
۱. مقدمه
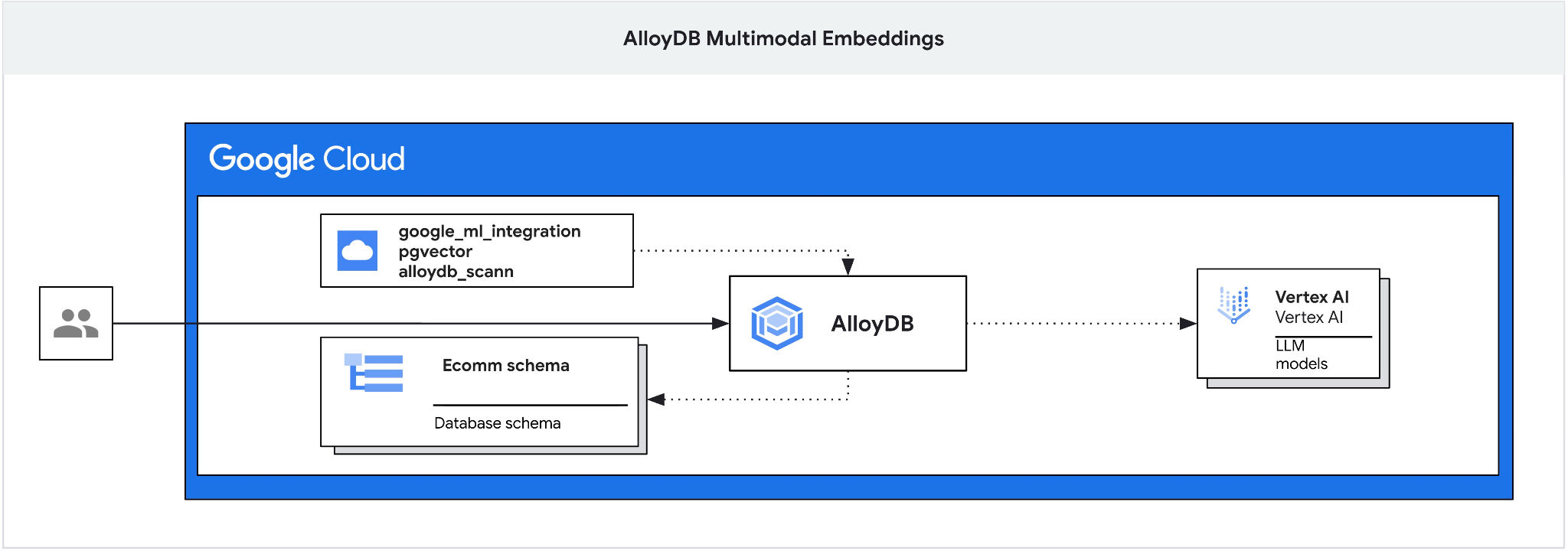
این آزمایشگاه کد، راهنمایی برای استقرار AlloyDB و بهرهبرداری از ادغام هوش مصنوعی برای جستجوی معنایی با استفاده از جاسازیهای چندوجهی ارائه میدهد. این آزمایشگاه بخشی از یک مجموعه آزمایشگاهی است که به ویژگیهای هوش مصنوعی AlloyDB اختصاص داده شده است. میتوانید اطلاعات بیشتر را در صفحه هوش مصنوعی AlloyDB در مستندات مطالعه کنید.
پیشنیازها
- درک اولیه از گوگل کلود، کنسول
- مهارتهای پایه در رابط خط فرمان و Cloud Shell
آنچه یاد خواهید گرفت
- نحوه استقرار AlloyDB برای Postgres
- نحوه استفاده از استودیوی AlloyDB
- نحوه استفاده از جستجوی برداری چندوجهی
- نحوه فعال کردن اپراتورهای هوش مصنوعی AlloyDB
- نحوه استفاده از عملگرهای مختلف هوش مصنوعی AlloyDB برای جستجوی چندوجهی
- نحوه استفاده از AlloyDB AI برای ترکیب نتایج جستجوی متن و تصویر
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم که از کنسول گوگل کلود و کلود شل پشتیبانی میکند
۲. تنظیمات و الزامات
راهاندازی پروژه
- وارد کنسول ابری گوگل شوید. اگر از قبل حساب جیمیل یا گوگل ورکاسپیس ندارید، باید یکی ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید.
- یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. برای ایجاد یک پروژه جدید در کنسول Google Cloud، در سربرگ، روی دکمه «انتخاب پروژه» کلیک کنید که یک پنجره بازشو باز میشود.

در پنجره انتخاب پروژه، دکمه «پروژه جدید» را فشار دهید که یک کادر محاورهای برای پروژه جدید باز میکند.
در کادر محاورهای، نام پروژه مورد نظر خود را وارد کرده و مکان را انتخاب کنید.
- نام پروژه ، نام نمایشی برای شرکتکنندگان این پروژه است. نام پروژه توسط APIهای گوگل استفاده نمیشود و میتوان آن را در هر زمانی تغییر داد.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد و غیرقابل تغییر است (پس از تنظیم، دیگر قابل تغییر نیست). کنسول گوگل کلود به طور خودکار یک شناسه منحصر به فرد تولید میکند، اما میتوانید آن را سفارشی کنید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید یا شناسه خودتان را برای بررسی در دسترس بودن آن ارائه دهید. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را که معمولاً با عبارت PROJECT_ID مشخص میشود، ارجاع دهید.
- برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
فعال کردن صورتحساب
برای فعال کردن پرداخت، دو گزینه دارید. میتوانید از حساب پرداخت شخصی خود استفاده کنید یا میتوانید با مراحل زیر اعتبار خود را بازخرید کنید.
استفاده از اعتبار گوگل کلود (اختیاری)
برای اجرای این کارگاه، به یک حساب صورتحساب با مقداری اعتبار نیاز دارید. برای شروع از اعتبارهای موجود در بنر بالای این codelab استفاده کنید. اگر از قبل به یک حساب صورتحساب متصل هستید، میتوانید از این مرحله صرف نظر کنید.
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۳ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
همچنین میتوانید دکمههای G و سپس S را فشار دهید. اگر در کنسول ابری گوگل باشید یا از این لینک استفاده کنید، این توالی، Cloud Shell را فعال میکند.
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. قبل از شروع
فعال کردن API
برای استفاده از AlloyDB ، Compute Engine ، Networking services و Vertex AI ، باید API های مربوط به آنها را در پروژه Google Cloud خود فعال کنید.
داخل Cloud Shell در ترمینال، مطمئن شوید که شناسه پروژه شما تنظیم شده است. شناسه پروژه باید در خط فرمان مانند زیر در داخل پرانتز نشان داده شود:
student@cloudshell:~ (test-project-001-402417)$
اگر شناسه پروژه در آنجا نشان داده نشده است، تب مرورگر خود را رفرش کنید و دوباره در Cloud Shell احراز هویت کنید.
متغیر محیطی PROJECT_ID را تنظیم کنید:
PROJECT_ID=$(gcloud config get-value project)
فعال کردن تمام سرویسهای لازم:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
خروجی مورد انتظار
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
۴. استقرار AlloyDB
ایجاد کلاستر و نمونه اولیه AlloyDB. روش زیر نحوه ایجاد یک کلاستر و نمونه AlloyDB را با استفاده از Google Cloud SDK شرح میدهد. اگر رویکرد کنسول را ترجیح میدهید، میتوانید مستندات اینجا را دنبال کنید.
قبل از ایجاد یک کلاستر AlloyDB، به یک محدوده IP خصوصی در VPC خود نیاز داریم تا توسط نمونه AlloyDB آینده مورد استفاده قرار گیرد. اگر آن را نداریم، باید آن را ایجاد کنیم، آن را به سرویسهای داخلی گوگل اختصاص دهیم و پس از آن میتوانیم کلاستر و نمونه را ایجاد کنیم.
ایجاد محدوده IP خصوصی
ما باید پیکربندی دسترسی به سرویس خصوصی (Private Service Access) را در VPC خود برای AlloyDB پیکربندی کنیم. فرض بر این است که ما شبکه VPC "پیشفرض" را در پروژه داریم و قرار است برای همه اقدامات از آن استفاده شود.
ایجاد محدوده IP خصوصی:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
ایجاد اتصال خصوصی با استفاده از محدوده IP اختصاص داده شده:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
ایجاد کلاستر AlloyDB
در این بخش، ما یک کلاستر AlloyDB در ناحیه us-central1 ایجاد میکنیم.
برای کاربر postgres رمز عبور تعریف کنید. میتوانید رمز عبور خودتان را تعریف کنید یا از یک تابع تصادفی برای تولید آن استفاده کنید.
export PGPASSWORD=`openssl rand -hex 12`
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
رمز عبور PostgreSQL را برای استفادههای بعدی یادداشت کنید.
echo $PGPASSWORD
در آینده برای اتصال به نمونه به عنوان کاربر postgres به آن رمز عبور نیاز خواهید داشت. پیشنهاد میکنم آن را جایی یادداشت یا کپی کنید تا بعداً بتوانید از آن استفاده کنید.
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
یک خوشه آزمایشی رایگان ایجاد کنید
اگر قبلاً از AlloyDB استفاده نکردهاید، میتوانید یک کلاستر آزمایشی رایگان ایجاد کنید:
منطقه و نام خوشه AlloyDB را تعریف کنید. ما قصد داریم از منطقه us-central1 و alloydb-aip-01 به عنوان نام خوشه استفاده کنیم:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
دستور زیر را برای ایجاد خوشه اجرا کنید:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
خروجی مورد انتظار کنسول:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
یک نمونه اصلی AlloyDB برای کلاستر ما در همان جلسه پوسته ابری ایجاد کنید. اگر اتصال شما قطع شد، باید متغیرهای محیطی منطقه و نام کلاستر را دوباره تعریف کنید.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
ایجاد کلاستر استاندارد AlloyDB
اگر این اولین کلاستر AlloyDB شما در پروژه نیست، با ایجاد یک کلاستر استاندارد ادامه دهید. اگر قبلاً در مرحله قبل یک کلاستر آزمایشی رایگان ایجاد کردهاید، از این مرحله صرف نظر کنید.
منطقه و نام خوشه AlloyDB را تعریف کنید. ما قصد داریم از منطقه us-central1 و alloydb-aip-01 به عنوان نام خوشه استفاده کنیم:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
دستور زیر را برای ایجاد خوشه اجرا کنید:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
خروجی مورد انتظار کنسول:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
یک نمونه اصلی AlloyDB برای کلاستر ما در همان جلسه پوسته ابری ایجاد کنید. اگر اتصال شما قطع شد، باید متغیرهای محیطی منطقه و نام کلاستر را دوباره تعریف کنید.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
۵. آمادهسازی پایگاه داده
ما باید یک پایگاه داده ایجاد کنیم، ادغام Vertex AI را فعال کنیم، اشیاء پایگاه داده را ایجاد کنیم و دادهها را وارد کنیم.
مجوزهای لازم را به AlloyDB اعطا کنید
مجوزهای Vertex AI را به عامل سرویس AlloyDB اضافه کنید.
با استفاده از علامت "+" در بالا، یک تب Cloud Shell دیگر باز کنید.
در تب جدید cloud shell دستور زیر را اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
با اجرای هر یک از دستورهای "exit" در تب، تب را ببندید:
exit
اتصال به استودیوی AlloyDB
در فصلهای بعدی، تمام دستورات SQL که نیاز به اتصال به پایگاه داده دارند، میتوانند در AlloyDB Studio اجرا شوند.
در یک برگه جدید، به صفحه خوشهها در AlloyDB برای Postgres بروید.
با کلیک روی نمونه اصلی، رابط کنسول وب را برای خوشه AlloyDB خود باز کنید.
سپس در سمت چپ روی AlloyDB Studio کلیک کنید:
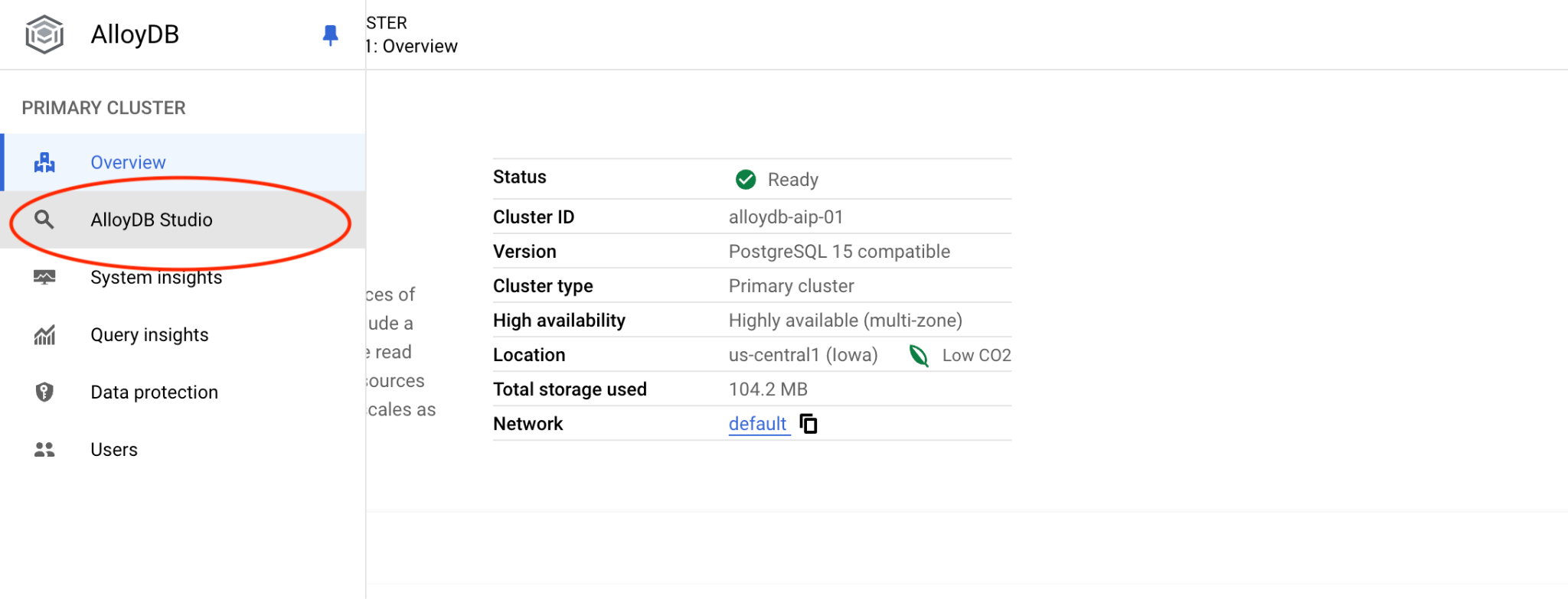
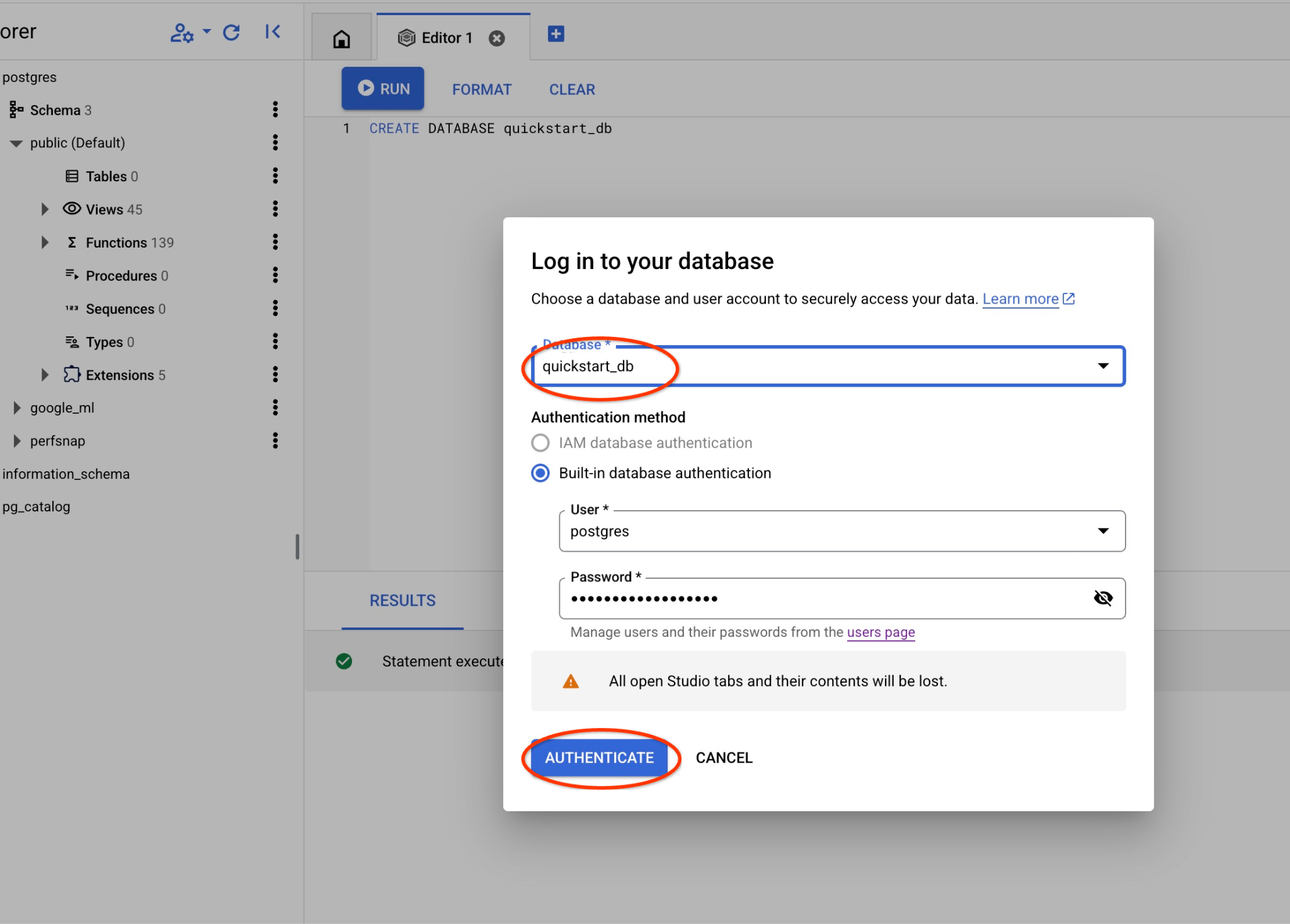
پایگاه داده postgres و کاربر postgres را انتخاب کنید و رمز عبوری که هنگام ایجاد کلاستر یادداشت کردهاید را وارد کنید. سپس روی دکمه "Authenticate" کلیک کنید. اگر رمز عبور را فراموش کردهاید یا این روش برای شما کار نمیکند، میتوانید رمز عبور را تغییر دهید. برای نحوه انجام این کار، مستندات را بررسی کنید.
رابط کاربری AlloyDB Studio باز خواهد شد. برای اجرای دستورات در پایگاه داده، روی تب "Untitled Query" در سمت راست کلیک کنید.
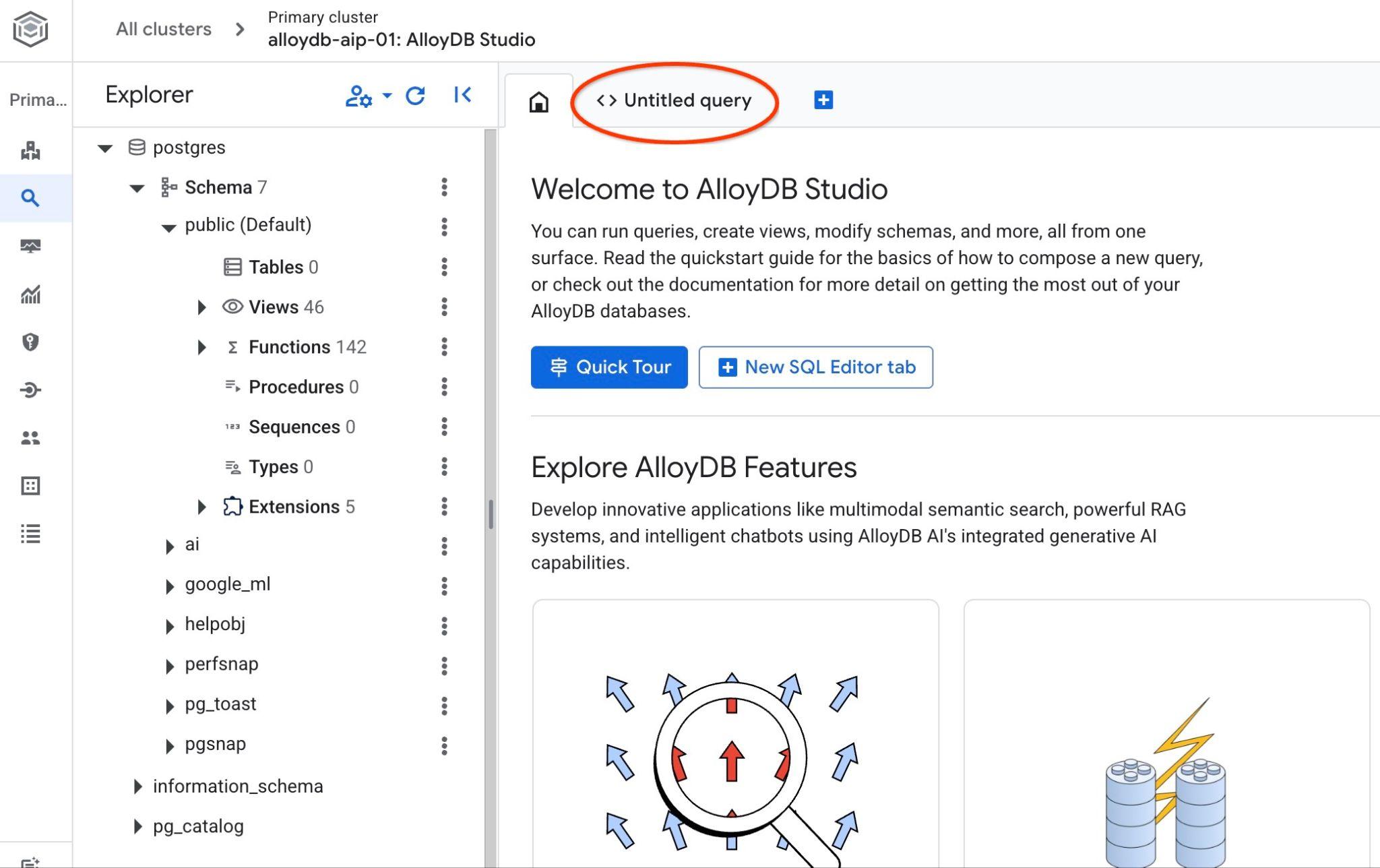
رابطی را باز میکند که میتوانید دستورات SQL را در آن اجرا کنید.
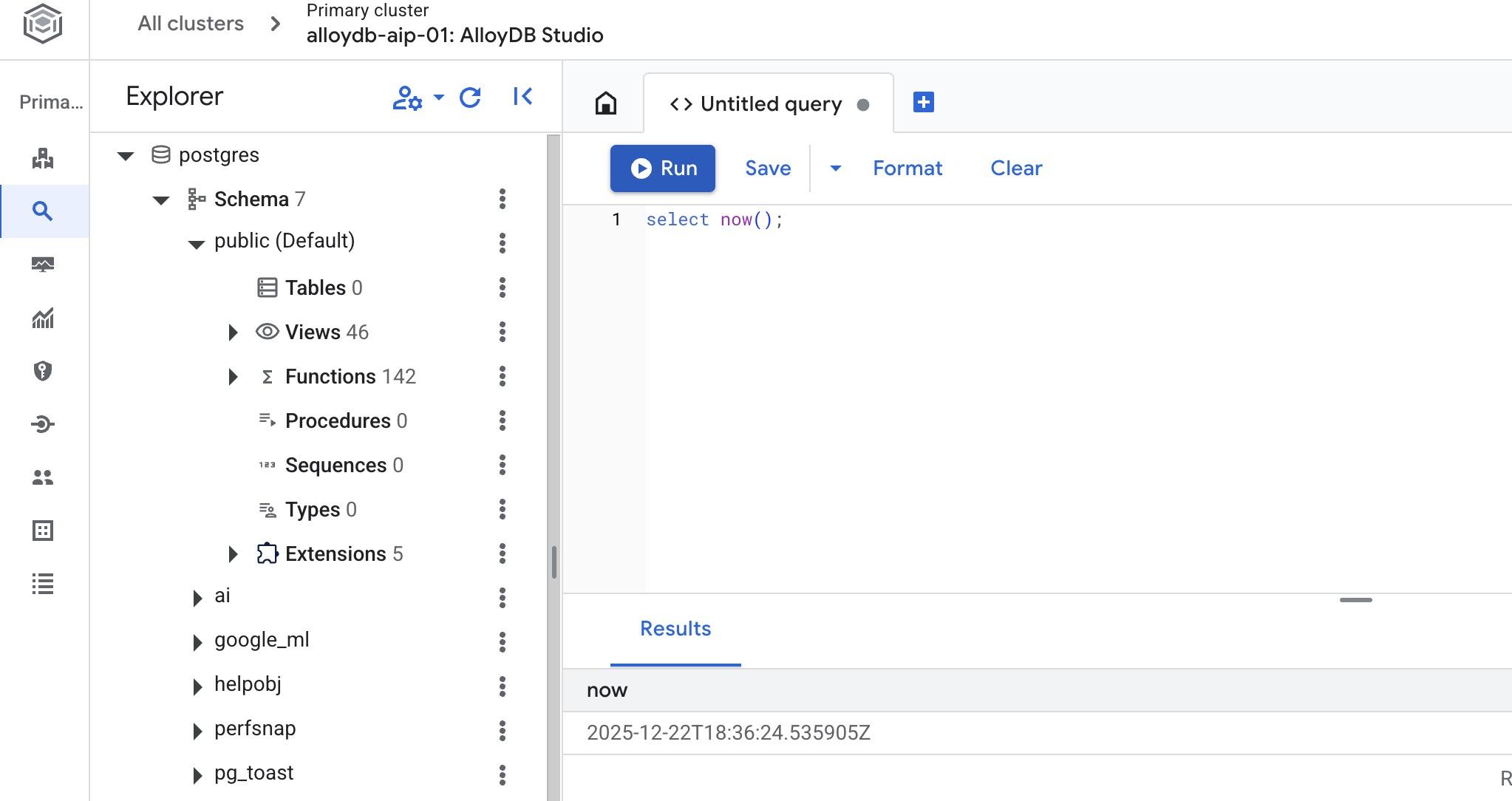
ایجاد پایگاه داده
ایجاد پایگاه داده با شروع سریع
در ویرایشگر استودیوی AlloyDB، دستور زیر را اجرا کنید.
ایجاد پایگاه داده:
CREATE DATABASE quickstart_db
خروجی مورد انتظار:
Statement executed successfully
اتصال به پایگاه دادهی quickstart_db
با استفاده از دکمه تغییر کاربر/پایگاه داده، دوباره به استودیو متصل شوید.
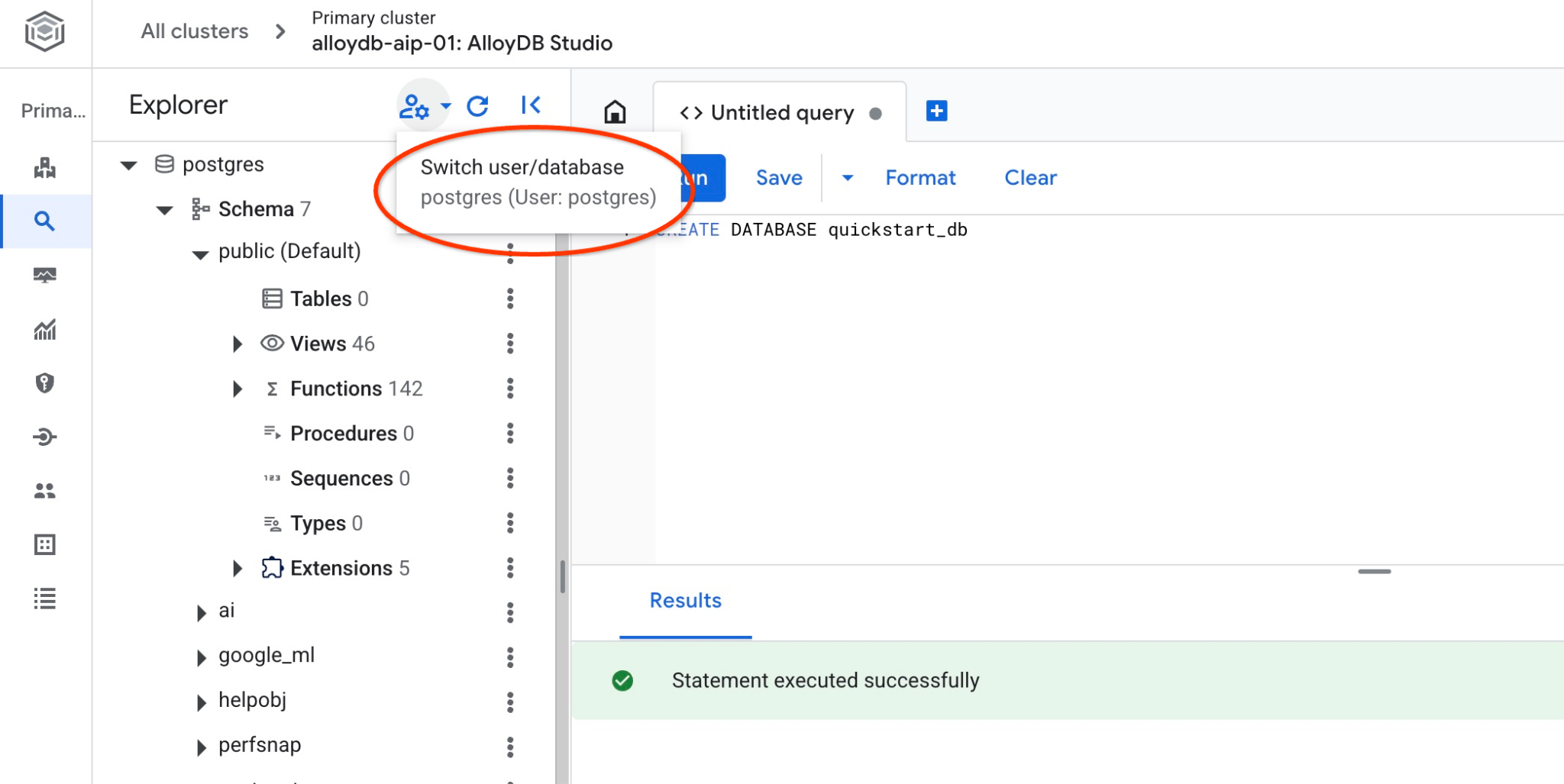
پایگاه داده جدید quickstart_db را از لیست کشویی انتخاب کنید و از همان نام کاربری و رمز عبور قبلی استفاده کنید.
این یک اتصال جدید باز میکند که در آن میتوانید با اشیاء پایگاه داده quickstart_db کار کنید.
۶. دادههای نمونه
حالا باید اشیاء را در پایگاه داده ایجاد کنیم و دادهها را بارگذاری کنیم. ما قصد داریم از یک مخزن فرضی "Cymbal" با دادههای فرضی استفاده کنیم.
قبل از وارد کردن دادهها، باید افزونههایی را که از انواع داده و شاخصها پشتیبانی میکنند، فعال کنیم. ما به دو افزونه نیاز داریم: یکی که از نوع داده برداری پشتیبانی میکند و دیگری که از شاخص AlloyDB ScaNN پشتیبانی میکند.
در AlloyDB Studio، به quickstart_db متصل شوید و دستور زیر را اجرا کنید:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
مجموعه دادهها به صورت یک فایل SQL آماده و قرار داده میشود که میتواند با استفاده از رابط import در پایگاه داده بارگذاری شود. در cloud Shell دستورات زیر را اجرا کنید:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
این دستور از AlloyDB SDK استفاده میکند و یک کاربر با نام agentspace_user ایجاد میکند و سپس دادههای نمونه را مستقیماً از سطل GCS به پایگاه داده وارد میکند و تمام اشیاء لازم را ایجاد کرده و دادهها را وارد میکند.
بعد از وارد کردن، میتوانیم جداول را در AlloyDB Studio بررسی کنیم. جداول در طرح ecomm قرار دارند:
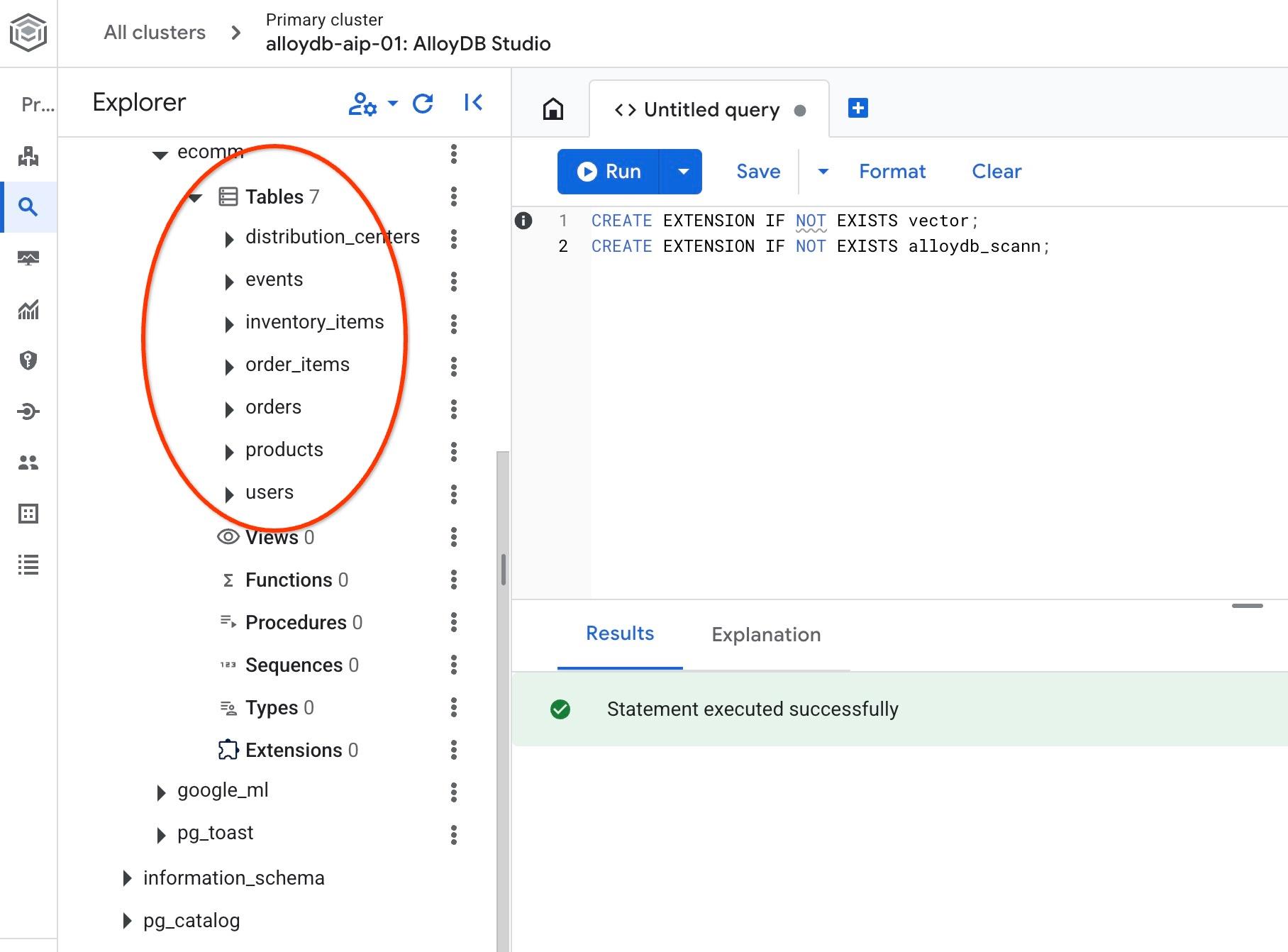
و تعداد ردیفهای یکی از جداول را بررسی کنید.
select count(*) from ecomm.products;
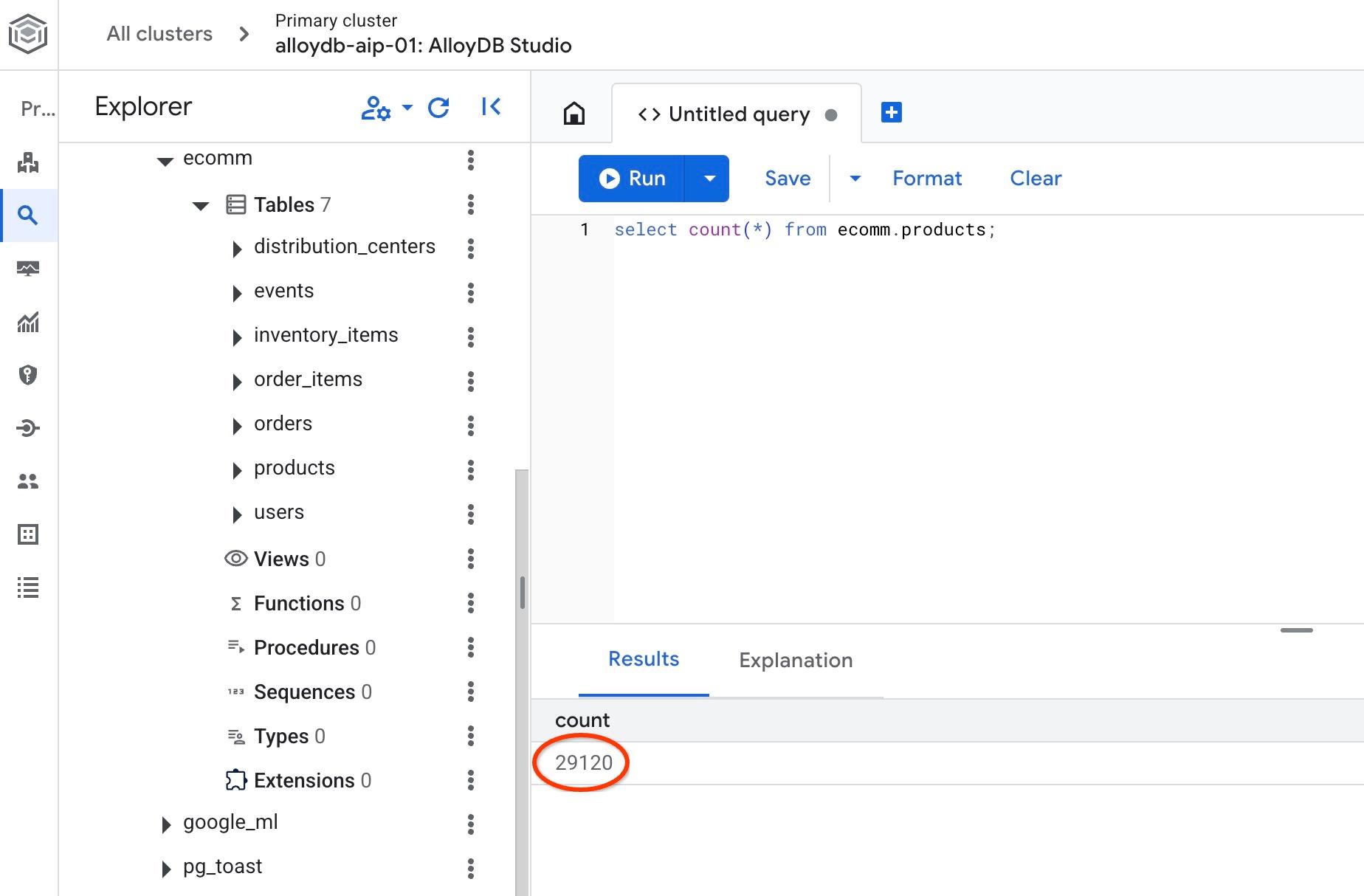
ما با موفقیت دادههای نمونه خود را وارد کردیم و میتوانیم مراحل بعدی را ادامه دهیم.
۷. جستجوی معنایی با استفاده از جاسازی متن
در این فصل سعی خواهیم کرد از جستجوی معنایی با استفاده از جاسازی متن استفاده کنیم و آن را با جستجوی سنتی متن و متن کامل Postgres مقایسه کنیم.
بیایید ابتدا جستجوی کلاسیک را با استفاده از PostgreSQL SQL استاندارد با عملگر LIKE امتحان کنیم.
در AlloyDB Studio به quickstart_db متصل شوید، و با استفاده از کوئری زیر، یک ژاکت بارانی جستجو کنید:
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
این کوئری هیچ ردیفی را برنمیگرداند، زیرا به کلمات دقیقی مانند شرایط مرطوب و ژاکت نیاز دارد که یا در نام محصول یا در توضیحات آن وجود داشته باشد. و «ژاکت شرایط مرطوب» با «ژاکت شرایط بارانی» یکسان نیست.
میتوانیم سعی کنیم تمام تغییرات ممکن را در جستجو لحاظ کنیم. بیایید سعی کنیم فقط دو کلمه را در جستجو لحاظ کنیم. برای مثال:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
این کار چندین ردیف را برمیگرداند، اما همه آنها کاملاً با درخواست ما برای ژاکتها مطابقت ندارند و مرتبسازی بر اساس ارتباط دشوار است. و برای مثال، اگر شرایط بیشتری مانند "برای مردان" و موارد دیگر اضافه کنیم، پیچیدگی پرسوجو به طور قابل توجهی افزایش مییابد. به عنوان جایگزین، میتوانیم جستجوی متن کامل را امتحان کنیم، اما حتی در آنجا نیز با محدودیتهایی مربوط به کلمات کم و بیش دقیق و ارتباط پاسخ مواجه میشویم.
اکنون میتوانیم جستجوی مشابهی را با استفاده از جاسازیها انجام دهیم. ما قبلاً جاسازیها را برای محصولات خود با استفاده از مدلهای مختلف از پیش محاسبه کردهایم. ما قصد داریم از آخرین مدل گوگل، gemini-embedding-001، استفاده کنیم. ما آنها را در ستون " product_embedding " از جدول ecomm.products ذخیره کردهایم. اگر با استفاده از عبارت زیر، یک پرسوجو برای شرط جستجوی "کاپشن بارانی مردانه" خود اجرا کنیم:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
این ابزار نه تنها کاپشنها را برای شرایط مرطوب برمیگرداند، بلکه تمام نتایج را نیز مرتب میکند و مرتبطترین نتایج را در بالا قرار میدهد.
پرسوجوی دارای جاسازیها، نتایجی در حدود ۹۰ تا ۱۵۰ میلیثانیه برمیگرداند که بخشی از این زمان صرف دریافت دادهها از مدل جاسازی ابری میشود. اگر به طرح اجرا نگاه کنیم، درخواست به مدل در زمان برنامهریزی گنجانده شده است. بخشی از پرسوجو که خود جستجو را انجام میدهد، بسیار کوتاه است. انجام جستجو در ۲۹ هزار رکورد با استفاده از شاخص AlloyDB ScaNN کمتر از ۷ میلیثانیه طول میکشد.
خروجی طرح اجرایی به صورت زیر است:
محدودیت (هزینه= ۲۷۰۹.۲۰ ... ۲۷۱۸.۸۲ ردیف = ۱۰ عرض = ۴۹۰) (زمان واقعی = ۶.۹۶۶ ... ۷.۰۴۹ ردیف = ۱۰ حلقه = ۱)
-> اسکن فهرست با استفاده از embedding_scann روی محصولات (هزینه=۲۷۰۹.۲۰..۳۰۷۳۶.۴۰ ردیف=۲۹۱۲۰ عرض=۴۹۰) (زمان واقعی=۶.۹۶۴..۷.۰۴۶ ردیف=۱۰ حلقه=۱)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
...
-0.0051468653,-0.012440448]'::بردار)
Limit: 10
زمان برنامهریزی: ۱۳۶.۵۷۹ میلیثانیه
زمان اجرا: ۶.۷۹۱ میلیثانیه
(۶ ردیف)
این جستجوی جاسازی متن با استفاده از مدل جاسازی فقط متن بود. اما ما برای محصولات خود تصاویر نیز داریم و میتوانیم از آنها در جستجو استفاده کنیم. در فصل بعدی نشان خواهیم داد که چگونه مدل چندوجهی از تصاویر برای جستجو استفاده میکند.
۸. استفاده از جستجوی چندوجهی
اگرچه جستجوی معنایی مبتنی بر متن مفید است، اما توصیف جزئیات پیچیده میتواند چالش برانگیز باشد. جستجوی چندوجهی AlloyDB با فعال کردن کشف محصول از طریق ورودی تصویر، مزیتی را ارائه میدهد. این امر به ویژه زمانی مفید است که نمایش بصری، هدف جستجو را مؤثرتر از توصیفات متنی به تنهایی روشن کند. به عنوان مثال - "یک کت مانند این را در تصویر برای من پیدا کنید".
بیایید به مثال ژاکت برگردیم. اگر تصویری از یک ژاکت مشابه آنچه میخواهم پیدا کنم، داشته باشم، میتوانم آن را به مدل جاسازی چندوجهی گوگل ارسال کنم و آن را با جاسازیهای تصاویر محصولاتم مقایسه کنم. در جدول ما، جاسازیهای تصاویر محصولاتمان را در ستون product_image_embedding محاسبه کردهایم و میتوانید مدل استفاده شده را در ستون product_image_embedding_model مشاهده کنید.
برای جستجوی خود میتوانیم از تابع image_embedding برای دریافت جاسازی تصویر خود و مقایسه آن با جاسازیهای از پیش محاسبهشده استفاده کنیم. برای فعال کردن این تابع، باید مطمئن شویم که از نسخه صحیح افزونه google_ml_integration استفاده میکنیم.
بیایید نسخه فعلی افزونه را بررسی کنیم. در AlloyDB Studio اجرا کنید.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
اگر نسخه کمتر از ۱.۵.۲ است، مراحل زیر را اجرا کنید.
CALL google_ml.upgrade_to_preview_version();
و نسخه افزونه را دوباره بررسی کنید. باید ۱.۵.۳ باشد.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
ما همچنین باید ویژگیهای موتور جستجوی هوش مصنوعی را در پایگاه داده خود فعال کنیم. این کار را میتوان با بهروزرسانی پرچم نمونه برای همه پایگاههای داده موجود در نمونه یا با فعال کردن آن فقط برای پایگاه داده خودمان انجام داد. دستور زیر را در AlloyDB Studio اجرا کنید تا آن را برای پایگاه داده quickstart_db فعال کنید.
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
حالا میتوانیم بر اساس تصویر جستجو کنیم. این نمونه تصویر من برای جستجو است، اما شما میتوانید از هر تصویر دلخواهی استفاده کنید. فقط کافی است آن را در فضای ذخیرهسازی گوگل یا سایر منابع عمومی آپلود کنید و URI را در کوئری قرار دهید.

و در آدرس gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png آپلود شده است.
جستجوی تصویر بر اساس تصاویر
ابتدا، سعی میکنیم فقط بر اساس تصویر جستجو کنیم:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
و ما توانستیم چند ژاکت گرم در موجودی پیدا کنیم. برای دیدن تصاویر میتوانید آنها را با استفاده از cloud SDK ( gcloud storage cp ) با وارد کردن ستون public_url دانلود کنید و سپس آن را با استفاده از هر ابزاری که با تصاویر کار میکند، باز کنید.
|
|
|
|




جستجوی تصویر، مواردی را که شبیه تصویر ما برای مقایسه هستند، برمیگرداند. همانطور که قبلاً اشاره کردم، میتوانید تصاویر خود را در یک سطل عمومی بارگذاری کنید و ببینید آیا میتواند انواع مختلف لباس را پیدا کند یا خیر.
ما از مدل 'multimodalembedding@001' گوگل برای جستجوی تصویر خود استفاده کردهایم. تابع image_embedding ما تصویر را به Vertex AI ارسال میکند، آن را به یک بردار تبدیل میکند و آن را برای مقایسه با بردارهای تصویر ذخیره شده در پایگاه داده ما برمیگرداند.
همچنین میتوانیم با استفاده از «EXPLAIN ANALYZE» سرعت عملکرد آن را با شاخص AlloyDB ScaNN خود بررسی کنیم.
خروجی مربوط به طرح اجرایی به صورت زیر است:
محدودیت (هزینه=۹۷۱.۷۰..۹۷۵.۵۵ ردیف=۴ عرض=۴۹۰) (زمان واقعی=۲.۴۵۳..۲.۴۷۷ ردیف=۴ حلقه=۱)
-> اسکن فهرست با استفاده از product_image_embedding_scann روی محصولات (هزینه = ۹۷۱.۷۰..۲۸۹۹۸.۹۰ ردیف = ۲۹۱۲۰ عرض = ۴۹۰) (زمان واقعی = ۲.۴۵۱..۲.۴۷۵ ردیف = ۴ حلقه = ۱)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
...
،-0.010307034،-0.010053742]'::بردار)
Limit: 4
زمان برنامهریزی: ۹۱۳.۳۲۲ میلیثانیه
زمان اجرا: ۲.۵۱۷ میلیثانیه
(۶ ردیف)
و دوباره مانند مثال قبلی میتوانیم ببینیم که بیشترین زمان صرف تبدیل تصویر ما به جاسازیها با استفاده از نقطه پایانی ابری شده است و خود جستجوی برداری تنها ۲.۵ میلیثانیه طول میکشد.
جستجوی تصویر بر اساس متن
با استفاده از چندوجهی، میتوانیم با استفاده از google_ml.text_embedding برای همان مدل، توضیحات متنی مربوط به ژاکتی که میخواهیم جستجو کنیم را به مدل ارسال کنیم و آن را با تصاویر جاسازیشده مقایسه کنیم تا ببینیم چه تصاویری را برمیگرداند.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
و ما یک ست کاپشن پفی با رنگهای خاکستری یا تیره گرفتیم.
|
|
|
|




ما یک مجموعه ژاکت کمی متفاوت دریافت کردهایم، اما بر اساس توضیحات ما هنگام جستجو در میان تصاویر جاسازیشده، ژاکتها را به درستی انتخاب کرد.
بیایید با استفاده از جاسازی تصویر جستجو، روش دیگری را برای جستجو در میان توضیحات امتحان کنیم.
جستجوی متن بر اساس تصاویر
ما سعی کردیم تصاویری را که از جاسازی تصویر ما عبور میکنند جستجو کنیم و آنها را با جاسازیهای تصویر از پیش محاسبه شده برای محصولات خود مقایسه کنیم. همچنین سعی کردیم با عبور یک جاسازی برای درخواست متن خود، تصاویر را جستجو کنیم و در میان همان جاسازی برای تصاویر محصول جستجو کنیم. اکنون بیایید سعی کنیم از یک جاسازی برای تصویر خود استفاده کنیم و آن را با جاسازیهای متنی برای توضیحات محصول مقایسه کنیم. این جاسازیها در ستون product_description_embedding ذخیره میشوند و از همان مدل multimodalembedding@001 استفاده میکنند.
سوال ما این است:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
و اینجا ما یک مجموعه ژاکت کمی متفاوت با رنگهای خاکستری یا تیره گرفتیم که برخی از آنها مشابه یا بسیار نزدیک به نمونههای انتخاب شده توسط روشهای دیگر جستجو بودند.
|
|
|
|



بر اساس جاسازی تصاویر، میتواند با جاسازیهای محاسبهشده برای توضیحات متن مقایسه کند و مجموعه صحیح محصولات را برگرداند.
جستجوی ترکیبی متن و تصویر
همچنین میتوانید ترکیب جاسازیهای متن و تصویر را با استفاده از، به عنوان مثال، ادغام رتبه متقابل، آزمایش کنید. در اینجا مثالی از چنین پرسوجویی آورده شده است که در آن دو جستجو را با اختصاص امتیاز به هر رتبه و مرتبسازی نتایج بر اساس امتیاز ترکیبی، ترکیب کردهایم.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
شما میتوانید با پارامترهای مختلف در پرسوجو بازی کنید و ببینید آیا میتوانید نتایج جستجوی خود را بهبود بخشید. علاوه بر این، میتوانید از سایر عملگرهای هوش مصنوعی نیز برای رتبهبندی نتایج، همانطور که در مستندات توضیح داده شده است، استفاده کنید.
این آزمایش به پایان میرسد. برای جلوگیری از هزینههای غیرمنتظره، توصیه میشود منابع بلااستفاده را حذف کنید.
۹. محیط را تمیز کنید
وقتی کار آزمایشگاهیتان تمام شد، نمونهها و کلاستر AlloyDB را از بین ببرید.
کلاستر AlloyDB و تمام نمونههای آن را حذف کنید.
اگر از نسخه آزمایشی AlloyDB استفاده کردهاید. اگر قصد دارید آزمایشگاهها و منابع دیگری را با استفاده از خوشه آزمایشی آزمایش کنید، خوشه آزمایشی را حذف نکنید. شما قادر به ایجاد خوشه آزمایشی دیگری در همان پروژه نخواهید بود.
خوشه با استفاده از گزینهی Force از بین میرود که تمام نمونههای متعلق به خوشه را نیز حذف میکند.
در پوسته ابری، اگر اتصال شما قطع شده و تمام تنظیمات قبلی از بین رفته است، متغیرهای پروژه و محیط را تعریف کنید:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
حذف خوشه:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
حذف پشتیبانهای AlloyDB
تمام پشتیبانهای AlloyDB را برای کلاستر حذف کنید:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
۱۰. تبریک
تبریک میگویم که آزمایشگاه کد را به پایان رساندید. شما یاد گرفتید که چگونه از جستجوی چندوجهی در AlloyDB با استفاده از توابع جاسازی برای متون و تصاویر استفاده کنید. میتوانید با استفاده از codelab برای اپراتورهای هوش مصنوعی AlloyDB، جستجوی چندوجهی را آزمایش کرده و آن را با تابع google_ml.rank بهبود بخشید.
مسیر یادگیری فضای ابری گوگل
این آزمایشگاه بخشی از پروژه «هوش مصنوعی آماده تولید با مسیر یادگیری ابری گوگل» است.
- برای پر کردن شکاف بین نمونه اولیه و تولید، برنامه درسی کامل را بررسی کنید .
- پیشرفت خود را با هشتگ
#ProductionReadyAIبه اشتراک بگذارید.
آنچه ما پوشش دادهایم
- نحوه استقرار AlloyDB برای Postgres
- نحوه استفاده از استودیوی AlloyDB
- نحوه استفاده از جستجوی برداری چندوجهی
- نحوه فعال کردن اپراتورهای هوش مصنوعی AlloyDB
- نحوه استفاده از عملگرهای مختلف هوش مصنوعی AlloyDB برای جستجوی چندوجهی
- نحوه استفاده از AlloyDB AI برای ترکیب نتایج جستجوی متن و تصویر
۱۱. نظرسنجی
خروجی: