
1. Einführung
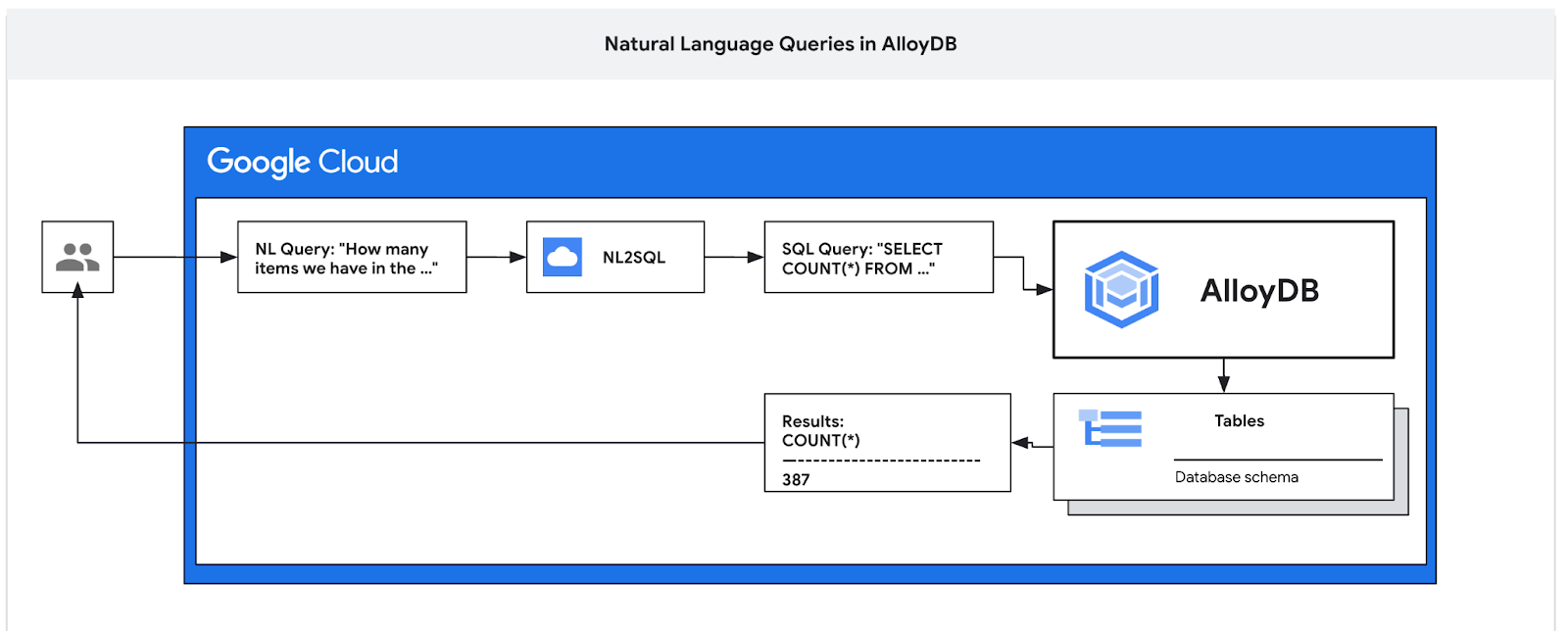
In diesem Codelab erfahren Sie, wie Sie AlloyDB bereitstellen und KI-Natural Language verwenden, um Daten abzufragen und die Konfiguration für vorhersagbare und effiziente Abfragen zu optimieren. Dieses Lab ist Teil einer Lab-Sammlung, die sich mit AlloyDB AI-Funktionen befasst. Weitere Informationen
Voraussetzungen
- Grundkenntnisse in Google Cloud und der Google Cloud Console
- Grundkenntnisse in der Befehlszeile und Cloud Shell
Lerninhalte
- AlloyDB for Postgres bereitstellen
- AlloyDB AI Natural Language aktivieren
- Konfiguration für KI-basierte natürliche Sprache erstellen und abstimmen
- SQL-Abfragen generieren und Ergebnisse mit natürlicher Sprache abrufen
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome, der die Google Cloud Console und die Cloud Shell unterstützt
2. Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

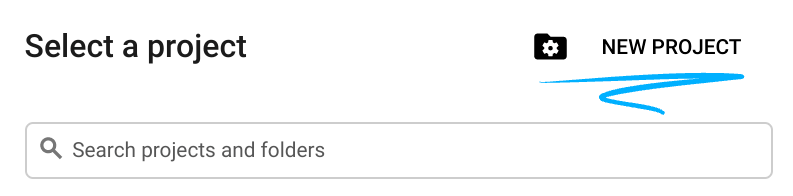
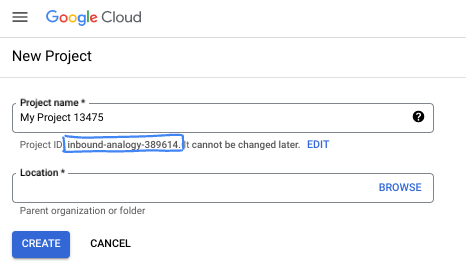
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie es mit einem eigenen Namen versuchen und sehen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/-APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um Kosten zu vermeiden, die über diese Anleitung hinausgehen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am kostenlosen Testzeitraum mit einem Guthaben von 300$ teilnehmen.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Hinweis
API aktivieren
Prüfen Sie in Cloud Shell, ob Ihre Projekt-ID eingerichtet ist:
gcloud config set project [YOUR-PROJECT-ID]
Legen Sie die Umgebungsvariable PROJECT_ID fest:
PROJECT_ID=$(gcloud config get-value project)
Aktivieren Sie alle erforderlichen Dienste:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Erwartete Ausgabe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB bereitstellen
AlloyDB-Cluster und primäre Instanz erstellen Im folgenden Verfahren wird beschrieben, wie Sie mit dem Google Cloud SDK einen AlloyDB-Cluster und eine AlloyDB-Instanz erstellen. Wenn Sie lieber die Console verwenden möchten, finden Sie hier die Dokumentation.
Bevor wir einen AlloyDB-Cluster erstellen, benötigen wir einen verfügbaren privaten IP-Adressbereich in unserer VPC, der von der zukünftigen AlloyDB-Instanz verwendet werden soll. Wenn wir sie nicht haben, müssen wir sie erstellen, sie für die Verwendung durch interne Google-Dienste zuweisen und erst dann können wir den Cluster und die Instanz erstellen.
Privaten IP-Bereich erstellen
Wir müssen den Zugriff auf private Dienste in unserer VPC für AlloyDB konfigurieren. Wir gehen hier davon aus, dass das VPC-Netzwerk „default“ im Projekt vorhanden ist und für alle Aktionen verwendet wird.
Erstellen Sie den privaten IP-Bereich:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Erstellen Sie eine private Verbindung mit dem zugewiesenen IP-Bereich:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB-Cluster erstellen
In diesem Abschnitt erstellen wir einen AlloyDB-Cluster in der Region „us-central1“.
Legen Sie ein Passwort für den Postgres-Nutzer fest. Sie können ein eigenes Passwort definieren oder eine Zufallsfunktion verwenden, um eines zu generieren.
export PGPASSWORD=`openssl rand -hex 12`
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Notieren Sie sich das PostgreSQL-Passwort für die spätere Verwendung.
echo $PGPASSWORD
Sie benötigen dieses Passwort später, um als Postgres-Nutzer eine Verbindung zur Instanz herzustellen. Ich empfehle, sie aufzuschreiben oder zu kopieren, damit Sie sie später verwenden können.
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Cluster im kostenlosen Testzeitraum erstellen
Wenn Sie AlloyDB noch nicht verwendet haben, können Sie einen kostenlosen Testcluster erstellen:
Definieren Sie die Region und den Namen des AlloyDB-Clusters. Wir verwenden die Region „us-central1“ und „alloydb-aip-01“ als Clusternamen:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Führen Sie den folgenden Befehl aus, um den Cluster zu erstellen:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Erwartete Konsolenausgabe:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Erstellen Sie in derselben Cloud Shell-Sitzung eine primäre AlloyDB-Instanz für unseren Cluster. Wenn die Verbindung getrennt wird, müssen Sie die Umgebungsvariablen für die Region und den Clusternamen noch einmal definieren.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard-Cluster erstellen
Wenn es nicht Ihr erster AlloyDB-Cluster im Projekt ist, fahren Sie mit der Erstellung eines Standardclusters fort.
Definieren Sie die Region und den Namen des AlloyDB-Clusters. Wir verwenden die Region „us-central1“ und „alloydb-aip-01“ als Clusternamen:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Führen Sie den folgenden Befehl aus, um den Cluster zu erstellen:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Erwartete Konsolenausgabe:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Erstellen Sie in derselben Cloud Shell-Sitzung eine primäre AlloyDB-Instanz für unseren Cluster. Wenn die Verbindung getrennt wird, müssen Sie die Umgebungsvariablen für die Region und den Clusternamen noch einmal definieren.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Datenbank vorbereiten
Wir müssen eine Datenbank erstellen, die Vertex AI-Integration aktivieren, Datenbankobjekte erstellen und die Daten importieren.
Erforderliche Berechtigungen für AlloyDB erteilen
Fügen Sie dem AlloyDB-Dienst-Agent Vertex AI-Berechtigungen hinzu.
Öffnen Sie oben einen weiteren Cloud Shell-Tab, indem Sie auf das Pluszeichen (+) klicken.
Führen Sie im neuen Cloud Shell-Tab Folgendes aus:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Schließen Sie den Tab, indem Sie entweder den Befehl „exit“ auf dem Tab ausführen:
exit
Verbindung zu AlloyDB Studio herstellen
In den folgenden Kapiteln können alle SQL-Befehle, für die eine Verbindung zur Datenbank erforderlich ist, alternativ in AlloyDB Studio ausgeführt werden. Um den Befehl auszuführen, müssen Sie die Webkonsolenschnittstelle für Ihren AlloyDB-Cluster öffnen. Klicken Sie dazu auf die primäre Instanz.
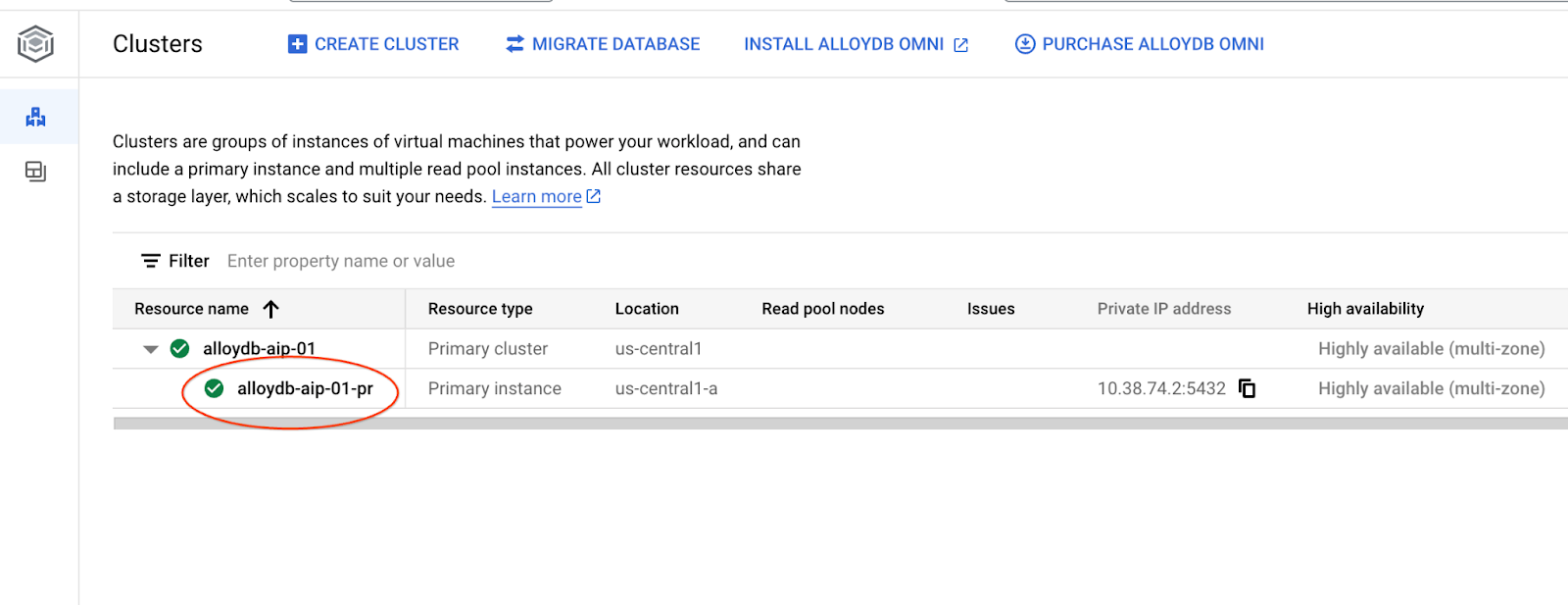
Klicken Sie dann links auf „AlloyDB Studio“:
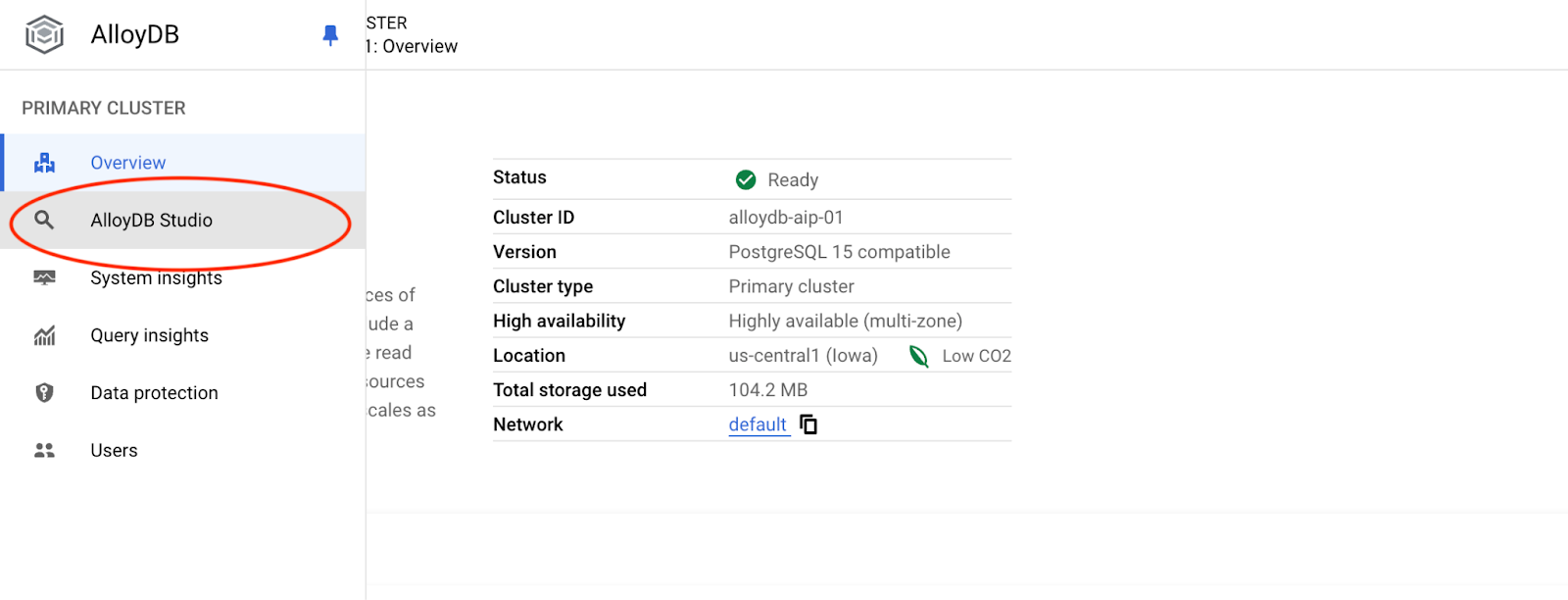
Wählen Sie die Postgres-Datenbank und den Nutzer „postgres“ aus und geben Sie das Passwort an, das beim Erstellen des Clusters angegeben wurde. Klicken Sie dann auf die Schaltfläche „Authentifizieren“.
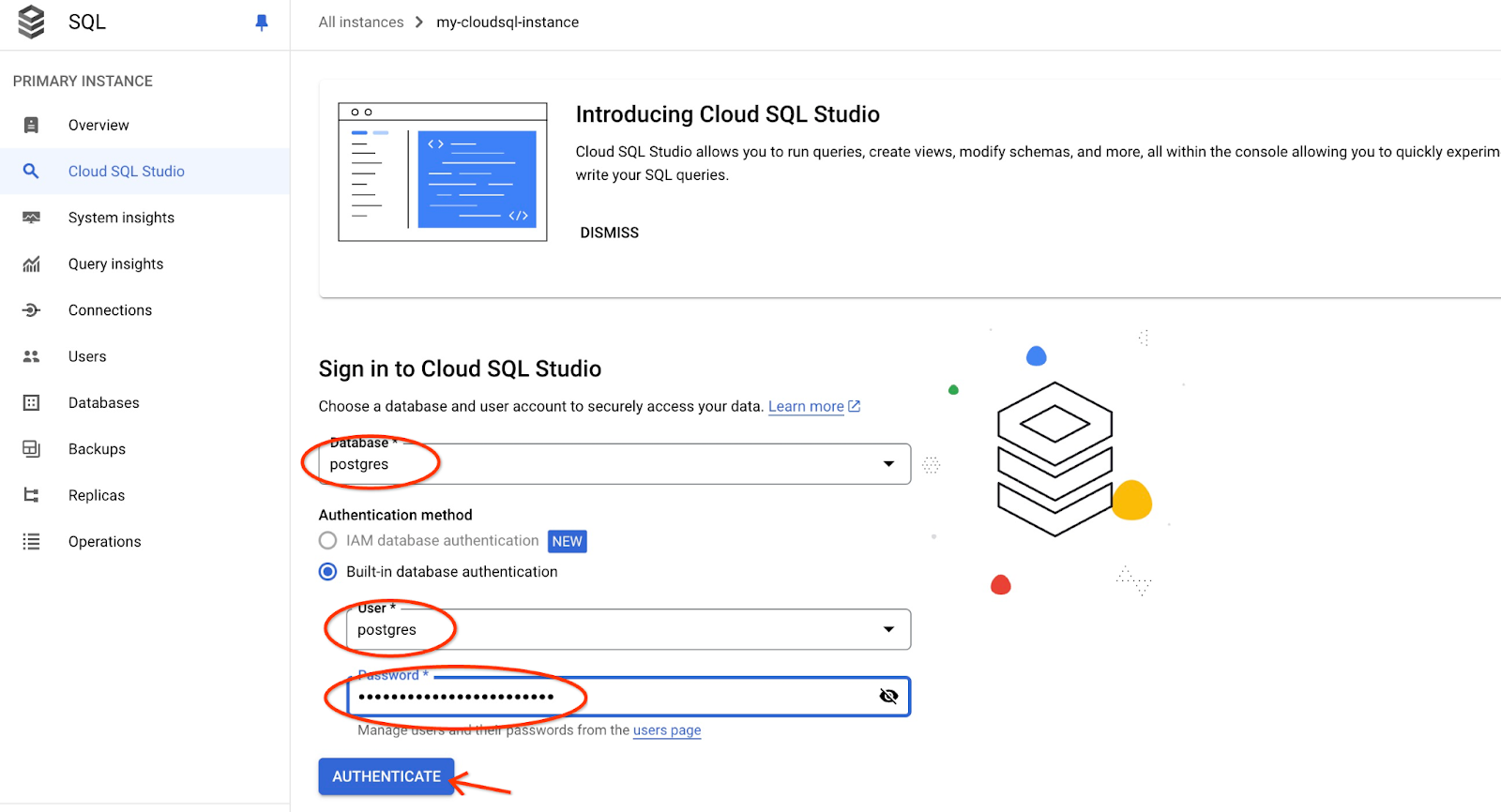
Die AlloyDB Studio-Benutzeroberfläche wird geöffnet. Wenn Sie die Befehle in der Datenbank ausführen möchten, klicken Sie rechts auf den Tab „Editor 1“.
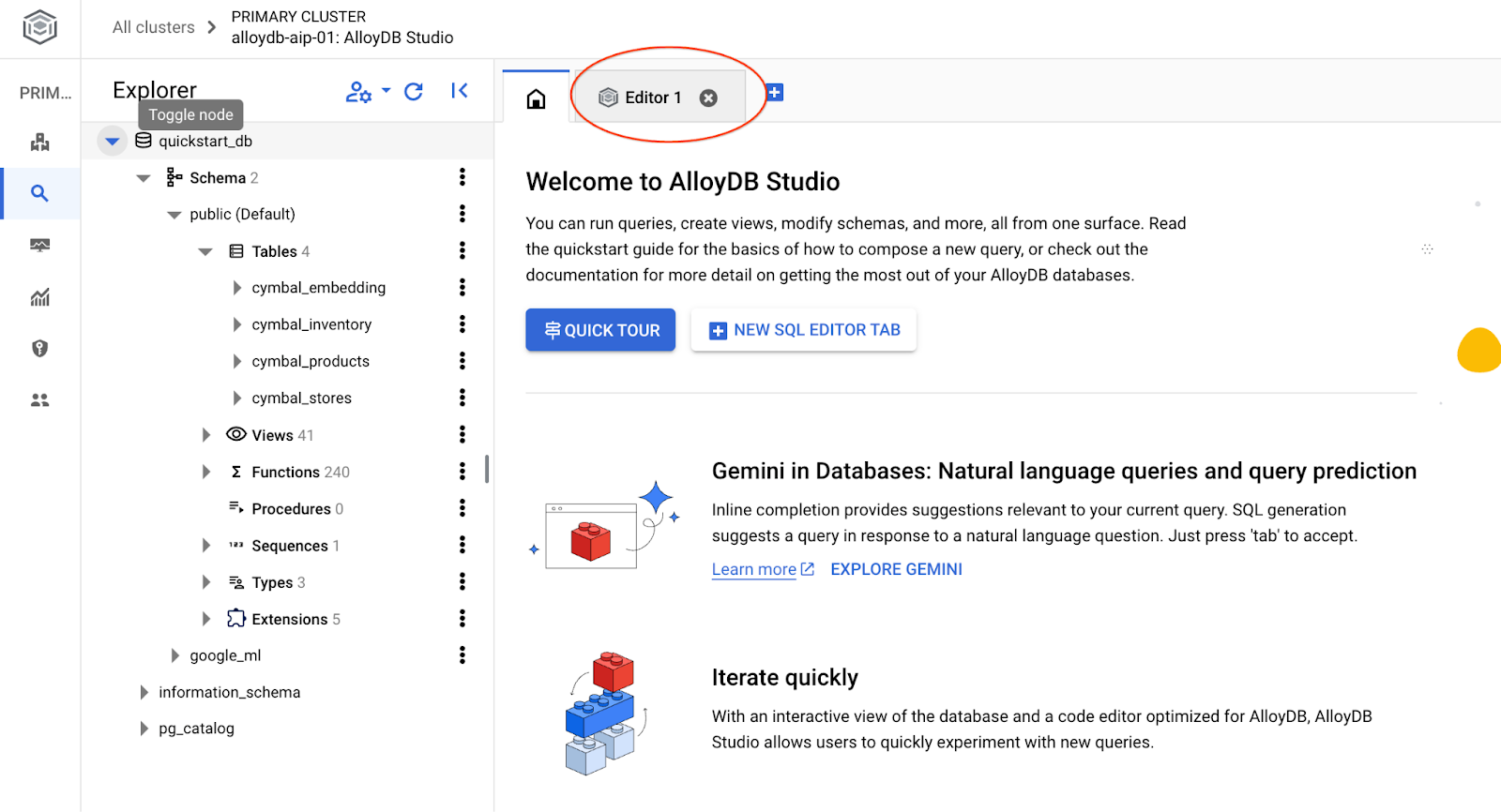
Dadurch wird eine Schnittstelle geöffnet, in der Sie SQL-Befehle ausführen können.
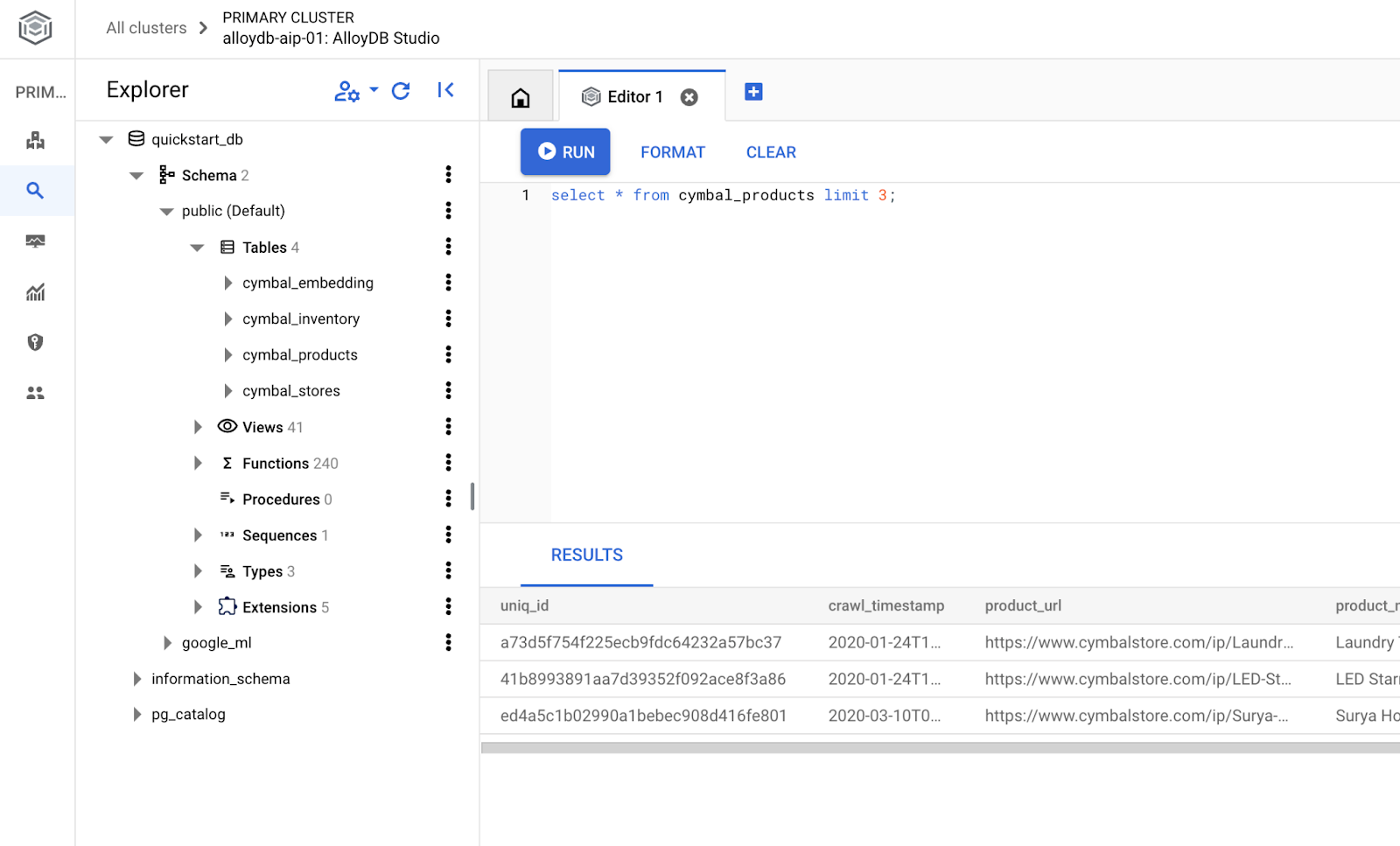
Datenbank erstellen
Schnellstart zum Erstellen von Datenbanken
Führen Sie im AlloyDB Studio-Editor den folgenden Befehl aus.
Datenbank erstellen:
CREATE DATABASE quickstart_db
Erwartete Ausgabe:
Statement executed successfully
Mit quickstart_db verbinden
Stellen Sie über die Schaltfläche zum Wechseln des Nutzers/der Datenbank eine neue Verbindung zum Studio her.
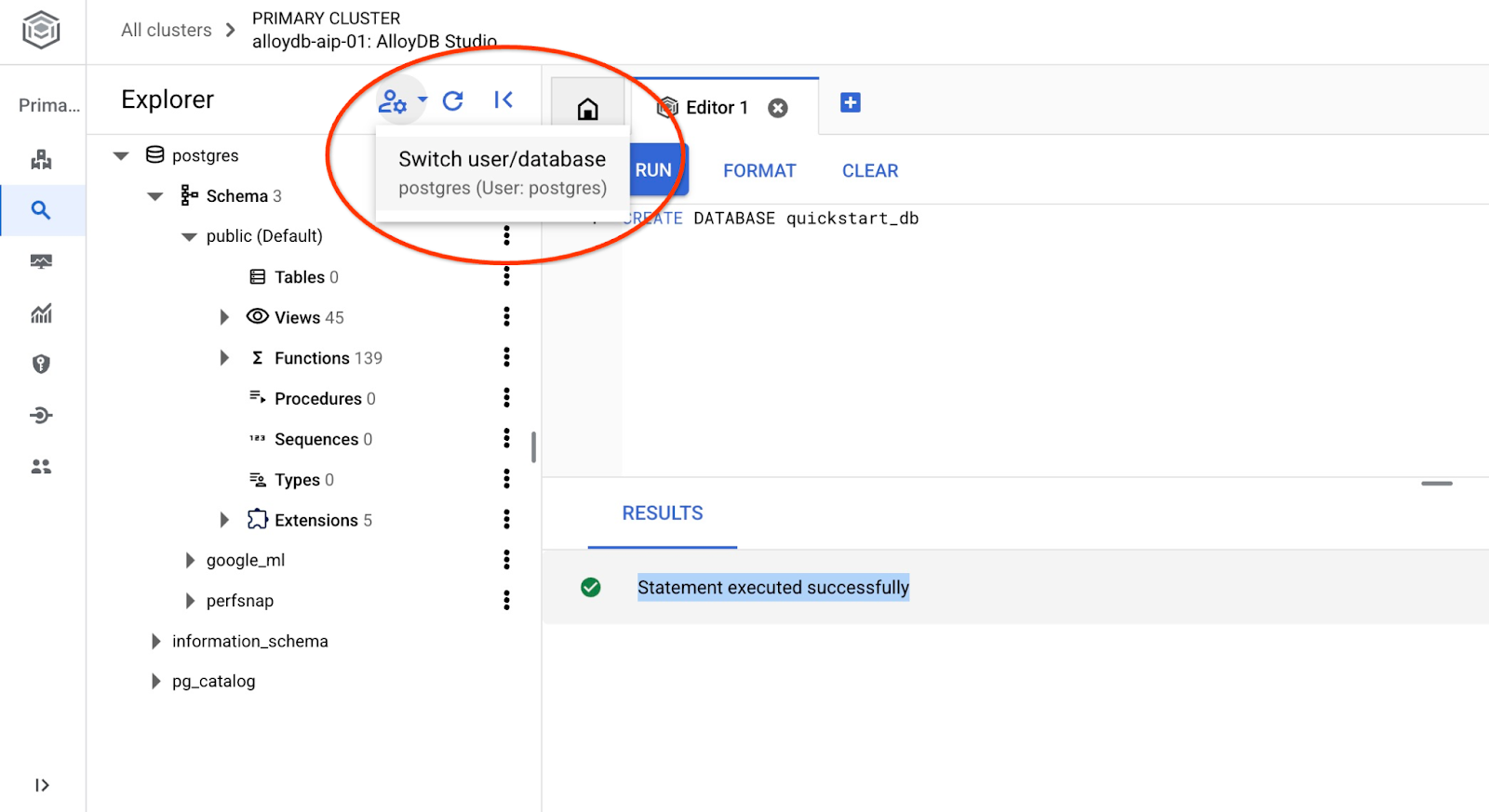
Wählen Sie in der Drop-down-Liste die neue Datenbank „quickstart_db“ aus und verwenden Sie denselben Nutzer und dasselbe Passwort wie zuvor.
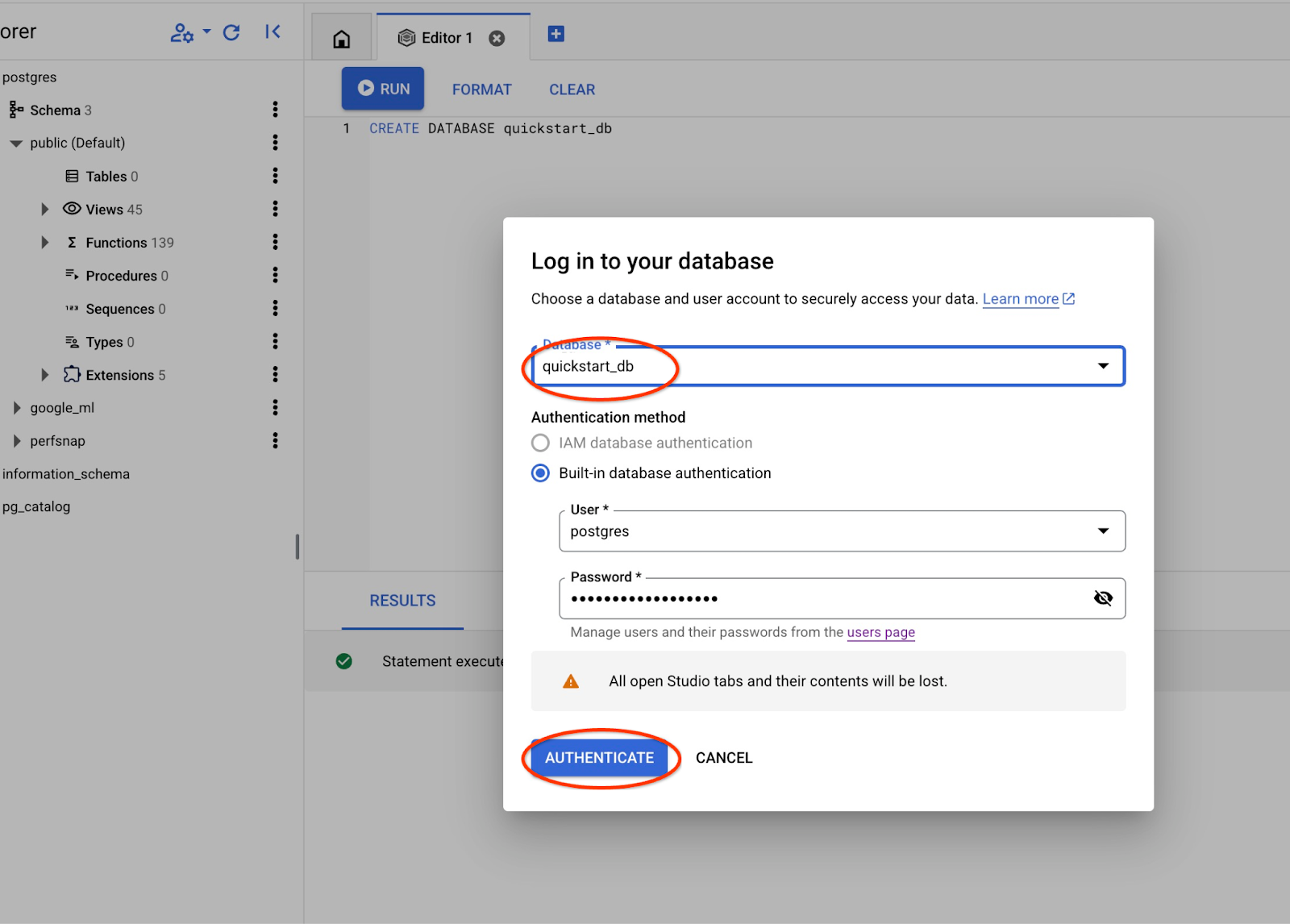
Dadurch wird eine neue Verbindung geöffnet, über die Sie mit Objekten aus der Datenbank „quickstart_db“ arbeiten können.
6. Beispieldaten
Jetzt müssen wir Objekte in der Datenbank erstellen und Daten laden. Wir verwenden den fiktiven Shop „Cymbal ecomm“ mit einer Reihe von Tabellen für Onlineshops. Sie enthält mehrere Tabellen, die über ihre Schlüssel verbunden sind, ähnlich einem relationalen Datenbankschema.
Das Dataset wird vorbereitet und als SQL-Datei gespeichert, die über die Importschnittstelle in die Datenbank geladen werden kann. Führen Sie in Cloud Shell die folgenden Befehle aus:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
Der Befehl verwendet das AlloyDB SDK, erstellt ein E-Commerce-Schema und importiert dann Beispieldaten direkt aus dem GCS-Bucket in die Datenbank. Dabei werden alle erforderlichen Objekte erstellt und Daten eingefügt.
Nach dem Import können wir die Tabellen in AlloyDB Studio prüfen.
Prüfen Sie die Anzahl der Zeilen in der Tabelle.
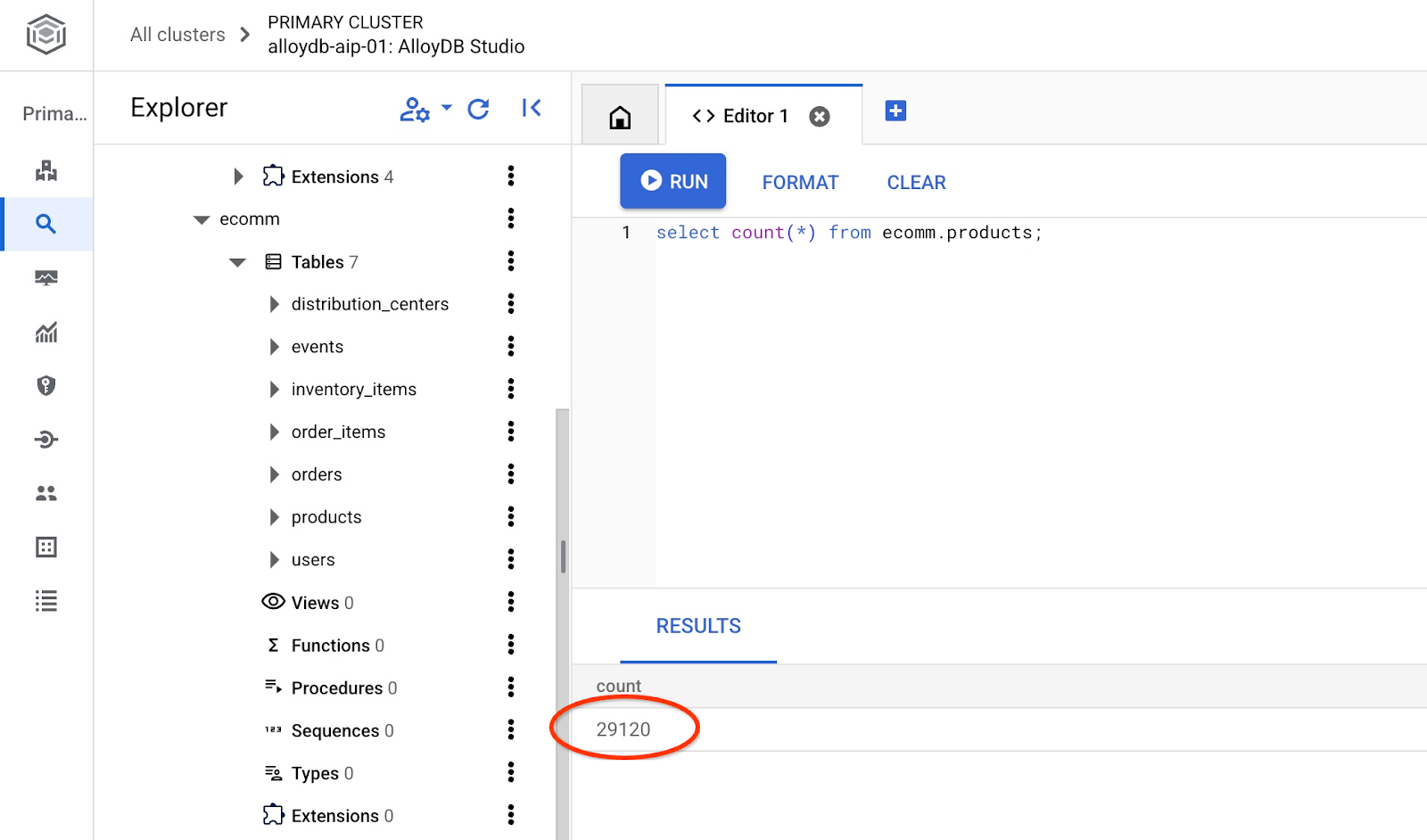
7. NL SQL konfigurieren
In diesem Kapitel konfigurieren wir NL für die Verwendung mit Ihrem Beispielschema.
Erweiterung „alloydb_nl_ai“ installieren
Wir müssen die Erweiterung „alloydb_ai_nl“ in unserer Datenbank installieren. Dazu müssen wir das Datenbank-Flag „alloydb_ai_nl.enabled“ auf „on“ setzen.
Führen Sie in der Cloud Shell-Sitzung Folgendes aus:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
Dadurch wird die Instanz aktualisiert. Sie können den Status der aktualisierten Instanz in der Webkonsole einsehen:
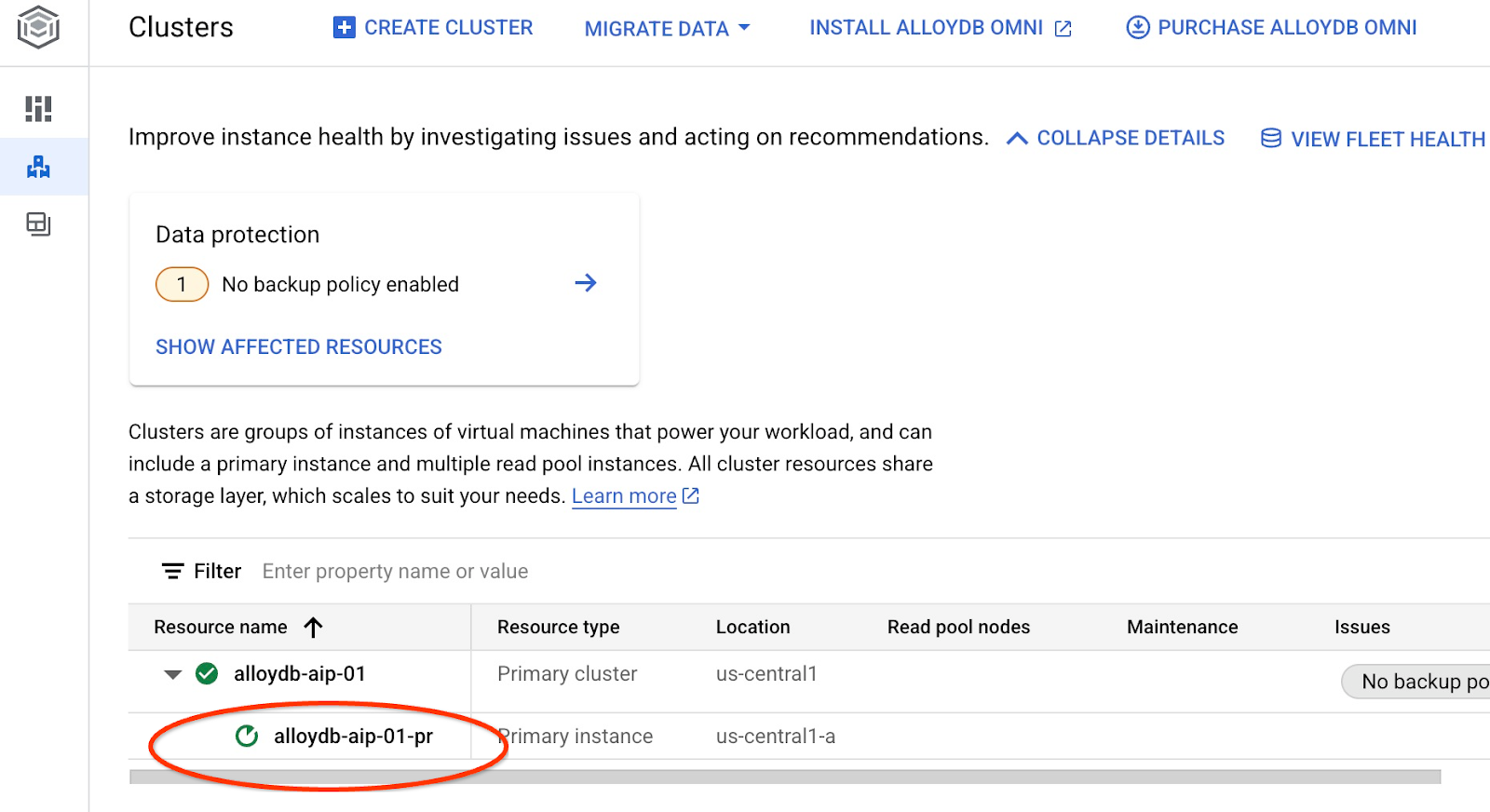
Wenn die Instanz aktualisiert wurde (der Instanzstatus ist grün), können Sie die Erweiterung „alloydb_ai_nl“ aktivieren.
In AlloyDB Studio ausführen
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
Konfiguration in natürlicher Sprache erstellen
Damit wir Erweiterungen verwenden können, müssen wir eine Konfiguration erstellen. Die Konfiguration ist erforderlich, um Anwendungen bestimmten Schemas, Abfragevorlagen und Modellendpunkten zuzuordnen. Erstellen wir eine Konfiguration mit der ID cymbal_ecomm_config.
In AlloyDB Studio ausführen
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
Jetzt können wir unser E-Commerce-Schema in der Konfiguration registrieren. Wir haben Daten in das E-Commerce-Schema importiert. Daher fügen wir dieses Schema unserer NL-Konfiguration hinzu.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. Kontext zu NL SQL hinzufügen
Allgemeinen Kontext hinzufügen
Wir können unserem registrierten Schema etwas Kontext hinzufügen. Der Kontext soll dazu beitragen, bessere Ergebnisse für Nutzeranfragen zu generieren. Wir können beispielsweise sagen, dass eine Marke die bevorzugte Marke für einen Nutzer ist, wenn sie nicht explizit definiert ist. Wir legen Clades (fiktive Marke) als Standardmarke fest.
Führen Sie in AlloyDB Studio Folgendes aus:
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
Sehen wir uns an, wie der allgemeine Kontext für uns funktioniert.
Führen Sie in AlloyDB Studio Folgendes aus:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
Die generierte Anfrage verwendet unsere Standardmarke, die zuvor im allgemeinen Kontext definiert wurde:
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
Wir können sie bereinigen und nur die SQL-Anweisung ausgeben lassen.
Beispiel:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Bereinigte Ausgabe:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
Sie haben festgestellt, dass automatisch die Tabelle „inventory_items“ anstelle von „products“ ausgewählt und für die Erstellung der Abfrage verwendet wurde. Das funktioniert in einigen Fällen, aber nicht bei unserem Schema. In unserem Fall dient die Tabelle „inventory_items“ dazu, Verkäufe nachzuverfolgen. Das kann irreführend sein, wenn Sie keine Insiderinformationen haben. Wir werden später sehen, wie wir unsere Anfragen genauer gestalten können.
Schemakontext
Der Schemakontext beschreibt Schemaobjekte wie Tabellen, Ansichten und einzelne Spalten, in denen Informationen als Kommentare in den Schemaobjekten gespeichert werden.
Wir können sie mit der folgenden Abfrage automatisch für alle Schemaobjekte in unserer definierten Konfiguration erstellen:
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
Der Parameter „TRUE“ weist uns an, den Kontext neu zu generieren und zu überschreiben. Die Ausführung dauert je nach Datenmodell einige Zeit. Je mehr Beziehungen und Verbindungen Sie haben, desto länger kann es dauern.
Nachdem wir den Kontext erstellt haben, können wir mit der folgenden Abfrage prüfen, was für die Tabelle „inventory_items“ erstellt wurde:
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
Bereinigte Ausgabe:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
In der Beschreibung fehlen einige wichtige Teile, die die Bewegung der Artikel in der Tabelle „inventory_items“ widerspiegeln. Wir können sie aktualisieren, indem wir diese wichtigen Informationen dem Kontext für die Beziehung „ecomm.inventory_items“ hinzufügen.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
Außerdem können wir die Richtigkeit der Beschreibung für unsere Produkttabelle überprüfen.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
Der automatisch generierte Kontext für die Produkttabelle war meiner Meinung nach sehr genau und musste nicht geändert werden.
Ich habe auch die Informationen zu den einzelnen Spalten in beiden Tabellen geprüft und sie sind ebenfalls korrekt.
Wenden wir den generierten Kontext für „ecomm.inventory_items“ und „ecomm.products“ auf unsere Konfiguration an.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
Erinnern Sie sich an unsere Anfrage zum Generieren von SQL für die Frage „Wie viele Produkte haben wir von unserer bevorzugten Marke?“ ? Wir können den Vorgang jetzt wiederholen und sehen, ob sich die Ausgabe ändert.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Hier ist die neue Ausgabe.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
Jetzt wird „ecomm.products“ geprüft, was genauer ist und etwa 300 Produkte anstelle von 5.000 Vorgängen mit Inventarelementen zurückgibt.
9. Mit dem Wertindex arbeiten
Durch die Wertverknüpfung werden natürlichsprachliche Anfragen optimiert, indem Wertformulierungen mit vorab registrierten Konzepttypen und Spaltennamen verknüpft werden. So lassen sich die Ergebnisse besser vorhersagen.
Wertindex konfigurieren
Wir können unsere Anfragen mit der Spalte „Marke“ in der Tabelle „Produkte“ stellen und nach Produkten mit stabileren Marken suchen, indem wir den Konzepttyp definieren und ihn der Spalte „ecomm.products.brand“ zuordnen.
Erstellen wir das Konzept und verknüpfen wir es mit der Spalte:
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
Sie können das Konzept überprüfen, indem Sie alloydb_ai_nl.list_concept_types() abfragen.
SELECT alloydb_ai_nl.list_concept_types();
Anschließend können wir den Index in unserer Konfiguration für alle erstellten und vordefinierten Zuordnungen erstellen:
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
Value Index verwenden
Wenn Sie eine Abfrage ausführen, um SQL mit Markennamen zu erstellen, aber nicht definieren, dass es sich um einen Markennamen handelt, kann die Einheit und Spalte richtig identifiziert werden. Hier ist die Abfrage:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
Die Ausgabe zeigt die korrekte Identifizierung des Wortes „Clades“ als Markenname.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. Mit Abfragevorlagen arbeiten
Mithilfe von Abfragevorlagen lassen sich stabile Abfragen für geschäftskritische Anwendungen definieren, wodurch die Unsicherheit verringert und die Genauigkeit verbessert wird.
Abfragevorlage erstellen
Wir erstellen eine Abfragevorlage, in der mehrere Tabellen zusammengeführt werden, um Informationen zu Kunden zu erhalten, die im letzten Jahr Produkte von „Republic Outpost“ gekauft haben. Wir wissen, dass in der Abfrage entweder die Tabelle „ecomm.products“ oder die Tabelle „ecomm.inventory_items“ verwendet werden kann, da beide Informationen zu den Marken enthalten. Die Tabelle products hat jedoch 15-mal weniger Zeilen und einen Index für den Primärschlüssel für den Join. Es kann effizienter sein, die Produkttabelle zu verwenden. Wir erstellen also eine Vorlage für die Abfrage.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
Wir können jetzt eine Abfrage erstellen lassen.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
Und es wird die gewünschte Ausgabe erzeugt.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
Alternativ können Sie die Abfrage direkt mit der folgenden Abfrage ausführen:
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
Die Ergebnisse werden im JSON-Format zurückgegeben und können geparst werden.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. Umgebung bereinigen
Löschen Sie die AlloyDB-Instanzen und den Cluster, wenn Sie mit dem Lab fertig sind.
AlloyDB-Cluster und alle Instanzen löschen
Sie haben die Testversion von AlloyDB verwendet. Löschen Sie den Testcluster nicht, wenn Sie planen, andere Labs und Ressourcen damit zu testen. Sie können keinen weiteren Testcluster im selben Projekt erstellen.
Der Cluster wird mit der Option „force“ zerstört, wodurch auch alle zum Cluster gehörenden Instanzen gelöscht werden.
Definieren Sie in Cloud Shell die Projekt- und Umgebungsvariablen, wenn die Verbindung getrennt wurde und alle vorherigen Einstellungen verloren gegangen sind:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Löschen Sie den Cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB-Sicherungen löschen
Löschen Sie alle AlloyDB-Sicherungen für den Cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs. Sie können jetzt versuchen, eigene Lösungen mit den NL2SQL-Funktionen von AlloyDB zu implementieren. Wir empfehlen Ihnen, andere Codelabs zu AlloyDB und AlloyDB AI auszuprobieren. In diesem Codelab erfahren Sie, wie multimodale Einbettungen in AlloyDB funktionieren.
Behandelte Themen
- AlloyDB for Postgres bereitstellen
- AlloyDB AI Natural Language aktivieren
- Konfiguration für KI-basierte natürliche Sprache erstellen und abstimmen
- SQL-Abfragen generieren und Ergebnisse mit natürlicher Sprache abrufen
13. Umfrage
Ausgabe: