
1. Введение
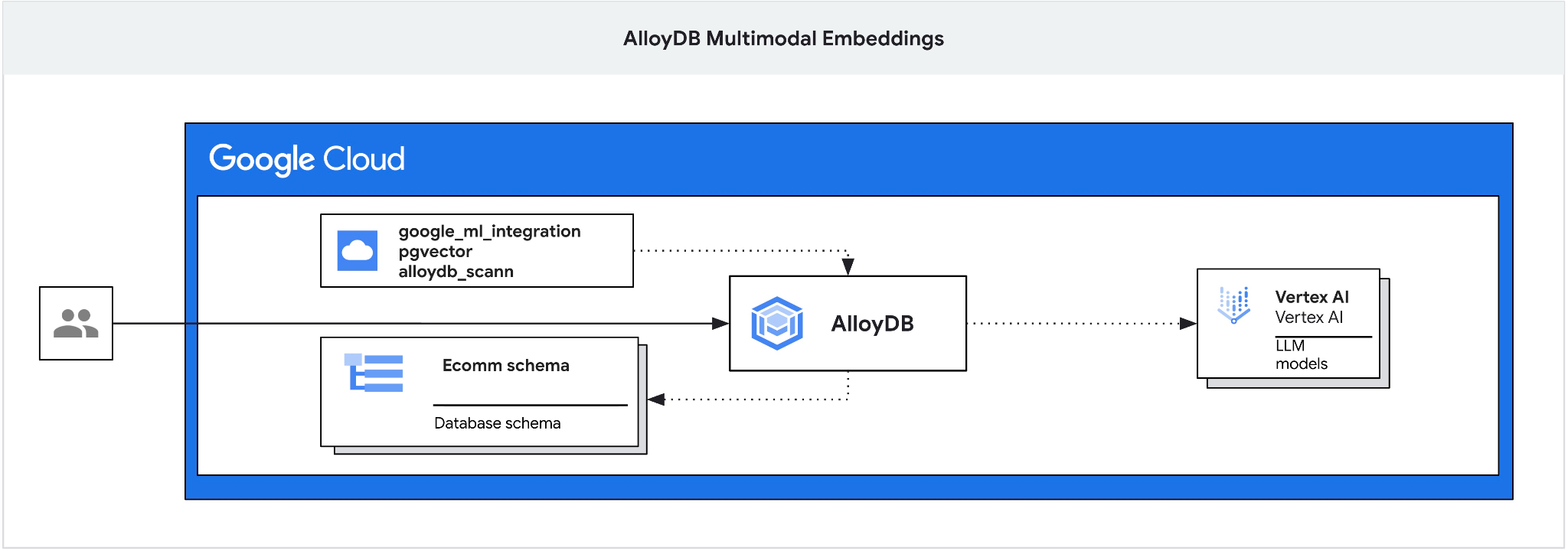
Этот практический урок покажет, как развернуть AlloyDB и использовать интеграцию ИИ для семантического поиска с помощью мультимодальных вложений. Этот урок является частью серии уроков, посвященных функциям ИИ в AlloyDB. Подробнее можно узнать на странице AlloyDB AI в документации.
Предварительные требования
- Базовое понимание Google Cloud и консоли.
- Базовые навыки работы с командной строкой и Cloud Shell.
Что вы узнаете
- Как развернуть AlloyDB для PostgreSQL
- Как использовать AlloyDB Studio
- Как использовать многомодальный векторный поиск
- Как включить операторы искусственного интеллекта AlloyDB
- Как использовать различные операторы искусственного интеллекта AlloyDB для многомодального поиска
- Как использовать AlloyDB AI для объединения результатов поиска текста и изображений.
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, такой как Chrome , поддерживающий консоль Google Cloud и Cloud Shell.
2. Настройка и требования
Настройка проекта
- Войдите в консоль Google Cloud . Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .
Используйте личный аккаунт вместо рабочего или учебного.
- Создайте новый проект или используйте существующий. Чтобы создать новый проект в консоли Google Cloud, в заголовке нажмите кнопку «Выбрать проект», после чего откроется всплывающее окно.

В окне «Выберите проект» нажмите кнопку «Новый проект», после чего откроется диалоговое окно для создания нового проекта.
В диалоговом окне введите желаемое название проекта и выберите местоположение.
- Название проекта — это отображаемое имя участников данного проекта. Название проекта не используется API Google и может быть изменено в любое время.
- Идентификатор проекта (Project ID) уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Google Cloud автоматически генерирует уникальный идентификатор, но вы можете настроить его. Если вам не нравится сгенерированный идентификатор, вы можете сгенерировать другой случайный или указать свой собственный, чтобы проверить его доступность. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта, который обычно обозначается заполнителем PROJECT_ID.
- К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
Включить выставление счетов
Для включения оплаты у вас есть два варианта. Вы можете использовать свой личный платежный аккаунт или обменять средства, выполнив следующие шаги.
Использовать кредиты Google Cloud (необязательно)
Для проведения этого мастер-класса вам потребуется платежный аккаунт с достаточным балансом. Используйте средства, указанные на баннере вверху этого руководства, чтобы начать. Если у вас уже есть платежный аккаунт, вы можете пропустить этот шаг.
Создайте личный платежный аккаунт.
Если вы настроили оплату с использованием кредитов Google Cloud, этот шаг можно пропустить.
Чтобы настроить личный платежный аккаунт, перейдите сюда, чтобы включить оплату в облачной консоли.
Несколько замечаний:
- Выполнение этой лабораторной работы должно обойтись менее чем в 3 доллара США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
В качестве альтернативы вы можете нажать G, а затем S. Эта последовательность активирует Cloud Shell, если вы находитесь в консоли Google Cloud, или воспользуйтесь этой ссылкой .
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Прежде чем начать
Включить API
Для использования AlloyDB , Compute Engine , сетевых сервисов и Vertex AI необходимо включить соответствующие API в вашем проекте Google Cloud.
В терминале Cloud Shell убедитесь, что идентификатор вашего проекта указан. Идентификатор проекта должен отображаться в скобках в командной строке следующим образом:
student@cloudshell:~ (test-project-001-402417)$
Если идентификатор проекта там не отображается, обновите вкладку браузера и повторно пройдите аутентификацию в Cloud Shell.
Установите переменную среды PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Включите все необходимые службы:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Ожидаемый результат
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Развертывание AlloyDB
Создание кластера AlloyDB и основного экземпляра. Следующая процедура описывает, как создать кластер и экземпляр AlloyDB с помощью Google Cloud SDK. Если вы предпочитаете использовать консольный подход, вы можете следовать документации здесь .
Перед созданием кластера AlloyDB нам необходим доступный диапазон частных IP-адресов в нашей VPC, который будет использоваться будущим экземпляром AlloyDB. Если его нет, нам нужно его создать, назначить для использования внутренними сервисами Google, после чего мы сможем создать кластер и экземпляр.
Создать частный диапазон IP-адресов
Нам необходимо настроить параметры доступа к частным сервисам (Private Service Access, VPC) в нашей VPC для AlloyDB. Предполагается, что в проекте используется «стандартная» сеть VPC, и она будет применяться для всех действий.
Создайте диапазон частных IP-адресов:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Создайте частное соединение, используя выделенный диапазон IP-адресов:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Создание кластера AlloyDB
В этом разделе мы создаём кластер AlloyDB в регионе us-central1.
Задайте пароль для пользователя postgres. Вы можете задать свой собственный пароль или использовать функцию генерации случайных чисел.
export PGPASSWORD=`openssl rand -hex 12`
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Запишите пароль от PostgreSQL для дальнейшего использования.
echo $PGPASSWORD
Этот пароль понадобится вам в будущем для подключения к экземпляру под учетной записью postgres. Я рекомендую записать его или скопировать куда-нибудь, чтобы иметь возможность использовать позже.
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723 (Note: Yours will be different!)
Создайте кластер для бесплатной пробной версии
Если вы раньше не использовали AlloyDB, вы можете создать бесплатный пробный кластер:
Определите регион и имя кластера AlloyDB. Мы будем использовать регион us-central1 и имя кластера alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Выполните команду для создания кластера:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Ожидаемый вывод в консоль:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Создайте основной экземпляр AlloyDB для нашего кластера в той же сессии Cloud Shell. Если вы отключены, вам потребуется заново определить переменные среды для региона и имени кластера.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Создание кластера AlloyDB Standard
Если это не первый ваш кластер AlloyDB в проекте, перейдите к созданию стандартного кластера. Если вы уже создали бесплатный пробный кластер на предыдущем шаге, пропустите этот шаг.
Определите регион и имя кластера AlloyDB. Мы будем использовать регион us-central1 и имя кластера alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Выполните команду для создания кластера:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Ожидаемый вывод в консоль:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Создайте основной экземпляр AlloyDB для нашего кластера в той же сессии Cloud Shell. Если вы отключены, вам потребуется заново определить переменные среды для региона и имени кластера.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Подготовка базы данных
Нам необходимо создать базу данных, включить интеграцию с Vertex AI, создать объекты базы данных и импортировать данные.
Предоставьте необходимые разрешения AlloyDB
Добавьте разрешения Vertex AI для агента службы AlloyDB.
Откройте еще одну вкладку Cloud Shell, используя знак "+" вверху.
В новой вкладке облачной оболочки выполните:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Закройте вкладку, выполнив одну из команд, указанных на вкладке, например, «Выход»:
exit
Подключитесь к AlloyDB Studio
В следующих главах все команды SQL, требующие подключения к базе данных, можно выполнить в AlloyDB Studio.
В новой вкладке перейдите на страницу «Кластеры» в AlloyDB для Postgres .
Откройте веб-консоль вашего кластера AlloyDB, щелкнув по основному экземпляру.
Затем нажмите на AlloyDB Studio слева:
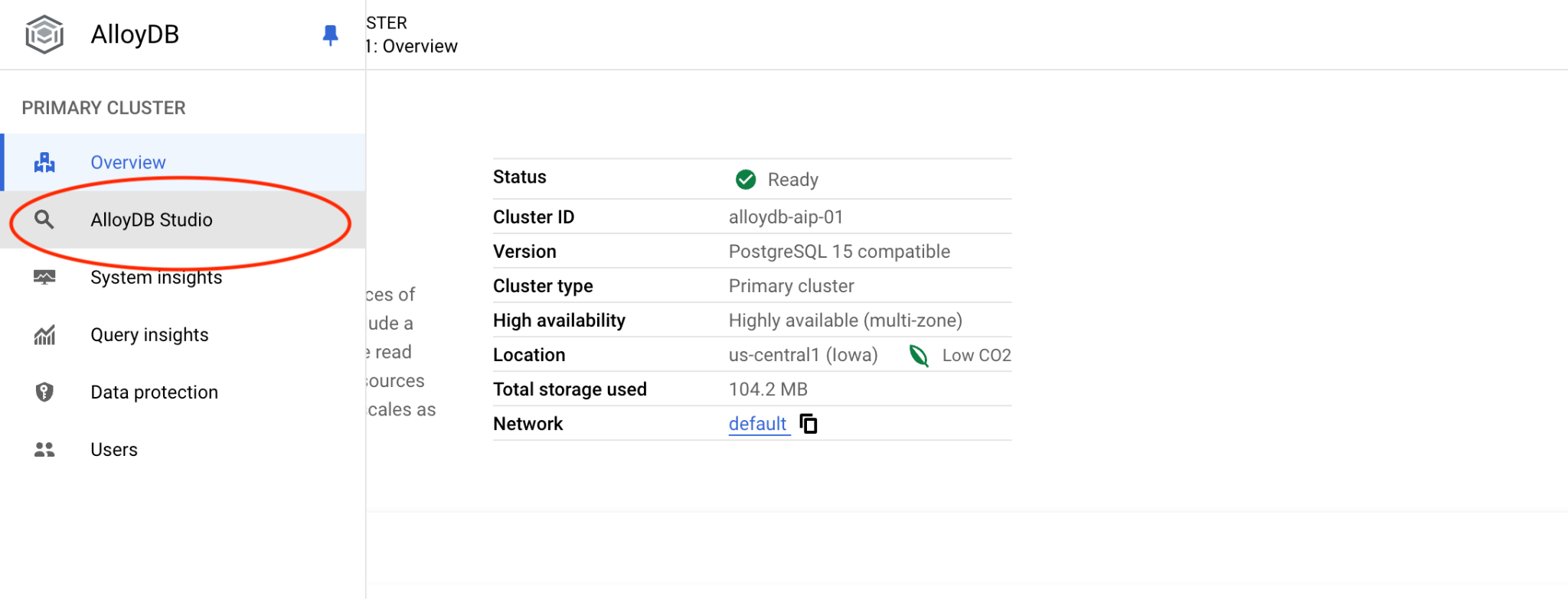
Выберите базу данных postgres, пользователя postgres и укажите пароль, который вы указали при создании кластера. Затем нажмите кнопку «Аутентифицировать». Если вы забыли записать пароль или он не работает, вы можете его изменить. Инструкции по этому поводу см. в документации .
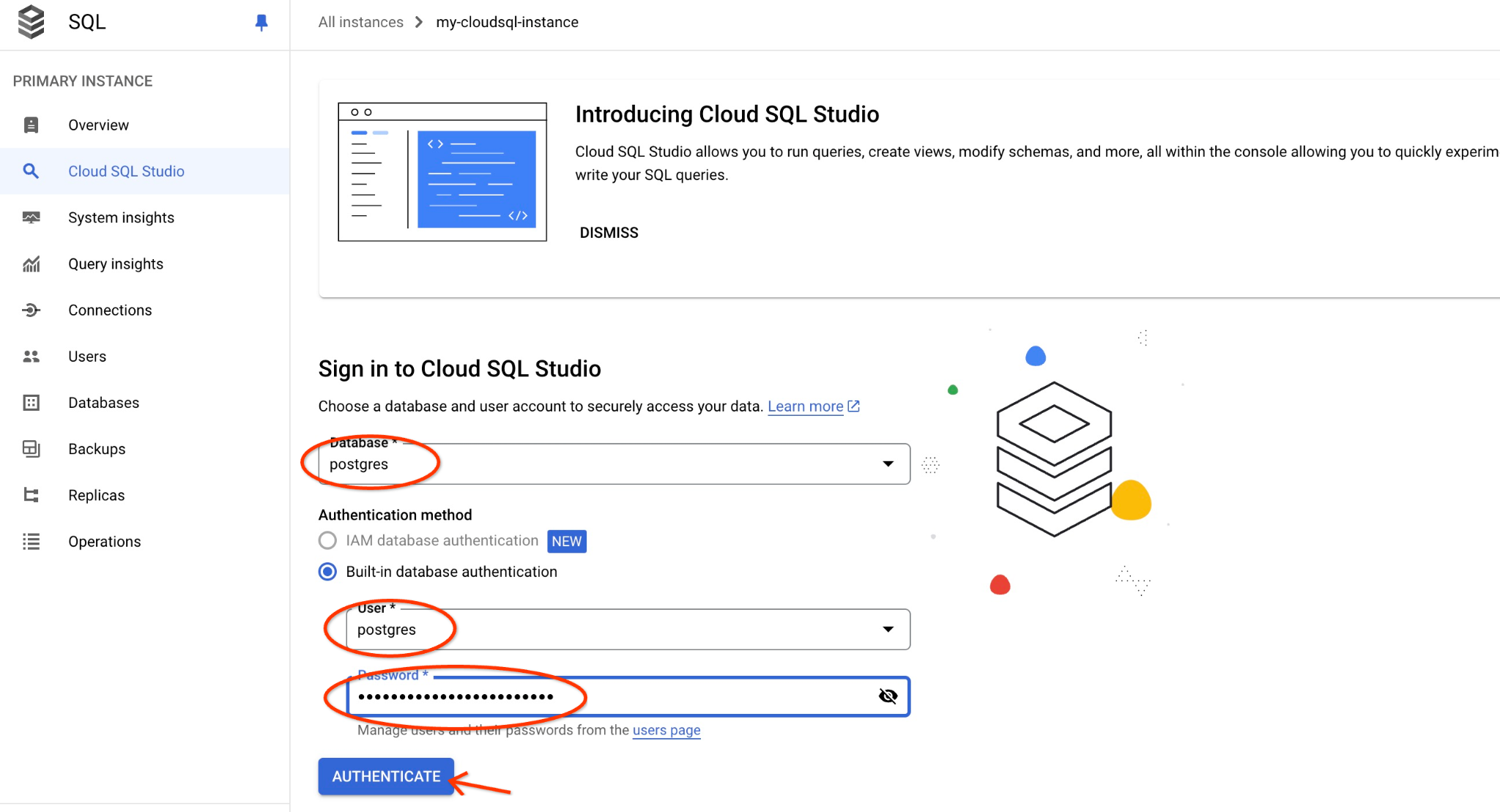
Откроется интерфейс AlloyDB Studio. Чтобы выполнить команды в базе данных, щелкните вкладку "Untitled Query" справа.
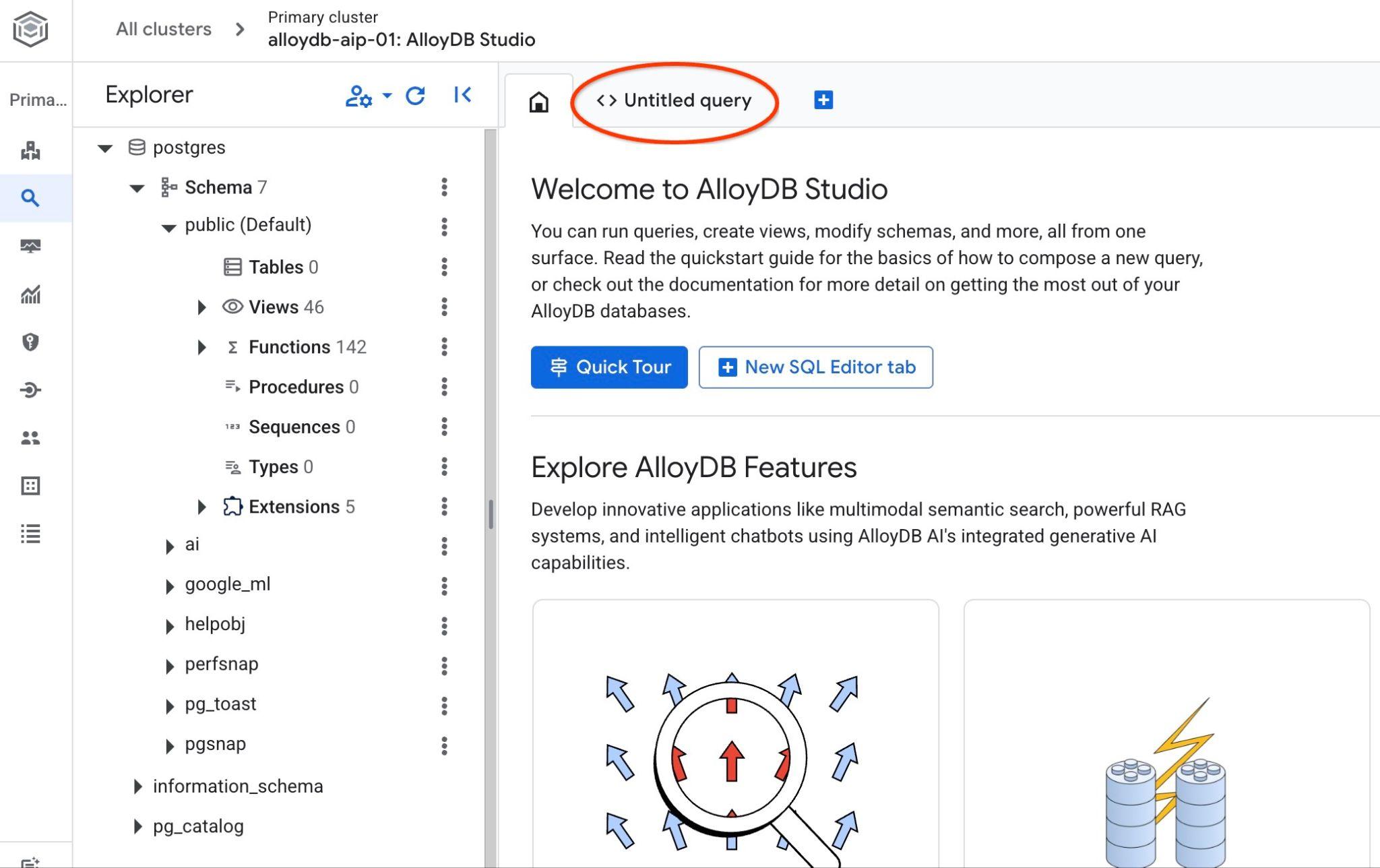
Это открывает интерфейс, в котором можно выполнять команды SQL.
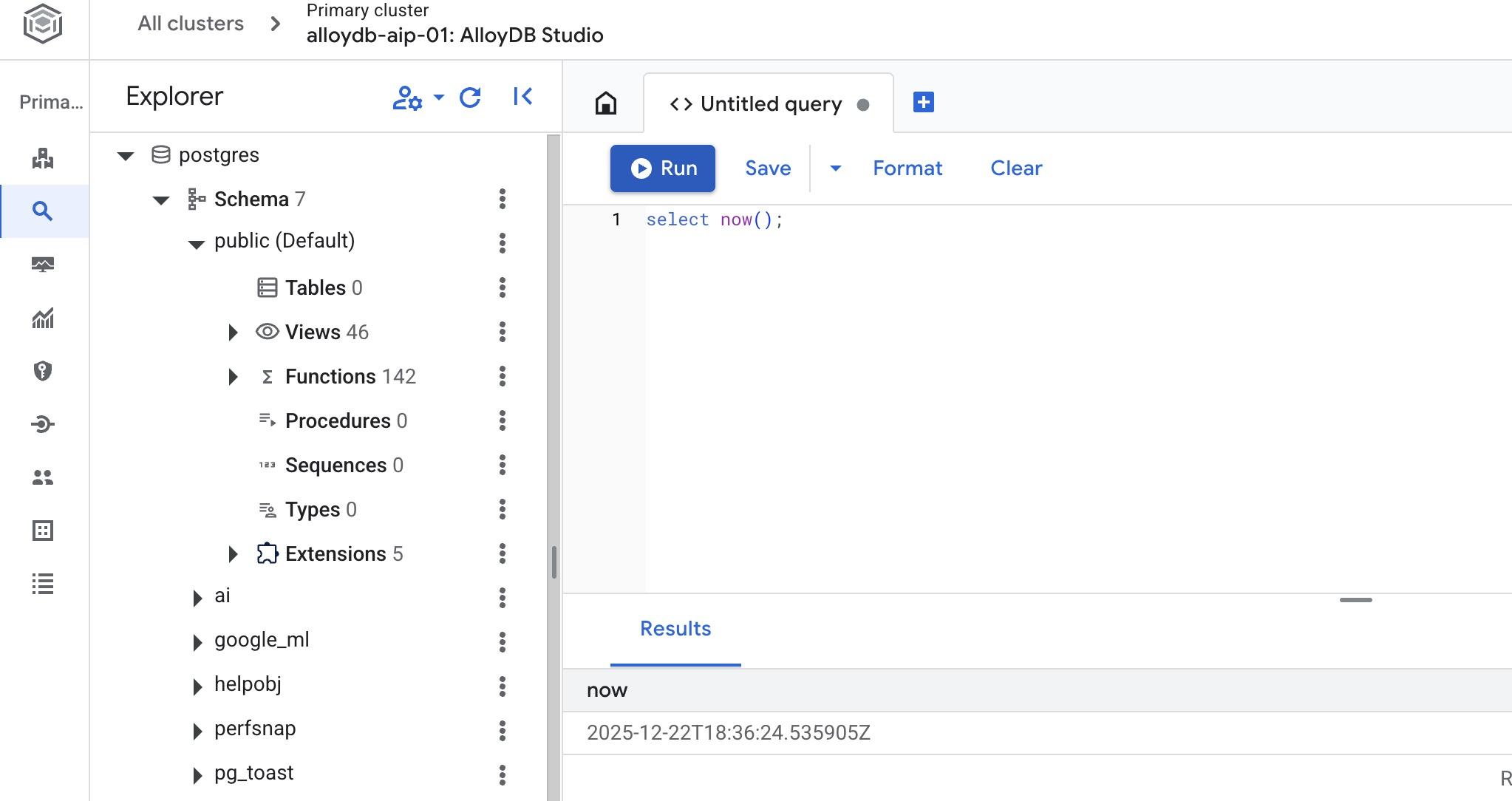
Создать базу данных
Быстрый старт создания базы данных.
В редакторе AlloyDB Studio выполните следующую команду.
Создать базу данных:
CREATE DATABASE quickstart_db
Ожидаемый результат:
Statement executed successfully
Подключитесь к quickstart_db
Для переключения между пользователем и базой данных повторно подключитесь к студии, используя соответствующую кнопку.
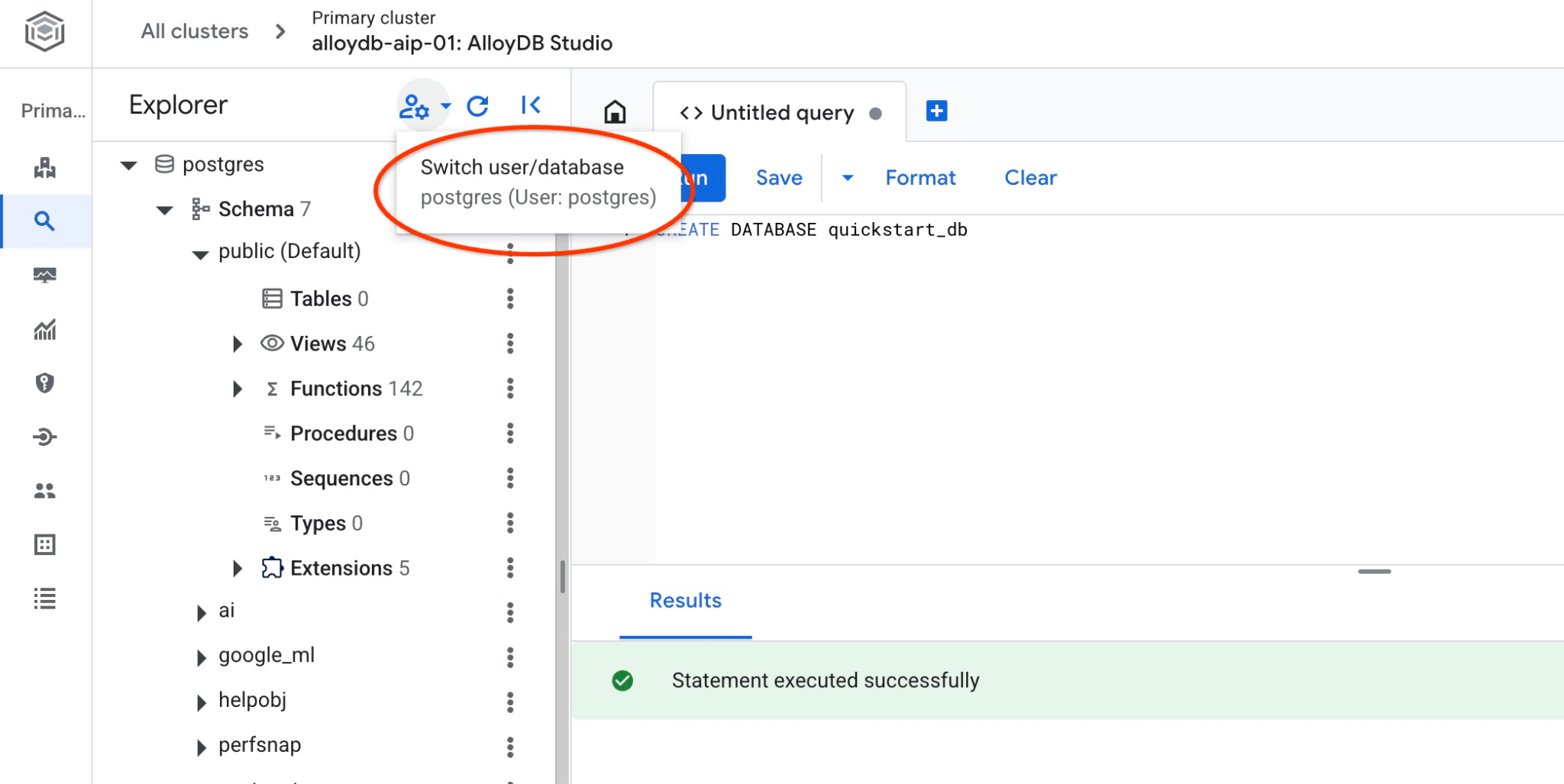
Выберите новую базу данных quickstart_db из выпадающего списка и используйте те же имя пользователя и пароль, что и раньше.
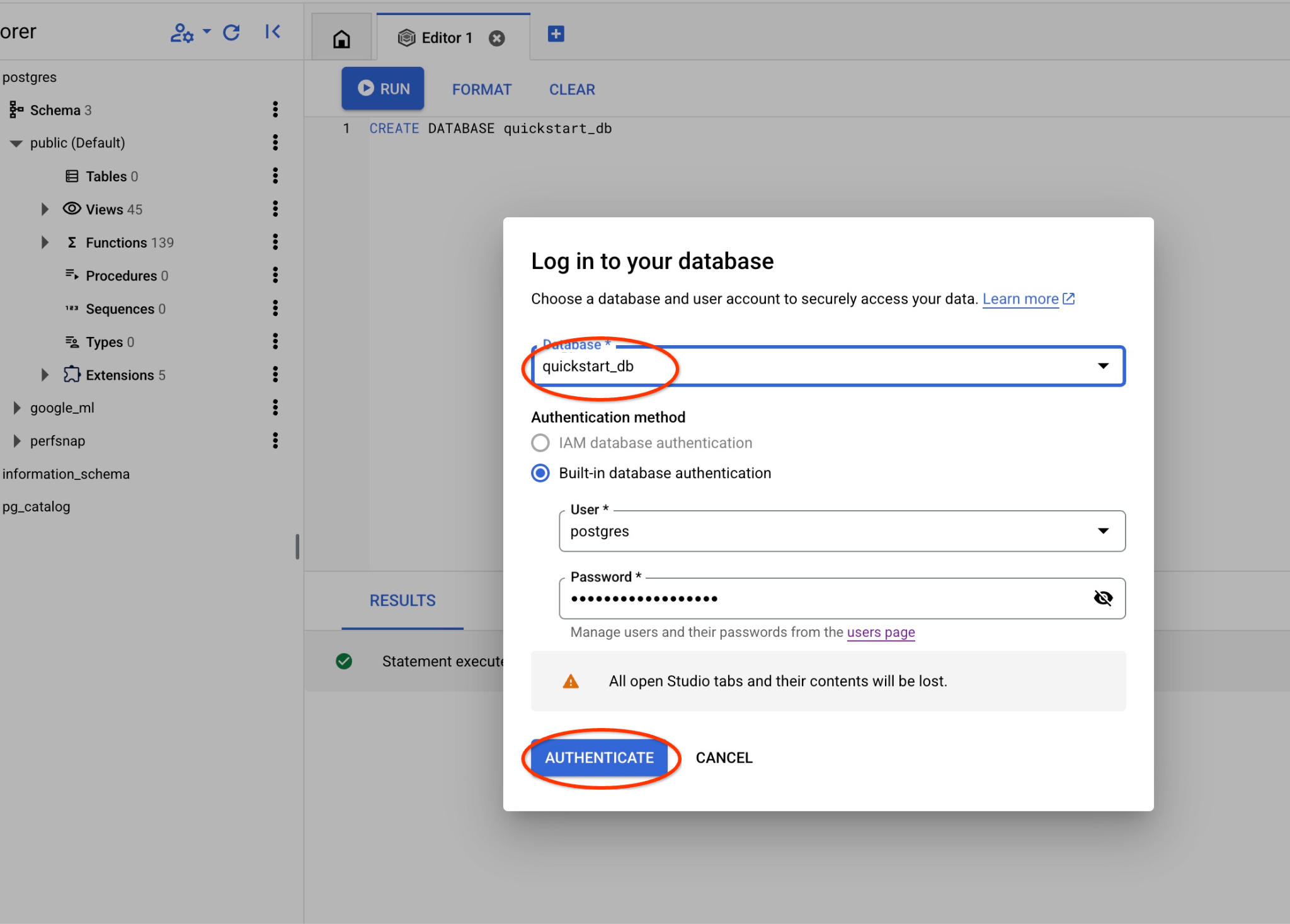
Это откроет новое соединение, через которое вы сможете работать с объектами из базы данных quickstart_db.
6. Пример данных
Теперь нам нужно создать объекты в базе данных и загрузить данные. Мы будем использовать вымышленное хранилище "Cymbal" с вымышленными данными.
Перед импортом данных необходимо включить расширения, поддерживающие типы данных и индексы. Нам нужны два расширения: одно, поддерживающее векторный тип данных, и другое, поддерживающее индекс AlloyDB ScaNN.
В AlloyDB Studio подключитесь к quickstart_db и выполните:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Набор данных подготавливается и размещается в виде SQL-файла, который можно загрузить в базу данных с помощью интерфейса импорта. В облачной оболочке выполните следующие команды:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic_vectors.sql' --user=postgres --sql
Эта команда использует SDK AlloyDB, создает пользователя с именем agentspace_user, а затем импортирует тестовые данные непосредственно из хранилища GCS в базу данных, создавая все необходимые объекты и вставляя данные.
После импорта мы можем проверить таблицы в AlloyDB Studio. Таблицы находятся в схеме ecomm:
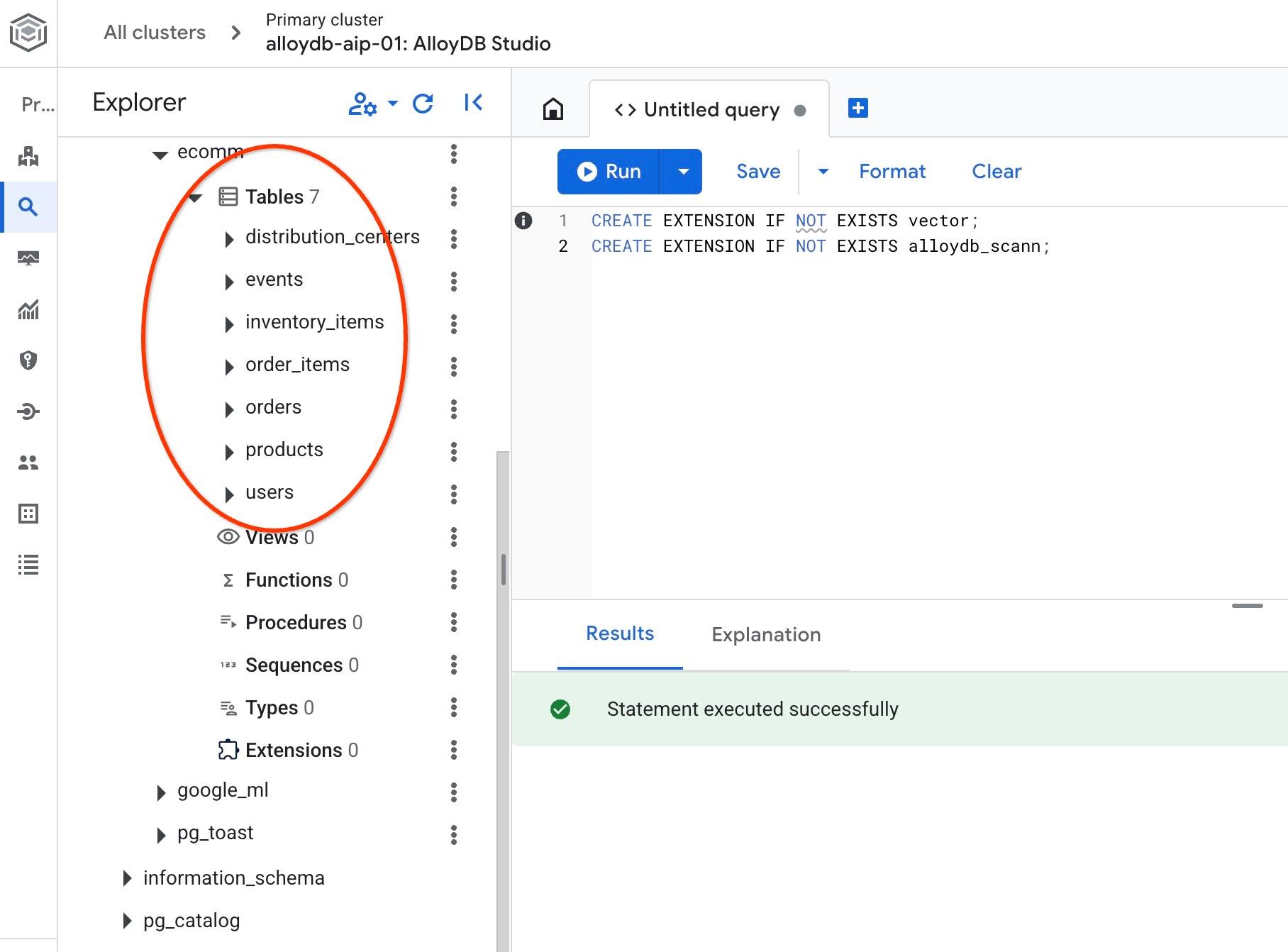
И проверьте количество строк в одной из таблиц.
select count(*) from ecomm.products;
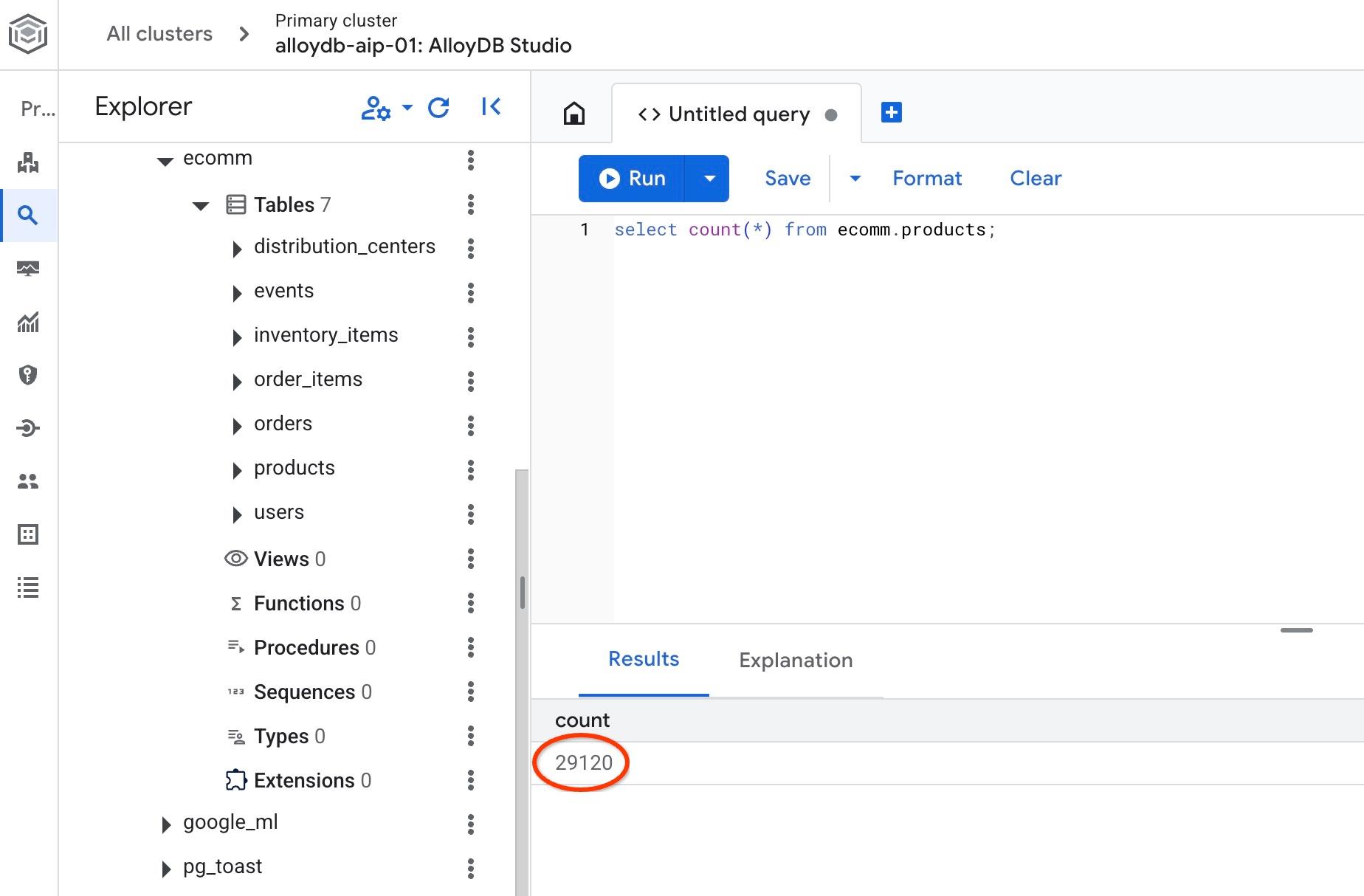
Мы успешно импортировали наши тестовые данные и можем перейти к следующим шагам.
7. Семантический поиск с использованием текстовых векторных представлений.
В этой главе мы попробуем использовать семантический поиск с помощью текстовых векторных представлений и сравним его с традиционным текстовым и полнотекстовым поиском в PostgreSQL.
Давайте сначала попробуем классический поиск, используя стандартный SQL-запрос PostgreSQL с оператором LIKE.
В AlloyDB Studio подключитесь к quickstart_db и попробуйте выполнить поиск дождевика, используя следующий запрос:
SET session.my_search_var='%wet%conditions%jacket%';
SELECT
name,
product_description,
retail_price, replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE current_setting('session.my_search_var')
OR product_description ILIKE current_setting('session.my_search_var')
LIMIT
10;
Запрос не возвращает ни одной строки, поскольку для его выполнения необходимы точные слова, такие как «влажные условия» и «куртка», которые должны присутствовать либо в названии товара, либо в описании. А «куртка для влажных условий» — это не то же самое, что «куртка для дождливых условий».
Мы можем попытаться включить в поиск все возможные варианты. Давайте попробуем включить всего два слова. Например:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM
ecomm.products
WHERE
name ILIKE '%wet%jacket%'
OR name ILIKE '%jacket%wet%'
OR name ILIKE '%jacket%'
OR name ILIKE '%%wet%'
OR product_description ILIKE '%wet%jacket%'
OR product_description ILIKE '%jacket%wet%'
OR product_description ILIKE '%jacket%'
OR product_description ILIKE '%wet%'
LIMIT
10;
В результате будет получено несколько строк, но не все из них идеально соответствуют нашему запросу на куртки, и сортировка по релевантности затруднительна. Кроме того, если мы добавим больше условий, таких как «для мужчин» и другие, это значительно усложнит запрос. В качестве альтернативы можно попробовать полнотекстовый поиск, но даже здесь мы сталкиваемся с ограничениями, связанными с более или менее точными словами и релевантностью ответа.
Теперь мы можем выполнить аналогичный поиск, используя эмбеддинги. Мы уже предварительно рассчитали эмбеддинги для наших товаров, используя различные модели. Мы собираемся использовать последнюю модель Google gemini-embedding-001. Мы сохранили их в столбце " product_embedding " таблицы ecomm.products . Если мы выполним запрос по нашему условию поиска "мужская дождевая куртка", используя следующий запрос:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_embedding <=> embedding ('gemini-embedding-001','wet conditions jacket for men')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
10;
Программа вернет не только куртки для дождливой погоды, но и все результаты будут отсортированы, при этом наиболее релевантные результаты будут отображаться вверху.
Запрос с использованием эмбеддингов возвращает результаты за 90-150 мс, при этом часть времени тратится на получение данных из модели облачного эмбеддинга. Если посмотреть на план выполнения, то запрос к модели включен в время планирования. Часть запроса, отвечающая за сам поиск, довольно короткая. Поиск в 29 000 записях с использованием индекса AlloyDB ScaNN занимает менее 7 мс.
Вот результат выполнения плана:
Ограничение (стоимость = 2709,20 - 2718,82 строк = 10, ширина = 490) (фактическое время = 6,966 - 7,049 строк = 10 циклов = 1)
-> Сканирование индекса с использованием embedding_scann для товаров (стоимость = 2709.20..30736.40, строк = 29120, ширины = 490) (фактическое время = 6.964..7.046, строк = 10, циклов = 1)
Order By: (product_embedding <=> '[-0.0020264734,-0.016582033,0.027258193
...
-0.0051468653,-0.012440448]'::вектор)
Limit: 10
Время планирования: 136,579 мс
Время выполнения: 6,791 мс
(6 рядов)
Это был поиск по встраиванию текста с использованием модели встраивания только текста. Но у нас также есть изображения наших товаров, и мы можем использовать их для поиска. В следующей главе мы покажем, как мультимодальная модель использует изображения для поиска.
8. Использование многомодального поиска
Хотя текстовый семантический поиск полезен, описание сложных деталей может быть непростой задачей. Мультимодальный поиск AlloyDB предоставляет преимущество, позволяя находить товары с помощью изображений. Это особенно полезно, когда визуальное представление более эффективно уточняет поисковый запрос, чем одни только текстовые описания. Например: «найдите мне пальто, похожее на то, что на картинке».
Вернемся к нашему примеру с курткой. Если у меня есть изображение куртки, похожей на ту, которую я хочу найти, я могу передать ее в модель мультимодального встраивания Google и сравнить с встраиваниями изображений моих товаров. В нашей таблице уже есть рассчитанные встраивания изображений наших товаров в столбце product_image_embedding , а используемую модель вы можете увидеть в столбце product_image_embedding_model .
Для поиска мы можем использовать функцию image_embedding , чтобы получить векторное представление для нашего изображения и сравнить его с предварительно рассчитанными векторными представлениями. Чтобы включить эту функцию, необходимо убедиться, что мы используем правильную версию расширения google_ml_integration .
Давайте проверим текущую версию расширения. В AlloyDB Studio выполните команду.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Если версия меньше 1.5.2, выполните следующую процедуру.
CALL google_ml.upgrade_to_preview_version();
И ещё раз проверьте версию расширения. Она должна быть 1.5.3.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Нам также необходимо включить функции механизма запросов на основе ИИ в нашей базе данных. Это можно сделать либо путем обновления флага экземпляра для всех баз данных на этом экземпляре, либо путем включения его только для нашей базы данных. Выполните следующую команду в AlloyDB Studio, чтобы включить его для базы данных quickstart_db.
ALTER DATABASE quickstart_db SET google_ml_integration.enable_ai_query_engine = 'on';
Теперь мы можем искать по изображению. Вот мой пример изображения для поиска, но вы можете использовать любое собственное изображение. Вам просто нужно загрузить его в хранилище Google или другой общедоступный ресурс и добавить URI в поисковый запрос.

И оно загружено по адресу gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png
Поиск изображений по картинкам
Сначала попробуем выполнить поиск только по изображению:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
И нам удалось найти несколько теплых курток в инвентаре. Чтобы посмотреть изображения, вы можете загрузить их с помощью облачного SDK ( gcloud storage cp ), указав столбец public_url , а затем открыть их с помощью любого инструмента, работающего с изображениями.
|
|
|
|




Поиск по изображениям выдает товары, похожие на предоставленное нами изображение для сравнения. Как я уже упоминал, вы можете попробовать загрузить свои собственные изображения в общедоступный репозиторий и посмотреть, сможет ли он найти разные типы одежды.
Для поиска изображений мы использовали модель Google 'multimodalembedding@001'. Наша функция image_embedding отправляет изображение в Vertex AI, преобразует его в вектор и возвращает для сравнения с векторами изображений, хранящимися в нашей базе данных.
Мы также можем проверить скорость работы индекса AlloyDB ScaNN с помощью функции "EXPLAIN ANALYZE".
Вот результат выполнения плана:
Ограничение (стоимость = 971,70 - 975,55 строк = 4, ширина = 490) (фактическое время = 2,453 - 2,477 строк = 4, циклов = 1)
-> Сканирование индекса с использованием функции product_image_embedding_scann для товаров (стоимость = 971,70 - 28998,90, строк = 29120, ширины = 490) (фактическое время = 2,451 - 2,475, строк = 4, циклов = 1)
Order By: (product_image_embedding <=> '[0.02119865,0.034206174,0.030682731,
...
,-0.010307034,-0.010053742]'::вектор)
Limit: 4
Время планирования: 913,322 мс
Время выполнения: 2,517 мс
(6 рядов)
И снова, как и в предыдущем примере, мы видим, что большая часть времени была потрачена на преобразование изображения в векторные представления с помощью облачной конечной точки, а сам векторный поиск занимает всего 2,5 мс.
Поиск изображений по тексту
С помощью мультимодального подхода мы также можем передать в модель текстовое описание искомой куртки, используя google_ml.text_embedding для той же модели, и сравнить его с векторными представлениями изображений, чтобы увидеть, какие изображения она возвращает.
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_image_embedding <=> google_ml.text_embedding (model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
А еще мы приобрели комплект пуховых курток серого или темного цвета.
|
|
|
|




Мы получили немного другой набор курток, но система правильно определила куртки на основе нашего описания при поиске по встроенным изображениям.
Давайте попробуем другой способ поиска среди описаний, используя наше векторное представление для искомого изображения.
Поиск текста по изображениям
Мы попытались найти изображения, передав им векторное представление (embedding), и сравнить его с предварительно рассчитанными векторными представлениями изображений для наших товаров. Мы также попытались найти изображения, передав векторное представление для нашего текстового запроса, и выполнить поиск среди изображений товаров с тем же векторным представлением. Давайте теперь попробуем использовать векторное представление для нашего изображения и сравнить его с векторными представлениями текста для описаний товаров. Эти векторные представления хранятся в столбце product_description_embedding и используют ту же модель multimodalembedding@001 .
Вот наш запрос:
SELECT
name,
product_description,
retail_price,
replace(product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url,
product_description_embedding <=> google_ml.image_embedding (model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector AS distance
FROM
ecomm.products
ORDER BY distance
LIMIT
4;
А здесь мы получили немного другой набор курток серых или темных цветов, некоторые из которых совпадают или очень близки к тем, которые были выбраны другими способами поиска.
|
|
|
|



На основе векторных представлений изображений система может сравнить их с вычисленными векторными представлениями текстового описания и вернуть правильный набор товаров.
Гибридный поиск текста и изображений
Вы также можете поэкспериментировать с объединением текстовых и графических вложений, используя, например, метод взаимного ранжирования. Вот пример такого запроса, где мы объединили два поиска, присвоив каждому рангу оценку и упорядочив результаты на основе объединенной оценки.
WITH image_search AS (
SELECT id,
RANK () OVER (ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector) AS rank
FROM ecomm.products
ORDER BY product_image_embedding <=>google_ml.image_embedding(model_id => 'multimodalembedding@001',image => 'gs://pr-public-demo-data/alloydb-retail-demo/user_photos/4.png', mimetype => 'image/png')::vector LIMIT 5
),
text_search AS (
SELECT id,
RANK () OVER (ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector) AS rank
FROM ecomm.products
ORDER BY product_description_embedding <=>google_ml.text_embedding(model_id => 'multimodalembedding@001',content => 'puffy jacket for men, grey or dark colour'
)::vector LIMIT 5
),
rrf_score AS (
SELECT
COALESCE(image_search.id, text_search.id) AS id,
COALESCE(1.0 / (60 + image_search.rank), 0.0) + COALESCE(1.0 / (60 + text_search.rank), 0.0) AS rrf_score
FROM image_search FULL OUTER JOIN text_search ON image_search.id = text_search.id
ORDER BY rrf_score DESC
)
SELECT
ep.name,
ep.product_description,
ep.retail_price,
replace(ep.product_image_uri,'gs://','https://storage.googleapis.com/') AS public_url
FROM ecomm.products ep, rrf_score
WHERE
ep.id=rrf_score.id
ORDER by rrf_score DESC
LIMIT 4;
Вы можете попробовать поэкспериментировать с различными параметрами запроса и посмотреть, сможете ли улучшить результаты поиска. Кроме того, вы также можете использовать другие операторы ИИ для ранжирования результатов, как описано в документации .
На этом лабораторная работа завершена. Во избежание непредвиденных расходов рекомендуется удалить неиспользованные ресурсы.
9. Очистка окружающей среды
После завершения лабораторной работы удалите экземпляры AlloyDB и кластер.
Удалите кластер AlloyDB и все его экземпляры.
Если вы использовали пробную версию AlloyDB, не удаляйте пробный кластер, если планируете тестировать другие тестовые среды и ресурсы с его помощью. Вы не сможете создать другой пробный кластер в том же проекте.
Кластер уничтожается с помощью опции force, которая также удаляет все экземпляры, принадлежащие кластеру.
В облачной оболочке укажите переменные проекта и среды на случай, если соединение было разорвано и все предыдущие настройки были потеряны:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Удалите кластер:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Удалить резервные копии AlloyDB
Удалите все резервные копии AlloyDB для кластера:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
10. Поздравляем!
Поздравляем с завершением практического занятия! Вы научились использовать мультимодальный поиск в AlloyDB с помощью функций встраивания текста и изображений. Вы можете попробовать протестировать мультимодальный поиск и улучшить его с помощью функции google_ml.rank, используя практическое занятие по операторам искусственного интеллекта в AlloyDB .
Программа обучения Google Cloud
Данная лабораторная работа является частью учебного курса "Готовый к внедрению ИИ в производство с использованием Google Cloud".
- Изучите полный учебный план , чтобы преодолеть разрыв между прототипом и серийным производством.
- Делитесь своими успехами, используя хэштег
#ProductionReadyAI.
Что мы рассмотрели
- Как развернуть AlloyDB для PostgreSQL
- Как использовать AlloyDB Studio
- Как использовать многомодальный векторный поиск
- Как включить операторы искусственного интеллекта AlloyDB
- Как использовать различные операторы искусственного интеллекта AlloyDB для многомодального поиска
- Как использовать AlloyDB AI для объединения результатов поиска текста и изображений.
11. Опрос
Выход: