
1. Introducción
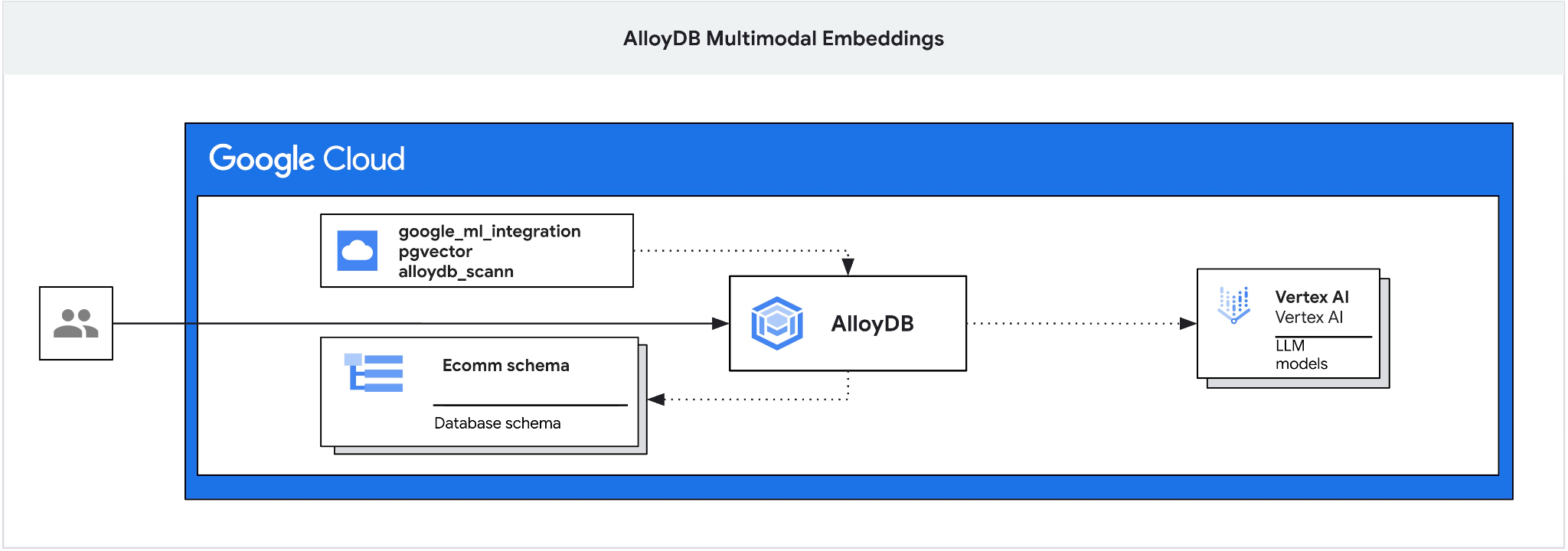
En este codelab, se proporciona una guía para implementar AlloyDB y aprovechar la integración de IA para la búsqueda semántica con embeddings multimodales. Este lab forma parte de una colección de labs dedicados a las funciones de AlloyDB AI. Puedes obtener más información en la página de AlloyDB AI en la documentación.
Requisitos previos
- Conocimientos básicos sobre Google Cloud y la consola
- Habilidades básicas de la interfaz de línea de comandos y de Cloud Shell
Qué aprenderás
- Cómo implementar AlloyDB para Postgres
- Cómo usar AlloyDB Studio
- Cómo usar la búsqueda de vectores multimodal
- Cómo habilitar los operadores de AlloyDB AI
- Cómo usar diferentes operadores de AlloyDB AI para la búsqueda multimodal
- Cómo usar AlloyDB AI para combinar los resultados de la búsqueda de imágenes y texto
Requisitos
- Una cuenta de Google Cloud y un proyecto de Google Cloud
- Un navegador web, como Chrome, que admita la consola de Google Cloud y Cloud Shell
2. Configuración y requisitos
Configuración del proyecto
- Accede a la consola de Google Cloud. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.
Usa una cuenta personal en lugar de una cuenta laboral o educativa.
- Crea un proyecto nuevo o reutiliza uno existente. Para crear un proyecto nuevo en la consola de Google Cloud, haz clic en el botón Seleccionar un proyecto del encabezado, que abrirá una ventana emergente.

En la ventana Select a project, presiona el botón New Project, que abrirá un cuadro de diálogo para el proyecto nuevo.
En el cuadro de diálogo, ingresa el nombre del proyecto que prefieras y elige la ubicación.
- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. El nombre del proyecto no se usa en las APIs de Google y se puede cambiar en cualquier momento.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Google Cloud genera automáticamente un ID único, pero puedes personalizarlo. Si no te gusta el ID generado, puedes generar otro aleatorio o proporcionar el tuyo para verificar su disponibilidad. En la mayoría de los codelabs, deberás hacer referencia al ID del proyecto, que suele identificarse con el marcador de posición PROJECT_ID.
- Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
Habilitar facturación
Para habilitar la facturación, tienes dos opciones. Puedes usar tu cuenta de facturación personal o canjear créditos siguiendo los pasos que se indican a continuación.
Canjea créditos de Google Cloud (opcional)
Para realizar este taller, necesitas una cuenta de facturación con algo de crédito. Usa los créditos del banner que se encuentra en la parte superior de este codelab para comenzar. Si ya te conectaste a una cuenta de facturación, puedes omitir este paso.
Configura una cuenta de facturación personal
Si configuraste la facturación con créditos de Google Cloud, puedes omitir este paso.
Para configurar una cuenta de facturación personal, ve aquí para habilitar la facturación en la consola de Cloud.
Algunas notas:
- Completar este lab debería costar menos de USD 3 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos pueden acceder a la prueba gratuita de USD 300.
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
También puedes presionar G y, luego, S. Esta secuencia activará Cloud Shell si estás en la consola de Google Cloud o usas este vínculo.
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
3. Antes de comenzar
Habilitar API
Para usar AlloyDB, Compute Engine, servicios de redes y Vertex AI, debes habilitar sus respectivas APIs en tu proyecto de Google Cloud.
En Cloud Shell, en la terminal, asegúrate de que tu ID del proyecto esté configurado. El ID del proyecto debe aparecer entre paréntesis en el símbolo del sistema, como se muestra a continuación:
student@cloudshell:~ (test-project-001-402417)$
Si el ID del proyecto no se muestra allí, actualiza la pestaña del navegador y vuelve a autenticarte en Cloud Shell.
Configura la variable de entorno PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Habilita todos los servicios necesarios con el siguiente comando:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Implementa AlloyDB
Crea un clúster y una instancia principal de AlloyDB. En el siguiente procedimiento, se describe cómo crear un clúster y una instancia de AlloyDB con el SDK de Google Cloud. Si prefieres el enfoque de la consola, puedes seguir la documentación aquí.
Antes de crear un clúster de AlloyDB, necesitamos un rango de IP privada disponible en nuestra VPC para que lo utilice la instancia futura de AlloyDB. Si no lo tenemos, debemos crearlo, asignarlo para que lo usen los servicios internos de Google y, después de eso, podremos crear el clúster y la instancia.
Crea un rango de IP privada
Debemos establecer la configuración del acceso privado a servicios en nuestra VPC para AlloyDB. Aquí, suponemos que tenemos la red de VPC “predeterminada” en el proyecto y que se utilizará para todas las acciones.
Crea el rango de IP privada:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Crea una conexión privada con el rango de IP asignado:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Crea un clúster de AlloyDB
En esta sección, crearemos un clúster de AlloyDB en la región us-central1.
Define la contraseña para el usuario de postgres. Puedes definir tu propia contraseña o usar una función aleatoria para generar una.
export PGPASSWORD=`openssl rand -hex 12`
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Toma nota de la contraseña de PostgreSQL para utilizarla más adelante.
echo $PGPASSWORD
Necesitarás esa contraseña en el futuro para conectarte a la instancia como usuario de postgres. Te sugiero que lo anotes o lo copies en algún lugar para poder usarlo más adelante.
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
Crea un clúster de prueba gratuita
Si nunca usaste AlloyDB, puedes crear un clúster de prueba gratuito:
Define la región y el nombre del clúster de AlloyDB. Usaremos la región us-central1 y alloydb-aip-01 como nombre del clúster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Ejecuta el comando para crear el clúster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Resultado esperado en la consola:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea una instancia principal de AlloyDB para nuestro clúster en la misma sesión de Cloud Shell. Si te desconectas, deberás volver a definir las variables de entorno de la región y el nombre del clúster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Crea un clúster estándar de AlloyDB
Si no es tu primer clúster de AlloyDB en el proyecto, continúa con la creación de un clúster estándar. Si ya creaste un clúster de prueba gratuita en el paso anterior, omite este paso.
Define la región y el nombre del clúster de AlloyDB. Usaremos la región us-central1 y alloydb-aip-01 como nombre del clúster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Ejecuta el comando para crear el clúster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Resultado esperado en la consola:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea una instancia principal de AlloyDB para nuestro clúster en la misma sesión de Cloud Shell. Si te desconectas, deberás volver a definir las variables de entorno de la región y el nombre del clúster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Prepara la base de datos
Debemos crear una base de datos, habilitar la integración de Vertex AI, crear objetos de base de datos y, luego, importar los datos.
Otorga los permisos necesarios a AlloyDB
Agrega permisos de Vertex AI al agente de servicio de AlloyDB.
Abre otra pestaña de Cloud Shell con el signo "+" en la parte superior.
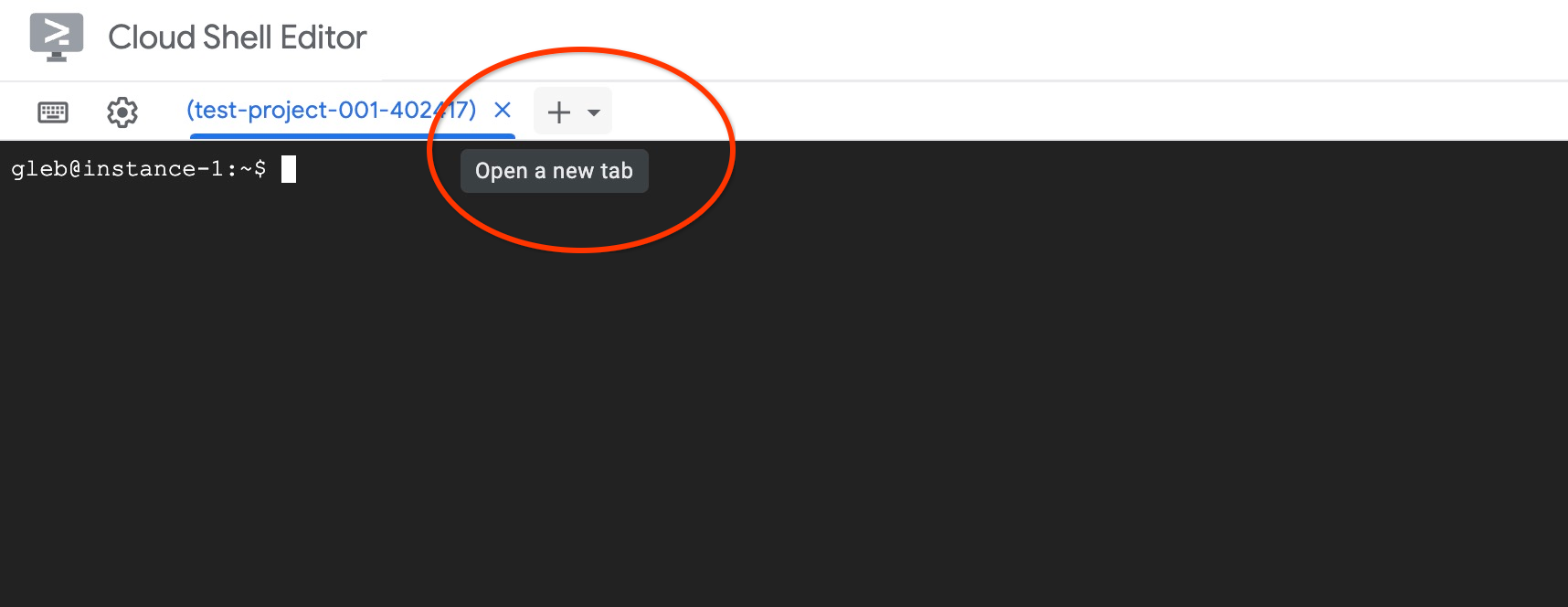
En la nueva pestaña de Cloud Shell, ejecuta lo siguiente:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Resultado esperado en la consola:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Cierra la pestaña con el comando de ejecución “exit” en la pestaña:
exit
Conéctate a AlloyDB Studio
En los siguientes capítulos, todos los comandos SQL que requieren conexión a la base de datos se pueden ejecutar en AlloyDB Studio.
En una pestaña nueva, navega a la página Clústeres en AlloyDB para Postgres.
Haz clic en la instancia principal para abrir la interfaz de la consola web de tu clúster de AlloyDB.
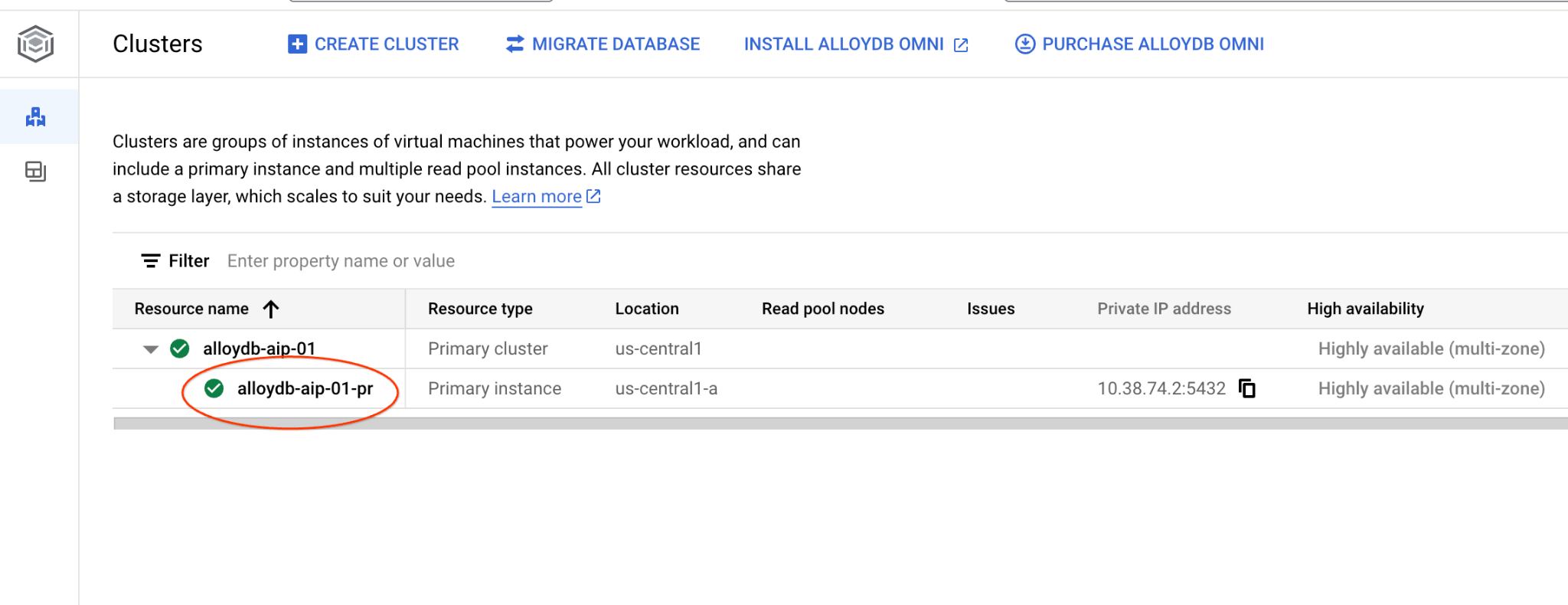
Luego, haz clic en AlloyDB Studio a la izquierda:
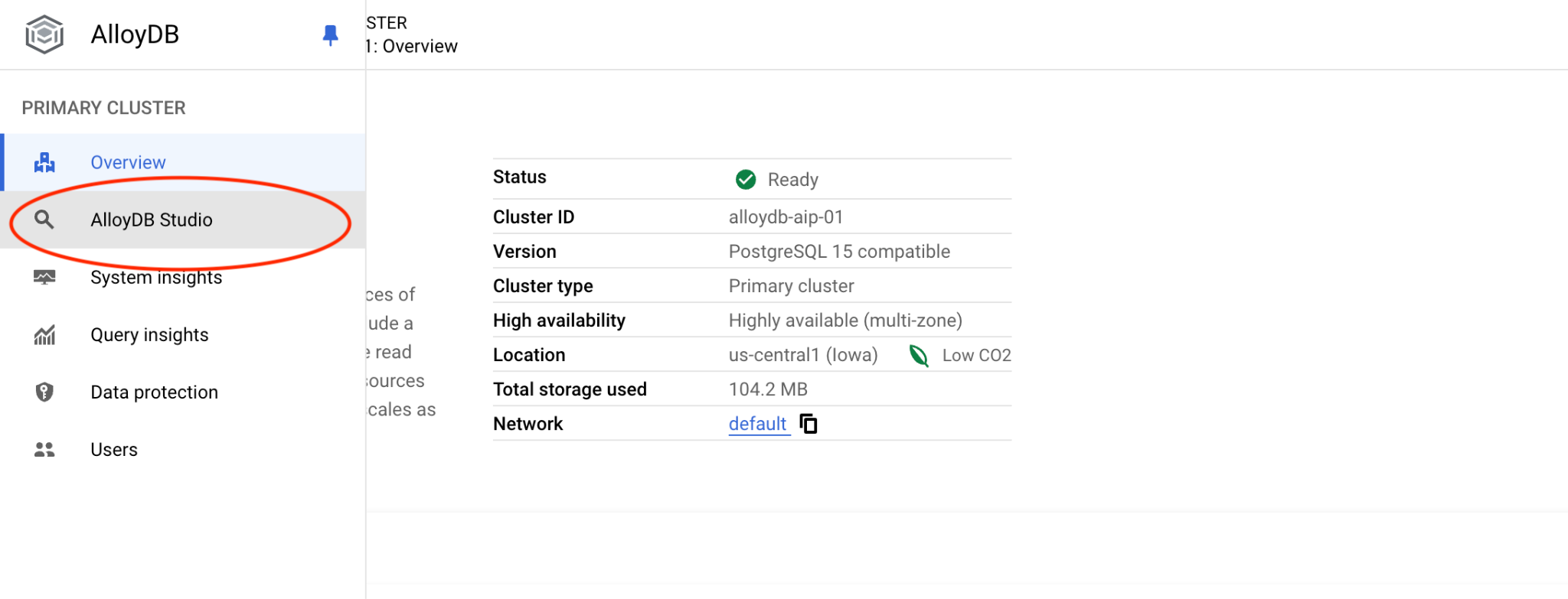
Elige la base de datos postgres, el usuario postgres y proporciona la contraseña que anotamos cuando creamos el clúster. Luego, haz clic en el botón "Autenticar". Si olvidaste anotar la contraseña o no te funciona, puedes cambiarla. Consulta la documentación para saber cómo hacerlo.
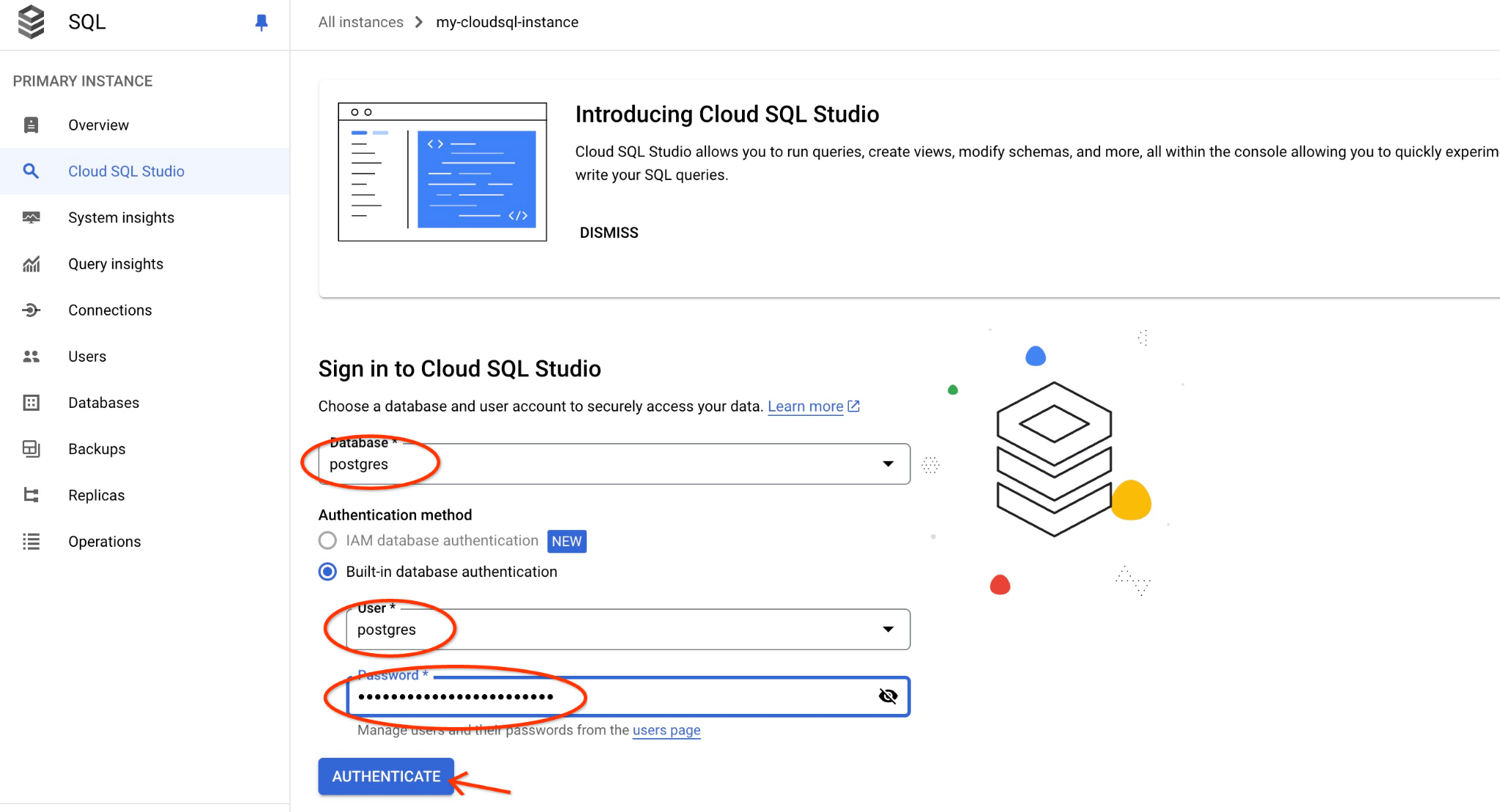
Se abrirá la interfaz de AlloyDB Studio. Para ejecutar los comandos en la base de datos, haz clic en la pestaña "Untitled Query" (Consulta sin título) que se encuentra a la derecha.
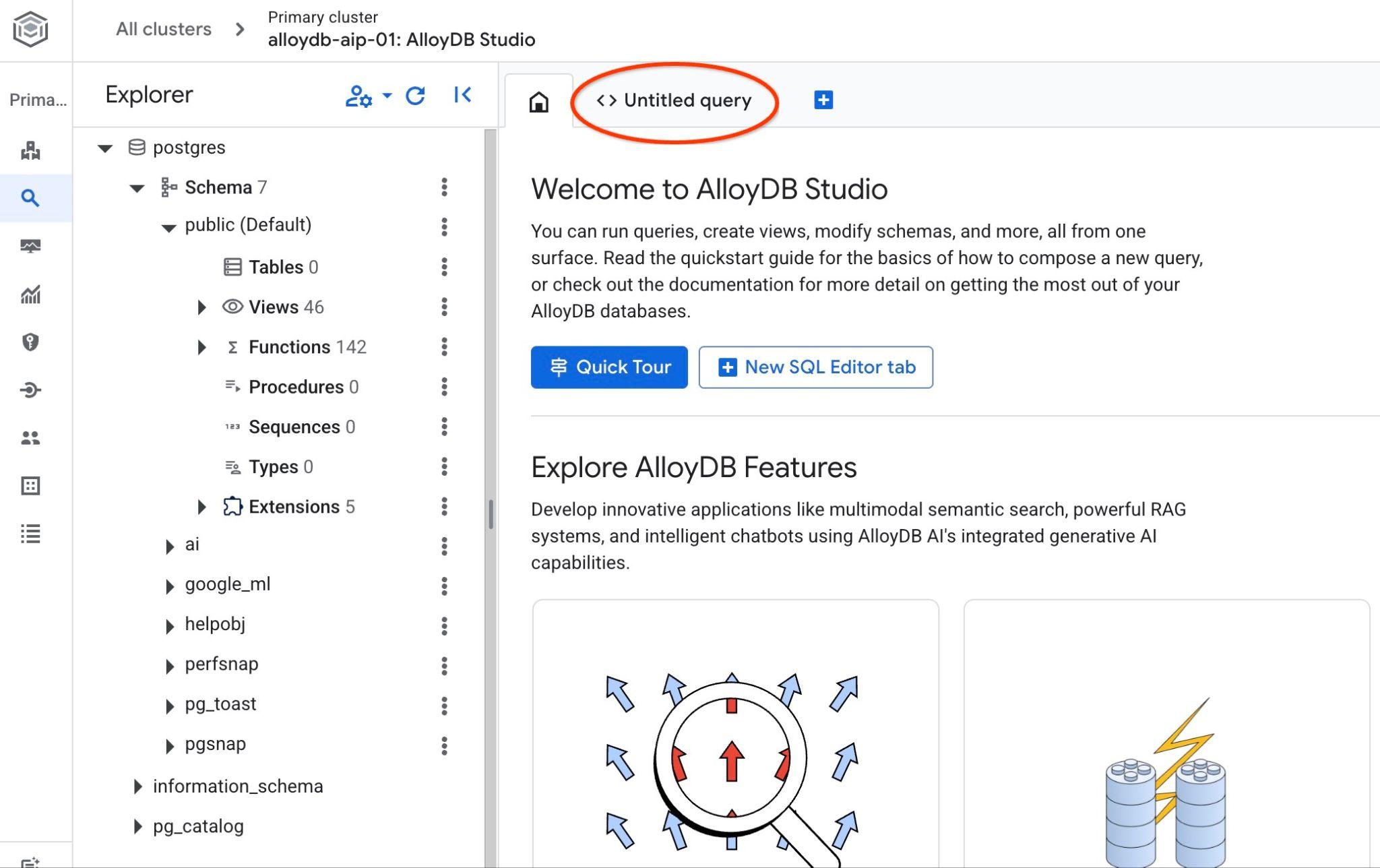
Se abre la interfaz en la que puedes ejecutar comandos de SQL.
Crea la base de datos
Guía de inicio rápido para crear una base de datos
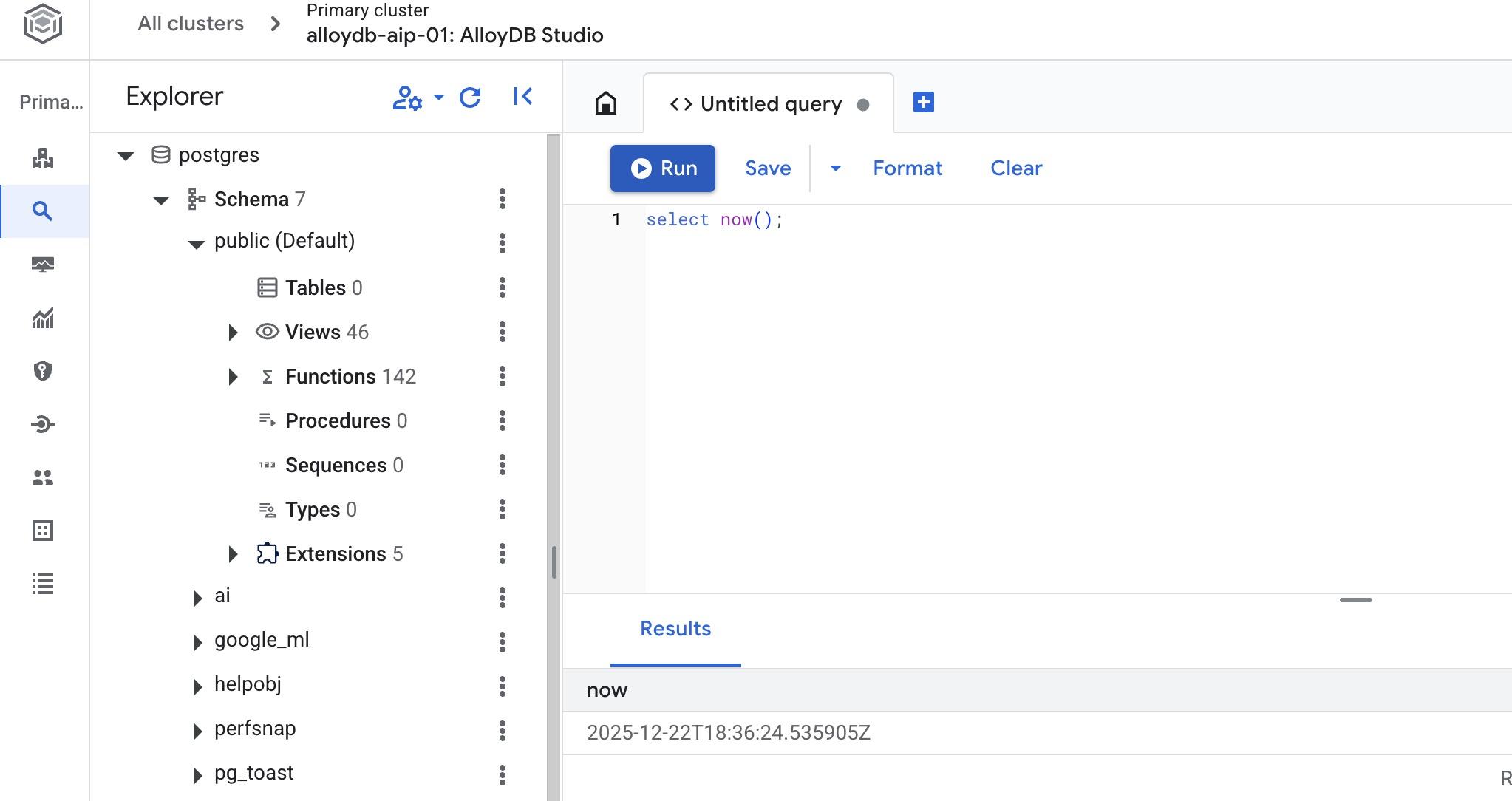
En el editor de AlloyDB Studio, ejecuta el siguiente comando.
Crea la base de datos:
CREATE DATABASE quickstart_db
Resultado esperado:
Statement executed successfully
Conéctate a quickstart_db
Vuelve a conectarte al estudio con el botón para cambiar de usuario o base de datos.
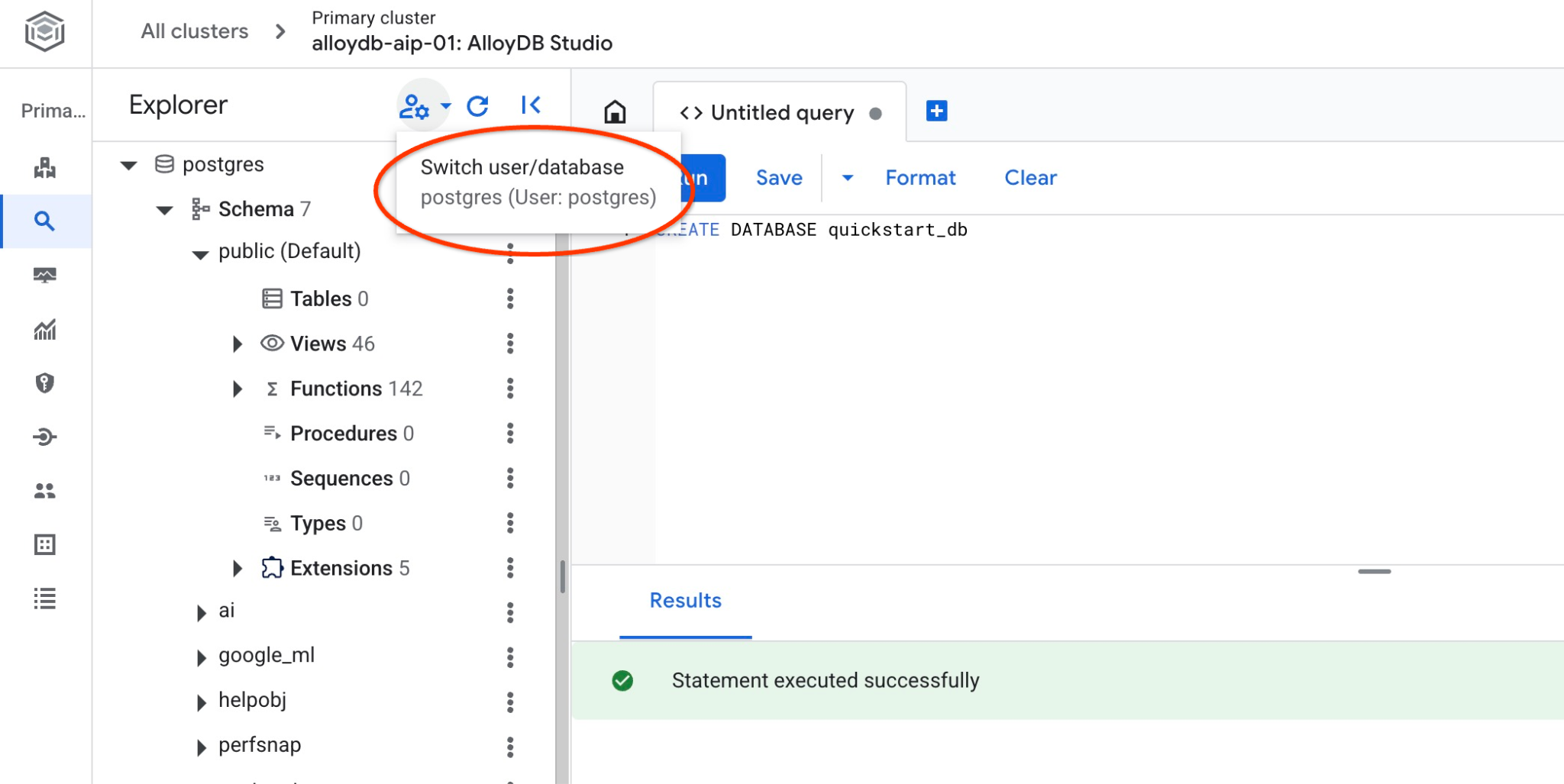
Elige la nueva base de datos quickstart_db en la lista desplegable y usa el mismo usuario y contraseña que antes.
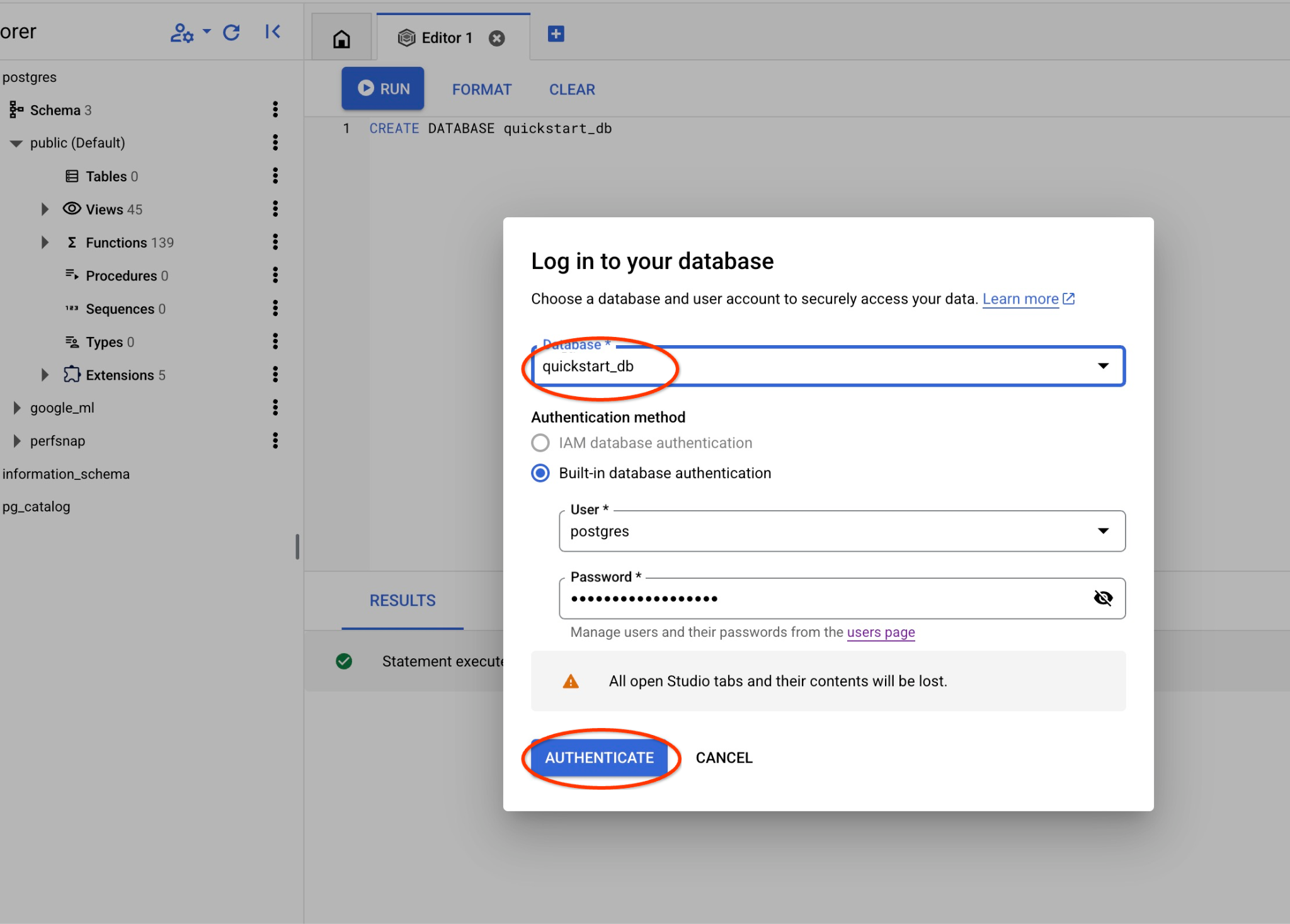
Se abrirá una nueva conexión en la que podrás trabajar con objetos de la base de datos quickstart_db.
6. Datos de muestra
Ahora debemos crear objetos en la base de datos y cargar datos. Usaremos una tienda ficticia llamada "Cymbal" con datos ficticios.
Antes de importar los datos, debemos habilitar las extensiones que admiten tipos de datos e índices. Necesitamos dos extensiones: una que admita el tipo de datos de vector y otra que admita el índice ScaNN de AlloyDB.
En AlloyDB Studio, conéctate a quickstart_db y ejecuta lo siguiente:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
El conjunto de datos se prepara y se coloca como un archivo SQL que se puede cargar en la base de datos con la interfaz de importación. En Cloud Shell, ejecuta los siguientes comandos:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
El comando usa el SDK de AlloyDB y crea un usuario con el nombre agentspace_user. Luego, importa datos de muestra directamente desde el bucket de GCS a la base de datos, creando todos los objetos necesarios e insertando datos.
Después de la importación, podemos verificar las tablas en AlloyDB Studio. Las tablas se encuentran en el esquema de comercio electrónico:
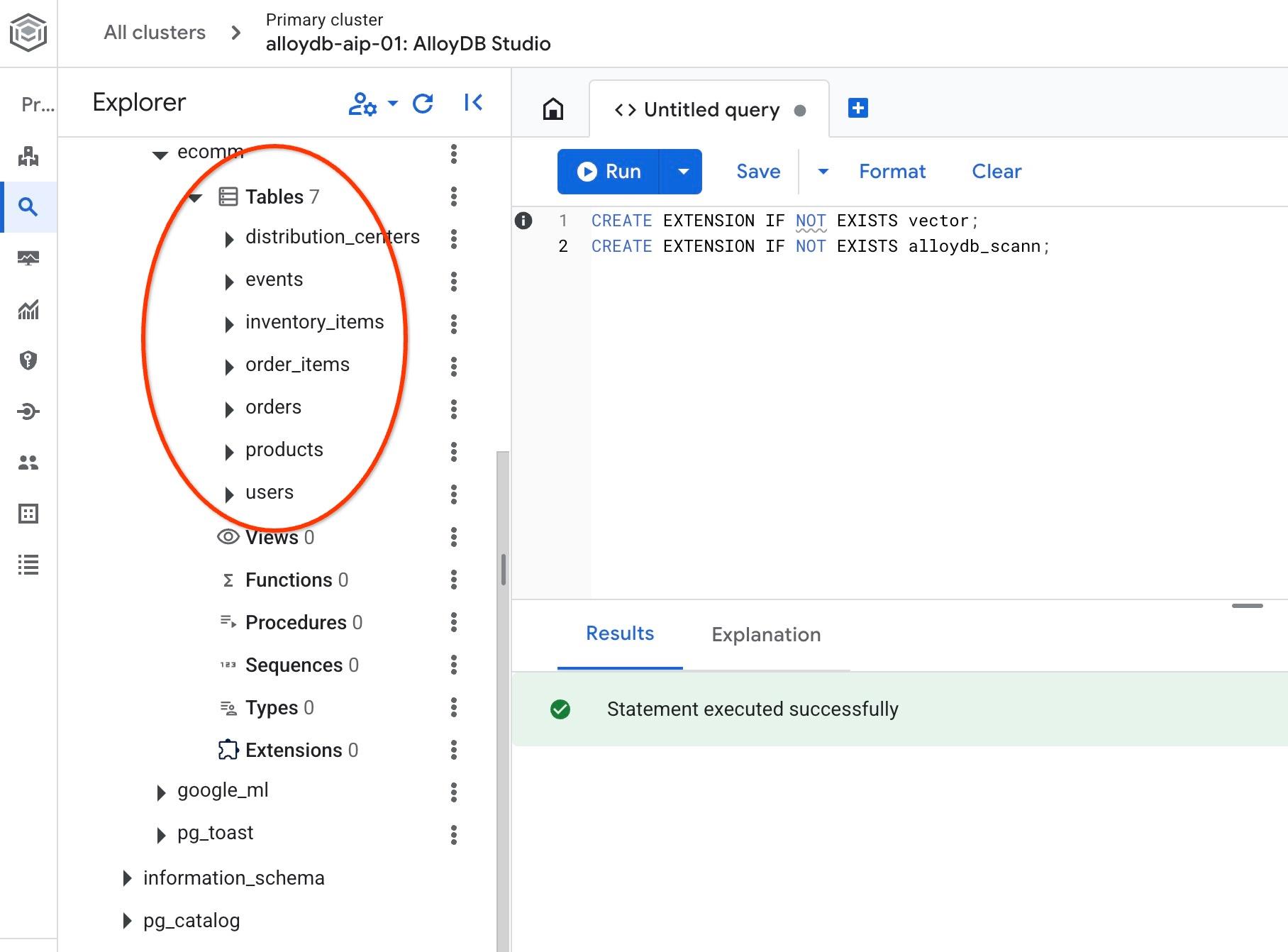
Verifica la cantidad de filas en una de las tablas.
select count(*) from ecomm.products;
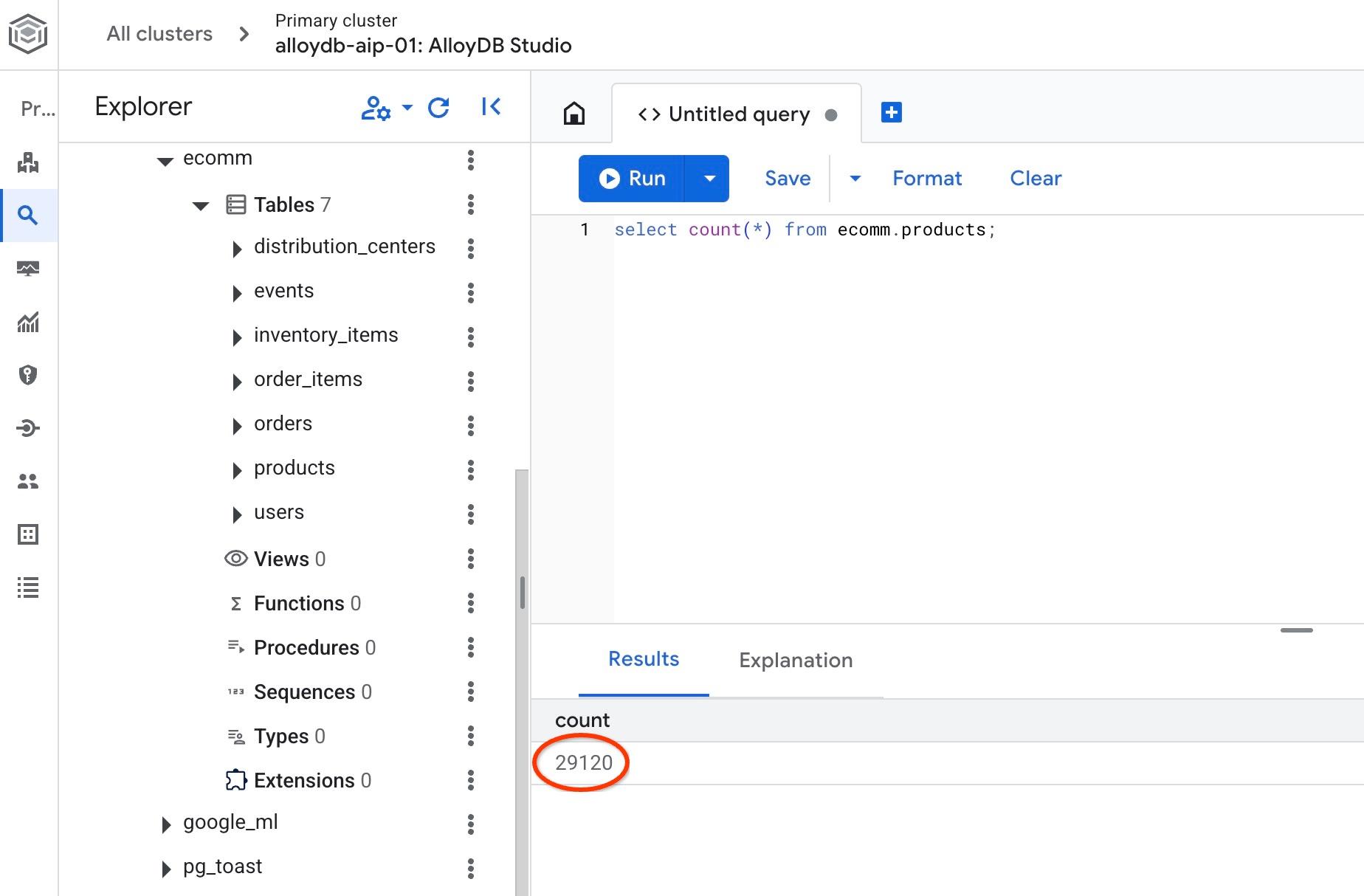
Importamos correctamente nuestros datos de muestra y podemos continuar con los próximos pasos.
7. Búsqueda semántica con incorporaciones de texto
En este capítulo, intentaremos usar la búsqueda semántica con embeddings de texto y la compararemos con la búsqueda de texto y de texto completo tradicional de Postgres.
Primero, probemos la búsqueda clásica con SQL de PostgreSQL estándar y el operador LIKE.
En AlloyDB Studio, conéctate a quickstart_db y trata de buscar un impermeable con la siguiente consulta:
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
La búsqueda no devuelve ninguna fila, ya que necesitaría palabras exactas como condiciones húmedas y chaqueta para estar en el nombre o la descripción del producto. Y la "chaqueta para condiciones húmedas" no es lo mismo que la "chaqueta para condiciones de lluvia".
Podemos intentar incluir todas las variaciones posibles en la búsqueda. Intentemos incluir solo dos palabras. Por ejemplo:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
Esto devolvería varias filas, pero no todas coinciden perfectamente con nuestra solicitud de chaquetas, y es difícil ordenarlas por relevancia. Por ejemplo, si agregamos más condiciones, como "para hombres" y otras, aumentaría significativamente la complejidad de la búsqueda. También podemos probar la búsqueda de texto completo, pero incluso allí nos encontramos con limitaciones relacionadas con palabras más o menos exactas y la relevancia de la respuesta.
Ahora podemos realizar una búsqueda similar con embeddings. Ya calculamos previamente los embeddings de nuestros productos con diferentes modelos. Usaremos el modelo gemini-embedding-001 más reciente de Google. Los almacenamos en la columna "product_embedding" de la tabla ecomm.products. Si ejecutamos una búsqueda para nuestra condición de búsqueda "chaqueta para lluvia para hombres" con la siguiente consulta:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
Devolverá no solo las chaquetas para condiciones húmedas, sino que también ordenará todos los resultados para colocar los más relevantes en la parte superior.
La búsqueda con incorporaciones devuelve resultados en un plazo de entre 90 y 150 ms, en el que se dedica una parte del tiempo a obtener los datos del modelo de incorporación en la nube. Si observamos el plan de ejecución, la solicitud al modelo se incluye en el tiempo de planificación. La parte de la consulta que realiza la búsqueda en sí es bastante corta. Se tarda menos de 7 ms en realizar la búsqueda en 29,000 registros con el índice de ScaNN de AlloyDB.
Este es el resultado del plan de ejecución:
Límite (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> Index Scan using embedding_scann on products (cost=2709.20..30736.40 rows=29120 width=490) (actual time=6.964..7.046 rows=10 loops=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
…
-0.0051468653,-0.012440448]'::vector)
Limit: 10
Tiempo de planificación: 136.579 ms
Tiempo de ejecución: 6.791 ms
(6 filas)
Esa fue la búsqueda de embedding de texto con el modelo de embedding solo de texto. Pero también tenemos imágenes de nuestros productos que podemos usar con la búsqueda. En el próximo capítulo, mostraremos cómo el modelo multimodal usa imágenes para la búsqueda.
8. Cómo usar la Búsqueda multimodal
Si bien la búsqueda semántica basada en texto es útil, describir detalles complejos puede ser un desafío. La búsqueda multimodal de AlloyDB ofrece una ventaja, ya que permite el descubrimiento de productos a través de la entrada de imágenes. Esto es especialmente útil cuando la representación visual aclara la intención de búsqueda de manera más eficaz que las descripciones textuales por sí solas. Por ejemplo, "encuéntrame un abrigo como este de la foto".
Volvamos a nuestro ejemplo de la chaqueta. Si tengo una foto de una chaqueta similar a lo que quiero encontrar, puedo pasarla al modelo de incorporación multimodal de Google y compararla con las incorporaciones de las imágenes de mis productos. En nuestra tabla, ya calculamos los embeddings de las imágenes de nuestros productos en la columna product_image_embedding, y puedes ver el modelo que se usó en la columna product_image_embedding_model.
Para nuestra búsqueda, podemos usar la función image_embedding para obtener la incorporación de nuestra imagen y compararla con las incorporaciones precalculadas. Para habilitar la función, debemos asegurarnos de que estamos usando la versión correcta de la extensión google_ml_integration.
Verifiquemos la versión actual de la extensión. En AlloyDB Studio, ejecuta
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Si la versión es anterior a la 1.5.2, ejecuta el siguiente procedimiento.
CALL google_ml.upgrade_to_preview_version();
Luego, vuelve a verificar la versión de la extensión. Debería ser 1.5.3.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
También debemos habilitar las funciones del motor de consultas de IA en nuestra base de datos. Esto se puede hacer actualizando la marca de instancia para todas las bases de datos de la instancia o habilitándola solo para nuestra base de datos. Ejecuta el siguiente comando en AlloyDB Studio para habilitarlo en la base de datos quickstart_db.
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
Ahora podemos buscar por imagen. Esta es mi imagen de muestra para la búsqueda, pero puedes usar cualquier imagen personalizada. Solo debes subirlo al almacenamiento de Google o a otro recurso disponible públicamente y colocar el URI en la búsqueda.

Se sube a gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png
Búsqueda de imágenes por imágenes
Primero, intentamos buscar solo por la imagen:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Y pudimos encontrar algunas chaquetas abrigadas en el inventario. Para ver las imágenes, puedes descargarlas con el SDK de Cloud (gcloud storage cp) proporcionando la columna public_url y, luego, abrirlas con cualquier herramienta que funcione con imágenes.
|
|
|
|




La búsqueda con imágenes devuelve elementos que se parecen a la imagen que proporcionamos para la comparación. Como ya mencioné, puedes intentar subir tus propias imágenes a un bucket público y ver si puede encontrar diferentes tipos de ropa.
Usamos el modelo "multimodalembedding@001" de Google para nuestra búsqueda con imágenes. Nuestra función image_embedding envía la imagen a Vertex AI, la convierte en un vector y la devuelve para compararla con los vectores de imagen almacenados en nuestra base de datos.
También podemos verificar con "EXPLAIN ANALYZE" qué tan rápido funciona con nuestro índice de ScaNN de AlloyDB.
Este es el resultado del plan de ejecución:
Límite (costo=971.70..975.55 filas=4 ancho=490) (tiempo real=2.453..2.477 filas=4 bucles=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
…
,-0.010307034,-0.010053742]'::vector)
Limit: 4
Tiempo de planificación: 913.322 ms
Tiempo de ejecución: 2.517 ms
(6 filas)
Y, de nuevo, como en el ejemplo anterior, podemos ver que la mayor parte del tiempo se dedicó a convertir nuestra imagen en embeddings con el extremo de Cloud, y la búsqueda de vectores en sí solo lleva 2.5 ms.
Búsqueda de imágenes por texto
Con la función multimodal, también podemos pasar una descripción de texto de la chaqueta que intentamos buscar al modelo usando google_ml.text_embedding para el mismo modelo y compararla con las incorporaciones de imágenes para ver qué imágenes devuelve.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Y obtuvimos un conjunto de chaquetas acolchadas con colores grises u oscuros.
|
|
|
|




Obtuvimos un conjunto de chaquetas ligeramente diferente, pero eligió correctamente las chaquetas según nuestra descripción cuando buscamos en las incorporaciones de imágenes.
Probemos otra forma de buscar entre las descripciones usando nuestra incorporación para la imagen de búsqueda.
Búsqueda de texto por imágenes
Intentamos buscar imágenes pasando la incorporación de nuestra imagen y compararla con las incorporaciones de imágenes precalculadas de nuestros productos. También intentamos buscar imágenes pasando una incorporación para nuestra solicitud de texto y buscar entre la misma incorporación las imágenes de los productos. Ahora intentemos usar un embedding para nuestra imagen y compararlo con los embeddings de texto de las descripciones de los productos. Estos embeddings se almacenan en la columna product_description_embedding y usan el mismo modelo multimodalembedding@001.
Esta es nuestra búsqueda:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Aquí obtuvimos un conjunto de chaquetas ligeramente diferente con colores grises u oscuros, en el que algunas son iguales o muy similares a las que elegimos en las otras formas de búsqueda.
|
|
|
|



Según el embedding de las imágenes, puede compararlo con los embeddings calculados para la descripción de texto y devolver el conjunto correcto de productos.
Búsqueda híbrida de texto y de imágenes
También puedes experimentar combinando embeddings de texto y de imagen, por ejemplo, con la fusión de rango recíproco. Este es un ejemplo de una consulta de este tipo en la que combinamos dos búsquedas, asignamos una puntuación a cada clasificación y ordenamos los resultados según la puntuación combinada.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
Puedes intentar jugar con diferentes parámetros en la búsqueda y ver si puedes mejorar los resultados. Además, también puedes usar otros operadores de IA para clasificar los resultados, como se describe en la documentación.
Aquí termina el lab. Para evitar cargos inesperados, te recomendamos que borres los recursos que no uses.
9. Limpia el entorno
Cuando termines el lab, destruye las instancias y el clúster de AlloyDB.
Borra el clúster de AlloyDB y todas las instancias
Si usaste la versión de prueba de AlloyDB No borres el clúster de prueba si planeas probar otros labs y recursos con él. No podrás crear otro clúster de prueba en el mismo proyecto.
El clúster se destruye con la opción force que también borra todas las instancias que pertenecen al clúster.
En Cloud Shell, define el proyecto y las variables de entorno si te desconectaste y se perdieron todos los parámetros de configuración anteriores:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Borra el clúster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Resultado esperado en la consola:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Borra las copias de seguridad de AlloyDB
Borra todas las copias de seguridad de AlloyDB del clúster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Resultado esperado en la consola:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. Felicitaciones
Felicitaciones por completar el codelab. Aprendiste a usar la búsqueda multimodal en AlloyDB con funciones de incorporación para textos e imágenes. Puedes intentar probar la búsqueda multimodal y mejorarla con la función google_ml.rank usando el codelab para los operadores de IA de AlloyDB.
Ruta de aprendizaje de Google Cloud
Este lab forma parte de la ruta de aprendizaje de IA lista para producción con Google Cloud.
- Explora el plan de estudios completo para cerrar la brecha entre el prototipo y la producción.
- Comparte tu progreso con el hashtag
#ProductionReadyAI.
Temas abordados
- Cómo implementar AlloyDB para Postgres
- Cómo usar AlloyDB Studio
- Cómo usar la búsqueda de vectores multimodal
- Cómo habilitar los operadores de AlloyDB AI
- Cómo usar diferentes operadores de AlloyDB AI para la búsqueda multimodal
- Cómo usar AlloyDB AI para combinar los resultados de la búsqueda de imágenes y texto
11. Encuesta
Resultado: