
1. はじめに
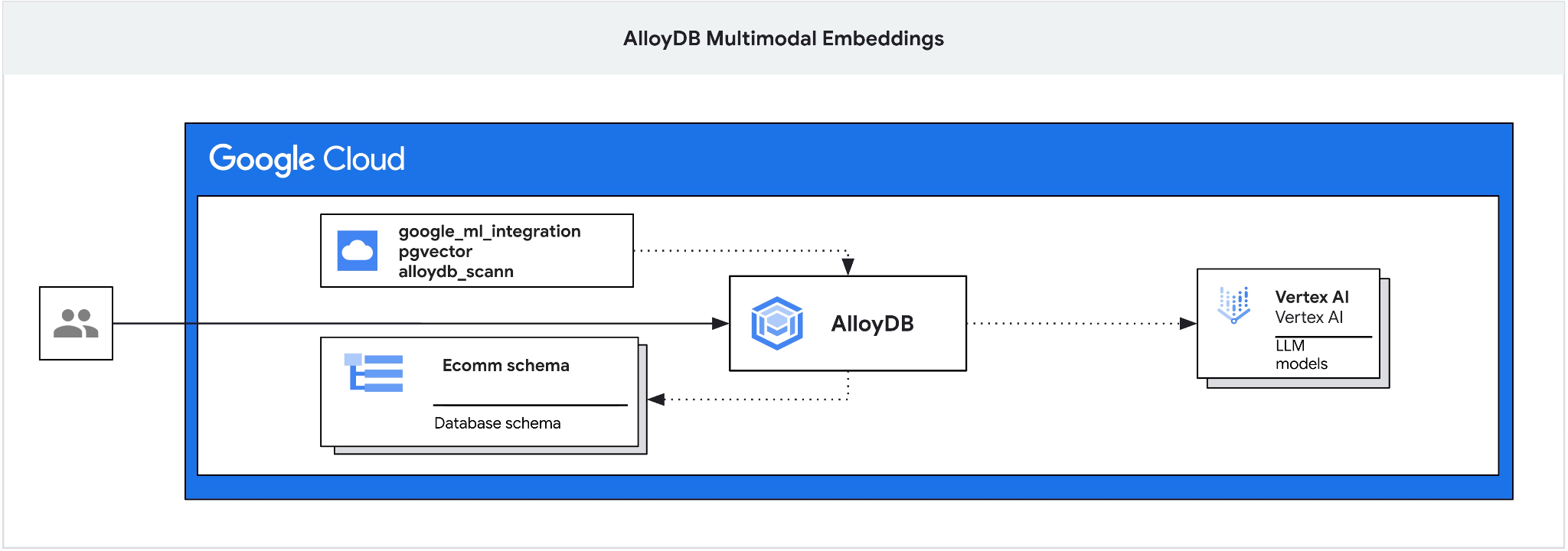
この Codelab では、AlloyDB をデプロイし、マルチモーダル エンベディングを使用したセマンティック検索に AI インテグレーションを活用する方法について説明します。このラボは、AlloyDB AI 機能専用のラボ コレクションの一部です。詳細については、ドキュメントの AlloyDB AI ページをご覧ください。
前提条件
- Google Cloud とコンソールの基本的な知識
- コマンドライン インターフェースと Cloud Shell の基本的なスキル
学習内容
- Postgres 用 AlloyDB をデプロイする方法
- AlloyDB Studio の使用方法
- マルチモーダル ベクトル検索の使用方法
- AlloyDB AI 演算子を有効にする方法
- マルチモーダル検索にさまざまな AlloyDB AI 演算子を使用する方法
- AlloyDB AI を使用してテキストと画像の検索結果を組み合わせる方法
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- Google Cloud コンソールと Cloud Shell をサポートするウェブブラウザ(Chrome など)
2. 設定と要件
プロジェクトのセットアップ
- Google Cloud コンソールにログインします。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。
仕事用または学校用アカウントではなく、個人アカウントを使用します。
- 新しいプロジェクトを作成するか、既存のプロジェクトを再利用します。Google Cloud コンソールで新しいプロジェクトを作成するには、ヘッダーで [プロジェクトを選択] ボタンをクリックします。ポップアップ ウィンドウが開きます。

[プロジェクトを選択] ウィンドウで [新しいプロジェクト] ボタンを押すと、新しいプロジェクトのダイアログ ボックスが開きます。
ダイアログ ボックスで、任意のプロジェクト名を入力し、ロケーションを選択します。
- プロジェクト名は、このプロジェクトの参加者に表示される名称です。プロジェクト名は Google API では使用されず、いつでも変更できます。
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Google Cloud コンソールでは一意の ID が自動的に生成されますが、カスタマイズすることもできます。生成された ID が気に入らない場合は、別のランダムな ID を生成するか、独自の ID を指定して使用可能かどうかを確認できます。ほとんどの Codelab では、プロジェクト ID を参照する必要があります。通常、プロジェクト ID はプレースホルダ PROJECT_ID で識別されます。
- なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
課金を有効にする
課金を有効にするには、次の 2 つの方法があります。個人用の請求先アカウントを使用するか、次の手順でクレジットを利用できます。
5 ドル分の Google Cloud クレジットを利用する(省略可)
このワークショップを実施するには、クレジットが設定された請求先アカウントが必要です。独自の請求を使用する予定の場合は、この手順をスキップできます。
- こちらのリンクをクリックし、個人の Google アカウントでログインします。
- 次のような出力が表示されます。

- [クレジットにアクセスするにはこちらをクリック] ボタンをクリックします。お支払い情報を設定するページが表示されます。無料トライアルの登録画面が表示された場合は、[キャンセル] をクリックして、お支払い情報のリンクに進みます。
- [Confirm] をクリックします。これで、Google Cloud Platform 無料トライアルの請求先アカウントに接続されました。
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 3 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud Console で、右上のツールバーにある Cloud Shell アイコンをクリックします。
または、G キーを押してから S キーを押します。このシーケンスは、Google Cloud コンソール内からアクセスした場合、またはこのリンクを使用した場合に Cloud Shell をアクティブにします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
3. はじめに
API を有効にする
AlloyDB、Compute Engine、ネットワーキング サービス、Vertex AI を使用するには、Google Cloud プロジェクトでそれぞれの API を有効にする必要があります。
Cloud Shell のターミナルで、プロジェクト ID が設定されていることを確認します。
gcloud config set project [YOUR-PROJECT-ID]
環境変数 PROJECT_ID を設定します。
PROJECT_ID=$(gcloud config get-value project)
必要なサービスをすべて有効にします。
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
想定される出力
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
API の概要
- AlloyDB API(
alloydb.googleapis.com)を使用すると、AlloyDB for PostgreSQL クラスタの作成、管理、スケーリングを行うことができます。要求の厳しいエンタープライズ トランザクション ワークロードと分析ワークロード用に設計された、PostgreSQL 互換のフルマネージド データベース サービスを提供します。 - Compute Engine API(
compute.googleapis.com)を使用すると、仮想マシン(VM)、永続ディスク、ネットワーク設定を作成して管理できます。これは、ワークロードの実行と、多くのマネージド サービスの基盤となるインフラストラクチャのホストに必要な、Infrastructure-as-a-Service(IaaS)の基盤となるものです。 - Cloud Resource Manager API(
cloudresourcemanager.googleapis.com)を使用すると、Google Cloud プロジェクトのメタデータと構成をプログラムで管理できます。これにより、リソースの整理、Identity and Access Management(IAM)ポリシーの処理、プロジェクト階層全体での権限の検証が可能になります。 - Service Networking API(
servicenetworking.googleapis.com)を使用すると、Virtual Private Cloud(VPC)ネットワークと Google のマネージド サービス間のプライベート接続の設定を自動化できます。AlloyDB などのサービスが他のリソースと安全に通信できるように、プライベート IP アクセスを確立するために必要です。 - Vertex AI API(
aiplatform.googleapis.com)を使用すると、アプリケーションで ML モデルを構築、デプロイ、スケーリングできます。これは、生成 AI モデル(Gemini など)へのアクセスやカスタムモデルのトレーニングなど、Google Cloud のすべての AI サービスに統合インターフェースを提供します。
4. AlloyDB をデプロイする
AlloyDB クラスタとプライマリ インスタンスを作成します。次の手順では、Google Cloud SDK を使用して AlloyDB クラスタとインスタンスを作成する方法について説明します。コンソールを使用する場合は、こちらのドキュメントをご覧ください。
AlloyDB クラスタを作成する前に、将来の AlloyDB インスタンスで使用する VPC で使用可能なプライベート IP 範囲が必要です。ない場合は、作成して内部の Google サービスで使用されるように割り当てる必要があります。その後、クラスタとインスタンスを作成できます。
プライベート IP 範囲を作成する
AlloyDB の VPC でプライベート サービス アクセス構成を構成する必要があります。ここでは、プロジェクトに「デフォルト」の VPC ネットワークがあり、すべてのアクションで使用されることを前提としています。
プライベート IP 範囲を作成します。
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
割り振られた IP 範囲を使用してプライベート接続を作成します。
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB クラスタを作成する
このセクションでは、us-central1 リージョンに AlloyDB クラスタを作成します。
postgres ユーザーのパスワードを定義します。独自のパスワードを定義することも、ランダム関数を使用してパスワードを生成することもできます。
export PGPASSWORD=`openssl rand -hex 12`
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
後で使用できるように PostgreSQL のパスワードをメモしておきます。
echo $PGPASSWORD
このパスワードは、後で postgres ユーザーとしてインスタンスに接続するために必要になります。後で使用できるように、書き留めるかどこかにコピーしておくことをおすすめします。
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
無料トライアル クラスタを作成する
AlloyDB を使用したことがない場合は、無料のトライアル クラスタを作成できます。
リージョンと AlloyDB クラスタ名を定義します。ここでは、us-central1 リージョンと alloydb-aip-01 をクラスタ名として使用します。
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
コマンドを実行してクラスタを作成します。
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
想定されるコンソール出力:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
同じ Cloud Shell セッションで、クラスタの AlloyDB プライマリ インスタンスを作成します。切断された場合は、リージョンとクラスタ名の環境変数を再度定義する必要があります。
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard クラスタを作成する
プロジェクトで最初の AlloyDB クラスタでない場合は、標準クラスタの作成に進みます。前のステップで無料トライアル クラスタをすでに作成している場合は、このステップをスキップしてください。
リージョンと AlloyDB クラスタ名を定義します。ここでは、us-central1 リージョンと alloydb-aip-01 をクラスタ名として使用します。
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
コマンドを実行してクラスタを作成します。
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
想定されるコンソール出力:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
同じ Cloud Shell セッションで、クラスタの AlloyDB プライマリ インスタンスを作成します。切断された場合は、リージョンとクラスタ名の環境変数を再度定義する必要があります。
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. データベースを準備する
データベースを作成し、Vertex AI インテグレーションを有効にして、データベース オブジェクトを作成し、データをインポートする必要があります。
AlloyDB に必要な権限を付与する
AlloyDB サービス エージェントに Vertex AI 権限を追加します。
上部の「+」記号を選択して、別の Cloud Shell タブを開きます。
新しい Cloud Shell タブで、次のコマンドを実行します。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
タブに実行コマンド「exit」を入力して、タブを閉じます。
exit
AlloyDB Studio に接続する
以降の章では、データベースへの接続が必要なすべての SQL コマンドを AlloyDB Studio で実行できます。
新しいタブで、AlloyDB for Postgres の [クラスタ] ページに移動します。
プライマリ インスタンスをクリックして、AlloyDB クラスタのウェブ コンソール インターフェースを開きます。
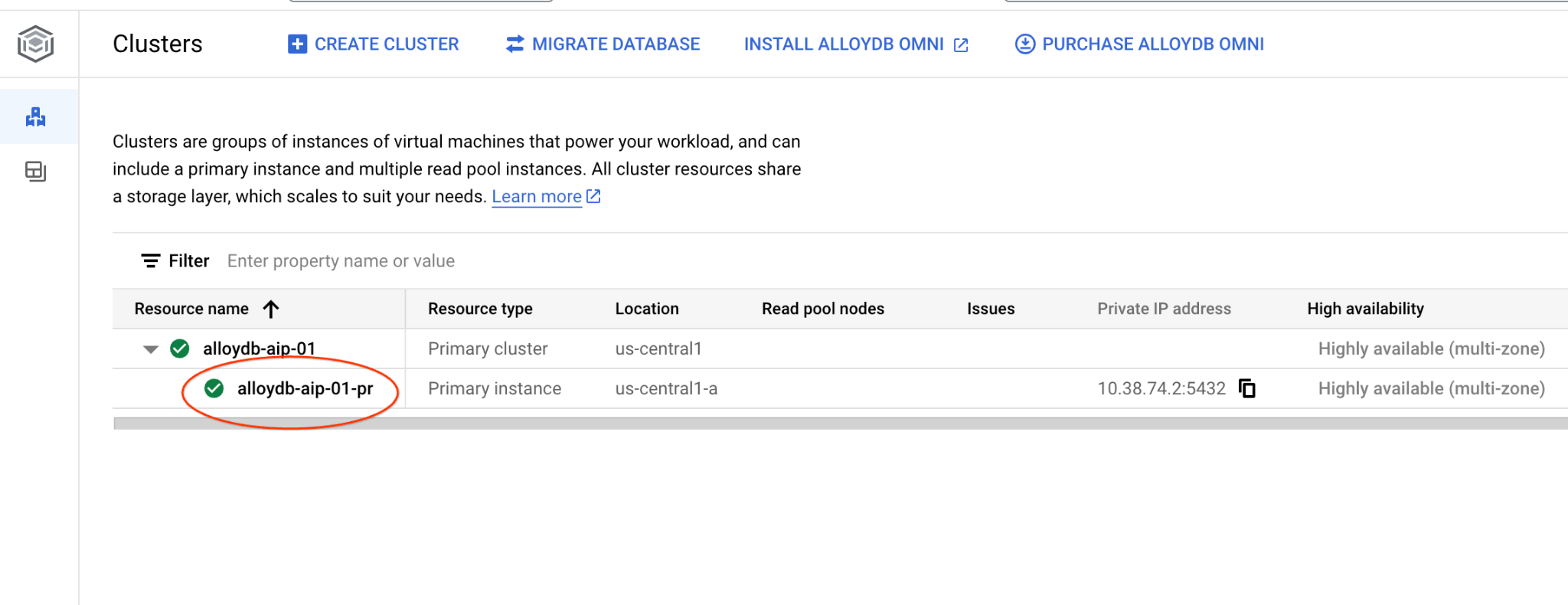
左側の [AlloyDB Studio] をクリックします。
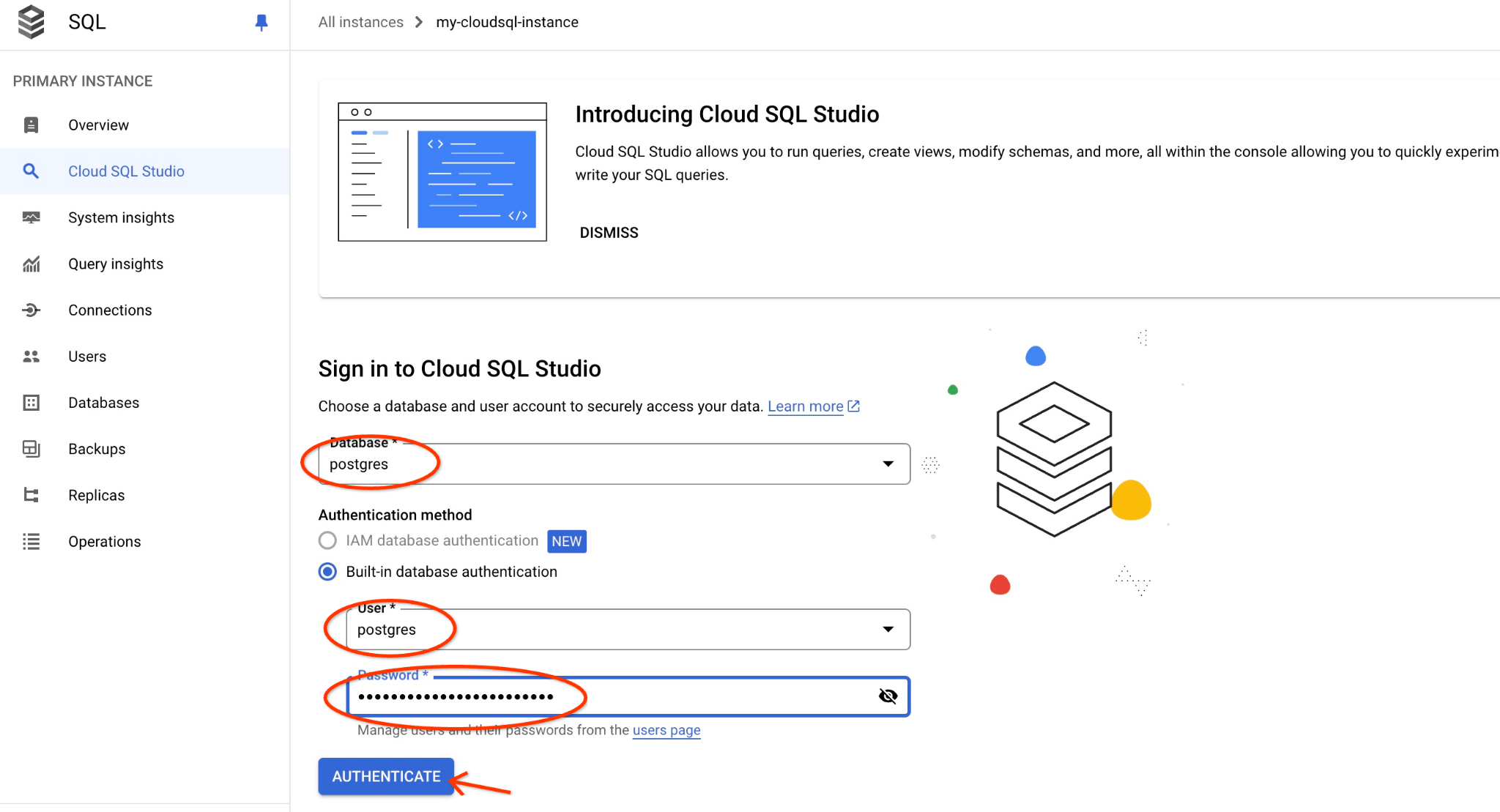
postgres データベースとユーザー postgres を選択し、クラスタの作成時にメモしたパスワードを入力します。[認証] ボタンをクリックします。パスワードをメモし忘れた場合や、パスワードが機能しない場合は、パスワードを変更できます。方法については、ドキュメントをご覧ください。
AlloyDB Studio インターフェースが開きます。データベースでコマンドを実行するには、右側の [無題のクエリ] タブをクリックします。
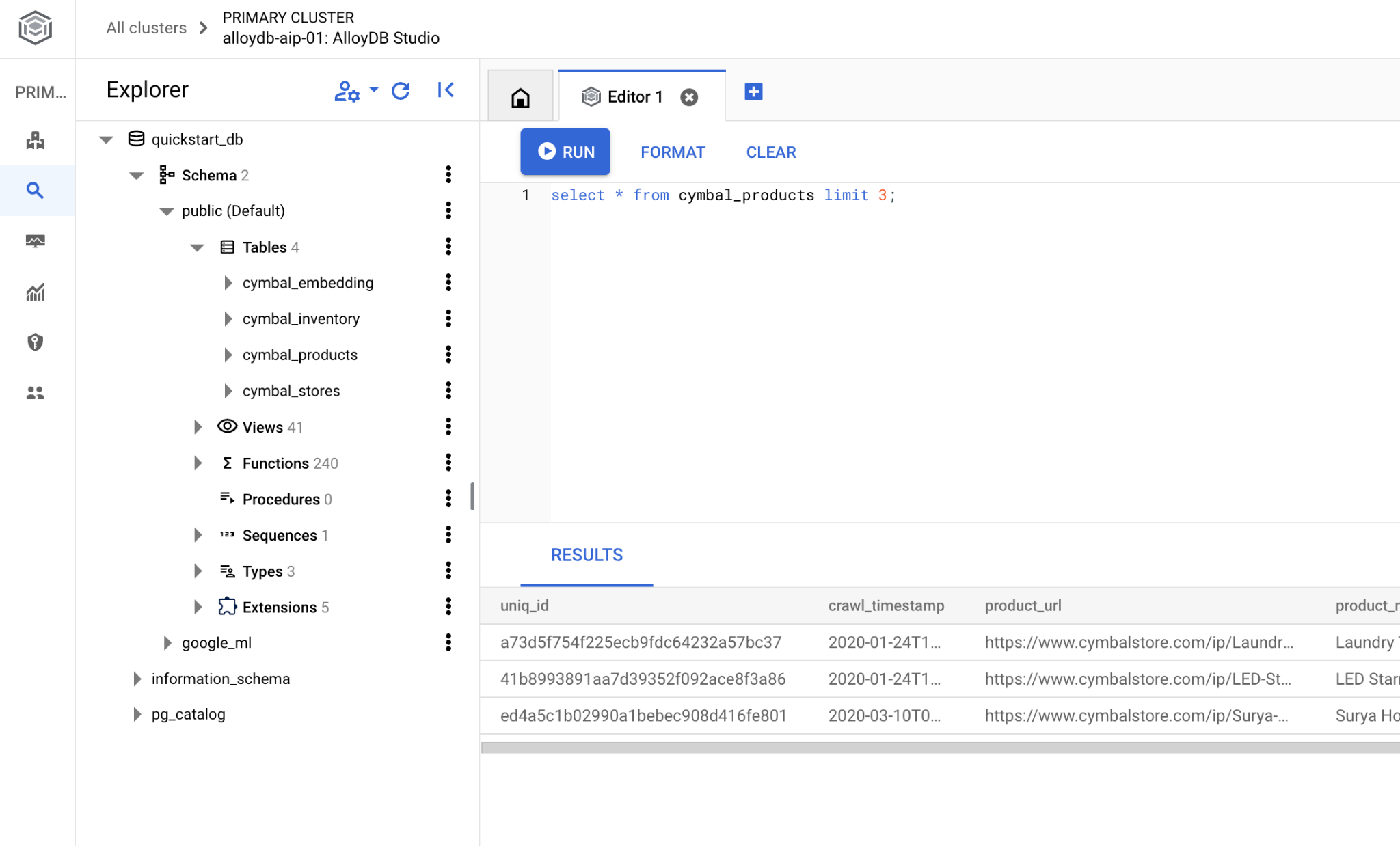
SQL コマンドを実行できるインターフェースが開きます。
データベースを作成する
データベースの作成クイックスタート。
AlloyDB Studio エディタで、次のコマンドを実行します。
データベースを作成します。
CREATE DATABASE quickstart_db
予想される出力:
Statement executed successfully
quickstart_db に接続する
ユーザー/データベースを切り替えるボタンを使用して、スタジオに再接続します。
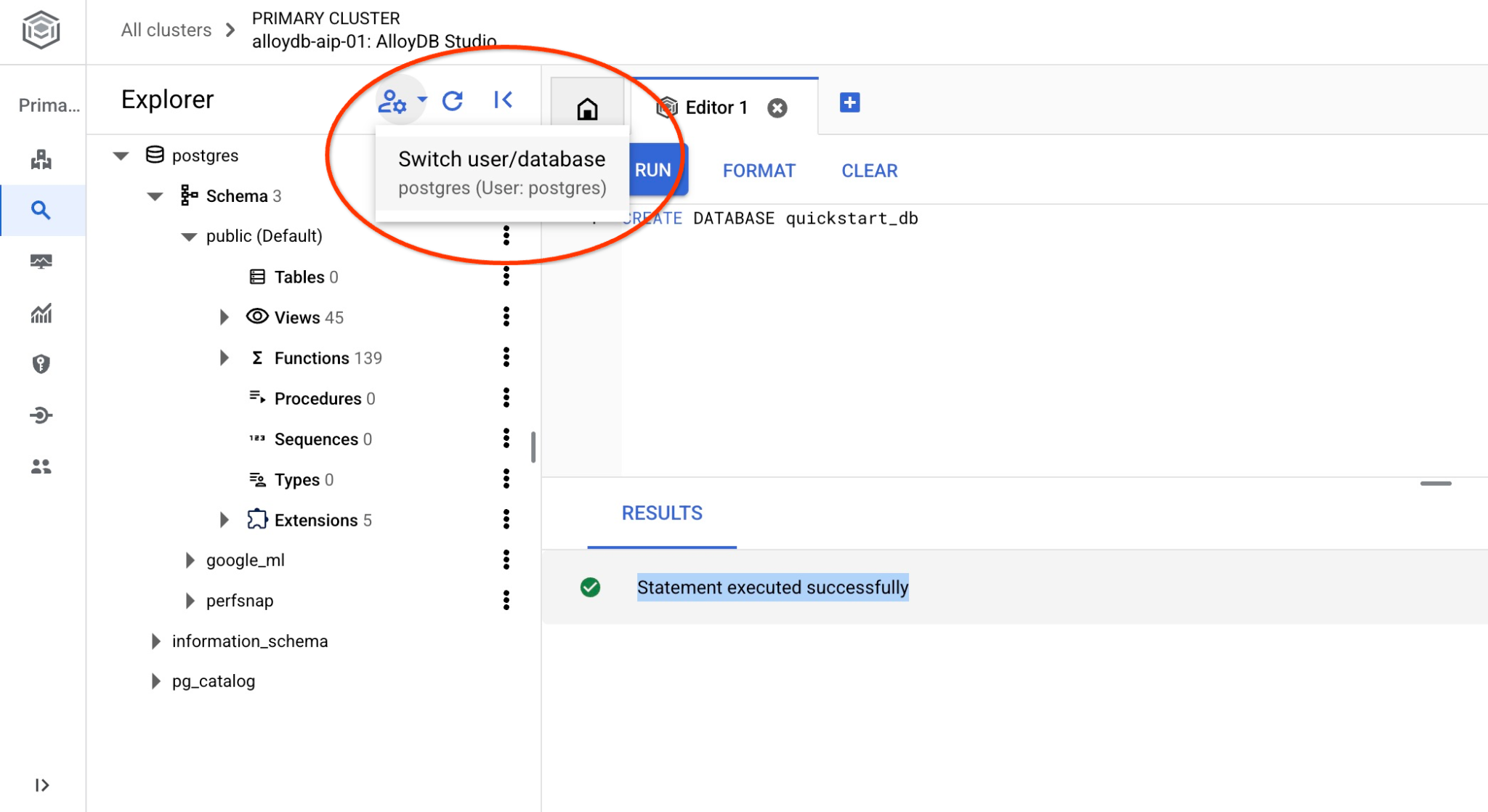
プルダウン リストから新しい quickstart_db データベースを選択し、以前と同じユーザーとパスワードを使用します。
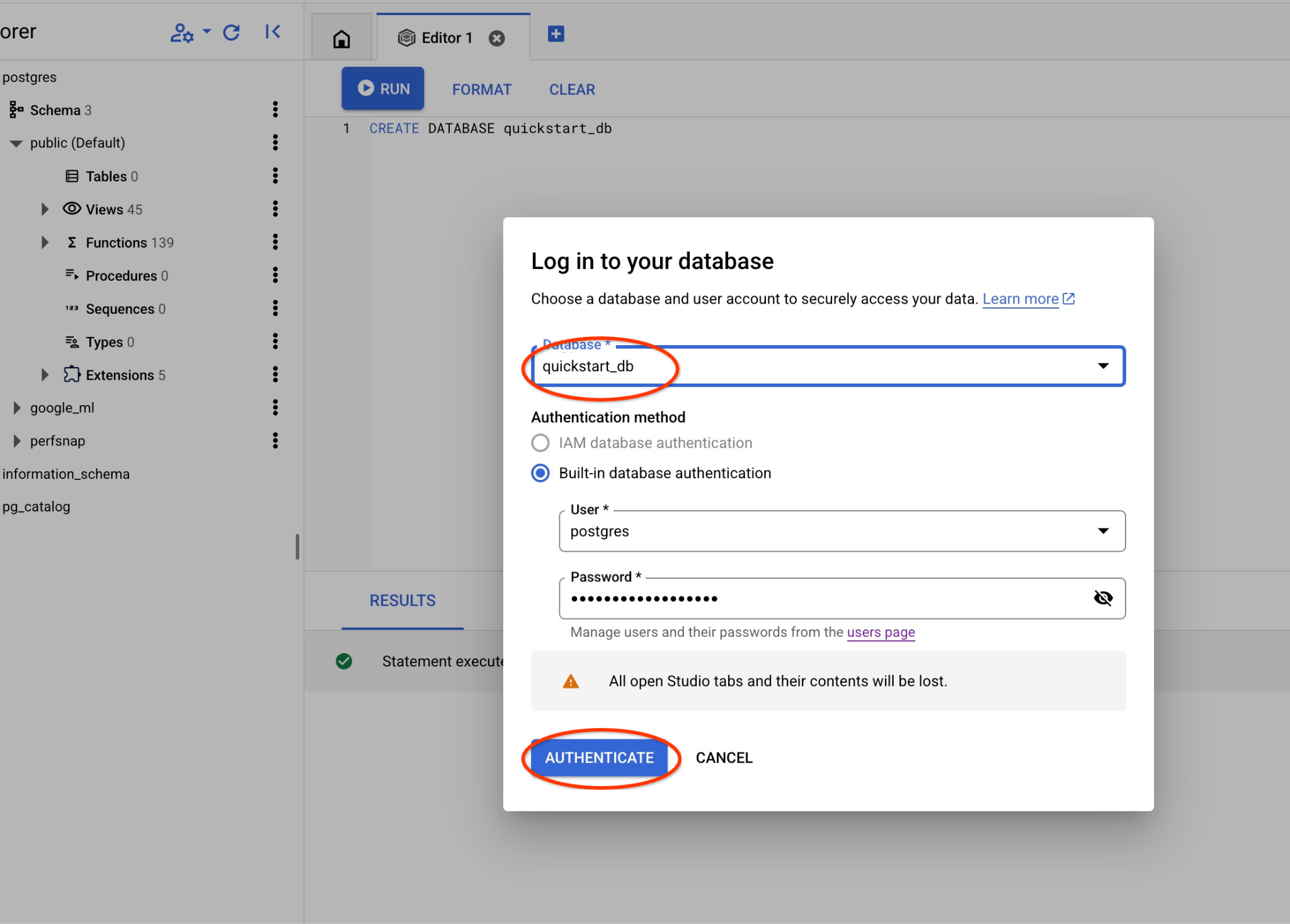
新しい接続が開き、quickstart_db データベースのオブジェクトを操作できます。
6. サンプルデータ
次に、データベースにオブジェクトを作成してデータを読み込む必要があります。架空のデータを含む架空の「Cymbal」ストアを使用します。
データをインポートする前に、データ型とインデックスをサポートする拡張機能を有効にする必要があります。ベクトルデータ型をサポートする拡張機能と、AlloyDB ScaNN インデックスをサポートする拡張機能の 2 つが必要です。
quickstart_db に接続する AlloyDB Studio で実行します。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
データセットは、インポート インターフェースを使用してデータベースに読み込むことができる SQL ファイルとして準備され、配置されます。Cloud Shell で、次のコマンドを実行します。
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
このコマンドは AlloyDB SDK を使用して agentspace_user という名前のユーザーを作成し、必要なオブジェクトをすべて作成してデータを挿入しながら、サンプルデータを GCS バケットからデータベースに直接インポートします。
インポート後、AlloyDB Studio でテーブルを確認できます。テーブルは ecomm スキーマにあります。
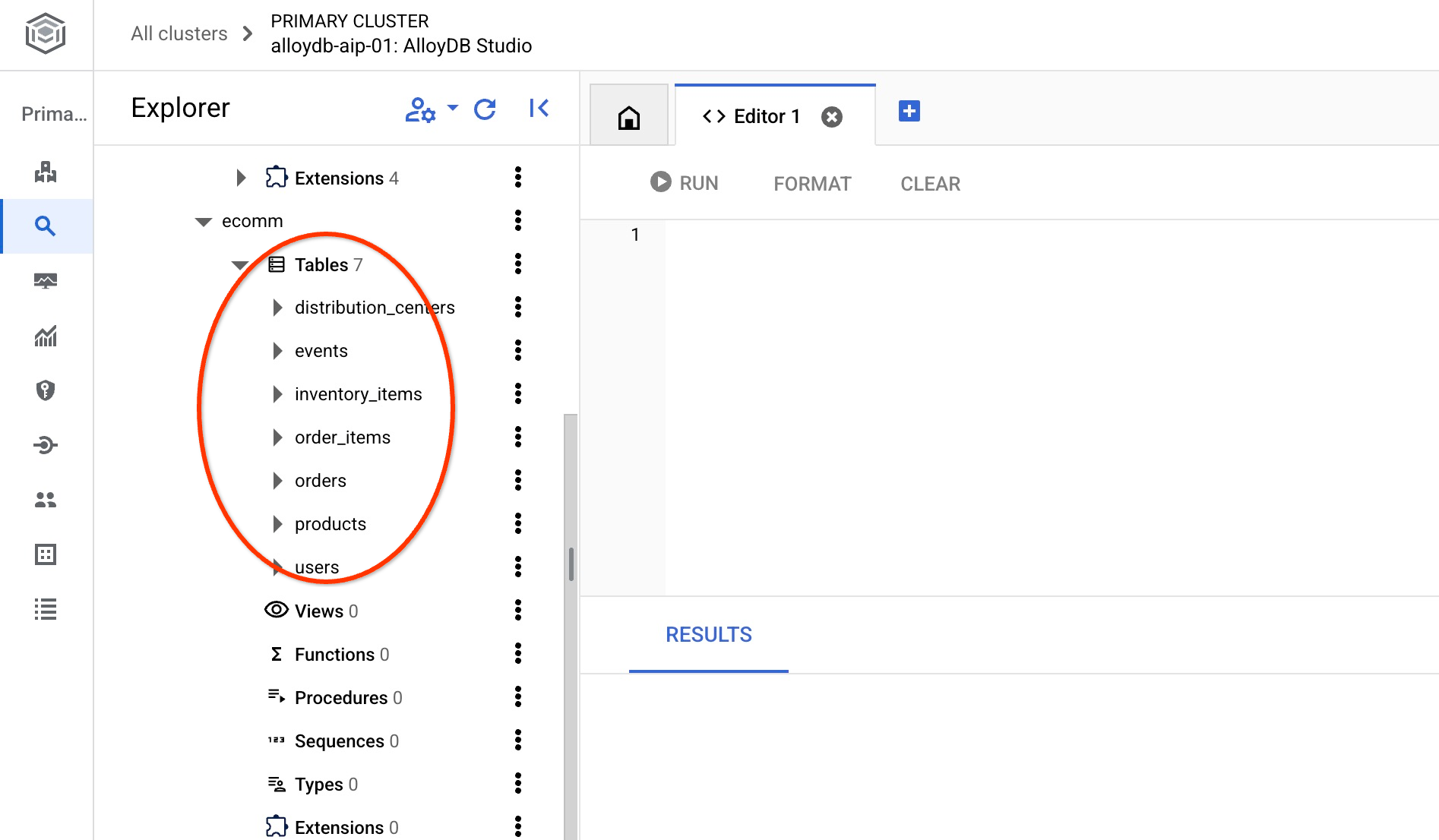
また、いずれかのテーブルの行数を確認します。
select count(*) from ecomm.products;
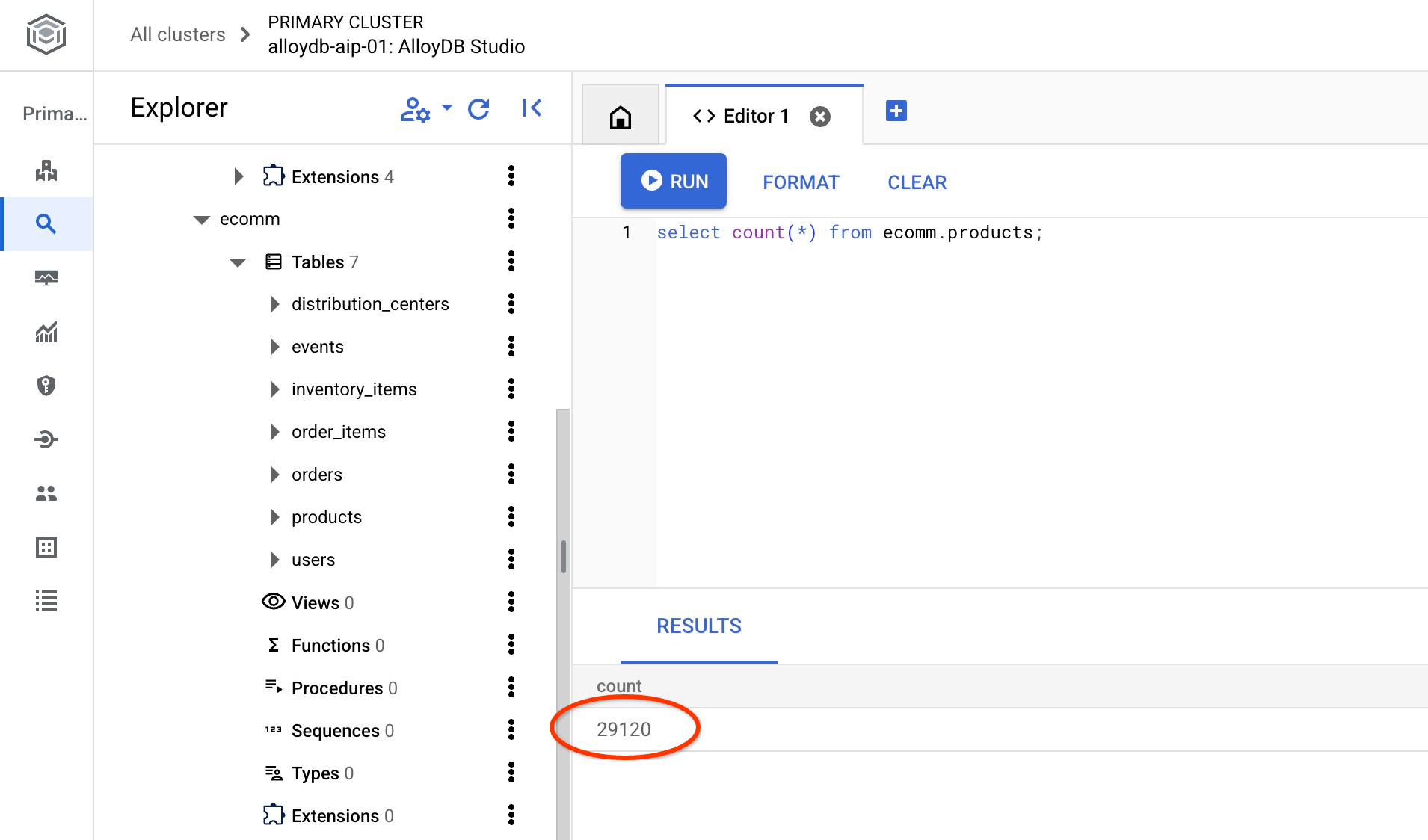
サンプルデータが正常にインポートされたので、次の手順に進みます。
7. テキスト エンベディングを使用したセマンティック検索
この章では、テキスト エンベディングを使用したセマンティック検索を試して、従来の Postgres テキスト検索および全文検索と比較します。
まず、LIKE 演算子を使用した標準 PostgreSQL SQL による従来の検索を試してみましょう。
quickstart_db に接続している AlloyDB Studio で、次のクエリを使用してレイン ジャケットを検索してみます。
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
このクエリでは、商品名または商品説明に「wet conditions」や「jacket」などの単語が正確に含まれている必要があるため、行は返されません。「雨天用ジャケット」と「雨天用ジャケット」は同じではありません。
検索に考えられるすべてのバリエーションを含めることができます。2 語だけを含めてみましょう。次に例を示します。
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
この場合、複数の行が返されますが、そのすべてがジャケットのリクエストに完全に一致するわけではなく、関連性で並べ替えるのは困難です。たとえば、「男性向け」などの条件を追加すると、クエリの複雑さが大幅に増します。全文検索を試すこともできますが、そこでも、ほぼ正確な単語や回答の関連性に関する制限に達します。
エンベディングを使用して類似検索を実行できるようになりました。さまざまなモデルを使用して、商品のエンベディングを事前に計算しています。ここでは、最新の Google の gemini-embedding-001 モデルを使用します。これらは ecomm.products テーブルの「product_embedding」列に保存されています。次のクエリを使用して「メンズ用レインジャケット」の検索条件でクエリを実行すると、
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
雨天用のジャケットだけでなく、すべての結果が関連性の高い順に並べ替えられて表示されます。
エンベディングを含むクエリは、90 ~ 150 ミリ秒で結果を返します。この時間の一部は、クラウド エンベディング モデルからデータを取得するために費やされます。実行プランを見ると、モデルへのリクエストがプランニング時間に含まれています。検索自体を行うクエリの部分は非常に短いです。AlloyDB ScaNN インデックスを使用すると、29,000 件のレコードの検索に 7 ミリ秒もかかりません。
実行プランの出力は次のとおりです。
Limit (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> Index Scan using embedding_scann on products (cost=2709.20..30736.40 rows=29120 width=490) (actual time=6.964..7.046 rows=10 loops=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
...
-0.0051468653,-0.012440448]'::vector)
Limit: 10
プランニング時間: 136.579 ミリ秒
実行時間: 6.791 ミリ秒
(6 rows)
これは、テキストのみのエンベディング モデルを使用したテキスト エンベディング検索です。また、商品の画像も用意されているため、検索に使用できます。次の章では、マルチモーダル モデルが検索に画像を使用する方法について説明します。
8. マルチモーダル検索を使用する
テキストベースのセマンティック検索は便利ですが、複雑な詳細を説明するのは難しい場合があります。AlloyDB のマルチモーダル検索は、画像入力による商品検出を可能にするという利点があります。これは、テキストの説明だけでは検索意図を効果的に明確にできない場合に特に役立ちます。たとえば、「この写真のコートに似たものを探して」と話しかけます。
ジャケットの例に戻りましょう。探したいジャケットに似た写真がある場合は、その写真を Google のマルチモーダル エンベディング モデルに渡して、商品の画像のエンベディングと比較できます。テーブルの product_image_embedding 列には、商品の画像のエンベディングがすでに計算されています。使用されたモデルは product_image_embedding_model 列で確認できます。
検索には、image_embedding 関数を使用して画像のエンベディングを取得し、事前に計算されたエンベディングと比較します。この関数を有効にするには、正しいバージョンの google_ml_integration 拡張機能を使用していることを確認する必要があります。
現在の拡張機能のバージョンを確認しましょう。AlloyDB Studio で実行します。
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
バージョンが 1.5.2 より前の場合は、次の手順を実行します。
CALL google_ml.upgrade_to_preview_version();
拡張機能のバージョンを再確認します。1.5.3 にする必要があります。
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
また、データベースで AI クエリ エンジン機能を有効にする必要があります。これは、インスタンス上のすべてのデータベースのインスタンス フラグを更新するか、データベースに対してのみ有効にすることで実行できます。AlloyDB Studio で次のコマンドを実行して、quickstart_db データベースで有効にします。
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
これで、画像で検索できるようになりました。検索用のサンプル画像を次に示しますが、任意のカスタム画像を使用できます。Google ストレージまたはその他の一般公開されているリソースにアップロードして、URI をクエリに配置するだけです。

gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png にアップロードされます。
画像で画像検索
まず、画像だけで検索してみます。
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
在庫の中から暖かいジャケットを見つけることができました。イメージを表示するには、public_url 列を指定して Cloud SDK(gcloud storage cp)を使用してダウンロードし、イメージを操作するツールで開きます。
|
|
|
|




画像検索では、比較用に提供した画像に類似したアイテムが返されます。すでに述べたように、独自の画像を公開バケットにアップロードして、さまざまな種類の服を検出できるかどうかを試すことができます。
画像検索には、Google の「multimodalembedding@001」モデルを使用しています。image_embedding 関数は、画像を Vertex AI に送信し、ベクトルに変換して返します。このベクトルは、データベース内の画像の保存済みベクトルと比較されます。
「EXPLAIN ANALYZE」を使用して、AlloyDB ScaNN インデックスでの動作速度を確認することもできます。
実行プランの出力は次のとおりです。
Limit (cost=971.70..975.55 rows=4 width=490) (actual time=2.453..2.477 rows=4 loops=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
...
,-0.010307034,-0.010053742]'::vector)
Limit: 4
Planning Time: 913.322 ms
実行時間: 2.517 ミリ秒
(6 rows)
前の例と同様に、ほとんどの時間がクラウド エンドポイントを使用して画像をエンベディングに変換するのに費やされ、ベクトル検索自体には 2.5 ミリ秒しかかかっていないことがわかります。
テキストによる画像検索
マルチモーダルでは、同じモデルの google_ml.text_embedding を使用して、検索しようとしているジャケットのテキスト説明をモデルに渡すこともできます。また、画像エンベディングと比較して、返される画像を確認することもできます。
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
そして、グレーまたはダークカラーのダウンジャケットのセットを手に入れました。
|
|
|
|




ジャケットのセットは少し異なりますが、説明に基づいて画像エンベディングを検索し、ジャケットを正しく選択しています。
検索画像のエンベディングを使用して、説明文を検索する別の方法を試してみましょう。
画像によるテキスト検索
画像のエンベディングを渡して画像を検索し、商品の事前計算された画像のエンベディングと比較しようとしました。また、テキスト リクエストのエンベディングを渡して画像を検索し、同じエンベディングで商品画像を検索することも試しました。画像にエンベディングを使用し、商品説明のテキスト エンベディングと比較してみましょう。エンベディングは product_description_embedding 列に保存され、同じ multimodalembedding@001 モデルを使用します。
クエリは次のとおりです。
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
ここでは、グレーまたはダークカラーのジャケットのセットが少し異なります。そのうちのいくつかは、別の検索方法で選択されたものと同じか、非常に近いものです。
|
|
|
|



上記のジャケットと同じものが、少し異なる順序で返されます。画像のエンベディングに基づいて、テキスト説明の計算されたエンベディングと比較し、正しい商品のセットを返すことができます。
テキストと画像のハイブリッド検索
相互ランク融合などを使用して、テキスト エンベディングと画像エンベディングの両方を組み合わせてテストすることもできます。次の例では、2 つの検索を組み合わせて、各ランクにスコアを割り当て、統合されたスコアに基づいて結果を並べ替えています。
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
クエリでさまざまなパラメータを試して、検索結果が改善されるかどうかを確認できます。
これでラボは終了です。予期しない課金が発生しないように、未使用のリソースを削除することをおすすめします。
また、ドキュメントに記載されているように、他の AI 演算子を使用して結果をランク付けすることもできます。
9. 環境をクリーンアップする
ラボの終了時に AlloyDB インスタンスとクラスタを破棄します。
AlloyDB クラスタとすべてのインスタンスを削除する
AlloyDB のトライアル版を使用したことがある場合。トライアル クラスタを使用して他のラボやリソースをテストする予定がある場合は、トライアル クラスタを削除しないでください。同じプロジェクトで別のトライアル クラスタを作成することはできません。
クラスタは force オプションで破棄され、クラスタに属するすべてのインスタンスも削除されます。
接続が切断され、以前の設定がすべて失われた場合は、Cloud Shell でプロジェクトと環境変数を定義します。
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
クラスタを削除します。
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB バックアップを削除する
クラスタの AlloyDB バックアップをすべて削除します。
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. 完了
以上で、この Codelab は完了です。テキストと画像のエンベディング関数を使用して AlloyDB でマルチモーダル検索を行う方法を学習しました。AlloyDB AI 演算子の Codelab を使用して、マルチモーダル検索をテストし、google_ml.rank 関数で改善できます。
Google Cloud 学習プログラム
このラボは、「Google Cloud でのプロダクション レディな AI の開発」学習プログラムの一部です。
- カリキュラム全体を確認して、プロトタイプから本番環境への移行をスムーズに行いましょう。
- ハッシュタグ
#ProductionReadyAIを使用して、進捗状況を共有しましょう。
学習した内容
- Postgres 用 AlloyDB をデプロイする方法
- AlloyDB Studio の使用方法
- マルチモーダル ベクトル検索の使用方法
- AlloyDB AI 演算子を有効にする方法
- マルチモーダル検索にさまざまな AlloyDB AI 演算子を使用する方法
- AlloyDB AI を使用してテキストと画像の検索結果を組み合わせる方法
11. アンケート
出力: