
1. Introdução
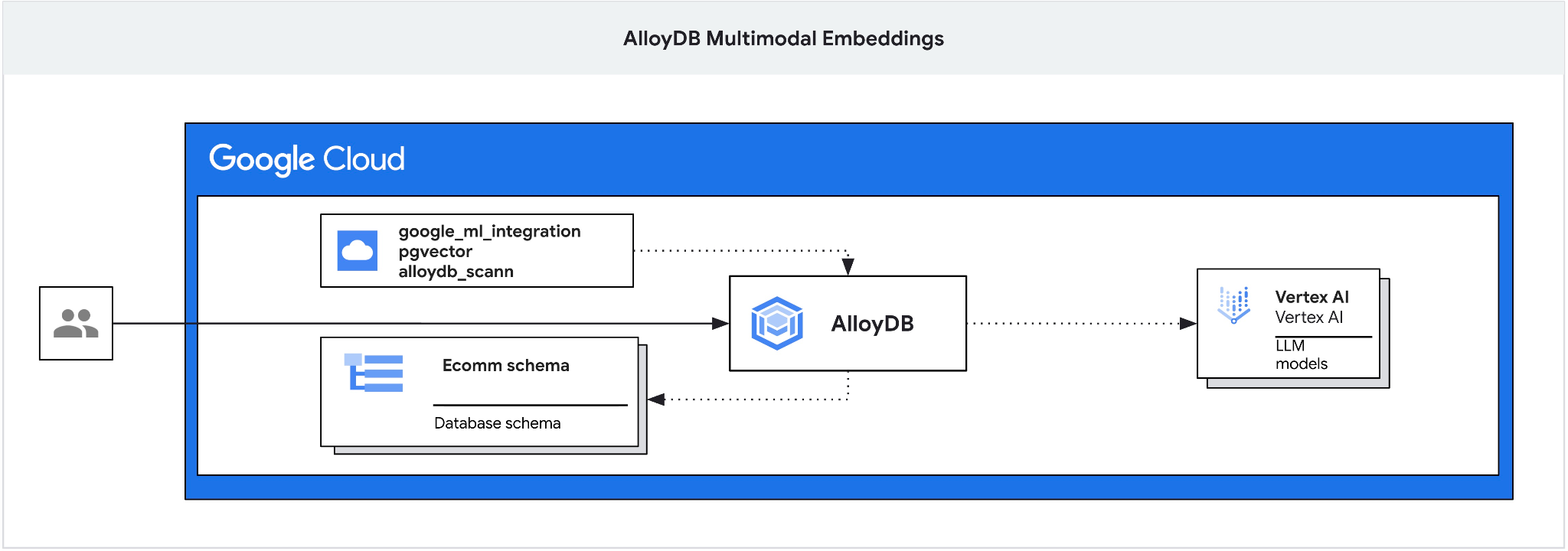
Este codelab ensina como implantar o AlloyDB e aproveitar a integração de IA para pesquisa semântica usando embeddings multimodais. Este laboratório faz parte de uma coleção dedicada aos recursos de IA do AlloyDB. Leia mais na página da IA do AlloyDB na documentação.
Pré-requisitos
- Conhecimentos básicos sobre o Google Cloud e o console
- Habilidades básicas na interface de linha de comando e no Cloud Shell
O que você vai aprender
- Como implantar o AlloyDB para Postgres
- Como usar o AlloyDB Studio
- Como usar a pesquisa vetorial multimodal
- Como ativar os operadores da IA do AlloyDB
- Como usar diferentes operadores de IA do AlloyDB para pesquisa multimodal
- Como usar a IA do AlloyDB para combinar resultados de pesquisa de texto e imagem
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome, que seja compatível com o console do Google Cloud e o Cloud Shell
2. Configuração e requisitos
Configuração do projeto
- Faça login no Console do Google Cloud. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
- Crie um projeto ou reutilize um existente. Para criar um projeto no console do Google Cloud, clique no botão "Selecionar um projeto" no cabeçalho, que vai abrir uma janela pop-up.

Na janela "Selecionar um projeto", clique no botão "Novo projeto", que vai abrir uma caixa de diálogo para o novo projeto.
Na caixa de diálogo, coloque o nome do projeto de sua preferência e escolha o local.
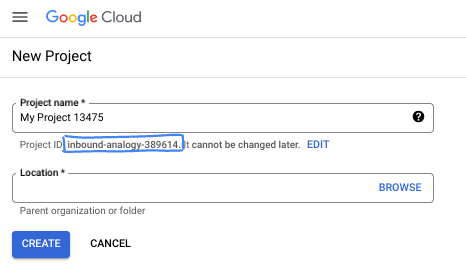
- O Nome do projeto é o nome de exibição para os participantes do projeto. O nome do projeto não é usado pelas APIs do Google e pode ser alterado a qualquer momento.
- O ID do projeto é exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Google Cloud gera automaticamente um ID exclusivo, mas você pode personalizá-lo. Se você não gostar do ID gerado, crie outro aleatório ou forneça o seu para verificar a disponibilidade. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, que normalmente é identificado com o marcador de posição PROJECT_ID.
- Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
Ativar faturamento
Para ativar o faturamento, você tem duas opções. Você pode usar sua conta de faturamento pessoal ou resgatar créditos seguindo estas etapas.
Resgatar créditos do Google Cloud (opcional)
Para fazer este workshop, você precisa de uma conta de faturamento com algum crédito. Use os créditos do banner na parte de cima deste codelab para começar. Se você já estiver conectado a uma conta de faturamento, pule esta etapa.
Configurar uma conta de faturamento pessoal
Se você configurou o faturamento usando créditos do Google Cloud, pule esta etapa.
Para configurar uma conta de faturamento pessoal, acesse este link para ativar o faturamento no console do Cloud.
Algumas observações:
- A conclusão deste laboratório custa menos de US $3 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
Ou pressione G e S. Essa sequência vai ativar o Cloud Shell se você estiver no console do Google Cloud ou usar este link.
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Antes de começar
Ativar API
Para usar o AlloyDB, o Compute Engine, os serviços de rede e a Vertex AI, é necessário ativar as APIs respectivas no seu projeto do Google Cloud.
No terminal do Cloud Shell, verifique se o ID do projeto está configurado. O ID do projeto vai aparecer entre parênteses no prompt de comando, como mostrado abaixo:
student@cloudshell:~ (test-project-001-402417)$
Se o ID do projeto não aparecer, atualize a guia do navegador e faça a autenticação novamente no Cloud Shell.
Defina a variável de ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Ative todos os serviços necessários:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Implantar o AlloyDB
Crie um cluster e uma instância principal do AlloyDB. O procedimento a seguir descreve como criar um cluster e uma instância do AlloyDB usando o SDK Google Cloud. Se preferir a abordagem do console, siga a documentação aqui.
Antes de criar um cluster do AlloyDB, é necessário ter um intervalo de IP privado disponível na VPC para ser usado pela instância futura do AlloyDB. Se não tivermos, precisamos criar e atribuir para uso por serviços internos do Google. Depois disso, será possível criar o cluster e a instância.
Criar um intervalo de IP privado
É preciso configurar o acesso a serviços particulares na VPC para o AlloyDB. Vamos supor que o projeto tem uma rede VPC "padrão" a ser usada para todas as ações.
Crie o intervalo de IP privado:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Crie uma conexão privada com o intervalo de IP alocado:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Criar cluster do AlloyDB
Nesta seção, vamos criar um cluster do AlloyDB na região us-central1.
Defina a senha do usuário postgres. Você pode definir sua própria senha ou usar uma função aleatória para gerar uma.
export PGPASSWORD=`openssl rand -hex 12`
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Anote a senha do PostgreSQL para uso futuro.
echo $PGPASSWORD
Você vai precisar dessa senha no futuro para se conectar à instância como o usuário postgres. Recomendamos anotar ou copiar em algum lugar para usar depois.
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
Criar um cluster de teste sem custo financeiro
Se você nunca usou o AlloyDB, crie um cluster de teste sem custo financeiro:
Defina a região e o nome do cluster do AlloyDB. Vamos usar a região us-central1 e alloydb-aip-01 como nome do cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Execute o comando para criar o cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Saída esperada do console:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crie uma instância principal do AlloyDB para o cluster na mesma sessão do Cloud Shell. Se você se desconectar, será necessário definir as variáveis de ambiente de região e nome do cluster novamente.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Criar cluster padrão do AlloyDB
Se não for seu primeiro cluster do AlloyDB no projeto, continue com a criação de um cluster padrão. Se você já criou um cluster de teste sem custo financeiro na etapa anterior, pule esta etapa.
Defina a região e o nome do cluster do AlloyDB. Vamos usar a região us-central1 e alloydb-aip-01 como nome do cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Execute o comando para criar o cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Saída esperada do console:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crie uma instância principal do AlloyDB para o cluster na mesma sessão do Cloud Shell. Se você se desconectar, será necessário definir as variáveis de ambiente de região e nome do cluster novamente.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Preparar banco de dados
Precisamos criar um banco de dados, ativar a integração da Vertex AI, criar objetos de banco de dados e importar os dados.
Conceder as permissões necessárias ao AlloyDB
Adicione permissões da Vertex AI ao agente de serviço do AlloyDB.
Abra outra guia do Cloud Shell pelo sinal "+" na parte superior.
Na nova guia do Cloud Shell, execute:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Feche a guia pelo comando de execução "sair" na guia:
exit
Conectar-se ao AlloyDB Studio
Nos capítulos a seguir, todos os comandos SQL que exigem conexão com o banco de dados podem ser executados no AlloyDB Studio.
Em uma nova guia, acesse a página "Clusters" no AlloyDB para Postgres.
Abra a interface do console da Web do cluster do AlloyDB clicando na instância principal.
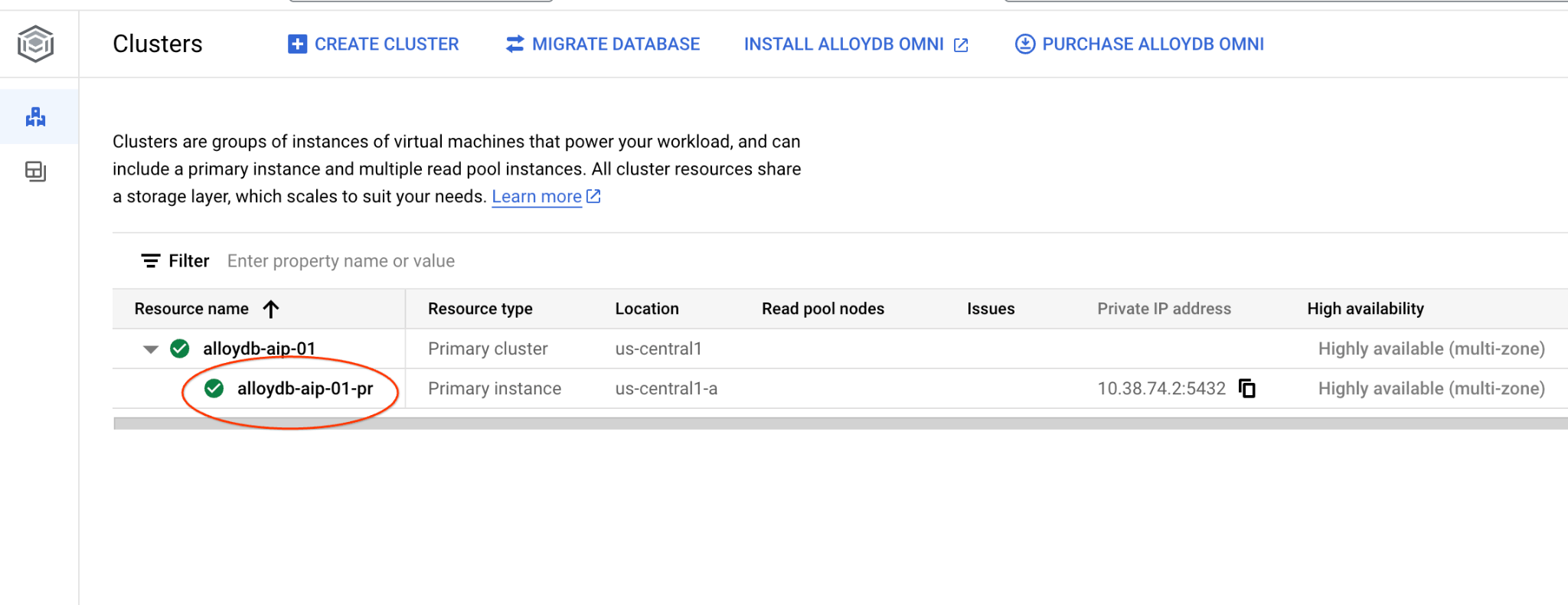
Em seguida, clique em "AlloyDB Studio" à esquerda:
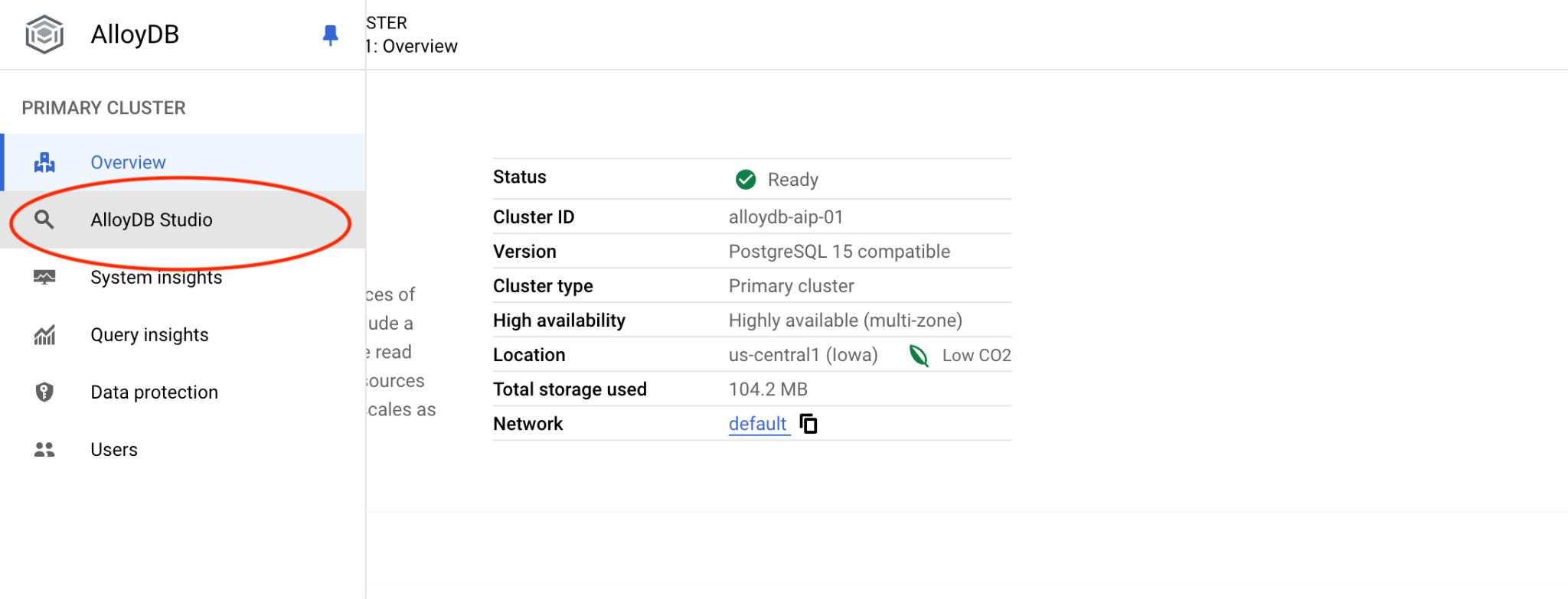
Escolha o banco de dados postgres, o usuário postgres e forneça a senha anotada quando criamos o cluster. Em seguida, clique no botão "Autenticar". Se você esqueceu a senha ou ela não funciona, é possível mudar a senha. Confira a documentação para saber como fazer isso.
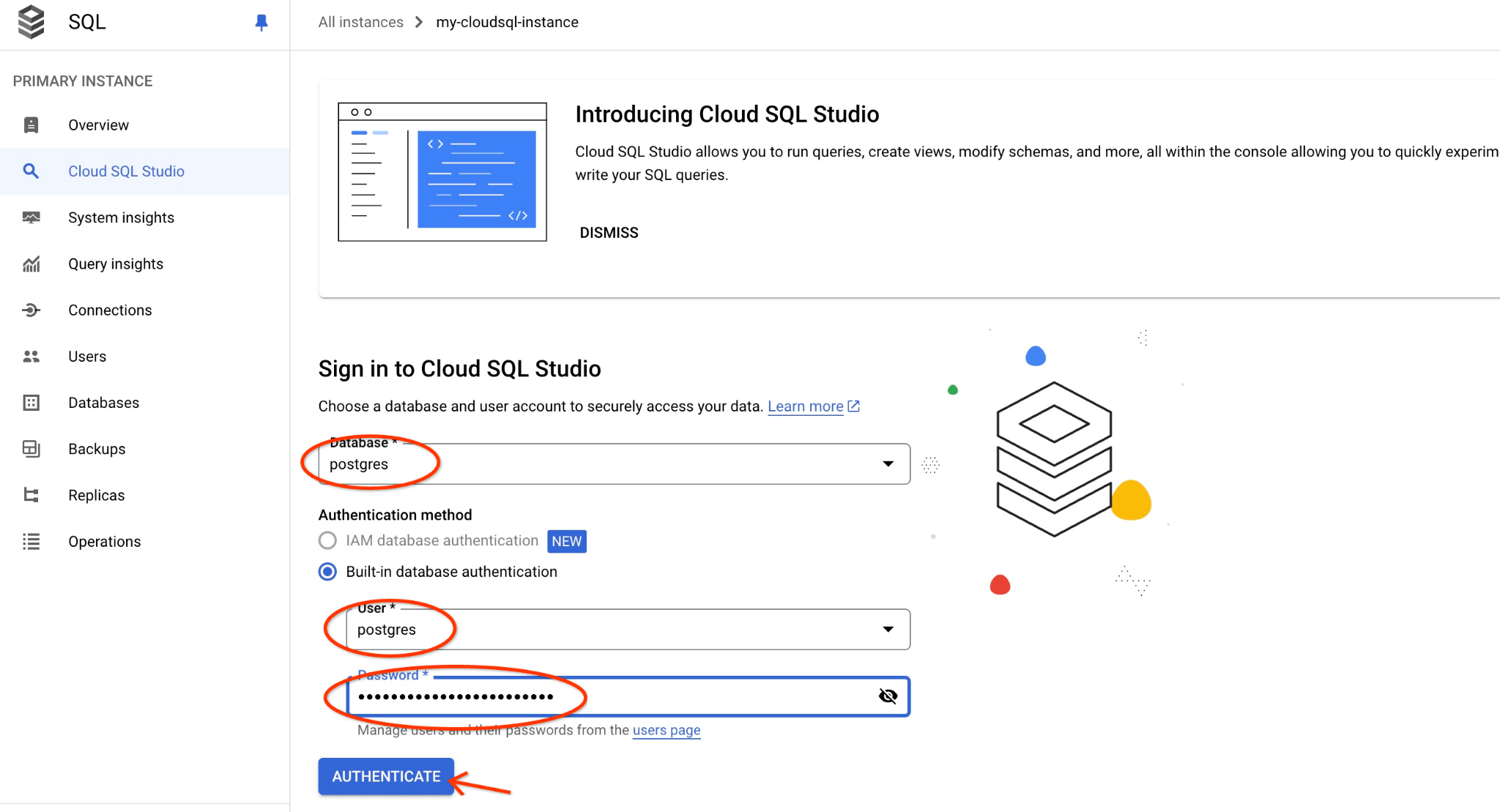
A interface do AlloyDB Studio será aberta. Para executar os comandos no banco de dados, clique na guia "Consulta sem título" à direita.
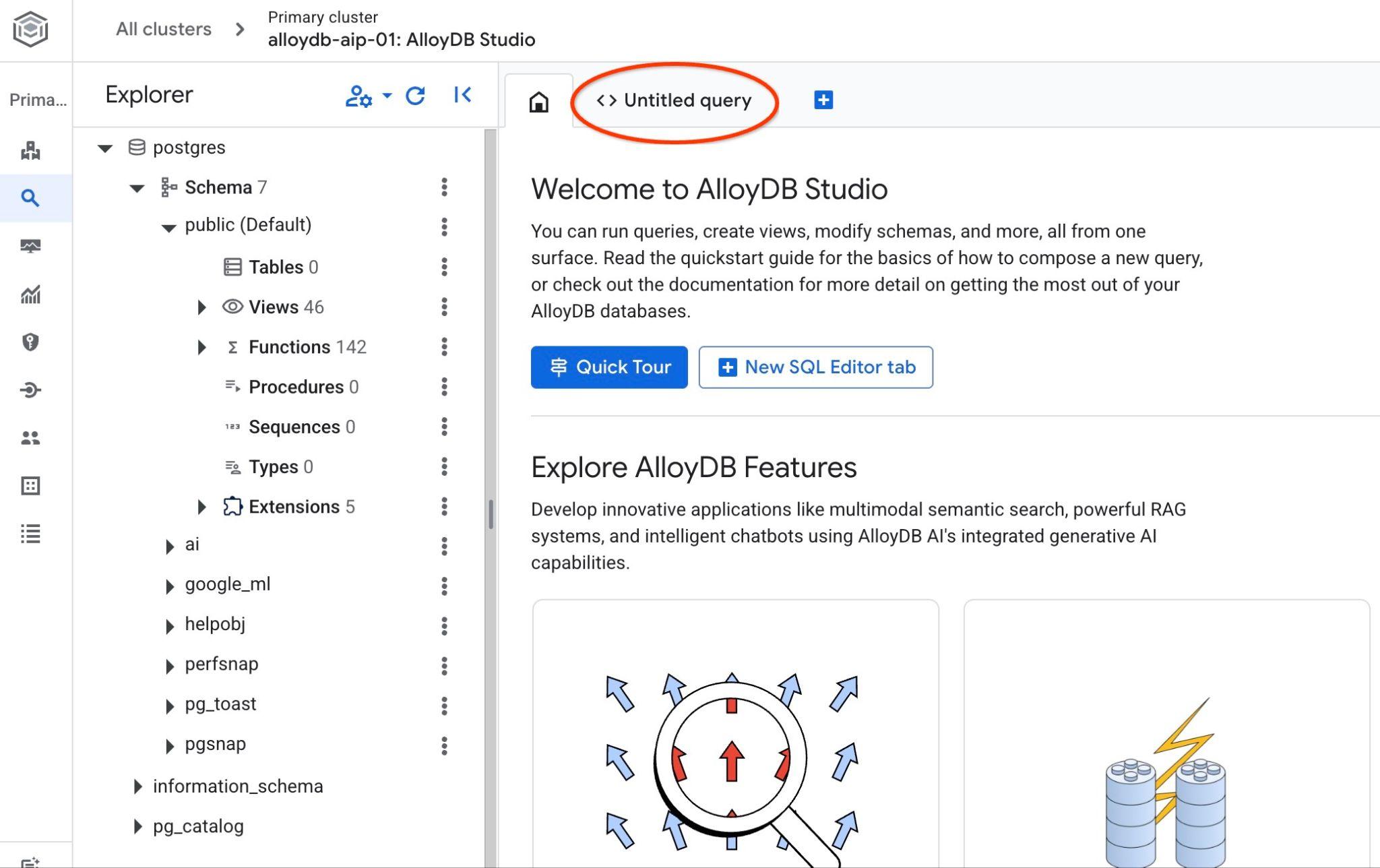
Ela abre a interface em que é possível executar comandos SQL.
Criar banco de dados
Início rápido para criar um banco de dados.
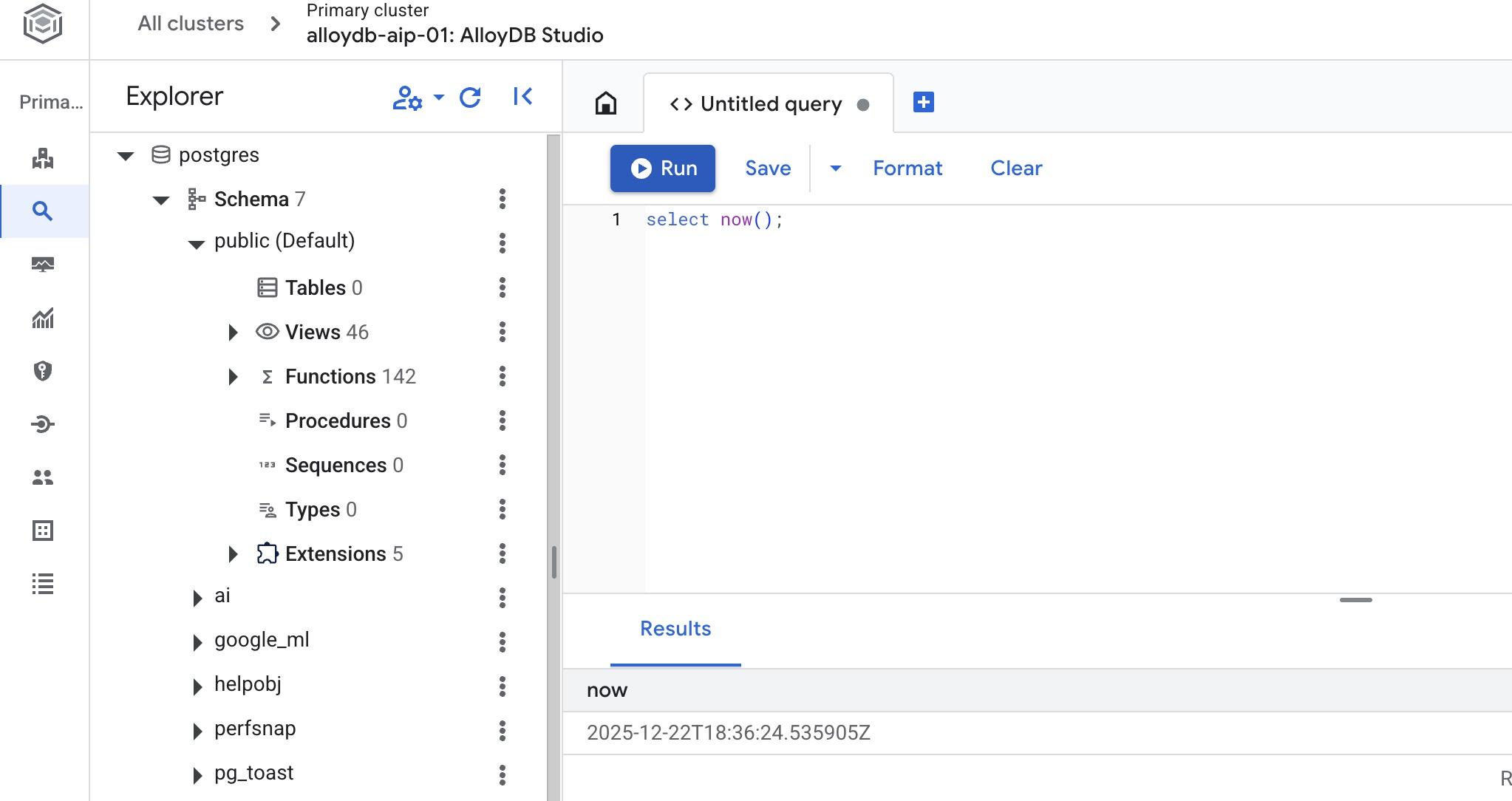
No editor do AlloyDB Studio, execute o seguinte comando.
Criar banco de dados:
CREATE DATABASE quickstart_db
Saída esperada:
Statement executed successfully
Conectar-se a quickstart_db
Reconecte-se ao estúdio usando o botão para mudar de usuário/banco de dados.
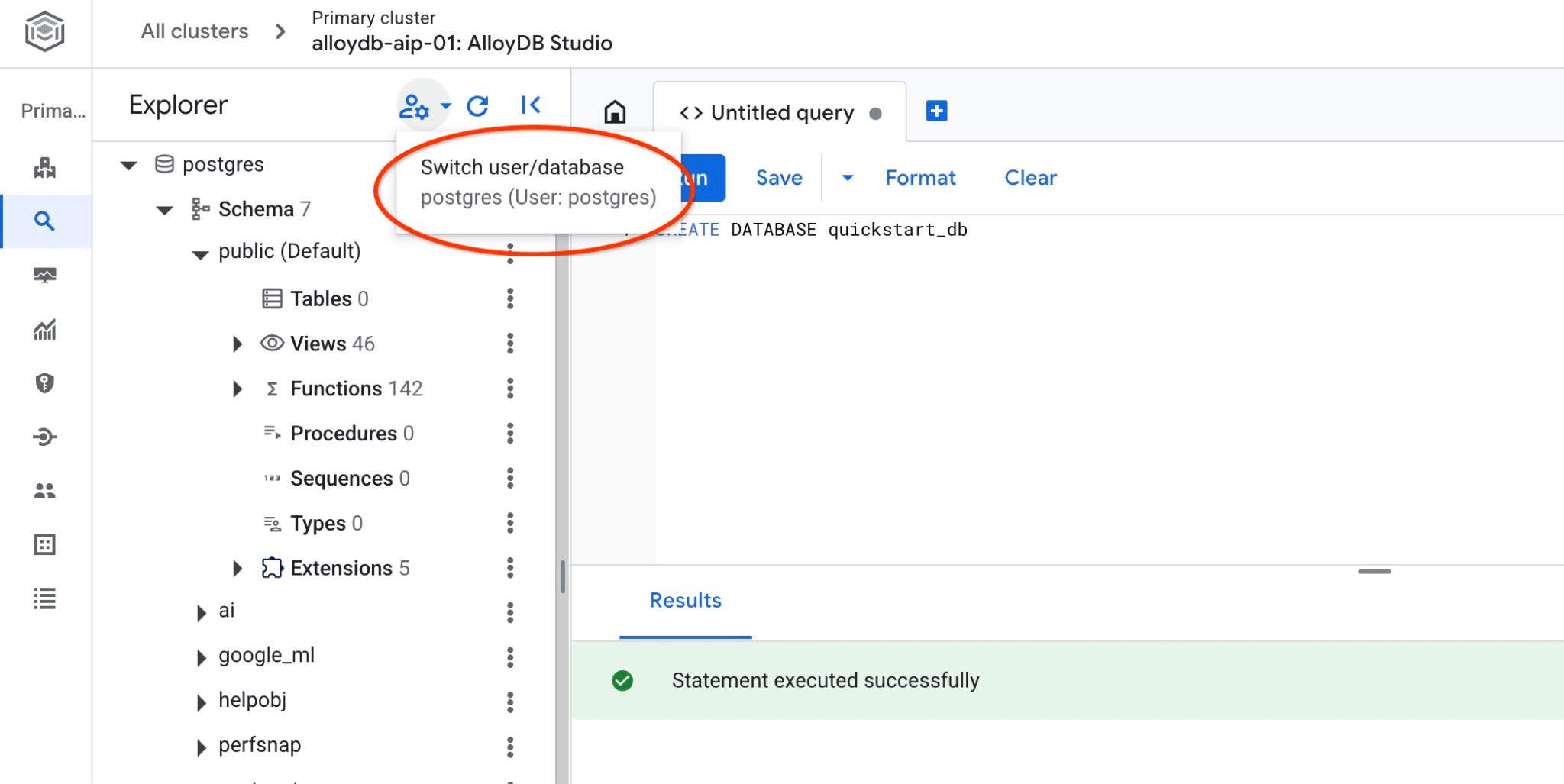
Escolha o novo banco de dados quickstart_db na lista suspensa e use o mesmo usuário e senha de antes.
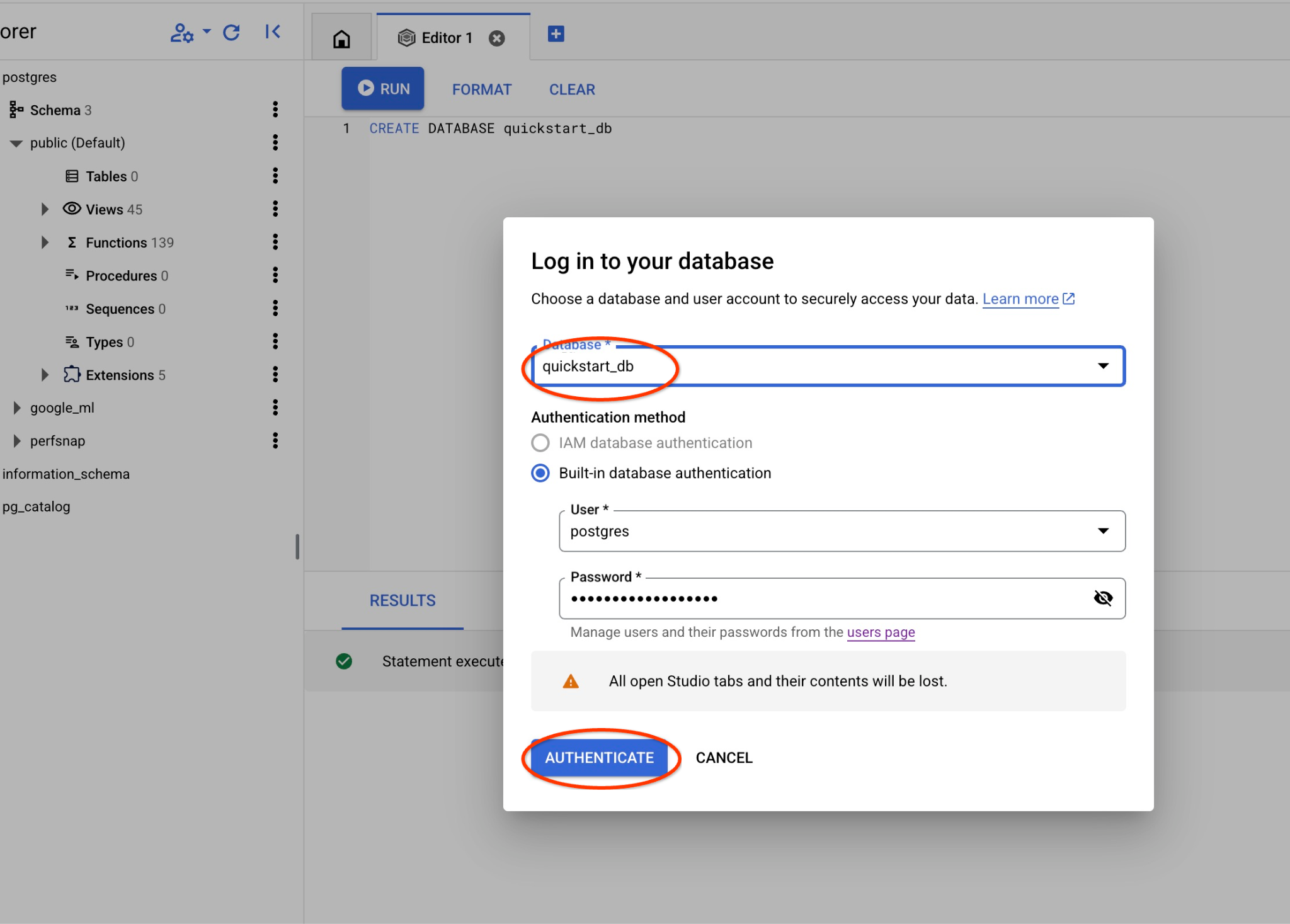
Isso vai abrir uma nova conexão em que você pode trabalhar com objetos do banco de dados quickstart_db.
6. Dados de amostra
Agora precisamos criar objetos no banco de dados e carregar dados. Vamos usar uma loja fictícia chamada "Cymbal" com dados fictícios.
Antes de importar os dados, precisamos ativar as extensões que oferecem suporte a tipos de dados e índices. Precisamos de duas extensões: uma que ofereça suporte ao tipo de dados de vetor e outra que ofereça suporte ao índice ScaNN do AlloyDB.
No AlloyDB Studio, conecte-se ao quickstart_db e execute:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
O conjunto de dados é preparado e colocado como um arquivo SQL que pode ser carregado no banco de dados usando a interface de importação. No Cloud Shell, execute os seguintes comandos:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
O comando usa o SDK do AlloyDB e cria um usuário com o nome agentspace_user. Em seguida, importa dados de amostra diretamente do bucket do GCS para o banco de dados, criando todos os objetos necessários e inserindo dados.
Depois da importação, podemos verificar as tabelas no AlloyDB Studio. As tabelas estão no esquema ecomm:
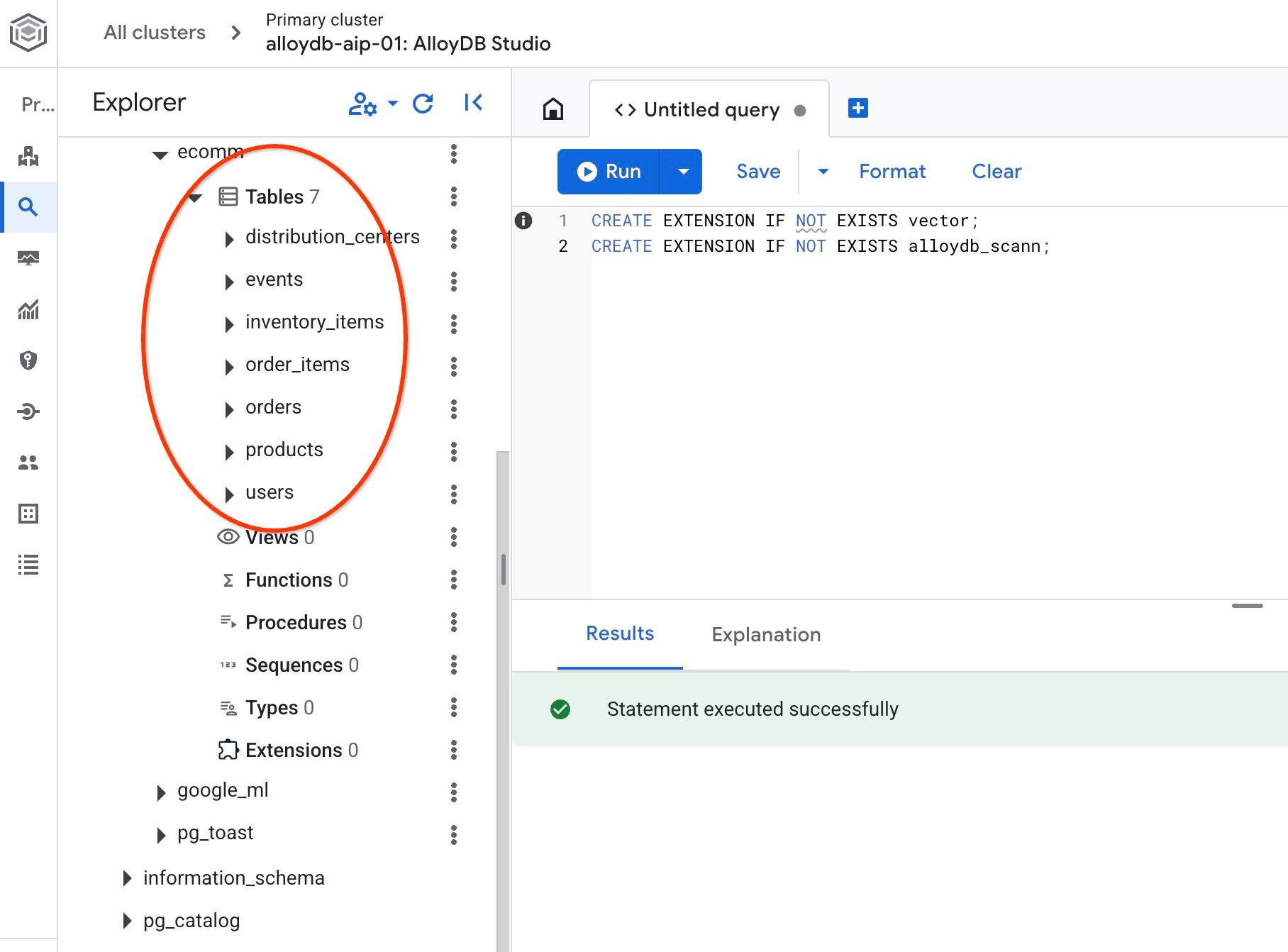
e verifique o número de linhas em uma das tabelas.
select count(*) from ecomm.products;
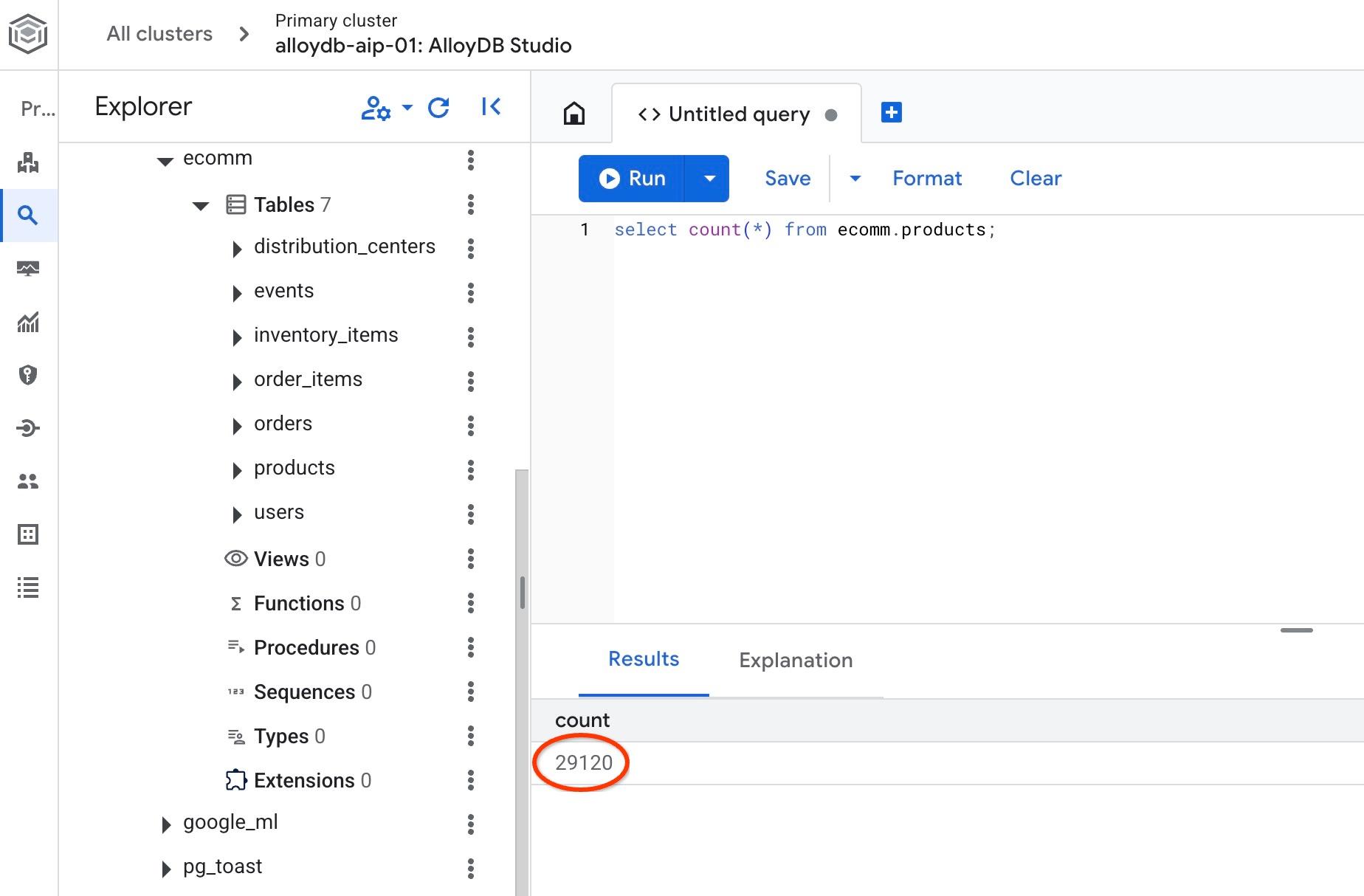
Importamos os dados de amostra com sucesso e podemos continuar com as próximas etapas.
7. Pesquisa semântica usando embeddings de texto
Neste capítulo, vamos tentar usar a pesquisa semântica com embeddings de texto e compará-la com a pesquisa tradicional de texto e de texto completo do Postgres.
Vamos tentar primeiro a pesquisa clássica usando o SQL padrão do PostgreSQL com o operador LIKE.
No AlloyDB Studio, conecte-se ao quickstart_db e tente pesquisar uma capa de chuva usando a seguinte consulta:
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
A consulta não retorna linhas porque precisaria de palavras exatas como "condições de chuva" e "jaqueta" no nome ou na descrição do produto. E a "jaqueta para condições de umidade" não é a mesma coisa que "jaqueta para condições de chuva".
Podemos tentar incluir todas as variações possíveis na pesquisa. Vamos tentar incluir apenas duas palavras. Exemplo:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
Isso retornaria várias linhas, mas nem todas corresponderiam perfeitamente ao nosso pedido de jaquetas, e seria difícil classificar por relevância. Por exemplo, se adicionarmos mais condições, como "para homens" e outras, a complexidade da consulta vai aumentar significativamente. Como alternativa, podemos tentar a pesquisa de texto completo, mas mesmo assim encontramos limitações relacionadas a palavras mais ou menos exatas e à relevância da resposta.
Agora podemos fazer uma pesquisa semelhante usando embeddings. Já pré-calculamos embeddings para nossos produtos usando modelos diferentes. Vamos usar o modelo mais recente do Google, o gemini-embedding-001. Eles foram armazenados na coluna product_embedding da tabela ecomm.products. Se executarmos uma consulta para a condição de pesquisa "jaqueta impermeável masculina" usando a seguinte consulta:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
Ele vai retornar não apenas as jaquetas para condições de chuva, mas também todos os resultados classificados, colocando os mais relevantes na parte superior.
A consulta com incorporações retorna resultados em 90 a 150 ms, e parte desse tempo é gasto para receber os dados do modelo de incorporação na nuvem. Se analisarmos o plano de execução, a solicitação ao modelo será incluída no tempo de planejamento. A parte da consulta que faz a pesquisa em si é bem curta. Leva menos de 7 ms para fazer a pesquisa em 29 mil registros usando o índice ScaNN do AlloyDB.
Confira a saída do plano de execução:
Limit (cost=2709.20..2718.82 rows=10 width=490) (actual time=6.966..7.049 rows=10 loops=1)
-> Index Scan using embedding_scann on products (cost=2709.20..30736.40 rows=29120 width=490) (actual time=6.964..7.046 rows=10 loops=1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
…
-0.0051468653,-0.012440448]'::vector)
Limit: 10
Tempo de planejamento: 136.579 ms
Tempo de execução: 6.791 ms
(6 linhas)
Essa foi a pesquisa de embeddings de texto usando o modelo de embedding somente de texto. Mas também temos imagens dos nossos produtos, que podem ser usadas com a pesquisa. No próximo capítulo, vamos mostrar como o modelo multimodal usa imagens para a pesquisa.
8. Como usar a pesquisa multimodal
Embora a pesquisa semântica baseada em texto seja útil, descrever detalhes complexos pode ser difícil. A pesquisa multimodal do AlloyDB oferece uma vantagem ao permitir a descoberta de produtos por entrada de imagem. Isso é especialmente útil quando a representação visual esclarece a intenção da pesquisa de forma mais eficaz do que apenas as descrições textuais. Por exemplo, "encontre um casaco como este na foto".
Vamos voltar ao exemplo da jaqueta. Se eu tiver uma foto de uma jaqueta semelhante ao que quero encontrar, posso transmiti-la ao modelo de embedding multimodal do Google e compará-la com embeddings de imagens dos meus produtos. Na nossa tabela, já temos embeddings calculados para imagens dos produtos na coluna product_image_embedding. O modelo usado pode ser visto na coluna product_image_embedding_model.
Para nossa pesquisa, podemos usar a função image_embedding para receber o embedding da nossa imagem e compará-lo com os embeddings pré-calculados. Para ativar a função, precisamos usar a versão certa da extensão google_ml_integration.
Vamos verificar a versão atual da extensão. No AlloyDB Studio, execute.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Se a versão for anterior à 1.5.2, siga o procedimento abaixo.
CALL google_ml.upgrade_to_preview_version();
e verifique novamente a versão da extensão. Ele precisa ser 1.5.3.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Também precisamos ativar os recursos do mecanismo de consulta de IA no nosso banco de dados. Isso pode ser feito atualizando a flag por instância para todos os bancos de dados na instância ou ativando apenas para nosso banco de dados. Execute o comando a seguir no AlloyDB Studio para ativar o banco de dados quickstart_db.
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
Agora podemos pesquisar por imagem. Esta é minha imagem de exemplo para pesquisa, mas você pode usar qualquer imagem personalizada. Basta fazer upload para o armazenamento do Google ou outro recurso disponível publicamente e colocar o URI na consulta.

e é enviado para gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png
Pesquisa de imagens por imagens
Primeiro, tentamos pesquisar apenas pela imagem:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
E encontramos algumas jaquetas quentinhas no inventário. Para ver as imagens, faça o download delas usando o SDK do Cloud (gcloud storage cp) fornecendo a coluna public_url e abra com qualquer ferramenta que funcione com imagens.
|
|
|
|




A pesquisa por imagens retorna itens semelhantes à imagem fornecida para comparação. Como já mencionei, você pode tentar fazer upload das suas próprias imagens para um bucket público e ver se ele consegue encontrar diferentes tipos de roupas.
Usamos o modelo "multimodalembedding@001" do Google para nossa pesquisa por imagens. Nossa função "image_embedding" envia a imagem para a Vertex AI, a converte em um vetor e a retorna para comparar com os vetores de imagem armazenados no banco de dados.
Também podemos verificar usando "EXPLAIN ANALYZE" para saber a velocidade com que ele funciona com nosso índice ScaNN do AlloyDB.
Confira a saída do plano de execução:
Limit (cost=971.70..975.55 rows=4 width=490) (actual time=2.453..2.477 rows=4 loops=1)
-> Index Scan using product_image_embedding_scann on products (cost=971.70..28998.90 rows=29120 width=490) (actual time=2.451..2.475 rows=4 loops=1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
…
,-0.010307034,-0.010053742]'::vector)
Limit: 4
Tempo de planejamento: 913.322 ms
Tempo de execução: 2.517 ms
(6 linhas)
Assim como no exemplo anterior, a maior parte do tempo foi gasto na conversão da imagem em embeddings usando o endpoint da nuvem.A pesquisa vetorial em si leva apenas 2,5 ms.
Pesquisa de imagens por texto
Com o recurso multimodal, também podemos transmitir uma descrição de texto da jaqueta que estamos tentando pesquisar para o modelo usando google_ml.text_embedding para o mesmo modelo e comparar com embeddings de imagens para ver quais imagens ele retorna.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
E recebemos um conjunto de jaquetas acolchoadas em cores cinza ou escuras.
|
|
|
|




Recebemos um conjunto um pouco diferente de jaquetas, mas ele escolheu corretamente as jaquetas com base na nossa descrição ao pesquisar as incorporações de imagens.
Vamos tentar outra maneira de pesquisar entre as descrições usando nossa incorporação para a imagem de pesquisa.
Pesquisa de texto por imagens
Tentamos pesquisar imagens transmitindo a incorporação da nossa imagem e comparando com incorporações de imagens pré-calculadas dos nossos produtos. Também tentamos pesquisar imagens transmitindo um embedding para nossa solicitação de texto e pesquisando entre o mesmo embedding para as imagens de produtos. Agora vamos usar um embedding para nossa imagem e compará-lo com embeddings de texto para as descrições de produtos. Esses embeddings são armazenados na coluna product_description_embedding e usam o mesmo modelo multimodalembedding@001.
Esta é a consulta:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
Aqui temos um conjunto ligeiramente diferente de jaquetas com cores cinza ou escuras, algumas delas iguais ou muito parecidas com as escolhidas nas outras formas de pesquisa.
|
|
|
|



Com base no embedding das imagens, ele pode comparar com os embeddings calculados para a descrição do texto e retornar o conjunto correto de produtos.
Pesquisa híbrida de texto e imagem
Você também pode combinar embeddings de texto e imagem usando, por exemplo, fusão de classificação recíproca. Confira um exemplo de consulta em que combinamos duas pesquisas, atribuindo uma pontuação a cada classificação e ordenando os resultados com base na pontuação combinada.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
Tente usar parâmetros diferentes na consulta para melhorar os resultados da pesquisa. Além disso, você também pode usar outros operadores de IA para classificar os resultados, conforme descrito na documentação.
O laboratório está concluído. Para evitar cobranças inesperadas, recomendamos excluir os recursos não utilizados.
9. Limpar o ambiente
Destrua as instâncias e o cluster do AlloyDB quando terminar o laboratório.
Excluir o cluster do AlloyDB e todas as instâncias
Se você usou a versão de teste do AlloyDB. Não exclua o cluster de teste se você planeja testar outros laboratórios e recursos usando esse cluster. Não será possível criar outro cluster de teste no mesmo projeto.
O cluster é destruído com a opção "force" que também exclui todas as instâncias pertencentes.
No Cloud Shell, defina o projeto e as variáveis de ambiente se tiver ocorrido uma desconexão e todas as configurações anteriores forem perdidas:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Exclua o cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Excluir backups do AlloyDB
Exclua todos os backups do AlloyDB do cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. Parabéns
Parabéns por concluir o codelab. Você aprendeu a usar a pesquisa multimodal no AlloyDB usando funções de embedding para textos e imagens. Teste e melhore a pesquisa multimodal com a função google_ml.rank usando o codelab para operadores de IA do AlloyDB.
Programa de aprendizado do Google Cloud
Este laboratório faz parte do programa de aprendizado "IA pronta para produção com o Google Cloud".
- Confira o currículo completo para diminuir a distância entre o protótipo e a produção.
- Compartilhe seu progresso com a hashtag
#ProductionReadyAI.
O que vimos
- Como implantar o AlloyDB para Postgres
- Como usar o AlloyDB Studio
- Como usar a pesquisa vetorial multimodal
- Como ativar os operadores da IA do AlloyDB
- Como usar diferentes operadores de IA do AlloyDB para pesquisa multimodal
- Como usar a IA do AlloyDB para combinar resultados de pesquisa de texto e imagem
11. Pesquisa
Saída: