
1. Introduction
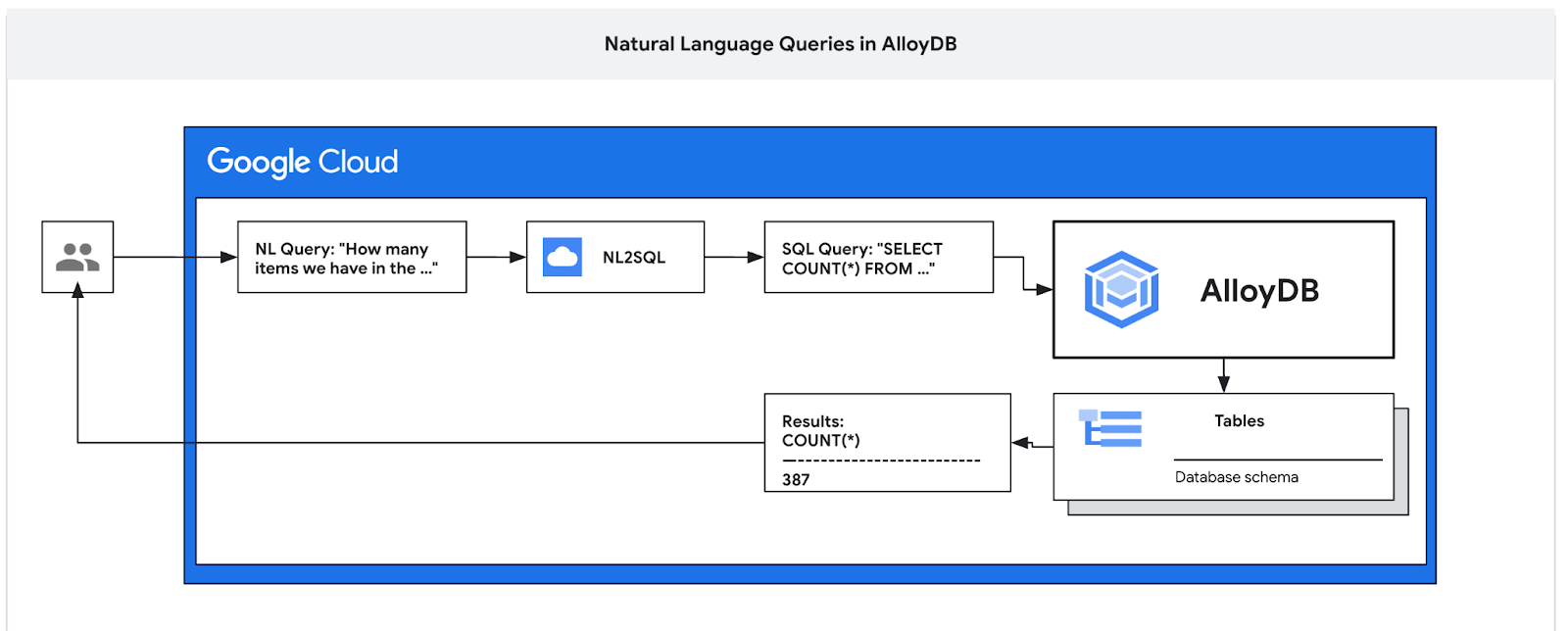
Dans cet atelier de programmation, vous allez apprendre à déployer AlloyDB et à utiliser le langage naturel de l'IA pour interroger des données et ajuster la configuration afin d'obtenir des requêtes prévisibles et efficaces. Cet atelier fait partie d'une collection d'ateliers consacrés aux fonctionnalités AlloyDB/AI. Pour en savoir plus, consultez la page AlloyDB AI dans la documentation.
Prérequis
- Connaissances de base concernant la console Google Cloud
- Compétences de base concernant l'interface de ligne de commande et Cloud Shell
Points abordés
- Déployer AlloyDB pour PostgreSQL
- Activer le langage naturel AlloyDB AI
- Créer et ajuster une configuration pour l'IA en langage naturel
- Générer des requêtes SQL et obtenir des résultats en langage naturel
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome, compatible avec la console Google Cloud et Cloud Shell
2. Préparation
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.

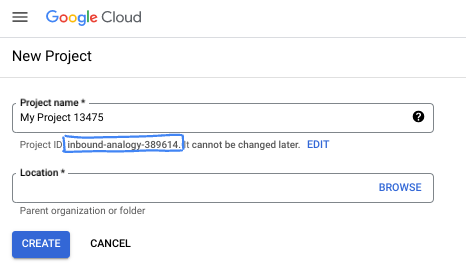
- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Activer l'API
Dans Cloud Shell, assurez-vous que l'ID de votre projet est configuré :
gcloud config set project [YOUR-PROJECT-ID]
Définissez la variable d'environnement PROJECT_ID :
PROJECT_ID=$(gcloud config get-value project)
Activez tous les services nécessaires :
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Résultat attendu
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Déployer AlloyDB
Créez un cluster AlloyDB et une instance principale. La procédure suivante explique comment créer un cluster et une instance AlloyDB à l'aide du SDK Google Cloud. Si vous préférez utiliser la console, vous pouvez consulter la documentation sur cette page.
Avant de créer un cluster AlloyDB, nous avons besoin d'une plage d'adresses IP privées disponible dans notre VPC, qui sera utilisée par la future instance AlloyDB. Si nous ne l'avons pas, nous devons le créer et l'attribuer pour qu'il soit utilisé par les services Google internes. Nous pourrons ensuite créer le cluster et l'instance.
Créer une plage d'adresses IP privées
Nous devons configurer l'accès au service privé dans notre VPC pour AlloyDB. L'hypothèse ici est que nous avons le réseau VPC "par défaut" dans le projet et qu'il sera utilisé pour toutes les actions.
Créez la plage d'adresses IP privées :
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Créez une connexion privée à l'aide de la plage d'adresses IP allouée :
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Créer un cluster AlloyDB
Dans cette section, nous allons créer un cluster AlloyDB dans la région us-central1.
Définissez le mot de passe de l'utilisateur postgres. Vous pouvez définir votre propre mot de passe ou utiliser une fonction aléatoire pour en générer un.
export PGPASSWORD=`openssl rand -hex 12`
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Notez le mot de passe PostgreSQL (il vous servira plus tard).
echo $PGPASSWORD
Vous aurez besoin de ce mot de passe à l'avenir pour vous connecter à l'instance en tant qu'utilisateur postgres. Je vous suggère de le noter ou de le copier quelque part pour pouvoir l'utiliser plus tard.
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Créer un cluster d'essai sans frais
Si vous n'avez jamais utilisé AlloyDB, vous pouvez créer un cluster d'essai sans frais :
Définissez la région et le nom du cluster AlloyDB. Nous allons utiliser la région us-central1 et alloydb-aip-01 comme nom de cluster :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Exécutez la commande pour créer le cluster :
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Résultat attendu sur la console :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Créez une instance principale AlloyDB pour le cluster dans la même session Cloud Shell. Si vous êtes déconnecté, vous devrez définir à nouveau les variables d'environnement pour la région et le nom du cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Créer un cluster AlloyDB Standard
Si ce n'est pas votre premier cluster AlloyDB dans le projet, créez un cluster standard.
Définissez la région et le nom du cluster AlloyDB. Nous allons utiliser la région us-central1 et alloydb-aip-01 comme nom de cluster :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Exécutez la commande pour créer le cluster :
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Résultat attendu sur la console :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Créez une instance principale AlloyDB pour le cluster dans la même session Cloud Shell. Si vous êtes déconnecté, vous devrez définir à nouveau les variables d'environnement pour la région et le nom du cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Résultat attendu sur la console :
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Préparer la base de données
Nous devons créer une base de données, activer l'intégration de Vertex AI, créer des objets de base de données et importer les données.
Accorder les autorisations nécessaires à AlloyDB
Ajoutez des autorisations Vertex AI à l'agent de service AlloyDB.
Ouvrez un autre onglet Cloud Shell à l'aide du signe "+" situé en haut.
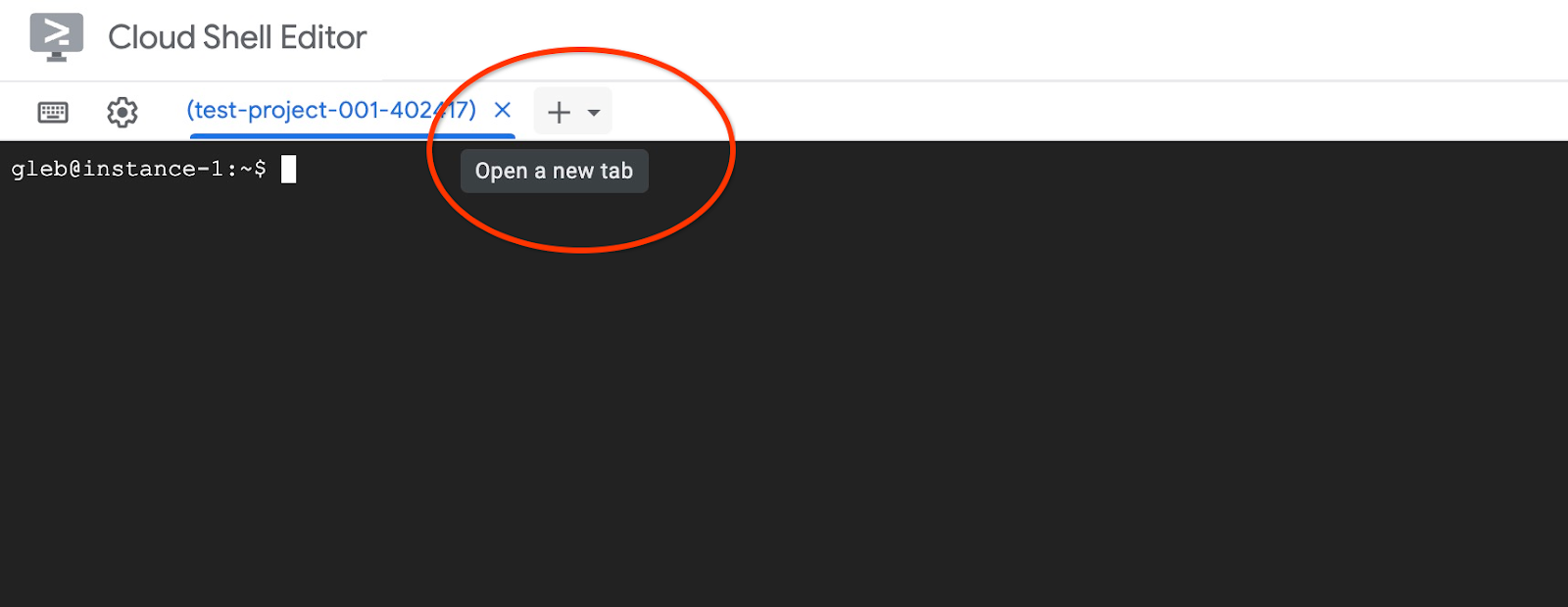
Dans le nouvel onglet Cloud Shell, exécutez :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Fermez l'onglet en exécutant la commande "exit" dans l'onglet :
exit
Se connecter à AlloyDB Studio
Dans les chapitres suivants, toutes les commandes SQL nécessitant une connexion à la base de données peuvent également être exécutées dans AlloyDB Studio. Pour exécuter la commande, vous devez ouvrir l'interface de la console Web de votre cluster AlloyDB en cliquant sur l'instance principale.
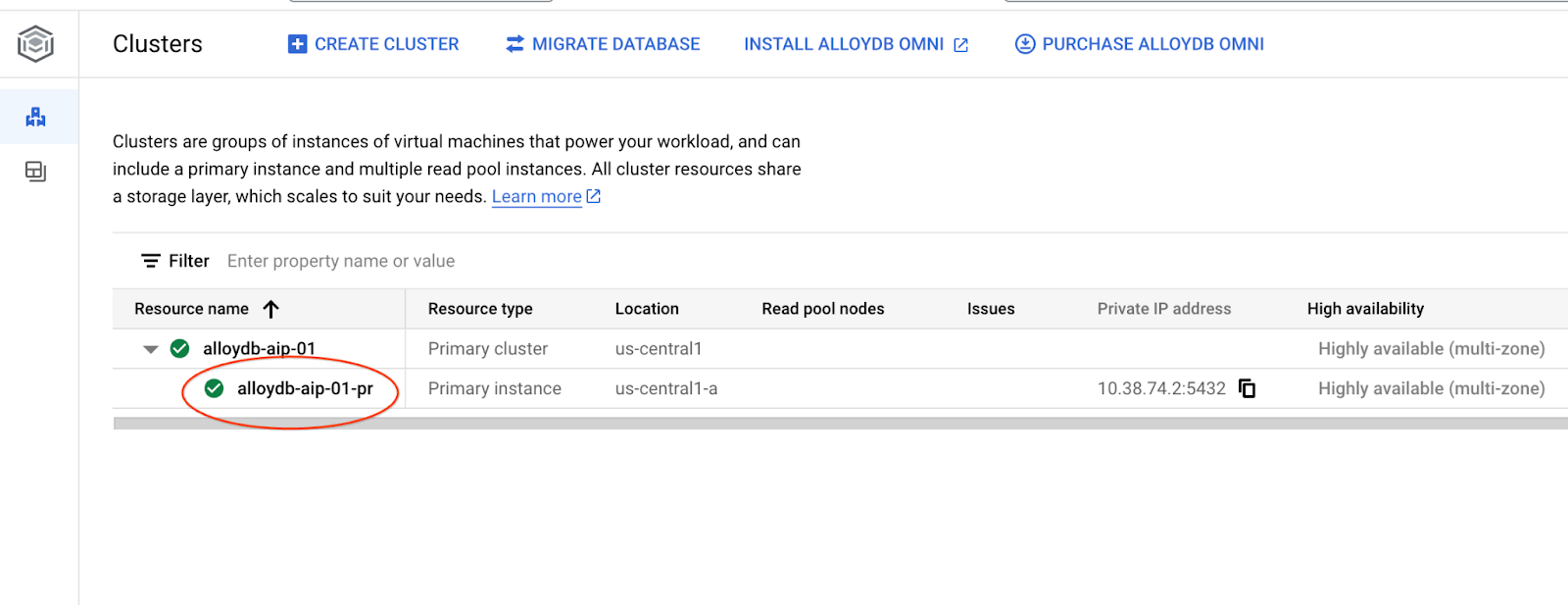
Cliquez ensuite sur AlloyDB Studio à gauche :
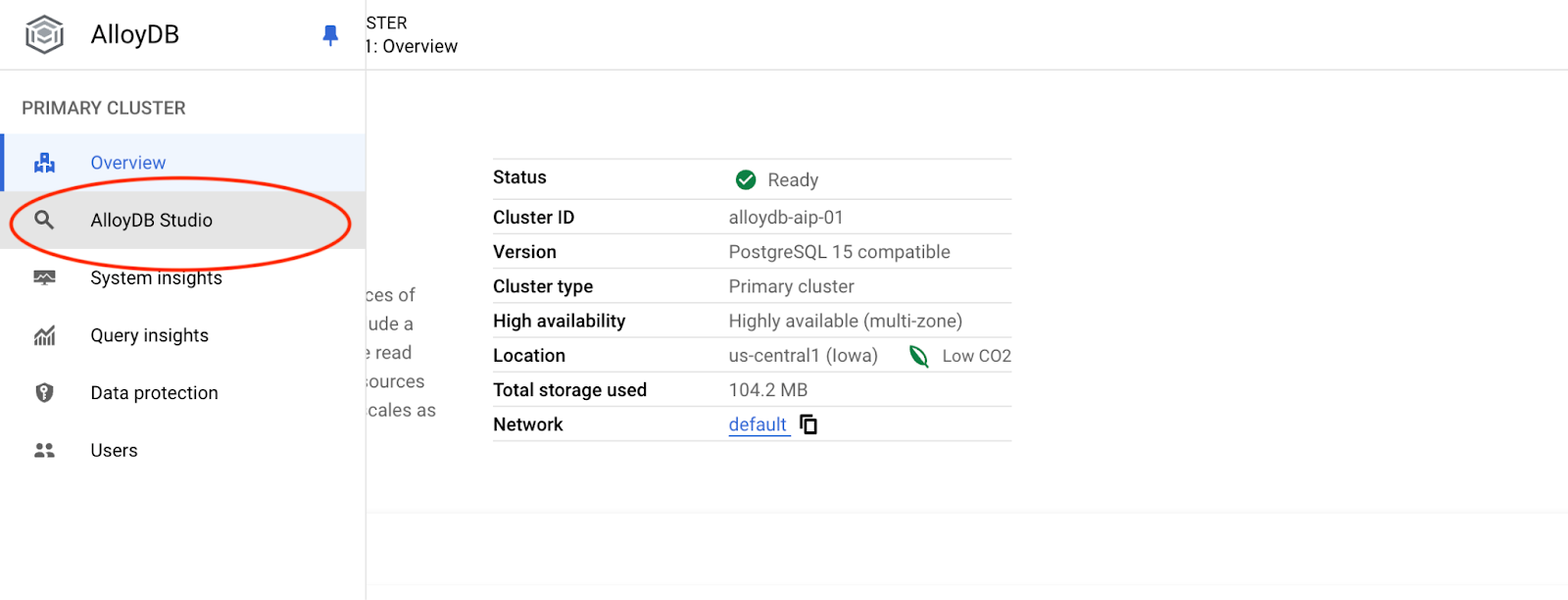
Choisissez la base de données postgres et l'utilisateur postgres, puis fournissez le mot de passe indiqué lors de la création du cluster. Cliquez ensuite sur le bouton "Authenticate" (S'authentifier).
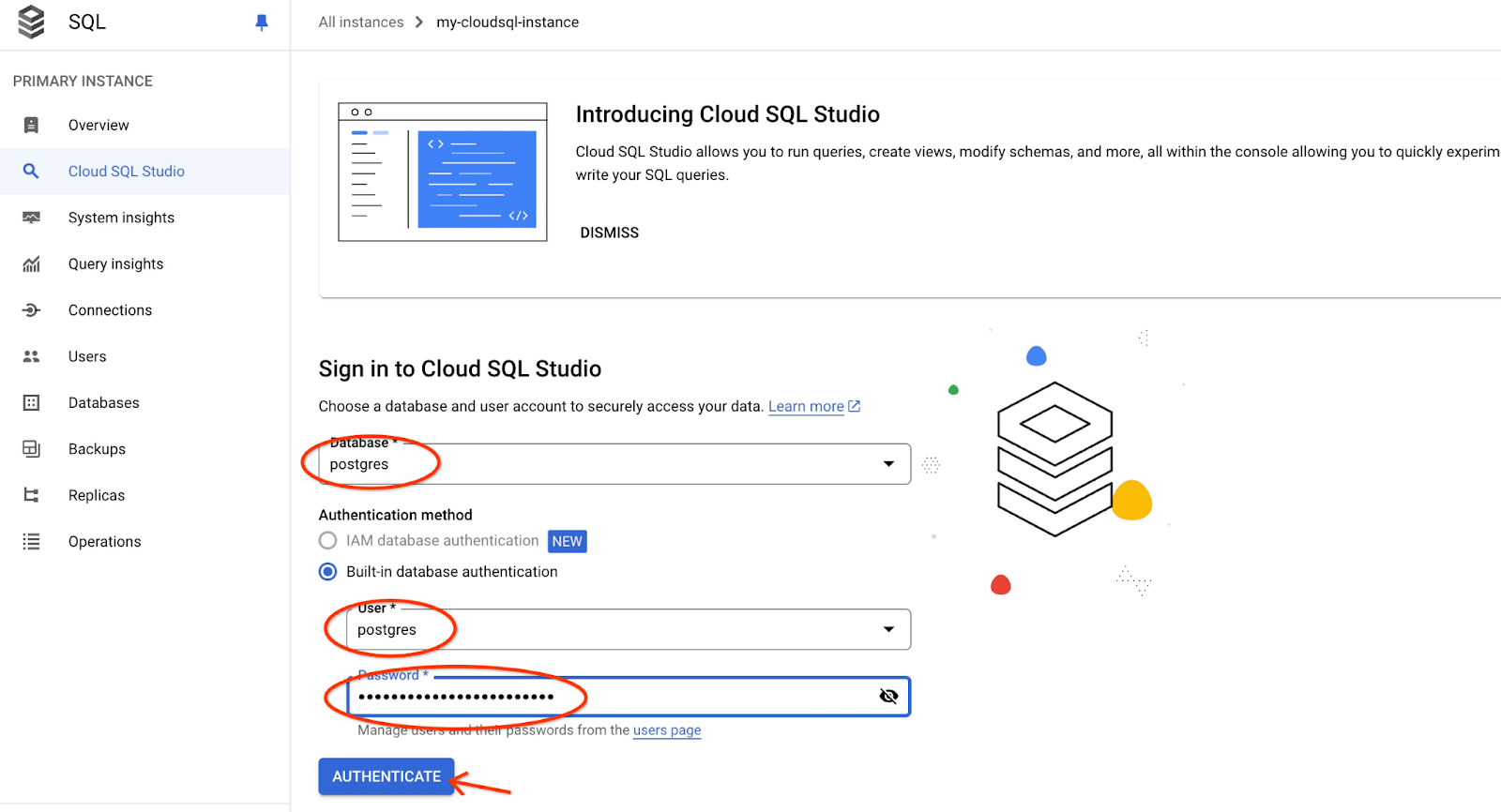
L'interface AlloyDB Studio s'ouvre. Pour exécuter les commandes dans la base de données, cliquez sur l'onglet "Editor 1" (Éditeur 1) à droite.
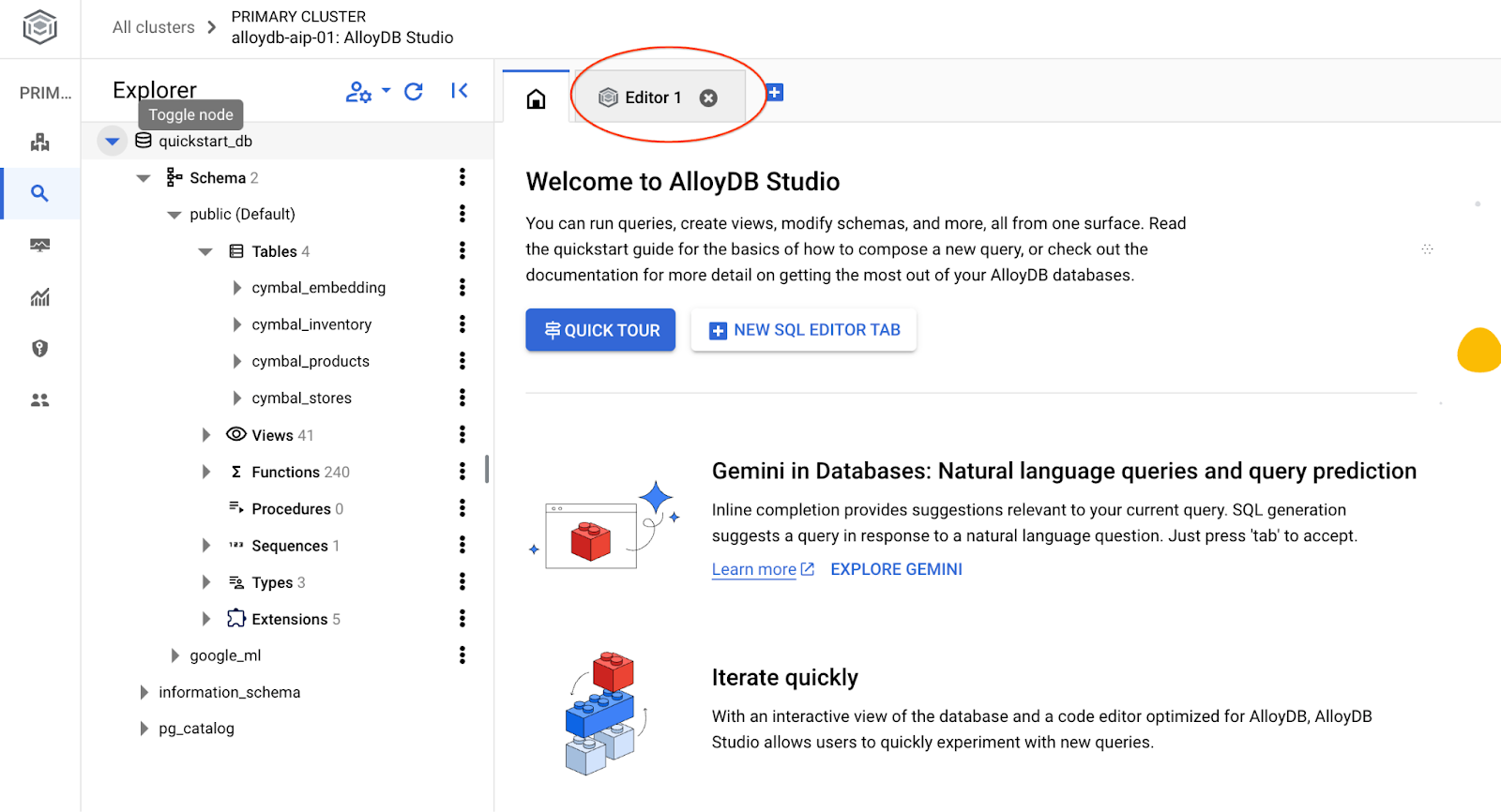
L'interface qui s'ouvre vous permet d'exécuter des commandes SQL.
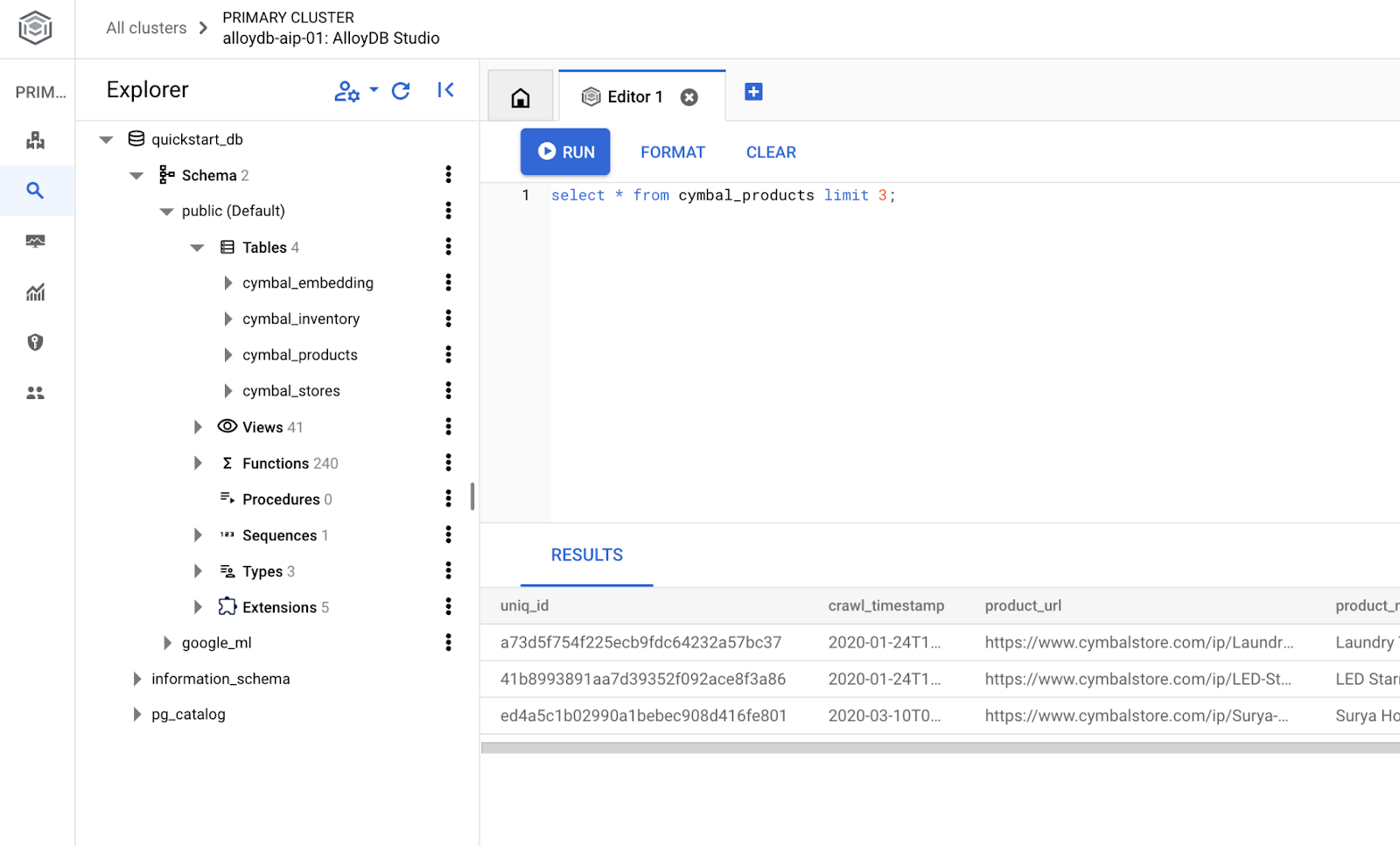
Créer une base de données
Créez un démarrage rapide de base de données.
Dans l'éditeur AlloyDB Studio, exécutez la commande suivante.
Créez une base de données :
CREATE DATABASE quickstart_db
Résultat attendu :
Statement executed successfully
Se connecter à quickstart_db
Reconnectez-vous au studio à l'aide du bouton permettant de changer d'utilisateur ou de base de données.
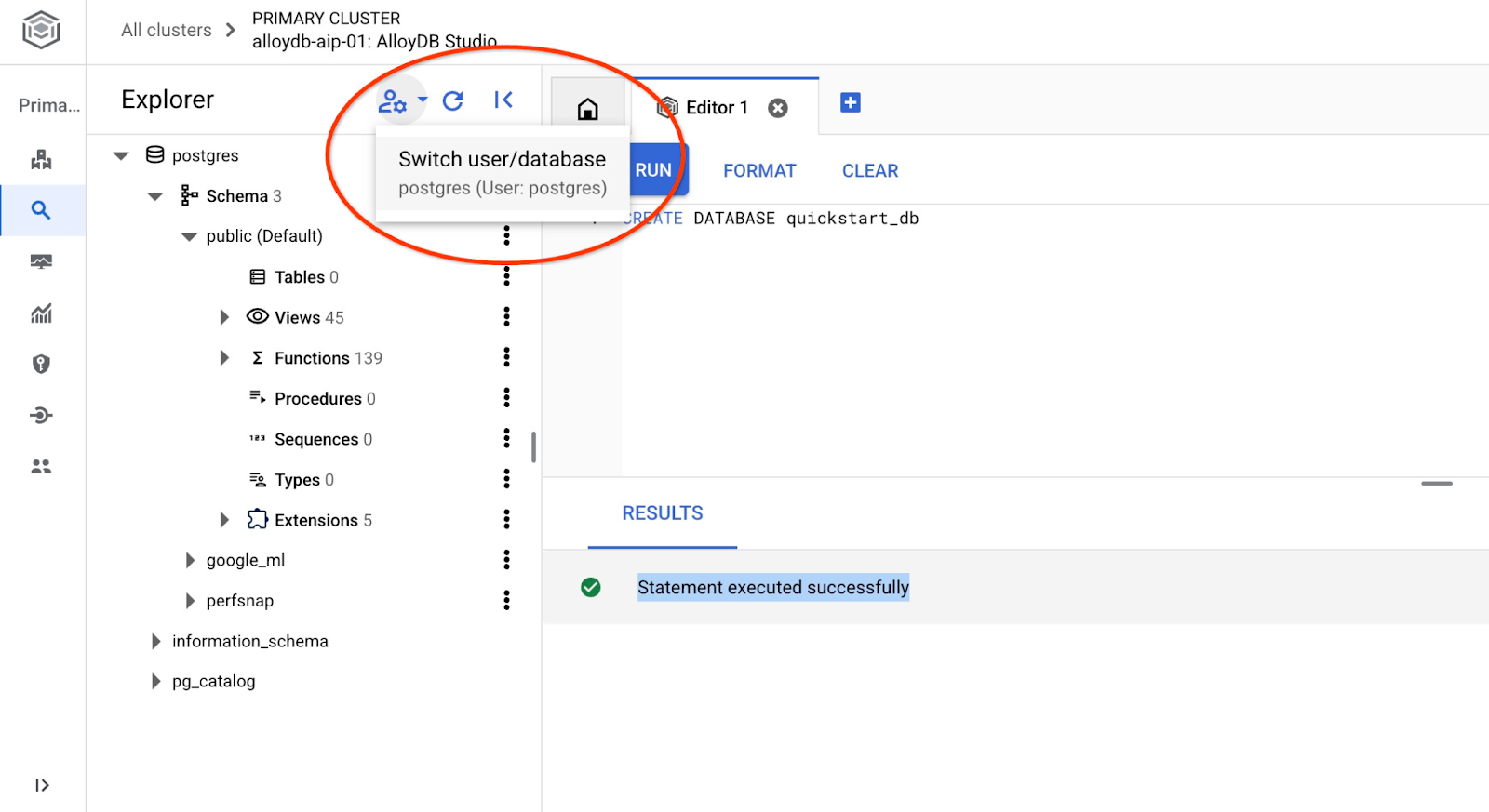
Dans la liste déroulante, sélectionnez la nouvelle base de données quickstart_db et utilisez les mêmes nom d'utilisateur et mot de passe qu'avant.
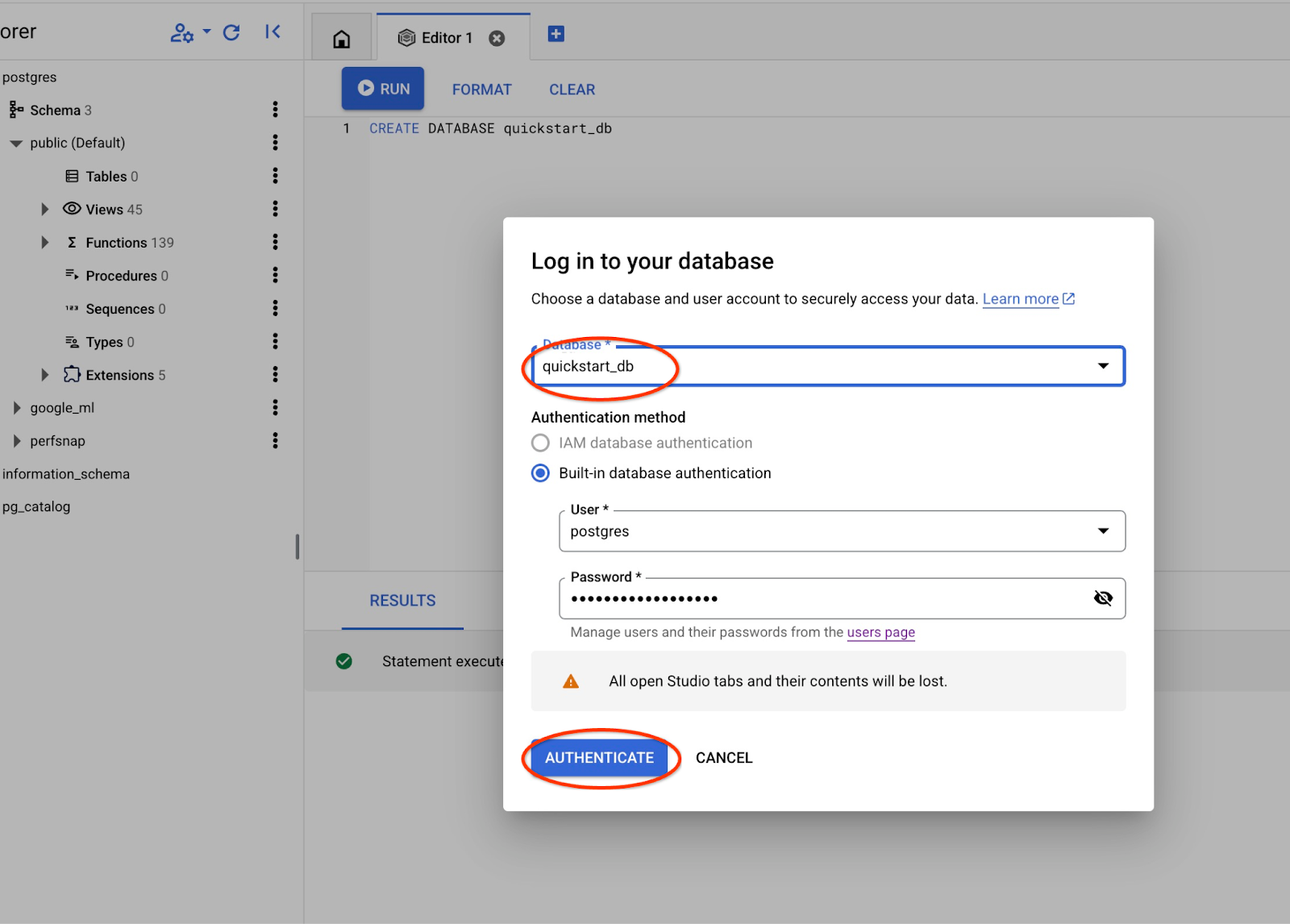
Une nouvelle connexion s'ouvre, vous permettant de travailler avec des objets de la base de données quickstart_db.
6. Exemples de données
Nous devons maintenant créer des objets dans la base de données et charger des données. Nous allons utiliser une boutique en ligne fictive "Cymbal ecomm" avec un ensemble de tables pour les boutiques en ligne. Elle contient plusieurs tables connectées par leurs clés, ce qui ressemble à un schéma de base de données relationnelle.
L'ensemble de données est préparé et placé sous la forme d'un fichier SQL qui peut être chargé dans la base de données à l'aide de l'interface d'importation. Dans Cloud Shell, exécutez les commandes suivantes :
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
La commande utilise le SDK AlloyDB et crée un schéma e-commerce, puis importe des exemples de données directement du bucket GCS vers la base de données, en créant tous les objets nécessaires et en insérant les données.
Une fois l'importation terminée, nous pouvons vérifier les tables dans AlloyDB Studio.
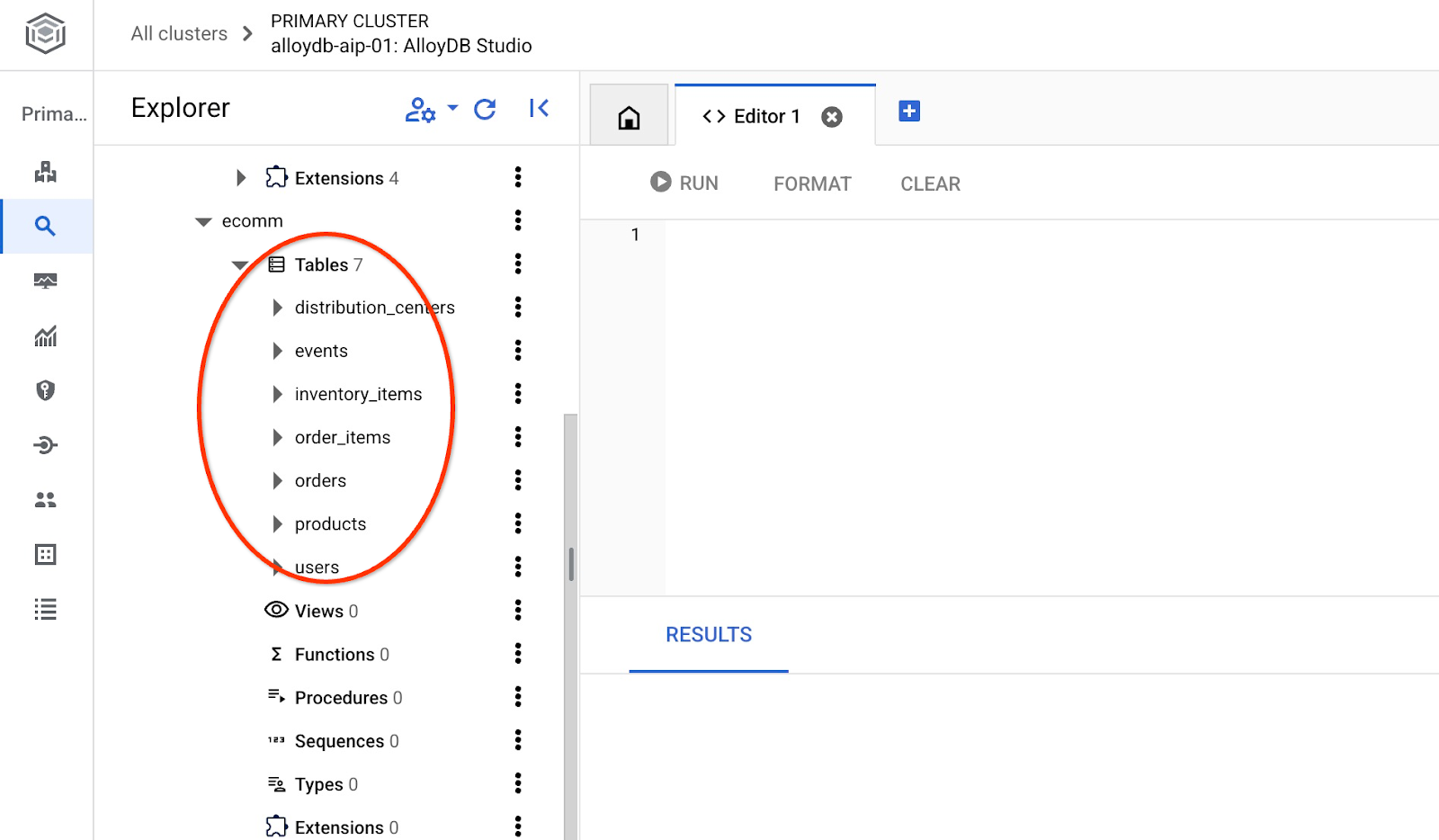
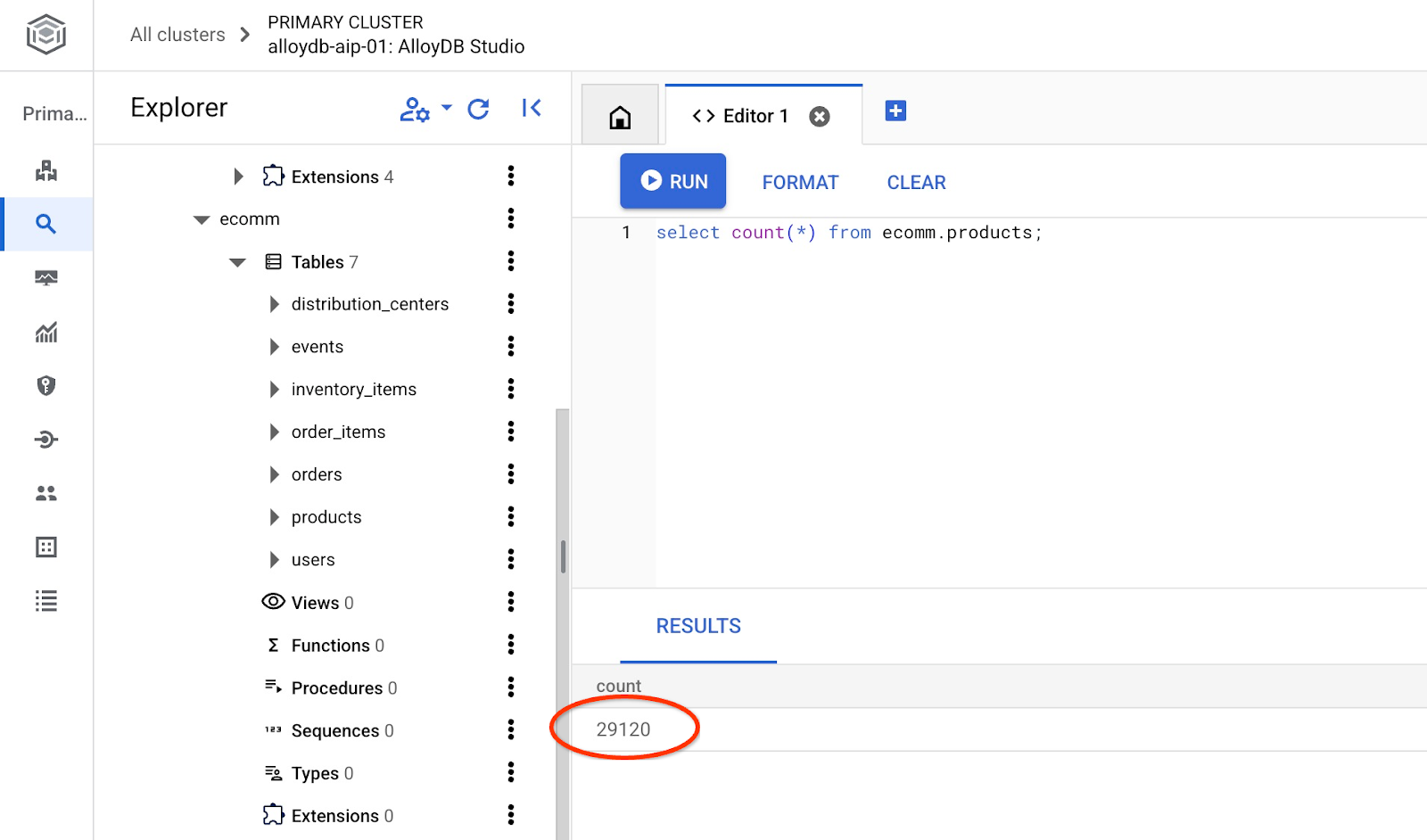
Vérifiez également le nombre de lignes dans la table.
7. Configurer le langage naturel pour SQL
Dans ce chapitre, nous allons configurer le langage naturel pour qu'il fonctionne avec votre exemple de schéma.
Installer l'extension alloydb_nl_ai
Nous devons installer l'extension alloydb_ai_nl dans notre base de données. Avant cela, nous devons activer le flag de base de données alloydb_ai_nl.enabled.
Dans la session Cloud Shell, exécutez
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
La mise à jour de l'instance commencera. Vous pouvez consulter l'état de l'instance en cours de mise à jour dans la console Web :
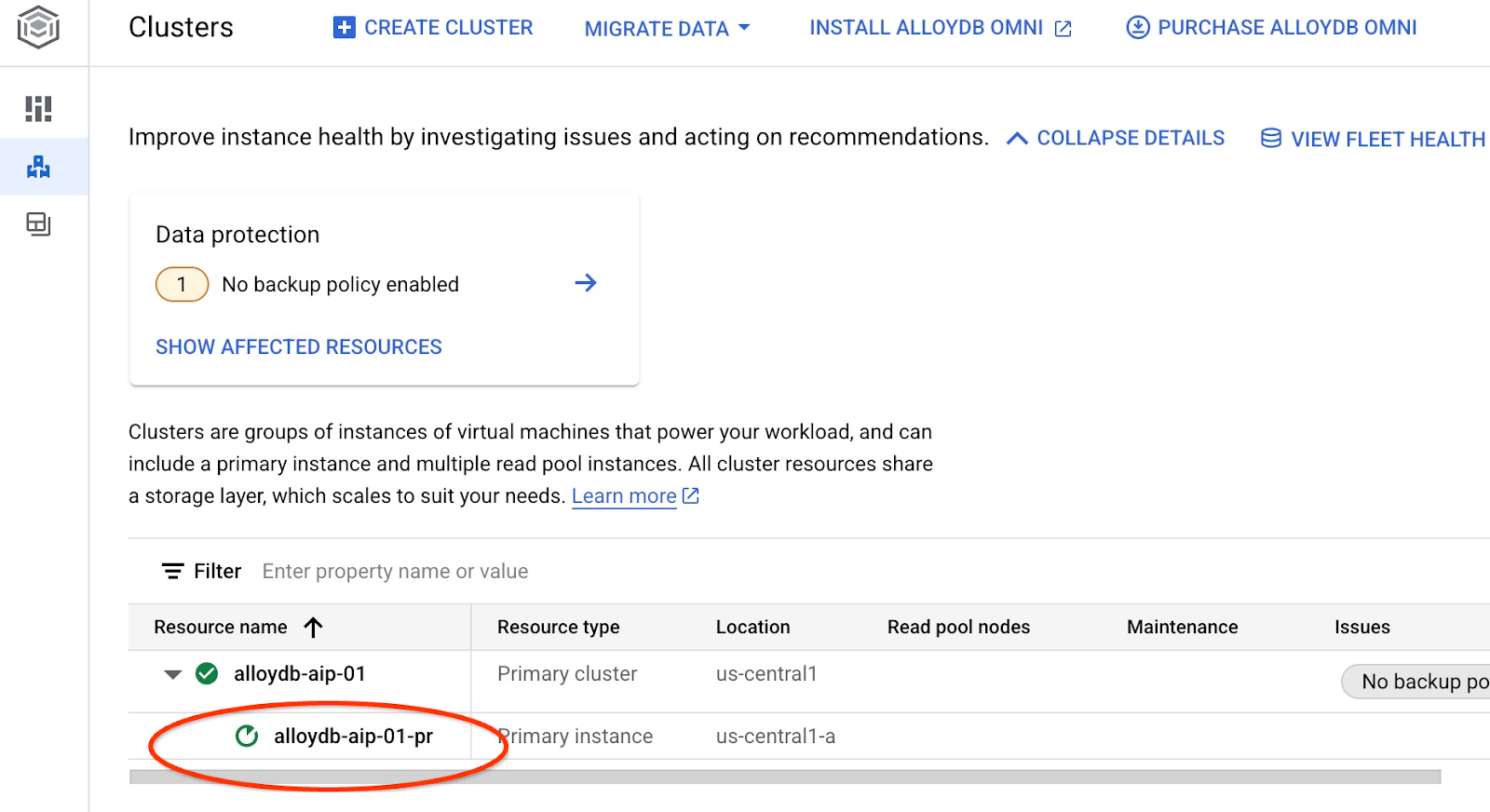
Une fois l'instance mise à jour (son état est vert), vous pouvez activer l'extension alloydb_ai_nl.
Dans AlloyDB Studio, exécutez
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
Créer une configuration en langage naturel
Pour utiliser les extensions, nous devons créer une configuration. Cette configuration est nécessaire pour associer des applications à certains schémas, modèles de requête et points de terminaison de modèle. Créons une configuration avec l'ID cymbal_ecomm_config.
Dans AlloyDB Studio, exécutez
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
Nous pouvons maintenant enregistrer notre schéma d'e-commerce dans la configuration. Nous avons importé des données dans le schéma "ecomm". Nous allons donc ajouter ce schéma à notre configuration en langage naturel.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. Ajouter du contexte au langage naturel et à SQL
Ajouter un contexte général
Nous pouvons ajouter du contexte à notre schéma enregistré. Le contexte est censé aider à générer de meilleurs résultats en réponse aux requêtes des utilisateurs. Par exemple, nous pouvons dire qu'une marque est la marque préférée d'un utilisateur lorsqu'elle n'est pas définie explicitement. Définissons Clades (marque fictive) comme marque par défaut.
Dans AlloyDB Studio, exécutez :
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
Vérifions comment le contexte général fonctionne pour nous.
Dans AlloyDB Studio, exécutez :
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
La requête générée utilise notre marque par défaut définie précédemment dans le contexte général :
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
Nous pouvons le nettoyer et ne générer que l'instruction SQL en sortie.
Exemple :
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Sortie effacée :
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
Vous avez remarqué qu'il avait automatiquement choisi la table "inventory_items" au lieu de "products" et l'avait utilisée pour créer la requête. Cette méthode peut fonctionner dans certains cas, mais pas pour notre schéma. Dans notre cas, la table "inventory_items" sert à suivre les ventes, ce qui peut être trompeur si vous ne disposez pas d'informations privilégiées. Nous verrons plus tard comment rendre nos requêtes plus précises.
Contexte du schéma
Le contexte de schéma décrit les objets de schéma tels que les tables, les vues et les colonnes individuelles stockant des informations sous forme de commentaires dans les objets de schéma.
Nous pouvons le créer automatiquement pour tous les objets de schéma dans notre configuration définie à l'aide de la requête suivante :
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
Le paramètre "TRUE" nous indique de régénérer le contexte et de l'écraser. L'exécution prendra un certain temps en fonction du modèle de données. Plus vous avez de relations et de connexions, plus cela peut prendre de temps.
Une fois le contexte créé, nous pouvons vérifier ce qu'il a créé pour la table des éléments d'inventaire à l'aide de la requête suivante :
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
Sortie effacée :
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
Il semble que la description manque certaines parties clés qui reflètent le mouvement des articles dans la table inventory_items. Nous pouvons le mettre à jour en ajoutant ces informations clés au contexte de la relation ecomm.inventory_items.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
Nous pouvons également vérifier l'exactitude de la description de notre tableau de produits.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
J'ai trouvé que le contexte généré automatiquement pour le tableau des produits était assez précis et ne nécessitait aucune modification.
J'ai également vérifié les informations de chaque colonne des deux tables et elles étaient également correctes.
Appliquons le contexte généré pour ecomm.inventory_items et ecomm.products à notre configuration.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
Vous souvenez-vous de notre requête pour générer du code SQL pour la question "Combien de produits avons-nous de notre marque préférée ?" ? Nous pouvons maintenant le répéter et voir si la sortie a changé.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Voici le nouveau résultat.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
Il vérifie désormais ecomm.products, ce qui est plus précis et renvoie environ 300 produits au lieu de 5 000 opérations avec des articles d'inventaire.
9. Utiliser l'index de valeur
L'association de valeurs enrichit les requêtes en langage naturel en associant des expressions de valeurs à des types de concepts et des noms de colonnes préenregistrés. Cela peut aider à rendre les résultats plus prévisibles.
Configurer l'index de valeur
Nous pouvons créer nos requêtes à l'aide de la colonne "Marque" de la table "Produits" et rechercher les produits dont les marques sont plus stables en définissant le type de concept et en l'associant à la colonne ecomm.products.brand.
Créons le concept et associons-le à la colonne :
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
Vous pouvez vérifier le concept en interrogeant alloydb_ai_nl.list_concept_types().
SELECT alloydb_ai_nl.list_concept_types();
Nous pouvons ensuite créer l'index dans notre configuration pour toutes les associations créées et prédéfinies :
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
Utiliser l'index de valeur
Si vous exécutez une requête pour créer un SQL à l'aide de noms de marques sans définir qu'il s'agit de noms de marques, cela permet d'identifier correctement l'entité et la colonne. Voici la requête :
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
Le résultat montre l'identification correcte du mot "Clades" comme nom de marque.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. Utiliser des modèles de requête
Les modèles de requêtes permettent de définir des requêtes stables pour les applications stratégiques, ce qui réduit l'incertitude et améliore la précision.
Créer un modèle de requête
Créons un modèle de requête qui joint plusieurs tables pour obtenir des informations sur les clients qui ont acheté des produits "Republic Outpost " l'année dernière. Nous savons que la requête peut utiliser la table ecomm.products ou la table ecomm.inventory_items, car elles contiennent toutes les deux des informations sur les marques. Toutefois, la table products comporte 15 fois moins de lignes et un index sur la clé primaire pour la jointure. Il peut être plus efficace d'utiliser le tableau des produits. Nous créons donc un modèle pour la requête.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
Nous pouvons maintenant demander à créer une requête.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
et produit le résultat souhaité.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
Vous pouvez également exécuter la requête directement à l'aide de la requête suivante :
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
Il renverra les résultats au format JSON, qui peuvent être analysés.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. Nettoyer l'environnement
Détruisez les instances et le cluster AlloyDB une fois l'atelier terminé.
Supprimer le cluster AlloyDB et toutes les instances
Si vous avez utilisé la version d'essai d'AlloyDB. Ne supprimez pas le cluster d'essai si vous prévoyez de tester d'autres ateliers et ressources à l'aide de ce cluster. Vous ne pourrez pas créer d'autre cluster d'essai dans le même projet.
Le cluster est détruit avec l'option "force", qui supprime également toutes les instances appartenant au cluster.
Dans Cloud Shell, définissez le projet et les variables d'environnement si vous avez été déconnecté et que tous les paramètres précédents sont perdus :
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Supprimez le cluster :
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Supprimer les sauvegardes AlloyDB
Supprimez toutes les sauvegardes AlloyDB du cluster :
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation. Vous pouvez désormais essayer d'implémenter vos propres solutions à l'aide des fonctionnalités NL2SQL d'AlloyDB. Nous vous recommandons d'essayer d'autres ateliers de programmation liés à AlloyDB et AlloyDB/AI. Pour découvrir comment fonctionnent les embeddings multimodaux dans AlloyDB, consultez cet atelier de programmation.
Points abordés
- Déployer AlloyDB pour PostgreSQL
- Activer le langage naturel AlloyDB AI
- Créer et ajuster une configuration pour l'IA en langage naturel
- Générer des requêtes SQL et obtenir des résultats en langage naturel
13. Enquête
Résultat :