
1. Introducción
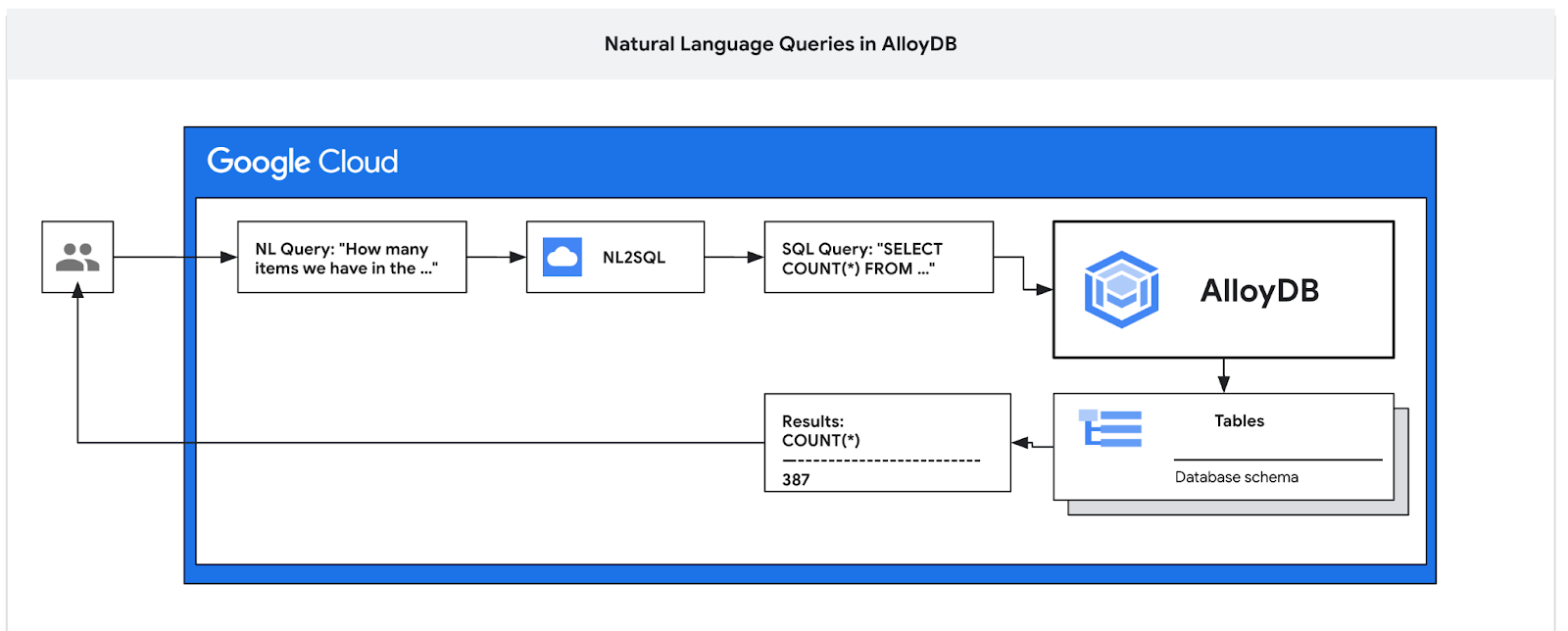
En este codelab, aprenderás a implementar AlloyDB y a usar el lenguaje natural de la IA para consultar datos y ajustar la configuración de las consultas predecibles y eficientes. Este lab forma parte de una colección de labs dedicados a las funciones de AlloyDB AI. Puedes obtener más información en la página de AlloyDB AI en la documentación.
Requisitos previos
- Conocimientos básicos sobre Google Cloud y la consola
- Habilidades básicas de la interfaz de línea de comandos y de Cloud Shell
Qué aprenderás
- Cómo implementar AlloyDB para PostgreSQL
- Cómo habilitar el lenguaje natural de AlloyDB AI
- Cómo crear y ajustar la configuración para el lenguaje natural de la IA
- Cómo generar consultas en SQL y obtener resultados con lenguaje natural
Requisitos
- Una cuenta de Google Cloud y un proyecto de Google Cloud
- Un navegador web, como Chrome, que admita la consola de Google Cloud y Cloud Shell
2. Configuración y requisitos
Configuración del entorno de autoaprendizaje
- Accede a Google Cloud Console y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.

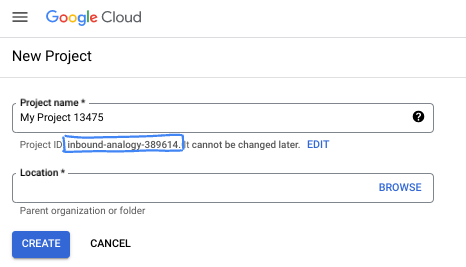
- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
3. Antes de comenzar
Habilitar API
En Cloud Shell, asegúrate de que tu ID del proyecto esté configurado:
gcloud config set project [YOUR-PROJECT-ID]
Configura la variable de entorno PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Habilita todos los servicios necesarios con el siguiente comando:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Implementa AlloyDB
Crea un clúster de AlloyDB y una instancia principal. En el siguiente procedimiento, se describe cómo crear un clúster y una instancia de AlloyDB con el SDK de Google Cloud. Si prefieres el enfoque de la consola, puedes seguir la documentación aquí.
Antes de crear un clúster de AlloyDB, necesitamos un rango de IP privada disponible en nuestra VPC para que lo utilice la instancia futura de AlloyDB. Si no lo tenemos, debemos crearlo, asignarlo para que lo usen los servicios internos de Google y, luego, podremos crear el clúster y la instancia.
Crea un rango de IP privada
Debemos establecer la configuración del acceso privado a servicios en nuestra VPC para AlloyDB. Aquí, suponemos que tenemos la red de VPC “predeterminada” en el proyecto y que se utilizará para todas las acciones.
Crea el rango de IP privada:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Crea una conexión privada con el rango de IP asignado:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Crea un clúster de AlloyDB
En esta sección, crearemos un clúster de AlloyDB en la región us-central1.
Define la contraseña para el usuario de postgres. Puedes definir tu propia contraseña o usar una función aleatoria para generar una.
export PGPASSWORD=`openssl rand -hex 12`
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Toma nota de la contraseña de PostgreSQL para utilizarla más adelante.
echo $PGPASSWORD
Necesitarás esa contraseña en el futuro para conectarte a la instancia como usuario de postgres. Te sugiero que la anotes o la copies en algún lugar para poder usarla más adelante.
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Crea un clúster de prueba gratuita
Si no usaste AlloyDB antes, puedes crear un clúster de prueba gratuito:
Define la región y el nombre del clúster de AlloyDB. Usaremos la región us-central1 y alloydb-aip-01 como nombre del clúster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Ejecuta el comando para crear el clúster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Resultado esperado en la consola:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea una instancia principal de AlloyDB para nuestro clúster en la misma sesión de Cloud Shell. Si te desconectas, deberás volver a definir las variables de entorno de la región y el nombre del clúster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Crea un clúster estándar de AlloyDB
Si no es tu primer clúster de AlloyDB en el proyecto, continúa con la creación de un clúster estándar.
Define la región y el nombre del clúster de AlloyDB. Usaremos la región us-central1 y alloydb-aip-01 como nombre del clúster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Ejecuta el comando para crear el clúster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Resultado esperado en la consola:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea una instancia principal de AlloyDB para nuestro clúster en la misma sesión de Cloud Shell. Si te desconectas, deberás volver a definir las variables de entorno de la región y el nombre del clúster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Resultado esperado en la consola:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Prepara la base de datos
Debemos crear una base de datos, habilitar la integración de Vertex AI, crear objetos de base de datos y, luego, importar los datos.
Otorga los permisos necesarios a AlloyDB
Agrega permisos de Vertex AI al agente de servicio de AlloyDB.
Abre otra pestaña de Cloud Shell con el signo "+" en la parte superior.
En la nueva pestaña de Cloud Shell, ejecuta lo siguiente:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Resultado esperado en la consola:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Cierra la pestaña con el comando de ejecución “exit” en la pestaña:
exit
Conéctate a AlloyDB Studio
En los siguientes capítulos, todos los comandos de SQL que requieren conexión a la base de datos se pueden ejecutar de forma alternativa en AlloyDB Studio. Para ejecutar el comando, haz clic en la instancia principal para abrir la interfaz de la consola web de tu clúster de AlloyDB.
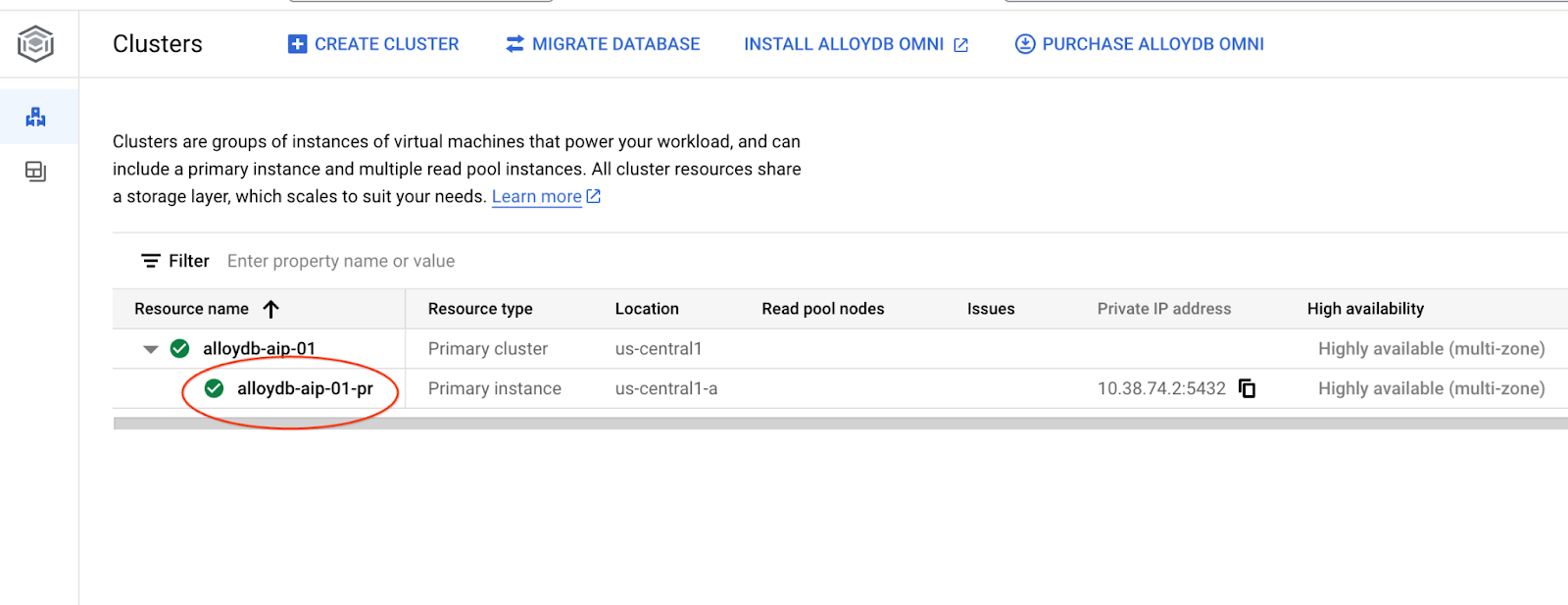
Luego, haz clic en AlloyDB Studio a la izquierda:
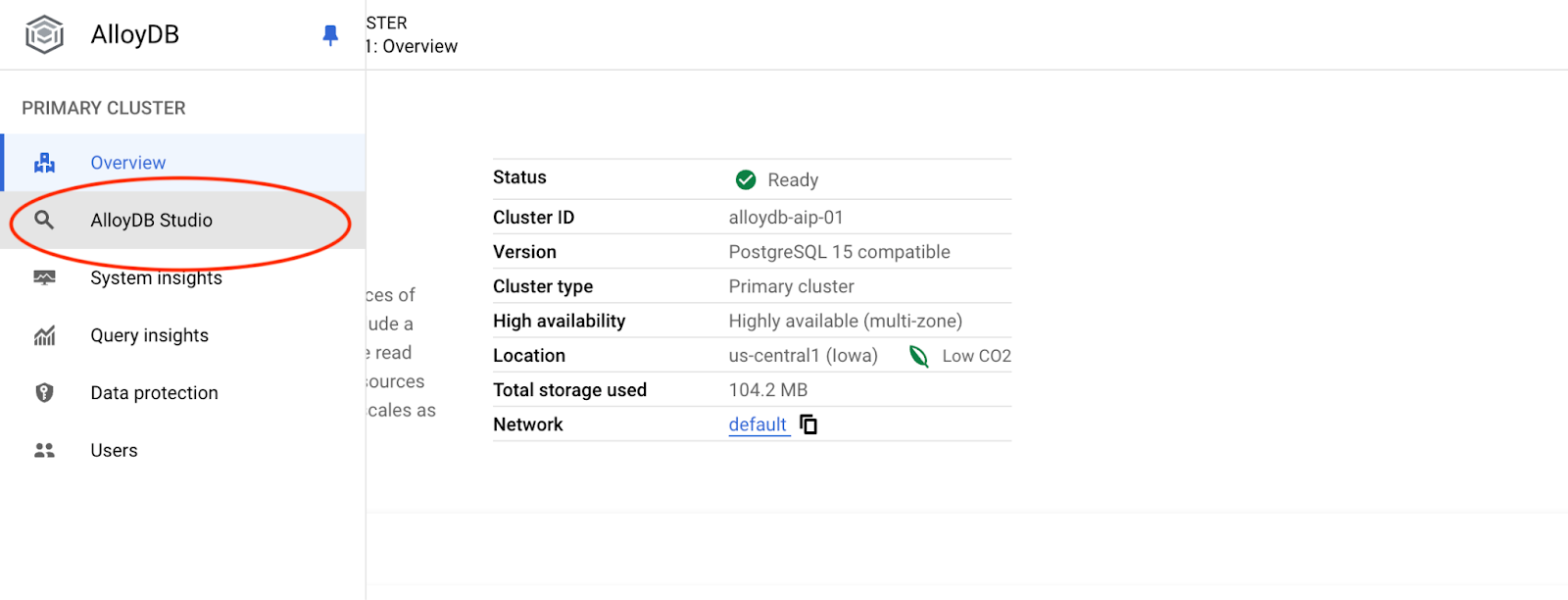
Elige la base de datos postgres, el usuario postgres y proporciona la contraseña que anotamos cuando creamos el clúster. Luego, haz clic en el botón "Autenticar".
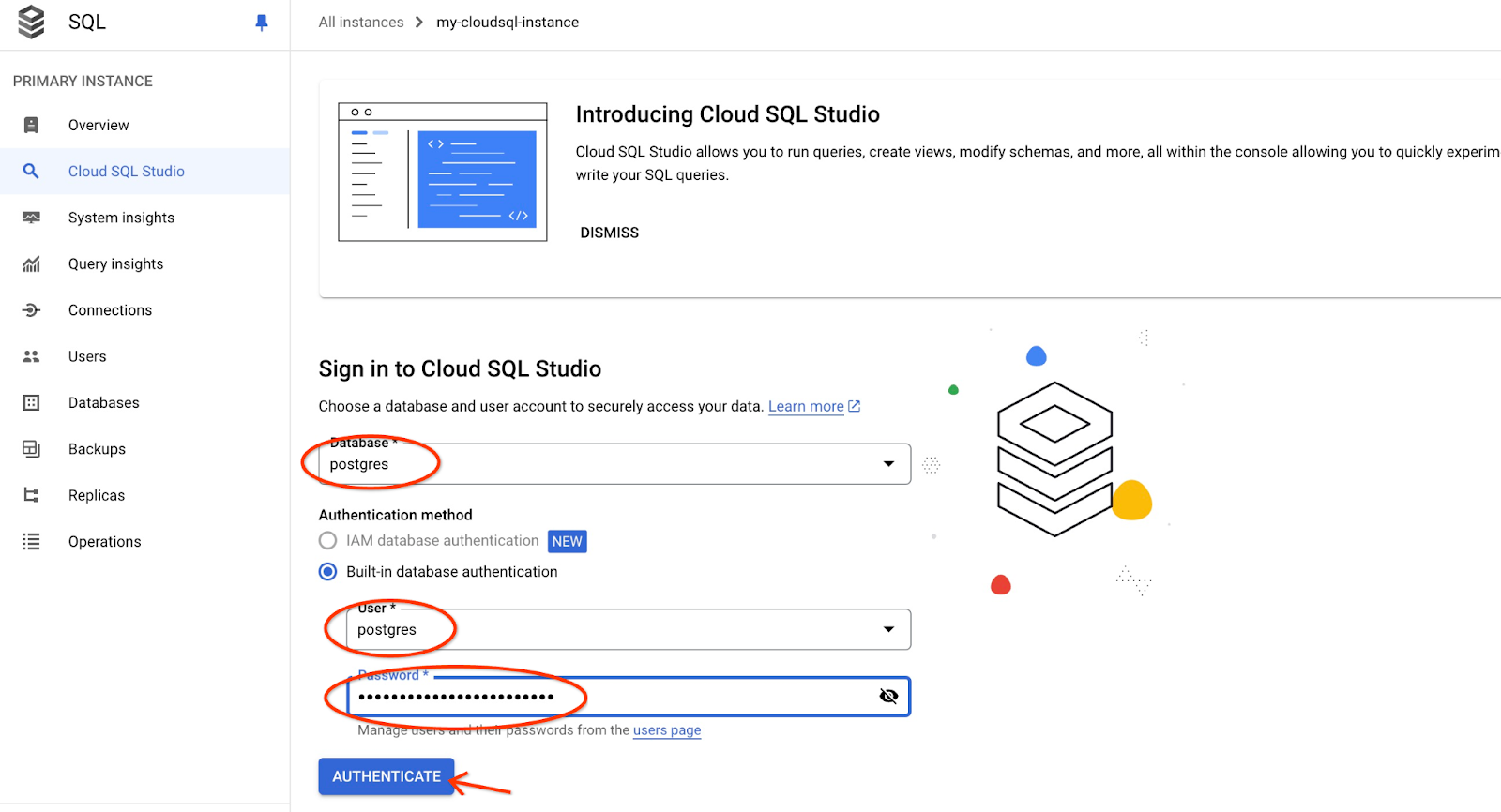
Se abrirá la interfaz de AlloyDB Studio. Para ejecutar los comandos en la base de datos, haz clic en la pestaña "Editor 1" que se encuentra a la derecha.
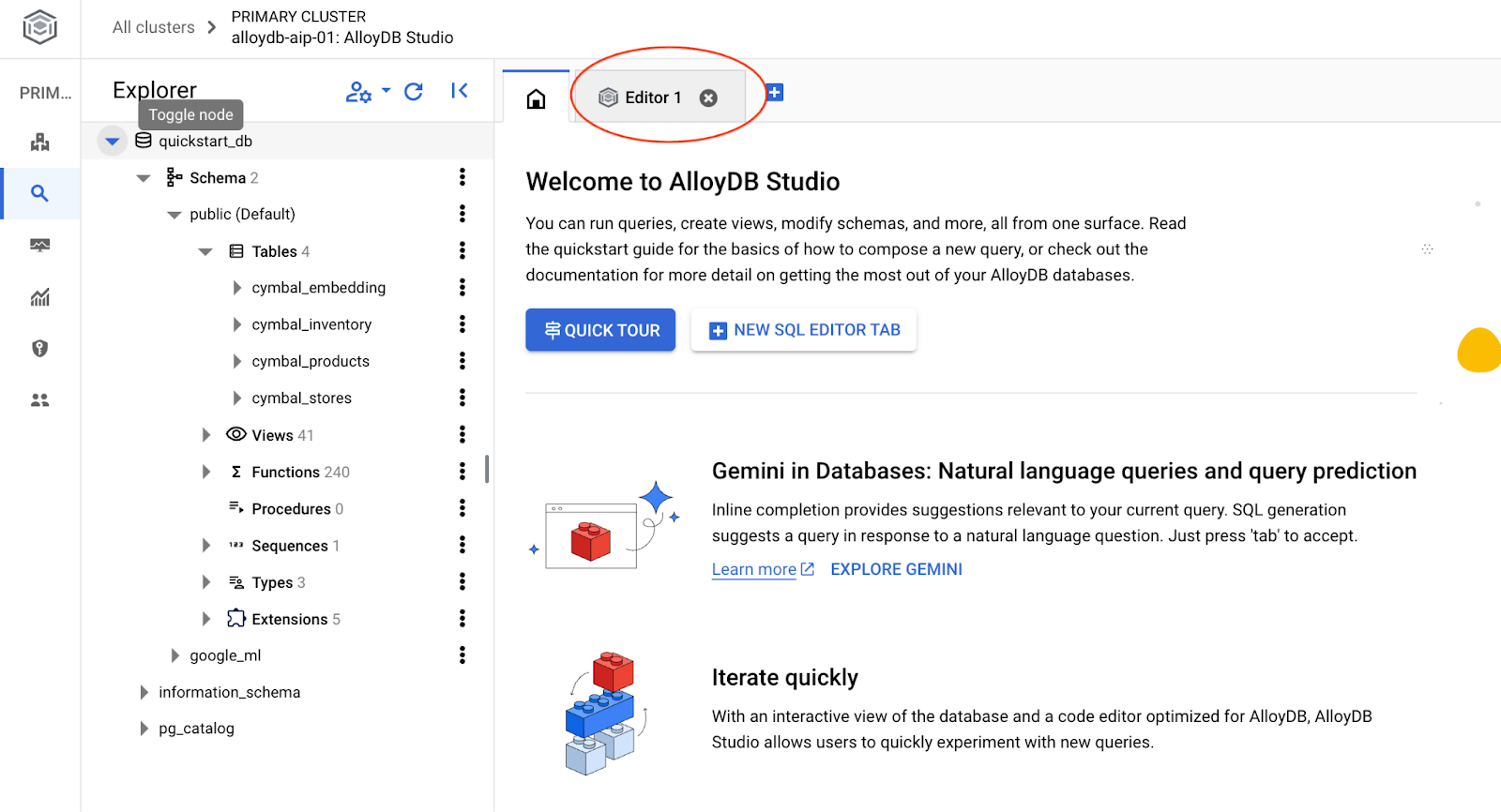
Se abre una interfaz en la que puedes ejecutar comandos de SQL.
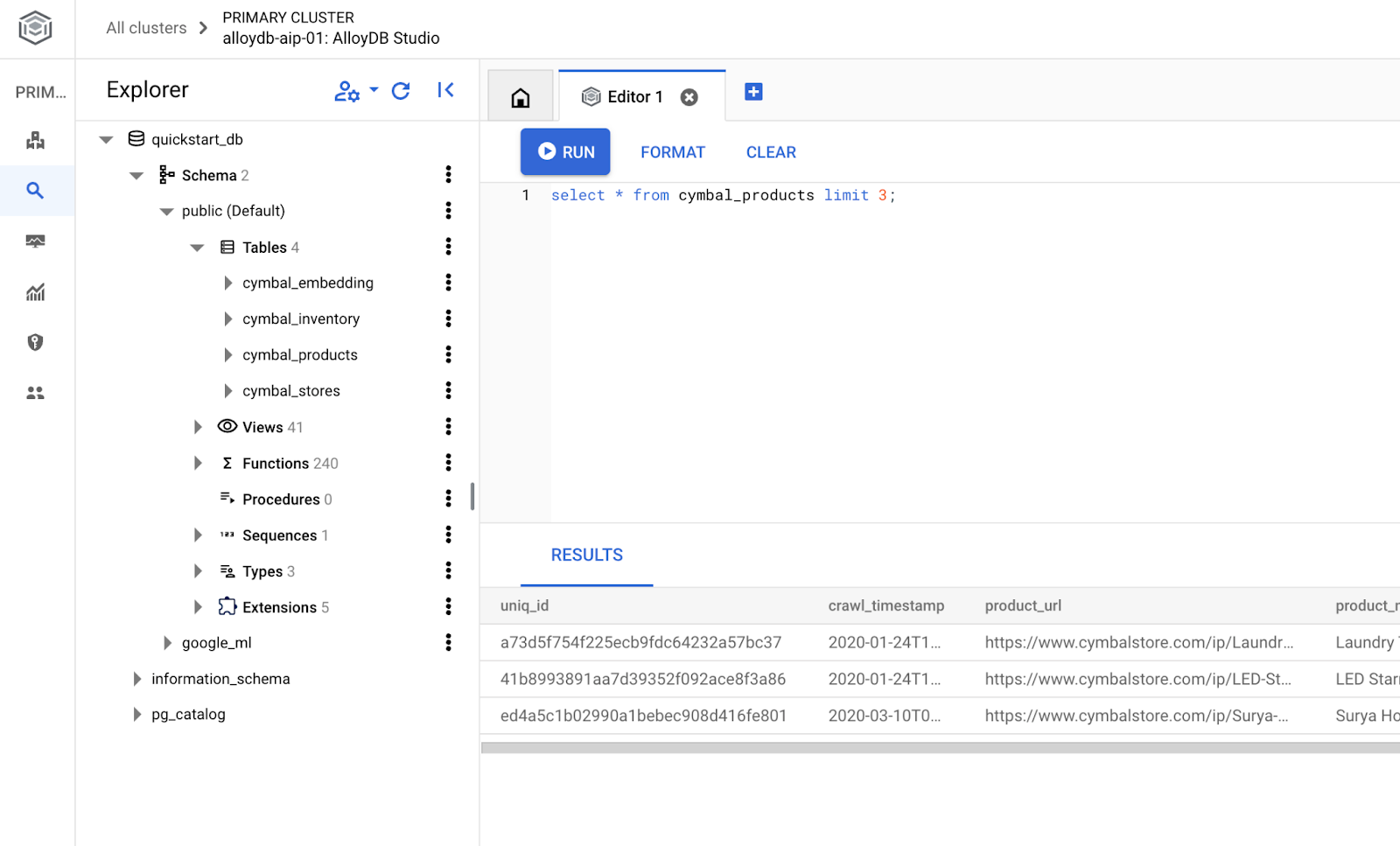
Crea la base de datos
Guía de inicio rápido para crear una base de datos
En el editor de AlloyDB Studio, ejecuta el siguiente comando.
Crea la base de datos:
CREATE DATABASE quickstart_db
Resultado esperado:
Statement executed successfully
Conéctate a quickstart_db
Vuelve a conectarte al estudio con el botón para cambiar de usuario o base de datos.
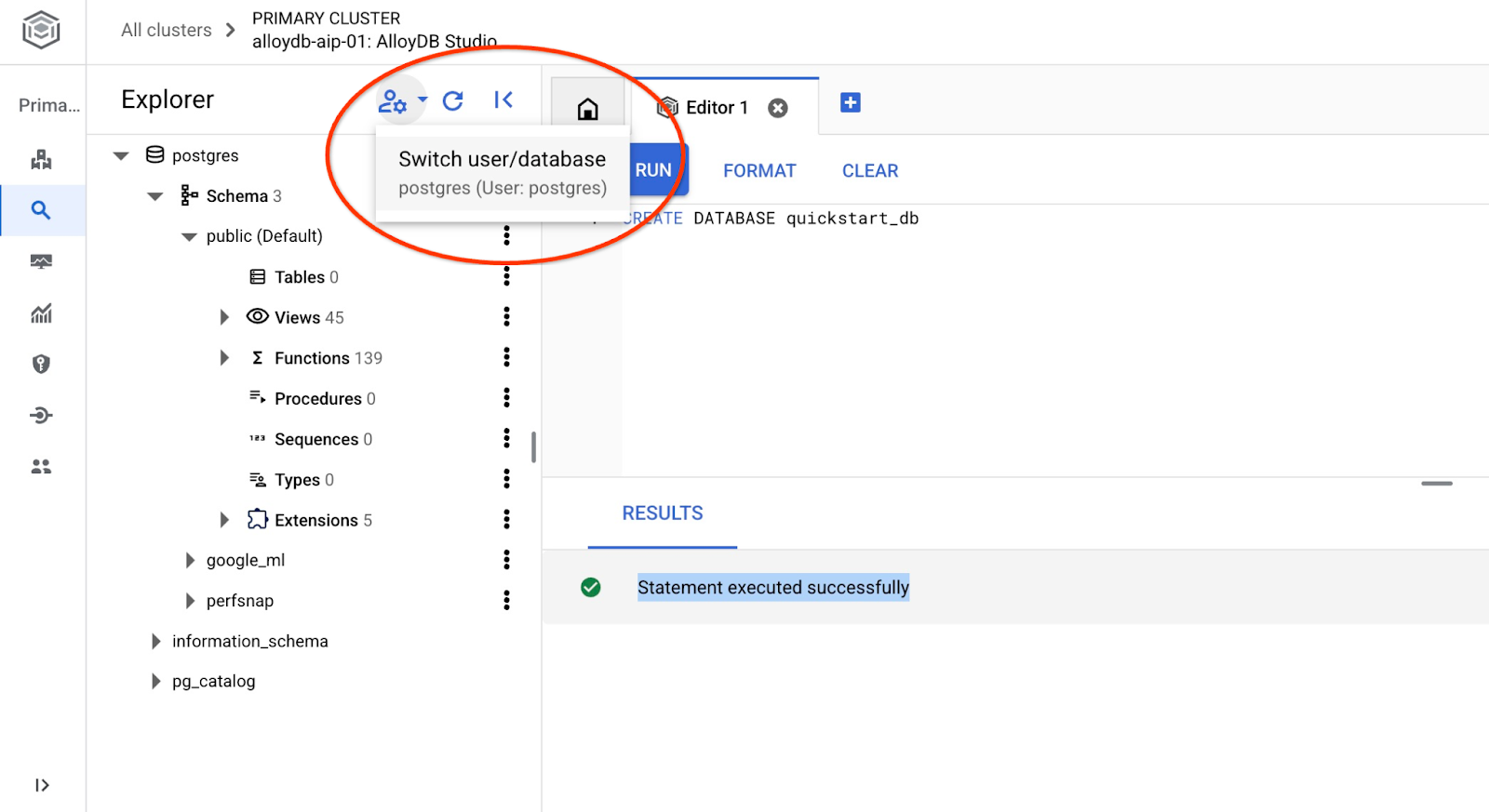
En la lista desplegable, selecciona la nueva base de datos quickstart_db y usa el mismo usuario y contraseña que antes.
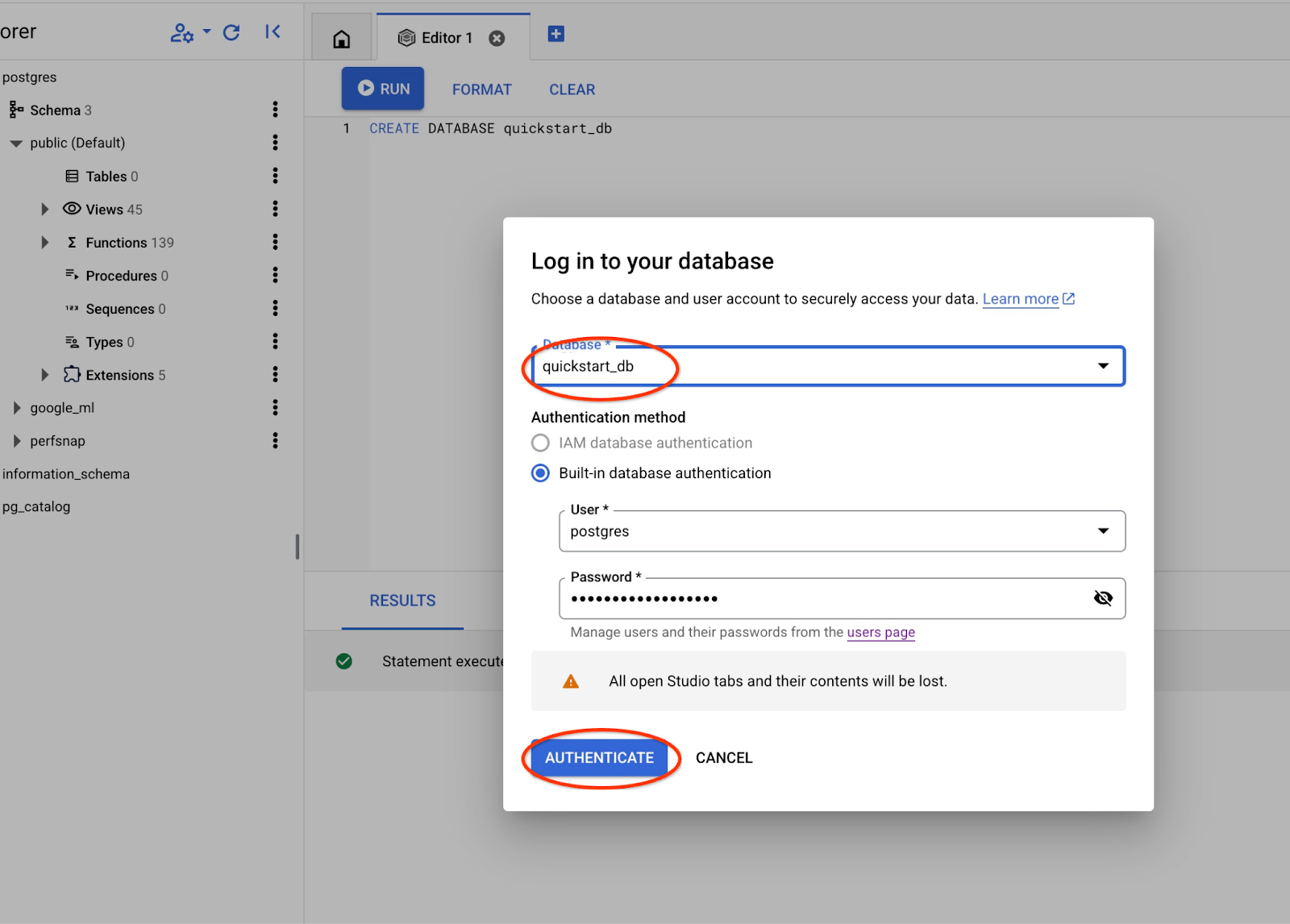
Se abrirá una nueva conexión en la que podrás trabajar con objetos de la base de datos quickstart_db.
6. Datos de muestra
Ahora debemos crear objetos en la base de datos y cargar datos. Usaremos una tienda ficticia de comercio electrónico llamada "Cymbal ecomm" con un conjunto de tablas para tiendas en línea. Contiene varias tablas conectadas por sus claves, lo que se asemeja a un esquema de base de datos relacional.
El conjunto de datos se prepara y se coloca como un archivo SQL que se puede cargar en la base de datos a través de la interfaz de importación. En Cloud Shell, ejecuta los siguientes comandos:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
El comando usa el SDK de AlloyDB y crea un esquema de comercio electrónico, y, luego, importa datos de muestra directamente desde el bucket de GCS a la base de datos, lo que crea todos los objetos necesarios y, luego, inserta los datos.
Después de la importación, podemos verificar las tablas en AlloyDB Studio.
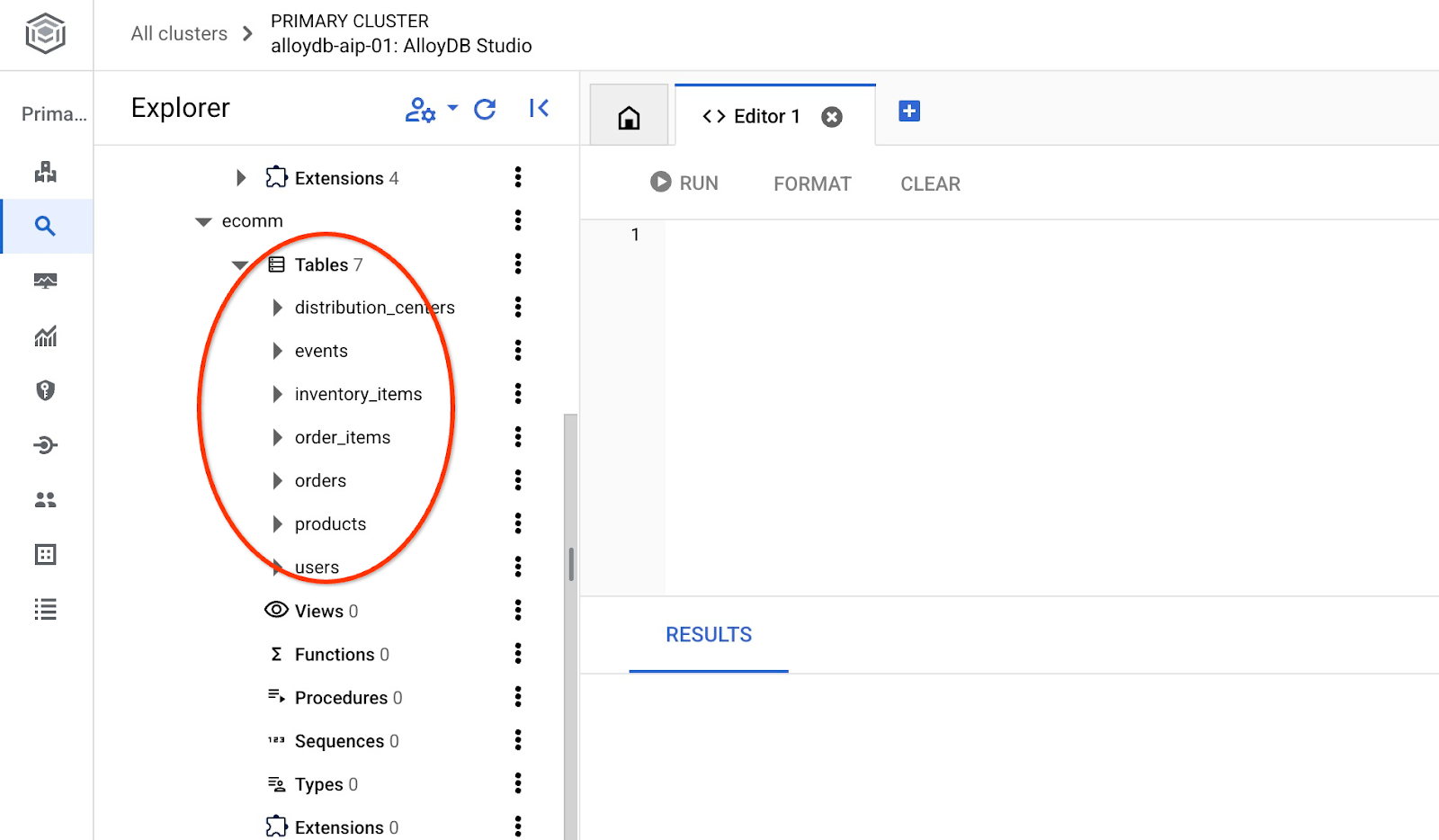
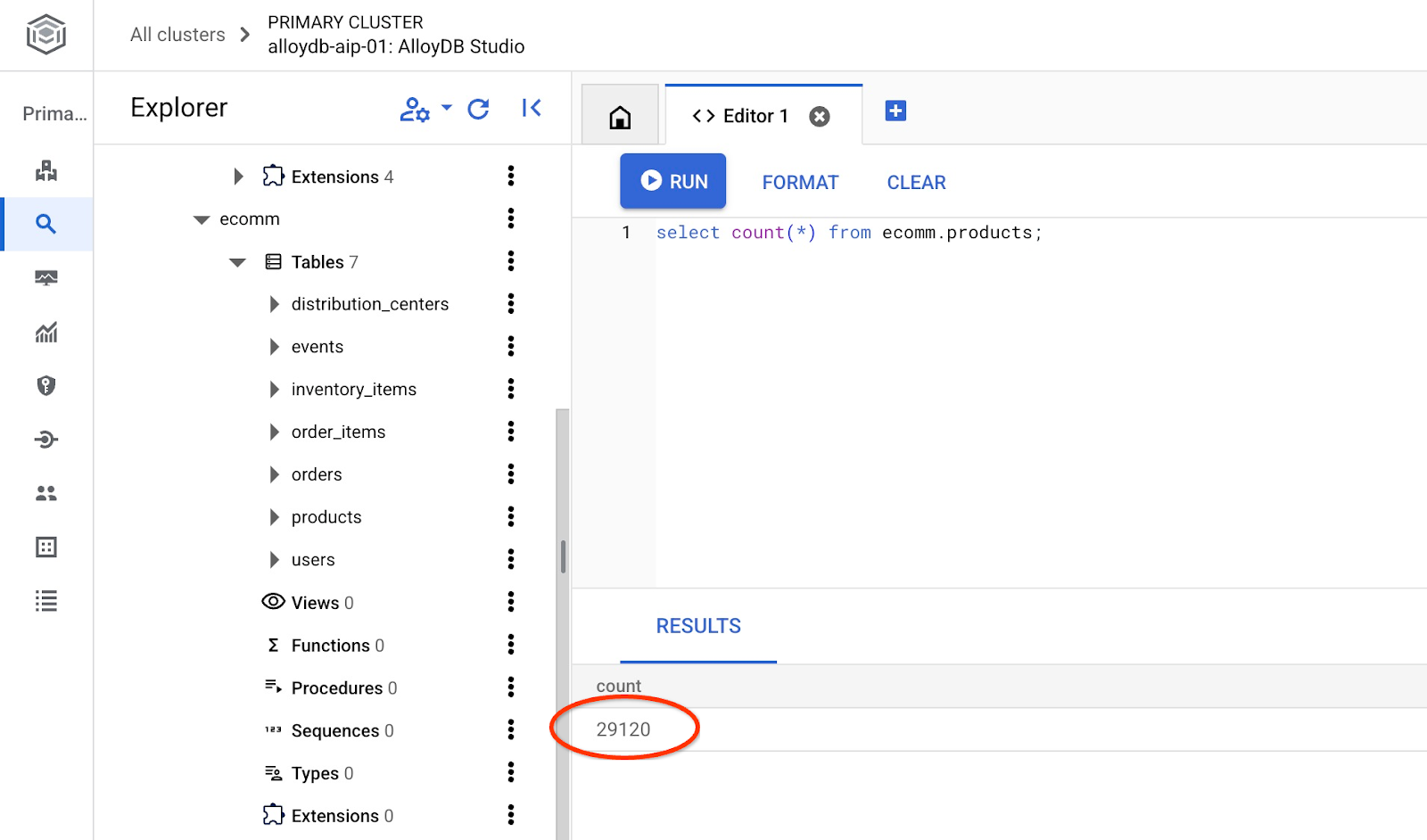
Verifica la cantidad de filas de la tabla.
7. Configura NL SQL
En este capítulo, configuraremos NL para que funcione con tu esquema de muestra
Instala la extensión alloydb_nl_ai
Debemos instalar la extensión alloydb_ai_nl en nuestra base de datos. Antes de hacerlo, debemos configurar la marca de base de datos alloydb_ai_nl.enabled como activada.
En la sesión de Cloud Shell, ejecuta el siguiente comando:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
Se iniciará la actualización de la instancia. Puedes ver el estado de la instancia en actualización en la consola web:
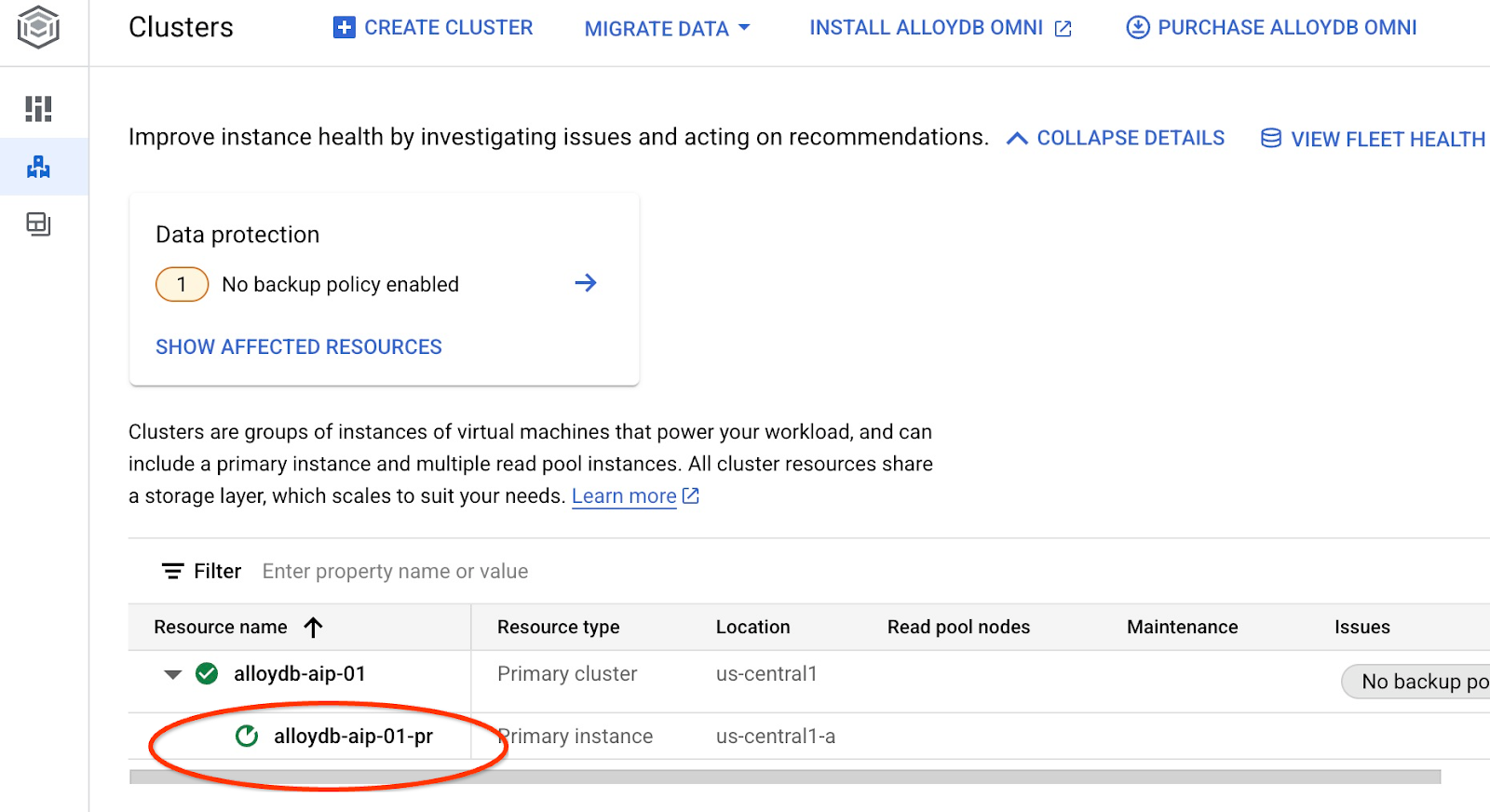
Cuando se actualice la instancia (el estado de la instancia es verde), podrás habilitar la extensión alloydb_ai_nl.
En AlloyDB Studio, ejecuta
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
Crea una configuración de lenguaje natural
Para usar extensiones, debemos crear una configuración. La configuración es necesaria para asociar aplicaciones a ciertos esquemas, plantillas de consultas y extremos de modelos. Creemos una configuración con el ID cymbal_ecomm_config.
En AlloyDB Studio, ejecuta
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
Ahora podemos registrar nuestro esquema de comercio electrónico en la configuración. Importamos datos al esquema de comercio electrónico, por lo que agregaremos ese esquema a nuestra configuración de NL.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. Agrega contexto a NL SQL
Agrega contexto general
Podemos agregar algo de contexto a nuestro esquema registrado. Se supone que el contexto ayuda a generar mejores resultados en respuesta a las solicitudes de los usuarios. Por ejemplo, podemos decir que una marca es la preferida para un usuario cuando no se define de forma explícita. Establezcamos Clades (marca ficticia) como nuestra marca predeterminada.
En AlloyDB Studio, ejecuta lo siguiente:
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
Verifiquemos cómo funciona el contexto general para nosotros.
En AlloyDB Studio, ejecuta lo siguiente:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
La búsqueda generada usa nuestra marca predeterminada definida anteriormente en el contexto general:
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
Podemos limpiarlo y producir solo la instrucción SQL como resultado.
Por ejemplo:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Resultado borrado:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
Notaste que eligió automáticamente la tabla inventory_items en lugar de products y la usó para compilar la consulta. Esto podría funcionar en algunos casos, pero no en nuestro esquema. En nuestro caso, la tabla inventory_items sirve para hacer un seguimiento de las ventas, lo que puede ser engañoso si no tienes información privilegiada. Más adelante, verificaremos cómo hacer que nuestras búsquedas sean más precisas.
Contexto del esquema
El contexto del esquema describe objetos del esquema, como tablas, vistas y columnas individuales que almacenan información como comentarios en los objetos del esquema.
Podemos crearla automáticamente para todos los objetos de esquema en nuestra configuración definida con la siguiente consulta:
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
El parámetro "TRUE" nos indica que debemos regenerar el contexto y sobrescribirlo. La ejecución tardará un tiempo según el modelo de datos. Cuantas más relaciones y conexiones tengas, más tiempo podría tardar.
Después de crear el contexto, podemos verificar lo que creó para la tabla de elementos del inventario con la siguiente consulta:
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
Resultado borrado:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
Parece que a la descripción le faltan algunas partes clave que reflejan el movimiento de los artículos en la tabla inventory_items. Podemos actualizarlo agregando esta información clave al contexto de la relación ecomm.inventory_items.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
También podemos verificar la precisión de la descripción de nuestra tabla de productos.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
Descubrí que el contexto generado automáticamente para la tabla de productos era bastante preciso y no requería ningún cambio.
También revisé la información de cada columna en ambas tablas y la encontré correcta.
Apliquemos el contexto generado para ecomm.inventory_items y ecomm.products a nuestra configuración.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
¿Recuerdas nuestra consulta para generar SQL para la pregunta "¿Cuántos productos tenemos de nuestra marca preferida?" ? Ahora podemos repetirlo y ver si cambia el resultado.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Este es el nuevo resultado.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
Ahora, se verifican los productos de ecomm, lo que es más preciso y devuelve alrededor de 300 productos en lugar de 5,000 operaciones con elementos de inventario.
9. Trabaja con el índice de valor
La vinculación de valores enriquece las búsquedas en lenguaje natural conectando frases de valor con tipos de conceptos y nombres de columnas previamente registrados. Puede ayudar a que los resultados sean más predecibles.
Configura el índice de valor
Podemos realizar nuestras búsquedas con la columna de marca en la tabla de productos y buscar productos con marcas más estables definiendo el tipo de concepto y asociándolo con la columna ecomm.products.brand.
Creemos el concepto y lo asociemos a la columna:
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
Puedes verificar el concepto consultando alloydb_ai_nl.list_concept_types().
SELECT alloydb_ai_nl.list_concept_types();
Luego, podemos crear el índice en nuestra configuración para todas las asociaciones creadas y prediseñadas:
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
Cómo usar el Índice de valor
Si ejecutas una consulta para crear un SQL con nombres de marcas, pero no defines que se trata de un nombre de marca, esto ayuda a identificar correctamente la entidad y la columna. Esta es la consulta:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
y el resultado muestra la identificación correcta de la palabra "Clades" como nombre de marca.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. Cómo trabajar con plantillas de consultas
Las plantillas de consultas ayudan a definir consultas estables para aplicaciones fundamentales para la empresa, lo que reduce la incertidumbre y mejora la precisión.
Cómo crear una plantilla de consulta
Creemos una plantilla de consulta que una varias tablas para obtener información sobre los clientes que compraron productos de "Republic Outpost" el año pasado. Sabemos que la consulta puede usar la tabla ecomm.products o la tabla ecomm.inventory_items, ya que ambas tienen información sobre las marcas. Sin embargo, la tabla products tiene 15 veces menos filas y un índice en la clave primaria para la unión. Podría ser más eficiente usar la tabla de productos. Por lo tanto, crearemos una plantilla para la búsqueda.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
Ahora podemos solicitar la creación de una consulta.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
Y produce el resultado deseable.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
También puedes ejecutar la consulta directamente con la siguiente consulta:
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
Devolverá resultados en formato JSON que se pueden analizar.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. Limpia el entorno
Cuando termines el lab, destruye las instancias y el clúster de AlloyDB.
Borra el clúster de AlloyDB y todas las instancias
Si usaste la versión de prueba de AlloyDB No borres el clúster de prueba si planeas probar otros labs y recursos con él. No podrás crear otro clúster de prueba en el mismo proyecto.
El clúster se destruye con la opción force que también borra todas las instancias que pertenecen al clúster.
En Cloud Shell, define el proyecto y las variables de entorno si te desconectaste y se perdieron todos los parámetros de configuración anteriores:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Borra el clúster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Resultado esperado en la consola:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Borra las copias de seguridad de AlloyDB
Borra todas las copias de seguridad de AlloyDB del clúster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Resultado esperado en la consola:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Felicitaciones
Felicitaciones por completar el codelab. Ahora puedes intentar implementar tus propias soluciones con las funciones de NL2SQL de AlloyDB. Te recomendamos que pruebes otros codelabs relacionados con AlloyDB y AlloyDB AI. Puedes verificar cómo funcionan los embeddings multimodales en AlloyDB en este codelab.
Temas abordados
- Cómo implementar AlloyDB para PostgreSQL
- Cómo habilitar el lenguaje natural de AlloyDB AI
- Cómo crear y ajustar la configuración para el lenguaje natural de la IA
- Cómo generar consultas en SQL y obtener resultados con lenguaje natural
13. Encuesta
Resultado: