
1. Einführung
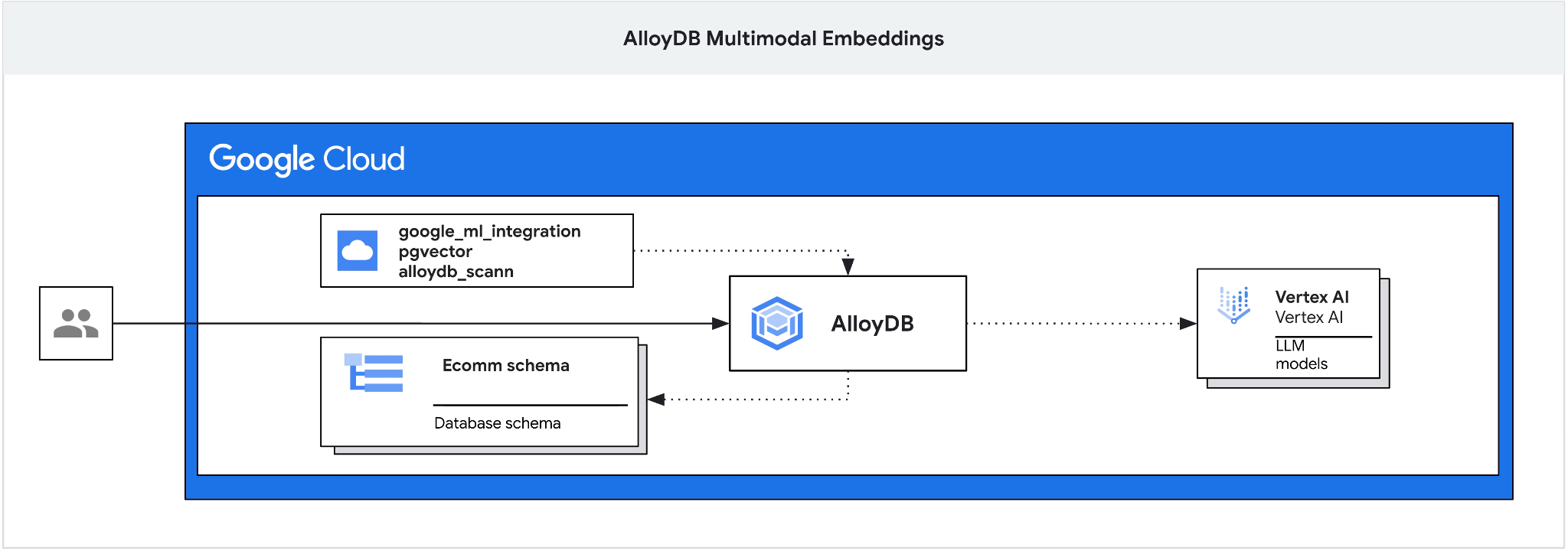
Dieses Codelab bietet eine Anleitung für die Bereitstellung von AlloyDB und die Nutzung der KI-Integration für die semantische Suche mit multimodalen Einbettungen. Dieses Lab ist Teil einer Lab-Sammlung, die sich mit AlloyDB AI-Funktionen befasst. Weitere Informationen
Voraussetzungen
- Grundkenntnisse in Google Cloud und der Google Cloud Console
- Grundkenntnisse in der Befehlszeile und Cloud Shell
Lerninhalte
- AlloyDB für Postgres bereitstellen
- AlloyDB Studio verwenden
- Multimodale Vektorsuche verwenden
- AlloyDB AI-Operatoren aktivieren
- Verschiedene AlloyDB AI-Operatoren für die multimodale Suche verwenden
- So kombinieren Sie Text- und Bildsuchergebnisse mit AlloyDB AI
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome, der die Google Cloud Console und die Cloud Shell unterstützt
2. Einrichtung und Anforderungen
Projekteinrichtung
- Melden Sie sich in der Google Cloud Console an. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.
Verwenden Sie stattdessen ein privates Konto anstelle eines Kontos einer Bildungseinrichtung.
- Erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Klicken Sie zum Erstellen eines neuen Projekts in der Google Cloud Console in der Kopfzeile auf die Schaltfläche „Projekt auswählen“, um ein Pop-up-Fenster zu öffnen.

Klicken Sie im Fenster „Projekt auswählen“ auf die Schaltfläche „Neues Projekt“, um ein Dialogfeld für das neue Projekt zu öffnen.
Geben Sie im Dialogfeld den gewünschten Projektnamen ein und wählen Sie den Speicherort aus.
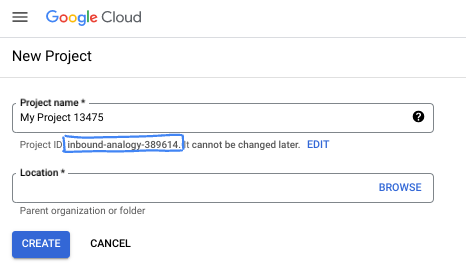
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Der Projektname wird von Google APIs nicht verwendet und kann jederzeit geändert werden.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich. Sie kann also nicht mehr geändert werden, nachdem sie festgelegt wurde. In der Google Cloud Console wird automatisch eine eindeutige ID generiert, die Sie aber anpassen können. Wenn Ihnen die generierte ID nicht gefällt, können Sie eine weitere zufällige ID generieren oder eine eigene ID angeben, um die Verfügbarkeit zu prüfen. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen, die in der Regel mit dem Platzhalter PROJECT_ID angegeben wird.
- Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
Abrechnung aktivieren
Sie haben zwei Möglichkeiten, die Abrechnung zu aktivieren. Sie können entweder Ihr privates Abrechnungskonto verwenden oder Guthaben mit den folgenden Schritten einlösen.
Google Cloud-Guthaben einlösen (optional)
Für diesen Workshop benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben einrichten, können Sie diesen Schritt überspringen.
Hier können Sie die Abrechnung in der Cloud Console aktivieren, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die für dieses Lab anfallenden Kosten für Cloud-Ressourcen sollten weniger als 3 $ betragen.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf den kostenlosen Testzeitraum mit einem Guthaben von 300 $.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Alternativ können Sie auch die Tasten „G“ und „S“ drücken. Wenn Sie sich in der Google Cloud Console befinden oder diesen Link verwenden, wird Cloud Shell durch diese Sequenz aktiviert.
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Hinweis
API aktivieren
Wenn Sie AlloyDB, Compute Engine, Netzwerkdienste und Vertex AI verwenden möchten, müssen Sie die entsprechenden APIs in Ihrem Google Cloud-Projekt aktivieren.
Prüfen Sie, ob Ihre Projekt-ID im Terminal in Cloud Shell eingerichtet ist. Die Projekt-ID sollte in der Eingabeaufforderung in Klammern angezeigt werden, wie hier:
student@cloudshell:~ (test-project-001-402417)$
Wenn die Projekt-ID dort nicht angezeigt wird, aktualisieren Sie den Browsertab und authentifizieren Sie sich noch einmal in Cloud Shell.
Legen Sie die Umgebungsvariable PROJECT_ID fest:
PROJECT_ID=$(gcloud config get-value project)
Aktivieren Sie alle erforderlichen Dienste:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Erwartete Ausgabe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB bereitstellen
Erstellen Sie einen AlloyDB-Cluster und eine primäre Instanz. Im folgenden Verfahren wird beschrieben, wie Sie mit dem Google Cloud SDK einen AlloyDB-Cluster und eine AlloyDB-Instanz erstellen. Wenn Sie lieber die Console verwenden möchten, finden Sie hier die Dokumentation.
Bevor wir einen AlloyDB-Cluster erstellen, benötigen wir einen verfügbaren privaten IP-Adressbereich in unserer VPC, der von der zukünftigen AlloyDB-Instanz verwendet werden soll. Wenn wir sie nicht haben, müssen wir sie erstellen, sie zur Verwendung durch interne Google-Dienste zuweisen und erst dann können wir den Cluster und die Instanz erstellen.
Privaten IP-Bereich erstellen
Wir müssen die Konfiguration für den Zugriff auf private Dienste in unserer VPC für AlloyDB konfigurieren. Wir gehen hier davon aus, dass das VPC-Standardnetzwerk im Projekt vorhanden ist und für alle Aktionen verwendet wird.
Erstellen Sie den privaten IP-Bereich:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Private Verbindung über den zugewiesenen IP-Bereich erstellen:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB-Cluster erstellen
In diesem Abschnitt erstellen wir einen AlloyDB-Cluster in der Region „us-central1“.
Legen Sie ein Passwort für den Postgres-Nutzer fest. Sie können ein eigenes Passwort definieren oder eine Zufallsfunktion verwenden, um eines zu generieren.
export PGPASSWORD=`openssl rand -hex 12`
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Notieren Sie sich das PostgreSQL-Passwort für die spätere Verwendung.
echo $PGPASSWORD
Sie benötigen dieses Passwort später, um als Postgres-Nutzer eine Verbindung zur Instanz herzustellen. Schreiben Sie sie auf oder kopieren Sie sie, damit Sie sie später verwenden können.
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
Cluster im kostenlosen Testzeitraum erstellen
Wenn Sie AlloyDB noch nicht verwendet haben, können Sie einen kostenlosen Testcluster erstellen:
Legen Sie die Region und den Namen des AlloyDB-Clusters fest. Wir verwenden die Region „us-central1“ und „alloydb-aip-01“ als Clusternamen:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Führen Sie den folgenden Befehl aus, um den Cluster zu erstellen:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Erwartete Konsolenausgabe:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Erstellen Sie in derselben Cloud Shell-Sitzung eine primäre AlloyDB-Instanz für unseren Cluster. Wenn die Verbindung getrennt wird, müssen Sie die Umgebungsvariablen für die Region und den Clusternamen noch einmal definieren.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard-Cluster erstellen
Wenn es nicht Ihr erster AlloyDB-Cluster im Projekt ist, fahren Sie mit dem Erstellen eines Standardclusters fort. Wenn Sie im vorherigen Schritt bereits einen Cluster im kostenlosen Testzeitraum erstellt haben, überspringen Sie diesen Schritt.
Legen Sie die Region und den Namen des AlloyDB-Clusters fest. Wir verwenden die Region „us-central1“ und „alloydb-aip-01“ als Clusternamen:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Führen Sie den folgenden Befehl aus, um den Cluster zu erstellen:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Erwartete Konsolenausgabe:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Erstellen Sie in derselben Cloud Shell-Sitzung eine primäre AlloyDB-Instanz für unseren Cluster. Wenn die Verbindung getrennt wird, müssen Sie die Umgebungsvariablen für die Region und den Clusternamen noch einmal definieren.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Datenbank vorbereiten
Wir müssen eine Datenbank erstellen, die Vertex AI-Integration aktivieren, Datenbankobjekte erstellen und die Daten importieren.
Erforderliche Berechtigungen für AlloyDB erteilen
Fügen Sie dem AlloyDB-Dienst-Agent Vertex AI-Berechtigungen hinzu.
Öffnen Sie oben über das Pluszeichen (+) einen weiteren Cloud Shell-Tab.
Führen Sie im neuen Cloud Shell-Tab Folgendes aus:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Schließen Sie den Tab, indem Sie den Befehl „exit“ auf dem Tab ausführen:
exit
Verbindung zu AlloyDB Studio herstellen
In den folgenden Kapiteln können alle SQL-Befehle, für die eine Verbindung zur Datenbank erforderlich ist, in AlloyDB Studio ausgeführt werden.
Rufen Sie in einem neuen Tab die Seite „Cluster“ in AlloyDB for Postgres auf.
Öffnen Sie die Webkonsolenoberfläche für Ihren AlloyDB-Cluster, indem Sie auf die primäre Instanz klicken.
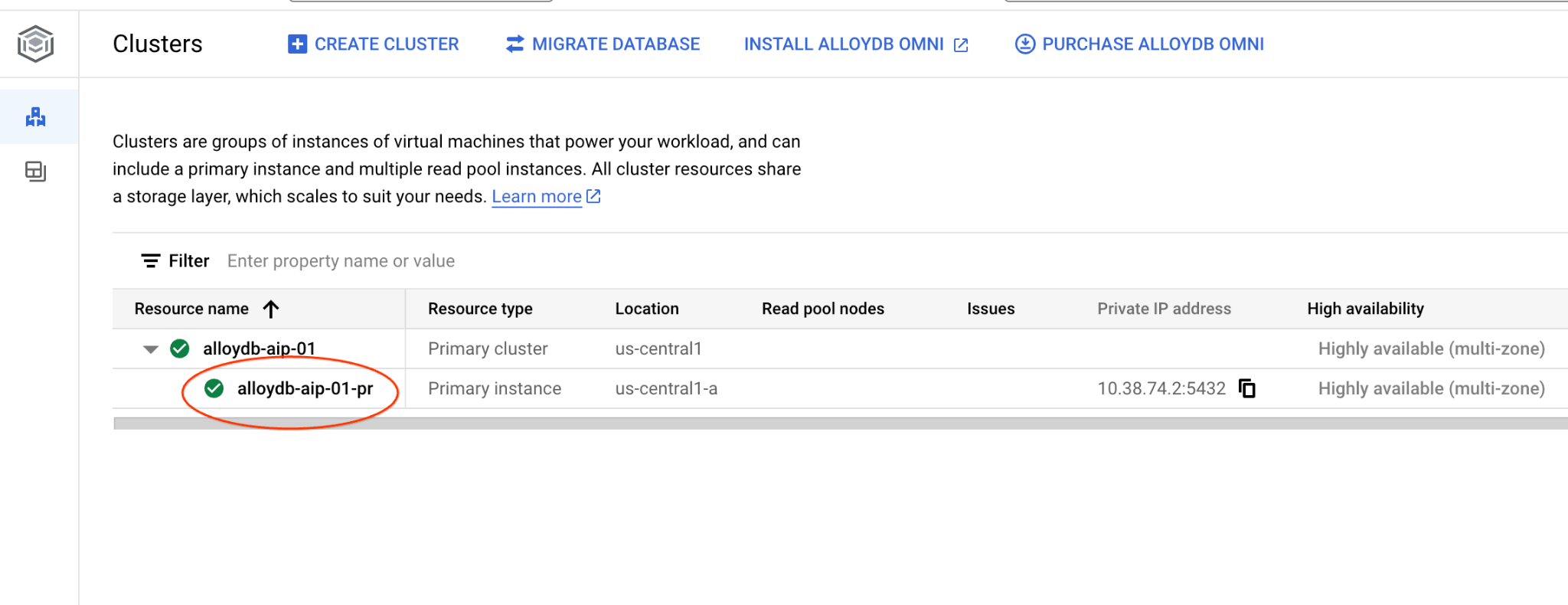
Klicken Sie dann links auf AlloyDB Studio:
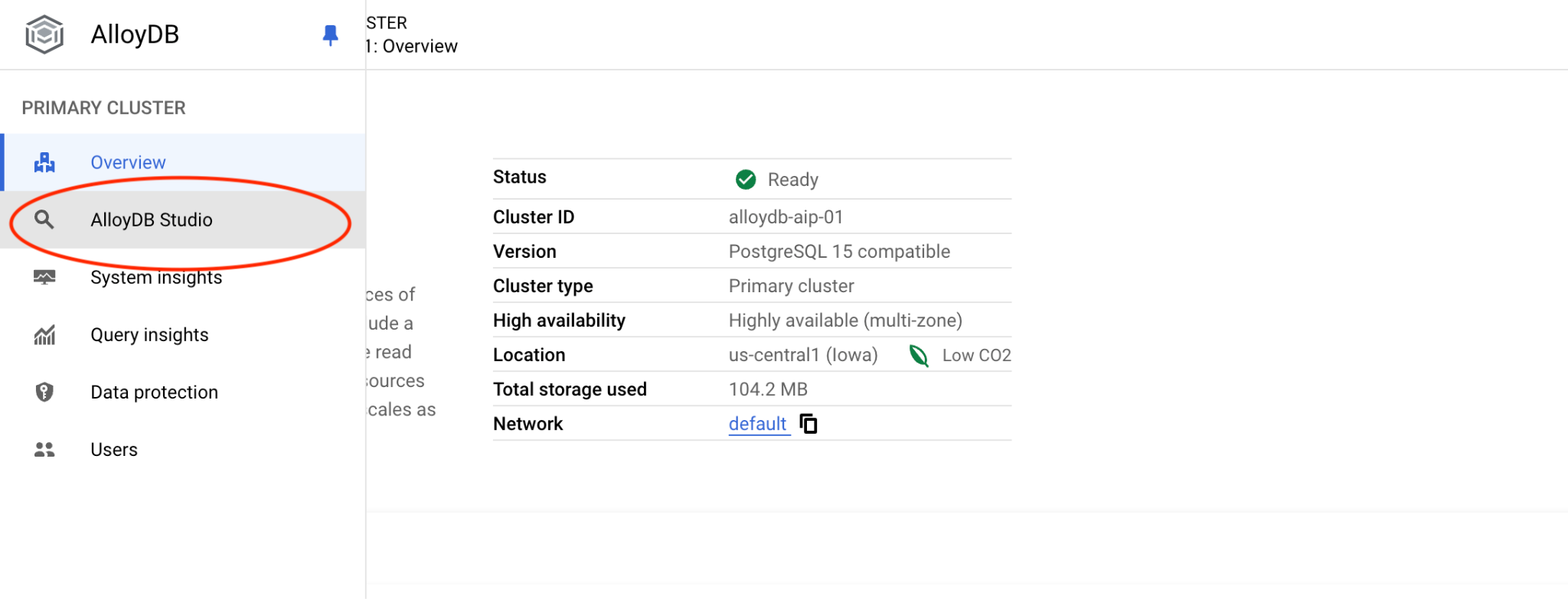
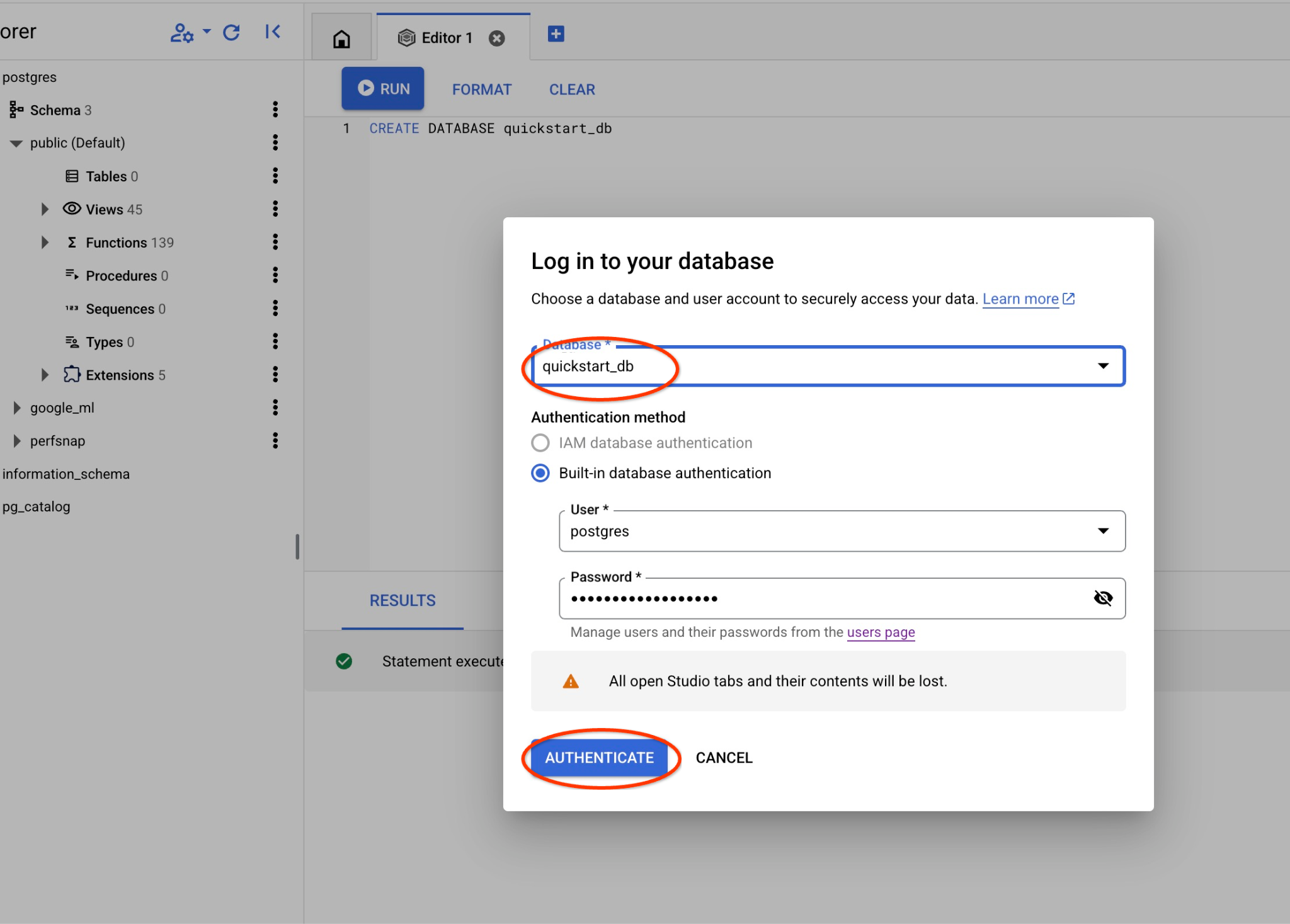
Wählen Sie die Postgres-Datenbank und den Nutzer „postgres“ aus und geben Sie das Passwort an, das beim Erstellen des Clusters angegeben wurde. Klicken Sie dann auf die Schaltfläche „Authentifizieren“. Wenn Sie das Passwort vergessen haben oder es nicht funktioniert, können Sie es ändern. Weitere Informationen
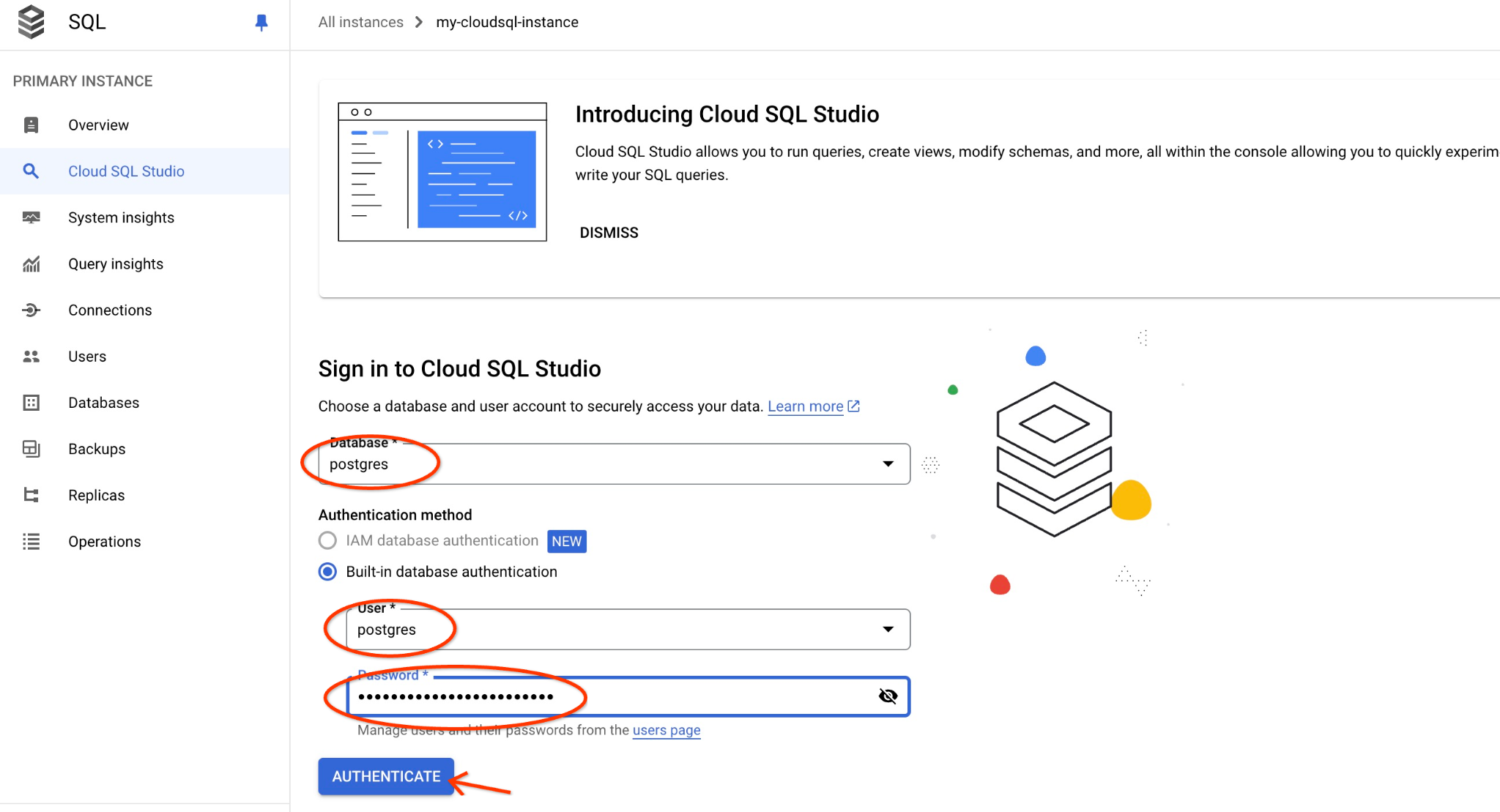
Die AlloyDB Studio-Benutzeroberfläche wird geöffnet. Wenn Sie die Befehle in der Datenbank ausführen möchten, klicken Sie rechts auf den Tab „Unbenannte Abfrage“.
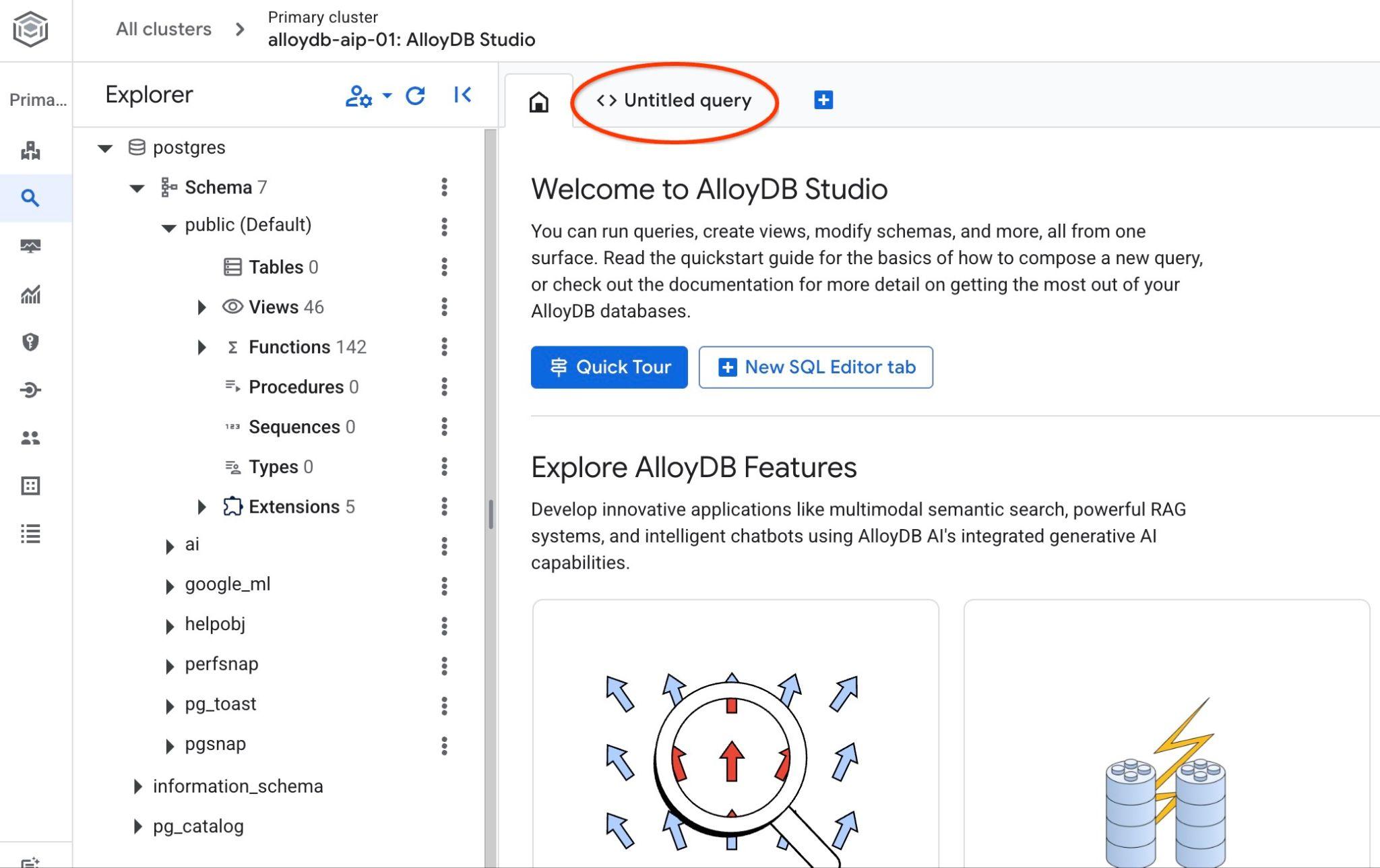
Dadurch wird die Benutzeroberfläche geöffnet, in der Sie SQL-Befehle ausführen können.
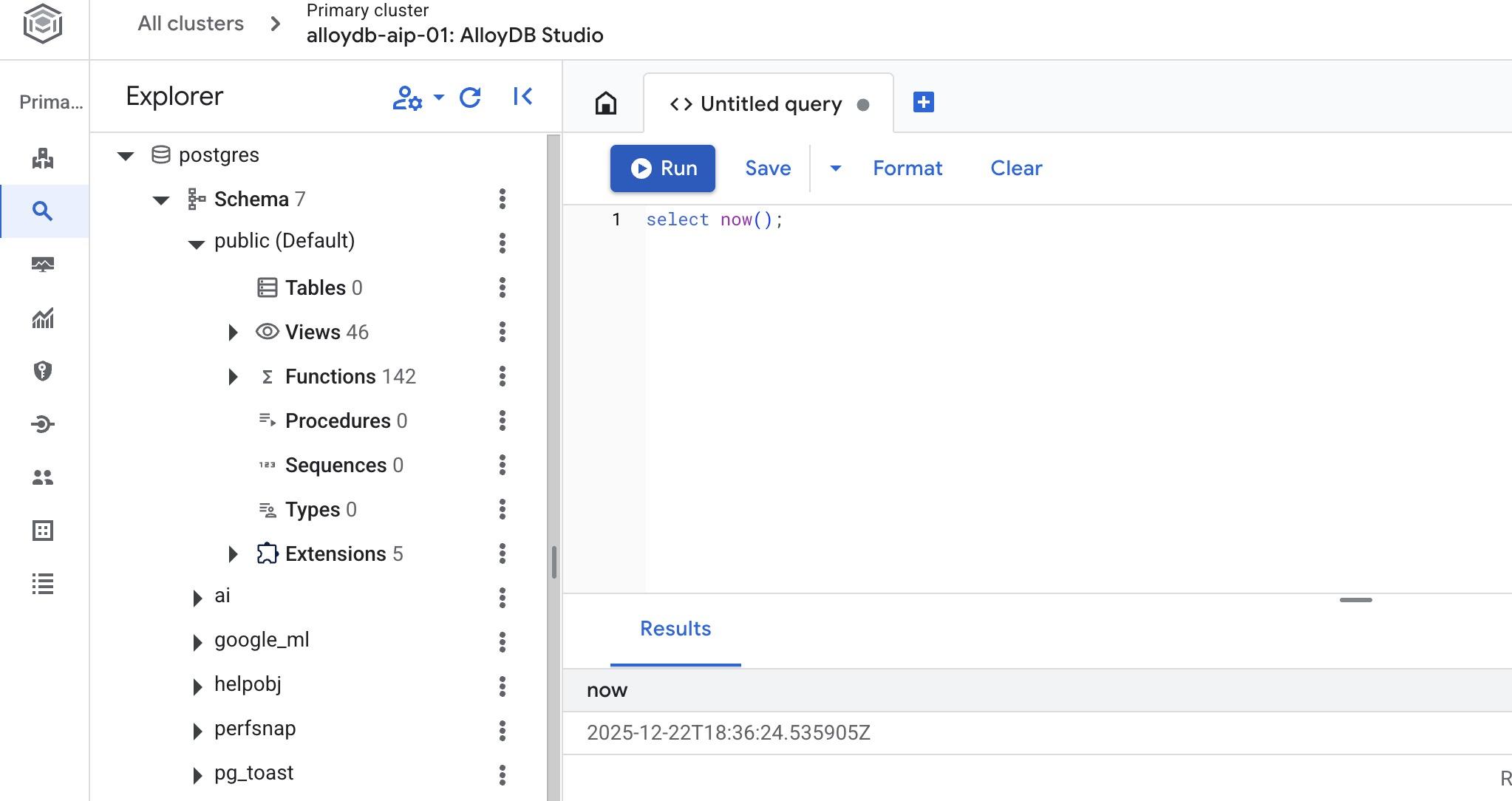
Datenbank erstellen
Schnellstart: Datenbank erstellen
Führen Sie im AlloyDB Studio-Editor den folgenden Befehl aus.
Datenbank erstellen:
CREATE DATABASE quickstart_db
Erwartete Ausgabe:
Statement executed successfully
Mit „quickstart_db“ verbinden
Stellen Sie über die Schaltfläche zum Wechseln des Nutzers/der Datenbank eine neue Verbindung zum Studio her.
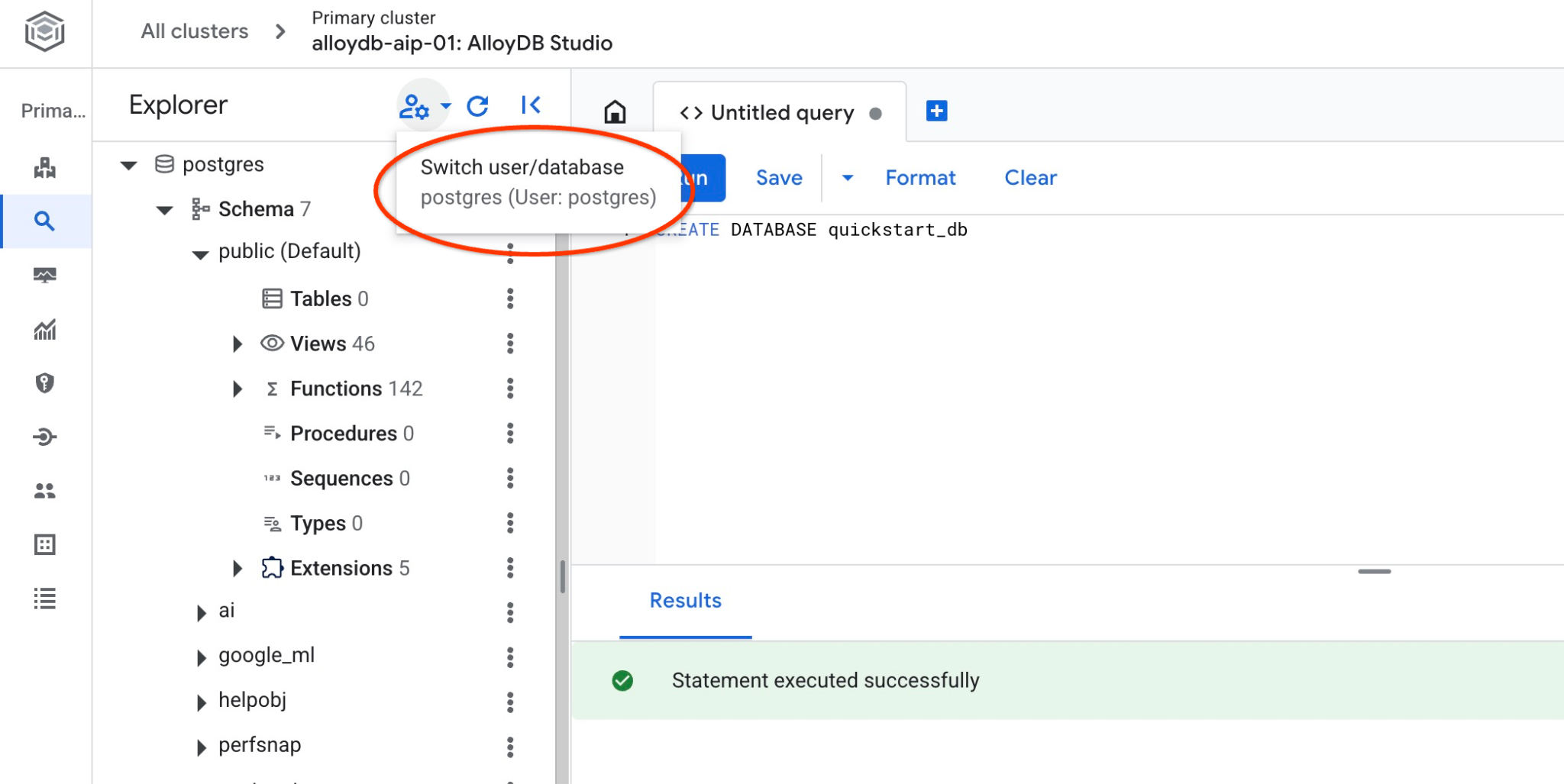
Wählen Sie die neue Datenbank „quickstart_db“ aus der Drop-down-Liste aus und verwenden Sie denselben Nutzer und dasselbe Passwort wie zuvor.
Dadurch wird eine neue Verbindung geöffnet, über die Sie mit Objekten aus der Datenbank „quickstart_db“ arbeiten können.
6. Beispieldaten
Jetzt müssen wir Objekte in der Datenbank erstellen und Daten laden. Wir verwenden einen fiktiven „Cymbal“-Shop mit fiktiven Daten.
Bevor wir die Daten importieren, müssen wir Erweiterungen aktivieren, die Datentypen und Indexe unterstützen. Wir benötigen zwei Erweiterungen: eine, die den Vektordatentyp unterstützt, und eine, die den AlloyDB ScaNN-Index unterstützt.
Stellen Sie in AlloyDB Studio eine Verbindung zu „quickstart_db“ her und führen Sie Folgendes aus:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Das Dataset wird als SQL-Datei vorbereitet und abgelegt, die über die Importschnittstelle in die Datenbank geladen werden kann. Führen Sie in Cloud Shell die folgenden Befehle aus:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
Mit dem Befehl wird das AlloyDB SDK verwendet, um einen Nutzer mit dem Namen „agentspace_user“ zu erstellen und dann Beispieldaten direkt aus dem GCS-Bucket in die Datenbank zu importieren. Dabei werden alle erforderlichen Objekte erstellt und Daten eingefügt.
Nach dem Import können wir die Tabellen in AlloyDB Studio prüfen. Die Tabellen befinden sich im Schema „ecomm“:
Prüfen Sie die Anzahl der Zeilen in einer der Tabellen.
select count(*) from ecomm.products;
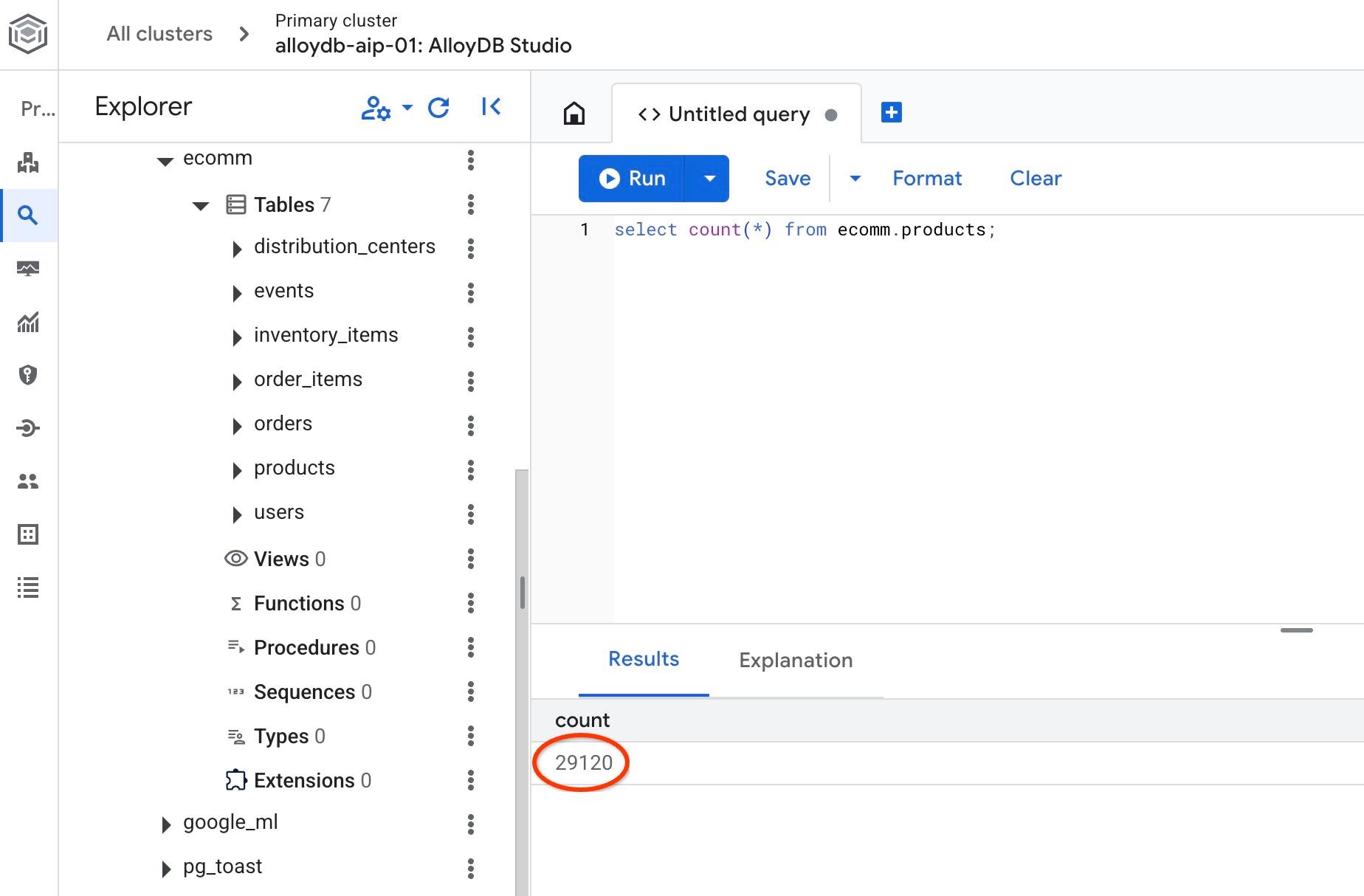
Wir haben unsere Beispieldaten erfolgreich importiert und können mit den nächsten Schritten fortfahren.
7. Semantische Suche mit Texteinbettungen
In diesem Kapitel werden wir versuchen, die semantische Suche mit Texteinbettungen zu verwenden und sie mit der herkömmlichen Postgres-Text- und Volltextsuche zu vergleichen.
Sehen wir uns zuerst die klassische Suche mit Standard-PostgreSQL-SQL und dem LIKE-Operator an.
Stellen Sie in AlloyDB Studio eine Verbindung zu „quickstart_db“ her und versuchen Sie, mit der folgenden Abfrage nach einer Regenjacke zu suchen:
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
Bei der Abfrage werden keine Zeilen zurückgegeben, da genaue Begriffe wie „nasse Bedingungen“ und „Jacke“ entweder im Produktnamen oder in der Beschreibung enthalten sein müssten. Eine „Jacke für nasse Bedingungen“ ist nicht dasselbe wie eine „Jacke für Regen“.
Wir können versuchen, alle möglichen Variationen in die Suche einzubeziehen. Versuchen wir es mit nur zwei Wörtern. Beispiel:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
Dadurch würden mehrere Zeilen zurückgegeben, aber nicht alle entsprechen perfekt unserer Anfrage nach Jacken und es ist schwierig, nach Relevanz zu sortieren. Wenn wir beispielsweise weitere Bedingungen wie „für Männer“ hinzufügen, würde die Komplexität der Anfrage erheblich zunehmen. Alternativ können wir die Volltextsuche ausprobieren, aber auch hier stoßen wir auf Einschränkungen in Bezug auf mehr oder weniger genaue Wörter und die Relevanz der Antwort.
Jetzt können wir eine ähnliche Suche mit Einbettungen durchführen. Wir haben bereits Embeddings für unsere Produkte mit verschiedenen Modellen vorab berechnet. Wir verwenden das aktuelle Modell „gemini-embedding-001“ von Google. Wir haben sie in der Spalte product_embedding der Tabelle ecomm.products gespeichert. Wenn wir mit der folgenden Abfrage eine Suche nach unserer Suchbedingung „Regenjacke für Herren“ durchführen:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
Es werden nicht nur die Jacken für nasse Bedingungen zurückgegeben, sondern alle Ergebnisse werden auch so sortiert, dass die relevantesten Ergebnisse oben stehen.
Die Abfrage mit Einbettungen gibt Ergebnisse in 90–150 ms zurück. Ein Teil der Zeit wird dafür benötigt, die Daten vom Cloud-Einbettungsmodell abzurufen. Wenn wir uns den Ausführungsplan ansehen, ist die Anfrage an das Modell in der Planungszeit enthalten. Der Teil der Abfrage, der die Suche selbst durchführt, ist recht kurz. Die Suche in 29.000 Datensätzen mit dem AlloyDB-ScaNN-Index dauert weniger als 7 ms.
Hier ist die Ausgabe des Ausführungsplans:
Limit (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> Index Scan using embedding_scann on products (cost=2709.20..30736.40 rows=29120 width=490) (actual time=6.964..7.046 rows=10 loops=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
…
-0.0051468653,-0.012440448]'::vector)
Limit: 10
Planungszeit: 136,579 ms
Ausführungszeit: 6,791 ms
(6 Zeilen)
Das war die Suche nach Texteinbettungen mit dem reinen Texteinbettungsmodell. Wir haben aber auch Bilder für unsere Produkte, die wir für die Suche verwenden können. Im nächsten Kapitel zeigen wir, wie das multimodale Modell Bilder für die Suche verwendet.
8. Multimodale Suche verwenden
Die textbasierte semantische Suche ist zwar nützlich, aber es kann schwierig sein, komplizierte Details zu beschreiben. Die multimodale Suche von AlloyDB bietet den Vorteil, dass Produkte über Bildeingaben gefunden werden können. Das ist besonders hilfreich, wenn die visuelle Darstellung die Suchabsicht besser verdeutlicht als reine Textbeschreibungen. Zum Beispiel: „Suche für mich einen Mantel wie diesen auf dem Bild.“
Kehren wir zu unserem Beispiel mit der Jacke zurück. Wenn ich ein Bild einer Jacke habe, die der Jacke, nach der ich suche, ähnelt, kann ich es an das multimodale Einbettungsmodell von Google übergeben und mit Einbettungen für Bilder meiner Produkte vergleichen. In unserer Tabelle haben wir bereits Einbettungen für Bilder unserer Produkte in der Spalte product_image_embedding berechnet. Das verwendete Modell sehen Sie in der Spalte product_image_embedding_model.
Für die Suche können wir die Funktion image_embedding verwenden, um eine Einbettung für unser Bild zu erhalten und sie mit den vorab berechneten Einbettungen zu vergleichen. Damit die Funktion aktiviert werden kann, muss die richtige Version der Erweiterung google_ml_integration verwendet werden.
Lass uns die aktuelle Erweiterungsversion überprüfen. Führen Sie den Befehl in AlloyDB Studio aus.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Wenn die Version niedriger als 1.5.2 ist, führen Sie die folgenden Schritte aus.
CALL google_ml.upgrade_to_preview_version();
Prüfen Sie dann noch einmal die Version der Erweiterung. Es sollte 1.5.3 sein.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Außerdem müssen wir die Funktionen der KI-Abfrage-Engine in unserer Datenbank aktivieren. Dies kann entweder durch Aktualisieren des Instanz-Flags für alle Datenbanken in der Instanz oder durch Aktivieren nur für unsere Datenbank erfolgen. Führen Sie den folgenden Befehl in AlloyDB Studio aus, um die Funktion für die Datenbank „quickstart_db“ zu aktivieren.
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
Jetzt können wir auch mit Bildern suchen. Hier ist mein Beispielbild für die Suche. Sie können aber ein beliebiges benutzerdefiniertes Bild verwenden. Sie müssen die Datei nur in den Google-Speicher oder eine andere öffentlich verfügbare Ressource hochladen und den URI in die Anfrage einfügen.

Die Datei wird in gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png hochgeladen.
Bildersuche anhand von Bildern
Zuerst versuchen wir, nur anhand des Bildes zu suchen:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Und wir konnten einige warme Jacken im Inventar finden. Wenn Sie die Bilder sehen möchten, können Sie sie mit dem Cloud SDK (gcloud storage cp) herunterladen, indem Sie die Spalte public_url angeben, und sie dann mit einem beliebigen Tool öffnen, das mit Bildern funktioniert.
|
|
|
|




Bei der Bildersuche werden Elemente zurückgegeben, die dem von uns zum Vergleich bereitgestellten Bild ähneln. Wie bereits erwähnt, können Sie versuchen, Ihre eigenen Bilder in einen öffentlichen Bucket hochzuladen und zu sehen, ob verschiedene Arten von Kleidung gefunden werden können.
Für unsere Bildersuche haben wir das Modell „multimodalembedding@001“ von Google verwendet. Unsere Funktion „image_embedding“ sendet das Bild an Vertex AI, wandelt es in einen Vektor um und gibt es zurück, damit es mit den gespeicherten Bildvektoren in unserer Datenbank verglichen werden kann.
Mit „EXPLAIN ANALYZE“ können wir auch prüfen, wie schnell es mit unserem AlloyDB ScaNN-Index funktioniert.
Hier ist die Ausgabe für den Ausführungsplan:
Limit (cost=971.70..975.55 rows=4 width=490) (actual time=2.453..2.477 rows=4 loops=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
…
,-0.010307034,-0.010053742]'::vector)
Limit: 4
Planungszeit: 913,322 ms
Ausführungszeit: 2.517 ms
(6 Zeilen)
Wie im vorherigen Beispiel sehen wir auch hier, dass der Großteil der Zeit für die Konvertierung unseres Bildes in Einbettungen über den Cloud-Endpunkt aufgewendet wurde und die Vektorsuche selbst nur 2,5 ms dauert.
Bildersuche mit Text
Mit multimodalen Modellen können wir auch eine Textbeschreibung der Jacke, nach der wir suchen, an das Modell übergeben. Dazu verwenden wir google_ml.text_embedding für dasselbe Modell und vergleichen die Ergebnisse mit Bildeinbettungen, um zu sehen, welche Bilder zurückgegeben werden.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Wir haben eine Reihe von Daunenjacken in Grau oder dunklen Farben erhalten.
|
|
|
|




Wir haben eine etwas andere Auswahl an Jacken erhalten, aber es wurden anhand unserer Beschreibung korrekt Jacken ausgewählt, als die Bild-Embeddings durchsucht wurden.
Wir versuchen es mit einer anderen Methode, um anhand der Einbettung des Suchbilds in Beschreibungen zu suchen.
Textsuche anhand von Bildern
Wir haben versucht, Bilder zu finden, indem wir die Einbettung für unser Bild übergeben und mit den vorab berechneten Bildeinbettungen für unsere Produkte verglichen haben. Außerdem haben wir versucht, nach Bildern zu suchen, indem wir ein Embedding für unsere Textanfrage übergeben und in demselben Embedding nach den Produktbildern gesucht haben. Wir versuchen jetzt, eine Einbettung für unser Bild zu verwenden und sie mit Texteinbettungen für die Produktbeschreibungen zu vergleichen. Diese Einbettungen werden in der Spalte product_description_embedding gespeichert und verwenden dasselbe Modell multimodalembedding@001.
Hier ist unsere Anfrage:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Hier haben wir eine etwas andere Auswahl an Jacken mit grauen oder dunklen Farben erhalten. Einige davon sind identisch oder sehr ähnlich zu den Jacken, die wir bei den anderen Suchmethoden ausgewählt haben.
|
|
|
|



Anhand des Embeddings für Bilder kann es mit den berechneten Embeddings für die Textbeschreibung verglichen werden, um die richtigen Produkte zurückzugeben.
Hybride Text- und Bildersuche
Sie können auch versuchen, Text- und Bildeinbettungen zu kombinieren, z. B. mit der Methode der reziproken Rangfusion. Hier ist ein Beispiel für eine solche Abfrage, in der wir zwei Suchen kombiniert, jedem Rang eine Punktzahl zugewiesen und die Ergebnisse anhand der kombinierten Punktzahl sortiert haben.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
Sie können mit verschiedenen Parametern in der Abfrage experimentieren, um die Suchergebnisse zu verbessern. Außerdem können Sie auch andere KI-Operatoren verwenden, um die Ergebnisse zu sortieren, wie in der Dokumentation beschrieben.
Damit ist das Lab abgeschlossen. Um unerwartete Kosten zu vermeiden, sollten Sie die nicht verwendeten Ressourcen löschen.
9. Umgebung bereinigen
Löschen Sie die AlloyDB-Instanzen und den Cluster, wenn Sie das Lab abgeschlossen haben.
AlloyDB-Cluster und alle Instanzen löschen
Wenn Sie die Testversion von AlloyDB verwendet haben. Löschen Sie den Testcluster nicht, wenn Sie planen, andere Labs und Ressourcen damit zu testen. Sie können keinen weiteren Testcluster im selben Projekt erstellen.
Der Cluster wird mit der Option „force“ zerstört, wodurch auch alle zum Cluster gehörenden Instanzen gelöscht werden.
Definieren Sie in Cloud Shell die Projekt- und Umgebungsvariablen, wenn die Verbindung getrennt wurde und alle vorherigen Einstellungen verloren gegangen sind:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Löschen Sie den Cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB-Sicherungen löschen
Löschen Sie alle AlloyDB-Sicherungen für den Cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs. Sie haben gelernt, wie Sie die multimodale Suche in AlloyDB mit Einbettungsfunktionen für Texte und Bilder verwenden. Sie können die multimodale Suche testen und mit der Funktion „google_ml.rank“ verbessern. Verwenden Sie dazu das Codelab für AlloyDB AI-Operatoren.
Google Cloud-Lernpfad
Dieses Lab ist Teil des Lernpfads „Produktionsreife KI mit Google Cloud“.
- Gesamten Lehrplan ansehen
- Teile deinen Fortschritt mit dem Hashtag
#ProductionReadyAI.
Behandelte Themen
- AlloyDB für Postgres bereitstellen
- AlloyDB Studio verwenden
- Multimodale Vektorsuche verwenden
- AlloyDB AI-Operatoren aktivieren
- Verschiedene AlloyDB AI-Operatoren für die multimodale Suche verwenden
- So kombinieren Sie Text- und Bildsuchergebnisse mit AlloyDB AI
11. Umfrage
Ausgabe: