
1. Introduction
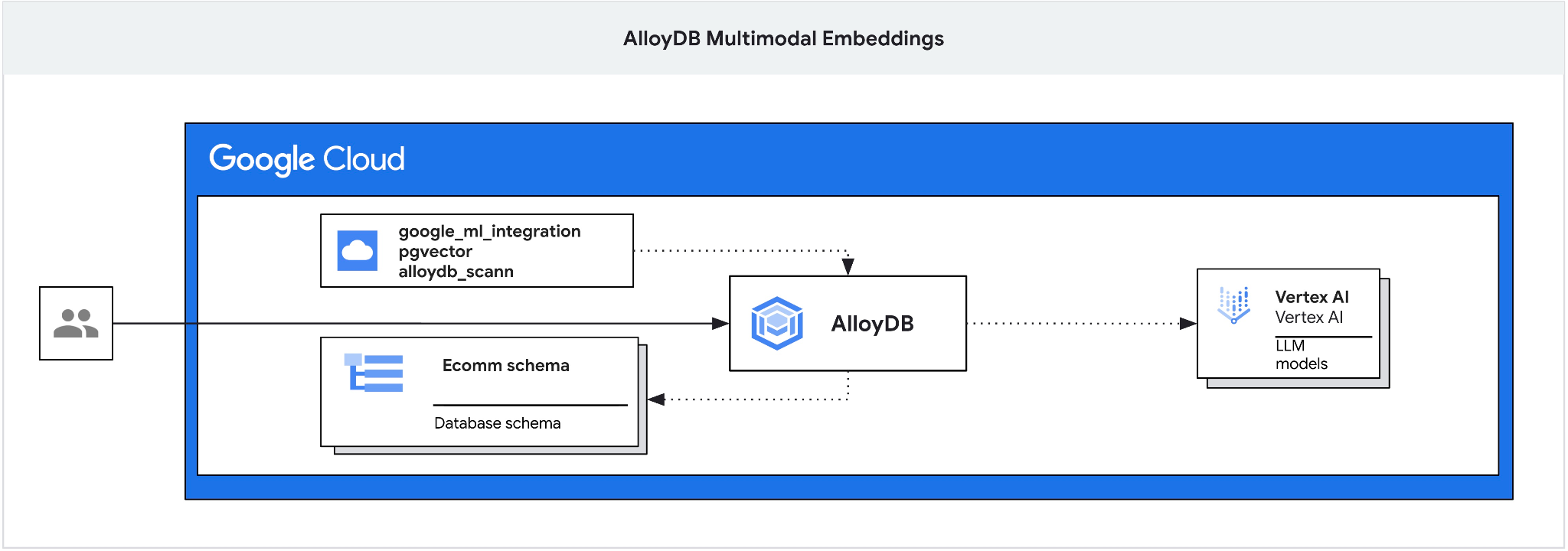
Cet atelier de programmation explique comment déployer AlloyDB et exploiter l'intégration de l'IA pour la recherche sémantique à l'aide d'embeddings multimodaux. Cet atelier fait partie d'une collection d'ateliers consacrée aux fonctionnalités d'AlloyDB AI. Pour en savoir plus, consultez la page AlloyDB AI dans la documentation.
Prérequis
- Connaissances de base concernant la console Google Cloud
- Compétences de base concernant l'interface de ligne de commande et Cloud Shell
Points abordés
- Déployer AlloyDB pour PostgreSQL
- Utiliser AlloyDB Studio
- Utiliser la recherche vectorielle multimodale
- Activer les opérateurs AlloyDB/AI
- Utiliser différents opérateurs AlloyDB AI pour la recherche multimodale
- Utiliser AlloyDB AI pour combiner les résultats de recherche de texte et d'images
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome compatible avec la console Google Cloud et Cloud Shell
2. Préparation
Configuration du projet
- Connectez-vous à la console Google Cloud. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
- Créez un projet ou réutilisez-en un. Pour créer un projet dans la console Google Cloud, cliquez sur le bouton "Sélectionner un projet" dans l'en-tête. Une fenêtre pop-up s'ouvre.

Dans la fenêtre "Sélectionner un projet", cliquez sur le bouton "Nouveau projet" pour ouvrir une boîte de dialogue pour le nouveau projet.
Dans la boîte de dialogue, saisissez le nom de projet de votre choix et sélectionnez l'emplacement.
- Le nom du projet est le nom à afficher pour les participants au projet. Le nom du projet n'est pas utilisé par les API Google et peut être modifié à tout moment.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Google Cloud génère automatiquement un ID unique, mais vous pouvez le personnaliser. Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire ou fournir le vôtre pour vérifier sa disponibilité. Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet, généralement identifié par le code de substitution PROJECT_ID.
- Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
Activer la facturation
Pour activer la facturation, deux options s'offrent à vous. Vous pouvez utiliser votre compte de facturation personnel ou échanger des crédits en suivant les étapes ci-dessous.
Utiliser 5 $de crédits Google Cloud (facultatif)
Pour suivre cet atelier, vous avez besoin d'un compte de facturation avec un certain crédit. Si vous prévoyez d'utiliser votre propre facturation, vous pouvez ignorer cette étape.
- Cliquez sur ce lien et connectez-vous avec un compte Google personnel.
- Le résultat qui s'affiche doit ressembler à ceci :

- Cliquez sur le bouton CLIQUEZ ICI POUR ACCÉDER À VOS CRÉDITS. Vous serez redirigé vers une page vous permettant de configurer votre profil de facturation. Si un écran d'inscription à un essai sans frais s'affiche, cliquez sur "Annuler", puis continuez à associer la facturation.
- Cliquez sur "Confirmer". Vous êtes maintenant connecté à un compte de facturation d'essai Google Cloud Platform.
Configurer un compte de facturation personnel
Si vous configurez la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, cliquez ici pour activer la facturation dans la console Cloud.
Remarques :
- Cet atelier devrait vous coûter moins de 3 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi que des frais supplémentaires ne vous soient facturés.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour un crédit de 300$.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Vous pouvez également appuyer sur G, puis sur S. Cette séquence activera Cloud Shell si vous êtes dans la console Google Cloud ou si vous utilisez ce lien.
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Activer l'API
Pour utiliser AlloyDB, Compute Engine, les services réseau et Vertex AI, vous devez activer leurs API respectives dans votre projet Google Cloud.
Dans Cloud Shell, dans le terminal, assurez-vous que l'ID de votre projet est configuré :
gcloud config set project [YOUR-PROJECT-ID]
Définissez la variable d'environnement PROJECT_ID :
PROJECT_ID=$(gcloud config get-value project)
Activez tous les services nécessaires :
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Résultat attendu
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Présentation des API
- L'API AlloyDB (
alloydb.googleapis.com) vous permet de créer, de gérer et de mettre à l'échelle des clusters AlloyDB pour PostgreSQL. Il s'agit d'un service de base de données entièrement géré et compatible avec PostgreSQL, conçu pour les charges de travail transactionnelles et analytiques d'entreprise exigeantes. - L'API Compute Engine (
compute.googleapis.com) vous permet de créer et de gérer des machines virtuelles (VM), des disques persistants et des paramètres réseau. Elle fournit la base IaaS (Infrastructure as a Service) requise pour exécuter vos charges de travail et héberger l'infrastructure sous-jacente de nombreux services gérés. - L'API Cloud Resource Manager (
cloudresourcemanager.googleapis.com) vous permet de gérer de façon programmatique les métadonnées et la configuration de votre projet Google Cloud. Il vous permet d'organiser les ressources, de gérer les stratégies IAM (Identity and Access Management) et de valider les autorisations dans la hiérarchie des projets. - L'API Service Networking (
servicenetworking.googleapis.com) vous permet d'automatiser la configuration de la connectivité privée entre votre réseau Virtual Private Cloud (VPC) et les services gérés de Google. Il est spécifiquement requis pour établir un accès par adresse IP privée pour des services tels qu'AlloyDB, afin qu'ils puissent communiquer de manière sécurisée avec vos autres ressources. - L'API Vertex AI (
aiplatform.googleapis.com) permet à vos applications de créer, de déployer et de mettre à l'échelle des modèles de machine learning. Elle fournit une interface unifiée pour tous les services d'IA de Google Cloud, y compris l'accès aux modèles d'IA générative (comme Gemini) et l'entraînement de modèles personnalisés.
4. Déployer AlloyDB
Créez un cluster AlloyDB et une instance principale. La procédure suivante explique comment créer un cluster et une instance AlloyDB à l'aide du SDK Google Cloud. Si vous préférez utiliser la console, vous pouvez consulter la documentation sur cette page.
Avant de créer un cluster AlloyDB, nous avons besoin d'une plage d'adresses IP privées disponible dans notre VPC, qui sera utilisée par la future instance AlloyDB. Si nous ne l'avons pas, nous devons le créer et l'attribuer pour qu'il soit utilisé par les services Google internes. Nous pourrons ensuite créer le cluster et l'instance.
Créer une plage d'adresses IP privées
Nous devons configurer l'accès aux services privés dans notre VPC pour AlloyDB. L'hypothèse ici est que nous avons le réseau VPC "par défaut" dans le projet et qu'il sera utilisé pour toutes les actions.
Créez la plage d'adresses IP privées :
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Créez une connexion privée à l'aide de la plage d'adresses IP allouée :
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Créer un cluster AlloyDB
Dans cette section, nous allons créer un cluster AlloyDB dans la région us-central1.
Définissez le mot de passe de l'utilisateur postgres. Vous pouvez définir votre propre mot de passe ou utiliser une fonction aléatoire pour en générer un.
export PGPASSWORD=`openssl rand -hex 12`
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Notez le mot de passe PostgreSQL (il vous servira plus tard).
echo $PGPASSWORD
Vous aurez besoin de ce mot de passe à l'avenir pour vous connecter à l'instance en tant qu'utilisateur postgres. Je vous suggère de le noter ou de le copier quelque part pour pouvoir l'utiliser plus tard.
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
Créer un cluster d'essai sans frais
Si vous n'avez jamais utilisé AlloyDB, vous pouvez créer un cluster d'essai sans frais :
Définissez la région et le nom du cluster AlloyDB. Nous allons utiliser la région us-central1 et alloydb-aip-01 comme nom de cluster :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Exécutez la commande pour créer le cluster :
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Résultat attendu sur la console :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Créez une instance principale AlloyDB pour le cluster dans la même session Cloud Shell. Si vous êtes déconnecté, vous devrez définir à nouveau les variables d'environnement pour la région et le nom du cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Créer un cluster AlloyDB Standard
Si ce n'est pas votre premier cluster AlloyDB dans le projet, créez un cluster standard. Si vous avez déjà créé un cluster d'essai sans frais à l'étape précédente, ignorez cette étape.
Définissez la région et le nom du cluster AlloyDB. Nous allons utiliser la région us-central1 et alloydb-aip-01 comme nom de cluster :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Exécutez la commande pour créer le cluster :
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Résultat attendu sur la console :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Créez une instance principale AlloyDB pour le cluster dans la même session Cloud Shell. Si vous êtes déconnecté, vous devrez définir à nouveau les variables d'environnement pour la région et le nom du cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Préparer la base de données
Nous devons créer une base de données, activer l'intégration de Vertex AI, créer des objets de base de données et importer les données.
Accorder les autorisations nécessaires à AlloyDB
Ajoutez des autorisations Vertex AI à l'agent de service AlloyDB.
Ouvrez un autre onglet Cloud Shell à l'aide du signe "+" situé en haut.
Dans le nouvel onglet Cloud Shell, exécutez :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Fermez l'onglet en exécutant la commande "exit" dans l'onglet :
exit
Se connecter à AlloyDB Studio
Dans les chapitres suivants, toutes les commandes SQL nécessitant une connexion à la base de données peuvent être exécutées dans AlloyDB Studio.
Dans un nouvel onglet, accédez à la page "Clusters" dans AlloyDB pour PostgreSQL.
Ouvrez l'interface de la console Web pour votre cluster AlloyDB en cliquant sur l'instance principale.
Cliquez ensuite sur AlloyDB Studio à gauche :
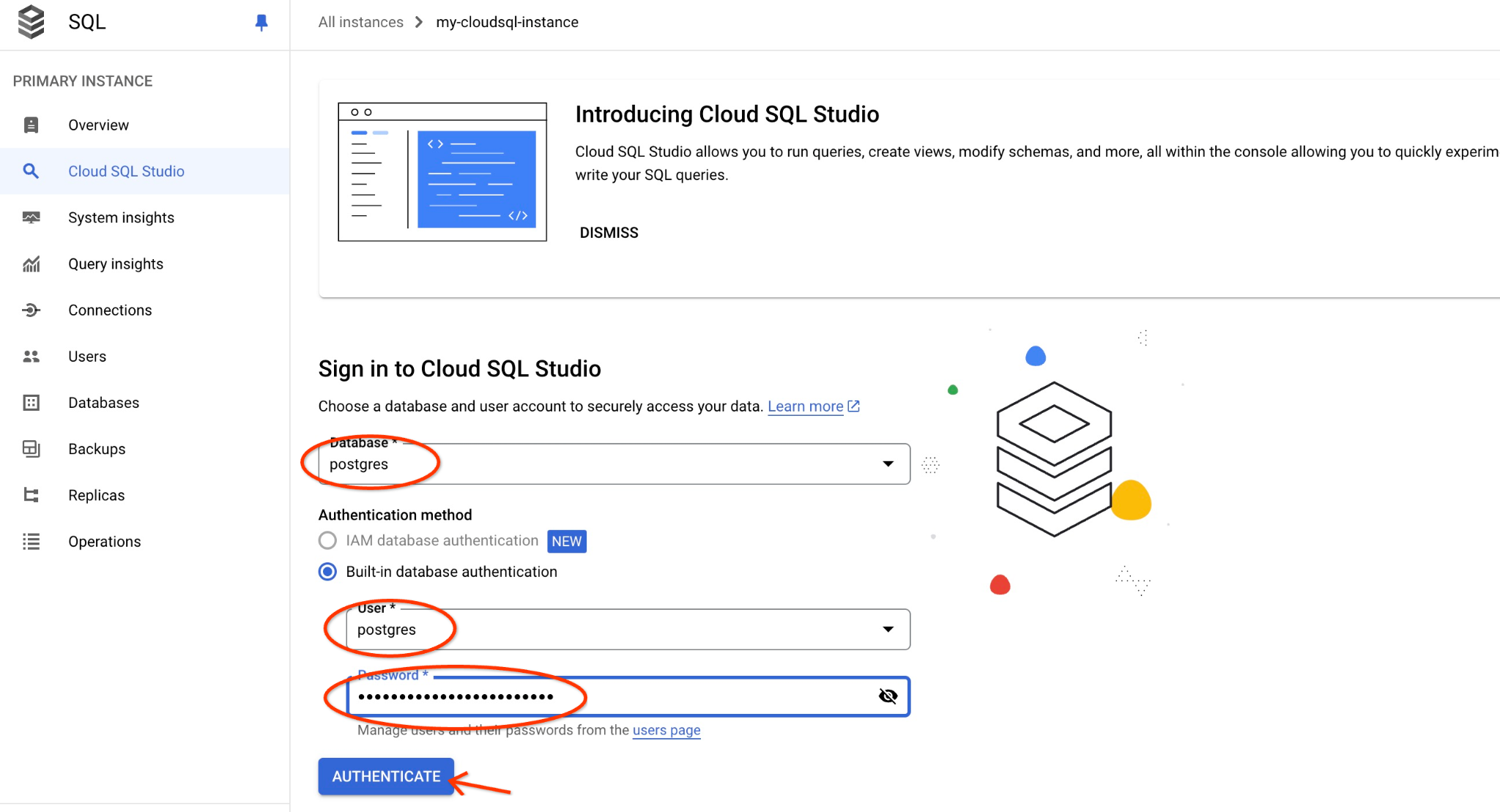
Choisissez la base de données postgres et l'utilisateur postgres, puis indiquez le mot de passe noté lors de la création du cluster. Cliquez ensuite sur le bouton "Authenticate" (S'authentifier). Si vous avez oublié de noter le mot de passe ou s'il ne fonctionne pas, vous pouvez le modifier. Pour savoir comment procéder, consultez la documentation.
L'interface AlloyDB Studio s'ouvre. Pour exécuter les commandes dans la base de données, cliquez sur l'onglet "Requête sans titre" à droite.
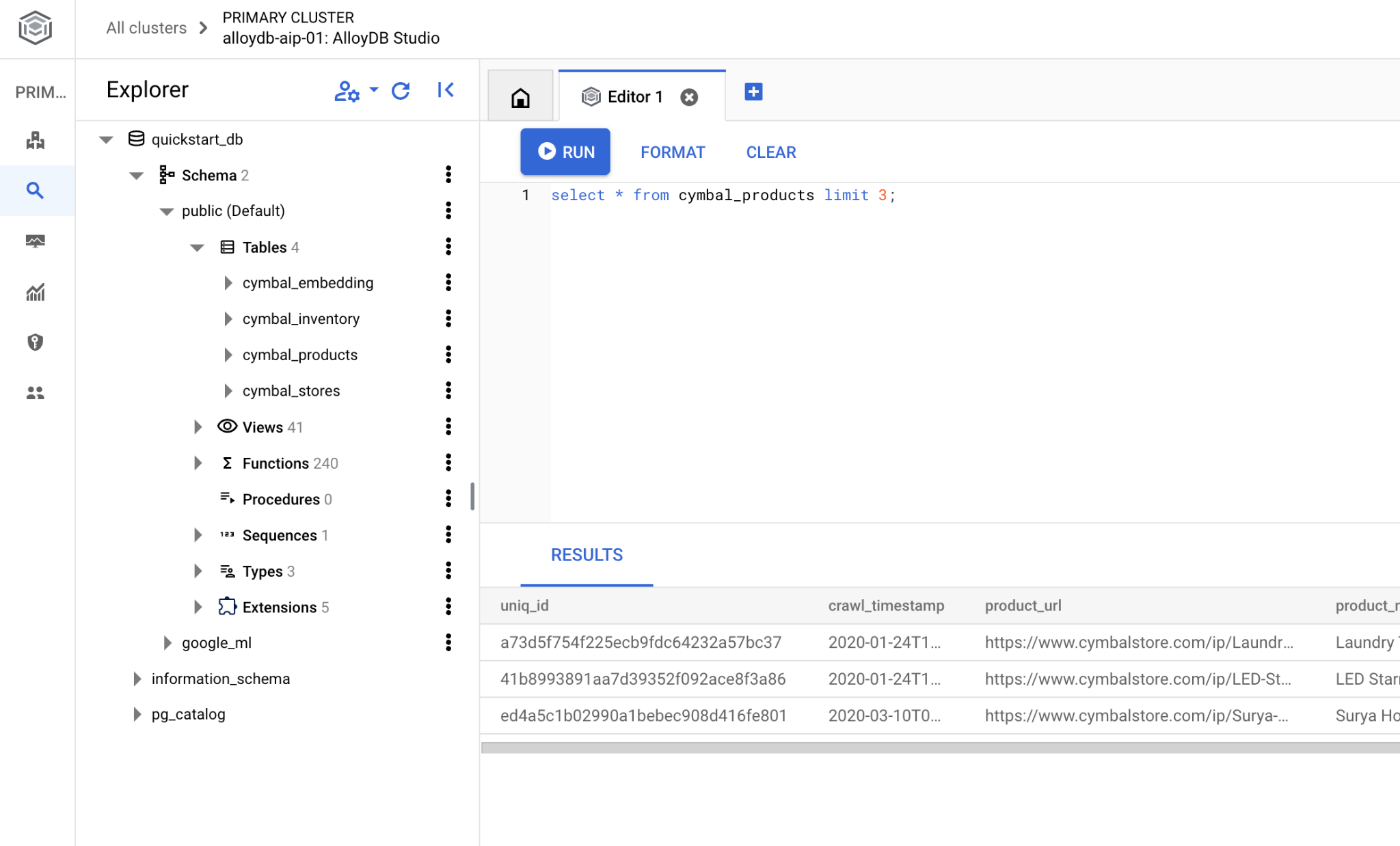
L'interface qui s'ouvre vous permet d'exécuter des commandes SQL.
Créer une base de données
Créez un démarrage rapide de base de données.
Dans l'éditeur AlloyDB Studio, exécutez la commande suivante.
Créez une base de données :
CREATE DATABASE quickstart_db
Résultat attendu :
Statement executed successfully
Se connecter à quickstart_db
Reconnectez-vous au studio à l'aide du bouton permettant de changer d'utilisateur ou de base de données.
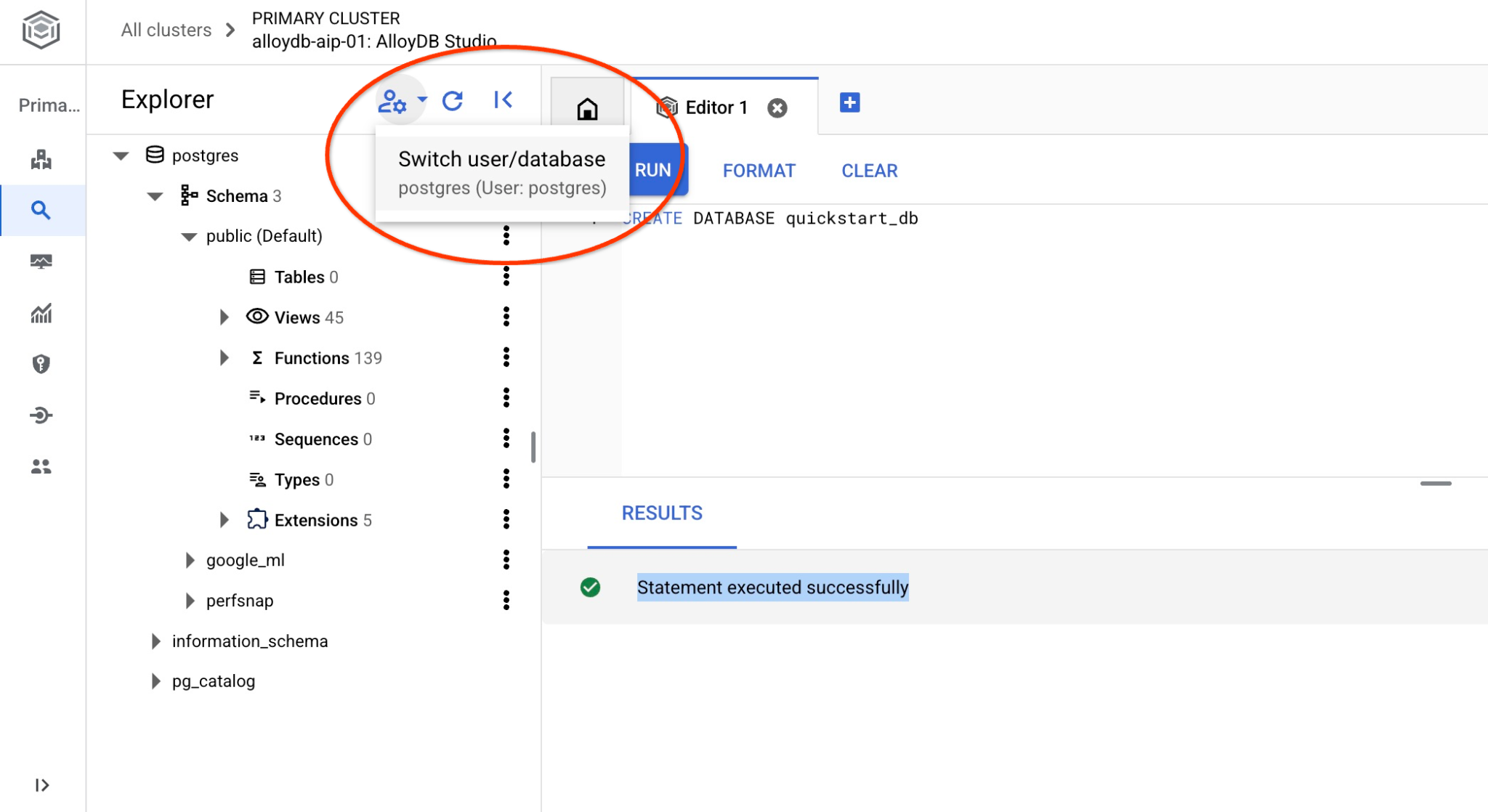
Dans la liste déroulante, sélectionnez la nouvelle base de données quickstart_db et utilisez les mêmes nom d'utilisateur et mot de passe qu'avant.
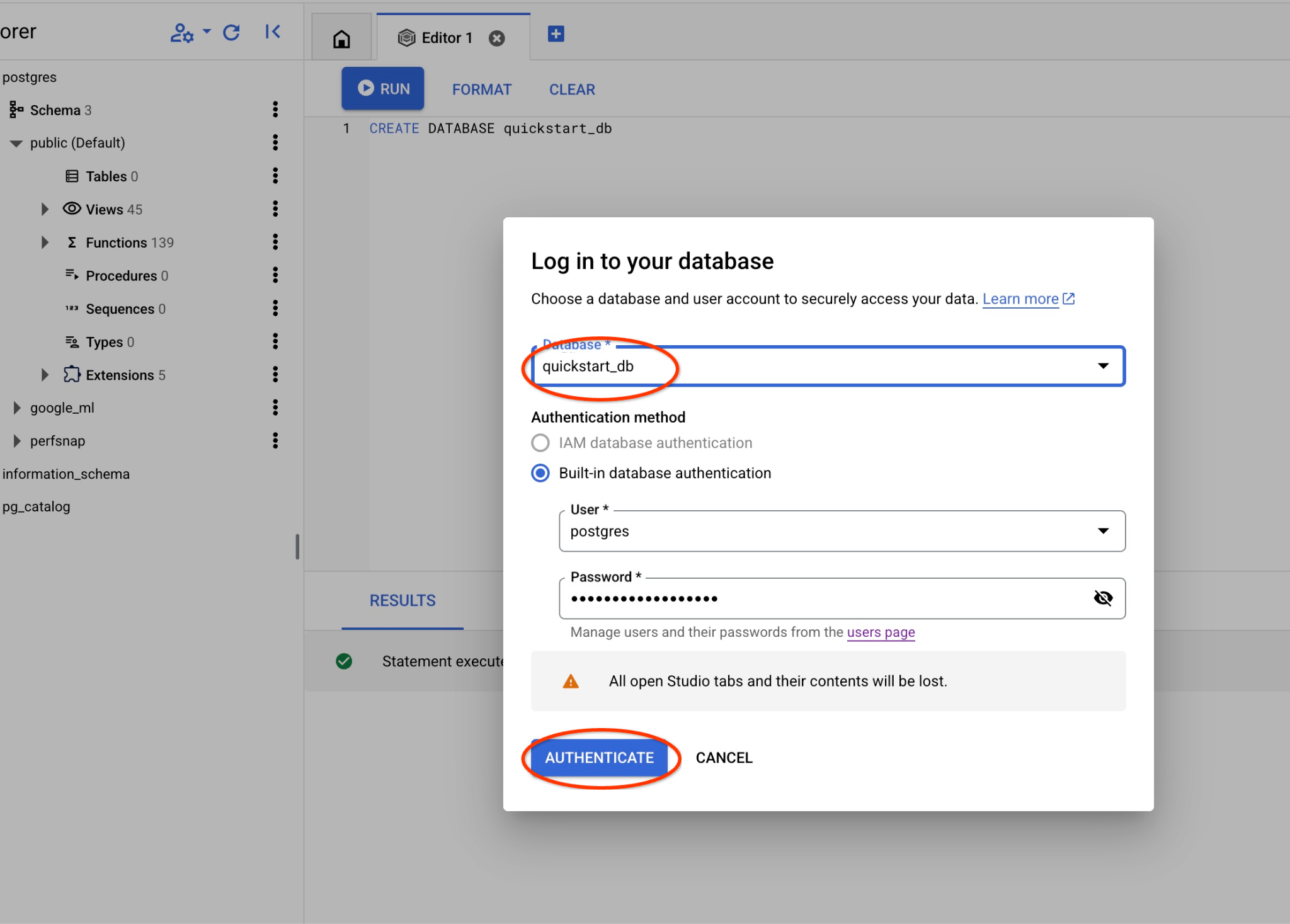
Une nouvelle connexion s'ouvre, vous permettant de travailler avec des objets de la base de données quickstart_db.
6. Exemples de données
Nous devons maintenant créer des objets dans la base de données et charger des données. Nous allons utiliser une boutique fictive "Cymbal" avec des données fictives.
Avant d'importer les données, nous devons activer les extensions compatibles avec les types de données et les index. Nous avons besoin de deux extensions : l'une compatible avec le type de données vectorielles et l'autre avec l'index AlloyDB ScaNN.
Dans AlloyDB Studio, connectez-vous à quickstart_db et exécutez la commande suivante :
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
L'ensemble de données est préparé et placé sous la forme d'un fichier SQL qui peut être chargé dans la base de données à l'aide de l'interface d'importation. Dans Cloud Shell, exécutez les commandes suivantes :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
La commande utilise le SDK AlloyDB et crée un utilisateur nommé "agentspace_user", puis importe des exemples de données directement depuis le bucket GCS vers la base de données, en créant tous les objets nécessaires et en insérant les données.
Une fois l'importation terminée, nous pouvons vérifier les tables dans AlloyDB Studio. Les tables se trouvent dans le schéma ecomm :
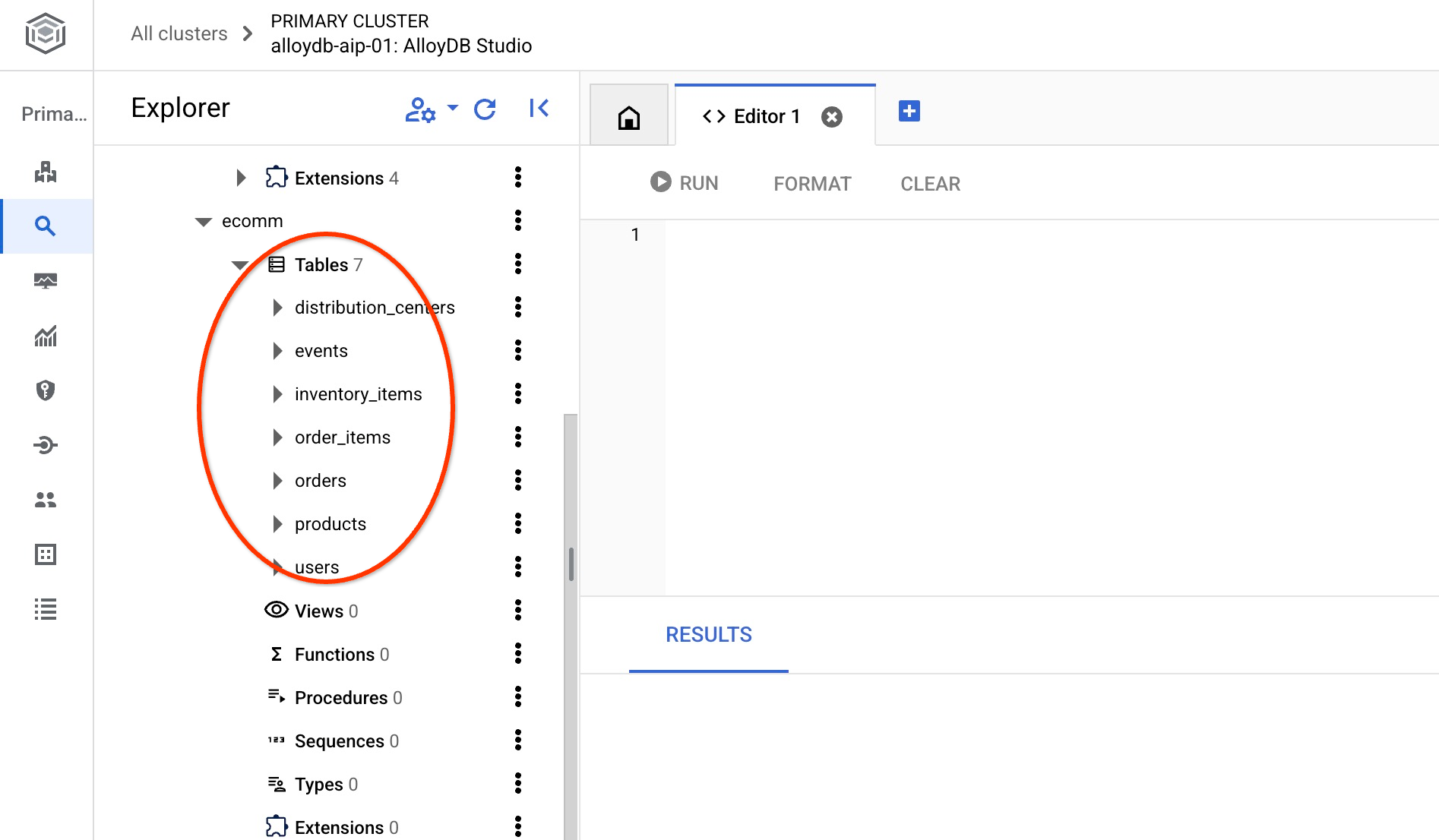
Vérifiez également le nombre de lignes dans l'une des tables.
select count(*) from ecomm.products;
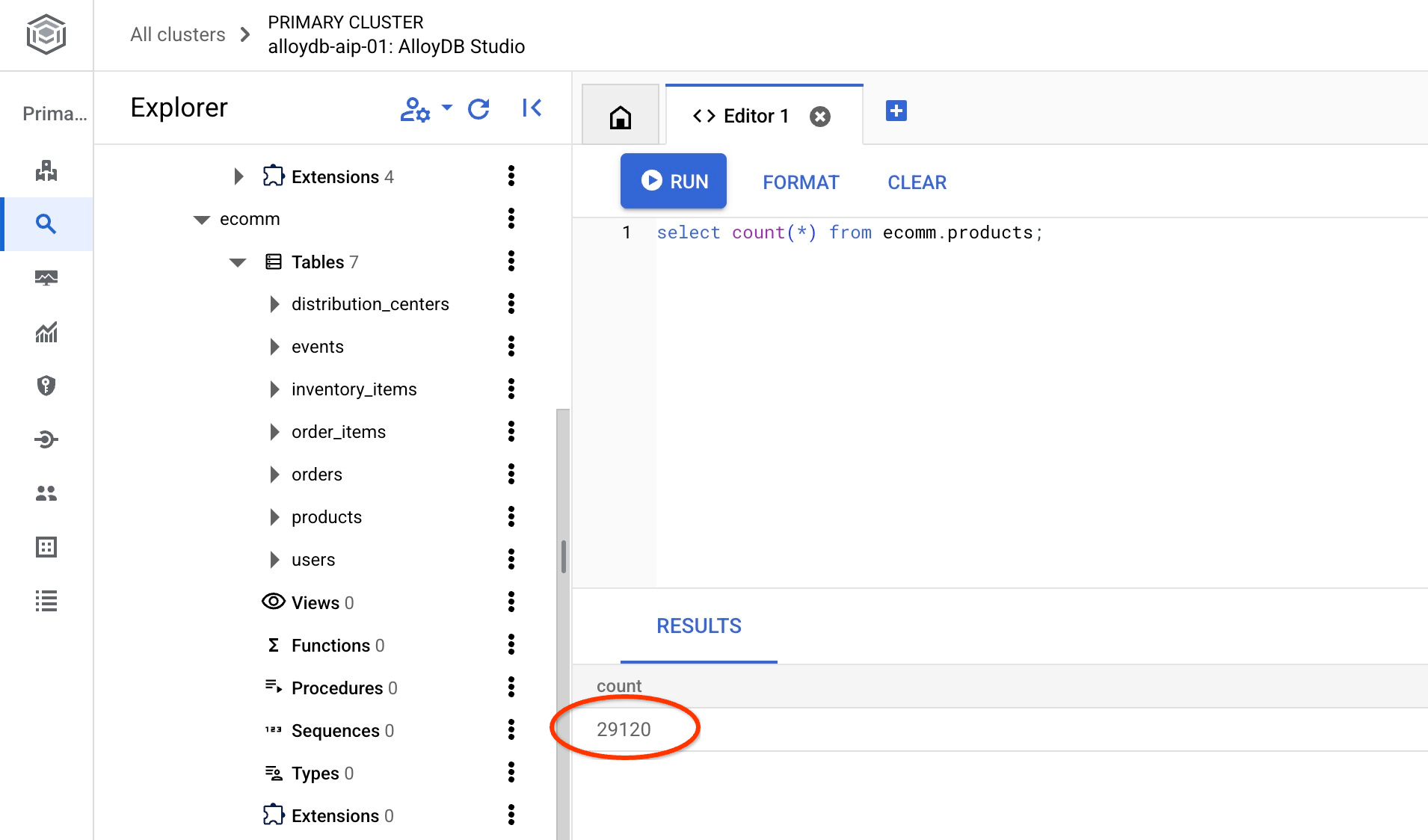
Nous avons bien importé nos données d'exemple et pouvons passer aux étapes suivantes.
7. Recherche sémantique à l'aide de représentations vectorielles continues de texte
Dans ce chapitre, nous allons essayer d'utiliser la recherche sémantique à l'aide d'embeddings textuels et la comparer à la recherche textuelle et en texte intégral Postgres traditionnelle.
Commençons par la recherche classique à l'aide du langage SQL PostgreSQL standard avec l'opérateur LIKE.
Dans AlloyDB Studio, connectez-vous à quickstart_db, puis essayez de rechercher un imperméable à l'aide de la requête suivante :
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
La requête ne renvoie aucune ligne, car elle aurait besoin de mots exacts comme "conditions humides" et "veste" dans le nom ou la description du produit. De même, une "veste pour temps humide" n'est pas la même chose qu'une "veste pour temps pluvieux".
Nous pouvons essayer d'inclure toutes les variantes possibles dans la recherche. Essayons d'inclure seulement deux mots. Exemple :
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
Cela renverrait plusieurs lignes, mais toutes ne correspondraient pas parfaitement à notre demande de vestes, et il serait difficile de les trier par pertinence. Par exemple, si nous ajoutons d'autres conditions comme "pour les hommes", la complexité de la requête augmente considérablement. Nous pouvons également essayer la recherche en texte intégral, mais nous rencontrons des limites liées à la précision des mots et à la pertinence de la réponse.
Nous pouvons maintenant effectuer une recherche similaire à l'aide d'embeddings. Nous avons déjà précalculé les embeddings de nos produits à l'aide de différents modèles. Nous allons utiliser le dernier modèle Gemini-embedding-001 de Google. Nous les avons stockés dans la colonne product_embedding de la table ecomm.products. Si nous exécutons une requête pour notre condition de recherche "veste de pluie homme" à l'aide de la requête suivante :
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
Il renverra non seulement les vestes pour temps humide, mais aussi tous les résultats seront triés en plaçant les plus pertinents en haut.
La requête avec des embeddings renvoie des résultats en 90 à 150 ms, dont une partie du temps est consacrée à l'obtention des données à partir du modèle d'embedding cloud. Si nous examinons le plan d'exécution, la requête adressée au modèle est incluse dans le temps de planification. La partie de la requête qui effectue la recherche elle-même est assez courte. Il faut moins de 7 ms pour effectuer la recherche dans 29 000 enregistrements à l'aide de l'index AlloyDB ScaNN.
Voici le résultat du plan d'exécution :
Limit (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> Index Scan using embedding_scann on products (cost=2709.20..30736.40 rows=29120 width=490) (actual time=6.964..7.046 rows=10 loops=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
…
-0.0051468653,-0.012440448]'::vector)
Limit: 10
Temps de planification : 136,579 ms
Durée d'exécution : 6,791 ms
(6 lignes)
Il s'agissait d'une recherche d'embedding textuel à l'aide du modèle d'embedding textuel uniquement. Mais nous avons aussi des images pour nos produits et nous pouvons les utiliser avec la recherche. Dans le chapitre suivant, nous verrons comment le modèle multimodal utilise les images pour la recherche.
8. Utiliser la recherche multimodale
Bien que la recherche sémantique basée sur le texte soit utile, il peut être difficile de décrire des détails complexes. La recherche multimodale d'AlloyDB offre un avantage en permettant la découverte de produits à partir d'images. Cela est particulièrement utile lorsque la représentation visuelle clarifie l'intention de recherche plus efficacement que les descriptions textuelles seules. Par exemple, "trouve-moi un manteau comme celui sur la photo".
Revenons à notre exemple de veste. Si j'ai une photo d'une veste similaire à celle que je recherche, je peux la transmettre au modèle d'embedding multimodal de Google et la comparer aux embeddings des images de mes produits. Dans notre tableau, nous avons déjà calculé les embeddings pour les images de nos produits dans la colonne product_image_embedding. Vous pouvez voir le modèle utilisé dans la colonne product_image_embedding_model.
Pour notre recherche, nous pouvons utiliser la fonction image_embedding afin d'obtenir l'embedding de notre image et de le comparer aux embeddings précalculés. Pour activer la fonction, nous devons nous assurer d'utiliser la bonne version de l'extension google_ml_integration.
Vérifions la version actuelle de l'extension. Dans AlloyDB Studio, exécutez :
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Si la version est antérieure à 1.5.2, exécutez la procédure suivante.
CALL google_ml.upgrade_to_preview_version();
Vérifiez à nouveau la version de l'extension. Il doit s'agir de la version 1.5.3.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Nous devons également activer les fonctionnalités du moteur de requête d'IA dans notre base de données. Pour ce faire, vous pouvez mettre à jour le flag d'instance pour toutes les bases de données de l'instance ou l'activer uniquement pour votre base de données. Exécutez la commande suivante dans AlloyDB Studio pour l'activer pour la base de données quickstart_db.
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
Nous pouvons maintenant effectuer des recherches par image. Voici un exemple d'image pour la recherche, mais vous pouvez utiliser n'importe quelle image personnalisée. Il vous suffit de l'importer dans le stockage Google ou une autre ressource accessible au public, puis d'insérer l'URI dans la requête.

Il est importé dans gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png.
Recherche d'images par images
Tout d'abord, nous essayons de rechercher uniquement par image :
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Nous avons pu trouver des vestes chaudes dans l'inventaire. Pour afficher les images, vous pouvez les télécharger à l'aide du SDK Cloud (gcloud storage cp) en fournissant la colonne public_url, puis les ouvrir à l'aide de n'importe quel outil fonctionnant avec des images.
|
|
|
|




La recherche d'images renvoie des éléments qui ressemblent à l'image fournie pour comparaison. Comme je l'ai déjà mentionné, vous pouvez essayer d'importer vos propres images dans un bucket public et voir si l'outil peut trouver différents types de vêtements.
Nous avons utilisé le modèle "multimodalembedding@001" de Google pour notre recherche d'images. Notre fonction image_embedding envoie l'image à Vertex AI, la convertit en vecteur et la renvoie pour la comparer aux vecteurs stockés pour les images de notre base de données.
Nous pouvons également vérifier la vitesse de fonctionnement avec notre index ScaNN AlloyDB à l'aide de "EXPLAIN ANALYZE".
Voici le résultat du plan d'exécution :
Limit (cost=971.70..975.55 rows=4 width=490) (actual time=2.453..2.477 rows=4 loops=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
…
,-0.010307034,-0.010053742]'::vector)
Limit: 4
Temps de planification : 913,322 ms
Durée d'exécution : 2,517 ms
(6 lignes)
Comme dans l'exemple précédent, nous pouvons constater que la majeure partie du temps a été consacrée à la conversion de notre image en embeddings à l'aide du point de terminaison cloud, et que la recherche vectorielle elle-même ne prend que 2,5 ms.
Recherche d'images par texte
Avec le multimodal, nous pouvons également transmettre une description textuelle de la veste que nous essayons de rechercher au modèle à l'aide de google_ml.text_embedding pour le même modèle et la comparer aux embeddings d'images pour voir quelles images il renvoie.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Nous avons obtenu un ensemble de doudounes grises ou de couleurs sombres.
|
|
|
|




Nous avons obtenu un ensemble de vestes légèrement différent, mais l'IA a correctement sélectionné les vestes en fonction de notre description et en recherchant dans les embeddings d'images.
Essayons une autre façon de rechercher des descriptions à l'aide de notre embedding pour l'image de recherche.
Recherche de texte par images
Nous avons essayé de rechercher des images en transmettant l'embedding de notre image et en le comparant aux embeddings d'images précalculés pour nos produits. Nous avons également essayé de rechercher des images en transmettant l'embedding pour notre requête textuelle et en effectuant une recherche parmi le même embedding pour les images de produits. Essayons maintenant d'utiliser l'embedding pour notre image et de le comparer aux embeddings de texte pour les descriptions de produits. L'embedding est stocké dans la colonne product_description_embedding et utilise le même modèle multimodalembedding@001.
Voici notre requête :
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Ici, nous avons un ensemble de vestes légèrement différent, avec des couleurs grises ou foncées, dont certaines sont identiques ou très proches de celles choisies par d'autres méthodes de recherche.
|
|
|
|



Elle renvoie les mêmes vestes que ci-dessus, mais dans un ordre légèrement différent. En se basant sur notre embedding pour les images, il peut comparer les embeddings calculés pour la description textuelle et renvoyer l'ensemble de produits approprié.
Recherche hybride textuelle et d'images
Vous pouvez également combiner des embeddings de texte et d'image, par exemple à l'aide de la fusion par rang réciproque. Voici un exemple de requête de ce type, dans laquelle nous avons combiné deux recherches en attribuant un score à chaque classement et en ordonnant les résultats en fonction du score combiné.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
Vous pouvez essayer de modifier différents paramètres dans la requête pour voir si cela peut améliorer vos résultats de recherche.
L'atelier est terminé. Pour éviter des frais inattendus, nous vous recommandons de supprimer les ressources inutilisées.
Vous pouvez également utiliser d'autres opérateurs d'IA pour classer les résultats, comme décrit dans la documentation.
9. Nettoyer l'environnement
Détruisez les instances et le cluster AlloyDB une fois l'atelier terminé.
Supprimer le cluster AlloyDB et toutes les instances
Si vous avez utilisé la version d'essai d'AlloyDB. Ne supprimez pas le cluster d'essai si vous prévoyez de tester d'autres ateliers et ressources à l'aide de ce cluster. Vous ne pourrez pas créer d'autre cluster d'essai dans le même projet.
Le cluster est détruit avec l'option "force", qui supprime également toutes les instances appartenant au cluster.
Dans Cloud Shell, définissez le projet et les variables d'environnement si vous avez été déconnecté et que tous les paramètres précédents sont perdus :
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Supprimez le cluster :
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Supprimer les sauvegardes AlloyDB
Supprimez toutes les sauvegardes AlloyDB du cluster :
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation. Vous avez appris à utiliser la recherche multimodale dans AlloyDB à l'aide de fonctions d'embedding pour les textes et les images. Vous pouvez essayer de tester la recherche multimodale et de l'améliorer avec la fonction google_ml.rank en utilisant l'atelier de programmation pour les opérateurs AlloyDB/AI.
Parcours de formation Google Cloud
Cet atelier fait partie du parcours de formation "IA prête pour la production avec Google Cloud".
- Explorez le programme complet pour combler le fossé entre le prototype et la production.
- Partagez votre progression avec le hashtag
#ProductionReadyAI.
Points abordés
- Déployer AlloyDB pour PostgreSQL
- Utiliser AlloyDB Studio
- Utiliser la recherche vectorielle multimodale
- Activer les opérateurs AlloyDB/AI
- Utiliser différents opérateurs AlloyDB AI pour la recherche multimodale
- Utiliser AlloyDB AI pour combiner les résultats de recherche de texte et d'images
11. Enquête
Résultat :