
1. परिचय
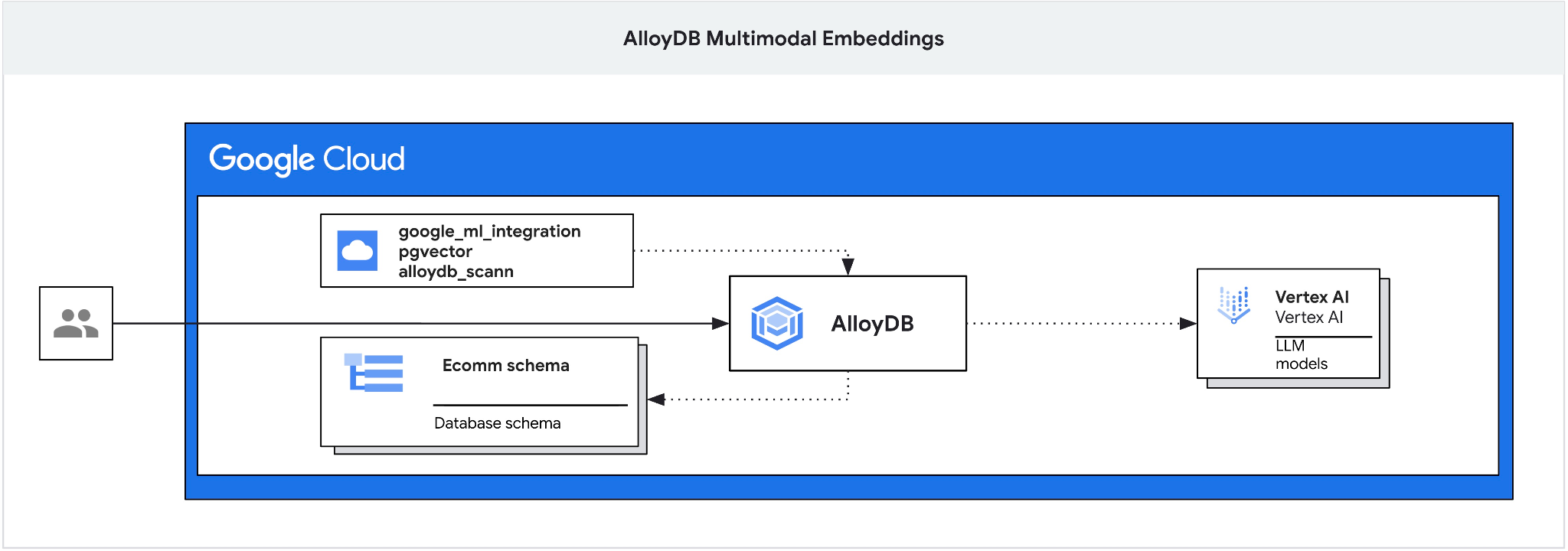
इस कोडलैब में, AlloyDB को डिप्लॉय करने और मल्टीमॉडल एम्बेडिंग का इस्तेमाल करके, सिमेंटिक सर्च के लिए एआई इंटिग्रेशन का फ़ायदा पाने के बारे में जानकारी दी गई है. यह लैब, AlloyDB की एआई सुविधाओं के लिए बनाए गए लैब कलेक्शन का हिस्सा है. दस्तावेज़ में, AlloyDB AI पेज पर जाकर इसके बारे में ज़्यादा पढ़ें.
ज़रूरी शर्तें
- Google Cloud और Console की बुनियादी जानकारी
- कमांड लाइन इंटरफ़ेस और Cloud Shell में बुनियादी कौशल
आपको क्या सीखने को मिलेगा
- Postgres के लिए AlloyDB को डिप्लॉय करने का तरीका
- AlloyDB Studio का इस्तेमाल कैसे करें
- मल्टीमॉडल वेक्टर सर्च का इस्तेमाल कैसे करें
- AlloyDB AI ऑपरेटर चालू करने का तरीका
- मल्टीमॉडल सर्च के लिए, AlloyDB AI के अलग-अलग ऑपरेटर इस्तेमाल करने का तरीका
- टेक्स्ट और इमेज के खोज नतीजों को एक साथ दिखाने के लिए, AlloyDB AI का इस्तेमाल कैसे करें
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- Google Cloud Console और Cloud Shell के साथ काम करने वाला वेब ब्राउज़र, जैसे कि Chrome
2. सेटअप और ज़रूरी शर्तें
प्रोजेक्ट सेटअप करना
- Google Cloud Console में साइन इन करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
- कोई नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. Google Cloud Console में नया प्रोजेक्ट बनाने के लिए, हेडर में मौजूद 'कोई प्रोजेक्ट चुनें' बटन पर क्लिक करें. इससे एक पॉप-अप विंडो खुलेगी.

'कोई प्रोजेक्ट चुनें' विंडो में, 'नया प्रोजेक्ट' बटन दबाएं. इससे नए प्रोजेक्ट के लिए एक डायलॉग बॉक्स खुलेगा.
डायलॉग बॉक्स में, प्रोजेक्ट का पसंदीदा नाम डालें और जगह चुनें.
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. प्रोजेक्ट के नाम का इस्तेमाल Google API नहीं करते हैं. इसे कभी भी बदला जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Google Cloud Console, अपने-आप एक यूनीक आईडी जनरेट करता है. हालांकि, इसे अपनी पसंद के मुताबिक बनाया जा सकता है. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा आईडी जनरेट करें. इसके अलावा, अपनी पसंद का आईडी डालकर भी देखा जा सकता है कि वह उपलब्ध है या नहीं. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी का रेफ़रंस देना होगा. इसे आम तौर पर, PROJECT_ID प्लेसहोल्डर से पहचाना जाता है.
- आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
बिलिंग चालू करें
बिलिंग चालू करने के लिए, आपके पास दो विकल्प हैं. आप अपने निजी बिलिंग खाते का इस्तेमाल कर सकते हैं या यहां दिए गए तरीके से क्रेडिट रिडीम कर सकते हैं.
Google Cloud क्रेडिट रिडीम करना (ज़रूरी नहीं है)
इस वर्कशॉप को चलाने के लिए, आपके पास कुछ क्रेडिट वाला बिलिंग खाता होना चाहिए. शुरू करने के लिए, इस कोडलैब के सबसे ऊपर मौजूद बैनर में दिए गए क्रेडिट का इस्तेमाल करें. अगर आपका खाता पहले से ही किसी बिलिंग खाते से कनेक्ट है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करना
अगर आपने Google Cloud क्रेडिट का इस्तेमाल करके बिलिंग सेट अप की है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करने के लिए, Cloud Console में बिलिंग की सुविधा चालू करने के लिए यहां जाएं.
ध्यान दें:
- इस लैब को पूरा करने में, क्लाउड संसाधनों पर 3 डॉलर से कम खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, संसाधनों को मिटाने का तरीका जानने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करें.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त क्रेडिट का इस्तेमाल कर सकते हैं.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसके अलावा, G और फिर S दबाकर भी यह सुविधा ऐक्सेस की जा सकती है. इस क्रम से, Cloud Shell चालू हो जाएगा. इसके लिए, आपको Google Cloud Console में होना चाहिए या इस लिंक का इस्तेमाल करना होगा.
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. शुरू करने से पहले
एपीआई चालू करना
AlloyDB, Compute Engine, नेटवर्किंग सेवाएं, और Vertex AI का इस्तेमाल करने के लिए, आपको अपने Google Cloud प्रोजेक्ट में इनसे जुड़े एपीआई चालू करने होंगे.
टर्मिनल में Cloud Shell के अंदर, पक्का करें कि आपका प्रोजेक्ट आईडी सेट अप हो. प्रोजेक्ट आईडी को कमांड प्रॉम्प्ट में, इस तरह से ब्रैकेट में दिखाया जाना चाहिए:
student@cloudshell:~ (test-project-001-402417)$
अगर आपको प्रोजेक्ट आईडी नहीं दिख रहा है, तो अपने ब्राउज़र टैब को रीफ़्रेश करें. इसके बाद, Cloud Shell में फिर से पुष्टि करें.
PROJECT_ID एनवायरमेंट वैरिएबल सेट करें:
PROJECT_ID=$(gcloud config get-value project)
ज़रूरी सभी सेवाएं चालू करें:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
अनुमानित आउटपुट
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB डिप्लॉय करना
AlloyDB क्लस्टर और प्राइमरी इंस्टेंस बनाएं. नीचे दी गई प्रोसेस में, Google Cloud SDK का इस्तेमाल करके AlloyDB क्लस्टर और इंस्टेंस बनाने का तरीका बताया गया है. अगर आपको कंसोल का इस्तेमाल करना है, तो यहां दिया गया दस्तावेज़ पढ़ें.
AlloyDB क्लस्टर बनाने से पहले, हमें अपने वीपीसी में एक उपलब्ध निजी आईपी रेंज की ज़रूरत होती है, ताकि आने वाले समय में AlloyDB इंस्टेंस इसका इस्तेमाल कर सके. अगर हमारे पास यह नहीं है, तो हमें इसे बनाना होगा. साथ ही, इसे Google की आंतरिक सेवाओं के लिए इस्तेमाल करने की अनुमति देनी होगी. इसके बाद, हम क्लस्टर और इंस्टेंस बना पाएंगे.
निजी आईपी रेंज बनाना
हमें AlloyDB के लिए, अपने वीपीसी में Private Service Access कॉन्फ़िगरेशन को कॉन्फ़िगर करना होगा. यहां यह मान लिया गया है कि प्रोजेक्ट में "डिफ़ॉल्ट" वीपीसी नेटवर्क है और इसका इस्तेमाल सभी कार्रवाइयों के लिए किया जाएगा.
निजी आईपी रेंज बनाएं:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
अलॉट की गई आईपी रेंज का इस्तेमाल करके, निजी कनेक्शन बनाएं:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
अनुमानित कंसोल आउटपुट:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB क्लस्टर बनाना
इस सेक्शन में, हम us-central1 क्षेत्र में एक AlloyDB क्लस्टर बना रहे हैं.
postgres उपयोगकर्ता के लिए पासवर्ड तय करें. आपके पास अपना पासवर्ड तय करने या पासवर्ड जनरेट करने के लिए, रैंडम फ़ंक्शन का इस्तेमाल करने का विकल्प होता है
export PGPASSWORD=`openssl rand -hex 12`
अनुमानित कंसोल आउटपुट:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
PostgreSQL का पासवर्ड नोट करें, ताकि इसे बाद में इस्तेमाल किया जा सके.
echo $PGPASSWORD
postgres उपयोगकर्ता के तौर पर इंस्टेंस से कनेक्ट करने के लिए, आपको आने वाले समय में इस पासवर्ड की ज़रूरत होगी. हमारा सुझाव है कि इसे लिख लें या कहीं कॉपी कर लें, ताकि बाद में इसका इस्तेमाल किया जा सके.
अनुमानित कंसोल आउटपुट:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
मुफ़्त में आज़माने के लिए क्लस्टर बनाना
अगर आपने पहले कभी AlloyDB का इस्तेमाल नहीं किया है, तो मुफ़्त में आज़माने के लिए क्लस्टर बनाया जा सकता है:
रीजन और AlloyDB क्लस्टर का नाम तय करें. हम us-central1 क्षेत्र और alloydb-aip-01 को क्लस्टर के नाम के तौर पर इस्तेमाल करने जा रहे हैं:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
क्लस्टर बनाने के लिए, यह कमांड चलाएं:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
अनुमानित कंसोल आउटपुट:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
उसी Cloud Shell सेशन में, हमारे क्लस्टर के लिए AlloyDB प्राइमरी इंस्टेंस बनाएं. अगर आपका कनेक्शन बंद हो जाता है, तो आपको क्षेत्र और क्लस्टर के नाम वाले एनवायरमेंट वैरिएबल फिर से तय करने होंगे.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
अनुमानित कंसोल आउटपुट:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard क्लस्टर बनाना
अगर यह प्रोजेक्ट में आपका पहला AlloyDB क्लस्टर नहीं है, तो स्टैंडर्ड क्लस्टर बनाएं. अगर आपने पिछले चरण में, बिना किसी शुल्क के आज़माने की सुविधा वाला क्लस्टर पहले ही बना लिया है, तो इस चरण को छोड़ दें.
रीजन और AlloyDB क्लस्टर का नाम तय करें. हम us-central1 क्षेत्र और alloydb-aip-01 को क्लस्टर के नाम के तौर पर इस्तेमाल करने जा रहे हैं:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
क्लस्टर बनाने के लिए, यह कमांड चलाएं:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
अनुमानित कंसोल आउटपुट:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
उसी Cloud Shell सेशन में, हमारे क्लस्टर के लिए AlloyDB प्राइमरी इंस्टेंस बनाएं. अगर आपका कनेक्शन बंद हो जाता है, तो आपको क्षेत्र और क्लस्टर के नाम वाले एनवायरमेंट वैरिएबल फिर से तय करने होंगे.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
अनुमानित कंसोल आउटपुट:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. डेटाबेस तैयार करना
हमें एक डेटाबेस बनाना होगा. साथ ही, Vertex AI इंटिग्रेशन को चालू करना होगा. इसके अलावा, डेटाबेस ऑब्जेक्ट बनाने होंगे और डेटा इंपोर्ट करना होगा.
AlloyDB को ज़रूरी अनुमतियां देना
AlloyDB सेवा एजेंट को Vertex AI की अनुमतियां दें.
सबसे ऊपर मौजूद "+" साइन का इस्तेमाल करके, Cloud Shell का कोई दूसरा टैब खोलें.
नए Cloud Shell टैब में यह कमांड चलाएं:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
अनुमानित कंसोल आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
टैब में "exit" कमांड डालकर टैब बंद करें:
exit
AlloyDB Studio से कनेक्ट करना
यहां दिए गए अध्यायों में, डेटाबेस से कनेक्ट करने के लिए ज़रूरी सभी SQL कमांड, AlloyDB Studio में एक्ज़ीक्यूट की जा सकती हैं.
नए टैब में, AlloyDB for PostgreSQL में क्लस्टर पेज पर जाएं.
प्राइमरी इंस्टेंस पर क्लिक करके, अपने AlloyDB क्लस्टर के लिए वेब कंसोल इंटरफ़ेस खोलें.
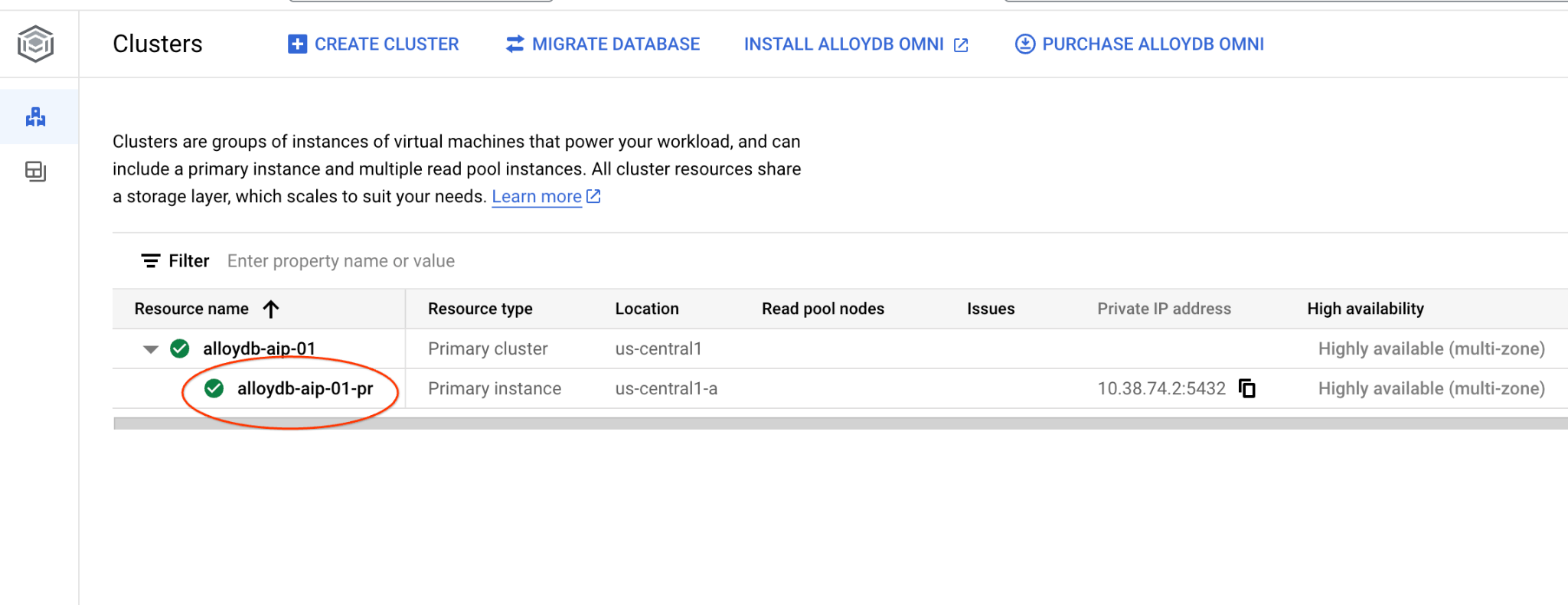
इसके बाद, बाईं ओर मौजूद AlloyDB Studio पर क्लिक करें:
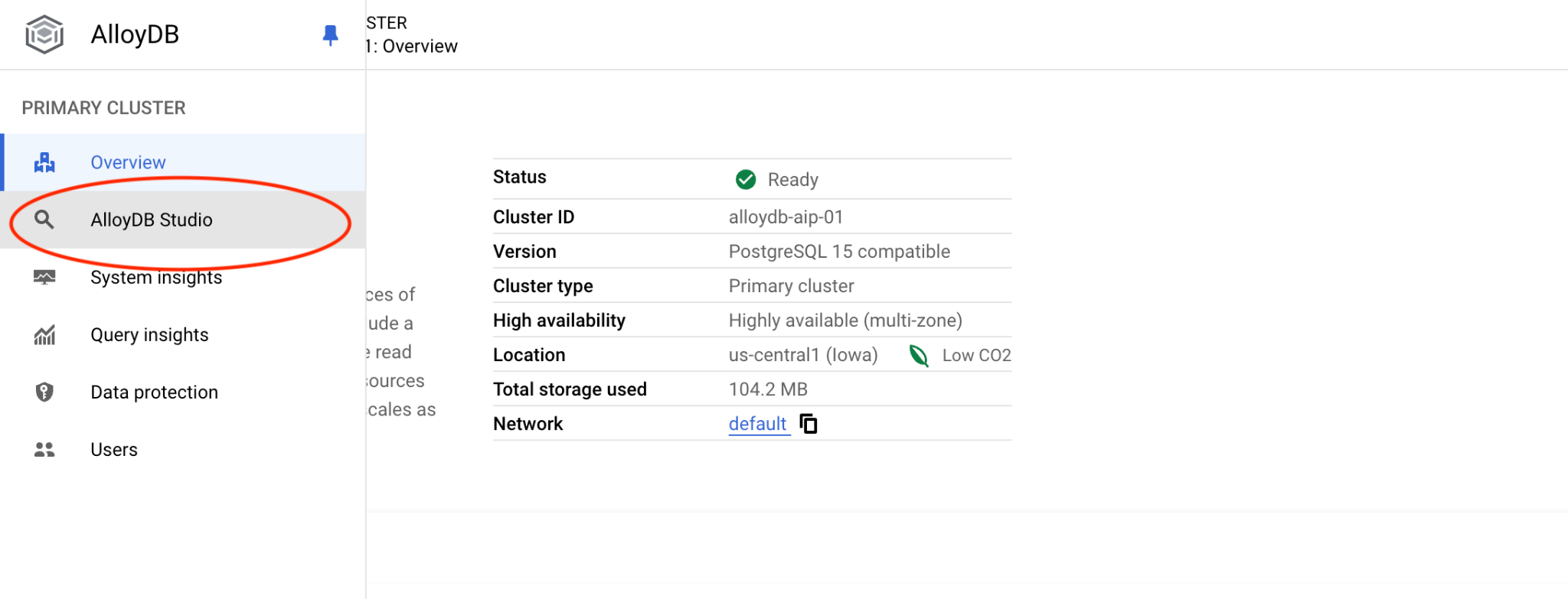
postgres डेटाबेस और postgres उपयोगकर्ता चुनें. साथ ही, क्लस्टर बनाते समय नोट किया गया पासवर्ड डालें. इसके बाद, "Authenticate" बटन पर क्लिक करें. अगर आपने पासवर्ड नोट नहीं किया है या वह काम नहीं कर रहा है, तो पासवर्ड बदला जा सकता है. ऐसा करने का तरीका जानने के लिए, दस्तावेज़ देखें.
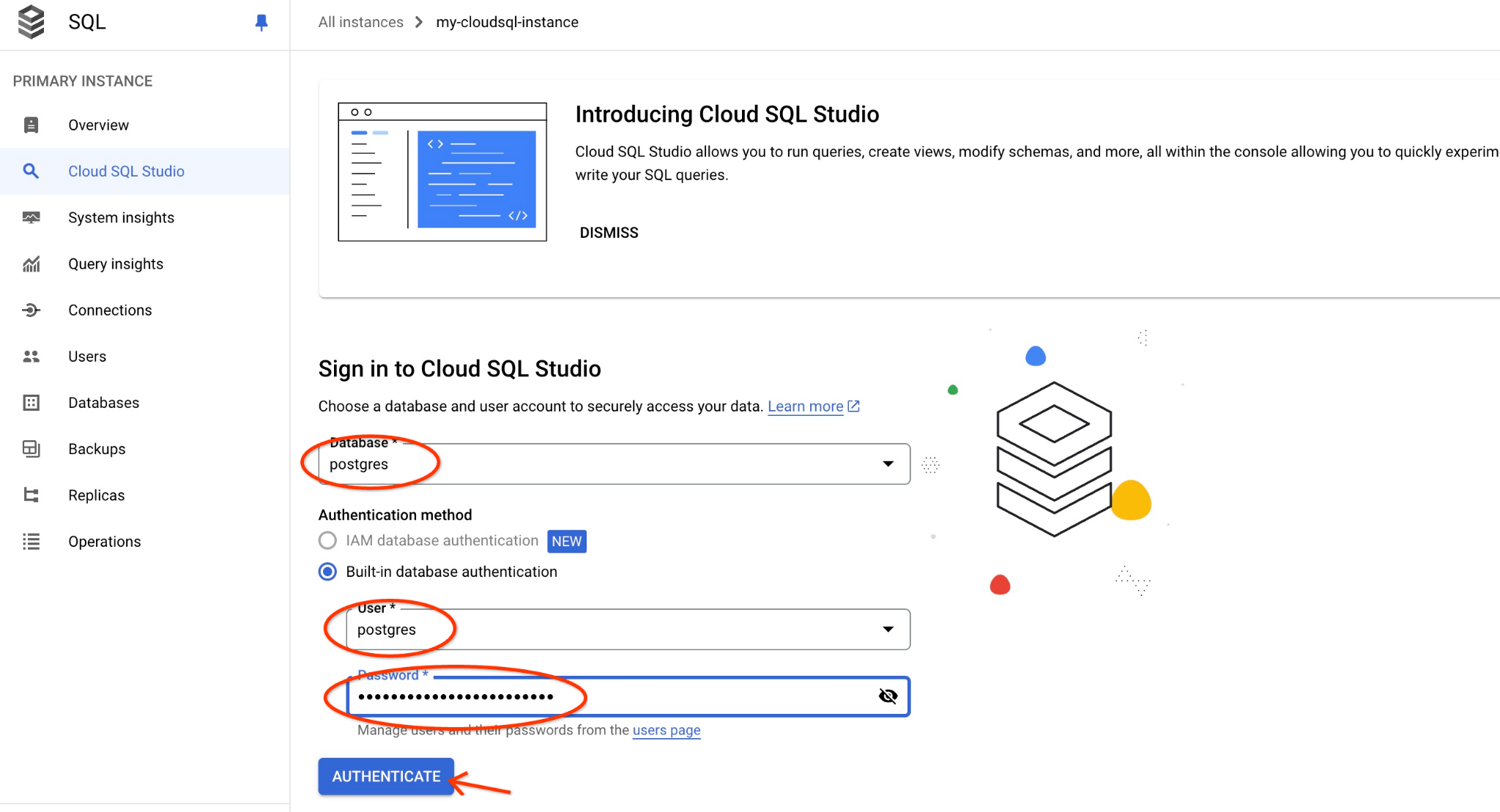
इससे AlloyDB Studio का इंटरफ़ेस खुल जाएगा. डेटाबेस में कमांड चलाने के लिए, दाईं ओर मौजूद "Untitled Query" टैब पर क्लिक करें.
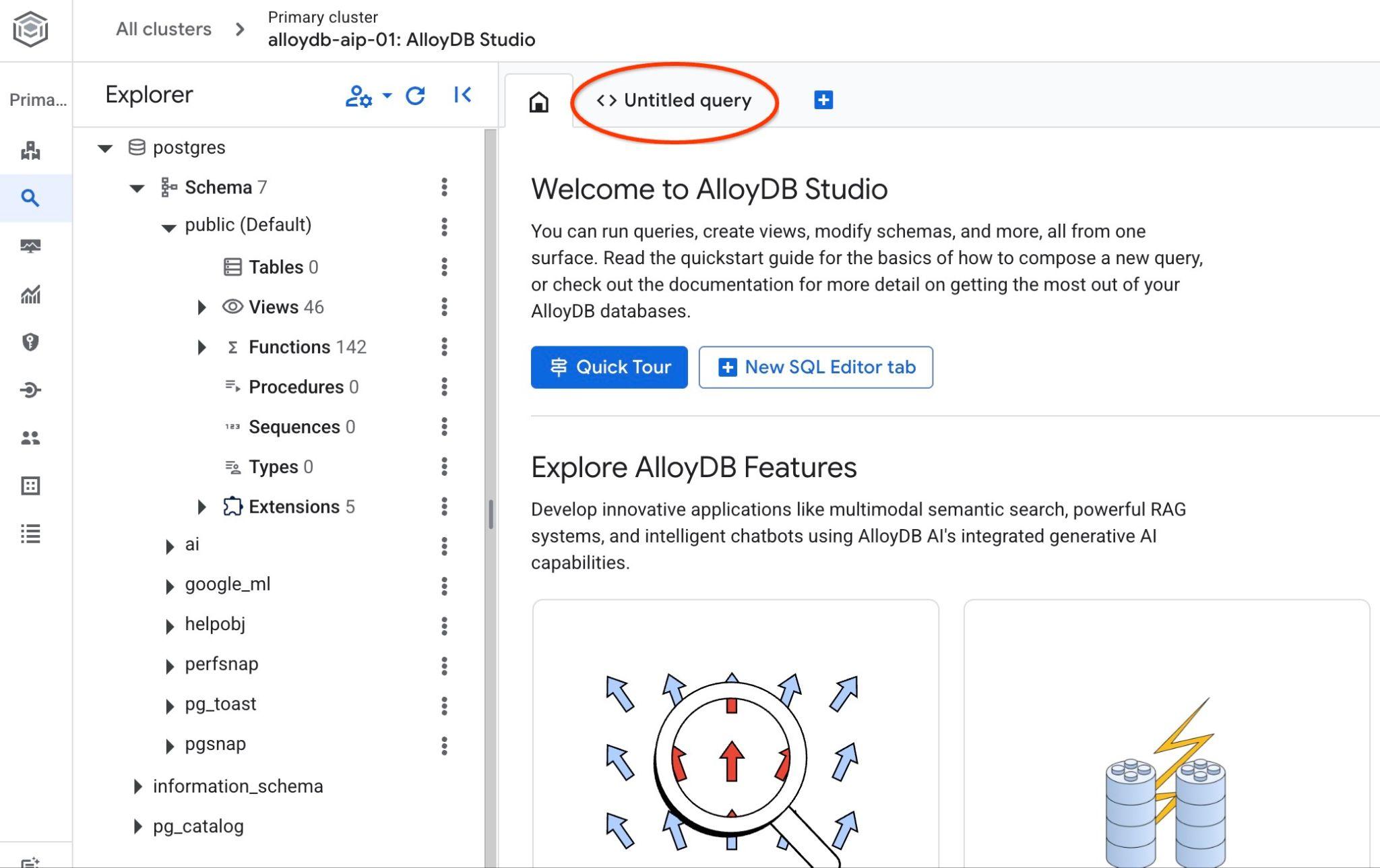
इससे वह इंटरफ़ेस खुलता है जहां एसक्यूएल कमांड चलाई जा सकती हैं
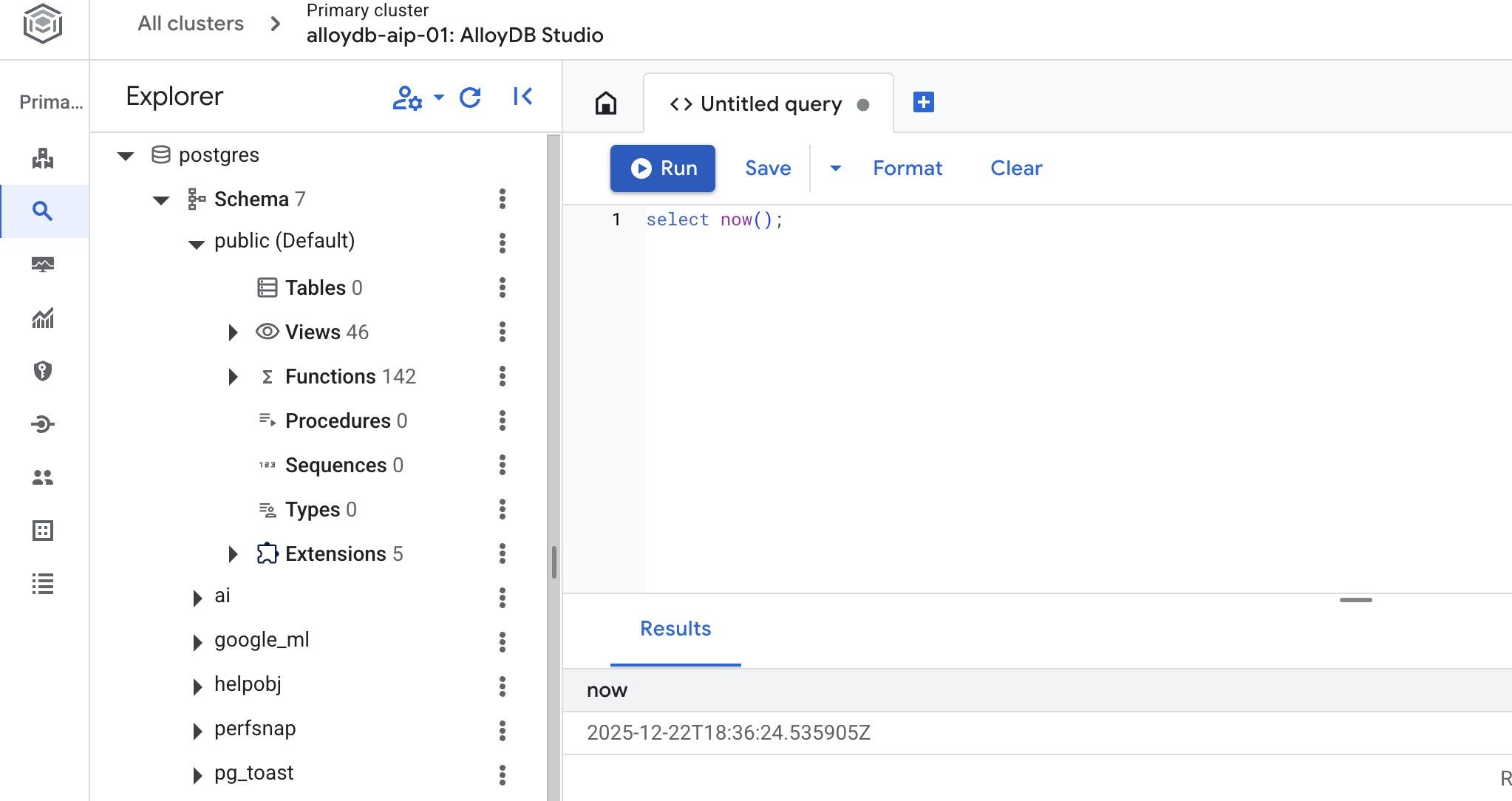
डेटाबेस बनाएं
डेटाबेस बनाने के बारे में क्विकस्टार्ट गाइड.
AlloyDB Studio Editor में, यह कमांड चलाएं.
डेटाबेस बनाएं:
CREATE DATABASE quickstart_db
अनुमानित आउटपुट:
Statement executed successfully
quickstart_db से कनेक्ट करें
उपयोगकर्ता/डेटाबेस बदलने के बटन का इस्तेमाल करके, स्टूडियो से फिर से कनेक्ट करें.
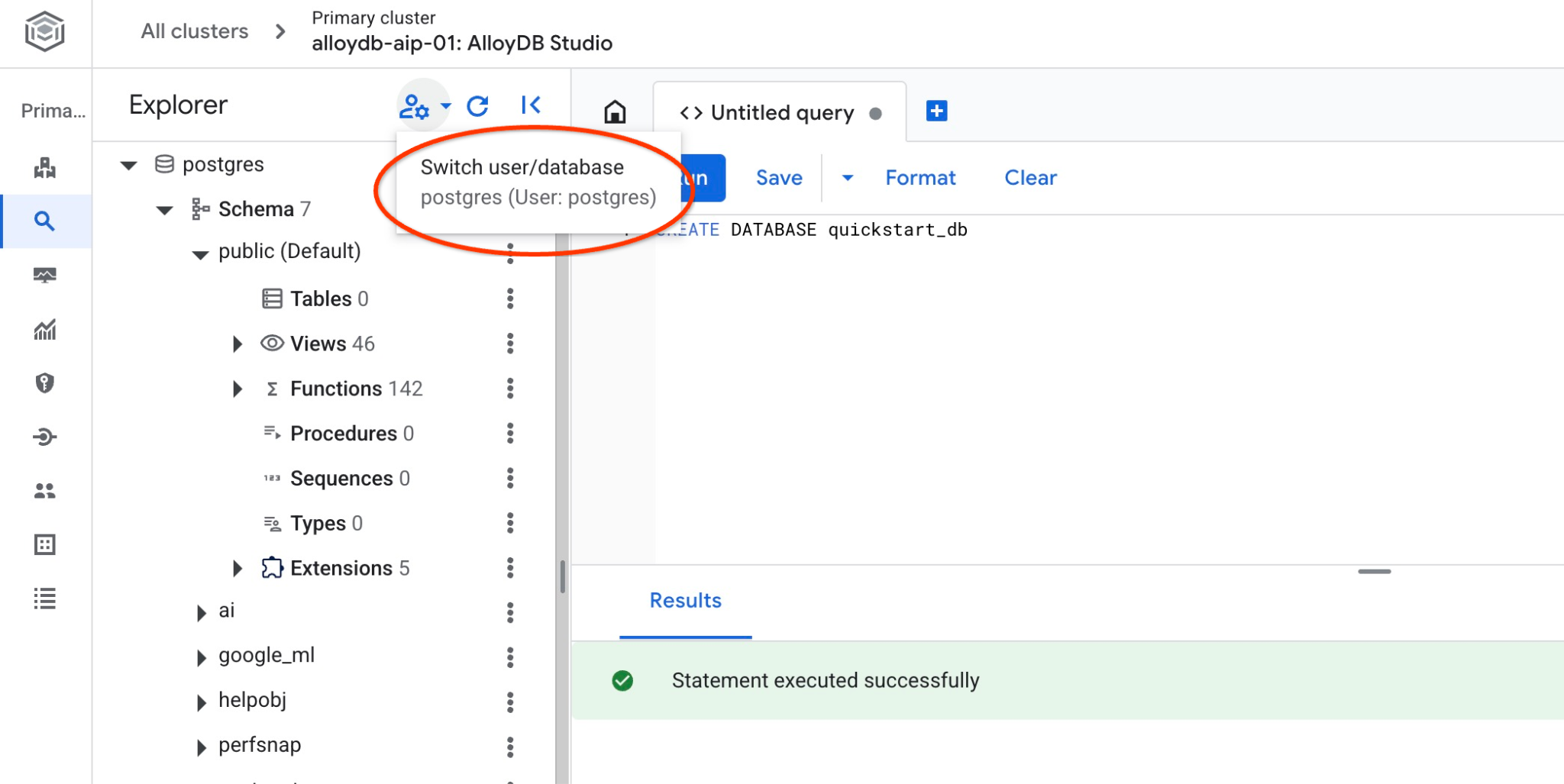
ड्रॉपडाउन सूची से नया quickstart_db डेटाबेस चुनें. साथ ही, पहले की तरह ही उपयोगकर्ता नाम और पासवर्ड का इस्तेमाल करें.
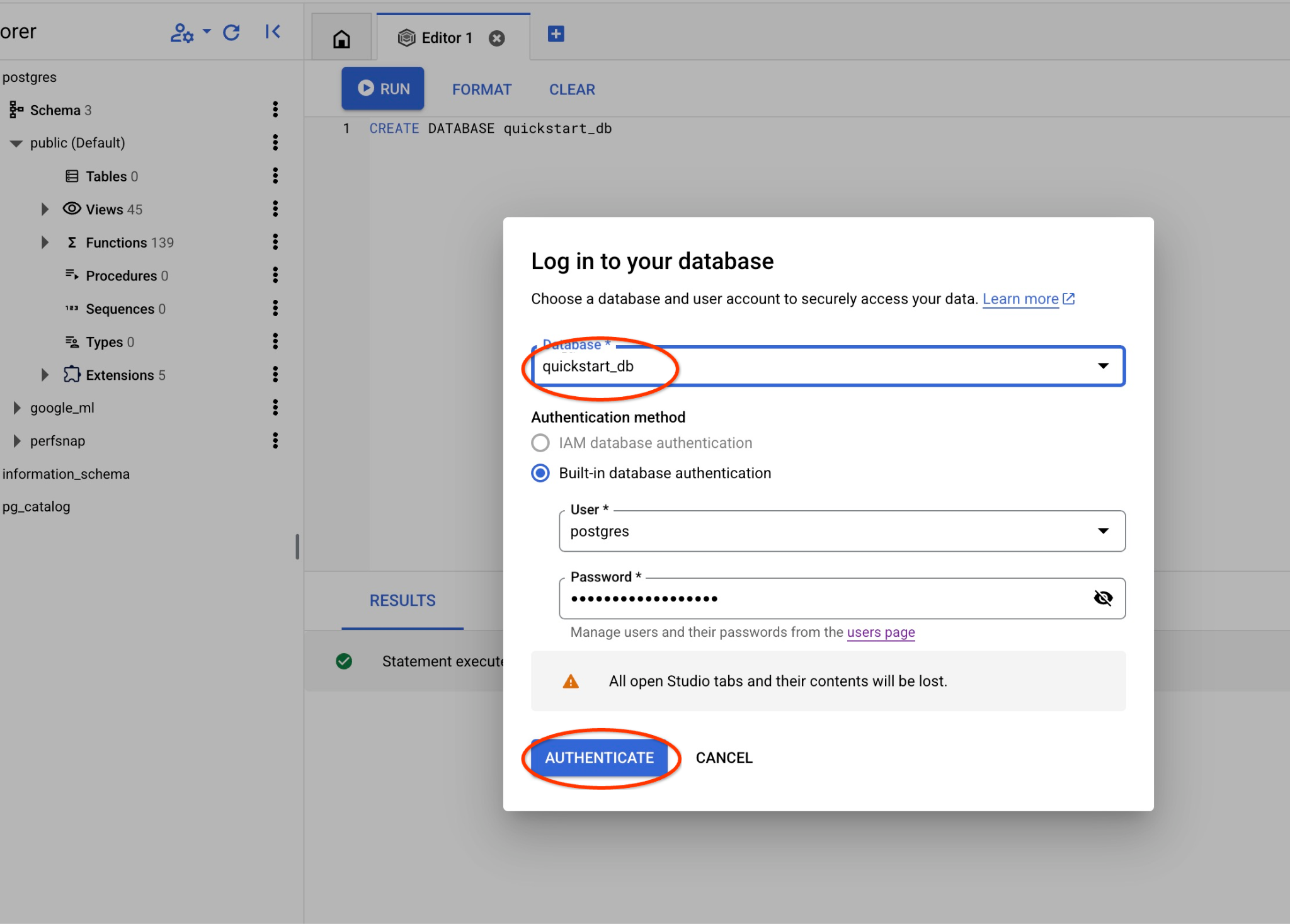
इससे एक नया कनेक्शन खुलेगा. यहां quickstart_db डेटाबेस के ऑब्जेक्ट के साथ काम किया जा सकता है.
6. सैंपल डेटा
अब हमें डेटाबेस में ऑब्जेक्ट बनाने और डेटा लोड करने की ज़रूरत है. हम काल्पनिक डेटा के साथ "Cymbal" नाम के काल्पनिक स्टोर का इस्तेमाल करेंगे.
डेटा इंपोर्ट करने से पहले, हमें डेटा टाइप और इंडेक्स के साथ काम करने वाले एक्सटेंशन चालू करने होंगे. हमें दो एक्सटेंशन की ज़रूरत है: एक जो वेक्टर डेटा टाइप के साथ काम करता हो और दूसरा जो AlloyDB ScaNN इंडेक्स के साथ काम करता हो.
AlloyDB Studio में, quickstart_db से कनेक्ट करें और यह कमांड चलाएं:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
डेटासेट को एसक्यूएल फ़ाइल के तौर पर तैयार किया जाता है और रखा जाता है. इसे इंपोर्ट इंटरफ़ेस का इस्तेमाल करके डेटाबेस में लोड किया जा सकता है. Cloud Shell में ये कमांड चलाएं:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
यह कमांड, AlloyDB SDK का इस्तेमाल करती है. इससे agentspace_user नाम का उपयोगकर्ता बनता है. इसके बाद, यह सीधे तौर पर GCS बकेट से डेटाबेस में सैंपल डेटा इंपोर्ट करती है. इससे सभी ज़रूरी ऑब्जेक्ट बनते हैं और डेटा डाला जाता है.
इंपोर्ट करने के बाद, हम AlloyDB Studio में टेबल देख सकते हैं. टेबल, ecomm स्कीमा में हैं:
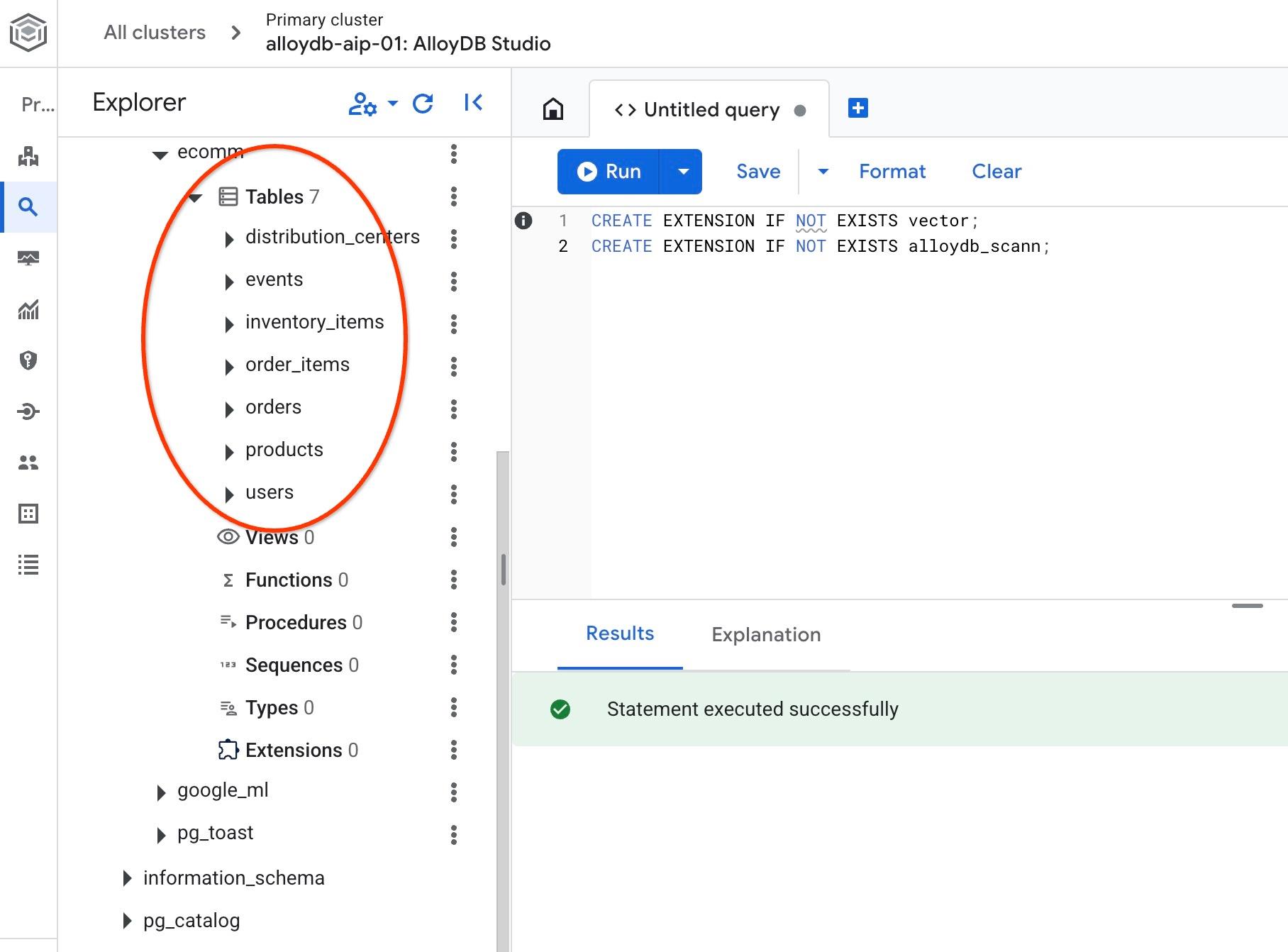
साथ ही, किसी एक टेबल में मौजूद लाइनों की संख्या की पुष्टि करें.
select count(*) from ecomm.products;
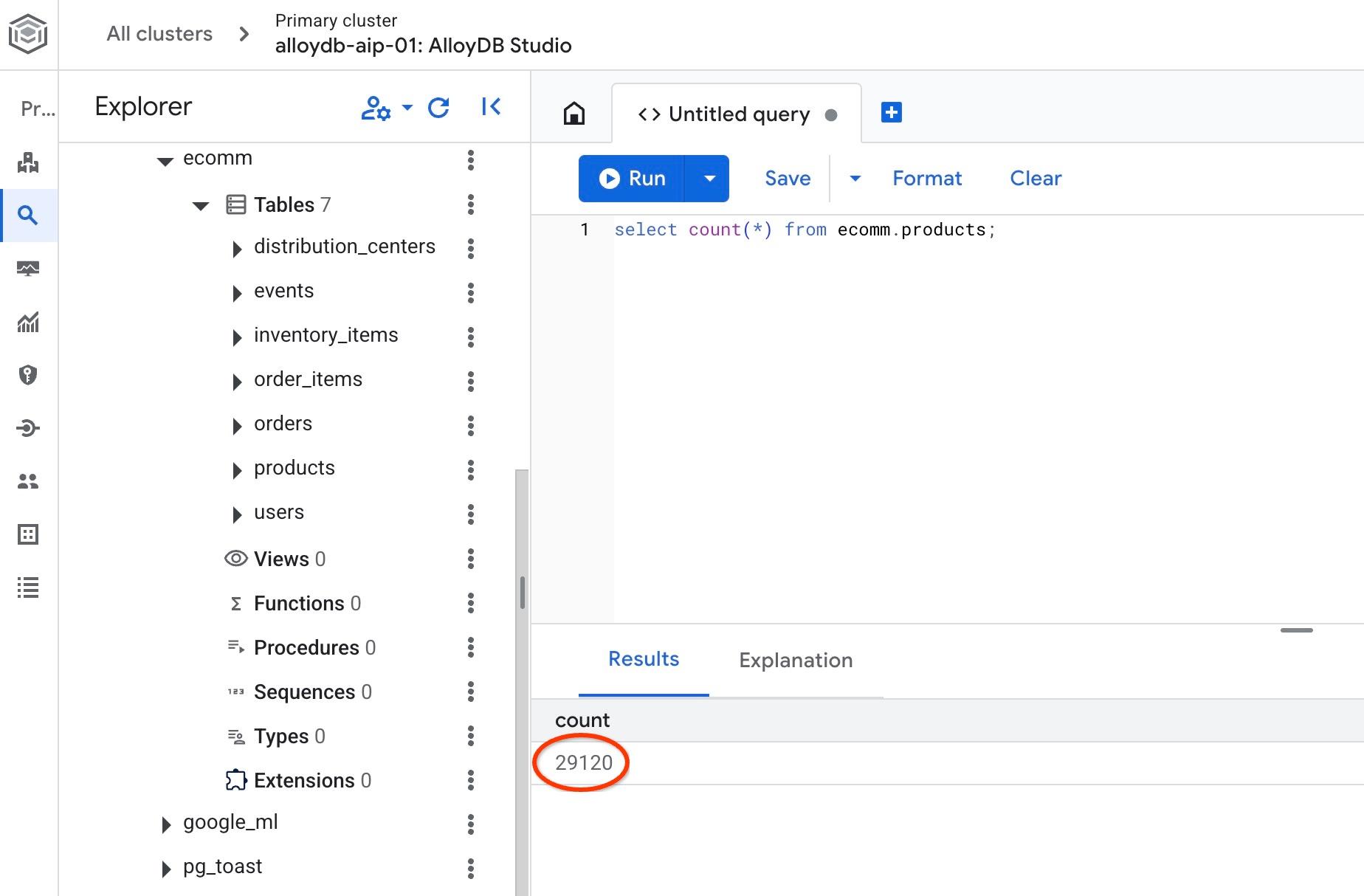
हमने अपना सैंपल डेटा इंपोर्ट कर लिया है. अब हम अगले चरणों को पूरा कर सकते हैं.
7. टेक्स्ट एम्बेडिंग का इस्तेमाल करके सिमैंटिक सर्च करना
इस चैप्टर में, हम टेक्स्ट एम्बेडिंग का इस्तेमाल करके सिमेंटिक सर्च करने की कोशिश करेंगे. साथ ही, इसकी तुलना Postgres के पारंपरिक टेक्स्ट और फ़ुलटेक्स्ट सर्च से करेंगे.
सबसे पहले, LIKE ऑपरेटर के साथ स्टैंडर्ड PostgreSQL एसक्यूएल का इस्तेमाल करके, क्लासिक तरीके से खोज करने की कोशिश करते हैं.
AlloyDB Studio में quickstart_db से कनेक्ट करें. इसके बाद, नीचे दी गई क्वेरी का इस्तेमाल करके रेन जैकेट खोजें:
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
क्वेरी से कोई भी लाइन नहीं मिलती है, क्योंकि प्रॉडक्ट के नाम या ब्यौरे में, 'बारिश के मौसम' और 'जैकेट' जैसे सटीक शब्दों का होना ज़रूरी है. साथ ही, ‘बारिश में पहनने वाली जैकेट' और ‘पानी से बचाने वाली जैकेट' एक जैसी नहीं होतीं.
हम खोज के सभी संभावित वर्शन शामिल करने की कोशिश कर सकते हैं. चलिए, सिर्फ़ दो शब्दों को शामिल करने की कोशिश करते हैं. उदाहरण के लिए:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
इससे कई लाइनें दिखेंगी, लेकिन उनमें से सभी जैकेट के लिए हमारे अनुरोध से पूरी तरह मेल नहीं खाती हैं. साथ ही, उन्हें काम के हिसाब से क्रम में लगाना मुश्किल है. उदाहरण के लिए, अगर हम "पुरुषों के लिए" जैसी और शर्तें जोड़ते हैं, तो क्वेरी काफ़ी जटिल हो जाएगी. इसके अलावा, हम पूरे टेक्स्ट को खोज सकते हैं. हालांकि, इसमें भी हमें कुछ समस्याएं आती हैं. जैसे, खोजे गए शब्दों का सटीक होना और जवाब का काम का होना.
अब हम एम्बेडिंग का इस्तेमाल करके, मिलती-जुलती खोज कर सकते हैं. हमने अलग-अलग मॉडल का इस्तेमाल करके, अपने प्रॉडक्ट के लिए एम्बेडिंग पहले से ही कैलकुलेट कर ली हैं. हम Google के नए gemini-embedding-001 मॉडल का इस्तेमाल करेंगे. हमने उन्हें ecomm.products टेबल के "product_embedding" कॉलम में सेव किया है. अगर हम "पुरुषों के लिए रेन जैकेट" की खोज की शर्त के लिए, यहां दी गई क्वेरी का इस्तेमाल करते हैं:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
इससे न सिर्फ़ बारिश के मौसम में पहनने वाली जैकेट के नतीजे मिलेंगे, बल्कि सभी नतीजों को इस तरह से क्रम में लगाया जाएगा कि सबसे काम के नतीजे सबसे ऊपर दिखें.
एम्बेडिंग वाली क्वेरी के नतीजे 90 से 150 मि॰से॰ में मिलते हैं. इसमें से कुछ समय, क्लाउड एम्बेडिंग मॉडल से डेटा पाने में लगता है. अगर हम एक्ज़ीक्यूशन प्लान को देखें, तो मॉडल से किए गए अनुरोध को प्लानिंग के समय में शामिल किया जाता है. क्वेरी का वह हिस्सा जो खोज करता है, वह काफ़ी छोटा है. AlloyDB ScaNN इंडेक्स का इस्तेमाल करके, 29 हज़ार रिकॉर्ड में खोज करने में सात मिलीसेकंड से भी कम समय लगता है.
यहां एक्ज़ीक्यूशन प्लान का आउटपुट दिया गया है:
Limit (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> Index Scan using embedding_scann on products (cost=2709.20..30736.40 rows=29120 width=490) (actual time=6.964..7.046 rows=10 loops=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
...
-0.0051468653,-0.012440448]'::vector)
Limit: 10
प्लानिंग में लगा समय: 136.579 मि॰से॰
लागू करने में लगा समय: 6.791 मि॰से॰
(छह लाइनें)
यह सिर्फ़ टेक्स्ट एम्बेडिंग मॉडल का इस्तेमाल करके, टेक्स्ट एम्बेडिंग की खोज की गई थी. हालांकि, हमारे पास अपने प्रॉडक्ट की इमेज भी हैं और हम उन्हें खोज के साथ इस्तेमाल कर सकते हैं. अगले चैप्टर में, हम दिखाएंगे कि मल्टीमॉडल मॉडल, खोज के लिए इमेज का इस्तेमाल कैसे करता है.
8. मल्टीमोडल सर्च का इस्तेमाल करना
टेक्स्ट के आधार पर सिमैंटिक सर्च की सुविधा काम की है. हालांकि, इसमें जटिल जानकारी देना मुश्किल हो सकता है. AlloyDB की मल्टीमॉडल सर्च सुविधा, इमेज इनपुट के ज़रिए प्रॉडक्ट खोजने की सुविधा देती है. यह सुविधा तब ज़्यादा काम आती है, जब सिर्फ़ टेक्स्ट के ब्यौरे के बजाय विज़ुअल से खोज के मकसद को ज़्यादा असरदार तरीके से समझाया जा सकता है. उदाहरण के लिए - "मुझे इस तस्वीर में दिख रहा कोट ढूंढकर दिखाओ".
आइए, जैकेट वाले उदाहरण पर वापस चलते हैं. अगर मेरे पास उस जैकेट की इमेज है जिसे मुझे ढूंढना है, तो मैं उसे Google के मल्टीमॉडल एम्बेडिंग मॉडल को भेज सकता हूं. इसके बाद, मैं उसकी तुलना अपने प्रॉडक्ट की इमेज के एम्बेडिंग से कर सकता हूं. हमारी टेबल में, हमने product_image_embedding कॉलम में अपने प्रॉडक्ट की इमेज के लिए एम्बेडिंग पहले ही कैलकुलेट कर ली हैं. साथ ही, product_image_embedding_model कॉलम में इस्तेमाल किए गए मॉडल को देखा जा सकता है.
खोज के लिए, हम image_embedding फ़ंक्शन का इस्तेमाल करके, अपनी इमेज के लिए एम्बेडिंग पा सकते हैं. साथ ही, इसकी तुलना पहले से कैलकुलेट की गई एम्बेडिंग से कर सकते हैं. इस फ़ंक्शन को चालू करने के लिए, हमें यह पक्का करना होगा कि हम google_ml_integration एक्सटेंशन के सही वर्शन का इस्तेमाल कर रहे हों.
आइए, एक्सटेंशन के मौजूदा वर्शन की पुष्टि करते हैं. AlloyDB Studio में एक्ज़ीक्यूट करें.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
अगर वर्शन 1.5.2 से कम है, तो यह तरीका अपनाएं.
CALL google_ml.upgrade_to_preview_version();
साथ ही, एक्सटेंशन का वर्शन फिर से देखें. यह 1.5.3 होना चाहिए.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
हमें अपने डेटाबेस में, एआई क्वेरी इंजन की सुविधाएं भी चालू करनी होंगी. इसे दो तरीकों से किया जा सकता है. पहला, इंस्टेंस पर मौजूद सभी डेटाबेस के लिए, इंस्टेंस फ़्लैग को अपडेट करके. दूसरा, सिर्फ़ हमारे डेटाबेस के लिए इसे चालू करके. इसे quickstart_db डेटाबेस के लिए चालू करने के लिए, AlloyDB Studio में यह कमांड चलाएं.
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
अब इमेज से खोजा जा सकता है. यहाँ खोज के लिए मेरी सैंपल इमेज दी गई है. हालाँकि, आपके पास किसी भी कस्टम इमेज का इस्तेमाल करने का विकल्प है. आपको बस इसे Google स्टोरेज या सार्वजनिक तौर पर उपलब्ध किसी अन्य संसाधन पर अपलोड करना होगा. इसके बाद, क्वेरी में यूआरआई डालना होगा.

इसे gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png पर अपलोड किया जाता है
इमेज की मदद से इमेज खोजना
सबसे पहले, हम सिर्फ़ इमेज की मदद से खोज करने की कोशिश करते हैं:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
साथ ही, हमें इन्वेंट्री में कुछ गर्म जैकेट भी मिलीं. इमेज देखने के लिए, उन्हें क्लाउड एसडीके (gcloud storage cp) का इस्तेमाल करके डाउनलोड करें. इसके लिए, public_url कॉलम की जानकारी दें. इसके बाद, इमेज के साथ काम करने वाले किसी भी टूल का इस्तेमाल करके इसे खोलें.
|
|
|
|




इमेज सर्च करने पर, ऐसे आइटम दिखते हैं जो तुलना के लिए दी गई हमारी इमेज से मिलते-जुलते हों. जैसा कि मैंने पहले ही बताया है, आपके पास अपनी इमेज को किसी सार्वजनिक बकेट में अपलोड करने का विकल्प है. इससे यह पता लगाया जा सकता है कि क्या यह अलग-अलग तरह के कपड़ों का पता लगा सकता है.
हमने इमेज सर्च के लिए, Google के ‘multimodalembedding@001' मॉडल का इस्तेमाल किया है. image_embedding फ़ंक्शन, इमेज को Vertex AI पर भेजता है. इसके बाद, Vertex AI उसे वेक्टर में बदलता है और वापस भेज देता है. ऐसा इसलिए किया जाता है, ताकि हम उसकी तुलना अपने डेटाबेस में सेव की गई इमेज के वेक्टर से कर सकें.
"EXPLAIN ANALYZE" का इस्तेमाल करके, यह भी देखा जा सकता है कि यह हमारे AlloyDB ScaNN इंडेक्स के साथ कितनी तेज़ी से काम करता है.
यहां एक्ज़ीक्यूशन प्लान का आउटपुट दिया गया है:
Limit (cost=971.70..975.55 rows=4 width=490) (actual time=2.453..2.477 rows=4 loops=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
...
,-0.010307034,-0.010053742]'::vector)
Limit: 4
प्लानिंग में लगा समय: 913.322 मि॰से॰
लागू करने में लगा समय: 2.517 मि॰से॰
(छह लाइनें)
पिछले उदाहरण की तरह, यहां भी हम देख सकते हैं कि क्लाउड एंडपॉइंट का इस्तेमाल करके, इमेज को एम्बेडिंग में बदलने में ज़्यादा समय लगा. वहीं, वेक्टर सर्च में सिर्फ़ 2.5 मि॰से॰ लगे.
टेक्स्ट की मदद से इमेज खोजना
मल्टीमॉडल की मदद से, हमें जिस जैकेट को खोजना है उसके बारे में टेक्स्ट में जानकारी दी जा सकती है. इसके लिए, google_ml.text_embedding का इस्तेमाल किया जा सकता है. साथ ही, इमेज एम्बेडिंग से तुलना करके यह देखा जा सकता है कि मॉडल कौनसी इमेज दिखाता है.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
इसके बाद, हमें ग्रे या गहरे रंग की पफ़ी जैकेट का एक सेट मिला.
|
|
|
|




हमें जैकेट का थोड़ा अलग सेट मिला है. हालांकि, इमेज एम्बेडिंग के ज़रिए खोज करते समय, इसने हमारी जानकारी के आधार पर जैकेट को सही तरीके से चुना है.
आइए, खोज के लिए इस्तेमाल की गई इमेज के एम्बेड किए गए डेटा की मदद से, ब्यौरों में खोज करने का कोई दूसरा तरीका आज़माएं.
इमेज की मदद से टेक्स्ट खोजना
हमने अपनी इमेज के लिए, एम्बेड करने की सुविधा का इस्तेमाल करके इमेज खोजने की कोशिश की. साथ ही, हमने अपने प्रॉडक्ट के लिए पहले से कैलकुलेट की गई इमेज एम्बेडिंग से उनकी तुलना की. हमने टेक्स्ट के अनुरोध के लिए एम्बेडिंग पास करके भी इमेज खोजने की कोशिश की. साथ ही, प्रॉडक्ट की इमेज के लिए उसी एम्बेडिंग में खोज की. अब हम अपनी इमेज के लिए एम्बेडिंग का इस्तेमाल करके देखते हैं और इसकी तुलना प्रॉडक्ट के ब्यौरे के लिए टेक्स्ट एम्बेडिंग से करते हैं. ये एम्बेडिंग, product_description_embedding कॉलम में सेव की जाती हैं. साथ ही, ये multimodalembedding@001 मॉडल का इस्तेमाल करती हैं.
हमारी क्वेरी यहां दी गई है:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
यहां हमें ग्रे या गहरे रंग की जैकेट का एक अलग सेट मिला है. इनमें से कुछ जैकेट, हमारी खोज के अन्य तरीकों से चुनी गई जैकेट से मिलती-जुलती हैं.
|
|
|
|



इमेज के लिए एम्बेडिंग के आधार पर, यह टेक्स्ट के ब्यौरे के लिए कैलकुलेट की गई एम्बेडिंग से तुलना कर सकता है. साथ ही, प्रॉडक्ट का सही सेट दिखा सकता है.
टेक्स्ट और इमेज, दोनों का इस्तेमाल करके खोज करना
टेक्स्ट और इमेज, दोनों के एम्बेडिंग को एक साथ इस्तेमाल करके भी एक्सपेरिमेंट किया जा सकता है. इसके लिए, उदाहरण के तौर पर रेसिप्रोकल रैंक फ़्यूज़न का इस्तेमाल किया जा सकता है. यहां ऐसी क्वेरी का एक उदाहरण दिया गया है, जिसमें हमने दो खोजों को मिलाकर, हर रैंक को एक स्कोर असाइन किया है. साथ ही, मिले हुए स्कोर के आधार पर नतीजों को क्रम से लगाया है.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
क्वेरी में अलग-अलग पैरामीटर इस्तेमाल करके देखें. इससे आपको खोज के बेहतर नतीजे मिल सकते हैं. इसके अलावा, दस्तावेज़ में बताए गए तरीके के मुताबिक, नतीजों को रैंक करने के लिए अन्य एआई ऑपरेटर का भी इस्तेमाल किया जा सकता है.
यह लैब यहीं खत्म होती है. अनचाहे शुल्क से बचने के लिए, इस्तेमाल न किए गए संसाधनों को मिटाने का सुझाव दिया जाता है.
9. पर्यावरण को साफ़-सुथरा रखना
लैब का काम पूरा हो जाने के बाद, AlloyDB इंस्टेंस और क्लस्टर मिटा दें.
AlloyDB क्लस्टर और सभी इंस्टेंस मिटाना
अगर आपने AlloyDB का मुफ़्त में आज़माने की सुविधा वाला वर्शन इस्तेमाल किया है. अगर आपको ट्रायल क्लस्टर का इस्तेमाल करके अन्य लैब और संसाधनों की जांच करनी है, तो ट्रायल क्लस्टर को न मिटाएं. आपके पास एक ही प्रोजेक्ट में, दूसरा ट्रायल क्लस्टर बनाने का विकल्प नहीं होगा.
फ़ोर्स विकल्प का इस्तेमाल करके क्लस्टर को डिस्ट्रॉय किया जाता है. इससे क्लस्टर से जुड़े सभी इंस्टेंस भी मिट जाते हैं.
अगर आपका कनेक्शन बंद हो गया है और पिछली सभी सेटिंग मिट गई हैं, तो क्लाउड शेल में प्रोजेक्ट और एनवायरमेंट वैरिएबल तय करें:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
क्लस्टर मिटाने के लिए:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
अनुमानित कंसोल आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB के बैकअप मिटाना
क्लस्टर के सभी AlloyDB बैकअप मिटाने के लिए:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
अनुमानित कंसोल आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. बधाई हो
कोड लैब पूरा करने के लिए बधाई. आपने टेक्स्ट और इमेज के लिए एम्बेडिंग फ़ंक्शन का इस्तेमाल करके, AlloyDB में मल्टीमॉडल सर्च का इस्तेमाल करने का तरीका सीखा. AlloyDB के एआई ऑपरेटर के लिए कोडलैब का इस्तेमाल करके, मल्टीमोडल सर्च को आज़माया जा सकता है. साथ ही, google_ml.rank फ़ंक्शन का इस्तेमाल करके इसे बेहतर बनाया जा सकता है.
Google Cloud का लर्निंग पाथ
यह लैब, Google Cloud के साथ प्रोडक्शन-रेडी एआई के लर्निंग पाथ का हिस्सा है.
- प्रोटोटाइप से प्रोडक्शन तक के अंतर को कम करने के लिए, पूरा पाठ्यक्रम देखें.
- अपनी प्रोग्रेस को
#ProductionReadyAIहैशटैग के साथ शेयर करें.
हमने क्या-क्या बताया
- Postgres के लिए AlloyDB को डिप्लॉय करने का तरीका
- AlloyDB Studio का इस्तेमाल कैसे करें
- मल्टीमॉडल वेक्टर सर्च का इस्तेमाल कैसे करें
- AlloyDB AI ऑपरेटर चालू करने का तरीका
- मल्टीमॉडल सर्च के लिए, AlloyDB AI के अलग-अलग ऑपरेटर इस्तेमाल करने का तरीका
- टेक्स्ट और इमेज के खोज नतीजों को एक साथ दिखाने के लिए, AlloyDB AI का इस्तेमाल कैसे करें
11. सर्वे
आउटपुट: