google Workspace 账号,则必须创建一个。
请改用个人账号,而非工作账号或学校账号。
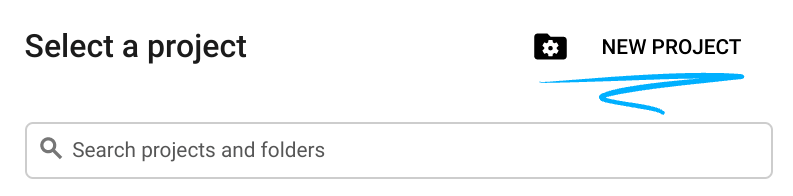
- 创建新项目或重复使用现有项目。如需在 Google Cloud 控制台中创建新项目,请在标题中点击“选择项目”按钮,系统随即会打开一个弹出式窗口。

在“选择项目”窗口中,按“新建项目”按钮,系统随即会打开一个用于创建新项目的对话框。
在对话框中,输入您偏好的项目名称,然后选择位置。
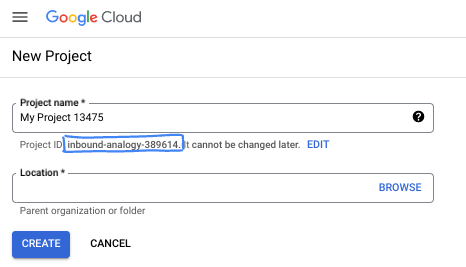
- 项目名称是此项目参与者的显示名称。Google API 不会使用项目名称,并且您可以随时更改项目名称。
- 项目 ID 在所有 Google Cloud 项目中是唯一的,并且是不可变的(一经设置便无法更改)。Google Cloud 控制台会自动生成一个唯一 ID,但您可以自定义该 ID。如果您不喜欢生成的 ID,可以生成另一个随机 ID,也可以提供自己的 ID 来检查其可用性。在大多数 Codelab 中,您都需要引用项目 ID,该 ID 通常用占位符 PROJECT_ID 标识。
- 此外,还有第三个值,即部分 API 使用的项目编号,供您参考。如需详细了解所有这三个值,请参阅文档。
启用结算功能
您可以通过以下两种方式启用结算功能。您可以使用个人结算账号,也可以按照以下步骤兑换积分。
兑换 5 美元的 Google Cloud 赠金(可选)
如需参加此研讨会,您需要拥有一个有一定信用额度的结算账号。如果您打算使用自己的结算方式,则可以跳过此步骤。
- 点击此链接,然后使用个人 Google 账号登录。
- 您会看到类似如下的内容:

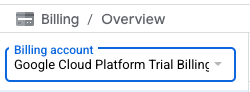
- 点击点击此处访问您的积分按钮。然后,您会进入一个页面,可以在其中设置结算资料。如果您看到免费试用订阅界面,请点击“取消”,然后继续关联结算信息。
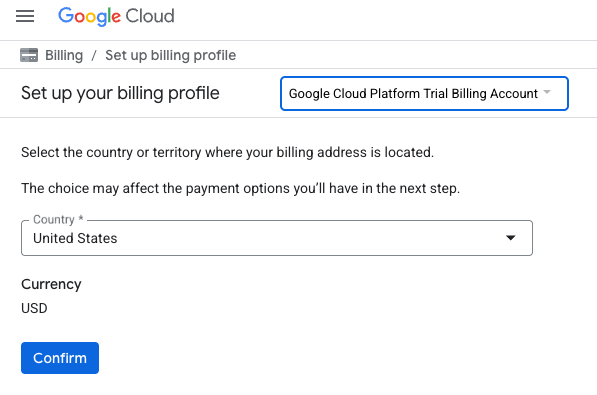
- 点击“确认”,系统会显示“您现已关联到 Google Cloud Platform 试用结算账号”。
设置个人结算账号
如果您使用 Google Cloud 抵用金设置了结算,则可以跳过此步骤。
如需设置个人结算账号,请点击此处在 Cloud 控制台中启用结算功能。
注意事项:
- 完成本实验的 Cloud 资源费用应低于 3 美元。
- 您可以按照本实验结束时的步骤删除资源,以避免产生更多费用。
- 新用户符合参与 $300 USD 免费试用计划的条件。
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
在 Google Cloud 控制台 中,点击右上角工具栏中的 Cloud Shell 图标:
或者,您也可以先按 G,再按 S。如果您位于 Google Cloud 控制台中,或者使用此链接,此序列将激活 Cloud Shell。
预配和连接到环境应该只需要片刻时间。完成后,您应该会看到如下内容:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的所有工作都可以在浏览器中完成。您无需安装任何程序。
3. 准备工作
启用 API
如需使用 AlloyDB、Compute Engine、网络服务和 Vertex AI,您需要在 Google Cloud 项目中启用它们各自的 API。
在 Cloud Shell 的终端中,确保项目 ID 已设置:
gcloud config set project [YOUR-PROJECT-ID]
设置环境变量 PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
启用所有必要的服务:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
预期输出
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
API 简介
- 借助 AlloyDB API (
alloydb.googleapis.com),您可以创建、管理和扩缩 AlloyDB for PostgreSQL 集群。它提供与 PostgreSQL 兼容的全代管式数据库服务,专为要求苛刻的企业事务性和分析性工作负载而设计。 - 借助 Compute Engine API (
compute.googleapis.com),您可以创建和管理虚拟机 (VM)、永久性磁盘和网络设置。它提供运行工作负载所需的核心基础设施即服务 (IaaS) 基础,并为许多托管服务托管底层基础架构。 - 借助 Cloud Resource Manager API (
cloudresourcemanager.googleapis.com),您可以以编程方式管理 Google Cloud 项目的元数据和配置。借助它,您可以整理资源、处理 Identity and Access Management (IAM) 政策,以及验证项目层次结构中的权限。 - 借助 Service Networking API (
servicenetworking.googleapis.com),您可以自动设置虚拟私有云 (VPC) 网络与 Google 的受管服务之间的专用连接。具体而言,需要为 AlloyDB 等服务建立专用 IP 访问通道,以便它们能够与其他资源安全地通信。 - Vertex AI API (
aiplatform.googleapis.com) 可让您的应用构建、部署和扩缩机器学习模型。它为所有 Google Cloud AI 服务提供统一的界面,包括访问生成式 AI 模型(例如 Gemini)和自定义模型训练。
4. 部署 AlloyDB
创建 AlloyDB 集群和主实例。以下步骤介绍了如何使用 Google Cloud SDK 创建 AlloyDB 集群和实例。如果您偏好使用控制台方法,可以点击此处查看相关文档。
在创建 AlloyDB 集群之前,我们需要在 VPC 中分配一个可用的专用 IP 范围,以供未来的 AlloyDB 实例使用。如果我们没有该服务账号,则需要创建该服务账号,并将其分配给内部 Google 服务使用,之后我们才能创建集群和实例。
创建专用 IP 范围
我们需要在 VPC 中为 AlloyDB 配置专用服务访问配置。这里假设我们的项目中有“默认”VPC 网络,它将用于所有操作。
创建专用 IP 范围:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
使用分配的 IP 范围创建专用连接:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
预期的控制台输出:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
创建 AlloyDB 集群
在本部分中,我们将在 us-central1 区域中创建一个 AlloyDB 集群。
为 postgres 用户定义密码。您可以自行定义密码,也可以使用随机函数生成密码
export PGPASSWORD=`openssl rand -hex 12`
预期的控制台输出:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
请记下该 PostgreSQL 密码,以备将来使用。
echo $PGPASSWORD
您日后需要使用该密码以 postgres 用户身份连接到实例。我建议将其写下来或复制到某个地方,以便日后使用。
预期的控制台输出:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
创建免费试用集群
如果您之前未使用过 AlloyDB,可以创建一个免费试用集群:
定义区域和 AlloyDB 集群名称。我们将使用 us-central1 区域,并将 alloydb-aip-01 作为集群名称:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
运行命令以创建集群:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
预期的控制台输出:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
在同一 Cloud Shell 会话中为集群创建 AlloyDB 主实例。如果您断开连接,则需要再次定义区域和集群名称环境变量。
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
预期的控制台输出:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
创建 AlloyDB Standard 集群
如果这不是您在项目中创建的第一个 AlloyDB 集群,请继续创建标准集群。如果您已在上一步中创建了免费试用集群,请跳过此步骤。
定义区域和 AlloyDB 集群名称。我们将使用 us-central1 区域,并将 alloydb-aip-01 作为集群名称:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
运行命令以创建集群:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
预期的控制台输出:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
在同一 Cloud Shell 会话中为集群创建 AlloyDB 主实例。如果您断开连接,则需要再次定义区域和集群名称环境变量。
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
预期的控制台输出:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. 准备数据库
我们需要创建数据库、启用 Vertex AI 集成、创建数据库对象并导入数据。
向 AlloyDB 授予必要权限
向 AlloyDB 服务代理添加 Vertex AI 权限。
使用顶部的“+”号打开另一个 Cloud Shell 标签页。
在新的 Cloud Shell 标签页中,执行以下命令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
预期的控制台输出:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
在标签页中执行命令“exit”,关闭该标签页:
exit
连接到 AlloyDB Studio
在以下章节中,所有需要连接到数据库的 SQL 命令都可以在 AlloyDB Studio 中执行。
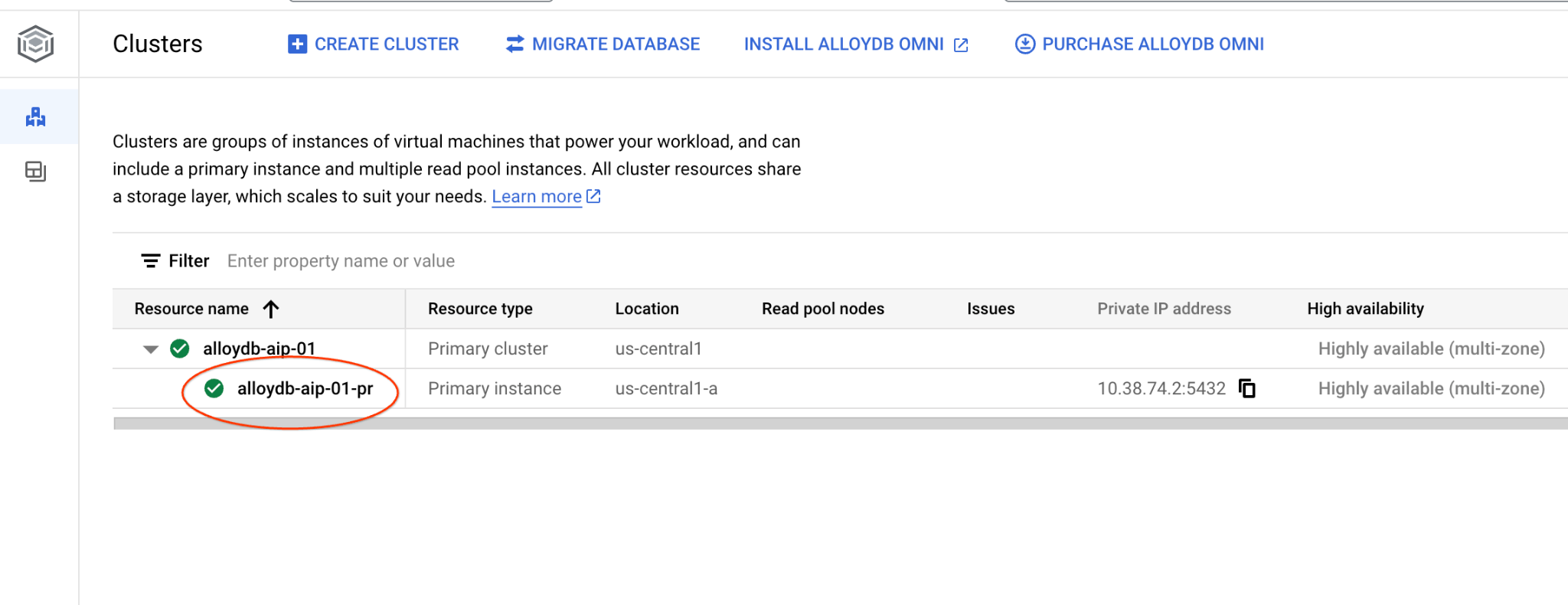
在新标签页中,前往 AlloyDB for Postgres 中的“集群”页面。
点击主实例,打开 AlloyDB 集群的 Web 控制台界面。
然后点击左侧的 AlloyDB Studio:
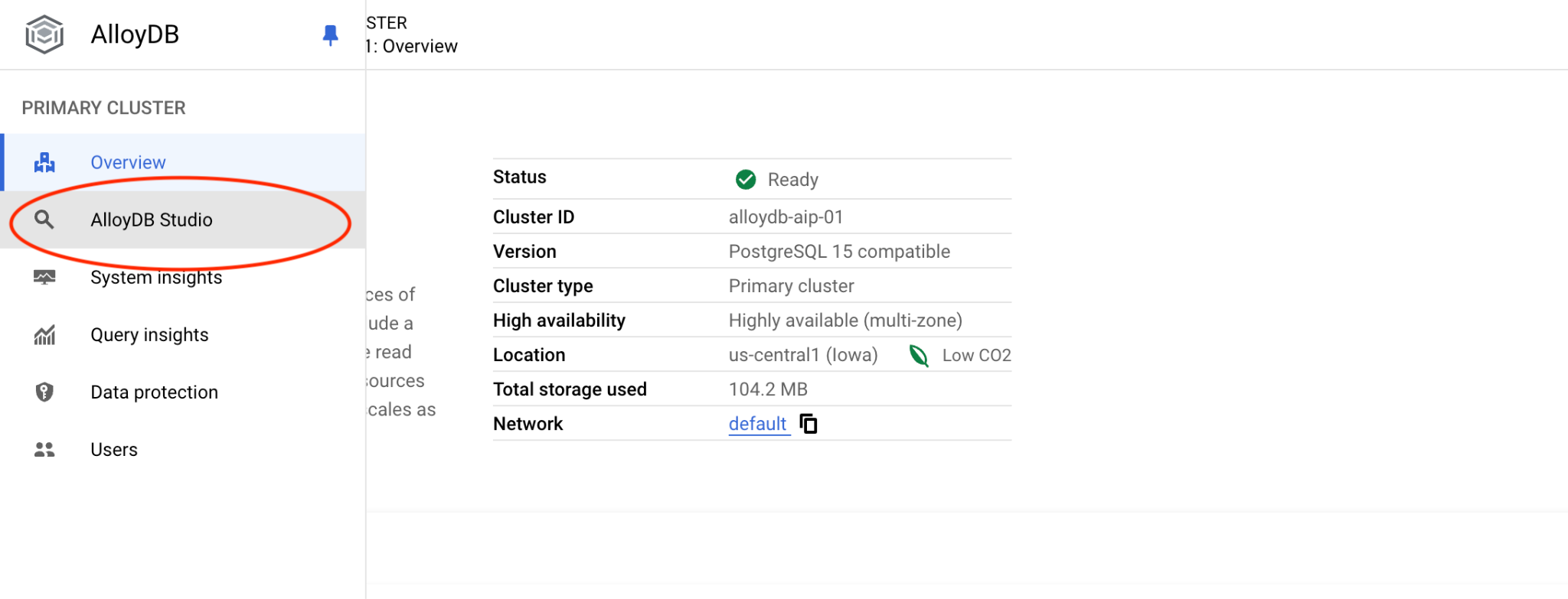
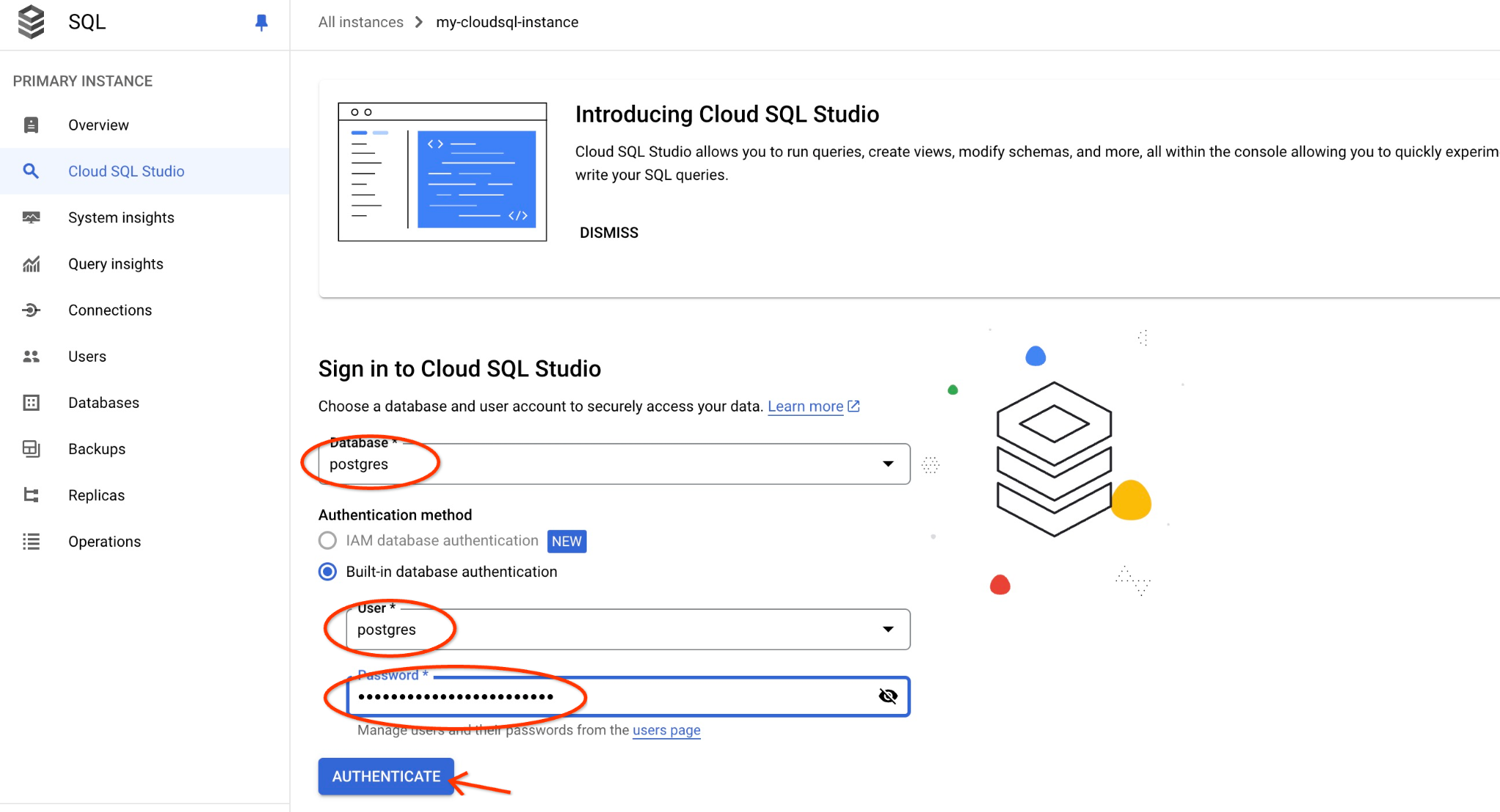
选择 postgres 数据库、用户 postgres,并提供我们在创建集群时记录的密码。然后点击“验证”按钮。如果您忘记记下密码,或者该密码无法使用,可以更改密码。如需了解如何执行此操作,请参阅文档。
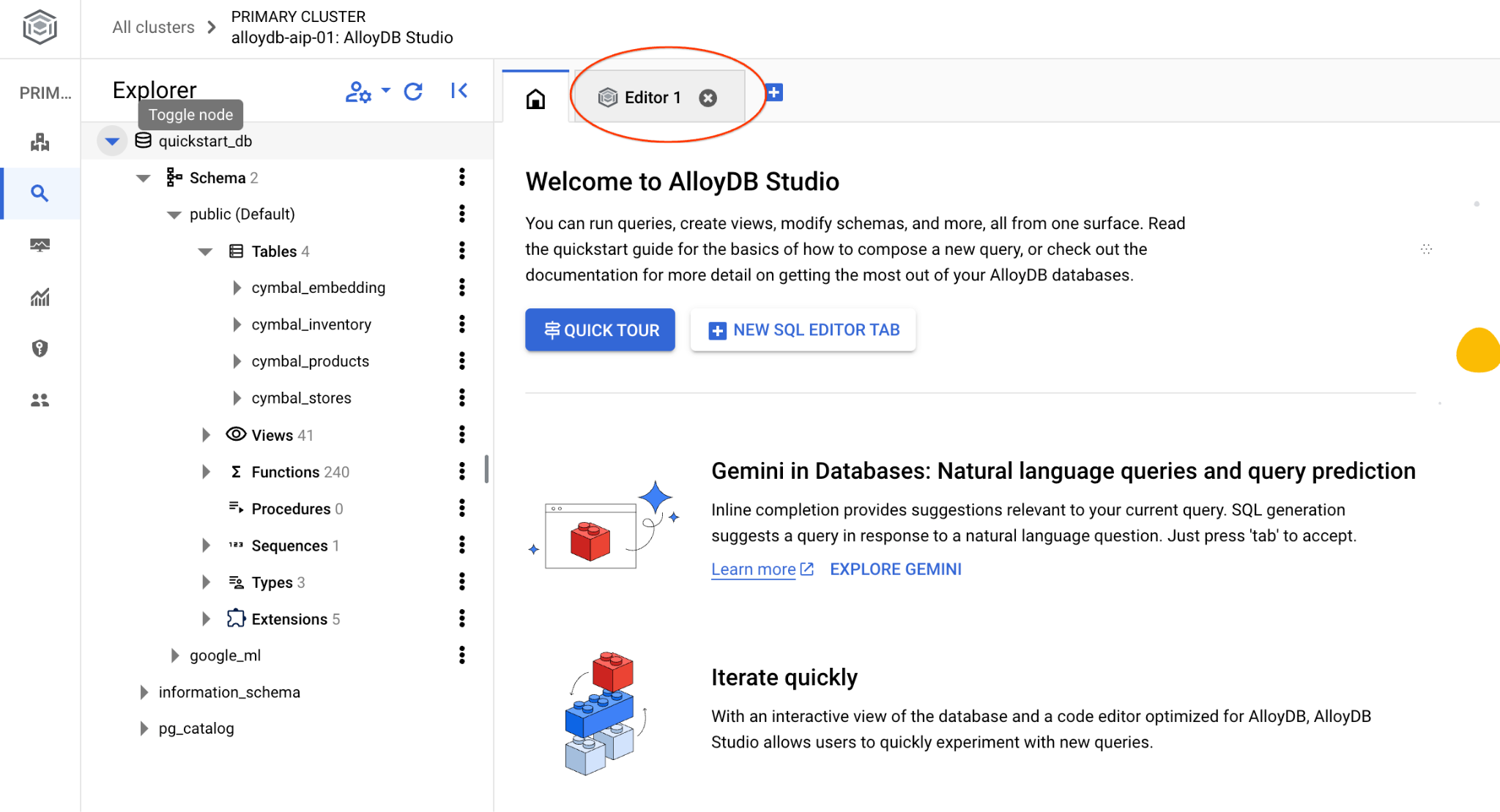
系统会打开 AlloyDB Studio 界面。如需在数据库中运行命令,请点击右侧的“无标题查询”标签页。
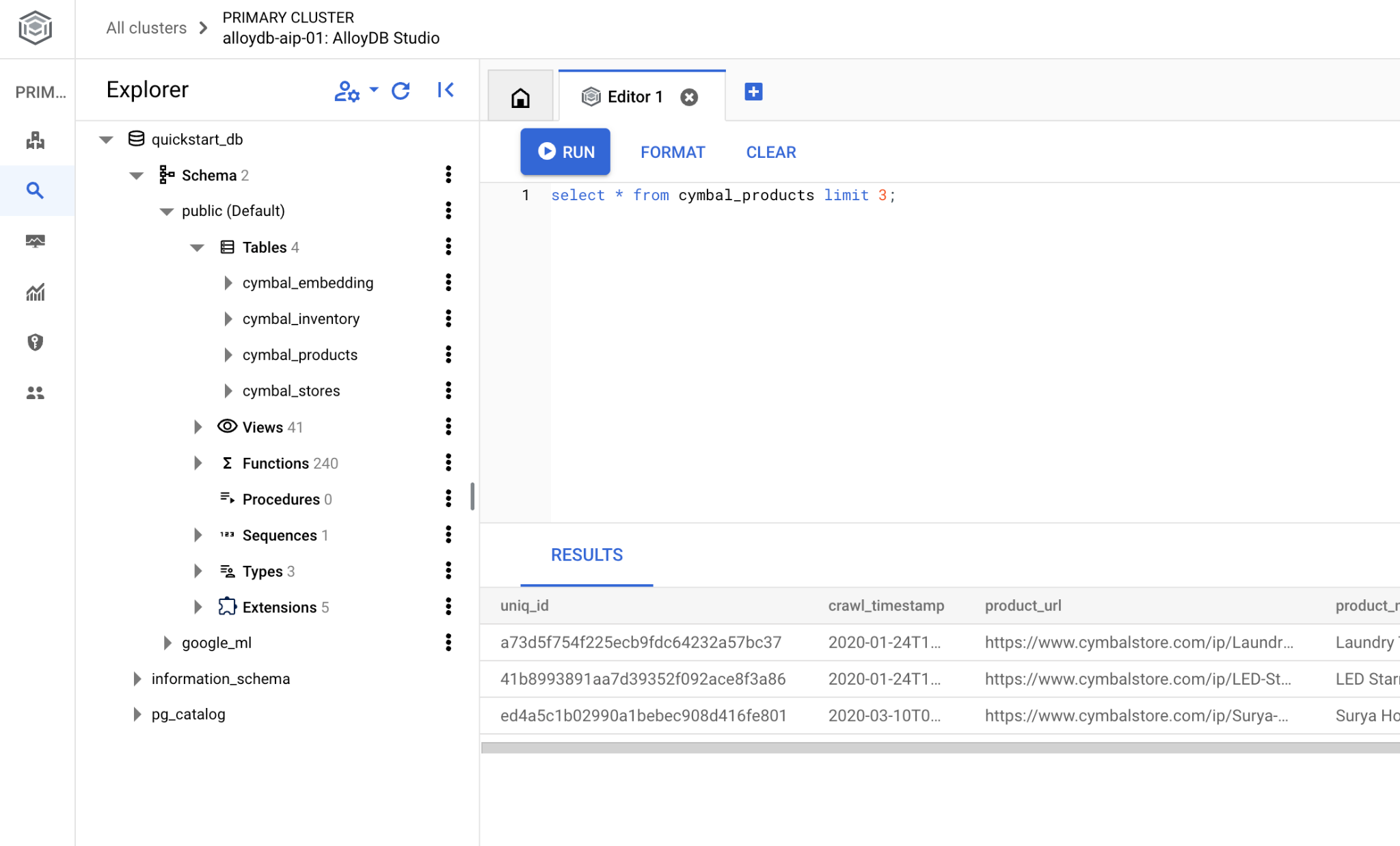
系统会打开一个界面,您可以在其中运行 SQL 命令
创建数据库
创建数据库快速入门。
在 AlloyDB Studio 编辑器中,执行以下命令。
创建数据库:
CREATE DATABASE quickstart_db
预期输出:
Statement executed successfully
连接到 quickstart_db
使用切换用户/数据库的按钮重新连接到 Studio。
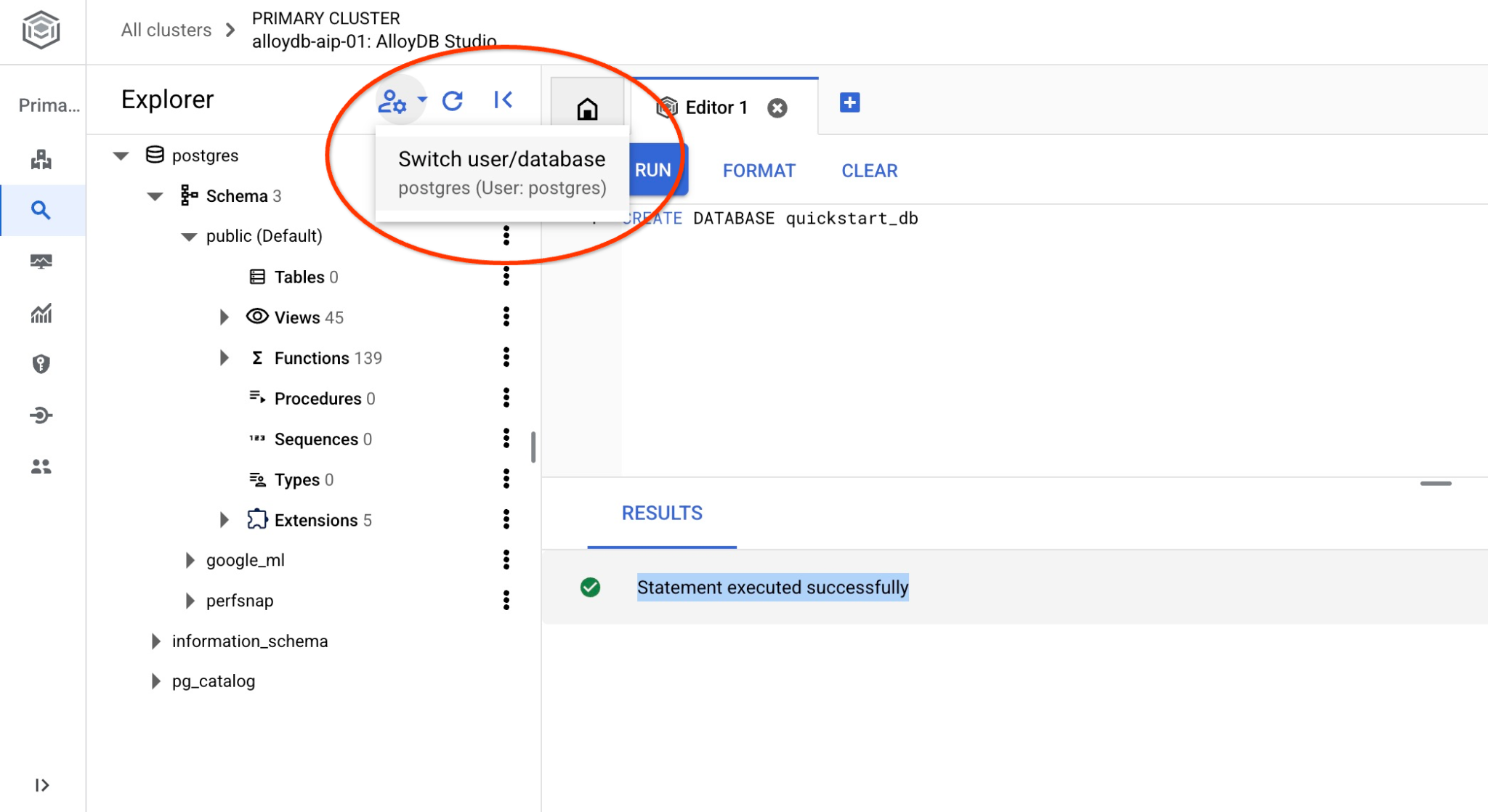
从下拉列表中选择新的 quickstart_db 数据库,并使用与之前相同的用户和密码。
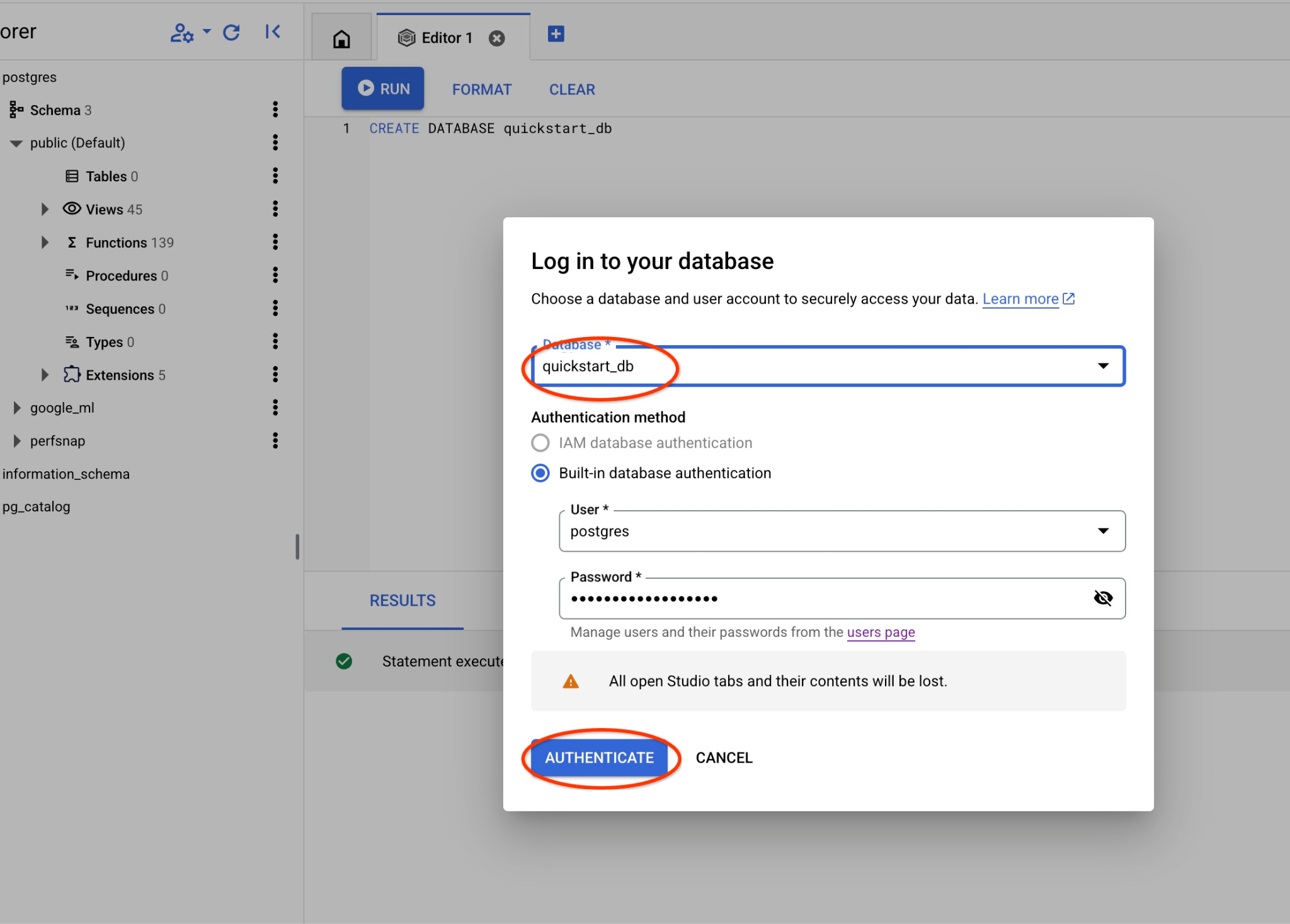
系统将打开一个新连接,您可以在其中处理 quickstart_db 数据库中的对象。
6. 示例数据
现在,我们需要在数据库中创建对象并加载数据。我们将使用虚构的“Cymbal”商店及其虚构的数据。
在导入数据之前,我们需要启用支持数据类型和索引的扩展程序。我们需要两个扩展程序,一个支持向量数据类型,另一个支持 AlloyDB ScaNN 索引。
在连接到 quickstart_db 的 AlloyDB Studio 中执行。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
数据集已准备好并以 SQL 文件形式放置,可以使用导入界面加载到数据库中。在 Cloud Shell 中,执行以下命令:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
该命令使用 AlloyDB SDK 创建名为 agentspace_user 的用户,然后直接从 GCS 存储分区将示例数据导入到数据库,创建所有必需的对象并插入数据。
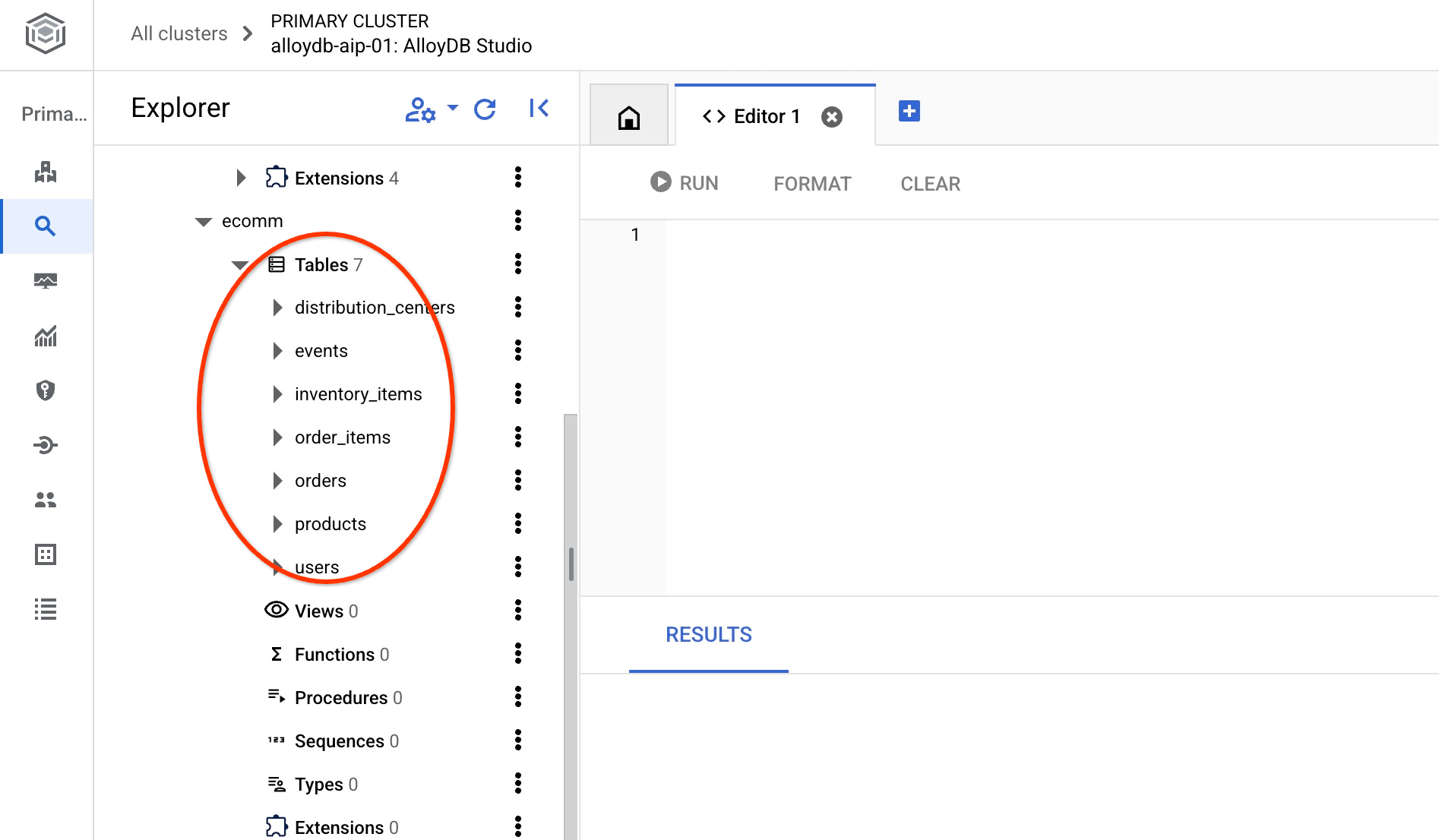
导入完成后,我们可以在 AlloyDB Studio 中查看表。这些表位于 ecomm 架构中:
并验证其中一个表中的行数。
select count(*) from ecomm.products;
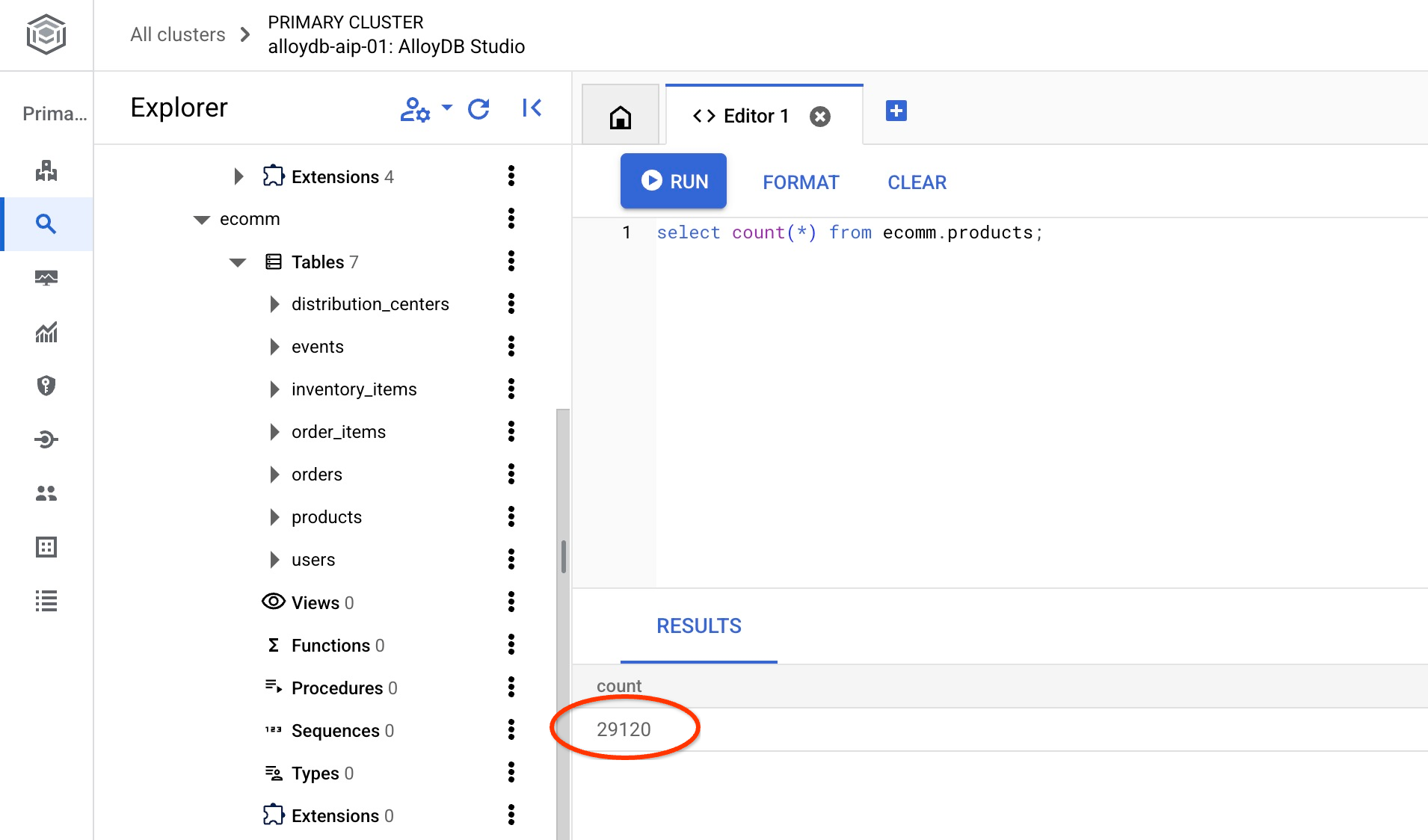
我们已成功导入示例数据,可以继续执行后续步骤。
7. 使用文本嵌入进行语义搜索
在本章中,我们将尝试使用文本嵌入进行语义搜索,并将其与传统的 Postgres 文本和全文搜索进行比较。
我们先尝试使用带有 LIKE 运算符的标准 PostgreSQL SQL 进行经典搜索。
在连接到 quickstart_db 的 AlloyDB Studio 中,尝试使用以下查询搜索雨衣:
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
由于商品名称或说明中需要包含“潮湿天气”和“夹克”等确切字词,因此该查询不会返回任何行。“湿滑路面专用夹克”与“雨天专用夹克”不同。
我们可以尝试在搜索中包含所有可能的变体。我们试着只包含两个字词。例如:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
这样会返回多行,但并非所有行都与我们对夹克的请求完全匹配,而且很难按相关性排序。例如,如果我们添加更多条件(例如“男士专用”等),查询的复杂性会显著增加。或者,我们可以尝试全文搜索,但即使这样,我们也会遇到与字词是否完全匹配以及回答的相关性相关的限制。
现在,我们可以使用嵌入进行相似搜索。我们已使用不同的模型预先计算了产品的嵌入内容。我们将使用 Google 最新的 gemini-embedding-001 模型。我们已将它们存储在 ecomm.products 表的“product_embedding”列中。如果我们使用以下查询针对“男士雨衣”搜索条件运行查询:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
系统不仅会返回适合潮湿环境的夹克,还会对所有结果进行排序,将最相关的结果放在顶部。
包含嵌入的查询会在 90-150 毫秒内返回结果,其中一部分时间用于从云端嵌入模型获取数据。如果我们查看执行计划,会发现对模型的请求包含在规划时间中。执行搜索的查询部分本身非常短。使用 AlloyDB ScaNN 索引在 2.9 万条记录中进行搜索所需的时间不到 7 毫秒。
以下是执行计划输出:
Limit (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> 使用 embedding_scann 在商品上进行索引扫描(费用=2709.20..30736.40 行数=29120 宽度=490)(实际时间=6.964..7.046 行数=10 循环次数=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
…
-0.0051468653,-0.012440448]'::vector)
Limit: 10
规划时间:136.579 毫秒
执行时间:6.791 毫秒
(6 行)
以上是使用仅限文本的嵌入模型进行的文本嵌入搜索。不过,我们也有产品图片,可以将其用于搜索。在下一章中,我们将展示多模态模型如何使用图片进行搜索。
8. 使用多模态搜索
虽然基于文本的语义搜索很有用,但描述复杂的细节可能很困难。AlloyDB 的多模态搜索功能可让用户通过输入图片来发现商品,从而提供优势。当视觉呈现比单纯的文字说明更能清晰表达搜索意图时,此功能尤其有用。例如,“帮我找一件像图片中这件一样的外套”。
我们回到夹克示例。如果我有一张夹克的照片,而我想要找到的夹克与照片中的夹克类似,那么我可以将这张照片传递给 Google 多模态嵌入模型,并将其与我的产品图片的嵌入进行比较。在我们的表中,product_image_embedding 列中已包含产品图片的计算嵌入,您可以在 product_image_embedding_model 列中查看所用的模型。
对于搜索,我们可以使用 image_embedding 函数获取图片的嵌入,并将其与预先计算的嵌入进行比较。如需启用该函数,我们需要确保使用的是正确版本的 google_ml_integration 扩展程序。
我们来验证一下当前的扩展程序版本。在 AlloyDB Studio 中执行。
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
如果版本低于 1.5.2,请运行以下程序。
CALL google_ml.upgrade_to_preview_version();
然后重新检查扩展程序的版本。应为 1.5.3。
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
我们还需要在数据库中启用 AI 查询引擎功能。您可以通过更新实例标志来为实例上的所有数据库启用此功能,也可以仅为我们的数据库启用此功能。在 AlloyDB Studio 中执行以下命令,以针对 quickstart_db 数据库启用该功能。
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
现在,我们可以按图片进行搜索了。以下是我的搜索图片示例,但您可以使用任何自定义图片。您只需将其上传到 Google 存储空间或其他公开可用的资源,然后将 URI 放入查询中即可。

并上传到 gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png
按图片搜索图片
首先,我们尝试仅通过图片进行搜索:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
我们还在库存中找到了一些保暖外套。如需查看图片,您可以使用 Cloud SDK (gcloud storage cp) 通过提供 public_url 列来下载图片,然后使用任何可处理图片的工具打开图片。
|
|
|
|




图片搜索会返回与我们提供的比较图片相似的商品。正如我之前提到的,您可以尝试将自己的图片上传到公开存储分区,看看它是否能找到不同类型的服装。
我们已将 Google 的“multimodalembedding@001”模型用于图片搜索。我们的 image_embedding 函数会将图片发送到 Vertex AI,将其转换为向量,然后返回以与数据库中存储的图片向量进行比较。
我们还可以使用“EXPLAIN ANALYZE”检查它在 AlloyDB ScaNN 索引中的运行速度。
以下是执行计划的输出:
Limit (cost=971.70..975.55 rows=4 width=490) (actual time=2.453..2.477 rows=4 loops=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
…
,-0.010307034,-0.010053742]'::vector)
Limit: 4
规划时间:913.322 毫秒
执行时间:2.517 毫秒
(6 行)
与上一个示例一样,我们可以看到,大部分时间都花在了使用云端点将图片转换为嵌入上,而向量搜索本身仅需 2.5 毫秒。
按文字搜索图片
借助多模态功能,我们还可以使用 google_ml.text_embedding 将要搜索的夹克的文本描述传递给同一模型,并将其与图片嵌入进行比较,以查看模型返回哪些图片。
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
我们获得了一套灰色或深色的蓬松外套。
|
|
|
|




我们获得了一组略有不同的夹克,但它根据我们的说明并通过搜索图片嵌入正确地挑选了夹克。
我们来尝试另一种方法,使用搜索图片的嵌入在说明中进行搜索。
按图片中的文字搜索
我们尝试搜索图片,方法是传递图片的嵌入内容,并与预先计算的商品图片嵌入内容进行比较。我们还尝试了以下操作:传递文本请求的嵌入来搜索图片,并在同一嵌入中搜索商品图片。现在,我们尝试使用图片嵌入,并与商品说明的文本嵌入进行比较。嵌入存储在 product_description_embedding 列中,并使用相同的 multimodalembedding@001 模型。
我们的查询如下:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
这里显示的是一组略有不同的夹克,颜色为灰色或深色,其中一些与通过不同搜索方式选择的夹克相同或非常接近。
|
|
|
|



它会返回与上述查询相同的夹克,但顺序略有不同。根据图片的嵌入,它可以与文本描述的计算嵌入进行比较,并返回正确的产品集。
文本 + 图片混合搜索
您还可以尝试将文本嵌入和图片嵌入结合在一起,例如使用倒数排名融合。以下是一个此类查询的示例,其中我们结合了两次搜索,为每个排名分配了一个得分,并根据组合得分对结果进行排序。
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
您可以尝试在查询中使用不同的参数,看看是否能改善搜索结果。
这样就完成了实验,为避免产生意外费用,建议您删除未使用的资源。
此外,您还可以使用其他 AI 运算符对结果进行排名,如文档中所述。
9. 清理环境
完成实验后销毁 AlloyDB 实例和集群。
删除 AlloyDB 集群和所有实例
如果您曾使用过 AlloyDB 试用版。如果您计划使用试用集群测试其他实验和资源,请勿删除该试用集群。您将无法在同一项目中创建其他试用集群。
系统会通过强制选项销毁集群,该选项还会删除属于该集群的所有实例。
如果您已断开连接且之前的所有设置都已丢失,请在 Cloud Shell 中定义项目和环境变量:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
删除集群:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
预期的控制台输出:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
删除 AlloyDB 备份
删除集群的所有 AlloyDB 备份:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
预期的控制台输出:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. 恭喜
恭喜您完成此 Codelab。您已了解如何使用文本和图片的嵌入函数在 AlloyDB 中使用多模态搜索。您可以尝试测试多模态搜索,并使用 AlloyDB AI 运算符 Codelab 通过 google_ml.rank 函数对其进行改进。
Google Cloud 学习路线
本实验是“可用于生产用途的 AI 与 Google Cloud”学习路线的组成部分。
- 探索完整课程,弥合从原型设计到生产的差距。
- 使用 #
#ProductionReadyAI分享您的进度。
所学内容
- 如何部署 AlloyDB for Postgres
- 如何使用 AlloyDB Studio
- 如何使用多模态向量搜索
- 如何启用 AlloyDB AI 运算符
- 如何使用不同的 AlloyDB AI 运算符进行多模态搜索
- 如何使用 AlloyDB AI 合并文本和图片搜索结果
11. 调查问卷
输出如下: