
1. Introduzione
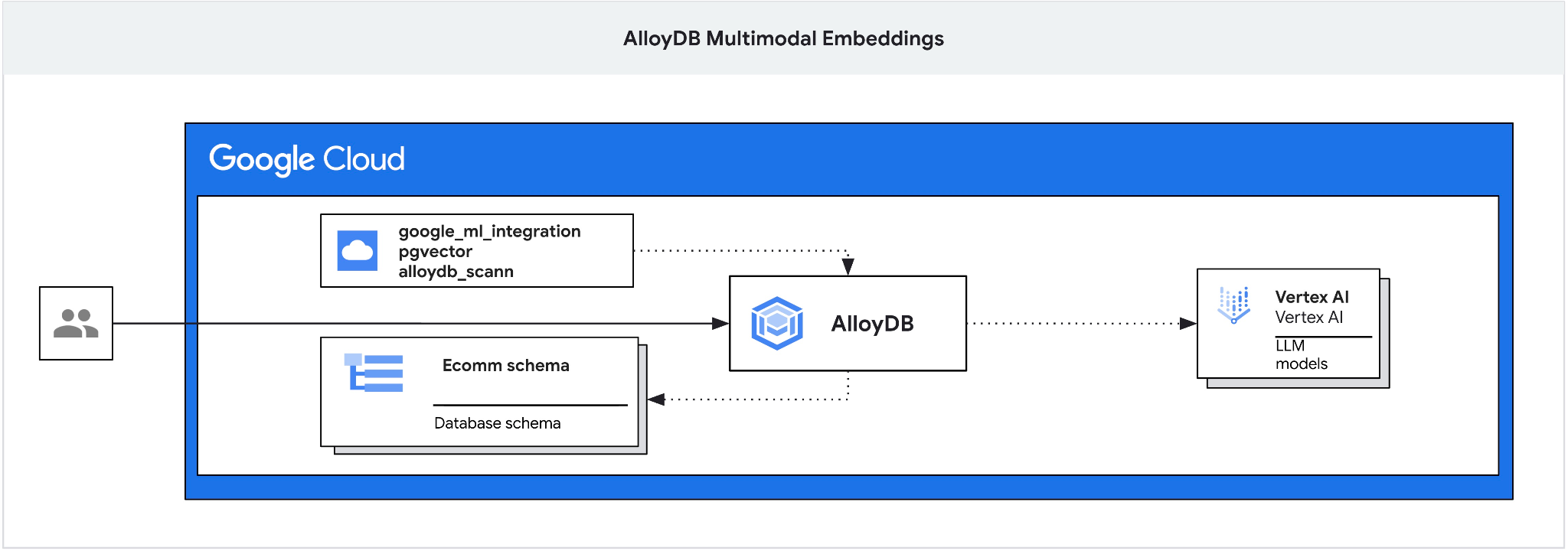
Questo codelab fornisce una guida per il deployment di AlloyDB e l'utilizzo dell'integrazione dell'AI per la ricerca semantica utilizzando gli embedding multimodali. Questo lab fa parte di una raccolta dedicata alle funzionalità di AI di AlloyDB. Per saperne di più, consulta la pagina di AlloyDB AI nella documentazione.
Prerequisiti
- Una conoscenza di base di Google Cloud e della console
- Competenze di base nell'interfaccia a riga di comando e in Cloud Shell
Cosa imparerai a fare
- Come eseguire il deployment di AlloyDB per PostgreSQL
- Come utilizzare AlloyDB Studio
- Come utilizzare la ricerca vettoriale multimodale
- Come attivare gli operatori AI di AlloyDB
- Come utilizzare diversi operatori AI di AlloyDB per la ricerca multimodale
- Come utilizzare l'AI di AlloyDB per combinare i risultati di ricerca di testo e immagini
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome che supporta la console Google Cloud e Cloud Shell
2. Configurazione e requisiti
Configurazione del progetto
- Accedi alla console Google Cloud. Se non hai già un account Gmail o Google Workspace, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
- Crea un nuovo progetto o riutilizzane uno esistente. Per creare un nuovo progetto nella console Google Cloud, fai clic sul pulsante Seleziona un progetto nell'intestazione per aprire una finestra popup.

Nella finestra Seleziona un progetto, premi il pulsante Nuovo progetto per aprire una finestra di dialogo per il nuovo progetto.
Nella finestra di dialogo, inserisci il nome del progetto che preferisci e scegli la posizione.
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. Il nome del progetto non viene utilizzato dalle API Google e può essere modificato in qualsiasi momento.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Google Cloud genera automaticamente un ID univoco, ma puoi personalizzarlo. Se non ti piace l'ID generato, puoi generarne un altro casuale o fornire il tuo per verificarne la disponibilità. Nella maggior parte dei codelab, devi fare riferimento all'ID progetto, che in genere è identificato con il segnaposto PROJECT_ID.
- Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
Abilita fatturazione
Per attivare la fatturazione, hai due opzioni. Puoi utilizzare il tuo account di fatturazione personale o riscattare i crediti seguendo questi passaggi.
Riscatta 5 $di crediti Google Cloud (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Se prevedi di utilizzare la tua fatturazione, puoi saltare questo passaggio.
- Fai clic su questo link e accedi con un Account Google personale.
- Visualizzerai un riquadro simile al seguente:

- Fai clic sul pulsante CLICCA QUI PER ACCEDERE AI TUOI CREDITI. Verrà visualizzata una pagina per configurare il tuo profilo di fatturazione. Se viene visualizzata una schermata di registrazione alla prova senza costi, fai clic su Annulla e continua a collegare la fatturazione.
- Fai clic su Conferma. Ora sei connesso a un account di fatturazione di prova di Google Cloud.
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione in Cloud Console.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 3 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
In alternativa, puoi premere G e poi S. Questa sequenza attiverà Cloud Shell se ti trovi nella console Google Cloud o utilizza questo link.
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere qualcosa di simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni di rete e l'autenticazione. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Prima di iniziare
Abilita l'API
Per utilizzare AlloyDB, Compute Engine, Servizi di rete e Vertex AI, devi abilitare le rispettive API nel tuo progetto Google Cloud.
All'interno di Cloud Shell nel terminale, assicurati che l'ID progetto sia configurato:
gcloud config set project [YOUR-PROJECT-ID]
Imposta la variabile di ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Attiva tutti i servizi necessari:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Output previsto:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Presentazione delle API
- L'API AlloyDB (
alloydb.googleapis.com) consente di creare, gestire e scalare i cluster AlloyDB per PostgreSQL. Fornisce un servizio di database completamente gestito e compatibile con PostgreSQL progettato per carichi di lavoro transazionali e analitici aziendali impegnativi. - L'API Compute Engine (
compute.googleapis.com) consente di creare e gestire macchine virtuali (VM), dischi permanenti e impostazioni di rete. Fornisce le basi di Infrastructure as a Service (IaaS) necessarie per eseguire i carichi di lavoro e ospitare l'infrastruttura sottostante per molti servizi gestiti. - L'API Cloud Resource Manager (
cloudresourcemanager.googleapis.com) ti consente di gestire in modo programmatico i metadati e la configurazione del tuo progetto Google Cloud. Consente di organizzare le risorse, gestire i criteri IAM (Identity and Access Management) e convalidare le autorizzazioni nella gerarchia dei progetti. - L'API Service Networking (
servicenetworking.googleapis.com) ti consente di automatizzare la configurazione della connettività privata tra la tua rete Virtual Private Cloud (VPC) e i servizi gestiti di Google. È necessario in particolare per stabilire l'accesso IP privato per servizi come AlloyDB, in modo che possano comunicare in modo sicuro con le altre risorse. - L'API Vertex AI (
aiplatform.googleapis.com) consente alle tue applicazioni di creare, eseguire il deployment e scalare modelli di machine learning. Fornisce l'interfaccia unificata per tutti i servizi di AI di Google Cloud, incluso l'accesso ai modelli di AI generativa (come Gemini) e l'addestramento di modelli personalizzati.
4. Esegui il deployment di AlloyDB
Crea il cluster AlloyDB e l'istanza principale. La seguente procedura descrive come creare un cluster e un'istanza AlloyDB utilizzando Google Cloud SDK. Se preferisci l'approccio della console, puoi seguire la documentazione qui.
Prima di creare un cluster AlloyDB, abbiamo bisogno di un intervallo di IP privati disponibile nel nostro VPC da utilizzare per la futura istanza AlloyDB. Se non lo abbiamo, dobbiamo crearlo, assegnarlo per l'utilizzo da parte dei servizi Google interni e solo dopo potremo creare il cluster e l'istanza.
Crea intervallo IP privato
Dobbiamo configurare l'accesso privato ai servizi nel nostro VPC per AlloyDB. Il presupposto è che nel progetto sia presente la rete VPC "default" e che verrà utilizzata per tutte le azioni.
Crea l'intervallo IP privato:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Crea una connessione privata utilizzando l'intervallo IP allocato:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Crea cluster AlloyDB
In questa sezione creiamo un cluster AlloyDB nella regione us-central1.
Definisci la password per l'utente postgres. Puoi definire una password personalizzata o utilizzare una funzione casuale per generarla.
export PGPASSWORD=`openssl rand -hex 12`
Output console previsto:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Prendi nota della password PostgreSQL per utilizzarla in futuro.
echo $PGPASSWORD
Avrai bisogno di questa password in futuro per connetterti all'istanza come utente postgres. Ti consiglio di annotarlo o copiarlo da qualche parte per poterlo utilizzare in un secondo momento.
Output console previsto:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
Creare un cluster di prova senza costi
Se non hai mai utilizzato AlloyDB, puoi creare un cluster di prova senza costi:
Definisci la regione e il nome del cluster AlloyDB. Utilizzeremo la regione us-central1 e alloydb-aip-01 come nome del cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Esegui il comando per creare il cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Output console previsto:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea un'istanza principale AlloyDB per il nostro cluster nella stessa sessione della shell Cloud. Se la connessione viene interrotta, dovrai definire nuovamente le variabili di ambiente del nome della regione e del cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Crea un cluster AlloyDB Standard
Se non è il tuo primo cluster AlloyDB nel progetto, procedi con la creazione di un cluster standard. Se hai già creato un cluster di prova senza costi nel passaggio precedente, salta questo passaggio.
Definisci la regione e il nome del cluster AlloyDB. Utilizzeremo la regione us-central1 e alloydb-aip-01 come nome del cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Esegui il comando per creare il cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Output console previsto:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea un'istanza principale AlloyDB per il nostro cluster nella stessa sessione della shell Cloud. Se la connessione viene interrotta, dovrai definire nuovamente le variabili di ambiente del nome della regione e del cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Prepara il database
Dobbiamo creare un database, abilitare l'integrazione di Vertex AI, creare oggetti di database e importare i dati.
Concedi le autorizzazioni necessarie ad AlloyDB
Aggiungi le autorizzazioni Vertex AI al service agent AlloyDB.
Apri un'altra scheda di Cloud Shell utilizzando il segno "+" in alto.
Nella nuova scheda di Cloud Shell, esegui:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Chiudi la scheda con il comando di esecuzione "exit":
exit
Connettersi ad AlloyDB Studio
Nei capitoli seguenti, tutti i comandi SQL che richiedono la connessione al database possono essere eseguiti in AlloyDB Studio.
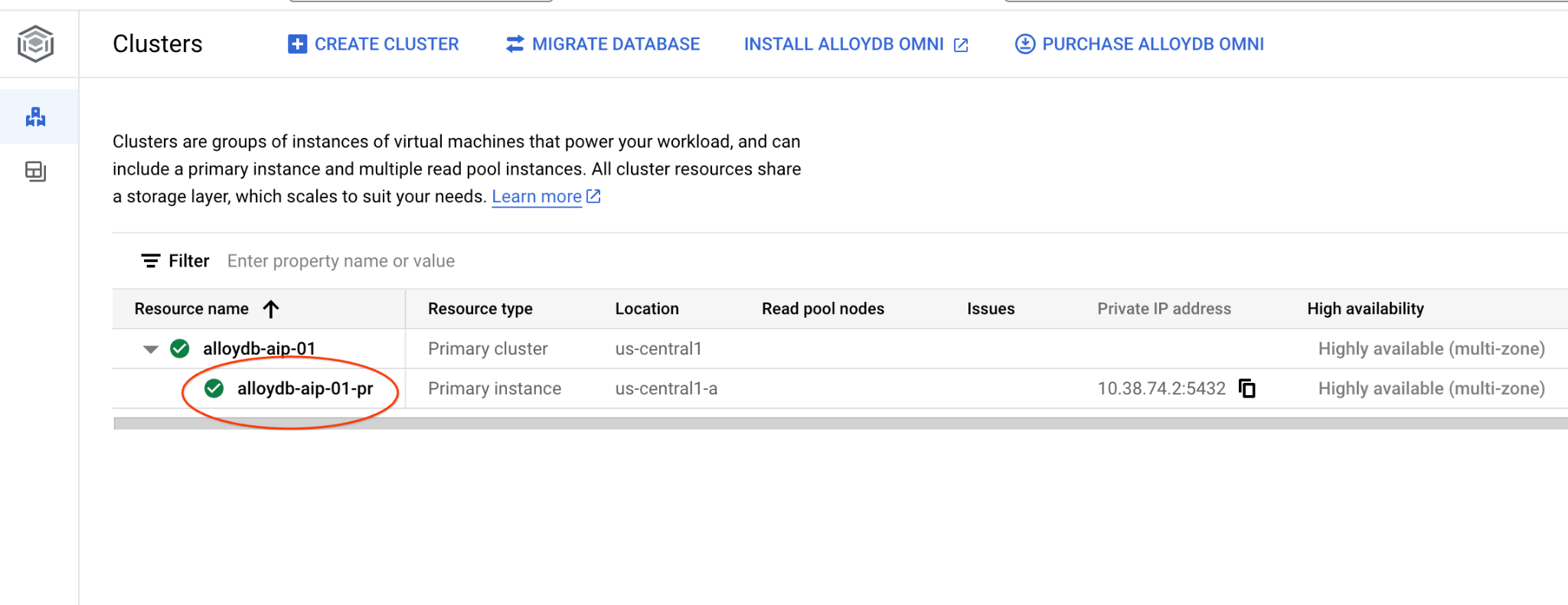
In una nuova scheda, vai alla pagina Cluster in AlloyDB per PostgreSQL.
Apri l'interfaccia della console web per il cluster AlloyDB facendo clic sull'istanza principale.
Quindi, fai clic su AlloyDB Studio a sinistra:
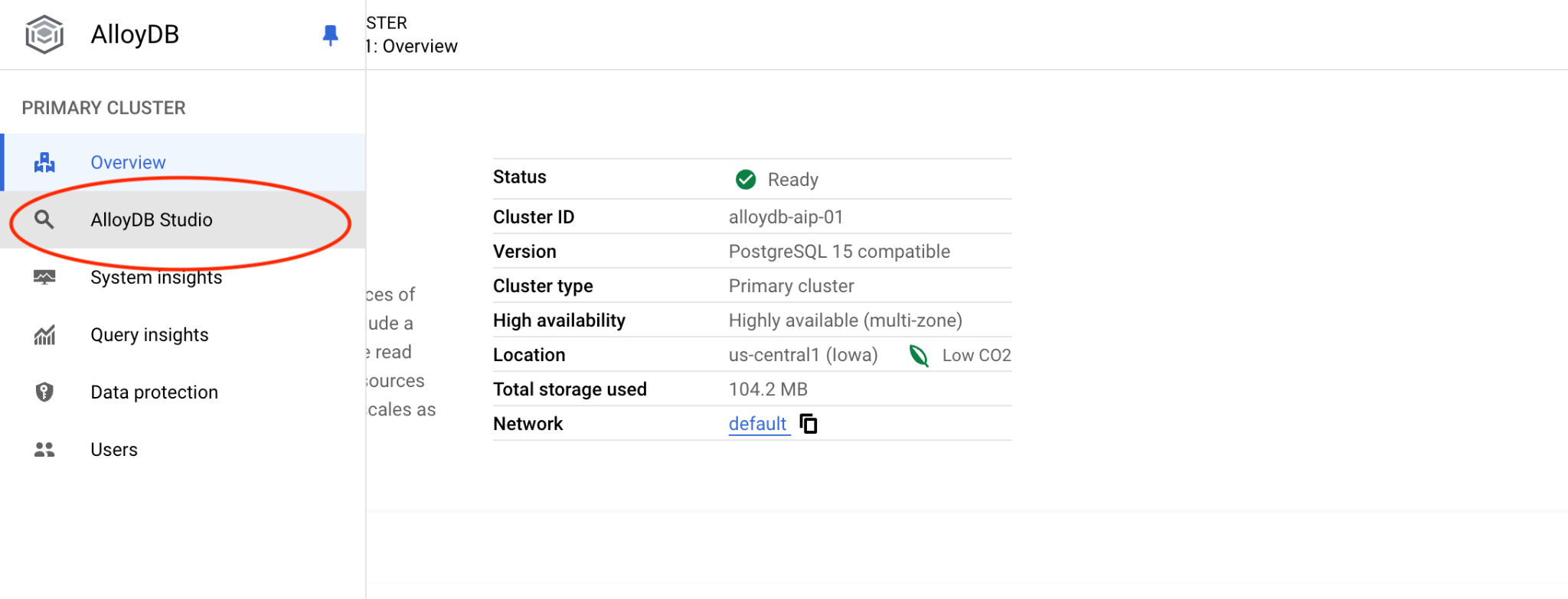
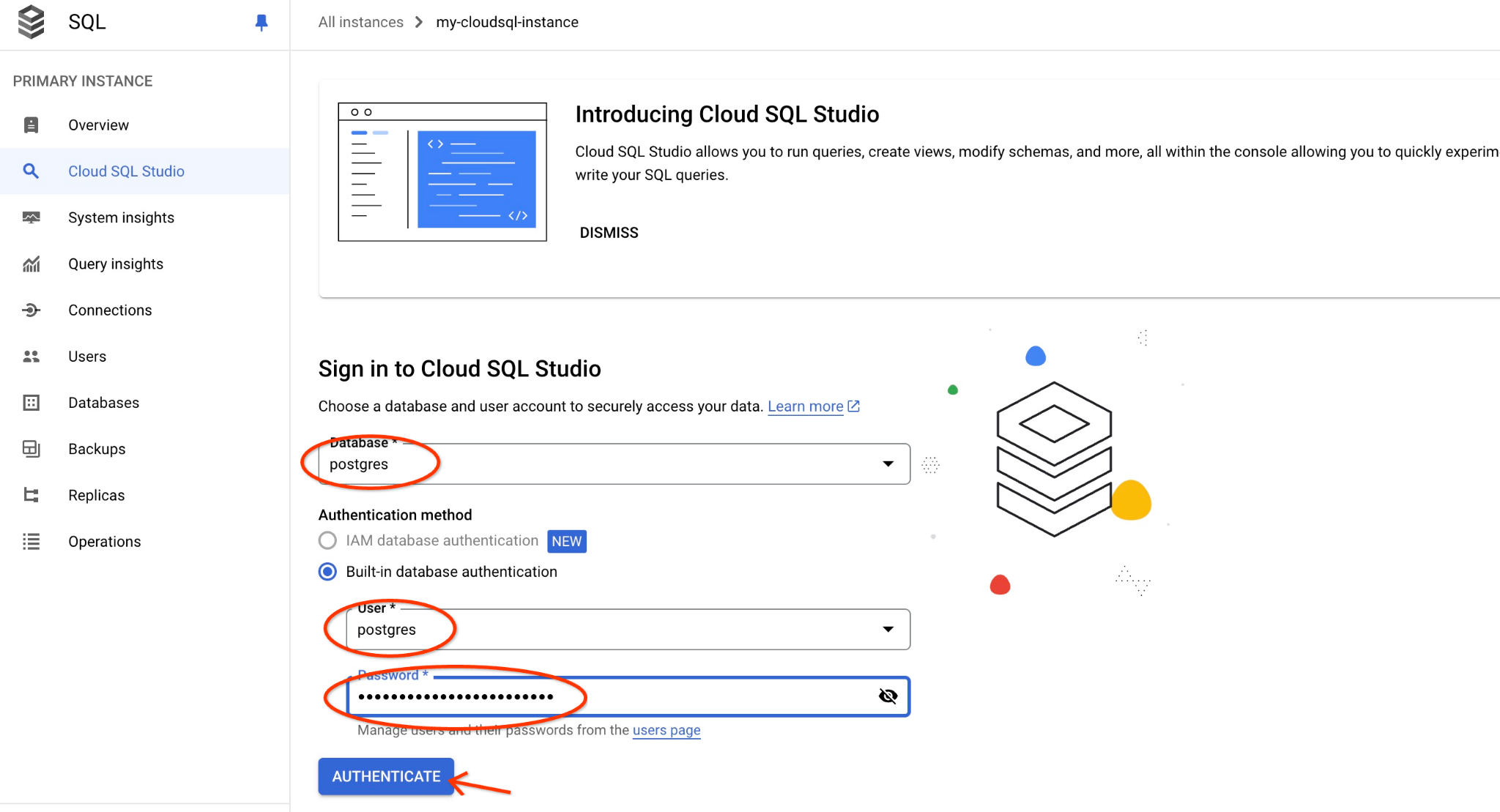
Scegli il database Postgres, l'utente Postgres e fornisci la password annotata quando abbiamo creato il cluster. A questo punto, fai clic sul pulsante "Autentica". Se hai dimenticato di annotare la password o non funziona, puoi cambiarla. Consulta la documentazione per scoprire come fare.
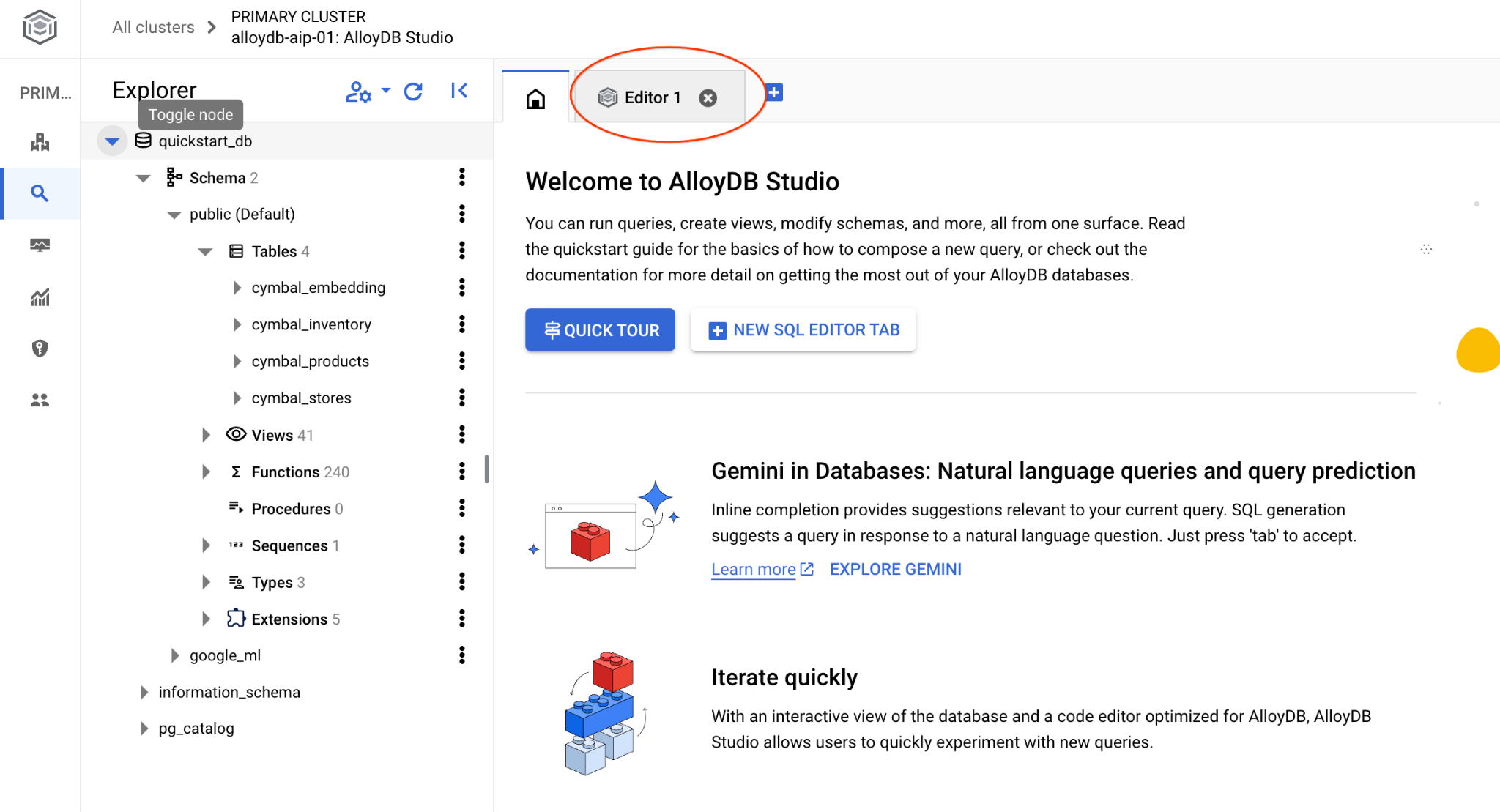
Si aprirà l'interfaccia di AlloyDB Studio. Per eseguire i comandi nel database, fai clic sulla scheda "Query senza titolo" a destra.
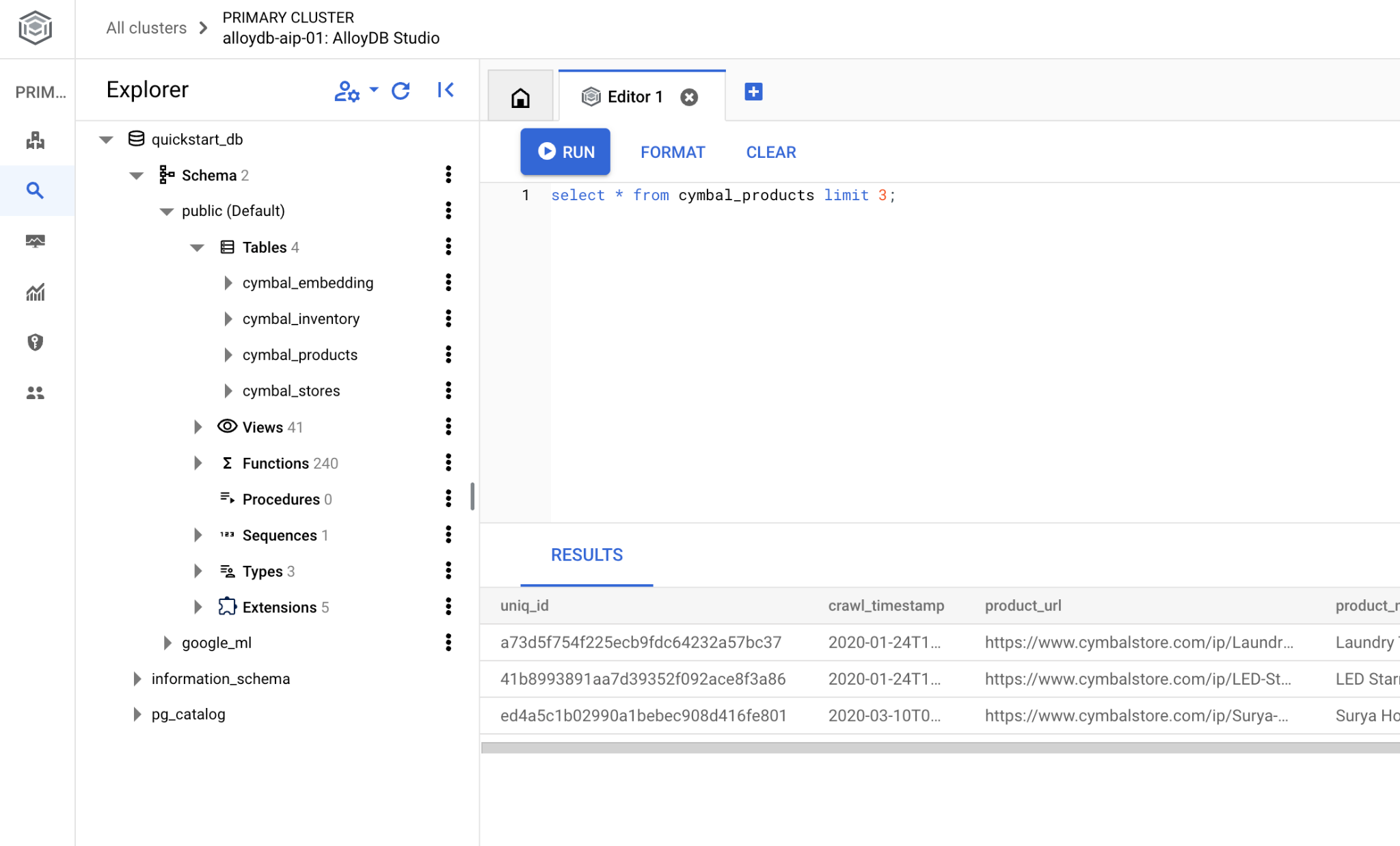
Si apre l'interfaccia in cui puoi eseguire i comandi SQL
Crea database
Guida rapida alla creazione di un database.
Nell'editor di AlloyDB Studio, esegui questo comando.
Crea database:
CREATE DATABASE quickstart_db
Output previsto:
Statement executed successfully
Connettiti a quickstart_db
Riconnettiti allo studio utilizzando il pulsante per cambiare utente/database.
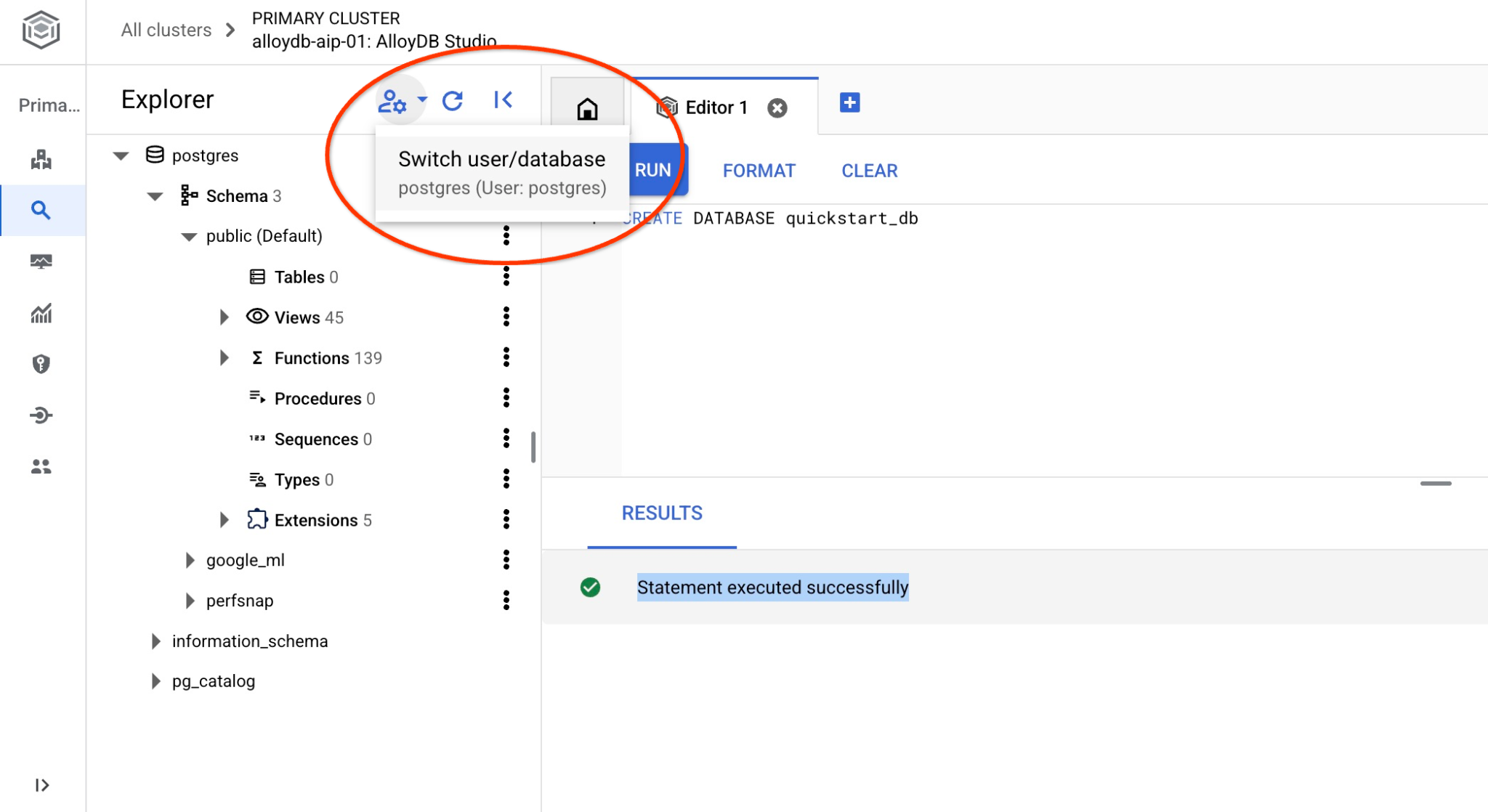
Seleziona il nuovo database quickstart_db dall'elenco a discesa e utilizza lo stesso utente e la stessa password di prima.
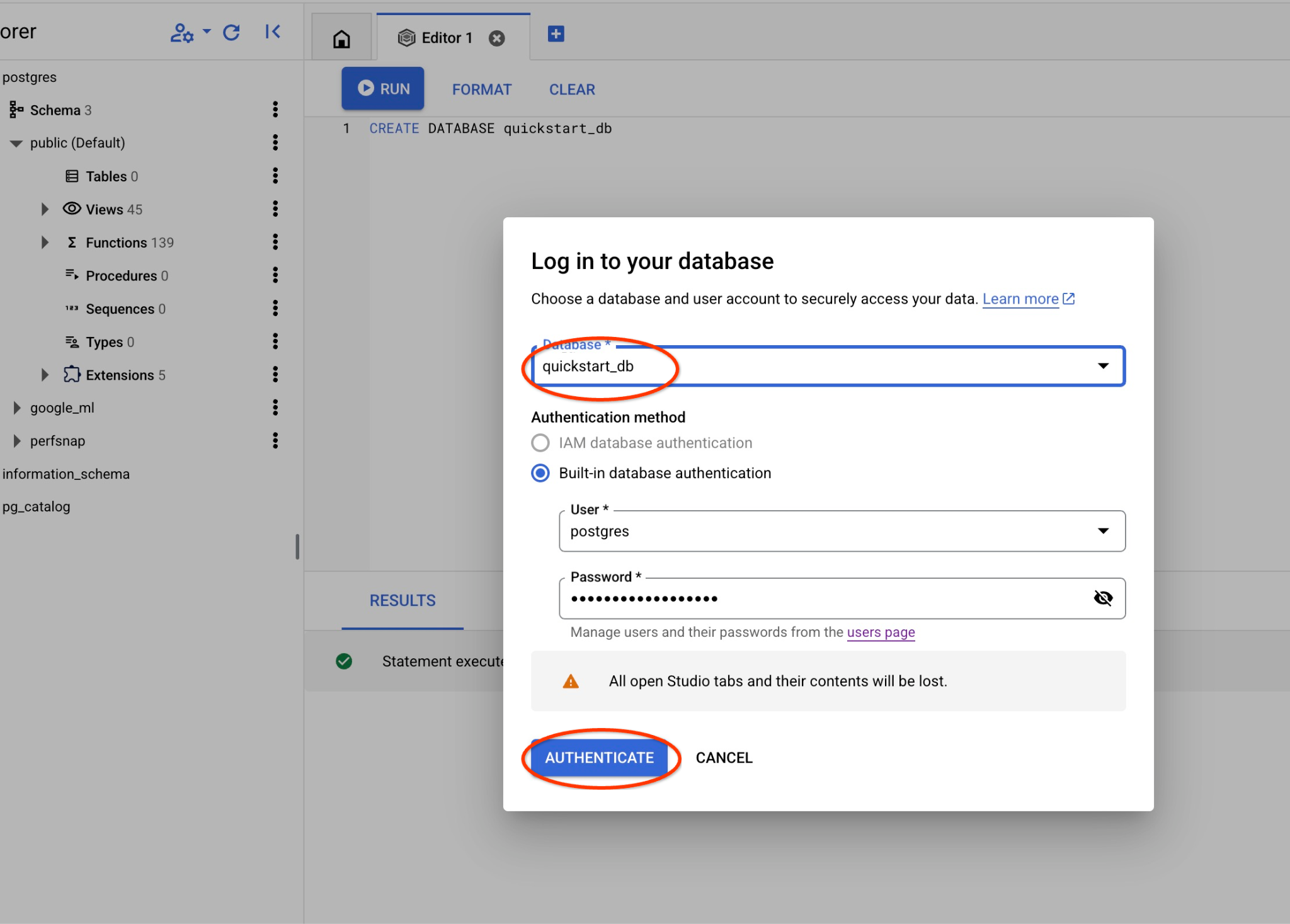
Si aprirà una nuova connessione in cui potrai lavorare con gli oggetti del database quickstart_db.
6. Dati di esempio
Ora dobbiamo creare oggetti nel database e caricare i dati. Useremo un negozio fittizio "Cymbal" con dati fittizi.
Prima di importare i dati, dobbiamo attivare le estensioni che supportano i tipi di dati e gli indici. Abbiamo bisogno di due estensioni: una che supporti il tipo di dati vettoriali e l'altra che supporti l'indice ScaNN di AlloyDB.
In AlloyDB Studio, connettiti a quickstart_db.
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Il set di dati viene preparato e inserito come file SQL che può essere caricato nel database utilizzando l'interfaccia di importazione. In Cloud Shell, esegui questi comandi:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
Il comando utilizza l'SDK AlloyDB e crea un utente con il nome agentspace_user, quindi importa i dati di esempio direttamente dal bucket GCS al database creando tutti gli oggetti necessari e inserendo i dati.
Dopo l'importazione, possiamo controllare le tabelle in AlloyDB Studio. Le tabelle sono nello schema ecomm:
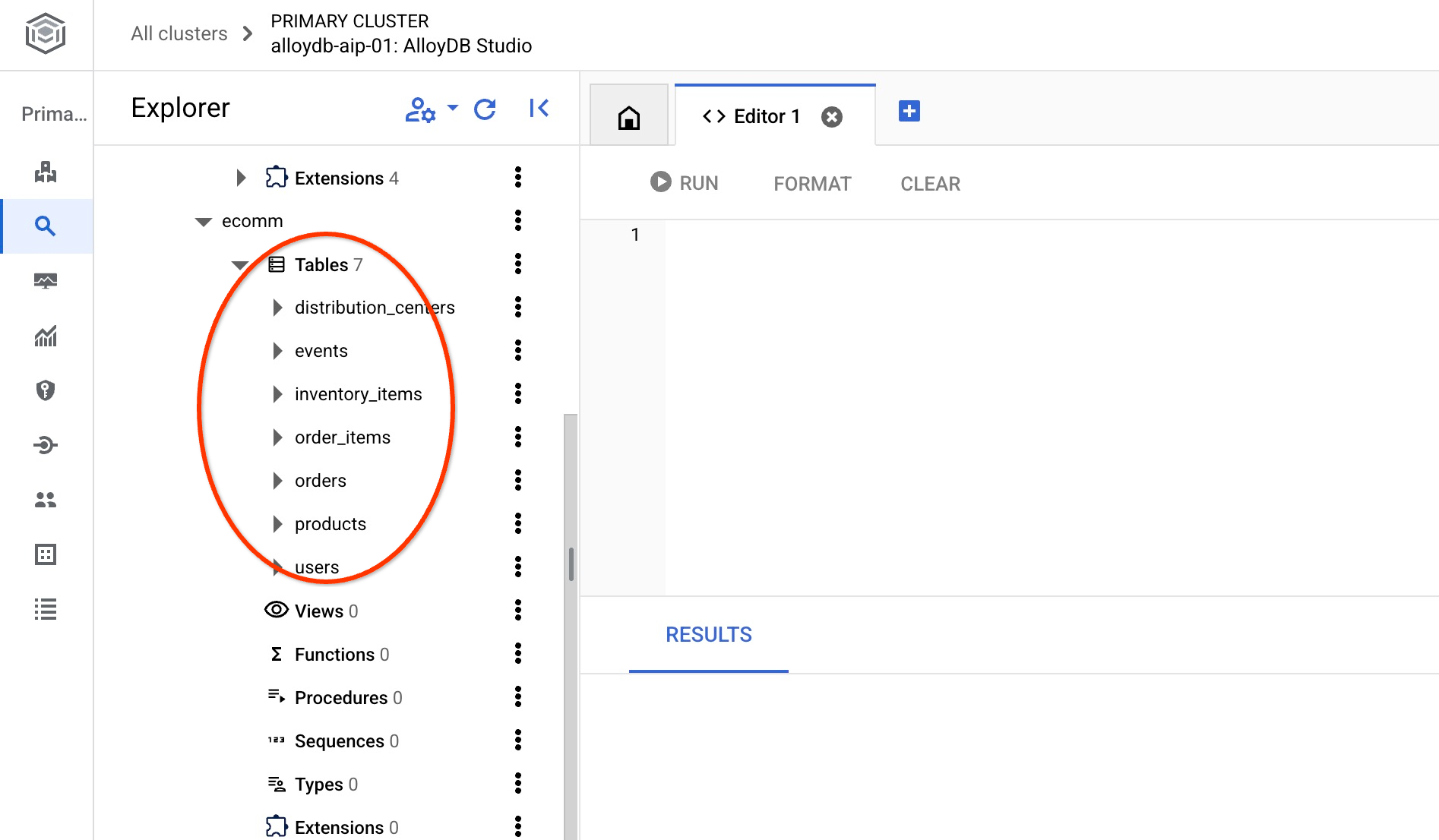
e verifica il numero di righe in una delle tabelle.
select count(*) from ecomm.products;
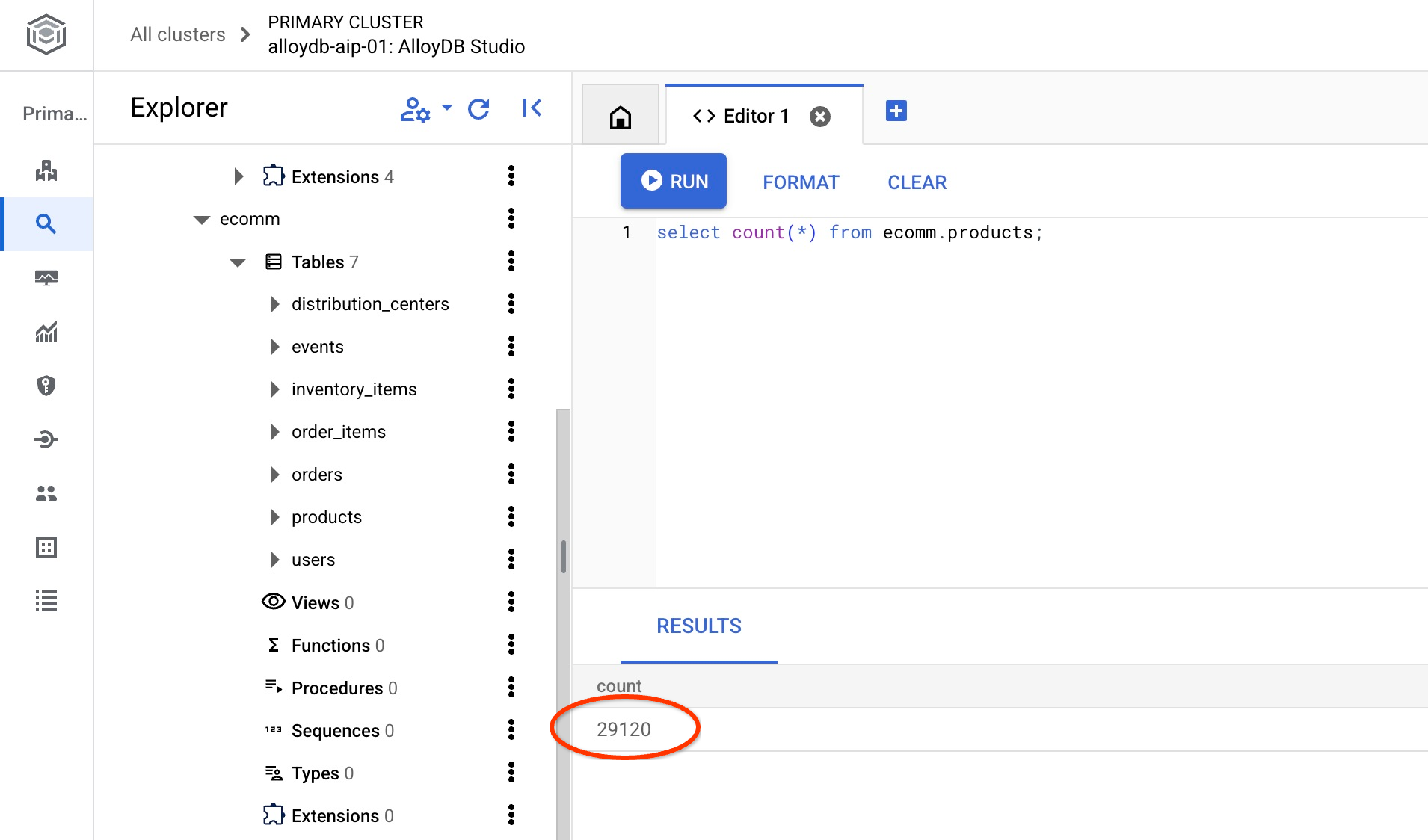
Abbiamo importato correttamente i dati di esempio e possiamo continuare con i passaggi successivi.
7. Ricerca semantica utilizzando gli incorporamenti di testo
In questo capitolo proveremo a utilizzare la ricerca semantica utilizzando gli incorporamenti di testo e la confronteremo con la ricerca di testo e full-text tradizionale di Postgres.
Proviamo prima la ricerca classica utilizzando SQL PostgreSQL standard con l'operatore LIKE.
In AlloyDB Studio, connettiti a quickstart_db e prova a cercare una giacca antipioggia utilizzando la seguente query:
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
La query non restituisce righe perché deve contenere parole esatte come condizioni di bagnato e giacca nel nome o nella descrizione del prodotto. Inoltre, la "giacca per condizioni di umidità" non è la stessa della "giacca per condizioni di pioggia".
Possiamo provare a includere tutte le possibili varianti nella ricerca. Proviamo a includere solo due parole. Ad esempio:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
Vengono restituite più righe, ma non tutte corrispondono perfettamente alla nostra richiesta di giacche ed è difficile ordinare per pertinenza. Se, ad esempio, aggiungiamo altre condizioni come "per uomo" e altre, la complessità della query aumenterà in modo significativo. In alternativa, possiamo provare la ricerca nel testo completo, ma anche in questo caso ci sono limitazioni relative a parole più o meno esatte e alla pertinenza della risposta.
Ora possiamo eseguire una ricerca simile utilizzando gli incorporamenti. Abbiamo già precalcolato gli incorporamenti per i nostri prodotti utilizzando modelli diversi. Utilizzeremo l'ultimo modello gemini-embedding-001 di Google. Li abbiamo memorizzati nella colonna "product_embedding" della tabella ecomm.products. Se eseguiamo una query per la condizione di ricerca "giacca antipioggia da uomo" utilizzando la seguente query:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
Verranno restituite non solo le giacche per condizioni di bagnato, ma tutti i risultati verranno ordinati in modo da mettere in evidenza quelli più pertinenti.
La query con incorporamenti restituisce risultati in 90-150 ms, dove una parte del tempo viene utilizzata per ottenere i dati dal modello di incorporamento cloud. Se esaminiamo il piano di esecuzione, la richiesta al modello è inclusa nel tempo di pianificazione. La parte della query che esegue la ricerca è piuttosto breve. La ricerca in 29.000 record utilizzando l'indice ScaNN di AlloyDB richiede meno di 7 ms.
Ecco l'output del piano di esecuzione:
Limite (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> Index Scan using embedding_scann on products (cost=2709.20..30736.40 rows=29120 width=490) (actual time=6.964..7.046 rows=10 loops=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
…
-0.0051468653,-0.012440448]'::vector)
Limit: 10
Tempo di pianificazione: 136,579 ms
Tempo di esecuzione: 6,791 ms
(6 righe)
Questa era la ricerca di embedding di testo che utilizzava il modello di embedding di solo testo. Ma abbiamo anche immagini dei nostri prodotti e possiamo utilizzarle con la ricerca. Nel capitolo successivo mostreremo come il modello multimodale utilizza le immagini per la ricerca.
8. Utilizzare la ricerca multimodale
Sebbene la ricerca semantica basata sul testo sia utile, descrivere dettagli complessi può essere difficile. La ricerca multimodale di AlloyDB offre un vantaggio consentendo la scoperta dei prodotti tramite l'input di immagini. Ciò è particolarmente utile quando la rappresentazione visiva chiarisce l'intento di ricerca in modo più efficace rispetto alle sole descrizioni testuali. Ad esempio, "trovami un cappotto come questo nella foto".
Torniamo all'esempio della giacca. Se ho la foto di una giacca simile a quella che voglio trovare, posso passarla al modello di incorporamento multimodale di Google e confrontarla con gli incorporamenti delle immagini dei miei prodotti. Nella nostra tabella abbiamo già calcolato gli incorporamenti per le immagini dei nostri prodotti nella colonna product_image_embedding e puoi vedere il modello utilizzato nella colonna product_image_embedding_model.
Per la nostra ricerca possiamo utilizzare la funzione image_embedding per ottenere l'incorporamento della nostra immagine e confrontarlo con gli incorporamenti precalcolati. Per attivare la funzione, dobbiamo assicurarci di utilizzare la versione corretta dell'estensione google_ml_integration.
Verifichiamo la versione attuale dell'estensione. In AlloyDB Studio esegui.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Se la versione è precedente alla 1.5.2, esegui la seguente procedura.
CALL google_ml.upgrade_to_preview_version();
e controlla di nuovo la versione dell'estensione. Dovrebbe essere 1.5.3.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Dobbiamo anche attivare le funzionalità del motore di query AI nel nostro database. Può essere eseguito aggiornando il flag per istanza per tutti i database dell'istanza o attivandolo solo per il nostro database. Esegui il seguente comando in AlloyDB Studio per abilitarlo per il database quickstart_db.
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
Ora possiamo cercare per immagine. Ecco la mia immagine di esempio per la ricerca, ma puoi utilizzare qualsiasi immagine personalizzata. Devi solo caricarlo nello spazio di archiviazione Google o in un'altra risorsa disponibile pubblicamente e inserire l'URI nella query.

e viene caricato in gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png
Ricerca immagini tramite immagini
Innanzitutto, proviamo a eseguire la ricerca solo in base all'immagine:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
E siamo riusciti a trovare alcune giacche calde nell'inventario. Per visualizzare le immagini, puoi scaricarle utilizzando Cloud SDK (gcloud storage cp) fornendo la colonna public_url e poi aprirle utilizzando qualsiasi strumento che funzioni con le immagini.
|
|
|
|




La ricerca di immagini restituisce elementi simili all'immagine fornita per il confronto. Come ho già detto, puoi provare a caricare le tue immagini in un bucket pubblico e vedere se riesce a trovare diversi tipi di vestiti.
Abbiamo utilizzato il modello "multimodalembedding@001" di Google per la nostra ricerca di immagini. La nostra funzione image_embedding invia l'immagine a Vertex AI, la converte in un vettore e la restituisce per confrontarla con i vettori archiviati per le immagini nel nostro database.
Possiamo anche verificare con "EXPLAIN ANALYZE" la velocità di funzionamento con il nostro indice ScaNN di AlloyDB.
Ecco l'output del piano di esecuzione:
Limit (cost=971.70..975.55 rows=4 width=490) (actual time=2.453..2.477 rows=4 loops=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
…
,-0.010307034,-0.010053742]'::vector)
Limit: 4
Tempo di pianificazione: 913,322 ms
Tempo di esecuzione: 2517 ms
(6 righe)
Come nell'esempio precedente, possiamo vedere che la maggior parte del tempo è stata dedicata alla conversione dell'immagine in embedding utilizzando l'endpoint cloud e la ricerca vettoriale stessa richiede solo 2,5 ms.
Ricerca immagini tramite testo
Con la modalità multimodale possiamo anche passare una descrizione testuale della giacca che stiamo cercando al modello utilizzando google_ml.text_embedding per lo stesso modello e confrontarla con gli incorporamenti delle immagini per vedere quali immagini restituisce.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Abbiamo ricevuto un set di giacche imbottite di colore grigio o scuro.
|
|
|
|




Abbiamo ottenuto un insieme leggermente diverso di giacche, ma ha scelto correttamente le giacche in base alla nostra descrizione e alla ricerca negli incorporamenti delle immagini.
Proviamo un altro modo per cercare tra le descrizioni utilizzando l'incorporamento dell'immagine di ricerca.
Ricerca testuale per immagini
Abbiamo provato a cercare immagini che superassero l'incorporamento per la nostra immagine e a confrontarle con gli incorporamenti delle immagini precalcolati per i nostri prodotti. Abbiamo anche provato a cercare immagini passando l'incorporamento per la nostra richiesta di testo e a cercare tra lo stesso incorporamento per le immagini dei prodotti. Ora proviamo a utilizzare l'incorporamento per la nostra immagine e confrontiamolo con gli incorporamenti di testo per le descrizioni dei prodotti. L'incorporamento è memorizzato nella colonna product_description_embedding e utilizza lo stesso modello multimodalembedding@001.
Ecco la nostra query:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Qui abbiamo un insieme leggermente diverso di giacche con colori grigi o scuri, alcune delle quali sono uguali o molto simili a quelle scelte con un altro metodo di ricerca.
|
|
|
|



e restituisce le stesse giacche di prima in un ordine leggermente diverso. In base all'incorporamento per le immagini, può confrontarlo con gli incorporamenti calcolati per la descrizione testuale e restituire il set corretto di prodotti.
Ricerca ibrida di testo e immagini
Puoi anche sperimentare la combinazione di incorporamenti di testo e immagini utilizzando, ad esempio, la fusione del rango reciproco. Ecco un esempio di query in cui abbiamo combinato due ricerche assegnando un punteggio a ogni ranking e ordinando i risultati in base al punteggio combinato.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
Puoi provare a modificare i parametri della query e vedere se riesci a migliorare i risultati di ricerca.
Il lab terminerà e, per evitare addebiti imprevisti, ti consigliamo di eliminare le risorse inutilizzate.
Oltre a questo, puoi utilizzare altri operatori di AI per classificare i risultati come descritto nella documentazione.
9. Pulizia dell'ambiente
Elimina le istanze e il cluster AlloyDB al termine del lab.
Elimina il cluster AlloyDB e tutte le istanze
Se hai utilizzato la versione di prova di AlloyDB. Non eliminare il cluster di prova se prevedi di testare altri lab e risorse utilizzando il cluster di prova. Non potrai creare un altro cluster di prova nello stesso progetto.
Il cluster viene eliminato con l'opzione force, che elimina anche tutte le istanze appartenenti al cluster.
In Cloud Shell definisci le variabili di progetto e di ambiente se la connessione è stata interrotta e tutte le impostazioni precedenti sono andate perse:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Elimina il cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Elimina i backup di AlloyDB
Elimina tutti i backup AlloyDB per il cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. Complimenti
Congratulazioni per aver completato il codelab. Hai imparato a utilizzare la ricerca multimodale in AlloyDB utilizzando le funzioni di incorporamento per testi e immagini. Puoi provare a testare la ricerca multimodale e migliorarla con la funzione google_ml.rank utilizzando il codelab per gli operatori AlloyDB AI.
Percorso di apprendimento di Google Cloud
Questo lab fa parte del percorso di apprendimento per l'AI pronta per la produzione con Google Cloud.
- Esplora il curriculum completo per colmare il divario tra prototipo e produzione.
- Condividi i tuoi progressi con l'hashtag
#ProductionReadyAI.
Argomenti trattati
- Come eseguire il deployment di AlloyDB per PostgreSQL
- Come utilizzare AlloyDB Studio
- Come utilizzare la ricerca vettoriale multimodale
- Come attivare gli operatori AI di AlloyDB
- Come utilizzare diversi operatori AI di AlloyDB per la ricerca multimodale
- Come utilizzare l'AI di AlloyDB per combinare i risultati di ricerca di testo e immagini
11. Sondaggio
Output: