
1. 소개
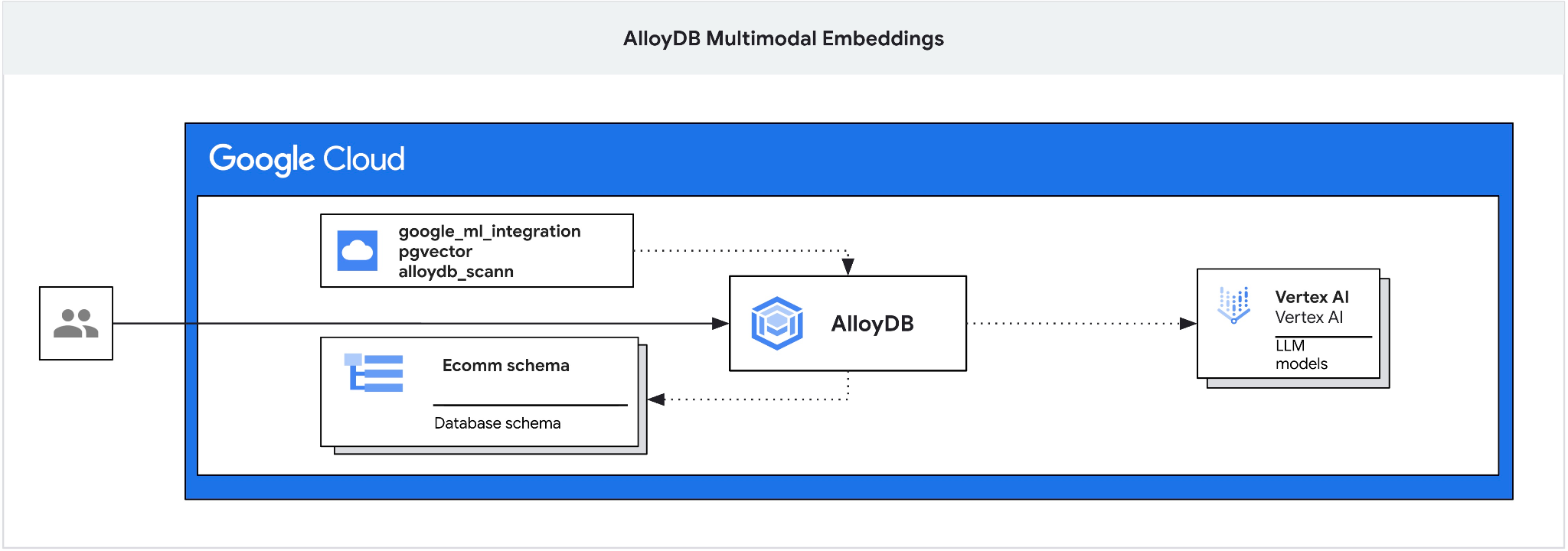
이 Codelab에서는 AlloyDB를 배포하고 AI 통합을 활용하여 멀티모달 임베딩을 사용한 시맨틱 검색을 수행하는 방법을 안내합니다. 이 실습은 AlloyDB AI 기능을 위한 실습 모음의 일부입니다. 자세한 내용은 문서의 AlloyDB AI 페이지를 참고하세요.
기본 요건
- Google Cloud, 콘솔에 관한 기본적인 이해
- 명령줄 인터페이스 및 Cloud Shell의 기본 기술
학습할 내용
- Postgres용 AlloyDB를 배포하는 방법
- AlloyDB Studio 사용 방법
- 멀티모달 벡터 검색 사용 방법
- AlloyDB AI 연산자를 사용 설정하는 방법
- 멀티모달 검색을 위해 다양한 AlloyDB AI 연산자를 사용하는 방법
- AlloyDB AI를 사용하여 텍스트 및 이미지 검색 결과를 결합하는 방법
필요한 항목
- Google Cloud 계정 및 Google Cloud 프로젝트
- Google Cloud 콘솔 및 Cloud Shell을 지원하는 웹브라우저(예: Chrome)
2. 설정 및 요구사항
프로젝트 설정
- Google Cloud 콘솔에 로그인합니다. 아직 Gmail이나 Google Workspace 계정이 없는 경우 계정을 만들어야 합니다.
직장 또는 학교 계정 대신 개인 계정을 사용하세요.
- 새 프로젝트를 만들거나 기존 프로젝트를 재사용합니다. Google Cloud 콘솔에서 새 프로젝트를 만들려면 헤더에서 프로젝트 선택 버튼을 클릭하여 팝업 창을 엽니다.

프로젝트 선택 창에서 새 프로젝트 버튼을 누르면 새 프로젝트 대화상자가 열립니다.
대화상자에서 원하는 프로젝트 이름을 입력하고 위치를 선택합니다.
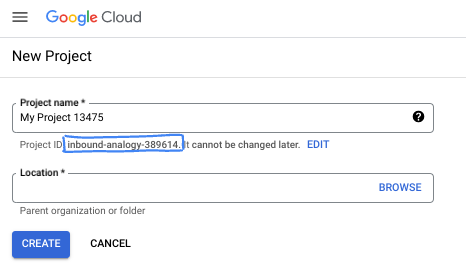
- 프로젝트 이름은 이 프로젝트 참가자의 표시 이름입니다. 프로젝트 이름은 Google API에서 사용되지 않으며 언제든지 변경할 수 있습니다.
- 프로젝트 ID는 모든 Google Cloud 프로젝트에서 고유하며, 변경할 수 없습니다 (설정된 후에는 변경할 수 없음). Google Cloud 콘솔에서 고유 ID를 자동으로 생성하지만 맞춤설정할 수 있습니다. 생성된 ID가 마음에 들지 않으면 다른 임의 ID를 생성하거나 자체 ID를 제공하여 사용 가능 여부를 확인할 수 있습니다. 대부분의 Codelab에서는 프로젝트 ID를 참조해야 합니다. 프로젝트 ID는 일반적으로 PROJECT_ID 자리표시자로 식별됩니다.
- 참고로 세 번째 값은 일부 API에서 사용하는 프로젝트 번호입니다. 이 세 가지 값에 대한 자세한 내용은 문서를 참고하세요.
결제 사용 설정
결제를 사용 설정하는 방법에는 두 가지가 있습니다. 개인 결제 계정을 사용하거나 다음 단계에 따라 크레딧을 사용할 수 있습니다.
Google Cloud 크레딧 사용 (선택사항)
이 워크숍을 진행하려면 크레딧이 있는 결제 계정이 필요합니다. 이 Codelab 상단의 배너에 있는 크레딧을 사용하여 시작하세요. 이미 결제 계정에 연결되어 있다면 이 단계를 건너뛰어도 됩니다.
개인 결제 계정 설정
Google Cloud 크레딧을 사용하여 결제를 설정한 경우 이 단계를 건너뛸 수 있습니다.
개인 결제 계정을 설정하려면 Cloud 콘솔에서 여기에서 결제를 사용 설정하세요.
참고 사항:
- 이 실습을 완료하는 데 드는 Cloud 리소스 비용은 미화 3달러 미만입니다.
- 이 실습이 끝나면 단계에 따라 리소스를 삭제하여 추가 요금이 발생하지 않도록 할 수 있습니다.
- 신규 사용자는 미화$300 상당의 무료 체험판을 이용할 수 있습니다.
Cloud Shell 시작
Google Cloud를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
Google Cloud Console의 오른쪽 상단 툴바에 있는 Cloud Shell 아이콘을 클릭합니다.
또는 G를 누른 다음 S를 누릅니다. Google Cloud 콘솔에 있거나 이 링크를 사용하는 경우 이 시퀀스를 통해 Cloud Shell이 활성화됩니다.
환경을 프로비저닝하고 연결하는 데 몇 분 정도 소요됩니다. 완료되면 다음과 같이 표시됩니다.

가상 머신에는 필요한 개발 도구가 모두 들어있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab의 모든 작업은 브라우저 내에서 수행할 수 있습니다. 아무것도 설치할 필요가 없습니다.
3. 시작하기 전에
API 사용 설정
AlloyDB, Compute Engine, 네트워킹 서비스, Vertex AI를 사용하려면 Google Cloud 프로젝트에서 각 API를 사용 설정해야 합니다.
터미널의 Cloud Shell 내에 프로젝트 ID가 설정되어 있는지 확인합니다. 프로젝트 ID는 다음과 같이 명령 프롬프트에서 괄호 안에 표시됩니다.
student@cloudshell:~ (test-project-001-402417)$
프로젝트 ID가 표시되지 않으면 브라우저 탭을 새로고침하고 Cloud Shell에서 다시 인증합니다.
환경 변수 PROJECT_ID를 설정합니다.
PROJECT_ID=$(gcloud config get-value project)
필요한 모든 서비스를 사용 설정합니다.
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
예상 출력
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB 배포
AlloyDB 클러스터 및 기본 인스턴스를 만듭니다. 다음 절차에서는 Google Cloud SDK를 사용하여 AlloyDB 클러스터와 인스턴스를 만드는 방법을 설명합니다. 콘솔 방식을 선호하는 경우 여기의 문서를 참고하세요.
AlloyDB 클러스터를 만들기 전에 향후 AlloyDB 인스턴스에서 사용할 수 있는 비공개 IP 범위가 VPC에 있어야 합니다. 이 계정이 없으면 계정을 만들어 내부 Google 서비스에서 사용하도록 할당해야 클러스터와 인스턴스를 만들 수 있습니다.
비공개 IP 범위 만들기
VPC에서 AlloyDB용 비공개 서비스 액세스 구성을 설정해야 합니다. 여기서는 프로젝트에 '기본' VPC 네트워크가 있고 이 네트워크가 모든 작업에 사용된다고 가정합니다.
비공개 IP 범위를 만듭니다.
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
할당된 IP 범위를 사용하여 비공개 연결을 만듭니다.
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB 클러스터 만들기
이 섹션에서는 us-central1 리전에 AlloyDB 클러스터를 만듭니다.
postgres 사용자의 비밀번호를 정의합니다. 비밀번호를 직접 정의하거나 무작위 함수를 사용하여 생성할 수 있습니다.
export PGPASSWORD=`openssl rand -hex 12`
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
나중에 사용할 수 있도록 PostgreSQL 비밀번호를 기록해 둡니다.
echo $PGPASSWORD
나중에 postgres 사용자로 인스턴스에 연결하려면 이 비밀번호가 필요합니다. 나중에 사용할 수 있도록 적어 두거나 어딘가에 복사해 두는 것이 좋습니다.
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
무료 체험판 클러스터 만들기
AlloyDB를 사용해 본 적이 없는 경우 무료 체험 클러스터를 만들 수 있습니다.
리전과 AlloyDB 클러스터 이름을 정의합니다. us-central1 리전과 alloydb-aip-01을 클러스터 이름으로 사용합니다.
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
명령어를 실행하여 클러스터를 만듭니다.
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
예상되는 콘솔 출력:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
동일한 Cloud Shell 세션에서 클러스터의 AlloyDB 기본 인스턴스를 만듭니다. 연결이 해제되면 리전 및 클러스터 이름 환경 변수를 다시 정의해야 합니다.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard 클러스터 만들기
프로젝트의 첫 번째 AlloyDB 클러스터가 아닌 경우 표준 클러스터 생성을 진행합니다. 이전 단계에서 무료 체험판 클러스터를 이미 만든 경우 이 단계를 건너뛰세요.
리전과 AlloyDB 클러스터 이름을 정의합니다. us-central1 리전과 alloydb-aip-01을 클러스터 이름으로 사용합니다.
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
명령어를 실행하여 클러스터를 만듭니다.
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
예상되는 콘솔 출력:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
동일한 Cloud Shell 세션에서 클러스터의 AlloyDB 기본 인스턴스를 만듭니다. 연결이 해제되면 리전 및 클러스터 이름 환경 변수를 다시 정의해야 합니다.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. 데이터베이스 준비
데이터베이스를 만들고, Vertex AI 통합을 사용 설정하고, 데이터베이스 객체를 만들고, 데이터를 가져와야 합니다.
AlloyDB에 필요한 권한 부여
AlloyDB 서비스 에이전트에 Vertex AI 권한을 추가합니다.
맨 위에 있는 '+' 기호를 사용하여 다른 Cloud Shell 탭을 엽니다.
새 Cloud Shell 탭에서 다음을 실행합니다.
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
탭에서 실행 명령어 'exit' 중 하나를 사용하여 탭을 닫습니다.
exit
AlloyDB Studio에 연결
다음 장에서는 데이터베이스에 연결해야 하는 모든 SQL 명령어를 AlloyDB Studio에서 실행할 수 있습니다.
새 탭에서 Postgres용 AlloyDB의 클러스터 페이지로 이동합니다.
기본 인스턴스를 클릭하여 AlloyDB 클러스터의 웹 콘솔 인터페이스를 엽니다.
그런 다음 왼쪽에서 AlloyDB Studio를 클릭합니다.
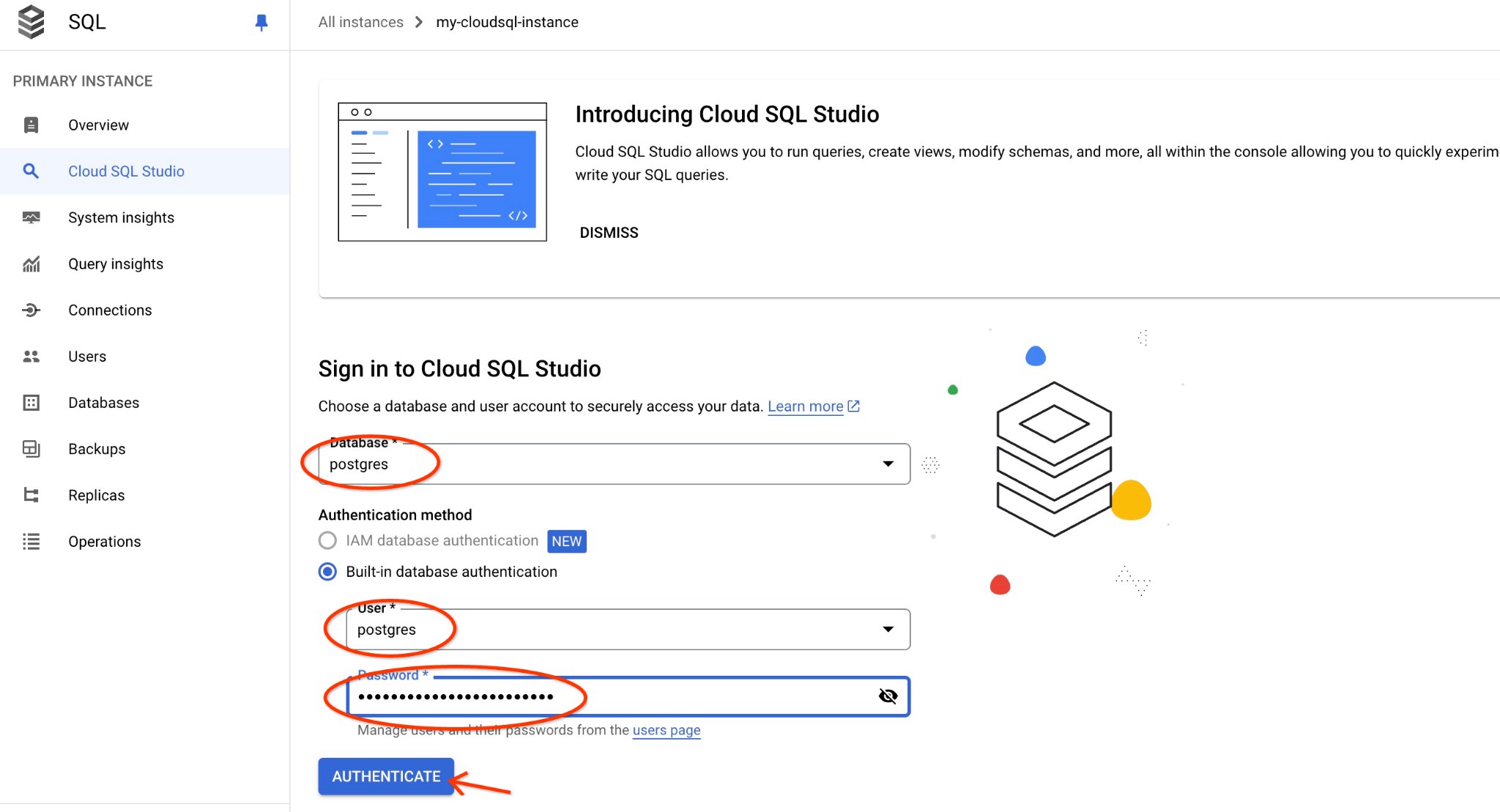
postgres 데이터베이스와 사용자 postgres를 선택하고 클러스터를 만들 때 기록해 둔 비밀번호를 입력합니다. 그런 다음 '인증' 버튼을 클릭합니다. 비밀번호를 적어 두는 것을 잊었거나 비밀번호가 작동하지 않는 경우 비밀번호를 변경할 수 있습니다. 이 작업을 수행하는 방법은 문서를 참고하세요.
AlloyDB Studio 인터페이스가 열립니다. 데이터베이스에서 명령어를 실행하려면 오른쪽의 '제목이 없는 쿼리' 탭을 클릭합니다.
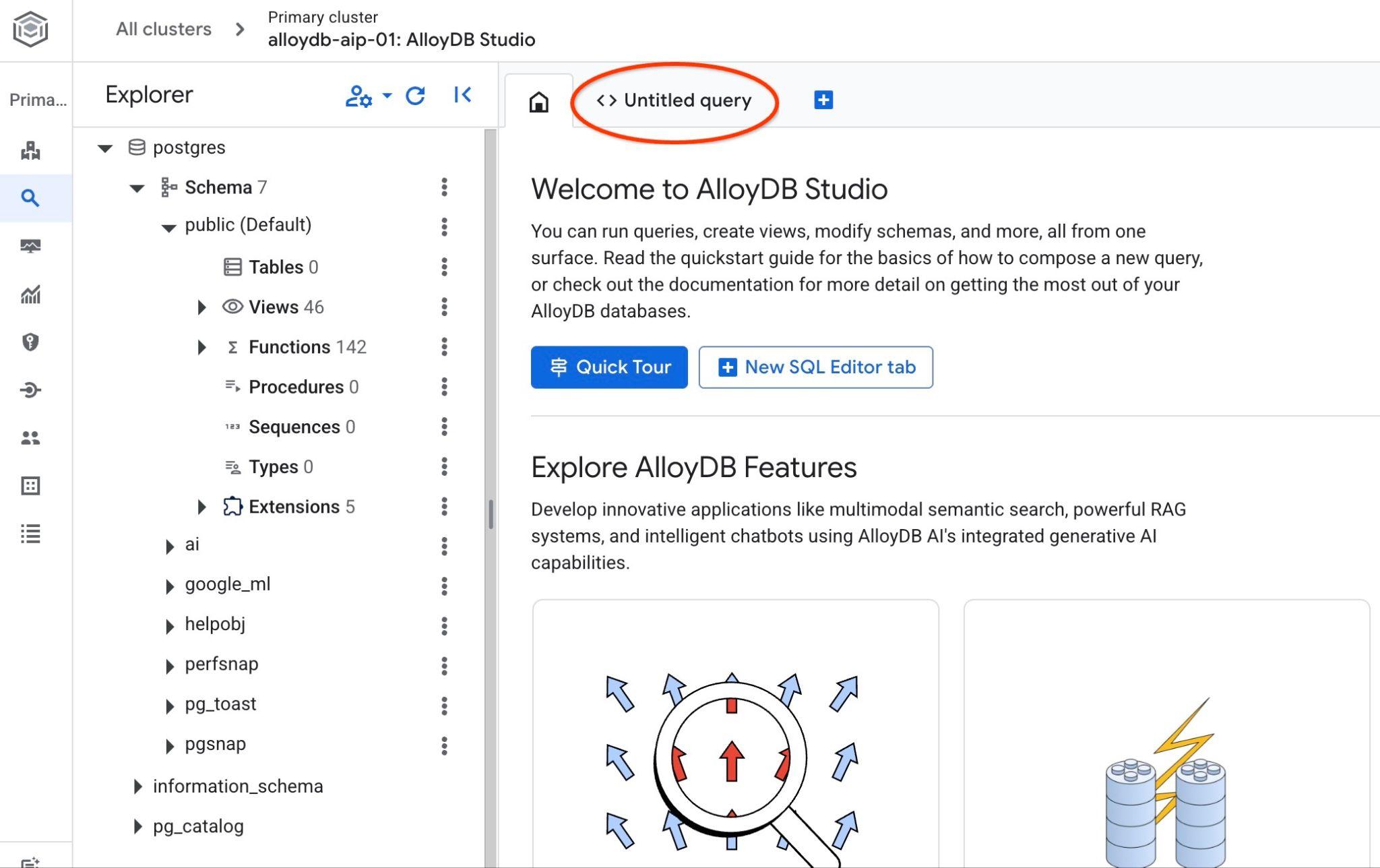
SQL 명령어를 실행할 수 있는 인터페이스가 열립니다.
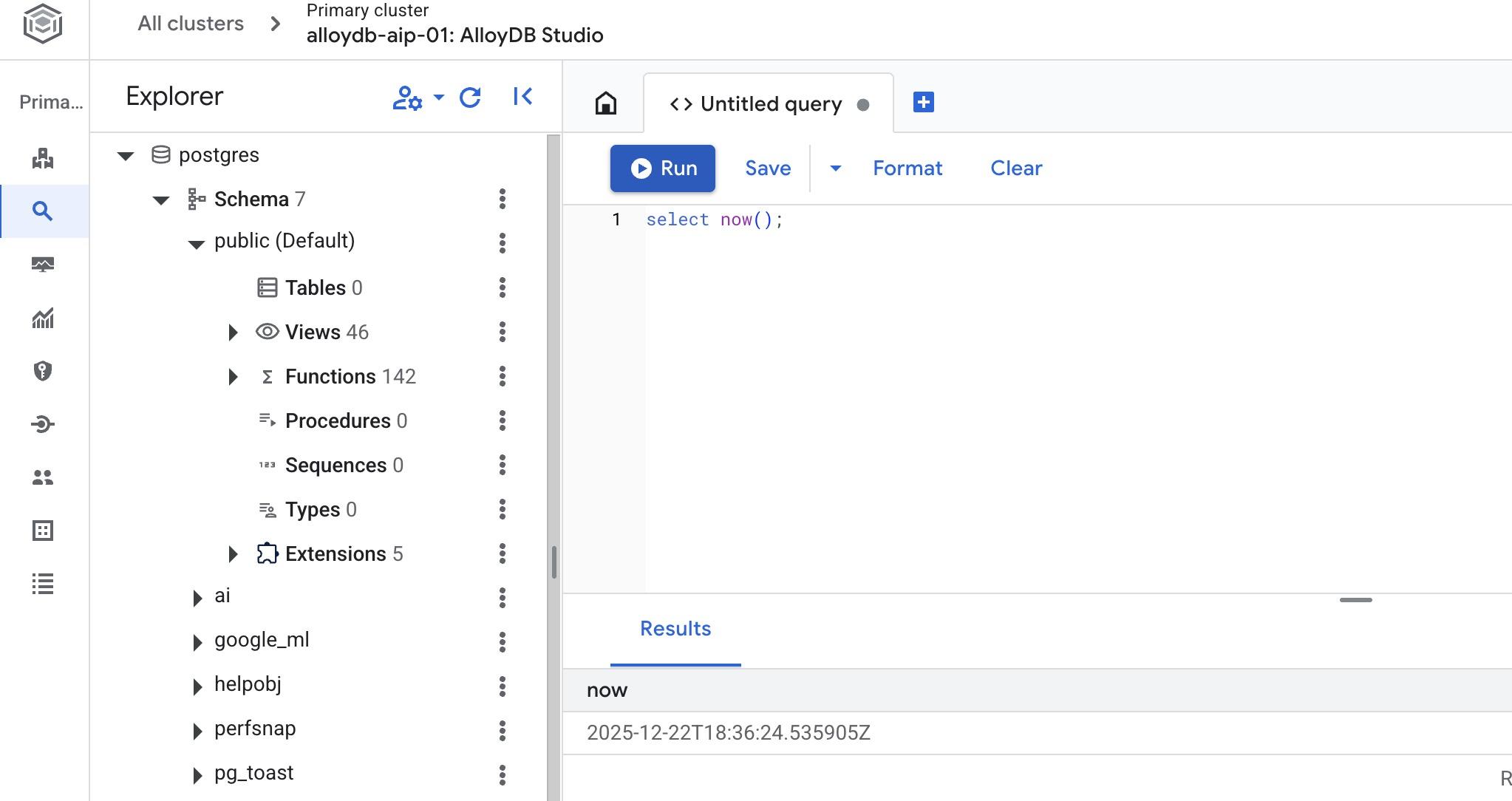
데이터베이스 만들기
데이터베이스 만들기 빠른 시작
AlloyDB Studio 편집기에서 다음 명령어를 실행합니다.
데이터베이스를 만듭니다.
CREATE DATABASE quickstart_db
예상 출력:
Statement executed successfully
quickstart_db에 연결
사용자/데이터베이스 전환 버튼을 사용하여 스튜디오에 다시 연결합니다.
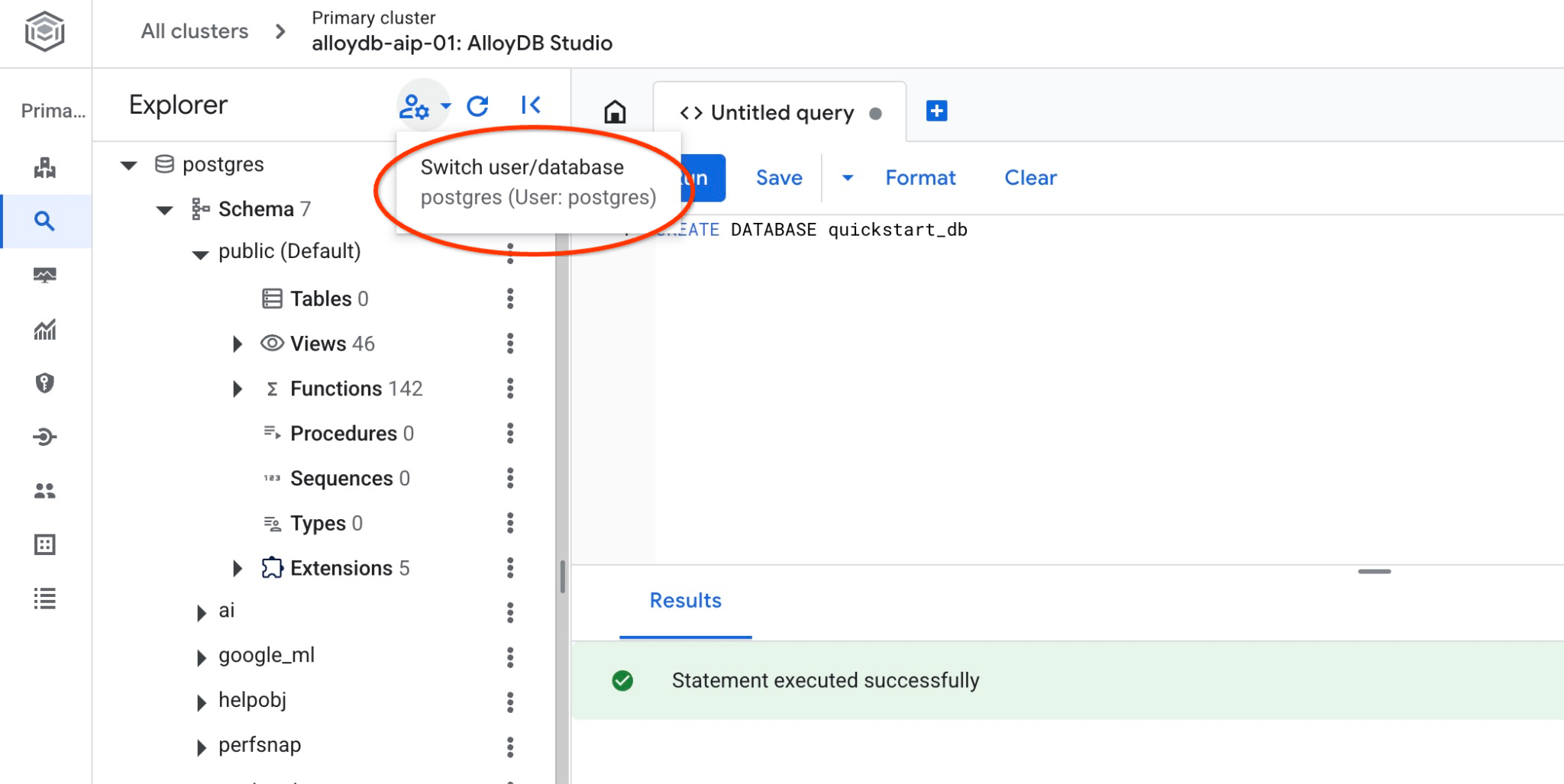
드롭다운 목록에서 새 quickstart_db 데이터베이스를 선택하고 이전과 동일한 사용자 및 비밀번호를 사용합니다.
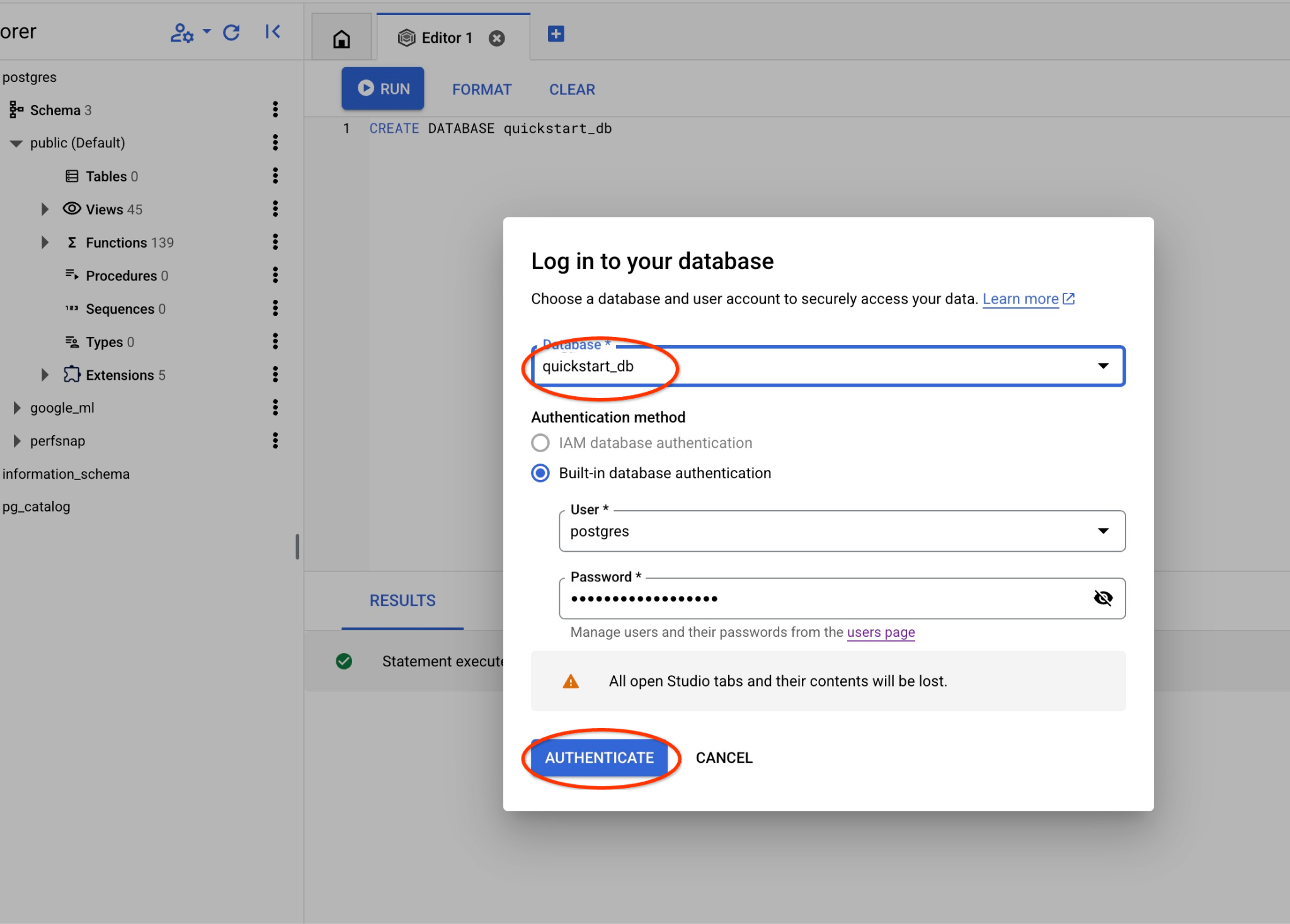
quickstart_db 데이터베이스의 객체를 사용할 수 있는 새 연결이 열립니다.
6. 샘플 데이터
이제 데이터베이스에서 객체를 만들고 데이터를 로드해야 합니다. 가상의 데이터가 포함된 가상의 'Cymbal' 스토어를 사용하겠습니다.
데이터를 가져오기 전에 데이터 유형과 색인을 지원하는 확장 프로그램을 사용 설정해야 합니다. 벡터 데이터 유형을 지원하는 확장 프로그램과 AlloyDB ScaNN 색인을 지원하는 확장 프로그램, 이렇게 두 가지 확장 프로그램이 필요합니다.
AlloyDB Studio에서 quickstart_db에 연결하고 다음을 실행합니다.
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
데이터 세트가 가져오기 인터페이스를 사용하여 데이터베이스에 로드할 수 있는 SQL 파일로 준비되고 배치됩니다. Cloud Shell에서 다음 명령어를 실행합니다.
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
이 명령어는 AlloyDB SDK를 사용하며, agentspace_user라는 사용자를 만든 다음 GCS 버킷에서 데이터베이스로 직접 샘플 데이터를 가져와 필요한 모든 객체를 만들고 데이터를 삽입합니다.
가져오기가 완료되면 AlloyDB Studio에서 테이블을 확인할 수 있습니다. 테이블은 ecomm 스키마에 있습니다.
테이블 중 하나의 행 수를 확인합니다.
select count(*) from ecomm.products;
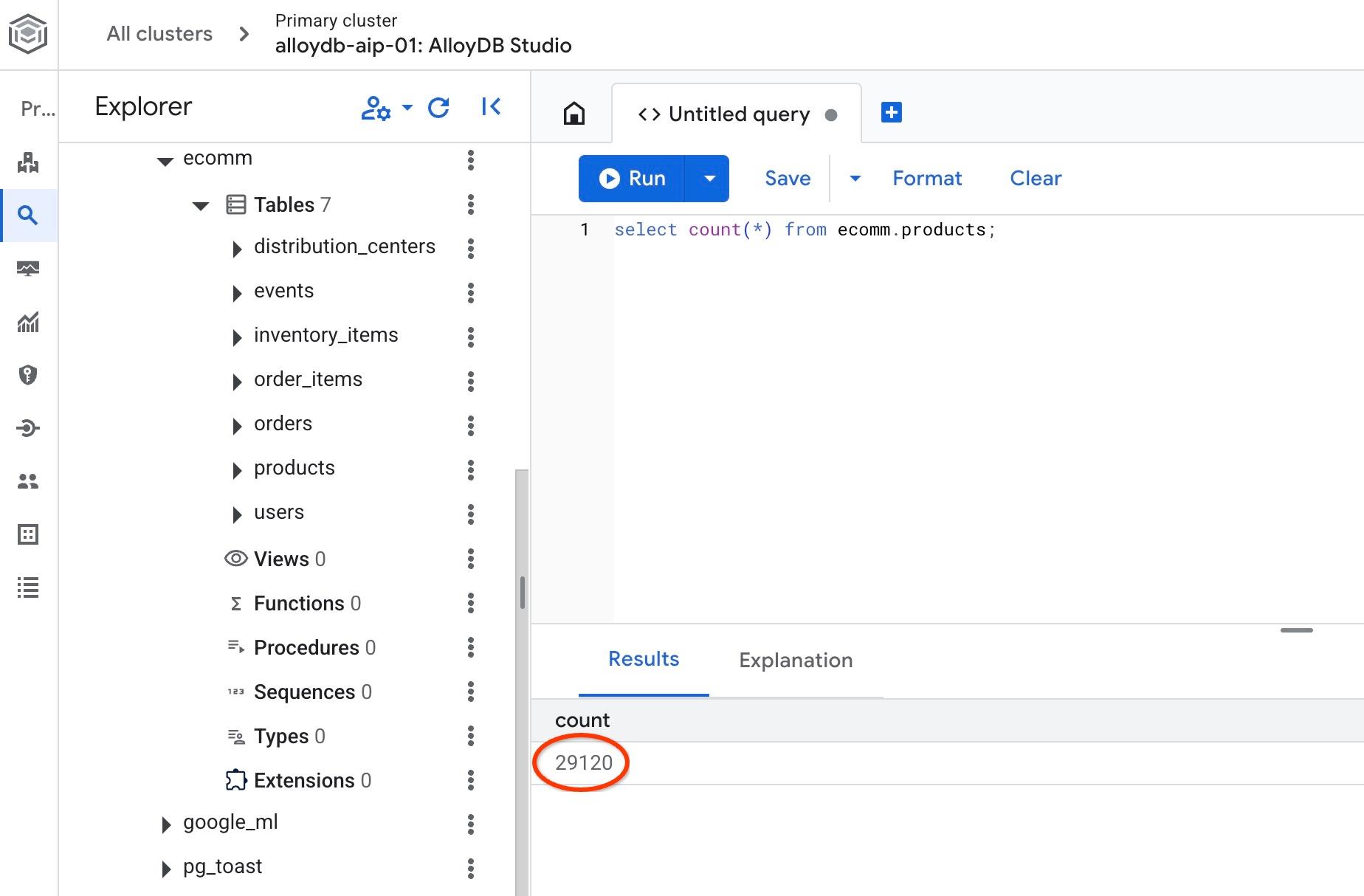
샘플 데이터를 가져왔으므로 다음 단계를 진행할 수 있습니다.
7. 텍스트 임베딩을 사용한 시맨틱 검색
이 장에서는 텍스트 임베딩을 사용하여 시맨틱 검색을 시도하고 기존 Postgres 텍스트 및 전체 텍스트 검색과 비교합니다.
먼저 LIKE 연산자를 사용하여 표준 PostgreSQL SQL을 사용하는 클래식 검색을 시도해 보겠습니다.
AlloyDB Studio에서 quickstart_db에 연결하고 다음 쿼리를 사용하여 레인코트를 검색해 보세요.
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
제품 이름이나 설명에 습한 환경, 재킷과 같은 정확한 단어가 있어야 하므로 쿼리에서 행이 반환되지 않습니다. '습한 환경용 재킷'은 '비 환경용 재킷'과 다릅니다.
검색에 가능한 모든 변형을 포함할 수 있습니다. 단어 두 개만 포함해 보겠습니다. 예를 들면 다음과 같습니다.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
이렇게 하면 여러 행이 반환되지만 모두 재킷에 대한 요청과 완벽하게 일치하지 않으며 관련성별로 정렬하기가 어렵습니다. 예를 들어 '남성용'과 같은 조건을 추가하면 쿼리의 복잡성이 크게 증가합니다. 전체 텍스트 검색을 시도할 수도 있지만, 여기에서도 정확한 단어의 수와 대답의 관련성과 관련된 제한이 있습니다.
이제 임베딩을 사용하여 유사한 검색을 할 수 있습니다. Google은 이미 다양한 모델을 사용하여 제품의 임베딩을 사전 계산했습니다. 최신 Google의 gemini-embedding-001 모델을 사용합니다. ecomm.products 테이블의 'product_embedding' 열에 저장했습니다. 다음 쿼리를 사용하여 '남성용 레인코트' 검색 조건에 대한 쿼리를 실행하면
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
젖은 날씨에 적합한 재킷뿐만 아니라 모든 결과가 가장 관련성 높은 결과가 상단에 표시되도록 정렬됩니다.
임베딩이 포함된 쿼리는 90~150ms 내에 결과를 반환하며, 이 시간의 일부는 클라우드 임베딩 모델에서 데이터를 가져오는 데 사용됩니다. 실행 계획을 살펴보면 모델에 대한 요청이 계획 시간에 포함되어 있습니다. 검색을 실행하는 쿼리 부분은 매우 짧습니다. AlloyDB ScaNN 색인을 사용하여 29,000개의 레코드에서 검색하는 데 7ms 미만이 걸립니다.
실행 계획 출력은 다음과 같습니다.
Limit (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> Index Scan using embedding_scann on products (cost=2709.20..30736.40 rows=29120 width=490) (actual time=6.964..7.046 rows=10 loops=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
...
-0.0051468653,-0.012440448]'::vector)
Limit: 10
계획 시간: 136.579ms
실행 시간: 6.791ms
(6개 행)
텍스트 전용 임베딩 모델을 사용한 텍스트 임베딩 검색이었습니다. 하지만 제품 이미지도 있으므로 검색에 사용할 수 있습니다. 다음 장에서는 멀티모달 모델이 검색에 이미지를 사용하는 방법을 보여줍니다.
8. 멀티모달 검색 사용
텍스트 기반 시맨틱 검색은 유용하지만 복잡한 세부정보를 설명하기는 어려울 수 있습니다. AlloyDB의 멀티모달 검색은 이미지 입력을 통한 제품 탐색을 지원하여 이점을 제공합니다. 이는 시각적 표현이 텍스트 설명만으로는 명확하지 않은 검색 의도를 더 효과적으로 설명할 때 특히 유용합니다. 예: '사진에 있는 것과 같은 코트를 찾아 줘.'
재킷 예시로 돌아가 보겠습니다. 찾고 싶은 재킷과 비슷한 사진이 있다면 Google 멀티모달 임베딩 모델에 전달하여 제품 이미지의 임베딩과 비교할 수 있습니다. 표에는 이미 product_image_embedding 열에 제품 이미지의 임베딩이 계산되어 있으며 product_image_embedding_model 열에 사용된 모델이 표시됩니다.
검색을 위해 image_embedding 함수를 사용하여 이미지의 임베딩을 가져와 미리 계산된 임베딩과 비교할 수 있습니다. 이 기능을 사용 설정하려면 올바른 버전의 google_ml_integration 확장 프로그램을 사용해야 합니다.
현재 확장 프로그램 버전을 확인해 보겠습니다. AlloyDB Studio에서 실행합니다.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
버전이 1.5.2 미만이면 다음 절차를 실행합니다.
CALL google_ml.upgrade_to_preview_version();
확장 프로그램의 버전을 다시 확인합니다. 1.5.3이어야 합니다.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
데이터베이스에서 AI 쿼리 엔진 기능도 사용 설정해야 합니다. 인스턴스의 모든 데이터베이스에 대해 인스턴스 플래그를 업데이트하거나 데이터베이스에 대해서만 사용 설정하면 됩니다. AlloyDB Studio에서 다음 명령어를 실행하여 quickstart_db 데이터베이스에 대해 사용 설정합니다.
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
이제 이미지로 검색할 수 있습니다. 다음은 검색을 위한 샘플 이미지이지만 원하는 맞춤 이미지를 사용할 수 있습니다. Google 스토리지 또는 공개적으로 사용 가능한 리소스에 업로드하고 URI를 쿼리에 넣기만 하면 됩니다.

gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png에 업로드됩니다.
이미지로 이미지 검색
먼저 이미지로만 검색해 보겠습니다.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
인벤토리에서 따뜻한 재킷을 찾을 수 있었습니다. 이미지를 보려면 public_url 열을 제공하여 Cloud SDK (gcloud storage cp)를 사용하여 이미지를 다운로드한 다음 이미지와 호환되는 도구를 사용하여 이미지를 엽니다.
|
|
|
|




이미지 검색은 비교를 위해 제공된 이미지와 유사한 항목을 반환합니다. 앞서 말씀드린 것처럼 공개 버킷에 자체 이미지를 업로드하여 다양한 유형의 옷을 찾을 수 있는지 확인해 보세요.
Google의 'multimodalembedding@001' 모델을 이미지 검색에 사용했습니다. image_embedding 함수는 이미지를 Vertex AI로 전송하고, 벡터로 변환한 후 데이터베이스에 저장된 이미지 벡터와 비교하기 위해 다시 반환합니다.
'EXPLAIN ANALYZE'를 사용하여 AlloyDB ScaNN 색인이 얼마나 빠르게 작동하는지 확인할 수도 있습니다.
실행 계획의 출력은 다음과 같습니다.
Limit (cost=971.70..975.55 rows=4 width=490) (actual time=2.453..2.477 rows=4 loops=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
...
,-0.010307034,-0.010053742]'::vector)
Limit: 4
계획 시간: 913.322ms
실행 시간: 2.517ms
(6개 행)
이전 예와 마찬가지로 클라우드 엔드포인트를 사용하여 이미지를 임베딩으로 변환하는 데 대부분의 시간이 소요되었으며 벡터 검색 자체는 2.5ms만 걸렸습니다.
텍스트로 이미지 검색
멀티모달을 사용하면 동일한 모델에 google_ml.text_embedding을 사용하여 검색하려는 재킷의 텍스트 설명을 모델에 전달하고 이미지 임베딩과 비교하여 반환되는 이미지를 확인할 수도 있습니다.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
회색 또는 어두운색의 패딩 재킷을 받았습니다.
|
|
|
|




약간 다른 재킷이 표시되었지만 이미지 삽입을 검색할 때 설명에 따라 재킷을 올바르게 선택했습니다.
검색 이미지의 삽입을 사용하여 설명 중에서 검색하는 다른 방법을 시도해 보겠습니다.
이미지로 텍스트 검색
이미지의 임베딩을 전달하여 이미지를 검색하고 제품의 사전 계산된 이미지 임베딩과 비교하려고 했습니다. 또한 텍스트 요청의 임베딩을 전달하여 이미지를 검색하고 제품 이미지의 동일한 임베딩 중에서 검색하려고 했습니다. 이제 이미지에 임베딩을 사용하고 제품 설명의 텍스트 임베딩과 비교해 보겠습니다. 이러한 임베딩은 product_description_embedding 열에 저장되며 동일한 multimodalembedding@001 모델을 사용합니다.
다음은 쿼리입니다.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
여기서는 회색 또는 어두운 색상의 재킷이 약간 다르게 표시되며, 일부는 다른 검색 방법으로 선택한 재킷과 동일하거나 매우 유사합니다.
|
|
|
|



이미지의 임베딩을 기반으로 텍스트 설명의 계산된 임베딩과 비교하여 올바른 제품 세트를 반환할 수 있습니다.
하이브리드 텍스트 및 이미지 검색
예를 들어 역수 순위 융합을 사용하여 텍스트와 이미지 임베딩을 함께 결합하는 실험을 할 수도 있습니다. 각 순위에 점수를 할당하고 결합된 점수를 기준으로 결과를 정렬하여 두 검색을 결합한 쿼리의 예는 다음과 같습니다.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
쿼리에서 다양한 매개변수를 사용해 검색 결과를 개선할 수 있는지 확인해 보세요. 또한 문서에 설명된 대로 다른 AI 연산자를 사용하여 결과를 순위 지정할 수도 있습니다.
이것으로 실습을 마칩니다. 예기치 않은 요금이 청구되지 않도록 사용하지 않는 리소스를 삭제하는 것이 좋습니다.
9. 환경 정리
실습을 마치면 AlloyDB 인스턴스와 클러스터를 폐기합니다.
AlloyDB 클러스터 및 모든 인스턴스 삭제
AlloyDB 무료 체험판을 사용한 경우 체험 클러스터를 사용하여 다른 실습과 리소스를 테스트할 계획이 있다면 체험 클러스터를 삭제하지 마세요. 동일한 프로젝트에서 다른 체험 클러스터를 만들 수 없습니다.
클러스터는 옵션 강제로 폐기되며, 클러스터에 속한 모든 인스턴스도 삭제됩니다.
연결이 끊어지고 이전 설정이 모두 손실된 경우 Cloud Shell에서 프로젝트와 환경 변수를 정의합니다.
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
다음과 같이 클러스터를 삭제합니다.
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB 백업 삭제
클러스터의 모든 AlloyDB 백업을 삭제합니다.
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
예상되는 콘솔 출력:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. 마무리
축하합니다. Codelab을 완료했습니다. 텍스트 및 이미지의 임베딩 함수를 사용하여 AlloyDB에서 멀티모달 검색을 사용하는 방법을 배웠습니다. AlloyDB AI 연산자 Codelab을 사용하여 멀티모달 검색을 테스트하고 google_ml.rank 함수로 개선할 수 있습니다.
Google Cloud 학습 과정
이 실습은 Google Cloud를 사용한 프로덕션 레디 AI 학습 과정의 일부입니다.
- 전체 교육과정을 살펴보고 프로토타입에서 프로덕션으로 전환하세요.
#ProductionReadyAI해시태그를 사용하여 진행 상황을 공유하세요.
학습한 내용
- Postgres용 AlloyDB를 배포하는 방법
- AlloyDB Studio 사용 방법
- 멀티모달 벡터 검색 사용 방법
- AlloyDB AI 연산자를 사용 설정하는 방법
- 멀티모달 검색을 위해 다양한 AlloyDB AI 연산자를 사용하는 방법
- AlloyDB AI를 사용하여 텍스트 및 이미지 검색 결과를 결합하는 방법
11. 설문조사
결과: