
۱. مقدمه
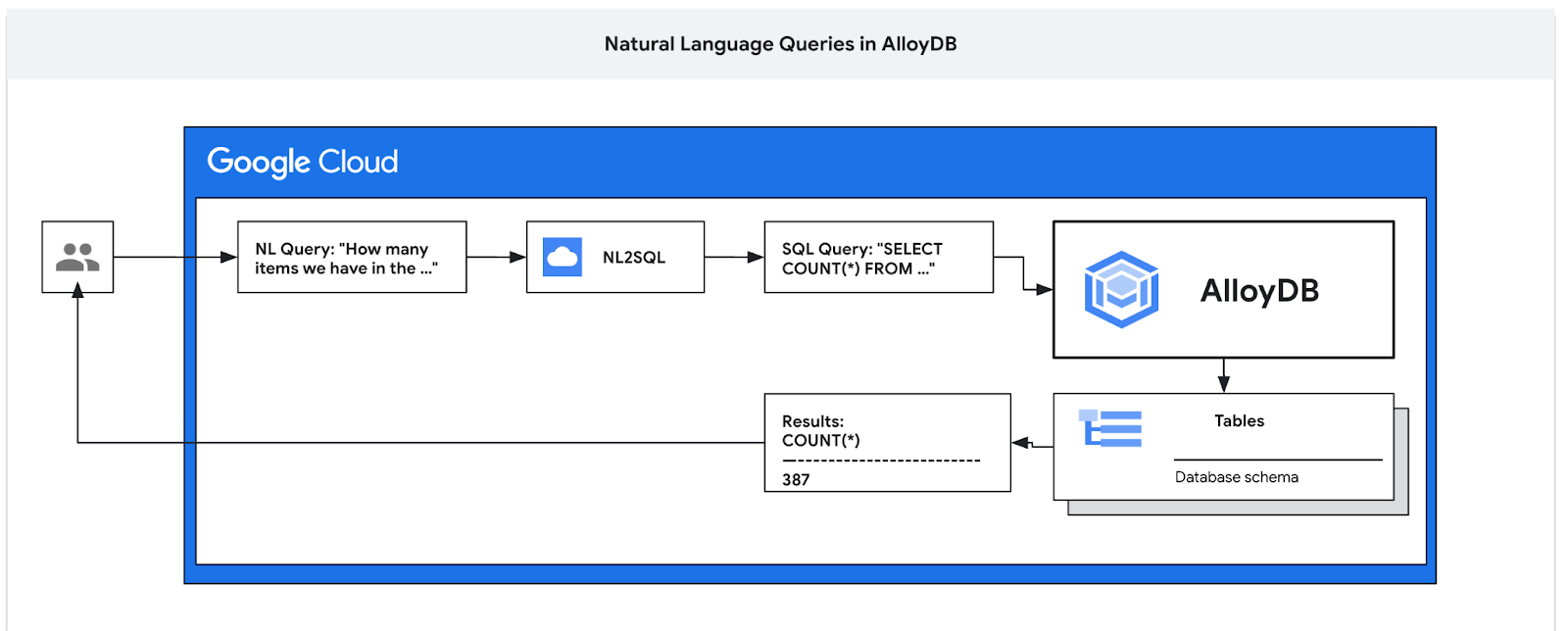
در این آزمایشگاه کد، نحوهی استقرار AlloyDB و استفاده از زبان طبیعی هوش مصنوعی برای پرسوجوی دادهها و تنظیم پیکربندی برای پرسوجوهای قابل پیشبینی و کارآمد را خواهید آموخت. این آزمایشگاه بخشی از مجموعهای از آزمایشگاههای اختصاص داده شده به ویژگیهای هوش مصنوعی AlloyDB است. میتوانید اطلاعات بیشتر را در صفحهی هوش مصنوعی AlloyDB در مستندات مطالعه کنید.
پیشنیازها
- درک اولیه از گوگل کلود، کنسول
- مهارتهای پایه در رابط خط فرمان و Cloud Shell
آنچه یاد خواهید گرفت
- نحوه استقرار AlloyDB برای Postgres
- نحوه فعال کردن زبان طبیعی AI در AlloyDB
- نحوه ایجاد و تنظیم پیکربندی برای زبان طبیعی هوش مصنوعی
- نحوه تولید کوئریهای SQL و دریافت نتایج با استفاده از زبان طبیعی
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم که از کنسول گوگل کلود و کلود شل پشتیبانی میکند
۲. تنظیمات و الزامات
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

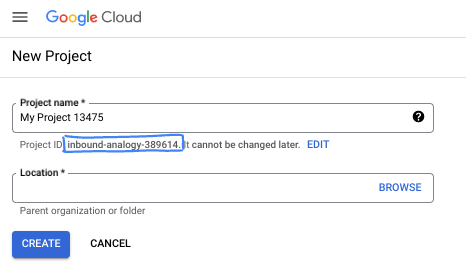
- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چیست. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. قبل از شروع
فعال کردن API
در داخل Cloud Shell، مطمئن شوید که شناسه پروژه شما تنظیم شده است:
gcloud config set project [YOUR-PROJECT-ID]
متغیر محیطی PROJECT_ID را تنظیم کنید:
PROJECT_ID=$(gcloud config get-value project)
فعال کردن تمام سرویسهای لازم:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
خروجی مورد انتظار
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
۴. استقرار AlloyDB
ایجاد کلاستر و نمونه اولیه AlloyDB. روش زیر نحوه ایجاد یک کلاستر و نمونه AlloyDB را با استفاده از Google Cloud SDK شرح میدهد. اگر رویکرد کنسول را ترجیح میدهید، میتوانید مستندات اینجا را دنبال کنید.
قبل از ایجاد یک کلاستر AlloyDB، به یک محدوده IP خصوصی در VPC خود نیاز داریم تا توسط نمونه AlloyDB آینده مورد استفاده قرار گیرد. اگر آن را نداریم، باید آن را ایجاد کنیم، آن را به سرویسهای داخلی گوگل اختصاص دهیم و پس از آن میتوانیم کلاستر و نمونه را ایجاد کنیم.
ایجاد محدوده IP خصوصی
ما باید پیکربندی دسترسی به سرویس خصوصی (Private Service Access) را در VPC خود برای AlloyDB پیکربندی کنیم. فرض بر این است که ما شبکه VPC "پیشفرض" را در پروژه داریم و قرار است برای همه اقدامات از آن استفاده شود.
ایجاد محدوده IP خصوصی:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
ایجاد اتصال خصوصی با استفاده از محدوده IP اختصاص داده شده:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
ایجاد کلاستر AlloyDB
در این بخش، ما یک کلاستر AlloyDB در ناحیه us-central1 ایجاد میکنیم.
برای کاربر postgres رمز عبور تعریف کنید. میتوانید رمز عبور خودتان را تعریف کنید یا از یک تابع تصادفی برای تولید آن استفاده کنید.
export PGPASSWORD=`openssl rand -hex 12`
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
رمز عبور PostgreSQL را برای استفادههای بعدی یادداشت کنید.
echo $PGPASSWORD
در آینده برای اتصال به نمونه به عنوان کاربر postgres به آن رمز عبور نیاز خواهید داشت. پیشنهاد میکنم آن را جایی یادداشت یا کپی کنید تا بعداً بتوانید از آن استفاده کنید.
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
یک خوشه آزمایشی رایگان ایجاد کنید
اگر قبلاً از AlloyDB استفاده نکردهاید، میتوانید یک کلاستر آزمایشی رایگان ایجاد کنید:
منطقه و نام خوشه AlloyDB را تعریف کنید. ما قصد داریم از منطقه us-central1 و alloydb-aip-01 به عنوان نام خوشه استفاده کنیم:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
دستور زیر را برای ایجاد خوشه اجرا کنید:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
خروجی مورد انتظار کنسول:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
یک نمونه اصلی AlloyDB برای کلاستر ما در همان جلسه پوسته ابری ایجاد کنید. اگر اتصال شما قطع شد، باید متغیرهای محیطی منطقه و نام کلاستر را دوباره تعریف کنید.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
ایجاد کلاستر استاندارد AlloyDB
اگر این اولین کلاستر AlloyDB شما در پروژه نیست، با ایجاد یک کلاستر استاندارد ادامه دهید.
منطقه و نام خوشه AlloyDB را تعریف کنید. ما قصد داریم از منطقه us-central1 و alloydb-aip-01 به عنوان نام خوشه استفاده کنیم:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
دستور زیر را برای ایجاد خوشه اجرا کنید:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
خروجی مورد انتظار کنسول:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
یک نمونه اصلی AlloyDB برای کلاستر ما در همان جلسه پوسته ابری ایجاد کنید. اگر اتصال شما قطع شد، باید متغیرهای محیطی منطقه و نام کلاستر را دوباره تعریف کنید.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
۵. آمادهسازی پایگاه داده
ما باید یک پایگاه داده ایجاد کنیم، ادغام Vertex AI را فعال کنیم، اشیاء پایگاه داده را ایجاد کنیم و دادهها را وارد کنیم.
مجوزهای لازم را به AlloyDB اعطا کنید
مجوزهای Vertex AI را به عامل سرویس AlloyDB اضافه کنید.
با استفاده از علامت "+" در بالا، یک تب Cloud Shell دیگر باز کنید.
در تب جدید cloud shell دستور زیر را اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
با اجرای هر یک از دستورهای "exit" در تب، تب را ببندید:
exit
اتصال به استودیوی AlloyDB
در فصلهای بعدی، تمام دستورات SQL که نیاز به اتصال به پایگاه داده دارند، میتوانند به صورت جایگزین در AlloyDB Studio اجرا شوند. برای اجرای دستور، باید با کلیک روی نمونه اصلی، رابط کنسول وب را برای خوشه AlloyDB خود باز کنید.
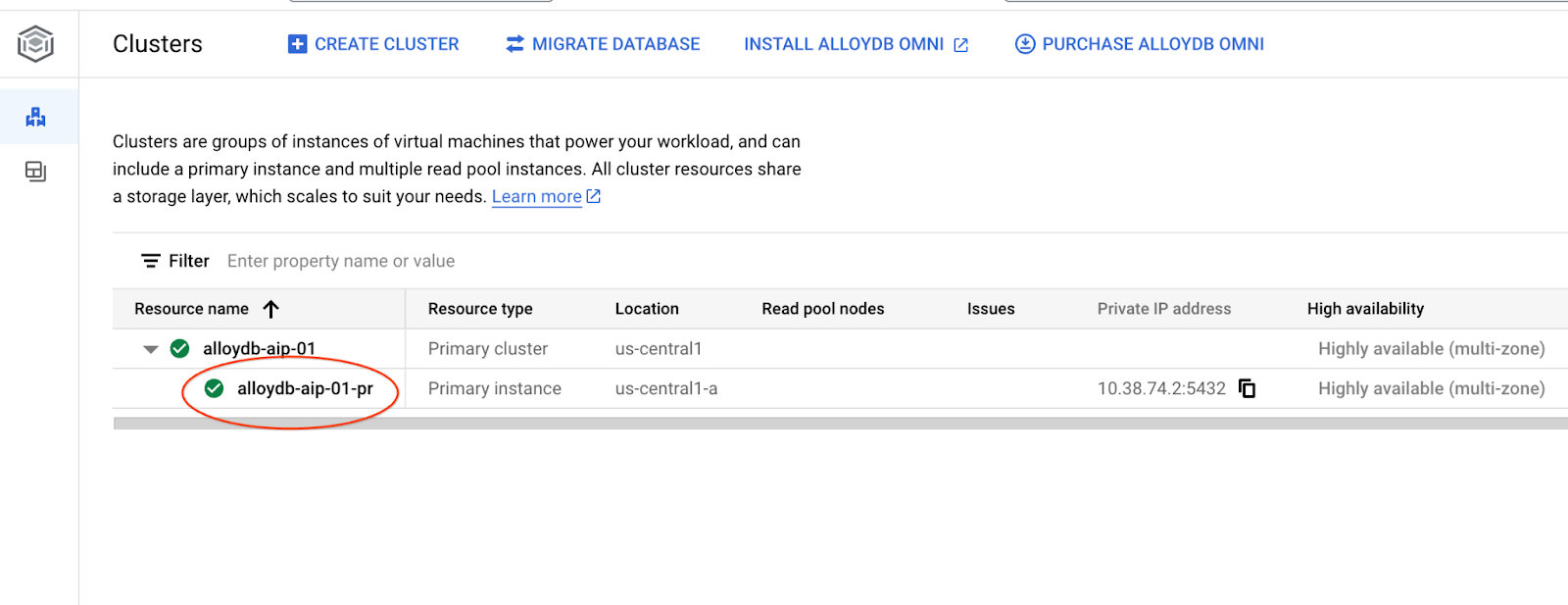
سپس در سمت چپ روی AlloyDB Studio کلیک کنید:
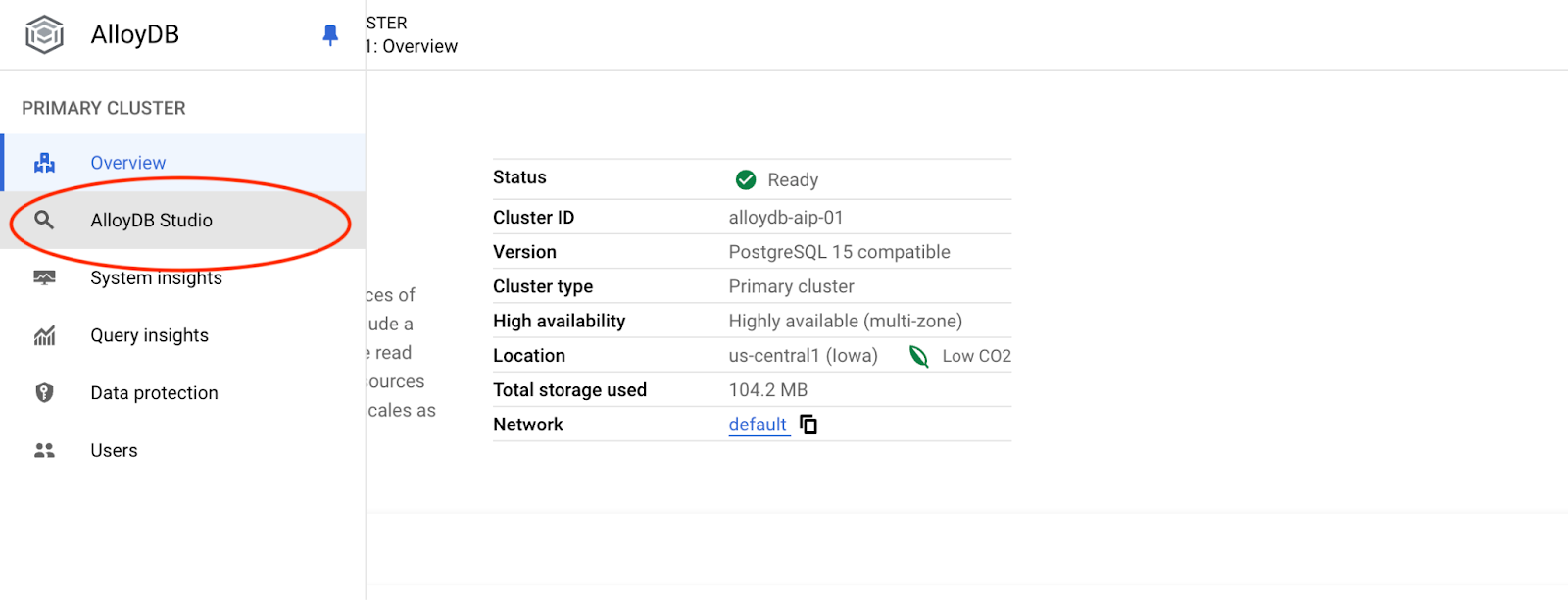
پایگاه داده postgres، نام کاربری postgres و رمز عبوری که هنگام ایجاد کلاستر یادداشت کردیم را انتخاب کنید. سپس روی دکمه "Authenticate" کلیک کنید.
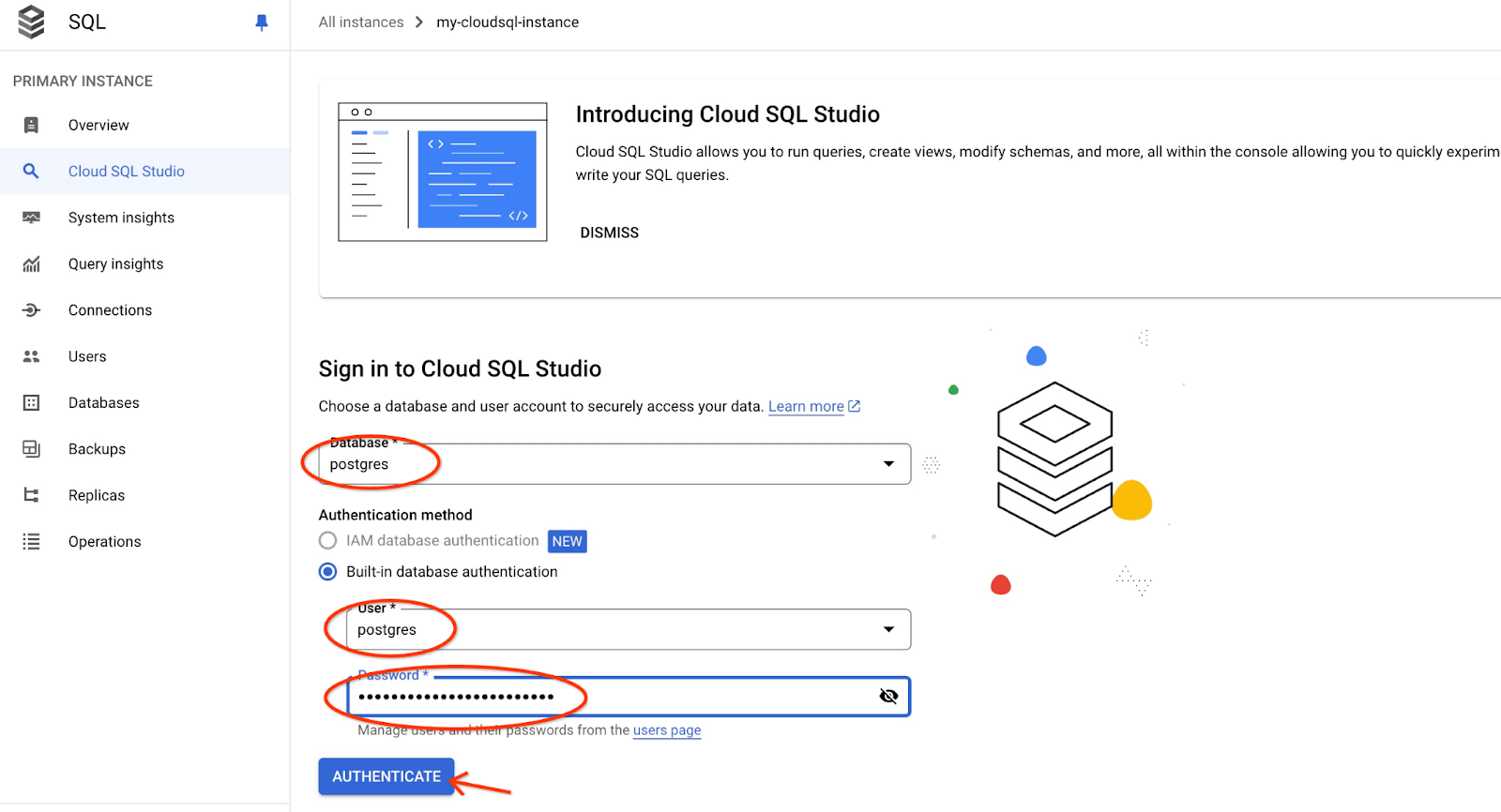
رابط کاربری AlloyDB Studio باز خواهد شد. برای اجرای دستورات در پایگاه داده، روی تب "Editor 1" در سمت راست کلیک کنید.
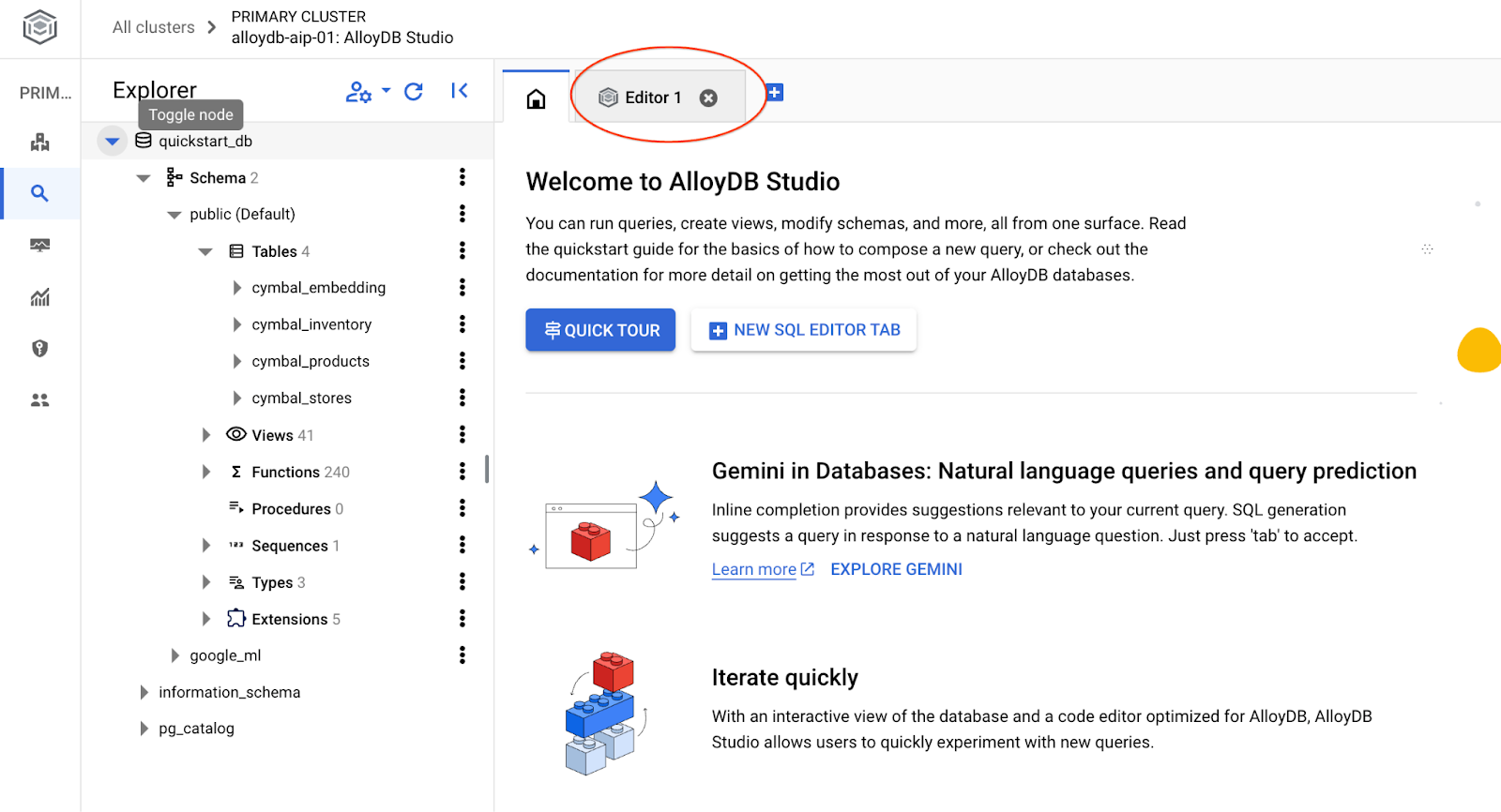
رابطی را باز میکند که میتوانید دستورات SQL را در آن اجرا کنید
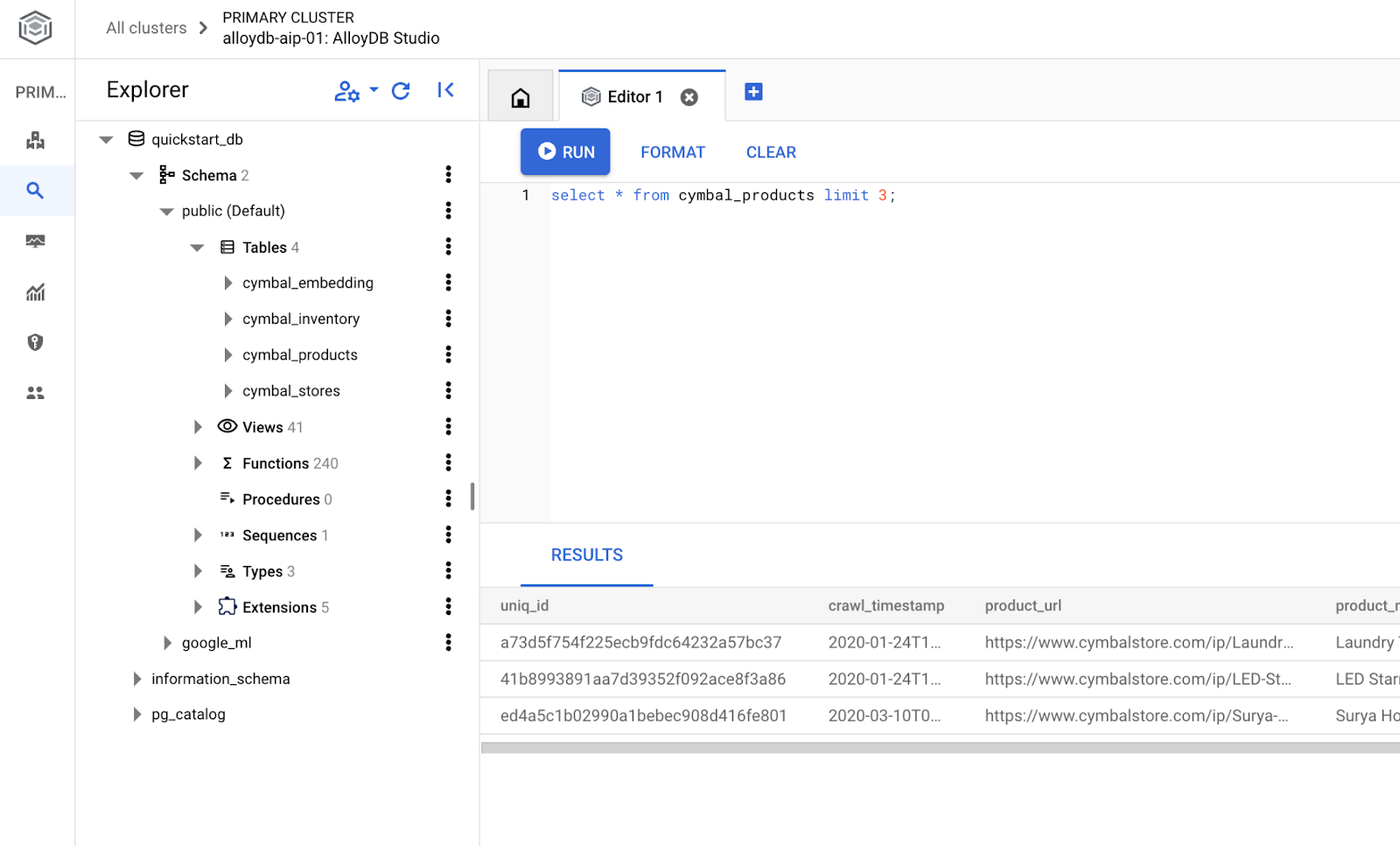
ایجاد پایگاه داده
ایجاد پایگاه داده با شروع سریع
در ویرایشگر استودیوی AlloyDB، دستور زیر را اجرا کنید.
ایجاد پایگاه داده:
CREATE DATABASE quickstart_db
خروجی مورد انتظار:
Statement executed successfully
اتصال به پایگاه دادهی quickstart_db
با استفاده از دکمه تغییر کاربر/پایگاه داده، دوباره به استودیو متصل شوید.
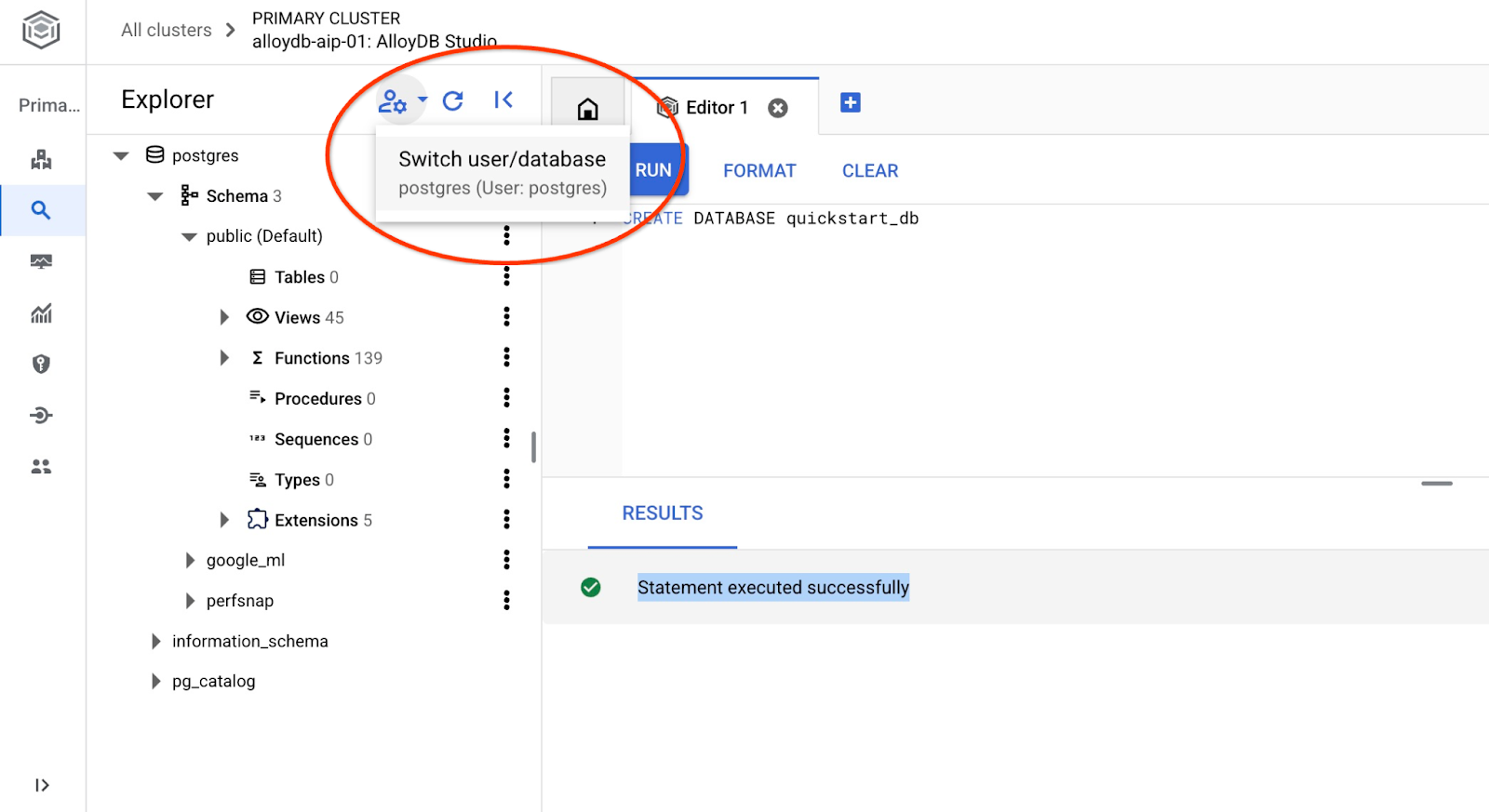
از لیست کشویی، پایگاه داده جدید quickstart_db را انتخاب کنید و از همان نام کاربری و رمز عبور قبلی استفاده کنید.
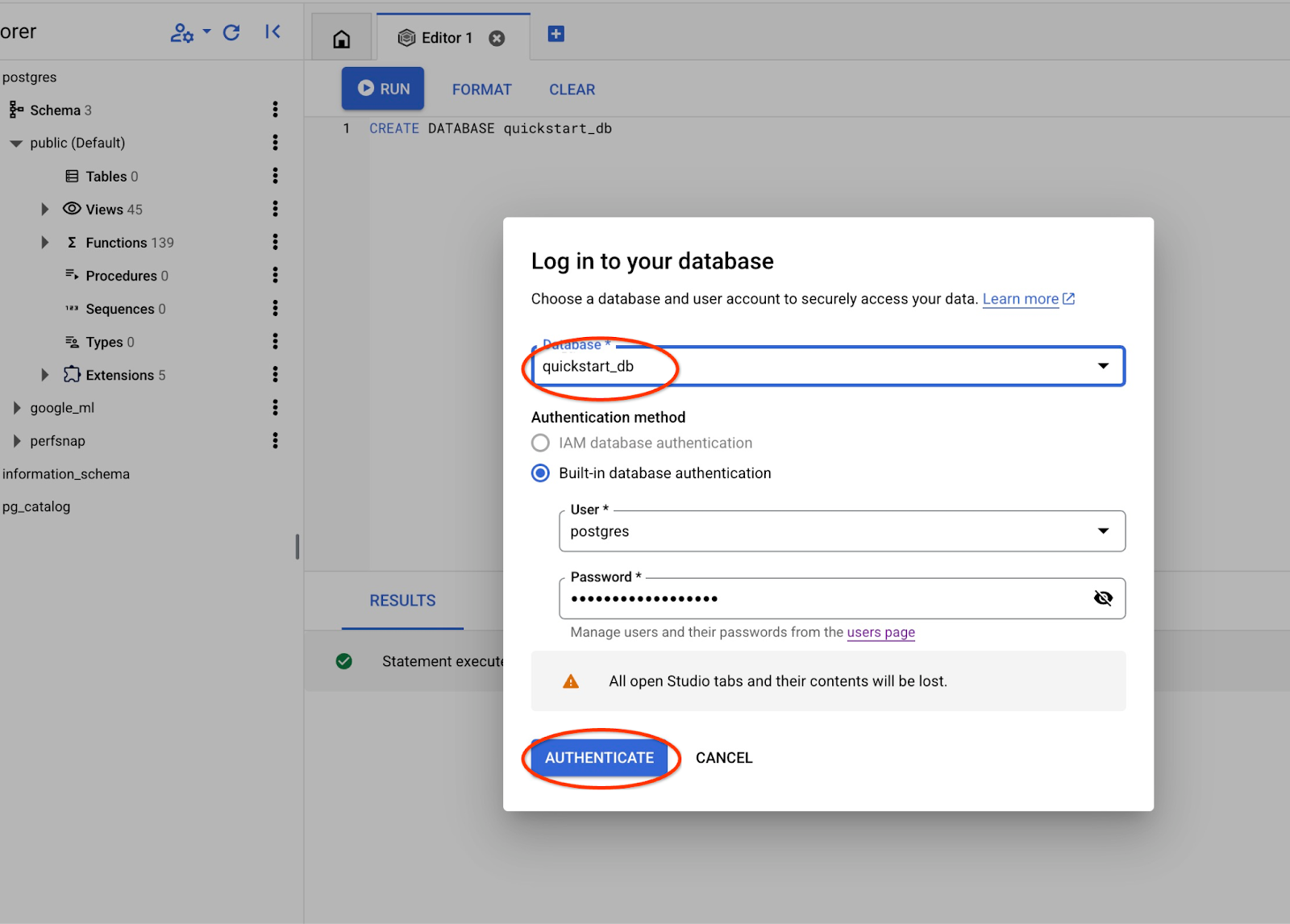
این یک اتصال جدید باز میکند که در آن میتوانید با اشیاء پایگاه داده quickstart_db کار کنید.
۶. دادههای نمونه
حالا باید اشیاء را در پایگاه داده ایجاد کنیم و دادهها را بارگذاری کنیم. ما قصد داریم از یک فروشگاه فرضی "Cymbal ecomm" با مجموعهای از جداول برای فروشگاههای آنلاین استفاده کنیم. این فروشگاه شامل چندین جدول است که با کلیدهایشان به هم متصل شدهاند و شبیه یک طرح پایگاه داده رابطهای هستند.
مجموعه دادهها به صورت یک فایل SQL آماده و قرار داده میشود که میتواند با استفاده از رابط import در پایگاه داده بارگذاری شود. در cloud Shell دستورات زیر را اجرا کنید:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
این دستور از AlloyDB SDK استفاده میکند و یک طرحواره ecomm ایجاد میکند و سپس دادههای نمونه را مستقیماً از سطل GCS به پایگاه داده وارد میکند و تمام اشیاء لازم را ایجاد کرده و دادهها را وارد میکند.
پس از وارد کردن، میتوانیم جداول را در AlloyDB Studio بررسی کنیم.
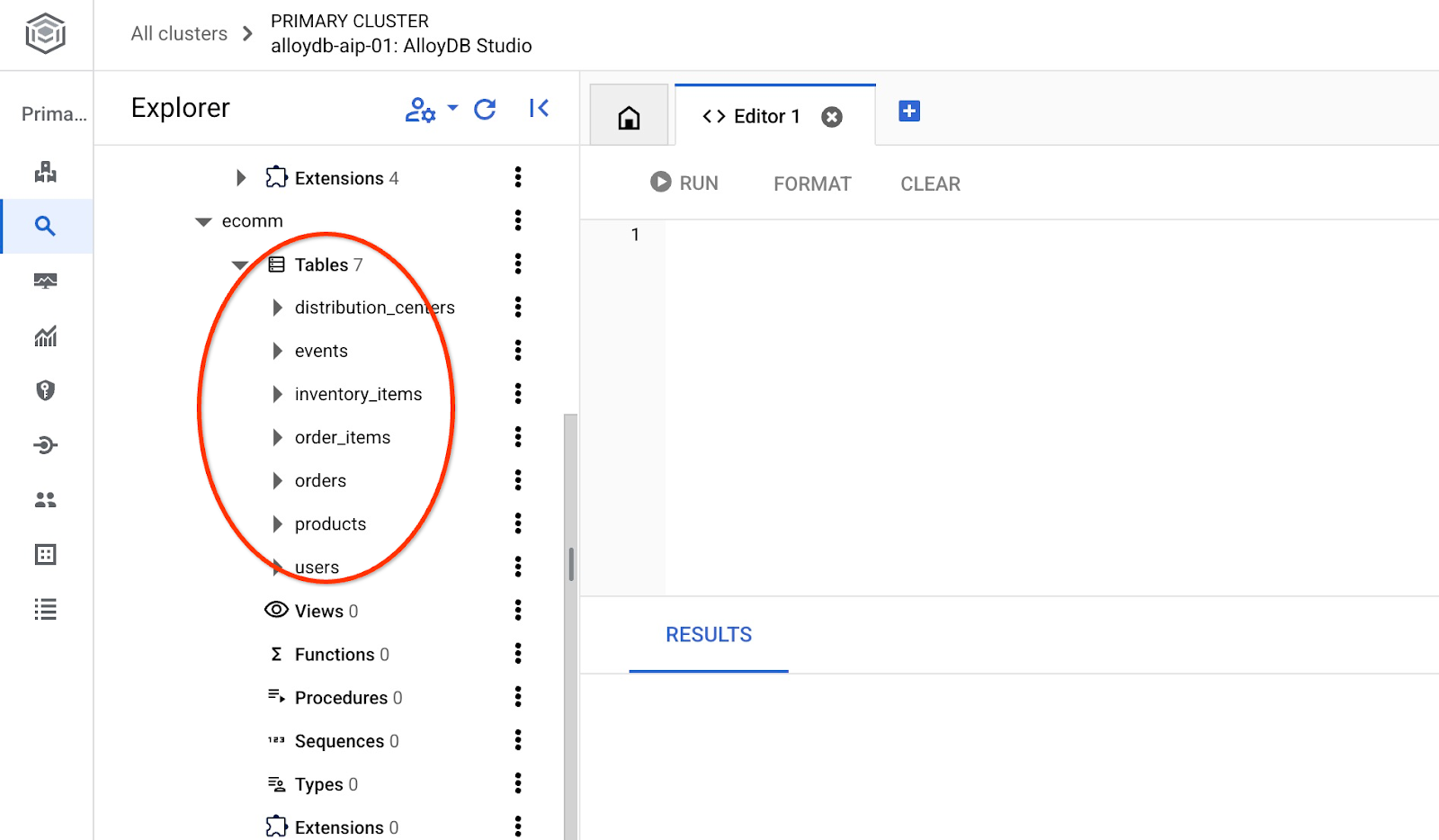
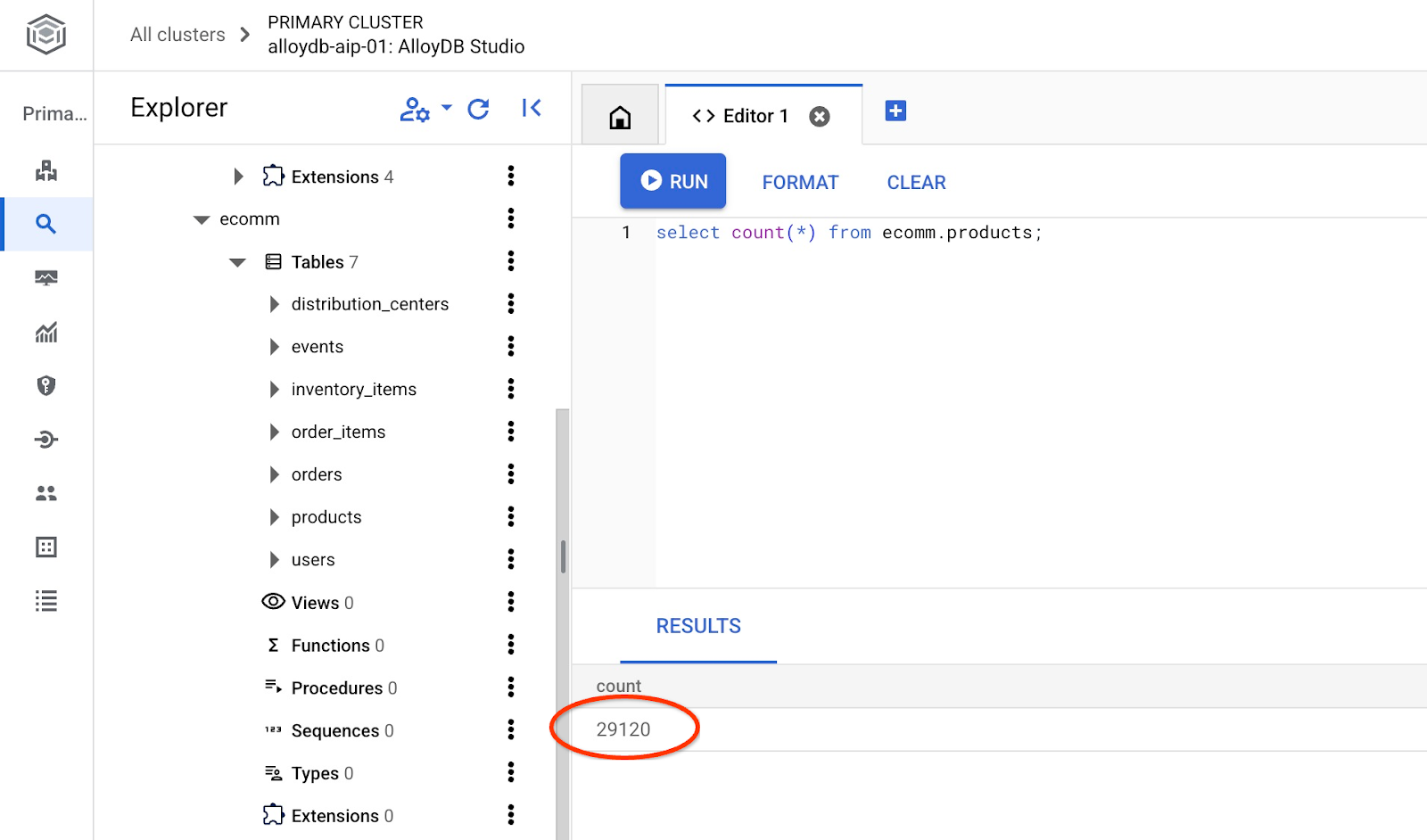
و تعداد سطرهای جدول را بررسی کنید.
۷. پیکربندی NL SQL
در این فصل، NL را برای کار با طرحواره نمونه شما پیکربندی خواهیم کرد.
افزونه alloydb_nl_ai را نصب کنید
ما باید افزونه alloydb_ai_nl را روی پایگاه داده خود نصب کنیم. قبل از انجام این کار، باید پرچم alloydb_ai_nl.enabled را روی روشن تنظیم کنیم.
در جلسه Cloud Shell اجرا کنید
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
این کار بهروزرسانی نمونه را آغاز میکند. میتوانید وضعیت بهروزرسانی نمونه را در کنسول وب مشاهده کنید:
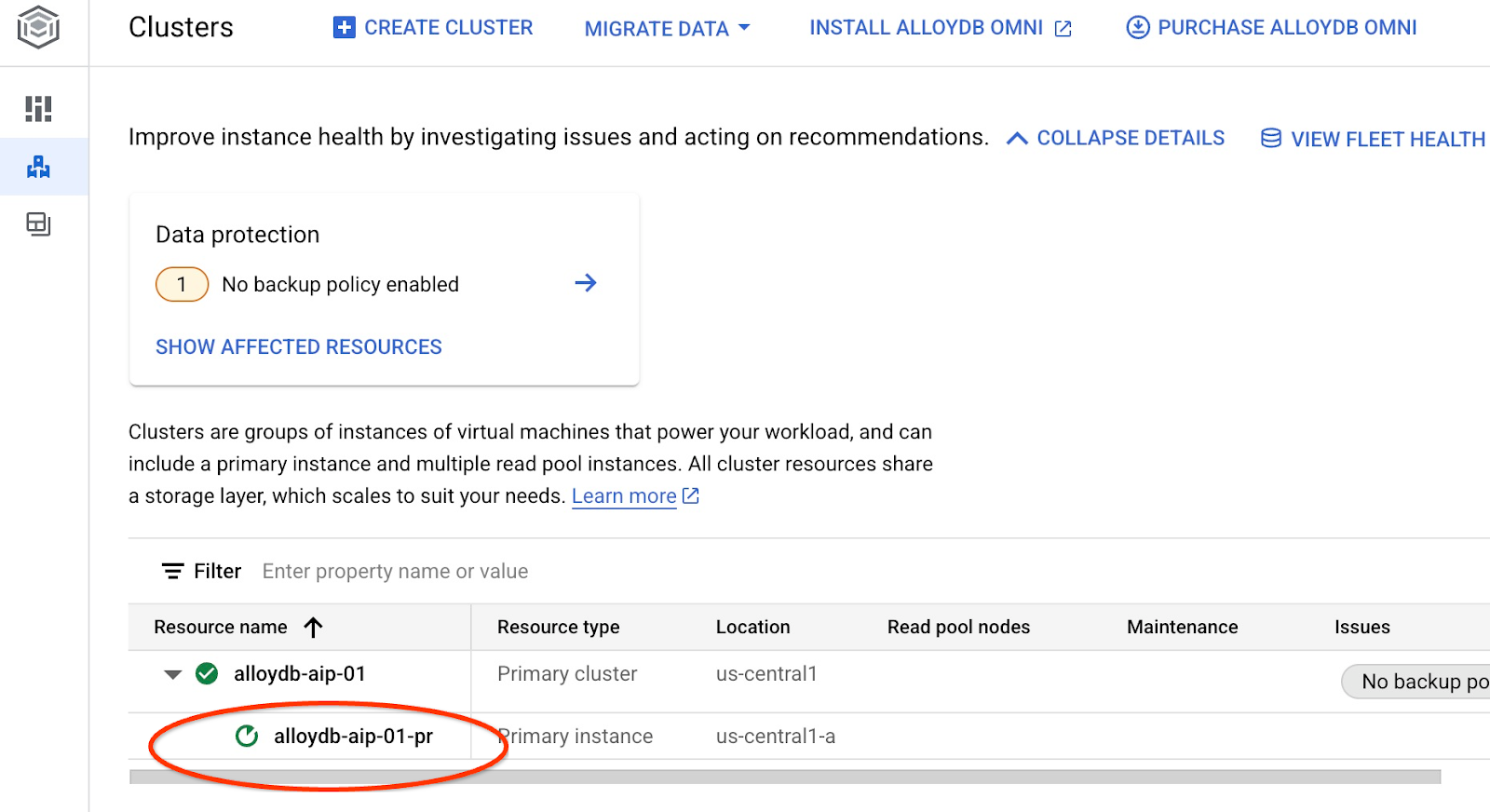
وقتی نمونه بهروزرسانی شد (وضعیت نمونه سبز است) میتوانید افزونه alloydb_ai_nl را فعال کنید.
در استودیوی AlloyDB اجرا کنید
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
ایجاد پیکربندی زبان طبیعی
برای استفاده از افزونهها، باید یک پیکربندی ایجاد کنیم. این پیکربندی برای مرتبط کردن برنامهها با طرحوارهها، قالبهای پرسوجو و نقاط پایانی مدل خاص ضروری است. بیایید یک پیکربندی با شناسه cymbal_ecomm_config ایجاد کنیم.
در استودیوی AlloyDB اجرا کنید
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
حالا میتوانیم طرحواره ecomm خود را در پیکربندی ثبت کنیم. ما دادهها را به طرحواره ecomm وارد کردهایم، بنابراین میخواهیم آن طرحواره را به پیکربندی NL خود اضافه کنیم.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
۸. اضافه کردن زمینه به SQL NL
زمینه کلی را اضافه کنید
میتوانیم برای طرحواره ثبتشدهمان زمینهای اضافه کنیم. قرار است این زمینه به تولید نتایج بهتر در پاسخ به درخواستهای کاربران کمک کند. برای مثال، میتوانیم بگوییم که یک برند، برند ترجیحی برای یک کاربر است، در حالی که به صراحت تعریف نشده است. بیایید Clades (برند خیالی) را به عنوان برند پیشفرض خود قرار دهیم.
در استودیوی AlloyDB دستور زیر را اجرا کنید:
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
بیایید بررسی کنیم که چارچوب کلی چگونه برای ما کار میکند.
در استودیوی AlloyDB دستور زیر را اجرا کنید:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
کوئری تولید شده از برند پیشفرض ما که قبلاً در متن کلی تعریف شده است، استفاده میکند:
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
میتوانیم آن را اصلاح کنیم و فقط دستور SQL را به عنوان خروجی تولید کنیم.
برای مثال:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
خروجی پاک شده:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
متوجه شدید که به طور خودکار جدول inventory_items را به جای products انتخاب کرده و از آن برای ساخت پرس و جو استفاده کرده است. این ممکن است برای برخی موارد کار کند اما برای طرح ما اینطور نیست. در مورد ما، جدول inventory_items برای ردیابی فروش استفاده میشود که اگر اطلاعات داخلی نداشته باشید، میتواند گمراه کننده باشد. بعداً بررسی خواهیم کرد که چگونه پرس و جوهای خود را دقیقتر کنیم.
زمینه طرحواره
زمینه طرحواره، اشیاء طرحواره مانند جداول، نماها و ستونهای منفرد را توصیف میکند که اطلاعات را به عنوان نظرات در اشیاء طرحواره ذخیره میکنند.
ما میتوانیم آن را به طور خودکار برای همه اشیاء طرحواره در پیکربندی تعریف شده خود با استفاده از پرس و جوی زیر ایجاد کنیم:
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
پارامتر "TRUE" ما را به بازسازی context و بازنویسی آن هدایت میکند. اجرا بسته به مدل داده مدتی طول خواهد کشید. هرچه روابط و ارتباطات بیشتری داشته باشید - ممکن است بیشتر طول بکشد.
پس از ایجاد context میتوانیم با استفاده از کوئری زیر، بررسی کنیم که چه چیزی برای جدول اقلام موجودی ایجاد شده است:
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
خروجی پاک شده:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
به نظر میرسد توضیحات فاقد برخی از بخشهای کلیدی است که نشان میدهد جدول inventory_items جابجایی اقلام را منعکس میکند. میتوانیم با اضافه کردن این اطلاعات کلیدی به متن رابطه ecomm.inventory_items آن را بهروزرسانی کنیم.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
همچنین میتوانیم صحت توضیحات جدول محصولات خود را تأیید کنیم.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
من متوجه شدم که زمینه تولید شده خودکار برای جدول محصولات کاملاً دقیق است و نیازی به هیچ تغییری ندارد.
من همچنین اطلاعات مربوط به هر ستون را در هر دو جدول بررسی کردم و آن را نیز صحیح یافتم.
بیایید زمینه تولید شده برای ecomm.inventory_items و ecomm.products را در پیکربندی خود اعمال کنیم.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
آیا کوئری ما برای تولید SQL برای سوال «چند محصول از برند مورد نظرمان داریم؟» را به خاطر دارید؟ اکنون میتوانیم آن را تکرار کنیم و ببینیم آیا خروجی تغییر میکند یا خیر.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
خروجی جدید اینجاست.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
و حالا در حال بررسی emm.products است که دقیقتر است و به جای ۵۰۰۰ عملیات با اقلام موجودی، حدود ۳۰۰ محصول را برمیگرداند.
۹. کار با شاخص ارزش
پیوند دادن مقادیر، با اتصال عبارات مقداری به انواع مفاهیم از پیش ثبتشده و نام ستونها، جستجوهای زبان طبیعی را غنیتر میکند. این امر میتواند به پیشبینیپذیرتر شدن نتایج کمک کند.
پیکربندی شاخص ارزش
ما میتوانیم کوئریهای خود را با استفاده از ستون brand در جدول products انجام دهیم و با تعریف نوع مفهوم و مرتبط کردن آن با ستون ecomm.products.brand، محصولات دارای برند را پایدارتر جستجو کنیم.
بیایید مفهوم را ایجاد کنیم و آن را با ستون مرتبط کنیم:
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
شما میتوانید با پرسوجو از تابع alloydb_ai_nl.list_concept_types()، این مفهوم را تأیید کنید.
SELECT alloydb_ai_nl.list_concept_types();
سپس میتوانیم در پیکربندی خود، برای همه انجمنهای ایجاد شده و از پیش ساخته شده، ایندکس ایجاد کنیم:
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
از شاخص ارزش استفاده کنید
اگر یک کوئری برای ایجاد یک SQL با استفاده از نامهای تجاری اجرا کنید، اما مشخص نکنید که این یک نام تجاری است، به شناسایی صحیح موجودیت و ستون کمک میکند. کوئری به این صورت است:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
و خروجی، شناسایی صحیح کلمه «Clades» را به عنوان یک نام تجاری نشان میدهد.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
۱۰. کار با قالبهای پرسوجو
قالبهای پرسوجو به تعریف پرسوجوهای پایدار برای برنامههای حیاتی کسبوکار کمک میکنند و عدم قطعیت را کاهش داده و دقت را بهبود میبخشند.
ایجاد یک الگوی پرس و جو
بیایید یک الگوی پرسوجو ایجاد کنیم که چندین جدول را به هم متصل میکند تا اطلاعات مربوط به مشتریانی را که سال گذشته محصولات "Republic Outpost" را خریداری کردهاند، دریافت کند. میدانیم که پرسوجو میتواند از جدول ecomm.products یا جدول ecomm.inventory_items استفاده کند، زیرا هر دو اطلاعاتی در مورد برندها دارند. اما جدول products، ۱۵ برابر ردیف کمتر و یک اندیس روی کلید اصلی برای اتصال دارد. استفاده از جدول products ممکن است کارآمدتر باشد. بنابراین، ما در حال ایجاد یک الگو برای پرسوجو هستیم.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
اکنون میتوانیم درخواست ایجاد یک پرسوجو (query) را بدهیم.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
و خروجی مطلوب را تولید میکند.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
یا میتوانید مستقیماً با استفاده از کوئری زیر، کوئری را اجرا کنید:
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
نتایج را در قالب JSON برمیگرداند که قابل تجزیه و تحلیل است.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
۱۱. محیط را تمیز کنید
وقتی کار آزمایشگاهیتان تمام شد، نمونهها و کلاستر AlloyDB را از بین ببرید.
کلاستر AlloyDB و تمام نمونههای آن را حذف کنید.
اگر از نسخه آزمایشی AlloyDB استفاده کردهاید. اگر قصد دارید آزمایشگاهها و منابع دیگری را با استفاده از خوشه آزمایشی آزمایش کنید، خوشه آزمایشی را حذف نکنید. شما قادر به ایجاد خوشه آزمایشی دیگری در همان پروژه نخواهید بود.
خوشه با استفاده از گزینهی Force از بین میرود که تمام نمونههای متعلق به خوشه را نیز حذف میکند.
در پوسته ابری، اگر اتصال شما قطع شده و تمام تنظیمات قبلی از بین رفته است، متغیرهای پروژه و محیط را تعریف کنید:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
حذف خوشه:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
حذف پشتیبانهای AlloyDB
تمام پشتیبانهای AlloyDB را برای کلاستر حذف کنید:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
خروجی مورد انتظار کنسول:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
۱۲. تبریک
تبریک میگویم که این آزمایشگاه کد را تکمیل کردید. اکنون میتوانید با استفاده از ویژگیهای NL2SQL در AlloyDB، راهحلهای خود را پیادهسازی کنید. توصیه میکنیم آزمایشگاههای کد دیگری مربوط به AlloyDB و AlloyDB AI را امتحان کنید. میتوانید نحوه عملکرد جاسازیهای چندوجهی در AlloyDB را در این آزمایشگاه کد بررسی کنید.
آنچه ما پوشش دادهایم
- نحوه استقرار AlloyDB برای Postgres
- نحوه فعال کردن زبان طبیعی AI در AlloyDB
- نحوه ایجاد و تنظیم پیکربندی برای زبان طبیعی هوش مصنوعی
- نحوه تولید کوئریهای SQL و دریافت نتایج با استفاده از زبان طبیعی
۱۳. نظرسنجی
خروجی: