
1. Wprowadzenie
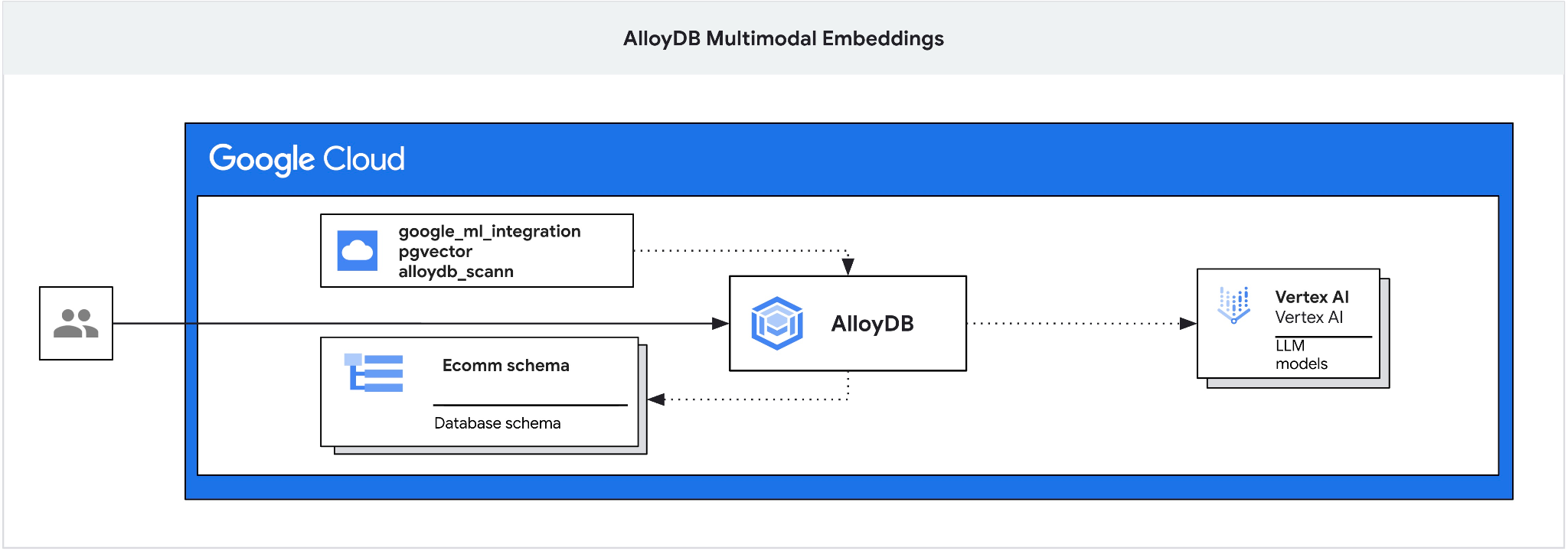
To ćwiczenie zawiera przewodnik po wdrażaniu AlloyDB i wykorzystywaniu integracji AI na potrzeby wyszukiwania semantycznego z użyciem wektorów dystrybucyjnych multimodalnych. Ten moduł należy do kolekcji modułów poświęconych funkcjom AlloyDB AI. Więcej informacji znajdziesz na stronie AlloyDB AI w dokumentacji.
Wymagania wstępne
- Podstawowa wiedza o Google Cloud i konsoli
- Podstawowe umiejętności w zakresie interfejsu wiersza poleceń i Cloud Shell
Czego się nauczysz
- Jak wdrożyć AlloyDB dla Postgres
- Jak korzystać z AlloyDB Studio
- Jak korzystać z wyszukiwania wektorowego wielomodalnego
- Włączanie operatorów AlloyDB AI
- Jak używać różnych operatorów AI AlloyDB do wyszukiwania multimodalnego
- Jak używać AlloyDB AI do łączenia wyników wyszukiwania tekstu i obrazów
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- Przeglądarka internetowa, np. Chrome, obsługująca konsolę Google Cloud i Cloud Shell
2. Konfiguracja i wymagania
Konfiguracja projektu
- Zaloguj się w konsoli Google Cloud. Jeśli nie masz jeszcze konta Gmail lub Google Workspace, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
- Utwórz nowy projekt lub użyj istniejącego. Aby utworzyć nowy projekt w konsoli Google Cloud, w nagłówku kliknij przycisk Wybierz projekt. Otworzy się okno wyskakujące.

W oknie Wybierz projekt kliknij przycisk Nowy projekt, który otworzy okno dialogowe nowego projektu.
W oknie dialogowym wpisz preferowaną nazwę projektu i wybierz lokalizację.
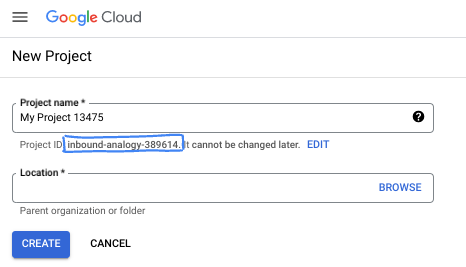
- Nazwa projektu to wyświetlana nazwa dla uczestników tego projektu. Nazwa projektu nie jest używana przez interfejsy API Google i można ją w każdej chwili zmienić.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Google Cloud automatycznie generuje unikalny identyfikator, ale możesz go dostosować. Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować kolejny losowy identyfikator lub podać własny, aby sprawdzić jego dostępność. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu, który jest zwykle oznaczony zmienną PROJECT_ID.
- Warto wiedzieć, że istnieje jeszcze trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
Włącz płatności
Aby włączyć płatności, masz 2 możliwości. Możesz użyć osobistego konta rozliczeniowego lub wykorzystać środki, wykonując te czynności.
Odbieranie środków w Google Cloud (opcjonalnie)
Aby przeprowadzić te warsztaty, musisz mieć konto rozliczeniowe z określonymi środkami. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w Cloud Console.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 3 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Możesz też nacisnąć G, a potem S. Ta sekwencja aktywuje Cloud Shell, jeśli korzystasz z konsoli Google Cloud. Możesz też użyć tego linku.
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Zanim zaczniesz
Włącz API
Aby korzystać z usług AlloyDB, Compute Engine, usług sieciowych i Vertex AI, musisz włączyć odpowiednie interfejsy API w projekcie Google Cloud.
W terminalu Cloud Shell sprawdź, czy identyfikator projektu jest skonfigurowany. Identyfikator projektu powinien być wyświetlany w nawiasach w wierszu poleceń, jak w tym przykładzie:
student@cloudshell:~ (test-project-001-402417)$
Jeśli identyfikator projektu nie jest widoczny, odśwież kartę przeglądarki i ponownie uwierzytelnij się w Cloud Shell.
Ustaw zmienną środowiskową PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Włącz wszystkie niezbędne usługi:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Oczekiwane dane wyjściowe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Wdrażanie AlloyDB
Utwórz klaster AlloyDB i instancję główną. Poniższa procedura opisuje, jak utworzyć klaster i instancję AlloyDB za pomocą pakietu SDK Google Cloud. Jeśli wolisz korzystać z konsoli, zapoznaj się z dokumentacją tutaj.
Przed utworzeniem klastra AlloyDB musimy mieć dostępny zakres prywatnych adresów IP w naszej sieci VPC, który będzie używany przez przyszłą instancję AlloyDB. Jeśli go nie mamy, musimy go utworzyć i przypisać do użytku przez wewnętrzne usługi Google. Dopiero wtedy będziemy mogli utworzyć klaster i instancję.
Tworzenie prywatnego zakresu adresów IP
Musimy skonfigurować prywatny dostęp do usług w naszej sieci VPC dla AlloyDB. Zakładamy, że w projekcie mamy sieć VPC „default”, która będzie używana do wszystkich działań.
Utwórz zakres prywatnych adresów IP:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Utwórz połączenie prywatne, używając przydzielonego zakresu adresów IP:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Tworzenie klastra AlloyDB
W tej sekcji utworzymy klaster AlloyDB w regionie us-central1.
Określ hasło użytkownika postgres. Możesz zdefiniować własne hasło lub użyć funkcji losowej, aby je wygenerować.
export PGPASSWORD=`openssl rand -hex 12`
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Zapisz hasło do PostgreSQL, aby użyć go w przyszłości.
echo $PGPASSWORD
To hasło będzie Ci potrzebne w przyszłości do połączenia z instancją jako użytkownik postgres. Proponuję zapisać go lub skopiować w inne miejsce, aby móc go później użyć.
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
Tworzenie bezpłatnego klastra próbnego
Jeśli nie używasz jeszcze AlloyDB, możesz utworzyć bezpłatny klaster wersji próbnej:
Określ region i nazwę klastra AlloyDB. Użyjemy regionu us-central1 i nazwy klastra alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Uruchom polecenie, aby utworzyć klaster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Oczekiwane dane wyjściowe konsoli:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Utwórz instancję główną AlloyDB dla klastra w tej samej sesji Cloud Shell. Jeśli połączenie zostanie przerwane, musisz ponownie zdefiniować zmienne środowiskowe regionu i nazwy klastra.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Tworzenie klastra AlloyDB Standard
Jeśli nie jest to Twój pierwszy klaster AlloyDB w projekcie, utwórz standardowy klaster. Jeśli w poprzednim kroku utworzono już bezpłatny klaster próbny, pomiń ten krok.
Określ region i nazwę klastra AlloyDB. Użyjemy regionu us-central1 i nazwy klastra alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Uruchom polecenie, aby utworzyć klaster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Oczekiwane dane wyjściowe konsoli:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Utwórz instancję główną AlloyDB dla klastra w tej samej sesji Cloud Shell. Jeśli połączenie zostanie przerwane, musisz ponownie zdefiniować zmienne środowiskowe regionu i nazwy klastra.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Przygotowywanie bazy danych
Musimy utworzyć bazę danych, włączyć integrację z Vertex AI, utworzyć obiekty bazy danych i zaimportować dane.
Przyznawanie AlloyDB niezbędnych uprawnień
Dodaj uprawnienia Vertex AI do agenta usługi AlloyDB.
Otwórz kolejną kartę Cloud Shell, klikając znak „+” u góry.
Na nowej karcie Cloud Shell wykonaj to polecenie:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Zamknij kartę, wpisując na niej polecenie „exit”:
exit
Łączenie się z AlloyDB Studio
W kolejnych rozdziałach wszystkie polecenia SQL wymagające połączenia z bazą danych można wykonywać w AlloyDB Studio.
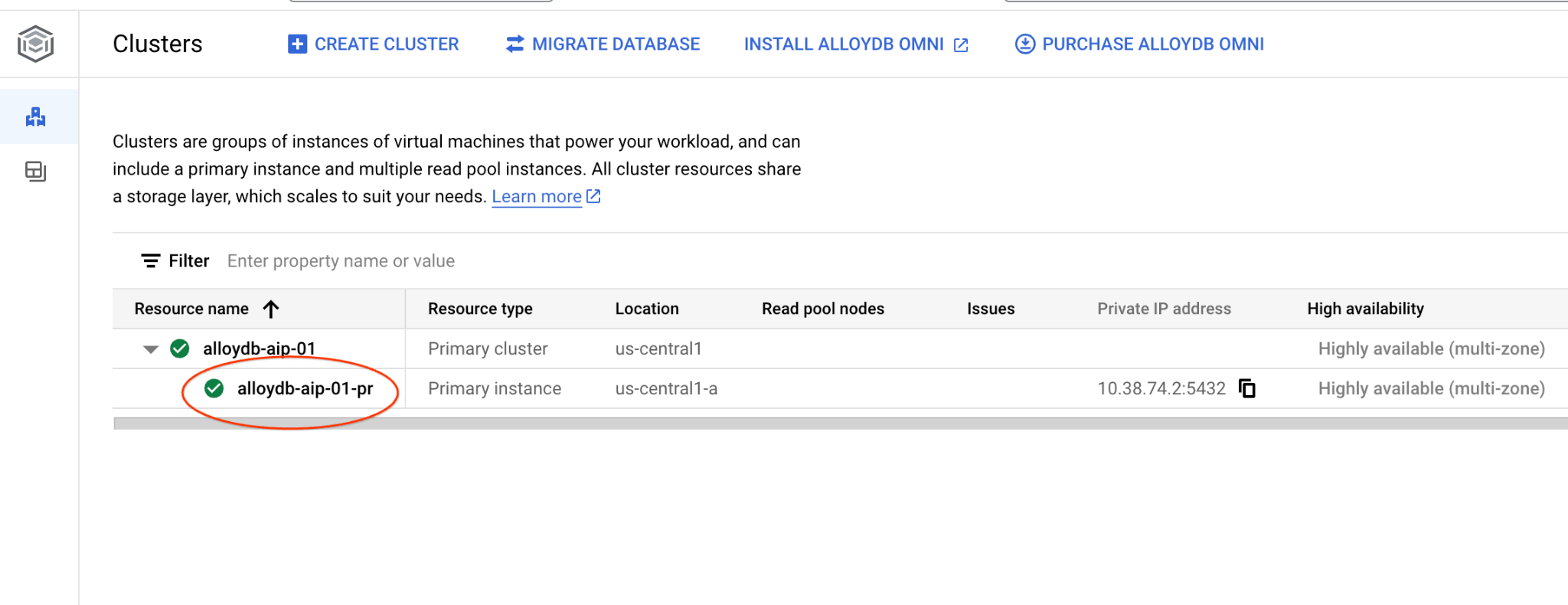
W nowej karcie otwórz stronę Klastry w AlloyDB for Postgres.
Otwórz interfejs konsoli internetowej klastra AlloyDB, klikając instancję główną.
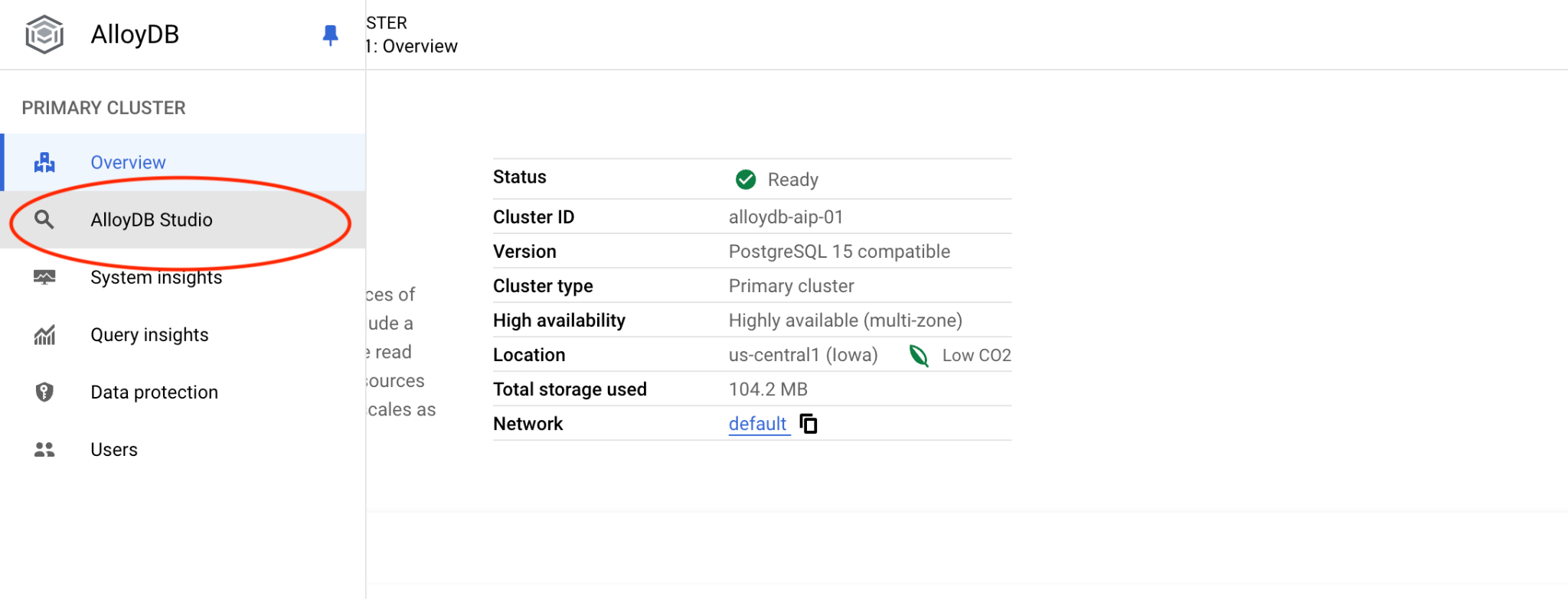
Następnie po lewej stronie kliknij AlloyDB Studio:
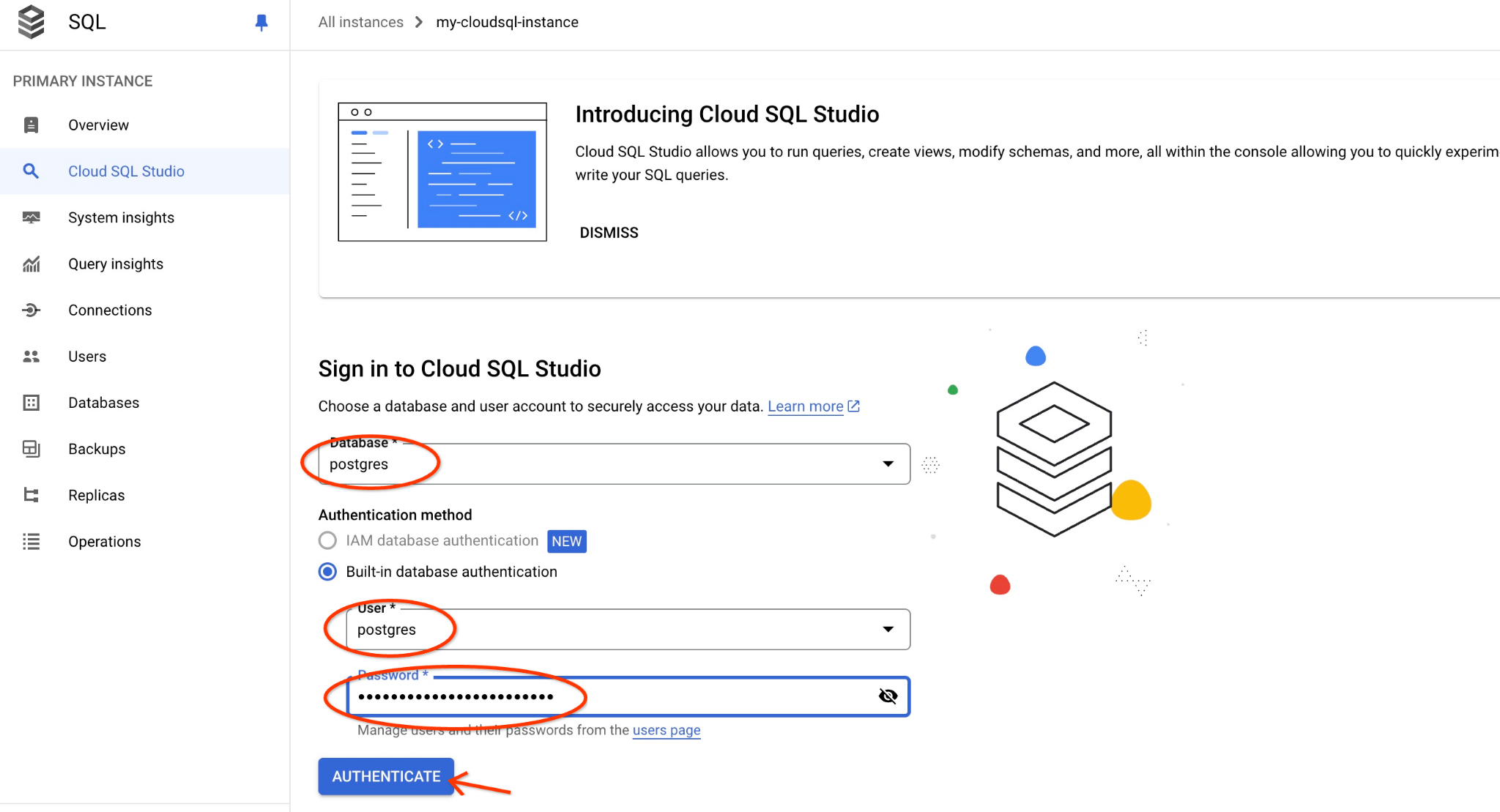
Wybierz bazę danych postgres, użytkownika postgres i podaj hasło zanotowane podczas tworzenia klastra. Następnie kliknij przycisk „Uwierzytelnij”. Jeśli nie pamiętasz hasła lub nie działa ono w Twoim przypadku, możesz je zmienić. Instrukcje znajdziesz w dokumentacji.
Otworzy się interfejs AlloyDB Studio. Aby uruchomić polecenia w bazie danych, kliknij kartę „Untitled Query” (Nienazwane zapytanie) po prawej stronie.
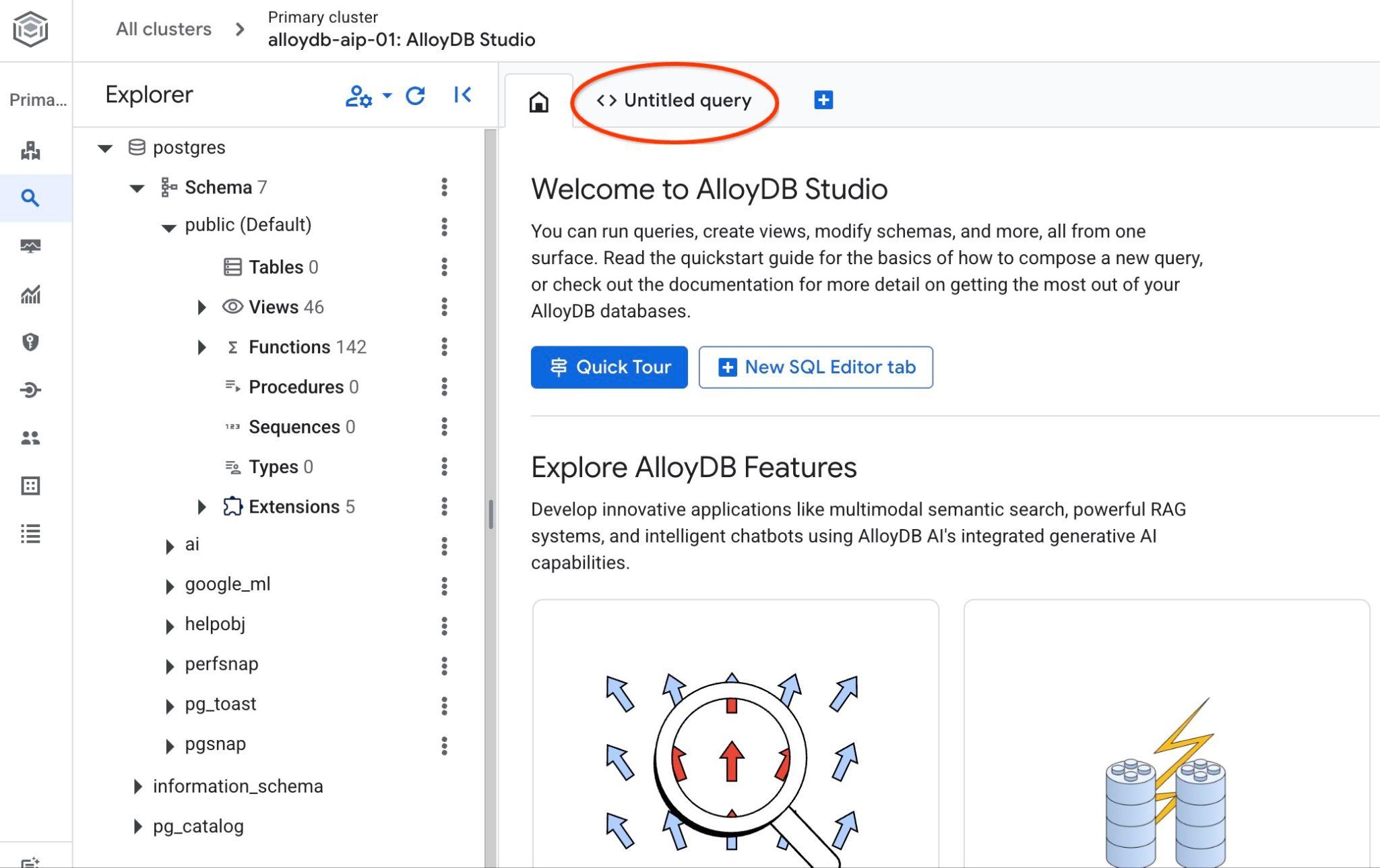
Otworzy się interfejs, w którym możesz uruchamiać polecenia SQL.
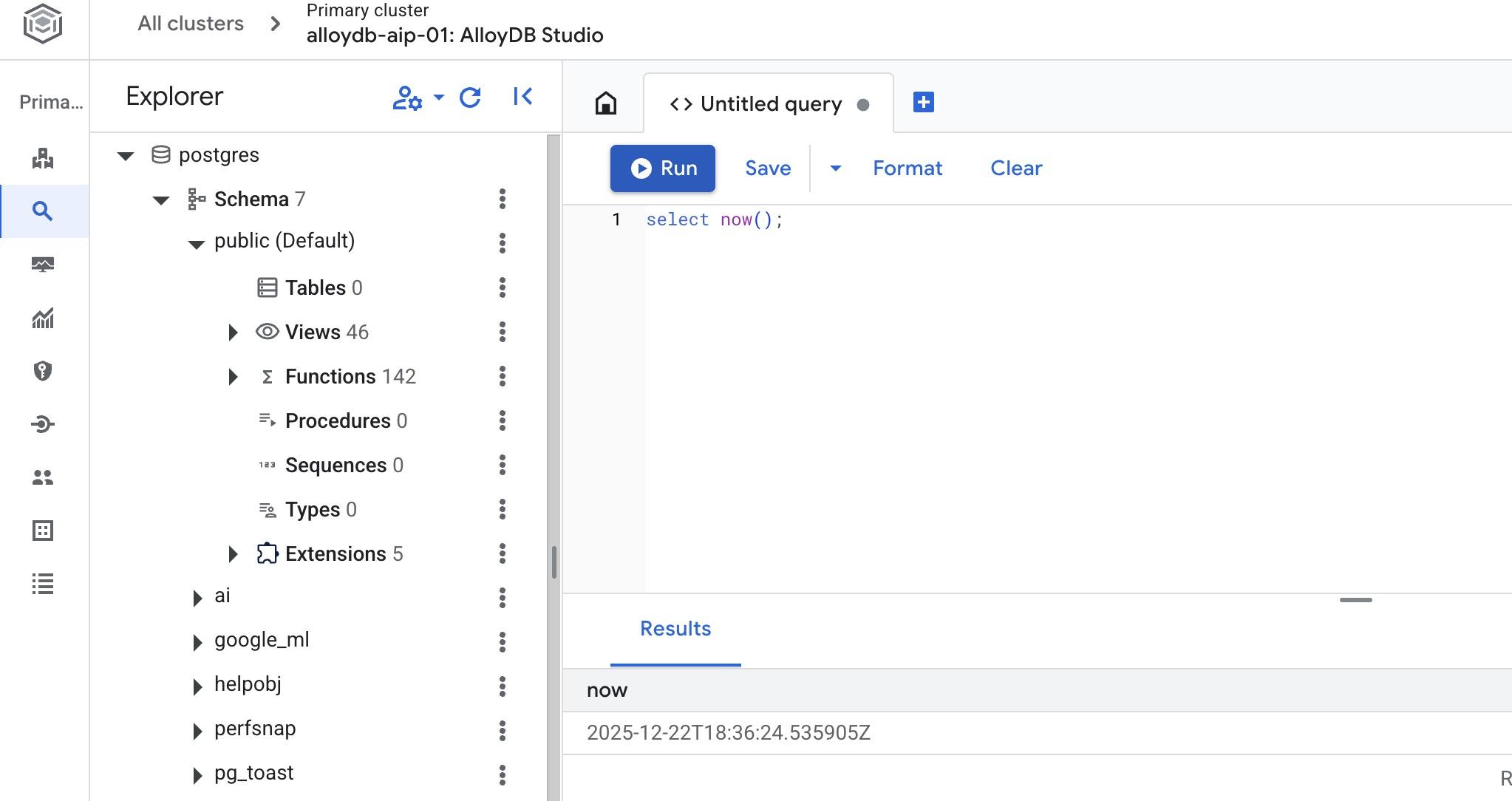
Utwórz bazę danych
Szybki start dotyczący tworzenia bazy danych.
W edytorze AlloyDB Studio wykonaj to polecenie.
Utwórz bazę danych:
CREATE DATABASE quickstart_db
Oczekiwane dane wyjściowe:
Statement executed successfully
Połącz się z bazą danych quickstart_db
Połącz się ponownie ze studiem, używając przycisku przełączania użytkownika lub bazy danych.
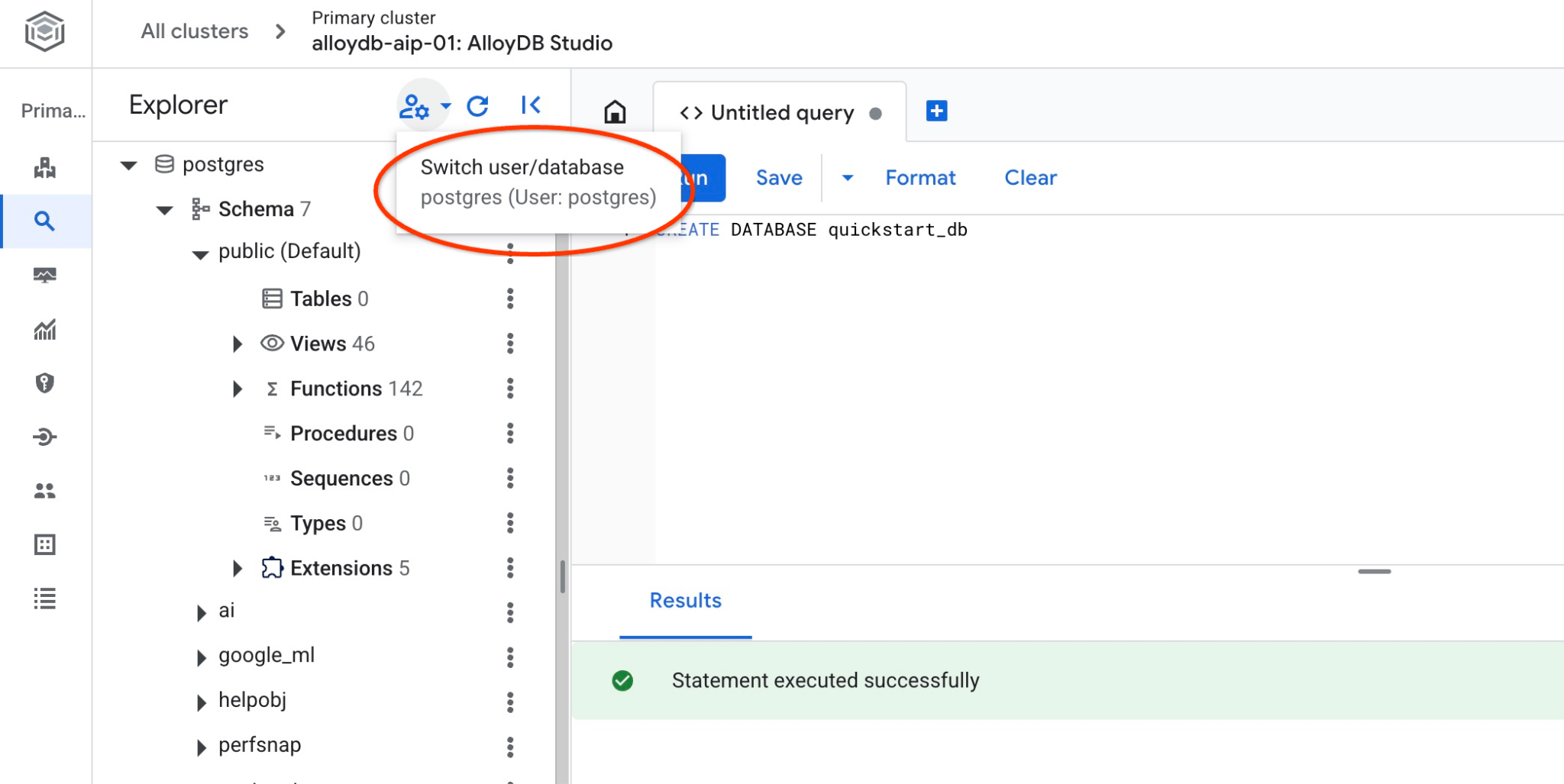
Na liście wybierz nową bazę danych quickstart_db i użyj tych samych danych logowania co wcześniej.
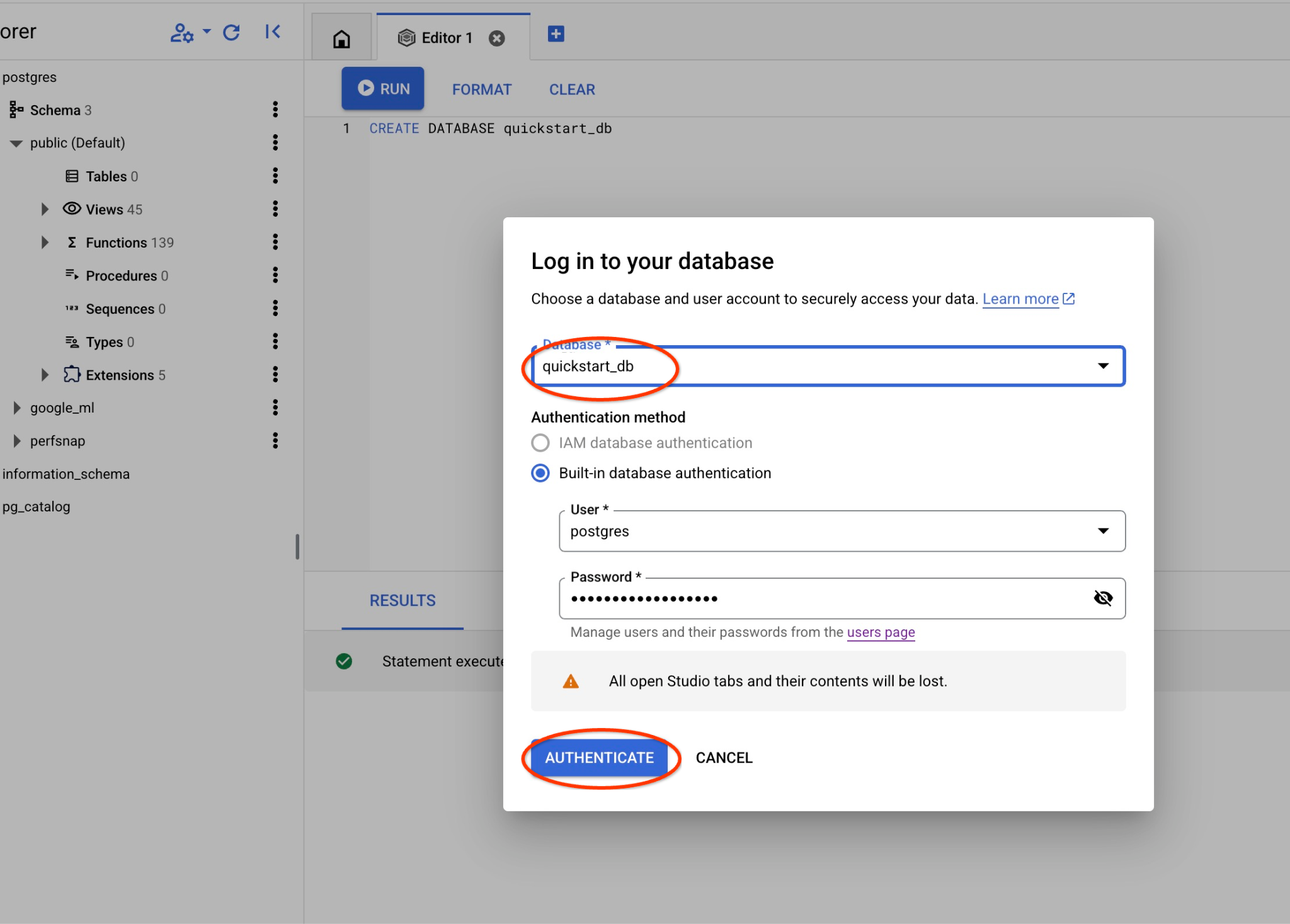
Otworzy się nowe połączenie, w którym możesz pracować z obiektami z bazy danych quickstart_db.
6. Przykładowe dane
Teraz musimy utworzyć obiekty w bazie danych i załadować dane. Użyjemy fikcyjnego sklepu „Cymbal” z fikcyjnymi danymi.
Zanim zaimportujemy dane, musimy włączyć rozszerzenia obsługujące typy danych i indeksy. Potrzebujemy 2 rozszerzeń: jednego, które obsługuje typ danych wektorowych, i drugiego, które obsługuje indeks ScaNN w AlloyDB.
W AlloyDB Studio połącz się z bazą danych quickstart_db i wykonaj to polecenie:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Zbiór danych jest przygotowywany i umieszczany jako plik SQL, który można załadować do bazy danych za pomocą interfejsu importu. W Cloud Shell uruchom te polecenia:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
Polecenie korzysta z pakietu SDK AlloyDB i tworzy użytkownika o nazwie agentspace_user, a następnie importuje przykładowe dane bezpośrednio z zasobnika GCS do bazy danych, tworząc wszystkie niezbędne obiekty i wstawiając dane.
Po zakończeniu importu możemy sprawdzić tabele w AlloyDB Studio. Tabele znajdują się w schemacie ecomm:
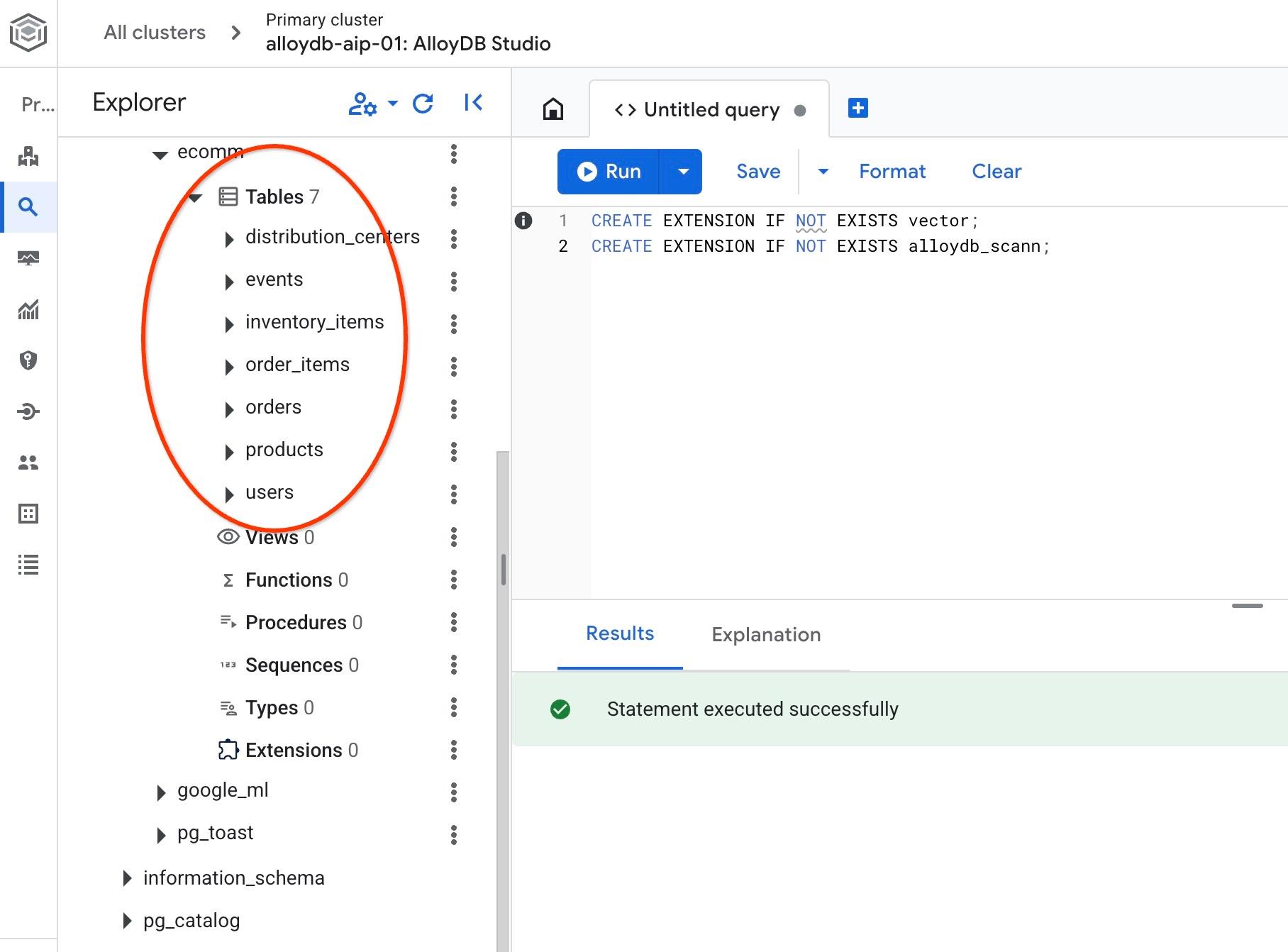
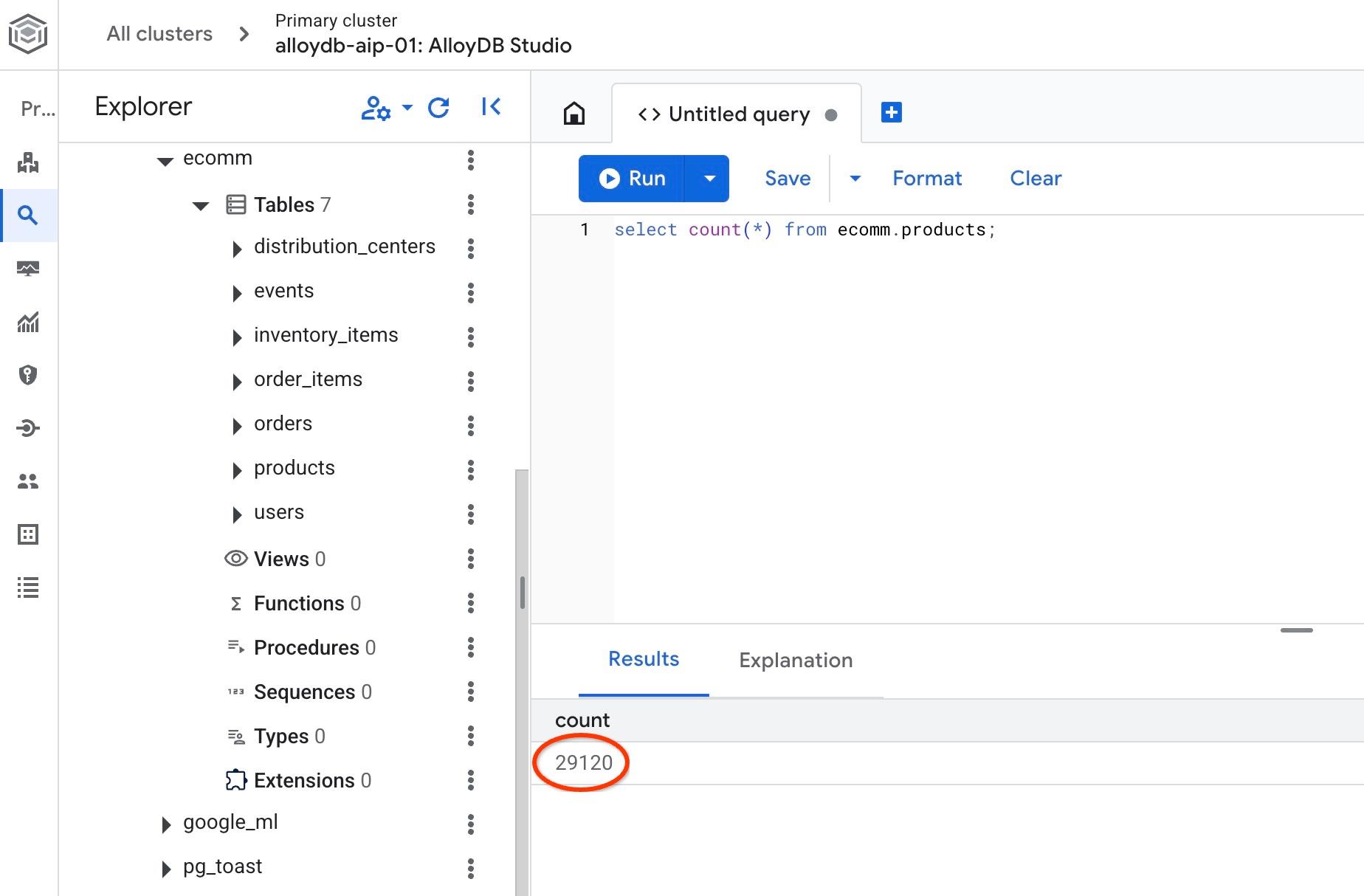
Sprawdź też liczbę wierszy w jednej z tabel.
select count(*) from ecomm.products;
Przykładowe dane zostały zaimportowane i możemy przejść do kolejnych kroków.
7. Wyszukiwanie semantyczne za pomocą wektorów dystrybucyjnych tekstu
W tym rozdziale spróbujemy użyć wyszukiwania semantycznego z użyciem wektorów dystrybucyjnych tekstu i porównamy je z tradycyjnym wyszukiwaniem tekstowym i pełnotekstowym w Postgres.
Najpierw wypróbujmy klasyczne wyszukiwanie za pomocą standardowego języka SQL PostgreSQL z operatorem LIKE.
W AlloyDB Studio połącz się z bazą danych quickstart_db i spróbuj wyszukać kurtkę przeciwdeszczową za pomocą tego zapytania:
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
Zapytanie nie zwraca żadnych wierszy, ponieważ wymagałoby dokładnych słów, takich jak „mokre warunki” i „kurtka”, w nazwie lub opisie produktu. „Kurtka na mokre warunki” to nie to samo co „kurtka na deszcz”.
Możemy spróbować uwzględnić w wyszukiwaniu wszystkie możliwe warianty. Spróbujmy użyć tylko dwóch słów. Na przykład:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
Zwróci to wiele wierszy, ale nie wszystkie będą idealnie pasować do naszej prośby o kurtki, a sortowanie według trafności będzie trudne. Jeśli na przykład dodamy więcej warunków, takich jak „dla mężczyzn”, znacznie zwiększy to złożoność zapytania. Możemy też spróbować wyszukiwania pełnotekstowego, ale nawet w tym przypadku napotykamy ograniczenia związane z mniej lub bardziej dokładnymi słowami i trafnością odpowiedzi.
Teraz możemy przeprowadzić podobne wyszukiwanie za pomocą reprezentacji właściwościowych. Wstępnie obliczyliśmy już wektory osadzeń dla naszych usług za pomocą różnych modeli. Będziemy używać najnowszego modelu gemini-embedding-001 od Google. Przechowujemy je w kolumnie „product_embedding” tabeli ecomm.products. Jeśli uruchomimy zapytanie dotyczące warunku wyszukiwania „kurtka przeciwdeszczowa męska” za pomocą tego zapytania:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
Wyświetli nie tylko kurtki na mokrą pogodę, ale też posortuje wszystkie wyniki, umieszczając na górze te najbardziej trafne.
Zapytanie z wektorami zwraca wyniki w ciągu 90–150 ms, przy czym część tego czasu jest poświęcana na pobieranie danych z modelu wektorów w chmurze. Jeśli przyjrzymy się planowi wykonania, zobaczymy, że żądanie do modelu jest uwzględnione w czasie planowania. Część zapytania, która wykonuje wyszukiwanie, jest dość krótka. Wyszukiwanie w 29 tys. rekordów za pomocą indeksu ScaNN w AlloyDB trwa mniej niż 7 ms.
Oto dane wyjściowe planu wykonania:
Limit (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> Index Scan using embedding_scann on products (cost=2709.20..30736.40 rows=29120 width=490) (actual time=6.964..7.046 rows=10 loops=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
…
-0.0051468653,-0.012440448]'::vector)
Limit: 10
Czas planowania: 136,579 ms
Czas wykonywania: 6,791 ms
(6 wierszy)
To było wyszukiwanie wektorów dystrybucyjnych tekstu za pomocą modelu wektorów dystrybucyjnych tekstu. Mamy też obrazy naszych produktów, których możemy użyć w wyszukiwaniu. W następnym rozdziale pokażemy, jak model multimodalny wykorzystuje obrazy do wyszukiwania.
8. Korzystanie z wyszukiwania wielomodalnego
Wyszukiwanie semantyczne oparte na tekście jest przydatne, ale opisywanie skomplikowanych szczegółów może być trudne. Wyszukiwanie multimodalne w AlloyDB zapewnia przewagę, ponieważ umożliwia odkrywanie produktów za pomocą obrazów. Jest to szczególnie przydatne, gdy wizualizacja lepiej wyjaśnia zamiar wyszukiwania niż sam opis tekstowy. Na przykład „znajdź mi płaszcz podobny do tego na zdjęciu”.
Wróćmy do przykładu z kurtką. Jeśli mam zdjęcie kurtki podobnej do tej, którą chcę znaleźć, mogę przekazać je do multimodalnego modelu osadzania Google i porównać z osadzaniem obrazów moich produktów. W naszej tabeli mamy już obliczone osadzanie obrazów produktów w kolumnie product_image_embedding, a model użyty do tego celu możesz zobaczyć w kolumnie product_image_embedding_model.
Do wyszukiwania możemy użyć funkcji image_embedding, aby uzyskać wektor dystrybucyjny obrazu i porównać go z wcześniej obliczonymi wektorami dystrybucyjnymi. Aby włączyć tę funkcję, musimy mieć pewność, że używamy odpowiedniej wersji rozszerzenia google_ml_integration.
Sprawdźmy aktualną wersję rozszerzenia. W AlloyDB Studio wykonaj:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Jeśli wersja jest starsza niż 1.5.2, wykonaj te czynności.
CALL google_ml.upgrade_to_preview_version();
i ponownie sprawdź wersję rozszerzenia. Powinna to być wersja 1.5.3.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Musimy też włączyć w naszej bazie danych funkcje silnika zapytań AI. Można to zrobić, aktualizując flagę instancji dla wszystkich baz danych w instancji lub włączając ją tylko w przypadku naszej bazy danych. Aby włączyć tę funkcję w bazie danych quickstart_db, wykonaj w AlloyDB Studio to polecenie:
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
Teraz możemy wyszukiwać za pomocą obrazu. Oto przykładowy obraz do wyszukiwania, ale możesz użyć dowolnego obrazu niestandardowego. Wystarczy przesłać go do pamięci Google lub innego publicznie dostępnego zasobu i umieścić identyfikator URI w zapytaniu.

Zostanie on przesłany do gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png
Wyszukiwanie obrazem
Najpierw spróbujemy wyszukać tylko na podstawie obrazu:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
W asortymencie znaleźliśmy ciepłe kurtki. Aby wyświetlić obrazy, możesz je pobrać za pomocą pakietu SDK Cloud (gcloud storage cp), podając kolumnę public_url, a następnie otworzyć je za pomocą dowolnego narzędzia obsługującego obrazy.
|
|
|
|




Wyszukiwanie obrazem zwraca elementy podobne do obrazu podanego do porównania. Jak już wspomniałem, możesz spróbować przesłać własne zdjęcia do publicznego zasobnika i sprawdzić, czy znajdzie różne rodzaje ubrań.
Do wyszukiwania obrazów używamy modelu Google „multimodalembedding@001”. Nasza funkcja image_embedding wysyła obraz do Vertex AI, przekształca go w wektor i zwraca go, aby porównać go z wektorami obrazów przechowywanymi w naszej bazie danych.
Możemy też sprawdzić za pomocą polecenia „EXPLAIN ANALYZE”, jak szybko działa z naszym indeksem AlloyDB ScaNN.
Oto dane wyjściowe planu wykonania:
Limit (cost=971.70..975.55 rows=4 width=490) (actual time=2.453..2.477 rows=4 loops=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
…
,-0.010307034,-0.010053742]'::vector)
Limit: 4
Czas planowania: 913,322 ms
Czas wykonywania: 2,517 ms
(6 wierszy)
Podobnie jak w poprzednim przykładzie widzimy, że najwięcej czasu zajęło przekształcenie obrazu w wektory dystrybucyjne przy użyciu punktu końcowego w chmurze, a samo wyszukiwanie wektorowe trwało tylko 2,5 ms.
Wyszukiwanie obrazów za pomocą tekstu
W przypadku multimodalnego wyszukiwania możemy też przekazać do modelu opis tekstowy kurtki, której szukamy, za pomocą google_ml.text_embedding dla tego samego modelu i porównać go z wektorami dystrybucyjnymi obrazów, aby sprawdzić, jakie obrazy zostaną zwrócone.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Otrzymaliśmy zestaw puchowych kurtek w szarych lub ciemnych kolorach.
|
|
|
|




Otrzymaliśmy nieco inny zestaw kurtek, ale podczas wyszukiwania w osadzonych obrazach prawidłowo wybrał kurtki na podstawie naszego opisu.
Spróbujmy innego sposobu wyszukiwania wśród opisów za pomocą reprezentacji właściwościowej obrazu wyszukiwania.
Wyszukiwanie tekstowe za pomocą obrazów
Próbowaliśmy wyszukać obrazy, przekazując osadzenie naszego obrazu, i porównać je z wstępnie obliczonymi osadzeniami obrazów naszych produktów. Spróbowaliśmy też wyszukać obrazy, przekazując osadzenie dla naszego żądania tekstowego i wyszukując wśród tego samego osadzenia obrazy produktów. Spróbujmy teraz użyć osadzania dla obrazu i porównać je z osadzaniem tekstu dla opisów produktów. Te osadzania są przechowywane w kolumnie product_description_embedding i korzystają z tego samego modelu multimodalembedding@001.
Oto nasze zapytanie:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
W tym przypadku otrzymaliśmy nieco inny zestaw kurtek w szarych lub ciemnych kolorach. Niektóre z nich są takie same lub bardzo podobne do tych, które zostały wybrane w inny sposób.
|
|
|
|



Na podstawie reprezentacji właściwościowych obrazów może porównać je z obliczonymi reprezentacjami właściwościowymi opisu tekstowego i zwrócić odpowiedni zestaw produktów.
Hybrydowe wyszukiwanie tekstu i obrazów
Możesz też eksperymentować z łączeniem osadzania tekstu i obrazu, np. za pomocą fuzji odwrotnych rang. Oto przykład takiego zapytania, w którym połączyliśmy 2 wyszukiwania, przypisując każdemu miejscu ocenę i porządkując wyniki na podstawie łącznej oceny.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
Możesz spróbować użyć w zapytaniu różnych parametrów i sprawdzić, czy uda Ci się poprawić wyniki wyszukiwania. Możesz też użyć innych operatorów AI, aby ocenić wyniki zgodnie z opisem w dokumentacji.
To koniec modułu. Aby uniknąć nieoczekiwanych opłat, zalecamy usunięcie nieużywanych zasobów.
9. Zwalnianie miejsca w środowisku
Po zakończeniu modułu zniszcz instancje i klaster AlloyDB.
Usuwanie klastra AlloyDB i wszystkich instancji
Jeśli korzystasz z wersji próbnej AlloyDB. Nie usuwaj klastra próbnego, jeśli planujesz testować inne laboratoria i zasoby przy jego użyciu. Nie będzie można utworzyć kolejnego klastra próbnego w tym samym projekcie.
Klaster zostanie zniszczony z użyciem opcji force, która powoduje też usunięcie wszystkich instancji należących do klastra.
W Cloud Shell zdefiniuj projekt i zmienne środowiskowe, jeśli połączenie zostało przerwane i wszystkie poprzednie ustawienia zostały utracone:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Usuń klaster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Usuwanie kopii zapasowych AlloyDB
Usuń wszystkie kopie zapasowe AlloyDB dla klastra:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. Gratulacje
Gratulujemy ukończenia ćwiczenia. Wiesz już, jak korzystać z wyszukiwania multimodalnego w AlloyDB za pomocą funkcji wektorów dystrybucyjnych tekstu i obrazów. Możesz przetestować wyszukiwanie multimodalne i ulepszyć je za pomocą funkcji google_ml.rank, korzystając z ćwiczeń z programowania dotyczących operatorów AI w AlloyDB.
Ścieżka szkoleniowa Google Cloud
Ten moduł jest częścią ścieżki szkoleniowej dotyczącej AI w Google Cloud gotowej do wdrożenia w środowisku produkcyjnym.
- Poznaj pełny program nauczania, aby przejść od prototypu do produkcji.
- Udostępnij swoje postępy z hashtagiem
#ProductionReadyAI.
Omówione zagadnienia
- Jak wdrożyć AlloyDB dla Postgres
- Jak korzystać z AlloyDB Studio
- Jak korzystać z wyszukiwania wektorowego wielomodalnego
- Włączanie operatorów AlloyDB AI
- Jak używać różnych operatorów AI AlloyDB do wyszukiwania multimodalnego
- Jak używać AlloyDB AI do łączenia wyników wyszukiwania tekstu i obrazów
11. Ankieta
Dane wyjściowe: